JP3913985B2 - 文書画像中の基本成分に基づく文字列抽出装置および方法 - Google Patents
文書画像中の基本成分に基づく文字列抽出装置および方法 Download PDFInfo
- Publication number
- JP3913985B2 JP3913985B2 JP2000611236A JP2000611236A JP3913985B2 JP 3913985 B2 JP3913985 B2 JP 3913985B2 JP 2000611236 A JP2000611236 A JP 2000611236A JP 2000611236 A JP2000611236 A JP 2000611236A JP 3913985 B2 JP3913985 B2 JP 3913985B2
- Authority
- JP
- Japan
- Prior art keywords
- character
- component
- basic
- character string
- components
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images














Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/40—Document-oriented image-based pattern recognition
- G06V30/41—Analysis of document content
- G06V30/414—Extracting the geometrical structure, e.g. layout tree; Block segmentation, e.g. bounding boxes for graphics or text
Description
また、特開平06−111060(光学的文字読取装置)では、カラー画像の色ごとの連結成分を基本成分とし、大きさが一定値以下の基本成分を文字成分とみなして抽出し、カラー画像中の文字列抽出を可能としている。
例えば、特開平05−028305(画像認識装置および認識方法)では、基本成分の近接性により文字列候補を生成し、文字認識結果の評価値により文字列らしいもののみを残して、基本成分の抽出ひいては文字列の抽出を行っている。
第1の考え方では、文字と図形のように異なる種類の情報に対応する基本成分が同じ程度の大きさを持つ場合に、文字成分抽出に失敗し、結果的に文字列抽出にも失敗してしまう。このため、抽出精度が充分でなくなる。
本実施形態においては、二値画像における黒画素連結成分の集合あるいはカラー画像における同一色画素の連結成分の集合のように、何らかの方法で得られた基本成分の集合に対して、基本成分間の包含関係を用いて文字成分であるか否かの判定を行う。そして、判定結果に基づいて文字成分の集合を抽出し、文字成分の集合から文字列を抽出する。
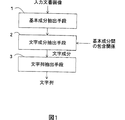
基本成分抽出部11は、入力された文書画像から基本成分の集合を抽出する。文字成分抽出部12は、基本成分の集合を入力とし、基本成分間の包含関係を用いて各基本成分が文字成分であるか否かを判定し、文字成分を抽出する。また、文字列抽出部13は、例えば、文字成分の同質性あるいは近接性に基づいて、文字列に対応する文字成分の部分集合を求める。
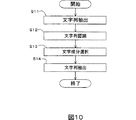
ステップS4の判定を行うために、例えば、各基本成分をあらかじめ文字認識しておくことが考えられる。この場合、入力された基本成分は、高い信頼度で文字成分であると判定されたものとそうでないものとに分類される。
次に、文字列抽出部13は、所定のしきい値以上の確信度を持つ文字列を抽出し、それらに含まれる文字成分を選択して、文字成分抽出部12に渡す(ステップS13)。
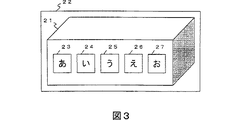
図11の基本成分抽出部は、連結成分抽出部71を含む。文書画像として二値画像が入力されたとき、連結成分抽出部71は、入力画像から黒画素連結成分を抽出し、それを基本成分として出力する。また、グレースケール文書のような多階調画像が入力されたとき、入力画像から画素レベルがほぼ同一である画素の連結成分を抽出し、それを基本成分として出力する。また、カラー文書のようなカラー画像が入力されたとき、入力画像から色がほぼ同一である画素の連結成分を抽出し、それを基本成分として出力する。
図15の基本成分抽出部は、二値画像生成部74、連結成分抽出部75、および外接矩形生成部72を含む。二値画像生成部74と連結成分抽出部75の処理については、図14の場合と同様である。外接矩形生成部72は、入力されたエッジ連結成分に外接する矩形を生成し、それを基本成分として出力する。
Claims (11)
- 入力された文書画像から基本成分の集合を抽出する基本成分抽出手段と、
前記基本成分の集合に含まれる基本成分間の包含関係を用いて基本成分が文字成分に対応するか否かを判定し、文字成分の集合を抽出する文字成分抽出手段と、
前記文字成分の集合を用いて文字列を抽出する文字列抽出手段とを備え、
前記文字成分抽出手段は、所定数以上の基本成分を含む基本成分、および、所定数以上の基本成分と重なり合っている基本成分を、文字成分ではないと判定することを特徴とする文字列抽出装置。 - 前記文字列抽出手段により抽出された文字列の認識を行って、文字列の確信度を求める文字列認識手段をさらに備え、前記文字成分抽出手段は、所定のしきい値以上の確信度を持つ文字列に含まれる文字成分を真の文字成分であると判定し、該しきい値より小さい確信度を持つ文字列に含まれる文字成分を文字成分ではないと判定して、新たな文字成分の集合を抽出し、該文字列抽出手段は、該新たな文字成分の集合を用いて、再度、文字列を抽出することを特徴とする請求項1記載の文字列抽出装置。
- 前記文字成分抽出手段と文字列抽出手段は、新たな文字成分の集合の抽出と文字列の再抽出を複数回繰り返すことを特徴とする請求項2記載の文字列抽出装置。
- 前記基本成分抽出手段は、前記文書画像として多階調画像が入力されたとき、該多階調画像において所定の範囲の階調レベルを持つ画素の連結成分を求め、該連結成分および該連結成分の外接図形のうち少なくとも一方を基本成分として抽出することを特徴とする請求項2または3記載の文字列抽出装置。
