JP4583375B2 - 同期スキーマの実装のためのシステム - Google Patents
同期スキーマの実装のためのシステム Download PDFInfo
- Publication number
- JP4583375B2 JP4583375B2 JP2006523856A JP2006523856A JP4583375B2 JP 4583375 B2 JP4583375 B2 JP 4583375B2 JP 2006523856 A JP2006523856 A JP 2006523856A JP 2006523856 A JP2006523856 A JP 2006523856A JP 4583375 B2 JP4583375 B2 JP 4583375B2
- Authority
- JP
- Japan
- Prior art keywords
- item
- version
- change unit
- type
- items
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images













































Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/10—File systems; File servers
- G06F16/17—Details of further file system functions
- G06F16/178—Techniques for file synchronisation in file systems
- G06F16/1787—Details of non-transparently synchronising file systems
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/28—Databases characterised by their database models, e.g. relational or object models
- G06F16/284—Relational databases
Description
(本出願は、内容全体がこれにより本出願に組み込まれている(便宜上部分的に要約されている)、同一出願人による、「SYSTEMS AND METHODS FOR REPRESENTING UNITS OF INFORMATION MANAGEABLE BY A HARDWARE/SOFTWARE INTERFACE SYSTEM BUT INDEPENDENT OF PHYSICAL REPRESENTATION」という表題の2003年8月21日に出願した米国特許出願第10/647,058号明細書(整理番号MSFT−1748)、「SYSTEMS AND METHODS FOR SEPARATING UNITS OF INFORMATION MANAGEABLE BY A HARDWARE/SOFTWARE INTERFACE SYSTEM FROM THEIR PHYSICAL ORGANIZATION」という表題の2003年8月21日に出願した米国特許出願第10/646,941号明細書(整理番号MSFT−1749)、「SYSTEMS AND METHODS FOR THE IMPLEMENTATION OF A BASE SCHEMA FOR ORGANIZING UNITS OF INFORMATION MANAGEABLE BY A HARDWARE/SOFTWARE INTERFACE SYSTEM」という表題の2003年8月21日に出願した米国特許出願第10/646,940号明細書(整理番号MSFT−1750)、「SYSTEMS AND METHOD FOR REPRESENTING RELATIONSHIPS BETWEEN UNITS OF INFORMATION MANAGEABLE BY A HARDWARE/SOFTWARE INTERFACE SYSTEM」という表題の2003年8月21日に出願した米国特許出願第10/646,645号明細書(整理番号MSFT−1752)、「SYSTEMS AND METHODS FOR INTERFACING APPLICATION PROGRAMS WITH AN ITEM-BASED STORAGE PLATFORM」という表題の2003年8月21日に出願した、米国特許出願第10/646,575号明細書(整理番号MSFT−2733)、「STORAGE PLATFORM FOR ORGANIZING, SEARCHING, AND SHARING DATA」という表題の2003年8月21日に出願した、米国特許出願第10/646,646号明細書(整理番号MSFT−2734)、「SYSTEMS AND METHODS FOR DATA MODELING IN AN ITEM-BASED STORAGE PLATFORM」という表題の2003年8月21日に出願した、米国特許出願第10/646,580号明細書(整理番号MSFT−2735)、「SYSTEMS AND METHODS FOR THE IMPLEMENTATION OF A DIGlTAL IMAGES SCHEMA FOR ORGANIZING UNITS OF INFORMATION MANAGEABLE BY A HARDWARE/SOFTWARE INTERFACE SYSTEM」という表題の2003年10月24日に出願した米国特許出願第10/692,779号明細書(整理番号MSFT−2829)、「SYSTEMS AND METHODS FOR PROVIDING SYNCHRONIZATION SERVICES FOR UNITS OF INFORMATION MANAGEABLE BY A HARDWARE/SOFTWARE INTERFACE SYSTEM」という表題の2003年10月24日に出願した米国特許出願第10/692,515号明細書(整理番号MSFT−2844)、「SYSTEMS AND METHODS FOR PROVIDING RELATIONAL AND HIERARCHICAL SYNCHRONIZATION SERVICES FOR UNITS OF INFORMATION MANAGEABLE BY A HARDWARE/SOFTWARE INTERFACE SYSTEM」という表題の2003年10月24日に出願した米国特許出願第10/692,508号明細書(整理番号MSFT−2845)、および「SYSTEMS AND METHODS FOR EXTENSIONS AND INHERITANCE FOR UNITS OF INFORMATION MANAGEABLE BY A HARDWARE/SOFTWARE INTERFACE SYSTEM」という表題の2003年10月24日に出願した米国特許出願第10/693,574号明細書(整理番号MSFT−2847)で開示されている発明の主題と関連している。)
I.はじめに
A.コンピューティング環境例
B.従来のファイルベースのストレージ
II.データの編成、検索、および共有のためのWINFSストレージプラットフォーム
A.用語
B.ストレージプラットフォームの概要
C.データモデル
1.Items
2.Itemの識別
3.Item FoldersおよびCategories
4.Schemas
a)Base Schema
b)Core Schema
5.関係
a)関係の宣言
b)保持関係
c)埋め込み関係
d)参照関係
e)規則と制約条件
f)関係の順序付け
6.拡張性
a)アイテム拡張
b)NestedElement型の拡張
D.データベースエンジン
1.UDTを使用したデータストアの実装
2.アイテムのマッピング
3.拡張マッピング
4.ネストされている要素のマッピング
5.オブジェクト識別
6.SQLオブジェクトの命名規則
7.列の命名規則
8.検索ビュー
a)アイテム
(1)マスターアイテム検索ビュー
(2)型付きアイテム検索ビュー
b)アイテム拡張
(1)マスター拡張検索ビュー
(2)型付き拡張検索ビュー
c)ネストされている要素
d)関係
(1)マスター関係検索ビュー
(2)関係インスタンス検索ビュー
9.更新
10.変更追跡&ツームストーン
a)変更追跡
(1)「マスター」検索ビューでの変更追跡
(2)「型付き」検索ビューでの変更追跡
b)ツームストーン
(1)アイテムツームストーン
(2)拡張ツームストーン
(3)関係ツームストーン
(4)ツームストーンのクリーンアップ
11.ヘルパAPIおよび関数
a)関数[System.Storage].GetItem
b)関数[System.Storage].GetExtension
c)関数[System.Storage].GetRelationship
12.メタデータ
a)スキーマメタデータ
b)インスタンスメタデータ
E.セキュリティ
F.通知および変更追跡
G.従来のファイルシステムの相互運用性
H.ストレージプラットフォームAPI
III.同期API
A.同期の概要
1.ストレージプラットフォームとストレージプラットフォームとの間の同期処理
a)同期(Sync)制御アプリケーション
b)スキーマ注釈
c)同期構成
(1)コミュニティフォルダ−マッピング
(2)プロファイル
(3)スケジュール
d)競合回避処理
(1)競合検出
(a)知識ベースの競合
(b)制約ベースの競合
(2)競合処理
(a)自動競合解決
(b)競合ログ作成
(c)競合の検査および解決
(d)レプリカの収束および競合解決の伝播
2.非ストレージプラットフォームデータストアの同期処理
a)同期サービス
(1)Change Enumeration
(2)Change Application
(3)Conflict Resolution
b)アダプタの実装
3.セキュリティ
4.管理可能性
B.同期処理APIの概要
1.一般的用語
2.同期処理APIの主要事項
C.同期処理APIサービス
1.変更列挙
2.変更適用
3.サンプルコード
4.API同期処理のメソッド
IV.結論
本発明の主題は、法的要件を満たすように特異性とともに説明されている。しかし、説明自体は、本発明のスコープを制限することを意図されていない。むしろ、発明者は、主張されている主題は、他の現在または将来の技術とともに、本明細書で説明されている活動または要素と類似しているが異なるステップまたはステップの組合せを含むように、他の方法でも具現化されうることを考察した。さらに、「ステップ」という用語は、本明細書では、採用されている方法の異なる要素を暗示するために使用される場合があるが、この用語は、個々のステップの順序が明示的に説明されていない場合、かつ説明されている場合を除き、本明細書で開示されている様々なステップ間の特定の順序を暗示するものとして解釈すべきではない。
本発明の数多くの実施形態は、コンピュータ上で実行することができる。図1および以下の説明は、本発明を実施できる適当なコンピューティング環境について簡潔に述べた一般的な説明である。必要というわけではないが、本発明の様々な態様は、クライアントワークステーションまたはサーバなどのコンピュータにより実行される、プログラムモジュールなどの、コンピュータ実行可能命令の一般的文脈において説明することができる。一般に、プログラムモジュールは、特定のタスクを実行する、または特定の抽象データ型を実装するルーチン、プログラム、オブジェクト、コンポーネント、データ構造などを含む。さらに、本発明は、ハンドヘルドデバイス、マルチプロセッサシステム、マイクロプロセッサベースのまたはプログラム可能な家電製品、ネットワークPC、ミニコンピュータ、メインフレームコンピュータなどを含む、他のコンピュータシステム構成を使用して実施できる。また、本発明は、通信ネットワークを通じてリンクされているリモート処理デバイスによりタスクが実行される分散コンピューティング環境で実施することもできる。分散コンピューティング環境では、プログラムモジュールは、ローカルおよびリモートの両方のメモリ記憶デバイス内に配置されうる。
ハードウェア/ソフトウェアインターフェースシステムのシェル(本明細書では単に「シェル」と呼ぶ)は、ハードウェア/ソフトウェアインターフェースシステムとの対話型エンドユーザインターフェースである。(シェルは、「コマンドインタプリタ」と呼ばれたり、オペレーティングシステムでは、「オペレーティングシステムシェル」と呼ばれたりもする。)シェルは、アプリケーションプログラムおよび/またはエンドユーザにより直接アクセス可能なハードウェア/ソフトウェアインターフェースシステムの外側の層である。シェルとは対照的に、カーネルはハードウェアコンポーネントと直接やり取りするハードウェア/ソフトウェアインターフェースシステムの一番内側の層である。
ほとんどの今日のコンピュータシステムでは、「ファイル」は、ハードウェア/ソフトウェアインターフェースシステムだけでなくアプリケーションプログラム、データセットなどをも含むことができる格納可能な情報のユニットである。現代的なすべてのハードウェア/ソフトウェアインターフェースシステム(Windows(登録商標)、Unix(登録商標)、Linux、Mac OS、仮想マシンシステムなど)では、ファイルは、ハードウェア/ソフトウェアインターフェースシステムにより操作可能な情報(例えば、データ、プログラムなど)の基本的に離散的(格納可能および取り出し可能な)ユニットである。ファイルのグループは、「フォルダ」単位で一般的には編成される。Microsoft Windows(登録商標)、Macintosh OS、および他のハードウェア/ソフトウェアインターフェースシステムは、フォルダとは、取り出し可能、移動可能、そして単一の情報ユニットとして他の何らかの手段により操作できるファイルのコレクションである。これらのフォルダは、次に、「ディレクトリ」(以下で詳述する)と呼ばれるツリーベースの階層型配列で編成される。DOS、z/OS、およびほとんどのUnix(登録商標)ベースのオペレーティングシステムなど他のいくつかのハードウェア/インターフェースシステムでは、「ディレクトリ」および/または「フォルダ」という用語は交換して使用することができ、また以前のAppleコンピュータシステム(例えば、Apple IIe)ではディレクトリの代わりに「カタログ」という用語を使用していたが、本明細書で使用されているように、これらの用語はすべて、同義語であり交換可能であるとみなし、階層型情報記憶構造およびそのフォルダおよびファイルコンポーネントに対する他のすべての相当する用語および参照を含むことを意図している。
本発明は、本明細書の前の方で説明したように参照により組み込まれている関連する発明と組み合わせて、データの編成、検索、および共有のためのストレージプラットフォームを対象とするものである。本発明のストレージプラットフォームは、上述の種類の既存のファイルシステムおよびデータベースシステムを超えてデータプラットフォームの概念を拡張し、広げるものであり、Itemsと呼ばれるデータの新しい形態を含む、すべての型のデータ用のストアとなるように設計されている。
本明細書で使用されているように、また請求項で使用されているように、以下の用語は以下の意味を持つ。
・ 「Item」は、単純ファイルとは異なり、ハードウェア/ソフトウェアインターフェースシステムシェルによりエンドユーザに対し公開されるすべてのオブジェクトにわたって一般的にサポートされるプロパティの基本集合を持つオブジェクトであるハードウェア/ソフトウェアインターフェースシステムにアクセスできる格納可能情報のユニットである。Itemsは、さらに、新しいプロパティおよび関係を導入することができる機能を含むすべてのItem型にわたって一般的にサポートされるプロパティおよび関係も有する(本明細書の後の方で詳述する)。
・ 「オペレーティングシステム」(OS)は、アプリケーションプログラムとコンピュータハードウェアとの間の媒介として動作する特別なプログラムである。オペレーティングシステムは、ほとんどの場合、シェルおよびカーネルを備える。
・ 「ハードウェア/ソフトウェアインターフェースシステム」は、コンピュータシステム上で実行されるコンピュータシステムおよびアプリケーションの基礎となるハードウェアコンポーネント間のインターフェースとして使用される、ソフトウェア、またはハードウェアとソフトウェアとの組合せである。ハードウェア/ソフトウェアインターフェースシステムは、通常、オペレーティングシステムを備える(いくつかの実施形態では、オペレーティングシステムのみからなる)。ハードウェア/ソフトウェアインターフェースシステムは、さらに、仮想マシンマネージャ(VMM)、共通言語ランタイム(CLR)またはその機能的等価物、Java(登録商標)仮想マシン(JVM)またはその機能的等価物、またはコンピュータシステム内のオペレーティングシステムの代わりとなる、またはそれへの追加となる他のそのようなソフトウェアコンポーネントを含むこともできる。ハードウェア/ソフトウェアインターフェースシステムの目的は、ユーザがアプリケーションプログラムを実行できるような環境を用意することである。ハードウェア/ソフトウェアインターフェースシステムの目標は、コンピュータシステムを使いやすくするだけでなく、コンピュータハードウェアを効率的な方法で利用できるようにすることである。
図3を参照すると、ストレージプラットフォーム300は、データベースエンジン314上に実装されたデータストア302を備える。一実施形態では、データベースエンジンは、オブジェクトリレーショナルの拡張機能を備えるリレーショナルデータベースエンジンを含む。一実施形態では、リレーショナルデータベースエンジン314は、Microsoft SQL Serverリレーショナルデータベースエンジンを含む。データストア302は、データの編成、検索、共有、同期、およびセキュリティをサポートするデータモデル304を実装する。データの特定の型は、スキーマ340などのスキーマで記述され、ストレージプラットフォーム300は、以下で詳しく説明するように、それらのスキーマを展開するとともに、それらのスキーマを拡張するためのツール346を備える。
本発明のストレージプラットフォーム300のデータストア302は、ストア内に置かれているデータの編成、検索、共有、同期、およびセキュリティをサポートするデータモデルを実装する。本発明のデータモデルでは、「Item」は、ストレージ情報の基本ニットである。このデータモデルは、以下で詳述するが、ItemsおよびItem拡張を宣言し、Items間の関係を確立し、Item FoldersとCategories内にItemsを編成するためのメカニズムを備える。
Itemは、単純ファイルとは異なり、ストレージプラットフォームによりエンドユーザまたはアプリケーションプログラムに対し公開されるすべてのオブジェクトにわたって一般的にサポートされるプロパティの基本集合を持つオブジェクトである格納可能情報のユニットである。Itemsは、さらに、以下で説明するように、新しいプロパティおよび関係を導入することができる機能を含むすべてのItem型にわたって一般的にサポートされるプロパティおよび関係も有する。
・ ItemのItem TypeおよびItemが他のItemの子型の場合(すべてのItemsがBase Schema内の単一ItemおよびItem Typeから派生する本発明のいくつかの実施形態の場合のように)は、任意の適用可能な子型情報(つまり、親Item Typeに関係する情報)。コピー元のオリジナルのItemが他のItemの子型の場合、そのコピーも、その同じItemの子型ともなりうる。
・ もしあればItemの複合型プロパティおよび拡張。オリジナルのItemが複合型のプロパティ(ネイティブまたは拡張)を持つ場合、そのコピーも同じ複合型を持ちうる。
・ 「所有関係」に関するItemのレコード、つまり、現在のItem(「Owning Item」)によって所有される他のItems(「Target Items」)のItemの自リスト。これは、以下で詳しく説明する、Item Foldersに関して特に関連性があり、規則では、すべてのItemsは少なくとも1つのItem Folderに属していなければならないことを以下で規定している。さらに、埋め込まれているアイテム−以下でさらに詳しく説明する−に関しては、埋め込みアイテムは、コピー、削除などのオペレーションに対して埋め込まれているItemの一部と考えられる。
Itemsは、ItemIDを持つ大域的アイテム空間(global items space)内で一意に識別される。Base.Item型は、ItemのIDを格納する型GUIDのItem IDフィールドを定義する。Itemは、データストア302内にちょうど1つのIDがなければならない。
以下で詳しく説明するが、Itemsのグループは、Item Folders(ファイルフォルダと混同すべきでない)と呼ばれる特別なItemsに編成されることができる。しかし、ほとんどのファイルシステムとは異なり、Itemは、複数のItem Folderに属すことができ、そのため、Itemが一方のItem Folderでアクセスされ改訂された場合、この改訂されたItemは、他方のItemフォルダから直接アクセスすることができる。本質的に、Itemへのアクセスは異なるItem Foldersから発生しうるが、実際にアクセスされる内容は、事実、まったく同じItemである。しかし、Item Folderは、必ずしも、そのメンバItemsのすべてを所有するわけではなく、または単に、他のフォルダとともにItemsを共同所有することができ、Item Folderを削除しても、その結果Itemの削除も必ずしも行われるわけではない。しかしながら、本発明のいくつかの実施形態では、Itemは、少なくとも1つのItem Folderに属していなければならず、したがって、特定のItemに対する単独のItem Folderが削除されると、ある実施形態では、Itemは自動的に削除されるか、または他の実施形態では、Itemは自動的に、既定のItem Folder(例えば、様々なファイル−フォルダベースのシステムで使用される類似名フォルダと概念上類似の「Trash Can」Item Folder)のメンバとなる。
a)Base Schema
Itemsの作成および使用に普遍的基盤を用意するため、本発明のストレージプラットフォームの様々な実施形態は、Itemsおよびプロパティの作成および編成に使用する概念フレームワークを確立するBase Schemaを備える。Base Schemaは、Itemsおよびプロパティのいくつかの特殊な型、および子型をさらに派生することができる派生元のこれらの特別な基礎型の特徴を定義する。このBase Schemaを使用することにより、プログラマは、Items(およびそれぞれの型)をプロパティ(およびそれぞれの型)から概念的に区別することができる。さらに、Base Schemaでは、すべてのItems(およびその対応するItem Types)がBase Schema内のこの基礎的Item(およびその対応するItem Type)から派生するときにすべてのItemsが所有することができるプロパティの基礎的集合を規定する。
本発明のストレージプラットフォームの様々な実施形態は、さらに、最上位レベルのItems型構造の概念フレームワークを提供するCore Schemaを含む。図8Aは、Core Schema内のItemsを例示するブロック図であり、図8Bは、Core Schema内のプロパティ型を例示するブロック図である。異なる拡張子(*.com、*.exe、*.bat、*.sysなど)を持つファイルとファイル−フォルダベースのシステムのそのような他の基準を持つファイルとの区別は、Core Schemaの関数に類似している。Core Schemaが、Itemベースのハードウェア/ソフトウェアインターフェースシステムでは、直接的に(Item型により)または間接的に(Item子型により)、すべてのItemsを、Itemベースのハードウェア/ソフトウェアインターフェースシステムが理解し、所定の予測可能な方法で処理できる1つまたは複数のCore Schema Item型に特徴付ける、コアItem型の集合を定義する。定義済みItem型は、Itemベースのハードウェア/ソフトウェアインターフェースシステム内の最も一般的なItemsを反映し、したがって、一定レベルの効率が、Core Schemaを含む定義済みItem型を認識するItemベースのハードウェア/ソフトウェアインターフェースシステムにより得られる。
・ Categories:このItem Type(およびそれから派生した子型)のItemsは、Itemベースのハードウェア/ソフトウェアインターフェースシステムの有効なCategoriesを表す。
・ Commodities:価値ある識別可能なものであるItems。
・ Devices:情報処理機能をサポートする論理構造を備えるItems。
・ Documents:Itemベースのハードウェア/ソフトウェアインターフェースシステムにより解釈されないが、代わりにドキュメント型に対応するアプリケーションプログラムにより解釈されるコンテンツを持つItems。
・ Events:環境内で生じた何らかの出来事を記録するItems。
・ Locations:物理的場所を表すItems(例えば、地理的位置)。
・ Messages:2つ以上のプリンシパルの間の通信のItems(以下に定義する)。
・ Principals:ItemIdだけでなく少なくとも1つの決定的に証明可能なIDを持つItems(例えば、人、組織、グループ、世帯、機関、サービスなどの識別)。
・ Statements:限定はしないが、ポリシー、サブスクリプション、信用などを含む環境に関する特別な情報を持つItems。
・ Certificates(Base Schema内の基礎のPropertyBase型から派生)
・ Principal Identity Keys(Base Schema内のIdentityKey型から派生)
・ Postal Address(Base Schema内のProperty型から派生)
・ Rich Text(Base Schema内のProperty型から派生)
・ EAddress(Base Schema内のProperty型から派生)
・ IdentitySecurityPackage(Base Schema内のRelationship型から派生)
・ RoleOccupancy(Base Schema内のRelationship型から派生)
・ BasicPresence(Base Schema内のRelationship型から派生)
Relationshipsは、一方のItemがソースとして指定され、他方のItemがターゲットとして指定されている2項関係である。ソースItemおよびターゲットItemは、この関係によって関連付けられる。ソースItemは、一般に、関係の存続期間を制御する。つまり、ソースItemが削除される、それらのItem間の関係も削除されるということである。
明示的関係型は、以下の要素により定義される。
・ 関係名は、Name属性で指定される。
・ 関係型として、Holding、Embedding、Referenceのうちの1つ。これは、Type属性で指定される。
・ ソースおよびターゲット終点。それぞれの終点で、参照されているItemの名前および型を指定する。
・ ソース終点フィールドは、一般的に、型ItemID(宣言されない)であり、関係インスタンスと同じデータストア内のItemを参照しなければならない。
・ HoldingおよびEmbedding関係については、ターゲット終点フィールドは、型ItemIDReferenceでなければならず、関係インスタンスと同じストア内のItemを参照しなければならない。Reference関係については、ターゲット終点は任意のItemReference型でよく、他のストレージプラットフォームのデータストア内のItemsを参照することができる。
・ オプションにより、スカラーまたはPropertyBase型の1つまたは複数のフィールドを宣言することができる。これらのフィールドは、関係に関連付けられたデータを格納することができる。
・ 関係インスタンスは、大域的関係テーブルに格納される。
・ すべての関係インスタンスは、組合せ(ソースItemID、関係ID)により一意に識別される。関係IDは、その型に関係なく与えられたItemをソースとするすべての関係について、与えられたソースItemID内で一意である。

保持関係は、ターゲットItemの参照カウントベースの存続期間管理をモデル化するために使用される。
埋め込み関係は、ターゲットItemの存続期間の排他的制御という概念をモデル化する。これらは、複合Itemsの概念を有効にする。
参照関係は、参照するItemの存続期間を制御しない。さらには、参照関係は、ターゲットの存在を保証せず、また関係宣言で指定された通りにターゲットの型も保証しない。これは、参照関係が懸垂になる可能性のあることを意味している。また、参照関係は、他のデータストア内のItemsを参照することができる。参照関係は、Webページ内のリンクに類似の概念として考えることができる。
以下の追加規則および制約条件を関係について適用する。
・ Itemは、(ちょうど1つの埋め込み関係)または(1つまたは複数の保持関係)のターゲットでなければならない。例外の1つは、ルートItemである。Itemは、0またはそれ以上の参照関係のターゲットとすることができる。
・ 埋め込み関係のターゲットであるItemは、保持関係のソースとすることはできない。これは、参照関係のソースとすることができる。
・ Itemは、ファイルから格上げされた場合保持関係のソースとすることはできない。これは、埋め込み関係および参照関係のソースとすることができる。
・ ファイルから格上げされたItemは、埋め込み関係のターゲットとすることはできない。
少なくとも一実施形態では、本発明のストレージプラットフォームは、関係の順序付けをサポートする。順序付けは、基本リレーショナル定義の中で「Order」という名前のプロパティを通じて実行される。Orderフィールド上には一意性制約条件はない。同じ「順序」プロパティ値を持つ関係の順序は保証されないが、低い「順序」の値を持つ関係の後、および高い「順序」フィールド値を持つ関係の前に、順序付けできることが保証される。
・ RelFirstは、順序値OrdFirstを持つ順序付きコレクション内の最初の関係である。
・ RelLastは、順序値OrdLastを持つ順序付きコレクション内の最後の関係である。
・ RelXは、順序値OrdXを持つコレクション内の与えられた関係である。
・ RelPrevは、順序値OrdPrevがOrdXよりも小さい、コレクション内のRelXとの最も近い関係である。
・ RelNextは、順序値OrdNextがOrdXよりも大きい、コレクション内のRelXとの最も近い関係である。
・ InsertBeforeFirst(SourceItemID,Relationship)は、関係を第1の関係としてコレクション内に挿入する。新しい関係の「Order」プロパティの値はOrdFirstよりも小さい場合がある。
・ InsertAfterLast(SourceItemID,Relationship)は、関係を最後の関係としてコレクション内に挿入する。新しい関係の「Order」プロパティの値はOrdLastよりも大きい場合がある。
・ InsertAt(SourceItemID,ord,Relationship)は、「Order」プロパティに対する指定された値を持つ関係を挿入する。
・ InsertBefore(SourceItemID,ord,Relationship)は、与えられた順序値を持つ関係の前に関係を挿入する。新しい関係には、OrdPrevとordの間の、しかもそれを含まない、「Order」値を割り当てることができる。
・ InsertAfter(SourceItemID,ord,Relationship)は、与えられた順序値を持つ関係の後に関係を挿入する。新しい関係には、ordとOrdNextの間の、しかもそれを含まない、「Order」値を割り当てることができる。
・ MoveBefore(SourceItemID,ord,RelationshipID)は、与えられた関係IDを持つ関係を指定された「Order」値を持つ関係の前に移動する。この関係には、OrdPrevとordの間の、しかもそれを含まない、新しい「Order」値を割り当てることができる。
・ MoveAfter(SourceItemID,ord,RelationshipID)は、与えられた関係IDを持つ関係を指定された「Order」値を持つ関係の後に移動する。この関係には、ordとOrdNextの間の、しかもそれを含まない、新しい順序値を割り当てることができる。
前述のRelationshipsは、ItemとそれのItem Folder(s)と間の関係を表すが、ItemからItem Folderに、Item FolderからItemに、またはその両方に論理的に拡張することができる。論理的にItemからItem Folderに拡張するRelationshipは、Item FolderがそのItemに対しパブリックであることを表し、そのItemとの帰属関係情報を共有するが、逆に、ItemからItem Folderへの論理的Relationshipが存在しないことは、Item FolderがそのItemに対しプライベートであり、そのItemとの帰属関係情報を共有しない。同様に、Item FolderからItemに論理的に拡張するRelationshipは、ItemがそのItem Folderに対しパブリックであり共有可能であることを表すが、Item FolderからItemへの論理的Relationshipが存在しないことは、Itemがプライベートであり、非共有可能であることを表す。そのため、Item Folderが他のシステムにエクスポートされる場合、それは新しい文脈で共有される「パブリック」Itemsであり、ItemがそのItems Folders内で他の共有可能なItemsを検索する場合、それは、Itemにそれに属する共有可能Itemsに関する情報を供給する「パブリック」Item Foldersである。
ストレージプラットフォームに対して、上述のように、スキーマの初期集合340を与えることが意図されている。しかし、それに加えて、少なくともいくつかの実施形態では、ストレージプラットフォームにより、独立系ソフトウェアベンダ(ISV)を含む顧客は、新しいスキーマ344(つまり、新しいItemおよびNested Element型)を作成することができる。このセクションでは、スキーマの初期集合340内で定義されているItem型およびNested Element型(または単純に、「Element」型)を拡張することによりそのようなスキーマを作成するためのメカニズムを取りあげる。
・ ISVは新しいItem型、つまり、子型Base.Itemを導入することが許される。
・ ISVは新しいNested Element型、つまり、子型Base.NestedElementを導入することが許される。
・ ISVは新しい拡張、つまり、子型Base.NestedElementを導入することが許される。
・ ISVは、ストレージプラットフォームのスキーマの初期集合340により定義されている型(Item、Nested Element、またはExtension型)をサブタイプ化することはできない。
Item拡張を行うために、データモデルで、さらに、Base.Extensionという名前の抽象型を定義する。これは、拡張型の階層に対するルート型である。アプリケーションでは、Base.Extensionをサブタイプ化して、特定の拡張型を作成することができる。
・ 拡張型はフィールドを持つ。
・ フィールドは、プリミティブまたはネスト要素型とすることができる。
・ 拡張型は、サブタイプ化することができる。
・ 拡張は、関係のソースおよびターゲットとすることはできない。
・ 拡張型インスタンスは、アイテムから独立しては存在し得ない。
・ 拡張型は、ストレージプラットフォームの型定義でのフィールド型として使用することはできない。
NestedElement型は、Item型と同じメカニズムで拡張されない。ネストされた要素の拡張は、ネストされた要素型のフィールドと同じメカニズムにより格納され、アクセスされる。
・ ネストされた要素拡張は、拡張型ではない。それらは、Base.Extension型をルートとする拡張型階層に属さない。
・ ネストされた要素拡張は、アイテムの他のフィールドとともに格納され、大域的にはアクセス可能でない−与えられた拡張型のすべてのインスタンスを取り出すクエリを作成できない。
・ これらの拡張は、他のネストされた要素(アイテムの)が格納されるとの同じ方法で格納される。他のネストされた集合のように、NestedElement拡張はUDTに格納される。これらは、ネストされた要素型のExtensionsフィールドを通じてアクセス可能である。
・ 多値プロパティにアクセスするために使用されるコレクションインターフェースも、型拡張の集合についてアクセスおよび反復するために使用される。
上述のように、データストアは、データベースエンジン上に実装される。本発明では、データベースエンジンは、オブジェクトリレーショナル拡張とともに、Microsoft SQL Serverエンジンなどの、SQLクエリ言語を実装するリレーショナルデータベースエンジンを含む。このセクションでは、データストアが実装するデータモデルのリレーショナルストアへのマッピングについて説明し、また本発明によるストレージプラットフォームクライアントによって消費される論理APIに関する情報も掲載する。しかし、異なるデータベースエンジンが使用される場合に、異なるマッピングを採用できることは理解される。実際、ストレージプラットフォームの概念データモデルをリレーショナルデータベースエンジン上に実装することに加えて、さらに、他のタイプのデータベース、例えば、オブジェクト指向およびXMLデータベース上に実装されることも可能である。
本発明の実施形態では、一実施形態ではMicrosoft SQL Serverエンジンを含むリレーショナルデータベースエンジン314は、組み込みスカラー型をサポートする。組み込みスカラー型は「ネイティブ」と「単純」である。それらは、ユーザが独自の型を定義することはできないという点でネイティブであり、複合構造をカプセル化できないという点で単純である。ユーザ定義型(これ以降、UDT)は、複合構造型を定義することによりユーザが型システムを拡張できるようにすることによりネイティブのスカラー型システムの上の、またそれを超える、型拡張性のためのメカニズムを用意する。UDTは、ユーザにより定義された後、型システムにおいて組み込みスカラー型が使用できる場所であればどこででも使用することができる。
Itemsが大域的に検索可能であることが望ましく、継承および型代替可能性に対する本発明のリレーショナルデータベースでのサポートがあれば、データベースストア内のItemストレージの1つの可能な実装は、すべてのItemsを型Base.Itemの列を含む単一テーブルに格納することである。型代替可能性を使用すると、すべての型のItemsを格納することが可能になり、またYukonの「is of(Type)」演算子を使用してItem型と子型により検索をフィルタ処理することが可能になる。
Extensionsは、Itemsに非常によく似ており、同じ要求条件のうちいくつかを持つ。継承をサポートする他のルート型として、Extensionsはストレージに対する同じ考慮事項とトレードオフの関係の多くの影響を受ける。このため、類似の型族マッピングは、単一テーブルアプローチではなく、むしろ、Extensionsに適用される。もちろん、他の実施形態では、単一テーブルアプローチを使用することが可能である。本発明の実施形態では、ExtensionはItemIDによりちょうど1つのItemに関連付けられ、Itemの文脈において一意であるExtensionIDを含む。Itemsの場合と同様に、ItemIDとExtensionIDのペアからなる、識別を与えられたExtensionを取り出す関数を用意することが可能である。Viewは、Extension型毎に作成され、Item型ビューに類似している。
Nested Elementsは、深くネストされた構造を形成するためにItems、Extensions、Relationships、または他のNested Elements内に埋め込むことができる型である。ItemsおよびExtensionsのように、Nested Elementsは、UDTとして実装されるが、ItemsとExtensions内に格納される。したがって、Nested Elementsは、そのItemおよびExtensionコンテナものを超えるストレージマッピングを持たない。つまり、NestedElement型のインスタンスを直接格納するテーブルはシステムにはなく、Nested Elements専用のビューもない。
データモデル内の各エンティティ、つまり、各Item、Extension、およびRelationshipは一意のキー値を持つ。Itemは、ItemIdにより一意に識別される。Extensionは、(ItemId,ExtensionId)の複合キーにより一意に識別される。Relationshipは、複合キー(ItemId,RelationshipId)により識別される。ItemId、ExtensionId、およびRelationshipIdはGUID値である。
データストア内に作成されたすべてのオブジェクトは、ストレージプラットフォームスキーマ名から派生されたSQLスキーマ名で格納することができる。例えば、ストレージプラットフォームBaseスキーマ(「Base」と呼ばれることが多い)は、「[System.Storage].Item」などの「[System.Storage]」SQLスキーマで型を生成することができる。生成された名前は、命名の競合をなくすため、修飾子が先頭に付けられる。適切であれば、感嘆符(!)が、名前の各論理部分の仕切として使用される。以下のテーブルは、データストア内のオブジェクトに使用される命名規則の概要である。それぞれのスキーマ要素(Item、Extension、Relationship、およびView)は、データストア内のインスタンスにアクセスするために使用される装飾された命名規則とともに一覧にされている。
オブジェクトモデルをストアにマッピングする場合、アプリケーションオブジェクトとともに追加情報が格納されているため、命名競合が発生する可能性がある。命名競合を回避するため、すべての非型固有列(型宣言で名前付きPropertyに直接マッピングされない列)の先頭に、下線(_)文字を付ける。本発明の実施形態では、下線(_)文字は、識別子プロパティの先頭文字としては禁止されている。さらに、CLRとデータストアとの間の命名規則の統一のため、ストレージプラットフォームの型またはスキーマ要素(関係など)のすべてのプロパティは、先頭文字を大文字にしていなければならない。
ビューは、格納されているコンテンツを検索するためストレージプラットフォームにより用意されている。SQLビューは、各ItemおよびExtension型に用意されている。さらに、ビューは、RelationshipsとViewsをサポートするためにも用意されている(Data Modelでの定義に従って)。ストレージプラットフォーム内のすべてのSQLビューおよび基礎のテーブルは読み取り専用である。データは、以下に詳述するように、ストレージプラットフォームAPIのUpdate()メソッドを使用して格納または変更することができる。
・ ItemId、ElementId、RelationshipId、...などのビュー結果の(複数の)論理「key」列。
・ TypeIdなどの結果の型に関するメタデータ情報。
・ Create Version、Update Version、...などの変更追跡列。
・ (複数の)型特有の列(宣言された型のProperties)
・ 型特有のビュー(族ビュー)も、オブジェクトを返すオブジェクト列を含む。
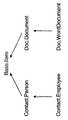
各Item検索ビューは、特定の型またはその子型のItemの各インスタンスに対する1つの行を含む。例えば、Documentに対するビューは、Document、LegaIDocument、およびReviewDocumentのインスタンスを返すことができる。この例では、Itemビューは、図29に示されているように概念化することができる。
ストレージプラットフォームのデータストアのそれぞれのインスタンスは、マスターアイテムビューという特別なItemビューを定義する。このビューは、データストア内のそれぞれのItemに関する概要情報を示す。ビューは、Item型プロパティ毎に1つの列を示し、列は、変更追跡および同期情報を供給するために使用されるItemおよび複数の列の型を記述している。マスターアイテムビューは、名前「[System.Storage].[Master!Item]」を使用してデータストア内で識別される。
各Item型は、さらに、検索ビューを持つ。ルートItemビューに似ているが、このビューは、さらに、「_Item」列を介してItemオブジェクトにアクセスできる。各型付きアイテム検索ビューは、名前[schemaName].[itemTypeName]を使用してデータストア内で識別される。例えば、[AcmeCorp.Doc].[OfficeDoc]。
WinFS Store内のすべてのItem Extensionsは、検索ビューを使用してアクセスすることもできる。
データストアのそれぞれのインスタンスは、マスター拡張ビューという特別なExtensionビューを定義する。このビューは、データストア内のそれぞれのExtensionに関する概要情報を示す。ビューは、Extensionプロパティ毎に1つの列を持ち、列は、変更追跡および同期情報を供給するために使用されるExtensionおよび複数の列の型を記述している。マスター拡張ビューは、名前「[System.Storage].[Master!Extension]」を使用してデータストア内で識別される。
各Extension型は、さらに、検索ビューを持つ。マスター拡張ビューに似ているが、このビューは、さらに、「_Extension」列を介してItemオブジェクトにアクセスできる。各型付き拡張検索ビューは、名前[schemaName].[Extension!extensionTypeName]を使用してデータストア内で識別される。例えば、[AcmeCorp.Doc][Extension!OfficeDocExt]。
すべてのネストされている要素は、Items、Extensions、またはRelationshipsインスタンス内に格納される。したがって、該当するItem、Extension、またはRelationship検察ビューにクエリを行うことで、これらはアクセスされる。
上述のように、Relationshipsは、ストレージプラットフォームのデータストア内にItems間のリンキングの基本ユニットを形成する。
それぞれのデータストアは、Master Relationship Viewを与える。このビューは、データストア内のすべての関係インスタンスに関する情報を示す。マスター関係ビューは、名前「[System.Storage].[Master!Relationship]」を使用してデータストア内で識別される。
それぞれの宣言されたRelationshipは、さらに、特定の関係のすべてのインスタンスを返す検索ビューを持つ。マスター関係ビューに似ているが、このビューは、さらに、関係データのプロパティ毎に名前付き列を示す。各関係インスタンス検索ビューは、名前[schemaName].[Relationship!relationshipName]を使用してデータストア内で識別される。例えば、[AcmeCorp.Doc].[Relationship!DocumentAuthor]。
ストレージプラットフォームのデータストア内のすべてのビューは読み取り専用である。データモデル要素(アイテム、拡張、または関係)の新しいインスタンスを作成する、または既存のインスタンスを更新するには、ストレージプラットフォームAPIのProcessOperationまたはProcessUpdategramメソッドが使用されなければならない。ProcessOperationメソッドは、実行されるアクションの詳細を決める「オペレーション」を消費するデータストアにより定義された単一のストアドプロシージャである。ProcessUpdategramメソッドは、実行されるアクションの集合の詳細を包括的に決める、「アップデートグラム」と呼ばれる、オペレーションの順序付き集合を受け取るストアドプロシージャである。
1.Itemオペレーション:
a.CreateItem(埋め込みまたは保持関係の文脈において新しいアイテムを作成する)
b.UpdateItem(既存のItemを更新する)
2.Relationshipオペレーション:
a.CreateRelationship(参照または保持関係のインスタンスを作成する)
b.UpdateRelationship(関係インスタンスを更新する)
c.DeleteRelationship(関係インスタンスを削除する)
3.Extensionオペレーション:
a.CreateExtension(既存のItemに拡張を追加する)
b.UpdateExtension(既存の拡張を更新する)
c.DeleteExtension(拡張を削除する)
10.変更追跡&ツームストーン
変更追跡およびツームストーンサービスは、以下で詳述するように、データストアにより提供される。このセクションでは、データストア内に公開された変更追跡情報の概要を述べる。
データストアによって与えられるそれぞれの検索ビューは、変更追跡情報を供給するために使用される列を含み、それらの列は、すべてのItem、Extension、およびRelationshipビュー間で共通である。ストレージプラットフォームのSchema Viewsは、スキーマデザイナにより明示的に定義され、変更追跡情報を自動的に供給することはしない−そのような情報は、ビュー自体が構築される検索ビューを通じて間接的に供給される。
マスター検索ビュー内の変更追跡情報は、要素の作成および更新バージョンに関する情報、要素を作成した同期パートナに関する情報、要素を最後に更新した同期パートナに関する情報、および作成および更新に関する各パートナからのバージョン番号を示す。同期関係にあるパートナ(後述)は、パートナキーにより識別される。型[System.Storage.Store].ChangeTrackingInfoの_ChangeTrackingInfoという名前の単一のUDTオブジェクトがこの情報のすべてを格納する。この型は、System.Storageスキーマで定義される。_ChangeTrackingInfoは、Item、Extension、およびRelationshipについてすべての大域的検索ビューで利用可能である。ChangeTrackingInfoの型定義は以下のとおりである。
大域的検索ビューと同じ情報を供給することに加えて、それぞれの型付き検索ビューは、同期トポロジ内の各要素の同期状態を記録した追加情報を供給する。
データストアは、Items、Extensions、およびRelationshipsのツームストーン情報を与える。ツームストーンビューは、ある場所にあるライブ状態のエンティティとツームストーン状態のエンティティ(live and tombstoned entities)(アイテム、拡張、および関係)の両方に関する情報を示す。アイテムおよび拡張ツームストーンビューは、対応するオブジェクトへのアクセスを行えないが、関係ツームストーンビューは、関係オブジェクトへのアクセスを行える(関係オブジェクトは、ツームストーン状態の関係の場合にはNULLである)。
アイテムツームストーンは、ビュー[System.Storage].[Tombstone!Item]を介してシステムから取り出される。
拡張ツームストーンは、ビュー[System.Storage].[Tombstone!Extension]を使用してシステムから取り出される。拡張変更追跡情報は、ExtensionIdプロパティの追加を含むItemsについて与えられる情報と類似している。
関係ツームストーンは、ビュー[System.Storage].[Tombstone!Relationship]を介してシステムから取り出される。関係ツームストーン情報は、Extensionsについて与えられる情報と類似している。しかし、追加情報は、関係インスタンスのターゲットItemRef上で与えられる。さらに、関係オブジェクトも選択される。
ツームストーン情報の際限のない増殖を防ぐために、データストアは、ツームストーンのクリーンアップタスクを用意している。このタスクは、ツームストーン情報をいつ破棄できるかを決定する。このタスクは、ローカルの作成/更新バージョンに対する限界を計算し、その後、旧いすべてのツームストーンバージョンを破棄することによりツームストーン情報を切り詰める。
Baseマッピングは、さらに、多数のヘルパ関数も備える。これらの関数は、データモデルに対する共通のオペレーションを補助するために用意されている。
ストアで表されるメタデータは、インスタンスメタデータ(Itemの型など)および型メタデータの2種類がある。
スキーマメタデータは、MetaスキーマからのItem型のインスタンスとしてデータストア内に格納される。
インスタンスメタデータは、Itemの型についてクエリを実行するためにアプリケーションによって使用され、これによりItemに関連付けられている拡張を見つける。Itemに対するItemIdが与えられれば、アプリケーションは、大域的アイテムビューにクエリを実行して、Itemの型を返し、この値を使用して、Meta.Typeビューにクエリを実行し、Itemの宣言された型に関する情報を返す。例えば、以下のようになる。
一般に、すべてのセキュリティ設定可能なオブジェクトは、図26に示されているアクセスマスク形式を使用してそのアクセス権をアレンジする。この形式では、下位16ビットはオブジェクト特有のアクセス権に、次の7ビットは標準アクセス権に使用され、これは、オブジェクトのほとんどの型に適用され、上位4ビットは各オブジェクト型で標準およびオブジェクト特有の権利の集合にマッピングできる汎用アクセス権を指定するために使用される。ACCESS_SYSTEM_SECURITYビットは、オブジェクトのSACLにアクセスする権利に対応する。
本発明の他の態様によれば、ストレージプラットフォームは、データ変更をアプリケーションで追跡できるようにする通知機能を備える。この機能は、主に、揮発性状態を維持するか、またはデータ変更イベントに関するビジネスロジックを実行するアプリケーション向けである。アプリケーションは、アイテム、アイテム拡張、およびアイテム関係に関する通知を登録する。通知は、データ変更がコミットされた後に非同期に送り出される。アプリケーション側では、アイテム、拡張、および関係型さらにオペレーションの種類により、通知をフィルタ処理することができる。
上述のように、本発明のストレージプラットフォームは、少なくとも一部の実施形態では、コンピュータシステムのハードウェア/ソフトウェアインターフェースシステムのなくてはならない一部として具現化されることを意図されている。例えば、本発明のストレージプラットフォームは、Microsoft Windows(登録商標)ファミリのオペレーティングシステムなどのオペレーティングシステムの重要な一部として具現化されることができる。そのようなキャパシティにおいて、ストレージプラットフォームAPIは、アプリケーションプログラムがオペレーティングシステムとやり取りするために使用するオペレーティングシステムAPIの一部となる。したがって、ストレージプラットフォームは、アプリケーションプログラムがオペレーティングシステムに関する情報を格納するために使用する手段となり、そのため、ストレージプラットフォームのItemベースのデータモデルは、そのようなオペレーティングシステムの従来のファイルシステムの代替えとなる。例えば、Microsoft Windows(登録商標)ファミリのオペレーティングシステムで具現化されているように、ストレージプラットフォームでは、そのオペレーティングシステムで実装されているNTFSファイルシステムを置き換えることも可能である。現在、アプリケーションプログラムは、Windows(登録商標)ファミリのオペレーティングシステムにより公開されているWin32 APIを通じてNTFSファイルシステムのサービスにアクセスしている。
ストレージプラットフォームは、アプリケーションプログラム側で上述のストレージプラットフォームの機能および能力にアクセスし、データストアに格納されているアイテムにアクセスするために使用できるAPIを備える。このセクションでは、本発明のストレージプラットフォームのストレージプラットフォームAPIの一実施形態について説明する。この機能に関する詳細は、本明細書の前の方で参照により組み込まれている関連出願で説明されているが、便宜のため以下にこの情報の一部をまとめた。
1.アプリケーション350a、350b、または350cは、ストレージプラットフォーム内のアイテムにバインドする。
2.フレームワーク2004は、バインドされたアイテムに対応するItemContextオブジェクト2202を作成し、アプリケーションに返す。
3.アプリケーションは、このItemContext上でFindをサブミットして、Itemsのコレクションを取得し、返されるコレクションは、概念上オブジェクトグラフ2204となる(関係により)。
4.アプリケーションは、データを変更、削除、および挿入する。
5.アプリケーションは、Update()メソッドを呼び出して変更を保存する。
Itemベースのハードウェア/ソフトウェアインターフェースシステムにおいて同期に対するいくつかのアプローチが考えられる。セクションAでは、本発明のいくつかの実施形態を開示し、セクションBでは、同期に関してAPIの様々な実施形態に注目する。
本発明のいくつかの実施形態において、図3に関し、ストレージプラットフォームは、(i)ストレージプラットフォーム(それぞれ自データストア302を備える)の複数のインスタンスが柔軟な規則の集まりに従ってその内容の部分の同期をとれるようにし、(ii)本発明のストレージプラットフォームのデータストアと専用プロトコルを実装する他のデータソースとの同期をとるサードパーティ用のインフラストラクチャを備える同期サービス330を提供する。
・ 他のレプリカがどの変更を認識するかを決定する。
・ このレプリカが認識しない変更に関する情報を要求する。
・ 他のレプリカが認識しない変更に関する情報を伝達する。
・ 2つの変更がいつ互いに競合するかを決定する。
・ 変更をローカルで適用する。
・ 競合する解決を他のレプリカに伝達し、収束を保証する。
・ 競合する解決に対する指定されたポリシーに基づき競合状態を解決する。
本発明のストレージプラットフォームの同期サービス330の主要な適用は、ストレージプラットフォームの複数のインスタンスの同期をとることである(それぞれ、自データストアを有する)。同期サービスは、ストレージプラットフォームのスキーマレベルで動作する(データベースエンジン314の基礎のテーブルではなく)。したがって、例えば、「Scopes」は、後述のように同期を定義するために使用される。
どのアプリケーションも、同期サービスに接続し、同期処理オペレーションを開始することができる。そのようなアプリケーションは、同期処理を実行するために必要なすべてのパラメータを用意する(以下のsyncプロファイルを参照)。このようなアプリケーションは、本明細書では、同期制御アプリケーション(SCA)と呼ばれる。
同期サービスの基本概念は、Change Unitの概念である。Change Unitは、ストレージプラットフォームにより個別に追跡されるスキーマ最小断片である。すべてのChange Unitについて、同期サービスは、最後のsync以降に変化したか、変化しなかったかを判別することができる。
データの特定の部分の同期を維持したいストレージプラットフォームパートナのグループは、syncコミュニティと呼ばれる。コミュニティのメンバが同期を維持したい場合、必ずしも、まったく同じ方法でデータを表すわけではない、つまり、syncパートナは、同期処理しているデータを変換することができる。
コミュニティフォルダマッピングは、個々のマシン上にXML構成ファイルとして格納される。それぞれのマッピングは、以下のスキーマを持つ。
/mappings/communityFolder
この要素は、このマッピングの対象となるコミュニティフォルダの名前を指定する。名前はフォルダの構文規則に従う。
この要素は、このマッピングの変換先のローカルフォルダの名前を指定する。名前はフォルダの構文規則に従う。フォルダは、マッピングが有効であるためにすでに存在していなければならない。このフォルダ内のアイテムは、このマッピングに従って同期対象とみなされる。
この要素は、アイテムをコミュニティフォルダからローカルフォルダに、またその逆方向に変換する方法を定義する。存在しない、または空の場合、変換は実行されない。特に、これは、IDがマッピングされないことを意味する。この構成は、主に、Folderのキャッシュを作成する際に使用される。
この要素は、コミュニティIDを再利用するのではなく、新しく生成されたローカルIDがコミュニティフォルダからマッピングされたアイテムのすべてに割り当てられることを要求する。Sync Runtimeは、アイテムの往復変換を行うIDマッピングを保持する。
この要素は、コミュニティフォルダ内のすべてのルートアイテムが指定されたルートの子にされることを要求する。
この要素は、このマッピングに対する要求が処理される際の権限を制御する。存在しない場合、送信者が想定される。
この要素が存在すると、このマッピングへのメッセージの送信者は、偽装され、要求はその信用証明書に従って処理されなければならない。
同期プロファイルは、同期をキックオフするために必要なパラメータ一式である。これは、SCAにより、同期処理を開始するためSync Runtimeによって供給される。ストレージプラットフォームとストレージプラットフォームとの間の同期をとるための同期プロファイルは、以下の情報を含む。
・ Local Folder、変更の送り元および送り先として使用される。
・ 同期をとるRemote Folder名−このFolderは、上で定義されたとおりにマッピングを使用してリモートパートナからパブリッシュされなければならない。
・ Direction−同期サービスは、送信のみ、受信のみ、および送受信同期をサポートする。
・ Local Filter−リモートパートナに送信するローカル情報を選択する。ローカルフォルダに対するストレージプラットフォームクエリとして表される。
・ Remote Filter−リモートパートナから取り出すリモート情報を選択する−コミュニティフォルダに対するストレージプラットフォームクエリとして表される。
・ Transformations−ローカル形式のアイテムの変換方法を定義する。
・ ローカルセキュリティ−リモート終点から取り出された変更がリモート終点(偽装)の許可を得て適用するか、またはローカルで同期を開始したユーザの許可を得て適用するかを指定する。
・ 競合解決ポリシー−競合が拒絶されるか、ログに記録されるか、または自動的に解決されるかを指定する−後者の場合、使用する競合リゾルバとともにそれに対する構成パラメータを指定する。
一実施形態では、同期サービスは、それ専用のスケジューリングインフラストラクチャを用意しない。その代わりに、このタスクを実行するために他のコンポーネントに頼る−Microsoft Windows(登録商標)オペレーティングシステムに付属するWindows(登録商標)Schedulerを使用する。同期サービスは、SCAとして動作し、XMLファイルに保存されている同期プロファイルに基づいて同期をトリガするコマンドラインユーティリティを備える。このユーティリティを使用すると、スケジュールに従って、またはユーザがログオンまたはログオフするなどのイベントへの応答として同期処理を実行するようにWindows(登録商標)Schedulerを非常に簡単に構成できる。
同期サービスにおける競合処理は、(1)変更適用時に実行される、競合検出−このステップでは、変更が安全に適用可能か判別する、(2)自動競合解決およびログ記録−このステップでは(競合が検出された直後に実行される)、競合を解決できるか自動競合リゾルバに問い合わせがゆき、できなればオプションで競合をログに記録できる、(3)競合検査および解決−このステップは、何らかの競合がログに記録されている場合に実行され、同期セッションの状況の外部で実行されるが、このときに、ログに記録された競合は解決され、ログから削除されるようにできる−の3つの段階に分けられる。
本発明の実施形態では、同期サービスは、知識ベースと制約ベースの2種類の競合を検出する。
知識ベースの競合は、2つのレプリカが同じChange Unitに対し独立の変更を加えたときに発生する。2つの変更は、それらがお互いについての知識なしで行われる場合に独立して呼び出される−つまり、第1のバージョンは、第2のバージョンについての知識の対象とならず、またその逆もいえる。同期サービスは、上述のように、レプリカの知識に基づいてそのようなすべての競合を自動的に検出する。
いっしょに適用された場合に独立の変更が完全性制約に違反する場合がある。例えば、2つのレプリカが同じディレクトリ内に同じ名前を持つファイルを作成しようとすると、そのような競合が発生するおそれがある。
競合が検出されると、同期サービスは、(1)変更を拒絶し、それを送信者に送り返すアクション、(2)競合を競合ログに記録するアクション、または(3)競合を自動的に解決するアクションのうちの1つ(同期プロファイル内の同期イニシエータにより選択される)を実行することができる。
同期サービスは、多数の既定の競合リゾルバを備える。このリストは以下のものを含む。
・ local−wins:ローカルに格納されているデータとの競合がある場合に受け取った変更を破棄する。
・ remote−wins:受け取った変更との競合がある場合にローカルデータを破棄する。
・ last−writer−wins:変更のタイムスタンプに基づきChange Unitに従ってlocal−winsまたはremote−winsのいずれかを選択する(同期サービスは、一般に、クロック値に依存しないことに注意されたい。この競合リゾルバはその規則に対する唯一の例外である)。
・ Deterministic:すべてのレプリカ上で同じであることを保証される方法で勝利者を選択するが、他の方法では意味がない−同期サービスの一実施形態では、この機能を実装するためにパートナIDの辞書式比較を使用する。
本当に特別な種類の競合リゾルバとして、Conflict Loggerがある。同期サービスは、競合を型ConflictRecordのItemsとしてログに記録する。これらの記録は、競合が生じているアイテムに再び関係する(アイテム自体が削除されていない限り)。それぞれの競合記録は、競合を引き起こした受け取った変更、競合のタイプ、更新−更新、更新−削除、削除−更新、挿入−挿入、または制約、および受け取った変更のバージョンとそれを送信するレプリカの知識を含む。ログに記録された競合は、後述のように、検査および解決のために使用できる。
同期サービスは、アプリケーション側で競合ログを調べ、その中の競合の解決を提案するためのAPIを備えている。このAPIにより、アプリケーションは、すべての競合、または与えられたItemに関係する競合を列挙することができる。これにより、さらに、そのようなアプリケーションは、ログに記録された競合を解決するために、(1)remote wins−ログに記録された変更を受け入れ、競合しているローカルの変更を上書きする、(2)local wins−ログに記録された変更の競合部分を無視する、および(3)suggest new change−アプリケーションが、オプションにより、競合を解決するマージを提案する場合、の3つの方法のうちの1つを使用することができる。アプリケーションにより競合が解決された後、同期サービスはそれらをログから削除する。
複雑な同期シナリオでは、同じ競合が複数のレプリカで検出される場合がある。このような状況が生じた場合、(1)競合が一方のレプリカで解決され、その解決が他方のレプリカに送られるようにすることができるか、または(2)競合が両方のレプリカ上で自動的に解決されるか、または(3)競合が両方のレプリカで手動で解決される(競合検査APIを通じて)。
本発明のストレージプラットフォームの他の態様によれば、ストレージプラットフォームは、ISVが、ストレージプラットフォームとMicrosoft Exchange、AD、Hotmailなどの従来システムとを同期させるSync Adaptersを実装するためのアーキテクチャを備える。Sync Adaptersは、後述のように、同期サービスにより提供される多くのSync Serviceを利用する。
同期サービスは、多数の同期サービスをアダプタ作成者に提供する。このセッションの残り部分では、ストレージプラットフォームが同期処理を実行しているマシンを「クライアント」と呼び、アダプタの通信先の非ストレージプラットフォームバックエンドを「サーバ」と呼ぶと都合がよい。
Change Enumerationを使用すると、同期サービスにより保持されている変更追跡データに基づき、同期処理アダプタは、データストアFolderに対しこのパートナとの同期が最後に試みられた以降に発生した変更を簡単に列挙することができる。
Change Applicationを使用すると、Sync Adapters側でバックエンドから受け取った変更をローカルストレージプラットフォームに適用することができる。アダプタは、変更をストレージプラットフォームスキーマに変換することが期待される。図24は、ストレージプラットフォームAPIクラスがストレージプラットフォームSchemaから生成されるプロセスを例示している。
上述のConflict Resolutionメカニズム(ログ記録および自動解決オプション)も、同期処理アダプタで利用できる。同期処理アダプタは、変更を適用する場合に競合解決のポリシーを指定することができる。指定した場合、競合は、指定された競合ハンドラに受け渡され、解決されるようにできる(可能ならば)。競合をログに記録することもできる。アダプタは、ローカル変更をバックエンドに適用しようと試みる際に競合を検出する可能性がある。このような場合、アダプタは、それでも、Sync Runtimeにその競合を受け渡し、ポリシーに従って解決することができる。さらに、同期処理アダプタは、同期サービスにより検出された競合が処理のため送り返されるように要求することもできる。これは、バックエンドが競合を格納または解決することができる場合に便利である。
いくつかの「アダプタ」が単に、ランタイムインターフェースを使用するアプリケーションである場合には、アダプタ側で標準アダプターインターフェースを実装することが奨励される。それらのインターフェースを使用することにより、Sync Controlling Applicationsは、与えられた同期プロファイルに従ってアダプタが同期処理を実行するよう要求し、進行中の同期処理をキャンセルし、進行中の同期に関する進行中報告(完了率)を受け取ることができる。
同期サービスは、ストレージプラットフォームにより実装されたセキュリティモデルに導入する物をできるだけ少なくしようとしている。同期処理のための新しい権利を定義するのではなく、既存の権利が使用される。特に、
・ データストアItemを読み込める人は誰でも、そのアイテムへの変更を列挙することができ、
・ データストアItemに書き込める人は誰でも、そのアイテムに変更を適用することができ、
・ データストアItemを拡張できる人は誰でも、そのアイテムに同期メタデータを関連付けることができるということである。
レプリカの分散コミュニティの監視は複雑な問題である。同期サービスは、「スイープ」アルゴリズムを使用して、レプリカのステータスに関する情報を収集し分配することができる。スイープアルゴリズムの特性は、構成されたすべてのレプリカに関する情報は、最終的に回収されること、および失敗(非応答)レプリカが検出されることを保証する。
分散化傾向を強めるデジタル世界において、個人とワークグループは、情報とデータを様々なデバイスおよび場所に格納することが多くなっている。これが、これらの独立した多くの場合本質的に異なるデータストアを常に、ユーザの介入を最小限に抑えて同期させることができるデータ同期サービスの開発の推進要因であった。
・ アプリケーションおよびサービスが異なる「WinFS」ストア間のデータを効率よく同期させることができる。
・ 開発者が「WinFS」ストアと非「WinFS」ストアとの間のデータの同期をとるリッチソリューションを構築することができる。
・ 開発者に、同期処理ユーザエクスペリエンス(synchronization user experience)をカスタマイズするのに適したインターフェースを提供する。
本明細書では、以下に、このセクションのIII.Bの後の方の説明に関連するいくつかの他の精緻化された定義および重要概念を示す。
・ 同期レプリカ(Sync Replica):ほとんどのアプリケーションは、WinFSストア内のアイテムの与えられた部分集合に対する変更の追跡、列挙、および同期処理にしか注目していない。同期処理オペレーションに関わるアイテムの集合は、同期レプリカと呼ばれる。レプリカは、与えられたWinFS包含階層(通常は、Folderアイテムをルートとする)内に含まれるアイテムに関して定義される。すべての同期サービスは、与えられたレプリカのコンテキスト内で実行される。WinFS Syncが、レプリカを定義し、管理し、クリーンアップするためのメカニズムを提供する。レプリカはすべて、与えられたWinFSストア内で一意にそれを識別するGUID識別子を持つ。
・ 同期パートナ(Sync Partner):同期パートナは、WinFSアイテム、拡張、および関係に対する変更に影響を及ぼすことが可能なエンティティとして定義される。したがって、すべてのWinFSストアは、同期パートナと呼ぶことができる。非WinFSストアと同期をとる場合、外部データソース(EDS)も同期パートナと呼ばれる。すべてのパートナは、それを一意に識別するGUID識別子を持つ。
・ 同期コミュニティ(Sync Community):同期コミュニティは、ピアツーピア同期処理オペレーションを使用して同期が保持されるレプリカのコレクションとして定義される。これらのレプリカは、すべて、同じWinFSストア、異なるWinFSストア内にあるか、さらには、非WinFSストア上の仮想レプリカとしてさえ現れることができる。WinFS Syncでは、特にコミュニティ内の同期処理オペレーションのみがWinFS Syncサービス(WinFSアダプタ)を通じて行われる場合に、コミュニティの特定のトポロジを規定または指令しない。同期アダプタ(以下に定義されている)は、独自のトポロジ制約を導入することができる。
・ 変更追跡、変更ユニット、およびバージョン:WinFSストアはすべて、すべてのローカルのWinFS Items、Extensions、およびRelationshipsへの変更を追跡する。変更は、スキーマ内で定義されている変更ユニット精度のレベルで追跡される。Item、Extension、およびRelationship型の最上位レベルのフィールドは、スキーマデザイナにより複数の変更ユニットに細分されることが可能であり、最小精度が1つの最上位レベルのフィールドとなる。変更追跡のために、すべての変更ユニットに、同期パートナidとバージョン番号のペアであるVersionが割り当てられる(バージョン番号は、パートナ特有の単調増加番号である)。Versionsは、ローカルのストア内で変更が生じたり、他のレプリカから取得されるときに更新される。
・ 同期知識:知識は、いつでも与えられた同期レプリカの状態を表す、つまり、ローカルまたは他のレプリカからの与えられたレプリカが認識するすべての変更に関するメタデータをカプセル化する。WinFS Syncは、同期処理オペレーション間で同期レプリカにする知識を保持し、更新する。注意すべき重要なこととして、知識表現により、コミュニティ全体に関して解釈できるのであって、知識が格納されている特定のレプリカに関してだけではないことである。
・ 同期アダプタ:同期アダプタは、Sync Runtime APIを通じてWinFS Syncサービスにアクセスし、WinFSデータと非WinFSデータストアとの同期をとることができるマネージドコードアプリケーションである。シナリオの要求条件に応じて、WinFSデータのどの部分集合およびどのようなWinFSデータ型の同期をとるかは、アダプタ開発者次第である。アダプタは、EDSとの通信、WinFSスキーマとEDSサポートスキーマとの間の変換、独自構成およびメタデータの定義および管理を受け持つ。アダプタでは、WinFS Sync Adapter APIを実装して、WinFS Syncチームにより提供されるアダプタの共通構成および制御インフラストラクチャを利用するよう強く奨励される。詳細については、文献(例えば、非特許文献1および非特許文献2)を参照されたい。
・ リモート知識:与えられた同期レプリカで他のレプリカから変更を取得したい場合、他のレプリカが変更を列挙する際に突き合わせるベースラインとして自分の持つ知識を提供する。同様に、与えられたレプリカ側で、他のレプリカに変更を送りたい場合に、競合の検出のためにリモートレプリカにより使用されることができるベースラインとして自分の持つ知識を提供する。同期変更の列挙および適用時に提供される他のレプリカに関する知識が、リモート知識と呼ばれる。
いくつかの実施形態では、同期APIは、同期構成APIと同期コントローラAPIの2つの部分に分けられる。同期構成APIを使用すると、アプリケーション側で、同期を構成し、2つのレプリカの間の特定の同期セッションのパラメータを指定することができる。与えられた同期セッションについて、構成パラメータは、同期をとるItemsの集合、同期のタイプ(一方向または両方向)、リモートデータソースに関する情報、および競合解決ポリシーを含む。同期コントローラAPIは、同期セッションを開始し、同期をキャンセルし、進行中の同期処理に関する進行状況およびエラー情報を受け取る。さらに、所定のスケジュールに従って同期処理を実行する必要のある特定の実施形態では、そのようなシステムは、スケジューリングをカスタマイズするためのスケジューリングメカニズムを備えることができる。
・ 「WinFS」アイテム、拡張、および関係への変更の追跡。
・ 与えられた過去の状態以降の効率的なインクリメント的変更列挙のサポート。
・ 「WinFS」への外部変更の適用。
・ 変更適用時の競合処理。
本発明のいくつかの実施形態は、変更列挙および変更適用という2つの基本サービスを含む同期サービスを対象とする。
本明細書の前の方で説明されているように、Change Enumerationを使用すると、同期処理アダプタは、同期サービスにより保持されている変更追跡データに基づき、このパートナとの同期が最後に試みられた以降に、データストアFolderに対し発生した変更を簡単に列挙することができる。変更列挙に関して、本発明のいくつかの実施形態は以下を対象とする。
・ 指定されたKnowledgeインスタンスに関して、与えられたレプリカ内のItems、Extensions、およびRelationshipsの変更の効率的列挙。
・ WinFSスキーマ内で指定された変更ユニット精度のレベルでの変更の列挙。
・ 複合アイテムに関して列挙された変更のグループ化。複合アイテムは、アイテム、そのすべての拡張、そのアイテムとのすべての保持関係、およびその埋め込まれたアイテムに対応するすべての複合アイテムからなる。アイテム間の参照関係の変更は、別々に列挙される。
・ 変更列挙に対するバッチ処理。バッチ処理の精度は、複合アイテムまたは関係変更(参照関係の)である。
・ 変更列挙時のレプリカ内のアイテムに対するフィルタの指定、例えば、レプリカは与えられたフォルダ内のすべてのアイテムからなるが、この特定の変更列挙については、アプリケーション側では、第1の名前が「A」で始まるすべてのContactアイテムに対する変更を列挙することのみを望む(このサポートはBマイルストーンの後に(post B−milestone)追加される)。
・ 個々の変更ユニット(または、アイテム、拡張、または関係全体)を知識の中で同期失敗として記録し、それらを次回に再列挙させることができる、列挙された変更に対するリモート知識の使用。
・ 変更列挙時に変更とともにメタデータを返すことによりWinFS同期メタデータを理解できる場合のある上級アダプタの使用。
本明細書のはじめの方で説明されているように、変更適用では、同期アダプタは、ストレージプラットフォームスキーマに変更を変換することが予期されているため、そのバックエンドから受け取った変更をローカルストレージプラットフォームに適用できる。変更適用に関して、本発明のいくつかの実施形態は以下を対象とする。
・ WinFS変更メタデータへの対応する更新のある、他のレプリカ(または非WinFSストア)からのインクリメント的変更の適用。
・ 変更ユニットの精度での変更適用後の競合の検出。
・ 変更適用後に個々の変更ユニットレベルで生じる成功、失敗、および競合の報告であって、アプリケーション(アダプタおよび同期制御アプリケーションを含む)がその情報を進捗状況、エラー、およびステータス報告およびもしあればそのバックエンド状態の更新に使用できるようにする報告。
・ 次の変更列挙オペレーションでアプリケーションにより供給された変更の「反映」を防ぐために変更適用時にリモート知識を更新すること。
・ WinFS同期メタデータを変更とともに理解し提供することができる上級アダプタの使用。
以下に、FOO同期アダプタが同期ランタイムとやり取りする方法を示すコードサンプルを掲載した(すべてのアダプタ特有の関数の先頭にはFOOが付いている)。
//レプリカアイテムidとリモートパートナidをプロファイルから取得する。
//ほとんどのアダプタは、同期プロファイルからこの情報を取得する。
Guid replicaItemId = FOO_GetReplicaId();
Guid remotePartnerId = FOO_Get_RemotePartnerId();
//
//上記のようにstoredKnowledgeIdを使用してストア内に格納されている知識を検索する。
//
ReplicaKnowledge remoteKnowledge = ...;
//
//ReplicaSynchronizerを初期化する。
//
ctx.ReplicaSynchronizer = new ReplicaSynchronizer( replicaItemId, remotePartnerId);
ctx.ReplicaSynchronizer.RemoteKnowledge = remoteKnowledge; ChangeReader reader = ctx.ReplicaSynchronizer.GetChangeReader();
//
//変更を列挙し、それらを処理する。
//
bool bChangesToRead = true;
while (bChangesToRead)
{
ChangeCollection<object> changes = null;
bChangesToRead = reader.ReadChanges( 10, out changes);
foreach (object change in changes)
{
//列挙されているオブジェクトを処理し、アダプタは、それ自体の
//スキーマ変換およびIDマッピングを実行する。この目的のために
//Ctxから追加オブジェクトを取り出して、変更がリモートストアに
//適用された後のアダプタメタデータを修正することすらできる。
ChangeStatus status = FOOProcessAndApplyToRemoteStore(change);
//学習された知識をステータスで更新する
reader.AcknowledgeChange ( changeStatus);
}
}
remoteKnowledge = ctx.ReplicaSynchronizer.GetUpdatedRemoteKnowledge(); reader.Close();
//
//もしあれば更新された知識とアダプタメタデータを保存する。
//
ctx.Update();
//
//変更適用のサンプル、まず最初に、前のようにstoredKnowledgeId
//を使用してリモート知識を初期化する。
//
remoteKnowledge = ...;
ctx.ReplicaSynchronizer.ConflictPolicy = conflictPolicy;
ctx.ReplicaSynchronizer.RemotePartnerId = remotePartnerId;
ctx.ReplicaSynchronizer.RemoteKnowledge = remoteKnowledge;
ctx.ReplicaSynchronizer.ChangeStatusEvent += FOO_OnChangeStatusEvent;
//
//リモートストアから変更を取得する。アダプタは、ストアから
//バックエンド特有のメタデータを取り出す役割を持つ。これは
//レプリカ上の拡張とすることができる。
//
object remoteAnchor = FOO_GetRemoteAnchorFromStore();
FOO_RemoteChangeCollection remoteChanges = FOO_GetRemoteChanges(remoteAnchor);
//
//変更コレクションを充填する。
//
foreach( FOO_RemoteChange change in remoteChanges)
{
//IDマッピングを実行する役割を持つアダプタ
Guid localId = FOO_MapRemoteId(change);
//例えば、Personオブジェクトの同期をとることにする。
ItemSearcher searcher = Person.GetSearcher(ctx);
searcher.Filters.Add("PersonId=@localId");
searcher.Parameters["PersonId"] = localId;
Person person = searcher.FindOne();
//
//アダプタは、リモート変更をPersonオブジェクト上の修正に変換する
//このアダプタの一部として、変更をリモートオブジェクトのアイテム
//レベルのバックエンド特有のメタデータに加えることさえできる。
//
FOO_TransformRemoteToLocal ( remoteChange, person);
}
ctx.Update();
//
//新しいリモートアンカーを保存する(これは、レプリカ上の拡張とすることができる)
//
FOO_SaveRemoteAnchor();
//
//これは、リモート知識の同期がとれていないので、通常のWinFS API保存である。
//
remoteKnowledge = ctx.ReplicaSynchronizer.GetUpdatedRemoteKnowledge();
ctx.Update();
ctx.Close();
//
//アダプタは、アプリケーションステータスコールバックの処理をコールバックする
//
void FOO_OnEntitySaved( object sender, ChangeStatusEventArgs args)
{
remoteAnchor.AcceptChange( args.ChangeStatus);
}
本発明の一実施形態では、WinFSストアと非WinFSストアとの間で同期をとることは、WinFSベースのハードウェア/ソフトウェアインターフェースシステムにより公開されている同期APIを介して可能である。
・ ハードウェア/ソフトウェアインターフェースシステム同期フレームワークにアダプタを登録する標準メカニズム
・ アダプタがその機能およびアダプタを初期化するために必要な構成情報の型を宣言する標準メカニズム
・ 初期化情報をアダプタに受け渡す標準メカニズム
・ アダプタが進捗状況を、同期を呼び出すアプリケーションに送り返して報告するメカニズム
・ 同期処理時に発生したエラーを報告するメカニズム
・ 進行中の同期処理オペレーションのキャンセルを要求するメカニズム
・ セキュリティ目的。アダプタは、特定のプロセスまたはサービスのプロセス空間内で実行されなければならない。
・ アダプタは、呼び出し側アプリケーションからの要求を処理する他に、他のソースからの要求−例えば、受け取ったネットワーク要求−を処理しなければならない。
以下は、本発明の様々な態様に対する同期スキーマの追加(またはより具体的な)態様である。
・ それぞれのレプリカは、データストアの全体から取り出した定義済み同期部分集合−複数のインスタンスを持つスライス−である。
・ 競合解決ポリシーは、それぞれのレプリカ(およびアダプタ/データソースの組合せ)により処理される−つまり、それぞれのレプリカは、自基準と競合解決スキーマに基づいて競合を解決することができる。さらに、データストアのそれぞれのインスタンスの違いが生じ、その結果、将来さらに競合が生じるが、更新された状態情報に反映されるような競合のインクリメント的および順次的列挙は、その更新された状態情報を受け取る他のレプリカからは見えない。
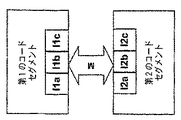
・ 同期スキーマのルートには、一意的なIDを持つルートフォルダ(実際には、ルートItem)を定義するための基本型を持つレプリカ、それがメンバである同期コミュニティに対するID、および特定のレプリカに対し必要な、または望ましい何らかのフィルタおよびその他の要素がある。
・ それぞれのレプリカの「マッピング」は、レプリカ内に保持され、したがって、任意の特定のレプリカのマッピングは、そのようなレプリカが関知している他のレプリカに制限される。このマッピングは、同期コミュニティ全体の部分集合しか含まないが、前記レプリカに対する変更は、それでも、共通の共有レプリカを介して同期コミュニティ全体に伝搬する(ただし、特定のレプリカは、不明なレプリカと他のどのレプリカをふつうに共有しているかを認識しない)。さらに、それぞれのレプリカは、同じ同期コミュニティにおいて異なる同期パートナとの異なる同期ビヘイビアを許容するように複数のマッピングを備えることができる。
・ レプリカのマッピングは、コミュニティ識別および同期パートナのマッピング識別を含むだけでよく、このため、レプリカは、同期パートナレプリカの物理的位置を必ずしも知らなくてもパートナと同期をとることができる(したがって、同期パートナレプリカのセキュリティが向上する)。
・ 同期スキーマは、すべてのレプリカから利用できる複数の定義済み競合ハンドラとともに、ユーザ/開発者定義済みカスタム競合ハンドラの機能を含む。スキーマは、さらに、3つの特別な「競合リゾルバ」として、(a)例えば、(i)同じ変更ユニットが2つの場所で変更された場合の取り扱い方法、(ii)変更ユニットが一方の場所で変更され、他方の場所で削除される場合の取り扱い方法、および(iii)2つの異なる変更ユニットが2つの異なる場所で同じ名前を持つ場合の取り扱い方法に基づく異なる方法で異なる競合を解決する競合「フィルタ」、(b)リストの各要素で競合が正常に解決されるまで順番に試みる一連のアクションを指定する場合の競合「ハンドラリスト」、および(c)競合を追跡するが、ユーザ介入なしでアクションをさらに実行することはしない「何もしない」ログを含むこともできる。
・ レプリカの同期スキーマおよび使用により、真の分散型ピアツーピアマルチマスター同期コミュニティが使用可能になる。さらに、同期コミュニティタイプはないが、同期コミュニティは、単に、レプリカ自体のコミュニティフィールドの中の値としてだけ存在する。
・ すべてのレプリカは、インクリメント的変更列挙を追跡し、同期コミュニティで知られている他のレプリカに対する状態情報を格納するため自メタデータを持つ。
・ 変更ユニットは、自メタデータを持ち、これは、パートナキーとパートナ変更番号を含むバージョン番号、各変更ユニットのItem/Extension/Relationshipのバージョニング、同期コミュニティからレプリカが見た/受信した変更に関する知識、GUIDおよびローカルID構成、およびクリーンアップのため参照関係上に格納されているGUIDを含む。
これまでに例示したように、本発明は、データの編成、検索、および共有のためのストレージプラットフォームを対象とする。本発明のストレージプラットフォームは、既存のファイルシステムおよびデータベースシステムを超えるデータストレージの概念を拡張し、広げるものであり、リレーショナル(表形式)データ、XML、およびItemsと呼ばれる新しいデータ形態などの、構造化、非構造化、または半構造化データを含むすべての型のデータ用のストアとなるように設計されている。本発明のストレージプラットフォームでは、共通のストレージ基盤および図式化されたデータを通じて、より効率的なアプリケーション開発を消費者、知識労働者、および企業向けに行うことができる。これは、データモデルに固有の機能を利用可能にするだけでなく、既存のファイルシステムおよびデータベースアクセス方法も包含し、拡張する機能豊富な拡張可能アプリケーションプログラミングインターフェースを備える。本発明の広範な概念から逸脱することなく、上述の実施形態に対し変更を加えられることは理解される。したがって、本発明は、開示されている特定の実施形態に限定されず、付属の請求項の定義に従って本発明の精神および範囲内にあるすべての修正形態を対象とすることを意図されている。
Claims (18)
- ハードウェア/ソフトウェアインターフェースシステム用ストレージプラットフォームの同期をとる方法であって、
第1のリレーショナルデータベースを第1のコンピューティングシステムが格納するステップであって、前記第1のリレーショナルデータベースはアイテムのローカルバージョンおよびフォルダアイテムを含み、前記アイテムのローカルバージョンは変更ユニットおよび第1のバージョン番号を含み、前記フォルダアイテムはコミュニティフォルダへマッピングされる、格納するステップと、
前記アイテムのローカルバージョンの変更ユニットにおける要素の値の変更毎に前記第1のバージョン番号を前記第1のコンピューティングシステムが1増加させるステップと、
第2のコンピューティングシステムから前記アイテムのリモートバージョンを前記第1のコンピューティングシステムが受信するステップであって、前記第2のコンピューティングシステムは第2のリレーショナルデータベースを格納し、前記第2のリレーショナルデータベースは前記アイテムのリモートバージョンを含み、前記アイテムのリモートバージョンは変更ユニットおよび第2のバージョン番号を含み、前記第2のコンピューティングシステムは前記アイテムのリモートバージョンの変更ユニットにおける要素の値の変更毎に前記第2のバージョン番号を1増加させるよう構成される、受信するステップと、
前記第2のバージョン番号が前記第1のバージョン番号よりも新しい場合、
前記コミュニティフォルダからのアイテムのリモートバージョンをローカルバージョンへ前記第1のコンピューティングシステムが変換するステップと、
前記アイテムのリモートバージョンの変換後、前記アイテムのローカルバージョンの変更ユニットにおける要素の値を前記アイテムのリモートバージョンの変更ユニットにおける要素の値により前記第1のコンピューティングシステムが取り替えるステップと
を備えたことを特徴とする方法。 - 前記変更ユニットは、Itemであることを特徴とする請求項1に記載の方法。
- 前記変更ユニットは、Propertyであることを特徴とする請求項1に記載の方法。
- 前記変更ユニットは、Nested ElementのPropertyを含まないことを特徴とする請求項1に記載の方法。
- 前記ストレージプラットフォームの複数のインスタンスは、マルチマスター同期コミュニティを含むことを特徴とする請求項1に記載の方法。
- 前記アイテムのローカルバージョンの変更ユニットにおける要素の値と前記アイテムのリモートバージョンの変更ユニットにおける要素の値との間の競合を前記第1のコンピューティングシステムが検出するステップと、
前記アイテムのローカルバージョンの変更ユニットにおける要素の値と前記アイテムのリモートバージョンの変更ユニットにおける要素の値との間の競合を前記第1のコンピューティングシステムが解決するステップと
をさらに備えたことを特徴とする請求項1に記載の方法。 - ハードウェア/ソフトウェアインターフェースシステム用ストレージプラットフォームの同期をとるコンピューティングシステムであって、
アイテムのローカルバージョンおよびフォルダアイテムを含む第1のリレーショナルデータベースであって、前記アイテムのローカルバージョンは変更ユニットおよび第1のバージョン番号を含み、前記フォルダアイテムはコミュニティフォルダへマッピングされる、第1のリレーショナルデータベースと、
前記アイテムのローカルバージョンの変更ユニットにおける要素の値の変更毎に前記第1のバージョン番号を1増加させる手段と、
別のコンピューティングシステムから前記アイテムのリモートバージョンを受信する手段であって、前記別のコンピューティングシステムは第2のリレーショナルデータベースを格納し、前記第2のリレーショナルデータベースは前記アイテムのリモートバージョンを含み、前記アイテムのリモートバージョンは変更ユニットおよび第2のバージョン番号を含み、前記別のコンピューティングシステムは前記アイテムのリモートバージョンの変更ユニットにおける要素の値の変更毎に前記第2のバージョン番号を1増加させるよう構成される、受信する手段と、
前記第2のバージョン番号が前記第1のバージョン番号よりも新しい場合、
前記コミュニティフォルダからのアイテムのリモートバージョンをローカルバージョンへ変換する手段と、
前記アイテムのリモートバージョンの変換後、前記アイテムのローカルバージョンの変更ユニットにおける要素の値を前記アイテムのリモートバージョンの変更ユニットにおける要素の値により取り替える手段と
を備えたことを特徴とするシステム。 - 前記変更ユニットは、Itemであることを特徴とする請求項7に記載のシステム。
- 前記変更ユニットは、Propertyであることを特徴とする請求項7に記載のシステム。
- 前記変更ユニットは、Nested ElementのPropertyを含まないことを特徴とする請求項7に記載のシステム。
- 前記ストレージプラットフォームの複数のインスタンスは、マルチマスター同期コミュニティを含むことを特徴とする請求項7に記載のシステム。
- 前記アイテムのローカルバージョンの変更ユニットにおける要素の値と前記アイテムのリモートバージョンの変更ユニットにおける要素の値との間の競合を検出する手段と、
前記アイテムのローカルバージョンの変更ユニットにおける要素の値と前記アイテムのリモートバージョンの変更ユニットにおける要素の値との間の競合を解決する手段と
をさらに備えたことを特徴とする請求項7に記載のシステム。 - コンピュータに、ハードウェア/ソフトウェアインターフェースシステム用ストレージプラットフォームの同期を実行させるためのプログラムを記録したコンピュータ可読記録媒体であって、
第1のリレーショナルデータベースを格納する手順であって、前記第1のリレーショナルデータベースはアイテムのローカルバージョンおよびフォルダアイテムを含み、前記アイテムのローカルバージョンは変更ユニットおよび第1のバージョン番号を含み、前記フォルダアイテムはコミュニティフォルダへマッピングされる、格納する手順と、
前記アイテムのローカルバージョンの変更ユニットにおける要素の値の変更毎に前記第1のバージョン番号を1増加させる手順と、
別のコンピューティングシステムから前記アイテムのリモートバージョンを受信する手順であって、前記別のコンピューティングシステムは第2のリレーショナルデータベースを格納し、前記第2のリレーショナルデータベースは前記アイテムのリモートバージョンを含み、前記アイテムのリモートバージョンは変更ユニットおよび第2のバージョン番号を含み、前記別のコンピューティングシステムは前記アイテムのリモートバージョンの変更ユニットにおける要素の値の変更毎に前記第2のバージョン番号を1増加させるよう構成される、受信する手順と、
前記第2のバージョン番号が前記第1のバージョン番号よりも新しい場合、
前記コミュニティフォルダからのアイテムのリモートバージョンをローカルバージョンへ変換する手順と、
前記アイテムのリモートバージョンの変換後、前記アイテムのローカルバージョンの変更ユニットにおける要素の値を前記アイテムのリモートバージョンの変更ユニットにおける要素の値により取り替える手順と
を実行させるプログラムを記録したことを特徴とするコンピュータ可読記録媒体。 - 前記変更ユニットは、Itemであることを特徴とする請求項13に記載のコンピュータ可読記録媒体。
- 前記変更ユニットは、Propertyであることを特徴とする請求項13に記載のコンピュータ可読記録媒体。
- 前記変更ユニットは、Nested ElementのPropertyを含まないことを特徴とする請求項13に記載のコンピュータ可読記録媒体。
- 前記ストレージプラットフォームの複数のインスタンスは、マルチマスター同期コミュニティを含むことを特徴とする請求項13に記載のコンピュータ可読記録媒体。
- 前記第1のコンピューティングシステムによって、前記アイテムのローカルバージョンの変更ユニットにおける要素の値と前記アイテムのリモートバージョンの変更ユニットにおける要素の値との間の競合を検出する手段と、
前記第1のコンピューティングシステムによって、前記アイテムのローカルバージョンの変更ユニットにおける要素の値と前記アイテムのリモートバージョンの変更ユニットにおける要素の値との間の競合を解決する手段と
を実行させるプログラムをさらに記録したことを特徴とする請求項13に記載のコンピュータ可読記録媒体。
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US10/646,632 US7529811B2 (en) | 2003-08-21 | 2003-08-21 | Systems and methods for the implementation of a core schema for providing a top-level structure for organizing units of information manageable by a hardware/software interface system |
| PCT/US2003/026144 WO2005029313A1 (en) | 2003-08-21 | 2003-08-21 | Systems and methods for data modeling in an item-based storage platform |
| US10/693,362 US8166101B2 (en) | 2003-08-21 | 2003-10-24 | Systems and methods for the implementation of a synchronization schemas for units of information manageable by a hardware/software interface system |
| PCT/US2004/024287 WO2005024626A1 (en) | 2003-08-21 | 2004-07-29 | Systems for the implementation of a synchronization schemas |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2007503049A JP2007503049A (ja) | 2007-02-15 |
| JP4583375B2 true JP4583375B2 (ja) | 2010-11-17 |
Family
ID=34279605
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2006523856A Expired - Fee Related JP4583375B2 (ja) | 2003-08-21 | 2004-07-29 | 同期スキーマの実装のためのシステム |
Country Status (5)
| Country | Link |
|---|---|
| EP (1) | EP1573508A4 (ja) |
| JP (1) | JP4583375B2 (ja) |
| KR (1) | KR101109399B1 (ja) |
| CN (1) | CN1739093B (ja) |
| WO (1) | WO2005024626A1 (ja) |
Families Citing this family (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8166101B2 (en) | 2003-08-21 | 2012-04-24 | Microsoft Corporation | Systems and methods for the implementation of a synchronization schemas for units of information manageable by a hardware/software interface system |
| US7590643B2 (en) | 2003-08-21 | 2009-09-15 | Microsoft Corporation | Systems and methods for extensions and inheritance for units of information manageable by a hardware/software interface system |
| US8131739B2 (en) | 2003-08-21 | 2012-03-06 | Microsoft Corporation | Systems and methods for interfacing application programs with an item-based storage platform |
| US8238696B2 (en) | 2003-08-21 | 2012-08-07 | Microsoft Corporation | Systems and methods for the implementation of a digital images schema for organizing units of information manageable by a hardware/software interface system |
| US7805422B2 (en) | 2005-02-28 | 2010-09-28 | Microsoft Corporation | Change notification query multiplexing |
| US7788163B2 (en) * | 2005-03-11 | 2010-08-31 | Chicago Mercantile Exchange Inc. | System and method of utilizing a distributed order book in an electronic trade match engine |
| US7991740B2 (en) * | 2008-03-04 | 2011-08-02 | Apple Inc. | Synchronization server process |
| WO2012047138A1 (en) * | 2010-10-04 | 2012-04-12 | Telefonaktiebolaget L M Ericsson (Publ) | Data model pattern updating in a data collecting system |
| TWI497311B (zh) * | 2013-03-28 | 2015-08-21 | Quanta Comp Inc | 跨裝置通訊傳輸系統及其方法 |
| US9542467B2 (en) | 2013-11-18 | 2017-01-10 | International Business Machines Corporation | Efficiently firing mapping and transform rules during bidirectional synchronization |
| US9367597B2 (en) | 2013-11-18 | 2016-06-14 | International Business Machines Corporation | Automatically managing mapping and transform rules when synchronizing systems |
| US10402744B2 (en) | 2013-11-18 | 2019-09-03 | International Busniess Machines Corporation | Automatically self-learning bidirectional synchronization of a source system and a target system |
| US10628424B2 (en) | 2016-09-15 | 2020-04-21 | Oracle International Corporation | Graph generation for a distributed event processing system |
Family Cites Families (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP0752653B1 (en) * | 1995-07-07 | 2003-01-15 | Sun Microsystems, Inc. | Method and system for synchronizing the execution of events during software testing |
| US5774717A (en) * | 1995-12-15 | 1998-06-30 | International Business Machines Corporation | Method and article of manufacture for resynchronizing client/server file systems and resolving file system conflicts |
| US5893106A (en) | 1997-07-11 | 1999-04-06 | International Business Machines Corporation | Object oriented server process framework with interdependent-object creation |
| US6553391B1 (en) * | 2000-06-08 | 2003-04-22 | International Business Machines Corporation | System and method for replicating external files and database metadata pertaining thereto |
| JP2002149464A (ja) * | 2000-08-17 | 2002-05-24 | Fusionone Inc | データ転送および同期システム用のベースローリングエンジン |
| DE60213419T2 (de) * | 2001-03-16 | 2007-10-31 | Novell, Inc., Provo | Client-server-modell zur synchronisation von dateien |
| US7711771B2 (en) * | 2001-05-25 | 2010-05-04 | Oracle International Corporation | Management and synchronization application for network file system |
| WO2003044698A1 (en) * | 2001-11-15 | 2003-05-30 | Visto Corporation | System and methods for asychronous synchronization |
| GB0128243D0 (en) * | 2001-11-26 | 2002-01-16 | Cognima Ltd | Cognima patent |
-
2004
- 2004-07-29 WO PCT/US2004/024287 patent/WO2005024626A1/en active Application Filing
- 2004-07-29 EP EP04757348A patent/EP1573508A4/en not_active Ceased
- 2004-07-29 CN CN2004800023968A patent/CN1739093B/zh not_active Expired - Fee Related
- 2004-07-29 KR KR1020057012324A patent/KR101109399B1/ko active IP Right Grant
- 2004-07-29 JP JP2006523856A patent/JP4583375B2/ja not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| CN1739093B (zh) | 2010-05-12 |
| EP1573508A4 (en) | 2006-04-26 |
| CN1739093A (zh) | 2006-02-22 |
| KR20070083241A (ko) | 2007-08-24 |
| KR101109399B1 (ko) | 2012-01-30 |
| WO2005024626A1 (en) | 2005-03-17 |
| JP2007503049A (ja) | 2007-02-15 |
| EP1573508A1 (en) | 2005-09-14 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP4583377B2 (ja) | ハードウェア/ソフトウェアインターフェースシステムにより管理可能な情報のユニットに対する関係および階層の同期サービスを実現するシステムおよび方法 | |
| JP4583376B2 (ja) | ハードウェア/ソフトウェアインタフェースシステムにより管理可能な情報のユニットに対する同期処理サービスを実現するシステムおよび方法 | |
| JP4738908B2 (ja) | ハードウェア/ソフトウェアインターフェースシステムにより管理可能な情報の単位のピアツーピア同期化のための競合処理を提供するためのシステムおよび方法 | |
| US8166101B2 (en) | Systems and methods for the implementation of a synchronization schemas for units of information manageable by a hardware/software interface system | |
| US7743019B2 (en) | Systems and methods for providing synchronization services for units of information manageable by a hardware/software interface system | |
| JP4394643B2 (ja) | アイテムベースのストレージプラットフォームにおけるデータモデリングのためのシステムおよび方法 | |
| US20050049994A1 (en) | Systems and methods for the implementation of a base schema for organizing units of information manageable by a hardware/software interface system | |
| JP2007521533A (ja) | アプリケーションプログラムをアイテムベースのストレージプラットフォームとインターフェースするためのシステムおよび方法 | |
| JP4583375B2 (ja) | 同期スキーマの実装のためのシステム | |
| JP4580389B2 (ja) | 仲介ファイルシステム共有または仲介デバイスを介してコンピュータシステムを同期させるためのシステムおよび方法 | |
| JP4580390B2 (ja) | ハードウェア/ソフトウェアインターフェイスシステムによって管理可能な情報単位の拡張および継承のためのシステムおよび方法 | |
| JP4394644B2 (ja) | データの編成、検索、および共有のためのストレージプラットフォーム | |
| KR101109390B1 (ko) | 하드웨어/소프트웨어 인터페이스 시스템에 의해 관리가능한 정보의 단위들에 대한 동기화 서비스를 제공하는시스템 및 방법 | |
| KR20060110733A (ko) | 중간 파일 시스템 공유 또는 장치를 통해 컴퓨터 시스템을동기화하는 시스템 및 방법 | |
| NZ540221A (en) | Systems and methods for extensions and inheritance for units of information manageable by a hardware/software interface system |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20070730 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20100413 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20100713 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20100824 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20100831 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 4583375 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20130910 Year of fee payment: 3 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| S111 | Request for change of ownership or part of ownership |
Free format text: JAPANESE INTERMEDIATE CODE: R313113 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| LAPS | Cancellation because of no payment of annual fees |