JP5121146B2 - 構造化文書管理装置、構造化文書管理プログラムおよび構造化文書管理方法 - Google Patents
構造化文書管理装置、構造化文書管理プログラムおよび構造化文書管理方法 Download PDFInfo
- Publication number
- JP5121146B2 JP5121146B2 JP2006045807A JP2006045807A JP5121146B2 JP 5121146 B2 JP5121146 B2 JP 5121146B2 JP 2006045807 A JP2006045807 A JP 2006045807A JP 2006045807 A JP2006045807 A JP 2006045807A JP 5121146 B2 JP5121146 B2 JP 5121146B2
- Authority
- JP
- Japan
- Prior art keywords
- data
- structured document
- structured
- path pattern
- stream
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images























Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/80—Information retrieval; Database structures therefor; File system structures therefor of semi-structured data, e.g. markup language structured data such as SGML, XML or HTML
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Databases & Information Systems (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Document Processing Apparatus (AREA)
Description
(1)複雑なXQueryの場合、複数のパスパターンがクエリに含まれる。複数のパスパターンへの照合を行うのに、同一構造化文書へのトラバースが繰り返し発生する。特にオンメモリにできないサイズを取り扱うケースでは、同一ページへのディスクI/Oが断続発生し、性能劣化が激しくなる。
(2)XQueryのサブセットであるXPathの場合でも、高ヒット時には性能劣化が発生する。つまり、構造化文書の集合の大半をトラバースするケースでは、大量のディスクI/Oが発生してしまう。
(参考文献1)Y. Diao, P.Fischer, and M.J.Franklin. YFilter: Efficient and Scalable Filtering of XML Documents. In The 18th International Conference of Data Engineering, San Jose, February 2002.
(参考文献2)I. Avila-Campillo, D. Raven, T. Green, A. Gupta, Y. Kadiyska, M.Onizuka, and D. Suciu. An XML Toolkit for Light-weight XML Stream Processing,2002.
(3)高ヒットでないXPathでは性能劣化が著しい。バックトラックベースであるため、CPU処理上のオーバヘッドも大きい。処理の特性上、索引を使った問合わせ処理が難しい。
本発明の第1の実施の形態を図1ないし図16に基づいて説明する。
(1)システムに格納された構造化文書データ集合に現れる全てのパスは、構造ガイドデータに現れる。
(2)構造ガイドデータに現れる全てのパスは、システムに格納された構造化文書データ集合に現れる。
(3)構造ガイドデータに現れるパスは全て一意的である。
E0 「ROOT」に対応する配列要素 (G)0
E1 「books」に対応する配列要素 (G)1
E2 「book」に対応する配列要素 (G)2
・・・ ・・・ ・・・
・・・ ・・・ ・・・
このように配列データ、つまり構造ストリームに変換することで、2次元的な構造的なデータを1次元の配列データとして扱えるようになる。
Q1:構造化文書DB「ROOT」の階層木の中に「book」という要素があり、この「book」という要素の中に、「author」という要素があり、この「author」という要素の中に、「first」という要素がある構造化文書データの「book」の一覧を返す。
「ROOT」 → (G)0
「book」 → (G)2
「author」 → (G)5
「first」 → (G)6
さらに、以下のルールで不要なノードを取り除く。
(1)出力ノード以外で中間ノードにあたり、AND条件がついていないもの G5
(2)ルートノードにあたるもの G0
その結果、図11に示すような第2次構造グラフが生成される。
(1)エントリーテーブル
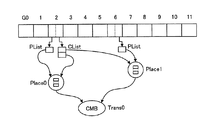
GIDに対応した配列要素を持つテーブル。構造ストリーム走査部28における構造ストリーム走査処理にて、構造ストリームデータの先頭要素から順にGIDを読み込んでいく。読み込んだGIDの位置はEIDで示される。読み込んだGIDに対応した手続きを実行する。手続きは、以下の2つである。
(1.1)PList
Placeに対してEID(Token(トークン)と呼ぶ)を追加(プッシュ)する。
(1.2)CList
Placeに対してクリアする。
(2)Place(プレース)
中間データであるTokenのキューを保持する記憶領域の役割を持つ。
(3)Trans(トランス)
PlaceとPlaceを接続し、上位Placeに保持されたTokenを下位Placeに流す(フロー)役割を持つ。TransにはAND、CMBなどのより詳しい役割が与えられる。AND、CMBに関する説明は以下の通りである。
(3.1)AND
上位のPlace集合の全てにTokenが存在すれば、下位のPlaceにToken(True)を流す。
(3.2)CMB
上位のPlace集合の全てにTokenが存在すれば、そのTokenの組み合わせを流す(出力する)。
E0[G0]を走査した時、
PList、CListが存在しないので、何もしない。
E1[G1]を走査した時、
PList、CListが存在しないので、何もしない。
E2[G2]を走査した時、
PList、CListが存在する。Place0、Place1をクリアし、Place0にToken 2をプッシュする。Place1が空なので、Trans0は何も出力しない。
・・・
・・・
E6[G6]を走査した時、
PListが存在する。Place1に6をプッシュする。Place0、Place1にTokenが入っているので、Trans0は出力ノードに当たるPlace0のToken 2を出力する。
・・・
・・・
E13[G2]を走査した時、
PList、CListが存在する。Place0、Place1をクリアし、Place0にToken 13をプッシュする。Place1が空なので、Trans0は何も出力しない。
・・・
E15[G6]を走査した時、
PListが存在する。Place1に15をプッシュする。Place0、Place1にTokenが入っているので、Trans0は出力ノードに当たるPlace0のToken 13を出力する。
・・・
上述したような処理により、2,13のTokenが出力されることになる。2は図4におけるE2に相当し、13は図4におけるE13に相当する。2,13のTokenは、検索インタフェース部26にて構造化文書DB21のテキストデータ領域21cに記憶されているテキストデータを取得し、構造化文書データとして文字列化され、結果データとしてクライアント端末3に出力される。
次に、本発明の第2の実施の形態を図17ないし図21に基づいて説明する。なお、前述した第1の実施の形態と同じ部分は同じ符号で示し説明も省略する。本実施の形態においては、第1の実施の形態とはクエリデータの種類が異なっている。
Q2:構造化文書DB「ROOT」の階層木の中に「book」という要素があり、この「book」という要素の中に、「author」という要素があり、この「author」という要素の中に、「first」と「last」という2つの要素がある構造化文書データの「book」の一覧を返す。
E0[G0]を走査した時、
PList、CListが存在しないので、何もしない。
E1[G1]を走査した時、
PList、CListが存在しないので、何もしない。
E2[G2]を走査した時、
PList、CListが存在する。Place0、Place3、Place4をクリアし、Place0にToken 2をプッシュする。Place3が空なので、Trans1は何も出力しない。
・・・
・・・
E5[G5]を走査した時、
PList、CListが存在する。Place1、Place2をクリアする。Place4にToken5をプッシュする。
E6[G6]を走査した時、
PListが存在する。Place1にToken 6をプッシュする。Place2が空なので、Trans0は何も出力しない。
・・・
E8[G5]を走査した時、
PList、CListが存在する。Place1、Place2をクリアする。Place4にToken8をプッシュする。
E9[G8]を走査した時、
PListが存在する。Place2にToken 9をプッシュする。Place1が空なので、Trans0は何も出力しない。
・・・
・・・
E14[G5]を走査した時、
PList、CListが存在する。Place1、Place2をクリアする。Place4にToken14をプッシュする。
E15[G6]を走査した時、
PListが存在する。Place1にToken 15をプッシュする。Place2が空なので、Trans0は何も出力しない。
・・・
E17[G8]を走査した時、
PListが存在する。Place2にToken 17をプッシュする。Place1、Place2、Place4にTokenが入っているので、Trans0はToken TrueをPlace3にプッシュする。Place0、Place3にTokenが入っているので、Trans1は出力ノードに当たるPlace0のToken 13を出力する。
・・・
上述したような処理により、13のTokenが出力されることになる。13は図4におけるE13に相当する。13のTokenは、検索インタフェース部26にて構造化文書DB21のテキストデータ領域21cに記憶されているテキストデータを取得し、構造化文書データとして文字列化され、結果データとしてクライアント端末3に出力される。
次に、本発明の第3の実施の形態を図22に基づいて説明する。なお、前述した第1の実施の形態または第2の実施の形態と同じ部分は同じ符号で示し説明も省略する。本実施の形態は、第1の実施の形態のクエリデータQ1と第2の実施の形態のクエリデータQ2とを同時に処理するようにしたものである。
(1)Trans0_1からは、2、13のTokenが出力されることになる。
(2)Trans1からは、13のTokenが出力されることになる。
次に、本発明の第4の実施の形態を図23および図24に基づいて説明する。なお、前述した第1の実施の形態ないし第3の実施の形態と同じ部分は同じ符号で示し説明も省略する。
「books」 複数の「book」と1つの「info」から構成される。+は1個以上の繰り返しを許容することを意味する。
「info」 「isbn」と「issuDate」から構成される。
「issueDate」 「year」、「month」、「day」から構成される。
(1)info
(2)isbn
(3)isbnテキスト
(4)issueDate
(5)year
(6)yearテキスト
(7)month
(8)monthテキスト
(9)day
(10)dayテキスト
の10個である。もちろん、これらの要素は構造化文書DB21の構造ガイドデータ領域21aに反映される。
//book[author[first]
に対応する第2構造グラフは、図11に示したように、
2 − 6
であった。対応する構造ガイドデータ領域21aの部分木があるが、先の(1)〜(10)に対応する構造ガイドデータ領域21aの部分木とは共有部分を持たない。
21a 構造ガイドデータ記憶手段
21b 構造ストリームデータ記憶手段
24 文書データ受付手段
25 構造ストリーム変換手段
26 クエリデータ受付手段
27 パスパターンコンパイル手段
28 構造ストリーム走査手段
Q1,Q2 クエリデータ
Claims (12)
- 記憶部を備える構造化文書管理装置であって、
階層化された論理構造を有している構造化文書データの入力を受け付ける文書データ受付手段と、
前記文書データ受付手段により受け付けた前記構造化文書データを構文解析して当該構造化文書データ集合の全体に渡るものであって格納先フォルダを示す一意なIDが割り当てられたガイドノードを含む階層構造情報の要約である構造ガイドデータを生成し、当該構造ガイドデータを用いて前記構造化文書データをルートノードに対応する前記IDから深さ優先で辿って行くときに通過するガイドノードに対応する前記IDを並べた1次元の配列データである構造ストリームデータに変換する構造ストリーム変換手段と、
前記構造ストリーム変換手段により変換された前記構造ストリームデータを前記記憶部に記憶する構造ストリームデータ記憶手段と、
前記構造ガイドデータを前記記憶部に記憶する構造ガイドデータ記憶手段と、
クエリデータの入力を受け付けるクエリデータ受付手段と、
前記クエリデータ受付手段により受け付けた前記クエリデータを構文解析してタグ間の関連をツリー形式で表現した第1次構造グラフを生成し、当該第1次構造グラフと前記構造ガイドデータ記憶手段により前記記憶部に記憶されている前記構造ガイドデータとを照合して前記IDに変換して不要なノードを取り除いた第2次構造グラフを生成し、前記IDに対応した配列要素を持ち前記IDに対応した手続きを実行するエントリーテーブルと前記IDの位置を示す中間データであるトークンのキューを保持する記憶領域要素であるプレースと前記プレース間を接続して上位のプレースに保持されたトークンを下位のプレースに流す役割を持つ要素であるトランスとを含み前記クエリデータに特化した処理手順を指定するパスパターン処理テーブルを、前記エントリーテーブルの前記IDに対応する手続きを張るとともに前記プレースと前記トランスとの間にリンクを張る処理を前記第2次構造グラフのルートノードから末端ノードまで再帰的に処理することによって生成するパスパターンコンパイル手段と、
前記記憶部から前記構造ストリームデータ集合を取得し、当該前記構造ストリームデータの要素と前記パスパターン処理テーブルの要素とを突き合わせることで、前記トークンで構成される結果データを生成する構造ストリーム走査手段と、
を備えることを特徴とする構造化文書管理装置。 - 前記パスパターンコンパイル手段は、複数の前記クエリデータを処理する場合、前記各クエリデータに係るそれぞれの前記パスパターン処理テーブルを合成して、複数の前記クエリデータのパスパターン処理テーブルとする、
ことを特徴とする請求項1記載の構造化文書管理装置。 - 前記パスパターンコンパイル手段は、前記構造化文書データの構造情報が定義されている場合、前記構造ストリームデータの一部をスキップする手続きを前記パスパターン処理テーブルに埋め込む、
ことを特徴とする請求項2記載の構造化文書管理装置。 - 前記パスパターンコンパイル手段は、前記構造化文書データの統計情報により構造情報が現れている場合、前記構造ストリームデータの一部をスキップする手続きを前記パスパターン処理テーブルに埋め込む、
ことを特徴とする請求項2記載の構造化文書管理装置。 - 記憶部を備える構造化文書管理装置を制御するコンピュータに、
階層化された論理構造を有している構造化文書データの入力を受け付ける文書データ受付機能と、
前記文書データ受付機能により受け付けた前記構造化文書データを構文解析して当該構造化文書データ集合の全体に渡るものであって格納先フォルダを示す一意なIDが割り当てられたガイドノードを含む階層構造情報の要約である構造ガイドデータを生成し、当該構造ガイドデータを用いて前記構造化文書データをルートノードに対応する前記IDから深さ優先で辿って行くときに通過するガイドノードに対応する前記IDを並べた1次元の配列データである構造ストリームデータに変換する構造ストリーム変換機能と、
前記構造ストリーム変換機能により変換された前記構造ストリームデータを前記記憶部に構造ストリームデータ記憶手段に記憶する機能と、
前記構造ガイドデータを前記記憶部に記憶する構造ガイドデータ記憶機能と、
クエリデータの入力を受け付けるクエリデータ受付機能と、
前記クエリデータ受付機能により受け付けた前記クエリデータを構文解析してタグ間の関連をツリー形式で表現した第1次構造グラフを生成し、当該第1次構造グラフと前記構造ガイドデータ記憶機能により前記記憶部に記憶されている前記構造ガイドデータとを照合して前記IDに変換して不要なノードを取り除いた第2次構造グラフを生成し、前記IDに対応した配列要素を持ち前記IDに対応した手続きを実行するエントリーテーブルと前記IDの位置を示す中間データであるトークンのキューを保持する記憶領域要素であるプレースと前記プレース間を接続して上位のプレースに保持されたトークンを下位のプレースに流す役割を持つ要素であるトランスとを含み前記クエリデータに特化した処理手順を指定するパスパターン処理テーブルを、前記エントリーテーブルの前記IDに対応する手続きを張るとともに前記プレースと前記トランスとの間にリンクを張る処理を前記第2次構造グラフのルートノードから末端ノードまで再帰的に処理することによって生成するパスパターンコンパイル機能と、
前記記憶部から前記構造ストリームデータ集合を取得し、当該前記構造ストリームデータの要素と前記パスパターン処理テーブルの要素とを突き合わせることで、前記トークンで構成される結果データを生成する構造ストリーム走査機能と、
を実行させることを特徴とする構造化文書管理プログラム。 - 前記パスパターンコンパイル機能は、複数の前記クエリデータを処理する場合、前記各クエリデータに係るそれぞれの前記パスパターン処理テーブルを合成して、複数の前記クエリデータのパスパターン処理テーブルとする、
ことを特徴とする請求項5記載の構造化文書管理プログラム。 - 前記パスパターンコンパイル機能は、前記構造化文書データの構造情報が定義されている場合、前記構造ストリームデータの一部をスキップする手続きを前記パスパターン処理テーブルに埋め込む、
ことを特徴とする請求項5記載の構造化文書管理プログラム。 - 前記パスパターンコンパイル機能は、前記構造化文書データの統計情報により構造情報が現れている場合、前記構造ストリームデータの一部をスキップする手続きを前記パスパターン処理テーブルに埋め込む、
ことを特徴とする請求項5記載の構造化文書管理プログラム。 - 構造化文書管理装置で実行される構造化文書管理方法であって、
前記構造化文書管理装置は、制御部と記憶部を備え、
前記制御部において実行される、
文書データ受付手段が、階層化された論理構造を有している構造化文書データの入力を受け付ける工程と、
構造ストリーム変換手段が、前記文書データ受付手段により受け付けた前記構造化文書データを構文解析して当該構造化文書データ集合の全体に渡るものであって格納先フォルダを示す一意なIDが割り当てられたガイドノードを含む階層構造情報の要約である構造ガイドデータを生成し、当該構造ガイドデータを用いて前記構造化文書データをルートノードに対応する前記IDから深さ優先で辿って行くときに通過するガイドノードに対応する前記IDを並べた1次元の配列データである構造ストリームデータに変換する工程と、
構造ストリームデータ記憶手段が、前記構造ストリーム変換手段により変換された前記構造ストリームデータを前記記憶部に記憶する工程と、
構造ガイドデータ記憶手段が、前記構造ガイドデータを前記記憶部に記憶する工程と、
クエリデータ受付手段が、クエリデータの入力を受け付ける工程と、
パスパターンコンパイル手段が、このクエリデータ受付手段により受け付けた前記クエリデータを構文解析してタグ間の関連をツリー形式で表現した第1次構造グラフを生成し、当該第1次構造グラフと前記構造ガイドデータ記憶手段により前記記憶部に記憶されている前記構造ガイドデータとを照合して前記IDに変換して不要なノードを取り除いた第2次構造グラフを生成し、前記IDに対応した配列要素を持ち前記IDに対応した手続きを実行するエントリーテーブルと前記IDの位置を示す中間データであるトークンのキューを保持する記憶領域要素であるプレースと前記プレース間を接続して上位のプレースに保持されたトークンを下位のプレースに流す役割を持つ要素であるトランスとを含み前記クエリデータに特化した処理手順を指定するパスパターン処理テーブルを、前記エントリーテーブルの前記IDに対応する手続きを張るとともに前記プレースと前記トランスとの間にリンクを張る処理を前記第2次構造グラフのルートノードから末端ノードまで再帰的に処理することによって生成する工程と、
構造ストリーム走査手段が、前記構造ストリームデータ記憶手段から前記構造ストリームデータ集合を取得し、当該前記構造ストリームデータの要素と前記パスパターン処理テーブルの要素とを突き合わせることで、前記トークンで構成される結果データを生成する工程と、
を含むことを特徴とする構造化文書管理方法。 - 前記パスパターンコンパイル工程は、複数の前記クエリデータを処理する場合、前記各クエリデータに係るそれぞれの前記パスパターン処理テーブルを合成して、複数の前記クエリデータのパスパターン処理テーブルとする、
ことを特徴とする請求項9記載の構造化文書管理方法。 - 前記パスパターンコンパイル工程は、前記構造化文書データの構造情報が定義されている場合、前記構造ストリームデータの一部をスキップする手続きを前記パスパターン処理テーブルに埋め込む、
ことを特徴とする請求項9記載の構造化文書管理方法。 - 前記パスパターンコンパイル工程は、前記構造化文書データの統計情報により構造情報が現れている場合、前記構造ストリームデータの一部をスキップする手続きを前記パスパターン処理テーブルに埋め込む、
ことを特徴とする請求項9記載の構造化文書管理方法。
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2006045807A JP5121146B2 (ja) | 2006-02-22 | 2006-02-22 | 構造化文書管理装置、構造化文書管理プログラムおよび構造化文書管理方法 |
| US11/524,621 US7975220B2 (en) | 2006-02-22 | 2006-09-21 | Apparatus, program product and method for structured document management |
| CNB200710005309XA CN100541493C (zh) | 2006-02-22 | 2007-02-14 | 用于结构化文档管理的装置和方法 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2006045807A JP5121146B2 (ja) | 2006-02-22 | 2006-02-22 | 構造化文書管理装置、構造化文書管理プログラムおよび構造化文書管理方法 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2007226452A JP2007226452A (ja) | 2007-09-06 |
| JP5121146B2 true JP5121146B2 (ja) | 2013-01-16 |
Family
ID=38429615
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2006045807A Active JP5121146B2 (ja) | 2006-02-22 | 2006-02-22 | 構造化文書管理装置、構造化文書管理プログラムおよび構造化文書管理方法 |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US7975220B2 (ja) |
| JP (1) | JP5121146B2 (ja) |
| CN (1) | CN100541493C (ja) |
Families Citing this family (21)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP5196924B2 (ja) * | 2007-09-11 | 2013-05-15 | 株式会社東芝 | データベース処理装置、方法及びプログラム |
| US8412516B2 (en) | 2007-11-27 | 2013-04-02 | Accenture Global Services Limited | Document analysis, commenting, and reporting system |
| US8271870B2 (en) | 2007-11-27 | 2012-09-18 | Accenture Global Services Limited | Document analysis, commenting, and reporting system |
| US8266519B2 (en) * | 2007-11-27 | 2012-09-11 | Accenture Global Services Limited | Document analysis, commenting, and reporting system |
| JP4796108B2 (ja) | 2008-09-26 | 2011-10-19 | 株式会社東芝 | 構造化文書検索装置、方法及びプログラム |
| JP5396843B2 (ja) * | 2008-12-11 | 2014-01-22 | 富士通株式会社 | 検索方法および検索装置 |
| CN101477532B (zh) * | 2008-12-23 | 2011-09-28 | 北京畅游天下网络技术有限公司 | 实现数据存储、读取的方法、装置及系统 |
| JP5262864B2 (ja) * | 2009-03-10 | 2013-08-14 | 富士通株式会社 | 記憶媒体、検索方法および検索装置 |
| JP5380542B2 (ja) | 2009-09-17 | 2014-01-08 | 株式会社東芝 | 管理装置 |
| EP2362333A1 (en) | 2010-02-19 | 2011-08-31 | Accenture Global Services Limited | System for requirement identification and analysis based on capability model structure |
| US9436763B1 (en) * | 2010-04-06 | 2016-09-06 | Facebook, Inc. | Infrastructure enabling intelligent execution and crawling of a web application |
| US8566731B2 (en) | 2010-07-06 | 2013-10-22 | Accenture Global Services Limited | Requirement statement manipulation system |
| US9400778B2 (en) | 2011-02-01 | 2016-07-26 | Accenture Global Services Limited | System for identifying textual relationships |
| US8935654B2 (en) | 2011-04-21 | 2015-01-13 | Accenture Global Services Limited | Analysis system for test artifact generation |
| CN102479248A (zh) * | 2011-05-30 | 2012-05-30 | 北京中科希望软件股份有限公司 | 一种电子文档结构化处理的方法和系统 |
| CN102662774B (zh) * | 2012-03-13 | 2014-06-25 | 中冶南方工程技术有限公司 | 多进程间结构化文档通信方法 |
| US8935267B2 (en) * | 2012-06-19 | 2015-01-13 | Marklogic Corporation | Apparatus and method for executing different query language queries on tree structured data using pre-computed indices of selective document paths |
| CN103827861B (zh) | 2012-09-07 | 2017-09-08 | 株式会社东芝 | 结构化文档管理装置及方法 |
| JP5422751B1 (ja) | 2012-09-20 | 2014-02-19 | 株式会社東芝 | 構造化文書管理装置、方法およびプログラム |
| US9928287B2 (en) | 2013-02-24 | 2018-03-27 | Technion Research & Development Foundation Limited | Processing query to graph database |
| KR101974341B1 (ko) * | 2014-01-23 | 2019-05-02 | 한화정밀기계 주식회사 | 계층적 데이터 분석 방법 및 그 프로그램이 기록된 기록 매체 |
Family Cites Families (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5467472A (en) * | 1994-04-15 | 1995-11-14 | Microsoft Corporation | Method and system for generating and maintaining property sets with unique format identifiers |
| JPH07319918A (ja) * | 1994-05-24 | 1995-12-08 | Fuji Xerox Co Ltd | 文書検索対象指示装置 |
| US5913214A (en) * | 1996-05-30 | 1999-06-15 | Massachusetts Inst Technology | Data extraction from world wide web pages |
| SE510000C2 (sv) * | 1997-07-21 | 1999-03-29 | Ericsson Telefon Ab L M | Struktur vid databas |
| JP2000057163A (ja) | 1998-08-12 | 2000-02-25 | Nec Corp | 構造化文書データベースシステム |
| JP3492246B2 (ja) | 1999-07-16 | 2004-02-03 | 富士通株式会社 | Xmlデータ検索処理方法および検索処理システム |
| US6502112B1 (en) * | 1999-08-27 | 2002-12-31 | Unisys Corporation | Method in a computing system for comparing XMI-based XML documents for identical contents |
| US8131773B2 (en) * | 2000-10-20 | 2012-03-06 | Sharp Kabushiki Kaisha | Search information managing for moving image contents |
| US7171404B2 (en) * | 2002-06-13 | 2007-01-30 | Mark Logic Corporation | Parent-child query indexing for XML databases |
| AU2003236543A1 (en) * | 2002-06-13 | 2003-12-31 | Mark Logic Corporation | A subtree-structured xml database |
| US7069504B2 (en) * | 2002-09-19 | 2006-06-27 | International Business Machines Corporation | Conversion processing for XML to XML document transformation |
| AU2002953555A0 (en) * | 2002-12-23 | 2003-01-16 | Canon Kabushiki Kaisha | Method for presenting hierarchical data |
| JP4247108B2 (ja) * | 2003-12-25 | 2009-04-02 | 株式会社東芝 | 構造化文書検索方法、構造化文書検索装置、及びプログラム |
| US7877366B2 (en) * | 2004-03-12 | 2011-01-25 | Oracle International Corporation | Streaming XML data retrieval using XPath |
-
2006
- 2006-02-22 JP JP2006045807A patent/JP5121146B2/ja active Active
- 2006-09-21 US US11/524,621 patent/US7975220B2/en active Active
-
2007
- 2007-02-14 CN CNB200710005309XA patent/CN100541493C/zh active Active
Also Published As
| Publication number | Publication date |
|---|---|
| CN100541493C (zh) | 2009-09-16 |
| US20070198559A1 (en) | 2007-08-23 |
| CN101025748A (zh) | 2007-08-29 |
| JP2007226452A (ja) | 2007-09-06 |
| US7975220B2 (en) | 2011-07-05 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5121146B2 (ja) | 構造化文書管理装置、構造化文書管理プログラムおよび構造化文書管理方法 | |
| US8484210B2 (en) | Representing markup language document data in a searchable format in a database system | |
| US7664773B2 (en) | Structured data storage method, structured data storage apparatus, and retrieval method | |
| JP4977128B2 (ja) | データベースからxml文書を動的に生成する方法 | |
| US20050060306A1 (en) | Apparatus, method, and program for retrieving structured documents | |
| JP2008052662A (ja) | 構造化文書管理システム及びプログラム | |
| JP2008090403A (ja) | 文書検索装置、文書検索方法および文書検索プログラム | |
| JP4247108B2 (ja) | 構造化文書検索方法、構造化文書検索装置、及びプログラム | |
| JP4796108B2 (ja) | 構造化文書検索装置、方法及びプログラム | |
| JP2005135199A (ja) | オートマトン作成方法、および、xmlデータ検索方法、ならびに、xmlデータ検索装置、xmlデータ検索プログラム、および、xmlデータ検索プログラムの記録媒体 | |
| JP3832693B2 (ja) | 構造化文書検索表示方法及び装置 | |
| Liu et al. | An XML-enabled data extraction toolkit for web sources | |
| JP3914081B2 (ja) | アクセス権限設定方法および構造化文書管理システム | |
| JP2006127235A (ja) | 構造化文書管理システム、構造化文書管理方法及びプログラム | |
| JP3632643B2 (ja) | 構造化文書管理装置 | |
| JP4649339B2 (ja) | XPath処理装置、XPath処理方法、XPath処理プログラム、および、記憶媒体 | |
| JP3842572B2 (ja) | 構造化文書管理方法および構造化文書管理装置およびプログラム | |
| JP3842576B2 (ja) | 構造化文書編集方法及び構造化文書編集システム | |
| JP5695586B2 (ja) | Xml文書検索装置及びプログラム | |
| JP2008243075A (ja) | 構造化文書管理装置及び方法 | |
| JP3842574B2 (ja) | 情報抽出方法および構造化文書管理装置およびプログラム | |
| JP2005018811A (ja) | 文字列検索装置 | |
| JP2004348485A (ja) | 構造化文書処理方法及び装置及び構造化文書処理プログラム及び構造化文書処理プログラムを格納した記憶媒体 | |
| JP2008140157A (ja) | 構造化文書処理装置 | |
| JP2003177923A (ja) | ポーティング支援システムにおける予約語変換方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20070903 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20090804 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20091005 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20100302 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20100428 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20100817 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20101117 |
|
| A911 | Transfer to examiner for re-examination before appeal (zenchi) |
Free format text: JAPANESE INTERMEDIATE CODE: A911 Effective date: 20101207 |
|
| A912 | Re-examination (zenchi) completed and case transferred to appeal board |
Free format text: JAPANESE INTERMEDIATE CODE: A912 Effective date: 20110128 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20120903 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20121023 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20151102 Year of fee payment: 3 |
|
| R151 | Written notification of patent or utility model registration |
Ref document number: 5121146 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R151 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20151102 Year of fee payment: 3 |
|
| S111 | Request for change of ownership or part of ownership |
Free format text: JAPANESE INTERMEDIATE CODE: R313114 Free format text: JAPANESE INTERMEDIATE CODE: R313111 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |