以下に本発明の実施の形態を説明するが、本発明の構成要件と、明細書または図面に記載の実施の形態との対応関係を例示すると、次のようになる。この記載は、本発明をサポートする実施の形態が、明細書または図面に記載されていることを確認するためのものである。従って、明細書または図面中には記載されているが、本発明の構成要件に対応する実施の形態として、ここには記載されていない実施の形態があったとしても、そのことは、その実施の形態が、その構成要件に対応するものではないことを意味するものではない。逆に、実施の形態が構成要件に対応するものとしてここに記載されていたとしても、そのことは、その実施の形態が、その構成要件以外の構成要件には対応しないものであることを意味するものでもない。
本発明の一側面の情報処理装置は、独立成分分析を実行する情報処理装置であって、信号を取得する取得手段(例えば、音信号取得部29)と、前記取得手段により取得された前記信号を用いて、前記独立成分分析の学習によって分離行列を求める学習手段(例えば、図8のバックグラウンド処理部72)と、前記取得手段により取得された前記信号に、前記学習手段により求められた前記分離行列を適用することによって、分離結果を生成する分離手段(たとえば、図8の信号処理部71)とを備え、前記学習手段は、前記信号を蓄積する第1の状態(例えば、「蓄積中」状態)と蓄積された前記信号を用いて前記独立成分分析に基づくバッチ処理を実行することにより前記分離行列を演算する第2の状態(例えば、「学習中」状態)の少なくとも2つの状態を有し、前記分離行列を学習により求める複数の演算手段(例えば、図8のスレッド101−1乃至101−N)と、複数の前記演算手段を制御する演算制御手段(例えば、図8のスレッド制御部91)とを備え、前記演算手段は、前記第1の状態および前記第2の状態のいずれの状態でもなく、処理を待機する第3の状態(例えば、「待機中」状態)を更に有することができ、前記演算制御手段は、前記演算手段における前記第3の状態の時間を制御することにより、複数の前記演算手段のそれぞれにおける前記第1の状態の開始タイミングが、前記分離行列の学習を行う単位期間であるブロック長よりも短い期間で略均等にずれるように、複数の前記演算手段を制御する。
前記演算制御手段は、前記演算手段が前記分離行列を求める学習に用いる分離行列の初期値として、複数の前記演算手段のいずれかにおいて最も新しく求められた前記分離行列とそれ以前に求められた過去の学習による分離行列とを用いて演算されて得られた値(例えば、W_init=(W[k]+W[k-1] +・・・+W[k-N])/(N+1)またはaW+(1-a)W_initなどであり、ここで、W[k]は、システムが起動されてからk番目に求められた分離行列である)が用いられるように、複数の前記演算手段を制御することができる。
本発明の一側面の情報処理方法は、独立成分分析を実行する情報処理装置の情報処理方法であって、信号を取得し(例えば、図12のステップS2の処理)、取得された前記信号を蓄積する第1の状態(例えば、「蓄積中」状態)と蓄積された前記信号を用いて前記独立成分分析に基づくバッチ処理を実行することにより前記分離行列を演算する第2の状態(例えば、「学習中」状態)の少なくとも2つの状態を有し、前記分離行列を学習により求める複数の演算部(例えば、図8のスレッド101−1乃至101−N)において、分離処理に用いられる分離行列を学習により求める処理を制御し(例えば、図12のステップS4の処理)、取得された前記信号に前記分離行列を適用することによって、分離結果を生成する(例えば、図12のステップS5の処理)ステップを含み、前記演算部は、前記第1の状態および前記第2の状態のいずれの状態でもなく、処理を待機する第3の状態(例えば、「待機中」状態)を更に有することができ、前記演算部における前記第3の状態の時間を制御することにより、複数の前記演算部のそれぞれにおける前記第1の状態の開始タイミングが、前記分離行列の学習を行う単位期間であるブロック長よりも短い期間で略均等にずれるように、複数の前記演算部による前記学習の処理が制御される。
本発明の一側面のプログラムは、独立成分分析を実行する処理をコンピュータに実行させるためのプログラムであって、信号の取得を制御し(例えば、図12のステップS2の処理)、取得が制御された前記信号を蓄積する第1の状態(例えば、「蓄積中」状態)と蓄積された前記信号を用いて前記独立成分分析に基づくバッチ処理を実行することにより前記分離行列を演算する第2の状態(例えば、「学習中」状態)の少なくとも2つの状態を有し、前記分離行列を学習により求める複数の演算部(例えば、図8のスレッド101−1乃至101−N)において、分離処理に用いられる分離行列を学習により求める処理を制御し(例えば、図12のステップS4の処理)、取得された前記信号に前記分離行列を適用することによって、分離結果を生成する(例えば、図12のステップS5の処理)ステップを含み、前記演算部は、前記第1の状態および前記第2の状態のいずれの状態でもなく、処理を待機する第3の状態(例えば、「待機中」状態)を更に有することができ、前記演算部における前記第3の状態の時間を制御することにより、複数の前記演算部のそれぞれにおける前記第1の状態の開始タイミングが、前記分離行列の学習を行う単位期間であるブロック長よりも短い期間で略均等にずれるように、複数の前記演算部による前記学習の処理が制御される処理をコンピュータに実行させる。
以下、図を参照して、本発明の実施の形態について説明する。
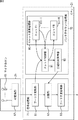
図3に、音源分離装置11のブロック図を示す。
CPU(Central Processing Unit)21−1乃至21−Pは、マルチプロセッサであり、ROM(Read Only Memory)22に記憶されているプログラム、または記憶部28からRAM(Random Access Memory)23にロードされたプログラムにしたがって、各種の処理を実行する。RAM23にはまた、CPU21が各種の処理を実行する上において必要なデータなども適宜記憶される。
CPU21、ROM22、およびRAM23は、バス24を介して相互に接続されている。このバス24にはまた、入出力インタフェース24も接続されている。
入出力インタフェース24には、キーボード、マウスなどよりなる入力部26、ディスプレイやスピーカなどよりなる出力部27、ハードディスクなどより構成される記憶部28、および、音信号を取得する音信号取得部29が接続されている。音信号取得部29は、例えば、複数のマイクロホンおよびAD変換部を含んで構成され、複数のマイクロホンによって集音された音信号を、AD変換部の処理によりデジタル信号に変換する。
入出力インタフェース24にはまた、必要に応じてドライブ30が接続され、磁気ディスク31、光ディスク32、光磁気ディスク33、もしくは、半導体メモリ34などが適宜装着され、それらから読み出されたコンピュータプログラムが、必要に応じて記憶部28にインストールされる。
CPU21は、音信号取得部29により取得された、複数のマイクによって集音され、デジタル信号に変換された音信号に対して、独立成分分析(independent component analysis: ICA)を実行するものである。
CPU21は、ICAを実行するにあたって、スレッドと称する処理の単位を用いて、逐次処理、すなわち、略リアルタイムで観測信号から分離信号を出力する処理を可能とするものである。
CPU21は、複数のスレッドを並行して動作させる。それぞれのスレッドは、少なくとも、観測信号の蓄積、および、分離行列の学習の2つの状態を有し、必要に応じて、待機の状態を取ることも可能である。スレッドは、これらの状態間の遷移を繰り返す。
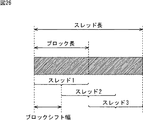
観測信号の蓄積中の状態において、スレッドは、一定時間の観測信号を蓄積する。この一定時間を、以下、1ブロック長と称するものとする。
分離行列の学習中の状態において、スレッドは、蓄積した観測信号から分離行列を求める学習処理を実行する。
待機中の状態において、スレッドは、観測信号の蓄積や学習処理を実行せずに、待機する。
CPU21においては、複数のスレッドが時刻をずらして起動される。また、ブロック長、分離行列の更新間隔、学習時間の最大値などは、それぞれ、設定可能なようになされている。
そして、ブロック長よりも短い間隔で異なるスレッドを起動する、換言すれば、複数のスレッドのそれぞれにおいて、上述した3つの状態の遷移タイミングを調整して所定時間だけずらすことにより、ブロック長よりも短い間隔で分離行列Wを更新できるようになり、ブロック長と追従遅れとのトレードオフを解消することが可能となる。
例えば、図4を用いて、複数のスレッドを並行して起動する場合の一例として、3つのスレッドが並行して起動されたときの状態遷移について説明する。
スレッド1乃至スレッド3のそれぞれでは、観測信号の「蓄積中」状態において、指定された時間、すなわち1ブロック長の観測信号がバッファに蓄えられる。指定された時間が経過した後、状態は、学習中に遷移する。
学習中の状態において、分離行列Wが収束するまで(または一定回数)学習処理ループが実行され、蓄積中の状態において蓄積された観測信号に対応した分離行列が求められる。分離行列Wが収束した後(または一定回数の学習処理ループが実行された後)状態は、待機中に遷移する。
そして、待機中の状態において、指定された時間だけ、観測信号の蓄積や学習は実行されず、待機される。待機中の状態を維持する時間は、学習にかかった時間によって決まる。すなわち、図5に示されるように、予め、「蓄積中」状態と「学習中」状態と「待機中」状態との合計の時間幅であるスレッド長(thread_len)が定められ、基本的には、「学習中」状態が終了したときからスレッド長が終了するまでの間の時間が、「待機中」状態の時間(待機時間)とされる。待機時間が過ぎた後、状態は、観測信号の「蓄積中」状態へ戻る。
これらの時間は、例えば、ミリ秒などの単位で管理してもよいが、短時間フーリエ変換で生成されるフレームを単位として計測するものとしても良い。以降の説明では、フレームを単位として計測する(たとえば、カウントアップをおこなう)ものとする。
そして、スレッド1乃至スレッド3のそれぞれは、所定のブロックシフト幅(Block_shift)だけずらして起動される。例えば、図4の場合においては、ブロック長の半分をブロックシフト幅としている。
スレッド1の「学習中」状態が終了した後、スレッド1により得られた学習結果、すなわち、スレッド1由来の分離行列W[1]を用いて、それぞれのスレッドは処理を実行することができる。そして、スレッド2の「学習中」状態が終了した後、スレッド1により得られた学習結果よりも新しい、スレッド2により得られた学習結果、すなわち、スレッド2由来の分離行列W[2]を用いてそれぞれのスレッドは処理を実行することができる。
以下同様に、所定のブロックシフト幅(Block_shift)だけずらして起動されるそれぞれのスレッド由来の最新の分離行列Wを用いて、それぞれのスレッドは処理を実行することが可能なようになされている。すなわち、ブロック長よりも短い間隔で分離行列Wを更新することができるので、ブロック長と更新間隔とのトレードオフを回避することができる。
また、学習時間がブロック長よりも長くなる可能性がある場合でも、その分だけ多くのスレッドを起動すれば、ブロック長や学習時間よりも短い間隔で分離行列Wを更新することができる。換言すれば、分離行列Wの更新頻度、すなわち追従遅れの度合いを、ブロック長や学習時間とは独立して設定することが可能になる。
また、学習時間が(スレッド長−ブロック長)よりも長くなってしまった場合、「学習中」状態の終了後、「待機中」状態に遷移せず、「蓄積中」状態に遷移するものとしても良い。
これらの状態遷移を管理するために、それぞれのスレッドごとに、カウンタを用いて、「蓄積中」状態の開始からカウントアップを始める。上述したように、「蓄積中」状態はブロック長(block_len)の間継続され、カウンタ値がブロック長(block_len)となったとき、状態は、「学習中」状態に遷移する。そして、「学習中」状態が終了してから、カウンタ値がスレッド長(thread_len)となるまでの間が、「待機中」状態となるのであるが、「学習中」状態が終了したとき、カウンタ値がスレッド長(thread_len)と等しいか、それよりも大きい場合、状態は、「学習中」状態の終了後、「待機中」状態に遷移せず、「蓄積中」状態に遷移するものとする。
すなわち、図6の状態遷移図に示されるように、システムの起動直後、各スレッドは「初期状態」にあるが、その内の1つが「蓄積中」状態となり、残りの全てのスレッドが「待機中」へ状態を遷移させる。すなわち、図4における場合では、スレッド1が、初期状態の後「蓄積中」へ遷移したスレッドであり、それ以外のスレッドが「初期状態」から「待機中」へ遷移したスレッドである。
「初期状態」から「待機中」へ遷移したスレッドにおける、最初の「待機中」から「蓄積中」への状態遷移について、「初期状態」から「待機中」へ状態が遷移したときのカウンタの値を、ブロックのシフト幅(block_shift)とスレッド長(thread_len)によって決まる所定の値とすることにより、「待機中」から「蓄積中」への状態の遷移の条件判断を、他と同様に実行可能なようにすることができる。
すなわち、図4におけるスレッド2およびスレッド3において、例えば、「初期状態」から最初の「待機中」に状態が遷移されたとき、スレッド2の状態遷移を管理するためのカウンタの値をthread_len−block_shiftに設定し、スレッド3の状態遷移を管理するためのカウンタの値を、thread_len−block_shift×2に設定する。そして、スレッド1において蓄積されている観測信号のフレームと連動して、それぞれのカウンタの値をインクリメントする。このようにすれば、それぞれのカウンタの値がthread_lenに達したとき、状態を「待機中」から「蓄積中」へ遷移すればよいので、他の「待機中」から「蓄積中」への状態の遷移と同様の条件で、状態遷移を制御することが可能となる。
「蓄積中」から「学習中」への状態の遷移、および、「待機中」または「学習中」から「蓄積中」への状態遷移については、カウンタの値に基づいて行なわれる。すなわち、それぞれのスレッドにおいて、「蓄積中」の開始時にカウンタの値は初期化(例えば、0にセット)され、観測信号が1フレーム分供給されるごとにカウンタの値が1インクリメントされ、カウンタの値がblock_lenと同じ値になったら、「学習中」へ状態が遷移される。
学習は、分離処理と並列にバックグラウンドで行なわれるが、その間も観測信号のフレームと連動してカウンタの値はインクリメントされる。
学習が終了した時、カウンタの値がthread_lenと比較される。カウンタの値がthread_lenより小さい場合、状態が「待機中」へ遷移される。待機中も学習中と同様に、観測信号のフレームと連動してカウンタがインクリメントされる。そして、待機中のカウンタ値がthread_lenと等しくなったとき、状態は、「蓄積中」に遷移され、観測信号の蓄積が開始されて、カウンタ値は初期化される。
そして、学習が終了した時、カウンタの値がthread_lenと同じか、または、大きい場合、状態は、「蓄積中」に遷移され、観測信号の蓄積が開始されて、カウンタ値は初期化される。
また、「初期状態」から「待機中」へ遷移したスレッドにおける、最初の「待機中」から「蓄積中」への状態遷移についてのみは、待機させたい時間、すなわちブロックのシフト幅(block_shift)に対応して定められる値をカウントすることにより状態遷移が実行される。
また、例えば、図4におけるスレッド2やスレッド3において、「初期状態」から「待機中」に状態を遷移せず、一定時間「初期状態」を保持した後、「蓄積中」に状態を遷移するようにしても良い。
例えば、図4におけるスレッド2において、「初期状態」の最初に、カウンタの値は初期化(たとえば、0にセット)され、スレッド1において蓄積されている観測信号のフレームと連動して、ブロックのシフト幅(block_shift)だけカウンタの値がインクリメントされたとき、状態が、「蓄積中」へ遷移されるようにしてもよい。同様に、スレッド3においては、「初期状態」の最初にカウンタの値は初期化され、ブロックのシフト幅(block_shift)の2倍の値にカウンタの値がインクリメントされたとき、状態が、「蓄積中」へ遷移されるようにしてもよい。
そして、並列して実行されるスレッドを、最低何個用意する必要があるかは、スレッド長とブロックのシフト幅とで決まる。スレッド長をthread_len、ブロックのシフト幅をblock_shiftとすると、必要なスレッドの個数は、thread_len/block_shiftの値の小数点以下を切り上げることにより求められる。換言すれば、並行して実行されるスレッドの数を、thread_len/block_shift以上であって、その近傍の整数とすると好適である。
例えば、図4における場合では、thread_len=1.5×block_len,block_shift=0.5×block_lenに設定してあるため、必要なスレッド数は、1.5/0.5=3である。
これに対して、例えば、図7に示されるように、thread_lenがblock_lenの2倍に設定されている場合、block_shift=0.5×block_lenであれば、必要スレッド数は、2/0.5=4となる。
図7に示される各スレッドは、図4に示される各スレッドよりも、「待機中」状態のために用意された時間が長い。「待機中」状態のための時間は、学習時間の超過に対するマージンでもあるため、図7に示される設定のほうが、図4における場合よりも学習時間の超過に対して頑強であり、学習時間が超過した場合であっても、以降の状態遷移のタイミングに影響を与える可能性が低い。換言すれば、スレッド長を大きな値に設定する、すなわち、スレッドを多数用意することにより、学習時間の超過に対するマージンを大きくすることが可能となる。
すなわち、図4における場合と、図7における場合で、ブロック長とブロックシフト幅が同一であれば、分離結果自体もほぼ同一となる。しかしながら、図4における場合と図7における場合では、スレッド長が異なるため、延長を含まない場合の学習時間の最大値は異なる。すなわち、図4においては、学習時間がブロック長の半分を超えると以降の処理の延期が必要になるのに対し、図においては、学習時間がブロック長と同じ時間を超えるまでは、それ以降の処理の延期が不要である。すなわち、ブロック長およびブロックシフト幅が同一でも、スレッド長を長くしてスレッド数を増やすことで、学習時間の超過に対する許容度を上げることができる。
このように、ブロック長、ブロックシフト幅、スレッド長などを適宜設定可能なようにすることにより、学習時間の超過に対する許容度の調整も可能となる。
なお、ここでいう「スレッド」は、並列動作を提供する仕組みであれば何でも良く、マルチスレッドの他、マルチプロセスを用いても構わないし、スレッドごとにプロセッサを用意してもよい。換言すれば、本発明は、例えば、図3におけるCPU21−1乃至21-Pのように、マルチプロセッサを有することなどによって並列動作が可能なシステムの上でICAを動かした場合に追従時間を短縮することができるものである。
また、図3におけるCPU21−1乃至21-Pに代わって、唯1つのCPU21を設けるようにした場合であっても、そのCPU21が並列処理を実行可能であれば、本発明を実現可能であることは言うまでもない。
また、スレッドの各状態に対応した処理のうち、真に並列処理が必要なのは「学習」処理のみであるため、「学習」処理のみをマルチスレッドで起動する一方で、それ以外の「蓄積」および「待機」の処理は、観測信号のサンプルやフレームに同期して処理するようにしてもよい。これにより、例えば、マルチプロセッサを有するシステムにおいて、最も負荷の軽いプロセッサに「学習」を担当させて適切に処理を分担させることが可能になる。
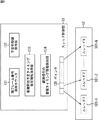
次に、図8を参照して、図4乃至図6を用いて説明した、複数スレッドを用いた学習処理を実行するCPU21が有する機能について説明する。すなわち、図8は、図3の音源分離装置11が有する機能を示す機能ブロック図である。
複数のマイクロホン61およびAD変換部62により構成される音信号取得部29により取得されてデジタルデータに変換された音信号は、主に観測信号の分離を行なう信号処理部71と、分離行列の学習処理を行なうバックグラウンド処理部72によって処理される。
信号処理部71は、フーリエ変換部81、分離部82、および、フーリエ逆変換部83の機能を含み、バックグラウンド処理部72は、スレッド制御部91、スレッド演算処理部92、および、分離行列保持部93から構成されている。信号処理部71とバックグラウンド処理部72とは並列で動作する。
フーリエ変換部81は、供給されたデータを、窓つきの短時間フーリエ変換によって周波数領域のデータへ変換し、分離部82およびスレッド制御部91に供給する。その際、フレームと呼ばれる一定個数のデータが生成される。以降の処理は、このフレームを単位として行なわれる。
分離部82は、フーリエ変換部81から供給された観測信号のフーリエ変換結果の1フレーム分であるX(t)(tは、フレーム番号であるものとする)と、分離行列保持部93から取得される、事前に求められた分離行列W[k](W[k]は、システムが起動されてからk番目に求められた分離行列である)とを乗じて、分離結果であるY(t)を生成して、フーリエ逆変換部83に供給する。
フーリエ逆変換部83は、分離部82から供給された分離結果Y(t)を時間領域の信号に変換し、例えば、音声認識などの後段の処理に対して供給する。後段の処理によっては、周波数領域のデータをそのまま使用する場合もあるので、その場合には、フーリエ逆変換を実行することなく、分離部82から供給された分離結果Y(t)を出力するものとしても良い。
スレッド制御部91は、フーリエ変換部81から供給された観測信号のフーリエ変換結果の1フレーム分であるX(t)を、スレッド演算処理部92に供給し、スレッド演算処理部92において実行される複数のスレッド101−1乃至101−Nの処理を制御する。そして、スレッド制御部91は、スレッド演算処理部92から供給された、学習の結果得られた分離処理用の分離行列Wを、分離行列保持部93に供給する。
スレッド演算処理部92において実行される複数のスレッド101−1乃至101−Nは、図4乃至図6を用いて説明したように、スレッド制御部91の制御に基づいて、状態を遷移し、それぞれ異なるタイミングで、与えられた観測信号を一定量だけ蓄積した後、ICAのバッチ処理を用いて観測信号から分離行列を求める学習処理を実行する。
分離行列保持部93は、スレッド制御部91から供給された、学習の結果得られた分離処理用の分離行列Wを保持する。
信号処理部71およびバックグラウンド処理部72のそれぞれにおいて実行される処理は、並行して実行される。したがって、音源分離装置11の機能全体としてみると、観測信号に対して分離行列Wを随時適用する処理により、分離結果が逐次生成される一方で、適用される分離行列Wが、学習処理により求められて、ある程度頻繁に(例えば、ブロック長よりも短い期間で)更新されて適用される。
図9は、スレッド制御部91が有する機能を更に詳細に示す、スレッド制御部91の機能ブロック図である。
現フレーム番号保持カウンタ131は、観測信号が1フレーム分供給されるごとに値が1インクリメントされ、所定の値に達すると初期値に戻るようになされている。なお、カウンタのインクリメントは、フレーム番号と同期させる代わりに、時間領域信号のサンプル番号と同期させても構わない。
学習初期値保持部132は、それぞれのスレッドにおいて学習処理を実行する場合の分離行列Wの初期値を保持するものである。分離行列Wの初期値は、基本的には最新の分離行列と同一だが、異なる値を用いるものとしても良い。
蓄積開始予定タイミング指定情報保持部133は、蓄積を開始するタイミングを複数のスレッド間で一定間隔にするために用いられる情報である。なお、蓄積開始予定タイミングは、相対時刻を用いて表されていてもよいし、相対時刻の代わりにフレーム番号で管理してもよいし、時間領域信号のサンプル番号で管理しても良い。これについては他の「タイミング」を管理するための情報についても同様である。
観測信号の蓄積タイミング情報保持部134は、分離部82で現在使用されている分離行列Wが、どのタイミングで取得された観測信号を基に学習されたものであるかを示す情報、すなわち、最新の分離行列に対応した観測信号の相対時刻またはフレーム番号を保持するものである。観測信号の蓄積タイミング情報保持部134には、対応する観測信号の蓄積開始タイミングと蓄積終了タイミングとの両方を格納しても良いが、ブロック長、すなわち、観測信号の蓄積時間が一定ならば、いずれか一方だけを保存すれば十分である。
また、スレッド制御部91は、それぞれのスレッドへリンクされているポインタ135を有し、これを用いて、複数のスレッドの処理を制御している。
次に、図10は、スレッド演算処理部92において実行されるそれぞれのスレッドの演算機能について説明するための機能ブロック図である。
スレッド101(複数のスレッド101−1乃至101−Nのそれぞれ)は、観測信号バッファ161、分離結果バッファ162、学習演算部163、および、分離行列保持部164の各モジュールの機能を用いて、バッチ処理のICAを実行する。
観測信号バッファ161は、スレッド制御部91から供給される観測信号を保持するものであり、その容量は、1ブロック長に対応する観測信号の容量と同じか、それよりも大きいものである。ただし、後述する「観測信号のフレーム間引き」を行なう場合は、間引く分だけバッファの大きさを小さくしても構わない。
分離結果バッファ162には、学習演算部163により演算された、分離行列収束前の分離結果が保持される。
学習演算部163は、観測信号バッファ161に蓄積されている観測信号を、分離行列保持部164に保持されている分離処理用の分離行列Wに基づいて分離して、分離結果バッファ162に蓄積するとともに、分離結果バッファ162に蓄積される分離結果を用いて、学習中の分離行列を更新する処理を実行する。
また、スレッドは、状態遷移マシンであり、現在の状態は、状態格納部165に格納されている。そして、スレッドの状態は、カウンタ166のカウンタ値によって、スレッド制御部91により制御される。
観測信号の開始・終了タイミング保持部167には、学習に使用されている観測信号の開始タイミングと終了タイミングを示す情報のうちの少なくともいずれか一方が保持されている。タイミングを示す情報は、上述したように、フレーム番号やサンプル番号であっても良いし、相対時刻情報であっても良い。ここでも、開始タイミングと終了タイミングとの両方を格納しても良いが、ブロック長、すなわち、観測信号の蓄積時間が一定ならば、いずれか一方だけを保存すれば十分である。
学習終了フラグ168は、学習が終了したことをスレッド制御部91に通知するために用いられるフラグである。スレッドの起動時においては、学習終了フラグ168はOFF(フラグが立っていない)にセットされ、学習が終了した時点でONにセットされる。そして、スレッド制御部91が、学習が終了したことを認識した後、スレッド制御部91の制御により、学習終了フラグ168は、再び、OFFにセットされる。
前処理用データ保持部169は、後述する前処理が施された観測信号を、元に戻す際に必要となるデータを保存しておく領域である。具体的には、例えば、前処理において、観測信号の正規化(分散を1に、平均を0にそろえる)が実行される場合、前処理用データ保持部169には、分散(または標準偏差やその逆数)や平均などの値が保持されるので、これを用いて正規化前の信号を復元することができる。また、例えば、前処理として無相関化(pre-whiteningとも称される)が実行される場合、前処理用データ保持部169には、無相関化で乗じた行列が保持される。
状態格納部165、カウンタ166、観測信号の開始・終了タイミング保持部167に保持される値は、スレッド制御部91の制御により書き換えられる。例えば、このスレッドにおいて学習処理ループが回っている間であっても、スレッド制御部91は、カウンタ166の値を変更することができる。
状態遷移の実装については、それぞれのスレッド101が自分自身のカウンタ166の値に基づいて状態を自発的に変化させるという仕様にしても良いし、スレッド制御部91がカウンタ166の値や学習終了フラグ168の値に応じて、対応するスレッドに対して「指定された状態に遷移せよ」というコマンド(以降「状態遷移コマンド」と称するものとする)を発行し、それぞれのスレッドは、供給されたコマンドに応じて、その状態を遷移させるという仕様としてもよい。
ここでは、スレッド制御部91がカウンタの値や学習終了フラグ168の値に応じて状態遷移コマンドを発行し、それぞれのスレッドは、供給されたコマンドに応じて、その状態を遷移させるそのコマンドを受けて状態を変化させる場合の処理を例として説明する。
図11のシーケンス図を参照して、スレッド制御部91による複数のスレッドの制御について説明する。図11においては、スレッド制御部91が、スレッド1およびスレッド2の2つのスレッドを制御する場合を例として説明するが、スレッド数は、3以上であってもよいことは言うまでもない。
なお、スレッド制御部91は、各スレッドのカウンタの値を参照したり変更(インクリメントや初期化や減算など)したりするため、厳密には、フレーム番号のインクリメントと同期して「カウンタ値」に関する情報が授受されるが、「カウンタ値」に関する情報の授受については、図11では省略する。
システムの起動直後、各スレッドは初期化されて「初期状態」とされる。そして、そのうちのいずれか一つ(ここでは、スレッド1)には、スレッド制御部91により、「蓄積中」へ状態を遷移させる状態遷移コマンドが発行されて、「蓄積中」状態に状態が遷移され、ほかのスレッド(ここでは、スレッド2)には、スレッド制御部91により、「待機中」へ状態を遷移させる状態遷移コマンドが発行されて、「待機中」状態に状態が遷移される。
「蓄積中」状態のスレッド1には、スレッド制御部91により観測信号が供給される。
そして、スレッド制御部91は、カウンタの値に基づいて、それぞれのスレッドの状態を遷移させる。具体的には、スレッド2が「待機中」状態に遷移されてから、ブロックシフト幅に対応する所定のカウント値がカウントされた場合、スレッド制御部91は、スレッド2に、「蓄積中」へ状態を遷移させる状態遷移コマンドを発行する。スレッド2の状態は、「蓄積中」に遷移され、スレッド制御部91から観測信号の供給を受ける。
また、スレッド1が「蓄積中」状態に遷移されてから、ブロック長に対応する所定のカウント値がカウントされた場合、スレッド制御部91は、スレッド1に、「学習中」へ状態を遷移させる状態遷移コマンドを発行する。スレッド1の状態は、「学習中」に遷移される。スレッド1において学習が終了し、分離行列Wの値が収束した場合、スレッド1の学習終了フラグ168がONとなって、スレッド制御部91は、学習の終了を認識することができ、スレッド1からスレッド制御部91に学習の結果得られた分離行列Wが供給される。
そして、学習の終了を認識し、分離行列Wの値の供給を受けたスレッド制御部91は、カウンタの値を参照し、カウンタの値から計算される蓄積開始タイミングが、蓄積開始予定タイミング指定情報保持部133に保持されている値から計算されるタイミングを超えていない場合、スレッド1に「待機中」へ状態を遷移させる状態遷移コマンドを発行する。スレッド1の状態は、「待機中」に遷移される。そして、スレッド制御部91は、カウンタの値がスレッド長となったとき、スレッド1に「蓄積中」へ状態を遷移させる状態遷移コマンドを発行する。スレッド1の状態は、「蓄積中」に遷移される。「蓄積中」状態のスレッド1には、スレッド制御部91により観測信号が供給される。
そして、同様に、スレッド2が「蓄積中」状態に遷移されてから、ブロック長に対応する所定のカウント値がカウントされた場合、スレッド制御部91は、スレッド2に、「学習中」へ状態を遷移させる状態遷移コマンドを発行する。スレッド2の状態は、「学習中」に遷移される。スレッド2において学習が終了し、分離行列Wの値が収束した場合、スレッド2の学習終了フラグ168がONとなって、スレッド制御部91は、学習の終了を認識することができ、スレッド2からスレッド制御部91に学習の結果得られた分離行列Wが供給される。
そして、学習の終了を認識し、分離行列Wの値の供給を受けたスレッド制御部91は、カウンタの値を参照し、カウンタの値から計算される蓄積開始タイミングが、蓄積開始予定タイミング指定情報保持部133に保持されている値から計算されるタイミングを超えていない場合、スレッド2に「待機中」へ状態を遷移させる状態遷移コマンドを発行する。スレッド2の状態は、「待機中」に遷移される。そして、スレッド制御部91は、カウンタの値がスレッド長となったとき、スレッド2に「蓄積中」へ状態を遷移させる状態遷移コマンドを発行する。スレッド2の状態は、「蓄積中」に遷移される。「蓄積中」状態のスレッド2には、スレッド制御部91により観測信号が供給される。
このようにして、状態遷移コマンドの発行と、状態遷移が繰り返されて、複数のスレッドにおいて、異なるタイミングで学習処理が行われて、分離行列Wがスレッド制御部91に供給される。そして、それらの学習処理も、最新の分離行列Wに基づいて実行される。
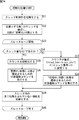
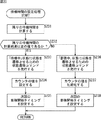
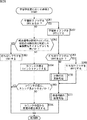
次に、図12のフローチャートを参照して、音源分離装置11において実行される、複数音源からの音の分離処理について説明する。
ステップS1において、図14のフローチャートを用いて後述する初期化処理が実行される。
ステップS2において、フーリエ変換部81は、音信号取得部29により複数のマイクで集音され、AD変換部62により所定のサンプルレートでサンプリングされてデジタル信号に変換された観測信号を取得する。
ステップS3において、フーリエ変換部81は、供給された観測信号に対して、短時間フーリエ変換を実行する。
図13を参照して、短時間フーリエ変換について説明する。
フーリエ変換部81は、図13の上段に示される観測信号xk(ここでは、kはマイクの番号)から、図中、α、β、γで示されるように、一定長を切り出し、それらにハニング窓やサイン窓等の窓関数を作用させる。この切り出した単位(図中のα、β、γ)がフレームである。そして、フーリエ変換部81は、1フレーム分のデータに短時間フーリエ変換をかけることにより、周波数領域のデータであるスペクトルXk(t)を得る(ここでは、tはフレーム番号)。また、図中、α、β、γで示されるように、切り出すフレームの間には重複があってもよい。これにより、連続するフレームのスペクトルXk(t-1)、Xk(t)、Xk(t+1)を、滑らかに変化させることができる。図13の下段に示される、スペクトルをフレーム番号に従って並べたものは、スペクトログラムと称される。
入力チャンネルが複数(マイクの個数分)あるため、フーリエ変換部81は、フーリエ変換をチャンネル数だけ行なう。以降では、全チャンネル、1フレーム分のフーリエ変換結果を、次の式(11)に示されるベクトルX(t)で表わすものとする。
なお、式(11)において、nは、チャンネル数、すなわち、マイク数であり、Mは、周波数ビンの総数であり、短時間フーリエ変換のポイント数をLとすると、M=L/2+1である。
ステップS4において、図15のフローチャートを用いて後述するスレッド制御処理が実行される。
ステップS5において、分離部82は、バックグラウンド処理部72の分離行列保持部93から取得した分離行列Wを用いて、ステップS3においてフーリエ変換された観測信号観測信号X(t)に対して分離処理を実行する。
すなわち、分離行列Wは、次の式(12)で表される。そして、次の式(13)で表される分離結果Y(t)は、式(14)を用いて求めることができる。
なお、式(12)で表わされる行列Wは、対角行列からなる疎行列であり、また、要素の0は、それぞれの対角行列において対角成分以外の値は常に0であることを表わしている。
ステップS6において、フーリエ逆変換部83は、分離結果Y(t)に対して、逆フーリエ変換を実行し、時間領域の信号に戻す。その際、必要に応じて overlap add(重複足し合わせ)が行なわれる。さらに、フレーム間で不連続性が発生するのを防ぐため、1フレーム分のデータの逆フーリエ変換結果に対して、サイン窓等の適切な窓関数を適用した上で overlap addが行なわれるようにしても良い。この処理は、weighted overlap add(WOLA)と称される。
フーリエ逆変換部83は、ステップS7において、逆フーリエ変換によって得られた信号、すなわち、時間領域の信号を、必要に応じてバッファリングし、ステップS8において、例えば、音声認識処理など、後段の所定の処理を実行するために出力する。
ステップS9において、フーリエ変換部81は、観測信号の取得が終了したか否かを判断する。ステップS9において、観測信号の取得が終了していないと判断された場合、処理は、ステップS2に戻り、それ以降の処理が繰り返される。ステップS9において、観測信号の取得が終了したと判断された場合、処理は終了される。
このような処理により、音源分離装置11において、複数音源からの音の分離が実行される。
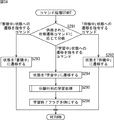
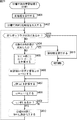
次に、図14のフローチャートを参照して、図12のステップS1において実行された、初期化処理について説明する。
ステップS31において、スレッド制御部91は、自分自身を初期化する。
具体的には、スレッド制御部91において、現フレーム番号保持カウンタ131が初期化されてその値が0とされ、学習初期値保持部132に適切な初期値が代入される。例えば、初期値は単位行列でも良いし、前回のシステム終了時の分離行列Wが保存されている場合は、前回のシステム終了時の分離行列W、またはこの分離行列に適切な変換を作用させたものを使用しても良い。また、例えば、画像や先見知識等の情報により、音源の方向がある程度の精度で推定できるような場合には、音源方向に基づいて初期値を算出して、設定するものとしてもよい。
そして、蓄積開始予定タイミング指定情報保持部133には、(必要スレッド数−1)×block_shiftの値が設定される。この値は、一番大きなスレッド番号を有するスレッドの蓄積が開始するタイミング(フレーム番号)である。そして、観測信号の蓄積タイミング情報保持部134には、最新の分離行列に対応した観測信号を示すタイミング情報(ブレーム番号または相対時刻情報)が保持されるので、ここでは、初期化されて、0が保持される。
なお、分離行列保持部93にも、初期化された場合の学習初期値保持部132と同様に、適切な初期値が保持される。すなわち、分離行列保持部93に保持される初期値は、単位行列でも良いし、前回のシステム終了時の分離行列が保存されている場合は、前回のシステム終了時の分離行列W、またはこの分離行列に適切な変換を作用させたものを使用しても良い。また、例えば、画像や先見知識等の情報により、音源の方向がある程度の精度で推定できるような場合には、音源方向に基づいて初期値を算出して、設定するものとしてもよい。
ステップS32において、スレッド制御部91は、スレッド演算処理部92において実行されるスレッドを必要な数iだけ確保し、それらの状態を「初期化」状態とする。
ここで、必要なスレッドの数iは、thread_len/block_shiftの小数点以下を切り上げる(すなわち、thread_len/block_shiftよりも大きく最も値の近い整数)ことにより求められる。
ステップS33において、スレッド制御部91は、スレッドループを開始して、全てのスレッドの初期化が終了するまで、初期化未処理のスレッドを検出して、ステップS34乃至ステップS39の処理を実行する。
ステップS34において、スレッド制御部91は、スレッド番号は1であるか否かを判断する。
ステップS34において、スレッド番号は1であると判断された場合、ステップS35において、スレッド制御部91は、スレッド番号1のスレッド(例えば、スレッド101−1)を制御して、そのカウンタ166を初期化(例えば、0にセット)する。
ステップS36において、スレッド制御部91は、スレッド番号1のスレッド(例えば、スレッド101−1)に、「蓄積中」状態に状態を遷移させるための状態遷移コマンドを発行して、処理は、後述するステップS39にすすむ。
ステップS34において、スレッド番号は1ではないと判断された場合、ステップS37において、スレッド制御部91は、対応するスレッド(スレッド101−2乃至スレッド101−iのうちのいずれか)のカウンタ166の値を、thread_len−block_shift×(スレッド番号-1)に設定する。
ステップS38において、スレッド制御部91は、「待機中」状態に状態を遷移させるための状態遷移コマンドを発行する。
ステップS36、または、ステップS38の処理の終了後、ステップS39において、スレッド制御部91は、スレッド内のまだ初期化されていない情報、すなわち、状態格納部165に格納された状態を示す情報、および、カウンタ166のカウンタ値以外の情報を初期化する。具体的には、例えば、スレッド制御部91は、学習終了フラグ168をOFFにセットし、観測信号の開始・終了タイミング保持部167、および、前処理用データ保持部169の値を初期化(例えば、0にセット)する。
スレッド演算処理部92に確保された全てのスレッド、すなわち、スレッド101−1乃至スレッド101−iが初期化された場合、ステップS40において、スレッドループが終了され、処理は、図12のステップS1に戻り、ステップS2に進む。
このような処理により、スレッド制御部91は、スレッド演算部に確保された複数のスレッドのすべてを初期化する。
なお、ここでは、立ち上げられたスレッドの数iだけ、ステップS33乃至ステップS40の処理のループが繰り返されるものとして説明したが、処理ループを繰り返す代わりに、スレッドの個数iの並列処理を実行するものとしてもよい。これ以降の処理ループを繰り返す部分についても、同様に、処理ループを繰り返す代わりに、並列処理を実行するようにしても良い。
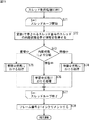
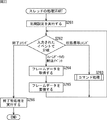
次に、図15のフローチャートを参照して、図12のステップS4において、スレッド制御部91によって実行される、スレッド制御処理について説明する。
ステップS71において、スレッド制御部91は、スレッドループを開始し、制御実行するスレッドのスレッド番号を示す変数sをs=1として、1つのスレッドの処理が終了すると変数sを1インクリメントして、s=iとなるまで、ステップS72乃至ステップS77のスレッドループの処理を繰り返し実行する。
ステップS72において、スレッド制御部91は、変数sで示されるスレッド番号のスレッドの状態格納部165に保持されている、そのスレッドの内部状態を示す情報を取得する。
ステップS73において、スレッド制御部91は、変数sで示されるスレッド番号のスレッドの内部状態を検出する。
ステップS73において、変数sで示されるスレッド番号のスレッドの状態は、「待機中」状態であると検出された場合、ステップS74において、スレッド制御部91は、図16のフローチャートを用いて後述する、待機中状態における処理を実行し、処理は、後述するステップS77に進む。
ステップS73において、変数sで示されるスレッド番号のスレッドの状態は、「蓄積中」状態であると検出された場合、ステップS75において、スレッド制御部91は、図17のフローチャートを用いて後述する、蓄積中状態における処理を実行し、処理は、後述するステップS77に進む。
ステップS73において、変数sで示されるスレッド番号のスレッドの状態は、「学習中」状態であると検出された場合、ステップS76において、スレッド制御部91は、図18のフローチャートを用いて後述する、学習中状態における処理を実行する。
ステップS74、ステップS75、または、ステップS76の処理の終了後、ステップS77において、スレッド制御部91は、変数sを1インクリメントする。そして、制御実行するスレッドのスレッド番号を示す変数sが、s=iとなったとき、スレッドループを終了する。
ステップS78において、スレッド制御部91は、現フレーム番号保持カウンタ131に保持されているフレーム番号を1インクリメントし、処理は、図12のステップS4に戻り、ステップS5に進む。
このような処理により、スレッド制御部91は、複数のスレッドの全てを、それらの状態に応じて制御することができる。
なお、ここでは、立ち上げられたスレッドの数iだけ、スレッドループが繰り返されるものとして説明したが、スレッドループを繰り返す代わりに、スレッドの個数iの並列処理を実行するものとしてもよい。
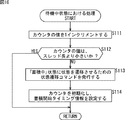
次に、図16のフローチャートを参照して、図15のステップS74において実行される、待機中状態における処理について説明する。
この待機中状態における処理は、図15を用いて説明したスレッド制御処理における変数sに対応するスレッドの状態が「待機中」状態であるときに、スレッド制御部91において実行される処理である。
ステップS111において、スレッド制御部91は、対応するスレッド101のカウンタ166を、1インクリメントする。
ステップS112において、スレッド制御部91は、対応するスレッド101のカウンタ166の値は、スレッド長(thread_len)より小さいか否かを判断する。ステップS112において、カウンタ166の値は、スレッド長より小さいと判断された場合、処理は、図15のステップS74に戻り、ステップS77に進む。
ステップS112において、カウンタ166の値は、スレッド長より小さくないと判断された場合、ステップS113において、スレッド制御部91は、「蓄積中」状態に状態を遷移させるための状態遷移コマンドを、対応するスレッド101に発行する。
すなわち、スレッド制御部91は、図6を用いて説明した状態遷移図において、「待機中」であるスレッドを、「蓄積中」に遷移させるための状態遷移コマンドを発行する。
ステップS114において、スレッド制御部91は、対応するスレッド101のカウンタ166を初期化(例えば、0にセット)し、観測信号の開始・終了タイミング保持部167に、観測信号の蓄積開始タイミング情報、すなわち、現フレーム番号保持カウンタ131に保持されている現在のフレーム番号、または、それと同等の相対時刻情報などを設定して、処理は、図15のステップS74に戻り、ステップS77に進む。
このような処理により、スレッド制御部91は、「待機中」状態であるスレッドを制御し、そのカウンタ166の値に基づいて、「蓄積中」に状態を遷移させることができる。
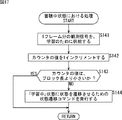
次に、図17のフローチャートを参照して、図15のステップS75において実行される、蓄積中状態における処理について説明する。
この蓄積中状態における処理は、図15を用いて説明したスレッド制御処理における変数sに対応するスレッドの状態が「蓄積中」状態であるときに、スレッド制御部91において実行される処理である。
ステップS141において、スレッド制御部91は、1フレーム分の観測信号X(t)を、学習のために、対応するスレッド101に供給する。この処理は、図9を用いて説明した、スレッド制御部91からそれぞれのスレッドへの観測信号の供給に対応する。
ステップS142において、スレッド制御部91は、対応するスレッド101のカウンタ166を、1インクリメントする。
ステップS143において、スレッド制御部91は、対応するスレッド101のカウンタ166の値は、ブロック長(block_len)より小さいか否か、換言すれば、対応するスレッドの観測信号バッファ161が満杯であるか否かを判断する。ステップS143において、カウンタ166の値は、ブロック長より小さい、換言すれば、対応するスレッドの観測信号バッファ161が満杯ではないと判断された場合、処理は、図15のステップS75に戻り、ステップS77に進む。
ステップS143において、カウンタ166の値は、ブロック長より小さくない、換言すれば、対応するスレッドの観測信号バッファ161が満杯であると判断された場合、ステップS144において、スレッド制御部91は、「学習中」状態に状態を遷移させるための状態遷移コマンドを、対応するスレッド101に発行して、処理は、図15のステップS75に戻り、ステップS77に進む。
すなわち、スレッド制御部91は、図6を用いて説明した状態遷移図において、「蓄積中」であるスレッドを、「学習中」に遷移させるための状態遷移コマンドを発行する。
このような処理により、スレッド制御部91は、「蓄積中」状態であるスレッドに観測信号を供給してその蓄積を制御し、そのカウンタ166の値に基づいて、「蓄積中」から「学習中」に状態を遷移させることができる。
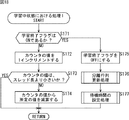
次に、図18のフローチャートを参照して、図15のステップS76において実行される、学習中状態における処理について説明する。
この学習中状態における処理は、図15を用いて説明したスレッド制御処理における変数sに対応するスレッドの状態が「学習中」状態であるときに、スレッド制御部91において実行される処理である。
ステップS171において、スレッド制御部91は、対応するスレッド101の学習終了フラグ168がONであるか否かを判断する。ステップS171において、学習フラグがONであると判断された場合、処理は、後述するステップS175に進む。
ステップS171において、学習フラグがONではないと判断された場合、すなわち、対応するスレッドにおいて学習処理が実行中である場合、ステップS172において、スレッド制御部91は、対応するスレッド101のカウンタ166を、1インクリメントする。
ステップS173において、スレッド制御部91は、対応するスレッド101のカウンタ166の値は、スレッド長(thread_len)より小さいか否かを判断する。ステップS173において、カウンタ166の値は、スレッド長より小さいと判断された場合、処理は、図15のステップS76に戻り、ステップS77に進む。
ステップS173において、カウンタ166の値は、スレッド長より小さくないと判断された場合、ステップS174において、スレッド制御部91は、カウンタ166の値から所定の値を減算し、処理は、図15のステップS76に戻り、ステップS77に進む。
学習中にカウンタの値がスレッド長に達した場合とは、学習にかかる時間が長くなってしまい、「待機中」状態の時間が存在しなくなった場合である。その場合、学習はまだ継続しており、観測信号バッファ161は利用されているため、次の蓄積を開始することができない。そこで、スレッド制御部91は、学習が終了するまで、次の蓄積の開始、すなわち、「蓄積中」状態へ状態を遷移させるための状態遷移コマンドの発行を延期する。そのため、スレッド制御部91は、カウンタ166の値から所定の値を減算する。減算する値は、例えば、1であっても良いが、それよりも大きな値でも良く、例えば、スレッド長の10%などといった値であっても良い。
なお、「蓄積中」状態への状態の遷移の延期を行なうと、蓄積開始時刻がスレッド間で不等間隔となり、最悪の場合、複数のスレッドでほぼ同一の区間の観測信号を蓄積してしまう可能性もある。そうなると、いくつかのスレッドが無意味になるだけでなく、例えば、CPU21が実行するOSのマルチスレッドの実装によっては、1つのCPU21で複数の学習が同時に動くことになって、更に学習時間が増大し、間隔が一層不均等になってしまう可能性がある。
そのような事態を防ぐためには、他のスレッドの待機時間を調整して蓄積開始タイミングが再び等間隔になるように調整すればよい。他のスレッドの待機時間の調整については、図20を用いて後述する。
ステップS171において、学習フラグがONであると判断された場合、すなわち、対応するスレッドにおいて学習処理が終了した場合、ステップS175において、スレッド制御部91は、対応するスレッド101の学習終了フラグ168をOFFにする。
ステップS176において、図19を用いて後述する、分離行列更新処理が実行され、学習によって求められた分離行列Wの値が最も新しい観測信号を基に算出されたものであった場合、分離部82による分離処理に用いられるとともに、他のスレッドの学習に反映される。
ステップS177において、図20を用いて後述する、待機時間の設定処理が実行されて、処理は、図15のステップS76に戻り、ステップS77に進む。
なお、図20を用いて後述する待機時間の設定処理において、スレッド制御部91は、対応するスレッドに対して、「待機中」か「蓄積中」かのいずれかの状態に状態を遷移させるための状態遷移コマンドを発行する。
このような処理により、スレッド制御部91は、対応するスレッドの学習終了フラグ168を参照して、「学習中」状態のスレッドの学習が終了したか否かを判断し、学習が終了した場合、分離行列Wを更新し、待機時間を設定するとともに、「学習中」状態から、「待機中」または「蓄積中」に状態を遷移させることができる。
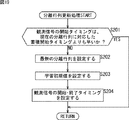
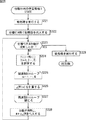
次に、図19のフローチャートを参照して、図18のステップS176において実行される、分離行列更新処理について説明する。
ステップS201において、スレッド制御部91は、スレッドの、観測信号の開始・終了タイミング保持部167に保持されている観測信号の開始タイミングは、観測信号の蓄積タイミング情報保持部134に保持されている、現在の分離行列に対応した蓄積開始タイミングよりも早いか否かを判断する。
すなわち、図7に示されるように、スレッド1の学習とスレッド2の学習とは、その一部で時間が重なっている。この図では、学習201のほうが、学習202より先に終了しているが、例えば、それぞれの学習にかかる時間によっては、学習201よりも学習202のほうが先に終了してしまう場合もあり得る。
ここで、ステップS201の判断が実行されず、学習の終了が遅いものが最新の分離行列として扱われてしまった場合、スレッド2由来の分離行列W2が、より古いタイミングで取得された観測信号によって学習されて得られたスレッド1由来の分離行列W1に上書きされてしまう。そこで、新しいタイミングで取得された観測信号によって得られた分離行列が最新の分離行列として扱われるように、観測信号の開始・終了タイミング保持部167に保持されている観測信号の開始タイミングと、観測信号の蓄積タイミング情報保持部134に保持されている現在の分離行列に対応した蓄積開始タイミングとが比較される。
ステップS201において、観測信号の開始タイミングは、現在の分離行列に対応した蓄積開始タイミングよりも早いと判断された場合、換言すれば、このスレッドの学習の結果得られた分離行列Wは、現在、観測信号の蓄積タイミング情報保持部134に保持されている分離行列Wよりも早いタイミングで観測された信号に基づいて学習されていると判断された場合、このスレッドの学習の結果得られた分離行列Wは利用されないので、処理は、図18のステップS176に戻り、ステップS177に進む。
ステップS201において、観測信号の開始タイミングは、現在の分離行列に対応した蓄積開始タイミングよりも早くないと判断された場合、すなわち、このスレッドの学習の結果得られた分離行列Wは、現在、観測信号の蓄積タイミング情報保持部134に保持されている分離行Wよりも遅いタイミングで観測された信号に基づいて学習されていると判断された場合、ステップS202において、スレッド制御部91は、対応するスレッドの学習によって得られた分離行列Wを取得し、分離行列保持部93に供給して、設定する。
ステップS203において、スレッド制御部91は、学習初期値保持部132に保持される、それぞれのスレッドにおける学習の初期値を設定する。
具体的には、スレッド制御部91は、学習初期値として、対応するスレッドの学習によって得られた分離行列Wを設定するものとしてもよいし、対応するスレッドの学習によって得られた分離行列Wを用いて演算される、分離行列Wとは異なる値を設定するものとしても良い。
ステップS204において、スレッド制御部91は、対応するスレッドの、観測信号の開始・終了タイミング保持部167に保持されているタイミング情報を、観測信号の蓄積タイミング情報保持部134に設定し、処理は、図18のステップS176に戻り、ステップS177に進む。
ステップS204の処理により、現在使用中、すなわち、分離行列保持部93に保持されている分離行列Wが、どの時間区間の観測信号から学習されたものであるかが示される。
このような処理により、新しいタイミングで取得された観測信号によって得られた分離行列が最新の分離行列として設定される。
なお、ステップS203の処理においては、学習初期値保持部132により保持されている学習の初期値は、最新の学習結果である分離行列Wと等しい値であっても良いし、これとは異なる値を用いるものとしても良い。
学習初期値保持部132により保持される学習の初期値を、最新の学習結果である分離行列Wと等しい値とした場合、異なるブロックから求まった分離行列の間でも、「どのチャンネルにどの音源が出力されるか」という対応関係が維持される可能性が高くなる。
これに対して、スレッドの個数やブロックのシフト幅の値によっては、最新の学習結果である分離行列Wと等しい値を学習初期値保持部132にしただけでは、「どのチャンネルにどの音源が出力されるか」という対応関係が維持されない場合もある。
具体的には、図7に示されるように4つのスレッドが並行して動作し、スレッド長はブロック長の2倍、ブロックのシフト幅はブロック長の1/2であり、また、学習に要する時間がブロックのシフト幅よりも長い場合、学習の初期値として最新の学習結果である分離行列Wを用いると、例えば、スレッド3に含まれる学習は、学習204−1も、学習204−2も、いずれにおいても、スレッド1に由来する分離行列Wを、初期値として利用することになる。そして、同様に、スレッド1に含まれる学習は、スレッド3に由来する分離行列Wを初期値として利用し、スレッド2に含まれる学習は、スレッド4に由来する分離行列Wを初期値として利用し、スレッド4に含まれる学習は、スレッド2に由来する分離行列Wを初期値として利用する。
すなわち、スレッド間の初期値の受け渡しに注目すると、スレッド1およびスレッド3の系列と、スレッ2およびスレッド4の系列とが存在し、これらの系列間では、初期値の相互利用はなされない。
このように、初期値の相互利用が行われない系列が複数存在すると、それらの系列間で分離行列が異なったものになる可能性があり、最悪の場合、分離行列が更新されるごとに、「どのチャンネルにどの音源が出力されるか」という対応関係が変化してしまう可能性がある。
そこで、初期値の相互利用が行われない系列ができることを防ぐために、学習の初期値として、最新の学習結果である分離行列の他に、それ以前の学習で求まった分離行列の値も反映させて算出される値(最新の学習結果である分離行列を分離行列W[k]として、分離行列W[k-1]、分離行列W[k-2]などの値も反映させて算出される値)を用いるようにすることができる。
例えば、学習の初期値をW_initとすると、学習初期値保持部132に保持される学習の初期値をW_init=W[k]としても良いし、W_init=(W[k]+W[k-1] +・・・+W[k-N])/(N+1)としてもよいし、所定の重み付け係数aを用いて、W_initにaW+(1-a)W_initを代入するようにしても良い。
次に、図20のフローチャートを参照して、図18のステップS177において実行される、待機時間の設定処理について説明する。
ステップS231において、スレッド制御部91は、残りの待機時間を計算する。
具体的には、スレッド制御部91は、残り待機時間(フレーム個数)をrest、蓄積開始予定タイミング指定情報保持部133に保持されている、蓄積開始予定タイミング(フレーム番号、または、対応する相対時刻)をCt、現フレーム番号保持カウンタ131に保持されている現フレーム番号をFt、ブロックのシフト幅をblock_shiftとして、残り待機時間restを、rest=Ct+block_shift−Ftを基に算出する。すなわち、Ct+block_shiftが、次々回蓄積開始予定時刻を意味するため、そこからFtを引くことで、「次々回蓄積開始予定時刻までの残り時間」が求まるのである。
ステップS232において、スレッド制御部91は、残りの待機時間restの計算結果は正の値であるか否かを判断する。ステップS232において、残りの待機時間restの計算結果は正の値ではない、すなわち、負の値であると判断された場合、処理は、後述するステップS236に進む。
ステップS232において、残りの待機時間restの計算結果は正の値であると判断された場合、ステップS233において、スレッド制御部91は、「待機中」状態に状態を遷移させるための状態遷移コマンドを、対応するスレッドに発行する。
ステップS234において、スレッド制御部91は、対応するスレッドのカウンタ166の値を、thread_len−restに設定する。そうすることで、カウンタの値が、thread_lenに達するまでの間は、「待機中」状態が継続される。
ステップS235において、スレッド制御部91は、蓄積開始予定タイミング指定情報保持部133に保持されている値Ctに、block_shiftの値を加算する、すなわち、蓄積開始予定タイミング指定情報保持部133に次回の蓄積開始タイミングである、Ct+block_shiftの値を設定し、処理は、図18のステップS177に戻り、図15のステップS76に戻り、ステップS77に進む。
ステップS232において、残りの待機時間restの計算結果は正の値ではない、すなわち、負の値であると判断された場合、予定された蓄積開始タイミングを過ぎているのにもかかわらず蓄積が始まっていないことを意味するので、直ちに蓄積を開始する必要がある。そこで、ステップS236において、スレッド制御部91は、「蓄積中」状態に状態を遷移させるための状態遷移コマンドを、対応するスレッドに発行する。
ステップS237において、スレッド制御部91は、カウンタの値を初期化(例えば0をセット)する。
ステップS238において、スレッド制御部91は、蓄積開始予定タイミング指定情報保持部133に次回の蓄積開始タイミング、すなわち、現フレーム番号であるFtを設定し、処理は、図18のステップS177に戻り、図15のステップS76に戻り、ステップS77に進む。
このような処理により、それぞれのスレッドにおける「学習中」状態にかかる時間に応じて、「待機中」状態とする時間を設定することができる。
具体的には、例えば、図21の図中aに示されるように、スレッド2の学習時間が長くなることにより、蓄積時間と学習時間の合計がスレッド長より長くなってしまい、学習終了タイミングがスレッド3の蓄積終了タイミングより遅くなった場合、スレッド2の状態は、「待機中」状態には遷移せず、「蓄積中」状態に遷移する。
このような状況において、残りの待機時間restの計算結果にかかわらず、次回の蓄積開始タイミングの設定を同一とした場合、図中、下向き矢印「↓」で示される蓄積が開始するタイミングと、図中、上向き矢印「↑」で示される学習が終了する(=分離行列が更新される)タイミングは、それ以降、それぞれのスレッド間で不均一になってしまう。
蓄積が開始するタイミングと分離行列が更新されるタイミングは、いずれも、スレッド間でできるだけ等間隔であることが望ましい。
そこで、ここでは、図22に示されるように、図22の図中cで示されるように、スレッド2の学習時間が長くなることにより、蓄積時間と学習時間の合計がスレッド長より長くなってしまい、学習終了タイミングがスレッド3の蓄積終了タイミングより遅くなった場合であっても、図中eおよびdに示されるように、待機時間を延長することにより蓄積開始タイミングが調整される。これにより、それ以降の蓄積が開始するタイミングと分離行列が更新されるタイミングは、いずれも、スレッド間で等間隔となる。
次に、図23のフローチャートを参照して、スレッド制御部91の制御に基づいて、スレッド演算処理部92において実行される、スレッド101の処理について説明する。すなわち、図23の処理は、上述したスレッド制御部91の処理と並行して実行されるものである。
スレッド101は、ステップS261において、初期設定される。そして、ステップS262において、スレッド制御部91から入力されたイベントによって、続く処理が分岐される。
イベントは、状態遷移コマンドが発行された場合、フレームデータが転送された場合、または、終了コマンドが発行された場合のいずれかのアクションが行なわれたときに発生する。
ステップS262において、状態遷移コマンドが入力されたと判断された場合、ステップS263において、図24のフローチャートを用いて後述するコマンド処理が実行され、処理は、ステップS262に戻り、それ以降の処理が繰り返される。
ステップS262において、フレームデータの転送イベントの入力を受けたと判断された場合、ステップS264において、スレッド101は、フレームデータを取得する。
ステップS265において、スレッド101は、取得したフレームデータを、観測信号バッファ161に蓄積し、処理は、ステップS262に戻り、それ以降の処理が繰り返される。
観測信号バッファ161は、配列またはスタックの構造をしており、観測信号はカウンタと同じ番号の個所に格納されるものとする。ただし、後述の「フレーム間引き」を行なう場合は、間引いた分だけ詰めて格納されるものとする。
ステップS262において、終了コマンドが入力されたと判断された場合、ステップS266において、スレッド101は、例えば、メモリの開放などの適切な終了前処理を実行し、処理が終了される。
このような処理により、スレッド制御部91の制御に基づいて、それぞれのスレッドにおいて処理が実行される。
次に、図24のフローチャートを参照して、図23のステップS263において実行される、コマンド処理について説明する。
ステップS291において、スレッド101は、供給された状態遷移コマンドに応じて、それ以降の処理を分岐する。
ステップS291において、供給された状態遷移コマンドは、「待機中」状態への遷移を指令するコマンドであると判断された場合、ステップS292において、スレッド101は、状態格納部165に、状態が「待機中」であることを示す情報を格納する、すなわち、状態を「待機中」に遷移して、処理は、図23のステップS263に戻り、ステップS262に進む。
ステップS291において、供給された状態遷移コマンドは、「蓄積中」状態への遷移を指令するコマンドであると判断された場合、ステップS293において、スレッド101は、状態格納部165に、状態が「蓄積中」であることを示す情報を格納する、すなわち、状態を「蓄積中」に遷移して、処理は、図23のステップS263に戻り、ステップS262に進む。
ステップS291において、供給された状態遷移コマンドは、「学習中」状態への遷移を指令するコマンドであると判断された場合、ステップS294において、スレッド101は、状態格納部165に、状態が「学習中」であることを示す情報を格納する、すなわち、状態を「学習中」に遷移する。
ステップS295において、図25を用いて後述する分離行列の学習処理が実行される。
ステップS296において、スレッド101は、学習が終了したことをスレッド制御部91へ通知するために、学習終了フラグ168をONにし、処理は、図23のステップS263に戻り、ステップS262に進む。
このような処理により、スレッド制御部91から供給された状態遷移コマンドに基づいて、それぞれのスレッドの状態が遷移される。
次に、図25のフローチャートを参照して、図24のステップS295において実行される処理の一例である、分離行列の学習処理1について説明する。
ステップS321において、スレッド101の学習演算部163は、観測信号バッファ161に蓄積された観測信号に対して、必要に応じて、前処理を実行する。
具体的には、学習演算部163は、観測信号バッファ161に蓄積された観測信号に対して、正規化や無相関化(pre-whitening)などの処理を行なう。例えば、正規化を行なう場合、学習演算部163は、観測信号バッファ161内の各周波数binについて観測信号の標準偏差を求め、標準偏差の逆数からなる対角行列をSとして、X'=SXを計算する。このXは、観測信号バッファ161内の全フレーム分の観測信号からなる行列であり、式(11)のX(t)をt=1乃至Tについて横方向に並べたもの、すなわち、X=[X(1),・・・X(T)](Tは総フレーム数、すなわち、ブロック長block_len)と表現される。
ステップS322において、学習演算部163は、分離行列の初期値として、スレッド制御部91から、スレッド制御部91の学習初期値保持部132により保持されている学習初期値W_initを取得する。上述したように、学習初期値保持部132に保持される学習初期値W_initは、W_init=W[k]としても良いし、W_init=(W[k]+W[k-1] +・・・+W[k-N])/(N+1)としてもよいし、所定の重み付け係数aを用いて、W_initにaW+(1-a)W_initを代入するようにしても良い。
ステップS323において、学習演算部163は、分離行列Wの値が収束したか否かを判断する。分離行列Wの値が収束したか否かは、例えば、分離行列の増分であるΔWがゼロ行列に近いかどうかで判定することができる。ゼロ行列の判定法としては、例えば、次の式(15)を用いて、分離行列のノルムを計算するとともに、分離行列の増分ΔWについても、同様にノルムを計算し、両者の比である‖ΔW‖/‖W‖が一定の値(例えば、1/1000)よりも小さい場合、分離行列Wが収束したと判定するものとしてもよい。‖ΔW‖を‖W‖で割る理由は、チャンネル数や観測信号などの違いを吸収するためである。
また、分離行列Wの値が収束したか否かの判断に代わって、単純に、学習処理ループが一定回数(例えば50回)回ったか否かを判定するものとしても良い。
ステップS323において、分離行列Wの値が収束したと判断された場合、処理は、後述するステップS330に進む。
すなわち、分離行列Wが収束するまで、学習処理ループが実行される。
ステップS323において、分離行列Wの値が収束していないと判断された場合、ステップS324において、学習演算部163は、次の式(16)または次の式(17)を計算する。式(16)は、前処理が実行されなかった場合の演算であり、式(17)は、前処理が実行されて、X'=SXが用いられる場合の演算である。
Y(t)=WX(t)(t=1,2,・・・,T)・・・(16)
Y(t)=WX'(t)(t=1,2,・・・,T)・・・(17)
ステップS325において、学習演算部163は、周波数binループを開始する。学習演算部163は、周波数binを示す変数ωをω=1(ωは1乃至M)とし、ステップS326の処理が実行されるごとに、周波数binを示す変数ωをω=ω+1として、変数ω=Mとなるまで、繰り返して処理を実行する。
ステップS326において、学習演算部163は、ΔW(ω)を計算する。ΔW(ω)の計算方法は、時間周波数領域のバッチ処理に適用可能であれば任意の方式が使用可能だが、例えば、特開2006-238409号公報に開示されているものと同様の方式を用いる場合には、次の式(18)に示されるΔW(ω)を計算する。
なお、式(18)におけるW(ω)は、上述した式(12)に示される分離行列Wからω番目の周波数ビンに対応する要素を抽出したものであり、次の式(19)で示される。ΔW(ω)についても同様である。Y(ω,t)も同様に、Y(t)からω番目の周波数ビンに対応する要素を抽出したものであり、式(20)で表わされる。また、式(18)における上付きのHはエルミート転置(ベクトルや行列を転置すると共に、各要素を共役複素数へ変換する)である。また、Et[]は観測信号バッファ内の全フレームについて平均を取ることを意味する。
そして、式(18)において、φω(Y(t))は、式(21)で表わされるベクトルである。式(21)の要素φkω(Yk(t))は、スコア関数や活性化関数と称され、引数のYk(t)に対応した多変量確率密度関数(PDF)の対数をω番目の引数で偏微分したものである(式(22))。式(18)において使用可能なPDFやスコア関数については、例えば、特開2006-238409号公報に開示されている。
ステップS327において、学習演算部163は、ω>Mである場合、すなわち、全ての周波数binにおけるΔWが求められた場合、周波数binループを閉じる。
ステップS328において、学習演算部163は、分離行列Wに、W+ηΔWを代入、すなわち、W←W+ηΔWとし、処理は、ステップS323に戻り、それ以降の処理が繰り返される。
ステップS323において、分離行列Wの値が収束したと判断された場合、ステップS329において、学習演算部163は、後処理を実行する。
具体的には、学習演算部163は、後処理として、分離行列を、正規化前の観測信号に対応させる処理と、周波数ビンの間のバランスを調整する、リスケーリング処理を実行する。
前処理として正規化が行なわれた場合、上述した処理により求められる分離行列Wは、正規化前の観測信号Xを分離して得られるものと等価ではなく、正規化後の観測信号X'を分離して得られたものである。そこで、上述した処理により求められた分離行列Wを補正して、正規化前の観測信号Xを分離して得られるものと等価なものに変換する。具体的には、正規化の際に作用させた行列Sを用いて、W←WSという補正を行なうものとすれば良い。
また、ICAのアルゴリズムによっては、分離結果Yの周波数ビン間のバランス(スケール)が、予想される原信号のものと異なっている場合がある。そのような場合には、後処理において周波数ビンのスケールを補正する、すなわち、リスケーリングする必要がある。
リスケーリングは、例えば、次の式(23)によって補正用行列Rを求め、補正用行列Rを、分離行列Wに乗じ、求められるRWを分離行列に代入する(すなわち、W←RWを行なう)ことにより実行される。なお、式(23)におけるdiag()は、与えられた行列から対角要素を抽出し、そこから対角行列を生成することを表わす。
また、リスケーリングとしては、平均二乗誤差である式(23)を最小にする係数λk(ω)を次の式(24)で求め、その係数を対角要素に持つ対角行列を、式(25)および式(26)で示されるRとしても良い。
以上の2つの補正をまとめると、次の式(27)のように表わせる。すなわち、後処理は、W←RWSという補正処理に対応する。
また、後述の変形例のように、分離行列の学習処理で求まったYを「遅延はあるが高精度の分離結果」として用いる場合には、Yに対してもリスケーリングを行なう必要がある。Yのリスケーリングは、式(27)に基づいて行なう。
そして、ステップS330の処理の終了後、処理は、図24のステップS295に戻り、ステップS296に進む。
このような処理により、分離行列の学習が実行される。
なお、分離行列の学習は、このフローチャートに示される処理と厳密に同一でなくても、一般的なバッチ処理を用いるものとしても良い。
また、以上説明した処理には、以下に示すような変形例が考えられる。
例えば、上述した処理においては、後処理において、W←RWSという補正処理を実行していたが、上述したように、学習初期値は、分離行列Wとは異なる値を用いるようにしても良いので、学習初期値は、上述した補正前の値を用いるものとしても良い。
すなわち、ステップS323において、分離行列Wの値が収束したと判断された場合、収束したと判断された分離行列W、すなわち、補正前の値を、学習初期値W_initとして用いるとともに、ステップS330において、学習演算部163は、後処理を実行して、補正して得られた分離行列Wを分離行列保持部93に供給して、分離部82による分離処理に用いるものとしても良い。
また、学習初期値W_initには、ステップS323において、分離行列Wの値が収束したと判断された場合、収束したと判断された分離行列W、すなわち、補正前の値に、上述したような重み付け平滑処理を施したものであっても良い。
また、上述した処理においては、図10を用いて説明したように、スレッド演算処理部92において実行されるそれぞれのスレッド101は、スレッド制御部91からそれぞれ観測信号の供給を受け、自分自身が管理する観測信号バッファ161に、供給された観測信号を蓄積して、これを用いて学習を行なうものとした。
しかしながら、それぞれのスレッドにおいては、「蓄積中」タイミングに重複があるので、それぞれのスレッドの観測信号バッファ161には、重複して同一のタイミングの観測信号が保持されることになる。
そこで、複数のスレッドのそれぞれが利用する観測信号用の共通バッファを設けることにより、同一の観測信号の重複した蓄積を省くようにしても良い。そうすることで、各スレッドが観測信号バッファを保持する場合に比べて、使用メモリ量を削減することができる。
観測信号用の共通バッファは、図26に示されるように、少なくとも1スレッド長の観測信号を保持することが可能であれば良く、それぞれのスレッドは、ブロックシフト幅に対応つけて、図26に示されるように、共通バッファの該当する1ブロック長の区間の観測信号を用いて処理を実行する。図26は、図7を共通バッファ化した場合に該当する。
図26の共通バッファは、リングバッファとして左右が繋がっているものとする。
なお、このように共通バッファを用いるようにした場合、前処理によって正規化されたり無相関化された観測信号X'は、他のスレッドの処理に影響を及ぼすことを避けるため、このバッファに上書きをすることはできない。したがって、このように共通バッファを用いるようにした場合、前処理によって得られた観測信号X'をバッファに上書きすることなく、前処理用の行列、すなわち、正規化や無相関化のための行列を求めて、その行列が別個に保存されるものとする。また、前処理は、学習処理中に実行するものとする。具体的には、前処理用行列をSとすると、学習処理において、Y(t)=WX(t)の演算に代わって、Y(t)=WSX(t)の演算を実行すればよい。
また、学習処理によって、分離行列Wと分離結果Y(Y=WX)が得られるが、信号処理部71においては、分離行列Wのみが利用され、分離結果Yは利用されない。
これに対して、学習に用いられた分離結果も信号処理部71に供給するものとしても良い。すなわち、分離部82により得られる分離結果は、図12を用いて説明した分離処理のステップS5において計算される、遅延の少ない分離結果Y(t)WX(t)と、学習処理から計算される、遅延はあるが高精度の分離結果との2つとなる。その場合、音声認識などの後段の処理は、これら2種類の分離結果を受け取り、必要に応じて、いずれかの適する分離結果を使用することができる。
なお、例えば、図4などに示されるように、各スレッドのブロックは重複するので、1つの時間区間が複数の分離結果(学習で求まる方の分離結果)に含まれることになるが、そのような場合には、それぞれのスレッドの間の学習により得られた分離結果を、区間をずらしつつ足し合わせ(overlap add)、確定した区間を、学習処理から計算される、遅延はあるが高精度の分離結果とすることができる。
なお、学習処理から計算される、遅延はあるが高精度の分離結果を生成するにあたっては、分離結果が欠損しない(すなわち、途切れない)ようにする必要がある。具体的には、例えば、上述したように、蓄積開始時間の延期を行なった場合、分離結果の欠損が発生する可能性があるため、スレッド長を十分長くして(すなわちスレッド数を十分多くして)、蓄積開始時間の延期が発生しないようにする必要がある。
また、学習に要する時間は、基本的にブロックの長さ(つまり観測信号のフレーム数)に比例する。すなわち、静止音源に対しての分離精度を上げることを意図してブロックを長く設定すると、その分だけ学習時間も増大して追従遅れが大きくなる。例えば、ブロック長を1秒長くすると、学習時間も増大するため、追従遅れの増加分は、1秒よりも大きな値となる。
このような学習時間の増大を防ぐためには、観測信号を間引いて用いると好適である。例えば、ブロック長を2倍にしても、偶数フレームのみ使用するなどして、観測信号を半分に間引けば、学習時間は増加しない。
観測信号の間引きは、1/nの間引き(nは正の自然数)の他に、nフレームの内のmフレーム(m、nともに正の自然数であり、n>m)を採用するといった、m/nの間引きでも良い。また、ブロック内の観測信号を一様に間引く代わりに、ブロックの始めの方、すなわち、古い観測信号は大きめに間引き、ブロックの後の方、すなわち、新しいの観測信号は、古い観測信号と比較して、間引きの割合を少なくするといった、ブロック内の時間によって傾斜的に行われる間引きであっても良い。
また、間引きの具体的な方法は、バッファに観測信号を格納する際に間引く(データ間引きと称する)ものであっても、バッファへは全ての観測信号を格納するが、例えば、偶数番目のフレームデータのみを用いるなど、学習では特定の番号のフレームデータのみを用いる(インデックス間引きと称する)であってもよい。
なお、上述したように、学習処理から計算される、遅延はあるが高精度の分離結果を生成するにあたっては、分離結果が欠損しない(すなわち、途切れない)ようにする必要があるので、観測信号の間引きと併用する場合には、データ間引きではなくインデックス間引きを用いる必要がある。
また、図19を用いて説明した分離行列更新処理においては、観測信号の開始タイミングと、現在の分離行列に対応した蓄積開始タイミングとを比較し、先に開始した学習がそれ以降に開始した学習よりも後に終了した場合には、その分離行列を破棄するようにしていた。
このように、後に開始された学習が、それ以前に開始されたいずれかの学習よりも先に終了した場合において、分離行列が採用される見込みのなくなった学習については、その学習処理を途中で打ち切ることで、計算量を削減することも可能である。
例えば、図27に示されるように、スレッド演算処理部92において実行される各スレッド101に、更に、打ち切りフラグ251を追加し、打ち切りフラグ251がONの場合、スレッド制御部91の処理により、このスレッドの学習を強制的に打ち切るものとしても良い。
なお、打ち切りフラグ251の初期値は、OFFであるものとし、スレッド制御部91は、図15のステップS76において実行される、学習中状態における処理において、学習終了フラグ168がONであるとき、観測信号の開始タイミングと、現在の分離行列に対応した蓄積開始タイミングとを比較し、観測信号の開始タイミングが、現在の分離行列に対応した蓄積開始タイミングよりも早い場合、打ち切りフラグ251をONにするものとする。
すなわち、スレッド制御部91は、図15のステップS76において、図18を用いて説明した学習中状態の処理1に代わって、図28の学習中状態の処理2を実行する。
ステップS361において、スレッド制御部91は、対応するスレッド101の学習終了フラグ168がONであるか否かを判断する。ステップS361において、学習フラグがONであると判断された場合、処理は、後述するステップS367に進む。
ステップS361において、学習フラグがONではないと判断された場合、すなわち、対応するスレッドにおいて学習処理が実行中である場合、ステップS362において、スレッド制御部91は、観測信号の開始タイミングは、現在の分離行列に対応した蓄積タイミングよりも早いか否かを判断する。
ステップS362において、観測信号の開始タイミングは、現在の分離行列に対応した蓄積タイミングよりも早いと判断された場合、ステップS363において、スレッド制御部91は、対応するスレッド101の打ち切りフラグ251をONにし、処理は、図15のステップS76に戻り、ステップS77に進む。
ステップS362において、観測信号の開始タイミングは、現在の分離行列に対応した蓄積タイミングよりも早くないと判断された場合、ステップS364において、スレッド制御部91は、対応するスレッド101のカウンタ166を、1インクリメントする。
ステップS365において、スレッド制御部91は、対応するスレッド101のカウンタ166の値は、スレッド長(thread_len)より小さいか否かを判断する。ステップS365において、カウンタ166の値は、スレッド長より小さいと判断された場合、処理は、図15のステップS76に戻り、ステップS77に進む。
ステップS365において、カウンタ166の値は、スレッド長より小さくないと判断された場合、ステップS366において、スレッド制御部91は、カウンタ166の値から所定の値を減算し、処理は、図15のステップS76に戻り、ステップS77に進む。
学習中にカウンタの値がスレッド長に達した場合とは、学習にかかる時間が所定よりも長くなってしまい、「待機中」状態の時間が存在しなくなった場合である。その場合、学習はまだ継続しており、観測信号バッファ161は利用されているため、次の蓄積を開始することができない。そこで、スレッド制御部91は、学習が終了するまで、次の蓄積の開始、すなわち、「「蓄積中」状態」へ状態を遷移させるための状態遷移コマンドの発行を延期する。そのため、スレッド制御部91は、カウンタ166の値から所定の値を減算する。減算する値は、例えば、1であっても良いが、それよりも大きな値でも良く、例えば、スレッド長の10%などといった値であっても良い。
ステップS361において、学習フラグがONであると判断された場合、すなわち、対応するスレッドにおいて学習処理が終了した場合、ステップS367において、スレッド制御部91は、対応するスレッド101の学習終了フラグ168をOFFにする。
ステップS368において、スレッド制御部91は、対応するスレッド101の打ち切りフラグ251がONであるか否かを判断する。
ステップS368において、対応するスレッド101の打ち切りフラグ251がONであると判断された場合、ステップS369において、スレッド制御部91は、対応するスレッド101の打ち切りフラグ251を初期化、すなわち、OFFとする
ステップS368において、対応するスレッド101の打ち切りフラグ251がONではない、すなわち、OFFであると判断された場合、ステップS370において、図19を用いて説明した分離行列更新処理が実行され、学習によって求められた分離行列Wの値が、他のスレッドの処理に反映される。
ステップS369、または、ステップS370の処理の終了後、ステップS371において、図20を用いて説明した、待機時間の設定処理が実行されて、処理は、図15のステップS76に戻り、ステップS77に進む。
このような処理により、スレッド制御部91は、分離行列が採用される見込みのなくなった学習については、その学習処理を途中で打ち切ることで、計算量を削減することができる。
そして、図28を用いて説明した処理により制御されるスレッド101は、図24のステップS295において、図25を用いて説明した分離行列の学習処理1に代わって、図29を用いて説明する分離行列の学習処理2を実行する。
ステップS401およびステップS402において、図25のステップS321およびステップS322と同様の処理が実行され、観測信号バッファ161に蓄積された観測信号に対して、必要に応じて、前処理が実行されて、分離行列の初期値として、スレッド制御部91から、スレッド制御部91の学習初期値保持部132により保持されている学習初期値W_initが取得される。
ステップS403において、学習演算部163は、打ち切りフラグ251がONであるか否かを判断する。ステップS403において、打ち切りフラグ251がONであると判断された場合、処理は、図24のステップS295に戻り、ステップS296に進む。すなわち、学習処理ループや後処理が実行されずに、分離行列の学習処理が終了される。
ステップS403において、打ち切りフラグ251がONではないと判断された場合、ステップS404乃至ステップS411において、ステップS323乃至ステップS330と同様の処理が実行されて、学習処理ループが実行され、ステップS410の処理の終了後、処理はステップS403に戻り、ステップS403において、打ち切りフラグ251がONであると判断された場合、または、ステップS411の処理が終了された場合、処理は、図24のステップS295に戻り、ステップS296に進む。
このようにして、スレッド制御部91およびスレッド101の双方の処理が変更されて、分離行列が採用される見込みのなくなった学習については、その学習処理を途中で打ち切ることで、計算量を削減することが可能となる。
このように、本発明を適用した独立成分分析においては、蓄積・学習・待機という3つの状態を繰り返す、スレッドと称される処理の単位を導入した。複数のスレッドを、時間をずらして起動することにより、ICAを用いたリアルタイム音源分離システムにおいて、観測信号を蓄積する時間と分離行列が更新される間隔とをある程度自由に設定することが可能となる。
特に、複数のスレッドの間で観測信号を重複させることが容易となり、従来のブロック単位のICAにおいて発生した、蓄積時間と更新間間隔とのトレードオフを解消することが可能となる。
図30を参照して、本発明を適用した独立成分分析におけるスレッドの状態遷移の例について説明する。
図30において、上段は、先頭から7000番目までのフレームについて各スレッドの状態をプロットしたものであり、下段はその内の4000フレームから6500フレームまでを拡大したものである。縦軸はスレッドの番号、横軸はフレーム番号であり、1フレームは10msである。また、ここでは、16kHzサンプリング、512ポイントFFT、160シフトが使用されているものとし、ブロック長、スレッド長、ブロックシフト幅は、それぞれ、300フレーム(3秒)、600フレーム(6秒)、150フレーム(1.5秒)である。また、学習ループは、‖ΔW‖/‖W‖<1/1000が満たされた場合、または、学習処理ループの実行回数が100に達した場合のいずれかに終了されるものとする。
図中、薄いハッチは学習中状態、濃いハッチは、蓄積中状態、白い部分は待機中状態を示している。図30において、それぞれのスレッドの各ブロックにおいて学習に要した時間を見ると、所定の時間(スレッド長−ブロック長)を超過しているものも存在している。しかしながら、上述した処理を実行することにより、蓄積開始時刻は略一定間隔となる。
例えば、図30の下段において、スレッド3の学習301とスレッド4の学習302とを比較すると、スレッド3の学習301の方が先に開始しているにもかかわらず、学習にかかる時間が所定の時間を超過しているため、スレッド4の学習302の方が先に終了している。
そこで、スレッド1の蓄積305に続く蓄積を、まだ学習中のスレッド3に代わって、既に学習が終了して待機中状態であるスレッド4に実行させる(蓄積304)ようにしても良い。そして、スレッド3は待機中303へ遷移した後、スレッド4の蓄積304の開始からブロックシフト幅に対応する時刻が経過した後に蓄積中状態に遷移される。その結果、スレッド3において学習時間の超過が発生した(学習301の処理)にも関わらず、以降の蓄積開始時刻はスレッド間で等間隔に保たれている。
また、スレッド2の学習306も、学習時間が所定の時間を超過している。スレッド3の蓄積307が終了した後、他のいずれかのスレッドで蓄積を開始しなければならないが、このタイミングにおいては、スレッド1は既に蓄積中状態であり、スレッド2およびスレッド4は、まだ学習中状態である。このため、いずれのスレッドも、その時点では蓄積を開始できない。そこで、スレッド2の学習306が終了した後、スレッド2は待機状態には遷移せず、すぐに「蓄積中」状態に遷移される(蓄積中308)。これにより、蓄積開始時刻の間隔が伸びるのを最小にすることができる。また、他のスレッドの待機時間309も調整され、再び蓄積開始時刻が等間隔となるように制御される。
このように制御することにより、学習時間が一時的に増大しても、蓄積開始時刻を略等間隔に保つことが可能となる。そして、分離行列がいずれのスレッドにおいて学習されたものであるか(図中、スレッドX由来と記載されている部分)を考えた場合、その平均は、ブロックシフト幅と略同等となり、できるだけ近い時間の学習結果を用いて分離処理を実行することができる。
本発明は、特に、スレッド間で蓄積の時間が重複すること、スレッド間で複数の学習が実行されること、および、学習が所定の時間を超過した場合であっても並列処理が破綻しないことに特徴を有している。
これにより、独立成分分析(independent component analysis: ICA)を行なうにあたって、従来のブロック単位のICAにおいて発生した、ブロックの長さと分離行列の更新間隔とのトレードオフを解消することが可能となる。
上述した一連の処理は、ソフトウェアにより実行することもできる。そのソフトウェアは、そのソフトウェアを構成するプログラムが、専用のハードウェアに組み込まれているコンピュータ、または、各種のプログラムをインストールすることで、各種の機能を実行することが可能な、例えば汎用のパーソナルコンピュータなどに、記録媒体からインストールされる。
この記録媒体は、図3に示すように、コンピュータとは別に、ユーザにプログラムを提供するために配布される、プログラムが記録されている磁気ディスク31(フレキシブルディスクを含む)、光ディスク32(CD-ROM(Compact Disk-Read Only Memory),DVD(Digital Versatile Disk)を含む)、光磁気ディスク33(MD(Mini-Disk)(商標)を含む)、もしくは半導体メモリ34などよりなるパッケージメディアなどにより構成される。
また、本明細書において、記録媒体に記録されるプログラムを記述するステップは、記載された順序に沿って時系列的に行われる処理はもちろん、必ずしも時系列的に処理されなくとも、並列的あるいは個別に実行される処理をも含むものである。
なお、本明細書において、システムとは、複数の装置により構成される装置全体を表すものである。
なお、本発明の実施の形態は、上述した実施の形態に限定されるものではなく、本発明の要旨を逸脱しない範囲において種々の変更が可能である。
11 音源分離装置, 21 CPU, 29 音信号取得部, 61 マイクロホン, 62 AD変換部, 71 信号処理部, 72 バックグラウンド処理部, 81 フーリエ変換部, 82 分離部, 83 フーリエ逆変換部, 91 スレッド処理部, 92 スレッド演算処理部, 93 分離行列保持部, 101 スレッド