JP6079433B2 - 移動平均処理プログラム、及びプロセッサ - Google Patents
移動平均処理プログラム、及びプロセッサ Download PDFInfo
- Publication number
- JP6079433B2 JP6079433B2 JP2013109210A JP2013109210A JP6079433B2 JP 6079433 B2 JP6079433 B2 JP 6079433B2 JP 2013109210 A JP2013109210 A JP 2013109210A JP 2013109210 A JP2013109210 A JP 2013109210A JP 6079433 B2 JP6079433 B2 JP 6079433B2
- Authority
- JP
- Japan
- Prior art keywords
- elements
- sum
- moving average
- input data
- data series
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images














Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30007—Arrangements for executing specific machine instructions to perform operations on data operands
- G06F9/3001—Arithmetic instructions
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F7/00—Methods or arrangements for processing data by operating upon the order or content of the data handled
- G06F7/38—Methods or arrangements for performing computations using exclusively denominational number representation, e.g. using binary, ternary, decimal representation
- G06F7/48—Methods or arrangements for performing computations using exclusively denominational number representation, e.g. using binary, ternary, decimal representation using non-contact-making devices, e.g. tube, solid state device; using unspecified devices
- G06F7/544—Methods or arrangements for performing computations using exclusively denominational number representation, e.g. using binary, ternary, decimal representation using non-contact-making devices, e.g. tube, solid state device; using unspecified devices for evaluating functions by calculation
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30007—Arrangements for executing specific machine instructions to perform operations on data operands
- G06F9/30018—Bit or string instructions
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30007—Arrangements for executing specific machine instructions to perform operations on data operands
- G06F9/30036—Instructions to perform operations on packed data, e.g. vector, tile or matrix operations
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30007—Arrangements for executing specific machine instructions to perform operations on data operands
- G06F9/30036—Instructions to perform operations on packed data, e.g. vector, tile or matrix operations
- G06F9/30038—Instructions to perform operations on packed data, e.g. vector, tile or matrix operations using a mask
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Software Systems (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Computational Mathematics (AREA)
- Mathematical Analysis (AREA)
- Mathematical Optimization (AREA)
- Pure & Applied Mathematics (AREA)
- Mathematical Physics (AREA)
- Computing Systems (AREA)
- Advance Control (AREA)
- Complex Calculations (AREA)
Description
本発明の諸態様を付記として以下に示す。
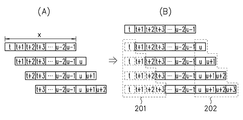
m個(mは2以上の整数)の演算処理を並列に実行し、かつ0番目から(m−1)番目の入力要素を基に、0番目からp番目(pは0〜m−1の整数)の前記入力要素の和を算出してp番目の結果要素としてそれぞれ返す部分総和命令を実行するプロセッサに、
入力データ系列のi番目から(i+m−1)番目(iは0及び自然数のうちの任意の数)の要素を0番目から(m−1)番目の前記入力要素とする前記部分総和命令を実行して第1のベクトルデータを取得する第1の演算処理と、
前記入力データ系列の(i+x)番目から(i+x+m−1)番目(xは自然数)の要素を0番目から(m−1)番目の前記入力要素とする前記部分総和命令を実行して第2のベクトルデータを取得する第2の演算処理と、
前記入力データ系列のi番目から(i+x−1)番目の要素の和に、前記第1のベクトルデータのp番目の要素を減算し、前記第2のベクトルデータのp番目の要素を加算する処理を、0番目から(m−1)番目の各要素について並列に行うことにより、互いに異なるm個の区間について要素の和を並列に算出する第3の演算処理と、
算出した各区間の要素の和から前記入力データ系列の移動平均を算出する移動平均処理とを実行させることを特徴とする移動平均処理プログラム。
(付記2)
値iをmずつ増加させて前記第1の演算処理、前記第2の演算処理、前記第3の演算処理、及び前記移動平均処理を1組として繰り返し実行し、
前の組の前記第3の演算処理における(i+m)番目から(i+x+m−1)番目の要素についての和を、次の組の前記第3の演算処理における前記入力データ系列のi番目から(i+x−1)番目の要素の和として演算を行うことを特徴とする付記1記載の移動平均処理プログラム。
(付記3)
前記入力データ系列は0番目から(n−1)番目(nは2以上の整数)の要素を有し、
前記入力データ系列を各区間についての要素数をx個とするように拡張し前記移動平均を算出することを特徴とする付記2記載の移動平均処理プログラム。
(付記4)
前記入力データ系列の0番目から(n−1)番目の要素に応じたマスクビットを生成し、
前記マスクビットに応じた要素のデータのロード処理及びストア処理を行うことを特徴とする付記3記載の移動平均処理プログラム。
(付記5)
前記入力データ系列を(−x)番目まで拡張し、前記入力データ系列の(−x)番目から(−1)番目の要素については前記マスクビットにより要素のロード処理を抑制することを特徴とする付記4記載の移動平均処理プログラム。
(付記6)
前記移動平均を求める最終の区間の要素数がb(bはx以下の任意の整数)である場合に、入力データ系列を(n+x−b−1)番目まで拡張し、入力データ系列のn番目から(n+x−b−1)番目までの要素のロード処理を抑制することを特徴とする付記4記載の移動平均処理プログラム。
(付記7)
算出された移動平均を格納する出力バッファを有し、
前記入力データ系列の拡張に応じて、前記出力バッファを拡張したことを特徴とする付記3記載の移動平均処理プログラム。
(付記8)
前記移動平均を求める初期の区間の要素数がa(aはx以下の任意の整数)である場合に、前記出力バッファの系列を(−a+1)番目まで拡張し、
前記出力バッファの系列の(−a+1)番目から(−1)番目の要素のストア処理を抑制することを特徴とする付記4記載の移動平均処理プログラム。
(付記9)
前記移動平均を算出する各区間の有効な要素数の逆数を格納した係数テーブルを有し、
前記平均化処理では、前記第3の演算処理の結果に、前記係数テーブルを参照して得られる逆数を乗算し移動平均を算出することを特徴とする付記1記載の移動平均処理プログラム。
(付記10)
前記プロセッサは、SIMD型のプロセッサであることを特徴とする付記4記載の移動平均処理プログラム。
(付記11)
入力データ系列の移動平均を複数の区間について並列に算出する演算処理部を有し、
前記演算処理部は、
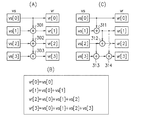
第1のSIMDレジスタの各要素に対して、前記入力データ系列のi番目から(i+p)番目(iは0及び自然数のうちの任意の数、pは0〜m−1の整数、mは2以上の整数)の要素の和を算出して前記第1のSIMDレジスタにp番目の要素として格納する第1の演算処理と、
第2のSIMDレジスタの各要素に対して、前記入力データ系列の(i+x)番目から(i+x+p)番目(xは自然数)の要素の和を算出して前記第2のSIMDレジスタにp番目の要素として格納する第2の演算処理と、
前記入力データ系列のi番目から(i+x−1)番目の要素の和に、前記第2のSIMDレジスタのp番目の要素を加算し、前記第1のSIMDレジスタのp番目の要素を減算して第3のSIMDレジスタにp番目の要素として格納する処理を0番目から(m−1)番目の各要素について並列に行うことにより、互いに異なるm個の区間について要素の和を並列に算出する第3の演算処理と、
前記第3のSIMDレジスタに格納された要素の和から平均値を算出する平均化処理とを実行することを特徴とするプロセッサ。
(付記12)
前記入力データ系列は0番目から(n−1)番目(nは2以上の整数)の要素を有し、
前記入力データ系列を各区間についての要素数をx個とするように拡張し前記平均値を算出することを特徴とする付記11記載のプロセッサ。
(付記13)
前記入力データ系列の0番目から(n−1)番目の要素に応じたマスクビットを生成し、
前記マスクビットに応じた要素のデータのロード処理及びストア処理を行うことを特徴とする付記12記載のプロセッサ。
(付記14)
前記移動平均を算出する各区間の有効な要素数の逆数を格納した係数テーブルを有し、
前記平均化処理では、前記第3の演算処理の結果に、前記係数テーブルを参照して得られる逆数を乗算し移動平均を算出することを特徴とする付記11記載のプロセッサ。
(付記15)
前記プロセッサは、SIMD型のプロセッサであることを特徴とする付記11記載のプロセッサ。
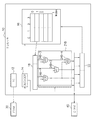
12 プログラムカウンタ
14 命令デコーダ
16 レジスタファイル
18、22 SIMDレジスタ
20 演算器
21 演算処理部
24 加算器
30 命令メモリ
40 データメモリ
Claims (7)
- m個(mは2以上の整数)の演算処理を並列に実行し、かつ0番目から(m−1)番目の入力要素を基に、0番目からp番目(pは0〜m−1の整数)の前記入力要素の和を算出してp番目の結果要素としてそれぞれ返す部分総和命令を実行するプロセッサに、
入力データ系列のi番目から(i+m−1)番目(iは0及び自然数のうちの任意の数)の要素を0番目から(m−1)番目の前記入力要素とする前記部分総和命令を実行して第1のベクトルデータを取得する第1の演算処理と、
前記入力データ系列の(i+x)番目から(i+x+m−1)番目(xは自然数)の要素を0番目から(m−1)番目の前記入力要素とする前記部分総和命令を実行して第2のベクトルデータを取得する第2の演算処理と、
前記入力データ系列のi番目から(i+x−1)番目の要素の和に、前記第1のベクトルデータのp番目の要素を減算し、前記第2のベクトルデータのp番目の要素を加算する処理を、0番目から(m−1)番目の各要素について並列に行うことにより、互いに異なるm個の区間について要素の和を並列に算出する第3の演算処理と、
算出した各区間の要素の和から前記入力データ系列の移動平均を算出する移動平均処理とを実行させることを特徴とする移動平均処理プログラム。 - 値iをmずつ増加させて前記第1の演算処理、前記第2の演算処理、前記第3の演算処理、及び前記移動平均処理を1組として繰り返し実行し、
前の組の前記第3の演算処理における(i+m)番目から(i+x+m−1)番目の要素についての和を、次の組の前記第3の演算処理における前記入力データ系列のi番目から(i+x−1)番目の要素の和として演算を行うことを特徴とする請求項1記載の移動平均処理プログラム。 - 前記入力データ系列は0番目から(n−1)番目(nは2以上の整数)の要素を有し、
前記入力データ系列を各区間についての要素数をx個とするように拡張し前記移動平均を算出することを特徴とする請求項2記載の移動平均処理プログラム。 - 前記入力データ系列の0番目から(n−1)番目の要素に応じたマスクビットを生成し、
前記マスクビットに応じた要素のデータのロード処理及びストア処理を行うことを特徴とする請求項3記載の移動平均処理プログラム。 - 算出された移動平均を格納する出力バッファを有し、
前記入力データ系列の拡張に応じて、前記出力バッファを拡張したことを特徴とする請求項3又は4記載の移動平均処理プログラム。 - 前記移動平均を算出する各区間の有効な要素数の逆数を格納した係数テーブルを有し、
前記平均化処理では、前記第3の演算処理の結果に、前記係数テーブルを参照して得られる逆数を乗算し移動平均を算出することを特徴とする請求項1〜5の何れか1項に記載の移動平均処理プログラム。 - 入力データ系列の移動平均を複数の区間について並列に算出する演算処理部を有し、
前記演算処理部は、
第1のSIMDレジスタの各要素に対して、前記入力データ系列のi番目から(i+p)番目(iは0及び自然数のうちの任意の数、pは0〜m−1の整数、mは2以上の整数)の要素の和を算出して前記第1のSIMDレジスタにp番目の要素として格納する第1の演算処理と、
第2のSIMDレジスタの各要素に対して、前記入力データ系列の(i+x)番目から(i+x+p)番目(xは自然数)の要素の和を算出して前記第2のSIMDレジスタにp番目の要素として格納する第2の演算処理と、
前記入力データ系列のi番目から(i+x−1)番目の要素の和に、前記第2のSIMDレジスタのp番目の要素を加算し、前記第1のSIMDレジスタのp番目の要素を減算して第3のSIMDレジスタにp番目の要素として格納する処理を0番目から(m−1)番目の各要素について並列に行うことにより、互いに異なるm個の区間について要素の和を並列に算出する第3の演算処理と、
前記第3のSIMDレジスタに格納された要素の和から平均値を算出する平均化処理とを実行することを特徴とするプロセッサ。
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2013109210A JP6079433B2 (ja) | 2013-05-23 | 2013-05-23 | 移動平均処理プログラム、及びプロセッサ |
| US14/246,757 US9436465B2 (en) | 2013-05-23 | 2014-04-07 | Moving average processing in processor and processor |
| CN201410177617.0A CN104182207A (zh) | 2013-05-23 | 2014-04-29 | 处理器中的移动平均处理及处理器 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2013109210A JP6079433B2 (ja) | 2013-05-23 | 2013-05-23 | 移動平均処理プログラム、及びプロセッサ |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2014229133A JP2014229133A (ja) | 2014-12-08 |
| JP6079433B2 true JP6079433B2 (ja) | 2017-02-15 |
Family
ID=51936204
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2013109210A Expired - Fee Related JP6079433B2 (ja) | 2013-05-23 | 2013-05-23 | 移動平均処理プログラム、及びプロセッサ |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US9436465B2 (ja) |
| JP (1) | JP6079433B2 (ja) |
| CN (1) | CN104182207A (ja) |
Families Citing this family (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20150052330A1 (en) * | 2013-08-14 | 2015-02-19 | Qualcomm Incorporated | Vector arithmetic reduction |
| US10296489B2 (en) * | 2014-12-27 | 2019-05-21 | Intel Corporation | Method and apparatus for performing a vector bit shuffle |
| JP6708016B2 (ja) * | 2016-06-27 | 2020-06-10 | 富士通株式会社 | 情報処理装置、情報処理方法及び情報処理プログラム |
| US10187203B2 (en) | 2016-08-30 | 2019-01-22 | Workday, Inc. | Secure storage encryption system |
| US10177908B2 (en) | 2016-08-30 | 2019-01-08 | Workday, Inc. | Secure storage decryption system |
| US10460118B2 (en) | 2016-08-30 | 2019-10-29 | Workday, Inc. | Secure storage audit verification system |
| CN107121581B (zh) * | 2017-04-25 | 2019-07-12 | 电子科技大学 | 一种数据采集系统的数据处理方法 |
| JP7243498B2 (ja) * | 2019-07-11 | 2023-03-22 | 富士通株式会社 | 演算処理装置、制御プログラム、及び制御方法 |
| CN114090081B (zh) * | 2021-11-19 | 2025-12-23 | 海光信息技术股份有限公司 | 数据处理方法及数据处理装置 |
Family Cites Families (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS63187366A (ja) * | 1987-01-30 | 1988-08-02 | Oki Electric Ind Co Ltd | 移動平均演算装置 |
| JPH0793548B2 (ja) | 1987-08-31 | 1995-10-09 | 三洋電機株式会社 | 標本化周波数変換回路 |
| JPH10143495A (ja) * | 1996-11-06 | 1998-05-29 | Nec Corp | 平均値演算方法及びその演算装置 |
| JPH10285502A (ja) | 1997-04-01 | 1998-10-23 | Nikon Corp | 情報処理システム、情報処理装置、情報処理方法、および、記憶媒体 |
| US7627624B2 (en) * | 2007-01-17 | 2009-12-01 | Chester Carroll | Digital signal averaging using parallel computation structures |
| JP2011233085A (ja) | 2010-04-30 | 2011-11-17 | Toyota Motor Corp | プロセッサ、電子制御ユニット、負荷分散方法 |
| JP2012075023A (ja) | 2010-09-29 | 2012-04-12 | On Semiconductor Trading Ltd | 受信装置 |
| WO2013095634A1 (en) * | 2011-12-23 | 2013-06-27 | Intel Corporation | Systems, apparatuses, and methods for performing a horizontal partial sum in response to a single instruction |
-
2013
- 2013-05-23 JP JP2013109210A patent/JP6079433B2/ja not_active Expired - Fee Related
-
2014
- 2014-04-07 US US14/246,757 patent/US9436465B2/en not_active Expired - Fee Related
- 2014-04-29 CN CN201410177617.0A patent/CN104182207A/zh active Pending
Also Published As
| Publication number | Publication date |
|---|---|
| JP2014229133A (ja) | 2014-12-08 |
| US9436465B2 (en) | 2016-09-06 |
| US20140351566A1 (en) | 2014-11-27 |
| CN104182207A (zh) | 2014-12-03 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6079433B2 (ja) | 移動平均処理プログラム、及びプロセッサ | |
| CN111213125B (zh) | 使用simd指令进行高效的直接卷积 | |
| US10140251B2 (en) | Processor and method for executing matrix multiplication operation on processor | |
| US9355061B2 (en) | Data processing apparatus and method for performing scan operations | |
| US7797363B2 (en) | Processor having parallel vector multiply and reduce operations with sequential semantics | |
| US9361242B2 (en) | Return stack buffer having multiple address slots per stack entry | |
| US8200948B2 (en) | Apparatus and method for performing re-arrangement operations on data | |
| US10567163B2 (en) | Processor with secure hash algorithm and digital signal processing method with secure hash algorithm | |
| US8433883B2 (en) | Inclusive “OR” bit matrix compare resolution of vector update conflict masks | |
| CN110321161B (zh) | 使用simd指令的向量函数快速查表法、系统及介质 | |
| CN110235099A (zh) | 用于处理输入操作数值的装置和方法 | |
| US9477442B2 (en) | Processor and control method of processor | |
| CN112650471A (zh) | 用于处理掩蔽数据的处理器和方法 | |
| US20100115232A1 (en) | Large integer support in vector operations | |
| US8938485B1 (en) | Integer division using floating-point reciprocal | |
| JP5862397B2 (ja) | 演算処理装置 | |
| CN102231624B (zh) | 面向向量处理器的浮点复数块fir的向量化实现方法 | |
| GB2523805A (en) | Data processing apparatus and method for performing vector scan operation | |
| WO2020031281A1 (ja) | 情報処理装置、情報処理方法、及びコンピュータ読み取り可能な記録媒体 | |
| JP5659772B2 (ja) | 演算処理装置 | |
| JP2016218528A (ja) | データ処理装置、およびデータ処理方法 | |
| JP2011145886A (ja) | 情報処理装置 | |
| JP2024087606A (ja) | プロセッサ、命令実行プログラムおよび情報処理装置 | |
| JP6060853B2 (ja) | プロセッサおよびプロセッサの処理方法 | |
| US9916108B2 (en) | Efficient loading and storing of data between memory and registers using a data structure for load and store addressing |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20160226 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20161214 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20161220 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20170102 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6079433 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| LAPS | Cancellation because of no payment of annual fees |