JP4586566B2 - Spoken dialogue system - Google Patents
Spoken dialogue system Download PDFInfo
- Publication number
- JP4586566B2 JP4586566B2 JP2005045861A JP2005045861A JP4586566B2 JP 4586566 B2 JP4586566 B2 JP 4586566B2 JP 2005045861 A JP2005045861 A JP 2005045861A JP 2005045861 A JP2005045861 A JP 2005045861A JP 4586566 B2 JP4586566 B2 JP 4586566B2
- Authority
- JP
- Japan
- Prior art keywords
- voice
- dialogue
- party
- dialogue system
- output
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images



Landscapes
- Navigation (AREA)
Description
本発明は、音声による対話をユーザと行う音声対話システムに関し、より詳細には、無線通信を介して接続される通信相手と行う対話を含むものに関する。 The present invention relates to a voice dialogue system that performs a voice dialogue with a user, and more particularly, to one that includes a dialogue with a communication partner connected via wireless communication.
従来から、乗員に代わって運転中の通話を代行する車両用通信代行装置が知られている(例えば、特許文献1)。本車両用通信代行装置は、音声対話機能を有しており、擬人化されたエージェントが通話相手と通話を行い、通話相手から取得した情報を乗員に伝えるものである。
上記の従来技術では、乗員が自分に話しかけていると誤解しないように、エージェントが通話相手と対話するときには、エージェントの音声が車室内に出力されない(聞こえない)設定になっている。しかしながら、乗員はエージェントが通話相手に対して話す内容を聞くことができないという問題が生ずるため、乗員に不都合となる場合がある。 In the above prior art, when the agent talks with the other party, the voice of the agent is not output (cannot be heard) to the passenger compartment so as not to misunderstand that the passenger is talking to himself / herself. However, the occupant may be inconvenient for the occupant because the agent may not be able to hear the content spoken to the other party.
そこで、本発明は、ユーザにとってより利便性の高い音声対話システムの提供を目的とする。 Accordingly, an object of the present invention is to provide a voice dialogue system that is more convenient for the user.
上記課題を解決するため、本発明の一局面によれば、
音声による対話をユーザと行う音声対話システムにおいて、
無線通信手段を介して接続される通信相手と該音声対話システムとの間で行う対話で用いる第1の音声と車室内の乗員と該音声対話システムとの間で行う対話で用いる第2の音声とを車室内に出力する音声出力手段を備え、
前記音声出力手段によって出力される第1及び第2の音声の音色を互いに異ならせることを特徴とする音声対話システムが提供される。
In order to solve the above problems, according to one aspect of the present invention,
In a voice dialogue system that performs voice dialogue with the user,
The first voice used in the dialogue between the communication partner connected via the wireless communication means and the voice dialogue system and the second voice used in the dialogue between the passenger in the vehicle cabin and the voice dialogue system And voice output means for outputting to the vehicle interior,
A voice dialogue system is provided, wherein the timbres of the first and second voices output by the voice output means are different from each other.
本局面によれば、乗員は、音声対話システムが通信相手に対して話す内容を聴取できるようになるともに、音声対話システムが自分に対して話しかけているのか通信相手に対して話しかけているのかを音色の違いによって容易に識別できるようになり誤解もなくなる。 According to this aspect, the occupant can listen to what the voice dialogue system speaks to the communication partner, and whether the voice dialogue system is talking to himself or to the communication partner. It can be easily identified by the difference in timbre, and there is no misunderstanding.
また、前記音声出力手段は、前記通信相手が発する第3の音声を車室内に出力することが好ましい。これにより、乗員は通話相手の音声も聴取可能になり、音声対話システムと通話相手との間の対話内容が理解できるようになる。 Moreover, it is preferable that the said audio | voice output means outputs the 3rd audio | voice which the said communicating party emits in a vehicle interior. As a result, the occupant can listen to the voice of the other party, and can understand the contents of the dialogue between the voice conversation system and the other party.
また、前記音声出力手段によって出力される第1乃至第3の音声の音色を互いに異ならせることが好ましい。これにより、通話相手が発する音声も音色の違いよって容易に識別可能である。特に、通話相手も本システムと同様の音声対話システムであれば、両システムが同じ音声であることも考えられるが、どちらの音声対話システムによる音声なのかを乗員は音色の違いによって容易に識別可能になる。 Moreover, it is preferable that the timbres of the first to third voices output by the voice output means are different from each other. As a result, the voice uttered by the other party can be easily identified by the difference in timbre. In particular, if the other party is also the same voice dialogue system as this system, it is possible that both systems are the same voice, but the occupant can easily identify which voice dialogue system is the voice by the difference in the timbre become.
また、音声出力の要否を指示する乗員からの入力に応じて、前記第1乃至第3の音声の中から出力すべき音声を選択する選択手段を備えることが好ましい。これにより、乗員は出力すべき音声を任意に選択でき、対話のやりとりの聞く・聞かないを選択することができる。 In addition, it is preferable to include selection means for selecting a sound to be output from the first to third sounds in response to an input from a passenger instructing whether or not sound output is necessary. As a result, the occupant can arbitrarily select the voice to be output, and can select whether or not to listen to the conversation.
また、前記通話相手と行う対話の成否を判断する判断手段を備え、前記音声出力手段は、前記判断手段により対話が成立しないと判断された場合、第1及び第3の音声の少なくとも一つを出力することが好ましい。これにより、音声対話システムが対話不能なやりとりでも、乗員が聞くことによって対話内容を把握することができるようになる。このとき、対話のやりとりを聞かないと選択していたとしても、同様に、乗員は対話内容を把握することができるようになる。 And determining means for determining whether or not the conversation with the call partner is successful. When the determination means determines that the conversation is not established, the sound output means outputs at least one of the first and third sounds. It is preferable to output. As a result, even when the voice dialogue system cannot communicate, the content of the dialogue can be grasped by listening to the passenger. At this time, even if it is selected not to listen to the conversation, the occupant can grasp the contents of the conversation.
また、前記音声出力手段によって出力されるそれぞれの音声の大きさを制御する音声制御手段を備えることが好ましい。これにより、音色を異ならせることによって音声の大きさに変化がでても、その大きさを調整することができるようになる。 In addition, it is preferable to include a voice control means for controlling the magnitude of each voice output by the voice output means. As a result, even if the sound volume changes due to different timbres, the sound volume can be adjusted.
また、前記音声出力手段によって出力されるそれぞれの音声の高さを制御する音声制御手段を備えることが好ましい。これにより、音色を異ならせることによって音声の高さに変化がでても、その高さを調整することができるようになる。 Moreover, it is preferable to provide a voice control means for controlling the height of each voice output by the voice output means. As a result, even if the sound level changes due to different timbres, the height can be adjusted.
本発明によれば、ユーザにとっての利便性をより高くすることができる。 According to the present invention, the convenience for the user can be further increased.
以下、本発明を実施するための最良の形態の説明を行う。 The best mode for carrying out the present invention will be described below.
[1.本実施形態の概要]
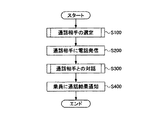
図1は、本実施形態の音声対話システムの概略動作を示すフローチャートである。本実施形態の音声対話システムは、運転者等の乗員の要求に基づいて乗員に代わって電話をかけ、通話相手と対話する中で乗員が要求する情報を取得し、その取得した情報を乗員に伝えるものである。図1における各ステップの詳細な説明については後述する。
[1. Overview of this embodiment]
FIG. 1 is a flowchart showing a schematic operation of the voice interaction system of the present embodiment. The voice interaction system of the present embodiment makes a call on behalf of the occupant based on the request of the occupant such as the driver, acquires information requested by the occupant during the conversation with the other party, and transmits the acquired information to the occupant. It is something to convey. A detailed description of each step in FIG. 1 will be described later.
[2.本実施形態の詳細]
図2は、音声対話システムを取り巻く全体的な概略構成を示した図である。図2に示されるように、車両100には、音声対話システムとして、制御装置10、入力装置20、出力装置30、記憶装置40及び通信装置50が搭載されている。また、通信装置50を介して、車両100から離れた場所に位置する施設200にアクセス可能なことが示されている。
[2. Details of this embodiment]
FIG. 2 is a diagram showing an overall schematic configuration surrounding the voice interaction system. As shown in FIG. 2, the
制御装置10は、音声認識手段11、音声合成手段12、対話制御手段13及び音声制御手段14を備えている。
The
音声認識手段11は、本音声対話システムと音声対話するユーザが話す音声を認識し、文字列に変換するものである。音声入力手段22から入力された音声について、特徴抽出、音素解析、単語解析及び構文解析を行うことによって、その入力された音声を文字列に変換する。 The voice recognition means 11 recognizes the voice spoken by the user who has a voice conversation with the voice dialogue system and converts it into a character string. The input speech is converted into a character string by performing feature extraction, phoneme analysis, word analysis, and syntax analysis on the speech input from the speech input means 22.
音声合成手段12は、文字列から音声を生成するものである。音声合成手段12は、文字列解析、韻律制御及び音声波形生成を行うことによって、音声出力手段31によって出力される音声や携帯電話機51を介して送信される音声を文字列から生成する。
The
対話制御手段13は、本音声対話システムとそのユーザとの間の音声による対話の流れを制御するものである。対話制御手段13は、音声認識手段11によって入力音声から変換された文字列を認識し、その認識された文字列の内容に応じた制御を行う。また、対話制御手段13は、出力すべき音声がある場合には、音声合成手段12によって生成される音声の元になる文字列を生成する。 The dialogue control means 13 controls the flow of dialogue by voice between the voice dialogue system and its user. The dialogue control means 13 recognizes the character string converted from the input voice by the voice recognition means 11, and performs control according to the content of the recognized character string. Further, when there is a voice to be output, the dialogue control means 13 generates a character string that is a source of the voice generated by the voice synthesis means 12.
このような音声対話技術は、例えば、電話によるお客様窓口などに採用されている自動応答システム(IVR:Interactive Voice Response)、カーナビゲーションシステムのルート検索に用いる音声認識、通信機能を搭載した際の音声合成による電子メール読み上げ等がよく知られている。 Such voice interaction technologies include, for example, an automatic response system (IVR: Interactive Voice Response) adopted at customer service by telephone, voice recognition used for route search in car navigation systems, and voice when equipped with communication functions. E-mail reading by synthesis is well known.
音声制御手段14は、音声合成手段12によって生成された音声波形(音波)を制御するものである。音声波形を制御することによって、「音の大きさ(音圧、音圧レベル)」「音の高さ」「音色」に変化を与えることができる。「音の大きさ」は音声波形の振幅によって決まり、「音の高さ」は音声波形の周波数によって決まり、「音色」は音声波形の形状によって決まる。音の大きさと音の高さについてそれぞれ同一な二つの音声波形(つまり、振幅、周波数が同一)を比べた場合、その音声波形の形状が異なれば、その音声の音色は互いに異なる。
The
入力装置20は、スイッチ(SW)入力手段21及び音声入力手段22を備えている。SW入力手段21には、例えば、プッシュSW、レバーSW及びタッチパネルディスプレイが挙げられる。制御装置10に対する乗員による操作入力を受け付けるインターフェースである。音声入力手段22は、車室内の音声を集音し、その集音された音声を音声認識手段11に供給する。また、音声入力手段22は、通信装置50を介して集音した通信相手の音声を音声認識手段11に供給する。
The
出力装置30は、音声出力手段31及び画像出力手段32を備えている。音声出力手段31は、上述の音声波形に基づいて車室内に実際の音声を出力する、いわゆるスピーカである。画像出力手段32は、乗員に対し視覚的な情報提供をする表示装置であって、より具体的には、TFT−LCD(薄膜トランジスタ方式液晶ディスプレイ)、自発光タイプのEL(Electro Luminescence)パネル、VFD(蛍光表示管)及びヘッドアップディスプレイ等がある。そして、画像出力手段32には、例えば、ナビゲーションシステム画面(メニュー画面や経路案内画面)、擬人化されたエージェントの像、音声対話のやりとりの中で認識され変換された文字列が表示される。
The
記憶装置40には、会話シナリオ41、施設情報42、選択施設情報43及び地図情報44が記憶されている。会話シナリオ41は、単語や構文の辞書データ及び文例であって、上述の音声対話の制御をする際に参照されるものである。施設情報42は、レストランや公園等の施設に関する位置情報や料金等の情報である。選定施設情報43は、後に詳述するが乗員が選定した施設に関する情報である。地図情報44は、GPSからの車両100の位置、地図データ、建物データ、道路データ等であって、ナビゲーションシステムが経路探索等をする際に参照されるものである。
The
通信装置50は、車外との無線通信を可能にする装置であって、より具体的には、携帯電話機51である。制御装置10は、携帯電話機51を介して車外の電話60を備える施設200に電話をかけ、電話の相手と対話することを可能にする。
The
[3.本実施形態の動作]
図を参照しながら、本実施形態の動作例について説明する。図1は、本実施形態の音声対話システムの概略動作を示すフローチャートである。ここでは、擬人化されたエージェントによって本音声対話システムの動作が表現されるものとする。エージェントは、乗員と対話を行ったり、乗員の好みや要求やそれらの学習結果に応じて最適な推奨案(例えば、乗員が好みそうなレストランが近くにあれば場所を案内してくれる)を提供してくれたりする。エージェントの容姿は、人間をはじめとして、動物、ロボット、漫画のキャラクター等、様々存在し、ユーザの好みによって選択可能なものである。エージェントは、ディスプレイ上を動くものであってもよいし、ホログラフィのようなものであってもよい。
[3. Operation of this embodiment]
An operation example of the present embodiment will be described with reference to the drawings. FIG. 1 is a flowchart showing a schematic operation of the voice interaction system of the present embodiment. Here, it is assumed that the operation of the spoken dialogue system is expressed by an anthropomorphic agent. Agents interact with the occupants and provide optimal recommendations based on the occupant's preferences, requirements, and learning results (eg, if a nearby restaurant is likely to be preferred by the occupant) I will do it. There are various types of agents such as humans, animals, robots, cartoon characters, and the like, which can be selected according to user preferences. The agent may move on the display or may be like holography.
以下、乗員が運転中に定食屋を探している状況において音声対話システム(エージェント)自らが定食屋に関する情報を取得するとともにその情報を乗員に提供するというケースに当てはめて、本実施形態の動作の一例を説明する。 Hereinafter, in a situation where the occupant is looking for a set meal while driving, the voice dialogue system (agent) himself acquires information about the set meal and provides the information to the occupant. An example will be described.
図1において、まず、乗員は通話相手の選定を行う(ステップ100)。ここでの通話相手は定食屋になる。図3を参照しながら、通信相手の選定について詳細に説明する。図3は、通信相手の選定についてのフローチャートである。乗員は、ナビゲーションシステムで施設一覧を画像出力手段32に表示させ、その施設一覧の中から定食屋を選択する(ステップ110)。乗員は、情報取得ボタンを押して、メニューの中から取得したい情報、例えば、「営業時間」や「待ち時間」を選択する(ステップ120)。ここで、優先度をつけて複数の定食屋を選択してもよい。優先度に応じて音声対話システムが電話をかける順番(情報を取得したい順番)が変わる。ただし、電話をかける順番は、記憶装置40に記憶されている施設情報42(現在値からの距離や定食屋の料金設定等)に応じて自動的に設定されるようにしてもよい。そして、乗員が施設選択完了ボタンを押すことによって、通話相手の選定が完了する(ステップ130)。
In FIG. 1, first, the occupant selects a call partner (step 100). The other party here is a canteen. The selection of the communication partner will be described in detail with reference to FIG. FIG. 3 is a flowchart for selecting a communication partner. The occupant causes the navigation system to display the facility list on the image output means 32, and selects a canteen from the facility list (step 110). The occupant presses the information acquisition button to select information to be acquired from the menu, for example, “business hours” or “waiting time” (step 120). Here, a plurality of set restaurants may be selected with priorities. The order in which the voice conversation system makes a call (the order in which information is to be acquired) changes according to the priority. However, the order of making a call may be automatically set according to the facility information 42 (distance from the current value, setting of a restaurant fee, etc.) stored in the
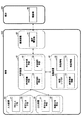
図1に戻り、エージェントは選択された定食屋に電話をかけ(ステップ200)、相手が電話に出た場合に対話を開始する(ステップ300)。図4は、エージェントと通話相手との間の音声対話についてのフローチャートである。エージェントは、相手が話した内容を認識し、電話に出た相手を特定する。特定できなかった場合、エージェントは通話相手に「もしもし、定食屋○○さんでよろしいですね?」と尋ねることによって相手を特定する。 Returning to FIG. 1, the agent calls the selected set restaurant (step 200) and starts a dialogue when the other party answers the call (step 300). FIG. 4 is a flowchart of the voice dialogue between the agent and the other party. The agent recognizes what the other party has spoken and identifies the other party who answered the call. When the agent cannot be identified, the agent identifies the other party by asking the other party, “What if you want to be a restaurant?”
次に、エージェントは、「こちららはドライバーエージェントシステムです。ドライバーに代わり、教えてほしいことがあります。まず「営業時間」について教えて下さい」と話して、自己紹介するとともに取得したい情報について尋ねる(ステップ310)。通話相手は、「営業時間は□□です」と答える。そして、エージェントは、自分の質問に対する通話相手の応答音声内容を受信し、その音声認識を行う(ステップ320)。音声認識を行ったエージェントは、「営業時間は□□でよろしいですね?」と通話相手に確認する(ステップ330)。OKであることを確認した場合、次の取得したい情報についての質問をする(ステップ350;No)。 Next, the agent says, “This is a driver agent system. There are things I want you to tell me on behalf of the driver. Please tell me about“ business hours ”first,” and introduce yourself and ask about the information you want to get ( Step 310). The other party answers “Business hours are □□”. Then, the agent receives the content of the response voice of the other party to the question, and recognizes the voice (step 320). The agent who has performed the speech recognition confirms with the other party that "Are you sure you want the business hours?" (Step 330). When confirming that it is OK, a question about the next information to be acquired is made (step 350; No).
エージェントは、次の質問として「現在どれくらいの「待ち時間」ですか?」と尋ねる(ステップ310)。尋ねられた通話相手は「待ち時間は△△です」と答える。その答えを音声認識したエージェントは、上記と同様に、「待ち時間は××でよろしいですね?」と通話相手に確認する(ステップ320,330)。ここで、その確認内容が間違っていると通話相手から指摘された場合や通話相手の音声認識が不可能な場合、エージェントは、通話相手に対して少し待って欲しい旨を話す(ステップ330;No)。 The agent asked the next question, “How much is the“ waiting time ”? (Step 310). The called party answers “waiting time is △△”. As described above, the agent who recognizes the answer by voice confirms with the other party that "waiting time is xx?" (Steps 320 and 330). Here, when the other party indicates that the confirmation content is wrong or when the other party cannot recognize the voice, the agent tells the other party that he / she wants to wait for a while (step 330; No). ).
エージェントは、「待ち時間について認識できません。対話内容を聞きますか?」と、乗員に対して情報取得できないため対話内容を聞くか否かを確認する(ステップ340)。乗員が「聞く」と答えると、その音声認識をしたエージェントは、車室内のスピーカを通して、その対話内容を乗員が聞くことができるようにする。エージェントは、再び、「現在どれくらいの待ち時間ですか?」と尋ねると、通話相手は「待ち時間は△△です」と答える。今度は、車室内の乗員でも通話相手の音声を聞くことができるようになるので、乗員は相手の音声を直接聞くことによって待ち時間を知ることができるようになる。そのとき、エージェントももちろん通話相手の話しを聞いており、「待ち時間△△」について音声認識をあらためて行っている。エージェントがそれでも音声認識できない場合は、「やっぱり、認識できませんでした。ごめんなさい。」と乗員に謝る。さらに、乗員の聞きたい情報が他にも出てきたならば、乗員が直接通話相手に話しかけ、その通話相手の応答する音声を聞くことができるようにしてもよい。要取得情報がすべて取得できたならば、エージェントは、「質問は以上です。ありがとうございました」と、通話相手に通話を終了する旨を伝える。 The agent confirms whether or not to listen to the dialogue content because the information cannot be obtained from the occupant, saying “Cannot recognize waiting time. Do you want to listen to the dialogue content?” (Step 340). When the occupant answers “listen”, the agent who has recognized the voice enables the occupant to hear the content of the conversation through the speaker in the vehicle interior. When the agent asks again, “How long is the waiting time?”, The other party answers “The waiting time is △△”. This time, even the passenger in the passenger compartment can hear the voice of the other party, so that the passenger can know the waiting time by directly listening to the voice of the other party. At that time, of course, the agent is also listening to the conversation of the other party, and recognizing the voice for “waiting time ΔΔ”. If the agent is still unable to recognize the voice, apologize to the occupant, “After all, I could not recognize it. Further, if other information that the occupant wants to hear comes out, the occupant may directly talk to the other party and hear the voice that the other party responds. If all the required information is acquired, the agent informs the other party that the call is to be terminated, saying "Thank you for the question. Thank you."
そして、エージェントは、「営業時間は□□で、待ち時間は△△です。次の候補も確認しますか?」と、取得した情報を乗員にディスプレイ表示とともに音声で伝え、次の候補の情報を取得するか否かを確認する(図1のステップ400)。乗員は「もう、確認しなくてよい」と答えれば、その音声が認識され、情報取得が終了する。
The agent then informs the passenger of the obtained information with a display on the display, saying, “Business hours are □□, wait time is △△. Do you want to check the next candidate?” Is confirmed (
このように、車室内のスピーカから流れる音声は、エージェントが通話相手に話しかける音声もあれば乗員に話しかける音声もあり、通話相手がエージェントに話しかける音声もあれば乗員に話しかける音声もあり、対話も入り組んでいる。したがって、乗員、特に運転中のドライバーは、誰が誰に話しかけているのかがわかりにくくなるおそれがある。エージェントや通話相手の話す言葉が質問形式であればなおさらである。そこで、本発明の音声対話システムでは、車室内のスピーカから出力される通話相手と行う対話で用いる音声と車室内の乗員と行う対話で用いる音声と通話相手が発する音声について、その音色を互いに異ならせるようにしている。 In this way, the voice that flows from the speaker in the passenger compartment includes the voice that the agent talks to the other party and the voice that talks to the occupant, the voice that the other party talks to the agent and the voice that talks to the occupant, and the conversation is complicated. It is out. Therefore, it may be difficult for passengers, particularly drivers who are driving, to understand who is talking to whom. This is especially true if the language spoken by the agent or the other party is a question format. Therefore, in the voice dialogue system of the present invention, the voices used in the dialogue with the call partner output from the speaker in the vehicle interior, the voices used in the dialogue with the passenger in the vehicle cabin, and the voice emitted by the call partner are different from each other. I try to make it.
図5は、対話音声の音色制御を示すフローチャートである。音声合成手段12は、エージェントが話す文章の文字列から音声波形を生成する(ステップ510)。生成された音声波形に基づいて、エージェントの音声が、車室内のスピーカを通して乗員に且つ携帯電話機51を介して通話相手に、出力される(ステップ520)。音声制御手段14は、音声波形の振幅や振動数や形状を調整することによって、乗員に話しかける音声と通話相手に話しかける音声の音色を互いに異なるように変える(ステップ530)。
FIG. 5 is a flowchart showing timbre control of dialogue voice. The
また、携帯電話機51を介して通話相手の音声が入力された場合(ステップ540)、車室内のスピーカを介して通話相手の音声が出力されるとともに(ステップ550)、音声認識手段11は通話相手の音声の音声認識を行う(ステップ560)。音声制御手段14は、ステップ530で行われたエージェントの音声の音色と異なる音色になるように、通話相手の音声の音声波形の振幅や振動数や形状を調整する(ステップ570)。
When the voice of the other party is input via the mobile phone 51 (step 540), the other party's voice is output via the speaker in the passenger compartment (step 550), and the voice recognition means 11 Is recognized (step 560). The
このように、車室内のスピーカから出力される通話相手と行う対話で用いる音声と車室内の乗員と行う対話で用いる音声の音色を互いに異ならせることによって、音声対話システムが自分(乗員)に対して話しかけているのか通信相手に対して話しかけているのかを容易に識別できるようになる。 In this way, the voice dialogue system makes it possible for the user (occupant) to change the timbre of the voice used in the dialogue with the other party that is output from the speaker in the passenger compartment and the voice used in the dialogue with the passenger in the passenger compartment. You can easily identify whether you are talking to a communication partner or talking to a communication partner.
以上、本発明の好ましい実施例について詳説したが、本発明は、上述した実施例に制限されることはなく、本発明の範囲を逸脱することなく、上述した実施例に種々の変形及び置換を加えることができる。 The preferred embodiments of the present invention have been described in detail above. However, the present invention is not limited to the above-described embodiments, and various modifications and substitutions can be made to the above-described embodiments without departing from the scope of the present invention. Can be added.
例えば、音声対話システム側から通話を発信する場合について上述したが、受信する場合についても同様に音声対話することは可能であり、そのときの音声の音色も互いに異ならせるようにすればよい。 For example, although the case where a call is made from the voice interactive system side has been described above, the case where the call is received is also possible to carry out a voice conversation in the same manner, and the timbre of the voice at that time may be made different from each other.
また、エージェントが電話をかけたときに電話がつながらない場合には、一定時間後にあらためて電話をかけるようにすればよい。この場合、エージェント自らが一定時間後に自動的に電話をかけなおすようにしてもよいし、乗員にあらためて電話をかけるか否かの判断を問い合わせるようにしてもよい。乗員に問い合わせることによって、待ってでも情報取得するのか、待たずに次の施設の情報取得に移行させるのかを乗員は選択することができる。 If the agent does not make a call when making a call, the call may be made again after a certain period of time. In this case, the agent himself / herself may automatically make a call again after a certain time, or the passenger may be inquired about whether or not to call again. By inquiring the occupant, the occupant can select whether to acquire information even after waiting or to shift to acquiring information of the next facility without waiting.
また、通話相手の言語を推定する手段を備えてもよい。記憶装置40内の会話シナリオ41を言語別に記憶し、通話相手の言語に応じてエージェントが話す言語を切り替えるようにしてもよい。これにより、言語の不一致によって対話ができないと認識されれば、通話相手が理解できる言語に切り替えて対話することにより、情報取得が可能となる。なお、この場合の言語は、人間が話す日本語や英語等であるが、上記例示のIVR等の通信相手が機械の場合にはその通信プロトコル等を相手に合わせて切り替えるようにしてもよい。
Moreover, you may provide the means to estimate the language of the other party. The
11 音声認識手段
12 音声合成手段
13 対話制御手段
14 音声制御手段
100 車両
200 施設
DESCRIPTION OF
Claims (4)
無線通信手段を介して接続される通信相手と該音声対話システムとの間で行う対話で用いる第1の音声と車室内の乗員と該音声対話システムとの間で行う対話で用いる第2の音声と前記通信相手が発する第3の音声とを車室内に出力する音声出力手段を備え、
前記音声出力手段によって出力される第1乃至第3の音声の音色を互いに異ならせることを特徴とする音声対話システム。 In a voice dialogue system that performs voice dialogue with the user,
The first voice used in the dialogue between the communication partner connected via the wireless communication means and the voice dialogue system and the second voice used in the dialogue between the passenger in the vehicle cabin and the voice dialogue system And a voice output means for outputting the third voice emitted by the communication partner to the passenger compartment,
Speech dialogue system, characterized in that different from each other the sound of the first to third sound output by the sound output unit.
無線通信手段を介して接続される通信相手と該音声対話システムとの間で行う対話で用いる第1の音声と車室内の乗員と該音声対話システムとの間で行う対話で用いる第2の音声と前記通信相手が発する第3の音声とを車室内に出力する音声出力手段と、
前記通話相手と行う対話の成否を判断する判断手段とを備え、
前記音声出力手段によって出力される第1及び第2の音声の音色を互いに異ならせ、
前記音声出力手段は、前記判断手段により対話が成立しないと判断された場合、第1及び第3の音声の少なくとも一つを出力することを特徴とする音声対話システム。 In a voice dialogue system that performs voice dialogue with the user,
The first voice used in the dialogue between the communication partner connected via the wireless communication means and the voice dialogue system and the second voice used in the dialogue between the passenger in the vehicle cabin and the voice dialogue system And voice output means for outputting the third voice uttered by the communication partner to the vehicle interior ;
Determining means for determining success or failure of the dialogue with the other party ;
Making the timbres of the first and second voices output by the voice output means different from each other ;
The voice dialogue system is characterized in that the voice output means outputs at least one of the first and third voices when the judgment means judges that the dialogue is not established .
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2005045861A JP4586566B2 (en) | 2005-02-22 | 2005-02-22 | Spoken dialogue system |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2005045861A JP4586566B2 (en) | 2005-02-22 | 2005-02-22 | Spoken dialogue system |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2006234953A JP2006234953A (en) | 2006-09-07 |
| JP2006234953A5 JP2006234953A5 (en) | 2007-11-01 |
| JP4586566B2 true JP4586566B2 (en) | 2010-11-24 |
Family
ID=37042709
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2005045861A Expired - Fee Related JP4586566B2 (en) | 2005-02-22 | 2005-02-22 | Spoken dialogue system |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP4586566B2 (en) |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6267636B2 (en) * | 2012-06-18 | 2018-01-24 | エイディシーテクノロジー株式会社 | Voice response device |
| JP2014048335A (en) * | 2012-08-29 | 2014-03-17 | Toshiba Tec Corp | Recognition dictionary generation device and recognition dictionary generation program |
| JP2015087649A (en) * | 2013-10-31 | 2015-05-07 | シャープ株式会社 | Utterance control device, method, utterance system, program, and utterance device |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH06209475A (en) * | 1993-01-11 | 1994-07-26 | Toshiba Corp | Multi-medium equipment |
| JP2003281652A (en) * | 2002-03-22 | 2003-10-03 | Equos Research Co Ltd | Emergency reporting device |
| JP2005012833A (en) * | 1995-01-11 | 2005-01-13 | Fujitsu Ltd | Voice response service apparatus |
-
2005
- 2005-02-22 JP JP2005045861A patent/JP4586566B2/en not_active Expired - Fee Related
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH06209475A (en) * | 1993-01-11 | 1994-07-26 | Toshiba Corp | Multi-medium equipment |
| JP2005012833A (en) * | 1995-01-11 | 2005-01-13 | Fujitsu Ltd | Voice response service apparatus |
| JP2003281652A (en) * | 2002-03-22 | 2003-10-03 | Equos Research Co Ltd | Emergency reporting device |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2006234953A (en) | 2006-09-07 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US7219063B2 (en) | Wirelessly delivered owner's manual | |
| JP3788203B2 (en) | Hand-free telephone equipment for automobiles | |
| US8618958B2 (en) | Navigation device | |
| EP2447926B1 (en) | Systems and methods for off-board voice automated vehicle navigation | |
| US8694244B2 (en) | Systems and methods for off-board voice-automated vehicle navigation | |
| US20120253823A1 (en) | Hybrid Dialog Speech Recognition for In-Vehicle Automated Interaction and In-Vehicle Interfaces Requiring Minimal Driver Processing | |
| EP1739546A2 (en) | Automobile interface | |
| CA2646340A1 (en) | Method for providing external user automatic speech recognition dictation recording and playback | |
| US20070073543A1 (en) | Supported method for speech dialogue used to operate vehicle functions | |
| JP4586566B2 (en) | Spoken dialogue system | |
| JP2019127192A (en) | On-vehicle device | |
| CN102055856B (en) | System and method for synchronizing languages | |
| JP6281202B2 (en) | Response control system and center | |
| JP2019121970A (en) | Interactive device | |
| JP2020113150A (en) | Voice translation interactive system | |
| JP2020060861A (en) | Agent system, agent method, and program | |
| US20100047748A1 (en) | System and method for studying a foreign language in a vehicle | |
| JP2006199281A (en) | Hands-free telephone device for automobile | |
| JP2004233676A (en) | Interaction controller | |
| JP4624825B2 (en) | Voice dialogue apparatus and voice dialogue method | |
| JPS58138134A (en) | Car telephone set | |
| JP2019212168A (en) | Speech recognition system and information processing device | |
| JPH08285628A (en) | On-vehicle navigation system | |
| CA2737850C (en) | Wirelessly delivered owner's manual | |
| JP2009025517A (en) | On-vehicle information providing interactive device |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20070907 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20070907 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20100119 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20100217 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20100810 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20100823 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20130917 Year of fee payment: 3 |
|
| LAPS | Cancellation because of no payment of annual fees |