JP4077904B2 - 情報処理装置およびその方法 - Google Patents
情報処理装置およびその方法 Download PDFInfo
- Publication number
- JP4077904B2 JP4077904B2 JP16020597A JP16020597A JP4077904B2 JP 4077904 B2 JP4077904 B2 JP 4077904B2 JP 16020597 A JP16020597 A JP 16020597A JP 16020597 A JP16020597 A JP 16020597A JP 4077904 B2 JP4077904 B2 JP 4077904B2
- Authority
- JP
- Japan
- Prior art keywords
- frame
- outline
- area
- tracing
- black
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
- 238000000034 method Methods 0.000 title claims description 65
- 230000010365 information processing Effects 0.000 title claims description 19
- 238000003672 processing method Methods 0.000 claims 10
- 238000010586 diagram Methods 0.000 description 20
- 230000006870 function Effects 0.000 description 9
- 238000012015 optical character recognition Methods 0.000 description 7
- 239000000284 extract Substances 0.000 description 3
- 230000000694 effects Effects 0.000 description 2
- 238000010276 construction Methods 0.000 description 1
- 238000013144 data compression Methods 0.000 description 1
- 238000001514 detection method Methods 0.000 description 1
- 238000000605 extraction Methods 0.000 description 1
- 238000007689 inspection Methods 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 238000000547 structure data Methods 0.000 description 1
Images






















Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/40—Document-oriented image-based pattern recognition
- G06V30/41—Analysis of document content
- G06V30/412—Layout analysis of documents structured with printed lines or input boxes, e.g. business forms or tables
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/10—Character recognition
- G06V30/14—Image acquisition
- G06V30/148—Segmentation of character regions
- G06V30/155—Removing patterns interfering with the pattern to be recognised, such as ruled lines or underlines
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/10—Character recognition
Landscapes
- Engineering & Computer Science (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Multimedia (AREA)
- Theoretical Computer Science (AREA)
- Artificial Intelligence (AREA)
- Character Input (AREA)
- Image Analysis (AREA)
- Processing Or Creating Images (AREA)
Description
【発明の属する技術分野】
本発明は、ブロックセレクション技法を利用するドキュメントページの画像データを解析する為のシステムに関する発明である。そして、特にドキュメントページの中の枠に付着したテキスト成分の抽出と識別を可能にするブロックセレクションシステムである。
【0002】
【従来の技術】
特願平6−320955(米国出願番号08/596,716)および特願平8−221834(米国出願番号08/514,252)に記述されているようなブロックセレクション技法は、ドキュメントページ中の異なるタイプの画像データを解析し識別するページ解析システムに使用される。更に、識別および解析結果は画像データに施されるべき光学式文字認識(OCR)、データ圧縮、データルーチン(data routing)、その他のようなタイプを決定するために使われる。例えば、テキストデータであることが示された画像データはOCR処理されるのに対し、ピクチャデータであることが示された画像データはOCR処理されない。結果として、異なるタイプの画像データをオペレーターの介入なしに自動入力し正確に処理することができる。
【0003】
ブロックセレクション技法の動作は、図1−図3のように一般的に記述される。図1は、代表的なドキュメントのページ101を示す。ページ101には、2カラムフォーマットであり、タイトル102を含み、水平線104、テキストデータ行を含むいくつかのテキストエリア105、106、107、テキストではないグラフィックイメージを含むハーフトーンのピクチャデータ108、テキスト情報を含むテーブル110、枠エリア116、見出しデータ126を付属したハーフトーンのピクチャエリア121、見出しデータ137が付着するピクチャエリア132、135が配置されている。ブロックセレクション技法は、画像データのタイプに従ってページ101のそれぞれのエリアの定義を試みる。図2のように、ブロックセレクション技法はそれぞれのエリアを定義し、階層的ツリー構造が生成される。
【0004】
図2の階層的ツリー(木)構造200は、画像データのそれぞれの識別されたエリアまたはブロックをそれぞれ表す複数のノードを含む。ツリーのそれぞれのノードは、対応する画像データのブロックの特徴を定義する特徴データを含む。例えば、特徴データは、ブロック位置データ、属性データ(テキスト、ピクチャ、テーブル、その他のようなを特定する)、サブ属性データ、子ノードまたは親ノードのポインターを含んでいる。子または「子孫」ノードは、画像データの大きなブロックの中にその全体が存在する画像データを表す。子ノードは、親ノードから枝別れしているノードのような階層的ツリー構造200として描かれる。例えば、枠116の中のテキストブロックは、枠116を表す親ノード212からの直接的な枝別れとして、ノード214,216のような階層的ツリー構造として描かれる。上述した特徴データに加えて、テキストブロックを表すノードは、そのブロックの読取り方向及び読取り順を定義する特徴データを含んでいる。それらのデータは、ページのテキストブロックをOCRする処理場合に有用である。
【0005】
【発明が解決しようとする課題】
