JP5284785B2 - コンテンツベースの音声再生強調 - Google Patents
コンテンツベースの音声再生強調 Download PDFInfo
- Publication number
- JP5284785B2 JP5284785B2 JP2008522799A JP2008522799A JP5284785B2 JP 5284785 B2 JP5284785 B2 JP 5284785B2 JP 2008522799 A JP2008522799 A JP 2008522799A JP 2008522799 A JP2008522799 A JP 2008522799A JP 5284785 B2 JP5284785 B2 JP 5284785B2
- Authority
- JP
- Japan
- Prior art keywords
- audio stream
- region
- relevance
- value
- enhancement
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images




Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/26—Speech to text systems
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/232—Orthographic correction, e.g. spell checking or vowelisation
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/30—Semantic analysis
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
- G10L15/18—Speech classification or search using natural language modelling
- G10L15/1807—Speech classification or search using natural language modelling using prosody or stress
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/22—Procedures used during a speech recognition process, e.g. man-machine dialogue
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/04—Time compression or expansion
Landscapes
- Engineering & Computer Science (AREA)
- Computational Linguistics (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Physics & Mathematics (AREA)
- Human Computer Interaction (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Theoretical Computer Science (AREA)
- Artificial Intelligence (AREA)
- Signal Processing (AREA)
- Quality & Reliability (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- General Health & Medical Sciences (AREA)
- Signal Processing For Digital Recording And Reproducing (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Machine Translation (AREA)
- Transition And Organic Metals Composition Catalysts For Addition Polymerization (AREA)
- Document Processing Apparatus (AREA)
Description
本出願は、参照により本明細書に組み込まれる、以下の同一人所有の米国特許出願に関連する。
人間の発話を転写することが、多くの状況において望ましい。法律専門分野においては、例えば、転写士は、供述書の文書による転写物を生成するために、公判および宣誓証言で得た供述を転写する。同様に、医療専門分野においては、医者および他の医療専門家によって口述された診断、予後診断、処方薬、ならびに他の情報の転写物が生成される。これらおよび他の分野の転写士は通常、得られる転写物に対する依存および不正確さから生じる可能性のある害(患者に誤った処方薬を与えるなど)のために、非常に正確(元の発話の語義内容(意味)と得られる転写物の語義内容との一致度の観点から測定される)であることが要求される。(1)発話が転写される発話者の特徴(例えば、訛り、音量、方言、速度)、(2)外部条件(例えば、背景の騒音)(3)転写士または転写システム(例えば、不完全な聴力または音声獲得能力、言語の不完全な理解力)、または(4)録音/伝送媒体(例えば、紙、アナログオーディオテープ、アナログ電話網、デジタル電話網に適用される圧縮アルゴリズム、携帯電話チャネルによる雑音/アーチファクト)におけるばらつきなどの様々な理由により、非常に正確な初期転写物を生成することは困難となる場合がある。
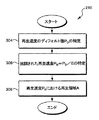
口頭の音声ストリームの原稿転写物を校正するプロセスを容易にするための技術が開示されている。一般に、原稿転写物の校正は、関連性が高いか、またはおそらく不正確に転写されている前記音声ストリームのこれらの領域を強調することにより、対応する前記口頭の音声ストリームを再生することによって容易にする。領域は、例えば、関連性が低く、またおそらく正確に転写されている領域より遅く再生することにより強調してもよい。正確に転写するために最も重要な前記音声ストリームのこれらの領域、および不正確に転写されている可能性の高いこれらの領域を強調することは、校正者が、これらの領域でのどのようなエラーでも正確に修正する可能性を向上させることによって、転写物全体の精度を向上させる。
Claims (9)
- (A)文書の一の領域と口頭の音声ストリームの対応する一の領域とから、前記文書の前記領域が、前記口頭の音声ストリームの前記対応する領域での内容を正確に表す可能性を特定するステップと、
(B)前記口頭の音声ストリームの前記領域での関連性の値を選択するステップであって、前記関連性の値が人間の校正者の注意を前記口頭の音声ストリームの前記領域に向けさせることの重要性の値を表しているものであるステップと、
(C)前記可能性および前記関連性の値から、再生されたとき、前記口頭の音声ストリームの前記領域に対する強調を変更するための強調係数を特定するステップであって、前記特定された可能性に関連した第1の重みを特定し、前記関連性の値に関連した第2の重みを特定し、且つ、前記第1及び第2の重みによってそれぞれ加重した前記特定された可能性と前記関連性の値との組み合わせから前記強調係数を特定する、ステップを含む方法。 - 前記ステップ(C)は、前記可能性および前記関連性の値から、前記口頭の音声ストリームの前記領域での再生速度を調整するための時間スケール調整係数を特定するステップを含む、
