JP5950737B2 - 情報抽出装置及びプログラム - Google Patents
情報抽出装置及びプログラム Download PDFInfo
- Publication number
- JP5950737B2 JP5950737B2 JP2012159901A JP2012159901A JP5950737B2 JP 5950737 B2 JP5950737 B2 JP 5950737B2 JP 2012159901 A JP2012159901 A JP 2012159901A JP 2012159901 A JP2012159901 A JP 2012159901A JP 5950737 B2 JP5950737 B2 JP 5950737B2
- Authority
- JP
- Japan
- Prior art keywords
- program
- analysis
- information
- unit
- analysis result
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images

Landscapes
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Description
例えば、特許文献1では、ソーシャル・ブックマークという、ウェブページにユーザがタグ(キーワード)を付加することでウェブページを分類できるサービスを利用し、各ウェブサイトに自動的に検索のためのキーワードを付与する技術が提案されている。
情報抽出装置1は、図1に示すように、第1抽出部11と、第1解析部12と、番組特定部13と、第2抽出部14と、第2解析部15と、比較部16と、判断部17と、追加部18を備える。
なお、第1抽出部11は、投稿型のウェブサイト2に投稿されているコメントに限らず、番組についてのコメントを抽出できればよい。
番組特定部13は、第1解析部12で解析された第1解析結果に基づいて、番組を特定する。
比較部16は、第1解析結果と、第2解析部15で解析された第2解析結果を比較する。
追加部18は、判断部17で情報を追加すると判断された場合、当該情報を番組特定部13で特定した番組の番組情報に追加する。
また、情報抽出装置1により抽出したキーワードを利用して、他のユーザにとって意外なコンテンツの検索や推薦に役立てることができる。
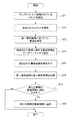
ステップST1において、第1抽出部11は、投稿型のウェブサイト2に投稿されているコメントを抽出する。
ステップST3において、番組特定部13は、ステップST2の工程により解析された第1解析結果に基づいて、番組を特定する。
ステップST5において、第2解析部15は、ステップST4の工程により抽出された番組情報を解析する。
ステップST7において、判断部17は、ステップST6の工程による比較結果に基づいて、第2解析結果に含まれていなかった情報であって、第1解析結果に含まれている情報を番組特定工程で特定した番組の番組情報に追加するか否かを判断する。追加すると判断した場合には、ステップST8に進み、追加しないと判断した場合には、一連の処理を終了する。
上述したように、情報抽出装置1は、番組ごとにレビュー投稿が可能なSNS(投稿型のウェブサイト2)を利用するものであり、ユーザの番組に対する自由な書き込みから、番組を検索するためのキーワードを自動抽出して、登録するものである。
このようにして、新たなメタデータをデータベース3に随時蓄積しておくことにより、例えば、ある別のユーザU2が「○○○(映画名)」というキーワードで番組を検索した場合に、番組PR1を「関連番組」として提供することが可能となり、ユーザU2に対して意外性のある番組提供を実現することができる。
さらに、単語群WL0から、人名、地名、番組タイトル、といった固有名詞(固有表現)のみを抽出し、それを単語リストWL1に含ませてもよい。
11 第1抽出部
12 第1解析部
13 番組特定部
14 第2抽出部
15 第2解析部
16 比較部
17 判断部
18 追加部
Claims (5)
- 番組についてのコメントを抽出する第1抽出部と、
前記第1抽出部により抽出されたコメントを解析する第1解析部と、
前記第1解析部で解析された第1解析結果に基づいて、番組を特定する番組特定部と、
前記番組特定部により特定された番組に関する番組情報をデータベースから抽出する第2抽出部と、
前記第2抽出部により抽出された番組情報を解析する第2解析部と、
前記第1解析結果と、前記第2解析部で解析された第2解析結果を比較する比較部と、
前記比較部による比較結果に基づいて、前記第2解析結果に含まれていなかった情報であって、前記第1解析結果に含まれている情報を前記番組特定部で特定した番組の番組情報に追加するか否かを判断する判断部と、
前記判断部で情報を追加すると判断された場合、当該情報を前記番組特定部で特定した番組の番組情報に追加する追加部を備える情報抽出装置。 - 前記第1解析部は、形態素解析により、前記第1抽出部により抽出されたコメントに含まれている全ての単語又は特定の品詞を対象として、特徴的なキーワードを前記第1解析結果として抽出し、
前記第2解析部は、形態素解析により、前記第2抽出部により抽出された番組情報に含まれている全ての単語又は特定の品詞を対象として、特徴的なキーワードを前記第2解析結果として抽出する請求項1記載の情報抽出装置。 - 前記第1解析部は、形態素解析により、前記第1抽出部により抽出されたコメントに含まれている語の中から、TF−IDF値が高い語のみ、又は話題性のある語を前記第1解析結果として抽出し、
前記第2解析部は、形態素解析により、前記第2抽出部により抽出された番組情報に含まれている語の中から、TF−IDF値が高い語のみ、又は話題性のある語を前記第2解析結果として抽出する請求項1記載の情報抽出装置。 - 前記第1解析部は、形態素解析により、前記第1抽出部により抽出されたコメントに含まれている固有表現を前記第1解析結果として抽出し、
前記第2解析部は、形態素解析により、前記第2抽出部により抽出された番組情報に含まれている固有表現を前記第2解析結果として抽出する請求項1記載の情報抽出装置。 - 番組についてのコメントを抽出する第1抽出工程と、
前記第1抽出工程により抽出されたコメントを解析する第1解析工程と、
前記第1解析工程で解析された第1解析結果に基づいて、番組を特定する番組特定工程と、
前記番組特定工程により特定された番組に関する番組情報をデータベースから抽出する第2抽出工程と、
前記第2抽出工程により抽出された番組情報を解析する第2解析工程と、
前記第1解析結果と、前記第2解析工程で解析された第2解析結果を比較する比較工程と、
前記比較工程による比較結果に基づいて、前記第2解析結果に含まれていなかった情報であって、前記第1解析結果に含まれている情報を前記番組特定工程で特定した番組の番組情報に追加するか否かを判断する判断工程と、
前記判断工程で情報を追加すると判断された場合、当該情報を前記番組特定工程で特定した番組の番組情報に追加する追加工程をコンピュータに実行させるためのプログラム。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2012159901A JP5950737B2 (ja) | 2012-07-18 | 2012-07-18 | 情報抽出装置及びプログラム |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2012159901A JP5950737B2 (ja) | 2012-07-18 | 2012-07-18 | 情報抽出装置及びプログラム |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2014021727A JP2014021727A (ja) | 2014-02-03 |
| JP5950737B2 true JP5950737B2 (ja) | 2016-07-13 |
Family
ID=50196532
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2012159901A Active JP5950737B2 (ja) | 2012-07-18 | 2012-07-18 | 情報抽出装置及びプログラム |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP5950737B2 (ja) |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2005209020A (ja) * | 2004-01-23 | 2005-08-04 | Sony Corp | 属性情報提供システム,属性情報管理装置,利用者端末,属性情報管理方法,およびコンピュータプログラム |
| JP2007274605A (ja) * | 2006-03-31 | 2007-10-18 | Fujitsu Ltd | 電子装置、放送番組情報の収集方法、その収集プログラム及びその収集システム |
| JP2011234198A (ja) * | 2010-04-28 | 2011-11-17 | Sony Corp | 情報提供方法、コンテンツ表示端末、携帯端末、サーバ装置、情報提供システム及びプログラム |
| JP2012129982A (ja) * | 2010-11-24 | 2012-07-05 | Jvc Kenwood Corp | 推定装置、推定方法、並びにプログラム |
-
2012
- 2012-07-18 JP JP2012159901A patent/JP5950737B2/ja active Active
Also Published As
| Publication number | Publication date |
|---|---|
| JP2014021727A (ja) | 2014-02-03 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US12499109B2 (en) | Retrieving context from previous sessions | |
| US12499152B1 (en) | Query modification based on non-textual resource context | |
| CN102708174B (zh) | 一种浏览器中的富媒体信息的展示方法和装置 | |
| CN105900087B (zh) | 用于查询答案的丰富内容 | |
| US10621187B2 (en) | Methods, systems, and media for providing a media search engine | |
| US20090094189A1 (en) | Methods, systems, and computer program products for managing tags added by users engaged in social tagging of content | |
| WO2015196910A1 (zh) | 基于搜索引擎的摘要信息提取方法、装置以及搜索引擎 | |
| US11748408B2 (en) | Analyzing user searches of verbal media content | |
| US20120278300A1 (en) | System, method, and user interface for a search engine based on multi-document summarization | |
| WO2015097702A1 (en) | System and methods for vocal commenting on selected web pages | |
| US20180285444A1 (en) | Rewriting contextual queries | |
| CN104090923B (zh) | 一种浏览器中的富媒体信息的展示方法和装置 | |
| CN104090757A (zh) | 针对浏览器的富媒体信息展示方法 | |
| US9811592B1 (en) | Query modification based on textual resource context | |
| US8290925B1 (en) | Locating product references in content pages | |
| KR20200049193A (ko) | 콘텐츠 추천 방법 및 이를 지원하는 서비스 장치 | |
| US10146849B2 (en) | Triggering answer boxes | |
| CN102436458B (zh) | 一种命令解析的方法及其系统 | |
| US9092463B2 (en) | Keyword generation | |
| CN101641710A (zh) | 使用场景相关元数据来定向广告 | |
| JP5950737B2 (ja) | 情報抽出装置及びプログラム | |
| AU2016204641A1 (en) | Infer a users interests and intentions by analyzing their interaction and behavior with content accessed in the past, present & future | |
| JP5573051B2 (ja) | ブックマークサービス提供装置、およびブックマークサービス提供装置の動作方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20150601 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20160425 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20160510 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20160607 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 5950737 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |