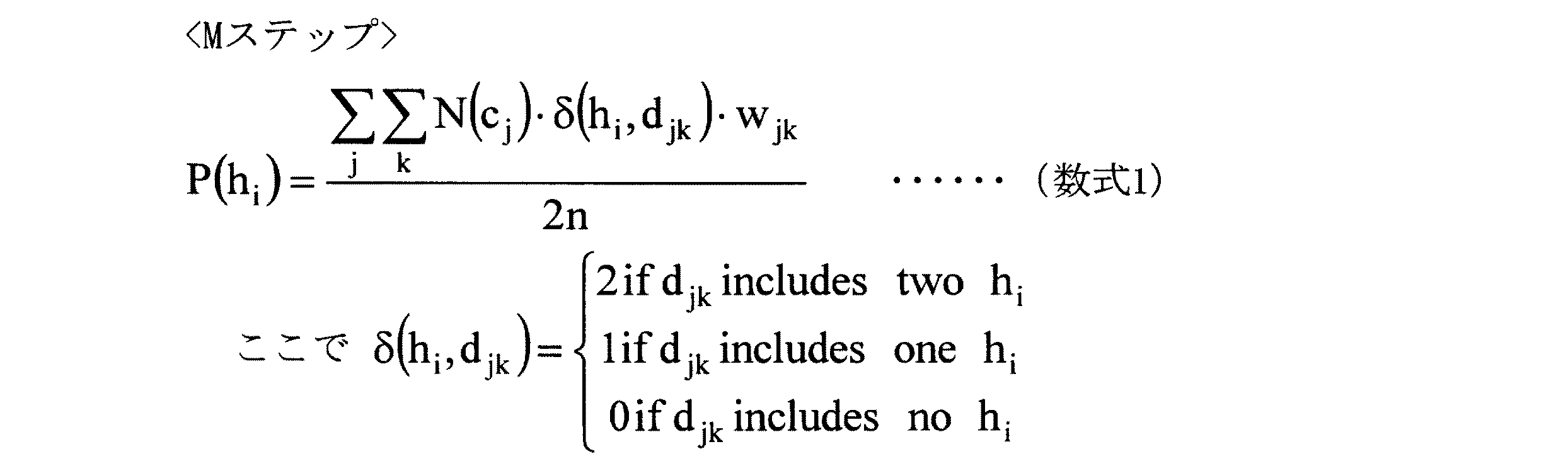以下に、本発明にかかるハプロタイプ推定装置、ハプロタイプ推定方法、および、プログラム、並びに、記録媒体の実施の形態を図面に基づいて詳細に説明する。なお、この実施の形態によりこの発明が限定されるものではない。
[本発明の原理]
以下、本発明の原理および概要について説明し、その後、本発明の構成および処理等について詳細に説明する。ここで、図5は、1座位当たりの二つの相同染色体に渡る総コピー数(コピー数の総和)の多型テーブルの一例を表す図である。図5において、Lは座位を表す。
図5に示すように、実験結果によっては、各個体(個体1、個体2、・・・)、各座位(L1、L2、L3、・・・)における、二つの相同染色体に渡る総コピー数の表(テーブル)が得られる場合(コピー数多型がある場合)があり、総コピー数は2に限られない。
また、実験によっては、総コピー数がはっきりと確定されず、例えば“0コピーあるいは1コピー”、“2よりは多いコピー数”など、コピー数の状態が唯一つに決まっていない総コピー数(すなわち曖昧な総コピー数)を含むデータが得られる場合がある。ここで、図6は、曖昧なコピー数を含む、1座位当たりの二つの相同染色体に渡る総コピー数のデータの一例を示す図である。
図6において、“0or1”は、0コピーあるいは1コピーで表し、“>2”は、2よりは多いコピー数を表している。実際に、実験で得られるデータは、このような曖昧なデータしか得られない場合があるので、このようなデータから、相同染色体1本上の一座位におけるコピー数と、そのコピー数をアレルと見た時の頻度、あるいはそのようなアレルの複数座位に渡る組合せとしてのハプロタイプとその頻度を推定する必要があった。
また、そのような総コピー数のデータに、それとは異なる座位における1座位当たりの遺伝子型データが組み合わさったデータから、ハプロタイプを推定する必要があった。ここで、図7は、1座位当たりの二つの相同染色体に渡る総コピー数のデータに、1座位当たりの遺伝子型データが組み合わさったデータの一例を示す図である。図7に示すように、座位L1およびL4では、1座位当たりの二つの相同染色体に渡る総コピー数を表しており、座位L2、L3、L5では、1座位当たりの遺伝子型データが表現されている。
ここで、「ハプロタイプ」とは、二つの相同染色体に渡る総コピー数(曖昧な総コピー数も含む。)が得られた座位に対しては、相同染色体1本上におけるコピー数をアレルとし、遺伝子型が得られた座位に対してはそこで既に定義されたアレルを使った、複数座位に渡るアレルの組合せのことである。ここで、図8は、本発明におけるハプロタイプの表現例を示す図である。図8において、N(L)は、相同染色体1本上の座位Lにおけるコピー数N(整数値)を表しており、A(L)は座位Lに対応するアレルAを表している。
図7において示されるような、二つの相同染色体に渡る総コピー数のデータは、遺伝子型データではないため、従来技術(1)を適用することができないという問題があった。また、その総コピー数データは塩基多型を考慮したコピー数多型に関する実験データとも異なり、さらに今回取り扱うハプロタイプはコピー単位の組合せのことではない為、従来技術(2)も適用することができないという問題があった。
本発明は、上述した種々の問題に鑑みて本発明者により鋭意検討された結果得られたものであり、一座位当たりの二つの相同染色体に渡る、コピー数の総和(以下、「総コピー数」と呼ぶ。)のデータを処理し、相同染色体1本上の一座位におけるコピー数と、そのコピー数をアレルと見たときの頻度、あるいは、そのようなアレルの複数座位に渡る組合せとしてのハプロタイプとその頻度を推定する。さらには、一座位当たりの二つの相同染色体に渡る総コピー数のデータに、それとは異なる座位における一座位当たりの遺伝子型データが組み合わさったデータから、上述した背景技術のようなハプロタイプとその頻度を推定する。
ここでは、本発明の原理を説明するために一例として、総コピー数と遺伝子型が組み合わさったデータからの推定について説明する。なぜなら、総コピー数と遺伝子型が組み合わさったデータからハプロタイプを推定することは、総コピー数データのみからハプロタイプを推定することを含むより一般的な推定であり、かつ、総コピー数データから複数座位に渡るハプロタイプとその頻度を推定することは、一座位におけるコピー数のアレルとその頻度を推定することを含むより一般的な推定であるからである。
与えられたデータからハプロタイプとその頻度を推定する原理は、各個体に対しデータと矛盾しないディプロタイプ(2つの相同染色体上それぞれにある2つのハプロタイプの組合せ)を見出し、データを利用してハプロタイプの頻度を計算することである。ここで、二つの相同染色体に渡る(確定された)総コピー数がデータとして得られた場合、「矛盾しない」とは、各座位に対しては、ディプロタイプから数えられるその座位のコピー数アレルのコピー数の和が、そのデータにおける総コピー数に一致するということである。例えば、上述の図7のデータの個体1、座位L1に対しては、図8におけるハプロタイプ1,ハプロタイプ2からなるディプロタイプを考えたとき、N11(L1)+N12(L1)がデータにおける総コピー数2に一致するということである。
また、総コピー数が曖昧な総コピー数である場合、「矛盾しない」とは、それが複数の総コピー数が提示されたもの(例えば、不等号を含まず“or”で複数の総コピー数が連結されたもの)であるときは、ディプロタイプから数えられるその座位のコピー数アレルのコピー数の和が、その複数の総コピー数のいずれかに一致するということである。例えば図7のデータの個体1、座位L4に対しては、図8におけるハプロタイプ1,ハプロタイプ2から成るディプロタイプを考えたとき、N41(L4)+N42(L4)が、データ「0or1」が提示する複数の総コピー数N=0,1のいずれかに一致するということである。また、曖昧な総コピー数が“ある数より大きい”など不等号で表現される総コピー数であるとき、「矛盾しない」とは、ディプロタイプから数えられるその座位のコピー数アレルのコピー数の和が、不等号で表現される条件を満たすということである。例えば、図7のデータの個体2、座位L1に対しては、図8におけるハプロタイプ1,ハプロタイプ2からなるディプロタイプを考えたとき、N11(L1)+N12(L1)がデータ「>2」によって表現された“2より大きい”を満たす、すなわちN11(L1)+N12(L1)>2を満たす、ということである。
また、遺伝子型がデータとして得られた各座位に対しては、上記「矛盾しない」とは、ディプロタイプから数えられるその座位の各アレルの数が、その遺伝子型データにおける各アレルの数(カウント数)と一致するということである。例えば、図7のデータの個体1、座位L2に対しては、図8におけるハプロタイプ1,ハプロタイプ2からなるディプロタイプを考えたとき、ディプロタイプのL2におけるA1,A2,A3,…の数それぞれ1,1,0,…(ディプロタイプ表現のA1(L2),A2(L2)から得られるカウント数)が、データにおけるA1,A2,A3,…の数にそれぞれ一致するということである。
以上、まとめると、「矛盾しない」とは、コピー数多型におけるコピー数の総和(2本の染色体に渡るコピー単位の総数)の条件や、塩基多型におけるカウント数(2本の染色体に渡る多型塩基に特異的なマーカー部位の総数)の条件に反しないことである。
ここでは、本発明の原理を1個体に対して説明したが、データの各座位における総コピー数及び各アレルの数が同じ個体(すなわち、コピー数データやカウント数データのパターンが同じ個体)は同じように扱えるので、それらの数のパターンでデータをまとめてパターン毎にインデックス(j)を付け、集団における特定のパターンを有する個体数N(cj)を保持しておいてもよい。以降、この数のパターンを「カウントパターン」と呼ぶ。(各カウントパターンに対し)与えられたデータと矛盾しないディプロタイプが見出せれば、Expectation−Maximization(EM)法やGibbsサンプリング法などによって、データからハプロタイプの頻度が計算できる。
各カウントパターンに対し、データと矛盾しないディプロタイプを見出す方法は種々考えられる。ここではデータと矛盾しない、あらゆる可能なディプロタイプを見出すことを想定して説明する。方法としては、例えば各カウントパターンに対し、まず一座位毎にデータと矛盾しないあらゆる可能な遺伝子型を見出し、それから全座位に渡ってあらゆる可能なディプロタイプを構成する方法が考えられる。ここで、図10は、本発明の概要を模式的に示したフロー図である。
その第一段階では、二本の相同染色体に渡る(確定された)総コピー数がデータとして得られた座位に対しては、その総コピー数と和が等しい(0を含む正の)整数値2つ一組をあらゆる組合せで作り、2つの整数値をそれぞれコピー数を表すアレルで、2つ一組を遺伝子型とすればよい。例えば、総コピー数がNのとき、[N/0],[N−1/1],[N−2/2],…,[0/N](ここで、[ ]は遺伝子型、あるいはディプロタイプを表し、“/”でアレルまたはハプロタイプを分ける位置を表す。)に対し、重複する冗長な遺伝子型を除いたものが、求める遺伝子型である。総コピー数が曖昧な、“or”で連結された総コピー数である場合は、それぞれの総コピー数に対して、これと同じ方法で遺伝子型を列挙すれば求められる。例えば、0or1or3の場合、総コピー数0に対し上と同じ方法で遺伝子型を列挙し(例えば、[0/0])、さらに総コピー数1に対し同じ方法で列挙し(例えば、[1/0])、さらに総コピー数3に対し同じ方法で列挙し(例えば、[3/0]、[2/1])、あらゆる組み合わせの遺伝子型(例えば、[0/0]、[1/0]、[3/0]、[2/1])を求める。
総コピー数が曖昧な、不等号で表現された総コピー数であり、しかも“Nより多いコピー数”を表す「>N」である場合は、アレルのコピー数にも“Nより多いコピー数”を表す「>N」を用意して{0,1,…,N,>N}の各要素をコピー数アレルとし、それら2つのコピー数の和が総コピー数の不等式条件(>N、即ちNより大きい)を満たすようなあらゆる2つ一組(同じコピー数アレルからなる組を含む。)を遺伝子型とすればよい(ここで、2つのコピー数の和を出す際、アレルコピー数>Nには、どんな数あるいは>Nが足されてもその総コピー数は>Nとなり、不等式条件は満たされる)。ここで、図9は、2つのコピー数アレルからなる遺伝子型とそのコピー数の和を一例として示す図である。
例えば、図9のように、{0,1,…,N,>N}から2つのコピー数アレルをあらゆる組合せで作って各組を遺伝子型とし、その2つのアレルのコピー数の和が不等式条件>Nを満たす組だけ選択すればそれが求める遺伝子型である。図9において、( )内の数字は2つのアレルのコピー数の和を表す。なお、総コピー数が“Nより少ないコピー数”を表す<Nである場合は、0or1or2…orN−1である場合と同じである。
遺伝子型がデータとして得られた座位に対しては、データにおける数の分だけアレルを表す文字(多型識別文字)を取り、これを2つに分けて組を作り、遺伝子型とすればよい。遺伝子型データの座位に関しては、一座位当たりのアレルの総数は必ず2であるので簡単にアレルを2つに分けられ、遺伝子型は唯一つ得られる。
第二段階においては、各座位の遺伝子型から、全座位に渡るあらゆる可能なディプロタイプを作る。これには、全座位に渡って一つずつ遺伝子型をあらゆる組合せで取り、その各組合せに対し、各座位の各遺伝子型が持つ2つのアレルから、全座位に渡るアレルの組合せとしてのハプロタイプ2つの組合せから構成されるディプロタイプを、2M−1個(ここでMは全座位数)のあらゆる組合せで作り、このディプロタイプの作成を遺伝子型の組合せ全部に対し行った後、最後に重複する冗長なディプロタイプを除けばよい。
例えば、座位L1の遺伝子型が[B11/B12],[B13/B14]、座位L2,L3の遺伝子型がそれぞれ[B21/B22],[B31/B32]であるとき(ここでBは、コピー数アレルあるいは遺伝子型データで定義されているアレルを表す。)、まず全座位に渡る遺伝子型の組合せ、[B11/B12],[B21/B22],[B31/B32]と[B13/B14],[B21/B22],[B31/B32]を取る。次に、最初の組合せ[B11/B12],[B21/B22],[B31/B32]に対しては、[B11B21B31/B12B22B32],[B11B21B32/B12B22B31],[B11B22B31/B12B21B32],[B11B22B32/B12B21B31]の23−1個のあらゆる組合せを列挙する。さらに、[B13/B14],[B21/B22],[B31/B32]に対しても、同様に23−1個のあらゆる組合せを列挙する。
最後に重複する冗長なディプロタイプを除く。図10に、あるカウントパターンc1に対し、データと矛盾しないディプロタイプを見出す方法の例を示した。その図において、L1,L3は二つの相同染色体に渡る総コピー数がデータとして得られた座位であり、L2は遺伝子型がデータとして得られた座位である。図10<SA−2>の記号(○の中に×)は、全座位に渡って一つずつ遺伝子型をあらゆる組合せで取ることを示す。
こうして得られたディプロタイプを用い、さらに与えられたデータを使って、ハプロタイプの頻度を求める。この方法も幾つか考えられるが、一例として、Expectation−Maximization(EM)法を用いてもよい。これは、得られたディプロタイプに対し、その存在の重みを割り付け、そのディプロタイプが含むハプロタイプの個数を、その重み分を考慮して数え、ハプロタイプの頻度を計算し(Mステップ)、次にそのハプロタイプ頻度からハーディ・ワインバーグの法則を使って、ディプロタイプの存在の重みを更新し(Eステップ)、さらにその更新された重みから、Mステップ、次にEステップ、さらにMステップ、…と手続きを繰り返して頻度を更新していく方法である。例えば、以下の数式1のようなMステップと、数式2−1の様なEステップを交互に行って、ハプロタイプの頻度の更新していく。
上記数式2−1において、Pは頻度、nは個体の総数、i,j,kはハプロタイプ、カウントパターン、カウントパターン内でのディプロタイプのインデックス、h,dはハプロタイプ、ディプロタイプ,N(c
j)はカウントパターンc
jを持つ個体の数、wはEM法における、カウントパターン内でのディプロタイプの重みを表す。数2−1におけるディプロタイプの頻度は、ハーディ・ワインバーグの法則から計算する。ハーディ・ワインバーグの法則とは遺伝学における自然法則であり、この法則によって、ディプロタイプを構成する2つのハプロタイプとその確率(あるいは頻度)が分かったとき、そのディプロタイプの確率(あるいは頻度)が計算できる。この法則は、例えば、以下の数2−2の様に表現される。以上のような方法で、ハプロタイプとその頻度を推定する。ここで、頻度の非常に低いハプロタイプは存在しないと解釈してもよい。
[本発明の概要]
まず、本発明は、集団における各個体の少なくともコピー数多型を含む実験データからハプロタイプを推定する、制御部と記憶部を少なくとも備えたハプロタイプ推定装置において実行される。
そして、図10に示すように、本ハプロタイプ推定装置は、個体毎に、実験データから得られた、標識によって特定されるマーカー部位に対応付けられたコピー数多型の総コピー数Nに対する一または複数の条件式を、マーカー部位の種類毎に記憶する多型テーブルを備える(SA−1)。ここで、コピー数Nに対する条件式は、コピー数の総和Nの条件を規定する一または複数の等式または不等式を含んでもよく、例えば、「N=2」や「N>0」や、「N=1or2」や「N≧2」等であってもよい。また、当該多型テーブルは、個体毎に、塩基多型を更に含む実験データから得られた、標識によって特定されるマーカー部位に対応付けられた多型塩基をカウントしたカウント数を、当該多型塩基の種類毎に更に格納されてもよい。
そして、本ハプロタイプ推定装置は、コピー数の総和Nについて、足し合わせた場合に、多型テーブルに記憶された総コピー数Nの条件式を満たす任意の2つの整数に分割する(SA−2)。例えば、本ハプロタイプ推定装置は、図5<SA−2>に示すように、総コピー数Nの条件式N=2の場合に、[2/0]または[1/1]に分割する。また、例えば、総コピー数Nの条件式N≦2の場合は、[2/0]、[1/1]、[1/0]または[0/0]に分割する。
そして、本ハプロタイプ推定装置は、分割された2つの整数をそれぞれ多型識別文字(例えば、「2」や「3」など)として表し、個体において(複数の座位に渡って)多型識別文字を列挙したハプロタイプ文字列の組合せ(ディプロタイプを表す。)として格納する(SA−3〜4)。ここで、図10<SA−3>に示すように、コピー数多型のコピー数を表す多型識別文字は、一例として、アラビア数字により表してもよい。ここで、図10<SA−4>に示すように、多型テーブルに個体毎の標識によって特定されるマーカー部位に対応付けられた多型塩基の種類毎の多型塩基のデータがある場合は、ハプロタイプ文字列の組合せにおいて、多型塩基の種類に対応付けた多型識別文字(例えば、「A1」や「A2」など)を更に列挙してもよい(例えば、「2A13/0A20」)。ここで、本ハプロタイプ推定装置は、まず遺伝子型の組合せを求めてから、次に全ての可能なハプロタイプの組合せ(ディプロタイプ)を求めてもよい。
すなわち、本ハプロタイプ推定装置は、一例として、図10に示すように、個体毎および座位(マーカー部位)毎の実験データ<SA−1>から、各座位における全ての可能な組合せを求め(SA−2)、次に、複数の座位に渡る全ての可能な遺伝子型の組合せを求め(SA−3)、最後に、遺伝子型の組合せから複数の座位に渡る全ての可能なハプロタイプの組合せ(ディプロタイプ)を表す文字列を求めてもよい(SA−4)。また、ここで、本ハプロタイプ推定装置は、作成したハプロタイプ文字列の組合せにおける多型識別文字が表す整数の和が、多型テーブルにおける総コピー数Nの条件式を満たすか否か(または多型塩基のカウント数と一致するか否か)を確認し、条件を満たさない場合に当該ハプロタイプ文字列を除外してもよい。また、ハプロタイプ推定装置は、作成したハプロタイプ文字列の組合せが他のハプロタイプ文字列の組合せと重複するか否か判断し、重複する場合に当該ハプロタイプ文字列の組合せを除外してもよい(SA−5)。
そして、本ハプロタイプ推定装置は、集団において、同一であるハプロタイプ文字列の数を集計し、ハプロタイプ文字列の集団における頻度を求め、当該頻度が所定の条件を満たす各個体のハプロタイプ文字列の組合せを、ハプロタイプの組合せとして推定する。ここで、本ハプロタイプ推定装置は、頻度をハーディ・ワインバーグ(Hardy−Weinberg)の法則に基づいて算出し、集団における頻度がハーディ・ワインバーグ平衡となる場合に所定の条件を満たすと判定してもよい。
また、本ハプロタイプ推定装置は、ハプロタイプの推定処理において、EM(Expectation−Maximization)法を用いて、集団におけるハプロタイプ文字列の頻度を、当該ハプロタイプ文字列を少なくとも一方に有する組合せの頻度により重み付けして算出するMステップと、組合せの頻度を、当該組合せを構成するハプロタイプ文字列の頻度の積により求め、当該組合せの頻度に基づいて重みを算出するEステップと、を頻度の値が収束するまで交互に繰り返すことにより所定の条件を満たす頻度を算出してもよい。EM法の詳細な処理については、後述する。以上で、本発明の概要の説明を終える。
[ハプロタイプ推定装置の構成]
まず、本ハプロタイプ推定装置の構成について説明する。図11は、本発明が適用される本ハプロタイプ推定装置の構成の一例を示すブロック図であり、該構成のうち本発明に関係する部分のみを概念的に示している。
図11において、ハプロタイプ推定装置100は、概略的に、ハプロタイプ推定装置100の全体を統括的に制御するCPU等の制御部102、通信回線等に接続されるルータ等の通信装置(図示せず)に接続される通信制御インターフェース部104、入力部112や出力部114に接続される入出力制御インターフェース部108、および、各種のデータベースやテーブルなどを格納する記憶部106を備えて構成されており、これら各部は任意の通信路を介して通信可能に接続されている。
記憶部106に格納される各種のデータベースやテーブル(多型テーブル106a〜実験データファイル106c)は、固定ディスク装置等のストレージ手段であり、各種処理に用いる各種のプログラムやテーブルやファイルやデータベース等を格納する。
これら記憶部106の各構成要素のうち、多型テーブル106aは、個体毎に、実験データから得られた、標識によって特定されるマーカー部位に対応付けられたコピー数多型の総コピー数N(二本の相同染色体上のコピー単位の数の総和)に対する一または複数の条件式をマーカー部位の種類毎(すなわちコピー多型の種類毎)にコピー数データとして記憶する多型テーブルである。ここで、多型テーブル106aは、個体毎に、塩基多型を更に含む実験データから得られた、標識によって特定されるマーカー部位に対応付けられた多型塩基をカウントしたカウント数を当該多型塩基の種類毎にカウント数データとして更に記憶してもよい。上述したように、図5や図6や図7や図10<SA−1>は、多型テーブル106aに格納されるコピー数データおよび/またはカウント数データの一例を示す。この多型テーブル106aに格納される情報は、一例として図7等に示すように、個体毎、座位毎(コピー数多型の種類に対応したマーカー部位毎、および/または、各座位における多型塩基の種類毎)のコピー数(条件式を含んでもよい。)/カウント数を定義している。ここで、コピー数Nに対する条件式は、コピー数の総和Nの条件を規定する一または複数の等式または不等式を含んでもよく、例えば、「N=3」や「N>0」、「N=1or2」、「N≠2」、「0<N≦2」等であってもよい。
