JP4457546B2 - 人工プロモーター候補の選択方法 - Google Patents
人工プロモーター候補の選択方法 Download PDFInfo
- Publication number
- JP4457546B2 JP4457546B2 JP2001530464A JP2001530464A JP4457546B2 JP 4457546 B2 JP4457546 B2 JP 4457546B2 JP 2001530464 A JP2001530464 A JP 2001530464A JP 2001530464 A JP2001530464 A JP 2001530464A JP 4457546 B2 JP4457546 B2 JP 4457546B2
- Authority
- JP
- Japan
- Prior art keywords
- sequence
- amino acid
- base sequence
- base
- promoter
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
- 150000001413 amino acids Chemical class 0.000 claims description 73
- 108090000623 proteins and genes Proteins 0.000 claims description 73
- 238000000034 method Methods 0.000 claims description 54
- 238000013518 transcription Methods 0.000 claims description 42
- 230000035897 transcription Effects 0.000 claims description 42
- 238000009499 grossing Methods 0.000 claims description 18
- 238000012546 transfer Methods 0.000 claims description 14
- 238000011144 upstream manufacturing Methods 0.000 claims description 13
- 125000003275 alpha amino acid group Chemical group 0.000 claims 4
- 229940024606 amino acid Drugs 0.000 description 48
- 235000001014 amino acid Nutrition 0.000 description 45
- 108700039691 Genetic Promoter Regions Proteins 0.000 description 18
- 108020004414 DNA Proteins 0.000 description 16
- 102000053602 DNA Human genes 0.000 description 16
- 108091028043 Nucleic acid sequence Proteins 0.000 description 8
- 238000001243 protein synthesis Methods 0.000 description 8
- 235000018102 proteins Nutrition 0.000 description 8
- 102000004169 proteins and genes Human genes 0.000 description 8
- 230000014616 translation Effects 0.000 description 8
- 238000010586 diagram Methods 0.000 description 5
- 108020004999 messenger RNA Proteins 0.000 description 5
- 238000012360 testing method Methods 0.000 description 5
- 102000004163 DNA-directed RNA polymerases Human genes 0.000 description 4
- 108090000626 DNA-directed RNA polymerases Proteins 0.000 description 4
- 206010028980 Neoplasm Diseases 0.000 description 4
- 201000011510 cancer Diseases 0.000 description 4
- 210000000349 chromosome Anatomy 0.000 description 4
- 238000013461 design Methods 0.000 description 4
- 230000002068 genetic effect Effects 0.000 description 4
- 108700007698 Genetic Terminator Regions Proteins 0.000 description 3
- 241000700605 Viruses Species 0.000 description 3
- 210000004027 cell Anatomy 0.000 description 3
- 230000008859 change Effects 0.000 description 3
- 238000002474 experimental method Methods 0.000 description 3
- 239000002773 nucleotide Substances 0.000 description 3
- 125000003729 nucleotide group Chemical group 0.000 description 3
- 230000005758 transcription activity Effects 0.000 description 3
- 108020004705 Codon Proteins 0.000 description 2
- OPTASPLRGRRNAP-UHFFFAOYSA-N cytosine Chemical compound NC=1C=CNC(=O)N=1 OPTASPLRGRRNAP-UHFFFAOYSA-N 0.000 description 2
- 230000000694 effects Effects 0.000 description 2
- 238000011156 evaluation Methods 0.000 description 2
- 238000001415 gene therapy Methods 0.000 description 2
- UYTPUPDQBNUYGX-UHFFFAOYSA-N guanine Chemical compound O=C1NC(N)=NC2=C1N=CN2 UYTPUPDQBNUYGX-UHFFFAOYSA-N 0.000 description 2
- 238000010187 selection method Methods 0.000 description 2
- RWQNBRDOKXIBIV-UHFFFAOYSA-N thymine Chemical compound CC1=CNC(=O)NC1=O RWQNBRDOKXIBIV-UHFFFAOYSA-N 0.000 description 2
- 108010020183 3-phosphoshikimate 1-carboxyvinyltransferase Proteins 0.000 description 1
- 229930024421 Adenine Natural products 0.000 description 1
- GFFGJBXGBJISGV-UHFFFAOYSA-N Adenine Chemical compound NC1=NC=NC2=C1N=CN2 GFFGJBXGBJISGV-UHFFFAOYSA-N 0.000 description 1
- 239000004475 Arginine Substances 0.000 description 1
- 238000012935 Averaging Methods 0.000 description 1
