JP5947237B2 - Emotion estimation device, emotion estimation method, and program - Google Patents
Emotion estimation device, emotion estimation method, and program Download PDFInfo
- Publication number
- JP5947237B2 JP5947237B2 JP2013059880A JP2013059880A JP5947237B2 JP 5947237 B2 JP5947237 B2 JP 5947237B2 JP 2013059880 A JP2013059880 A JP 2013059880A JP 2013059880 A JP2013059880 A JP 2013059880A JP 5947237 B2 JP5947237 B2 JP 5947237B2
- Authority
- JP
- Japan
- Prior art keywords
- emotion
- word
- value
- negative
- user
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images







Landscapes
- Machine Translation (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Description
本発明は、感情推定装置、感情推定方法、および、プログラムに関する。 The present invention relates to an emotion estimation device, an emotion estimation method, and a program.
従来、一般的にネガティブな発言、ポジティブな発言に用いられる単語を教師データとして用いることで、発言者であるユーザの感情を推定する技術がある。例えば、ユーザごとに、そのユーザが怒っている場合に使われる単語や文章の組み立て方等を教師データとして用意しておき、その教師データを用いて、入力されたテキストや音声に対して分析を行い、ユーザが怒っているか否かを判断する技術がある。この技術によれば、コールセンタ等でユーザ(お客)が怒っていると判断されたとき、その旨をコールセンタのスタッフ等に通知することができる(特許文献1参照)。 2. Description of the Related Art Conventionally, there is a technique for estimating the emotion of a user who is a speaker by using, as teacher data, words that are generally used for negative speech and positive speech. For example, for each user, prepare as teacher data how to assemble words and sentences used when the user is angry, and use the teacher data to analyze the input text and voice There is a technique for determining whether or not a user is angry. According to this technique, when it is determined that the user (customer) is angry at the call center or the like, the fact can be notified to the call center staff or the like (see Patent Document 1).
しかし、ユーザごとの意思表示の表現にはユーザ(個人)の判断基準に基づくバイアスがかかっていることが多い。例えば、いつもネガティブな発言をしているユーザのネガティブな単語を含む発言と、いつもポジティブな発言をしているユーザのネガティブな単語を含む発言とでは、同じ単語を含む発言であっても、それぞれのユーザでその発言の意味するネガティブさが異なる可能性が高い。つまり、特許文献1のように、ユーザの感情を、単語の有する一般的な判断基準(一般的にネガティブな発言、ポジティブな発言に用いられる単語)だけを用いて推定する技術では、必ずしもユーザの感情を正確に推定することができない。そこで、本発明は、前記した課題を解決し、ユーザの感情の推定精度を向上させることを目的とする。
However, the expression of intention display for each user is often biased based on the judgment criteria of the user (individual). For example, an utterance that includes a negative word of a user who always makes a negative utterance and an utterance that contains a negative word of a user who always makes a positive utterance, There is a high possibility that the negative meaning of the remarks is different among users. In other words, as in
前記した課題を解決するため、本発明は、ユーザごとの発言内容を示した過去ログを格納する過去ログ記録部と、ある特定の感情とその相反する感情を示す語句である感情表記ワードを格納する一般感情表記ワード記録部と、前記一般感情表記ワード記録部を参照して、前記ユーザの過去ログから、前記感情表記ワードのいずれかを含む発言を検索する感情表記ワード検索部と、前記ユーザの過去ログから、前記検索された感情表記ワードを含む発言を中心として前後所定範囲内の発言である周辺発言を抽出する前後発言抽出部と、前記ユーザごとに、前記発言に含まれる単語それぞれの前記ある特定の感情の強さの度合いを表す感情ベクトルの値を示した教師データを作成する特徴量抽出部と、前記ユーザの前記教師データを用いて、前記ユーザの発言が意味する前記ある特定の感情の傾向を判断し、前記判断結果を出力する発言解析部とを備え、前記特徴量抽出部は、前記単語それぞれの感情ベクトルの値を決定するとき、前記感情表記ワード検索部により検索された発言に含まれる感情表記ワードに対し、前記発言に含まれる感情表記ワードが示す感情の種別に応じた所定の感情の強さの度合いを示す値を前記感情表記ワードの感情ベクトルの値として付与し、前記発言の周辺発言の単語のうち、前記感情表記ワード以外の単語それぞれに対する感情ベクトルの値として、前記感情表記ワードに付与した前記感情ベクトルの値と比較して前記ある特定の感情の強さの度合いを軽減した所定の値を付与することを特徴とする感情推定装置とした。
In order to solve the above-described problems, the present invention stores a past log recording unit that stores a past log that indicates the content of a message for each user, and an emotion notation word that is a phrase that indicates a specific emotion and an opposite emotion. A general emotion expression word recording unit, an emotion expression word search unit that refers to the general emotion expression word recording unit, and searches the user's past log for a statement including any of the emotion expression words, and the user From the past log, a front-rear speech extraction unit that extracts a peripheral speech that is a speech within a predetermined range around the speech including the searched emotion notation word, and for each user, each word included in the speech Using a feature quantity extraction unit that creates teacher data indicating a value of an emotion vector representing the degree of strength of the specific emotion, and using the teacher data of the user, A speech analysis unit that determines a tendency of the specific emotion that the user's speech means, and outputs the determination result, wherein the feature amount extraction unit determines the value of the emotion vector of each of the words , A value indicating the degree of strength of a predetermined emotion according to the type of emotion indicated by the emotion notation word included in the statement with respect to the emotion notation word included in the statement searched by the emotion notation word search unit The value of the emotion vector given to the emotion notation word is given as the value of the emotion vector of the emotion notation word, and the value of the emotion vector for each word other than the emotion notation word among the words of the surrounding speech of the statement In comparison, the emotion estimation apparatus is characterized in that a predetermined value that reduces the degree of strength of the specific emotion is given.
このような感情推定装置によれば、ユーザの発言解析に用いる教師データについて、一般的に用いられる感情表記ワードのほかに、当該ユーザがそのワード(単語)の周辺発言で用いる単語にも所定の感情ベクトルの値を付与する。つまり、感情推定装置は、ユーザの普段の発言傾向を反映して教師データを作成するので、ユーザの発言から感情推定を行う際の感情精度を向上させることができる。 According to such an emotion estimation apparatus, in addition to a commonly used emotion notation word for teacher data used for user speech analysis, a predetermined word is used for words used by the user in surrounding speech of the word (word). Gives the value of the emotion vector. That is, since the emotion estimation device creates teacher data reflecting the user's usual speech tendency, emotion accuracy when performing emotion estimation from the user's speech can be improved.
本発明によれば、ユーザの感情の推定精度を向上させることができる。 According to the present invention, it is possible to improve the estimation accuracy of a user's emotion.
(実施の形態)
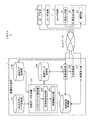
以下、図面を参照しながら、本発明を実施の形態を説明する。まず、図1を用いて、感情推定装置1を含むシステムの構成例を説明する。システムは、例えば、図1に示すように、感情推定装置1とユーザ端末2とを備え、感情推定装置1とユーザ端末2とは、ネットワーク(インターネットやLAN(Local Area Network)等)により接続される。感情推定装置1は、ネットワーク経由で、ユーザ端末2から、ユーザの発言内容(例えば、Twitter(登録商標)、Facebook(登録商標)、ブログ、チャット等における発言内容)を受信すると、この発言内容を過去ログとして蓄積し、各ユーザの過去ログの内容から、ユーザの現在の発言の解析を行うための教師モデルを作成する。この発言の解析とは、ユーザの発言が意味する感情の傾向を判断することであり、本実施の形態においては、感情推定装置1が、ユーザの発言がネガティブな感情を意味するものか、ポジティブな感情を意味するものかの判断する場合を例に説明する。また、この教師モデルは、ユーザごとに、各単語のある特定の感情の強さの度合いを示す感情ベクトルの値を示したものであり、本実施の形態においては、この感情ベクトルの値として、ネガポジ値を用いる場合を例に説明する。このネガポジ値は、各単語のポジティブ(またはネガティブ)な感情の強さの度合いであるポジティブ度(またはネガティブ度)を「0〜1」の値で示したものである。感情推定装置1は、教師データのネガポジ値に、ユーザそれぞれの発言が意味する感情の傾向(例えば、ネガティブな発言が多いか、ポジティブな発言が多いか)を反映させる。そして、感情推定装置1は、当該ユーザに関する教師モデルを用いて、ユーザの現在の発言の示す感情(例えば、ネガティブかポジティブか)の推定(解析)を行う。
(Embodiment)
Hereinafter, embodiments of the present invention will be described with reference to the drawings. First, a configuration example of a system including the
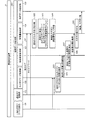
ここで、図2を用いて、図1の感情推定装置1の概要を説明する。感情推定装置1は、ユーザごとの発言の過去ログ(発言ログ)を蓄積している。ここでの過去ログは、ユーザごとに、そのユーザの発言が発言日時とともに時系列で記録されたテキストデータであり、例えば、符号201に示す内容であるものとする。ここでは、感情推定装置1は、ユーザの発言からネガティブワードとして「どうせ」という単語を含む発言とその周辺発言の単語を抽出して、それぞれの単語にネガポジ値(各単語のネガティブ度(またはポジティブ度)を示す値)を付与し、教師データに記録する場合を例に説明する。また、以下の説明において、ネガポジ値は、最もネガティブ「0」〜ニュートラル「0.5」〜最もネガティブ「1」であるものとする。
Here, the outline of the
(S1)
感情推定装置1は、ユーザの過去ログを検索し、ネガティブワード「どうせ」が含まれた発言を抽出する。ここでは、時刻「10:04:30」における「どうせ私なんて」という発言が抽出された場合を考える。
(S1)
The
(S2)
次に、感情推定装置1は、過去ログからS1で抽出した発言(例えば、「どうせ私なんて」)の前後数分間の発言(周辺発言)を抽出する。例えば、感情推定装置1は、符号202に示すように、「どうせ私なんて」を中心とした前後数分間の発言「やばい」「全然できなかった」「どうせ私なんて」「。。。。」「うーん」の発言を抽出する。
(S2)
Next, the
(S3)
その後、感情推定装置1は、S1で抽出したユーザの発言およびS2で抽出したその周辺発言に対し、形態素解析等を行い、単語の抽出を行う。そして、感情推定装置1は、抽出した単語それぞれに付与するネガポジ値を付与する。例えば、感情推定装置1は、一般ワード(ここでは、S1で検索された発言に含まれるネガティブワード)のネガポジ値を「0」、周辺単語(S2で検索された周辺発言に含まれる単語)のネガポジ値を比較的ネガティブなネガポジ値である「0.2」を付与する(符号203参照)。つまり、当該単語がネガティブワードではなくても、その周辺に登場する単語ならば、その単語は、当該ユーザにとってネガティブな意味で使われる可能性が高い単語なので、感情推定装置1は、ネガティブワードのネガポジ値よりも若干ネガティブ度を軽減したネガポジ値を付与する。そして、感情推定装置1は、抽出した単語と付与したネガポジ値とのペアを当該ユーザの教師データとして記録する。なお、S3において付与するネガポジ値は、そのユーザの日常の発言がネガポジ(ネガティブ、ポジティブ)のどちらが多いかによって調整される。
(S3)
Thereafter, the
例えば、感情推定装置1が、S1でネガティブワード「どうせ」を含む発言を抽出した場合、そのネガティブワードを含む発言をしたユーザが日常において発言のネガポジ割合の等しい人であれば、一般ワード(ネガティブワード)のネガポジ値を「0」、その周辺単語のネガポジ値を「0.2」のままとする。一方、そのユーザが普段ネガ(ネガティブな)発言の割合の多い人であれば、一般ワード(ネガティブワード)のネガポジ値を「0.4」、その周辺単語のネガポジ値を「0.5」にする。つまり、ネガポジ値を全体的にポジティブ寄りに修正する。さらに、そのユーザが普段ポジ(ポジティブな)発言が多い人であれば、一般ワード(ネガティブワード)のネガポジ値を「0」のままとするが、その周辺単語のネガポジ値を「0.1」にする。つまり、ネガポジ値を全体的にネガティブ寄りに修正する。なお、ここで、一般ワード(ネガティブワード)のネガポジ値を「0」のままとしたのは、ネガポジ値は0未満の値はとらないからである。
For example, when the
感情推定装置1は、このようなS1〜S3の処理を、ユーザの発言内からネガティブワードを発見するたびに実行し、当該ユーザの教師データを作成する。
The
(S4)
そして、感情推定装置1は、当該ユーザの教師データを用いて、当該ユーザの発言がネガティブなものかポジティブなものかの解析を行い、その結果を出力する。例えば、感情推定装置1は、解析の結果を記憶部の所定領域に記憶したり、解析の結果、ユーザがネガティブな発言をしたと判断したとき、その旨をそのユーザのユーザ端末2へ送信したりする。なお、ここでは説明を省略したが、感情推定装置1は、予め登録されたポジティブワードを含む発言と、その周辺発言の単語についても同様の手順により、各単語にネガポジ値を付与し、教師データに記録する。このときの手順は後記する。
(S4)
Then, the
図1に戻り、感情推定装置1を詳細に説明する。感情推定装置1は、記憶部、制御部、および、入出力部(いずれも図示省略)を備えるコンピュータにより実現される。記憶部は、制御部が教師データの作成や発言解析に用いる各種情報(ネガポジワード、過去ログ等)を格納する。制御部は、主に、教師データの作成と、その教師データを用いた発言解析とを行う。入出力部は、感情推定装置1へのユーザの発言の入力を受け付けたり、解析結果を出力したりする。
Returning to FIG. 1, the
図1の一般ネガポジワード記録部131、過去ログ記録部132、教師データ記録部133、および、解析結果記録部134は、前記した記憶部に含まれ、教師データ作成部121、および、発言解析部125は、前記した制御部に含まれる。
The general negative / positive
一般ネガポジワード記録部(一般感情表記ワード記録部)131は、ある特定の感情とその感情と相反する感情を示す語句(感情表記ワード)を格納する。例えば、この一般ネガポジワード記録部131は、一般的な意味で、ネガティブな感情を示す単語であるネガティブワードと、一般的な意味でポジティブな感情を示す単語であるポジティブワード(両者をまとめて「ネガポジワード」とする)を格納する。例えば、ネガティブワードは、「どうせ」等であり、ポジティブワードは、「うれしい」や「楽しい」等である。このネガポジワードは、入出力部経由で登録される。なお、以下の説明において、感情表記ワードが、前記したネガポジワードである場合を例に説明するが、ネガポジワード以外であってももちろんよく、例えば、「うれしい、悲しい」「好き、嫌い」、「安心、不安」、「楽しい、怖い」、「可愛い、気持ち悪い」といった語句を用いてもよい。
The general negative / positive word recording unit (general emotion notation word recording unit) 131 stores a phrase (emotion notation word) indicating a specific emotion and an emotion opposite to that emotion. For example, the general negative / positive
過去ログ記録部132は、ユーザごとの発言内容を示した過去ログを格納する。この過去ログは、当該ユーザの発言内容を、その発言の発言日時等とともに示した情報である。この発言内容は、例えば、ユーザ端末2から入出力部経由で入力され、格納される。
The past
教師データ記録部133は、教師データ作成部121により作成された教師データを格納する。この教師データは、ユーザごとに、そのユーザの発言の単語それぞれのネガティブ度(またはポジティブ度)を示すネガポジ値を示した情報である。このネガポジ値は、前記したとおり、例えば、最もネガティブな単語の値を「0」、ニュートラルな単語の値を「0.5」、最もポジティブな単語の値を「1」として、数値化したものである。つまり、ネガティブ度が高い単語ほど、ネガポジ値は「0」に近い値であり、ポジティブ度が高い単語ほど、ネガポジ値は「1」に近い値となる。ネガポジ値の表し方は、上記の方法以外であってももちろんよい。
The teacher
解析結果記録部134は、発言解析部125による各ユーザの発言の解析結果(当該ユーザの発言に対し、その発言がネガティブなものかポジティブなものかの解析の結果)を格納する。
The analysis
教師データ作成部121は、ネガポジワード検索部122、前後発言抽出部123、および、特徴量抽出部124を備える。
The teacher
ネガポジワード検索部(感情表記ワード検索部)122は、一般ネガポジワード記録部131に格納される感情表記ワード(例えば、ネガポジワード)を参照して、ユーザの過去ログ(過去ログ記録部132に格納)から、感情表記ワード(例えば、ネガポジワード)のいずれかを含む発言を検索する。
The negative / positive word search unit (emotion expression word search unit) 122 refers to the emotion expression word (for example, negative / positive word) stored in the general negative / positive
前後発言抽出部123は、検索されたネガポジワードを含む発言を中心として前後所定範囲内の発言である周辺発言を抽出する。周辺発言は、例えば、ネガポジワードを含む発言の前後数分間の発言や、前後数個分の発言等である。この周辺発言の範囲は、日ごろのユーザの発言頻度によって変更可能である。例えば、比較的発言頻度が多いユーザについては、周辺発言として抽出する範囲を広くしてもよい。
The front / rear
特徴量抽出部124は、ユーザの発言およびその周辺発言の単語それぞれにネガポジ値を付与した教師データを作成する。
The feature
ここでの各単語へのネガポジ値の付与方法の詳細は、後記するが、例えば、以下の処理を行う。まず、特徴量抽出部124は、ネガポジワード検索部122により検索された発言が、ネガティブワードを含む発言であるとき、(1)この発言に含まれるネガティブワードに対し付与するネガポジ値を、最もネガティブであることを示すネガポジ値(例えば、「0」)とする。次に、(2)この発言の周辺発言の単語(周辺単語)それぞれに対し付与するネガポジ値を、ネガティブワードに付与したネガポジ値(例えば、「0」)よりもネガティブ度を軽減した値(例えば、「0.2」)とする。その後、特徴量抽出部124は、(3)当該ユーザが比較的ネガティブワードの発言が多いユーザならば、(1)および(2)で決定したネガポジ値について、さらにネガティブ度を軽減した値(例えば、ネガティブワード「0.4」、周辺単語「0.5」)にする。一方、特徴量抽出部124は、当該ユーザが、ポジティブワードの発言が比較的多いユーザならば、(1)および(2)で決定したネガポジ値について、ネガティブ度を高くした値(例えば、ネガティブワード「0」、周辺単語「0.1」)にする。つまり、同じ単語であっても普段のユーザの発言傾向によって、その単語の意味するネガティブ度(ポジティブ度)が異なるので、特徴量抽出部124は、そのユーザの発言傾向に基づき、各単語のネガポジ値の調整を行う。なお、当該ユーザは比較的ネガティブワードの発言が多いユーザか否かは、特徴量抽出部124が当該ユーザの過去ログ(過去ログ記録部132に格納)と、ネガポジワード(一般ネガポジワード記録部131に格納)とを参照して判断する。
つまり、特徴量抽出部124は、単語それぞれのネガポジ値を決定するとき、一般ネガポジワード検索部122により検索された発言に含まれるネガポジワードに対し、発言に含まれるネガポジワードの示す、ある特定の感情(例えば、ポジティブな感情またはネガティブな感情)の強さの度合いを示す値をこの単語のネガポジ値とする。また、特徴量抽出部124は、この発言の周辺発言の単語のうち、ネガポジワード以外の単語それぞれに対するネガポジ値として、ネガポジワードに付与したネガポジ値と比較してその感情の強さの度合いを軽減した所定の値とする。さらに、特徴量抽出部124は、ユーザの過去ログとネガポジワードとを参照して、ユーザの発言において、ある特定の感情(例えば、ネガティブ)を示す単語の発言頻度が所定の閾値よりも多いと判断された場合は、ネガポジワードに付与されたネガポジ値について、特定の感情(例えば、ネガティブな感情)の強さの度合いを軽減した値に修正し、ある特定の感情と相反する感情(例えば、ポジティブ感情)を示す単語の発言頻度が所定の閾値よりも多いと判断された場合は、ネガポジワードに付与されたネガポジ値について、ある特定の感情(例えば、ネガティブな感情)の強さの度合いを増大した値に修正する。
Details of the method for assigning a negative / positive value to each word here will be described later. For example, the following processing is performed. First, when the utterance searched by the negative / positive
That is, when the feature
このように、特徴量抽出部124は、同じネガティブな意味合いの単語でも、その単語を含む発言をしたユーザが普段からネガティブな発言をするユーザならば、その単語のネガポジ値の示すネガティブ度を低減し、その単語を含む発言をしたユーザが、普段はポジティブな発言をするユーザならば、その単語のネガポジ値の示すネガティブ度を高くする。すなわち、特徴量抽出部124は、各ユーザが、ネガティブな発言が多いか、ポジティブな発言が多いかを考慮して、教師データのネガポジ値の調整を行うので、感情推定の精度の高い教師データを作成することができる。
As described above, the feature
発言解析部125は、当該ユーザの教師データを用いて、入出力部経由でユーザ端末2から入力される当該ユーザの発言について、その発言の意味する感情(例えば、ネガティブな感情かポジティブな感情か)の傾向を解析する。例えば、発言解析部125は、ユーザの発言のネガポジ値(発言に含まれる単語のネガポジ値の平均値)の示すネガティブ度が所定の閾値を超えるとき、ユーザの発言がネガティブである旨の解析結果(判断結果)を出力する。この解析結果は、解析結果記録部134等に出力する。また、発言解析部125は、この解析結果を、警告発信部126(後記)経由で、ユーザ端末2へ送信してもよい。
The
警告発信部126および結果表示部127は、装備しない場合と、装備する場合とがあり、装備する場合については後記する。
The
次に、図1を参照しつつ、図3を用いて、感情推定装置1の処理手順の概要を説明する。まず、事前準備として、感情推定装置1は、一般ネガポジワード記録部131にネガポジワードを登録しておく(S11)。また、感情推定装置1は、過去ログ記録部132にユーザごとの過去の発言ログを蓄積する(S12)。
Next, the outline of the processing procedure of the
そして、教師データ作成部121は、一般ネガポジワード記録部131に登録されたネガポジワードと、過去ログ記録部132に蓄積された当該ユーザの発言の過去ログとを参照して、当該ユーザの教師データを作成する(S13)。ここでの教師データの作成手順の詳細は後記する。そして、教師データ作成部121は、作成した教師データを教師データ記録部133に格納する(S14)。
Then, the teacher
ユーザ端末2の発言入力部21から発言が入力され(S15)、感情推定装置1の発言解析部125がこの発言を受信すると(S16)、この発言の発言元のユーザの教師データを教師データ記録部133から読み出し、この教師データを参照して、発言を解析する(S17)。そして、発言解析部125は解析結果を解析結果記録部134へ出力する(S18)。
When a utterance is input from the
次に、図4を用いて、図3のS13を詳細に説明する。まず、教師データ作成部121の特徴量抽出部124は、各ユーザの発言の過去ログから、当該ユーザがどれぐらいの頻度でネガティブな発言をしているのか、またポジティブな発言をしているのかを分析する。すなわち、教師データ作成部121は、まず、過去ログ記録部132からユーザそれぞれの過去ログを取得する(S21)。そして、特徴量抽出部124は、一般ネガポジワード記録部131に登録されているネガポジワードを参照して、当該ユーザの過去ログのネガポジを分析する(S22)。つまり、特徴量抽出部124は、一般ネガポジワード記録部131に登録されているネガポジワードを参照して、当該ユーザの過去ログに登場する各単語のネガポジ(ネガティブかポジティブか)を判断する。そして、特徴量抽出部124は、当該ユーザの過去ログ全体におけるネガティブワードおよびポジティブワードそれぞれの登場頻度をカウントし(S23)、カウントした登場頻度をネガポジ頻度情報として感情推定装置1の記憶部の所定領域に記録する(S24)。
Next, S13 of FIG. 3 will be described in detail with reference to FIG. First, the feature
また、教師データ作成部121のネガポジワード検索部122は、一般ネガポジワード記録部131に示されるネガポジワードと、過去ログ記録部132に蓄積された当該ユーザの発言の過去ログとを参照して、当該ユーザの過去ログからネガポジワードを含む発言を抽出し(S25)、この検索にヒットした発言と、その発言日時とを前後発言抽出部123へ出力する(S26)。
Further, the negative / positive
前後発言抽出部123は、当該ユーザの過去ログから、検索にヒットした発言の前後数分間の発言(周辺発言)を抽出する(S27)。そして、S25で検索した発言とその周辺発言とを特徴量抽出部124へ出力する(S28)。
The forward / backward
特徴量抽出部124は、S25で抽出した発言とその周辺発言に含まれる各単語のネガポジ値を付与する(S29)。つまり、[単語、ネガポジ値]のペアを当該ユーザの教師データに記録する。なお、特徴量抽出部124は、S24における各単語のネガポジ値の付与にあたり、周辺発言の単語のネガポジ値についてはネガティブワード(またはポジティブワード)よりもネガティブ度(またはポジティブ度)を軽減した値とする。例えば、ネガティブワードの周辺発言のネガポジ値は「0(最もネガティブ度の高い値)」よりもネガティブ度を軽減した値である「0.2」とする。また、ポジティブワードの周辺発言のネガポジ値は「1(最もポジティブ度の高い値)」よりもポジティブ度を軽減した値である「0.8」とする。
The feature
また、特徴量抽出部124は、S24で記録したネガポジ頻度情報を参照し、当該ユーザがネガティブな発言が多いユーザか、ポジティブな発言が多いユーザかを判断する。例えば、特徴量抽出部124は、前記したネガポジ頻度情報を参照し、当該ユーザのネガティブワードの発言頻度が所定の閾値よりも多いとき、当該ユーザはネガティブな発言が多いと判断する。一方、当該ユーザのポジティブワードの発言頻度が所定の閾値よりも多いとき、ポジティブな発言が多いと判断する。特徴量抽出部124は、当該ユーザがネガティブな発言が多いユーザか、ポジティブな発言が多いユーザかによりネガポジ値の調整を行う。ここでのネガポジ値の調整の詳細は後記する。そして、特徴量抽出部124は、各単語のネガポジ値を決定すると、その決定したネガポジ値と、単語とのペアを当該ユーザの教師データに記録する。
Further, the feature
次に、図5を用いて、図3のS17を詳細に説明する。図5に示すように、感情推定装置1の発言解析部125は、ユーザ端末2の発言入力部21経由で入力された発言を受信すると、当該ユーザ端末2のユーザの教師データをもとに、当該発言を、ポジティブな発言、ネガティブな発言、ニュートラルな発言のいずれかに分類して、解析結果記録部134に格納する。なお、ユーザの発言の分類は、例えば、発言解析部125が、当該発言に含まれる各単語のネガポジ値の合計値を単語数で割った値a、つまり単語1つあたりのネガポジ値の平均値が、以下の表1に示されるどの範囲に属するか判断することにより行われる。
Next, S17 in FIG. 3 will be described in detail with reference to FIG. As shown in FIG. 5, when the

なお、発言の分類は、上記の3段階に限定されない。例えば、ポジティブ、ややポジティブ、ニュートラル、ややネガティブ、ネガティブの5段階の分類であってもよいし、それ以上の段階の分類であってもよい。この場合、感情推定装置1にそれぞれの分類に対応するaの値の範囲を設定しておくものとする。
Note that the categorization of comments is not limited to the above three stages. For example, it may be classified into five levels of positive, slightly positive, neutral, slightly negative, and negative, or may be classified at a higher level. In this case, it is assumed that a range of a values corresponding to each classification is set in the
次に、図1を参照しつつ、図6を用いて、図4のS25からS29までの処理の詳細を説明する。まず、図1の教師データ作成部121において、過去ログ記録部132に新たな発言ログが格納されたことを検知すると(S100)、教師データ作成部121のネガポジワード検索部122は、当該発言の発言元のユーザの教師データの作成が初回であるか否かを判断する(S101)。初回と判断された場合(S101のYes)、ネガポジワード検索部122は、過去ログ記録部132から当該ユーザの最も古いログ(発言ログ)から時系列順に検索し、一般ネガポジワード記録部131に登録されているネガティブワードまたはポジティブワードを含む発言を抽出する(S102)。一方、教師データの作成が初回ではないと判断された場合(S101のNo)、ネガポジワード検索部122は、過去ログ記録部132から前回検索した箇所から時系列順に検索し、一般ネガポジワード記録部131に登録されているネガティブワードまたはポジティブワードを抽出する(S103)。
Next, details of the processing from S25 to S29 in FIG. 4 will be described with reference to FIG. 1 and FIG. First, when the teacher
S101,S102の後、前後発言抽出部123は、過去ログ記録部132における当該ユーザの過去ログから、S102またはS103で抽出した発言の前後数分間の発言(周辺発言)を取得する(S104)。
After S101 and S102, the forward / backward
S104の後、特徴量抽出部124は、一般ネガポジワード記録部131に示されるネガポジワードを参照して、S102またはS103で抽出した単語がネガティブワードであると判断したとき(S105のYes)、図7のS110へ進む。一方、S102またはS103で抽出した単語がネガティブワードではないと判断したとき(S105のNo)、図8のS120へ進む。
After S104, the feature
図7のS110において、特徴量抽出部124は、一般ワード(ここでは、一般ワードはネガティブワードなので「一般ネガティブワード」と呼ぶ)のネガポジ値を最もネガティブな値である「0」とし、その周辺単語のネガポジ値を比較的ネガティブな値である「0.2」とする。その後、特徴量抽出部124は、当該ユーザの過去ログと、一般ネガポジワード記録部131に登録されたネガポジワードとを参照して、当該発言のユーザが普段ネガティブな発言が多いか否かを判断する(S111)。ここでの判断方法はさまざまな方法が考えられるが、例えば、特徴量抽出部124が、当該ユーザの過去ログを参照して、前記した表1等のような判断基準により、ユーザの各発言を、ポジティブな発言、ネガティブな発言、ニュートラルな発言のいずれかに分類する。そして、特徴量抽出部124は、3種類の発言のうち、ネガティブな発言が最も多いユーザについて、そのユーザは普段ネガティブな発言が多いユーザと判断し(S111のYes)、そのユーザの一般ネガティブワードのネガポジ値を「0」から「0.4」に修正し、その周辺単語のネガポジ値を「0.2」から「0.5」に修正する(S112)。つまり、特徴量抽出部124は、S110で付与した一般ネガティブワードおよびその周辺単語のネガポジ値のネガティブ度を低減する。すなわち、一般ネガティブワードおよびその周辺単語のネガポジ値をポジティブ寄りに修正する。
In S110 of FIG. 7, the feature
一方、特徴量抽出部124は、3種類の発言のうち、最も多い発言がネガティブな発言ではないユーザについては普段ネガティブな発言の多くないユーザと判断し(S111のNo)、一般ネガティブワードのネガポジ値を「0」のままにし、周辺単語のネガポジ値を「0.2」から「0.1」に修正する(S113)。
On the other hand, the feature
特徴量抽出部124は、S112およびS113でネガポジ値を与えた単語が、既に当該ユーザの教師データに登録されていないかを判断し(S114)、まだ登録されていなければ(S114のYes)、[単語、ネガポジ値]のペアを当該ユーザの教師データに登録する(S115)。そして、S100へ戻る。一方、S112およびS113でネガポジ値を与えた単語が、既に当該ユーザの教師データに登録されていれば(S114のNo)、S112またはS113で付与したネガポジ値−0.1を計算し、計算した値を付与した[単語、ネガポジ値]のペアを当該ユーザの教師データに登録する(S116)。そして、S100へ戻る。ただし、ネガポジ値は0以上の値とし、S116の計算の結果、値が0より小さい値になったときは、値を0とする。このようにすることで、例えば、ネガティブワードの周辺単語について、ネガティブワードの周辺単語として抽出されるたびに、当該単語のネガポジ値が減っていく(ネガティブ度を増す)ことになる。よって、教師モデルにおけるネガポジ値の精度を向上させることができる。
The feature
次に、図8のS120以降の処理を説明する。特徴量抽出部124は、一般ワード(ここでは、一般ワードはポジティブワードなので「一般ポジティブワード」と呼ぶ))のネガポジ値を最もポジティブな値である「1」とし、その周辺単語のネガポジ値を比較的ポジティブな値である「0.8」とする(S120)。その後、特徴量抽出部124は、当該ユーザの過去ログと、一般ネガポジワード記録部131に登録されたネガポジワードとを参照して、当該発言のユーザが普段ポジティブな発言が多いか否かを判断する(S121)。ここでの判断はS111と同様に、特徴量抽出部124が、当該ユーザの発言は、前記した3種類の発言のうち、どの発言が最も多いかにより行われる。ここで、特徴量抽出部124が、当該ユーザは、普段ポジティブな発言が多いユーザと判断したとき(S121のYes)、当該ユーザの一般ポジティブワードのネガポジ値を「1」から「0.6」に修正し、その周辺単語のネガポジ値を「0.8」から「0.5」に修正する(S122)。つまり、特徴量抽出部124は、S110で付与した一般ポジティブワードおよびその周辺単語のネガポジ値のポジティブ度を低減する。すなわち、一般ポジティブワードおよびその周辺単語のネガポジ値をネガティブ寄りに修正する。
Next, the processing after S120 in FIG. 8 will be described. The feature
一方、特徴量抽出部124は、当該ユーザは普段ポジティブな発言が多くないユーザと判断したとき(S121のNo)、一般ポジティブワードのネガポジ値を「1」のままにし、その周辺単語のネガポジ値を「0.9」に修正する(S123)。そして、S100へ戻る。
On the other hand, when the feature
特徴量抽出部124は、S112およびS113でネガポジ値を与えた単語が、既に当該ユーザの教師データに登録されていないか否かを判断し(S124)、登録されていなければ(S124のYes)、[単語,ネガポジ値]のペアを当該ユーザの教師データに記録する(S125)。一方、S112およびS113でネガポジ値を与えた単語が、既に当該ユーザの教師データに登録されていれば(S124のNo)、S122またはS123で付与したネガポジ値+0.1を計算し、計算した値を付与した[単語、ネガポジ値]のペアを当該ユーザの教師データに登録する(S126)。そして、S100へ戻る。ただし、ネガポジ値は1以下の値とし、S126の計算の結果、値が1より大きい値になったときは、値を「1」とする。このようにすることで、例えば、ポジティブワードの周辺単語について、ポジティブワードの周辺語として抽出されるたびに、当該単語のネガポジ値が増加していく(ポジティブ度を増す)ことになる。よって、教師モデルにおけるネガポジ値の精度を向上させることができる。
The feature
以上説明したとおり、感情推定装置1の教師データ作成部121は、ユーザごとに当該ユーザはネガティブ発言が多いか、ポジティブ発言が多いか等を考慮して、ユーザごとの教師データを作成する。つまり、教師データ作成部121は感情推定精度の高い教師データを作成する。
As described above, the teacher
なお、感情推定装置1の特徴量抽出部124は、図6〜図8に示す処理に基づき教師データの各単語のネガポジ値を付与した後、ネガポジ値の調整を行うようにしてもよい。例えば、特徴量抽出部124は、ユーザの教師データにおける、ネガティブワードおよびその周辺発言に含まれる単語のうち、当該ユーザの過去ログにおいて、ポジティブワードを含む発言の周辺発言にも登場する単語があれば、その単語のネガポジ値を、ネガティブ度を軽減した値に修正する。つまり、特徴量抽出部124は、比較的ネガティブな発言であっても当該ユーザの過去の発言においてポジティブワードの周辺単語としても登場する単語については、ネガティブ度はさほど高くない可能性があるので、ネガポジ値をよりポジティブ寄りの値に修正する。
Note that the feature
また、特徴量抽出部124は、ユーザの教師データにおける、ポジティブワードおよびその周辺発言に含まれる単語のうち、当該ユーザの過去ログにおいて、ネガティブワードを含む発言の周辺発言にも登場する単語についても、その単語のネガポジ値を、ポジティブ度を軽減した値に修正する。つまり、特徴量抽出部124は、比較的ポジティブな発言であっても、当該ユーザの過去の発言においてネガティブワードの周辺単語としても登場する単語については、ポジティブ度はさほど高くない可能性があるので、ネガポジ値をよりネガティブ寄りの値に修正する。ただし、ここでも、ネガポジ値の値は0〜1までの間とする。つまり、ネガポジ値は「1」で頭打ち、「0」で底打ちとする。
The feature
このようにネガポジ値の調整を行うことで、特徴量抽出部124はユーザの教師データの精度をさらに向上させることができる。
By adjusting the negative / positive value in this way, the feature
なお、感情推定装置1は、図1に示すように、警告発信部126をさらに備えていてもよい。この警告発信部126は、発言解析部が含まれていた場合、その旨の警告をユーザ端末2へ送信する。例えば、感情推定装置1は、ユーザ端末2の発言入力部21経由で入力されたユーザの発言をリアルタイムで受信し、発言解析部125が、受信した発言の発言解析を行う。そして、発言解析の結果、その発言にネガティブ発言が含まれていた場合、警告発信部126は、ユーザ端末2へ警告を送信する。この警告は、ユーザ端末2の警告表示部22により表示装置(図示省略)等に表示される。これにより、ユーザ端末2のユーザは、自分がネガティブな発言をしたか否かをリアルタイムに知ることができる。なお、感情推定装置1はユーザ端末2からこのような警告を送信するか否かの設定を受信しておき、このような警告を送信する旨が設定されているユーザ端末2に対し、警告を送信するようにしてもよい。
The
また、感情推定装置1は、図1に示す結果表示部127を備えていてもよい。この結果表示部127は、ユーザ端末2からの要求に応じてユーザの過去所定期間における発言の解析結果を送信する。結果表示部127は、ユーザ端末2の閲覧部23から過去所定期間における発言の解析結果の閲覧要求を受け付けると、解析結果記録部134に格納された当該ユーザの過去所定期間の発言の解析結果をユーザ端末2へ送信する。そして、この解析結果を受信したユーザ端末2は、閲覧部23によりこの解析結果を表示装置等に表示させる。これにより、ユーザ端末2のユーザは、自分の過去の発言における感情(ネガティブ、ポジティブ)の推移等を知ることができる。
Moreover, the
また、感情推定装置1の一般ネガポジワード記録部131に登録されるネガポジワードは、一般的な意味でのネガティブワードおよびポジティブワードのみならず、ユーザそれぞれが設定したネガティブワードおよびポジティブワードを含んでいてもよい。例えば、ユーザAのネガティブワードとして「微妙」という単語が登録されていた場合、感情推定装置1が、ユーザAの「微妙」という単語を含む発言の入力を受け付けたときは、この単語のネガポジ値を「0」とする。このように一般ネガポジワード記録部131がユーザ特有のネガポジワードをさらに登録しておくことで、特徴量抽出部124は、感情推定精度の高い教師データを作成することができる。
Further, the negative / positive words registered in the general negative / positive
また、一般ネガポジワード記録部131は、ネガポジワードの単語ごとに、その単語に付与するネガポジ値の設定情報をさらに含んでいてもよい。例えば、一般ネガポジワード記録部131は、「どうせ」という単語についてはネガポジ値を「0」とするが、「面倒」という単語についてはネガポジ値を「0.1」とする、という情報をさらに含んでいてもよい。つまり、前記した実施の形態において、特徴量抽出部124は、発言に登場する単語のうち、一般ネガポジワード記録部131に登録されるネガティブワードに対してはネガポジ値「0」を付与し(図7のS110参照)、ポジティブワードにはネガポジ値「1」を付与する(図8のS120参照)ことしたが、一般ネガポジワード記録部131に設定された当該単語のネガポジ値を付与するようにしてもよい。このようにすることで、特徴量抽出部124は教師データにおける各単語のネガポジ値として、より細やかな値を設定できので、感情推定精度の高い教師データを作成することができる。
Further, the general negative / positive
なお、前記した実施の形態において、特徴量抽出部124が作成するネガポジ頻度情報は、ユーザの発言に含まれる単語のネガポジ値の範囲ごとに、その範囲のネガポジ値を持つ単語の登場頻度を示した情報であってもよい(表2参照)。ここでのネガポジ頻度情報の作成は、当該ユーザの教師データを参照して行われる。
In the above-described embodiment, the negative / positive frequency information created by the feature
そして、特徴量抽出部124は、このネガポジ値の範囲ごとの登場頻度の値をもとに、スコアを計算し、そのスコア値をもとに、各ユーザがネガティブな発言が多いか、ポジティブな発言が多いか(あるいは、それともそのどちらでもないか)を判断するようにしてもよい。
Then, the feature
また、前記した実施の形態において説明した感情推定装置1が実行する処理をコンピュータが実行可能な言語で記述したプログラムで実現してもよい。この場合、コンピュータがプログラムを実行することにより、実施の形態と同様の効果を得ることができる。さらに、かかるプログラムをコンピュータ読み取り可能な記録媒体に記録して、この記録媒体に記録されたプログラムをコンピュータに読み込ませて実行することにより前記した実施の形態と同様の処理を実現してもよい。以下に、図1に示した感情推定装置1と同様の機能を実現するプログラムを実行するコンピュータの一例を説明する。
Further, the processing executed by the
図9に例示するように、コンピュータ1000は、例えば、メモリ1010と、CPU1020と、ハードディスクドライブインタフェース1030と、ディスクドライブインタフェース1040と、シリアルポートインタフェース1050と、ビデオアダプタ1060と、ネットワークインタフェース1070とを有し、これらの各部はバス1080によって接続される。
As illustrated in FIG. 9, the computer 1000 includes, for example, a
メモリ1010は、図9に例示するように、ROM(Read Only Memory)1011及びRAM1012を含む。ROM1011は、例えば、BIOS(Basic Input Output System)等のブートプログラムを記憶する。ハードディスクドライブインタフェース1030は、図9に例示するように、ハードディスクドライブ1031に接続される。ディスクドライブインタフェース1040は、図9に例示するように、ディスクドライブ1041に接続される。例えば磁気ディスクや光ディスク等の着脱可能な記憶媒体が、ディスクドライブに挿入される。シリアルポートインタフェース1050は、図9に例示するように、例えばマウス1051、キーボード1052に接続される。ビデオアダプタ1060は、図9に例示するように、例えばディスプレイ1061に接続される。
The
ここで、図9に例示するように、ハードディスクドライブ1031は、例えば、OS1091、アプリケーションプログラム1092、プログラムモジュール1093、プログラムデータ1094を記憶する。すなわち、プログラムは、コンピュータ1000によって実行される指令が記述されたプログラムモジュールとして、例えばハードディスクドライブ1031に記憶される。
Here, as illustrated in FIG. 9, the hard disk drive 1031 stores, for example, an
また、上記実施形態で説明した各種データは、プログラムデータとして、例えばメモリ1010やハードディスクドライブ1031に記憶される。そして、CPU1020が、メモリ1010やハードディスクドライブ1031に記憶されたプログラムモジュール1093やプログラムデータ1094を必要に応じてRAM1012に読み出し、アクセス監視手順、アクセス制御手順、プロセス監視手順、プロセス制御手順を実行する。
The various data described in the above embodiment is stored as program data, for example, in the
なお、プログラムに係るプログラムモジュール1093やプログラムデータ1094は、ハードディスクドライブ1031に記憶される場合に限られず、例えば着脱可能な記憶媒体に記憶され、ディスクドライブ等を介してCPU1020によって読み出されてもよい。あるいは、監視プログラムに係るプログラムモジュール1093やプログラムデータ1094は、ネットワーク(LAN、WAN(Wide Area Network)等)を介して接続された他のコンピュータに記憶され、ネットワークインタフェース1070を介してCPU1020によって読み出されてもよい。
Note that the
1 感情推定装置
2 ユーザ端末
21 発言入力部
22 警告表示部
23 閲覧部
121 教師データ作成部
122 ネガポジワード検索部(感情表記ワード検索部)
123 前後発言抽出部
124 特徴量抽出部
125 発言解析部
126 警告発信部
127 結果表示部
131 一般ネガポジワード記録部(一般感情表記ワード記録部)
132 過去ログ記録部
133 教師データ記録部
134 解析結果記録部
DESCRIPTION OF
123 Pre- and
132 Past
Claims (7)
ある特定の感情とその相反する感情を示す語句である感情表記ワードを格納する一般感情表記ワード記録部と、
前記一般感情表記ワード記録部を参照して、前記ユーザの過去ログから、前記感情表記ワードのいずれかを含む発言を検索する感情表記ワード検索部と、
前記ユーザの過去ログから、前記検索された感情表記ワードを含む発言を中心として前後所定範囲内の発言である周辺発言を抽出する前後発言抽出部と、
前記ユーザごとに、前記発言に含まれる単語それぞれの前記ある特定の感情の強さの度合いを表す感情ベクトルの値を示した教師データを作成する特徴量抽出部と、
前記ユーザの前記教師データを用いて、前記ユーザの発言が意味する前記ある特定の感情の傾向を判断し、前記判断結果を出力する発言解析部とを備え、
前記特徴量抽出部は、
前記単語それぞれの感情ベクトルの値を決定するとき、前記感情表記ワード検索部により検索された発言に含まれる感情表記ワードに対し、前記発言に含まれる感情表記ワードが示す感情の種別に応じた所定の感情の強さの度合いを示す値を前記感情表記ワードの感情ベクトルの値として付与し、前記発言の周辺発言の単語のうち、前記感情表記ワード以外の単語それぞれに対する感情ベクトルの値として、前記感情表記ワードに付与した前記感情ベクトルの値と比較して前記ある特定の感情の強さの度合いを軽減した所定の値を付与し、
前記ユーザの過去ログと前記感情表記ワードとを参照して、前記ユーザの発言において、前記ある特定の感情を示す前記感情表記ワードの発言頻度が所定の閾値よりも多いと判断された場合は、前記感情表記ワードに付与された前記感情ベクトルの値について、前記ある特定の感情の強さの度合いを軽減した値に修正し、前記ある特定の感情と相反する感情を示す感情表記ワードの発言頻度が所定の閾値よりも多いと判断された場合は、前記感情表記ワードに付与された前記感情ベクトルの値について、前記ある特定の感情の強さの度合いを増大した値に修正する
ことを特徴とする感情推定装置。 A past log recording unit for storing a past log indicating the content of a message for each user;
A general emotion notation word recording unit for storing an emotion notation word which is a phrase indicating a specific emotion and an opposite emotion;
Referring to the general emotion expression word recording unit, an emotion expression word search unit for searching a remark including any of the emotion expression words from the past log of the user;
Before-and-after utterance extraction unit for extracting a peripheral utterance that is a utterance within a predetermined range around the utterance including the searched emotion expression word from the user's past log;
A feature amount extraction unit that creates teacher data indicating a value of an emotion vector representing the degree of strength of the specific emotion of each word included in the utterance for each user;
Using the teacher data of the user, and determining a tendency of the certain emotion that means the user's remarks, and a remark analysis unit that outputs the determination result,
The feature amount extraction unit includes:
When determining the value of the emotion vector for each of the words, a predetermined value corresponding to the type of emotion indicated by the emotion expression word included in the statement with respect to the emotion expression word included in the statement searched by the emotion expression word search unit A value indicating the degree of emotion strength is given as the value of the emotion vector of the emotion notation word, and the value of the emotion vector for each of the words other than the emotion notation word among the words of the surrounding speech of the statement, A predetermined value that reduces the degree of strength of the specific emotion compared to the value of the emotion vector assigned to the emotion notation word ,
With reference to the user's past log and the emotion notation word, in the user's remarks, when it is determined that the remark frequency of the emotion notation word indicating the specific emotion is greater than a predetermined threshold, The value of the emotion vector assigned to the emotion notation word is corrected to a value that reduces the degree of strength of the specific emotion, and the frequency of the emotion notation word indicating an emotion that conflicts with the specific emotion Is determined to be greater than a predetermined threshold, the value of the emotion vector assigned to the emotion notation word is corrected to an increased value of the strength of the specific emotion. Emotion estimation device.
前記発言に含まれる前記感情表記ワードが示す感情の種別がネガティブである場合、
ネガティブな感情を示す前記感情表記ワードに対する前記感情ベクトルの値として、ネガティブな感情の強さの度合いを示すネガティブ度としての所定の値を付与し、前記発言の周辺発言の単語のうち、前記感情表記ワード以外の単語それぞれに対する前記感情ベクトルの値として、前記ネガティブな感情を示す感情表記ワードに付与した前記感情ベクトルの値と比較してネガティブ度を軽減した所定の値を付与し、
前記発言に含まれる前記感情表記ワードが示す感情の種別がポジティブである場合、
ポジティブな感情を示す前記感情表記ワードに対する前記感情ベクトルの値として、ポジティブな感情の強さの度合いを示すポジティブ度としての所定の値を付与し、前記発言の周辺発言の単語のうち、前記感情表記ワード以外の単語それぞれに対する前記感情ベクトルの値として、前記ポジティブな感情を示す感情表記ワードに付与した前記感情ベクトルの値と比較してポジティブ度を軽減した所定の値を付与する
ことを特徴とする請求項1に記載の感情推定装置。 The feature amount extraction unit further includes:
When the emotion type indicated by the emotion notation word included in the statement is negative,
As the value of the emotion vector for the emotion notation word indicating negative emotion, a predetermined value as a negative degree indicating the degree of strength of negative emotion is given, and the emotion among the words of the peripheral statements of the statement As a value of the emotion vector for each word other than a notation word, a predetermined value with a reduced negative degree compared to the value of the emotion vector given to the emotion notation word indicating the negative emotion is given,
When the emotion type indicated by the emotion notation word included in the statement is positive,
As a value of the emotion vector for the emotion notation word indicating positive emotion, a predetermined value as a positive degree indicating the degree of strength of positive emotion is given, and the emotion among the words of the peripheral statements of the statement The emotion vector value for each word other than the notation word is given a predetermined value with a reduced positive degree compared to the emotion vector value given to the emotion notation word indicating the positive emotion, The emotion estimation apparatus according to claim 1 .
