JP5120850B2 - ストリーム・レジスタを用いてスヌープ要求をフィルタする方法、装置及びコンピュータ・プログラム - Google Patents
ストリーム・レジスタを用いてスヌープ要求をフィルタする方法、装置及びコンピュータ・プログラム Download PDFInfo
- Publication number
- JP5120850B2 JP5120850B2 JP2008504137A JP2008504137A JP5120850B2 JP 5120850 B2 JP5120850 B2 JP 5120850B2 JP 2008504137 A JP2008504137 A JP 2008504137A JP 2008504137 A JP2008504137 A JP 2008504137A JP 5120850 B2 JP5120850 B2 JP 5120850B2
- Authority
- JP
- Japan
- Prior art keywords
- snoop
- cache
- address
- register
- filter
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images



















Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F12/00—Accessing, addressing or allocating within memory systems or architectures
- G06F12/02—Addressing or allocation; Relocation
- G06F12/08—Addressing or allocation; Relocation in hierarchically structured memory systems, e.g. virtual memory systems
- G06F12/0802—Addressing of a memory level in which the access to the desired data or data block requires associative addressing means, e.g. caches
- G06F12/0806—Multiuser, multiprocessor or multiprocessing cache systems
- G06F12/0815—Cache consistency protocols
- G06F12/0831—Cache consistency protocols using a bus scheme, e.g. with bus monitoring or watching means
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F12/00—Accessing, addressing or allocating within memory systems or architectures
- G06F12/02—Addressing or allocation; Relocation
- G06F12/08—Addressing or allocation; Relocation in hierarchically structured memory systems, e.g. virtual memory systems
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F12/00—Accessing, addressing or allocating within memory systems or architectures
- G06F12/02—Addressing or allocation; Relocation
- G06F12/08—Addressing or allocation; Relocation in hierarchically structured memory systems, e.g. virtual memory systems
- G06F12/0802—Addressing of a memory level in which the access to the desired data or data block requires associative addressing means, e.g. caches
- G06F12/0806—Multiuser, multiprocessor or multiprocessing cache systems
- G06F12/0815—Cache consistency protocols
- G06F12/0817—Cache consistency protocols using directory methods
- G06F12/0822—Copy directories
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F13/00—Interconnection of, or transfer of information or other signals between, memories, input/output devices or central processing units
- G06F13/14—Handling requests for interconnection or transfer
- G06F13/20—Handling requests for interconnection or transfer for access to input/output bus
- G06F13/28—Handling requests for interconnection or transfer for access to input/output bus using burst mode transfer, e.g. direct memory access DMA, cycle steal
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F2212/00—Indexing scheme relating to accessing, addressing or allocation within memory systems or architectures
- G06F2212/50—Control mechanisms for virtual memory, cache or TLB
- G06F2212/507—Control mechanisms for virtual memory, cache or TLB using speculative control
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02D—CLIMATE CHANGE MITIGATION TECHNOLOGIES IN INFORMATION AND COMMUNICATION TECHNOLOGIES [ICT], I.E. INFORMATION AND COMMUNICATION TECHNOLOGIES AIMING AT THE REDUCTION OF THEIR OWN ENERGY USE
- Y02D10/00—Energy efficient computing, e.g. low power processors, power management or thermal management
Description
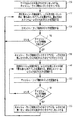
関連するプロセッサのキャッシュ・メモリ・レベル中にロードされているデータのキャッシュ・ライン・アドレスを追跡するようになされた第一メモリ格納手段と、
一つ以上のメモリ書き込み元からのスヌープ要求を受信するための手段と、
受信したスヌープ要求のアドレスを前記メモリ格納手段に格納されているアドレスと対比する手段と、
メモリ格納手段中のアドレスとの一致を受けて受信したスヌープ要求を転送するか、さもなくば、スヌープ要求を廃棄するための手段と、
を含み、
これらによりプロセッシング・ユニットに転送されるスヌープ要求の数が大幅に削減され、それによって、コンピューティング環境のパフォーマンスが増進される。
プロセッシング・ユニット中の各スヌープ・フィルタ・デバイスについて、
関連するプロセッサのキャッシュ・メモリ・レベル中にロードされているデータのキャッシュ・ライン・アドレスを追跡記録し、キャッシュ・ライン・アドレスを第一メモリ格納手段に保存するステップと、
複数のメモリ書き込み元からスヌープ要求を受信するステップと、
受信したスヌープ要求のアドレスをメモリ格納手段中に格納されたアドレスと対比するステップと、
メモリ格納手段中のアドレスとの一致を受けて、受信したスヌープ要求をプロセッサに転送するか、さもなくば、スヌープ要求を廃棄するステップと、
を含み、
これにより、プロセッシング・ユニットに転送されるスヌープ要求の数が大幅に削減され、コンピューティング環境のパフォーマンスが向上する。

ベース=0x1708fb1 マスク=0x7ffffff バリッド=1
となる。
ベース=0x1708fb1 マスク=0x7fffffc バリッド=1
となる。
1. アドレス中の、ストリーム・レジスタ・アドレスと異なるビットの数。
この数をsで表す。例えば、シグネチャをある定数Mに対するmin(M,s)に設定するなど、短縮係数を用いてスペースを節減することができる。
2. アドレスがNビットの場合、シグネチャは、あらゆるビットがゼロ値の長さB=(N+1)のベクトルである、但し、s=iの場合ビットiは1とする。スペースを節減するため、これを長さB+1(B+1<N)に切り詰めることができよう、min(s,B)=iの場合ビットiは1である。
3. アドレスをkヶ(k>1)のビット群に分割する。群iの長さはL(i)であり、M(i)=L(i)+1とする。s(i)を、群i中のストリーム・レジスタと異なる群i中のアドレス・ビットの数とする。このとき、シグネチャは、(s(1),s(2),…,s(k))で与えられ、これは単に各群の異なったビットの数である。これらの群については、互いに素なビットのセットにも、部分的にオーバーラップしているビットのセット(すなわち、アドレスの一部のビットが複数の群に在る)にも構成することができる。シグネチャの長さは、B(1)+…+B(k)であり、B(i)は、s(i)が取り得るあらゆる値を表すために必要なビットの数である。
4. 上記の(2)と(3)との組み合わせ。この組み合わせにおいて、シグネチャは、各々の群に対応するkビットのベクトルから成る。s(j)=iの場合、群j中のビットiは1にセットされる。群iがL(i)ビット長さの場合、s(i)が取り得るあらゆる値を符号化するためにはM(i)=(L(i)+1)のビットが必要となる。シグネチャはM(1)+…+M(k)ビットの長さとなる。例えば、ある定数Mに対して、min(M,s(j))=iとし群j中のビットiを1に設定するなどして、短縮係数を使いスペースを節減することができる。
5. 上記の(3)と同様であるが、s(1),…,s(k)の別の一意的な組み合わせとしてM(1)×…×M(k)がある。
6. アドレスをkヶ(k>1)のビット群に分割し、p(i)を、群i中のアドレス・ビットのパリティとする。このとき、シグネチャは、(p(1),p(2),…,p(k))で与えられる。
7. 上記の(6)と同様であるが、2kのパリティの組み合わせの各々を整数qに符号化し、長さ2kのゼロのビット・ベクトルを戻す、但しビットqは1とする。
この他に多くのシグネチャが可能なことは言うまでもない。
1. S_new=max(S_old,V)。これは、ストリーム・レジスタと異なるビットの最大数を追跡記録する。
2. S_new=S_oldビット単位又は(bit−wide−or)V。これは、異なるビットのスコアボードを保持する。
3. S_new=max(S_old,V)。これは、各群中のストリーム・レジスタと異なるビットの最大数を追跡記録する。
4. S_new=S_oldビット単位又はV。これは、各群中の異なるビットのスコアボードを保持する。
5. S_new=S_oldビット単位又はV。これは、各群中の同時に生じた異なるビットのスコアボードを保持する。
6. S_new=S_oldビット単位又はV。これは各群中のパリティのスコアボードを保持する。
7. S_new=S_oldビット単位又はV。これは各群中の同時に生じたパリティのスコアボードを保持する。
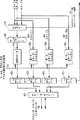
200b L1キャッシュ2
200n L1キャッシュN
250 システム・ローカル・バス
260 2点間相互接続
240a〜240n スヌープ・フィルタ
230 主メモリ
Claims (27)
- 複数のプロセッシング・ユニットを有するコンピューティング環境の各プロセッシング・ユニットに関連付けられたスヌープ・フィルタであって、前記複数のプロセッシング・ユニットの1つのプロセッシング・ユニットそれぞれは当該1つのプロセッシング・ユニットに対応する1つのスヌープ・フィルタに関連付けられており、前記複数のプロセッシング・ユニットの1つのプロセッシング・ユニットそれぞれは、当該1つのプロセッシング・ユニットに関連付けられた一つ以上のキャッシュ・メモリを有し、
前記スヌープ・フィルタは、
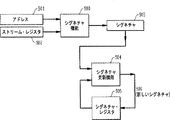
関連するプロセッシング・ユニットのキャッシュ・メモリ・レベル中にロードされたデータのキャッシュ・ライン・アドレスを追跡するようになされた第一メモリ格納手段であって、前記第一メモリ格納手段は、第一の複数ストリーム・レジスタ・セットを含み、各ストリーム・レジスタ・セットは、1つ又は複数のストリーム・レジスタを含み、各ストリーム・レジスタは、ベース・レジスタおよび対応するマスク・レジスタを含み、前記ベース・レジスタは、前記ストリーム・レジスタによって表される前記キャッシュ・ライン・アドレスすべてに共通するアドレス・ビットを追跡し、前記対応するマスク・レジスタは、これに対応するベース・レジスタに含まれる前に記録されたアドレスとの違いを表すビットを追跡し、当該違いを表すビットの位置は前記ベース・レジスタの対応するビットが判断外であることを示すように前記マスク・レジスタにおいて示される、前記第一メモリ格納手段と、
一つ以上のメモリ書き込み元からのスヌープ要求を受信する手段と、
受信したスヌープ要求のアドレスを、前記第一メモリ格納手段の前記複数のストリーム・レジスタ・セットに格納されたアドレス群と対比するためのスヌープ・チェック・ロジック手段と、
前記複数のストリーム・レジスタ・セットに格納されたアドレスとの一致を受けて、前記受信したスヌープ要求を前記プロセッシング・ユニットに転送し、又は、一致しない場合は前記スヌープ要求を廃棄するための手段と
を含む、前記スヌープ・フィルタ。 - これにより、プロセッシング・ユニットに転送されるスヌープ要求の数が削減し、これによって前記コンピューティング環境のパフォーマンスを上げる、請求項1に記載のスヌープ・フィルタ。
- 前記スヌープ要求のメモリ書き込み元は、前記複数のプロセッシング・ユニットの一つ、又はダイレクト・メモリ・アクセス(DMA)エンジンを含む、請求項1に記載のスヌープ・フィルタ。
- 各前記スヌープ・フィルタは
複数のポート・スヌープ・フィルタと連通し、スヌープ要求のサブセットを受信し、エンキューし、そして、該スヌープ・フィルタの前記関連するプロセッシング・ユニットに転送する複数のプロセッサ・スヌープ・フィルタ・キュー手段
をさらに含む、請求項1に記載のスヌープ・フィルタ。 - 各前記スヌープ・フィルタは
前記スヌープ・フィルタ・キュー手段間をすべて調停し、前記複数のプロセッサ・スヌープ・フィルタ・キュー手段の各々から送られるすべてのスヌープ要求を逐次化し、前記関連するプロセッシング・ユニットに転送する手段
をさらに含む、請求項4に記載のスヌープ・フィルタ。 - 実施された各キャッシュ・ロードに対し、前記第一メモリ格納手段のキャッシュ・ライン・アドレスで更新するための手段をさらに含み、
前記更新するための手段は、レジスタ選定基準に基づきどのストリーム・ベース・レジスタ及びマスク・レジスタのセットを更新するかを判定するための手段を含む、請求項1に記載のスヌープ・フィルタ。 - 前記レジスタ選定基準は、前記ストリーム・レジスタ・セットと前記キャッシュ・ライン・ロード・アドレスとの間の最小ハミング距離、又は、前記ベース・レジスタの最上位部のビット群と前記キャッシュ・ライン・ロード・アドレスの同ビットとの最も近い一致を含む、請求項6に記載のスヌープ・フィルタ。
- 前記判定するための手段は、ライン・ロード・アドレスと、すべてのベース・レジスタの内容とを、その関連マスク・レジスタにより対比し、前記選定基準に従い最も近い一致を選定するための手段を含む、請求項6に記載のスヌープ・フィルタ。
- 前記第一メモリ格納手段のキャッシュ・ライン・アドレスで更新するための前記手段は、対セットの対応するマスク・レジスタの関連ビットを更新するための手段、又は、対セットの対応するベース・レジスタの内容を置換えるための手段を含む、請求項6に記載のスヌープ・フィルタ。
- 前記スヌープ・チェック・ロジック手段は、
キャッシュ・ライン内のオフセットに対応する低位のビットを除去することによって、受信したスヌープ・アドレスをスヌープ・ライン・アドレスに変換するための手段と、
ベース・レジスタの内容を、対応するマスク・レジスタの内容と組み合わせた前記スヌープ・ライン・アドレスと対比し、当該特定のキャッシュ・ライン・アドレスにおける前記キャッシュ・メモリ・レベル中にデータが所在する可能性を示す結果信号を得るロジックを実行するための第一手段と
を含む、請求項1に記載のスヌープ・フィルタ。 - 前記第一手段は、前記スヌープ・ライン・アドレスを、前記第一の複数ストリーム・レジスタ・セットの内容と並行して対比する、請求項10に記載のスヌープ・フィルタ。
- 前記スヌープ要求を受信する手段は、前記コンピューティング環境の専用メモリ書き込み元からのスヌープ要求を受信する複数の専用入力ポートを含む、請求項1に記載のスヌープ・フィルタ。
- 前記スヌープ・フィルタは、前記複数の専用入力ポートと連通し並列に動作する複数のポート・スヌープ・フィルタをさらに含み、
前記複数のポート・スヌープ・フィルタの各々がスヌープ・チェック・ロジック手段を実行して、それぞれの前記専用書き込み元から受信したスヌープ要求をフィルタリングし、同時にそれら要求のサブセットをその関連するプロセッシング・ユニットに転送する、請求項12に記載のスヌープ・フィルタ。 - 前記スヌープ・フィルタは、
前記複数の専用入力ポートと連通し並列に動作する複数のキュー・デバイスであって、前記複数のキュー・デバイスの各々はそれぞれの専用メモリ書き込み元から受信した受信スヌープ要求をエンキューする、キュー・デバイスと、
前記エンキューされたスヌープ要求を前記スヌープ・チェック・ロジック手段に転送する調停多重化手段と
をさらに含む、請求項12に記載のスヌープ・フィルタ。 - 前記キャッシュ・メモリ・レベル中のあらゆるキャッシュ・ラップが、前のキャッシュ・ラップ検知状態から置換えられたがどうかを追跡するためのキャッシュ・ラップ検出手段をさらに含む、請求項1に記載のスヌープ・フィルタ。
- 前記更新するための手段によってキャッシュ・メモリ中にロードされたデータのキャッシュ・ライン・アドレスを追跡するための、前記第一の複数ストリーム・レジスタ・セットと対称になる第二の複数ストリーム・レジスタ・セットを有する第二メモリ格納手段をさらに含み、
前記スヌープ・チェック・ロジック手段は、前記受信スヌープ要求の前記アドレスを前記第二の複数ストリーム・レジスタ・セット中に格納されたアドレス群と対比する手段を含む、
請求項6に記載のスヌープ・フィルタ。 - 前記第一の複数ストリーム・レジスタ・セットにより追跡されるキャッシュ・メモリ・ラインに対しキャッシュ・ラップ検知状態が検出されると、前記第二の複数ストリーム・レジスタ・セットの前記更新が行われる前に、前記第二の複数ストリーム・レジスタ・セットをリセットするための手段をさらに含む、請求項16に記載のスヌープ・フィルタ。
- 前記第二の複数ストリーム・レジスタ・セットにより追跡されるキャッシュ・メモリ・ラインに対しキャッシュ・ラップ検知状態が検出されると、前記第一の複数ストリーム・レジスタ・セットをリセットするための手段をさらに含み、
前記第一の複数ストリーム・レジスタ・セットの更新が再実施される、
請求項17に記載のスヌープ・フィルタ。 - 前記第一の複数ストリーム・レジスタ・セットに対応する第二の複数ストリーム・レジスタ・セットを有する第二メモリ格納手段と、
全キャッシュ・ラインが置換えられたことを示すキャッシュ・ラップ状態の検出を受けて、前記第二の複数ストリーム・レジスタ・セットを前記第一の複数ストリーム・レジスタ・セットの内容に置き換えるための手段であって、前記スヌープ・チェック・ロジック手段は、前記受信したスヌープ要求の前記アドレスを、前記第二の複数ストリーム・レジスタ・セットとさらに対比する、前記置き換えるための手段と
をさらに含む、請求項1に記載のスヌープ・フィルタ。 - 前記第二の複数ストリーム・レジスタ・セットが前記第一の複数ストリーム・レジスタ・セットの前記内容に置き換えられた後、前記第一の複数ストリーム・レジスタ・セットをリセットするための手段をさらに含む、請求項19に記載のスヌープ・フィルタ。
- 前記第一メモリ格納手段は、関連するプロセッシング・ユニットのキャッシュ・メモリ・レベル中にロードされたデータのキャッシュ・ライン・アドレスを追跡するようになっており、前記キャッシュの対応する一つ以上の区分化サブセットに関する内容を有する一つ以上の第一の複数ストリーム・レジスタ・セットを含み、
前記キャッシュ・ラップ検出手段は、前記キャッシュの前記一つ以上の区分化サブセットそれぞれのあらゆるキャッシュ・ラインが、前の各キャッシュ・ラップ検知状態から置き換えられているかどうかを追跡する、
請求項15に記載のスヌープ・フィルタ。 - 各々が前記第二の複数ストリーム・レジスタ・セットとして動作する、一つ以上の第二メモリ格納手段と、
キャッシュ・ラップ状態の検出に先だって、前記第一の複数ストリーム・レジスタ・セットの内容を前記一つ以上の第二の複数ストリーム・レジスタ・セットの各々にコピーするための手段であって、前記第一の複数ストリーム・レジスタ・セットの内容は、より高い頻度で更新されリセットされる、前記コピーするための手段と
をさらに含む、請求項21に記載のスヌープ・フィルタ。 - 複数のプロセッシング・ユニットを有するコンピューティング環境でキャッシュ・コヒーレンシをサポートするためのスヌープ・フィルタリング方法であって、前記複数のプロセッシング・ユニットの1つのプロセッシング・ユニットそれぞれは当該1つのプロセッシング・ユニットに対応する1つのスヌープ・フィルタに関連付けられており、前記複数のプロセッシング・ユニットの1つのプロセッシング・ユニットそれぞれは、当該1つのプロセッシング・ユニットに関連付けられた一つ以上のキャッシュ・メモリを有し、
前記方法は、
プロセッシング・ユニット中の各スヌープ・フィルタに対し、
関連するプロセッシング・ユニットのキャッシュ・メモリ・レベル中にロードされたデータのキャッシュ・ラインのアドレスを追跡し、キャッシュ・ライン・アドレスを第一メモリ格納手段中に格納するステップであって、前記第一メモリ格納手段は、第一の複数ストリーム・レジスタ・セットを含み、各ストリーム・レジスタ・セットは、1つ又は複数のストリーム・レジスタを含み、各ストリーム・レジスタは、ベース・レジスタおよび対応するマスク・レジスタを含み、前記ベース・レジスタは、前記ストリーム・レジスタによって表される前記キャッシュ・ライン・アドレスすべてに共通するアドレス・ビットを追跡し、前記対応するマスク・レジスタは、これに対応するベース・レジスタに含まれる前に記録されたアドレスとの違いを表すビットを追跡し、当該違いを表すビットの位置は前記ベース・レジスタの対応するビットが判断外であることを示すように前記マスク・レジスタにおいて示される、前記格納するステップと、
一つ以上のメモリ書き込み元からスヌープ要求を受信するステップと、
受信したスヌープ要求のアドレスを、前記第一メモリ格納手段の前記複数のストリーム・レジスタ・セットに格納されたアドレス群と対比するステップと、
前記複数のストリーム・レジスタ・セットに格納されたアドレスとの一致を受けて、前記受信したスヌープ要求を前記プロセッシング・ユニットに転送し、又は一致しない場合は前記スヌープ要求を廃棄するステップと
を含む、前記方法。 - これにより、プロセッシング・ユニットに転送されるスヌープ要求の数が削減し、これによって前記コンピューティング環境のパフォーマンスを上げる、請求項23に記載の方法。
- 前記各スヌープ・フィルタは、前記メモリ書き込み元の各々と連通する複数のポート・スヌープ・フィルタを含み、
前記受信したスヌープ要求を転送するステップは、
前記スヌープ・フィルタの前記関連するプロセッシング・ユニットに転送予定のスヌープ要求のサブセットを、ポート・スヌープ・フィルタに対応するそれぞれのプロセッサ・スヌープ・フィルタ・キュー手段中にエンキューするステップ
を含む、請求項23又は24に記載の方法。 - 前記第一メモリ格納手段を、実施された各キャッシュ・ロードに対するキャッシュ・ライン・アドレスで更新するステップをさらに含む、請求項23又は24に記載の方法。
- 複数のプロセッシング・ユニットを有するコンピューティング環境においてコンピュータにキャッシュ・コヒーレンシをサポートするためのスヌープ・フィルタリングのためのコンピュータ・プログラムであって、前記複数のプロセッシング・ユニットの1つのプロセッシング・ユニットそれぞれは当該1つのプロセッシング・ユニットに対応する1つのスヌープ・フィルタに関連付けられており、前記複数のプロセッシング・ユニットの1つのプロセッシング・ユニットそれぞれは、当該1つのプロセッシング・ユニットに関連付けられた一つ以上のキャッシュ・メモリを有し、前記コンピュータに請求項23〜26のいずれか一項に記載の方法の各ステップを実行させる前記コンピュータ・プログラム。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US11/093,130 | 2005-03-29 | ||
| US11/093,130 US7392351B2 (en) | 2005-03-29 | 2005-03-29 | Method and apparatus for filtering snoop requests using stream registers |
| PCT/US2006/010038 WO2006104747A2 (en) | 2005-03-29 | 2006-03-17 | Method and apparatus for filtering snoop requests using stream registers |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2008535093A JP2008535093A (ja) | 2008-08-28 |
| JP2008535093A5 JP2008535093A5 (ja) | 2012-05-10 |
| JP5120850B2 true JP5120850B2 (ja) | 2013-01-16 |
Family
ID=37053890
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2008504137A Expired - Fee Related JP5120850B2 (ja) | 2005-03-29 | 2006-03-17 | ストリーム・レジスタを用いてスヌープ要求をフィルタする方法、装置及びコンピュータ・プログラム |
Country Status (6)
| Country | Link |
|---|---|
| US (2) | US7392351B2 (ja) |
| EP (1) | EP1864224B1 (ja) |
| JP (1) | JP5120850B2 (ja) |
| KR (1) | KR101013237B1 (ja) |
| CN (1) | CN100568206C (ja) |
| WO (1) | WO2006104747A2 (ja) |
Families Citing this family (41)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2007031696A1 (en) * | 2005-09-13 | 2007-03-22 | Arm Limited | Cache miss detection in a data processing apparatus |
| WO2007099273A1 (en) * | 2006-03-03 | 2007-09-07 | Arm Limited | Monitoring values of signals within an integrated circuit |
| WO2007101969A1 (en) * | 2006-03-06 | 2007-09-13 | Arm Limited | Accessing a cache in a data processing apparatus |
| US20080056230A1 (en) * | 2006-08-29 | 2008-03-06 | Santhanakrishnan Geeyarpuram N | Opportunistic channel unblocking mechanism for ordered channels in a point-to-point interconnect |
| US20080183972A1 (en) * | 2007-01-26 | 2008-07-31 | James Norris Dieffenderfer | Snoop Filtering Using a Snoop Request Cache |
| US7937535B2 (en) * | 2007-02-22 | 2011-05-03 | Arm Limited | Managing cache coherency in a data processing apparatus |
| ATE516542T1 (de) | 2007-10-18 | 2011-07-15 | Nxp Bv | Schaltung und verfahren mit cachekohärenz- belastungssteuerung |
| US7996626B2 (en) * | 2007-12-13 | 2011-08-09 | Dell Products L.P. | Snoop filter optimization |
| JP5206385B2 (ja) * | 2008-12-12 | 2013-06-12 | 日本電気株式会社 | バウンダリ実行制御システム、バウンダリ実行制御方法、及びバウンダリ実行制御プログラム |
| US8447934B2 (en) * | 2010-06-30 | 2013-05-21 | Advanced Micro Devices, Inc. | Reducing cache probe traffic resulting from false data sharing |
| WO2013188460A2 (en) | 2012-06-15 | 2013-12-19 | Soft Machines, Inc. | A virtual load store queue having a dynamic dispatch window with a distributed structure |
| WO2013188701A1 (en) | 2012-06-15 | 2013-12-19 | Soft Machines, Inc. | A method and system for implementing recovery from speculative forwarding miss-predictions/errors resulting from load store reordering and optimization |
| KR101832574B1 (ko) * | 2012-06-15 | 2018-02-26 | 인텔 코포레이션 | 모든 store들이 캐시의 모든 워드들에 대한 검사를 스누핑해야만 하는 것을 방지하기 위해 store들을 필터링하는 방법 및 시스템 |
| EP2862068B1 (en) | 2012-06-15 | 2022-07-06 | Intel Corporation | Reordered speculative instruction sequences with a disambiguation-free out of order load store queue |
| KR101993562B1 (ko) | 2012-06-15 | 2019-09-30 | 인텔 코포레이션 | Load store 재정렬 및 최적화를 구현하는 명령어 정의 |
| WO2013188754A1 (en) | 2012-06-15 | 2013-12-19 | Soft Machines, Inc. | A disambiguation-free out of order load store queue |
| WO2013188705A2 (en) | 2012-06-15 | 2013-12-19 | Soft Machines, Inc. | A virtual load store queue having a dynamic dispatch window with a unified structure |
| US9274955B2 (en) * | 2012-08-17 | 2016-03-01 | Futurewei Technologies, Inc. | Reduced scalable cache directory |
| US9251073B2 (en) | 2012-12-31 | 2016-02-02 | Intel Corporation | Update mask for handling interaction between fills and updates |
| WO2014142939A1 (en) | 2013-03-15 | 2014-09-18 | Intel Corporation | Providing snoop filtering associated with a data buffer |
| US9058273B1 (en) | 2013-12-20 | 2015-06-16 | International Business Machines Corporation | Frequency determination across an interface of a data processing system |
| US9639470B2 (en) * | 2014-08-26 | 2017-05-02 | Arm Limited | Coherency checking of invalidate transactions caused by snoop filter eviction in an integrated circuit |
| US9727466B2 (en) * | 2014-08-26 | 2017-08-08 | Arm Limited | Interconnect and method of managing a snoop filter for an interconnect |
| US9507716B2 (en) * | 2014-08-26 | 2016-11-29 | Arm Limited | Coherency checking of invalidate transactions caused by snoop filter eviction in an integrated circuit |
| US9892803B2 (en) * | 2014-09-18 | 2018-02-13 | Via Alliance Semiconductor Co., Ltd | Cache management request fusing |
| KR102485999B1 (ko) * | 2015-07-01 | 2023-01-06 | 삼성전자주식회사 | 마스터-사이드 필터를 포함하는 캐시 코히런트 시스템과 이를 포함하는 데이터 처리 시스템 |
| US9626232B2 (en) * | 2015-07-23 | 2017-04-18 | Arm Limited | Event queue management |
| US10268586B2 (en) * | 2015-12-08 | 2019-04-23 | Via Alliance Semiconductor Co., Ltd. | Processor with programmable prefetcher operable to generate at least one prefetch address based on load requests |
| US10157133B2 (en) | 2015-12-10 | 2018-12-18 | Arm Limited | Snoop filter for cache coherency in a data processing system |
| US9900260B2 (en) | 2015-12-10 | 2018-02-20 | Arm Limited | Efficient support for variable width data channels in an interconnect network |
| US10262721B2 (en) * | 2016-03-10 | 2019-04-16 | Micron Technology, Inc. | Apparatuses and methods for cache invalidate |
| US9990292B2 (en) * | 2016-06-29 | 2018-06-05 | Arm Limited | Progressive fine to coarse grain snoop filter |
| US10346307B2 (en) | 2016-09-28 | 2019-07-09 | Samsung Electronics Co., Ltd. | Power efficient snoop filter design for mobile platform |
| US10621090B2 (en) * | 2017-01-12 | 2020-04-14 | International Business Machines Corporation | Facility for extending exclusive hold of a cache line in private cache |
| US10042766B1 (en) | 2017-02-02 | 2018-08-07 | Arm Limited | Data processing apparatus with snoop request address alignment and snoop response time alignment |
| GB2571538B (en) * | 2018-02-28 | 2020-08-19 | Imagination Tech Ltd | Memory interface |
| US10761985B2 (en) * | 2018-08-02 | 2020-09-01 | Xilinx, Inc. | Hybrid precise and imprecise cache snoop filtering |
| CN109582895A (zh) * | 2018-12-04 | 2019-04-05 | 山东浪潮通软信息科技有限公司 | 一种缓存实现方法 |
| US10635591B1 (en) * | 2018-12-05 | 2020-04-28 | Advanced Micro Devices, Inc. | Systems and methods for selectively filtering, buffering, and processing cache coherency probes |
| US10657055B1 (en) * | 2018-12-13 | 2020-05-19 | Arm Limited | Apparatus and method for managing snoop operations |
| US11593273B2 (en) * | 2019-01-30 | 2023-02-28 | Intel Corporation | Management of cache use requests sent to remote cache devices |
Family Cites Families (23)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5014327A (en) * | 1987-06-15 | 1991-05-07 | Digital Equipment Corporation | Parallel associative memory having improved selection and decision mechanisms for recognizing and sorting relevant patterns |
| JP3027843B2 (ja) * | 1993-04-23 | 2000-04-04 | 株式会社日立製作所 | バススヌ−プ方法 |
| US5778424A (en) * | 1993-04-30 | 1998-07-07 | Avsys Corporation | Distributed placement, variable-size cache architecture |
| US5655100A (en) * | 1995-03-31 | 1997-08-05 | Sun Microsystems, Inc. | Transaction activation processor for controlling memory transaction execution in a packet switched cache coherent multiprocessor system |
| US5659710A (en) * | 1995-11-29 | 1997-08-19 | International Business Machines Corporation | Cache coherency method and system employing serially encoded snoop responses |
| US5966729A (en) * | 1997-06-30 | 1999-10-12 | Sun Microsystems, Inc. | Snoop filter for use in multiprocessor computer systems |
| US6460119B1 (en) * | 1997-12-29 | 2002-10-01 | Intel Corporation | Snoop blocking for cache coherency |
| US6272604B1 (en) * | 1999-05-20 | 2001-08-07 | International Business Machines Corporation | Contingent response apparatus and method for maintaining cache coherency |
| US6389517B1 (en) * | 2000-02-25 | 2002-05-14 | Sun Microsystems, Inc. | Maintaining snoop traffic throughput in presence of an atomic operation a first port for a first queue tracks cache requests and a second port for a second queue snoops that have yet to be filtered |
| US6934817B2 (en) * | 2000-03-31 | 2005-08-23 | Intel Corporation | Controlling access to multiple memory zones in an isolated execution environment |
| US6598123B1 (en) * | 2000-06-28 | 2003-07-22 | Intel Corporation | Snoop filter line replacement for reduction of back invalidates in multi-node architectures |
| US6810467B1 (en) * | 2000-08-21 | 2004-10-26 | Intel Corporation | Method and apparatus for centralized snoop filtering |
| US20030131201A1 (en) * | 2000-12-29 | 2003-07-10 | Manoj Khare | Mechanism for efficiently supporting the full MESI (modified, exclusive, shared, invalid) protocol in a cache coherent multi-node shared memory system |
| US7472231B1 (en) * | 2001-09-07 | 2008-12-30 | Netapp, Inc. | Storage area network data cache |
| US6823409B2 (en) * | 2001-09-28 | 2004-11-23 | Hewlett-Packard Development Company, L.P. | Coherency control module for maintaining cache coherency in a multi-processor-bus system |
| US6829665B2 (en) | 2001-09-28 | 2004-12-07 | Hewlett-Packard Development Company, L.P. | Next snoop predictor in a host controller |
| US6842827B2 (en) * | 2002-01-02 | 2005-01-11 | Intel Corporation | Cache coherency arrangement to enhance inbound bandwidth |
| US6857048B2 (en) | 2002-01-17 | 2005-02-15 | Intel Corporation | Pseudo least-recently-used (PLRU) replacement method for a multi-node snoop filter |
| US6959364B2 (en) | 2002-06-28 | 2005-10-25 | Intel Corporation | Partially inclusive snoop filter |
| TW560035B (en) * | 2002-07-05 | 2003-11-01 | Via Tech Inc | Interlayer disposition structure of multi-layer circuit board |
| US7117312B1 (en) * | 2003-11-17 | 2006-10-03 | Sun Microsystems, Inc. | Mechanism and method employing a plurality of hash functions for cache snoop filtering |
| US7308538B2 (en) * | 2004-11-04 | 2007-12-11 | International Business Machines Corporation | Scope-based cache coherence |
| US7475167B2 (en) * | 2005-04-15 | 2009-01-06 | Intel Corporation | Offloading data path functions |
-
2005
- 2005-03-29 US US11/093,130 patent/US7392351B2/en not_active Expired - Fee Related
-
2006
- 2006-03-17 CN CNB2006800101519A patent/CN100568206C/zh not_active Expired - Fee Related
- 2006-03-17 EP EP06739000.5A patent/EP1864224B1/en not_active Not-in-force
- 2006-03-17 WO PCT/US2006/010038 patent/WO2006104747A2/en active Application Filing
- 2006-03-17 KR KR1020077021818A patent/KR101013237B1/ko not_active IP Right Cessation
- 2006-03-17 JP JP2008504137A patent/JP5120850B2/ja not_active Expired - Fee Related
-
2008
- 2008-06-11 US US12/137,325 patent/US8135917B2/en not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| US20060224836A1 (en) | 2006-10-05 |
| EP1864224B1 (en) | 2013-05-08 |
| WO2006104747A2 (en) | 2006-10-05 |
| CN101189590A (zh) | 2008-05-28 |
| EP1864224A2 (en) | 2007-12-12 |
| US8135917B2 (en) | 2012-03-13 |
| US7392351B2 (en) | 2008-06-24 |
| WO2006104747A3 (en) | 2007-12-21 |
| EP1864224A4 (en) | 2011-08-10 |
| KR101013237B1 (ko) | 2011-02-08 |
| KR20070119653A (ko) | 2007-12-20 |
| US20080244194A1 (en) | 2008-10-02 |
| JP2008535093A (ja) | 2008-08-28 |
| CN100568206C (zh) | 2009-12-09 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5120850B2 (ja) | ストリーム・レジスタを用いてスヌープ要求をフィルタする方法、装置及びコンピュータ・プログラム | |
| US8677073B2 (en) | Snoop filter for filtering snoop requests | |
| US8103836B2 (en) | Snoop filtering system in a multiprocessor system | |
| JP2008535093A5 (ja) | ||
| US7386683B2 (en) | Method and apparatus for filtering snoop requests in a point-to-point interconnect architecture | |
| US7386685B2 (en) | Method and apparatus for filtering snoop requests using multiple snoop caches | |
| US7305522B2 (en) | Victim cache using direct intervention | |
| US7305523B2 (en) | Cache memory direct intervention | |
| US8108619B2 (en) | Cache management for partial cache line operations | |
| TWI506433B (zh) | 監測過濾機構 | |
| US6272602B1 (en) | Multiprocessing system employing pending tags to maintain cache coherence | |
| US8117401B2 (en) | Interconnect operation indicating acceptability of partial data delivery | |
| US7958309B2 (en) | Dynamic selection of a memory access size | |
| US8015364B2 (en) | Method and apparatus for filtering snoop requests using a scoreboard | |
| US7617366B2 (en) | Method and apparatus for filtering snoop requests using mulitiple snoop caches | |
| JP3732397B2 (ja) | キャッシュシステム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20081209 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20081209 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20111220 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A821 Effective date: 20120228 |
|
| A524 | Written submission of copy of amendment under section 19 (pct) |
Free format text: JAPANESE INTERMEDIATE CODE: A524 Effective date: 20120228 |
|
| RD12 | Notification of acceptance of power of sub attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7432 Effective date: 20120228 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A821 Effective date: 20120228 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20120713 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20120820 Free format text: JAPANESE INTERMEDIATE CODE: A821 Effective date: 20120820 |
|
| TRDD | Decision of grant or rejection written | ||
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A821 Effective date: 20120928 |
|
| RD14 | Notification of resignation of power of sub attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7434 Effective date: 20120928 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20120928 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20121016 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20151102 Year of fee payment: 3 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| LAPS | Cancellation because of no payment of annual fees |