JP3705331B2 - Hypertext analysis apparatus and method, and storage medium storing hypertext analysis program - Google Patents
Hypertext analysis apparatus and method, and storage medium storing hypertext analysis program Download PDFInfo
- Publication number
- JP3705331B2 JP3705331B2 JP34575998A JP34575998A JP3705331B2 JP 3705331 B2 JP3705331 B2 JP 3705331B2 JP 34575998 A JP34575998 A JP 34575998A JP 34575998 A JP34575998 A JP 34575998A JP 3705331 B2 JP3705331 B2 JP 3705331B2
- Authority
- JP
- Japan
- Prior art keywords
- hyperlink
- hypertext
- cluster
- analysis
- cohesion degree
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
- 238000004458 analytical method Methods 0.000 title claims description 48
- 238000000034 method Methods 0.000 title claims description 19
- 230000008569 process Effects 0.000 claims description 9
- 238000011156 evaluation Methods 0.000 claims description 5
- 238000007493 shaping process Methods 0.000 claims description 5
- 238000004364 calculation method Methods 0.000 claims description 3
- 238000010586 diagram Methods 0.000 description 22
- 239000013598 vector Substances 0.000 description 9
- 230000007704 transition Effects 0.000 description 7
- 230000001174 ascending effect Effects 0.000 description 2
- 230000008859 change Effects 0.000 description 2
- 230000000694 effects Effects 0.000 description 2
- 239000003795 chemical substances by application Substances 0.000 description 1
- 239000002131 composite material Substances 0.000 description 1
- 238000004590 computer program Methods 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- 230000008878 coupling Effects 0.000 description 1
- 238000010168 coupling process Methods 0.000 description 1
- 238000005859 coupling reaction Methods 0.000 description 1
- 230000005611 electricity Effects 0.000 description 1
- 230000006870 function Effects 0.000 description 1
- 230000010365 information processing Effects 0.000 description 1
- 230000005389 magnetism Effects 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
Images








Landscapes
- Computer And Data Communications (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Information Transfer Between Computers (AREA)
Description
【0001】
【発明の属する技術分野】
本発明は、ネットワーク上に構成されるハイパーテキストシステムにおいて、その構成の優劣を判断するための知識を発見するためにハイパーリンク構造を解析するハイパーテキスト解析装置及びハイパーテキスト解析方法と、そのハイパーテキスト解析装置または方法をコンピュータで実現するためのハイパーテキスト解析プログラムを記録した記録媒体に関するものである。
【0002】
【従来の技術】
ネットワーク上に構成されるハイパーテキストシステム(例えば、WorldWide Web:以降Webと略す)では、ハイパーテキストを格納しているサーバにおいてユーザ(訪問者)のアクセス履歴を記録することができる。このアクセス履歴には、一般に、アクセスしてきたユーザが使用しているコンピュータの識別子(インターネットを利用しているのであればIPアドレス)、アクセスしてきた時刻、アクセスしたノードのサーバ上での識別子(WebではURL)が含まれる。