また、ハプロタイプ文字列ファイル106bは、多型テーブル106aに記憶された個体のコピー数データおよび/またはカウント数データに基づいて算出された、取り得るハプロタイプ文字列の組合せを記憶するハプロタイプ文字列記憶手段である。ハプロタイプ文字列ファイル106bは、一例として、ハプロタイプ文字列を、図8に示したようなハプロタイプ表現形式で記憶してもよい。
また、実験データファイル106cは、集団における各個体の少なくともコピー数多型を含む実験データを記憶する実験データ記憶手段である。ここで、実験データは、一塩基多型等の塩基多型のデータ(遺伝子型データ等)を含んでもよい。一例として、コピー数多型のコピー単位上の、標識によって特定されるマーカー部位に対応付けられた多型塩基を示す実験データ(DNAチップやPCR等による実験データなど)を記憶してもよい。また、標識としては、蛍光色素プローブの他、蛍光特性を持たない色素や、放射性同位体、GFP・GRPなどのタンパク質、Hisタグ、ビオチン化などによって識別可能なプローブ等を用いてもよい。
また、図11において、通信制御インターフェース部104は、ハプロタイプ推定装置100とネットワーク300(またはルータ等の通信装置)との間における通信制御を行う。すなわち、通信制御インターフェース部104は、他の端末と通信回線を介してデータを通信する機能を有する。
また、図11において、入出力制御インターフェース部108は、入力部112や出力部114の制御を行う。ここで、出力部114としては、モニタ(家庭用テレビを含む。)の他、スピーカ等を用いることができる。また、入力部112としては、キーボード、マウス、およびマイク等を用いることができる。
また、図11において、制御部102は、OS(Operating System)等の制御プログラム、各種の処理手順等を規定したプログラム、および所要データを格納するための内部メモリを有し、これらのプログラム等により、種々の処理を実行するための情報処理を行う。制御部102は、機能概念的に、コピー数総和分割部102a、ハプロタイプ文字列格納部102b、ハプロタイプ推定部102c、多型テーブル作成部102eを備えて構成されている。なお、理解の容易のために上述した記号を用いて説明することがある。
このうち、コピー数総和分割部102aは、コピー数の総和Nについて、足し合わせた場合に、多型テーブル106aに記憶された総コピー数Nの条件式を満たす任意の2つの整数に分割するコピー数総和分割手段である。ここで、コピー数総和分割部102aは、総コピー数Nの条件式が曖昧な数を規定している場合(例えば、「N=2」ではなく「N>2」など)には、2つの整数の少なくとも一方を曖昧な整数(例えば、[>2/0])に分割してもよい。
また、ハプロタイプ文字列格納部102bは、コピー数総和分割部102aにより分割された2つの整数をそれぞれ多型識別文字(例えば、アラビア数字の「0」や「1」)として表し、個体において多型識別文字を列挙したハプロタイプ文字列の組合せ(例えば、「302/021」)としてハプロタイプ文字列ファイル106bに格納するハプロタイプ文字列格納手段である。ここで、ハプロタイプ文字列格納部102bは、多型テーブル106aに、個体毎に、塩基多型を更に含む実験データ(遺伝子型データ)から得られた、標識によって特定されるマーカー部位に対応付けられた多型塩基が、当該多型塩基の種類毎に格納されている場合(すなわち、カウント数データが格納されている場合)に、ハプロタイプ文字列の組合せにおいて、多型塩基の種類に対応付けた多型識別文字を更に列挙してもよい(例えば、「302A1/021A2」)。ここで、ハプロタイプ文字列格納部102bは、作成したハプロタイプ文字列の組合せにおける対応する多型識別文字が表す整数の和(二本の相同染色体上のコピー多型のコピー数の和を表している。)が、多型テーブル106aにおける総コピー数Nの条件式を満たすか否か確認し、条件式を満たさない場合に当該ハプロタイプ文字列を除外してもよい。また、ハプロタイプ文字列格納部102bは、作成したハプロタイプ文字列の組合せにおける多型塩基を表す多型識別文字の数が、多型テーブル106aに格納されたカウント数データと一致するか否か確認し、一致しない場合に当該ハプロタイプ文字列を除外してもよい。また、ハプロタイプ文字列格納部102bは、作成したハプロタイプ文字列の組合せが他のハプロタイプ文字列と重複するか否か判断し、重複する場合に当該ハプロタイプ文字列を除外してもよい。
また、ハプロタイプ推定部102cは、ハプロタイプ文字列ファイル106bを参照して、集団において、同一であるハプロタイプ文字列の数を集計し、当該ハプロタイプ文字列の集団における頻度を求め、当該頻度が所定の条件を満たす各個体のハプロタイプ文字列の組合せを、ハプロタイプの組合せとして推定するハプロタイプ推定手段である。ここで、ハプロタイプ推定部102cは、ハプロタイプ文字列の頻度を、ハーディ・ワインバーグの法則に基づいて算出し、所定の条件を、集団におけるハーディ・ワインバーグ平衡としてもよい。
ここで、ハプロタイプ推定部102cは、図11に示すように、ハプロタイプ頻度算出部102dを備えて構成される。ハプロタイプ頻度算出部102dは、EM(Expectation−Maximization)法を用いて、集団におけるハプロタイプ文字列の頻度を、当該ハプロタイプ文字列を少なくとも一方に有する組合せの頻度により重み付けして算出するMステップと、ハプロタイプの組合せの頻度を、当該組合せを構成する2つのハプロタイプ文字列の頻度の積により求め、当該組合せの頻度に基づいて重みを算出するEステップと、を頻度の値が収束するまで交互に繰り返すハプロタイプ頻度算出手段である。ここで、ハプロタイプ頻度算出部102dは、Mステップにおいて算出されたハプロタイプ文字列の頻度と、前回のMステップにおいて算出されたハプロタイプ文字列の頻度と、の対数尤度差を求め、対数尤度差が所定の閾値以下となった場合に、頻度の値が収束したと判定してもよい。これにより、EM法の収束条件を適切に設定することができるので、精度を保証しながら計算時間を節約することができる。
また、ここで、ハプロタイプ頻度算出部102dは、Mステップにおいて、下記の数式1に基づいて、ハプロタイプ文字列の頻度P(h
i)を算出し、Eステップにおいて、下記の数式2に基づいてハプロタイプ文字列の組合せの頻度P(d
jk)を求め、重みw
jkとして当該ハプロタイプ文字列の組合せの頻度を集団における組合せの頻度の総和で除して算出してもよい。
ここで、P(h
i)はハプロタイプ文字列の頻度を表し、hはハプロタイプ文字列を表し、iはハプロタイプ文字列のインデックスを表す。また、nは集団を構成する個体の数、jは、多型テーブル106aにおけるコピー数データおよび/またはカウント数データのパターン(以下「カウントパターン」と呼ぶ。)のインデックス、kはハプロタイプ文字列の組合せのインデックスである。また、N(c
j)は、カウントパターンj(「c
j」と表記する。)を持つ個体の数を表す。また、δ(h
i,d
jk)は、ハプロタイプ文字列の組合せd
jkが一方に当該ハプロタイプ文字列h
iを有する場合に1を返し、両方に当該ハプロタイプ文字列h
iを有する場合に2を返し、当該ハプロタイプ文字列h
iを持たない場合に0を返す関数であり、dはハプロタイプ文字列の組合せを表す。また、w
jkはハプロタイプ文字列の組合せの頻度による重み(当該ハプロタイプ文字列の組合せd
jkの頻度を、組合せd
jkの頻度の総和で除した数)である。
ここで、P(d
jk)は、ハプロタイプ文字列の組合せの頻度を表す。また、h
lおよびh
mは当該組合せを構成する2つのハプロタイプ文字列を表し、P(h
l)およびP(h
m)は、当該2つのハプロタイプ文字列の頻度をそれぞれ表す。
また、多型テーブル作成部102eは、実験データファイル106cに記憶された個体毎の実験データを用いて、標識によって特定されるマーカー部位に対応付けられた総コピー数N(二本の染色体に渡るコピー単位の数の総和)をコピー数多型の種類毎にコピー数データとして、および/または、標識によって特定されるマーカー部位に対応付けられた多型塩基をカウントしたカウント数を多型塩基の種類毎にカウント数データとして、多型テーブル106aに格納する多型テーブル作成手段である。ここで、格納されるカウント数およびコピー数は、一意に特定される数に限られず、曖昧な数(例えば、「>5」、「1or2」、「≠0」)であってもよい。
ここで、本ハプロタイプ推定装置100は、ルータ等の通信装置および専用線等の有線または無線の通信回線を介して、ネットワーク300に通信可能に接続されてもよい。この場合、本システムは、概略的にハプロタイプ推定装置100と、コピー数データやカウント数データ等に関する外部データベースやハプロタイプ推定プログラム等の外部プログラム等を提供する外部システム200とを、ネットワーク300を介して通信可能に接続して構成される。ここで、図11において、ネットワーク300は、ハプロタイプ推定装置100と外部システム200とを相互に接続する機能を有し、例えば、インターネット等である。
ここで、外部システム200は、ネットワーク300を介して、ハプロタイプ推定装置100と相互に接続され、利用者に対してコピー数データやカウント数データ等に関する外部データベースやハプロタイプ推定プログラム等の外部プログラム等を実行するウェブサイトを提供する機能を有する。ここで、外部システム200は、WEBサーバやASPサーバ等として構成していてもよく、そのハードウェア構成は、一般に市販されるワークステーション、パーソナルコンピュータ等の情報処理装置およびその付属装置により構成していてもよい。また、外部システム200の各機能は、外部システム200のハードウェア構成中のCPU、ディスク装置、メモリ装置、入力装置、出力装置、通信制御装置等およびそれらを制御するプログラム等により実現される。以上で、本ハプロタイプ推定装置100の構成の説明を終える。
[本ハプロタイプ推定装置100の処理]
次に、このように構成された実施の形態における本ハプロタイプ推定装置100の処理の一例について、以下に図12〜図14を参照して詳細に説明する。
[ハプロタイプ推定処理]
本実施の形態におけるハプロタイプ推定処理の一例について、以下に図12を参照して説明する。ここで、図12は、本ハプロタイプ推定装置100のハプロタイプ推定処理の一例を示す図である。
図12に示すように、コピー数総和分割部102aは、コピー数の総和Nについて、足し合わせた場合に、多型テーブルに記憶された総コピー数Nの条件式を満たす任意の2つの整数に分割する(SB−1)。ここで、コピー数総和分割部102aは、総コピー数Nの条件式が曖昧な数を規定している場合(例えば、「N>2」)には、2つの整数を曖昧な整数(例えば、[>2/0])で分割してもよい。
そして、ハプロタイプ文字列格納部102bは、コピー数総和分割部102aにより分割された2つの整数をそれぞれ多型識別文字として表し、個体における多型識別文字を複数の座位に渡って列挙したハプロタイプ文字列の組合せを、とりうる全ての組み合せで算出してハプロタイプ文字列ファイル106bに格納する(SB−2)。なお、多型テーブル106aに、遺伝子型データから得られた、標識によって特定されるマーカー部位に対応付けられた多型塩基のカウント数が、多型塩基の種類毎に格納されている場合には、ハプロタイプ文字列格納部102bは、多型塩基の種類に対応付けた多型識別文字を加えて、ハプロタイプ文字列の組合せに列挙してもよい。ここで、ハプロタイプ文字列格納部102bは、作成したハプロタイプ文字列の組合せにおける対応する多型識別文字が表す整数の和(二本の相同染色体上のコピー多型のコピー数の和を表している。)が、多型テーブル106aにおける総コピー数Nの条件式を満たすか否か確認し、条件式を満たさない場合に当該ハプロタイプ文字列を除外してもよい。また、ハプロタイプ文字列格納部102bは、作成したハプロタイプ文字列の組合せが他のハプロタイプ文字列と重複するか否か判断し、重複する場合に当該ハプロタイプ文字列を除外してもよい。
そして、ハプロタイプ推定部102cは、ハプロタイプ文字列格納部102bにより個体毎に格納されたハプロタイプ文字列の組合せを記憶するハプロタイプ文字列ファイルハプロタイプ文字列ファイル106bを参照して、集団において、同一であるハプロタイプ文字列の数を集計する(SB−3)。
そして、ハプロタイプ推定部102cは、ハプロタイプ文字列の集団における頻度を計算する(SB−4)。ここで、ハプロタイプ推定部102cは、ハプロタイプ文字列の頻度をハーディ・ワインバーグの法則により算出してもよい。
そして、ハプロタイプ推定部102cは、ハプロタイプ文字列の頻度が所定の条件を満たす各個体のハプロタイプ文字列の組合せを抽出し、ハプロタイプの組合せとして推定する(SB−5)。ここで、ハプロタイプ推定部102cは、所定の条件として、集団におけるハーディ・ワインバーグ平衡を設定してもよい。以上で、本実施の形態におけるハプロタイプ推定処理を終える。
[EM法による処理]
ハプロタイプ推定部102cの処理によるEM法の詳細な処理の一例について説明する。すなわち、ハプロタイプ推定部102cは、ハプロタイプ頻度算出部102dの処理により、集団におけるハプロタイプ文字列の頻度を、EM(Expectation−Maximization)法を用いて、効率よく計算する。
ここで、EM法とは、得られたディプロタイプ(本実施の形態においては、ハプロタイプ文字列の組合せとして表す。)に対し、その存在の重みを割り付け、そのディプロタイプが含むハプロタイプの個数を、重み分を考慮して数え、ハプロタイプの頻度を計算し(Mステップ)、次にそのハプロタイプ頻度からハーディ・ワインバーグの法則を使って、ディプロタイプの存在の重みを更新し(Eステップ)、さらにその更新された重みから、Mステップ、次にEステップ、さらにMステップ、・・・と処理を繰り返して、頻度を更新していく方法である。例えば、下記の数式1に基づくMステップと、下記の数式2(数式2−1および数式2−2)に基づくEステップを交互に行うことにより、ハプロタイプの頻度の更新していく。
また、P(h
i)はハプロタイプ文字列の頻度を表し、hはハプロタイプ文字列を表し、iはハプロタイプ文字列のインデックスを表す。また、nは集団を構成する個体の数、jはカウントパターン(多型テーブル106aにおけるコピー数データおよび/またはカウント数データのパターン)のインデックス、kはハプロタイプ文字の組合せのインデックス、N(c
j)はカウントパターン(c
j)を持つ個体の数を表す。また、δ(h
i,d
jk)は、ハプロタイプ文字列の組合せd
jkが一方に当該ハプロタイプ文字列h
iを有する場合に1を返し、両方に当該ハプロタイプ文字列h
iを有する場合に2を返し、当該ハプロタイプ文字列h
iを持たない場合に0を返す関数であり、dはハプロタイプ文字列の組合せを表す。また、w
jkは下記の数式2−1に基づくハプロタイプ文字列の組合せの頻度による重みである。
ここでP(d
jk)は、ハーディ・ワインバーグの法則を表す下記の数式2−2に基づいて計算する。
ここで、上記の数式2−2は、ハーディ・ワインバーグの法則を示している。ハーディ・ワインバーグの法則とは遺伝学における自然法則であり、この法則によって、ディプロタイプを構成する2つのハプロタイプとその確率(あるいは頻度)が分かった時、そのディプロタイプの確率(あるいは頻度)が計算できる。なお、上記EM法においては、頻度の非常に低いハプロタイプは存在しないと解釈される。このように、ハプロタイプ推定部102cは、ハプロタイプ頻度算出部102dの処理により、一例として上記のEM法を用いて、ハプロタイプの組合せとその頻度を推定する。ここで、ハプロタイプ頻度算出部102dは、下記の数式に基づいて、Mステップにおいて算出されたハプロタイプ文字列の頻度と、前回のMステップにおいて算出されたハプロタイプ文字列の頻度と、の対数尤度差を求め、対数尤度差が所定の閾値以下となった場合に、頻度の値が収束したと判定してもよい。
以上で、EM法による処理の一例の説明を終える。
[実施例]
本実施の形態を、プログラミング言語Perlで実装した実施例について、以下に図13〜図14を参照して説明する。図13は、本実装の枠組みを示すフローチャートである。図14は、コピー数総和分割処理およびハプロタイプ文字列格納処理の一例を示すフローチャートである。なお、以下の説明において、説明の簡単のために、本実施の形態におけるハプロタイプ文字列を単に「ハプロタイプ」と、ハプロタイプ文字列の組合せを「ディプロタイプ」と述べる場合がある。
図13に示すように、まず、ハプロタイプ推定装置100は、多型テーブル106aを参照してデータ(例えば、図5、図6、図7等に示した多型テーブルのデータ)を読み込む(SC−1)。ここで、ハプロタイプ推定装置は、EM法において収束判定に使われる数値も読み込んでもよい。
次に、ハプロタイプ推定装置100は、コピー数総和分割処理およびハプロタイプ文字列格納処理として、データと矛盾しないディプロタイプを全て算出する(SC−2)。具体的には、以下のSC−21〜SC−25を行う。
すなわち、取り得るハプロタイプの組合せを過不足なく求めるため(多型テーブル106aのコピー数データおよび/またはカウント数データと矛盾しないディプロタイプを見出すため)、ハプロタイプ推定装置は、ディプロタイプ(ハプロタイプの組合せ)を構成する。ここで、データと矛盾しないディプロタイプとは、作成したディプロタイプ(2本の相同染色体に渡る文字の集合)において、コピー数多型におけるコピー数の総和(2本の染色体に渡るコピー単位の総数)の条件や、塩基多型におけるカウント数(2本の染色体に渡る多型塩基に特異的なマーカー部位の総数)の条件に反しないことである。具体的には、多型識別文字が表す2本の染色体上のコピー数を足し合わせたとき、多型テーブル106aに記憶されたコピー数データの条件に反しない(各コピー多型の総コピー数Nの条件を満たす)ことである。また、多型識別文字が表す2本の染色体上の多型塩基をカウントしたとき、多型テーブル106aに記憶されたカウント数データのカウント数と一致するということである。ここで、図14は、コピー数データおよび/またはカウント数データの全パターンにおいて、そのカウントパターンと矛盾しないディプロタイプを作成する処理の一例を示すフローチャートである。
図14に示すように、まず、ハプロタイプ推定装置100は、多型テーブル106aに記憶されたコピー数データおよび/またはカウント数データから全カウントパターンを算出する(読み出す)(SC−21)。
つぎに、ハプロタイプ推定装置100は、カウントパターン(ci)のイテレーション(iイテレーション)に入る。ここでiイテレーションは、最初iを1に初期化し、1イテレーション毎にiを1ずつ増加させ、“i<=カウントパターンの個数”である限り繰り返すこととする。
iイテレーション内において、ハプロタイプ推定装置100は、コピー数総和分割部102aおよびハプロタイプ文字列格納部102bの処理により、各座位に渡って遺伝子型を算出する(SC−22)。コピー数総和分割部102aは、二つの相同染色体に渡る(確定された)総コピー数の座位に対しては、その総コピー数と和が等しい(0を含む正の)整数値2つ一組をあらゆる組合せで作る。ハプロタイプ文字列格納部102bは、その2つの整数値を、アレルを表す文字(多型識別文字)として扱う。多型テーブル106aに格納された総コピー数Nが曖昧な、“or”で連結された総コピー数である場合は、コピー数総和分割部102aは、それぞれの総コピー数に対して、上記と同じ方法でそれぞれ2つ一組を作る。多型テーブル106aに格納された総コピー数が曖昧な、整数Nより少ないコピー数である事を表す“<N”である場合は、コピー数総和分割部102aは、“<N”を“0or1or2…orN−1”に変換して、それぞれについて上と同じ方法で2つ一組を作る。多型テーブル106aに格納された総コピー数が曖昧な、Nより多いコピー数である事を表す“>N”である場合は、{0,1,…,N,>N}の各要素をアレルを表す文字(多型識別文字)として、図9に示すように、あらゆる2つ一組を列挙してその2つの和を出し、それが総コピー数の不等式条件(>N、即ちNより大きい)を満たす組だけ選択する。ただし和を出す際、アレルコピー数“>N”には、どんな数あるいは“>N”が足されてもその総コピー数は“>N”となり、不等式条件は満たされる。遺伝子型の座位に対しては、データにおける数の分だけアレルを表す文字(多型識別文字)を取り、2つ一組を作る(その他、適宜、特願2007−237139号を参照)。
そして、ハプロタイプ推定装置100は、各座位に渡って1つずつ遺伝子型を総当たりで取って、全座位に渡る遺伝子型のあらゆる組合せを作る(SC−23)。
そして、ハプロタイプ推定装置100は、作成した遺伝子型の組合せに関するイテレーション(jイテレーション)に入る。ここで、jイテレーションは、最初jを1に初期化し、1イテレーション毎に1ずつ増加させ、“j<=遺伝子の組合せの個数”である限り繰り返すこととする。
jイテレーション内において、ハプロタイプ文字列格納部102bは、遺伝子型の組合せjに対し、全座位に渡って各遺伝子型からアレルを1つずつ取って、座位の順に多型識別文字を並べた文字列を作り、その文字列をハプロタイプ文字列とする。このとき、ハプロタイプ文字列格納部102bは、各遺伝子型からアレルを1つずつ取った際残った方のアレルからも座位の順にアレル文字を並べた文字列を作り、その文字列をペア(組合せ)となるもう一つのハプロタイプ文字列として、ディプロタイプ(ハプロタイプ文字列の組合せ)を作る(SC−24)。この、全座位に渡って各遺伝子型からアレルを一つずつ取ることは総当たりで行って、あらゆる可能な2M−1個(ここでMは全座位数)のディプロタイプを得る。ハプロタイプ推定装置100は、このディプロタイプの作成を遺伝子型の組合せ全部に対して行い、jイテレーションを終了する。
そして、ハプロタイプ文字列格納部102bは、得られたハプロタイプ文字列の組合せ(ディプロタイプ)から、重複する冗長なディプロタイプを除外する(SC−25)。すなわち、ハプロタイプ文字列格納部102bは、作成したハプロタイプ文字列の組合せが他のハプロタイプ文字列の組合せと重複するか否か判断し、重複する場合に当該ハプロタイプ文字列の組合せを除外する。ここで、ハプロタイプ文字列格納部102bは、作成したハプロタイプ文字列の組合せにおいて、対応する多型識別文字が表す整数の和が、多型テーブル106aにおけるコピー数の総和Nの条件式を満たすか否か確認し、条件式を満たさない場合に当該ハプロタイプ文字列を除外してもよい。
ハプロタイプ推定装置100は、上記の処理を各カウントパターンに対して行い、iイテレーションを終え、最終的に、データと矛盾しない全ディプロタイプを算出し、ハプロタイプ文字列ファイル106bに格納する。以上が、取り得るハプロタイプの組合せを求めるための処理である。
再び、図13に戻り、ハプロタイプ推定部102cは、ハプロタイプ頻度算出部102dの処理により、EM法を用いて、ハプロタイプ文字列ファイル106bに記憶されたハプロタイプ文字列の組合せに基づいて、ハプロタイプ文字列の頻度を計算する。
すなわち、まず、ハプロタイプ頻度算出部102dは、各カウントパターン(ci)に対し、各ハプロタイプの組合せの存在の重みを初期化する(SC−3)。本実施例においては、初期値として重みを平等に割り付けた。すなわち、初期値の重みは、wjk=1/njである。ここでwは重み、jはカウントパターンのインデックス、kはカウントパターン内でのディプロタイプのインデックスであり、njはカウントパターン内でのディプロタイプの総数である。
次にSC−4に移り、ハプロタイプ推定部102cは、EM法のMステップを数式1に基づいて行う。そして、対数尤度を下記の数式に従って計算し、記憶部106に保存する。下記の数式において、記号は上述と同様である。ここで対数尤度とは、計算されたディプロタイプの頻度がどれくらいデータを説明しているかの指標であり、本実施例においては、これをEM法の収束の判定に用いる。ハプロタイプ推定部102cは、収束判定において、前回のSC−4イテレーションで保存された対数尤度と今回のSC−4イテレーションで計算された対数尤度との差を計算し、その差が一定値以内ならば、もはや対数尤度は改善されないと判定し、SC−5に処理を移す。そうでなければ、SC−4内にとどまり、ハプロタイプ推定部102cは、数式2に従って、EM法のEステップを行う。そしてSC−4のイテレーションを繰り返す。
そして、ハプロタイプ推定部102cは、上記条件によってSC−5に処理を移した場合(対数尤度差一定値以内の場合)、ハプロタイプ及びその頻度を結果ファイルに(出力部114などに)出力する(SC−5)。以上で、本実施例の説明を終える。
[実証シミュレーション]
本実施の形態がコピー数多型及び一座位当たりの遺伝子型に関するデータから、ハプロタイプとその頻度を推定できるかどうかを確かめる為、シミュレーション実験を行った。実験は四つのタイプからハプロタイプとその頻度を推定できるかどうかシミュレーションを行った。すなわち、(1)一座位における二つの相同染色体に渡る総コピー数のデータから、その座位における相同染色体1本上のコピー数と、そのコピー数をアレルと見た時の頻度を推定できるかどうか、(2)(複数座位に渡る)一座位当たりの二つの相同染色体に渡る総コピー数のデータから、ハプロタイプとその頻度を推定できるかどうか、(3)一座位当たりの二つの相同染色体に渡る総コピー数のデータに、それとは異なる座位において、一座位当たりのSNPの遺伝子型データが組み合わさったデータから、ハプロタイプとその頻度を推定できるかどうか、(4)一座位当たりの二つの相同染色体に渡る総コピー数が曖昧な総コピー数を含む場合のデータに、それとは異なる座位において、一座位当たりのSNP の遺伝子型データが組み合わさったデータから、ハプロタイプとその頻度を推定できるかどうか、についてシミュレーション実験を行った。図15は、シミュレーションの枠組みを示すフローチャートである。
図15に示すように、まず、SD−1において、ハプロタイプ推定装置は、ハプロタイプ(あるいはコピー数アレル)とその確率が書かれたファイルを読み込む。また、ハプロタイプ推定装置は、以下で用いる個体の数も読み込む。曖昧な総コピー数を含むデータを作成する場合は、曖昧でない総コピー数を曖昧な総コピー数に変換する表(例えば総コピー数0と1はいずれも0or1に変換する、3以上の総コピー数はどれも>2に変換する、等の対応づけが定義された表)が書かれたファイルも読み込む。
そして、SD−2において、ハプロタイプ推定装置は、読み込んだハプロタイプから構成しうるあらゆる2つ1組(ハプロタイプ2つから構成される1組)を作成し、1組を1つのディプロタイプとして、ハーディ・ワインバーグの法則(数式2−2参照)に基づいて、読み込んだハプロタイプの確率から全ディプロタイプの確率を計算する。
そして、SD−3において、ハプロタイプ推定装置は、ディプロタイプとその確率から、ディプロタイプの多項分布を構成し、与えられた個体の数だけディプロタイプをランダム抽出する。これは、例えば、R言語を使って、rmultinom(1,size=個体の数,prob=c(ディプロタイプ1の確率、ディプロタイプ2の確率、ディプロタイプ3の確率、…))の様なコマンドで簡単に実施できる。抽出されたディプロタイプの1つ1つが、1つ1つの個体に相当する。
そして、SD−4において、ハプロタイプ推定装置は、各個体が持つディプロタイプを構成する2つのハプロタイプの各座位に対し、コピー数の座位の時は2つのハプロタイプに渡る総コピー数、SNPの座位の時は各塩基の数を数え、データを作成する。例えば、個体が持つディプロタイプが[1A21/1A12]であったら、L1,L3はコピー数の座位であるのでそれぞれ総コピー数は2(1+1),3(1+2)、L2はSNPの座位であるので、A1,A2の数を数えそれぞれ1,1となる。曖昧な総コピー数を含むデータを作成する場合は、入力で読み込んだ変換表に基づいて総コピー数を曖昧な総コピー数に変換する。
最後にSD−5において、ハプロタイプ推定装置は、データをファイルに出力する。