前記ユーザの発言において、前記ある特定の感情としてネガティブな感情を示す感情表記ワードであるネガティブワードの発言頻度が所定の閾値よりも多いと判断された場合、前記ネガティブワードに付与された前記感情ベクトルの値について、ネガティブな感情の強さの度合いであるネガティブ度を軽減した値に修正し、前記ネガティブな感情と反対のポジティブな感情を示す感情表記ワードであるポジティブワードの発言頻度が所定の閾値よりも多いと判断された場合、前記ネガティブワードである感情表記ワードに付与された感情ベクトルの値について、ネガティブ度を高くした値に修正し、
前記ユーザの発言において、前記ある特定の感情としてポジティブな感情を示す感情表記ワードであるポジティブワードの発言頻度が所定の閾値よりも多いと判断された場合、前記ポジティブワードに付与された前記感情ベクトルの値について、ポジティブな感情の強さの度合いであるポジティブ度を軽減した値に修正し、前記ポジティブな感情と反対のネガティブな感情を示す感情表記ワードであるネガティブワードの発言頻度が所定の閾値よりも多いと判断された場合、前記ポジティブワードである感情表記ワードに付与された感情ベクトルの値について、ポジティブ度を高くした値に修正する、
ことを特徴とする請求項2に記載の感情推定装置。 The feature amount extraction unit further includes:
In the user's utterance, when it is determined that the utterance frequency of a negative word, which is an emotion expression word indicating negative emotion as the specific emotion, is higher than a predetermined threshold, the emotion vector assigned to the negative word The value of the positive word is corrected to a value that reduces the negative degree, which is the degree of strength of negative emotion, and the utterance frequency of a positive word that is an emotion expression word indicating a positive emotion opposite to the negative emotion is a predetermined threshold value If it is determined that there are more than, the value of the emotion vector given to the emotion expression word that is the negative word is corrected to a value with a higher negative degree,
In the user's utterance, when it is determined that the utterance frequency of a positive word that is an emotion expression word indicating a positive emotion as the specific emotion is higher than a predetermined threshold, the emotion vector assigned to the positive word The value of the negative word is corrected to a value that reduces the positive degree, which is the degree of the strength of positive emotion, and the negative word utterance frequency indicating the negative emotion opposite to the positive emotion is a predetermined threshold value. If it is determined that there are more than, the value of the emotion vector assigned to the emotion notation word that is the positive word is corrected to a value with a higher positive degree.
The emotion estimation apparatus according to claim 2 , wherein:
前記ユーザの教師データにおける、前記ネガティブワードおよびその周辺発言に含まれる単語のうち、前記ユーザの過去ログにおいて、前記ポジティブワードを含む発言の周辺発言にも登場する単語の感情ベクトルの値について、ネガティブ度を軽減した値に修正することを特徴とする請求項3に記載の感情推定装置。 The feature extraction unit further includes:
Among the words included in the negative word and the surrounding utterances in the user's teacher data, the negative emotion value of the word that also appears in the peripheral utterance of the utterance including the positive word in the user's past log. The emotion estimation apparatus according to claim 3 , wherein the emotion is corrected to a value with a reduced degree.
前記ユーザの教師データにおける、前記ポジティブワードおよびその周辺発言に含まれる単語のうち、前記ユーザの過去ログにおいて、前記ネガティブワードを含む発言の周辺発言にも登場する単語の感情ベクトルの値について、ポジティブ度を軽減した値に修正することを特徴とする請求項3または請求項4に記載の感情推定装置。 The feature extraction unit further includes:
Among the words included in the positive word and the surrounding utterances in the user's teacher data, positive about the emotion vector value of the word that also appears in the peripheral utterances of the utterance including the negative word in the user's past log The emotion estimation apparatus according to claim 3 or 4 , wherein the emotion is corrected to a value with a reduced degree.
ある特定の感情とその相反する感情を示す語句である感情表記ワードを格納する一般感情表記ワード記録部を参照して、ユーザごとの発言内容を示した過去ログから、ネガティブまたはポジティブな感情を示す語句である感情表記ワードのいずれかを含む発言を検索する感情表記ワード検索ステップと、
前記ユーザの過去ログから、前記検索された感情表記ワードを含む発言を中心として前後所定範囲内の発言である周辺発言を抽出する前後発言抽出ステップと、
前記ユーザごとに、前記発言の単語それぞれの意味する個人の感情の強さの度合いを表す感情ベクトルの値を示した教師データを作成する特徴量抽出ステップと、
前記ユーザの前記教師データを用いて、前記ユーザの発言が意味する前記ある特定の感情の傾向を判断して、前記判断結果を出力する発言解析ステップとを実行し、
前記特徴量抽出ステップは、
前記単語それぞれの感情ベクトルの値を決定するとき、前記感情表記ワード検索ステップにより検索された発言に含まれる感情表記ワードに対し、前記発言に含まれる感情表記ワードが示す感情の種別に応じた所定の感情の強さの度合いを示す値を前記感情表記ワードの感情ベクトルの値として付与し、前記発言の周辺発言の単語のうち、前記感情表記ワード以外の単語それぞれに対する感情ベクトルの値として、前記感情表記ワードに付与した前記感情ベクトルの値と比較して前記ある特定の感情の強さの度合いを軽減した所定の値を付与し、
前記ユーザの過去ログと前記感情表記ワードとを参照して、前記ユーザの発言において、前記ある特定の感情を示す前記感情表記ワードの発言頻度が所定の閾値よりも多いと判断された場合は、前記感情表記ワードに付与された前記感情ベクトルの値について、前記ある特定の感情の強さの度合いを軽減した値に修正し、前記ある特定の感情と相反する感情を示す感情表記ワードの発言頻度が所定の閾値よりも多いと判断された場合は、前記感情表記ワードに付与された前記感情ベクトルの値について、前記ある特定の感情の強さの度合いを増大した値に修正する
ことを特徴とする感情推定方法。 Emotion estimation device
Refers to the general emotion notation word recording unit that stores the emotion notation word, which is a phrase indicating a specific emotion and the opposite emotion, and indicates negative or positive emotion from the past log showing the content of each user's utterance An emotion expression word search step for searching for a statement including any of the emotion expression words that are phrases;
Before-and-after utterance extraction step of extracting peripheral utterances that are utterances within a predetermined range around the utterance including the searched emotion expression word from the user's past log;
A feature amount extraction step for creating teacher data indicating a value of an emotion vector representing the degree of the strength of personal emotion that each of the words of the speech means for each user,
Using the teacher data of the user, determining a tendency of the certain emotion that the user's statement means, and executing a statement analysis step of outputting the determination result;
The feature amount extraction step includes:
When determining the value of the emotion vector for each of the words, a predetermined value corresponding to the type of emotion indicated by the emotion notation word included in the statement with respect to the emotion notation word included in the statement searched by the emotion notation word search step A value indicating the degree of emotion strength is given as the value of the emotion vector of the emotion notation word, and the value of the emotion vector for each of the words other than the emotion notation word among the words of the surrounding speech of the statement, A predetermined value that reduces the degree of strength of the specific emotion compared to the value of the emotion vector assigned to the emotion notation word ,
With reference to the user's past log and the emotion notation word, in the user's remarks, when it is determined that the remark frequency of the emotion notation word indicating the specific emotion is greater than a predetermined threshold, The value of the emotion vector assigned to the emotion notation word is corrected to a value that reduces the degree of strength of the specific emotion, and the frequency of the emotion notation word indicating an emotion that conflicts with the specific emotion Is determined to be greater than a predetermined threshold, the value of the emotion vector assigned to the emotion notation word is corrected to an increased value of the strength of the specific emotion. Emotion estimation method.
ある特定の感情とその相反する感情を示す語句である感情表記ワードを格納する一般感情表記ワード記録部を参照して、ユーザごとの発言内容を示した過去ログから、ネガティブまたはポジティブな感情を示す語句である感情表記ワードのいずれかを含む発言を検索する感情表記ワード検索ステップと、
前記ユーザの過去ログから、前記検索された感情表記ワードを含む発言を中心として前後所定範囲内の発言である周辺発言を抽出する前後発言抽出ステップと、
前記ユーザごとに、前記発言の単語それぞれの意味する個人の感情の強さの度合いを表す感情ベクトルの値を示した教師データを作成する特徴量抽出ステップと、
前記ユーザの前記教師データを用いて、前記ユーザの発言が意味する前記ある特定の感情の傾向を判断して、前記判断結果を出力する発言解析ステップとを実行させ、
前記特徴量抽出ステップは、
前記単語それぞれの感情ベクトルの値を決定するとき、前記感情表記ワード検索ステップにより検索された発言に含まれる感情表記ワードに対し、前記発言に含まれる感情表記ワードが示す感情の種別に応じた所定の感情の強さの度合いを示す値を前記感情表記ワードの感情ベクトルの値として付与し、前記発言の周辺発言の単語のうち、前記感情表記ワード以外の単語それぞれに対する感情ベクトルの値として、前記感情表記ワードに付与した前記感情ベクトルの値と比較して前記ある特定の感情の強さの度合いを軽減した所定の値を付与し、
前記ユーザの過去ログと前記感情表記ワードとを参照して、前記ユーザの発言において、前記ある特定の感情を示す前記感情表記ワードの発言頻度が所定の閾値よりも多いと判断された場合は、前記感情表記ワードに付与された前記感情ベクトルの値について、前記ある特定の感情の強さの度合いを軽減した値に修正し、前記ある特定の感情と相反する感情を示す感情表記ワードの発言頻度が所定の閾値よりも多いと判断された場合は、前記感情表記ワードに付与された前記感情ベクトルの値について、前記ある特定の感情の強さの度合いを増大した値に修正する
ためのプログラム。 Emotion estimation device
Refers to the general emotion notation word recording unit that stores the emotion notation word, which is a phrase indicating a specific emotion and the opposite emotion, and indicates negative or positive emotion from the past log showing the content of each user's utterance An emotion expression word search step for searching for a statement including any of the emotion expression words that are phrases;
Before-and-after utterance extraction step of extracting peripheral utterances that are utterances within a predetermined range around the utterance including the searched emotion expression word from the user's past log;
A feature amount extraction step for creating teacher data indicating a value of an emotion vector representing the degree of the strength of personal emotion that each of the words of the speech means for each user,
Using the teacher data of the user to determine the tendency of the certain emotion that the user's statement means, and to execute a statement analysis step of outputting the determination result;
The feature amount extraction step includes:
When determining the value of the emotion vector for each of the words, a predetermined value corresponding to the type of emotion indicated by the emotion notation word included in the statement with respect to the emotion notation word included in the statement searched by the emotion notation word search step A value indicating the degree of emotion strength is given as the value of the emotion vector of the emotion notation word, and the value of the emotion vector for each of the words other than the emotion notation word among the words of the surrounding speech of the statement, A predetermined value that reduces the degree of strength of the specific emotion compared to the value of the emotion vector assigned to the emotion notation word ,
With reference to the user's past log and the emotion notation word, in the user's remarks, when it is determined that the remark frequency of the emotion notation word indicating the specific emotion is greater than a predetermined threshold, The value of the emotion vector assigned to the emotion notation word is corrected to a value that reduces the degree of strength of the specific emotion, and the frequency of the emotion notation word indicating an emotion that conflicts with the specific emotion A program for correcting the value of the emotion vector assigned to the emotion notation word to a value that increases the degree of strength of the specific emotion when it is determined that is greater than a predetermined threshold .
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2013059880A JP5947237B2 (en) | 2013-03-22 | 2013-03-22 | Emotion estimation device, emotion estimation method, and program |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2013059880A JP5947237B2 (en) | 2013-03-22 | 2013-03-22 | Emotion estimation device, emotion estimation method, and program |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2014186451A JP2014186451A (en) | 2014-10-02 |
| JP5947237B2 true JP5947237B2 (en) | 2016-07-06 |
Family
ID=51833989
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2013059880A Active JP5947237B2 (en) | 2013-03-22 | 2013-03-22 | Emotion estimation device, emotion estimation method, and program |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP5947237B2 (en) |
Families Citing this family (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6285377B2 (en) * | 2015-02-26 | 2018-02-28 | 日本電信電話株式会社 | Communication skill evaluation feedback device, communication skill evaluation feedback method, and communication skill evaluation feedback program |
| JP6617053B2 (en) * | 2016-02-29 | 2019-12-04 | Kddi株式会社 | Utterance semantic analysis program, apparatus and method for improving understanding of context meaning by emotion classification |
| JP6605410B2 (en) * | 2016-07-15 | 2019-11-13 | Kddi株式会社 | Emotion factor estimation support device, emotion factor estimation support method, and emotion factor estimation support program |
| CN107506349A (en) * | 2017-08-04 | 2017-12-22 | 卓智网络科技有限公司 | A kind of user's negative emotions Forecasting Methodology and system based on network log |
| CN111259674B (en) * | 2020-01-13 | 2023-07-25 | 山东浪潮科学研究院有限公司 | Text proofreading and emotion analysis method, equipment and medium based on GAN network |
| WO2022024355A1 (en) * | 2020-07-31 | 2022-02-03 | 株式会社I’mbesideyou | Emotion analysis system |
| JP7368335B2 (en) * | 2020-09-24 | 2023-10-24 | Kddi株式会社 | Programs, devices and methods for interacting with positive parroting responses |
Family Cites Families (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6622140B1 (en) * | 2000-11-15 | 2003-09-16 | Justsystem Corporation | Method and apparatus for analyzing affect and emotion in text |
| JP2002230011A (en) * | 2001-02-05 | 2002-08-16 | Seiko Epson Corp | Sensitivity recognizing system |
| JP2004280190A (en) * | 2003-03-12 | 2004-10-07 | Nippon Telegr & Teleph Corp <Ntt> | Word of mouth information analysis method |
| JP3903993B2 (en) * | 2004-02-05 | 2007-04-11 | セイコーエプソン株式会社 | Sentiment recognition device, sentence emotion recognition method and program |
| US8352405B2 (en) * | 2011-04-21 | 2013-01-08 | Palo Alto Research Center Incorporated | Incorporating lexicon knowledge into SVM learning to improve sentiment classification |
-
2013
- 2013-03-22 JP JP2013059880A patent/JP5947237B2/en active Active
Also Published As
| Publication number | Publication date |
|---|---|
| JP2014186451A (en) | 2014-10-02 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5947237B2 (en) | Emotion estimation device, emotion estimation method, and program | |
| JP5775466B2 (en) | Chat extraction system, method, and program for extracting chat part from conversation | |
| US10650801B2 (en) | Language recognition method, apparatus and device and computer storage medium | |
| JP2015506515A (en) | Method, apparatus and computer storage medium for automatically adding tags to a document | |
| JP5496863B2 (en) | Emotion estimation apparatus, method, program, and recording medium | |
| JP6429706B2 (en) | Voice dialogue apparatus, voice dialogue method and program | |
| EP3542282B1 (en) | Autonomously providing search results post-facto, including in conversational assistant context | |
| WO2017020454A1 (en) | Search method and apparatus | |
| CN111883137B (en) | Text processing method and device based on voice recognition | |
| US20200219487A1 (en) | Information processing apparatus and information processing method | |
| WO2016015431A1 (en) | Search method, apparatus and device and non-volatile computer storage medium | |
| JP2016192020A5 (en) | ||
| US11082369B1 (en) | Domain-specific chatbot utterance collection | |
| CN112836016B (en) | Conference summary generation method, device, equipment and storage medium | |
| WO2014036827A1 (en) | Text correcting method and user equipment | |
| JP6165657B2 (en) | Information processing apparatus, information processing method, and program | |
| KR101625787B1 (en) | Method and server for estimating the sentiment value of word | |
| JP2018185561A (en) | Dialogue support system, dialogue support method, and dialogue support program | |
| JP5084297B2 (en) | Conversation analyzer and conversation analysis program | |
| KR20130022075A (en) | Method for building emotional lexical information and apparatus for the same | |
| CN111881672A (en) | Intention identification method | |
| Malandrakis et al. | Sail: Sentiment analysis using semantic similarity and contrast features | |
| JP2006209332A (en) | Sense of value estimation method and device and its program | |
| WO2024037483A1 (en) | Text processing method and apparatus, and electronic device and medium | |
| US11763803B1 (en) | System, method, and computer program for extracting utterances corresponding to a user problem statement in a conversation between a human agent and a user |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20150226 |
|
| RD02 | Notification of acceptance of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7422 Effective date: 20151001 |
|
| RD04 | Notification of resignation of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7424 Effective date: 20151005 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20151211 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20151215 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20160127 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20160531 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20160602 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 5947237 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |