JP4931311B2 - ニューラルネットワーク素子 - Google Patents
ニューラルネットワーク素子 Download PDFInfo
- Publication number
- JP4931311B2 JP4931311B2 JP2001532486A JP2001532486A JP4931311B2 JP 4931311 B2 JP4931311 B2 JP 4931311B2 JP 2001532486 A JP2001532486 A JP 2001532486A JP 2001532486 A JP2001532486 A JP 2001532486A JP 4931311 B2 JP4931311 B2 JP 4931311B2
- Authority
- JP
- Japan
- Prior art keywords
- neural network
- processing element
- network element
- value
- activity level
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
- 238000013528 artificial neural network Methods 0.000 title claims abstract description 67
- 238000012545 processing Methods 0.000 claims abstract description 113
- 230000004044 response Effects 0.000 claims abstract description 14
- 230000000694 effects Effects 0.000 claims description 56
- 238000004422 calculation algorithm Methods 0.000 claims description 12
- 230000001537 neural effect Effects 0.000 claims description 9
- 238000000034 method Methods 0.000 claims description 7
- 240000002627 Cordeauxia edulis Species 0.000 claims 1
- 210000002569 neuron Anatomy 0.000 description 43
- 230000006870 function Effects 0.000 description 15
- 230000004913 activation Effects 0.000 description 6
- 238000004364 calculation method Methods 0.000 description 6
- 238000010304 firing Methods 0.000 description 5
- 230000010354 integration Effects 0.000 description 5
- 230000008859 change Effects 0.000 description 4
- 238000004891 communication Methods 0.000 description 4
- 238000010586 diagram Methods 0.000 description 3
- 230000006399 behavior Effects 0.000 description 2
- 238000005516 engineering process Methods 0.000 description 2
- 230000007717 exclusion Effects 0.000 description 2
- 230000002401 inhibitory effect Effects 0.000 description 2
- 230000002123 temporal effect Effects 0.000 description 2
- 230000002238 attenuated effect Effects 0.000 description 1
- 230000008901 benefit Effects 0.000 description 1
- 238000006243 chemical reaction Methods 0.000 description 1
- 238000004590 computer program Methods 0.000 description 1
- 238000012790 confirmation Methods 0.000 description 1
- 230000008878 coupling Effects 0.000 description 1
- 238000010168 coupling process Methods 0.000 description 1
- 238000005859 coupling reaction Methods 0.000 description 1
- 230000002964 excitative effect Effects 0.000 description 1
- 230000010365 information processing Effects 0.000 description 1
- 239000011159 matrix material Substances 0.000 description 1
- 235000019988 mead Nutrition 0.000 description 1
- 238000005259 measurement Methods 0.000 description 1
- 238000012544 monitoring process Methods 0.000 description 1
- 230000003121 nonmonotonic effect Effects 0.000 description 1
- 230000002093 peripheral effect Effects 0.000 description 1
- 230000008569 process Effects 0.000 description 1
- 238000013139 quantization Methods 0.000 description 1
- 230000003252 repetitive effect Effects 0.000 description 1
Images






Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/06—Physical realisation, i.e. hardware implementation of neural networks, neurons or parts of neurons
- G06N3/063—Physical realisation, i.e. hardware implementation of neural networks, neurons or parts of neurons using electronic means
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Theoretical Computer Science (AREA)
- General Engineering & Computer Science (AREA)
- Neurology (AREA)
- Data Mining & Analysis (AREA)
- Evolutionary Computation (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Computing Systems (AREA)
- Artificial Intelligence (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Computational Linguistics (AREA)
- Image Analysis (AREA)
- Complex Calculations (AREA)
- Thermistors And Varistors (AREA)
- Magnetic Resonance Imaging Apparatus (AREA)
- Transition And Organic Metals Composition Catalysts For Addition Polymerization (AREA)
- Polyethers (AREA)
- Image Processing (AREA)
- Facsimile Image Signal Circuits (AREA)
- Circuit For Audible Band Transducer (AREA)
- Feedback Control In General (AREA)
Description
(技術分野)
本発明は、ニューラルネットワーク素子に関する。
【0002】
(背景技術)
ニューラルネットワークは、生物学的に着想された情報処理のための計算アーキテクチャである。通常のプログラム内蔵型コンピュータで実行される通常のアルゴリズムでは解くことが困難な問題を解くためにニューラルネットワークを使用することが多くなっている。一般的には、これらの問題は株式市場予測、画像認識、音声認識のようなパターンマッチング問題である。いくつかのニューラルネットワークの応用例は商業的に重要である。例えば、多くのラップトップパーソナルコンピュータのタッチパッドは、信頼性を高めるためにニューラルネットワークを使用している(ニューラルシステムは比較的ノイズ不感性である。)。
【0003】
ニューロンは、概して多入力、単一出力のデバイスである。1個のニューロンからの出力信号はそのニューロンに対する入力の重み付けされた総和の関数であり、以下の等式により表すことができる。
【0004】
【数1】
ここで、Xjはニューロンへの入力(場合によっては他のニューロンからの)、Wijは入力に適用される荷重、以下の総和はニューロンの活性レベル(ニューロンの状態の内的測定値)である。
【0006】
【数2】
Tiはニューロンの閾値、fiは活性関数(これは通常非線形である。)、Yiはi次のニューロンの出力である。活性レベルが閾値を越えるとニューロンにより出力が生成される。
【0008】
所定の入力と関連する荷重は正であってもよく、この場合にはその入力で受信された信号は活性レベルを増加させる。従って、正の荷重は興奮性の入力とみなすことができる。ある場合には、所定の入力と関連する荷重は負であってもよく、この場合にはその入力で受信された信号は活性レベルを減少させる。従って、負の荷重は抑制性の入力とみなすことができる。
【0009】
ニューロン間の接続は荷重の値を調整することにより強められ、あるいは弱められる。例えば、所定のニューロンの特定の入力と関連する荷重がこの入力で信号が受信される度に減少してもよい。繰り返し信号(すなわち、同じ入力で複数回受信される信号)が、その入力と関連する荷重を漸次増加させてもよい。次ににその入力で信号が受信されるとニューロンの活性レベルが一層増加する。
【0010】
活性関数は通常すべてのニューロンについて同一であって、固定されており、シグモイド関数(sigmoid function)が頻繁に使用される。
【0011】
既知のニューラルネットワークにおけるi次のニューロンの活性度は、荷重Wijの値により決定される入力Xjの単調関数(monotonic function)に限定されている。この限定により、既知のニューラルネットワークはより複雑で非単調の挙動をエミュレートする能力が制限されている。
【0012】
(発明の開示)
(発明が解決しようとする技術的課題)
本発明の目的は、前述の不都合を解消するニューラルネットワークの素子を提供することにある。
【0013】
(その解決方法)
従って、第1の発明は、複数の入力と、少なくとも一つのプロセッシング要素と、少なくとも一つの出力と、それぞれ前記少なくとも一つのプロセッシング要素に対応するアドレスに値を記憶するデジタルメモリとを備える、ニューラルネットワーク素子であって、前記少なくとも一つのプロセッシング要素は、入力信号に応答して前記デジタルメモリからの値を受信するように構成され、かつ前記デジタルメモリから受信された値に応じて複数の操作の一つを実行するように命令される、ニューラルネットワーク素子を提供する。
【0014】
プロセッシング要素により受信された値が常にプロセッシング要素の活性レベルに加算される(値が常に荷重である)先行技術のニューラルネットワークとは対照的である。本発明のプロセッシング要素は、複数の命令を実行可能であり、従って、受信された値はプロセッシング要素に命令のうち実行するものを選択させる命令として機能する。
【0015】
プロセッシング要素の活性レベルはプロセッシング要素の興奮度を示す内的値である。
【0016】
好適には、前記操作は、前記少なくとも一つのプロセッシング要素の活性レベルへの前記値の加算である。
【0017】
好適には、前記操作は、少なくとも一つのプロセッシング要素の活性レベルの零への減衰であり、この減衰は前記活性レベルが負であれば前記活性レベルを増加させ、前記活性レベルが正であれば前記活性レベルを減少させることによるものである。
【0018】
好適には、前記減衰の速度は前記デジタルメモリから受信された値に依存する。
【0019】
好適には、前記減衰はクロックにより制御される。
【0020】
好適には、前記操作は、前記少なくとも一つのプロセッシング要素による出力の生成と、その少なくとも一つのプロセッシング要素の活性レベルの予め定められた最小レベルへのリセットとを含む。
【0021】
好適には、前記操作は、前記少なくとも一つのプロセッシング要素により出力を生成することなく、その少なくとも一つのプロセッシング要素の活性レベルをリセットすることを含む。
【0022】
好適には、前記操作は、自動学習アルゴリズムに基づいて、前記少なくとも一つの活性レベルを前記デジタルメモリに保持された値を変更することを含む。
【0023】
好適には、前記操作は、自動学習アルゴリズムに基づいて、前記デジタルメモリに保持された値を変更することを含む。
【0024】
好適には、前記自動学習アルゴリズムは、ヘブ学習アルゴリズムを備える。
【0025】
好適には、前記ニューラルネットワーク素子により生成される出力は、前記出力を発生した前記プロセッシング要素の個々のアドレスの番号を含む。
【0026】
好適には、前記ニューラルネットワーク素子は、前記プロセッシング要素から受信された信号パルスの時系列順序を決定し、各信号パルスを番号により表すように構成された調停及びエンコード手段を備える。例えば、各ニューロン出力がそれ自体のピンを有していれば、256本のピンが8本のピンに置換され(この場合、8ビットの2進数が使用される。)、外部通信(off-chip communication)についてのピンの制限の問題が解決されるので、この構成は有利である。
【0027】
好適には、ニューラルネットワーク素子は、前記デジタルメモリに対する読出線アクセスを有する通常のプロセッサをさらに備える。
【0028】
好適には、前記通常のプロセッサによる前記デジタルメモリへのアクセスは、前記ニューラルプロセッシング要素により要求されるアクセスに対して非同期で調停される。
【0029】
好適には、多数のニューラルネットワーク素子が通常のプロセッサの並列ネットワークにより管理される。
【0030】
前記デジタルメモリはランダムアクセスメモリであることが好ましい。
【0031】
好適には、前記素子は非同期法で作動する。あるいは、ニューラルネットワーク素子はクロックで作動してもよい。
【0032】
第2の発明は、少なくとも一つのプロセッシング要素にそれぞれ対応するデジタルメモリのアドレスに値を記憶し、前記少なくとも一つのプロセッシング要素に値を伝送し、かつ前記デジタルメモリから受信された値に応じて前記プロセッシング要素で複数の操作のうちの一つを実行する、ニューラルネットワーク素子を操作する方法を提供する。
【0033】
この方法は、前述の第1の発明における好適ないしは好ましい特徴を含むものであってもよい。
【0034】
(発明を実施するための最良の形態)
添付図面を参照して本発明の特定の実施形態を単なる例として説明する。
【0035】
図1に示すニューラルネットワークは、1024個の入力(input)1、ランダムアクセスメモリ(RAM)2、256個のプロセッシング要素3、及び256個の出力(output)4を備えている。
【0036】
各入力は先行するニューラルネットワーク素子から信号を搬送する。各入力は1ビットの情報のみを搬送する。換言すれば、各入力は「オン」又は「オフ」である。入力信号は入力に対するパルスの形態を取る。
【0037】
RAM2は値の組を格納している。個々の入力及び出力の組み合わせに、RAMの異なるアドレスが割り当てられている(アドレスの個数は1024×256である。)。図1では、読み手の補助と図示の目的のみで、RAMを列及び行を備える二次元のマトリクスとみなすことができ、各行は特定の入力に属する値のすべてを含み、各列は特定のプロセッシング要素に属する値のすべてを含んでいる。後に詳述するように、RAMのアドレスのうちのかなりの部分が零の値を含んでいてもよい。
【0038】
所定の入力で受信されたパルスに応じて、RAM2はその入力に対応する行に配置された値を検索する。各値はその値が配置されている列と対応するプロセッシング要素3へ送られる。プロセッシング要素3の活性レベル(プロセッシング要素3の状態の内的測定値)は、受信された値に応じて変更される。各プロセッシング要素3はニューロンとして機能し、1024個の入力と1個の出力を有している。
【0039】
先行技術と異なり、RAM2に記憶される値は荷重であってもよく、命令(instruction)であってもよい。プロセッシング要素3に送られた値が命令である場合、後に詳述するように、プロセッシング要素3は命令に応じた操作を実行する。プロセッシング要素3に送られた値が荷重である場合、その荷重はプロセッシング要素3の活性レベルに加算される。「i」のプロセッシングユニットの操作は、数学的に以下のように表すことができる。
【0040】
【数3】
ここでXjはニューロンに対する入力、Wijは荷重、下記の総和はニューロンの活性レベルである。
【0042】
【数4】
Tiはニューロンの閾値、fiは活性関数(これは通常非線形である。)、Yiはi次のニューロンの出力である。活性レベルが閾値を越えるとニューロンにより出力が生成される(これは事実上ニューロンの発火(firing)である。)。
【0044】
本実施形態では、特定の入力を示すjは1から1024であり、特定の出力を示すiは1から256の間である。
【0045】
多くの先行技術のニューラルネットワークは、アナログ出力値を生成するニューロンを備えている。例えば、前記の等式において、ニューロンの出力Yiは0と1の間の値を有する数であった。この出力が後続するニューロンに入力されると荷重が乗算され、この乗算の結果がその後続するニューロンの活性レベルに加算される。
【0046】
説明している本発明の実施形態は、アナログのニューラルネットワークとは異なり、プロセッシング要素(ニューロン)は2種類の出力、すなわち1又は0(ないしは「オン」又は「オフ」と等価)の出力のみが可能な態様で機能する。プロセッシング要素の活性レベルがその閾値を越える度にプロセッシング要素により出力パルスが生成される。外部の観察者から見れば、プロセッシング要素のパルス出力は、アナログ出力と等価とみなし得る。例えば、あるプロセッシングユニットが1秒間に23個のパルスを生成したとすると、これは0.23の概念的なアナログ値(notional analogue value)と等価とみなすことができる。以下、プロセッシング要素によるパルスの生成を「パルス速度エンコーディング(pulse rate encoding)」と呼ぶ。
【0047】
一見すると、アナログ信号を使用する場合と比較すると、パルス速度エンコーディングは計算上非常に集約的であるように認められる。例えば、ニューロンの所定の入力に割り当てられた荷重に1回の計算で0.23のアナログ信号を乗算し、その後ニューロンの活性レベルに加算することができる。これとは対照的に、パルス速度エンコーディングを使用すると、荷重をニューロンの活性レベルに対して23回(すなわちパルス毎に)加算しなければならず、23回の独立した計算が必要となる。しかしながら、所定のニューロンからの出力がないことが頻繁にある。パルス速度エンコーディングを使用すると、この場合には入力パルスはまったく受信されないので、計算はまったく実行されない。これとは対照的に、公知のアナログニューラルネットワークでは、出力の零の値は、偶然に零となった有効な出力値である。ニューロンの荷重に零が乗算され、その積(これも零である。)がニューロンの活性レベルに加算される。このニューロンの活性レベルにまったく影響しない計算は頻繁に現れ、計算上非常に無駄である。パルス速度エンコーディングを使用すれば、この無駄な零の乗算を回避することができる。
【0048】
ニューラルネットワーク素子は、256個のプロセッシング要素3を備えている。各プロセッシング要素3はニューロンとして可能し、1024個の入力と1個の出力を備えている。各プロセッシング要素と後続する各ニューラルネットワーク素子との間に個別の接続が設けられているとすると、接続の個数は急激に非実用的な程に多数となる。この問題を回避するため、図2に示すように、プロセッシング要素からの出力は、すべて単一の8ビットの出力ライン5に送られている。所定のプロセッシング要素からの出力パルスは、そのプロセッシング要素を代表する8ビットの2進数に変換され、この8ビットの2進数は出力ラインにより搬送される。この変換は、「アドレス−イベントエンコーディング(addressed-event encoding)」と呼ぶことができ、調停及びエンコーディングユニット(arbitrate and encoding unit)6により実行される。
【0049】
調停及びエンコーディングユニット6の操作は図3に概略的に図示されている。このユニット6は2つの機能を備えている。すなわち、ユニット6は出力ライン5に送られるパルスの時系列順序(chronological order)を決定し、各出力をその出力を生成したプロセッシング要素を示す数字に変換する。これらの2つの機能はユニット6により同時に達成される。図3のユニット6は8個のプロセッシング要素の組について示している。
【0050】
ユニット6の第1層は、4個の調停及びエンコーディングブロック10〜13を備えている。第1の調停及びエンコーディングブロック10の入力側は、2個の入力a及びbと、2個の確認応答出力(acknowledgement output)aack及びbackとを備えている。プロセッシング要素の出力がハイとなると、それが入力aで受信され、ブロック10の第1の出力yがハイとなり、第2の出力zが同時に入力aを示す1ビットの数(この場合、2進数は「1」である。)を出力する。次に、確認応答出力aackがハイとなり、それによってプロセッシング要素に対してブロック10により出力が処理されたことが示される。その後、プロセッシング要素の出力がローとなる。
【0051】
入力aと入力bがほぼ同時にハイとなったとすると、いずれの入力が最初にハイとなったかをザイツ相互排除要素(Seitz mutual exclusion element)が決定する(相互排除要素はアディソン・ウェスレイ(Addison Wesley)から出版されたメッド(Mead)及びコンウェイ(Conway)の「VLSIシステム入門(Introduction to VLSI system)」の260頁等に記載されている。)。これによってブロック10からの出力が生成される。出力が生成され、確認応答が適切なプロセッシング要素に返信されると、入力のうちの後者がブロック10により処理及び出力される。
【0052】
ユニット6の第2層は一対の調停及びエンコーディングブロック14,15を備えている。この対のうち第1のブロック14を参照すると、2個の入力y,wが先行するブロック10,11の出力に接続されている。ブロック14の第1の出力uは入力信号に応じてハイとなり、同時に第2の出力vが2ビットの数を出力する。2ビットの数の最上位の桁が入力yを表し、2ビットの数の最下位の桁が先行するブロック10の入力aを表している。よって、2ビットの数は2進数の「11」である。
【0053】
ユニット6の最終の第3層は先行する層と同様に機能する。最終の層を含む単一のブロック16からの出力は、3ビットの2進数であり、この例では数「111」である。
【0054】
図1の説明では、先行する要素3からの出力はパルスの形態で述べている。図3の説明では、プロセッシング要素からの出力は、確認応答信号がプロセッシング要素により受信された後にのみ終了する連続的なハイとして述べている。調停及びエンコーディングユニット6を正確に機能させるためには、この変更が必要となる。
【0055】
図2では、8ビットの2進数の出力を生成するために、8層の調停及びエンコーディングブロックが必要となる。
【0056】
図2を参照すると、4本の8ビットの入力ライン19がプロセッシング要素3及びRAM2に接続されている。調停及びエンコーディングユニット20が4本の入力ライン19間を調停するために使用されている。調停及びエンコーディングユニット20は図2に概略的に示しかつ上述したような態様で機能する。この例では、調停及びエンコーディングユニットは2層のブロックを含んでいる。調停及びエンコーディングユニットは、10ビットの出力を備え追加の2ビットは、4本の8ビットの入力ライン19間の識別のために使用されている。
【0057】
調停及びエンコーディングユニット20の10ビットの出力はデコーダ21に接続されている。デコーダは個々の受信した10ビットの入力数をそれぞれ対応する1ビットの出力ライン1の出力に変換する(従って、出力ラインは1024本ある。)。出力ライン1は図1に示す出力ラインに対応している。
【0058】
本発明の実施形態で使用されているパルス速度エンコーディングシステムでは、ニューラルネットワーク素子間の通信は1μsのタイムスケールで行われる。これは1kHz以下の速度で発火する現在のニューロンの時間解像度と比較すると瞬間的である。
【0059】
ニューラルネットワーク素子がデジタルであるため、アナログのニューラルネットワーク素子にはない自由度が得られる。詳細には、RAM2に広範囲の値を記憶することができ、これによっていくつかの値をプロセッシング要素3に対する「命令」として使用することができる。この「命令」という用語は、プロセッシング要素が単に活性レベルに値を加算するのではなく操作の実行を命令されるということを指している。既知である先行技術のニューラルネットワークでは、ニューロンにより実行される機能は常に同じであり、活性レベルに値が加算される。命令を使用することにより、プロセッシング要素3はそれらの操作において大幅に柔軟性が向上する。
【0060】
命令を使用することにより、生物学的実際のニューロンにより近似する特性を有するニューラルネットワークが得られる。この特性の一つは、「漏洩性のある(leaky)」統合化である。換言すれば、ある期間に入力される活性度(がなければ、活性レベルが減衰するという特性である。他の特性は「屈折性(refraction)」であり、プロセッシング要素3は発火後のある期間はすべての入力を無視する。この特性によりプロセッシング要素の最大発火速度(すなわち、プロセッシング要素3が出力パルスを生成可能な速度)が制限され、それによってニューロンの活性度が絶えず増加することに起因してネットワークが不安定になることが防止される。屈折性及び漏洩性のある統合化は、ある程度リアルタイムに依存するということを包含している。
【0061】
屈折性及び漏洩性のある統合化は、リアルタイム参照イベント(real-time reference event)、例えば32kHzのクロック(図1及び図2には図示せず。)を使用することにより、説明した本発明の実施形態において実現される。クロックからのパルスは8ビットの入力を介して特定の2進数(例えば00000001)として伝送される。漏洩性のある統合化が必要であれば、この入力された数に対応するRAMの各アドレスに記憶された値は、プロセッシング要素に対して活性レベルが正であれば活性レベルを減少させることを命令し、活性レベルが負であれば活性レベルを増加させることを命令する。RAMに保持された値を異ならせることで、漏洩性のある統合化の速度を異ならせること、例えば、各クロックパルスに応じた減少/増加や、2個のクロックパルス毎の減少/増加を命令してもよい。
【0062】
命令は自動学習アルゴリズム(例えばヘブの学習アルゴリズム(Hebbian learning algorithms))により調整すべき否かの決定を与えるものであってもよい。自動学習能力があるニューロンの例として、以下のニューロン挙動を図4に示すようにモデル化することができる。
【0063】
プロセッシング要素の活性レベルは{−L,+T}の範囲で機能し、−Lは不応答レベル(refractory level)、Tは閾値である。閾値Tに達するとプロセッシング要素がパルスを出力し、活性レベルは−Lにリセットされる。{−L,0}はプロセッシング要素の不応答範囲であり、入力パルスに応じてプロセッシング要素に荷重が送られると、荷重は活性レベルに加算されず(活性レベルは変化しない。)、荷重自体は減少される。{0,F}は漏洩性の興奮範囲(excited range)であり、入力パルスに応じてプロセッシング要素に荷重が送られると、荷重が活性レベルに加算され、学習法により荷重自体は変化しない。{F,T}は強く刺激される範囲であり、入力パルスに応じて荷重がプロセッシング要素に送られると、荷重が活性レベルに加算され、荷重自体が増加される。
【0064】
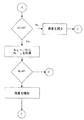
図3に図示されたモデルに従って動作するように構成されたプロセッシングユニットの動作は図5aから図5cのフローチャートに概略的に図示されている。
【0065】
最初に図5aを参照すると、所定の入力jでパルスが受信される。所定の要素についてこの入力jと関連する値は、RAMから取得され、プロセッシング要素に送られる。値は3つの範囲のうちの一つに入る。3つの範囲には、活性レベルに加算される荷重と対応する第1の範囲と、活性レベルの加算及びプロセッシング要素に対するこの入力と関連する荷重の増加の命令に対応する第2の範囲と、荷重以外の命令を含む第3の範囲とがある。
【0066】
図5aの残りの部分は、第1の範囲に入る値を扱っている。値はプロセッシング要素の活性レベルに加算される(荷重が負であれば活性レベルが減少される。)。値の加算後の活性レベルが閾値Tより小さければ、それ以上の操作はなされない。活性レベルが閾値Tより大きければ、プロセッシング要素はパルスを出力し、プロセッシング要素の活性レベルは−Lまで減少される。
【0067】
値が第2の範囲に入れば、フローチャートに図示されたプロセッシング要素による操作は図5bに分岐する。プロセッシング要素の活性レベルが0以上であれば、値はプロセッシング要素の活性レベルに加算される。これに続いて、活性レベルがFよりも大きければ、RAMに保存された値が増加される。
【0068】
プロセッシング要素の活性レベルがゼロ未満であれば、値は活性レベルに加算されず、RAMに保存された値が減少される。
【0069】
値が第3の範囲に入れば、他の形態の命令であることを示している。例えば、図5cに示すように、プロセッシング要素が活性レベルとかかわりなくパルスを発生し、活性レベルを不応答レベルにリセットするように命令してもよい。
【0070】
適切な値が選択されればニューラルネットワークが安定するヘブの学習アルゴリズムは、数的な荷重の処理から独立して活性レベルを−Lから0へ戻す手順によるものであり、従って、上述のように実行される「期間にわたる零に向けての増加」の命令の使用によるものである。
【0071】
プロセッシング要素がRAMの値メモリに記憶された値により規定される他の命令を実行可能であってもよいことは、当業者の理解するところである。例えば、ニューロンの発火を行うことなく、活性レベルを不応答レベルにリセットしてもよい。これは強度の抑制性入力を模している。
【0072】
図1を参照すると、ニューラルネットワーク素子は、RAM値記憶部(RAM value store)4に対する読出線アクセス(read-wire access)を備える通常のプロセッサ(図示せず。)を含んでいてもよい。また、プロセッサは、ニューラルネットワーク素子に組み込まれたインターフェース周辺機器を使用して、ニューロン活性度ストリームに対する入力及び出力を監視及び生成可能であってもよい。
【0073】
プロセッサがRAM値記憶部4にアクセスし、ネットワークがその時点で飽和に近い状態で作動していなければ、ニューラルプロセッシングに対する影響を最低限としつつ、ニューロン活性度ストリームが完全に機能しているネットワークに対して非同期で調停される。一つの監視プロセッサが多数のニューラルネットワーク素子を管理してもよいが、非常に大型のシステムではこのようなプロセッサが数個必要となる。1ギガビットのDRAM技術に基づいて実行する場合には、各チップが監視プロセッサを有する。よって、ニューラルネットワークは、通常のプロセッサの並列ネットワークにより管理され、非常に多数のニューラルネットワークとして実行してもよい。アーキテクチャが通常のマシンに容易に接続されることは、本発明の利点である。制御プロセッサはアーキテクチャの柔軟性を大幅に拡張し、ニューラルプロセッシングと通常のシーケンシャルマシン
との間の閉じた結合(close coupling)をもたらす。
【0074】
通信がクロック化されたロジックを使用して実行されれば、時間発火情報(temporal firing information)が量子化される。非同期のロジックが使用すれば、この量子化は回避される。従って、非同期のロジックを使用すると有利である。
【0075】
図示の実施形態では1個のプロセッシング要素が1個のニューロンに対応するが、プロセッシング要素が複数のニューロンの計算を実行する役割を有していてもよいことは明らかである。
【図面の簡単な説明】
【図1】 本発明に係るニューラルネットワーク素子の実施形態の概略図である。
【図2】 調停及びエンコード手段を含むニューラルネットワーク素子の概略図である。
【図3】 図2に図示された調停及びエンコード手段の概略図である。
【図4】 ヘブの学習則を示すグラフである。
【図5a】 ニューラルネットワーク素子の処理を示すフローチャートである。
【図5b】 ニューラルネットワーク素子の処理を示すフローチャートである。
【図5c】 ニューラルネットワーク素子の処理を示すフローチャートである。
【符号の説明】
1 入力
2 ランダムアクセスメモリ(RAM)
3 プロセッシング要素
4 出力
5 出力ライン
6,20 調停及びエンコーディングユニット
19 入力ライン
21 デコーダ
Claims (18)
- 複数の入力部と、少なくとも一つのプロセッシング要素と、少なくとも一つの出力部と、それぞれ前記少なくとも一つのプロセッシング要素に対応するアドレスに値を記憶するデジタルメモリとを備える、ニューラルネットワーク素子であって、
前記少なくとも一つのプロセッシング要素は、他のニューラルネットワーク素子のプロセッシング要素からの入力信号に応答して前記デジタルメモリからの命令を含む値を受信するように構成され、かつ前記デジタルメモリから受信された値に応じて複数の操作の一つを実行するように命令され、
前記複数の操作の各々は、前記少なくとも一つのプロセッシング要素の活性レベルを変更し、前記活性レベルは前記プロセッシング要素の興奮度を示す内的値である、ニューラルネットワーク素子。 - 前記操作は、前記少なくとも一つのプロセッシング要素の活性レベルへの前記値の加算である、請求項1に記載のニューラルネットワーク素子。
- 前記操作は、少なくとも一つのプロセッシング要素の活性レベルの零への減衰であり、この減衰は前記活性レベルが負であれば前記活性レベルを増加させ、前記活性レベルが正であれば前記活性レベルを減少させることによるものである、請求項1に記載のニューラルネットワーク素子。
- 前記減衰の速度は前記デジタルメモリから受信された値に依存する、請求項3に記載のニューラルネットワーク素子。
- 前記減衰はクロックにより制御される、請求項3又は請求項4に記載のニューラルネットワーク素子。
- 前記操作は、前記少なくとも一つのプロセッシング要素による出力の生成と、その少なくとも一つのプロセッシング要素の活性レベルの予め定められた最小レベルへのリセットとを含む、請求項1に記載のニューラルネットワーク素子。
- 前記操作は、前記少なくとも一つのプロセッシング要素により出力を生成することなく、その少なくとも一つのプロセッシング要素の活性レベルをリセットすることを含む、請求項1に記載のニューラルネットワーク素子。
- 前記操作は、自動学習アルゴリズムに基づいて、前記少なくとも一つの活性レベルを前記デジタルメモリに保持された値に変更することを含む、請求項1に記載のニューラルネットワーク素子。
- 前記操作は、自動学習アルゴリズムに基づいて、前記デジタルメモリに保持された値を変更することを含む、請求項1又は請求項8に記載のニューラルネットワーク素子。
- 前記自動学習アルゴリズムは、ヘブ学習アルゴリズムを備える請求項8又は請求項9に記載のニューラルネットワーク素子。
- 前記ニューラルネットワーク素子により生成される出力は、前記出力を発生した前記プロセッシング要素の個々のアドレスの番号を含む、請求項1に記載のニューラルネットワーク素子。
- 前記ニューラルネットワーク素子は、前記プロセッシング要素から受信された信号パルスの時系列順序を決定し、各信号パルスを出力を発生したプロセッシング要素のアドレスを表す番号により表すように構成された調停及びエンコード手段を備える、請求項11に記載のニューラルネットワーク素子。
- 前記デジタルメモリに対する読出線アクセスを有する通常のプロセッサをさらに備える、請求項1に記載のニューラルネットワーク素子。
- 前記通常のプロセッサによる前記デジタルメモリへのアクセスは、前記ニューラルプロセッシング要素により要求されるアクセスに対して非同期で調停される、請求項13に記載のニューラルネットワーク素子。
- 多数のニューラルネットワーク素子が通常のプロセッサの並列ネットワークにより管理される、請求項13又は請求項14に記載のニューラルネットワーク素子。
- 前記デジタルメモリはランダムアクセスメモリである、請求項1に記載のニューラルネットワーク素子。
- 前記素子は非同期法で作動する請求項1に記載のニューラルネットワーク素子。
- 複数の入力部と、少なくとも一つのプロセッシング要素と、少なくとも一つの出力部と、それぞれ前記少なくとも一つのプロセッシング要素に対応するアドレスに値を記憶するデジタルメモリとを備えるニューラルネットワーク素子を操作する方法であって、
前記少なくとも一つのプロセッシング要素にそれぞれ対応する前記デジタルメモリのアドレスに値を記憶し、
他のニューラルネットワーク素子のプロセッシング要素からの入力信号に応答して前記少なくとも一つのプロセッシング要素に命令を含む値を伝送し、かつ
前記デジタルメモリから受信された値に応じて前記プロセッシング要素で複数の操作のうちの一つを実行し、
前記複数の操作の各々は、前記少なくとも一つのプロセッシング要素の活性レベルを変更し、前記活性レベルは前記プロセッシング要素の興奮度を示す内的値である、
ニューラルネットワーク素子を操作する方法。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| GBGB9924310.7A GB9924310D0 (en) | 1999-10-15 | 1999-10-15 | Neural network component |
| GB9924310.7 | 1999-10-15 | ||
| PCT/GB2000/003957 WO2001029766A2 (en) | 1999-10-15 | 2000-10-16 | Neural network component |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2003512683A JP2003512683A (ja) | 2003-04-02 |
| JP2003512683A5 JP2003512683A5 (ja) | 2007-11-15 |
| JP4931311B2 true JP4931311B2 (ja) | 2012-05-16 |
Family
ID=10862720
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2001532486A Expired - Fee Related JP4931311B2 (ja) | 1999-10-15 | 2000-10-16 | ニューラルネットワーク素子 |
Country Status (9)
| Country | Link |
|---|---|
| US (1) | US7457787B1 (ja) |
| EP (1) | EP1224619B1 (ja) |
| JP (1) | JP4931311B2 (ja) |
| AT (1) | ATE457503T1 (ja) |
| AU (1) | AU7806500A (ja) |
| DE (1) | DE60043824D1 (ja) |
| ES (1) | ES2338751T3 (ja) |
| GB (1) | GB9924310D0 (ja) |
| WO (1) | WO2001029766A2 (ja) |
Families Citing this family (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8515885B2 (en) | 2010-10-29 | 2013-08-20 | International Business Machines Corporation | Neuromorphic and synaptronic spiking neural network with synaptic weights learned using simulation |
| US8812414B2 (en) | 2011-05-31 | 2014-08-19 | International Business Machines Corporation | Low-power event-driven neural computing architecture in neural networks |
| US8843425B2 (en) * | 2011-07-29 | 2014-09-23 | International Business Machines Corporation | Hierarchical routing for two-way information flow and structural plasticity in neural networks |
| US8909576B2 (en) * | 2011-09-16 | 2014-12-09 | International Business Machines Corporation | Neuromorphic event-driven neural computing architecture in a scalable neural network |
| US8924322B2 (en) * | 2012-06-15 | 2014-12-30 | International Business Machines Corporation | Multi-processor cortical simulations with reciprocal connections with shared weights |
| US9218564B2 (en) | 2012-07-30 | 2015-12-22 | International Business Machines Corporation | Providing transposable access to a synapse array using a recursive array layout |
| US8918351B2 (en) | 2012-07-30 | 2014-12-23 | International Business Machines Corporation | Providing transposable access to a synapse array using column aggregation |
| US9159020B2 (en) | 2012-09-14 | 2015-10-13 | International Business Machines Corporation | Multiplexing physical neurons to optimize power and area |
| US8990130B2 (en) | 2012-11-21 | 2015-03-24 | International Business Machines Corporation | Consolidating multiple neurosynaptic cores into one memory |
| US9558443B2 (en) | 2013-08-02 | 2017-01-31 | International Business Machines Corporation | Dual deterministic and stochastic neurosynaptic core circuit |
| US9852006B2 (en) | 2014-03-28 | 2017-12-26 | International Business Machines Corporation | Consolidating multiple neurosynaptic core circuits into one reconfigurable memory block maintaining neuronal information for the core circuits |
| US10410109B2 (en) | 2014-08-25 | 2019-09-10 | International Business Machines Corporation | Peripheral device interconnections for neurosynaptic systems |
| US10832137B2 (en) | 2018-01-30 | 2020-11-10 | D5Ai Llc | Merging multiple nodal networks |
| EP3701351A4 (en) * | 2018-01-30 | 2021-01-27 | D5Ai Llc | SELF-ORGANIZING PARTIALLY ORGANIZED NETWORKS |
Family Cites Families (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5148385A (en) * | 1987-02-04 | 1992-09-15 | Texas Instruments Incorporated | Serial systolic processor |
| JP2588195B2 (ja) * | 1987-05-28 | 1997-03-05 | 株式会社東芝 | パルス入力装置 |
| JP3210319B2 (ja) | 1990-03-01 | 2001-09-17 | 株式会社東芝 | ニューロチップおよびそのチップを用いたニューロコンピュータ |
| DE4215179A1 (de) * | 1991-05-08 | 1992-11-12 | Caterpillar Inc | Prozessor und verarbeitendes element zum gebrauch in einem neural- oder nervennetzwerk |
| US6894639B1 (en) * | 1991-12-18 | 2005-05-17 | Raytheon Company | Generalized hebbian learning for principal component analysis and automatic target recognition, systems and method |
| US5278945A (en) * | 1992-01-10 | 1994-01-11 | American Neuralogical, Inc. | Neural processor apparatus |
| US5404556A (en) * | 1992-06-15 | 1995-04-04 | California Institute Of Technology | Apparatus for carrying out asynchronous communication among integrated circuits |
| US5920852A (en) * | 1996-04-30 | 1999-07-06 | Grannet Corporation | Large memory storage and retrieval (LAMSTAR) network |
| CA2293477A1 (en) * | 1997-06-11 | 1998-12-17 | The University Of Southern California | Dynamic synapse for signal processing in neural networks |
| US6516309B1 (en) * | 1998-07-17 | 2003-02-04 | Advanced Research & Technology Institute | Method and apparatus for evolving a neural network |
-
1999
- 1999-10-15 GB GBGB9924310.7A patent/GB9924310D0/en not_active Ceased
-
2000
- 2000-10-16 DE DE60043824T patent/DE60043824D1/de not_active Expired - Lifetime
- 2000-10-16 AU AU78065/00A patent/AU7806500A/en not_active Abandoned
- 2000-10-16 US US10/110,477 patent/US7457787B1/en not_active Expired - Fee Related
- 2000-10-16 WO PCT/GB2000/003957 patent/WO2001029766A2/en active Application Filing
- 2000-10-16 AT AT00968107T patent/ATE457503T1/de not_active IP Right Cessation
- 2000-10-16 EP EP00968107A patent/EP1224619B1/en not_active Expired - Lifetime
- 2000-10-16 JP JP2001532486A patent/JP4931311B2/ja not_active Expired - Fee Related
- 2000-10-16 ES ES00968107T patent/ES2338751T3/es not_active Expired - Lifetime
Also Published As
| Publication number | Publication date |
|---|---|
| WO2001029766A3 (en) | 2002-04-25 |
| JP2003512683A (ja) | 2003-04-02 |
| EP1224619B1 (en) | 2010-02-10 |
| GB9924310D0 (en) | 1999-12-15 |
| US7457787B1 (en) | 2008-11-25 |
| ES2338751T3 (es) | 2010-05-12 |
| DE60043824D1 (de) | 2010-03-25 |
| WO2001029766A2 (en) | 2001-04-26 |
| ATE457503T1 (de) | 2010-02-15 |
| AU7806500A (en) | 2001-04-30 |
| EP1224619A2 (en) | 2002-07-24 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR102592146B1 (ko) | 시냅스 가중치 학습을 위한 뉴런 회로, 시스템 및 방법 | |
| JP4931311B2 (ja) | ニューラルネットワーク素子 | |
| Rao | Bayesian computation in recurrent neural circuits | |
| US10671912B2 (en) | Spatio-temporal spiking neural networks in neuromorphic hardware systems | |
| CN111417963A (zh) | 改进的尖峰神经网络 | |
| US20120109864A1 (en) | Neuromorphic and synaptronic spiking neural network with synaptic weights learned using simulation | |
| Qiao et al. | A neuromorphic-hardware oriented bio-plausible online-learning spiking neural network model | |
| US11080592B2 (en) | Neuromorphic architecture for feature learning using a spiking neural network | |
| CN112598119B (zh) | 一种面向液体状态机的神经形态处理器片上存储压缩方法 | |
| CN111340194B (zh) | 脉冲卷积神经网络神经形态硬件及其图像识别方法 | |
| CN112163672A (zh) | 基于wta学习机制的交叉阵列脉冲神经网络硬件系统 | |
| CN113627603B (zh) | 在芯片中实现异步卷积的方法、类脑芯片及电子设备 | |
| CN113723594A (zh) | 一种脉冲神经网络目标识别方法 | |
| WO2024216856A1 (zh) | 类脑突触学习方法及类脑技术的神经形态硬件系统 | |
| CN113269113A (zh) | 人体行为识别方法、电子设备和计算机可读介质 | |
| WO1993018474A1 (en) | Devices for use in neural processing | |
| Clarkson et al. | Generalization in probabilistic RAM nets | |
| KR102191346B1 (ko) | 버스트 스파이크에 기반한 스파이킹 신경망 생성 방법 및 스파이킹 신경망 기반 추론 장치 | |
| KR20200108173A (ko) | 스파이킹 뉴럴 네트워크에 대한 연산량을 감소시키는 stdp 기반의 뉴로모픽 연산처리장치 | |
| CN115409217A (zh) | 一种基于多专家混合网络的多任务预测性维护方法 | |
| CN113269313A (zh) | 突触权重训练方法、电子设备和计算机可读介质 | |
| CN113379043A (zh) | 一种脉冲神经网络 | |
| WO2024116229A1 (ja) | 信号処理装置 | |
| Averkin et al. | Evolution of Artificial Neural Networks | |
| Aleksander | Are special chips necessary for neural computing? |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20070926 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20070926 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20110201 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20110427 |
|
| A602 | Written permission of extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A602 Effective date: 20110510 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20110527 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20110628 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20111027 |
|
| A911 | Transfer to examiner for re-examination before appeal (zenchi) |
Free format text: JAPANESE INTERMEDIATE CODE: A911 Effective date: 20111212 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20120117 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20120214 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20150224 Year of fee payment: 3 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| LAPS | Cancellation because of no payment of annual fees |