JP4110012B2 - Conversation control device and conversation control method - Google Patents
Conversation control device and conversation control method Download PDFInfo
- Publication number
- JP4110012B2 JP4110012B2 JP2003047893A JP2003047893A JP4110012B2 JP 4110012 B2 JP4110012 B2 JP 4110012B2 JP 2003047893 A JP2003047893 A JP 2003047893A JP 2003047893 A JP2003047893 A JP 2003047893A JP 4110012 B2 JP4110012 B2 JP 4110012B2
- Authority
- JP
- Japan
- Prior art keywords
- morpheme
- information
- morpheme information
- unit
- searched
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Lifetime
Links
Images

























Landscapes
- Machine Translation (AREA)
Description
【0001】
【発明の属する技術分野】
本発明は、会話制御装置及び会話制御方法に関する。
【0002】
【従来の技術】
従来からの会話制御装置においては、利用者からの発話内容に基づいて、その発話内容に対応する予め格納された回答文を出力することができる(例えば、特許文献1。)。このため、利用者は、会話制御装置からの回答文により、擬似的に他の利用者と話をしているような感覚を味わうことができた。
【0003】
【特許文献1】
特開2002−169804号(第10−26頁、図16)
【0004】
【発明が解決しようとする課題】
しかしながら、利用者の発話内容が複数の意味に捉えられ、その発話内容に対応する回答文が複数あるような場合には、会話制御装置は、最初に検索された回答文を出力していた。このため、会話制御装置は、利用者の発話内容が複数の意味に捉えられる場合には、予め展開したい特定の話題に関係する発話内容の意味に捉え、その捉えた発話内容の意味に対応する回答文を出力することができなかった。
【0005】
例えば、利用者からの発話内容が{IRを教えて下さい}である場合は、その発話内容は、遊技機における演出画像のIR(イナズマ ラッシュ)又は会社のIR(Investor Relations)の意味に捉えられることがある。この場合、会話制御装置は、各回答文の中から、遊技機における演出画像のIR(イナズマ ラッシュ)に対応する回答文を最初に検索したときには、その最初に検索した回答文を出力していた。
【0006】
すなわち、会話制御装置は、会社のIRに対応する回答文を出力したいときであっても、演出画像のIR(イナズマ ラッシュ)に対応する回答文を最初に検索したときには、その最初に検索した回答文を自動的に出力していた。このため、予め展開させたい特定の話題に関係する回答文を出力することのできるシステムの開発が望まれていた。
【0007】
そこで、本発明は以上の点に鑑みてなされたものであり、利用者が複数の意味に捉えられる同一の発話内容を複数発話した場合には、前回の回答文とは異なる回答文を出力することのできる会話制御装置及び会話制御方法を提供することを課題とする。
【0008】
【課題を解決するための手段】
本発明は、上記課題を解決するために、利用者から入力された入力情報に基づいて、同一の入力情報が最初に取得された時から所定の時間が経過した場合には、最初に取得された同一の入力情報に対応する回答文とは異なる回答文を検索することを特徴とする。
【0009】
すなわち、本発明は、利用者から入力された入力情報に基づいて、予め記憶された複数のフレーズの中から、入力情報を含む各フレーズを検索し、検索された各フレーズに基づいて、前回検索されたフレーズが今回検索された各フレーズに含まれ、前回のフレーズが検索された時から所定の時間が経過した場合には、前回検索されたフレーズとは異なるフレーズを、今回検索された各フレーズの中から選出し、選出されたフレーズに基づいて、フレーズに対応する回答文を検索することを特徴とする。
【0010】
この場合には、例えば、検索された入力情報(IRを教えて)を含む各フレーズとして、フレーズ1(A装置のIRを教えて)及びフレーズ2(B装置のIRを教えて)が検索され、それらの各フレーズの中に前回検索されたフレーズ1(A装置のIRを教えて)が含まれ、そのフレーズ1(A装置のIRを教えて)が前回検索された時から所定の時間が経過した場合には、会話制御装置は、前回検索されたフレーズ1とは異なるフレーズ2を選出し、選出したフレーズ2に対応する回答文を出力することができる。
【0011】
これにより、入力情報が複数の意味に捉えられ、その各意味の中に前回用いた意味が含まれ、且つその意味が用いられた時から所定の時間が経過した場合には、会話制御装置は、その時間に応じて前回用いた意味とは異なる意味を選択し、選択した意味に対応する回答文を出力することができる。この結果、利用者が特定の発話内容を発話し、その発話をした時から所定の時間が経過した後に、その発話内容と同一の内容が再度繰り返し入力された場合には、会話制御装置は、その時間に応じて現在の話題を異なる話題に振り向けるような回答文を出力することができる。
【0012】
上記発明においては、フレーズには一つの文字、複数の文字列又はこれらの組み合わせからなる形態素を示す第二形態素情報が含まれ、複数の第二形態素情報には利用者への回答文が対応付けられ、各第二形態素情報及び各回答文を予め記憶し、利用者から入力された入力情報に含まれる文字列に基づいて、文字列の最小単位を構成する少なくとも一つの形態素を第一形態素情報として抽出し、抽出された第一形態素情報に基づいて、予め記憶された各第二形態素情報の中から、第一形態素情報を含む第二形態素情報を複数検索し、前回検索された第二形態素情報が今回検索された各第二形態素情報に含まれ、前回の第二形態素情報が検索された時から所定の時間が経過した場合には、前回検索された第二形態素情報とは異なる第二形態素情報を、今回検索された各第二形態素情報の中から選出し、選出された第二形態素情報に基づいて、第二形態素情報に対応付けられた回答文を検索することが好ましい。
【0013】
このような本願に係る発明によれば、前回検索された第二形態素情報が今回検索された各第二形態素情報に含まれ、前回の第二形態素情報が検索された時から所定の時間が経過した場合には、会話制御装置は、前回検索された第二形態素情報とは異なる第二形態素情報を、今回検索された各第二形態素情報の中から選出し、選出した第二形態素情報に対応付けられた回答文を出力することができる。
【0014】
具体的には、例えば、利用者が”財務情報を教えて”{第一形態素情報(財務情報;教えて)}と発話した場合には、その発話内容には、A会社、B会社・・・等の複数の会社における財務情報が含まれることになる。ここで、利用者の発話内容を構成する第一形態素情報を含む第二形態素情報が複数検索されるということは、利用者の発話内容が多義的な意味を含むことを意味する。
【0015】
この場合には、会話制御装置は、例えば第一形態素情報(財務情報;教えて)を含む第二形態素情報として、(A会社;財務情報;教えて),(B会社;財務情報;教えて)・・・を検索することになる。この際、会話制御装置が、第二形態素情報(A会社;財務情報;教えて)を前回検索し、その前回検索をした時から所定の時間が経過したときは、会話制御装置は、第二形態素情報(A会社;財務情報;教えて)とは異なる第二形態素情報(B会社;財務情報;教えて)を検索する。会話制御装置は、検索した第二形態素情報(B会社;財務情報;教えて)に対応付けられた回答文(B会社の財務情報は、〜です)を出力する。
【0016】
すなわち、利用者が複数の意味に捉えられる同一の発話内容を複数発話し、その発話を最初にした時から所定の時間が経過した場合には、会話制御装置は、前回の回答文とは異なる回答文を出力する。これにより、上記所定時間が短く設定されていれば、短い時間内で回答文が逐一変更されるので、会話制御装置は、恰も前に回答した内容を忘れやすいかの印象を利用者に与えさせることのできる機器として用いることができる。
【0017】
一方、上記所定時間が長く設定されていれば、回答文があまり変更されないので、会話制御装置は、恰も前に回答した内容をしつこく発話するかの印象を利用者に与えさせることのできる機器として用いることができる。
【0018】
特に、会話制御装置は、上記入力情報に含まれる日本語特有な助詞(て・に・を・・等)を除いた形態素を用いて該当する回答文を検索するので、その各形態素から把握することができる意味内容に基づいて、予め作成された回答文をより的確に検索することができる。すなわち、会話制御装置は、単に入力情報の全体をキーワードとして、そのキーワードに関連付けられた回答文を検索するよりも、より入力情報に適した回答文を検索することができる。
【0019】
更に、会話制御装置は、第一形態素情報を含む第二形態素情報を検索するので、利用者からの入力情報と完全に一致する第二形態素情報を検索する必要がない。この結果、会話制御装置を開発する開発者は、利用者から入力されると予想される入力情報に対応する膨大な回答文を予め記憶する必要がなくなり、記憶部の容量を低減させることができる。
なお、前回の回答文とは異なる回答文には、予め展開させたい内容が含まれることが好ましい。この場合には、例えば、同じ発話内容が繰り返して発話されたときは、会話制御装置は、現在の話題を他の話題に振り向けるような回答文を出力することができる。
【0020】
これにより、前回と同一の発話内容が入力され、その同一の発話内容が入力されてから所定の時間が経過した場合には、例えば、ゲームに登場するキャラクターは、現在のストーリを他のストーリへと変更させるための回答文を出力することができる。
【0021】
なお、上記発明においては、一つの文字、複数の文字列又はこれらの組み合わせからなる形態素を示す複数の第二形態素情報には、利用者への回答文が対応付けられており、各第二形態素情報及び各回答文を予め記憶し、利用者から入力された入力情報に含まれる文字列に基づいて、文字列の最小単位を構成する少なくとも一つの形態素を第一形態素情報として抽出し、抽出された第一形態素情報に基づいて、予め記憶された各第二形態素情報の中から、第一形態素情報を含む第二形態素情報を複数検索し、前回検索された第二形態素情報が今回検索された各第二形態素情報に含まれ、今回検索された各第二形態素情報が所定の基準回数を越えて検索された場合には、前回検索された第二形態素情報とは異なる第二形態素情報を、今回検索された各第二形態素情報の中から選出し、選出された第二形態素情報に基づいて、第二形態素情報に対応付けられた回答文を検索することが好ましい。
【0022】
この場合には、前回検索された第二形態素情報が今回検索された各第二形態素情報に含まれ、今回検索された各第二形態素情報が所定の基準回数を越えて検索された場合には、会話制御装置は、前回検索された第二形態素情報とは異なる第二形態素情報を、今回検索された各第二形態素情報の中から選出し、選出した第二形態素情報に対応付けられた回答文を出力することができる。
【0023】
すなわち、利用者が複数の意味に捉えられる同一の発話内容を複数発話し、その同一の発話内容が基準回数を越えて発話された場合には、会話制御装置は、前回の回答文とは異なる回答文を出力する。これにより、上記基準回数が少なく設定されていれば、回答文が逐一変更されるので、会話制御装置は、恰も前に回答した内容を忘れやすいかの印象を利用者に与えさせることのできる機器として用いることができる。
【0024】
一方、上記基準回数が多く設定されていれば、回答文があまり変更されないので、会話制御装置は、恰も前に回答した内容をしつこく発話するかの印象を利用者に与えさせることのできる機器として用いることができる。
【0025】
【発明の実施の形態】
[第一実施形態]
(会話制御システムの基本構成)
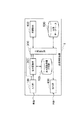
本発明に係る会話制御システムについて図面を参照しながら説明する。図1は、本実施形態に係る会話制御装置1を有する会話制御システムの概略構成図である。
【0026】
同図に示すように、会話制御装置1は、入力部100と、音声認識部200と、会話制御部300と、文解析部400と、会話データベース500と、出力部600と、音声認識辞書記憶部700とを備えている。
【0027】
尚、本実施形態では、説明の便宜上、利用者の発話内容(この発話内容は、入力情報の一種)に限定して説明するが、この利用者の発話内容に限定されるものではなく、キーボード等から入力された入力情報であってもよい。従って、以下に示す「発話内容」は、「発話内容」を「入力情報」に置き換えて説明することもできる。
【0028】
同様にして、後述の説明では、説明の便宜上、「発話文のタイプ」(発話種類)に限定して説明するが、この「発話文のタイプ」に限定されるのではなく、キーボードなどから入力された入力情報の種類を示す「入力種類」であってもよい。従って、以下に示す「発話文のタイプ」(発話種類)は、「発話種類」を「入力種類」に置き換えて説明することもできる。
【0029】
入力部100は、利用者からの入力情報を取得する取得手段であり、本実施形態では、マイクロホン、キーボード等が挙げられる。この入力部100は、利用者から入力された入力情報に基づいて、入力情報を示す文字列を特定する文字認識手段でもある。
【0030】
ここで、入力情報とは、キーボード等を通じて入力された文字、記号、音声等を意味するものである。具体的に、入力部100は、利用者の入力情報(音声以外)を取得し、取得した入力情報を会話制御部300に出力する。また、利用者からの発話内容(この発話内容は、音声からなるものであり、入力情報の一種である)をマイクロホンなどで取得した入力部100は、取得した発話内容を構成する音声を音声信号として音声認識部200に出力する。
【0031】
音声認識部200は、入力部100で取得した発話内容に基づいて、発話内容に含まれる文字列を特定する文字認識手段である。具体的には、入力部100から音声信号が入力された音声認識部200は、入力された音声信号を解析し、解析した音声信号に対応する文字列を、音声認識辞書記憶部700に格納されている辞書を用いて特定し、特定した文字列を文字列信号として会話制御部300に出力する。音声認識辞書記憶部700は、標準的な音声信号に対応する辞書を格納しているものである。
【0032】
前記文解析部400は、入力部100又は音声認識部200で特定された文字列を解析するものであり、本実施形態では、図2に示すように、形態素抽出部410と、文節解析部420と、文構造解析部430と、発話種類判定部440と、形態素データベース450と、発話種類データベース460とを有している。
【0033】
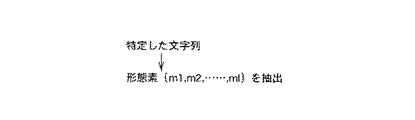
形態素抽出部410は、入力部100又は音声認識部200で特定された文字列に基づいて、文字列の最小単位を構成する少なくとも一つの形態素を第一形態素情報として抽出する形態素抽出手段である。
【0034】
具体的に、管理部310から文字列信号が入力された形態素抽出部410は、入力された文字列信号に対応する文字列の中から各形態素を抽出する。ここで、形態素とは、本実施形態では、文字列に現された語構成の最小単位を意味するものとする。この語構成の最小単位としては、図3に示すように、例えば、名詞、形容詞、動詞などの品詞が挙げられる。各形態素は、本実施形態では、m1、m2、・・・、mlと表現する。
【0035】
即ち、形態素抽出部410は、入力された文字列信号に対応する文字列と、形態素データベース450に予め格納されている名詞、形容詞、動詞などの形態素群とを照合し、文字列の中から形態素群と一致する各形態素(m1、m2、・・・)を抽出し、抽出した各形態素を抽出信号として文節解析部420に出力する。
【0036】
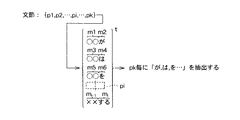
文節解析部420は、形態素抽出部410で抽出された各形態素に基づいて、各形態素を文節形式に変換する変換手段である。具体的に、形態素抽出部410から抽出信号が入力された文節解析部420は、入力された抽出信号に対応する各形態素を用いて文節形式にまとめる。
【0037】
ここで、文節形式とは、本実施形態では、日本語文法において、自立語又は自立語に一つ以上の付属語がついた文、或いは、日本語文法の意味を崩さない程度に文字列をできるだけ細かく区切った一区切りの文を意味する。この文節は、本実施形態では、p1、p2、・・・pkと表現する。
【0038】
即ち、文節解析部420は、図4に示すように、入力された抽出信号に対応する各形態素に基づいて各形態素の係り受け要素(例えば、が(m2)・は(m4)・を(m5)・・)を抽出し、抽出した係り受け要素に基づいて各形態素を各文節にまとめることを行う。同図に示す「t」は、転置を意味する。
【0039】
各形態素を各文節にまとめた文節解析部420は、各形態素をまとめた各文節と、各文節を構成する各形態素とを含む文型情報を文型信号として文構造解析部430及び発話種類判定部440に出力する。
【0040】
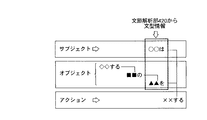
文構造解析部430は、文節解析部420で分節された第一形態素情報の各形態素を主体格、対象格などの各属性に分類する分類手段である。具体的に、文節解析部420から文型信号が入力された文構造解析部430は、入力された文型信号に対応する各形態素と各形態素からなる文節とに基づいて、文節に含まれる各形態素の「格構成」を決定する。
【0041】
ここで、「格構成」とは、文節における実質的な概念を示す格(属性)を意味するものであり、本実施形態では、例えば、主語・主格を意味するサブジェクト(主体格)、対象を意味するオブジェクト(対象格)、動作を意味するアクション、時間を意味するタイム(テンス、アスペクト)、場所を意味するロケーション等が挙げられる。本実施形態では、サブジェクト、オブジェクト、アクションの三要素の「格」(格構成)に対応付けられた各形態素を第一形態素情報とする。
【0042】
即ち、文構造解析部430は、図5に示すように、例えば、各形態素の係り受け要素が”が”又は”は”である場合は、その係り受け要素の前にある形態素がサブジェクト(主語又は主格)であると判断する。また、文構造解析部430は、例えば、各形態素の係り受け要素が”の”又は”を”である場合は、その係り受け要素の前にある形態素がオブジェクト(対象)であると判断する。
【0043】
更に、文構造解析部430は、例えば、各形態素の係り受け要素が”する”である場合は、その係り受け要素の前にある形態素がアクション(述語;この述語は動詞、形容詞などから構成される)であると判断する。
【0044】
各文節を構成する各形態素の「格構成」を決定した文構造解析部430は、決定した「格構成」に対応付けられた第一形態素情報に基づいて、後述する話題(トピック)の範囲を特定させるための話題検索命令信号を反射的判定部320に出力する。
【0045】
発話種類判定部440は、文節解析部420で特定された文節に基づいて、発話内容(入力情報)の種類を示す発話種類(入力種類)を特定する種類特定手段である。具体的に、文節解析部420から入力された文型信号に対応する各形態素と各形態素から構成される文節とに基づいて、「発話文のタイプ」(発話種類)を判定する。
【0046】
ここで、「発話文のタイプ」は、本実施形態では、図6に示すように、陳述文(D;Declaration)、感想文(I;Impression)、条件文(C;Condition)、結果文(E;Effect)、時間文(T;Time)、場所文(L;Location)、反発文(N;Negation)などから構成されるものである。これらの各文は、図6に示すように、肯定文(A;Answer)又は質問文(Q;Question)で表現される。
【0047】
陳述文とは、利用者の意見又は考えなどからなる文を意味するものであり、本実施形態では、図6に示すように、例えば”佐藤が好きだ”などの文が挙げられる。感想文とは、利用者が抱く感想からなる文を意味するものである。場所文とは、場所的な要素からなる文を意味するものである。
【0048】
結果文とは、話題に対して文が結果の要素を含む文から構成されるものを意味する。時間文とは、話題に関わる時間的な要素を含む文から構成されるものを意味する。
【0049】
条件文とは、一つの発話を話題と捉えた場合に、話題の前提、話題が成立している条件や理由などの要素を含む文から構成されるものを意味する。反発文とは、発話相手に対して反発するような要素を含む文から構成されるものを意味する。各「発話文のタイプ」についての例文は、図6に示す通りである。
【0050】
即ち、発話種類判定部440は、入力された文型信号に対応する各文節に基づいて、その各文節と発話種類データベース460に格納されている各辞書とを照合し、各文節の中から、各辞書に関係する文要素を抽出する。各文節の中から各辞書に関係する文要素を抽出した発話種類判定部440は、抽出した文要素に基づいて、「発話文のタイプ」を判定する。文要素とは、文字列の種類を特定するための分の種別を意味し、文要素は、本実施形態では、上記説明した定義句(〜のことだ)などが挙げられる。
【0051】
ここで、上記発話種類データベース460は、図7に示すように、定義句(例えば、〜のことだ)に関係する辞書を備えた定義表現事例辞書、肯定句(例えば、賛成、同感、ピンポーン)に関係する辞書を備えた肯定事例辞書、結果句(例えば、それで、だから)に関係する辞書を備えた結果表現事例辞書、挨拶句(例えば、こんにちは)に関係する辞書を備えた挨拶事例辞書、否定句(例えば、馬鹿言うんじゃないよ、反対)に関係する辞書を備えた否定事例辞書などから構成され、各辞書は、「発話文のタイプ」と関連付けられている。
【0052】
これにより、発話種類判定部440は、文節と発話種類データベース460に格納されている各辞書とを照合し、文節の中から各辞書に関連する文要素を抽出し、抽出した文要素に関連付けられた判定の種類を参照することで、「発話文のタイプ」を判定することができる。
【0053】
この発話種類判定部440は、後述する話題検索部360からの指示に基づいて、該当する利用者に特定の回答文を検索させるための回答検索命令信号を回答文検索部370に出力する。
【0054】
前記会話データベース500は、一つの文字、複数の文字列又はこれらの組み合わせからなる各形態素を示す第二形態素情報と、発話内容に対する利用者への回答文とを予め相互に関連付けて複数記憶する形態素抽記憶手段である。また、会話データベース500は、複数の回答文に対応付けられた各回答文の種類を示す回答種類を、第二形態素情報に関連付けて予め複数記憶するものでもある。
【0055】
更に、会話データベース500は、利用者から入力されるであろう入力内容又は利用者への回答文に関連性のある範囲を構成する形態素を示す談話範囲(キーワード)を予め複数記憶するものでもある。この談話範囲(キーワード)には、一つの文字、複数の文字列又はこれらの組み合わせからなる形態素を示す第二形態素情報が複数関連付けられ、各第二形態素情報には、利用者への回答文がそれぞれに関連付けてられている。
【0056】
更にまた、会話データベース500は、第二形態素情報を構成する各要素を、主格からなる主体各、目的格からなる対象格などの属性に分類して記憶するものでもある。
【0057】
この会話データベース500は、図8に示すように、本実施形態では、大きく分けると、利用者から発話されるであろう発話内容又は利用者への回答文について関連性のある範囲を意味する談話範囲(ディスコース)と、利用者が発話している内容に最も密接な関連性のある範囲を意味する話題(トピック)とから構成されている。同図に示すように、”談話範囲”は、本実施形態では、”話題”の上位概念として位置付けるものとする。
【0058】
各談話範囲は、図9に示すように、階層構造となるように構成することができる。同図に示すように、例えば、ある談話範囲(映画)に対する上位概念の談話範囲(娯楽)は、上の階層構造に位置するようにし、談話範囲(映画)に対する下位概念の談話範囲(映画の属性、上映映画)は、下の階層構造に位置するようにすることができる。即ち、各談話範囲は、本実施形態では、他の談話範囲との間で上位概念、下位概念、同義語、対義語の関係が明確となる階層位置に配置することかできる。
【0059】
上述の如く、談話範囲は、各話題から構成されるものであり、本実施形態では、例えば、談話範囲がA映画名であれば、A映画名に関係する複数の話題を含んでいる。
【0060】
この話題は、一つの文字、複数の文字列又はこれらの組み合わせからなる形態素、即ち、利用者から発話されるであろう発話内容を構成する各形態素を意味するものであり、本実施形態では、サブジェクト(主体格)、オブジェクト(対象格)、アクションの「格」(属性)に対応付けられた各形態素からなるものである。これら三要素に対応付けられた各形態素は、本実施形態では、話題タイトル(この話題タイトルは、”話題”の下位概念に相当するものである)(第二形態素情報)と表現することにする。
【0061】
尚、話題タイトルには、上記三要素に対応付けられた各形態素に限定されるものではなく、他の「格」、即ち、時間を意味するタイム(テンス、アスペクト)、場所を意味するロケーション、条件を意味するコンディション、感想を意味するインプレッション、結果を意味するエフェクトなどに対応付けられた各形態素を有してもよい。
【0062】
この話題タイトル(第二形態素情報)は、本実施形態では、会話データベース500に予め格納されているものであり、上記第一形態素情報(利用者が発話した発話内容から導かれたもの)とは区別されるものである。
【0063】
例えば、話題タイトルは、談話範囲が”A映画名”である場合には、図10に示すように、サブジェクト(A映画名)、オブジェクト(監督)、アクション(素晴らしい){これは、”A映画名の監督は素晴らしい”を意味する}から構成されるものである。
【0064】
話題タイトルのうち、「格構成」(サブジェクト、オブジェクト、アクションなど)に対応付けられた形態素がない場合は、その部分については、本実施形態では、”*”を示すことにする。
【0065】
例えば、{A映画名って?}の文を話題タイトル(サブジェクト;オブジェクト;アクション)に変換すると、{A映画名って?}の文のうち、”A映画名”がサブジェクトとして特定することができるが、その他”オブジェクト””アクション”は文の要素になっていないので、話題タイトルは、”サブジェクト”(A映画名);”オブジェクト”なし(*);”アクション”なし(*)となる(図10参照)。
【0066】
回答文は、本実施形態では、各話題タイトル(第二形態素情報)に関連付けられている(図8参照)。回答文は、本実施形態では、本実施形態では、図11に示すように、利用者から発話された発話文のタイプに対応した回答をするために、陳述文(D;Declaration)、感想文(I;Impression)、条件文(C;Condition)、結果文(E;Effect)、時間文(T;Time)、場所文(L;Location)、否定文(N;Negation)などのタイプ(回答種類)に分類されている。
【0067】
即ち、各回答文は、図12に示すように、例えば、談話範囲(佐藤){下位概念;ホームラン、上位概念;草野球、同義語;パンダ佐藤・佐藤選手・パンダ}及び各話題タイトルと関連付けられている。
【0068】
同図に示すように、例えば、話題タイトル1−1が{(佐藤;*;好きだ):これは、上述の如く(サブジェクト;オブジェクト;アクション)の順番からなるものである。この順番は、以下同様とする}である場合は、その話題タイトル1−1に対応する回答文1−1は、(DA;陳述肯定文”佐藤が好きです”)、(IA;感想肯定文”佐藤がとても好きです”)、(CA;条件肯定文”佐藤のホームランはとても印象的だからです”)、(EA;結果肯定文”いつも佐藤の出る試合をテレビ観戦してしまいます”)、(TA;時間肯定文”実は、甲子園での5打席連続敬遠から好きになっています”)、(LA;場所肯定文”打撃に立ったときの真剣な顔が好きですね”)、(NA;反発肯定文”佐藤を嫌いな人とは話したくないですね、さよなら”)などが挙げられる。
【0069】
前記会話制御部300は、本実施形態では、図2に示すように、管理部310と、反射的判定部320と、鸚鵡返し判定部330と、談話範囲決定部340と、省略文補完部350と、話題検索部360と、回答文検索部370とを有している。
【0070】
前記管理部310は、会話制御部300の全体を制御するものである。具体的に、入力部100又は音声認識部200から文字列が入力された管理部310は、入力された文字列を文字列信号として形態素抽出部410に出力する。また、管理部310は、回答文検索部370で検索された回答文を出力部600に出力する。
【0071】
反射的判定部320は、形態素抽出部410で抽出された第一形態素情報と各定型内容を照合し、各定型内容の中から、第一形態素情報を含む定型内容を検索する定型取得手段である。
【0072】
ここで、定型内容とは、利用者からの発話内容に対して定型的な内容を回答するための反射要素情報を意味し、この反射要素情報は、反射要素データベース801(定型記憶手段)に予め複数記憶されている。反射要素情報としては、本実施形態では、図13に示すように、例えば”おはよう”、”こんにちは”、”こんばんわ”、”やあ”などの「挨拶的要素」、「なるほど」、「本当?」などの「定型的要素」などが挙げられる。
【0073】
具体的に、文構造解析部430から話題検索命令信号が入力された反射的判定部320は、入力された話題検索命令信号に含まれる第一形態素情報と反射要素データベース801に記憶されている各反射要素情報とを照合し、各反射要素情報の中から、第一形態素情報を含む反射要素情報を検索し、検索した反射要素情報を管理部310に出力する。
【0074】
即ち、反射要素情報をD1、第一形態素情報をWとすると、反射的判定部320は、W∩D1≠φ(φ;空集合)の関係が成立していると判断した場合は、上記反射的な回答を行うための処理を行う。
【0075】
例えば、利用者が”おはよう”という発話内容を発した場合には、反射的判定部320は、発話内容”おはよう”と各反射要素情報とを照合し、各反射要素情報の中から、発話内容”おはよう”を含む(と一致する)反射要素情報”おはよう”を検索し、検索した反射要素情報”おはよう”を管理部310に出力する。
【0076】
反射的判定部320は、各反射要素情報の中から、発話内容を含む反射要素情報を検索することができない場合には、文構造解析部430から入力された話題検索命令信号を鸚鵡返し判定部330に出力する。
【0077】
鸚鵡返し判定部330は、形態素抽出部410で抽出された現在の第一形態素情報と、鸚鵡返し要素データベース802に記憶されている過去の回答文とを照合し、現在の第一形態素情報が過去の回答文に含まれる場合には、合意内容を取得する定型取得手段である。
【0078】
ここで、鸚鵡返しとは、本実施形態では、利用者の発話内容をそのまま(又はそれに近い内容を)言い返すことを意味する。鸚鵡返し要素は、本実施形態では、直前に会話制御装置1から出力された回答文を構成する第一形態素情報などからなるのもであり、図14に示すように、例えば、”馬は美しい”(馬;*;美しい)、”佐藤が好きです”(佐藤;*;好きです)などが挙げられる。
【0079】
また、鸚鵡返し要素データベース802は、利用者から入力された入力情報に合意するための合意内容を予め記憶する合意記憶手段でもある。合意内容には、例えば、前回、利用者から入力された入力情報(利用者により前回の入力情報が”A映画名の監督はS氏ですか”である場合には、合意内容としては、”A映画名の監督はS氏です”)、又は ”その通りです”、”本当です”などが挙げられる。
【0080】
具体的に、反射的判定部320から話題検索命令信号が入力された鸚鵡返し判定部330は、各鸚鵡返し要素毎に、入力された話題検索命令信号に含まれる第一形態素情報と鸚鵡返し要素を構成する各形態素とを照合し、鸚鵡返し要素の中に第一形態素情報が含まれているかを判断する(図14参照)。
【0081】
鸚鵡返し判定部330は、各鸚鵡返し要素の中に第一形態素情報が含まれていると判断した場合には、合意内容を取得し、取得した合意内容からなる回答文を管理部310に出力(鸚鵡返し処理)する。即ち、鸚鵡返し要素(前回の回答文など)をS、第一形態素情報をWとすると、鸚鵡返し判定部330は、W⊂S、W≠φの関係が成立している場合には、上記に示す鸚鵡返し処理を行う。
【0082】
例えば、会話制御装置1が回答文として”A映画名の監督はS氏です”(A映画名の監督;S氏;*)(この順番は、サブジェクト;オブジェクト;アクションの順番、以下同様とする)を出力し、その後、利用者が出力された回答文に対して”A映画名の監督はS氏ですか”(A映画名の監督;S氏;*)と発話した場合には、鸚鵡返し判定部330は、利用者の第一形態素情報(A映画名の監督;S氏;*)と回答文の各形態素(A映画名の監督;S氏;*)とが一致しているので、利用者は回答文に対して鸚鵡返しを行っていると断定し、記憶されている合意内容”その通りです”などを取得し、取得した合意内容を出力する。
【0083】
また、鸚鵡返し判定部330は、形態素抽出部410で抽出された現在の第一形態素情報と、鸚鵡返し要素データベース802に記憶されている過去の第一形態素情報とを照合し、現在の第一形態素情報が過去の第一形態素情報に含まれる場合には、反発内容を取得する定型取得手段でもある。
【0084】
具体的には、利用者が”馬は美しい”という発話内容を発話し、会話制御装置1が回答文として”馬は躍動感があって良いですね”の内容を出力した場合に、後に利用者が”馬は美しい”という発話内容を繰り返したときは、鸚鵡返し判定部330は、現在の発話内容”馬は美しい”を構成する各形態素(第一形態素情報){馬;*;美しい}と前の発話内容”馬は美しい”を構成する各形態素(第一形態素情報){馬;*;美しい}とが一致しているので、利用者は会話制御装置1からの回答文”馬は躍動感があって良いですね”については全く聞いていないものと断定することができる。
【0085】
この場合、鸚鵡返し判定部330は、利用者が会話制御装置1からの回答文を聞いていないので、記憶された反発内容(例えば、同じ内容を繰り返さないでよ”など)取得し、取得した反発内容を出力することができる。
【0086】
一方、鸚鵡返し判定部330は、第一形態素情報が前回の回答文の内容と同一、又は第一形態素情報が前回の第一形態素情報と同一でないと判断した場合には、反射的判定部320から入力された話題検索命令信号を談話範囲決定部340に出力する。
【0087】
尚、上記の鸚鵡返し判定部330は、「会話制御装置1の回答文」に対して利用者が鸚鵡返しを行った場合の処理を示してきたが、更に以下の処理も行うことができる。例えば、出力部600が”馬は美しい”という回答文を出力した場合、この回答文に対して利用者が”どうして馬は美しいの?”、”どうして美しいの?”、又は”どうして?”と発話した場合に対して行う鸚鵡返し判定部330の処理である。
【0088】
この場合、鸚鵡返し判定部330は、出力した回答文S”馬は美しい”と利用者からの発話内容W(”どうして馬は美しいの?(疑問文)”又は”どうして美しいの?(疑問文)”)とを照合すると、(W−c)⊂S、S≠φ、c≠φ(このcは、Wの発話種類を意味し、この発話種類は、後述する発話種類判定部440で判定されるものである。発話種類には、後述するように、例えば、疑問文などが挙げられる。)の関係が成立するので、”条件付”の鸚鵡返し処理(回答文に対して利用者が疑問文付きの鸚鵡返しを行った場合の処理)を行う。
【0089】
”条件付”の鸚鵡返し処理としては、例えば、会話制御装置1が”馬は美しいね”の回答文を出力した場合に、上記利用者が”どうして馬は美しいの?”の発話内容を発したときは、利用者の疑問等を解消するため、鸚鵡返し判定部330が”だって馬は美しいじゃない”などの回答文を鸚鵡返し要素データベース802の中から取得し、取得した回答文を管理部310に出力する処理を行う。
【0090】
談話範囲決定部340は、文節解析部420で抽出された第一形態素情報と予め記憶された各談話範囲とを照合し、各談話範囲の中から、第一形態素情報に含まれる形態素と一致する談話範囲を検索する談話範囲検索手段である。
【0091】
具体的に、鸚鵡返し判定部330から話題検索命令信号が入力された談話範囲決定部340は、入力された談話検索命令信号に基づいて、利用者の談話範囲を決定する。即ち、談話範囲決定部340は、入力された検索命令信号に基づいて、会話データベース500の中から、利用者が発話している内容について関連性のある範囲(談話範囲)を検索する。
【0092】
例えば、談話範囲決定部340は、入力された話題検索命令信号に含まれる第一形態素情報が(面白い映画;*;ある){面白い映画はある?}である場合には、この第一形態素情報と談話範囲群とを照合し、談話範囲群に第一形態素情報を構成する形態素(例えば”映画”)が含まれているときは、第一形態素情報に含まれる”映画”を談話範囲として決定する。この場合、談話範囲決定部340は、第一形態素情報に談話範囲”映画”が含まれているので、入力された第一形態素情報を話題検索命令信号に含めて話題検索部360に出力する。
【0093】
一方、談話範囲決定部340は、第一形態素情報に談話範囲群が含まれていない場合には、入力された第一形態素情報を話題検索命令信号に含めて省略文補完部350に出力する。
【0094】
これにより、後述する話題検索部360は、談話範囲決定部340で決定された”談話範囲”に属する各「話題タイトル」と、文構造解析部430で特定された第一形態素情報とを照合することができるので、”全て”の「話題タイトル」(第二形態素情報)と第一形態素情報とを照合する必要がなくなり、後述する回答文検索部370は、最終的な回答文を検索するまでの時間を短縮することができる。
【0095】
尚、談話範囲決定部340は、上記の如く、第一形態素情報と談話範囲群とを照合し、談話範囲群に第一形態素情報の形態素が含まれていれば、その形態素を談話範囲として決定していたが、これに限定されるものではなく、鸚鵡返し判定部330で直前に検索された鸚鵡返し要素の形態素、又は利用者が発話した発話内容を構成する形態素を談話範囲として決定しても良い。後述する省略文補完部350は、上記談話範囲決定部340で決定された談話範囲を用いて、その談話範囲を、形態素が省略されている第一形態素情報に付加することができる。
【0096】
省略文補完部350は、文節解析部420で抽出された第一形態素情報に基づいて第一形態素情報を構成する各属性(サブジェクト、オブジェクト、アクションなど)の中から、形態素を含まない属性を検索する属性検索手段である。また、省略文補完部350は、検索した属性に基づいて、属性に、談話範囲決定部340で検索された談話範囲を構成する形態素を付加する形態素付加手段でもある。
【0097】
具体的に、談話範囲決定部340から話題検索命令信号が入力された省略文補完部350は、入力された談話検索命令信号に含まれる第一形態素情報に基づいて、第一形態素情報からなる発話内容が省略文であるかを判定し、第一形態素情報からなる発話内容が省略文である場合には、第一形態素情報が属する談話範囲の形態素を、第一形態素情報に付加する。
【0098】
例えば、省略文補完部350は、入力された話題検索命令信号に含まれる第一形態素情報を構成する形態素が(監督;*;*)(監督は?)(この文は、”何の”監督であるかが不明であるので、省略文を意味する。)である場合には、談話範囲決定部340で決定された談話範囲(A映画名;このA映画名は映画のタイトルを示すものである)に属する第一形態素情報であれば、第一形態素情報を構成する形態素に、決定された談話範囲(A映画名)を第一形態素情報に付加(”A映画名”の監督;*;*)する。
【0099】
即ち、第一形態素情報をW、決定された談話範囲をDとすると、省略文補完部350は、Wに談話範囲Dを付加し、付加後の第一形態素情報を話題検索命令信号に含めて話題検索部360に出力する。
【0100】
これにより、第一形態素情報が省略文であり、日本語として明解でない場合であっても、省略文補完部350は、第一形態素情報がある談話範囲に属している場合には、例えば、その談話範囲D(A映画名)を第一形態素情報W(監督;*;*)に付加し、第一形態素情報をW’(A映画名の監督;*;*){A映画名の監督は?}として扱うことができるので、利用者の発話内容が省略文である場合であっても、前に決定された談話範囲に基づいて省略文を補完することができ、省略文を明確にすることができる。
【0101】
このため、省略文補完部350が、第一形態素情報を構成する発話内容が省略文であっても、第一形態素情報を構成する発話内容が適正な日本語となるように、第一形態素情報に特定の形態素を補完することができるので、話題検索部360は、補完後の第一形態素情報に基づいて、第一形態素情報に関連する最適な「話題タイトル」(第二形態素情報)を取得することができ、回答文検索部370は、話題検索部360で取得された「話題タイトル」に基づいて利用者の発話内容により適した回答文を出力することができる。
【0102】
話題検索部360は、文節解析部420で抽出された第一形態素情報又は省略文補完部350で補完された第一形態素情報と、各第二形態素情報とを照合し、各第二形態素情報の中から、第一形態素情報を構成する形態素を含む第二形態素情報を検索する第一検索手段である。
【0103】
具体的に、談話範囲決定部340又は省略文補完部350から話題検索命令信号が入力された話題検索部360は、入力された話題検索命令信号に含まれる第一形態素情報に基づいて、談話範囲決定部340で決定された談話範囲に属する各「話題タイトル」(第二形態素情報)の中から、第一形態素情報の形態素を含む「話題タイトル」を検索し、この検索結果を検索結果信号として回答文検索部370及び発話種類判定部440に出力する。
【0104】
例えば、第一形態素情報を構成する「格構成」が(佐藤;*;好きだ){佐藤は好きだ}である場合には、話題検索部360は、図12に示すように、上記「格構成」に属する各形態素(佐藤;*;好きだ)と談話範囲(佐藤)に属する各話題タイトル1−1〜1−4とを照合し、各話題タイトル1−1〜1−4の中から「格構成」に属する各形態素(佐藤;*;好きだ)と一致(又は近似)する話題タイトル1−1(佐藤;*;好きだ)を検索し、この検索結果を検索結果信号として回答文検索部370及び発話種類判定部440に出力する。
【0105】
話題検索部360から検索結果信号が入力された発話種類判定部440は、入力された検索結果信号に基づいて、該当する利用者に対して回答する特定の回答文を検索させるための回答検索命令信号(この回答検索命令信号には、判定した「発話文のタイプ」も含まれる)を回答文検索部370に出力する。
【0106】
回答文検索部370は、話題検索部360で検索された第二形態素情報(話題タイトル)に基づいて、第二形態素情報に関連付けられた回答文を取得する回答取得手段である。また、回答文検索部370は、話題検索部360で検索された第二形態素情報に基づいて、特定された利用者の発話種類と第二形態素情報に関連付けられた各回答種類とを照合し、各回答種類の中から、利用者の発話種類と一致する回答種類を検索する第二検索手段でもある。
【0107】
具体的に、話題検索部360から検索結果信号と、発話種類判定部440から回答検索命令信号とが入力された回答文検索部370は、入力された検索結果信号に対応する話題タイトル(検索結果によるもの;第二形態素情報)と回答検索命令信号に対応する「発話文のタイプ」(発話種類)とに基づいて、その「話題タイトル」に関連付けられている回答文群の中から、「発話文のタイプ」(DA、IA、CAなど)と一致する回答種類(この回答種類は、図11に示す「回答文のタイプ」を意味する)からなる回答文を検索する。
【0108】
例えば、回答文検索部370は、検索結果に対応する話題タイトルが図12に示す話題タイトル1−1(佐藤;*;好きだ)である場合は、その話題タイトル1−1に関連付けられている回答文1−1(DA、IA、CAなど)の中から、発話種類判定部440で判定された「発話文のタイプ」(例えばDA;発話種類)と一致する回答種類(DA)からなる回答文1−1(DA;(私も)佐藤が好きです)を検索し、この検索した回答文を回答文信号として管理部310に出力する。
【0109】
回答文検索部370から回答文信号が入力された管理部310は、入力された回答文信号を出力部600に出力する。また、反射的判定部320から反射要素情報、又は鸚鵡返し判定部330から鸚鵡返し処理の内容が入力された管理部310は、入力された反射要素情報に対応する回答文、入力された鸚鵡返し処理の内容に対応する回答文を出力部600に出力する。
【0110】
出力部600は、回答文検索部370で取得された回答文を出力する出力手段であり、本実施形態では、例えば、スピーカ、ディスプレイなどが挙げられる。具体的に、管理部310から回答文が入力された出力部600は、入力された回答文{例えば、私も佐藤が好きです}を出力する。
【0111】
(会話制御装置を用いた会話制御方法)
上記構成を有する会話制御装置1による会話制御方法は、以下の手順により実施することができる。図15は、本実施形態に係る会話制御方法の手順を示すフロー図である。
【0112】
先ず、入力部100が、利用者からの発話内容を取得するステップを行う(S101)。具体的に入力部100は、利用者の発話内容を構成する音声を取得し、取得した音声を音声信号として音声認識部200に出力する。また、入力部100は、利用者から入力された入力情報(音声以外)に基づいて、入力情報(音声以外)に含まれる文字列を特定し、特定した文字列を文字列信号として会話制御部300に出力する。
【0113】
次いで、音声認識部200が、入力部100で取得した発話内容に基づいて、発話内容に含まれる文字列を特定するステップを行う(S102)。具体的には、入力部100から音声信号が入力された音声認識部200は、入力された音声信号を解析し、解析した音声信号に対応する文字列を、音声認識辞書記憶部700に格納されている辞書を用いて特定し、特定した文字列を文字列信号として会話制御部300に出力する。
【0114】
そして、形態素抽出部410が、音声認識部200で特定された文字列に基づいて、文字列の最小単位を構成する各形態素を第一形態素情報として抽出するステップを行う(S103)。
【0115】