一般的なブロックテキストセレクション技法では、テキストデータ行が他のデータと隣接または重なり合っている場合、テキストブロックはしばしば誤って識別されることがある。この問題は、ドキュメント画像に含まれるテーブル画像を処理する際にしばしば遭遇する。テーブルセルの枠サイズが小さい為、しばしば、それらの枠の一つによって周りを囲まれたテキスト枠に付着されることになる。従って、このテキストは、ピクチャ画像として、または、枠の一部として識別されるか、あるいは、ノイズとして識別されてブロックセレクション技法によって、必要のないデータとして無視される。このテキストは、テキストブロックとして識別されない為、このテキストブロックは、OCR処理されず、従って、そのブロックの中のテキスト文字に、テキストエディターはアクセスできない。更に、残るテキストブロックのドキュメントの読取り順は、誤った識別をされたテキストブロックを考慮せずに、割り当てられる。従って、読取り順が誤っている為に、正しく識別されたテキストブロックでさえ、誤って処理される。
【0006】
従って、本発明は、テーブルセルの枠に付着したテキストデータを識別し抽出することが可能な情報処理装置およびその方法を提供することを目的とする。
【0007】
【課題を解決するための手段】
本発明は、前記の目的を達成する一手段として、以下の構成を備える。
【0008】
本発明のある面によれば、本発明は、テーブルセルの枠からテキストデータを識別し、抽出する方法であり、ドキュメントの中の連結成分をトレース、連結成分の内側の白い輪郭をトレースし、トレースした白い輪郭を基に枠の輪郭を定義し、枠の輪郭の内側の独立した連結成分を識別し、そして、枠の輪郭の内側に初期の矩形エリアを定義するステップを含む。
【0009】
初期の矩形エリアは、独立した連結成分が識別された場合、独立連結成分をもとに定義され、独立連結成分が識別されない場合、白い輪郭をもとに定義され、小さい独立連結成分が識別された場合、独立した連結成分、輪郭および独立連結成分から枠の輪郭の縁までの距離を基に定義される。この方法は、その上、拡張された文字エリアを生成する為に、水平または垂直方向において初期の矩形エリアからの黒画素を検出し、それぞれの白い輪郭に対する拡張された文字エリアの内側にある境界画素を定め、拡張された文字エリアの内側にある境界画素間に置かれた黒画素を識別し、少なくとも一つの連結成分を形成するために拡張された文字エリアの内側にある境界画素間に置かれた黒画素を結合し、以下の条件を満たせば、すくなくとも一つの連結成分をテキスト成分として認識する。つまり、(1)前記少なくとも1つの連結成分の高さは、第三のあらかじめ決められた閾値よりも小さくはない。また、前記少なくとも1つの連結成分の縦横の比は、第四のあらかじめ決められた閾値より大きくはない。(2)前記少なくとも1つの連結成分の幅は、第五のあらかじめ決められた閾値より小さくはない。また、前記少なくとも1つの連結成分の縦横の比は、第六のあらかじめ決められた閾値より大きくはない。(3)前記少なくとも1つの連結した成分の幅または高さは、第七のあらかじめ決められた閾値より大きい。
また、前記少なくとも1つのテキスト成分は独立し連結成分と別の独立し連結成分との間にある。そして、(4)連結成分のグループは、前記少なくとも1つの連結成分を含み、別の連結成分は、同列または同行において上記(1)、(2)を満たす。そして、前記拡張された文字エリアに対応する階層的ツリー構造の文字ノードを定義し、前記少なくとも一つの連結成分といくつかの識別された独立した連結成分の両方を含んでいる。
【0010】
別の面によれば、本発明は、テーブル画像の中の枠に付着する連結成分がテキスト成分かどうか決定するための方法であり、枠の輪郭の内側に初期の矩形エリアを定義し抽出された文字エリアを生成する為に水平または垂直方向において初期の矩形エリアから黒画素を検出し、拡張された文字エリアの内部にある境界画素を定め、拡張された文字エリアの内側にある境界画素間に置かれた黒画素を識別し、少なくとも1つの連結成分を形成する為に拡張された文字エリアの内部にある境界画素間に置かれた黒画素を結合し、そして、あらかじめ決められた閾値の大きさに基づきテキスト成分として前記少なくとも一つの連結成分を認識するステップを含む。
【0011】
【発明の実施の形態】
以下、本発明にかかる一実施形態の枠に付着したテキストを抽出するシステムについて図を参照して詳細に説明する。なお、本発明は、特願平6−320955(米国出願番号08/596,716)および特願平8−221834(米国出願番号08/514,252)に鑑みてなされたものである。
【0012】
図3は、本発明の実施の形態の一例を表す装置の外観を示す図である。
【0013】
図3に示されるコンピュータシステム310は、例えば、Macintosh(登録商標)またはIBM PC、PC互換機である。このシステムは、Microsoft Windows(登録商標)のようなウィンドウズ環境をもつ。コンピュータシステム310は、カラーモニタのようなディスプレイ画面312、ユーザコマンドを入力する為のキーボード313、ディスプレイ画面上312に表示されたオブジェクトを操作し、ポインティングするためのマウスのようなポインティングデバイスを備える。
【0014】
コンピュータシステム310は、圧縮または非圧縮の何らかのドキュメント画像ファイルも含むデータファイルを記憶する為、そして、本発明を具体化するブロックセレクションアプリケーションプログラムを含むアプリケーションプログラムファイルを記憶する為のコンピュータディスク311のような大容量の記憶装置を含む。また、ブロックセレクション技法に従って処理されたドキュメントページに対応する様々な階層的ツリー(木)構造データもディスク311に保存されている。
【0015】
本発明の実行においては、ドキュメントのそれぞれのページをスキャンするスキャナ316によって複数のページドキュメント(原稿)の画像が入力され、それらのページのビットマップ画像データがコンピュータシステム310に供給される。
画像データはまた、ネットワークインタフェース324を通ってネットワークから入力、あるいは、ファクシミリ/モデムインタフェース326を通ってWWW(World Wide Web)から入力等のようにスキャナに限らず様々な他のソースからコンピュータシステム310に入力される。プリンタ318は、処理されたドキュメント画像を出力する為に提供される。
【0016】
なお、図3に示されるプログラム可能な汎用のコンピュータシステムでも、専用またはスタンドアローンコンピュータあるいは他のタイプのデータ処理装置でも、本発明の実行に利用することができる。
【0017】
図4は、コンピュータシステム310の内部構成例を示す詳細なブロック図である。図4に示されるように、コンピュータシステム310は、コンピュータバス421とインタフェースする中央演算処理装置(CPU)を含む。スキャナインタフェース422、プリンタインタフェース423、ネットワークインタフェース424、FAX/MODEMインタフェース426、ディスプレイインタフェース427、キーボードインタフェース428、マウスインタフェース429、メインランダムアクセスメモリー(RAM)430、ディスク装置311もまた、コンピュータバス421にインタフェースされる。
【0018】
メインメモリー430は、本発明によるブロックセレクション技法の処理ステップのような記憶された処理ステップを実行するCPU420にRAM記憶を提供するため、コンピュータバス421にインタフェースする。特に、CPU420は、ディスク311からメインメモリー430へ処理ステップをロードして、ドキュメント画像の中のテーブルセルの枠に付着したテキストデータを識別し抽出するために、メインメモリー430から処理ステップを実行する。
【0019】
キーボード413またはマウス414のどちらかを用いて入力されたユーザの指示に従って、他の記憶されたアプリケーションプログラムは画像処理とデータ操作を提供する。例えば、Windows用のWordPerfect(登録商標)デスクトップワードプロセッシングプログラムは、ドキュメントにブロックセレクション技法を適用する前後にドキュメントを生成し、操作し、見る為に、オペレータによって起動される。同様に、ページ解析プログラムは、ドキュメントページにブロックセレクション技法を施すため、そして、ウィンドウズ環境を介しオペレータにブロックセレクション技法の結果を表示するために実行される。 図5A、図5B、図6にドキュメントの中のテーブルを識別する本発明によるブロックセレクション技法のやり方については、その概略を説明する。
【0020】
ドキュメントを解析する処理を始めるために、解析されるドキュメントがスキャナ316に挿入される。順番に、スキャナ316は、ドキュメントを表すビットマップ画像を生成する。その画像データは、さらに処理する為にコンピュータバス421を経てディスク311を記憶される。ディスク311に記憶されたブロックセレクションプログラムは、ドキュメント画像データのブロックセレクション技法を実行する為の処理ステップを含む。
【0021】
その処理ステップは、メインメモリー430に記憶され、CPU420によって実行される。
【0022】
上述したように、ブロックセレクション技法の処理ステップは、ドキュメント画像の中の画像データの異なったタイプを識別する。
【0023】
この説明において、ドキュメントページが図5Aのドキュメントページ501のようなテーブルを含んでいると仮定する。
【0024】
第一に、本発明によるブロックセレクション技法は、ページの中の連結成分をトレースすることによってドキュメントページの中の画像データを識別することを試みる。連結成分は、白画素によって完全に囲まれた黒画素のグループである。例えば、図5Aは、それぞれの連結成分であるテーブル500、502、504を含んでいるドキュメントページ501を示す。連結成分をトレースする為のある技法は、特願平6−320955(米国出願番号08/596,716)に開示されている。
【0025】
トレースは、選択された部分の右下部から左まで、画像データのその選択部分をスキャンすることによって実行され、縁に達する度に、または、所望するセクションの走査位置に出会う前に方向を変える。もし、黒画素に出会ったならば、いくつかの隣接画素もまた、黒かどうか決定する為に隣接した画素が検査される。一つの隣接黒画素が見つかったら、その隣接黒画素から画像の外側がトレースされるまで、検査を進める。本発明に従えば、ピクチャ504のような連結成分の内側の部分をトレースする必要はない。
【0026】
ピクチャ504がトレースされた後、スキャンは新しい黒画素に出会うまで進み、テーブル500のトレースに着手する。上記の処理は、画像の中の全ての連結成分がトレースされるまで続けられる。
【0027】
一旦、連結成分がトレースされると、それぞれの連結成分は、矩形化される。例えば、図5Bに示されるように矩形化は、トレースされた連結成分を完全に包みこみできる限り小さい矩形エリアを定義することからなる。このように、矩形507、509、510は、テーブル500とピクチャ502、504の周りに描かれる。これらの矩形のそれぞれのサイズは、外接連結成分がテーブルかどうか決定するために閾値のサイズと比較される。従って、矩形507のサイズは閾値のサイズよりも大きい為、テーブル500は、それがテーブルかどうか決定する為の処理を更に受ける。
【0028】
テーブル500の詳細図は、図6に示される。テーブル500は、テーブルセル601と602のようないくつかの独特のセルを含む。テーブルセル601は、セル枠に付着していないテキスト(以下「独立テキスト」と呼ぶ)604を含む。テーブルセル602は、独立テキスト605と、セル枠に付着したテキスト(以下「付着テキスト」と呼ぶ)606およびセル枠に付着したデータ(以下「付着データ」と呼ぶ)607を含む。
【0029】
テーブル500がテーブルかどうか決定する為に、テーブルの中の白い輪郭がトレースされる。繰り返すが、この技法は、上述した特願平6−320955(米国出願番号08/596,716)に開示されているので、以下は一般的なことのみを記述する。
【0030】
白い輪郭は、連結成分に関する上述と同様な方法でトレースされるが、しかし、白画素は、黒画素よりも詳しく調べられる。従って、テーブル500の内部は右下部から左上部へ白画素についてスキャンされる。最初の白画素に出会ったとき、いくつかの隣接画素もまた白がどうかを決定する為隣接画素が検査される。全ての白い輪郭が、トレースされた黒画素によって囲まれるまでトレースを続ける。例えば、テーブル500の白い輪郭は、図6に符号610で示される。
【0031】
その内部の白い輪郭に基づくテーブルの識別法の詳細は、特願平8−221834(米国出願番号08/514,252)に開示されている。簡単に説明すると、一旦、テーブル500内部の白い輪郭がトレースされると、白い輪郭の数はあらかじめ決められた別の閾値と比較される。テーブル500の場合、白い輪郭の数は、この閾値よりも大きい。従って、テーブル500は、それがテーブルかどうか決定する為にさらに解析される。
【0032】
特に、テーブル500のあるセルに属する白い輪郭610は、まとめてグループ化される。例えば、テーブルセル602の中の白い輪郭は、矩形エリアを形成するように見えるので、閾値と一まとめにグループ化される。これらの白い輪郭を一まとめにグループ化する為の方法の詳細もまた、前述の特願平8−221834(米国出願番号08/514,252)に開示されている。
【0033】
これらのグルーブ化された白い輪郭は、連結成分に関して上述したように矩形化される。しかしながら、上述した矩形化とは違って、これらの白い輪郭の矩形化は、グループの中のトレースされた全ての白い輪郭を完全に包み込むもっとも小さい矩形である枠の輪郭を生成する。白い輪郭のグループが矩形化された後、グループレートとして知られる、輪郭がグループ化された頻度が調べられる。
【0034】
テーブル500のグループレートが低いため、テーブル500はテーブルに決定される。このようにして、階層的ツリー構造のテーブルノードは、テーブル500のそれぞれのセルに対応する子ノードを持つように生成される。それぞれのセルは、セルの中の白い輪郭の矩形化によって生成された枠の輪郭によって外接エリアに等しいエリアをもっていると定義される。同様に、テーブル500のそれぞれのセルを表すノードは、セルの中の白い輪郭を表す子ノードを持っている。図7Aおよび7Bは、テーブルセルの例を示し、それらは、白い輪郭と枠の輪郭に対応する。
【0035】
例えば、図7Aは白い輪郭のトレースが実行された後の「空」のテーブルセル603の内部を示す。図7Aに示されるように、テーブルセル603の中に単一の白い輪郭610が存在する。なお、白い輪郭610はテーブルセル603のそれぞれの縁に直接隣接する、または、連結成分が、セルの中に存在する場合、白い輪郭610は連結成分に隣接する。同様に図7Bは、独立した連結成分604を含むテーブルセル601の中のトレースされた白い輪郭610を示す。
【0036】
図7Cは、トレースされた白い輪郭610を示し、テーブルセル602の中の704、706は付着した連結成分606および607と、独立した連結成分605の両方を含んでいる。また、図7Cは、排他的なエリアに周囲を囲まれた白い輪郭の中の上述した方法のトレース結果を示す。結果として、トレース後、別の白い輪郭の中に白い輪郭は存在しない。
【0037】
テーブル500に戻って、それぞれの白い輪郭の中の連結成分は、矩形化およびそれぞれのセルの中の独立した連結成分を識別とする為に上述したようにトレースされる。この動作が実行された後、階層的ツリー構造は独立した連結成分を表すノードについて更新される。
【0038】
しかしながら、それぞれの白い輪郭の中の連結成分をトレースしている時、本発明は、図7Cに示されるテーブルセル602の構成要素606のような付着した連結成分をトレースし識別することはできない。特に、上述した輪郭のトレース方法は、テーブルセル602に付着した連結成分606の辺をトレースすることはできない。付着した連結成分606は適切にトレースできないので、矩形化できず、識別もできず、ノードによって表すこともできない。
【0039】
したがって、テーブルセルの中に付着したテキストデータが存在するかどうか識別する為に、初期の矩形エリアが定義される。例えば、テーブルセル603の中に独立した連結成分が無いときは、初期の矩形エリアは図8Aに示されるように定義される。特に、矩形エリアとして定義される矩形エリア801は、枠の輪郭708の水平方向の中間点に対して左右に面を置かれ、枠の輪郭708の天の1画素下から枠の輪郭708の底の1画素上まで伸ばされる。
【0040】
独立した連結成分がテーブルセルの中に存在する場合、識別された連結成分は、枠の輪郭708に関して上述したように矩形化され、それによって、全ての独立した連結成分に外接する矩形が生成される。
【0041】
図8Bに例を示す、テーブルセル602の中の文字列「ABC hij」のそれぞれが、テーブルセル602に接すると仮定する。この場合、外接矩形エリア802の面積は、閾値X2と比較される。エリアの面積が閾値X2よりも小さい場合、外接矩形802のそれぞれの辺は、黒画素を含んでいる行または列に達するまで拡張される。それらの辺は、一つずつまたは同時に拡張することができる。図8Bに示されるように、枠の輪郭708から指定の距離において、黒画素に出会った辺は、その最初の位置にとどまる。初期の矩形エリアは、結果矩形804として定義される。
【0042】
テーブルセル602に戻り、外接矩形エリアの面積が、あらかじめ決められた閾値X2よりも大きい場合、初期の矩形エリアは、図8Cに示されるような外接矩形エリア805として定義される。
【0043】
一旦、初期の矩形エリアが定義されると、そのエリアは、テーブルセル602の中に位置する付着した連結成分を含むように拡張される。
【0044】
初期の矩形を拡張する為に行または列方向の全体が初期の矩形エリアのある辺に直接隣接する探索エリアが定義される。例えば、図9に示されるように、探索エリア901は、初期の矩形エリア805に隣接していると定義される。
【0045】
一旦、探索エリアが定義されると探索エリアの画素はそれぞれ検査される。いくつかの黒画素が探索エリアに存在する場合、初期の矩形エリア805は、探索エリアを含むように拡張される。図9Bに示されるように、付着した連結成分606の為に、初期の矩形エリア805の左側の辺が、探索エリア901を含むように拡張される。
【0046】
黒画素が探索エリアで検出されず、かつ、探索エリアと初期の矩形エリア805に対向する枠の輪郭708の境界978との間の距離があらかじめ決められた距離X3よりも大きい場合、探索エリアは再定義される。
【0047】
探索エリアは、前の探索エリアに隣接する画素グループとして、前述した枠の輪郭708に向かって再定義される。それから処理は上述のようにつづけられる。
【0048】
黒画素が探索エリアの中で検出されず、かつ、境界928までの距離が距離X3に等しいかまたは小さい場合、連結成分はテーブルセル602のこちら側には付着していないと仮定される。拡張された矩形の全ての辺が検査されていないのであれば、新しい探索エリアは、画素の行または列方向が初期の矩形エリア805の別の辺に直接隣接する新たな探索エリアが定義され、上記の処理が繰り返される。なお、本発明の別の面によれば、それぞれの辺は同時に拡張される。図9Dは、テーブルセル602および上記の拡張プロセスが完了した後の拡張された文字エリア910を示す。
【0049】
さらに、上記の拡張処理が完了した後、初期の矩形エリアは今、 枠の輪郭708の境界上にある黒画素を含む枠の輪郭708の中にある黒画素を含む。さらに、この処理の作用によって、拡張された矩形エリア910は、テーブルセル602の中にある付着した連結成分と独立した連結成分のすべてを含んでいるもっとも小さい矩形になる。
【0050】
拡張された矩形エリア910およびテーブルセル602の中の白い輪郭は、拡張されたテキストエリア910の中の黒画素のグループを結合するために使われる。黒画素は付着した連結成分を抽出するために結合される。
【0051】
黒画素を結合するために、拡張された文字エリア910の最初の行1001が選択される。選択された行1001のなかにある境界画素が識別される。境界画素は選択された白い輪郭の境界上にある特定の行のすべての画素である。例えば、行1002の画素w1、w2、w3、w4は境界画素である。
【0052】
識別された境界画素は、テーブルセル602の左端から連続的に番号が付けられる。それぞれの白い輪郭が現在選択された行について解析されると、次の行が解析される。そうでなければ、他の白い輪郭が選択される。一つ以上の白い輪郭の境界画素が単一の行にある場合、それらの境界画素には、その行の境界画素に割り当てられた最後の番号から連続的に番号が付けられる。例えば、行1002の場合、境界画素w1、w2、w3とw4が白い輪郭704の解析の間に識別される。その後、2つの境界画素が白い輪郭704に対応すると識別される。これらの境界画素はそれぞれ番号を付けられたw5とw6である。なお、このナンバリング体系は単一の行にある境界画素にだけ適用され、そして境界線画素のナンバリングは新しい行が分析されるたびにw1にリセットされる。
【0053】
新しい行が解析される前に、黒い境界画素が識別される。黒い画素は、拡張された矩形エリア910の上にある選択された行の黒画素である。例えば、行1001が選択されると、黒画素Pが識別される。
【0054】
一旦、セル602の中の境界画素と黒い境界画素とが識別されると、偶数番号と奇数番号の境界画素間にある黒画素が検出される。例えば、図10Bに示されるように、黒画素は行1002の境界画素w2とw5間、境界画素w6とw3の間で検出される。加えて、行1008の中では、境界画素w2とw3間で黒画素が、検出される。このようにして拡張された文字エリア910の各行について黒画素が検出される。
【0055】
本発明は、それから、偶数番号の境界画素と黒い境界画素間にある黒画素を検出する。例えば、行1001の画素w2と黒い境界画素Pの間にある黒画素が検出される。同様に、黒い境界画素と奇数番号の境界画素間にある黒画素が検出される。
【0056】
検出された黒画素それぞれは、付着した連結成分を形成するために一まとめにグループ化される。例えば、図10Bで、隣接した黒画素は、付着した連結成分「A」を形成するために一まとめにグループ化される。
【0057】
形成された付着した連結成分は、それが水平線であるかどうか決定するために調べられる。従って、構成要素の高さがあらかじめ決められた閾値X4よりも小さく、かつ、その構成要素の縦横の比があらかじめ決められた閾値X5より大きい場合、その構成要素は水平線であると指定される。
【0058】
同様に、構成要素の幅があらかじめ決められた閾値X6よりも小さく、かつ、その構成要素の縦横の比があらかじめ決められた閾値X7よりも大きいとき、その構成要素は垂直線であると指定される。
【0059】
構成要素の高さまたは幅があらかじめ決められた閾値X8より小さく、かつ、すべてのテキスト連結成分の天、底または左右のいずれかの辺に、その構成要素が一致する場合、その構成要素はテーブルセル602の一部に指定される。
【0060】
最終的に、構成要素は、その行または列に他の構成要素が置かれているかどうかを決定するために解析される。構成要素の行または列は、水平および垂直線ついて上述したように検査される。構成要素の列または行が垂直または水平線のどちらかの基準を満たすなら、その構成要素は破線で示される。
【0061】
上記の4つの基準が満たされない場合、付着した連結成分はテキスト成分であると仮定される。したがって、付着したテキスト606を表すノードが生成される。
【0062】
このようにして、テーブルセル602の中のテキストはOCRシステムで自動的に処理することができるようになる。その後、キーボード313とマウス314を利用して、ディスク311に記憶されたワードプロセッシングアプリケーションにより、そのテキストはさらに処理することができるようになり、そして完全なドキュメント画像をプリンタ318を使って出力することができる。 付着したテキスト/文字データを識別し、抽出する操作を図11A、11B、11C、11Dのフローチャートと図5から図10に基づき詳細に説明する。
【0063】
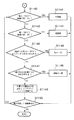
ステップS1101で、ドキュメント画像の連結成分がトレースされる。上述したように、そして図5Aに示されるように、テーブル500を識別するために、テーブル500の外側の黒画素がトレースされる。テーブル500のトレース後、トレース結果は、トレースされた構成要素の大きさが、トレースした成分がテーブルであることを表すあらかじめ決められた閾値の大きさに等しいかまたは大きいかどうかを決定する為のステップS1102で用いられる。テーブル500の大きさはそのあらかじめ決められた閾値より大きいと決定された場合、そして画像の識別のステップS1103に進み、ここで、テーブル500の中の白い輪郭610がトレースされる。
【0064】
ステップS1104で、トレースされた連結成分の中の白い輪郭の数が、あらかじめ決められた数より小さいならば、その連結成分はテーブルではない。しかし、テーブル500の中の白い輪郭610の数があらかじめ決められた数より大きければ、フローは、テーブル500がテーブルであるかどうか決定する為にステップS1104からステップS1105に進む。
【0065】
ステップS1105で、図7に示され、符号708で示される枠の輪郭を形成するために、白い輪郭はグループ化され矩形化される。ステップS1106で、白い輪郭がグループ化される頻度が、あらかじめ決められたレートより小さい場合、その白い輪郭を含んでいる連結成分はテーブルであると決定される。テーブル500の場合、その白い輪郭610のグループ化レートが小さい為、テーブル500はテーブルであると決定される。フローは、それからステップS1107に進む。
【0066】
ステップS1107で、テーブル500の各セルの白い輪郭の中の独立した連結成分が、トレースされる。一旦、これらの成分がトレースされると、それらの成分を表すノードが生成され、階層的ツリー構造の中の独立した連結成分を含む白い輪郭を表すノードから下った位置にそれらのノードが配置される。この時点で、階層的ツリー構造はテーブル500の中の付着した連結成分を表すノードを含んでいない。
【0067】
従って、ステップS1109で、独立した連結成分が存在しないと判定されるならば、フローはステップS1110に進み、図8Aに示されるように、初期の矩形エリアが、定義される。
【0068】
しかし、ステップS1109で独立した連結成分が存在すると判定される場合、フローは、ステップS1109からステップS1111に進む。ステップS1111で、独立した連結成分は、図8Bと8Cの矩形802と805のような外接矩形を形成する為に矩形化される。その後、外接矩形の面積は、ステップS1112において閾値X2と比較される。
【0069】
図8Bの矩形802の場合のように外接矩形の面積がX2より小さい場合、外接矩形802の各辺は黒い画素を含んでいる行または列に届くまで拡張される。フローはステップS1114に進み、そこで、枠の輪郭708から指定された距離までに黒画素に出会わなかった辺は、その最初の位置にとどまり、そして初期の矩形のエリアは結果として矩形804が定義される。
【0070】
矩形805の場合のように、外接矩形の面積があらかじめ決められた閾値の値X2より大きい場合、フローはステップS1115へ進み、そこで、初期の矩形エリアは外接矩形805が定義される。
【0071】
上記ステップに従って定義された初期の矩形エリアは、枠の中で独立した連結成分および付着した連結成分の周りを囲む拡張された矩形エリアを生成する為に使われる。
【0072】
従って、ステップS1116で、探索エリアは、初期の矩形エリアのある辺に行または列の全体が直接隣接するように定義される。例えば、図9Aは、探索エリア901が初期の矩形エリア805に隣接していることを示す。
【0073】
探索エリア901の中の画素は、ステップS1117で検査される。黒画素が探索エリアに存在するならば、フローはステップS1119へ進み、そこで、初期の矩形エリア805は探索エリア901を含むように拡張される。例えば、付着した連結成分606の為に、初期の矩形エリア805の左辺は、探索エリア901を含む為に図9Bのように拡張される。
【0074】
フローは、ステップS1120へ進み、そこで、探索エリア901は、その中の画素が初期の矩形エリア805に対向する枠の輪郭708の境界978の上にあるかが検査される。そうであるならば、フローはステップS1124へ進む。そうでなければ、フローはステップS1121へ進み、そこで、図9Cに示されるように、探索エリアは前の探索エリアから枠の輪郭708の境界978に向かって、前の検出エリアに隣接する画素902のグループになるように再定義される。フローは、それからステップS1117に進み、上述の処理を継続する。
【0075】
他方、黒画素がステップS1117で検出されないならば、フローはステップS1122に進み、そこで、探索エリアと初期の矩形エリア805に対向する枠の輪郭708の境界970との間の距離が、あらかじめ決められた距離X3と比較される。その距離がX3より大きいなら、フローはステップS1123に進む。ステップS1123で、探索エリアは、ステップS1121に関して上述したように再定義される。フローはステップS1117に戻って、そして上述の処理を継続する。
【0076】
ステップS1122において、その距離が距離X3より小さいかまたは等しいならば、連結成分はテーブルセル502のこの辺に付着していないと仮定され、フローはステップS1124に進む。初期の矩形エリア805の4つの辺のそれぞれに隣接している画素が検査されていない場合、フローはステップS1116に戻り、そこで新しい探索エリアに、オリジナルの初期の矩形エリア805の別の辺に直接隣接する画素の行あるいは列として定義される。そうでなければ、フローはそれからステップS1124からステップS1125へ進む。ここで、図9Dに示されるように、初期の矩形エリア805が、テーブルセル502の中のすべての付着した連結成分を含むように拡張される。
【0077】
拡張された文字エリア910の最初の行1001がステップS1126で解析のために選択される。それから、ステップS1127で、枠の輪郭708の中の白い輪郭が解析のために選択される。ステップS1129で、選択された行1001にある境界画素が識別される。境界画素は、選択された白い輪郭の境界の上にある特定の行の全ての画素である。例えば図10Aにおいて、行1002の画素w1、w2、w3およびw4は境界画素である。
【0078】
次に、ステップS1130で、識別された境界画素はテーブルセル502の左を端から連続的に番号を付けられる。ステップS1131で、それぞれの白い輪郭が、現在の選択行について解析されたと判断されると、フローはステップS1134に進む。そうでなければ、フローはステップS1132に進み、そこで、の中で別の白い輪郭が選択される。フローはそれからステップS1129に戻り、上述した処理を行う。
【0079】
ステップS1130で単一の行の解析が繰り返されている場合、識別された境界画素には、その行の境界画素に割り当てられた最後の番号に続く番号が連続的につけられる。例えば図10Aにおいて、行1002の場合、境界画素w1,w2,w3,w4は、白い輪郭610を解析している間に識別される。その後、二つの境界画素は、白い輪郭704に対応して識別される。これらの境界画素には、それぞれw5,w6の番号がつけられる。
【0080】
上述したように、ステップS1134は、すべての白い輪郭が単一の行に関して解析されたならば実行される。ステップS1134は、拡張された矩形エリア910にある選択行の黒画素を含む黒い境界画素が識別される。例えば、行1006が選択されたとき、黒画素Pが識別される。
【0081】
拡張された矩形エリア910のすべての行が解析されていないならば、フローはステップS1135からS1136へ進み、そこで、拡張された矩形エリア910の次の行が選択され、フローはステップS1127へ戻る。他方、ステップS1135において、解析された最後の行が拡張された矩形エリア910の一番下の行1004であったならば、フローはステップS1137へ進み、各行の境界画素が解析される。特に、単一の行の偶数番号と奇数番号の境界画素間にある黒画素が検出される。図10Bに示すように、行1002の境界画素w2とw5間および境界画素w6とw3間で黒画素が検出される。さらに、行1006において境界画素w2とw3間の黒画素が検出される。このようにして、拡張された矩形エリア910の各行の黒画素が検出される。
【0082】
ステップS1138で、偶数番号の境界画素と黒い境界画素間にある黒画素が検出される。例えば、行1001の画素w2と黒い境界画素Pの間にある黒画素が検出される。同様に、ステップS1138で、黒い境界画素と奇数番号の境界画素間にあるいくつかの黒画素が検出される。
【0083】
ステップS1137とステップS1138で検出された全ての隣接する黒画素は、ステップS1139で付着した連結成分を形成するために一まとめにグループ化される。例えば、図10Bにおいては、隣接する黒画素は、付着した連結成分「A」を形成するために一まとめにグループ化される。一旦、各付着した連結成分の各黒画素がグループ化され、ステップS1139で形成された付着した連続した成分は、それらがテキスト成分かどうか決定する為に検査される。
【0084】
ステップS1140において、付着した連結成分は、それが水平線かどうか決定する為に検査される。従って、その構成要素の高さがあらかじめ決められた閾値X4よりも小さく、かつ、その構成要素の縦横の比があらかじめ決められた閾値X5よりも大きい場合は、フローはステップS1141に進み、そこで、その構成要素が水平線として指定される。フローはステップS1150に進む。
【0085】
付着した連結成分が、ステップS1140の基準を満たさないならば、フローはステップS1142に進み、そこで、その付着した連結成分が、垂直線かどうか決定する為に検査される。従って、その構成要素の幅があらかじめ決められた閾値X6よりも小さく、かつ、その構成要素の縦横の比があらかじめ決められた閾値X7よりも大きい場合は、フローはステップS1144に進む。ステップS1144は、その構成要素は、垂直線として指定され、フローはステップS1150に進む。
【0086】
ステップS1145は、その成分がテーブルセル502の一部かどうかを決定する。従って、ステップS1145で、その成分の高さまたは幅があらかじめ決められた閾値X8よりも小さく、かつ、その成分が天、底、または枠の中の全てのテキスト連結成分の左右どちらかの辺と同じ場合、フローはステップS1146に進み、そこで、その成分は、テーブルセル502の一部として指定され、フローはステップS1150に進む。