請求項1に記載の方法。 - (D)強調が調整される音声ストリームを生成するために前記強調係数に従って、前記口頭の音声ストリームの前記領域での強調を変更するステップをさらに含む、請求項1記載の方法。
- 前記ステップ(A)は、(A)(1)前記文書の前記領域が、前記口頭の音声ストリームの前記対応する領域での前記内容を正確に表す信頼度を表す信頼値から前記可能性を特定するステップであって、
前記信頼値は、前記口頭の音声ストリームの前記領域に基づき、前記文書の前記領域を生成した自動転写システムによって提供されるステップを含む、請求項1記載の方法。 - 文書の一の領域と口頭の音声ストリームの対応する一の領域とから、前記文書の前記領域が、前記口頭の音声ストリームの対応する前記領域での内容を正確に表す可能性を特定するための正確性特定手段と、
前記口頭の音声ストリームの前記領域の関連性の値を選択する関連性特定手段であって、前記関連性の値が人間の校正者の注意を前記口頭の音声ストリームの前記領域に向けさせることの重要性の値を表しているものである関連性特定手段と、
前記可能性および前記関連性の値から、再生されたとき、前記口頭の音声ストリームの前記領域に置かれる強調を変更するために強調係数を特定するための第2の特定手段と、
を含む器具。 - (A)文書の一の領域と特定の内容とから、前記文書の前記領域が前記特定の内容を正確に表す可能性を特定するステップと、
(B)口頭の音声ストリームの領域の関連性の値を選択するステップであって、前記関連性の値が人間の校正者の注意を前記口頭の音声ストリームの前記領域に向けさせることの重要性の値を表しているものであるステップと、
(C)前記可能性および前記関連性の値から、強調係数を特定するステップであって、前記特定された可能性に関連した第1の重みを特定し、前記関連性の値に関連した第2の重みを特定し、且つ、前記第1及び第2の重みによってそれぞれ加重した前記特定された可能性と前記関連性の値との組み合わせから前記強調係数を特定する、ステップと、
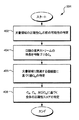
(D)前記強調係数によって特定された強調を有する前記文書の前記領域を表す音声ストリームを再生するためのテキスト発話エンジンを使用するステップと、
を含む、方法。 - (E)前記音声ストリームに基づき、前記文書のエラーを修正するステップ、
をさらに含む、請求項6記載の方法。 - 文書の一の領域と特定の内容とから、前記文書の領域が、前記特定の内容を正確に表す可能性を特定するための正確性特定手段と、
口頭の音声ストリームの前記領域の関連性の値を選択する関連性特定手段であって、前記関連性の値が人間の校正者の注意を前記口頭の音声ストリームの前記領域に向けさせることの重要性の値を表しているものである関連性特定手段と、
前記可能性および前記関連性の値から、強調係数を特定するための第2の特定手段であって、前記特定された可能性に関連した第1の重みを特定し、前記関連性の値に関連した第2の重みを特定し、且つ、前記第1及び第2の重みによってそれぞれ加重した前記特定された可能性と前記関連性の値との組み合わせから前記強調係数を特定する、第2の特定手段と、
前記強調係数によって特定された強調を有する前記文書の前記領域を表す音声ストリームを再生するためのテキスト発話エンジンと、
含む、器具。 - 前記第2の特定手段は、前記可能性および前記関連性の値から、前記音声ストリームの再生速度を調整するための時間スケール調整係数を特定するための手段を含む、請求項8に記載の器具。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US11/187,119 | 2005-07-22 | ||
| US11/187,119 US7844464B2 (en) | 2005-07-22 | 2005-07-22 | Content-based audio playback emphasis |
| PCT/US2006/026141 WO2007018842A2 (en) | 2005-07-22 | 2006-07-06 | Content-based audio playback emphasis |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2009503560A JP2009503560A (ja) | 2009-01-29 |
| JP2009503560A5 JP2009503560A5 (ja) | 2009-08-13 |
| JP5284785B2 true JP5284785B2 (ja) | 2013-09-11 |
Family
ID=37718652
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2008522799A Expired - Fee Related JP5284785B2 (ja) | 2005-07-22 | 2006-07-06 | コンテンツベースの音声再生強調 |
Country Status (6)
| Country | Link |
|---|---|
| US (4) | US7844464B2 (ja) |
| EP (1) | EP1908055B1 (ja) |
| JP (1) | JP5284785B2 (ja) |
| AT (1) | ATE454691T1 (ja) |
| DE (1) | DE602006011622D1 (ja) |
| WO (1) | WO2007018842A2 (ja) |
Families Citing this family (47)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8335688B2 (en) * | 2004-08-20 | 2012-12-18 | Multimodal Technologies, Llc | Document transcription system training |
| US7844464B2 (en) * | 2005-07-22 | 2010-11-30 | Multimodal Technologies, Inc. | Content-based audio playback emphasis |
| US7502741B2 (en) * | 2005-02-23 | 2009-03-10 | Multimodal Technologies, Inc. | Audio signal de-identification |
| US7640158B2 (en) | 2005-11-08 | 2009-12-29 | Multimodal Technologies, Inc. | Automatic detection and application of editing patterns in draft documents |
| US20070250311A1 (en) * | 2006-04-25 | 2007-10-25 | Glen Shires | Method and apparatus for automatic adjustment of play speed of audio data |
| WO2007150004A2 (en) * | 2006-06-22 | 2007-12-27 | Multimodal Technologies, Inc. | Verification of extracted data |
| US20080177623A1 (en) * | 2007-01-24 | 2008-07-24 | Juergen Fritsch | Monitoring User Interactions With A Document Editing System |
| KR100883657B1 (ko) * | 2007-01-26 | 2009-02-18 | 삼성전자주식회사 | 음성 인식 기반의 음악 검색 방법 및 장치 |
| US8019608B2 (en) | 2008-08-29 | 2011-09-13 | Multimodal Technologies, Inc. | Distributed speech recognition using one way communication |
| US8572488B2 (en) * | 2010-03-29 | 2013-10-29 | Avid Technology, Inc. | Spot dialog editor |
| US9558755B1 (en) | 2010-05-20 | 2017-01-31 | Knowles Electronics, Llc | Noise suppression assisted automatic speech recognition |
| US9715540B2 (en) * | 2010-06-24 | 2017-07-25 | International Business Machines Corporation | User driven audio content navigation |
| US20120035922A1 (en) * | 2010-08-05 | 2012-02-09 | Carroll Martin D | Method and apparatus for controlling word-separation during audio playout |
| US8959102B2 (en) | 2010-10-08 | 2015-02-17 | Mmodal Ip Llc | Structured searching of dynamic structured document corpuses |
| GB2502944A (en) * | 2012-03-30 | 2013-12-18 | Jpal Ltd | Segmentation and transcription of speech |
| US9412372B2 (en) * | 2012-05-08 | 2016-08-09 | SpeakWrite, LLC | Method and system for audio-video integration |
| US9575960B1 (en) * | 2012-09-17 | 2017-02-21 | Amazon Technologies, Inc. | Auditory enhancement using word analysis |
| US9640194B1 (en) | 2012-10-04 | 2017-05-02 | Knowles Electronics, Llc | Noise suppression for speech processing based on machine-learning mask estimation |
| US9135916B2 (en) | 2013-02-26 | 2015-09-15 | Honeywell International Inc. | System and method for correcting accent induced speech transmission problems |
| US11022456B2 (en) | 2013-07-25 | 2021-06-01 | Nokia Technologies Oy | Method of audio processing and audio processing apparatus |
| US9293150B2 (en) | 2013-09-12 | 2016-03-22 | International Business Machines Corporation | Smoothening the information density of spoken words in an audio signal |
| CN105335595A (zh) | 2014-06-30 | 2016-02-17 | 杜比实验室特许公司 | 基于感受的多媒体处理 |
| CN106797512B (zh) * | 2014-08-28 | 2019-10-25 | 美商楼氏电子有限公司 | 多源噪声抑制的方法、系统和非瞬时计算机可读存储介质 |
| US10169826B1 (en) * | 2014-10-31 | 2019-01-01 | Intuit Inc. | System and method for generating explanations for tax calculations |
| US10387970B1 (en) | 2014-11-25 | 2019-08-20 | Intuit Inc. | Systems and methods for analyzing and generating explanations for changes in tax return results |
| US20160336023A1 (en) * | 2015-05-13 | 2016-11-17 | Nuance Communications, Inc. | Methods and apparatus for improving understandability of audio corresponding to dictation |
| US9852743B2 (en) * | 2015-11-20 | 2017-12-26 | Adobe Systems Incorporated | Automatic emphasis of spoken words |
| US12020334B2 (en) | 2016-10-26 | 2024-06-25 | Intuit Inc. | Methods, systems and computer program products for generating and presenting explanations for tax questions |
| US20180130484A1 (en) | 2016-11-07 | 2018-05-10 | Axon Enterprise, Inc. | Systems and methods for interrelating text transcript information with video and/or audio information |
| US11316865B2 (en) | 2017-08-10 | 2022-04-26 | Nuance Communications, Inc. | Ambient cooperative intelligence system and method |
| US10546655B2 (en) | 2017-08-10 | 2020-01-28 | Nuance Communications, Inc. | Automated clinical documentation system and method |
| US11227688B2 (en) | 2017-10-23 | 2022-01-18 | Google Llc | Interface for patient-provider conversation and auto-generation of note or summary |
| US11743243B2 (en) | 2017-10-31 | 2023-08-29 | Conduent Business Services, Llc | Post billing short-range communications HCE (host card emulation) method and system |
| US10657202B2 (en) | 2017-12-11 | 2020-05-19 | International Business Machines Corporation | Cognitive presentation system and method |
| WO2019173331A1 (en) | 2018-03-05 | 2019-09-12 | Nuance Communications, Inc. | System and method for review of automated clinical documentation |
| US11250383B2 (en) | 2018-03-05 | 2022-02-15 | Nuance Communications, Inc. | Automated clinical documentation system and method |
| US11515020B2 (en) | 2018-03-05 | 2022-11-29 | Nuance Communications, Inc. | Automated clinical documentation system and method |
| US11245950B1 (en) * | 2019-04-24 | 2022-02-08 | Amazon Technologies, Inc. | Lyrics synchronization |
| US11216480B2 (en) | 2019-06-14 | 2022-01-04 | Nuance Communications, Inc. | System and method for querying data points from graph data structures |
| US11227679B2 (en) | 2019-06-14 | 2022-01-18 | Nuance Communications, Inc. | Ambient clinical intelligence system and method |
| US11043207B2 (en) | 2019-06-14 | 2021-06-22 | Nuance Communications, Inc. | System and method for array data simulation and customized acoustic modeling for ambient ASR |
| US11531807B2 (en) | 2019-06-28 | 2022-12-20 | Nuance Communications, Inc. | System and method for customized text macros |
| KR102914202B1 (ko) * | 2019-09-18 | 2026-01-20 | 엘지전자 주식회사 | 단어 사용 빈도를 고려하여 사용자의 음성을 인식하는 인공 지능 장치 및 그 방법 |
| US11670408B2 (en) | 2019-09-30 | 2023-06-06 | Nuance Communications, Inc. | System and method for review of automated clinical documentation |
| CA3162501A1 (en) | 2019-12-18 | 2021-06-24 | Lutron Technology Company Llc | Optimization of load control environments |
| US11222103B1 (en) | 2020-10-29 | 2022-01-11 | Nuance Communications, Inc. | Ambient cooperative intelligence system and method |
| US12443388B2 (en) * | 2023-06-13 | 2025-10-14 | Sony Group Corporation | Audio skip back response to noise interference |
Family Cites Families (75)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4674065A (en) * | 1982-04-30 | 1987-06-16 | International Business Machines Corporation | System for detecting and correcting contextual errors in a text processing system |
| US4696039A (en) | 1983-10-13 | 1987-09-22 | Texas Instruments Incorporated | Speech analysis/synthesis system with silence suppression |
| JPS61233832A (ja) | 1985-04-08 | 1986-10-18 | Toshiba Corp | 読合わせ校正装置 |
| US5418717A (en) * | 1990-08-27 | 1995-05-23 | Su; Keh-Yih | Multiple score language processing system |
| US5832430A (en) * | 1994-12-29 | 1998-11-03 | Lucent Technologies, Inc. | Devices and methods for speech recognition of vocabulary words with simultaneous detection and verification |
| US5659771A (en) * | 1995-05-19 | 1997-08-19 | Mitsubishi Electric Information Technology Center America, Inc. | System for spelling correction in which the context of a target word in a sentence is utilized to determine which of several possible words was intended |
| US5828994A (en) | 1996-06-05 | 1998-10-27 | Interval Research Corporation | Non-uniform time scale modification of recorded audio |
| US20020032571A1 (en) * | 1996-09-25 | 2002-03-14 | Ka Y. Leung | Method and apparatus for storing digital audio and playback thereof |
| US5893062A (en) | 1996-12-05 | 1999-04-06 | Interval Research Corporation | Variable rate video playback with synchronized audio |
| US6122613A (en) * | 1997-01-30 | 2000-09-19 | Dragon Systems, Inc. | Speech recognition using multiple recognizers (selectively) applied to the same input sample |
| US6064957A (en) * | 1997-08-15 | 2000-05-16 | General Electric Company | Improving speech recognition through text-based linguistic post-processing |
| US6006183A (en) * | 1997-12-16 | 1999-12-21 | International Business Machines Corp. | Speech recognition confidence level display |
| US6782510B1 (en) * | 1998-01-27 | 2004-08-24 | John N. Gross | Word checking tool for controlling the language content in documents using dictionaries with modifyable status fields |
| US6304848B1 (en) * | 1998-08-13 | 2001-10-16 | Medical Manager Corp. | Medical record forming and storing apparatus and medical record and method related to same |
| US6490563B2 (en) * | 1998-08-17 | 2002-12-03 | Microsoft Corporation | Proofreading with text to speech feedback |
| US6064965A (en) * | 1998-09-02 | 2000-05-16 | International Business Machines Corporation | Combined audio playback in speech recognition proofreader |
| US6064961A (en) * | 1998-09-02 | 2000-05-16 | International Business Machines Corporation | Display for proofreading text |
| US6338038B1 (en) * | 1998-09-02 | 2002-01-08 | International Business Machines Corp. | Variable speed audio playback in speech recognition proofreader |
| US6285978B1 (en) * | 1998-09-24 | 2001-09-04 | International Business Machines Corporation | System and method for estimating accuracy of an automatic natural language translation |
| US6161087A (en) | 1998-10-05 | 2000-12-12 | Lernout & Hauspie Speech Products N.V. | Speech-recognition-assisted selective suppression of silent and filled speech pauses during playback of an audio recording |
| US6374225B1 (en) | 1998-10-09 | 2002-04-16 | Enounce, Incorporated | Method and apparatus to prepare listener-interest-filtered works |
| US6571210B2 (en) * | 1998-11-13 | 2003-05-27 | Microsoft Corporation | Confidence measure system using a near-miss pattern |
| US6611802B2 (en) * | 1999-06-11 | 2003-08-26 | International Business Machines Corporation | Method and system for proofreading and correcting dictated text |
| US6332122B1 (en) * | 1999-06-23 | 2001-12-18 | International Business Machines Corporation | Transcription system for multiple speakers, using and establishing identification |
| US6490558B1 (en) * | 1999-07-28 | 2002-12-03 | Custom Speech Usa, Inc. | System and method for improving the accuracy of a speech recognition program through repetitive training |
| US6418410B1 (en) * | 1999-09-27 | 2002-07-09 | International Business Machines Corporation | Smart correction of dictated speech |
| US6963837B1 (en) * | 1999-10-06 | 2005-11-08 | Multimodal Technologies, Inc. | Attribute-based word modeling |
| US6446041B1 (en) * | 1999-10-27 | 2002-09-03 | Microsoft Corporation | Method and system for providing audio playback of a multi-source document |
| US6912498B2 (en) * | 2000-05-02 | 2005-06-28 | Scansoft, Inc. | Error correction in speech recognition by correcting text around selected area |