具体的に、管理部310から文字列信号が入力された形態素抽出部410は、入力された文字列信号に対応する文字列と、形態素データベース450に予め格納されている名詞、形容詞、動詞などの形態素群とを照合し、文字列の中から形態素群と一致する各形態素(m1、m2、・・・)を抽出し、抽出した各形態素を抽出信号として文節解析部420に出力する。
【0116】
そして、文節解析部420は、形態素抽出部410で抽出された各形態素に基づいて、各形態素を文節形式にまとめるステップを行う(S104)。具体的に、形態素抽出部410から抽出信号が入力された文節解析部420は、入力された抽出信号に対応する各形態素を用いて文節形式にまとめる。
【0117】
即ち、文節解析部420は、図4に示すように、入力された抽出信号に対応する各形態素に基づいて各形態素の係り受け要素(例えば、が・は・を・・)を抽出し、抽出した係り受け要素に基づいて各形態素を各文節にまとめることを行う。
【0118】
各形態素を各文節にまとめた文節解析部420は、各形態素をまとめた各文節と、各文節を構成する各形態素とを含む文型情報を文型信号として文構造解析部430及び発話種類判定部440に出力する。
【0119】
その後、文構造解析部430が、文節解析部420で分節された第一形態素情報の各形態素を主体格、対象格などの各属性に分類するステップを行う(S105)。具体的に、文節解析部420から文型信号が入力された文構造解析部430は、入力された文型信号に対応する各形態素と各形態素からなる文節とに基づいて、文節に含まれる各形態素の「格構成」を決定する。
【0120】
即ち、文構造解析部430は、図5に示すように、例えば、各形態素の係り受け要素が”が”又は”は”である場合は、その係り受け要素の前にある形態素がサブジェクト(主語又は主格)であると判断する。また、文構造解析部430は、例えば、各形態素の係り受け要素が”の”又は”を”である場合は、その係り受け要素の前にある形態素がオブジェクト(対象)であると判断する。
【0121】
更に、文構造解析部430は、例えば、各形態素の係り受け要素が”する”である場合は、その係り受け要素の前にある形態素がアクション(述語;この述語は動詞、形容詞などから構成される)であると判断する。
【0122】
各文節を構成する各形態素の「格構成」を決定した文構造解析部430は、決定した「格構成」に対応付けられた第一形態素情報に基づいて、後述する話題(トピック)の範囲を特定させるための話題検索命令信号を話題検索部360に出力する。
【0123】
次いで、発話種類判定部440は、文節解析部420で特定された文節に基づいて、発話内容の種類を示す発話種類を特定するステップを行う(S106)。具体的に、文節解析部420から入力された文型信号に対応する各形態素と各形態素から構成される文節とに基づいて、「発話文のタイプ」(発話種類)を判定する。
【0124】
即ち、発話種類判定部440は、入力された文型信号に対応する各文節に基づいて、その各文節と発話種類データベース460に格納されている各辞書とを照合し、各文節の中から、各辞書に関係する文要素を抽出する。各文節の中から各辞書に関係する文要素を抽出した発話種類判定部440は、抽出した文要素に基づいて、「発話文のタイプ」を判定する。
【0125】
この発話種類判定部440は、後述する話題検索部360からの指示に基づいて、該当する利用者に特定の回答文を検索させるための回答検索命令信号を回答文検索部370に出力する。
【0126】
次いで、反射的判定部320が、形態素抽出部410で抽出された第一形態素情報と各定型内容を照合し、各定型内容の中から、第一形態素情報を含む定型内容を検索するステップを行う(S107;反射的処理)。
【0127】
具体的に、文構造解析部430から話題検索命令信号が入力された反射的判定部320は、入力された話題検索命令信号に含まれる第一形態素情報と反射要素データベース801に記憶されている各反射要素情報(定型内容)とを照合し、各反射要素情報の中から、第一形態素情報を含む反射要素情報を検索し、検索した反射要素情報を管理部310に出力する。
【0128】
反射的判定部320は、各反射要素情報の中から、第一形態素情報を含む反射要素情報を検索することができない場合には、文構造解析部430から入力された話題検索命令信号を鸚鵡返し判定部330に出力する。
【0129】
次いで、鸚鵡返し判定部330が、形態素抽出部410で抽出された第一形態素情報と各鸚鵡返し要素を照合し、各鸚鵡返し要素の中から、第一形態素情報を含む鸚鵡返し要素を検索するステップを行う(S108;鸚鵡返し処理)。
【0130】
鸚鵡返し判定部330は、各鸚鵡返し要素の中に第一形態素情報が含まれていると判断した場合には、第一形態素情報を含む鸚鵡返し要素を取得し、取得した鸚鵡返し要素からなる回答文を管理部310に出力(鸚鵡返し処理)する。即ち、鸚鵡返し要素(前回出力された回答文、前回利用者が発話した発話内容など)をS、第一形態素情報をWとすると、鸚鵡返し判定部330は、W⊂S、W≠φの関係が成立している場合には、上記に示す鸚鵡返し処理を行う。
【0131】
一方、鸚鵡返し判定部330は、各鸚鵡返し要素の中に第一形態素情報が含まれていないと判断した場合には、反射的判定部320から入力された話題検索命令信号を談話範囲決定部340に出力する。
【0132】
そして、談話範囲決定部340が、文節解析部420で抽出された第一形態素と各談話範囲とを照合し、各談話範囲の中から、第一形態素情報を含む談話範囲を検索(決定)するステップを行う(S109)。
【0133】
具体的に、鸚鵡返し判定部330から話題検索命令信号が入力された談話範囲決定部340は、入力された検索命令信号に基づいて、会話データベース500の中から、利用者が発話している内容について関連性のある範囲(談話範囲)を検索する。
【0134】
例えば、談話範囲決定部340は、入力された話題検索命令信号に含まれる第一形態素情報が(面白い映画;*;ある){面白い映画はある?}である場合には、この第一形態素情報と談話範囲群とを照合し、談話範囲群に第一形態素情報を構成する形態素(例えば”映画”)が含まれているときは、第一形態素情報に含まれる”映画”を談話範囲として決定する。この場合、談話範囲決定部340は、第一形態素情報に談話範囲”映画”が含まれているので、入力された第一形態素情報を話題検索命令信号に含めて話題検索部360に出力する。
【0135】
一方、談話範囲決定部340は、第一形態素情報に談話範囲群が含まれていない場合には、入力された第一形態素情報を話題検索命令信号に含めて省略文補完部350に出力する。
【0136】
次いで、省略文補完部350が、文節解析部420で抽出された第一形態素情報に基づいて第一形態素情報を構成する各属性(サブジェクト、オブジェクト、アクションなど)の中から、形態素を含まない属性を検索するステップを行う。その後、省略文補完部350が、検索した形態素を含まない属性に基づいて、その属性に、談話範囲決定部340で検索された談話範囲を構成する形態素を付加するステップを行う(S110;省略文を補完)。
【0137】
具体的に、談話範囲決定部340から話題検索命令信号が入力された省略文補完部350は、入力された談話検索命令信号に含まれる第一形態素情報に基づいて、第一形態素情報からなる発話内容が省略文であるかを判定し、第一形態素情報からなる発話内容が省略文である場合には、第一形態素情報が属する談話範囲の形態素を、第一形態素情報に付加する。
【0138】
例えば、省略文補完部350は、入力された話題検索命令信号に含まれる第一形態素情報を構成する形態素が(監督;*;*)(監督は?)(この文は、”何の”監督であるかが不明であるので、省略文を意味する。)である場合には、前に談話範囲決定部340で決定された談話範囲(A映画名;このA映画名とは映画のタイトルを示すものである)に属する第一形態素情報であれば、第一形態素情報を構成する形態素に、決定された談話範囲の形態素(A映画名)を第一形態素情報に付加(”A映画名”の監督;*;*)する。
【0139】
即ち、第一形態素情報をW、決定された談話範囲をDとすると、省略文補完部350は、第一形態素情報Wに談話範囲Dを付加し、付加後の第一形態素情報を話題検索命令信号に含めて話題検索部360に出力する。
【0140】
次いで、話題検索部360が、文節解析部420で抽出された第一形態素情報又は省略文補完部350で補完された第一形態素情報と、各第二形態素情報とを照合し、各第二形態素情報の中から、第一形態素情報を構成する形態素を含む第二形態素情報を検索するステップを行う(S111)。
【0141】
具体的に、談話範囲決定部340又は省略文補完部350から話題検索命令信号が入力された話題検索部360は、入力された話題検索命令信号に含まれる第一形態素情報に基づいて、談話範囲決定部340で決定された談話範囲に属する各「話題タイトル」(第二形態素情報)の中から、第一形態素情報の形態素を含む「話題タイトル」を検索し、この検索結果を検索結果信号として回答文検索部370及び発話種類判定部440に出力する。
【0142】
例えば、第一形態素情報を構成する「格構成」が(佐藤;*;好きだ){佐藤は好きだ}である場合には、話題検索部360は、図12に示すように、上記「格構成」に属する各形態素(佐藤;*;好きだ)と談話範囲(佐藤)に属する各話題タイトル1−1〜1−4とを照合し、各話題タイトル1−1〜1−4の中から「格構成」に属する各形態素(佐藤;*;好きだ)と一致(又は近似)する話題タイトル1−1(佐藤;*;好きだ)を検索し、この検索結果を検索結果信号として回答文検索部370及び発話種類判定部440に出力する。
【0143】
話題検索部360から検索結果信号が入力された発話種類判定部440は、入力された検索結果信号に基づいて、該当する利用者に対して回答する特定の回答文を検索させるための回答検索命令信号(この回答検索命令信号には、判定した「発話文のタイプ」も含まれる)を回答文検索部370に出力する。
【0144】
そして、回答文検索部370が、話題検索部360で検索された第二形態素情報に基づいて、特定された利用者の発話種類と第二形態素情報に関連付けられた各回答種類とを照合し、各回答種類の中から、利用者の発話種類と一致する回答種類を検索し、検索した回答種類に基づいて回答種類に関連付けられている回答文を取得するステップを行う(S112)。
【0145】
具体的に、話題検索部360から検索結果信号と、発話種類判定部440から回答検索命令信号とが入力された回答文検索部370は、入力された検索結果信号に対応する話題タイトル(検索結果によるもの;第二形態素情報)と回答検索命令信号に対応する「発話文のタイプ」(発話種類)とに基づいて、その「話題タイトル」に関連付けられている回答文群の中から、「発話文のタイプ」(DA、IA、CAなど)と一致する回答種類(この回答種類は、図11に示す「回答文のタイプ」を意味する)からなる回答文を検索する。
【0146】
例えば、回答文検索部370は、検索結果に対応する話題タイトルが図12に示す話題タイトル1−1(佐藤;*;好きだ)である場合は、その話題タイトル1−1に関連付けられている回答文1−1(DA、IA、CAなど)の中から、発話種類判定部440で判定された「発話文のタイプ」(例えばDA;発話種類)と一致する回答種類(DA)からなる回答文1−1(DA;(私も)佐藤が好きです)を検索し、この検索した回答文を回答文信号として管理部310に出力する。
【0147】
次いで、回答文検索部370から回答文信号が入力された管理部310は、入力された回答文信号を出力部600に出力する。また、反射的判定部320から反射要素情報、又は鸚鵡返し判定部330から鸚鵡返し処理の内容が入力された管理部310は、入力された反射要素情報に対応する回答文、入力された鸚鵡返し処理の内容に対応する回答文を出力部600に出力する(S113)。管理部310から回答文が入力された出力部600は、入力された回答文{例えば、私も佐藤が好きです}を出力する。
【0148】
(会話制御装置及び会話制御方法による作用及び効果)
上記構成を有する本願に係る発明によれば、反射的判定部320が、利用者から発話された発話内容を構成する第一形態素情報と予め記憶された各定型内容とを照合し、各定型内容の中から、第一形態素情報を含む定型内容を検索することができるので、反射的判定部320は、例えば第一形態素情報が”こんにちは”などの定型内容である場合には、この定型内容と同一の定型内容”こんにちは”等を回答することができる。
【0149】
また、反射的判定部320は、利用者の発話内容が定型内容である場合には、その定型内容(挨拶など)を回答するので、利用者は、最初に、会話制御装置1との間で意思の疎通をしているような感覚を味わうことができる。
【0150】
また、鸚鵡返し判定部330が、現在の第一形態素情報と過去の回答文とを照合し、現在の第一形態素情報が過去の回答文に含まれていない場合には、予め記憶してある合意内容を取得することができるので、鸚鵡返し判定部330は、利用者から現在入力された入力情報と過去の回答文とが一致していれば、利用者が過去の回答文に対して鸚鵡返し(利用者が回答文に対して聞き直していること)の入力情報を入力したものと断定することができる。
【0151】
この場合、鸚鵡返し判定部330は、利用者が過去の回答文に対して鸚鵡返しを行っているので、記憶されている合意内容を取得し、取得した合意内容(例えば、”その通りです”など)を出力することができる。これにより、利用者は、会話制御装置1から出力された回答文の意味が分からなければ、もう一度聞き直して、再度回答文を聞き直すことができるので、恰も他の利用者と会話しているような感覚を味わうことができる。
【0152】
また、鸚鵡返し判定部330が、現在の第一形態素情報と過去の第一形態素情報とを照合し、現在の第一形態素情報が過去の第一形態素情報に含まれる場合には、反発内容を取得することができるので、鸚鵡返し判定部330は、前回入力された入力情報が今回入力された入力情報に含まれている場合には、利用者が前の入力情報と同一の内容を反復して入力したものと判断することができ、利用者が会話制御装置からの回答文に対して適切に回答していないものと断定することができる。
【0153】
この場合、鸚鵡返し判定部330は、利用者が前回の回答文に対して適切に回答していないので、利用者に対して反発するため、記憶されている反発内容を取得し、取得した反発内容を出力する。これにより、利用者は、会話制御装置1からの回答文に対して適切な入力情報を入力しなければ、会話制御装置1から反発内容が出力されるので、恰も他の利用者と会話しているような感覚を味わうことができる。
【0154】
また、話題検索部360は、第一形態素情報と近似する第二形態素情報を検索するには、”談話範囲”に属する各第二形態素情報と第一形態素情報とを照合すればよく、”全て”の第二形態素情報と第一形態素情報とを照合する必要がないので、第一形態素情報と近似している第二形態素情報を検索するまでの時間を短縮することができる。
【0155】
この結果、話題検索部360が、第一形態素情報と近似している第二形態素情報を短時間で検索(ピンポイント検索)することができるので、回答文検索部370は、話題検索部360で検索された第二形態素情報に基づいて第二形態素情報に関連付けられている回答文を短時間で取得することができ、会話制御装置1は、利用者からの発話内容に対して迅速に回答することができる。
【0156】
また、話題検索部360が、各第二形態素情報の中から、第一形態素情報を構成する形態素(利用者の発話内容を構成する要素)を含む第二形態素情報を検索し、回答文検索部370が、話題検索部360で検索された第二形態素情報に基づいて、第二形態素情報に関連付けられた回答文を取得することができるので、回答文検索部370は、利用者の発話内容を構成する各形態素(第一形態素情報)に基づいて、各形態素により構築される意味空間(主体、対象等)を考慮し、かかる意味空間に基づいて予め作成された回答文を取得することができることとなり、単に発話内容の全体をキーワードとして、そのキーワードに関連付けられた回答文を取得するよりも、より発話内容に適した回答文を取得することができる。
【0157】
また、話題検索部360は、第一形態素情報を含む第二形態素情報を検索するので、利用者の発話内容と完全に一致する第二形態素情報を検索する必要がなく、会話制御装置1を開発する開発者は、利用者から発話されるであろう発話内容に対応する膨大な回答文を予め記憶する必要がなくなり、記憶部の容量を低減させることができる。
【0158】
更に、回答文検索部370が、”談話範囲”に属する各第二形態素情報に関連付けられた回答種類(陳述、肯定、場所、反発など)の中から、利用者の発話種類と一致する回答種類を検索し、検索した回答種類に基づいて回答種類に対応付けられた回答文を取得することができるので、会話制御装置1は、利用者の会話内容を構成する発話種類、例えば、利用者が単に意見を述べたもの、利用者が抱く感想からなるもの、利用者が場所的な要素を述べたものなどに基づいて、複数の回答文の中から利用者の発話種類にマッチした回答文を取得することができることとなり、該当する利用者に対してより最適な回答をすることができる。
【0159】
更にまた、回答文検索部370は、談話範囲決定部340で検索された”談話範囲”にのみ属する各第二形態素情報に関連付けられた回答種類の中から、利用者の発話種類と一致する回答種類を検索(ピンポイント検索が可能)するだけでよいので、”全て”の第二形態素情報に関連付けられた回答種類と利用者の発話種類とを逐一検索する必要がなくなり、利用者の発話種類に対応する最適な回答文を短時間で取得することができる。
【0160】
最後に、省略文補完部350は、利用者の発話内容を構成する第一形態素情報が省略文であり、日本語として明解でない場合であっても、第一形態素情報がある談話範囲に属している場合には、その談話範囲を第一形態素情報に付加し、省略文からなる第一形態素情報を補完することができる。
【0161】
これにより、省略文補完部350は、第一形態素情報を構成する発話内容が省略文であっても、第一形態素情報を構成する発話内容が適正な日本語となるように、第一形態素情報に特定の形態素(談話範囲を構成する形態素など)を補完することができるので、話題検索部360は、省略文補完部350で補完された補完後の第一形態素情報に基づいて、第一形態素情報に関連する最適な第二形態素情報を取得することができ、回答文検索部370は、話題検索部360で取得された第二形態素情報に基づいて利用者の発話内容により適した回答文を出力することができる。
【0162】
この結果、会話制御装置1は、利用者からの入力情報が省略文であったとしても、ニューロネットワーク、AI知能などの機能を用いることなく、過去の検索結果を通じて、その省略文が何を意味するのかを推論することができ、会話制御装置1の開発者は、ニューロネットワーク、AI知能を搭載する必要がないので、会話制御装置1のシステムをより簡便に構築することができる。
【0163】
[変更例]
尚、本発明は、上記実施形態に限定されるものではなく、以下に示すような変更を加えることができる。
【0164】
(第一変更例)
本変更例においては、会話データベース500は、複数の形態素の集合からなる集合群の全体を示す要素情報を、集合群に関連付けて複数記憶する要素記憶手段であってもよい。更に、形態素抽出部410は、文字列から抽出した形態素と各集合群とを照合し、各集合群中から、抽出された形態素を含む集合群を選択し、選択した集合群に関連付けられた要素情報を第一形態素情報として抽出してもよい。
【0165】
図16に示すように、利用者が発話した文字列に含まれる各形態素には、類似しているものがある。例えば、図16に示すように、集合群の全体を示す要素情報を「贈答」とすると、「贈答」は、プレゼント、贈り物、御歳暮、御中元、お祝いなど(集合群)と相互に類似しているので、形態素抽出部410は、「贈答」に類似する形態素(上記のプレゼントなど)がある場合には、その類似する形態素については、「贈答」として取り扱うことができる。
【0166】
即ち、形態素抽出部410は、例えば、文字列から抽出した形態素が「プレゼント」である場合には、図16に示すように、「プレゼント」を代表する要素情報が「贈答」であるので、上記「プレゼント」を「贈答」に置き換えることができる。
【0167】
これにより、形態素抽出部410が相互に類似する形態素を整理することができるので、会話制御装置を開発する開発者は、相互に類似した各第一形態素情報から把握される意味空間に対応した第二形態素情報及び第二形態素情報に関係する回答文を逐一作成する必要がなくなり、結果的に、記憶部に格納させるデータ量を低減させることができる。
【0168】
(第二変更例)
図17に示すように、本変更例においては、割合計算部361と、選択部362とを話題検索部360に備えてもよい。
【0169】
割合計算部361は、形態素抽出部410で抽出された第一形態素情報と各第二情報とを照合し、各第二形態素情報毎に、第二形態素情報に対して第一形態素情報が占める割合を計算する計算手段である。
【0170】
具体的に、文構造解析部430から話題検索命令信号が入力された割合計算部361は、図17に示すように、入力された話題検索命令信号に含まれる第一形態素情報に基づいて、第一形態素情報と会話データベース500に格納されている談話範囲に属する各話題タイトル(第二形態素情報)とを照合し、各話題タイトル毎に、それぞれの話題タイトルの中に、第一形態素情報が占める割合を計算する。
【0171】
例えば、図18に示すように、利用者から発話された発話文を構成する第一形態素情報が(佐藤;*;好きだ){佐藤は好きだ}である場合は、割合計算部361は、「格構成」に属する各形態素(佐藤;*;好きだ)と話題タイトルに含まれる各形態素(佐藤;*;好きだ)とを照合し、上記話題タイトルに、「格構成」に属する各形態素(佐藤;*;好きだ)が含まれる割合を、100%であると計算する。割合計算部361は、これらの計算を話題タイトル毎に行い、計算した各割合を割合信号として選択部362に出力する。
【0172】
選択部362は、割合計算部361で各第二形態素情報毎に計算された各割合の大きさに応じて、各第二形態素情報の中から、一の第二形態素情報を選択する選択手段である。
【0173】
具体的に、割合計算部361から割合信号が入力された選択部362は、入力された割合信号に含まれる各割合(「格構成」の要素/「話題タイトル」の要素×100)の中から、例えば割合の高い話題タイトルを選択する(図18参照)。割合の高い話題タイトルを選択した選択部362は、選択した話題タイトルを検索結果信号として回答文検索部370及び発話種類判定部440に出力する。回答文検索部370は、選択部362で選択された話題タイトルに基づいて、話題タイトルに関連付けられた回答文を取得する。
【0174】
これにより、選択部362が、各第二形態素情報毎に、第二形態素情報に対して該第一形態素情報が占める割合を計算し、各第二形態素情報毎に計算された各割合の大きさに応じて、各第二形態素情報の中から、一の第二形態素情報を選択することができるので、選択部362は、例えば、第一形態素情報(利用者の発話内容を構成するもの)が第二形態素情報に占める割合の大きい第二形態素情報を、複数ある第二形態素情報群の中から取得することができれば、第一形態素情報から把握される意味空間を踏襲した第二形態素情報をより的確に取得することができ、結果的に、回答文検索部370は、利用者の発話内容に対して最適な回答をすることができる。
【0175】