【0003】
アクセス履歴を解析して、個々のユーザが遷移したハイパーリンクの経路を特定するには、基本的には、各コンピュータ毎にアクセスしたノードを時刻順に並べればよい。しかし、コンピュータのキャッシュ機能等により完全な経路を特定することは困難であった。
【0004】
これに対し、例えば、C.Shahabi,A.M.Zarkesh,J.Adibi,and V.Shah,“Knowledge Discoveryfrom Users Web−Page Navigation”,in Proc. of IEEE RIDE, 1997.では、リモートエージェントを使うことによりキャッシュへのアクセスを認識している。これによって、より正確な経路を得ることができるようになった。ただし、ユーザのコンピュータ側でリモートエージェントプログラムをロードするためのコスト(時間とスペース)が犠牲となるという不具合がある。
【0005】
アクセス履歴を利用して重要経路を発見する技術としては、例えば、J.Borges and M.Levene,“Mining Association Rules in Hypertext Databases”,in Proc. of KDD,1998.に記載されている技術がある。この技術は、まずアクセス履歴を収集して、ハイパーリンクのトラフィック量を重みとする有向グラフでハイパー構造を表現する。この有向グラフにおいて、ノードAからノードBへの遷移をA→Bと記し、これを結合規則と呼ぶ。結合規則は、コンフィデンス値(=Aを起点とする遷移の総数に対するA→Bの遷移の総数)とサポート値(=有向グラフ中のすべてのアークの遷移数の平均値に対するA→Bの遷移の総数)によって評価される。さらに、結合規則を合成した合成結合規則(A→B)&(B→C)&(C→D)&...を定義して3つ以上のノードの遷移を評価している。
【0006】
この手法では、コンピュータ識別子(IPアドレス)の情報は利用していないので、合成結合規則においては、単にトラフィック量が多いハイパーリンクの組み合わせ経路を発見しているに過ぎない。例えば、(A→B)&(B→C)という合成結合規則が、高いコンフィデンス値とサポート値を持っていることがわかったとしても、実際に、A→B→Cという経路を辿ったユーザが多かったとは限らない。
【0007】
このように従来技術によって、ユーザのアクセス経路を特定したり、重要経路を発見することは可能である。しかし、ハイパーテキストシステム(例えば、Webサイト)の構成の優劣を判断するような知識を得ることはできなかった。
【0008】
【発明が解決しようとする課題】
本発明は、上述した事情に鑑みてなされたもので、アクセス履歴からユーザのアクセス傾向を認識できるとともに、ハイパーテキストシステムの構成の優劣を判断するような知識を得ることを支援するハイパーテキスト解析装置及びハイパーテキスト解析方法を提供することを目的とするものである。また、そのハイパーテキスト解析装置または方法をコンピュータで実現するためのハイパーテキスト解析プログラムを記録した記録媒体を提供することを目的とするものである。
【0009】
【課題を解決するための手段】
本発明は、ハイパーテキストシステムへのアクセス履歴情報に基づいて該ハイパーテキストシステムを構成するノードに対してクラスタリングを行い、得られた各クラスタについて該クラスタを構成するノード間のハイパーリンク結束度を計算し、計算したハイパーリンク結束度を表示することを特徴とするものである。表示されるハイパーリンク結束度は、ユーザがアクセスした履歴に基づいた値であるから、ユーザのアクセス傾向を示している。そのため、ハイパーリンク結束度を得ることによって、例えばハイパーテキストシステム(例えばWebサイト)のハイパーリンク構成などとともに、ハイパーテキストシステムの構成の優劣を判断することが可能となる。
【0010】
【発明の実施の形態】
図1は、本発明の第1の実施の形態を示す構成図、図2は、Webの一例の説明図である。図中、1はWebサーバ、2はハイパーテキスト解析装置、11はアクセス履歴情報、21はアクセス傾向解析部、22はハイパーリンク構成解析部、23はハイパーリンク結束度表示部である。ネットワーク上に構成されるハイパーテキストシステムのなかで代表的なものはWebである。以下、Webを例として説明する。
【0011】
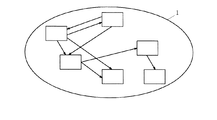
Webサーバ1は、ネットワーク上で情報を発信する手段である。Webサーバ1には、図2に示すように、ユーザに提供したい情報がノード(矩形で示す)とハイパーリンク(矢線で示す)によるハイパー構造で貯えられている。ユーザはWebサーバ1にアクセスすることでコンテンツを入手できる。このとき、Webサーバ1では、一般に、ユーザのアクセスがある毎に、ユーザのコンピュータを識別するためのコンピュータ識別子(IPアドレス)とアクセス時刻とユーザのアクセスしたノードのあるアドレス(URL)をアクセス履歴情報11として記録している。
【0012】
ハイパーテキスト解析装置2は、アクセス傾向解析部21,ハイパーリンク構成解析部22,ハイパーリンク結束度表示部23などを有している。アクセス傾向解析部21は、Webサーバ1上のノード群に対し、それぞれに対応するアクセス履歴情報11を用いてクラスタリングの処理を施す。このクラスタリングの処理には既存の技術を使用することができる。例えば、Agglomerative Hierarchical Clusteringによるクラスタリングの方法では、以下の1,2,3のステップを行う。
1.Webサーバ1上の各ノードをそれぞれ一つのクラスタとする。
2.各クラスタ間の類似度を計算し、最大類似度を持つクラスタ同士を一つのクラスタにマージする。
3.クラスタが一つになるまで2の処理を繰り返す。
この過程の途中で順次生成されるそれぞれのクラスタをクラスタリングの処理結果として得る。例えば1.の処理において生成される各ノードのみのクラスタ、そのクラスタをマージした各クラスタ、最後に生成された1つのクラスタなどがクラスタリング結果となる。なお、上述のクラスタリングの方法は、例えば、E.M.Voorhees,“Implementing Agglomerative Hierarchical Clustering Algorithms for Use in Document Retrieval”,Information Processing&Management,Vol.22,No.6,1986等に記載されている。
【0013】
アクセス傾向解析部21では、上述のクラスタリング処理の2.の処理における類似度計算において、アクセス履歴情報11の重複度合いを利用する。具体的には、例えば、アクセス履歴情報11の中のIPアドレスに注目して、クラスタ間で共有するIPアドレスの数を類似度と定義する。または、クラスタ間で共有するIPアドレスの数を当該二つのクラスタが持つ全てのIPアドレスの数で割った値を類似度と定義する。ここで、クラスタが持つIPアドレスとは、クラスタを構成する各ノードへのアクセス履歴を全てマージして、その中に出現するIPアドレスのことである。IPアドレスの数は、このようなIPアドレスから重複を排除した異なるIPアドレスを計数した値とすることができる。なお、IPアドレスを用いる代わりに、例えばアクセス履歴情報11中のアクセス時刻を用いてもよい。この場合、秒や分単位ではなく日付や月の単位で取り扱うとよい。
【0014】
あるいは、類似度計算として、各クラスタを該クラスタに対応するアクセス履歴情報11を項とし、該アクセス履歴情報の出現頻度を該項の値とするようなベクトルを生成して、ベクトル間の内積値の大小を類似度として用いてもよい。
【0015】
ハイパーリンク構成解析部22は、アクセス傾向解析部21で生成された各クラスタについて、クラスタを構成するノード間のハイパーリンク結束度(以下、単に結束度と呼ぶ)を計算する。結束度は、例えば、ノード間に一つ以上のハイパーリンクが存在すれば、そのノード間には結合があると定義したときに、クラスタを構成するノード間結合の総数を、クラスタを構成する全てのノードから二つを選ぶ組み合わせ数で割った値とすることができる。すなわち、ノード間結合の総数をL、ノード数をNとしたとき、
結束度=L/NC2
で計算することができる。ハイパーリンク構成解析部22で計算した、各クラスタの結束度の値は、ハイパーリンク結束度表示部23に渡される。
【0016】
ハイパーリンク結束度表示部23は、ハイパーリンク構成解析部22で計算された結束度の値を、利用しやすい形態で表示する。図3は、ハイパーリンク結束度表示部による表示の一例の説明図である。例えば、結束度の値をいくつかのセグメントに分け、各セグメントに入るクラスタの数を棒グラフで表示することができる。図3では、クラスタ数の分布を縦軸とし、結束度を横軸として、二つのWebサイト(WebサイトAとWebサイトB)について並べて表示したものである。前述のように、各クラスタはアクセス履歴情報を基に構成されているので、各クラスタを構成するノード群は、例えば、同一のユーザから前後してアクセスされる傾向が強いものである。ノード群の結束度が高いと、ユーザにとってはノード間遷移のための経路が多数提供されることになるので効率よくブラウジングできることになる。一方、該ノード群の結束度が低いとブラウジング効率は悪くなる。図3では、WebサイトAの方は結束度が低いクラスタが多数あり、WebサイトBの方は結束度が高いクラスタが多数あるということが一目でわかる。この表示によって、WebサイトBの方がWebサイトAよりも優れた構成でハイパーテキストシステムが構築されていると容易に判断できる。
【0017】
ハイパーリンク結束度表示部23は、図3に示す表示形態のほか、各種の表示形態により結束度を表示することが可能である。図4は、ハイパーリンク結束度表示部による表示の別の例の説明図である。図4に示した例では、クラスタのサイズと結束度の値の関係を表示している。図中の点は、それぞれがクラスタを示している。クラスタのサイズとしては、例えば、クラスタを構成するノード数や、クラスタを構成する各ノードが持つ単語の総数や、クラスタを構成する各ノードのファイルサイズの総計などを用いることができる。図4に示した例では、クラスタのサイズとしてクラスタを構成するノード数を用いて表示した例を示している。このような表示を行った場合、同じクラスタサイズであれば、結束度が高いほど優れた構成であると判断することができる。また、このような表示によって、クラスタサイズに注目しながら、各クラスタの構成の優劣を俯瞰することができる。
【0018】
図5は、ハイパーリンク結束度表示部による表示の別の例においてクラスタを選択した場合の表示例の説明図である。図4に示したような結束度の表示が行われているとき、クラスタを表す点をマウス等のポインティングデバイスで選択すると、図5に示すように、選択されたクラスタを構成するノードのURL(識別子)を表示できるように構成することができる。あるいは、URLではなく、ノードのタイトルを表示してもよい。さらに、図5に示すように表示されたノード(URLで表示されている)をマウス等のポインティングデバイスで選択すると、ネットワークを通じて選択したノードにアクセスして、そのノードのコンテンツを獲得し、そのコンテンツを表示するようにしてもよい。このような表示によって、Webサイトの管理者は、Webサイト内の問題箇所にアクセスしてコンテンツを参照することができ、さらに編集することができるので、Webサイト内の構成を容易に改善して行くことができる。
【0019】
