JP4251726B2 - ファイル管理方法 - Google Patents
ファイル管理方法 Download PDFInfo
- Publication number
- JP4251726B2 JP4251726B2 JP19459099A JP19459099A JP4251726B2 JP 4251726 B2 JP4251726 B2 JP 4251726B2 JP 19459099 A JP19459099 A JP 19459099A JP 19459099 A JP19459099 A JP 19459099A JP 4251726 B2 JP4251726 B2 JP 4251726B2
- Authority
- JP
- Japan
- Prior art keywords
- file
- field
- block
- record
- internal
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Lifetime
Links
Images









Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/10—File systems; File servers
- G06F16/11—File system administration, e.g. details of archiving or snapshots
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y10—TECHNICAL SUBJECTS COVERED BY FORMER USPC
- Y10S—TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y10S707/00—Data processing: database and file management or data structures
- Y10S707/99931—Database or file accessing
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y10—TECHNICAL SUBJECTS COVERED BY FORMER USPC
- Y10S—TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y10S707/00—Data processing: database and file management or data structures
- Y10S707/99931—Database or file accessing
- Y10S707/99932—Access augmentation or optimizing
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y10—TECHNICAL SUBJECTS COVERED BY FORMER USPC
- Y10S—TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y10S707/00—Data processing: database and file management or data structures
- Y10S707/99931—Database or file accessing
- Y10S707/99933—Query processing, i.e. searching
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y10—TECHNICAL SUBJECTS COVERED BY FORMER USPC
- Y10S—TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y10S707/00—Data processing: database and file management or data structures
- Y10S707/99931—Database or file accessing
- Y10S707/99937—Sorting
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y10—TECHNICAL SUBJECTS COVERED BY FORMER USPC
- Y10S—TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y10S707/00—Data processing: database and file management or data structures
- Y10S707/99941—Database schema or data structure
- Y10S707/99942—Manipulating data structure, e.g. compression, compaction, compilation
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y10—TECHNICAL SUBJECTS COVERED BY FORMER USPC
- Y10S—TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y10S707/00—Data processing: database and file management or data structures
- Y10S707/99941—Database schema or data structure
- Y10S707/99943—Generating database or data structure, e.g. via user interface
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y10—TECHNICAL SUBJECTS COVERED BY FORMER USPC
- Y10S—TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y10S707/00—Data processing: database and file management or data structures
- Y10S707/99951—File or database maintenance
- Y10S707/99952—Coherency, e.g. same view to multiple users
- Y10S707/99953—Recoverability
Description
【発明の属する技術分野】
本発明はファイル管理方法、特にデータベース処理など大量に記憶されたデータから必要なデータだけを効率良く読み出すための改良されたファイル管理方法に関する。
【0002】
【従来の技術】