また、選択部362は、複数の話題タイトルの中から、割合計算部361で計算された割合の高い話題タイトルを選択することができるので、利用者の発話文に含まれる「格構成」に属する各形態素と会話データベース500に格納されている各話題タイトルとが完全に一致しなくても、「格構成」に属する各形態素に密接する話題タイトルを取得することができる。
【0176】
この結果、選択部362が第一形態素情報を構成する「格構成」に密接する話題タイトルを取得することができるので、会話制御装置1を開発する開発者は、第一形態素情報を構成する「格構成」と完全に一致する話題タイトルを会話データベース500に逐一格納する必要がなくなるので、会話データベース500の容量を低減させることができる。
【0177】
更に、割合計算部361は、談話範囲決定部340で検索された”談話範囲”にのみ属する各第二形態素情報毎に、第二形態素情報に対して該第一形態素情報が占める割合を計算するので、”全て”の第二形態素情報に対して第一形態素情報が占める割合を計算する必要がなくなり、第一形態素情報から構成される意味空間を踏襲した第二形態素情報をより短時間で取得することができ、結果的に、取得した第二形態素情報に基づいて利用者からの発話内容に対しての最適な回答文を迅速に出力することができる。
【0178】
尚、割合計算部361は、分類された各属性に属する第一形態素情報の各形態素と、予め記憶された各属性に属する各第二形態素情報の各形態素とを各属性毎に照合し、各第二形態素情報の中から、少なくとも一の属性に第一形態素情報の各形態素を含む第二形態素情報を検索する第一検索手段であってもよい。
【0179】
具体的に、話題検索命令信号が入力された割合計算部361は、入力された話題検索命令信号に含まれる「格構成」の各「格」(サブジェクト;オブジェクト;アクション)毎に、その「格」に属する各形態素と、同一の「格」からなる話題タイトルの「格」に属する各形態素とを照合し、互いの「格」を構成する形態素が同一か否かを判定する。
【0180】
例えば、図19に示すように、割合計算部361は、「格構成」の「格」の形態素が(犬;人;噛んだ){犬が人を噛んだ}である場合は、それらの形態素”犬”、”人”、”噛んだ”と、それらの形態素を構成する「格」と同一の「格」からなる話題タイトルの形態素”犬”、”人”、”噛んだ”とを照合し、話題タイトルを構成する各形態素”犬”、”人”、”噛んだ”のうち、各形態素に対応する「格」と同一の「格」からなる「格構成」の形態素”犬”、”人”、”噛んだ”と一致している割合を算出(100%)する。
【0181】
もし、話題タイトルを構成する要素が(人;犬;噛んだ){人が犬を噛んだ}である場合には、割合計算部361は、上記と同様の手順により、二つの格に属する形態素が異なるので、「格構成」を構成する形態素と「話題タイトル」との「格」毎の一致度を33%であると算出する(図19参照)。
【0182】
割合を計算した割合計算部361は、各割合の中から、割合の高い話題タイトルを選択し、選択した話題タイトルを検索結果信号として回答文検索部370及び発話種類判定部440に出力する。
【0183】
これにより、割合計算部361が、分類された各「格構成」(主体格、対象格など)に属する第一形態素情報の各形態素と、予め記憶された話題タイトルとを各「格」毎に照合し、各話題タイトルの中から、少なくとも一の「格」に第一形態素情報の各形態素を含む第二形態素情報を検索することができるので、割合計算部361は、通常の語順とは異なるものから構成される発話内容、例えば”人が犬を噛む”である場合には、主体格の形態素が”人”、対象格の形態素が”犬”であることから、その各「格」と一致する第二形態素情報を検索することができ、その第二形態素情報(人;犬;噛む)に関連付けられている回答文{”本当に?”又は”意味がよくわかんないよ”など}を取得することができる。
【0184】
即ち、割合計算部361は、識別が困難な発話内容、例えば”人が犬を噛む”と”犬が人を噛む”とを識別することができるので、その識別した発話内容に最適な回答、前者については例えば”本当に?”、後者については例えば”大丈夫?”をすることができる。
【0185】
また、割合計算部361は、”談話範囲”に属する各第二形態素情報の中から、少なくとも一の属性に第一形態素情報の形態素を含む第二形態素情報を検索すればよいので、”全て”の第二形態素情報の中から、一の第二形態素情報を取得する必要がなくなり、第一形態素情報から構成される意味空間を踏襲した第二形態素情報をより短時間で取得することができ、結果的に、会話制御装置1は、取得した第二形態素情報に基づいて利用者からの発話内容に対しての最適な回答文を迅速に出力することができる。
【0186】
尚、選択部362は、予め定められた優先順位に従って各話題タイトルの中から、一の話題タイトルを選択してもよい。この優先順位とは、話題タイトルとして選出されるための優先度を意味するものである。この優先順位は、開発段階で開発者が予め定めるものである。
【0187】
(第三変更例)
図20に示すように、本変更例においては、上記実施形態及び各変更例に限定されるものではなく、会話制御装置1a,1bにある通信部800と、通信ネットワーク1000を介してデータの送受信をするための通信部900と、通信部900に接続された各会話データベース500b〜500dと、サーバ2a〜2cとを備えてもよい(会話制御システム)。
【0188】
ここで、通信ネットワーク1000とは、データを送受信する通信網を意味するものであり、本実施形態では、例えば、インターネットなどが挙げられる。尚、本変更例では、便宜上、会話データベース500b〜500d、サーバ2a〜2cを限定しているが、これに限定されるものではなく、更に他の会話データベースを設けてもよい。
【0189】
これにより、会話制御部300は、会話制御装置1aの内部に配置してある会話データベース500aのみならず、その他の会話制御装置1b、他の会話データベース500b〜500d、サーバ2a〜2cをも参照することができるので、例えば、会話データベース500aの中から、話題検索命令信号に含まれる「格構成」に属する各形態素(第一形態素情報)と関連する談話範囲等を検索することができない場合であっても、その他の会話制御装置1b、会話データベース500b〜500d、サーバ2a〜2cを参照することにより、上記「格構成」と関連する談話範囲等を検索することができ、利用者の発話文により適した回答文を検索することができる。
【0190】
(第四変更例)
文構造解析部430は、特定した第一形態素情報を構成する各「格構成」及び各「格構成」に対応付けられた各形態素を会話データベース500に記憶するものであってもよい。回答文検索部370は、検索した回答文を構成する各「格構成」及び各「格構成」に対応付けられた各形態素を会話データベース500に記憶するものであってもよい。
【0191】
談話範囲決定部340は、検索した談話範囲を会話データベース500に記憶するものであってもよい。話題検索部360は、検索した第二形態素情報を会話データベース500に記憶するものであってもよい。
【0192】
上記第一形態素情報と、第二形態素情報と、第一形態素情報又は第二形態素情報を構成する各「格構成」及び各「格構成」に対応付けられた各形態素と、検索した回答文を構成する各「格構成」及び各「格構成」に対応付けられた各形態素と、検索した談話範囲とは、それらを相互に関連付けて履歴形態素情報として会話データベース500又は鸚鵡返し要素データベース802に記憶することができる。
【0193】
省略文補完部350は、文節解析部420で抽出された第一形態素情報に基づいて第一形態素情報を構成する各属性(サブジェクト、オブジェクト、アクションなど;格構成)の中から、形態素を含まない属性を検索し、検索した属性に基づいてその属性に、会話データベース500又は鸚鵡返し要素データベース802に記憶された履歴形態素情報を付加する。
【0194】
具体的に、談話範囲決定部340から話題検索命令信号が入力された省略文補完部350は、入力された談話検索命令信号に含まれる第一形態素情報に基づいて、第一形態素情報からなる発話内容が省略文であるかを判定し、第一形態素情報からなる発話内容が省略文(例えば、サブジェクト、オブジェクト、又はアクションに所定の形態素を有しないなど)である場合には、会話データベース500又は鸚鵡返し要素データベース802に記憶されている履歴形態情報を、第一形態素情報に付加する。
【0195】
即ち、履歴形態情報に含まれるサブジェクトをS1、オブジェクトをO1、アクションA1、談話範囲をD1とし、省略された第一形態素情報をWとすると、補完後の第一形態素情報W1は、S1∪W、O1∪W、A1∪W、又はD1∪Wとして表現することができる。
【0196】
話題検索部360は、省略文補完部350で補完された第一形態素情報W1と各第二形態素情報とを照合し、各「話題タイトル」(第二形態素情報)の中から、第一形態素情報W1を含む第二形態素情報を検索し、検索した話題タイトルを検索結果信号として回答文検索部370及び発話種類判定部440に出力する。
【0197】
これにより、第一形態素情報からなる発話内容が省略文であり、日本語として明解でない場合であっても、省略文補完部350は、会話データベース500に記憶されている履歴形態情報を用いて、省略された第一形態素情報の形態素を補完することができるので、省略された第一形態素情報からなる発話内容を明確にすることができる。
【0198】
このため、省略文補完部350が、第一形態素情報を構成する発話内容が省略文である場合には、第一形態素情報からなる発話内容が適正な日本語となるように、第一形態素情報に省略された形態素を補完することができるので、話題検索部360は、形態素が補完された第一形態素情報に基づいて、その第一形態素情報と関連する最適な「話題タイトル」(第二形態素情報)を取得することができ、回答文検索部370は、話題検索部360で取得された最適な「話題タイトル」に基づいて、利用者の発話内容により適した回答文を出力することができる。
【0199】
(第五変更例)
話題検索部360は、図21に示すように、削除部363と、談話付加部364とを備えてもよい。削除部363は、検索した第二形態素情報に基づいて、第二形態素情報と談話範囲決定部340で検索された談話範囲とを照合し、第二形態素情報を構成する各形態素の中から、談話範囲と一致する形態素を削除する削除手段である。
【0200】
具体的に、省略文補完部350から話題検索命令信号が入力された話題検索部360は、入力された話題検索命令信号に含まれる第一形態素情報と、談話範囲決定部340で決定された談話範囲に属する各第二形態素情報とを照合し、各第二形態素情報の中から、第一形態素情報と一致する第二形態素情報を検索する。
【0201】
そして、削除部363は、検索された第二形態素情報に基づいて、その第二形態素情報と談話範囲決定部340で決定された談話範囲を構成する形態素とを照合し、第二形態素情報の中から、談話範囲を構成する形態素と一致する形態素を削除し、形態素が削除された第二形態素情報を削除信号として談話付加部364に出力する。
【0202】
即ち、削除部363は、第二形態素情報を構成する各形態素t1から、談話範囲決定部340で決定された現在の談話範囲D2(このD2は、形態素からなるものである)を取り除く(取り除いた結果をt2とすると、t2=t1−D2)。
【0203】
談話付加部364は、削除部363で形態素が削除された第二形態素情報に基づいて、談話範囲決定部340で検索された談話範囲に関連付けられた他の談話範囲を取得し、取得した他の談話範囲を構成する形態素を、第二形態素情報に付加する談話付加手段である。
【0204】
具体的には、現在の談話範囲D2が回答文K1と関連性のある談話範囲をDKとすると、回答文K1又は現在の談話範囲D2と関連性(兄弟関係にあるもの)のある他の談話範囲D3は、D3=D2∪DKとして表現することができるので、他の談話範囲D3を構成する形態素を付加した後の第二形態素情報W2は、W2=t2∪D3とすることができる。
【0205】
例えば、第二形態素情報を構成する各形態素t1が(A映画名;*;面白い){A映画名は面白い?}であり、談話範囲決定部340で決定された現在の談話範囲D2が(A映画名)である場合には、削除部363は、先ず、各形態素t1(A映画名;*;面白い)から談話範囲D2(A映画名)を削除し、削除した結果をt2(*;*;面白い)とする(t2=t1−D2)。
【0206】
現在の談話範囲D2(A映画名)と関連性のある他の談話範囲D3が”B映画名”である場合には、他の談話範囲D3を構成する形態素を付加した後の第二形態素情報W2は、t2∪D3であるので、(B映画名;*;面白い){B映画名は面白い?}とすることができる。
【0207】
これにより、利用者の発話内容が”A映画名は面白い?”である場合には、談話付加部364は、利用者の発話内容を構成する各形態素(A映画名;*;面白い)と一致する第二形態素情報(A映画名;*;面白い)を、他の第二形態素情報(B映画名;*;面白い){B映画名は面白い?}に変更することができるので、回答文検索部370は、談話付加部364で変更された第二形態素情報に関連付けられた回答文(例えば、”B映画名は面白いよ”)を取得し、取得した回答文を出力することができる。
【0208】
この結果、回答文検索部370は、利用者の発話内容に対する回答文を直接的に出力するわけではないが、談話付加部364で付加された形態素を含む第二形態素情報に基づいて、発話内容に関連する回答文を出力することができるので、出力部600は、回答文検索部370で検索された回答文に基づいて、さらに人間味のある回答文を出力することができる。
【0209】
尚、談話付加部364は、形態素が削除された第二形態素情報に他の談話範囲を付加するものだけに限定されるものではなく、形態素が削除された第二形態素情報に履歴形態素情報(会話データベース500に記憶されている)を付加するものであってもよい。
【0210】
(第六変更例)
話題検索部360は、各第二形態素情報の中から、第一形態素情報を含む第二形態素情報を検索することができない場合に、第一形態素情報と各回答文とを照合し、各回答文の中から、第一形態素情報を含む回答文を検索することができたときは、検索した回答文に関連付けられている第二形態素情報を取得する第一検索手段であってもよい。
【0211】
具体的に、省略文補完部350から話題検索命令信号が入力された話題検索部360は、入力された話題検索命令信号に含まれる第一形態素情報に基づいて、第一形態素情報と各第二形態素情報とを照合し、各第二形態素情報の中から、第一形態素情報と一致する第二形態素情報を取得することができない場合には、図22に示すように、第一形態素情報と、第二形態素情報に関連付けられている回答文とを照合する。
【0212】
この照合により、話題検索部360は、回答文の中に第一形態素情報を構成する形態素(アクション又はアクションに対応付けられた形態素)が含まれていると判断した場合には、その回答文に関連付けられている第二形態素情報を検索する。
【0213】
これにより、話題検索部360は、各第二形態素情報の中から、第一形態素情報と一致する第二形態素情報を検索することができなくても、各回答文の中から、第一形態素情報を構成する形態素(アクション又はアクションに対応付けられた形態素)を含む回答文を特定し、この特定した回答文に関連付けられている第二形態素情報を検索することができるので、利用者の発話内容を構成する第一形態素情報に対応する第二形態素情報を適切に検索することができる。
【0214】
この結果、話題検索部360が第一形態素情報に対応する最適な第二形態素情報を検索することができるので、回答文検索部370は、話題検索部360で検索された最適な第二形態素情報に基づいて、利用者の発話内容に対する適切な回答文を取得することができる。
【0215】
[プログラム]
上記会話制御システム及び会話制御方法で説明した内容は、パーソナルコンピュータ等の汎用コンピュータにおいて、所定のプログラム言語を利用するための専用プログラムを実行することにより実現することができる。
【0216】
ここで、プログラム言語としては、利用者が求める話題、ある事柄に対する利用者の感情度、又は陳述文、肯定文、疑問文、反発文などの種類をその意味内容に応じて形態素と関連付けて階層的にデータベースに蓄積するための言語、本実施形態では、例えば、発明者らが開発したDKML(Discourse Knowledge Markup Language)、XML(eXtensible Markup Language)、C言語等が挙げられる。
【0217】
即ち、会話制御装置1は、各会話データベース500a〜500dに格納されているデータ(第二形態素情報、定型内容、回答文、回答種類、集合群、談話範囲、要素情報などの記憶情報)、その他の各部を、DKML(Discourse Knowledge Markup Language)、XML(eXtensible Markup Language)等で構築し、この構築した記憶情報等を利用するためのプログラムを実行することにより実現することができる。
【0218】
このような本実施形態に係るプログラムによれば、利用者の発話内容を構成する各形態素を特定し、特定した各形態素から把握される意味内容を解析して、解析した意味内容に関連付けられている予め作成された回答文を出力することで、利用者の発話内容に対応する最適な回答文を出力することができるという作用効果を奏する会話制御装置、会話制御システム及び会話制御方法を一般的な汎用コンピュータで容易に実現することができる。
【0219】
また、会話制御装置1を開発する開発者は、利用者の発話内容に対する回答文を検索するための第二形態素情報等を、データベースにおいて前記言語を用いて階層的に構築することができるので、会話制御装置1は、利用者の発話内容に基づいて発話内容に対する回答文を、階層的な手順を経てデータベースから取得することができる。
【0220】
即ち、会話制御装置1は、利用者の発話内容の階層(例えば、データベースに蓄積されている第二形態素情報に対して上位概念にあるのか、又は下位概念にあるのか)を見極めて、見極めた階層に基づいて予め蓄積された各回答文の中から、適切な回答文を取得することができる。
【0221】
このため、会話制御装置1は、利用者の発話内容からなる第一形態素情報と、予め記憶されている”全て”の第二形態素情報とを逐一照合することなく、ある特定の階層に属する各第二形態素情報と第一形態素情報とを照合すればよいので、第一形態素情報と近似する第二形態素情報を短時間で取得することができる。
【0222】
更に、上記通信部800と通信部900との間の通信は、通信ネットワーク1000を介して、DKML等からなるプロトコルによってデータを送受信してもよい。これにより、会話制御装置1は、例えば、会話制御装置1に利用者の発話内容に適した回答文がない場合には、通信ネットワーク1000を通じて、DKML等の約束事に従って、利用者の発話内容に適した回答文(DKMLなどで記述されたもの)を検索し、検索した回答文を取得することができる(図20参照)。
【0223】
尚、プログラムは、記録媒体に記録することができる。この記録媒体は、図23に示すように、例えば、ハードディスク1100、フレキシブルディスク1200、コンパクトディスク1300、ICチップ1400、カセットテープ1500などが挙げられる。このようなプログラムを記録した記録媒体によれば、プログラムの保存、運搬、販売などを容易に行うことができる。
【0224】
[第二実施形態]
(会話制御装置の基本構成)
本発明の第二実施形態について図面を参照しながら説明する。本実施形態における会話制御装置1は、第一実施形態における会話制御部300の内部構造とほぼ同じであるが、選出部380(選出手段)を有する点、回答文検索部370の機能が一部異なる点で相違する(図24参照)。この相違する点以外は、第一実施形態及び変更例の構造と同じであるので、相違する点以外の構造についての説明は省略する。
【0225】
なお、本実施形態では、上記第一実施形態における諸機能、例えば鸚鵡返し処理、反射的処理等なども当然に有し、またそれら機能に対応する効果も当然に奏する。なお、本実施形態では、後述する第一形態素情報及び話題タイトルは、第一実施形態のように、第一形態素情報及び話題タイトルに属する各形態素がサブジェクト、オブジェクト、アクション等の「格」構成に関係なく含まれていてもよい。
【0226】
第一実施形態では、会話制御装置1が、利用者からの発話内容に基づいて、その発話内容に対応する回答文を出力する処理について説明した。本実施形態では、同一の発話内容が最初に発話された時から所定の時間が経過した場合には、会話制御装置が、前回の回答文とは異なる回答文を出力する処理について説明する。本実施形態における会話制御装置1の構造は以下の通りである。なお、本実施形態における会話制御方法及びプログラムは、会話制御装置1における処理内容と同様の処理内容で実行することができる。
【0227】
図25に示すように、本実施形態では、フレーズには、一つの文字、複数の文字列又はこれらの組み合わせからなる形態素を示す話題タイトルが含まれ、この各話題タイトルには、利用者への回答文が対応付けられている。フレーズは、本実施形態では、図25に示す話題タイトルを用いる。また、共通する形態素を含む話題タイトルには、回答文として選出されるための優先順位が対応付けられている。上記各フレーズ、各話題タイトル及び各回答文は、会話データベース500(形態素記憶手段)に予め記憶されている。
【0228】
図25に示すように、例えば、話題タイトル1が(A装置;IR(イナズマ ラッシュ);教えて){A装置のIR(イナズマ ラッシュ)を教えて}である場合には、その話題タイトル1を構成する共通の形態素(IR;教えて)を含む話題タイトルとしては、話題タイトル2(A会社;IR(Investor Relations);教えて){A会社のIR(Investor Relations)を教えて}又は話題タイトル3(B会社;IR(Investor Relations);教えて){B会社のIR(Investor Relations)を教えて}が挙げられる。
【0229】
話題検索部360(第一検索手段)は、利用者から入力された入力情報に基づいて、予め記憶された複数のフレーズの中から、入力情報を含む各フレーズを検索するものである。具体的に、談話範囲決定部340又は省略文補完部350から第一形態素情報が入力された話題検索部360は、入力された第一形態素情報に基づいて、その第一形態素情報を含む話題タイトル(これはフレーズに含まれる)を複数検索する。
【0230】
選出部380(選出手段)は、話題検索部360で各話題タイトルが検索された場合には、検索された各話題タイトルに対応付けられた各優先順位の大きさに応じて、一の話題タイトルを選出するものである。具体的には、図24に示すように、文構造解析部430で第一形態素情報(IR;教えて)が抽出された場合には、話題検索部360は、第一形態素情報(IR;教えて)を含む話題タイトル1〜話題タイトル3を特定する。
【0231】
特定した話題タイトル1に対応付けられた優先順位が1であるので、選出部380は、話題タイトル1〜話題タイトル3の中から、優先順位1に対応付けられた話題タイトル1を選出する。すなわち、選出部380は、話題検索部360で複数の話題タイトルが検索された場合には、その検索された各話題タイトルに対応付けられた各優先順位の中から、最も高い優先順位を特定し、特定した優先順位に対応付けられた話題タイトルを選出する。なお、選出部380は、上記各優先順位の中から、最も低い優先順位を特定し、特定した優先順位に対応付けられた話題タイトルを選出してもよい。
【0232】
