JP3892829B2 - 情報処理システムおよびメモリ管理方法 - Google Patents
情報処理システムおよびメモリ管理方法 Download PDFInfo
- Publication number
- JP3892829B2 JP3892829B2 JP2003185416A JP2003185416A JP3892829B2 JP 3892829 B2 JP3892829 B2 JP 3892829B2 JP 2003185416 A JP2003185416 A JP 2003185416A JP 2003185416 A JP2003185416 A JP 2003185416A JP 3892829 B2 JP3892829 B2 JP 3892829B2
- Authority
- JP
- Japan
- Prior art keywords
- thread
- vpu
- memory
- processor
- local
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images











































Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F15/00—Digital computers in general; Data processing equipment in general
- G06F15/16—Combinations of two or more digital computers each having at least an arithmetic unit, a program unit and a register, e.g. for a simultaneous processing of several programs
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/54—Interprogram communication
- G06F9/544—Buffers; Shared memory; Pipes
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/50—Allocation of resources, e.g. of the central processing unit [CPU]
- G06F9/5005—Allocation of resources, e.g. of the central processing unit [CPU] to service a request
- G06F9/5011—Allocation of resources, e.g. of the central processing unit [CPU] to service a request the resources being hardware resources other than CPUs, Servers and Terminals
- G06F9/5016—Allocation of resources, e.g. of the central processing unit [CPU] to service a request the resources being hardware resources other than CPUs, Servers and Terminals the resource being the memory
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Software Systems (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Computer Hardware Design (AREA)
- Multi Processors (AREA)
- Memory System (AREA)
- Memory System Of A Hierarchy Structure (AREA)
Description
【発明の属する技術分野】
本発明は複数のプロセッサを含む情報処理システムおよび同システムで用いられるメモリ管理方法に関する。
【0002】
【従来の技術】
従来より、サーバコンピュータのような計算機システムにおいては、その演算処理能力の向上を図るために、マルチプロセッサ、並列プロセッサのようなシステムアーキテクチャが利用されている。マルチプロセッサおよび並列プロセッサのどちらも、複数のプロセッサユニットを利用することによって演算処理の並列化を実現している。
複数のプロセッサユニットを備えたシステムとしては、例えば、1台の高速CPU、複数台の低速CPU、および共有メモリを備えたシステムが知られている(例えば、特許文献1参照)。このシステムにおいては、高速CPUおよび複数台の低速CPUに対する処理プログラムのプロセス群の割付は、プロセス群の並列動作度の大小および処理時間の大小に応じて行われる。
【0003】
ところで、最近では、計算機システムのみならず、例えば、AV(オーディオ・ビデオ)データのような大容量のデータをリアルタイムに処理する組み込み機器においても、その演算処理能力の向上のためにマルチプロセッサ、並列プロセッサのようなシステムアーキテクチャの導入が要求されている。
【0004】
【特許文献1】
特開平10−143380号公報
【0005】
【発明が解決しようとする課題】
しかし、複数のプロセッサを含むシステムアーキテクチャを前提としたリアルタイム処理システムの報告はほとんどなされていないのが現状である。
リアルタイム処理システムにおいては、ある許容時間時間の制限内に個々の処理を完了することが要求される。しかし、マルチプロセッサ、並列プロセッサのようなシステムアーキテクチャをリアルタイム処理システムに適用した場合においては、共有メモリに対するアクセスの競合、メモリバスのバンド幅の制約などにより、複数のプロセッサそれぞれの性能を十分に活用できなくなるという問題が生じる。また互いに異なるプロセッサによって実行されるスレッド間でデータを受け渡すための通信も共有メモリ上のバッファを介して行われるので、頻繁に相互作用を行うスレッド間においてはその通信に関するレイテンシが大きな問題となる。
【0006】
本発明は上述の事情を考慮してなされたものであり、複数のプロセッサを用いて複数のスレッドを効率よく並列に実行することが可能な情報処理システムおよびメモリ管理方法を提供することを目的とする。
【0007】
【課題を解決するための手段】
上述の課題を解決するため、本発明の情報処理システムは、第1のローカルメモリを有する第1のプロセッサと、第2のローカルメモリを有する第2のプロセッサと、第3のローカルメモリを有する第3のプロセッサと、前記第1のプロセッサによって実行される第1のスレッドの実効アドレス空間の一部に、前記第1のスレッドとの相互作用を行う第2のスレッドが実行される前記第2および第3の一方のプロセッサに対応する前記第2および第3の一方のローカルメモリをマッピングする手段と、前記第2のスレッドが実行されるプロセッサが前記第2および第3の一方のプロセッサから他方のプロセッサに変更された場合、前記第1のスレッドの実効アドレス空間の前記一部に、前記第2および第3の一方のローカルメモリに代えて他方のローカルメモリをマッピングする手段とを具備することを特徴とする。
【0008】
この情報処理システムにおいては、各プロセッサにローカルメモリが設けられているので、各スレッドは共有メモリをアクセスせずとも、プロセッサ内のローカルメモリをアクセスするだけでプログラムを実行することができる。また、相互作用を行う相手のスレッドが実行されるプロセッサに応じて、実効アドレス空間にマッピングされる、相手のスレッドに対応するプロセッサのローカルメモリが自動的に変更されるので、各スレッドは相手のスレッドがディスパッチされるプロセッサを意識することなく、相手のスレッドとの相互作用を効率よく行うことが出来る。よって、複数のスレッドを効率よく並列に実行することが可能となる。
【0009】
【発明の実施の形態】
以下、図面を参照して本発明の実施形態を説明する。
図1には、本発明の一実施形態に係るリアルタイム処理システムを実現するための計算機システムの構成例が示されている。この計算機システムは、リアルタイム性が要求される各種処理をその時間的な制約条件の範囲内で実行する情報処理システムであり、汎用計算機として利用できるほか、リアルタイム性が要求される処理を実行するための様々な電子機器用の埋め込みシステムとして利用することができる。図1に示されているように、この計算機システムにおいては、マスタープロセッサユニット(MPU11:Master Processing Unit)11と、複数のバーサタイルプロセッサユニット(VPU:Versatile Processing Unit)12と、メインメモリ14と、入出力制御装置15とが、接続装置13によって相互に接続されている。接続装置13は、例えば、クロスバスイッチのような相互結合網、あるいはバスによって構成されている。リング状のバス構造を用いることも出来る。MPU11は計算機システムの動作を制御するメインプロセッサである。オペレーティングシステム(OS:Operating System)は、主にMPU11によって実行される。OSの一部の機能はVPU12や入出力制御装置15で分担して実行することもできる。各VPU12は、MPU11の管理の下で各種の処理を実行するプロセッサである。MPU11は、複数のVPU12に処理を振り分けて並列に実行させるための制御を行う。これにより高速で効率よい処理の実行を行うことが出来る。メインメモリ14は、MPU11、複数のVPU12および入出力制御装置15によって共有される記憶装置(共有メモリ)である。OSおよびアプリケーションプログラムはメインメモリ14に格納される。入出力制御装置15には、ひとつあるいは複数の入出力デバイス(入出力装置)16が接続される。入出力制御装置15はブリッジとも呼ばれる。
【0010】
接続装置15はデータ転送レートを保証するQoS機能を持つ。この機能は、接続装置15を介したデータ転送を予約されたバンド幅(転送速度)で実行することによって実現される。QoS機能は、たとえば、あるVPU12からメモリ14に5Mbpsでライトデータを送信する場合、あるいはあるVPU12と別のVPU12との間で100Mbpsでデータ転送する場合に利用される。VPU12は接続装置13に対してバンド幅(転送速度)を指定(予約)する。接続装置13は指定されたバンド幅を要求したVPU12に対して優先的に割り当てる。あるVPU12のデータ転送に対してバンド幅が予約されたならば、そのVPU12によるデータ転送中に他のVPU12、MPU11あるいは入出力制御装置15が大量のデータ転送を行っても、予約されたバンド幅は確保される。この機能は、特に、リアルタイム処理を行う計算機にとって重要な機能である。
【0011】
図1の構成では、MPU11が1つ、VPU12が4つ、メモリ14が1つ、入出力制御装置が1つであるが、VPU12の個数は制限されない。またMPU11を持たない構成も可能である。この場合、MPU11の行う処理は、ある一つのVPU12が担当する。つまり、仮想的なMPU11の役割をVPUが兼ねる。
【0012】
図2には、MPU11と各VPU12の構成が示されている。MPU11は処理ユニット21およびメモリ管理ユニット22を備えている。処理ユニット21は、メモリ管理ユニット22を通してメモリ14をアクセスする。メモリ管理ユニット22は、仮想記憶管理と、メモリ管理ユニット22内のキャッシュメモリの管理を行うユニットである。各VPU12は、処理ユニット31、ローカルストレージ(ローカルメモリ)32、およびメモリコントローラ33を備えている。各VPU12の処理ユニット31は、そのVPU内部のローカルストレージ32を直接アクセスすることができる。メモリコントローラ33は、ローカルストレージ32とメモリ14の間のデータ転送を行うDMAコントローラの役割を持つ。このメモリコントローラ33は、接続装置14のQoS機能を利用できるように構成されており、バンド幅を予約する機能および予約したバンド幅でデータ入出力を行う機能を有している。またメモリコントローラ33は、MPU11のメモリ管理ユニット22と同様の仮想記憶管理機能を持つ。VPU12の処理ユニット31はローカルストレージ32を主記憶として使用する。処理ユニット31はメモリ14に対して直接的にアクセスするのではなく、メモリコントローラ33に指示して、メモリ14の内容をローカルストレージ32に転送して読んだり、ローカルストレージ32の内容をメモリ14に書いたりする。
【0013】
MPU11のメモリ管理ユニット22およびVPU12のメモリコントローラ33それぞれによって実行される仮想記憶管理は、たとえば図3のように実施することができる。MPU11の処理ユニット21あるいはVPU12のメモリコントローラ33から見たアドレスは、図3の上の部分に示すような64ビットのアドレスである。この64ビットのアドレスは、上位の36ビットがセグメント番号、中央の16ビットがページ番号、下位の12ビットがページオフセットである。このアドレスから、実際に接続装置13を通してアクセスする実アドレス空間への変換は、セグメントテーブル50およびページテーブル60を用いて実行される。セグメントテーブル50およびページテーブル60は、メモリ管理ユニット22およびメモリコントローラ33に各々設けられている。
【0014】
MPU11および各VPU12から見た実アドレス(RA)空間には、図4に示すように、たとえば以下のようなデータがマッピングされている。
1.メモリ(主記憶装置)
2.MPU11の各種制御レジスタ
3.各VPU12の各種制御レジスタ
4.各VPU12のローカルストレージ
5.各種入出力デバイス(入出力装置)の制御レジスタ(入出力制御装置の制御レジスタも含む)
MPU11および各VPU12は、実アドレス空間の該当するアドレスにアクセスすることで、1〜5の各データを読み書きすることができる。特に、実アドレス空間にアクセスすることで、どのMPU11からでも、あるいはどのVPU12からでも、さらに入出力制御装置15からでも、任意のVPU12のローカルストレージ32にアクセスすることができることは重要である。またセグメントテーブルあるいはページテーブルを用いて、VPU12のローカルストレージ32の内容が自由に読み書きされないように保護することもできる。
MPU11あるいはVPU12からみたアドレス空間は、図3の仮想記憶メカニズムを用いて、たとえば図5に示すようにマッピングされる。MPU11あるいはVPU12上で実行しているプログラムから直接見えるのは、実効アドレス(EA;Effective Address)空間である。EAは、セグメントテーブル50によって、仮想アドレス(VA;Virtual Address)空間にマッピングされる。さらにVAは、ページテーブル60によって、実アドレス(RA;Real Address)空間にマップされる。このRAが、図4で説明したような構造を持っている。
【0015】
MPU11は制御レジスタ等のハードウェア機構によって、例えば、各VPU12のレジスタの読み書き、各VPU12のプログラムの実行開始/停止などの、各VPU12の管理を行うことができる。また、MPU11とVPU12の間、あるいはあるVPU12と他のVPU12の間の通信や同期は、メールボックスやイベントフラグなどのハードウェア機構によって行うことが出来る。
【0016】
この実施形態の計算機システムは、従来ハードウェアで実現されていたようなリアルタイム性の要求の厳しい機器の動作を、ソフトウェアを用いて実現することを可能にする。例えば、あるVPU12があるハードウェアを構成するある幾つかのハードウェアコンポーネントに対応する演算処理を実行し、それと並行して、他のVPU12が他の幾つかのハードウェアコンポーネントに対応する演算処理を実行する。
【0017】
図6はデジタルテレビ放送の受信機の簡略化したハードウェア構成を示している。図6においては、受信した放送信号はDEMUX(デマルチプレクサ)回路101によって音声データと映像データと字幕データそれぞれに対応する圧縮符号化されたデータストリームに分解される。圧縮符号化された音声データストリームはA−DEC(音声デコーダ)回路102によってデコードされる。圧縮符号化された映像データストリームはV−DEC(映像デコーダ)回路103によってデコードされる。デコードされた映像データストリームはPROG(プログレッシブ変換)回路105に送られ、そこでプログレッシブ映像信号に変換するためのプログレッシブ変換処理が施される。プログレッシブ変換された映像データストリームはBLEND(画像合成)回路106に送られる。字幕データストリームはTEXT(字幕処理)回路104によって字幕の映像に変換された後、BLEND回路106に送られる。BLEND回路106は、PROG回路105から送られてくる映像と、TEXT回路104から送られてくる字幕映像とを合成して、映像ストリームとして出力する。この一連の処理が、映像のフレームレート(たとえば、1秒間に30コマ、32コマ、または60コマ)に従って、繰り返し実行される。
【0018】
図6のようなハードウェアの動作をソフトウェアによって実行するために、本実施形態では、たとえば図7に示すように、図6のハードウェアの動作をソフトウェアとして実現したプログラムモジュール100を用意する。このプログラムモジュール100は、複数の処理要素の組み合わせから構成されるリアルタイム処理を計算機システムに実行させるためのアプリケーションプログラムであり、マルチスレッドプログラミングを用いて記述されている。このプログラムモジュール100は、図6のハードウェアコンポーネント群に対応する複数の処理要素それぞれに対応した手順を記述した複数のプログラム111〜116を含んでいる。すなわち、プログラムモジュール100には、DEMUXプログラム111、A−DECプログラム112、V−DECプログラム113、TEXTプログラム114、PROGプログラム115、およびBLENDプログラム116が含まれている。DEMUXプログラム111、A−DECプログラム112、V−DECプログラム113、TEXTプログラム114、PROGプログラム115、およびBLENDプログラム116は、それぞれ図6のDEMUX回路101、A−DEC回路102、V−DEC回路103、TEXT回路104、PROG回路105、およびBLEND回路106に対応する処理を実行するためのプログラムであり、それぞれスレッドとして実行される。つまり、プログラムモジュール100の実行時には、DEMUXプログラム111、A−DECプログラム112、V−DECプログラム113、TEXTプログラム114、PROGプログラム115、およびBLENDプログラム116それぞれに対応するスレッドが生成され、生成されたスレッドそれぞれが1以上のVPU12にディスパッチされて実行される。VPU12のローカルストレージ32にはそのVPU12にディスパッチされたスレッドに対応するプログラムがロードされ、スレッドはローカルストレージ32上のプログラムを実行する。デジタルテレビ放送の受信機を構成するハードウェアモジュール群それぞれに対応するプログラム111〜116と、構成記述117と呼ぶデータとをパッケージ化したものが、デジタルテレビ放送の受信機を実現するプログラムモジュール100になる。
【0019】
構成記述117は、プログラムモジュール100内の各プログラム(スレッド)をどのように組み合わせて実行するべきかを示す情報であり、プログラム111〜116間の入出力関係および各プログラムの処理に必要なコスト(時間)などを示す。図8には構成記述117の例が示されている。
【0020】
図8の構成記述117の例では、スレッドとして動作する各モジュール(プログラムモジュール100内の各プログラム)に対して、その入力につながるモジュール、その出力がつながるモジュール、そのモジュールの実行に要するコスト、出力がつながるモジュールそれぞれへの出力に必要なバッファサイズが記述されている。たとえば、番号▲3▼のV−DECプログラムは、番号▲1▼のDEMUXプログラムの出力を入力とし、その出力は番号▲5▼のPROGプログラムに向かっており、その出力に必要なバッファは1MBで、番号▲3▼のV−DECプログラム自体の実行コストは50であることを示している。なお、実行に必要なコストは、実行に必要な時間(実行期間)やステップ数などを単位として記述することができる。また、何らかの仮想的な仕様のVPUで実行した場合の時間を単位とすることも可能である。計算機によってVPUの仕様や処理性能が異なる場合もあるので、このように仮想的な単位を設けてコストを表現するのは望ましい形態である。図8に示した構成記述117に従って実行する場合の、プログラム間のデータの流れは図9の通りである。
【0021】
さらに、構成記述117には、プログラム111〜116それぞれに対応するスレッド間の結合属性を示す結合属性情報がスレッドパラメータとして記述されている。なお、スレッドパラメータはプログラム111〜116中にコードとして直接記述することも可能である。
【0022】
次に、図10、図11を参照して、プログラム111〜116が本実施形態の計算機システムによってどのように実行されるかを説明する。ここでは、VPU0とVPU1の2つのVPU12が計算機システムに設けられている構成を想定する。毎秒30フレームで映像を表示する場合の、各VPU12に対するプログラムの割り当てを時間を追って記入したのが図10である。ここでは周期1の間で1フレーム分の音声と映像を出力している。まず、VPU0でDEMUXプログラムが処理を行い、その結果の音声と映像と字幕のデータをバッファに書き込む。その後VPU1でA−DECプログラムとTEXTプログラムを順次実行し、それぞれの処理結果をバッファに書き込む。VPU0では、次にV−DECプログラムが映像データの処理を行い、結果をバッファに書き込む。VPU0では、続いてPROGプログラムが処理を行い、結果をバッファに書き込む。この時点で、VPU1でのTEXTの処理は終わっているので、最後のBLENDプログラムの実行をVPU0で行い、最終的な映像データを作成する。この処理の流れを、毎周期繰り返すように実行する。
【0023】
ここで説明したように、所望の動作を滞りなく行えるように、各VPU12上で、いつ、どのプログラムを実行するかを決める作業を、スケジューリングとよぶ。スケジューリングを行うモジュールをスケジューラとよぶ。本実施形態では、プログラムモジュール100中に含まれる上述の構成記述117に基づいてスケジューリングが行われる。
【0024】
図11は、毎秒60フレームで表示する場合の実行の様子を示している。図10と異なるのは、図10では毎秒30フレームだったので、1周期(1/30秒)で1フレーム分の処理を完了できたのに対し、図11では毎秒60フレーム処理する必要がある点である。すなわち、1周期(1/60秒)では1フレーム分の処理を完了できないので、図11では、複数(ここでは2)周期にまたがったソフトウェアパイプライン処理を行っている。たとえば周期1のはじめに入力された信号に対して、VPU0でDEMUX処理とV−DEC処理を行う。その後、周期2においてVPU1でA−DEC、TEXT、PROG、BLENDの各処理を行って最終的な映像データを出力する。周期2ではVPU0は次のフレームのDEMUXとV−DECの処理を行っている。このように、VPU0によるDEMUX,V−DECの処理と、VPU1によるA−DEC、TEXT、PROG、BLENDの処理を、2周期にまたがってパイプライン的に実行する。
【0025】
なお、図7に示したプログラムモジュール100は、本実施形態の計算機システムを組み込んだ機器内のフラッシュROMやハードディスクに予め記録しておいてもよいが、ネットワークを介して流通させるようにしてもよい。この場合、本実施形態の計算機システムによって実行される処理の内容は、ネットワークを介してダウンロードしたプログラムモジュールの種類に応じて決まる。よって、例えば本実施形態の計算機システムを組み込んだ機器に、様々な専用ハードウェアそれぞれに対応するリアルタイム処理を実行させることが出来る。例えば、新しいコンテンツの再生に必要な新しいプレーヤーソフトウェアやデコーダソフトウェアや暗号ソフトウェアなどを、本実施形態の計算機システムで実行可能なプログラムモジュールとして、コンテンツと一緒に配布することで、本実施形態の計算機システムを搭載した機器であれば、いずれの機器でも、その能力が許す範囲内で、そのコンテンツを再生することができる。
【0026】
(オペレーティングシステム)
本計算機システムでは、システム内にOS(オペレーティングシステム)をひとつだけ実装する場合には、図12に示すように、そのOS201がすべての実資源(たとえば、MPU11、VPU12、メモリ14、入出力制御装置15、入出力装置16など)を管理する。
一方、仮想計算機方式を用いて、複数のOSを同時に動作させることも可能である。この場合には、図13に示すように、まず仮想計算機OS301を実装し、それがすべての実資源(たとえば、MPU11、VPU12、メモリ14、入出力制御装置15、入出力装置16など)を管理する。仮想計算機OS301はホストOSと称されることもある。さらに仮想計算機OS301の上に、ひとつ以上のOS(ゲストOSとも呼ぶ)を実装する。各ゲストOS302,303は、図14に示すように、仮想計算機OS301によって与えられる仮想的な計算機資源から構成される計算機上で動作し、ゲストOS302,303の管理するアプリケーションプログラムに各種のサービスを提供する。図14の例では、ゲストOS302は、1つのMPU11と、2つのVPU12と、メモリ14とから構成される計算機上で動いていると思っており、ゲストOS303は1つのMPU11と、4つのVPU12と、メモリ14とから構成される計算機上で動いていると思っている。ゲストOS302からみたVPU12や、ゲストOS303からみたVPU12が、実際には実資源のどのVPU12に対応しているかは、仮想計算機OS301が管理している。ゲストOS302,303は、その対応を意識する必要はない。
【0027】