| US6505153B1 (en) | 2000-05-22 | 2003-01-07 | Compaq Information Technologies Group, L.P. | Efficient method for producing off-line closed captions |
| US6735562B1 (en) * | 2000-06-05 | 2004-05-11 | Motorola, Inc. | Method for estimating a confidence measure for a speech recognition system |
| US7003456B2 (en) * | 2000-06-12 | 2006-02-21 | Scansoft, Inc. | Methods and systems of routing utterances based on confidence estimates |
| US6795806B1 (en) * | 2000-09-20 | 2004-09-21 | International Business Machines Corporation | Method for enhancing dictation and command discrimination |
| US20020077833A1 (en) * | 2000-12-20 | 2002-06-20 | Arons Barry M. | Transcription and reporting system |
| US20020156816A1 (en) * | 2001-02-13 | 2002-10-24 | Mark Kantrowitz | Method and apparatus for learning from user self-corrections, revisions and modifications |
| US7062437B2 (en) * | 2001-02-13 | 2006-06-13 | International Business Machines Corporation | Audio renderings for expressing non-audio nuances |
| US7039585B2 (en) * | 2001-04-10 | 2006-05-02 | International Business Machines Corporation | Method and system for searching recorded speech and retrieving relevant segments |
| US6973428B2 (en) | 2001-05-24 | 2005-12-06 | International Business Machines Corporation | System and method for searching, analyzing and displaying text transcripts of speech after imperfect speech recognition |
| GB0113570D0 (en) * | 2001-06-04 | 2001-07-25 | Hewlett Packard Co | Audio-form presentation of text messages |
| JP4128342B2 (ja) * | 2001-07-19 | 2008-07-30 | 三菱電機株式会社 | 対話処理装置及び対話処理方法並びにプログラム |
| DE10138408A1 (de) * | 2001-08-04 | 2003-02-20 | Philips Corp Intellectual Pty | Verfahren zur Unterstützung des Korrekturlesens eines spracherkannten Textes mit an die Erkennungszuverlässigkeit angepasstem Wiedergabegeschwindigkeitsverlauf |
| EP1442451B1 (en) * | 2001-10-31 | 2006-05-03 | Koninklijke Philips Electronics N.V. | Method of and system for transcribing dictations in text files and for revising the texts |
| US20030144885A1 (en) * | 2002-01-29 | 2003-07-31 | Exscribe, Inc. | Medical examination and transcription method, and associated apparatus |
| US7266127B2 (en) | 2002-02-08 | 2007-09-04 | Lucent Technologies Inc. | Method and system to compensate for the effects of packet delays on speech quality in a Voice-over IP system |
| US6625387B1 (en) | 2002-03-01 | 2003-09-23 | Thomson Licensing S.A. | Gated silence removal during video trick modes |
| US7130528B2 (en) | 2002-03-01 | 2006-10-31 | Thomson Licensing | Audio data deletion and silencing during trick mode replay |
| US7292975B2 (en) * | 2002-05-01 | 2007-11-06 | Nuance Communications, Inc. | Systems and methods for evaluating speaker suitability for automatic speech recognition aided transcription |
| US7249012B2 (en) * | 2002-11-20 | 2007-07-24 | Microsoft Corporation | Statistical method and apparatus for learning translation relationships among phrases |
| JP2004191620A (ja) | 2002-12-11 | 2004-07-08 | Pentax Corp | 記録媒体、再生装置、及び記録媒体の再生方法 |
| US7117437B2 (en) * | 2002-12-16 | 2006-10-03 | Palo Alto Research Center Incorporated | Systems and methods for displaying interactive topic-based text summaries |
| WO2004066271A1 (ja) * | 2003-01-20 | 2004-08-05 | Fujitsu Limited | 音声合成装置,音声合成方法および音声合成システム |
| GB2399427A (en) * | 2003-03-12 | 2004-09-15 | Canon Kk | Apparatus for and method of summarising text |