- 前記基本成分抽出手段は、前記文書画像としてカラー画像が入力されたとき、該カラー画像において所定の範囲の色情報を持つ画素の連結成分を求め、該連結成分および該連結成分の外接図形のうち少なくとも一方を基本成分として抽出することを特徴とする請求項2または3記載の文字列抽出装置。
- 前記基本成分抽出手段は、前記文書画像として多階調画像が入力されたとき、該多階調画像において所定の範囲の階調レベルを持つ画素の連結成分を求め、該連結成分の外接図形に含まれる画像を二値化して二値画像を生成し、得られた二値画像における画素連結成分および該画素連結成分の外接図形のうち少なくとも一方を基本成分として抽出することを特徴とする請求項2または3記載の文字列抽出装置。
- 前記基本成分抽出手段は、前記文書画像としてカラー画像が入力されたとき、該カラー画像において所定の範囲の色情報を持つ画素の連結成分を求め、該連結成分の外接図形に含まれる画像を二値化して二値画像を生成し、得られた二値画像における画素連結成分および該画素連結成分の外接図形のうち少なくとも一方を基本成分として抽出することを特徴とする請求項2または3記載の文字列抽出装置。
- 前記基本成分抽出手段は、前記文書画像として多階調画像およびカラー画像のうちの一方が入力されたとき、該文書画像のエッジ二値画像を生成し、得られたエッジ二値画像におけるエッジ連結成分を求め、該エッジ連結成分および該エッジ連結成分の外接図形のうち少なくとも一方を基本成分として抽出することを特徴とする請求項2または3記載の文字列抽出装置。
- 前記基本成分抽出手段は、前記文書画像として多階調画像およびカラー画像のうちの一方が入力されたとき、該文書画像のエッジ二値画像を生成し、得られたエッジ二値画像におけるエッジ連結成分を求め、該エッジ連結成分の外接図形に含まれる画像を二値化して二値画像を生成し、得られた二値画像における画素連結成分および該画素連結成分の外接図形のうち少なくとも一方を基本成分として抽出することを特徴とする請求項2または3記載の文字列抽出装置。
- 入力された文書画像に含まれる文字成分の集合に基づいて文字列を抽出するコンピュータのためのプログラムを記録した記録媒体であって、
前記文書画像から基本成分の集合を抽出するステップと、
前記文書画像に含まれる基本成分間の包含関係を用いて基本成分が文字成分に対応するか否かを判定するステップと、
所定数以上の基本成分を含む基本成分を、文字成分ではないと判定するステップと、
判定結果に基づいて前記文字成分の集合を抽出するステップと、
前記文字成分の集合を用いて文字列を抽出するステップと、
抽出された文字列の認識を行って文字列の確信度を求めるステップと、
所定のしきい値以上の確信度を持つ文字列に含まれる文字成分を真の文字成分であると判定し、該しきい値より小さい確信度を持つ文字列に含まれる文字成分を文字成分ではないと判定して、新たな文字成分の集合を抽出するステップと、
前記新たな文字成分の集合を用いて、再度、文字列を抽出するステップと
を含む処理を前記コンピュータに実行させるためのプログラムを記録したコンピュータ読み取り可能な記録媒体。 - 入力された文書画像から基本成分の集合を抽出し、
前記基本成分の集合に含まれる基本成分間の包含関係を用いて基本成分が文字成分に対応するか否かを判定し、
所定数以上の基本成分を含む基本成分を、文字成分ではないと判定し、
判定結果に基づいて文字成分の集合を抽出し、
前記文字成分の集合を用いて文字列を抽出し、
抽出された文字列の認識を行って文字列の確信度を求め、
所定のしきい値以上の確信度を持つ文字列に含まれる文字成分を真の文字成分であると判定し、該しきい値より小さい確信度を持つ文字列に含まれる文字成分を文字成分ではないと判定して、新たな文字成分の集合を抽出し、
前記新たな文字成分の集合を用いて、再度、文字列を抽出する
ことを特徴とする文字列抽出方法。
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP1999/001986 WO2000062243A1 (fr) | 1999-04-14 | 1999-04-14 | Procede et dispositif d'extraction de chaines de caracteres utilisant un composant de base d'une image de document |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP3913985B2 true JP3913985B2 (ja) | 2007-05-09 |
Family
ID=14235475
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2000611236A Expired - Fee Related JP3913985B2 (ja) | 1999-04-14 | 1999-04-14 | 文書画像中の基本成分に基づく文字列抽出装置および方法 |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US6701015B2 (ja) |
| JP (1) | JP3913985B2 (ja) |
| WO (1) | WO2000062243A1 (ja) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8447113B2 (en) | 2008-11-12 | 2013-05-21 | Fujitsu Limited | Character area extracting device, imaging device having character area extracting function, recording medium saving character area extracting programs, and character area extracting method |
Families Citing this family (17)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20080057386A1 (en) * | 2002-10-15 | 2008-03-06 | Polyplus Battery Company | Ionically conductive membranes for protection of active metal anodes and battery cells |
| US7428700B2 (en) * | 2003-07-28 | 2008-09-23 | Microsoft Corporation | Vision-based document segmentation |
| JP4587698B2 (ja) * | 2004-04-21 | 2010-11-24 | オムロン株式会社 | 文字成分抽出装置 |
| JP2006085582A (ja) * | 2004-09-17 | 2006-03-30 | Fuji Xerox Co Ltd | 文書処理装置およびプログラム |
| JP4543873B2 (ja) | 2004-10-18 | 2010-09-15 | ソニー株式会社 | 画像処理装置および処理方法 |
| KR100727961B1 (ko) * | 2005-07-29 | 2007-06-13 | 삼성전자주식회사 | N-업 디스플레이 방법 및 장치, 그를 이용한 화상 형성장치 |
| US7557963B2 (en) * | 2005-08-12 | 2009-07-07 | Seiko Epson Corporation | Label aided copy enhancement |
| US7596270B2 (en) * | 2005-09-23 | 2009-09-29 | Dynacomware Taiwan Inc. | Method of shuffling text in an Asian document image |
| FR2895622A1 (fr) * | 2005-12-27 | 2007-06-29 | France Telecom | Interfonctionnement de services de telephonie sur ip |
| US20070253040A1 (en) * | 2006-04-28 | 2007-11-01 | Eastman Kodak Company | Color scanning to enhance bitonal image |
| US7873215B2 (en) * | 2007-06-27 | 2011-01-18 | Seiko Epson Corporation | Precise identification of text pixels from scanned document images |
| CN101436248B (zh) * | 2007-11-14 | 2012-10-24 | 佳能株式会社 | 用于根据图像生成文本字符串的方法和设备 |
| JP4960897B2 (ja) | 2008-01-30 | 2012-06-27 | 株式会社リコー | 画像処理装置、画像処理方法、プログラム、記憶媒体 |
| JP4549400B2 (ja) * | 2008-03-04 | 2010-09-22 | 富士通株式会社 | 文書認識プログラム、文書認識装置、および文書認識方法 |
| JP4998496B2 (ja) | 2009-03-16 | 2012-08-15 | 富士ゼロックス株式会社 | 画像処理装置、情報処理装置および画像読取装置 |
| US8837830B2 (en) * | 2012-06-12 | 2014-09-16 | Xerox Corporation | Finding text in natural scenes |
| US10210384B2 (en) * | 2016-07-25 | 2019-02-19 | Intuit Inc. | Optical character recognition (OCR) accuracy by combining results across video frames |
Family Cites Families (22)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5448692A (en) * | 1991-03-27 | 1995-09-05 | Ricoh Company, Ltd. | Digital image processing device involving processing of areas of image, based on respective contour line traces |
| IL98293A (en) * | 1991-05-28 | 1994-04-12 | Scitex Corp Ltd | A method for distinguishing between text and graphics |
| JPH0528305A (ja) * | 1991-07-24 | 1993-02-05 | Fujitsu Ltd | 画像認識装置及び認識方法 |
| JP2579397B2 (ja) * | 1991-12-18 | 1997-02-05 | インターナショナル・ビジネス・マシーンズ・コーポレイション | 文書画像のレイアウトモデルを作成する方法及び装置 |
| JP2789971B2 (ja) * | 1992-10-27 | 1998-08-27 | 富士ゼロックス株式会社 | 表認識装置 |
| EP0633539B1 (en) * | 1993-06-30 | 2001-02-21 | Canon Kabushiki Kaisha | Document processing method and apparatus |
| JPH07168911A (ja) * | 1993-12-16 | 1995-07-04 | Matsushita Electric Ind Co Ltd | 文書認識装置 |
| US5588072A (en) * | 1993-12-22 | 1996-12-24 | Canon Kabushiki Kaisha | Method and apparatus for selecting blocks of image data from image data having both horizontally- and vertically-oriented blocks |
| JPH0855188A (ja) * | 1994-06-06 | 1996-02-27 | Toshiba Corp | 文字認識方式 |
| JP3260979B2 (ja) * | 1994-07-15 | 2002-02-25 | 株式会社リコー | 文字認識方法 |
| JP3724847B2 (ja) * | 1995-06-05 | 2005-12-07 | 株式会社日立製作所 | 構造化文書差分抽出方法および装置 |
| JP3476595B2 (ja) * | 1995-06-26 | 2003-12-10 | シャープ株式会社 | 画像領域分割方法、および画像2値化方法 |
| JP3689455B2 (ja) * | 1995-07-03 | 2005-08-31 | キヤノン株式会社 | 情報処理方法及び装置 |
| JP3425834B2 (ja) * | 1995-09-06 | 2003-07-14 | 富士通株式会社 | 文書画像からのタイトル抽出装置および方法 |
| JPH0981743A (ja) * | 1995-09-14 | 1997-03-28 | Toshiba Corp | 文字・図形処理装置及び文字・図形処理方法 |
| US6353840B2 (en) * | 1997-08-15 | 2002-03-05 | Ricoh Company, Ltd. | User-defined search template for extracting information from documents |
| JP4071328B2 (ja) * | 1997-11-18 | 2008-04-02 | 富士通株式会社 | 文書画像処理装置および方法 |
| JP4170441B2 (ja) * | 1997-11-28 | 2008-10-22 | 富士通株式会社 | 文書画像傾き検出装置および文書画像傾き検出プログラムの記憶媒体 |
| JP4100746B2 (ja) * | 1998-01-09 | 2008-06-11 | キヤノン株式会社 | 画像処理装置及び方法 |
| US6269188B1 (en) * | 1998-03-12 | 2001-07-31 | Canon Kabushiki Kaisha | Word grouping accuracy value generation |
| JP3531468B2 (ja) * | 1998-03-30 | 2004-05-31 | 株式会社日立製作所 | 文書処理装置及び方法 |
| KR100294924B1 (ko) * | 1999-06-24 | 2001-07-12 | 윤종용 | 영상분할 장치 및 방법 |
-
1999
- 1999-04-14 JP JP2000611236A patent/JP3913985B2/ja not_active Expired - Fee Related
- 1999-04-14 WO PCT/JP1999/001986 patent/WO2000062243A1/ja active Application Filing
-
2001
- 2001-09-25 US US09/960,978 patent/US6701015B2/en not_active Expired - Fee Related
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8447113B2 (en) | 2008-11-12 | 2013-05-21 | Fujitsu Limited | Character area extracting device, imaging device having character area extracting function, recording medium saving character area extracting programs, and character area extracting method |
Also Published As
| Publication number | Publication date |
|---|---|
| WO2000062243A1 (fr) | 2000-10-19 |
| US6701015B2 (en) | 2004-03-02 |
| US20020012465A1 (en) | 2002-01-31 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP3913985B2 (ja) | 文書画像中の基本成分に基づく文字列抽出装置および方法 | |
| US8442319B2 (en) | System and method for classifying connected groups of foreground pixels in scanned document images according to the type of marking | |
| EP0543599B1 (en) | Method and apparatus for image hand markup detection | |
| Jain et al. | Document representation and its application to page decomposition | |
| US8649600B2 (en) | System and method for segmenting text lines in documents | |
| JP3904840B2 (ja) | 多値画像から罫線を抽出する罫線抽出装置 | |
| KR100383372B1 (ko) | 패턴 추출 장치, 패턴 추출 방법, 및 기억 매체 | |
| EP1971957B1 (en) | Methods and apparatuses for extending dynamic handwriting recognition to recognize static handwritten and machine generated text | |
| JP6838209B1 (ja) | 文書画像解析装置、文書画像解析方法およびプログラム | |
| NO20161728A1 (en) | Written text transformer | |
| Demilew et al. | Ancient Geez script recognition using deep learning | |
| US10586125B2 (en) | Line removal method, apparatus, and computer-readable medium | |
| Akinbade et al. | An adaptive thresholding algorithm-based optical character recognition system for information extraction in complex images | |
| Nayak et al. | Odia running text recognition using moment-based feature extraction and mean distance classification technique | |
| JP2002015280A (ja) | 画像認識装置、画像認識方法および画像認識プログラムを記録したコンピュータ読取可能な記録媒体 | |
| Rani et al. | 2d morphable feature space for handwritten character recognition | |
| Baig et al. | Automatic segmentation and reconstruction of historical manuscripts in gradient domain | |
| US10657404B2 (en) | Character recognition device, character recognition method, and character recognition program | |
| Qin et al. | Laba: Logical layout analysis of book page images in arabic using multiple support vector machines | |
| Chowdhury et al. | Bengali handwriting recognition and conversion to editable text | |
| US20090245658A1 (en) | Computer-readable recording medium having character recognition program recorded thereon, character recognition device, and character recognition method | |
| JP2011018311A (ja) | 画像検索装置、画像検索プログラムおよび記録媒体 | |
| JP6503850B2 (ja) | 範囲指定プログラム、範囲指定方法および範囲指定装置 | |
| JP4651407B2 (ja) | 画像処理装置およびコンピュータプログラムおよび記憶媒体 | |
| Elmore et al. | A morphological image preprocessing suite for ocr on natural scene images |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20040906 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20060530 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20060714 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20060815 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20060928 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20061031 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20061122 |
|
| A911 | Transfer to examiner for re-examination before appeal (zenchi) |
Free format text: JAPANESE INTERMEDIATE CODE: A911 Effective date: 20070109 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20070130 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20070201 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20110209 Year of fee payment: 4 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20110209 Year of fee payment: 4 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20120209 Year of fee payment: 5 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20130209 Year of fee payment: 6 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20130209 Year of fee payment: 6 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20140209 Year of fee payment: 7 |
|
| LAPS | Cancellation because of no payment of annual fees |