JP5268825B2 - モデルパラメータ推定装置、方法及びプログラム - Google Patents
モデルパラメータ推定装置、方法及びプログラム Download PDFInfo
- Publication number
- JP5268825B2 JP5268825B2 JP2009189111A JP2009189111A JP5268825B2 JP 5268825 B2 JP5268825 B2 JP 5268825B2 JP 2009189111 A JP2009189111 A JP 2009189111A JP 2009189111 A JP2009189111 A JP 2009189111A JP 5268825 B2 JP5268825 B2 JP 5268825B2
- Authority
- JP
- Japan
- Prior art keywords
- importance
- symbol
- model parameter
- parameter estimation
- list
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images







Description

・各リストにおいて、重要度の値が大きいものから順に所定の個数(例えば1〜50個程度)を抽出
・予め定めた値以上の重要度を持つものを抽出
・重要度の値が大きいものから順次等間隔で抽出
することなどが考えられる。また、これらを複合し、例えば、予め定めた値以上の重要度を持つシンボル系列を抽出したものと、予め定めた値より小さい重要度を持つシンボル系列について所定の個数をランダムに又は重要度の値が大きいものから順次等間隔で抽出したものの組み合わせとして抽出しても構わない。
日本語話し言葉コーパス(CSJ)を用い、本発明の効果を検証する。CSJは講演音声データとその書き起こしからなるデータベースである。なお、検証にあたり、図4に示す学習用と開発・評価用セットを用意した。
Claims (7)
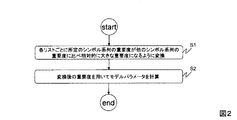
- それぞれ重要度ei,jが割り当てられ素性ベクトルで表現された複数のシンボル系列fi,jからなる、1以上のリストi(iはリストのインデックス(i=1、2、・・・、N)、jは各iにおけるシンボル系列のインデックス(j=1、2、・・・、ni))と、それぞれ素性ベクトルで表現された各リストiの正解シンボル系列fi,0とが入力され、モデルパラメータwを推定するモデルパラメータ推定装置であって、
上記重要度ei,jを、リストごとに所定のシンボル系列の重要度の値と上記所定のシンボル系列以外のシンボル系列の重要度の値との差が大きくなるように変換する重要度変換部と、
上記シンボル系列fi,jと上記正解シンボル系列fi,0と上記変換後の重要度とから、モデルパラメータwを推定するモデルパラメータ推定部と、
を備え、
上記所定のシンボル系列は、上記複数のシンボル系列f i,j の中から、上記重要度e i,j の値が大きいものを優先してシンボル系列f i,j を抽出したものであるモデルパラメータ推定装置。 - 請求項1に記載のモデルパラメータ推定装置において、
上記所定のシンボル系列は、上記重要度の値が大きいものから順に予め定めた個数のシンボル系列fi,jを抽出したものであることを特徴とするモデルパラメータ推定装置。 - 請求項1に記載のモデルパラメータ推定装置において、
上記所定のシンボル系列は、予め定めた値以上の重要度を持つシンボル系列fi,jを抽出したもの、又は重要度の値が大きいものから順次等間隔で抽出したものであることを特徴とするモデルパラメータ推定装置。 - それぞれ重要度ei,jが割り当てられ素性ベクトルで表現された複数のシンボル系列fi,jからなる、1以上のリストi(iはリストのインデックス(i=1、2、・・・、N)、jは各iにおけるシンボル系列のインデックス(j=1、2、・・・、ni))と、それぞれ素性ベクトルで表現された各リストiの正解シンボル系列fi,0とが入力され、モ
デルパラメータwを推定するモデルパラメータ推定方法であって、
上記重要度ei,jを、リストごとに所定のシンボル系列の重要度の値と上記所定のシンボル系列以外のシンボル系列の重要度の値との差が大きくなるように変換する重要度変換ステップと、
上記シンボル系列fi,jと上記正解シンボル系列fi,0と上記変換後の重要度とから、モデルパラメータwを推定するモデルパラメータ推定ステップと、
を実行し、
上記所定のシンボル系列は、上記複数のシンボル系列f i,j の中から、上記重要度e i,j の値が大きいものを優先してシンボル系列f i,j を抽出したものであるモデルパラメータ推定方法。 - 請求項4に記載のモデルパラメータ推定方法において、
上記所定のシンボル系列は、上記重要度の値が大きいものから順に予め定めた個数のシンボル系列fi,jを抽出したものであることを特徴とするモデルパラメータ推定方法。 - 請求項4に記載のモデルパラメータ推定方法において、
上記所定のシンボル系列は、予め定めた値以上の重要度を持つシンボル系列fi,jを抽出したもの、又は重要度の値が大きいものから順次等間隔で抽出したものであることを特徴とするモデルパラメータ推定方法。 - 請求項1乃至3のいずれかに記載の装置としてコンピュータを機能させるためのプログラム。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2009189111A JP5268825B2 (ja) | 2009-08-18 | 2009-08-18 | モデルパラメータ推定装置、方法及びプログラム |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2009189111A JP5268825B2 (ja) | 2009-08-18 | 2009-08-18 | モデルパラメータ推定装置、方法及びプログラム |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2011039965A JP2011039965A (ja) | 2011-02-24 |
| JP5268825B2 true JP5268825B2 (ja) | 2013-08-21 |
Family
ID=43767638
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2009189111A Active JP5268825B2 (ja) | 2009-08-18 | 2009-08-18 | モデルパラメータ推定装置、方法及びプログラム |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP5268825B2 (ja) |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP5264649B2 (ja) * | 2009-08-18 | 2013-08-14 | 日本電信電話株式会社 | 情報圧縮型モデルパラメータ推定装置、方法及びプログラム |
| JP5780516B2 (ja) * | 2011-06-24 | 2015-09-16 | 日本電信電話株式会社 | モデル縮減装置とその方法とプログラム |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8831943B2 (en) * | 2006-05-31 | 2014-09-09 | Nec Corporation | Language model learning system, language model learning method, and language model learning program |