また、選出部380及び回答文検索部370は、入力部100で取得された入力情報に基づいて同一の入力情報が最初に取得された時から所定の時間が経過した場合には、最初に取得された同一の入力情報に対応する回答文とは異なる回答文を検索するものである。
【0233】
すなわち、選出部380(選出手段)は、話題検索部360で検索された各フレーズに基づいて、検索されたフレーズが今回検索された各フレーズに含まれ、前回のフレーズが検索された時から所定の時間が経過した場合には、前回検索されたフレーズとは異なるフレーズを、今回検索された各フレーズの中から選出する。ここで、選出部380は、自部にあるタイマー機能を用いて、前回のフレーズが検索された時から所定の時間が経過したか否かを判断する。回答文検索部370(第二検索手段)は、選出部380で選出されたフレーズに基づいて、フレーズに対応する回答文を検索する。
【0234】
具体的に、選出部380は、本実施形態では、前回検索(又は選出)された話題タイトルが話題検索部360で今回検索された各話題タイトルに含まれ、その前回の話題タイトルが検索された時から所定の時間が経過した場合には、その前回検索(又は選出)された話題タイトルとは異なる話題タイトルを、今回検索された各話題タイトルの中から選出する。
【0235】
図25及び図26に示すように、例えば、選出部380は、前回検索(又は選出)された話題タイトル1(A装置;IR;教えて)が今回検索された話題タイトル1〜話題タイトル3に含まれ、前回の話題タイトル1(A装置;IR;教えて)が検索された時から「所定の時間」が経過した場合には、前回検索(又は選出)された話題タイトル1(A装置;IR;教えて)に対応付けられた優先順位1を特定する。
【0236】
この選出部380は、特定した優先順位1の次の優先順位2に対応付けられた話題タイトル2(A会社;IR;教えて)を、今回検索された話題タイトル1〜3の中から選出する。なお、上記「所定の時間」は、図25に示すように、本実施形態では、優先順位に対応付けられた適用時間に該当するものである。この所定の時間は、外部からの操作指示により可変することができる。
【0237】
一方、選出部380は、前回の話題タイトル1(A装置;IR;教えて)が検索された時から所定の時間が経過していない場合には、前回検索された話題タイトル1(A装置;IR;教えて)を他の話題タイトル2,3に優先して用いる。そして、選出部380は、上記所定の時間が経過した後に、前回検索された話題タイトル1を含む話題タイトル1〜3が再度検索された場合には、前回の話題タイトル1に対応付けられた優先順位1の次の優先順位2を特定し、その特定した優先順位2に対応付けられた話題タイトル2を選出する。
【0238】
回答文検索部370は、例えば選出部380で話題タイトル2(A会社;IR;教えて)が選出された場合には、その話題タイトル2に対応付けられた回答文2(A会社のIRは〜です)を検索する。出力部600は、回答文検索部370で検索された回答文2(A会社のIRは〜です)を出力する。
【0239】
(会話制御装置を用いた会話制御方法)
上記構成を有する会話制御装置1による会話制御方法は、以下の手順により実施することができる。図27は、本実施形態に係る会話制御方法の手順を示すフロー図である。図27に示す(S201)〜(S204)までの処理は上記第一実施形態における(S101)〜(S104)までの処理と同様であるので、詳細な説明は省略する。
【0240】
図27に示すように、話題検索部360が、談話範囲決定部340又は省略文補完部350から入力された第一形態素情報に基づいて、その第一形態素情報を含む話題タイトル(これはフレーズに含まれる)を複数検索するステップを行う(S205)。そして、選出部380が、前回検索された話題タイトルが話題検索部360で今回検索された各話題タイトルに含まれ、その前回の話題タイトルが検索された時から所定の時間が経過した場合には、その前回検索された話題タイトルとは異なる話題タイトルを、今回検索された各話題タイトルの中から選出する(S206,S208)。
【0241】
図25及び図26に示すように、例えば、選出部380は、前回検索(又は選出)された話題タイトル1(A装置;IR;教えて)が今回検索された話題タイトル1〜話題タイトル3に含まれ、前回の話題タイトル1(A装置;IR;教えて)が検索された時から「所定の時間」が経過した場合には、前回検索(又は選出)された話題タイトル1(A装置;IR;教えて)に対応付けられた優先順位1を特定する。この選出部380は、特定した優先順位1の次の優先順位2に対応付けられた話題タイトル2(A会社;IR;教えて)を、今回検索された話題タイトル1〜3の中から選出する。
【0242】
一方、選出部380は、前回の話題タイトル1(A装置;IR;教えて)が検索された時から所定の時間が経過していない場合には、前回検索された話題タイトル1(A装置;IR;教えて)を他の話題タイトル2,3に優先して用いる。また、前回の話題タイトルが今回検索された各話題タイトルの中に含まれない場合には、選出部380は、今回検索された各話題タイトルの中から、最も高い優先順位に対応付けられた話題タイトルを検索する(S206,S207)。
【0243】
そして、選出部380は、上記所定の時間が経過した後に、話題検索部360で前回検索された話題タイトル1を含む話題タイトル1〜3が再度検索された場合には、前回の話題タイトル1に対応付けられた優先順位1の次の優先順位2を特定し、その特定した優先順位2に対応付けられた話題タイトル2を選出する。
【0244】
次いで、回答文検索部370が、例えば選出部380で話題タイトル2(A会社;IR;教えて)が選出された場合には、その話題タイトル2に対応付けられた回答文2(A会社のIRは〜です)を検索するステップを行う(S209)。出力部600は、回答文検索部370で検索された回答文2(A会社のIRは〜です)を出力する。
【0245】
(会話制御装置及び会話制御方法による作用及び効果)
上記構成を有する発明によれば、前回検索された話題タイトルが今回検索された各話題タイトルに含まれ、前回の話題タイトルが検索された時から所定の時間が経過した場合には、選出部350は、前回検索された話題タイトルに対応付けられた優先順位を特定し、特定した優先順位の次の優先順位に対応付けられた話題タイトルを、今回検索された各話題タイトルの中から選出することができる。
【0246】
具体的には、例えば、利用者が”財務情報を教えて”{第一形態素情報(財務情報;教えて)}と発話した場合には、その発話内容には、A会社、B会社・・・等の複数の会社における財務情報が含まれることになる。ここで、利用者の発話内容を構成する話題タイトルを含む話題タイトルが複数検索されたということは、利用者の発話内容が多義的な意味を包含することを意味する。
【0247】
この場合には、話題検索部360は、例えば第一形態素情報(財務情報;教えて)を含む話題タイトルとして、(A会社;財務情報;教えて)、(B会社;財務情報;教えて)・・・を検索することになる。この際、話題検索部360が、話題タイトル(A会社;財務情報;教えて)を前回検索し、その前回検索をした時から所定の時間が経過したときは、選出部380は、前回検索された話題タイトル(A会社;財務情報;教えて)に対応付けられた優先順位(例えば”1”)を特定する。
【0248】
この選出部380は、特定した優先順位の次の優先順位(例えば”2”)に対応付けられた話題タイトル(B会社;財務情報;教えて)を検索することを行う。回答文検索部370は、検索した話題タイトル(B会社;財務情報;教えて)に対応付けられた回答文(B会社の財務情報は、〜です)を出力する。
【0249】
すなわち、利用者が複数の意味に捉えられる同一の発話内容を複数発話し、その発話を最初にした時から所定時間が経過した場合には、回答文検索部370は、前回の回答文とは異なる回答文を出力する。これにより、上記所定時間が短く設定されていれば、短い時間内で回答文が逐一変更されるので、会話制御装置1は、恰も前に回答した内容を忘れやすいかの印象を利用者に与えさせることのできる機器として用いることができる。
【0250】
一方、上記所定時間が長く設定されていれば、回答文があまり変更されないので、会話制御装置1は、恰も前に回答した内容をしつこく発話するかの印象を利用者に与えさせることのできる機器として用いることができる。
【0251】
また、回答文検索部370は、上記入力情報に含まれる日本語特有な助詞(て・に・を・・等)を除いた形態素を用いて該当する回答文を検索するので、その各形態素から把握することができる意味内容に基づいて、予め作成された回答文をより的確に検索することができる。すなわち、回答文検索部370は、単に入力情報の全体をキーワードとして、そのキーワードに関連付けられた回答文を検索するよりも、より入力情報に適した回答文を検索することができる。
【0252】
更に、回答文検索部370は、第一形態素情報を含む話題タイトルを検索するので、利用者からの入力情報と完全に一致する話題タイトルを検索する必要がない。この結果、会話制御装置1を開発する開発者は、利用者から入力されると予想される入力情報に対応する膨大な回答文を予め記憶する必要がなくなり、記憶部の容量を低減させることができる。
【0253】
(変更例)
なお、本発明は、上記実施形態に限定されるものではなく、以下に示すような変更を加えることができる。選出部380及び回答文検索部370は、入力部100で取得された同一の入力情報が基準回数を越えて取得された場合には、同一の入力情報に対応する回答文とは異なる回答文を検索するものである。
【0254】
すなわち、選出部380は、前回検索された話題タイトルが今回検索された各話題タイトルに含まれ、今回検索された各話題タイトルが所定の基準回数を越えて検索された場合には、前回検索された話題タイトルとは異なる話題タイトルを、今回検索された各話題タイトルの中から選出するものである。回答文検索部370は、選出部380で選出された話題タイトルに基づいて、話題タイトルに対応付けられた回答文を検索するものである。
【0255】
具体的には、図28及び図29に示すように、選出部380は、例えば、前回検索された話題タイトル1(A装置;IR;教えて)が今回検索された話題タイトル1〜話題タイトル3に含まれ、今回検索された話題タイトル1〜話題タイトル3が所定の基準回数(例えば、5回)を越えて過去に検索されたか否かを特定する。
【0256】
この選出部380は、その検索された回数が所定の基準回数(例えば、5回)を越えた場合には、前回検索された話題タイトル1(A装置;IR;教えて)に対応付けられた優先順位1を特定する。選出部380は、特定した優先順位1の次の優先順位2に対応付けられた話題タイトル2(A会社;IR;教えて)を、今回検索された話題タイトル1〜話題タイトル3の中から選出する。
【0257】
一方、選出部380は、検索された回数が基準回数(例えば、5回)を越えていない場合には、前回検索された話題タイトル1(A装置;IR;教えて)を他の話題タイトルに優先して用いる。その後、回答文検索部370は、選出部380で選出された話題タイトルに基づいて、話題タイトルに対応付けられた回答文を検索する。回答文検索部370は、管理部310を介して検索した回答文を出力部600に出力する。
【0258】
この場合には、利用者が複数の意味に捉えられる同一の発話内容を複数発話し、その同一の発話内容が基準回数を越えて発話された場合にも、回答文検索部370は、前回の回答文とは異なる回答文を出力することができる。これにより、上記基準回数が少なく設定されていれば、回答文が逐一変更されるので、会話制御装置1は、恰も前に回答した内容を忘れやすいかの印象を利用者に与えさせることのできる機器として用いることができる。
【0259】
一方、上記基準回数が多く設定されていれば、回答文があまり変更されないので、会話制御装置は、恰も前に回答した内容をしつこく発話するかの印象を利用者に与えさせることのできる機器として用いることができる。
【0260】
なお、前回の回答文とは異なる回答文には、予め展開させたい内容が含まれることが望ましい。この場合には、例えば、同じ発話内容が繰り返して発話されたときは、会話制御装置は、現在の話題を他の話題に誘導させるような回答文を出力することができる。
【0261】
これにより、前回と同一の発話内容が入力され、その同一の発話内容が入力されてから所定の時間が経過した場合には、例えば、ゲーム(RPG、推理ゲーム等)に登場するキャラクターは、現在のストーリを他のストーリへと誘導する回答文を出力することができる。
【0262】
【発明の効果】
以上説明したように本発明によれば、利用者が複数の意味に捉えられる同一の発話内容を複数発話し、且つその同一の発話内容が最初に発話された時から所定の時間が経過した場合には、前回の回答文とは異なる回答文を出力することができる。
【図面の簡単な説明】
【図1】第一実施形態に係る会話制御システムの概略構成を示すブロック図である。
【図2】第一実施形態における会話制御部及び文解析部の内部構造を示すブロック図である。
【図3】第一実施形態における形態素抽出部で抽出する各形態素の内容を示す図である。
【図4】第一実施形態における文節解析部で抽出する各文節の内容を示す図である。
【図5】第一実施形態における文構造解析部で特定する「格」の内容を示す図である。
【図6】第一実施形態における発話種類判定部で特定する「発話文のタイプ」を示す図である。
【図7】第一実施形態における発話種類データベースで格納する各辞書の内容を示す図である。
【図8】第一実施形態における会話データベースの内部で構築される階層構造の内容を示す図である。
【図9】第一実施形態における会話データベースの内部で構築される階層構造の詳細な関係を示す図である。
【図10】第一実施形態における会話データベースの内部で構築される「話題タイトル」の内容を示す図である。
【図11】第一実施形態における会話データベースの内部で構築される「話題タイトル」に関連付けられている「回答文のタイプ」の内容を示す図である。
【図12】第一実施形態における会話データベースの内部で構築される「談話範囲」に属する「話題タイトル」及び「回答文」の内容を示す図である。
【図13】第一実施形態における反射要素データベースで記憶する反射要素情報の内容を示す図である。
【図14】第一実施形態における鸚鵡返し要素データベースで記憶する鸚鵡返し要素、鸚鵡返し要素の形態素の内容を示す図である。
【図15】第一実施形態に係る会話制御方法の手順を示すフロー図である。
【図16】第一変更例における形態素抽出部で整理する発話内容を示す図である。
【図17】第二変更例における話題検索部の内部構成を示す図である。
【図18】第二変更例における割合計算部が「格構成」に属する各形態素と各「話題タイトル」とを「話題タイトル」毎に照合する様子を示す図である。
【図19】第二変更例における割合計算部が「各構成」に属する各形態素と「話題タイトル」に属する各形態素とを「格」毎に照合する様子を示す図である。
【図20】第三変更例における会話制御システムの概略構成を示す図である。
【図21】第五変更例における話題検索部の内部構成を示す図である。
【図22】第六変更例における話題検索部が第一形態素情報と、話題タイトル又は回答文とを照合する様子を示す図である。
【図23】第一実施形態におけるプログラムを格納する記録媒体を示す図である。
【図24】第二実施形態に係る会話制御装置の内部構成を示すブロック図である。
【図25】第二実施形態における会話データベースの内部で構築される「話題タイトル」及び「回答文」の内容を示す図である(その1)。
【図26】第二実施形態における選出部で話題タイトルが選出される様子を示す図である(その1)。
【図27】第二実施形態における会話制御方法の処理手順を示す図である。
【図28】第二実施形態における会話データベースの内部で構築される「話題タイトル」及び「回答文」の内容を示す図である(その2)。
【図29】第二実施形態における選出部で話題タイトルが選出される様子を示す図である(その2)。
【符号の説明】
1…会話制御装置、2…サーバ、100…入力部、200…音声認識部、300…会話制御部、310…管理部、320…反射的判定部、330…鸚鵡返し判定部、340…談話範囲決定部、350…省略文補完部、350…選出部、360…話題検索部、361…割合計算部、362…選択部、363…削除部、364…談話付加部、370…回答文検索部、380…選出部、400…文解析部、410…形態素抽出部、420…文節解析部、430…文構造解析部、440…発話種類判定部、450…形態素データベース、460…発話種類データベース、500…会話データベース、600…出力部、700…音声認識辞書記憶部、800…通信部、801…反射要素データベース、802…鸚鵡返し要素データベース、900…通信部、1000…通信ネットワーク、1100…ハードディスク、1200…フレキシブルディスク、1300…コンパクトディスク、1400…ICチップ、1500…カセットテープ[0001]
BACKGROUND OF THE INVENTION
The present invention relates to a conversation control device and a conversation control method.
[0002]
[Prior art]
A conventional conversation control device can output a pre-stored answer sentence corresponding to the utterance content based on the utterance content from the user (for example, Patent Document 1). For this reason, the user was able to experience a feeling of talking with another user in a pseudo manner by using the reply sentence from the conversation control device.
[0003]
[Patent Document 1]
JP 2002-169804 (page 10-26, FIG. 16)
[0004]
[Problems to be solved by the invention]
However, when the user's utterance content is captured in a plurality of meanings and there are a plurality of answer sentences corresponding to the utterance contents, the conversation control device outputs the answer sentence searched first. For this reason, when the user's utterance content is captured in a plurality of meanings, the conversation control device captures the meaning of the utterance content related to a specific topic to be developed in advance, and corresponds to the captured utterance content. Answer text could not be output.
[0005]
For example, if the utterance content from the user is {Tell me about IR}, the utterance content is captured in the meaning of IR (Inazumarush) of the production image on the gaming machine or IR (Investor Relations) of the company Sometimes. In this case, when the conversation control device first searches for an answer sentence corresponding to the IR (Inazu mash) of the effect image on the gaming machine from among the answer sentences, the conversation control apparatus outputs the answer sentence searched first. .
[0006]
That is, even when the conversation control device wants to output an answer sentence corresponding to the IR of the company, when it first searches for an answer sentence corresponding to the IR (Inazu mash) of the production image, the answer that is searched first The sentence was output automatically. For this reason, it has been desired to develop a system that can output an answer sentence related to a specific topic to be developed in advance.
[0007]
Therefore, the present invention has been made in view of the above points, and when a user utters a plurality of the same utterance contents captured in a plurality of meanings, an answer sentence different from the previous answer sentence is output. It is an object of the present invention to provide a conversation control device and a conversation control method that can be used.
[0008]
[Means for Solving the Problems]
In order to solve the above problem, the present invention is based on the input information input from the user, and when the same input information is first acquired, it is acquired first. It is characterized in that an answer sentence different from the answer sentence corresponding to the same input information is searched.
[0009]
That is, the present invention searches each phrase including input information from a plurality of phrases stored in advance based on input information input from a user, and searches the previous time based on each searched phrase. The phrase searched is included in each phrase searched this time, and when a predetermined time has passed since the previous phrase was searched, a phrase different from the phrase searched last time is changed to each phrase searched this time. And selecting an answer sentence corresponding to the phrase based on the selected phrase.
[0010]
In this case, for example, phrase 1 (tell IR of device A) and phrase 2 (tell IR of device B) are searched as phrases including the searched input information (tell IR). The phrase 1 (tell me the IR of the device A) was included in each of these phrases, and a predetermined time from when the phrase 1 (tell me the IR of the device A) was last searched. When the time has elapsed, the conversation control device can select a
[0011]
As a result, when the input information is captured in a plurality of meanings, the meanings used last time are included in each meaning, and the predetermined time has elapsed since the meaning was used, the conversation control device Depending on the time, a meaning different from the meaning used last time can be selected, and an answer sentence corresponding to the selected meaning can be output. As a result, when the user utters a specific utterance content and the same content as the utterance content is repeatedly input after a predetermined time has elapsed since the utterance, the conversation control device An answer sentence that directs the current topic to a different topic according to the time can be output.
[0012]
In the said invention, the phrase contains the 2nd morpheme information which shows the morpheme which consists of one character, several character strings, or these combination, and the response sentence to a user is matched with several 2nd morpheme information. Each of the second morpheme information and each answer sentence is stored in advance, and at least one morpheme constituting the minimum unit of the character string is determined based on the character string included in the input information input by the user. Based on the extracted first morpheme information, a plurality of second morpheme information including the first morpheme information is searched from the previously stored second morpheme information, and the second morpheme searched last time If the information is included in each second morpheme information searched this time, and a predetermined time has elapsed since the previous second morpheme information was searched, the second morpheme information different from the previously searched second morpheme information Morphology And elected from among the second morpheme information retrieved this time, based on the second morpheme information elected, it is preferable to find the answer sentence associated with the second morpheme information.
[0013]
According to the invention according to the present application, the second morpheme information searched last time is included in each second morpheme information searched this time, and a predetermined time has elapsed since the last time the second morpheme information was searched. In this case, the conversation control device selects second morpheme information different from the previously searched second morpheme information from each second morpheme information searched this time, and corresponds to the selected second morpheme information. Attached answer sentences can be output.
[0014]
Specifically, for example, when a user utters “Tell me financial information” {First morpheme information (financial information; tell me)}, the contents of the utterance include Company A, Company B・ Financial information on multiple companies is included. Here, the fact that a plurality of second morpheme information including the first morpheme information constituting the utterance content of the user is searched means that the utterance content of the user has an ambiguous meaning.
[0015]
In this case, the conversation control device, for example, as the second morpheme information including the first morpheme information (financial information; tell me), (company A; financial information; tell me), (company B; financial information; tell me) ) ... will be searched. At this time, if the conversation control device searches the second morpheme information (A company; financial information; tell me) last time and a predetermined time has passed since the previous search, the conversation control device Second morpheme information (company B; financial information; tell me) different from morpheme information (company A; financial information; tell me) is searched. The conversation control device outputs an answer sentence (the financial information of company B is ~) associated with the searched second morpheme information (company B; financial information; tell me).
[0016]
That is, when the user utters a plurality of the same utterance contents that can be captured in a plurality of meanings and a predetermined time has elapsed since the utterance was first made, the conversation control device is different from the previous answer sentence. Output answer text. As a result, if the predetermined time is set to be short, the answer sentences are changed one by one within a short time, so that the conversation control device gives the user an impression that it is easy to forget the contents that have been answered before. It can be used as a device that can.
[0017]
On the other hand, if the predetermined time is set to be long, the answer sentence is not changed so much, so the conversation control device is a device that can give the user the impression of persistently speaking the content that was previously answered. Can be used.
[0018]
In particular, the conversation control device searches for a corresponding answer sentence using a morpheme excluding Japanese-specific particles included in the input information, and grasps it from each morpheme. Based on the meaning content that can be made, it is possible to search for a reply sentence prepared in advance more accurately. That is, the conversation control device can search for an answer sentence more suitable for the input information than simply searching for an answer sentence associated with the keyword using the entire input information as a keyword.
[0019]
Furthermore, since the conversation control device searches for the second morpheme information including the first morpheme information, it is not necessary to search for the second morpheme information that completely matches the input information from the user. As a result, the developer who develops the conversation control device does not need to store a huge amount of answer sentences corresponding to input information expected to be input from the user in advance, and can reduce the capacity of the storage unit. .
In addition, it is preferable that the answer sentence different from the previous answer sentence includes the content to be developed in advance. In this case, for example, when the same utterance content is repeatedly uttered, the conversation control device can output an answer sentence that directs the current topic to another topic.
[0020]
As a result, when the same utterance content as the previous time is input and a predetermined time has elapsed since the input of the same utterance content, for example, the character appearing in the game changes the current story to another story. An answer sentence for changing can be output.
[0021]
In the above invention, a plurality of second morpheme information indicating a morpheme composed of one character, a plurality of character strings, or a combination thereof is associated with an answer sentence to the user, and each second morpheme Information and each answer sentence are stored in advance, and at least one morpheme constituting the minimum unit of the character string is extracted as the first morpheme information and extracted based on the character string included in the input information input from the user. Based on the first morpheme information, a plurality of second morpheme information including the first morpheme information is searched from each second morpheme information stored in advance, and the previously searched second morpheme information is searched this time. If each second morpheme information that is included in each second morpheme information and searched this time exceeds a predetermined reference number of times, second morpheme information that is different from the previously searched second morpheme information, Searched this time Elected from among the second morpheme information based on the second morpheme information elected, it is preferable to find the answer sentence associated with the second morpheme information.
[0022]
In this case, the second morpheme information searched last time is included in each second morpheme information searched this time, and each second morpheme information searched this time is searched beyond a predetermined reference number. The conversation control device selects second morpheme information different from the previously searched second morpheme information from the second morpheme information searched this time, and a response associated with the selected second morpheme information. A sentence can be output.
[0023]
In other words, if the user utters the same utterance content captured in multiple meanings and the same utterance content is uttered beyond the reference count, the conversation control device is different from the previous answer sentence. Output answer text. As a result, if the reference number is set to be small, the answer sentences are changed one by one, so that the conversation control device can give the user the impression that it is easy to forget the contents that were answered before. Can be used as
[0024]
On the other hand, if the reference number is set to a large number, the answer text is not changed so much, so the conversation control device is a device that can give the user the impression of persistently speaking the content that was answered before. Can be used.
[0025]
DETAILED DESCRIPTION OF THE INVENTION
[First embodiment]
(Basic configuration of conversation control system)
A conversation control system according to the present invention will be described with reference to the drawings. FIG. 1 is a schematic configuration diagram of a conversation control system having a
[0026]
As shown in the figure, the
[0027]
In the present embodiment, for convenience of explanation, the description is limited to the user's utterance content (this utterance content is a kind of input information), but is not limited to the user's utterance content, and the keyboard. The input information may be input from the above. Therefore, the “utterance content” shown below can be described by replacing “utterance content” with “input information”.
[0028]
Similarly, in the following description, for convenience of explanation, the description will be limited to the “spoken sentence type” (speech type), but is not limited to this “spoken sentence type”, and input from a keyboard or the like. It may be an “input type” indicating the type of input information. Accordingly, the following “speech sentence type” (speech type) can be described by replacing “speech type” with “input type”.
[0029]
The
[0030]
Here, the input information means characters, symbols, voices and the like input through a keyboard or the like. Specifically, the
[0031]
The
[0032]
The
[0033]
The
[0034]
Specifically, the
[0035]
That is, the
[0036]
The
[0037]
Here, in this embodiment, the phrase format is a sentence in which the independent grammar or one or more attached words are attached to the independent grammar in the Japanese grammar, or a character string that does not destroy the meaning of the Japanese grammar. Means a sentence that is separated as finely as possible. This clause is expressed as p1, p2,... Pk in this embodiment.
[0038]
That is, the
[0039]
The
[0040]
The sentence
[0041]
Here, the “case structure” means a case (attribute) indicating a substantial concept in the clause. In the present embodiment, for example, a subject (subject) that represents a subject / subject, Examples include a meaning object (target case), an action meaning an action, a time meaning (tense, aspect), a location meaning a place, and the like. In this embodiment, each morpheme associated with the “case” (case configuration) of the three elements of the subject, the object, and the action is used as the first morpheme information.
[0042]
That is, as shown in FIG. 5, for example, when the dependency element of each morpheme is “” or “is”, the sentence
[0043]
Further, for example, when the dependency element of each morpheme is “Yes”, the sentence
[0044]
The sentence
[0045]
The utterance
[0046]
In this embodiment, as shown in FIG. 6, the “spoken sentence type” is a statement sentence (D; Declaration), an impression sentence (I; Impression), a conditional sentence (C; Condition), and a result sentence ( E; Effect, time sentence (T; Time), location sentence (L; Location), repulsive sentence (N; Negation), and the like. Each of these sentences is expressed by an affirmative sentence (A; Answer) or a question sentence (Q; Question) as shown in FIG.
[0047]
The statement sentence means a sentence composed of a user's opinion or idea, and in this embodiment, as shown in FIG. 6, for example, a sentence such as “I like Sato” can be cited. An impression sentence means the sentence which consists of an impression which a user holds. A place sentence means a sentence made up of place elements.
[0048]
The result sentence means a sentence composed of sentences including a result element for a topic. A time sentence means a sentence composed of sentences including temporal elements related to a topic.
[0049]
The conditional sentence means a sentence composed of sentences including elements such as a premise of a topic, a condition and a reason why the topic is established, when one utterance is regarded as a topic. The repulsive sentence means a sentence composed of a sentence including an element that repels the utterance partner. An example sentence for each “spoken sentence type” is as shown in FIG.
[0050]
That is, the utterance
[0051]
Here, as shown in FIG. 7, the
[0052]
As a result, the utterance
[0053]
The utterance
[0054]
The
[0055]
Furthermore, the
[0056]
Furthermore, the
[0057]
As shown in FIG. 8, in the present embodiment, the
[0058]
Each discourse range can be configured to have a hierarchical structure as shown in FIG. As shown in the figure, for example, a higher level discourse range (entertainment) for a certain discourse range (movie) is positioned in the upper hierarchical structure, and a lower level discourse range (movie) for the discourse range (movie). The attribute (movie) can be located in the lower hierarchical structure. That is, in the present embodiment, each discourse range can be arranged at a hierarchical position where the relationship between the higher concept, the lower concept, the synonym, and the synonym becomes clear with other discourse ranges.
[0059]
As described above, the discourse range is composed of topics, and in this embodiment, for example, if the discourse range is an A movie name, it includes a plurality of topics related to the A movie name.
[0060]
This topic means a morpheme composed of a single character, a plurality of character strings, or a combination thereof, that is, each morpheme constituting speech content that will be uttered by the user. Each morpheme is associated with a subject (subject), an object (target case), and an action “case” (attribute). In this embodiment, each morpheme associated with these three elements is expressed as a topic title (this topic title corresponds to a subordinate concept of “topic”) (second morpheme information). .
[0061]
The topic title is not limited to each morpheme associated with the above three elements, but other “cases”, that is, time (tense, aspect) meaning time, location meaning place, You may have each morpheme matched with the condition which means a condition, the impression which means an impression, the effect which means a result, etc.
[0062]
In this embodiment, the topic title (second morpheme information) is stored in advance in the
[0063]
For example, if the talk range is “A movie name”, as shown in FIG. 10, the subject title is subject (A movie name), object (director), action (great) {this is “A movie name” The director of the name is composed of "meaning great".
[0064]
If there is no morpheme associated with “case composition” (subject, object, action, etc.) among the topic titles, “*” is indicated for the portion in the present embodiment.
[0065]
For example, {A movie name? } Is converted into a topic title (subject; object; action). }, “A movie name” can be specified as a subject, but “object” and “action” are not elements of the sentence, so the topic title is “subject” (A movie name) “No object” (*); no “action” (*) (see FIG. 10).
[0066]
In the present embodiment, the answer sentence is associated with each topic title (second morpheme information) (see FIG. 8). In this embodiment, as shown in FIG. 11, the answer sentence is a statement sentence (D; Declaration), an impression sentence in order to make an answer corresponding to the type of utterance sentence uttered by the user. Types such as (I; Impression), conditional statement (C; Condition), result statement (E; Effect), time statement (T; Time), location statement (L; Location), negative statement (N; Negation) Type).
[0067]
That is, as shown in FIG. 12, each answer sentence is associated with, for example, a discourse range (Sato) {subordinate concept; home run, superordinate concept; grass baseball, synonym; panda Sato, Sato player, panda} and each topic title. It has been.
[0068]
As shown in the figure, for example, the topic title 1-1 is {(Sato; *; I like): this consists of the order of (subject; object; action) as described above. If the order is the same below, the answer sentence 1-1 corresponding to the topic title 1-1 is (DA; statement affirmation “I like Sato”), (IA; comment affirmation) "I like Sato very much"), (CA; conditional affirmation sentence "Sato's home run is very impressive"), (EA; a result affirming sentence "I always watch Sato's games on TV"), (TA: Time affirmative sentence "I actually like it from the five-bats continual refrain in Koshien"), (LA; Place affirmative sentence "I like the serious face when standing on the blow"), (NA A repulsive affirmative sentence "I don't want to talk to people who don't like Sato, goodbye").
[0069]
In the present embodiment, as shown in FIG. 2, the
[0070]
The
[0071]
The
[0072]
Here, the standard content means reflection element information for replying a standard content to the utterance content from the user, and this reflection element information is stored in the reflection element database 801 (standard storage means) in advance. A plurality are stored. As the reflective element information, in the present embodiment, as shown in FIG. 13, for example, "Good morning", "Hello", "Good evening", "greeting elements" such as "Hey", "I see", "Really?""Typicalelements" such as
[0073]
Specifically, the
[0074]
That is, assuming that the reflection element information is D1 and the first morpheme information is W, the
[0075]
For example, when the user utters the utterance content “Good morning”, the
[0076]
When the
[0077]
The
[0078]
Here, “turnback” means to say back the content of the user's utterance as it is (or content close to it) in this embodiment. In this embodiment, the return element is composed of first morpheme information constituting the answer sentence output from the
[0079]
Further, the
[0080]
Specifically, the
[0081]
If it is determined that the first morpheme information is included in each return element, the
[0082]
For example, the
[0083]
Further, the
[0084]
Specifically, when the user utters the utterance content “Horse is beautiful” and the
[0085]
In this case, since the user has not heard the answer sentence from the
[0086]
On the other hand, if the
[0087]
In addition, although the said
[0088]
In this case, the
[0089]
For example, when the
[0090]
The discourse
[0091]
Specifically, the conversation
[0092]
For example, the discourse
[0093]
On the other hand, when the first morpheme information does not include a discourse range group, the conversation
[0094]
Thereby, the
[0095]
As described above, the discourse
[0096]
The abbreviated
[0097]
Specifically, the abbreviated
[0098]
For example, the abbreviation
[0099]
That is, assuming that the first morpheme information is W and the determined discourse range is D, the abbreviated
[0100]
Thereby, even if the first morpheme information is an abbreviated sentence and it is not clear as Japanese, the abbreviated
[0101]
For this reason, the first morpheme information is set so that the abbreviated
[0102]
The
[0103]
Specifically, the
[0104]
For example, when the “case configuration” constituting the first morpheme information is (Sato; *; I like) {I like Sato}, the
[0105]
The utterance
[0106]
The answer
[0107]
Specifically, the answer
[0108]
For example, when the topic title corresponding to the search result is the topic title 1-1 (Sato; *; I like) shown in FIG. 12, the answer
[0109]
The
[0110]
The
[0111]
(Conversation control method using conversation control device)
The conversation control method by the
[0112]
First, the
[0113]
Next, the
[0114]
And the
[0115]
Specifically, the
[0116]
Then, the
[0117]
That is, as shown in FIG. 4, the
[0118]
The
[0119]
Thereafter, the sentence
[0120]
That is, as shown in FIG. 5, for example, when the dependency element of each morpheme is “” or “is”, the sentence
[0121]
Further, for example, when the dependency element of each morpheme is “Yes”, the sentence
[0122]
The sentence
[0123]
Next, the utterance
[0124]
That is, the utterance
[0125]
The utterance
[0126]
Next, the
[0127]
Specifically, the
[0128]
When the reflection element information cannot be searched for the reflection element information including the first morpheme information from the reflection element information, the
[0129]
Next, the
[0130]
When it is determined that the first morpheme information is included in each return element, the
[0131]
On the other hand, when determining that the first morpheme information is not included in each return element, the
[0132]
Then, the discourse
[0133]
Specifically, the conversation
[0134]
For example, the discourse
[0135]
On the other hand, when the first morpheme information does not include a discourse range group, the conversation
[0136]
Next, the abbreviation
[0137]
Specifically, the abbreviated
[0138]
For example, the abbreviation
[0139]
That is, assuming that the first morpheme information is W and the determined discourse range is D, the abbreviated
[0140]
Next, the
[0141]
Specifically, the
[0142]
For example, when the “case configuration” constituting the first morpheme information is (Sato; *; I like) {I like Sato}, the
[0143]
The utterance
[0144]
Then, the answer
[0145]
Specifically, the answer
[0146]
For example, when the topic title corresponding to the search result is the topic title 1-1 (Sato; *; I like) shown in FIG. 12, the answer
[0147]
Next, the
[0148]
(Operation and effect of conversation control device and conversation control method)
According to the invention according to the present application having the above-described configuration, the
[0149]
In addition, when the user's utterance content is a fixed content, the
[0150]
Further, the
[0151]
In this case, since the user has turned back the past answer sentence, the
[0152]
Further, the
[0153]
In this case, since the user does not appropriately reply to the previous response sentence, the
[0154]
Further, in order to search for the second morpheme information approximate to the first morpheme information, the
[0155]
As a result, the
[0156]
Moreover, the
[0157]
Further, since the
[0158]
Furthermore, the answer
[0159]
Furthermore, the answer
[0160]
Finally, the abbreviated
[0161]
Thus, the abbreviated
[0162]
As a result, even if the input information from the user is an abbreviated sentence, the
[0163]
[Example of change]
In addition, this invention is not limited to the said embodiment, The change as shown below can be added.
[0164]
(First change example)
In this modification, the
[0165]
As shown in FIG. 16, some morphemes included in the character string uttered by the user are similar. For example, as shown in FIG. 16, if the element information indicating the entire group is “gift”, the “gift” is similar to a present, gift, year-end gift, mid-year gift, celebration, etc. (group). Therefore, when there is a morpheme similar to “gift” (such as the present), the
[0166]
That is, for example, when the morpheme extracted from the character string is “present”, the
[0167]
This allows the
[0168]
(Second modified example)
As shown in FIG. 17, in the present modification example, the
[0169]
The
[0170]
Specifically, the
[0171]
For example, as shown in FIG. 18, when the first morpheme information constituting the utterance sentence uttered by the user is (Sato; *; I like) {I like Sato}, the
[0172]
The
[0173]
Specifically, the
[0174]
Accordingly, the
[0175]
Further, since the
[0176]
As a result, since the
[0177]
Further, the
[0178]
The
[0179]
Specifically, the
[0180]
For example, as illustrated in FIG. 19, when the “case” morpheme of “case configuration” is (dog; person; bitten) {dog bites a person}, the
[0181]
If the element constituting the topic title is (person; dog; bite) {person bites the dog}, the
[0182]
The
[0183]
As a result, the
[0184]
That is, since the
[0185]
Further, the
[0186]
Note that the
[0187]
(Third change example)
As shown in FIG. 20, the present modification is not limited to the above-described embodiment and each modification, and data is transmitted and received via the
[0188]
Here, the
[0189]
Thereby, the
[0190]
(Fourth change example)
The sentence
[0191]
The conversation
[0192]
The first morpheme information, the second morpheme information, each “case composition” that constitutes the first morpheme information or the second morpheme information, each morpheme associated with each “case composition”, and the retrieved answer sentence Each "case structure" and each morpheme associated with each "case structure" and the searched discourse range are associated with each other and stored in the
[0193]
The abbreviated
[0194]
Specifically, the abbreviated
[0195]
That is, assuming that the subject included in the history form information is S1, the object is O1, the action A1, the discourse range is D1, and the omitted first morpheme information is W, the supplemented first morpheme information W1 is S1SW , O1∪W, A1∪W, or D1∪W.
[0196]
The
[0197]
Thereby, even if the utterance content composed of the first morpheme information is an abbreviated sentence and is not clear as Japanese, the abbreviated
[0198]
For this reason, when the abbreviated
[0199]
(Fifth change example)
The
[0200]
Specifically, the
[0201]
Then, based on the searched second morpheme information, the
[0202]
That is, the
[0203]
The
[0204]
Specifically, when the current discourse range D2 is related to the answer sentence K1, and the discourse range is DK, other discourses related to the answer sentence K1 or the current discourse range D2 (those that have a sibling relationship). Since the range D3 can be expressed as D3 = D2∪DK, the second morpheme information W2 after adding the morpheme constituting the other discourse range D3 can be set to W2 = t2∪D3.
[0205]
For example, each morpheme t1 constituting the second morpheme information is (A movie name; *; interesting) {A movie name is interesting? }, And the current discourse range D2 determined by the discourse
[0206]
When the other conversation range D3 related to the current conversation range D2 (A movie name) is “B movie name”, the second morpheme information after adding the morpheme constituting the other conversation range D3 W2 is t2∪D3, so (B movie name; *; funny) {B movie name is interesting? }.
[0207]
Thereby, when the user's utterance content is “A movie name is interesting?”, The
[0208]
As a result, the answer
[0209]
Note that the
[0210]
(Sixth change example)
When the
[0211]
Specifically, the
[0212]
When the
[0213]
Thereby, even if the
[0214]
As a result, since the
[0215]
[program]
The contents described in the conversation control system and the conversation control method can be realized by executing a dedicated program for using a predetermined program language in a general-purpose computer such as a personal computer.
[0216]
Here, as the programming language, the topic that the user wants, the user's emotional level for a certain matter, or the type of statement sentence, affirmative sentence, question sentence, repulsive sentence, etc. are associated with the morpheme according to the semantic content In this embodiment, for example, DKML (Discourse Knowledge Markup Language), XML (eXtensible Markup Language), C language, etc. developed by the inventors can be used.
[0217]
That is, the
[0218]
According to such a program according to the present embodiment, each morpheme constituting the utterance content of the user is identified, the semantic content grasped from each identified morpheme is analyzed, and associated with the analyzed semantic content. Generally, a conversation control device, a conversation control system, and a conversation control method that have the effect of being able to output an optimal answer sentence corresponding to a user's utterance content by outputting a previously prepared answer sentence. It can be easily realized by a general purpose computer.
[0219]
In addition, since the developer who develops the
[0220]
In other words, the
[0221]
For this reason, the
[0222]
Furthermore, communication between the
[0223]
The program can be recorded on a recording medium. As shown in FIG. 23, examples of the recording medium include a
[0224]
[Second Embodiment]
(Basic configuration of conversation control device)
A second embodiment of the present invention will be described with reference to the drawings. The
[0225]
In addition, in this embodiment, it naturally has various functions in the first embodiment, for example, a turning process, a reflective process, and the like, and an effect corresponding to these functions is naturally produced. In the present embodiment, first morpheme information and topic titles described later have a “case” configuration in which each morpheme belonging to the first morpheme information and topic title is a subject, object, action, etc., as in the first embodiment. It may be included regardless.
[0226]
In the first embodiment, the process in which the
[0227]
As shown in FIG. 25, in the present embodiment, the phrase includes a topic title indicating a morpheme composed of one character, a plurality of character strings, or a combination thereof, and each topic title includes a topic to the user. Answer sentences are associated. In this embodiment, the topic uses the topic title shown in FIG. Moreover, the priority order for selecting as an answer sentence is matched with the topic title containing a common morpheme. Each phrase, each topic title, and each answer sentence is stored in advance in the conversation database 500 (morpheme storage means).
[0228]
As shown in FIG. 25, for example, when the
[0229]
The topic search unit 360 (first search means) searches each phrase including input information from a plurality of phrases stored in advance based on the input information input by the user. Specifically, the
[0230]
When each topic title is searched for by the
[0231]
Since the priority order associated with the identified
[0232]
In addition, the
[0233]
That is, the selection unit 380 (selection means) is based on each phrase searched by the
[0234]
Specifically, in the present embodiment, the
[0235]
As shown in FIG. 25 and FIG. 26, for example, the
[0236]
This
[0237]
On the other hand, if a predetermined time has not elapsed since the previous topic title 1 (A device; IR; tell me) has been searched, the
[0238]
When the topic title 2 (A company; IR; tell me) is selected by the
[0239]
(Conversation control method using conversation control device)
The conversation control method by the
[0240]
As shown in FIG. 27, the
[0241]
As shown in FIG. 25 and FIG. 26, for example, the
[0242]
On the other hand, if a predetermined time has not elapsed since the previous topic title 1 (A device; IR; tell me) has been searched, the
[0243]
Then, when the
[0244]
Next, when the topic title 2 (A company; IR; tell me) is selected by the
[0245]
(Operation and effect of conversation control device and conversation control method)
According to the invention having the above configuration, when the topic title searched last time is included in each topic title searched this time and a predetermined time has passed since the previous topic title was searched, the
[0246]
Specifically, for example, when a user utters “Tell me financial information” {First morpheme information (financial information; tell me)}, the contents of the utterance include Company A, Company B・ Financial information on multiple companies is included. Here, the fact that a plurality of topic titles including topic titles constituting the user's utterance content are searched means that the user's utterance content includes ambiguous meanings.
[0247]
In this case, the
[0248]
The
[0249]
That is, when the user utters a plurality of the same utterance contents captured by a plurality of meanings and a predetermined time has elapsed since the utterance was first made, the answer
[0250]
On the other hand, if the predetermined time is set to be long, the answer text is not changed so much, so that the
[0251]
In addition, the answer
[0252]
Furthermore, since the answer
[0253]
(Example of change)
In addition, this invention is not limited to the said embodiment, The change as shown below can be added. When the same input information acquired by the
[0254]
In other words, the
[0255]
Specifically, as illustrated in FIGS. 28 and 29, the
[0256]
When the number of times of search exceeds a predetermined reference number (for example, 5 times), the
[0257]
On the other hand, if the number of times of search does not exceed the reference number (for example, 5 times), the
[0258]
In this case, even when the user utters a plurality of the same utterance contents captured in a plurality of meanings and the same utterance contents are uttered exceeding the reference number, the answer
[0259]
On the other hand, if the reference number is set to a large number, the answer text is not changed so much, so the conversation control device is a device that can give the user the impression of persistently speaking the content that was answered before. Can be used.
[0260]
It should be noted that it is desirable that the answer sentence different from the previous answer sentence includes the contents to be developed in advance. In this case, for example, when the same utterance content is uttered repeatedly, the conversation control device can output an answer sentence that guides the current topic to another topic.
[0261]
Thereby, when the same utterance content as the previous time is input and a predetermined time has passed since the input of the same utterance content, for example, a character appearing in a game (RPG, reasoning game, etc.) An answer sentence that guides the story to another story can be output.
[0262]
【The invention's effect】
As described above, according to the present invention, when a user utters a plurality of the same utterance contents captured in a plurality of meanings and a predetermined time has elapsed since the same utterance contents were first uttered. Can output an answer sentence different from the previous answer sentence.
[Brief description of the drawings]
FIG. 1 is a block diagram showing a schematic configuration of a conversation control system according to a first embodiment.
FIG. 2 is a block diagram showing an internal structure of a conversation control unit and a sentence analysis unit in the first embodiment.
FIG. 3 is a diagram showing the contents of each morpheme extracted by a morpheme extraction unit in the first embodiment.
FIG. 4 is a diagram showing the contents of each phrase extracted by a phrase analysis unit in the first embodiment.
FIG. 5 is a diagram showing the contents of “case” specified by the sentence structure analysis unit in the first embodiment.
FIG. 6 is a diagram showing an “uttered sentence type” specified by an utterance type determining unit in the first embodiment.
FIG. 7 is a diagram showing the contents of each dictionary stored in the utterance type database in the first embodiment.
FIG. 8 is a diagram showing the contents of a hierarchical structure built inside the conversation database in the first embodiment.
FIG. 9 is a diagram showing a detailed relationship of a hierarchical structure built inside the conversation database in the first embodiment.
FIG. 10 is a diagram showing the content of a “topic title” built inside the conversation database in the first embodiment.
FIG. 11 is a diagram showing the content of “answer sentence type” associated with “topic title” built inside the conversation database in the first embodiment.
FIG. 12 is a diagram showing the contents of “topic title” and “answer text” belonging to “discourse range” built inside the conversation database in the first embodiment.
FIG. 13 is a diagram showing the contents of reflection element information stored in the reflection element database in the first embodiment.
FIG. 14 is a diagram showing the contents of a wrapping element and a morpheme of the wrapping element stored in the wrapping element database in the first embodiment.
FIG. 15 is a flowchart showing a procedure of a conversation control method according to the first embodiment.
FIG. 16 is a diagram showing utterance contents organized by a morpheme extraction unit in the first modification.
FIG. 17 is a diagram illustrating an internal configuration of a topic search unit in a second modified example.
FIG. 18 is a diagram illustrating a state in which the ratio calculation unit in the second modification collates each morpheme belonging to “case configuration” and each “topic title” for each “topic title”.
FIG. 19 is a diagram illustrating a state in which the ratio calculation unit in the second modified example collates each morpheme belonging to “each component” and each morpheme belonging to “topic title” for each “case”.
FIG. 20 is a diagram showing a schematic configuration of a conversation control system in a third modified example.
FIG. 21 is a diagram illustrating an internal configuration of a topic search unit in a fifth modification example.
FIG. 22 is a diagram illustrating a state in which the topic search unit in the sixth modification collates first morpheme information with a topic title or an answer sentence.
FIG. 23 is a diagram showing a recording medium for storing a program in the first embodiment.
FIG. 24 is a block diagram showing an internal configuration of a conversation control device according to a second embodiment.
FIG. 25 is a diagram showing the contents of “topic title” and “answer text” constructed in the conversation database in the second embodiment (part 1);
FIG. 26 is a diagram showing a state where topic titles are selected by a selection unit according to the second embodiment (part 1);
FIG. 27 is a diagram illustrating a processing procedure of a conversation control method according to the second embodiment.
FIG. 28 is a diagram showing the contents of “topic title” and “answer text” constructed in the conversation database in the second embodiment (part 2);
FIG. 29 is a diagram showing how topic titles are selected by a selection unit according to the second embodiment (part 2);
[Explanation of symbols]
DESCRIPTION OF
Claims (4)
利用者から入力された前記入力情報に基づいて、同一の該入力情報が最初に取得された時から所定の時間が経過した場合には、最初に取得された同一の該入力情報に対応する前記回答文とは異なる回答文を検索する検索手段を有し、
さらに、
前記検索手段は、
利用者から入力された前記入力情報に基づいて、予め記憶された複数のフレーズの中から、該入力情報を含む各フレーズを検索する第一検索手段と、
前記第一検索手段で検索された前記各フレーズに基づいて、前回検索されたフレーズが今回検索された前記各フレーズに含まれ、前回の該フレーズが検索された時から所定の時間が経過した場合には、前回検索された該フレーズとは異なるフレーズを、今回検索された前記各フレーズの中から選出する選出手段と、
前記選出手段で選出された前記フレーズに基づいて、該フレーズに対応する前記回答文を検索する第二検索手段とを有することを特徴とする会話制御装置。A conversation control device that searches for an answer sentence corresponding to input information including an utterance content input by a user,
Based on the input information input from the user, when a predetermined time has passed since the same input information was first acquired, the first input information corresponding to the same input information acquired first Having a search means for searching for an answer sentence different from the answer sentence ,
further,
The search means includes
First search means for searching for each phrase including the input information from a plurality of phrases stored in advance based on the input information input by the user;
When the phrase searched last time is included in each phrase searched this time based on each phrase searched by the first search means, and a predetermined time has elapsed since the last time the phrase was searched A selection means for selecting a phrase different from the previously searched phrase from the phrases searched this time;
A conversation control apparatus comprising: second search means for searching for the answer sentence corresponding to the phrase based on the phrase selected by the selection means.
利用者から入力された前記入力情報に含まれる文字列に基づいて、該文字列の最小単位を構成する少なくとも一つの形態素を第一形態素情報として抽出する形態素抽出手段と、
前記フレーズには、一つの文字、複数の文字列又はこれらの組み合わせからなる形態素を示す第二形態素情報が含まれ、前記各第二形態素情報には、利用者への回答文が対応付けられており、前記各第二形態素情報及び前記各回答文を予め記憶する形態素記憶手段とを有し、
前記第一検索手段は、前記形態素抽出手段で抽出された前記第一形態素情報に基づいて、予め記憶された前記各第二形態素情報の中から、該第一形態素情報を含む前記第二形態素情報を複数検索し、
前記選出手段は、前記第一検索手段で検索された前記各第二形態素情報に基づいて、前回検索された第二形態素情報が今回検索された前記各第二形態素情報に含まれ、前回の該第二形態素情報が検索された時から所定の時間が経過した場合には、前回検索された該第二形態素情報とは異なる前記第二形態素情報を、今回検索された前記各第二形態素情報の中から選出し、
前記第二検索手段は、前記選出手段で選出された前記第二形態素情報に基づいて、該第二形態素情報に対応付けられた前記回答文を検索することを特徴とする会話制御装置。The conversation control device according to claim 1,
Morpheme extraction means for extracting at least one morpheme constituting the minimum unit of the character string as first morpheme information based on a character string included in the input information input from a user;
The phrase includes second morpheme information indicating a morpheme composed of one character, a plurality of character strings, or a combination thereof, and each second morpheme information is associated with an answer sentence to the user. Morpheme storage means for storing each of the second morpheme information and each answer sentence in advance,
The first search unit includes the second morpheme information including the first morpheme information from the second morpheme information stored in advance based on the first morpheme information extracted by the morpheme extraction unit. Search multiple times,
The selection means includes, based on the second morpheme information searched by the first search means, the second morpheme information searched last time is included in the second morpheme information searched this time, When a predetermined time has elapsed since the second morpheme information was searched, the second morpheme information different from the second morpheme information searched last time is used as the second morpheme information searched this time. Selected from the inside,
The conversation control device, wherein the second search unit searches the answer sentence associated with the second morpheme information based on the second morpheme information selected by the selection unit.
検索手段が、利用者から入力された前記入力情報に基づいて、同一の該入力情報が最初に取得された時から所定の時間が経過した場合には、最初に取得された同一の該入力情報に対応する前記回答文とは異なる回答文を検索するステップを有し、
さらに、
前記検索手段が、利用者から入力された前記入力情報に基づいて、同一の該入力情報が最初に取得された時から所定の時間が経過した場合には、最初に取得された同一の該入力情報に対応する前記回答文とは異なる回答文を検索するステップは、
第一検索手段が、利用者から入力された前記入力情報に基づいて、予め記憶された複数のフレーズの中から、該入力情報を含む各フレーズを検索するステップと、
選出手段が、前記第一検索手段で検索された前記各フレーズに基づいて、前回検索されたフレーズが今回検索された前記各フレーズに含まれ、前回の該フレーズが検索された時から所定の時間が経過した場合には、前回検索された該フレーズとは異なるフレーズを、今回検索された前記各フレーズの中から選出するステップと、
第二検索手段が、前記選出手段で選出された前記フレーズに基づいて、該フレーズに対応する前記回答文を検索するステップとを有することを特徴とする会話制御方法。A conversation control method in which a computer searches for an answer sentence corresponding to input information including utterance content input by a user,
Based on the input information input by the user, when the predetermined time has elapsed from when the same input information is first acquired , the search means acquires the same input information acquired first Searching for an answer sentence different from the answer sentence corresponding to
further,
Based on the input information input by the user, when the predetermined time has elapsed from when the same input information was first acquired, the search means receives the same input acquired first The step of searching for an answer sentence different from the answer sentence corresponding to the information includes:
A step first search means, based on the input information entered by the user, looking from a plurality of phrases stored in advance, each phrase comprising an input information,
Based on each phrase searched by the first search means, the selection means includes the phrase searched last time in each of the phrases searched this time, and a predetermined time from when the previous phrase was searched If There has elapsed comprises the steps of selecting a different phrase from among the currently retrieved each phrase with the phrases previously retrieved,
Conversation control method the second search means, based on said phrase is selected in the selecting means, and having a retrieving said reply sentence corresponding to the phrase.
形態素抽出手段が、利用者から入力された前記入力情報に含まれる文字列に基づいて、該文字列の最小単位を構成する少なくとも一つの形態素を第一形態素情報として抽出するステップを有し、
前記フレーズには、一つの文字、複数の文字列又はこれらの組み合わせからなる形態素を示す第二形態素情報が含まれ、前記各第二形態素情報には、利用者への回答文が対応付けられており、前記各第二形態素情報及び前記各回答文を予め形態素記憶手段が記憶し、
前記第一検索手段は、前記形態素抽出手段で抽出された前記第一形態素情報に基づいて、予め記憶された前記各第二形態素情報の中から、該第一形態素情報を含む前記第二形態素情報を複数検索し、
前記選出手段は、前記第一検索手段で検索された前記各第二形態素情報に基づいて、前回検索された第二形態素情報が今回検索された前記各第二形態素情報に含まれ、前回の該第二形態素情報が検索された時から所定の時間が経過した場合には、前回検索された該第二形態素情報とは異なる前記第二形態素情報を、今回検索された前記各第二形態素情報の中から選出し、
前記第二検索手段は、前記選出手段で選出された前記第二形態素情報に基づいて、該第二形態素情報に対応付けられた前記回答文を検索することを特徴とする会話制御方法。 The conversation control method according to claim 3,
The morpheme extraction means has a step of extracting at least one morpheme constituting the minimum unit of the character string as the first morpheme information based on the character string included in the input information input from the user,
The phrase includes second morpheme information indicating a morpheme composed of one character, a plurality of character strings, or a combination thereof, and each second morpheme information is associated with an answer sentence to the user. The morpheme storage means stores the second morpheme information and the answer sentences in advance ,
The first search unit includes the second morpheme information including the first morpheme information from the second morpheme information stored in advance based on the first morpheme information extracted by the morpheme extraction unit. Search multiple times,
The selection means includes, based on the second morpheme information searched by the first search means, the second morpheme information searched last time is included in the second morpheme information searched this time, When a predetermined time has elapsed since the second morpheme information was searched, the second morpheme information different from the second morpheme information searched last time is used as the second morpheme information searched this time. Selected from the inside,
The second searching means, a conversation control method characterized by, based on the second morpheme information elected by the selecting means, for retrieving the answer sentence associated with said second morpheme information.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2003047893A JP4110012B2 (en) | 2003-02-25 | 2003-02-25 | Conversation control device and conversation control method |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2003047893A JP4110012B2 (en) | 2003-02-25 | 2003-02-25 | Conversation control device and conversation control method |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2004258904A JP2004258904A (en) | 2004-09-16 |
| JP4110012B2 true JP4110012B2 (en) | 2008-07-02 |
Family
ID=33114014
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2003047893A Expired - Lifetime JP4110012B2 (en) | 2003-02-25 | 2003-02-25 | Conversation control device and conversation control method |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP4110012B2 (en) |
Families Citing this family (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8126713B2 (en) | 2002-04-11 | 2012-02-28 | Shengyang Huang | Conversation control system and conversation control method |
| JP4846336B2 (en) | 2005-10-21 | 2011-12-28 | 株式会社ユニバーサルエンターテインメント | Conversation control device |
| JP4849663B2 (en) | 2005-10-21 | 2012-01-11 | 株式会社ユニバーサルエンターテインメント | Conversation control device |
| JP4849662B2 (en) | 2005-10-21 | 2012-01-11 | 株式会社ユニバーサルエンターテインメント | Conversation control device |
-
2003
- 2003-02-25 JP JP2003047893A patent/JP4110012B2/en not_active Expired - Lifetime
Also Published As
| Publication number | Publication date |
|---|---|
| JP2004258904A (en) | 2004-09-16 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP3997105B2 (en) | Conversation control system, conversation control device | |
| JP4279883B2 (en) | Conversation control system, conversation control method, program, and recording medium recording program | |
| JP4110012B2 (en) | Conversation control device and conversation control method | |
| JP2004258902A (en) | Conversation control device and conversation control method | |
| JP4110011B2 (en) | Conversation control device and conversation control method | |
| JP4413486B2 (en) | Home appliance control device, home appliance control method and program | |
| JP4751563B2 (en) | Product discharge device, product discharge control method and program | |
| JP4913850B2 (en) | Information processing system and information processing method | |
| JP3923378B2 (en) | Robot control apparatus, robot control method and program | |
| JP4205370B2 (en) | Conversation control system, conversation control method and program | |
| JP3927067B2 (en) | Conversation control system, conversation control device, conversation control method, program, and recording medium recording program | |
| JP4109964B2 (en) | Information output device, information output method, and program | |
| JP4253487B2 (en) | Information acquisition device | |
| JP4038399B2 (en) | Face image display device, face image display method and program | |
| JP4402868B2 (en) | Information acquisition apparatus, information acquisition method, and program | |
| JP4434553B2 (en) | Information processing system, information processing apparatus, information processing method, program, and recording medium recording the program | |
| JP4274760B2 (en) | Map output device, map output method and program | |
| JP4116367B2 (en) | Conversation control system, conversation control method, program | |
| JP4188622B2 (en) | Access system and access control method | |
| JP3947421B2 (en) | Conversation control system, conversation control method, program, and recording medium recording program | |
| JP4243079B2 (en) | Premium discharging device, premium discharging control method and program | |
| JP4312443B2 (en) | Information notification system, information notification control method and program | |
| JP4316839B2 (en) | Conversation control device and conversation control method | |
| JP4832701B2 (en) | Game machine, game control method, control program | |
| JP4751565B2 (en) | Conversation control device, conversation control method, and program |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20051024 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20080115 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20080311 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20080401 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20080407 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20110411 Year of fee payment: 3 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 4110012 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20110411 Year of fee payment: 3 |
|
| S531 | Written request for registration of change of domicile |
Free format text: JAPANESE INTERMEDIATE CODE: R313532 |
|
| S533 | Written request for registration of change of name |
Free format text: JAPANESE INTERMEDIATE CODE: R313533 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20110411 Year of fee payment: 3 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20120411 Year of fee payment: 4 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20120411 Year of fee payment: 4 |
|
| S631 | Written request for registration of reclamation of domicile |
Free format text: JAPANESE INTERMEDIATE CODE: R313631 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20120411 Year of fee payment: 4 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20120411 Year of fee payment: 4 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20130411 Year of fee payment: 5 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20140411 Year of fee payment: 6 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| S111 | Request for change of ownership or part of ownership |
Free format text: JAPANESE INTERMEDIATE CODE: R313117 |
|
| R360 | Written notification for declining of transfer of rights |
Free format text: JAPANESE INTERMEDIATE CODE: R360 |
|
| R360 | Written notification for declining of transfer of rights |
Free format text: JAPANESE INTERMEDIATE CODE: R360 |
|
| R371 | Transfer withdrawn |
Free format text: JAPANESE INTERMEDIATE CODE: R371 |
|
| S111 | Request for change of ownership or part of ownership |
Free format text: JAPANESE INTERMEDIATE CODE: R313117 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| EXPY | Cancellation because of completion of term |