ノン・パイプラインとパイプラインとの性能差は明確である。基本的に同一命令であれば、パイプラインの段数だけスループットは確実に向上する。たとえば、4段のパイプラインでは、スループットは4倍以上となることが期待でき、8段のパイプラインであれば、8倍という計算となり、スーパー・パイプライン技術は、更に性能を2倍以上向上させたことになる。実際は、プロセスの進歩に従い、クリティカルパスを細分化可能な為、動作周波数の上限を大きく改善するという効果も期待出来るので、その貢献度は更に大きいものとなって現われる。しかしながら、分岐命令のディレイ(ペナルティ)は解消されておらず、スーパー・パイプライン方式のマシンが成功するか否かは、メモリアクセスや分岐に対応した深い段数の遅延を、コンパイラによる命令スケジューリングなどによってどこまで処理できるかにかかっている。
次に、スーパー・スケーラ技術であるが、これは内部のデータパスを高性能化し、プログラムカウンタ近傍の命令を同時実行するものである。この技術はコンパイラの最適化技術の進歩にも支えられて、4命令から8命令程度の同時実行が可能になったとされている。しかしながら、命令自体はその直前の演算結果やレジスタの結果を頻繁に使用する事が多く、ピーク性能は別にして、フォワーディングや命令再配置、アウト・オブ・オーダ、レジスタリネーミング等の各種テクニックを駆使したとしても同時実行可能な命令数は平均的には上記よりかなり低い値とならざるを得ない。特に、条件分岐命令等を複数実行することは不可能なので、スーパー・スケーラ技術の効果は更に低いものとなる。したがって、プロセッサの性能向上への貢献度としては、平均2.0から2.5倍程度と思われる。非常に相性の良いアプリケーションが仮にあったとしても、現実的な貢献度は4倍以下と考えられる。
VLIW技術が、次の技術として浮上する。これは、予めデータパスを並列実行可能なように構成しておき、コンパイラがこの並列実行を高めるように、最適化を行い目的のVLIW命令コードを生成するという考え方であり、極めて合理的な考え方を採用している。これにより、スーパー・スケーラのように1つ1つの命令の並列実行の可能性をチェックする回路が不要なので、並列実行を行うハードウェアの実装手段としては、極めて有望とされているものである。しかしながら、条件分岐命令などを複数実行できないことは上記と同様であり、そのため、実際の性能に対する貢献度としては、3.5倍〜5倍程度と考えられる。しかしながら、画像処理や特殊データ処理を必要とするアプリケーションの処理を用途とするプロセッサを考えると、VLIWも最適な解決策とはならない。特に演算結果の連続処理を要求されるような用途では、汎用レジスタにデータを抱えながらの演算やデータ処理には限界があるからである。これは従来のパイプライン技術でも同様である。
一方、各種のマトリックス計算やベクトル計算等は、専用回路によりこれを実現した方が高い性能を得られることは過去の経験から良く知られている。このため、現在、世界最高性能を目指す最先端の実装技術では、VLIWをベースにアプリケーション目的に応じて、各種の専用演算回路を実装して、最高性能を目指すという考え方が主流になりつつある。
しかしながら、VLIWは、プログラムカウンタ近傍の並列処理実行効率を改善する技術であり、例えば2つ以上のオブジェクトを同時に実行したり、2つ以上の関数を実行するにはあまり有効な手段とはならない。また、各種の専用演算回路を実装することはハードウェアが増加することとなり、その一方で、ソフトウェアのフレキシビリティーが低下することを意味する。さらに、条件分岐を実行するときに発生するペナルティの問題を本質的に解決し難い。
そこで、本発明においては、これらの従来のプロセッサを高速化する技術と異なった視点から上記の問題を検討し、新たな解決策を提供することを目的としている。すなわち、パイプラインのようにスループットの向上を図ることができると共に、条件分岐を実行する際のペナルティを解決することが可能な制御方法を提供することを目的としている。さらに、複雑なデータ処理であっても、それらのデータ処理に特化した多種多様な専用回路を用いなくても、それぞれのデータ処理をフレキシブルに、そして高速に実行可能な制御方法を提供することも本発明の目的としている。
本発明の一態様は、再構成可能なデータ処理装置の制御方法である。データ処理装置は、演算または他のデータ処理を実行する複数の処理ユニットであって、それぞれ独自のコンフィグレーションメモリを備え、入力および/または出力インタフェースおよび処理内容が変更される複数の処理ユニットと、前記複数の処理ユニットの入力および/または出力インタフェースおよび処理内容を規定する制御ユニットとを含み、複数の処理ユニットの少なくとも一部を用いて少なくとも1つのデータフローが構成される。制御方法は、制御ユニットが、複数の処理ユニットの少なくとも一部の処理ユニットの独自のコンフィグレーションメモリのデータをそれぞれ、特定のデータ処理の実行が決定される1または数クロック前に書き換える工程と、制御ユニットが、少なくとも一部の処理ユニットに対し、それら少なくとも一部の処理ユニットが、共に、それぞれの入力および/または出力インタフェースおよび処理内容を、それぞれの独自のコンフィグレーションメモリに記憶されたデータにしたがって切り替える命令を出し、それら少なくとも一部の処理ユニットにより特定のデータ処理を実行するデータフローを再構成する工程とを有する。これにより、ハードウェアを随時、実行される蓋然性の高い特定のデータ処理に適した構成に変更でき、さらに、複雑なデータ処理であっても、それらのデータ処理に特化した多種多様な専用回路を用いずに、それぞれのデータ処理をフレキシブルに、そして高速に実行できる。複数の処理ユニットにより複数のデータ処理をそれぞれ実行可能な複数のデータフローを構成可能であれば、再構成する工程では、他のデータ処理と並列して、特定のデータ処理を実行するデータフローを再構成することができる。
本発明の他の態様の1つは、演算または他のデータ処理を実行する複数の処理ユニットであって、それぞれ独自のコンフィグレーションメモリを備え、入力および/または出力インタフェースおよび処理内容が変更される複数の処理ユニットと、複数の処理ユニットの入力および/または出力インタフェースおよび処理内容を規定する制御ユニットとを有し、複数の処理ユニットの少なくとも一部を用いて少なくとも1つのデータフローが構成される、再構成可能なデータ処理装置である。制御ユニットは、複数の処理ユニットの少なくとも一部の処理ユニットの独自のコンフィグレーションメモリのデータをそれぞれ、特定のデータ処理の実行が決定される1または数クロック前に書き換える機能と、少なくとも一部の処理ユニットに対し、それら少なくとも一部の処理ユニットが、共に、それぞれの入力および/または出力インタフェースおよび処理内容を、それぞれの独自のコンフィグレーションメモリに記憶されたデータにしたがって切り替える命令を出し、少なくとも一部の処理ユニットにより特定のデータ処理を実行するデータフローを再構成する機能とを含む。
すなわち、本願の発明者は、上記のような問題がノン・パイプライン技術から今までの技術に用いられている命令セットの制約から上記のような問題が生じていることを見出した。例えば、プロセッサにおけるデータ処理を規定するプログラム(マイクロコード、アセンブリコード、機械語など)の命令セット(命令フォーマット)は命令操作(実行命令)とその命令を実行する際に使用するレジスタなどの環境またはインタフェースを規定するオペランドとが組み合わせされたニーモニックコードである。したがって、命令セットを見れば、それによって指示されている処理の内容を完全に把握できるが、命令セットをデコードするまで処理の内容については全く判らない。そこで、本発明のひとつの形態においては、命令セットの構成方法そのものを大幅に変更することにより、従来技術では対応の難しかった上記の問題を上手く解決し、データ処理装置の性能を飛躍的に向上できるようにしている。
この発明においては、データ処理装置を構成する少なくとも1つの処理ユニットで実行する演算または他のデータ処理の内容を指示する実行命令を記述(記載)可能な第1のフィールドと、実行命令で実行する演算または他のデータ処理が実行可能な状態に処理ユニットを設定する準備情報を記述(記載)可能な第2のフィールドとを備えた命令セットを設け、第1のフィールドに記述された実行命令の内容に対し、独立した演算または他のデータ処理の準備情報が第2のフィールドに記述できるようにしている。したがって、この命令セットを有する制御プログラム製品あるいは制御プログラム装置を提供することができる。この制御プログラムは、データ処理装置が読み取り可能な適当な記録媒体に記録して提供でき、また、その制御プログラムを、コンピュータネットワークあるいはその他の通信を介して伝送される伝送媒体に埋め込んで提供できる。
処理ユニットは、データ処理装置を構成する適当な機能的あるいはデータパス的に分割可能な単位であり、制御ユニット、算術演算ユニット、さらには、ある程度コンパクトなデータパスを備えてテンプレート的に取り扱い可能な特定のデータパスを具備した処理ユニットあるいはデータフロー処理ユニットなどが含まれる。
さらに、このデータ処理装置は、演算または他のデータ処理を実行する少なくとも1つの処理ユニットと、処理ユニットで実行する演算または他のデータ処理の内容を指示する実行命令を記述可能な第1のフィールド、および実行命令で実行する演算または他のデータ処理が実行可能な状態に処理ユニットを設定する準備情報を記述可能な第2のフィールドとを具備する命令セットをフェッチするユニットと、第1のフィールドの実行命令をデコードし、その実行命令の演算または他のデータ処理が実行できるように予め設定された処理ユニットにより当該演算または他のデータ処理を進める第1の実行制御ユニットと、第2のフィールドの準備情報をデコードし、第1の実行制御ユニットの実行内容とは独立して処理ユニットの状態を演算または他のデータ処理が実行できるように設定する第2の実行制御ユニットとを有する。
また、上記の、演算または他のデータ処理を実行する少なくとも1つの処理ユニットを有するデータ処理装置の制御方法は、上記の第1のフィールドおよび第2のフィールドとを具備する命令セットをフェッチする工程と、第1のフィールドの実行命令をデコードし、その実行命令の演算または他のデータ処理が実行できるように予め設定された処理ユニットにより当該演算または他のデータ処理を進める第1の制御工程と、この第1の制御工程とは独立して、第2のフィールドの準備情報をデコードし処理ユニットの状態を演算または他のデータ処理が実行できるように設定する第2の制御工程とを有する。
本発明の1つの形態にかかる命令セットは、実行命令を記述する第1のフィールドと、この実行命令とは独立し、レジスタの情報およびイミーディエイトなどの準備情報(準備命令)を記述する第2のフィールドとを備えたものである。したがって、算術命令などにおいては、第1のフィールドにADDなどの命令操作が記述され、第2のフィールドにレジスタを特定する命令あるいは情報が記述されるので、一見、従来のアセンブルコードと同様の命令セットとなる。しかしながら、実行命令と準備情報は独立であり、同じ命令セット内では対応していない。このため、その命令セットでは制御ユニットなどのデータ処理装置の処理ユニットで実行される処理が特定されないという特性を備えている。すなわち、本発明にかかる命令セットは従来のニーモニックコードとは大きく異なるものである。そして、従来は1つの命令セットの中に記述されていた命令操作とそれに対応するオペランドを個別に、独立して定義できるようにすることにより、従来の命令セットでは実現できない処理を簡単に実行することができる。
まず、第2のフィールドに、後続の命令セットの第1のフィールドに記述される実行命令を実行するための準備情報を記述することができる。これにより、実行命令を備えた命令セットが表れる前に、その実行命令を実行するための準備を行うことができる。すなわち、実行命令で実行する演算またはその他のデータ処理が実行可能な状態に処理ユニットを設定することができる。例えば、ある命令セット(命令フォーマットあるいは命令レコード)の第1のフィールドにデータ処理装置のある制御ユニットに含まれる少なくとも1つの算術論理演算ユニットを操作する命令を記述し、それに先立つ命令セットの第2のフィールドに、その少なくとも1つの算術論理演算ユニットに用いられるソース側のレジスタあるいはディスティネーション側のレジスタといった算術論理演算ユニットのインタフェースを規定する命令あるいは情報を記述することができる。これにより、実行命令がフェッチされる前に、算術論理演算ユニットのレジスタ情報がデコードされ、レジスタがセットされ、その後にフェッチされた実行命令により所定の論理演算が実行され、その結果が指定されたレジスタに保存される。ディスティネーション側のレジスタは実行命令と共に第1のフィールドに記述することも可能である。
したがって、この命令セットにおいても、パイプライン処理と同様にデータ処理を多段階に分けて実行することが可能でありスループットを向上することができる。また、例えば、ADD,R0,R1,#1234Hという命令は、レジスタR1と#01234Hを加算してこれをレジスタR0に格納するという意味になるが、ハードウェア構成上は、前の命令セットの実行サイクルとオーバラップさせて、ADDという実行命令を実行する1CLK前にレジスタR0と「#01234H」を算術論理演算ユニットである算術加算器ADDが属するデータパスの入力レジスタにリードを実行しておくと高速実行させる観点からは、都合が良い。つまり、AC特性上は、純粋に算術加算を行うようにできるので、実行周波数特性が向上する。パイプライン処理において、パイプライン段数を増加させて、レジスタファイルからのリードサイクル専用に1ステージ消費する設計方針により、この問題をある程度回避することができる。しかしながら、その結果、遅延は確実に増加することになるのに対し、本発明においては遅延を増加させずに問題を解決できる。
そして、この命令セットにおいては、準備情報を実行命令に先立って記述できるので、条件分岐命令などの分岐命令においては、分岐先の情報が実行命令に先立って制御ユニットに与えることができる。すなわち、従来のニーモニックコードでは、命令セットの内容は人間が一目で分かるが、その命令セットが表れるまで処理内容が判らなかった。これに対し、本発明にかかる命令セットでは、命令セットの内容は一目では分からないが、実行命令が表れる前に、その実行命令に関連する情報が分かる。したがって、実行命令に先立って分岐先が判るので、その分岐先の命令セットをフェッチすることも可能であり、さらには、分岐先の実行命令に先立ってその準備を行うことも可能となる。
一般に、現在のCPU/DSPの殆どがパイプライン処理を後段(時間軸が後方)にシフトすることで、処理の高速化を図ることに成功しているが、プログラムの分岐時やCALL/RET実行時には、この問題が表面化する。つまり、先行してフェッチアドレス情報が得られていない為に、本質的にペナルティとなり、原理的にこれを解消することができない。もちろん、分岐予測やディレイディド・ブランチ、高速ブランチバッファ、或いはDSPにて採用されている高速ループ処理技術等は、このペナルティをかなり緩和する事に成功しているが、連続分岐が数多く発生したりすると、その問題点が表面化し、本質的な解決にはなっていないことは周知の事実である。
また、後続命令が必要とするレジスタ情報が先に得られない為に、パイプライン処理を高速化する為のフォワーディング処理やバイパス処理の複雑さが増大し、従来技術で高速化を図ろうとすること自体が膨大なハードウェア・コストの上昇を招く要因となる。
したがって、従来の命令セットでは、分岐先のアドレス情報はデコード後にしか得られず、条件分岐を実行するときに発生するペナルティを本質的に解決し難いのに対し、本発明の命令セットにおいては、分岐先の情報を事前に与えることができるので、条件分岐を実行するときのペナルティを無くすことができる。さらに、ハードウェアに余裕があれば、分岐先の準備命令をフェッチして、それに続く実行命令のための準備を行うことも可能となる。分岐条件が整わない場合は、その準備が無駄になるだけであり、実行時間のペナルティになることはない。
また、後続命令が必要とするレジスタ情報が、実行命令と同時に、あるいは先立って判るので、ハードウェア・コストを増大させずに高速化を図ることが可能となる。つまり、本発明において、従来はハードウェア側にて行っていたパイプライン処理の1ステージ分の処理を、コンパイル時やアッセンブル時に、ソフトウェア処理により静的に事前に実現する事に成功している。
本発明の対象となるデータ処理装置としては、準備情報に基づく処理を実行する第2の実行制御ユニットは、FPGA(Field Programmable Gate Arrays)のようにトランジスタ間の接続を変更可能なアーキテクチャを動的に制御できるものであっても良い。しかしながら、FPGAは、ハードウェアをダイナミックに変更するには時間がかかり、また、その時間を短縮するためのハードウェアが必要となる。例えば、FPGAの再構成情報を二面以上のRAMに保持し、バックグラウンドで実行する事により、見かけ上短い時間で動的なアーキテクチャ変更を行う方式も可能であるが、もし、数クロック以内にこの再構成を行う事を可能とするためには、考えられる組み合わせの数の再構成情報を全て格納するRAMを実装する必要があり、これは、本質的にFPGAの再構成時間が大きく掛かるという経済的な問題を一切解決していない。また、FPGAが、本来ハードウェアのゲートに注目したマッピングを効率良く実現しようとするために抱えている問題、即ち実用上のAC特性の悪さをについては、当面解決出来そうも無い。
これに対し、本発明において、準備情報として、処理ユニットの入力および/または出力インタフェースを、その処理ユニットの実行時期とは独立して、別に規定し、第2の実行制御ユニットあるいは第2の制御工程において、処理ユニットの入力および/または出力インタフェースを、その処理ユニットの実行時期とは独立して、別に設定することが可能となる。このため、複数の処理ユニットを備えたデータ処理装置においては、第2の実行制御ユニットあるいは第2の制御工程において、これらの処理ユニットによるデータパスの組み合わせを制御することが可能となる。すなわち、第2のフィールドに、データ処理装置に含まれる少なくとも1つの算術論理演算ユニットなどの処理ユニットのインタフェースを規定する命令を記載あるいは記述することにより、データフロー指定を行うことが可能となる。これにより、データパスの独立性を高めることが可能となり結果的にデータフロー指定を別命令プログラムを実行しながら行ったり、アイドル状態にある制御ユニットあるいはデータ処理装置の内部のデータパスを、外部の他の制御ユニットあるいはデータ処理装置において実行されている緊急度の高い処理のために貸し出すことも許す構造を容易に提供可能である。
さらに、準備情報に、処理ユニットの処理内容または回路構成も規定する情報を採用し、第2の実行制御ユニットまたは第2の制御工程により、処理ユニットの処理内容または回路構成も規定することによりさらにフレキシブルにデータパスを構成することができる。
また、第2の実行制御ユニットあるいは第2の制御工程に、レジスタ情報をデコードしてフェッチするなどの算術論理演算ユニットのインタフェースや、他の処理ユニットのインタフェースを規定するスケジューラとしての機能を持たせてデータパスの組み合わせを管理することにより、多種多様なデータ処理に対応することができる。例えば、ある一定時間だけ、マトリックス計算を行い、その後にフィルター処理を行う場合は、予めそれらの処理に必要なデータ処理装置内部の処理ユニット間の接続を指定し、時間を計数するカウンターを使ってこれを実現する事が出来る。計数カウンターを別の比較回路や外部イベント検出器に置き換える事で、より複雑で柔軟性のあるスケジューリング処理を実現可能となる。
個々の処理ユニットにFPGAのアーキテクチャを採用することが可能である。しかしながら、ハードウェアをダイナミックに変更するには時間がかかり、また、その時間を短縮するためのハードウェアが必要となる。このため、アプリケーションの実行中に処理ユニット内部のハードウェアを動的に制御することは難しい。仮に、これを複数のRAMをバンク構成にして、瞬時に切り換える方式にしたとしても、数クロック〜数十クロック単位での切り換えを実現する為には、相当数のバンク構成が必要となり、基本的にFPGA内部のマクロセル一つ一つが独立してプログラム構成可能な構造にすると同時に、この切り換えタイミングを検出し、プログラムによる制御機構を持たせる必要がある。しかし、このような構成に対処することは現状のFPGAでは不十分である。さらに、対処可能となったとしても、動的に制御するためには切替のタイミングなどを制御するために、本発明にあるような新しい命令制御機構が必要である事を意味する。
このため、本発明においては、処理ユニットとして、特定の内部データパスを備えた回路ユニットを採用することが望ましい。すなわち、ある程度コンパクトなデータパスを備えた処理ユニットをテンプレート的に用意しておき、そのデータパス間の組み合わせを指示してデータフロー型の処理に持ち込むと共に、準備情報あるいは準備命令により、処理ユニットの内部データパスの一部を選択して処理ユニットの処理内容を変更することにより、さらにフレキシブルに、そして短時間にハードウェアを再構成できる。
たとえば、適当な論理ゲートと、この論理ゲートと入出力インタフェースを接続する内部データパスを予め備えたテンプレート的に使用可能な特定のデータパスを備えた処理ユニットは、以下の説明においてはテンプレートと称されている。このような処理ユニットであれば、入出力されるデータの順番を変えたり、論理ゲート間の接続あるいは選択を変えることにより処理ユニットの処理内容を変更できる。そして、トランジスタレベルで回路を再構成するFPGAに比較すると、予め用意された内部データパスの一部を選択するだけで良いので、短時間で処理内容を変更できる。さらに、予め用意された内部データパスを使用するので、冗長な回路要素は少なく、トランジスタの面積利用効率も高い。したがって、実装密度も高く、経済的である。さらに、高速処理に適したデータパスを構築でき、AC特性も高い。このため、本発明においては、準備情報により、第2の実行制御ユニットおよび第2の制御工程において、処理ユニットの内部データパスの一部を選択可能とすることが望ましい。
さらに、準備情報に基づき設定された各処理ユニットのインタフェースを保持するスケジュールを管理するように、第2の実行制御ユニットは処理ユニットのインタフェースを管理するスケジューラとしての機能を備えていることが望ましい。
また、準備情報により、複数の処理ユニットにより構成される処理ブロックの入力および/または出力インタフェースを規定できるようにすることが望ましい。複数の処理ユニットのインタフェースを1つ命令で変更可能とすることにより、複数の処理ユニットが関連するデータパスの変更が1命令で処理することができる。したがって、第2の実行制御ユニットあるいは工程では、準備情報に基づき、複数の処理ユニットにより構成される処理ブロックの入力および/または出力インタフェースを変更可能であることが望ましい。
さらに、処理ブロックの入力および/または出力インタフェースを規定する複数のコンフィグレーションデータを格納したメモリを設け、準備情報によりメモリに格納された複数のコンフィグレーションデータの1つを選択し、処理ブロックの入力および/または出力インタフェースを変更できるようにすることが望ましい。データフロー指定命令によりコンフィグレーションデータを指定できるようにすることにより、命令自体は冗長にせずに複数の処理ユニットのインタフェースの変更をプログラムから制御することができる。
さらに、処理ユニットとして算術論理演算ユニットを備えた汎用処理に適した第1の制御ユニットと、処理ユニットとして特定のデータパスを具備する複数のデータフロー処理ユニットを備えた専用処理に適した第2の制御ユニットとを設けることにより、ネットワーク処理や画像処理などの高速性およびリアルタイム性が要求される処理に適したシステムLSIを提供することが可能となる。そして、本発明の命令セットであれば、第1のフィールドに、算術論理演算ユニットを操作する実行命令を記述でき、第2のフィールドに、算術論理演算ユニットおよび/またはデータフロー処理ユニットのインタフェースを規定する準備情報が記述することが可能であり、上記のシステムLSIの制御に適したプログラム製品を提供できる。
従来は、複雑なデータ処理は、専用回路を用意し、その専用回路を用いる専用命令化するしか対応方法が無くハードウェアコストが増大する。これに対し、本発明の命令セットにおいては、実行命令とは独立して第2のフィールドにより論理演算ユニットのインターフェースおよびその処理内容を記述できるので、パイプライン制御やデータパス制御の構造を命令セットの中に取り込むことが可能となる。したがって、本発明は、プログラムカウンタ近傍の並列処理を実行だけでなく、2つ以上オブジェクトの同時擬似実行や2つ以上の関数の同時擬似実行に有効な手段を提供することになる。つまり、従来の命令セットでは、2つ以上のコンテキストの異なるデータ処理やアルゴリズム実行等の、それぞれ離れたプログラムカウンタに基づく処理が同時に起動ができなかったのに対し、本発明の命令セットを用いてデータフローを適当に定義することにより、プログラムカウンタにかかわらずに処理を実行することが可能となる。
したがって、本発明の命令セットを用いると、並列処理に対して、予めアプリケーション側から見て性能向上に有効と思われるデータパスを第2のフィールドを用いてソフトウェアから組み込むことが可能であり、それにより実現されたデータパス(データフロー)を必要に応じて、さらにソフトウェアから命令レベルで起動することができる。このデータパスは、特定の目的に対応したデータ処理だけでなく、一般のステートマシンを起動するような目的にも使用可能なので、極めて自由度が高い。
また、この第2のフィールドの情報により、先行して次命令の準備サイクルを簡単に発生させることが可能となるために、従来はその演算対象をレジスタにせざるを得なかったものが、バッファリングを前提とすればメモリ(シングルポート/デュアルポート)やレジスタファイルで代用可能となる。すなわち、第2のフィールドに、処理ユニットなどに含まれるレジスタまたはバッファとメモリの間の入出力を指示する命令を記述することを可能とし、第2の実行制御ユニットまたは第2の制御工程において、レジスタまたはバッファとメモリの間の入出力を制御する機能を持つようにすれば、実行命令とは独立してメモリに対する入出力を行うことができる。
このことは、1つ1つの命令シーケンスの関連性を高めると同時にハードウェアリソースの競合を事前に回避する事に貢献するので、複数命令の並列同時実行や外部からの割り込み要因への対応を早めることが可能となる。そして、基本的に、メモリをレジスタと見なせるので、高速なタスクスイッチの実現が可能となる。さらに、従来のファーストフェッチのペナルティを消せないキャッシュ・メモリの代わりに、プリローディング型の高速バッファを採用する事も可能となる為、100%のヒット率を保証しながら一切ペナルティの発生しない高速の組み込みシステムの実現も可能となる。
すなわち、メモリをレジスタとみなせるようにすることにより、割り込み等の複数の非同期処理要求に対し高速対応が可能となり、複雑なデータ処理や連続データ処理への対応を非常にフレキシブルに行うことができる。また、レジスタの対比および復帰に時間がかからないので、タスクスイッチ等への高速対応が極めて簡単である。そして、外部メモリと内部メモリのアクセススピード差の影響を完全に消すことができるので、キャッシュは、ファーストフェッチ・ペナルティの問題を効率良く解決できるといったメリットを得ることができる。したがって、CALL/RETや割り込み処理/IRETを高速で処理することができるので、イベントに対する応答環境を簡単に構築でき、イベントによってデータ処理性能が低下するのを防止できる。
さらに、第1または第2のフィールドを、VLIWのように、複数の実行命令または準備命令を記述なフィールドとし、第1または第2の実行制御ユニットが第1または第2のフィールドに記述された複数の独立した実行命令または準備命令を独立して処理可能な複数の実行制御部を備えているようにすれば、さらにパフォーマンスを向上できる。
そして、本発明にかかる制御ユニットをコアあるいは周辺回路に採用したデータ処理装置を実現することにより、上述したようなメリットを活かし、処理速度が速く、さらに経済的なデータ処理装置を提供できる。
本発明においては、再構成可能なハードウェアを有するデータ処理装置の制御方法であって、第1のデータ処理の実行が決定される1または数クロック前に、ハードウェアの少なくとも一部を、第1のデータ処理を実行するように再構成する工程を有するデータ処理装置の制御方法を提供する。これにより、ハードウェアを随時、実行される蓋然性の高い特定のデータ処理に適した構成に変更でき、さらに、複雑なデータ処理であっても、それらのデータ処理に特化した多種多様な専用回路を用いずに、それぞれのデータ処理をフレキシブルに、そして高速に実行できる。
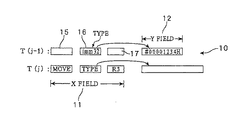
以下に図面を参照して、本発明をさらに詳しく説明する。図1に、本発明にかかる命令セット(命令フォーマット)の構成を示してある。本発明にかかる命令セット(DAP/DNAの命令セット)10は、第1のフィールドである命令実行基本フィールド(Xフィールド)11と呼ばれる部分と、次の命令実行の効率化を図ることができる第2のフィールドである次命令実行準備サイクル(追加フィールドあるいはYフィールド)12と呼ばれる2つのフィールドを備えている。命令実行基本フィールド(Xフィールド)11は、加減演算、論理和、論理積、比較などのデータの演算、および分岐などのその他の各種のデータ処理の内容を指定し、その結果が格納される先(ディスティネーション)を指定する。また、Xフィールド11は、命令長の使用効率を上げるために実際に実行される命令の情報しか含まない。一方、追加フィールド(Yフィールド)12は、同一の命令セットのXフィールド11の実行命令とは独立した命令(情報)が記述可能であり、たとえば、次の命令の実行準備サイクルに割当てられる。
さらに詳しく命令セット10を説明すると、Xフィールド11は、算術論理演算ユニットなどの処理ユニットに対する命令操作あるいは実行命令(Execution ID)を記述する実行命令フィールド15と、Yフィールド12の有効/無効およびYフィールド12で示す準備命令(準備情報)のタイプを示すフィールド(タイプフィールド)16と、ディスティネーションのレジスタを示すフィールド17とを備えている。タイプフィールド16の内容は、Yフィールド12に関連したものであり、Xフィールド11の他のフィールドの内容とは独立して定義できることは上述した通りである。
また、Yフィールド12は、タイプフィールド16によって規定される準備情報が記述される。このYフィールド12に記述される準備情報は、演算または他のデータ処理を実行可能な状態にするための情報であり、図2に具体的な幾つかの例を示してある。先ず、TYPEフィールド16はXフィールド11に含まれているが、実行命令フィールド15とは独立あるいは無関係に記述できる。そして、Yフィールド12には、アドレスID(AID)21と、それによって利用目的が規定されるアドレス情報22、たとえば、アドレス(ADRS)、入出力アドレス(ADRS.FROM/TO)などを記述するアドレス情報フィールド26として利用することができる。このYフィールド12に記述されたアドレス情報は、レジスタあるいはバッファとメモリ(レジスタファイルを含む)との間のリードおよびライトに用いられ、DMAのようにブロック転送も可能な構成になっている。さらに、入出力(R/W)だけでなく、分岐命令を実行したときの分岐先を示すアドレス(フェッチアドレス、F)、並列実行するときのスタートアドレス(D)などの情報もアドレス情報としてYフィールド12に記述することができる。
また、レジスタタイプの命令、たとえば、算術演算あるいはその他の論理演算命令(MOVE、メモリーリード/ライトなども含む)に対してソース側となるレジスタ(Reg)の情報あるいは即値(イミーディエイト、imm)を規定する情報23もYフィールド12に記述することができる。すなわち、Yフィールド12を以降の実行命令のためのソースを規定するフィールド27として利用することができる。
さらに、Yフィールド12には、算術論理演算ユニット(ALU)あるいは他のデータ処理ユニット、たとえば所定のデータパスを備えたテンプレートのインタフェース(ソース、ディスティネーション)および処理内容の組み合わせを規定する情報25も記述することが可能である。すなわち、Yフィールド12は、リコンフィグラブルなデータパスなどを、特定のデータ処理を行うために、それらのパイプライン(データフローあるいはデータパス)を定義するためのデータフロー指定命令25を記述するフィールド28として利用することができる。もちろん、Yフィールド12には、そのデータフローをスタートする情報および終了する情報を記述することが可能である。したがって、Yフィールド12を用いてリコンフィグラブルなデータパスを定義して生成したデータフローにより、コードRAMからコードをフェッチするプログラムカウンタとは独立した処理を行うことができる。
なお、図1および図2に示した命令セットのフォーマットは、本発明にかかる2つの独立した命令フィールドを備えた命令セットの一例であり、これに限定されないことはもちろんである。たとえば、XおよびYフィールド内でのフィールドの位置は限定されるものではない。また、独立したフィールド、例えば、タイプフィールド16の位置は、本例に限定される必要はなく、Yフィールド12の先頭に位置させることも可能である。また、Xフィールド11とYフィールド12の順番を変えることも可能である。本例においては、実行命令が記述されるXフィールド11にYフィールド12の情報を含ませることによりXフィールド11をデコードすることで、Yフィールド12に準備情報があるか否か、およびその情報の種類を判断できるようにしている。
また、以下ではXフィールド11およびYフィールド12に実行命令あるいは準備命令が記載あるいは記述された例を説明するが、これらのフィールドに命令を記述せず(NOPを記述し)、Xフィールド11あるいはYフィールド12だけが意味を持つような命令セットも可能である。さらに、Xフィールド11に記述された実行命令にかかるレジスタ情報などのオペランドを備えた準備命令、すなわち、同一命令セット10のYフィールド12に、Xフィールド11の実行命令に対し独立していない準備命令が同時に記述された命令セットも可能である。そして、これらの命令セットを、本発明の、Xフィールド11とYフィールド12が独立し、同一命令セット内では無関係となった命令セットと混在してプログラミングすることも可能である。以下では本発明をわかりやすく説明するためにそのような例を具体的には記載していない。しかしながら、Xフィールド11とYフィールド12に記述された内容が独立した命令セット10と、XフィールドとYフィールドに記述された内容が関連した命令セットが混在したプログラム製品あるいはプログラムを記録した記録媒体なども本発明の範囲に含まれる。
図3に、本例の命令セット10の簡単な例を示してある。j−1番目の命令セット10であるT(j−1)は、そのXフィールド11のタイプフィールド16に、同一の命令セットのYフィールド12に32ビットのイミーディエイトが記述されていることが示されている。そして、その命令セットT(j−1)のYフィールド12には、イミーディエイトとして「#00001234H」が記載されている。次のj番目の命令セットT(j)には、Xフィールド11の実行命令フィールド15にMOVEが記述され、ディスティネーションフィールド17にレジスタR3が記載されている。このため、このj番目の命令セットT(j)をフェッチすると、制御ユニットのALUは、前の命令フィールドT(j−1)に定義されたイミーディエイト「#00001234H」をレジスタR3に格納する。
このようにして、本例の命令セット10(以降では、j番目の命令セット10を命令セットT(j)で示す)では、実行命令が記述された命令セットT(j)の前の命令セットT(j−1)によりその実行命令の準備が行われる。したがって、命令セットT(j)だけでは制御ユニットを構成するALUが実行する処理内容は判らないが、2つの命令セットT(j−1)およびT(j)によりALUが実行する処理内容は一義的に決定される。また、命令セットT(j−1)の実行命令フィールド15には、その命令セットのYフィールド12とは独立して命令セットT(j−1)の前の命令セットのYフィールド12により準備された処理を実行する命令が記述されている。さらに、命令セットT(j)のタイプフィールド16およびYフィールド12には、次の命令セットの実行命令フィールドに記述された実行命令の準備をする情報が記述されている。
本例では、ある実行命令がXフィールド11に記述された命令セットT(j)の直前の命令セットT(j−1)のYフィールド12に、その実行命令の準備情報(準備命令)が記述されている。すなわち、準備命令のレイテンシーが1クロックの例となっているが、準備情報が記述される命令セットは、直前の命令セットにかぎられるものではない。例えば、複数のALUを備えた制御ユニットの制御プログラム、あるいは後述するデータフロー制御を目的とする準備命令などであれば直前の命令セットである必要はない。準備命令によってセットされたALUの状態(環境あるいはインタフェース)あるいはテンプレートの構成が、その準備命令に対応する実行命令を備えた命令セットがフェッチされて実行されるまで保持されるのであれば、実行命令を備えた命令セット10の数命令前の命令セット10のYフィールド12で準備命令を記述できる。
図4に、図3に示した命令セットによりレジスタとして機能するレジスタファイルあるいはメモリに値が格納される様子を示してある。プロセッサがj−1番目の命令セットT(j−1)をフェッチして、そのYフィールド12の準備命令によりイミーディエイト「#00001234H」がプロセッサのALUのソース側のレジスタDP0.Rにラッチされる。そして、プロセッサが次のj番目の命令セットT(j)をフェッチし、そのXフィールド11の実行命令であるMOVEを実行するサイクルでバッファ29bにストアされる。その後、メモリまたはレジスタファイル29aのレジスタR3のアドレスにバッファ29bの値が格納される。したがって、格納先がレジスタではなくメモリであっても、本例の命令セット10を用いると、準備情報に基づく処理を実行命令に先立って行うことにより、実行命令のサイクルでデータをロードあるいはストアすることができる。
図5に、本例の命令セット10により処理内容が記述されたプログラムを実行可能な制御ユニット30を備えたプロセッサ(データ処理装置)38の概略構成を示してある。本例の命令セット10を具備したマイクロコードあるいはマイクロプログラム18はコードROM39に記憶されている。制御ユニット30は、コードROM39からマイクロプログラムの命令セット10をプログラムカウンタによって随時フェッチするフェッチユニット31と、フェッチされた命令セット10のXフィールド11をデコードしてALU34の処理内容を決定あるいはアサートすると共に、ALU34の論理演算結果をディスティネーションのレジスタ34dを選択してラッチする機能を備えた第1の実行制御ユニット32を備えている。
さらに、制御ユニット30は、フェッチされた命令セット10のYフィールド12をXフィールド11のタイプフィールド16の情報に基づいてデコードし、演算処理ユニット(ALU)34のソース側のレジスタ34sを選択する機能を備えた第2の実行制御ユニット33を備えている。この第2の実行制御ユニット33は、タイプフィールド16の情報を除き、Yフィールド12の命令あるいは情報をXフィールド11の内容とは独立して解釈することができる。第2の実行制御ユニット33は、さらに、Yフィールド12に記述された情報がデータフローを規定するものであれば、ALU34のソース側およびディスティネーション側の選択あるいは設定、すなわち、ALU34のインタフェースを決定し、さらに、その状態を所定のクロックあるいは解除の指示があるまで連続的に保持する機能も備えている。また、Yフィールド12の情報がデータフローを規定する場合は、この第2の実行制御ユニット33は、さらに、ALU34の処理内容も決定し、その状態を所定の期間保持する。
したがって、第1の実行制御ユニット32は、Xフィールド11の実行命令をデコードし、その実行命令の演算または他のデータ処理が実行できるように予め設定された処理ユニットにより演算または他のデータ処理を進める第1の制御工程を行う。一方、第2の実行制御ユニット33は、Yフィールド12の準備情報をデコードし、第1の実行制御ユニット32の実行内容、およびこの第1の実行制御ユニット32で行われる第1の制御工程とは独立に、処理ユニットの状態を演算または他のデータ処理が実行できるように設定する第2の制御工程を行う。
本例の制御ユニット30は、さらに、このような実行制御ユニット32および33と、ALU34の組み合わせを複数備えており、これらによって様々な処理が実行できるようになっている。したがって、本例の制御ユニット30をコアあるいは周辺回路として画像データを高速で処理するようなDSP、汎用のデジタル処理を高速で行えるCPUあるいはMPUなどを構成することが可能である。
図6ないし図9に、本例の制御ユニット30で実行するプログラムの一例を示してある。図6に示したサンプルプログラム41は、従来のCPUあるいはDSPで実行可能なように作成した例である。このプログラムは、#STARTのアドレスから始まるテーブルから最も大きな値を抽出し、最終データであることを示す#ENDを検出すると終了するプログラムである。
図7に記載したプログラム42は、図6と同じ処理を本発明にかかる命令セットを実行可能な制御ユニット30に適したプログラムに変換したものであり、2命令を1つの命令セットで実行できる例を示してある。図7に示したプログラムは、コンパイラを通して本発明にかかる命令セットの実行プログラムに変換され、制御ユニット30で実行される。
図8にコンパイルされた本発明の命令セット10を有するプログラム43を示してあり、このような命令セット10を有するプログラム製品18がROM39、RAMあるいは他の適当なデータ処理装置で読取可能な記録媒体に記憶されて提供される。また、ネットワーク環境で交換される伝送媒体にプログラム製品43あるいは18を埋め込んで流通することも可能である。このプログラム43と、プログラム42とを比較すると判るように、第1の番目の命令セット10のYフィールド12で2番目の命令セット10の実行命令15の準備が行われる。すなわち、タイプフィールド16に準備情報としてイミーディエイトがYフィールド12に記述されていることが示されており、Yフィールド12をデコードした第2の実行制御ユニット32によりイミーディエイトがALU34のソースとなるキャッシュあるいはレジスタに提供される。そして、2番目の命令セット10を実行するときは、その実行命令を行う準備が整ったALU34に対し実行命令15を行うことができる。すなわち、ディスティネーションフィールド17に規定されたレジスタに対し、実行命令フィールド15のMOVE命令を単に実行するだけになる。
同様に、2番目の命令セット10のYフィールド12には、次の3番目の命令セット10の実行命令フィールド15の実行命令、MOVEおよびADDの準備情報として、ソース側のレジスタを設定する命令が記述されている。このため、タイプフィールド16にはレジスタとイミーディエイトがYフィールド12に記述されていることが定義されている。
本例のプログラム43は、3番目以降の命令セット10も上記と同様であり、3番目の命令セット10のタイプフィールド16およびYフィールド12に、次の4番目の命令セット10の実行命令15の準備情報が記述されている。4番目の命令セット10の実行命令15は、比較処理(CMP)と、条件分岐処理(JCC)である。このため、3番目の命令セット10では、そのタイプフィールド16とYフィールド12とにより、次の実行命令15で比較対象となるレジストR1と#ENDのイミーディエイトの値(#FFFFFFFFH)と、分岐先#LNEXTのアドレス(#00000500H)が準備情報として記述されている。したがって、4番目の命令セット10の実行命令15を実行するときは、比較回路として動作する演算処理ユニット34に入力値がセットされているので、そのサイクルで比較結果を出す。また、ジャンプアドレスがフェッチアドレスレジスタにセットされているので、実行命令15の条件分岐では、比較結果によって、そのサイクルで遷移先の命令セット10をフェッチすることができる。
4番目の命令セット10では、そのタイプフィールド16およびYフィールド12により、次の5番目の命令セット10の実行命令15である比較処理(CMP)と条件分岐処理(JCC)の準備情報として、比較するレジスタの情報(R0およびR1)と、分岐先#LOOPのアドレス(#00000496H)が記述されている。したがって、4番目の命令セットと同様に、5番目の命令セット10を実行すると、すでにXフィールド11に記述されたCMPとJCCを演算処理ユニット34で実行するインタフェースは整っているので、そのサイクルで比較および条件分岐処理が実行される。
その5番目の命令セット10のYフィールド12には、次の6番目の命令セット10の実行命令である移行処理(MOVE)および分岐処理(JMP)の準備情報として、ソース側のレジスタ情報(R1)と遷移先#LOOPのアドレスが記述されている。したがって、6番目の命令セット10を実行すると、そのサイクルでデータをディスティネーションのレジスタR0に格納し、遷移先の#LOOPのアドレスから命令をフェッチすることができる。
このように、本発明の命令セットによれば、実行命令と、その実行命令を行うためのインタフェースなどを記述した準備命令とを分離することができ、さらに、準備命令を実行命令に先立ってフェッチされる命令セットに記述して処理することができる。したがって、各々の命令セットに記述された実行命令を行うときは、ALU34のソース側にデータがリードされているので純粋に算術命令だけを行うようになる。このため、AC特性が良く、実行周波数特性が向上する。さらに、実行命令に対する前後の差はあるが、従来のパイプラインと同様に、命令フェッチ、レジスタデコード、処理実行などを段階的に行うことが可能であり、スループットも向上できる。
また、本例のプログラムは2命令を1命令セットに記述できるようになっているので、VLIWと同様にプログラムカウンタの近傍の複数の命令を並列実行することにより処理速度を向上することができる。
さらに、4番目の命令セットの実行命令フィールド15には条件分岐が記述されており、その分岐先のアドレスは、この命令セットに先行する3番目の命令セットのYフィールド12に記述されている。したがって、4番目の命令セットを実行する際に、あるいはそれに先立ってフェッチレジスタに分岐先のアドレスをセットし、分岐条件が成立したときにペナルティなく分岐先の命令セットをフェッチあるいは実行することができる。さらには、分岐先の命令をプリフェッチしておくことも可能であり、分岐先の実行命令を実行する準備を事前に整えておくことも可能となる。したがって、分岐先の命令であっても1クロックの無駄もなく実行することが可能であり、1クロック単位で処理を正確に定義することができる。
図9には、さらに、本発明の命令セット10のYフィールド12を用いてデータフローを定義し、そのデータフローにより上記と同様の処理を行う、本発明のプログラム44を示してある。このプログラム44に記述されたデータフロー指定命令25の内、DFLWIは、データフローの初期設定を行う命令であり、DFLWCはデータフロー(データパス)を構成する演算処理ユニット34の接続情報(インタフェースの情報)および処理内容を規定する命令である。また、DFLWTはデータフローの終了条件を規定する命令であり、最後に、このようにして定義されたデータフローにデータを入力して処理を行うDFLWSが記述されている。これらのデータフロー指定命令25は、Yフィールド12に準備情報として記述され、第2の実行制御ユニット33でデコードされ、処理ユニット34でデータ処理を行うための構成(コンフィグレーション)がセットされる。
図9に示した本例のプログラム44を実行する際には、プログラムのデータフロー指定にしたがって第2の実行制御ユニット33が、第2の制御工程として処理ユニットの入力および/または出力インタフェースを、その処理ユニットの実行時期とは独立して設定し、さらに、処理ユニットの処理内容も規定する処理を行う。また、第2の実行制御ユニット33は、スケジューラ36としても機能し、第2の制御工程として各処理ユニットのインタフェースを維持するスケジュールを管理する。
このため、図10に示すように、スケジューラ36として機能する第2の実行制御ユニット33により、3つの演算処理ユニット34のインタフェース(入出力)と、その処理内容が規定され、その状態あるいはコンフィグレーションが終了条件が成立するまで保持される。したがって、これらの演算処理ユニット34により構成されるデータフローあるいはデータパスにより、プログラムカウンタとは独立して次々と図6に示した処理と同じ処理が進行する。すなわち、データフロー指定を行うことにより、3つの演算処理ユニット34によって制御ユニット30の中に、その処理のための専用回路が事前に設けられた状態となり、プログラムカウンタの制御から外れて最大値を求める処理を実行することができる。そして、DP1.R1と#ENDが同じになることをDP1.SUBとしての機能を果たすALU34で判断するとデータフローが終了する。
したがって、図9から判るように、データフローを定義することにより分岐命令を用いずに図6あるいは図7に記載されたプログラムを同じ処理を実行することができる。このため、汎用の制御ユニット30でありながら、専用回路を備えた制御ユニットと同様に特定の処理を非常に高速に効率良く行うことが可能となる。
本発明にかかる命令セットおよび制御ユニットにより、様々な処理を行うデータフローあるいは疑似データフローを制御ユニットに設けることができる。これらのデータフローはテンプレートとして他の処理あるいは他のプログラムにも適用できるものであり、ソフトウェアを用いてハードウェアを随時、特定のデータ処理に適した構成に変更でき、それを他のプログラムあるいは他のハードウェアにおいても実現できることを意味する。そして、このようなデータフローを複数設定することも可能であり、マルチコマンドストリームをソフトウェアを用いて制御ユニットの中に定義することができる。したがって、複数の処理を並列実行することが極めて簡単となり、その実行内容をプログラミングにより自由に制御することができる。
図11に、本例のXフィールド11およびYフィールド12を備えた命令セット10によりデータフローを定義することができる複数の処理ユニット(テンプレート)を備えたデータ処理装置の概略構成を、システムLSI50のイメージで示してある。このシステムLSI50は、データの処理動作を行うプロセッサ領域51と、そのプロセッサ領域51の処理を制御するプログラム18が格納されたコードRAM52と、その他の制御情報あるいは処理用のデータを記憶し、さらに、一次的なワーク領域ともなるデータRAM53とを備えている。プロセッサ領域51は、プログラムコードをフェッチするフェッチユニット(FU)55と、多目的な処理を行う汎用的なデータ処理ユニット(多目的ALU、第1の制御ユニット)56と、データフロー方式でデータを処理することができるデータフロー処理ユニット(DFU、第2の制御ユニット)57とを備えている。
本例のLSI50は、1つの命令セット10に1組のXフィールド11およびYフィールド12を含んだプログラムコードをデコードして処理を実行できるようになっている。このため、FU55は、フェッチした命令セット10のXフィールド11の命令を格納できるフェッチレジスタ(FR(X))61xと、Yフィールド12の命令を格納できるフェッチレジスタ(FR(Y))61yとを備えている。また、FR(X)61xにラッチされた命令をデコードするXデコーダ62xと、FR(Y)61yにラッチされた命令をデコードするYデコーダ62yとを備えている。また、これらのデコーダ62xおよび62yのデコード結果により次の命令セットのアドレスが格納され、プログラムカウンタとして機能するレジスタ(PC)63を備えている。したがって、コードRAM52に格納されているプログラムの所定のアドレスから次の命令セットを随時フェッチすることができる。
本例のLSI50においては、Xデコーダ62xが上述した第1の実行制御ユニット32としての機能を果たす。したがって、Xデコーダ62xが、命令セット10のXフィールド11に記述された実行命令に基づき、本発明の第1の制御工程を実行する。また、Yデコーダ62yが第2の実行制御ユニット33としての機能を果たす。したがって、Yデコーダ62yが、命令セット10のYフィールド12に記述された準備情報に基づき、本発明の第2の制御工程を実行する。すなわち、本例のデータ処理装置の制御においては、フェッチユニット55において、本発明の命令セットをフェッチする工程が行われ、Xデコーダ62xにおいて、第1のフィールドの実行命令をデコードし、その実行命令の演算または他のデータ処理が実行できるように予め設定された処理ユニットにより当該演算または他のデータ処理を進める第1の制御工程が行われ、Yデコーダ62yにおいて、第1の制御工程とは独立して、第2のフィールドの準備情報をデコードし処理ユニットの状態を演算または他のデータ処理が実行できるように設定する第2の制御工程が行われる。
多目的ALU56は、図5で説明した演算ユニット(ALU)34と、このALU34の入出力のデータを格納するレジスタ群35とを備えている。FU55でデコードされた命令がALU34の実行命令と準備情報であれば、Xデコーダ62xでデコードされた信号φxと、Yデコーダ62yでデコードされた信号φyは多目的ALU56に供給され、上記にて説明したようにALU34における処理が実行される。
DFU57は、様々な処理を行うデータフローあるいは疑似データフローを構成するための複数のテンプレート71が配置されたテンプレート領域72を備えている。それぞれのテンプレート71は、図9および図10に基づき説明したように、演算処理ユニット(ALU)などのような特定のデータパスあるいはデータフローとしての機能を備えている処理ユニット(処理回路)である。そして、Yフィールド12に準備情報として記述されたデータフロー指定命令25をYデコーダ62yがデコードし、その信号φyにより、DFU57の処理ユニットであるテンプレート71それぞれのインタフェースと処理内容を規定することができる。
したがって、これらのテンプレート71の接続および処理内容をYフィールド12に記述したデータフロー指定命令25によって変更することが可能である。このため、これらのテンプレート71の組み合わせにより、テンプレート領域72に特定のデータ処理に適したデータパスをプログラム18によりフレキシブルに構成することが可能となる。したがって、プロセッサ51の中に、特定の処理のための専用回路が設けられた状態となり、そこでの処理をプログラムカウンタの制御から外れて実行することができる。すなわち、データフロー指定命令25によりテンプレート71の入出力と処理内容を変更することができるので、本例のプロセッサ51はソフトウェアを用いてハードウェアを随時、特定のデータ処理に適した構成に変更することができる。
図12(a)に示したように、本例のプロセッサ51のDFU57で入力データφinに処理を施して出力データφoutにする場合、たとえば、図12(b)に示すように、テンプレート1−1、1−2および1−3を直列に繋いであるデータ処理を行うようにテンプレート71のインタフェースをデータフロー指定命令25で設定することができる。同様に、テンプレート領域72の他のテンプレート71に対してもそれらのインタフェースをセットして複数のテンプレート71を適当に組み合わせてデータパスあるいはデータフローを構成することが可能であり、テンプレート領域72に入力データφinの処理に適した専用処理ユニットあるいは専用データパス73を複数個、プログラム18により随時構築することができる。
一方、入力データφinに対する処理が変わったときは、図12(c)に示すように、データフロー指定命令25によりテンプレート71の間の接続を変えることが可能である。すなわち、データフロー指定命令25をYデコーダ62yがデコードし、該当するテンプレート71のインタフェースを変更することができる。このようなYデコーダ62yの制御(第2の制御工程)により、テンプレート1−1、2−nおよびm−nを直列に接続して、他の異なる処理を実行するのに適した1つあるいは複数のデータパス73をテンプレート領域72に構築することが可能である。
また、テンプレート71を単独で、あるいは複数のテンプレート71を組み合わせて構成された処理ユニットは、並列して実行される他の処理あるいは他のプログラムに割り当てることも可能である。複数のプロセッサ51が適当なバスで接続されていれば、他のプロセッサ51が主として行っているデータ処理のためにテンプレート71を組み合わせたトレイン(データパス)73を構成することも可能であり、テンプレート71というデータ処理資源を極めて有効に活用することができる。
さらに、ANDやORなどの単純な論理ゲートの実現をもカバーする目的のFPGAとは異なり、本発明に係るテンプレート71は、ALUなどとしての機能あるいは論理ゲートを基本的に備えた特定のデータパスを内部に実装する、より高いレベルのデータ処理ユニットである。そして、データフロー指定命令25により、テンプレート71のインタフェースを定義する、あるいは再定義することにより、それらの組み合わせを変えて特定の処理に適したさらに大きなデータパスを構成している。さらに、データフロー指定命令25によりテンプレート71で実行する処理内容を定義できるが、その際も、テンプレート71の内部のALUあるいは他の論理ゲートなどの接続を変更することで、テンプレート71の内部データパスの一部を選択する形で、テンプレート71で実行する処理内容を定義するようにしている。
したがって、本例のテンプレート71が複数配置されたDFU57のハードウェアを特定のデータ処理に適した構成に変更するときには、FPGAのようにチップ全体を、あるいは限定された論理ブロック単位でもマッピングしなおす必要はなく、テンプレート71あるいはテンプレート領域72に予め設けられたデータパスを切り替えたり、それらの一部を選択することによりに、予め用意されたALUあるいは論理ゲートを用いて所望のデータパスを実現することができる。すなわち、テンプレート71の内部では論理ゲートのコネクションを必要な範囲で設定しなおし、テンプレート71の間でもそのコネクションを必要な範囲で設定し直すだけでよい。このため、極めて短時間に、クロック単位で、ハードウェアを特定のデータ処理に適した構成に変更することができる。
さらに、論理ゲートが内蔵されていないFPGAでは、極めて汎用的である反面、特定のアプリケーションの機能を実現するロジック回路を形成するためには無駄となる配線も多く、冗長で信号経路も短くはならない。したがって、実行するアプリケーションに特化したASICに対して実装面積が大きくなり、また、AC特性も劣化する。これに対し、予め適当な論理ゲートを内蔵している本例のテンプレート71を採用したプロセッサ51では、FPGAのように膨大な無駄な領域が発生するのを防止でき、AC特性も改善することができる。したがって、テンプレート71をベースとした本例のデータ処理ユニット57は、ハードウェアをプログラムで変更可能なリコンフィグラブルな構成の処理装置であり、FPGAを採用した処理装置に対し、より高いレベルでソフトウェアのフレキシビリティとハードウェアの高速性とを備えたデータ処理装置を提供することができる。
そして、本例のテンプレート71は、適当な論理ゲートを予め内蔵しているので、特定のアプリケーションの処理を実現するために必要な論理ゲートを適当な実装密度で実現することができる。このため、テンプレート71を用いたデータ処理ユニットは経済的である。また、FPGAでデータ処理装置を構成した場合には、実装密度の低下をカバーするために、論理を再構成するプログラムのダウンロードを頻繁に行うことを検討する必要があり、そのための時間も処理速度が低下する原因となる。これに対し、本例のテンプレート71を用いたプロセッサ51では、実装密度が高いので、実装密度の低下をカバーする必然性は減少し、そのためにハードウェアを再構成する要求は少なくなる。そして、ハードウェアの再構成もクロック単位で制御することができる。これらの点でも、FPGAをベースとしたリコンフィグラブルな処理装置と異なり、ハードウェアをソフトウェアにより再構築できる処理装置であって、コンパクトで実行速度の速いデータ処理装置を提供することができる。
さらに、図11に示したDFU57は、テンプレート領域72に配置されたテンプレート71のインタフェースおよび処理内容(以降においてはコンフィグレーションデータ)を一括して定義あるいはセットすることができるコンフィグレーションレジスタ(CREG)75と、そのCREG75にセットする複数のコンフィグレーションデータCi(iは適当な整数を示す、以下においても同様である)を記憶したコンフィグレーションRAM(CRAM)76を備えている。そして、データフロー指定命令25として「DFSET Ci」といった命令が用意されており、Yデコーダ62yがこの命令をデコードすると、CRAM76に記憶されているコンフィグレーションデータCiの中から所望のデータがCREG75にロードされる。その結果、テンプレート領域72に配置された複数のテンプレート71のコンフィグレーションを一括して変更できる。あるいは、複数のテンプレート71からなる処理ブロック単位でそのコンフィグレーションを変更することができる。
また、DFLWIあるいはDFLWCといった上記のようなデータフロー指定命令25をYデコーダ62yがデコードすることにより、個々のテンプレート71のコンフィグレーションを設定あるいは変更することも可能である。したがって、本例のDFU57では、多くの情報が必要となる複数のテンプレート71のコンフィグレーションを1命令で変更することが可能であり、命令効率がよく、さらに、再構成のために消費される時間が短縮されている。
さらに、本例のDFU57は、CRAM76にブロック単位でコンフィグレーションデータをダウンロードするコントローラ77を備えている。また、データフロー指定命令25として「DFLOAD BCi」が用意されており、Yデコーダ62yがこの命令をデコードすると、データRAM53などに予め用意されている多数のコンフィグレーションデータ78の中から、進行中の処理あるいは今後発生するであろう処理のためのコンフィグレーションデータCiを予めコンフィグレーションメモリであるCRAM76にダウンロードしておくことができる。このような構成によりCRAM76に小容量の高速な連想メモリなどを採用することが可能となり、さらに短時間でハードウェアをフレキシブルに変更することができる。
図13に、テンプレート71の一例を示してある。このテンプレート71は、DFU57に用意されたデータフローRAM(DFRAM)79を介して他のテンプレート71とデータを交換することができる構成となっており、I/Oインタフェース81を介して他のテンプレート71の処理結果が入力キャッシュ82a〜82dに入力され、処理された結果が出力キャッシュ83a〜83dに出力される。このテンプレート71は、これらの入力キャッシュ82a〜82dに各々ストアされたデータA、B、CおよびDに対し以下の処理を実行し、演算結果は出力キャッシュ83bに、比較した結果は出力キャッシュ83cにストアすることができるデータパス88を備えている。このテンプレート71の処理結果は、再びI/Oインタフェース81およびDFRAM79を介して他のテンプレートに出力される。
IF A == ?
THEN (C+B)==D
ELSE (C-B)==D ・・・(A)
このテンプレート71は、独自のコンフィグレーションレジスタ84を備えており、このレジスタ84に格納されるデータによって複数のセレクタ89を制御し、制御部85、加算器86、比較器87などの論理ゲートに入力する信号を選択することができる。したがって、テンプレート71は、コンフィグレーションレジスタ84のデータを変更することにより、データパス88の一部を用いた処理も可能であり、たとえば、制御部85を用いずに、以下のような処理を実行させることも可能である。
(B+C)==D
(B-C)==D ・・・(B)
また、同様にコンフィグレーションレジスタ84のデータを変えることにより、このテンプレート71は、データパス88の一部を用いて、制御部85による条件判定回路、加算器86を用いた加減演算回路、比較器87を用いた比較回路としても使用することができる。これらの論理ゲートはテンプレート71に予め作りこまれた専用回路で構成されているので、回路構成としても、処理時間としても無駄がない。そして、入力および出力データのコンフィグレーションは、コンフィグレーションレジスタ84によって制御されるインタフェース81により変更することが可能であり、所望のデータ処理を行うデータフローの全部あるいは一部を、本例のテンプレート71で処理することができる。
このテンプレート71は、さらに、独自のコンフィグレーションレジスタ84のデータを上述したCREG75からのデータと、FU55のYデコーダ(YDEC)62yからのデータのいずれに基づいても書き換えることが可能であり、その選択はYデコーダ62yからの信号により制御することができる。すなわち、上述したようなテンプレート71のコンフィグレーションは、データフロー指定命令25に基づきYデコーダ62yあるいはこのYデコーダ62yで実行される第2の制御工程によって行うことができる。さらに、DFSET命令などによりCRAM76に記憶されたコンフィグレーションデータCiにしたがって、他のテンプレートと共にコンフィグレーションを変えてハードウェア構成を変更することも可能である。また、データフロー指定命令25によりコンフィグレーションレジスタ84のデータを設定できるので、テンプレート71の特定のデータパス88を部分的に選択して使用することも可能である。
このため、テンプレート71を個別でもグループあるいはブロック単位でもデータフロー指定命令25によってコンフィグレーションを変え、プロセッサ51のデータパスをフレキシブルに構成することができる。
テンプレート71の構成は本例に限定されるものではなく、他のデータ処理を実現可能なように論理ゲートを組み合わせた、適当な種類と数のテンプレートを用意しておくことにより、それらの組み合わせを変えたり、処理内容の一部を変更することにより、多くのデータ処理をテンプレート71を組み合わせたデータパスにより処理することができる。すなわち、本発明によれば、ある程度コンパクトなデータパスを幾種類かのテンプレートとして用意しておき、そのデータパス間の組み合わせを指示して、データフロー型の処理に持ち込むことにより高性能化を図ることが可能である。そして、テンプレートでは対応できない処理は、プロセッサ51の多目的ALU56の機能を用いて実行することが可能である。さらに、本例の多目的ALU56は命令セット10のYフィールド12に記述された準備命令により分岐などにより発生するペナルティを最小限に止められるようになっている。このため、本例のプロセッサ51を搭載したシステムLSI50により、プログラムで処理を記述するのと同様に柔軟にハードウェアを変更し、高速処理あるいはリアルタイム処理が可能な高性能のLSIを提供することができる。また、アプリケーションの変更や仕様変更などに対して柔軟に対応でき、仕様変更などに伴い処理性能が低下することも防止できる。
システムLSI50を開発あるいは設計する時点で、システムLSI50を用いて実行するアプリケーションの概要が判明している場合には、そのアプリケーションの処理に適した構成のテンプレートを中心にテンプレート領域72を構成することが可能であり、より多くのデータ処理をデータフロー型の処理で実行し、処理性能を高めることが可能である。汎用的なLSIを提供する場合には、浮動小数点演算、乗除算、画像処理などの汎用のアプリケーションで多く発生する処理に適したテンプレートを中心にテンプレート領域72を構成することが可能である。
このように、本発明にかかる命令セットおよびデータ処理装置により、様々な処理を行うデータフローあるいは疑似データフローを備えたLSIを提供することが可能であり、ソフトウェアを用いてデータフローを実行するハードウェアを随時、特定のデータ処理に適した構成に変更できる。また、上記に説明した、テンプレートの組み合わせによりデータフロー型の処理を実行するアーキテクチャ、すなわち、DFU57あるいはテンプレート領域72は、Xフィールド11およびYフィールド12を備えた命令セット10とは独立して、制御ユニットあるいはプロセッサなどのデータ処理装置に組み込むことが可能である。そして、FPGAよりも高速処理が可能であり、ハードウェアの変更に係る時間も短く、AC特性も良いデータ処理装置を提供することができる。
また、本例のDFU57あるいはテンプレート領域72を、従来型の汎用の組込プロセッサ、すなわち、ニーモニックなコードで動作するプロセッサと共に組み込んでシステムLSIを構成することも可能であり、テンプレート71で対応できない処理は、汎用のプロセッサで処理することができる。しかしながら、従来のプロセッサでは、分岐のペナルティや、演算処理のためのレジスタを準備するためにクロックを消費するなどの問題があることは上述した通りであり、本例のX−Yフィールドを備えた命令セット10をデコードして実行できるプロセッサ51のような形態が望ましい。
さらに、本例のプロセッサ51および命令セット10であれば、Yフィールド12を用い、他の処理と並列して、DFU57のコンフィグレーションをデータ処理を実行する前に設定あるいは変更することが可能であり、処理効率およびプログラム効率の面で優れている。従来のニーモニックな命令コードと、データフロー型の命令コードとを1つの命令セットに記述することによりプログラム効率を高めることも可能である。しかしながら、本例の命令セット10のYフィールド12の機能は、データフロー型の命令コードを記述するだけでないことは上述したとおりである。
また、本発明に係るプロセッサは、Yフィールド12により実行に先立って物理的なデータパスの構成を変えることができる。これに対し、従来のプロセッサでは、複数のマルチプロセッサ間の接続方法が、共有メモリ等を通す方法しか存在せず、アイドル状態のプロセッサが存在しても、その内部のデータ処理ユニットを外部から利用する方法が無かった。本発明にかかるデータ処理装置においては、適当なデータフローを設定することにより、余っているハードウェアを他の制御ユニットあるいはデータ処理装置により使用するといったことも可能となる。
さらに、副次的な効果として、命令実行シーケンスの効率化と内部データパスの独立性の確保と自由度(流用度)の向上により、本発明にかかる制御ユニットあるいはそれを用いたプロセッサにおいては、実行するハードウェアに余裕さえあれば、全く性質の異なるコンテキストの命令シーケンスを同時に供給しても問題無く実行することが可能となる。
更に、現在、ハードウェアとソフトウェアの強調設計によるメリットが盛んに指摘されるようになったが、本発明による命令セットおよび制御ユニットを採用することにより、ユーザ側の要求するアルゴリズムやデータ処理を許されるハードウェア・コストでどう効率良く経済的に実現可能かという事に対しする1つの回答を与えることができる。例えば、ハードウェア・コストを最小に抑制しながら、性能向上に貢献可能なデータパス(データフロー)を、過去のデータパスに関する構成結果情報である本発明にかかる命令セット(旧DAP/DNA)のデータ情報と、その後に追加されるハードウェア構成情報およびデータ処理を実行するシーケンス情報から新しいタイプの組み合わせ結果、すなわち、新しいデータフローを定義するソフトウェアを導き、極めて無駄の少ない最適解を提供することが可能となる。
また、従来は、ハードウェア構成が要素化され難いために、その相互の組み合わせ自体の柔軟性が無く、基本的には、性能を上げるために1つ新規のデータパスを追加するというようなやり方が主流であった。そして、性能向上のための情報蓄積の点でも、実際にそれを実現する上で必要となるハードウェア情報の追加という観点でも、数値化し難くデータベース化することは困難であった。これに対し、本発明によれば、ある程度コンパクトなデータパスをいくつかテンプレート的に用意しておき、そのデータパス間の組み合わせを指示して、データフロー型の処理に持ち込むことにより高性能化を図ることが可能である。そして、極めて細かい単位でのハードウェアとソフトウェアとの連携の見積もりが容易となる。また、ハードウェアとソフトウェアのトレードオフ情報を蓄積することも可能で、データパス単位でその組み合わせの可能性が、処理性能に対する貢献度と密接に結びつくことになる。したがって、ハードウェアとソフトウェアの緊密な実行性能データや処理要求に応じた性能コストの正確な見積もりを蓄積することが可能となる。もちろん、これらのデータパスは主要な処理あるいは汎用的な処理の実行を停止させないで実現することも可能となるため、性能要求に対して、何をどれだけどのように追加すれば、どのような結果が期待出来るということを、純粋に過去に蓄積された本発明にかかる命令セットおよびハードウェアのデータから予測する事が可能とする。
これは、現在行われている設計コストや仕様策定コストの著しい低減に貢献するだけで無く、次の新しい設計に対して、新規に追加すべきハードウェアとソフトウェアのトレードオフを必要最小限で完了させる事に貢献する。また、処理形態に応じて、内部のデータパスを外部へ貸し出しする事も容易にする為、ハードウェアのリソースシェアリング化が可能となり、複数の本発明にかかるモジュール(DAP/DNAモジュール)の間で並列処理化を極め、コンパクトなハードウェアで実現する事が可能となる。
なお、上記に示したデータ処理装置および命令セットなどは、本発明の一例に過ぎず、たとえば、データ処理装置においては、コードRAMあるいはデータRAMなどを外部のRAMあるいはROMとしたり、これらに加えて外部のDRAMあるいはSRAMなどとのインタフェースを設けることも可能である。さらに、外部の他のデバイスと接続するための入出力インタフェースなど、システムLSIなどのデータ処理装置として公知の機能を備えたデータ処理装置も本発明に含まれる。したがって、本発明は以下の請求の範囲の記載により理解および把握され、それらの請求の範囲に含まれる変形例は全て本発明の範囲に含まれる。
また、本発明の命令セットおよびデータ処理装置により提供される新しいプログラミング環境においては、上述した以外にも特殊な命令を設けることが可能である。例えば、現在のプログラムとは別に、1つ以上のオブジェクト(プログラム)を同時に起動し、並列処理起動を命令レベルでサポートするXFORK、オブジェクト(プログラム)間の同期を指定するXSYNK、並列処理間のパイプライン結合を命令するXPIPE、現在のオブジェクトを終了し、次のオブジェクトを起動するXSWITCHなどが考えられている。
以上に説明したように、上記にかかる命令セットおよびそれを用いたプログラミングおよびそれを実行可能なデータ処理装置の技術は、従来の命令セットの構成方法そのものを大幅に変更するものであり、これにより、従来技術では対応の難しかった上述したような問題を上手く解決し、大きな性能向上を図ることができる。
すなわち、上記において説明した命令セットは、命令セットの構成方法を従来の命令セットの構成方法とは全く異なる視点から見直すことにより、従来技術では解決の極めて困難と思われる多くの問題を、極めて効率良く解決している。実際、従来技術においては、その命令セットの構成法とハードウェアによる命令供給(入手)方法が、極めて画一的で伝統的な先入観により実現されていたため、本質的な意味での解決を遠ざけており、その問題点を全て膨大で複雑なハードウェア構成により解決しようとすることで社会へ貢献すべきテクノロジーとその上に構築される各種の情報処理製品の開発コストを膨大に引き上げる原因となっていた。本発明は、これを本来あるべきアプリケーション要求を優先した命令セットを実現することにより、単に製品性能の効率化に止まらず、その高い開発効率と製品の品質保証を得やすい手段を提供することができる。
また、上記においては、性能向上に貢献可能なデータパス(データフロー)をテンプレートという資産と、それを使用する命令セットという資産で蓄積できる。さらに、その後に追加されるハードウェア構成情報およびデータ処理を実行するシーケンス情報に基づき随時更新し最適解を求めるようにすることができる。したがって、従来存在したアプリケーション間の資産の共有化とハードウェア資産の共有化、及び高性能化に対する適切なハードウェア投資がより健全な方向へ向かい、ネットワーク化社会を構築する上でのテクノロジー・インフラとしても大きく貢献可能となることが期待できる。
上記において説明したデータ処理装置は、様々なデータ処理を実行可能なプロセッサあるいはLSIなどとして提供することが可能であり、電子素子の集積回路のみならず、光素子、さらには電子素子および光素子を集積した光集積回路装置にも適用することができる。特に、本発明の命令セットを備えた制御プログラムおよびデータ処理装置においては、データ処理を柔軟に、そして高速に実行できるので、ネットワーク処理や、画像処理などの高速性およびリアルタイム性能を要求されるデータ処理装置に好適なものである。