【0087】
ステップS1147で、ほかの成分がその行または列に位置するかどうか決定するためにその成分は解析される。他の成分が位置するならば、成分の行または列が、水平および垂直線について、上述したように検査される。その成分の行または列が、水平または垂直線のいずれかの基準を満たすならば、その成分は、ステップS1148の中で破線の一部として指定される。フローはそれから、ステップS1120に進む。
【0088】
ステップS1140、S1142、S1145またはS1147で示した必要条件が満たされないならば、ステップS1149で、付着した連結成分はテキスト成分であると仮定される。従って、独立テキスト606を表すノードが生成される。
【0089】
フローは、それから、ステップS1150に進み、テーブルセル502の中に未解析の付着した連結成分があるならば、フローはステップS1140に戻る。全ての付着した連結成分が解析されたならば、本発明のフローは終了する。
【0090】
なお、本発明は、いくつかのページ解析システムを一まとめにしてもよく、上記したブロックセレクション技法に制限されない。さらに、本発明は、装飾用の境界線などのように、枠がテーブルのセルを表すかどうかにかかわらず、外接する枠に付着したテキストデータを識別し、抽出するために利用することができる。
【0091】
本発明に関して、現状を考慮した好ましい実施形態を上述したが、本発明は、上記の実施形態に制限されるものではない。
【0092】
反対に、本発明は様々な変形をカバーするように意図され、それと等しい構成が特許請求の範囲およびその精神に含まれている。
【0093】
【他の実施形態】
なお、本発明は、複数の機器(例えばホストコンピュータ,インタフェイス機器,リーダ,プリンタなど)から構成されるシステムに適用しても、一つの機器からなる装置(例えば、複写機,ファクシミリ装置など)に適用してもよい。
【0094】
また、本発明の目的は、前述した実施形態の機能を実現するソフトウェアのプログラムコードを記録した記憶媒体を、システムあるいは装置に供給し、そのシステムあるいは装置のコンピュータ(またはCPUやMPU)が記憶媒体に格納されたプログラムコードを読出し実行することによっても、達成されることは言うまでもない。この場合、記憶媒体から読出されたプログラムコード自体が前述した実施形態の機能を実現することになり、そのプログラムコードを記憶した記憶媒体は本発明を構成することになる。プログラムコードを供給するための記憶媒体としては、例えば、フロッピディスク,ハードディスク,光ディスク,光磁気ディスク,CD-ROM,CD-R,CD-R/W,DVD-ROM,DVD-RAM,磁気テープ,不揮発性のメモリカード,ROMなどを用いることができる。
【0095】
また、コンピュータが読出したプログラムコードを実行することにより、前述した実施形態の機能が実現されるだけでなく、そのプログラムコードの指示に基づき、コンピュータ上で稼働しているOS(オペレーティングシステム)などが実際の処理の一部または全部を行い、その処理によって前述した実施形態の機能が実現される場合も含まれることは言うまでもない。
【0096】
さらに、記憶媒体から読出されたプログラムコードが、コンピュータに挿入された機能拡張カードやコンピュータに接続された機能拡張ユニットに備わるメモリに書込まれた後、そのプログラムコードの指示に基づき、その機能拡張カードや機能拡張ユニットに備わるCPUなどが実際の処理の一部または全部を行い、その処理によって前述した実施形態の機能が実現される場合も含まれることは言うまでもない。
【0097】
【発明の効果】
以上説明したように、本発明によれば、テーブルセルの枠に付着したテキストデータを識別し抽出する為の情報処理装置およびその方法を提供することができる。
【0098】
【図面の簡単な説明】
【図1】ドキュメントページの概要を示す図、
【図2】ブロックセレクション技法によって作られた階層的ツリー構造の概要を示す図、
【図3】本発明にかかる一実施形態の情報処理システムの構成例を示す図、
【図4】本発明にかかる一実施形態の情報処理装置の構成例を示すブロック図、
【図5A】連結成分の輪郭トレースを説明するための図、
【図5B】連結成分の輪郭トレースを説明するための図、
【図6】解析されるドキュメントの中のテーブルの概要を示す図、
【図7A】白い輪郭のトレースを説明するための図、
【図7B】白い輪郭のトレースを説明するための図、
【図7C】白い輪郭のトレースを説明するための図、
【図8A】初期の矩形エリアを定義する方法を説明するための図、
【図8B】初期の矩形エリアを定義する方法を説明するための図、
【図8C】初期の矩形エリアを定義する方法を説明するための図、
【図9A】初期の矩形エリアを拡張する方法を説明するための図、
【図9B】初期の矩形エリアを拡張する方法を説明するための図、
【図9C】初期の矩形エリアを拡張する方法を説明するための図、
【図9D】初期の矩形エリアを拡張する方法を説明するための図、
【図10A】付着した連結成分を形成するための黒画素をグループ化する方法を説明するための図、
【図10B】付着した連結成分を形成するための黒画素をグループ化する方法を説明するための図、
【図11A】連結成分に付着したテキストを識別し抽出するための方法を示すフローチャート、
【図11B】連結成分に付着したテキストを識別し抽出するための方法を示すフローチャート、
【図11C】連結成分に付着したテキストを識別し抽出するための方法を示すフローチャート、
【図11D】連結成分に付着したテキストを識別し抽出するための方法を示すフローチャートである。
Claims (11)
- ドキュメント画像データを解析してテーブルの枠に付着するテキスト成分を識別する情報処理装置における情報処理方法であって、
第一トレーシング手段が、ドキュメント画像データに含まれる黒画素の連結成分をトレースする第一トレーシングステップと、
第二トレーシング手段が、前記第一トレーシングステップで得た連結成分内において、白画素の輪郭をトレースする第二トレーシングステップと、
第一定義手段が、前記第二トレーシングステップでトレースされた白画素の輪郭に基づいて、テーブルの枠の輪郭を定義する第一定義ステップと、
第二定義手段が、前記枠の輪郭内に初期エリアを定義する第二定義ステップと、
生成手段が、拡張処理として、前記枠の輪郭内において探索エリアを定義し、該定義した探索エリアに黒画素が存在すると判断した場合は該探索エリアを含むように前記初期エリアを拡張する処理を実行し、該拡張処理後の初期エリアを文字エリアとして生成する生成ステップと、
識別手段が、前記文字エリア内における前記白画素の輪郭の境界に基づいて黒画素を検出し、当該検出した黒画素のうち隣接する黒画素をグループ化した結果に基づいて前記テーブルの枠に付着するテキスト成分を識別する識別ステップと、
を有することを特徴とする情報処理方法。 - 前記第二定義ステップでは、前記白画素の輪郭内において枠に付着していない黒画素の連結成分が検出され、当該検出された枠に付着していない黒画素連結成分に基づいて、前記初期エリアが定義されることを特徴とする請求項1に記載の情報処理方法。
- 前記第二定義ステップでは、前記枠の輪郭内における予め定められた位置に前記初期エリアが定義されることを特徴とする請求項1に記載の情報処理方法。
- 前記第二定義ステップでは、前記白画素の輪郭において枠に付着していない黒画素の連結成分が検出されたかどうかが判断され、
前記枠に付着していない黒画素連結成分が検出されたと判断された場合は、前記枠に付着していない黒画素連結成分に基づいて前記初期エリアが定義され、
前記枠に付着していない黒画素連結成分が検出されなかったと判断された場合は、前記枠の輪郭内における予め定められた位置に前記初期エリアが定義されることを特徴とする請求項1に記載の情報処理方法。 - 前記識別ステップでは、前記文字エリア内の連結成分の高さと幅と縦横比とに基づいて、テキスト成分が識別されることを特徴とする請求項1に記載の情報処理方法。
- 前記生成ステップでは、前記拡張処理を行った後に、前記探索エリアを再定義して該拡張処理を繰り返し実行することで、前記文字エリアを生成することを特徴とする請求項1に記載の情報処理方法。
- 前記生成ステップでは、前記定義した探索エリアに黒画素が存在しないと判断した場合は、前記探索エリアが前記枠の輪郭から予め定められた距離内にあるか否かを更に判断し、該距離内でないと判断した場合は前記探索エリアを再定義して前記拡張処理を行い、該距離内であると判断した場合は、当該黒画素が存在しないと判断された探索エリアによる拡張を行わずに前記初期エリアの対応する辺についての拡張処理を終了することを特徴とする請求項1乃至6のいずれか1項に記載の情報処理方法。
- 第三定義手段が、前記識別ステップで識別されたテキスト成分をノードとして有する階層ツリー構造を定義する第三定義ステップを、更に有することを特徴とする請求項1に記載の情報処理方法。
- 前記第一定義ステップでは、前記トレースされた白画素の輪郭がグループ化され矩形化されることにより、前記枠の輪郭が定義されることを特徴とする請求項1に記載の情報処理方法。
- ドキュメント画像データを解析してテーブルの枠に付着するテキスト成分を識別する情報処理装置であって、
ドキュメント画像データに含まれる黒画素の連結成分をトレースする第一トレーシング手段と、
前記第一トレーシング手段で得た連結成分内において、白画素の輪郭をトレースする第二トレーシング手段と、
前記第二トレーシング手段でトレースされた白画素の輪郭に基づいて、テーブルの枠の輪郭を定義する第一定義手段と、
前記枠の輪郭内に初期エリアを定義する第二定義手段と、
拡張処理として、前記枠の輪郭内において探索エリアを定義し、該定義した探索エリアに黒画素が存在すると判断した場合は該探索エリアを含むように前記初期エリアを拡張する処理を実行し、該拡張処理後の初期エリアを文字エリアとして生成する生成手段と、
前記文字エリア内における前記白画素の輪郭の境界に基づいて黒画素を検出し、当該検出した黒画素のうち隣接する黒画素をグループ化した結果に基づいて前記テーブルの枠に付着するテキスト成分を識別する識別手段と、
を有することを特徴とする情報処理装置。 - ドキュメント画像データを解析してテーブルの枠に付着するテキスト成分を識別する情報処理方法をコンピュータに実行させるためのプログラムを記録したコンピュータ読取可能な記録媒体であって、前記方法は、
ドキュメント画像データに含まれる黒画素の連結成分をトレースする第一トレーシングステップと、
前記第一トレーシングステップで得た連結成分内において、白画素の輪郭をトレースする第二トレーシングステップと、
前記第二トレーシングステップでトレースされた白画素の輪郭に基づいて、テーブルの枠の輪郭を定義する第一定義ステップと、
前記枠の輪郭内に初期エリアを定義する第二定義ステップと、
拡張処理として、前記枠の輪郭内において探索エリアを定義し、該定義した探索エリアに黒画素が存在すると判断した場合は該探索エリアを含むように前記初期エリアを拡張する処理を実行し、該拡張処理後の初期エリアを文字エリアとして生成する生成ステップと、
前記文字エリア内における前記白画素の輪郭の境界に基づいて黒画素を検出し、当該検出した黒画素のうち隣接する黒画素をグループ化した結果に基づいて前記テーブルの枠に付着するテキスト成分を識別する識別ステップと、
を備えることを特徴とする記録媒体。
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US08/664,675 US6157738A (en) | 1996-06-17 | 1996-06-17 | System for extracting attached text |
| US08/664675 | 1996-06-17 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JPH1083431A JPH1083431A (ja) | 1998-03-31 |
| JP4077904B2 true JP4077904B2 (ja) | 2008-04-23 |
Family
ID=24666972
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP16020597A Expired - Fee Related JP4077904B2 (ja) | 1996-06-17 | 1997-06-17 | 情報処理装置およびその方法 |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US6157738A (ja) |
| EP (1) | EP0814422B1 (ja) |
| JP (1) | JP4077904B2 (ja) |
| DE (1) | DE69718243T2 (ja) |
Families Citing this family (18)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6112216A (en) * | 1997-12-19 | 2000-08-29 | Microsoft Corporation | Method and system for editing a table in a document |
| US6330357B1 (en) * | 1999-04-07 | 2001-12-11 | Raf Technology, Inc. | Extracting user data from a scanned image of a pre-printed form |
| JP3204259B2 (ja) * | 1999-10-06 | 2001-09-04 | インターナショナル・ビジネス・マシーンズ・コーポレーション | 文字列抽出方法、手書き文字列抽出方法、文字列抽出装置、および画像処理装置 |
| JP3425408B2 (ja) * | 2000-05-31 | 2003-07-14 | 株式会社東芝 | 文書読取装置 |
| EP1271403B1 (en) * | 2001-06-26 | 2005-03-09 | Nokia Corporation | Method and device for character location in images from digital camera |
| JP2004088585A (ja) * | 2002-08-28 | 2004-03-18 | Fuji Xerox Co Ltd | 画像処理システムおよびその方法 |
| JP4897520B2 (ja) * | 2006-03-20 | 2012-03-14 | 株式会社リコー | 情報配信システム |
| US20070253615A1 (en) * | 2006-04-26 | 2007-11-01 | Yuan-Hsiang Chang | Method and system for banknote recognition |
| US8331680B2 (en) * | 2008-06-23 | 2012-12-11 | International Business Machines Corporation | Method of gray-level optical segmentation and isolation using incremental connected components |
| CN102314608A (zh) * | 2010-06-30 | 2012-01-11 | 汉王科技股份有限公司 | 文字图像中行提取的方法和装置 |
| US20130163871A1 (en) * | 2011-12-22 | 2013-06-27 | General Electric Company | System and method for segmenting image data to identify a character-of-interest |
| US9842281B2 (en) * | 2014-06-05 | 2017-12-12 | Xerox Corporation | System for automated text and halftone segmentation |
| US20160055376A1 (en) * | 2014-06-21 | 2016-02-25 | iQG DBA iQGATEWAY LLC | Method and system for identification and extraction of data from structured documents |
| CN104268545B (zh) * | 2014-09-15 | 2017-09-29 | 同方知网(北京)技术有限公司 | 一种电子档版式文件中的表格区域识别与内容栅格化方法 |
| JP6173542B1 (ja) * | 2016-08-10 | 2017-08-02 | 株式会社Pfu | 画像処理装置、画像処理方法、および、プログラム |
| CN115240214A (zh) * | 2021-04-09 | 2022-10-25 | 华南理工大学广州学院 | 一种表格结构识别方法 |
| CN113221778B (zh) * | 2021-05-19 | 2022-05-10 | 北京航空航天大学杭州创新研究院 | 手写表格的检测与识别方法及装置 |
| CN113901950A (zh) * | 2021-11-05 | 2022-01-07 | 上海派拉软件股份有限公司 | 一种高准确率的表格ocr识别方法及系统 |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4377803A (en) * | 1980-07-02 | 1983-03-22 | International Business Machines Corporation | Algorithm for the segmentation of printed fixed pitch documents |
| JPS63268081A (ja) * | 1987-04-17 | 1988-11-04 | インタ−ナショナル・ビジネス・マシ−ンズ・コ−ポレ−ション | 文書の文字を認識する方法及び装置 |
| US5588072A (en) * | 1993-12-22 | 1996-12-24 | Canon Kabushiki Kaisha | Method and apparatus for selecting blocks of image data from image data having both horizontally- and vertically-oriented blocks |
| US5848186A (en) * | 1995-08-11 | 1998-12-08 | Canon Kabushiki Kaisha | Feature extraction system for identifying text within a table image |
-
1996
- 1996-06-17 US US08/664,675 patent/US6157738A/en not_active Expired - Lifetime
-
1997
- 1997-06-11 EP EP97304087A patent/EP0814422B1/en not_active Expired - Lifetime
- 1997-06-11 DE DE69718243T patent/DE69718243T2/de not_active Expired - Lifetime
- 1997-06-17 JP JP16020597A patent/JP4077904B2/ja not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| US6157738A (en) | 2000-12-05 |
| DE69718243T2 (de) | 2003-08-28 |
| EP0814422A3 (en) | 1998-01-28 |
| EP0814422A2 (en) | 1997-12-29 |
| EP0814422B1 (en) | 2003-01-08 |
| JPH1083431A (ja) | 1998-03-31 |
| DE69718243D1 (de) | 2003-02-13 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP4077904B2 (ja) | 情報処理装置およびその方法 | |
| JP3950498B2 (ja) | イメージ処理方法及び装置 | |
| US6173073B1 (en) | System for analyzing table images | |
| US5893127A (en) | Generator for document with HTML tagged table having data elements which preserve layout relationships of information in bitmap image of original document | |
| US6903751B2 (en) | System and method for editing electronic images | |
| EP0758775B1 (en) | Feature extraction system | |
| JP3359095B2 (ja) | 画像処理方法及び装置 | |
| US5987171A (en) | Page analysis system | |
| US6711292B2 (en) | Block selection of table features | |
| EP0690415B1 (en) | Editing scanned document images using simple interpretations | |
| US5509092A (en) | Method and apparatus for generating information on recognized characters | |
| JPH0668300A (ja) | 文書画像のレイアウトモデルを作成する方法及び装置 | |
| CN114004204B (zh) | 基于计算机视觉的表格结构重建与文字提取方法和系统 | |
| JPH10162150A (ja) | ページ解析システム | |
| JPH08185474A (ja) | 文書画像分割装置 | |
| US9189459B2 (en) | Document image layout apparatus | |
| JP2008108114A (ja) | 文書処理装置および文書処理方法 | |
| JP4390523B2 (ja) | 最小領域による合成画像の分割 | |
| JPH08320914A (ja) | 表認識方法および装置 | |
| JPH0612540B2 (ja) | 文書作成支援装置 | |
| JP2004282701A5 (ja) | ||
| JP4574347B2 (ja) | 画像処理装置、方法及びプログラム | |
| JPH02138674A (ja) | 文書処理方法及び装置 | |
| JPH07296109A (ja) | 画像処理方法とその装置 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20040531 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20040531 |
|
| RD01 | Notification of change of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7426 Effective date: 20040531 |
|
| RD03 | Notification of appointment of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7423 Effective date: 20040531 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20061127 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20071026 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20071225 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20080128 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20080204 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20110208 Year of fee payment: 3 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20120208 Year of fee payment: 4 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20130208 Year of fee payment: 5 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20140208 Year of fee payment: 6 |
|
| LAPS | Cancellation because of no payment of annual fees |