以下に添付図面を参照して、この発明にかかる検索支援装置、検索支援方法、および検索支援プログラムの最良な実施の形態を詳細に説明する。
(第1の実施の形態)
上述のように、連想検索システムでは、徘徊問題が発生しうる。また、連想検索システムを含むいずれの検索システムも検索条件を満たす文書を返すことができるが、それだけではユーザの要求を満たすには不十分である。すなわち、探求検索タスクでは、文書の中に記載されている、ユーザにとっての新規情報が重要であって、単に条件を満たす文書が得られればよいものではない。しかし、従来のシステムでは、返された各文書の中からユーザが新規情報を探す作業が強いられていた。
一方、複数文書の新規情報を統合する技術として複数文書要約システムが知られている。しかし要約の観点は十人十色であり、このようなシステムがユーザの望む要約を生成できるとは限らない。これに対し、事実優先・意見優先など要求タイプを事前入力するシステムが存在する。しかし要求タイプの種類が少ないため、情報要求としては十分ではない。また現在の技術的限界として、単数文書要約における文選定は実用レベルであるが、異なる文書の文脈統合は実用レベルでない。
一方、探求検索タスクでは、その情報収集プロセスの複雑さゆえ、調査途中結果をメモなどにまとめることが多い(以下、このようにしてまとめた文書をユーザサマリという)。第1の実施の形態にかかる検索支援装置は、この点に着眼し、サマリ作成作業を含む探求検索タスクを支援する装置であって、その一部機能として、サマリ文脈に基づいて必要な情報を検索・提示する装置を実現する。これにより、上記のような各問題を包括的に解決しうる装置を実現できる。なお、このような装置は一例であって、上記徘徊問題を解消するためには、例えばサマリ作成機能を備える必要はない。
ここで、本実施の形態の検索支援装置の具体的な機能構成の概要について説明する。検索支援装置は、コピーペースト機能および構造テキスト編集機能を有する。構造テキスト編集機能とは、箇条書きなどにより構造化されたテキスト(以下、構造テキストという)を編集する機能をいう。
そして、検索支援装置は、テキスト編集中に任意のカーソル位置で特定キーが押下されたときに情報提示機能を呼び出す。情報提示機能は、後述する文書検索処理および重要文選定処理により獲得したパッセージ群の候補を提示する。パッセージとは、文、章、節、および段落などの意味単位で文書を分割した文書の構成単位をいう。ユーザが候補の1つを選択すると、カーソル位置に当パッセージが挿入される。
文書検索処理では、検索支援装置は、サマリ内のカーソルより構造上位のパッセージ群から内容語を抽出し、tf−idf(Term Frequency−Inverse Document Frequency)などによる一般的な重要度をベースにカーソルにより近い位置に存在する文に含まれる内容語に傾斜加重した重みつき要求ベクトル(文書検索用ベクトル)を生成する。そして、検索支援装置は、この文書検索用ベクトルを元に関連文書を検索する。
重要文選定処理では、検索支援装置は、検索した各文書から、タイトル、位置情報、出現頻度、語彙結束性、カバレッジ、および文構造制約を素性としたエドムンソン(H.P.Edmundson. New methods in automatic abstracting. Journal of ACM, Vol.16, No.2, pp264-285, 1969)の手法などにより、重要文(重要パッセージ)を選定する。ただし、語彙結束性評価への入力は前段で求めた文書検索用ベクトルとし、カバレッジ性評価への入力は、ユーザサマリのカーソルと構造同位のパッセージ群(後述)とする点が従来と異なる。これにより、従来と同様の単文書内での重要パッセージ判定結果に、ユーザサマリに対する情報の親和性・新規性が加味される。以上によって得た文スコアを所属文書のスコアと合算し、スコア上位のパッセージを返却する。
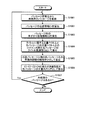
次に、画面イメージを参照しながら(図1)、本実施の形態の検索支援装置の機能の概要について説明する。図1は、第1の実施の形態の検索支援装置で表示される編集画面の一例を示す図である。
同図は、サマリを編集するためのサマリ編集ウィンドウ10と、サマリ編集ウィンドウ10内で指定されたカーソル位置に応じて検索されたパッセージの候補を表示するパッセージ候補ウィンドウ11とを含む編集画面の例が示されている。
ユーザは、サマリ編集ウィンドウ10内でキーボード・マウスなどを用いることにより構造テキストを作成および編集することができる。このテキストが上述のユーザサマリに相当する。ユーザサマリはユーザによる調査結果をまとめた文書となる。
サマリ編集ウィンドウ10は、テキストを編集できるほか、少なくとも箇条書きなどパッセージ同士の構造的関係を表す表現を入力することができる。好ましくは、太字・色変更などの文字修飾、および図表表現などの、例えばHTML(HyperText Markup Language)が有するプレゼンテーション表現機能をサポートしてもよい。その場合、ユーザは調査結果をよりわかりやすくまとめることができよう。
また好ましくは、外部の文書からのコピーペースト機能をサポートとしてもよい。その場合、ユーザは当該ツール以外のツールを用いて調査した結果を当該サマリに反映することもできる。すなわちユーザは、様々な検索ツールを併用して調査を進めることができるようになる。
ユーザは、パッセージ候補ウィンドウ11によって、文献DB(文書記憶部(後述))に記憶されている複数の文書内のパッセージ群を検索し取り込むことができる。例えば、ユーザがサマリ編集ウィンドウ10上で空パッセージ(例えば箇条書き形式の表現ならば、中点だけが存在する行)にカーソルを置いて特定キーを押下するとパッセージ候補ウィンドウ11が表示される。なお、この操作を以降の説明の簡便化のため「パッセージ検索呼び出し操作」と呼ぶことにする。パッセージ候補ウィンドウ11には、ユーザサマリの文脈に沿って文書記憶部の文書群から検索されたパッセージ群の候補が表示される。ユーザが候補の1つを選択すると、サマリ編集ウィンドウ10のカーソル位置に選択されたパッセージが挿入される。
ユーザは、サマリ編集ウィンドウ10とパッセージ候補ウィンドウ11とを用いた以上の作業を繰り返すことで、探求検索タスクを進めることができるようになっている。パッセージ候補ウィンドウ11によって挿入されたパッセージ群も、一般的なテキストとして加筆・修正・削除などの編集処理を行うことが可能である。
なお、同図は、以下のようなユーザ操作により作成されたコンテンツ(文書)の例を示している。
(1)「株価」を手入力する。
(2)「2008/8/28」を手入力する。
(3)その構造下位で「パッセージ検索呼び出し操作」を行い、表示された候補の1つを挿入する。この作業を反復する。
(4)ただし(3)の作業で、興味のない内容を一部削る、パッセージ構造を変更するなど、調査目的や興味に基づいて適宜修正を加えるものとする。
(5)また(3)の作業で、所望のパッセージ候補が表示されないときは、構造下位で自分の興味ある話題語を記載してから「パッセージ検索呼び出し操作」を行う。
また、本実施の形態では、オプショナルな機能として多段階パッセージ検索機能を利用することができる。「多段階パッセージ検索機能」とは、パッセージ候補ウィンドウ11内で、さらに関連するパッセージ群を検索して別のウィンドウに表示する機能をいう。例えば、パッセージ候補ウィンドウ11に表示された候補パッセージ群の特定の候補パッセージ上で特定キーが押下されたときに、その候補パッセージをサマリに挿入したと仮定した上で、その候補パッセージに関連するパッセージ群を検索して、さらなるポップアップウィンドウに検索されたパッセージ候補を提示するように構成することができる。このポップアップウィンドウ上でもまた同様の操作を行うことができる。すなわち、再帰的な操作が可能である。
また、2種類の特定キーを用意し、特定キーの一方が押下されたときに、表示済み候補パッセージの子供となる候補パッセージを検索し、他方が押下されたときに、表示済み候補パッセージの兄弟となる候補パッセージを検索するように構成してもよい。子孫のポップアップウィンドウ上で候補の1つを選択すると、それまでに選択した祖先のパッセージ群すべてが組み立てられた状態で一括してサマリ編集ウィンドウ10内のユーザサマリ本文へ挿入される。
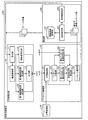
次に、本実施の形態の検索支援装置の構成の詳細について図2を用いて説明する。図2は、第1の実施の形態にかかる検索支援装置100の構成の一例を示すブロック図である。同図に示すように、検索支援装置100は、文脈解析部110と、パッセージ検索部120と、編集部130と、文書記憶部140と、を備えている。
なお、パッセージ検索(取込含む)機能は、編集部130、文脈解析部110、およびパッセージ検索部120の循環的なデータのやり取りとして実現される。文書記憶部140は、検索対象となる複数の文書を記憶する記憶部である。
編集部130は、上述のような各種ユーザ操作を受付け、受付けたユーザ操作に応じた処理を各構成部に指示する。例えば、編集部130は、「パッセージ検索呼び出し操作」を受理すると、内部に保存しているユーザサマリおよびカーソル位置を文脈解析部110へ渡す。また、編集部130は、表示装置(図示せず)を備え、表示装置に表示された画面上でテキストを編集する方法などの、従来から用いられているあらゆる方法により、ユーザサマリを編集する機能を備えている。
文脈解析部110は、受理したユーザサマリおよびカーソル位置をユーザの情報要求として解析し、関連文書の検索に用いる形式(ベクトル形式)で表した情報要求、および、検索結果の重要度を判定するための情報を出力する。具体的には、文脈解析部110は、単語一般重要度ベクトルAおよび単語個別重要度ベクトルBを、情報要求としてパッセージ検索部120に出力する。また、文脈解析部110は、単語既知度ベクトルCを、重要度を判定するための情報としてパッセージ検索部120に出力する。
本実施の形態では、文脈解析部110が、ユーザサマリ内の単語の重要度やパッセージ間の階層構造に応じた情報要求を作成するため、ユーザの要求をより適切に反映した情報要求を作成することができる。すなわち、本実施の形態によれば、重みが徐々に小さくなるが、過去に編集した上位階層のパッセージ内の単語も常に情報要求に含めるため、情報要求の一貫性を保つことができる。これにより、システムにより生成される検索要求がユーザが望む本来の要求から逸れて探求の方向性を見失う徘徊問題を解消することが可能となる。なお、上記各ベクトルA〜Cの作成方法の詳細は後述する。
パッセージ検索部120は、受理した情報要求表現であるベクトルA〜Cを元に、文書記憶部140内に格納されている文書群から、情報要求を満たす適切なパッセージ群を順位つきで取得し、パッセージ候補として編集部130に出力する。なお、編集部130は、このパッセージ候補を上述のパッセージ候補ウィンドウ11に表示する。
次に、文脈解析部110の機能構成の詳細について説明する。同図に示すように、文脈解析部110は、受付部111と、構造解析部112と、第1単語重要度算出部113と、第2単語重要度算出部114と、既知度算出部115と、出力部116と、を備えている。
受付部111は、構造解析の対象となる入力文書であるユーザサマリと、ユーザサマリ内で指定された文字の位置(カーソル位置)との入力を編集部130から受付ける。なお、カーソル位置は、ユーザサマリ内のパッセージのいずれか1つを特定できればよい。例えば、ユーザサマリ内で指定された1文字以上の文字(文字列)の位置をカーソル位置として受付けるように構成してもよい。
構造解析部112は、入力されたユーザサマリをパッセージに分割し、各パッセージ間の階層構造を解析し、パッセージ間の親子関係および兄弟関係などの構造関係が付与されたパッセージ群を生成する。
第1単語重要度算出部113は、生成された構造関係付きパッセージ群を元に、文書群全体の単語分布から単語一般重要度ベクトルAを算出する。具体的には、第1単語重要度算出部113は、カーソル位置の文字が含まれるパッセージより階層構造が上位のパッセージ群(以下、構造上位パッセージという)から内容語の一般重要度(第1単語重要度)を算出し、算出した一般重要度を重みとする重み付き単語ベクトルである単語一般重要度ベクトルAを作成する。
一般重要度は、文書記憶部140に記憶された複数の文書内での単語の重要性の度合いを表す。すなわち、一般重要度は、ユーザサマリの文脈と関係なく、文書記憶部140内に含まれる単語の単語分布を元にした「人間一般として何を知りたいか」に関する手がかりである。また、内容語とは、検索語として有用と思われる単語を意味する。1つの例としては、日本語ならば「は」「を」「が」など助詞を除いたすべての形態素を内容語とする方法がある。また、例えば経済専用の検索ツールとして構成するのであれば、予め用意してある経済用語集に含まれる語を内容語とする方法もある。
第2単語重要度算出部114は、生成された構造関係付きパッセージ群を元に、構造上位パッセージから単語個別重要度ベクトルBを算出する。具体的には、第2単語重要度算出部114は、構造上位パッセージ群に含まれる内容語について、ユーザ個人にとっての重要度を表す個別重要度(第2単語重要度)を算出し、算出した個別重要度を重みとする重み付き単語ベクトルである単語個別重要度ベクトルBを作成する。
個別重要度は、ユーザサマリ内での単語の重要性の度合いを表す。すなわち、個別重要度は、ユーザサマリのカーソル位置での文脈をバイアスとして用いた、「次にユーザは何を知りたいか」(ユーザの注目度)に関する手がかりである。なお、個別重要度は、より上位のパッセージほど小さい値となるように算出される(後述)。
既知度算出部115は、生成された構造関係付きパッセージ群を元に、カーソル位置の文字が含まれるパッセージと階層構造上の階層位置が同位のパッセージ(以下、構造同位パッセージという)から、単語既知度ベクトルCを算出する。具体的には、既知度算出部115は、構造同位パッセージ群に含まれる内容語について、ユーザサマリ内でユーザが既に知っている度合いを表す既知度を算出し、算出した既知度を重みとする重み付き単語ベクトルである単語既知度ベクトルCを作成する。既知度は、ユーザサマリのカーソル位置での文脈をバイアスとして用いた、「次にユーザは何を知りたくないか」に関する手がかりである。
出力部116は、作成された単語一般重要度ベクトルA、単語個別重要度ベクトルB、および単語既知度ベクトルCをパッセージ検索部120に出力する。後述するように、単語一般重要度ベクトルAおよび単語個別重要度ベクトルBは、文書記憶部140に記憶された文書を検索するための検索条件として利用される。また、単語既知度ベクトルCは、検索した文書内の各パッセージの重要度(サマリ内重要度)を算出するための情報として利用される。
次に、パッセージ検索部120の機能構成の詳細について説明する。同図に示すように、パッセージ検索部120は、文書検索部121と、パッセージ分割部122と、第1パッセージ重要度算出部123と、第2パッセージ重要度算出部124と、総合重要度算出部125と、パッセージ選択部126と、を備えている。
文書検索部121は、第1単語重要度算出部113によって生成された単語一般重要度ベクトルAと、第2単語重要度算出部114によって生成された単語個別重要度ベクトルBと、を用いて、ユーザサマリに関連する文書を文書記憶部140から検索し、検索した文書ごとにユーザサマリと関連する度合いを表す関連度を算出する。
より具体的には、文書検索部121は、単語一般重要度ベクトルAと単語個別重要度ベクトルBとから検索用のベクトルである文書検索用ベクトル(詳細は後述)を生成し、文書記憶部140内の文書の特徴を表す文書ベクトルと文書検索用ベクトルとの間のコサイン尺度を関連度として算出する。なお、文書の文書ベクトルとは、例えば単語ごとの出現頻度またはtf−idfなどをベクトル化したものである。
パッセージ分割部122は、検索された各文書をパッセージ単位に分割する。パッセージ分割部122は、さらに、分割したパッセージの照応解決処理を実行する。すなわち、パッセージ分割部122は、分割したパッセージに、他のパッセージに含まれる対象を指し示す照応表現が含まれる場合に、当該他のパッセージから照応表現の指示対象を表す名詞句を取得し、名詞句で照応表現を置換する。
第1パッセージ重要度算出部123は、分割された各パッセージについて、パッセージが所属する文書の中での当該パッセージの重要性の度合いを表すスコアである文書内重要度(第1パッセージ重要度)を算出する。文書内重要度は、ユーザにとって重要かという観点は含まれていない。文書内重要度の算出方法としては、例えば上述のエドムンソンで用いられているような、単文書要約の文選定処理の1つとして知られる手法を用いることができる。
具体的には、第1パッセージ重要度算出部123は、パッセージiの文書内重要度PScore_iを、以下の(1)式により算出する。
PScore_i=W11×C1_i+W12×C2_i+W13×C3_i+W14×C4_i ・・・(1)
なお、パッセージiとは、分割されたn個のパッセージのうちi番目(1≦i≦n)のパッセージを意味する。W11〜W14は、予め定められた重み付け係数を表す。また、C1_i、C2_i、C3_i、およびC4_iは、それぞれ位置情報、手がかり表現情報、タイトル関連性、および出現頻度を表す。これらの各変数の算出方法については後述する。
第2パッセージ重要度算出部124は、分割された各パッセージについて、ユーザサマリ内のカーソル位置における当該パッセージの重要性の度合いを表すスコアであるサマリ内重要度(第2パッセージ重要度)を算出する。算出方法の詳細は後述する。
総合重要度算出部125は、文書内重要度とサマリ内重要度との重み付け線形和(重み付け加算)により、各パッセージの総合重要度を算出する。具体的には、総合重要度算出部125は、以下の(2)式により総合重要度Score_iを算出する。
Score_i=W21×DScore_i+W22×PScore_i+W23×SScore_i ・・・(2)
ただし、DScore_iはパッセージiが含まれる文書の関連度、PScore_iはパッセージiの文書内重要度、SScore_iはパッセージiのサマリ重要度、W21〜W23は予め定められた正数を表す。
パッセージ選択部126は、総合重要度が付与されたパッセージ群を元に、ユーザに提示すべきパッセージ群を順位付きで選択する。本実施の形態では、パッセージ選択部126は、できるだけ重要度の高いパッセージ群を優先して選択するとともに、パッセージ間の内容ができるだけ重ならないように選択するパッセージ候補を決定する。
次に、編集部130の機能構成の詳細について説明する。同図に示すように、編集部130は、候補選択部131と、多段階検索部132と、編集結果記憶部133と、を備えている。
編集結果記憶部133は、編集部130の編集機能により編集された結果であるユーザサマリのテキストと現在のカーソル位置とを記憶する。
なお、上述の文書記憶部140および編集結果記憶部133は、HDD(Hard Disk Drive)、光ディスク、メモリカード、RAM(Random Access Memory)などの一般的に利用されているあらゆる記憶媒体により構成することができる。
候補選択部131は、パッセージ選択部126によって選択されたパッセージ候補を、例えば図1に示すパッセージ候補ウィンドウ11にリスト形式で表示する。そして、候補選択部131は、ユーザによりパッセージ候補のいずれか1つが選択された場合に、サマリ編集ウィンドウ10上のカーソル位置に選択されたパッセージを挿入する。また、候補選択部131は、挿入処理に応じて編集結果記憶部133のユーザサマリの内容を更新する。なお、多段階検索部132により多段階パッセージ検索機能が実行されていた場合は、多段階に検索されたパッセージ群をすべて合成した内容を、サマリ編集ウィンドウ10上のカーソル位置に挿入し、編集結果記憶部133の格納内容を更新する。
多段階検索部132は、上述の多段階パッセージ検索機能を実現する。
次に、このように構成された第1の実施の形態にかかる検索支援装置100による検索支援処理について図3を用いて説明する。図3は、第1の実施の形態における検索支援処理の全体の流れを示すフローチャートである。
同図の検索支援処理は、ユーザがユーザサマリの任意のカーソル位置で特定キーを押下したときに開始される。これにより、編集部130は、ユーザサマリと、指定されたカーソル位置とを文脈解析部110に入力する。
受付部111は、入力されたユーザサマリとカーソル位置とを受付ける(ステップS301)。次に、構造解析部112が、ユーザサマリの階層構造を解析する構造解析処理を実行する(ステップS302)。構造解析処理の詳細は後述する。
次に、第1単語重要度算出部113が、構造解析部112による解析結果を元に単語一般重要度ベクトルAを算出する一般重要度算出処理を実行する(ステップS303)。また、第2単語重要度算出部114が、構造解析部112による解析結果を元に単語個別重要度ベクトルBを算出する個別重要度算出処理を実行する(ステップS304)。さらに、既知度算出部115が、構造解析部112による解析結果を元に単語既知度ベクトルCを算出する既知度算出処理を実行する(ステップS305)。
一般重要度算出処理、個別重要度算出処理、および既知度算出処理の詳細については後述する。なお、同図ではこれらの各処理を順次実行するように記載しているが、実行順序はこれに限られず、各処理を任意の順序で実行することができる。また、各処理の2つ以上を並列に実行してもよい。各処理の処理結果は、出力部116によりパッセージ検索部120に出力される。
次に、パッセージ検索部120の文書検索部121が、単語一般重要度ベクトルAおよび単語個別重要度ベクトルBを元に、文書記憶部140からユーザサマリに関連する文書を検索する文書検索処理を実行する(ステップS306)。次に、パッセージ分割部122が、検索された文書を各パッセージに分割するパッセージ分割処理を実行する(ステップS307)。次に、第1パッセージ重要度算出部123が、分割された各パッセージの文書内重要度を算出する文書内重要度算出処理を実行する(ステップS308)。さらに、第2パッセージ重要度算出部124が、分割された各パッセージのサマリ内重要度を算出するサマリ内重要度算出処理を実行する(ステップS309)。
文書検索処理、文書内重要度算出処理、およびサマリ内重要度算出処理の詳細については後述する。なお、文書内重要度算出処理およびサマリ内重要度算出処理の実行順序は同図に示すものに限られるものではない。両処理を並列に実行してもよい。
文書内重要度算出処理およびサマリ内重要度算出処理の後、総合重要度算出部125が、上記(2)式により、検索文書のスコア、文書内重要度、およびサマリ内重要度の重み付け線形和である総合重要度を算出する(ステップS310)。
次に、パッセージ選択部126が、総合重要度を元にユーザに提示すべきパッセージ群(パッセージ候補)を選択するパッセージ選択処理を実行する(ステップS311)。パッセージ選択処理の詳細は後述する。選択されたパッセージ候補は、編集部130の候補選択部131に送出される。
次に、候補選択部131が、パッセージ選択処理によって選択されたパッセージ候補を表示する(ステップS312)。ユーザが表示されたパッセージ候補からいずれかのパッセージ候補を選択した場合は、候補選択部131が、選択が指定されたパッセージを選択し、編集画面の表示を更新するとともに、編集結果記憶部133に更新内容を保存する(ステップS313)。
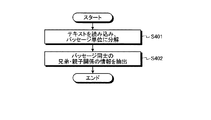
次に、ステップS302の構造解析処理の詳細について図4を用いて説明する。図4は、第1の実施の形態における構造解析処理の全体の流れを示すフローチャートである。
まず、構造解析部112は、ユーザサマリを読み込みパッセージ単位に分解する(ステップS401)。構造解析部112によるパッセージ分解処理は従来から用いられているあらゆる方法を適用できる。例えば、図1のような箇条書きテキストに対しては、構造解析部112は、1つの箇条書き項目を1つのパッセージとして分解する方法を適用することができる。この場合、パッセージが1つの文に相当するとは限らない。
入力テキストとして、図1のような箇条書きテキストではなく、単なるプレーンテキストを受付けた場合は、文字列の並びを解析することによりパッセージ単位に分解するように構成してもよい。例えば、行頭に「*」などの所定の記号が存在する場合に、この行は箇条書きとして記載されていると判断するといったルールをベースに構造を抽出することができる。
次に、構造解析部112は、分割して得られたパッセージ群について、パッセージ同士の兄弟関係および親子関係を抽出する(ステップS402)。例えば、図1のような箇条書きテキストに対しては、構造解析部112は、箇条書きなどの書式表現を分析することにより、兄弟関係および親子関係を抽出できる。例えば図1のテキストの場合、最上位のパッセージが「株価」、その子供のパッセージが「2008/8/28」、さらにその子供のパッセージ群が「株価平均は小反発・・・」であることを抽出できる。
以上の処理により、パッセージ間の階層構造関係すなわち親子関係および兄弟関係が付与されたパッセージ群を得ることができる。
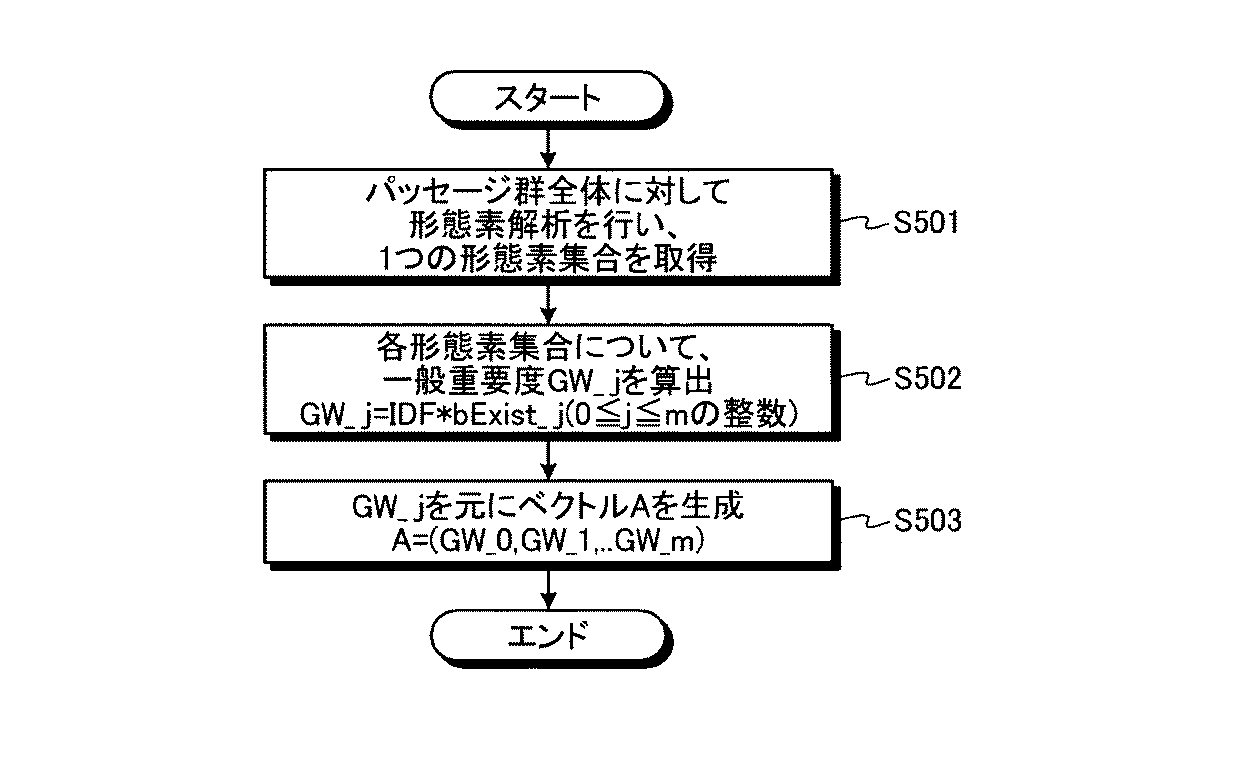
次に、ステップS303の一般重要度算出処理の詳細について図5を用いて説明する。図5は、第1の実施の形態における一般重要度算出処理の全体の流れを示すフローチャートである。
まず、第1単語重要度算出部113は、カーソルが所属するパッセージより上位の構造上位パッセージ群の全体に対して形態素解析を行い、1つの形態素集合を取得する(ステップS501)。次に、第1単語重要度算出部113は、形態素集合内の各形態素(各内容語)について、以下の(3)式により一般重要度GW_jを算出する(ステップS502)。
GW_j=idf(j)×bExist_j ・・・(3)
ただし、jは0≦j≦mを満たす整数(mは内容語の種類数)、idf(j)は内容語jの全文書中における逆出現頻度(Inverse Document Frequency)、bExist_jは形態素集合内に内容語jが存在する場合は1を、存在しない場合は0となる変数を表す。ここで全文書というのは、文書記憶部にある文書群である。あるいはWeb文書群などですでに算出済のidf値を用いても良い。なお、idfの代わりに別の重要度指標を用いてもよい。
次に、第1単語重要度算出部113は、算出したGW_jを要素とする以下の(4)式のベクトルを、単語一般重要度ベクトルAとして算出し(ステップS503)、一般重要度算出処理を終了する。
A=(GW_0,GW_1,・・・,GW_m) ・・・(4)
次に、ステップS304の個別重要度算出処理の詳細について図6を用いて説明する。図6は、第1の実施の形態における個別重要度算出処理の全体の流れを示すフローチャートである。
まず、第2単語重要度算出部114は、カーソルが所属するパッセージより上位の構造上位パッセージ群の全体に対して形態素解析を行い、1つの形態素集合を取得する(ステップS601)。次に、第2単語重要度算出部114は、形態素集合内の各内容語について、以下の(5)式により個別重要度IW_jを算出する(ステップS602)。
ただし、jは0≦j≦mを満たす整数(mは内容語の種類数)、T_jは形態素集合のうち内容語jである形態素を集めたサブ集合、dist(t)は形態素tが出現したパッセージと、カーソルが存在するパッセージとの階層的距離を表す。階層的距離とは、階層構造上で、一方のパッセージから他方のパッセージに達するまでの階層数をいう。例えば、形態素tが出現したパッセージとカーソルが存在するパッセージとが同一の場合は、階層的距離は0となる。
図1の例では、最上位から第6位のパッセージにカーソルが存在する。この場合、「NYMEX」から始まるパッセージ内に含まれる各形態素tに対するdist(t)の算出結果は1となる。また、最上位のパッセージ内に含まれる形態素t(すなわち「株価」)のdist(t)の算出結果は5となる。
なお、階層的距離を、パッセージ階層間に含まれるテキストの文字数などをベースに算出するように構成してもよい。例えば、パッセージ階層間に含まれる文字数が多い場合に、階層的距離を大きくするように構成してもよい。このような構成により、パッセージのテキスト量に応じて重みを変化させることができる。
次に、第2単語重要度算出部114は、算出したIW_jを要素とする以下の(6)式のベクトルを、単語個別重要度ベクトルBとして算出し(ステップS603)、個別重要度算出処理を終了する。
B=(IW_0,IW_1,・・・,IW_m) ・・・(6)
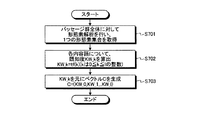
次に、ステップS305の既知度算出処理の詳細について図7を用いて説明する。図7は、第1の実施の形態における既知度算出処理の全体の流れを示すフローチャートである。
まず、既知度算出部115は、カーソルが所属するパッセージと同位の構造同位パッセージ群の全体に対して形態素解析を行い、1つの形態素集合を取得する(ステップS701)。次に、既知度算出部115は、形態素集合内の各内容語について、以下の(7)式により既知度KW_kを算出する(ステップS702)。
KW_k=tf(k) ・・・(7)
ただし、kは0≦i≦lを満たす整数(lは内容語の種類数)、tfは単語の出現頻度(term frequency)を示す。なお、tfの代わりに、別の重要度指標を用いてもよい。
次に、既知度算出部115は、算出したKW_kを要素とする以下の(8)式のベクトルを、単語既知度ベクトルCとして算出し(ステップS703)、既知度算出処理を終了する。
C=(KW_0,KW_1,・・・,KW_l) ・・・(8)
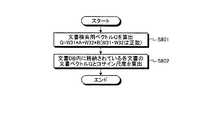
次に、ステップS306の文書検索処理の詳細について図8を用いて説明する。図8は、第1の実施の形態における文書検索処理の全体の流れを示すフローチャートである。
まず、文書検索部121は、単語一般重要度ベクトルAおよび単語個別重要度ベクトルBの重み付け線形和である文書検索用ベクトルQを、以下の(9)式を用いて算出する(ステップS801)。文書検索用ベクトルQは、重み付きの単語ベクトルとなる。
Q=W31×A+W32×B(W31,W32は正数) ・・・(9)
なお、文脈解析部110の出力部116が単語一般重要度ベクトルAおよび単語個別重要度ベクトルBから文書検索用ベクトルQを生成し、パッセージ検索部120に出力するように構成してもよい。
次に、文書検索部121は、文書記憶部140内に格納されている各文書の文書ベクトルと文書検索用ベクトルQとのコサイン尺度を関連度として算出する(ステップS802)。これにより文書ごとに関連度が得られる。すなわち関連度付きの文書群が得られる。なお、後続の処理効率化のため、関連度が所定の閾値を下回っている文書を出力に含めないように構成してもよい。また、関連度が上位の所定数の文書のみを関連文書として検索するように構成してもよい。
次に、ステップS307のパッセージ分割処理の詳細について図9を用いて説明する。図9は、第1の実施の形態におけるパッセージ分割処理の全体の流れを示すフローチャートである。
まず、パッセージ分割部122は、検索された各文書を、表層レベルでパッセージ単位に分割する(ステップS901)。例えば、文書がプレーンテキストの場合、パッセージ分割部122は、「。」、「、」、「?」、および「!」など終末記号に基づいて文書を文単位に分解する。なお、分割方法はこれに限られず、従来から用いられているあらゆる方法を適用できる。例えば、改行記号に基づいてパラグラフとみなせる単位で文書を分解するように構成してもよい。
また、例えばHTML形式の文書の場合、終末記号による分割が適用できない場合がある。例えば、レイアウト的に距離を開けること、または、罫線や配色などを用いることにより、テキストが相互に分割されていることを示すようにHTML文書が記載されている場合が挙げられる。このような場合は、例えば、HTMLの表示イメージをレイアウト解析することによりテキストの分割位置を特定し、パッセージ単位に分割するように構成すればよい。
このようにして得られたパッセージは、文法的解釈を行っていないため、そのパッセージのみでは内容として完結していない場合がある。すなわち、当該パッセージ以外のパッセージ等から情報が得られなければ意味がわからない状態になっている可能性がある。
例えば「その結果上昇した。」という文では、主語が何なのか(何が上昇したのか)が省略されている。また、「上昇」の原因となった「その」が何を指すのかを表す照応詞の解決がなされていない。このため、この文のみでは意味を理解することができない。
そこで、パッセージ分割部122は、構文解析や照応解析を実行し、必要に応じて抽出したパッセージを修正する(ステップS902〜ステップS903)。
具体的には、パッセージ分割部122は、分割したパッセージに、「その」、「あの」、および「この」などの照応詞が含まれる場合は、1つ前のパッセージの中から、先行詞である可能性が高い名詞句を抽出し、照応詞を抽出した名詞句で置き換える(ステップS902)。また、パッセージ分割部122は、分割したパッセージを構文解析し、主語が省略されていることが判明した場合、1つ前のパッセージの中から対応する名詞句を検索して主語として追加する(ステップS903)。
次に、ステップS308の文書内重要度算出処理の詳細について図10を用いて説明する。図10は、第1の実施の形態における文書内重要度算出処理の全体の流れを示すフローチャートである。
まず、第1パッセージ重要度算出部123は、パッセージ分割処理により得られたパッセージ群の集合(パッセージ群集合)から、未処理のパッセージ(パッセージiとする)を取得する(ステップS1001)。次に、第1パッセージ重要度算出部123は、パッセージiの位置情報C1_iを算出する(ステップS1002)。
位置情報C1_iは、当該パッセージが、所属する文書内のいずれの位置に存在しているかを表す指標である。例えば、ニュース記事などでは、文書の先頭から3文以内に存在する文は非常に重要度が高いと言われている。位置情報C1_iはこのような知見を元に、例えば文書の先頭から所定数のパッセージである場合に高い値となり、それ以外の場合は文書の後ろに存在するほど小さくなる値となるように算出される。
次に、第1パッセージ重要度算出部123は、パッセージiの手がかり表現情報C2_iを算出する(ステップS1003)。
手がかり表現情報C2_iは、予め定められた表層表現(手がかり表現)を含むか否かによりパッセージの重要度を決定するための指標である。例えば論文などでは「本研究(で)は」、「まとめると」、および「我々は」などの表現を含む文は、論文の主題を表すと考えられる。第1パッセージ重要度算出部123は、このような知見を元に、例えば所定の手がかり表現とスコアとを対応付ける辞書を用いて、パッセージに含まれる手がかり表現に対応づけられたスコアを、手がかり表現情報C2_iとして算出する。
次に、第1パッセージ重要度算出部123は、パッセージiのタイトル関連性C3_iを算出する。タイトル関連性C3_iは、タイトルと一致するパッセージまたはタイトルと関連するパッセージは重要であるとする指標である。第1パッセージ重要度算出部123は、文書にタイトル(またはHTMLのメタタグなどのようなタイトルに準じるコンテンツ)が存在する場合、この指標の一例として、タイトルの文書ベクトルと評価対象のパッセージの文書ベクトルとのコサイン尺度をタイトル関連性C3_iとして算出する(ステップS1004)。タイトルの文書ベクトルおよびパッセージの文書ベクトルは、tf−idfなどにより算出する。
次に、第1パッセージ重要度算出部123は、パッセージiの出現頻度C4_iを算出する。出現頻度C4_iは、所属する文書内の他のパッセージと強い関連性を持つパッセージが重要であることを表す指標である。語彙的結束性とも呼ばれる。第1パッセージ重要度算出部123は、この指標の一例として、評価対象のパッセージと他のパッセージとの単語共起数の総和を出現頻度C4_iとして算出する(ステップS1005)。
次に、第1パッセージ重要度算出部123は、各パッセージについて、C1_i〜C4_iを予め定めた重み付け係数で重み付け加算することにより、当パッセージの文書内重要度を算出する(ステップS1006)。具体的には、第1パッセージ重要度算出部123は、パッセージiの文書内重要度PScore_iを上記(1)式により算出する。
次に、第1パッセージ重要度算出部123は、未処理のパッセージが存在するか否かを判断し(ステップS1007)、存在する場合は(ステップS1007:YES)、未処理のパッセージを取得して処理を繰り返す(ステップS1001)。存在しない場合は(ステップS1007:NO)、文書内重要度算出処理を終了する。
次に、ステップS309のサマリ内重要度算出処理の詳細について図11を用いて説明する。図11は、第1の実施の形態におけるサマリ内重要度算出処理の全体の流れを示すフローチャートである。
まず、第2パッセージ重要度算出部124は、単語一般重要度ベクトルA、単語個別重要度ベクトルB、および単語既知度ベクトルCを用いて、サマリ内重要度評価用ベクトルQを以下の(10)式により算出する。
Q=W41×A+W42×B−W43×C ・・・(10)
なお、W41,W42,およびW43は予め定められた正数を表す。結果として得られるサマリ内重要度評価用ベクトルQは、重み付きの単語ベクトルとなる。
次に、第2パッセージ重要度算出部124は、パッセージ分割処理により得られたパッセージ群集合から、未処理のパッセージ(パッセージiとする)を取得する(ステップS1102)。次に、第2パッセージ重要度算出部124は、サマリ内重要度評価用ベクトルQと、パッセージiの文書ベクトルとのコサイン尺度を、パッセージiのサマリ内重要度として算出する(ステップS1103)。なお、第2パッセージ重要度算出部124は、パッセージiの文書ベクトルを例えばtf−idfを用いて算出する。
次に、第2パッセージ重要度算出部124は、未処理のパッセージが存在するか否かを判断し(ステップS1104)、存在する場合は(ステップS1104:YES)、未処理のパッセージを取得して処理を繰り返す(ステップS1101)。存在しない場合は(ステップS1104:NO)、サマリ内重要度算出処理を終了する。
次に、ステップS311のパッセージ選択処理の詳細について図12を用いて説明する。図12は、第1の実施の形態におけるパッセージ選択処理の全体の流れを示すフローチャートである。
まず、パッセージ選択部126は、パッセージ分割処理により得られたパッセージ群集合から、未処理のパッセージ(パッセージiとする)を取得する(ステップS1201)。次に、パッセージ選択部126は、以下の(11)式により、パッセージiの提示有効度を算出する(ステップS1202)。
ただし、Score_iはパッセージiの総合重要度、NSは未選択のパッセージ群、sim(i,h)はパッセージiとパッセージhとの類似度を表す。提示有効度は、各パッセージの重要度と新規性(例えば、すでに提示決定されたパッセージと内容がかぶる場合は新規性はないと判断される)とを考慮に入れた指標である。
次に、パッセージ選択部126は、算出した提示有効度のうち、最も高い提示有効度を示すパッセージを提示候補として決定する(ステップS1203)。次に、パッセージ選択部126は、一定数(例えば10件)の候補が決定されたか否かを判断する(ステップS1204)。決定されていない場合(ステップS1204:NO)、未処理のパッセージを選択して処理を繰り返す(ステップS1201)。
一定数の候補が決定された場合(ステップS1204:YES)、パッセージ選択部126は、提示有効度の高い順に決定されたパッセージ候補を出力し(ステップS1205)、パッセージ選択処理を終了する。
次に、多段階検索部132による多段階パッセージ検索機能の詳細について図13を用いて説明する。図13は、第1の実施の形態における多段階パッセージ検索処理の全体の流れを示すフローチャートである。以下では、子供となるパッセージを検索するための入力キーを特定キー1とし、兄弟となるパッセージを検索するための入力キーを特定キー2とする。
まず、多段階検索部132は、パッセージ候補ウィンドウで、特定キー1が押下されたか否かを判断する(ステップS1301)。押下された場合(ステップS1301:YES)、多段階検索部132は、編集結果記憶部133から、ユーザサマリとカーソル位置とを読み出し、メモリバッファ等の記憶部(図示せず)上にロードする(ステップS1303)。
次に、多段階検索部132は、メモリバッファ内で、パッセージ候補ウィンドウ上でフォーカスされているパッセージを、サマリのカーソル位置へ挿入する(ステップS1304)。次に、多段階検索部132は、メモリバッファ内で、挿入したパッセージの子供として空パッセージを生成し、その空パッセージ上にカーソルを置く(ステップS1305)。次に、多段階検索部132は、メモリバッファ上で生成されたサマリとカーソル位置とを文脈解析部110に送信する(ステップS1306)。
ステップS1301で特定キー1が押下されていない場合(ステップS1301:NO)、多段階検索部132は、さらに、特定キー2が押下されたか否かを判断する(ステップS1302)。押下された場合(ステップS1302:YES)、多段階検索部132は、編集結果記憶部133から、ユーザサマリとカーソル位置とを読み出し、メモリバッファ上にロードする(ステップS1307)。
次に、多段階検索部132は、メモリバッファ内で、パッセージ候補ウィンドウ上でフォーカスされているパッセージを、サマリのカーソル位置へ挿入する(ステップS1308)。次に、多段階検索部132は、メモリバッファ内で、挿入したパッセージの兄弟として空パッセージを生成し、その空パッセージ上にカーソルを置く(ステップS1309)。次に、多段階検索部132は、メモリバッファ上で生成されたサマリとカーソル位置とを文脈解析部110に送信する(ステップS1310)。
なお、同図では省略しているが、ステップS1306およびステップS1310の後は、図3と同様の処理により、送信されたユーザサマリとカーソル位置とを元に関連するパッセージが文書記憶部140の文書から選択され、編集部130に出力される。
ステップS1302で特定キー2が押下されていないと判断された場合(ステップS1302:NO)、多段階パッセージ検索処理を終了する。
(変形例)
上記第1の実施の形態では、構造解析部112は、箇条書きなどで表現されたユーザサマリを解析することにより、階層構造を求めていた。本変形例では、ユーザによって編集されたサマリテキストが、箇条書き表現などにより構造が明示化されていない場合であっても、第1の実施の形態と同等のパッセージ検索機能を提供可能とする。具体的には、本変形例の構造解析部112は、入力されたテキスト(ユーザサマリ)を修辞解析することで論理構造を認識する。
図14は、本変形例の検索支援装置で表示される編集画面の一例を示す図である。同図に示すように、本変形例のサマリ編集ウィンドウ1410内のテキストの内容は、図1のサマリ編集ウィンドウ10内のテキストの内容と同じである。しかし、本変形例では、箇条書きが示されていないこと、および、文と文との接続する語句として「・・・の背景としては」などをユーザが加筆している点が異なっている。
本変形例では、構造解析部112は、入力されたユーザサマリに対して、RST(修辞構造理論)に基づく論理構造解析を行う。RSTでは、パッセージ間の関係をツリー構造で表現するとともに、ツリー構造の各ノード間に24種類のラベルを付与する。本変形例ではラベルを利用しないため、解析結果としてラベルが得られても破棄する。
なお、第1の実施の形態の構造解析手法と、本変形例の構造解析手法とを組み合わせることで、箇条書きなどの明示的に構造が示された記述と、明示的に構造が示されない記述とが混在したテキストを取り扱うように構成することが可能である。具体的には、最初に明示的に示された箇条書き記述を元にツリー構造(階層構造)を作成した後、ツリーの各ノードに対して、RSTに基づく論理構造解析を行えばよい。
次に、本変形例の構造解析処理の詳細について図15を用いて説明する。図15は、第1の実施の形態の変形例における構造解析処理の全体の流れを示すフローチャートである。
まず、構造解析部112は、第1の実施の形態と同様に(図4のステップS401)、プレーンテキスト形式で表現されたユーザサマリを読み込みパッセージ単位に分解する(ステップS1501)。プレーンテキストに対しては、構造解析部112は、「。」、「、」、「?」、および「!」など終末記号に基づいてテキストを文単位に分解する。なお、分割方法はこれに限られず、従来から用いられているあらゆる方法を適用できる。例えば、上述のパッセージ分割部122と同様に、改行記号に基づいてパラグラフとみなせる単位で文書を分解するように構成してもよい。また、例えばHTML形式の文書の場合、HTMLの表示イメージをレイアウト解析することによりテキストの分割位置を特定し、パッセージ単位に分割するように構成してもよい。
次に、構造解析部112は、RST解析用の手がかり語辞書を参照して、パッセージ間の上下関係を同定する(ステップS1502)。例えば、「・・・(パッセージA)。その結果、(パッセージB)・・・」のように2つのパッセージが記載されている場合、「その結果」という手がかり語を判断材料として、パッセージAが親、パッセージBが子であり、両者の関係は「証拠/原因」であることが解析される。なお、RSTでは親を核、子を衛星と呼ぶ。手がかり語辞書とは、このようにパッセージ間の関係の同定材料になる特別な言い回しを集めたデータベースである。
本ステップでは、隣接するパッセージ間に手がかり語が存在するか否かを照合し、照合した場合は、両者の関係を同定する処理を反復的に行い、最終的にツリー構造を作成する。
このように、本変形例は、例えば他人に配布する清書された報告書などのようなプレーンテキストを作成する場合に、第1の実施の形態よりも有用となる可能性がある。すなわち、第1の実施の形態が想定しているテキスト表現は、他人へも配布可能な清書されたレポートというよりは、自分専用の調査メモという色彩が強い。これに対して、本変形例が想定しているテキスト表現は、他人へも配布可能なレポートと似た表現が許されている。このため、最終的な生成物の形に向かって調査を進めていくことが可能となり、作業効率化が期待される。
なお、第1の実施の形態の実現方法と、本変形例の実現方法とを組み合わせることで、箇条書きなど明示的に構造が示された記述と、上記で説明した明示的に示されない記述とが混在したテキストを取り扱うことも可能である。
このように、第1の実施の形態にかかる検索支援装置では、ユーザサマリ内の単語の重要度やパッセージ間の階層構造に応じた文書検索用ベクトルを作成できるため、キーワード入力の検索システムでは不可能な精度の高い情報要求をかけることができるとともに、ユーザはクエリ作成作業から解放される。また、ユーザサマリを検索要求の源とすることで、関連文書検索の徘徊問題を回避することができる。また、パッセージを検索結果として取得できるため、ユーザが文書中から新規情報を探す作業を低減できる。また、パッセージ挿入後のサマリ編集はユーザが行うため、複数文書要約技術では文脈統合が実用レベルに達していないという問題を回避可能となる。
(第2の実施の形態)
第1の実施の形態では、探求検索を目的として、ユーザがサマリを作成することを前提としていた。第2の実施の形態は、ユーザがサマリを作成することなく探求検索を行う。具体的には、第2の実施の形態の検索支援装置は、ユーザがWeb上の文書等を閲覧するときに効率的に探求検索を実行可能とする装置である。
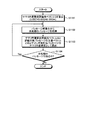
次に、画面イメージを参照しながら(図16)、本実施の形態の検索支援装置の機能の概要について説明する。図16は、第2の実施の形態の検索支援装置で表示される編集画面の一例を示す図である。
ユーザは、閲覧ウィンドウ1610によって、例えばWeb文書などの所望の文書を閲覧することができる。第1の実施の形態と同様に、閲覧ウィンドウ1610内の任意の箇所にカーソルを設定することができる。また、特定キーが押下されると、パッセージ候補ウィンドウ11が表示される。
パッセージ候補ウィンドウ11には、閲覧文書のカーソル位置の文脈に沿って文書群から検索されたパッセージ群の候補が表示される。ユーザがパッセージ候補の1つを選択すると、そのパッセージの原文書が閲覧ウィンドウ1610に表示される。
また、第1の実施の形態と同様に、多段階パッセージ検索機能も利用できる。多段階パッセージ検索機能を用いて、ウィンドウを複数呼び出し、最終的にパッセージを選択した場合、選択したパッセージの原文書が閲覧ウィンドウ1610に表示される。
なお、キーワードの代わりに文やパッセージをユーザに入力させ、入力された文やパッセージに適合する文書群を返すフレーズ検索システム(関連文書検索システム)が知られている。フレーズ検索システムは、文書のうち範囲指定内の指定パッセージのみを用いて情報要求を生成する。これに対して、本実施の形態の検索支援装置は、カーソル近辺に存在するパッセージ、すなわち指定パッセージだけでなく、階層構造や文字的距離に基づく傾斜加重を施した上で、文書全体にわたって指定パッセージの前後に存在するパッセージも含めて情報要求を生成する。このため、本実施の形態の検索支援装置による検索結果は、文書全体の内容や文脈を織り込んだ内容となる点が、従来のフレーズ検索システムと異なっている。
次に、本実施の形態の検索支援装置の構成の詳細について図17を用いて説明する。図17は、第2の実施の形態にかかる検索支援装置200の構成の一例を示すブロック図である。同図に示すように、検索支援装置200は、文脈解析部110と、パッセージ検索部120と、閲覧部230と、文書記憶部140と、を備えている。
第2の実施の形態では、編集部130の代わりに閲覧部230を追加したことが第1の実施の形態と異なっている。その他の構成および機能は、第1の実施の形態にかかる検索支援装置100の構成を表すブロック図である図2と同様であるので、同一符号を付し、ここでの説明は省略する。
閲覧部230は、表示装置(図示せず)に、検索されたテキストを閲覧可能に表示する機能を備えている。閲覧部230は、編集部130のように表示されたテキストを編集する機能を備える必要はない。
閲覧部230は、候補選択部231と、多段階検索部232と、閲覧結果記憶部233とを備えている。
閲覧結果記憶部233は、検索された文書と現在のカーソル位置とを記憶する。
候補選択部231および多段階検索部232は、ユーザによりパッセージ候補が選択された後の動作が、それぞれ第1の実施の形態の候補選択部131および多段階検索部132と異なる。すなわち、候補選択部231および多段階検索部232は、ユーザがパッセージ候補の1つを選択すると、選択されたパッセージ候補の原文書の内容を文書記憶部140から読み出し、読み出した文書内容を閲覧結果記憶部233に格納する。
このように、第2の実施の形態にかかる検索支援装置では、ユーザがWeb上の文書等を閲覧するときにも、第1の実施の形態と同様の手法により、効率的に探求検索を実行することが可能となる。
(第3の実施の形態)
第3の実施の形態にかかる検索支援装置は、指定された形態素の品詞に応じて予め定められた修辞語を検索キーワードとして検索要求に付加する。これにより、形態素の品詞に応じてより適切なパッセージ候補を検索することが可能となる。
次に、画面イメージを参照しながら(図18)、本実施の形態の検索支援装置の機能の概要について説明する。図18は、第3の実施の形態の検索支援装置で表示される編集画面の一例を示す図である。
ユーザは、サマリ編集ウィンドウ1810内でキーボード・マウスなどを用いることにより構造テキスト(ユーザサマリ)を作成および編集することができる。本実施の形態では、ユーザサマリ内の各形態素が、その品詞に応じて異なる表示態様で強調表示される点が、第1および第2の実施の形態と異なる。
具体的には、動作性名詞または動詞は矩形の枠で囲まれて表示される。また、動作性名詞以外の名詞は下線が付されて表示される。編集などによりユーザサマリが更新されるたびに(例えば文字が入力されるごとに)、適切なタイミングで名詞の品詞の判定処理および表示態様の変更処理が行われ、常に正しい表示態様により表示されるものとする。このハイライト(強調表示)は後述のパッセージ検索機能で利用される。
なお、上記のような強調表示のための表示態様は一例であり、従来から用いられているあらゆる強調表示方法を適用できる。例えば、文字色、フォントの種類、およびフォントサイズ等の表示態様を品詞ごとに変更するように構成してもよい。以下では、動作性名詞または動詞に対する強調表示を第1ハイライトといい、動作性名詞以外の名詞に対する強調表示を第2ハイライトという。
ユーザは、パッセージ候補ウィンドウ1811によって、文献DBに記憶されている複数の文書内のパッセージ群を検索し取り込むことができる。本実施の形態では、検索機能を利用するための操作方法として2種類の操作方法を用いる。
1つは、第1ハイライト上でマウスクリックなどの特定キーを押下する操作である。第1ハイライトで表示された形態素は、動作性名詞または動詞であり、この操作により、動作性名詞または動詞が表す動作がなぜ起こったのか、を説明するパッセージが検索される。具体的には、上記操作により「それはなぜ?」という質問、すなわち原因や背景などを要求する質問が、検索要求に付加され、この結果、原因や背景を説明するパッセージが検索される。例えば、ユーザが、サマリ編集ウィンドウ1810内の最下層のパッセージ(図18参照)に含まれる単語「上昇」の上で特定キーを押下すると、「上昇」という動作の主語が「原油先物価格」であることが同定された上で、原油先物価格がなぜ上昇したのか、に関する説明として適切なパッセージ群がパッセージ候補として検索され、パッセージ候補ウィンドウ1811に提示される。
もう1つは、第2ハイライト上でマウスクリックなどの特定キーを押下する操作である。第2ハイライトで表示された形態素は、動作性名詞以外の名詞であり、この操作により、その名詞がどのようなものなのかを説明するパッセージが検索される。具体的には、上記操作により「それは何?」という質問、すなわち定義などを要求する質問が、検索要求に付加され、この結果、名詞の定義等を説明するパッセージが検索される。例えば、ユーザが、サマリ編集ウィンドウ1810内の最下層のパッセージ(図18参照)に含まれる単語「NYMEX」の上で特定キーを押下すると、ニューヨーク・マーカンタイル取引所に関する説明として適切なパッセージ群がパッセージ候補として検索され、パッセージ候補ウィンドウ1811に提示される。
第1および第2の実施の形態の情報要求は、「もっと詳しく」というような漠然とした要求と言えるが、第3の実施の形態の情報要求は、「それは何?」「それはなぜ?」などのように的を絞った要求である。探求検索は、情報の収集過程でユーザの精通度が動的に変化するため、情報要求を変更する操作(コマンド)を適宜使い分けられることにより、ユーザの利便性を向上させることができる。
なお、上記説明では、品詞種別に応じた質問の種類(質問タイプ)として、定義(それは何?)および理由(それはなぜ?)の2つのみを挙げた。しかし、質問タイプはこれらに限られるものではなく、この他にも様々な質問タイプを用いることができる。例えば、動作性名詞または動詞に対する質問タイプとして、結果(それでどうなる?)を用いるように構成してもよい。上記例の場合、「原油先物価格が上昇した結果どうなるのか?」という質問が追加される。RSTでは24種類のパッセージ間関係を定義しているため、RSTに基づいて24種類の質問を利用することもできる。本実施の形態では、説明の簡便性のため、2種類の質問のみを取り扱う。
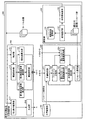
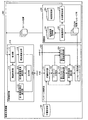
次に、本実施の形態の検索支援装置の構成の詳細について図19を用いて説明する。図19は、第3の実施の形態にかかる検索支援装置300の構成の一例を示すブロック図である。同図に示すように、検索支援装置300は、文脈解析部310と、パッセージ検索部320と、編集部330と、文書記憶部140と、を備えている。
第3の実施の形態では、文脈解析部310に係り受け解析部317と生成部318とを追加したこと、パッセージ検索部320の文書検索部321と第2パッセージ重要度算出部324の機能、および、編集部330の機能が第1の実施の形態と異なっている。その他の構成および機能は、第1の実施の形態にかかる検索支援装置100の構成を表すブロック図である図2と同様であるので、同一符号を付し、ここでの説明は省略する。
編集部330は、各種ユーザ操作を受付け、受付けたユーザ操作に応じた処理を各構成部に指示する。本実施の形態では、編集部330は、ユーザサマリおよびカーソル位置に加え、カーソル位置の単語を表す指定形態素と、指定形態素の品詞を表す品詞情報とを文脈解析部310へ渡す点が、第1の実施の形態の編集部130と異なっている。
なお、カーソル位置の代わりに、指定形態素の位置を表す情報を渡すように構成してもよい。すなわち、指定された位置に対応するパッセージが特定可能な情報であればどのような情報を渡してもよい。また、品詞情報を渡さずに、文脈解析部310内で指定形態素の品詞を判定するように構成してもよい。
係り受け解析部317は、カーソル位置の単語を含む文の句構造(係り受け構造)を解析する。日本語のテキストに対しては、係り受け解析部317は、例えばKNPやCabochaなどの解析手法を適用して句構造解析を実行することができる。
以下に、句構造解析結果の例を示す。以下の(入力)に示すテキストに対して、係り受け解析部317は、以下の(出力)に示す解析結果を出力する。
(入力)「NYMEXの時間外取引で原油先物価格が1バレル=119ドル台に上昇」
(出力)(((((NYMEX)の)時間外取引)で[adv])(((1バレル=119ドル台)に[adv])(((原油先物価格)が[np])(上昇した[vp]))))
なお、記号「()」はツリー構造を示す。すなわち、「上昇した[vp]」がツリーのルートであり、「原油先物価格が[np]」がその直下ノードとなる。「原油価格が上昇した」に対して2つの副詞句(adv)がぶら下がる。また()内の最後尾に記載される[]は、句の種別を示す。なお、上記以外の句構造の表現を用いるように構成してもよい。
生成部318は、指定形態素と句構造解析結果とを用いて、文書検索用ベクトルに追加する質問を表すベクトルである質問ベクトルを生成する。生成部318は、例えば以下の(12)式ような質問ベクトルDを生成する。
D=(QW_0,QW_1,・・・,QW_n) ・・・(12)
QW_iは、指定形態素が属する文に含まれる形態素および修辞語(後述)に含まれる形態素のうち、i番目の形態素(1≦i≦n)に対する重み、nは指定形態素が属する文に含まれる形態素および修辞語に含まれる形態素の総数を表す。重みQW_iの算出方法、および質問ベクトルDの算出方法の詳細は後述する。
文書検索部321は、単語一般重要度ベクトルA、単語個別重要度ベクトルB、に加え、質問ベクトルDを用いて、関連文書を検索する点が、第1の実施の形態の文書検索部121と異なっている。
第2パッセージ重要度算出部324は、単語一般重要度ベクトルA、単語個別重要度ベクトルB、および単語既知度ベクトルCに加え、質問ベクトルDを用いて、サマリ内重要度評価用ベクトルQを算出する点が、第1の実施の形態の第2パッセージ重要度算出部124と異なっている。
次に、このように構成された第3の実施の形態にかかる検索支援装置300による検索支援処理について図20を用いて説明する。図20は、第3の実施の形態における検索支援処理の全体の流れを示すフローチャートである。
第3の実施の形態では、ステップS2001の受付処理、ステップS2006およびステップS2007が追加されたこと、文書検索処理(ステップS2008)、および、サマリ内重要度算出処理(ステップS2011)が第1の実施の形態と異なっている。その他のステップは、第1の実施の形態にかかる検索支援装置100における検索支援処理(図3)と同様の処理なので、その説明を省略する。
ステップS2001では、受付部311が、ユーザサマリおよびカーソル位置とともに、指定形態素および品詞情報の入力を受付ける(ステップS2001)。また、ステップS2006では、係り受け解析部317が、入力されたユーザサマリの指定形態素を含む文の句構造解析(係り受け解析)を実行する(ステップS2006)。その後、生成部318が、句構造解析結果を元に質問ベクトルDを生成する質問生成処理を実行する(ステップS2007)。質問生成処理の詳細については後述する。
なお、係り受け解析処理(ステップS2006)および質問生成処理(ステップS2007)は、ステップS2003〜ステップS2005の各処理の後に実行する必要はない。ステップS2003〜ステップS2005の各処理の前に実行してもよいし、並列的に実行するように構成してもよい。
ステップS2008の文書検索処理、および、ステップS2011のサマリ内重要度算出処理の詳細は後述する。
次に、ステップS2007の質問生成処理の詳細について図21を用いて説明する。図21は、第3の実施の形態における質問生成処理の全体の流れを示すフローチャートである。
まず、生成部318は、スコアXを1.0に初期化する(ステップS2101)。次に、生成部318は、句構造解析結果を参照して、指定形態素が句構造のいずれのノードに含まれるかを照合し、照合したノードを現在ノードとして選択する(ステップS2102)。
次に、生成部318は、現在ノード内の内容語を抽出し、内容語に対する重みQW_iとしてスコアXを付与する(ステップS2103)。なお、iは処理ごとに1加算されるカウンタ値(0以上)とする。
次に、生成部318は、スコアXの値を、現在の値の9割の値に更新する(ステップS2104)。次に、生成部318は、現在ノードの子ノード群を取得する(ステップS2105)。そして、生成部318は、子ノードが取得できたか否かを判断する(ステップS2106)。取得できた場合(ステップS2106:YES)、生成部318は、子ノードを現在ノードとして選択し(ステップS2107)、処理を繰り返す(ステップS2103)。なお、子ノードが複数取得された場合は、各子ノードに対して処理を繰り返す。
子ノードが取得できなかった場合(ステップS2106:NO)、生成部318は、指定形態素の品詞に対応する修辞語を、予め定められた修辞語辞書(図示せず)等を参照して取得する(ステップS2108)。指定形態素の品詞は、入力された品詞情報から判別することができる。
例えば、生成部318は、指定形態素が動作性名詞または動詞の場合、理由に相当する修辞語として予め定められた修辞語群を修辞語辞書から取得する。また、生成部318は、指定形態素が動作性名詞以外の名詞の場合は、定義に相当する修辞語として予め定められた修辞語群を修辞語辞書から取得する。なお、修辞語を、「^その結果.*」および「^背景として.*」のように正規表現で記述するように構成してもよい。
なお、生成部318は、修辞語に含まれる形態素のスコアとして「1.0」を付与する。また、修辞語に含まれる形態素と抽出された内容語とが一致する場合は、当該形態素のスコアを「1.0」で更新する。
次に、生成部318は、抽出した各内容語および修辞語のスコア(重みQW_i)を要素とする質問ベクトルDを生成する(ステップS2109)。これにより、修辞語を検索キーワードとして含む検索要求(文書検索用ベクトル)を生成可能となる。
例えば、「NYMEXの時間外取引で原油先物価格が1バレル=119ドル台に上昇」が入力された上記例では、「原油先物価格」、「上昇」、および「NYMEX」が内容語として抽出され、それぞれの重みとして「1.0」、「0.9」、および「0.81」が与えられる。さらに、修辞語群として、「^その結果」および「^背景として.*」が取得されたとする。この場合、生成部318は、これらの内容語および修辞語の各重みを要素とする質問ベクトルDを生成する。
次に、ステップS2008の文書検索処理の詳細について図22を用いて説明する。図22は、第3の実施の形態における文書検索処理の全体の流れを示すフローチャートである。
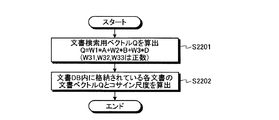
まず、文書検索部321は、単語一般重要度ベクトルA、単語個別重要度ベクトルB、および質問ベクトルDの重み付け線形和である文書検索用ベクトルQを、以下の(13)式を用いて算出する(ステップS2201)。
Q=W31×A+W32×B+W33×D(W31,W32,W33は正数) ・・・(13)
次に、文書検索部321は、文書記憶部140内に格納されている各文書の文書ベクトルと文書検索用ベクトルQとのコサイン尺度を関連度として算出し(ステップS2202)、文書検索処理を終了する。
次に、ステップS2011のサマリ内重要度算出処理の詳細について図23を用いて説明する。図23は、第3の実施の形態におけるサマリ内重要度算出処理の全体の流れを示すフローチャートである。
まず、第2パッセージ重要度算出部324は、質問ベクトルDに含まれる正規表現で記述された修辞パタン(修辞語)に適合するパッセージ群のみを取り出す(ステップS2301)。
次に、第2パッセージ重要度算出部324は、単語一般重要度ベクトルA、単語個別重要度ベクトルB、単語既知度ベクトルC、および質問ベクトルDを用いて、サマリ内重要度評価用ベクトルQを以下の(14)式により算出する(ステップS2302)。
Q=W41×A+W42×B−W43×C+W44×D ・・・(14)
なお、W41,W42,W43、およびW44は予め定められた正数を表す。結果として得られるサマリ内重要度評価用ベクトルQは、重み付きの単語ベクトルとなる。
ステップS2303からステップS2305までの、コサイン尺度算出処理は、第1の実施の形態にかかる検索支援装置100におけるステップS1102からステップS1104までと同様の処理なので、その説明を省略する。
このように、第3の実施の形態にかかる検索支援装置では、指定された形態素の品詞に応じて予め定められた修辞語を検索要求に付加することができる。これにより、形態素の品詞に応じてより適切なパッセージ候補を検索することが可能となる。
(第4の実施の形態)
第4の実施の形態にかかる検索支援装置は、ユーザがサマリを編集した履歴を表す編集履歴情報を用いることにより、より高精度に関連するパッセージを検索する。
図24は、第4の実施の形態にかかる検索支援装置400の構成の一例を示すブロック図である。図24に示すように、検索支援装置400は、文脈解析部410と、パッセージ検索部420と、編集部430と、文書記憶部140と、を備えている。
第4の実施の形態では、文脈解析部410の第2単語重要度算出部414の機能、パッセージ検索部420の第2パッセージ重要度算出部424の機能、および、編集部430に履歴記憶部434を追加したことが第1の実施の形態と異なっている。その他の構成および機能は、第1の実施の形態にかかる検索支援装置100の構成を表すブロック図である図2と同様であるので、同一符号を付し、ここでの説明は省略する。
履歴記憶部434は、ユーザによるユーザサマリの編集履歴を記憶する。具体的には、履歴記憶部434は、ユーザサマリのテキストのうち、ユーザが独自に記述した部分と、外部からコピーペースト(引用)した部分とを判別する判定情報、および、コピーペーストした部分については、いずれの文書から引用したかを特定可能な引用元情報(例えばURLなど)を記憶する。
編集部430は、この引用元情報を用いて、引用元の原文書を表示する機能を備える。具体的には、ユーザが任意のテキスト上でダブルクリックなど所定操作を行い、そのテキストが引用により追加されたテキストであった場合、編集部430は、引用元情報を参照して当該テキストの引用元となる原文書を取得し、編集画面に表示する。
第2単語重要度算出部414は、構造上位パッセージ群に含まれる各形態素(内容語)のうち、ユーザが独自に記述した形態素(すなわち引用された記述ではない部分)については、重み(個別重要度)を高める処置をする点が、第1の実施の形態の第2単語重要度算出部114と異なっている。ユーザ自身が記述した部分は、ユーザの意思が強く現れていることを織り込むためである。
第2パッセージ重要度算出部424は、ユーザサマリ内のカーソル直前のパッセージと同じ文書に所属するパッセージ(すなわち引用元が同じパッセージ)については、スコア(サマリ内重要度)を高める処置をする点が、第1の実施の形態の第2パッセージ重要度算出部124と異なっている。パッセージが同じ文書からの引用であれば、話題の結束性(つながり)がより高いと期待されるためである。なお、カーソル直前のパッセージとは、カーソルが所属するパッセージの1つ上位のパッセージを意味する。
次に、このように構成された第4の実施の形態にかかる検索支援装置400による検索支援処理について説明する。本実施の形態では、個別重要度算出処理およびサマリ内重要度算出処理の内容が第1の実施の形態と異なっている。その他の処理は、第1の実施の形態にかかる検索支援装置100の検索支援処理を表す図3と同様であるため、その説明を省略する。
次に、本実施の形態の個別重要度算出処理の詳細について図25を用いて説明する。図25は、第4の実施の形態における個別重要度算出処理の全体の流れを示すフローチャートである。
本実施の形態では、ステップS2502で算出する個別重要度IW_jの算出式が第1の実施の形態と異なっている。その他のステップは、第1の実施の形態にかかる検索支援装置100における個別重要度算出処理(図6)と同様の処理なので、その説明を省略する。
ステップS2502で、第2単語重要度算出部414は、形態素集合内の各内容語について、以下の(15)式により個別重要度IW_jを算出する(ステップS602)。
ただし、jは0≦i≦mを満たす整数(mは内容語の種類数)、T_jは形態素集合のうち内容語jである形態素を集めたサブ集合、dist(t)は形態素tが出現したパッセージと、カーソルが存在するパッセージとの階層的距離を表す。また、org(t)は、形態素tがユーザ自身によって記述された形態素である場合にWORG1を返し、それ以外の場合にWORG2を返す関数を表す(WORG1およびWORG2は正数、かつ、WORG1>WORG2)。このような関数org(t)を用いることにより、第2単語重要度算出部414は、ユーザが独自に記述した形態素の個別重要度を高めることができる。
次に、本実施の形態のサマリ内重要度算出処理の詳細について図26を用いて説明する。図26は、第4の実施の形態におけるサマリ内重要度算出処理の全体の流れを示すフローチャートである。
本実施の形態では、ステップS2604およびステップS2605が追加されたことが第1の実施の形態と異なっている。その他のステップは、第1の実施の形態にかかる検索支援装置100におけるサマリ内重要度算出処理(図11)と同様の処理なので、その説明を省略する。
ステップS2603でコサイン尺度(サマリ内重要度)を算出後、第2パッセージ重要度算出部424は、パッセージiが、ユーザサマリ内のカーソル直前のパッセージと同じ文書から引用されたパッセージであるか否かを判断する(ステップS2604)。同じ文書から引用されたパッセージであった場合(ステップS2604:YES)、第2パッセージ重要度算出部424は、算出したサマリ内重要度に予め定められた正数W44を加算する(ステップS2605)。正数W44を加算後、または、パッセージiがユーザサマリ内のカーソル直前のパッセージと同じ文書から引用されたパッセージでないと判断した場合(ステップS2604:NO)、第2パッセージ重要度算出部424は、未処理のパッセージが存在するか否かを判断する(ステップS2606)。この後の処理は、図11と同様である。
このように、第4の実施の形態にかかる検索支援装置では、ユーザがサマリを編集した履歴を表す編集履歴情報を用いることにより、ユーザの意思が強く現れている内容語に関連するパッセージを高精度に検索できる。また、パッセージの引用関係を参照することにより、話題が関連するパッセージを高精度に検索できる。これにより、ユーザの要求を適切に反映した関連パッセージをより高精度に検索することができる。
次に、第1〜第4の実施の形態にかかる検索支援装置のハードウェア構成について図27を用いて説明する。図27は、第1〜第4の実施の形態にかかる検索支援装置のハードウェア構成を示す説明図である。
第1〜第4の実施の形態にかかる検索支援装置は、CPU(Central Processing Unit)51などの制御装置と、ROM(Read Only Memory)52やRAM53などの記憶装置と、ネットワークに接続して通信を行う通信I/F54と、HDD(Hard Disk Drive)、CD(Compact Disc)ドライブ装置などの外部記憶装置と、ディスプレイ装置などの表示装置と、キーボードやマウスなどの入力装置と、各部を接続するバス61を備えており、通常のコンピュータを利用したハードウェア構成となっている。
第1〜第4の実施の形態にかかる検索支援装置で実行される検索支援プログラムは、インストール可能な形式又は実行可能な形式のファイルでCD−ROM(Compact Disk Read Only Memory)、フレキシブルディスク(FD)、CD−R(Compact Disk Recordable)、DVD(Digital Versatile Disk)等のコンピュータで読み取り可能な記録媒体に記録されて提供される。
また、第1〜第4の実施の形態にかかる検索支援装置で実行される検索支援プログラムを、インターネット等のネットワークに接続されたコンピュータ上に格納し、ネットワーク経由でダウンロードさせることにより提供するように構成してもよい。また、第1〜第4の実施の形態にかかる検索支援装置で実行される検索支援プログラムをインターネット等のネットワーク経由で提供または配布するように構成してもよい。
また、第1〜第4の実施の形態の検索支援プログラムを、ROM等に予め組み込んで提供するように構成してもよい。
第1〜第4の実施の形態にかかる検索支援装置で実行される検索支援プログラムは、上述した各部(文脈解析部等)を含むモジュール構成となっており、実際のハードウェアとしてはCPU51(プロセッサ)が上記記憶媒体から検索支援プログラムを読み出して実行することにより上記各部が主記憶装置上にロードされ、上述した各部が主記憶装置上に生成されるようになっている。
なお、本発明は、上記実施の形態そのままに限定されるものではなく、実施段階ではその要旨を逸脱しない範囲で構成要素を変形して具体化することができる。また、上記実施の形態に開示されている複数の構成要素の適宜な組み合わせにより、種々の発明を形成することができる。例えば、実施の形態に示される全構成要素からいくつかの構成要素を削除してもよい。さらに、異なる実施の形態にわたる構成要素を適宜組み合わせてもよい。
本発明の他の第1の発明は、請求項2に記載の発明において、前記位置の文字を含む前記パッセージと前記階層構造が同位の前記パッセージに含まれる単語それぞれについて、前記入力文書内でのユーザが既に知っている度合いを表す既知度を算出する既知度算出部をさらに備え、前記第2パッセージ重要度算出部は、前記既知度が大きい前記単語を含む前記パッセージに対して、前記既知度が小さい前記単語を含む前記パッセージより小さい前記第2パッセージ重要度を算出すること、を特徴とする。
本発明の他の第2の発明は、請求項2に記載の発明において、前記第2パッセージ重要度算出部は、前記位置の文字を含む前記パッセージの1つ上位の前記上位パッセージである直前パッセージが含まれる文書に属する前記パッセージに対して、前記直前パッセージが含まれる文書に属さない前記パッセージより大きい前記第2パッセージ重要度を算出すること、を特徴とする。
本発明の他の第3の発明は、請求項2に記載の発明において、前記分割部は、さらに、分割した前記パッセージに、他の前記パッセージに含まれる対象を指し示す照応表現が含まれるか否かを判断し、前記照応表現が含まれる場合に、他の前記パッセージから前記照応表現の指示対象を表す名詞句を取得し、前記名詞句で前記照応表現を置換すること、を特徴とする。
本発明の他の第4の発明は、請求項2に記載の発明において、前記分割部は、さらに、分割した前記パッセージに、主語が省略された文が含まれるか否かを判断し、前記主語が省略された文が含まれる場合に、他の前記パッセージから前記主語を表す名詞句を取得し、前記主語が省略された文に前記名詞句を主語として追加すること、を特徴とする。
本発明の他の第5の発明は、請求項2に記載の発明において、前記パッセージ選択部は、分割された前記パッセージのうち、前記総合重要度が大きく、かつ、選択済みの前記パッセージとの間の類似度が小さい前記パッセージを優先して選択すること、を特徴とする。