JP6090431B2 - 分散処理のための情報処理方法、情報処理装置及びプログラム、並びに分散処理システム - Google Patents
分散処理のための情報処理方法、情報処理装置及びプログラム、並びに分散処理システム Download PDFInfo
- Publication number
- JP6090431B2 JP6090431B2 JP2015507761A JP2015507761A JP6090431B2 JP 6090431 B2 JP6090431 B2 JP 6090431B2 JP 2015507761 A JP2015507761 A JP 2015507761A JP 2015507761 A JP2015507761 A JP 2015507761A JP 6090431 B2 JP6090431 B2 JP 6090431B2
- Authority
- JP
- Japan
- Prior art keywords
- data
- file
- information processing
- information
- identification information
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000012545 processing Methods 0.000 title claims description 161
- 230000010365 information processing Effects 0.000 title claims description 112
- 238000003672 processing method Methods 0.000 title claims description 27
- 238000007726 management method Methods 0.000 claims description 108
- 238000000034 method Methods 0.000 claims description 75
- 230000008569 process Effects 0.000 claims description 64
- 238000013500 data storage Methods 0.000 claims description 37
- 230000005540 biological transmission Effects 0.000 claims description 4
- 239000000284 extract Substances 0.000 claims description 2
- 238000000605 extraction Methods 0.000 claims 2
- 238000004891 communication Methods 0.000 description 35
- 238000010586 diagram Methods 0.000 description 22
- 230000004044 response Effects 0.000 description 10
- 238000013523 data management Methods 0.000 description 7
- 238000005516 engineering process Methods 0.000 description 4
- 238000010923 batch production Methods 0.000 description 2
- 230000010076 replication Effects 0.000 description 2
- 241001522296 Erithacus rubecula Species 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 230000003111 delayed effect Effects 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 230000006870 function Effects 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 238000012544 monitoring process Methods 0.000 description 1
- 230000009467 reduction Effects 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 239000004065 semiconductor Substances 0.000 description 1
Images



















Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F12/00—Accessing, addressing or allocating within memory systems or architectures
- G06F12/02—Addressing or allocation; Relocation
- G06F12/08—Addressing or allocation; Relocation in hierarchically structured memory systems, e.g. virtual memory systems
- G06F12/0802—Addressing of a memory level in which the access to the desired data or data block requires associative addressing means, e.g. caches
- G06F12/0866—Addressing of a memory level in which the access to the desired data or data block requires associative addressing means, e.g. caches for peripheral storage systems, e.g. disk cache
- G06F12/0871—Allocation or management of cache space
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F12/00—Accessing, addressing or allocating within memory systems or architectures
- G06F12/02—Addressing or allocation; Relocation
- G06F12/08—Addressing or allocation; Relocation in hierarchically structured memory systems, e.g. virtual memory systems
- G06F12/0802—Addressing of a memory level in which the access to the desired data or data block requires associative addressing means, e.g. caches
- G06F12/0875—Addressing of a memory level in which the access to the desired data or data block requires associative addressing means, e.g. caches with dedicated cache, e.g. instruction or stack
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/10—File systems; File servers
- G06F16/17—Details of further file system functions
- G06F16/172—Caching, prefetching or hoarding of files
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/10—File systems; File servers
- G06F16/18—File system types
- G06F16/182—Distributed file systems
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F2212/00—Indexing scheme relating to accessing, addressing or allocation within memory systems or architectures
- G06F2212/31—Providing disk cache in a specific location of a storage system
- G06F2212/314—In storage network, e.g. network attached cache
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F2212/00—Indexing scheme relating to accessing, addressing or allocation within memory systems or architectures
- G06F2212/45—Caching of specific data in cache memory
- G06F2212/452—Instruction code
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F2212/00—Indexing scheme relating to accessing, addressing or allocation within memory systems or architectures
- G06F2212/60—Details of cache memory
- G06F2212/6042—Allocation of cache space to multiple users or processors
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- Databases & Information Systems (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Description
本発明は、分散処理技術に関する。
近年、ウェブサイト、センサ或いは携帯端末等において発生する大量のデータ(以下、ビッグデータと呼ぶ)を短時間で処理する技術が求められている。
ビッグデータを処理する技術として、ハドゥープ(Hadoop)という分散処理フレームワークが知られている。Hadoopにおいては、マップリデュース(MapReduce)という分散処理方式に基づき1つのファイルを複数のファイルに分割し、複数のノードがファイルを並列処理する。Hadoopは、ノード数の増加に応じて処理性能が線形に高くなることを特徴とする。そのため、Hadoopを利用すれば、例えば数ペタバイト以上のデータを数十から数千のノードで処理するような大規模なシステムを比較的容易に実現することができる。
Hadoopは、分散処理を効果的に行うため、HDFS(Hadoop Distributed File System)と呼ばれる分散ファイルシステムを採用している。HDFSは、ファイルを特定の大きさに分割し、分割されたファイルを複数のサーバに分散して格納すると共に、分割されたファイルの複製を生成し、複製元のファイルを保持するサーバとは別のサーバに保持させる。分散処理においては、複製元のファイル及び複製されたファイルのいずれかを処理すればよいため、HDFSが作業プロセスが空いているサーバに処理を振り分けることにより、サーバのリソース(CPU(Central Processing Unit)資源等)を有効に利用できる。
しかし、HDFS等の分散ファイルシステムは、処理の振り分けの際にOS(Operating System)のキャッシュの状態を考慮しない。そのため、分散処理システムは、あるサーバのキャッシュ上にデータがあってもそれを考慮せず別のサーバに処理を振り分けてしまうので、ディスクI/O(Input/Output)が発生する。ディスクI/Oは時間がかかる処理であり、例えば数ギガバイトのデータの処理に要する時間の約半分をディスクのシーク時間が占めることがある。
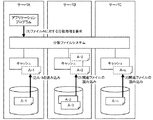
図1を用いて、分散ファイルシステムによるビッグデータの処理について説明する。サーバAのディスクにはファイルAが格納されており、サーバBのディスクにはファイルBが格納されており、サーバCのディスクにはファイルBの複製及びファイルCが格納されている。また、サーバCのキャッシュにはファイルBが展開されている。分散処理システムにおけるいずれかのサーバに配置されたアプリケーションプログラムは、ファイルA、ファイルB、ファイルCの順に処理を行う。アプリケーションプログラムは、サーバAにおけるファイルAに対する処理をした後、サーバB又はサーバCにおけるファイルBに対して処理をする。サーバCにおけるファイルBに対して処理をすれば、キャッシュを利用できるためディスクI/Oは発生しない。しかし、サーバB又はサーバCのいずれを選択するかは、サーバB又はサーバCにおける空きプロセスの状況等によるため、サーバBを選択する場合もある。その場合にはディスクI/Oが発生するため、ファイルに対する処理の完了までの時間が大幅に遅れる。
よって、ファイルに対する処理を短時間で完了させるという観点から、分散処理システムにおけるキャッシュヒット率を向上させることが好ましい。
分散処理及びキャッシュの管理については、例えば以下のような技術が知られている。具体的には、MapReduce処理システムが、処理対象のデータを、データの更新頻度に基づき複数のグループに分け、グループに含まれるデータの更新頻度に基づきグループ更新頻度を計算する。そして、MapReduce処理システムは、グループ更新頻度が閾値以下であるグループに対するMapReduce処理段階の部分的結果を生成し、生成された部分的結果をキャッシュする。これによりMapReduce処理においてキャッシュを有効に利用する。
また、キャッシュの有効利用に関して、以下のような技術も存在する。具体的には、ファイルのオープン時にファイルの全体又は部分領域のデータを多重化して複数のドライブに分散配置すると共に、ファイルのクローズ時にファイルの多重化データを消去する。
また、複数のクライアントから特定のファイルサーバにアクセス要求が集中することによるスループットの低下を防ぐ技術が存在する。具体的には、マスタファイルサーバが、負荷が軽いファイルサーバを選定し、選定されたファイルサーバに、クライアントから伝送されたファイルアクセス要求を分配する。
また、広域ネットワークの状態に関わらず高速なファイルアクセスを提供するための技術が存在する。具体的には、キャッシュサーバは、ファイルアクセスを記録するアクセス履歴データベースを有しており、アクセス履歴データベースによってアクセス頻度が高いファイルの更新間隔を分析し、先読みすべきファイルを決定する。そして、キャッシュサーバは、広域ネットワークが空いている時間帯にアクセス頻度が高いファイルを先読みし、クライアントからの要求に対し先読みしたファイルを渡す。
また、クライアントにログインするユーザ毎に、使用頻度が高いファイルを優先的にキャッシングすることにより、キャッシュヒット率を向上させ、ファイルアクセスを高速化する技術が存在する。
しかしながら、これらの技術を利用したとしても、分散処理システムにおけるキャッシュヒット率を十分に向上させることができない場合がある。また、サーバにおけるキャッシュを有効に利用するという観点において、従来技術は十分ではない。
Jeffrey Dean and Sanjay Ghemawat,"MapReduce: Simplified Data Processing on Large Clusters",[online],2004年12月,Symposium on Operating System Design and Implementation 2004 ,[平成25年1月10日検索],インターネット<URL:http://research.google.com/archive/mapreduce.html>
従って、本発明の目的は、1つの側面では、分散処理システムにおけるキャッシュヒット率を向上させるための技術を提供することである。
本発明の第1の態様に係る情報処理方法は、複数の情報処理装置によりデータの処理を行う分散処理システムにおいて実行される情報処理方法である。そして、本情報処理方法は、複数の情報処理装置のうちいずれかの情報処理装置である第1の情報処理装置が、第1の情報処理装置が管理する第1のデータに対するアクセスがあった場合に、複数の情報処理装置のうちデータ間の関連性を管理する情報処理装置から、第1のデータと所定の関連性を有する第2のデータの識別情報及び当該第2のデータを管理する情報処理装置の識別情報を取得し、第2のデータを管理する情報処理装置が第1の情報処理装置である場合に、第2のデータをデータ格納部から読み出し、キャッシュに展開する処理を含む。
本発明の第2の態様に係る情報処理方法は、複数の情報処理装置によりデータの処理を行う分散処理システムにおいて実行される情報処理方法である。そして、本情報処理方法は、複数の情報処理装置のうちいずれかの情報処理装置である第1の情報処理装置が、複数の情報処理装置のうち第1のデータを管理する情報処理装置から、第1のデータと所定の関連性を有するデータについての情報を要求する第1の要求を受信した場合に、データの識別情報と当該データと所定の関連性を有するデータの識別情報とを対応付けて格納する関連データ格納部から、第1のデータと所定の関連性を有する第2のデータの識別情報を抽出し、抽出された第2のデータの識別情報と当該第2のデータを管理する情報処理装置の識別情報とを、第1の要求の送信元の情報処理装置に送信する処理を含む。
分散処理システムにおけるキャッシュヒット率を向上させることができるようになる。
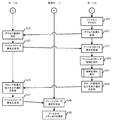
図2に、本実施の形態における分散処理システムの概要を示す。例えばインターネットであるネットワーク5には、管理サーバ1と、複数のサーバ3とが接続されている。図2に示した分散処理システムにおいては、サーバ3におけるアプリケーションプログラム35が、複数のサーバ3のうちいずれかのサーバ3が管理するファイルに対する処理を行う。
管理サーバ1は、システム管理部100と、関連ファイルデータ格納部108と、ログ格納部109とを有する。システム管理部100は、通信制御部101と、システムデータ管理部102と、構成管理部103と、インデックス管理部105、メタデータ管理部106及び統計データ管理部107を含むファイル管理部104とを有する。
通信制御部101は、通信のための処理を行う。システムデータ管理部102は、分散処理システムにおいて共有するデータ(例えばファイルのブロックサイズ又は複製されたファイルの数等)を管理する。構成管理部103は、分散処理システムにおけるクラスタの構成の管理及び死活監視等を行う。ファイル管理部104は、関連ファイルデータ格納部108に格納されているデータ及びログ格納部109に格納されているデータを管理する処理等を行う。インデックス管理部105は、各サーバ3が管理しているファイルを二分木構造のファイルインデックスにより管理する。メタデータ管理部106は、ファイルのメタデータ(例えば、ファイルのサイズ及びファイルの所有者等)を管理する。統計データ管理部107は、ログ格納部109に格納されているデータを用いてファイル間の統計的関連を特定することにより、関連ファイルデータ格納部108に格納されているデータを更新する。
図3に、関連ファイルデータ格納部108に格納される関連ファイルデータの一例を示す。図3の例では、関連ファイルデータは、ファイルの識別子とそのファイルに関連するファイル(以下、関連ファイルと呼ぶ)の識別子とを含む。関連ファイルは、特定のファイルに対するアクセスがあった場合に、そのアクセスがあったタイミングの近傍のタイミングにおいてアクセスされる可能性が高いファイルである。
関連性には、構成的関連性と統計的関連性とユーザの指定による関連性とがある。図3に示した関連ファイルデータは、構成的関連性に基づき生成された関連ファイルデータである。構成的関連性があるファイルとは、例えば、元は1つであったファイルを分割することにより得られた複数のファイル、同一又は近傍のディレクトリに格納されているファイル、又は同じタイムスタンプを有するファイル等である。構成的関連性があるファイルは、例えばバッチ処理のような一括処理において一遍にアクセスされる可能性が高い。図3に示した関連ファイルデータは、ファイルA−1、ファイルA−2及びファイルA−3はファイルAを分割することにより得られたファイルであるため、これらのファイルが構成的関連を有していることを表している。また、ファイルB−1は、ファイルA−1と同一又は近傍のディレクトリに格納されているか又は同一のタイムスタンプを有している。
図4に、統計的関連性に基づき生成された関連ファイルデータの一例を示す。図4の例では、関連ファイルデータは、ファイルの識別子と、関連ファイルの識別子と、関連ファイルにアクセスされた回数を示す数値とを含む。関連ファイルにアクセスされた回数は、対象のファイルに対するアクセスがあった後所定時間内に関連ファイルにアクセスがあった回数を表す。
統計的関連性に基づき生成された関連ファイルデータは、図5に示すように、統計データ管理部107がログ格納部109に格納されているアクセスログに基づき生成する。図5の左側には、アクセスログが示されており、図5の右側には統計的関連性に基づき生成された関連ファイルデータが示されている。例えばバッチ処理等においては、所定の時刻にファイルにアクセスしたり、所定の順番でファイルにアクセスすることがある。そこで、アクセスログを利用し、所定の条件(例えば、所定時間内のアクセスであるという条件、所定のアクセス順序であるという条件、又は所定の利用者によるアクセスであるという条件等)に合致すると判断された場合には、関連ファイルであるとみなす。
なお、統計的関連性に基づく関連ファイルデータは、関連性が高い(例えば、アクセス回数が多い)関連ファイルほどチェーン構造における先頭に近付くように生成される。
なお、ユーザの指定により関連性を定義すれば、アクセスパターンが固定されている場合に特に有効である。
図6に、関連ファイルデータ格納部108の詳細なデータ構造の一例を示す。関連ファイルの情報は、分散ファイルシステムが管理するファイルの情報の属性の一つである。図6の例では、インデックス管理部105が管理するファイルインデックス50に、ファイル情報51へのリンクが張られている。ファイル情報51の構造体には、そのファイルの関連ファイルの情報へのポインタメンバが含まれる。
関連ファイルデータ52はチェーン構造であり、関連ファイルの情報へのリンクが連結される。関連ファイルデータ52の構造体には、ファイル識別子と、関連付けられるファイル情報のアドレスと、関連ファイルの格納場所を示す情報と、アクセス回数を示すカウンタと、次の関連ファイルのアドレスとが含まれる。カウンタの値が大きいほどアクセスされる可能性が高い関連ファイルであるため、優先的にキャッシュ36に展開される。
図2の説明に戻り、サーバ3は、クライアント管理部30と、アプリケーションプログラム35と、キャッシュ36と、ファイル格納部37とを有する。クライアント管理部30は、通信制御部31と、アクセス制御部33及び先読み処理部34を含むファイル管理部32とを有する。先読み処理部34は、取得部341と、キャッシュ処理部342とを有する。
通信制御部31は、通信のための処理を実行する。アクセス制御部33は、ファイルアクセスを制御する処理を行う。取得部341は、関連ファイルの情報を管理サーバ1から取得する処理等を行う。キャッシュ処理部342は、関連ファイルをキャッシュ36に展開する処理等を行う。アプリケーションプログラム35は、ファイル格納部37に格納されているファイルに対する処理を行う。キャッシュ36は、例えばメモリ領域等に確保されたディスクキャッシュである。ファイル格納部37は、例えばハードディスク等に確保された、ファイルを格納するための領域である。
次に、図7乃至図19を用いて、図2に示したシステムの動作について説明する。まず、図7乃至図14を用いて、アプリケーションプログラム35がファイルに対するアクセスを行う場合の動作について説明する。
図2に示したシステムにおける複数のサーバ3のうちいずれかのサーバ3(ここでは、サーバAとする)におけるアプリケーションプログラム35は、特定のファイルに対するアクセスを行うとする。この場合、サーバAにおけるアプリケーションプログラム35は、アクセス対象のファイルの指定を含むファイルオープン要求を管理サーバ1に送信する(図7:ステップS1)。
管理サーバ1における通信制御部101は、ファイルオープン要求をサーバAから受信すると(ステップS3)、ファイル管理部104に出力する。ファイル管理部104におけるインデックス管理部105は、ファイルオープン要求において指定されたファイルの格納場所をファイルインデックス50を用いて特定する(ステップS5)。インデックス管理部105は、ファイルの格納場所を示すデータを通信制御部101に出力する。
ファイル管理部104は、ログ格納部109に格納されているアクセスログ及び関連ファイルデータ格納部108に格納されているデータを更新する(ステップS7)。具体的には、ファイル管理部104における統計データ管理部107が、今回のアクセスについてのデータをアクセスログに追加することでアクセスログを更新する。また、統計データ管理部107は、アクセスログの更新を反映するように関連ファイルデータ格納部108に格納されているデータを更新する。
通信制御部101は、インデックス管理部105から受け取った、ファイルの格納場所を示すデータを、サーバAに送信する(ステップS9)。
サーバAにおけるアプリケーションプログラム35は、ファイルの格納場所を示すデータを管理サーバ1から受信する(ステップS11)。そして、アプリケーションプログラム35は、ファイルの格納場所(ここではサーバBとする)を示すデータに従い、アクセス対象のファイルの指定を含むファイルオープン要求をサーバBに送信する(ステップS13)。
サーバBは、ファイルオープン要求をサーバAから受信する(ステップS15)。そして、サーバBにおけるアクセス制御部33は、ファイルオープン要求において指定されたファイルのオープン処理(すなわち、ファイルの使用を開始するための処理)を実行し、ファイルをキャッシュ36に展開する(ステップS17)。なお、ファイルオープン要求において指定されたファイルは、ファイル格納部37から読み出される。
そして、先読み処理部34は、先読み処理を実行する(ステップS19)。先読み処理については、図8A乃至図10を用いて説明する。
まず、先読み処理部34は、アクセス対象のファイルについて関連ファイルリストを要求する関連ファイル要求を管理サーバ1に送信する(図8A:ステップS61)。
図8Bを用いて、関連ファイル要求を受信した管理サーバ1の処理について説明する。管理サーバ1における通信制御部101は、関連ファイル要求をサーバBから受信する(図8B:ステップS62)。通信制御部101は、関連ファイル要求をファイル管理部104に出力する。
ファイル管理部104は、アクセス対象のファイルに対応する関連ファイルの識別子及び当該関連ファイルの格納場所(すなわち、関連ファイルを管理するサーバの識別子)を関連ファイルデータ格納部108から抽出する(ステップS63)。ファイル管理部104は、関連ファイルの識別子及び関連ファイルを管理するサーバの識別子を通信制御部101に出力する。なお、関連ファイルの識別子及び当該関連ファイルを管理するサーバの識別子は複数である場合もある。また、関連ファイルが無い場合もある。
通信制御部101は、関連ファイルの識別子及び当該関連ファイルを管理するサーバの識別子を含む関連ファイルリストをサーバBに送信する(ステップS64)。そして処理を終了する。
これに応じ、サーバBにおける先読み処理部34は、関連ファイルリストを管理サーバ1から受信し(ステップS65)、メインメモリ等の記憶装置に格納する。
先読み処理部34は、関連ファイルリストに未処理の関連ファイルが有るか判断する(ステップS66)。未処理の関連ファイルが無い場合(ステップS66:Noルート)、元の処理に戻る。未処理の関連ファイルが有る場合(ステップS66:Yesルート)、先読み処理部34は、未処理の関連ファイルを1つ特定し、当該関連ファイルが自サーバ(すなわちサーバB)に有るか判断する(ステップS67)。ステップS67の判断は、関連ファイルを管理するサーバの識別子が自サーバを示しているか否かにより行う。なお、ステップS67において特定された関連ファイルを「処理対象の関連ファイル」と呼ぶ。
処理対象の関連ファイルが自サーバに無い場合(ステップS67:Noルート)、先読み処理部34は、処理対象の関連ファイルを管理するサーバ(ここでは、サーバCとする)に先読み処理要求を送信する(ステップS69)。ステップS69の先読み処理要求に応じ、サーバCは、先読み処理(ステップS19)を実行する。そして処理は端子Dを介してステップS66に戻る。
一方、処理対象の関連ファイルが自サーバに有る場合(ステップS67:Yesルート)、先読み処理部34は、キャッシュ36の使用量が閾値以下であるか判断する(ステップS71)。キャッシュ36の使用量が閾値以下ではない場合(ステップS71:Noルート)、キャッシュ溢れが発生する可能性があるので、処理対象の関連ファイルをキャッシュ36に展開せず、元の処理に戻る。キャッシュ36の使用量が閾値以下である場合(ステップS71:Yesルート)、先読み処理部34は、処理対象の関連ファイルが既にキャッシュ36に展開されているか判断する(ステップS73)。
処理対象の関連ファイルが既にキャッシュ36に展開されている場合(ステップS73:Yesルート)、処理対象の関連ファイルをキャッシュ36に展開しなくてもよいので、処理は端子Dを介してステップS66の処理に戻る。一方、処理対象の関連ファイルがキャッシュ36に展開されていない場合(ステップS73:Noルート)、先読み処理部34は、アクセス制御部33に処理対象の関連ファイルのオープン処理を実行することを要求する。これに応じ、アクセス制御部33は、処理対象の関連ファイルのオープン処理を実行する(ステップS75)。そして処理は端子Dを介してステップS66に戻る。
以上のような処理を実行すれば、特定のファイルに対してアクセスがあった場合に、そのファイルに関連するファイルがキャッシュ36に展開されるようになる。関連ファイルは、特定のファイルに対するアクセスがあった場合にアクセスされる可能性が高いファイルであるから、分散処理システムにおけるキャッシュヒット率を向上させることができるようになる。
図9を用いて、先読み処理についてより具体的に説明する。例えば、サーバAにおけるアプリケーションプログラム35がファイルAに対する分散処理を要求したとする(図9における(1))。ファイルAは、分散ファイルシステムによってファイルA−1、A−2、・・・、A−nのn個(nは2以上の自然数)に分割されており、分割されたファイルはサーバA乃至Cに分散して格納されている。ここで、ファイルA−1がサーバAのファイル格納部37からキャッシュ36に展開され、アプリケーションプログラム35による処理に供される(図9における(2))。この際、サーバBにおけるファイルA−2及びファイルA−3、並びにサーバCにおけるファイルA−nもキャッシュ36に展開される(図9における(3))。そのため、アプリケーションプログラム35がファイルA−2乃至A−nについて処理する際には、これらのファイルは事前にキャッシュ36に展開されているので、ディスクI/Oは発生しない。従って、ファイルAの処理を高速で行うことができるようになる。
なお、上で述べた例では、各サーバがファイル格納部37を有するとして説明したが、図10に示すように、複数のサーバに対して共有のファイル格納部37を1つ設けるような場合(以下、共有ディスク型の場合と呼ぶ)にも先読み処理は有効である。図10の例では、ファイル格納部37が3つの部分に分けられている。この場合、ファイルA−1乃至A−3のいずれかに対するアクセスがあった場合には、サーバA乃至サーバCのうちいずれかのサーバが、共有のファイル格納部37からファイルを読み出し、キャッシュ36に展開する。これにより、ディスクI/Oは発生しなくなるので、ファイルAの処理を高速で行うことができるようになる。なお、キャッシュ36への展開を行なうサーバは、例えばラウンドロビン或いはキャッシュ36の使用状況等に基づき分散ファイルシステムにより決定される。
図7の説明に戻り、サーバBにおける通信制御部31は、オープン処理の完了を示す通知をサーバAに送信する(ステップS21)。
サーバAにおけるアプリケーションプログラム35は、オープン処理の完了を示す通知を受信すると(ステップS23)、オープン処理が行われたファイルに対するファイルアクセス要求(例えば、参照要求)をサーバBに送信する(ステップS25)。
サーバBにおける通信制御部31は、ファイルアクセス要求を受信する(ステップS27)。通信制御部31は、ファイルアクセス要求をファイル管理部32に出力する。処理は端子A乃至Cを介して図11の処理に移行する。
図11の説明に移行し、ファイル管理部32におけるアクセス制御部33は、ファイル格納部37に格納されているファイルに対するアクセスを行う(ステップS29)。アクセス制御部33は、アクセス結果(例えば、ファイルアクセス要求が参照要求である場合には、参照した結果)を通信制御部31に出力する。
通信制御部31は、アクセス結果をファイルアクセス要求の送信元であるサーバAに送信する(ステップS31)。
サーバAにおけるアプリケーションプログラム35は、アクセス結果を受信する(ステップS33)。その後、アプリケーションプログラム35は、アクセス対象のファイルについてファイルクローズ要求をサーバBに送信する(ステップS35)。
サーバBにおける通信制御部31は、ファイルクローズ要求を受信する(ステップS37)。通信制御部31は、ファイルクローズ要求をファイル管理部32に出力する。
ファイル管理部32におけるアクセス制御部33は、アクセス対象のファイルについてクローズ処理(すなわち、ファイルの使用を終了するための処理)を実行する(ステップS39)。また、ファイル管理部32における先読み処理部34は、破棄処理を実行する(ステップS41)。破棄処理については、図12及び図13を用いて説明する。
まず、先読み処理部34は、キャッシュ36に展開されているアクセス対象のファイルを削除する(図12:ステップS81)。
先読み処理部34は、ステップS65において受信した関連ファイルリストに、自サーバが管理する関連ファイルであり且つ未処理の関連ファイルが有るか判断する(ステップS83)。
未処理の関連ファイルが無い場合(ステップS85:Noルート)、元の処理に戻る。一方、未処理の関連ファイルが有る場合(ステップS85:Yesルート)、先読み処理部34は、未処理の関連ファイルを1つ特定する(以下では、特定されたファイルを「処理対象の関連ファイル」と呼ぶ)。そして、先読み処理部34は、キャッシュ36の使用量が閾値以下であるか判断する(ステップS87)。
キャッシュ36の使用量が閾値以下ではない場合(ステップS87:Noルート)、処理対象の関連ファイルをキャッシュ36に展開することはできないので、元の処理に戻る。一方、キャッシュ36の使用量が閾値以下である場合(ステップS87:Yesルート)、先読み処理部34は、処理対象の関連ファイルが既にキャッシュ36に展開されているか判断する(ステップS89)。
処理対象の関連ファイルが既にキャッシュ36に展開されている場合(ステップS89:Yesルート)、処理対象の関連ファイルをキャッシュ36に展開しなくてもよいので、ステップS83の処理に戻る。一方、処理対象の関連ファイルがキャッシュ36に展開されていない場合(ステップS89:Noルート)、先読み処理部34は、アクセス制御部33に処理対象の関連ファイルのオープン処理を実行することを要求する。これに応じ、アクセス制御部33は、処理対象の関連ファイルのオープン処理を実行する(ステップS91)。そしてステップS83に戻る。
以上のような処理を実行すれば、クローズ処理が完了したファイルについてはキャッシュ36から削除されるので、キャッシュ36を無駄に使用することが無くなる。また、図13に示すように、キャッシュ36の使用量は閾値以下になるように制御されている。図13に示す例においては、処理済みであるファイルA−1がキャッシュ36から削除されており、代わりに関連ファイルであるファイルA−4がキャッシュ36に展開される。このようにすることで、未処理の関連ファイルがキャッシュ36に展開されやすくなるので、キャッシュヒット率をさらに向上させることができるようになる。
図11の説明に戻り、サーバBにおける通信制御部31は、クローズ処理の完了を示す通知をサーバAに送信する(ステップS43)。
サーバAにおけるアプリケーションプログラム35は、クローズ処理の完了を示す通知をサーバBから受信する(ステップS45)。そして、アプリケーションプログラム35は、アクセス対象のファイルについてファイルクローズ要求を管理サーバ1に送信する(ステップS47)。
管理サーバ1における通信制御部101は、サーバAからファイルクローズ要求を受信し(ステップS49)、ファイル管理部104に出力する。そして、ファイル管理部104は、アクセス対象のファイルのステータス(ここでは、状態についての情報を意味する)を更新する(ステップS51)。具体的には、アクセス対象のファイルについて、オープン又はクローズの状態、ロックの状態、ファイルサイズ、又は更新の日時等を更新し、図示しない記憶装置に記憶する。
以上のような処理を実行すれば、分散処理システムにおけるキャッシュヒット率を向上させ、ファイルに対する処理を高速で行うことができるようになる。
通常、キャッシュはアプリケーションプログラムの都合とは無関係にリフレッシュされる。しかし、本実施の形態においては、関連性があるファイルがキャッシュに残りやすいため、高速にファイルの処理をすることを期待できる。図14を用いて、図1と同様の状況において本実施の形態の処理を行なった場合について説明する。本実施の形態の処理によれば、アプリケーションプログラム35がサーバBにアクセスした際にはファイルBがキャッシュ36に展開されている可能性が高く、またアプリケーションプログラム35がサーバCにアクセスした際にはファイルCがキャッシュ36に展開されている可能性が高い。よって、ファイルB及びファイルCについてディスクI/Oが発生する可能性は低くなるので、ファイルに対する処理の完了までの時間を短くすることができるようになる。
なお、データ処理を高速化する一つの方法として、OSのキャッシュとは別にアプリケーションプログラムのためのメモリ領域(以下、アプリケーションキャッシュと呼ぶ)を確保し、そこに予めデータを展開しておきアクセスするという方法が知られている。この方法によれば、独自のメモリ領域であればデータの取捨選択をも完全にコントロールできるため、効率的なアクセスが可能になる。但し、アプリケーションキャッシュを設けたとしてもOSのキャッシュが無くなるわけではないので、メモリ領域を2倍使用することになる。
これに対し、本実施の形態において説明した方法であれば、アプリケーションキャッシュを利用する方法と比べると、メモリの使用量は1/2程度に節約できる。
次に、図15乃至図17を用いて、ファイルを格納する際の動作について説明する。なお、図15のフローは、処理の要点を示しており、通常の分散ファイルシステムが行う処理(例えば、ステータス更新、ファイルのロック及びクラスタ構成の管理等)については省略している。
まず、サーバ3(ここでは、サーバAとする)におけるファイル管理部32は、例えばアプリケーションプログラム35によりファイルが生成された場合に、当該ファイルを分散して格納することを要求するファイル格納要求を生成する。そして、ファイル管理部32は、ファイル格納要求を管理サーバ1に送信する(図15:ステップS101)。なお、ファイル格納要求には、ファイルそのものを含ませるようにしてもよいし、ファイルサイズの情報等を含ませるようにしてもよい。
管理サーバ1における通信制御部101は、ファイル格納要求を受信すると(ステップS103)、ファイル格納要求をファイル管理部104に出力する。
ファイル管理部104は、ファイル格納要求において格納が要求されているファイルの格納場所を決定する(ステップS105)。例えば、ファイル格納部37の空き容量が多いサーバをファイルの格納場所とする。また、ファイルサイズが大きい場合にはファイルを分割することになるため、複数のサーバをファイルの格納場所に決定する。
ファイル管理部104は、関連ファイルデータ格納部108に格納されているデータを更新する(ステップS107)。ステップS107においては、構成的関連に基づき関連ファイルデータを更新する。例えばファイルが特定のディレクトリに格納される場合には、そのディレクトリに格納されている他のファイルと構成的関連性を有することになるので、新たな構成的関連性に基づき更新を行う。また、ファイルが分割される場合には、分割後の複数のファイルは構成的関連性を有することになるので、新たな構成的関連性に基づき更新を行う。
ファイル管理部104は、ファイルの格納場所を示すデータを通信制御部101に出力する(ステップS109)。そして、通信制御部101は、ファイルの格納場所を示すデータ(ここでは、サーバBを示しているとする)をサーバAに送信する。
サーバAにおけるファイル管理部32は、ファイルの格納場所を示すデータを受信すると(ステップS111)、ファイルの格納場所を示すデータに従い、ファイル格納要求をサーバBに送信する(ステップS113)。ステップS113において送信するファイル格納要求には、ファイルが含まれる。なお、ファイルの格納場所となるサーバが複数ある場合には、複数のサーバに対してファイル格納要求を送信する。
サーバBにおける通信制御部31は、ファイル格納要求を受信する(ステップS115)。通信制御部31は、ファイル格納要求をアクセス制御部33に出力する。
アクセス制御部33は、ファイル格納要求に含まれるファイルをファイル格納部37に格納する(ステップS117)。
以上のような処理を実行すれば、ファイルをファイル格納部37に格納する際には、ファイルの構成的関連性に基づき関連ファイルデータを更新できるようになる。
図16を用いて、ファイルの構成的関連性に基づく関連ファイルデータの更新について具体的に説明する。例えば、いずれかのサーバにおけるアプリケーションプログラム35がファイルAについてファイル格納要求を出力したとする。ファイルAは、分散ファイルシステムによってファイルA−1、ファイルA−2及びファイルA−3の3つに分割され、分割されたファイルはサーバA乃至Cに分散して格納される。また、ファイルA−1はサーバAのファイル格納部37においてファイルB−1と同じディレクトリに格納されており、ファイルA−2はサーバBのファイル格納部37においてファイルB−2と同じディレクトリに格納されており、ファイルA−3はサーバCのファイル格納部37においてファイルB−3と同じディレクトリに格納されているとする。このような場合、管理サーバ1における関連ファイルデータ格納部108は、例えば図16の160に示した状態に更新される。この例においては、ファイルA−1の関連ファイルはファイルA−2、ファイルA−3及びファイルB−1であり、ファイルA−2の関連ファイルはファイルA−1、ファイルA−3及びファイルB−2であり、ファイルA−3の関連ファイルはファイルA−1、ファイルA−2及びファイルB−3である。
なお、図16においては、ファイルA−1の関連ファイルにファイルB−2及びファイルB−3が含まれておらず、同じディレクトリに格納されているファイルB−1に限定されている。これは、ファイルB−1のスプリットファイル(ここでは、ファイルB−2及びファイルB−3)まで関連ファイルとすると、ファイルA−1の関連ファイルの数が膨大になるからである。ファイルA−2及びファイルA−3についても同様である。
また、共有ディスク型の場合においても、ファイルの構成的関連性に基づく関連ファイルデータの更新を同様に行なうことができる。例えば図17に示すように、複数のサーバに対して共有のファイル格納部37が1つ設けられており、ファイル格納部37が3つの部分に分けられているとする。ファイルAは、分散ファイルシステムによってファイルA−1、ファイルA−2及びファイルA−3の3つに分割され、分割されたファイルは共有のファイル格納部37における部分p1乃至p3に分散して格納される。また、ファイルA−1はファイル格納部37の部分p1においてファイルB−1と同じディレクトリに格納されており、ファイルA−2はファイル格納部37の部分p2においてファイルB−2と同じディレクトリに格納されており、ファイルA−3はファイル格納部37の部分p3においてファイルB−3と同じディレクトリに格納されているとする。このような場合にも、管理サーバ1における関連ファイルデータ格納部108は、図17の170に示した状態に更新される。すなわち、ファイルA−1の関連ファイルはファイルA−2、ファイルA−3及びファイルB−1であり、ファイルA−2の関連ファイルはファイルA−1、ファイルA−3及びファイルB−2であり、ファイルA−3の関連ファイルはファイルA−1、ファイルA−2及びファイルB−3である。
次に、図18を用いて、ユーザが関連を指定する場合の動作について説明する。
まず、ユーザは、対象ファイル及び当該対象ファイルに関連する関連ファイルをサーバ3における入力部(例えばキーボード又はマウス等)を使用して入力する。サーバ3におけるファイル管理部32は、対象ファイル及び関連ファイルの指定を受け付ける。そして、ファイル管理部32は、対象ファイル及び関連ファイルの指定を含む更新要求を管理サーバ1に送信する(図18:ステップS121)。
管理サーバ1における通信制御部101は、サーバ3から更新要求を受信し(ステップS123)、ファイル管理部104に出力する。
ファイル管理部104は、更新要求において指定されている対象ファイルについての関連ファイルデータを関連ファイルデータ格納部108から特定する(ステップS125)。そして、ファイル管理部104は、更新要求におけるユーザの指定に従い関連ファイルデータを生成し、特定された関連ファイルデータを生成された関連ファイルデータで更新する(ステップS127)。なお、指定された対象ファイルについての関連ファイルデータが関連ファイルデータ格納部108に無い場合には、生成された関連ファイルデータを関連ファイルデータ格納部108に格納する。
ファイル管理部104は、更新完了を示す通知を通信制御部101に出力する。通信制御部101は、更新完了を示す通知をサーバ3に送信する(ステップS129)。
サーバ3における通信制御部31は、更新完了を示す通知を管理サーバ1から受信する(ステップS131)。通信制御部31は、更新完了を示す通知をファイル管理部32に出力する。
ファイル管理部32における先読み処理部34は、先読み処理を実行する(ステップS133)。先読み処理については、図8A乃至図10を用いて説明をしたとおりである。なお、このようなタイミングで先読み処理を実行するのは、ユーザが関連を指定する場合には即ファイルに対する処理を行なう場合が多いと考えられるからである。
以上のような処理を実行すれば、ユーザの意図を関連ファイルデータ格納部108に適切に反映することができるようになる。
図19に、キャッシュのライフサイクルの一例を示す。図19の例は、サーバA及びサーバBにおけるキャッシュ36のライフサイクルを示している。図19において、キャッシュ36にファイルが展開されている時間を、白色の長方形で表す。
例えばサーバAにおける特定のファイルに対するアクセスがあった場合、サーバAにおける先読み処理部34は、管理サーバ1に関連ファイル要求を送信する(図19:1001)。これに応じ、管理サーバ1におけるファイル管理部104は、関連ファイルリストをサーバAに送信する(図19:1002)。ここで、関連ファイルリストには、サーバAが管理するファイルの識別情報と、サーバBが管理するファイルの識別情報とが含まれるとする。
サーバAにおける先読み処理部34は、サーバBに対し、先読み処理要求を送信する(図19:1004)。サーバBにおける先読み処理部34は、先読み処理要求を受信すると、応答を返す(図19:1005)。
サーバBにおける先読み処理部34は、関連ファイル要求を管理サーバ1に送信する(図19:1006)。これに応じ、管理サーバ1におけるファイル管理部104は、関連ファイルリストをサーバBに送信する(図19:1007)。
一方、サーバAにおける先読み処理部34は、サーバAが管理する関連ファイルをキャッシュ36に展開する(図19:1008)。また、サーバBにおける先読み処理部34は、サーバBが管理する関連ファイルをキャッシュ36に展開する(図19:1009)。
サーバAにおけるアプリケーションプログラム35は、ファイルクローズ要求を管理サーバ1に送信する(図19:1010)。管理サーバ1におけるファイル管理部104は、ファイルクローズ要求を受信すると、ファイルのステータスの更新等を行い、クローズの完了をサーバAに通知する(図19:1011)。
サーバAにおける先読み処理部34は、クローズの完了を管理サーバ1から通知されたことを契機として、キャッシュ36に展開されているファイルを削除する(図19:1012)。また、先読み処理部34は、残りの関連ファイルをキャッシュ36に展開する(図19:1013)。
一方、サーバBにおけるアプリケーションプログラム35は、ファイルクローズ要求を管理サーバ1に送信する(図19:1014)。管理サーバ1におけるファイル管理部104は、ファイルクローズ要求を受信すると、ファイルのステータスの更新等を行い、クローズの完了をサーバBに通知する(図19:1015)。
サーバBにおける先読み処理部34は、クローズの完了を管理サーバ1から通知されたことを契機として、キャッシュ36に展開されているファイルを削除する(図19:1016)。また、先読み処理部34は、残りの関連ファイルをキャッシュ36に展開する(図19:1017)。
以上のような処理が繰り返し行われることで、分散処理システムにおいてファイルに対する処理が進行する。
以上本発明の一実施の形態を説明したが、本発明はこれに限定されるものではない。例えば、上で説明した管理サーバ1及びサーバ3の機能ブロック構成は実際のプログラムモジュール構成に一致しない場合もある。
また、上で説明した各テーブルの構成は一例であって、上記のような構成でなければならないわけではない。さらに、処理フローにおいても、処理結果が変わらなければ処理の順番を入れ替えることも可能である。さらに、並列に実行させるようにしても良い。
なお、上で述べた例では、ファイルアクセス要求として参照要求を示したが、参照要求に限られるわけではない。例えば、ファイルに対する書き込み要求であってもよい。
また、図7及び図11に示したフローにおいては、サーバBが管理サーバ1から関連ファイルリストを取得する例を示した。しかし、このような例に限られるわけではない。例えば、サーバAが管理サーバ1からファイルの格納場所を示す情報を受信する際に関連ファイルリストを受信し、サーバAが関連ファイルリストをサーバBに送信するようにしてもよい。
また、上では管理サーバ1がサーバ3の動作を行う例を示していないが、管理サーバ1がサーバ3の動作をも行なうようにしてもよい。
また、上で述べたように、共有ディスク型の場合であっても、本実施の形態の処理を適用可能である。共有ディスク型の場合のシステムは、例えば図20に示すようなシステムであればよい。具体的には、複数のサーバ3に対して1つのファイル格納部70を設ければよい。
なお、上で述べた管理サーバ1及びサーバ3は、コンピュータ装置であって、図21に示すように、メモリ2501とCPU(Central Processing Unit)2503とハードディスク・ドライブ(HDD:Hard Disk Drive)2505と表示装置2509に接続される表示制御部2507とリムーバブル・ディスク2511用のドライブ装置2513と入力装置2515とネットワークに接続するための通信制御部2517とがバス2519で接続されている。オペレーティング・システム(OS:Operating System)及び本実施例における処理を実施するためのアプリケーション・プログラムは、HDD2505に格納されており、CPU2503により実行される際にはHDD2505からメモリ2501に読み出される。CPU2503は、アプリケーション・プログラムの処理内容に応じて表示制御部2507、通信制御部2517、ドライブ装置2513を制御して、所定の動作を行わせる。また、処理途中のデータについては、主としてメモリ2501に格納されるが、HDD2505に格納されるようにしてもよい。本発明の実施例では、上で述べた処理を実施するためのアプリケーション・プログラムはコンピュータ読み取り可能なリムーバブル・ディスク2511に格納されて頒布され、ドライブ装置2513からHDD2505にインストールされる。インターネットなどのネットワーク及び通信制御部2517を経由して、HDD2505にインストールされる場合もある。このようなコンピュータ装置は、上で述べたCPU2503、メモリ2501などのハードウエアとOS及びアプリケーション・プログラムなどのプログラムとが有機的に協働することにより、上で述べたような各種機能を実現する。
以上述べた本発明の実施の形態をまとめると、以下のようになる。
本実施の形態の第1の態様に係る情報処理方法は、複数の情報処理装置によりデータの処理を行う分散処理システムにおいて実行される情報処理方法である。そして、本情報処理方法は、複数の情報処理装置のうちいずれかの情報処理装置である第1の情報処理装置が、(A)第1の情報処理装置が管理する第1のデータに対するアクセスがあった場合に、複数の情報処理装置のうちデータ間の関連性を管理する情報処理装置から、第1のデータと所定の関連性を有する第2のデータの識別情報及び当該第2のデータを管理する情報処理装置の識別情報を取得し、(B)第2のデータを管理する情報処理装置が第1の情報処理装置である場合に、第2のデータをデータ格納部から読み出し、キャッシュに展開する処理を含む。
第1のデータと所定の関連性を有する第2のデータがアクセスされるタイミングは、第1のデータがアクセスされるタイミングの近傍である可能性が高い。そこで、上で述べたようにすれば、分散処理システムにおけるキャッシュヒット率を向上させることができるようになる。
また、上で述べた本情報処理方法が、(C)第2のデータを管理する情報処理装置が第1の情報処理装置ではない場合に、複数の情報処理装置のうち第2のデータを管理する情報処理装置に対し、第2のデータをキャッシュに展開することを要求する第1の要求を送信する処理をさらに含むようにしてもよい。このようにすれば、第1の情報処理装置が第2のデータを管理していない場合にも対処できるようになる。
また、上で述べた本情報処理方法が、(D)第1のデータに対するアクセスが終了した場合に、キャッシュに展開されている第1のデータを削除する処理をさらに含むようにしてもよい。このようにすれば、キャッシュ溢れの発生を抑制できるようになる。
また、上で述べた所定の関連性が、データの内容の関連性、データの格納場所に基づく関連性、データのタイムスタンプに基づく関連性、データに対するアクセスの履歴に基づく関連性及びユーザにより指定された関連性の少なくともいずれかであってもよい。
本実施の第2の態様に係る情報処理方法は、複数の情報処理装置によりデータの処理を行う分散処理システムにおいて実行される情報処理方法である。そして、本情報処理方法は、複数の情報処理装置のうちいずれかの情報処理装置である第1の情報処理装置が、(E)複数の情報処理装置のうち第1のデータを管理する情報処理装置から、第1のデータと所定の関連性を有するデータについての情報を要求する第1の要求を受信した場合に、データの識別情報と当該データと所定の関連性を有するデータの識別情報とを対応付けて格納する関連データ格納部から、第1のデータと所定の関連性を有する第2のデータの識別情報を抽出し、(F)抽出された第2のデータの識別情報と当該第2のデータを管理する情報処理装置の識別情報とを、第1の要求の送信元の情報処理装置に送信する処理を含む。
このようにすれば、第1のデータにアクセスがあった場合に第2のデータをキャッシュに展開できるようになるので、分散処理システムにおけるキャッシュヒット率を向上させることができるようになる。
また、上で述べた本情報処理方法が、(G)データの内容の関連性、データの格納場所及びデータのタイムスタンプの少なくともいずれかに基づき、関連データ格納部に格納されているデータを更新する処理をさらに含むようにしてもよい。このような事項はデータの関連性に関わっているため、このような事項に基づき更新を行えば、関連性を有するデータとして適切なデータを特定できるようになる。
また、上で述べた本情報処理方法が、(H)分散処理システムにおけるデータへのアクセスの履歴に基づき、関連データ格納部に格納されているデータを更新する処理をさらに含むようにしてもよい。例えばアクセスの順序或いはアクセスパターン等はデータの関連性に関わっているため、アクセスの履歴に基づき更新を行えば、関連性を有するデータとして適切なデータを特定できるようになる。
また、上で述べた本情報処理方法が、(I)ユーザからの指定を受け付けた場合に、当該指定に従い、関連データ格納部に格納されているデータを更新する処理をさらに含むようにしてもよい。このようにすれば、ユーザの意図どおりにキャッシュへの展開を行えるようになる。
なお、上記方法による処理をコンピュータに行わせるためのプログラムを作成することができ、当該プログラムは、例えばフレキシブルディスク、CD−ROM、光磁気ディスク、半導体メモリ、ハードディスク等のコンピュータ読み取り可能な記憶媒体又は記憶装置に格納される。尚、中間的な処理結果はメインメモリ等の記憶装置に一時保管される。
Claims (11)
- データの処理を行う複数の情報処理装置と管理装置とを含む分散処理システムにおいて実行される情報処理方法であって、
前記複数の情報処理装置のうち第1の情報処理装置が、
前記第1の情報処理装置が管理する第1のデータに対するアクセスがあった場合に、前記管理装置から、前記第1のデータに対するアクセスの後にアクセスされる可能性を有する第2のデータの識別情報及び当該第2のデータを管理する情報処理装置の識別情報を取得し、
前記第2のデータを管理する情報処理装置が前記第1の情報処理装置である場合に、前記第2のデータをデータ格納部から読み出し、キャッシュに展開する
処理を実行する情報処理方法。 - 前記第1の情報処理装置が、
前記第2のデータを管理する情報処理装置が前記第1の情報処理装置とは異なる第2の情報処理装置である場合に、前記第2の情報処理装置に対し、前記第2のデータをキャッシュに展開することを要求する第1の要求を送信する
処理をさらに実行する請求項1記載の情報処理方法。 - 前記第1の情報処理装置が、
前記第1のデータに対するアクセスが終了した場合に、前記キャッシュに展開されている前記第1のデータを削除する
処理をさらに実行する請求項1又は2記載の情報処理方法。 - データの処理を行う複数の情報処理装置と管理装置とを含む分散処理システムにおいて実行される情報処理方法であって、
前記管理装置が、
前記複数の情報処理装置のうち第1のデータを管理する第1の情報処理装置から、前記第1のデータの識別情報を含む要求を受信した場合に、データの識別情報と当該データに対するアクセスの後にアクセスされる可能性を有するデータの識別情報とを対応付けて格納する関連データ格納部から、前記第1のデータに対するアクセスの後にアクセスされる可能性を有する第2のデータの識別情報を抽出し、
抽出された前記第2のデータの識別情報と当該第2のデータを管理する情報処理装置の識別情報とを、前記第1の情報処理装置に送信する
処理を実行する情報処理方法。 - 前記管理装置が、
データの内容の関連性、データの格納場所及びデータのタイムスタンプの少なくともいずれかに基づき、前記関連データ格納部に格納されているデータを更新する
処理をさらに実行する請求項4記載の情報処理方法。 - 前記管理装置が、
前記分散処理システムにおけるデータへのアクセスの履歴に基づき、前記関連データ格納部に格納されているデータを更新する
処理をさらに実行する請求項4記載の情報処理方法。 - データの処理を行う複数の情報処理装置と管理装置とを含む分散処理システムにおいてキャッシュを管理するためのプログラムであって、
前記複数の情報処理装置のうち第1の情報処理装置に、
前記第1の情報処理装置が管理する第1のデータに対するアクセスがあった場合に、前記管理装置から、前記第1のデータに対するアクセスの後にアクセスされる可能性を有する第2のデータの識別情報及び当該第2のデータを管理する情報処理装置の識別情報を取得し、
前記第2のデータを管理する情報処理装置が前記第1の情報処理装置である場合に、前記第2のデータをデータ格納部から読み出し、キャッシュに展開する
処理を実行させるためのプログラム。 - データの処理を行う複数の情報処理装置と管理装置とを含む分散処理システムにおいてキャッシュを管理するためのプログラムであって、
前記管理装置に、
前記複数の情報処理装置のうち第1のデータを管理する第1の情報処理装置から、前記第1のデータの識別情報を含む要求を受信した場合に、データの識別情報と当該データに対するアクセスの後にアクセスされる可能性を有するデータの識別情報とを対応付けて格納する関連データ格納部から、前記第1のデータに対するアクセスの後にアクセスされる可能性を有する第2のデータの識別情報を抽出し、
抽出された前記第2のデータの識別情報と当該第2のデータを管理する情報処理装置の識別情報とを、前記第1の情報処理装置に送信する
処理を実行させるためのプログラム。 - データの処理を行う複数の情報処理装置と管理装置とを含む分散処理システムにおける前記複数の情報処理装置に含まれる第1の情報処理装置であって、
第1のデータに対するアクセスがあった場合に、前記管理装置から、前記第1のデータに対するアクセスの後にアクセスされる可能性を有する第2のデータの識別情報及び当該第2のデータを管理する情報処理装置の識別情報を取得する取得部と、
前記第2のデータを管理する情報処理装置が前記第1の情報処理装置である場合に、前記第2のデータをデータ格納部から読み出し、キャッシュに展開するキャッシュ処理部と、
を有する第1の情報処理装置。 - データの処理を行う複数の情報処理装置と管理装置とを含む分散処理システムにおける前記管理装置であって、
データの識別情報と当該データに対するアクセスの後にアクセスされる可能性を有するデータの識別情報とを対応付けて格納する関連データ格納部と、
第1のデータを管理する第1の情報処理装置から、前記第1のデータの識別情報を含む要求を受信した場合に、前記関連データ格納部から、前記第1のデータに対するアクセスの後にアクセスされる可能性を有する第2のデータの識別情報を抽出する抽出部と、
抽出された前記第2のデータの識別情報と当該第2のデータを管理する情報処理装置の識別情報とを、前記第1の情報処理装置に送信する送信部と、
を有する管理装置。 - データの処理を行う複数の情報処理装置と管理装置とを含む分散処理システムであって、
前記複数の情報処理装置のうち第1の情報処理装置が、
前記第1の情報処理装置が管理する第1のデータに対するアクセスがあった場合に、前記管理装置から、前記第1のデータに対するアクセスの後にアクセスされる可能性を有する第2のデータの識別情報及び当該第2のデータを管理する情報処理装置の識別情報を、前記第1のデータの識別情報を含む要求を前記管理装置に送信することにより取得する取得部と、
前記第2のデータを管理する情報処理装置が前記第1の情報処理装置である場合に、前記第2のデータをデータ格納部から読み出し、キャッシュに展開するキャッシュ処理部と、
を有し、
前記管理装置が、
データの識別情報と当該データに対するアクセスの後にアクセスされる可能性を有するデータの識別情報とを対応付けて格納する関連データ格納部と、
前記第1の情報処理装置から前記要求を受信した場合に、前記関連データ格納部から、前記第1のデータの識別情報に対応付けられている前記第2のデータの識別情報を抽出する抽出部と、
抽出された前記第2のデータの識別情報と当該第2のデータを管理する情報処理装置の識別情報とを、前記第1の情報処理装置に送信する送信部と、
を有する分散処理システム。
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2013/058930 WO2014155553A1 (ja) | 2013-03-27 | 2013-03-27 | 分散処理のための情報処理方法、情報処理装置及びプログラム、並びに分散処理システム |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JPWO2014155553A1 JPWO2014155553A1 (ja) | 2017-02-16 |
| JP6090431B2 true JP6090431B2 (ja) | 2017-03-08 |
Family
ID=51622632
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2015507761A Active JP6090431B2 (ja) | 2013-03-27 | 2013-03-27 | 分散処理のための情報処理方法、情報処理装置及びプログラム、並びに分散処理システム |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US10049049B2 (ja) |
| JP (1) | JP6090431B2 (ja) |
| WO (1) | WO2014155553A1 (ja) |
Families Citing this family (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR101918806B1 (ko) * | 2015-06-30 | 2018-11-14 | 전자부품연구원 | 분산 파일 시스템의 읽기 성능 극대화를 위한 캐시 관리 방법 |
| US20170374684A1 (en) * | 2016-06-24 | 2017-12-28 | Chittabrata Ghosh | Identifier assignment for unassociated stations |
| JP6798211B2 (ja) * | 2016-09-21 | 2020-12-09 | 日本電気株式会社 | 並列計算機システムおよび管理方法 |
| US11294876B2 (en) * | 2017-06-01 | 2022-04-05 | Oracle International Corporation | System and method for generating a multi dimensional data cube for analytics using a map-reduce program |
| SG11202002775RA (en) | 2019-09-12 | 2020-04-29 | Alibaba Group Holding Ltd | Log-structured storage systems |
| SG11202002732TA (en) | 2019-09-12 | 2020-04-29 | Alibaba Group Holding Ltd | Log-structured storage systems |
| SG11202002587TA (en) | 2019-09-12 | 2020-04-29 | Alibaba Group Holding Ltd | Log-structured storage systems |
| WO2019228571A2 (en) | 2019-09-12 | 2019-12-05 | Alibaba Group Holding Limited | Log-structured storage systems |
| EP3695328A4 (en) | 2019-09-12 | 2020-12-09 | Alibaba Group Holding Limited | NEWSPAPER STRUCTURE STORAGE SYSTEMS |
| CN111566611B (zh) * | 2019-09-12 | 2023-08-04 | 创新先进技术有限公司 | 日志结构存储系统 |
| EP3682344A4 (en) | 2019-09-12 | 2020-12-02 | Advanced New Technologies Co., Ltd. | ENERGY STORAGE SYSTEMS |
| EP3695304B1 (en) | 2019-09-12 | 2023-04-12 | Advanced New Technologies Co., Ltd. | Log-structured storage systems |
| US10942852B1 (en) | 2019-09-12 | 2021-03-09 | Advanced New Technologies Co., Ltd. | Log-structured storage systems |
Family Cites Families (17)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP3485598B2 (ja) | 1993-05-27 | 2004-01-13 | 株式会社日立製作所 | ファイルの配置方法、データ多重化方法及びデータ処理システム |
| US5511177A (en) | 1991-11-21 | 1996-04-23 | Hitachi, Ltd. | File data multiplexing method and data processing system |
| JPH06332782A (ja) | 1993-03-22 | 1994-12-02 | Hitachi Ltd | ファイルサーバシステム及びそのファイルアクセス制御方法 |
| US5548724A (en) | 1993-03-22 | 1996-08-20 | Hitachi, Ltd. | File server system and file access control method of the same |
| JP3140621B2 (ja) | 1993-09-28 | 2001-03-05 | 株式会社日立製作所 | 分散ファイルシステム |
| JP3117003B2 (ja) | 1997-07-03 | 2000-12-11 | 日本電気株式会社 | 広域分散ファイルシステム |
| JP3997774B2 (ja) * | 2001-12-11 | 2007-10-24 | ソニー株式会社 | データ処理システム、データ処理方法、および情報処理装置、並びにコンピュータ・プログラム |
| JP2004118482A (ja) * | 2002-09-26 | 2004-04-15 | Toshiba Corp | 記憶装置、および、キャッシュ方法 |
| JP4631301B2 (ja) | 2004-03-31 | 2011-02-16 | 株式会社日立製作所 | 記憶装置のキャッシュ管理方法 |
| JP4706220B2 (ja) * | 2004-09-29 | 2011-06-22 | ソニー株式会社 | 情報処理装置および方法、記録媒体、並びにプログラム |
| JP4524656B2 (ja) * | 2005-08-04 | 2010-08-18 | ソニー株式会社 | 情報処理装置および方法、並びにプログラム |
| JP4763587B2 (ja) * | 2006-12-11 | 2011-08-31 | 株式会社ソニー・コンピュータエンタテインメント | キャッシュサーバ、キャッシュサーバの制御方法、プログラム及び情報記憶媒体 |
| JP5229731B2 (ja) | 2008-10-07 | 2013-07-03 | インターナショナル・ビジネス・マシーンズ・コーポレーション | 更新頻度に基づくキャッシュ機構 |
| JP5569074B2 (ja) * | 2010-03-19 | 2014-08-13 | 日本電気株式会社 | ストレージシステム |
| US9576068B2 (en) * | 2010-10-26 | 2017-02-21 | Good Technology Holdings Limited | Displaying selected portions of data sets on display devices |
| JP5761200B2 (ja) * | 2010-11-09 | 2015-08-12 | 日本電気株式会社 | 情報処理装置 |
| JP5817558B2 (ja) | 2012-01-27 | 2015-11-18 | 富士通株式会社 | 情報処理装置、分散処理システム、キャッシュ管理プログラムおよび分散処理方法 |
-
2013
- 2013-03-27 WO PCT/JP2013/058930 patent/WO2014155553A1/ja active Application Filing
- 2013-03-27 JP JP2015507761A patent/JP6090431B2/ja active Active
-
2015
- 2015-09-21 US US14/860,169 patent/US10049049B2/en active Active
Also Published As
| Publication number | Publication date |
|---|---|
| US20160011980A1 (en) | 2016-01-14 |
| JPWO2014155553A1 (ja) | 2017-02-16 |
| US10049049B2 (en) | 2018-08-14 |
| WO2014155553A1 (ja) | 2014-10-02 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6090431B2 (ja) | 分散処理のための情報処理方法、情報処理装置及びプログラム、並びに分散処理システム | |
| JP6356273B2 (ja) | バッチ最適化レンダリング及びフェッチアーキテクチャ | |
| CN102667772B (zh) | 文件级分级存储管理系统、方法和设备 | |
| US8904377B2 (en) | Reconfiguration of computer system to allow application installation | |
| US20090216789A1 (en) | Management of time-variant data schemas in data warehouses | |
| US20100325363A1 (en) | Hierarchical object caching based on object version | |
| JP2017504874A (ja) | クラスター化されたインメモリデータベースの設計及び実施 | |
| JP2010092222A (ja) | 更新頻度に基づくキャッシュ機構 | |
| CN109981659A (zh) | 基于数据去重技术的网络资源预取方法以及系统 | |
| CN109460345B (zh) | 实时数据的计算方法及系统 | |
| GB2519113A (en) | Generation of combined documents from content and layout documents based on semantically neutral elements | |
| CN114756509B (zh) | 文件系统的操作方法、系统、设备以及存储介质 | |
| CN107220248B (zh) | 一种用于存储数据的方法和装置 | |
| US20210012025A1 (en) | System and method for session-aware datastore for the edge | |
| JP6568985B2 (ja) | バッチ最適化レンダリング及びフェッチアーキテクチャ | |
| Yan et al. | Hmfs: efficient support of small files processing over HDFS | |
| Konishetty et al. | Implementation and evaluation of scalable data structure over hbase | |
| US11086557B2 (en) | Continuous asynchronous replication from on-premises storage to cloud object stores | |
| US20240070079A1 (en) | Prefetching cached data for predicted accesses | |
| Nimishan et al. | An approach to improve the performance of web proxy cache replacement using machine learning techniques | |
| Mir et al. | An Optimal Solution for small file problem in Hadoop. | |
| Chen et al. | Cora: Data correlations-based storage policies for cloud object storage | |
| Qu et al. | HBelt: Integrating an incremental ETL pipeline with a big data store for real-time analytics | |
| Huang et al. | Multi-grained Trace Collection, Analysis, and Management of Diverse Container Images | |
| Vinutha et al. | In-Memory Cache and Intra-Node Combiner Approaches for Optimizing Execution Time in High-Performance Computing |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20161019 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20170110 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20170123 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6090431 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |