JP4491482B2 - 障害回復方法、計算機、クラスタシステム、管理計算機及び障害回復プログラム - Google Patents
障害回復方法、計算機、クラスタシステム、管理計算機及び障害回復プログラム Download PDFInfo
- Publication number
- JP4491482B2 JP4491482B2 JP2007307106A JP2007307106A JP4491482B2 JP 4491482 B2 JP4491482 B2 JP 4491482B2 JP 2007307106 A JP2007307106 A JP 2007307106A JP 2007307106 A JP2007307106 A JP 2007307106A JP 4491482 B2 JP4491482 B2 JP 4491482B2
- Authority
- JP
- Japan
- Prior art keywords
- computer
- failure
- occurred
- data
- storage unit
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images










Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/07—Responding to the occurrence of a fault, e.g. fault tolerance
- G06F11/16—Error detection or correction of the data by redundancy in hardware
- G06F11/20—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements
- G06F11/202—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements where processing functionality is redundant
- G06F11/2023—Failover techniques
- G06F11/2025—Failover techniques using centralised failover control functionality
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/07—Responding to the occurrence of a fault, e.g. fault tolerance
- G06F11/0703—Error or fault processing not based on redundancy, i.e. by taking additional measures to deal with the error or fault not making use of redundancy in operation, in hardware, or in data representation
- G06F11/0706—Error or fault processing not based on redundancy, i.e. by taking additional measures to deal with the error or fault not making use of redundancy in operation, in hardware, or in data representation the processing taking place on a specific hardware platform or in a specific software environment
- G06F11/0709—Error or fault processing not based on redundancy, i.e. by taking additional measures to deal with the error or fault not making use of redundancy in operation, in hardware, or in data representation the processing taking place on a specific hardware platform or in a specific software environment in a distributed system consisting of a plurality of standalone computer nodes, e.g. clusters, client-server systems
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/07—Responding to the occurrence of a fault, e.g. fault tolerance
- G06F11/16—Error detection or correction of the data by redundancy in hardware
- G06F11/20—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements
- G06F11/202—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements where processing functionality is redundant
- G06F11/2043—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements where processing functionality is redundant where the redundant components share a common memory address space
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/07—Responding to the occurrence of a fault, e.g. fault tolerance
- G06F11/0703—Error or fault processing not based on redundancy, i.e. by taking additional measures to deal with the error or fault not making use of redundancy in operation, in hardware, or in data representation
- G06F11/0793—Remedial or corrective actions
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/07—Responding to the occurrence of a fault, e.g. fault tolerance
- G06F11/14—Error detection or correction of the data by redundancy in operation
- G06F11/1402—Saving, restoring, recovering or retrying
- G06F11/1415—Saving, restoring, recovering or retrying at system level
- G06F11/1438—Restarting or rejuvenating
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/07—Responding to the occurrence of a fault, e.g. fault tolerance
- G06F11/16—Error detection or correction of the data by redundancy in hardware
- G06F11/20—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements
- G06F11/202—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements where processing functionality is redundant
- G06F11/2041—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements where processing functionality is redundant with more than one idle spare processing component
Description
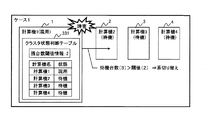
図1は、本発明の第1の実施の形態のクラスタシステムの一例を示すシステム構成図である。
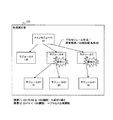
本発明の第1の実施の形態では、回復判断テーブル303を各計算機が保持していたが、本発明の第2の実施の形態では、管理計算機が回復判断テーブル303を保持する。さらに、管理計算機によってプロセスの障害回復方法が決定され、各計算機に指示される。
11 管理計算機
21 CPU
22 ディスプレイ装置
23 キーボード
24 マウス
25 ネットワークインタフェースカード
26 ハードディスク装置
27 メモリ
100 処理管理部
101 処理データ管理部
102 処理実行部
103 処理データ
104 データ転送部
108 データ量取得部
110 障害回復部
201 負荷情報管理部
202 負荷情報判断部
203 負荷情報転送部
301 クラスタ情報管理部
302 クラスタ情報転送部
303 回復判断テーブル
311 クラスタ状態判断テーブル
321 負荷状態判断テーブル
331 クラスタ状態判断テーブル
Claims (11)
- 業務処理を実行する第1の計算機と、前記第1の計算機によって処理されるデータの複製を保持する第2の計算機とを含むクラスタシステムにおいて、前記第1の計算機で発生した障害を回復する方法であって、
前記第1の計算機は、第1のプロセッサと、前記第1のプロセッサに接続される第1の記憶部と、前記第2の計算機に接続される第1のインタフェースとを備え、
前記第2の計算機は、第2のプロセッサと、前記第2のプロセッサに接続される第2の記憶部と、前記第1の計算機に接続される第2のインタフェースとを備え、
前記第1の記憶部は、前記業務処理で使用されるデータを記憶し、
前記クラスタシステムは、当該クラスタシステムの状態を含むシステム情報を保持し、
前記障害回復方法は、
前記第1の記憶部に記憶されたデータを、前記第2の計算機に送信し、
前記第1の計算機から送信されたデータを、前記第2の記憶部に記憶し、
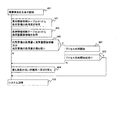
前記第1の計算機に障害が発生した場合には、前記システム情報に基づいて、前記障害が発生した処理を前記第1の計算機で再開始するか、又は、前記障害が発生した処理を前記第2の計算機が実行するか、を判定し、
前記障害が発生した処理を前記第1の計算機で再開始する場合には、前記第2の記憶部に格納されたデータを前記第2の計算機から前記第1の計算機に送信し、前記第1の計算機に送信されたデータを前記第1の記憶部に記憶し、前記障害が発生した処理を再開始し、
前記障害が発生した処理を前記第2の計算機が実行する場合には、前記第2の計算機が、前記障害が発生した処理を実行することを特徴とする障害回復方法。 - 前記システム情報は、前記第2の計算機の数を含み、
前記障害回復方法は、前記第1の計算機の障害発生時に、前記第2の計算機の数が所定の閾値よりも小さい場合には、前記障害が発生した処理を前記第1の計算機で再開始することを特徴とする請求項1に記載の障害回復方法。 - 前記システム情報は、前記第1の計算機で実行される処理を構成する各モジュールによって使用されるデータ量を含み、
前記障害回復方法は、
前記第1の計算機の障害発生時に、障害が発生したモジュールを特定し、
前記特定されたモジュールによって使用されるデータ量を前記システム情報から取得し、
前記取得されたデータ量が所定の閾値よりも小さい場合には、前記障害が発生した処理を前記第1の計算機で再開始することを特徴とする請求項1に記載の障害回復方法。 - 前記システム情報は、前記第1の計算機及び前記第2の計算機の負荷情報を含み、
前記障害回復方法は、前記第1の計算機の障害発生時に、前記第1の計算機の負荷が所定の閾値よりも小さい場合には、前記障害が発生した処理を前記第1の計算機で再開始することを特徴とする請求項1に記載の障害回復方法。 - 前記障害回復方法は、
前記第1の計算機の障害発生時に、前記第1の計算機の負荷が所定の閾値以上の場合には、最も負荷の少ない計算機を選択し、
前記選択された計算機が、前記障害が発生した処理を実行することを指示することを特徴とする請求項4に記載の障害回復方法。 - 業務処理を実行する第1の計算機と、前記第1の計算機によって処理されるデータの複製を保持する第2の計算機とを含むクラスタシステムに含まれる第1の計算機であって、
プロセッサと、前記プロセッサに接続される記憶部と、前記第2の計算機に接続されるインタフェースとを備え、
前記記憶部は、
前記業務処理で使用されるデータを記憶し、
前記クラスタシステムの状態を含むシステム情報を記憶し、
前記プロセッサは、
前記記憶部に記憶されたデータを、前記第2の計算機に送信し、
前記第1の計算機に障害が発生した場合には、前記システム情報に基づいて、前記障害が発生した処理を再開始するか、又は、前記障害が発生した処理を前記第2の計算機が実行するか、を判定し、
前記障害が発生した処理を再開始する場合には、前記第2の計算機から前記第1の計算機によって処理されるデータの複製を取得し、前記取得されたデータを前記記憶部に記憶し、前記障害が発生した処理を再開始し、
前記障害が発生した処理を前記第2の計算機が実行する場合には、前記第2の計算機に前記障害が発生した処理を実行するように指示することを特徴とする計算機。 - 前記システム情報は、前記第2の計算機の数を含み、
前記プロセッサは、前記第1の計算機の障害発生時に、前記第2の計算機の数が所定の閾値よりも小さい場合には、前記障害が発生した処理を再開始することを特徴とする請求項6に記載の計算機。 - 前記システム情報は、前記第1の計算機で実行される処理を構成する各モジュールによって使用されるデータ量を含み、
前記プロセッサは、
前記第1の計算機の障害発生時に、障害が発生したモジュールを特定し、
前記特定されたモジュールによって使用されるデータ量を前記システム情報から取得し、
前記取得されたデータ量が所定の閾値よりも小さい場合には、前記障害が発生した処理を再開始することを特徴とする請求項6に記載の計算機。 - 前記システム情報は、前記第1の計算機及び前記第2の計算機の負荷情報を含み、
前記プロセッサは、前記第1の計算機の障害発生時に、前記第1の計算機の負荷が所定の閾値よりも小さい場合には、前記障害が発生した処理を再開始することを特徴とする請求項6に記載の計算機。 - 前記プロセッサは、
前記第1の計算機の障害発生時に、前記第1の計算機の負荷が所定の閾値以上の場合には、最も負荷の少ない計算機を選択し、
前記選択された計算機に、前記障害が発生した処理を実行するように指示することを特徴とする請求項9に記載の計算機。 - 業務処理を実行する第1の計算機と、前記第1の計算機によって処理されるデータの複製を保持する第2の計算機と、前記第1の計算機及び前記第2の計算機を管理する管理計算機とを含むクラスタシステムであって、
前記第1の計算機は、第1のプロセッサと、前記第1のプロセッサに接続される第1の記憶部と、前記第2の計算機に接続される第1のインタフェースとを備え、
前記第2の計算機は、第2のプロセッサと、前記第2のプロセッサに接続される第2の記憶部と、前記第1の計算機に接続される第2のインタフェースとを備え、
前記管理計算機は、第3のプロセッサと、前記第3のプロセッサに接続される第3の記憶部と、前記第1の計算機及び前記第2の計算機に接続される第3のインタフェースとを備え、
前記第1の記憶部は、前記業務処理で使用されるデータを記憶し、
前記第3の記憶部は、前記クラスタシステムの状態を含むシステム情報を記憶し、
前記第1の計算機は、前記第1の記憶部に記憶されたデータを前記第2の計算機に送信し、
前記第2の計算機は、前記第1の計算機から送信されたデータを、前記第2の記憶部に記憶し、
前記管理計算機は、
前記第1の計算機に障害が発生した場合には、前記システム情報に基づいて、前記障害が発生した処理を前記第1の計算機で再開始するか、又は、前記障害が発生した処理を前記第2の計算機が実行するか、を判定し、
前記障害が発生した処理を前記第1の計算機で再開始する場合には、前記第1の計算機に前記障害が発生した処理の再開始を指示し、
前記第1の計算機は、前記第2の記憶部に格納されたデータを前記第2の計算機から取得し、前記第2の計算機から取得したデータを前記第1の記憶部に記憶し、前記障害が発生した処理を再開始し、
前記管理計算機は、
前記障害が発生した処理を前記第2の計算機が実行する場合には、前記システム情報に基づいて、前記障害が発生した処理を継続する第2の計算機を選択し、
前記選択された第2の計算機に、前記障害が発生した処理を実行することを指示し、
前記選択された第2の計算機は、前記障害が発生した処理を実行することを特徴とするクラスタシステム。
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2007307106A JP4491482B2 (ja) | 2007-11-28 | 2007-11-28 | 障害回復方法、計算機、クラスタシステム、管理計算機及び障害回復プログラム |
| US12/041,059 US7886181B2 (en) | 2007-11-28 | 2008-03-03 | Failure recovery method in cluster system |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2007307106A JP4491482B2 (ja) | 2007-11-28 | 2007-11-28 | 障害回復方法、計算機、クラスタシステム、管理計算機及び障害回復プログラム |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2009129409A JP2009129409A (ja) | 2009-06-11 |
| JP2009129409A5 JP2009129409A5 (ja) | 2009-09-24 |
| JP4491482B2 true JP4491482B2 (ja) | 2010-06-30 |
Family
ID=40670784
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2007307106A Expired - Fee Related JP4491482B2 (ja) | 2007-11-28 | 2007-11-28 | 障害回復方法、計算機、クラスタシステム、管理計算機及び障害回復プログラム |
Country Status (2)
| Country | Link |
|---|---|
| US (1) | US7886181B2 (ja) |
| JP (1) | JP4491482B2 (ja) |
Families Citing this family (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8880931B2 (en) | 2010-01-04 | 2014-11-04 | Nec Corporation | Method, distributed system and computer program for failure recovery |
| WO2011099380A1 (ja) * | 2010-02-10 | 2011-08-18 | 三菱電機株式会社 | 必須データ管理システム及び計算機及び必須データ管理プログラム及び記録媒体及び通信方法 |
| US9901246B2 (en) | 2014-02-05 | 2018-02-27 | Verathon Inc. | Cystoscopy system including a catheter endoscope and method of use |
| US11075806B1 (en) | 2016-06-30 | 2021-07-27 | Juniper Networks, Inc. | Hierarchical naming scheme for state propagation within network devices |
| US11316744B2 (en) | 2016-12-21 | 2022-04-26 | Juniper Networks, Inc. | Organizing execution of distributed operating systems for network devices |
| US10887173B2 (en) | 2016-12-21 | 2021-01-05 | Juniper Networks, Inc. | Communicating state information in distributed operating systems |
| US11316775B2 (en) * | 2016-12-21 | 2022-04-26 | Juniper Networks, Inc. | Maintaining coherency in distributed operating systems for network devices |
| US10409697B2 (en) * | 2017-02-23 | 2019-09-10 | Salesforce.Com, Inc. | Automated self-healing database system and method for implementing the same |
| US11095742B2 (en) | 2019-03-27 | 2021-08-17 | Juniper Networks, Inc. | Query proxy for delivery of dynamic system state |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH05250197A (ja) * | 1992-03-04 | 1993-09-28 | Nec Commun Syst Ltd | 自律系構成回路の制御方式 |
Family Cites Families (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2730534B2 (ja) | 1995-12-18 | 1998-03-25 | 日本電気株式会社 | データ通信網端末のデータバックアップ方法とその装置 |
| US7111084B2 (en) * | 2001-12-28 | 2006-09-19 | Hewlett-Packard Development Company, L.P. | Data storage network with host transparent failover controlled by host bus adapter |
| US7318116B2 (en) * | 2002-11-08 | 2008-01-08 | International Business Machines Corporation | Control path failover in an automated data storage library |
| JP2005018510A (ja) * | 2003-06-27 | 2005-01-20 | Hitachi Ltd | データセンタシステム及びその制御方法 |
| JP2005301436A (ja) * | 2004-04-07 | 2005-10-27 | Hitachi Ltd | クラスタシステムおよびクラスタシステムにおける障害回復方法 |
| US7480827B2 (en) * | 2006-08-11 | 2009-01-20 | Chicago Mercantile Exchange | Fault tolerance and failover using active copy-cat |
-
2007
- 2007-11-28 JP JP2007307106A patent/JP4491482B2/ja not_active Expired - Fee Related
-
2008
- 2008-03-03 US US12/041,059 patent/US7886181B2/en not_active Expired - Fee Related
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH05250197A (ja) * | 1992-03-04 | 1993-09-28 | Nec Commun Syst Ltd | 自律系構成回路の制御方式 |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2009129409A (ja) | 2009-06-11 |
| US20090138757A1 (en) | 2009-05-28 |
| US7886181B2 (en) | 2011-02-08 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP4491482B2 (ja) | 障害回復方法、計算機、クラスタシステム、管理計算機及び障害回復プログラム | |
| EP3694148B1 (en) | Configuration modification method for storage cluster, storage cluster and computer system | |
| JP5851503B2 (ja) | 高可用性仮想機械環境におけるアプリケーションの高可用性の提供 | |
| US6687849B1 (en) | Method and apparatus for implementing fault-tolerant processing without duplicating working process | |
| EP2434729A2 (en) | Method for providing access to data items from a distributed storage system | |
| US7620845B2 (en) | Distributed system and redundancy control method | |
| JP2008097276A (ja) | 障害回復方法、計算機システム及び管理サーバ | |
| JP5672304B2 (ja) | 障害リカバリのための方法、分散システム、およびコンピュータプログラム | |
| JP5948933B2 (ja) | ジョブ継続管理装置、ジョブ継続管理方法、及び、ジョブ継続管理プログラム | |
| US8015432B1 (en) | Method and apparatus for providing computer failover to a virtualized environment | |
| CN108737153B (zh) | 区块链灾备系统、方法、服务器和计算机可读存储介质 | |
| JP2007304845A (ja) | 仮想計算機システムおよびソフトウェア更新方法 | |
| US20130061086A1 (en) | Fault-tolerant system, server, and fault-tolerating method | |
| US8621260B1 (en) | Site-level sub-cluster dependencies | |
| JP4796086B2 (ja) | クラスタシステム及び同システムにおいてマスタノードを選択する方法 | |
| JP2005250840A (ja) | 耐障害システムのための情報処理装置 | |
| JP2009003537A (ja) | 計算機 | |
| JP2009265973A (ja) | データ同期システム、障害復旧方法、及び、プログラム | |
| CN112269693B (zh) | 一种节点自协调方法、装置和计算机可读存储介质 | |
| JP2008276281A (ja) | データ同期システム、方法、及び、プログラム | |
| CN109947593B (zh) | 数据容灾方法、系统、策略仲裁装置和存储介质 | |
| Tikotekar et al. | On the survivability of standard MPI applications | |
| Limaye et al. | Reliability-aware resource management for computational grid/cluster environments | |
| JP2007094604A (ja) | 災害対策用コンピュータバックアップ方式 | |
| JP6090335B2 (ja) | 情報処理装置 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20090806 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20090806 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20100119 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20100311 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20100330 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20100405 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20130409 Year of fee payment: 3 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20130409 Year of fee payment: 3 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20140409 Year of fee payment: 4 |
|
| LAPS | Cancellation because of no payment of annual fees |