以上で説明したシミュレーションの枠組みを使って、まず上述の実験(1)の場合について、図16で示されたコピー数アレルとその確率、さらに個体の数500を読み込み、データ図17を作成した。次に、本実施の形態が図17のデータだけから、図16で示されたコピー数アレルとその確率(頻度)を推定(再現)できるか試験した。これは言い換えれば、不完全な観測データからの母集団比率の推定問題である。本実施の形態適用の際、EM法において収束判定に使われる対数尤度差は0.001未満とした。適用の結果、コピー数アレルとその頻度に関し、図18のような結果を得た。図18(再現データ)にあって図16(元データ)にないコピー数アレルの頻度は全て低い。上述のように、これらは存在しないと解釈される。図16にあるコピー数アレルは全て図18に現れており、かつ、それら推定頻度も正解頻度とほぼ等しい。よって、本実施の形態はコピー数アレルとその頻度を推定出来ることが実証された。
同様に、上述の実験(2)の場合についても、図19で示されたハプロタイプとその確率、さらに個体の数500を読み込み、データ図20を作成した。次に本実施の形態が図20のデータだけから、図19で示されたハプロタイプとその確率を推定できるか試験した。本実施の形態適用の際、EM法において収束判定に使われる対数尤度差は上と同じとした。適用の結果、ハプロタイプとその頻度に関し、図21のような結果を得た。図21(再現データ)にあって図19(元データ)にないハプロタイプの頻度は全て低い。上述のように、これらは存在しないと解釈される。図19にあるハプロタイプは全て図21に現れており、かつ、それら推定頻度も正解頻度とほぼ等しい。よって、本実施の形態はコピー数アレルの組合せとしてのハプロタイプとその頻度を推定出来ることが実証された。
同様に、上述の実験(3)の場合についても、図22で示されたハプロタイプとその確率、さらに個体の数500を読み込み、データ図23を作成した。次に本実施の形態が図23のデータだけから、図22で示されたハプロタイプとその確率を推定できるか試験した。本実施の形態適用の際、EM法において収束判定に使われる対数尤度差は上と同じとした。適用の結果、ハプロタイプとその頻度に関し、図24のような結果を得た。上述の実験結果と同様、この結果が示す通り、本実施の形態はコピー数アレルとSNPアレルの組合せとしてのハプロタイプとその頻度を推定出来ることが実証された。
同様に、上述の実験(4)の場合についても、図25で示されたハプロタイプとその確率、さらに個体の数500を読み込み、データ図26を作成した。この際、総コピー数0と1はいずれも曖昧な総コピー数0or1に変換し、3以上の総コピー数はどれも曖昧な総コピー数>2に変換した。次に、本実施の形態が図26のデータだけから、図25で示されたハプロタイプとその確率を推定できるか試験した。本実施の形態適用の際、EM法において収束判定に使われる対数尤度差は上と同じとした。適用の結果、ハプロタイプとその頻度に関し、図27のような結果を得た。上述の実験結果と同様、この結果が示す通り、曖昧な総コピー数を含むデータの場合においても、本実施の形態はコピー数アレルとSNPアレルの組合せとしてのハプロタイプとその頻度を推定出来ることが実証された。
[他の実施の形態]
さて、これまで本発明の実施の形態について説明したが、本発明は、上述した実施の形態以外にも、上記特許請求の範囲に記載した技術的思想の範囲内において種々の異なる実施の形態にて実施されてよいものである。
特に、上述の実施の形態において、上述した構成・処理以外にも、適宜、特願2007−237139に記載の事項を補ってもよいものである。
また、ハプロタイプ推定装置100がスタンドアローンの形態で処理を行う場合を一例に説明したが、ハプロタイプ推定装置100とは別筐体で構成されるクライアント端末からの要求に応じて処理を行い、その処理結果を当該クライアント端末に返却するように構成してもよい。
また、実施の形態において説明した各処理のうち、自動的に行われるものとして説明した処理の全部または一部を手動的に行うこともでき、あるいは、手動的に行われるものとして説明した処理の全部または一部を公知の方法で自動的に行うこともできる。
このほか、上記文献中や図面中で示した処理手順、制御手順、具体的名称、各処理の登録データ等のパラメータを含む情報、データベース構成については、特記する場合を除いて任意に変更することができる。
また、ハプロタイプ推定装置100に関して、図示の各構成要素は機能概略的なものであり、必ずしも物理的に図示の如く構成されていることを要しない。
例えば、ハプロタイプ推定装置100の各装置が備える処理機能、特に制御部102にて行われる各処理機能については、その全部または任意の一部を、CPU(Central Processing Unit)および当該CPUにて解釈実行されるプログラムにて実現することができ、あるいは、ワイヤードロジックによるハードウェアとして実現することも可能である。尚、プログラムは、後述する記録媒体に記録されており、必要に応じてハプロタイプ推定装置100に機械的に読み取られる。すなわち、ROMまたはHDなどの記憶部106などは、OS(Operating System)として協働してCPUに命令を与え、各種処理を行うためのコンピュータプログラムが記録されている。このコンピュータプログラムは、RAMにロードされることによって実行され、CPUと協働して制御部を構成する。
また、このコンピュータプログラムは、ハプロタイプ推定装置100に対して任意のネットワーク300を介して接続されたアプリケーションプログラムサーバに記憶されていてもよく、必要に応じてその全部または一部をダウンロードすることも可能である。
また、本発明に係るプログラムを、コンピュータ読み取り可能な記録媒体に格納することもできる。ここで、この「記録媒体」とは、フレキシブルディスク、光磁気ディスク、ROM、EPROM、EEPROM、CD−ROM、MO、DVD等の任意の「可搬用の物理媒体」、あるいは、LAN、WAN、インターネットに代表されるネットワークを介してプログラムを送信する場合の通信回線や搬送波のように、短期にプログラムを保持する「通信媒体」を含むものとする。
また、「プログラム」とは、任意の言語や記述方法にて記述されたデータ処理方法であり、ソースコードやバイナリコード等の形式を問わない。なお、「プログラム」は必ずしも単一的に構成されるものに限られず、複数のモジュールやライブラリとして分散構成されるものや、OS(Operating System)に代表される別個のプログラムと協働してその機能を達成するものをも含む。なお、実施の形態に示した各装置において記録媒体を読み取るための具体的な構成、読み取り手順、あるいは、読み取り後のインストール手順等については、周知の構成や手順を用いることができる。
記憶部106に格納される各種のデータベース等(多型テーブル106a〜実験データファイル106c)は、RAM、ROM等のメモリ装置、ハードディスク等の固定ディスク装置、フレキシブルディスク、光ディスク等のストレージ手段であり、各種処理やウェブサイト提供に用いる各種のプログラムやテーブルやデータベースやウェブページ用ファイル等を格納する。
また、ハプロタイプ推定装置100は、既知のパーソナルコンピュータ、ワークステーション等の情報処理装置を接続し、該情報処理装置に本発明の方法を実現させるソフトウェア(プログラム、データ等を含む)を実装することにより実現してもよい。
更に、装置の分散・統合の具体的形態は図示するものに限られず、その全部または一部を、各種の付加等に応じた任意の単位で、機能的または物理的に分散・統合して構成することができる。