JP5255769B2 - テキストフォーマッティング及びスピーチ認識のためのトピック特有のモデル - Google Patents
テキストフォーマッティング及びスピーチ認識のためのトピック特有のモデル Download PDFInfo
- Publication number
- JP5255769B2 JP5255769B2 JP2006540704A JP2006540704A JP5255769B2 JP 5255769 B2 JP5255769 B2 JP 5255769B2 JP 2006540704 A JP2006540704 A JP 2006540704A JP 2006540704 A JP2006540704 A JP 2006540704A JP 5255769 B2 JP5255769 B2 JP 5255769B2
- Authority
- JP
- Japan
- Prior art keywords
- text
- section
- topic
- speech recognition
- specific
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
- 238000000034 method Methods 0.000 claims description 90
- 238000013179 statistical model Methods 0.000 claims description 78
- 238000012545 processing Methods 0.000 claims description 21
- 230000008569 process Effects 0.000 claims description 19
- 238000012549 training Methods 0.000 claims description 18
- 238000012986 modification Methods 0.000 claims description 11
- 230000004048 modification Effects 0.000 claims description 11
- 230000008859 change Effects 0.000 claims description 3
- 238000004590 computer program Methods 0.000 claims 6
- 238000013518 transcription Methods 0.000 description 15
- 230000035897 transcription Effects 0.000 description 15
- 230000011218 segmentation Effects 0.000 description 12
- 230000006978 adaptation Effects 0.000 description 8
- 238000013507 mapping Methods 0.000 description 6
- 230000001419 dependent effect Effects 0.000 description 5
- 238000010586 diagram Methods 0.000 description 4
- 238000013459 approach Methods 0.000 description 2
- 238000006243 chemical reaction Methods 0.000 description 2
- 238000000605 extraction Methods 0.000 description 2
- 230000007704 transition Effects 0.000 description 2
- BSYNRYMUTXBXSQ-UHFFFAOYSA-N Aspirin Chemical compound CC(=O)OC1=CC=CC=C1C(O)=O BSYNRYMUTXBXSQ-UHFFFAOYSA-N 0.000 description 1
- 229960001138 acetylsalicylic acid Drugs 0.000 description 1
- 230000009471 action Effects 0.000 description 1
- 230000008901 benefit Effects 0.000 description 1
- 238000012937 correction Methods 0.000 description 1
- 230000003247 decreasing effect Effects 0.000 description 1
- 229940079593 drug Drugs 0.000 description 1
- 239000003814 drug Substances 0.000 description 1
- JEIPFZHSYJVQDO-UHFFFAOYSA-N ferric oxide Chemical compound O=[Fe]O[Fe]=O JEIPFZHSYJVQDO-UHFFFAOYSA-N 0.000 description 1
- 238000009472 formulation Methods 0.000 description 1
- 230000006870 function Effects 0.000 description 1
- 230000014509 gene expression Effects 0.000 description 1
- 239000000203 mixture Substances 0.000 description 1
- 230000001915 proofreading effect Effects 0.000 description 1
- 238000010561 standard procedure Methods 0.000 description 1
- 238000007619 statistical method Methods 0.000 description 1
Images






Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
- G10L15/18—Speech classification or search using natural language modelling
- G10L15/183—Speech classification or search using natural language modelling using context dependencies, e.g. language models
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/10—Text processing
- G06F40/103—Formatting, i.e. changing of presentation of documents
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/205—Parsing
- G06F40/216—Parsing using statistical methods
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/28—Constructional details of speech recognition systems
- G10L15/32—Multiple recognisers used in sequence or in parallel; Score combination systems therefor, e.g. voting systems
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Computational Linguistics (AREA)
- Theoretical Computer Science (AREA)
- Artificial Intelligence (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Health & Medical Sciences (AREA)
- Human Computer Interaction (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Probability & Statistics with Applications (AREA)
- Machine Translation (AREA)
- Document Processing Apparatus (AREA)
Description
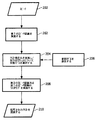
402 セクション
404 セクション
406 統計モデル
408 統計モデル
410 言語モデル
412 規則
414 規則
416 言語モデル
418 規則
420 規則
700 コンピュータシステム
702 スピーチ
704 テキスト
706 処理ユニット
708 テキスト記憶モジュール
710 構造化されたテキスト記憶モジュール
712 言語モデルモジュール
Claims (13)
- 訓練データに基づいて及び/又は手動のコーディングによってそれぞれ生成される複数の統計モデルの組を使用してテキストを変更する、コンピュータによって実施される方法であって、
格納された命令を実行する処理ユニットを動作させて前記テキストをトピックごとに複数のセクションにセグメント化するステップと、
格納された命令を実行する処理ユニットを動作させて、前記セクションのテキストの解析に従って、前記統計モデルの組のうちの1つを各セクションに対応付けるステップと、
格納された命令を実行する処理ユニットにより、前記セクションに対応付けられる前記統計モデルの規則及び語彙を用いて、各セクションごとにテキスト変更プロシージャを実施し、前記セクション内のテキストを変更するステップと、を含み、
前記テキスト変更プロシージャが、テキストフォーマッティングプロセスを含み、前記対応付けられた統計モデルは、前記テキストフォーマッティングプロセスについて、前記セクションのトピックに特有のフォーマッティング規則を提供する、
方法。 - 第1のスピーチ認識パスによって前記テキストを生成するステップ、
を更に有し、
前記変更プロシージャは、各セクションに対応付けられる前記統計モデルの言語モデル及び/又はスピーチ認識パラメータを使用する、第2のスピーチ認識パスを含む、請求項1に記載の方法。 - 各統計モデルは、トピック特有の言語モデル及びトピック特有のフォーマッティング規則を含み、前記言語モデルは、トピック特有の語彙を有する、請求項1または請求項2に記載の方法。
- 統計モデルに対応付けられる前記セクションが解析され、前記統計モデルは前記解析されたセクションに適応される、請求項1乃至請求項3のいずれか1項に記載の方法。
- 前記統計モデルは、更に、トピック特有のスピーチ認識パスを提供するために、トピック特有のスピーチ認識パラメータを含む、請求項2乃至請求項4のいずれか1項に記載の方法。
- 訓練データに基づいて及び/又は手動のコーディングによって生成される統計モデルの組を使用して、テキストを変更するコンピュータシステムであって、
前記テキストをトピックごとに複数のセクションにセグメント化する手段と、
各セクションに前記統計モデルの組のうちの1つを対応付ける手段と、
前記セクションに対応付けられる前記統計モデルに関して、各セクションごとにテキスト変更プロシージャを実施する手段と、を有し、
前記テキスト変更プロシージャを実施する前記手段は、テキストフォーマッティングプロシージャを達成するように構成され、前記対応付けられた統計モデルは、前記テキストフォーマッティングプロシージャについて、前記セクションのトピックに特有のフォーマッティング規則を提供する、
コンピュータシステム。 - 前記テキストは、第1のスピーチ認識パスによって生成され、前記テキスト変更プロシージャを実施する前記手段は、各セクションに対応付けられる前記統計モデルの言語モデル及び/又はスピーチ認識パラメータを使用して、第2のスピーチ認識パスを達成するように構成される、請求項6に記載のコンピュータシステム。
- 各統計モデルは、トピック特有の言語モデル及びトピック特有のフォーマッティング規則を含み、前記言語モデルは、トピック特有の語彙を有する、請求項6または請求項7に記載のコンピュータシステム。
- 統計モデルを解析されたセクションに適応させるために、統計モデルに対応付けられる前記セクションを解析する手段を更に有する、請求項6乃至請求項8のいずれか1項に記載のコンピュータシステム。
- 訓練データに基づいて及び/又は手動のコーディングによって生成される統計モデルの組を使用して、テキストを変更するコンピュータプログラムであって、
処理ユニットにより実行されると該処理ユニットに、
前記テキストをトピックごとに複数のセクションにセグメント化するステップと、
各セクションに前記統計モデルの組のうちの1つを対応付けるステップと、
テキストフォーマッティングプロシージャを実行し、前記対応付けられた統計モデルが、前記テキストフォーマッティングプロシージャについて、前記セクションのトピックに特有のフォーマッティング規則を提供することにより、前記セクションに対応付けられる統計モデルに関して、各セクションごとにテキスト変更プロシージャを実施するステップと、
を実行させるコンピュータプログラム。 - 前記テキストは、第1のスピーチ認識パスによって生成され、前記テキスト変更プロシージャを実施する前記手段は、各セクションに対応付けられる言語モデル及び/又はスピーチ認識パラメータを使用して、第2のスピーチ認識パスを達成するように構成される、請求項10に記載のコンピュータプログラム。
- 各統計モデルは、トピック特有の言語モデル及びトピック特有のフォーマッティング規則を含み、前記言語モデルは、トピック特有の語彙を有する、請求項10または請求項11に記載のコンピュータプログラム。
- 統計モデルを解析されたセクションに適応させるために、統計モデルに対応付けられるセクションを解析する手段を更に有する、請求項10乃至12のいずれか1項に記載のコンピュータプログラム。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP03104314.4 | 2003-11-21 | ||
| EP03104314 | 2003-11-21 | ||
| PCT/IB2004/052403 WO2005050621A2 (en) | 2003-11-21 | 2004-11-12 | Topic specific models for text formatting and speech recognition |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2011106732A Division JP5330450B2 (ja) | 2003-11-21 | 2011-05-11 | テキストフォーマッティング及びスピーチ認識のためのトピック特有のモデル |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2007512608A JP2007512608A (ja) | 2007-05-17 |
| JP2007512608A5 JP2007512608A5 (ja) | 2007-12-27 |
| JP5255769B2 true JP5255769B2 (ja) | 2013-08-07 |
Family
ID=34610118
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2006540704A Expired - Fee Related JP5255769B2 (ja) | 2003-11-21 | 2004-11-12 | テキストフォーマッティング及びスピーチ認識のためのトピック特有のモデル |
| JP2011106732A Expired - Fee Related JP5330450B2 (ja) | 2003-11-21 | 2011-05-11 | テキストフォーマッティング及びスピーチ認識のためのトピック特有のモデル |
Family Applications After (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2011106732A Expired - Fee Related JP5330450B2 (ja) | 2003-11-21 | 2011-05-11 | テキストフォーマッティング及びスピーチ認識のためのトピック特有のモデル |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US8041566B2 (ja) |
| EP (2) | EP1687807B1 (ja) |
| JP (2) | JP5255769B2 (ja) |
| WO (1) | WO2005050621A2 (ja) |
Families Citing this family (76)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7490092B2 (en) | 2000-07-06 | 2009-02-10 | Streamsage, Inc. | Method and system for indexing and searching timed media information based upon relevance intervals |
| US20050216256A1 (en) * | 2004-03-29 | 2005-09-29 | Mitra Imaging Inc. | Configurable formatting system and method |
| US7844464B2 (en) * | 2005-07-22 | 2010-11-30 | Multimodal Technologies, Inc. | Content-based audio playback emphasis |
| KR100755677B1 (ko) * | 2005-11-02 | 2007-09-05 | 삼성전자주식회사 | 주제 영역 검출을 이용한 대화체 음성 인식 장치 및 방법 |
| WO2007066304A1 (en) * | 2005-12-08 | 2007-06-14 | Koninklijke Philips Electronics N.V. | Method and system for dynamic creation of contexts |
| US8301448B2 (en) | 2006-03-29 | 2012-10-30 | Nuance Communications, Inc. | System and method for applying dynamic contextual grammars and language models to improve automatic speech recognition accuracy |
| FR2902542B1 (fr) * | 2006-06-16 | 2012-12-21 | Gilles Vessiere Consultants | Correcteur semantiques, syntaxique et/ou lexical, procede de correction, ainsi que support d'enregistrement et programme d'ordinateur pour la mise en oeuvre de ce procede |
| US8510113B1 (en) * | 2006-08-31 | 2013-08-13 | At&T Intellectual Property Ii, L.P. | Method and system for enhancing a speech database |
| WO2008066166A1 (fr) * | 2006-11-30 | 2008-06-05 | National Institute Of Advanced Industrial Science And Technology | Système de site web pour recherche de données vocales |
| US8165985B2 (en) * | 2007-10-12 | 2012-04-24 | Palo Alto Research Center Incorporated | System and method for performing discovery of digital information in a subject area |
| US8671104B2 (en) | 2007-10-12 | 2014-03-11 | Palo Alto Research Center Incorporated | System and method for providing orientation into digital information |
| US8073682B2 (en) | 2007-10-12 | 2011-12-06 | Palo Alto Research Center Incorporated | System and method for prospecting digital information |
| US8595004B2 (en) * | 2007-12-18 | 2013-11-26 | Nec Corporation | Pronunciation variation rule extraction apparatus, pronunciation variation rule extraction method, and pronunciation variation rule extraction program |
| US8010545B2 (en) * | 2008-08-28 | 2011-08-30 | Palo Alto Research Center Incorporated | System and method for providing a topic-directed search |
| US8209616B2 (en) * | 2008-08-28 | 2012-06-26 | Palo Alto Research Center Incorporated | System and method for interfacing a web browser widget with social indexing |
| US20100057577A1 (en) * | 2008-08-28 | 2010-03-04 | Palo Alto Research Center Incorporated | System And Method For Providing Topic-Guided Broadening Of Advertising Targets In Social Indexing |
| US20100057536A1 (en) * | 2008-08-28 | 2010-03-04 | Palo Alto Research Center Incorporated | System And Method For Providing Community-Based Advertising Term Disambiguation |
| CA2680304C (en) * | 2008-09-25 | 2017-08-22 | Multimodal Technologies, Inc. | Decoding-time prediction of non-verbalized tokens |
| US8549016B2 (en) * | 2008-11-14 | 2013-10-01 | Palo Alto Research Center Incorporated | System and method for providing robust topic identification in social indexes |
| US20100145720A1 (en) * | 2008-12-05 | 2010-06-10 | Bruce Reiner | Method of extracting real-time structured data and performing data analysis and decision support in medical reporting |
| US8713016B2 (en) | 2008-12-24 | 2014-04-29 | Comcast Interactive Media, Llc | Method and apparatus for organizing segments of media assets and determining relevance of segments to a query |
| US9442933B2 (en) | 2008-12-24 | 2016-09-13 | Comcast Interactive Media, Llc | Identification of segments within audio, video, and multimedia items |
| US11531668B2 (en) | 2008-12-29 | 2022-12-20 | Comcast Interactive Media, Llc | Merging of multiple data sets |
| US8356044B2 (en) * | 2009-01-27 | 2013-01-15 | Palo Alto Research Center Incorporated | System and method for providing default hierarchical training for social indexing |
| US8452781B2 (en) * | 2009-01-27 | 2013-05-28 | Palo Alto Research Center Incorporated | System and method for using banded topic relevance and time for article prioritization |
| US8239397B2 (en) * | 2009-01-27 | 2012-08-07 | Palo Alto Research Center Incorporated | System and method for managing user attention by detecting hot and cold topics in social indexes |
| US8176043B2 (en) | 2009-03-12 | 2012-05-08 | Comcast Interactive Media, Llc | Ranking search results |
| US8290273B2 (en) * | 2009-03-27 | 2012-10-16 | Raytheon Bbn Technologies Corp. | Multi-frame videotext recognition |
| US20100250614A1 (en) * | 2009-03-31 | 2010-09-30 | Comcast Cable Holdings, Llc | Storing and searching encoded data |
| US8533223B2 (en) | 2009-05-12 | 2013-09-10 | Comcast Interactive Media, LLC. | Disambiguation and tagging of entities |
| US9892730B2 (en) * | 2009-07-01 | 2018-02-13 | Comcast Interactive Media, Llc | Generating topic-specific language models |
| US9031944B2 (en) | 2010-04-30 | 2015-05-12 | Palo Alto Research Center Incorporated | System and method for providing multi-core and multi-level topical organization in social indexes |
| US20110307252A1 (en) * | 2010-06-15 | 2011-12-15 | Microsoft Corporation | Using Utterance Classification in Telephony and Speech Recognition Applications |
| US8606581B1 (en) * | 2010-12-14 | 2013-12-10 | Nuance Communications, Inc. | Multi-pass speech recognition |
| US8838449B2 (en) * | 2010-12-23 | 2014-09-16 | Microsoft Corporation | Word-dependent language model |
| US9053750B2 (en) * | 2011-06-17 | 2015-06-09 | At&T Intellectual Property I, L.P. | Speaker association with a visual representation of spoken content |
| RU2500024C2 (ru) * | 2011-12-27 | 2013-11-27 | Общество С Ограниченной Ответственностью "Центр Инноваций Натальи Касперской" | Способ автоматизированного определения языка и (или) кодировки текстового документа |
| US9652452B2 (en) | 2012-01-06 | 2017-05-16 | Yactraq Online Inc. | Method and system for constructing a language model |
| US8374865B1 (en) * | 2012-04-26 | 2013-02-12 | Google Inc. | Sampling training data for an automatic speech recognition system based on a benchmark classification distribution |
| US9620111B1 (en) * | 2012-05-01 | 2017-04-11 | Amazon Technologies, Inc. | Generation and maintenance of language model |
| US9069798B2 (en) * | 2012-05-24 | 2015-06-30 | Mitsubishi Electric Research Laboratories, Inc. | Method of text classification using discriminative topic transformation |
| US9697834B2 (en) * | 2012-07-26 | 2017-07-04 | Nuance Communications, Inc. | Text formatter with intuitive customization |
| US9135231B1 (en) | 2012-10-04 | 2015-09-15 | Google Inc. | Training punctuation models |
| KR20140116642A (ko) * | 2013-03-25 | 2014-10-06 | 삼성전자주식회사 | 음성 인식 기반의 기능 제어 방법 및 장치 |
| US9575958B1 (en) * | 2013-05-02 | 2017-02-21 | Athena Ann Smyros | Differentiation testing |
| US9728184B2 (en) | 2013-06-18 | 2017-08-08 | Microsoft Technology Licensing, Llc | Restructuring deep neural network acoustic models |
| US20140379334A1 (en) * | 2013-06-20 | 2014-12-25 | Qnx Software Systems Limited | Natural language understanding automatic speech recognition post processing |
| US9589565B2 (en) | 2013-06-21 | 2017-03-07 | Microsoft Technology Licensing, Llc | Environmentally aware dialog policies and response generation |
| US9311298B2 (en) | 2013-06-21 | 2016-04-12 | Microsoft Technology Licensing, Llc | Building conversational understanding systems using a toolset |
| US10438581B2 (en) * | 2013-07-31 | 2019-10-08 | Google Llc | Speech recognition using neural networks |
| US10515631B2 (en) * | 2013-12-17 | 2019-12-24 | Koninklijke Philips N.V. | System and method for assessing the cognitive style of a person |
| US9529794B2 (en) | 2014-03-27 | 2016-12-27 | Microsoft Technology Licensing, Llc | Flexible schema for language model customization |
| US9614724B2 (en) | 2014-04-21 | 2017-04-04 | Microsoft Technology Licensing, Llc | Session-based device configuration |
| US20150325236A1 (en) * | 2014-05-08 | 2015-11-12 | Microsoft Corporation | Context specific language model scale factors |
| US10111099B2 (en) | 2014-05-12 | 2018-10-23 | Microsoft Technology Licensing, Llc | Distributing content in managed wireless distribution networks |
| US9874914B2 (en) | 2014-05-19 | 2018-01-23 | Microsoft Technology Licensing, Llc | Power management contracts for accessory devices |
| US9717006B2 (en) | 2014-06-23 | 2017-07-25 | Microsoft Technology Licensing, Llc | Device quarantine in a wireless network |
| WO2015199653A1 (en) * | 2014-06-24 | 2015-12-30 | Nuance Communications, Inc. | Methods and apparatus for joint stochastic and deterministic dictation formatting |
| US10115394B2 (en) * | 2014-07-08 | 2018-10-30 | Mitsubishi Electric Corporation | Apparatus and method for decoding to recognize speech using a third speech recognizer based on first and second recognizer results |
| US20160098645A1 (en) * | 2014-10-02 | 2016-04-07 | Microsoft Corporation | High-precision limited supervision relationship extractor |
| US9502032B2 (en) | 2014-10-08 | 2016-11-22 | Google Inc. | Dynamically biasing language models |
| US9858923B2 (en) | 2015-09-24 | 2018-01-02 | Intel Corporation | Dynamic adaptation of language models and semantic tracking for automatic speech recognition |
| US20170229124A1 (en) * | 2016-02-05 | 2017-08-10 | Google Inc. | Re-recognizing speech with external data sources |
| JP6675078B2 (ja) * | 2016-03-15 | 2020-04-01 | パナソニックIpマネジメント株式会社 | 誤認識訂正方法、誤認識訂正装置及び誤認識訂正プログラム |
| US9978367B2 (en) | 2016-03-16 | 2018-05-22 | Google Llc | Determining dialog states for language models |
| US10311860B2 (en) | 2017-02-14 | 2019-06-04 | Google Llc | Language model biasing system |
| US11010601B2 (en) | 2017-02-14 | 2021-05-18 | Microsoft Technology Licensing, Llc | Intelligent assistant device communicating non-verbal cues |
| US10467509B2 (en) | 2017-02-14 | 2019-11-05 | Microsoft Technology Licensing, Llc | Computationally-efficient human-identifying smart assistant computer |
| US11100384B2 (en) | 2017-02-14 | 2021-08-24 | Microsoft Technology Licensing, Llc | Intelligent device user interactions |
| US10565986B2 (en) * | 2017-07-20 | 2020-02-18 | Intuit Inc. | Extracting domain-specific actions and entities in natural language commands |
| US10672380B2 (en) | 2017-12-27 | 2020-06-02 | Intel IP Corporation | Dynamic enrollment of user-defined wake-up key-phrase for speech enabled computer system |
| CN109979435B (zh) * | 2017-12-28 | 2021-10-22 | 北京搜狗科技发展有限公司 | 数据处理方法和装置、用于数据处理的装置 |