| JP5025261B2 (ja) * | 2003-03-31 | 2012-09-12 | ニュアンス コミュニケーションズ オーストリア ゲーエムベーハー | 信頼水準の指示により音声認識の結果を訂正するためのシステム |
| US20040243545A1 (en) * | 2003-05-29 | 2004-12-02 | Dictaphone Corporation | Systems and methods utilizing natural language medical records |
| US7383172B1 (en) * | 2003-08-15 | 2008-06-03 | Patrick William Jamieson | Process and system for semantically recognizing, correcting, and suggesting domain specific speech |
| US7274775B1 (en) * | 2003-08-27 | 2007-09-25 | Escription, Inc. | Transcription playback speed setting |
| US7346506B2 (en) * | 2003-10-08 | 2008-03-18 | Agfa Inc. | System and method for synchronized text display and audio playback |
| WO2005050621A2 (en) * | 2003-11-21 | 2005-06-02 | Philips Intellectual Property & Standards Gmbh | Topic specific models for text formatting and speech recognition |
| US8200487B2 (en) * | 2003-11-21 | 2012-06-12 | Nuance Communications Austria Gmbh | Text segmentation and label assignment with user interaction by means of topic specific language models and topic-specific label statistics |
| US20070067168A1 (en) * | 2003-11-28 | 2007-03-22 | Koninklijke Philips Electronics N.V. | Method and device for transcribing an audio signal |
| US7542971B2 (en) * | 2004-02-02 | 2009-06-02 | Fuji Xerox Co., Ltd. | Systems and methods for collaborative note-taking |
| US7584103B2 (en) * | 2004-08-20 | 2009-09-01 | Multimodal Technologies, Inc. | Automated extraction of semantic content and generation of a structured document from speech |
| US8412521B2 (en) * | 2004-08-20 | 2013-04-02 | Multimodal Technologies, Llc | Discriminative training of document transcription system |
| US20130304453A9 (en) * | 2004-08-20 | 2013-11-14 | Juergen Fritsch | Automated Extraction of Semantic Content and Generation of a Structured Document from Speech |
| US7844464B2 (en) * | 2005-07-22 | 2010-11-30 | Multimodal Technologies, Inc. | Content-based audio playback emphasis |
| KR100655491B1 (ko) * | 2004-12-21 | 2006-12-11 | 한국전자통신연구원 | 음성인식 시스템에서의 2단계 발화 검증 방법 및 장치 |
| US7912713B2 (en) * | 2004-12-28 | 2011-03-22 | Loquendo S.P.A. | Automatic speech recognition system and method using weighted confidence measure |
| US8175877B2 (en) * | 2005-02-02 | 2012-05-08 | At&T Intellectual Property Ii, L.P. | Method and apparatus for predicting word accuracy in automatic speech recognition systems |
| US7502741B2 (en) * | 2005-02-23 | 2009-03-10 | Multimodal Technologies, Inc. | Audio signal de-identification |
| US7640158B2 (en) * | 2005-11-08 | 2009-12-29 | Multimodal Technologies, Inc. | Automatic detection and application of editing patterns in draft documents |
| WO2007150004A2 (en) * | 2006-06-22 | 2007-12-27 | Multimodal Technologies, Inc. | Verification of extracted data |
| JP4875752B2 (ja) * | 2006-11-22 | 2012-02-15 | マルチモーダル・テクノロジーズ・インク | 編集可能なオーディオストリームにおける音声の認識 |
| WO2008073850A2 (en) * | 2006-12-08 | 2008-06-19 | Sri International | Method and apparatus for reading education |
| US7933777B2 (en) * | 2008-08-29 | 2011-04-26 | Multimodal Technologies, Inc. | Hybrid speech recognition |
| CA2680304C (en) * | 2008-09-25 | 2017-08-22 | Multimodal Technologies, Inc. | Decoding-time prediction of non-verbalized tokens |
-
2005
- 2005-07-22 US US11/187,119 patent/US7844464B2/en not_active Expired - Fee Related
-
2006
- 2006-07-06 DE DE602006011622T patent/DE602006011622D1/de active Active
- 2006-07-06 JP JP2008522799A patent/JP5284785B2/ja not_active Expired - Fee Related
- 2006-07-06 WO PCT/US2006/026141 patent/WO2007018842A2/en not_active Ceased
- 2006-07-06 AT AT06786330T patent/ATE454691T1/de not_active IP Right Cessation
- 2006-07-06 EP EP06786330A patent/EP1908055B1/en not_active Not-in-force
-
2010
- 2010-08-20 US US12/859,883 patent/US8768706B2/en not_active Expired - Fee Related
-
2014
- 2014-06-27 US US14/317,873 patent/US9135917B2/en not_active Expired - Fee Related
-
2015
- 2015-09-11 US US14/852,021 patent/US9454965B2/en not_active Expired - Lifetime
Also Published As
| Publication number | Publication date |
|---|---|
| ATE454691T1 (de) | 2010-01-15 |
| US20070033032A1 (en) | 2007-02-08 |
| EP1908055A2 (en) | 2008-04-09 |
| EP1908055B1 (en) | 2010-01-06 |
| US9454965B2 (en) | 2016-09-27 |
| US20140309995A1 (en) | 2014-10-16 |
| US7844464B2 (en) | 2010-11-30 |
| WO2007018842A2 (en) | 2007-02-15 |
| WO2007018842A3 (en) | 2007-10-04 |
| US20100318347A1 (en) | 2010-12-16 |
| US20160005402A1 (en) | 2016-01-07 |
| US9135917B2 (en) | 2015-09-15 |
| DE602006011622D1 (de) | 2010-02-25 |
| JP2009503560A (ja) | 2009-01-29 |
| EP1908055A4 (en) | 2008-11-26 |
| US8768706B2 (en) | 2014-07-01 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5284785B2 (ja) | コンテンツベースの音声再生強調 | |
| US7292975B2 (en) | Systems and methods for evaluating speaker suitability for automatic speech recognition aided transcription | |
| JP5255769B2 (ja) | テキストフォーマッティング及びスピーチ認識のためのトピック特有のモデル | |
| US9552809B2 (en) | Document transcription system training | |
| JP5167256B2 (ja) | コンピュータ実装方法 | |
| JP2018077870A (ja) | 音声認識方法 | |
| CN109584906B (zh) | 口语发音评测方法、装置、设备及存储设备 | |
| CN1585969A (zh) | 在预定窗口编辑文本的装置 | |
| US12531051B2 (en) | System and method for secure processing of speech signals using pseudo-speech representations | |
| Badenhorst et al. | Automated Enhancement of isiZulu Data Collection for the African Health Research Institute | |
| CN121260177A (zh) | 一种用于语音克隆的提示音获取方法 | |
| JP2022129403A (ja) | 制御プログラム、制御方法、および情報処理装置 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20090623 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20090623 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20111013 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20111018 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20120110 |
|
| A602 | Written permission of extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A602 Effective date: 20120117 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20120214 |
|
| A711 | Notification of change in applicant |
Free format text: JAPANESE INTERMEDIATE CODE: A712 Effective date: 20120411 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20120904 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20130104 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20130220 |
|
| A911 | Transfer to examiner for re-examination before appeal (zenchi) |
Free format text: JAPANESE INTERMEDIATE CODE: A911 Effective date: 20130225 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20130507 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20130530 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 5284785 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| LAPS | Cancellation because of no payment of annual fees |