- 108010073254 Colicins Proteins 0.000 description 1
- 108090000790 Enzymes Proteins 0.000 description 1
- 102000004190 Enzymes Human genes 0.000 description 1
- 241000588724 Escherichia coli Species 0.000 description 1
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 1
- ODKSFYDXXFIFQN-BYPYZUCNSA-P L-argininium(2+) Chemical compound NC(=[NH2+])NCCC[C@H]([NH3+])C(O)=O ODKSFYDXXFIFQN-BYPYZUCNSA-P 0.000 description 1
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 1
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 1
- OAICVXFJPJFONN-UHFFFAOYSA-N Phosphorus Chemical compound [P] OAICVXFJPJFONN-UHFFFAOYSA-N 0.000 description 1
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 1
- 101100020617 Solanum lycopersicum LAT52 gene Proteins 0.000 description 1
- 239000002253 acid Substances 0.000 description 1
- 229960000643 adenine Drugs 0.000 description 1
- 235000004279 alanine Nutrition 0.000 description 1
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 1
- 235000003704 aspartic acid Nutrition 0.000 description 1
- OQFSQFPPLPISGP-UHFFFAOYSA-N beta-carboxyaspartic acid Natural products OC(=O)C(N)C(C(O)=O)C(O)=O OQFSQFPPLPISGP-UHFFFAOYSA-N 0.000 description 1
- 230000015572 biosynthetic process Effects 0.000 description 1
- 238000006243 chemical reaction Methods 0.000 description 1
- 210000000805 cytoplasm Anatomy 0.000 description 1
- 229940104302 cytosine Drugs 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 230000001747 exhibiting effect Effects 0.000 description 1
- 239000000284 extract Substances 0.000 description 1
- 238000000605 extraction Methods 0.000 description 1
- 230000006870 function Effects 0.000 description 1
- 230000014509 gene expression Effects 0.000 description 1
- 230000002209 hydrophobic effect Effects 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 230000000977 initiatory effect Effects 0.000 description 1
- 229960000310 isoleucine Drugs 0.000 description 1
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 description 1
- 238000012067 mathematical method Methods 0.000 description 1
- 230000007246 mechanism Effects 0.000 description 1
- 210000004940 nucleus Anatomy 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 238000003909 pattern recognition Methods 0.000 description 1
- 229910052698 phosphorus Inorganic materials 0.000 description 1
- 239000011574 phosphorus Substances 0.000 description 1
- 230000000704 physical effect Effects 0.000 description 1
- 239000013612 plasmid Substances 0.000 description 1
- 230000008569 process Effects 0.000 description 1
- 238000012545 processing Methods 0.000 description 1
- 238000007634 remodeling Methods 0.000 description 1
- 210000003705 ribosome Anatomy 0.000 description 1
- 238000003786 synthesis reaction Methods 0.000 description 1
- 229940113082 thymine Drugs 0.000 description 1
- 239000013598 vector Substances 0.000 description 1
- 239000013603 viral vector Substances 0.000 description 1
Images















Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/10—Processes for the isolation, preparation or purification of DNA or RNA
- C12N15/1034—Isolating an individual clone by screening libraries
- C12N15/1089—Design, preparation, screening or analysis of libraries using computer algorithms
Landscapes
- Chemical & Material Sciences (AREA)
- Engineering & Computer Science (AREA)
- Life Sciences & Earth Sciences (AREA)
- Health & Medical Sciences (AREA)
- Genetics & Genomics (AREA)
- General Engineering & Computer Science (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Wood Science & Technology (AREA)
- Organic Chemistry (AREA)
- Biomedical Technology (AREA)
- Zoology (AREA)
- Biotechnology (AREA)
- Analytical Chemistry (AREA)
- Molecular Biology (AREA)
- Plant Pathology (AREA)
- Physics & Mathematics (AREA)
- Microbiology (AREA)
- Bioinformatics & Computational Biology (AREA)
- Biophysics (AREA)
- Biochemistry (AREA)
- General Health & Medical Sciences (AREA)
- Crystallography & Structural Chemistry (AREA)
- Measuring Or Testing Involving Enzymes Or Micro-Organisms (AREA)
Description
本発明は、人工プロモーター候補の選択技術に係り、さらに詳しくは仮想的に作成したプロモーター候補の中から有効な人工プロモーター候補を選択する、人工プロモータ候補の選択技術に関する。
背景技術
生命科学の発展に伴い染色体の構造が分子レベルで解明されている。それによると染色体中に存在するDNA(デオキシリボ核酸)分子は、DNAの連続する一本の糸のようなものであることが判明している。このDNAには、アデニン(a)、グアニン(g)、シトシン(c)、チミン(t)という主として4種類の塩基があり、染色体中に存在するDNA分子はそれらの組み合わせからなり、糖、リン酸とが結合して構成されており、染色体中に存在するDNA分子は塩基配列が異なることにより種々の情報を有することになる。
そして、DNAを解析することにより、DNA分子を構成する一部分が遺伝情報を担う構造単位で遺伝形質を規定する因子、即ち遺伝子であることが判明しており、特にタンパク質やtRNA、rRNAなどの一次構造を規定している遺伝子が構造遺伝子として定義されている。遺伝子によるタンパク質合成のメカニズムについて図18に基づいて説明する。
図18に示すように遺伝子は、プロモーター領域と、転写領域(タンパク質のアミノ酸配列情報を有する構造遺伝子の領域)と、ターミネーター領域の3つの領域に区分けされる。プロモーター領域は、転写の開始をコントロールする役割を持ち、転写領域は実際に転写される領域であり、ターミネーター領域は転写の終了を制御する役割を持っている。なお、転写が開始される部位を転写開始点という。
このような構造を有する遺伝子においてタンパク質の合成は以下の手順で行われる。まず、RNAポリメレース(DNA配列を転写する酵素)が、プロモーター領域の少し手前のDNA配列に結合し、プロモーター領域に向かって移動する。そして、RNAポリメレースが、プロモーター領域を越えて転写領域側に移動すると、転写領域のDNA配列に対応したメッセンジャーRNAを合成する。そして、RNAポリメレースがターミネーター領域にくるとDNA配列の転写を終了する。その後、このメッセンジャーRNAは、核から細胞質へ移動し、リボゾームと結合する。リボゾームは、メッセンジャーRNAに基づいてタンパク質の合成を行う。このように、遺伝子のDNA配列が転写され、その転写されたものに従って所定のタンパク質が合成される。
ここで、上述したタンパク質の合成を行う頻度は、RNAポリメレースがメッセンジャーRNAを転写する頻度に係り、メッセンジャーRNAが転写される頻度は遺伝子のプロモーター領域により制御される。
したがって、プロモーター領域のDNA配列を人工的に操作することにより、タンパク質合成頻度の高いプロモーターや、タンパク質合成頻度の遅いプロモーターを得ることが理論的に可能となる。
このため、近年このプロモーター領域のDNA配列を人工的に作り替えてタンパク質合成頻度を積極的に制御しようとする試みが盛んに行なわれるようになっている。なぜなら、タンパク質の合成頻度を制御することができれば、例えば転写活性の高いプロモーターの利用によって特定のタンパク質を人工的に大量発現することが可能になるからである。さらに、人工的に特定のタンパク質を大量発現することが可能となれば、例えば遺伝子治療において、がん細胞に十分なウイルスを感染させ(遺伝子治療においては、弱毒されたウイルスが正常遺伝子を細胞内に運搬するウイルスベクターとして使用される)、導入した正常遺伝子(強力な人工プロモーターを組み込んだもの)から、がんを抑えるのに十分な量のタンパク質を特異的に発現させるという分子レベルでの治療が可能になる。
しかしながら、現在のところ、このような転写活性の高い人工プロモーター、すなわち、その様な特性を発揮するDNA配列を有する人工プロモーターを設計する手法は確立されておらず、構造遺伝子(検定用遺伝子)の前にランダムに塩基を配列させて合成したもの(プロモーター候補)を結合して、検定用遺伝子が発現したかどうかで、プロモーター候補の有効性を見ることが行われている。
このような方法では、実験を行なう人工プロモーター候補の塩基配列をランダムに決定するため、無限とも考えられる塩基配列(4の階乗)のなかから、効果の高い人工プロモーターに適した塩基配列を見つけることは困難なことである。
そこで、本発明は上述した問題を解決するためになされたものであり、その目的は、実験を行なう前に、考えられる塩基配列の中から予めプロモーターとして有効に機能する可能性の高い塩基配列を選出することにより、実際に実験を行なう塩基配列の数を少なくすることができる人工プロモーター候補の選択方法を提供することを目的とする。
発明の開示
本発明者は、今までに知られているプロモーターについてその塩基配列に関する特徴を検討した結果、プロモーターと構造遺伝子を結合させた塩基配列から所定のパターンで抽出して得た仮想アミノ酸配列における個々のアミノ酸に基づくインデックス値による曲線を作成すると、その曲線は転写開始点近傍で正負の逆転を起こす傾向が非常に高いことを見出し、本発明を完成したのである。
すなわち、本発明の人工プロモーター候補の選択方法は、構造遺伝子の転写領域における転写開始点近傍の仮想アミノ酸配列から得られるアミノ酸インデックス曲線に対し、正負が逆転したアミノ酸インデックス曲線となる仮想アミノ酸配列から得られる塩基配列を有するDNAを人工プロモーター候補として選択することを特徴とする。
本発明の人工プロモーター候補の選択方法は、プロモーターと構造遺伝子を含む所与の塩基配列の転写開始点近傍における構造遺伝子の転写領域における転写開始点近傍の仮想アミノ酸配列から得られるアミノ酸インデックス曲線とプロモーターの塩基配列から得られる仮想アミノ酸配列のアミノ酸インデックス曲線が、転写開始点近傍で正負が逆転する傾向が極めて高いという新規な事実に基づくものであり、例えば、構造遺伝子の転写開始点近傍における仮想アミノ酸配列のアミノ酸のインデックス値から構造遺伝子側の曲線を求めておき、転写開始点近傍で正負が反転するようにプロモーター領域の仮想アミノ酸配列を求めて塩基配列を決定することもでき、また、例えば、予め任意に設定された塩基配列を構造遺伝子の上流に結合し、その結合した塩基配列から求められる仮想アミノ酸配列のインデックス曲線が転写開始点近傍における構造遺伝子側の曲線と正負が反転しているかどうかで、任意に設定した仮想アミノ酸配列の有効性を判定することもできる。
また、本発明の他の人工プロモーター候補の選択方法は、選択対象の人工プロモーターの塩基配列を人工プロモーターが接続される構造遺伝子の塩基配列の上流に結合し、その結合した塩基配列から得られる仮想アミノ酸配列に基づくアミノ酸インデックス曲線が転写開始点近傍で正負が逆転するようなものであるとき、前記人工プロモーターを当該構造遺伝子のプロモーター候補として選択することを特徴とする。
すなわち、塩基配列の判明している構造遺伝子に対する有効な人工プロモーター候補を選択する際には、任意に設定された塩基配列を前記構造遺伝子の上流に結合し、その結合した塩基配列の少なくとも転写開始点近傍を含む所定の領域における塩基配列から所定のパターンで抽出して得た仮想アミノ酸配列に基づくインデックス曲線が転写開始点近傍で正負が逆転するようなものであるとき、前記任意に設定された塩基配列を人工プロモーター候補として選択するというものである。
なお、所与の塩基配列から仮想アミノ酸配列を抽出する方法及びその仮想アミノ酸配列に基づくインデックス曲線の表現方法は、転写開始点における変化を見やすくする目的で適宜設定することができる。
例えば、所与の塩基配列から仮想アミノ酸配列を抽出する一つの方法としては、選択対象である人工プロモーターの塩基配列から得られる仮想アミノ酸配列が、当該塩基配列から1塩基ずつずらしながら得られる3塩基から形成されるアミノ酸単位により作成されていても良い。
ただし、仮想アミノ酸配列を抽出する方法としては、上記した塩基配列から1塩基ずつずらしながら3塩基単位を抽出する方法以外にも様々な方法で抽出することができ、例えば、塩基配列の中から連続して隣合う3塩基を抽出したり、1塩基ずつ飛ばして3塩基を抽出したり、または2塩基ずつ飛ばして3塩基を抽出するようにしても良い。
また、本発明の他の人工プロモーター候補の選択方法は、有効な人工プロモーター候補を選択するに際して、選択対象の人工プロモーターの塩基配列と構造遺伝子の上流の塩基配列とを結合して塩基配列を得る工程、当該塩基配列の先頭部分に存在する人工プロモーターの塩基配列から1塩基ずつずらしながら3塩基単位を抽出し、それにより形成される仮想アミノ酸配列における個々のアミノ酸のインデックス値からなる第1の数列を得る工程、前記第1の数列をスムージング化することにより第2の数列を得る工程、および、前記第2の数列が転写開始点近傍で正負の反転をしている場合に、前記人工プロモーターを有効な人工プロモーター候補として選択する工程を有する。
この人工プロモーター候補を選択する方法では、まず仮想的に作成した人工プロモーターの塩基配列を構造遺伝子の塩基配列の上流に結合した塩基配列を作成する。具体的には、転写対象とする構造遺伝子の塩基配列の上流に人工プロモーターの塩基配列を結合することにより一定の塩基配列が得られる。
既に説明したように人工プロモーターとして考えられる塩基配列の数は非常に多くの数となるため、この作業はコンピュータを利用して行なうことが好ましい。コンピュータにより自動的に人工プロモーターの塩基配列を作成することにより効率的に作業を進めることができる。ただし、ある程度効果がありそうな人工プロモーターの塩基配列が予測されるときには、研究者等が手作業にて塩基配列を設計しても良い。例えば、既知のプロモーターの塩基配列の一部を修正して、人工プロモーターの塩基配列を設計する場合である。
次に、この塩基配列の先頭部分に存在する人工プロモータの塩基配列から一定の方式で3塩基単位づつ抽出して仮想アミノ酸配列を作成し、それらの個々のアミノ酸のインデックス値を求めてアミノ酸インデックス値からなる第1の数列を作成する。
ここで、アミノ酸インデックス値(例えば、transfer free energy to lipophilic phase von Heijne−Blomberg 1979等)とは、アミノ酸の物性を様々な角度から計測し、数値化したものであり、その種類は現在434種あり、インターネット上で公開されている。このようにアミノ酸インデックス値に変換するのは、塩基配列のみの解析からではわからない何らかの高次の情報が事象の背後に潜んでいると推察されるためである。
次に、この第1の数列をスムージング化することにより第2の数列を作成する。スムージング化は、例えばその数値の後ろに続く所定個数(例えば、3〜6個)の数値を足し合わせその平均を採る方法、又はその数値の前に続く所定個数(例えば、3〜6個)の数値を足し合わせその平均を採る方法、さらにその数値の前後に連続する所定の個数(3〜6個)の数値を足し合わせその平均を採る方法等を採用することができる。また、上述した各方法においては、足し合わせた数値の和を足し合わせた数値の数で割ることにより平均を求めたが、足し合わせた数値をそのまま採用しても良い。このようにしても、後述するグラフ化の段階で、グラフの縮尺を調整することにより、そのグラフは同一のパターンを有するためである。さらに、スムージング化は、上述した方法に限られず、データのスムージング化に関する種々の数学的手法をも使用することができ、例えば移動平均法等により行うこともできる。すなわち、後述するスムージング化された数列をグラフ化した際に、そのグラフのパターン(変動の様子)が認識できる程度にスムージング化できればどのような手法であっても良い。
そして、この第2の数列が転写開始点近傍で正負の反転をしているか否かを判定し、正負の反転をしている場合に、前記人工プロモーターを有効な人工プロモーター候補として選出する。
なお、第2の数列が転写開始点近傍で正負の反転をしているか否かを判定する際、数列とそれに対応する数値を図式化してインデックス曲線を作成すると、転写開始点近傍の領域でインデックス曲線の正負が逆転(反転)する傾向が明瞭になり判定が容易になる。
上述した本発明の人工プロモータ候補の選択方法によれば、数多くの仮想人工プロモーターの中からプロモーターとして機能する可能性の高い人工プロモーター候補を選出することができ、これにより、実際に効果を確認するために実験しなければならないプロモーターの数を少なくすることができる。
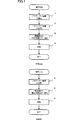
すなわち、従来のプロモーターの設計方法では、図1の下段に示すようにプロモーター候補をランダムな塩基配列の基に合成し(S1)、そのプロモーター候補を構造遺伝子(検定用遺伝子)と結合し(S2)、その結合したものを細胞内に導入し、その遺伝子発現を確認することによりそのプロモーター候補の有用性を決定していた。一方、本発明によれば、図1の上段に示すように、ステップS1で上述したプロモーター候補の選出をした後に、プロモーター候補の合成(S2)・構造遺伝子(検定用遺伝子)の結合(S3)・実験(S4)というステップで行うことができ、実際に合成し実験するプロモーター候補の数を少なくすることができる。
発明を実施するための最良の形態
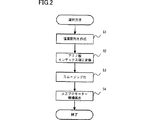
以下、本発明の人工プロモーター候補の選択方法を具現化した実施の形態について説明する。図2に人工プロモーター候補を選択するための手順を示す。
図2に示すように本発明に係る人工プロモーター候補選択方法では、まず仮想人工プロモーターの塩基配列と構造遺伝子(検定遺伝子)の塩基配列とを結合した塩基配列を作成する(S1)。
図3に基づいてさらに具体的に説明する。図3に示すように、仮想的に作成した人工プロモーターの塩基配列をgatct・・caとし、構造遺伝子の塩基配列をcccgtccag・・とする。このステップS1の工程では、構造遺伝子の塩基配列cccgtccag・・の前に、人工プロモーターの塩基配列gatct・・caを結合し、塩基配列gatct・・cacccgtccag・・を作成する。
次に、この塩基配列の先頭の塩基から所定のパターンで3塩基単位ずつ抽出して得られる仮想アミノ酸配列から、それらを構成するアミノ酸のインデックス値からなる第1の数列を作成する(S2)。
塩基配列から3塩基単位を連続して抽出する方法を例に説明する。まずパターン1は上述した塩基配列gatct・・の先頭から1塩基づつずらしながら3塩基単位を連続して抽出する方法で、1番目の3塩基はgat、2番目の3塩基はatc、3番目の3塩基はtct、・・というように抽出する方法である。
ここで、図4(遺伝コード表)に示すように、gatという3つの塩基は、アスパラギン酸(D:以下、アミノ酸をアミノ酸の一文字記号で表す。)に対応し、atcはイソロイシン(I)に対応し、同様にtctはセリン(S)に対応する。したがって、塩基配列から1塩基づつずらしながら3塩基単位で抽出したものは、D,I,S,L,S・・という仮想アミノ酸配列で表すことができる。
仮想アミノ酸配列を作成したら、次にこの仮想アミノ酸配列を形成する個々のアミノ酸をそれぞれのインデックス値に変換した数列を作成する。各アミノ酸(20種類)のアミノ酸インデックス値の一例としてvon Heijne−Blombergのtransfer free energy to lipophilic phaseを、図5に例示した。したがって、上記のように作成したアミノ酸配列から、23.22,−18.32,−1.54,−17.79,−1.54,………という数列(第1数列)が形成される。これが、請求項にいう第1の数列に相当する。
ここで、アミノ酸配列において終止コドン(X)が存在する場合には、アミノ酸に対応せずアミノ酸インデックス値が存在しないため、本実施の形態では、アミノ酸インデックス値を0として第1数列を作成した。終止コドン(X)を取り除いてしまうと、結果的に塩基配列からある塩基を取り除くこととなり、アミノ酸インデックス値が変わってしまうからである。
次に、この第1数列(23.22,−18.32,−1.54,−17.79,−1.54,………)のスムージング化を行う(S3)。ここで、第1数列のスムージング化を行うのは、第1数列のアミノ酸インデックス値は、隣接する数値の変動が激しいためアミノ酸インデックス値の変化の様子(パターン)が認識し難いためである。したがって、スムージング化は、スムージング化された数値をグラフ化した際に、そのグラフがある一定のパターンを有することが判別できる程度に行えば良い。
スムージング化の手法としては、データ処理の分野で既知の様々な手法を使用することができるが、ここでは、上述した第1数列の数値を、その数値から後ろにある所定の個数(3個)の数値の平均値に置き換えることによりスムージング化した数列を得る場合を例に説明する。
第1数列((23.22,−18.32,−1.54,−17.79,−1.54,………)最初の3つの数値の平均は{23.22+(−18.32)+(−1.54)}/3=1.12であり、次の3つの数値の平均は{−18.32+(−1.54)+(−17.79)}/3=−12.55であり、その次の3つの数値の平均は{(−1.54)+(−17.79)+(−1.54)}/3=−6.96である。これ以降も同様の手順により平均値を求めることができる。
このように第1数列を所定個数毎に平均値化し置換することにより、第1数列をスムージング化した第2数列(1.12,−12.55,−6.96,………)を得る。これが、請求項の第2の数列に相当する。
次いで、第2数列が転写開始点近傍で正負の反転をしているか否かを判定し、正負の反転をしている場合に、前記人工プロモーターを有効な人工プロモータ候補として選出する。
好ましい判定方法は、この第2数列をグラフ化することによりインデックス曲線を得て、そのインデックス曲線のパターンにより、その人工プロモーターを評価する方法である(S4)。
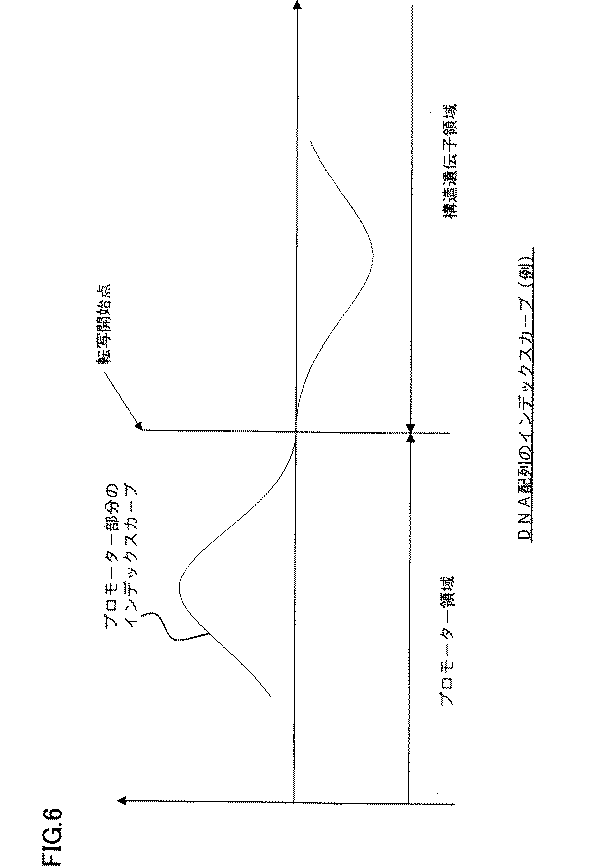
即ち、上述した第2数列(1.12,−12.55,−6.96,………)に基づいて、横軸に数列の番号、縦軸にスムージング化されたアミノ酸インデックス値をプロットすることによりインデックス曲線を得るのである。図6に転写開始点近傍におけるインデックス曲線の例を概念的に示している。
プロモーターとして機能する可能性が高い人工プロモーター候補を選出する際には、転写開始点近傍の仮想アミノ酸配列のインデックス曲線パターンで判定することできる。
すなわち、既に説明したように、既知のプロモーターのインデックス曲線は転写開始点近傍において、後述する図15に認められる様にその正負が反転している傾向が極めて高い。したがって、仮想人工プロモーターの塩基配列と構造遺伝子の塩基配列を結合してできる仮想アミノ酸配列のインデックス曲線を作成した際に、転写開始点近傍でインデックス曲線の正負が反転している場合、その塩基配列を有する仮想人工プロモーターは、当該構造遺伝子に有効な人工プロモーター候補として選出することができる。
以上説明した人工プロモーター候補の選択方法が有効であることを塩基配列既知の遺伝子(プロモーター領域部位)を用いて以下に説明する。
既知の遺伝子(プロモータ領域部位)として、J01567 Plasmid Colicin E1(from E.coli)strong promoter region DNA、X87994 C.xyli DNA for strong promoter(569bp)、EPD31005(+)Ph EPSP synthase P2+及びEPD35038(+)Le LAT52;range−499 to 100を選択した。
J01567とX87994の塩基配列についてはDDBJ(DNA Data Bank of Japan)に登録されているデータを利用し、他の塩基配列についてはEPD(Eukaryotic Promoter Database)に登録されているデータを利用した(但し、X87994については481番目以降の配列データを用いた。)。
それらの塩基配列は図7〜図10に示す通りである。すなわち、J01567は、図7に示す塩基配列を有し、その転写開始点は84番目である。また、X87994は、図8に示す塩基配列を有し、その転写開始点は542番目である(但し、後述の図15では481番目以降が示されているので、図15(b)において転写開始点は62番目である)。また、EPD31005は、図9に示す塩基配列を有し、その転写開始点は140番目である。さらに、EPD35038は、図10に示す塩基配列を有し、その転写開始点は140番目である。
上記の塩基配列からインデックス曲線を上記記載の手順で作成した。具体的な手順を図7に示される塩基配列を有するJ01567を例に、図11〜図14を用いて説明する。なお、以下に説明するインデックス曲線の作成方法は単なる例示であって、本発明を限定するものではない。
(1)図11に示したJ01567の塩基配列の先頭から、連続する3個の塩基を単位として抽出する操作を1塩基ずつずらしながら最後の塩基まで繰り返して3個の塩基を単位とする図12に示される配列を作成する。
(2)上記(1)で得られた配列(図12)から、3個の塩基からなる単位をアミノ酸に変換して仮想アミノ酸配列を作成する。
(3)上記(2)で得られた配列における各アミノ酸に対して疎水性アミノ酸インデックス値を対応させたアミノ酸インデックス値からなる図13に示される数列を作成する。
(4)上記(3)で得られた数列(図13)において各数値の前方5個の数値を合計した値を対応させた図14で示される数列を作成する。
(5)上記(4)で得られた数列(図14)を塩基の先頭からの位置を横軸にしてその位置に対応するアミノ酸インデックス値を縦軸に表わすことによりインデックス曲線を得る。
作成したインデックス曲線を図15に示す(但し、これらの図は正負の逆転を見やすくするために棒グラフ形式で示してある)。
図15には上記4種の遺伝子の塩基配列から求めたインデックス曲線をそれぞれ示すが、いずれも転写開始点近傍で正負が反転していることを示している。
以上のことからも明らかな様に、仮想人工プロモーターの塩基配列と構造遺伝子の塩基配列を結合してできる仮想アミノ酸配列のインデックス曲線を作成した際に、転写開始点近傍でインデックス曲線の正負が反転している場合、その塩基配列を有する仮想人工プロモーターを当該構造遺伝子の有効な人工プロモーター候補として選出することができる。そして、選出された人工プロモーター候補については、実際にそのDNAを合成し、構造遺伝子と結合して実験を行い最終的な評価を行うこととなる。
以上詳述したように、上述した手順により人工プロモーター候補を選出すれば、実際に合成して実験を行う人工プロモーター候補の数を格段に減らすことができ、また、有効な人工プロモーター候補延いてはその塩基配列を効率良く設計することが可能となる。
また、有効な人工プロモーター候補の塩基配列を設計する場合、判定すべき領域を転写開始点近傍の領域のインデックス曲線に限定できるため、その判定を容易に行うことができる。
本発明の方法により、転写活性の高い人工プロモーター候補を効率良く設計することができれば、例えば遺伝子治療の分野において有用なプロモーターを効率的に設計することができる。例えば、ガン細胞に十分なウイルス(正常な遺伝子を運ぶベクターウイルス)を感染させ、導入した正常遺伝子からガンを抑えるのに十分な量のタンパク質を特異的に発現させる治療に応用することができる。これは、正常遺伝子を特異的かつ強力に発現させるためには、人工的に強いプロモーターを設計することが必要となるからである。
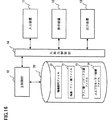
上述した本発明に係る人工プロモーター候補の選出を、好適に実施することができる人工プロモーター候補選出装置の一実施の形態について説明する。図16に本実施の形態に係る人工プロモーター候補選出装置のハードウェア構成図を示す。
本実施の形態に係る人工プロモーター候補選出装置は、図16に示すように人工プロモーター候補選出装置全体を統括的に制御するプログラムされた主制御部(以下、主制御部という)10と、主制御部10に接続され各種データを記憶する記憶装置20と、入出力制御部14を介して主制御部10に接続されるキーボードやマウス等のポインティングデバイスからなる入力装置11と、インデックス曲線等の画像を表示するディスプレイ等の表示装置12と、選出されたプロモーター候補の塩基配列をプリントアウトするプリンター等の出力装置13を備える。
主制御部10は、OS(Operating System)等の制御プログラム、入力された塩基配列からアミノ酸インデックス値に変換した第1の数列を作成するための変換プログラム、第1の数列をスムージング化するためのプログラム、スムージング化されたデータを表示装置12に表示するための画像処理プログラムや所要データを格納するための内部メモリを有している。
記憶装置20は、ハードディスクやフレキシブルディスク、あるいは光ディスク等の記憶手段であり、塩基配列ファイル21と、塩基−アミノ酸ファイル22、アミノ酸インデックス値ファイル23と、選出された人工プロモーター候補の塩基配列を記憶する人工プロモーター候補ファイル24が格納されている。
塩基配列ファイル21は、仮想的に作成した人工プロモーター候補の塩基配列と構造遺伝子の塩基配列とを結合した塩基配列を記憶するファイルである。すなわち、入力装置11のキーボード等からオペレータにより入力された塩基配列のデータが、記憶装置22の中に格納される。
塩基−アミノ酸ファイル22は、3塩基を組み合わせることにより、どのようなアミノ酸が合成されるかのデータを記憶したファイルであり、具体的には図4に示すようなデータが記憶されている。
アミノ酸インデックス値ファイル23は、アラニン,アルギニン等の各種アミノ酸のアミノ酸インデックス値を記憶するファイルである。具体的には、図5に示すようなデータにより、アミノ酸インデックス値ファイル23が構成される。
人工プロモータ候補ファイル24は、インデックス曲線を判定した結果、人工プロモーターとして有効に機能する可能性が高いものとして選出された人工プロモーターの塩基配列を記憶するファイルである。
次に、本実施の形態の人工プロモーター候補選出装置を使用して入力された塩基配列から人工プロモーター候補を選出する手順を図17に基づいて説明する。図17は人工プロモーター候補を選出する時の手順を説明するためのフローチャートである。
まず、オペレータは、入力装置11から、仮想プロモーターの塩基配列と構造遺伝子の塩基配列を結合した仮想塩基配列を入力する(S1)。なお、オペレータにより入力された塩基は表示装置12上に、例えば、a,g,c,t等と表示され、オペレータは入力内容を確認しながら入力作業を行うことができる。この塩基配列は、入出力制御部14及び主制御部10を介して記憶装置20内の塩基配列ファイル21の中に格納される。ここでは入力された塩基配列が1つ(人工プロモーター候補が一つ)である場合を例に説明する。
次に、オペレータは、入力装置11から、ステップS1で入力した塩基配列から3塩基単位を抽出する方式を入力する(S2)。本実施の形態のプロモーター候補選出装置では、図3に示すように、連続して3塩基を抽出する方式1と、1塩基づつ飛ばして3塩基を抽出する方式2と、2塩基づつ飛ばして3塩基を抽出する方式3が選択できるようになっている(図3参照)。
さらに、オペレータは、入力装置11から、スムージングパターンを入力する(S3)。本実施の形態の人工プロモーター候補選出装置においては、平均値を取るための数値の数(3〜10個)を入力するようになっている。
ステップS1〜S3により入力事項が入力されると、主制御部10は、ステップS2で入力された抽出パターンに従って、ステップS1で入力された塩基配列から3塩基を抽出し、その塩基配列から形成される仮想アミノ酸配列をアミノ酸インデックス値に変換することにより第1の数列を作成する(S4)。すなわち、塩基配列ファイル21に格納されている塩基配列から3塩基単位ずつ抽出し、その塩基配列に対応するアミノ酸を塩基−アミノ酸ファイル22のデータに基づいて判断し、アミノ酸インデックス値ファイル22のデータを基に、第1の数列に変換する。作成された第1の数列は、主制御部10内の内部メモリに格納される。
次に、主制御部10は、内部メモリに格納している第1の数列に対してスムージングを行う(S5)。そして、主制御部10は、スムージング化された数値に基づいて表示装置12上にインデックス曲線を表示する(S6)。本実施の形態のスムージングは、S3で入力された個数(例えば、3個)の数値の平均値を取ることにより行っている。具体的な手順に付いては、既に説明した通りである。
そして、表示装置12上に表示されたインデックス曲線に基づいて、オペレータが、その仮想塩基配列を有するプロモーターの有効性を判定する(S7)。具体的には、入力された塩基配列のインデックス曲線を表示装置12上に表示し、オペレータが表示されているインデックス曲線を見て、転写開始点近傍で正負が反転しているか否かを判断する。
S7のステップで、人工プロモーターとして機能する可能性が高いと判断された場合には、その塩基配列を有するものを人工プロモーター候補として選出される(S8)。選出された人工プロモーター候補の塩基配列は、記憶装置20内の人工プロモータ候補ファイル24内に格納され、オペレータの要求により随時、表示装置12上に表示、又は出力装置(プリンター)に出力されるようになっている。
以上、詳述したように、本実施形態に係る人工プロモーター候補選出装置では、オペレータにより仮想プロモーター候補の塩基配列と目的とする構造遺伝子の塩基配列とを結合した塩基配列を入力するだけで、その仮想プロモーター候補の塩基配列が人工プロモーターとして機能する可能性を有するか否かを判断できる。したがって、実際に合成して実験する人工プロモーター候補をある程度絞り込むことができるので、これにより効率的に人工プロモーターの設計を行うことができる。
なお、上述した実施の形態では、塩基配列を一つ(人工プロモーター候補が一つ)だけ入力する例について説明したが、複数の塩基配列(人工プロモーター候補が複数)を一度に入力して記憶装置20の塩基配列ファイル21に格納するようにしても良い。この場合には、塩基配列ファイル21内に格納されている各塩基配列について、図17のステップS2〜S8を繰り返すこととなる。
また、上述した実施の形態のように塩基配列をオペレータにより入力するのではなく、人工プロモーター候補選出装置への入力事項は、仮想プロモーターを構成する塩基の数と構造遺伝子の塩基配列のみとし、主制御部10により考え得る塩基配列の全てを作成するようにしても良い。
すなわち、DNAはa,g,c,tの四種類の塩基により構成されるため、プロモーター領域の塩基の数(n)が決まれば、考え得る塩基配列(4n個)を全て作成することができ、自動的に作成されたものと構造遺伝子の塩基配列を結合すれば良い。このようないわゆる塩基配列自動作成手段を人工プロモーター候補選出装置内に設ければ、効率的に人工プロモーター候補を作成し、その有効性を判断することができるため、従来の人工プロモーターをランダムに作成したときと比較して漏れのない塩基配列の評価を行うことができる。
また、上述した実施の形態では、インデックス曲線の判定をオペレータ(研究者)が、表示装置12上に表示されたインデックス曲線を見て行うようにしたが、このような形態をとることなく、コンピュータによるパターン認識技術を利用して、主制御部10により自動的に行うようにしても良い。また、塩基配列を主制御部10により自動的に作成する塩基配列自動作成手段と組み合わせ、主制御部10により自動的にインデックス曲線の判定を行うことにより、塩基配列の数が多くなっても、全ての塩基配列について自動的に評価することができる。
以上、本発明の実施の形態について詳細に説明したが、これらは例示に過ぎず、本発明は当業者の知識に基づいて種々の変更、改良を施した形態で実施することができる。
【配列表】
【図面の簡単な説明】
図1は、本発明の効果を説明するための図面である。
図2は、本発明の人工プロモーター候補を選出するための手順を説明するためのフローチャートである。
図3は、塩基配列からアミノ酸インデックス配列に変換する手順を説明するための図面である。
図4は、遺伝コード表を示す図面である。
図5は、アミノ酸インデックス値の一例を示す図面である。
図6は、インデックス曲線を概念的に説明するための図面である。
図7は、遺伝子J01567のプロモータ領域部位における塩基配列を示す図面である。
図8は、遺伝子X87994のプロモータ領域部位における塩基配列を示す図面である。
図9は、遺伝子EPD31005のプロモータ領域部位における塩基配列を示す図面である。
図10は、遺伝子EPD35038のプロモータ領域における塩基配列を示す図面である。
図11は、遺伝子J01567のプロモータ領域部位における塩基配列を上流から順に1塩基ずつ示した図面である。
図12は、図11に示す塩基配列から3塩基を1単位として抽出することで作成した配列を示す図面である。
図13は、図12に示す配列の各3塩基をアミノ酸インデックス値に変換した数列を示す図面である。
図14は、図13に示す数列をスムージング化した数列を示す図面である。
図15は、既知のプロモーターのインデックス曲線の一例を示す図面である。
図16は、本発明の一実施の形態に係る人工プロモーター候補選出装置のハードウェア構成図を示す図面である。
図17は、図16に示す人工プロモーター候補選出装置において、人工プロモーター候補を選出する手順を示したフローチャートである。
図18は、DNAの転写からタンパク質合成までを説明するための図面である。
Claims (6)
- 選択対象の人口プロモーターの塩基配列を人口プロモーターが接続される構造遺伝子の塩基配列の上流に結合し、
その結合された塩基配列から1塩基ずつずらしながら得られる3塩基から形成されるアミノ酸単位により仮想アミノ酸配列を作成し、
その作成された仮想アミノ酸配列に対して、「transfer free energy to lipophilic phase」のアミノ酸インデックス値を用いて、当該仮想アミノ酸配列における個々のアミノ酸のアミノ酸インデックス値からなるアミノ酸インデックス曲線を作成し、
その作成されたアミノ酸インデックス曲線が転写開始点近傍で正負が逆転するようなものであるとき、前記人工プロモーターを当該構造遺伝子のプロモーター候補として選択することを特徴とする人工プロモーター候補の選択方法。 - 有効な人工プロモーター候補を選択するに際して、選択対象の人工プロモーターの塩基配列と構造遺伝子の上流の塩基配列とを結合して塩基配列を得る工程、
当該塩基配列の先頭部分に存在する人工プロモーターの塩基配列から1塩基ずつずらしながら3塩基単位を抽出して仮想アミノ酸配列を作成し、「transfer free energy to lipophilic phase」のアミノ酸インデックス値を用いて、その仮想アミノ酸配列の個々のアミノ酸のインデックス値からなる第1の数列を得る工程、
前記第1の数列をスムージング化することにより第2の数列を得る工程、
および、
前記第2の数列が転写開始点近傍で正負の反転をしている場合に、前記人工プロモーターを有効な人工プロモーター候補として選択する工程を有する人工プロモーター候補の選択方法。 - 選択対象の人口プロモーターの塩基配列と人口プロモーターが接続される構造遺伝子の上流の塩基配列とを結合して得られた塩基配列から1塩基ずつずらしながら得られる3塩基から形成されるアミノ酸単位により作成した仮想アミノ酸配列に対して、「transfer free energy to lipophilic phase」のアミノ酸インデックス値を用いて、その仮想アミノ酸配列における個々のアミノ酸のアミノ酸インデックス値からなるアミノ酸インデックス曲線を得る手段と、
そのアミノ酸インデックス曲線取得手段で得られたアミノ酸インデックス曲線が転写開始点近傍で正負が逆転するようなものであるとき、前記人工プロモーターを当該構造遺伝子のプロモーター候補として選択するプロモータ候補選択手段とを備えた人工プロモーターの選択装置。 - 有効な人工プロモーター候補を選択するに際して、選択対象の人工プロモーターの塩基配列と構造遺伝子の上流の塩基配列とを結合した塩基配列を得る塩基配列取得手段、
その塩基配列取得手段で得られた塩基配列の先頭部分に存在する人工プロモーターの塩基配列から1塩基ずつずらしながら3塩基単位で抽出して仮想アミノ酸配列を形成し、「transfer free energy to lipophilic phase」のアミノ酸インデックス値を用いて、その仮想アミノ酸配列の個々のアミノ酸のインデックス値からなる第1の数列を得る第1数列取得手段、
その第1数列取得手段で得られた第1の数列をスムージング化することにより第2の数列を得る第2数列取得手段、
および、
前記第2数列取得手段で得られた第2の数列が転写開始点近傍で正負の反転をしている場合に、前記人工プロモーターを有効な人工プロモーター候補として選択する選択手段とを有する人工プロモーター候補の選択装置。 - コンピュータに、選択対象の人口プロモーターの塩基配列と人口プロモーターが接続される構造遺伝子の上流の塩基配列とを結合した塩基配列を入力装置から得る工程、
入力装置から得た塩基配列から1塩基ずつずらしながら得られる3塩基から形成されるアミノ酸単位により仮想アミノ酸配列を作成する工程、
その作成された仮想アミノ酸配列に対して、「transfer free energy to lipophilic phase」のアミノ酸インデックス値を用いて、当該仮想アミノ酸配列における個々のアミノ酸のアミノ酸インデックス値からなるアミノ酸インデックス曲線を作成する工程、
その作成されたアミノ酸インデックス曲線が転写開始点近傍で正負が逆転するようなものであるとき、前記人工プロモーターを当該構造遺伝子のプロモーター候補として選択する工程、を実行させるためのプログラムを記憶したコンピュータ読み取り可能な記憶媒体。 - コンピュータに、有効な人工プロモーター候補を選択するに際して、選択対象の人工プロモーターの塩基配列と構造遺伝子の上流の塩基配列と結合した塩基配列を入力装置から得る工程、
入力装置から得た塩基配列の先頭部分に存在する人工プロモーターの塩基配列から1塩基ずつずらしながら3塩基単位で抽出し、「transfer free energy to lipophilic phase」のアミノ酸インデックス値を用いて、抽出した3塩基単位により形成されるアミノ酸配列の個々のアミノ酸のインデックス値からなる第1の数列を得る工程、
前記第1の数列をスムージング化することにより第2の数列を得る工程、
および
前記第2の数列が転写開始点近傍で正負の反転をしている場合に、前記人工プロモーターを有効な人工プロモーター候補として選択する工程、を実行させるためのプログラムを記憶したコンピュータ読み取り可能な記憶媒体。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP29129599 | 1999-10-13 | ||
| JP11-291295 | 1999-10-13 | ||
| PCT/JP2000/007105 WO2001027259A1 (fr) | 1999-10-13 | 2000-10-12 | Criblage de candidats comme promoteur artificiel |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JPWO2001027259A1 JPWO2001027259A1 (ja) | 2003-05-07 |
| JP4457546B2 true JP4457546B2 (ja) | 2010-04-28 |
Family
ID=17767047
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2001530464A Expired - Fee Related JP4457546B2 (ja) | 1999-10-13 | 2000-10-12 | 人工プロモーター候補の選択方法 |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US6907393B1 (ja) |
| EP (1) | EP1245672B1 (ja) |
| JP (1) | JP4457546B2 (ja) |
| DE (1) | DE60040928D1 (ja) |
| WO (1) | WO2001027259A1 (ja) |
-
2000
- 2000-10-12 DE DE60040928T patent/DE60040928D1/de not_active Expired - Fee Related
- 2000-10-12 US US10/110,242 patent/US6907393B1/en not_active Expired - Fee Related
- 2000-10-12 EP EP00966459A patent/EP1245672B1/en not_active Expired - Lifetime
- 2000-10-12 WO PCT/JP2000/007105 patent/WO2001027259A1/ja not_active Ceased
- 2000-10-12 JP JP2001530464A patent/JP4457546B2/ja not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| EP1245672B1 (en) | 2008-11-26 |
| US6907393B1 (en) | 2005-06-14 |
| EP1245672A1 (en) | 2002-10-02 |
| DE60040928D1 (de) | 2009-01-08 |
| WO2001027259A1 (fr) | 2001-04-19 |
| EP1245672A4 (en) | 2004-09-15 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Taskiran et al. | Cell-type-directed design of synthetic enhancers | |
| Tunney et al. | Accurate design of translational output by a neural network model of ribosome distribution | |
| Lambert et al. | Similarity regression predicts evolution of transcription factor sequence specificity | |
| Novák et al. | TAREAN: a computational tool for identification and characterization of satellite DNA from unassembled short reads | |
| Von Heijne | Sequence analysis in molecular biology: treasure trove or trivial pursuit | |
| Moffitt et al. | High-throughput single-cell gene-expression profiling with multiplexed error-robust fluorescence in situ hybridization | |
| Mizuguchi et al. | Cohesin-dependent globules and heterochromatin shape 3D genome architecture in S. pombe | |
| Shalem et al. | Systematic dissection of the sequence determinants of gene 3’end mediated expression control | |
| CN108359712B (zh) | 一种快速高效筛选SgRNA靶向DNA序列的方法 | |
| Kudo et al. | Multiplexed, image-based pooled screens in primary cells and tissues with PerturbView | |
| Miyamoto et al. | Recognition of RNA editing sites is directed by unique proteins in chloroplasts: biochemical identification of cis-acting elements and trans-acting factors involved in RNA editing in tobacco and pea chloroplasts | |
| Aerts | Computational strategies for the genome-wide identification of cis-regulatory elements and transcriptional targets | |
| Light et al. | Orphans and new gene origination, a structural and evolutionary perspective | |
| Yap et al. | High performance computational methods for biological sequence analysis | |
| US20100185397A1 (en) | Method for identifying nucleotide sequence, method for acquiring secondary structure of nucleic acid molecule, apparatus for identifying nucleotide sequence, apparatus for acquiring secondary structure of nucleic acid molecule, program for identifying nucleotide sequence, and program for acquiring secondary structure of nucleic acid molecule | |
| Yang et al. | Image-based 3D genomics through chromatin tracing | |
| Sankar et al. | Genetic elements promote retention of extrachromosomal DNA in cancer cells | |
| Chen et al. | DECODE: A De ep-learning Framework for Co n de nsing Enhancers and Refining Boundaries with Large-scale Functional Assays | |
| Su et al. | The promising role of nanopore sequencing in cancer diagnostics and treatment | |
| CN106636065B (zh) | 一种全基因组高效基因区富集测序方法 | |
| Cicconetti et al. | 3plex enables deep computational investigation of triplex forming lncRNAs | |
| JP4457546B2 (ja) | 人工プロモーター候補の選択方法 | |
| JPWO2001027259A1 (ja) | 人工プロモーター候補の選択方法 | |
| CN105969769B (zh) | 控制基因在玉米籽粒中特异表达的启动子及其获得方法和应用 | |
| Samee et al. | Prediction of promotors in agrobacterium and klebsiella using novel feature engineering and ensemble learning approach |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20070214 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20091013 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20091210 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20100119 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20100201 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20130219 Year of fee payment: 3 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20130219 Year of fee payment: 3 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20130219 Year of fee payment: 3 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20140219 Year of fee payment: 4 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| LAPS | Cancellation because of no payment of annual fees |