データがレコード単位に格納されたファイルから所望するデータを取り出す場合、当該データを含むレコード全体を入出力バッファに書き込み、その入出力バッファの中から該当するフィールドのみを切り出す処理が必要であった。つまり、例えば512バイトで1レコードが形成されている場合には、所望するデータが4バイトであっても1レコードすなわち512バイト分をファイルから読み出さなければならなかった。例をあげて説明すると、社員データベースの中から氏名と住所だけを取り出して社員の住所録を作成する場合、上記のデータ読出し方法に従えば社員全員のレコードを入出力バッファへ読み出して、その中から氏名と住所だけを取り出さなければならない。このような方法だと必要以外のデータも読み出さなくてはならず、効率的でないし、処理負荷が無用に増大してしまう。
【0003】
そこで、本願と同一の出願人は、データをレコード単位に読み出すのではなく各レコードにおいてフィールド単位で読み出すことができるようにしたファイル管理方法を提案した(特願平09−319527号、以下「先行文献」)。
【0004】
この管理方法について図9を用いて説明する。元ファイル1には複数のフィールド2から構成されるレコ−ド3が複数格納されているとき、レコード3を一定件数、例えばNレコードずつ分割する。次に、分割した各グループにおいて各レコードの先頭から順に一フィールドずつ分割することによって同一位置のフィールドをまとめたブロック4を生成する。そして、分割した各グループにおいて分割したブロック4を先頭から行方向に順次連結してグループ5を再編成する。これをレコード3の全件について行い、その後グループ5を連結することで転置ファイル6を生成する。
【0005】
このような構成の転置ファイル6を生成することにより、例えば、上記例において各レコード3に含まれる氏名のみを取り出したいときには氏名が記憶されたフィールド2を含むブロック4のみを順次読み出せば、社員番号や年齢など氏名以外のデータを社員データベースから読み出す必要がないので、入出力データ量の少ない効率的なデータ読出し処理を行うことができる。
【0006】
ところで、先行文献においては、処理速度の高速化を実現するためにブロック4を構成する各フィールド(以下、「内部フィールド」)2を固定長としている。特に、内部フィールド長をワード境界などの固定境界と合致させることでディスク装置に対する物理的な入出力回数が増えないように配慮している。従って、元ファイル1を構成する各フィールド(以下、「論理フィールド」)が可変長である場合、図10に示したように、論理フィールドを1乃至複数の固定境界に従った固定長の内部フィールドに変換していた。そして、論理フィールドのデータで満たされなかった内部フィールド内の領域に対してパディング(padding)を施している。
【0007】
なお、転置ファイルの生成処理の説明に関し、元ファイル1に含まれるフィールド2からブロック4が生成されるように図9を用いて上述したが、実際には、論理フィールドから固定長の内部フィールドに変換する処理と、内部フィールドを集めてブロック4を生成する処理という2段階の手順で構成されている。
【0008】
【発明が解決しようとする課題】
しかしながら、先行文献では、内部フィールドを固定長としていたため、論理フィールドが内部フィールドを超えているときには、固定長の内部フィールド内に納まるように論理フィールドを複数に分割していた。この結果、分割された論理フィールドへの読出し処理は、複数の内部フィールドに対して読出し処理が発生してしまう。
【0009】
また、ブロックも一定数の内部フィールドを集めて生成していたので、元ファイルに登録されるレコードの書き込みタイミングや登録数によっては物理的な入出力処理まで考慮すると必ずしも効率的な処理が行えなかった。
【0010】
本発明は以上のような問題を解決するためになされたものであり、その目的は、より柔軟にかつ効率的にファイル管理を行うことのできる改良されたファイル管理方法を提供することにある。
【0011】
【課題を解決するための手段】
以上のような目的を達成するために、本発明に係るファイル管理方法は、少なくとも1つの可変長のフィールドを含むレコードを複数格納した元ファイルの管理を行うファイル管理方法において、元ファイルに格納されたレコードを構成する各フィールドをそれぞれ、データの区切りを示す固定境界と区切りが合致する1つの内部フィールドに変換するフィールド変換ステップと、変換された内部フィールドにより構成される全レコードを、複数の群に分割することによってレコードグループを生成するレコードグループ生成ステップと、各レコードグループにおいて、各レコードにおける同一フィールドが同じグループに含まれるように分割することでブロックを生成するブロック生成ステップと、レコ−ドグループ毎に、当該レコ−ドグループにおいて生成されたブロックを並べて含むグループを生成し、更にその生成したグループを並べて含むファイルを転置ファイルとして生成する転置ファイル生成ステップとを含み、元ファイルからのデータ読出し要求に対して転置ファイルにアクセスを行うものである。
【0012】
また、前記フィールド変換ステップは、内部フィールドに空き領域を付加することによって各内部フィールドの区切りを物理的な処理単位となる境界に合致させるものである。
【0013】
また、前記レコードグループ生成ステップは、各レコードグループに含まれるレコード数を可変とし、転置ファイルへのアクセス時には予め設定された各レコードグループに含まれるレコード数を参照することによってフィールドデータの格納位置を特定するものである。
【0014】
更に、前記ブロック生成ステップは、小さいサイズのブロックに空き領域を付加することによって全ブロックの大きさを統一するものである。
【0015】
また、前記ブロック生成ステップは、各レコードにおいて同一位置にあるフィールドが複数含まれるようにブロックを生成するものである。
【0016】
更に、前記ブロック生成ステップは、隣接していないフィールドによってブロックを生成するものである。
【0017】
また、前記ブロック生成ステップは、生成したブロックサイズが物理的な最小入出力単位の整数倍と一致しないときには、最小入出力単位の整数倍になるように当該ブロックに空き領域を付加するものである。
【0018】
【発明の実施の形態】
以下、図面に基づいて、本発明の好適な実施の形態について説明する。
【0019】
実施の形態1.
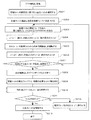
図1は、本発明に係るファイル管理方法の実施の形態1に用いられる転置ファイルの生成方法を示すための模式図であり、図2は、元ファイルに含まれているレコードを構成する論理フィールドの構造と本実施の形態におけるファイル管理システムが取り扱う内部フィールドの構造並びに各フィールドの対応関係を示した図である。これらの図及び図3に示したフローチャートを用いて本実施の形態における転置ファイル生成処理について説明する。
【0020】
本実施の形態におけるこの処理の手順自体は、先行文献に記載された手順と基本的には同様である。すなわち、元ファイルの論理フィールドを内部フィールドに変換し、同一の内部フィールドをまとめることでブロックを生成し、そのブロックを連結することで転置ファイルを生成する。以下、この各処理について詳述する。
【0021】