図6は、ハイパーリンク結束度表示部による表示の別の例においてクラスタを選択した場合の別の表示例の説明図である。図5に示した例と同様に、図4に示したような結束度の表示が行われているとき、クラスタを表す点をマウス等のポインティングデバイスで選択することにより、図6に示すように選択したクラスタを構成するノードとそのノード間のハイパーリンクを表示することもできる。ここで、ノードのラベル(図6中では、N1,N2,…,N10)は、URLでもタイトルでもよい。このような表示を行うことによって、Webサイトの管理者は、Webサイト内の問題箇所を容易に発見することができる。例えば図6に示したクラスタ内のハイパーリンクの表示例では、N1〜N7とN8〜N10の間にハイパーリンクがないのでユーザは両グループ間を容易に行き来できないことがわかる。
【0020】
図7は、ハイパーリンク結束度表示部による表示のさらに別の例の説明図である。この例では、クラスタ内のノード間の類似度と結束度の値との関係を表示した例を示している。クラスタ内のノード間の類似度としては、例えばアクセス傾向解析部21においてクラスタ生成時に用いた類似度の値を用いることができる。このような表示において、同じクラスタ内類似度であれば、結束度が高いほど優れた構成であると判断することができる。このような表示によって、クラスタ内のノード間の類似度に注目しながら、各クラスタの構成の優劣を俯瞰することができる。
【0021】
なお、ハイパーリンク結束度表示部23では、上述の各例に示した表示形態によらず、任意の形態で結束度を表示させることができる。
【0022】
図8は、本発明の第2の実施の形態を示す構成図である。図中、図1と同様の部分には同じ符号を付して説明を省略する。24は識別子獲得部である。識別子獲得部24は、アクセス履歴情報11の中からWebサーバ1上の各ノード毎に予め定めたある一定期間にアクセスしてきたコンピュータの識別子(例えばIPアドレス)を獲得する。
【0023】
アクセス傾向解析部21は、第1の実施の形態と同様に、Webサーバ1上のノード群に対し、それぞれに対応するアクセス履歴情報11を用いてクラスタリングの処理を施す。このクラスタリングの処理において類似度を計算する際に、識別子獲得部24において獲得したコンピュータの識別子の重複度合いを利用することができる。
【0024】
図9は、識別子獲得部における処理の一例を示すフローチャートである。まず、S31において、アクセス履歴情報11の中から、予め定められた期間内のアクセスに関するものだけを抽出し、残りを破棄する。S32において、S31で抽出されたアクセス履歴情報11に存在する全てのコンピュータ識別子(IPアドレス)のうちの異なる識別子の数(異なり数)Nを求める。次にS33において、アクセス履歴情報11に存在する全てのノードについて、各ノード毎に次元数Nのベクトルを生成する。ここで、ベクトルの各項は、アルファベットの昇順(あるいは降順)に並べた互いに異なるコンピュータ識別子(IPアドレス)に対応する。各項の初期値は0としておく。次にS34において、アクセス履歴情報11の中から各ノードにアクセスしてきたコンピュータのコンピュータ識別子(IPアドレス)を取り出し、対応するベクトルの項に1を加える。この処理を、アクセス履歴情報11すべてについて、順に行う。
【0025】
このようにして得られたN次元のベクトルを用いて、アクセス傾向解析部21では、ベクトル間の内積値の大小を類似度としてクラスタリングをすることができる。ここでクラスタとクラスタをマージする際は、それぞれのベクトルの和を取れば、これがマージされたクラスタのベクトルとなる。
【0026】
以降の処理は上述の第1の実施の形態と同様である。ハイパーリンク構成解析部22において結束度を計算し、ハイパーリンク結束度表示部23において結束度を表示する。このとき、上述のような各種の表示形態あるいはそれ以外の各種の表示形態で結束度を表示することができる。
【0027】
図10は、本発明の第3の実施の形態を示す構成図である。図中、図1と同様の部分には同じ符号を付して説明を省略する。25はコンピュータ識別子整形部である。コンピュータ識別子整形部25は、Webサーバ1に対するアクセスのうち、ユーザ(=人間)によって操作されるコンピュータからのものではなく、Webを網羅的にアクセスして自動的に情報を収集している情報収集ロボットのようなコンピュータによるアクセスを排除する。例えば、ある慣習に従って情報収集ロボットがアクセスする特殊なノード(Webでは、例えばルート直下に置かれるrobots.txtという名のファイル)へのアクセスの有無によって、情報収集ロボットからのアクセスであるか否かを判断することができる。あるいは、短期間に多数のノードを網羅的にアクセスするという情報収集ロボットに特徴的な振る舞いの有無や、既知の情報収集ロボットのコンピュータ識別子であるか否かによっても、情報収集ロボットを識別することができる。情報収集ロボットからのアクセスであると判断されたコンピュータについては、そのコンピュータ識別子に関わるアクセス履歴情報11を、識別子獲得部24において獲得しないようにすることができる。
【0028】
これによって、情報収集ロボットのようなWebを網羅的にアクセスして自動的に情報を収集しているコンピュータによるアクセスを排除し、解析結果に対するこれらの影響を除去することができ、ユーザのアクセス動向を正しく反映した解析結果を得ることができる。
【0029】
なお、この第3の実施の形態におけるその他の構成および動作は、上述の第2の実施の形態と同様である。
【0030】
図11は、本発明の第4の実施の形態を示す構成図である。図中、図1と同様の部分には同じ符号を付して説明を省略する。26はハイパーリンク結束度評価部である。ハイパーリンク結束度評価部26は、ハイパーリンク構成解析部22で得られた各クラスタの結束度の値を予め定められた閾値と比較し、結束度が閾値よりも小さなクラスタをハイパーリンク結束度表示部23に渡す。これによって、ハイパーリンク結束度表示部23では結束度が小さい、すなわち構成が劣るクラスタとそのクラスタを構成するノードを容易に得ることができる。
【0031】
図12は、ハイパーリンク結束度表示部による表示のさらに別の例の説明図である。図12に示した表示例では、結束度の値が小さい順にクラスタおよびそのクラスタを構成するノードの識別子(URL)を表示している。クラスタは「ID」の欄に示している。ここで「ID」は、クラスタを参照するためにユニークにつけられた番号である。例えば、アクセス傾向解析部21におけるクラスタ生成時に、生成された順に番号を付与すればよい。このような表示によって、構成上劣っている部分から表示されるので、ユーザが利用する上でネックとなっている部分を容易に知ることができる。もちろん、この第4の実施の形態においても、第1の実施の形態で示したような各種の表示形態あるいはその他の表示形態で結束度を表示することが可能である。また、第2,第3の実施の形態で説明した識別子獲得部24,コンピュータ識別子整形部25などを設けてもよい。
【0032】
上述の実施の形態は、コンピュータプログラムによっても実現することが可能である。その場合、そのプログラムおよびそのプログラムが用いるデータなどは、コンピュータが読み取り可能な記憶媒体に記録しておくことも可能である。記憶媒体とは、コンピュータのハードウェア資源に備えられている読取装置に対して、プログラムの記述内容に応じて、磁気、光、電気等のエネルギーの変化状態を引き起こして、それに対応する信号の形式で、読取装置にプログラムの記述内容を伝達できるものである。例えば、磁気ディスク、光ディスク、CD−ROM、コンピュータに内蔵されるメモリ等である。
【0033】
【発明の効果】
以上の説明から明らかなように、本発明によれば、ユーザのアクセス履歴情報に基づいて、ハイパーテキストシステムを構成するノードに対してクラスタリングを行い、得られた各クラスタを構成するノード間のハイパーリンク結束度を計算する。このハイパーリンク結束度によって、ハイパーテキストシステムの構成の優劣を容易に判断することが可能になる。例えばWebの管理者は、構成に問題がある部分に変更を加えて、より良い構成のハイパーテキストシステムを構築することができるという効果がある。
【図面の簡単な説明】
【図1】 本発明の第1の実施の形態を示す構成図である。
【図2】 Webの一例の説明図である。
【図3】 ハイパーリンク結束度表示部による表示の一例の説明図である。
【図4】 ハイパーリンク結束度表示部による表示の別の例の説明図である。
【図5】 ハイパーリンク結束度表示部による表示の別の例においてクラスタを選択した場合の表示例の説明図である。
【図6】 ハイパーリンク結束度表示部による表示の別の例においてクラスタを選択した場合の別の表示例の説明図である。
【図7】 ハイパーリンク結束度表示部による表示のさらに別の例の説明図である。
【図8】 本発明の第2の実施の形態を示す構成図である。
【図9】 識別子獲得部における処理の一例を示すフローチャートである。
【図10】 本発明の第3の実施の形態を示す構成図である。
【図11】 本発明の第4の実施の形態を示す構成図である。
【図12】 ハイパーリンク結束度表示部による表示のさらに別の例の説明図である。
【符号の説明】
1…Webサーバ、2…ハイパーテキスト解析装置、11…アクセス履歴情報、21…アクセス傾向解析部、22…ハイパーリンク構成解析部、23…ハイパーリンク結束度表示部、24…識別子獲得部、25…コンピュータ識別子整形部、26…ハイパーリンク結束度評価部。[0001]
BACKGROUND OF THE INVENTION
The present invention relates to a hypertext analysis apparatus and a hypertext analysis method for analyzing a hyperlink structure in order to discover knowledge for determining the superiority or inferiority of the configuration in a hypertext system configured on a network, and the hypertext The present invention relates to a recording medium on which a hypertext analysis program for realizing an analysis apparatus or method by a computer is recorded.
[0002]
[Prior art]
In a hypertext system (for example, World Wide Web: hereinafter abbreviated as “Web”) configured on a network, a user (visitor) access history can be recorded in a server storing hypertext. This access history generally includes the identifier of the computer used by the accessing user (IP address if the Internet is used), the time of access, the identifier on the server of the accessed node (Web URL).
[0003]
In order to analyze the access history and identify the path of the hyperlink to which each user has transitioned, basically, the accessed nodes may be arranged in time order for each computer. However, it has been difficult to specify a complete path by a computer cache function or the like.
[0004]
In contrast, for example, C.I. Shahabi, A .; M.M. Zarkesh, J. et al. Adibi, and V.D. Shah, “Knowledge Discovery from Users Web-Page Navigation”, Proc. of IEEE RIDE, 1997. The remote agent is used to recognize access to the cache. As a result, a more accurate route can be obtained. However, there is a problem that the cost (time and space) for loading the remote agent program on the user's computer side is sacrificed.
[0005]
As a technique for finding an important route using an access history, for example, J.A. Borges and M.M. Levene, “Minning Association Rules in Hypertext Databases”, Proc. of KDD, 1998. There are techniques described in. This technique first collects access histories and expresses the hyper structure with a directed graph weighted by the amount of hyperlink traffic. In this directed graph, the transition from node A to node B is denoted as A → B, and this is called a combination rule. The join rule is: a confidence value (= total number of transitions A → B with respect to the total number of transitions starting from A) and a support value (= total number of transitions A → B with respect to an average value of the number of transitions of all arcs in the directed graph). ). Further, a combined coupling rule (A → B) & (B → C) & (C → D) &. . . Is defined, and transitions of three or more nodes are evaluated.
[0006]
In this method, since information of a computer identifier (IP address) is not used, the combined link rule merely finds a hyperlink combination route with a large traffic volume. For example, even if it is found that the composite combination rule (A → B) & (B → C) has a high confidence value and support value, the user who actually followed the path of A → B → C It was not always the case.
[0007]
As described above, it is possible to specify the access route of the user or discover the important route by the conventional technique. However, it has not been possible to obtain knowledge for judging the superiority or inferiority of the configuration of a hypertext system (for example, a website).
[0008]
[Problems to be solved by the invention]
The present invention has been made in view of the above-described circumstances, and is capable of recognizing a user's access tendency from an access history, and a hypertext analysis apparatus that assists in obtaining knowledge for determining the superiority or inferiority of the configuration of a hypertext system. It is another object of the present invention to provide a hypertext analysis method. It is another object of the present invention to provide a recording medium on which a hypertext analysis program for realizing the hypertext analysis apparatus or method by a computer is recorded.
[0009]
[Means for Solving the Problems]
The present invention performs clustering on the nodes constituting the hypertext system based on the access history information to the hypertext system, and calculates the hyperlink cohesion degree between the nodes constituting the cluster for each obtained cluster. Then, the calculated hyperlink cohesion degree is displayed. Since the displayed hyperlink cohesion is a value based on the history accessed by the user, it indicates the user's access tendency. Therefore, by obtaining the hyperlink cohesion degree, for example, it is possible to determine the superiority or inferiority of the configuration of the hypertext system together with the hyperlink configuration of the hypertext system (for example, Web site).
[0010]
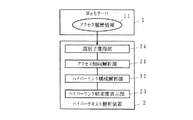
DETAILED DESCRIPTION OF THE INVENTION
FIG. 1 is a configuration diagram showing a first embodiment of the present invention, and FIG. 2 is an explanatory diagram of an example of the Web. In the figure, 1 is a Web server, 2 is a hypertext analysis device, 11 is access history information, 21 is an access trend analysis unit, 22 is a hyperlink configuration analysis unit, and 23 is a hyperlink cohesion degree display unit. A typical hypertext system configured on a network is the Web. Hereinafter, the Web will be described as an example.
[0011]
The
[0012]
The
1. Each node on the
2. The similarity between the clusters is calculated, and the clusters having the maximum similarity are merged into one cluster.
3.
Each cluster sequentially generated during this process is obtained as a clustering processing result. For example: The cluster of only each node generated in the process of FIG. 5, each cluster obtained by merging the clusters, one cluster generated last, and the like are clustering results. Note that the above-described clustering method is, for example, E.I. M.M. Voorhees, “Implementing Aggregative Hierarchical Clustering Algorithms for Use in Document Retrieval”, Information Processing & Management, Vol. 22, no. 6, 1986, and the like.
[0013]
In the access
[0014]
Alternatively, as similarity calculation, a vector is generated in which each cluster has the
[0015]
The hyperlink
Cohesion degree = L / NC 2
Can be calculated with The value of the cohesion degree of each cluster calculated by the hyperlink
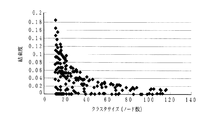
[0016]
The hyperlink cohesion
[0017]
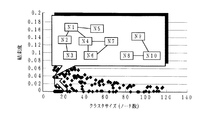
The hyperlink cohesion
[0018]
FIG. 5 is an explanatory diagram of a display example when a cluster is selected in another example of display by the hyperlink cohesion degree display unit. When the cohesion degree display as shown in FIG. 4 is performed, if a point representing a cluster is selected with a pointing device such as a mouse, as shown in FIG. 5, the URLs of the nodes constituting the selected cluster ( Identifier) can be displayed. Alternatively, the title of the node may be displayed instead of the URL. Further, when a node (displayed by URL) displayed as shown in FIG. 5 is selected with a pointing device such as a mouse, the selected node is accessed through the network, and the content of the node is acquired. May be displayed. With such a display, the website administrator can access the problem part in the website, refer to the content, and further edit it, so that the configuration in the website can be easily improved. can go.
[0019]
FIG. 6 is an explanatory diagram of another display example when a cluster is selected in another example of display by the hyperlink cohesion degree display unit. As in the example shown in FIG. 5, when the cohesion degree display as shown in FIG. 4 is performed, a point representing a cluster is selected by a pointing device such as a mouse, as shown in FIG. It is also possible to display hyperlinks between nodes constituting the selected cluster. Here, the labels of the nodes (N1, N2,..., N10 in FIG. 6) may be URLs or titles. By performing such display, the administrator of the Web site can easily find the problem part in the Web site. For example, in the display example of the hyperlink in the cluster shown in FIG. 6, since there is no hyperlink between N1 to N7 and N8 to N10, the user cannot easily go back and forth between the two groups.
[0020]
FIG. 7 is an explanatory diagram of still another example of display by the hyperlink cohesion degree display unit. In this example, the relationship between the similarity between nodes in the cluster and the value of cohesion is displayed. As the similarity between the nodes in the cluster, for example, the value of the similarity used at the time of cluster generation in the access
[0021]
The hyperlink cohesion
[0022]
FIG. 8 is a block diagram showing a second embodiment of the present invention. In the figure, the same parts as those in FIG.
[0023]
As in the first embodiment, the access
[0024]
FIG. 9 is a flowchart illustrating an example of processing in the identifier acquisition unit. First, in S31, only access related information within a predetermined period is extracted from the
[0025]
Using the N-dimensional vector thus obtained, the access
[0026]
The subsequent processing is the same as that in the first embodiment. The hyperlink
[0027]
FIG. 10 is a block diagram showing a third embodiment of the present invention. In the figure, the same parts as those in FIG.
[0028]
As a result, it is possible to eliminate access by a computer that collects information automatically by comprehensively accessing the Web, such as an information collecting robot, and to remove these influences on analysis results. It is possible to obtain an analysis result that correctly reflects.
[0029]
Note that other configurations and operations in the third embodiment are the same as those in the second embodiment described above.
[0030]
FIG. 11 is a block diagram showing a fourth embodiment of the present invention. In the figure, the same parts as those in FIG.
[0031]
FIG. 12 is an explanatory diagram of still another example of display by the hyperlink cohesion degree display unit. In the display example shown in FIG. 12, the cluster and the identifiers (URLs) of the nodes constituting the cluster are displayed in ascending order of cohesion value. The cluster is shown in the “ID” column. Here, “ID” is a number uniquely assigned to refer to the cluster. For example, when the cluster is generated in the access
[0032]
The above-described embodiment can also be realized by a computer program. In that case, the program, data used by the program, and the like can be recorded in a computer-readable storage medium. A storage medium is a signal format that causes a state of change in energy such as magnetism, light, electricity, etc. according to the description of a program to a reader provided in the hardware resources of a computer. Thus, the description content of the program can be transmitted to the reading device. For example, a magnetic disk, an optical disk, a CD-ROM, a memory built in a computer, and the like.
[0033]
【The invention's effect】
As is clear from the above description, according to the present invention, clustering is performed on the nodes constituting the hypertext system based on the user access history information, and the obtained hypertext between the nodes constituting each cluster is obtained. Calculate link cohesion. Based on the degree of hyperlink cohesion, it is possible to easily determine the superiority or inferiority of the configuration of the hypertext system. For example, there is an effect that a Web administrator can change a portion having a configuration problem to construct a hypertext system having a better configuration.
[Brief description of the drawings]
FIG. 1 is a configuration diagram showing a first embodiment of the present invention.
FIG. 2 is an explanatory diagram of an example of the Web.
FIG. 3 is an explanatory diagram of an example of display by a hyperlink cohesion degree display unit.
FIG. 4 is an explanatory diagram of another example of display by a hyperlink cohesion degree display unit.
FIG. 5 is an explanatory diagram of a display example when a cluster is selected in another example of display by the hyperlink cohesion degree display unit.
FIG. 6 is an explanatory diagram of another display example when a cluster is selected in another example of display by the hyperlink cohesion degree display unit.
FIG. 7 is an explanatory diagram of still another example of display by a hyperlink cohesion degree display unit.
FIG. 8 is a block diagram showing a second embodiment of the present invention.
FIG. 9 is a flowchart illustrating an example of processing in an identifier acquisition unit.
FIG. 10 is a configuration diagram showing a third embodiment of the present invention.
FIG. 11 is a block diagram showing a fourth embodiment of the present invention.
FIG. 12 is an explanatory diagram of still another example of display by the hyperlink cohesion degree display unit.
[Explanation of symbols]
DESCRIPTION OF
Claims (7)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP34575998A JP3705331B2 (en) | 1998-12-04 | 1998-12-04 | Hypertext analysis apparatus and method, and storage medium storing hypertext analysis program |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP34575998A JP3705331B2 (en) | 1998-12-04 | 1998-12-04 | Hypertext analysis apparatus and method, and storage medium storing hypertext analysis program |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2000172665A JP2000172665A (en) | 2000-06-23 |
| JP3705331B2 true JP3705331B2 (en) | 2005-10-12 |
Family
ID=18378788
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP34575998A Expired - Fee Related JP3705331B2 (en) | 1998-12-04 | 1998-12-04 | Hypertext analysis apparatus and method, and storage medium storing hypertext analysis program |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP3705331B2 (en) |
Families Citing this family (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP3705330B2 (en) * | 1998-12-04 | 2005-10-12 | 富士ゼロックス株式会社 | Hypertext structure change support device and method, and storage medium storing hypertext structure change support program |
| JP3863740B2 (en) * | 2001-07-19 | 2006-12-27 | 日立電子サービス株式会社 | Web server performance monitoring service system |
| JP4394335B2 (en) | 2002-07-23 | 2010-01-06 | 富士通株式会社 | Site evaluation system and site evaluation program |
| US7627872B2 (en) | 2002-07-26 | 2009-12-01 | Arbitron Inc. | Media data usage measurement and reporting systems and methods |
| WO2005081116A1 (en) * | 2004-01-05 | 2005-09-01 | Yasuo Nishizawa | Integrated intelligent seo transaction platform |
| JP4633162B2 (en) | 2008-12-01 | 2011-02-16 | 株式会社エヌ・ティ・ティ・ドコモ | Index generation system, information retrieval system, and index generation method |
| JP2010157151A (en) * | 2008-12-29 | 2010-07-15 | Kan:Kk | System and method for analyzing access |
| JP5411815B2 (en) * | 2010-07-23 | 2014-02-12 | 株式会社Nttドコモ | Network evaluation support apparatus and network evaluation support method |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2861908B2 (en) * | 1996-01-16 | 1999-02-24 | 日本電気株式会社 | Browsing device |
| JPH1069423A (en) * | 1996-08-28 | 1998-03-10 | Nec Corp | Hypermedia system and its directory data managing method |
-
1998
- 1998-12-04 JP JP34575998A patent/JP3705331B2/en not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| JP2000172665A (en) | 2000-06-23 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US7363282B2 (en) | Search system using user behavior data | |
| US7590619B2 (en) | Search system using user behavior data | |
| Baumgarten et al. | User-driven navigation pattern discovery from internet data | |
| US9300755B2 (en) | System and method for determining information reliability | |
| US5940831A (en) | Hypermedia system and method of managing directories and directory data originating from a node link structure in a directory server | |
| Pandian et al. | A Unified Model for Preprocessing and Clustering Technique for Web Usage Mining. | |
| KR20110009098A (en) | Search result ranking using editing distance and document information | |
| JPH09153059A (en) | History display device | |
| JP2000011005A (en) | Data analysis method and apparatus, and computer-readable recording medium recording data analysis program | |
| US20060248057A1 (en) | Systems and methods for discovery of data that needs improving or authored using user search results diagnostics | |
| KR100987330B1 (en) | Multi-concept network creation system and method based on user web usage information | |
| US8234584B2 (en) | Computer system, information collection support device, and method for supporting information collection | |
| JP3705331B2 (en) | Hypertext analysis apparatus and method, and storage medium storing hypertext analysis program | |
| JP2005107688A (en) | Information display method and system, and information display program | |
| KR100557874B1 (en) | Recording medium storing computer information analysis method and method | |
| JP2010134651A (en) | Merchandise id server device, and method for controlling the same | |
| JP5100855B2 (en) | Latent class analyzer, latent class analyzing method and program | |
| JP5384567B2 (en) | Latent class analyzer, latent class analyzing method and program | |
| JP3719342B2 (en) | Hypertext analysis apparatus and method, and storage medium storing hypertext analysis program | |
| Dohare et al. | Novel web usage mining for web mining techniques | |
| KR20130082882A (en) | Item recommendation method and apparatus using conversion pattern analysis of user behavior | |
| KR101267918B1 (en) | Apparatus and method for providing the search report related with tag information connected to the internet resource and computer readable medium processing the method | |
| Lebib et al. | Knowledge Discovery from Log Data Analysis in a Multi-source Search System based on Deep Cleaning. | |
| US20060026187A1 (en) | Apparatus, method, and program for processing data | |
| Li et al. | SearchGen: a synthetic workload generator for scientific literature digital libraries and search engines |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20050223 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20050418 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20050706 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20050719 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20090805 Year of fee payment: 4 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20100805 Year of fee payment: 5 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20110805 Year of fee payment: 6 |
|
| LAPS | Cancellation because of no payment of annual fees |