| WO2019140027A1 (en) * | 2018-01-10 | 2019-07-18 | Takeda Pharmaceutical Company Limited | Method and system for managing clinical trial participation |
| US11514914B2 (en) * | 2019-02-08 | 2022-11-29 | Jpmorgan Chase Bank, N.A. | Systems and methods for an intelligent virtual assistant for meetings |
| US11257484B2 (en) * | 2019-08-21 | 2022-02-22 | Microsoft Technology Licensing, Llc | Data-driven and rule-based speech recognition output enhancement |
| CN117764069B (zh) * | 2024-02-22 | 2024-05-07 | 深圳华强电子网集团股份有限公司 | 一种基于元器件行业的中英文混编文本的切词方法 |
Family Cites Families (20)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS61221898A (ja) * | 1985-03-27 | 1986-10-02 | 株式会社東芝 | 金銭登録機 |
| JPH03104295U (ja) * | 1990-02-07 | 1991-10-29 | ||
| US5623681A (en) * | 1993-11-19 | 1997-04-22 | Waverley Holdings, Inc. | Method and apparatus for synchronizing, displaying and manipulating text and image documents |
| US5623679A (en) * | 1993-11-19 | 1997-04-22 | Waverley Holdings, Inc. | System and method for creating and manipulating notes each containing multiple sub-notes, and linking the sub-notes to portions of data objects |
| US5675710A (en) * | 1995-06-07 | 1997-10-07 | Lucent Technologies, Inc. | Method and apparatus for training a text classifier |
| US6279017B1 (en) * | 1996-08-07 | 2001-08-21 | Randall C. Walker | Method and apparatus for displaying text based upon attributes found within the text |
| US6052657A (en) * | 1997-09-09 | 2000-04-18 | Dragon Systems, Inc. | Text segmentation and identification of topic using language models |
| US6104989A (en) | 1998-07-29 | 2000-08-15 | International Business Machines Corporation | Real time detection of topical changes and topic identification via likelihood based methods |
| US6188976B1 (en) | 1998-10-23 | 2001-02-13 | International Business Machines Corporation | Apparatus and method for building domain-specific language models |
| US6253177B1 (en) * | 1999-03-08 | 2001-06-26 | International Business Machines Corp. | Method and system for automatically determining whether to update a language model based upon user amendments to dictated text |
| US6526380B1 (en) * | 1999-03-26 | 2003-02-25 | Koninklijke Philips Electronics N.V. | Speech recognition system having parallel large vocabulary recognition engines |
| US6327561B1 (en) * | 1999-07-07 | 2001-12-04 | International Business Machines Corp. | Customized tokenization of domain specific text via rules corresponding to a speech recognition vocabulary |
| US6529902B1 (en) * | 1999-11-08 | 2003-03-04 | International Business Machines Corporation | Method and system for off-line detection of textual topical changes and topic identification via likelihood based methods for improved language modeling |
| JP3958908B2 (ja) * | 1999-12-09 | 2007-08-15 | 日本放送協会 | 書き起こしテキスト自動生成装置、音声認識装置および記録媒体 |
| US20020087315A1 (en) | 2000-12-29 | 2002-07-04 | Lee Victor Wai Leung | Computer-implemented multi-scanning language method and system |
| JP3782943B2 (ja) * | 2001-02-20 | 2006-06-07 | インターナショナル・ビジネス・マシーンズ・コーポレーション | 音声認識装置、コンピュータ・システム、音声認識方法、プログラムおよび記録媒体 |
| US20030018668A1 (en) * | 2001-07-20 | 2003-01-23 | International Business Machines Corporation | Enhanced transcoding of structured documents through use of annotation techniques |
| JP3896269B2 (ja) * | 2001-10-16 | 2007-03-22 | 東日本旅客鉄道株式会社 | 簡易式カード決済システム、ならびにそのプログラム、および記録媒体 |
| US20030145310A1 (en) * | 2001-10-31 | 2003-07-31 | Metacyber. Net. | Computer memory structure for storing original source information and associated interpretative information |
| US7117437B2 (en) * | 2002-12-16 | 2006-10-03 | Palo Alto Research Center Incorporated | Systems and methods for displaying interactive topic-based text summaries |
-
2004
- 2004-11-12 EP EP04799133.6A patent/EP1687807B1/en not_active Not-in-force
- 2004-11-12 JP JP2006540704A patent/JP5255769B2/ja not_active Expired - Fee Related
- 2004-11-12 EP EP12173403.2A patent/EP2506252B1/en not_active Not-in-force
- 2004-11-12 WO PCT/IB2004/052403 patent/WO2005050621A2/en active Application Filing
- 2004-11-12 US US10/595,830 patent/US8041566B2/en not_active Expired - Fee Related
-
2011
- 2011-05-11 JP JP2011106732A patent/JP5330450B2/ja not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| JP2011186491A (ja) | 2011-09-22 |
| EP2506252A2 (en) | 2012-10-03 |
| EP2506252B1 (en) | 2019-06-05 |
| JP2007512608A (ja) | 2007-05-17 |
| US20070271086A1 (en) | 2007-11-22 |
| EP1687807A2 (en) | 2006-08-09 |
| WO2005050621A2 (en) | 2005-06-02 |
| EP2506252A3 (en) | 2012-11-28 |
| EP1687807B1 (en) | 2016-03-16 |
| US8041566B2 (en) | 2011-10-18 |
| JP5330450B2 (ja) | 2013-10-30 |
| WO2005050621A3 (en) | 2005-10-27 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5255769B2 (ja) | テキストフォーマッティング及びスピーチ認識のためのトピック特有のモデル | |
| US9552809B2 (en) | Document transcription system training | |
| US9520124B2 (en) | Discriminative training of document transcription system | |
| US6910012B2 (en) | Method and system for speech recognition using phonetically similar word alternatives | |
| US6839667B2 (en) | Method of speech recognition by presenting N-best word candidates | |
| EP0867857B1 (en) | Enrolment in speech recognition | |
| US7315811B2 (en) | System and method for accented modification of a language model | |
| US6535849B1 (en) | Method and system for generating semi-literal transcripts for speech recognition systems | |
| US11810471B2 (en) | Computer implemented method and apparatus for recognition of speech patterns and feedback | |
| KR20050076697A (ko) | 컴퓨터 구현 음성 인식 시스템 및 이 시스템으로 학습하는방법 | |
| US6963834B2 (en) | Method of speech recognition using empirically determined word candidates | |
| WO2006034152A2 (en) | Discriminative training of document transcription system | |
| JP2002341891A (ja) | 音声認識装置および音声認識方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20071109 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20071109 |
|
| RD02 | Notification of acceptance of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7422 Effective date: 20090519 |
|
| A711 | Notification of change in applicant |
Free format text: JAPANESE INTERMEDIATE CODE: A711 Effective date: 20090715 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20100629 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20100927 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20110111 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20110511 |
|
| A911 | Transfer to examiner for re-examination before appeal (zenchi) |
Free format text: JAPANESE INTERMEDIATE CODE: A911 Effective date: 20110519 |
|
| A912 | Re-examination (zenchi) completed and case transferred to appeal board |
Free format text: JAPANESE INTERMEDIATE CODE: A912 Effective date: 20110715 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20130220 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20130422 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 5255769 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20160426 Year of fee payment: 3 |
|
| S111 | Request for change of ownership or part of ownership |
Free format text: JAPANESE INTERMEDIATE CODE: R313113 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| LAPS | Cancellation because of no payment of annual fees |