仮想計算機OS301は、計算機システム全体の資源を時分割で各ゲストOS302,303に割り当てるように、ゲストOS302,303のスケジューリングを行う。例えば、ゲストOSOS302がリアルタイム処理を行うものであるとする。たとえば1秒間に30回、正しいペースで処理を行いたい場合には、各ゲストOS302はそのパラメタを仮想計算機OS301に設定する。仮想計算機OS301は、1/30秒に1回、確実にそのゲストOS301に必要なだけの処理時間が割り当てられるようにスケジューリングを行う。リアルタイム性を要求しない処理を行うゲストOSには、リアルタイム性を要求するゲストOSよりも低い優先度で、処理時間の割り当てを行うように、スケジューリングが行われる。図15は、時間軸を横にとって、ゲストOS302とゲストOS303が切り替わりながら動いている様子を示している。ゲストOS302が動いている間は、MPU11と全てのVPU12がゲストOS302の資源として使用され、ゲストOS303が動いている間は、MPU11と全てのVPU12がゲストOS303の資源として使用される。
【0028】
図16は別の動作モードを示している。ターゲットアプリケーションによってはVPU12をずっと占有して利用したい場合がある。たとえば、常にデータやイベントを監視し続けることが必要なアプリケーションがこれに相当する。このようなときには、特定のVPU12を特定のゲストOSによって占有するように、仮想計算機301のスケジューラがスケジュール管理する。図16では、VPU4をゲストOS301の専用資源に指定した場合の例である。仮想計算機OS301がゲストOS302(OS1)とゲストOS303(OS2)を切り替えても、VPU4は常にゲストOS301(OS1)の管理下で動作し続ける。
【0029】
さて、複数のVPU12を用いてプログラムを動作させるために、本実施形態では、複数のVPU12それぞれに割り当てるスレッドをスケジューリングするためのスケジューラを含む、VPU実行環境と呼ぶソフトウェアモジュールを用いる。本計算機システムにOSがひとつしか搭載されていない場合は、図17に示すようにそのOS201にVPU実行環境401を実装する。この時、VPU実行環境401は、OS201のカーネル内に実装することもできるし、ユーザプログラムレベルで実装することもできるし、両者に分割して協調して動作するように実装することも出来る。一方、仮想計算機OS上でひとつあるいは複数のOSを動作させる場合、VPU実行環境401を実装する方式には、次のような方式がある。
1.仮想計算機OS301の中にVPU実行環境401を実装する方式(図18)
2.VPU実行環境401を仮想計算機OS301が管理するひとつのOSとして実装する方式(図19)。図19では、仮想計算機OS301上で動作するゲストOS304自体がVPU実行環境401である。
3.仮想計算機OS301が管理する各ゲストOSに、それぞれ専用のVPU実行環境401を実装する方式(図20)。図20においては、ゲストOS302,303にそれぞれVPU実行環境401,402が実装されている。VPU実行環境401,402は、仮想計算機OS301の提供するゲストOS間の通信機能を用いて、必要に応じて、互いに連携して動作する。
4.仮想計算機OS301が管理するゲストOSのうちのひとつにVPU実行環境401を実装して、VPU実行環境を持たないゲストOSは、仮想計算機OS301の提供するゲストOS間の通信機能を用いて、VPU実行環境401を持つゲストOSのVPU実行環境401を利用する方式(図21)。
【0030】
これらの方式のメリットは以下のとおりである。
方式1のメリット
・仮想計算機OSの持つゲストOS(仮想計算機OSが管理する対象のOS)のスケジューリングと、VPU12のスケジューリングを一体化できるので、効率良く、きめ細かなスケジューリングができ、資源を有効利用できる。
・複数のゲストOS間でVPU実行環境を共有できるので、新しいゲストOSを導入する場合に新しくVPU実行環境を作らなくてもよい。
方式2のメリット
・仮想計算機OSの上にあるゲストOS間でVPU12のスケジューラを共有できるので、効率良く、きめ細かなスケジューリングができ、資源を有効利用できる。
・複数のゲストOS間でVPU実行環境を共有できるので、新しいゲストを導入する場合に新しくVPU実行環境を作らなくてもよい。
・VPU実行環境を仮想計算機OSや特定のゲストOSに依存せずに作れるので、標準化がしやすく、取り替えて使うことも出来る。特定の組み込み機器に適応したVPU実行環境を作って、その機器の特性を活かしたスケジューリング等を行うことで、効率良い実行ができる。
方式3のメリット
・各ゲストOSに対してVPU実行環境を最適に実装できるので、効率良く、きめ細かなスケジューリングができ、資源を有効利用できる。
【0031】
方式4のメリット
・すべてのゲストOSがVPU実行環境を実装する必要がないので、新しいゲストOSを追加しやすい。
このように、いずれの方式でもVPU実行環境を実装することができる。また、このほかにも適宜実施可能である。
【0032】
(サービスプロバイダ)
本実施形態の計算機システムにおいては、VPU実行環境401は、各VPU12に関連する各種資源(各VPUの処理時間、メモリ、接続装置のバンド幅、など)の管理とスケジューリング機能の他に、さまざまなサービス(ネットワークを使った通信機能、ファイルの入出力機能、コーデックなどのライブラリ機能の呼び出し、ユーザとのインタフェース処理、入出力デバイスを使った入出力処理、日付や時間の読み出し、など)を提供する。これらのサービスは、VPU12上で動作するアプリケーションプログラムから呼び出されて、簡単なサービスの場合にはそのVPU12上のサービスプログラムで処理される。しかし通信やファイルの処理などVPU12だけでは処理できないサービスに関しては、MPU11上のサービスプログラムによって処理する。このようなサービスを提供するプログラムを、サービスプロバイダ(SP)と呼ぶ。
【0033】
図22にVPU実行環境のひとつの実施例を示す。VPU実行環境の主要部分はMPU11上に存在する。これが、MPU側VPU実行環境501である。各VPU12上には、そのVPU12内で処理可能なサービスを実行する最小限の機能のみを持つVPU側VPU実行環境502が存在する。MPU側VPU実行環境501の機能は、大きく、VPUコントロール511と、サービスブローカ512の2つに分けられる。VPUコントロール512は、主に、各VPU12に関連する各種資源(VPUの処理時間、メモリ、仮想空間、接続装置のバンド幅、など)の管理機構や、同期機構や、セキュリティの管理機構や、スケジューリング機能を提供する。スケジューリング結果に基づいてVPU12上のプログラムのディスパッチを行うのは、このVPUコントロール511である。サービスブローカ512は、VPU12上のアプリケーションが呼び出したサービス要求を受けて、適当なサービスプログラム(サービスプロバイダ)を呼び出してそのサービスを提供する。
VPU側VPU実行環境502は、主に、VPU12上のアプリケーションプログラムが呼び出したサービス要求を受けて、VPU12内で処理できるものは処理し、そうでないものはMPU側VPU実行環境501のサービスブローカ512に処理を依頼する働きをする。
【0034】
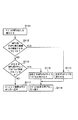
図23に、VPU側VPU実行環境502がサービス要求を処理する手順を示す。VPU側VPU実行環境502はアプリケーションプログラムからのサービス呼び出しを受け取ると(ステップS101)、VPU実行環境502内で処理できるサービスであるかどうかを判別し(ステップS102)、それであれば、対応するサービスを実行して、結果を呼び出し元へ返す(ステップS103,S107)。一方、VPU実行環境502内で処理できるサービスではないならば、該当するサービスを実行可能なサービスプログラムがVPU12上で実行可能なプログラムとして登録されているかどうかを判断する(ステップS104)。登録されているならば、当該サービスプログラムを実行し、結果を呼び出し元へ返す(ステップS105,S107)。登録されていないならば、サービスブローカ512に処理を依頼し、そしてサービスブローカ512から返されるサービスの結果を呼び出し元へ返す(ステップS106,S107)。
【0035】
図24に、MPU側VPU実行環境501のサービスブローカ512が、VPU側VPU実行環境502から要求されたサービスを処理する手順を示す。サービスブローカ512はVPU側VPU実行環境502からのサービス呼び出しを受け取ると(ステップS111)、VPU実行環境501内で処理できるサービスであるかどうかを判別し(ステップS112)、それであれば、対応するサービスを実行して、結果を呼び出し元のVPU側VPU実行環境502へ返す(ステップS113,S114)。一方、VPU実行環境501内で処理できるサービスではないならば、該当するサービスを実行可能なサービスプログラムがMPU11上で実行可能なプログラムとして登録されているかどうかを判断する(ステップS114)。登録されているならば、当該サービスプログラムを実行し、結果を呼び出し元のVPU側VPU実行環境502へ返す(ステップS116,S114)。登録されていないならば、エラーを呼び出し元のVPU側VPU実行環境502へ返す(ステップS117)。
【0036】
なお、VPU12で実行するプログラムが発行するサービス要求には、サービスの実行結果のリプライを返すものもあれば、要求を出すだけでリプライの無いものもある。また、リプライ先は、通常は要求を出したスレッドであるが、リプライ先として他のスレッド、スレッドグループ、あるいはプロセスを指定することもできる。そのため、サービス要求のメッセージには、リプライ先の指定も含めることが好ましい。サービスブローカ512は、広く使われているオブジェクトリクエストブローカを用いて実現することができる。
【0037】
(リアルタイム処理)
本実施形態の計算機システムはリアルタイム処理システムとして機能する。この場合、そのリアルタイム処理システムの対象とする処理は、大きく、
1.ハードリアルタイム処理
2.ソフトリアルタイム処理
3.ベストエフォート処理(ノンリアルタイム処理)
の3種類に分類できる。1と2がいわゆるリアルタイム処理と呼ばれるものである。本実施形態のリアルタイム処理システムは、多くの既存のOSと同様、スレッドとプロセスの概念を持っている。ここではまず、本実施形態のリアルタイム処理システムにおけるスレッドとプロセスに関して説明する。
【0038】
スレッドには、次の3つのクラスがある。
1.ハードリアルタイムクラス
このスレッドクラスは、その時間要件(timing requirements)は非常に重要で、その要件が満たされなかった際に重大な状況になるような、重要なアプリケーションに用いる。
2.ソフトリアルタイムクラス
このスレッドクラスは、例えその時間要件が満たされなかった場合においても、その品質が低下するだけのアプリケーションに用いる。
3.ベストエフォートクラス
このスレッドクラスは、その要件の中に一切の時間要件を含まないアプリケーションに用いる。
【0039】
スレッドは本アルタイム処理システム内において処理を実行する実体である。スレッドには、そのスレッドが実行するプログラムが関連付けられている。各スレッドは、スレッドコンテクストと呼ぶ、それぞれのスレッドに固有の情報を保持している。スレッドコンテクストには、たとえば、プロセッサのレジスタの値や、スタックなどの情報が含まれている。
本リアルタイム処理システムにおいては、MPUスレッドとVPUスレッドの2種類のスレッドが存在する。これら2つのスレッドは、そのスレッドが実行されるプロセッサ(MPU11かVPU12)によって分類されており、スレッドとしてのモデルは全く同じである。VPUスレッドのスレッドコンテクストには、VPU12のローカルストレージ32の内容や、メモリコントローラ33の持つDMAコントローラの状態なども含む。
【0040】
複数のスレッドをグループとしてまとめたものを、スレッドグループと呼ぶ。スレッドグループは、グループに含まれるスレッドすべてに対して同じ属性を与える、などの処理を効率よく簡単にできるメリットがある。ハードリアルタイムクラスまたはソフトリアルタイムクラスのスレッドグループは、密結合スレッドグループ(tightly coupled thread group)と疎結合スレッドグループ(loosely coupled thread group)の2種類に大別される。密結合スレッドグループ(tightly coupled thread group)と疎結合スレッドグループ(loosely coupled thread group)はスレッドグループに付加された属性情報(結合属性情報)によって識別される。アプリケーションプログラム内のコードまたは上述の構成記述によってスレッドグループの結合属性を明示的に指定することができる。
密結合スレッドグループは互いに協調して動作する複数のスレッドの集合から構成されるスレッドグループである。すなわち、密結合スレッドグループは、そのグループに属するスレッド群が、お互いに密接に連携して動作することを示す。密接な連携とは、例えば,頻繁にスレッド間で通信あるいは同期処理などの相互作用(interaction)を行ったり、あるいは、レイテンシ(latency)(遅延)の小さい相互作用を必要とする場合などである。一方、疎結合スレッドグループは、密結合スレッドグループに比べてそのグループに属するスレッド群間の密接な連携が不要であるスレッドグループであり、スレッド群はメモリ14上のバッファを介してデータ受け渡しのための通信を行う。
【0041】
(密結合スレッドグループ)
図25に示すように、密結合スレッドグループに属するスレッド群にはそれぞれ別のVPUが割り当てられ、各スレッドが同時に実行される。密結合スレッドグループに属するスレッドを、密結合スレッド(tightly coupled thread)と呼ぶ。この場合、密結合スレッドグループに属する密結合スレッドそれぞれの実行期間がそれら密結合スレッドの個数と同数のVPUそれぞれに対して予約され、それら密結合スレッドが同時に実行される。図25においては、ある密結合スレッドグループにスレッドA,Bの2つが密結合スレッドとして含まれており、それらスレッドA,BがそれぞれVPU0,VPU1によって同時に実行されている様子を示している。スレッドA,Bをそれぞれ別のVPUによって同時に実行することを保証することにより、各スレッドは相手のスレッドが実行されているVPUのローカルストレージや制御レジスタを通じて相手のスレッドとの通信を直接的に行うことが出来る。図26は、スレッドA,Bがそれぞれ実行されるVPU0,VPU1のローカルストレージを介してスレッドA,B間の通信が実行される様子を示している。この場合、スレッドAが実行されるVPU0においては、そのスレッドAのEA空間の一部に、通信相手のスレッドBが実行されるVPU1のローカルストレージ32に対応するRA空間がマッピングされる。このマッピングのためのアドレス変換は、VPU0のメモリコントローラ33内に設けられたアドレス変換ユニット331がセグメントテーブルおよびページテーブルを用いて実行する。スレッドBが実行されるVPU1においては、そのスレッドBのEA空間の一部に、通信相手のスレッドAが実行されるVPU0のローカルストレージ32に対応するRA空間がマッピングされる。このマッピングのためのアドレス変換は、VPU1のメモリコントローラ33内に設けられたアドレス変換ユニット331がセグメントテーブルおよびページテーブルを用いて実行する。図27には、VPU0上で実行されるスレッドAが自身のEA空間にスレッドBが実行されるVPU1のローカルストレージ(LS1)32をマッピングし、VPU1上で実行されるスレッドBが自身のEA空間にスレッドAが実行されるVPU0のローカルストレージ(LS0)32をマッピングした様子が示されている。例えば、スレッドAはスレッドBに引き渡すべきデータがローカルストレージLS0上に準備できた時点で、そのことを示すフラグをローカルストレージLS0またはスレッドBが実行されるVPU1のローカルストレージLS1にセットする。スレッドBはそのフラグのセットに応答して、ローカルストレージLS0上のデータをリードする。
【0042】
このように、結合属性情報によって密結合関係にあるスレッドを特定できるようにすると共に、結合関係にあるスレッドA,Bがそれぞれ別のVPUによって同時に実行されることを保証することにより、スレッドA,B間の通信、同期に関するインタラクションをより軽量で且つ遅延無く行うことが可能となる。
【0043】
(疎結合スレッドグループ)
疎結合スレッドグループに属するスレッド群それぞれの実行時間は、それらスレッド群間の入出力関係によって決定され、たとえ実行順序の制約がないスレッド同士であってもそれらが同時に実行されることは保証されない。疎結合スレッドグループ属するスレッドを、疎結合スレッド(loosely coupled thread)と呼ぶ。図28においては、ある疎結合スレッドグループにスレッドC,Dの2つが疎結合スレッドとして含まれており、それらスレッドC,DがそれぞれVPU0,VPU1によって実行されている様子を示している。図28に示すように、各スレッドの実行時間はばらばらになる。スレッドC,D間の通信は、図29に示すように、メインメモリ14上に用意したバッファを介して行われる。スレッドCはローカルストレージLS0に用意したデータをDMA転送によってメインメモリ14上に用意したバッファに書き込み、スレッドDはその開始時にDMA転送によってメインメモリ14上のバッファからローカルストレージLS1にデータを読み込む。
【0044】
(プロセスとスレッド)
プロセスは,図30に示すように、一つのアドレス空間と一つ以上のスレッドから構成される。一つのプロセスに含まれるスレッドの数と種類は,どのような組み合わせでも構わない。例えば,VPUスレッドのみから構成されるプロセスも構築可能であるし,VPUスレッドとMPUスレッドが混在するプロセスも構築可能である。スレッドがスレッド固有の情報としてスレッドコンテクストを保持しているのと同様に,プロセスもプロセス固有の情報としてプロセスコンテクストを保持する。このプロセスコンテクストには,プロセスに固有であるアドレス空間と,プロセスが含んでいる全スレッドのスレッドコンテクストが含まれる。プロセスのアドレス空間は,プロセスに属するすべてのスレッド間で共有することができる。一つのプロセスは,複数のスレッドグループを含むことができる。しかし,一つのスレッドグループが複数のプロセスに属することはできない。このため,あるプロセスに属するスレッドグループは,そのプロセスに固有であるということになる。本実施形態のリアルタイム処理システムにおいて、スレッドを新しく生成する方式には、Thread first modelとAddress space first modelの2種類がある。Address space first modelは既存のOSで採用されているのと同様の方式で、MPUスレッドにもVPUスレッドにも適用できる。一方、Thread first modelはVPUスレッドにしか適用できない方式で、本発明のリアルタイム処理システムに特有の方式である。Thread first modelでは,既存のスレッド(新しくスレッドを作りたいと思っている側のスレッド。新しく作るスレッドの親になるスレッドのこと。)は,まず新規スレッドが実行するプログラムを指定して,新規スレッドにプログラムの実行を開始させる。この時、プログラムはVPU12のローカルストレージに格納され、所定の実行開始番地から処理が開始される。この時点では、この新規スレッドにはアドレス空間が関連付けられていないので、自身のローカルストレージはアクセスできるが、メモリ14はアクセスできない。その後,新規スレッドは,必要に応じて自身でVPU実行環境のサービスを呼び出してアドレス空間を生成して関連付けたり、MPU11側の処理によってアドレス空間を関連付けられたりして、メモリ14にアクセスできるようになる。Address space first modelでは,既存のスレッドは,新しくアドレス空間を生成するか、あるいは既存のアドレス空間を指定して、そのアドレス空間に新規スレッドが実行するプログラムを配置する。そして新規スレッドにそのプログラムの実行を開始させる。Thread first modelのメリットは、ローカルストレージだけで動作するので、スレッドの生成やディスパッチや終了処理などのオーバーヘッドを小さくできることである。
【0045】
(スレッド群のスケジューリング)
次に、図31のフローチャートを参照して、VPU実行環境401によって実行されるスケジューリング処理について説明する。VPU実行環境401内のスケジューラは、スケジュール対象のスレッド群にスレッドグループ単位で付加されている結合属性情報に基づいて、スレッド間の結合属性をチェックし(ステップS121)、各スレッドグループ毎にそのスレッドグループが密結合スレッドグループおよび疎結合スレッドグループのいずれであるかを判別する(ステップS122)。結合属性のチェックは、プログラムコード中のスレッドに関する記述あるいは上述の構成記述117中のスレッドパラメータを参照することによって行われる。このようにして、密結合スレッドグループおよび疎結合スレッドグループをそれぞれ特定することにより、スケジュール対象のスレッド群は密結合スレッドグループと疎結合スレッドグループとに分離される。
【0046】
密結合スレッドグループに属するスレッド群に対するスケジューリングは次のように行われる。すなわち、VPU実行環境401内のスケジューラは、スケジュール対象のスレッド群から選択された密結合スレッドグループに属するスレッド群がそれぞれ別のVPUによって同時に実行されるように、その密結合スレッドグループに属するスレッド群と同数のVPUそれぞれの実行期間を予約し、スレッド群をそれら予約したVPUそれぞれに同時にディスパッチする(ステップS123)。そして、スケジューラは、各スレッドが実行されるVPU内のアドレス変換ユニット331を用いて、各スレッドのEA空間の一部に、協調して相互作用を行う相手となる他のスレッドが実行されるVPUのローカルストレージに対応するRA空間をマッピングする(ステップS124)。一方、スケジュール対象のスレッド群から選択された疎結合スレッドグループに属する疎結合スレッド群については、スケジューラは、それらスレッド群間の入出力関係に基づいてそれらスレッド群を1以上のVPUに順次ディスパッチする(ステップS125)。
【0047】
(ローカルストレージのマッピング)
本実施形態のリアルタイム処理システムにおいて、MPUスレッドとVPUスレッドの間、あるいはVPUスレッドと他のVPUスレッドの間で、何らかの通信や同期を行いながら協調して動作を行う場合には、協調相手のVPUスレッドのローカルストレージにアクセスする必要がある。たとえば、より軽量で高速な同期機構は、ローカルストレージ上に同期変数を割り付けて実装する。そのため、あるVPU12のローカルストレージを、他のVPU12あるいはMPU11のスレッドが直接アクセスする必要がある。図4に示す例のように、各VPU12のローカルストレージが実アドレス空間に割り付けられている場合、セグメントテーブルやページテーブルを適切に設定すれば、相手のVPU12のローカルストレージを直接アクセスすることができる。しかしこの場合に、大きく2つの問題が生じる。
【0048】
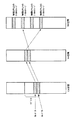
第1の問題は、VPUスレッドのディスパッチ先VPU12の変更に関する問題である。図32のように,VPUスレッドAとBが存在し,それぞれVPU0とVPU1で動いているとする。そして,このスレッドAとBはお互いのスレッドと協調したいので,お互いのスレッドのLS(ローカルストレージ)を,自分のEA空間にマッピングしているとする。また,VPU0,1,2のLS0,1,2はそれぞれ図32のようにRA空間に存在するとする。この時,VPUスレッドAが,自分のEA空間にマッピングしているのは,VPUスレッドBが動いているVPUのLS,つまり,VPU1のLSであるLS1である。逆に,VPUスレッドBが,自分のEA空間にマッピングしているのは,VPUスレッドAが動いているVPUのLS,つまり,VPU0のLSであるLS0である。その後,VPU実行環境の中のスケジューラによって、VPUスレッドAを実行するVPUがディスパッチされて,VPUスレッドAは,VPU2で動くことになったとする。この時、もはやVPUスレッドAはVPU0では動いていないので,VPUスレッドBが,自分のEA空間にマッピングしているVPU0のLSは,意味がなくなる。この場合,スレッドBが,スレッドAのディスパッチ先VPUが変更になったことを知らなくてもいいように,システムは何らかの方法でLS0にマッピングされていたEA空間のアドレスをLS2にマッピングして、スレッドBから、スレッドAのローカルストレージとしてVPU2のLSであるLS2が見えるようにする必要がある。
【0049】
第2の問題は、物理VPUと論理VPUの対応関係の問題である。VPUをVPUスレッドに割り当てるまでには,実際には,2つのレベルがある。一つは論理VPUのVPUスレッドへの割り当てであり,もう一つが物理VPUの論理VPUへの割り当てである。物理VPUとは,仮想計算機OS301が管理している物理的なVPU12である。そして,論理VPUとは,仮想計算機OS301がゲストOS割り当てた、論理的なVPUのことである。この関係は図14にも示している。たとえば、VPU実行環境401が論理的なVPUを管理する場合、図32の例で、VPUスレッドの割り当て対象となるVPUは論理VPUである。
【0050】
図33は,この2つのレベルの割り当ての概念を示している。直前に説明した第1の問題は,図33の上の段に位置する,VPUスレッドの論理VPUへの割り当て問題に相当する。第2の問題である物理VPUの論理VPUへの割り当て問題は,下の段に位置する割り当てに相当する。図33では,4つの物理VPUから,3つのVPUを選択し,3つの論理VPUに割り当てていることを示している。もし,この物理VPUと論理VPUの対応関係が変わった場合,VPUスレッドの論理VPUへの割り当てが変更になっていなくても,適切な設定の変更が必要となる。例えば,変更後の論理VPUのLSに対するアクセスが,正しい物理VPUのLSを指すように,LSに対応するページテーブルエントリを入れ換える,などである。
【0051】
ある時刻に,図34のように,物理VPU1,2,3が論理VPU0,1,2にそれぞれ割り当てられているとする。そして,論理VPU1はVPUスレッドAに,そして論理VPU2はVPUスレッドBに割り当てられていたとする。そして,VPUスレッドAとBは,それぞれ,お互いに,相手の動作している物理VPUのLSを自分のEA空間にマッピングしているとする。VPUスレッドAのEA空間にはVPUスレッドBが実行されている物理VPU3のLS3が,そしてVPUスレッドBのEA空間にはVPUスレッドAが実行されている物理VPU2のLS2がマッピングされている。その後,ある時刻に,仮想計算機OS301によって、論理VPU0,1が物理VPU0,1に,再割り当てされたとする。すると,今までVPUスレッドAが動作していた論理VPU1は,物理VPU2から物理VPU1へと変化する。論理VPUのVPUスレッドへの割り当ては変化していないが,物理VPUと論理VPUの対応関係が変化したことになる。このため,VPUスレッドBがEA空間にマッピングしている,VPUスレッドAの動作しているVPUのLSを,LS2からLS1に変更し,正しくアクセスできるようにする必要がある。
【0052】
これらの2つの問題を解決するために、本実施形態のリアルタイム処理システムでは、スレッドから見たEA空間の固定アドレスに、必ず相手のスレッドを実行しているVPUのローカルストレージがマップされて見えるように仮想記憶機構を制御する。すなわち、VPUスケジューラによる論理VPUのディスパッチ時、および仮想計算機OS等による物理VPUと論理VPUの対応関係の切り替え時に、適宜ページテーブルやセグメントテーブルを書き換えることで、VPU上で動作しているスレッドからは、いつも同じ番地に相手のスレッドを実行しているVPUのローカルストレージが見えるようにする。
【0053】
まず、2つのスレッドのEA空間の関係について説明する、2つのスレッドのEA空間は、次の3つのいずれかのパターンで共有あるいは非共有になっている。
1.共有EA型: 2つのスレッド1,2がセグメントテーブルもページテーブルも共有している(図35)
2.共有VA型: 2つのスレッド1,2は、ページテーブルは共有するが、セグメントテーブルは共有せず、それぞれが持っている(図36)
3.非共有型: 2つのスレッド1,2はページテーブルもセグメントテーブルも共有せず、それぞれが持っている(図37)
以下、1の共有EA型を例に、VPUのローカルストレージをどのようにマップするように制御するかについて説明する。
まず、図38に示すように、VA空間上に各論理VPUに対応した領域を設け、そこに、その論理VPUが対応付けられている物理VPUのローカルストレージがマップされるように、ページテーブルを設定する。この例の場合、物理VPU0,1,2がそれぞれ論理VPU0,1,2に対応付けられている状態を示している。次に、スレッドAからはスレッドBを実行しているVPUのローカルストレージが、固定アドレスであるセグメントaの領域に見えるように、セグメントテーブルを設定する。また、スレッドBからはスレッドAを実行している論理VPUのローカルストレージが、固定アドレスであるセグメントbに見えるように、セグメントテーブルを設定する。この例では、スレッドAは論理VPU2で、スレッドBは論理VPU1で実行している状況を示している。ここで、VPU実行環境401のスケジューラが、スレッドBを論理VPU0にディスパッチしたとする。この時、VPU実行環境401は、図39に示すように、スレッドAからは固定アドレスであるセグメントaを通して、スレッドBを現在実行している論理VPU0のローカルストレージを見えるように、VPU実行環境401はセグメントテーブルを自動的に書き換える。
さらにここで、たとえば仮想計算機OS301がゲストOSのディスパッチをしたため、物理VPUと論理VPUの対応が変化したとする。このとき、たとえば図40に示すように、VPU実行環境401は、ページテーブルを書き換えて、VA空間上に固定されている論理VPUのローカルストレージの領域が、正しい物理VPUのローカルストレージの領域を指すようにする。図40の例では、物理VPU1,2,3が論理VPU0,1,2に対応するように変更されたため、ページテーブルを書き換えて、現在の正しいマッピングになるようにしている。
【0054】
このように、VPU実行環境401のスケジューラのディスパッチによって、スレッドを実行する論理VPUが変更になった場合には、EA空間からVA空間へのマッピングを行っているセグメントテーブルを書き換えて、第1の問題を解決している。また、仮想計算機OS301などによって、物理VPUと論理VPUの対応が変更になった場合は、VA空間からRA空間へのマッピングを行っているページテーブルを書き換えて、第2の問題を解決している。
このようして、相互作用を行う相手のスレッドが実行されるプロセッサに応じて、実効アドレス空間にマッピングされる、相手のスレッドに対応するプロセッサのローカルメモリが自動的に変更することにより、各スレッドは相手のスレッドがディスパッチされるプロセッサを意識することなく、相手のスレッドとの相互作用を効率よく行うことが出来る。よって、複数のスレッドを効率よく並列に実行することが可能となる。
【0055】
以上、共有EA型の場合の例を説明したが、2の共有VA型、3の非共有型についても、セグメントテーブルまたはページテーブルを書き換えることにより、同様にして第1の問題および第2の問題を解決することができる。
【0056】
上記の第1および第2の問題を解決する別の方法について述べる。ここでも、共有EA型の場合を例に説明する。図41に示すように、協調して動作する複数のVPUスレッドがある場合、それらのスレッドを実行するVPUのローカルストレージを、セグメント上に連続してマップするように、ページテーブルとセグメントテーブルを設定する。図41の例の場合、スレッドAは物理VPU2で、スレッドBは物理VPU0で実行されており、それぞれのVPUのローカルストレージが同一のセグメントに連続して配置されるように、ページテーブルとセグメントテーブルを設定している。ここで、VPU実行環境401のスケジューラによってスレッドを実行する論理VPUがディスパッチされたり、仮想計算機OS301等によって物理VPUと論理VPUの対応が変更になった場合には、それぞれの変更がスレッドAおよびスレッドBに対して隠蔽されるように、ページテーブルを書き換えて、VA空間とRA空間のマップを変更する。たとえば図42は、スレッドAを実行しているVPUが物理VPU1に、スレッドBを実行しているVPUが物理VPU3に変更になった場合のマッピングを示している。この変更が行われても、スレッドAおよびスレッドBからは、固定したアドレスを持つセグメント内の、所定の領域をアクセスすることで、常に相手のスレッドを実行しているVPUのローカルストレージをアクセスすることができる。
【0057】
次に、図43のフローチャートを参照して、VPU実行環境401によって実行されるアドレス管理処理の手順について説明する。VPU実行環境401は、各スレッドのEA空間上の固定アドレスに、相手スレッドを実行しているVPUのローカルストレージに対応するRA空間をマッピングする(ステップS201)。この後、VPU実行環境401は、相手スレッドのディスパッチ先VPUの変更あるいは論理VPUと物理VPUの対応関係の変更に起因して、相手スレッドが実行されるVPUが変更されたかどうかを判別する(ステップS202)。相手スレッドが実行されるVPUが変更されたならば、VPU実行環境401は、セグメントテーブルまたはページテーブルの内容を書き換えて、各スレッドのEA空間上の固定アドレスにマッピングされているローカルストレージを、相手スレッドが実行されるVPUに合わせて変更する(ステップS203)。
【0058】
これまでの例では、蜜結合スレッドグループのように、互いにVPUによって実行中のスレッド間で、相手のスレッドを実行しているVPUのローカルストレージをアクセスする方式を説明した。しかし、疎結合スレッドグループなど、協調して動作するスレッドが必ずしも同時にVPUに割り当てられて実行していない場合も存在する。そのような場合でも、EA空間上には相手のスレッドを実行しているVPU12のローカルストレージをマップする領域は存在するので、その領域を以下のように用いて対処する。
【0059】
第1の方法: 相手のスレッドが実行中で無い場合には、そのスレッドに対応するVPUのローカルストレージをマップする領域にアクセスすると、スレッドは相手のスレッドが実行開始するまで待たされるようにする。
第2の方法: 相手のスレッドが実行中で無い場合には、そのスレッドに対応するVPUのローカルストレージをマップする領域にアクセスすると、スレッドは例外発生やエラーコードによって、その旨を知る。
【0060】
第3の方法: スレッドの終了時に、そのスレッドを最後に実行していたときのローカルストレージの内容をメモリに保存しておき、そのスレッドに対応付けられたローカルストレージを指すページテーブルあるいはセグメントテーブルのエントリからは、そのメモリ領域を指すようにマッピングを制御する。この方式により、相手のスレッドが実行中でなくても、相手のスレッドに対応付けられたローカルストレージがあたかもあるように、スレッドの実行を続けることができる。図44および図45に具体例を示す。
▲1▼: いま、スレッドA,BがそれぞれVPU0,1で実行されており、スレッドBのEA空間には相手のスレッドAが実行されているVPU0のローカルストレージLS0がマッピングされているとする。
▲2▼: スレッドAの終了時には、スレッドAまたはVPU実行環境401は、スレッドAが実行されているVPU0のローカルストレージLS0の内容をメモリ14に保存する(ステップS211)。
▲3▼: VPU実行環境401は、スレッドBのEA空間にマッピングされている相手先スレッドAのローカルストレージのアドレス空間を、VPU0のLS0から、LS0の内容が保存されたメモリ14上のメモリ領域に変更する(ステップS212)。これにより、スレッドBは、相手のスレッドAが実行中でなくなった後も、その動作を継続することができる。
▲4▼: スレッドAに再びVPUが割り当てられたとき、VPU実行環境401は、メモリ14上のメモリ領域をスレッドAが実行されるVPUのローカルストレージに戻す(ステップS213)。たとえばスレッドAに再びVPU0が割り当てられたときは、メモリ14上のメモリ領域の内容は、VPU0のローカルストレージLS0に戻される。
▲5▼: VPU実行環境401は、スレッドBのEA空間にマッピングされている相手先スレッドAのローカルストレージのアドレス空間を、スレッドAが実行されるVPUのローカルストレージに変更する(ステップS214)。たとえばスレッドAに再びVPU0が割り当てられたときは、スレッドBのEA空間にマッピングされている相手先スレッドAのローカルストレージのアドレス空間は、VPU0のローカルストレージLS0に戻される。
【0061】
なお、スレッドAにVPU2が割り当てられたときは、メモリ14上のメモリ領域の内容は、VPU2のローカルストレージLS2に復元される。そして、スレッドBのEA空間にマッピングされている相手先スレッドAのローカルストレージのアドレス空間は、VPU2のローカルストレージLS2に変更される。
【0062】
なお、図1の計算機システムに設けられたMPU11と複数のVPU12は。それらを1チップ上に混載した並列プロセッサとして実現することもできる。この場合も、MPU11によって実行されるVPU実行環境、あるいは特定の一つのVPUなどによって実行されるVPU実行環境が、複数のVPU12に対するスケジューリングおよびアドレス管理を行うことが出来る。
【0063】
またVPU実行環境として動作するプログラムまたはそのVPU実行環境を含むオペレーティングシステムなどのプログラムをコンピュータ読み取り可能な記憶媒体に記憶することにより、その記憶媒体を通じて当該プログラムを、ローカルプロセッサをそれぞれ有する複数のプロセッサを含むコンピュータに導入して実行するだけで、本実施形態と同様の効果を得ることが出来る。
【0064】
また、本発明は上記実施形態そのままに限定されるものではなく、実施段階ではその要旨を逸脱しない範囲で構成要素を変形して具体化できる。また、上記実施形態に開示されている複数の構成要素の適宜な組み合わせにより、種々の発明を形成できる。例えば、実施形態に示される全構成要素から幾つかの構成要素を削除してもよい。さらに、異なる実施形態にわたる構成要素を適宜組み合わせてもよい。
【0065】
【発明の効果】
以上説明したように、本発明によれば、複数のプロセッサを用いて複数のスレッドを効率よく並列に実行することが可能となる。
【図面の簡単な説明】
【図1】 本発明の一実施形態に係るリアルタイム処理システムを構成する計算機システムの例を示すブロック図。
【図2】 同実施形態のリアルタイム処理システムに設けられたMPUおよびVPUそれぞれの構成を示すブロック図。
【図3】 同実施形態のリアルタイム処理システムで用いられる仮想アドレス変換機構の例を示す図。
【図4】 同実施形態のリアルタイム処理システムにおける実アドレス空間にマッピングされるデータの例を示す図。
【図5】 同実施形態のリアルタイム処理システムにおける実効アドレス空間、仮想アドレス空間、実アドレス空間を説明するための図。
【図6】 デジタルテレビ放送の受信機の構成を示すブロック図。
【図7】 同実施形態のリアルタイム処理システムによって実行されるプログラムモジュールの構成の例を示す図。
【図8】 図7のプログラムモジュール内に含まれる構成記述の例を示す図。
【図9】 図7のプログラムモジュールに対応するプログラム間のデータの流れを示す図。
【図10】 図7のプログラムモジュールが2つのVPUによって並列に実行される様子を示す図。
【図11】 図7のプログラムモジュールが2つのVPUによってパイプライン形式で実行される様子を示す図。
【図12】 同実施形態のリアルタイム処理システムにおけるオペレーティングシステムの実装形態の例を示す図。
【図13】 同実施形態のリアルタイム処理システムにおけるオペレーティングシステムの実装形態の他の例を示す図。
【図14】 同実施形態のリアルタイム処理システムにおける仮想計算機OSとゲストOSとの関係を示す図。
【図15】 同実施形態のリアルタイム処理システムにおいて複数のゲストOSに時分割で資源が割り当てられる様子を示す図。
【図16】 同実施形態のリアルタイム処理システムにおいてある特定のゲストOSによって特定の資源が専有される様子を示す図。
【図17】 同実施形態のリアルタイム処理システムにおいてスケジューラとして用いられるVPU実行環境を示す図。
【図18】 同実施形態のリアルタイム処理システムで用いられる仮想計算機OSにVPU実行環境を実装した例を示す図。
【図19】 同実施形態のリアルタイム処理システムで用いられる一つのゲストOSとしてVPU実行環境を実装する例を示す図。
【図20】 同実施形態のリアルタイム処理システムで用いられる複数のゲストOSそれぞれにVPU実行環境を実装する例を示す図。
【図21】 同実施形態のリアルタイム処理システムで用いられる一つのゲストOSにVPU実行環境を実装する例を示す図。
【図22】 同実施形態のリアルタイム処理システムで用いられるMPU側VPU実行環境とVPU側VPU実行環境を説明するための図。
【図23】 同実施形態のリアルタイム処理システムで用いられるVPU側VPU実行環境によって実行される処理手順を示すフローチャート。
【図24】 同実施形態のリアルタイム処理システムで用いられるMPU側VPU実行環境によって実行される処理手順を示すフローチャート。
【図25】 同実施形態のリアルタイム処理システムにおいて密結合スレッドグループに属するスレッド群がそれぞれ別のプロセッサによって同時に実行される様子を示す図。
【図26】 同実施形態のリアルタイム処理システムにおける密結合スレッド間の相互作用を説明するための図。
【図27】 同実施形態のリアルタイム処理システムにおいて各密結合スレッドの実効アドレス空間に相手のスレッドが実行されるVPUのローカルストレージがマッピングされる様子を示す図。
【図28】 同実施形態のリアルタイム処理システムにおける疎結合スレッドグループに属するスレッド群に対するプロセッサの割り当てを説明するための図。
【図29】 同実施形態のリアルタイム処理システムにおける疎結合スレッド間の相互作用を説明するための図。
【図30】 同実施形態のリアルタイム処理システムにおけるプロセスとスレッドとの関係を説明するための図。
【図31】 同実施形態のリアルタイム処理システムにおけるスケジューリング処理の手順を示すフローチャート。
【図32】 同実施形態のリアルタイム処理システムにおけるローカルストレージのマッピングに関する第1の問題を説明するための図。
【図33】 同実施形態のリアルタイム処理システムにおける物理VPUと論理VPUとの関係を示す図。
【図34】 同実施形態のリアルタイム処理システムにおけるローカルストレージのマッピングに関する第2の問題を説明するための図。
【図35】 同実施形態のリアルタイム処理システムにおける実効アドレス空間共有モデルを示す図。
【図36】 同実施形態のリアルタイム処理システムにおける仮想アドレス空間共有モデルを示す図。
【図37】 同実施形態のリアルタイム処理システムにおける非共有モデルを示す図。
【図38】 同実施形態のリアルタイム処理システムにおけるローカルストレージのマッピング変更を説明するための第1の図。
【図39】 同実施形態のリアルタイム処理システムにおけるローカルストレージのマッピング変更を説明するための第2の図。
【図40】 同実施形態のリアルタイム処理システムにおけるローカルストレージのマッピング変更を説明するための第3の図。
【図41】 同実施形態のリアルタイム処理システムにおけるローカルストレージのマッピング変更を説明するための第4の図。
【図42】 同実施形態のリアルタイム処理システムにおけるローカルストレージのマッピング変更を説明するための第5の図。
【図43】 同実施形態のリアルタイム処理システムにおいてローカルストレージのマッピング変更を行うために実行されるアドレス管理処理の手順を示すフローチャート。
【図44】 同実施形態のリアルタイム処理システムにおいて実行されるローカルストレージとメモリとの間のマッピング変更を説明するための図。
【図45】 同実施形態のリアルタイム処理システムにおいて実行されるローカルストレージとメモリとの間のマッピング変更処理の手順を示すフローチャート。
【符号の説明】
11…MPU(Master Processing Unit)、12…VPU(Slave Processing Unit)、14…メインメモリ、21…処理ユニット、22…メモリ管理ユニット、31…処理ユニット、32…ローカルストレージ、33…メモリコントローラ、50…セグメントテーブル、60…ページテーブル、100…プログラムモジュール、117…構成記述、331…アドレス変換ユニット、401…VPU実行環境。
Claims (12)
- 第1のローカルメモリを有する第1のプロセッサと、
第2のローカルメモリを有する第2のプロセッサと、
第3のローカルメモリを有する第3のプロセッサと、
前記第1のプロセッサによって実行される第1のスレッドの実効アドレス空間の一部に、前記第1のスレッドとの相互作用を行う第2のスレッドが実行される前記第2および第3の一方のプロセッサに対応する前記第2および第3の一方のローカルメモリをマッピングする手段と、
前記第2のスレッドが実行されるプロセッサが前記第2および第3の一方のプロセッサから他方のプロセッサに変更された場合、前記第1のスレッドの実効アドレス空間の前記一部に、前記第2および第3の一方のローカルメモリに代えて他方のローカルメモリをマッピングする手段とを具備することを特徴とする情報処理システム。 - 前記第1のプロセッサ、前記第2のプロセッサ、および前記第3のプロセッサによって共有される共有メモリと、
前記第2のスレッドの実行が停止される場合、前記第2のスレッドが実行されていた前記第2および第3の一方のプロセッサに対応する前記第2および第3の一方のローカルメモリの内容を前記共有メモリ上のメモリ領域に保存する手段と、
前記第1のスレッドの実効アドレス空間の前記一部に、前記第2および第3の一方のローカルメモリに代えて前記共有メモリ上の前記メモリ領域をマッピングする手段とをさらに具備することを特徴とする請求項1記載の情報処理システム。 - 前記第2のスレッドが前記第2および第3の一方のプロセッサによって実行再開される場合、前記共有メモリ上の前記メモリ領域の内容を前記第2および第3の一方のプロセッサに対応する前記第2および第3の一方のローカルメモリに復元する手段と、
前記第1のスレッドの実効アドレス空間の前記一部に、前記共有メモリ上の前記メモリ領域に代えて前記第2および第3の一方のローカルメモリをマッピングする手段とをさらに具備することを特徴とする請求項2記載の情報処理システム。 - 前記第2のスレッドが前記第2および第3の他方のプロセッサによって実行再開される場合、前記共有メモリ上の前記メモリ領域の内容を前記第2および第3の他方のプロセッサに対応する前記第2および第3の他方のローカルメモリに復元する手段と、
前記第1のスレッドの実効アドレス空間の前記一部に、前記共有メモリ上の前記メモリ領域に代えて前記第2および第3の他方のローカルメモリをマッピングする手段とをさらに具備することを特徴とする請求項2記載の情報処理システム。 - 第1のローカルメモリを有する第1のプロセッサ、第2のローカルメモリを有する第2のプロセッサ、および第3のローカルメモリを有する第3のプロセッサを含む情報処理システムにおいてスレッド間の通信に用いられるローカルメモリを管理するメモリ管理方法であって、
前記第1のプロセッサによって実行される第1のスレッドの実効アドレス空間の一部に、前記第1のスレッドとの相互作用を行う第2のスレッドが実行される前記第2および第3の一方のプロセッサに対応する前記第2および第3の一方のローカルメモリをマッピングするステップと、
前記第2のスレッドが実行されるプロセッサが前記第2および第3の一方のプロセッサから他方のプロセッサに変更された場合、前記第1のスレッドの実効アドレス空間の前記一部に、前記第2および第3の一方のローカルメモリに代えて他方のローカルメモリをマッピングするステップとを具備することを特徴とするメモリ管理方法。 - 前記第2のスレッドの実行が停止される場合、前記第2のスレッドが実行されていた前記第2および第3の一方のプロセッサに対応する前記第2および第3の一方のローカルメモリの内容を、前記第1のプロセッサ、前記第2のプロセッサ、および前記第3のプロセッサによって共有される共有メモリ上のメモリ領域に保存するステップと、
前記第1のスレッドの実効アドレス空間の前記一部に、前記第2および第3の一方のローカルメモリに代えて前記共有メモリ上の前記メモリ領域をマッピングするステップとをさらに具備することを特徴とする請求項5記載のメモリ管理方法。 - 前記第2のスレッドが前記第2および第3の一方のプロセッサによって実行再開される場合、前記共有メモリ上の前記メモリ領域の内容を前記第2および第3の一方のプロセッサに対応する前記第2および第3の一方のローカルメモリに復元するステップと、
前記第1のスレッドの実効アドレス空間の前記一部に、前記共有メモリ上の前記メモリ領域に代えて前記第2および第3の一方のローカルメモリをマッピングするステップとをさらに具備することを特徴とする請求項6記載のメモリ管理方法。 - 前記第2のスレッドが前記第2および第3の他方のプロセッサによって実行再開される場合、前記共有メモリ上の前記メモリ領域の内容を前記第2および第3の他方のプロセッサに対応する前記第2および第3の他方のローカルメモリに復元するステップと、
前記第1のスレッドの実効アドレス空間の前記一部に、前記共有メモリ上の前記メモリ領域に代えて前記第2および第3の他方のローカルメモリをマッピングするステップとをさらに具備することを特徴とする請求項6記載のメモリ管理方法。 - 第1のローカルメモリを有する第1のプロセッサ、第2のローカルメモリを有する第2のプロセッサ、および第3のローカルメモリを有する第3のプロセッサを含むコンピュータに、スレッド間の通信に用いられるローカルメモリを管理させるプログラムであって、
前記第1のプロセッサによって実行される第1のスレッドの実効アドレス空間の一部に、前記第1のスレッドとの相互作用を行う第2のスレッドが実行される前記第2および第3の一方のプロセッサに対応する前記第2および第3の一方のローカルメモリをマッピングする処理を、前記コンピュータに実行させる手順と、
前記第2のスレッドが実行されるプロセッサが前記第2および第3の一方のプロセッサから他方のプロセッサに変更された場合、前記第1のスレッドの実効アドレス空間の前記一部に、前記第2および第3の一方のローカルメモリに代えて他方のローカルメモリをマッピングする処理を、前記コンピュータに実行させる手順とを具備することを特徴とするプログラム。 - 前記第2のスレッドの実行が停止される場合、前記第2のスレッドが実行されていた前記第2および第3の一方のプロセッサに対応する前記第2および第3の一方のローカルメモリの内容を、前記第1のプロセッサ、前記第2のプロセッサ、および前記第3のプロセッサによって共有される共有メモリ上のメモリ領域に保存する処理を、前記コンピュータに実行させる手順と、
前記第1のスレッドの実効アドレス空間の前記一部に、前記第2および第3の一方のローカルメモリに代えて前記共有メモリ上の前記メモリ領域をマッピングする処理を、前記コンピュータに実行させる手順とをさらに具備することを特徴とする請求項9記載のプログラム。 - 前記第2のスレッドが前記第2および第3の一方のプロセッサによって実行再開される場合、前記共有メモリ上の前記メモリ領域の内容を前記第2および第3の一方のプロセッサに対応する前記第2および第3の一方のローカルメモリに復元する処理を、前記コンピュータに実行させる手順と、
前記第1のスレッドの実効アドレス空間の前記一部に、前記共有メモリ上の前記メモリ領域に代えて前記第2および第3の一方のローカルメモリをマッピングする処理を、前記コンピュータに実行させる手順とをさらに具備することを特徴とする請求項10記載のプログラム。 - 前記第2のスレッドが前記第2および第3の他方のプロセッサによって実行再開される場合、前記共有メモリ上の前記メモリ領域の内容を前記第2および第3の他方のプロセッサに対応する前記第2および第3の他方のローカルメモリに復元する処理を、前記コンピュータに実行させる手順と、
前記第1のスレッドの実効アドレス空間の前記一部に、前記共有メモリ上の前記メモリ領域に代えて前記第2および第3の他方のローカルメモリをマッピングする処理を、前記コンピュータに実行させる手順とをさらに具備することを特徴とする請求項10記載のプログラム。
Priority Applications (6)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2003185416A JP3892829B2 (ja) | 2003-06-27 | 2003-06-27 | 情報処理システムおよびメモリ管理方法 |
| KR1020040013136A KR100608220B1 (ko) | 2003-06-27 | 2004-02-26 | 정보처리시스템 및 메모리 관리방법과 이 방법을 실행하기 위한 프로그램을 기록한 기록매체 |
| CNB2004100073028A CN100416540C (zh) | 2003-06-27 | 2004-02-27 | 信息处理系统和存储器管理方法 |
| US10/808,320 US7356666B2 (en) | 2003-06-27 | 2004-03-25 | Local memory management system with plural processors |
| EP04251822A EP1492015A3 (en) | 2003-06-27 | 2004-03-26 | Information processing system including processors and memory managing method used in the same system |
| US11/751,728 US7739457B2 (en) | 2003-06-27 | 2007-05-22 | Local memory management system with plural processors |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2003185416A JP3892829B2 (ja) | 2003-06-27 | 2003-06-27 | 情報処理システムおよびメモリ管理方法 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2005018620A JP2005018620A (ja) | 2005-01-20 |
| JP3892829B2 true JP3892829B2 (ja) | 2007-03-14 |
Family
ID=33411151
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2003185416A Expired - Fee Related JP3892829B2 (ja) | 2003-06-27 | 2003-06-27 | 情報処理システムおよびメモリ管理方法 |
Country Status (5)
| Country | Link |
|---|---|
| US (2) | US7356666B2 (ja) |
| EP (1) | EP1492015A3 (ja) |
| JP (1) | JP3892829B2 (ja) |
| KR (1) | KR100608220B1 (ja) |
| CN (1) | CN100416540C (ja) |
Families Citing this family (44)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP3892829B2 (ja) * | 2003-06-27 | 2007-03-14 | 株式会社東芝 | 情報処理システムおよびメモリ管理方法 |
| JP3889726B2 (ja) * | 2003-06-27 | 2007-03-07 | 株式会社東芝 | スケジューリング方法および情報処理システム |
| JP4025260B2 (ja) | 2003-08-14 | 2007-12-19 | 株式会社東芝 | スケジューリング方法および情報処理システム |
| JP4197672B2 (ja) * | 2004-09-30 | 2008-12-17 | 株式会社東芝 | マルチプロセッサ計算機及びプログラム |
| JP4197673B2 (ja) * | 2004-09-30 | 2008-12-17 | 株式会社東芝 | マルチプロセッサ計算機及びタスク実行方法 |
| JP4606142B2 (ja) * | 2004-12-01 | 2011-01-05 | 株式会社ソニー・コンピュータエンタテインメント | スケジューリング方法、スケジューリング装置およびマルチプロセッサシステム |
| JP4893621B2 (ja) * | 2005-05-20 | 2012-03-07 | ソニー株式会社 | 信号処理装置 |
| US7526634B1 (en) * | 2005-12-19 | 2009-04-28 | Nvidia Corporation | Counter-based delay of dependent thread group execution |
| CN100454899C (zh) * | 2006-01-25 | 2009-01-21 | 华为技术有限公司 | 一种网络处理装置及方法 |
| US8578347B1 (en) * | 2006-12-28 | 2013-11-05 | The Mathworks, Inc. | Determining stack usage of generated code from a model |
| US20080244538A1 (en) * | 2007-03-26 | 2008-10-02 | Nair Sreekumar R | Multi-core processor virtualization based on dynamic binary translation |
| US8014136B2 (en) * | 2007-04-26 | 2011-09-06 | Jupiter IP, LLC | Modular computer system |
| JP4903092B2 (ja) | 2007-07-05 | 2012-03-21 | 株式会社リコー | 画像処理装置、画像処理制御方法、及び画像処理制御プログラム |
| US20090125706A1 (en) * | 2007-11-08 | 2009-05-14 | Hoover Russell D | Software Pipelining on a Network on Chip |
| US8261025B2 (en) | 2007-11-12 | 2012-09-04 | International Business Machines Corporation | Software pipelining on a network on chip |
| US7873701B2 (en) * | 2007-11-27 | 2011-01-18 | International Business Machines Corporation | Network on chip with partitions |
| US8275947B2 (en) * | 2008-02-01 | 2012-09-25 | International Business Machines Corporation | Mechanism to prevent illegal access to task address space by unauthorized tasks |
| US8239879B2 (en) | 2008-02-01 | 2012-08-07 | International Business Machines Corporation | Notification by task of completion of GSM operations at target node |
| US8255913B2 (en) | 2008-02-01 | 2012-08-28 | International Business Machines Corporation | Notification to task of completion of GSM operations by initiator node |
| US8214604B2 (en) | 2008-02-01 | 2012-07-03 | International Business Machines Corporation | Mechanisms to order global shared memory operations |
| US8200910B2 (en) | 2008-02-01 | 2012-06-12 | International Business Machines Corporation | Generating and issuing global shared memory operations via a send FIFO |
| US8146094B2 (en) * | 2008-02-01 | 2012-03-27 | International Business Machines Corporation | Guaranteeing delivery of multi-packet GSM messages |
| US8484307B2 (en) | 2008-02-01 | 2013-07-09 | International Business Machines Corporation | Host fabric interface (HFI) to perform global shared memory (GSM) operations |
| US7873879B2 (en) * | 2008-02-01 | 2011-01-18 | International Business Machines Corporation | Mechanism to perform debugging of global shared memory (GSM) operations |
| US8423715B2 (en) | 2008-05-01 | 2013-04-16 | International Business Machines Corporation | Memory management among levels of cache in a memory hierarchy |
| US8438578B2 (en) | 2008-06-09 | 2013-05-07 | International Business Machines Corporation | Network on chip with an I/O accelerator |
| US9086913B2 (en) * | 2008-12-31 | 2015-07-21 | Intel Corporation | Processor extensions for execution of secure embedded containers |
| EP2450135B1 (en) | 2009-06-29 | 2019-05-01 | Kyocera Corporation | Cutting tool with insert and holder |
| JP2011095852A (ja) * | 2009-10-27 | 2011-05-12 | Toshiba Corp | キャッシュメモリ制御回路 |
| JP2012173870A (ja) * | 2011-02-18 | 2012-09-10 | Toshiba Corp | 半導体装置及びメモリ保護方法 |
| US8719464B2 (en) * | 2011-11-30 | 2014-05-06 | Advanced Micro Device, Inc. | Efficient memory and resource management |
| WO2014188643A1 (ja) * | 2013-05-24 | 2014-11-27 | 日本電気株式会社 | スケジュールシステム、スケジュール方法、及び、記録媒体 |
| JP2014078214A (ja) * | 2012-09-20 | 2014-05-01 | Nec Corp | スケジュールシステム、スケジュール方法、スケジュールプログラム、及び、オペレーティングシステム |
| JP6582367B2 (ja) * | 2014-07-18 | 2019-10-02 | 富士通株式会社 | 情報処理装置、情報処理装置の制御方法および情報処理装置の制御プログラム |
| JP2016115253A (ja) * | 2014-12-17 | 2016-06-23 | 富士通株式会社 | 情報処理装置、メモリ管理方法およびメモリ管理プログラム |
| JP6859755B2 (ja) * | 2017-03-02 | 2021-04-14 | 富士通株式会社 | 情報処理装置、情報処理装置の制御方法および情報処理装置の制御プログラム |
| US20200334076A1 (en) * | 2019-04-19 | 2020-10-22 | Nvidia Corporation | Deep learning thread communication |
| US11438414B2 (en) | 2019-05-28 | 2022-09-06 | Micron Technology, Inc. | Inter operating system memory services over communication network connections |
| US12436804B2 (en) | 2019-05-28 | 2025-10-07 | Micron Technology, Inc. | Memory as a service for artificial neural network (ANN) applications |
| US11061819B2 (en) | 2019-05-28 | 2021-07-13 | Micron Technology, Inc. | Distributed computing based on memory as a service |
| US11100007B2 (en) | 2019-05-28 | 2021-08-24 | Micron Technology, Inc. | Memory management unit (MMU) for accessing borrowed memory |
| US11256624B2 (en) | 2019-05-28 | 2022-02-22 | Micron Technology, Inc. | Intelligent content migration with borrowed memory |
| US11334387B2 (en) * | 2019-05-28 | 2022-05-17 | Micron Technology, Inc. | Throttle memory as a service based on connectivity bandwidth |
| US11231963B2 (en) * | 2019-08-15 | 2022-01-25 | Intel Corporation | Methods and apparatus to enable out-of-order pipelined execution of static mapping of a workload |
Family Cites Families (20)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4539637A (en) | 1982-08-26 | 1985-09-03 | At&T Bell Laboratories | Method and apparatus for handling interprocessor calls in a multiprocessor system |
| JPH02242434A (ja) | 1989-03-16 | 1990-09-26 | Hitachi Ltd | タスクのスケジューリング方法 |
| JPH04245745A (ja) | 1991-01-30 | 1992-09-02 | Nec Corp | サービス速度設定回路 |
| JPH04246745A (ja) | 1991-02-01 | 1992-09-02 | Canon Inc | 情報処理装置及びその方法 |
| US5269013A (en) * | 1991-03-20 | 1993-12-07 | Digital Equipment Corporation | Adaptive memory management method for coupled memory multiprocessor systems |
| JPH07302246A (ja) * | 1994-05-09 | 1995-11-14 | Toshiba Corp | スケジューリング方式 |
| JPH08180025A (ja) * | 1994-12-21 | 1996-07-12 | Toshiba Corp | スケジューリング装置 |
| JPH10143380A (ja) * | 1996-11-07 | 1998-05-29 | Hitachi Ltd | マルチプロセッサシステム |
| US6289424B1 (en) * | 1997-09-19 | 2001-09-11 | Silicon Graphics, Inc. | Method, system and computer program product for managing memory in a non-uniform memory access system |
| US6212544B1 (en) * | 1997-10-23 | 2001-04-03 | International Business Machines Corporation | Altering thread priorities in a multithreaded processor |
| JPH11316691A (ja) | 1998-05-06 | 1999-11-16 | Sega Enterp Ltd | オペレーティングシステムの実行方法及び、これを用いた情報処理装置 |
| US6314501B1 (en) | 1998-07-23 | 2001-11-06 | Unisys Corporation | Computer system and method for operating multiple operating systems in different partitions of the computer system and for allowing the different partitions to communicate with one another through shared memory |
| US6622155B1 (en) * | 1998-11-24 | 2003-09-16 | Sun Microsystems, Inc. | Distributed monitor concurrency control |
| JP3557947B2 (ja) | 1999-05-24 | 2004-08-25 | 日本電気株式会社 | 複数のプロセッサで同時にスレッドの実行を開始させる方法及びその装置並びにコンピュータ可読記録媒体 |
| EP1290560A2 (en) * | 2000-05-19 | 2003-03-12 | Neale Bremner Smith | Distributed processing multi-processor computer |
| JP2002163239A (ja) * | 2000-11-22 | 2002-06-07 | Toshiba Corp | マルチプロセッサシステムおよびその制御方法 |
| US7454600B2 (en) * | 2001-06-22 | 2008-11-18 | Intel Corporation | Method and apparatus for assigning thread priority in a processor or the like |
| JP3892829B2 (ja) * | 2003-06-27 | 2007-03-14 | 株式会社東芝 | 情報処理システムおよびメモリ管理方法 |
| US7380039B2 (en) * | 2003-12-30 | 2008-05-27 | 3Tera, Inc. | Apparatus, method and system for aggregrating computing resources |
| JP4246745B2 (ja) | 2006-03-06 | 2009-04-02 | イー・アイ・デュポン・ドウ・ヌムール・アンド・カンパニー | ブラシ用モノフィラメント及びブラシ用モノフィラメントの製造方法 |
-
2003
- 2003-06-27 JP JP2003185416A patent/JP3892829B2/ja not_active Expired - Fee Related
-
2004
- 2004-02-26 KR KR1020040013136A patent/KR100608220B1/ko not_active Expired - Fee Related
- 2004-02-27 CN CNB2004100073028A patent/CN100416540C/zh not_active Expired - Fee Related
- 2004-03-25 US US10/808,320 patent/US7356666B2/en not_active Expired - Fee Related
- 2004-03-26 EP EP04251822A patent/EP1492015A3/en not_active Withdrawn
-
2007
- 2007-05-22 US US11/751,728 patent/US7739457B2/en not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| CN1577310A (zh) | 2005-02-09 |
| US7356666B2 (en) | 2008-04-08 |
| US20040268083A1 (en) | 2004-12-30 |
| US20070220230A1 (en) | 2007-09-20 |
| EP1492015A3 (en) | 2007-08-15 |
| CN100416540C (zh) | 2008-09-03 |
| KR100608220B1 (ko) | 2006-08-08 |
| KR20050000488A (ko) | 2005-01-05 |
| US7739457B2 (en) | 2010-06-15 |
| JP2005018620A (ja) | 2005-01-20 |
| EP1492015A2 (en) | 2004-12-29 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP3892829B2 (ja) | 情報処理システムおよびメモリ管理方法 | |
| JP4028444B2 (ja) | スケジューリング方法およびリアルタイム処理システム | |
| JP3889726B2 (ja) | スケジューリング方法および情報処理システム | |
| JP3920818B2 (ja) | スケジューリング方法および情報処理システム | |
| JP4057989B2 (ja) | スケジューリング方法および情報処理システム | |
| US7464379B2 (en) | Method and system for performing real-time operation | |
| US7661107B1 (en) | Method and apparatus for dynamic allocation of processing resources | |
| WO2010095182A1 (ja) | マルチスレッドプロセッサ及びデジタルテレビシステム | |
| CN113076189B (zh) | 具有多数据通路的数据处理系统及用多数据通路构建虚拟电子设备 | |
| CN113076180B (zh) | 上行数据通路的构建方法及数据处理系统 | |
| CN113535345A (zh) | 下行数据通路的构建方法及设备 | |
| CN113535377A (zh) | 数据通路、其资源管理方法及其信息处理设备 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20060719 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20060725 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20060922 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20061205 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20061207 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20091215 Year of fee payment: 3 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20101215 Year of fee payment: 4 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20111215 Year of fee payment: 5 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20121215 Year of fee payment: 6 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20121215 Year of fee payment: 6 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20131215 Year of fee payment: 7 |
|
| LAPS | Cancellation because of no payment of annual fees |