ステップ101において、まず、図2に示したようにレコードを構成するM個の各論理フィールドField0,Field1,...,Field(M-1)をM個の内部フィールドField#0,Field#1,...,Field#(M-1)に変換する。本実施の形態においては、この変換を行う際、内部フィールドを可変長とすることで論理フィールドと内部フィールドとを1対1に対応付けできるようにしたことを特徴としている。すなわち、従来においては、全内部フィールドを同一長としていたので、可変長である論理フィールドは、その長さに応じて1乃至複数の内部フィールドに割り当てられていた。しかし、この方法だと、内部フィールド長より長い論理フィールドは複数に分断されてしまい、その結果、一つのフィールドデータを読み出すために物理的には複数の入出力処理が発生する場合があり必ずしも効率的でない。また、一般にメモリアクセスは隣接した連続するアドレスに対して一括して行うと効率的であることが多いため、一つのフィールドデータが格納されるバッファ上のメモリアドレスが物理的に分散すると、必ずしも効率的に処理を行うことができない。そこで、本実施の形態においては、内部フィールドを可変長とし、論理フィールドの長さに応じて内部フィールドの長さを決定するようにした。
【0022】
また、本実施の形態においては、処理効率を向上させるために固定境界、例えばワード境界に内部フィールドの区切りを合致させることにしている。つまり、内部フィールドの区切りがワード境界に合致するように必要に応じて空き領域を設け、その空き領域に図2に示したようにpadding(パディング)を挿入する。この空き領域の大きさは、論理フィールド長と固定境界を意識した内部フィールド長との差分に相当する。従って、図2におけるField1とField#1の関係から明らかなように、論理フィールドの対応する内部フィールドの長さがその論理フィールドと一致するとは限らない。なお、図2にはデータの後ろにパディングを挿入した例を示したが、一内部フィールド内におけるパディングの挿入箇所及び数はこの例に限定されるものではない。
【0023】
以上のようにして元ファイルに含まれていたレコードが内部フィールドにより構成されるレコードへ変換されると、次に、変換されたレコードを複数の群に分割することによってレコードグループ11を生成する(ステップ102)。本実施の形態の場合、先行文献と同様に元ファイルを予め決められたNレコードずつに分割して等しい大きさのレコードグループ11を生成するものとする。
【0024】
続いて、各レコードグループ11内においてブロック12を生成する(ステップ103)。これは、各レコードグループ11に対して同じように処理される。また、各レコードグループ11における生成ブロック数は全て同じであり、本実施の形態の場合、レコードを先頭から一内部フィールドずつ行方向へ順番に分割する。そして、分割した同一の内部フィールドをまとめることによってブロック12を生成する。つまり、一のレコードグループ11における一のブロック12は、図1に示したように、例えば1番目からN番目のレコードにおける同一内部レコードField#0により生成されることになる。端的に言うと、このブロック生成処理は、各レコードを行方向に一内部フィールドずつ分割した後、内部フィールドを列方向にまとめてブロックを生成することになる。結果として、内部フィールドの数と等しい個数のブロック12が各レコードグループ11において生成されることになる。本実施の形態のように、固定数Nのレコードで構成されるレコードグループを一内部グループずつに分割してブロックを生成する場合の処理自体は先行文献と同じである。
【0025】
そして、最後に転置ファイルを生成するわけであるが(ステップ104)、ここでは、まず最初に各レコードグループ11において生成されたブロック12を先頭から順番に連結していくことによってグループ13を新たに生成する。図1に基づけば、横(行)方向に並んでいるブロック12をグループというファイルに順番(列方向)に追加登録していくようなイメージである。この処理ではレコードグループ数個のグループ13が作成されることになる。各レコードグループ11に対してブロック生成処理が行われると、各グループ13を連結することで転置ファイル14を生成する。なお、レコードグループ11と、レコードグループ11に対応するグループ13とは、それぞれを構成する内部フィールドは同一であるが、内部フィールドの並び順の相違により内部構造が異なるので、異なる符号を付け異なる構成要素として示している。
【0026】
以上のようにして、単一の元ファイルからフィールドが転置した単一の転置ファイル14が生成される。
【0027】
本実施の形態では、以上のようにして転置ファイル14を事前に生成し、元ファイルからのデータ読出し要求に対して転置ファイル14へアクセスを行うことで処理効率を向上させることを特徴としている。次に、本実施の形態におけるファイル管理方法に基づくレコードの読出し処理について説明する。
【0028】
例えば、社員データベースの中から「氏名」という論理フィールドField1に格納されているフィールドデータのみを全て取り出したいという要求が送られてきた場合、本実施の形態においては、論理フィールドField1に対応した転置ファイル14内の内部フィールドField#1からデータが取り出されることになる。このとき、内部フィールドField#1はブロック単位にまとめられて格納されているので、ファイル管理システムは、転置ファイル14における各グループ13から内部フィールドField#1を含むブロックのみを読み出せばよい。もし、元ファイルに対して内部フィールドField#1を読出しにいくのであれば、結果として元ファイル全体をアクセスしなければならないが、転置ファイル14では、内部フィールドField#1をまとめてブロック化してあるので、不要なデータを読み出すことなく「氏名」を効率的に読み出すことができる。
【0029】
また、本実施の形態において元ファイルから転置ファイルを生成する処理の流れは基本的には先行文献と同様であるが、内部フィールドを可変長にしたことによりフィールドデータが分断されて転置ファイル14に格納されることはないので、物理的な入出力処理回数の増加を防止することができる。
【0030】
一般に、論理フィールドに対して内部フィールドが極端に短い場合、記憶領域が分散するため処理効率が低下するおそれがある。また、論理フィールドに対して内部フィールドが極端に長い場合、従来においては記憶装置上に無駄な領域が生じる。論理フィールド長は様々であるのに対し、内部フィールド長を従来のように固定長にしていたのでは上記の問題が生じうる。そこで、本実施の形態によれば、内部フィールドを可変長にしたことによりこれらの両方の問題をバランス良く解決することができる。すなわち、短い論理フィールドに対しては短い内部フィールドを採用し、長い論理フィールドに対しては長い内部フィールドを採用するという適切な内部フィールド長の調整を行うことで処理効率の低下を防止し、また、無駄な記憶領域を極力削減することができる。この場合でも上述した固定境界に内部フィールド長を合致させるようにパディングを付加することは当然ながら可能である。
【0031】
実施の形態2.
図4は、本発明に係るファイル管理方法の実施の形態2に用いられる転置ファイルの生成方法を示すための模式図である。
【0032】
例えば、社員番号、氏名、入社日、所属、年齢、住所というフィールドデータの順番で構成されるレコードが社員データベースに登録されているとする。この社員データベースの中から氏名と住所だけを取り出して社員の住所録を作成する場合、氏名と住所を登録するために設けられた各フィールドは、レコード上の隣接していない位置に設けられているため、氏名と住所の各データは、上記実施の形態1に示した読出し処理を利用してもそれぞれ異なる物理的な入出力処理により別個に読み出される可能性が高い。
【0033】
そこで、転置ファイルを生成する際、上記実施の形態1においては、元ファイルに格納されるレコードを一内部フィールドずつに分割し、そして内部フィールドの並び順にブロックを生成していたところを、本実施の形態では、元ファイル(社員データベース)に格納されるレコード上離れた位置にある内部フィールドを関連づけて、複数の内部フィールドが含まれるようにブロックを生成できるようにしたことを特徴としている。これにより、元ファイルでは離れた位置にあっても同時に利用される頻度が高いことが予めわかっている場合には、該当するフィールドを同一ブロック内にまとめて転置ファイルを生成することにより読出し処理の効率を向上させることができる。
【0034】
本実施の形態における転置ファイル生成処理は、図3に示したブロック生成処理(ステップ103)においてレコードを先頭から一内部フィールドずつ行方向へ順番に分割した後、同一ブロック12に含ませたい複数の内部フィールドを取り出してブロック化する。それ以外は実施の形態1と同じなので説明を省略する。
【0035】
ところで、一般にファイルの検索効率を向上させる手段として索引を付加する方法がある。なお、本実施の形態においても索引技術は適用可能である。索引を付加することによって目的とするレコードを含まない入出力単位(例えばディスクのセクタ、クラスタ等)を読み飛ばすことができる。索引の効果を高めるには、入出力単位当たりのレコード数を少なくした方がよい。なぜなら、入出力単位の中に1つでも目的とするレコードが含まれているときには入出力単位全体を読み出さなくてはならないからである。入出力単位当たりのレコード数を少なくする方法として内部フィールドを長くする方法も考えられるが、内部フィールドを単純に長くするとパディングを書き込む領域が増えてしまい、記憶領域の利用効率が低下してしまう。
【0036】
そこで、本実施の形態のように複数の内部フィールドをまとめてブロックを生成すれば、最小入出力単位当たりのレコード数を減らすことで索引の効果を高めることができるとともに記憶領域の利用効率の低下をも防止することができる。
【0037】
なお、本実施の形態では、本実施の形態における効果をより顕著にするために一ブロックに含ませる内部フィールドを隣接していない位置にある場合を例にしたが、隣接した位置にある内部フィールドで一ブロックを生成するようにしてもよい。
【0038】
実施の形態3.
上記実施の形態1では、各レコードグループに含まれるレコード数を固定としたが、本実施の形態では可変としたことを特徴としている。図5は、本発明に係るファイル管理方法の実施の形態3に用いられる転置ファイルの生成方法を示すための模式図である。本実施の形態では、各レコードグループに含まれるレコード数を管理するための手段として管理ファイル15が必要になる。
【0039】
例えば、販売に伴い発生する売上データを販売管理システムの販売実績データベース(元ファイル)に逐次蓄積していく場合、売上数は日々異なるため販売実績データベースへの登録レコード数は毎日同じにはならない。ここで、従来にようにレコードグループAを登録データ数Nの固定数で生成するとする。例えばd日の登録レコード数がNに満たない登録データ数pが発生したとすると、(d+1)日に発生した登録レコード数のうち登録データ数(N−p)をレコードグループAに付加することで充満する。この際、内部処理では、レコードグループAに含まれる全レコードを所定の入出力バッファへ読み出し、その入出力バッファの空き領域に(N−p)レコードを書き込んだ後に入出力バッファの内容をディスク装置に書き込む。いわゆるread−modify−writeの手順を踏む必要がある。つまり、所定のレコード数Nが書き込まれていないレコードグループにレコードを追加登録する際には登録済みのレコードを必ず読み出すことになり効率的でない。そこで、本実施の形態では、レコードグループに含まれるレコード数を可変としたことで、上記例において日毎にレコードグループを生成するようにすれば、登録済みのレコードを読み出す必要がなくなる。
【0040】
以下、本実施の形態における転置ファイル生成処理について説明するが、本実施の形態における処理手順自体は実施の形態1と同じであり、図3に示したフローチャートに沿って処理が実行される。本実施の形態は、このうちレコードグループ生成処理(ステップ102)のみが実施の形態1と異なるので、この処理についてのみ説明する。
【0041】
ステップ101において内部フィールドに変換された全レコードは、複数の群に分割されることによってレコードグループ11が生成される。このとき、本実施の形態においては、管理ファイル15に設定された各レコード数の値に基づき全レコードは複数の群に分割される。
【0042】
管理ファイル15には、各レコードグループに含まれることになるレコード数と各レコードグループにおけるブロックサイズがレコードグループを生成する前に予め設定されている。上記レコード数は、元ファイルに登録されたレコード数によって特定することができる。また、ブロックサイズはレコード数とレコードを構成する各フィールド長とを得ることで事前に求めることができる。また、本実施の形態では、各レコードグループ11のブロックサイズが求まったときにその中で最大値のブロックサイズを管理ファイル15に別途保持しておく。
【0043】
ステップ102では、管理ファイル15に設定されたレコード数N0,N1,...に基づき先頭のレコードから順次グループ分けを行うことでレコードグループ11を生成する。このようにして、全レコードを複数のレコードグループに分割した後は、実施の形態1と同様にしてブロック12を生成し、そのブロック12を連結することでグループ13を生成し、そのグループ13を連結することで転置ファイル14を生成する。
【0044】
次に、本実施の形態におけるファイル管理方法に基づくフィールドデータの読出し処理について図6に示したフローチャートを用いて説明する。
【0045】
ファイル管理システムは、要求されたフィールドデータを転置ファイル14から読み出す。この際、内部処理では、要求されたデータを含むブロックを入出力バッファへ読み出すことになるが、ブロックサイズが可変の場合その読出し先となる入出力バッファをどのような大きさにするかが問題となる。そこで、本実施の形態では、最大ブロックサイズを管理ファイル15に設定してあるので、その最大ブロックサイズに等しいあるいは読み出すフィールドデータの個数に応じて最大ブロックサイズの整数倍の大きさの入出力バッファを用意すればよい。
【0046】
ファイル管理システムは、入出力バッファを確保すると(ステップ201)、その後は管理ファイル15に設定されているレコード数を参照することによって要求されたフィールドデータの格納位置を特定して当該フィールドデータを順次読み出す。すなわち、ファイル管理システムは、管理ファイル15の読出し位置を先頭グループに位置づけて(ステップ202)、当該グループに含まれる各ブロックの当該グループにおけるオフセットを得る(ステップ203)。レコードフォーマットは既知なので、そのオフセットは容易に求まる。
【0047】
このように、管理ファイル15に基づき各グループの先頭位置及び各グループ内における各ブロックのオフセット位置が求まると、読出し対象となるフィールドデータの格納位置を特定できるので(ステップ204)、後は転置ファイル14の特定したグループにおいて特定したブロックから読出し対象とされたフィールドデータを順次読み出せばよい(ステップ205〜210)。本実施の形態では、転置ファイル14からの読出し処理を非同期に行っている。そして、先頭のグループに対する処理が終了すると、次のグループに処理を移行し、最終的には転置ファイル14に含まれる全グループに対して前述した読出し処理を施す(ステップ211,212)。
【0048】
以上のようにして、各グループ13へのデータ読出し処理が終了すると、この時点で入出力バッファを解放する(ステップ213)。
【0049】
本実施の形態によれば、図6に示したデータ構造の管理ファイル15を設けるだけで、各レコードグループ11を可変としてもフィールドデータの読出しを容易に行うことができる。
【0050】
なお、上記説明では、管理ファイル15に最大ブロックサイズを設けることで読出し処理の開始前に必要なバッファサイズを確保することができるようにしたが、ブロックからフィ−ルドデータを読み出す度に必要なバッファの獲得と解放を繰り返し行うようにしてもよい。これにより、必要最小限のサイズのバッファでメモリを確保することができるので、メモリを効率的に使用することができる。必要なときにバッファの獲得と解放を繰り返し行うように処理することは、特にブロックサイズに極端なばらつきがある場合には効果的である。
【0051】
また、本実施の形態では、管理ファイル15を別個な構成として設けたが、転置ファイル14の内部に組み込んでもよいし、障害対策としてレコード数等の情報を管理ファイル15と転置ファイル14の双方に持たせて二重化するようにしてもよい。
【0052】
実施の形態4.
上記実施の形態3においては、各レコードグループ11を構成するレコード数を可変にしたことによって各ブロックの大きさも一定ではない。しかし、ブロックサイズを固定にしておいた方が処理の都合上好ましい場合もある。そのような場合には、ブロックサイズを固定とするために転置ファイル14において最大ブロックサイズではないブロックには空き領域を設けることで全ブロックサイズを統一するようにしたことを特徴としている。
【0053】
図7は、本発明に係るファイル管理方法の実施の形態4に用いられる転置ファイルの生成方法を示すための模式図である。転置ファイル14に示したように各ブロックを最大ブロックサイズに統一し、空き領域16にはパディングを施す。このため、管理ファイル15には、実施の形態3と異なって各グループに含まれるレコード数のみが設定されることになる。
【0054】
なお、パディングを施すときには実際にデータを書き込まなくてもよい。ファイルシステムによっては、ディスク領域を消費せずに論理的に空き領域を確保することができる場合がある。このような場合は、データを書き込まずに空き領域を単に確保することによってディスク容量の節約を図ることができる。
【0055】
実施の形態5.
図8は、本発明に係るファイル管理方法の実施の形態5に用いられる転置ファイルの生成方法を示すための模式図である。本実施の形態においては、ブロック12の大きさが物理的な入出力単位の整数倍でないときに、その整数倍でないブロック12にパディングを施すことによってその整数倍にすることで処理効率の低下を防止することを特徴としている。
【0056】
すなわち、ディスク装置などの記憶装置では、物理的に入出力できる最小単位は固定されている場合が多い。この最小単位を以下セクタサイズと呼ぶ。ディスク装置に格納されているファイルにアクセスを行うときの入出力単位がセクタサイズの整数倍であれば、記憶装置と入出力バッファとの間で直接入出力を行うことができる。しかし、入出力単位がセクタサイズの整数倍でなければ、ディスク装置内のデータをメモリにいったん読み出した後、改めて入出力バッファにコピーを行うようにしなければ入出力を行えない場合がある。
【0057】
このことは、本実施の形態においても同様なことがいえ、効率的な入出力を行うためにはブロック12の大きさをセクタサイズの整数倍にすることが望ましい。上記各実施の形態においては、内部フィールド長をワード境界などの固定境界に合致させるようにはしたが、内部フィールドをまとめて生成するブロック12の大きさが必ずしもセクタサイズの整数倍になるとは限らない。例えば、セクタサイズが512バイト、ワード境界が4バイトである場合、10バイトの論理フィールドは12バイトの内部フィールドに変換されるが、このとき12×42+8=512であるから12バイト長の内部フィールドをまとめて生成されたブロック12は、セクタサイズの整数倍にはならない。
【0058】
そこで、本実施の形態においては、内部フィールドをまとめてブロック12を生成した結果、そのブロック12の大きさがセクタサイズの整数倍にならなかったときにはパディングを施してセクタサイズの整数倍となるように調整することになる(図3のステップ103)。このようなブロックサイズの調整を行うようにすることで入出力処理の効率化を図ることができる。
【0059】
【発明の効果】
本発明によれば、内部フィールドを可変長としたことにより、元ファイルのレコードを構成する各論理フィールドを分断することなく内部フィールドと1対1に対応付けしてフィールド変換できるようにしたので、一フィールドデータの読出し処理に伴う物理的な入出力処理の増加を抑止することができる。これにより、データ読出し処理を高速化することができる。
【0060】
また、空き領域を内部フィールドに付加することによって各内部フィールドの区切りを物理的な処理単位となる境界に合致させることができるので、効率的な読出し処理を実現することができる。
【0061】
また、レコードグループに含まれるレコード数を固定とした場合において固定数のレコードで満たされていないレコードグループに対しては、ディスク装置からレコードバッファ全体を読み出し、レコードを書き込んだ後、レコードグループを書き戻さなくてはならなかった。つまり、使用しない登録済みのレコードまで読み出さなくてはならなかったが、本発明においては各レコードグループに含まれるレコード数を可変としたことで、登録したところまでのレコード数でレコードグループを生成することができるので、そのような登録済みのレコードまで読み出す必要がなくなる。
【0062】
また、ブロックの大きさを統一できるようにしたので、処理効率の向上を図ることができる。
【0063】
また、複数の内部フィールドをまとめてブロック化しておくことで複数のフィールドデータをより少ない入出力回数で効率よく読み出すことができる。
【0064】
特に、元ファイルでは離れた位置にあっても同時に利用されることが予めわかっている場合には、該当する内部フィールドをまとめてブロックを生成することにより読出し処理をより効率的に行うことができる。
【0065】
また、内部フィールドをまとめてブロックを生成した結果、そのブロックサイズが物理的な最小入出力単位の整数倍にならなかったときにはパディングを施してその最小入出力単位の整数倍となるように調整するようにしたので、入出力処理を効率的に行うことができる。
【図面の簡単な説明】
【図1】 本発明に係るファイル管理方法の実施の形態1に用いられる転置ファイルの生成方法を示すための模式図である。
【図2】 実施の形態1において元ファイルの論理フィールドと内部フィールドとの対応関係を示したレコード構造図である。
【図3】 実施の形態1における転置ファイル生成処理の流れを示したフローチャートである。
【図4】 本発明に係るファイル管理方法の実施の形態2に用いられる転置ファイルの生成方法を示すための模式図である。
【図5】 本発明に係るファイル管理方法の実施の形態3に用いられる転置ファイルの生成方法を示すための模式図である。
【図6】 実施の形態3におけるデータ読出し処理を示したフローチャートである。
【図7】 本発明に係るファイル管理方法の実施の形態4に用いられる転置ファイルの生成方法を示すための模式図である。
【図8】 本発明に係るファイル管理方法の実施の形態5に用いられる転置ファイルの生成方法を示すための模式図である。
【図9】 従来のファイル管理方法において転置ファイルの生成方法を示すための模式図である。
【図10】 従来において元ファイルの論理フィールドと内部フィールドとの対応関係を示したレコード構造図である。
【符号の説明】
11 レコードグループ、12 ブロック、13 グループ、14 転置ファイル、15 管理ファイル、16 空き領域。
Claims (7)
- 少なくとも1つの可変長のフィールドを含むレコードを複数格納した元ファイルの管理を行うファイル管理方法において、
元ファイルに格納されたレコードを構成する各フィールドをそれぞれ、データの区切りを示す固定境界と区切りが合致する1つの内部フィールドに変換するフィールド変換ステップと、
変換された内部フィールドにより構成される全レコードを、複数の群に分割することによってレコードグループを生成するレコードグループ生成ステップと、
各レコードグループにおいて、各レコードにおける同一フィールドが同じグループに含まれるように分割することでブロックを生成するブロック生成ステップと、
レコ−ドグループ毎に、当該レコ−ドグループにおいて生成されたブロックを並べて含むグループを生成し、更にその生成したグループを並べて含むファイルを転置ファイルとして生成する転置ファイル生成ステップと、
を含み、元ファイルからのデータ読出し要求に対して転置ファイルにアクセスを行うことを特徴とするファイル管理方法。 - 前記フィールド変換ステップは、内部フィールドに空き領域を付加することによって各内部フィールドの区切りを物理的な処理単位となる境界に合致させることを特徴とする請求項1記載のファイル管理方法。
- 前記レコードグループ生成ステップは、各レコードグループに含まれるレコード数を可変とし、転置ファイルへのアクセス時には予め設定された各レコードグループに含まれるレコード数を参照することによってフィールドデータの格納位置を特定することを特徴とする請求項1記載のファイル管理方法。
- 前記ブロック生成ステップは、小さいサイズのブロックに空き領域を付加することによって全ブロックの大きさを統一することを特徴とする請求項3記載のファイル管理方法。
- 前記ブロック生成ステップは、各レコードにおいて同一位置にあるフィールドが複数含まれるようにブロックを生成することを特徴とする請求項1記載のファイル管理方法。
- 前記ブロック生成ステップは、隣接していないフィールドによってブロックを生成することを特徴とする請求項5記載のファイル管理方法。
- 前記ブロック生成ステップは、生成したブロックサイズが物理的な最小入出力単位の整数倍と一致しないときには、最小入出力単位の整数倍になるように当該ブロックに空き領域を付加することを特徴とする請求項1記載のファイル管理方法。
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP19459099A JP4251726B2 (ja) | 1999-07-08 | 1999-07-08 | ファイル管理方法 |
| CA002287608A CA2287608C (en) | 1999-07-08 | 1999-10-26 | File management method using transposed file |
| US09/427,113 US6397223B1 (en) | 1999-07-08 | 1999-10-26 | File management method using transposed file |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP19459099A JP4251726B2 (ja) | 1999-07-08 | 1999-07-08 | ファイル管理方法 |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2001022617A JP2001022617A (ja) | 2001-01-26 |
| JP2001022617A5 JP2001022617A5 (ja) | 2006-04-06 |
| JP4251726B2 true JP4251726B2 (ja) | 2009-04-08 |
Family
ID=16327085
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP19459099A Expired - Lifetime JP4251726B2 (ja) | 1999-07-08 | 1999-07-08 | ファイル管理方法 |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US6397223B1 (ja) |
| JP (1) | JP4251726B2 (ja) |
| CA (1) | CA2287608C (ja) |
Families Citing this family (31)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7031987B2 (en) * | 1997-05-30 | 2006-04-18 | Oracle International Corporation | Integrating tablespaces with different block sizes |
| JP3318834B2 (ja) * | 1999-07-30 | 2002-08-26 | 三菱電機株式会社 | データファイルシステム及びデータ検索方法 |
| JP3573012B2 (ja) * | 1999-09-29 | 2004-10-06 | 三菱電機株式会社 | データ管理装置およびデータ管理方法 |
| US6542893B1 (en) * | 2000-02-29 | 2003-04-01 | Unisys Corporation | Database sizer for preemptive multitasking operating system |
| US6757673B2 (en) * | 2000-10-09 | 2004-06-29 | Town Compass Llc | Displaying hierarchial relationship of data accessed via subject index |
| KR100706503B1 (ko) * | 2000-12-19 | 2007-04-10 | 엘지전자 주식회사 | 메모리 영역 사용 방법 |
| US20060169597A1 (en) * | 2001-03-14 | 2006-08-03 | Applied Materials, Inc. | Method and composition for polishing a substrate |
| US7693839B2 (en) * | 2001-05-22 | 2010-04-06 | Pitney Bowes Inc. | System and method for obtaining and tracking up-to the-minute delivery locations of employees via a database system |
| US8244702B2 (en) * | 2002-02-26 | 2012-08-14 | International Business Machines Corporation | Modification of a data repository based on an abstract data representation |
| US6996558B2 (en) * | 2002-02-26 | 2006-02-07 | International Business Machines Corporation | Application portability and extensibility through database schema and query abstraction |
| US7981561B2 (en) * | 2005-06-15 | 2011-07-19 | Ati Properties, Inc. | Interconnects for solid oxide fuel cells and ferritic stainless steels adapted for use with solid oxide fuel cells |
| US7096217B2 (en) | 2002-10-31 | 2006-08-22 | International Business Machines Corporation | Global query correlation attributes |
| US7254590B2 (en) * | 2003-12-03 | 2007-08-07 | Informatica Corporation | Set-oriented real-time data processing based on transaction boundaries |
| US7900133B2 (en) | 2003-12-09 | 2011-03-01 | International Business Machines Corporation | Annotation structure type determination |
| US7302447B2 (en) * | 2005-01-14 | 2007-11-27 | International Business Machines Corporation | Virtual columns |
| US20060116999A1 (en) * | 2004-11-30 | 2006-06-01 | International Business Machines Corporation | Sequential stepwise query condition building |
| US7461052B2 (en) * | 2004-12-06 | 2008-12-02 | International Business Machines Corporation | Abstract query plan |
| US8112459B2 (en) * | 2004-12-17 | 2012-02-07 | International Business Machines Corporation | Creating a logical table from multiple differently formatted physical tables having different access methods |
| US7333981B2 (en) * | 2004-12-17 | 2008-02-19 | International Business Machines Corporation | Transformation of a physical query into an abstract query |
| US8131744B2 (en) * | 2004-12-17 | 2012-03-06 | International Business Machines Corporation | Well organized query result sets |
| US7321895B2 (en) * | 2005-01-14 | 2008-01-22 | International Business Machines Corporation | Timeline condition support for an abstract database |
| US7624097B2 (en) * | 2005-01-14 | 2009-11-24 | International Business Machines Corporation | Abstract records |
| US8122012B2 (en) * | 2005-01-14 | 2012-02-21 | International Business Machines Corporation | Abstract record timeline rendering/display |
| US8095553B2 (en) * | 2005-03-17 | 2012-01-10 | International Business Machines Corporation | Sequence support operators for an abstract database |
| US7444332B2 (en) * | 2005-11-10 | 2008-10-28 | International Business Machines Corporation | Strict validation of inference rule based on abstraction environment |
| US7440945B2 (en) * | 2005-11-10 | 2008-10-21 | International Business Machines Corporation | Dynamic discovery of abstract rule set required inputs |
| US20070112827A1 (en) * | 2005-11-10 | 2007-05-17 | International Business Machines Corporation | Abstract rule sets |
| US8140557B2 (en) | 2007-05-15 | 2012-03-20 | International Business Machines Corporation | Ontological translation of abstract rules |
| JP5544118B2 (ja) * | 2009-06-30 | 2014-07-09 | 株式会社日立製作所 | データ処理装置、及び処理方法 |
| JP5337745B2 (ja) | 2010-03-08 | 2013-11-06 | 株式会社日立製作所 | データ処理装置 |
| CN101976226B (zh) * | 2010-10-20 | 2012-05-30 | 青岛海信宽带多媒体技术有限公司 | 一种数据存储方法 |
Family Cites Families (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5327341A (en) * | 1991-10-28 | 1994-07-05 | Whalen Edward J | Computerized file maintenance system for managing medical records including narrative reports |
| JP3609841B2 (ja) * | 1992-11-25 | 2005-01-12 | 富士通株式会社 | ファイル管理装置 |
| US5991753A (en) * | 1993-06-16 | 1999-11-23 | Lachman Technology, Inc. | Method and system for computer file management, including file migration, special handling, and associating extended attributes with files |
| US5499358A (en) * | 1993-12-10 | 1996-03-12 | Novell, Inc. | Method for storing a database in extended attributes of a file system |
| US6175835B1 (en) * | 1996-07-26 | 2001-01-16 | Ori Software Development, Ltd. | Layered index with a basic unbalanced partitioned index that allows a balanced structure of blocks |
| US5986652A (en) * | 1997-10-21 | 1999-11-16 | International Business Machines Corporation | Method for editing an object wherein steps for creating the object are preserved |
| US6108004A (en) * | 1997-10-21 | 2000-08-22 | International Business Machines Corporation | GUI guide for data mining |
| JP3024619B2 (ja) * | 1997-11-20 | 2000-03-21 | 三菱電機株式会社 | ファイル管理方法 |
-
1999
- 1999-07-08 JP JP19459099A patent/JP4251726B2/ja not_active Expired - Lifetime
- 1999-10-26 CA CA002287608A patent/CA2287608C/en not_active Expired - Lifetime
- 1999-10-26 US US09/427,113 patent/US6397223B1/en not_active Expired - Lifetime
Also Published As
| Publication number | Publication date |
|---|---|
| CA2287608A1 (en) | 2001-01-08 |
| CA2287608C (en) | 2003-09-16 |
| US6397223B1 (en) | 2002-05-28 |
| JP2001022617A (ja) | 2001-01-26 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP4251726B2 (ja) | ファイル管理方法 | |
| US8255398B2 (en) | Compression of sorted value indexes using common prefixes | |
| EP0166148B1 (en) | Memory assignment method for computer based systems | |
| US5586292A (en) | Data processing method using record division storing scheme and apparatus therefor | |
| US6725225B1 (en) | Data management apparatus and method for efficiently generating a blocked transposed file and converting that file using a stored compression method | |
| CN108021717B (zh) | 一种轻量级嵌入式文件系统的实现方法 | |
| CN107391544B (zh) | 列式存储数据的处理方法、装置、设备及计算机储存介质 | |
| CN107741947B (zh) | 基于hdfs文件系统的随机数密钥的存储与获取方法 | |
| EP0921527A2 (en) | File managing method | |
| US4630030A (en) | Compression of data for storage | |
| CN100410945C (zh) | 一种实现论坛的方法及系统 | |
| CN106709014A (zh) | 一种文件系统转换方法及装置 | |
| US20110099347A1 (en) | Managing allocation and deallocation of storage for data objects | |
| JP2001265628A (ja) | ファイル記録管理システム | |
| US20080114780A1 (en) | Efficient database data type for large objects | |
| JP4251725B2 (ja) | ファイル管理方法 | |
| US5978810A (en) | Data management system and method for storing a long record in a set of shorter keyed records | |
| US7720805B1 (en) | Sequential unload processing of IMS databases | |
| JP5626561B2 (ja) | 情報処理システム及びそのデータ管理方法 | |
| JP2001022623A (ja) | ファイル管理方法 | |
| US6154792A (en) | Method and computer program product for paging control using a reference structure including a reference bitmap | |
| CN111930320B (zh) | 一种基于分布式存储数据的内存优化方法及其系统 | |
| JPS5851348A (ja) | 可変長レコ−ドの高速アクセス方式 | |
| JP6901005B2 (ja) | 情報蓄積装置、データ処理システム、およびプログラム | |
| CN115982156A (zh) | 数据处理方法、装置、计算机设备、存储介质和程序产品 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20060124 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20060124 |
|
| RD04 | Notification of resignation of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7424 Effective date: 20060124 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20081028 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20081218 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20090120 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20090120 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 4251726 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20120130 Year of fee payment: 3 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20130130 Year of fee payment: 4 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20130130 Year of fee payment: 4 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| EXPY | Cancellation because of completion of term |