| JP4981579B2 (ja) * | 2007-08-20 | 2012-07-25 | 日本電信電話株式会社 | 誤り訂正モデルの学習方法、装置、プログラム、このプログラムを記録した記録媒体 |
-
2009
- 2009-08-18 JP JP2009189111A patent/JP5268825B2/ja active Active
Also Published As
| Publication number | Publication date |
|---|---|
| JP2011039965A (ja) | 2011-02-24 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US10490182B1 (en) | Initializing and learning rate adjustment for rectifier linear unit based artificial neural networks | |
| KR102167719B1 (ko) | 언어 모델 학습 방법 및 장치, 음성 인식 방법 및 장치 | |
| Schuster et al. | Japanese and korean voice search | |
| US8478591B2 (en) | Phonetic variation model building apparatus and method and phonetic recognition system and method thereof | |
| US8959014B2 (en) | Training acoustic models using distributed computing techniques | |
| US8666739B2 (en) | Method for estimating language model weight and system for the same | |
| JP2018081298A (ja) | 自然語処理方法及び装置と自然語処理モデルを学習する方法及び装置 | |
| JP5932869B2 (ja) | N−gram言語モデルの教師無し学習方法、学習装置、および学習プログラム | |
| JP5752060B2 (ja) | 情報処理装置、大語彙連続音声認識方法及びプログラム | |
| JP6051004B2 (ja) | 音声認識装置、誤り修正モデル学習方法、及びプログラム | |
| US20150179169A1 (en) | Speech Recognition By Post Processing Using Phonetic and Semantic Information | |
| KR102199246B1 (ko) | 신뢰도 측점 점수를 고려한 음향 모델 학습 방법 및 장치 | |
| Gondala et al. | Error-driven pruning of language models for virtual assistants | |
| JP5268825B2 (ja) | モデルパラメータ推定装置、方法及びプログラム | |
| JP5914054B2 (ja) | 言語モデル作成装置、音声認識装置、およびそのプログラム | |
| Karanasou et al. | Discriminative training of a phoneme confusion model for a dynamic lexicon in ASR | |
| JP2016024325A (ja) | 言語モデル生成装置、およびそのプログラム、ならびに音声認識装置 | |
| JP6350935B2 (ja) | 音響モデル生成装置、音響モデルの生産方法、およびプログラム | |
| JP4964194B2 (ja) | 音声認識モデル作成装置とその方法、音声認識装置とその方法、プログラムとその記録媒体 | |
| JP5264649B2 (ja) | 情報圧縮型モデルパラメータ推定装置、方法及びプログラム | |
| Davel et al. | Efficient generation of pronunciation dictionaries: machine learning factors during bootstrapping | |
| US20150206539A1 (en) | Enhanced human machine interface through hybrid word recognition and dynamic speech synthesis tuning | |
| JP5295037B2 (ja) | ConditionalRandomFieldsもしくはGlobalConditionalLog−linearModelsを用いる学習装置及びその学習装置におけるパラメータ学習方法、プログラム | |
| KR20200120595A (ko) | 언어 모델 학습 방법 및 장치, 음성 인식 방법 및 장치 | |
| Audhkhasi et al. | Empirical link between hypothesis diversity and fusion performance in an ensemble of automatic speech recognition systems. |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| RD03 | Notification of appointment of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7423 Effective date: 20110721 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20110825 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20130214 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20130226 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20130408 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20130430 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20130507 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 5268825 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| S531 | Written request for registration of change of domicile |
Free format text: JAPANESE INTERMEDIATE CODE: R313531 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |