JP2023527869A - Treatments for age-related disorders - Google Patents
Treatments for age-related disorders Download PDFInfo
- Publication number
- JP2023527869A JP2023527869A JP2022573633A JP2022573633A JP2023527869A JP 2023527869 A JP2023527869 A JP 2023527869A JP 2022573633 A JP2022573633 A JP 2022573633A JP 2022573633 A JP2022573633 A JP 2022573633A JP 2023527869 A JP2023527869 A JP 2023527869A
- Authority
- JP
- Japan
- Prior art keywords
- amino acids
- soluble
- binding domain
- target binding
- tgf
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images

















































































































































































































































































































































































Classifications
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
- A61K38/16—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- A61K38/17—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- A61K38/177—Receptors; Cell surface antigens; Cell surface determinants
- A61K38/179—Receptors; Cell surface antigens; Cell surface determinants for growth factors; for growth regulators
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
- A61K38/16—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- A61K38/17—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- A61K38/177—Receptors; Cell surface antigens; Cell surface determinants
- A61K38/1793—Receptors; Cell surface antigens; Cell surface determinants for cytokines; for lymphokines; for interferons
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
- A61K38/16—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- A61K38/17—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- A61K38/19—Cytokines; Lymphokines; Interferons
- A61K38/20—Interleukins [IL]
- A61K38/2086—IL-13 to IL-16
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
- A61K38/16—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- A61K38/17—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- A61K38/36—Blood coagulation or fibrinolysis factors
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P29/00—Non-central analgesic, antipyretic or antiinflammatory agents, e.g. antirheumatic agents; Non-steroidal antiinflammatory drugs [NSAID]
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P39/00—General protective or antinoxious agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K2300/00—Mixtures or combinations of active ingredients, wherein at least one active ingredient is fully defined in groups A61K31/00 - A61K41/00
Abstract

その必要がある対象における自然発生及び/若しくは治療誘導性老化細胞及び罹患細胞を死滅させるか又は前記老化細胞及び罹患細胞の数を低減させ、その必要がある対象における自然発生及び/若しくは治療誘導性老化細胞及び罹患細胞の蓄積を減少させる方法が本明細書に提供され、前記方法は、1つ以上の共通ガンマ鎖ファミリーサイトカイン受容体活性化物質及び/又はTGF-β受容体の活性化の減少をもたらす1つ以上の作用物質の治療有効量を対象に投与することを含む。
【選択図】図263
Killing or reducing the number of naturally occurring and/or treatment-induced senescent and diseased cells in a subject in need thereof, naturally occurring and/or treatment-induced in a subject in need thereof Provided herein are methods of reducing the accumulation of senescent and diseased cells, said methods comprising reducing activation of one or more common gamma chain family cytokine receptor activators and/or TGF-β receptors. administering to the subject a therapeutically effective amount of one or more agents that provide
[Selection drawing] Fig. 263
Description
関連出願の相互参照
本出願は、参照により全体が本明細書に組み込まれる、2020年6月1日に出願された米国仮特許出願第63/032,933号、2020年6月1日に出願された国際特許出願第PCT/US2020/035598号、及び2020年11月25日に出願された米国仮特許出願第63/118,536号に対する優先権を主張する。
CROSS-REFERENCE TO RELATED APPLICATIONS This application is filed June 1, 2020, U.S. Provisional Patent Application No. 63/032,933, filed June 1, 2020, which is hereby incorporated by reference in its entirety. International Patent Application No. PCT/US2020/035598, filed Nov. 25, 2020, and U.S. Provisional Patent Application No. 63/118,536, filed Nov. 25, 2020.
技術分野
本開示は、免疫学及び細胞生物学の分野に関する。
TECHNICAL FIELD This disclosure relates to the fields of immunology and cell biology.
背景
老化は、表現型の変化、アポトーシスへの耐性、及び損傷を感知するシグナル伝達経路の活性化を伴う不可逆的な成長停止の一形態である。細胞老化は、増殖する能力を失った培養ヒト線維芽細胞で最初に説明され、約50回の集団倍加(ヘイフリック限界と称される)後に永久停止に達した。老化は、酸化的ストレス及び遺伝毒性ストレス、DNA損傷、テロメア摩滅、発がん性活性化、ミトコンドリア機能障害、又は化学療法剤を含む、広範囲の内因性及び外因性傷害によって誘導され得るストレス応答とみなされる。
BACKGROUND Senescence is a form of irreversible growth arrest that involves phenotypic changes, resistance to apoptosis, and activation of injury-sensing signaling pathways. Cellular senescence was first described in cultured human fibroblasts that lost the ability to proliferate, reaching permanent arrest after approximately 50 population doublings (termed the Hayflick limit). Aging is viewed as a stress response that can be induced by a wide range of endogenous and exogenous insults, including oxidative and genotoxic stress, DNA damage, telomere attrition, oncogenic activation, mitochondrial dysfunction, or chemotherapeutic agents. .
老化細胞は、代謝的に活性を維持し、それらの分泌表現型を介して組織の止血、疾患、加齢に影響を及ぼし得る。老化は、生理学的プロセスとみなされており、創傷治癒、組織の恒常性、再生、及び線維症の調節を促進する上で重要である。例えば、老化細胞の一過性の誘導は、治癒中に観察され、創傷の消散に寄与する。老化はまた、腫瘍抑制において役割を果たす。老化細胞の蓄積は、加齢及び加齢関連疾患及び状態も促進する。老化の表現型は、慢性炎症反応も引き起こし、その結果、慢性炎症状態を増強して、腫瘍の成長を促進する可能性がある。老化と加齢との間の関連性は、当初、老化細胞が加齢組織に蓄積するという観察に基づいていた。トランスジェニックモデルの使用により、多くの加齢関連障害において老化細胞を体系的に検出することが可能になった。老化細胞を選択的に排除するための戦略は、老化細胞が加齢関連障害において因果的役割を果たすことができることを実証している。 Senescent cells remain metabolically active and can influence tissue hemostasis, disease and aging through their secretory phenotype. Aging is regarded as a physiological process that is important in promoting wound healing, tissue homeostasis, regeneration, and regulation of fibrosis. For example, transient induction of senescent cells is observed during healing and contributes to wound resolution. Aging also plays a role in tumor suppression. Accumulation of senescent cells also promotes aging and age-related diseases and conditions. The senescent phenotype may also induce chronic inflammatory responses, thereby enhancing the chronic inflammatory state and promoting tumor growth. The link between senescence and aging was originally based on the observation that senescent cells accumulate in aging tissue. The use of transgenic models has made it possible to systematically detect senescent cells in many age-related disorders. Strategies to selectively eliminate senescent cells demonstrate that senescent cells can play a causal role in age-related disorders.
細胞老化は、最初の成長停止後に獲得される一連の進行性かつ表現型が多様な細胞状態である(van Deursen,Nature 509(7501):439-446,2014(非特許文献1))。したがって、老化細胞は、ほとんど共有されていない核となる特性を持つ不均一な細胞集団である(Dou et al.,Nature 550(7676):402-406,2017(非特許文献2))。したがって、一般的な老化細胞除去薬の標的を同定することは困難である。これは更に、全身投与により老化細胞を選択的、安全、かつ効果的に除去する老化細胞除去剤を開発するという目標の達成を妨げる。上述のように、免疫細胞は、老化細胞が生理的役割を果たした後、老化細胞を自然に除去するためのエフェクター細胞である(Brighton et al.,Elife 6,2017(非特許文献3))。老化プロセス中の免疫系の弱体化により、老化細胞が蓄積することを可能にする(Karin et al.,Nat.Comm.10(1):5495,2019(非特許文献4)、Chambers et al.,J.Allergy Clin.Immunol.145(5):1323-1331,2020(非特許文献5))。 Cellular senescence is a series of progressive and phenotypically diverse cellular states acquired after initial growth arrest (van Deursen, Nature 509(7501):439-446, 2014). Senescent cells are therefore a heterogeneous cell population with few shared nuclear properties (Dou et al., Nature 550(7676):402-406, 2017). Therefore, it is difficult to identify targets for common senolytic drugs. This further hinders the goal of developing senolytic agents that selectively, safely and effectively eliminate senescent cells by systemic administration. As described above, immune cells are effector cells for the natural elimination of senescent cells after they have fulfilled their physiological roles (Brighton et al., Elife 6, 2017 (Non-Patent Document 3)). . Weakening of the immune system during the aging process allows senescent cells to accumulate (Karin et al., Nat. Comm. 10(1):5495, 2019, Chambers et al. , J. Allergy Clin. Immunol.145(5):1323-1331, 2020 (Non-Patent Document 5)).
概要
本発明は、TGF-β受容体又は共通ガンマ鎖ファミリーサイトカイン受容体活性化物質(例えば、ガンマ鎖サイトカイン及びそれらの同族受容体の複合体)の活性化の減少をもたらす作用物質の哺乳動物への皮下投与により、免疫細胞を促進及び活性化して、インビボで効果的、選択的、かつ安全に老化細胞を低減させる能力を回復するという発見に基づいている。この発見を考慮して、TGF-β受容体の活性化の減少をもたらす1つ以上の作用物質の治療有効量を対象に投与することを含む、対象における自然発生及び/若しくは治療誘導性老化細胞を死滅させるか又は老化細胞の数を低減させる方法が本明細書に提供される。TGF-β受容体の活性化の減少をもたらす1つ以上の作用物質の治療有効量を対象に投与することを含む、対象における自然発生及び/又は治療誘導性老化細胞の蓄積を減少させる方法も本明細書に提供される。TGF-β受容体の活性化の減少をもたらす1つ以上の作用物質の治療有効量を対象に投与することを含む、対象における自然発生及び/又は治療誘導性老化細胞のマーカーのレベルを減少させる方法も本明細書に提供される。TGF-β受容体の活性化の減少をもたらす1つ以上の作用物質の治療有効量を対象に投与することを含む、対象における自然発生及び/又は治療誘導性老化細胞の活性を低減させる方法も本明細書に提供される。TGF-β受容体の活性化の減少をもたらす1つ以上の作用物質の治療有効量を対象に投与することを含む、対象における自然発生及び/又は治療誘導性老化細胞に由来する1つ以上の老化関連分泌表現型(「SASP」)因子のレベル及び/又は活性を減少させる方法も本明細書に提供される。
SUMMARY The present invention provides agents in mammals that result in decreased activation of TGF-beta receptors or common gamma chain family cytokine receptor activators (e.g., complexes of gamma chain cytokines and their cognate receptors). It is based on the discovery that subcutaneous administration of AG stimulates and activates immune cells to restore the ability to effectively, selectively and safely reduce senescent cells in vivo. In view of this discovery, spontaneous and/or treatment-induced senescent cells in a subject comprising administering to the subject a therapeutically effective amount of one or more agents that result in decreased activation of TGF-β receptors. Provided herein are methods of killing cells or reducing the number of senescent cells. Also a method of reducing spontaneous and/or treatment-induced accumulation of senescent cells in a subject comprising administering to the subject a therapeutically effective amount of one or more agents that result in reduced activation of TGF-β receptors. provided herein. Reducing levels of markers of spontaneous and/or treatment-induced senescence in a subject comprising administering to the subject a therapeutically effective amount of one or more agents that result in reduced activation of TGF-beta receptors Methods are also provided herein. Also a method of reducing spontaneous and/or treatment-induced senescent cell activity in a subject comprising administering to the subject a therapeutically effective amount of one or more agents that result in reduced activation of TGF-beta receptors. provided herein. one or more treatments derived from naturally occurring and/or treatment-induced senescent cells in a subject, comprising administering to the subject a therapeutically effective amount of one or more agents that result in decreased activation of TGF-β receptors. Also provided herein are methods of reducing the level and/or activity of senescence-associated secretory phenotype (“SASP”) factors.
治療有効量の1つ以上の共通のガンマ鎖ファミリーサイトカイン受容体活性化物質(例えば、ガンマ鎖サイトカイン及びそれらの同族受容体の複合体)を対象に投与することを含む、対象における自然発生及び/若しくは治療誘導性老化細胞を死滅させるか又は老化細胞の数を低減させる方法(及び老化細胞の蓄積を減少させる又は老化細胞のマーカーを低減させる方法)も本明細書に提供される。治療有効量の1つ以上の共通ガンマ鎖ファミリーサイトカイン受容体活性化物質を対象に投与することを含む、対象における自然発生及び/又は治療誘導性老化細胞の活性を低減させる方法も本明細書に提供される。治療有効量の1つ以上の共通ガンマ鎖ファミリーサイトカイン受容体活性化物質を対象に投与することを含む、対象における自然発生及び/又は治療誘導性老化細胞に由来する1つ以上のSASP因子のレベル及び/又は活性を減少させる方法も本明細書に提供される。 naturally-occurring and/or Alternatively, methods of killing treatment-induced senescent cells or reducing the number of senescent cells (and methods of reducing accumulation of senescent cells or reducing markers of senescent cells) are also provided herein. Also herein are methods of reducing spontaneous and/or treatment-induced senescent cell activity in a subject comprising administering to the subject a therapeutically effective amount of one or more common gamma chain family cytokine receptor activators. provided. Levels of one or more SASP factors derived from spontaneous and/or treatment-induced senescent cells in a subject, comprising administering to the subject a therapeutically effective amount of one or more common gamma chain family cytokine receptor activators. Also provided herein are methods of reducing activity and/or activity.
本発明はまた、がんを有する哺乳動物へのNK細胞活性化物質の投与が腫瘍阻害をもたらし、糖尿病動物モデルへのNK細胞活性化物質の投与が皮膚及び毛髪の外観及び質感の改善、並びに血糖値の減少を示したという発見に基づいている。本明細書に提供されるこの発見を考慮して、加齢関連疾患又は状態の治療を必要とする対象において加齢関連疾患又は状態を治療する方法であって、加齢関連疾患又は状態を有すると同定される対象に、1つ以上のナチュラルキラー(NK)細胞活性化物質の治療有効量及び/又は活性化されたNK細胞の治療有効数を投与することを含む、方法が、本明細書に提供される。老化細胞の死滅又は老化細胞の数の低減を必要とする対象において老化細胞を死滅させる又は老化細胞の数を低減させる方法であって、当該対象に、治療有効数の1つ以上のナチュラルキラー(NK)細胞活性化物質の治療有効量及び/又は活性化されたNK細胞を投与することを含む、方法も本明細書に提供される。ある期間にわたる皮膚及び/又は毛髪の質感及び/又は外観の改善を必要とする対象において皮膚及び/又は毛髪の質感及び/又は外観を改善する方法であって、当該対象に、治療有効数の1つ以上のナチュラルキラー(NK)細胞活性化物質の治療有効量及び/又は活性化されたNK細胞を投与することを含む、方法も本明細書に提供される。ある期間にわたる肥満の治療の支援を必要とする対象において肥満の治療を支援する方法であって、当該対象に、治療有効数の1つ以上のナチュラルキラー(NK)細胞活性化物質の治療有効量及び/又は活性化されたNK細胞を投与することを含む、方法も本明細書に提供される。 The present invention also provides that administration of NK cell activators to mammals with cancer results in tumor inhibition, administration of NK cell activators to diabetic animal models improves the appearance and texture of skin and hair, and It is based on the finding that it showed a reduction in blood sugar levels. In view of this discovery provided herein, a method of treating an age-related disease or condition in a subject in need thereof comprises: A method comprising administering to a subject identified as a therapeutically effective amount of one or more natural killer (NK) cell activators and/or a therapeutically effective number of activated NK cells is described herein provided to A method of killing senescent cells or reducing the number of senescent cells in a subject in need of killing senescent cells or reducing the number of senescent cells, said subject comprising a therapeutically effective number of one or more natural killers ( Also provided herein are methods comprising administering a therapeutically effective amount of a NK) cell activator and/or activated NK cells. 1. A method of improving skin and/or hair texture and/or appearance in a subject in need thereof over a period of time, comprising administering to said subject a therapeutically effective number of 1 Also provided herein are methods comprising administering therapeutically effective amounts of one or more natural killer (NK) cell activators and/or activated NK cells. A method of helping treat obesity in a subject in need of help treating obesity over a period of time comprising administering to the subject a therapeutically effective amount of one or more natural killer (NK) cell activators Also provided herein are methods comprising administering and/or activated NK cells.
TGF-β受容体の活性化の減少をもたらす1つ以上の作用物質の治療有効量を対象に投与することを含む、対象における自然発生及び/若しくは治療誘導性老化細胞を死滅させるか又は老化細胞の数を低減させる方法が本明細書に提供される。 Killing spontaneous and/or treatment-induced senescent cells or senescent cells in a subject comprising administering to the subject a therapeutically effective amount of one or more agents that result in decreased activation of TGF-β receptors Provided herein are methods of reducing the number of .
TGF-β受容体の活性化の減少をもたらす1つ以上の作用物質の治療有効量を対象に投与することを含む、対象における自然発生及び/又は治療誘導性老化細胞の蓄積を減少させる方法も本明細書に提供される。 Also methods of reducing spontaneous and/or treatment-induced accumulation of senescent cells in a subject comprising administering to the subject a therapeutically effective amount of one or more agents that result in reduced activation of TGF-β receptors. provided herein.
TGF-β受容体の活性化の減少をもたらす1つ以上の作用物質の治療有効量を対象に投与することを含む、対象における自然発生及び/又は治療誘導性老化細胞のマーカーのレベルを減少させる方法も本明細書に提供される。 Reducing levels of spontaneous and/or treatment-induced markers of senescent cells in a subject comprising administering to the subject a therapeutically effective amount of one or more agents that result in reduced activation of TGF-beta receptors A method is also provided herein.
TGF-β受容体の活性化の減少をもたらす1つ以上の作用物質の治療有効量を対象に投与することを含む、対象における自然発生及び/又は治療誘導性老化細胞の活性を低減させる方法も本明細書に提供される。 Also a method of reducing spontaneous and/or treatment-induced senescent cell activity in a subject comprising administering to the subject a therapeutically effective amount of one or more agents that result in reduced activation of TGF-β receptors. provided herein.
TGF-β受容体の活性化の減少をもたらす1つ以上の作用物質の治療有効量を対象に投与することを含む、対象における自然発生及び/又は治療誘導性老化細胞に由来する1つ以上のSASP因子のレベル及び/又は活性を減少させる方法も本明細書に提供される。 one or more treatments derived from naturally occurring and/or treatment-induced senescent cells in a subject, comprising administering to the subject a therapeutically effective amount of one or more agents that result in decreased activation of TGF-β receptors. Also provided herein are methods of reducing the level and/or activity of SASP factors.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、対象は、加齢関連疾患又は炎症性疾患を有すると以前に診断又は同定されている。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、加齢関連疾患は、炎症老化関連である。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、加齢関連疾患は、アルツハイマー病、動脈瘤、嚢胞性線維症、膵炎における線維症、緑内障、高血圧症、炎症性腸疾患、椎間板変性、骨関節炎、2型真性糖尿病、脂肪萎縮、リポジストロフィー、アテローム性動脈硬化症、白内障、COPD、特発性肺線維症、腎移植不全、肝線維症、骨量喪失、心筋梗塞、サルコペニア、創傷治癒、脱毛症、心筋細胞肥大、骨関節炎、パーキンソン病、加齢関連肺組織弾性喪失、加齢関連黄斑変性、悪液質、糸球体硬化症、肝硬変、NAFLD、骨粗しょう症、筋萎縮性側索硬化症、ハンチントン病、脊髄小脳失調症、多発性硬化症、神経変性、発作、がん、認知症、血管疾患、感染感受性、慢性炎症、及び腎機能障害の群から選択される。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、加齢関連疾患は、固形腫瘍、血液腫瘍、肉腫、骨肉腫、膠芽細胞腫、神経芽細胞腫、黒色腫、横紋筋肉腫、ユーイング肉腫、骨肉腫、B細胞新生物、多発性骨髄腫、B細胞リンパ腫、B細胞非ホジキンリンパ腫、ホジキンリンパ腫、慢性リンパ球性白血病(CLL)、急性骨髄性白血病(AML)、慢性骨髄性白血病(CML)、急性リンパ性白血病(ALL)、骨髄異形成症候群(MDS)、皮膚T細胞リンパ腫、網膜芽細胞腫、胃がん、尿路上皮がん、肺がん、腎細胞がん、胃食道がん、膵臓がん、前立腺がん、乳がん、結腸直腸がん、卵巣がん、非小細胞肺がん、扁平上皮細胞頭頸部がん、子宮内膜がん、子宮頸がん、肝臓がん、及び肝細胞がんからなる群から選択されるがんである。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、炎症性疾患は、リウマチ性関節炎、炎症性腸疾患、エリテマトーデス、ループス腎炎、糖尿病性腎症、CNS損傷、アルツハイマー病、パーキンソン病、筋萎縮性側索硬化症、クローン病、多発性硬化症、ギラン・バレー症候群、乾癬、グレーブス病、潰瘍性大腸炎、非アルコール性脂肪性肝炎、気分障害、及びがん治療関連認知障害の群から選択される。
In some embodiments of any of the methods described herein, the subject has been previously diagnosed or identified as having an age-related disease or an inflammatory disease. In some embodiments of any of the methods described herein, the age-related disease is inflammatory senescence-related. In some embodiments of any of the methods described herein, the age-related disease is Alzheimer's disease, aneurysm, cystic fibrosis, fibrosis in pancreatitis, glaucoma, hypertension, inflammatory bowel disease disease, disc degeneration, osteoarthritis,
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、治療誘導性老化細胞は、化学療法誘導性老化細胞である。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、TGF-β受容体の活性化の減少をもたらす1つ以上の作用物質の投与は、対象における標的組織の自然発生老化細胞及び/又は治療誘導性老化細胞の数又は活性の減少をもたらす。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、標的組織は、脂肪組織、膵臓組織、肝臓組織、腎臓組織、肺組織、心臓組織、血管系、骨組織、中枢神経系(CNS)組織、眼組織、皮膚組織、筋肉組織、及び二次リンパ器官組織の群から選択される。 In some embodiments of any of the methods described herein, the treatment-induced senescent cells are chemotherapy-induced senescent cells. In some embodiments of any of the methods described herein, administration of one or more agents that result in decreased activation of TGF-β receptors is associated with spontaneous aging of target tissues in the subject. resulting in a decrease in the number or activity of cells and/or treatment-induced senescent cells. In some embodiments of any of the methods described herein, the target tissue is adipose tissue, pancreatic tissue, liver tissue, kidney tissue, lung tissue, heart tissue, vasculature, bone tissue, central nervous system tissue. system (CNS) tissue, ocular tissue, skin tissue, muscle tissue, and secondary lymphoid organ tissue.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、TGFβ受容体は、TGF-β受容体II(TGFβRII)である。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、TGFβ受容体は、TGFβRIIIである。 In some embodiments of any of the methods described herein, the TGFβ receptor is TGF-β receptor II (TGFβRII). In some embodiments of any of the methods described herein, the TGFβ receptor is TGFβRIII.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、TGF-β受容体の活性化の減少をもたらす1つ以上の作用物質のうちの少なくとも1つは、可溶性TGF-β受容体、TGF-β受容体の細胞外ドメイン、TGF-βに特異的に結合する抗体、TGF-β受容体に結合するアンタゴニスト抗体、潜在関連ペプチド(「LAP」)に結合する作用物質、又はTGF-β/LAP複合体に結合する作用物質である。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、TGF-β受容体の活性化の減少をもたらす1つ以上の作用物質は、LAPへの又はTGF-β/LAP複合体への結合を介してTGF-β受容体の活性化を減少させる。 In some embodiments of any of the methods described herein, at least one of the one or more agents that result in decreased TGF-β receptor activation is soluble TGF-β an agent that binds to a receptor, an extracellular domain of a TGF-beta receptor, an antibody that specifically binds to TGF-beta, an antagonistic antibody that binds to a TGF-beta receptor, a latent associated peptide ("LAP"), or An agent that binds to the TGF-β/LAP complex. In some embodiments of any of the methods described herein, the one or more agents that result in decreased activation of TGF-β receptors are to LAP or to TGF-β/LAP complexes. It reduces TGF-β receptor activation through binding to the body.
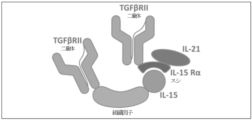
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、TGF-β受容体の活性化の減少をもたらす1つ以上の作用物質のうちの少なくとも1つは、(a)(i)第1の標的結合ドメイン、(ii)可溶性組織因子ドメイン、及び(iii)一対の親和性ドメインの第1のドメインを含む第1のキメラポリペプチドと、(b)(i)一対の親和性ドメインの第2のドメイン、及び(ii)第2の標的結合ドメインを含む第2のキメラポリペプチドと、を含む多鎖キメラポリペプチドであり、第1の標的結合ドメイン及び第2の標的結合ドメインのうちの一方若しくは両方は、TGF-β受容体のリガンドに特異的に結合するか、又は第1の標的結合ドメイン及び第2の標的結合ドメインのうちの一方若しくは両方は、TGF-β受容体に特異的に結合するアンタゴニスト抗原結合ドメインである。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、TGF-β受容体は、TGFβRIIである。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、TGF-β受容体は、TGFβRIIIである。 In some embodiments of any of the methods described herein, at least one of the one or more agents that result in decreased activation of the TGF-β receptor comprises (a) ( a first chimeric polypeptide comprising a first of i) a first target binding domain, (ii) a soluble tissue factor domain, and (iii) a pair of affinity domains; and (b) (i) an affinity pair and (ii) a second chimeric polypeptide comprising a second target binding domain, wherein the first target binding domain and the second target binding domain. Either one or both of the domains specifically bind to a ligand of the TGF-beta receptor, or one or both of the first target binding domain and the second target binding domain bind to the TGF-beta receptor. It is an antagonist antigen-binding domain that specifically binds to the body. In some embodiments of any of the methods described herein, the TGF-β receptor is TGFβRII. In some embodiments of any of the methods described herein, the TGF-β receptor is TGFβRIII.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び可溶性組織因子ドメインは、第1のキメラポリペプチド内で互いに直接隣接している。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1のキメラポリペプチドは、第1のキメラポリペプチド内の第1の標的結合ドメインと可溶性組織因子ドメインとの間にリンカー配列を更に含む。 In some embodiments of any of the methods described herein, the first target binding domain and the soluble tissue factor domain are directly adjacent to each other within the first chimeric polypeptide. In some embodiments of any of the methods described herein, the first chimeric polypeptide has a further includes a linker sequence.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性組織因子ドメイン、及び一対の親和性ドメインの第1のドメインは、第1のキメラポリペプチド内で互いに直接隣接している。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1のキメラポリペプチドは、第1のキメラポリペプチド内の可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間にリンカー配列を更に含む。 In some embodiments of any of the methods described herein, the soluble tissue factor domain and the first domain of the pair of affinity domains are directly adjacent to each other within the first chimeric polypeptide. ing. In some embodiments of any of the methods described herein, the first chimeric polypeptide comprises a first affinity domain paired with a soluble tissue factor domain within the first chimeric polypeptide. It further contains a linker sequence between the domains.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、一対の親和性ドメインの第2のドメイン及び第2の標的結合ドメインは、第2のキメラポリペプチド内で互いに直接隣接している。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチド内の一対の親和性ドメインの第2のドメインと第2の標的結合ドメインとの間にリンカー配列を更に含む。 In some embodiments of any of the methods described herein, the second domain and second target binding domain of the pair of affinity domains are directly adjacent to each other within the second chimeric polypeptide. are doing. In some embodiments of any of the methods described herein, the second chimeric polypeptide comprises the second domain and the second of the pair of affinity domains within the second chimeric polypeptide. It further comprises a linker sequence between it and the target binding domain.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは、同じ抗原に特異的に結合する。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは、異なる抗原に特異的に結合する。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1のキメラポリペプチドは、1つ以上の追加の標的結合ドメインを更に含む。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第2のキメラポリペプチドは、1つ以上の追加の標的結合ドメインを更に含む。 In some embodiments of any of the methods described herein, the first target binding domain and the second target binding domain specifically bind the same antigen. In some embodiments of any of the methods described herein, the first target binding domain and the second target binding domain specifically bind different antigens. In some embodiments of any of the methods described herein, the first chimeric polypeptide further comprises one or more additional target binding domains. In some embodiments of any of the methods described herein, the second chimeric polypeptide further comprises one or more additional target binding domains.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性組織因子ドメインは、可溶性ヒト組織因子ドメインである。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性ヒト組織因子ドメインは、配列番号93と少なくとも80%同一である配列を含む。 In some embodiments of any of the methods described herein, the soluble tissue factor domain is a soluble human tissue factor domain. In some embodiments of any of the methods described herein, the soluble human tissue factor domain comprises a sequence that is at least 80% identical to SEQ ID NO:93.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、一対の親和性ドメインは、ヒトIL-15受容体のアルファ鎖(IL15Rα)由来のスシドメイン、及び可溶性IL-15である。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性IL-15は、D8N又はD8Aアミノ酸置換を有する。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性IL-15は、IL-15活性を低減又は排除するための変異を含む。 In some embodiments of any of the methods described herein, the pair of affinity domains is a sushi domain from the alpha chain of the human IL-15 receptor (IL15Rα) and a soluble IL-15 be. In some embodiments of any of the methods described herein, the soluble IL-15 has a D8N or D8A amino acid substitution. In some embodiments of any of the methods described herein, the soluble IL-15 comprises mutations to reduce or eliminate IL-15 activity.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、一対の親和性ドメインは、バルナーゼとバルンスター(barnstar)、PKAとAKAP、変異RNase I断片に基づくアダプター/ドッキングタグモジュール、並びに、タンパク質シンタキシン、シナプトタグミン、シナプトブレビン、及びSNAP25の相互作用に基づくSNAREモジュールの群から選択される。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、一対の親和性ドメインの第1のドメイン又は第2のドメインは、可溶性共通ガンマ鎖ファミリーサイトカイン、又は共通ガンマ鎖ファミリーサイトカイン受容体に特異的に結合する抗原結合ドメインである。 In some embodiments of any of the methods described herein, the pair of affinity domains are barnase and barnstar, PKA and AKAP, adapter/docking tag modules based on mutated RNase I fragments. , and the group of SNARE modules based on the interaction of proteins syntaxin, synaptotagmin, synaptobrevin, and SNAP25. In some embodiments of any of the methods described herein, the first domain or the second domain of the pair of affinity domains is a soluble common gamma chain family cytokine or a common gamma chain family cytokine An antigen-binding domain that specifically binds to a receptor.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは、可溶性TGF-β受容体を含む。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性TGF-β受容体は、可溶性TGFβRIIである。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性TGFβRIIは、配列番号183と少なくとも80%同一である第1の配列、及び配列番号183と少なくとも80%同一である第2の配列を含み、第1及び第2の配列は、リンカーによって分離されている。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性TGFβRIIは、配列番号183と少なくとも90%同一である第1の配列、及び配列番号183と少なくとも90%同一である第2の配列を含む。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性TGFβRIIは、配列番号183の第1の配列、及び配列番号183の第2の配列を含む。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、リンカーは、配列番号102の配列を含む。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性TGFβRIIは、配列番号188と少なくとも80%同一である配列を含む。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性TGFβRIIは、配列番号188と少なくとも90%同一である配列を含む。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性TGF-βRIIは、配列番号188の配列を含む。 In some embodiments of any of the methods described herein, the first target binding domain and the second target binding domain comprise a soluble TGF-beta receptor. In some embodiments of any of the methods described herein, the soluble TGF-β receptor is soluble TGFβRII. In some embodiments of any of the methods described herein, the soluble TGFβRII is a first sequence that is at least 80% identical to SEQ ID NO: 183 and at least 80% identical to SEQ ID NO: 183 A second sequence, wherein the first and second sequences are separated by a linker. In some embodiments of any of the methods described herein, the soluble TGFβRII is a first sequence that is at least 90% identical to SEQ ID NO: 183 and at least 90% identical to SEQ ID NO: 183 Contains a second array. In some embodiments of any of the methods described herein, the soluble TGFβRII comprises the first sequence of SEQ ID NO:183 and the second sequence of SEQ ID NO:183. In some embodiments of any of the methods described herein, the linker comprises the sequence of SEQ ID NO:102. In some embodiments of any of the methods described herein, the soluble TGFβRII comprises a sequence that is at least 80% identical to SEQ ID NO:188. In some embodiments of any of the methods described herein, the soluble TGFβRII comprises a sequence that is at least 90% identical to SEQ ID NO:188. In some embodiments of any of the methods described herein, the soluble TGF-βRII comprises the sequence of SEQ ID NO:188.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1のキメラポリペプチドは、配列番号236と少なくとも80%同一である配列を含む。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1のキメラポリペプチドは、配列番号236と少なくとも90%同一である配列を含む。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1のキメラポリペプチドは、配列番号236の配列を含む。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第2のキメラポリペプチドは、配列番号193と少なくとも80%同一である配列を含む。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1のキメラポリペプチドは、配列番号236と少なくとも80%同一である配列を含む。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第2のキメラポリペプチドは、配列番号193と少なくとも90%同一である配列を含む。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第2のキメラポリペプチドは、配列番号193の配列を含む。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1のキメラポリペプチドは、配列番号236の配列を含む。 In some embodiments of any of the methods described herein, the first chimeric polypeptide comprises a sequence that is at least 80% identical to SEQ ID NO:236. In some embodiments of any of the methods described herein, the first chimeric polypeptide comprises a sequence that is at least 90% identical to SEQ ID NO:236. In some embodiments of any of the methods described herein, the first chimeric polypeptide comprises the sequence of SEQ ID NO:236. In some embodiments of any of the methods described herein, the second chimeric polypeptide comprises a sequence that is at least 80% identical to SEQ ID NO:193. In some embodiments of any of the methods described herein, the first chimeric polypeptide comprises a sequence that is at least 80% identical to SEQ ID NO:236. In some embodiments of any of the methods described herein, the second chimeric polypeptide comprises a sequence that is at least 90% identical to SEQ ID NO:193. In some embodiments of any of the methods described herein, the second chimeric polypeptide comprises the sequence of SEQ ID NO:193. In some embodiments of any of the methods described herein, the first chimeric polypeptide comprises the sequence of SEQ ID NO:236.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、TGF-β受容体の活性化の減少をもたらす1つ以上の作用物質のうちの少なくとも1つは、(i)第1の標的結合ドメイン、(ii)可溶性組織因子ドメイン、及び(iii)第2の標的結合ドメインを含む一本鎖キメラポリペプチドであり、第1の標的結合ドメイン及び第2の標的結合ドメインのうちの一方若しくは両方は、TGF-β受容体のリガンドに特異的に結合するか、又は第1の標的結合ドメイン及び第2の標的結合ドメインのうちの一方若しくは両方は、TGF-β受容体に特異的に結合するアンタゴニスト抗原結合ドメインである。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、TGF-β受容体は、TGF-βRIIである。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、TGF-β受容体は、TGFβRIIIである。 In some embodiments of any of the methods described herein, at least one of the one or more agents that result in decreased TGF-β receptor activation is (i) a second A single chain chimeric polypeptide comprising one target binding domain, (ii) a soluble tissue factor domain, and (iii) a second target binding domain, wherein specifically binds to a ligand of the TGF-beta receptor, or one or both of the first target binding domain and the second target binding domain are specific for the TGF-beta receptor It is an antagonist antigen-binding domain that specifically binds. In some embodiments of any of the methods described herein, the TGF-β receptor is TGF-βRII. In some embodiments of any of the methods described herein, the TGF-β receptor is TGFβRIII.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び可溶性組織因子ドメインは、互いに直接隣接している。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、一本鎖キメラポリペプチドは、第1の標的結合ドメインと可溶性組織因子ドメインとの間にリンカー配列を更に含む。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性組織因子ドメインと第2の標的結合ドメインは、互いに直接隣接している。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、一本鎖キメラポリペプチドは、可溶性組織因子ドメインと第2の標的結合ドメインとの間にリンカー配列を更に含む。 In some embodiments of any of the methods described herein, the first target binding domain and the soluble tissue factor domain are directly adjacent to each other. In some embodiments of any of the methods described herein, the single chain chimeric polypeptide further comprises a linker sequence between the first target binding domain and the soluble tissue factor domain. In some embodiments of any of the methods described herein, the soluble tissue factor domain and the second target binding domain are directly adjacent to each other. In some embodiments of any of the methods described herein, the single chain chimeric polypeptide further comprises a linker sequence between the soluble tissue factor domain and the second target binding domain.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは、同じ抗原に特異的に結合する。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは、異なる抗原に特異的に結合する。 In some embodiments of any of the methods described herein, the first target binding domain and the second target binding domain specifically bind the same antigen. In some embodiments of any of the methods described herein, the first target binding domain and the second target binding domain specifically bind different antigens.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性組織因子ドメインは、可溶性ヒト組織因子ドメインである。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性ヒト組織因子ドメインは、配列番号93と少なくとも80%同一である配列を含む。 In some embodiments of any of the methods described herein, the soluble tissue factor domain is a soluble human tissue factor domain. In some embodiments of any of the methods described herein, the soluble human tissue factor domain comprises a sequence that is at least 80% identical to SEQ ID NO:93.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、一本鎖キメラポリペプチドは、そのN末端及び/又はC末端に1つ以上の追加の標的結合ドメインを更に含む。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び/又は第2の標的結合ドメインは、可溶性TGF-β受容体を含む。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性TGF-β受容体は、可溶性TGF-βRIIである。 In some embodiments of any of the methods described herein, the single-chain chimeric polypeptide further comprises one or more additional target binding domains at its N-terminus and/or C-terminus. In some embodiments of any of the methods described herein, the first target binding domain and/or the second target binding domain comprise a soluble TGF-beta receptor. In some embodiments of any of the methods described herein, the soluble TGF-β receptor is soluble TGF-βRII.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性TGF-βRIIは、配列番号183と少なくとも80%同一である第1の配列、及び配列番号183と少なくとも80%同一である第2の配列を含み、第1及び第2の配列は、リンカーによって分離されている。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性TGFβRIIは、配列番号183と少なくとも90%同一である第1の配列、及び配列番号183と少なくとも90%同一である第2の配列を含む。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性TGFβRIIは、配列番号183の第1の配列、及び配列番号183の第2の配列を含む。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、リンカーは、配列番号102の配列を含む。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性TGFβRIIは、配列番号188と少なくとも80%同一である配列を含む。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性TGFβRIIは、配列番号188と少なくとも90%同一である配列を含む。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性TGFβRIIは、配列番号188の配列を含む。 In some embodiments of any of the methods described herein, the soluble TGF-βRII comprises a first sequence that is at least 80% identical to SEQ ID NO: 183 and a sequence that is at least 80% identical to SEQ ID NO: 183 and the first and second sequences are separated by a linker. In some embodiments of any of the methods described herein, the soluble TGFβRII is a first sequence that is at least 90% identical to SEQ ID NO: 183 and at least 90% identical to SEQ ID NO: 183 Contains a second array. In some embodiments of any of the methods described herein, the soluble TGFβRII comprises the first sequence of SEQ ID NO:183 and the second sequence of SEQ ID NO:183. In some embodiments of any of the methods described herein, the linker comprises the sequence of SEQ ID NO:102. In some embodiments of any of the methods described herein, the soluble TGFβRII comprises a sequence that is at least 80% identical to SEQ ID NO:188. In some embodiments of any of the methods described herein, the soluble TGFβRII comprises a sequence that is at least 90% identical to SEQ ID NO:188. In some embodiments of any of the methods described herein, the soluble TGFβRII comprises the sequence of SEQ ID NO:188.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、方法は、TGF-β受容体の活性化の減少をもたらす1つ以上の作用物質の2回以上の用量を対象に投与することを含む。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、2回以上の用量のうちの任意の2回の連続用量は、約1週間~約1年間隔で投与される。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、2回以上の用量のうちの任意の2回の連続用量は、約1週間~約6ヶ月間隔で投与される。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、2回以上の用量のうちの任意の2回の連続用量は、約1週間~約2ヶ月間隔で投与される。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、2回以上の用量のうちの任意の2回の連続用量は、約1週間~約1ヶ月間隔で投与される。 In some embodiments of any of the methods described herein, the method is directed to two or more doses of one or more agents that result in decreased activation of the TGF-β receptor. including administering. In some embodiments of any of the methods described herein, any two consecutive doses of the two or more doses are administered about one week to about one year apart. In some embodiments of any of the methods described herein, any two consecutive doses of the two or more doses are administered about one week to about six months apart. In some embodiments of any of the methods described herein, any two consecutive doses of the two or more doses are administered about one week to about two months apart. In some embodiments of any of the methods described herein, any two consecutive doses of the two or more doses are administered about one week to about one month apart.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、2回以上の用量が皮下投与によって投与される。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、2回以上の用量が筋肉内投与によって投与される。 In some embodiments of any of the methods described herein, two or more doses are administered by subcutaneous administration. In some embodiments of any of the methods described herein, two or more doses are administered by intramuscular administration.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、2回以上の用量は、約1年~約60年の期間にわたって投与される。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、2回以上の用量は、約1年~約50年の期間にわたって投与される。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、2回以上の用量は、約1年~約40年の期間にわたって投与される。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、2回以上の用量は、約1年~約30年の期間にわたって投与される。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、2回以上の用量は、約1年~約20年の期間にわたって投与される。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、2回以上の用量は、約1年~約10年の期間にわたって投与される。 In some embodiments of any of the methods described herein, the two or more doses are administered over a period of about 1 year to about 60 years. In some embodiments of any of the methods described herein, the two or more doses are administered over a period of about 1 year to about 50 years. In some embodiments of any of the methods described herein, the two or more doses are administered over a period of about 1 year to about 40 years. In some embodiments of any of the methods described herein, the two or more doses are administered over a period of about 1 year to about 30 years. In some embodiments of any of the methods described herein, the two or more doses are administered over a period of about 1 year to about 20 years. In some embodiments of any of the methods described herein, the two or more doses are administered over a period of about 1 year to about 10 years.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、TGF-β受容体の活性化の減少をもたらす1つ以上の作用物質の初回投与は、対象が少なくとも30歳に達したときに始まる。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、TGF-β受容体の活性化の減少をもたらす1つ以上の作用物質の初回投与は、対象が少なくとも40歳に達したときに始まる。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、TGF-β受容体の活性化の減少をもたらす1つ以上の作用物質の初回投与は、対象が少なくとも50歳に達したときに始まる。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、TGF-β受容体の活性化の減少をもたらす1つ以上の作用物質の初回投与は、対象が少なくとも60歳に達したときに始まる。 In some embodiments of any of the methods described herein, the first administration of one or more agents that results in decreased TGF-β receptor activation is administered until the subject reaches at least 30 years of age. It starts when In some embodiments of any of the methods described herein, the first administration of one or more agents that results in decreased TGF-β receptor activation is administered until the subject reaches at least 40 years of age. It starts when In some embodiments of any of the methods described herein, the first administration of one or more agents that results in decreased TGF-β receptor activation is administered until the subject reaches at least 50 years of age. It starts when In some embodiments of any of the methods described herein, the first administration of one or more agents that results in decreased TGF-β receptor activation is administered until the subject reaches at least 60 years of age. It starts when
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、2回以上の用量の各々は、TGF-β受容体の活性化の減少をもたらす各作用物質約0.01mg/kg~TGF-β受容体の活性化の減少をもたらす各作用物質約10mg/kgの投薬量で投与される。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、2回以上の用量の各々は、TGF-β受容体の活性化の減少をもたらす各作用物質約0.02mg/kg~TGF-β受容体の活性化の減少をもたらす各作用物質約5mg/kgの投薬量で投与される。 In some embodiments of any of the methods described herein, each of the two or more doses is about 0.01 mg/kg of each agent that results in decreased activation of the TGF-β receptor. ˜10 mg/kg of each agent that results in decreased activation of the TGF-β receptor. In some embodiments of any of the methods described herein, each of the two or more doses is about 0.02 mg/kg of each agent that results in decreased activation of the TGF-beta receptor. ˜5 mg/kg of each agent that results in decreased activation of the TGF-β receptor.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、対象は、加齢関連疾患又は炎症性疾患を有すると診断も同定もされていない。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、対象は、化学療法剤で以前に治療されたことがない。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、対象は、細胞老化を誘導する治療剤で以前に治療されたことがない。 In some embodiments of any of the methods described herein, the subject has not been diagnosed or identified as having an age-related disease or an inflammatory disease. In some embodiments of any of the methods described herein, the subject has not been previously treated with a chemotherapeutic agent. In some embodiments of any of the methods described herein, the subject has not been previously treated with a therapeutic agent that induces cellular senescence.
加齢関連疾患又は状態の治療を必要とする対象において加齢関連疾患又は状態を治療する方法であって、加齢関連疾患又は状態を有すると同定される対象に、治療有効量の1つ以上のナチュラルキラー(NK)細胞活性化物質を投与することを含む、方法が、本明細書に提供される。 A method of treating an age-related disease or condition in a subject in need thereof, comprising administering to a subject identified as having an age-related disease or condition a therapeutically effective amount of one or more Provided herein are methods comprising administering a natural killer (NK) cell activator of
老化細胞の死滅又は老化細胞の数の減少を必要とする対象において老化細胞を死滅させる又は老化細胞の数を減少させる方法であって、当該対象に、治療有効量の1つ以上のナチュラルキラー(NK)細胞活性化物質を投与することを含む、方法も本明細書に提供される。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、老化細胞は、老化がん細胞、老化単球、老化リンパ球、老化星状細胞、老化ミクログリア、老化ニューロン、老化組織線維芽細胞、老化皮膚線維芽細胞、老化ケラチノサイト、又は他の分化組織特異的な分裂機能細胞である。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、老化がん細胞は、化学療法誘導性老化細胞又は放射線によって誘導された老化細胞である。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、対象は、加齢関連疾患又は状態を有すると同定又は診断されている。 A method of killing senescent cells or reducing the number of senescent cells in a subject in need of killing senescent cells or reducing the number of senescent cells, comprising administering to the subject a therapeutically effective amount of one or more natural killers ( NK) Methods are also provided herein comprising administering a cell activator. In some embodiments of any of the methods described herein, the senescent cells are senescent cancer cells, senescent monocytes, senescent lymphocytes, senescent astrocytes, senescent microglia, senescent neurons, senescent tissue Fibroblasts, senescent skin fibroblasts, senescent keratinocytes, or other differentiated tissue-specific dividing functional cells. In some embodiments of any of the methods described herein, the senescent cancer cells are chemotherapy-induced senescent cells or radiation-induced senescent cells. In some embodiments of any of the methods described herein, the subject has been identified or diagnosed as having an age-related disease or condition.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、加齢関連疾患又は状態は、がん、自己免疫疾患、代謝性疾患、神経変性疾患、心臓血管疾患、皮膚疾患、早老症、及び脆弱性疾患の群から選択される。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、がんは、固形腫瘍、血液腫瘍、肉腫、骨肉腫、膠芽細胞腫、神経芽細胞腫、黒色腫、横紋筋肉腫、ユーイング肉腫、骨肉腫、B細胞新生物、多発性骨髄腫、B細胞リンパ腫、B細胞非ホジキンリンパ腫、ホジキンリンパ腫、慢性リンパ球性白血病(CLL)、急性骨髄性白血病(AML)、慢性骨髄性白血病(CML)、急性リンパ性白血病(ALL)、骨髄異形成症候群(MDS)、皮膚T細胞リンパ腫、網膜芽細胞腫、胃がん、尿路上皮がん、肺がん、腎細胞がん、胃食道がん、膵臓がん、前立腺がん、乳がん、結腸直腸がん、卵巣がん、非小細胞肺がん、扁平上皮細胞頭頸部がん、子宮内膜がん、子宮頸がん、肝臓がん、及び肝細胞がんの群から選択される。 In some embodiments of any of the methods described herein, the age-related disease or condition is cancer, autoimmune disease, metabolic disease, neurodegenerative disease, cardiovascular disease, skin disease, It is selected from the group of progeria and frailty diseases. In some embodiments of any of the methods described herein, the cancer is solid tumor, hematologic tumor, sarcoma, osteosarcoma, glioblastoma, neuroblastoma, melanoma, rhabdomyo sarcoma, Ewing's sarcoma, osteosarcoma, B-cell neoplasm, multiple myeloma, B-cell lymphoma, B-cell non-Hodgkin's lymphoma, Hodgkin's lymphoma, chronic lymphocytic leukemia (CLL), acute myeloid leukemia (AML), chronic Myelogenous leukemia (CML), acute lymphocytic leukemia (ALL), myelodysplastic syndrome (MDS), cutaneous T-cell lymphoma, retinoblastoma, gastric cancer, urothelial cancer, lung cancer, renal cell carcinoma, gastroesophageal cancer, pancreatic cancer, prostate cancer, breast cancer, colorectal cancer, ovarian cancer, non-small cell lung cancer, squamous cell head and neck cancer, endometrial cancer, cervical cancer, liver cancer, and hepatocellular carcinoma.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、自己免疫疾患は、1型糖尿病である。
In some embodiments of any of the methods described herein, the autoimmune disease is
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、代謝性疾患は、肥満、脂肪異栄養症、及び2型糖尿病の群から選択される。
In some embodiments of any of the methods described herein, the metabolic disease is selected from the group of obesity, lipodystrophy, and
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、神経変性疾患は、アルツハイマー病、パーキンソン病、及び認知症の群から選択される。 In some embodiments of any of the methods described herein, the neurodegenerative disease is selected from the group Alzheimer's disease, Parkinson's disease, and dementia.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、心臓血管疾患は、冠状動脈疾患、アテローム性動脈硬化症、及び肺動脈性肺高血圧症の群から選択される。 In some embodiments of any of the methods described herein, the cardiovascular disease is selected from the group of coronary artery disease, atherosclerosis, and pulmonary arterial hypertension.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、皮膚疾患は、創傷治癒、脱毛症、しわ、老人性黒子、皮膚の菲薄化、色素性乾皮症、及び先天性角化異常症の群から選択される。 In some embodiments of any of the methods described herein, the skin disorder is wound healing, alopecia, wrinkles, senile lentigines, skin thinning, xeroderma pigmentosum, and congenital Selected from the group of dyskeratosis.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、早老症は、早老症及びハッチンソン・ギルフォード早老症症候群の群から選択される。 In some embodiments of any of the methods described herein, the progeria is selected from the group of progeria and Hutchinson-Gilford progeria syndrome.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、脆弱性疾患は、脆弱、ワクチン接種に対する応答、骨粗しょう症、及びサルコペニアの群から選択される。 In some embodiments of any of the methods described herein, the fragility disease is selected from the group of fragility, response to vaccination, osteoporosis, and sarcopenia.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、加齢関連疾患又は状態は、骨関節炎、脂肪萎縮、特発性肺線維症、腎移植不全、肝線維症、骨量喪失、サルコペニア、加齢関連肺組織弾性喪失、骨粗しょう症、加齢関連腎機能障害、及び化学的に誘導された腎機能障害の群から選択される。 In some embodiments of any of the methods described herein, the age-related disease or condition is osteoarthritis, fat wasting, idiopathic pulmonary fibrosis, renal graft failure, liver fibrosis, bone mass loss, sarcopenia, age-related pulmonary tissue elastic loss, osteoporosis, age-related renal dysfunction, and chemically induced renal dysfunction.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、加齢関連疾患又は状態は、2型糖尿病又はアテローム性動脈硬化症である。
In some embodiments of any of the methods described herein, the age-related disease or condition is
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、投与は、対象における標的組織の老化細胞の数の減少をもたらす。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、脂肪組織、膵臓組織、肝臓組織、肺組織、血管系、骨組織、中枢神経系(CNS)組織、眼組織、皮膚組織、筋肉組織、及び二次リンパ器官組織の群から選択される。 In some embodiments of any of the methods described herein, administering results in a decrease in the number of senescent cells in the target tissue in the subject. In some embodiments of any of the methods described herein, adipose tissue, pancreatic tissue, liver tissue, lung tissue, vasculature, bone tissue, central nervous system (CNS) tissue, ocular tissue, skin It is selected from the group of tissue, muscle tissue and secondary lymphoid organ tissue.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、投与は、活性化されたNK細胞におけるCD25、CD69、mTORC1、SREBP1、IFN-γ、及びグランザイムBの発現レベルの増加をもたらす。 In some embodiments of any of the methods described herein, administering increases expression levels of CD25, CD69, mTORC1, SREBP1, IFN-γ, and granzyme B on activated NK cells bring.
加齢関連疾患又は状態の治療を必要とする対象において加齢関連疾患又は状態を治療する方法であって、加齢関連疾患又は状態を有すると同定される対象に、治療有効数の活性化されたNK細胞を投与することを含む、方法も本明細書に提供される。 A method of treating an age-related disease or condition in a subject in need of treatment of an age-related disease or condition, comprising administering to a subject identified as having an age-related disease or condition a therapeutically effective number of activated Also provided herein are methods comprising administering NK cells.
老化細胞の死滅又は老化細胞の数の減少を必要とする対象において老化細胞を死滅させる又は老化細胞の数を減少させる方法であって、当該対象に、治療有効数の活性化されたNK細胞を投与することを含む、方法も本明細書に提供される。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、老化細胞は、老化がん細胞、老化単球、老化リンパ球、老化星状細胞、老化ミクログリア、老化ニューロン、老化組織線維芽細胞、老化皮膚線維芽細胞、老化ケラチノサイト、又は他の分化組織特異的な分裂機能細胞である。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、老化がん細胞は、化学療法誘導性老化細胞又は放射線によって誘導された老化細胞である。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、対象は、加齢関連疾患又は状態を有すると同定又は診断されている。 A method of killing senescent cells or reducing the number of senescent cells in a subject in need of killing senescent cells or reducing the number of senescent cells, comprising administering to the subject a therapeutically effective number of activated NK cells. Methods are also provided herein that include administering. In some embodiments of any of the methods described herein, the senescent cells are senescent cancer cells, senescent monocytes, senescent lymphocytes, senescent astrocytes, senescent microglia, senescent neurons, senescent tissue Fibroblasts, senescent skin fibroblasts, senescent keratinocytes, or other differentiated tissue-specific dividing functional cells. In some embodiments of any of the methods described herein, the senescent cancer cells are chemotherapy-induced senescent cells or radiation-induced senescent cells. In some embodiments of any of the methods described herein, the subject has been identified or diagnosed as having an age-related disease or condition.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、加齢関連疾患又は状態は、がん、自己免疫疾患、代謝性疾患、神経変性疾患、心臓血管疾患、皮膚疾患、早老症、及び脆弱性疾患の群から選択される。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、がんは、固形腫瘍、血液腫瘍、肉腫、骨肉腫、膠芽細胞腫、神経芽細胞腫、黒色腫、横紋筋肉腫、ユーイング肉腫、骨肉腫、B細胞新生物、多発性骨髄腫、B細胞リンパ腫、B細胞非ホジキンリンパ腫、ホジキンリンパ腫、慢性リンパ球性白血病(CLL)、急性骨髄性白血病(AML)、慢性骨髄性白血病(CML)、急性リンパ性白血病(ALL)、骨髄異形成症候群(MDS)、皮膚T細胞リンパ腫、網膜芽細胞腫、胃がん、尿路上皮がん、肺がん、腎細胞がん、胃食道がん、膵臓がん、前立腺がん、乳がん、結腸直腸がん、卵巣がん、非小細胞肺がん、扁平上皮細胞頭頸部がん、子宮内膜がん、子宮頸がん、肝臓がん、及び肝細胞がんの群から選択される。 In some embodiments of any of the methods described herein, the age-related disease or condition is cancer, autoimmune disease, metabolic disease, neurodegenerative disease, cardiovascular disease, skin disease, It is selected from the group of progeria and frailty diseases. In some embodiments of any of the methods described herein, the cancer is solid tumor, hematologic tumor, sarcoma, osteosarcoma, glioblastoma, neuroblastoma, melanoma, rhabdomyo sarcoma, Ewing's sarcoma, osteosarcoma, B-cell neoplasm, multiple myeloma, B-cell lymphoma, B-cell non-Hodgkin's lymphoma, Hodgkin's lymphoma, chronic lymphocytic leukemia (CLL), acute myeloid leukemia (AML), chronic Myelogenous leukemia (CML), acute lymphocytic leukemia (ALL), myelodysplastic syndrome (MDS), cutaneous T-cell lymphoma, retinoblastoma, gastric cancer, urothelial cancer, lung cancer, renal cell carcinoma, gastroesophageal cancer, pancreatic cancer, prostate cancer, breast cancer, colorectal cancer, ovarian cancer, non-small cell lung cancer, squamous cell head and neck cancer, endometrial cancer, cervical cancer, liver cancer, and hepatocellular carcinoma.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、自己免疫疾患は、1型糖尿病である。
In some embodiments of any of the methods described herein, the autoimmune disease is
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、代謝性疾患は、肥満、脂肪異栄養症、及び2型糖尿病の群から選択される。
In some embodiments of any of the methods described herein, the metabolic disease is selected from the group of obesity, lipodystrophy, and
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、神経変性疾患は、アルツハイマー病、パーキンソン病、及び認知症の群から選択される。 In some embodiments of any of the methods described herein, the neurodegenerative disease is selected from the group Alzheimer's disease, Parkinson's disease, and dementia.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、心臓血管疾患は、冠状動脈疾患、アテローム性動脈硬化症、及び肺動脈性肺高血圧症の群から選択される。 In some embodiments of any of the methods described herein, the cardiovascular disease is selected from the group of coronary artery disease, atherosclerosis, and pulmonary arterial hypertension.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、皮膚疾患は、創傷治癒、脱毛症、しわ、老人性黒子、皮膚の菲薄化、色素性乾皮症、及び先天性角化異常症の群から選択される。 In some embodiments of any of the methods described herein, the skin disorder is wound healing, alopecia, wrinkles, senile lentigines, skin thinning, xeroderma pigmentosum, and congenital Selected from the group of dyskeratosis.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、早老症は、早老症及びハッチンソン・ギルフォード早老症症候群の群から選択される。 In some embodiments of any of the methods described herein, the progeria is selected from the group of progeria and Hutchinson-Gilford progeria syndrome.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、脆弱性疾患は、脆弱、ワクチン接種に対する応答、骨粗しょう症、及びサルコペニアの群から選択される。 In some embodiments of any of the methods described herein, the fragility disease is selected from the group of fragility, response to vaccination, osteoporosis, and sarcopenia.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、加齢関連疾患又は状態は、加齢関連黄斑変性、骨関節炎、脂肪萎縮、特発性肺線維症、腎移植不全、肝線維症、骨量喪失、サルコペニア、加齢関連肺組織弾性喪失、骨粗しょう症、加齢関連腎機能障害、及び化学的に誘導された腎機能障害の群から選択される。 In some embodiments of any of the methods described herein, the age-related disease or condition is age-related macular degeneration, osteoarthritis, fat wasting, idiopathic pulmonary fibrosis, renal transplant failure, selected from the group of liver fibrosis, bone loss, sarcopenia, age-related loss of lung tissue elasticity, osteoporosis, age-related renal dysfunction, and chemically induced renal dysfunction.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態は、休止NK細胞を得ることと、1つ以上の休止NK細胞活性化物質を含む液体培養培地中でインビトロで休止NK細胞を接触させることであって、この接触が、その後、対象に投与される活性化されたNK細胞の発生をもたらす、接触させることと、を更に含む。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、休止NK細胞は、対象から得られた自己NK細胞である。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、休止NK細胞は、同種異系の休止NK細胞である。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、休止NK細胞は、人工NK細胞である。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、休止NK細胞は、ハプロタイプ一致の休止NK細胞である。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、休止NK細胞は、キメラ抗原受容体又は組換えT細胞受容体を有する遺伝子操作されたNK細胞である。本明細書に記載の方法のいずれかのいくつかの実施形態は、活性化されたNK細胞が対象に投与される前に、活性化されたNK細胞を単離することを更に含む。本明細書に記載の方法のいずれかのいくつかの実施形態は、対象に投与する前に、キメラ抗原受容体又は組換えT細胞受容体をコードする核酸を、休止NK細胞又は活性化されたNK細胞に導入することを更に含む。 Some embodiments of any of the methods described herein involve obtaining resting NK cells and resting NK cells in vitro in a liquid culture medium comprising one or more resting NK cell activators. contacting with, which contacting results in the generation of activated NK cells that are then administered to the subject. In some embodiments of any of the methods described herein, the resting NK cells are autologous NK cells obtained from the subject. In some embodiments of any of the methods described herein, the resting NK cells are allogeneic resting NK cells. In some embodiments of any of the methods described herein, the resting NK cells are induced NK cells. In some embodiments of any of the methods described herein, the resting NK cells are haploidentical resting NK cells. In some embodiments of any of the methods described herein, the resting NK cells are genetically engineered NK cells with chimeric antigen receptors or recombinant T cell receptors. Some embodiments of any of the methods described herein further comprise isolating the activated NK cells before the activated NK cells are administered to the subject. Some embodiments of any of the methods described herein involve administering a nucleic acid encoding a chimeric antigen receptor or recombinant T cell receptor to resting NK cells or activated NK cells prior to administration to a subject. Further comprising introducing into NK cells.
ある期間にわたる皮膚及び/又は毛髪の質感及び/又は外観の改善を必要とする対象において皮膚及び/又は毛髪の質感及び/又は外観を改善する方法であって、当該対象に、治療有効量の1つ以上のナチュラルキラー(NK)細胞活性化物質を投与することを含む、方法も本明細書に提供される。 A method of improving skin and/or hair texture and/or appearance in a subject in need thereof over a period of time comprising administering to the subject a therapeutically effective amount of 1 Also provided herein are methods comprising administering one or more natural killer (NK) cell activators.
ある期間にわたる皮膚及び/又は毛髪の質感及び/又は外観の改善を必要とする対象において皮膚及び/又は毛髪の質感及び/又は外観を改善する方法であって、当該対象に、治療有効数の活性化されたNK細胞を投与することを含む、方法も本明細書に提供される。本明細書に記載の方法のうちのいずれかのいくつかの実施形態は、休止NK細胞を得ることと、1つ以上の休止NK細胞活性化物質を含む液体培養培地中でインビトロで休止NK細胞を接触させることであって、この接触が、その後、対象に投与される活性化されたNK細胞の発生をもたらす、接触させることと、を更に含む。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、休止NK細胞は、対象から得られた自己NK細胞である。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、休止NK細胞は、同種異系の休止NK細胞である。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、休止NK細胞は、人工NK細胞である。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、休止NK細胞は、ハプロタイプ一致の休止NK細胞である。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、休止NK細胞は、キメラ抗原受容体又は組換えT細胞受容体を有する遺伝子操作されたNK細胞である。本明細書に記載の方法のいずれかのいくつかの実施形態は、活性化されたNK細胞が対象に投与される前に、活性化されたNK細胞を単離することを更に含む。 1. A method of improving skin and/or hair texture and/or appearance in a subject in need thereof over a period of time, comprising administering to said subject a therapeutically effective number of active Also provided herein are methods comprising administering the transformed NK cells. Some embodiments of any of the methods described herein involve obtaining resting NK cells and resting NK cells in vitro in a liquid culture medium comprising one or more resting NK cell activators. contacting with, which contacting results in the generation of activated NK cells that are then administered to the subject. In some embodiments of any of the methods described herein, the resting NK cells are autologous NK cells obtained from the subject. In some embodiments of any of the methods described herein, the resting NK cells are allogeneic resting NK cells. In some embodiments of any of the methods described herein, the resting NK cells are induced NK cells. In some embodiments of any of the methods described herein, the resting NK cells are haploidentical resting NK cells. In some embodiments of any of the methods described herein, the resting NK cells are genetically engineered NK cells with chimeric antigen receptors or recombinant T cell receptors. Some embodiments of any of the methods described herein further comprise isolating the activated NK cells before the activated NK cells are administered to the subject.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、この方法は、ある期間にわたる対象の皮膚の質感及び/又は外観の改善を提供する。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、この方法は、ある期間にわたる対象の皮膚におけるしわの形成速度の減少をもたらす。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、この方法は、ある期間にわたる対象の皮膚の着色の改善をもたらす。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、この方法は、ある期間にわたる対象の皮膚の老人性色素斑の低減をもたらす。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、この方法は、ある期間にわたる対象の皮膚の質感の改善をもたらす。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、この方法は、ある期間にわたる対象の毛髪の質感及び/又は外観の改善を提供する。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、この方法は、ある期間にわたる対象における白髪の形成速度の減少をもたらす。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、この方法は、ある期間にわたる対象の白髪の数の減少をもたらす。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、この方法は、経時的な対象における脱毛速度の減少をもたらす。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、この方法は、ある期間にわたる対象の毛髪の質感の改善をもたらす。 In some embodiments of any of the methods described herein, the method provides an improvement in the subject's skin texture and/or appearance over time. In some embodiments of any of the methods described herein, the method results in a decrease in the rate of wrinkle formation in the subject's skin over a period of time. In some embodiments of any of the methods described herein, the method provides an improvement in skin pigmentation of the subject over time. In some embodiments of any of the methods described herein, the method results in a reduction of age spots in the subject's skin over time. In some embodiments of any of the methods described herein, the method results in an improvement in the subject's skin texture over time. In some embodiments of any of the methods described herein, the method provides an improvement in the texture and/or appearance of the subject's hair over time. In some embodiments of any of the methods described herein, the method results in a decrease in the rate of gray hair formation in the subject over a period of time. In some embodiments of any of the methods described herein, the method results in a decrease in the number of gray hairs in the subject over time. In some embodiments of any of the methods described herein, the method results in a decrease in hair loss rate in the subject over time. In some embodiments of any of the methods described herein, the method provides an improvement in the subject's hair texture over time.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、期間は、約1ヶ月間~約10年間である。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、この方法は、ある期間にわたる対象の皮膚における老化皮膚線維芽細胞の数の減少をもたらす。 In some embodiments of any of the methods described herein, the time period is from about 1 month to about 10 years. In some embodiments of any of the methods described herein, the method results in a decrease in the number of senescent skin fibroblasts in the subject's skin over time.
ある期間にわたる肥満の治療の支援を必要とする対象において肥満の治療を支援する方法であって、当該対象に、治療有効量の1つ以上のナチュラルキラー(NK)細胞活性化物質を投与することを含む、方法も本明細書に提供される。 A method of helping treat obesity in a subject in need of help treating obesity over a period of time comprising administering to the subject a therapeutically effective amount of one or more natural killer (NK) cell activators. A method is also provided herein, comprising:
ある期間にわたる肥満の治療の支援を必要とする対象において肥満の治療を支援する方法であって、当該対象に、治療有効数の活性化されたNK細胞を投与することを含む、方法も本明細書に提供される。本明細書に記載の方法のうちのいずれかのいくつかの実施形態は、休止NK細胞を得ることと、1つ以上の休止NK細胞活性化物質を含む液体培養培地中でインビトロで休止NK細胞を接触させることであって、この接触が、その後、対象に投与される活性化されたNK細胞の発生をもたらす、接触させることと、を更に含む。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、休止NK細胞は、対象から得られた自己NK細胞である。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、休止NK細胞は、同種異系の休止NK細胞である。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、休止NK細胞は、人工NK細胞である。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、休止NK細胞は、ハプロタイプ一致の休止NK細胞である。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、休止NK細胞は、キメラ抗原受容体又は組換えT細胞受容体を有する遺伝子操作されたNK細胞である。本明細書に記載の方法のいずれかのいくつかの実施形態は、活性化されたNK細胞が対象に投与される前に、活性化されたNK細胞を単離することを更に含む。 Also herein is a method of helping treat obesity in a subject in need of help treating obesity over a period of time comprising administering to the subject a therapeutically effective number of activated NK cells. provided in the book. Some embodiments of any of the methods described herein involve obtaining resting NK cells and resting NK cells in vitro in a liquid culture medium comprising one or more resting NK cell activators. contacting with, which contacting results in the generation of activated NK cells that are then administered to the subject. In some embodiments of any of the methods described herein, the resting NK cells are autologous NK cells obtained from the subject. In some embodiments of any of the methods described herein, the resting NK cells are allogeneic resting NK cells. In some embodiments of any of the methods described herein, the resting NK cells are induced NK cells. In some embodiments of any of the methods described herein, the resting NK cells are haploidentical resting NK cells. In some embodiments of any of the methods described herein, the resting NK cells are genetically engineered NK cells with chimeric antigen receptors or recombinant T cell receptors. Some embodiments of any of the methods described herein further comprise isolating the activated NK cells before the activated NK cells are administered to the subject.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、この方法は、ある期間にわたる対象の体重の減少をもたらす。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、この方法は、ある期間にわたる対象の肥満度指数(BMI)の減少をもたらす。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、この方法は、対象における前糖尿病から2型糖尿病への進行速度の減少をもたらす。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、この方法は、対象における空腹時血糖値の減少をもたらす。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、この方法は、対象におけるインスリン感受性の増加をもたらす。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、この方法は、対象におけるアテローム性動脈硬化症の重症度の減少をもたらす。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、期間は、約2週間~約10年間である。
In some embodiments of any of the methods described herein, the method results in weight loss in the subject over a period of time. In some embodiments of any of the methods described herein, the method results in a decrease in body mass index (BMI) of the subject over time. In some embodiments of any of the methods described herein, the method results in a reduction in the rate of progression from pre-diabetes to
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、1つ以上のNK細胞活性化物質のうちの少なくとも1つは、IL-2受容体、IL-7受容体、IL-12受容体、IL-15受容体、IL-18受容体、IL-21受容体、IL-33受容体、CD16、CD69、CD25、CD59、CD352、NKp80、DNAM-1、2B4、NKp30、NKp44、NKp46、NKG2D、KIR2DS1、KIR2Ds2/3、KIR2DL4、KIR2DS4、KIR2DS5、及びKIR3DS1のうちの1つ以上の活性化をもたらす。 In some embodiments of any of the methods described herein, at least one of the one or more NK cell activators is IL-2 receptor, IL-7 receptor, IL -12 receptor, IL-15 receptor, IL-18 receptor, IL-21 receptor, IL-33 receptor, CD16, CD69, CD25, CD59, CD352, NKp80, DNAM-1, 2B4, NKp30, NKp44 , NKp46, NKG2D, KIR2DS1, KIR2Ds2/3, KIR2DL4, KIR2DS4, KIR2DS5, and KIR3DS1.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、IL-2受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、IL-2受容体に特異的に結合する可溶性IL-2又はアゴニスト抗体である。 In some embodiments of any of the methods described herein, at least one of the one or more NK cell activators that result in IL-2 receptor activation is IL-2 A soluble IL-2 or agonistic antibody that specifically binds to the receptor.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、IL-7受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、IL-7受容体に特異的に結合する可溶性IL-7又はアゴニスト抗体である。 In some embodiments of any of the methods described herein, at least one of the one or more NK cell activators that result in IL-7 receptor activation is IL-7 A soluble IL-7 or agonistic antibody that specifically binds to the receptor.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、IL-12受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、IL-12受容体に特異的に結合する可溶性IL-12又はアゴニスト抗体である。 In some embodiments of any of the methods described herein, at least one of the one or more NK cell activators that result in IL-12 receptor activation is IL-12 A soluble IL-12 or agonistic antibody that specifically binds to the receptor.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、IL-15受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、IL-15受容体に特異的に結合する可溶性IL-15又はアゴニスト抗体である。 In some embodiments of any of the methods described herein, at least one of the one or more NK cell activators that result in IL-15 receptor activation is IL-15 A soluble IL-15 or agonistic antibody that specifically binds to the receptor.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、IL-21受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、IL-21受容体に特異的に結合する可溶性IL-21又はアゴニスト抗体である。 In some embodiments of any of the methods described herein, at least one of the one or more NK cell activators that result in IL-21 receptor activation is IL-21 A soluble IL-21 or agonistic antibody that specifically binds to the receptor.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、IL-33受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、IL-33受容体に特異的に結合する可溶性IL-33又はアゴニスト抗体である。 In some embodiments of any of the methods described herein, at least one of the one or more NK cell activators that result in IL-33 receptor activation is IL-33 A soluble IL-33 or agonistic antibody that specifically binds to the receptor.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、CD16受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、CD16に特異的に結合するアゴニスト抗体である。 In some embodiments of any of the methods described herein, at least one of the one or more NK cell activators that result in activation of the CD16 receptor is specifically It is an agonistic antibody that binds.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、CD69受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、CD69に特異的に結合するアゴニスト抗体である。 In some embodiments of any of the methods described herein, at least one of the one or more NK cell activators that result in CD69 receptor activation is specifically directed to CD69 It is an agonistic antibody that binds.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、CD25又はCD59受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、CD25又はCD59に特異的に結合するアゴニスト抗体である。 In some embodiments of any of the methods described herein, at least one of the one or more NK cell activators that result in activation of CD25 or CD59 receptors is CD25 or CD59 is an agonistic antibody that specifically binds to
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、CD352受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、CD352に特異的に結合するアゴニスト抗体である。 In some embodiments of any of the methods described herein, at least one of the one or more NK cell activators that result in CD352 receptor activation is specifically directed to CD352 It is an agonistic antibody that binds.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、NKp80受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、NKp80に特異的に結合するアゴニスト抗体である。 In some embodiments of any of the methods described herein, at least one of the one or more NK cell activators that result in activation of the NKp80 receptor is specifically It is an agonistic antibody that binds.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、DNAM-1受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、DNAM-1に特異的に結合するアゴニスト抗体である。 In some embodiments of any of the methods described herein, at least one of the one or more NK cell activators that result in DNAM-1 receptor activation is DNAM-1 is an agonistic antibody that specifically binds to
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、2B4受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、2B4に特異的に結合するアゴニスト抗体である。 In some embodiments of any of the methods described herein, at least one of the one or more NK cell activators that result in activation of the 2B4 receptor is specifically It is an agonistic antibody that binds.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、NKp30受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、NKp30に特異的に結合するアゴニスト抗体である。 In some embodiments of any of the methods described herein, at least one of the one or more NK cell activators that result in activation of the NKp30 receptor is specifically It is an agonistic antibody that binds.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、NKp44受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、NKp44に特異的に結合するアゴニスト抗体である。 In some embodiments of any of the methods described herein, at least one of the one or more NK cell activators that result in activation of the NKp44 receptor is specifically It is an agonistic antibody that binds.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、NKp46受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、NKp46に特異的に結合するアゴニスト抗体である。 In some embodiments of any of the methods described herein, at least one of the one or more NK cell activators that result in activation of the NKp46 receptor is specifically It is an agonistic antibody that binds.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、NKG2D受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、NKG2Dに特異的に結合するアゴニスト抗体である。 In some embodiments of any of the methods described herein, at least one of the one or more NK cell activators that result in NKG2D receptor activation is specifically directed to NKG2D It is an agonistic antibody that binds.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、KIR2DS1受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、KIR2DS1に特異的に結合するアゴニスト抗体である。 In some embodiments of any of the methods described herein, at least one of the one or more NK cell activators that result in activation of the KIR2DS1 receptor is specifically It is an agonistic antibody that binds.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、KIR2DS2/3受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、KIR2DS2/3に特異的に結合するアゴニスト抗体である。 In some embodiments of any of the methods described herein, at least one of the one or more NK cell activators that result in activation of the KIR2DS2/3 receptor is KIR2DS2/3 is an agonistic antibody that specifically binds to
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、KIR2DL4受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、KIR2DL4に特異的に結合するアゴニスト抗体である。 In some embodiments of any of the methods described herein, at least one of the one or more NK cell activators that result in activation of the KIR2DL4 receptor is specifically It is an agonistic antibody that binds.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、KIR2DS4受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、KIR2DS4に特異的に結合するアゴニスト抗体である。 In some embodiments of any of the methods described herein, at least one of the one or more NK cell activators that result in activation of the KIR2DS4 receptor is specifically It is an agonistic antibody that binds.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、KIR2DS5受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、KIR2DS5に特異的に結合するアゴニスト抗体である。 In some embodiments of any of the methods described herein, at least one of the one or more NK cell activators that result in activation of the KIR2DS5 receptor is specifically It is an agonistic antibody that binds.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、KIR3DS1受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、KIR3DS1に特異的に結合するアゴニスト抗体である。 In some embodiments of any of the methods described herein, at least one of the one or more NK cell activators that result in activation of the KIR3DS1 receptor is specifically It is an agonistic antibody that binds.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、1つ以上のNK細胞活性化物質のうちの少なくとも1つは、PD-1、TGF-β受容体、TIGIT、CD1、TIM-3、Siglec-7、IRP60、Tactile、IL1R8、NKG2A/KLRD1、KIR2DL1、KIR2DL2/3、KIR2DL5、KIR3DL1、KIR3DL2、ILT2/LIR-1、及びLAG-2のうちの1つ以上の活性化の減少をもたらす。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、PD-1の活性化の減少をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、PD-1に特異的に結合するアンタゴニスト抗体、可溶性PD-1、可溶性PD-L1、又はPD-L1に特異的に結合する抗体である。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、TGF-β受容体の活性化の減少をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、可溶性TGF-β受容体、TGF-βに特異的に結合する抗体、又はTGF-β受容体に特異的に結合するアンタゴニスト抗体である。 In some embodiments of any of the methods described herein, at least one of the one or more NK cell activators is PD-1, TGF-beta receptor, TIGIT, CD1 , TIM-3, Siglec-7, IRP60, Tactile, IL1R8, NKG2A/KLRD1, KIR2DL1, KIR2DL2/3, KIR2DL5, KIR3DL1, KIR3DL2, ILT2/LIR-1, and LAG-2 result in a decrease in In some embodiments of any of the methods described herein, at least one of the one or more NK cell activators that result in decreased activation of PD-1 is PD-1 soluble PD-1, soluble PD-L1, or an antibody that specifically binds to PD-L1. In some embodiments of any of the methods described herein, at least one of the one or more NK cell activators that result in decreased TGF-β receptor activation is a soluble A TGF-beta receptor, an antibody that specifically binds to TGF-beta, or an antagonistic antibody that specifically binds to a TGF-beta receptor.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、TIGITの活性化の減少をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、TIGITに特異的に結合するアンタゴニスト抗体、可溶性TIGIT、又はTIGITのリガンドに特異的に結合する抗体である。 In some embodiments of any of the methods described herein, at least one of the one or more NK cell activators that result in decreased activation of TIGIT is specifically An antagonist antibody that binds, a soluble TIGIT, or an antibody that specifically binds to a ligand of TIGIT.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、CD1の活性化の減少をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、CD1に特異的に結合するアンタゴニスト抗体、可溶性CD1、又はCD1のリガンドに特異的に結合する抗体である。 In some embodiments of any of the methods described herein, at least one of the one or more NK cell activators that result in decreased activation of CD1 is specifically An antagonist antibody that binds, soluble CD1, or an antibody that specifically binds to a ligand of CD1.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、TIM-3の活性化の減少をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、TIM-3に特異的に結合すアンタゴニスト抗体、可溶性TIM-3、又はTIM-3のリガンドに特異的に結合する抗体である。 In some embodiments of any of the methods described herein, at least one of the one or more NK cell activators that result in decreased activation of TIM-3 is soluble TIM-3, or an antibody that specifically binds to a ligand of TIM-3.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、Siglec-7の活性化の減少をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、Siglec-7に特異的に結合するアンタゴニスト抗体、又はSiglec-7のリガンドに特異的に結合する抗体である。 In some embodiments of any of the methods described herein, at least one of the one or more NK cell activators that result in decreased Siglec-7 activation is Siglec-7 or an antibody that specifically binds to a ligand of Siglec-7.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、IRP60の活性化の減少をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、IRP60に特異的に結合するアンタゴニスト抗体、又はIRP60のリガンドに特異的に結合する抗体である。 In some embodiments of any of the methods described herein, at least one of the one or more NK cell activators that result in decreased activation of IRP60 is specifically An antagonist antibody that binds, or an antibody that specifically binds to a ligand of IRP60.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、Tactileの活性化の減少をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、Tactileに特異的に結合するアンタゴニスト抗体、又はTactileのリガンドに特異的に結合する抗体である。 In some embodiments of any of the methods described herein, at least one of the one or more NK cell activators that result in decreased activation of Tactile is specifically An antagonist antibody that binds, or an antibody that specifically binds to a ligand of Tactile.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、IL1R8の活性化の減少をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、IL1R8に特異的に結合するアンタゴニスト抗体、又はIL1R8のリガンドに特異的に結合する抗体である。 In some embodiments of any of the methods described herein, at least one of the one or more NK cell activators that result in decreased activation of IL1R8 is specifically An antagonist antibody that binds, or an antibody that specifically binds to a ligand of IL1R8.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、NKG2A/KLRD1の活性化の減少をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、NKG2A/KLRD1に特異的に結合するアンタゴニスト抗体、又はNKG2A/KLRD1のリガンドに特異的に結合する抗体である。 In some embodiments of any of the methods described herein, at least one of the one or more NK cell activators that result in decreased activation of NKG2A/KLRD1 is NKG2A/KLRD1 or an antibody that specifically binds to a ligand of NKG2A/KLRD1.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、KIR2DL1の活性化の減少をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、KIR2DL1に特異的に結合するアンタゴニスト抗体、又はKIR2DL1のリガンドに特異的に結合する抗体である。 In some embodiments of any of the methods described herein, at least one of the one or more NK cell activators that result in decreased activation of KIR2DL1 is specifically An antagonist antibody that binds, or an antibody that specifically binds to a ligand of KIR2DL1.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、KIR2DL2/3の活性化の減少をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、KIR2DL2/3に特異的に結合するアンタゴニスト抗体、又はKIR2DL2/3のリガンドに特異的に結合する抗体である。 In some embodiments of any of the methods described herein, at least one of the one or more NK cell activators that result in decreased activation of KIR2DL2/3 is KIR2DL2/3 or an antibody that specifically binds to a ligand of KIR2DL2/3.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、KIR2DL5の活性化の減少をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、KIR2DL5に特異的に結合するアンタゴニスト抗体、又はKIR2DL5のリガンドに特異的に結合する抗体である。 In some embodiments of any of the methods described herein, at least one of the one or more NK cell activators that result in decreased activation of KIR2DL5 is specifically An antagonist antibody that binds, or an antibody that specifically binds to a ligand of KIR2DL5.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、KIR3DL1の活性化の減少をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、KIR3DL1に特異的に結合するアンタゴニスト抗体、又はKIR3DL1のリガンドに特異的に結合する抗体である。 In some embodiments of any of the methods described herein, at least one of the one or more NK cell activators that result in decreased activation of KIR3DL1 is specifically An antagonist antibody that binds, or an antibody that specifically binds to a ligand of KIR3DL1.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、KIR3DL2の活性化の減少をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、KIR3DL2に特異的に結合するアンタゴニスト抗体、又はKIR3DL2のリガンドに特異的に結合する抗体である。 In some embodiments of any of the methods described herein, at least one of the one or more NK cell activators that result in decreased activation of KIR3DL2 is specifically An antagonist antibody that binds, or an antibody that specifically binds to a ligand of KIR3DL2.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、ILT2/LIR-1の活性化の減少をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、ILT2/LIR-1に特異的に結合するアンタゴニスト抗体、又はILT2/LIR-1のリガンドに特異的に結合する抗体である。 In some embodiments of any of the methods described herein, at least one of the one or more NK cell activators that result in decreased activation of ILT2/LIR-1 is ILT2 An antagonist antibody that specifically binds to /LIR-1 or an antibody that specifically binds to a ligand of ILT2/LIR-1.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、LAG-2の活性化の減少をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、LAG-2に特異的に結合するアンタゴニスト抗体、又はLAG-2のリガンドに特異的に結合する抗体である。 In some embodiments of any of the methods described herein, at least one of the one or more NK cell activators that result in decreased activation of LAG-2 is LAG-2 or an antibody that specifically binds to a ligand of LAG-2.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、1つ以上のNK細胞活性化物質のうちの少なくとも1つは、(i)第1の標的結合ドメイン、(ii)可溶性組織因子ドメイン、及び(iii)第2の標的結合ドメインを含む、一本鎖キメラポリペプチドである。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメインと可溶性組織因子ドメインは、互いに直接隣接している。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、一本鎖キメラポリペプチドは、第1の標的結合ドメインと可溶性組織因子ドメインとの間にリンカー配列を更に含む。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性組織因子ドメインと第2の標的結合ドメインは、互いに直接隣接している。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、一本鎖キメラポリペプチドは、可溶性組織因子ドメインと第2の標的結合ドメインとの間にリンカー配列を更に含む。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメインと第2の標的結合ドメインは、互いに直接隣接している。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、一本鎖キメラポリペプチドは、第1の標的結合ドメインと第2の標的結合ドメインとの間にリンカー配列を更に含む。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第2の標的結合ドメインと可溶性組織因子ドメインは、互いに直接隣接している。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、一本鎖キメラポリペプチドは、第2の標的結合ドメインと可溶性組織因子ドメインとの間にリンカー配列を更に含む。 In some embodiments of any of the methods described herein, at least one of the one or more NK cell activators comprises (i) the first target binding domain, (ii) A single chain chimeric polypeptide comprising a soluble tissue factor domain and (iii) a second target binding domain. In some embodiments of any of the methods described herein, the first target binding domain and the soluble tissue factor domain are directly adjacent to each other. In some embodiments of any of the methods described herein, the single chain chimeric polypeptide further comprises a linker sequence between the first target binding domain and the soluble tissue factor domain. In some embodiments of any of the methods described herein, the soluble tissue factor domain and the second target binding domain are directly adjacent to each other. In some embodiments of any of the methods described herein, the single chain chimeric polypeptide further comprises a linker sequence between the soluble tissue factor domain and the second target binding domain. In some embodiments of any of the methods described herein, the first target binding domain and the second target binding domain are directly adjacent to each other. In some embodiments of any of the methods described herein, the single chain chimeric polypeptide further comprises a linker sequence between the first target binding domain and the second target binding domain . In some embodiments of any of the methods described herein, the second target binding domain and the soluble tissue factor domain are directly adjacent to each other. In some embodiments of any of the methods described herein, the single chain chimeric polypeptide further comprises a linker sequence between the second target binding domain and the soluble tissue factor domain.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは、同じ抗原に特異的に結合する。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは、同じエピトープに特異的に結合する。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは、同じアミノ酸配列を含む。 In some embodiments of any of the methods described herein, the first target binding domain and the second target binding domain specifically bind the same antigen. In some embodiments of any of the methods described herein, the first target binding domain and the second target binding domain specifically bind the same epitope. In some embodiments of any of the methods described herein, the first target binding domain and the second target binding domain comprise the same amino acid sequence.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは、異なる抗原に特異的に結合する。 In some embodiments of any of the methods described herein, the first target binding domain and the second target binding domain specifically bind different antigens.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方が、抗原結合ドメインである。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは各々、抗原結合ドメインである。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、抗原結合ドメインは、scFv又は単一ドメイン抗体を含む。 In some embodiments of any of the methods described herein, one or both of the first target binding domain and the second target binding domain are antigen binding domains. In some embodiments of any of the methods described herein, the first target binding domain and the second target binding domain are each antigen binding domains. In some embodiments of any of the methods described herein, the antigen binding domain comprises a scFv or single domain antibody.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方は、CD16a、CD33、CD20、CD19、CD22、CD123、PDL-1、TIGIT、PD-1、TIM3、CTLA4、MICA、MICB、IL-6、IL-8、TNFα、CD26、CD36、ULBP2、CD30、CD200、IGF-1R、MUC4AC、MUC5AC、Trop-2、CMET、EGFR、HER1、HER2、HER3、PSMA、CEA、B7H3、EPCAM、BCMA、P-カドヘリン、CEACAM5、UL16結合タンパク質、HLA-DR、DLL4、TYRO3、AXL、MER、CD122、CD155、PDGF-DD、TGF-β受容体II(TGF-βRII)リガンド、TGF-βRIIIリガンド、DNAM1リガンド、NKp46リガンド、NKp44リガンド、NKG2Dリガンド、NKp30リガンド、scMHCIリガンド、scMHCIIリガンド、scTCRリガンド、PDGF-DD受容体、幹細胞因子(SCF)受容体、幹細胞様チロシンキナーゼ3リガンド(FLT3L)受容体、MICA受容体、MICB受容体、ULP16結合タンパク質受容体、CD155受容体、及びCD122受容体の群から選択される標的に結合する。
In some embodiments of any of the methods described herein, one or both of the first target binding domain and the second target binding domain are CD16a, CD33, CD20, CD19, CD22, CD123 , PDL-1, TIGIT, PD-1, TIM3, CTLA4, MICA, MICB, IL-6, IL-8, TNFα, CD26, CD36, ULBP2, CD30, CD200, IGF-1R, MUC4AC, MUC5AC, Trop-2 , CMET, EGFR, HER1, HER2, HER3, PSMA, CEA, B7H3, EPCAM, BCMA, P-cadherin, CEACAM5, UL16 binding protein, HLA-DR, DLL4, TYRO3, AXL, MER, CD122, CD155, PDGF-DD , TGF-β receptor II (TGF-βRII) ligand, TGF-βRIII ligand, DNAM1 ligand, NKp46 ligand, NKp44 ligand, NKG2D ligand, NKp30 ligand, scMHCI ligand, scMHCII ligand, scTCR ligand, PDGF-DD receptor, stem cell binding to a target selected from the group of factor (SCF) receptor, stem cell-
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方が、可溶性インターロイキン又はサイトカインタンパク質である。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性インターロイキン又はサイトカインタンパク質は、IL-1、IL-2、IL-3、IL-7、IL-8、IL-10、IL-12、IL-15、IL-17、IL-18、IL-21、PDGF-DD、及びSCFの群から選択される。 In some embodiments of any of the methods described herein, one or both of the first target binding domain and the second target binding domain are soluble interleukin or cytokine proteins. In some embodiments of any of the methods described herein, the soluble interleukin or cytokine protein is IL-1, IL-2, IL-3, IL-7, IL-8, IL- 10, IL-12, IL-15, IL-17, IL-18, IL-21, PDGF-DD, and SCF.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方が、可溶性インターロイキン又はサイトカイン受容体である。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性インターロイキン又はサイトカイン受容体は、可溶性TGF-β受容体II(TGF-βRII)、可溶性TGF-βRIII、可溶性TNFα受容体、可溶性IL-4受容体、又は可溶性IL-10受容体である。 In some embodiments of any of the methods described herein, one or both of the first target binding domain and the second target binding domain is a soluble interleukin or cytokine receptor. In some embodiments of any of the methods described herein, the soluble interleukin or cytokine receptor is soluble TGF-β receptor II (TGF-βRII), soluble TGF-βRIII, soluble TNFα receptor soluble IL-4 receptor, or soluble IL-10 receptor.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性組織因子ドメインは、可溶性ヒト組織因子ドメインである。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性ヒト組織因子ドメインは、配列番号93と少なくとも80%同一である配列を含む。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性ヒト組織因子ドメインは、配列番号93と少なくとも90%同一である配列を含む。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性ヒト組織因子ドメインは、配列番号93と少なくとも95%同一である配列を含む。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性ヒト組織因子ドメインは、成熟野生型ヒト組織因子タンパク質のアミノ酸20位に対応するアミノ酸の位置にリジン、成熟野生型ヒト組織因子タンパク質のアミノ酸22位に対応するアミノ酸の位置にイソロイシン、成熟野生型ヒト組織因子タンパク質のアミノ酸45位に対応するアミノ酸の位置にトリプトファン、成熟野生型ヒト組織因子タンパク質のアミノ酸58位に対応するアミノ酸の位置にアスパラギン酸、成熟野生型ヒト組織因子タンパク質のアミノ酸94位に対応するアミノ酸の位置にチロシン、成熟野生型ヒト組織因子タンパク質のアミノ酸135位に対応するアミノ酸の位置にアルギニン、及び成熟野生型ヒト組織因子タンパク質のアミノ酸140位に対応するアミノ酸の位置にフェニルアラニンのうちの1つ以上を含まない。
In some embodiments of any of the methods described herein, the soluble tissue factor domain is a soluble human tissue factor domain. In some embodiments of any of the methods described herein, the soluble human tissue factor domain comprises a sequence that is at least 80% identical to SEQ ID NO:93. In some embodiments of any of the methods described herein, the soluble human tissue factor domain comprises a sequence that is at least 90% identical to SEQ ID NO:93. In some embodiments of any of the methods described herein, the soluble human tissue factor domain comprises a sequence that is at least 95% identical to SEQ ID NO:93. In some embodiments of any of the methods described herein, the soluble human tissue factor domain has a lysine at the amino acid position corresponding to
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性ヒト組織因子ドメインは、成熟野生型ヒト組織因子タンパク質のアミノ酸20位に対応するアミノ酸の位置にリジン、成熟野生型ヒト組織因子タンパク質のアミノ酸22位に対応するアミノ酸の位置にイソロイシン、成熟野生型ヒト組織因子タンパク質のアミノ酸45位に対応するアミノ酸の位置にトリプトファン、成熟野生型ヒト組織因子タンパク質のアミノ酸58位に対応するアミノ酸の位置にアスパラギン酸、成熟野生型ヒト組織因子タンパク質のアミノ酸94位に対応するアミノ酸の位置にチロシン、成熟野生型ヒト組織因子タンパク質のアミノ酸135位に対応するアミノ酸の位置にアルギニン、及び成熟野生型ヒト組織因子タンパク質のアミノ酸140位に対応するアミノ酸の位置にフェニルアラニンのうちのいずれも含まない。
In some embodiments of any of the methods described herein, the soluble human tissue factor domain has a lysine at the amino acid position corresponding to
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性組織因子ドメインは、第VIIa因子結合することができない。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性組織因子ドメインは、不活性第X因子を第Xa因子に変換しない。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、一本鎖キメラポリペプチドは、哺乳動物における血液凝固を刺激しない。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、一本鎖キメラポリペプチドは、そのN末端及び/又はC末端に1つ以上の追加の標的結合ドメインを更に含む。 In some embodiments of any of the methods described herein, the soluble tissue factor domain is incapable of binding Factor VIIa. In some embodiments of any of the methods described herein, the soluble tissue factor domain does not convert inactive factor X to factor Xa. In some embodiments of any of the methods described herein, the single chain chimeric polypeptide does not stimulate blood clotting in the mammal. In some embodiments of any of the methods described herein, the single-chain chimeric polypeptide further comprises one or more additional target binding domains at its N-terminus and/or C-terminus.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、一本鎖キメラポリペプチドは、そのN末端に1つ以上の追加の標的結合ドメインを含む。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、1つ以上の追加の標的結合ドメインは、第1の標的結合ドメイン、第2の標的結合ドメイン、又は可溶性組織因子ドメインに直接隣接している。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、一本鎖キメラポリペプチドは、少なくとも1つの追加の標的結合ドメインのうちの1つと第1の標的結合ドメイン、第2の標的結合ドメイン、又は可溶性組織因子ドメインとの間にリンカー配列を更に含む。 In some embodiments of any of the methods described herein, the single chain chimeric polypeptide comprises one or more additional target binding domains at its N-terminus. In some embodiments of any of the methods described herein, the one or more additional target binding domains are a first target binding domain, a second target binding domain, or a soluble tissue factor domain. directly adjacent to In some embodiments of any of the methods described herein, the single chain chimeric polypeptide comprises one of the at least one additional target binding domain and the first target binding domain, the second or the soluble tissue factor domain.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、一本鎖キメラポリペプチドは、そのC末端に1つ以上の追加の標的結合ドメインを含む。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、1つ以上の追加の標的結合ドメインのうちの1つは、第1の標的結合ドメイン、第2の標的結合ドメイン、又は可溶性組織因子ドメインに直接隣接している。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、一本鎖キメラポリペプチドは、少なくとも1つの追加の標的結合ドメインのうちの1つと第1の標的結合ドメイン、第2の標的結合ドメイン、又は可溶性組織因子ドメインとの間にリンカー配列を更に含む。 In some embodiments of any of the methods described herein, the single chain chimeric polypeptide comprises one or more additional target binding domains at its C-terminus. In some embodiments of any of the methods described herein, one of the one or more additional target binding domains is the first target binding domain, the second target binding domain, or directly adjacent to the soluble tissue factor domain. In some embodiments of any of the methods described herein, the single chain chimeric polypeptide comprises one of the at least one additional target binding domain and the first target binding domain, the second or the soluble tissue factor domain.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、一本鎖キメラポリペプチドは、そのN末端及びC末端に1つ以上の追加の標的結合ドメインを含む。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、N末端における1つ以上の追加の抗原結合ドメインのうちの1つは、第1の標的結合ドメイン、第2の標的結合ドメイン、又は可溶性組織因子ドメインに直接隣接している。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、一本鎖キメラポリペプチドは、N末端における1つ以上の追加の抗原結合ドメインのうちの1つと第1の標的結合ドメイン、第2の標的結合ドメイン、又は可溶性組織因子ドメインとの間にリンカー配列を更に含む。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、C末端における1つ以上の追加の抗原結合ドメインのうちの1つは、第1の標的結合ドメイン、第2の標的結合ドメイン、又は可溶性組織因子ドメインに直接隣接している。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、一本鎖キメラポリペプチドは、C末端における1つ以上の追加の抗原結合ドメインのうちの1つと第1の標的結合ドメイン、第2の標的結合ドメイン、又は可溶性組織因子ドメインとの間にリンカー配列を更に含む。 In some embodiments of any of the methods described herein, the single chain chimeric polypeptide comprises one or more additional target binding domains at its N-terminus and C-terminus. In some embodiments of any of the methods described herein, one of the one or more additional antigen binding domains at the N-terminus is the first target binding domain, the second target Directly adjacent to the binding domain, or soluble tissue factor domain. In some embodiments of any of the methods described herein, the single chain chimeric polypeptide comprises one of the one or more additional antigen binding domains at the N-terminus and the first target binding domain. Further comprising a linker sequence between the domain, the second target binding domain, or the soluble tissue factor domain. In some embodiments of any of the methods described herein, one of the one or more additional antigen binding domains at the C-terminus is the first target binding domain, the second target Directly adjacent to the binding domain, or soluble tissue factor domain. In some embodiments of any of the methods described herein, the single chain chimeric polypeptide comprises one of the one or more additional antigen binding domains at the C-terminus and the first target binding domain. Further comprising a linker sequence between the domain, the second target binding domain, or the soluble tissue factor domain.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの2つ以上は、同じ抗原に特異的に結合する。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの2つ以上は、同じエピトープに特異的に結合する。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの2つ以上は、同じアミノ酸配列を含む。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインは各々、同じ抗原に特異的に結合する。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインは各々、同じエピトープに特異的に結合する。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインは各々、同じアミノ酸配列を含む。 In some embodiments of any of the methods described herein, two or more of the first target binding domain, the second target binding domain, and one or more additional target binding domains specifically bind to the same antigen. In some embodiments of any of the methods described herein, two or more of the first target binding domain, the second target binding domain, and one or more additional target binding domains specifically bind to the same epitope. In some embodiments of any of the methods described herein, two or more of the first target binding domain, the second target binding domain, and one or more additional target binding domains contain the same amino acid sequence. In some embodiments of any of the methods described herein, the first target binding domain, the second target binding domain, and the one or more additional target binding domains each bind to the same antigen. Binds specifically. In some embodiments of any of the methods described herein, the first target binding domain, the second target binding domain, and the one or more additional target binding domains are each directed to the same epitope. Binds specifically. In some embodiments of any of the methods described herein, the first target binding domain, the second target binding domain, and the one or more additional target binding domains each have the same amino acid sequence including.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインは、異なる抗原に特異的に結合する。 In some embodiments of any of the methods described herein, the first target binding domain, the second target binding domain, and the one or more additional target binding domains are specific for different antigens. physically connect.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の標的結合ドメインのうちの1つ以上は、抗原結合ドメインである。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインは各々、抗原結合ドメインである。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、抗原結合ドメインは、scFv又は単一ドメイン抗体を含む。 In some embodiments of any of the methods described herein, one or more of the first target binding domain, the second target binding domain, and the one or more target binding domains are It is an antigen-binding domain. In some embodiments of any of the methods described herein, the first target binding domain, the second target binding domain, and the one or more additional target binding domains are each an antigen binding domain is. In some embodiments of any of the methods described herein, the antigen binding domain comprises a scFv or single domain antibody.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の標的結合ドメインのうちの1つ以上は、CD16a、CD33、CD20、CD19、CD22、CD123、PDL-1、TIGIT、PD-1、TIM3、CTLA4、MICA、MICB、IL-6、IL-8、TNFα、CD26、CD36、ULBP2、CD30、CD200、IGF-1R、MUC4AC、MUC5AC、Trop-2、CMET、EGFR、HER1、HER2、HER3、PSMA、CEA、B7H3、EPCAM、BCMA、P-カドヘリン、CEACAM5、UL16結合タンパク質、HLA-DR、DLL4、TYRO3、AXL、MER、CD122、CD155、PDGF-DD、TGF-β受容体II(TGF-βRII)リガンド、TGF-βRIIIリガンド、DNAM1リガンド、NKp46リガンド、NKp44リガンド、NKG2Dリガンド、NKp30リガンド、scMHCIリガンド、scMHCIIリガンド、scTCRリガンド、PDGF-DD受容体、幹細胞因子(SCF)受容体、幹細胞様チロシンキナーゼ3リガンド(FLT3L)受容体、MICA受容体、MICB受容体、ULP16結合タンパク質受容体、CD155受容体、及びCD122受容体の群から選択される標的に特異的に結合する。
In some embodiments of any of the methods described herein, one or more of the first target binding domain, the second target binding domain, and the one or more target binding domains are CD16a, CD33, CD20, CD19, CD22, CD123, PDL-1, TIGIT, PD-1, TIM3, CTLA4, MICA, MICB, IL-6, IL-8, TNFα, CD26, CD36, ULBP2, CD30, CD200, IGF-1R, MUC4AC, MUC5AC, Trop-2, CMET, EGFR, HER1, HER2, HER3, PSMA, CEA, B7H3, EPCAM, BCMA, P-cadherin, CEACAM5, UL16 binding protein, HLA-DR, DLL4, TYRO3, AXL, MER, CD122, CD155, PDGF-DD, TGF-β receptor II (TGF-βRII) ligand, TGF-βRIII ligand, DNAM1 ligand, NKp46 ligand, NKp44 ligand, NKG2D ligand, NKp30 ligand, scMHCI ligand, scMHCII ligand , scTCR ligand, PDGF-DD receptor, stem cell factor (SCF) receptor, stem cell-
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの1つ以上は、可溶性インターロイキン又はサイトカインタンパク質である。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性インターロイキン又はサイトカインタンパク質は、IL-1、IL-2、IL-3、IL-7、IL-8、IL-10、IL-12、IL-15、IL-17、IL-18、IL-21、PDGF-DD、及びSCFの群から選択される。 In some embodiments of any of the methods described herein, one or more of the first target binding domain, the second target binding domain, and one or more additional target binding domains is a soluble interleukin or cytokine protein. In some embodiments of any of the methods described herein, the soluble interleukin or cytokine protein is IL-1, IL-2, IL-3, IL-7, IL-8, IL- 10, IL-12, IL-15, IL-17, IL-18, IL-21, PDGF-DD, and SCF.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの1つ以上は、可溶性インターロイキン又はサイトカイン受容体である。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性受容体は、可溶性TGF-β受容体II(TGF-βRII)、可溶性TGF-βRIII、可溶性TNFα受容体、可溶性IL-4受容体、又は可溶性IL-10受容体である。 In some embodiments of any of the methods described herein, one or more of the first target binding domain, the second target binding domain, and one or more additional target binding domains is a soluble interleukin or cytokine receptor. In some embodiments of any of the methods described herein, the soluble receptor is soluble TGF-β receptor II (TGF-βRII), soluble TGF-βRIII, soluble TNFα receptor, soluble IL -4 receptor, or soluble IL-10 receptor.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、1つ以上のNK細胞活性化物質のうちの少なくとも1つは、(a)(i)第1の標的結合ドメイン、(ii)可溶性組織因子ドメイン、及び(iii)一対の親和性ドメインの第1のドメインを含む、第1のキメラポリペプチドと、(b)(i)一対の親和性ドメインの第2のドメイン及び(ii)第2の標的結合ドメインを含む、第2のキメラポリペプチドと、を含む多鎖キメラポリペプチドであり、第1のキメラポリペプチドと第2のキメラポリペプチドが、一対の親和性ドメインの第1のドメインと第2のドメインとの結合を介して会合する。 In some embodiments of any of the methods described herein, at least one of the one or more NK cell activators comprises (a)(i) a first target binding domain; (ii) a soluble tissue factor domain, and (iii) a first domain of a pair of affinity domains; and (b) (i) a second domain of the pair of affinity domains and (ii) a second chimeric polypeptide comprising a second target binding domain, wherein the first chimeric polypeptide and the second chimeric polypeptide comprise a pair of affinity domains associates through binding of the first and second domains of
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び可溶性組織因子ドメインは、第1のキメラポリペプチド内で互いに直接隣接している。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1のキメラポリペプチドは、第1のキメラポリペプチド内の第1の標的結合ドメインと可溶性組織因子ドメインとの間にリンカー配列を更に含む。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインは、第1のキメラポリペプチド内で互いに直接隣接している。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1のキメラポリペプチドは、第1のキメラポリペプチド内の可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間にリンカー配列を更に含む。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、一対の親和性ドメインの第2のドメインと第2の標的結合ドメインは、第2のキメラポリペプチド内で互いに直接隣接している。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチド内の一対の親和性ドメインの第2のドメインと第2の標的結合ドメインとの間にリンカー配列を更に含む。 In some embodiments of any of the methods described herein, the first target binding domain and the soluble tissue factor domain are directly adjacent to each other within the first chimeric polypeptide. In some embodiments of any of the methods described herein, the first chimeric polypeptide has a further includes a linker sequence. In some embodiments of any of the methods described herein, the soluble tissue factor domain and the first domain of the paired affinity domains are directly adjacent to each other within the first chimeric polypeptide. there is In some embodiments of any of the methods described herein, the first chimeric polypeptide comprises a first affinity domain paired with a soluble tissue factor domain within the first chimeric polypeptide. It further contains a linker sequence between the domains. In some embodiments of any of the methods described herein, the second domain and the second target binding domain of the pair of affinity domains are directly adjacent to each other within the second chimeric polypeptide. are doing. In some embodiments of any of the methods described herein, the second chimeric polypeptide comprises the second domain and the second of the pair of affinity domains within the second chimeric polypeptide. It further comprises a linker sequence between it and the target binding domain.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは、同じ抗原に特異的に結合する。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは、同じエピトープに特異的に結合する。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは、同じアミノ酸配列を含む。 In some embodiments of any of the methods described herein, the first target binding domain and the second target binding domain specifically bind the same antigen. In some embodiments of any of the methods described herein, the first target binding domain and the second target binding domain specifically bind the same epitope. In some embodiments of any of the methods described herein, the first target binding domain and the second target binding domain comprise the same amino acid sequence.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは、異なる抗原に特異的に結合する。 In some embodiments of any of the methods described herein, the first target binding domain and the second target binding domain specifically bind different antigens.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方が、抗原結合ドメインである。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは各々、抗原結合ドメインである。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、抗原結合ドメインは、scFv又は単一ドメイン抗体を含む。 In some embodiments of any of the methods described herein, one or both of the first target binding domain and the second target binding domain are antigen binding domains. In some embodiments of any of the methods described herein, the first target binding domain and the second target binding domain are each antigen binding domains. In some embodiments of any of the methods described herein, the antigen binding domain comprises a scFv or single domain antibody.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方は、CD16a、CD33、CD20、CD19、CD22、CD123、PDL-1、TIGIT、PD-1、TIM3、CTLA4、MICA、MICB、IL-6、IL-8、TNFα、CD26、CD36、ULBP2、CD30、CD200、IGF-1R、MUC4AC、MUC5AC、Trop-2、CMET、EGFR、HER1、HER2、HER3、PSMA、CEA、B7H3、EPCAM、BCMA、P-カドヘリン、CEACAM5、UL16結合タンパク質、HLA-DR、DLL4、TYRO3、AXL、MER、CD122、CD155、PDGF-DD、TGF-β受容体II(TGF-βRII)リガンド、TGF-βRIIIリガンド、DNAM1リガンド、NKp46リガンド、NKp44リガンド、NKG2Dリガンド、NKp30リガンド、scMHCIリガンド、scMHCIIリガンド、scTCRリガンド、PDGF-DD受容体、幹細胞因子(SCF)受容体、幹細胞様チロシンキナーゼ3リガンド(FLT3L)受容体、MICA受容体、MICB受容体、ULP16結合タンパク質受容体、CD155受容体、及びCD122受容体の群から選択される標的に特異的に結合する。
In some embodiments of any of the methods described herein, one or both of the first target binding domain and the second target binding domain are CD16a, CD33, CD20, CD19, CD22, CD123 , PDL-1, TIGIT, PD-1, TIM3, CTLA4, MICA, MICB, IL-6, IL-8, TNFα, CD26, CD36, ULBP2, CD30, CD200, IGF-1R, MUC4AC, MUC5AC, Trop-2 , CMET, EGFR, HER1, HER2, HER3, PSMA, CEA, B7H3, EPCAM, BCMA, P-cadherin, CEACAM5, UL16 binding protein, HLA-DR, DLL4, TYRO3, AXL, MER, CD122, CD155, PDGF-DD , TGF-β receptor II (TGF-βRII) ligand, TGF-βRIII ligand, DNAM1 ligand, NKp46 ligand, NKp44 ligand, NKG2D ligand, NKp30 ligand, scMHCI ligand, scMHCII ligand, scTCR ligand, PDGF-DD receptor, stem cell specific for a target selected from the group of factor (SCF) receptor, stem cell-
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方が、可溶性インターロイキン又はサイトカインタンパク質である。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性インターロイキン又はサイトカインタンパク質は、IL-1、IL-2、IL-3、IL-7、IL-8、IL-10、IL-12、IL-15、IL-17、IL-18、IL-21、PDGF-DD、及びSCFの群から選択される。 In some embodiments of any of the methods described herein, one or both of the first target binding domain and the second target binding domain are soluble interleukin or cytokine proteins. In some embodiments of any of the methods described herein, the soluble interleukin or cytokine protein is IL-1, IL-2, IL-3, IL-7, IL-8, IL- 10, IL-12, IL-15, IL-17, IL-18, IL-21, PDGF-DD, and SCF.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方が、可溶性インターロイキン又はサイトカイン受容体である。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性受容体は、可溶性TGF-β受容体II(TGF-βRII)、可溶性TGF-βRIII、可溶性TNFα受容体、可溶性IL-4受容体、又は可溶性IL-10受容体である。 In some embodiments of any of the methods described herein, one or both of the first target binding domain and the second target binding domain is a soluble interleukin or cytokine receptor. In some embodiments of any of the methods described herein, the soluble receptor is soluble TGF-β receptor II (TGF-βRII), soluble TGF-βRIII, soluble TNFα receptor, soluble IL -4 receptor, or soluble IL-10 receptor.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1のキメラポリペプチドは、1つ以上の追加の標的結合ドメインを更に含み、1つ以上の追加の抗原結合ドメインのうちの少なくとも1つは、可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間に位置付けられている。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1のキメラポリペプチドは、可溶性組織因子ドメインと1つ以上の追加の抗原結合ドメインのうちの少なくとも1つとの間にリンカー配列、及び/又は1つ以上の追加の抗原結合ドメインのうちの少なくとも1つと一対の親和性ドメインの第1のドメインとの間にリンカー配列を更に含む。 In some embodiments of any of the methods described herein, the first chimeric polypeptide further comprises one or more additional target binding domains and one or more additional antigen binding domains at least one of which is positioned between the soluble tissue factor domain and the first of the pair of affinity domains. In some embodiments of any of the methods described herein, the first chimeric polypeptide is between the soluble tissue factor domain and at least one of the one or more additional antigen binding domains. and/or a linker sequence between at least one of the one or more additional antigen binding domains and the first domain of the pair of affinity domains.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1のキメラポリペプチドは、第1のキメラポリペプチドのN末端及び/又はC末端に1つ以上の追加の標的結合ドメインを更に含む。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、1つ以上の追加の標的結合ドメインのうちの少なくとも1つは、第1のキメラポリペプチド内の一対の親和性ドメインの第1のドメインに直接隣接している。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1のキメラポリペプチドは、1つ以上の追加の標的結合ドメインのうちの少なくとも1つと一対の親和性ドメインの第1のドメインとの間にリンカー配列を更に含む。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、1つ以上の追加の標的結合ドメインのうちの少なくとも1つは、第1のキメラポリペプチド内の第1の標的結合ドメインに直接隣接している。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1のキメラポリペプチドは、1つ以上の追加の標的結合ドメインのうちの少なくとも1つと第1の標的結合ドメインとの間にリンカー配列を更に含む。 In some embodiments of any of the methods described herein, the first chimeric polypeptide comprises one or more additional targets at the N-terminus and/or C-terminus of the first chimeric polypeptide. Further comprising a binding domain. In some embodiments of any of the methods described herein, at least one of the one or more additional target binding domains is a pair of affinity domains within the first chimeric polypeptide. directly adjacent to the first domain of In some embodiments of any of the methods described herein, the first chimeric polypeptide comprises at least one of the one or more additional target binding domains and a first pair of affinity domains. It further contains a linker sequence between one domain. In some embodiments of any of the methods described herein, at least one of the one or more additional target binding domains is the first target binding domain within the first chimeric polypeptide. Directly adjacent to the domain. In some embodiments of any of the methods described herein, the first chimeric polypeptide comprises at least one of the one or more additional target binding domains and the first target binding domain. further includes a linker sequence between
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、1つ以上の追加の標的結合ドメインのうちの少なくとも1つは、第1のキメラポリペプチドのN末端及び/又はC末端に配置されており、1つ以上の追加の標的結合ドメインのうちの少なくとも1つは、第1のキメラポリペプチド内の可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間に位置付けられている。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、N末端に配置された1つ以上の追加の標的結合ドメインのうちの少なくとも1つの追加の標的結合ドメインは、第1のキメラポリペプチド内の第1の標的結合ドメイン又は一対の親和性ドメインの第1のドメインに直接隣接している。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1のキメラポリペプチドは、第1のキメラポリペプチド内の少なくとも1つの追加の標的結合ドメインと第1の標的結合ドメイン又は一対の親和性ドメインの第1のドメインとの間に配置されたリンカー配列を更に含む。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、C末端に配置された1つ以上の追加の標的結合ドメインのうちの少なくとも1つの追加の標的結合ドメインは、第1のキメラポリペプチド内の標的結合ドメイン又は第1の一対の親和性ドメインの第1のドメインに直接隣接している。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1のキメラポリペプチドは、第1のキメラポリペプチド内の少なくとも1つの追加の標的結合ドメインと第1の標的結合ドメイン又は一対の親和性ドメインの第1のドメインとの間に配置されたリンカー配列を更に含む。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間に位置付けられた1つ以上の追加の標的結合ドメインのうちの少なくとも1つは、可溶性組織因子ドメイン、及び/又は一対の親和性ドメインの第1のドメインに直接隣接している。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1のキメラポリペプチドは、(i)可溶性組織因子ドメインと、可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間に位置付けられた1つ以上の追加の標的結合ドメインのうちの少なくとも1つとの間、及び/又は(ii)一対の親和性ドメインの第1のドメインと、可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間に位置付けられた1つ以上の追加の標的結合ドメインのうちの少なくとも1つとの間に配置されたリンカー配列を更に含む。 In some embodiments of any of the methods described herein, at least one of the one or more additional target binding domains are N-terminal and/or C-terminal of the first chimeric polypeptide. terminally positioned, at least one of the one or more additional target binding domains is between the soluble tissue factor domain and the first of the pair of affinity domains in the first chimeric polypeptide is positioned in In some embodiments of any of the methods described herein, at least one additional target binding domain of the one or more additional target binding domains located N-terminally comprises the first immediately adjacent to the first target binding domain or the first domain of a pair of affinity domains within the chimeric polypeptide of . In some embodiments of any of the methods described herein, the first chimeric polypeptide comprises at least one additional target binding domain within the first chimeric polypeptide and the first target binding domain. Further comprising a linker sequence interposed between the domain or the first domain of the pair of affinity domains. In some embodiments of any of the methods described herein, at least one additional target binding domain of the one or more additional target binding domains located C-terminally comprises the first immediately adjacent to the target binding domain or the first domain of the first pair of affinity domains in the chimeric polypeptide of . In some embodiments of any of the methods described herein, the first chimeric polypeptide comprises at least one additional target binding domain within the first chimeric polypeptide and the first target binding domain. Further comprising a linker sequence interposed between the domain or the first domain of the pair of affinity domains. In some embodiments of any of the methods described herein, one or more additional target-binding domains positioned between the soluble tissue factor domain and the first domain of the pair of affinity domains At least one of the domains is directly adjacent to the soluble tissue factor domain and/or the first domain of the pair of affinity domains. In some embodiments of any of the methods described herein, the first chimeric polypeptide comprises (i) a soluble tissue factor domain and a first affinity domain paired with the soluble tissue factor domain; and/or (ii) the first domain of the pair of affinity domains and the soluble tissue factor domain; Further comprising a linker sequence disposed between at least one of the one or more additional target binding domains positioned between the first domain of the pair of affinity domains.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチドのN末端及び/又はC末端に1つ以上の追加の標的結合ドメインを更に含む。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、1つ以上の追加の標的結合ドメインのうちの少なくとも1つは、第2のキメラポリペプチド内の一対の親和性ドメインの第2のドメインに直接隣接している。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチド内の1つ以上の追加の標的結合ドメインのうちの少なくとも1つと一対の親和性ドメインの第2のドメインとの間にリンカー配列を更に含む。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、1つ以上の追加の標的結合ドメインのうちの少なくとも1つは、第2のキメラポリペプチド内の第2の標的結合ドメインに直接隣接している。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチド内の1つ以上の追加の標的結合ドメインのうちの少なくとも1つと第2の標的結合ドメインとの間にリンカー配列を更に含む。 In some embodiments of any of the methods described herein, the second chimeric polypeptide comprises one or more additional targets at the N-terminus and/or C-terminus of the second chimeric polypeptide. Further comprising a binding domain. In some embodiments of any of the methods described herein, at least one of the one or more additional target binding domains is a pair of affinity domains within the second chimeric polypeptide. directly adjacent to the second domain of In some embodiments of any of the methods described herein, the second chimeric polypeptide comprises at least one of the one or more additional target binding domains within the second chimeric polypeptide. Further comprising a linker sequence between the second domain of the pair of affinity domains. In some embodiments of any of the methods described herein, at least one of the one or more additional target binding domains is a second target binding domain within the second chimeric polypeptide. Directly adjacent to the domain. In some embodiments of any of the methods described herein, the second chimeric polypeptide comprises at least one of the one or more additional target binding domains within the second chimeric polypeptide. further comprising a linker sequence between the domain and the second target binding domain.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの2つ以上は、同じ抗原に特異的に結合する。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの2つ以上は、同じエピトープに特異的に結合する。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの2つ以上は、同じアミノ酸配列を含む。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインは各々、同じ抗原に特異的に結合する。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインは各々、同じエピトープに特異的に結合する。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインは各々、同じアミノ酸配列を含む。 In some embodiments of any of the methods described herein, two or more of the first target binding domain, the second target binding domain, and one or more additional target binding domains specifically bind to the same antigen. In some embodiments of any of the methods described herein, two or more of the first target binding domain, the second target binding domain, and one or more additional target binding domains specifically bind to the same epitope. In some embodiments of any of the methods described herein, two or more of the first target binding domain, the second target binding domain, and one or more additional target binding domains contain the same amino acid sequence. In some embodiments of any of the methods described herein, the first target binding domain, the second target binding domain, and the one or more additional target binding domains each bind to the same antigen. Binds specifically. In some embodiments of any of the methods described herein, the first target binding domain, the second target binding domain, and the one or more additional target binding domains are each directed to the same epitope. Binds specifically. In some embodiments of any of the methods described herein, the first target binding domain, the second target binding domain, and the one or more additional target binding domains each have the same amino acid sequence including.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインは、異なる抗原に特異的に結合する。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の標的結合ドメインのうちの1つ以上は、抗原結合ドメインである。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインは各々、抗原結合ドメインである。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、抗原結合ドメインは、scFvを含む。 In some embodiments of any of the methods described herein, the first target binding domain, the second target binding domain, and the one or more additional target binding domains are specific for different antigens. physically connect. In some embodiments of any of the methods described herein, one or more of the first target binding domain, the second target binding domain, and the one or more target binding domains are It is an antigen-binding domain. In some embodiments of any of the methods described herein, the first target binding domain, the second target binding domain, and the one or more additional target binding domains are each an antigen binding domain is. In some embodiments of any of the methods described herein, the antigen binding domain comprises scFv.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の標的結合ドメインのうちの1つ以上は、CD16a、CD33、CD20、CD19、CD22、CD123、PDL-1、TIGIT、PD-1、TIM3、CTLA4、MICA、MICB、IL-6、IL-8、TNFα、CD26、CD36、ULBP2、CD30、CD200、IGF-1R、MUC4AC、MUC5AC、Trop-2、CMET、EGFR、HER1、HER2、HER3、PSMA、CEA、B7H3、EPCAM、BCMA、P-カドヘリン、CEACAM5、UL16結合タンパク質、HLA-DR、DLL4、TYRO3、AXL、MER、CD122、CD155、PDGF-DD、TGF-β受容体II(TGF-βRII)リガンド、TGF-βRIIIリガンド、DNAM1リガンド、NKp46リガンド、NKp44リガンド、NKG2Dリガンド、NKp30リガンド、scMHCIリガンド、scMHCIIリガンド、scTCRリガンド、PDGF-DD受容体、幹細胞因子(SCF)受容体、幹細胞様チロシンキナーゼ3リガンド(FLT3L)受容体、MICA受容体、MICB受容体、ULP16結合タンパク質受容体、CD155受容体、及びCD122受容体の群から選択される標的に特異的に結合する。
In some embodiments of any of the methods described herein, one or more of the first target binding domain, the second target binding domain, and the one or more target binding domains are CD16a, CD33, CD20, CD19, CD22, CD123, PDL-1, TIGIT, PD-1, TIM3, CTLA4, MICA, MICB, IL-6, IL-8, TNFα, CD26, CD36, ULBP2, CD30, CD200, IGF-1R, MUC4AC, MUC5AC, Trop-2, CMET, EGFR, HER1, HER2, HER3, PSMA, CEA, B7H3, EPCAM, BCMA, P-cadherin, CEACAM5, UL16 binding protein, HLA-DR, DLL4, TYRO3, AXL, MER, CD122, CD155, PDGF-DD, TGF-β receptor II (TGF-βRII) ligand, TGF-βRIII ligand, DNAM1 ligand, NKp46 ligand, NKp44 ligand, NKG2D ligand, NKp30 ligand, scMHCI ligand, scMHCII ligand , scTCR ligand, PDGF-DD receptor, stem cell factor (SCF) receptor, stem cell-
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの1つ以上は、可溶性インターロイキン又はサイトカインタンパク質である。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性インターロイキン又はサイトカインタンパク質は、IL-1、IL-2、IL-3、IL-7、IL-8、IL-10、IL-12、IL-15、IL-17、IL-18、IL-21、PDGF-DD、及びSCFの群から選択される。 In some embodiments of any of the methods described herein, one or more of the first target binding domain, the second target binding domain, and one or more additional target binding domains is a soluble interleukin or cytokine protein. In some embodiments of any of the methods described herein, the soluble interleukin or cytokine protein is IL-1, IL-2, IL-3, IL-7, IL-8, IL- 10, IL-12, IL-15, IL-17, IL-18, IL-21, PDGF-DD, and SCF.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの1つ以上は、可溶性インターロイキン又はサイトカイン受容体である。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性受容体は、可溶性TGF-β受容体II(TGF-βRII)、可溶性TGF-βRIII、可溶性TNFα受容体、可溶性IL-4受容体、又は可溶性IL-10受容体である。 In some embodiments of any of the methods described herein, one or more of the first target binding domain, the second target binding domain, and one or more additional target binding domains is a soluble interleukin or cytokine receptor. In some embodiments of any of the methods described herein, the soluble receptor is soluble TGF-β receptor II (TGF-βRII), soluble TGF-βRIII, soluble TNFα receptor, soluble IL -4 receptor, or soluble IL-10 receptor.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性組織因子ドメインは、可溶性ヒト組織因子ドメインである。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性ヒト組織因子ドメインは、配列番号93と少なくとも80%同一である配列を含む。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性ヒト組織因子ドメインは、配列番号93と少なくとも90%同一である配列を含む。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性ヒト組織因子ドメインは、配列番号93と少なくとも95%同一である配列を含む。 In some embodiments of any of the methods described herein, the soluble tissue factor domain is a soluble human tissue factor domain. In some embodiments of any of the methods described herein, the soluble human tissue factor domain comprises a sequence that is at least 80% identical to SEQ ID NO:93. In some embodiments of any of the methods described herein, the soluble human tissue factor domain comprises a sequence that is at least 90% identical to SEQ ID NO:93. In some embodiments of any of the methods described herein, the soluble human tissue factor domain comprises a sequence that is at least 95% identical to SEQ ID NO:93.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性ヒト組織因子ドメインは、成熟野生型ヒト組織因子タンパク質のアミノ酸20位に対応するアミノ酸の位置にリジン、成熟野生型ヒト組織因子タンパク質のアミノ酸22位に対応するアミノ酸の位置にイソロイシン、成熟野生型ヒト組織因子タンパク質のアミノ酸45位に対応するアミノ酸の位置にトリプトファン、成熟野生型ヒト組織因子タンパク質のアミノ酸58位に対応するアミノ酸の位置にアスパラギン酸、成熟野生型ヒト組織因子タンパク質のアミノ酸94位に対応するアミノ酸の位置にチロシン、成熟野生型ヒト組織因子タンパク質のアミノ酸135位に対応するアミノ酸の位置にアルギニン、及び成熟野生型ヒト組織因子タンパク質のアミノ酸140位に対応するアミノ酸の位置にフェニルアラニンのうちの1つ以上を含まない。
In some embodiments of any of the methods described herein, the soluble human tissue factor domain has a lysine at the amino acid position corresponding to
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性ヒト組織因子ドメインは、成熟野生型ヒト組織因子タンパク質のアミノ酸20位に対応するアミノ酸の位置にリジン、成熟野生型ヒト組織因子タンパク質のアミノ酸22位に対応するアミノ酸の位置にイソロイシン、成熟野生型ヒト組織因子タンパク質のアミノ酸45位に対応するアミノ酸の位置にトリプトファン、成熟野生型ヒト組織因子タンパク質のアミノ酸58位に対応するアミノ酸の位置にアスパラギン酸、成熟野生型ヒト組織因子タンパク質のアミノ酸94位に対応するアミノ酸の位置にチロシン、成熟野生型ヒト組織因子タンパク質のアミノ酸135位に対応するアミノ酸の位置にアルギニン、及び成熟野生型ヒト組織因子タンパク質のアミノ酸140位に対応するアミノ酸の位置にフェニルアラニンのうちのいずれも含まない。
In some embodiments of any of the methods described herein, the soluble human tissue factor domain has a lysine at the amino acid position corresponding to
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性組織因子ドメインは、第VIIa因子に結合することができない。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性組織因子ドメインは、不活性第X因子を第Xa因子に変換しない。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、多鎖キメラポリペプチドは、哺乳動物における血液凝固を刺激しない。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、一対の親和性ドメインは、ヒトIL-15受容体のアルファ鎖(IL-15Rα)由来のスシドメイン、及び可溶性IL-15である。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性IL-15は、D8N又はD8Aアミノ酸置換を有する。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、ヒトIL-15Rαは、成熟全長IL-15Rαである。
In some embodiments of any of the methods described herein, the soluble tissue factor domain is unable to bind Factor VIIa. In some embodiments of any of the methods described herein, the soluble tissue factor domain does not convert inactive factor X to factor Xa. In some embodiments of any of the methods described herein, the multichain chimeric polypeptide does not stimulate blood clotting in the mammal. In some embodiments of any of the methods described herein, the pair of affinity domains is a sushi domain derived from the alpha chain of the human IL-15 receptor (IL-15Rα) and a soluble IL-
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、一対の親和性ドメインは、バルナーゼとバルンスター、PKAとAKAP、変異RNase I断片に基づくアダプター/ドッキングタグモジュール、並びに、タンパク質シンタキシン、シナプトタグミン、シナプトブレビン、及びSNAP25の相互作用に基づくSNAREモジュールの群から選択される。 In some embodiments of any of the methods described herein, the pair of affinity domains are barnase and barnstar, PKA and AKAP, an adapter/docking tag module based on a mutated RNase I fragment, and It is selected from the group of SNARE modules based on the interaction of proteins syntaxin, synaptotagmin, synaptobrevin and SNAP25.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、1つ以上のNK細胞活性化物質のうちの少なくとも1つは、(a)第1及び第2のキメラポリペプチドであって、各々が、(i)第1の標的結合ドメイン、(ii)Fcドメイン、及び(iii)一対の親和性ドメインの第1のドメインを含む、第1及び第2のキメラポリペプチド、(b)第3及び第4のキメラポリペプチドであって、各々が、(i)一対の親和性ドメインの第2のドメイン及び(ii)第2の標的結合ドメインを含む、第3及び第4のキメラポリペプチド、を含む多鎖キメラポリペプチドであり、第1及び第2のキメラポリペプチド並びに第3及び第4のキメラポリペプチドは、一対の親和性ドメインの第1のドメインと第2のドメインとの結合を介して会合し、かつ第1及び第2のキメラポリペプチドは、それらのFcドメインを介して会合する。 In some embodiments of any of the methods described herein, at least one of the one or more NK cell activators is (a) the first and second chimeric polypeptides first and second chimeric polypeptides, each comprising (i) a first target binding domain, (ii) an Fc domain, and (iii) a first of a pair of affinity domains; b) third and fourth chimeric polypeptides, each comprising (i) a second of a pair of affinity domains and (ii) a second target binding domain; a chimeric polypeptide, wherein the first and second chimeric polypeptides and the third and fourth chimeric polypeptides are a first domain and a second domain of a pair of affinity domains; and the first and second chimeric polypeptides associate through their Fc domains.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメインとFcドメインは、第1及び第2のキメラポリペプチド内で互いに直接隣接している。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1及び第2のキメラポリペプチドは、第1及び第2のキメラポリペプチド内の第1の標的結合ドメインとFcドメインとの間にリンカー配列を更に含む。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、Fcドメインと一対の親和性ドメインの第1のドメインは、第1及び第2のキメラポリペプチド内で互いに直接隣接している。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1のキメラポリペプチドは、第1及び第2のキメラポリペプチド内のFcドメインと一対の親和性ドメインの第1のドメインとの間にリンカー配列を更に含む。 In some embodiments of any of the methods described herein, the first target binding domain and the Fc domain are directly adjacent to each other within the first and second chimeric polypeptides. In some embodiments of any of the methods described herein, the first and second chimeric polypeptides comprise the first target binding domain and Fc within the first and second chimeric polypeptides. It further contains a linker sequence between the domains. In some embodiments of any of the methods described herein, the Fc domain and the first domain of the paired affinity domains are directly adjacent to each other within the first and second chimeric polypeptides. ing. In some embodiments of any of the methods described herein, the first chimeric polypeptide comprises a first affinity domain paired with an Fc domain in the first and second chimeric polypeptides. further comprises a linker sequence between the domains of
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、一対の親和性ドメインの第2のドメインと第2の標的結合ドメインは、第3及び第4のキメラポリペプチド内で互いに直接隣接している。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第3及び第4のキメラポリペプチドは、第3及び第4のキメラポリペプチド内の一対の親和性ドメインの第2のドメインと第2の標的結合ドメインとの間にリンカー配列を更に含む。 In some embodiments of any of the methods described herein, the second domain of the pair of affinity domains and the second target binding domain are within the third and fourth chimeric polypeptides directly adjacent to each other. In some embodiments of any of the methods described herein, the third and fourth chimeric polypeptides are the second of the pair of affinity domains within the third and fourth chimeric polypeptides. and the second target binding domain.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは、同じ抗原に特異的に結合する。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは、同じエピトープに特異的に結合する。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは、同じアミノ酸配列を含む。 In some embodiments of any of the methods described herein, the first target binding domain and the second target binding domain specifically bind the same antigen. In some embodiments of any of the methods described herein, the first target binding domain and the second target binding domain specifically bind the same epitope. In some embodiments of any of the methods described herein, the first target binding domain and the second target binding domain comprise the same amino acid sequence.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは、異なる抗原に特異的に結合する。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方は、抗原結合ドメインである。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは各々、抗原結合ドメインである。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、抗原結合ドメインは、scFv又は単一ドメイン抗体を含む。 In some embodiments of any of the methods described herein, the first target binding domain and the second target binding domain specifically bind different antigens. In some embodiments of any of the methods described herein, one or both of the first target binding domain and the second target binding domain are antigen binding domains. In some embodiments of any of the methods described herein, the first target binding domain and the second target binding domain are each antigen binding domains. In some embodiments of any of the methods described herein, the antigen binding domain comprises a scFv or single domain antibody.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方は、CD16a、CD33、CD20、CD19、CD22、CD123、PDL-1、TIGIT、PD-1、TIM3、CTLA4、MICA、MICB、IL-6、IL-8、TNFα、CD26、CD36、ULBP2、CD30、CD200、IGF-1R、MUC4AC、MUC5AC、Trop-2、CMET、EGFR、HER1、HER2、HER3、PSMA、CEA、B7H3、EPCAM、BCMA、P-カドヘリン、CEACAM5、UL16結合タンパク質、HLA-DR、DLL4、TYRO3、AXL、MER、CD122、CD155、PDGF-DD、TGF-β受容体II(TGF-βRII)リガンド、TGF-βRIIIリガンド、DNAM1リガンド、NKp46リガンド、NKp44リガンド、NKG2Dリガンド、NKp30リガンド、scMHCIリガンド、scMHCIIリガンド、scTCRリガンド、PDGF-DD受容体、幹細胞因子(SCF)受容体、幹細胞様チロシンキナーゼ3リガンド(FLT3L)受容体、MICA受容体、MICB受容体、ULP16結合タンパク質受容体、CD155受容体、及びCD122受容体の群から選択される標的に特異的に結合する。
In some embodiments of any of the methods described herein, one or both of the first target binding domain and the second target binding domain are CD16a, CD33, CD20, CD19, CD22, CD123 , PDL-1, TIGIT, PD-1, TIM3, CTLA4, MICA, MICB, IL-6, IL-8, TNFα, CD26, CD36, ULBP2, CD30, CD200, IGF-1R, MUC4AC, MUC5AC, Trop-2 , CMET, EGFR, HER1, HER2, HER3, PSMA, CEA, B7H3, EPCAM, BCMA, P-cadherin, CEACAM5, UL16 binding protein, HLA-DR, DLL4, TYRO3, AXL, MER, CD122, CD155, PDGF-DD , TGF-β receptor II (TGF-βRII) ligand, TGF-βRIII ligand, DNAM1 ligand, NKp46 ligand, NKp44 ligand, NKG2D ligand, NKp30 ligand, scMHCI ligand, scMHCII ligand, scTCR ligand, PDGF-DD receptor, stem cell specific for a target selected from the group of factor (SCF) receptor, stem cell-
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方が、可溶性インターロイキン又はサイトカインタンパク質である。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性インターロイキン又はサイトカインタンパク質は、IL-1、IL-2、IL-3、IL-7、IL-8、IL-10、IL-12、IL-15、IL-17、IL-18、IL-21、PDGF-DD、及びSCFの群から選択される。 In some embodiments of any of the methods described herein, one or both of the first target binding domain and the second target binding domain are soluble interleukin or cytokine proteins. In some embodiments of any of the methods described herein, the soluble interleukin or cytokine protein is IL-1, IL-2, IL-3, IL-7, IL-8, IL- 10, IL-12, IL-15, IL-17, IL-18, IL-21, PDGF-DD, and SCF.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方が、可溶性インターロイキン又はサイトカイン受容体である。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性受容体は、可溶性TGF-β受容体II(TGF-βRII)、可溶性TGF-βRIII、可溶性TNFα受容体、可溶性IL-4受容体、又は可溶性IL-10受容体である。 In some embodiments of any of the methods described herein, one or both of the first target binding domain and the second target binding domain is a soluble interleukin or cytokine receptor. In some embodiments of any of the methods described herein, the soluble receptor is soluble TGF-β receptor II (TGF-βRII), soluble TGF-βRIII, soluble TNFα receptor, soluble IL -4 receptor, or soluble IL-10 receptor.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性組織因子ドメインは、血液凝固を刺激しない可溶性ヒト組織因子ドメインである。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、可溶性組織因子ドメインは、野生型可溶性ヒト組織因子からの配列を含むか、又はそれからなる。 In some embodiments of any of the methods described herein, the soluble tissue factor domain is a soluble human tissue factor domain that does not stimulate blood clotting. In some embodiments of any of the methods described herein, the soluble tissue factor domain comprises or consists of a sequence from wild-type soluble human tissue factor.
治療有効量の1つ以上の共通ガンマ鎖ファミリーサイトカイン受容体活性化物質を対象に投与することを含む、対象における自然発生及び/若しくは治療誘導性老化細胞を死滅させるか又は老化細胞の数を低減させる方法が本明細書に提供される。 Killing spontaneous and/or treatment-induced senescent cells or reducing the number of senescent cells in a subject comprising administering to the subject a therapeutically effective amount of one or more common gamma chain family cytokine receptor activators Provided herein is a method of causing.
治療有効量の1つ以上の共通ガンマ鎖ファミリーサイトカイン受容体活性化物質を対象に投与することを含む、対象における自然発生及び/又は治療誘導性老化細胞の蓄積を減少させる方法も本明細書に提供される。 Also herein are methods of reducing spontaneous and/or treatment-induced accumulation of senescent cells in a subject comprising administering to the subject a therapeutically effective amount of one or more common gamma chain family cytokine receptor activators. provided.
治療有効量の1つ以上の共通ガンマ鎖ファミリーサイトカイン受容体活性化物質を対象に投与することを含む、対象における自然発生及び/又は治療誘導性老化細胞のマーカーのレベルを減少させる方法も本明細書に提供される。 Also herein are methods of reducing the levels of markers of spontaneous and/or treatment-induced senescent cells in a subject comprising administering to the subject a therapeutically effective amount of one or more common gamma chain family cytokine receptor activators. provided in the book.
治療有効量の1つ以上の共通ガンマ鎖ファミリーサイトカイン受容体活性化物質を対象に投与することを含む、対象における自然発生及び/又は治療誘導性老化細胞の活性を低減させる方法も本明細書に提供される。 Also herein are methods of reducing spontaneous and/or treatment-induced senescent cell activity in a subject comprising administering to the subject a therapeutically effective amount of one or more common gamma chain family cytokine receptor activators. provided.
治療有効量の1つ以上の共通ガンマ鎖ファミリーサイトカイン受容体活性化物質を対象に投与することを含む、対象における自然発生及び/又は治療誘導性老化細胞に由来する1つ以上のSASP因子のレベル及び/又は活性を減少させる方法も本明細書に提供される。 Levels of one or more SASP factors derived from spontaneous and/or treatment-induced senescent cells in a subject, comprising administering to the subject a therapeutically effective amount of one or more common gamma chain family cytokine receptor activators. Also provided herein are methods of reducing activity and/or activity.
いくつかの実施形態では、対象は、加齢関連疾患又は炎症性疾患を有すると以前に診断又は同定されている。いくつかの実施形態では、加齢関連疾患は、炎症老化関連である。 In some embodiments, the subject has been previously diagnosed or identified as having an age-related disease or an inflammatory disease. In some embodiments, the age-related disease is inflammatory senescence-related.
いくつかの実施形態では、加齢関連疾患は、アルツハイマー病、動脈瘤、嚢胞性線維症、膵炎における線維症、緑内障、高血圧症、特発性肺線維症、炎症性腸疾患、椎間板変性、骨関節炎、2型真性糖尿病、脂肪萎縮、リポジストロフィー、アテローム性動脈硬化症、白内障、COPD、腎移植不全、肝線維症、骨量喪失、心筋梗塞、サルコペニア、創傷治癒、脱毛症、心筋細胞肥大、骨関節炎、パーキンソン病、加齢関連肺組織弾性喪失、加齢関連黄斑変性、悪液質、糸球体硬化症、肝硬変、NAFLD、骨粗しょう症、筋萎縮性側索硬化症、ハンチントン病、脊髄小脳失調症、多発性硬化症、神経変性、発作、がん、認知症、血管疾患、感染感受性、慢性炎症、及び腎機能障害の群から選択される。
In some embodiments, the age-related disease is Alzheimer's disease, aneurysm, cystic fibrosis, fibrosis in pancreatitis, glaucoma, hypertension, idiopathic pulmonary fibrosis, inflammatory bowel disease, disc degeneration, osteoarthritis ,
いくつかの実施形態では、加齢関連疾患は、固形腫瘍、血液腫瘍、肉腫、骨肉腫、膠芽細胞腫、神経芽細胞腫、黒色腫、横紋筋肉腫、ユーイング肉腫、骨肉腫、B細胞新生物、多発性骨髄腫、B細胞リンパ腫、B細胞非ホジキンリンパ腫、ホジキンリンパ腫、慢性リンパ性白血病(CLL)、急性骨髄性白血病(AML)、慢性骨髄性白血病(CML)、急性リンパ性白血病(ALL)、骨髄異形成症候群(MDS)、皮膚T細胞リンパ腫、網膜芽細胞腫、胃がん、尿路上皮がん、肺がん、腎細胞がん、胃食道がん、膵臓がん、前立腺がん、乳がん、結腸直腸がん、卵巣がん、非小細胞肺がん、扁平上皮細胞頭頸部がん、子宮内膜がん、子宮頸がん、肝臓がん、及び肝細胞がんの群から選択されるがんである。 In some embodiments, the age-related disease is solid tumor, hematological tumor, sarcoma, osteosarcoma, glioblastoma, neuroblastoma, melanoma, rhabdomyosarcoma, Ewing's sarcoma, osteosarcoma, B cell Neoplasm, multiple myeloma, B cell lymphoma, B cell non-Hodgkin lymphoma, Hodgkin lymphoma, chronic lymphocytic leukemia (CLL), acute myelogenous leukemia (AML), chronic myelogenous leukemia (CML), acute lymphocytic leukemia ( ALL), myelodysplastic syndrome (MDS), cutaneous T-cell lymphoma, retinoblastoma, gastric cancer, urothelial cancer, lung cancer, renal cell cancer, gastroesophageal cancer, pancreatic cancer, prostate cancer, breast cancer , colorectal cancer, ovarian cancer, non-small cell lung cancer, squamous cell head and neck cancer, endometrial cancer, cervical cancer, liver cancer, and hepatocellular carcinoma It is.
いくつかの実施形態では、炎症性疾患は、リウマチ性関節炎、炎症性腸疾患、エリテマトーデス、ループス腎炎、糖尿病性腎症、CNS損傷、アルツハイマー病、パーキンソン病、筋萎縮性側索硬化症、クローン病、多発性硬化症、ギラン・バレー症候群、乾癬、グレーブス病、潰瘍性大腸炎、非アルコール性脂肪性肝炎、気分障害、及びがん治療関連認知障害の群から選択される。 In some embodiments, the inflammatory disease is rheumatoid arthritis, inflammatory bowel disease, lupus erythematosus, lupus nephritis, diabetic nephropathy, CNS injury, Alzheimer's disease, Parkinson's disease, amyotrophic lateral sclerosis, Crohn's disease , multiple sclerosis, Guillain-Barré syndrome, psoriasis, Graves' disease, ulcerative colitis, non-alcoholic steatohepatitis, mood disorders, and cancer therapy-related cognitive impairment.
いくつかの実施形態では、治療誘導性老化細胞は、化学療法誘導性老化細胞である。いくつかの実施形態では、1つ以上の共通のガンマ鎖ファミリーサイトカイン受容体活性化物質の投与は、対象における標的組織の自然発生老化細胞及び/又は治療誘導性老化細胞の数の減少をもたらす。いくつかの実施形態では、標的組織は、脂肪組織、膵臓組織、肝臓組織、腎臓組織、肺組織、血管系、骨組織、中枢神経系(CNS)組織、眼組織、皮膚組織、筋肉組織、及び二次リンパ器官組織の群から選択される。 In some embodiments, the treatment-induced senescent cells are chemotherapy-induced senescent cells. In some embodiments, administration of one or more common gamma chain family cytokine receptor activators results in a reduction in the number of spontaneous and/or treatment-induced senescent cells in target tissues in a subject. In some embodiments, the target tissue is adipose tissue, pancreatic tissue, liver tissue, kidney tissue, lung tissue, vasculature, bone tissue, central nervous system (CNS) tissue, eye tissue, skin tissue, muscle tissue, and Selected from the group of secondary lymphoid organ tissues.
いくつかの実施形態では、1つ以上の共通ガンマ鎖ファミリーサイトカイン受容体活性化物質のうちの少なくとも1つは、共通ガンマ鎖ファミリーサイトカイン又はその機能的断片の複合体と、共通ガンマ鎖ファミリーサイトカイン又はその機能的断片に特異的に結合する抗体又は抗体断片との複合体である。 In some embodiments, at least one of the one or more common gamma chain family cytokine receptor activators is a conjugate of a common gamma chain family cytokine or functional fragment thereof and a common gamma chain family cytokine or A conjugate with an antibody or antibody fragment that specifically binds to a functional fragment thereof.
いくつかの実施形態では、1つ以上の共通ガンマ鎖ファミリーサイトカイン受容体活性化物質のうちの少なくとも1つは、(i)第1の標的結合ドメイン、(ii)可溶性組織因子ドメイン、及び(iii)第2の標的結合ドメインを含む一本鎖キメラポリペプチドであり、第1の標的結合ドメイン及び第2の標的結合ドメインのうちの一方又は両方は、可溶性共通ガンマ鎖ファミリーサイトカイン、共通ガンマ鎖ファミリーサイトカイン受容体に特異的に結合するアゴニスト抗原結合ドメイン、可溶性共通ガンマ鎖ファミリーサイトカイン受容体、又は共通ガンマ鎖ファミリーサイトカインに特異的に結合する抗原結合ドメインである。 In some embodiments, at least one of the one or more common gamma chain family cytokine receptor activators comprises (i) the first target binding domain, (ii) the soluble tissue factor domain, and (iii) ) a single chain chimeric polypeptide comprising a second target binding domain, wherein one or both of the first target binding domain and the second target binding domain are a soluble common gamma chain family cytokine, a common gamma chain family An agonist antigen binding domain that specifically binds to a cytokine receptor, a soluble common gamma chain family cytokine receptor, or an antigen binding domain that specifically binds to a common gamma chain family cytokine.
いくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインのうちの一方又は両方は、可溶性共通ガンマ鎖ファミリーサイトカインを含む。いくつかの実施形態では、可溶性共通ガンマ鎖ファミリーサイトカインは、可溶性IL-2、可溶性IL-4、可溶性IL-7、可溶性IL-9、可溶性IL-15、及び可溶性IL-21からなる群から選択される。いくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインのうちの一方又は両方は、共通ガンマ鎖ファミリーサイトカイン受容体に特異的に結合するアゴニスト抗原結合ドメインを含む。いくつかの実施形態では、共通ガンマ鎖ファミリーサイトカイン受容体は、IL-2、IL-4、IL-7、IL-9、IL-15、及びIL-21のうちの1つ以上に対する受容体である。いくつかの実施形態では、アゴニスト抗原結合ドメインは、scFv、VHH、又はVNARである。 In some embodiments, one or both of the first target binding domain and the second target binding domain comprise a soluble common gamma chain family cytokine. In some embodiments, the soluble common gamma chain family cytokine is selected from the group consisting of soluble IL-2, soluble IL-4, soluble IL-7, soluble IL-9, soluble IL-15, and soluble IL-21 be done. In some embodiments, one or both of the first target binding domain and the second target binding domain comprise an agonist antigen binding domain that specifically binds to a common gamma chain family cytokine receptor. In some embodiments, the common gamma chain family cytokine receptor is a receptor for one or more of IL-2, IL-4, IL-7, IL-9, IL-15, and IL-21. be. In some embodiments, the agonist antigen binding domain is a scFv, VHH, or VNAR.
いくつかの実施形態では、第1の標的結合ドメインと可溶性組織因子ドメインは、互いに直接隣接している。いくつかの実施形態では、一本鎖キメラポリペプチドは、第1の標的結合ドメインと可溶性組織因子ドメインとの間にリンカー配列を更に含む。いくつかの実施形態では、可溶性組織因子ドメインと第2の標的結合ドメインは、互いに直接隣接している。いくつかの実施形態では、一本鎖キメラポリペプチドは、可溶性組織因子ドメインと第2の標的結合ドメインとの間にリンカー配列を更に含む。いくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは、同じ抗原に特異的に結合する。いくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは、同じエピトープに特異的に結合する。いくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは、同じアミノ酸配列を含む。いくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは、異なる抗原に特異的に結合する。 In some embodiments, the first target binding domain and the soluble tissue factor domain are directly adjacent to each other. In some embodiments, the single chain chimeric polypeptide further comprises a linker sequence between the first target binding domain and the soluble tissue factor domain. In some embodiments, the soluble tissue factor domain and the second target binding domain are directly adjacent to each other. In some embodiments, the single chain chimeric polypeptide further comprises a linker sequence between the soluble tissue factor domain and the second target binding domain. In some embodiments, the first target binding domain and the second target binding domain specifically bind the same antigen. In some embodiments, the first target binding domain and the second target binding domain specifically bind the same epitope. In some embodiments, the first target binding domain and the second target binding domain comprise the same amino acid sequence. In some embodiments, the first target binding domain and the second target binding domain specifically bind different antigens.
いくつかの実施形態では、可溶性組織因子ドメインは、可溶性ヒト組織因子ドメインである。いくつかの実施形態では、可溶性ヒト組織因子ドメインは、配列番号93と少なくとも80%同一である配列を含む。いくつかの実施形態では、一本鎖キメラポリペプチドは、そのN末端及び/又はC末端に1つ以上の追加の標的結合ドメインを更に含む。 In some embodiments, the soluble tissue factor domain is a soluble human tissue factor domain. In some embodiments, the soluble human tissue factor domain comprises a sequence that is at least 80% identical to SEQ ID NO:93. In some embodiments, the single chain chimeric polypeptide further comprises one or more additional target binding domains at its N-terminus and/or C-terminus.
いくつかの実施形態では、1つ以上の共通ガンマ鎖ファミリーサイトカイン受容体活性化物質のうちの少なくとも1つは、(a)(i)第1の標的結合ドメイン、(ii)可溶性組織因子ドメイン、及び(iii)一対の親和性ドメインの第1のドメインを含む第1のキメラポリペプチドと、(b)(i)一対の親和性ドメインの第2のドメイン、及び(ii)第2の標的結合ドメインを含む第2のキメラポリペプチドと、を含む多鎖キメラポリペプチドであり、第1の標的結合ドメイン及び第2の標的結合ドメインのうちの一方又は両方は、可溶性共通ガンマ鎖ファミリーサイトカイン、共通ガンマ鎖ファミリーサイトカイン受容体に特異的に結合するアゴニスト抗原結合ドメイン、可溶性共通ガンマ鎖ファミリーサイトカイン受容体、又は共通ガンマ鎖ファミリーサイトカインに特異的に結合する抗原結合ドメインである。 In some embodiments, at least one of the one or more common gamma chain family cytokine receptor activators comprises (a) (i) a first target binding domain, (ii) a soluble tissue factor domain; and (iii) a first chimeric polypeptide comprising a first of a pair of affinity domains, and (b) (i) a second of the pair of affinity domains, and (ii) a second target binding a second chimeric polypeptide comprising a domain, wherein one or both of the first target binding domain and the second target binding domain are a soluble common gamma chain family cytokine, the common An agonist antigen binding domain that specifically binds a gamma chain family cytokine receptor, a soluble common gamma chain family cytokine receptor, or an antigen binding domain that specifically binds a common gamma chain family cytokine.
いくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインのうちの一方又は両方は、可溶性共通ガンマ鎖ファミリーサイトカインを含む。いくつかの実施形態では、可溶性共通ガンマ鎖ファミリーサイトカインは、可溶性IL-2、可溶性IL-4、可溶性IL-7、可溶性IL-9、可溶性IL-15、及び可溶性IL-21の群から選択される。いくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインのうちの一方又は両方は、共通ガンマ鎖ファミリーサイトカイン受容体に特異的に結合するアゴニスト抗原結合ドメインを含む。いくつかの実施形態では、共通ガンマ鎖ファミリーサイトカイン受容体は、IL-2、IL-4、IL-7、IL-9、IL-15、及びIL-21のうちの1つ以上に対する受容体である。いくつかの実施形態では、アゴニスト抗原結合ドメインは、scFv、VHH、又はVNARである。 In some embodiments, one or both of the first target binding domain and the second target binding domain comprise a soluble common gamma chain family cytokine. In some embodiments, the soluble common gamma chain family cytokine is selected from the group of soluble IL-2, soluble IL-4, soluble IL-7, soluble IL-9, soluble IL-15, and soluble IL-21. be. In some embodiments, one or both of the first target binding domain and the second target binding domain comprise an agonist antigen binding domain that specifically binds to a common gamma chain family cytokine receptor. In some embodiments, the common gamma chain family cytokine receptor is a receptor for one or more of IL-2, IL-4, IL-7, IL-9, IL-15, and IL-21. be. In some embodiments, the agonist antigen binding domain is a scFv, VHH, or VNAR.
いくつかの実施形態では、第1の標的結合ドメインと可溶性組織因子ドメインは、第1のキメラポリペプチド内で互いに直接隣接している。いくつかの実施形態では、第1のキメラポリペプチドは、第1のキメラポリペプチド内の第1の標的結合ドメインと可溶性組織因子ドメインとの間にリンカー配列を更に含む。いくつかの実施形態では、可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインは、第1のキメラポリペプチド内で互いに直接隣接している。いくつかの実施形態では、第1のキメラポリペプチドは、第1のキメラポリペプチド内の可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間にリンカー配列を更に含む。いくつかの実施形態では、一対の親和性ドメインの第2のドメインと第2の標的結合ドメインは、第2のキメラポリペプチド内で互いに直接隣接している。いくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチド内の一対の親和性ドメインの第2のドメインと第2の標的結合ドメインとの間にリンカー配列を更に含む。 In some embodiments, the first target binding domain and the soluble tissue factor domain are directly adjacent to each other within the first chimeric polypeptide. In some embodiments, the first chimeric polypeptide further comprises a linker sequence between the first target binding domain and the soluble tissue factor domain within the first chimeric polypeptide. In some embodiments, the soluble tissue factor domain and the first domain of the pair of affinity domains are directly adjacent to each other within the first chimeric polypeptide. In some embodiments, the first chimeric polypeptide further comprises a linker sequence between the soluble tissue factor domain and the first of the pair of affinity domains within the first chimeric polypeptide. In some embodiments, the second domain and the second target binding domain of the pair of affinity domains are directly adjacent to each other within the second chimeric polypeptide. In some embodiments, the second chimeric polypeptide further comprises a linker sequence between the second of the pair of affinity domains and the second target binding domain within the second chimeric polypeptide.
いくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは、同じ抗原に特異的に結合する。いくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは、異なる抗原に特異的に結合する。いくつかの実施形態では、第1のキメラポリペプチドは、1つ以上の追加の標的結合ドメインを更に含む。いくつかの実施形態では、第2のキメラポリペプチドは、1つ以上の追加の標的結合ドメインを更に含む。 In some embodiments, the first target binding domain and the second target binding domain specifically bind the same antigen. In some embodiments, the first target binding domain and the second target binding domain specifically bind different antigens. In some embodiments, the first chimeric polypeptide further comprises one or more additional target binding domains. In some embodiments, the second chimeric polypeptide further comprises one or more additional target binding domains.
いくつかの実施形態では、可溶性組織因子ドメインは、可溶性ヒト組織因子ドメインである。いくつかの実施形態では、可溶性ヒト組織因子ドメインは、配列番号93と少なくとも80%同一である配列を含む。いくつかの実施形態では、一対の親和性ドメインは、ヒトIL-15受容体のアルファ鎖(IL15Rα)由来のスシドメイン、及び可溶性IL-15である。いくつかの実施形態では、一対の親和性ドメインは、バルナーゼとバルンスター、PKAとAKAP、変異RNase I断片に基づくアダプター/ドッキングタグモジュール、並びに、タンパク質シンタキシン、シナプトタグミン、シナプトブレビン、及びSNAP25の相互作用に基づくSNAREモジュールの群から選択される。 In some embodiments, the soluble tissue factor domain is a soluble human tissue factor domain. In some embodiments, the soluble human tissue factor domain comprises a sequence that is at least 80% identical to SEQ ID NO:93. In some embodiments, the pair of affinity domains is a sushi domain from the alpha chain of the human IL-15 receptor (IL15Rα) and soluble IL-15. In some embodiments, the paired affinity domains are barnase and barnstar, PKA and AKAP, adapter/docking tag modules based on mutated RNase I fragments, and proteins syntaxin, synaptotagmin, synaptobrevin, and SNAP25 interactions. It is selected from a group of SNARE modules based on
いくつかの実施形態では、一対の親和性ドメインの第1のドメイン又は第2のドメインは、可溶性共通ガンマ鎖ファミリーサイトカイン、又は共通ガンマ鎖ファミリーサイトカイン受容体に特異的に結合する抗原結合ドメインである。いくつかの実施形態では、1つ以上の共通ガンマ鎖ファミリーサイトカイン受容体活性化物質のうちの少なくとも1つは、可溶性IL-15、又はIL-15アゴニストである。いくつかの実施形態では、可溶性IL-15は、配列番号82と少なくとも90%同一である。いくつかの実施形態では、IL-15アゴニストは、IL-15と可溶性IL-15受容体(IL-15R)の全部又は一部との複合体を含む。いくつかの実施形態では、可溶性IL-15Rの一部は、IL-15Rαの一部である。いくつかの実施形態では、可溶性IL-15Rαの一部は、IL-15Rαのスシドメインである。いくつかの実施形態では、IL-15アゴニストは、Fcドメインを更に含む。いくつかの実施形態では、IL-15アゴニストは、IL-15とIL-15Rα由来のスシドメインとを含む融合タンパク質を含む。いくつかの実施形態では、1つ以上の共通ガンマ鎖ファミリーサイトカイン受容体活性化物質のうちの1つは、可溶性IL-2又はIL-2アゴニストである。いくつかの実施形態では、1つ以上の共通ガンマ鎖ファミリーサイトカイン受容体活性化物質のうちの1つは、共通ガンマ鎖ファミリーサイトカインに特異的に結合する抗体又は抗原結合抗体断片である。 In some embodiments, the first domain or the second domain of the pair of affinity domains is an antigen binding domain that specifically binds to a soluble common gamma chain family cytokine or a common gamma chain family cytokine receptor . In some embodiments, at least one of the one or more common gamma chain family cytokine receptor activators is soluble IL-15, or an IL-15 agonist. In some embodiments, the soluble IL-15 is at least 90% identical to SEQ ID NO:82. In some embodiments, the IL-15 agonist comprises a complex of IL-15 and all or part of the soluble IL-15 receptor (IL-15R). In some embodiments, the portion of soluble IL-15R is a portion of IL-15Rα. In some embodiments, the portion of soluble IL-15Rα is the sushi domain of IL-15Rα. In some embodiments the IL-15 agonist further comprises an Fc domain. In some embodiments, the IL-15 agonist comprises a fusion protein comprising IL-15 and a sushi domain from IL-15Rα. In some embodiments, one of the one or more common gamma chain family cytokine receptor activators is a soluble IL-2 or IL-2 agonist. In some embodiments, one of the one or more common gamma chain family cytokine receptor activators is an antibody or antigen-binding antibody fragment that specifically binds to a common gamma chain family cytokine.
いくつかの実施形態では、この方法は、1つ以上の共通ガンマ鎖ファミリーサイトカイン受容体活性化物質の1回、2回以上の用量を対象に投与することを含む。いくつかの実施形態では、2回以上の用量のうちの任意の2回の連続用量は、約1週間~約1年間隔で投与される。いくつかの実施形態では、2回以上の用量のうちの任意の2回の連続用量は、約1週間~約6ヶ月間隔で投与される。いくつかの実施形態では、2回以上の用量のうちの任意の2回の連続用量は、約1週間~約2ヶ月間隔で投与される。いくつかの実施形態では、2回以上の用量のうちの任意の2回の連続用量は、約1週間~約1ヶ月間隔で投与される。 In some embodiments, the method comprises administering to the subject one, two or more doses of one or more common gamma chain family cytokine receptor activators. In some embodiments, any two consecutive doses of the two or more doses are administered about one week to about one year apart. In some embodiments, any two consecutive doses of the two or more doses are administered about one week to about six months apart. In some embodiments, any two consecutive doses of the two or more doses are administered about one week to about two months apart. In some embodiments, any two consecutive doses of the two or more doses are administered about one week to about one month apart.
いくつかの実施形態では、1回、2回以上の用量は、皮下投与によって投与される。いくつかの実施形態では、2回以上の用量は、筋肉内投与によって投与される。いくつかの実施形態では、2回以上の用量は、約1年~約60年の期間にわたって投与される。いくつかの実施形態では、2回以上の用量は、約1年~約50年の期間にわたって投与される。いくつかの実施形態では、2回以上の用量は、約1年~約40年の期間にわたって投与される。いくつかの実施形態では、2回以上の用量は、約1年~約30年の期間にわたって投与される。いくつかの実施形態では、2回以上の用量は、約1年~約20年の期間にわたって投与される。いくつかの実施形態では、2回以上の用量は、約1年~約10年の期間にわたって投与される。 In some embodiments, one, two or more doses are administered by subcutaneous administration. In some embodiments, two or more doses are administered by intramuscular administration. In some embodiments, two or more doses are administered over a period of about 1 year to about 60 years. In some embodiments, two or more doses are administered over a period of about 1 year to about 50 years. In some embodiments, two or more doses are administered over a period of about 1 year to about 40 years. In some embodiments, two or more doses are administered over a period of about 1 year to about 30 years. In some embodiments, two or more doses are administered over a period of about 1 year to about 20 years. In some embodiments, two or more doses are administered over a period of about 1 year to about 10 years.
いくつかの実施形態では、2回以上の用量の各々は、各共通ガンマ鎖ファミリーサイトカイン受容体活性化物質約0.01mg/kg~各共通ガンマ鎖ファミリーサイトカイン受容体活性化物質約10mg/kgの投薬量で投与される。いくつかの実施形態では、2回以上の用量の各々は、各共通ガンマ鎖ファミリーサイトカイン受容体活性化物質約0.02mg/kg~各共通ガンマ鎖ファミリーサイトカイン受容体活性化物質約5mg/kgの投薬量で投与される。 In some embodiments, each of the two or more doses is from about 0.01 mg/kg of each common gamma chain family cytokine receptor activator to about 10 mg/kg of each common gamma chain family cytokine receptor activator. Dosage is administered. In some embodiments, each of the two or more doses is from about 0.02 mg/kg of each common gamma chain family cytokine receptor activator to about 5 mg/kg of each common gamma chain family cytokine receptor activator. Dosage is administered.
いくつかの実施形態では、1つ以上の共通ガンマ鎖ファミリーサイトカイン受容体活性化物質の初回投与は、対象が少なくとも30歳に達したときに始まる。いくつかの実施形態では、1つ以上の共通ガンマ鎖ファミリーサイトカイン受容体活性化物質の初回投与は、対象が少なくとも40歳に達したときに始まる。いくつかの実施形態では、1つ以上の共通ガンマ鎖ファミリーサイトカイン受容体活性化物質の初回投与は、対象が少なくとも50歳に達したときに始まる。いくつかの実施形態では、1つ以上の共通ガンマ鎖ファミリーサイトカイン受容体活性化物質の初回投与は、対象が少なくとも60歳に達したときに始まる。 In some embodiments, the first administration of one or more common gamma chain family cytokine receptor activators begins when the subject reaches at least 30 years of age. In some embodiments, the first administration of one or more common gamma chain family cytokine receptor activators begins when the subject reaches at least 40 years of age. In some embodiments, the first administration of one or more common gamma chain family cytokine receptor activators begins when the subject reaches at least 50 years of age. In some embodiments, the first administration of one or more common gamma chain family cytokine receptor activators begins when the subject reaches at least 60 years of age.
いくつかの実施形態では、対象は、加齢関連疾患又は炎症性疾患を有すると診断も同定もされていない。いくつかの実施形態では、対象は、化学療法剤で以前に治療されたことがない。いくつかの実施形態では、対象は、細胞老化を誘導する治療剤で以前に治療されたことがない。いくつかの実施形態では、この方法は、TGF-β受容体の活性化の減少をもたらす少なくとも1つ以上の作用物質を対象に投与することを更に含む。いくつかの実施形態では、TGF-β受容体の活性化の減少をもたらす作用物質は、可溶性TGF-β受容体、TGF-β受容体の細胞外ドメイン、TGF-βに特異的に結合する抗体、TGF-β受容体に結合するアンタゴニスト抗体、LAPに結合する作用物質、又はTGF-β/LAP複合体に結合する作用物質である。いくつかの実施形態では、TGF-βの活性化の減少をもたらす1つ以上の作用物質は、LAPへの又はTGF-β/LAP複合体への結合を介してTGF-β受容体の活性化を減少させる。 In some embodiments, the subject has not been diagnosed or identified as having an age-related disease or an inflammatory disease. In some embodiments, the subject has not been previously treated with a chemotherapeutic agent. In some embodiments, the subject has not been previously treated with a therapeutic agent that induces cellular senescence. In some embodiments, the method further comprises administering to the subject at least one or more agents that result in decreased activation of TGF-β receptors. In some embodiments, the agent that results in decreased TGF-beta receptor activation is a soluble TGF-beta receptor, an extracellular domain of a TGF-beta receptor, an antibody that specifically binds to TGF-beta , an antagonist antibody that binds to the TGF-β receptor, an agent that binds to LAP, or an agent that binds to the TGF-β/LAP complex. In some embodiments, the one or more agents that result in decreased activation of TGF-β are activated TGF-β receptors through binding to LAP or to the TGF-β/LAP complex. decrease.
いくつかの実施形態では、可溶性ヒト組織因子ドメインは、血液凝固を開始しない。いくつかの実施形態では、この方法は、チェックポイント阻害物質、化学療法薬、及び治療用抗体等の作用物質の組み合わせの群から選択される追加の治療剤を投与することを更に含む。 In some embodiments, the soluble human tissue factor domain does not initiate blood clotting. In some embodiments, the method further comprises administering an additional therapeutic agent selected from the group of combinations of agents such as checkpoint inhibitors, chemotherapeutic agents, and therapeutic antibodies.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、一本鎖キメラポリペプチドは、37℃で少なくとも10日間、ヒト血清中で安定である。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、多鎖キメラポリペプチドは、37℃で少なくとも10日間、ヒト血清中で安定である。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、一本鎖キメラポリペプチドは、著しい凝固活性は有さない。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、多鎖キメラポリペプチドは、著しい凝固活性は有さない。 In some embodiments of any of the methods described herein, the single-chain chimeric polypeptide is stable in human serum at 37° C. for at least 10 days. In some embodiments of any of the methods described herein, the multichain chimeric polypeptide is stable in human serum at 37° C. for at least 10 days. In some embodiments of any of the methods described herein, the single chain chimeric polypeptide does not have significant clotting activity. In some embodiments of any of the methods described herein, the multichain chimeric polypeptide does not have significant clotting activity.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、この方法は、対象における老化した免疫細胞の若返りをもたらす。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、老化した免疫細胞の若返りは、対象における罹患細胞又は感染病原体の数の低減をもたらす。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、老化した免疫細胞には、老化したNK細胞、老化したNKT細胞、老化したT細胞、老化したB細胞、老化した単球、老化したマクロファージ、老化した好中球、老化した好塩基球、老化した好酸球、老化したクッパー細胞、及び老化したミクロギア(microgial)細胞のうちの1つ以上が含まれる。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、罹患細胞には、がん細胞、ウイルス感染細胞、及び細胞内細菌感染細胞が含まれる。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、感染病原体には、ウイルス、細菌、真菌、及び寄生虫が含まれる。 In some embodiments of any of the methods described herein, the method results in rejuvenation of aged immune cells in the subject. In some embodiments of any of the methods described herein, rejuvenation of aged immune cells results in a reduction in the number of diseased cells or infectious agents in the subject. In some embodiments of any of the methods described herein, the senescent immune cells include senescent NK cells, senescent NKT cells, senescent T cells, senescent B cells, senescent single cells. One or more of spheres, senescent macrophages, senescent neutrophils, senescent basophils, senescent eosinophils, senescent Kupffer cells, and senescent microgial cells. In some embodiments of any of the methods described herein, diseased cells include cancer cells, virus-infected cells, and intracellular bacteria-infected cells. In some embodiments of any of the methods described herein, infectious agents include viruses, bacteria, fungi, and parasites.
本明細書で使用される場合、「キメラ」という用語は、元来2つの異なる源(例えば、同じ種又は異なる種由来の、例えば、2つの異なる天然に存在するタンパク質)に由来するアミノ酸配列(例えば、ドメイン)を含むポリペプチドを指す。例えば、キメラポリペプチドは、少なくとも2つの異なる天然に存在するヒトタンパク質由来のドメインを含み得る。いくつかの例では、キメラポリペプチドは、合成配列であるドメイン(例えば、scFv)及び天然に存在するタンパク質(例えば、天然に存在するヒトタンパク質)に由来するドメインを含み得る。いくつかの実施形態では、キメラポリペプチドは、合成配列である少なくとも2つの異なるドメイン(例えば、2つの異なるscFv)を含み得る。 As used herein, the term "chimera" refers to amino acid sequences (e.g., two different naturally occurring proteins, originally from two different sources, e.g., from the same or different species) ( For example, it refers to a polypeptide comprising a domain). For example, a chimeric polypeptide can contain domains from at least two different naturally occurring human proteins. In some examples, a chimeric polypeptide can include domains that are synthetic sequences (eg, scFv) and domains derived from naturally occurring proteins (eg, naturally occurring human proteins). In some embodiments, a chimeric polypeptide can comprise at least two different domains (eg, two different scFvs) that are synthetic sequences.
「活性化されたNK細胞」は、例えば、休止NK細胞と比較して、CD25、CD69、MTOR-C1、SREBP、IFN-γ、及びグランザイム(例えば、グランザイムB)のうちの2つ以上(例えば、3つ、4つ、5つ、又は6つ)の発現レベルの増加を示すNK細胞である。CD25、CD69、MTOR-C1、SREBP、IFN-γ、及びグランザイム(例えば、グランザイムB)の発現レベルを同定するための例示的な方法が、本明細書に記載されている。 An "activated NK cell" is, for example, two or more of CD25, CD69, MTOR-C1, SREBP, IFN-γ, and a granzyme (e.g., granzyme B) compared to a resting NK cell (e.g., , 3, 4, 5, or 6) NK cells showing increased expression levels. Exemplary methods for identifying expression levels of CD25, CD69, MTOR-C1, SREBP, IFN-γ, and granzymes (eg, granzyme B) are described herein.
「休止NK細胞」は、例えば、活性化されたNK細胞と比較して、CD25、CD69、MTOR-C1、SREBP、IFN-γ、及びグランザイム(例えば、グランザイムB)のうちの2つ以上(例えば、3つ、4つ、5つ、又は6つ)の減少した発現を有するNK細胞である。 A “resting NK cell” is, for example, two or more of CD25, CD69, MTOR-C1, SREBP, IFN-γ, and a granzyme (eg, granzyme B) compared to an activated NK cell (eg, , 3, 4, 5, or 6) NK cells with decreased expression.
「NK細胞活性化物質」は、活性化されたNK細胞に進化させるために、休止NK細胞を(単独で、又は追加のNK細胞活性化物質と組み合わせて)誘導又は促進する作用物質である。NK細胞活性化物質の非限定的な例及び態様は、本明細書に記載されている。 An "NK cell activator" is an agent that induces or promotes (alone or in combination with additional NK cell activators) resting NK cells to evolve into activated NK cells. Non-limiting examples and aspects of NK cell activators are described herein.
「抗原結合ドメイン」とは、1つ以上の異なる抗原に特異的に結合することができる1つ以上のタンパク質ドメイン(例えば、単一のポリペプチド由来のアミノ酸から形成されるか、又は2つ以上のポリペプチド(例えば、同じ又は異なるポリペプチド)由来のアミノ酸から形成される)である。いくつかの例では、抗原結合ドメインは、天然に存在する抗体と同様の特異性及び親和性で抗原又はエピトープに結合することができる。いくつかの実施形態では、抗原結合ドメインは、抗体又はその断片であり得る。いくつかの実施形態では、抗原結合ドメインは、代替足場を含み得る。抗原結合ドメインの非限定的な例が本明細書に記載されている。抗原結合ドメインの追加の例が当該技術分野で既知である。 An "antigen-binding domain" is one or more protein domains (e.g., formed from amino acids from a single polypeptide, or formed from two or more antigens) capable of specifically binding to one or more different antigens. (eg, formed from amino acids from the same or different polypeptides). In some instances, an antigen binding domain can bind an antigen or epitope with specificity and affinity similar to a naturally occurring antibody. In some embodiments, the antigen binding domain can be an antibody or fragment thereof. In some embodiments, antigen binding domains may include alternative scaffolds. Non-limiting examples of antigen binding domains are described herein. Additional examples of antigen binding domains are known in the art.
「可溶性組織因子ドメイン」とは、膜貫通ドメイン及び細胞内ドメインを欠く野生型哺乳動物組織因子タンパク質(例えば、野生型ヒト組織因子タンパク質)のセグメントと少なくとも70%の同一性(例えば、少なくとも75%の同一性、少なくとも80%の同一性、少なくとも85%の同一性、少なくとも90%の同一性、少なくとも95%の同一性、少なくとも99%の同一性、又は100%同一性)を有するポリペプチドを指す。可溶性組織因子ドメインの非限定的な例が本明細書に記載されている。 A "soluble tissue factor domain" is at least 70% identical (e.g., at least 75% identity, at least 80% identity, at least 85% identity, at least 90% identity, at least 95% identity, at least 99% identity, or 100% identity) Point. Non-limiting examples of soluble tissue factor domains are described herein.
「可溶性インターロイキンタンパク質」という用語は、成熟分泌インターロイキンタンパク質又はその生物学的に活性な断片を指すために本明細書で使用される。いくつかの例では、可溶性インターロイキンタンパク質は、野生型成熟分泌哺乳動物インターロイキンタンパク質(例えば、野生型ヒトインターロイキンタンパク質)と少なくとも70%同一、少なくとも75%同一、少なくとも80%同一、少なくとも85%同一、少なくとも90%同一、少なくとも95%同一、少なくとも99%同一、又は100%同一であり、かつその生物学的活性を保持する配列を含み得る。可溶性インターロイキンタンパク質の非限定的な例が本明細書に記載されている。 The term "soluble interleukin protein" is used herein to refer to a mature secreted interleukin protein or a biologically active fragment thereof. In some examples, the soluble interleukin protein is at least 70% identical, at least 75% identical, at least 80% identical, at least 85% identical to a wild-type mature secreted mammalian interleukin protein (e.g., wild-type human interleukin protein) It can include sequences that are identical, at least 90% identical, at least 95% identical, at least 99% identical, or 100% identical and retain their biological activity. Non-limiting examples of soluble interleukin proteins are described herein.
「可溶性サイトカインタンパク質」という用語は、成熟分泌サイトカインタンパク質又はその生物学的に活性な断片を指すために本明細書で使用される。いくつかの例では、可溶性サイトカインタンパク質は、野生型成熟分泌哺乳動物インターロイキンタンパク質(例えば、野生型ヒトインターロイキンタンパク質)と少なくとも70%同一、少なくとも75%同一、少なくとも80%同一、少なくとも85%同一、少なくとも90%同一、少なくとも95%同一、少なくとも99%同一、又は100%同一であり、かつその生物学的活性を保持する配列を含み得る。可溶性サイトカインタンパク質の非限定的な例が本明細書に記載されている。 The term "soluble cytokine protein" is used herein to refer to a mature secreted cytokine protein or biologically active fragment thereof. In some examples, the soluble cytokine protein is at least 70% identical, at least 75% identical, at least 80% identical, at least 85% identical to a wild-type mature secreted mammalian interleukin protein (e.g., wild-type human interleukin protein) , at least 90% identical, at least 95% identical, at least 99% identical, or 100% identical and retains its biological activity. Non-limiting examples of soluble cytokine proteins are described herein.
「可溶性インターロイキン受容体」という用語は、本明細書で最も広い意味で使用され、(例えば、生理学的条件下で、例えば、室温のリン酸緩衝生理食塩水中で)その天然リガンドのうちの1つ以上に結合することができる膜貫通ドメイン(及び任意に細胞内ドメイン)を欠くポリペプチドを指す。例えば、可溶性インターロイキン受容体は、野生型インターロイキン受容体の細胞外ドメインと少なくとも70%同一(例えば、少なくとも75%同一、少なくとも80%同一、少なくとも85%同一、少なくとも90%同一、少なくとも95%同一、少なくとも99%同一、又は100%同一)であり、かつその天然リガンドのうちの1つ以上に特異的に結合する能力を保持するが、その膜貫通ドメインを欠く(任意に更に細胞内ドメインを欠く)配列を含み得る。可溶性インターロイキン受容体の非限定的な例が本明細書に記載されている。 The term "soluble interleukin receptor" is used in the broadest sense herein and refers to one of its natural ligands (e.g., under physiological conditions, e.g., in phosphate-buffered saline at room temperature). Refers to a polypeptide that lacks a transmembrane domain (and optionally an intracellular domain) capable of binding more than one. For example, the soluble interleukin receptor is at least 70% identical (e.g., at least 75% identical, at least 80% identical, at least 85% identical, at least 90% identical, at least 95% identical, at least 99% identical, or 100% identical) and retains the ability to specifically bind to one or more of its natural ligands, but lacks its transmembrane domain (optionally also the intracellular domain). ) sequence. Non-limiting examples of soluble interleukin receptors are described herein.
「可溶性サイトカイン受容体」という用語は、本明細書で最も広い意味で使用され、(例えば、生理学的条件下で、例えば、室温のリン酸緩衝生理食塩水中で)その天然リガンドのうちの1つ以上に結合することができる膜貫通ドメイン(及び任意に細胞内ドメイン)を欠くポリペプチドを指す。例えば、可溶性サイトカイン受容体は、野生型サイトカイン受容体の細胞外ドメインと少なくとも70%同一(例えば、少なくとも75%同一、少なくとも80%同一、少なくとも85%同一、少なくとも90%同一、少なくとも95%同一、少なくとも99%同一、又は100%同一)であり、かつその天然リガンドのうちの1つ以上に特異的に結合する能力を保持するが、その膜貫通ドメインを欠く(任意に更に細胞内ドメインを欠く)配列を含み得る。可溶性サイトカイン受容体の非限定的な例が本明細書に記載されている。 The term "soluble cytokine receptor" is used in the broadest sense herein and refers to one of its natural ligands (e.g., under physiological conditions, e.g., in phosphate-buffered saline at room temperature). It refers to a polypeptide that lacks a transmembrane domain (and optionally an intracellular domain) capable of binding to a molecule. For example, the soluble cytokine receptor is at least 70% identical (e.g., at least 75% identical, at least 80% identical, at least 85% identical, at least 90% identical, at least 95% identical, at least 99% identical, or 100% identical) and retains the ability to specifically bind to one or more of its natural ligands, but lacks its transmembrane domain (optionally also lacking an intracellular domain). ) may contain an array. Non-limiting examples of soluble cytokine receptors are described herein.
「抗体」という用語は、本明細書でその最も広い意味で使用され、抗原又はエピトープに特異的に結合する1つ以上の抗原結合ドメインを含むある特定のタイプの免疫グロブリン分子を含む。抗体には、具体的には、例えば、インタクトな抗体(例えば、インタクトな免疫グロブリン)、抗体断片、及び多重特異性抗体が含まれる。抗原結合ドメインの一例は、VH-VL二量体によって形成された抗原結合ドメインである。抗体の追加の例が本明細書に記載されている。抗体の追加の例は当該技術分野で既知である。 The term "antibody" is used herein in its broadest sense and includes certain types of immunoglobulin molecules that contain one or more antigen binding domains that specifically bind an antigen or epitope. Antibodies specifically include, for example, intact antibodies (eg, intact immunoglobulins), antibody fragments, and multispecific antibodies. One example of an antigen binding domain is an antigen binding domain formed by a VH-VL dimer. Additional examples of antibodies are described herein. Additional examples of antibodies are known in the art.
「親和性」とは、抗原結合部位とその結合パートナー(例えば、抗原又はエピトープ)との間の非共有相互作用の合計の強さを指す。別途指示されない限り、本明細書で使用される場合、「親和性」とは、抗原結合ドメインのメンバーと抗原又はエピトープとの間の1:1相互作用を反映する内因性結合親和性を指す。分子XのそのパートナーYに対する親和性は、解離平衡定数(KD)で表され得る。解離平衡定数に寄与する動力学的成分は、以下でより詳細に記載される。親和性は、本明細書に記載の方法を含む、当該技術分野で既知の一般的な方法によって測定され得る。親和性は、例えば、表面プラズモン共鳴(SPR)技術(例えば、BIACORE(登録商標))又は生体層干渉法(例えば、FORTEBIO(登録商標))を使用して決定され得る。抗原結合ドメイン及びその対応する抗原又はエピトープに対する親和性を決定するための追加の方法は、当該技術分野で既知である。 "Affinity" refers to the total strength of non-covalent interactions between an antigen-binding site and its binding partner (eg, antigen or epitope). Unless otherwise indicated, "affinity" as used herein refers to the intrinsic binding affinity that reflects a 1:1 interaction between a member of an antigen binding domain and an antigen or epitope. The affinity of molecule X for its partner Y can be expressed as a dissociation equilibrium constant (K D ). The kinetic components that contribute to the dissociation equilibrium constant are described in more detail below. Affinity can be measured by common methods known in the art, including those described herein. Affinity can be determined, for example, using surface plasmon resonance (SPR) technology (eg, BIACORE®) or biolayer interferometry (eg, FORTEBIO®). Additional methods for determining affinity for antigen binding domains and their corresponding antigens or epitopes are known in the art.
本明細書で使用される「一本鎖ポリペプチド」とは、一本のタンパク質鎖を指す。 As used herein, "single-chain polypeptide" refers to a single protein chain.
本明細書で使用される「多鎖ポリペプチド」とは、2つ以上(例えば、3、4、5、6、7、8、9、又は10)のタンパク質鎖(例えば、少なくとも第1のキメラポリペプチド及び第2のポリペプチド)を含むポリペプチドを指し、2つ以上のタンパク質鎖が非共有結合を介して結合して、四次構造を形成する。 As used herein, a "multi-chain polypeptide" refers to two or more (e.g., 3, 4, 5, 6, 7, 8, 9, or 10) protein chains (e.g., at least a first chimeric It refers to a polypeptide, including a polypeptide and a second polypeptide), in which two or more protein chains are joined via non-covalent bonds to form a quaternary structure.
「親和性ドメイン対」という用語は、1×10-7M未満(例えば、1×10-8M未満、1×10-9M未満、1×10-10M未満、又は1×10-11M未満)のKDで互いに特異的に結合する2つの異なるタンパク質ドメインである。いくつかの例では、一対の親和性ドメインは、一対の天然に存在するタンパク質であり得る。いくつかの実施形態では、一対の親和性ドメインは、一対の合成タンパク質であり得る。一対の親和性ドメインの非限定的な例が本明細書に記載されている。 The term "affinity domain pair" means less than 1×10 −7 M (eg, less than 1×10 −8 M, less than 1×10 −9 M, less than 1×10 −10 M, or less than 1×10 −11 M) are two different protein domains that specifically bind to each other with a K D less than M). In some examples, the pair of affinity domains can be a pair of naturally occurring proteins. In some embodiments, the pair of affinity domains can be a pair of synthetic proteins. Non-limiting examples of paired affinity domains are described herein.
「エピトープ」という用語は、抗原結合ドメインに特異的に結合する抗原の一部を意味する。エピトープは、例えば、表面接触可能アミノ酸残基及び/又は糖側鎖からなり得、特定の三次元構造特性、並びに特定の電荷特性を有し得る。立体配座エピトープ及び非立体配座エピトープは、変性溶媒の存在下で前者への結合が失われる可能性があるが、後者への結合が失われる可能性がないという点で区別される。エピトープは、結合に直接関与するアミノ酸残基、及び結合に直接関与しない他のアミノ酸残基を含み得る。抗原結合ドメインが結合するエピトープを同定するための方法は、当該技術分野で既知である。 The term "epitope" refers to that portion of an antigen that specifically binds to the antigen binding domain. Epitopes can consist, for example, of surface accessible amino acid residues and/or sugar side chains and can have specific three dimensional structural characteristics, as well as specific charge characteristics. Conformational and non-conformational epitopes are distinguished in that binding to the former, but not the latter, can be lost in the presence of denaturing solvents. An epitope can include amino acid residues that are directly involved in binding and other amino acid residues that are not directly involved in binding. Methods for identifying epitopes bound by antigen binding domains are known in the art.
「治療」という用語は、障害の少なくとも1つの症状を改善することを意味する。いくつかの例では、治療される障害はがんであり、がんの少なくとも1つの症状を改善することは、異常な増殖、遺伝子発現、シグナル伝達、翻訳、及び/又は因子の分泌を減少させることを含む。一般に、治療方法は、かかる治療を必要とするか、又はかかる治療を必要とすると決定された対象に、治療有効量の障害の少なくとも1つの症状を軽減する組成物を投与することを含む。 The term "treating" means ameliorating at least one symptom of a disorder. In some examples, the disorder being treated is cancer and ameliorating at least one symptom of cancer is reducing abnormal proliferation, gene expression, signaling, translation, and/or secretion of factors. including. Generally, methods of treatment comprise administering to a subject in need of such treatment or determined to be in need of such treatment a therapeutically effective amount of a composition that reduces at least one symptom of the disorder.
他に定義されない限り、本明細書で使用される全ての技術用語及び科学用語は、本発明が属する当業者によって一般に理解されるのと同じ意味を有する。方法及び材料は、本発明で使用するために本明細書に記載されており、当該技術分野で周知である他の好適な方法及び材料も使用することができる。材料、方法、及び実施例は、単なる例示であり、限定することを意図するものではない。本明細書に記載の全ての刊行物、特許出願、特許、配列、データベースエントリ、及び他の参考文献は、参照によりそれらの全体が組み込まれる。矛盾が生じた場合、定義を含む本明細書が制御するものとする。 Unless defined otherwise, all technical and scientific terms used herein have the same meaning as commonly understood by one of ordinary skill in the art to which this invention belongs. Methods and materials are described herein for use in the present invention, and other suitable methods and materials known in the art can also be used. The materials, methods, and examples are illustrative only and not intended to be limiting. All publications, patent applications, patents, sequences, database entries, and other references mentioned herein are incorporated by reference in their entirety. In case of conflict, the present specification, including definitions, will control.
本発明の他の特徴及び利点は、以下の詳細な説明及び図、並びに特許請求の範囲から明らかになるであろう。 Other features and advantages of the invention will become apparent from the following detailed description and figures, and from the claims.
詳細な説明
TGF-β受容体の活性化の減少をもたらす1つ以上の作用物質の治療有効量を対象に投与することを含む、対象における自然発生及び/若しくは治療誘導性老化細胞を死滅させるか又は老化細胞の数を低減させる方法が本明細書に提供される。TGF-β受容体の活性化の減少をもたらす1つ以上の作用物質の治療有効量を対象に投与することを含む、対象における自然発生及び/又は治療誘導性老化細胞の蓄積を減少させる方法も本明細書に提供される。TGF-β受容体の活性化の減少をもたらす1つ以上の作用物質の治療有効量を対象に投与することを含む、対象における自然発生及び/又は治療誘導性老化細胞のマーカーのレベルを減少させる方法も本明細書に提供される。TGF-β受容体の活性化の減少をもたらす1つ以上の作用物質の治療有効量を対象に投与することを含む、対象における自然発生及び/又は治療誘導性老化細胞の活性を低減させる方法も本明細書に提供される。TGF-β受容体の活性化の減少をもたらす1つ以上の作用物質の治療有効量を対象に投与することを含む、対象における自然発生及び/又は治療誘導性老化細胞に由来するSASP因子のレベル又は活性を減少させる方法も本明細書に提供される。
DETAILED DESCRIPTION Killing spontaneous and/or treatment-induced senescent cells in a subject comprising administering to the subject a therapeutically effective amount of one or more agents that result in decreased activation of TGF-β receptors. Alternatively, provided herein are methods of reducing the number of senescent cells. Also methods of reducing spontaneous and/or treatment-induced accumulation of senescent cells in a subject comprising administering to the subject a therapeutically effective amount of one or more agents that result in reduced activation of TGF-β receptors. provided herein. Reducing levels of spontaneous and/or treatment-induced markers of senescent cells in a subject comprising administering to the subject a therapeutically effective amount of one or more agents that result in reduced activation of TGF-beta receptors A method is also provided herein. Also a method of reducing spontaneous and/or treatment-induced senescent cell activity in a subject comprising administering to the subject a therapeutically effective amount of one or more agents that result in reduced activation of TGF-β receptors. provided herein. Levels of SASP factors derived from spontaneous and/or treatment-induced senescent cells in a subject, including administering to the subject a therapeutically effective amount of one or more agents that result in decreased activation of TGF-β receptors. Or methods of reducing activity are also provided herein.
治療有効量の1つ以上の共通ガンマ鎖ファミリーサイトカイン受容体活性化物質を対象に投与することを含む、対象における自然発生及び/若しくは治療誘導性老化細胞を死滅させるか又は老化細胞の数を低減させる方法が本明細書に更に提供される。治療有効量の1つ以上の共通ガンマ鎖ファミリーサイトカイン受容体活性化物質を対象に投与することを含む、対象における自然発生及び/又は治療誘導性老化細胞の蓄積を減少させる方法も本明細書に提供される。治療有効量の1つ以上の共通ガンマ鎖ファミリーサイトカイン受容体活性化物質を対象に投与することを含む、対象における自然発生及び/又は治療誘導性老化細胞のマーカーのレベルを減少させる方法も本明細書に提供される。治療有効量の1つ以上の共通ガンマ鎖ファミリーサイトカイン受容体活性化物質を対象に投与することを含む、対象における自然発生及び/又は治療誘導性老化細胞の活性を低減させる方法も本明細書に提供される。治療有効量の1つ以上の共通ガンマ鎖ファミリーサイトカイン受容体活性化物質を対象に投与することを含む、対象における自然発生及び/又は治療誘導性老化細胞に由来する1つ以上のSASP因子のレベル及び/又は活性を減少させる方法も本明細書に提供される。 Killing spontaneous and/or treatment-induced senescent cells or reducing the number of senescent cells in a subject comprising administering to the subject a therapeutically effective amount of one or more common gamma chain family cytokine receptor activators Further provided herein is a method of causing. Also herein are methods of reducing spontaneous and/or treatment-induced accumulation of senescent cells in a subject comprising administering to the subject a therapeutically effective amount of one or more common gamma chain family cytokine receptor activators. provided. Also herein are methods of reducing the levels of markers of spontaneous and/or treatment-induced senescent cells in a subject comprising administering to the subject a therapeutically effective amount of one or more common gamma chain family cytokine receptor activators. provided in the book. Also herein are methods of reducing spontaneous and/or treatment-induced senescent cell activity in a subject comprising administering to the subject a therapeutically effective amount of one or more common gamma chain family cytokine receptor activators. provided. Levels of one or more SASP factors derived from spontaneous and/or treatment-induced senescent cells in a subject, comprising administering to the subject a therapeutically effective amount of one or more common gamma chain family cytokine receptor activators. Also provided herein are methods of reducing activity and/or activity.
加齢関連疾患又は状態の治療を必要とする対象において加齢関連疾患又は状態を治療する方法であって、加齢関連疾患又は状態を有すると同定される対象に、治療有効数の1つ以上のナチュラルキラー(NK)細胞活性化物質の治療有効量及び/又は活性化されたNK細胞を投与することを含む、方法が、本明細書に提供される。老化細胞の死滅又は老化細胞の数の減少を必要とする対象において老化細胞を死滅させる又は老化細胞の数を減少させる方法であって、当該対象に、治療有効数の1つ以上のNK細胞活性化物質の治療有効量及び/又は活性化されたNK細胞を投与することを含む、方法も本明細書に提供される。ある期間にわたる皮膚及び/又は毛髪の質感及び/又は外観の改善を必要とする対象において皮膚及び/又は毛髪の質感及び/又は外観を改善する方法であって、当該対象に、治療有効数の1つ以上のナチュラルキラー(NK)細胞活性化物質の治療有効量及び/又は活性化されたNK細胞を投与することを含む、方法も本明細書に提供される。ある期間にわたる肥満の治療の支援を必要とする対象において肥満の治療を支援する方法であって、当該対象に、治療有効数の1つ以上のナチュラルキラー(NK)細胞活性化物質の治療有効量及び/又は活性化されたNK細胞を投与することを含む、方法も本明細書に提供される。 A method of treating an age-related disease or condition in a subject in need of treatment of an age-related disease or condition comprising administering to a subject identified as having an age-related disease or condition a therapeutically effective number of one or more Provided herein are methods comprising administering a therapeutically effective amount of a natural killer (NK) cell activator of and/or activated NK cells. A method of killing senescent cells or reducing the number of senescent cells in a subject in need of killing senescent cells or reducing the number of senescent cells, said subject comprising a therapeutically effective number of one or more active NK cells Also provided herein are methods comprising administering a therapeutically effective amount of a stimulator and/or activated NK cells. 1. A method of improving skin and/or hair texture and/or appearance in a subject in need thereof over a period of time, comprising administering to said subject a therapeutically effective number of 1 Also provided herein are methods comprising administering therapeutically effective amounts of one or more natural killer (NK) cell activators and/or activated NK cells. A method of helping treat obesity in a subject in need of help treating obesity over a period of time comprising administering to the subject a therapeutically effective amount of one or more natural killer (NK) cell activators Also provided herein are methods comprising administering and/or activated NK cells.
活性化されたNK細胞
本明細書に記載の方法のうちのいずれかのいくつかの実施形態は、対象(例えば、本明細書に記載の例示的な対象のうちのいずれか)に、治療有効数の活性化されたNK細胞(例えば、ヒト活性化されたNK細胞)を投与することを含み得る。活性化されたNK細胞は、例えば、休止NK細胞(例えば、ヒト休止NK細胞)と比較して、CD25、CD69、MTOR-C1、SREBP1、IFN-γ、及びグランザイム(例えば、グランザイムB)のうちの2つ以上(例えば、3つ、4つ、5つ、又は6つ)の発現レベルの増加を示すNK細胞(例えば、ヒトNK細胞)である。例えば、活性化NK細胞は、例えば、休止NK細胞(例えば、ヒト活性化NK細胞)と比較して、CD25、CD69、MTOR-C1、SREBP1、IFN-γ、及びグランザイム(例えば、グランザイムB)のうちの2つ以上(例えば、3つ、4つ、5つ、又は6つ)の発現レベルの少なくとも10%増加(例えば、少なくとも15%増加、少なくとも20%増加、少なくとも25%増加、少なくとも30%増加、少なくとも35%増加、少なくとも40%増加、少なくとも45%増加、少なくとも50%増加、少なくとも55%増加、少なくとも60%増加、少なくとも65%増加、少なくとも70%増加、少なくとも75%増加、少なくとも80%増加、少なくとも85%増加、少なくとも90%増加、少なくとも95%増加、少なくとも100%増加、少なくとも120%増加、少なくとも140%増加、少なくとも160%増加、少なくとも180%増加、少なくとも200%増加、少なくとも220%増加、少なくとも240%増加、少なくとも260%増加、少なくとも280%増加、又は少なくとも300%増加)を有し得る。
Activated NK Cells Some embodiments of any of the methods described herein provide a subject (e.g., any of the exemplary subjects described herein) with a therapeutically effective administration of a number of activated NK cells (eg, human activated NK cells). Activated NK cells are, for example, CD25, CD69, MTOR-C1, SREBP1, IFN-γ, and granzymes (eg, granzyme B) compared to resting NK cells (eg, human resting NK cells). NK cells (eg, human NK cells) that exhibit increased expression levels of 2 or more (eg, 3, 4, 5, or 6) of For example, activated NK cells are, for example, CD25, CD69, MTOR-C1, SREBP1, IFN-γ, and granzymes (eg, granzyme B) compared to resting NK cells (eg, human activated NK cells). at least a 10% increase (e.g., at least a 15% increase, at least a 20% increase, at least a 25% increase, at least a 30% increase in the expression level of two or more (e.g., three, four, five, or six) of increase, at least 35% increase, at least 40% increase, at least 45% increase, at least 50% increase, at least 55% increase, at least 60% increase, at least 65% increase, at least 70% increase, at least 75% increase, at least 80% increase, at least 85% increase, at least 90% increase, at least 95% increase, at least 100% increase, at least 120% increase, at least 140% increase, at least 160% increase, at least 180% increase, at least 200% increase, at least 220% increase, at least 240% increase, at least 260% increase, at least 280% increase, or at least 300% increase).
いくつかの実施形態では、活性化NK細胞は、例えば、休止NK細胞(例えば、ヒト活性化NK細胞)と比較して、CD25、CD59、CD352、NKp80、DNAM-1、2B4、NKp30、NKp44、NKp46、NKG2D、CD16、KIR2DS1、KIR2Ds2/3、KIR2DL4、KIR2DS4、KIR2DS5、KIR3DS1、NKG2C、CCR7、CXCR3、L-セレクチン、CXCR1、CXCR2、CX3CR1、ChemR23、CXCR4、CCR5、S1P5、c-Kit、mTORC1のうちの2つ以上(例えば、3つ、4つ、5つ、6つ、7つ、8つ、9つ、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、又は29)の発現レベルの少なくとも10%増加(例えば、少なくとも15%増加、少なくとも20%増加、少なくとも25%増加、少なくとも30%増加、少なくとも35%増加、少なくとも40%増加、少なくとも45%増加、少なくとも50%増加、少なくとも55%増加、少なくとも60%増加、少なくとも65%増加、少なくとも70%増加、少なくとも75%増加、少なくとも80%増加、少なくとも85%増加、少なくとも90%増加、少なくとも95%増加、少なくとも100%増加、少なくとも120%増加、少なくとも140%増加、少なくとも160%増加、少なくとも180%増加、少なくとも200%増加、少なくとも220%増加、少なくとも240%増加、少なくとも260%増加、少なくとも280%増加、又は少なくとも300%増加)を任意に更に有し得る。 In some embodiments, activated NK cells are, for example, CD25, CD59, CD352, NKp80, DNAM-1, 2B4, NKp30, NKp44, compared to resting NK cells (eg, human activated NK cells). NKp46, NKG2D, CD16, KIR2DS1, KIR2Ds2/3, KIR2DL4, KIR2DS4, KIR2DS5, KIR3DS1, NKG2C, CCR7, CXCR3, L-selectin, CXCR1, CXCR2, CX3CR1, ChemR23, CXCR4, CCR5, S1P5, c- Kit, mTORC1 2 or more of (e.g., 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20 , 21, 22, 23, 24, 25, 26, 27, 28, or 29) at least 10% increase (e.g., at least 15% increase, at least 20% increase, at least 25% increase, at least 30% increase) , at least 35% increase, at least 40% increase, at least 45% increase, at least 50% increase, at least 55% increase, at least 60% increase, at least 65% increase, at least 70% increase, at least 75% increase, at least 80% increase , at least 85% increase, at least 90% increase, at least 95% increase, at least 100% increase, at least 120% increase, at least 140% increase, at least 160% increase, at least 180% increase, at least 200% increase, at least 220% increase , at least a 240% increase, at least a 260% increase, at least a 280% increase, or at least a 300% increase).
例えば、活性化NK細胞(例えば、ヒト活性化NK細胞)は、例えば、休止NK細胞(例えば、ヒト休止NK細胞)と比較して、CD25、CD69、mTORC1、SREBP1、IFN-γ、及びグランザイム(例えば、グランザイムB)のうちの2つ以上(例えば、3つ、4つ、5つ、又は6つ)の発現レベルの約10%増加~約500%増加、約10%増加~約450%増加、約10%増加~約400%増加、約10%増加~約350%増加、約10%増加~約300%増加、約10%増加~約280%増加、約10%増加~約260%増加、約10%増加~約240%増加、約10%増加~約220%増加、約10%増加~約200%増加、約10%増加~約180%増加、約10%増加~約160%増加、約10%増加~約140%増加、約10%増加~約120%増加、約10%増加~約100%増加、約10%増加~約80%増加、約10%増加~約60%増加、約10%増加~約40%増加、約10%増加~約20%増加、20%増加~約500%増加、約20%増加~約450%増加、約20%増加~約400%増加、約20%増加~約350%増加、約20%増加~約300%増加、約20%増加~約280%増加、約20%増加~約260%増加、約20%増加~約240%増加、約20%増加~約220%増加、約20%増加~約200%増加、約20%増加~約180%増加、約20%増加~約160%増加、約20%増加~約140%増加、約20%増加~約120%増加、約20%増加~約100%増加、約20%増加~約80%増加、約20%増加~約60%増加、約20%増加~約40%増加、40%増加~約500%増加、約40%増加~約450%増加、約40%増加~約400%増加、約40%増加~約350%増加、約40%増加~約300%増加、約40%増加~約280%増加、約40%増加~約260%増加、約40%増加~約240%増加、約40%増加~約220%増加、約40%増加~約200%増加、約40%増加~約180%増加、約40%増加~約160%増加、約40%増加~約140%増加、約40%増加~約120%増加、約40%増加~約100%増加、約40%増加~約80%増加、約40%増加~約60%増加、60%増加~約500%増加、約60%増加~約450%増加、約60%増加~約400%増加、約60%増加~約350%増加、約60%増加~約300%増加、約60%増加~約280%増加、約60%増加~約260%増加、約60%増加~約240%増加、約60%増加~約220%増加、約60%増加~約200%増加、約60%増加~約180%増加、約60%増加~約160%増加、約60%増加~約140%増加、約60%増加~約120%増加、約60%増加~約100%増加、約60%増加~約80%増加、80%増加~約500%増加、約80%増加~約450%増加、約80%増加~約400%増加、約80%増加~約350%増加、約80%増加~約300%増加、約80%増加~約280%増加、約80%増加~約260%増加、約80%増加~約240%増加、約80%増加~約220%増加、約80%増加~約200%増加、約80%増加~約180%増加、約80%増加~約160%増加、約80%増加~約140%増加、約80%増加~約120%増加、約80%増加~約100%増加、100%増加~約500%増加、約100%増加~約450%増加、約100%増加~約400%増加、約100%増加~約350%増加、約100%増加~約300%増加、約100%増加~約280%増加、約100%増加~約260%増加、約100%増加~約240%増加、約100%増加~約220%増加、約100%増加~約200%増加、約100%増加~約180%増加、約100%増加~約160%増加、約100%増加~約140%増加、約100%増加~約120%増加、120%増加~約500%増加、約120%増加~約450%増加、約120%増加~約400%増加、約120%増加~約350%増加、約120%増加~約300%増加、約120%増加~約280%増加、約120%増加~約260%増加、約120%増加~約240%増加、約120%増加~約220%増加、約120%増加~約200%増加、約120%増加~約180%増加、約120%増加~約160%増加、約120%増加~約140%増加、140%増加~約500%増加、約140%増加~約450%増加、約140%増加~約400%増加、約140%増加~約350%増加、約140%増加~約300%増加、約140%増加~約280%増加、約140%増加~約260%増加、約140%増加~約240%増加、約140%増加~約220%増加、約140%増加~約200%増加、約140%増加~約180%増加、約140%増加~約160%増加、160%増加~約500%増加、約160%増加~約450%増加、約160%増加~約400%増加、約160%増加~約350%増加、約160%増加~約300%増加、約160%増加~約280%増加、約160%増加~約260%増加、約160%増加~約240%増加、約160%増加~約220%増加、約160%増加~約200%増加、約160%増加~約180%増加、180%増加~約500%増加、約180%増加~約450%増加、約180%増加~約400%増加、約180%増加~約350%増加、約180%増加~約300%増加、約180%増加~約280%増加、約180%増加~約260%増加、約180%増加~約240%増加、約180%増加~約220%増加、約180%増加~約200%増加、200%増加~約500%増加、約200%増加~約450%増加、約200%増加~約400%増加、約200%増加~約350%増加、約200%増加~約300%増加、約200%増加~約280%増加、約200%増加~約260%増加、約200%増加~約240%増加、約200%増加~約220%増加、220%増加~約500%増加、約220%増加~約450%増加、約220%増加~約400%増加、約220%増加~約350%増加、約220%増加~約300%増加、約220%増加~約280%増加、約220%増加~約260%増加、約220%増加~約240%増加、240%増加~約500%増加、約240%増加~約450%増加、約240%増加~約400%増加、約240%増加~約350%増加、約240%増加~約300%増加、約240%増加~約280%増加、約240%増加~約260%増加、260%増加~約500%増加、約260%増加~約450%増加、約260%増加~約400%増加、約260%増加~約350%増加、約260%増加~約300%増加、約260%増加~約280%増加、280%増加~約500%増加、約280%増加~約450%増加、約280%増加~約400%増加、約280%増加~約350%増加、約280%増加~約300%増加、300%増加~約500%増加、約300%増加~約450%増加、約300%増加~約400%増加、約300%増加~約350%増加、350%増加~約500%増加、約350%増加~約450%増加、約350%増加~約400%増加、400%増加~約500%増加、約400%増加~約450%増加、又は400%増加~約500%増加を有し得る。 For example, activated NK cells (e.g., human activated NK cells) have, e.g., CD25, CD69, mTORC1, SREBP1, IFN-γ, and granzyme ( For example, about 10% to about 500% increase, about 10% to about 450% increase in expression levels of two or more (eg, 3, 4, 5, or 6) of granzyme B) , about 10% increase to about 400% increase, about 10% increase to about 350% increase, about 10% increase to about 300% increase, about 10% increase to about 280% increase, about 10% increase to about 260% increase , about 10% increase to about 240% increase, about 10% increase to about 220% increase, about 10% increase to about 200% increase, about 10% increase to about 180% increase, about 10% increase to about 160% increase , about 10% increase to about 140% increase, about 10% increase to about 120% increase, about 10% increase to about 100% increase, about 10% increase to about 80% increase, about 10% increase to about 60% increase , about 10% to about 40% increase, about 10% to about 20% increase, 20% to about 500% increase, about 20% to about 450% increase, about 20% to about 400% increase, about 20% increase to about 350% increase, about 20% increase to about 300% increase, about 20% increase to about 280% increase, about 20% increase to about 260% increase, about 20% increase to about 240% increase, about 20% increase to about 220% increase, about 20% increase to about 200% increase, about 20% increase to about 180% increase, about 20% increase to about 160% increase, about 20% increase to about 140% increase, about 20% increase to about 120% increase, about 20% increase to about 100% increase, about 20% increase to about 80% increase, about 20% increase to about 60% increase, about 20% increase to about 40% increase, 40% increase to about 500% increase, about 40% increase to about 450% increase, about 40% increase to about 400% increase, about 40% increase to about 350% increase, about 40% increase to about 300% increase, about 40% increase to about 280% increase, about 40% increase to about 260% increase, about 40% increase to about 240% increase, about 40% increase to about 220% increase, about 40% increase to about 200% increase, about 40% increase to about 180% increase, about 40% increase to about 160% increase, about 40% increase to about 140% increase, about 40% increase to about 120% increase, about 40% increase to about 100% increase, about 40% increase to about 80% increase, about 40% increase to about 60% increase, 60% increase to about 500% increase, about 60% increase to about 450% increase, about 60% increase to about 400% increase, about 60 % increase to about 350% increase, about 60% increase to about 300% increase, about 60% increase to about 280% increase, about 60% increase to about 260% increase, about 60% increase to about 240% increase, about 60 % increase to about 220% increase, about 60% increase to about 200% increase, about 60% increase to about 180% increase, about 60% increase to about 160% increase, about 60% increase to about 140% increase, about 60 % increase to about 120% increase, about 60% increase to about 100% increase, about 60% increase to about 80% increase, 80% increase to about 500% increase, about 80% increase to about 450% increase, about 80% Increase to about 400% increase, about 80% increase to about 350% increase, about 80% increase to about 300% increase, about 80% increase to about 280% increase, about 80% increase to about 260% increase, about 80% Increase to about 240% increase, about 80% increase to about 220% increase, about 80% increase to about 200% increase, about 80% increase to about 180% increase, about 80% increase to about 160% increase, about 80% Increase to about 140% increase, about 80% increase to about 120% increase, about 80% increase to about 100% increase, 100% increase to about 500% increase, about 100% increase to about 450% increase, about 100% increase ~ about 400% increase, about 100% increase to about 350% increase, about 100% increase to about 300% increase, about 100% increase to about 280% increase, about 100% increase to about 260% increase, about 100% increase ~ about 240% increase, about 100% increase to about 220% increase, about 100% increase to about 200% increase, about 100% increase to about 180% increase, about 100% increase to about 160% increase, about 100% increase ~ About 140% increase, about 100% increase ~ About 120% increase, 120% increase ~ About 500% increase, About 120% increase ~ About 450% increase, About 120% increase ~ About 400% increase, About 120% increase ~ About 350% increase, about 120% increase to about 300% increase, about 120% increase to about 280% increase, about 120% increase to about 260% increase, about 120% increase to about 240% increase, about 120% increase ~ about 220% increase, about 120% increase to about 200% increase, about 120% increase to about 180% increase, about 120% increase to about 160% increase, about 120% increase to about 140% increase, 140% increase to about 500% increase, about 140% increase to about 450% increase, about 140% increase to about 400% increase, about 140% increase to about 350% increase, about 140% increase to about 300% increase, about 140% increase to about 280% increase, about 140% increase to about 260% increase, about 140% increase to about 240% increase, about 140% increase to about 220% increase, about 140% increase to about 200% increase, about 140% increase to about 180% increase, about 140% increase to about 160% increase, 160% increase to about 500% increase, about 160% increase to about 450% increase, about 160% increase to about 400% increase, about 160% increase to about 350 % increase, about 160% increase to about 300% increase, about 160% increase to about 280% increase, about 160% increase to about 260% increase, about 160% increase to about 240% increase, about 160% increase to about 220% % increase, about 160% increase to about 200% increase, about 160% increase to about 180% increase, 180% increase to about 500% increase, about 180% increase to about 450% increase, about 180% increase to about 400% increase, about 180% increase to about 350% increase, about 180% increase to about 300% increase, about 180% increase to about 280% increase, about 180% increase to about 260% increase, about 180% increase to about 240% increase, about 180% increase to about 220% increase, about 180% increase to about 200% increase, 200% increase to about 500% increase, about 200% increase to about 450% increase, about 200% increase to about 400% increase , about 200% increase to about 350% increase, about 200% increase to about 300% increase, about 200% increase to about 280% increase, about 200% increase to about 260% increase, about 200% increase to about 240% increase , about 200% increase to about 220% increase, 220% increase to about 500% increase, about 220% increase to about 450% increase, about 220% increase to about 400% increase, about 220% increase to about 350% increase, about 220% increase to about 300% increase, about 220% increase to about 280% increase, about 220% increase to about 260% increase, about 220% increase to about 240% increase, 240% increase to about 500% increase, about 240% increase to about 450% increase, about 240% increase to about 400% increase, about 240% increase to about 350% increase, about 240% increase to about 300% increase, about 240% increase to about 280% increase, about 240% increase to about 260% increase, 260% increase to about 500% increase, about 260% increase to about 450% increase, about 260% increase to about 400% increase, about 260% increase to about 350% increase, about 260 % increase to about 300% increase, about 260% increase to about 280% increase, 280% increase to about 500% increase, about 280% increase to about 450% increase, about 280% increase to about 400% increase, about 280% Increase to about 350% increase, about 280% increase to about 300% increase, 300% increase to about 500% increase, about 300% increase to about 450% increase, about 300% increase to about 400% increase, about 300% increase ~ about 350% increase, 350% increase to about 500% increase, about 350% increase to about 450% increase, about 350% increase to about 400% increase, 400% increase to about 500% increase, about 400% increase to about It can have a 450% increase, or a 400% increase to about a 500% increase.
いくつかの実施形態では、活性化されたNK細胞は、CD25、CD59、CD352、NKp80、DNAM-1、2B4、NKp30、NKp44、NKp46、NKG2D、CD16、KIR2DS1、KIR2Ds2/3、KIR2DL4、KIR2DS4、KIR2DS5、KIR3DS1、NKG2C、CCR7、CXCR3、L-セレクチン、CXCR1、CXCR2、CX3CR1、ChemR23、CXCR4、CCR5、S1P5、c-Kit、mTORC1のうちの2つ以上(例えば、3つ、4つ、5つ、6つ、7つ、8つ、9つ、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、又は29)の発現レベルにおいて、約10%増加~約500%増加(例えば、又は本明細書に記載のこの範囲の部分的範囲のうちのいずれか)を更に有し得る(例えば、休止NK細胞(例えば、ヒト活性化されたNK細胞)と比較して)。 In some embodiments, the activated NK cells are CD25, CD59, CD352, NKp80, DNAM-1, 2B4, NKp30, NKp44, NKp46, NKG2D, CD16, KIR2DS1, KIR2Ds2/3, KIR2DL4, KIR2DS4, KIR2DS5 , KIR3DS1, NKG2C, CCR7, CXCR3, L-selectin, CXCR1, CXCR2, CX3CR1, ChemR23, CXCR4, CCR5, S1P5, c-Kit, mTORC1 (e.g., three, four, five, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, or 29) can further have from about a 10% increase to about a 500% increase (eg, or any of the subranges of this range described herein) in the expression level of (eg, resting NK cells (e.g. compared to human activated NK cells).
CD25、CD69、CD59、CD352、NKp80、DNAM-1、2B4、NKp30、NKp44、NKp46、NKG2D、CD16、KIR2DS1、KIR2Ds2/3、KIR2DL4、KIR2DS4、KIR2DS5、KIR3DS1、NKG2C、CCR7、CXCR3、L-セレクチン、CXCR1、CXCR2、CX3CR1、ChemR23、CXCR4、CCR5、S1P5、c-Kit、mTORC1、MYC、SREBP1、IFN-γ、及びグランザイム(例えば、グランザイムB)の発現レベルを決定するために使用することができるアッセイの非限定的な例には、例えば、免疫ブロット法、蛍光支援細胞選別、酵素結合免疫吸着アッセイ、及びRT-PCRが含まれる。 CD25, CD69, CD59, CD352, NKp80, DNAM-1, 2B4, NKp30, NKp44, NKp46, NKG2D, CD16, KIR2DS1, KIR2Ds2/3, KIR2DL4, KIR2DS4, KIR2DS5, KIR3DS1, NKG2C, CCR7, CXCR3, L- selectins, Assays that can be used to determine expression levels of CXCR1, CXCR2, CX3CR1, ChemR23, CXCR4, CCR5, S1P5, c-Kit, mTORC1, MYC, SREBP1, IFN-γ, and granzymes (eg, granzyme B) Non-limiting examples of include, eg, immunoblotting, fluorescence-assisted cell sorting, enzyme-linked immunosorbent assay, and RT-PCR.
CD25の発現レベルを決定するために使用することができる市販のELISAアッセイの非限定的な例は、Diaclone、Covalab Biotechnology、及びCaltag Medsystemsから入手可能である。成熟ヒトCD25のタンパク質及びcDNA配列を、以下に示す。
成熟ヒトCD25タンパク質(配列番号1)


Mature human CD25 protein (SEQ ID NO: 1)
CD69の発現レベルを決定するために使用することができる市販のELISAアッセイの非限定的な例は、RayBiotech、Novus Biologicals、及びAviscera Bioscienceから入手可能である。成熟ヒトCD69のタンパク質及びcDNA配列を、以下に示す。
成熟ヒトCD69タンパク質(配列番号3)


Mature human CD69 protein (SEQ ID NO: 3)
成熟ヒトCD59のタンパク質及びcDNA配列を、以下に示す。
成熟ヒトCD59タンパク質(配列番号5)


Mature human CD59 protein (SEQ ID NO:5)
成熟ヒトCD352のタンパク質及びcDNA配列を、以下に示す。
成熟ヒトCD352タンパク質(配列番号7)


Mature human CD352 protein (SEQ ID NO: 7)
成熟ヒトNKp80のタンパク質及びcDNA配列を、以下に示す。
成熟ヒトNKp80タンパク質(配列番号9)


Mature human NKp80 protein (SEQ ID NO: 9)
成熟ヒトDNAM-1のタンパク質及びcDNA配列を、以下に示す。
成熟ヒトDNAM-1タンパク質(配列番号11)


Mature human DNAM-1 protein (SEQ ID NO: 11)
成熟ヒト2B4のタンパク質及びcDNA配列を、以下に示す。
成熟ヒト2B4タンパク質(配列番号13)


Mature human 2B4 protein (SEQ ID NO: 13)
成熟ヒトNKp30のタンパク質及びcDNA配列を、以下に示す。
成熟ヒトNKp30タンパク質(配列番号15)


Mature human NKp30 protein (SEQ ID NO: 15)
成熟ヒトNKp44のタンパク質及びcDNA配列を、以下に示す。
成熟ヒトNKp44タンパク質(配列番号17)


Mature human NKp44 protein (SEQ ID NO: 17)
成熟ヒトNKp46のタンパク質及びcDNA配列を、以下に示す。
成熟ヒトNKp46タンパク質(配列番号19)


Mature human NKp46 protein (SEQ ID NO: 19)
成熟ヒトNKG2Dのタンパク質及びcDNA配列を、以下に示す。
成熟ヒトNKG2Dタンパク質(配列番号21)


Mature human NKG2D protein (SEQ ID NO: 21)
成熟ヒトCD16aのタンパク質及びcDNA配列を、以下に示す。
成熟ヒトCD16aタンパク質(配列番号23)


Mature human CD16a protein (SEQ ID NO:23)
成熟ヒトCD16bのタンパク質及びcDNA配列を、以下に示す。
成熟ヒトCD16bタンパク質(配列番号25)


Mature human CD16b protein (SEQ ID NO:25)
成熟ヒトKIR2DS1のタンパク質及びcDNA配列を、以下に示す。
ヒトKIR2DS1タンパク質(配列番号27)


Human KIR2DS1 protein (SEQ ID NO:27)
成熟ヒトKIR2DS2のタンパク質及びcDNA配列を、以下に示す。
ヒトKIR2DS2タンパク質(配列番号29)


Human KIR2DS2 protein (SEQ ID NO:29)
成熟ヒトKIR2DS3のタンパク質及びcDNA配列を、以下に示す。
成熟ヒトKIR2DS3タンパク質(配列番号31)


Mature human KIR2DS3 protein (SEQ ID NO:31)
成熟ヒトKIR2DL4のタンパク質及びcDNA配列を、以下に示す。
成熟ヒトKIR2DL4タンパク質(配列番号33)


Mature human KIR2DL4 protein (SEQ ID NO:33)
成熟ヒトKIR2DS4のタンパク質及びcDNA配列を、以下に示す。
成熟ヒトKIR2DS4タンパク質(配列番号35)


Mature human KIR2DS4 protein (SEQ ID NO:35)
成熟ヒトKIR2DS5のタンパク質及びcDNA配列を、以下に示す。
成熟ヒトKIR2DS5(配列番号37)


Mature human KIR2DS5 (SEQ ID NO:37)
成熟ヒトKIR3DS1のタンパク質及びcDNA配列を、以下に示す。
成熟ヒトKIR3DS1cDNA(配列番号39)


Mature human KIR3DS1 cDNA (SEQ ID NO:39)
成熟ヒトNKG2Cのタンパク質及びcDNA配列を、以下に示す。
成熟ヒトNKG2Cタンパク質(配列番号41)


Mature human NKG2C protein (SEQ ID NO: 41)
成熟ヒトCCR7のタンパク質及びcDNA配列を、以下に示す。
成熟ヒトCCR7タンパク質(配列番号43)


Mature human CCR7 protein (SEQ ID NO: 43)
成熟ヒトCXCR3のタンパク質とcDNAの配列を、以下に示す。
成熟ヒトCXCR3タンパク質(配列番号45)


Mature human CXCR3 protein (SEQ ID NO:45)
成熟ヒトL-セレクチンのタンパク質及びcDNA配列を、以下に示す。
成熟ヒトL-セレクチンタンパク質(配列番号47)


Mature human L-selectin protein (SEQ ID NO:47)
成熟ヒトCXCR1のタンパク質及びcDNA配列を、以下に示す。
成熟ヒトCXCR1タンパク質(配列番号49)


Mature human CXCR1 protein (SEQ ID NO:49)
成熟ヒトCXCR2のタンパク質及びcDNA配列を、以下に示す。
成熟ヒトCXCR2タンパク質(配列番号51)


Mature human CXCR2 protein (SEQ ID NO: 51)
成熟ヒトCX3CR1のタンパク質及びcDNA配列を、以下に示す。
成熟ヒトCX3CR1タンパク質(配列番号53)


Mature human CX3CR1 protein (SEQ ID NO:53)
成熟ヒトChemR23のタンパク質及びcDNA配列を、以下に示す。
成熟ヒトChemR23タンパク質(配列番号55)


Mature human ChemR23 protein (SEQ ID NO:55)
成熟ヒトCXCR4のタンパク質及びcDNA配列を、以下に示す。
成熟ヒトCXCR4タンパク質(配列番号57)


Mature human CXCR4 protein (SEQ ID NO:57)
成熟ヒトCCR5のタンパク質及びcDNAの配列を、以下に示す。
成熟ヒトCCR5タンパク質(配列番号59)


Mature human CCR5 protein (SEQ ID NO:59)
成熟ヒトS1P5のタンパク質及びcDNA配列を、以下に示す。
成熟ヒトS1P5タンパク質(配列番号61)


Mature human S1P5 protein (SEQ ID NO: 61)
成熟ヒトC-kitのタンパク質及びcDNA配列を、以下に示す。
成熟ヒトC-kitタンパク質(配列番号63)



Mature human C-kit protein (SEQ ID NO: 63)
成熟ヒトmTORのタンパク質及びcDNA配列を、以下に示す。
成熟ヒトmTORタンパク質(配列番号65)





Mature human mTOR protein (SEQ ID NO: 65)
SREBP1の発現レベルを決定するために使用することができる市販のELISAアッセイの非限定的な例は、Novus Biologicals及びAbcamから入手可能である。成熟ヒトSREBP1のタンパク質及びcDNA配列を、以下に示す。
成熟ヒトSREBP1タンパク質(配列番号67)
MDEPPFSEAALEQALGEPCDLDAALLTDIEDMLQLINNQDSDFPGLFDPPYAGSGAGGTDPASPDTSSPGSLSPPPATLSSSLEAFLSGPQAAPSPLSPPQPAPTPLKMYPSMPAFSPGPGIKEESVPLSILQTPTPQPLPGALLPQSFPAPAPPQFSSTPVLGYPSPPGGFSTGSPPGNTQQPLPGLPLASPPGVPPVSLHTQVQSVVPQQLLTVTAAPTAAPVTTTVTSQIQQVPVLLQPHFIKADSLLLTAMKTDGATVKAAGLSPLVSGTTVQTGPLPTLVSGGTILATVPLVVDAEKLPINRLAAGSKAPASAQSRGEKRTAHNAIEKRYRSSINDKIIELKDLVVGTEAKLNKSAVLRKAIDYIRFLQHSNQKLKQENLSLRTAVHKSKSLKDLVSACGSGGNTDVLMEGVKTEVEDTLTPPPSDAGSPFQSSPLSLGSRGSGSGGSGSDSEPDSPVFEDSKAKPEQRPSLHSRGMLDRSRLALCTLVFLCLSCNPLASLLGARGLPSPSDTTSVYHSPGRNVLGTESRDGPGWAQWLLPPVVWLLNGLLVLVSLVLLFVYGEPVTRPHSGPAVYFWRHRKQADLDLARGDFAQAAQQLWLALRALGRPLPTSHLDLACSLLWNLIRHLLQRLWVGRWLAGRAGGLQQDCALRVDASASARDAALVYHKLHQLHTMGKHTGGHLTATNLALSALNLAECAGDAVSVATLAEIYVAAALRVKTSLPRALHFLTRFFLSSARQACLAQSGSVPPAMQWLCHPVGHRFFVDGDWSVLSTPWESLYSLAGNPVDPLAQVTQLFREHLLERALNCVTQPNPSPGSADGDKEFSDALGYLQLLNSCSDAAGAPAYSFSISSSMATTTGVDPVAKWWASLTAVVIHWLRRDEEAAERLCPLVEHLPRVLQESERPLPRAALHSFKAARALLGCAKAESGPASLTICEKASGYLQDSLATTPASSSIDKAVQLFLCDLLLVVRTSLWRQQQPPAPAPAAQGTSSRPQASALELRGFQRDLSSLRRLAQSFRPAMRRVFLHEATARLMAGASPTRTHQLLDRSLRRRAGPGGKGGAVAELEPRPTRREHAEALLLASCYLPPGFLSAPGQRVGMLAEAARTLEKLGDRRLLHDCQQMLMRLGGGTTVTSS
ヒトSREBP1 cDNA(配列番号68)



Mature human SREBP1 protein (SEQ ID NO: 67)
MDEPPFSEAALEQALGEPCDLDAALLTDDIEDMLQLINNQDSDFPGLFDPPYAGSGAGGTDPASPDTSSPGSLSPPPATLSSLEAFLSGPQAAPSPLSPPQPAPTPLKMYPSMPAFSPGPGIKEESVPLSILQTPTPQPLPGALLPQSFPAPAPPQFSSTP VLGYPSPPGGFSTGSPPGNNTQQPLPGLPLASPPGVPPVSLHTQVQSVVPQQLLTVTAAPTAAPVTTTVTSQIQQVPVLLQPHFIKADSLLLTAMKTDGATVKAAGLSPLVSGTTVQTGPLPTLVSGGTILATVPLVVDAEKLPINRLAAG SKAPASAQSRGEKRTAHNAIEKRYRSSINDKIIELKDLVVGTEAKLNKSAVLRKAIDYIRFLQHSNQKLKQENLSLRTAVHKSKSLKDLVSACGSGGNTDVLMEGVKTEVEDTLTPPPSDAGSPFQSSPLSLGSRGSGSGGSGSDSEPDSPV FEDSKAKPEQRPSLHSRGMLDRSRLALCTLVFLCLSCNPLASLLGARGLPSPPSDTTSVYHSPGRNVLGTESRDGPGWAQWLLPPVVWLLNGLLVLVSLVLLFVYGEPVTRPHSGPAVYFWRHRKQADLDLARGDFAQAAQQLWLALRAL GRPLPTSHLDLACSLLWNLIRHLLQRLWVGRWLAGRAGGLQQDCALRVDASASARDAALVYHKLHQLHTMGKHTGGHLTATNLALSALNLAECAGDAVSVATLAEIYVAAALRVKTSLPRALHFLTRFFLSSARQACLAQSGSVPPA MQWLCHPVGHRFFVDGDWSVLSTPWESLYSLAGNPVDPLAQVTQLFREHLLERALNCVTQPNPSPGSADGDKEFSDALGYLQLLNSCSDAAGAPAYSFSISSSMATTTGVDPVAKWWASLTAVVIHWLRRDEEAAERLCPLVEHLPR VLQESERPLPRAALHSFKAARALLGCAKAAESGPASLTICEKASGYLQDSLATTPASSSIDKAVQLFLCDLLLLVVRTSLWRQQPPAPAPAAQGTSSRPQASALELRGFQRDLSSLRRLLAQSFRPAMRRVFLHEATARLMMAGASPTRTHQLLDRSLR RRAGPGGKGGAVAELEPRPTRREHAEALLLASCYLPPGFLSAPGQRVGMLAEAARTLEKLGDRRLLHDCQQMLMRLGGGTTVTSS
Human SREBP1 cDNA (SEQ ID NO: 68)
IFN-γの発現レベルを決定するために使用することができる市販のELISAアッセイの非限定的な例は、R&D Systems、Thermo Fisher Scientific、Abcam、Enzo Life Sciences、及びRayBiotechから入手可能である。成熟ヒトIFN-γのタンパク質及びcDNA配列を、以下に示す。
成熟ヒトIFN-γ(配列番号69)


Mature human IFN-γ (SEQ ID NO: 69)
グランザイムBの発現レベルを決定するために使用できる市販のELISAアッセイの非限定的な例は、RayBiotech、Thermo Fisher Scientific、及びR&D Systemsから入手可能である。成熟ヒトグランザイムBのタンパク質及びcDNA配列を、以下に示す。
成熟ヒトグランザイムB(配列番号71)


Mature human granzyme B (SEQ ID NO: 71)
MYCの発現レベルを決定するために使用することができる市販のELISAアッセイの非限定的な例は、Invitrogen、LSBio、Biocodon Technologies、及びElisa Genieから入手可能である。成熟ヒトMYCのタンパク質及びcDNA配列を、以下に示す。
ヒトMycタンパク質(配列番号329)


Human Myc protein (SEQ ID NO:329)
いくつかの実施形態では、活性化NK細胞(例えば、ヒト活性化NK細胞)は、休止NK細胞(例えば、ヒト休止NK細胞)と比較して、対象(例えば、本明細書に記載の対象のいずれか)又はインビトロにおける老化細胞(例えば、本明細書に記載の老化細胞のいずれか)を死滅させる能力の増加(例えば、少なくとも10%増加、少なくとも20%増加、少なくとも30%増加、少なくとも40%増加、少なくとも50%増加、少なくとも60%増加、少なくとも70%増加、少なくとも80%増加、少なくとも90%増加、少なくとも100%増加、少なくとも120%増加、少なくとも140%増加、少なくとも160%増加、少なくとも180%増加、少なくとも200%増加、少なくとも220%増加、少なくとも240%増加、少なくとも260%増加、少なくとも280%増加、又は少なくとも300%増加)を示し得る。 In some embodiments, activated NK cells (e.g., human activated NK cells) are more effective than resting NK cells (e.g., human resting NK cells) in a subject (e.g., a subject described herein). any) or increased ability (e.g., at least 10% increase, at least 20% increase, at least 30% increase, at least 40%) to kill senescent cells (e.g., any of the senescent cells described herein) in vitro increase, at least 50% increase, at least 60% increase, at least 70% increase, at least 80% increase, at least 90% increase, at least 100% increase, at least 120% increase, at least 140% increase, at least 160% increase, at least 180% increase, at least 200% increase, at least 220% increase, at least 240% increase, at least 260% increase, at least 280% increase, or at least 300% increase).
いくつかの実施形態では、活性化されたNK細胞(例えば、ヒト活性化されたNK細胞)は、対象(例えば、本明細書に記載の対象のうちのいずれか)における、又はインビボでの老化細胞(例えば、本明細書に記載の老化細胞のうちのいずれか)を死滅させる能力の約10%増加~約500%増加(又は本明細書に記載のこの範囲の部分的範囲のうちのいずれか)を示し得る(休止NK細胞(例えば、ヒト休止NK細胞)と比較して)。 In some embodiments, activated NK cells (e.g., human activated NK cells) undergo senescence in a subject (e.g., any of the subjects described herein) or in vivo. From about a 10% increase to about a 500% increase in the ability to kill a cell (e.g., any of the senescent cells described herein) (or any subrange of this range described herein) (compared to resting NK cells (eg, human resting NK cells)).
いくつかの実施形態では、活性化NK細胞(例えば、ヒト活性化NK細胞)は、例えば、休止NK細胞(例えば、ヒト休止NK細胞)と比較して、老化細胞又は標的細胞上に存在する抗原に特異的に結合する抗体の存在下での接触細胞傷害性アッセイにおける細胞傷害性活性の増加(例えば、少なくとも10%増加、少なくとも20%増加、少なくとも30%増加、少なくとも40%増加、少なくとも50%増加、少なくとも60%増加、少なくとも70%増加、少なくとも80%増加、少なくとも90%増加、少なくとも100%増加、少なくとも120%増加、少なくとも140%増加、少なくとも160%増加、少なくとも180%増加、少なくとも200%増加、少なくとも220%増加、少なくとも240%増加、少なくとも260%増加、少なくとも280%増加、又は少なくとも300%増加)を示し得る。 In some embodiments, activated NK cells (e.g., human activated NK cells) are, for example, antigen present on senescent cells or target cells compared to resting NK cells (e.g., human resting NK cells). an increase in cytotoxic activity in a contact cytotoxicity assay in the presence of an antibody that specifically binds to increase, at least 60% increase, at least 70% increase, at least 80% increase, at least 90% increase, at least 100% increase, at least 120% increase, at least 140% increase, at least 160% increase, at least 180% increase, at least 200% increase, at least 220% increase, at least 240% increase, at least 260% increase, at least 280% increase, or at least 300% increase).
いくつかの実施形態では、活性化NK細胞(例えば、ヒト活性化NK細胞)は、例えば、休止NK細胞(例えば、ヒト休止NK細胞)と比較して、老化細胞又は標的細胞上に存在する抗原に特異的に結合する抗体の存在下での接触細胞傷害性アッセイにおける細胞傷害性活性の増加(例えば、約10%増加~約500%増加、又は本明細書に記載のこの範囲の部分的範囲のうちのいずれか)を示し得る。 In some embodiments, activated NK cells (e.g., human activated NK cells) are, for example, antigen present on senescent cells or target cells compared to resting NK cells (e.g., human resting NK cells). An increase in cytotoxic activity in a contact cytotoxicity assay in the presence of an antibody that specifically binds to the ).
いくつかの実施形態は、活性化されたNK細胞は、休止NK細胞を得ることと、1つ以上の休止NK細胞活性化物質を含む液体培養培地中でインビトロで休止NK細胞を接触させることであって、この接触が、その後、対象に投与される活性化されたNK細胞の発生をもたらす、接触させることと、を含む方法によって産生され得る。これらの方法のいくつかの例では、休止NK細胞は、対象から得られた自己NK細胞である。これらの方法のいくつかの例では、休止NK細胞は、対象から得られた自己NK細胞である。これらの方法のいくつかの例では、休止NK細胞は、ハプロタイプ一致の休止NK細胞である。これらの方法のいくつかの例では、休止NK細胞は、同種異系の休止NK細胞である。これらの方法のいくつかの例では、休止NK細胞は、人工NK細胞である。これらの方法のいずれかのいくつかの例では、休止NK細胞は、キメラ抗原受容体又は組換えT細胞受容体を有する遺伝子操作されたNK細胞である。 In some embodiments, the activated NK cells are obtained by obtaining resting NK cells and contacting the resting NK cells in vitro in a liquid culture medium comprising one or more resting NK cell activators. contacting that results in the generation of activated NK cells that are then administered to the subject. In some examples of these methods, the resting NK cells are autologous NK cells obtained from the subject. In some examples of these methods, the resting NK cells are autologous NK cells obtained from the subject. In some examples of these methods, the resting NK cells are haploidentical resting NK cells. In some examples of these methods, the resting NK cells are allogeneic resting NK cells. In some examples of these methods, the resting NK cells are induced NK cells. In some examples of any of these methods, the resting NK cells are genetically engineered NK cells with chimeric antigen receptors or recombinant T cell receptors.
これらの方法のいくつかの例では、液体培養培地は、無血清液体培養培地である。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、液体培養培地は、化学的に定義された液体培養培地である。これらの方法のいくつかの例は、活性化されたNK細胞を単離すること(及び任意選択で、活性化されたNK細胞の治療有効量を、対象、例えば、本明細書に記載の対象のうちのいずれかに更に投与すること)を更に含む。 In some examples of these methods, the liquid culture medium is a serum-free liquid culture medium. In some embodiments of any of the methods described herein, the liquid culture medium is a chemically defined liquid culture medium. Some examples of these methods include isolating activated NK cells (and optionally administering a therapeutically effective amount of the activated NK cells to a subject, e.g., a subject described herein). further administering to any of
これらの方法のいくつかの実施形態では、接触ステップは、約2時間~約20日(例えば、約2時間~約18日、約2時間~約16日、約2時間~約14日、約2時間~約12日、約2時間~約10日、約2時間~約8日、約2時間~約7日、約2時間~約6日、約2時間~約5日、約2時間~約4日、約2時間~約3日、約2時間~約2日、約2時間~約1日、約6時間~約18日、約6時間~約16日、約6時間~約14日、約6時間~約12日、約6時間~約10日、約6時間~約8日、約6時間~約7日、約6時間~約6日、約6時間~約5日、約6時間~約4日、約6時間~約3日、約6時間~約2日、約6時間~約1日、約12時間~約18日、約12時間~約16日、約12時間~約14日、約12時間~約12日、約12時間~約10日、約12時間~約8日、約12時間~約7日、約12時間~約6日、約12時間~約5日、約12時間~約4日、約12時間~約3日、約12時間~約2日、約12時間~約1日、約1日~約18日、約1日~約16日、約1日~約15日、約1日~約14日、約1日~約12日、約1日~約10日、約1日~約8日、約1日~約7日、約1日~約6日、約1日~約5日、約1日~約4日、約1日~約3日、約1日~約2日、約2日~約18日、約2日~約16日、約2日~約14日、約2日~約12日、約2日~約10日、約2日~約8日、約2日~約7日、約2日~約6日、約2日~約5日、約2日~約4日、約2日~約3日、約3日~約18日、約3日~約16日、約3日~約14日、約3日~約12日、約3日~約10日、約3日~約8日、約3日~約7日、約3日~約6日、約3日~約5日、約3日~約4日、約4日~約18日、約4日~約16日、約4日~約14日、約4日~約12日、約4日~約10日、約4日~約8日、約4日~約7日、約4日~約6日、約4日~約5日、約5日~約18日、約5日~約16日、約5日~約14日、約5日~約12日、約5日~約10日、約5日~約8日、約5日~約7日、約5日~約6日、約6日~約18日、約6日~約16日、約6日~約14日、約6日~約12日、約6日~約10日、約6日~約8日、約6日~約7日、約7日~約18日、約7日~約16日、約7日~約14日、約7日~約12日、約7日~約10日、約7日~約8日、約8日~約18日、約8日~約16日、約8日~約14日、約8日~約12日、約8日~約10日、約9日~約18日、約9日~約16日、約9日~約14日、約9日~約12日、約12日~約18日、約12日~約16日、約12日~約14日、約14日~約18日、約14日~約16日、又は約16日~約18日の期間にわたって実施される。 In some embodiments of these methods, the contacting step is from about 2 hours to about 20 days (eg, from about 2 hours to about 18 days, from about 2 hours to about 16 days, from about 2 hours to about 14 days, from about 2 hours to about 12 days, about 2 hours to about 10 days, about 2 hours to about 8 days, about 2 hours to about 7 days, about 2 hours to about 6 days, about 2 hours to about 5 days, about 2 hours ~ about 4 days, about 2 hours to about 3 days, about 2 hours to about 2 days, about 2 hours to about 1 day, about 6 hours to about 18 days, about 6 hours to about 16 days, about 6 hours to about 14 days, about 6 hours to about 12 days, about 6 hours to about 10 days, about 6 hours to about 8 days, about 6 hours to about 7 days, about 6 hours to about 6 days, about 6 hours to about 5 days , about 6 hours to about 4 days, about 6 hours to about 3 days, about 6 hours to about 2 days, about 6 hours to about 1 day, about 12 hours to about 18 days, about 12 hours to about 16 days, about 12 hours to about 14 days, about 12 hours to about 12 days, about 12 hours to about 10 days, about 12 hours to about 8 days, about 12 hours to about 7 days, about 12 hours to about 6 days, about 12 hours ~ about 5 days, about 12 hours to about 4 days, about 12 hours to about 3 days, about 12 hours to about 2 days, about 12 hours to about 1 day, about 1 day to about 18 days, about 1 day to about 16 days, about 1 to about 15 days, about 1 to about 14 days, about 1 to about 12 days, about 1 to about 10 days, about 1 to about 8 days, about 1 to about 7 days , about 1 to about 6 days, about 1 to about 5 days, about 1 to about 4 days, about 1 to about 3 days, about 1 to about 2 days, about 2 to about 18 days, about 2 days to about 16 days, about 2 days to about 14 days, about 2 days to about 12 days, about 2 days to about 10 days, about 2 days to about 8 days, about 2 days to about 7 days, about 2 days ~ about 6 days, about 2 days to about 5 days, about 2 days to about 4 days, about 2 days to about 3 days, about 3 days to about 18 days, about 3 days to about 16 days, about 3 days to about 14 days, about 3 days to about 12 days, about 3 days to about 10 days, about 3 days to about 8 days, about 3 days to about 7 days, about 3 days to about 6 days, about 3 days to about 5 days , about 3 days to about 4 days, about 4 days to about 18 days, about 4 days to about 16 days, about 4 days to about 14 days, about 4 days to about 12 days, about 4 days to about 10 days, about 4 days to about 8 days, about 4 days to about 7 days, about 4 days to about 6 days, about 4 days to about 5 days, about 5 days to about 18 days, about 5 days to about 16 days, about 5 days ~ about 14 days, about 5 days to about 12 days, about 5 days to about 10 days, about 5 days to about 8 days, about 5 days to about 7 days, about 5 days to about 6 days, about 6 days to about 18 days, about 6 days to about 16 days, about 6 days to about 14 days, about 6 days to about 12 days, about 6 days to about 10 days, about 6 days to about 8 days, about 6 days to about 7 days , about 7 days to about 18 days, about 7 days to about 16 days, about 7 days to about 14 days, about 7 days to about 12 days, about 7 days to about 10 days, about 7 days to about 8 days, about 8 days to about 18 days, about 8 days to about 16 days, about 8 days to about 14 days, about 8 days to about 12 days, about 8 days to about 10 days, about 9 days to about 18 days, about 9 days ~ about 16 days, about 9 days to about 14 days, about 9 days to about 12 days, about 12 days to about 18 days, about 12 days to about 16 days, about 12 days to about 14 days, about 14 days to about It is conducted over a period of 18 days, about 14 days to about 16 days, or about 16 days to about 18 days.
NK細胞活性化物質
1つ以上のNK細胞活性化物質の使用又は投与を含む方法が、本明細書に提供される。いくつかの実施形態では、NK細胞活性化物質は、タンパク質であり得る。いくつかの実施形態では、NK細胞活性化物質は、一本鎖キメラポリペプチド(例えば、本明細書に記載の一本鎖キメラポリペプチドのうちのいずれか)、多鎖キメラポリペプチド(例えば、本明細書に記載の多鎖キメラポリペプチドのうちのいずれか、例えば、本明細書に記載の例示的なタイプA及びタイプB多鎖キメラポリペプチド)、抗体、組換えサイトカイン又はインターロイキン(例えば、本明細書に記載の組換えサイトカイン又はインターロイキンのうちのいずれか)、及び可溶性インターロイキン又はサイトカイン受容体(例えば、本明細書に記載の可溶性インターロイキン又はサイトカイン受容体のうちのいずれか)であり得る。いくつかの実施形態では、NK細胞活性化物質は、小分子(例えば、グリコーゲン合成酵素キナーゼ-3(GSK3)阻害物質、例えば、Cichocki et al.,Cancer Res.77:5664-5675,2017に記載されるようなCHIR99021)、又はアプタマーであり得る。
NK Cell Activators Methods are provided herein that involve the use or administration of one or more NK cell activators. In some embodiments, NK cell activators can be proteins. In some embodiments, the NK cell activator is a single-chain chimeric polypeptide (e.g., any of the single-chain chimeric polypeptides described herein), a multi-chain chimeric polypeptide (e.g., Any of the multi-chain chimeric polypeptides described herein (e.g., exemplary type A and type B multi-chain chimeric polypeptides described herein), antibodies, recombinant cytokines or interleukins (e.g., , any of the recombinant cytokines or interleukins described herein), and a soluble interleukin or cytokine receptor (e.g., any of the soluble interleukins or cytokine receptors described herein) can be In some embodiments, the NK cell activator is a small molecule (e.g., a glycogen synthase kinase-3 (GSK3) inhibitor, e.g., Cichocki et al., Cancer Res. 77:5664-5675, 2017). CHIR99021), or an aptamer.
本明細書に提供される1つ以上のNK細胞活性化物質のうちのいずれかのいくつかの実施形態では、1つ以上のNK細胞活性化物質のうちの少なくとも1つは、1つ以上のNK細胞活性化物質の不在下で、活性化のレベルと比較して、IL-2受容体、IL-7受容体、IL-12受容体、IL-15受容体、IL-18受容体、IL-21受容体、IL-33受容体、CD16、CD69、CD25、CD59、CD352、NKp80、DNAM-1、2B4、NKp30、NKp44、NKp46、NKG2D、KIR2DS1、KIR2Ds2/3、KIR2DL4、KIR2DS4、KIR2DS5、及びKIR3DS1(例えば、免疫細胞、例えば、ヒト免疫細胞、例えば、ヒトNK細胞において)のうちの1つ以上(例えば、2つ、3つ、4つ、5つ、6つ、7つ、又は8つ)の活性化をもたらす。 In some embodiments of any of the one or more NK cell activating agents provided herein, at least one of the one or more NK cell activating agents comprises one or more IL-2 receptor, IL-7 receptor, IL-12 receptor, IL-15 receptor, IL-18 receptor, IL compared to levels of activation in the absence of NK cell activators -21 receptor, IL-33 receptor, CD16, CD69, CD25, CD59, CD352, NKp80, DNAM-1, 2B4, NKp30, NKp44, NKp46, NKG2D, KIR2DS1, KIR2Ds2/3, KIR2DL4, KIR2DS4, KIR2DS5, and one or more (e.g., 2, 3, 4, 5, 6, 7, or 8) of KIR3DS1 (e.g., in immune cells, e.g., human immune cells, e.g., human NK cells) ).
いくつかの実施形態では、IL-2受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、可溶性IL-2又はIL-2受容体に特異的に結合するアゴニスト抗体である。 In some embodiments, at least one of the one or more NK cell activators that result in IL-2 receptor activation specifically binds to soluble IL-2 or IL-2 receptor It is an agonistic antibody.
いくつかの実施形態では、IL-7受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、可溶性IL-7又はIL-7受容体に特異的に結合するアゴニスト抗体である。 In some embodiments, at least one of the one or more NK cell activators that result in IL-7 receptor activation specifically binds to soluble IL-7 or IL-7 receptor It is an agonistic antibody.
いくつかの実施形態では、IL-12受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、可溶性IL-12又はIL-12受容体に特異的に結合するアゴニスト抗体である。 In some embodiments, at least one of the one or more NK cell activators that result in IL-12 receptor activation specifically binds to soluble IL-12 or IL-12 receptor It is an agonistic antibody.
いくつかの実施形態では、IL-15受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、可溶性IL-15又はIL-15受容体に特異的に結合するアゴニスト抗体である。 In some embodiments, at least one of the one or more NK cell activators that result in IL-15 receptor activation specifically binds to soluble IL-15 or IL-15 receptor It is an agonistic antibody.
いくつかの実施形態では、IL-21受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、可溶性IL-21又はIL-21受容体に特異的に結合するアゴニスト抗体である。 In some embodiments, at least one of the one or more NK cell activators that result in IL-21 receptor activation specifically binds to soluble IL-21 or IL-21 receptor It is an agonistic antibody.
いくつかの実施形態では、IL-33受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、可溶性IL-33又はIL-33受容体に特異的に結合するアゴニスト抗体である。 In some embodiments, at least one of the one or more NK cell activators that result in IL-33 receptor activation specifically binds to soluble IL-33 or IL-33 receptor It is an agonistic antibody.
いくつかの実施形態では、CD16の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、CD16に特異的に結合するアゴニスト抗体である。 In some embodiments, at least one of the one or more NK cell activators that result in activation of CD16 is an agonistic antibody that specifically binds CD16.
いくつかの実施形態では、CD69の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、CD69に特異的に結合するアゴニスト抗体である。 In some embodiments, at least one of the one or more NK cell activators that result in activation of CD69 is an agonistic antibody that specifically binds CD69.
いくつかの実施形態では、CD25、CD59の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、CD25、CD59に特異的に結合するアゴニスト抗体である。 In some embodiments, at least one of the one or more NK cell activators that result in activation of CD25, CD59 is an agonistic antibody that specifically binds CD25, CD59.
いくつかの実施形態では、CD352の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、CD352に特異的に結合するアゴニスト抗体である。 In some embodiments, at least one of the one or more NK cell activators that result in activation of CD352 is an agonistic antibody that specifically binds CD352.
いくつかの実施形態では、NKp80の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、NKp80に特異的に結合するアゴニスト抗体である。 In some embodiments, at least one of the one or more NK cell activators that result in activation of NKp80 is an agonistic antibody that specifically binds NKp80.
いくつかの実施形態では、DNAM-1の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、DNAM-1に特異的に結合するアゴニスト抗体である。 In some embodiments, at least one of the one or more NK cell activators that result in activation of DNAM-1 is an agonistic antibody that specifically binds DNAM-1.
いくつかの実施形態では、2B4の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、2B4に特異的に結合するアゴニスト抗体である。 In some embodiments, at least one of the one or more NK cell activators that result in activation of 2B4 is an agonistic antibody that specifically binds 2B4.
いくつかの実施形態では、NKp30の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、NKp30に特異的に結合するアゴニスト抗体である。 In some embodiments, at least one of the one or more NK cell activators that result in activation of NKp30 is an agonistic antibody that specifically binds NKp30.
いくつかの実施形態では、NKp44の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、NKp44に特異的に結合するアゴニスト抗体である。 In some embodiments, at least one of the one or more NK cell activators that result in activation of NKp44 is an agonistic antibody that specifically binds NKp44.
いくつかの実施形態では、NKp46の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、NKp46に特異的に結合するアゴニスト抗体である。 In some embodiments, at least one of the one or more NK cell activators that result in activation of NKp46 is an agonistic antibody that specifically binds NKp46.
いくつかの実施形態では、NKG2Dの活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、NKG2Dに特異的に結合するアゴニスト抗体である。 In some embodiments, at least one of the one or more NK cell activators that result in activation of NKG2D is an agonistic antibody that specifically binds NKG2D.
いくつかの実施形態では、KIR2DS1の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、KIT2DS1に特異的に結合するアゴニスト抗体である。 In some embodiments, at least one of the one or more NK cell activators that result in activation of KIR2DS1 is an agonistic antibody that specifically binds KIT2DS1.
いくつかの実施形態では、KIR2DS2/3の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、KIT2DS2/3に特異的に結合するアゴニスト抗体である。 In some embodiments, at least one of the one or more NK cell activators that result in activation of KIR2DS2/3 is an agonistic antibody that specifically binds KIT2DS2/3.
いくつかの実施形態では、KIR2DL4の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、KIT2DL4に特異的に結合するアゴニスト抗体である。 In some embodiments, at least one of the one or more NK cell activators that result in activation of KIR2DL4 is an agonistic antibody that specifically binds KIT2DL4.
いくつかの実施形態では、KIR2DS4の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、KIT2DS4に特異的に結合するアゴニスト抗体である。 In some embodiments, at least one of the one or more NK cell activators that result in activation of KIR2DS4 is an agonistic antibody that specifically binds KIT2DS4.
いくつかの実施形態では、KIR2DS5の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、KIT2DS5に特異的に結合するアゴニスト抗体である。 In some embodiments, at least one of the one or more NK cell activators that result in activation of KIR2DS5 is an agonistic antibody that specifically binds KIT2DS5.
いくつかの実施形態では、KIR3DS1の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、KIT3DS1に特異的に結合するアゴニスト抗体である。 In some embodiments, at least one of the one or more NK cell activators that result in activation of KIR3DS1 is an agonistic antibody that specifically binds KIT3DS1.
本明細書に提供される1つ以上のNK細胞活性化物質のうちのいずれかのいくつかの実施形態では、1つ以上のNK細胞活性化物質のうちの少なくとも1つ(例えば、2つ、3つ、4つ、又は5つ)は、1つ以上のNK細胞活性化物質の不在下で、活性化レベルと比較して、PD-1、TGF-β受容体、TIGIT、CD1、TIM-3、Siglec-7、IRP60、Tactile、IL1R8、NKG2A/KLRD1、KIR2DL1、KIR2DL2/3、KIR2DL5、KIR3DL1、KIR3DL2、ILT2/LIR-1、及びLAG-2(例えば、免疫細胞、例えば、ヒト免疫細胞、例えば、ヒトNK細胞において)のうちの1つ以上の活性化の減少をもたらす。 In some embodiments of any of the one or more NK cell activators provided herein, at least one of the one or more NK cell activators (e.g., two, 3, 4, or 5) compared to activation levels in the absence of one or more NK cell activators, PD-1, TGF-β receptor, TIGIT, CD1, TIM- 3, Siglec-7, IRP60, Tactile, IL1R8, NKG2A/KLRD1, KIR2DL1, KIR2DL2/3, KIR2DL5, KIR3DL1, KIR3DL2, ILT2/LIR-1, and LAG-2 (e.g. immune cells, e.g. human immune cells, for example, in human NK cells).
いくつかの実施形態では、TGF-β受容体の活性化の減少をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、可溶性TGF-β受容体、TGF-βに特異的に結合する抗体、又はTGF-β受容体に特異的に結合するアンタゴニスト抗体である。 In some embodiments, at least one of the one or more NK cell activators that result in decreased TGF-β receptor activation is specifically directed to the soluble TGF-β receptor, TGF-β A binding antibody, or an antagonistic antibody that specifically binds to the TGF-β receptor.
いくつかの実施形態では、TIGITの活性化の減少をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、TIGITに特異的に結合するアンタゴニスト抗体、可溶性TIGIT、又はTIGITのリガンドに特異的に結合する抗体である。 In some embodiments, at least one of the one or more NK cell activators that result in decreased activation of TIGIT is an antagonist antibody that specifically binds TIGIT, soluble TIGIT, or a ligand of TIGIT. It is an antibody that specifically binds.
いくつかの実施形態では、CD1の活性化の減少をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、CD1に特異的に結合するアンタゴニスト抗体、可溶性CD1、又はCD1のリガンドに特異的に結合する抗体である。 In some embodiments, at least one of the one or more NK cell activators that result in decreased activation of CD1 is an antagonist antibody that specifically binds CD1, soluble CD1, or a ligand for CD1. It is an antibody that specifically binds.
いくつかの実施形態では、TIM-3の活性化の減少をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、TIM-3に特異的に結合するアンタゴニスト抗体、可溶性TIM-3、又はTIM-3のリガンドに特異的に結合する抗体である。 In some embodiments, at least one of the one or more NK cell activators that result in decreased activation of TIM-3 is an antagonist antibody that specifically binds TIM-3, soluble TIM-3 , or an antibody that specifically binds to a ligand of TIM-3.
いくつかの実施形態では、Siglec-7の活性化の減少をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、Siglec-7に特異的に結合するアンタゴニスト抗体、可溶性Siglec-7、又はSiglec-7のリガンドに特異的に結合する抗体である。 In some embodiments, at least one of the one or more NK cell activators that result in decreased activation of Siglec-7 is an antagonist antibody that specifically binds Siglec-7, soluble Siglec-7 , or an antibody that specifically binds to a ligand of Siglec-7.
いくつかの実施形態では、IRP-60の活性化の減少をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、IRP-60に特異的に結合するアンタゴニスト抗体、可溶性IRP-60、又はIRP-60のリガンドに特異的に結合する抗体である。 In some embodiments, at least one of the one or more NK cell activators that result in decreased activation of IRP-60 is an antagonist antibody that specifically binds IRP-60, soluble IRP-60 , or an antibody that specifically binds to a ligand of IRP-60.
いくつかの実施形態では、Tactileの活性化の減少をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、Tactileに特異的に結合するアンタゴニスト抗体、可溶性Tactile、又はTactileのリガンドに特異的に結合する抗体である。 In some embodiments, at least one of the one or more NK cell activators that result in decreased activation of Tactile is an antagonist antibody that specifically binds Tactile, a soluble Tactile, or a ligand of Tactile. It is an antibody that specifically binds.
いくつかの実施形態では、IL1R8の活性化の減少をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、IL1R8に特異的に結合するアンタゴニスト抗体、可溶性IL1R8、又はIL1R8のリガンドに特異的に結合する抗体である。 In some embodiments, at least one of the one or more NK cell activators that result in decreased activation of IL1R8 is an antagonist antibody that specifically binds IL1R8, soluble IL1R8, or a ligand of IL1R8. It is an antibody that specifically binds.
いくつかの実施形態では、NKG2A/KLRD1の活性化の減少をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、NKG2A/KLRD1に特異的に結合するアンタゴニスト抗体、可溶性NKG2A/KLRD1、又はNKG2A/KLRD1のリガンドに特異的に結合する抗体である。 In some embodiments, at least one of the one or more NK cell activators that result in decreased activation of NKG2A/KLRD1 is an antagonist antibody that specifically binds NKG2A/KLRD1, soluble NKG2A/KLRD1 , or an antibody that specifically binds to a ligand of NKG2A/KLRD1.
いくつかの実施形態では、KIR2DL1の活性化の減少をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、KIR2DL1に特異的に結合するアンタゴニスト抗体、可溶性KIR2DL1、又はKIR2DL1のリガンドに特異的に結合する抗体である。 In some embodiments, at least one of the one or more NK cell activators that result in decreased activation of KIR2DL1 is an antagonist antibody that specifically binds KIR2DL1, a soluble KIR2DL1, or a ligand of KIR2DL1. It is an antibody that specifically binds.
いくつかの実施形態では、KIR2DL2/3の活性化の減少をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、KIR2DL2/3に特異的に結合するアンタゴニスト抗体、可溶性KIR2DL2/3、又はKIR2DL2/3のリガンドに特異的に結合する抗体である。 In some embodiments, at least one of the one or more NK cell activators that result in decreased activation of KIR2DL2/3 is an antagonist antibody that specifically binds KIR2DL2/3, soluble KIR2DL2/3 , or an antibody that specifically binds to a ligand of KIR2DL2/3.
いくつかの実施形態では、KIR2DL5の活性化の減少をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、KIR2DL5に特異的に結合するアンタゴニスト抗体、可溶性KIR2DL5、又はKIR2DL5のリガンドに特異的に結合する抗体である。 In some embodiments, at least one of the one or more NK cell activators that result in decreased activation of KIR2DL5 is an antagonist antibody that specifically binds KIR2DL5, soluble KIR2DL5, or a ligand of KIR2DL5. It is an antibody that specifically binds.
いくつかの実施形態では、KIR3DL1の活性化の減少をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、KIR3DL1に特異的に結合するアンタゴニスト抗体、可溶性KIR3DL1、又はKIR3DL1のリガンドに特異的に結合する抗体である。 In some embodiments, at least one of the one or more NK cell activators that result in decreased activation of KIR3DL1 is an antagonist antibody that specifically binds KIR3DL1, a soluble KIR3DL1, or a ligand of KIR3DL1. It is an antibody that specifically binds.
いくつかの実施形態では、KIR3DL2の活性化の減少をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、KIR3DL2に特異的に結合するアンタゴニスト抗体、可溶性KIR3DL2、又はKIR3DL2のリガンドに特異的に結合する抗体である。 In some embodiments, at least one of the one or more NK cell activators that result in decreased activation of KIR3DL2 is an antagonist antibody that specifically binds KIR3DL2, soluble KIR3DL2, or a ligand of KIR3DL2. It is an antibody that specifically binds.
いくつかの実施形態では、ILT2/LIR-1の活性化の減少をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、ILT2/LIR-1に特異的に結合するアンタゴニスト抗体、可溶性ILT2/LIR-1、又はILT2/LIR-1のリガンドに特異的に結合する抗体である。 In some embodiments, at least one of the one or more NK cell activators that result in decreased activation of ILT2/LIR-1 is an antagonist antibody that specifically binds to ILT2/LIR-1; An antibody that specifically binds to soluble ILT2/LIR-1 or a ligand of ILT2/LIR-1.
いくつかの実施形態では、LAG2の活性化の減少をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つは、LAG2に特異的に結合するアンタゴニスト抗体、可溶性LAG2、又はLAG2のリガンドに特異的に結合する抗体である。 In some embodiments, at least one of the one or more NK cell activators that result in decreased activation of LAG2 is an antagonist antibody that specifically binds LAG2, a soluble LAG2, or a ligand of LAG2. It is an antibody that specifically binds.
NK細胞活性化物質の非限定的な例を、以下に説明し、任意の組み合わせで使用することができる。 Non-limiting examples of NK cell activators are described below and can be used in any combination.
いくつかの例では、NK細胞活性化物質は、可溶性PD-1、可溶性PD-L1、可溶性TIGIT、可溶性CD1、又は可溶性TIM-3であり得る。可溶性PD-1、PD-L1、TIGIT、CD1、及びTIM-3の非限定的な例を、以下に示す。
ヒト可溶性PD-1(配列番号73)





Human soluble PD-1 (SEQ ID NO:73)
いくつかの実施形態では、可溶性PD-1タンパク質は、配列番号73と少なくとも80%同一、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一である配列を含み得る。 In some embodiments, the soluble PD-1 protein is at least 80% identical, at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical to SEQ ID NO:73 It can include sequences that are % identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical.
いくつかの実施形態では、可溶性PD-L1タンパク質は、配列番号74と少なくとも80%同一、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一である配列を含み得る。 In some embodiments, the soluble PD-L1 protein is at least 80% identical, at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical to SEQ ID NO:74 It can include sequences that are % identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical.
いくつかの実施形態では、可溶性TIGITタンパク質は、配列番号75と少なくとも80%同一、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一である配列を含み得る。 In some embodiments, the soluble TIGIT protein is at least 80% identical, at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical to SEQ ID NO:75 , at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical.
いくつかの実施形態では、可溶性CD1Aタンパク質は、配列番号76と少なくとも80%同一、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一である配列を含み得る。 In some embodiments, the soluble CD1A protein is at least 80% identical, at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical to SEQ ID NO:76 , at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical.
いくつかの実施形態では、可溶性TIM3タンパク質は、配列番号77と少なくとも80%同一、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一である配列を含み得る。 In some embodiments, the soluble TIM3 protein is at least 80% identical, at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical to SEQ ID NO:77 , at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical.
組換え抗体
いくつかの例では、NK活性化物質は、IL-2受容体に特異的に結合するアゴニスト抗体(例えば、Gaulton et al.,Clinical Immunology and Immunopathology36(1):18-29,1985に記載されているものを参照)、IL-7受容体に特異的に結合するアゴニスト抗体、IL-12受容体に特異的に結合するアゴニスト抗体(例えば、Rogge et al.,J.Immunol.162(7):3926-3932,1999に記載されているものを参照)、IL-15受容体に特異的に結合するアゴニスト抗体、IL-21受容体に特異的に結合するアゴニスト抗体(例えば、米国特許出願公開第2006/159655号に記載されているものを参照)、IL-33受容体に特異的に結合するアゴニスト抗体(例えば、米国特許出願公開第2007/160579号に記載されているものを参照)、PD-1に特異的に結合するアンタゴニスト抗体(例えば、米国特許出願公開第7,521,051号に記載されているものを参照)、PD-L1に特異的に結合する抗体(例えば、米国特許第8,217,149号に記載されているものを参照)、TGF-β受容体に特異的に結合する抗体、TGF-β受容体に特異的に結合するアンタゴニスト抗体(例えば、欧州特許出願公開第1245676A1号に記載されているものを参照)、TIGITに特異的に結合するアンタゴニスト抗体(例えば、WO2017/053748に記載されているものを参照)、TIGITのリガンドに特異的に結合する抗体(例えば、WO2011/127324に記載されているものを参照)、CD1に特異的に結合するアゴニスト抗体(例えば、Szalay et al.,J.Immunol.162(12):6955-6958,1999に記載されているものを参照)、CD1のリガンドに特異的に結合する抗体(例えば、Kain et al.,Immunity41(4):543-554,2014に記載されているものを参照)、TIM-3に特異的に結合するアンタゴニスト抗体(例えば、米国特許出願公開第2015/218274号に記載されているものを参照)、TIM-3のリガンドに特異的に結合する抗体(例えば、米国特許出願公開第2017/283499号に記載されているものを参照)、CD69に特異的に結合するアゴニスト抗体(例えば、Moretta et al.,Journal of Experimental Medicine174:1393,1991に記載されているものを参照)、CD25、CD59に特異的に結合するアゴニスト抗体、CD352に特異的に結合するアゴニスト抗体(例えば、Yigit et al.,Oncotarget 7:26346-26360,2016に記載されているものを参照)、NKp80に特異的に結合するアゴニスト抗体(例えば、Peipp et al.,Oncotarget6:32075-32088,2015に記載されているものを参照)、DNAM-1に特異的に結合するアゴニスト抗体、2B4に特異的に結合するアゴニスト抗体(例えば、Sandusky et al.,European J.Immunol.36:3268-3276,2006に記載されているものを参照)、NKp30に特異的に結合するアゴニスト抗体(例えば、Kellner et al.,OncoImmunology5:1-12,2016に記載されているものを参照)、NKp44に特異的に結合するアゴニスト抗体、NKp46に特異的に結合するアゴニスト抗体(例えば、Xiong et al.,J.Clin.Invest.123:4264-4272,2013に記載されているものを参照)、NKG2Dに特異的に結合するアゴニスト抗体(例えば、Kellner et al.,OncoImmunology5:1-12,2016に記載されているものを参照)、KIR2DS1に特異的に結合するアゴニスト抗体(例えば、Xiong et al.,J.Clin.Invest.123:4264-4272,2013に記載されているものを参照)、KIR2Ds2/3に特異的に結合するアゴニスト抗体(例えば、Borgerding et al.,Exp.Hematology38:213-221,2010に記載されているものを参照)、KIR2DL4に特異的に結合するアゴニスト抗体(例えば、Miah et al.,J.Immunol.180:2922-32,2008に記載されているものを参照)、KIR2DS4に特異的に結合するアゴニスト抗体(例えば、Czaja et al.,Genes and Immunity15:33-37,2014に記載されているものを参照)、KIR2DS5に特異的に結合するアゴニスト抗体(例えば、Czaja et al.,Genes and Immunity15:33-37,2014に記載されているものを参照)、KIR3DS1に特異的に結合するアゴニスト抗体(例えば、Czaja et al.,Genes and Immunity15:33-37,2014に記載されているものを参照)、Siglec-7に特異的に結合するアンタゴニスト抗体(例えば、Hudak et al.,Nature Chemical Biology10:69-75,2014に記載されているものを参照)、IRP60に特異的に結合するアンタゴニスト抗体(例えば、Bachelet et al.,J.Biol.Chem.281:27190-27196,2006に記載されているものを参照)、Tactileに特異的に結合するアンタゴニスト抗体(例えば、Brooks et al.,Eur.J.Cancer61(Suppl.1):S189,2016に記載されているものを参照)、IL1R8に特異的に結合するアンタゴニスト抗体(例えば、Molgora et al.,Frontiers Immunol.7:1,2016に記載されているものを参照)、NKG2A/KLRD1に特異的に結合するアンタゴニスト抗体(例えば、Kim et al.,Infection Immunity76:5873-5882,2008に記載されているものを参照)、KIR2DL1に特異的に結合するアンタゴニスト抗体(例えば、Weiner et al.,Cell148:1081-1084,2012に記載されているものを参照)、KIR2DL2/3に特異的に結合するアンタゴニスト抗体(例えば、Weiner et al.,Cell148:1081-1084,2012に記載されているものを参照)、KIR2DL5に特異的に結合するアンタゴニスト抗体(例えば、US9,067,997に記載されているものを参照)、及びKIR3DL1に特異的に結合するアンタゴニスト抗体(例えば、US9,067,997に記載されているものを参照)、KIR3DL2に特異的に結合するアンタゴニスト抗体(例えば、US9,067,997に記載されているものを参照)、ILT2/LIR-1に特異的に結合するアンタゴニスト抗体(例えば、US8,133,485に記載されているものを参照)、及びLAG-2に特異的に結合するアンタゴニスト抗体、であり得る。
Recombinant Antibodies In some examples, the NK activator is an agonistic antibody that specifically binds to the IL-2 receptor (see, for example, Gaulton et al., Clinical Immunology and Immunopathology 36(1):18-29, 1985). described), agonistic antibodies that specifically bind to the IL-7 receptor, agonistic antibodies that specifically bind to the IL-12 receptor (e.g., Rogge et al., J. Immunol. 162 ( 7):3926-3932, 1999), agonistic antibodies that specifically bind to the IL-15 receptor, agonistic antibodies that specifically bind to the IL-21 receptor (e.g., US Pat. Agonist antibodies that specifically bind to the IL-33 receptor (see, for example, those described in US Patent Application Publication No. 2007/160579). ), antagonist antibodies that specifically bind to PD-1 (see, for example, those described in US Patent Application Publication No. 7,521,051), antibodies that specifically bind to PD-L1 (for example, US Pat. No. 8,217,149), antibodies that specifically bind to TGF-β receptors, antagonist antibodies that specifically bind to TGF-β receptors (see, for example, European Patent Antagonist antibodies that specifically bind to TIGIT (see, for example, those described in WO2017/053748), antibodies that specifically bind to ligands of TIGIT (see, for example, those described in WO2011/127324), agonistic antibodies that specifically bind to CD1 (see, for example, Szalay et al., J. Immunol. 162(12):6955-6958, 1999). antibodies that specifically bind to ligands of CD1 (see, for example, those described in Kain et al., Immunity 41(4):543-554, 2014), specific for TIM-3 antagonist antibodies that specifically bind to ligands of TIM-3 (see, for example, those described in US Patent Application Publication No. 2015/218274), antibodies that specifically bind to ligands of TIM-3 (for example, US Patent Application Publication No. 2017/ 283499), agonistic antibodies that specifically bind to CD69 (eg, Moretta et al. , Journal of Experimental Medicine 174:1393, 1991), agonistic antibodies that specifically bind to CD25, CD59, agonistic antibodies that specifically bind to CD352 (e.g., Yigit et al., Oncotarget 7 : 26346-26360, 2016), agonist antibodies that specifically bind to NKp80 (see, for example, Peipp et al., Oncotarget 6:32075-32088, 2015), Agonist antibodies that specifically bind to DNAM-1, agonist antibodies that specifically bind to 2B4 (see, for example, those described in Sandusky et al., European J. Immunol. 36:3268-3276, 2006) , an agonistic antibody that specifically binds to NKp30 (see, for example, those described in Kellner et al., OncoImmunology 5:1-12, 2016), an agonistic antibody that specifically binds to NKp44, an agonistic antibody that specifically binds to NKp46 Agonist antibodies that bind (see, for example, those described in Xiong et al., J. Clin. Invest. 123:4264-4272, 2013), agonist antibodies that specifically bind to NKG2D (for example, Kellner et al. ., OncoImmunology 5:1-12, 2016), agonistic antibodies that specifically bind to KIR2DS1 (see, for example, Xiong et al., J. Clin. Invest. 123:4264-4272, 2013). described), agonistic antibodies that specifically bind to KIR2Ds2/3 (see, for example, those described in Borgerding et al., Exp. Hematology 38:213-221, 2010), specific for KIR2DL4 agonistic antibodies that specifically bind to KIR2DS4 (see, for example, those described in Miah et al., J. Immunol. 180:2922-32, 2008), agonistic antibodies that specifically bind to KIR2DS4 (for example, Czaja et al. ., Genes and Immunity 15:33-37, 2014), agonistic antibodies that specifically bind to KIR2DS5 (eg, Czaja et al. , Genes and Immunity 15:33-37, 2014), agonistic antibodies that specifically bind to KIR3DS1 (for example, as described in Czaja et al., Genes and Immunity 15:33-37, 2014). antagonist antibodies that specifically bind to Siglec-7 (see, for example, those described in Hudak et al., Nature Chemical Biology 10:69-75, 2014), specifically bind to IRP60 (see, eg, Bachelet et al., J. Biol. Chem. 281:27190-27196, 2006), antagonist antibodies that specifically bind to Tactile (eg, Brooks et al. , Eur. J. Cancer61 (Suppl.1): S189, 2016), antagonist antibodies that specifically bind to IL1R8 (e.g., Molgora et al., Frontiers Immunol. 7:1, 2016). ), an antagonist antibody that specifically binds to NKG2A/KLRD1 (see, for example, Kim et al., Infection Immunity 76:5873-5882, 2008), specific for KIR2DL1 antagonist antibodies that specifically bind to KIR2DL2/3 (see, for example, those described in Weiner et al., Cell 148:1081-1084, 2012), antagonist antibodies that specifically bind to KIR2DL2/3 (see, for example, Weiner et al., Cell 148:1081-1084, 2012), antagonist antibodies that specifically bind to KIR2DL5 (see, for example, those described in US 9,067,997), and KIR3DL1 specifically. Antagonist antibodies that bind (see, for example, those described in US 9,067,997), antagonist antibodies that specifically bind to KIR3DL2 (see, for example, those described in US 9,067,997), ILT2 /LIR-1 (see, for example, that described in US Pat. No. 8,133,485) and an antagonist antibody that specifically binds LAG-2.
NK細胞活性化物質である組換え抗体は、例示的なタイプの抗体(例えば、ヒト又はヒト化抗体)のうちのいずれか、又は本明細書に記載の例示的な抗体断片のうちのいずれかであり得る。NK細胞活性化物質である組換え抗体は、例えば、本明細書に記載の抗原結合ドメインのうちのいずれかを含むことができる。 Recombinant antibodies that are NK cell activators are any of the exemplary types of antibodies (e.g., human or humanized antibodies) or any of the exemplary antibody fragments described herein can be A recombinant antibody that is an NK cell activator can include, for example, any of the antigen binding domains described herein.
組換えインターロイキン又はサイトカイン
いくつかの例では、NK活性化物質は、例えば、可溶性IL-2、可溶性IL-7、可溶性IL-12、可溶性IL-15、可溶性IL-21、及び可溶性IL-33であり得る。可溶性IL-12、IL-15、IL-21、及びIL-33の非限定的な例を、以下に提供する。
ヒト可溶性IL-2(配列番号78)







Human soluble IL-2 (SEQ ID NO:78)
いくつかの実施形態では、可溶性IL-2タンパク質は、配列番号78と少なくとも80%同一、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一である配列を含み得る。 In some embodiments, the soluble IL-2 protein is at least 80% identical, at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical to SEQ ID NO:78. It can include sequences that are % identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical.
いくつかの実施形態では、可溶性IL-7タンパク質は、配列番号79と少なくとも80%同一、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一である配列を含み得る。 In some embodiments, the soluble IL-7 protein is at least 80% identical, at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical to SEQ ID NO:79. It can include sequences that are % identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical.
いくつかの実施形態では、可溶性IL-2タンパク質は、配列番号80と少なくとも80%同一、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一である配列と、配列番号81と少なくとも80%同一、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一である配列と、を含む。 In some embodiments, the soluble IL-2 protein is at least 80% identical, at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical to SEQ ID NO:80. % identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical to a sequence that is at least 80% identical, at least 82% identical, at least 84% identical to SEQ ID NO:81 , at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical; including.
いくつかの実施形態では、可溶性IL-15タンパク質は、配列番号82と少なくとも80%同一、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一である配列を含み得る。 In some embodiments, the soluble IL-15 protein is at least 80% identical, at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical to SEQ ID NO:82. It can include sequences that are % identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical.
いくつかの実施形態では、可溶性IL-21タンパク質は、配列番号83と少なくとも80%同一、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一である配列を含み得る。 In some embodiments, the soluble IL-21 protein is at least 80% identical, at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical to SEQ ID NO:83. It can include sequences that are % identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical.
いくつかの実施形態では、可溶性IL-33タンパク質は、配列番号84と少なくとも80%同一、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一である配列を含み得る。 In some embodiments, the soluble IL-33 protein is at least 80% identical, at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical to SEQ ID NO:84. It can include sequences that are % identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical.
可溶性サイトカイン又はインターロイキン受容体
本明細書に記載の可溶性サイトカイン又はインターロイキン受容体のうちのいずれかのいくつかの例では、可溶性サイトカイン又はインターロイキン受容体は、可溶性TGF-β受容体であり得る。いくつかの例では、可溶性TGF-β受容体は、可溶性TGF-β受容体I(TGF-βRI)(例えば、Docagne et al.,Journal of Biological Chemistry276(49):46243-46250,2001に記載されているものを参照)、可溶性TGF-β受容体II(TGF-βRII)(例えば、Yung et al.,Am.J.Resp.Crit.Care Med.194(9):1140-1151,2016に記載されているものを参照)、可溶性TGF-βRIII(例えば、Heng et al.,Placenta57:320,2017に記載されているものを参照)である。いくつかの例では、可溶性TGF-β受容体は、TGF-βの受容体「トラップ」である(例えば、Zwaagstra et al.,Mol.Cancer Ther.11(7):1477-1487,2012に記載されているもの、及びDe Crescenzo et al.Transforming Growth Factor-β in Cancer Therapy,Volume II,pp671-684に記載されているものを参照)。
Soluble Cytokine or Interleukin Receptors In some examples of any of the soluble cytokines or interleukin receptors described herein, the soluble cytokine or interleukin receptor can be a soluble TGF-beta receptor. . In some examples, the soluble TGF-beta receptor is soluble TGF-beta receptor I (TGF-βRI) (see, eg, Docagne et al., Journal of Biological Chemistry 276(49):46243-46250, 2001). 194(9):1140-1151, 2016), soluble TGF-β receptor II (TGF-βRII) (eg, Yung et al., Am. J. Resp. Crit. Care Med. 194(9): 1140-1151, 2016). and soluble TGF-βRIII (see, eg, Heng et al., Placenta 57:320, 2017). In some instances, the soluble TGF-β receptor is a receptor “trap” for TGF-β (see, eg, Zwaagstra et al., Mol. Cancer Ther. 11(7):1477-1487, 2012). and those described in De Crescenzo et al., Transforming Growth Factor-β in Cancer Therapy, Volume II, pp 671-684).
可溶性サイトカイン又は可溶性インターロイキン受容体の追加の例は、当該技術分野で既知である。 Additional examples of soluble cytokines or soluble interleukin receptors are known in the art.
一本鎖キメラポリペプチド
NK細胞活性化物質の非限定的な例は、(i)第1の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の標的結合ドメインのうちのいずれか)、(ii)可溶性組織因子ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な可溶性組織因子ドメインのうちのいずれか)、及び(iii)第2の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の標的結合ドメインのうちのいずれか)を含む一本鎖キメラポリペプチドである。
Non-limiting examples of single chain chimeric polypeptide NK cell activators include (i) a first target binding domain (e.g., one of the target binding domains described herein or known in the art) either), (ii) a soluble tissue factor domain (e.g., any of the exemplary soluble tissue factor domains described herein or known in the art), and (iii) a second target binding A single chain chimeric polypeptide comprising a domain (eg, any of the target binding domains described herein or known in the art).
本明細書に記載の一本鎖キメラポリペプチドのうちのいずれかのいくつかの例では、一本鎖キメラポリペプチドは、約50アミノ酸~約3000アミノ酸、約50アミノ酸~約2500アミノ酸、約50アミノ酸~約2000アミノ酸、約50アミノ酸~約1500アミノ酸、約50アミノ酸~約1000アミノ酸、約50アミノ酸~約950アミノ酸、約50アミノ酸~約900アミノ酸、約50アミノ酸~約850アミノ酸、約50アミノ酸~約800アミノ酸、約50アミノ酸~約750アミノ酸、約50アミノ酸~約700アミノ酸、約50アミノ酸~約650アミノ酸、約50アミノ酸~約600アミノ酸、約50アミノ酸~約550アミノ酸、約50アミノ酸~約500アミノ酸、約50アミノ酸~約480アミノ酸、約50アミノ酸~約460アミノ酸、約50アミノ酸~約440アミノ酸、約50アミノ酸~約420アミノ酸、約50アミノ酸~約400アミノ酸、約50アミノ酸~約380アミノ酸、約50アミノ酸~約360アミノ酸、約50アミノ酸~約340アミノ酸、約50アミノ酸~約320アミノ酸、約50アミノ酸~約300アミノ酸、約50アミノ酸~約280アミノ酸、約50アミノ酸~約260アミノ酸、約50アミノ酸~約240アミノ酸、約50アミノ酸~約220アミノ酸、約50アミノ酸~約200アミノ酸、約50アミノ酸~約150アミノ酸、約50アミノ酸~約100アミノ酸、約100アミノ酸~約3000アミノ酸、約100アミノ酸~約2500アミノ酸、約100アミノ酸~約2000アミノ酸、約100アミノ酸~約1500アミノ酸、約100アミノ酸~約1000アミノ酸、約100アミノ酸~約950アミノ酸、約100アミノ酸~約900アミノ酸、約100アミノ酸~約850アミノ酸、約100アミノ酸~約800アミノ酸、約100アミノ酸~約750アミノ酸、約100アミノ酸~約700アミノ酸、約100アミノ酸~約650アミノ酸、約100アミノ酸~約600アミノ酸、約100アミノ酸~約550アミノ酸、約100アミノ酸~約500アミノ酸、約100アミノ酸~約480アミノ酸、約100アミノ酸~約460アミノ酸、約100アミノ酸~約440アミノ酸、約100アミノ酸~約420アミノ酸、約100アミノ酸~約400アミノ酸、約100アミノ酸~約380アミノ酸、約100アミノ酸~約360アミノ酸、約100アミノ酸~約340アミノ酸、約100アミノ酸~約320アミノ酸、約100アミノ酸~約300アミノ酸、約100アミノ酸~約280アミノ酸、約100アミノ酸~約260アミノ酸、約100アミノ酸~約240アミノ酸、約100アミノ酸~約220アミノ酸、約100アミノ酸~約200アミノ酸、約100アミノ酸~約150アミノ酸、約150アミノ酸~約3000アミノ酸、約150アミノ酸~約2500アミノ酸、約150アミノ酸~約2000アミノ酸、約150アミノ酸~約1500アミノ酸、約150アミノ酸~約1000アミノ酸、約150アミノ酸~約950アミノ酸、約150アミノ酸~約900アミノ酸、約150アミノ酸~約850アミノ酸、約150アミノ酸~約800アミノ酸、約150アミノ酸~約750アミノ酸、約150アミノ酸~約700アミノ酸、約150アミノ酸~約650アミノ酸、約150アミノ酸~約600アミノ酸、約150アミノ酸~約550アミノ酸、約150アミノ酸~約500アミノ酸、約150アミノ酸~約480アミノ酸、約150アミノ酸~約460アミノ酸、約150アミノ酸~約440アミノ酸、約150アミノ酸~約420アミノ酸、約150アミノ酸~約400アミノ酸、約150アミノ酸~約380アミノ酸、約150アミノ酸~約360アミノ酸、約150アミノ酸~約340アミノ酸、約150アミノ酸~約320アミノ酸、約150アミノ酸~約300アミノ酸、約150アミノ酸~約280アミノ酸、約150アミノ酸~約260アミノ酸、約150アミノ酸~約240アミノ酸、約150アミノ酸~約220アミノ酸、約150アミノ酸~約200アミノ酸、約200アミノ酸~約3000アミノ酸、約200アミノ酸~約2500アミノ酸、約200アミノ酸~約2000アミノ酸、約200アミノ酸~約1500アミノ酸、約200アミノ酸~約1000アミノ酸、約200アミノ酸~約950アミノ酸、約200アミノ酸~約900アミノ酸、約200アミノ酸~約850アミノ酸、約200アミノ酸~約800アミノ酸、約200アミノ酸~約750アミノ酸、約200アミノ酸~約700アミノ酸、約200アミノ酸~約650アミノ酸、約200アミノ酸~約600アミノ酸、約200アミノ酸~約550アミノ酸、約200アミノ酸~約500アミノ酸、約200アミノ酸~約480アミノ酸、約200アミノ酸~約460アミノ酸、約200アミノ酸~約440アミノ酸、約200アミノ酸~約420アミノ酸、約200アミノ酸~約400アミノ酸、約200アミノ酸~約380アミノ酸、約200アミノ酸~約360アミノ酸、約200アミノ酸~約340アミノ酸、約200アミノ酸~約320アミノ酸、約200アミノ酸~約300アミノ酸、約200アミノ酸~約280アミノ酸、約200アミノ酸~約260アミノ酸、約200アミノ酸~約240アミノ酸、約200アミノ酸~約220アミノ酸、約220アミノ酸~約3000アミノ酸、約220アミノ酸~約2500アミノ酸、約220アミノ酸~約2000アミノ酸、約220アミノ酸~約1500アミノ酸、約220アミノ酸~約1000アミノ酸、約220アミノ酸~約950アミノ酸、約220アミノ酸~約900アミノ酸、約220アミノ酸~約850アミノ酸、約220アミノ酸~約800アミノ酸、約220アミノ酸~約750アミノ酸、約220アミノ酸~約700アミノ酸、約220アミノ酸~約650アミノ酸、約220アミノ酸~約600アミノ酸、約220アミノ酸~約550アミノ酸、約220アミノ酸~約500アミノ酸、約220アミノ酸~約480アミノ酸、約220アミノ酸~約460アミノ酸、約220アミノ酸~約440アミノ酸、約220アミノ酸~約420アミノ酸、約220アミノ酸~約400アミノ酸、約220アミノ酸~約380アミノ酸、約220アミノ酸~約360アミノ酸、約220アミノ酸~約340アミノ酸、約220アミノ酸~約320アミノ酸、約220アミノ酸~約300アミノ酸、約220アミノ酸~約280アミノ酸、約220アミノ酸~約260アミノ酸、約220アミノ酸~約240アミノ酸、約240アミノ酸~約3000アミノ酸、約240アミノ酸~約2500アミノ酸、約240アミノ酸~約2000アミノ酸、約240アミノ酸~約1500アミノ酸、約240アミノ酸~約1000アミノ酸、約240アミノ酸~約950アミノ酸、約240アミノ酸~約900アミノ酸、約240アミノ酸~約850アミノ酸、約240アミノ酸~約800アミノ酸、約240アミノ酸~約750アミノ酸、約240アミノ酸~約700アミノ酸、約240アミノ酸~約650アミノ酸、約240アミノ酸~約600アミノ酸、約240アミノ酸~約550アミノ酸、約240アミノ酸~約500アミノ酸、約240アミノ酸~約480アミノ酸、約240アミノ酸~約460アミノ酸、約240アミノ酸~約440アミノ酸、約240アミノ酸~約420アミノ酸、約240アミノ酸~約400アミノ酸、約240アミノ酸~約380アミノ酸、約240アミノ酸~約360アミノ酸、約240アミノ酸~約340アミノ酸、約240アミノ酸~約320アミノ酸、約240アミノ酸~約300アミノ酸、約240アミノ酸~約280アミノ酸、約240アミノ酸~約260アミノ酸、約260アミノ酸~約3000アミノ酸、約260アミノ酸~約2500アミノ酸、約260アミノ酸~約2000アミノ酸、約260アミノ酸~約1500アミノ酸、約260アミノ酸~約1000アミノ酸、約260アミノ酸~約950アミノ酸、約260アミノ酸~約900アミノ酸、約260アミノ酸~約850アミノ酸、約260アミノ酸~約800アミノ酸、約260アミノ酸~約750アミノ酸、約260アミノ酸~約700アミノ酸、約260アミノ酸~約650アミノ酸、約260アミノ酸~約600アミノ酸、約260アミノ酸~約550アミノ酸、約260アミノ酸~約500アミノ酸、約260アミノ酸~約480アミノ酸、約260アミノ酸~約460アミノ酸、約260アミノ酸~約440アミノ酸、約260アミノ酸~約420アミノ酸、約260アミノ酸~約400アミノ酸、約260アミノ酸~約380アミノ酸、約260アミノ酸~約360アミノ酸、約260アミノ酸~約340アミノ酸、約260アミノ酸~約320アミノ酸、約260アミノ酸~約300アミノ酸、約260アミノ酸~約280アミノ酸、約280アミノ酸~約3000アミノ酸、約280アミノ酸~約2500アミノ酸、約280アミノ酸~約2000アミノ酸、約280アミノ酸~約1500アミノ酸、約280アミノ酸~約1000アミノ酸、約280アミノ酸~約950アミノ酸、約280アミノ酸~約900アミノ酸、約280アミノ酸~約850アミノ酸、約280アミノ酸~約800アミノ酸、約280アミノ酸~約750アミノ酸、約280アミノ酸~約700アミノ酸、約280アミノ酸~約650アミノ酸、約280アミノ酸~約600アミノ酸、約280アミノ酸~約550アミノ酸、約280アミノ酸~約500アミノ酸、約280アミノ酸~約480アミノ酸、約280アミノ酸~約460アミノ酸、約280アミノ酸~約440アミノ酸、約280アミノ酸~約420アミノ酸、約280アミノ酸~約400アミノ酸、約280アミノ酸~約380アミノ酸、約280アミノ酸~約360アミノ酸、約280アミノ酸~約340アミノ酸、約280アミノ酸~約320アミノ酸、約280アミノ酸~約300アミノ酸、約300アミノ酸~約3000アミノ酸、約300アミノ酸~約2500アミノ酸、約300アミノ酸~約2000アミノ酸、約300アミノ酸~約1500アミノ酸、約300アミノ酸~約1000アミノ酸、約300アミノ酸~約950アミノ酸、約300アミノ酸~約900アミノ酸、約300アミノ酸~約850アミノ酸、約300アミノ酸~約800アミノ酸、約300アミノ酸~約750アミノ酸、約300アミノ酸~約700アミノ酸、約300アミノ酸~約650アミノ酸、約300アミノ酸~約600アミノ酸、約300アミノ酸~約550アミノ酸、約300アミノ酸~約500アミノ酸、約300アミノ酸~約480アミノ酸、約300アミノ酸~約460アミノ酸、約300アミノ酸~約440アミノ酸、約300アミノ酸~約420アミノ酸、約300アミノ酸~約400アミノ酸、約300アミノ酸~約380アミノ酸、約300アミノ酸~約360アミノ酸、約300アミノ酸~約340アミノ酸、約300アミノ酸~約320アミノ
酸、約320アミノ酸~約3000アミノ酸、約320アミノ酸~約2500アミノ酸、約320アミノ酸~約2000アミノ酸、約320アミノ酸~約1500アミノ酸、約320アミノ酸~約1000アミノ酸、約320アミノ酸~約950アミノ酸、約320アミノ酸~約900アミノ酸、約320アミノ酸~約850アミノ酸、約320アミノ酸~約800アミノ酸、約320アミノ酸~約750アミノ酸、約320アミノ酸~約700アミノ酸、約320アミノ酸~約650アミノ酸、約320アミノ酸~約600アミノ酸、約320アミノ酸~約550アミノ酸、約320アミノ酸~約500アミノ酸、約320アミノ酸~約480アミノ酸、約320アミノ酸~約460アミノ酸、約320アミノ酸~約440アミノ酸、約320アミノ酸~約420アミノ酸、約320アミノ酸~約400アミノ酸、約320アミノ酸~約380アミノ酸、約320アミノ酸~約360アミノ酸、約320アミノ酸~約340アミノ酸、約340アミノ酸~約3000アミノ酸、約340アミノ酸~約2500アミノ酸、約340アミノ酸~約2000アミノ酸、約340アミノ酸~約1500アミノ酸、約340アミノ酸~約1000アミノ酸、約340アミノ酸~約950アミノ酸、約340アミノ酸~約900アミノ酸、約340アミノ酸~約850アミノ酸、約340アミノ酸~約800アミノ酸、約340アミノ酸~約750アミノ酸、約340アミノ酸~約700アミノ酸、約340アミノ酸~約650アミノ酸、約340アミノ酸~約600アミノ酸、約340アミノ酸~約550アミノ酸、約340アミノ酸~約500アミノ酸、約340アミノ酸~約480アミノ酸、約340アミノ酸~約460アミノ酸、約340アミノ酸~約440アミノ酸、約340アミノ酸~約420アミノ酸、約340アミノ酸~約400アミノ酸、約340アミノ酸~約380アミノ酸、約340アミノ酸~約360アミノ酸、約360アミノ酸~約3000アミノ酸、約360アミノ酸~約2500アミノ酸、約360アミノ酸~約2000アミノ酸、約360アミノ酸~約1500アミノ酸、約360アミノ酸~約1000アミノ酸、約360アミノ酸~約950アミノ酸、約360アミノ酸~約900アミノ酸、約360アミノ酸~約850アミノ酸、約360アミノ酸~約800アミノ酸、約360アミノ酸~約750アミノ酸、約360アミノ酸~約700アミノ酸、約360アミノ酸~約650アミノ酸、約360アミノ酸~約600アミノ酸、約360アミノ酸~約550アミノ酸、約360アミノ酸~約500アミノ酸、約360アミノ酸~約480アミノ酸、約360アミノ酸~約460アミノ酸、約360アミノ酸~約440アミノ酸、約360アミノ酸~約420アミノ酸、約360アミノ酸~約400アミノ酸、約360アミノ酸~約380アミノ酸、約380アミノ酸~約3000アミノ酸、約380アミノ酸~約2500アミノ酸、約380アミノ酸~約2000アミノ酸、約380アミノ酸~約1500アミノ酸、約380アミノ酸~約1000アミノ酸、約380アミノ酸~約950アミノ酸、約380アミノ酸~約900アミノ酸、約380アミノ酸~約850アミノ酸、約380アミノ酸~約800アミノ酸、約380アミノ酸~約750アミノ酸、約380アミノ酸~約700アミノ酸、約380アミノ酸~約650アミノ酸、約380アミノ酸~約600アミノ酸、約380アミノ酸~約550アミノ酸、約380アミノ酸~約500アミノ酸、約380アミノ酸~約480アミノ酸、約380アミノ酸~約460アミノ酸、約380アミノ酸~約440アミノ酸、約380アミノ酸~約420アミノ酸、約380アミノ酸~約400アミノ酸、約400アミノ酸~約3000アミノ酸、約400アミノ酸~約2500アミノ酸、約400アミノ酸~約2000アミノ酸、約400アミノ酸~約1500アミノ酸、約400アミノ酸~約1000アミノ酸、約400アミノ酸~約950アミノ酸、約400アミノ酸~約900アミノ酸、約400アミノ酸~約850アミノ酸、約400アミノ酸~約800アミノ酸、約400アミノ酸~約750アミノ酸、約400アミノ酸~約700アミノ酸、約400アミノ酸~約650アミノ酸、約400アミノ酸~約600アミノ酸、約400アミノ酸~約550アミノ酸、約400アミノ酸~約500アミノ酸、約400アミノ酸~約480アミノ酸、約400アミノ酸~約460アミノ酸、約400アミノ酸~約440アミノ酸、約400アミノ酸~約420アミノ酸、約420アミノ酸~約3000アミノ酸、約420アミノ酸~約2500アミノ酸、約420アミノ酸~約2000アミノ酸、約420アミノ酸~約1500アミノ酸、約420アミノ酸~約1000アミノ酸、約420アミノ酸~約950アミノ酸、約420アミノ酸~約900アミノ酸、約420アミノ酸~約850アミノ酸、約420アミノ酸~約800アミノ酸、約420アミノ酸~約750アミノ酸、約420アミノ酸~約700アミノ酸、約420アミノ酸~約650アミノ酸、約420アミノ酸~約600アミノ酸、約420アミノ酸~約550アミノ酸、約420アミノ酸~約500アミノ酸、約420アミノ酸~約480アミノ酸、約420アミノ酸~約460アミノ酸、約420アミノ酸~約440アミノ酸、約440アミノ酸~約3000アミノ酸、約440アミノ酸~約2500アミノ酸、約440アミノ酸~約2000アミノ酸、約440アミノ酸~約1500アミノ酸、約440アミノ酸~約1000アミノ酸、約440アミノ酸~約950アミノ酸、約440アミノ酸~約900アミノ酸、約440アミノ酸~約850アミノ酸、約440アミノ酸~約800アミノ酸、約440アミノ酸~約750アミノ酸、約440アミノ酸~約700アミノ酸、約440アミノ酸~約650アミノ酸、約440アミノ酸~約600アミノ酸、約440アミノ酸~約550アミノ酸、約440アミノ酸~約500アミノ酸、約440アミノ酸~約480アミノ酸、約440アミノ酸~約460アミノ酸、約460アミノ酸~約3000アミノ酸、約460アミノ酸~約2500アミノ酸、約460アミノ酸~約2000アミノ酸、約460アミノ酸~約1500アミノ酸、約460アミノ酸~約1000アミノ酸、約460アミノ酸~約950アミノ酸、約460アミノ酸~約900アミノ酸、約460アミノ酸~約850アミノ酸、約460アミノ酸~約800アミノ酸、約460アミノ酸~約750アミノ酸、約460アミノ酸~約700アミノ酸、約460アミノ酸~約650アミノ酸、約460アミノ酸~約600アミノ酸、約460アミノ酸~約550アミノ酸、約460アミノ酸~約500アミノ酸、約460アミノ酸~約480アミノ酸、約480アミノ酸~約3000アミノ酸、約480アミノ酸~約2500アミノ酸、約480アミノ酸~約2000アミノ酸、約480アミノ酸~約1500アミノ酸、約480アミノ酸~約1000アミノ酸、約480アミノ酸~約950アミノ酸、約480アミノ酸~約900アミノ酸、約480アミノ酸~約850アミノ酸、約480アミノ酸~約800アミノ酸、約480アミノ酸~約750アミノ酸、約480アミノ酸~約700アミノ酸、約480アミノ酸~約650アミノ酸、約480アミノ酸~約600アミノ酸、約480アミノ酸~約550アミノ酸、約480アミノ酸~約500アミノ酸、約500アミノ酸~約3000アミノ酸、約500アミノ酸~約2500アミノ酸、約500アミノ酸~約2000アミノ酸、約500アミノ酸~約1500アミノ酸、約500アミノ酸~約1000アミノ酸、約500アミノ酸~約950アミノ酸、約500アミノ酸~約900アミノ酸、約500アミノ酸~約850アミノ酸、約500アミノ酸~約800アミノ酸、約500アミノ酸~約750アミノ酸、約500アミノ酸~約700アミノ酸、約500アミノ酸~約650アミノ酸、約500アミノ酸~約600アミノ酸、約500アミノ酸~約550アミノ酸、約550アミノ酸~約3000アミノ酸、約550アミノ酸~約2500アミノ酸、約550アミノ酸~約2000アミノ酸、約550アミノ酸~約1500アミノ酸、約550アミノ酸~約1000アミノ酸、約550アミノ酸~約950アミノ酸、約550アミノ酸~約900アミノ酸、約550アミノ酸~約850アミノ酸、約550アミノ酸~約800アミノ酸、約550アミノ酸~約750アミノ酸、約550アミノ酸~約700アミノ酸、約550アミノ酸~約650アミノ酸、約550アミノ酸~約600アミノ酸、約600アミノ酸~約3000アミノ酸、約600アミノ酸~約2500アミノ酸、約600アミノ酸~約2000アミノ酸、約600アミノ酸~約1500アミノ酸、約600アミノ酸~約1000アミノ酸、約600アミノ酸~約950アミノ酸、約600アミノ酸~約900アミノ酸、約600アミノ酸~約850アミノ酸、約600アミノ酸~約800アミノ酸、約600アミノ酸~約750アミノ酸、約600アミノ酸~約700アミノ酸、約600アミノ酸~約650アミノ酸、約650アミノ酸~約3000アミノ酸、約650アミノ酸~約2500アミノ酸、約650アミノ酸~約2000アミノ酸、約650アミノ酸~約1500アミノ酸、約650アミノ酸~約1000アミノ酸、約650アミノ酸~約950アミノ酸、約650アミノ酸~約900アミノ酸、約650アミノ酸~約850アミノ酸、約650アミノ酸~約800アミノ酸、約650アミノ酸~約750アミノ酸、約650アミノ酸~約700アミノ酸、約700アミノ酸~約3000アミノ酸、約700アミノ酸~約2500アミノ酸、約700アミノ酸~約2000アミノ酸、約700アミノ酸~約1500アミノ酸、約700アミノ酸~約1000アミノ酸、約700アミノ酸~約950アミノ酸、約700アミノ酸~約900アミノ酸、約700アミノ酸~約850アミノ酸、約700アミノ酸~約800アミノ酸、約700アミノ酸~約750アミノ酸、約750アミノ酸~約3000アミノ酸、約750アミノ酸~約2500アミノ酸、約750アミノ酸~約2000アミノ酸、約750アミノ酸~約1500アミノ酸、約750アミノ酸~約1000アミノ酸、約750アミノ酸~約950アミノ酸、約750アミノ酸~約900アミノ酸、約750アミノ酸~約850アミノ酸、約750アミノ酸~約800アミノ酸、約800アミノ酸~約3000アミノ酸、約800アミノ酸~約2500アミノ酸、約800アミノ酸~約2000アミノ酸、約800アミノ酸~約1500アミノ酸、約800アミノ酸~約1000アミノ酸、約800アミノ酸~約950アミノ酸、約800アミノ酸~約900アミノ酸、約800アミノ酸~約850アミノ酸、約850アミノ酸~約3000アミノ酸、約850アミノ酸~約2500アミノ酸、約850アミノ酸~約2000アミノ酸、約850アミノ酸~約1500アミノ酸、約850アミノ酸~約1000アミノ酸、約850アミノ酸~約950アミノ酸、約850アミノ酸~約900アミノ酸、約900アミノ酸~約3000アミノ酸、約900アミノ酸~約2500アミノ酸、約900アミノ酸~約2000アミノ酸、約900アミノ酸~約1500アミノ酸、約900アミノ酸~約1000アミノ酸、約900アミノ酸~約950アミノ酸、約950アミノ酸~約3000アミノ酸、約950アミノ酸~約2500アミノ酸、約950アミノ酸~約2000アミノ酸、約950アミノ酸~約1500アミノ酸、約950アミノ酸~約1000アミノ酸、約1000アミノ酸~約3000アミノ酸、約1000アミノ酸~約2500アミノ酸、約1000アミノ酸~約2000アミノ酸、約1000アミノ酸~約1500アミノ酸、約1500アミノ酸~約3000アミノ酸、約1500アミノ酸~約2500アミノ酸、約1500アミノ酸~約2000アミノ酸、約2000アミノ酸~約3000アミノ酸、約2000アミノ酸~約2500アミノ酸、又は約2500アミノ酸~約3000アミノ酸の全長を有し得る。
In some examples of any of the single chain chimeric polypeptides described herein, the single chain chimeric polypeptide is about 50 amino acids to about 3000 amino acids, about 50 amino acids to about 2500 amino acids, about 50 amino acids to about 2000 amino acids, about 50 amino acids to about 1500 amino acids, about 50 amino acids to about 1000 amino acids, about 50 amino acids to about 950 amino acids, about 50 amino acids to about 900 amino acids, about 50 amino acids to about 850 amino acids, about 50 amino acids to about 800 amino acids, about 50 amino acids to about 750 amino acids, about 50 amino acids to about 700 amino acids, about 50 amino acids to about 650 amino acids, about 50 amino acids to about 600 amino acids, about 50 amino acids to about 550 amino acids, about 50 amino acids to about 500 amino acids amino acids, about 50 amino acids to about 480 amino acids, about 50 amino acids to about 460 amino acids, about 50 amino acids to about 440 amino acids, about 50 amino acids to about 420 amino acids, about 50 amino acids to about 400 amino acids, about 50 amino acids to about 380 amino acids, about 50 amino acids to about 360 amino acids, about 50 amino acids to about 340 amino acids, about 50 amino acids to about 320 amino acids, about 50 amino acids to about 300 amino acids, about 50 amino acids to about 280 amino acids, about 50 amino acids to about 260 amino acids, about 50 amino acids to about 240 amino acids, about 50 amino acids to about 220 amino acids, about 50 amino acids to about 200 amino acids, about 50 amino acids to about 150 amino acids, about 50 amino acids to about 100 amino acids, about 100 amino acids to about 3000 amino acids, about 100 amino acids to about 2500 amino acids, about 100 amino acids to about 2000 amino acids, about 100 amino acids to about 1500 amino acids, about 100 amino acids to about 1000 amino acids, about 100 amino acids to about 950 amino acids, about 100 amino acids to about 900 amino acids, about 100 amino acids to about 850 amino acids amino acids, about 100 amino acids to about 800 amino acids, about 100 amino acids to about 750 amino acids, about 100 amino acids to about 700 amino acids, about 100 amino acids to about 650 amino acids, about 100 amino acids to about 600 amino acids, about 100 amino acids to about 550 amino acids, about 100 amino acids to about 500 amino acids, about 100 amino acids to about 480 amino acids, about 100 amino acids to about 460 amino acids, about 100 amino acids to about 440 amino acids, about 100 amino acids to about 420 amino acids, about 100 amino acids to about 400 amino acids, about 100 amino acids to about 380 amino acids, about 100 amino acids to about 360 amino acids, about 100 amino acids to about 340 amino acids, about 100 amino acids to about 320 amino acids, about 100 amino acids to about 300 amino acids, about 100 amino acids to about 280 amino acids, about 100 amino acids to about 260 amino acids, about 100 amino acids to about 240 amino acids, about 100 amino acids to about 220 amino acids, about 100 amino acids to about 200 amino acids, about 100 amino acids to about 150 amino acids, about 150 amino acids to about 3000 amino acids, about 150 amino acids to about 2500 amino acids amino acids, about 150 amino acids to about 2000 amino acids, about 150 amino acids to about 1500 amino acids, about 150 amino acids to about 1000 amino acids, about 150 amino acids to about 950 amino acids, about 150 amino acids to about 900 amino acids, about 150 amino acids to about 850 amino acids, about 150 amino acids to about 800 amino acids, about 150 amino acids to about 750 amino acids, about 150 amino acids to about 700 amino acids, about 150 amino acids to about 650 amino acids, about 150 amino acids to about 600 amino acids, about 150 amino acids to about 550 amino acids, about 150 amino acids to about 500 amino acids, about 150 amino acids to about 480 amino acids, about 150 amino acids to about 460 amino acids, about 150 amino acids to about 440 amino acids, about 150 amino acids to about 420 amino acids, about 150 amino acids to about 400 amino acids, about 150 amino acids to about 380 amino acids, about 150 amino acids to about 360 amino acids, about 150 amino acids to about 340 amino acids, about 150 amino acids to about 320 amino acids, about 150 amino acids to about 300 amino acids, about 150 amino acids to about 280 amino acids, about 150 amino acids to about 260 amino acids amino acids, about 150 amino acids to about 240 amino acids, about 150 amino acids to about 220 amino acids, about 150 amino acids to about 200 amino acids, about 200 amino acids to about 3000 amino acids, about 200 amino acids to about 2500 amino acids, about 200 amino acids to about 2000 amino acids, about 200 amino acids to about 1500 amino acids, about 200 amino acids to about 1000 amino acids, about 200 amino acids to about 950 amino acids, about 200 amino acids to about 900 amino acids, about 200 amino acids to about 850 amino acids, about 200 amino acids to about 800 amino acids, about 200 amino acids to about 750 amino acids, about 200 amino acids to about 700 amino acids, about 200 amino acids to about 650 amino acids, about 200 amino acids to about 600 amino acids, about 200 amino acids to about 550 amino acids, about 200 amino acids to about 500 amino acids, about 200 amino acids to about 480 amino acids, about 200 amino acids to about 460 amino acids, about 200 amino acids to about 440 amino acids, about 200 amino acids to about 420 amino acids, about 200 amino acids to about 400 amino acids, about 200 amino acids to about 380 amino acids, about 200 amino acids to about 360 amino acids amino acids, about 200 amino acids to about 340 amino acids, about 200 amino acids to about 320 amino acids, about 200 amino acids to about 300 amino acids, about 200 amino acids to about 280 amino acids, about 200 amino acids to about 260 amino acids, about 200 amino acids to about 240 amino acids, about 200 amino acids to about 220 amino acids, about 220 amino acids to about 3000 amino acids, about 220 amino acids to about 2500 amino acids, about 220 amino acids to about 2000 amino acids, about 220 amino acids to about 1500 amino acids, about 220 amino acids to about 1000 amino acids, about 220 amino acids to about 950 amino acids, about 220 amino acids to about 900 amino acids, about 220 amino acids to about 850 amino acids, about 220 amino acids to about 800 amino acids, about 220 amino acids to about 750 amino acids, about 220 amino acids to about 700 amino acids, about 220 amino acids to about 650 amino acids, about 220 amino acids to about 600 amino acids, about 220 amino acids to about 550 amino acids, about 220 amino acids to about 500 amino acids, about 220 amino acids to about 480 amino acids, about 220 amino acids to about 460 amino acids, about 220 amino acids to about 440 amino acids amino acids, about 220 amino acids to about 420 amino acids, about 220 amino acids to about 400 amino acids, about 220 amino acids to about 380 amino acids, about 220 amino acids to about 360 amino acids, about 220 amino acids to about 340 amino acids, about 220 amino acids to about 320 amino acids, about 220 amino acids to about 300 amino acids, about 220 amino acids to about 280 amino acids, about 220 amino acids to about 260 amino acids, about 220 amino acids to about 240 amino acids, about 240 amino acids to about 3000 amino acids, about 240 amino acids to about 2500 amino acids, about 240 amino acids to about 2000 amino acids, about 240 amino acids to about 1500 amino acids, about 240 amino acids to about 1000 amino acids, about 240 amino acids to about 950 amino acids, about 240 amino acids to about 900 amino acids, about 240 amino acids to about 850 amino acids, about 240 amino acids to about 800 amino acids, about 240 amino acids to about 750 amino acids, about 240 amino acids to about 700 amino acids, about 240 amino acids to about 650 amino acids, about 240 amino acids to about 600 amino acids, about 240 amino acids to about 550 amino acids, about 240 amino acids to about 500 amino acids amino acids, about 240 amino acids to about 480 amino acids, about 240 amino acids to about 460 amino acids, about 240 amino acids to about 440 amino acids, about 240 amino acids to about 420 amino acids, about 240 amino acids to about 400 amino acids, about 240 amino acids to about 380 amino acids, about 240 amino acids to about 360 amino acids, about 240 amino acids to about 340 amino acids, about 240 amino acids to about 320 amino acids, about 240 amino acids to about 300 amino acids, about 240 amino acids to about 280 amino acids, about 240 amino acids to about 260 amino acids, about 260 amino acids to about 3000 amino acids, about 260 amino acids to about 2500 amino acids, about 260 amino acids to about 2000 amino acids, about 260 amino acids to about 1500 amino acids, about 260 amino acids to about 1000 amino acids, about 260 amino acids to about 950 amino acids, about 260 amino acids to about 900 amino acids, about 260 amino acids to about 850 amino acids, about 260 amino acids to about 800 amino acids, about 260 amino acids to about 750 amino acids, about 260 amino acids to about 700 amino acids, about 260 amino acids to about 650 amino acids, about 260 amino acids to about 600 amino acids amino acids, about 260 amino acids to about 550 amino acids, about 260 amino acids to about 500 amino acids, about 260 amino acids to about 480 amino acids, about 260 amino acids to about 460 amino acids, about 260 amino acids to about 440 amino acids, about 260 amino acids to about 420 amino acids, about 260 amino acids to about 400 amino acids, about 260 amino acids to about 380 amino acids, about 260 amino acids to about 360 amino acids, about 260 amino acids to about 340 amino acids, about 260 amino acids to about 320 amino acids, about 260 amino acids to about 300 amino acids, about 260 amino acids to about 280 amino acids, about 280 amino acids to about 3000 amino acids, about 280 amino acids to about 2500 amino acids, about 280 amino acids to about 2000 amino acids, about 280 amino acids to about 1500 amino acids, about 280 amino acids to about 1000 amino acids, about 280 amino acids to about 950 amino acids, about 280 amino acids to about 900 amino acids, about 280 amino acids to about 850 amino acids, about 280 amino acids to about 800 amino acids, about 280 amino acids to about 750 amino acids, about 280 amino acids to about 700 amino acids, about 280 amino acids to about 650 amino acids amino acids, about 280 amino acids to about 600 amino acids, about 280 amino acids to about 550 amino acids, about 280 amino acids to about 500 amino acids, about 280 amino acids to about 480 amino acids, about 280 amino acids to about 460 amino acids, about 280 amino acids to about 440 amino acids, about 280 amino acids to about 420 amino acids, about 280 amino acids to about 400 amino acids, about 280 amino acids to about 380 amino acids, about 280 amino acids to about 360 amino acids, about 280 amino acids to about 340 amino acids, about 280 amino acids to about 320 amino acids, about 280 amino acids to about 300 amino acids, about 300 amino acids to about 3000 amino acids, about 300 amino acids to about 2500 amino acids, about 300 amino acids to about 2000 amino acids, about 300 amino acids to about 1500 amino acids, about 300 amino acids to about 1000 amino acids, about 300 amino acids to about 950 amino acids, about 300 amino acids to about 900 amino acids, about 300 amino acids to about 850 amino acids, about 300 amino acids to about 800 amino acids, about 300 amino acids to about 750 amino acids, about 300 amino acids to about 700 amino acids, about 300 amino acids to about 650 amino acids amino acids, about 300 amino acids to about 600 amino acids, about 300 amino acids to about 550 amino acids, about 300 amino acids to about 500 amino acids, about 300 amino acids to about 480 amino acids, about 300 amino acids to about 460 amino acids, about 300 amino acids to about 440 amino acids, about 300 amino acids to about 420 amino acids, about 300 amino acids to about 400 amino acids, about 300 amino acids to about 380 amino acids, about 300 amino acids to about 360 amino acids, about 300 amino acids to about 340 amino acids, about 300 amino acids to about 320 amino acids, about 320 amino acids to about 3000 amino acids, about 320 amino acids to about 2500 amino acids, about 320 amino acids to about 2000 amino acids, about 320 amino acids to about 1500 amino acids, about 320 amino acids to about 1000 amino acids, about 320 amino acids to about 950 amino acids, about 320 amino acids to about 900 amino acids, about 320 amino acids to about 850 amino acids, about 320 amino acids to about 800 amino acids, about 320 amino acids to about 750 amino acids, about 320 amino acids to about 700 amino acids, about 320 amino acids to about 650 amino acids, about 320 amino acids to about 600 amino acids amino acids, about 320 amino acids to about 550 amino acids, about 320 amino acids to about 500 amino acids, about 320 amino acids to about 480 amino acids, about 320 amino acids to about 460 amino acids, about 320 amino acids to about 440 amino acids, about 320 amino acids to about 420 amino acids, about 320 amino acids to about 400 amino acids, about 320 amino acids to about 380 amino acids, about 320 amino acids to about 360 amino acids, about 320 amino acids to about 340 amino acids, about 340 amino acids to about 3000 amino acids, about 340 amino acids to about 2500 amino acids, about 340 amino acids to about 2000 amino acids, about 340 amino acids to about 1500 amino acids, about 340 amino acids to about 1000 amino acids, about 340 amino acids to about 950 amino acids, about 340 amino acids to about 900 amino acids, about 340 amino acids to about 850 amino acids, about 340 amino acids to about 800 amino acids, about 340 amino acids to about 750 amino acids, about 340 amino acids to about 700 amino acids, about 340 amino acids to about 650 amino acids, about 340 amino acids to about 600 amino acids, about 340 amino acids to about 550 amino acids, about 340 amino acids to about 500 amino acids amino acids, about 340 amino acids to about 480 amino acids, about 340 amino acids to about 460 amino acids, about 340 amino acids to about 440 amino acids, about 340 amino acids to about 420 amino acids, about 340 amino acids to about 400 amino acids, about 340 amino acids to about 380 amino acids, about 340 amino acids to about 360 amino acids, about 360 amino acids to about 3000 amino acids, about 360 amino acids to about 2500 amino acids, about 360 amino acids to about 2000 amino acids, about 360 amino acids to about 1500 amino acids, about 360 amino acids to about 1000 amino acids, about 360 amino acids to about 950 amino acids, about 360 amino acids to about 900 amino acids, about 360 amino acids to about 850 amino acids, about 360 amino acids to about 800 amino acids, about 360 amino acids to about 750 amino acids, about 360 amino acids to about 700 amino acids, about 360 amino acids to about 650 amino acids, about 360 amino acids to about 600 amino acids, about 360 amino acids to about 550 amino acids, about 360 amino acids to about 500 amino acids, about 360 amino acids to about 480 amino acids, about 360 amino acids to about 460 amino acids, about 360 amino acids to about 440 amino acids amino acids, about 360 amino acids to about 420 amino acids, about 360 amino acids to about 400 amino acids, about 360 amino acids to about 380 amino acids, about 380 amino acids to about 3000 amino acids, about 380 amino acids to about 2500 amino acids, about 380 amino acids to about 2000 amino acids, about 380 amino acids to about 1500 amino acids, about 380 amino acids to about 1000 amino acids, about 380 amino acids to about 950 amino acids, about 380 amino acids to about 900 amino acids, about 380 amino acids to about 850 amino acids, about 380 amino acids to about 800 amino acids, about 380 amino acids to about 750 amino acids, about 380 amino acids to about 700 amino acids, about 380 amino acids to about 650 amino acids, about 380 amino acids to about 600 amino acids, about 380 amino acids to about 550 amino acids, about 380 amino acids to about 500 amino acids, about 380 amino acids to about 480 amino acids, about 380 amino acids to about 460 amino acids, about 380 amino acids to about 440 amino acids, about 380 amino acids to about 420 amino acids, about 380 amino acids to about 400 amino acids, about 400 amino acids to about 3000 amino acids, about 400 amino acids to about 2500 amino acids amino acids, about 400 amino acids to about 2000 amino acids, about 400 amino acids to about 1500 amino acids, about 400 amino acids to about 1000 amino acids, about 400 amino acids to about 950 amino acids, about 400 amino acids to about 900 amino acids, about 400 amino acids to about 850 amino acids, about 400 amino acids to about 800 amino acids, about 400 amino acids to about 750 amino acids, about 400 amino acids to about 700 amino acids, about 400 amino acids to about 650 amino acids, about 400 amino acids to about 600 amino acids, about 400 amino acids to about 550 amino acids, about 400 amino acids to about 500 amino acids, about 400 amino acids to about 480 amino acids, about 400 amino acids to about 460 amino acids, about 400 amino acids to about 440 amino acids, about 400 amino acids to about 420 amino acids, about 420 amino acids to about 3000 amino acids, about 420 amino acids to about 2500 amino acids, about 420 amino acids to about 2000 amino acids, about 420 amino acids to about 1500 amino acids, about 420 amino acids to about 1000 amino acids, about 420 amino acids to about 950 amino acids, about 420 amino acids to about 900 amino acids, about 420 amino acids to about 850 amino acids amino acids, about 420 amino acids to about 800 amino acids, about 420 amino acids to about 750 amino acids, about 420 amino acids to about 700 amino acids, about 420 amino acids to about 650 amino acids, about 420 amino acids to about 600 amino acids, about 420 amino acids to about 550 amino acids, about 420 amino acids to about 500 amino acids, about 420 amino acids to about 480 amino acids, about 420 amino acids to about 460 amino acids, about 420 amino acids to about 440 amino acids, about 440 amino acids to about 3000 amino acids, about 440 amino acids to about 2500 amino acids, about 440 amino acids to about 2000 amino acids, about 440 amino acids to about 1500 amino acids, about 440 amino acids to about 1000 amino acids, about 440 amino acids to about 950 amino acids, about 440 amino acids to about 900 amino acids, about 440 amino acids to about 850 amino acids, about 440 amino acids to about 800 amino acids, about 440 amino acids to about 750 amino acids, about 440 amino acids to about 700 amino acids, about 440 amino acids to about 650 amino acids, about 440 amino acids to about 600 amino acids, about 440 amino acids to about 550 amino acids, about 440 amino acids to about 500 amino acids amino acids, about 440 amino acids to about 480 amino acids, about 440 amino acids to about 460 amino acids, about 460 amino acids to about 3000 amino acids, about 460 amino acids to about 2500 amino acids, about 460 amino acids to about 2000 amino acids, about 460 amino acids to about 1500 amino acids, about 460 amino acids to about 1000 amino acids, about 460 amino acids to about 950 amino acids, about 460 amino acids to about 900 amino acids, about 460 amino acids to about 850 amino acids, about 460 amino acids to about 800 amino acids, about 460 amino acids to about 750 amino acids, about 460 amino acids to about 700 amino acids, about 460 amino acids to about 650 amino acids, about 460 amino acids to about 600 amino acids, about 460 amino acids to about 550 amino acids, about 460 amino acids to about 500 amino acids, about 460 amino acids to about 480 amino acids, about 480 amino acids to about 3000 amino acids, about 480 amino acids to about 2500 amino acids, about 480 amino acids to about 2000 amino acids, about 480 amino acids to about 1500 amino acids, about 480 amino acids to about 1000 amino acids, about 480 amino acids to about 950 amino acids, about 480 amino acids to about 900 amino acids amino acids, about 480 amino acids to about 850 amino acids, about 480 amino acids to about 800 amino acids, about 480 amino acids to about 750 amino acids, about 480 amino acids to about 700 amino acids, about 480 amino acids to about 650 amino acids, about 480 amino acids to about 600 amino acids, about 480 amino acids to about 550 amino acids, about 480 amino acids to about 500 amino acids, about 500 amino acids to about 3000 amino acids, about 500 amino acids to about 2500 amino acids, about 500 amino acids to about 2000 amino acids, about 500 amino acids to about 1500 amino acids, about 500 amino acids to about 1000 amino acids, about 500 amino acids to about 950 amino acids, about 500 amino acids to about 900 amino acids, about 500 amino acids to about 850 amino acids, about 500 amino acids to about 800 amino acids, about 500 amino acids to about 750 amino acids, about 500 amino acids to about 700 amino acids, about 500 amino acids to about 650 amino acids, about 500 amino acids to about 600 amino acids, about 500 amino acids to about 550 amino acids, about 550 amino acids to about 3000 amino acids, about 550 amino acids to about 2500 amino acids, about 550 amino acids to about 2000 amino acids amino acids, about 550 amino acids to about 1500 amino acids, about 550 amino acids to about 1000 amino acids, about 550 amino acids to about 950 amino acids, about 550 amino acids to about 900 amino acids, about 550 amino acids to about 850 amino acids, about 550 amino acids to about 800 amino acids, about 550 amino acids to about 750 amino acids, about 550 amino acids to about 700 amino acids, about 550 amino acids to about 650 amino acids, about 550 amino acids to about 600 amino acids, about 600 amino acids to about 3000 amino acids, about 600 amino acids to about 2500 amino acids, about 600 amino acids to about 2000 amino acids, about 600 amino acids to about 1500 amino acids, about 600 amino acids to about 1000 amino acids, about 600 amino acids to about 950 amino acids, about 600 amino acids to about 900 amino acids, about 600 amino acids to about 850 amino acids, about 600 amino acids to about 800 amino acids, about 600 amino acids to about 750 amino acids, about 600 amino acids to about 700 amino acids, about 600 amino acids to about 650 amino acids, about 650 amino acids to about 3000 amino acids, about 650 amino acids to about 2500 amino acids, about 650 amino acids to about 2000 amino acids amino acids, about 650 amino acids to about 1500 amino acids, about 650 amino acids to about 1000 amino acids, about 650 amino acids to about 950 amino acids, about 650 amino acids to about 900 amino acids, about 650 amino acids to about 850 amino acids, about 650 amino acids to about 800 amino acids, about 650 amino acids to about 750 amino acids, about 650 amino acids to about 700 amino acids, about 700 amino acids to about 3000 amino acids, about 700 amino acids to about 2500 amino acids, about 700 amino acids to about 2000 amino acids, about 700 amino acids to about 1500 amino acids, about 700 amino acids to about 1000 amino acids, about 700 amino acids to about 950 amino acids, about 700 amino acids to about 900 amino acids, about 700 amino acids to about 850 amino acids, about 700 amino acids to about 800 amino acids, about 700 amino acids to about 750 amino acids, about 750 amino acids to about 3000 amino acids, about 750 amino acids to about 2500 amino acids, about 750 amino acids to about 2000 amino acids, about 750 amino acids to about 1500 amino acids, about 750 amino acids to about 1000 amino acids, about 750 amino acids to about 950 amino acids, about 750 amino acids to about 900 amino acids amino acids, about 750 amino acids to about 850 amino acids, about 750 amino acids to about 800 amino acids, about 800 amino acids to about 3000 amino acids, about 800 amino acids to about 2500 amino acids, about 800 amino acids to about 2000 amino acids, about 800 amino acids to about 1500 amino acids, about 800 amino acids to about 1000 amino acids, about 800 amino acids to about 950 amino acids, about 800 amino acids to about 900 amino acids, about 800 amino acids to about 850 amino acids, about 850 amino acids to about 3000 amino acids, about 850 amino acids to about 2500 amino acids, about 850 amino acids to about 2000 amino acids, about 850 amino acids to about 1500 amino acids, about 850 amino acids to about 1000 amino acids, about 850 amino acids to about 950 amino acids, about 850 amino acids to about 900 amino acids, about 900 amino acids to about 3000 amino acids, about 900 amino acids to about 2500 amino acids, about 900 amino acids to about 2000 amino acids, about 900 amino acids to about 1500 amino acids, about 900 amino acids to about 1000 amino acids, about 900 amino acids to about 950 amino acids, about 950 amino acids to about 3000 amino acids, about 950 amino acids to about 2500 amino acids amino acids, about 950 amino acids to about 2000 amino acids, about 950 amino acids to about 1500 amino acids, about 950 amino acids to about 1000 amino acids, about 1000 amino acids to about 3000 amino acids, about 1000 amino acids to about 2500 amino acids, about 1000 amino acids to about 2000 amino acids, about 1000 amino acids to about 1500 amino acids, about 1500 amino acids to about 3000 amino acids, about 1500 amino acids to about 2500 amino acids, about 1500 amino acids to about 2000 amino acids, about 2000 amino acids to about 3000 amino acids, about 2000 amino acids to about 2500 amino acids, or about It can have a total length of 2500 amino acids to about 3000 amino acids.
本明細書に記載の一本鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)と可溶性組織因子ドメイン(例えば、本明細書に記載の例示的な可溶性組織因子ドメインのうちのいずれか)は、互いに直接隣接している。本明細書に記載の一本鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、一本鎖キメラポリペプチドは、第1の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)と可溶性組織因子ドメイン(例えば、本明細書に記載の例示的な可溶性組織因子ドメインのうちのいずれか)との間にリンカー配列(例えば、本明細書に記載の又は当該技術分野で既知の例示的なリンカー配列のうちのいずれか)を更に含む。本明細書に記載の一本鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、可溶性組織因子ドメイン(例えば、本明細書に記載の例示的な可溶性組織因子ドメインのうちのいずれか)及び第2の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)は、互いに直接隣接している。本明細書に記載の一本鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、一本鎖キメラポリペプチドは、可溶性組織因子ドメイン(例えば、本明細書に記載の例示的な可溶性組織因子ドメインのうちのいずれか)と第2の標的結合ドメイン(本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)との間にリンカー配列(例えば、本明細書に記載の又は当該技術分野で既知の例示的なリンカー配列のうちのいずれか)を更に含む。 In some embodiments of any of the single chain chimeric polypeptides described herein, the first target binding domain (e.g., an exemplary any of the target binding domains) and the soluble tissue factor domain (eg, any of the exemplary soluble tissue factor domains described herein) are directly adjacent to each other. In some embodiments of any of the single chain chimeric polypeptides described herein, the single chain chimeric polypeptide comprises a first target binding domain (e.g., a any of the exemplary target binding domains known in the art) and the soluble tissue factor domain (e.g., any of the exemplary soluble tissue factor domains described herein). (eg, any of the exemplary linker sequences described herein or known in the art). In some embodiments of any of the single chain chimeric polypeptides described herein, a soluble tissue factor domain (e.g., any of the exemplary soluble tissue factor domains described herein) ) and the second target binding domain (eg, any of the exemplary target binding domains described herein or known in the art) are directly adjacent to each other. In some embodiments of any of the single-chain chimeric polypeptides described herein, the single-chain chimeric polypeptide comprises a soluble tissue factor domain (e.g., exemplary soluble tissue factor domain) and the second target binding domain (any of the exemplary target binding domains described herein or known in the art) (e.g., , any of the exemplary linker sequences described herein or known in the art).
本明細書に記載の一本鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)と第2の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)は、互いに直接隣接している。本明細書に記載の一本鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、一本鎖キメラポリペプチドは、第1の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)と第2の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)との間にリンカー配列(例えば、本明細書に記載の又は当該技術分野で既知の例示的なリンカー配列のうちのいずれか)を更に含む。本明細書に記載の一本鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第2の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)と可溶性組織因子ドメイン(例えば、本明細書に記載の例示的な可溶性組織因子ドメインのうちのいずれか)は、互いに直接隣接している。本明細書に記載の一本鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、一本鎖キメラポリペプチドは、第2の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)と可溶性組織因子ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な可溶性組織因子ドメインのうちのいずれか)との間にリンカー配列(例えば、本明細書に記載の又は当該技術分野で既知の例示的なリンカー配列のうちのいずれか)を更に含む。 In some embodiments of any of the single chain chimeric polypeptides described herein, the first target binding domain (e.g., an exemplary any of the target binding domains) and the second target binding domain (e.g., any of the exemplary target binding domains described herein or known in the art) are immediately adjacent to each other. ing. In some embodiments of any of the single chain chimeric polypeptides described herein, the single chain chimeric polypeptide comprises a first target binding domain (e.g., a any of the exemplary target binding domains known in the art) and a second target binding domain (e.g., any of the exemplary target binding domains described herein or known in the art) or ) (eg, any of the exemplary linker sequences described herein or known in the art). In some embodiments of any of the single chain chimeric polypeptides described herein, a second target binding domain (e.g., an exemplary any of the target binding domains) and the soluble tissue factor domain (eg, any of the exemplary soluble tissue factor domains described herein) are directly adjacent to each other. In some embodiments of any of the single chain chimeric polypeptides described herein, the single chain chimeric polypeptide comprises a second target binding domain (e.g., a any of the exemplary target binding domains known in the art) and a soluble tissue factor domain (e.g., any of the exemplary soluble tissue factor domains described herein or known in the art) ) (eg, any of the exemplary linker sequences described herein or known in the art).
いくつかの実施形態では、一本鎖キメラポリペプチドは、
QIVLTQSPAIMSASPGEKVTMTCSASSSVSYMNWYQQKSGTSPKRWIYDTSKLASGVPAHFRGSGSGTSYSLTISGMEAEDAATYYCQQWSSNPFTFGSGTKLEINRGGGGSGGGGSGGGGSQVQLQQSGAELARPGASVKMSCKASGYTFTRYTMHWVKQRPGQGLEWIGYINPSRGYTNYNQKFKDKATLTTDKSSSTAYMQLSSLTSEDSAVYYCARYYDDHYCLDYWGQGTTLTVSSSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFREVQLQQSGPELVKPGASVKMSCKASGYTFTSYVIQWVKQKPGQGLEWIGSINPYNDYTKYNEKFKGKATLTSDKSSITAYMEFSSLTSEDSALYYCARWGDGNYWGRGTTLTVSSGGGGSGGGGSGGGGSDIEMTQSPAIMSASLGERVTMTCTASSSVSSSYFHWYQQKPGSSPKLCIYSTSNLASGVPPRFSGSGSTSYSLTISSMEAEDAATYFCHQYHRSPTFGGGTKLETKR(配列番号85)、と少なくとも70%同一(例えば、少なくとも75%同一、少なくとも80%同一、少なくとも85%同一、少なくとも90%同一、少なくとも95%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the single-chain chimeric polypeptide comprises
QIVLTQSPAIMSASPGEKVTMTCSASSSVSYMNWYQQKSGTSPKRWIYDTSKLASGVPAHFRGSGSGTSYSLTISGMEAEDAATYYCQQWSSNPFTFGSGTKLEINRGGGGSGGGGGSGGGGGSQVQLQQSGAELARPGASVK MSCKASGYTFTRYTMHWVKQRPGQGLEWIGYINPSRGYTNYNQKFKDKATLTTDKSSSTAYMQLSSLTSEDSAVYYCARYYDDHYCLDYWGQGTTLTVSSSSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKS GDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNNTNEFLIDVDKGEN YCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFREVQLQQSGPELVKPGASVKMSCKASGYTFTSYVIQWVKQKPGQGLEWIGSINPYNDYTKYNEKFKGKATLTSDKSSSITAYMEFSSLTSEDSALYYCARWGDGNYWGRGTT at least 70% identical (e.g., at least 75% identical to , at least 80% identical, at least 85% identical, at least 90% identical, at least 95% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、一本鎖キメラポリペプチドは、
CAGATCGTGCTGACCCAAAGCCCCGCCATCATGAGCGCTAGCCCCGGTGAGAAGGTGACCATGACATGCTCCGCTTCCAGCTCCGTGTCCTACATGAACTGGTATCAGCAGAAAAGCGGAACCAGCCCCAAAAGGTGGATCTACGACACCAGCAAGCTGGCCTCCGGAGTGCCCGCTCATTTCCGGGGCTCTGGATCCGGCACCAGCTACTCTTTAACCATTTCCGGCATGGAAGCTGAAGACGCTGCCACCTACTATTGCCAGCAATGGAGCAGCAACCCCTTCACATTCGGATCTGGCACCAAGCTCGAAATCAATCGTGGAGGAGGTGGCAGCGGCGGCGGTGGATCCGGCGGAGGAGGAAGCCAAGTTCAACTCCAGCAGAGCGGCGCTGAACTGGCCCGGCCCGGCGCCTCCGTCAAGATGAGCTGCAAGGCTTCCGGCTATACATTTACTCGTTACACAATGCATTGGGTCAAGCAGAGGCCCGGTCAAGGTTTAGAGTGGATCGGATATATCAACCCTTCCCGGGGCTACACCAACTATAACCAAAAGTTCAAGGATAAAGCCACTTTAACCACTGACAAGAGCTCCTCCACCGCCTACATGCAGCTGTCCTCTTTAACCAGCGAGGACTCCGCTGTTTACTACTGCGCTAGGTATTACGACGACCACTACTGTTTAGACTATTGGGGACAAGGTACCACTTTAACCGTCAGCAGCTCCGGCACCACCAATACCGTGGCCGCTTATAACCTCACATGGAAGAGCACCAACTTCAAGACAATTCTGGAATGGGAACCCAAGCCCGTCAATCAAGTTTACACCGTGCAGATCTCCACCAAATCCGGAGACTGGAAGAGCAAGTGCTTCTACACAACAGACACCGAGTGTGATTTAACCGACGAAATCGTCAAGGACGTCAAGCAAACCTATCTGGCTCGGGTCTTTTCCTACCCCGCTGGCAATGTCGAGTCCACCGGCTCCGCTGGCGAGCCTCTCTACGAGAATTCCCCCGAATTCACCCCTTATTTAGAGACCAATTTAGGCCAGCCTACCATCCAGAGCTTCGAGCAAGTTGGCACCAAGGTGAACGTCACCGTCGAGGATGAAAGGACTTTAGTGCGGCGGAATAACACATTTTTATCCCTCCGGGATGTGTTCGGCAAAGACCTCATCTACACACTGTACTATTGGAAGTCCAGCTCCTCCGGCAAAAAGACCGCTAAGACCAACACCAACGAGTTTTTAATTGACGTGGACAAAGGCGAGAACTACTGCTTCAGCGTGCAAGCCGTGATCCCTTCTCGTACCGTCAACCGGAAGAGCACAGATTCCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGGTCCAGCTGCAGCAGAGCGGACCCGAACTCGTGAAACCCGGTGCTTCCGTGAAAATGTCTTGTAAGGCCAGCGGATACACCTTCACCTCCTATGTGATCCAGTGGGTCAAACAGAAGCCCGGACAAGGTCTCGAGTGGATCGGCAGCATCAACCCTTACAACGACTATACCAAATACAACGAGAAGTTTAAGGGAAAGGCTACTTTAACCTCCGACAAAAGCTCCATCACAGCCTACATGGAGTTCAGCTCTTTAACATCCGAGGACAGCGCTCTGTACTATTGCGCCCGGTGGGGCGACGGCAATTACTGGGGACGGGGCACAACACTGACCGTGAGCAGCGGAGGCGGAGGCTCCGGCGGAGGCGGATCTGGCGGTGGCGGCTCCGACATCGAGATGACCCAGTCCCCCGCTATCATGTCCGCCTCTTTAGGCGAGCGGGTCACAATGACTTGTACAGCCTCCTCCAGCGTCTCCTCCTCCTACTTCCATTGGTACCAACAGAAACCCGGAAGCTCCCCTAAACTGTGCATCTACAGCACCAGCAATCTCGCCAGCGGCGTGCCCCCTAGGTTTTCCGGAAGCGGAAGCACCAGCTACTCTTTAACCATCTCCTCCATGGAGGCTGAGGATGCCGCCACCTACTTTTGTCACCAGTACCACCGGTCCCCCACCTTCGGAGGCGGCACCAAACTGGAGACAAAGAGG(配列番号86)、と少なくとも70%同一(例えば、少なくとも75%同一、少なくとも80%同一、少なくとも85%同一、少なくとも90%同一、少なくとも95%同一、少なくとも99%同一、又は100%同一)である配列を含む核酸によってコードされる。
In some embodiments, the single-chain chimeric polypeptide comprises
CAGATCGTGCTGACCCAAAGCCCCCGCCATCATGAGCGCTAGCCCCGGTGAGAAGGTGACCATGACATGCTCCGCTTCCAGCTCCGTGTCCTACATGAACTGGTATCAGCAGAAAAGCGGAACCAGCCCCAAAGGTGGATCTACGACACCAGCAAGCTGGCCTCCGGAGTGCCCG CTCATTTCCGGGGCTCTGGATCCGGCACCAGCTACTCTTTAACCATTTCGGCATGGAAGCTGAAGACGCTGCCACCTACTATTGCCAGCAATGGAGCAGCAACCCCCTTCACATTCGGATCTGGCACCAAGCTCGAAAATCAATCGTGGAGGAGGTGGCAGCGGCGGCGGTGGAT CCGGCGGAGGAGGAAGCCAAGTTCAACTCCAGCAGAGCGGCGCTGAACTGGCCCGGCCCGGCGCCTCCGTCAAGATGAGCTGCAAGGCTTCCGGCTATACATTTTACTCGTTACACAATGCATTGGGTCAAGCAGAGGCCCCGGTCAAGGTTTAGAGTGGATCGGATATAT CAACCCTTCCCGGGGGCTACACCAACTATAACCAAAGTTCAAGGATAAAGCCACTTTAACCACTGACAAGAGCTCCTCCACCGCCTACATGCAGCTGTCCTCTTTAACCAGCGAGGACTCCGCTGTTACTACTGCGCTAGGGTATTACGACGACCACTACTGTTTAGACTATTGGGGACAAGGGTACC ACTTTAACCGTCAGCAGCTCCGGCACCACCAATACCGTGGCCGCTTATAACCTCACATGGAAGAGCACCAACTTCAAGACAATTCTGGAATGGGAACCCAAGCCCCGTCAATCAAGTTTACACCGTGCAGATCTCCACCAAAATCCGGAGACTGGGAAGAGCAAGTGCTTCTACACAACAGACACCGAGTGT GATTTAACCGACGAAATCGTCAAGGACGTCAAGCAAACCTATCTGGCTCGGGTCTTTTTCCTACCCCCGCTGGCAATGTCGAGTCCACCGGCTCCGCTGGCGAGCTCTCTACGAGAATTCCCCCGAATTCACCCCTTATTTAGAGACCAATTTAGGCCAGCTACCATCCAGAGCTTCGAGCAAG TTGGCACCAAGGTGAACGTCACCGTCGAGGATGAAAGGACTTTAGTGCGGCGGAATAACACATTTTTTATCCCTCCGGGATGTGTTCGGCAAAGACCTCATCTACACACTGTACTATTGGAAGTCCAGCTCCTCCGGCAAAAAAGACCGCTAAGACCAACACCAACGAGTTTTT ATTGACGTGGACAAAGGCGAGAACTACTGCTTCAGCGTGCAAGCCGTGATCCCTTCGTACCGTCAACCGGAAGAGCACAGATTCCCCCGTTGAGTGCATGGGCCAAGAAAGGGCGAGTTCCGGGAGGTCCAGCTGCAGCAGAGCGGACCCGAACTCGTGAAACCCGG TGCTTCCGTGAAATGTCTTGTAAGGCCAGCGGATACACCTTCACCTCCTATGTGATCCAGTGGGTCAAACAGAAGCCCCGGACAAGGTCTCGAGTGGATCGGCAGCATCAACCCTTACAACGACTATACCAAATACAACGAGAAGTTTAAGGGAAAGGCTACTTTTAACCTCCGACAA AAGCTCCATCACAGCCCTACATGGAGTTCAGCTCTTTAACATCCGAGGACAGCGCTCTGTACTATTGCGCCCGGTGGGGCGACGGCCAATTACTGGGGACGGGGCACAACACTGACCGTGAGCAGCGGAGGCGGAGGCTCCGGCGGAGGCGGATCTGGCGGTGGCGGCTCCGAC ATCGAGATGACCCAGTCCCCCGCTATCATGTCCGCCTCTTTAGGCGAGCGGGTCACAATGACTTGTACAGCCTCCTCCAGCGTCTCCTCCTCCTACTTCCATTGGTACCAACAGAAACCGGAAGCTCCCCTAAACTGTGCCATCTACAGCACCAGCAATCTCGCCAGCGGCGTGCCCCCTA at least 70% identical (e.g., at least 75% identical, at least 80% identical , at least 85% identical, at least 90% identical, at least 95% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、一本鎖キメラポリペプチドは、
MKWVTFISLLFLFSSAYSQIVLTQSPAIMSASPGEKVTMTCSASSSVSYMNWYQQKSGTSPKRWIYDTSKLASGVPAHFRGSGSGTSYSLTISGMEAEDAATYYCQQWSSNPFTFGSGTKLEINRGGGGSGGGGSGGGGSQVQLQQSGAELARPGASVKMSCKASGYTFTRYTMHWVKQRPGQGLEWIGYINPSRGYTNYNQKFKDKATLTTDKSSSTAYMQLSSLTSEDSAVYYCARYYDDHYCLDYWGQGTTLTVSSSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFREVQLQQSGPELVKPGASVKMSCKASGYTFTSYVIQWVKQKPGQGLEWIGSINPYNDYTKYNEKFKGKATLTSDKSSITAYMEFSSLTSEDSALYYCARWGDGNYWGRGTTLTVSSGGGGSGGGGSGGGGSDIEMTQSPAIMSASLGERVTMTCTASSSVSSSYFHWYQQKPGSSPKLCIYSTSNLASGVPPRFSGSGSTSYSLTISSMEAEDAATYFCHQYHRSPTFGGGTKLETKR(配列番号87)、と少なくとも70%同一(例えば、少なくとも75%同一、少なくとも80%同一、少なくとも85%同一、少なくとも90%同一、少なくとも95%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the single-chain chimeric polypeptide comprises
MKWVTFISLLFLFSSAYSQIVLTQSPAIMSASPGEKVTMTCSASSSVSYMNWYQQKSGTSPKRWIYDTSKLASGVPAHFRGSGSGTSSYSLTISGMEAEDAATYYCQWSSNPFTFGSGTKLEINRGGGGSGGGGSGGGGG SQVQLQQSGAELARPGASVKMSCKASGYTFTRYTMHWVKQRPGQGLEWIGYINPSRGYTNYNQKFKDKATLTTTDKSSSSTAYMQLSSLTSEDSAVYYCARYYDDHYCLDYWGQGTTLTVSSSGTTNTVAAYNLTWKSTNFKTILE WEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNNTFLSLRDVFGKDLIYTLYYWKSSSSG KKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFREVQLQQSGPELVKPGASVKMSCKASGYTFTSYVIQWVKQKPGQGLEWIGSINPYNDYTKYNEKFKGKATLTSDKSSITAYMEFSLTSEDSAL YYCARWGDGNYWGRGTTLTVSSGGGGSGGGGGSGGGSDIEMTQSPAIMSASLGERVTMTCTASSSVSSSYFHWYQQKPGSSPKLCIYSTSNLASGVPPRFSGSGSTSYSLTISSMEAEDAATYFCHQYHRSPTFGGGTKLETKR (SEQ ID NO: 87 ), at least 70% identical (e.g., at least 75% identical, at least 80% identical, at least 85% identical, at least 90% identical, at least 95% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、一本鎖キメラポリペプチドは、
ATGAAGTGGGTGACCTTCATCAGCTTATTATTTTTATTCAGCTCCGCCTATTCCCAGATCGTGCTGACCCAAAGCCCCGCCATCATGAGCGCTAGCCCCGGTGAGAAGGTGACCATGACATGCTCCGCTTCCAGCTCCGTGTCCTACATGAACTGGTATCAGCAGAAAAGCGGAACCAGCCCCAAAAGGTGGATCTACGACACCAGCAAGCTGGCCTCCGGAGTGCCCGCTCATTTCCGGGGCTCTGGATCCGGCACCAGCTACTCTTTAACCATTTCCGGCATGGAAGCTGAAGACGCTGCCACCTACTATTGCCAGCAATGGAGCAGCAACCCCTTCACATTCGGATCTGGCACCAAGCTCGAAATCAATCGTGGAGGAGGTGGCAGCGGCGGCGGTGGATCCGGCGGAGGAGGAAGCCAAGTTCAACTCCAGCAGAGCGGCGCTGAACTGGCCCGGCCCGGCGCCTCCGTCAAGATGAGCTGCAAGGCTTCCGGCTATACATTTACTCGTTACACAATGCATTGGGTCAAGCAGAGGCCCGGTCAAGGTTTAGAGTGGATCGGATATATCAACCCTTCCCGGGGCTACACCAACTATAACCAAAAGTTCAAGGATAAAGCCACTTTAACCACTGACAAGAGCTCCTCCACCGCCTACATGCAGCTGTCCTCTTTAACCAGCGAGGACTCCGCTGTTTACTACTGCGCTAGGTATTACGACGACCACTACTGTTTAGACTATTGGGGACAAGGTACCACTTTAACCGTCAGCAGCTCCGGCACCACCAATACCGTGGCCGCTTATAACCTCACATGGAAGAGCACCAACTTCAAGACAATTCTGGAATGGGAACCCAAGCCCGTCAATCAAGTTTACACCGTGCAGATCTCCACCAAATCCGGAGACTGGAAGAGCAAGTGCTTCTACACAACAGACACCGAGTGTGATTTAACCGACGAAATCGTCAAGGACGTCAAGCAAACCTATCTGGCTCGGGTCTTTTCCTACCCCGCTGGCAATGTCGAGTCCACCGGCTCCGCTGGCGAGCCTCTCTACGAGAATTCCCCCGAATTCACCCCTTATTTAGAGACCAATTTAGGCCAGCCTACCATCCAGAGCTTCGAGCAAGTTGGCACCAAGGTGAACGTCACCGTCGAGGATGAAAGGACTTTAGTGCGGCGGAATAACACATTTTTATCCCTCCGGGATGTGTTCGGCAAAGACCTCATCTACACACTGTACTATTGGAAGTCCAGCTCCTCCGGCAAAAAGACCGCTAAGACCAACACCAACGAGTTTTTAATTGACGTGGACAAAGGCGAGAACTACTGCTTCAGCGTGCAAGCCGTGATCCCTTCTCGTACCGTCAACCGGAAGAGCACAGATTCCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGGTCCAGCTGCAGCAGAGCGGACCCGAACTCGTGAAACCCGGTGCTTCCGTGAAAATGTCTTGTAAGGCCAGCGGATACACCTTCACCTCCTATGTGATCCAGTGGGTCAAACAGAAGCCCGGACAAGGTCTCGAGTGGATCGGCAGCATCAACCCTTACAACGACTATACCAAATACAACGAGAAGTTTAAGGGAAAGGCTACTTTAACCTCCGACAAAAGCTCCATCACAGCCTACATGGAGTTCAGCTCTTTAACATCCGAGGACAGCGCTCTGTACTATTGCGCCCGGTGGGGCGACGGCAATTACTGGGGACGGGGCACAACACTGACCGTGAGCAGCGGAGGCGGAGGCTCCGGCGGAGGCGGATCTGGCGGTGGCGGCTCCGACATCGAGATGACCCAGTCCCCCGCTATCATGTCCGCCTCTTTAGGCGAGCGGGTCACAATGACTTGTACAGCCTCCTCCAGCGTCTCCTCCTCCTACTTCCATTGGTACCAACAGAAACCCGGAAGCTCCCCTAAACTGTGCATCTACAGCACCAGCAATCTCGCCAGCGGCGTGCCCCCTAGGTTTTCCGGAAGCGGAAGCACCAGCTACTCTTTAACCATCTCCTCCATGGAGGCTGAGGATGCCGCCACCTACTTTTGTCACCAGTACCACCGGTCCCCCACCTTCGGAGGCGGCACCAAACTGGAGACAAAGAGG(配列番号88)、と少なくとも70%同一(例えば、少なくとも75%同一、少なくとも80%同一、少なくとも85%同一、少なくとも90%同一、少なくとも95%同一、少なくとも99%同一、又は100%同一)である配列を含む核酸によってコードされる。
In some embodiments, the single-chain chimeric polypeptide comprises
ATGAAGTGGGTGACCTTCATCAGCTTATTATTTTATTCAGCTCCGCCTATTCCCAGATCGTGCTGACCCAAAGCCCCCGCCATCATGAGCGCTAGCCCCGGTGAGAAGGTGACCATGACATGCTCCGCTTCCAGCTCCGTGTCCTACATGAACTGGTATCAGCAGAAAAGCGGAAC CAGCCCCAAAAGGTGGATCTACGACACCAGCAAGCTGGCCTCCGGAGTGCCCGCTCATTTCCGGGGCTCTGGATCCGGCACCAGCTACTCTTTAACCATTTCCGGCATGGAAGCCTGAAGACGCTGCCACCTACTATTGCCAGCCAATGGAGCAGCAACCCCTTCACATTCGGATCTGGC ACCAAGCTCGAAAATCAATCGTGGAGGAGGTGGCAGCGGCGGCGGGTGGATCCGGCGGAGGAGGAAGCCAAGTTCAACTCCAGCAGAGCGGCGCTGAACTGGCCCGGCCCCGGCGCCTCCGTCAAGATGAGCTGCAAGGCTTCCGGCTATACATTTACTCGTTACACAATG CATTGGGTCAAGCAGAGGCCCGGTCAAGGTTTAGAGTGGATCGGATATATCAACCCTTCCCGGGGGCTACACCAACTATAACCAAAGTTCAAGGATAAAGCCACTTTAACCACTGACAAGAGCTCCTCCACCGCCTACATGCAGCTGTCCTCTTTAACCAGCGGAGGACTCCGCTGTTACT ACTGCGCTAGGTATTACGACGACCACTACTGTTTAGACTATTGGGGACAAGGTACCACTTTTAACCGTCAGCAGCTCCGGCACCACCAATACCGTGGCCGCTTATAACCTCACATGGAAGAGCACCAACTTCAGACAATTCTGGAATGGGAACCCAAGCCCCGTCAATCAAGTTTACACCGTGCAG ATCTCCACCAAATCCGGAGACTGGAAGAGCAAGTGCTTTCACACAACAGACACCGAGTGTGATTTAACCGACGAAAATCGTCAAGGACGTCAAGCAAACCTATCTGGCTCGGGTCTTTTCCTACCCCGCTGGCAATGTCGAGTCCACCGGCTCCGCTGGCGAGCTCTCTACGAGAATTCCCCCGA ATTCACCCTTATTTAGAGACCAATTTAGGCCAGCTCTACCATCCAGAGCTTCGAGCAAGTTTGGCACCAAGGTGAACGTCACCGTCGAGGATGAAAGGACTTTAGTGCGGCGGAATAACACATTTTTATCCCCTCCGGGATGTGTTCGGCAAAGACCTCATCTACACACTGTACTATTG GAAGTCCAGCTCCTCCGGCAAAAAGACCGCTAAGACCAACACCAACGAGTTTTAATTGACGTGGACAAAGGCGAGAACTACTGCTTCAGCGTGCAAGCCGTGATCCCTTCGTACCGTCAACCGGAAGAGCACAGATTCCCCCGTTGAGTGCATGGGCCAAGAAAAGGGGC GAGTTCCGGGAGGTCCAGCTGCAGCAGAGCGGACCCGAACTCGTGAAACCCCGGTGCTTCCGTGAAAATGTCTTGTAAGGCCAGCGGATACACCTTCACCTCCTATGTGATCCAGTGGGTCAAACAGAAGCCCGGACAAGGTCTCGAGTGGATCGGCAGCATCAACCCTTA CAACGACTATACCAAATACAACGAGAAGTTTAAGGGAAAGGCTACTTTTAACCTCCGACAAAAGCTCCATCACAGCCTACATGGAGTTCAGCTCTTTAACATCCGAGGACAGCGCTCTGTACTATTGCGCCCCGGTGGGGGCGACGGCCAATTACTGGGGACGGGGGCCACAACACTGACCGTGAGCAGC GGAGGCGGAGGCTCCGGCGGAGGCGGATCTGGCGGTGGCGGCTCCGACATCGAGATGACCCAGTCCCCCGCTATCATGTCCGCCTCTTTAGGCGAGCGGGTCACAATGACTTGTACAGCCTCCTCCAGCGTCCTCCTCCTCCTACTTCCATTGGTACCAACAGAAACCCGGAAGCT CCCCTAAACTGTGCATCTACAGCACCAGCAATCTCGCCAGCGGCGTGTGCCCCCTAGGTTTTCCGGAAGCGGAAGCACCAGCTACTCTTTAACCCATCTCCTCCATGGAGGCTGAGGATGCCGCCACCTACTTTTGTCACCAGTACCACCGGTCCCCCACCTTCGGAGGCGGCACCAA ACTGGAGACAAAGAGG (SEQ ID NO: 88), at least 70% identical (e.g., at least 75% identical, at least 80% identical, at least 85% identical, at least 90% identical, at least 95% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、一本鎖キメラポリペプチドは、
VQLQQSGPELVKPGASVKMSCKASGYTFTSYVIQWVKQKPGQGLEWIGSINPYNDYTKYNEKFKGKATLTSDKSSITAYMEFSSLTSEDSALYYCARWGDGNYWGRGTTLTVSSGGGGSGGGGSGGGGSDIEMTQSPAIMSASLGERVTMTCTASSSVSSSYFHWYQQKPGSSPKLCIYSTSNLASGVPPRFSGSGSTSYSLTISSMEAEDAATYFCHQYHRSPTFGGGTKLETKRSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFREQIVLTQSPAIMSASPGEKVTMTCSASSSVSYMNWYQQKSGTSPKRWIYDTSKLASGVPAHFRGSGSGTSYSLTISGMEAEDAATYYCQQWSSNPFTFGSGTKLEINRGGGGSGGGGSGGGGSQVQLQQSGAELARPGASVKMSCKASGYTFTRYTMHWVKQRPGQGLEWIGYINPSRGYTNYNQKFKDKATLTTDKSSSTAYMQLSSLTSEDSAVYYCARYYDDHYCLDYWGQGTTLTVSS(配列番号89)、と少なくとも70%同一(例えば、少なくとも75%同一、少なくとも80%同一、少なくとも85%同一、少なくとも90%同一、少なくとも95%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the single-chain chimeric polypeptide comprises
VQLQQSGPELVKPGASVKMSCKASGYTFTSYVIQWVKQKPGQGLEWIGSINPYNDYTKYNEKFKGKATLTSDKSSSITAYMEFSSLTSEDSALYYCARWGDGNYWGRGTTLTVSSGGGGGSGGGGSGGGGSDIEMTQSPAIM SASLGERVTMTCTASSVSSSSYFHWYQQKPGSSPKLCIYSTSNLASGVPPRFSGSGSTSYSLTISSMEAEDAATYFCHQYHRSPTFGGGTKLETKRSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTD TECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTV NRKSTDSPVECMGQEKGEFREQIVLTQSPAIMSASPGEKVTMTCSASSSVSYMNWYQQKSGTSPKRWIYDTSKLASGVPAHFRGSGSGTSSYSLTISGMEAEDAATYYCQWSSSNPFTFGSGTKLEINRGGGGSGGGGSGGGGS at least 70% identical (e.g., at least 75% identical, at least 80% identical, at least 85% identical, at least 90% identical, at least 95% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、一本鎖キメラポリペプチドは、
GTGCAGCTGCAGCAGTCCGGACCCGAACTGGTCAAGCCCGGTGCCTCCGTGAAAATGTCTTGTAAGGCTTCTGGCTACACCTTTACCTCCTACGTCATCCAATGGGTGAAGCAGAAGCCCGGTCAAGGTCTCGAGTGGATCGGCAGCATCAATCCCTACAACGATTACACCAAGTATAACGAAAAGTTTAAGGGCAAGGCCACTCTGACAAGCGACAAGAGCTCCATTACCGCCTACATGGAGTTTTCCTCTTTAACTTCTGAGGACTCCGCTTTATACTATTGCGCTCGTTGGGGCGATGGCAATTATTGGGGCCGGGGAACTACTTTAACAGTGAGCTCCGGCGGCGGCGGAAGCGGAGGTGGAGGATCTGGCGGTGGAGGCAGCGACATCGAGATGACACAGTCCCCCGCTATCATGAGCGCCTCTTTAGGAGAACGTGTGACCATGACTTGTACAGCTTCCTCCAGCGTGAGCAGCTCCTATTTCCACTGGTACCAGCAGAAACCCGGCTCCTCCCCTAAACTGTGTATCTACTCCACAAGCAATTTAGCTAGCGGCGTGCCTCCTCGTTTTAGCGGCTCCGGCAGCACCTCTTACTCTTTAACCATTAGCTCTATGGAGGCCGAAGATGCCGCCACATACTTTTGCCATCAGTACCACCGGTCCCCTACCTTTGGCGGAGGCACAAAGCTGGAGACCAAGCGGAGCGGCACCACCAACACAGTGGCCGCCTACAATCTGACTTGGAAATCCACCAACTTCAAGACCATCCTCGAGTGGGAGCCCAAGCCCGTTAATCAAGTTTATACCGTGCAGATTTCCACCAAGAGCGGCGACTGGAAATCCAAGTGCTTCTATACCACAGACACCGAGTGCGATCTCACCGACGAGATCGTCAAAGACGTGAAGCAGACATATTTAGCTAGGGTGTTCTCCTACCCCGCTGGAAACGTGGAGAGCACCGGATCCGCTGGAGAGCCTTTATACGAGAACTCCCCCGAATTCACCCCCTATCTGGAAACCAATTTAGGCCAGCCCACCATCCAGAGCTTCGAACAAGTTGGCACAAAGGTGAACGTCACCGTCGAAGATGAGAGGACTTTAGTGCGGAGGAACAATACATTTTTATCCTTACGTGACGTCTTCGGCAAGGATTTAATCTACACACTGTATTACTGGAAGTCTAGCTCCTCCGGCAAGAAGACCGCCAAGACCAATACCAACGAATTTTTAATTGACGTGGACAAGGGCGAGAACTACTGCTTCTCCGTGCAAGCTGTGATCCCCTCCCGGACAGTGAACCGGAAGTCCACCGACTCCCCCGTGGAGTGCATGGGCCAAGAGAAGGGAGAGTTTCGTGAGCAGATCGTGCTGACCCAGTCCCCCGCTATTATGAGCGCTAGCCCCGGTGAAAAGGTGACTATGACATGCAGCGCCAGCTCTTCCGTGAGCTACATGAACTGGTATCAGCAGAAGTCCGGCACCAGCCCTAAAAGGTGGATCTACGACACCAGCAAGCTGGCCAGCGGCGTCCCCGCTCACTTTCGGGGCTCCGGCTCCGGAACAAGCTACTCTCTGACCATCAGCGGCATGGAAGCCGAGGATGCCGCTACCTATTACTGTCAGCAGTGGAGCTCCAACCCCTTCACCTTTGGATCCGGCACCAAGCTCGAGATTAATCGTGGAGGCGGAGGTAGCGGAGGAGGCGGATCCGGCGGTGGAGGTAGCCAAGTTCAGCTCCAGCAAAGCGGCGCCGAACTCGCTCGGCCCGGCGCTTCCGTGAAGATGTCTTGTAAGGCCTCCGGCTATACCTTCACCCGGTACACAATGCACTGGGTCAAGCAACGGCCCGGTCAAGGTTTAGAGTGGATTGGCTATATCAACCCCTCCCGGGGCTATACCAACTACAACCAGAAGTTCAAGGACAAAGCCACCCTCACCACCGACAAGTCCAGCAGCACCGCTTACATGCAGCTGAGCTCTTTAACATCCGAGGATTCCGCCGTGTACTACTGCGCTCGGTACTACGACGATCATTACTGCCTCGATTACTGGGGCCAAGGTACCACCTTAACAGTCTCCTCC(配列番号90)、と少なくとも70%同一(例えば、少なくとも75%同一、少なくとも80%同一、少なくとも85%同一、少なくとも90%同一、少なくとも95%同一、少なくとも99%同一、又は100%同一)である配列を含む核酸によってコードされる。
In some embodiments, the single-chain chimeric polypeptide comprises
GTGCAGCTGCAGCAGTCCGGACCCGAACTGGTCAAGCCCGGTGCCTCCGTGAAAATGTCTTGTAAGGCTTCTGGCTACACCTTTACCTCCTACGTCATCCAATGGGTGAAGCAGAAGCCCCGGTCAAGGTTCTCGAGTGGATCGGCAGCATCAATCCCTACAACGATTACAC CAAGTATAACGAAAAGTTTAAGGGCAAGGCCACTCTGACAAGCGCACAAGAGCTCCATTACGCCTACATGGAGTTTTCCTCTTTAACTTCTGAGGACTCCGCTTTATACTATTGCGCTCGTTGGGGGCGATGGCAATTATTGGGGCCGGGGGAACTACTTTTAACAGTGAGCTCCGGCG GCGGCGGAAGCGGAGGTGGAGGATCTGGCGGTGGAGGCAGCGACATCGAGATGACACAGTCCCCCGCTATCATGAGCGCCTCTTTAGGAGAACGTGTGACCATGACTTGTACAGCTTCCTCCAGCGTGGAGCAGCTCCTATTTCCACTGGTACCAGCAGAAACCCGGCTCCTCCCCTA AACTGTGTATCTACTCCACAAGCAATTTAGCTAGCGGCGTGCCTCCTCGTTTTAGCGGCTCCGGCAGCACCTCTCTACTCTTTAACCATTAGCTCTATGGAGGCCGAAGATGCCGCCACATACTTTTGCCATCAGTACCACCGGTCCCCTACCTTTGGCGGGAGGCACAAAGCTGGAGA CCAAGCGGAGCGGCACCACCAACACAGTGGCCGCCTACAATCTGACTTGGAAATCCCACCAACTTCAAGACCATCCTCGAGTGGAGCCCAAGCCCCGTTAATCAAGTTTATACCGTGCAGATTTCCCACCAAGAGCGGCGACTGGAAATCCAAGTGCTTCTATACCACAGACACCGAGTGCGATCT CACCGACGAGATCGTCAAAGACGTGAAGCAGACATATTTAGCTAGGGGTGTTCTCCTACCCCGCTGGAACGTGGGAGAGCACCGGATCCGCTGGAGAGCCTTTATACGAGAACTCCCCCCGAATTCACCCCCTATCTGGAAAACCAATTTAGGCCAGCCCACCATCCAGAGCTTCGAACAAGTTGGCACA AAGGTGAACGTCACCGTCGAAGATGAGAGGACTTTAGTGCGGAGGAACAATACATTTTTATCCTTACGTGACGTCTTCGGCAAGGATTTAATCTACACACTGTATTACTGGAAGTCTAGGCTCCTCCGGCAAGAAGACCGCCAAGACCAATACCAACGAATTTTTAATTGACGTGGACAA GGGCGAGAACTACTGCTTCTCCGTGCAAGCCTGTGATCCCCTCCCGGACAGTGAACCGGAAGTCCACCGACTCCCCCGTGGAGTGCATGGGCCAAGAGAAGGGGAGAGTTTCGTGAGCAGATCGTGCTGACCCAGTCCCCCGCTATTATGAGCGCTAGCCCCGGTGAAAAGGTGA CTATGACATGCAGCGCCAGCTCTTCCGTGAGCTACATGAACTGGTATCAGCAGAAGTCCGGCACCAGCCCTAAAAGGTGGATCTACGACACCAGCAAGCTGGCCAGCGGCGTCCCCGCTCACTTTCGGGGCTCCGGCTCCGGAACAAGCTACTCTCTGACCATCAGCGGCATGGAAG CCGAGGATGCCGCTACCTATTACTGTCAGCAGTGGAGCTCCAACCCCTTCACCTTTGGATCCGGCACCAAGCTCGAGATTAATCGTGGAGGCGGAGGTAGCGGAGGAGGCGGATCCGGCGGGTGGAGGTAGCCAAGTTCAGCTCCAGCAAAGCGGCGCCGAACTCGCTCGG CCCGGCGCTTCCGTGAAGATGTCTTGTAAGGCCTCCGGCTATACCTTTCACCCGGTACACAATGCACTGGGTCAAGCAACGGCCCGGTCAAGGTTTAGAGTGGATTGGCTATATCAACCCCTCCCGGGGGCTATACCAACTACAACCAGAAGTTCAAGGACAAAGCCACCCTCACCACCGACA AGTCCAGCAGCACCGCTTACATGCAGCTGAGCTCTTAACATCCGAGGATTCCGCCGTGTACTACTGCGCTCGGTACTACGACGATCATTACTGCCTCGATTACTGGGGCCAAGGTACCACCTTAACAGTCTCCTCC (SEQ ID NO: 90), and at least 70% identical (e.g., at least 75% identical, at least 80% identical, at least 85% identical, at least 90% identical, at least 95% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、一本鎖キメラポリペプチドは、
MKWVTFISLLFLFSSAYSVQLQQSGPELVKPGASVKMSCKASGYTFTSYVIQWVKQKPGQGLEWIGSINPYNDYTKYNEKFKGKATLTSDKSSITAYMEFSSLTSEDSALYYCARWGDGNYWGRGTTLTVSSGGGGSGGGGSGGGGSDIEMTQSPAIMSASLGERVTMTCTASSSVSSSYFHWYQQKPGSSPKLCIYSTSNLASGVPPRFSGSGSTSYSLTISSMEAEDAATYFCHQYHRSPTFGGGTKLETKRSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFREQIVLTQSPAIMSASPGEKVTMTCSASSSVSYMNWYQQKSGTSPKRWIYDTSKLASGVPAHFRGSGSGTSYSLTISGMEAEDAATYYCQQWSSNPFTFGSGTKLEINRGGGGSGGGGSGGGGSQVQLQQSGAELARPGASVKMSCKASGYTFTRYTMHWVKQRPGQGLEWIGYINPSRGYTNYNQKFKDKATLTTDKSSSTAYMQLSSLTSEDSAVYYCARYYDDHYCLDYWGQGTTLTVSS(配列番号91)、と少なくとも70%同一(例えば、少なくとも75%同一、少なくとも80%同一、少なくとも85%同一、少なくとも90%同一、少なくとも95%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the single-chain chimeric polypeptide comprises
MKWVTFISLLFLFSSAYSVQLQQSGPELVKPGASVKMSCKASGYTFTSYVIQWVKQKPGQGLEWIGSINPYNDYTKYNEKFKGKATLTSDKSSSITAYMEFSSLTSEDSALYYCARWGDGNYWGRGTTLTVSSGGGGSG GGGSGGGGSDIEMTQSPAIMSASLGERVTMTCTASSVSSSSYFHWYQQKPGSSPKLCIYSTSNLASGVPPRFSGSGSTSYSLTISSMEAEDAATYFCHQYHRSPTFGGGTKLETKRSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQ ISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVD KGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFREQIVLTQSPAIMSASPGEKVTMTCSASSSVSYMNWYQQKSGTSPKRWIYDTSKLASGVPAHFRGSGSGTSYSLTISGMEAEDAATYCQQWSSNPFTFGSGTKLEIN RGGGGSGGGGSGGGGSQVQLQQSGAELARPGASVKMSCKASGYTFTRYTMHWVKQRPGQGLEWIGYINPSRGYTNYNQKFKDKATLTTDKSSSSTAYMQLSSLTSEDSAVYYCARYYDDHYCLDYWGQGTTLTVSS (SEQ ID NO: 91) at least 70% identical (e.g., at least 75% identical, at least 80% identical, at least 85% identical, at least 90% identical, at least 95% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、一本鎖キメラポリペプチドは、
ATGAAATGGGTCACCTTCATCTCTTTACTGTTTTTATTTAGCAGCGCCTACAGCGTGCAGCTGCAGCAGTCCGGACCCGAACTGGTCAAGCCCGGTGCCTCCGTGAAAATGTCTTGTAAGGCTTCTGGCTACACCTTTACCTCCTACGTCATCCAATGGGTGAAGCAGAAGCCCGGTCAAGGTCTCGAGTGGATCGGCAGCATCAATCCCTACAACGATTACACCAAGTATAACGAAAAGTTTAAGGGCAAGGCCACTCTGACAAGCGACAAGAGCTCCATTACCGCCTACATGGAGTTTTCCTCTTTAACTTCTGAGGACTCCGCTTTATACTATTGCGCTCGTTGGGGCGATGGCAATTATTGGGGCCGGGGAACTACTTTAACAGTGAGCTCCGGCGGCGGCGGAAGCGGAGGTGGAGGATCTGGCGGTGGAGGCAGCGACATCGAGATGACACAGTCCCCCGCTATCATGAGCGCCTCTTTAGGAGAACGTGTGACCATGACTTGTACAGCTTCCTCCAGCGTGAGCAGCTCCTATTTCCACTGGTACCAGCAGAAACCCGGCTCCTCCCCTAAACTGTGTATCTACTCCACAAGCAATTTAGCTAGCGGCGTGCCTCCTCGTTTTAGCGGCTCCGGCAGCACCTCTTACTCTTTAACCATTAGCTCTATGGAGGCCGAAGATGCCGCCACATACTTTTGCCATCAGTACCACCGGTCCCCTACCTTTGGCGGAGGCACAAAGCTGGAGACCAAGCGGAGCGGCACCACCAACACAGTGGCCGCCTACAATCTGACTTGGAAATCCACCAACTTCAAGACCATCCTCGAGTGGGAGCCCAAGCCCGTTAATCAAGTTTATACCGTGCAGATTTCCACCAAGAGCGGCGACTGGAAATCCAAGTGCTTCTATACCACAGACACCGAGTGCGATCTCACCGACGAGATCGTCAAAGACGTGAAGCAGACATATTTAGCTAGGGTGTTCTCCTACCCCGCTGGAAACGTGGAGAGCACCGGATCCGCTGGAGAGCCTTTATACGAGAACTCCCCCGAATTCACCCCCTATCTGGAAACCAATTTAGGCCAGCCCACCATCCAGAGCTTCGAACAAGTTGGCACAAAGGTGAACGTCACCGTCGAAGATGAGAGGACTTTAGTGCGGAGGAACAATACATTTTTATCCTTACGTGACGTCTTCGGCAAGGATTTAATCTACACACTGTATTACTGGAAGTCTAGCTCCTCCGGCAAGAAGACCGCCAAGACCAATACCAACGAATTTTTAATTGACGTGGACAAGGGCGAGAACTACTGCTTCTCCGTGCAAGCTGTGATCCCCTCCCGGACAGTGAACCGGAAGTCCACCGACTCCCCCGTGGAGTGCATGGGCCAAGAGAAGGGAGAGTTTCGTGAGCAGATCGTGCTGACCCAGTCCCCCGCTATTATGAGCGCTAGCCCCGGTGAAAAGGTGACTATGACATGCAGCGCCAGCTCTTCCGTGAGCTACATGAACTGGTATCAGCAGAAGTCCGGCACCAGCCCTAAAAGGTGGATCTACGACACCAGCAAGCTGGCCAGCGGCGTCCCCGCTCACTTTCGGGGCTCCGGCTCCGGAACAAGCTACTCTCTGACCATCAGCGGCATGGAAGCCGAGGATGCCGCTACCTATTACTGTCAGCAGTGGAGCTCCAACCCCTTCACCTTTGGATCCGGCACCAAGCTCGAGATTAATCGTGGAGGCGGAGGTAGCGGAGGAGGCGGATCCGGCGGTGGAGGTAGCCAAGTTCAGCTCCAGCAAAGCGGCGCCGAACTCGCTCGGCCCGGCGCTTCCGTGAAGATGTCTTGTAAGGCCTCCGGCTATACCTTCACCCGGTACACAATGCACTGGGTCAAGCAACGGCCCGGTCAAGGTTTAGAGTGGATTGGCTATATCAACCCCTCCCGGGGCTATACCAACTACAACCAGAAGTTCAAGGACAAAGCCACCCTCACCACCGACAAGTCCAGCAGCACCGCTTACATGCAGCTGAGCTCTTTAACATCCGAGGATTCCGCCGTGTACTACTGCGCTCGGTACTACGACGATCATTACTGCCTCGATTACTGGGGCCAAGGTACCACCTTAACAGTCTCCTCC(配列番号92)、と少なくとも70%同一(例えば、少なくとも75%同一、少なくとも80%同一、少なくとも85%同一、少なくとも90%同一、少なくとも95%同一、少なくとも99%同一、又は100%同一)である配列を含む核酸によってコードされる。
In some embodiments, the single-chain chimeric polypeptide comprises
ATGAAATGGGTCACCTTCATCTCTTTACTGTTTTATTTAGCAGCGCCTACAGCGTGCAGCTGCAGCAGTCCGGACCCGAACTGGTCAAGCCCCGGTGCCTCCGTGAAAATGTCTTGTAAGGCTTCTGGCTACACCTTTACCTCCTACGTCATCCAATGGGTGAAGCAGAA GCCCGGTCAAGGTCTCGAGTGGATCGGCAGCATCAATCCCTACAACGATTACACCAAGTATAACGAAAAGTTTAAGGGCAAGGCCACTCTGACAAGCGCAAGAGCTCCATTACCGCTACATGGAGTTTTCCCTCTTAACTTCTGAGGACTCCGCTTTATACACTATTGCGCTCGTTGG GGCGATGGCAATTATTGGGGCCGGGGGAACTACTTTAACAGTGAGCTCCGGCGGCGGCGGAAGCGGAGGTGGAGGATCTGGCGGTGGAGGCAGCGACATCGAGATGACACAGTCCCCCGCTATCATGAGCGCCCTCTTTAGGAGAACGTGTGACCATGACTTGTACAGCTTCCT CCAGCGTGAGCAGCTCCTATTTCCACTGGTACCAGCAGAAACCCGGCTCCTCCCCTAAACTGTGTATCTACTCCACAAGCCAATTTAGCTAGCGGCGTTGCCTCCTCGTTTTAGCGGCTCCGGCAGCACCTCTCTACTCTTTAACCATTAGCTCTATGGAGGCCCGAAGATGCCGCCACATACT TTTGCCATCAGTACCACCGGTCCCCTACCTTTTGGCGGAGGCACAAAGCTGGAGACCAAGCGGGAGCGGCACCACCAACACAGTGGCCGCCTACAATCTGACTTGGAAATCCCACCAACTTCAAGACCATCCTCGAGTGGGAGCCCCAAGCCCCGTTAATCAAGTTTATACCGTGCAGATTTCCCAC CAAGAGCGGGCGACTGGAAATCCAAGTGCTTCTATACCAGACACCGAGTGCGATCTCACCGACGAGATCGTCAAAGACGTGAAGCAGACATATTTAGCTAGGGGTGTTCTCTCACCCCGCTGGAAAACGTGGAGAGCACCGGATCCGCTGGAGAGCCTTTATACGAGAACTCCCCCGAATTCACCCC CTATCTGGAAACCAATTTAGGCCAGCCCACCATCCAGAGCTTCGAACAAGTTGGCACAAAGGTGAACGTCACCGTCGAAGATGAGAGGACTTTAGTGCGCGGAGGAACAATACATTTTTATCCTTACGTGACGTCTTCGGCAAGGATTTAATCTACACACTGTATTACTGGAAGTCTAGCT CCTCCGGCAAGAAGACCGCCAAGACCAATACCAACGAATTTTTAATTGACGTGGACAAGGGCGAGAACTACTGCTTCTCCGTGCAAGCTGTGATCCCCTCCCCGGACAGTGAACCGGAAGTCCACCGACTCCCCCGTGGAGTGCATGGGCCAAGAGAAGGGGAGAGTTTCGTGAGCAGAT CGTGCTGACCCAGTCCCCCGCTATTATGAGCGCTAGCCCCGGTGAAAAGGTGACTATGACATGCAGCGCCAGCTCTTCCGTGAGCTACATGAACTGGTATCAGCAGAAGTCCGGCACCAGCCCTAAAGGTGGATCTACGACACCAGCAAGCTGGCCAGCGGCGTCCCCCGCTCACT TTCGGGGCTCCGGCTCCGGAACAAGCTACTCTCTGACCATCAGCGGCATGGAAGCCGAGGATGCCGCTACCTATTACTGTCAGCAGTGGAGCTCCAACCCCTTCACCTTTGGATCCGGCACCAAGCTCGAGATTAATCGTGGAGGCGGAGGTAGCGGAGGAGGCGGATCCGGCGGG TGGAGGTAGCCAAGTTCAGCTCCAGCAAAGCGGCGCCGAACTCGCTCGGCCCGGCGCTTCCGTGAAGATGTCTTGTAAGGCCTCCGGCTATACCTTCACCCGGTACACAATGCACTGGGTCAAGCAACGGCCCGGTCAAGGTTTAGAGTGGATTGGCTATATCAACCCCCT CCCGGGGCTATACCAACTACAACCAGAAGTTCAAGGACAAAGCCACCCTCACCACCGACAAGTCCAGCAGCACCGCTTACATGCAGCTGAGCTCTTTAACATCCGAGGATTCCGCCGTGTACTACTGCGCTCGGTACTACGACGATCATTACTGCCTCGATTACTGGGGGCCAAGGTACCACCTTAACA GTCTCCTCC (SEQ ID NO: 92), at least 70% identical (e.g., at least 75% identical, at least 80% identical, at least 85% identical, at least 90% identical, at least 95% identical, at least 99% identical, or 100% identical).
本明細書に記載の一本鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態は、そのN末端及び/又はC末端に1つ以上(例えば、2、3、4、5、6、7、8、9、又は10)の追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)を更に含み得る。 Some embodiments of any of the single-chain chimeric polypeptides described herein have one or more (e.g., 2, 3, 4, 5, 6, 7, 8, 9, or 10) additional target binding domains (eg, any of the exemplary target binding domains described herein or known in the art).
いくつかの実施形態では、一本鎖キメラポリペプチドは、そのN末端に1つ以上(例えば、2、3、4、5、6、7、8、9、又は10)の追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)を含み得る。いくつかの実施形態では、一本鎖キメラポリペプチドのN末端の1つ以上の追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)のうちの1つは、第1の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、第2の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、又は可溶性組織因子ドメイン(例えば、本明細書に記載の例示的な可溶性組織因子ドメインのうちのいずれか)に直接隣接し得る。いくつかの実施形態では、一本鎖キメラポリペプチドは、一本鎖キメラポリペプチドのN末端の少なくとも1つの追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)のうちの1つと、第1の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、第2の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、又は可溶性組織因子ドメイン(例えば、本明細書に記載の例示的な可溶性組織因子ドメインのうちのいずれか)との間に、リンカー配列(例えば、本明細書に記載の又は当該技術分野で既知の例示的なリンカー配列のうちのいずれか)を更に含む。 In some embodiments, the single-chain chimeric polypeptide has one or more (eg, 2, 3, 4, 5, 6, 7, 8, 9, or 10) additional target binding domains at its N-terminus. (eg, any of the exemplary target binding domains described herein or known in the art). In some embodiments, one or more additional target binding domains at the N-terminus of the single-chain chimeric polypeptide (e.g., among exemplary target binding domains described herein or known in the art) a first target binding domain (e.g., any of the exemplary target binding domains described herein or known in the art), a second target binding domains (e.g., any of the exemplary target binding domains described herein or known in the art), or soluble tissue factor domains (e.g., exemplary soluble tissue either of the factor domains). In some embodiments, the single-chain chimeric polypeptide comprises at least one additional target-binding domain (e.g., examples described herein or known in the art) at the N-terminus of the single-chain chimeric polypeptide. any of the exemplary target binding domains) and the first target binding domain (e.g., any of the exemplary target binding domains described herein or known in the art) ), a second target binding domain (e.g., any of the exemplary target binding domains described herein or known in the art), or a soluble tissue factor domain (e.g., described herein) a linker sequence (e.g., any of the exemplary linker sequences described herein or known in the art) between the include.
本明細書に記載の一本鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、一本鎖キメラポリペプチドは、そのC末端に1つ以上(例えば、2、3、4、5、6、7、8、9、又は10)の追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)を含む。いくつかの実施形態では、一本鎖キメラポリペプチドのC末端の1つ以上の追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)のうちの1つは、第1の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、第2の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、又は可溶性組織因子ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な可溶性組織因子ドメインのうちのいずれか)に直接隣接している。いくつかの実施形態では、一本鎖キメラポリペプチドは、一本鎖キメラポリペプチドのC末端の少なくとも1つの追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)のうちの1つと、第1の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、第2の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、又は可溶性組織因子ドメイン(例えば、本明細書に記載の例示的な可溶性組織因子ドメインのうちのいずれか)との間に、リンカー配列(例えば、本明細書に記載の又は当該技術分野で既知の例示的なリンカー配列のうちのいずれか)を更に含む。 In some embodiments of any of the single chain chimeric polypeptides described herein, the single chain chimeric polypeptide has one or more (e.g., 2, 3, 4, 5) at its C-terminus. , 6, 7, 8, 9, or 10) additional target binding domains (eg, any of the exemplary target binding domains described herein or known in the art). In some embodiments, one or more additional target binding domains at the C-terminus of the single-chain chimeric polypeptide (e.g., among exemplary target binding domains described herein or known in the art) a first target binding domain (e.g., any of the exemplary target binding domains described herein or known in the art), a second target A binding domain (e.g., any of the exemplary target binding domains described herein or known in the art), or a soluble tissue factor domain (e.g., described herein or known in the art) any of the known exemplary soluble tissue factor domains). In some embodiments, the single-chain chimeric polypeptide comprises at least one additional target-binding domain (e.g., examples described herein or known in the art) at the C-terminus of the single-chain chimeric polypeptide. any of the exemplary target binding domains) and the first target binding domain (e.g., any of the exemplary target binding domains described herein or known in the art) ), a second target binding domain (e.g., any of the exemplary target binding domains described herein or known in the art), or a soluble tissue factor domain (e.g., described herein) a linker sequence (e.g., any of the exemplary linker sequences described herein or known in the art) between the include.
本明細書に記載の一本鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、一本鎖キメラポリペプチドは、そのN末端及びそのC末端に1つ以上(例えば、2、3、4、5、6、7、8、9、又は10)の追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)を含む。いくつかの実施形態では、一本鎖キメラポリペプチドのN末端の1つ以上の追加の抗原結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)のうちの1つは、第1の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、第2の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、又は可溶性組織因子ドメイン(例えば、本明細書に記載の例示的な可溶性組織因子ドメインのうちのいずれか)に直接隣接している。いくつかの実施形態では、一本鎖キメラポリペプチドは、N末端の1つ以上の追加の抗原結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)のうちの1つと、第1の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、第2の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、又は可溶性組織因子ドメイン(例えば、例示的な可溶性組織因子ドメインのうちのいずれか)との間に、リンカー配列(例えば、本明細書に記載の又は当該技術分野で既知の例示的なリンカー配列のうちのいずれか)を更に含む。いくつかの実施形態では、C末端の1つ以上の追加の抗原結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)のうちの1つは、第1の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、第2の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、又は可溶性組織因子ドメイン(例えば、例示的な可溶性組織因子ドメインのうちのいずれか)に直接隣接している。いくつかの実施形態では、一本鎖キメラポリペプチドは、C末端の1つ以上の追加の抗原結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)のうちの1つと、第1の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、第2の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、又は可溶性組織因子ドメイン(例えば、本明細書に記載の例示的な可溶性組織因子ドメインのうちのいずれか)との間に、リンカー配列(例えば、本明細書に記載の又は当該技術分野で既知の例示的なリンカー配列のうちのいずれか)を更に含む。 In some embodiments of any of the single chain chimeric polypeptides described herein, the single chain chimeric polypeptide has one or more (e.g., 2, 3) at its N-terminus and its C-terminus. , 4, 5, 6, 7, 8, 9, or 10) additional target binding domains (e.g., any of the exemplary target binding domains described herein or known in the art) including. In some embodiments, one or more additional antigen binding domains at the N-terminus of the single-chain chimeric polypeptide (e.g., among exemplary target binding domains described herein or known in the art) a first target binding domain (e.g., any of the exemplary target binding domains described herein or known in the art), a second target binding domains (e.g., any of the exemplary target binding domains described herein or known in the art), or soluble tissue factor domains (e.g., exemplary soluble tissue either of the factor domains). In some embodiments, the single-chain chimeric polypeptide has one or more additional antigen binding domains at the N-terminus (e.g., one of the exemplary target binding domains described herein or known in the art). and a first target binding domain (e.g., any of the exemplary target binding domains described herein or known in the art), a second target A binding domain (e.g., any of the exemplary target binding domains described herein or known in the art) or a soluble tissue factor domain (e.g., any of the exemplary soluble tissue factor domains) or ) between them (eg, any of the exemplary linker sequences described herein or known in the art). In some embodiments, the C-terminal one or more additional antigen binding domains (e.g., any of the exemplary target binding domains described herein or known in the art) One, a first target binding domain (e.g., any of the exemplary target binding domains described herein or known in the art), a second target binding domain (e.g., or immediately adjacent to a soluble tissue factor domain (e.g., any of the exemplary soluble tissue factor domains) there is In some embodiments, the single chain chimeric polypeptide has one or more additional antigen binding domains at the C-terminus (e.g., one of the exemplary target binding domains described herein or known in the art). and a first target binding domain (e.g., any of the exemplary target binding domains described herein or known in the art), a second target binding domains (e.g., any of the exemplary target binding domains described herein or known in the art), or soluble tissue factor domains (e.g., exemplary soluble tissue any of the factor domains), further comprising a linker sequence (eg, any of the exemplary linker sequences described herein or known in the art).
本明細書に記載の一本鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、第2の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、及び1つ以上の追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)のうちの2つ以上(例えば、3、4、5、6、7、8、9、又は10)は、同じ抗原に特異的に結合する。いくつかの実施形態では、第1の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、第2の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、及び1つ以上の追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)のうちの2つ以上(例えば、3、4、5、6、7、8、9、又は10)は、同じエピトープに特異的に結合する。いくつかの実施形態では、第1の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、第2の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、及び1つ以上の追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)のうちの2つ以上(例えば、3、4、5、6、7、8、9、又は10)は、同じアミノ酸配列を含む。 In some embodiments of any of the single chain chimeric polypeptides described herein, the first target binding domain (e.g., an exemplary any of the target binding domains), a second target binding domain (e.g., any of the exemplary target binding domains described herein or known in the art), and one or more Two or more (e.g., 3, 4, 5, 6, 7, 8, 9, or 10) specifically bind to the same antigen. In some embodiments, a first target binding domain (e.g., any of the exemplary target binding domains described herein or known in the art), a second target binding domain (e.g., , any of the exemplary target binding domains described herein or known in the art), and one or more additional target binding domains (e.g., described herein or known in the art) two or more (e.g., 3, 4, 5, 6, 7, 8, 9, or 10) of the exemplary target binding domains known in do. In some embodiments, a first target binding domain (e.g., any of the exemplary target binding domains described herein or known in the art), a second target binding domain (e.g., , any of the exemplary target binding domains described herein or known in the art), and one or more additional target binding domains (e.g., described herein or known in the art) Two or more (eg, 3, 4, 5, 6, 7, 8, 9, or 10) of the (any of the exemplary target binding domains known in ) comprise the same amino acid sequence.
本明細書に記載の一本鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、第2の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、及び1つ以上(例えば、2、3、4、5、6、7、8、9、又は10)の追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)は各々、同じ抗原に特異的に結合する。いくつかの実施形態では、第1の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、第2の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、及び1つ以上(例えば、2、3、4、5、6、7、8、9、又は10)の追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)は各々、同じエピトープに特異的に結合する。いくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上(例えば、2、3、4、5、6、7、8、9、又は10)の追加の標的結合ドメインは各々、同じアミノ酸配列を含む。 In some embodiments of any of the single chain chimeric polypeptides described herein, the first target binding domain (e.g., an exemplary any of the target binding domains), a second target binding domain (e.g., any of the exemplary target binding domains described herein or known in the art), and one or more ( 2, 3, 4, 5, 6, 7, 8, 9, or 10) additional target binding domains (e.g., of exemplary target binding domains described herein or known in the art) any of them) each specifically binds the same antigen. In some embodiments, a first target binding domain (e.g., any of the exemplary target binding domains described herein or known in the art), a second target binding domain (e.g., , any of the exemplary target binding domains described herein or known in the art), and one or more (e.g., 2, 3, 4, 5, 6, 7, 8, 9, or 10) additional target binding domains (eg, any of the exemplary target binding domains described herein or known in the art) each specifically bind the same epitope. In some embodiments, the first target binding domain, the second target binding domain, and one or more (e.g., 2, 3, 4, 5, 6, 7, 8, 9, or 10) additional Each target binding domain contains the same amino acid sequence.
本明細書に記載の一本鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、第2の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、及び1つ以上(例えば、2、3、4、5、6、7、8、9、又は10)の追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)は、異なる抗原に特異的に結合する。 In some embodiments of any of the single chain chimeric polypeptides described herein, the first target binding domain (e.g., an exemplary any of the target binding domains), a second target binding domain (e.g., any of the exemplary target binding domains described herein or known in the art), and one or more ( 2, 3, 4, 5, 6, 7, 8, 9, or 10) additional target binding domains (e.g., of exemplary target binding domains described herein or known in the art) any of them) specifically bind to different antigens.
一本鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の標的結合ドメインのうちの1つ以上が、抗原結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)である。本明細書に記載の一本鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインは各々、抗原結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)である。いくつかの実施形態では、抗原結合ドメインは、scFv又は単一ドメイン抗体を含み得る。 In some embodiments of any of the single-chain chimeric polypeptides, one or more of the first target binding domain, the second target binding domain, and one or more of the target binding domains are antigen A binding domain (eg, any of the exemplary target binding domains described herein or known in the art). In some embodiments of any of the single-chain chimeric polypeptides described herein, the first target binding domain, the second target binding domain, and one or more additional target binding domains are Each is an antigen binding domain (eg, any of the exemplary target binding domains described herein or known in the art). In some embodiments, an antigen binding domain may comprise a scFv or single domain antibody.
本明細書に記載の一本鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、第2の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、及び1つ以上の追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)のうちの1つ以上(例えば、2、3、4、5、6、7、8、9、又は10)は、CD16a、CD28、CD3、CD33、CD20、CD19、CD22、CD123、IL-1R、IL-1、VEGF、IL-6R、IL-4、IL-10、PDL-1、TIGIT、PD-1、TIM3、CTLA4、MICA、MICB、IL-6、IL-8、TNFα、CD26、CD36、ULBP2、CD30、CD200、IGF-1R、MUC4AC、MUC5AC、Trop-2、CMET、EGFR、HER1、HER2、HER3、PSMA、CEA、B7H3、EPCAM、BCMA、P-カドヘリン、CEACAM5、UL16結合タンパク質、HLA-DR、DLL4、TYRO3、AXL、MER、CD122、CD155、PDGF-DD、TGF-β受容体II(TGF-βRII)リガンド、TGF-βRIIIリガンド、DNAM1リガンド、NKp46リガンド、NKp44リガンド、NKG2Dリガンド、NKp30リガンド、scMHCIリガンド、scMHCIIリガンド、scTCRリガンド、IL-1受容体、IL-2受容体、IL-3受容体、IL-7受容体、IL-8受容体、IL-10受容体、IL-12受容体、IL-15受容体、IL-17受容体、IL-18受容体、IL-21受容体、PDGF-DD受容体、幹細胞因子(SCF)受容体、幹細胞様チロシンキナーゼ3リガンド(FLT3L)受容体、MICA受容体、MICB受容体、ULP16結合タンパク質受容体、CD155受容体、CD122受容体、及びCD28受容体からなる群から選択される標的に特異的に結合する。 In some embodiments of any of the single chain chimeric polypeptides described herein, the first target binding domain (e.g., an exemplary any of the target binding domains), a second target binding domain (e.g., any of the exemplary target binding domains described herein or known in the art), and one or more one or more (e.g., 2, 3, 4, 5, 6, 7, 8, 9, or 10) is CD16a, CD28, CD3, CD33, CD20, CD19, CD22, CD123, IL-1R, IL-1, VEGF, IL-6R, IL-4, IL-10 , PDL-1, TIGIT, PD-1, TIM3, CTLA4, MICA, MICB, IL-6, IL-8, TNFα, CD26, CD36, ULBP2, CD30, CD200, IGF-1R, MUC4AC, MUC5AC, Trop-2 , CMET, EGFR, HER1, HER2, HER3, PSMA, CEA, B7H3, EPCAM, BCMA, P-cadherin, CEACAM5, UL16 binding protein, HLA-DR, DLL4, TYRO3, AXL, MER, CD122, CD155, PDGF-DD , TGF-β receptor II (TGF-βRII) ligand, TGF-βRIII ligand, DNAM1 ligand, NKp46 ligand, NKp44 ligand, NKG2D ligand, NKp30 ligand, scMHCI ligand, scMHCII ligand, scTCR ligand, IL-1 receptor, IL -2 receptor, IL-3 receptor, IL-7 receptor, IL-8 receptor, IL-10 receptor, IL-12 receptor, IL-15 receptor, IL-17 receptor, IL-18 receptor, IL-21 receptor, PDGF-DD receptor, stem cell factor (SCF) receptor, stem cell-like tyrosine kinase 3 ligand (FLT3L) receptor, MICA receptor, MICB receptor, ULP16 binding protein receptor, CD155 It specifically binds to a target selected from the group consisting of the receptor, CD122 receptor, and CD28 receptor.
本明細書に記載の一本鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、第2の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、及び1つ以上の追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)のうちの1つ以上が、可溶性インターロイキン又はサイトカインタンパク質である。可溶性インターロイキンタンパク質及び可溶性サイトカインタンパク質の非限定的な例には、IL-1、IL-2、IL-3、IL-7、IL-8、IL-10、IL-12、IL-15、IL-17、IL-18、IL-21、PDGF-DD、及びSCFが挙げられる。 In some embodiments of any of the single chain chimeric polypeptides described herein, the first target binding domain (e.g., an exemplary any of the target binding domains), a second target binding domain (e.g., any of the exemplary target binding domains described herein or known in the art), and one or more One or more of the additional target binding domains (eg, any of the exemplary target binding domains described herein or known in the art) are soluble interleukin or cytokine proteins. Non-limiting examples of soluble interleukin proteins and soluble cytokine proteins include IL-1, IL-2, IL-3, IL-7, IL-8, IL-10, IL-12, IL-15, IL -17, IL-18, IL-21, PDGF-DD, and SCF.
本明細書に記載の一本鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、第2の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、及び1つ以上の追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)のうちの1つ以上が、可溶性インターロイキン又はサイトカイン受容体である。可溶性インターロイキン受容体及び可溶性サイトカイン受容体の非限定的な例には、可溶性TGF-β受容体II(TGF-βRII)、可溶性TGF-βRIII、可溶性NKG2D、可溶性NKP30、可溶性NKp44、可溶性NKp46、可溶性DNAM1、scMHCI、scMHCII、scTCR、可溶性CD155、可溶性CD122、可溶性CD3、又は可溶性CD28が挙げられる。 In some embodiments of any of the single chain chimeric polypeptides described herein, the first target binding domain (e.g., an exemplary any of the target binding domains), a second target binding domain (e.g., any of the exemplary target binding domains described herein or known in the art), and one or more one or more of the additional target binding domains (e.g., any of the exemplary target binding domains described herein or known in the art) are soluble interleukins or cytokine receptors . Non-limiting examples of soluble interleukin receptors and soluble cytokine receptors include soluble TGF-β receptor II (TGF-βRII), soluble TGF-βRIII, soluble NKG2D, soluble NKP30, soluble NKp44, soluble NKp46, soluble DNAM1, scMHCI, scMHCII, scTCR, soluble CD155, soluble CD122, soluble CD3, or soluble CD28.
本明細書に記載の一本鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン(例えば、本明細書に記載の標的結合ドメインのうちのいずれか)、第2の標的結合ドメイン(例えば、本明細書に記載の標的結合ドメインのうちのいずれか)、及び1つ以上の標的結合ドメイン(例えば、本明細書に記載の標的結合ドメインのうちのいずれか)は各々独立して、CD16a、CD33、CD20、CD19、CD22、CD123、PDL-1、TIGIT、PD-1、TIM3、CTLA4、MICA、MICB、IL-6、IL-8、TNFα、CD26、CD36、ULBP2、CD30、CD200、IGF-1R、MUC4AC、MUC5AC、Trop-2、CMET、EGFR、HER1、HER2、HER3、PSMA、CEA、B7H3、EPCAM、BCMA、P-カドヘリン、CEACAM5、UL16結合タンパク質、HLA-DR、DLL4、TYRO3、AXL、MER、CD122、CD155、PDGF-DD、TGF-β受容体II(TGF-βRII)リガンド、TGF-βRIIIリガンド、DNAM1リガンド、NKp46リガンド、NKp44リガンド、NKG2Dリガンド、NKP30リガンド、scMHCIリガンド、scMHCIIリガンド、scTCRリガンド、PDGF-DD受容体、幹細胞因子(SCF)受容体、幹細胞様チロシンキナーゼ3リガンド(FLT3L)受容体、MICA受容体、MICB受容体、ULP16結合タンパク質受容体、CD155受容体、及びCD122受容体の群から選択される標的に特異的に結合することができる。 In some embodiments of any of the single chain chimeric polypeptides described herein, the first target binding domain (e.g., any of the target binding domains described herein); a second target binding domain (e.g., any of the target binding domains described herein) and one or more target binding domains (e.g., any of the target binding domains described herein) ) are each independently CD16a, CD33, CD20, CD19, CD22, CD123, PDL-1, TIGIT, PD-1, TIM3, CTLA4, MICA, MICB, IL-6, IL-8, TNFα, CD26, CD36 , ULBP2, CD30, CD200, IGF-1R, MUC4AC, MUC5AC, Trop-2, CMET, EGFR, HER1, HER2, HER3, PSMA, CEA, B7H3, EPCAM, BCMA, P-cadherin, CEACAM5, UL16 binding protein, HLA -DR, DLL4, TYRO3, AXL, MER, CD122, CD155, PDGF-DD, TGF-β receptor II (TGF-βRII) ligand, TGF-βRIII ligand, DNAM1 ligand, NKp46 ligand, NKp44 ligand, NKG2D ligand, NKP30 ligand, scMHC I ligand, scMHC II ligand, scTCR ligand, PDGF-DD receptor, stem cell factor (SCF) receptor, stem cell-like tyrosine kinase 3 ligand (FLT3L) receptor, MICA receptor, MICB receptor, ULP16 binding protein receptor , CD155 receptor, and CD122 receptor.
本明細書に記載の一本鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、第2の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、及び1つ以上の追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)のうちの1つ以上が、可溶性インターロイキン又はサイトカインタンパク質である。本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、可溶性インターロイキン又はサイトカインタンパク質は、IL-1、IL-2、IL-3、IL-7、IL-8、IL-10、IL-12、IL-15、IL-17、IL-18、IL-21、PDGF-DD、及びSCFの群から選択される。 In some embodiments of any of the single chain chimeric polypeptides described herein, the first target binding domain (e.g., an exemplary any of the target binding domains), a second target binding domain (e.g., any of the exemplary target binding domains described herein or known in the art), and one or more One or more of the additional target binding domains (eg, any of the exemplary target binding domains described herein or known in the art) are soluble interleukin or cytokine proteins. In some embodiments of any of the multichain chimeric polypeptides described herein, the soluble interleukin or cytokine protein is IL-1, IL-2, IL-3, IL-7, IL- 8, IL-10, IL-12, IL-15, IL-17, IL-18, IL-21, PDGF-DD, and SCF.
本明細書に記載の一本鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、第2の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、及び1つ以上の追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)のうちの1つ以上が、可溶性インターロイキン又はサイトカイン受容体である。本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、可溶性受容体は、可溶性TGF-β受容体II(TGF-βRII)、可溶性TGF-βRIII、可溶性TNFα受容体、可溶性IL-4受容体、又は可溶性IL-10受容体である。 In some embodiments of any of the single chain chimeric polypeptides described herein, the first target binding domain (e.g., an exemplary any of the target binding domains), a second target binding domain (e.g., any of the exemplary target binding domains described herein or known in the art), and one or more one or more of the additional target binding domains (e.g., any of the exemplary target binding domains described herein or known in the art) are soluble interleukins or cytokine receptors . In some embodiments of any of the multichain chimeric polypeptides described herein, the soluble receptor is soluble TGF-β receptor II (TGF-βRII), soluble TGF-βRIII, soluble TNFα receptor soluble IL-4 receptor, or soluble IL-10 receptor.
多鎖キメラポリペプチド-タイプA
NK細胞活性化物質の非限定的な例は、(a)(i)第1の標的結合ドメイン、(ii)可溶性組織因子ドメイン、及び(iii)一対の親和性ドメインの第1のドメインを含む、第1のキメラポリペプチドと、(b)(i)一対の親和性ドメインの第2のドメイン及び(ii)第2の標的結合ドメインを含む、第2のキメラポリペプチドと、を含む多鎖キメラポリペプチドであり、第1のキメラポリペプチドと第2のキメラポリペプチドが一対の親和性ドメインの第1のドメインと第2のドメインとの結合を介して会合する。
Multichain Chimeric Polypeptide-Type A
Non-limiting examples of NK cell activators include (a) (i) a first target binding domain, (ii) a soluble tissue factor domain, and (iii) the first of a pair of affinity domains , a first chimeric polypeptide, and (b) a second chimeric polypeptide comprising (i) a second of the pair of affinity domains and (ii) a second target binding domain. It is a chimeric polypeptide wherein a first chimeric polypeptide and a second chimeric polypeptide associate through binding of the first and second domains of a pair of affinity domains.
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの例では、第1のキメラポリペプチド及び/又は第2のキメラポリペプチドの全長は各々独立して、約50アミノ酸~約3000アミノ酸、約50アミノ酸~約2500アミノ酸、約50アミノ酸~約2000アミノ酸、約50アミノ酸~約1500アミノ酸、約50アミノ酸~約1000アミノ酸、約50アミノ酸~約950アミノ酸、約50アミノ酸~約900アミノ酸、約50アミノ酸~約850アミノ酸、約50アミノ酸~約800アミノ酸、約50アミノ酸~約750アミノ酸、約50アミノ酸~約700アミノ酸、約50アミノ酸~約650アミノ酸、約50アミノ酸~約600アミノ酸、約50アミノ酸~約550アミノ酸、約50アミノ酸~約500アミノ酸、約50アミノ酸~約480アミノ酸、約50アミノ酸~約460アミノ酸、約50アミノ酸~約440アミノ酸、約50アミノ酸~約420アミノ酸、約50アミノ酸~約400アミノ酸、約50アミノ酸~約380アミノ酸、約50アミノ酸~約360アミノ酸、約50アミノ酸~約340アミノ酸、約50アミノ酸~約320アミノ酸、約50アミノ酸~約300アミノ酸、約50アミノ酸~約280アミノ酸、約50アミノ酸~約260アミノ酸、約50アミノ酸~約240アミノ酸、約50アミノ酸~約220アミノ酸、約50アミノ酸~約200アミノ酸、約50アミノ酸~約150アミノ酸、約50アミノ酸~約100アミノ酸、約100アミノ酸~約3000アミノ酸、約100アミノ酸~約2500アミノ酸、約100アミノ酸~約2000アミノ酸、約100アミノ酸~約1500アミノ酸、約100アミノ酸~約1000アミノ酸、約100アミノ酸~約950アミノ酸、約100アミノ酸~約900アミノ酸、約100アミノ酸~約850アミノ酸、約100アミノ酸~約800アミノ酸、約100アミノ酸~約750アミノ酸、約100アミノ酸~約700アミノ酸、約100アミノ酸~約650アミノ酸、約100アミノ酸~約600アミノ酸、約100アミノ酸~約550アミノ酸、約100アミノ酸~約500アミノ酸、約100アミノ酸~約480アミノ酸、約100アミノ酸~約460アミノ酸、約100アミノ酸~約440アミノ酸、約100アミノ酸~約420アミノ酸、約100アミノ酸~約400アミノ酸、約100アミノ酸~約380アミノ酸、約100アミノ酸~約360アミノ酸、約100アミノ酸~約340アミノ酸、約100アミノ酸~約320アミノ酸、約100アミノ酸~約300アミノ酸、約100アミノ酸~約280アミノ酸、約100アミノ酸~約260アミノ酸、約100アミノ酸~約240アミノ酸、約100アミノ酸~約220アミノ酸、約100アミノ酸~約200アミノ酸、約100アミノ酸~約150アミノ酸、約150アミノ酸~約3000アミノ酸、約150アミノ酸~約2500アミノ酸、約150アミノ酸~約2000アミノ酸、約150アミノ酸~約1500アミノ酸、約150アミノ酸~約1000アミノ酸、約150アミノ酸~約950アミノ酸、約150アミノ酸~約900アミノ酸、約150アミノ酸~約850アミノ酸、約150アミノ酸~約800アミノ酸、約150アミノ酸~約750アミノ酸、約150アミノ酸~約700アミノ酸、約150アミノ酸~約650アミノ酸、約150アミノ酸~約600アミノ酸、約150アミノ酸~約550アミノ酸、約150アミノ酸~約500アミノ酸、約150アミノ酸~約480アミノ酸、約150アミノ酸~約460アミノ酸、約150アミノ酸~約440アミノ酸、約150アミノ酸~約420アミノ酸、約150アミノ酸~約400アミノ酸、約150アミノ酸~約380アミノ酸、約150アミノ酸~約360アミノ酸、約150アミノ酸~約340アミノ酸、約150アミノ酸~約320アミノ酸、約150アミノ酸~約300アミノ酸、約150アミノ酸~約280アミノ酸、約150アミノ酸~約260アミノ酸、約150アミノ酸~約240アミノ酸、約150アミノ酸~約220アミノ酸、約150アミノ酸~約200アミノ酸、約200アミノ酸~約3000アミノ酸、約200アミノ酸~約2500アミノ酸、約200アミノ酸~約2000アミノ酸、約200アミノ酸~約1500アミノ酸、約200アミノ酸~約1000アミノ酸、約200アミノ酸~約950アミノ酸、約200アミノ酸~約900アミノ酸、約200アミノ酸~約850アミノ酸、約200アミノ酸~約800アミノ酸、約200アミノ酸~約750アミノ酸、約200アミノ酸~約700アミノ酸、約200アミノ酸~約650アミノ酸、約200アミノ酸~約600アミノ酸、約200アミノ酸~約550アミノ酸、約200アミノ酸~約500アミノ酸、約200アミノ酸~約480アミノ酸、約200アミノ酸~約460アミノ酸、約200アミノ酸~約440アミノ酸、約200アミノ酸~約420アミノ酸、約200アミノ酸~約400アミノ酸、約200アミノ酸~約380アミノ酸、約200アミノ酸~約360アミノ酸、約200アミノ酸~約340アミノ酸、約200アミノ酸~約320アミノ酸、約200アミノ酸~約300アミノ酸、約200アミノ酸~約280アミノ酸、約200アミノ酸~約260アミノ酸、約200アミノ酸~約240アミノ酸、約200アミノ酸~約220アミノ酸、約220アミノ酸~約3000アミノ酸、約220アミノ酸~約2500アミノ酸、約220アミノ酸~約2000アミノ酸、約220アミノ酸~約1500アミノ酸、約220アミノ酸~約1000アミノ酸、約220アミノ酸~約950アミノ酸、約220アミノ酸~約900アミノ酸、約220アミノ酸~約850アミノ酸、約220アミノ酸~約800アミノ酸、約220アミノ酸~約750アミノ酸、約220アミノ酸~約700アミノ酸、約220アミノ酸~約650アミノ酸、約220アミノ酸~約600アミノ酸、約220アミノ酸~約550アミノ酸、約220アミノ酸~約500アミノ酸、約220アミノ酸~約480アミノ酸、約220アミノ酸~約460アミノ酸、約220アミノ酸~約440アミノ酸、約220アミノ酸~約420アミノ酸、約220アミノ酸~約400アミノ酸、約220アミノ酸~約380アミノ酸、約220アミノ酸~約360アミノ酸、約220アミノ酸~約340アミノ酸、約220アミノ酸~約320アミノ酸、約220アミノ酸~約300アミノ酸、約220アミノ酸~約280アミノ酸、約220アミノ酸~約260アミノ酸、約220アミノ酸~約240アミノ酸、約240アミノ酸~約3000アミノ酸、約240アミノ酸~約2500アミノ酸、約240アミノ酸~約2000アミノ酸、約240アミノ酸~約1500アミノ酸、約240アミノ酸~約1000アミノ酸、約240アミノ酸~約950アミノ酸、約240アミノ酸~約900アミノ酸、約240アミノ酸~約850アミノ酸、約240アミノ酸~約800アミノ酸、約240アミノ酸~約750アミノ酸、約240アミノ酸~約700アミノ酸、約240アミノ酸~約650アミノ酸、約240アミノ酸~約600アミノ酸、約240アミノ酸~約550アミノ酸、約240アミノ酸~約500アミノ酸、約240アミノ酸~約480アミノ酸、約240アミノ~約460アミノ酸、約240アミノ酸~約440アミノ酸、約240アミノ酸~約420アミノ酸、約240アミノ酸~約400アミノ酸、約240アミノ酸~約380アミノ酸、約240アミノ酸~約360アミノ酸、約240アミノ酸~約340アミノ酸、約240アミノ酸~約320アミノ酸、約240アミノ酸~約300アミノ酸、約240アミノ酸~約280アミノ酸、約240アミノ酸~約260アミノ酸、約260アミノ酸~約3000アミノ酸、約260アミノ酸~約2500アミノ酸、約260アミノ酸~約2000アミノ酸、約260アミノ酸~約1500アミノ酸、約260アミノ酸~約1000アミノ酸、約260アミノ酸~約950アミノ酸、約260アミノ酸~約900アミノ酸、約260アミノ酸~約850アミノ酸、約260アミノ酸~約800アミノ酸、約260アミノ酸~約750アミノ酸、約260アミノ酸~約700アミノ酸、約260アミノ酸~約650アミノ酸、約260アミノ酸~約600アミノ酸、約260アミノ酸~約550アミノ酸、約260アミノ酸~約500アミノ酸、約260アミノ酸~約480アミノ酸、約260アミノ酸~約460アミノ酸、約260アミノ酸~約440アミノ酸、約260アミノ酸~約420アミノ酸、約260アミノ酸~約400アミノ酸、約260アミノ酸~約380アミノ酸、約260アミノ酸~約360アミノ酸、約260アミノ酸~約340アミノ酸、約260アミノ酸~約320アミノ酸、約260アミノ酸~約300アミノ酸、約260アミノ酸~約280アミノ酸、約280アミノ酸~約3000アミノ酸、約280アミノ酸~約2500アミノ酸、約280アミノ酸~約2000アミノ酸、約280アミノ酸~約1500アミノ酸、約280アミノ酸~約1000アミノ酸、約280アミノ酸~約950アミノ酸、約280アミノ酸~約900アミノ酸、約280アミノ酸~約850アミノ酸、約280アミノ酸~約800アミノ酸、約280アミノ酸~約750アミノ酸、約280アミノ酸~約700アミノ酸、約280アミノ酸~約650アミノ酸、約280アミノ酸~約600アミノ酸、約280アミノ酸~約550アミノ酸、約280アミノ酸~約500アミノ酸、約280アミノ酸~約480アミノ酸、約280アミノ酸~約460アミノ酸、約280アミノ酸~約440アミノ酸、約280アミノ酸~約420アミノ酸、約280アミノ酸~約400アミノ酸、約280アミノ酸~約380アミノ酸、約280アミノ酸~約360アミノ酸、約280アミノ酸~約340アミノ酸、約280アミノ酸~約320アミノ酸、約280アミノ酸~約300アミノ酸、約300アミノ酸~約3000アミノ酸、約300アミノ酸~約2500アミノ酸、約300アミノ酸~約2000アミノ酸、約300アミノ酸~約1500アミノ酸、約300アミノ酸~約1000アミノ酸、約300アミノ酸~約950アミノ酸、約300アミノ酸~約900アミノ酸、
約300アミノ酸~約850アミノ酸、約300アミノ酸~約800アミノ酸、約300アミノ酸~約750アミノ酸、約300アミノ酸~約700アミノ酸、約300アミノ酸~約650アミノ酸、約300アミノ酸~約600アミノ酸、約300アミノ酸~約550アミノ酸、約300アミノ酸~約500アミノ酸、約300アミノ酸~約480アミノ酸、約300アミノ酸~約460アミノ酸、約300アミノ酸~約440アミノ酸、約300アミノ酸~約420アミノ酸、約300アミノ酸~約400アミノ酸、約300アミノ酸~約380アミノ酸、約300アミノ酸~約360アミノ酸、約300アミノ酸~約340アミノ酸、約300アミノ酸~約320アミノ酸、約320アミノ酸~約3000アミノ酸、約320アミノ酸~約2500アミノ酸、約320アミノ酸~約2000アミノ酸、約320アミノ酸~約1500アミノ酸、約320アミノ酸~約1000アミノ酸、約320アミノ酸~約950アミノ酸、約320アミノ酸~約900アミノ酸、約320アミノ酸~約850アミノ酸、約320アミノ酸~約800アミノ酸、約320アミノ酸~約750アミノ酸、約320アミノ酸~約700アミノ酸、約320アミノ酸~約650アミノ酸、約320アミノ酸~約600アミノ酸、約320アミノ酸~約550アミノ酸、約320アミノ酸~約500アミノ酸、約320アミノ酸~約480アミノ酸、約320アミノ酸~約460アミノ酸、約320アミノ酸~約440アミノ酸、約320アミノ酸~約420アミノ酸、約320アミノ酸~約400アミノ酸、約320アミノ酸~約380アミノ酸、約320アミノ酸~約360アミノ酸、約320アミノ酸~約340アミノ酸、約340アミノ酸~約3000アミノ酸、約340アミノ酸~約2500アミノ酸、約340アミノ酸~約2000アミノ酸、約340アミノ酸~約1500アミノ酸、約340アミノ酸~約1000アミノ酸、約340アミノ酸~約950アミノ酸、約340アミノ酸~約900アミノ酸、約340アミノ酸~約850アミノ酸、約340アミノ酸~約800アミノ酸、約340アミノ酸~約750アミノ酸、約340アミノ酸~約700アミノ酸、約340アミノ酸~約650アミノ酸、約340アミノ酸~約600アミノ酸、約340アミノ酸~約550アミノ酸、約340アミノ酸~約500アミノ酸、約340アミノ酸~約480アミノ酸、約340アミノ酸~約460アミノ酸、約340アミノ酸~約440アミノ酸、約340アミノ酸~約420アミノ酸、約340アミノ酸~約400アミノ酸、約340アミノ酸~約380アミノ酸、約340アミノ酸~約360アミノ酸、約360アミノ酸~約3000アミノ酸、約360アミノ酸~約2500アミノ酸、約360アミノ酸~約2000アミノ酸、約360アミノ酸~約1500アミノ酸、約360アミノ酸~約1000アミノ酸、約360アミノ酸~約950アミノ酸、約360アミノ酸~約900アミノ酸、約360アミノ酸~約850アミノ酸、約360アミノ酸~約800アミノ酸、約360アミノ酸~約750アミノ酸、約360アミノ酸~約700アミノ酸、約360アミノ酸~約650アミノ酸、約360アミノ酸~約600アミノ酸、約360アミノ酸~約550アミノ酸、約360アミノ酸~約500アミノ酸、約360アミノ酸~約480アミノ酸、約360アミノ酸~約460アミノ酸、約360アミノ酸~約440アミノ酸、約360アミノ酸~約420アミノ酸、約360アミノ酸~約400アミノ酸、約360アミノ酸~約380アミノ酸、約380アミノ酸~約3000アミノ酸、約380アミノ酸~約2500アミノ酸、約380アミノ酸~約2000アミノ酸、約380アミノ酸~約1500アミノ酸、約380アミノ酸~約1000アミノ酸、約380アミノ酸~約950アミノ酸、約380アミノ酸~約900アミノ酸、約380アミノ酸~約850アミノ酸、約380アミノ酸~約800アミノ酸、約380アミノ酸~約750アミノ酸、約380アミノ酸~約700アミノ酸、約380アミノ酸~約650アミノ酸、約380アミノ酸~約600アミノ酸、約380アミノ酸~約550アミノ酸、約380アミノ酸~約500アミノ酸、約380アミノ酸~約480アミノ酸、約380アミノ酸~約460アミノ酸、約380アミノ酸~約440アミノ酸、約380アミノ酸~約420アミノ酸、約380アミノ酸~約400アミノ酸、約400アミノ酸~約3000アミノ酸、約400アミノ酸~約2500アミノ酸、約400アミノ酸~約2000アミノ酸、約400アミノ酸~約1500アミノ酸、約400アミノ酸~約1000アミノ酸、約400アミノ酸~約950アミノ酸、約400アミノ酸~約900アミノ酸、約400アミノ酸~約850アミノ酸、約400アミノ酸~約800アミノ酸、約400アミノ酸~約750アミノ酸、約400アミノ酸~約700アミノ酸、約400アミノ酸~約650アミノ酸、約400アミノ酸~約600アミノ酸、約400アミノ酸~約550アミノ酸、約400アミノ酸~約500アミノ酸、約400アミノ酸~約480アミノ酸、約400アミノ酸~約460アミノ酸、約400アミノ酸~約440アミノ酸、約400アミノ酸~約420アミノ酸、約420アミノ酸~約3000アミノ酸、約420アミノ酸~約2500アミノ酸、約420アミノ酸~約2000アミノ酸、約420アミノ酸~約1500アミノ酸、約420アミノ酸~約1000アミノ酸、約420アミノ酸~約950アミノ酸、約420アミノ酸~約900アミノ酸、約420アミノ酸~約850アミノ酸、約420アミノ酸~約800アミノ酸、約420アミノ酸~約750アミノ酸、約420アミノ酸~約700アミノ酸、約420アミノ酸~約650アミノ酸、約420アミノ酸~約600アミノ酸、約420アミノ酸~約550アミノ酸、約420アミノ酸~約500アミノ酸、約420アミノ酸~約480アミノ酸、約420アミノ酸~約460アミノ酸、約420アミノ酸~約440アミノ酸、約440アミノ酸~約3000アミノ酸、約440アミノ酸~約2500アミノ酸、約440アミノ酸~約2000アミノ酸、約440アミノ酸~約1500アミノ酸、約440アミノ酸~約1000アミノ酸、約440アミノ酸~約950アミノ酸、約440アミノ酸~約900アミノ酸、約440アミノ酸~約850アミノ酸、約440アミノ酸~約800アミノ酸、約440アミノ酸~約750アミノ酸、約440アミノ酸~約700アミノ酸、約440アミノ酸~約650アミノ酸、約440アミノ酸~約600アミノ酸、約440アミノ酸~約550アミノ酸、約440アミノ酸~約500アミノ酸、約440アミノ酸~約480アミノ酸、約440アミノ酸~約460アミノ酸、約460アミノ酸~約3000アミノ酸、約460アミノ酸~約2500アミノ酸、約460アミノ酸~約2000アミノ酸、約460アミノ酸~約1500アミノ酸、約460アミノ酸~約1000アミノ酸、約460アミノ酸~約950アミノ酸、約460アミノ酸~約900アミノ酸、約460アミノ酸~約850アミノ酸、約460アミノ酸~約800アミノ酸、約460アミノ酸~約750アミノ酸、約460アミノ酸~約700アミノ酸、約460アミノ酸~約650アミノ酸、約460アミノ酸~約600アミノ酸、約460アミノ酸~約550アミノ酸、約460アミノ酸~約500アミノ酸、約460アミノ酸~約480アミノ酸、約480アミノ酸~約3000アミノ酸、約480アミノ酸~約2500アミノ酸、約480アミノ酸~約2000アミノ酸、約480アミノ酸~約1500アミノ酸、約480アミノ酸~約1000アミノ酸、約480アミノ酸~約950アミノ酸、約480アミノ酸~約900アミノ酸、約480アミノ酸~約850アミノ酸、約480アミノ酸~約800アミノ酸、約480アミノ酸~約750アミノ酸、約480アミノ酸~約700アミノ酸、約480アミノ酸~約650アミノ酸、約480アミノ酸~約600アミノ酸、約480アミノ酸~約550アミノ酸、約480アミノ酸~約500アミノ酸、約500アミノ酸~約3000アミノ酸、約500アミノ酸~約2500アミノ酸、約500アミノ酸~約2000アミノ酸、約500アミノ酸~約1500アミノ酸、約500アミノ酸~約1000アミノ酸、約500アミノ酸~約950アミノ酸、約500アミノ酸~約900アミノ酸、約500アミノ酸~約850アミノ酸、約500アミノ酸~約800アミノ酸、約500アミノ酸~約750アミノ酸、約500アミノ酸~約700アミノ酸、約500アミノ酸~約650アミノ酸、約500アミノ酸~約600アミノ酸、約500アミノ酸~約550アミノ酸、約550アミノ酸~約3000アミノ酸、約550アミノ酸~約2500アミノ酸、約550アミノ酸~約2000アミノ酸、約550アミノ酸~約1500アミノ酸、約550アミノ酸~約1000アミノ酸、約550アミノ酸~約950アミノ酸、約550アミノ酸~約900アミノ酸、約550アミノ酸~約850アミノ酸、約550アミノ酸~約800アミノ酸、約550アミノ酸~約750アミノ酸、約550アミノ酸~約700アミノ酸、約550アミノ酸~約650アミノ酸、約550アミノ酸~約600アミノ酸、約600アミノ酸~約3000アミノ酸、約600アミノ酸~約2500アミノ酸、約600アミノ酸~約2000アミノ酸、約600アミノ酸~約1500アミノ酸、約600アミノ酸~約1000アミノ酸、約600アミノ酸~約950アミノ酸、約600アミノ酸~約900アミノ酸、約600アミノ酸~約850アミノ酸、約600アミノ酸~約800アミノ酸、約600アミノ酸~約750アミノ酸、約600アミノ酸~約700アミノ酸、約600アミノ酸~約650アミノ酸、約650アミノ酸~約3000アミノ酸、約650アミノ酸~約2500アミノ酸、約650アミノ酸~約2000アミノ酸、約650アミノ酸~約1500アミノ酸、約650アミノ酸~約1000アミノ酸、約650アミノ酸~約950アミノ酸、約650アミノ酸~約900アミノ酸、約650アミノ酸~約850アミノ酸、約650アミノ酸~約800アミノ酸、約650アミノ酸~約750アミノ酸、約650アミノ酸~約700アミノ酸、約700アミノ酸~約3000アミノ酸、約700アミノ酸~約2500アミノ酸、約700アミノ酸~約2000アミノ酸、約700アミノ酸~約1500アミノ酸、約700アミノ酸~約1000アミノ酸、約700アミノ酸~約950アミノ酸、約700アミノ酸~約900アミノ酸、
約700アミノ酸~約850アミノ酸、約700アミノ酸~約800アミノ酸、約700アミノ酸~約750アミノ酸、約750アミノ酸~約3000アミノ酸、約750アミノ酸~約2500アミノ酸、約750アミノ酸~約2000アミノ酸、約750アミノ酸~約1500アミノ酸、約750アミノ酸~約1000アミノ酸、約750アミノ酸~約950アミノ酸、約750アミノ酸~約900アミノ酸、約750アミノ酸~約850アミノ酸、約750アミノ酸~約800アミノ酸、約800アミノ酸~約3000アミノ酸、約800アミノ酸~約2500アミノ酸、約800アミノ酸~約2000アミノ酸、約800アミノ酸~約1500アミノ酸、約800アミノ酸~約1000アミノ酸、約800アミノ酸~約950アミノ酸、約800アミノ酸~約900アミノ酸、約800アミノ酸~約850アミノ酸、約850アミノ酸~約3000アミノ酸、約850アミノ酸~約2500アミノ酸、約850アミノ酸~約2000アミノ酸、約850アミノ酸~約1500アミノ酸、約850アミノ酸~約1000アミノ酸、約850アミノ酸~約950アミノ酸、約850アミノ酸~約900アミノ酸、約900アミノ酸~約3000アミノ酸、約900アミノ酸~約2500アミノ酸、約900アミノ酸~約2000アミノ酸、約900アミノ酸~約1500アミノ酸、約900アミノ酸~約1000アミノ酸、約900アミノ酸~約950アミノ酸、約950アミノ酸~約3000アミノ酸、約950アミノ酸~約2500アミノ酸、約950アミノ酸~約2000アミノ酸、約950アミノ酸~約1500アミノ酸、約950アミノ酸~約1000アミノ酸、約1000アミノ酸~約3000アミノ酸、約1000アミノ酸~約2500アミノ酸、約1000アミノ酸~約2000アミノ酸、約1000アミノ酸~約1500アミノ酸、約1500アミノ酸~約3000アミノ酸、約1500アミノ酸~約2500アミノ酸、約1500アミノ酸~約2000アミノ酸、約2000アミノ酸~約3000アミノ酸、約2000アミノ酸~約2500アミノ酸、又は約2500アミノ酸~約3000アミノ酸であり得る。
In some examples of any of the multi-chain chimeric polypeptides described herein, the total length of the first chimeric polypeptide and/or the second chimeric polypeptide are each independently from about 50 amino acids to about 3000 amino acids, about 50 amino acids to about 2500 amino acids, about 50 amino acids to about 2000 amino acids, about 50 amino acids to about 1500 amino acids, about 50 amino acids to about 1000 amino acids, about 50 amino acids to about 950 amino acids, about 50 amino acids to about 900 amino acids amino acids, about 50 amino acids to about 850 amino acids, about 50 amino acids to about 800 amino acids, about 50 amino acids to about 750 amino acids, about 50 amino acids to about 700 amino acids, about 50 amino acids to about 650 amino acids, about 50 amino acids to about 600 amino acids, about 50 amino acids to about 550 amino acids, about 50 amino acids to about 500 amino acids, about 50 amino acids to about 480 amino acids, about 50 amino acids to about 460 amino acids, about 50 amino acids to about 440 amino acids, about 50 amino acids to about 420 amino acids, about 50 amino acids to about 400 amino acids, about 50 amino acids to about 380 amino acids, about 50 amino acids to about 360 amino acids, about 50 amino acids to about 340 amino acids, about 50 amino acids to about 320 amino acids, about 50 amino acids to about 300 amino acids, about 50 amino acids to about 280 amino acids, about 50 amino acids to about 260 amino acids, about 50 amino acids to about 240 amino acids, about 50 amino acids to about 220 amino acids, about 50 amino acids to about 200 amino acids, about 50 amino acids to about 150 amino acids, about 50 amino acids to about 100 amino acids amino acids, about 100 amino acids to about 3000 amino acids, about 100 amino acids to about 2500 amino acids, about 100 amino acids to about 2000 amino acids, about 100 amino acids to about 1500 amino acids, about 100 amino acids to about 1000 amino acids, about 100 amino acids to about 950 amino acids, about 100 amino acids to about 900 amino acids, about 100 amino acids to about 850 amino acids, about 100 amino acids to about 800 amino acids, about 100 amino acids to about 750 amino acids, about 100 amino acids to about 700 amino acids, about 100 amino acids to about 650 amino acids, about 100 amino acids to about 600 amino acids, about 100 amino acids to about 550 amino acids, about 100 amino acids to about 500 amino acids, about 100 amino acids to about 480 amino acids, about 100 amino acids to about 460 amino acids, about 100 amino acids to about 440 amino acids, about 100 amino acids to about 420 amino acids, about 100 amino acids to about 400 amino acids, about 100 amino acids to about 380 amino acids, about 100 amino acids to about 360 amino acids, about 100 amino acids to about 340 amino acids, about 100 amino acids to about 320 amino acids, about 100 amino acids to about 300 amino acids amino acids, about 100 amino acids to about 280 amino acids, about 100 amino acids to about 260 amino acids, about 100 amino acids to about 240 amino acids, about 100 amino acids to about 220 amino acids, about 100 amino acids to about 200 amino acids, about 100 amino acids to about 150 amino acids, about 150 amino acids to about 3000 amino acids, about 150 amino acids to about 2500 amino acids, about 150 amino acids to about 2000 amino acids, about 150 amino acids to about 1500 amino acids, about 150 amino acids to about 1000 amino acids, about 150 amino acids to about 950 amino acids, about 150 amino acids to about 900 amino acids, about 150 amino acids to about 850 amino acids, about 150 amino acids to about 800 amino acids, about 150 amino acids to about 750 amino acids, about 150 amino acids to about 700 amino acids, about 150 amino acids to about 650 amino acids, about 150 amino acids to about 600 amino acids, about 150 amino acids to about 550 amino acids, about 150 amino acids to about 500 amino acids, about 150 amino acids to about 480 amino acids, about 150 amino acids to about 460 amino acids, about 150 amino acids to about 440 amino acids, about 150 amino acids to about 420 amino acids amino acids, about 150 amino acids to about 400 amino acids, about 150 amino acids to about 380 amino acids, about 150 amino acids to about 360 amino acids, about 150 amino acids to about 340 amino acids, about 150 amino acids to about 320 amino acids, about 150 amino acids to about 300 amino acids, about 150 amino acids to about 280 amino acids, about 150 amino acids to about 260 amino acids, about 150 amino acids to about 240 amino acids, about 150 amino acids to about 220 amino acids, about 150 amino acids to about 200 amino acids, about 200 amino acids to about 3000 amino acids, about 200 amino acids to about 2500 amino acids, about 200 amino acids to about 2000 amino acids, about 200 amino acids to about 1500 amino acids, about 200 amino acids to about 1000 amino acids, about 200 amino acids to about 950 amino acids, about 200 amino acids to about 900 amino acids, about 200 amino acids to about 850 amino acids, about 200 amino acids to about 800 amino acids, about 200 amino acids to about 750 amino acids, about 200 amino acids to about 700 amino acids, about 200 amino acids to about 650 amino acids, about 200 amino acids to about 600 amino acids, about 200 amino acids to about 550 amino acids amino acids, about 200 amino acids to about 500 amino acids, about 200 amino acids to about 480 amino acids, about 200 amino acids to about 460 amino acids, about 200 amino acids to about 440 amino acids, about 200 amino acids to about 420 amino acids, about 200 amino acids to about 400 amino acids, about 200 amino acids to about 380 amino acids, about 200 amino acids to about 360 amino acids, about 200 amino acids to about 340 amino acids, about 200 amino acids to about 320 amino acids, about 200 amino acids to about 300 amino acids, about 200 amino acids to about 280 amino acids, about 200 amino acids to about 260 amino acids, about 200 amino acids to about 240 amino acids, about 200 amino acids to about 220 amino acids, about 220 amino acids to about 3000 amino acids, about 220 amino acids to about 2500 amino acids, about 220 amino acids to about 2000 amino acids, about 220 amino acids to about 1500 amino acids, about 220 amino acids to about 1000 amino acids, about 220 amino acids to about 950 amino acids, about 220 amino acids to about 900 amino acids, about 220 amino acids to about 850 amino acids, about 220 amino acids to about 800 amino acids, about 220 amino acids to about 750 amino acids amino acids, about 220 amino acids to about 700 amino acids, about 220 amino acids to about 650 amino acids, about 220 amino acids to about 600 amino acids, about 220 amino acids to about 550 amino acids, about 220 amino acids to about 500 amino acids, about 220 amino acids to about 480 amino acids, about 220 amino acids to about 460 amino acids, about 220 amino acids to about 440 amino acids, about 220 amino acids to about 420 amino acids, about 220 amino acids to about 400 amino acids, about 220 amino acids to about 380 amino acids, about 220 amino acids to about 360 amino acids, about 220 amino acids to about 340 amino acids, about 220 amino acids to about 320 amino acids, about 220 amino acids to about 300 amino acids, about 220 amino acids to about 280 amino acids, about 220 amino acids to about 260 amino acids, about 220 amino acids to about 240 amino acids, about 240 amino acids to about 3000 amino acids, about 240 amino acids to about 2500 amino acids, about 240 amino acids to about 2000 amino acids, about 240 amino acids to about 1500 amino acids, about 240 amino acids to about 1000 amino acids, about 240 amino acids to about 950 amino acids, about 240 amino acids to about 900 amino acids amino acids, about 240 amino acids to about 850 amino acids, about 240 amino acids to about 800 amino acids, about 240 amino acids to about 750 amino acids, about 240 amino acids to about 700 amino acids, about 240 amino acids to about 650 amino acids, about 240 amino acids to about 600 amino acids, about 240 amino acids to about 550 amino acids, about 240 amino acids to about 500 amino acids, about 240 amino acids to about 480 amino acids, about 240 amino acids to about 460 amino acids, about 240 amino acids to about 440 amino acids, about 240 amino acids to about 420 amino acids, about 240 amino acids to about 400 amino acids, about 240 amino acids to about 380 amino acids, about 240 amino acids to about 360 amino acids, about 240 amino acids to about 340 amino acids, about 240 amino acids to about 320 amino acids, about 240 amino acids to about 300 amino acids, about 240 amino acids to about 280 amino acids, about 240 amino acids to about 260 amino acids, about 260 amino acids to about 3000 amino acids, about 260 amino acids to about 2500 amino acids, about 260 amino acids to about 2000 amino acids, about 260 amino acids to about 1500 amino acids, about 260 amino acids to about 1000 amino acids amino acids, about 260 amino acids to about 950 amino acids, about 260 amino acids to about 900 amino acids, about 260 amino acids to about 850 amino acids, about 260 amino acids to about 800 amino acids, about 260 amino acids to about 750 amino acids, about 260 amino acids to about 700 amino acids, about 260 amino acids to about 650 amino acids, about 260 amino acids to about 600 amino acids, about 260 amino acids to about 550 amino acids, about 260 amino acids to about 500 amino acids, about 260 amino acids to about 480 amino acids, about 260 amino acids to about 460 amino acids, about 260 amino acids to about 440 amino acids, about 260 amino acids to about 420 amino acids, about 260 amino acids to about 400 amino acids, about 260 amino acids to about 380 amino acids, about 260 amino acids to about 360 amino acids, about 260 amino acids to about 340 amino acids, about 260 amino acids to about 320 amino acids, about 260 amino acids to about 300 amino acids, about 260 amino acids to about 280 amino acids, about 280 amino acids to about 3000 amino acids, about 280 amino acids to about 2500 amino acids, about 280 amino acids to about 2000 amino acids, about 280 amino acids to about 1500 amino acids amino acids, about 280 amino acids to about 1000 amino acids, about 280 amino acids to about 950 amino acids, about 280 amino acids to about 900 amino acids, about 280 amino acids to about 850 amino acids, about 280 amino acids to about 800 amino acids, about 280 amino acids to about 750 amino acids, about 280 amino acids to about 700 amino acids, about 280 amino acids to about 650 amino acids, about 280 amino acids to about 600 amino acids, about 280 amino acids to about 550 amino acids, about 280 amino acids to about 500 amino acids, about 280 amino acids to about 480 amino acids, about 280 amino acids to about 460 amino acids, about 280 amino acids to about 440 amino acids, about 280 amino acids to about 420 amino acids, about 280 amino acids to about 400 amino acids, about 280 amino acids to about 380 amino acids, about 280 amino acids to about 360 amino acids, about 280 amino acids to about 340 amino acids, about 280 amino acids to about 320 amino acids, about 280 amino acids to about 300 amino acids, about 300 amino acids to about 3000 amino acids, about 300 amino acids to about 2500 amino acids, about 300 amino acids to about 2000 amino acids, about 300 amino acids to about 1500 amino acids amino acids, about 300 amino acids to about 1000 amino acids, about 300 amino acids to about 950 amino acids, about 300 amino acids to about 900 amino acids,
about 300 amino acids to about 850 amino acids, about 300 amino acids to about 800 amino acids, about 300 amino acids to about 750 amino acids, about 300 amino acids to about 700 amino acids, about 300 amino acids to about 650 amino acids, about 300 amino acids to about 600 amino acids, about 300 amino acids to about 550 amino acids, about 300 amino acids to about 500 amino acids, about 300 amino acids to about 480 amino acids, about 300 amino acids to about 460 amino acids, about 300 amino acids to about 440 amino acids, about 300 amino acids to about 420 amino acids, about 300 amino acids to about 400 amino acids, about 300 amino acids to about 380 amino acids, about 300 amino acids to about 360 amino acids, about 300 amino acids to about 340 amino acids, about 300 amino acids to about 320 amino acids, about 320 amino acids to about 3000 amino acids, about 320 amino acids to about 2500 amino acids amino acids, about 320 amino acids to about 2000 amino acids, about 320 amino acids to about 1500 amino acids, about 320 amino acids to about 1000 amino acids, about 320 amino acids to about 950 amino acids, about 320 amino acids to about 900 amino acids, about 320 amino acids to about 850 amino acids, about 320 amino acids to about 800 amino acids, about 320 amino acids to about 750 amino acids, about 320 amino acids to about 700 amino acids, about 320 amino acids to about 650 amino acids, about 320 amino acids to about 600 amino acids, about 320 amino acids to about 550 amino acids, about 320 amino acids to about 500 amino acids, about 320 amino acids to about 480 amino acids, about 320 amino acids to about 460 amino acids, about 320 amino acids to about 440 amino acids, about 320 amino acids to about 420 amino acids, about 320 amino acids to about 400 amino acids, about 320 amino acids to about 380 amino acids, about 320 amino acids to about 360 amino acids, about 320 amino acids to about 340 amino acids, about 340 amino acids to about 3000 amino acids, about 340 amino acids to about 2500 amino acids, about 340 amino acids to about 2000 amino acids, about 340 amino acids to about 1500 amino acids amino acids, about 340 amino acids to about 1000 amino acids, about 340 amino acids to about 950 amino acids, about 340 amino acids to about 900 amino acids, about 340 amino acids to about 850 amino acids, about 340 amino acids to about 800 amino acids, about 340 amino acids to about 750 amino acids, about 340 amino acids to about 700 amino acids, about 340 amino acids to about 650 amino acids, about 340 amino acids to about 600 amino acids, about 340 amino acids to about 550 amino acids, about 340 amino acids to about 500 amino acids, about 340 amino acids to about 480 amino acids, about 340 amino acids amino acids to about 460 amino acids, about 340 amino acids to about 440 amino acids, about 340 amino acids to about 420 amino acids, about 340 amino acids to about 400 amino acids, about 340 amino acids to about 380 amino acids, about 340 amino acids to about 360 amino acids, about 360 amino acids to about 3000 amino acids, about 360 amino acids to about 2500 amino acids, about 360 amino acids to about 2000 amino acids, about 360 amino acids to about 1500 amino acids, about 360 amino acids to about 1000 amino acids, about 360 amino acids to about 950 amino acids, about 360 amino acids to about 900 amino acids amino acids, about 360 amino acids to about 850 amino acids, about 360 amino acids to about 800 amino acids, about 360 amino acids to about 750 amino acids, about 360 amino acids to about 700 amino acids, about 360 amino acids to about 650 amino acids, about 360 amino acids to about 600 amino acids, about 360 amino acids to about 550 amino acids, about 360 amino acids to about 500 amino acids, about 360 amino acids to about 480 amino acids, about 360 amino acids to about 460 amino acids, about 360 amino acids to about 440 amino acids, about 360 amino acids to about 420 amino acids, about 360 amino acids to about 400 amino acids, about 360 amino acids to about 380 amino acids, about 380 amino acids to about 3000 amino acids, about 380 amino acids to about 2500 amino acids, about 380 amino acids to about 2000 amino acids, about 380 amino acids to about 1500 amino acids, about 380 amino acids to about 1000 amino acids, about 380 amino acids to about 950 amino acids, about 380 amino acids to about 900 amino acids, about 380 amino acids to about 850 amino acids, about 380 amino acids to about 800 amino acids, about 380 amino acids to about 750 amino acids, about 380 amino acids to about 700 amino acids amino acids, about 380 amino acids to about 650 amino acids, about 380 amino acids to about 600 amino acids, about 380 amino acids to about 550 amino acids, about 380 amino acids to about 500 amino acids, about 380 amino acids to about 480 amino acids, about 380 amino acids to about 460 amino acids, about 380 amino acids to about 440 amino acids, about 380 amino acids to about 420 amino acids, about 380 amino acids to about 400 amino acids, about 400 amino acids to about 3000 amino acids, about 400 amino acids to about 2500 amino acids, about 400 amino acids to about 2000 amino acids, about 400 amino acids to about 1500 amino acids, about 400 amino acids to about 1000 amino acids, about 400 amino acids to about 950 amino acids, about 400 amino acids to about 900 amino acids, about 400 amino acids to about 850 amino acids, about 400 amino acids to about 800 amino acids, about 400 amino acids to about 750 amino acids, about 400 amino acids to about 700 amino acids, about 400 amino acids to about 650 amino acids, about 400 amino acids to about 600 amino acids, about 400 amino acids to about 550 amino acids, about 400 amino acids to about 500 amino acids, about 400 amino acids to about 480 amino acids amino acids, about 400 amino acids to about 460 amino acids, about 400 amino acids to about 440 amino acids, about 400 amino acids to about 420 amino acids, about 420 amino acids to about 3000 amino acids, about 420 amino acids to about 2500 amino acids, about 420 amino acids to about 2000 amino acids, about 420 amino acids to about 1500 amino acids, about 420 amino acids to about 1000 amino acids, about 420 amino acids to about 950 amino acids, about 420 amino acids to about 900 amino acids, about 420 amino acids to about 850 amino acids, about 420 amino acids to about 800 amino acids, about 420 amino acids to about 750 amino acids, about 420 amino acids to about 700 amino acids, about 420 amino acids to about 650 amino acids, about 420 amino acids to about 600 amino acids, about 420 amino acids to about 550 amino acids, about 420 amino acids to about 500 amino acids, about 420 amino acids to about 480 amino acids, about 420 amino acids to about 460 amino acids, about 420 amino acids to about 440 amino acids, about 440 amino acids to about 3000 amino acids, about 440 amino acids to about 2500 amino acids, about 440 amino acids to about 2000 amino acids, about 440 amino acids to about 1500 amino acids amino acids, about 440 amino acids to about 1000 amino acids, about 440 amino acids to about 950 amino acids, about 440 amino acids to about 900 amino acids, about 440 amino acids to about 850 amino acids, about 440 amino acids to about 800 amino acids, about 440 amino acids to about 750 amino acids, about 440 amino acids to about 700 amino acids, about 440 amino acids to about 650 amino acids, about 440 amino acids to about 600 amino acids, about 440 amino acids to about 550 amino acids, about 440 amino acids to about 500 amino acids, about 440 amino acids to about 480 amino acids, about 440 amino acids amino acids to about 460 amino acids, about 460 amino acids to about 3000 amino acids, about 460 amino acids to about 2500 amino acids, about 460 amino acids to about 2000 amino acids, about 460 amino acids to about 1500 amino acids, about 460 amino acids to about 1000 amino acids, about 460 amino acids to about 950 amino acids, about 460 amino acids to about 900 amino acids, about 460 amino acids to about 850 amino acids, about 460 amino acids to about 800 amino acids, about 460 amino acids to about 750 amino acids, about 460 amino acids to about 700 amino acids, about 460 amino acids to about 650 amino acids amino acids, about 460 amino acids to about 600 amino acids, about 460 amino acids to about 550 amino acids, about 460 amino acids to about 500 amino acids, about 460 amino acids to about 480 amino acids, about 480 amino acids to about 3000 amino acids, about 480 amino acids to about 2500 amino acids, about 480 amino acids to about 2000 amino acids, about 480 amino acids to about 1500 amino acids, about 480 amino acids to about 1000 amino acids, about 480 amino acids to about 950 amino acids, about 480 amino acids to about 900 amino acids, about 480 amino acids to about 850 amino acids, about 480 amino acids to about 800 amino acids, about 480 amino acids to about 750 amino acids, about 480 amino acids to about 700 amino acids, about 480 amino acids to about 650 amino acids, about 480 amino acids to about 600 amino acids, about 480 amino acids to about 550 amino acids, about 480 amino acids to about 500 amino acids, about 500 amino acids to about 3000 amino acids, about 500 amino acids to about 2500 amino acids, about 500 amino acids to about 2000 amino acids, about 500 amino acids to about 1500 amino acids, about 500 amino acids to about 1000 amino acids, about 500 amino acids to about 950 amino acids amino acids, about 500 amino acids to about 900 amino acids, about 500 amino acids to about 850 amino acids, about 500 amino acids to about 800 amino acids, about 500 amino acids to about 750 amino acids, about 500 amino acids to about 700 amino acids, about 500 amino acids to about 650 amino acids, about 500 amino acids to about 600 amino acids, about 500 amino acids to about 550 amino acids, about 550 amino acids to about 3000 amino acids, about 550 amino acids to about 2500 amino acids, about 550 amino acids to about 2000 amino acids, about 550 amino acids to about 1500 amino acids, about 550 amino acids to about 1000 amino acids, about 550 amino acids to about 950 amino acids, about 550 amino acids to about 900 amino acids, about 550 amino acids to about 850 amino acids, about 550 amino acids to about 800 amino acids, about 550 amino acids to about 750 amino acids, about 550 amino acids to about 700 amino acids, about 550 amino acids to about 650 amino acids, about 550 amino acids to about 600 amino acids, about 600 amino acids to about 3000 amino acids, about 600 amino acids to about 2500 amino acids, about 600 amino acids to about 2000 amino acids, about 600 amino acids to about 1500 amino acids amino acids, about 600 amino acids to about 1000 amino acids, about 600 amino acids to about 950 amino acids, about 600 amino acids to about 900 amino acids, about 600 amino acids to about 850 amino acids, about 600 amino acids to about 800 amino acids, about 600 amino acids to about 750 amino acids, about 600 amino acids to about 700 amino acids, about 600 amino acids to about 650 amino acids, about 650 amino acids to about 3000 amino acids, about 650 amino acids to about 2500 amino acids, about 650 amino acids to about 2000 amino acids, about 650 amino acids to about 1500 amino acids, about 650 amino acids to about 1000 amino acids, about 650 amino acids to about 950 amino acids, about 650 amino acids to about 900 amino acids, about 650 amino acids to about 850 amino acids, about 650 amino acids to about 800 amino acids, about 650 amino acids to about 750 amino acids, about 650 amino acids to about 700 amino acids, about 700 amino acids to about 3000 amino acids, about 700 amino acids to about 2500 amino acids, about 700 amino acids to about 2000 amino acids, about 700 amino acids to about 1500 amino acids, about 700 amino acids to about 1000 amino acids, about 700 amino acids to about 950 amino acids amino acids, from about 700 amino acids to about 900 amino acids;
about 700 amino acids to about 850 amino acids, about 700 amino acids to about 800 amino acids, about 700 amino acids to about 750 amino acids, about 750 amino acids to about 3000 amino acids, about 750 amino acids to about 2500 amino acids, about 750 amino acids to about 2000 amino acids, about 750 amino acids to about 1500 amino acids, about 750 amino acids to about 1000 amino acids, about 750 amino acids to about 950 amino acids, about 750 amino acids to about 900 amino acids, about 750 amino acids to about 850 amino acids, about 750 amino acids to about 800 amino acids, about 800 amino acids to about 3000 amino acids, about 800 amino acids to about 2500 amino acids, about 800 amino acids to about 2000 amino acids, about 800 amino acids to about 1500 amino acids, about 800 amino acids to about 1000 amino acids, about 800 amino acids to about 950 amino acids, about 800 amino acids to about 900 amino acids amino acids, about 800 amino acids to about 850 amino acids, about 850 amino acids to about 3000 amino acids, about 850 amino acids to about 2500 amino acids, about 850 amino acids to about 2000 amino acids, about 850 amino acids to about 1500 amino acids, about 850 amino acids to about 1000 amino acids, about 850 amino acids to about 950 amino acids, about 850 amino acids to about 900 amino acids, about 900 amino acids to about 3000 amino acids, about 900 amino acids to about 2500 amino acids, about 900 amino acids to about 2000 amino acids, about 900 amino acids to about 1500 amino acids, about 900 amino acids to about 1000 amino acids, about 900 amino acids to about 950 amino acids, about 950 amino acids to about 3000 amino acids, about 950 amino acids to about 2500 amino acids, about 950 amino acids to about 2000 amino acids, about 950 amino acids to about 1500 amino acids, about 950 amino acids to about 1000 amino acids, about 1000 amino acids to about 3000 amino acids, about 1000 amino acids to about 2500 amino acids, about 1000 amino acids to about 2000 amino acids, about 1000 amino acids to about 1500 amino acids, about 1500 amino acids to about 3000 amino acids, about 1500 amino acids to about 2500 amino acids amino acids, about 1500 amino acids to about 2000 amino acids, about 2000 amino acids to about 3000 amino acids, about 2000 amino acids to about 2500 amino acids, or about 2500 amino acids to about 3000 amino acids.
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン(例えば、本明細書に記載の第1の標的結合ドメインのうちのいずれか)と可溶性組織因子ドメイン(例えば、本明細書に記載の例示的な可溶性組織因子ドメインのうちのいずれか)は、第1のキメラポリペプチド内で互いに直接隣接している。本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1のキメラポリペプチドは、第1のキメラポリペプチド内の第1の標的結合ドメイン(本明細書に記載の例示的な第1の標的結合ドメインのうちのいずれか)と可溶性組織因子ドメイン(例えば、本明細書に記載の例示的な可溶性組織因子ドメインのうちのいずれか)との間にリンカー配列(例えば、本明細書に記載の又は当該技術分野で既知の例示的なリンカー配列のうちのいずれか)を更に含む。 In some embodiments of any of the multichain chimeric polypeptides described herein, the first target binding domain (e.g., any of the first target binding domains described herein ) and a soluble tissue factor domain (eg, any of the exemplary soluble tissue factor domains described herein) are directly adjacent to each other within the first chimeric polypeptide. In some embodiments of any of the multi-chain chimeric polypeptides described herein, the first chimeric polypeptide is a first target binding domain (herein any of the exemplary first target binding domains described in ) and a soluble tissue factor domain (e.g., any of the exemplary soluble tissue factor domains described herein). Further includes sequences (eg, any of the exemplary linker sequences described herein or known in the art).
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、可溶性組織因子ドメイン(例えば、本明細書に記載の例示的な可溶性組織因子ドメインのうちのいずれか)と一対の親和性ドメインの第1のドメイン(例えば、本明細書に記載の例示的な一対の親和性ドメインのうちのいずれかの例示的な第1のドメインのうちのいずれか)は、第1のキメラポリペプチド内で互いに直接隣接している。本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1のキメラポリペプチドは、第1のキメラポリペプチド内の可溶性組織因子ドメイン(本明細書に記載の例示的な可溶性組織因子ドメインのうちのいずれか)と一対の親和性ドメインの第1のドメイン(例えば、本明細書に記載の例示的な一対の親和性ドメインのうちのいずれかの例示的な第1のドメインのうちのいずれか)との間にリンカー配列(例えば、本明細書に記載の又は当該技術分野で既知の例示的なリンカー配列のうちのいずれか)を更に含む。 In some embodiments of any of the multi-chain chimeric polypeptides described herein, a soluble tissue factor domain (e.g., any of the exemplary soluble tissue factor domains described herein) and the first domain of the pair of affinity domains (e.g., any of the exemplary first domains of any of the exemplary pairs of affinity domains described herein) is the first directly adjacent to each other within one chimeric polypeptide. In some embodiments of any of the multi-chain chimeric polypeptides described herein, the first chimeric polypeptide comprises a soluble tissue factor domain (described herein) within the first chimeric polypeptide. ) and the first domain of the pair of affinity domains (e.g., any of the exemplary pair of affinity domains described herein). first domain) (eg, any of the exemplary linker sequences described herein or known in the art).
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、一対の親和性ドメインの第2のドメイン(例えば、本明細書に記載の例示的な一対の親和性ドメインのうちのいずれかの例示的な第2のドメインのうちのいずれか)と第2の標的結合ドメイン(例えば、本明細書に記載の例示的な第2の標的結合ドメインのうちのいずれか)は、第2のキメラポリペプチド内で互いに直接隣接している。本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチド内の一対の親和性ドメインの第2のドメイン(例えば、本明細書に記載の例示的な一対の親和性ドメインのうちのいずれかの例示的な第2のドメインのうちのいずれか)と第2の標的結合ドメイン(例えば、本明細書に記載の例示的な第2の標的結合ドメインのうちのいずれか)との間にリンカー配列(例えば、本明細書に記載の又は当該技術分野で既知の例示的なリンカー配列のうちのいずれか)を更に含む。 In some embodiments of any of the multi-chain chimeric polypeptides described herein, the second domain of the pair of affinity domains (e.g., an exemplary affinity pair described herein any of the exemplary second domains of any of the domains) and a second target binding domain (e.g., any of the exemplary second target binding domains described herein) ) are immediately adjacent to each other in the second chimeric polypeptide. In some embodiments of any of the multi-chain chimeric polypeptides described herein, the second chimeric polypeptide is the second domain of the pair of affinity domains within the second chimeric polypeptide. (e.g., any of the exemplary second domains of any of the exemplary paired affinity domains described herein) and a second target binding domain (e.g., any of the exemplary second target binding domains described) and a linker sequence (e.g., any of the exemplary linker sequences described herein or known in the art) further includes
多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1のキメラポリペプチドは、1つ以上(例えば、2、3、4、5、6、7、8、9、又は10)の追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)を更に含み、1つ以上の追加の抗原結合ドメインのうちの少なくとも1つが、可溶性組織因子ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な可溶性組織因子ドメインのうちのいずれか)と一対の親和性ドメインの第1のドメイン(例えば、本明細書に記載の例示的な一対の親和性ドメインのうちのいずれかの例示的な第1のドメインのうちのいずれか)との間に位置付けられている。いくつかの実施形態では、第1のキメラポリペプチドは、可溶性組織因子ドメイン(例えば、本明細書に記載の例示的な可溶性組織因子ドメインのうちのいずれか)と1つ以上の追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)のうちの少なくとも1つとの間にリンカー配列(例えば、本明細書に記載の又は当該技術分野で既知の例示的なリンカー配列のうちのいずれか)、及び/又は1つ以上の追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)のうちの少なくとも1つと一対の親和性ドメインの第1のドメイン(例えば、本明細書に記載の例示的な一対の親和性ドメインのうちのいずれかの本明細書に記載の例示的な第1のドメインのうちのいずれか)との間にリンカー配列(例えば、本明細書に記載の又は当該技術分野で既知の例示的なリンカー配列のうちのいずれか)を更に含み得る。 In some embodiments of any of the multi-chain chimeric polypeptides, the first chimeric polypeptide has one or more (eg, 2, 3, 4, 5, 6, 7, 8, 9, or 10 ) (e.g., any of the exemplary target binding domains described herein or known in the art) of the one or more additional antigen binding domains is a soluble tissue factor domain (e.g., any of the exemplary soluble tissue factor domains described herein or known in the art) and the first domain of a pair of affinity domains ( for example, any of the exemplary first domains of any of the exemplary pair of affinity domains described herein). In some embodiments, the first chimeric polypeptide comprises a soluble tissue factor domain (eg, any of the exemplary soluble tissue factor domains described herein) and one or more additional target-binding domains. a linker sequence (e.g., as described herein or any of the exemplary linker sequences known in the art), and/or one or more additional target binding domains (e.g., exemplary targets described herein or known in the art) binding domain) and the first domain of the pair of affinity domains (e.g., any of the exemplary pair of affinity domains described herein). a linker sequence (e.g., any of the exemplary linker sequences described herein or known in the art) between the can further include
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1のキメラポリペプチドは、第1のキメラポリペプチドのN末端及び/又はC末端に1つ以上(例えば、2、3、4、5、6、7、8、9、又は10)の追加の標的結合ドメインを更に含む。いくつかの実施形態では、1つ以上の追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)のうちの少なくとも1つは、第1のキメラポリペプチド内の一対の親和性ドメインの第1のドメイン(例えば、本明細書に記載の例示的な一対の親和性ドメインのうちのいずれかの本明細書に記載の例示的な第1のドメインのうちのいずれか)に直接隣接している。いくつかの実施形態では、第1のキメラポリペプチドは、1つ以上の追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)のうちの少なくとも1つと一対の親和性ドメインの第1のドメイン(例えば、本明細書に記載の例示的な一対の親和性ドメインのうちのいずれかの本明細書に記載の例示的な第1のドメインのうちのいずれか)との間にリンカー配列(例えば、本明細書に記載の又は当該技術分野で既知の例示的なリンカー配列のうちのいずれか)を更に含む。いくつかの実施形態では、1つ以上の追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)のうちの少なくとも1つは、第1のキメラポリペプチド内の第1の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)に直接隣接している。いくつかの実施形態では、第1のキメラポリペプチドは、1つ以上の追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)のうちの少なくとも1つと第1の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)との間にリンカー配列(例えば、本明細書に記載の又は当該技術分野で既知の例示的なリンカー配列のうちのいずれか)を更に含む。 In some embodiments of any of the multichain chimeric polypeptides described herein, the first chimeric polypeptide has one or more at the N-terminus and/or C-terminus of the first chimeric polypeptide. (eg, 2, 3, 4, 5, 6, 7, 8, 9, or 10) additional target binding domains. In some embodiments, at least one of one or more additional target binding domains (e.g., any of the exemplary target binding domains described herein or known in the art) is the first domain of the pair of affinity domains within the first chimeric polypeptide (e.g., any exemplary pair of affinity domains described herein) directly adjacent to the first domain). In some embodiments, the first chimeric polypeptide comprises one or more additional target binding domains (e.g., any of the exemplary target binding domains described herein or known in the art). ) and the first domain of the pair of affinity domains (e.g., the exemplary affinity domain described herein of any of the exemplary pair of affinity domains described herein) any of the first domains) and a linker sequence (eg, any of the exemplary linker sequences described herein or known in the art). In some embodiments, at least one of one or more additional target binding domains (e.g., any of the exemplary target binding domains described herein or known in the art) immediately flanks a first target binding domain (e.g., any of the exemplary target binding domains described herein or known in the art) within the first chimeric polypeptide . In some embodiments, the first chimeric polypeptide comprises one or more additional target binding domains (e.g., any of the exemplary target binding domains described herein or known in the art). ) and the first target binding domain (e.g., any of the exemplary target binding domains described herein or known in the art) a linker sequence (e.g., , any of the exemplary linker sequences described herein or known in the art).
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、1つ以上の追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)のうちの少なくとも1つは、第1のキメラポリペプチドのN末端及び/又はC末端に配置されており、1つ以上の追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)のうちの少なくとも1つは、第1のキメラポリペプチド内の可溶性組織因子ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な可溶性組織因子ドメインのうちのいずれか)と一対の親和性ドメインの第1のドメイン(例えば、本明細書に記載の例示的な一対の親和性ドメインのうちのいずれかの例示的な第1のドメインのうちのいずれか)との間に位置付けられている。いくつかの実施形態では、N末端に配置された1つ以上の追加の標的結合ドメインのうちの少なくとも1つの追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)は、第1のキメラポリペプチド内の第1の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)又は一対の親和性ドメインの第1のドメイン(例えば、本明細書に記載の例示的な一対の親和性ドメインのうちのいずれかの本明細書に記載の例示的な第1のドメインのうちのいずれか)に直接隣接している。いくつかの実施形態では、第1のキメラポリペプチドは、第1のキメラポリペプチド内の少なくとも1つの追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)と第1の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)又は一対の親和性ドメインの第1のドメイン(例えば、本明細書に記載の例示的な一対の親和性ドメインのうちのいずれかの本明細書に記載の例示的な第1のドメインのうちのいずれか)との間に配置されたリンカー配列(例えば、本明細書に記載の又は当該技術分野で既知のリンカー配列のうちのいずれか)を更に含む。いくつかの実施形態では、C末端に配置された1つ以上の追加の標的結合ドメインのうちの少なくとも1つの追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)は、第1のキメラポリペプチド内の第1の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)又は一対の親和性ドメインの第1のドメイン(例えば、本明細書に記載の例示的な一対の親和性ドメインのうちのいずれかの例示的な第1のドメインのうちのいずれか)に直接隣接している。いくつかの実施形態では、第1のキメラポリペプチドは、第1のキメラポリペプチド内の少なくとも1つの追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)と第1の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)又は一対の親和性ドメインの第1のドメイン(例えば、本明細書に記載の例示的な一対の親和性ドメインのうちのいずれかの本明細書に記載の例示的な第1のドメインのうちのいずれか)との間に配置されたリンカー配列(例えば、本明細書に記載の又は当該技術分野で既知の例示的なリンカー配列のうちのいずれか)を更に含む。いくつかの実施形態では、可溶性組織因子ドメイン(例えば、本明細書に記載の例示的な可溶性組織因子ドメインのうちのいずれか)と一対の親和性ドメインの第1のドメイン(例えば、本明細書に記載の第1のドメインのうちのいずれか又は本明細書に記載の例示的な一対の親和性ドメインのうちのいずれか)との間に位置付けられた1つ以上の追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)のうちの少なくとも1つは、可溶性組織因子ドメイン、及び/又は一対の親和性ドメインの第1のドメインに直接隣接している。いくつかの実施形態では、第1のキメラポリペプチドは、(i)可溶性組織因子ドメイン(例えば、本明細書に記載の例示的な可溶性組織因子のうちのいずれか)と、可溶性組織因子ドメイン(例えば、本明細書に記載の例示的な可溶性組織因子のうちのいずれか)と一対の親和性ドメインの第1のドメイン(例えば、本明細書に記載の例示的な一対の親和性ドメインのうちのいずれかの例示的な第1のドメインのうちのいずれか)との間に位置付けられた1つ以上の追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)のうちの少なくとも1つとの間、及び/又は(ii)一対の親和性ドメインの第1のドメインと、可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間に位置付けられた1つ以上の追加の標的結合ドメインのうちの少なくとも1つとの間に配置されたリンカー配列(例えば、本明細書に記載の又は当該技術分野で既知の例示的なリンカー配列のうちのいずれか)を更に含む。 In some embodiments of any of the multi-chain chimeric polypeptides described herein, one or more additional target binding domains (e.g., examples described herein or known in the art) at least one of the target binding domains (any of the specific target binding domains) is located at the N-terminus and/or C-terminus of the first chimeric polypeptide, and one or more additional target binding domains (e.g. , any of the exemplary target binding domains described herein or known in the art) is a soluble tissue factor domain within the first chimeric polypeptide (e.g., the present any of the exemplary soluble tissue factor domains described herein or known in the art) and the first domain of a pair of affinity domains (e.g., the exemplary pair of any of the exemplary first domains of any of the affinity domains). In some embodiments, at least one additional target binding domain of the one or more additional target binding domains located at the N-terminus (e.g., examples described herein or known in the art) The first target binding domain in the first chimeric polypeptide (e.g., any of the exemplary target binding domains described herein or known in the art) any of the affinity domains described herein) or the first domain of a pair of affinity domains (e.g., an exemplary first domain described herein of any of an exemplary pair of affinity domains described herein). domain). In some embodiments, the first chimeric polypeptide comprises at least one additional target binding domain within the first chimeric polypeptide (e.g., exemplary domains described herein or known in the art). any of the target binding domains) and a first target binding domain (e.g., any of the exemplary target binding domains described herein or known in the art) or a pair of affinity domains (e.g., any of the exemplary first domains described herein of any of the exemplary paired affinity domains described herein) of further comprising a linker sequence (eg, any of the linker sequences described herein or known in the art) located in the . In some embodiments, at least one additional target binding domain of the one or more additional target binding domains located at the C-terminus (e.g., examples described herein or known in the art) The first target binding domain in the first chimeric polypeptide (e.g., any of the exemplary target binding domains described herein or known in the art) either) or the first domain of a pair of affinity domains (e.g., any exemplary first domain of any of the exemplary pair of affinity domains described herein) or ). In some embodiments, the first chimeric polypeptide comprises at least one additional target binding domain within the first chimeric polypeptide (e.g., exemplary domains described herein or known in the art). any of the target binding domains) and a first target binding domain (e.g., any of the exemplary target binding domains described herein or known in the art) or a pair of affinity domains (e.g., any of the exemplary first domains described herein of any of the exemplary paired affinity domains described herein) of (eg, any of the exemplary linker sequences described herein or known in the art) located in the . In some embodiments, a soluble tissue factor domain (e.g., any of the exemplary soluble tissue factor domains described herein) and a first domain of a pair of affinity domains (e.g., or any of the exemplary paired affinity domains described herein) and one or more additional target binding domains ( For example, at least one of the exemplary target binding domains described herein or known in the art) is a soluble tissue factor domain, and/or the first of a pair of affinity domains. directly adjacent to one domain. In some embodiments, the first chimeric polypeptide comprises (i) a soluble tissue factor domain (e.g., any of the exemplary soluble tissue factor described herein) and a soluble tissue factor domain ( e.g., any of the exemplary soluble tissue factor described herein) and the first domain of the pair of affinity domains (e.g., of the exemplary pair of affinity domains described herein) one or more additional target binding domains (e.g., any of the exemplary first domains described herein or known in the art) positioned between and/or (ii) the first domain of the pair of affinity domains and the soluble tissue factor domain and the first of the pair of affinity domains. One or more additional target binding domains positioned between one domain and at least one of the one or more additional target binding domains (e.g., the examples described herein or known in the art). any of the appropriate linker sequences).
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチドのN末端及び/又はC末端に1つ以上(例えば、2、3、4、5、6、7、8、9、又は10)の追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)を更に含む。いくつかの実施形態では、1つ以上の追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)のうちの少なくとも1つは、第2のキメラポリペプチド内の一対の親和性ドメインの第2のドメイン(例えば、本明細書に記載の例示的な一対の親和性ドメインのうちのいずれかの例示的な第2のドメインのうちのいずれか)に直接隣接している。いくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチド内の1つ以上の追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)のうちの少なくとも1つと一対の親和性ドメインの第2のドメイン(例えば、本明細書に記載の例示的な一対の親和性ドメインのうちのいずれかの本明細書に記載の例示的な第2のドメインのうちのいずれか)との間にリンカー配列(例えば、本明細書に記載の又は当該技術分野で既知の例示的なリンカー配列のうちのいずれか)を更に含む。いくつかの実施形態では、1つ以上の追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)のうちの少なくとも1つは、第2のキメラポリペプチド内の第2の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の標的結合ドメインのうちのいずれか)に直接隣接している。いくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチド内の1つ以上の追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)のうちの少なくとも1つと第2の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)との間にリンカー配列(例えば、本明細書に記載の又は当該技術分野で既知の例示的なリンカー配列のうちのいずれか)を更に含む。 In some embodiments of any of the multi-chain chimeric polypeptides described herein, the second chimeric polypeptide has one or more at the N-terminal and/or C-terminal end of the second chimeric polypeptide. (e.g., 2, 3, 4, 5, 6, 7, 8, 9, or 10) additional target binding domains (e.g., exemplary target binding domains described herein or known in the art) any of). In some embodiments, at least one of one or more additional target binding domains (e.g., any of the exemplary target binding domains described herein or known in the art) is the second domain of the pair of affinity domains within the second chimeric polypeptide (e.g., the exemplary second domain of any of the exemplary pair of affinity domains described herein directly adjacent to the In some embodiments, the second chimeric polypeptide comprises one or more additional target binding domains within the second chimeric polypeptide (e.g., exemplary domains described herein or known in the art). any of the exemplary affinity domain pairs described herein) and the second domain of the pair of affinity domains (e.g., any of the exemplary pair of affinity domains described herein). any of the exemplary second domains described herein) and a linker sequence (e.g., any of the exemplary linker sequences described herein or known in the art) ) further includes. In some embodiments, at least one of one or more additional target binding domains (e.g., any of the exemplary target binding domains described herein or known in the art) immediately flanks a second target binding domain (eg, any of the target binding domains described herein or known in the art) within the second chimeric polypeptide. In some embodiments, the second chimeric polypeptide comprises one or more additional target binding domains within the second chimeric polypeptide (e.g., exemplary domains described herein or known in the art). and a second target binding domain (e.g., any of the exemplary target binding domains described herein or known in the art) further includes a linker sequence (eg, any of the exemplary linker sequences described herein or known in the art) between.
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの2つ以上(例えば、3つ以上、4つ以上、5つ以上、6つ以上、7つ以上、8つ以上、9つ以上、10以上、又はそれ以上)が、同じ抗原に特異的に結合する。いくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの2つ以上(例えば、3つ以上、4つ以上、5つ以上、6つ以上、7つ以上、8つ以上、9つ以上、10以上、又はそれ以上)が、同じエピトープに特異的に結合する。いくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの2つ以上(例えば、3つ以上、4つ以上、5つ以上、6つ以上、7つ以上、8つ以上、9つ以上、10以上、又はそれ以上)が、同じアミノ酸配列を含む。いくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインは各々、同じ抗原に特異的に結合する。いくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインは各々、同じエピトープに特異的に結合する。いくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインは各々、同じアミノ酸配列を含む。 In some embodiments of any of the multichain chimeric polypeptides described herein, of the first target binding domain, the second target binding domain, and one or more additional target binding domains are specifically directed to the same antigen Join. In some embodiments, two or more (e.g., three or more, four or more, five more, 6 or more, 7 or more, 8 or more, 9 or more, 10 or more, or more) specifically bind to the same epitope. In some embodiments, two or more (e.g., three or more, four or more, five , 6 or more, 7 or more, 8 or more, 9 or more, 10 or more, or more) comprise the same amino acid sequence. In some embodiments, the first target binding domain, the second target binding domain, and the one or more additional target binding domains each specifically bind the same antigen. In some embodiments, the first target binding domain, the second target binding domain, and the one or more additional target binding domains each specifically bind the same epitope. In some embodiments, the first target binding domain, the second target binding domain, and the one or more additional target binding domains each comprise the same amino acid sequence.
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインは、異なる抗原に特異的に結合する。本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの1つ以上(例えば、2つ以上、3つ以上、4つ以上、5つ以上、6つ以上、7つ以上、8つ以上、9つ以上、10以上、又はそれ以上)が、抗原結合ドメインである。いくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインは各々、抗原結合ドメイン(例えば、scFv又は単一ドメイン抗体)である。 In some embodiments of any of the multichain chimeric polypeptides described herein, the first target binding domain, the second target binding domain, and one or more additional target binding domains are Binds specifically to different antigens. In some embodiments of any of the multichain chimeric polypeptides described herein, of the first target binding domain, the second target binding domain, and one or more additional target binding domains one or more (e.g., 2 or more, 3 or more, 4 or more, 5 or more, 6 or more, 7 or more, 8 or more, 9 or more, 10 or more, or more) of is a domain. In some embodiments, the first target binding domain, the second target binding domain, and the one or more additional target binding domains are each antigen binding domains (eg, scFvs or single domain antibodies).
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、第2の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、及び1つ以上の追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)のうちの1つ以上(例えば、2、3、4、5、6、7、8、9、又は10)は、CD16a、CD28、CD3、CD33、CD20、CD19、CD22、CD123、IL-1R、IL-1、VEGF、IL-6R、IL-4、IL-10、PDL-1、TIGIT、PD-1、TIM3、CTLA4、MICA、MICB、IL-6、IL-8、TNFα、CD26、CD36、ULBP2、CD30、CD200、IGF-1R、MUC4AC、MUC5AC、Trop-2、CMET、EGFR、HER1、HER2、HER3、PSMA、CEA、B7H3、EPCAM、BCMA、P-カドヘリン、CEACAM5、UL16結合タンパク質、HLA-DR、DLL4、TYRO3、AXL、MER、CD122、CD155、PDGF-DD、TGF-β受容体II(TGF-βRII)リガンド、TGF-βRIIIリガンド、DNAM1リガンド、NKp46リガンド、NKp44リガンド、NKG2Dリガンド、NKP30リガンド、scMHCIリガンド、scMHCIIリガンド、scTCRリガンド、IL-1受容体、IL-2受容体、IL-3受容体、IL-7受容体、IL-8受容体、IL-10受容体、IL-12受容体、IL-15受容体、IL-17受容体、IL-18受容体、IL-21受容体、PDGF-DD受容体、幹細胞因子(SCF)受容体、幹細胞様チロシンキナーゼ3リガンド(FLT3L)受容体、MICA受容体、MICB受容体、ULP16結合タンパク質受容体、CD155受容体、CD122受容体、及びCD28受容体からなる群から選択される標的に特異的に結合する。 In some embodiments of any of the multi-chain chimeric polypeptides described herein, the first target binding domain (e.g., exemplary targets described herein or known in the art) binding domain), a second target binding domain (e.g., any of the exemplary target binding domains described herein or known in the art), and one or more additional (e.g., any of the exemplary target binding domains described herein or known in the art) of (e.g., 2, 3, 4, 5, 6) of , 7, 8, 9, or 10) is CD16a, CD28, CD3, CD33, CD20, CD19, CD22, CD123, IL-1R, IL-1, VEGF, IL-6R, IL-4, IL-10, PDL-1, TIGIT, PD-1, TIM3, CTLA4, MICA, MICB, IL-6, IL-8, TNFα, CD26, CD36, ULBP2, CD30, CD200, IGF-1R, MUC4AC, MUC5AC, Trop-2, CMET, EGFR, HER1, HER2, HER3, PSMA, CEA, B7H3, EPCAM, BCMA, P-cadherin, CEACAM5, UL16 binding protein, HLA-DR, DLL4, TYRO3, AXL, MER, CD122, CD155, PDGF-DD, TGF-β receptor II (TGF-βRII) ligand, TGF-βRIII ligand, DNAM1 ligand, NKp46 ligand, NKp44 ligand, NKG2D ligand, NKP30 ligand, scMHCI ligand, scMHCII ligand, scTCR ligand, IL-1 receptor, IL- 2 receptor, IL-3 receptor, IL-7 receptor, IL-8 receptor, IL-10 receptor, IL-12 receptor, IL-15 receptor, IL-17 receptor, IL-18 receptor receptor, IL-21 receptor, PDGF-DD receptor, stem cell factor (SCF) receptor, stem cell-like tyrosine kinase 3 ligand (FLT3L) receptor, MICA receptor, MICB receptor, ULP16 binding protein receptor, CD155 receptor specifically binds to a target selected from the group consisting of receptors, CD122 receptors, and CD28 receptors.
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、第2の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、及び1つ以上の追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)のうちの1つ以上が、可溶性インターロイキン又はサイトカインタンパク質である。可溶性インターロイキンタンパク質及び可溶性サイトカインタンパク質の非限定的な例には、IL-1、IL-2、IL-3、IL-7、IL-8、IL-10、IL-12、IL-15、IL-17、IL-18、IL-21、PDGF-DD、及びSCFが挙げられる。 In some embodiments of any of the multi-chain chimeric polypeptides described herein, the first target binding domain (e.g., exemplary targets described herein or known in the art) binding domain), a second target binding domain (e.g., any of the exemplary target binding domains described herein or known in the art), and one or more additional one or more of the target binding domains of (eg, any of the exemplary target binding domains described herein or known in the art) are soluble interleukin or cytokine proteins. Non-limiting examples of soluble interleukin proteins and soluble cytokine proteins include IL-1, IL-2, IL-3, IL-7, IL-8, IL-10, IL-12, IL-15, IL -17, IL-18, IL-21, PDGF-DD, and SCF.
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、第2の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、及び1つ以上の追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)のうちの1つ以上が、可溶性インターロイキン又はサイトカイン受容体である。可溶性インターロイキン受容体及び可溶性サイトカイン受容体の非限定的な例には、可溶性TGF-β受容体II(TGF-βRII)、可溶性TGF-βRIII、可溶性NKG2D、可溶性NKP30、可溶性NKp44、可溶性NKp46、可溶性DNAM1、scMHCI、scMHCII、scTCR、可溶性CD155、可溶性CD122、可溶性CD3、又は可溶性CD28が挙げられる。 In some embodiments of any of the multi-chain chimeric polypeptides described herein, the first target binding domain (e.g., exemplary targets described herein or known in the art) binding domain), a second target binding domain (e.g., any of the exemplary target binding domains described herein or known in the art), and one or more additional (eg, any of the exemplary target binding domains described herein or known in the art) of is a soluble interleukin or cytokine receptor. Non-limiting examples of soluble interleukin receptors and soluble cytokine receptors include soluble TGF-β receptor II (TGF-βRII), soluble TGF-βRIII, soluble NKG2D, soluble NKP30, soluble NKp44, soluble NKp46, soluble DNAM1, scMHCI, scMHCII, scTCR, soluble CD155, soluble CD122, soluble CD3, or soluble CD28.
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン(例えば、本明細書に記載の標的結合ドメインのうちのいずれか)、第2の標的結合ドメイン(例えば、本明細書に記載の標的結合ドメインのうちのいずれか)、及び1つ以上の標的結合ドメイン(例えば、本明細書に記載の標的結合ドメインのうちのいずれか)は各々独立して、CD16a、CD33、CD20、CD19、CD22、CD123、PDL-1、TIGIT、PD-1、TIM3、CTLA4、MICA、MICB、IL-6、IL-8、TNFα、CD26、CD36、ULBP2、CD30、CD200、IGF-1R、MUC4AC、MUC5AC、Trop-2、CMET、EGFR、HER1、HER2、HER3、PSMA、CEA、B7H3、EPCAM、BCMA、P-カドヘリン、CEACAM5、UL16結合タンパク質、HLA-DR、DLL4、TYRO3、AXL、MER、CD122、CD155、PDGF-DD、TGF-β受容体II(TGF-βRII)リガンド、TGF-βRIIIリガンド、DNAM1リガンド、NKp46リガンド、NKp44リガンド、NKG2Dリガンド、NKp30リガンド、scMHCIリガンド、scMHCIIリガンド、scTCRリガンド、PDGF-DD受容体、幹細胞因子(SCF)受容体、幹細胞様チロシンキナーゼ3リガンド(FLT3L)受容体、MICA受容体、MICB受容体、ULP16結合タンパク質受容体、CD155受容体、及びCD122受容体の群から選択される標的に特異的に結合することができる。 In some embodiments of any of the multichain chimeric polypeptides described herein, the first target binding domain (e.g., any of the target binding domains described herein), the second 2 target binding domains (e.g., any of the target binding domains described herein) and one or more target binding domains (e.g., any of the target binding domains described herein) are each independently CD16a, CD33, CD20, CD19, CD22, CD123, PDL-1, TIGIT, PD-1, TIM3, CTLA4, MICA, MICB, IL-6, IL-8, TNFα, CD26, CD36, ULBP2, CD30, CD200, IGF-1R, MUC4AC, MUC5AC, Trop-2, CMET, EGFR, HER1, HER2, HER3, PSMA, CEA, B7H3, EPCAM, BCMA, P-cadherin, CEACAM5, UL16 binding protein, HLA- DR, DLL4, TYRO3, AXL, MER, CD122, CD155, PDGF-DD, TGF-β receptor II (TGF-βRII) ligand, TGF-βRIII ligand, DNAM1 ligand, NKp46 ligand, NKp44 ligand, NKG2D ligand, NKp30 ligand , scMHCI ligand, scMHCII ligand, scTCR ligand, PDGF-DD receptor, stem cell factor (SCF) receptor, stem cell-like tyrosine kinase 3 ligand (FLT3L) receptor, MICA receptor, MICB receptor, ULP16 binding protein receptor, It can specifically bind to a target selected from the group of CD155 receptor and CD122 receptor.
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、第2の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)の一方又は両方、及び1つ以上の追加の結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)は、可溶性インターロイキン又はサイトカインタンパク質である。本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、可溶性インターロイキン又はサイトカインタンパク質は、IL-1、IL-2、IL-3、IL-7、IL-8、IL-10、IL-12、IL-15、IL-17、IL-18、IL-21、PDGF-DD、及びSCFの群から選択される。 In some embodiments of any of the multi-chain chimeric polypeptides described herein, the first target binding domain (e.g., exemplary targets described herein or known in the art) binding domain), one or both of a second target binding domain (e.g., any of the exemplary target binding domains described herein or known in the art), and 1 The one or more additional binding domains (eg, any of the exemplary target binding domains described herein or known in the art) are soluble interleukin or cytokine proteins. In some embodiments of any of the multichain chimeric polypeptides described herein, the soluble interleukin or cytokine protein is IL-1, IL-2, IL-3, IL-7, IL- 8, IL-10, IL-12, IL-15, IL-17, IL-18, IL-21, PDGF-DD, and SCF.
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方が、可溶性インターロイキン又はサイトカイン受容体である。本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、可溶性受容体は、可溶性TGF-β受容体II(TGF-βRII)、可溶性TGF-βRIII、可溶性TNFα受容体、可溶性IL-4受容体、又は可溶性IL-10受容体である。 In some embodiments of any of the multichain chimeric polypeptides described herein, one or both of the first target binding domain and the second target binding domain are soluble interleukins or cytokine receptors. is. In some embodiments of any of the multichain chimeric polypeptides described herein, the soluble receptor is soluble TGF-β receptor II (TGF-βRII), soluble TGF-βRIII, soluble TNFα receptor soluble IL-4 receptor, or soluble IL-10 receptor.
多鎖キメラポリペプチド-タイプB
NK細胞活性化物質の非限定的な例は、(a)第1及び第2のキメラポリペプチドであって、各々が、(i)第1の標的結合ドメイン、(ii)Fcドメイン、及び(iii)一対の親和性ドメインの第1のドメインを含む、第1及び第2のキメラポリペプチドと、(b)第3及び第4のキメラポリペプチドであって、各々が、(i)一対の親和性ドメインの第2のドメイン及び(ii)第2の標的結合ドメインを含む、第3及び第4のキメラポリペプチドと、を含む多鎖キメラポリペプチドであり、第1及び第2のキメラポリペプチド並びに第3及び第4のキメラポリペプチドは、一対の親和性ドメインの第1のドメインと第2のドメインとの結合を介して会合し、かつ第1及び第2のキメラポリペプチドは、それらのFcドメインを介して会合する。
Multichain Chimeric Polypeptides - Type B
A non-limiting example of an NK cell activator is (a) first and second chimeric polypeptides, each comprising (i) a first target binding domain, (ii) an Fc domain, and ( iii) first and second chimeric polypeptides comprising a first of a pair of affinity domains; and (b) third and fourth chimeric polypeptides, each comprising (i) a pair of a second domain of the affinity domain and (ii) third and fourth chimeric polypeptides comprising a second target binding domain, wherein the first and second chimeric polypeptides The peptide and the third and fourth chimeric polypeptides are associated through binding of the first and second domains of the pair of affinity domains, and the first and second chimeric polypeptides are associates through the Fc domain of
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン(例えば、本明細書に記載の第1の標的結合ドメインのうちのいずれか)とFcドメイン(例えば、本明細書に記載の例示的なFcドメインのうちのいずれか)は、第1及び第2のキメラポリペプチド内で互いに直接隣接している。本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1及び第2のキメラポリペプチドは、第1及び第2のキメラポリペプチド内の第1の標的結合ドメイン(本明細書に記載の例示的な第1の標的結合ドメインのうちのいずれか)とFcドメイン(例えば、本明細書に記載の例示的なFcドメインのうちのいずれか)との間にリンカー配列(例えば、本明細書に記載の又は当該技術分野で既知の例示的なリンカー配列のうちのいずれか)を更に含む。 In some embodiments of any of the multichain chimeric polypeptides described herein, the first target binding domain (e.g., any of the first target binding domains described herein ) and an Fc domain (eg, any of the exemplary Fc domains described herein) are directly adjacent to each other in the first and second chimeric polypeptides. In some embodiments of any of the multi-chain chimeric polypeptides described herein, the first and second chimeric polypeptides are linked to the first target within the first and second chimeric polypeptides. Between a binding domain (any of the exemplary first target binding domains described herein) and an Fc domain (e.g., any of the exemplary Fc domains described herein) further includes a linker sequence (eg, any of the exemplary linker sequences described herein or known in the art).
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、Fcドメイン(例えば、本明細書に記載の例示的なFcドメインのうちのいずれか)と一対の親和性ドメインの第1のドメイン(例えば、本明細書に記載の例示的な一対の親和性ドメインのうちのいずれかの例示的な第1のドメインのうちのいずれか)は、第1及び第2のキメラポリペプチド内で互いに直接隣接している。本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1及び第2のキメラポリペプチドは、第1及び第2のキメラポリペプチド内のFcドメイン(本明細書に記載の例示的なFcドメインのうちのいずれか)と一対の親和性ドメインの第1のドメイン(例えば、本明細書に記載の例示的な一対の親和性ドメインのうちのいずれかの例示的な第1のドメインのうちのいずれか)との間にリンカー配列(例えば、本明細書に記載の又は当該技術分野で既知の例示的なリンカー配列のうちのいずれか)を更に含む。 In some embodiments of any of the multi-chain chimeric polypeptides described herein, an Fc domain (e.g., any of the exemplary Fc domains described herein) and a pair of affinity A first domain of a sex domain (e.g., any of the exemplary first domains of any of an exemplary pair of affinity domains described herein) is a first and a second are immediately adjacent to each other within the chimeric polypeptide of . In some embodiments of any of the multi-chain chimeric polypeptides described herein, the first and second chimeric polypeptides are Fc domains within the first and second chimeric polypeptides (this any of the exemplary Fc domains described herein) and the first domain of the pair of affinity domains (e.g., any of the exemplary pair of affinity domains described herein) any of the exemplary first domains) and a linker sequence (eg, any of the exemplary linker sequences described herein or known in the art).
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、一対の親和性ドメインの第2のドメイン(例えば、本明細書に記載の例示的な一対の親和性ドメインのうちのいずれかの例示的な第2のドメインのうちのいずれか)と第2の標的結合ドメイン(例えば、本明細書に記載の例示的な第2の標的結合ドメインのうちのいずれか)は、第3及び第4のキメラポリペプチド内で互いに直接隣接している。本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第3及び第4のキメラポリペプチドは、第3及び第4のキメラポリペプチド内の一対の親和性ドメインの第2のドメイン(例えば、本明細書に記載の例示的な一対の親和性ドメインのうちのいずれかの例示的な第2のドメインのうちのいずれか)と第2の標的結合ドメイン(例えば、本明細書に記載の例示的な第2の標的結合ドメインのうちのいずれか)との間にリンカー配列(例えば、本明細書に記載の又は当該技術分野で既知の例示的なリンカー配列のうちのいずれか)を更に含む。 In some embodiments of any of the multi-chain chimeric polypeptides described herein, the second domain of the pair of affinity domains (e.g., an exemplary affinity pair described herein any of the exemplary second domains of any of the domains) and a second target binding domain (e.g., any of the exemplary second target binding domains described herein) ) are immediately adjacent to each other within the third and fourth chimeric polypeptides. In some embodiments of any of the multi-chain chimeric polypeptides described herein, the third and fourth chimeric polypeptides have a pair of affinities within the third and fourth chimeric polypeptides. A second domain of domains (e.g., any of the exemplary second domains of any of the exemplary pair of affinity domains described herein) and a second target binding domain ( e.g., any of the exemplary second target binding domains described herein) and a linker sequence (e.g., an exemplary linker sequence described herein or known in the art) any of).
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは、同じ抗原に特異的に結合する。本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは、同じエピトープに特異的に結合する。本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは、同じアミノ酸配列を含む。本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは、異なる抗原に特異的に結合する。本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方が、抗原結合ドメイン(例えば、本明細書に記載の例示的な第2の標的結合ドメインのうちのいずれか)である。本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは各々、抗原結合ドメイン(例えば、本明細書に記載の例示的な第2の標的結合ドメインのうちのいずれか)である。本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、抗原結合ドメイン(例えば、本明細書に記載の例示的な第2の標的結合ドメインのうちのいずれか)は、scFv又は単一ドメイン抗体を含む。 In some embodiments of any of the multi-chain chimeric polypeptides described herein, the first target binding domain and the second target binding domain specifically bind the same antigen. In some embodiments of any of the multichain chimeric polypeptides described herein, the first target binding domain and the second target binding domain specifically bind the same epitope. In some embodiments of any of the multi-chain chimeric polypeptides described herein, the first target binding domain and the second target binding domain comprise the same amino acid sequence. In some embodiments of any of the multi-chain chimeric polypeptides described herein, the first target binding domain and the second target binding domain specifically bind different antigens. In some embodiments of any of the multi-chain chimeric polypeptides described herein, one or both of the first target binding domain and the second target binding domain are antigen binding domains (e.g., any of the exemplary second target binding domains described herein). In some embodiments of any of the multi-chain chimeric polypeptides described herein, the first target binding domain and the second target binding domain are each an antigen binding domain (e.g., any of the described exemplary second target binding domains). In some embodiments of any of the multi-chain chimeric polypeptides described herein, the antigen binding domain (e.g., any of the exemplary second target binding domains described herein) ) include scFv or single domain antibodies.
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)及び第2の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)の一方又は両方が、CD16a、CD28、CD3、CD33、CD20、CD19、CD22、CD123、IL-1R、IL-1、VEGF、IL-6R、IL-4、IL-10、PDL-1、TIGIT、PD-1、TIM3、CTLA4、MICA、MICB、IL-6、IL-8、TNFα、CD26、CD36、ULBP2、CD30、CD200、IGF-1R、MUC4AC、MUC5AC、Trop-2、CMET、EGFR、HER1、HER2、HER3、PSMA、CEA、B7H3、EPCAM、BCMA、P-カドヘリン、CEACAM5、UL16結合タンパク質、HLA-DR、DLL4、TYRO3、AXL、MER、CD122、CD155、PDGF-DD、TGF-β受容体II(TGF-βRII)リガンド、TGF-βRIIIリガンド、DNAM1リガンド、NKp46リガンド、NKp44リガンド、NKG2Dリガンド、NKp30リガンド、scMHCIリガンド、scMHCIIリガンド、scTCRリガンド、IL-1受容体、IL-2受容体、IL-3受容体、IL-7受容体、IL-8受容体、IL-10受容体、IL-12受容体、IL-15受容体、IL-17受容体、IL-18受容体、IL-21受容体、PDGF-DD受容体、幹細胞因子(SCF)受容体、幹細胞様チロシンキナーゼ3リガンド(FLT3L)受容体、MICA受容体、MICB受容体、ULP16結合タンパク質受容体、CD155受容体、CD122受容体、及びCD28受容体からなる群から選択される標的に特異的に結合する。 In some embodiments of any of the multi-chain chimeric polypeptides described herein, the first target binding domain (e.g., exemplary targets described herein or known in the art) binding domain) and the second target binding domain (e.g., any of the exemplary target binding domains described herein or known in the art) are CD16a , CD28, CD3, CD33, CD20, CD19, CD22, CD123, IL-1R, IL-1, VEGF, IL-6R, IL-4, IL-10, PDL-1, TIGIT, PD-1, TIM3, CTLA4 , MICA, MICB, IL-6, IL-8, TNFα, CD26, CD36, ULBP2, CD30, CD200, IGF-1R, MUC4AC, MUC5AC, Trop-2, CMET, EGFR, HER1, HER2, HER3, PSMA, CEA , B7H3, EPCAM, BCMA, P-cadherin, CEACAM5, UL16 binding protein, HLA-DR, DLL4, TYRO3, AXL, MER, CD122, CD155, PDGF-DD, TGF-β receptor II (TGF-βRII) ligand, TGF-βRIII ligand, DNAM1 ligand, NKp46 ligand, NKp44 ligand, NKG2D ligand, NKp30 ligand, scMHCI ligand, scMHCII ligand, scTCR ligand, IL-1 receptor, IL-2 receptor, IL-3 receptor, IL-7 receptor, IL-8 receptor, IL-10 receptor, IL-12 receptor, IL-15 receptor, IL-17 receptor, IL-18 receptor, IL-21 receptor, PDGF-DD receptor , stem cell factor (SCF) receptor, stem cell-like tyrosine kinase 3 ligand (FLT3L) receptor, MICA receptor, MICB receptor, ULP16-binding protein receptor, CD155 receptor, CD122 receptor, and CD28 receptor specifically binds to a target selected from
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)及び第2の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)の一方又は両方が、可溶性インターロイキン又はサイトカインタンパク質である。可溶性インターロイキンタンパク質及び可溶性サイトカインタンパク質の非限定的な例には、IL-1、IL-2、IL-3、IL-7、IL-8、IL-10、IL-12、IL-15、IL-17、IL-18、IL-21、PDGF-DD、及びSCFが挙げられる。 In some embodiments of any of the multi-chain chimeric polypeptides described herein, the first target binding domain (e.g., exemplary targets described herein or known in the art) binding domain) and the second target binding domain (e.g., any of the exemplary target binding domains described herein or known in the art) are soluble interleukin or cytokine protein. Non-limiting examples of soluble interleukin proteins and soluble cytokine proteins include IL-1, IL-2, IL-3, IL-7, IL-8, IL-10, IL-12, IL-15, IL -17, IL-18, IL-21, PDGF-DD, and SCF.
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)の一方又は両方が、可溶性インターロイキン又はサイトカイン受容体である。可溶性インターロイキン受容体及び可溶性サイトカイン受容体の非限定的な例には、可溶性TGF-β受容体II(TGF-βRII)、可溶性TGF-βRIII、可溶性NKG2D、可溶性NKp30、可溶性NKp44、可溶性NKp46、可溶性DNAM1、scMHCI、scMHCII、scTCR、可溶性CD155、可溶性CD122、可溶性CD3、又は可溶性CD28が挙げられる。 In some embodiments of any of the multichain chimeric polypeptides described herein, the first target binding domain and the second target binding domain (e.g., as described herein or in the art) one or both of the exemplary target binding domains known in ) are soluble interleukins or cytokine receptors. Non-limiting examples of soluble interleukin receptors and soluble cytokine receptors include soluble TGF-β receptor II (TGF-βRII), soluble TGF-βRIII, soluble NKG2D, soluble NKp30, soluble NKp44, soluble NKp46, soluble DNAM1, scMHCI, scMHCII, scTCR, soluble CD155, soluble CD122, soluble CD3, or soluble CD28.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは各々独立して、CD16a、CD33、CD20、CD19、CD22、CD123、PDL-1、TIGIT、PD-1、TIM3、CTLA4、MICA、MICB、IL-6、IL-8、TNFα、CD26、CD36、ULBP2、CD30、CD200、IGF-1R、MUC4AC、MUC5AC、Trop-2、CMET、EGFR、HER1、HER2、HER3、PSMA、CEA、B7H3、EPCAM、BCMA、P-cadherin、CEACAM5、UL16結合タンパク質、HLA-DR、DLL4、TYRO3、AXL、MER、CD122、CD155、PDGF-DD、TGF-β受容体II(TGF-βRII)リガンド、TGF-βRIIIリガンド、DNAM1リガンド、NKp46リガンド、NKp44リガンド、NKG2Dリガンド、NKp30リガンド、scMHCIリガンド、scMHCIIリガンド、scTCRリガンド、PDGF-DD受容体、幹細胞因子(SCF)受容体、幹細胞様チロシンキナーゼ3リガンド(FLT3L)受容体、MICA受容体、MICB受容体、ULP16結合タンパク質受容体、CD155受容体、及びCD122受容体の群から選択される標的に特異的に結合することができる。
In some embodiments of any of the methods described herein, the first target binding domain and the second target binding domain are each independently CD16a, CD33, CD20, CD19, CD22, CD123. , PDL-1, TIGIT, PD-1, TIM3, CTLA4, MICA, MICB, IL-6, IL-8, TNFα, CD26, CD36, ULBP2, CD30, CD200, IGF-1R, MUC4AC, MUC5AC, Trop-2 , CMET, EGFR, HER1, HER2, HER3, PSMA, CEA, B7H3, EPCAM, BCMA, P-cadherin, CEACAM5, UL16 binding protein, HLA-DR, DLL4, TYRO3, AXL, MER, CD122, CD155, PDGF-DD , TGF-β receptor II (TGF-βRII) ligand, TGF-βRIII ligand, DNAM1 ligand, NKp46 ligand, NKp44 ligand, NKG2D ligand, NKp30 ligand, scMHCI ligand, scMHCII ligand, scTCR ligand, PDGF-DD receptor, stem cell specific for a target selected from the group of factor (SCF) receptor, stem cell-
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方が、可溶性インターロイキン又はサイトカインタンパク質である。本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、可溶性インターロイキン又はサイトカインタンパク質は、IL-1、IL-2、IL-3、IL-7、IL-8、IL-10、IL-12、IL-15、IL-17、IL-18、IL-21、PDGF-DD、及びSCFの群から選択される。 In some embodiments of any of the multichain chimeric polypeptides described herein, one or both of the first target binding domain and the second target binding domain are soluble interleukin or cytokine proteins. be. In some embodiments of any of the multichain chimeric polypeptides described herein, the soluble interleukin or cytokine protein is IL-1, IL-2, IL-3, IL-7, IL- 8, IL-10, IL-12, IL-15, IL-17, IL-18, IL-21, PDGF-DD, and SCF.
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方が、可溶性インターロイキン又はサイトカイン受容体である。本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、可溶性受容体は、可溶性TGF-β受容体II(TGF-βRII)、可溶性TGF-βRIII、可溶性TNFα受容体、可溶性IL-4受容体、又は可溶性IL-10受容体である。 In some embodiments of any of the multichain chimeric polypeptides described herein, one or both of the first target binding domain and the second target binding domain are soluble interleukins or cytokine receptors. is. In some embodiments of any of the multichain chimeric polypeptides described herein, the soluble receptor is soluble TGF-β receptor II (TGF-βRII), soluble TGF-βRIII, soluble TNFα receptor soluble IL-4 receptor, or soluble IL-10 receptor.
組織因子
ヒト組織因子は、以下の3つのドメイン:(1)219アミノ酸N末端細胞外ドメイン(残基1~219)、(2)22アミノ酸膜貫通ドメイン(残基220~242)、及び(3)21アミノ酸細胞質C末端尾部(残基242~263)((UniProtKB識別子番号:P13726)を含む263アミノ酸膜貫通タンパク質である。細胞質尾部は、Ser253及びSer258に2つのリン酸化部位を含み、Cys245に1つのS-パルミトイル化部位を含む。細胞質ドメインの欠失又は変異が組織因子凝固活性に影響を及ぼすことは見出されなかった。組織因子は、Cys245のタンパク質の細胞内ドメイン内に1つのS-パルミトイル化部位を有する。Cys245は、細胞内ドメインのアミノ酸末端に位置し、膜表面の近くにある。組織因子膜貫通ドメインは、単一膜貫通α-ヘリックスで構成されている。
Tissue Factor Human tissue factor has three domains: (1) a 219 amino acid N-terminal extracellular domain (residues 1-219), (2) a 22 amino acid transmembrane domain (residues 220-242), and (3) ) is a 263 amino acid transmembrane protein containing a 21 amino acid cytoplasmic C-terminal tail (residues 242-263) ((UniProtKB identifier number: P13726). The cytoplasmic tail contains two phosphorylation sites at Ser253 and Ser258, It contains a single S-palmitoylation site.Deletion or mutation of the cytoplasmic domain was not found to affect tissue factor clotting activity.Tissue factor contains a single S-palmitoylation site within the intracellular domain of the protein at Cys245. -has a palmitoylation site Cys245 is located at the amino terminus of the intracellular domain and near the membrane surface The tissue factor transmembrane domain is composed of a single transmembrane α-helix.
2つのフィブロネクチンIII型ドメインで構成されている組織因子の細胞外ドメインは、6アミノ酸リンカーを介して膜貫通ドメインに連結されている。このリンカーは、組織因子細胞外ドメインをその膜貫通ドメイン及び細胞質ドメインから分離するために立体配座可動性を提供する。各組織因子フィブロネクチンIII型モジュールは、2つの重複βシートで構成されており、上部のシートドメインには3つの逆平行βストランドが含まれており、下部のシートには4つのβストランドが含まれている。βストランドは、ストランドβAとβB、βCとβD、及びβEとβFの間のβループによって連結されており、これらの全ての立体配座が2つのモジュール内で保存されている。βストランドを連結する3つの短いα-ヘリックスセグメントが存在する。組織因子の特有の特徴は、フィブロネクチンスーパーファミリーの共通要素ではないストランドβ10とストランドβ11との間の17アミノ酸β-ヘアピンである。N末端ドメインには、β6Fとβ7Gとの間に12アミノ酸ループも含まれており、これは、C末端ドメインには存在せず、組織因子に特有のものである。かかるフィブロネクチンIII型ドメイン構造は、免疫グロブリン様タンパク質ファミリー折り畳みの特徴であり、多種多様な細胞外タンパク質間で保存されている。 The extracellular domain of tissue factor, composed of two fibronectin type III domains, is linked to the transmembrane domain via a 6 amino acid linker. This linker provides conformational flexibility to separate the tissue factor extracellular domain from its transmembrane and cytoplasmic domains. Each tissue factor fibronectin type III module is composed of two overlapping β-sheets, with the upper sheet domain containing 3 antiparallel β-strands and the lower sheet containing 4 β-strands. ing. The β-strands are linked by β-loops between strands βA and βB, βC and βD, and βE and βF, all of which are conformationally conserved within the two modules. There are three short α-helical segments connecting the β-strands. A unique feature of tissue factor is a 17 amino acid β-hairpin between strands β10 and β11 that is not a common member of the fibronectin superfamily. The N-terminal domain also contains a 12-amino acid loop between β6F and β7G, which is absent in the C-terminal domain and unique to tissue factor. Such fibronectin type III domain structures are characteristic of the immunoglobulin-like protein family fold and are conserved among a wide variety of extracellular proteins.
チモーゲンFVIIは、それが組織に結合して活性組織因子-FVIIa複合体を形成すると、タンパク質限定分解によってFVIIaに迅速に変換される。およそ0.1nM(血漿FVIIの1%)の濃度で酵素として循環するFVIIaも、組織因子に直接結合することができる。組織因子-FVIIa複合体上の組織因子とFVIIaの間のアロステリック相互作用は、FVIIaの酵素活性を大幅に増加させ、小さい発色性ペプチジル基質の加水分解速度をおよそ20~100倍増加させ、天然高分子基質FIX及びFXの活性化速度をほぼ100万倍増加させる。組織因子への結合時のFVIIaの活性部位のアロステリック活性化と協調して、リン脂質二重層上での組織因子-FVIIa複合体の形成(すなわち、膜表面上のホスファチジル-L-セリンの曝露時)は、Ca2+依存的様式でFIX又はFXの活性化速度を更に1,000倍増加させる。遊離FVIIaと比較した組織因子-FVIIa-リン脂質複合体によるFX活性化のおよそ100万倍の全体的な増加は、凝固カスケードの臨界調節点である。 The zymogen FVII is rapidly converted to FVIIa by limited proteolysis when it binds to tissue to form an active tissue factor-FVIIa complex. FVIIa, which circulates as an enzyme at concentrations of approximately 0.1 nM (1% of plasma FVII), can also bind directly to tissue factor. The allosteric interaction between tissue factor and FVIIa on the tissue factor-FVIIa complex greatly increases the enzymatic activity of FVIIa, increasing the rate of hydrolysis of small chromogenic peptidyl substrates by approximately 20-100 fold and increasing the rate of hydrolysis of small chromogenic peptidyl substrates. Increases the rate of activation of the molecular substrates FIX and FX by nearly a million fold. Formation of the tissue factor-FVIIa complex on the phospholipid bilayer (i.e., upon exposure of phosphatidyl-L-serine on the membrane surface) in concert with allosteric activation of the active site of FVIIa upon binding to tissue factor ) increases the activation rate of FIX or FX an additional 1,000-fold in a Ca 2+ -dependent manner. The approximately one million-fold overall increase in FX activation by tissue factor-FVIIa-phospholipid complexes compared to free FVIIa is a critical regulatory point in the coagulation cascade.
FVIIは、約50kDaの一本鎖ポリペプチドであり、406個のアミノ酸残基からなり、N末端γ-カルボキシグルタミン酸リッチ(GLA)ドメイン、2つの上皮成長因子様ドメイン(EGF1及びEFG2)、及びC末端セリンプロテアーゼドメインを有する。FVIIは、EGF2とプロテアーゼドメインとの間の短いリンカー領域におけるIle-154-Arg152結合の特異的タンパク質分解切断によってFVIIaに活性化される。この切断により、軽鎖及び重鎖がCys135及びCys262の単一ジスルフィド結合によって一緒に保持されるようになる。FVIIaは、そのN末端GLAドメインを介してCa2+依存的様式でリン脂質膜に結合する。GLAドメインのすぐC末端側に、芳香族スタック及び2つのEGFドメインが存在する。芳香族スタックは、GLAドメインを、単一のCa2+イオンに結合するEGF1ドメインに連結する。このCa2+結合部位の占有により、FVIIaアミド分解活性及び組織因子会合が増加する。触媒トライアドは、His193、Asp242、及びSer344からなり、FVIIaプロテアーゼドメイン内での単一のCa2+イオンの結合は、その触媒活性に不可欠である。FVIIのFVIIaへのタンパク質分解活性は、Ile153で新たに形成されたアミノ末端を解放して、折り返し、活性化ポケットに挿入されて、Asp343のカルボン酸塩と塩橋を形成して、オキシアニオンホールを生成する。この塩橋の形成は、FVIIa活性に不可欠である。しかしながら、オキシアニオンホールの形成は、タンパク質分解活性化時に遊離FVIIaでは生じない。結果として、FVIIaは、血漿プロテアーゼ阻害物質によってほとんど認識されないチモーゲン様状態で循環し、それがおよそ90分の半減期で循環することを可能にする。 FVII is a single-chain polypeptide of approximately 50 kDa, consisting of 406 amino acid residues, containing an N-terminal γ-carboxyglutamate-rich (GLA) domain, two epidermal growth factor-like domains (EGF1 and EFG2), and a C It has a terminal serine protease domain. FVII is activated to FVIIa by specific proteolytic cleavage of the Ile- 154 -Arg 152 bond in the short linker region between EGF2 and the protease domain. This cleavage causes the light and heavy chains to be held together by a single disulfide bond at Cys 135 and Cys 262 . FVIIa binds to phospholipid membranes in a Ca 2+ -dependent manner via its N-terminal GLA domain. Immediately C-terminal to the GLA domain is an aromatic stack and two EGF domains. An aromatic stack connects the GLA domain to an EGF1 domain that binds a single Ca 2+ ion. Occupancy of this Ca 2+ -binding site increases FVIIa amidolytic activity and tissue factor association. The catalytic triad consists of His 193 , Asp 242 and Ser 344 and binding of a single Ca 2+ ion within the FVIIa protease domain is essential for its catalytic activity. The proteolytic activity of FVII to FVIIa releases the newly formed amino terminus at Ile 153 , folds back, inserts into the activation pocket and forms a salt bridge with the carboxylate of Asp 343 to form an oxy Generates anion holes. Formation of this salt bridge is essential for FVIIa activity. However, oxyanion hole formation does not occur with free FVIIa upon proteolytic activation. As a result, FVIIa circulates in a zymogen-like state that is poorly recognized by plasma protease inhibitors, allowing it to circulate with a half-life of approximately 90 minutes.
膜表面上でのFVIIa活性部位の組織因子媒介性位置付けは、同族基質に対するFVIIaに重要である。遊離FVIIaは、その活性部位が膜表面の約80Å上に位置付けられた膜に結合すると、安定した拡張構造をとる。FVIIaが組織因子に結合すると、FVa活性部位は、膜に約6Å近づいて再位置付けられる。この調節は、FVIIa触媒トライアドの標的基質切断部位との適切な整列を助け得る。GLAドメインレスFVIIaを使用して、活性部位が依然として膜上から同様の距離で位置付けられたことが示されており、組織因子がFVIIa-膜相互作用の不在下でさえもFVIIa活性部位位置付けを完全に支援することができることを示す。追加のデータは、組織因子細胞外ドメインが何らかの方法で膜表面に繋留されている限り、組織因子が完全なFVIIaタンパク質分解活性を支援することを示した。しかしながら、FVIIaの活性部位を膜表面から80Å超えて上昇させることにより、組織因子-FVIIa複合体がFXを活性化する能力が大幅に低下したが、組織因子-FVIIaアミド分解活性は低下しなかった。 Tissue factor-mediated positioning of the FVIIa active site on the membrane surface is important for FVIIa to its cognate substrates. Free FVIIa adopts a stable extended conformation when bound to the membrane with its active site positioned approximately 80 Å above the membrane surface. Upon binding of FVIIa to tissue factor, the FVa active site is repositioned approximately 6 Å closer to the membrane. This regulation may aid proper alignment of the FVIIa catalytic triad with the target substrate cleavage site. Using GLA domain-less FVIIa, it was shown that the active site was still positioned at a similar distance from the membrane, indicating that tissue factor completely reversed FVIIa active site positioning even in the absence of FVIIa-membrane interaction. Show that you can help Additional data indicated that tissue factor supports full FVIIa proteolytic activity as long as the tissue factor extracellular domain is somehow tethered to the membrane surface. However, raising the active site of FVIIa beyond 80 Å from the membrane surface greatly reduced the ability of the tissue factor-FVIIa complex to activate FX, but not the tissue factor-FVIIa amidolytic activity. .
アラニンスキャニング変異誘発は、FVIIaとの相互作用のための組織因子細胞外ドメインにおける特定のアミノ酸側鎖の役割を評価するために使用されている(Gibbs et al.,Biochemistry33(47):14003-14010,1994、Schullek et al.,J Biol Chem269(30):19399-19403,1994)。アラニン置換は、アラニン置換がFVIIa結合に対して5~10倍低い親和性を引き起こす限定された数の残基位置を同定した。これらの残基側鎖の大半が、高分子リガンド相互作用と調和して、結晶構造における溶媒に十分に曝露されることが見出された。FVIIaリガンド結合部位は、2つのモジュール間の境界の広範な領域にわたって位置する。C-モジュールにおいて、突出したB-Cループ上に位置する残基Arg135及びPhe140は、FVIIaとの独立した接触を提供する。Leu133は、指様の構造の基部に位置し、2つのモジュール間の隙間にパッキングされている。これにより、Lys20、Thr60、Asp58、及びIle22からなる重要な結合残基の主要なクラスターに連続性が提供される。Thr60は、部分的にのみ溶媒に曝露されており、リガンドと有意に接触するのではなく、局所的な構造的役割を果たし得る。結合部位は、Glu24及びGln110、並びに潜在的により遠位の残基Val207を含むモジュール間角度の凹面側に伸びている。結合領域は、Asp58から、Lys48、Lys46、Gln37、Asp44、及びTrp45によって形成された凸面領域に伸びている。Trp45及びAsp44は、FVIIaと独立して相互作用せず、Trp45位での変異効果が、隣接するAsp44及びGln37側鎖の局所的パッキングのためのこの側鎖の構造的重要性を反映し得ることを示す。相互作用領域は、N-モジュール内に疎水性クラスターの一部を形成する2つの表面露出芳香族残基Phe76及びTyr78を更に含む。 Alanine scanning mutagenesis has been used to assess the role of specific amino acid side chains in the tissue factor extracellular domain for interaction with FVIIa (Gibbs et al., Biochemistry 33(47):14003-14010 , 1994, Schullek et al., J Biol Chem 269(30):19399-19403, 1994). Alanine substitution identified a limited number of residue positions where alanine substitution caused a 5-10 fold lower affinity for FVIIa binding. Most of these residue side chains were found to be fully exposed to solvent in the crystal structure, consistent with macromolecular ligand interactions. The FVIIa ligand binding site is located over a broad area of the boundary between the two modules. In the C-module, residues Arg 135 and Phe 140 , located on the protruding BC loop, provide independent contacts with FVIIa. Leu 133 is located at the base of the finger-like structure and is packed in the gap between the two modules. This provides continuity to a major cluster of key binding residues consisting of Lys 20 , Thr 60 , Asp 58 and Ile 22 . Thr 60 is only partially solvent exposed and may play a local structural role rather than making significant contact with the ligand. The binding site extends on the concave side of the intermodular angle including Glu24 and Gln110 and potentially the more distal residue Val207 . The binding region extends from Asp58 to a convex region formed by Lys 48 , Lys 46 , Gln 37 , Asp 44 and Trp 45 . Trp 45 and Asp 44 do not interact independently with FVIIa and the effect of mutations at Trp 45 may be the structural importance of this side chain for the local packing of adjacent Asp 44 and Gln 37 side chains. It shows that it can reflect The interacting region further contains two surface-exposed aromatic residues Phe 76 and Tyr 78 that form part of the hydrophobic cluster within the N-module.
組織因子-FVIIaの既知の生理学的基質は、FVII、FIX、及びFX、並びにある特定のプロテイナーゼ活性化受容体である。変異分析により、変異すると、小さいペプチジル基質に対する完全なFVIIaアミド分解活性を支持するが、高分子基質(すなわち、FVII、FIX、及びFX)の活性化を支持する能力を欠くいくつかの残基が同定されている(Ruf et al.,J Biol Chem267(31):22206-22210,1992、Ruf et al.,J Biol Chem267(9):6375-6381,1992、Huang et al.,J Biol Chem271(36):21752-21757,1996、Kirchhofer et al.,Biochemistry39(25):7380-7387,2000)。残基159~165の組織因子ループ領域、及びこの可動性ループ内の又はそれに隣接する残基が、組織因子-FVIIa複合体のタンパク質分解活性に不可欠であることが示されている。これは、FVIIa活性部位からかなり離れた組織因子の提案された基質結合エキソサイト領域を定義する。グリシン残基をわずかによりかさばったアラニン残基で置換することにより、組織因子-FVIIaのタンパク質分解活性が著しく損なわれる。これは、グリシンによってもたらされる可動性が組織因子高分子基質認識のための残基159~165のループに不可欠であることを示唆する。 Known physiological substrates of tissue factor-FVIIa are FVII, FIX, and FX, and certain proteinase-activated receptors. Mutational analysis revealed several residues that, when mutated, support full FVIIa amidolytic activity towards small peptidyl substrates but lack the ability to support activation of macromolecular substrates (i.e., FVII, FIX, and FX). (Ruf et al., J Biol Chem 267(31):22206-22210, 1992; Ruf et al., J Biol Chem 267(9): 6375-6381, 1992; Huang et al., J Biol Chem 271 ( 36):21752-21757, 1996, Kirchhofer et al., Biochemistry 39(25):7380-7387, 2000). The tissue factor loop region of residues 159-165, and residues within or adjacent to this flexible loop, have been shown to be essential for the proteolytic activity of the tissue factor-FVIIa complex. This defines a proposed substrate-binding exosite region of tissue factor that is well distant from the FVIIa active site. Replacing glycine residues with slightly more bulky alanine residues significantly impairs the proteolytic activity of tissue factor-FVIIa. This suggests that the flexibility provided by glycine is essential for the loop of residues 159-165 for tissue factor macromolecular substrate recognition.
残基Lys165及びLys166が基質認識及び結合に重要であることも実証されている。これらの残基のいずれかをアラニンに変異させることにより、組織因子補因子機能が大幅に低下する。Lys165とLys166は互いに外方に向いており、Lys165は、大半の組織因子-FVIIa構造内でFVIIaの方を指し、Lys166は、結晶構造内の基質結合エキソサイト領域を指している。FVIIaのLys165とFVIIaのGla35との間の推定塩橋形成は、組織因子のFVIIaのGLAドメインとの相互作用が基質認識を調節するという概念を支持するであろう。これらの結果は、組織因子外部ドメインのC末端部分が、FIX及びFXのGLAドメイン、隣接する可能性のあるEGF1ドメインと直接相互作用し、FVIIa GLAドメインの存在がこれらの相互作用を直接又は間接的のいずれかで調節し得ることを示唆する。 It has also been demonstrated that residues Lys 165 and Lys 166 are important for substrate recognition and binding. Mutating any of these residues to alanine greatly reduces tissue factor cofactor function. Lys 165 and Lys 166 point outwards toward each other, with Lys 165 pointing toward FVIIa in most tissue factor-FVIIa structures and Lys 166 pointing toward the substrate-binding exosite region in crystal structures. . A putative salt bridge formation between FVIIa Lys 165 and FVIIa Gla 35 would support the notion that the interaction of tissue factor with the FVIIa GLA domain regulates substrate recognition. These results suggest that the C-terminal portion of the tissue factor ectodomain directly interacts with the GLA domains of FIX and FX, possibly adjacent EGF1 domains, and that the presence of the FVIIa GLA domain regulates these interactions either directly or indirectly. This suggests that it can be regulated by either target.
可溶性組織因子ドメイン
本明細書に記載のポリペプチド、組成物、又は方法のうちのいずれかのいくつかの実施形態では、可溶性組織因子ドメインは、シグナル配列、膜貫通ドメイン、及び細胞内ドメインを欠く野生型組織因子ポリペプチドであり得る。いくつかの例では、可溶性組織因子ドメインは、組織因子変異体であり得、野生型組織因子ポリペプチドが、シグナル配列、膜貫通ドメイン、及び細胞内ドメインを欠き、選択されたアミノ酸で更に修飾されている。いくつかの例では、可溶性組織因子ドメインは、可溶性ヒト組織因子ドメインであり得る。いくつかの例では、可溶性組織因子ドメインは、可溶性マウス組織因子ドメインであり得る。いくつかの例では、可溶性組織因子ドメインは、可溶性ラット組織因子ドメインであり得る。可溶性ヒト組織因子ドメイン、可溶性マウス組織因子ドメイン、可溶性ラット組織因子ドメイン、及び変異体可溶性組織因子ドメインの非限定的な例が以下に示される。
例示的な可溶性ヒト組織因子ドメイン(配列番号93)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
可溶性ヒト組織因子ドメイン(配列番号94)をコードする例示的な核酸
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
例示的な可溶性マウス組織因子ドメイン(配列番号95)
agipekafnltwistdfktilewqpkptnytytvqisdrsrnwknkcfsttdtecdltdeivkdvtwayeakvlsvprrnsvhgdgdqlvihgeeppftnapkflpyrdtnlgqpviqqfeqdgrklnvvvkdsltlvrkngtfltlrqvfgkdlgyiityrkgsstgkktnitntnefsidveegvsycffvqamifsrktnqnspgsstvcteqwksflge
例示的な可溶性ラット組織因子ドメイン(配列番号96)
Agtppgkafnltwistdfktilewqpkptnytytvqisdrsrnwkykctgttdtecdltdeivkdvnwtyearvlsvpwrnsthgketlfgthgeeppftnarkflpyrdtkigqpviqkyeqggtklkvtvkdsftlvrkngtfltlrqvfgndlgyiltyrkdsstgrktntthtneflidvekgvsycffaqavifsrktnhkspesitkcteqwksvlge
例示的な変異体可溶性ヒト組織因子ドメイン(配列番号97)
SGTTNTVAAYNLTWKSTNFATALEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECALTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVARNNTALSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
例示的な変異体可溶性ヒト組織因子ドメイン(配列番号98)
SGTTNTVAAYNLTWKSTNFATALEWEPKPVNQVYTVQISTKSGDAKSKCFYTTDTECALTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLAENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVARNNTALSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
Soluble Tissue Factor Domain In some embodiments of any of the polypeptides, compositions, or methods described herein, the soluble tissue factor domain lacks a signal sequence, a transmembrane domain, and an intracellular domain. It can be a wild-type tissue factor polypeptide. In some instances, the soluble tissue factor domain can be a tissue factor variant, wherein the wild-type tissue factor polypeptide lacks the signal sequence, transmembrane domain, and intracellular domain and is further modified with selected amino acids. ing. In some examples, the soluble tissue factor domain can be a soluble human tissue factor domain. In some examples, the soluble tissue factor domain can be a soluble mouse tissue factor domain. In some examples, the soluble tissue factor domain can be a soluble rat tissue factor domain. Non-limiting examples of soluble human tissue factor domains, soluble mouse tissue factor domains, soluble rat tissue factor domains, and variant soluble tissue factor domains are provided below.
Exemplary Soluble Human Tissue Factor Domain (SEQ ID NO:93)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTF LSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
Exemplary Nucleic Acid Encoding a Soluble Human Tissue Factor Domain (SEQ ID NO: 94) AGCGGCCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAACCATCCTCGAATGGGAACCCAAACCGTTTACACAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTAT ACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTTAGCTACCCCGCCGGCAATGTGGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCC AAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCA ACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAGGGCGAGTTCCGGGAG
Exemplary Soluble Mouse Tissue Factor Domain (SEQ ID NO:95)
agipekafnltwistdfktilewqpkptnytytvqisdrsrnwknkcfsttdtecdltdeivkdvtwayeakvlsvprrnsvhgdgdqlvihgeeppftnapkflpyrdtnlgqpviqqfeqdgrk lnvvvkdsltlvrkngtfltlrqvfgkdlgyiityrkgsstgkktnitntnefsidveegvsycffvqamifsrktnqnspgsstvcteqwksflge
Exemplary Soluble Rat Tissue Factor Domain (SEQ ID NO:96)
Agtppgkafnltwistdfktilewqpkptnytytvqisdrsrnwkykctgttdtecdltdeivkdvnwtyearvlsvpwrnsthgketlfgthgeeppftnarkflpyrdtkigqpviqkyeqggtklkvt vkdsftlvrkngtfltlrqvfgndlgyiltyrkdsstgrktntthtneflidvekgvsycffaqavifsrktnhkspesitkcteqwksvlge
Exemplary Mutant Soluble Human Tissue Factor Domain (SEQ ID NO:97)
SGTTNTVAAYNLTWKSTNFATALEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECALTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVARNNTALSL RDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
Exemplary Mutant Soluble Human Tissue Factor Domain (SEQ ID NO:98)
SGTTNTVAAYNLTWKSTNFATALEWEPKPVNQVYTVQISTKSGDAKSKCFYTTDTECALTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLAENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVARNNTALSLR DVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
いくつかの実施形態では、可溶性組織因子ドメインは、配列番号93、95、96、97、又は98と少なくとも70%同一、少なくとも72%同一、少なくとも74%同一、少なくとも76%同一、少なくとも78%同一、少なくとも80%同一、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一である配列を含み得る。いくつかの実施形態では、可溶性組織因子ドメインは、1~20個のアミノ酸(例えば、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、又は20個のアミノ酸)がそのN末端から除去された、及び/又は1~20個のアミノ酸(例えば、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、又は20個のアミノ酸)がそのC末端から除去された、配列番号93、95、96、97、又は98の配列を含み得る。 In some embodiments, the soluble tissue factor domain is at least 70% identical, at least 72% identical, at least 74% identical, at least 76% identical, at least 78% identical to SEQ ID NO: 93, 95, 96, 97, or 98 , at least 80% identical, at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical , may include sequences that are at least 99% identical, or 100% identical. In some embodiments, the soluble tissue factor domain is 1-20 amino acids (eg, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 amino acids) were removed from its N-terminus, and/or 1-20 amino acids (eg, 2, 3, 4, 5, 6, 7, 8, 9 , 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, or 20 amino acids) removed from its C-terminus. can include
当該技術分野で理解され得るように、当業者であれば、異なる哺乳動物種間で保存されているアミノ酸の変異がタンパク質の活性及び/又は構造的安定性を低下させる可能性が高い一方で、異なる哺乳動物種間で保存されていないアミノ酸の変異がタンパク質の活性及び/又は構造的安定性を低下させる可能性が低いことを理解するであろう。 As can be appreciated in the art, it is likely that amino acid variations that are conserved among different mammalian species will reduce protein activity and/or structural stability, while those skilled in the art will likely It will be appreciated that amino acid mutations that are not conserved among different mammalian species are unlikely to reduce protein activity and/or structural stability.
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの例では、可溶性組織因子ドメインは、第VIIa因子に結合することができない。本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの例では、可溶性組織因子ドメインは、不活性第X因子を第Xa因子に変換しない。本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、多鎖キメラポリペプチドは、哺乳動物における血液凝固を刺激しない。 In some instances of any of the multichain chimeric polypeptides described herein, the soluble tissue factor domain is unable to bind Factor VIIa. In some examples of any of the multichain chimeric polypeptides described herein, the soluble tissue factor domain does not convert inactive factor X to factor Xa. In some embodiments of any of the multi-chain chimeric polypeptides described herein, the multi-chain chimeric polypeptide does not stimulate blood clotting in a mammal.
いくつかの例では、可溶性組織因子ドメインは、可溶性ヒト組織因子ドメインであり得る。いくつかの実施形態では、可溶性組織因子ドメインは、可溶性マウス組織因子ドメインであり得る。いくつかの実施形態では、可溶性組織因子ドメインは、可溶性ラット組織因子ドメインであり得る。 In some examples, the soluble tissue factor domain can be a soluble human tissue factor domain. In some embodiments, the soluble tissue factor domain can be a soluble mouse tissue factor domain. In some embodiments, the soluble tissue factor domain can be a soluble rat tissue factor domain.
いくつかの例では、可溶性組織因子ドメインは、成熟野生型ヒト組織因子タンパク質のアミノ酸20位に対応するアミノ酸の位置にリジン、成熟野生型ヒト組織因子タンパク質のアミノ酸22位に対応するアミノ酸の位置にイソロイシン、成熟野生型ヒト組織因子タンパク質のアミノ酸45位に対応するアミノ酸の位置にトリプトファン、成熟野生型ヒト組織因子タンパク質のアミノ酸58位に対応するアミノ酸の位置にアスパラギン酸、成熟野生型ヒト組織因子タンパク質のアミノ酸94位に対応するアミノ酸の位置にチロシン、成熟野生型ヒト組織因子タンパク質のアミノ酸135位に対応するアミノ酸の位置にアルギニン、及び成熟野生型ヒト組織因子タンパク質のアミノ酸140位に対応するアミノ酸の位置にフェニルアラニンのうちの1つ以上(例えば、2、3、4、5、6、又は7つ)を含まない。いくつかの実施形態では、変異体可溶性組織因子は、配列番号97又は配列番号98のアミノ酸配列を有する。
In some examples, the soluble tissue factor domain has a lysine at the amino acid position corresponding to
いくつかの例では、可溶性組織因子ドメインは、配列番号94と少なくとも70%同一、少なくとも72%同一、少なくとも74%同一、少なくとも76%同一、少なくとも78%同一、少なくとも80%同一、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一である配列を含む核酸によってコードされ得る。 In some examples, the soluble tissue factor domain is at least 70% identical, at least 72% identical, at least 74% identical, at least 76% identical, at least 78% identical, at least 80% identical, at least 82% identical to SEQ ID NO:94 , at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical can be encoded by a nucleic acid comprising a sequence that is
いくつかの実施形態では、可溶性組織因子ドメインは、約20アミノ酸~約220アミノ酸、約20アミノ酸~約215アミノ酸、約20アミノ酸~約210アミノ酸、約20アミノ酸~約205アミノ酸、約20アミノ酸~約200アミノ酸、約20アミノ酸~約195アミノ酸、約20アミノ酸~約190アミノ酸、約20アミノ酸~約185アミノ酸、約20アミノ酸~約180アミノ酸、約20アミノ酸~約175アミノ酸、約20アミノ酸~約170アミノ酸、約20アミノ酸~約165アミノ酸、約20アミノ酸~約160アミノ酸、約20アミノ酸~約155アミノ酸、約20アミノ酸~約150アミノ酸、約20アミノ酸~約145アミノ酸、約20アミノ酸~約140アミノ酸、約20アミノ酸~約135アミノ酸、約20アミノ酸~約130アミノ酸、約20アミノ酸~約125アミノ酸、約20アミノ酸~約120アミノ酸、約20アミノ酸~約115アミノ酸、約20アミノ酸~約110アミノ酸、約20アミノ酸~約105アミノ酸、約20アミノ酸~約100アミノ酸、約20アミノ酸~約95アミノ酸、約20アミノ酸~約90アミノ酸、約20アミノ酸~約85アミノ酸、約20アミノ酸~約80アミノ酸、約20アミノ酸~約75アミノ酸、約20アミノ酸~約70アミノ酸、約20アミノ酸~約60アミノ酸、約20アミノ酸~約50アミノ酸、約20アミノ酸~約40アミノ酸、約20アミノ酸~約30アミノ酸、約30アミノ酸~約220アミノ酸、約30アミノ酸~約215アミノ酸、約30アミノ酸~約210アミノ酸、約30アミノ酸~約205アミノ酸、約30アミノ酸~約200アミノ酸、約30アミノ酸~約195アミノ酸、約30アミノ酸~約190アミノ酸、約30アミノ酸~約185アミノ酸、約30アミノ酸~約180アミノ酸、約30アミノ酸~約175アミノ酸、約30アミノ酸~約170アミノ酸、約30アミノ酸~約165アミノ酸、約30アミノ酸~約160アミノ酸、約30アミノ酸~約155アミノ酸、約30アミノ酸~約150アミノ酸、約30アミノ酸~約145アミノ酸、約30アミノ酸~約140アミノ酸、約30アミノ酸~約135アミノ酸、約30アミノ酸~約130アミノ酸、約30アミノ酸~約125アミノ酸、約30アミノ酸~約120アミノ酸、約30アミノ酸~約115アミノ酸、約30アミノ酸~約110アミノ酸、約30アミノ酸~約105アミノ酸、約30アミノ酸~約100アミノ酸、約30アミノ酸~約95アミノ酸、約30アミノ酸~約90アミノ酸、約30アミノ酸~約85アミノ酸、約30アミノ酸~約80アミノ酸、約30アミノ酸~約75アミノ酸、約30アミノ酸~約70アミノ酸、約30アミノ酸~約60アミノ酸、約30アミノ酸~約50アミノ酸、約30アミノ酸~約40アミノ酸、約40アミノ酸~約220アミノ酸、約40アミノ酸~約215アミノ酸、約40アミノ酸~約210アミノ酸、約40アミノ酸~約205アミノ酸、約40アミノ酸~約200アミノ酸、約40アミノ酸~約195アミノ酸、約40アミノ酸~約190アミノ酸、約40アミノ酸~約185アミノ酸、約40アミノ酸~約180アミノ酸、約40アミノ酸~約175アミノ酸、約40アミノ酸~約170アミノ酸、約40アミノ酸~約165アミノ酸、約40アミノ酸~約160アミノ酸、約40アミノ酸~約155アミノ酸、約40アミノ酸~約150アミノ酸、約40アミノ酸~約145アミノ酸、約40アミノ酸~約140アミノ酸、約40アミノ酸~約135アミノ酸、約40アミノ酸~約130アミノ酸、約40アミノ酸~約125アミノ酸、約40アミノ酸~約120アミノ酸、約40アミノ酸~約115アミノ酸、約40アミノ酸~約110アミノ酸、約40アミノ酸~約105アミノ酸、約40アミノ酸~約100アミノ酸、約40アミノ酸~約95アミノ酸、約40アミノ酸~約90アミノ酸、約40アミノ酸~約85アミノ酸、約40アミノ酸~約80アミノ酸、約40アミノ酸~約75アミノ酸、約40アミノ酸~約70アミノ酸、約40アミノ酸~約60アミノ酸、約40アミノ酸~約50アミノ酸、約50アミノ酸~約220アミノ酸、約50アミノ酸~約215アミノ酸、約50アミノ酸~約210アミノ酸、約50アミノ酸~約205アミノ酸、約50アミノ酸~約200アミノ酸、約50アミノ酸~約195アミノ酸、約50アミノ酸~約190アミノ酸、約50アミノ酸~約185アミノ酸、約50アミノ酸~約180アミノ酸、約50アミノ酸~約175アミノ酸、約50アミノ酸~約170アミノ酸、約50アミノ酸~約165アミノ酸、約50アミノ酸~約160アミノ酸、約50アミノ酸~約155アミノ酸、約50アミノ酸~約150アミノ酸、約50アミノ酸~約145アミノ酸、約50アミノ酸~約140アミノ酸、約50アミノ酸~約135アミノ酸、約50アミノ酸~約130アミノ酸、約50アミノ酸~約125アミノ酸、約50アミノ酸~約120アミノ酸、約50アミノ酸~約115アミノ酸、約50アミノ酸~約110アミノ酸、約50アミノ酸~約105アミノ酸、約50アミノ酸~約100アミノ酸、約50アミノ酸~約95アミノ酸、約50アミノ酸~約90アミノ酸、約50アミノ酸~約85アミノ酸、約50アミノ酸~約80アミノ酸、約50アミノ酸~約75アミノ酸、約50アミノ酸~約70アミノ酸、約50アミノ酸~約60アミノ酸、約60アミノ酸~約220アミノ酸、約60アミノ酸~約215アミノ酸、約60アミノ酸~約210アミノ酸、約60アミノ酸~約205アミノ酸、約60アミノ酸~約200アミノ酸、約60アミノ酸~約195アミノ酸、約60アミノ酸~約190アミノ酸、約60アミノ酸~約185アミノ酸、約60アミノ酸~約180アミノ酸、約60アミノ酸~約175アミノ酸、約60アミノ酸~約170アミノ酸、約60アミノ酸~約165アミノ酸、約60アミノ酸~約160アミノ酸、約60アミノ酸~約155アミノ酸、約60アミノ酸~約150アミノ酸、約60アミノ酸~約145アミノ酸、約60アミノ酸~約140アミノ酸、約60アミノ酸~約135アミノ酸、約60アミノ酸~約130アミノ酸、約60アミノ酸~約125アミノ酸、約60アミノ酸~約120アミノ酸、約60アミノ酸~約115アミノ酸、約60アミノ酸~約110アミノ酸、約60アミノ酸~約105アミノ酸、約60アミノ酸~約100アミノ酸、約60アミノ酸~約95アミノ酸、約60アミノ酸~約90アミノ酸、約60アミノ酸~約85アミノ酸、約60アミノ酸~約80アミノ酸、約60アミノ酸~約75アミノ酸、約60アミノ酸~約70アミノ酸、約70アミノ酸~約220アミノ酸、約70アミノ酸~約215アミノ酸、約70アミノ酸~約210アミノ酸、約70アミノ酸~約205アミノ酸、約70アミノ酸~約200アミノ酸、約70アミノ酸~約195アミノ酸、約70アミノ酸~約190アミノ酸、約70アミノ酸~約185アミノ酸、約70アミノ酸~約180アミノ酸、約70アミノ酸~約175アミノ酸、約70アミノ酸~約170アミノ酸、約70アミノ酸~約165アミノ酸、約70アミノ酸~約160アミノ酸、約70アミノ酸~約155アミノ酸、約70アミノ酸~約150アミノ酸、約70アミノ酸~約145アミノ酸、約70アミノ酸~約140アミノ酸、約70アミノ酸~約135アミノ酸、約70アミノ酸~約130アミノ酸、約70アミノ酸~約125アミノ酸、約70アミノ酸~約120アミノ酸、約70アミノ酸~約115アミノ酸、約70アミノ酸~約110アミノ酸、約70アミノ酸~約105アミノ酸、約70アミノ酸~約100アミノ酸、約70アミノ酸~約95アミノ酸、約70アミノ酸~約90アミノ酸、約70アミノ酸~約85アミノ酸、約70アミノ酸~約80アミノ酸、約80アミノ酸~約220アミノ酸、約80アミノ酸~約215アミノ酸、約80アミノ酸~約210アミノ酸、約80アミノ酸~約205アミノ酸、約80アミノ酸~約200アミノ酸、約80アミノ酸~約195アミノ酸、約80アミノ酸~約190アミノ酸、約80アミノ酸~約185アミノ酸、約80アミノ酸~約180アミノ酸、約80アミノ酸~約175アミノ酸、約80アミノ酸~約170アミノ酸、約80アミノ酸~約165アミノ酸、約80アミノ酸~約160アミノ酸、約80アミノ酸~約155アミノ酸、約80アミノ酸~約150アミノ酸、約80アミノ酸~約145アミノ酸、約80アミノ酸~約140アミノ酸、約80アミノ酸~約135アミノ酸、約80アミノ酸~約130アミノ酸、約80アミノ酸~約125アミノ酸、約80アミノ酸~約120アミノ酸、約80アミノ酸~約115アミノ酸、約80アミノ酸~約110アミノ酸、約80アミノ酸~約105アミノ酸、約80アミノ酸~約100アミノ酸、約80アミノ酸~約95アミノ酸、約80アミノ酸~約90アミノ酸、約90アミノ酸~約220アミノ酸、約90アミノ酸~約215アミノ酸、約90アミノ酸~約210アミノ酸、約90アミノ酸~約205アミノ酸、約90アミノ酸~約200アミノ酸、約90アミノ酸~約195アミノ酸、約90アミノ酸~約190アミノ酸、約90アミノ酸~約185アミノ酸、約90アミノ酸~約180アミノ酸、約90アミノ酸~約175アミノ酸、約90アミノ酸~約170アミノ酸、約90アミノ酸~約165アミノ酸、約90アミノ酸~約160アミノ酸、約90アミノ酸~約155アミノ酸、約90アミノ酸~約150アミノ酸、約90アミノ酸~約145アミノ酸、約90アミノ酸~約140アミノ酸、約90アミノ酸~約135アミノ酸、約90アミノ酸~約130アミノ酸、約90アミノ酸~約125アミノ酸、約90アミノ酸~約120アミノ酸、約90アミノ酸~約115アミノ酸、約90アミノ酸~約110アミノ酸、約90アミノ酸~約105アミノ酸、約90アミノ酸~約100アミノ酸、約100アミノ酸~約220アミノ酸、約100アミノ酸~約215アミノ酸、約100アミノ酸~約210アミノ酸、約100アミノ酸~約205アミノ酸、約100アミノ酸~約200アミノ酸、約100アミノ酸~約195アミノ酸、約100アミノ酸~約190アミノ酸、約100アミノ酸~約185アミノ酸、約100アミノ酸~約180アミノ酸、約100アミノ酸~約175アミノ酸、約100アミノ酸~約170アミノ酸、約100アミノ酸~約165アミノ酸、約100アミノ酸~約160アミノ酸、約100アミノ酸~約155アミノ酸、約100アミノ酸~約150アミノ酸、約100アミノ酸~約145アミノ酸、約100アミノ酸~約140アミノ酸、約100アミノ酸~約135アミノ酸、約100アミノ酸~約130アミノ酸、約100アミノ酸~約125アミノ酸、約100アミノ酸~約120アミノ酸、約100アミノ酸~約115アミノ酸、約100アミノ酸~約110アミノ酸、約110アミノ酸~約220アミノ酸、約110アミノ酸~約215アミノ酸、約110アミノ酸~約210アミノ酸、約110アミノ酸~約205アミノ酸、約110アミノ酸~約200アミノ酸、約110アミノ酸~約195アミノ酸、約110アミノ酸~約190アミノ酸、約110アミノ酸~約185アミノ酸、
約110アミノ酸~約180アミノ酸、約110アミノ酸~約175アミノ酸、約110アミノ酸~約170アミノ酸、約110アミノ酸~約165アミノ酸、約110アミノ酸~約160アミノ酸、約110アミノ酸~約155アミノ酸、約110アミノ酸~約150アミノ酸、約110アミノ酸~約145アミノ酸、約110アミノ酸~約140アミノ酸、約110アミノ酸~約135アミノ酸、約110アミノ酸~約130アミノ酸、約110アミノ酸~約125アミノ酸、約110アミノ酸~約120アミノ酸、約110アミノ酸~約115アミノ酸、約115アミノ酸~約220アミノ酸、約115アミノ酸~約215アミノ酸、約115アミノ酸~約210アミノ酸、約115アミノ酸~約205アミノ酸、約115アミノ酸~約200アミノ酸、約115アミノ酸~約195アミノ酸、約115アミノ酸~約190アミノ酸、約115アミノ酸~約185アミノ酸、約115アミノ酸~約180アミノ酸、約115アミノ酸~約175アミノ酸、約115アミノ酸~約170アミノ酸、約115アミノ酸~約165アミノ酸、約115アミノ酸~約160アミノ酸、約115アミノ酸~約155アミノ酸、約115アミノ酸~約150アミノ酸、約115アミノ酸~約145アミノ酸、約115アミノ酸~約140アミノ酸、約115アミノ酸~約135アミノ酸、約115アミノ酸~約130アミノ酸、約115アミノ酸~約125アミノ酸、約115アミノ酸~約120アミノ酸、約120アミノ酸~約220アミノ酸、約120アミノ酸~約215アミノ酸、約120アミノ酸~約210アミノ酸、約120アミノ酸~約205アミノ酸、約120アミノ酸~約200アミノ酸、約120アミノ酸~約195アミノ酸、約120アミノ酸~約190アミノ酸、約120アミノ酸~約185アミノ酸、約120アミノ酸~約180アミノ酸、約120アミノ酸~約175アミノ酸、約120アミノ酸~約170アミノ酸、約120アミノ酸~約165アミノ酸、約120アミノ酸~約160アミノ酸、約120アミノ酸~約155アミノ酸、約120アミノ酸~約150アミノ酸、約120アミノ酸~約145アミノ酸、約120アミノ酸~約140アミノ酸、約120アミノ酸~約135アミノ酸、約120アミノ酸~約130アミノ酸、約120アミノ酸~約125アミノ酸、約125アミノ酸~約220アミノ酸、約125アミノ酸~約215アミノ酸、約125アミノ酸~約210アミノ酸、約125アミノ酸~約205アミノ酸、約125アミノ酸~約200アミノ酸、約125アミノ酸~約195アミノ酸、約125アミノ酸~約190アミノ酸、約125アミノ酸~約185アミノ酸、約125アミノ酸~約180アミノ酸、約125アミノ酸~約175アミノ酸、約125アミノ酸~約170アミノ酸、約125アミノ酸~約165アミノ酸、約125アミノ酸~約160アミノ酸、約125アミノ酸~約155アミノ酸、約125アミノ酸~約150アミノ酸、約125アミノ酸~約145アミノ酸、約125アミノ酸~約140アミノ酸、約125アミノ酸~約135アミノ酸、約125アミノ酸~約130アミノ酸、約130アミノ酸~約220アミノ酸、約130アミノ酸~約215アミノ酸、約130アミノ酸~約210アミノ酸、約130アミノ酸~約205アミノ酸、約130アミノ酸~約200アミノ酸、約130アミノ酸~約195アミノ酸、約130アミノ酸~約190アミノ酸、約130アミノ酸~約185アミノ酸、約130アミノ酸~約180アミノ酸、約130アミノ酸~約175アミノ酸、約130アミノ酸~約170アミノ酸、約130アミノ酸~約165アミノ酸、約130アミノ酸~約160アミノ酸、約130アミノ酸~約155アミノ酸、約130アミノ酸~約150アミノ酸、約130アミノ酸~約145アミノ酸、約130アミノ酸~約140アミノ酸、約130アミノ酸~約135アミノ酸、約135アミノ酸~約220アミノ酸、約135アミノ酸~約215アミノ酸、約135アミノ酸~約210アミノ酸、約135アミノ酸~約205アミノ酸、約135アミノ酸~約200アミノ酸、約135アミノ酸~約195アミノ酸、約135アミノ酸~約190アミノ酸、約135アミノ酸~約185アミノ酸、約135アミノ酸~約180アミノ酸、約135アミノ酸~約175アミノ酸、約135アミノ酸~約170アミノ酸、約135アミノ酸~約165アミノ酸、約135アミノ酸~約160アミノ酸、約135アミノ酸~約155アミノ酸、約135アミノ酸~約150アミノ酸、約135アミノ酸~約145アミノ酸、約135アミノ酸~約140アミノ酸、約140アミノ酸~約220アミノ酸、約140アミノ酸~約215アミノ酸、約140アミノ酸~約210アミノ酸、約140アミノ酸~約205アミノ酸、約140アミノ酸~約200アミノ酸、約140アミノ酸~約195アミノ酸、約140アミノ酸~約190アミノ酸、約140アミノ酸~約185アミノ酸、約140アミノ酸~約180アミノ酸、約140アミノ酸~約175アミノ酸、約140アミノ酸~約170アミノ酸、約140アミノ酸~約165アミノ酸、約140アミノ酸~約160アミノ酸、約140アミノ酸~約155アミノ酸、約140アミノ酸~約150アミノ酸、約140アミノ酸~約145アミノ酸、約145アミノ酸~約220アミノ酸、約145アミノ酸~約215アミノ酸、約145アミノ酸~約210アミノ酸、約145アミノ酸~約205アミノ酸、約145アミノ酸~約200アミノ酸、約145アミノ酸~約195アミノ酸、約145アミノ酸~約190アミノ酸、約145アミノ酸~約185アミノ酸、約145アミノ酸~約180アミノ酸、約145アミノ酸~約175アミノ酸、約145アミノ酸~約170アミノ酸、約145アミノ酸~約165アミノ酸、約145アミノ酸~約160アミノ酸、約145アミノ酸~約155アミノ酸、約145アミノ酸~約150アミノ酸、約150アミノ酸~約220アミノ酸、約150アミノ酸~約215アミノ酸、約150アミノ酸~約210アミノ酸、約150アミノ酸~約205アミノ酸、約150アミノ酸~約200アミノ酸、約150アミノ酸~約195アミノ酸、約150アミノ酸~約190アミノ酸、約150アミノ酸~約185アミノ酸、約150アミノ酸~約180アミノ酸、約150アミノ酸~約175アミノ酸、約150アミノ酸~約170アミノ酸、約150アミノ酸~約165アミノ酸、約150アミノ酸~約160アミノ酸、約150アミノ酸~約155アミノ酸、約155アミノ酸~約220アミノ酸、約155アミノ酸~約215アミノ酸、約155アミノ酸~約210アミノ酸、約155アミノ酸~約205アミノ酸、約155アミノ酸~約200アミノ酸、約155アミノ酸~約195アミノ酸、約155アミノ酸~約190アミノ酸、約155アミノ酸~約185アミノ酸、約155アミノ酸~約180アミノ酸、約155アミノ酸~約175アミノ酸、約155アミノ酸~約170アミノ酸、約155アミノ酸~約165アミノ酸、約155アミノ酸~約160アミノ酸、約160アミノ酸~約220アミノ酸、約160アミノ酸~約215アミノ酸、約160アミノ酸~約210アミノ酸、約160アミノ酸~約205アミノ酸、約160アミノ酸~約200アミノ酸、約160アミノ酸~約195アミノ酸、約160アミノ酸~約190アミノ酸、約160アミノ酸~約185アミノ酸、約160アミノ酸~約180アミノ酸、約160アミノ酸~約175アミノ酸、約160アミノ酸~約170アミノ酸、約160アミノ酸~約165アミノ酸、約165アミノ酸~約220アミノ酸、約165アミノ酸~約215アミノ酸、約165アミノ酸~約210アミノ酸、約165アミノ酸~約205アミノ酸、約165アミノ酸~約200アミノ酸、約165アミノ酸~約195アミノ酸、約165アミノ酸~約190アミノ酸、約165アミノ酸~約185アミノ酸、約165アミノ酸~約180アミノ酸、約165アミノ酸~約175アミノ酸、約165アミノ酸~約170アミノ酸、約170アミノ酸~約220アミノ酸、約170アミノ酸~約215アミノ酸、約170アミノ酸~約210アミノ酸、約170アミノ酸~約205アミノ酸、約170アミノ酸~約200アミノ酸、約170アミノ酸~約195アミノ酸、約170アミノ酸~約190アミノ酸、約170アミノ酸~約185アミノ酸、約170アミノ酸~約180アミノ酸、約170アミノ酸~約175アミノ酸、約175アミノ酸~約220アミノ酸、約175アミノ酸~約215アミノ酸、約175アミノ酸~約210アミノ酸、約175アミノ酸~約205アミノ酸、約175アミノ酸~約200アミノ酸、約175アミノ酸~約195アミノ酸、約175アミノ酸~約190アミノ酸、約175アミノ酸~約185アミノ酸、約175アミノ酸~約180アミノ酸、約180アミノ酸~約220アミノ酸、約180アミノ酸~約215アミノ酸、約180アミノ酸~約210アミノ酸、約180アミノ酸~約205アミノ酸、約180アミノ酸~約200アミノ酸、約180アミノ酸~約195アミノ酸、約180アミノ酸~約190アミノ酸、約180アミノ酸~約185アミノ酸、約185アミノ酸~約220アミノ酸、約185アミノ酸~約215アミノ酸、約185アミノ酸~約210アミノ酸、約185アミノ酸~約205アミノ酸、約185アミノ酸~約200アミノ酸、約185アミノ酸~約195アミノ酸、約185アミノ酸~約190アミノ酸、約190アミノ酸~約220アミノ酸、約190アミノ酸~約215アミノ酸、約190アミノ酸~約210アミノ酸、約190アミノ酸~約205アミノ酸、約190アミノ酸~約200アミノ酸、約190アミノ酸~約195アミノ酸、約195アミノ酸~約220アミノ酸、約195アミノ酸~約215アミノ酸、約195アミノ酸~約210アミノ酸、約195アミノ酸~約205アミノ酸、約195アミノ酸~約200アミノ酸、約200アミノ酸~約220アミノ酸、約200アミノ酸~約215アミノ酸、約200アミノ酸~約210アミノ酸、約200アミノ酸~約205アミノ酸、約205アミノ酸~約220アミノ酸、約205アミノ酸~約215アミノ酸、約205アミノ酸~約210アミノ酸、約210アミノ酸~約220アミノ酸、約210アミノ酸~約215アミノ酸、又は約215アミノ酸~約220アミノ酸の全長を有し得る。
In some embodiments, the soluble tissue factor domain is about 20 amino acids to about 220 amino acids, about 20 amino acids to about 215 amino acids, about 20 amino acids to about 210 amino acids, about 20 amino acids to about 205 amino acids, about 20 amino acids to about 200 amino acids, about 20 amino acids to about 195 amino acids, about 20 amino acids to about 190 amino acids, about 20 amino acids to about 185 amino acids, about 20 amino acids to about 180 amino acids, about 20 amino acids to about 175 amino acids, about 20 amino acids to about 170 amino acids , about 20 amino acids to about 165 amino acids, about 20 amino acids to about 160 amino acids, about 20 amino acids to about 155 amino acids, about 20 amino acids to about 150 amino acids, about 20 amino acids to about 145 amino acids, about 20 amino acids to about 140 amino acids, about 20 amino acids to about 135 amino acids, about 20 amino acids to about 130 amino acids, about 20 amino acids to about 125 amino acids, about 20 amino acids to about 120 amino acids, about 20 amino acids to about 115 amino acids, about 20 amino acids to about 110 amino acids, about 20 amino acids to about 105 amino acids, about 20 amino acids to about 100 amino acids, about 20 amino acids to about 95 amino acids, about 20 amino acids to about 90 amino acids, about 20 amino acids to about 85 amino acids, about 20 amino acids to about 80 amino acids, about 20 amino acids to about 75 amino acids, about 20 amino acids to about 70 amino acids, about 20 amino acids to about 60 amino acids, about 20 amino acids to about 50 amino acids, about 20 amino acids to about 40 amino acids, about 20 amino acids to about 30 amino acids, about 30 amino acids to about 220 amino acids , about 30 amino acids to about 215 amino acids, about 30 amino acids to about 210 amino acids, about 30 amino acids to about 205 amino acids, about 30 amino acids to about 200 amino acids, about 30 amino acids to about 195 amino acids, about 30 amino acids to about 190 amino acids, about 30 amino acids to about 185 amino acids, about 30 amino acids to about 180 amino acids, about 30 amino acids to about 175 amino acids, about 30 amino acids to about 170 amino acids, about 30 amino acids to about 165 amino acids, about 30 amino acids to about 160 amino acids, about 30 amino acids to about 155 amino acids, about 30 amino acids to about 150 amino acids, about 30 amino acids to about 145 amino acids, about 30 amino acids to about 140 amino acids, about 30 amino acids to about 135 amino acids, about 30 amino acids to about 130 amino acids, about 30 amino acids to about 125 amino acids, about 30 amino acids to about 120 amino acids, about 30 amino acids to about 115 amino acids, about 30 amino acids to about 110 amino acids, about 30 amino acids to about 105 amino acids, about 30 amino acids to about 100 amino acids, about 30 amino acids to about 95 amino acids , about 30 amino acids to about 90 amino acids, about 30 amino acids to about 85 amino acids, about 30 amino acids to about 80 amino acids, about 30 amino acids to about 75 amino acids, about 30 amino acids to about 70 amino acids, about 30 amino acids to about 60 amino acids, about 30 amino acids to about 50 amino acids, about 30 amino acids to about 40 amino acids, about 40 amino acids to about 220 amino acids, about 40 amino acids to about 215 amino acids, about 40 amino acids to about 210 amino acids, about 40 amino acids to about 205 amino acids, about 40 amino acids to about 200 amino acids, about 40 amino acids to about 195 amino acids, about 40 amino acids to about 190 amino acids, about 40 amino acids to about 185 amino acids, about 40 amino acids to about 180 amino acids, about 40 amino acids to about 175 amino acids, about 40 amino acids to about 170 amino acids, about 40 amino acids to about 165 amino acids, about 40 amino acids to about 160 amino acids, about 40 amino acids to about 155 amino acids, about 40 amino acids to about 150 amino acids, about 40 amino acids to about 145 amino acids, about 40 amino acids to about 140 amino acids , about 40 amino acids to about 135 amino acids, about 40 amino acids to about 130 amino acids, about 40 amino acids to about 125 amino acids, about 40 amino acids to about 120 amino acids, about 40 amino acids to about 115 amino acids, about 40 amino acids to about 110 amino acids, about 40 amino acids to about 105 amino acids, about 40 amino acids to about 100 amino acids, about 40 amino acids to about 95 amino acids, about 40 amino acids to about 90 amino acids, about 40 amino acids to about 85 amino acids, about 40 amino acids to about 80 amino acids, about 40 amino acids to about 75 amino acids, about 40 amino acids to about 70 amino acids, about 40 amino acids to about 60 amino acids, about 40 amino acids to about 50 amino acids, about 50 amino acids to about 220 amino acids, about 50 amino acids to about 215 amino acids, about 50 amino acids to about 210 amino acids, about 50 amino acids to about 205 amino acids, about 50 amino acids to about 200 amino acids, about 50 amino acids to about 195 amino acids, about 50 amino acids to about 190 amino acids, about 50 amino acids to about 185 amino acids, about 50 amino acids to about 180 amino acids , about 50 amino acids to about 175 amino acids, about 50 amino acids to about 170 amino acids, about 50 amino acids to about 165 amino acids, about 50 amino acids to about 160 amino acids, about 50 amino acids to about 155 amino acids, about 50 amino acids to about 150 amino acids, about 50 amino acids to about 145 amino acids, about 50 amino acids to about 140 amino acids, about 50 amino acids to about 135 amino acids, about 50 amino acids to about 130 amino acids, about 50 amino acids to about 125 amino acids, about 50 amino acids to about 120 amino acids, about 50 amino acids to about 115 amino acids, about 50 amino acids to about 110 amino acids, about 50 amino acids to about 105 amino acids, about 50 amino acids to about 100 amino acids, about 50 amino acids to about 95 amino acids, about 50 amino acids to about 90 amino acids, about 50 amino acids to about 85 amino acids, about 50 amino acids to about 80 amino acids, about 50 amino acids to about 75 amino acids, about 50 amino acids to about 70 amino acids, about 50 amino acids to about 60 amino acids, about 60 amino acids to about 220 amino acids, about 60 amino acids to about 215 amino acids , about 60 amino acids to about 210 amino acids, about 60 amino acids to about 205 amino acids, about 60 amino acids to about 200 amino acids, about 60 amino acids to about 195 amino acids, about 60 amino acids to about 190 amino acids, about 60 amino acids to about 185 amino acids, about 60 amino acids to about 180 amino acids, about 60 amino acids to about 175 amino acids, about 60 amino acids to about 170 amino acids, about 60 amino acids to about 165 amino acids, about 60 amino acids to about 160 amino acids, about 60 amino acids to about 155 amino acids, about 60 amino acids to about 150 amino acids, about 60 amino acids to about 145 amino acids, about 60 amino acids to about 140 amino acids, about 60 amino acids to about 135 amino acids, about 60 amino acids to about 130 amino acids, about 60 amino acids to about 125 amino acids, about 60 amino acids to about 120 amino acids, about 60 amino acids to about 115 amino acids, about 60 amino acids to about 110 amino acids, about 60 amino acids to about 105 amino acids, about 60 amino acids to about 100 amino acids, about 60 amino acids to about 95 amino acids, about 60 amino acids to about 90 amino acids , about 60 amino acids to about 85 amino acids, about 60 amino acids to about 80 amino acids, about 60 amino acids to about 75 amino acids, about 60 amino acids to about 70 amino acids, about 70 amino acids to about 220 amino acids, about 70 amino acids to about 215 amino acids, about 70 amino acids to about 210 amino acids, about 70 amino acids to about 205 amino acids, about 70 amino acids to about 200 amino acids, about 70 amino acids to about 195 amino acids, about 70 amino acids to about 190 amino acids, about 70 amino acids to about 185 amino acids, about 70 amino acids to about 180 amino acids, about 70 amino acids to about 175 amino acids, about 70 amino acids to about 170 amino acids, about 70 amino acids to about 165 amino acids, about 70 amino acids to about 160 amino acids, about 70 amino acids to about 155 amino acids, about 70 amino acids to about 150 amino acids, about 70 amino acids to about 145 amino acids, about 70 amino acids to about 140 amino acids, about 70 amino acids to about 135 amino acids, about 70 amino acids to about 130 amino acids, about 70 amino acids to about 125 amino acids, about 70 amino acids to about 120 amino acids , about 70 amino acids to about 115 amino acids, about 70 amino acids to about 110 amino acids, about 70 amino acids to about 105 amino acids, about 70 amino acids to about 100 amino acids, about 70 amino acids to about 95 amino acids, about 70 amino acids to about 90 amino acids, about 70 amino acids to about 85 amino acids, about 70 amino acids to about 80 amino acids, about 80 amino acids to about 220 amino acids, about 80 amino acids to about 215 amino acids, about 80 amino acids to about 210 amino acids, about 80 amino acids to about 205 amino acids, about 80 amino acids to about 200 amino acids, about 80 amino acids to about 195 amino acids, about 80 amino acids to about 190 amino acids, about 80 amino acids to about 185 amino acids, about 80 amino acids to about 180 amino acids, about 80 amino acids to about 175 amino acids, about 80 amino acids to about 170 amino acids, about 80 amino acids to about 165 amino acids, about 80 amino acids to about 160 amino acids, about 80 amino acids to about 155 amino acids, about 80 amino acids to about 150 amino acids, about 80 amino acids to about 145 amino acids, about 80 amino acids to about 140 amino acids , about 80 amino acids to about 135 amino acids, about 80 amino acids to about 130 amino acids, about 80 amino acids to about 125 amino acids, about 80 amino acids to about 120 amino acids, about 80 amino acids to about 115 amino acids, about 80 amino acids to about 110 amino acids, about 80 amino acids to about 105 amino acids, about 80 amino acids to about 100 amino acids, about 80 amino acids to about 95 amino acids, about 80 amino acids to about 90 amino acids, about 90 amino acids to about 220 amino acids, about 90 amino acids to about 215 amino acids, about 90 amino acids to about 210 amino acids, about 90 amino acids to about 205 amino acids, about 90 amino acids to about 200 amino acids, about 90 amino acids to about 195 amino acids, about 90 amino acids to about 190 amino acids, about 90 amino acids to about 185 amino acids, about 90 amino acids to about 180 amino acids, about 90 amino acids to about 175 amino acids, about 90 amino acids to about 170 amino acids, about 90 amino acids to about 165 amino acids, about 90 amino acids to about 160 amino acids, about 90 amino acids to about 155 amino acids, about 90 amino acids to about 150 amino acids , about 90 amino acids to about 145 amino acids, about 90 amino acids to about 140 amino acids, about 90 amino acids to about 135 amino acids, about 90 amino acids to about 130 amino acids, about 90 amino acids to about 125 amino acids, about 90 amino acids to about 120 amino acids, about 90 amino acids to about 115 amino acids, about 90 amino acids to about 110 amino acids, about 90 amino acids to about 105 amino acids, about 90 amino acids to about 100 amino acids, about 100 amino acids to about 220 amino acids, about 100 amino acids to about 215 amino acids, about 100 amino acids to about 210 amino acids, about 100 amino acids to about 205 amino acids, about 100 amino acids to about 200 amino acids, about 100 amino acids to about 195 amino acids, about 100 amino acids to about 190 amino acids, about 100 amino acids to about 185 amino acids, about 100 amino acids to about 180 amino acids, about 100 amino acids to about 175 amino acids, about 100 amino acids to about 170 amino acids, about 100 amino acids to about 165 amino acids, about 100 amino acids to about 160 amino acids, about 100 amino acids to about 155 amino acids, about 100 amino acids to about 150 amino acids , about 100 amino acids to about 145 amino acids, about 100 amino acids to about 140 amino acids, about 100 amino acids to about 135 amino acids, about 100 amino acids to about 130 amino acids, about 100 amino acids to about 125 amino acids, about 100 amino acids to about 120 amino acids, about 100 amino acids to about 115 amino acids, about 100 amino acids to about 110 amino acids, about 110 amino acids to about 220 amino acids, about 110 amino acids to about 215 amino acids, about 110 amino acids to about 210 amino acids, about 110 amino acids to about 205 amino acids, about 110 amino acids to about 200 amino acids, about 110 amino acids to about 195 amino acids, about 110 amino acids to about 190 amino acids, about 110 amino acids to about 185 amino acids,
about 110 amino acids to about 180 amino acids, about 110 amino acids to about 175 amino acids, about 110 amino acids to about 170 amino acids, about 110 amino acids to about 165 amino acids, about 110 amino acids to about 160 amino acids, about 110 amino acids to about 155 amino acids, about 110 amino acids to about 150 amino acids, about 110 amino acids to about 145 amino acids, about 110 amino acids to about 140 amino acids, about 110 amino acids to about 135 amino acids, about 110 amino acids to about 130 amino acids, about 110 amino acids to about 125 amino acids, about 110 amino acids to about 120 amino acids, about 110 amino acids to about 115 amino acids, about 115 amino acids to about 220 amino acids, about 115 amino acids to about 215 amino acids, about 115 amino acids to about 210 amino acids, about 115 amino acids to about 205 amino acids, about 115 amino acids to about 200 amino acids amino acids, about 115 amino acids to about 195 amino acids, about 115 amino acids to about 190 amino acids, about 115 amino acids to about 185 amino acids, about 115 amino acids to about 180 amino acids, about 115 amino acids to about 175 amino acids, about 115 amino acids to about 170 amino acids, about 115 amino acids to about 165 amino acids, about 115 amino acids to about 160 amino acids, about 115 amino acids to about 155 amino acids, about 115 amino acids to about 150 amino acids, about 115 amino acids to about 145 amino acids, about 115 amino acids to about 140 amino acids, about 115 amino acids to about 135 amino acids, about 115 amino acids to about 130 amino acids, about 115 amino acids to about 125 amino acids, about 115 amino acids to about 120 amino acids, about 120 amino acids to about 220 amino acids, about 120 amino acids to about 215 amino acids, about 120 amino acids to about 210 amino acids, about 120 amino acids to about 205 amino acids, about 120 amino acids to about 200 amino acids, about 120 amino acids to about 195 amino acids, about 120 amino acids to about 190 amino acids, about 120 amino acids to about 185 amino acids, about 120 amino acids to about 180 amino acids amino acids, about 120 amino acids to about 175 amino acids, about 120 amino acids to about 170 amino acids, about 120 amino acids to about 165 amino acids, about 120 amino acids to about 160 amino acids, about 120 amino acids to about 155 amino acids, about 120 amino acids to about 150 amino acids, about 120 amino acids to about 145 amino acids, about 120 amino acids to about 140 amino acids, about 120 amino acids to about 135 amino acids, about 120 amino acids to about 130 amino acids, about 120 amino acids to about 125 amino acids, about 125 amino acids to about 220 amino acids, about 125 amino acids to about 215 amino acids, about 125 amino acids to about 210 amino acids, about 125 amino acids to about 205 amino acids, about 125 amino acids to about 200 amino acids, about 125 amino acids to about 195 amino acids, about 125 amino acids to about 190 amino acids, about 125 amino acids to about 185 amino acids, about 125 amino acids to about 180 amino acids, about 125 amino acids to about 175 amino acids, about 125 amino acids to about 170 amino acids, about 125 amino acids to about 165 amino acids, about 125 amino acids to about 160 amino acids, about 125 amino acids to about 155 amino acids amino acids, about 125 amino acids to about 150 amino acids, about 125 amino acids to about 145 amino acids, about 125 amino acids to about 140 amino acids, about 125 amino acids to about 135 amino acids, about 125 amino acids to about 130 amino acids, about 130 amino acids to about 220 amino acids, about 130 amino acids to about 215 amino acids, about 130 amino acids to about 210 amino acids, about 130 amino acids to about 205 amino acids, about 130 amino acids to about 200 amino acids, about 130 amino acids to about 195 amino acids, about 130 amino acids to about 190 amino acids, about 130 amino acids to about 185 amino acids, about 130 amino acids to about 180 amino acids, about 130 amino acids to about 175 amino acids, about 130 amino acids to about 170 amino acids, about 130 amino acids to about 165 amino acids, about 130 amino acids to about 160 amino acids, about 130 amino acids to about 155 amino acids, about 130 amino acids to about 150 amino acids, about 130 amino acids to about 145 amino acids, about 130 amino acids to about 140 amino acids, about 130 amino acids to about 135 amino acids, about 135 amino acids to about 220 amino acids, about 135 amino acids to about 215 amino acids amino acids, about 135 amino acids to about 210 amino acids, about 135 amino acids to about 205 amino acids, about 135 amino acids to about 200 amino acids, about 135 amino acids to about 195 amino acids, about 135 amino acids to about 190 amino acids, about 135 amino acids to about 185 amino acids, about 135 amino acids to about 180 amino acids, about 135 amino acids to about 175 amino acids, about 135 amino acids to about 170 amino acids, about 135 amino acids to about 165 amino acids, about 135 amino acids to about 160 amino acids, about 135 amino acids to about 155 amino acids, about 135 amino acids to about 150 amino acids, about 135 amino acids to about 145 amino acids, about 135 amino acids to about 140 amino acids, about 140 amino acids to about 220 amino acids, about 140 amino acids to about 215 amino acids, about 140 amino acids to about 210 amino acids, about 140 amino acids to about 205 amino acids, about 140 amino acids to about 200 amino acids, about 140 amino acids to about 195 amino acids, about 140 amino acids to about 190 amino acids, about 140 amino acids to about 185 amino acids, about 140 amino acids to about 180 amino acids, about 140 amino acids to about 175 amino acids amino acids, about 140 amino acids to about 170 amino acids, about 140 amino acids to about 165 amino acids, about 140 amino acids to about 160 amino acids, about 140 amino acids to about 155 amino acids, about 140 amino acids to about 150 amino acids, about 140 amino acids to about 145 amino acids, about 145 amino acids to about 220 amino acids, about 145 amino acids to about 215 amino acids, about 145 amino acids to about 210 amino acids, about 145 amino acids to about 205 amino acids, about 145 amino acids to about 200 amino acids, about 145 amino acids to about 195 amino acids, about 145 amino acids amino acids to about 190 amino acids, about 145 amino acids to about 185 amino acids, about 145 amino acids to about 180 amino acids, about 145 amino acids to about 175 amino acids, about 145 amino acids to about 170 amino acids, about 145 amino acids to about 165 amino acids, about 145 amino acids to about 160 amino acids, about 145 amino acids to about 155 amino acids, about 145 amino acids to about 150 amino acids, about 150 amino acids to about 220 amino acids, about 150 amino acids to about 215 amino acids, about 150 amino acids to about 210 amino acids, about 150 amino acids to about 205 amino acids amino acids, about 150 amino acids to about 200 amino acids, about 150 amino acids to about 195 amino acids, about 150 amino acids to about 190 amino acids, about 150 amino acids to about 185 amino acids, about 150 amino acids to about 180 amino acids, about 150 amino acids to about 175 amino acids, about 150 amino acids to about 170 amino acids, about 150 amino acids to about 165 amino acids, about 150 amino acids to about 160 amino acids, about 150 amino acids to about 155 amino acids, about 155 amino acids to about 220 amino acids, about 155 amino acids to about 215 amino acids, about 155 amino acids to about 210 amino acids, about 155 amino acids to about 205 amino acids, about 155 amino acids to about 200 amino acids, about 155 amino acids to about 195 amino acids, about 155 amino acids to about 190 amino acids, about 155 amino acids to about 185 amino acids, about 155 amino acids to about 180 amino acids, about 155 amino acids to about 175 amino acids, about 155 amino acids to about 170 amino acids, about 155 amino acids to about 165 amino acids, about 155 amino acids to about 160 amino acids, about 160 amino acids to about 220 amino acids, about 160 amino acids to about 215 amino acids amino acids, about 160 amino acids to about 210 amino acids, about 160 amino acids to about 205 amino acids, about 160 amino acids to about 200 amino acids, about 160 amino acids to about 195 amino acids, about 160 amino acids to about 190 amino acids, about 160 amino acids to about 185 amino acids, about 160 amino acids to about 180 amino acids, about 160 amino acids to about 175 amino acids, about 160 amino acids to about 170 amino acids, about 160 amino acids to about 165 amino acids, about 165 amino acids to about 220 amino acids, about 165 amino acids to about 215 amino acids, about 165 amino acids to about 210 amino acids, about 165 amino acids to about 205 amino acids, about 165 amino acids to about 200 amino acids, about 165 amino acids to about 195 amino acids, about 165 amino acids to about 190 amino acids, about 165 amino acids to about 185 amino acids, about 165 amino acids to about 180 amino acids, about 165 amino acids to about 175 amino acids, about 165 amino acids to about 170 amino acids, about 170 amino acids to about 220 amino acids, about 170 amino acids to about 215 amino acids, about 170 amino acids to about 210 amino acids, about 170 amino acids to about 205 amino acids amino acids, about 170 amino acids to about 200 amino acids, about 170 amino acids to about 195 amino acids, about 170 amino acids to about 190 amino acids, about 170 amino acids to about 185 amino acids, about 170 amino acids to about 180 amino acids, about 170 amino acids to about 175 amino acids, about 175 amino acids to about 220 amino acids, about 175 amino acids to about 215 amino acids, about 175 amino acids to about 210 amino acids, about 175 amino acids to about 205 amino acids, about 175 amino acids to about 200 amino acids, about 175 amino acids to about 195 amino acids, about 175 amino acids to about 190 amino acids, about 175 amino acids to about 185 amino acids, about 175 amino acids to about 180 amino acids, about 180 amino acids to about 220 amino acids, about 180 amino acids to about 215 amino acids, about 180 amino acids to about 210 amino acids, about 180 amino acids to about 205 amino acids, about 180 amino acids to about 200 amino acids, about 180 amino acids to about 195 amino acids, about 180 amino acids to about 190 amino acids, about 180 amino acids to about 185 amino acids, about 185 amino acids to about 220 amino acids, about 185 amino acids to about 215 amino acids amino acids, about 185 amino acids to about 210 amino acids, about 185 amino acids to about 205 amino acids, about 185 amino acids to about 200 amino acids, about 185 amino acids to about 195 amino acids, about 185 amino acids to about 190 amino acids, about 190 amino acids to about 220 amino acids, about 190 amino acids to about 215 amino acids, about 190 amino acids to about 210 amino acids, about 190 amino acids to about 205 amino acids, about 190 amino acids to about 200 amino acids, about 190 amino acids to about 195 amino acids, about 195 amino acids to about 220 amino acids, about 195 amino acids to about 215 amino acids, about 195 amino acids to about 210 amino acids, about 195 amino acids to about 205 amino acids, about 195 amino acids to about 200 amino acids, about 200 amino acids to about 220 amino acids, about 200 amino acids to about 215 amino acids, about 200 amino acids to about 210 amino acids, about 200 amino acids to about 205 amino acids, about 205 amino acids to about 220 amino acids, about 205 amino acids to about 215 amino acids, about 205 amino acids to about 210 amino acids, about 210 amino acids to about 220 amino acids, about 210 amino acids to about 215 amino acids amino acids, or from about 215 amino acids to about 220 amino acids.
リンカー配列
いくつかの実施形態では、リンカー配列は、可動性リンカー配列であり得る。使用され得るリンカー配列の非限定的な例は、Klein et al.,Protein Engineering,Design&Selection27(10):325-330,2014、Priyanka et al.,Protein Sci.22(2):153-167,2013に記載されている。いくつかの例では、リンカー配列は、合成リンカー配列である。
Linker Sequences In some embodiments, a linker sequence can be a flexible linker sequence. Non-limiting examples of linker sequences that can be used are described in Klein et al. , Protein Engineering, Design & Selection 27(10): 325-330, 2014, Priyanka et al. , Protein Sci. 22(2):153-167, 2013. In some examples, the linker sequence is a synthetic linker sequence.
本明細書に記載の一本鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、1、2、3、4、5、6、7、8、9、又は10個のリンカー配列(例えば、同じ又は異なるリンカー配列、例えば、本明細書に記載の又は当該技術分野で既知の例示的なリンカー配列のうちのいずれか)を含み得る。本明細書に記載の一本鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、1、2、3、4、5、6、7、8、9、又は10個のリンカー配列(例えば、同じ又は異なるリンカー配列、例えば、本明細書に記載の又は当該技術分野で既知の例示的なリンカー配列のうちのいずれか)を含み得る。 In some embodiments of any of the single chain chimeric polypeptides described herein, 1, 2, 3, 4, 5, 6, 7, 8, 9, or 10 linker sequences ( For example, they may contain the same or different linker sequences, such as any of the exemplary linker sequences described herein or known in the art. In some embodiments of any of the single chain chimeric polypeptides described herein, 1, 2, 3, 4, 5, 6, 7, 8, 9, or 10 linker sequences ( For example, they may contain the same or different linker sequences, such as any of the exemplary linker sequences described herein or known in the art.
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1のキメラポリペプチドは、1、2、3、4、5、6、7、8、9、又は10個のリンカー配列(例えば、同じ又は異なるリンカー配列、例えば、本明細書に記載の又は当該技術分野で既知の例示的なリンカー配列のうちのいずれか)を含み得る。本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第2のキメラポリペプチドは、1、2、3、4、5、6、7、8、9、又は10個のリンカー配列(例えば、同じ又は異なるリンカー配列、例えば、本明細書に記載の又は当該技術分野で既知の例示的なリンカー配列のうちのいずれか)を含み得る。 In some embodiments of any of the multi-chain chimeric polypeptides described herein, the first chimeric polypeptide is 1, 2, 3, 4, 5, 6, 7, 8, 9, or 10 linker sequences (eg, the same or different linker sequences, eg, any of the exemplary linker sequences described herein or known in the art). In some embodiments of any of the multi-chain chimeric polypeptides described herein, the second chimeric polypeptide is 1, 2, 3, 4, 5, 6, 7, 8, 9, or 10 linker sequences (eg, the same or different linker sequences, eg, any of the exemplary linker sequences described herein or known in the art).
いくつかの実施形態では、リンカー配列は、1アミノ酸~約100アミノ酸、1アミノ酸~約90アミノ酸、1アミノ酸~約80アミノ酸、1アミノ酸~約70アミノ酸、1アミノ酸~約60アミノ酸、1アミノ酸~約50アミノ酸、1アミノ酸~約45アミノ酸、1アミノ酸~約40アミノ酸、1アミノ酸~約35アミノ酸、1アミノ酸~約30アミノ酸、1アミノ酸~約25アミノ酸、1アミノ酸~約24アミノ酸、1アミノ酸~約22アミノ酸、1アミノ酸~約20アミノ酸、1アミノ酸~約18アミノ酸、1アミノ酸~約16アミノ酸、1アミノ酸~約14アミノ酸、1アミノ酸~約12アミノ酸、1アミノ酸~約10アミノ酸、1アミノ酸~約8アミノ酸、1アミノ酸~約6アミノ酸、1アミノ酸~約4アミノ酸、約2アミノ酸~約100アミノ酸、約2アミノ酸~約90アミノ酸、約2アミノ酸~約80アミノ酸、約2アミノ酸~約70アミノ酸、約2アミノ酸~約60アミノ酸、約2アミノ酸~約50アミノ酸、約2アミノ酸~約45アミノ酸、約2アミノ酸~約40アミノ酸、約2アミノ酸~約35アミノ酸、約2アミノ酸~約30アミノ酸、約2アミノ酸~約25アミノ酸、約2アミノ酸~約24アミノ酸、約2アミノ酸~約22アミノ酸、約2アミノ酸~約20アミノ酸、約2アミノ酸~約18アミノ酸、約2アミノ酸~約16アミノ酸、約2アミノ酸~約14アミノ酸、約2アミノ酸~約12アミノ酸、約2アミノ酸~約10アミノ酸、約2アミノ酸~約8アミノ酸、約2アミノ酸~約6アミノ酸、約2アミノ酸~約4アミノ酸、約4アミノ酸~約100アミノ酸、約4アミノ酸~約90アミノ酸、約4アミノ酸~約80アミノ酸、約4アミノ酸~約70アミノ酸、約4アミノ酸~約60アミノ酸、約4アミノ酸~約50アミノ酸、約4アミノ酸~約45アミノ酸、約4アミノ酸~約40アミノ酸、約4アミノ酸~約35アミノ酸、約4アミノ酸~約30アミノ酸、約4アミノ酸~約25アミノ酸、約4アミノ酸~約24アミノ酸、約4アミノ酸~約22アミノ酸、約4アミノ酸~約20アミノ酸、約4アミノ酸~約18アミノ酸、約4アミノ酸~約16アミノ酸、約4アミノ酸~約14アミノ酸、約4アミノ酸~約12アミノ酸、約4アミノ酸~約10アミノ酸、約4アミノ酸~約8アミノ酸、約4アミノ酸~約6アミノ酸、約6アミノ酸~約100アミノ酸、約6アミノ酸~約90アミノ酸、約6アミノ酸~約80アミノ酸、約6アミノ酸~約70アミノ酸、約6アミノ酸~約60アミノ酸、約6アミノ酸~約50アミノ酸、約6アミノ酸~約45アミノ酸、約6アミノ酸~約40アミノ酸、約6アミノ酸~約35アミノ酸、約6アミノ酸~約30アミノ酸、約6アミノ酸~約25アミノ酸、約6アミノ酸~約24アミノ酸、約6アミノ酸~約22アミノ酸、約6アミノ酸~約20アミノ酸、約6アミノ酸~約18アミノ酸、約6アミノ酸~約16アミノ酸、約6アミノ酸~約14アミノ酸、約6アミノ酸~約12アミノ酸、約6アミノ酸~約10アミノ酸、約6アミノ酸~約8アミノ酸、約8アミノ酸~約100アミノ酸、約8アミノ酸~約90アミノ酸、約8アミノ酸~約80アミノ酸、約8アミノ酸~約70アミノ酸、約8アミノ酸~約60アミノ酸、約8アミノ酸~約50アミノ酸、約8アミノ酸~約45アミノ酸、約8アミノ酸~約40アミノ酸、約8アミノ酸~約35アミノ酸、約8アミノ酸~約30アミノ酸、約8アミノ酸~約25アミノ酸、約8アミノ酸~約24アミノ酸、約8アミノ酸~約22アミノ酸、約8アミノ酸~約20アミノ酸、約8アミノ酸~約18アミノ酸、約8アミノ酸~約16アミノ酸、約8アミノ酸~約14アミノ酸、約8アミノ酸~約12アミノ酸、約8アミノ酸~約10アミノ酸、約10アミノ酸~約100アミノ酸、約10アミノ酸~約90アミノ酸、約10アミノ酸~約80アミノ酸、約10アミノ酸~約70アミノ酸、約10アミノ酸~約60アミノ酸、約10アミノ酸~約50アミノ酸、約10アミノ酸~約45アミノ酸、約10アミノ酸~約40アミノ酸、約10アミノ酸~約35アミノ酸、約10アミノ酸~約30アミノ酸、約10アミノ酸~約25アミノ酸、約10アミノ酸~約24アミノ酸、約10アミノ酸~約22アミノ酸、約10アミノ酸~約20アミノ酸、約10アミノ酸~約18アミノ酸、約10アミノ酸~約16アミノ酸、約10アミノ酸~約14アミノ酸、約10アミノ酸~約12アミノ酸、約12アミノ酸~約100アミノ酸、約12アミノ酸~約90アミノ酸、約12アミノ酸~約80アミノ酸、約12アミノ酸~約70アミノ酸、約12アミノ酸~約60アミノ酸、約12アミノ酸~約50アミノ酸、約12アミノ酸~約45アミノ酸、約12アミノ酸~約40アミノ酸、約12アミノ酸~約35アミノ酸、約12アミノ酸~約30アミノ酸、約12アミノ酸~約25アミノ酸、約12アミノ酸~約24アミノ酸、約12アミノ酸~約22アミノ酸、約12アミノ酸~約20アミノ酸、約12アミノ酸~約18アミノ酸、約12アミノ酸~約16アミノ酸、約12アミノ酸~約14アミノ酸、約14アミノ酸~約100アミノ酸、約14アミノ酸~約90アミノ酸、約14アミノ酸~約80アミノ酸、約14アミノ酸~約70アミノ酸、約14アミノ酸~約60アミノ酸、約14アミノ酸~約50アミノ酸、約14アミノ酸~約45アミノ酸、約14アミノ酸~約40アミノ酸、約14アミノ酸~約35アミノ酸、約14アミノ酸~約30アミノ酸、約14アミノ酸~約25アミノ酸、約14アミノ酸~約24アミノ酸、約14アミノ酸~約22アミノ酸、約14アミノ酸~約20アミノ酸、約14アミノ酸~約18アミノ酸、約14アミノ酸~約16アミノ酸、約16アミノ酸~約100アミノ酸、約16アミノ酸~約90アミノ酸、約16アミノ酸~約80アミノ酸、約16アミノ酸~約70アミノ酸、約16アミノ酸~約60アミノ酸、約16アミノ酸~約50アミノ酸、約16アミノ酸~約45アミノ酸、約16アミノ酸~約40アミノ酸、約16アミノ酸~約35アミノ酸、約16アミノ酸~約30アミノ酸、約16アミノ酸~約25アミノ酸、約16アミノ酸~約24アミノ酸、約16アミノ酸~約22アミノ酸、約16アミノ酸~約20アミノ酸、約16アミノ酸~約18アミノ酸、約18アミノ酸~約100アミノ酸、約18アミノ酸~約90アミノ酸、約18アミノ酸~約80アミノ酸、約18アミノ酸~約70アミノ酸、約18アミノ酸~約60アミノ酸、約18アミノ酸~約50アミノ酸、約18アミノ酸~約45アミノ酸、約18アミノ酸~約40アミノ酸、約18アミノ酸~約35アミノ酸、約18アミノ酸~約30アミノ酸、約18アミノ酸~約25アミノ酸、約18アミノ酸~約24アミノ酸、約18アミノ酸~約22アミノ酸、約18アミノ酸~約20アミノ酸、約20アミノ酸~約100アミノ酸、約20アミノ酸~約90アミノ酸、約20アミノ酸~約80アミノ酸、約20アミノ酸~約70アミノ酸、約20アミノ酸~約60アミノ酸、約20アミノ酸~約50アミノ酸、約20アミノ酸~約45アミノ酸、約20アミノ酸~約40アミノ酸、約20アミノ酸~約35アミノ酸、約20アミノ酸~約30アミノ酸、約20アミノ酸~約25アミノ酸、約20アミノ酸~約24アミノ酸、約20アミノ酸~約22アミノ酸、約22アミノ酸~約100アミノ酸、約22アミノ酸~約90アミノ酸、約22アミノ酸~約80アミノ酸、約22アミノ酸~約70アミノ酸、約22アミノ酸~約60アミノ酸、約22アミノ酸~約50アミノ酸、約22アミノ酸~約45アミノ酸、約22アミノ酸~約40アミノ酸、約22アミノ酸~約35アミノ酸、約22アミノ酸~約30アミノ酸、約22アミノ酸~約25アミノ酸、約22アミノ酸~約24アミノ酸、約25アミノ酸~約100アミノ酸、約25アミノ酸~約90アミノ酸、約25アミノ酸~約80アミノ酸、約25アミノ酸~約70アミノ酸、約25アミノ酸~約60アミノ酸、約25アミノ酸~約50アミノ酸、約25アミノ酸~約45アミノ酸、約25アミノ酸~約40アミノ酸、約25アミノ酸~約35アミノ酸、約25アミノ酸~約30アミノ酸、約30アミノ酸~約100アミノ酸、約30アミノ酸~約90アミノ酸、約30アミノ酸~約80アミノ酸、約30アミノ酸~約70アミノ酸、約30アミノ酸~約60アミノ酸、約30アミノ酸~約50アミノ酸、約30アミノ酸~約45アミノ酸、約30アミノ酸~約40アミノ酸、約30アミノ酸~約35アミノ酸、約35アミノ酸~約100アミノ酸、約35アミノ酸~約90アミノ酸、約35アミノ酸~約80アミノ酸、約35アミノ酸~約70アミノ酸、約35アミノ酸~約60アミノ酸、約35アミノ酸~約50アミノ酸、約35アミノ酸~約45アミノ酸、約35アミノ酸~約40アミノ酸、約40アミノ酸~約100アミノ酸、約40アミノ酸~約90アミノ酸、約40アミノ酸~約80アミノ酸、約40アミノ酸~約70アミノ酸、約40アミノ酸~約60アミノ酸、約40アミノ酸~約50アミノ酸、約40アミノ酸~約45アミノ酸、約45アミノ酸~約100アミノ酸、約45アミノ酸~約90アミノ酸、約45アミノ酸~約80アミノ酸、約45アミノ酸~約70アミノ酸、約45アミノ酸~約60アミノ酸、約45アミノ酸~約50アミノ酸、約50アミノ酸~約100アミノ酸、約50アミノ酸~約90アミノ酸、約50アミノ酸~約80アミノ酸、約50アミノ酸~約70アミノ酸、約50アミノ酸~約60アミノ酸、約60アミノ酸~約100アミノ酸、約60アミノ酸~約90アミノ酸、約60アミノ酸~約80アミノ酸、約60アミノ酸~約70アミノ酸、約70アミノ酸~約100アミノ酸、約70アミノ酸~約90アミノ酸、約70アミノ酸~約80アミノ酸、約80アミノ酸~約100アミノ酸、約80アミノ酸~約90アミノ酸、又は約90アミノ酸~約100アミノ酸の全長を有し得る。 In some embodiments, the linker sequence is 1 amino acid to about 100 amino acids, 1 amino acid to about 90 amino acids, 1 amino acid to about 80 amino acids, 1 amino acid to about 70 amino acids, 1 amino acid to about 60 amino acids, 1 amino acid to about 50 amino acids, 1 amino acid to about 45 amino acids, 1 amino acid to about 40 amino acids, 1 amino acid to about 35 amino acids, 1 amino acid to about 30 amino acids, 1 amino acid to about 25 amino acids, 1 amino acid to about 24 amino acids, 1 amino acid to about 22 amino acids amino acids, 1 amino acid to about 20 amino acids, 1 amino acid to about 18 amino acids, 1 amino acid to about 16 amino acids, 1 amino acid to about 14 amino acids, 1 amino acid to about 12 amino acids, 1 amino acid to about 10 amino acids, 1 amino acid to about 8 amino acids , 1 amino acid to about 6 amino acids, 1 amino acid to about 4 amino acids, about 2 amino acids to about 100 amino acids, about 2 amino acids to about 90 amino acids, about 2 amino acids to about 80 amino acids, about 2 amino acids to about 70 amino acids, about 2 amino acids to about 60 amino acids, about 2 amino acids to about 50 amino acids, about 2 amino acids to about 45 amino acids, about 2 amino acids to about 40 amino acids, about 2 amino acids to about 35 amino acids, about 2 amino acids to about 30 amino acids, about 2 amino acids to about 25 amino acids, about 2 amino acids to about 24 amino acids, about 2 amino acids to about 22 amino acids, about 2 amino acids to about 20 amino acids, about 2 amino acids to about 18 amino acids, about 2 amino acids to about 16 amino acids, about 2 amino acids to about 14 amino acids , about 2 amino acids to about 12 amino acids, about 2 amino acids to about 10 amino acids, about 2 amino acids to about 8 amino acids, about 2 amino acids to about 6 amino acids, about 2 amino acids to about 4 amino acids, about 4 amino acids to about 100 amino acids, about 4 amino acids to about 90 amino acids, about 4 amino acids to about 80 amino acids, about 4 amino acids to about 70 amino acids, about 4 amino acids to about 60 amino acids, about 4 amino acids to about 50 amino acids, about 4 amino acids to about 45 amino acids, about 4 amino acids to about 40 amino acids, about 4 amino acids to about 35 amino acids, about 4 amino acids to about 30 amino acids, about 4 amino acids to about 25 amino acids, about 4 amino acids to about 24 amino acids, about 4 amino acids to about 22 amino acids, about 4 amino acids to about 20 amino acids, about 4 amino acids to about 18 amino acids, about 4 amino acids to about 16 amino acids, about 4 amino acids to about 14 amino acids, about 4 amino acids to about 12 amino acids, about 4 amino acids to about 10 amino acids, about 4 amino acids to about 8 amino acids , about 4 amino acids to about 6 amino acids, about 6 amino acids to about 100 amino acids, about 6 amino acids to about 90 amino acids, about 6 amino acids to about 80 amino acids, about 6 amino acids to about 70 amino acids, about 6 amino acids to about 60 amino acids, about 6 amino acids to about 50 amino acids, about 6 amino acids to about 45 amino acids, about 6 amino acids to about 40 amino acids, about 6 amino acids to about 35 amino acids, about 6 amino acids to about 30 amino acids, about 6 amino acids to about 25 amino acids, about 6 amino acids to about 24 amino acids, about 6 amino acids to about 22 amino acids, about 6 amino acids to about 20 amino acids, about 6 amino acids to about 18 amino acids, about 6 amino acids to about 16 amino acids, about 6 amino acids to about 14 amino acids, about 6 amino acids to about 12 amino acids, about 6 amino acids to about 10 amino acids, about 6 amino acids to about 8 amino acids, about 8 amino acids to about 100 amino acids, about 8 amino acids to about 90 amino acids, about 8 amino acids to about 80 amino acids, about 8 amino acids to about 70 amino acids , about 8 amino acids to about 60 amino acids, about 8 amino acids to about 50 amino acids, about 8 amino acids to about 45 amino acids, about 8 amino acids to about 40 amino acids, about 8 amino acids to about 35 amino acids, about 8 amino acids to about 30 amino acids, about 8 amino acids to about 25 amino acids, about 8 amino acids to about 24 amino acids, about 8 amino acids to about 22 amino acids, about 8 amino acids to about 20 amino acids, about 8 amino acids to about 18 amino acids, about 8 amino acids to about 16 amino acids, about 8 amino acids to about 14 amino acids, about 8 amino acids to about 12 amino acids, about 8 amino acids to about 10 amino acids, about 10 amino acids to about 100 amino acids, about 10 amino acids to about 90 amino acids, about 10 amino acids to about 80 amino acids, about 10 amino acids to about 70 amino acids, about 10 amino acids to about 60 amino acids, about 10 amino acids to about 50 amino acids, about 10 amino acids to about 45 amino acids, about 10 amino acids to about 40 amino acids, about 10 amino acids to about 35 amino acids, about 10 amino acids to about 30 amino acids , about 10 amino acids to about 25 amino acids, about 10 amino acids to about 24 amino acids, about 10 amino acids to about 22 amino acids, about 10 amino acids to about 20 amino acids, about 10 amino acids to about 18 amino acids, about 10 amino acids to about 16 amino acids, about 10 amino acids to about 14 amino acids, about 10 amino acids to about 12 amino acids, about 12 amino acids to about 100 amino acids, about 12 amino acids to about 90 amino acids, about 12 amino acids to about 80 amino acids, about 12 amino acids to about 70 amino acids, about 12 amino acids to about 60 amino acids, about 12 amino acids to about 50 amino acids, about 12 amino acids to about 45 amino acids, about 12 amino acids to about 40 amino acids, about 12 amino acids to about 35 amino acids, about 12 amino acids to about 30 amino acids, about 12 amino acids to about 25 amino acids, about 12 amino acids to about 24 amino acids, about 12 amino acids to about 22 amino acids, about 12 amino acids to about 20 amino acids, about 12 amino acids to about 18 amino acids, about 12 amino acids to about 16 amino acids, about 12 amino acids to about 14 amino acids , about 14 amino acids to about 100 amino acids, about 14 amino acids to about 90 amino acids, about 14 amino acids to about 80 amino acids, about 14 amino acids to about 70 amino acids, about 14 amino acids to about 60 amino acids, about 14 amino acids to about 50 amino acids, about 14 amino acids to about 45 amino acids, about 14 amino acids to about 40 amino acids, about 14 amino acids to about 35 amino acids, about 14 amino acids to about 30 amino acids, about 14 amino acids to about 25 amino acids, about 14 amino acids to about 24 amino acids, about 14 amino acids to about 22 amino acids, about 14 amino acids to about 20 amino acids, about 14 amino acids to about 18 amino acids, about 14 amino acids to about 16 amino acids, about 16 amino acids to about 100 amino acids, about 16 amino acids to about 90 amino acids, about 16 amino acids to about 80 amino acids, about 16 amino acids to about 70 amino acids, about 16 amino acids to about 60 amino acids, about 16 amino acids to about 50 amino acids, about 16 amino acids to about 45 amino acids, about 16 amino acids to about 40 amino acids, about 16 amino acids to about 35 amino acids , about 16 amino acids to about 30 amino acids, about 16 amino acids to about 25 amino acids, about 16 amino acids to about 24 amino acids, about 16 amino acids to about 22 amino acids, about 16 amino acids to about 20 amino acids, about 16 amino acids to about 18 amino acids, about 18 amino acids to about 100 amino acids, about 18 amino acids to about 90 amino acids, about 18 amino acids to about 80 amino acids, about 18 amino acids to about 70 amino acids, about 18 amino acids to about 60 amino acids, about 18 amino acids to about 50 amino acids, about 18 amino acids to about 45 amino acids, about 18 amino acids to about 40 amino acids, about 18 amino acids to about 35 amino acids, about 18 amino acids to about 30 amino acids, about 18 amino acids to about 25 amino acids, about 18 amino acids to about 24 amino acids, about 18 amino acids to about 22 amino acids, about 18 amino acids to about 20 amino acids, about 20 amino acids to about 100 amino acids, about 20 amino acids to about 90 amino acids, about 20 amino acids to about 80 amino acids, about 20 amino acids to about 70 amino acids, about 20 amino acids to about 60 amino acids , about 20 amino acids to about 50 amino acids, about 20 amino acids to about 45 amino acids, about 20 amino acids to about 40 amino acids, about 20 amino acids to about 35 amino acids, about 20 amino acids to about 30 amino acids, about 20 amino acids to about 25 amino acids, about 20 amino acids to about 24 amino acids, about 20 amino acids to about 22 amino acids, about 22 amino acids to about 100 amino acids, about 22 amino acids to about 90 amino acids, about 22 amino acids to about 80 amino acids, about 22 amino acids to about 70 amino acids, about 22 amino acids to about 60 amino acids, about 22 amino acids to about 50 amino acids, about 22 amino acids to about 45 amino acids, about 22 amino acids to about 40 amino acids, about 22 amino acids to about 35 amino acids, about 22 amino acids to about 30 amino acids, about 22 amino acids to about 25 amino acids, about 22 amino acids to about 24 amino acids, about 25 amino acids to about 100 amino acids, about 25 amino acids to about 90 amino acids, about 25 amino acids to about 80 amino acids, about 25 amino acids to about 70 amino acids, about 25 amino acids to about 60 amino acids , about 25 amino acids to about 50 amino acids, about 25 amino acids to about 45 amino acids, about 25 amino acids to about 40 amino acids, about 25 amino acids to about 35 amino acids, about 25 amino acids to about 30 amino acids, about 30 amino acids to about 100 amino acids, about 30 amino acids to about 90 amino acids, about 30 amino acids to about 80 amino acids, about 30 amino acids to about 70 amino acids, about 30 amino acids to about 60 amino acids, about 30 amino acids to about 50 amino acids, about 30 amino acids to about 45 amino acids, about 30 amino acids to about 40 amino acids, about 30 amino acids to about 35 amino acids, about 35 amino acids to about 100 amino acids, about 35 amino acids to about 90 amino acids, about 35 amino acids to about 80 amino acids, about 35 amino acids to about 70 amino acids, about 35 amino acids to about 60 amino acids, about 35 amino acids to about 50 amino acids, about 35 amino acids to about 45 amino acids, about 35 amino acids to about 40 amino acids, about 40 amino acids to about 100 amino acids, about 40 amino acids to about 90 amino acids, about 40 amino acids to about 80 amino acids , about 40 amino acids to about 70 amino acids, about 40 amino acids to about 60 amino acids, about 40 amino acids to about 50 amino acids, about 40 amino acids to about 45 amino acids, about 45 amino acids to about 100 amino acids, about 45 amino acids to about 90 amino acids, about 45 amino acids to about 80 amino acids, about 45 amino acids to about 70 amino acids, about 45 amino acids to about 60 amino acids, about 45 amino acids to about 50 amino acids, about 50 amino acids to about 100 amino acids, about 50 amino acids to about 90 amino acids, about 50 amino acids to about 80 amino acids, about 50 amino acids to about 70 amino acids, about 50 amino acids to about 60 amino acids, about 60 amino acids to about 100 amino acids, about 60 amino acids to about 90 amino acids, about 60 amino acids to about 80 amino acids, about 60 amino acids to about 70 amino acids, about 70 amino acids to about 100 amino acids, about 70 amino acids to about 90 amino acids, about 70 amino acids to about 80 amino acids, about 80 amino acids to about 100 amino acids, about 80 amino acids to about 90 amino acids, or about 90 amino acids to about 100 amino acids It can have the full length of amino acids.
いくつかの実施形態では、リンカーは、グリシン(Gly又はG)残基に富む。いくつかの実施形態では、リンカーは、セリン(Ser又はS)残基に富む。いくつかの実施形態では、リンカーは、グリシン残基及びセリン残基に富む。いくつかの実施形態では、リンカーは、1つ以上のグリシン-セリン残基対(GS)、例えば、1、2、3、4、5、6、7、8、9、10、又はそれ以上のGS対を有する。いくつかの実施形態では、リンカーは、1つ以上のGly-Gly-Gly-Ser(GGGS)(配列番号99)配列、例えば、1、2、3、4、5、6、7、8、9、10、又はそれ以上のGGGS(配列番号99)配列を有する。いくつかの実施形態では、リンカーは、1つ以上のGly-Gly-Gly-Gly-Ser(GGGGS)配列、例えば、1、2、3、4、5、6、7、8、9、10、又はそれ以上のGGGGS(配列番号100)配列を有する。いくつかの実施形態では、リンカーは、1つ以上のGly-Gly-Ser-Gly(GGSG)(配列番号101)配列、例えば、1、2、3、4、5、6、7、8、9、10、又はそれ以上のGGSG(配列番号101)配列を有する。いくつかの実施形態では、リンカーは、GGSSRSSSSGGGGSGGGG(配列番号222)を含む。 In some embodiments, the linker is rich in glycine (Gly or G) residues. In some embodiments, the linker is rich in serine (Ser or S) residues. In some embodiments, the linker is rich in glycine and serine residues. In some embodiments, the linker comprises one or more glycine-serine residue pairs (GS), such as 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, or more It has a GS pair. In some embodiments, the linker is one or more Gly-Gly-Gly-Ser (GGGS) (SEQ ID NO:99) sequences, such as 1, 2, 3, 4, 5, 6, 7, 8, 9 , 10, or more GGGS (SEQ ID NO: 99) sequences. In some embodiments, the linker is one or more Gly-Gly-Gly-Gly-Ser (GGGGS) sequences, such as 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, or more GGGGS (SEQ ID NO: 100) sequence. In some embodiments, the linker is one or more Gly-Gly-Ser-Gly (GGSG) (SEQ ID NO: 101) sequences, such as 1, 2, 3, 4, 5, 6, 7, 8, 9 , 10, or more GGSG (SEQ ID NO: 101) sequences. In some embodiments, the linker comprises GGSSRSSSSSGGGGGSGGGG (SEQ ID NO:222).
いくつかの実施形態では、リンカー配列は、GGGGSGGGGSGGGGS(配列番号102)を含み得るか、又はそれからなり得る。いくつかの実施形態では、リンカー配列は、GGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCT(配列番号103)を含むか、又はそれからなる核酸によってコードされ得る。いくつかの実施形態では、リンカー配列は、GGGSGGGS(配列番号104)を含み得るか、又はそれからなり得る。 In some embodiments, the linker sequence may comprise or consist of GGGGSGGGGSGGGGGS (SEQ ID NO: 102). In some embodiments, the linker sequence can be encoded by a nucleic acid comprising or consisting of GGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCT (SEQ ID NO: 103). In some embodiments, the linker sequence can comprise or consist of GGGSGGGS (SEQ ID NO: 104).
標的結合ドメイン
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び/又は追加の1つ以上の標的結合ドメインは、抗原結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な抗原結合ドメインのうちのいずれか)、可溶性インターロイキン又はサイトカインタンパク質(例えば、本明細書に記載の例示的な可溶性インターロイキンタンパク質又は可溶性サイトカインタンパク質のうちのいずれか)、及び可溶性インターロイキン又はサイトカイン受容体(例えば、本明細書に記載の例示的な可溶性インターロイキン受容体又は可溶性サイトカイン受容体のうちのいずれか)であり得る。
Target Binding Domains In some embodiments of any of the multichain chimeric polypeptides described herein, the first target binding domain, the second target binding domain, and/or the additional one or more A target binding domain may be an antigen binding domain (e.g., any of the exemplary antigen binding domains described herein or known in the art), a soluble interleukin or cytokine protein (e.g., any of the exemplary soluble interleukin proteins or soluble cytokine proteins described herein) and a soluble interleukin or cytokine receptor (e.g., an exemplary soluble interleukin receptor or soluble cytokine receptor described herein) ).
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び/又は1つ以上の追加の標的結合ドメインは各々独立して、約5アミノ酸~約1000アミノ酸、約5アミノ酸~約950アミノ酸、約5アミノ酸~約900アミノ酸、約5アミノ酸~約850アミノ酸、約5アミノ酸~約800アミノ酸、約5アミノ酸~約750アミノ酸、約5アミノ酸~約700アミノ酸、約5アミノ酸~約650アミノ酸、約5アミノ酸~約600アミノ酸、約5アミノ酸~約550アミノ酸、約5アミノ酸~約500アミノ酸、約5アミノ酸~約450アミノ酸、約5アミノ酸~約400アミノ酸、約5アミノ酸~約350アミノ酸、約5アミノ酸~約300アミノ酸、約5アミノ酸~約280アミノ酸、約5アミノ酸~約260アミノ酸、約5アミノ酸~約240アミノ酸、約5アミノ酸~約220アミノ酸、約5アミノ酸~約200アミノ酸、約5アミノ酸~約195アミノ酸、約5アミノ酸~約190アミノ酸、約5アミノ酸~約185アミノ酸、約5アミノ酸~約180アミノ酸、約5アミノ酸~約175アミノ酸、約5アミノ酸~約170アミノ酸、約5アミノ酸~約165アミノ酸、約5アミノ酸~約160アミノ酸、約5アミノ酸~約155アミノ酸、約5アミノ酸~約150アミノ酸、約5アミノ酸~約145アミノ酸、約5アミノ酸~約140アミノ酸、約5アミノ酸~約135アミノ酸、約5アミノ酸~約130アミノ酸、約5アミノ酸~約125アミノ酸、約5アミノ酸~約120アミノ酸、約5アミノ酸~約115アミノ酸、約5アミノ酸~約110アミノ酸、約5アミノ酸~約105アミノ酸、約5アミノ酸~約100アミノ酸、約5アミノ酸~約95アミノ酸、約5アミノ酸~約90アミノ酸、約5アミノ酸~約85アミノ酸、約5アミノ酸~約80アミノ酸、約5アミノ酸~約75アミノ酸、約5アミノ酸~約70アミノ酸、約5アミノ酸~約65アミノ酸、約5アミノ酸~約60アミノ酸、約5アミノ酸~約55アミノ酸、約5アミノ酸~約50アミノ酸、約5アミノ酸~約45アミノ酸、約5アミノ酸~約40アミノ酸、約5アミノ酸~約35アミノ酸、約5アミノ酸~約30アミノ酸、約5アミノ酸~約25アミノ酸、約5アミノ酸~約20アミノ酸、約5アミノ酸~約15アミノ酸、約5アミノ酸~約10アミノ酸、約10アミノ酸~約1000アミノ酸、約10アミノ酸~約950アミノ酸、約10アミノ酸~約900アミノ酸、約10アミノ酸~約850アミノ酸、約10アミノ酸~約800アミノ酸、約10アミノ酸~約750アミノ酸、約10アミノ酸~約700アミノ酸、約10アミノ酸~約650アミノ酸、約10アミノ酸~約600アミノ酸、約10アミノ酸~約550アミノ酸、約10アミノ酸~約500アミノ酸、約10アミノ酸~約450アミノ酸、約10アミノ酸~約400アミノ酸、約10アミノ酸~約350アミノ酸、約10アミノ酸~約300アミノ酸、約10アミノ酸~約280アミノ酸、約10アミノ酸~約260アミノ酸、約10アミノ酸~約240アミノ酸、約10アミノ酸~約220アミノ酸、約10アミノ酸~約200アミノ酸、約10アミノ酸~約195アミノ酸、約10アミノ酸~約190アミノ酸、約10アミノ酸~約185アミノ酸、約10アミノ酸~約180アミノ酸、約10アミノ酸~約175アミノ酸、約10アミノ酸~約170アミノ酸、約10アミノ酸~約165アミノ酸、約10アミノ酸~約160アミノ酸、約10アミノ酸~約155アミノ酸、約10アミノ酸~約150アミノ酸、約10アミノ酸~約145アミノ酸、約10アミノ酸~約140アミノ酸、約10アミノ酸~約135アミノ酸、約10アミノ酸~約130アミノ酸、約10アミノ酸~約125アミノ酸、約10アミノ酸~約120アミノ酸、約10アミノ酸~約115アミノ酸、約10アミノ酸~約110アミノ酸、約10アミノ酸~約105アミノ酸、約10アミノ酸~約100アミノ酸、約10アミノ酸~約95アミノ酸、約10アミノ酸~約90アミノ酸、約10アミノ酸~約85アミノ酸、約10アミノ酸~約80アミノ酸、約10アミノ酸~約75アミノ酸、約10アミノ酸~約70アミノ酸、約10アミノ酸~約65アミノ酸、約10アミノ酸~約60アミノ酸、約10アミノ酸~約55アミノ酸、約10アミノ酸~約50アミノ酸、約10アミノ酸~約45アミノ酸、約10アミノ酸~約40アミノ酸、約10アミノ酸~約35アミノ酸、約10アミノ酸~約30アミノ酸、約10アミノ酸~約25アミノ酸、約10アミノ酸~約20アミノ酸、約10アミノ酸~約15アミノ酸、約15アミノ酸~約1000アミノ酸、約15アミノ酸~約950アミノ酸、約15アミノ酸~約900アミノ酸、約15アミノ酸~約850アミノ酸、約15アミノ酸~約800アミノ酸、約15アミノ酸~約750アミノ酸、約15アミノ酸~約700アミノ酸、約15アミノ酸~約650アミノ酸、約15アミノ酸~約600アミノ酸、約15アミノ酸~約550アミノ酸、約15アミノ酸~約500アミノ酸、約15アミノ酸~約450アミノ酸、約15アミノ酸~約400アミノ酸、約15アミノ酸~約350アミノ酸、約15アミノ酸~約300アミノ酸、約15アミノ酸~約280アミノ酸、約15アミノ酸~約260アミノ酸、約15アミノ酸~約240アミノ酸、約15アミノ酸~約220アミノ酸、約15アミノ酸~約200アミノ酸、約15アミノ酸~約195アミノ酸、約15アミノ酸~約190アミノ酸、約15アミノ酸~約185アミノ酸、約15アミノ酸~約180アミノ酸、約15アミノ酸~約175アミノ酸、約15アミノ酸~約170アミノ酸、約15アミノ酸~約165アミノ酸、約15アミノ酸~約160アミノ酸、約15アミノ酸~約155アミノ酸、約15アミノ酸~約150アミノ酸、約15アミノ酸~約145アミノ酸、約15アミノ酸~約140アミノ酸、約15アミノ酸~約135アミノ酸、約15アミノ酸~約130アミノ酸、約15アミノ酸~約125アミノ酸、約15アミノ酸~約120アミノ酸、約15アミノ酸~約115アミノ酸、約15アミノ酸~約110アミノ酸、約15アミノ酸~約105アミノ酸、約15アミノ酸~約100アミノ酸、約15アミノ酸~約95アミノ酸、約15アミノ酸~約90アミノ酸、約15アミノ酸~約85アミノ酸、約15アミノ酸~約80アミノ酸、約15アミノ酸~約75アミノ酸、約15アミノ酸~約70アミノ酸、約15アミノ酸~約65アミノ酸、約15アミノ酸~約60アミノ酸、約15アミノ酸~約55アミノ酸、約15アミノ酸~約50アミノ酸、約15アミノ酸~約45アミノ酸、約15アミノ酸~約40アミノ酸、約15アミノ酸~約35アミノ酸、約15アミノ酸~約30アミノ酸、約15アミノ酸~約25アミノ酸、約15アミノ酸~約20アミノ酸、約20アミノ酸~約1000アミノ酸、約20アミノ酸~約950アミノ酸、約20アミノ酸~約900アミノ酸、約20アミノ酸~約850アミノ酸、約20アミノ酸~約800アミノ酸、約20アミノ酸~約750アミノ酸、約20アミノ酸~約700アミノ酸、約20アミノ酸~約650アミノ酸、約20アミノ酸~約600アミノ酸、約20アミノ酸~約550アミノ酸、約20アミノ酸~約500アミノ酸、約20アミノ酸~約450アミノ酸、約20アミノ酸~約400アミノ酸、約20アミノ酸~約350アミノ酸、約20アミノ酸~約300アミノ酸、約20アミノ酸~約280アミノ酸、約20アミノ酸~約260アミノ酸、約20アミノ酸~約240アミノ酸、約20アミノ酸~約220アミノ酸、約20アミノ酸~約200アミノ酸、約20アミノ酸~約195アミノ酸、約20アミノ酸~約190アミノ酸、約20アミノ酸~約185アミノ酸、約20アミノ酸~約180アミノ酸、約20アミノ酸~約175アミノ酸、約20アミノ酸~約170アミノ酸、約20アミノ酸~約165アミノ酸、約20アミノ酸~約160アミノ酸、約20アミノ酸~約155アミノ酸、約20アミノ酸~約150アミノ酸、約20アミノ酸~約145アミノ酸、約20アミノ酸~約140アミノ酸、約20アミノ酸~約135アミノ酸、約20アミノ酸~約130アミノ酸、約20アミノ酸~約125アミノ酸、約20アミノ酸~約120アミノ酸、約20アミノ酸~約115アミノ酸、約20アミノ酸~約110アミノ酸、約20アミノ酸~約105アミノ酸、約20アミノ酸~約100アミノ酸、約20アミノ酸~約95アミノ酸、約20アミノ酸~約90アミノ酸、約20アミノ酸~約85アミノ酸、約20アミノ酸~約80アミノ酸、約20アミノ酸~約75アミノ酸、約20アミノ酸~約70アミノ酸、約20アミノ酸~約65アミノ酸、約20アミノ酸~約60アミノ酸、約20アミノ酸~約55アミノ酸、約20アミノ酸~約50アミノ酸、約20アミノ酸~約45アミノ酸、約20アミノ酸~約40アミノ酸、約20アミノ酸~約35アミノ酸、約20アミノ酸~約30アミノ酸、約20アミノ酸~約25アミノ酸、約25アミノ酸~約1000アミノ酸、約25アミノ酸~約950アミノ酸、約25アミノ酸~約900アミノ酸、約25アミノ酸~約850アミノ酸、約25アミノ酸~約800アミノ酸、約25アミノ酸~約750アミノ酸、約25アミノ酸~約700アミノ酸、約25アミノ酸~約650アミノ酸、約25アミノ酸~約600アミノ酸、約25アミノ酸~約550アミノ酸、約25アミノ酸~約500アミノ酸、約25アミノ酸~約450アミノ酸、約25アミノ酸~約400アミノ酸、約25アミノ酸~約350アミノ酸、約25アミノ酸~約300アミノ酸、約25アミノ酸~約280アミノ酸、約25アミノ酸~約260アミノ酸、約25アミノ酸~約240アミノ酸、約25アミノ酸~約220アミノ酸、約25アミノ酸~約200アミノ酸、約25アミノ酸~約195アミノ酸、約25アミノ酸~約190アミノ酸、約25アミノ酸~約185アミノ酸、約25アミノ酸~約180アミノ酸、約25アミノ酸~約175アミノ酸、約25アミノ酸~約170アミノ酸、約25アミノ酸~約165アミノ酸、約25アミノ酸~約160アミノ酸、約25アミノ酸~約155アミノ酸、約25アミノ酸~約150アミノ酸、約25アミノ酸~約145アミノ酸、約25アミノ酸~約140アミノ酸、約25アミノ酸~約135アミノ酸、約25アミノ酸~約130アミノ酸、約25アミノ酸~約125アミノ酸、約25アミノ酸~約120アミノ酸、約25アミノ酸~約115アミノ酸、約25アミノ酸~約110アミノ酸、約25アミノ酸~約105アミノ酸、
約25アミノ酸~約100アミノ酸、約25アミノ酸~約95アミノ酸、約25アミノ酸~約90アミノ酸、約25アミノ酸~約85アミノ酸、約25アミノ酸~約80アミノ酸、約25アミノ酸~約75アミノ酸、約25アミノ酸~約70アミノ酸、約25アミノ酸~約65アミノ酸、約25アミノ酸~約60アミノ酸、約25アミノ酸~約55アミノ酸、約25アミノ酸~約50アミノ酸、約25アミノ酸~約45アミノ酸、約25アミノ酸~約40アミノ酸、約25アミノ酸~約35アミノ酸、約25アミノ酸~約30アミノ酸、約30アミノ酸~約1000アミノ酸、約30アミノ酸~約950アミノ酸、約30アミノ酸~約900アミノ酸、約30アミノ酸~約850アミノ酸、約30アミノ酸~約800アミノ酸、約30アミノ酸~約750アミノ酸、約30アミノ酸~約700アミノ酸、約30アミノ酸~約650アミノ酸、約30アミノ酸~約600アミノ酸、約30アミノ酸~約550アミノ酸、約30アミノ酸~約500アミノ酸、約30アミノ酸~約450アミノ酸、約30アミノ酸~約400アミノ酸、約30アミノ酸~約350アミノ酸、約30アミノ酸~約300アミノ酸、約30アミノ酸~約280アミノ酸、約30アミノ酸~約260アミノ酸、約30アミノ酸~約240アミノ酸、約30アミノ酸~約220アミノ酸、約30アミノ酸~約200アミノ酸、約30アミノ酸~約195アミノ酸、約30アミノ酸~約190アミノ酸、約30アミノ酸~約185アミノ酸、約30アミノ酸~約180アミノ酸、約30アミノ酸~約175アミノ酸、約30アミノ酸~約170アミノ酸、約30アミノ酸~約165アミノ酸、約30アミノ酸~約160アミノ酸、約30アミノ酸~約155アミノ酸、約30アミノ酸~約150アミノ酸、約30アミノ酸~約145アミノ酸、約30アミノ酸~約140アミノ酸、約30アミノ酸~約135アミノ酸、約30アミノ酸~約130アミノ酸、約30アミノ酸~約125アミノ酸、約30アミノ酸~約120アミノ酸、約30アミノ酸~約115アミノ酸、約30アミノ酸~約110アミノ酸、約30アミノ酸~約105アミノ酸、約30アミノ酸~約100アミノ酸、約30アミノ酸~約95アミノ酸、約30アミノ酸~約90アミノ酸、約30アミノ酸~約85アミノ酸、約30アミノ酸~約80アミノ酸、約30アミノ酸~約75アミノ酸、約30アミノ酸~約70アミノ酸、約30アミノ酸~約65アミノ酸、約30アミノ酸~約60アミノ酸、約30アミノ酸~約55アミノ酸、約30アミノ酸~約50アミノ酸、約30アミノ酸~約45アミノ酸、約30アミノ酸~約40アミノ酸、約30アミノ酸~約35アミノ酸、約35アミノ酸~約1000アミノ酸、約35アミノ酸~約950アミノ酸、約35アミノ酸~約900アミノ酸、約35アミノ酸~約850アミノ酸、約35アミノ酸~約800アミノ酸、約35アミノ酸~約750アミノ酸、約35アミノ酸~約700アミノ酸、約35アミノ酸~約650アミノ酸、約35アミノ酸~約600アミノ酸、約35アミノ酸~約550アミノ酸、約35アミノ酸~約500アミノ酸、約35アミノ酸~約450アミノ酸、約35アミノ酸~約400アミノ酸、約35アミノ酸~約350アミノ酸、約35アミノ酸~約300アミノ酸、約35アミノ酸~約280アミノ酸、約35アミノ酸~約260アミノ酸、約35アミノ酸~約240アミノ酸、約35アミノ酸~約220アミノ酸、約35アミノ酸~約200アミノ酸、約35アミノ酸~約195アミノ酸、約35アミノ酸~約190アミノ酸、約35アミノ酸~約185アミノ酸、約35アミノ酸~約180アミノ酸、約35アミノ酸~約175アミノ酸、約35アミノ酸~約170アミノ酸、約35アミノ酸~約165アミノ酸、約35アミノ酸~約160アミノ酸、約35アミノ酸~約155アミノ酸、約35アミノ酸~約150アミノ酸、約35アミノ酸~約145アミノ酸、約35アミノ酸~約140アミノ酸、約35アミノ酸~約135アミノ酸、約35アミノ酸~約130アミノ酸、約35アミノ酸~約125アミノ酸、約35アミノ酸~約120アミノ酸、約35アミノ酸~約115アミノ酸、約35アミノ酸~約110アミノ酸、約35アミノ酸~約105アミノ酸、約35アミノ酸~約100アミノ酸、約35アミノ酸~約95アミノ酸、約35アミノ酸~約90アミノ酸、約35アミノ酸~約85アミノ酸、約35アミノ酸~約80アミノ酸、約35アミノ酸~約75アミノ酸、約35アミノ酸~約70アミノ酸、約35アミノ酸~約65アミノ酸、約35アミノ酸~約60アミノ酸、約35アミノ酸~約55アミノ酸、約35アミノ酸~約50アミノ酸、約35アミノ酸~約45アミノ酸、約35アミノ酸~約40アミノ酸、約40アミノ酸~約1000アミノ酸、約40アミノ酸~約950アミノ酸、約40アミノ酸~約900アミノ酸、約40アミノ酸~約850アミノ酸、約40アミノ酸~約800アミノ酸、約40アミノ酸~約750アミノ酸、約40アミノ酸~約700アミノ酸、約40アミノ酸~約650アミノ酸、約40アミノ酸~約600アミノ酸、約40アミノ酸~約550アミノ酸、約40アミノ酸~約500アミノ酸、約40アミノ酸~約450アミノ酸、約40アミノ酸~約400アミノ酸、約40アミノ酸~約350アミノ酸、約40アミノ酸~約300アミノ酸、約40アミノ酸~約280アミノ酸、約40アミノ酸~約260アミノ酸、約40アミノ酸~約240アミノ酸、約40アミノ酸~約220アミノ酸、約40アミノ酸~約200アミノ酸、約40アミノ酸~約195アミノ酸、約40アミノ酸~約190アミノ酸、約40アミノ酸~約185アミノ酸、約40アミノ酸~約180アミノ酸、約40アミノ酸~約175アミノ酸、約40アミノ酸~約170アミノ酸、約40アミノ酸~約165アミノ酸、約40アミノ酸~約160アミノ酸、約40アミノ酸~約155アミノ酸、約40アミノ酸~約150アミノ酸、約40アミノ酸~約145アミノ酸、約40アミノ酸~約140アミノ酸、約40アミノ酸~約135アミノ酸、約40アミノ酸~約130アミノ酸、約40アミノ酸~約125アミノ酸、約40アミノ酸~約120アミノ酸、約40アミノ酸~約115アミノ酸、約40アミノ酸~約110アミノ酸、約40アミノ酸~約105アミノ酸、約40アミノ酸~約100アミノ酸、約40アミノ酸~約95アミノ酸、約40アミノ酸~約90アミノ酸、約40アミノ酸~約85アミノ酸、約40アミノ酸~約80アミノ酸、約40アミノ酸~約75アミノ酸、約40アミノ酸~約70アミノ酸、約40アミノ酸~約65アミノ酸、約40アミノ酸~約60アミノ酸、約40アミノ酸~約55アミノ酸、約40アミノ酸~約50アミノ酸、約40アミノ酸~約45アミノ酸、約45アミノ酸~約1000アミノ酸、約45アミノ酸~約950アミノ酸、約45アミノ酸~約900アミノ酸、約45アミノ酸~約850アミノ酸、約45アミノ酸~約800アミノ酸、約45アミノ酸~約750アミノ酸、約45アミノ酸~約700アミノ酸、約45アミノ酸~約650アミノ酸、約45アミノ酸~約600アミノ酸、約45アミノ酸~約550アミノ酸、約45アミノ酸~約500アミノ酸、約45アミノ酸~約450アミノ酸、約45アミノ酸~約400アミノ酸、約45アミノ酸~約350アミノ酸、約45アミノ酸~約300アミノ酸、約45アミノ酸~約280アミノ酸、約45アミノ酸~約260アミノ酸、約45アミノ酸~約240アミノ酸、約45アミノ酸~約220アミノ酸、約45アミノ酸~約200アミノ酸、約45アミノ酸~約195アミノ酸、約45アミノ酸~約190アミノ酸、約45アミノ酸~約185アミノ酸、約45アミノ酸~約180アミノ酸、約45アミノ酸~約175アミノ酸、約45アミノ酸~約170アミノ酸、約45アミノ酸~約165アミノ酸、約45アミノ酸~約160アミノ酸、約45アミノ酸~約155アミノ酸、約45アミノ酸~約150アミノ酸、約45アミノ酸~約145アミノ酸、約45アミノ酸~約140アミノ酸、約45アミノ酸~約135アミノ酸、約45アミノ酸~約130アミノ酸、約45アミノ酸~約125アミノ酸、約45アミノ酸~約120アミノ酸、約45アミノ酸~約115アミノ酸、約45アミノ酸~約110アミノ酸、約45アミノ酸~約105アミノ酸、約45アミノ酸~約100アミノ酸、約45アミノ酸~約95アミノ酸、約45アミノ酸~約90アミノ酸、約45アミノ酸~約85アミノ酸、約45アミノ酸~約80アミノ酸、約45アミノ酸~約75アミノ酸、約45アミノ酸~約70アミノ酸、約45アミノ酸~約65アミノ酸、約45アミノ酸~約60アミノ酸、約45アミノ酸~約55アミノ酸、約45アミノ酸~約50アミノ酸、約50アミノ酸~約1000アミノ酸、約50アミノ酸~約950アミノ酸、約50アミノ酸~約900アミノ酸、約50アミノ酸~約850アミノ酸、約50アミノ酸~約800アミノ酸、約50アミノ酸~約750アミノ酸、約50アミノ酸~約700アミノ酸、約50アミノ酸~約650アミノ酸、約50アミノ酸~約600アミノ酸、約50アミノ酸~約550アミノ酸、約50アミノ酸~約500アミノ酸、約50アミノ酸~約450アミノ酸、約50アミノ酸~約400アミノ酸、約50アミノ酸~約350アミノ酸、約50アミノ酸~約300アミノ酸、約50アミノ酸~約280アミノ酸、約50アミノ酸~約260アミノ酸、約50アミノ酸~約240アミノ酸、約50アミノ酸~約220アミノ酸、約50アミノ酸~約200アミノ酸、約50アミノ酸~約195アミノ酸、約50アミノ酸~約190アミノ酸、約50アミノ酸~約185アミノ酸、約50アミノ酸~約180アミノ酸、約50アミノ酸~約175アミノ酸、約50アミノ酸~約170アミノ酸、約50アミノ酸~約165アミノ酸、約50アミノ酸~約160アミノ酸、約50アミノ酸~約155アミノ酸、約50アミノ酸~約150アミノ酸、約50アミノ酸~約145アミノ酸、約50アミノ酸~約140アミノ酸、約50アミノ酸~約135アミノ酸、約50アミノ酸~約130アミノ酸、約50アミノ酸~約125アミノ酸、約50アミノ酸~約120アミノ酸、約50アミノ酸~約115アミノ酸、約50アミノ酸~約110アミノ酸、約50アミノ酸~約105アミノ酸、約50アミノ酸~約100アミノ酸、約50アミノ酸~約95アミノ酸、約50アミノ酸~約90アミノ酸、約50アミノ酸~約85アミノ酸、約50アミノ酸~約80アミノ酸、約50アミノ酸~約75アミノ酸、約50アミノ酸~約70アミノ酸、約50アミノ酸~約65アミノ酸、約50アミノ酸~約60アミノ酸、約50アミノ酸~約55アミノ酸、約55アミノ酸~約1000アミノ酸、約55アミノ酸~約950アミノ酸、約55アミノ酸~約900アミノ酸、約55アミノ酸~約850アミノ酸、約55アミノ酸~約800アミノ酸、約55アミノ酸~約750アミノ酸、約55アミノ酸~約700アミノ酸、約55アミノ酸~約650アミノ酸、約55アミノ酸~約600アミノ酸、
約55アミノ酸~約550アミノ酸、約55アミノ酸~約500アミノ酸、約55アミノ酸~約450アミノ酸、約55アミノ酸~約400アミノ酸、約55アミノ酸~約350アミノ酸、約55アミノ酸~約300アミノ酸、約55アミノ酸~約280アミノ酸、約55アミノ酸~約260アミノ酸、約55アミノ酸~約240アミノ酸、約55アミノ酸~約220アミノ酸、約55アミノ酸~約200アミノ酸、約55アミノ酸~約195アミノ酸、約55アミノ酸~約190アミノ酸、約55アミノ酸~約185アミノ酸、約55アミノ酸~約180アミノ酸、約55アミノ酸~約175アミノ酸、約55アミノ酸~約170アミノ酸、約55アミノ酸~約165アミノ酸、約55アミノ酸~約160アミノ酸、約55アミノ酸~約155アミノ酸、約55アミノ酸~約150アミノ酸、約55アミノ酸~約145アミノ酸、約55アミノ酸~約140アミノ酸、約55アミノ酸~約135アミノ酸、約55アミノ酸~約130アミノ酸、約55アミノ酸~約125アミノ酸、約55アミノ酸~約120アミノ酸、約55アミノ酸~約115アミノ酸、約55アミノ酸~約110アミノ酸、約55アミノ酸~約105アミノ酸、約55アミノ酸~約100アミノ酸、約55アミノ酸~約95アミノ酸、約55アミノ酸~約90アミノ酸、約55アミノ酸~約85アミノ酸、約55アミノ酸~約80アミノ酸、約55アミノ酸~約75アミノ酸、約55アミノ酸~約70アミノ酸、約55アミノ酸~約65アミノ酸、約55アミノ酸~約60アミノ酸、約60アミノ酸~約1000アミノ酸、約60アミノ酸~約950アミノ酸、約60アミノ酸~約900アミノ酸、約60アミノ酸~約850アミノ酸、約60アミノ酸~約800アミノ酸、約60アミノ酸~約750アミノ酸、約60アミノ酸~約700アミノ酸、約60アミノ酸~約650アミノ酸、約60アミノ酸~約600アミノ酸、約60アミノ酸~約550アミノ酸、約60アミノ酸~約500アミノ酸、約60アミノ酸~約450アミノ酸、約60アミノ酸~約400アミノ酸、約60アミノ酸~約350アミノ酸、約60アミノ酸~約300アミノ酸、約60アミノ酸~約280アミノ酸、約60アミノ酸~約260アミノ酸、約60アミノ酸~約240アミノ酸、約60アミノ酸~約220アミノ酸、約60アミノ酸~約200アミノ酸、約60アミノ酸~約195アミノ酸、約60アミノ酸~約190アミノ酸、約60アミノ酸~約185アミノ酸、約60アミノ酸~約180アミノ酸、約60アミノ酸~約175アミノ酸、約60アミノ酸~約170アミノ酸、約60アミノ酸~約165アミノ酸、約60アミノ酸~約160アミノ酸、約60アミノ酸~約155アミノ酸、約60アミノ酸~約150アミノ酸、約60アミノ酸~約145アミノ酸、約60アミノ酸~約140アミノ酸、約60アミノ酸~約135アミノ酸、約60アミノ酸~約130アミノ酸、約60アミノ酸~約125アミノ酸、約60アミノ酸~約120アミノ酸、約60アミノ酸~約115アミノ酸、約60アミノ酸~約110アミノ酸、約60アミノ酸~約105アミノ酸、約60アミノ酸~約100アミノ酸、約60アミノ酸~約95アミノ酸、約60アミノ酸~約90アミノ酸、約60アミノ酸~約85アミノ酸、約60アミノ酸~約80アミノ酸、約60アミノ酸~約75アミノ酸、約60アミノ酸~約70アミノ酸、約60アミノ酸~約65アミノ酸、約65アミノ酸~約1000アミノ酸、約65アミノ酸~約950アミノ酸、約65アミノ酸~約900アミノ酸、約65アミノ酸~約850アミノ酸、約65アミノ酸~約800アミノ酸、約65アミノ酸~約750アミノ酸、約65アミノ酸~約700アミノ酸、約65アミノ酸~約650アミノ酸、約65アミノ酸~約600アミノ酸、約65アミノ酸~約550アミノ酸、約65アミノ酸~約500アミノ酸、約65アミノ酸~約450アミノ酸、約65アミノ酸~約400アミノ酸、約65アミノ酸~約350アミノ酸、約65アミノ酸~約300アミノ酸、約65アミノ酸~約280アミノ酸、約65アミノ酸~約260アミノ酸、約65アミノ酸~約240アミノ酸、約65アミノ酸~約220アミノ酸、約65アミノ酸~約200アミノ酸、約65アミノ酸~約195アミノ酸、約65アミノ酸~約190アミノ酸、約65アミノ酸~約185アミノ酸、約65アミノ酸~約180アミノ酸、約65アミノ酸~約175アミノ酸、約65アミノ酸~約170アミノ酸、約65アミノ酸~約165アミノ酸、約65アミノ酸~約160アミノ酸、約65アミノ酸~約155アミノ酸、約65アミノ酸~約150アミノ酸、約65アミノ酸~約145アミノ酸、約65アミノ酸~約140アミノ酸、約65アミノ酸~約135アミノ酸、約65アミノ酸~約130アミノ酸、約65アミノ酸~約125アミノ酸、約65アミノ酸~約120アミノ酸、約65アミノ酸~約115アミノ酸、約65アミノ酸~約110アミノ酸、約65アミノ酸~約105アミノ酸、約65アミノ酸~約100アミノ酸、約65アミノ酸~約95アミノ酸、約65アミノ酸~約90アミノ酸、約65アミノ酸~約85アミノ酸、約65アミノ酸~約80アミノ酸、約65アミノ酸~約75アミノ酸、約65アミノ酸~約70アミノ酸、約70アミノ酸~約1000アミノ酸、約70アミノ酸~約950アミノ酸、約70アミノ酸~約900アミノ酸、約70アミノ酸~約850アミノ酸、約70アミノ酸~約800アミノ酸、約70アミノ酸~約750アミノ酸、約70アミノ酸~約700アミノ酸、約70アミノ酸~約650アミノ酸、約70アミノ酸~約600アミノ酸、約70アミノ酸~約550アミノ酸、約70アミノ酸~約500アミノ酸、約70アミノ酸~約450アミノ酸、約70アミノ酸~約400アミノ酸、約70アミノ酸~約350アミノ酸、約70アミノ酸~約300アミノ酸、約70アミノ酸~約280アミノ酸、約70アミノ酸~約260アミノ酸、約70アミノ酸~約240アミノ酸、約70アミノ酸~約220アミノ酸、約70アミノ酸~約200アミノ酸、約70アミノ酸~約195アミノ酸、約70アミノ酸~約190アミノ酸、約70アミノ酸~約185アミノ酸、約70アミノ酸~約180アミノ酸、約70アミノ酸~約175アミノ酸、約70アミノ酸~約170アミノ酸、約70アミノ酸~約165アミノ酸、約70アミノ酸~約160アミノ酸、約70アミノ酸~約155アミノ酸、約70アミノ酸~約150アミノ酸、約70アミノ酸~約145アミノ酸、約70アミノ酸~約140アミノ酸、約70アミノ酸~約135アミノ酸、約70アミノ酸~約130アミノ酸、約70アミノ酸~約125アミノ酸、約70アミノ酸~約120アミノ酸、約70アミノ酸~約115アミノ酸、約70アミノ酸~約110アミノ酸、約70アミノ酸~約105アミノ酸、約70アミノ酸~約100アミノ酸、約70アミノ酸~約95アミノ酸、約70アミノ酸~約90アミノ酸、約70アミノ酸~約85アミノ酸、約70アミノ酸~約80アミノ酸、約70アミノ酸~約75アミノ酸、約75アミノ酸~約1000アミノ酸、約75アミノ酸~約950アミノ酸、約75アミノ酸~約900アミノ酸、約75アミノ酸~約850アミノ酸、約75アミノ酸~約800アミノ酸、約75アミノ酸~約750アミノ酸、約75アミノ酸~約700アミノ酸、約75アミノ酸~約650アミノ酸、約75アミノ酸~約600アミノ酸、約75アミノ酸~約550アミノ酸、約75アミノ酸~約500アミノ酸、約75アミノ酸~約450アミノ酸、約75アミノ酸~約400アミノ酸、約75アミノ酸~約350アミノ酸、約75アミノ酸~約300アミノ酸、約75アミノ酸~約280アミノ酸、約75アミノ酸~約260アミノ酸、約75アミノ酸~約240アミノ酸、約75アミノ酸~約220アミノ酸、約75アミノ酸~約200アミノ酸、約75アミノ酸~約195アミノ酸、約75アミノ酸~約190アミノ酸、約75アミノ酸~約185アミノ酸、約75アミノ酸~約180アミノ酸、約75アミノ酸~約175アミノ酸、約75アミノ酸~約170アミノ酸、約75アミノ酸~約165アミノ酸、約75アミノ酸~約160アミノ酸、約75アミノ酸~約155アミノ酸、約75アミノ酸~約150アミノ酸、約75アミノ酸~約145アミノ酸、約75アミノ酸~約140アミノ酸、約75アミノ酸~約135アミノ酸、約75アミノ酸~約130アミノ酸、約75アミノ酸~約125アミノ酸、約75アミノ酸~約120アミノ酸、約75アミノ酸~約115アミノ酸、約75アミノ酸~約110アミノ酸、約75アミノ酸~約105アミノ酸、約75アミノ酸~約100アミノ酸、約75アミノ酸~約95アミノ酸、約75アミノ酸~約90アミノ酸、約75アミノ酸~約85アミノ酸、約75アミノ酸~約80アミノ酸、約80アミノ酸~約1000アミノ酸、約80アミノ酸~約950アミノ酸、約80アミノ酸~約900アミノ酸、約80アミノ酸~約850アミノ酸、約80アミノ酸~約800アミノ酸、約80アミノ酸~約750アミノ酸、約80アミノ酸~約700アミノ酸、約80アミノ酸~約650アミノ酸、約80アミノ酸~約600アミノ酸、約80アミノ酸~約550アミノ酸、約80アミノ酸~約500アミノ酸、約80アミノ酸~約450アミノ酸、約80アミノ酸~約400アミノ酸、約80アミノ酸~約350アミノ酸、約80アミノ酸~約300アミノ酸、約80アミノ酸~約280アミノ酸、約80アミノ酸~約260アミノ酸、約80アミノ酸~約240アミノ酸、約80アミノ酸~約220アミノ酸、約80アミノ酸~約200アミノ酸、約80アミノ酸~約195アミノ酸、約80アミノ酸~約190アミノ酸、約80アミノ酸~約185アミノ酸、約80アミノ酸~約180アミノ酸、約80アミノ酸~約175アミノ酸、約80アミノ酸~約170アミノ酸、約80アミノ酸~約165アミノ酸、約80アミノ酸~約160アミノ酸、約80アミノ酸~約155アミノ酸、約80アミノ酸~約150アミノ酸、約80アミノ酸~約145アミノ酸、約80アミノ酸~約140アミノ酸、約80アミノ酸~約135アミノ酸、約80アミノ酸~約130アミノ酸、約80アミノ酸~約125アミノ酸、約80アミノ酸~約120アミノ酸、約80アミノ酸~約115アミノ酸、約80アミノ酸~約110アミノ酸、約80アミノ酸~約105アミノ酸、約80アミノ酸~約100アミノ酸、約80アミノ酸~約95アミノ酸、約80アミノ酸~約90アミノ酸、約80アミノ酸~約85アミノ酸、約85アミノ酸~約1000アミノ酸、約85アミノ酸~約950アミノ酸、約85アミノ酸~約900アミノ酸、約85アミノ酸~約850アミノ酸、約85アミノ酸~約800アミノ酸、約85アミノ酸~約750アミノ酸、約85アミノ酸~約700アミノ酸、約85アミノ酸~約650アミノ酸、約85アミノ酸~約600アミノ酸、約85アミノ酸~約550アミノ酸、約85アミノ酸~約500アミノ酸、約85アミノ酸~約450アミノ酸、約85アミノ酸~約400アミノ酸、約85アミノ酸~約350アミノ酸、約85アミノ酸~約300アミノ酸、約85アミノ酸~約280アミノ酸、約85アミノ酸~約260アミノ酸、約85アミノ酸~約240アミノ酸、約85アミノ酸~約220アミノ酸、約85アミノ酸~約200アミノ酸、約85アミノ酸~約195アミノ酸、約85アミノ酸~約190アミノ酸、約85アミノ酸~約185アミノ酸、約85アミノ酸~約180アミノ酸、約85アミノ酸~約175アミノ酸、約85アミノ酸~約170アミノ酸、約85アミノ酸~約165アミノ酸、
約85アミノ酸~約160アミノ酸、約85アミノ酸~約155アミノ酸、約85アミノ酸~約150アミノ酸、約85アミノ酸~約145アミノ酸、約85アミノ酸~約140アミノ酸、約85アミノ酸~約135アミノ酸、約85アミノ酸~約130アミノ酸、約85アミノ酸~約125アミノ酸、約85アミノ酸~約120アミノ酸、約85アミノ酸~約115アミノ酸、約85アミノ酸~約110アミノ酸、約85アミノ酸~約105アミノ酸、約85アミノ酸~約100アミノ酸、約85アミノ酸~約95アミノ酸、約85アミノ酸~約90アミノ酸、約90アミノ酸~約1000アミノ酸、約90アミノ酸~約950アミノ酸、約90アミノ酸~約900アミノ酸、約90アミノ酸~約850アミノ酸、約90アミノ酸~約800アミノ酸、約90アミノ酸~約750アミノ酸、約90アミノ酸~約700アミノ酸、約90アミノ酸~約650アミノ酸、約90アミノ酸~約600アミノ酸、約90アミノ酸~約550アミノ酸、約90アミノ酸~約500アミノ酸、約90アミノ酸~約450アミノ酸、約90アミノ酸~約400アミノ酸、約90アミノ酸~約350アミノ酸、約90アミノ酸~約300アミノ酸、約90アミノ酸~約280アミノ酸、約90アミノ酸~約260アミノ酸、約90アミノ酸~約240アミノ酸、約90アミノ酸~約220アミノ酸、約90アミノ酸~約200アミノ酸、約90アミノ酸~195アミノ酸、約90アミノ酸~約190アミノ酸、約90アミノ酸~約185アミノ酸、約90アミノ酸~約180アミノ酸、約90アミノ酸~約175アミノ酸、約90アミノ酸~約170アミノ酸、約90アミノ酸~約165アミノ酸、約90アミノ酸~約160アミノ酸、約90アミノ酸~約155アミノ酸、約90アミノ酸~約150アミノ酸、約90アミノ酸~約145アミノ酸、約90アミノ酸~約140アミノ酸、約90アミノ酸~約135アミノ酸、約90アミノ酸~約130アミノ酸、約90アミノ酸~約125アミノ酸、約90アミノ酸~約120アミノ酸、約90アミノ酸~約115アミノ酸、約90アミノ酸~約110アミノ酸、約90アミノ酸~約105アミノ酸、約90アミノ酸~約100アミノ酸、約90アミノ酸~約95アミノ酸、約95アミノ酸~約1000アミノ酸、約95アミノ酸~約950アミノ酸、約95アミノ酸~約900アミノ酸、約95アミノ酸~約850アミノ酸、約95アミノ酸~約800アミノ酸、約95アミノ酸~約750アミノ酸、約95アミノ酸~約700アミノ酸、約95アミノ酸~約650アミノ酸、約95アミノ酸~約600アミノ酸、約95アミノ酸~約550アミノ酸、約95アミノ酸~約500アミノ酸、約95アミノ酸~約450アミノ酸、約95アミノ酸~約400アミノ酸、約95アミノ酸~約350アミノ酸、約95アミノ酸~約300アミノ酸、約95アミノ酸~約280アミノ酸、約95アミノ酸~約260アミノ酸、約95アミノ酸~約240アミノ酸、約95アミノ酸~約220アミノ酸、約95アミノ酸~約200アミノ酸、約95アミノ酸~約195アミノ酸、約95アミノ酸~約190アミノ酸、約95アミノ酸~約185アミノ酸、約95アミノ酸~約180アミノ酸、約95アミノ酸~約175アミノ酸、約95アミノ酸~約170アミノ酸、約95アミノ酸~約165アミノ酸、約95アミノ酸~約160アミノ酸、約95アミノ酸~約155アミノ酸、約95アミノ酸~約150アミノ酸、約95アミノ酸~約145アミノ酸、約95アミノ酸~約140アミノ酸、約95アミノ酸~約135アミノ酸、約95アミノ酸~約130アミノ酸、約95アミノ酸~約125アミノ酸、約95アミノ酸~約120アミノ酸、約95アミノ酸~約115アミノ酸、約95アミノ酸~約110アミノ酸、約95アミノ酸~約105アミノ酸、約95アミノ酸~約100アミノ酸、約100アミノ酸~約1000アミノ酸、約100アミノ酸~約950アミノ酸、約100アミノ酸~約900アミノ酸、約100アミノ酸~約850アミノ酸、約100アミノ酸~約800アミノ酸、約100アミノ酸~約750アミノ酸、約100アミノ酸~約700アミノ酸、約100アミノ酸~約650アミノ酸、約100アミノ酸~約600アミノ酸、約100アミノ酸~約550アミノ酸、約100アミノ酸~約500アミノ酸、約100アミノ酸~約450アミノ酸、約100アミノ酸~約400アミノ酸、約100アミノ酸~約350アミノ酸、約100アミノ酸~約300アミノ酸、約100アミノ酸~約280アミノ酸、約100アミノ酸~約260アミノ酸、約100アミノ酸~約240アミノ酸、約100アミノ酸~約220アミノ酸、約100アミノ酸~約200アミノ酸、約100アミノ酸~約195アミノ酸、約100アミノ酸~約190アミノ酸、約100アミノ酸~約185アミノ酸、約100アミノ酸~約180アミノ酸、約100アミノ酸~約175アミノ酸、約100アミノ酸~約170アミノ酸、約100アミノ酸~約165アミノ酸、約100アミノ酸~約160アミノ酸、約100アミノ酸~約155アミノ酸、約100アミノ酸~約150アミノ酸、約100アミノ酸~約145アミノ酸、約100アミノ酸~約140アミノ酸、約100アミノ酸~約135アミノ酸、約100アミノ酸~約130アミノ酸、約100アミノ酸~約125アミノ酸、約100アミノ酸~約120アミノ酸、約100アミノ酸~約115アミノ酸、約100アミノ酸~約110アミノ酸、約100アミノ酸~約105アミノ酸、約105アミノ酸~約1000アミノ酸、約105アミノ酸~約950アミノ酸、約105アミノ酸~約900アミノ酸、約105アミノ酸~約850アミノ酸、約105アミノ酸~約800アミノ酸、約105アミノ酸~約750アミノ酸、約105アミノ酸~約700アミノ酸、約105アミノ酸~約650アミノ酸、約105アミノ酸~約600アミノ酸、約105アミノ酸~約550アミノ酸、約105アミノ酸~約500アミノ酸、約105アミノ酸~約450アミノ酸、約105アミノ酸~約400アミノ酸、約105アミノ酸~約350アミノ酸、約105アミノ酸~約300アミノ酸、約105アミノ酸~約280アミノ酸、約105アミノ酸~約260アミノ酸、約105アミノ酸~約240アミノ酸、約105アミノ酸~約220アミノ酸、約105アミノ酸~約200アミノ酸、約105アミノ酸~約195アミノ酸、約105アミノ酸~約190アミノ酸、約105アミノ酸~約185アミノ酸、約105アミノ酸~約180アミノ酸、約105アミノ酸~約175アミノ酸、約105アミノ酸~約170アミノ酸、約105アミノ酸~約165アミノ酸、約105アミノ酸~約160アミノ酸、約105アミノ酸~約155アミノ酸、約105アミノ酸~約150アミノ酸、約105アミノ酸~約145アミノ酸、約105アミノ酸~約140アミノ酸、約105アミノ酸~約135アミノ酸、約105アミノ酸~約130アミノ酸、約105アミノ酸~約125アミノ酸、約105アミノ酸~約120アミノ酸、約105アミノ酸~約115アミノ酸、約105アミノ酸~約110アミノ酸、約110アミノ酸~約1000アミノ酸、約110アミノ酸~約950アミノ酸、約110アミノ酸~約900アミノ酸、約110アミノ酸~約850アミノ酸、約110アミノ酸~約800アミノ酸、約110アミノ酸~約750アミノ酸、約110アミノ酸~約700アミノ酸、約110アミノ酸~約650アミノ酸、約110アミノ酸~約600アミノ酸、約110アミノ酸~約550アミノ酸、約110アミノ酸~約500アミノ酸、約110アミノ酸~約450アミノ酸、約110アミノ酸~約400アミノ酸、約110アミノ酸~約350アミノ酸、約110アミノ酸~約300アミノ酸、約110アミノ酸~約280アミノ酸、約110アミノ酸~約260アミノ酸、約110アミノ酸~約240アミノ酸、約110アミノ酸~約220アミノ酸、約110アミノ酸~約200アミノ酸、約110アミノ酸~約195アミノ酸、約110アミノ酸~約190アミノ酸、約110アミノ酸~約185アミノ酸、約110アミノ酸~約180アミノ酸、約110アミノ酸~約175アミノ酸、約110アミノ酸~約170アミノ酸、約110アミノ酸~約165アミノ酸、約110アミノ酸~約160アミノ酸、約110アミノ酸~約155アミノ酸、約110アミノ酸~約150アミノ酸、約110アミノ酸~約145アミノ酸、約110アミノ酸~約140アミノ酸、約110アミノ酸~約135アミノ酸、約110アミノ酸~約130アミノ酸、約110アミノ酸~約125アミノ酸、約110アミノ酸~約120アミノ酸、約110アミノ酸~約115アミノ酸、約115アミノ酸~約1000アミノ酸、約115アミノ酸~約950アミノ酸、約115アミノ酸~約900アミノ酸、約115アミノ酸~約850アミノ酸、約115アミノ酸~約800アミノ酸、約115アミノ酸~約750アミノ酸、約115アミノ酸~約700アミノ酸、約115アミノ酸~約650アミノ酸、約115アミノ酸~約600アミノ酸、約115アミノ酸~約550アミノ酸、約115アミノ酸~約500アミノ酸、約115アミノ酸~約450アミノ酸、約115アミノ酸~約400アミノ酸、約115アミノ酸~約350アミノ酸、約115アミノ酸~約300アミノ酸、約115アミノ酸~約280アミノ酸、約115アミノ酸~約260アミノ酸、約115アミノ酸~約240アミノ酸、約115アミノ酸~約220アミノ酸、約115アミノ酸~約200アミノ酸、約115アミノ酸~約195アミノ酸、約115アミノ酸~約190アミノ酸、約115アミノ酸~約185アミノ酸、約115アミノ酸~約180アミノ酸、約115アミノ酸~約175アミノ酸、約115アミノ酸~約170アミノ酸、約115アミノ酸~約165アミノ酸、約115アミノ酸~約160アミノ酸、約115アミノ酸~約155アミノ酸、約115アミノ酸~約150アミノ酸、約115アミノ酸~約145アミノ酸、約115アミノ酸~約140アミノ酸、約115アミノ酸~約135アミノ酸、約115アミノ酸~約130アミノ酸、約115アミノ酸~約125アミノ酸、約115アミノ酸~約120アミノ酸、約120アミノ酸~約1000アミノ酸、約120アミノ酸~約950アミノ酸、約120アミノ酸~約900アミノ酸、約120アミノ酸~約850アミノ酸、約120アミノ酸~約800アミノ酸、約120アミノ酸~約750アミノ酸、約120アミノ酸~約700アミノ酸、約120アミノ酸~約650アミノ酸、約120アミノ酸~約600アミノ酸、約120アミノ酸~約550アミノ酸、約120アミノ酸~約500アミノ酸、約120アミノ酸~約450アミノ酸、約120アミノ酸~約400アミノ酸、約120アミノ酸~約350アミノ酸、約120アミノ酸~約300アミノ酸、約120アミノ酸~約280アミノ酸、約120アミノ酸~約260アミノ酸、約120アミノ酸~約240アミノ酸、約120アミノ酸~約220アミノ酸、約120アミノ酸~約200アミノ酸、約120アミノ酸~約195アミノ酸、約120アミノ酸~約190アミノ酸、約120アミノ酸~約185アミノ酸、約120アミノ酸~約180アミノ酸、約120アミノ酸~約175アミノ酸、約120アミノ酸~約170アミノ酸、約120アミノ酸~約165アミノ酸、約120アミノ酸~約160アミノ酸、約120アミノ酸~約155アミノ酸、約120アミノ酸~約150アミノ酸、約120アミノ酸~約145アミノ酸、約120アミノ酸~約140アミノ酸、約120アミノ酸~約135アミノ酸、約120アミノ酸~約130アミノ酸、約120アミノ酸~約125アミノ酸、約125アミノ酸~約1000アミノ酸、約125アミノ酸~約950アミノ酸、約125アミノ酸~約900アミノ酸、約125アミノ酸~約850アミノ酸、約125アミノ酸~約800アミノ酸、約125アミノ酸~約750アミノ酸、約125アミノ酸~約700アミノ酸、約125アミノ酸~約650アミノ酸、約125アミノ酸~約
600アミノ酸、約125アミノ酸~約550アミノ酸、約125アミノ酸~約500アミノ酸、約125アミノ酸~約450アミノ酸、約125アミノ酸~約400アミノ酸、約125アミノ酸~約350アミノ酸、約125アミノ酸~約300アミノ酸、約125アミノ酸~約280アミノ酸、約125アミノ酸~約260アミノ酸、約125アミノ酸~約240アミノ酸、約125アミノ酸~約220アミノ酸、約125アミノ酸~約200アミノ酸、約125アミノ酸~約195アミノ酸、約125アミノ酸~約190アミノ酸、約125アミノ酸~約185アミノ酸、約125アミノ酸~約180アミノ酸、約125アミノ酸~約175アミノ酸、約125アミノ酸~約170アミノ酸、約125アミノ酸~約165アミノ酸、約125アミノ酸~約160アミノ酸、約125アミノ酸~約155アミノ酸、約125アミノ酸~約150アミノ酸、約125アミノ酸~約145アミノ酸、約125アミノ酸~約140アミノ酸、約125アミノ酸~約135アミノ酸、約125アミノ酸~約130アミノ酸、約130アミノ酸~約1000アミノ酸、約130アミノ酸~約950アミノ酸、約130アミノ酸~約900アミノ酸、約130アミノ酸~約850アミノ酸、約130アミノ酸~約800アミノ酸、約130アミノ酸~約750アミノ酸、約130アミノ酸~約700アミノ酸、約130アミノ酸~約650アミノ酸、約130アミノ酸~約600アミノ酸、約130アミノ酸~約550アミノ酸、約130アミノ酸~約500アミノ酸、約130アミノ酸~約450アミノ酸、約130アミノ酸~約400アミノ酸、約130アミノ酸~約350アミノ酸、約130アミノ酸~約300アミノ酸、約130アミノ酸~約280アミノ酸、約130アミノ酸~約260アミノ酸、約130アミノ酸~約240アミノ酸、約130アミノ酸~約220アミノ酸、約130アミノ酸~約200アミノ酸、約130アミノ酸~約195アミノ酸、約130アミノ酸~約190アミノ酸、約130アミノ酸~約185アミノ酸、約130アミノ酸~約180アミノ酸、約130アミノ酸~約175アミノ酸、約130アミノ酸~約170アミノ酸、約130アミノ酸~約165アミノ酸、約130アミノ酸~約160アミノ酸、約130アミノ酸~約155アミノ酸、約130アミノ酸~約150アミノ酸、約130アミノ酸~約145アミノ酸、約130アミノ酸~約140アミノ酸、約130アミノ酸~約135アミノ酸、約135アミノ酸~約1000アミノ酸、約135アミノ酸~約950アミノ酸、約135アミノ酸~約900アミノ酸、約135アミノ酸~約850アミノ酸、約135アミノ酸~約800アミノ酸、約135アミノ酸~約750アミノ酸、約135アミノ酸~約700アミノ酸、約135アミノ酸~約650アミノ酸、約135アミノ酸~約600アミノ酸、約135アミノ酸~約550アミノ酸、約135アミノ酸~約500アミノ酸、約135アミノ酸~約450アミノ酸、約135アミノ酸~約400アミノ酸、約135アミノ酸~約350アミノ酸、約135アミノ酸~約300アミノ酸、約135アミノ酸~約280アミノ酸、約135アミノ酸~約260アミノ酸、約135アミノ酸~約240アミノ酸、約135アミノ酸~約220アミノ酸、約135アミノ酸~約200アミノ酸、約135アミノ酸~約195アミノ酸、約135アミノ酸~約190アミノ酸、約135アミノ酸~約185アミノ酸、約135アミノ酸~約180アミノ酸、約135アミノ酸~約175アミノ酸、約135アミノ酸~約170アミノ酸、約135アミノ酸~約165アミノ酸、約135アミノ酸~約160アミノ酸、約135アミノ酸~約155アミノ酸、約135アミノ酸~約150アミノ酸、約135アミノ酸~約145アミノ酸、約135アミノ酸~約140アミノ酸、約140アミノ酸~約1000アミノ酸、約140アミノ酸~約950アミノ酸、約140アミノ酸~約900アミノ酸、約140アミノ酸~約850アミノ酸、約140アミノ酸~約800アミノ酸、約140アミノ酸~約750アミノ酸、約140アミノ酸~約700アミノ酸、約140アミノ酸~約650アミノ酸、約140アミノ酸~約600アミノ酸、約140アミノ酸~約550アミノ酸、約140アミノ酸~約500アミノ酸、約140アミノ酸~約450アミノ酸、約140アミノ酸~約400アミノ酸、約140アミノ酸~約350アミノ酸、約140アミノ酸~約300アミノ酸、約140アミノ酸~約280アミノ酸、約140アミノ酸~約260アミノ酸、約140アミノ酸~約240アミノ酸、約140アミノ酸~約220アミノ酸、約140アミノ酸~約200アミノ酸、約140アミノ酸~約195アミノ酸、約140アミノ酸~約190アミノ酸、約140アミノ酸~約185アミノ酸、約140アミノ酸~約180アミノ酸、約140アミノ酸~約175アミノ酸、約140アミノ酸~約170アミノ酸、約140アミノ酸~約165アミノ酸、約140アミノ酸~約160アミノ酸、約140アミノ酸~約155アミノ酸、約140アミノ酸~約150アミノ酸、約140アミノ酸~約145アミノ酸、約145アミノ酸~約1000アミノ酸、約145アミノ酸~約950アミノ酸、約145アミノ酸~約900アミノ酸、約145アミノ酸~約850アミノ酸、約145アミノ酸~約800アミノ酸、約145アミノ酸~約750アミノ酸、約145アミノ酸~約700アミノ酸、約145アミノ酸~約650アミノ酸、約145アミノ酸~約600アミノ酸、約145アミノ酸~約550アミノ酸、約145アミノ酸~約500アミノ酸、約145アミノ酸~約450アミノ酸、約145アミノ酸~約400アミノ酸、約145アミノ酸~約350アミノ酸、約145アミノ酸~約300アミノ酸、約145アミノ酸~約280アミノ酸、約145アミノ酸~約260アミノ酸、約145アミノ酸~約240アミノ酸、約145アミノ酸~約220アミノ酸、約145アミノ酸~約200アミノ酸、約145アミノ酸~約195アミノ酸、約145アミノ酸~約190アミノ酸、約145アミノ酸~約185アミノ酸、約145アミノ酸~約180アミノ酸、約145アミノ酸~約175アミノ酸、約145アミノ酸~約170アミノ酸、約145アミノ酸~約165アミノ酸、約145アミノ酸~約160アミノ酸、約145アミノ酸~約155アミノ酸、約145アミノ酸~約150アミノ酸、約150アミノ酸~約1000アミノ酸、約150アミノ酸~約950アミノ酸、約150アミノ酸~約900アミノ酸、約150アミノ酸~約850アミノ酸、約150アミノ酸~約800アミノ酸、約150アミノ酸~約750アミノ酸、約150アミノ酸~約700アミノ酸、約150アミノ酸~約650アミノ酸、約150アミノ酸~約600アミノ酸、約150アミノ酸~約550アミノ酸、約150アミノ酸~約500アミノ酸、約150アミノ酸~約450アミノ酸、約150アミノ酸~約400アミノ酸、約150アミノ酸~約350アミノ酸、約150アミノ酸~約300アミノ酸、約150アミノ酸~約280アミノ酸、約150アミノ酸~約260アミノ酸、約150アミノ酸~約240アミノ酸、約150アミノ酸~約220アミノ酸、約150アミノ酸~約200アミノ酸、約150アミノ酸~約195アミノ酸、約150アミノ酸~約190アミノ酸、約150アミノ酸~約185アミノ酸、約150アミノ酸~約180アミノ酸、約150アミノ酸~約175アミノ酸、約150アミノ酸~約170アミノ酸、約150アミノ酸~約165アミノ酸、約150アミノ酸~約160アミノ酸、約150アミノ酸~約155アミノ酸、約155アミノ酸~約1000アミノ酸、約155アミノ酸~約950アミノ酸、約155アミノ酸~約900アミノ酸、約155アミノ酸~約850アミノ酸、約155アミノ酸~約800アミノ酸、約155アミノ酸~約750アミノ酸、約155アミノ酸~約700アミノ酸、約155アミノ酸~約650アミノ酸、約155アミノ酸~約600アミノ酸、約155アミノ酸~約550アミノ酸、約155アミノ酸~約500アミノ酸、約155アミノ酸~約450アミノ酸、約155アミノ酸~約400アミノ酸、約155アミノ酸~約350アミノ酸、約155アミノ酸~約300アミノ酸、約155アミノ酸~約280アミノ酸、約155アミノ酸~約260アミノ酸、約155アミノ酸~約240アミノ酸、約155アミノ酸~約220アミノ酸、約155アミノ酸~約200アミノ酸、約155アミノ酸~約195アミノ酸、約155アミノ酸~約190アミノ酸、約155アミノ酸~約185アミノ酸、約155アミノ酸~約180アミノ酸、約155アミノ酸~約175アミノ酸、約155アミノ酸~約170アミノ酸、約155アミノ酸~約165アミノ酸、約155アミノ酸~約160アミノ酸、約160アミノ酸~約1000アミノ酸、約160アミノ酸~約950アミノ酸、約160アミノ酸~約900アミノ酸、約160アミノ酸~約850アミノ酸、約160アミノ酸~約800アミノ酸、約160アミノ酸~約750アミノ酸、約160アミノ酸~約700アミノ酸、約160アミノ酸~約650アミノ酸、約160アミノ酸~約600アミノ酸、約160アミノ酸~約550アミノ酸、約160アミノ酸~約500アミノ酸、約160アミノ酸~約450アミノ酸、約160アミノ酸~約400アミノ酸、約160アミノ酸~約350アミノ酸、約160アミノ酸~約300アミノ酸、約160アミノ酸~約280アミノ酸、約160アミノ酸~約260アミノ酸、約160アミノ酸~約240アミノ酸、約160アミノ酸~約220アミノ酸、約160アミノ酸~約200アミノ酸、約160アミノ酸~約195アミノ酸、約160アミノ酸~約190アミノ酸、約160アミノ酸~約185アミノ酸、約160アミノ酸~約180アミノ酸、約160アミノ酸~約175アミノ酸、約160アミノ酸~約170アミノ酸、約160アミノ酸~約165アミノ酸、約165アミノ酸~約1000アミノ酸、約165アミノ酸~約950アミノ酸、約165アミノ酸~約900アミノ酸、約165アミノ酸~約850アミノ酸、約165アミノ酸~約800アミノ酸、約165アミノ酸~約750アミノ酸、約165アミノ酸~約700アミノ酸、約165アミノ酸~約650アミノ酸、約165アミノ酸~約
600アミノ酸、約165アミノ酸~約550アミノ酸、約165アミノ酸~約500アミノ酸、約165アミノ酸~約450アミノ酸、約165アミノ酸~約400アミノ酸、約165アミノ酸~約350アミノ酸、約165アミノ酸~約300アミノ酸、約165アミノ酸~約280アミノ酸、約165アミノ酸~約260アミノ酸、約165アミノ酸~約240アミノ酸、約165アミノ酸~約220アミノ酸、約165アミノ酸~約200アミノ酸、約165アミノ酸~約195アミノ酸、約165アミノ酸~約190アミノ酸、約165アミノ酸~約185アミノ酸、約165アミノ酸~約180アミノ酸、約165アミノ酸~約175アミノ酸、約165アミノ酸~約170アミノ酸、約170アミノ酸~約1000アミノ酸、約170アミノ酸~約950アミノ酸、約170アミノ酸~約900アミノ酸、約170アミノ酸~約850アミノ酸、約170アミノ酸~約800アミノ酸、約170アミノ酸~約750アミノ酸、約170アミノ酸~約700アミノ酸、約170アミノ酸~約650アミノ酸、約170アミノ酸~約600アミノ酸、約170アミノ酸~約550アミノ酸、約170アミノ酸~約500アミノ酸、約170アミノ酸~約450アミノ酸、約170アミノ酸~約400アミノ酸、約170アミノ酸~約350アミノ酸、約170アミノ酸~約300アミノ酸、約170アミノ酸~約280アミノ酸、約170アミノ酸~約260アミノ酸、約170アミノ酸~約240アミノ酸、約170アミノ酸~約220アミノ酸、約170アミノ酸~約200アミノ酸、約170アミノ酸~約195アミノ酸、約170アミノ酸~約190アミノ酸、約170アミノ酸~約185アミノ酸、約170アミノ酸~約180アミノ酸、約170アミノ酸~約175アミノ酸、約175アミノ酸~約1000アミノ酸、約175アミノ酸~約950アミノ酸、約175アミノ酸~約900アミノ酸、約175アミノ酸~約850アミノ酸、約175アミノ酸~約800アミノ酸、約175アミノ酸~約750アミノ酸、約175アミノ酸~約700アミノ酸、約175アミノ酸~約650アミノ酸、約175アミノ酸~約600アミノ酸、約175アミノ酸~約550アミノ酸、約175アミノ酸~約500アミノ酸、約175アミノ酸~約450アミノ酸、約175アミノ酸~約400アミノ酸、約175アミノ酸~約350アミノ酸、約175アミノ酸~約300アミノ酸、約175アミノ酸~約280アミノ酸、約175アミノ酸~約260アミノ酸、約175アミノ酸~約240アミノ酸、約175アミノ酸~約220アミノ酸、約175アミノ酸~約200アミノ酸、約175アミノ酸~約195アミノ酸、約175アミノ酸~約190アミノ酸、約175アミノ酸~約185アミノ酸、約175アミノ酸~約180アミノ酸、約180アミノ酸~約1000アミノ酸、約180アミノ酸~約950アミノ酸、約180アミノ酸~約900アミノ酸、約180アミノ酸~約850アミノ酸、約180アミノ酸~約800アミノ酸、約180アミノ酸~約750アミノ酸、約180アミノ酸~約700アミノ酸、約180アミノ酸~約650アミノ酸、約180アミノ酸~約600アミノ酸、約180アミノ酸~約550アミノ酸、約180アミノ酸~約500アミノ酸、約180アミノ酸~約450アミノ酸、約180アミノ酸~約400アミノ酸、約180アミノ酸~約350アミノ酸、約180アミノ酸~約300アミノ酸、約180アミノ酸~約280アミノ酸、約180アミノ酸~約260アミノ酸、約180アミノ酸~約240アミノ酸、約180アミノ酸~約220アミノ酸、約180アミノ酸~約200アミノ酸、約180アミノ酸~約195アミノ酸、約180アミノ酸~約190アミノ酸、約180アミノ酸~約185アミノ酸、約185アミノ酸~約1000アミノ酸、約185アミノ酸~約950アミノ酸、約185アミノ酸~約900アミノ酸、約185アミノ酸~約850アミノ酸、約185アミノ酸~約800アミノ酸、約185アミノ酸~約750アミノ酸、約185アミノ酸~約700アミノ酸、約185アミノ酸~約650アミノ酸、約185アミノ酸~約600アミノ酸、約185アミノ酸~約550アミノ酸、約185アミノ酸~約500アミノ酸、約185アミノ酸~約450アミノ酸、約185アミノ酸~約400アミノ酸、約185アミノ酸~約350アミノ酸、約185アミノ酸~約300アミノ酸、約185アミノ酸~約280アミノ酸、約185アミノ酸~約260アミノ酸、約185アミノ酸~約240アミノ酸、約185アミノ酸~約220アミノ酸、約185アミノ酸~約200アミノ酸、約185アミノ酸~約195アミノ酸、約185アミノ酸~約190アミノ酸、約190アミノ酸~約1000アミノ酸、約190アミノ酸~約950アミノ酸、約190アミノ酸~約900アミノ酸、約190アミノ酸~約850アミノ酸、約190アミノ酸~約800アミノ酸、約190アミノ酸~約750アミノ酸、約190アミノ酸~約700アミノ酸、約190アミノ酸~約650アミノ酸、約190アミノ酸~約600アミノ酸、約190アミノ酸~約550アミノ酸、約190アミノ酸~約500アミノ酸、約190アミノ酸~約450アミノ酸、約190アミノ酸~約400アミノ酸、約190アミノ酸~約350アミノ酸、約190アミノ酸~約300アミノ酸、約190アミノ酸~約280アミノ酸、約190アミノ酸~約260アミノ酸、約190アミノ酸~約240アミノ酸、約190アミノ酸~約220アミノ酸、約190アミノ酸~約200アミノ酸、約190アミノ酸~約195アミノ酸、約195アミノ酸~約1000アミノ酸、約195アミノ酸~約950アミノ酸、約195アミノ酸~約900アミノ酸、約195アミノ酸~約850アミノ酸、約195アミノ酸~約800アミノ酸、約195アミノ酸~約750アミノ酸、約195アミノ酸~約700アミノ酸、約195アミノ酸~約650アミノ酸、約195アミノ酸~約600アミノ酸、約195アミノ酸~約550アミノ酸、約195アミノ酸~約500アミノ酸、約195アミノ酸~約450アミノ酸、約195アミノ酸~約400アミノ酸、約195アミノ酸~約350アミノ酸、約195アミノ酸~約300アミノ酸、約195アミノ酸~約280アミノ酸、約195アミノ酸~約260アミノ酸、約195アミノ酸~約240アミノ酸、約195アミノ酸~約220アミノ酸、約195アミノ酸~約200アミノ酸、約200アミノ酸~約1000アミノ酸、約200アミノ酸~約950アミノ酸、約200アミノ酸~約900アミノ酸、約200アミノ酸~約850アミノ酸、約200アミノ酸~約800アミノ酸、約200アミノ酸~約750アミノ酸、約200アミノ酸~約700アミノ酸、約200アミノ酸~約650アミノ酸、約200アミノ酸~約600アミノ酸、約200アミノ酸~約550アミノ酸、約200アミノ酸~約500アミノ酸、約200アミノ酸~約450アミノ酸、約200アミノ酸~約400アミノ酸、約200アミノ酸~約350アミノ酸、約200アミノ酸~約300アミノ酸、約200アミノ酸~約280アミノ酸、約200アミノ酸~約260アミノ酸、約200アミノ酸~約240アミノ酸、約200アミノ酸~約220アミノ酸、約220アミノ酸~約1000アミノ酸、約220アミノ酸~約950アミノ酸、約220アミノ酸~約900アミノ酸、約220アミノ酸~約850アミノ酸、約220アミノ酸~約800アミノ酸、約220アミノ酸~約750アミノ酸、約220アミノ酸~約700アミノ酸、約220アミノ酸~約650アミノ酸、約220アミノ酸~約600アミノ酸、約220アミノ酸~約550アミノ酸、約220アミノ酸~約500アミノ酸、約220アミノ酸~約450アミノ酸、約220アミノ酸~約400アミノ酸、約220アミノ酸~約350アミノ酸、約220アミノ酸~約300アミノ酸、約220アミノ酸~約280アミノ酸、約220アミノ酸~約260アミノ酸、約220アミノ酸~約240アミノ酸、約240アミノ酸~約1000アミノ酸、約240アミノ酸~約950アミノ酸、約240アミノ酸~約900アミノ酸、約240アミノ酸~約850アミノ酸、約240アミノ酸~約800アミノ酸、約240アミノ酸~約750アミノ酸、約240アミノ酸~約700アミノ酸、約240アミノ酸~約650アミノ酸、約240アミノ酸~約600アミノ酸、約240アミノ酸~約550アミノ酸、約240アミノ酸~約500アミノ酸、約240アミノ酸~約450アミノ酸、約240アミノ酸~約400アミノ酸、約240アミノ酸~約350アミノ酸、約240アミノ酸~約300アミノ酸、約240アミノ酸~約280アミノ酸、約240アミノ酸~約260アミノ酸、約260アミノ酸~約1000アミノ酸、約260アミノ酸~約950アミノ酸、約260アミノ酸~約900アミノ酸、約260アミノ酸~約850アミノ酸、約260アミノ酸~約800アミノ酸、約260アミノ酸~約750アミノ酸、約260アミノ酸~約700アミノ酸、約260アミノ酸~約650アミノ酸、約260アミノ酸~約600アミノ酸、約260アミノ酸~約550アミノ酸、約260アミノ酸~約500アミノ酸、約260アミノ酸~約450アミノ酸、約260アミノ酸~約400アミノ酸、約260アミノ酸~約350アミノ酸、約260アミノ酸~約300アミノ酸、約260アミノ酸~約280アミノ酸、約280アミノ酸~約1000アミノ酸、約280アミノ酸~約950アミノ酸、約280アミノ酸~約900アミノ酸、約280アミノ酸~約850アミノ酸、約280アミノ酸~約800アミノ酸、約280アミノ酸~約750アミノ酸、約280アミノ酸~約700アミノ酸、約280アミノ酸~約650アミノ酸、約280アミノ酸~約600アミノ酸、約280アミノ酸~約550アミノ酸、約280アミノ酸~約500アミノ酸、約280アミノ酸~約450アミノ酸、約280アミノ酸~約400アミノ酸、約280アミノ酸~約350アミノ酸、約280アミノ酸~約300アミノ酸、約300アミノ酸~約1000アミノ酸、約300アミノ酸~約950アミノ酸、約300アミノ酸~約900アミノ酸、約300アミノ酸~約850アミノ酸、約300アミノ酸~約800アミノ酸、約300アミノ酸~約750アミノ酸、約300アミノ酸~約700アミノ酸、約300アミノ酸~約650アミノ酸、約300アミノ酸~約600アミノ酸、約300アミノ酸~約550アミノ酸、約300アミノ酸~約500アミノ酸、約300アミノ酸~約450アミノ酸、約300アミノ酸~約400アミノ酸、約300アミノ酸~約350アミノ酸、約350アミノ酸~約1000アミノ酸、約350アミノ酸~約950アミノ酸、約350アミノ酸~約900アミノ酸、約350アミノ酸~約850アミノ酸、約350アミノ酸~約800アミノ酸、約350アミノ酸~約750アミノ酸、約350アミノ酸~約700アミノ酸、約350アミノ酸~約650アミノ酸、約350アミノ酸~約600アミノ酸、約350アミノ酸~約550アミノ酸、約350アミノ酸~約500アミノ酸、約350アミノ酸~約450アミノ酸、約350アミノ酸~約400アミノ酸、約400アミノ酸~約1000アミノ酸、約400アミノ酸~約950アミノ酸、約400アミノ酸~約900アミノ酸、約400アミノ酸~約850アミノ酸、約400アミノ酸~約800アミノ酸、約400アミノ酸~約750アミノ酸、約400アミノ酸~約700アミノ酸、約400アミノ酸~約650アミノ酸、約400アミノ酸~約600アミノ酸、約400アミノ酸~約550アミノ酸、約400アミノ酸~約500アミノ酸、約400アミノ酸~約450アミノ酸、約450アミノ酸~約1000アミノ酸、約450アミノ酸~約950アミノ酸、約450アミノ酸~約900アミノ酸、約450アミノ酸~約850アミノ酸、約450アミノ酸~約800アミノ酸、約450アミノ酸~約750アミノ酸、約450アミノ酸~約700アミノ酸、約45
0アミノ酸~約650アミノ酸、約450アミノ酸~約600アミノ酸、約450アミノ酸~約550アミノ酸、約450アミノ酸~約500アミノ酸、約500アミノ酸~約1000アミノ酸、約500アミノ酸~約950アミノ酸、約500アミノ酸~約900アミノ酸、約500アミノ酸~約850アミノ酸、約500アミノ酸~約800アミノ酸、約500アミノ酸~約750アミノ酸、約500アミノ酸~約700アミノ酸、約500アミノ酸~約650アミノ酸、約500アミノ酸~約600アミノ酸、約500アミノ酸~約550アミノ酸、約550アミノ酸~約1000アミノ酸、約550アミノ酸~約950アミノ酸、約550アミノ酸~約900アミノ酸、約550アミノ酸~約850アミノ酸、約550アミノ酸~約800アミノ酸、約550アミノ酸~約750アミノ酸、約550アミノ酸~約700アミノ酸、約550アミノ酸~約650アミノ酸、約550アミノ酸~約600アミノ酸、約600アミノ酸~約1000アミノ酸、約600アミノ酸~約950アミノ酸、約600アミノ酸~約900アミノ酸、約600アミノ酸~約850アミノ酸、約600アミノ酸~約800アミノ酸、約600アミノ酸~約750アミノ酸、約600アミノ酸~約700アミノ酸、約600アミノ酸~約650アミノ酸、約650アミノ酸~約1000アミノ酸、約650アミノ酸~約950アミノ酸、約650アミノ酸~約900アミノ酸、約650アミノ酸~約850アミノ酸、約650アミノ酸~約800アミノ酸、約650アミノ酸~約750アミノ酸、約650アミノ酸~約700アミノ酸、約700アミノ酸~約1000アミノ酸、約700アミノ酸~約950アミノ酸、約700アミノ酸~約900アミノ酸、約700アミノ酸~約850アミノ酸、約700アミノ酸~約800アミノ酸、約700アミノ酸~約750アミノ酸、約750アミノ酸~約1000アミノ酸、約750アミノ酸~約950アミノ酸、約750アミノ酸~約900アミノ酸、約750アミノ酸~約850アミノ酸、約750アミノ酸~約800アミノ酸、約800アミノ酸~約1000アミノ酸、約800アミノ酸~約950アミノ酸、約800アミノ酸~約900アミノ酸、約800アミノ酸~約850アミノ酸、約850アミノ酸~約1000アミノ酸、約850アミノ酸~約950アミノ酸、約850アミノ酸~約900アミノ酸、約900アミノ酸~約1000アミノ酸、約900アミノ酸~約950アミノ酸、又は約950アミノ酸~約1000アミノ酸の総アミノ酸数を有し得る。
In some embodiments of any of the multichain chimeric polypeptides described herein, the first target binding domain, the second target binding domain, and/or one or more additional target binding domains each independently from about 5 amino acids to about 1000 amino acids, from about 5 amino acids to about 950 amino acids, from about 5 amino acids to about 900 amino acids, from about 5 amino acids to about 850 amino acids, from about 5 amino acids to about 800 amino acids, from about 5 amino acids to about 750 amino acids, about 5 amino acids to about 700 amino acids, about 5 amino acids to about 650 amino acids, about 5 amino acids to about 600 amino acids, about 5 amino acids to about 550 amino acids, about 5 amino acids to about 500 amino acids, about 5 amino acids to about 450 amino acids amino acids, about 5 amino acids to about 400 amino acids, about 5 amino acids to about 350 amino acids, about 5 amino acids to about 300 amino acids, about 5 amino acids to about 280 amino acids, about 5 amino acids to about 260 amino acids, about 5 amino acids to about 240 amino acids, about 5 amino acids to about 220 amino acids, about 5 amino acids to about 200 amino acids, about 5 amino acids to about 195 amino acids, about 5 amino acids to about 190 amino acids, about 5 amino acids to about 185 amino acids, about 5 amino acids to about 180 amino acids, about 5 amino acids to about 175 amino acids, about 5 amino acids to about 170 amino acids, about 5 amino acids to about 165 amino acids, about 5 amino acids to about 160 amino acids, about 5 amino acids to about 155 amino acids, about 5 amino acids to about 150 amino acids, about 5 amino acids to about 145 amino acids, about 5 amino acids to about 140 amino acids, about 5 amino acids to about 135 amino acids, about 5 amino acids to about 130 amino acids, about 5 amino acids to about 125 amino acids, about 5 amino acids to about 120 amino acids, about 5 amino acids to about 115 amino acids amino acids, about 5 amino acids to about 110 amino acids, about 5 amino acids to about 105 amino acids, about 5 amino acids to about 100 amino acids, about 5 amino acids to about 95 amino acids, about 5 amino acids to about 90 amino acids, about 5 amino acids to about 85 amino acids, about 5 amino acids to about 80 amino acids, about 5 amino acids to about 75 amino acids, about 5 amino acids to about 70 amino acids, about 5 amino acids to about 65 amino acids, about 5 amino acids to about 60 amino acids, about 5 amino acids to about 55 amino acids, about 5 amino acids to about 50 amino acids, about 5 amino acids to about 45 amino acids, about 5 amino acids to about 40 amino acids, about 5 amino acids to about 35 amino acids, about 5 amino acids to about 30 amino acids, about 5 amino acids to about 25 amino acids, about 5 amino acids to about 20 amino acids, about 5 amino acids to about 15 amino acids, about 5 amino acids to about 10 amino acids, about 10 amino acids to about 1000 amino acids, about 10 amino acids to about 950 amino acids, about 10 amino acids to about 900 amino acids, about 10 amino acids to about 850 amino acids amino acids, about 10 amino acids to about 800 amino acids, about 10 amino acids to about 750 amino acids, about 10 amino acids to about 700 amino acids, about 10 amino acids to about 650 amino acids, about 10 amino acids to about 600 amino acids, about 10 amino acids to about 550 amino acids, about 10 amino acids to about 500 amino acids, about 10 amino acids to about 450 amino acids, about 10 amino acids to about 400 amino acids, about 10 amino acids to about 350 amino acids, about 10 amino acids to about 300 amino acids, about 10 amino acids to about 280 amino acids, about 10 amino acids to about 260 amino acids, about 10 amino acids to about 240 amino acids, about 10 amino acids to about 220 amino acids, about 10 amino acids to about 200 amino acids, about 10 amino acids to about 195 amino acids, about 10 amino acids to about 190 amino acids, about 10 amino acids to about 185 amino acids, about 10 amino acids to about 180 amino acids, about 10 amino acids to about 175 amino acids, about 10 amino acids to about 170 amino acids, about 10 amino acids to about 165 amino acids, about 10 amino acids to about 160 amino acids, about 10 amino acids to about 155 amino acids amino acids, about 10 amino acids to about 150 amino acids, about 10 amino acids to about 145 amino acids, about 10 amino acids to about 140 amino acids, about 10 amino acids to about 135 amino acids, about 10 amino acids to about 130 amino acids, about 10 amino acids to about 125 amino acids, about 10 amino acids to about 120 amino acids, about 10 amino acids to about 115 amino acids, about 10 amino acids to about 110 amino acids, about 10 amino acids to about 105 amino acids, about 10 amino acids to about 100 amino acids, about 10 amino acids to about 95 amino acids, about 10 amino acids to about 90 amino acids, about 10 amino acids to about 85 amino acids, about 10 amino acids to about 80 amino acids, about 10 amino acids to about 75 amino acids, about 10 amino acids to about 70 amino acids, about 10 amino acids to about 65 amino acids, about 10 amino acids to about 60 amino acids, about 10 amino acids to about 55 amino acids, about 10 amino acids to about 50 amino acids, about 10 amino acids to about 45 amino acids, about 10 amino acids to about 40 amino acids, about 10 amino acids to about 35 amino acids, about 10 amino acids to about 30 amino acids amino acids, about 10 amino acids to about 25 amino acids, about 10 amino acids to about 20 amino acids, about 10 amino acids to about 15 amino acids, about 15 amino acids to about 1000 amino acids, about 15 amino acids to about 950 amino acids, about 15 amino acids to about 900 amino acids, about 15 amino acids to about 850 amino acids, about 15 amino acids to about 800 amino acids, about 15 amino acids to about 750 amino acids, about 15 amino acids to about 700 amino acids, about 15 amino acids to about 650 amino acids, about 15 amino acids to about 600 amino acids, about 15 amino acids to about 550 amino acids, about 15 amino acids to about 500 amino acids, about 15 amino acids to about 450 amino acids, about 15 amino acids to about 400 amino acids, about 15 amino acids to about 350 amino acids, about 15 amino acids to about 300 amino acids, about 15 amino acids to about 280 amino acids, about 15 amino acids to about 260 amino acids, about 15 amino acids to about 240 amino acids, about 15 amino acids to about 220 amino acids, about 15 amino acids to about 200 amino acids, about 15 amino acids to about 195 amino acids, about 15 amino acids to about 190 amino acids amino acids, about 15 amino acids to about 185 amino acids, about 15 amino acids to about 180 amino acids, about 15 amino acids to about 175 amino acids, about 15 amino acids to about 170 amino acids, about 15 amino acids to about 165 amino acids, about 15 amino acids to about 160 amino acids, about 15 amino acids to about 155 amino acids, about 15 amino acids to about 150 amino acids, about 15 amino acids to about 145 amino acids, about 15 amino acids to about 140 amino acids, about 15 amino acids to about 135 amino acids, about 15 amino acids to about 130 amino acids, about 15 amino acids to about 125 amino acids, about 15 amino acids to about 120 amino acids, about 15 amino acids to about 115 amino acids, about 15 amino acids to about 110 amino acids, about 15 amino acids to about 105 amino acids, about 15 amino acids to about 100 amino acids, about 15 amino acids to about about 95 amino acids, about 15 amino acids to about 90 amino acids, about 15 amino acids to about 85 amino acids, about 15 amino acids to about 80 amino acids, about 15 amino acids to about 75 amino acids, about 15 amino acids to about 70 amino acids, about 15 amino acids to about 65 amino acids amino acids, about 15 amino acids to about 60 amino acids, about 15 amino acids to about 55 amino acids, about 15 amino acids to about 50 amino acids, about 15 amino acids to about 45 amino acids, about 15 amino acids to about 40 amino acids, about 15 amino acids to about 35 amino acids, about 15 amino acids to about 30 amino acids, about 15 amino acids to about 25 amino acids, about 15 amino acids to about 20 amino acids, about 20 amino acids to about 1000 amino acids, about 20 amino acids to about 950 amino acids, about 20 amino acids to about 900 amino acids, about 20 amino acids to about 850 amino acids, about 20 amino acids to about 800 amino acids, about 20 amino acids to about 750 amino acids, about 20 amino acids to about 700 amino acids, about 20 amino acids to about 650 amino acids, about 20 amino acids to about 600 amino acids, about 20 amino acids to about 550 amino acids, about 20 amino acids to about 500 amino acids, about 20 amino acids to about 450 amino acids, about 20 amino acids to about 400 amino acids, about 20 amino acids to about 350 amino acids, about 20 amino acids to about 300 amino acids, about 20 amino acids to about 280 amino acids amino acids, about 20 amino acids to about 260 amino acids, about 20 amino acids to about 240 amino acids, about 20 amino acids to about 220 amino acids, about 20 amino acids to about 200 amino acids, about 20 amino acids to about 195 amino acids, about 20 amino acids to about 190 amino acids, about 20 amino acids to about 185 amino acids, about 20 amino acids to about 180 amino acids, about 20 amino acids to about 175 amino acids, about 20 amino acids to about 170 amino acids, about 20 amino acids to about 165 amino acids, about 20 amino acids to about 160 amino acids, about 20 amino acids to about 155 amino acids, about 20 amino acids to about 150 amino acids, about 20 amino acids to about 145 amino acids, about 20 amino acids to about 140 amino acids, about 20 amino acids to about 135 amino acids, about 20 amino acids to about 130 amino acids, about 20 amino acids to about 125 amino acids, about 20 amino acids to about 120 amino acids, about 20 amino acids to about 115 amino acids, about 20 amino acids to about 110 amino acids, about 20 amino acids to about 105 amino acids, about 20 amino acids to about 100 amino acids, about 20 amino acids to about 95 amino acids amino acids, about 20 amino acids to about 90 amino acids, about 20 amino acids to about 85 amino acids, about 20 amino acids to about 80 amino acids, about 20 amino acids to about 75 amino acids, about 20 amino acids to about 70 amino acids, about 20 amino acids to about 65 amino acids, about 20 amino acids to about 60 amino acids, about 20 amino acids to about 55 amino acids, about 20 amino acids to about 50 amino acids, about 20 amino acids to about 45 amino acids, about 20 amino acids to about 40 amino acids, about 20 amino acids to about 35 amino acids, about 20 amino acids to about 30 amino acids, about 20 amino acids to about 25 amino acids, about 25 amino acids to about 1000 amino acids, about 25 amino acids to about 950 amino acids, about 25 amino acids to about 900 amino acids, about 25 amino acids to about 850 amino acids, about 25 amino acids to about 800 amino acids, about 25 amino acids to about 750 amino acids, about 25 amino acids to about 700 amino acids, about 25 amino acids to about 650 amino acids, about 25 amino acids to about 600 amino acids, about 25 amino acids to about 550 amino acids, about 25 amino acids to about 500 amino acids amino acids, about 25 amino acids to about 450 amino acids, about 25 amino acids to about 400 amino acids, about 25 amino acids to about 350 amino acids, about 25 amino acids to about 300 amino acids, about 25 amino acids to about 280 amino acids, about 25 amino acids to about 260 amino acids, about 25 amino acids to about 240 amino acids, about 25 amino acids to about 220 amino acids, about 25 amino acids to about 200 amino acids, about 25 amino acids to about 195 amino acids, about 25 amino acids to about 190 amino acids, about 25 amino acids to about 185 amino acids, about 25 amino acids to about 180 amino acids, about 25 amino acids to about 175 amino acids, about 25 amino acids to about 170 amino acids, about 25 amino acids to about 165 amino acids, about 25 amino acids to about 160 amino acids, about 25 amino acids to about 155 amino acids, about 25 amino acids to about 150 amino acids, about 25 amino acids to about 145 amino acids, about 25 amino acids to about 140 amino acids, about 25 amino acids to about 135 amino acids, about 25 amino acids to about 130 amino acids, about 25 amino acids to about 125 amino acids, about 25 amino acids to about 120 amino acids amino acids, about 25 amino acids to about 115 amino acids, about 25 amino acids to about 110 amino acids, about 25 amino acids to about 105 amino acids,
about 25 amino acids to about 100 amino acids, about 25 amino acids to about 95 amino acids, about 25 amino acids to about 90 amino acids, about 25 amino acids to about 85 amino acids, about 25 amino acids to about 80 amino acids, about 25 amino acids to about 75 amino acids, about 25 amino acids to about 70 amino acids, about 25 amino acids to about 65 amino acids, about 25 amino acids to about 60 amino acids, about 25 amino acids to about 55 amino acids, about 25 amino acids to about 50 amino acids, about 25 amino acids to about 45 amino acids, about 25 amino acids to about 40 amino acids, about 25 amino acids to about 35 amino acids, about 25 amino acids to about 30 amino acids, about 30 amino acids to about 1000 amino acids, about 30 amino acids to about 950 amino acids, about 30 amino acids to about 900 amino acids, about 30 amino acids to about 850 amino acids amino acids, about 30 amino acids to about 800 amino acids, about 30 amino acids to about 750 amino acids, about 30 amino acids to about 700 amino acids, about 30 amino acids to about 650 amino acids, about 30 amino acids to about 600 amino acids, about 30 amino acids to about 550 amino acids, about 30 amino acids to about 500 amino acids, about 30 amino acids to about 450 amino acids, about 30 amino acids to about 400 amino acids, about 30 amino acids to about 350 amino acids, about 30 amino acids to about 300 amino acids, about 30 amino acids to about 280 amino acids, about 30 amino acids to about 260 amino acids, about 30 amino acids to about 240 amino acids, about 30 amino acids to about 220 amino acids, about 30 amino acids to about 200 amino acids, about 30 amino acids to about 195 amino acids, about 30 amino acids to about 190 amino acids, about 30 amino acids to about 185 amino acids, about 30 amino acids to about 180 amino acids, about 30 amino acids to about 175 amino acids, about 30 amino acids to about 170 amino acids, about 30 amino acids to about 165 amino acids, about 30 amino acids to about 160 amino acids, about 30 amino acids to about 155 amino acids amino acids, about 30 amino acids to about 150 amino acids, about 30 amino acids to about 145 amino acids, about 30 amino acids to about 140 amino acids, about 30 amino acids to about 135 amino acids, about 30 amino acids to about 130 amino acids, about 30 amino acids to about 125 amino acids, about 30 amino acids to about 120 amino acids, about 30 amino acids to about 115 amino acids, about 30 amino acids to about 110 amino acids, about 30 amino acids to about 105 amino acids, about 30 amino acids to about 100 amino acids, about 30 amino acids to about 95 amino acids, about 30 amino acids to about 90 amino acids, about 30 amino acids to about 85 amino acids, about 30 amino acids to about 80 amino acids, about 30 amino acids to about 75 amino acids, about 30 amino acids to about 70 amino acids, about 30 amino acids to about 65 amino acids, about 30 amino acids to about 60 amino acids, about 30 amino acids to about 55 amino acids, about 30 amino acids to about 50 amino acids, about 30 amino acids to about 45 amino acids, about 30 amino acids to about 40 amino acids, about 30 amino acids to about 35 amino acids, about 35 amino acids to about 1000 amino acids amino acids, about 35 amino acids to about 950 amino acids, about 35 amino acids to about 900 amino acids, about 35 amino acids to about 850 amino acids, about 35 amino acids to about 800 amino acids, about 35 amino acids to about 750 amino acids, about 35 amino acids to about 700 amino acids, about 35 amino acids to about 650 amino acids, about 35 amino acids to about 600 amino acids, about 35 amino acids to about 550 amino acids, about 35 amino acids to about 500 amino acids, about 35 amino acids to about 450 amino acids, about 35 amino acids to about 400 amino acids, about 35 amino acids to about 350 amino acids, about 35 amino acids to about 300 amino acids, about 35 amino acids to about 280 amino acids, about 35 amino acids to about 260 amino acids, about 35 amino acids to about 240 amino acids, about 35 amino acids to about 220 amino acids, about 35 amino acids to about 200 amino acids, about 35 amino acids to about 195 amino acids, about 35 amino acids to about 190 amino acids, about 35 amino acids to about 185 amino acids, about 35 amino acids to about 180 amino acids, about 35 amino acids to about 175 amino acids, about 35 amino acids to about 170 amino acids amino acids, about 35 amino acids to about 165 amino acids, about 35 amino acids to about 160 amino acids, about 35 amino acids to about 155 amino acids, about 35 amino acids to about 150 amino acids, about 35 amino acids to about 145 amino acids, about 35 amino acids to about 140 amino acids, about 35 amino acids to about 135 amino acids, about 35 amino acids to about 130 amino acids, about 35 amino acids to about 125 amino acids, about 35 amino acids to about 120 amino acids, about 35 amino acids to about 115 amino acids, about 35 amino acids to about 110 amino acids, about 35 amino acids to about 105 amino acids, about 35 amino acids to about 100 amino acids, about 35 amino acids to about 95 amino acids, about 35 amino acids to about 90 amino acids, about 35 amino acids to about 85 amino acids, about 35 amino acids to about 80 amino acids, about 35 amino acids to about 75 amino acids, about 35 amino acids to about 70 amino acids, about 35 amino acids to about 65 amino acids, about 35 amino acids to about 60 amino acids, about 35 amino acids to about 55 amino acids, about 35 amino acids to about 50 amino acids, about 35 amino acids to about 45 amino acids amino acids, about 35 amino acids to about 40 amino acids, about 40 amino acids to about 1000 amino acids, about 40 amino acids to about 950 amino acids, about 40 amino acids to about 900 amino acids, about 40 amino acids to about 850 amino acids, about 40 amino acids to about 800 amino acids, about 40 amino acids to about 750 amino acids, about 40 amino acids to about 700 amino acids, about 40 amino acids to about 650 amino acids, about 40 amino acids to about 600 amino acids, about 40 amino acids to about 550 amino acids, about 40 amino acids to about 500 amino acids, about 40 amino acids to about 450 amino acids, about 40 amino acids to about 400 amino acids, about 40 amino acids to about 350 amino acids, about 40 amino acids to about 300 amino acids, about 40 amino acids to about 280 amino acids, about 40 amino acids to about 260 amino acids, about 40 amino acids to about 240 amino acids, about 40 amino acids to about 220 amino acids, about 40 amino acids to about 200 amino acids, about 40 amino acids to about 195 amino acids, about 40 amino acids to about 190 amino acids, about 40 amino acids to about 185 amino acids, about 40 amino acids to about 180 amino acids amino acids, about 40 amino acids to about 175 amino acids, about 40 amino acids to about 170 amino acids, about 40 amino acids to about 165 amino acids, about 40 amino acids to about 160 amino acids, about 40 amino acids to about 155 amino acids, about 40 amino acids to about 150 amino acids, about 40 amino acids to about 145 amino acids, about 40 amino acids to about 140 amino acids, about 40 amino acids to about 135 amino acids, about 40 amino acids to about 130 amino acids, about 40 amino acids to about 125 amino acids, about 40 amino acids to about 120 amino acids, about 40 amino acids to about 115 amino acids, about 40 amino acids to about 110 amino acids, about 40 amino acids to about 105 amino acids, about 40 amino acids to about 100 amino acids, about 40 amino acids to about 95 amino acids, about 40 amino acids to about 90 amino acids, about 40 amino acids to about 85 amino acids, about 40 amino acids to about 80 amino acids, about 40 amino acids to about 75 amino acids, about 40 amino acids to about 70 amino acids, about 40 amino acids to about 65 amino acids, about 40 amino acids to about 60 amino acids, about 40 amino acids to about 55 amino acids amino acids, about 40 amino acids to about 50 amino acids, about 40 amino acids to about 45 amino acids, about 45 amino acids to about 1000 amino acids, about 45 amino acids to about 950 amino acids, about 45 amino acids to about 900 amino acids, about 45 amino acids to about 850 amino acids, about 45 amino acids to about 800 amino acids, about 45 amino acids to about 750 amino acids, about 45 amino acids to about 700 amino acids, about 45 amino acids to about 650 amino acids, about 45 amino acids to about 600 amino acids, about 45 amino acids to about 550 amino acids, about 45 amino acids to about 500 amino acids, about 45 amino acids to about 450 amino acids, about 45 amino acids to about 400 amino acids, about 45 amino acids to about 350 amino acids, about 45 amino acids to about 300 amino acids, about 45 amino acids to about 280 amino acids, about 45 amino acids to about 260 amino acids, about 45 amino acids to about 240 amino acids, about 45 amino acids to about 220 amino acids, about 45 amino acids to about 200 amino acids, about 45 amino acids to about 195 amino acids, about 45 amino acids to about 190 amino acids, about 45 amino acids to about 185 amino acids amino acids, about 45 amino acids to about 180 amino acids, about 45 amino acids to about 175 amino acids, about 45 amino acids to about 170 amino acids, about 45 amino acids to about 165 amino acids, about 45 amino acids to about 160 amino acids, about 45 amino acids to about 155 amino acids, about 45 amino acids to about 150 amino acids, about 45 amino acids to about 145 amino acids, about 45 amino acids to about 140 amino acids, about 45 amino acids to about 135 amino acids, about 45 amino acids to about 130 amino acids, about 45 amino acids to about 125 amino acids, about 45 amino acids to about 120 amino acids, about 45 amino acids to about 115 amino acids, about 45 amino acids to about 110 amino acids, about 45 amino acids to about 105 amino acids, about 45 amino acids to about 100 amino acids, about 45 amino acids to about 95 amino acids, about 45 amino acids to about 90 amino acids, about 45 amino acids to about 85 amino acids, about 45 amino acids to about 80 amino acids, about 45 amino acids to about 75 amino acids, about 45 amino acids to about 70 amino acids, about 45 amino acids to about 65 amino acids, about 45 amino acids to about 60 amino acids amino acids, about 45 amino acids to about 55 amino acids, about 45 amino acids to about 50 amino acids, about 50 amino acids to about 1000 amino acids, about 50 amino acids to about 950 amino acids, about 50 amino acids to about 900 amino acids, about 50 amino acids to about 850 amino acids, about 50 amino acids to about 800 amino acids, about 50 amino acids to about 750 amino acids, about 50 amino acids to about 700 amino acids, about 50 amino acids to about 650 amino acids, about 50 amino acids to about 600 amino acids, about 50 amino acids to about 550 amino acids, about 50 amino acids to about 500 amino acids, about 50 amino acids to about 450 amino acids, about 50 amino acids to about 400 amino acids, about 50 amino acids to about 350 amino acids, about 50 amino acids to about 300 amino acids, about 50 amino acids to about 280 amino acids, about 50 amino acids to about 260 amino acids, about 50 amino acids to about 240 amino acids, about 50 amino acids to about 220 amino acids, about 50 amino acids to about 200 amino acids, about 50 amino acids to about 195 amino acids, about 50 amino acids to about 190 amino acids, about 50 amino acids to about 185 amino acids amino acids, about 50 amino acids to about 180 amino acids, about 50 amino acids to about 175 amino acids, about 50 amino acids to about 170 amino acids, about 50 amino acids to about 165 amino acids, about 50 amino acids to about 160 amino acids, about 50 amino acids to about 155 amino acids, about 50 amino acids to about 150 amino acids, about 50 amino acids to about 145 amino acids, about 50 amino acids to about 140 amino acids, about 50 amino acids to about 135 amino acids, about 50 amino acids to about 130 amino acids, about 50 amino acids to about 125 amino acids, about 50 amino acids to about 120 amino acids, about 50 amino acids to about 115 amino acids, about 50 amino acids to about 110 amino acids, about 50 amino acids to about 105 amino acids, about 50 amino acids to about 100 amino acids, about 50 amino acids to about 95 amino acids, about 50 amino acids to about 90 amino acids, about 50 amino acids to about 85 amino acids, about 50 amino acids to about 80 amino acids, about 50 amino acids to about 75 amino acids, about 50 amino acids to about 70 amino acids, about 50 amino acids to about 65 amino acids, about 50 amino acids to about 60 amino acids amino acids, about 50 amino acids to about 55 amino acids, about 55 amino acids to about 1000 amino acids, about 55 amino acids to about 950 amino acids, about 55 amino acids to about 900 amino acids, about 55 amino acids to about 850 amino acids, about 55 amino acids to about 800 amino acids, about 55 amino acids to about 750 amino acids, about 55 amino acids to about 700 amino acids, about 55 amino acids to about 650 amino acids, about 55 amino acids to about 600 amino acids,
about 55 amino acids to about 550 amino acids, about 55 amino acids to about 500 amino acids, about 55 amino acids to about 450 amino acids, about 55 amino acids to about 400 amino acids, about 55 amino acids to about 350 amino acids, about 55 amino acids to about 300 amino acids, about 55 amino acids to about 280 amino acids, about 55 amino acids to about 260 amino acids, about 55 amino acids to about 240 amino acids, about 55 amino acids to about 220 amino acids, about 55 amino acids to about 200 amino acids, about 55 amino acids to about 195 amino acids, about 55 amino acids to about 190 amino acids, about 55 amino acids to about 185 amino acids, about 55 amino acids to about 180 amino acids, about 55 amino acids to about 175 amino acids, about 55 amino acids to about 170 amino acids, about 55 amino acids to about 165 amino acids, about 55 amino acids to about 160 amino acids amino acids, about 55 amino acids to about 155 amino acids, about 55 amino acids to about 150 amino acids, about 55 amino acids to about 145 amino acids, about 55 amino acids to about 140 amino acids, about 55 amino acids to about 135 amino acids, about 55 amino acids to about 130 amino acids, about 55 amino acids to about 125 amino acids, about 55 amino acids to about 120 amino acids, about 55 amino acids to about 115 amino acids, about 55 amino acids to about 110 amino acids, about 55 amino acids to about 105 amino acids, about 55 amino acids to about 100 amino acids, about 55 amino acids to about 95 amino acids, about 55 amino acids to about 90 amino acids, about 55 amino acids to about 85 amino acids, about 55 amino acids to about 80 amino acids, about 55 amino acids to about 75 amino acids, about 55 amino acids to about 70 amino acids, about 55 amino acids to about 65 amino acids, about 55 amino acids to about 60 amino acids, about 60 amino acids to about 1000 amino acids, about 60 amino acids to about 950 amino acids, about 60 amino acids to about 900 amino acids, about 60 amino acids to about 850 amino acids, about 60 amino acids to about 800 amino acids amino acids, about 60 amino acids to about 750 amino acids, about 60 amino acids to about 700 amino acids, about 60 amino acids to about 650 amino acids, about 60 amino acids to about 600 amino acids, about 60 amino acids to about 550 amino acids, about 60 amino acids to about 500 amino acids, about 60 amino acids to about 450 amino acids, about 60 amino acids to about 400 amino acids, about 60 amino acids to about 350 amino acids, about 60 amino acids to about 300 amino acids, about 60 amino acids to about 280 amino acids, about 60 amino acids to about 260 amino acids, about 60 amino acids to about 240 amino acids, about 60 amino acids to about 220 amino acids, about 60 amino acids to about 200 amino acids, about 60 amino acids to about 195 amino acids, about 60 amino acids to about 190 amino acids, about 60 amino acids to about 185 amino acids, about 60 amino acids to about 180 amino acids, about 60 amino acids to about 175 amino acids, about 60 amino acids to about 170 amino acids, about 60 amino acids to about 165 amino acids, about 60 amino acids to about 160 amino acids, about 60 amino acids to about 155 amino acids, about 60 amino acids to about 150 amino acids amino acids, about 60 amino acids to about 145 amino acids, about 60 amino acids to about 140 amino acids, about 60 amino acids to about 135 amino acids, about 60 amino acids to about 130 amino acids, about 60 amino acids to about 125 amino acids, about 60 amino acids to about 120 amino acids, about 60 amino acids to about 115 amino acids, about 60 amino acids to about 110 amino acids, about 60 amino acids to about 105 amino acids, about 60 amino acids to about 100 amino acids, about 60 amino acids to about 95 amino acids, about 60 amino acids to about 90 amino acids, about 60 amino acids to about 85 amino acids, about 60 amino acids to about 80 amino acids, about 60 amino acids to about 75 amino acids, about 60 amino acids to about 70 amino acids, about 60 amino acids to about 65 amino acids, about 65 amino acids to about 1000 amino acids, about 65 amino acids to about 950 amino acids, about 65 amino acids to about 900 amino acids, about 65 amino acids to about 850 amino acids, about 65 amino acids to about 800 amino acids, about 65 amino acids to about 750 amino acids, about 65 amino acids to about 700 amino acids, about 65 amino acids to about 650 amino acids amino acids, about 65 amino acids to about 600 amino acids, about 65 amino acids to about 550 amino acids, about 65 amino acids to about 500 amino acids, about 65 amino acids to about 450 amino acids, about 65 amino acids to about 400 amino acids, about 65 amino acids to about 350 amino acids, about 65 amino acids to about 300 amino acids, about 65 amino acids to about 280 amino acids, about 65 amino acids to about 260 amino acids, about 65 amino acids to about 240 amino acids, about 65 amino acids to about 220 amino acids, about 65 amino acids to about 200 amino acids, about 65 amino acids to about 195 amino acids, about 65 amino acids to about 190 amino acids, about 65 amino acids to about 185 amino acids, about 65 amino acids to about 180 amino acids, about 65 amino acids to about 175 amino acids, about 65 amino acids to about 170 amino acids, about 65 amino acids to about 165 amino acids, about 65 amino acids to about 160 amino acids, about 65 amino acids to about 155 amino acids, about 65 amino acids to about 150 amino acids, about 65 amino acids to about 145 amino acids, about 65 amino acids to about 140 amino acids, about 65 amino acids to about 135 amino acids amino acids, about 65 amino acids to about 130 amino acids, about 65 amino acids to about 125 amino acids, about 65 amino acids to about 120 amino acids, about 65 amino acids to about 115 amino acids, about 65 amino acids to about 110 amino acids, about 65 amino acids to about 105 amino acids, about 65 amino acids to about 100 amino acids, about 65 amino acids to about 95 amino acids, about 65 amino acids to about 90 amino acids, about 65 amino acids to about 85 amino acids, about 65 amino acids to about 80 amino acids, about 65 amino acids to about 75 amino acids, about 65 amino acids to about 70 amino acids, about 70 amino acids to about 1000 amino acids, about 70 amino acids to about 950 amino acids, about 70 amino acids to about 900 amino acids, about 70 amino acids to about 850 amino acids, about 70 amino acids to about 800 amino acids, about 70 amino acids to about 750 amino acids, about 70 amino acids to about 700 amino acids, about 70 amino acids to about 650 amino acids, about 70 amino acids to about 600 amino acids, about 70 amino acids to about 550 amino acids, about 70 amino acids to about 500 amino acids, about 70 amino acids to about 450 amino acids amino acids, about 70 amino acids to about 400 amino acids, about 70 amino acids to about 350 amino acids, about 70 amino acids to about 300 amino acids, about 70 amino acids to about 280 amino acids, about 70 amino acids to about 260 amino acids, about 70 amino acids to about 240 amino acids, about 70 amino acids to about 220 amino acids, about 70 amino acids to about 200 amino acids, about 70 amino acids to about 195 amino acids, about 70 amino acids to about 190 amino acids, about 70 amino acids to about 185 amino acids, about 70 amino acids to about 180 amino acids, about 70 amino acids to about 175 amino acids, about 70 amino acids to about 170 amino acids, about 70 amino acids to about 165 amino acids, about 70 amino acids to about 160 amino acids, about 70 amino acids to about 155 amino acids, about 70 amino acids to about 150 amino acids, about 70 amino acids to about 145 amino acids, about 70 amino acids to about 140 amino acids, about 70 amino acids to about 135 amino acids, about 70 amino acids to about 130 amino acids, about 70 amino acids to about 125 amino acids, about 70 amino acids to about 120 amino acids, about 70 amino acids to about 115 amino acids amino acids, about 70 amino acids to about 110 amino acids, about 70 amino acids to about 105 amino acids, about 70 amino acids to about 100 amino acids, about 70 amino acids to about 95 amino acids, about 70 amino acids to about 90 amino acids, about 70 amino acids to about 85 amino acids, about 70 amino acids to about 80 amino acids, about 70 amino acids to about 75 amino acids, about 75 amino acids to about 1000 amino acids, about 75 amino acids to about 950 amino acids, about 75 amino acids to about 900 amino acids, about 75 amino acids to about 850 amino acids, about 75 amino acids to about 800 amino acids, about 75 amino acids to about 750 amino acids, about 75 amino acids to about 700 amino acids, about 75 amino acids to about 650 amino acids, about 75 amino acids to about 600 amino acids, about 75 amino acids to about 550 amino acids, about 75 amino acids to about 500 amino acids, about 75 amino acids to about 450 amino acids, about 75 amino acids to about 400 amino acids, about 75 amino acids to about 350 amino acids, about 75 amino acids to about 300 amino acids, about 75 amino acids to about 280 amino acids, about 75 amino acids to about 260 amino acids amino acids, about 75 amino acids to about 240 amino acids, about 75 amino acids to about 220 amino acids, about 75 amino acids to about 200 amino acids, about 75 amino acids to about 195 amino acids, about 75 amino acids to about 190 amino acids, about 75 amino acids to about 185 amino acids, about 75 amino acids to about 180 amino acids, about 75 amino acids to about 175 amino acids, about 75 amino acids to about 170 amino acids, about 75 amino acids to about 165 amino acids, about 75 amino acids to about 160 amino acids, about 75 amino acids to about 155 amino acids, about 75 amino acids to about 150 amino acids, about 75 amino acids to about 145 amino acids, about 75 amino acids to about 140 amino acids, about 75 amino acids to about 135 amino acids, about 75 amino acids to about 130 amino acids, about 75 amino acids to about 125 amino acids, about 75 amino acids to about 120 amino acids, about 75 amino acids to about 115 amino acids, about 75 amino acids to about 110 amino acids, about 75 amino acids to about 105 amino acids, about 75 amino acids to about 100 amino acids, about 75 amino acids to about 95 amino acids, about 75 amino acids to about 90 amino acids amino acids, about 75 amino acids to about 85 amino acids, about 75 amino acids to about 80 amino acids, about 80 amino acids to about 1000 amino acids, about 80 amino acids to about 950 amino acids, about 80 amino acids to about 900 amino acids, about 80 amino acids to about 850 amino acids, about 80 amino acids to about 800 amino acids, about 80 amino acids to about 750 amino acids, about 80 amino acids to about 700 amino acids, about 80 amino acids to about 650 amino acids, about 80 amino acids to about 600 amino acids, about 80 amino acids to about 550 amino acids, about 80 amino acids to about 500 amino acids, about 80 amino acids to about 450 amino acids, about 80 amino acids to about 400 amino acids, about 80 amino acids to about 350 amino acids, about 80 amino acids to about 300 amino acids, about 80 amino acids to about 280 amino acids, about 80 amino acids to about 260 amino acids, about 80 amino acids to about 240 amino acids, about 80 amino acids to about 220 amino acids, about 80 amino acids to about 200 amino acids, about 80 amino acids to about 195 amino acids, about 80 amino acids to about 190 amino acids, about 80 amino acids to about 185 amino acids amino acids, about 80 amino acids to about 180 amino acids, about 80 amino acids to about 175 amino acids, about 80 amino acids to about 170 amino acids, about 80 amino acids to about 165 amino acids, about 80 amino acids to about 160 amino acids, about 80 amino acids to about 155 amino acids, about 80 amino acids to about 150 amino acids, about 80 amino acids to about 145 amino acids, about 80 amino acids to about 140 amino acids, about 80 amino acids to about 135 amino acids, about 80 amino acids to about 130 amino acids, about 80 amino acids to about 125 amino acids, about 80 amino acids to about 120 amino acids, about 80 amino acids to about 115 amino acids, about 80 amino acids to about 110 amino acids, about 80 amino acids to about 105 amino acids, about 80 amino acids to about 100 amino acids, about 80 amino acids to about 95 amino acids, about 80 amino acids to about 90 amino acids, about 80 amino acids to about 85 amino acids, about 85 amino acids to about 1000 amino acids, about 85 amino acids to about 950 amino acids, about 85 amino acids to about 900 amino acids, about 85 amino acids to about 850 amino acids, about 85 amino acids to about 800 amino acids amino acids, about 85 amino acids to about 750 amino acids, about 85 amino acids to about 700 amino acids, about 85 amino acids to about 650 amino acids, about 85 amino acids to about 600 amino acids, about 85 amino acids to about 550 amino acids, about 85 amino acids to about 500 amino acids, about 85 amino acids to about 450 amino acids, about 85 amino acids to about 400 amino acids, about 85 amino acids to about 350 amino acids, about 85 amino acids to about 300 amino acids, about 85 amino acids to about 280 amino acids, about 85 amino acids to about 260 amino acids, about 85 amino acids to about 240 amino acids, about 85 amino acids to about 220 amino acids, about 85 amino acids to about 200 amino acids, about 85 amino acids to about 195 amino acids, about 85 amino acids to about 190 amino acids, about 85 amino acids to about 185 amino acids, about 85 amino acids to about 180 amino acids, about 85 amino acids to about 175 amino acids, about 85 amino acids to about 170 amino acids, about 85 amino acids to about 165 amino acids,
about 85 amino acids to about 160 amino acids, about 85 amino acids to about 155 amino acids, about 85 amino acids to about 150 amino acids, about 85 amino acids to about 145 amino acids, about 85 amino acids to about 140 amino acids, about 85 amino acids to about 135 amino acids, about 85 amino acids to about 130 amino acids, about 85 amino acids to about 125 amino acids, about 85 amino acids to about 120 amino acids, about 85 amino acids to about 115 amino acids, about 85 amino acids to about 110 amino acids, about 85 amino acids to about 105 amino acids, about 85 amino acids to about 100 amino acids, about 85 amino acids to about 95 amino acids, about 85 amino acids to about 90 amino acids, about 90 amino acids to about 1000 amino acids, about 90 amino acids to about 950 amino acids, about 90 amino acids to about 900 amino acids, about 90 amino acids to about 850 amino acids amino acids, about 90 amino acids to about 800 amino acids, about 90 amino acids to about 750 amino acids, about 90 amino acids to about 700 amino acids, about 90 amino acids to about 650 amino acids, about 90 amino acids to about 600 amino acids, about 90 amino acids to about 550 amino acids, about 90 amino acids to about 500 amino acids, about 90 amino acids to about 450 amino acids, about 90 amino acids to about 400 amino acids, about 90 amino acids to about 350 amino acids, about 90 amino acids to about 300 amino acids, about 90 amino acids to about 280 amino acids, about 90 amino acids to about 260 amino acids, about 90 amino acids to about 240 amino acids, about 90 amino acids to about 220 amino acids, about 90 amino acids to about 200 amino acids, about 90 amino acids to about 195 amino acids, about 90 amino acids to about 190 amino acids, about 90 amino acids to about 185 amino acids, about 90 amino acids to about 180 amino acids, about 90 amino acids to about 175 amino acids, about 90 amino acids to about 170 amino acids, about 90 amino acids to about 165 amino acids, about 90 amino acids to about 160 amino acids, about 90 amino acids to about 155 amino acids , about 90 amino acids to abou
0 amino acids to about 650 amino acids, about 450 amino acids to about 600 amino acids, about 450 amino acids to about 550 amino acids, about 450 amino acids to about 500 amino acids, about 500 amino acids to about 1000 amino acids, about 500 amino acids to about 950 amino acids, about 500 amino acids to about 900 amino acids, about 500 amino acids to about 850 amino acids, about 500 amino acids to about 800 amino acids, about 500 amino acids to about 750 amino acids, about 500 amino acids to about 700 amino acids, about 500 amino acids to about 650 amino acids, about 500 amino acids to about 600 amino acids, about 500 amino acids to about 550 amino acids, about 550 amino acids to about 1000 amino acids, about 550 amino acids to about 950 amino acids, about 550 amino acids to about 900 amino acids, about 550 amino acids to about 850 amino acids, about 550 amino acids to about 800 amino acids , about 550 to about 750 amino acids, about 550 to about 700 amino acids, about 550 to about 650 amino acids, about 550 to about 600 amino acids, about 600 to about 1000 amino acids, about 600 to about 950 amino acids, about 600 amino acids to about 900 amino acids, about 600 amino acids to about 850 amino acids, about 600 amino acids to about 800 amino acids, about 600 amino acids to about 750 amino acids, about 600 amino acids to about 700 amino acids, about 600 amino acids to about 650 amino acids, about 650 amino acids to about 1000 amino acids, about 650 amino acids to about 950 amino acids, about 650 amino acids to about 900 amino acids, about 650 amino acids to about 850 amino acids, about 650 amino acids to about 800 amino acids, about 650 amino acids to about 750 amino acids, about 650 amino acids to about 700 amino acids, about 700 amino acids to about 1000 amino acids, about 700 amino acids to about 950 amino acids, about 700 amino acids to about 900 amino acids, about 700 amino acids to about 850 amino acids, about 700 amino acids to about 800 amino acids, about 700 amino acids to about 750 amino acids , about 750 to about 1000 amino acids, about 750 to about 950 amino acids, about 750 to about 900 amino acids, about 750 to about 850 amino acids, about 750 to about 800 amino acids, about 800 to about 1000 amino acids, about 800 amino acids to about 950 amino acids, about 800 amino acids to about 900 amino acids, about 800 amino acids to about 850 amino acids, about 850 amino acids to about 1000 amino acids, about 850 amino acids to about 950 amino acids, about 850 amino acids to about 900 amino acids, about 900 amino acids It can have a total number of amino acids from to about 1000 amino acids, from about 900 amino acids to about 950 amino acids, or from about 950 amino acids to about 1000 amino acids.
本明細書に記載の標的結合ドメインのうちのいずれも、1×10-7M未満、1×10-8M未満、1×10-9M未満、1×10-10M未満、1×10-11M未満、1×10-12M未満、又は1×10-13M未満の解離平衡定数(KD)でその標的に結合することができる。いくつかの実施形態では、本明細書に提供される抗原結合タンパク質構築物は、約1×10-3M~約1×10-5M、約1×10-4M~約1×10-6M、約1×10-5M~約1×10-7M、約1×10-6M~約1×10-8M、約1×10-7M~約1×10-9M、約1×10-8M~約1×10-10M、又は約1×10-9M~約1×10-11M(これらの上限及び下限も含む)のKDで特定の抗原に結合することができる。 Any of the target binding domains described herein are less than 1×10 −7 M, less than 1×10 −8 M, less than 1×10 −9 M, less than 1×10 −10 M, 1×10 It can bind its target with a dissociation equilibrium constant (K D ) of less than −11 M, less than 1×10 −12 M, or less than 1×10 −13 M. In some embodiments, the antigen binding protein constructs provided herein are about 1×10 −3 M to about 1×10 −5 M, about 1×10 −4 M to about 1×10 −6 M, about 1×10 −5 M to about 1×10 −7 M, about 1×10 −6 M to about 1×10 −8 M, about 1×10 −7 M to about 1×10 −9 M, binds to a particular antigen with a K D of from about 1×10 −8 M to about 1×10 −10 M, or from about 1×10 −9 M to about 1×10 −11 M, including these upper and lower limits can do.
本明細書に記載の標的結合ドメインのうちのいずれも、約1pM~約30nM(例えば、約1pM~約25nM、約1pM~約20nM、約1pM~約15nM、約1pM~約10nM、約1pM~約5nM、約1pM~約2nM、約1pM~約1nM、約1pM~約950pM、約1pM~約900pM、約1pM~約850pM、約1pM~約800pM、約1pM~約750pM、約1pM~約700pM、約1pM~約650pM、約1pM~約600pM、約1pM~約550pM、約1pM~約500pM、約1pM~約450pM、約1pM~約400pM、約1pM~約350pM、約1pM~約300pM、約1pM~約250pM、約1pM~約200pM、約1pM~約150pM、約1pM~約100pM、約1pM~約90pM、約1pM~約80pM、約1pM~約70pM、約1pM~約60pM、約1pM~約50pM、約1pM~約40pM、約1pM~約30pM、約1pM~約20pM、約1pM~約10pM、約1pM~約5pM、約1pM~約4pM、約1pM~約3pM、約1pM~約2pM、約2pM~約30nM、約2pM~約25nM、約2pM~約20nM、約2pM~約15nM、約2pM~約10nM、約2pM~約5nM、約2pM~約2nM、約2pM~約1nM、約2pM~約950pM、約2pM~約900pM、約2pM~約850pM、約2pM~約800pM、約2pM~約750pM、約2pM~約700pM、約2pM~約650pM、約2pM~約600pM、約2pM~約550pM、約2pM~約500pM、約2pM~約450pM、約2pM~約400pM、約2pM~約350pM、約2pM~約300pM、約2pM~約250pM、約2pM~約200pM、約2pM~約150pM、約2pM~約100pM、約2pM~約90pM、約2pM~約80pM、約2pM~約70pM、約2pM~約60pM、約2pM~約50pM、約2pM~約40pM、約2pM~約30pM、約2pM~約20pM、約2pM~約10pM、約2pM~約5pM、約2pM~約4pM、約2pM~約3pM、約5pM~約30nM、約5pM~約25nM、約5pM~約20nM、約5pM~約15nM、約5pM~約10nM、約5pM~約5nM、約5pM~約2nM、約5pM~約1nM、約5pM~約950pM、約5pM~約900pM、約5pM~約850pM、約5pM~約800pM、約5pM~約750pM、約5pM~約700pM、約5pM~約650pM、約5pM~約600pM、約5pM~約550pM、約5pM~約500pM、約5pM~約450pM、約5pM~約400pM、約5pM~約350pM、約5pM~約300pM、約5pM~約250pM、約5pM~約200pM、約5pM~約150pM、約5pM~約100pM、約5pM~約90pM、約5pM~約80pM、約5pM~約70pM、約5pM~約60pM、約5pM~約50pM、約5pM~約40pM、約5pM~約30pM、約5pM~約20pM、約5pM~約10pM、約10pM~約30nM、約10pM~約25nM、約10pM~約20nM、約10pM~約15nM、約10pM~約10nM、約10pM~約5nM、約10pM~約2nM、約10pM~約1nM、約10pM~約950pM、約10pM~約900pM、約10pM~約850pM、約10pM~約800pM、約10pM~約750pM、約10pM~約700pM、約10pM~約650pM、約10pM~約600pM、約10pM~約550pM、約10pM~約500pM、約10pM~約450pM、約10pM~約400pM、約10pM~約350pM、約10pM~約300pM、約10pM~約250pM、約10pM~約200pM、約10pM~約150pM、約10pM~約100pM、約10pM~約90pM、約10pM~約80pM、約10pM~約70pM、約10pM~約60pM、約10pM~約50pM、約10pM~約40pM、約10pM~約30pM、約10pM~約20pM、約15pM~約30nM、約15pM~約25nM、約15pM~約20nM、約15pM~約15nM、約15pM~約10nM、約15pM~約5nM、約15pM~約2nM、約15pM~約1nM、約15pM~約950pM、約15pM~約900pM、約15pM~約850pM、約15pM~約800pM、約15pM~約750pM、約15pM~約700pM、約15pM~約650pM、約15pM~約600pM、約15pM~約550pM、約15pM~約500pM、約15pM~約450pM、約15pM~約400pM、約15pM~約350pM、約15pM~約300pM、約15pM~約250pM、約15pM~約200pM、約15pM~約150pM、約15pM~約100pM、約15pM~約90pM、約15pM~約80pM、約15pM~約70pM、約15pM~約60pM、約15pM~約50pM、約15pM~約40pM、約15pM~約30pM、約15pM~約20pM、約20pM~約30nM、約20pM~約25nM、約20pM~約20nM、約20pM~約15nM、約20pM~約10nM、約20pM~約5nM、約20pM~約2nM、約20pM~約1nM、約20pM~約950pM、約20pM~約900pM、約20pM~約850pM、約20pM~約800pM、約20pM~約750pM、約20pM~約700pM、約20pM~約650pM、約20pM~約600pM、約20pM~約550pM、約20pM~約500pM、約20pM~約450pM、約20pM~約400pM、約20pM~約350pM、約20pM~約300pM、約20pM~約250pM、約20pM~約20pM、約200pM~約150pM、約20pM~約100pM、約20pM~約90pM、約20pM~約80pM、約20pM~約70pM、約20pM~約60pM、約20pM~約50pM、約20pM~約40pM、約20pM~約30pM、約30pM~約30nM、約30pM~約25nM、約30pM~約30nM、約30pM~約15nM、約30pM~約10nM、約30pM~約5nM、約30pM~約2nM、約30pM~約1nM、約30pM~約950pM、約30pM~約900pM、約30pM~約850pM、約30pM~約800pM、約30pM~約750pM、約30pM~約700pM、約30pM~約650pM、約30pM~約600pM、約30pM~約550pM、約30pM~約500pM、約30pM~約450pM、約30pM~約400pM、約30pM~約350pM、約30pM~約300pM、約30pM~約250pM、約30pM~約200pM、約30pM~約150pM、約30pM~約100pM、約30pM~約90pM、約30pM~約80pM、約30pM~約70pM、約30pM~約60pM、約30pM~約50pM、約30pM~約40pM、約40pM~約30nM、約40pM~約25nM、約40pM~約30nM、約40pM~約15nM、約40pM~約10nM、約40pM~約5nM、約40pM~約2nM、約40pM~約1nM、約40pM~約950pM、約40pM~約900pM、約40pM~約850pM、約40pM~約800pM、約40pM~約750pM、約40pM~約700pM、約40pM~約650pM、約40pM~約600pM、約40pM~約550pM、約40pM~約500pM、約40pM~約450pM、約40pM~約400pM、約40pM~約350pM、約40pM~約300pM、約40pM~約250pM、約40pM~約200pM、約40pM~約150pM、約40pM~約100pM、約40pM~約90pM、約40pM~約80pM、約40pM~約70pM、約40pM~約60pM、約40pM~約50pM、約50pM~約30nM、約50pM~約25nM、約50pM~約30nM、約50pM~約15nM、約50pM~約10nM、約50pM~約5nM、約50pM~約2nM、約50pM~約1nM、約50pM~約950pM、約50pM~約900pM、約50pM~約850pM、約50pM~約800pM、約50pM~約750pM、約50pM~約700pM、約50pM~約650pM、約50pM~約600pM、約50pM~約550pM、約50pM~約500pM、約50pM~約450pM、約50pM~約400pM、約50pM~約350pM、約50pM~約300pM、約50pM~約250pM、約50pM~約200pM、約50pM~約150pM、約50pM~約100pM、約50pM~約90pM、約50pM~約80pM、約50pM~約70pM、約50pM~約60pM、約60pM~約30nM、約60pM~約25nM、約60pM~約30nM、約60pM~約15nM、約60pM~約10nM、約60pM~約5nM、約60pM~約2nM、約60pM~約1nM、約60pM~約950pM、約60pM~約900pM、約60pM~約850pM、約60pM~約800pM、約60pM~約750pM、約60pM~約700pM、約60pM~約650pM、約60pM~約600pM、約60pM~約550pM、約60pM~約500pM、約60pM~約450pM、約60pM~約400pM、約60pM~約350pM、約60pM~約300pM、約60pM~約250pM、約60pM~約200pM、約60pM~約150pM、約60pM~約100pM、約60pM~約90pM、約60pM~約80pM、約60pM~約70pM、約70pM~約30nM、約70pM~約25nM、約70pM~約30nM、約70pM~約15nM、約70pM~約10nM、約70pM~約5nM、約70pM~約2nM、約70pM~約1nM、約70pM~約950pM、約70pM~約900pM、約70pM~約850pM、約70pM~約800pM、約70pM~約750pM、約70pM~約700pM、約70pM~約650pM、約70pM~約600pM、約70pM~約550pM、約70pM~約500pM、約70pM~約450pM、約70pM~約400pM、約70pM~約350pM、約70pM~約300pM、約70pM~約250pM、約70pM~約200pM、約70pM~約150pM、約70pM~約100pM、約70pM~約90pM、約70pM~約80pM、約80pM~約30nM、約80pM~約25nM、約80pM~約30nM、約80pM~約15nM、約80pM~約10nM、約80pM~約5nM、約80pM~約2nM、約80pM~約1nM、約80pM~約950pM、約80pM~約900pM、約80pM~約850pM、約80pM~約800pM、約80pM~約750pM、約80pM~約700pM、約80pM~約650pM、約80pM~約600pM、約80pM~約550pM、約80pM~約500pM、約80pM~約450pM、約80pM~約400pM、約80pM~約350pM、約80pM~約300pM、約80pM~約250pM、
約80pM~約200pM、約80pM~約150pM、約80pM~約100pM、約80pM~約90pM、約90pM~約30nM、約90pM~約25nM、約90pM~約30nM、約90pM~約15nM、約90pM~約10nM、約90pM~約5nM、約90pM~約2nM、約90pM~約1nM、約90pM~約950pM、約90pM~約900pM、約90pM~約850pM、約90pM~約800pM、約90pM~約750pM、約90pM~約700pM、約90pM~約650pM、約90pM~約600pM、約90pM~約550pM、約90pM~約500pM、約90pM~約450pM、約90pM~約400pM、約90pM~約350pM、約90pM~約300pM、約90pM~約250pM、約90pM~約200pM、約90pM~約150pM、約90pM~約100pM、約100pM~約30nM、約100pM~約25nM、約100pM~約30nM、約100pM~約15nM、約100pM~約10nM、約100pM~約5nM、約100pM~約2nM、約100pM~約1nM、約100pM~約950pM、約100pM~約900pM、約100pM~約850pM、約100pM~約800pM、約100pM~約750pM、約100pM~約700pM、約100pM~約650pM、約100pM~約600pM、約100pM~約550pM、約100pM~約500pM、約100pM~約450pM、約100pM~約400pM、約100pM~約350pM、約100pM~約300pM、約100pM~約250pM、約100pM~約200pM、約100pM~約150pM、約150pM~約30nM、約150pM~約25nM、約150pM~約30nM、約150pM~約15nM、約150pM~約10nM、約150pM~約5nM、約150pM~約2nM、約150pM~約1nM、約150pM~約950pM、約150pM~約900pM、約150pM~約850pM、約150pM~約800pM、約150pM~約750pM、約150pM~約700pM、約150pM~約650pM、約150pM~約600pM、約150pM~約550pM、約150pM~約500pM、約150pM~約450pM、約150pM~約400pM、約150pM~約350pM、約150pM~約300pM、約150pM~約250pM、約150pM~約200pM、約200pM~約30nM、約200pM~約25nM、約200pM~約30nM、約200pM~約15nM、約200pM~約10nM、約200pM~約5nM、約200pM~約2nM、約200pM~約1nM、約200pM~約950pM、約200pM~約900pM、約200pM~約850pM、約200pM~約800pM、約200pM~約750pM、約200pM~約700pM、約200pM~約650pM、約200pM~約600pM、約200pM~約550pM、約200pM~約500pM、約200pM~約450pM、約200pM~約400pM、約200pM~約350pM、約200pM~約300pM、約200pM~約250pM、約300pM~約30nM、約300pM~約25nM、約300pM~約30nM、約300pM~約15nM、約300pM~約10nM、約300pM~約5nM、約300pM~約2nM、約300pM~約1nM、約300pM~約950pM、約300pM~約900pM、約300pM~約850pM、約300pM~約800pM、約300pM~約750pM、約300pM~約700pM、約300pM~約650pM、約300pM~約600pM、約300pM~約550pM、約300pM~約500pM、約300pM~約450pM、約300pM~約400pM、約300pM~約350pM、約400pM~約30nM、約400pM~約25nM、約400pM~約30nM、約400pM~約15nM、約400pM~約10nM、約400pM~約5nM、約400pM~約2nM、約400pM~約1nM、約400pM~約950pM、約400pM~約900pM、約400pM~約850pM、約400pM~約800pM、約400pM~約750pM、約400pM~約700pM、約400pM~約650pM、約400pM~約600pM、約400pM~約550pM、約400pM~約500pM、約500pM~約30nM、約500pM~約25nM、約500pM~約30nM、約500pM~約15nM、約500pM~約10nM、約500pM~約5nM、約500pM~約2nM、約500pM~約1nM、約500pM~約950pM、約500pM~約900pM、約500pM~約850pM、約500pM~約800pM、約500pM~約750pM、約500pM~約700pM、約500pM~約650pM、約500pM~約600pM、約500pM~約550pM、約600pM~約30nM、約600pM~約25nM、約600pM~約30nM、約600pM~約15nM、約600pM~約10nM、約600pM~約5nM、約600pM~約2nM、約600pM~約1nM、約600pM~約950pM、約600pM~約900pM、約600pM~約850pM、約600pM~約800pM、約600pM~約750pM、約600pM~約700pM、約600pM~約650pM、約700pM~約30nM、約700pM~約25nM、約700pM~約30nM、約700pM~約15nM、約700pM~約10nM、約700pM~約5nM、約700pM~約2nM、約700pM~約1nM、約700pM~約950pM、約700pM~約900pM、約700pM~約850pM、約700pM~約800pM、約700pM~約750pM、約800pM~約30nM、約800pM~約25nM、約800pM~約30nM、約800pM~約15nM、約800pM~約10nM、約800pM~約5nM、約800pM~約2nM、約800pM~約1nM、約800pM~約950pM、約800pM~約900pM、約800pM~約850pM、約900pM~約30nM、約900pM~約25nM、約900pM~約30nM、約900pM~約15nM、約900pM~約10nM、約900pM~約5nM、約900pM~約2nM、約900pM~約1nM、約900pM~約950pM、約1nM~約30nM、約1nM~約25nM、約1nM~約20nM、約1nM~約15nM、約1nM~約10nM、約1nM~約5nM、約2nM~約30nM、約2nM~約25nM、約2nM~約20nM、約2nM~約15nM、約2nM~約10nM、約2nM~約5nM、約4nM~約30nM、約4nM~約25nM、約4nM~約20nM、約4nM~約15nM、約4nM~約10nM、約4nM~約5nM、約5nM~約30nM、約5nM~約25nM、約5nM~約20nM、約5nM~約15nM、約5nM~約10nM、約10nM~約30nM、約10nM~約25nM、約10nM~約20nM、約10nM~約15nM、約15nM~約30nM、約15nM~約25nM、約15nM~約20nM、約20nM~約30nM、及び約20nM~約25nM)のKDでその標的に結合することができる。
Any of the target binding domains described herein are about 1 pM to about 30 nM (eg, about 1 pM to about 25 nM, about 1 pM to about 20 nM, about 1 pM to about 15 nM, about 1 pM to about 10 nM, about 1 pM to about 5 nM, about 1 pM to about 2 nM, about 1 pM to about 1 nM, about 1 pM to about 950 pM, about 1 pM to about 900 pM, about 1 pM to about 850 pM, about 1 pM to about 800 pM, about 1 pM to about 750 pM, about 1 pM to about 700 pM About 1 pM to about 250 pM, about 1 pM to about 200 pM, about 1 pM to about 150 pM, about 1 pM to about 100 pM, about 1 pM to about 90 pM, about 1 pM to about 80 pM, about 1 pM to about 70 pM, about 1 pM to about 60 pM, about 1 pM to about 50 pM, about 1 pM to about 40 pM, about 1 pM to about 30 pM, about 1 pM to about 20 pM, about 1 pM to about 10 pM, about 1 pM to about 5 pM, about 1 pM to about 4 pM, about 1 pM to about 3 pM, about 1 pM to about 2 pM About 2 pM to about 950 pM, about 2 pM to about 900 pM, about 2 pM to about 850 pM, about 2 pM to about 800 pM, about 2 pM to about 750 pM, about 2 pM to about 700 pM, about 2 pM to about 650 pM, about 2 pM to about 600 pM, about 2 pM to about 550 pM, about 2 pM to about 500 pM, about 2 pM to about 450 pM, about 2 pM to about 400 pM, about 2 pM to about 350 pM, about 2 pM to about 300 pM, about 2 pM to about 250 pM, about 2 pM to about 200 pM, about 2 pM to about 150 pM about 2 pM to about 100 pM, about 2 pM to about 90 pM, about 2 pM to about 80 pM, about 2 pM to about 70 pM, about 2 pM to about 60 pM, about 2 pM to about 50 pM, about 2 pM to about 40 pM, about 2 pM to about 20 pM, about 2 pM to about 10 pM, about 2 pM to about 5 pM, about 2 pM to about 4 pM, about 2 pM to about 3 pM, about 5 pM to about 30 nM, about 5 pM to about 25 nM, about 5 pM to about 20 nM, about 5 pM to about 15 nM, about 5 pM to about 10 nM, about 5 pM to about 5 nM, about 5 pM to about 2 nM, about 5 pM to about 1 nM, about 5 pM to about 950 pM, about 5 pM to about 900 pM, about 5 pM to about 850 pM, about 5 pM to about 800 pM About 5 pM to about 350 pM, about 5 pM to about 300 pM, about 5 pM to about 250 pM, about 5 pM to about 200 pM, about 5 pM to about 150 pM, about 5 pM to about 100 pM, about 5 pM to about 90 pM, about 5 pM to about 80 pM, about 5 pM to about 70 pM, about 5 pM to about 60 pM, about 5 pM to about 50 pM, about 5 pM to about 40 pM, about 5 pM to about 30 pM, about 5 pM to about 20 pM, about 5 pM to about 10 pM, about 10 pM to about 30 nM, about 10 pM to about 25 nM About 10 pM to about 850 pM, about 10 pM to about 800 pM, about 10 pM to about 750 pM, about 10 pM to about 700 pM, about 10 pM to about 650 pM, about 10 pM to about 600 pM, about 10 pM to about 550 pM, about 10 pM to about 500 pM, about 10 pM to about 450 pM, about 10 pM to about 400 pM, about 10 pM to about 350 pM, about 10 pM to about 300 pM, about 10 pM to about 250 pM, about 10 pM to about 200 pM, about 10 pM to about 150 pM, about 10 pM to about 100 pM, about 10 pM to about 90 pM About 15 pM to about 25 nM, about 15 pM to about 20 nM, about 15 pM to about 15 nM, about 15 pM to about 10 nM, about 15 pM to about 5 nM, about 15 pM to about 2 nM, about 15 pM to about 1 nM, about 15 pM to about 950 pM, about 15 pM to about 900 pM, about 15 pM to about 850 pM, about 15 pM to about 800 pM, about 15 pM to about 750 pM, about 15 pM to about 700 pM, about 15 pM to about 650 pM, about 15 pM to about 600 pM, about 15 pM to about 550 pM, about 15 pM to about 500 pM About 15 pM to about 90 pM, about 15 pM to about 80 pM, about 15 pM to about 70 pM, about 15 pM to about 60 pM, about 15 pM to about 50 pM, about 15 pM to about 40 pM, about 15 pM to about 30 pM, about 15 pM to about 20 pM, about 20 pM to about 30 nM, about 20 pM to about 25 nM, about 20 pM to about 20 nM, about 20 pM to about 15 nM, about 20 pM to about 10 nM, about 20 pM to about 5 nM, about 20 pM to about 2 nM, about 20 pM to about 1 nM, about 20 pM to about 950 pM About 20 pM to about 500 pM, about 20 pM to about 450 pM, about 20 pM to about 400 pM, about 20 pM to about 350 pM, about 20 pM to about 300 pM, about 20 pM to about 250 pM, about 20 pM to about 20 pM, about 200 pM to about 150 pM, about 20 pM to about 100 pM, about 20 pM to about 90 pM, about 20 pM to about 80 pM, about 20 pM to about 70 pM, about 20 pM to about 60 pM, about 20 pM to about 50 pM, about 20 pM to about 40 pM, about 20 pM to about 30 pM, about 30 pM to about 30 nM About 30 pM to about 900 pM, about 30 pM to about 850 pM, about 30 pM to about 800 pM, about 30 pM to about 750 pM, about 30 pM to about 700 pM, about 30 pM to about 650 pM, about 30 pM to about 600 pM, about 30 pM to about 550 pM, about 30 pM to about 500 pM, about 30 pM to about 450 pM, about 30 pM to about 400 pM, about 30 pM to about 350 pM, about 30 pM to about 300 pM, about 30 pM to about 250 pM, about 30 pM to about 200 pM, about 30 pM to about 150 pM, about 30 pM to about 100 pM About 40 pM to about 30 nM, about 40 pM to about 15 nM, about 40 pM to about 10 nM, about 40 pM to about 5 nM, about 40 pM to about 2 nM, about 40 pM to about 1 nM, about 40 pM to about 950 pM, about 40 pM to about 900 pM, about 40 pM to about 850 pM, about 40 pM to about 800 pM, about 40 pM to about 750 pM, about 40 pM to about 700 pM, about 40 pM to about 650 pM, about 40 pM to about 600 pM, about 40 pM to about 550 pM, about 40 pM to about 500 pM, about 40 pM to about 450 pM About 40 pM to about 80 pM, about 40 pM to about 70 pM, about 40 pM to about 60 pM, about 40 pM to about 50 pM, about 50 pM to about 30 nM, about 50 pM to about 25 nM, about 50 pM to about 30 nM, about 50 pM to about 15 nM, about 50 pM to about 10 nM, about 50 pM to about 5 nM, about 50 pM to about 2 nM, about 50 pM to about 1 nM, about 50 pM to about 950 pM, about 50 pM to about 900 pM, about 50 pM to about 850 pM, about 50 pM to about 800 pM, about 50 pM to about 750 pM About 50 pM to about 300 pM, about 50 pM to about 250 pM, about 50 pM to about 200 pM, about 50 pM to about 150 pM, about 50 pM to about 100 pM, about 50 pM to about 90 pM, about 50 pM to about 80 pM, about 50 pM to about 70 pM, about 50 pM to about 60 pM, about 60 pM to about 30 nM, about 60 pM to about 25 nM, about 60 pM to about 30 nM, about 60 pM to about 15 nM, about 60 pM to about 10 nM, about 60 pM to about 5 nM, about 60 pM to about 2 nM, about 60 pM to about 1 nM About 60 pM to about 550 pM, about 60 pM to about 500 pM, about 60 pM to about 450 pM, about 60 pM to about 400 pM, about 60 pM to about 350 pM, about 60 pM to about 300 pM, about 60 pM to about 250 pM, about 60 pM to about 200 pM, about 60 pM to about 150 pM, about 60 pM to about 100 pM, about 60 pM to about 90 pM, about 60 pM to about 80 pM, about 60 pM to about 70 pM, about 70 pM to about 30 nM, about 70 pM to about 25 nM, about 70 pM to about 30 nM, about 70 pM to about 15 nM About 70 pM to about 750 pM, about 70 pM to about 700 pM, about 70 pM to about 650 pM, about 70 pM to about 600 pM, about 70 pM to about 550 pM, about 70 pM to about 500 pM, about 70 pM to about 450 pM, about 70 pM to about 400 pM, about 70 pM to about 350 pM, about 70 pM to about 300 pM, about 70 pM to about 250 pM, about 70 pM to about 200 pM, about 70 pM to about 150 pM, about 70 pM to about 100 pM, about 70 pM to about 90 pM, about 70 pM to about 80 pM, about 80 pM to about 30 nM About 80 pM to about 900 pM, about 80 pM to about 850 pM, about 80 pM to about 800 pM, about 80 pM to about 750 pM, about 80 pM to about 700 pM, about 80 pM to about 650 pM, about 80 pM to about 600 pM, about 80 pM to about 550 pM, about 80 pM to about 500 pM, about 80 pM to about 450 pM, about 80 pM to about 400 pM, about 80 pM to about 350 pM, about 80 pM to about 300 pM, about 80 pM to about 250 pM,
about 80 pM to about 200 pM, about 80 pM to about 150 pM, about 80 pM to about 100 pM, about 80 pM to about 90 pM, about 90 pM to about 30 nM, about 90 pM to about 25 nM, about 90 pM to about 30 nM, about 90 pM to about 15 nM, about 90 pM to about 10 nM, about 90 pM to about 5 nM, about 90 pM to about 2 nM, about 90 pM to about 1 nM, about 90 pM to about 950 pM, about 90 pM to about 900 pM, about 90 pM to about 850 pM, about 90 pM to about 800 pM, about 90 pM to about 750 pM, about 90 pM to about 700 pM, about 90 pM to about 650 pM, about 90 pM to about 600 pM, about 90 pM to about 550 pM, about 90 pM to about 500 pM, about 90 pM to about 450 pM, about 90 pM to about 400 pM, about 90 pM to about 350 pM, about 90 pM to about 300 pM, about 90 pM to about 250 pM, about 90 pM to about 200 pM, about 90 pM to about 150 pM, about 90 pM to about 100 pM, about 100 pM to about 30 nM, about 100 pM to about 25 nM, about 100 pM to about 30 nM, about 100 pM to about 15 nM, about 100 pM to about 10 nM, about 100 pM to about 5 nM, about 100 pM to about 2 nM, about 100 pM to about 1 nM, about 100 pM to about 950 pM, about 100 pM to about 900 pM, about 100 pM to about 850 pM, about 100 pM to about 800 pM, about 100 pM to about 750 pM, about 100 pM to about 700 pM, about 100 pM to about 650 pM, about 100 pM to about 600 pM, about 100 pM to about 550 pM, about 100 pM to about 500 pM, about 100 pM to about 450 pM, about 100 pM to about 400 pM, about 100 pM to about 350 pM, about 100 pM to about 300 pM, about 100 pM to about 250 pM, about 100 pM to about 200 pM, about 100 pM to about 150 pM, about 150 pM to about 30 nM, about 150 pM to about 25 nM, about 150 pM to about 30 nM, about 150 pM to about 15 nM, about 150 pM to about 10 nM, about 150 pM to about 5 nM, about 150 pM to about 2 nM, about 150 pM to about 1 nM, about 150 pM to about 950 pM, about 150 pM to about 900 pM, about 150 pM to about 850 pM, about 150 pM to about 800 pM, about 150 pM to about 750 pM, about 150 pM to about 700 pM, about 150 pM to about 650 pM, about 150 pM to about 600 pM, about 150 pM to about 550 pM, about 150 pM to about 500 pM, about 150 pM to about 450 pM, about 150 pM to about 400 pM, about 150 pM to about 350 pM, about 150 pM to about 300 pM, about 150 pM to about 250 pM, about 150 pM to about 200 pM, about 200 pM to about 30 nM, about 200 pM to about 25 nM, about 200 pM to about 30 nM, about 200 pM to about 15 nM, about 200 pM to about 10 nM, about 200 pM to about 5 nM, about 200 pM to about 2 nM, about 200 pM to about 1 nM, about 200 pM to about 950 pM, about 200 pM to about 900 pM, about 200 pM to about 850 pM, about 200 pM to about 800 pM, about 200 pM to about 750 pM, about 200 pM to about 700 pM, about 200 pM to about 650 pM, about 200 pM to about 600 pM, about 200 pM to about 550 pM, about 200 pM to about 500 pM, about 200 pM to about 450 pM, about 200 pM to about 400 pM, about 200 pM to about 350 pM, about 200 pM to about 300 pM, about 200 pM to about 250 pM, about 300 pM to about 30 nM, about 300 pM to about 25 nM, about 300 pM to about 30 nM, about 300 pM to about 15 nM, about 300 pM to about 10 nM, about 300 pM to about 5 nM, about 300 pM to about 2 nM, about 300 pM to about 1 nM, about 300 pM to about 950 pM, about 300 pM to about 900 pM, about 300 pM to about 850 pM, about 300 pM to about 800 pM, about 300 pM to about 750 pM, about 300 pM to about 700 pM, about 300 pM to about 650 pM, about 300 pM to about 600 pM, about 300 pM to about 550 pM, about 300 pM to about 500 pM, about 300 pM to about 450 pM, about 300 pM to about 400 pM, about 300 pM to about 350 pM, about 400 pM to about 30 nM, about 400 pM to about 25 nM, about 400 pM to about 30 nM, about 400 pM to about 15 nM, about 400 pM to about 10 nM, about 400 pM to about 5 nM, about 400 pM to about 2 nM, about 400 pM to about 1 nM, about 400 pM to about 950 pM, about 400 pM to about 900 pM, about 400 pM to about 850 pM, about 400 pM to about 800 pM, about 400 pM to about 750 pM, about 400 pM to about 700 pM, about 400 pM to about 650 pM, about 400 pM to about 600 pM, about 400 pM to about 550 pM, about 400 pM to about 500 pM, about 500 pM to about 30 nM, about 500 pM to about 25 nM, about 500 pM to about 30 nM, about 500 pM to about 15 nM, about 500 pM to about 10 nM, about 500 pM to about 5 nM, about 500 pM to about 2 nM, about 500 pM to about 1 nM, about 500 pM to about 950 pM, about 500 pM to about 900 pM, about 500 pM to about 850 pM, about 500 pM to about 800 pM, about 500 pM to about 750 pM, about 500 pM to about 700 pM, about 500 pM to about 650 pM, about 500 pM to about 600 pM, about 500 pM to about 550 pM, about 600 pM to about 30 nM, about 600 pM to about 25 nM, about 600 pM to about 30 nM, about 600 pM to about 15 nM, about 600 pM to about 10 nM, about 600 pM to about 5 nM, about 600 pM to about 2 nM, about 600 pM to about 1 nM, about 600 pM to about 950 pM, about 600 pM to about 900 pM, about 600 pM to about 850 pM, about 600 pM to about 800 pM, about 600 pM to about 750 pM, about 600 pM to about 700 pM, about 600 pM to about 650 pM, about 700 pM to about 30 nM, about 700 pM to about 25 nM, about 700 pM to about 30 nM, about 700 pM to about 15 nM, about 700 pM to about 10 nM, about 700 pM to about 5 nM, about 700 pM to about 2 nM, about 700 pM to about 1 nM, about 700 pM to about 950 pM, about 700 pM to about 900 pM, about 700 pM to about 850 pM, about 700 pM to about 800 pM, about 700 pM to about 750 pM, about 800 pM to about 30 nM, about 800 pM to about 25 nM, about 800 pM to about 30 nM, about 800 pM to about 15 nM, about 800 pM to about 10 nM, about 800 pM to about 5 nM, about 800 pM to about 2 nM, about 800 pM to about 1 nM, about 800 pM to about 950 pM, about 800 pM to about 900 pM, about 800 pM to about 850 pM, about 900 pM to about 30 nM, about 900 pM to about 25 nM, about 900 pM to about 30 nM, about 900 pM to about 15 nM, about 900 pM to about 10 nM, about 900 pM to about 5 nM, about 900 pM to about 2 nM, about 900 pM to about 1 nM, about 900 pM to about 950 pM, about 1 nM to about 30 nM, about 1 nM to about 25 nM, about 1 nM to about 20 nM, about 1 nM to about 15 nM, about 1 nM to about 10 nM, about 1 nM to about 5 nM, about 2 nM to about 30 nM, about 2 nM to about 25 nM, about 2 nM to about 20 nM, about 2 nM to about 15 nM, about 2 nM to about 10 nM, about 2 nM to about 5 nM, about 4 nM to about 30 nM, about 4 nM to about 25 nM, about 4 nM to about 20 nM, about 4 nM to about 15 nM, about 4 nM to about 10 nM, about 4 nM to about 5 nM, about 5 nM to about 30 nM, about 5 nM to about 25 nM, about 5 nM to about 20 nM, about 5 nM to about 15 nM, about 5 nM to about 10 nM, about 10 nM to about 30 nM, about 10 nM to about 25 nM, about 10 nM to about 20 nM, about 10 nM to about 15 nM, about 15 nM about 30 nM, about 15 nM to about 25 nM, about 15 nM to about 20 nM, about 20 nM to about 30 nM, and about 20 nM to about 25 nM).
本明細書に記載の標的結合ドメインのうちのいずれも、約1nM~約10nM(例えば、約1nM~約9nM、約1nM~約8nM、約1nM~約7nM、約1nM~約6nM、約1nM~約5nM、約1nM~約4nM、約1nM~約3nM、約1nM~約2nM、約2nM~約10nM、約2nM~約9nM、約2nM~約8nM、約2nM~約7nM、約2nM~約6nM、約2nM~約5nM、約2nM~約4nM、約2nM~約3nM、約3nM~約10nM、約3nM~約9nM、約3nM~約8nM、約3nM~約7nM、約3nM~約6nM、約3nM~約5nM、約3nM~約4nM、約4nM~約10nM、約4nM~約9nM、約4nM~約8nM、約4nM~約7nM、約4nM~約6nM、約4nM~約5nM、約5nM~約10nM、約5nM~約9nM、約5nM~約8nM、約5nM~約7nM、約5nM~約6nM、約6nM~約10nM、約6nM~約9nM、約6nM~約8nM、約6nM~約7nM、約7nM~約10nM、約7nM~約9nM、約7nM~約8nM、約8nM~約10nM、約8nM~約9nM、及び約9nM~約10nM)のKDでその標的に結合することができる。 Any of the target binding domains described herein are about 1 nM to about 10 nM (eg, about 1 nM to about 9 nM, about 1 nM to about 8 nM, about 1 nM to about 7 nM, about 1 nM to about 6 nM, about 1 nM to about 5 nM, about 1 nM to about 4 nM, about 1 nM to about 3 nM, about 1 nM to about 2 nM, about 2 nM to about 10 nM, about 2 nM to about 9 nM, about 2 nM to about 8 nM, about 2 nM to about 7 nM, about 2 nM to about 6 nM About 3 nM to about 5 nM, about 3 nM to about 4 nM, about 4 nM to about 10 nM, about 4 nM to about 9 nM, about 4 nM to about 8 nM, about 4 nM to about 7 nM, about 4 nM to about 6 nM, about 4 nM to about 5 nM, about 5 nM to about 10 nM, about 5 nM to about 9 nM, about 5 nM to about 8 nM, about 5 nM to about 7 nM, about 5 nM to about 6 nM, about 6 nM to about 10 nM, about 6 nM to about 9 nM, about 6 nM to about 8 nM, about 6 nM to about 7 nM , about 7 nM to about 10 nM , about 7 nM to about 9 nM, about 7 nM to about 8 nM, about 8 nM to about 10 nM, about 8 nM to about 9 nM, and about 9 nM to about 10 nM). .
当該技術分野で既知の様々な異なる方法を使用して、本明細書に記載の抗原結合タンパク質構築物のうちのいずれのKD値も決定することができる(例えば、電気泳動移動度シフトアッセイ、フィルター結合アッセイ、表面プラズモン共鳴、及び生体分子結合反応速度アッセイ等)。 K D values for any of the antigen binding protein constructs described herein can be determined using a variety of different methods known in the art (e.g., electrophoretic mobility shift assays, filter binding assays, surface plasmon resonance, and biomolecule binding kinetic assays, etc.).
抗原結合ドメイン
本明細書に記載の一本鎖又は多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは、同じ抗原に特異的に結合する。これらの一本鎖又は多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは、同じエピトープに特異的に結合する。これらの一本鎖又は多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは、同じアミノ酸配列を含む。
Antigen Binding Domains In some embodiments of any of the single-chain or multi-chain chimeric polypeptides described herein, the first target binding domain and the second target binding domain are specific for the same antigen. connect to each other. In some embodiments of these single-chain or multi-chain chimeric polypeptides, the first target binding domain and the second target binding domain specifically bind the same epitope. In some embodiments of these single-chain or multi-chain chimeric polypeptides, the first target binding domain and the second target binding domain comprise the same amino acid sequence.
本明細書に記載の一本鎖又は多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは、異なる抗原に特異的に結合する。 In some embodiments of any of the single- or multi-chain chimeric polypeptides described herein, the first target-binding domain and the second target-binding domain specifically bind to different antigens. do.
本明細書に記載の一本鎖又は多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方が、抗原結合ドメインである。本明細書に記載の一本鎖又は多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは各々、抗原結合ドメインである。本明細書に記載の一本鎖又は多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、抗原結合ドメインは、scFv又は単一ドメイン抗体(例えば、VaHH又はVNARドメイン)を含むか、又はそれである。 In some embodiments of any of the single- or multi-chain chimeric polypeptides described herein, one or both of the first target binding domain and the second target binding domain is an antigen binding domain is. In some embodiments of any of the single- or multi-chain chimeric polypeptides described herein, the first target binding domain and the second target binding domain are each antigen binding domains. In some embodiments of any of the single- or multi-chain chimeric polypeptides described herein, the antigen-binding domain is a scFv or single domain antibody (eg, Va H H or V NAR domains) contains or is
いくつかの例では、抗原結合ドメイン(例えば、本明細書に記載の抗原結合ドメインのうちのいずれか)は、CD16a(例えば、米国特許第9,035,026号に記載のものを参照のこと)、CD28(例えば、米国特許第7,723,482号に記載のものを参照のこと)、CD3(例えば、米国特許第9,226,962号に記載のものを参照のこと)、CD33(例えば、米国特許第8,759,494号に記載のものを参照のこと)、CD20(例えば、WO2014/026054に記載のものを参照のこと)、CD19(例えば、米国特許第9,701,758号に記載のものを参照のこと)、CD22(例えば、WO2003/104425に記載のものを参照のこと)、CD123(例えば、WO2014/130635に記載のものを参照のこと)、IL-1R(例えば、米国特許第8,741,604号に記載のものを参照のこと)、IL-1(例えば、WO2014/095808に記載のものを参照のこと)、VEGF(例えば、米国特許第9,090,684号に記載のものを参照のこと)、IL-6R(例えば、米国特許第7,482,436号に記載のものを参照のこと)、IL-4(例えば、米国特許出願公開第2012/0171197号に記載のものを参照のこと)、IL-10(例えば、米国特許出願公開2016/0340413第号に記載のものを参照のこと)、PDL-1(例えば、Drees et al.,Protein Express.Purif.94:60-66,2014に記載のものを参照のこと)、TIGIT(例えば、米国特許出願公開第2017/0198042号に記載のものを参照のこと)、PD-1(例えば、米国特許第7,488,802号に記載のものを参照のこと)、TIM3(例えば、米国特許第8,552,156号に記載のものを参照のこと)、CTLA4(例えば、WO2012/120125に記載のものを参照のこと)、MICA(例えば、WO2016/154585に記載のものを参照のこと)、MICB(例えば、米国特許第8,753,640号に記載のものを参照のこと)、IL-6(例えば、Gejima et al.,Human Antibodies11(4):121-129,2002に記載のものを参照のこと)、IL-8(例えば、米国特許第6,117,980号に記載のものを参照のこと)、TNFα(例えば、Geng et al.,Immunol.Res.62(3):377-385,2015に記載のものを参照のこと)、CD26(例えば、WO2017/189526に記載のものを参照のこと)、CD36(例えば、米国特許出願公開第2015/0259429号に記載のものを参照のこと)、ULBP2(例えば、米国特許第9,273,136号に記載のものを参照のこと)、CD30(例えば、Homach et al.,Scand.J.Immunol.48(5):497-501,1998に記載のものを参照のこと)、CD200(例えば、米国特許第9,085,623号に記載のものを参照のこと)、IGF-1R(例えば、米国特許出願公開第2017/0051063号に記載のものを参照のこと)、MUC4AC(例えば、WO2012/170470に記載のものを参照のこと)、MUC5AC(例えば、米国特許第9,238,084号に記載のものを参照のこと)、Trop-2(例えば、WO2013/068946に記載のものを参照のこと)、CMET(例えば、Edwardraja et al.,Biotechnol.Bioeng.106(3):367-375,2010に記載のものを参照のこと)、EGFR(例えば、Akbari et al.,Protein Expr.Purif.127:8-15,2016に記載のものを参照のこと)、HER1(例えば、米国特許出願公開第2013/0274446号に記載のものを参照のこと)、HER2(例えば、Cao et al.,Biotechnol.Lett.37(7):1347-1354,2015に記載のものを参照のこと)、HER3(例えば、米国特許第9,505,843号に記載のものを参照のこと)、PSMA(例えば、Parker et al.,Protein Expr.Purif.89(2):136-145,2013に記載のものを参照のこと)、CEA(例えば、WO1995/015341に記載のものを参照のこと)、B7H3(例えば、米国特許第9,371,395号に記載のものを参照のこと)、EPCAM(例えば、WO2014/159531に記載のものを参照のこと)、BCMA(例えば、Smith et al.,Mol.Ther.26(6):1447-1456,2018に記載のものを参照のこと)、P-cadherin(例えば、米国特許第7,452,537号に記載のものを参照のこと)、CEACAM5(例えば、米国特許第9,617,345号に記載のものを参照のこと)、UL16結合タンパク質(例えば、WO2017/083612に記載のものを参照のこと)、HLA-DR(例えば、Pistillo et al.,Exp.Clin.Immunogenet.14(2):123-130,1997を参照のこと)、DLL4(例えば、WO2014/007513に記載のものを参照のこと)、TYRO3(例えば、WO2016/166348に記載のものを参照のこと)、AXL(例えば、WO2012/175692に記載のものを参照のこと)、MER(例えば、WO2016/106221に記載のものを参照のこと)、CD122(例えば、米国特許出願公開第2016/0367664号に記載のものを参照のこと)、CD155(例えば、WO2017/149538に記載のものを参照のこと)、又はPDGF-DD(例えば、米国特許第9,441,034号に記載のものを参照のこと)のうちのいずれか1つに特異的に結合することができる。 In some examples, the antigen binding domain (e.g., any of the antigen binding domains described herein) is CD16a (e.g., see those described in US Pat. No. 9,035,026). ), CD28 (see, for example, US Pat. No. 7,723,482), CD3 (see, for example, US Pat. No. 9,226,962), CD33 (see, for example, US Pat. No. 9,226,962). See, for example, US Pat. No. 8,759,494), CD20 (see, for example, WO2014/026054), CD19 (see, for example, US Pat. No. 9,701,758). CD22 (see, for example, WO2003/104425), CD123 (see, for example, WO2014/130635), IL-1R (for example, see , see, US Pat. No. 8,741,604), IL-1 (see, for example, WO2014/095808), VEGF (see, for example, US Pat. No. 9,090, 684), IL-6R (see, for example, US Pat. No. 7,482,436), IL-4 (see, for example, US Patent Application Publication No. 2012/ 0171197), IL-10 (see, e.g., US Patent Application Publication No. 2016/0340413), PDL-1 (e.g., Drees et al., Protein Express 94:60-66, 2014), TIGIT (see, eg, US Patent Application Publication No. 2017/0198042), PD-1 (see, eg, US See, for example, US Pat. No. 7,488,802), TIM3 (see, for example, US Pat. No. 8,552,156), CTLA4 (see, for example, WO2012/120125). ), MICA (see, for example, WO2016/154585), MICB (see, for example, US Pat. No. 8,753,640), IL- 6 (see, for example, Gejima et al., Human Antibodies 11(4):121-129, 2002), IL-8 (see, for example, US Pat. No. 6,117,980). see), TNFα (eg Geng et al. , Immunol. Res. 62(3):377-385, 2015), CD26 (see, e.g., WO2017/189526), CD36 (e.g., US Patent Application Publication No. 2015/0259429). ULBP2 (see, e.g., U.S. Patent No. 9,273,136), CD30 (e.g., Homach et al., Scand. J. Immunol. 48 ( 5):497-501, 1998), CD200 (see, for example, US Pat. No. 9,085,623), IGF-1R (see, for example, US patent applications). See, for example, Publication No. 2017/0051063), MUC4AC (see, for example, WO2012/170470), MUC5AC (for example, as described in U.S. Pat. No. 9,238,084). ), Trop-2 (see, eg, WO2013/068946), CMET (see, eg, Edwarddraja et al., Biotechnol. Bioeng. 106(3):367-375, 2010). EGFR (see, for example, Akbari et al., Protein Expr. Purif. 127:8-15, 2016), HER1 (see, for example, US Patent Application Publication No. 2013/ 0274446), HER2 (see, eg, Cao et al., Biotechnol. Lett. 37(7):1347-1354, 2015), HER3 (see, eg, US 9,505,843), PSMA (see, for example, Parker et al., Protein Expr. Purif. 89(2):136-145, 2013). ), CEA (see, for example, WO 1995/015341), B7H3 (see, for example, US Pat. No. 9,371,395), EPCAM (see, for example, WO 2014/159531). BCMA (see, for example, Smith et al., Mol. Ther. 26(6):1447-1456, 2018), P-cadherin (see, for example, US Patent 7,452,537), CEACAM5 (see, for example, US Pat. No. 9,617,345), UL16 binding proteins (see, for example, WO2017/083612). see description), HLA-DR (eg Pistillo et al. , Exp. Clin. Immunogenet. 14(2):123-130, 1997), DLL4 (see, for example, WO2014/007513), TYRO3 (see, for example, WO2016/166348), AXL (see, e.g., described in WO2012/175692), MER (see, e.g., described in WO2016/106221), CD122 (see, e.g., US Patent Application Publication No. 2016/0367664) ), CD155 (see, for example, WO2017/149538), or PDGF-DD (see, for example, US Pat. No. 9,441,034). can specifically bind to any one of them.
本明細書に記載の一本鎖又は多鎖キメラポリペプチドのうちのいずれかに存在する抗原結合ドメインは各々独立して、VHHドメイン、VNARドメイン、及びscFvからなる群から選択される。いくつかの実施形態では、本明細書に記載の抗原結合ドメインのうちのいずれかは、BiTe、(scFv)2、ナノボディ、ナノボディ-HSA、DART、TandAb、scDiabody、scDiabody-CH3、scFv-CH-CL-scFv、HSAbody、scDiabody-HAS、又はタンデム-scFvである。一本鎖キメラポリペプチド又は多鎖キメラポリペプチドのうちのいずれかで使用することができる抗原結合ドメインの追加の例は、当該技術分野で既知である。 Each antigen-binding domain present in any of the single- or multi-chain chimeric polypeptides described herein is independently selected from the group consisting of VHH domains, VNAR domains, and scFv. In some embodiments, any of the antigen binding domains described herein are BiTe, (scFv) 2 , Nanobody, Nanobody-HSA, DART, TandAb, scDiabody, scDiabody-CH3, scFv-CH- CL-scFv, HSAbody, scDiabody-HAS, or tandem-scFv. Additional examples of antigen binding domains that can be used in either single-chain chimeric polypeptides or multi-chain chimeric polypeptides are known in the art.
VHHドメインは、ラクダ科動物に見られ得る単一単量体可変抗体ドメインである。VNARドメインは、軟骨魚に見られ得る単一単量体可変抗体ドメインである。VHHドメイン及びVNARドメインの非限定的な態様は、例えば、Cromie et al.,Curr.Top.Med.Chem.15:2543-2557,2016、De Genst et al.,Dev.Comp.Immunol.30:187-198,2006、De Meyer et al.,Trends Biotechnol.32:263-270,2014、Kijanka et al.,Nanomedicine10:161-174,2015、Kovaleva et al.,Expert.Opin.Biol.Ther.14:1527-1539,2014、Krah et al.,Immunopharmacol.Immunotoxicol.38:21-28,2016、Mujic-Delic et al.,Trends Pharmacol.Sci.35:247-255,2014、Muyldermans,J.Biotechnol.74:277-302,2001、Muyldermans et al.,Trends Biochem.Sci.26:230-235,2001、Muyldermans,Ann.Rev.Biochem.82:775-797,2013、Rahbarizadeh et al.,Immunol.Invest.40:299-338,2011、Van Audenhove et al.,EBioMedicine 8:40-48,2016、Van Bockstaele et al.,Curr.Opin.Investig.Drugs 10:1212-1224,2009、Vincke et al.,Methods Mol.Biol.911:15-26,2012、及びWesolowski et al.,Med.Microbiol.Immunol.198:157-174,2009に記載されている。 VHH domains are single monomeric variable antibody domains that can be found in camelids. VNAR domains are single monomeric variable antibody domains that can be found in cartilaginous fish. Non-limiting aspects of V H H domains and V NAR domains are described, for example, in Cromie et al. , Curr. Top. Med. Chem. 15:2543-2557, 2016, De Genst et al. , Dev. Comp. Immunol. 30:187-198, 2006, De Meyer et al. , Trends Biotechnol. 32:263-270, 2014, Kijanka et al. , Nanomedicine 10:161-174, 2015, Kovaleva et al. , Expert. Opin. Biol. Ther. 14:1527-1539, 2014, Krah et al. , Immunopharmacol. Immunotoxicol. 38:21-28, 2016, Music-Delic et al. , Trends Pharmacol. Sci. 35:247-255, 2014; Biotechnol. 74:277-302, 2001, Muyldermans et al. , Trends Biochem. Sci. 26:230-235, 2001, Muyldermans, Ann. Rev. Biochem. 82:775-797, 2013, Rahbarizadeh et al. , Immunol. Invest. 40:299-338, 2011, Van Audenhove et al. , EBioMedicine 8:40-48, 2016, Van Bockstaele et al. , Curr. Opin. Investig. Drugs 10:1212-1224, 2009, Vincke et al. , Methods Mol. Biol. 911:15-26, 2012, and Wesolowski et al. , Med. Microbiol. Immunol. 198:157-174, 2009.
いくつかの実施形態では、本明細書に記載の一本鎖又は多鎖キメラポリペプチド内の抗原結合ドメインは各々、いずれもVHHドメインであるか、又は少なくとも1つの抗原結合ドメインがVHHドメインである。いくつかの実施形態では、本明細書に記載の一本鎖又は多鎖キメラポリペプチド内の抗原結合ドメインは各々、いずれもVNARドメインであるか、又は少なくとも1つの抗原結合ドメインがVNARドメインである。いくつかの実施形態では、本明細書に記載の一本鎖又は多鎖キメラポリペプチドの抗原結合ドメインは各々、いずれもscFvドメインであるか、又は少なくとも1つの抗原結合ドメインがscFvドメインである。 In some embodiments, each of the antigen binding domains within the single-chain or multi-chain chimeric polypeptides described herein are both VHH domains, or at least one antigen binding domain is a VHH domain . In some embodiments, each of the antigen binding domains within the single or multi-chain chimeric polypeptides described herein are both VNAR domains, or at least one antigen binding domain is a VNAR domain. . In some embodiments, each of the antigen binding domains of the single or multi-chain chimeric polypeptides described herein are both scFv domains, or at least one antigen binding domain is an scFv domain.
いくつかの実施形態では、一本鎖又は多鎖キメラポリペプチドに存在する2つ以上のポリペプチドは、集合して(例えば、非共有結合的に集合して)、本明細書に記載の抗原結合ドメインのうちのいずれか、例えば、抗体の抗原結合断片(例えば、本明細書に記載の抗体の抗原結合断片のうちのいずれか)、VHH-scAb、VHH-Fab、二重scFab、F(ab’)2、ダイアボディ、crossMab、DAF(ツーインワン)、DAF(フォーインワン)、DutaMab、DT-IgG、ノブ・イン・ホール共通軽鎖、ノブ・イン・ホール集合体、電荷対、Fabアーム交換、SEEDbody、LUZ-Y、Fcab、κλ-ボディ、直交Fab、DVD-IgG、IgG(H)-scFv、scFv-(H)IgG、IgG(L)-scFv、scFv-(L)IgG、IgG(L,H)-Fv、IgG(H)-V、V(H)-IgG、IgG(L)-V、V(L)-IgG、KIH IgG-scFab、2scFv-IgG、IgG-2scFv、scFv4-Ig、Zybody、DVI-IgG、ダイアボディ-CH3、トリプルボディ、ミノ抗体、ミニボディ、TriBiミニボディ、scFv-CH3 KIH、Fab-scFv、F(ab’)2-scFv2、scFv-KIH、Fab-scFv-Fc、四価HCAb、scダイアボディ-Fc、ダイアボディ-Fc、タンデムscFv-Fc、イントラボディ、ドック・アンド・ロック、lmmTAC、IgG-IgGコンジュゲート、Cov-X-Body、及びscFv1-PEG-scFv2を形成することができる。これらの要素の説明については、例えば、全体が本明細書に組み込まれるSpiess et al.,Mol.Immunol.67:95-106,2015を参照されたい。抗体の抗原結合断片の非限定的な例には、Fv断片、Fab断片、F(ab’)2断片、及びFab’断片が挙げられる。抗体の抗原結合断片の追加の例は、IgGの抗原結合断片(例えば、IgG1、IgG2、IgG3、又はIgG4の抗原結合断片)(例えば、ヒト又はヒト化IgG、例えば、ヒト又はヒト化IgG1、IgG2、IgG3、又はIgG4の抗原結合断片)、IgAの抗原結合断片(例えば、IgA1又はIgA2の抗原結合断片)(例えば、ヒト又はヒト化IgA、例えば、ヒト又はヒト化IgA1又はIgA2の抗原結合断片)、IgDの抗原結合断片(例えば、ヒト又はヒト化IgDの抗原結合断片)、IgEの抗原結合断片(例えば、ヒト又はヒト化IgEの抗原結合断片)、又はIgMの抗原結合断片(例えば、ヒト又はヒト化IgMの抗原結合断片)である。 In some embodiments, two or more polypeptides present in a single-chain or multi-chain chimeric polypeptide are assembled (e.g., non-covalently assembled) to form an antigen described herein. Any of the binding domains, e.g., an antigen-binding fragment of an antibody (e.g., any of the antigen-binding fragments of an antibody described herein), VHH-scAb, VHH-Fab, double scFab, F ( ab') 2, diabody, crossMab, DAF (two-in-one), DAF (four-in-one), DutaMab, DT-IgG, knob-in-hole common light chain, knob-in-hole assembly, charge pair, Fab arm exchange , SEEDbody, LUZ-Y, Fcab, κλ-body, Orthogonal Fab, DVD-IgG, IgG(H)-scFv, scFv-(H)IgG, IgG(L)-scFv, scFv-(L)IgG, IgG ( L,H)-Fv, IgG(H)-V, V(H)-IgG, IgG(L)-V, V(L)-IgG, KIH IgG-scFab, 2scFv-IgG, IgG-2scFv, scFv4- Ig, Zybody, DVI-IgG, Diabody-CH3, Triplebody, Minobody, Minibody, TriBi Minibody, scFv-CH3 KIH, Fab-scFv, F(ab')2-scFv2, scFv-KIH, Fab- scFv-Fc, tetravalent HCAb, sc diabody-Fc, diabody-Fc, tandem scFv-Fc, intrabody, dock and lock, lmmTAC, IgG-IgG conjugate, Cov-X-Body, and scFv1- PEG-scFv2 can be formed. For a description of these elements, see, for example, Spiess et al. , Mol. Immunol. 67:95-106, 2015. Non-limiting examples of antigen-binding fragments of antibodies include Fv, Fab, F(ab') 2 , and Fab' fragments. Additional examples of antigen-binding fragments of antibodies include antigen-binding fragments of IgG (e.g., antigen-binding fragments of IgG1, IgG2, IgG3, or IgG4) (e.g., human or humanized IgG, e.g., human or humanized IgG1, IgG2 , IgG3, or IgG4), antigen-binding fragments of IgA (e.g., antigen-binding fragments of IgA1 or IgA2) (e.g., human or humanized IgA, e.g., antigen-binding fragments of human or humanized IgA1 or IgA2) , an antigen-binding fragment of IgD (e.g., an antigen-binding fragment of human or humanized IgD), an antigen-binding fragment of IgE (e.g., an antigen-binding fragment of human or humanized IgE), or an antigen-binding fragment of IgM (e.g., human or antigen-binding fragment of humanized IgM).
「Fv」断片は、1つの重鎖可変ドメイン及び1つの軽鎖可変ドメインを有する非共有結合二量体を含む。 An "Fv" fragment comprises a non-covalently associated dimer with one heavy and one light chain variable domain.
「Fab」断片は、Fv断片の重鎖及び軽鎖可変ドメインに加えて、軽鎖の定常ドメイン及び重鎖の第1の定常ドメイン(CH1)を含む。 A "Fab" fragment contains, in addition to the heavy and light chain variable domains of the Fv fragment, the constant domain of the light chain and the first constant domain of the heavy chain (C H1 ).
「F(ab’)2」断片には、ヒンジ領域の近くでジスルフィド結合によって結合された2つのFab断片が含まれる。 An “F(ab′) 2 ” fragment contains two Fab fragments joined by disulfide bonds near the hinge region.
「二重可変ドメイン免疫グロブリン」又は「DVD-Ig」とは、例えば、各々参照により全体が組み込まれる、DiGiammarino et al.,Methods Mol.Biol.899:145-156,2012、Jakob et al.,MABs5:358-363,2013、及び米国特許第7,612,181号、同第8,258,268号、同第8,586,714号、同第8,716,450号、同第8,722,855号、同第8,735,546号、及び同第8,822,645号に記載の多価及び多重特異性結合タンパク質を指す。 A "dual variable domain immunoglobulin" or "DVD-Ig" is defined, for example, in DiGiammarino et al. , Methods Mol. Biol. 899:145-156, 2012, Jakob et al. , MABs 5:358-363, 2013, and U.S. Pat. , 722,855, 8,735,546, and 8,822,645.
DARTは、例えば、Garber,Nature Reviews Drug Discovery 13:799-801,2014に記載されている。 DART is described, for example, in Garber, Nature Reviews Drug Discovery 13:799-801, 2014.
本明細書に記載の抗原結合ドメインのうちのいずれかのいくつかの実施形態では、タンパク質、炭水化物、脂質、及びそれらの組み合わせからなる群から選択される抗原に結合することができる。 Some embodiments of any of the antigen binding domains described herein are capable of binding antigens selected from the group consisting of proteins, carbohydrates, lipids, and combinations thereof.
抗原結合ドメインの追加の例及び態様は、当該技術分野で既知である。 Additional examples and embodiments of antigen binding domains are known in the art.
可溶性インターロイキン又はサイトカインタンパク質
本明細書に記載の一本鎖又は多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方は、可溶性インターロイキンタンパク質又は可溶性サイトカインタンパク質であり得る。いくつかの実施形態では、可溶性インターロイキン又は可溶性サイトカインタンパク質は、IL-2、IL-3、IL-7、IL-8、IL-10、IL-12、IL-15、IL-17、IL-18、IL-21、PDGF-DD、及びSCFの群から選択される。可溶性IL-2、IL-3、IL-7、IL-8、IL-10、IL-15、IL-17、IL-18、IL-21、PDGF-DD、及びSCFの非限定的な例が、以下に提供される。
ヒト可溶性IL-3(配列番号105)








Human soluble IL-3 (SEQ ID NO: 105)
可溶性インターロイキンタンパク質及び可溶性サイトカインタンパク質の追加の例は、当該技術分野で既知である。 Additional examples of soluble interleukin proteins and soluble cytokine proteins are known in the art.
可溶性受容体
本明細書に記載の一本鎖又は多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方が、可溶性インターロイキン受容体又は可溶性サイトカイン受容体である。いくつかの実施形態では、可溶性受容体は、可溶性TGF-β受容体II(TGF-β RII)である(例えば、Yung et al.,Am.J.Resp.Crit.Care Med.194(9):1140-1151,2016に記載のものを参照のこと)、可溶性TGF-βRIII(例えば、Heng et al.,Placenta 57:320,2017に記載のものを参照のこと)、可溶性NKG2D(例えば、Cosman et al.,Immunity 14(2):123-133,2001、Costa et al.,Front.Immunol.,Vol.9,Article 1150,May 29,2018、doi:10.3389/fimmu.2018.01150を参照のこと)、可溶性NKp30(例えば、Costa et al.,Front.Immunol.,Vol.9,Article1150,May29,2018、doi:10.3389/fimmu.2018.01150を参照のこと)、可溶性NKp44(例えば、Costa et al.,Front.Immunol.,Vol.9,Article 1150,May 29,2018、doi:10.3389/fimmu.2018.01150に記載のものを参照のこと)、可溶性NKp46(例えば、Mandelboim et al.,Nature 409:1055-1060,2001、Costa et al.,Front.Immunol.,Vol.9,Article 1150,May 29,2018、doi:10.3389/fimmu.2018.01150を参照のこと)、可溶性DNAM1(例えば、Costa et al.,Front.Immunol.,Vol.9,Article 1150,May 29,2018、doi:10.3389/fimmu.2018.01150に記載のものを参照のこと)、scMHCI(例えば、Washburn et al.,PLoS One 6(3):e18439,2011に記載のものを参照のこと)、scMHCII(例えば、Bishwajit et al.,Cellular Immunol.170(1):25-33,1996に記載のものを参照のこと)、scTCR(例えば、Weber et al.,Nature 356(6372):793-796,1992に記載のものを参照のこと)、可溶性CD155(例えば、Tahara-Hanaoka et al.,Int.Immunol.16(4):533-538,2004に記載のものを参照のこと)、又は可溶性CD28(例えば、Hebbar et al.,Clin.Exp.Immunol.136:388-392,2004を参照のこと)。
Soluble Receptors In some embodiments of any of the single-chain or multi-chain chimeric polypeptides described herein, one or both of the first target binding domain and the second target binding domain are Soluble interleukin receptors or soluble cytokine receptors. In some embodiments, the soluble receptor is soluble TGF-beta receptor II (TGF-beta RII) (eg, Yung et al., Am. J. Resp. Crit. Care Med. 194 (9) : 1140-1151, 2016), soluble TGF-βRIII (see, for example, Heng et al., Placenta 57:320, 2017), soluble NKG2D (see, for example, Cosman et al., Immunity 14(2): 123-133, 2001, Costa et al., Front. Immunol., Vol.9, Article 1150, May 29, 2018, doi: 10.3389/fimmu.2018.01150 see), soluble NKp30 (see, e.g., Costa et al., Front. Immunol., Vol. 9, Article 1150, May 29, 2018, doi: 10.3389/fimmu.2018.01150), soluble NKp44 ( See, for example, Costa et al., Front. Immunol., Vol.9, Article 1150, May 29, 2018, doi: 10.3389/fimmu. See Mandelboim et al., Nature 409:1055-1060, 2001, Costa et al., Front. ), soluble DNAM1 (see, for example, Costa et al., Front. Immunol., Vol. 9, Article 1150, May 29, 2018, doi: 10.3389/fimmu.2018.01150) , scMHC I (see, e.g., Washburn et al., PLoS One 6(3):e18439, 2011), scMHC II (e.g., Bishwajit et al., Cellular Immunol. 170(1):25-33). , 1996), scTCR (see, for example, Weber et al., Nature 356(6372):793-796, 1992), soluble CD155 (see, for example, Tahara-Hanaoka et al. , Int. Immunol. 16(4):533-538, 2004), or soluble CD28 (see, eg, Hebbar et al., Clin. Exp. Immunol. 136:388-392, 2004).
可溶性インターロイキン受容体及び可溶性サイトカイン受容体の追加の例は、当該技術分野で既知である。 Additional examples of soluble interleukin receptors and soluble cytokine receptors are known in the art.
一対の親和性ドメイン
いくつかの実施形態では、多鎖キメラポリペプチドは、1)一対の親和性ドメインの第1のドメインを含む第1のキメラポリペプチドと、2)一対の親和性ドメインの第2のドメインを含む第2のキメラポリペプチドとを含み、これにより、第1のキメラポリペプチド及び第2のキメラポリペプチドが一対の親和性ドメインの第1のドメイン及び第2のドメインの結合を介して会合するようになる。いくつかの実施形態では、一対の親和性ドメインは、ヒトIL-15受容体のアルファ鎖(IL-15Rα)由来のスシドメイン、及び可溶性IL-15である。スシドメイン、別名、ショートコンセンサスリピート又は1型糖タンパク質モチーフは、タンパク質-タンパク質相互作用の一般的なモチーフである。スシドメインは、補体成分C1r、C1s、H因子、C2m、並びに非免疫学的分子第XIII因子及びβ2-糖タンパク質を含むいくつかのタンパク質結合分子上で同定されている。典型的なスシドメインは、およそ60個のアミノ酸残基を有し、4つのシステインを含む(Ranganathan,Pac.Symp Biocomput.2000:155-67)。第1のシステインは第3のシステインとジスルフィド結合を形成することができ、第2のシステインは第4のシステインとジスルフィド架橋を形成することができる。一対の親和性ドメインの一方のメンバーが可溶性IL-15であるいくつかの実施形態では、可溶性IL-15は、D8N又はD8Aアミノ酸置換を有する。一対の親和性ドメインの一方のメンバーがヒトIL-15受容体アルファ鎖(IL-15Rα)であるいくつかの実施形態では、ヒトIL-15Rαは、成熟全長IL-15Rαである。いくつかの実施形態では、一対の親和性ドメインは、バルナーゼとバルンスターである。いくつかの実施形態では、一対の親和性ドメインは、PKA及びAKAPである。いくつかの実施形態では、一対の親和性ドメインは、変異RNase I断片に基づくアダプター/ドッキングタグモジュール(Rossi,Proc Natl Acad Sci USA.103:6841-6846,2006、Sharkey et al.,Cancer Res.68:5282-5290,2008、Rossi et al.,Trends Pharmacol Sci.33:474-481,2012)、又はタンパク質シンタキシン、シナプトタグミン、シナプトブレビン、及びSNAP25の相互作用に基づくSNAREモジュール(Deyev et al.,Nat Biotechnol.1486-1492,2003)である。
Pair of Affinity Domains In some embodiments, the multi-chain chimeric polypeptide comprises: 1) a first chimeric polypeptide comprising a first domain of a pair of affinity domains; and a second chimeric polypeptide comprising two domains, whereby the first chimeric polypeptide and the second chimeric polypeptide effect binding of the first and second domains of a pair of affinity domains. will meet through In some embodiments, the pair of affinity domains is a sushi domain from the alpha chain of the human IL-15 receptor (IL-15Rα) and soluble IL-15. Sushi domains, also known as short consensus repeats or
いくつかの実施形態では、多鎖キメラポリペプチドの第1のキメラポリペプチドは、一対の親和性ドメインの第1のドメインを含み、多鎖キメラポリペプチドの第2のキメラポリペプチドは、一対の親和性ドメインの第2のドメインを含み、一対の親和性ドメインの第1のドメイン及び一対の親和性ドメインの第2のドメインは、1×10-7M未満、1×10-8M未満、1×10-9M未満、1×10-10M未満、1×10-11M未満、1×10-12M未満、又は1×10-13M未満の解離平衡定数(KD)で互いに結合する。いくつかの実施形態では、一対の親和性ドメインの第1のドメイン及び一対の親和性ドメインの第2のドメインは、約1×10-4M~約1×10-6M、約1×10-5M~約1×10-7M、約1×10-6M~約1×10-8M、約1×10-7M~約1×10-9M、約1×10-8M~約1×10-10M、約1×10-9M~約1×10-11M、約1×10-10M~約1×10-12M、約1×10-11M~約1×10-13M、約1×10-4M~約1×10-5M、約1×10-5M~約1×10-6M、約1×10-6M~約1×10-7M、約1×10-7M~約1×10-8M、約1×10-8M~約1×10-9M、約1×10-9M~約1×10-10M、約1×10-10M~約1×10-11M、約1×10-11M~約1×10-12M、又は約1×10-12M~約1×10-13M(これらの上限及び下限も含む)のKDで互いに結合する。当該技術分野で既知の様々な異なる方法のうちのいずれかを使用して、一対の親和性ドメインの第1のドメイン及び一対の親和性ドメインの第2のドメインの結合のKD値を決定することができる(例えば、電気泳動移動度シフトアッセイ、フィルター結合アッセイ、表面プラズモン共鳴、及び生体分子結合反応速度アッセイ等)。 In some embodiments, the first chimeric polypeptide of the multi-chain chimeric polypeptide comprises a first of a pair of affinity domains and the second chimeric polypeptide of the multi-chain chimeric polypeptide comprises a pair of a second domain of affinity domains, wherein the first domain of the pair of affinity domains and the second domain of the pair of affinity domains are less than 1×10 −7 M, less than 1×10 −8 M; with a dissociation equilibrium constant (K D ) of less than 1×10 −9 M, less than 1×10 −10 M, less than 1×10 −11 M, less than 1×10 −12 M, or less than 1×10 −13 M Join. In some embodiments, the first domain of the pair of affinity domains and the second domain of the pair of affinity domains are about 1×10 −4 M to about 1×10 −6 M, about 1×10 −5 M to about 1×10 −7 M, about 1×10 −6 M to about 1×10 −8 M, about 1×10 −7 M to about 1×10 −9 M, about 1×10 −8 M to about 1×10 −10 M, about 1×10 −9 M to about 1×10 −11 M, about 1×10 −10 M to about 1×10 −12 M, about 1×10 −11 M to About 1×10 −13 M, about 1×10 −4 M to about 1×10 −5 M, about 1×10 −5 M to about 1×10 −6 M, about 1× 10 −6 M to about 1 ×10 −7 M, about 1×10 −7 M to about 1×10 −8 M, about 1×10 −8 M to about 1×10 −9 M, about 1×10 −9 M to about 1×10 −10 M, about 1×10 −10 M to about 1×10 −11 M, about 1×10 −11 M to about 1×10 −12 M, or about 1×10 −12 M to about 1×10 − They bind to each other with a K D of 13 M (including these upper and lower limits). Determine the KD value for binding of the first domain of the pair of affinity domains and the second domain of the pair of affinity domains using any of a variety of different methods known in the art (eg, electrophoretic mobility shift assays, filter binding assays, surface plasmon resonance, biomolecule binding kinetic assays, etc.).
いくつかの実施形態では、多鎖キメラポリペプチドの第1のキメラポリペプチドは、一対の親和性ドメインの第1のドメインを含み、多鎖キメラポリペプチドの第2のキメラポリペプチドは、一対の親和性ドメインの第2のドメインを含み、一対の親和性ドメインの第1のドメイン、一対の親和性ドメインの第2のドメイン、又はそれらの両方が、約10~100アミノ酸長である。例えば、一対の親和性ドメインの第1のドメイン、一対の親和性ドメインの第2のドメイン、又はそれらの両方は、約10~100アミノ酸長、約15~100アミノ酸長、約20~100アミノ酸長、約25~100アミノ酸長、約30~100アミノ酸長、約35~100アミノ酸長、約40~100アミノ酸長、約45~100アミノ酸長、約50~100アミノ酸長、約55~100アミノ酸長、約60~100アミノ酸長、約65~100アミノ酸長、約70~100アミノ酸長、約75~100アミノ酸長、約80~100アミノ酸長、約85~100アミノ酸長、約90~100アミノ酸長、約95~100アミノ酸長、約10~95アミノ酸長、約10~90アミノ酸長、約10~85アミノ酸長、約10~80アミノ酸長、約10~75アミノ酸長、約10~70アミノ酸長、約10~65アミノ酸長、約10~60アミノ酸長、約10~55アミノ酸長、約10~50アミノ酸長、約10~45アミノ酸長、約10~40アミノ酸長、約10~35アミノ酸長、約10~30アミノ酸長、約10~25アミノ酸長、約10~20アミノ酸長、約10~15アミノ酸長、約20~30アミノ酸長、約30~40アミノ酸長、約40~50アミノ酸長、約50~60アミノ酸長、約60~70アミノ酸長、約70~80アミノ酸長、約80~90アミノ酸長、約90~100アミノ酸長、約20~90アミノ酸長、約30~80アミノ酸長、約40~70アミノ酸長、約50~60アミノ酸長、又はそれらの間の任意の範囲であり得る。いくつかの実施形態では、一対の親和性ドメインの第1のドメイン、一対の親和性ドメインの第2のドメイン、又はそれらの両方が、約10、15、20、25、30、35、40、45、50、55、60、65、70、75、80、85、90、95、又は100アミノ酸長である。 In some embodiments, the first chimeric polypeptide of the multi-chain chimeric polypeptide comprises a first of a pair of affinity domains and the second chimeric polypeptide of the multi-chain chimeric polypeptide comprises a pair of Including a second domain of affinity domains, wherein the first domain of the pair of affinity domains, the second domain of the pair of affinity domains, or both are about 10-100 amino acids in length. For example, the first domain of the pair of affinity domains, the second domain of the pair of affinity domains, or both are about 10-100 amino acids long, about 15-100 amino acids long, about 20-100 amino acids long , about 25-100 amino acids long, about 30-100 amino acids long, about 35-100 amino acids long, about 40-100 amino acids long, about 45-100 amino acids long, about 50-100 amino acids long, about 55-100 amino acids long, about 60-100 amino acids long, about 65-100 amino acids long, about 70-100 amino acids long, about 75-100 amino acids long, about 80-100 amino acids long, about 85-100 amino acids long, about 90-100 amino acids long, about 95-100 amino acids long, about 10-95 amino acids long, about 10-90 amino acids long, about 10-85 amino acids long, about 10-80 amino acids long, about 10-75 amino acids long, about 10-70 amino acids long, about 10 ~65 amino acids long, about 10-60 amino acids long, about 10-55 amino acids long, about 10-50 amino acids long, about 10-45 amino acids long, about 10-40 amino acids long, about 10-35 amino acids long, about 10- 30 amino acids long, about 10-25 amino acids long, about 10-20 amino acids long, about 10-15 amino acids long, about 20-30 amino acids long, about 30-40 amino acids long, about 40-50 amino acids long, about 50-60 Amino acid length, about 60-70 amino acids, about 70-80 amino acids, about 80-90 amino acids, about 90-100 amino acids, about 20-90 amino acids, about 30-80 amino acids, about 40-70 amino acids long, about 50-60 amino acids long, or any range therebetween. In some embodiments, the first domain of the pair of affinity domains, the second domain of the pair of affinity domains, or both are about 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, or 100 amino acids long.
いくつかの実施形態では、本明細書に開示される一対の親和性ドメインの第1及び/又は第2のドメインのうちのいずれかは、一対の親和性ドメインの第1及び/又は第2のドメインの機能が損なわれないままである限り、そのN末端及び/又はC末端に1つ以上の追加のアミノ酸(例えば、1、2、3、5、6、7、8、9、10、又はそれ以上のアミノ酸)を含み得る。例えば、ヒトIL-15受容体アルファ鎖(IL-15Rα)由来のスシドメインは、可溶性IL-15に結合する能力を依然として保持しながら、N末端及び/又はC末端に1つ以上の追加のアミノ酸を含むことができる。加えて又はあるいは、可溶性IL-15は、ヒトIL-15受容体アルファ鎖(IL-15Rα)由来のスシドメインに結合する能力を依然として保持しながら、N末端及び/又はC末端に1つ以上の追加のアミノ酸を含むことができる。 In some embodiments, any of the first and/or second domains of a pair of affinity domains disclosed herein is the first and/or second domain of the pair of affinity domains One or more additional amino acids (e.g., 1, 2, 3, 5, 6, 7, 8, 9, 10, or more amino acids). For example, the sushi domain from the human IL-15 receptor alpha chain (IL-15Rα) has one or more additional amino acids at the N-terminus and/or C-terminus while still retaining the ability to bind soluble IL-15. can include Additionally or alternatively, soluble IL-15 may have at its N-terminus and/or C-terminus one or more Additional amino acids can be included.
IL-15受容体アルファのアルファ鎖(IL-15Rα)由来のスシドメインの非限定的な例は、ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR(配列番号113)と少なくとも70%同一、少なくとも75%同一、少なくとも80%同一、少なくとも85%同一、少なくとも90%同一、少なくとも95%同一、少なくとも99%同一、又は100%同一である配列を含み得る。いくつかの実施形態では、IL-15Rαアルファ鎖由来のスシドメインは、ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG(配列番号114)を含む核酸によってコードされる。 Non-limiting examples of sushi domains from the alpha chain of IL-15 receptor alpha (IL-15Rα) are at least 70% identical, at least 75% identical, at least 80% identical, at least 85 It can include sequences that are % identical, at least 90% identical, at least 95% identical, at least 99% identical, or 100% identical. In some embodiments, the sushi domain from the IL-15Rα alpha chain is ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATA AGGCTACCAACGTGGCTCACTGGACAACACCCTTTTTAAAGTGCATCCGG (SEQ ID NO: 114).
いくつかの実施形態では、可溶性IL-15は、NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(配列番号115)と少なくとも70%同一、少なくとも75%同一、少なくとも80%同一、少なくとも85%同一、少なくとも90%同一、少なくとも95%同一、少なくとも99%同一、又は100%同一である配列を含み得る。いくつかの実施形態では、可溶性IL-15は、AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(配列番号116)の配列を含む核酸によってコードされ得る。 In some embodiments, the soluble IL-15 is at least 70% identical to, at least 7 5% identical, at least 80% identical, at least 85% identical, at least 90% identical, at least 95% identical, It can include sequences that are at least 99% identical, or 100% identical. In some embodiments, the soluble IL-15 is AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGA GAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATAC It can be encoded by a nucleic acid comprising the sequence of CTCC (SEQ ID NO: 116).
シグナル配列
いくつかの実施形態では、一本鎖キメラポリペプチドは、そのN末端にシグナル配列を含む。いくつかの実施形態では、多鎖キメラポリペプチドは、そのN末端にシグナル配列を含む第1のキメラポリペプチドを含む。いくつかの実施形態では、多鎖キメラポリペプチドは、そのN末端にシグナル配列を含む第2のキメラポリペプチドを含む。いくつかの実施形態では、多鎖キメラポリペプチドの第1のキメラポリペプチド及び多鎖キメラポリペプチドの第2のキメラポリペプチドの両方がシグナル配列を含む。当業者に理解されるように、シグナル配列は、タンパク質を分泌経路に指向するいくつかの内因的に産生されたタンパク質のN末端に存在するアミノ酸配列である(例えば、タンパク質は、ある特定の細胞内オルガネラに存在するか、細胞膜に存在するか、又は細胞から分泌されるように指示される)。シグナル配列は不均一であり、それらの一次アミノ酸配列が大きく異なる。しかしながら、シグナル配列は、典型的には、16~30アミノ酸長であり、親水性の通常は正に帯電したN末端領域、中央の疎水性ドメイン、及びシグナルペプチダーゼの切断部位を含むC末端領域を含む。
Signal Sequence In some embodiments, the single-chain chimeric polypeptide includes a signal sequence at its N-terminus. In some embodiments, a multichain chimeric polypeptide comprises a first chimeric polypeptide that includes a signal sequence at its N-terminus. In some embodiments, the multichain chimeric polypeptide comprises a second chimeric polypeptide that includes a signal sequence at its N-terminus. In some embodiments, both the first chimeric polypeptide of the multi-chain chimeric polypeptide and the second chimeric polypeptide of the multi-chain chimeric polypeptide comprise a signal sequence. As understood by those of skill in the art, a signal sequence is an amino acid sequence present at the N-terminus of some endogenously produced proteins that directs the protein into the secretory pathway (e.g., proteins are produced in certain cells located in an internal organelle, located in the cell membrane, or directed to be secreted from the cell). Signal sequences are heterogeneous and differ greatly in their primary amino acid sequences. However, signal sequences are typically 16-30 amino acids in length and comprise a hydrophilic, usually positively charged, N-terminal region, a central hydrophobic domain, and a C-terminal region containing a cleavage site for the signal peptidase. include.
いくつかの実施形態では、多鎖キメラポリペプチドの第1のキメラポリペプチド、多鎖キメラポリペプチドの第2のキメラポリペプチド、又はそれらの両方、又は一本鎖キメラポリペプチドは、アミノ酸配列MKWVTFISLLFLFSSAYS(配列番号117)を有するシグナル配列を含む。いくつかの実施形態では、多鎖キメラポリペプチドの第1のキメラポリペプチド、多鎖キメラポリペプチドの第2のキメラポリペプチド、又はそれらの両方、又は一本鎖キメラポリペプチドは、核酸配列ATGAAATGGGTGACCTTTATTTCTTTACTGTTCCTCTTTAGCAGCGCCTACTCC(配列番号118)、ATGAAGTGGGTCACATTTATCTCTTTACTGTTCCTCTTCTCCAGCGCCTACAGC(配列番号119)、又はATGAAATGGGTGACCTTTATTTCTTTACTGTTCCTCTTTAGCAGCGCCTACTCC(配列番号120)によってコードされるシグナル配列を含む。 In some embodiments, the first chimeric polypeptide of a multi-chain chimeric polypeptide, the second chimeric polypeptide of a multi-chain chimeric polypeptide, or both, or the single-chain chimeric polypeptide has the amino acid sequence MKWVTFISLLFLFSSAYS (SEQ ID NO: 117). In some embodiments, the first chimeric polypeptide of a multi-chain chimeric polypeptide, the second chimeric polypeptide of a multi-chain chimeric polypeptide, or both, or the single-chain chimeric polypeptide comprises the nucleic acid sequence (SEQ ID NO: 118), ATGAAGTGGGTCACATTTATCTCTTTACTGTTCCTCTTCTCCAGCGCCTACAGC (SEQ ID NO: 119), or ATGAAATGGGTGGACCTTTTATTTCTTTACTGTTCCTCTTAGCAGCGCCTACTCC (SEQ ID NO: 120).
いくつかの実施形態では、多鎖キメラポリペプチドの第1のキメラポリペプチド、多鎖キメラポリペプチドの第2のキメラポリペプチド、又はそれらの両方、又は一本鎖キメラポリペプチドは、アミノ酸配列MKCLLYLAFLFLGVNC(配列番号121)を有するシグナル配列を含む。いくつかの実施形態では、多鎖キメラポリペプチドの第1のキメラポリペプチド、多鎖キメラポリペプチドの第2のキメラポリペプチド、又はその両方、又は一本鎖キメラポリペプチドは、アミノ酸配列MGQIVTMFEALPHIIDEVINIVIIVLIIITSIKAVYNFATCGILALVSFLFLAGRSCG(配列番号122)を有するシグナル配列を含む。いくつかの実施形態では、多鎖キメラポリペプチドの第1のキメラポリペプチド、多鎖キメラポリペプチドの第2のキメラポリペプチド、又はその両方、又は一本鎖キメラポリペプチドは、アミノ酸配列MPNHQSGSPTGSSDLLLSGKKQRPHLALRRKRRREMRKINRKVRRMNLAPIKEKTAWQHLQALISEAEEVLKTSQTPQNSLTLFLALLSVLGPPVTG(配列番号123)を有するシグナル配列を含む。いくつかの実施形態では、多鎖キメラポリペプチドの第1のキメラポリペプチド、多鎖キメラポリペプチドの第2のキメラポリペプチド、又はその両方、又は一本鎖キメラポリペプチドは、アミノ酸配列MDSKGSSQKGSRLLLLLVVSNLLLCQGVVS(配列番号124)を有するシグナル配列を含む。当業者であれば、本明細書に記載の多鎖キメラポリペプチドの第1のキメラポリペプチド及び/又は第2のキメラポリペプチド、又は一本鎖キメラポリペプチドにおける使用に適切な他のシグナル配列を認識しているであろう。 In some embodiments, the first chimeric polypeptide of a multi-chain chimeric polypeptide, the second chimeric polypeptide of a multi-chain chimeric polypeptide, or both, or the single-chain chimeric polypeptide has the amino acid sequence MKCLLYLAFLFLGVNC (SEQ ID NO: 121). In some embodiments, the first chimeric polypeptide of the multi-chain chimeric polypeptide, the second chimeric polypeptide of the multi-chain chimeric polypeptide, or both, or the single-chain chimeric polypeptide has the amino acid sequence MGQIVTMFEALPHIIIDEVINIVIIVLIIITSIKAVYNFATCGILALVSFLFLAGRSCG ( including a signal sequence having SEQ ID NO: 122). In some embodiments, the first chimeric polypeptide of a multi-chain chimeric polypeptide, the second chimeric polypeptide of a multi-chain chimeric polypeptide, or both, or the single-chain chimeric polypeptide has the amino acid sequence MPNHQSGSPTGSSDLLLLSGKKQRPHLALRRRKRRREMRKINRKVRRMNLAPIKEKTAWQHLQALISEAEEVLKTSQTPQNSLT LFLALLSVLGPPVTG( including a signal sequence having SEQ ID NO: 123). In some embodiments, the first chimeric polypeptide of the multi-chain chimeric polypeptide, the second chimeric polypeptide of the multi-chain chimeric polypeptide, or both, or the single-chain chimeric polypeptide has the amino acid sequence MDSKGSSQKGSRLLLLLVVSSNLLLCQGVVS ( SEQ ID NO: 124). Those skilled in the art will appreciate other signal sequences suitable for use in the first and/or second chimeric polypeptides of the multi-chain chimeric polypeptides described herein, or single-chain chimeric polypeptides. would be aware of
いくつかの実施形態では、多鎖キメラポリペプチドの第1のキメラポリペプチド、多鎖キメラポリペプチドの第2のキメラポリペプチド、又はそれらの両方、又は一本鎖キメラポリペプチドは、約10~100アミノ酸長であるシグナル配列を含む。例えば、シグナル配列は、約10~100アミノ酸長、約15~100アミノ酸長、約20~100アミノ酸長、約25~100アミノ酸長、約30~100アミノ酸長、約35~100アミノ酸長、約40~100アミノ酸長、約45~100アミノ酸長、約50~100アミノ酸長、約55~100アミノ酸長、約60~100アミノ酸長、約65~100アミノ酸長、約70~100アミノ酸長、約75~100アミノ酸長、約80~100アミノ酸長、約85~100アミノ酸長、約90~100アミノ酸長、約95~100アミノ酸長、約10~95アミノ酸長、約10~90アミノ酸長、約10~85アミノ酸長、約10~80アミノ酸長、約10~75アミノ酸長、約10~70アミノ酸長、約10~65アミノ酸長、約10~60アミノ酸長、約10~55アミノ酸長、約10~50アミノ酸長、約10~45アミノ酸長、約10~40アミノ酸長、約10~35アミノ酸長、約10~30アミノ酸長、約10~25アミノ酸長、約10~20アミノ酸長、約10~15アミノ酸長、約20~30アミノ酸長、約30~40アミノ酸長、約40~50アミノ酸長、約50~60アミノ酸長、約60~70アミノ酸長、約70~80アミノ酸長、約80~90アミノ酸長、約90~100アミノ酸長、約20~90アミノ酸長、約30~80アミノ酸長、約40~70アミノ酸長、約50~60アミノ酸長、又はそれらの間の任意の範囲であり得る。いくつかの実施形態では、シグナル配列は、約10、15、20、25、30、35、40、45、50、55、60、65、70、75、80、85、90、95、又は100アミノ酸長である。 In some embodiments, the first chimeric polypeptide of the multi-chain chimeric polypeptide, the second chimeric polypeptide of the multi-chain chimeric polypeptide, or both, or the single-chain chimeric polypeptide is about 10 to It contains a signal sequence that is 100 amino acids long. For example, the signal sequence is about 10-100 amino acids long, about 15-100 amino acids long, about 20-100 amino acids long, about 25-100 amino acids long, about 30-100 amino acids long, about 35-100 amino acids long, about 40 ~100 amino acids long, about 45-100 amino acids long, about 50-100 amino acids long, about 55-100 amino acids long, about 60-100 amino acids long, about 65-100 amino acids long, about 70-100 amino acids long, about 75- 100 amino acids long, about 80-100 amino acids long, about 85-100 amino acids long, about 90-100 amino acids long, about 95-100 amino acids long, about 10-95 amino acids long, about 10-90 amino acids long, about 10-85 Amino acid length, about 10-80 amino acids, about 10-75 amino acids, about 10-70 amino acids, about 10-65 amino acids, about 10-60 amino acids, about 10-55 amino acids, about 10-50 amino acids long, about 10-45 amino acids long, about 10-40 amino acids long, about 10-35 amino acids long, about 10-30 amino acids long, about 10-25 amino acids long, about 10-20 amino acids long, about 10-15 amino acids long , about 20-30 amino acids long, about 30-40 amino acids long, about 40-50 amino acids long, about 50-60 amino acids long, about 60-70 amino acids long, about 70-80 amino acids long, about 80-90 amino acids long, It can be about 90-100 amino acids long, about 20-90 amino acids long, about 30-80 amino acids long, about 40-70 amino acids long, about 50-60 amino acids long, or any range therebetween. In some embodiments, the signal sequence is about 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, or 100 Amino acid length.
いくつかの実施形態では、本明細書に開示されるシグナル配列のうちのいずれかは、シグナル配列の機能が損なわれないままである限り、そのN末端及び/又はC末端に1つ以上の追加のアミノ酸(例えば、1、2、3、5、6、7、8、9、10、又はそれ以上のアミノ酸)を含み得る。例えば、アミノ酸配列MKCLLYLAFLFLGVNC(配列番号125)を有するシグナル配列は、多鎖キメラポリペプチドの第1のキメラポリペプチド、多鎖キメラポリペプチドの第2のキメラポリペプチド、又はそれらの両方、又は一本鎖キメラポリペプチドを分泌経路に指向する能力を依然として保持しながら、N末端又はC末端に1つ以上の追加のアミノ酸を含むことができる。 In some embodiments, any of the signal sequences disclosed herein have one or more additional amino acids (eg, 1, 2, 3, 5, 6, 7, 8, 9, 10, or more amino acids). For example, a signal sequence having the amino acid sequence MKCLLYLAFLFLGVNC (SEQ ID NO: 125) can be used in the first chimeric polypeptide of the multi-chain chimeric polypeptide, the second chimeric polypeptide of the multi-chain chimeric polypeptide, or both or one One or more additional amino acids can be included at the N-terminus or C-terminus while still retaining the ability to direct the chain chimeric polypeptide into the secretory pathway.
いくつかの実施形態では、多鎖キメラポリペプチドの第1のキメラポリペプチド、多鎖キメラポリペプチドの第2のキメラポリペプチド、又はそれらの両方、又は一本鎖キメラポリペプチドは、多鎖キメラポリペプチドを細胞外空間に指向するシグナル配列を含む。かかる実施形態は、単離及び/又は精製が比較的容易な一本鎖キメラポリペプチドを生成するのに有用である。 In some embodiments, the first chimeric polypeptide of a multi-chain chimeric polypeptide, the second chimeric polypeptide of a multi-chain chimeric polypeptide, or both, or the single-chain chimeric polypeptide is a multi-chain chimeric polypeptide It contains a signal sequence that directs the polypeptide into the extracellular space. Such embodiments are useful for producing single-chain chimeric polypeptides that are relatively easy to isolate and/or purify.
ペプチドタグ
いくつかの実施形態では、一本鎖キメラポリペプチド、(例えば、キメラポリペプチドのN末端又はC末端に)ペプチドタグを含む。いくつかの実施形態では、多鎖キメラポリペプチドは、(例えば、第1のキメラポリペプチドのN末端又はC末端に)ペプチドタグを含む第1のキメラポリペプチドを含む。いくつかの実施形態では、多鎖キメラポリペプチドは、(例えば、第2のキメラポリペプチドのN末端又はC末端に)ペプチドタグを含む第2のキメラポリペプチドを含む。いくつかの実施形態では、多鎖キメラポリペプチドの第1のキメラポリペプチド及び多鎖キメラポリペプチドの第2のキメラポリペプチドの両方がペプチドタグを含む。いくつかの実施形態では、多鎖キメラポリペプチドの第1のキメラポリペプチド、多鎖キメラポリペプチドの第2のキメラポリペプチド、又はそれらの両方、又は一本鎖キメラポリペプチドは、2つ以上のペプチドタグを含む。
Peptide Tags In some embodiments, the single-chain chimeric polypeptides comprise a peptide tag (eg, at the N-terminus or C-terminus of the chimeric polypeptide). In some embodiments, a multichain chimeric polypeptide comprises a first chimeric polypeptide comprising a peptide tag (eg, at the N-terminus or C-terminus of the first chimeric polypeptide). In some embodiments, a multichain chimeric polypeptide comprises a second chimeric polypeptide comprising a peptide tag (eg, at the N-terminus or C-terminus of the second chimeric polypeptide). In some embodiments, both the first chimeric polypeptide of the multi-chain chimeric polypeptide and the second chimeric polypeptide of the multi-chain chimeric polypeptide comprise a peptide tag. In some embodiments, the first chimeric polypeptide of the multi-chain chimeric polypeptide, the second chimeric polypeptide of the multi-chain chimeric polypeptide, or both, or the single-chain chimeric polypeptide is two or more of peptide tags.
多鎖キメラポリペプチドの第1のキメラポリペプチド、多鎖キメラポリペプチドの第2のキメラポリペプチド、又はそれらの両方、又は一本鎖キメラポリペプチドに含まれ得る例示的なペプチドタグには、AviTag(GLNDIFEAQKIEWHE、配列番号126)、カルモジュリンタグ(KRRWKKNFIAVSAANRFKKISSSGAL、配列番号127)、ポリグルタミン酸タグ(EEEEEE、配列番号128)、Eタグ(GAPVPYPDPLEPR、配列番号129)、FLAGタグ(DYKDDDDK、配列番号130)、HAタグ、血球凝集素由来のペプチド(YPYDVPDYA、配列番号131)、hisタグ(HHHHH(配列番号132)、HHHHHH(配列番号133)、HHHHHHH(配列番号134)、HHHHHHHH(配列番号135)、HHHHHHHHH(配列番号136)、又はHHHHHHHHHH(配列番号137))、mycタグ(EQKLISEEDL、配列番号138)、NEタグ(TKENPRSNQEESYDDNES、配列番号139)、Sタグ(KETAAAKFERQHMDS、配列番号140)、SBPタグ(MDEKTTGWRGGHVVEGLAGELEQLRARLEHHPQGQREP、配列番号141)、Softag1(SLAELLNAGLGGS、配列番号142)、Softag3(TQDPSRVG、配列番号143)、Spotタグ(PDRVRAVSHWSS、配列番号144)、Strepタグ(WSHPQFEK、配列番号145)、TCタグ(CCPGCC、配列番号146)、Tyタグ(EVHTNQDPLD、配列番号147)、V5タグ(GKPIPNPLLGLDST、配列番号148)、VSVタグ(YTDIEMNRLGK、配列番号149)、及びXpressタグ(DLYDDDDK、配列番号150)が挙げられるが、これらに限定されない。いくつかの実施形態では、組織因子タンパク質は、ペプチドタグである。 Exemplary peptide tags that may be included in a first chimeric polypeptide of a multi-chain chimeric polypeptide, a second chimeric polypeptide of a multi-chain chimeric polypeptide, or both, or a single-chain chimeric polypeptide include: AviTag (GLNDIFEAQKIEWHE, SEQ. 130), HA tag, hemagglutinin-derived peptide (YPYDVPDYA, SEQ ID NO: 131), his tag (HHHHH (SEQ ID NO: 132), HHHHHH (SEQ ID NO: 133), HHHHHHH (SEQ ID NO: 134), HHHHHHHH (SEQ ID NO: 135), HHHHHHHHH ( SEQ ID NO: 136), or HHHHHHHHHH (SEQ ID NO: 137)), myc tag (EQKLISEEDL, SEQ ID NO: 138), NE tag (TKENPRSNQEESYDDNES, SEQ ID NO: 139), S tag (KETAAAKFERQHMDS, SEQ ID NO: 140), SBP tag (MDEKTTGWRGGHVVEGLA GELEQLRARLEHHPQGQREP, sequence No. 141), Softag1 (SLAELLNAGLGGS, SEQ ID NO: 142), Softag3 (TQDPSRVG, SEQ ID NO: 143), Spot tag (PDRVRAVSHWSS, SEQ ID NO: 144), Strep tag (WSHPQFEK, SEQ ID NO: 145), TC tag (CCPGCC, SEQ ID NO: 146 ), Ty tag (EVHTNQDPLD, SEQ ID NO: 147), V5 tag (GKPIPNPLLGLDST, SEQ ID NO: 148), VSV tag (YTDIEMNRLGK, SEQ ID NO: 149), and Xpress tag (DLYDDDDK, SEQ ID NO: 150). not. In some embodiments, the tissue factor protein is a peptide tag.
多鎖キメラポリペプチドの第1のキメラポリペプチド、多鎖キメラポリペプチドの第2のキメラポリペプチド、又はそれらの両方、又は一本鎖キメラポリペプチドに含まれ得るペプチドタグは、それぞれ、多鎖キメラポリペプチド又は一本鎖キメラポリペプチドに関連する様々な用途のうちのいずれかに使用され得る。例えば、ペプチドタグは、多鎖キメラポリペプチド又は一本鎖キメラポリペプチドの精製に使用され得る。1つの非限定的な例として、多鎖キメラポリペプチドの第1のキメラポリペプチド(例えば、組換え発現された第1のキメラポリペプチド)、多鎖キメラポリペプチドの第2のキメラポリペプチド(例えば、組換え発現された第2のキメラポリペプチド)、又はそれらの両方、又は一本鎖キメラポリペプチドが、mycタグを含み得、mycタグ付き第1キメラポリペプチド、mycタグ付き第2キメラポリペプチド、又はそれらの両方、又は一本鎖キメラポリペプチドを含む多鎖キメラポリペプチドは、mycタグを認識する抗体を使用して精製され得る。mycタグを認識する抗体の1つの非限定的な例は、非営利Developmental Studies Hybridoma Bankから入手可能な9E10である。別の非限定的な例として、多鎖キメラポリペプチドの第1のキメラポリペプチド(例えば、組換え発現された第1のキメラポリペプチド)、多鎖キメラポリペプチドの第2のキメラポリペプチド(例えば、組換え発現された第2のキメラポリペプチド)、又はそれらの両方、又は一本鎖キメラポリペプチドが、ヒスチジンタグを含み得、ヒスチジンタグ付き第1キメラポリペプチド、ヒスチジンタグ付き第2キメラポリペプチド、又はそれらの両方、又はヒスチジンタグ付き一本鎖キメラポリペプチドを含む多鎖キメラポリペプチドは、ニッケル又はコバルトキレートを使用して精製され得る。当業者であれば、一本鎖又は多鎖キメラポリペプチドの精製に使用するためにそれらのタグに結合する他の好適なタグ及び作用物質を認識しているであろう。いくつかの実施形態では、ペプチドタグは、精製後に、多鎖キメラポリペプチドの第1のキメラポリペプチド及び/若しくは第2のキメラポリペプチド、又は一本鎖キメラポリペプチドから除去される。いくつかの実施形態では、ペプチドタグは、精製後に、多鎖キメラポリペプチドの第1のキメラポリペプチド及び/若しくは第2のキメラポリペプチド、又は一本鎖キメラポリペプチドから除去されない。 A peptide tag that may be included in a first chimeric polypeptide of a multi-chain chimeric polypeptide, a second chimeric polypeptide of a multi-chain chimeric polypeptide, or both, or a single-chain chimeric polypeptide, is each a multi-chain Any of a variety of uses involving chimeric polypeptides or single-chain chimeric polypeptides can be used. For example, peptide tags can be used for purification of multi-chain chimeric polypeptides or single-chain chimeric polypeptides. As one non-limiting example, a first chimeric polypeptide of a multi-chain chimeric polypeptide (e.g., a recombinantly expressed first chimeric polypeptide), a second chimeric polypeptide of a multi-chain chimeric polypeptide ( e.g., a recombinantly expressed second chimeric polypeptide), or both, or a single chain chimeric polypeptide, may comprise a myc tag, the myc tagged first chimeric polypeptide, the myc tagged second chimeric polypeptide Polypeptides, or both, or multiple-chain chimeric polypeptides, including single-chain chimeric polypeptides, can be purified using an antibody that recognizes the myc-tag. One non-limiting example of an antibody that recognizes the myc tag is 9E10 available from the non-commercial Development Studies Hybridoma Bank. As another non-limiting example, a first chimeric polypeptide of a multi-chain chimeric polypeptide (e.g., a recombinantly expressed first chimeric polypeptide), a second chimeric polypeptide of a multi-chain chimeric polypeptide ( e.g., a recombinantly expressed second chimeric polypeptide), or both, or a single chain chimeric polypeptide can include a histidine tag, a histidine-tagged first chimeric polypeptide, a histidine-tagged second chimeric polypeptide, Polypeptides, or both, or multi-chain chimeric polypeptides, including histidine-tagged single-chain chimeric polypeptides, can be purified using nickel or cobalt chelates. Those skilled in the art will recognize other suitable tags and agents to bind to those tags for use in purifying single-chain or multi-chain chimeric polypeptides. In some embodiments, the peptide tag is removed from the first chimeric polypeptide and/or the second chimeric polypeptide of a multi-chain chimeric polypeptide or the single-chain chimeric polypeptide after purification. In some embodiments, the peptide tag is not removed from the first chimeric polypeptide and/or the second chimeric polypeptide of a multi-chain chimeric polypeptide, or the single-chain chimeric polypeptide after purification.
多鎖キメラポリペプチドの第1のキメラポリペプチド、多鎖キメラポリペプチドの第2のキメラポリペプチド、又はそれらの両方、又は一本鎖キメラポリペプチドに含まれ得るペプチドタグは、それぞれ、例えば、多鎖キメラポリペプチド若しくは一本鎖キメラポリペプチドの免疫沈降、多鎖キメラポリペプチド若しくは一本鎖キメラポリペプチドの画像化(例えば、ウエスタンブロッティング、ELISA、フローサイトメトリー、及び/又は免疫細胞化学による)、及び/又はそれぞれ、多鎖キメラポリペプチド若しくは一本鎖キメラポリペプチドの可溶化に使用され得る。 A peptide tag that may be included in a first chimeric polypeptide of a multi-chain chimeric polypeptide, a second chimeric polypeptide of a multi-chain chimeric polypeptide, or both, or a single-chain chimeric polypeptide may each be, for example, Immunoprecipitation of multi-chain chimeric polypeptides or single-chain chimeric polypeptides, imaging of multi-chain chimeric polypeptides or single-chain chimeric polypeptides (e.g., by Western blotting, ELISA, flow cytometry, and/or immunocytochemistry) ), and/or for solubilization of multi-chain chimeric polypeptides or single-chain chimeric polypeptides, respectively.
いくつかの実施形態では、多鎖キメラポリペプチドの第1のキメラポリペプチド、多鎖キメラポリペプチドの第2のキメラポリペプチド、又はそれらの両方、又は一本鎖キメラポリペプチドは、約10~100アミノ酸長であるペプチドタグを含む。例えば、ペプチドタグは、約10~100アミノ酸長、約15~100アミノ酸長、約20~100アミノ酸長、約25~100アミノ酸長、約30~100アミノ酸長、約35~100アミノ酸長、約40~100アミノ酸長、約45~100アミノ酸長、約50~100アミノ酸長、約55~100アミノ酸長、約60~100アミノ酸長、約65~100アミノ酸長、約70~100アミノ酸長、約75~100アミノ酸長、約80~100アミノ酸長、約85~100アミノ酸長、約90~100アミノ酸長、約95~100アミノ酸長、約10~95アミノ酸長、約10~90アミノ酸長、約10~85アミノ酸長、約10~80アミノ酸長、約10~75アミノ酸長、約10~70アミノ酸長、約10~65アミノ酸長、約10~60アミノ酸長、約10~55アミノ酸長、約10~50アミノ酸長、約10~45アミノ酸長、約10~40アミノ酸長、約10~35アミノ酸長、約10~30アミノ酸長、約10~25アミノ酸長、約10~20アミノ酸長、約10~15アミノ酸長、約20~30アミノ酸長、約30~40アミノ酸長、約40~50アミノ酸長、約50~60アミノ酸長、約60~70アミノ酸長、約70~80アミノ酸長、約80~90アミノ酸長、約90~100アミノ酸長、約20~90アミノ酸長、約30~80アミノ酸長、約40~70アミノ酸長、約50~60アミノ酸長、又はそれらの間の任意の範囲であり得る。いくつかの実施形態では、ペプチドタグは、約10、15、20、25、30、35、40、45、50、55、60、65、70、75、80、85、90、95、又は100アミノ酸長である。 In some embodiments, the first chimeric polypeptide of the multi-chain chimeric polypeptide, the second chimeric polypeptide of the multi-chain chimeric polypeptide, or both, or the single-chain chimeric polypeptide is about 10 to It contains a peptide tag that is 100 amino acids long. For example, peptide tags are about 10-100 amino acids long, about 15-100 amino acids long, about 20-100 amino acids long, about 25-100 amino acids long, about 30-100 amino acids long, about 35-100 amino acids long, about 40 ~100 amino acids long, about 45-100 amino acids long, about 50-100 amino acids long, about 55-100 amino acids long, about 60-100 amino acids long, about 65-100 amino acids long, about 70-100 amino acids long, about 75- 100 amino acids long, about 80-100 amino acids long, about 85-100 amino acids long, about 90-100 amino acids long, about 95-100 amino acids long, about 10-95 amino acids long, about 10-90 amino acids long, about 10-85 Amino acid length, about 10-80 amino acids, about 10-75 amino acids, about 10-70 amino acids, about 10-65 amino acids, about 10-60 amino acids, about 10-55 amino acids, about 10-50 amino acids long, about 10-45 amino acids long, about 10-40 amino acids long, about 10-35 amino acids long, about 10-30 amino acids long, about 10-25 amino acids long, about 10-20 amino acids long, about 10-15 amino acids long , about 20-30 amino acids long, about 30-40 amino acids long, about 40-50 amino acids long, about 50-60 amino acids long, about 60-70 amino acids long, about 70-80 amino acids long, about 80-90 amino acids long, It can be about 90-100 amino acids long, about 20-90 amino acids long, about 30-80 amino acids long, about 40-70 amino acids long, about 50-60 amino acids long, or any range therebetween. In some embodiments, the peptide tag has about 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, or 100 Amino acid length.
多鎖キメラポリペプチドの第1のキメラポリペプチド、多鎖キメラポリペプチドの第2のキメラポリペプチド、又はそれらの両方、又は一本鎖キメラポリペプチドに含まれるペプチドタグは、任意の好適な長さのものであり得る。例えば、ペプチドタグは、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、又はそれ以上のアミノ酸長であり得る。一本鎖又は多鎖キメラポリペプチドが2つ以上のペプチドタグを含む実施形態では、2つ以上のペプチドタグは、同じ長さ又は異なる長さのものであり得る。いくつかの実施形態では、本明細書に開示されるペプチドタグのうちのいずれかは、ペプチドタグの機能が損なわれないままである限り、N末端及び/又はC末端に1つ以上の追加のアミノ酸(例えば、1、2、3、5、6、7、8、9、10、又はそれ以上のアミノ酸)を含み得る。例えば、アミノ酸配列EQKLISEEDL(配列番号138)を有するmycタグは、抗体(例えば、9E10)によって結合される能力を依然として保持しながら、(例えば、ペプチドタグのN末端及び/又はC末端)に1つ以上の追加のアミノ酸を含み得る。 The peptide tag contained in the first chimeric polypeptide of the multi-chain chimeric polypeptide, the second chimeric polypeptide of the multi-chain chimeric polypeptide, or both, or the single-chain chimeric polypeptide can be of any suitable length. can be as small as For example, peptide tags can be 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, or more amino acids long. In embodiments in which the single-chain or multi-chain chimeric polypeptide comprises more than one peptide tag, the two or more peptide tags can be of the same length or different lengths. In some embodiments, any of the peptide tags disclosed herein include one or more additional peptides at the N-terminus and/or C-terminus, so long as the function of the peptide tag remains intact. It may contain amino acids (eg, 1, 2, 3, 5, 6, 7, 8, 9, 10, or more amino acids). For example, a myc tag having the amino acid sequence EQKLISEEDL (SEQ ID NO: 138) has one Additional amino acids above may be included.
一本鎖キメラポリペプチドの例示的な実施形態-タイプA
本明細書に記載の一本鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び/又は第2の標的結合ドメインは独立して、CD3(例えば、ヒトCD3)又はCD28(例えば、ヒトCD28)に特異的に結合することができる。いくつかの実施形態では、第1の標的結合ドメインはCD3(例えば、ヒトCD3)に特異的に結合し、第2の標的結合ドメインはCD28(例えば、ヒトCD28)に特異的に結合する。いくつかの実施形態では、第1の標的結合ドメインはCD28(例えば、ヒトCD28)に特異的に結合し、第2の標的結合ドメインはCD3(例えば、ヒトCD3)に特異的に結合する。
Exemplary Embodiments of Single Chain Chimeric Polypeptides—Type A
In some embodiments of any of the single chain chimeric polypeptides described herein, the first target binding domain and/or the second target binding domain are independently CD3 (e.g., human CD3) or CD28 (eg, human CD28). In some embodiments, the first target binding domain specifically binds CD3 (eg, human CD3) and the second target binding domain specifically binds CD28 (eg, human CD28). In some embodiments, the first target binding domain specifically binds CD28 (eg, human CD28) and the second target binding domain specifically binds CD3 (eg, human CD3).
これらの一本鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメインと可溶性組織因子ドメインは、互いに直接隣接している。これらの一本鎖キメラポリペプチドのいくつかの実施形態では、一本鎖キメラポリペプチドは、第1の標的結合ドメインと可溶性組織因子ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these single chain chimeric polypeptides, the first target binding domain and the soluble tissue factor domain are directly adjacent to each other. In some embodiments of these single chain chimeric polypeptides, the single chain chimeric polypeptide has a linker sequence between the first target binding domain and the soluble tissue factor domain (e.g., any of the exemplary linkers).
これらの一本鎖キメラポリペプチドのいくつかの実施形態では、可溶性組織因子ドメインと第2の標的結合ドメインは、互いに直接隣接している。これらの一本鎖キメラポリペプチドのいくつかの実施形態では、一本鎖キメラポリペプチドは、可溶性組織因子ドメインと第2の標的結合ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these single chain chimeric polypeptides, the soluble tissue factor domain and the second target binding domain are directly adjacent to each other. In some embodiments of these single-chain chimeric polypeptides, the single-chain chimeric polypeptide has a linker sequence (e.g., as described herein) between the soluble tissue factor domain and the second target binding domain. any of the exemplary linkers).
これらの一本鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方が、抗原結合ドメインである。これらの一本鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは各々、抗原結合ドメイン(例えば、本明細書に記載の例示的な抗原結合ドメインのうちのいずれか)である。これらの一本鎖キメラポリペプチドのいくつかの実施形態では、抗原結合ドメインは、scFv又は単一ドメイン抗体を含む。 In some embodiments of these single chain chimeric polypeptides, one or both of the first target binding domain and the second target binding domain is an antigen binding domain. In some embodiments of these single chain chimeric polypeptides, the first target binding domain and the second target binding domain are each an antigen binding domain (e.g., exemplary antigen binding domains described herein). either). In some embodiments of these single chain chimeric polypeptides, the antigen binding domain comprises a scFv or single domain antibody.
CD3に特異的に結合するscFvの非限定的な例は、
QIVLTQSPAIMSASPGEKVTMTCSASSSVSYMNWYQQKSGTSPKRWIYDTSKLASGVPAHFRGSGSGTSYSLTISGMEAEDAATYYCQQWSSNPFTFGSGTKLEINRGGGGSGGGGSGGGGSQVQLQQSGAELARPGASVKMSCKASGYTFTRYTMHWVKQRPGQGLEWIGYINPSRGYTNYNQKFKDKATLTTDKSSSTAYMQLSSLTSEDSAVYYCARYYDDHYCLDYWGQGTTLTVSS(配列番号151)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
A non-limiting example of a scFv that specifically binds to CD3 is
QIVLTQSPAIMSASPGEKVTMTCSASSSVSYMNWYQQKSGTSPKRWIYDTSKLASGVPAHFRGSGSGTSYSLTISGMEAEDAATYYCQQWSSNPFTFGSGTKLEINRGGGGSGGGGGSGGGGGSQVQLQQSGAELARPGASVK at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 8 8% identical, at least 90% identical, at least 92% identical, at least 94% identical , at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、CD3に特異的に結合するscFvは、
CAGATCGTGCTGACCCAAAGCCCCGCCATCATGAGCGCTAGCCCCGGTGAGAAGGTGACCATGACATGCTCCGCTTCCAGCTCCGTGTCCTACATGAACTGGTATCAGCAGAAAAGCGGAACCAGCCCCAAAAGGTGGATCTACGACACCAGCAAGCTGGCCTCCGGAGTGCCCGCTCATTTCCGGGGCTCTGGATCCGGCACCAGCTACTCTTTAACCATTTCCGGCATGGAAGCTGAAGACGCTGCCACCTACTATTGCCAGCAATGGAGCAGCAACCCCTTCACATTCGGATCTGGCACCAAGCTCGAAATCAATCGTGGAGGAGGTGGCAGCGGCGGCGGTGGATCCGGCGGAGGAGGAAGCCAAGTTCAACTCCAGCAGAGCGGCGCTGAACTGGCCCGGCCCGGCGCCTCCGTCAAGATGAGCTGCAAGGCTTCCGGCTATACATTTACTCGTTACACAATGCATTGGGTCAAGCAGAGGCCCGGTCAAGGTTTAGAGTGGATCGGATATATCAACCCTTCCCGGGGCTACACCAACTATAACCAAAAGTTCAAGGATAAAGCCACTTTAACCACTGACAAGAGCTCCTCCACCGCCTACATGCAGCTGTCCTCTTTAACCAGCGAGGACTCCGCTGTTTACTACTGCGCTAGGTATTACGACGACCACTACTGTTTAGACTATTGGGGACAAGGTACCACTTTAACCGTCAGCAGC(配列番号152)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされ得る。
In some embodiments, the scFv that specifically binds to CD3 is
CAGATCGTGCTGACCCAAAGCCCCCGCCATCATGAGCGCTAGCCCCGGTGAGAAGGTGACCATGACATGCTCCGCTTCCAGCTCCGTGTCCTACATGAACTGGTATCAGCAGAAAAGCGGAACCAGCCCCAAAGGTGGATCTACGACACCAGCAAGCTGGCCTCCGGAGTGCCCG CTCATTTCCGGGGCTCTGGATCCGGCACCAGCTACTCTTTAACCATTTCGGCATGGAAGCTGAAGACGCTGCCACCTACTATTGCCAGCAATGGAGCAGCAACCCCCTTCACATTCGGATCTGGCACCAAGCTCGAAAATCAATCGTGGAGGAGGTGGCAGCGGCGGCGGTGGAT CCGGCGGAGGAGGAAGCCAAGTTCAACTCCAGCAGAGCGGCGCTGAACTGGCCCGGCCCGGCGCCTCCGTCAAGATGAGCTGCAAGGCTTCCGGCTATACATTTTACTCGTTACACAATGCATTGGGTCAAGCAGAGGCCCCGGTCAAGGTTTAGAGTGGATCGGATATAT CAACCCTTCCCGGGGGCTACACCAACTATAACCAAAGTTCAAGGATAAAGCCACTTTAACCACTGACAAGAGCTCCTCCACCGCCTACATGCAGCTGTCCTCTTTAACCAGCGAGGACTCCGCTGTTACTACTGCGCTAGGGTATTACGACGACCACTACTGTTTAGACTATTGGGGACAAGGGTACC ACTTTAACCGTCAGCAGC (SEQ ID NO: 152), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
CD28に特異的に結合するscFvの非限定的な例は、
VQLQQSGPELVKPGASVKMSCKASGYTFTSYVIQWVKQKPGQGLEWIGSINPYNDYTKYNEKFKGKATLTSDKSSITAYMEFSSLTSEDSALYYCARWGDGNYWGRGTTLTVSSGGGGSGGGGSGGGGSDIEMTQSPAIMSASLGERVTMTCTASSSVSSSYFHWYQQKPGSSPKLCIYSTSNLASGVPPRFSGSGSTSYSLTISSMEAEDAATYFCHQYHRSPTFGGGTKLETKR(配列番号153)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
Non-limiting examples of scFv that specifically bind CD28 are:
VQLQQSGPELVKPGASVKMSCKASGYTFTSYVIQWVKQKPGQGLEWIGSINPYNDYTKYNEKFKGKATLTSDKSSSITAYMEFSSLTSEDSALYYCARWGDGNYWGRGTTLTVSSGGGGGSGGGGSGGGGSDIEMTQSPAIM SASLGERVTMTCTASSVSSSSYFHWYQQKPGSSPKLCIYSTSNLASGVPPRFSGSGSTSYSLTISSMEAEDAATYFCHQYHRSPTFGGGTKLETKR (SEQ ID NO: 153), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical , at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、CD28に特異的に結合するscFvは、
GTCCAGCTGCAGCAGAGCGGACCCGAACTCGTGAAACCCGGTGCTTCCGTGAAAATGTCTTGTAAGGCCAGCGGATACACCTTCACCTCCTATGTGATCCAGTGGGTCAAACAGAAGCCCGGACAAGGTCTCGAGTGGATCGGCAGCATCAACCCTTACAACGACTATACCAAATACAACGAGAAGTTTAAGGGAAAGGCTACTTTAACCTCCGACAAAAGCTCCATCACAGCCTACATGGAGTTCAGCTCTTTAACATCCGAGGACAGCGCTCTGTACTATTGCGCCCGGTGGGGCGACGGCAATTACTGGGGACGGGGCACAACACTGACCGTGAGCAGCGGAGGCGGAGGCTCCGGCGGAGGCGGATCTGGCGGTGGCGGCTCCGACATCGAGATGACCCAGTCCCCCGCTATCATGTCCGCCTCTTTAGGCGAGCGGGTCACAATGACTTGTACAGCCTCCTCCAGCGTCTCCTCCTCCTACTTCCATTGGTACCAACAGAAACCCGGAAGCTCCCCTAAACTGTGCATCTACAGCACCAGCAATCTCGCCAGCGGCGTGCCCCCTAGGTTTTCCGGAAGCGGAAGCACCAGCTACTCTTTAACCATCTCCTCCATGGAGGCTGAGGATGCCGCCACCTACTTTTGTCACCAGTACCACCGGTCCCCCACCTTCGGAGGCGGCACCAAACTGGAGACAAAGAGG(配列番号154)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされ得る。
In some embodiments, the scFv that specifically binds to CD28 is
GTCCAGCTGCAGCAGAGCGGACCCGAACTCGTGAAACCCGGTGCTTCCGTGAAAATGTCTTGTAAGGCCAGCGGATACACCTTTCACCTCCTATGTGATCCAGTGGGTCAAAACAGAAGCCCGGACAAGGTCTCGAGTGGATCGGCAGCATCAACCCTTACAACGACTATACCA AATACAACGAGAAGTTTAAGGGAAAGGCTACTTTAACCTCCGACAAAAGCTCCATCACAGCCTACATGGAGTTCAGCTCTTTAACATCCGAGGACAGCGCTCTGTACTATTGCGCCCGGTGGGGGCGACGGCAATTACTGGGGACGGGGCACAACACTGACCGTGAGCAGCGGAGGCGGA GGCTCCGGCGGAGGCGGATCTGGCGGTGGCGGCTCCGACATCGAGATGACCCAGTCCCCCGCTATCATGTCCGCCTCTTTAGGCGAGCGGTCACAATGACTTGTACAGCCTCCTCCAGCGTCCTCCTCCTCCTACTTCCATTGGTACCAACAGAAACCCGGAAGCTCCCCTAAACTG TGCATCTACAGCACCAGCAATCTCGCCAGCGGCGTGCCCCCTAGGTTTTCCGGAAGCGGAAGCACCAGCTACTCTTTAACCATCTCCTCCATGGAGGCTGGATGCCGCCACCTACTTTTTGTCACCAGTACCCACCGGTCCCCCACCTTCGGAGGCGGCACCAAACTGGAGACAA AGAGG (SEQ ID NO: 154), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの一本鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン及び/又は第2の標的結合ドメインは、可溶性受容体(例えば、可溶性CD28受容体又は可溶性CD3受容体)である。これらの一本鎖キメラポリペプチドのいくつかの実施形態では、可溶性組織因子ドメインは、本明細書に記載の例示的な可溶性組織因子ドメインのうちのいずれかであり得る。 In some embodiments of these single-chain chimeric polypeptides, the first target binding domain and/or the second target binding domain are soluble receptors (eg, soluble CD28 receptor or soluble CD3 receptor). be. In some embodiments of these single-chain chimeric polypeptides, the soluble tissue factor domain can be any of the exemplary soluble tissue factor domains described herein.
いくつかの実施形態では、一本鎖キメラポリペプチドは、
QIVLTQSPAIMSASPGEKVTMTCSASSSVSYMNWYQQKSGTSPKRWIYDTSKLASGVPAHFRGSGSGTSYSLTISGMEAEDAATYYCQQWSSNPFTFGSGTKLEINRGGGGSGGGGSGGGGSQVQLQQSGAELARPGASVKMSCKASGYTFTRYTMHWVKQRPGQGLEWIGYINPSRGYTNYNQKFKDKATLTTDKSSSTAYMQLSSLTSEDSAVYYCARYYDDHYCLDYWGQGTTLTVSSSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFREVQLQQSGPELVKPGASVKMSCKASGYTFTSYVIQWVKQKPGQGLEWIGSINPYNDYTKYNEKFKGKATLTSDKSSITAYMEFSSLTSEDSALYYCARWGDGNYWGRGTTLTVSSGGGGSGGGGSGGGGSDIEMTQSPAIMSASLGERVTMTCTASSSVSSSYFHWYQQKPGSSPKLCIYSTSNLASGVPPRFSGSGSTSYSLTISSMEAEDAATYFCHQYHRSPTFGGGTKLETKR(配列番号155)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the single-chain chimeric polypeptide comprises
QIVLTQSPAIMSASPGEKVTMTCSASSSVSYMNWYQQKSGTSPKRWIYDTSKLASGVPAHFRGSGSGTSYSLTISGMEAEDAATYYCQQWSSNPFTFGSGTKLEINRGGGGSGGGGGSGGGGGSQVQLQQSGAELARPGASVK MSCKASGYTFTRYTMHWVKQRPGQGLEWIGYINPSRGYTNYNQKFKDKATLTTDKSSSTAYMQLSSLTSEDSAVYYCARYYDDHYCLDYWGQGTTLTVSSSSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKS GDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNNTNEFLIDVDKGEN YCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFREVQLQQSGPELVKPGASVKMSCKASGYTFTSYVIQWVKQKPGQGLEWIGSINPYNDYTKYNEKFKGKATLTSDKSSSITAYMEFSSLTSEDSALYYCARWGDGNYWGRGTT at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、一本鎖キメラポリペプチドは、
CAGATCGTGCTGACCCAAAGCCCCGCCATCATGAGCGCTAGCCCCGGTGAGAAGGTGACCATGACATGCTCCGCTTCCAGCTCCGTGTCCTACATGAACTGGTATCAGCAGAAAAGCGGAACCAGCCCCAAAAGGTGGATCTACGACACCAGCAAGCTGGCCTCCGGAGTGCCCGCTCATTTCCGGGGCTCTGGATCCGGCACCAGCTACTCTTTAACCATTTCCGGCATGGAAGCTGAAGACGCTGCCACCTACTATTGCCAGCAATGGAGCAGCAACCCCTTCACATTCGGATCTGGCACCAAGCTCGAAATCAATCGTGGAGGAGGTGGCAGCGGCGGCGGTGGATCCGGCGGAGGAGGAAGCCAAGTTCAACTCCAGCAGAGCGGCGCTGAACTGGCCCGGCCCGGCGCCTCCGTCAAGATGAGCTGCAAGGCTTCCGGCTATACATTTACTCGTTACACAATGCATTGGGTCAAGCAGAGGCCCGGTCAAGGTTTAGAGTGGATCGGATATATCAACCCTTCCCGGGGCTACACCAACTATAACCAAAAGTTCAAGGATAAAGCCACTTTAACCACTGACAAGAGCTCCTCCACCGCCTACATGCAGCTGTCCTCTTTAACCAGCGAGGACTCCGCTGTTTACTACTGCGCTAGGTATTACGACGACCACTACTGTTTAGACTATTGGGGACAAGGTACCACTTTAACCGTCAGCAGCTCCGGCACCACCAATACCGTGGCCGCTTATAACCTCACATGGAAGAGCACCAACTTCAAGACAATTCTGGAATGGGAACCCAAGCCCGTCAATCAAGTTTACACCGTGCAGATCTCCACCAAATCCGGAGACTGGAAGAGCAAGTGCTTCTACACAACAGACACCGAGTGTGATTTAACCGACGAAATCGTCAAGGACGTCAAGCAAACCTATCTGGCTCGGGTCTTTTCCTACCCCGCTGGCAATGTCGAGTCCACCGGCTCCGCTGGCGAGCCTCTCTACGAGAATTCCCCCGAATTCACCCCTTATTTAGAGACCAATTTAGGCCAGCCTACCATCCAGAGCTTCGAGCAAGTTGGCACCAAGGTGAACGTCACCGTCGAGGATGAAAGGACTTTAGTGCGGCGGAATAACACATTTTTATCCCTCCGGGATGTGTTCGGCAAAGACCTCATCTACACACTGTACTATTGGAAGTCCAGCTCCTCCGGCAAAAAGACCGCTAAGACCAACACCAACGAGTTTTTAATTGACGTGGACAAAGGCGAGAACTACTGCTTCAGCGTGCAAGCCGTGATCCCTTCTCGTACCGTCAACCGGAAGAGCACAGATTCCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGGTCCAGCTGCAGCAGAGCGGACCCGAACTCGTGAAACCCGGTGCTTCCGTGAAAATGTCTTGTAAGGCCAGCGGATACACCTTCACCTCCTATGTGATCCAGTGGGTCAAACAGAAGCCCGGACAAGGTCTCGAGTGGATCGGCAGCATCAACCCTTACAACGACTATACCAAATACAACGAGAAGTTTAAGGGAAAGGCTACTTTAACCTCCGACAAAAGCTCCATCACAGCCTACATGGAGTTCAGCTCTTTAACATCCGAGGACAGCGCTCTGTACTATTGCGCCCGGTGGGGCGACGGCAATTACTGGGGACGGGGCACAACACTGACCGTGAGCAGCGGAGGCGGAGGCTCCGGCGGAGGCGGATCTGGCGGTGGCGGCTCCGACATCGAGATGACCCAGTCCCCCGCTATCATGTCCGCCTCTTTAGGCGAGCGGGTCACAATGACTTGTACAGCCTCCTCCAGCGTCTCCTCCTCCTACTTCCATTGGTACCAACAGAAACCCGGAAGCTCCCCTAAACTGTGCATCTACAGCACCAGCAATCTCGCCAGCGGCGTGCCCCCTAGGTTTTCCGGAAGCGGAAGCACCAGCTACTCTTTAACCATCTCCTCCATGGAGGCTGAGGATGCCGCCACCTACTTTTGTCACCAGTACCACCGGTCCCCCACCTTCGGAGGCGGCACCAAACTGGAGACAAAGAGG(配列番号156)と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the single-chain chimeric polypeptide comprises
CAGATCGTGCTGACCCAAAGCCCCCGCCATCATGAGCGCTAGCCCCGGTGAGAAGGTGACCATGACATGCTCCGCTTCCAGCTCCGTGTCCTACATGAACTGGTATCAGCAGAAAAGCGGAACCAGCCCCAAAGGTGGATCTACGACACCAGCAAGCTGGCCTCCGGAGTGCCCG CTCATTTCCGGGGCTCTGGATCCGGCACCAGCTACTCTTTAACCATTTCGGCATGGAAGCTGAAGACGCTGCCACCTACTATTGCCAGCAATGGAGCAGCAACCCCCTTCACATTCGGATCTGGCACCAAGCTCGAAAATCAATCGTGGAGGAGGTGGCAGCGGCGGCGGTGGAT CCGGCGGAGGAGGAAGCCAAGTTCAACTCCAGCAGAGCGGCGCTGAACTGGCCCGGCCCGGCGCCTCCGTCAAGATGAGCTGCAAGGCTTCCGGCTATACATTTTACTCGTTACACAATGCATTGGGTCAAGCAGAGGCCCCGGTCAAGGTTTAGAGTGGATCGGATATAT CAACCCTTCCCGGGGGCTACACCAACTATAACCAAAGTTCAAGGATAAAGCCACTTTAACCACTGACAAGAGCTCCTCCACCGCCTACATGCAGCTGTCCTCTTTAACCAGCGAGGACTCCGCTGTTACTACTGCGCTAGGGTATTACGACGACCACTACTGTTTAGACTATTGGGGACAAGGGTACC ACTTTAACCGTCAGCAGCTCCGGCACCACCAATACCGTGGCCGCTTATAACCTCACATGGAAGAGCACCAACTTCAAGACAATTCTGGAATGGGAACCCAAGCCCCGTCAATCAAGTTTACACCGTGCAGATCTCCACCAAAATCCGGAGACTGGGAAGAGCAAGTGCTTCTACACAACAGACACCGAGTGT GATTTAACCGACGAAATCGTCAAGGACGTCAAGCAAACCTATCTGGCTCGGGTCTTTTTCCTACCCCCGCTGGCAATGTCGAGTCCACCGGCTCCGCTGGCGAGCTCTCTACGAGAATTCCCCCGAATTCACCCCTTATTTAGAGACCAATTTAGGCCAGCTACCATCCAGAGCTTCGAGCAAG TTGGCACCAAGGTGAACGTCACCGTCGAGGATGAAAGGACTTTAGTGCGGCGGAATAACACATTTTTTATCCCTCCGGGATGTGTTCGGCAAAGACCTCATCTACACACTGTACTATTGGAAGTCCAGCTCCTCCGGCAAAAAAGACCGCTAAGACCAACACCAACGAGTTTTT ATTGACGTGGACAAAGGCGAGAACTACTGCTTCAGCGTGCAAGCCGTGATCCCTTCGTACCGTCAACCGGAAGAGCACAGATTCCCCCGTTGAGTGCATGGGCCAAGAAAGGGCGAGTTCCGGGAGGTCCAGCTGCAGCAGAGCGGACCCGAACTCGTGAAACCCGG TGCTTCCGTGAAATGTCTTGTAAGGCCAGCGGATACACCTTCACCTCCTATGTGATCCAGTGGGTCAAACAGAAGCCCCGGACAAGGTCTCGAGTGGATCGGCAGCATCAACCCTTACAACGACTATACCAAATACAACGAGAAGTTTAAGGGAAAGGCTACTTTTAACCTCCGACAA AAGCTCCATCACAGCCCTACATGGAGTTCAGCTCTTTAACATCCGAGGACAGCGCTCTGTACTATTGCGCCCGGTGGGGCGACGGCCAATTACTGGGGACGGGGCACAACACTGACCGTGAGCAGCGGAGGCGGAGGCTCCGGCGGAGGCGGATCTGGCGGTGGCGGCTCCGAC ATCGAGATGACCCAGTCCCCCGCTATCATGTCCGCCTCTTTAGGCGAGCGGGTCACAATGACTTGTACAGCCTCCTCCAGCGTCTCCTCCTCCTACTTCCATTGGTACCAACAGAAACCGGAAGCTCCCCTAAACTGTGCCATCTACAGCACCAGCAATCTCGCCAGCGGCGTGCCCCCTA at least 80% identical (e.g., at least 82% identical, at least 84% identical , at least 86% identical, at least 88% identical, at least 90% identical , at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、一本鎖キメラポリペプチドは、
MKWVTFISLLFLFSSAYSQIVLTQSPAIMSASPGEKVTMTCSASSSVSYMNWYQQKSGTSPKRWIYDTSKLASGVPAHFRGSGSGTSYSLTISGMEAEDAATYYCQQWSSNPFTFGSGTKLEINRGGGGSGGGGSGGGGSQVQLQQSGAELARPGASVKMSCKASGYTFTRYTMHWVKQRPGQGLEWIGYINPSRGYTNYNQKFKDKATLTTDKSSSTAYMQLSSLTSEDSAVYYCARYYDDHYCLDYWGQGTTLTVSSSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFREVQLQQSGPELVKPGASVKMSCKASGYTFTSYVIQWVKQKPGQGLEWIGSINPYNDYTKYNEKFKGKATLTSDKSSITAYMEFSSLTSEDSALYYCARWGDGNYWGRGTTLTVSSGGGGSGGGGSGGGGSDIEMTQSPAIMSASLGERVTMTCTASSSVSSSYFHWYQQKPGSSPKLCIYSTSNLASGVPPRFSGSGSTSYSLTISSMEAEDAATYFCHQYHRSPTFGGGTKLETKR(配列番号157)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the single-chain chimeric polypeptide comprises
MKWVTFISLLFLFSSAYSQIVLTQSPAIMSASPGEKVTMTCSASSSVSYMNWYQQKSGTSPKRWIYDTSKLASGVPAHFRGSGSGTSSYSLTISGMEAEDAATYYCQWSSNPFTFGSGTKLEINRGGGGSGGGGSGGGGG SQVQLQQSGAELARPGASVKMSCKASGYTFTRYTMHWVKQRPGQGLEWIGYINPSRGYTNYNQKFKDKATLTTTDKSSSSTAYMQLSSLTSEDSAVYYCARYYDDHYCLDYWGQGTTLTVSSSGTTNTVAAYNLTWKSTNFKTILE WEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNNTFLSLRDVFGKDLIYTLYYWKSSSSG KKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFREVQLQQSGPELVKPGASVKMSCKASGYTFTSYVIQWVKQKPGQGLEWIGSINPYNDYTKYNEKFKGKATLTSDKSSITAYMEFSLTSEDSAL YYCARWGDGNYWGRGTTLTVSSGGGGSGGGGGSGGGSDIEMTQSPAIMSASLGERVTMTCTASSSVSSSYFHWYQQKPGSSPKLCIYSTSNLASGVPPRFSGSGSTSYSLTISSMEAEDAATYFCHQYHRSPTFGGGTKLETKR (SEQ ID NO: 15 7), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、一本鎖キメラポリペプチドは、
ATGAAGTGGGTGACCTTCATCAGCTTATTATTTTTATTCAGCTCCGCCTATTCCCAGATCGTGCTGACCCAAAGCCCCGCCATCATGAGCGCTAGCCCCGGTGAGAAGGTGACCATGACATGCTCCGCTTCCAGCTCCGTGTCCTACATGAACTGGTATCAGCAGAAAAGCGGAACCAGCCCCAAAAGGTGGATCTACGACACCAGCAAGCTGGCCTCCGGAGTGCCCGCTCATTTCCGGGGCTCTGGATCCGGCACCAGCTACTCTTTAACCATTTCCGGCATGGAAGCTGAAGACGCTGCCACCTACTATTGCCAGCAATGGAGCAGCAACCCCTTCACATTCGGATCTGGCACCAAGCTCGAAATCAATCGTGGAGGAGGTGGCAGCGGCGGCGGTGGATCCGGCGGAGGAGGAAGCCAAGTTCAACTCCAGCAGAGCGGCGCTGAACTGGCCCGGCCCGGCGCCTCCGTCAAGATGAGCTGCAAGGCTTCCGGCTATACATTTACTCGTTACACAATGCATTGGGTCAAGCAGAGGCCCGGTCAAGGTTTAGAGTGGATCGGATATATCAACCCTTCCCGGGGCTACACCAACTATAACCAAAAGTTCAAGGATAAAGCCACTTTAACCACTGACAAGAGCTCCTCCACCGCCTACATGCAGCTGTCCTCTTTAACCAGCGAGGACTCCGCTGTTTACTACTGCGCTAGGTATTACGACGACCACTACTGTTTAGACTATTGGGGACAAGGTACCACTTTAACCGTCAGCAGCTCCGGCACCACCAATACCGTGGCCGCTTATAACCTCACATGGAAGAGCACCAACTTCAAGACAATTCTGGAATGGGAACCCAAGCCCGTCAATCAAGTTTACACCGTGCAGATCTCCACCAAATCCGGAGACTGGAAGAGCAAGTGCTTCTACACAACAGACACCGAGTGTGATTTAACCGACGAAATCGTCAAGGACGTCAAGCAAACCTATCTGGCTCGGGTCTTTTCCTACCCCGCTGGCAATGTCGAGTCCACCGGCTCCGCTGGCGAGCCTCTCTACGAGAATTCCCCCGAATTCACCCCTTATTTAGAGACCAATTTAGGCCAGCCTACCATCCAGAGCTTCGAGCAAGTTGGCACCAAGGTGAACGTCACCGTCGAGGATGAAAGGACTTTAGTGCGGCGGAATAACACATTTTTATCCCTCCGGGATGTGTTCGGCAAAGACCTCATCTACACACTGTACTATTGGAAGTCCAGCTCCTCCGGCAAAAAGACCGCTAAGACCAACACCAACGAGTTTTTAATTGACGTGGACAAAGGCGAGAACTACTGCTTCAGCGTGCAAGCCGTGATCCCTTCTCGTACCGTCAACCGGAAGAGCACAGATTCCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGGTCCAGCTGCAGCAGAGCGGACCCGAACTCGTGAAACCCGGTGCTTCCGTGAAAATGTCTTGTAAGGCCAGCGGATACACCTTCACCTCCTATGTGATCCAGTGGGTCAAACAGAAGCCCGGACAAGGTCTCGAGTGGATCGGCAGCATCAACCCTTACAACGACTATACCAAATACAACGAGAAGTTTAAGGGAAAGGCTACTTTAACCTCCGACAAAAGCTCCATCACAGCCTACATGGAGTTCAGCTCTTTAACATCCGAGGACAGCGCTCTGTACTATTGCGCCCGGTGGGGCGACGGCAATTACTGGGGACGGGGCACAACACTGACCGTGAGCAGCGGAGGCGGAGGCTCCGGCGGAGGCGGATCTGGCGGTGGCGGCTCCGACATCGAGATGACCCAGTCCCCCGCTATCATGTCCGCCTCTTTAGGCGAGCGGGTCACAATGACTTGTACAGCCTCCTCCAGCGTCTCCTCCTCCTACTTCCATTGGTACCAACAGAAACCCGGAAGCTCCCCTAAACTGTGCATCTACAGCACCAGCAATCTCGCCAGCGGCGTGCCCCCTAGGTTTTCCGGAAGCGGAAGCACCAGCTACTCTTTAACCATCTCCTCCATGGAGGCTGAGGATGCCGCCACCTACTTTTGTCACCAGTACCACCGGTCCCCCACCTTCGGAGGCGGCACCAAACTGGAGACAAAGAGG(配列番号158)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the single-chain chimeric polypeptide comprises
ATGAAGTGGGTGACCTTCATCAGCTTATTATTTTATTCAGCTCCGCCTATTCCCAGATCGTGCTGACCCAAAGCCCCCGCCATCATGAGCGCTAGCCCCGGTGAGAAGGTGACCATGACATGCTCCGCTTCCAGCTCCGTGTCCTACATGAACTGGTATCAGCAGAAAAGCGGAAC CAGCCCCAAAAGGTGGATCTACGACACCAGCAAGCTGGCCTCCGGAGTGCCCGCTCATTTCCGGGGCTCTGGATCCGGCACCAGCTACTCTTTAACCATTTCCGGCATGGAAGCCTGAAGACGCTGCCACCTACTATTGCCAGCCAATGGAGCAGCAACCCCTTCACATTCGGATCTGGC ACCAAGCTCGAAAATCAATCGTGGAGGAGGTGGCAGCGGCGGCGGGTGGATCCGGCGGAGGAGGAAGCCAAGTTCAACTCCAGCAGAGCGGCGCTGAACTGGCCCGGCCCCGGCGCCTCCGTCAAGATGAGCTGCAAGGCTTCCGGCTATACATTTACTCGTTACACAATG CATTGGGTCAAGCAGAGGCCCGGTCAAGGTTTAGAGTGGATCGGATATATCAACCCTTCCCGGGGGCTACACCAACTATAACCAAAGTTCAAGGATAAAGCCACTTTAACCACTGACAAGAGCTCCTCCACCGCCTACATGCAGCTGTCCTCTTTAACCAGCGGAGGACTCCGCTGTTACT ACTGCGCTAGGTATTACGACGACCACTACTGTTTAGACTATTGGGGACAAGGTACCACTTTTAACCGTCAGCAGCTCCGGCACCACCAATACCGTGGCCGCTTATAACCTCACATGGAAGAGCACCAACTTCAGACAATTCTGGAATGGGAACCCAAGCCCCGTCAATCAAGTTTACACCGTGCAG ATCTCCACCAAATCCGGAGACTGGAAGAGCAAGTGCTTTCACACAACAGACACCGAGTGTGATTTAACCGACGAAAATCGTCAAGGACGTCAAGCAAACCTATCTGGCTCGGGTCTTTTCCTACCCCGCTGGCAATGTCGAGTCCACCGGCTCCGCTGGCGAGCTCTCTACGAGAATTCCCCCGA ATTCACCCTTATTTAGAGACCAATTTAGGCCAGCTCTACCATCCAGAGCTTCGAGCAAGTTTGGCACCAAGGTGAACGTCACCGTCGAGGATGAAAGGACTTTAGTGCGGCGGAATAACACATTTTTATCCCCTCCGGGATGTGTTCGGCAAAGACCTCATCTACACACTGTACTATTG GAAGTCCAGCTCCTCCGGCAAAAAGACCGCTAAGACCAACACCAACGAGTTTTAATTGACGTGGACAAAGGCGAGAACTACTGCTTCAGCGTGCAAGCCGTGATCCCTTCGTACCGTCAACCGGAAGAGCACAGATTCCCCCGTTGAGTGCATGGGCCAAGAAAAGGGGC GAGTTCCGGGAGGTCCAGCTGCAGCAGAGCGGACCCGAACTCGTGAAACCCCGGTGCTTCCGTGAAAATGTCTTGTAAGGCCAGCGGATACACCTTCACCTCCTATGTGATCCAGTGGGTCAAACAGAAGCCCGGACAAGGTCTCGAGTGGATCGGCAGCATCAACCCTTA CAACGACTATACCAAATACAACGAGAAGTTTAAGGGAAAGGCTACTTTAACCTCCGACAAAAGCTCCATCACAGCCTACATGGAGTTCAGCTCTTTAACATCCGAGGACAGCGCTCTGTACTATTGCGCCCCGGTGGGGGCGACGGCCAATTACTGGGGACGGGGGCCACAACACTGACCGTGAGCAGC GGAGGCGGAGGCTCCGGCGGAGGCGGATCTGGCGGTGGCGGCTCCGACATCGAGATGACCCAGTCCCCCGCTATCATGTCCGCCTCTTAGGCGAGCGGGTCACAATGACTTGTACAGCCTCCTCCAGCGTCCTCCTCCTCCTACTTCCATTGGTACCAACAGAAACCCGGAAGCT CCCCTAAACTGTGCATCTACAGCACCAGCAATCTCGCCAGCGGGCGTGCCCCCTAGAGGTTTTCCGGAAGCGGAAGCACCAGCTACTCTTTAACCCATCTCCTCCATGGAGGCTGAGGATGCCGCCACCTACTTTTGTCACCAGTACCACCGGTCCCCCACCTTCGGAGGCGGCACCAA ACTGGAGACAAAGAGG (SEQ ID NO: 158), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
一本鎖キメラポリペプチドの例示的な実施形態-タイプB
本明細書に記載の一本鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び/又は第2の標的結合ドメインは独立して、IL-2受容体(例えば、ヒトIL-2受容体)に特異的に結合することができる。
Exemplary Embodiments of Single Chain Chimeric Polypeptides—Type B
In some embodiments of any of the single-chain chimeric polypeptides described herein, the first target binding domain and/or the second target binding domain are independently IL-2 receptor (eg, human IL-2 receptor).
これらの一本鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメインと可溶性組織因子ドメインは、互いに直接隣接している。これらの一本鎖キメラポリペプチドのいくつかの実施形態では、一本鎖キメラポリペプチドは、第1の標的結合ドメインと可溶性組織因子ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these single chain chimeric polypeptides, the first target binding domain and the soluble tissue factor domain are directly adjacent to each other. In some embodiments of these single chain chimeric polypeptides, the single chain chimeric polypeptide has a linker sequence between the first target binding domain and the soluble tissue factor domain (e.g., any of the exemplary linkers).
これらの一本鎖キメラポリペプチドのいくつかの実施形態では、可溶性組織因子ドメインと第2の標的結合ドメインは、互いに直接隣接している。これらの一本鎖キメラポリペプチドのいくつかの実施形態では、一本鎖キメラポリペプチドは、可溶性組織因子ドメインと第2の標的結合ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these single chain chimeric polypeptides, the soluble tissue factor domain and the second target binding domain are directly adjacent to each other. In some embodiments of these single-chain chimeric polypeptides, the single-chain chimeric polypeptide has a linker sequence (e.g., a linker sequence described herein) between the soluble tissue factor domain and the second target binding domain. any of the exemplary linkers).
これらの一本鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは、可溶性ヒトIL-2タンパク質である。IL-2受容体に特異的に結合するIL-2タンパク質の非限定的な例は、
APTSSSTKKTQLQLEHLLLDLQMILNGINNYKNPKLTRMLTFKFYMPKKATELKHLQCLEEELKPLEEVLNLAQSKNFHLRPRDLISNINVIVLELKGSETTFMCEYADETATIVEFLNRWITFCQSIISTLT(配列番号78)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments of these single chain chimeric polypeptides, the first target binding domain and the second target binding domain are soluble human IL-2 proteins. A non-limiting example of an IL-2 protein that specifically binds to the IL-2 receptor is
APTSSSTKKTQLQLEHLLLDLQMILNGINNYKNPKLTRMLTFKFYMPKKATELKHLQCLEEELKPLEEVLNLAQSKNFHLPRRDLISNINVIVLELKGSETTFMCEYADETATIVEFLNRWITFCQSIISTLT (SEQ ID NO: 78), at least 80% identical to (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, sequences that are at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、IL-2受容体に特異的に結合するIL-2タンパク質は、
GCACCTACTTCAAGTTCTACAAAGAAAACACAGCTACAACTGGAGCATTTACTGCTGGATTTACAGATGATTTTGAATGGAATTAATAATTACAAGAATCCCAAACTCACCAGGATGCTCACATTTAAGTTTTACATGCCCAAGAAGGCCACAGAACTGAAACATCTTCAGTGTCTAGAAGAAGAACTCAAACCTCTGGAGGAAGTGCTAAATTTAGCTCAAAGCAAAAACTTTCACTTAAGACCCAGGGACTTAATCAGCAATATCAACGTAATAGTTCTGGAACTAAAGGGATCTGAAACAACATTCATGTGTGAATATGCTGATGAGACAGCAACCATTGTAGAATTTCTGAACAGATGGATTACCTTTTGTCAAAGCATCATCTCAACACTAACT(配列番号159)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされ得る。
In some embodiments, the IL-2 protein that specifically binds to the IL-2 receptor is
GCACCTACTTCAAGTTTCTACAAAGAAAACACAGCTACAACTGGAGCATTTACTGCTGGATTTACAGATGATTTTGAATGGAATTAATAATTACAAGAATCCCAAACTCACCAGGATGCTCACATTTAAGTTTTTACATGCCCAAGAAGGCCACAGAACTGAAACATCTTCAGTGTCTAGAAGA AGAACTCAAAACCTCTGGAGGAAGTGCTAAAATTTAGCTACAAAGCAAAACTTTCACTTAAGACCCAGGGGACTTAATCAGCAATATCAACGTAATAGTTTCTGGAACTAAAGGGATCTGAAAACAATTCATGTGTGAATATGCTGATGAGACAGCAACCATTGTAGAATTTCTGAACAGATGGATTACCT at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、IL-2受容体に特異的に結合するIL-2タンパク質は、
GCCCCCACCTCCTCCTCCACCAAGAAGACCCAGCTGCAGCTGGAGCATTTACTGCTGGATTTACAGATGATTTTAAACGGCATCAACAACTACAAGAACCCCAAGCTGACTCGTATGCTGACCTTCAAGTTCTACATGCCCAAGAAGGCCACCGAGCTGAAGCATTTACAGTGTTTAGAGGAGGAGCTGAAGCCCCTCGAGGAGGTGCTGAATTTAGCCCAGTCCAAGAATTTCCATTTAAGGCCCCGGGATTTAATCAGCAACATCAACGTGATCGTTTTAGAGCTGAAGGGCTCCGAGACCACCTTCATGTGCGAGTACGCCGACGAGACCGCCACCATCGTGGAGTTTTTAAATCGTTGGATCACCTTCTGCCAGTCCATCATCTCCACTTTAACC(配列番号160)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされ得る。
In some embodiments, the IL-2 protein that specifically binds to the IL-2 receptor is
GCCCCCACCTCCTCCTCCACCAAGAAGACCCAGCTGCAGCTGGAGCATTTACTGCTGGATTTACAGATGATTTTAAACGGCATCAACAACTACAAGAACCCCCAAGCTGACTCGTATGCTGACCTTCAAGTTTCTACATGCCCAAGAAGGCCACCGAGCTGAAGCATTTACAGTGTTTAGAGGAGGA GCTGAAGCCCCTCGAGGAGGTGCTGAATTTAGCCCAGTCCAAGAATTTCCATTTAAGGCCCCGGGATTTAATCAGCAACATCAACGTGATCGTTTTAGAGCTGAAGGGCTCCGAGACCACCTTCATGTGCGAGTACGCCGACGAGACCGCCACCATCGTGGAGTTTTTAAATCGTTGGG At least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの一本鎖キメラポリペプチドのいくつかの実施形態では、可溶性組織因子ドメインは、本明細書に記載の例示的な可溶性組織因子ドメインのうちのいずれかであり得る。 In some embodiments of these single-chain chimeric polypeptides, the soluble tissue factor domain can be any of the exemplary soluble tissue factor domains described herein.
いくつかの実施形態では、一本鎖キメラポリペプチドは、
APTSSSTKKTQLQLEHLLLDLQMILNGINNYKNPKLTRMLTFKFYMPKKATELKHLQCLEEELKPLEEVLNLAQSKNFHLRPRDLISNINVIVLELKGSETTFMCEYADETATIVEFLNRWITFCQSIISTLTSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFREAPTSSSTKKTQLQLEHLLLDLQMILNGINNYKNPKLTRMLTFKFYMPKKATELKHLQCLEEELKPLEEVLNLAQSKNFHLRPRDLISNINVIVLELKGSETTFMCEYADETATIVEFLNRWITFCQSIISTLT(配列番号161)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the single-chain chimeric polypeptide comprises
APTSSSTKKTQLQLEHLLLDLQMILNGINNYKNPKLTRMLTFKFYMPKKATELKHLQCLEEELKPLEEVLNLAQSKNFHLRPRDLISNINVIVLKGSETTFMCEYADETATIVEFLNRWITFCQSIISTLTSGTTNTVAAYNLTW KSTN FKTILEWEPKKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNNTFLSLRDVFGKDLIYTLY YWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFREAPTSSSTKKTQLQLEHLLLDLQMILNGINNYKNPKLTRMLTFKFYMPKKATELKHLQCLEEELKPLEEVLNLAQSKNFHLRP at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% sequences that are identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、一本鎖キメラポリペプチドは、
GCCCCCACCTCCTCCTCCACCAAGAAGACCCAGCTGCAGCTGGAGCATTTACTGCTGGATTTACAGATGATTTTAAACGGCATCAACAACTACAAGAACCCCAAGCTGACTCGTATGCTGACCTTCAAGTTCTACATGCCCAAGAAGGCCACCGAGCTGAAGCATTTACAGTGTTTAGAGGAGGAGCTGAAGCCCCTCGAGGAGGTGCTGAATTTAGCCCAGTCCAAGAATTTCCATTTAAGGCCCCGGGATTTAATCAGCAACATCAACGTGATCGTTTTAGAGCTGAAGGGCTCCGAGACCACCTTCATGTGCGAGTACGCCGACGAGACCGCCACCATCGTGGAGTTTTTAAATCGTTGGATCACCTTCTGCCAGTCCATCATCTCCACTTTAACCAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGGCACCTACTTCAAGTTCTACAAAGAAAACACAGCTACAACTGGAGCATTTACTGCTGGATTTACAGATGATTTTGAATGGAATTAATAATTACAAGAATCCCAAACTCACCAGGATGCTCACATTTAAGTTTTACATGCCCAAGAAGGCCACAGAACTGAAACATCTTCAGTGTCTAGAAGAAGAACTCAAACCTCTGGAGGAAGTGCTAAATTTAGCTCAAAGCAAAAACTTTCACTTAAGACCCAGGGACTTAATCAGCAATATCAACGTAATAGTTCTGGAACTAAAGGGATCTGAAACAACATTCATGTGTGAATATGCTGATGAGACAGCAACCATTGTAGAATTTCTGAACAGATGGATTACCTTTTGTCAAAGCATCATCTCAACACTAACT(配列番号162)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the single-chain chimeric polypeptide comprises
GCCCCCACCTCCTCCTCCACCAAGAAGACCCAGCTGCAGCTGGAGCATTTACTGCTGGATTTACAGATGATTTTAAACGGCATCAACAACTACAAGAACCCCCAAGCTGACTCGTATGCTGACCTTCAAGTTTCTACATGCCCAAGAAGGCCACCGAGCTGAAGCATTTACAGTGTTTAGAGGAGGA GCTGAAGCCCCTCGAGGAGGTGCTGAATTTAGCCCAGTCCAAGAATTTCCATTTAAGGCCCCGGGATTTAATCAGCAACATCAACGTGATCGTTTTAGAGCTGAAGGGCTCCGAGACCACCTTCATGTGCGAGTACGCCGACGAGACCGCCACCATCGTGGAGTTTTTAAATCGTTGGG ATCACCTTCTGCCAGTCCATCATCTCCACTTTAACCAGCGGCCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAACCATCCTCGAATGGGAACCCAAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTT TCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCA CCATCCAAAGCTTTGAGCAAGTTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAA AACCAACACAAACGAGTTTTTTAATCGACGTGGATAAAGGCGAAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGGAGTTCCGGGAGGCACCTACTTCAAGTTCT ACAAAGAAAAACACAGCTACAACTGGAGCATTTACTGCTGGATTTACAGATGATTTTGAATGGAATTAATAATTACAAGAATCCCAAACTCACCAGGATGCTCACATTTAAGTTTTTACATGCCCAAGAAGGCCACAGAACTGAAACATCTTCAGTGTCTAGAAGAAGAACTCAAACCTCTGGAGGAA GTGCTAAATTTAGCTCAAAGCAAAACTTTTCACTTAAGACCCAGGGGACTTAATCAGCAATATCAACGTAATAGGTTCTGGAACTAAAGGGGATCTGAACAACATTCATGTGTGAATATGCTGATGAGACAGCAACCATTGTAGAATTTCTGAACAGATGGATTACCTTTTGTCAAAGCATCATCT CAACACTAACT (SEQ ID NO: 162), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical % identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、一本鎖キメラポリペプチドは、
MKWVTFISLLFLFSSAYSAPTSSSTKKTQLQLEHLLLDLQMILNGINNYKNPKLTRMLTFKFYMPKKATELKHLQCLEEELKPLEEVLNLAQSKNFHLRPRDLISNINVIVLELKGSETTFMCEYADETATIVEFLNRWITFCQSIISTLTSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFREAPTSSSTKKTQLQLEHLLLDLQMILNGINNYKNPKLTRMLTFKFYMPKKATELKHLQCLEEELKPLEEVLNLAQSKNFHLRPRDLISNINVIVLELKGSETTFMCEYADETATIVEFLNRWITFCQSIISTLT(配列番号163)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the single-chain chimeric polypeptide comprises
MKWVTFISLLFLFSSSAYSAPTSSSSTKKTQLQLEHLLLDLQMILNGINNYKNPKLTRMLTFKFYMPKKATELKHLQCLEEELKPLEEVLNLAQSKNFHLRPRDLISNINVIVLELKGSETTFMCEYADETATIVEFLNRWITFCQSIIST LTSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTF LSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFREAPTSSSTKKTQLQLEHLLLDLQMILNGINNYKNPKLTRMLTFKFYMPKKATELKHLQCLEEELKPL at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% sequences that are identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、一本鎖キメラポリペプチドは、
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCGCCCCCACCTCCTCCTCCACCAAGAAGACCCAGCTGCAGCTGGAGCATTTACTGCTGGATTTACAGATGATTTTAAACGGCATCAACAACTACAAGAACCCCAAGCTGACTCGTATGCTGACCTTCAAGTTCTACATGCCCAAGAAGGCCACCGAGCTGAAGCATTTACAGTGTTTAGAGGAGGAGCTGAAGCCCCTCGAGGAGGTGCTGAATTTAGCCCAGTCCAAGAATTTCCATTTAAGGCCCCGGGATTTAATCAGCAACATCAACGTGATCGTTTTAGAGCTGAAGGGCTCCGAGACCACCTTCATGTGCGAGTACGCCGACGAGACCGCCACCATCGTGGAGTTTTTAAATCGTTGGATCACCTTCTGCCAGTCCATCATCTCCACTTTAACCAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGGCACCTACTTCAAGTTCTACAAAGAAAACACAGCTACAACTGGAGCATTTACTGCTGGATTTACAGATGATTTTGAATGGAATTAATAATTACAAGAATCCCAAACTCACCAGGATGCTCACATTTAAGTTTTACATGCCCAAGAAGGCCACAGAACTGAAACATCTTCAGTGTCTAGAAGAAGAACTCAAACCTCTGGAGGAAGTGCTAAATTTAGCTCAAAGCAAAAACTTTCACTTAAGACCCAGGGACTTAATCAGCAATATCAACGTAATAGTTCTGGAACTAAAGGGATCTGAAACAACATTCATGTGTGAATATGCTGATGAGACAGCAACCATTGTAGAATTTCTGAACAGATGGATTACCTTTTGTCAAAGCATCATCTCAACACTAACT(配列番号164)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the single-chain chimeric polypeptide comprises
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCCGCCCCCACCTCCTCCTCCACCAAGAAGACCCAGCTGCAGCTGGAGCATTTACTGCTGGATTTACAGATGATTTTAAACGCATCAACAACTACAGAACCCCAAGCTGACTCGTATGCTGACCTTCAA GTTCTACATGCCCAAGAAGGCCACCGAGCTGAAGCATTTACAGTGTTTAGAGGAGGAGCTGAAGCCCCTCGAGGAGGTGCTGAATTTAGCCCAGTCCAAGAATTTCCATTTAAGGCCCCGGGATTTAATCAGCAACATCAACGTGATCGTTTTAGAGCTGAAGGGCTCCGAGACCACCTTCAT GTGCGAGTACGCCGACGAGACCGCCACCATCGTGGAGTTTTTAAATCGTTGGATCACCTTCTGCCAGTCCATCATCTCCACTTTTAACCAGCGGCCAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAAACCCGTTAACCA AGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGGAGAGCACTGGTTCCGCTGGC GAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAA GATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAACCAACACAAAACGAGTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAG TGCATGGGCCAAGAAAGGGCGAGTTCCGGGAGGCACCTACTTCAAGTTTCTACAAAAGAAAAACACGCTACAACTGGAGCATTTACTGCTGGATTTACAGATGATTTTGAATGGAATTAATAATTACAGAATCCCAAACTCACCAGGATGCTCACATTTTAAGTTTTTACATGCCCAAGA AGGCCACAGAACTGAAACATCTTCAGTGTCTAGAAGAAGAACTCAAACCTCTGGAGGAAGTGCTAAAATTTAGCTCAAAGCAAAACTTTTCACTTAAGACCCAGGGGACTTAATCAGCAATATCAACGTAATAGTTCTGGAACTAAAGGGATCTGAAACAACATTCATGTGTGAATATGCTGATGAGA CAGCAACCATTGTAGAATTTCTGAACAGATGGATTACCTTTTGTCAAAGCATCATCTCAACACTAACT (SEQ ID NO: 164), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical to % identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
一本鎖キメラポリペプチドの例示的な実施形態-タイプC
本明細書に記載の一本鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び/又は第2の標的結合ドメインは独立して、IL-15受容体(例えば、ヒトIL-15受容体)に特異的に結合することができる。
Exemplary Embodiments of Single Chain Chimeric Polypeptides—Type C
In some embodiments of any of the single-chain chimeric polypeptides described herein, the first target binding domain and/or the second target binding domain are independently IL-15 receptor (eg, human IL-15 receptor).
これらの一本鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメインと可溶性組織因子ドメインは、互いに直接隣接している。これらの一本鎖キメラポリペプチドのいくつかの実施形態では、一本鎖キメラポリペプチドは、第1の標的結合ドメインと可溶性組織因子ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these single chain chimeric polypeptides, the first target binding domain and the soluble tissue factor domain are directly adjacent to each other. In some embodiments of these single chain chimeric polypeptides, the single chain chimeric polypeptide has a linker sequence between the first target binding domain and the soluble tissue factor domain (e.g., any of the exemplary linkers).
これらの一本鎖キメラポリペプチドのいくつかの実施形態では、可溶性組織因子ドメインと第2の標的結合ドメインは、互いに直接隣接している。これらの一本鎖キメラポリペプチドのいくつかの実施形態では、一本鎖キメラポリペプチドは、可溶性組織因子ドメインと第2の標的結合ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these single chain chimeric polypeptides, the soluble tissue factor domain and the second target binding domain are directly adjacent to each other. In some embodiments of these single-chain chimeric polypeptides, the single-chain chimeric polypeptide has a linker sequence (e.g., a linker sequence described herein) between the soluble tissue factor domain and the second target binding domain. any of the exemplary linkers).
これらの一本鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは、可溶性ヒトIL-15タンパク質である。IL-15受容体に特異的に結合するIL-15タンパク質の非限定的な例は、
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(配列番号82)と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments of these single chain chimeric polypeptides, the first target binding domain and the second target binding domain are soluble human IL-15 protein. A non-limiting example of an IL-15 protein that specifically binds to the IL-15 receptor is
at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 84% identical, at least 8 6% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、IL-15受容体に特異的に結合するIL-15タンパク質は、
AACTGGGTGAACGTGATCAGCGATTTAAAGAAGATCGAGGATTTAATCCAGAGCATGCACATCGACGCCACTCTGTACACTGAGAGCGACGTGCACCCTAGCTGCAAGGTGACTGCCATGAAGTGCTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGCGATGCCAGCATCCACGACACTGTGGAGAATTTAATCATTTTAGCCAACAACTCTTTAAGCAGCAACGGCAACGTGACAGAGAGCGGCTGCAAGGAGTGCGAGGAGCTGGAGGAGAAGAACATCAAGGAGTTTTTACAGAGCTTCGTGCACATCGTGCAGATGTTCATCAACACTAGC(配列番号165)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされ得る。
In some embodiments, the IL-15 protein that specifically binds to the IL-15 receptor is
AACTGGGTGAACGTGATCAGCGATTTAAAGAAGATCGAGGATTTAATCCAGAGCATGCACATCGACGCCCACTCTGTACACTGAGAGCGACGTGCACCCTAGGCTGCAAGGTGACTGCCATGAAGTGCTTTTTACTGGAGCTGCCAAGTTATCTCTTTAGAGAGCGGCGATGCCAG CATCCACGACACTGTGGAGAATTTAATCATTTTAGCCAACAACTCTTTAAGCAGCAACGGCAACGTGACAGAGAGCGGCTGCAAGGAGTGCGAGGAGCTGGAGGAGAAGAACATCAAGGAGTTTTTACAGAGCTTCGTGCACATCGTGCAGATGTTCATCAACACTAGC (SEQ ID NO: 165), at least 80% identical to (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical to , at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、IL-15受容体に特異的に結合するIL-15タンパク質は、
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(配列番号166)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされ得る。
In some embodiments, the IL-15 protein that specifically binds to the IL-15 receptor is
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTACTGGAGCTGCCAAGTTATCTCTTTAGAGAGCGGGAGACGCTAGCAT CCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCCAAGGAGTGCGAAGAGCTGGAGGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC (SEQ ID NO: 166), and at least 8 0% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical , at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの一本鎖キメラポリペプチドのいくつかの実施形態では、可溶性組織因子ドメインは、本明細書に記載の例示的な可溶性組織因子ドメインのうちのいずれかであり得る。 In some embodiments of these single-chain chimeric polypeptides, the soluble tissue factor domain can be any of the exemplary soluble tissue factor domains described herein.
いくつかの実施形態では、一本鎖キメラポリペプチドは、
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTSSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(配列番号167)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the single-chain chimeric polypeptide comprises
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTSSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQV YTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNE FLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNNVTESGCKECEELEEKNIKEFLQSFVHIV QMFINTS (SEQ ID NO: 167), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% sequences that are identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、一本鎖キメラポリペプチドは、
AACTGGGTGAACGTGATCAGCGATTTAAAGAAGATCGAGGATTTAATCCAGAGCATGCACATCGACGCCACTCTGTACACTGAGAGCGACGTGCACCCTAGCTGCAAGGTGACTGCCATGAAGTGCTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGCGATGCCAGCATCCACGACACTGTGGAGAATTTAATCATTTTAGCCAACAACTCTTTAAGCAGCAACGGCAACGTGACAGAGAGCGGCTGCAAGGAGTGCGAGGAGCTGGAGGAGAAGAACATCAAGGAGTTTTTACAGAGCTTCGTGCACATCGTGCAGATGTTCATCAACACTAGCAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(配列番号168)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the single-chain chimeric polypeptide comprises
AACTGGGTGAACGTGATCAGCGATTTAAAGAAGATCGAGGATTTAATCCAGAGCATGCACATCGACGCCCACTCTGTACACTGAGAGCGACGTGCACCCTAGGCTGCAAGGTGACTGCCATGAAGTGCTTTTTACTGGAGCTGCCAAGTTATCTCTTTAGAGAGCGGCGATGCCAG CATCCACGACACTGTGGAGAATTTAATCATTTTAGCCAACAACTCTTTAAGCAGCAACGGCAACGTGACAGAGAGCGGCTGCAAGGAGTGCGAGGAGCTGGAGGGAGAAGAACATCAAGGAGTTTTTACAGAGCTTCGTGCACATCGTGCAGATGTTCATCAACACTAGCAGCGGCACAACCA ACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAG ATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTTGAGCAAGTTGGCACAAAGGTGAATGTGA CAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAAACGAGTTTTTTAATCGACGTGGATAAAGGCGGAA AACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAAGAAGATCGAAGATTTAATTCAGTCCATGCATAT CGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGT at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、一本鎖キメラポリペプチドは、
MKWVTFISLLFLFSSAYSNWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTSSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(配列番号169)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the single-chain chimeric polypeptide comprises
MKWVTFISLLFLFSSAYSNWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTSSGTTNTVAAYNLTWK STNFKTILEWEPKKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNNTFLSLRDVFGKDLIYTLYY WKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVIDLKKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEEL EEKNIKEFLQSFVHIVQMFINTS (SEQ ID NO: 169), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% sequences that are identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、一本鎖キメラポリペプチドは、
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCAACTGGGTGAACGTGATCAGCGATTTAAAGAAGATCGAGGATTTAATCCAGAGCATGCACATCGACGCCACTCTGTACACTGAGAGCGACGTGCACCCTAGCTGCAAGGTGACTGCCATGAAGTGCTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGCGATGCCAGCATCCACGACACTGTGGAGAATTTAATCATTTTAGCCAACAACTCTTTAAGCAGCAACGGCAACGTGACAGAGAGCGGCTGCAAGGAGTGCGAGGAGCTGGAGGAGAAGAACATCAAGGAGTTTTTACAGAGCTTCGTGCACATCGTGCAGATGTTCATCAACACTAGCAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(配列番号170)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the single-chain chimeric polypeptide comprises
ATGAAGTGGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCCAACTGGGTGAACGTGATCAGCGATTTAAAGAAGATCGAGGATTTAATCCAGAGCATGCACATCGACGCCACTCTGTACACTGAGAGCGACGTGCACCCTAGCTGCAAGGTGACTGCCAT GAAGTGCTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGCGATGCCAGCATCCACGACACTGTGGAGAATTTAATCATTTTAGCCAACAACTCTTTAAGCAGCAACGGCAACGTGACAGAGAGCGGCTGCAAGGAGTGCGAGGAGCTGGAGGGAGAAGAACATCAAGGAGTTTT TACAGAGCTTCGTGCACATCGTGCAGATGTTCATCAACACTTAGCAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAACCATCCTCGAATGGGAACCCAAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAG TCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCGCCGGCCAATGTGGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATAGAGAACAGCCCCGAATTTACCCCCTTACCTCGAGACCAAT TTAGGACAGCCCCACCATCCAAAGCTTTGAGCAAGTTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAA GAAGACAGCTAAACCAACACAAACGAGTTTTTTAATCGACGTGGATAAAGGGCGAAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAGGGCGAGTTCGGGAGAACTGG GTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGT at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92 % identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
例示的な多鎖キメラポリペプチド-タイプA
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは各々独立して、IL-18受容体又はIL-12受容体に特異的に結合する。これらの多鎖キメラポリペプチドのいくつかの例では、第1の標的結合ドメインと可溶性組織因子ドメインは、第1のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの例では、第1のキメラポリペプチドは、第1のキメラポリペプチド内の第1の標的結合ドメインと可溶性組織因子ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。
Exemplary Multichain Chimeric Polypeptides—Type A
In some embodiments of any of the multichain chimeric polypeptides described herein, the first target binding domain and the second target binding domain are each independently IL-18 receptor or IL It specifically binds to -12 receptors. In some examples of these multichain chimeric polypeptides, the first target binding domain and the soluble tissue factor domain are directly adjacent to each other within the first chimeric polypeptide. In some examples of these multichain chimeric polypeptides, the first chimeric polypeptide has a linker sequence (e.g., any of the exemplary linkers described herein).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、一対の親和性ドメインの第2のドメインと第2の標的結合ドメインは、第2のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチド内の一対の親和性ドメインの第2のドメインと第2の標的結合ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these multichain chimeric polypeptides, the second domain and the second target binding domain of the pair of affinity domains are directly adjacent to each other within the second chimeric polypeptide. In some embodiments of these multichain chimeric polypeptides, the second chimeric polypeptide is a combination of the second of the pair of affinity domains within the second chimeric polypeptide and the second target binding domain. Further includes a linker sequence (eg, any of the exemplary linkers described herein) in between.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性組織因子ドメインは、本明細書に記載の例示的な可溶性組織因子ドメインのうちのいずれかであり得る。これらの多鎖キメラポリペプチドのいくつかの実施形態では、一対の親和性ドメインは、本明細書に記載の例示的な一対の親和性ドメインのうちのいずれかであり得る。 In some embodiments of these multichain chimeric polypeptides, the soluble tissue factor domain can be any of the exemplary soluble tissue factor domains described herein. In some embodiments of these multi-chain chimeric polypeptides, the pair of affinity domains can be any of the exemplary pair of affinity domains described herein.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方が、アゴニスト抗原結合ドメインである。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは各々、アゴニスト抗原結合ドメインである。これらの多鎖キメラポリペプチドのいくつかの実施形態では、抗原結合ドメインは、scFv又は単一ドメイン抗体を含む。 In some embodiments of these multi-chain chimeric polypeptides, one or both of the first target binding domain and the second target binding domain are agonist antigen binding domains. In some embodiments of these multichain chimeric polypeptides, the first target binding domain and the second target binding domain are each agonist antigen binding domains. In some embodiments of these multi-chain chimeric polypeptides, the antigen binding domain comprises a scFv or single domain antibody.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方が、可溶性IL-15又は可溶性IL-18である。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは各々独立して、可溶性IL-15又は可溶性IL-18である。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインの両方が、IL-18受容体又はIL-12受容体に特異的に結合する。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは、同じエピトープに特異的に結合する。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは、同じアミノ酸配列を含む。 In some embodiments of these multichain chimeric polypeptides, one or both of the first target binding domain and the second target binding domain is soluble IL-15 or soluble IL-18. In some embodiments of these multichain chimeric polypeptides, the first target binding domain and the second target binding domain are each independently soluble IL-15 or soluble IL-18. In some embodiments of these multichain chimeric polypeptides, both the first target binding domain and the second target binding domain specifically bind to IL-18 receptor or IL-12 receptor. In some embodiments of these multichain chimeric polypeptides, the first target binding domain and the second target binding domain specifically bind the same epitope. In some embodiments of these multichain chimeric polypeptides, the first target binding domain and the second target binding domain comprise the same amino acid sequence.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメインはIL-12受容体に特異的に結合し、第2の標的結合ドメインはIL-18受容体に特異的に結合する。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメインはIL-18受容体に特異的に結合し、第2の標的結合ドメインはIL-12受容体に特異的に結合する。 In some embodiments of these multichain chimeric polypeptides, the first target binding domain specifically binds the IL-12 receptor and the second target binding domain specifically binds the IL-18 receptor. Join. In some embodiments of these multichain chimeric polypeptides, the first target binding domain specifically binds the IL-18 receptor and the second target binding domain specifically binds the IL-12 receptor. Join.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメインは、可溶性IL-18(例えば、可溶性ヒトIL-18)を含む。 In some embodiments of these multichain chimeric polypeptides, the first target binding domain comprises soluble IL-18 (eg, soluble human IL-18).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトIL-18は、
YFGKLESKLSVIRNLNDQVLFIDQGNRPLFEDMTDSDCRDNAPRTIFIISMYKDSQPRGMAVTISVKCEKISTLSCENKIISFKEMNPPDNIKDTKSDIIFFQRSVPGHDNKMQFESSSYEGYFLACEKERDLFKLILKKEDELGDRSIMFTVQNED(配列番号109)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multi-chain chimeric polypeptides, the soluble human IL-18 is
YFGKLESKLSVIRNLNDQVLFIDQGNRPLFEDMTDSDCRDNAPRTIFIISMYKDSQPRGMAVTISVKCEKISTLSCENKIISFKEMNPPDNIKDTKSDIIFFQRSVPGHDNKMQFESSSYEGYFLACEKERDLFKLILLKEDELGDRSIMFT VQNED (SEQ ID NO: 109), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, sequences that are at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトIL-18は、
TACTTCGGCAAACTGGAATCCAAGCTGAGCGTGATCCGGAATTTAAACGACCAAGTTCTGTTTATCGATCAAGGTAACCGGCCTCTGTTCGAGGACATGACCGACTCCGATTGCCGGGACAATGCCCCCCGGACCATCTTCATTATCTCCATGTACAAGGACAGCCAGCCCCGGGGCATGGCTGTGACAATTAGCGTGAAGTGTGAGAAAATCAGCACTTTATCTTGTGAGAACAAGATCATCTCCTTTAAGGAAATGAACCCCCCCGATAACATCAAGGACACCAAGTCCGATATCATCTTCTTCCAGCGGTCCGTGCCCGGTCACGATAACAAGATGCAGTTCGAATCCTCCTCCTACGAGGGCTACTTTTTAGCTTGTGAAAAGGAGAGGGATTTATTCAAGCTGATCCTCAAGAAGGAGGACGAGCTGGGCGATCGTTCCATCATGTTCACCGTCCAAAACGAGGAT(配列番号171)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multi-chain chimeric polypeptides, the soluble human IL-18 is
TACTTCGGCAAAACTGGAATCCAAGCTGAGCGTGATCCGGAATTTAAAACGACCAAGTTCTGTTTATCGATCAAGGTAACCGGCCTCTGTTCGAGGACATGACCGACTCCGATTGCCGGGACAATGCCCCCCGGACCATCTTCATTATCTCCATGTACAAGGACAGCCAGCCCCCGGGGCAT GGCTGTGACAATTAGCGTGAAGTGTGAGAAAATCAGCACTTTATCTTGTGAGAACAAGATCATCTCTTTAAGGAAATGAACCCCCCCCGATAACATCAAGGACACCAAGTCCGATATCATCTTCTTCCAGCGGTCCGTGCCCGGTCACGATAACAAGATGCAGTTCGAATCCTCCTCCTAC GAGGGCTACTTTTTAGCTTGTGAAAAGGAGAGGGATTTATTCAAGCTGATCCTCAAGAAGGAGGACGAGCTGGGCGGATCGTTCCATCATGTTCACCGTCCAAACGAGGAT (SEQ ID NO: 171), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2の標的結合ドメインは、可溶性IL-12(例えば、可溶性ヒトIL-12)を含む。これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトIL-15は、可溶性ヒトIL-12β(p40)配列及び可溶性ヒトIL-12α(p35)配列を含む。これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性IL-15ヒトIL-15は、可溶性IL-12β(p40)配列と可溶性ヒトIL-12α(p35)配列との間にリンカー配列(例えば、本明細書に記載の例示的なリンカー配列のうちのいずれか)を更に含む。これらの多鎖キメラポリペプチドのいくつかの例では、リンカー配列は、GGGGSGGGGSGGGGS(配列番号102)を含む。 In some embodiments of these multichain chimeric polypeptides, the second target binding domain comprises soluble IL-12 (eg, soluble human IL-12). In some embodiments of these multichain chimeric polypeptides, the soluble human IL-15 comprises a soluble human IL-12β (p40) sequence and a soluble human IL-12α (p35) sequence. In some embodiments of these multichain chimeric polypeptides, the soluble IL-15 human IL-15 has a linker sequence ( For example, any of the exemplary linker sequences described herein). In some examples of these multichain chimeric polypeptides, the linker sequence comprises GGGGSGGGGSGGGGGS (SEQ ID NO: 102).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトIL-12β(p40)配列は、
IWELKKDVYVVELDWYPDAPGEMVVLTCDTPEEDGITWTLDQSSEVLGSGKTLTIQVKEFGDAGQYTCHKGGEVLSHSLLLLHKKEDGIWSTDILKDQKEPKNKTFLRCEAKNYSGRFTCWWLTTISTDLTFSVKSSRGSSDPQGVTCGAATLSAERVRGDNKEYEYSVECQEDSACPAAEESLPIEVMVDAVHKLKYENYTSSFFIRDIIKPDPPKNLQLKPLKNSRQVEVSWEYPDTWSTPHSYFSLTFCVQVQGKSKREKKDRVFTDKTSATVICRKNASISVRAQDRYYSSSWSEWASVPCS(配列番号81)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multi-chain chimeric polypeptides, the soluble human IL-12β (p40) sequence is
IWELKKDVYVVELDWYPDAPGEMVVLTCDTPEEDGITWTLDQSSEVLGSGKTLTIQVKEFGDAGQYTCHKGGEVLSHSLLLHKKEDGIWSTDILKDQKEPKNKTFLRCEAKNYSGRFTCWWLTTISTDLTFSVKSSR GSSDPQGVTCGAATLSAERVRGDNKEYEYSVECQEDSACPAAEESLPIEVMVDAVHKLKYENYTSSFFIRDIIKPDPPKNLQLKPLKNSRQVEVSWEYPDTWSTPHSYFSLTFCVQVQGKSKREKKDRVFTDKTSATVICRKNASISVRA QDRYYSSSWSEWASVPCS (SEQ ID NO: 81), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical , at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトIL-12β(p40)は、
ATTTGGGAACTGAAGAAGGACGTCTACGTGGTCGAACTGGACTGGTATCCCGATGCTCCCGGCGAAATGGTGGTGCTCACTTGTGACACCCCCGAAGAAGACGGCATCACTTGGACCCTCGATCAGAGCAGCGAGGTGCTGGGCTCCGGAAAGACCCTCACAATCCAAGTTAAGGAGTTCGGAGACGCTGGCCAATACACATGCCACAAGGGAGGCGAGGTGCTCAGCCATTCCTTATTATTATTACACAAGAAGGAAGACGGAATCTGGTCCACCGACATTTTAAAAGATCAGAAGGAGCCCAAGAATAAGACCTTTTTAAGGTGTGAGGCCAAAAACTACAGCGGTCGTTTCACTTGTTGGTGGCTGACCACCATTTCCACCGATTTAACCTTCTCCGTGAAAAGCAGCCGGGGAAGCTCCGACCCTCAAGGTGTGACATGTGGAGCCGCTACCCTCAGCGCTGAGAGGGTTCGTGGCGATAACAAGGAATACGAGTACAGCGTGGAGTGCCAAGAAGATAGCGCTTGTCCCGCTGCCGAAGAATCTTTACCCATTGAGGTGATGGTGGACGCCGTGCACAAACTCAAGTACGAGAACTACACCTCCTCCTTCTTTATCCGGGACATCATTAAGCCCGATCCTCCTAAGAATTTACAGCTGAAGCCTCTCAAAAATAGCCGGCAAGTTGAGGTCTCTTGGGAATATCCCGACACTTGGAGCACACCCCACAGCTACTTCTCTTTAACCTTTTGTGTGCAAGTTCAAGGTAAAAGCAAGCGGGAGAAGAAAGACCGGGTGTTTACCGACAAAACCAGCGCCACCGTCATCTGTCGGAAGAACGCCTCCATCAGCGTGAGGGCTCAAGATCGTTATTACTCCAGCAGCTGGTCCGAGTGGGCCAGCGTGCCTTGTTCC(配列番号172)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multichain chimeric polypeptides, the soluble human IL-12β (p40) is
ATTTGGGAACTGAAGAAGGACGTCTACGTGGTCGAACTGGACTGGTATCCCGATGCTCCCGGCGAAATGGTGGTGCTCACTTGTGACACCCCCGAAGAAGACGGCATCACTTGGACCCTCGATCAGAGCAGCGAGGTGCTGGGCTCCGGAAGAACCCTCACAATCCAAGTTAA GGAGTTCGGAGACGCTGGCCAATACACATGCCACAAGGGGAGGCGCGAGGTGCTCAGCCATTCCTTATTATTATTACACAAGAAGGAAGACGGAATCTGGTCCACCGACATTTTAAAGATCAGAAGGAGCCCAAGAATAAGACCTTTTTAAGGTGTGAGGCCAAAAAAACTACAGCGGG TCGTTTTCACTTGTTGGTGGCTGACCACCATTTCCACCGATTTAACCTTTCTCCGTGAAAGCAGCCGGGGGAAGCTCCGACCCTCAAGGTGTGACATGTGGAGCCGCTACCCTCAGCGCTGAGAGGGTTCGTGGCGCGATACAAGGAATACGAGTACAGCGTGGAGTGCCAAGA AGATAGCGCTTGTCCCCGCTGCCGAAGAATCTTTACCCATTGAGGTGATGGTGGACGCCGTGCACAAAACTCAAGTACGAGAACTACACCCTCCTCCTTCTTATCCGGGACATCATTAAGCCCCGATCCTCCTAAGAATTTACAGCTGAAGCCTCTCAAAAAATAGCCGGCAAGTTGAGGTCT CTTGGGAATATCCCGACACTTGGAGCACACCCCACAGCTACTTCTCTTTAACCTTTTGTGTGCAAGTTCAAGGTAAAAGCAAGCGGGAGAAGAAAGACCGGGTGTTTACCGACAAAAACCAGCGCCACCGTCATCTGTCGGAAGAACGCTCCATCAGCGTGAGGGCTCAAGATC GTTATTACTCCAGCAGCTGGTCCGAGTGGGCCAGCGTGCCTTGTTCC (SEQ ID NO: 172), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトIL-12α(p35)は、
RNLPVATPDPGMFPCLHHSQNLLRAVSNMLQKARQTLEFYPCTSEEIDHEDITKDKTSTVEACLPLELTKNESCLNSRETSFITNGSCLASRKTSFMMALCLSSIYEDLKMYQVEFKTMNAKLLMDPKRQIFLDQNMLAVIDELMQALNFNSETVPQKSSLEEPDFYKTKIKLCILLHAFRIRAVTIDRVMSYLNAS(配列番号80)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multi-chain chimeric polypeptides, the soluble human IL-12α (p35) is
RNLPVATPDPGMFPCLHHSQNLLRAVSNMLQKARQTLEFYPCTSEEIDHEDITKDKTSTVEACLPLELTKNESCLNSRETSFITNGSCLASRKTSFMMALCLSSSIYEDLKMYQVEFKTMNAKLMDPKRQIFLDQNMLAAVIDELMQALN FNSETVPQKSSLEEPDFYKTKIKLCILLHAFRIRAVTIDRVMSYLNAS (SEQ ID NO: 80), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical , at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトIL-12α(p35)は、
CGTAACCTCCCCGTGGCTACCCCCGATCCCGGAATGTTCCCTTGTTTACACCACAGCCAGAATTTACTGAGGGCCGTGAGCAACATGCTGCAGAAAGCTAGGCAGACTTTAGAATTTTACCCTTGCACCAGCGAGGAGATCGACCATGAAGATATCACCAAGGACAAGACATCCACCGTGGAGGCTTGTTTACCTCTGGAGCTGACAAAGAACGAGTCTTGTCTCAACTCTCGTGAAACCAGCTTCATCACAAATGGCTCTTGTTTAGCTTCCCGGAAGACCTCCTTTATGATGGCTTTATGCCTCAGCTCCATCTACGAGGATTTAAAGATGTACCAAGTGGAGTTCAAGACCATGAACGCCAAGCTGCTCATGGACCCTAAACGGCAGATCTTTTTAGACCAGAACATGCTGGCTGTGATTGATGAGCTGATGCAAGCTTTAAACTTCAACTCCGAGACCGTCCCTCAGAAGTCCTCCCTCGAGGAGCCCGATTTTTACAAGACAAAGATCAAACTGTGCATTTTACTCCACGCCTTTAGGATCCGGGCCGTGACCATTGACCGGGTCATGAGCTATTTAAACGCCAGC(配列番号173)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multi-chain chimeric polypeptides, the soluble human IL-12α (p35) is
CGTAACCTCCCCGTGGCTACCCCCGATCCCCGGAATGTTCCCTTGTTTACACCACAGCCAGAATTTACTGAGGGCCGTGAGCAACATGCTGCAGAAAGCTAGGCAGACTTTAGAATTTTACCCTTGCACCAGCGAGGAGATCGACCATGAAGATATCACCAAGGACAAGACATCCACCGTGGAGG CTTGTTTACCTCTGGAGCTGACAAAGAACGAGTCTTTGTCTCAACTCTCGTGAAACCAGCTTCATCACAAATGGCTCTTGTTTAGCTTCCCGGAAGACCTCCTTTATGATGGCTTTATGCCTCAGCTCCATCTACGAGGATTTAAAAGATGTACCAAGTGGAGTTCAAGACCCATGAACGCCAA GCTGCTCATGGACCCTAAACGGCAGATCTTTTTTAGACCAGAACATGCTGGCTGTGATTGATGAGCTGATGCAAGCTTTAAACTTCAACTCCGAGACCGTCCCTCAGAAGTCCTCCCTCGAGGAGCCCGATTTTTACAAGACAAAGATCAAACTGTGCATTTACTCCACGCCTTTAGGATCCG GGCCGTGACCATTGACCGGGTCATGAGCTATTAAACGCCAGC (SEQ ID NO: 173), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical % identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
YFGKLESKLSVIRNLNDQVLFIDQGNRPLFEDMTDSDCRDNAPRTIFIISMYKDSQPRGMAVTISVKCEKISTLSCENKIISFKEMNPPDNIKDTKSDIIFFQRSVPGHDNKMQFESSSYEGYFLACEKERDLFKLILKKEDELGDRSIMFTVQNEDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(配列番号174)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the first chimeric polypeptide is
YFGKLESKLSVIRNLNDQVLFIDQGNRPLFEDMTDSDCRDNAPRTIFIISMYKDSQPRGMAVTISVKCEKISTLSCENKIISFKEMNPPDNIKDTKSDIIFFQRSVPGHDNKMQFESSSYEGYFLACEKERDLFKLILLKEDELGDRSIMFT VQNEDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRR NNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVIDLKKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVE at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% sequences that are identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
TACTTCGGCAAACTGGAATCCAAGCTGAGCGTGATCCGGAATTTAAACGACCAAGTTCTGTTTATCGATCAAGGTAACCGGCCTCTGTTCGAGGACATGACCGACTCCGATTGCCGGGACAATGCCCCCCGGACCATCTTCATTATCTCCATGTACAAGGACAGCCAGCCCCGGGGCATGGCTGTGACAATTAGCGTGAAGTGTGAGAAAATCAGCACTTTATCTTGTGAGAACAAGATCATCTCCTTTAAGGAAATGAACCCCCCCGATAACATCAAGGACACCAAGTCCGATATCATCTTCTTCCAGCGGTCCGTGCCCGGTCACGATAACAAGATGCAGTTCGAATCCTCCTCCTACGAGGGCTACTTTTTAGCTTGTGAAAAGGAGAGGGATTTATTCAAGCTGATCCTCAAGAAGGAGGACGAGCTGGGCGATCGTTCCATCATGTTCACCGTCCAAAACGAGGATAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(配列番号175)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the first chimeric polypeptide is
TACTTCGGCAAAACTGGAATCCAAGCTGAGCGTGATCCGGAATTTAAAACGACCAAGTTCTGTTTATCGATCAAGGTAACCGGCCTCTGTTCGAGGACATGACCGACTCCGATTGCCGGGACAATGCCCCCCGGACCATCTTCATTATCTCCATGTACAAGGACAGCCAGCCCCCGGGGCAT GGCTGTGACAATTAGCGTGAAGTGTGAGAAAATCAGCACTTTATCTTGTGAGAACAAGATCATCTCTTTAAGGAAATGAACCCCCCCGATAACATCAAGGACACCAAGTCCGATATCATCTTCTTCCAGCGGTCCGTGCCCGGTCACGATAACAAGATGCAGTTCGAATCCTCCTCCTAC GAGGGCTACTTTTTAGCTTGTGAAAAGGAGAGGGGATTATTCAAGCTGATCCTCAAGAAGGAGGACGAGCTGGGCGGATCGTTCCATCATGTTCACCGTCCAAACGAGGATAGCGGCCACAACCAACACAGTCGCGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCAT CCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAAACAGACCTACCTCGCCCGGGTGTTTTAGCTACCCCGCCGGCCA ATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGACAACACCTTTCTCA GCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAAT AGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCCACTTTATACAGAATCCGACGTGCACCCCCTCTTGTAAGGTGACC GCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCACGGCCAACGTGACAGAGTCCGGCTGCCAAGGAGTGCGAAGAGCTGGAGGGAGAAGAACATCAAGGAGTT TCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC (SEQ ID NO: 175), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical to % identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
MKWVTFISLLFLFSSAYSYFGKLESKLSVIRNLNDQVLFIDQGNRPLFEDMTDSDCRDNAPRTIFIISMYKDSQPRGMAVTISVKCEKISTLSCENKIISFKEMNPPDNIKDTKSDIIFFQRSVPGHDNKMQFESSSYEGYFLACEKERDLFKLILKKEDELGDRSIMFTVQNEDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(配列番号176)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the first chimeric polypeptide is
MKWVTFISLLFLFSSAYSYFGKLESKLSVIRNLNDQVLFIDQGNRPLFEDMTDSDCRDNAPRTIFIISMYKDSQPRGMAVTISVKCEKISTLSCENKIISFKEMNPPDNIKDTKSSDIIFQRSVPGHDNKMQFESSSYEGYFLACEKERD LFKLILKKEDELGDRSIMFTVQNEDSGTTNTVAAYNLTWKSTNFKTILEWEPKKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQV GTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCF LLELQVISLESGDASIHDTVENLIILANSLSSNGNVTESGNIKEFLQSFVHIVQMFINTS (SEQ ID NO: 176), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% sequences that are identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
ATGAAGTGGGTCACATTTATCTCTTTACTGTTCCTCTTCTCCAGCGCCTACAGCTACTTCGGCAAACTGGAATCCAAGCTGAGCGTGATCCGGAATTTAAACGACCAAGTTCTGTTTATCGATCAAGGTAACCGGCCTCTGTTCGAGGACATGACCGACTCCGATTGCCGGGACAATGCCCCCCGGACCATCTTCATTATCTCCATGTACAAGGACAGCCAGCCCCGGGGCATGGCTGTGACAATTAGCGTGAAGTGTGAGAAAATCAGCACTTTATCTTGTGAGAACAAGATCATCTCCTTTAAGGAAATGAACCCCCCCGATAACATCAAGGACACCAAGTCCGATATCATCTTCTTCCAGCGGTCCGTGCCCGGTCACGATAACAAGATGCAGTTCGAATCCTCCTCCTACGAGGGCTACTTTTTAGCTTGTGAAAAGGAGAGGGATTTATTCAAGCTGATCCTCAAGAAGGAGGACGAGCTGGGCGATCGTTCCATCATGTTCACCGTCCAAAACGAGGATAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(配列番号177)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the first chimeric polypeptide is
ATGAAGTGGGTCACATTTATCCTCTTTACTGTTCCTCTTCTCCAGCGCCTACAGCTACTTCGGCAAAACTGGAATCCAAGCTGAGCGTGATCCGGAATTTAAAACGACCAAGTTCTGTTTATCGATCAAGGTAACCGGCCTCTGTTCGAGGACATGACCGACTCCGATTGCCCGGGA CAATGCCCCCCGGACCATCTTCATTATCTCCATGTACAAGGACAGCCAGCCCCGGGGCATGGCTGTGACAATTAGCGTGAAGTGTGAGAAAATCAGCACTTTATCTTTGTGAGAACAAGATCATCTCCTTTAAGGAAATGAACCCCCCCGATAACATCAAGGACACCAAGTCCGATATCATCTTCTTCCA GCGGTCCGTGCCCGGGTCACGATAACAAGATGCAGTTCGAATCCTCCTCCTACGAGGGCTACTTTTTAGCTTGTGAAAAGGAGAGGGATTTATTCAAGCTGATCCTCAAGAAGGAGGACGAGCTGGGCGCGATCGTTTCCATCATGTTCACCGTCCAAAACGAGGATAGCGG CACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAACCATCCTCGAATGGGAACCCAAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCCGACACCGAGTGCGATCTCACCGATGAGATCGT GAAAGATGTGAAACAGACCTACCTCGCCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCCACCATCCAAAGCTTTTGAGCAAGTTTGGCACAAAGGTGA ATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAACCAACACAAACGAGTTTTAATCGACGTGGATAAAG GCGAAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGGCGAGTTCCGGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAAGAAGATCGAAGATTTAATTCAGTCCAT GCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGA CAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC (SEQ ID NO: 177), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, to % identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
IWELKKDVYVVELDWYPDAPGEMVVLTCDTPEEDGITWTLDQSSEVLGSGKTLTIQVKEFGDAGQYTCHKGGEVLSHSLLLLHKKEDGIWSTDILKDQKEPKNKTFLRCEAKNYSGRFTCWWLTTISTDLTFSVKSSRGSSDPQGVTCGAATLSAERVRGDNKEYEYSVECQEDSACPAAEESLPIEVMVDAVHKLKYENYTSSFFIRDIIKPDPPKNLQLKPLKNSRQVEVSWEYPDTWSTPHSYFSLTFCVQVQGKSKREKKDRVFTDKTSATVICRKNASISVRAQDRYYSSSWSEWASVPCSGGGGSGGGGSGGGGSRNLPVATPDPGMFPCLHHSQNLLRAVSNMLQKARQTLEFYPCTSEEIDHEDITKDKTSTVEACLPLELTKNESCLNSRETSFITNGSCLASRKTSFMMALCLSSIYEDLKMYQVEFKTMNAKLLMDPKRQIFLDQNMLAVIDELMQALNFNSETVPQKSSLEEPDFYKTKIKLCILLHAFRIRAVTIDRVMSYLNASITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR(配列番号178)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the second chimeric polypeptide is
IWELKKDVYVVELDWYPDAPGEMVVLTCDTPEEDGITWTLDQSSEVLGSGKTLTIQVKEFGDAGQYTCHKGGEVLSHSLLLLLHKKEDGIWSTDILKDQKEPKNKTFLRCEAKNYSGRFTCWWLTTISTDLTFSVKSSR GSSDPQGVTCGAATLSAERVRGDNKEYEYSVECQEDSACPAAEESLPIEVMVDAVHKLKYENYTSSFFIRDIIKPDPPKNLQLKPLKNSRQVEVSWEYPDTWSTPHSYFSLTFCVQVQGKSKREKKDRVFTDKTSATVICRKNASISVRA QDRYYSSSWSEWASVPCSGGGGSGGGGGSGGGGSRNLPVATPDPGMFPCLHHSQNLLRAVSNMLQKARQTLEFYPCTSEEIDHEDITKDKTSTVEACLPLELTKNESCLNSRETSFITNGSCLASRKTSFMMALCLSSSIYEDLKMYQV EFKTMNAKLLMDPKRQIFLDQNMLAVIDELMQALNFNSETVPQKSSLEEPDFYKTKIKLCILLHAFRIRAVTIDRVMSYLNASITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSSLTECVLNKATNVAHWTTPSLKCIR (SEQ ID NO: 178 ), and at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical to % identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
ATTTGGGAACTGAAGAAGGACGTCTACGTGGTCGAACTGGACTGGTATCCCGATGCTCCCGGCGAAATGGTGGTGCTCACTTGTGACACCCCCGAAGAAGACGGCATCACTTGGACCCTCGATCAGAGCAGCGAGGTGCTGGGCTCCGGAAAGACCCTCACAATCCAAGTTAAGGAGTTCGGAGACGCTGGCCAATACACATGCCACAAGGGAGGCGAGGTGCTCAGCCATTCCTTATTATTATTACACAAGAAGGAAGACGGAATCTGGTCCACCGACATTTTAAAAGATCAGAAGGAGCCCAAGAATAAGACCTTTTTAAGGTGTGAGGCCAAAAACTACAGCGGTCGTTTCACTTGTTGGTGGCTGACCACCATTTCCACCGATTTAACCTTCTCCGTGAAAAGCAGCCGGGGAAGCTCCGACCCTCAAGGTGTGACATGTGGAGCCGCTACCCTCAGCGCTGAGAGGGTTCGTGGCGATAACAAGGAATACGAGTACAGCGTGGAGTGCCAAGAAGATAGCGCTTGTCCCGCTGCCGAAGAATCTTTACCCATTGAGGTGATGGTGGACGCCGTGCACAAACTCAAGTACGAGAACTACACCTCCTCCTTCTTTATCCGGGACATCATTAAGCCCGATCCTCCTAAGAATTTACAGCTGAAGCCTCTCAAAAATAGCCGGCAAGTTGAGGTCTCTTGGGAATATCCCGACACTTGGAGCACACCCCACAGCTACTTCTCTTTAACCTTTTGTGTGCAAGTTCAAGGTAAAAGCAAGCGGGAGAAGAAAGACCGGGTGTTTACCGACAAAACCAGCGCCACCGTCATCTGTCGGAAGAACGCCTCCATCAGCGTGAGGGCTCAAGATCGTTATTACTCCAGCAGCTGGTCCGAGTGGGCCAGCGTGCCTTGTTCCGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCTCGTAACCTCCCCGTGGCTACCCCCGATCCCGGAATGTTCCCTTGTTTACACCACAGCCAGAATTTACTGAGGGCCGTGAGCAACATGCTGCAGAAAGCTAGGCAGACTTTAGAATTTTACCCTTGCACCAGCGAGGAGATCGACCATGAAGATATCACCAAGGACAAGACATCCACCGTGGAGGCTTGTTTACCTCTGGAGCTGACAAAGAACGAGTCTTGTCTCAACTCTCGTGAAACCAGCTTCATCACAAATGGCTCTTGTTTAGCTTCCCGGAAGACCTCCTTTATGATGGCTTTATGCCTCAGCTCCATCTACGAGGATTTAAAGATGTACCAAGTGGAGTTCAAGACCATGAACGCCAAGCTGCTCATGGACCCTAAACGGCAGATCTTTTTAGACCAGAACATGCTGGCTGTGATTGATGAGCTGATGCAAGCTTTAAACTTCAACTCCGAGACCGTCCCTCAGAAGTCCTCCCTCGAGGAGCCCGATTTTTACAAGACAAAGATCAAACTGTGCATTTTACTCCACGCCTTTAGGATCCGGGCCGTGACCATTGACCGGGTCATGAGCTATTTAAACGCCAGCATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG(配列番号179)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the second chimeric polypeptide is
ATTTGGGAACTGAAGAAGGACGTCTACGTGGTCGAACTGGACTGGTATCCCGATGCTCCCGGCGAAATGGTGGTGCTCACTTGTGACACCCCCGAAGAAGACGGCATCACTTGGACCCTCGATCAGAGCAGCGAGGTGCTGGGCTCCGGAAGAACCCTCACAATCCAAGTTAA GGAGTTCGGAGACGCTGGCCAATACACATGCCACAAGGGGAGGCGCGAGGTGCTCAGCCATTCCTTATTATTATTACACAAGAAGGAAGACGGAATCTGGTCCACCGACATTTTAAAGATCAGAAGGAGCCCAAGAATAAGACCTTTTTAAGGTGTGAGGCCAAAAAAACTACAGCGGG TCGTTTTCACTTGTTGGTGGCTGACCACCATTTCCACCGATTTAACCTTTCTCCGTGAAAGCAGCCGGGGGAAGCTCCGACCCTCAAGGTGTGACATGTGGAGCCGCTACCCTCAGCGCTGAGAGGGTTCGTGGCGCGATACAAGGAATACGAGTACAGCGTGGAGTGCCAAGA AGATAGCGCTTGTCCCCGCTGCCGAAGAATCTTTACCCATTGAGGTGATGGTGGACGCCGTGCACAAAACTCAAGTACGAGAACTACACCCTCCTCCTTCTTATCCGGGACATCATTAAGCCCCGATCCTCCTAAGAATTTACAGCTGAAGCCTCTCAAAAAATAGCCGGCAAGTTGAGGTCT CTTGGGAATATCCCGACACTTGGAGCACACCCCACAGCTACTTCTCTTTAACCTTTTGTGTGCAAGTTCAAGGTAAAAGCAAGCGGGAGAAGAAAGACCGGGTGTTTACCGACAAAAACCAGCGCCACCGTCATCTGTCGGAAGAACGCTCCATCAGCGTGAGGGCTCAAGATC GTTATTACTCCAGCAGCTGGTCCGAGTGGGCCAGCGTGCCTTGTTCCGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCTCGTAACCTCCCCGTGGCTACCCCCCGATCCCCGGAATGTTCCCTTGTTTACACCACAGCCAGAATTTACTGAGGGCCGTGGA GCAACATGCTGCAGAAAGCTAGGCAGACTTTAGAATTTTACCCTTGCACCAGCGAGGAGATCGACCATGAAGATATCACCAAGGACAAGACATCCACCGTGGAGGCTTGTTTACCTCTGGAGCTGACAAAGAACGAGTCTTGTCCTCAACTCTCGTGAAAACCAGCTTCATCACAAATGGCTCTTGT TTAGCTTCCCGGAAGACCTCCTTTATGATGGCTTTATGCCTCAGCTCCATCTACGAGGATTTAAAAGATGTACCAAGTGGAGTTCAAGACCATGAACGCCAAGCTGCTCATGGACCCTAAACGGCAGATCTTTTTAGACCAGAACATGCTGGCTGTGATTGATGAGCTGATGCAAGCTTTAA ACTTCAACTCCGAGACCGTCCCTCAGAAGTCCTCCCTCGAGGAGCCCGATTTTTACAAGACAAAGATCAAAACTGTGCATTTTTACTCACGCCTTTAGGATCCGGGCCGTGACCATTGACCGGGTCATGAGCTATTAAACGCCAGCATTACATGCCCCCTCCCCATGAGCGTGGAGCACGCC GACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTAAAGTGCATCCGG (SEQ ID NO: 179), and at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
MKWVTFISLLFLFSSAYSIWELKKDVYVVELDWYPDAPGEMVVLTCDTPEEDGITWTLDQSSEVLGSGKTLTIQVKEFGDAGQYTCHKGGEVLSHSLLLLHKKEDGIWSTDILKDQKEPKNKTFLRCEAKNYSGRFTCWWLTTISTDLTFSVKSSRGSSDPQGVTCGAATLSAERVRGDNKEYEYSVECQEDSACPAAEESLPIEVMVDAVHKLKYENYTSSFFIRDIIKPDPPKNLQLKPLKNSRQVEVSWEYPDTWSTPHSYFSLTFCVQVQGKSKREKKDRVFTDKTSATVICRKNASISVRAQDRYYSSSWSEWASVPCSGGGGSGGGGSGGGGSRNLPVATPDPGMFPCLHHSQNLLRAVSNMLQKARQTLEFYPCTSEEIDHEDITKDKTSTVEACLPLELTKNESCLNSRETSFITNGSCLASRKTSFMMALCLSSIYEDLKMYQVEFKTMNAKLLMDPKRQIFLDQNMLAVIDELMQALNFNSETVPQKSSLEEPDFYKTKIKLCILLHAFRIRAVTIDRVMSYLNASITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR(配列番号180)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the second chimeric polypeptide is
MKWVTFISLLFLFSSAYSIWELKKDVYVVELDWYPDAPGEMVVLTCDTPEEDGITWTLDQSSEVLGSGKTLTIQVKEFGDAGQYTCHKGGEVLSHSLLLLHKKEDGIWSTDILKDQKEPKNKTFLRCEAKNYSGRFTCWW LTTISTDLTFSVKSSRGSSDPQGVTCGAATTLSAERVRGDNKEYEYSVECQEDSACPAAEESLPIEVMVDAVHKLKYENYTSSFFIRDIIKPDPPKNLQLKPLKNSRQVEVSWEYPDTWSTPHSYFSLTFCVQVQGKSKREKKDRVF TDKTSATVICRKNASISVRAQDRYYSSSWSEWASVPCSGGGGGSGGGGSGGGGSRNLPPVATPDPGMFPCLHHSQNLLRAVSNMLQKARQTLEFYPCTSEEIDHEDITKDKTSTVEACLPLELTKNESCLNSRETSFITNGSCLASRKTSF MMALCLSSIYEDLKMYQVEFKTMNAKLLMDPKRQIFLDQNMLAVIDELMQALNFNSETVPQKSSLEEPDFYKTKIKLCILLHAFRIRAVTIDRVMSYLNASITCPPPMSVEHADIWVKSYSLYSRRYICNSGFKRKAGTSSLTECVLNKATNV AHWTTPSLKCIR (SEQ ID NO: 180), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical % identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
ATGAAATGGGTGACCTTTATTTCTTTACTGTTCCTCTTTAGCAGCGCCTACTCCATTTGGGAACTGAAGAAGGACGTCTACGTGGTCGAACTGGACTGGTATCCCGATGCTCCCGGCGAAATGGTGGTGCTCACTTGTGACACCCCCGAAGAAGACGGCATCACTTGGACCCTCGATCAGAGCAGCGAGGTGCTGGGCTCCGGAAAGACCCTCACAATCCAAGTTAAGGAGTTCGGAGACGCTGGCCAATACACATGCCACAAGGGAGGCGAGGTGCTCAGCCATTCCTTATTATTATTACACAAGAAGGAAGACGGAATCTGGTCCACCGACATTTTAAAAGATCAGAAGGAGCCCAAGAATAAGACCTTTTTAAGGTGTGAGGCCAAAAACTACAGCGGTCGTTTCACTTGTTGGTGGCTGACCACCATTTCCACCGATTTAACCTTCTCCGTGAAAAGCAGCCGGGGAAGCTCCGACCCTCAAGGTGTGACATGTGGAGCCGCTACCCTCAGCGCTGAGAGGGTTCGTGGCGATAACAAGGAATACGAGTACAGCGTGGAGTGCCAAGAAGATAGCGCTTGTCCCGCTGCCGAAGAATCTTTACCCATTGAGGTGATGGTGGACGCCGTGCACAAACTCAAGTACGAGAACTACACCTCCTCCTTCTTTATCCGGGACATCATTAAGCCCGATCCTCCTAAGAATTTACAGCTGAAGCCTCTCAAAAATAGCCGGCAAGTTGAGGTCTCTTGGGAATATCCCGACACTTGGAGCACACCCCACAGCTACTTCTCTTTAACCTTTTGTGTGCAAGTTCAAGGTAAAAGCAAGCGGGAGAAGAAAGACCGGGTGTTTACCGACAAAACCAGCGCCACCGTCATCTGTCGGAAGAACGCCTCCATCAGCGTGAGGGCTCAAGATCGTTATTACTCCAGCAGCTGGTCCGAGTGGGCCAGCGTGCCTTGTTCCGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCTCGTAACCTCCCCGTGGCTACCCCCGATCCCGGAATGTTCCCTTGTTTACACCACAGCCAGAATTTACTGAGGGCCGTGAGCAACATGCTGCAGAAAGCTAGGCAGACTTTAGAATTTTACCCTTGCACCAGCGAGGAGATCGACCATGAAGATATCACCAAGGACAAGACATCCACCGTGGAGGCTTGTTTACCTCTGGAGCTGACAAAGAACGAGTCTTGTCTCAACTCTCGTGAAACCAGCTTCATCACAAATGGCTCTTGTTTAGCTTCCCGGAAGACCTCCTTTATGATGGCTTTATGCCTCAGCTCCATCTACGAGGATTTAAAGATGTACCAAGTGGAGTTCAAGACCATGAACGCCAAGCTGCTCATGGACCCTAAACGGCAGATCTTTTTAGACCAGAACATGCTGGCTGTGATTGATGAGCTGATGCAAGCTTTAAACTTCAACTCCGAGACCGTCCCTCAGAAGTCCTCCCTCGAGGAGCCCGATTTTTACAAGACAAAGATCAAACTGTGCATTTTACTCCACGCCTTTAGGATCCGGGCCGTGACCATTGACCGGGTCATGAGCTATTTAAACGCCAGCATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG(配列番号181)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the second chimeric polypeptide is
ATGAAATGGGTGACCTTTATTTCTTTACTGTTCCTCTTTAGCAGCGCCTACTCCATTTGGGGAACTGAAGAAGGACGTCTACGTGGTCGAACTGGACTGGTATCCCGATGCTCCCGGCGAAAATGGTGGTGCTCACTTGTGACACCCCCCGAAGAAGACGGCATCACTTGGACCCT CGATCAGAGCAGCGAGGTGCTGGGCTCCGGAAAGACCCTCACAATCCAAGTTAAGGAGTTCGGAGACGCTGGCCAATACACATGCCACAAGGGAGGCGAGGTGCTCAGCCATTCCTTTATTATTATTACACAGAAGGAAGACGGGAATCTGGGTCCACCGACATTTTTAAAGATCAGAAG GAGCCCAAGAATAAGACCTTTTTTAAGGTGTGAGGCCAAAAACTACAGCGGGTCGTTTTCACTTGTTGGTGGCTGACCACCATTTCCACCGATTTAACCTTTCTCCGTGAAAAGCAGCCGGGGAAGCTCCGACCCTCAAGGTGTGACATGTGGAGCCGCTACCCCTCAGCGCTGAGA GGGTTCGTGGCGCGATAACAAGGAATACGAGTACAGCGTGGAGTGCCAAGAAGATAGCGCTTGTCCCGCTGCCGAAGAATCTTTACCCATTGAGGTGATGGTGGACGCCGTGCACAAACTCAAGTACGAGAACTACACCTCCTCCTTCTTTATCCGGGACATCATTAAGCCCCGATC CTCCTAAGAATTTACAGCTGAAGCCTCTCAAAATAGCCGGCAAGTTGAGGTCTCTTGGGGAATATCCCGACACTTGGAGCACACCCCCACAGCCTACTTCTCTTTAACCTTTTGTGTGCAAGTTCAAGGTAAAAGCAAGCGGGAGAAGAAAGACCGGGTGTTTACCGACAAAACCAGC GCCACCGTCATCTGTCGGAAGAACGCCTCCATCAGCGTGAGGGCTCAAGATCGTTATTACTCCAGCAGCTGGTCCGAGTGGGCCAGCGTGCCTTGTTCCGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGCGGCGGAGGATCTCGTAACCTCCCCGTGGCTACCCCCC GATCCCGGAATGTTCCCTTGTTTACACCACAGCCAGAATTTACTGAGGGCCGTGAGCAACATGCTGCAGAAAGCTAGGCAGACTTTAGAATTTTACCCTTGCACCAGCGAGGAGATCGACCATGAAGATATCACCAAGGACAAGACATCCACCGTGGAGGCTTGTTTACCTCTGGAGCTGACAAA GAACGAGTCTTGTCTCAACTCTCGTGAAAACCAGCTTCATCACAAATGGCTCTTGTTTAGCTTCCCGGAAGACCTCCTTTATGATGGCTTTATGCCTCAGCTCCATCTACGAGGATTTAAAGATGTACCAAGTGGAGTTCAAGACCATGAACGCCAAGCTGCTCATGGACCCTAAACGGCAG ATCTTTTAGACCAGAACATGCTGGCTGTGATTGATGAGCTGATGCAAGCTTTAAAACTTCAACTCCGAGACCGTCCCTCAGAAGTCCTCCCTCGAGGAGCCCCGATTTTTACAAGACAAAGATCAAACTGTGCATTTTACTCCACGCCTTTTAGGATCCGGGCCGTGACCATTGACCGGGTCAT GAGCTATTTAAAACGCCAGCATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCCTCACCGAGTGCGTGCTGATAAGGCTACCAACGTG GCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG (SEQ ID NO: 181), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
例示的な多鎖キメラポリペプチド-タイプB
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは各々独立して、IL-21受容体又はTGF-βに特異的に結合する。これらの多鎖キメラポリペプチドのいくつかの例では、第1の標的結合ドメイン及び可溶性組織因子ドメインは、第1のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの例では、第1のキメラポリペプチドは、第1のキメラポリペプチド内の第1の標的結合ドメインと可溶性組織因子ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。
Exemplary Multichain Chimeric Polypeptides—Type B
In some embodiments of any of the multichain chimeric polypeptides described herein, the first target binding domain and the second target binding domain are each independently IL-21 receptor or TGF. - binds specifically to β; In some examples of these multichain chimeric polypeptides, the first target binding domain and the soluble tissue factor domain are directly adjacent to each other within the first chimeric polypeptide. In some examples of these multichain chimeric polypeptides, the first chimeric polypeptide has a linker sequence (e.g., any of the exemplary linkers described herein).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインは、第1のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1のキメラポリペプチドは、第1のキメラポリペプチド内の可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these multi-chain chimeric polypeptides, the soluble tissue factor domain and the first of the paired affinity domains are directly adjacent to each other within the first chimeric polypeptide. In some embodiments of these multi-chain chimeric polypeptides, the first chimeric polypeptide is between the soluble tissue factor domain and the first of the pair of affinity domains within the first chimeric polypeptide. Further includes a linker sequence (eg, any of the exemplary linkers described herein).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、一対の親和性ドメインの第2のドメインと第2の標的結合ドメインは、第2のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチド内の一対の親和性ドメインの第2のドメインと第2の標的結合ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these multi-chain chimeric polypeptides, the second domain and the second target binding domain of the pair of affinity domains are directly adjacent to each other within the second chimeric polypeptide. In some embodiments of these multichain chimeric polypeptides, the second chimeric polypeptide is a combination of the second of the pair of affinity domains within the second chimeric polypeptide and the second target binding domain. Further includes a linker sequence (eg, any of the exemplary linkers described herein) in between.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性組織因子ドメインは、本明細書に記載の例示的な可溶性組織因子ドメインのうちのいずれかであり得る。これらの多鎖キメラポリペプチドのいくつかの実施形態では、一対の親和性ドメインは、本明細書に記載の例示的な一対の親和性ドメインのうちのいずれかであり得る。 In some embodiments of these multichain chimeric polypeptides, the soluble tissue factor domain can be any of the exemplary soluble tissue factor domains described herein. In some embodiments of these multi-chain chimeric polypeptides, the pair of affinity domains can be any of the exemplary pair of affinity domains described herein.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方が、可溶性IL-21(例えば、可溶性ヒトIL-21ポリペプチド)又は可溶性TGF-β受容体(例えば、可溶性TGFRβRII受容体)である。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは各々独立して、可溶性IL-21又は可溶性TGF-β受容体(例えば、可溶性TGFRβRII受容体)である。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインの両方が、IL-21受容体又はTGF-βに特異的に結合する。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは、同じエピトープに特異的に結合する。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは、同じアミノ酸配列を含む。 In some embodiments of these multichain chimeric polypeptides, one or both of the first and second target binding domains are soluble IL-21 (eg, soluble human IL-21 polypeptide) or A soluble TGF-β receptor (eg, a soluble TGFRβRII receptor). In some embodiments of these multichain chimeric polypeptides, the first target binding domain and the second target binding domain are each independently a soluble IL-21 or a soluble TGF-β receptor (eg, soluble TGFRβRII). receptor). In some embodiments of these multichain chimeric polypeptides, both the first target binding domain and the second target binding domain specifically bind to the IL-21 receptor or TGF-β. In some embodiments of these multichain chimeric polypeptides, the first target binding domain and the second target binding domain specifically bind the same epitope. In some embodiments of these multichain chimeric polypeptides, the first target binding domain and the second target binding domain comprise the same amino acid sequence.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメインはIL-21受容体に特異的に結合し、第2の標的結合ドメインはTGF-βに特異的に結合する。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメインはTGF-βに特異的に結合し、第2の標的結合ドメインはIL-21受容体に特異的に結合する。 In some embodiments of these multichain chimeric polypeptides, the first target binding domain specifically binds IL-21 receptor and the second target binding domain specifically binds TGF-β. . In some embodiments of these multichain chimeric polypeptides, the first target binding domain specifically binds TGF-β and the second target binding domain specifically binds IL-21 receptor. .
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメインは、可溶性IL-21(例えば、可溶性ヒトIL-21)を含む。これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトIL-21は、
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS(配列番号83)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multichain chimeric polypeptides, the first target binding domain comprises soluble IL-21 (eg, soluble human IL-21). In some embodiments of these multi-chain chimeric polypeptides, the soluble human IL-21 is
at least 80% identical to QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS (SEQ ID NO: 83), (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, sequences that are at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトIL-21は、
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC(配列番号182)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multi-chain chimeric polypeptides, the soluble human IL-21 is
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCG CCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCCTCCACAAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCCTGCTGCAGAAGAT GATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC (SEQ ID NO: 182), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2の標的結合ドメインは、可溶性TGF-β受容体(例えば、可溶性TGFRβRII受容体(例えば、可溶性ヒトTGFRβRII受容体))を含む。これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトTGFRβRIIは、第1の可溶性ヒトTGFRβRII配列及び第2の可溶性ヒトTGFRβRII配列を含む。これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトTGFRβRIIは、第1の可溶性ヒトTGFRβRII配列と第2の可溶性ヒトTGFRβRII配列との間に配置されたリンカーを含む。これらの多鎖キメラポリペプチドのいくつかの例では、リンカーは、配列GGGGSGGGGSGGGGS(配列番号102)を含む。 In some embodiments of these multichain chimeric polypeptides, the second target binding domain comprises a soluble TGF-β receptor (eg, a soluble TGFRβRII receptor (eg, a soluble human TGFRβRII receptor)). In some embodiments of these multichain chimeric polypeptides, the soluble human TGFRβRII comprises a first soluble human TGFRβRII sequence and a second soluble human TGFRβRII sequence. In some embodiments of these multichain chimeric polypeptides, the soluble human TGFRβRII comprises a linker positioned between the first soluble human TGFRβRII sequence and the second soluble human TGFRβRII sequence. In some examples of these multichain chimeric polypeptides, the linker comprises the sequence GGGGSGGGGSGGGGGS (SEQ ID NO: 102).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の可溶性ヒトTGFRβRII受容体配列は、
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD(配列番号183)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multichain chimeric polypeptides, the first soluble human TGFRβRII receptor sequence is
at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, sequences that are at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2の可溶性ヒトTGFRβRII受容体配列は、
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD(配列番号184)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multichain chimeric polypeptides, the second soluble human TGFRβRII receptor sequence is
at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, sequences that are at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の可溶性ヒトTGFRβRII受容体配列は、
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCACGATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGAT(配列番号185)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multichain chimeric polypeptides, the first soluble human TGFRβRII receptor sequence is
ATCCCCCCCCCATGTGCCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCACGATCACCTCCATCTGCGAGAAGCCCCAA GAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGAACCTTCTTTATGTGTTCCTGTAGCAG CGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGAT (SEQ ID NO: 185), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2の可溶性ヒトTGFRβRII受容体配列は、
ATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCACAATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC(配列番号186)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multichain chimeric polypeptides, the second soluble human TGFRβRII receptor sequence is
ATTCCTCCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCACAATCACCTCCATCTGTGAGAAGCCTCAGGAGG TGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAAACCGTCTGCCCACGATCCCCAAGCTGCCCTACCCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAAGAGAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGC at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトTGFRβRII受容体は、
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCACGATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCACAATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC(配列番号187)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multichain chimeric polypeptides, the soluble human TGFRβRII receptor is
ATCCCCCCCCCATGTGCCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCACGATCACCTCCATCTGCGAGAAGCCCCAA GAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGAACCTTCTTTATGTGTTCCTGTAGCAG CGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCC CCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGGACAACCAGAAGTCCTGTATGAGCAACTGCACAATCACCTCCATCTGTGAGAAGCCTCAGGAGGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCCACGATCCCCAAGCTGCCCTAC CACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCCGAC (SEQ ID NO: 187), and at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、ヒトTGFβRII受容体は、
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD(配列番号188)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multichain chimeric polypeptides, the human TGFβRII receptor is
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNSITSITSICEKPQEVCVAVWRKNDINITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPDGGGGGSGGGGGSGGGGGSIPPHV at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical , at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDSSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(配列番号189)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the first chimeric polypeptide is
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDSSGTTNTVAAYNLTW KSTN FKTILEWEPKKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNNTFLSLRDVFGKDLIYTLY YWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVIDLKKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECE ELEEKNIKEFLQSFVHIVQMFINTS (SEQ ID NO: 189), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% sequences that are identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCCTCCGGCACCACCAATACCGTGGCCGCTTATAACCTCACATGGAAGAGCACCAACTTCAAGACAATTCTGGAATGGGAACCCAAGCCCGTCAATCAAGTTTACACCGTGCAGATCTCCACCAAATCCGGAGACTGGAAGAGCAAGTGCTTCTACACAACAGACACCGAGTGTGATTTAACCGACGAAATCGTCAAGGACGTCAAGCAAACCTATCTGGCTCGGGTCTTTTCCTACCCCGCTGGCAATGTCGAGTCCACCGGCTCCGCTGGCGAGCCTCTCTACGAGAATTCCCCCGAATTCACCCCTTATTTAGAGACCAATTTAGGCCAGCCTACCATCCAGAGCTTCGAGCAAGTTGGCACCAAGGTGAACGTCACCGTCGAGGATGAAAGGACTTTAGTGCGGCGGAATAACACATTTTTATCCCTCCGGGATGTGTTCGGCAAAGACCTCATCTACACACTGTACTATTGGAAGTCCAGCTCCTCCGGCAAAAAGACCGCTAAGACCAACACCAACGAGTTTTTAATTGACGTGGACAAAGGCGAGAACTACTGCTTCAGCGTGCAAGCCGTGATCCCTTCTCGTACCGTCAACCGGAAGAGCACAGATTCCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(配列番号190)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the first chimeric polypeptide is
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCG CCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCCTCCACAAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCCTGCTGCAGAAGAT GATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCCTCCGGCACCACCAATACCGTGGCCGCTTATAACCTCACATGGAAGAGCACCAACTTCAAGACAATTCTGGAATGGGAACCCAAGCCCCGTCAATCAAGTTTACACCGTGCAGATCTCCACCAAATCCGGAGACTGGAAGAGCAAGT GCTTCTACACAACAGACACCGAGTGTGATTTAACCGACGAAATCGTCAAGGACGTCAAGCAAACCTATCTGGCTCGGGTCTTTTCCTACCCCGCTGGCAATGTCGAGTCCACCGGCTCCGCTGGCGAGCCTCTTACGAGAATTCCCCCCGAATTCACCCCTTATTTAGAGAGACCAATTTAGGCCA GCCTACCATCCAGAGCTTCGAGCAAGTTGGCACCAAGGTGAACGTCACCGTCGAGGATGAAAGGACTTTAGTGCGGCGGGAATAACACATTTTTATCCCTCCGGATGTGTTCGGCAAAGACCTCATCTACACACTGTACTATTGGAAGTCCAGCTCCTCCGGCAAAAGACCG CTAAGACCAACACCAACGAGTTTTTTAATTGACGTGGACAAAGGCGAGAACTACTGCTTCAGCGTGCAAGCCGTGATCCCCTTCGTACCGTCAACCGGAAGAGCACAGATTCCCCCGTTGAGTGCATGGGCCAAGAAAGGGCGAGTTCCGGGGAGAACTGGGTGAACGTCAT CAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATC ATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC (SEQ ID NO: 190), at least 80% identical (e.g., at least 82% identical, at least 84 % identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92 % identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
MKWVTFISLLFLFSSAYSQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDSSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(配列番号191)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the first chimeric polypeptide is
MKWVTFISLLFFSSAYSQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGS EDSSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNT FLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENL at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% sequences that are identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCCAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCCTCCGGCACCACCAATACCGTGGCCGCTTATAACCTCACATGGAAGAGCACCAACTTCAAGACAATTCTGGAATGGGAACCCAAGCCCGTCAATCAAGTTTACACCGTGCAGATCTCCACCAAATCCGGAGACTGGAAGAGCAAGTGCTTCTACACAACAGACACCGAGTGTGATTTAACCGACGAAATCGTCAAGGACGTCAAGCAAACCTATCTGGCTCGGGTCTTTTCCTACCCCGCTGGCAATGTCGAGTCCACCGGCTCCGCTGGCGAGCCTCTCTACGAGAATTCCCCCGAATTCACCCCTTATTTAGAGACCAATTTAGGCCAGCCTACCATCCAGAGCTTCGAGCAAGTTGGCACCAAGGTGAACGTCACCGTCGAGGATGAAAGGACTTTAGTGCGGCGGAATAACACATTTTTATCCCTCCGGGATGTGTTCGGCAAAGACCTCATCTACACACTGTACTATTGGAAGTCCAGCTCCTCCGGCAAAAAGACCGCTAAGACCAACACCAACGAGTTTTTAATTGACGTGGACAAAGGCGAGAACTACTGCTTCAGCGTGCAAGCCGTGATCCCTTCTCGTACCGTCAACCGGAAGAGCACAGATTCCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(配列番号192)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the first chimeric polypeptide is
ATGAAGTGGGGTGACCTTCATCAGCCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCCAGGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGA CCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTAC GAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCACGGCTCCGAGGACTCCTCCGGCACCACCAATACCGTGGCCGCTTATAACCTCACATGGAAGAGCACCAACTTCAAGACAATTCTGGAATGGGAACCCCAAGC CCGTCAATCAAGTTTACACCGTGCAGATCTCCACCAAATCCCGGAGACTGGAAGAGCAAGTGCTTCTACACAACAGACACCGAGTGTGATTTAACCGACGAAAATCGTCAAGGACGTCAAGCAAACCTATCTGGCTCGGTCTTTTTCTCACCCCGCTGGCAATGTCGAGTCCACCGGCTCCGCT GGCGAGCCTCTCTACGAGAATTCCCCCGAATTCACCCTTATTTAGAGACCAATTTAGGCCAGCCTACCATCCAGAGCTTCGAGCAAGTTGGCACCAAGGTGAACGTCACCGTCGAGGATGAAAAGGACTTTAGTGCGCGCGGAATAACACATTTTTATCCCCTCCGGGATGGTGTTCGGCA AAGACCTCATCTACACACTGTACTATTGGAAGTCCAGCTCCTCCGGCAAAAGACCGCTAAGACCAACACCAACGAGTTTTTTAATTGACGTGGACAAAGGCGAGAACTACTGCTTCAGCGTGCAAGCCGTGATCCCTTCTCGTACCGTCAACCGGAAGAGCACAGATTCCCCCGTTTGAG TGCATGGGCCAAGAAAGGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGAATTTAATTCAGTCCATGCATATCGACGCCACTTTATACAGAATCCGACGTGCACCCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTG CAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTTGTGCACATTGTCC AGATGTTCATCAATACCTCC (SEQ ID NO: 192), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% % identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR(配列番号193)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the second chimeric polypeptide is
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNCSITSICEKPQEVCVAVWRKNDINITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPDGGGGGSGGGGGSGGGGSIPPHV QKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADIWVKSYSLYSRERYICNSG FKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR (SEQ ID NO: 193), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% sequences that are identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCACGATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCACAATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACATCACGTGTCCTCCTCCTATGTCCGTGGAACACGCAGACATCTGGGTCAAGAGCTACAGCTTGTACTCCAGGGAGCGGTACATTTGTAACTCTGGTTTCAAGCGTAAAGCCGGCACGTCCAGCCTGACGGAGTGCGTGTTGAACAAGGCCACGAATGTCGCCCACTGGACAACCCCCAGTCTCAAATGTATTAGA(配列番号194)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the second chimeric polypeptide is
ATCCCCCCCCCATGTGCCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCACGATCACCTCCATCTGCGAGAAGCCCCAA GAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGAACCTTCTTTATGTGTTCCTGTAGCAG CGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCC CCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGGACAACCAGAAGTCCTGTATGAGCAACTGCACAATCACCTCCATCTGTGAGAAGCCTCAGGAGGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCCACGATCCCCAAGCTGCCCTAC CACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACATCACGTGTCCTCCTCCTATGTCCG TGGAACACGCAGACATCTGGGTCAAGAGCTACAGCTTGTACTCCAGGGAGCGGTACATTTGTAACTCTGGTTTCAAGCGTAAAGCCGGCACGTCCAGCCTGACGGGAGTGCGTGTTGAACAAGGCCCACGAATGTCGCCCACTGGACAACCCCCAGTCTCAAATGTATTAGA (sequence No. 194), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical , at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR(配列番号195)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the second chimeric polypeptide is
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGG GSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADI at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% sequences that are identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCACGATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCACAATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACATCACGTGTCCTCCTCCTATGTCCGTGGAACACGCAGACATCTGGGTCAAGAGCTACAGCTTGTACTCCAGGGAGCGGTACATTTGTAACTCTGGTTTCAAGCGTAAAGCCGGCACGTCCAGCCTGACGGAGTGCGTGTTGAACAAGGCCACGAATGTCGCCCACTGGACAACCCCCAGTCTCAAATGTATTAGA(配列番号196)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the second chimeric polypeptide is
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCCATCCCCCCCCATGTGCAAAGAGCGTGAACAACGATATGATCGTGACCGACAACACGGCGCCGTGAAGTTTCCCCAGCTCTGCCAAGTTTCTGCGATGTCAGGGTTCAGCACCTGCGA TAATCAGAAGTCCTGCATGTCCAACTGCACGATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGC ATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCCACGTGCA GAAGAGCGTGGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAAATTCTGCGATGTGAGGTTTTCCACCTGCGGACAACCAGAAGTCCTGTATGAGCCAACTGCACAATCACCTCCATCTGTGAGAAGCCTCAGGAGGGTGTGCGTGGCTGTCT GGCGGAAGAATGACGAGAATATCACCCTGGAAAACCGTCTGCCACGATCCCCAAGCTGCCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAAGAGAAAAGAAGCCTGGCGGAGACCTTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCAT CTTTAGCGAGGAATACAATACCAGCAACCCCCGACATCACGTGTCCTCCCTCCTAGTCCGTGGAACACGCAGACATCTGGGTCAAGAGCTACAGCTTGTACTCCAGGGAGCGGTACATTTGTAACTCTGGTTTCAAGCGTAAAGCCGGCACGTCCAGCCTGACGGAGTGCGTG at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical , at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
例示的な多鎖キメラポリペプチド-タイプC
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは各々独立して、IL-7受容体又はIL-21受容体に特異的に結合する。これらの多鎖キメラポリペプチドのいくつかの例では、第1の標的結合ドメインと可溶性組織因子ドメインは、第1のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの例では、第1のキメラポリペプチドは、第1のキメラポリペプチド内の第1の標的結合ドメインと可溶性組織因子ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。
Exemplary Multichain Chimeric Polypeptides—Type C
In some embodiments of any of the multichain chimeric polypeptides described herein, the first target binding domain and the second target binding domain are each independently IL-7 receptor or IL It specifically binds to the -21 receptor. In some examples of these multichain chimeric polypeptides, the first target binding domain and the soluble tissue factor domain are directly adjacent to each other within the first chimeric polypeptide. In some examples of these multichain chimeric polypeptides, the first chimeric polypeptide has a linker sequence (e.g., any of the exemplary linkers described herein).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインは、第1のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1のキメラポリペプチドは、第1のキメラポリペプチド内の可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these multi-chain chimeric polypeptides, the soluble tissue factor domain and the first of the paired affinity domains are directly adjacent to each other within the first chimeric polypeptide. In some embodiments of these multi-chain chimeric polypeptides, the first chimeric polypeptide is between the soluble tissue factor domain and the first of the pair of affinity domains within the first chimeric polypeptide. Further includes a linker sequence (eg, any of the exemplary linkers described herein).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、一対の親和性ドメインの第2のドメインと第2の標的結合ドメインは、第2のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチド内の一対の親和性ドメインの第2のドメインと第2の標的結合ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these multi-chain chimeric polypeptides, the second domain and the second target binding domain of the pair of affinity domains are directly adjacent to each other within the second chimeric polypeptide. In some embodiments of these multichain chimeric polypeptides, the second chimeric polypeptide is a combination of the second of the pair of affinity domains within the second chimeric polypeptide and the second target binding domain. Further includes a linker sequence (eg, any of the exemplary linkers described herein) in between.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性組織因子ドメインは、本明細書に記載の例示的な可溶性組織因子ドメインのうちのいずれかであり得る。これらの多鎖キメラポリペプチドのいくつかの実施形態では、一対の親和性ドメインは、本明細書に記載の例示的な一対の親和性ドメインのうちのいずれかであり得る。 In some embodiments of these multichain chimeric polypeptides, the soluble tissue factor domain can be any of the exemplary soluble tissue factor domains described herein. In some embodiments of these multi-chain chimeric polypeptides, the pair of affinity domains can be any of the exemplary pair of affinity domains described herein.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方が、可溶性IL-21(例えば、可溶性ヒトIL-21ポリペプチド)又は可溶性IL-7(例えば、可溶性ヒトIL-7ポリペプチド)である。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは各々独立して、可溶性IL-21又は可溶性IL-7である。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインの両方が、IL-21受容体又はIL-7受容体に特異的に結合する。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは、同じエピトープに特異的に結合する。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは、同じアミノ酸配列を含む。 In some embodiments of these multichain chimeric polypeptides, one or both of the first and second target binding domains are soluble IL-21 (eg, soluble human IL-21 polypeptide) or Soluble IL-7 (eg, soluble human IL-7 polypeptide). In some embodiments of these multichain chimeric polypeptides, the first target binding domain and the second target binding domain are each independently soluble IL-21 or soluble IL-7. In some embodiments of these multichain chimeric polypeptides, both the first target binding domain and the second target binding domain specifically bind to IL-21 receptor or IL-7 receptor. In some embodiments of these multichain chimeric polypeptides, the first target binding domain and the second target binding domain specifically bind the same epitope. In some embodiments of these multichain chimeric polypeptides, the first target binding domain and the second target binding domain comprise the same amino acid sequence.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメインはIL-21受容体に特異的に結合し、第2の標的結合ドメインはIL-7受容体に特異的に結合する。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメインはIL-7受容体に特異的に結合し、第2の標的結合ドメインはIL-21受容体に特異的に結合する。 In some embodiments of these multichain chimeric polypeptides, the first target binding domain specifically binds the IL-21 receptor and the second target binding domain specifically binds the IL-7 receptor. Join. In some embodiments of these multichain chimeric polypeptides, the first target binding domain specifically binds the IL-7 receptor and the second target binding domain specifically binds the IL-21 receptor. Join.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメインは、可溶性IL-21(例えば、可溶性ヒトIL-21)を含む。 In some embodiments of these multichain chimeric polypeptides, the first target binding domain comprises soluble IL-21 (eg, soluble human IL-21).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトIL-21は、
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS(配列番号83)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multi-chain chimeric polypeptides, the soluble human IL-21 is
at least 80% identical to QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS (SEQ ID NO: 83), (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, sequences that are at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトIL-21は、
CAAGGTCAAGATCGCCACATGATTAGAATGCGTCAACTTATAGATATTGTTGATCAGCTGAAAAATTATGTGAATGACTTGGTCCCTGAATTTCTGCCAGCTCCAGAAGATGTAGAGACAAACTGTGAGTGGTCAGCTTTTTCCTGTTTTCAGAAGGCCCAACTAAAGTCAGCAAATACAGGAAACAATGAAAGGATAATCAATGTATCAATTAAAAAGCTGAAGAGGAAACCACCTTCCACAAATGCAGGGAGAAGACAGAAACACAGACTAACATGCCCTTCATGTGATTCTTATGAGAAAAAACCACCCAAAGAATTCCTAGAAAGATTCAAATCACTTCTCCAAAAGATGATTCATCAGCATCTGTCCTCTAGAACACACGGAAGTGAAGATTCC(配列番号197)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multi-chain chimeric polypeptides, the soluble human IL-21 is
CAAGGTCAAGATCGCCACATGATTAGAATGCGTCAACTTATAGATATTGTTGATCAGCTGAAAATTATGTGAATGACTTGGTCCCTGAATTTCTGCCAGCTCCAGAAGATGTAGAGACAAAACTGTGAGTGGTCAGCTTTTTCCTGTTTTCAGAAGGCCCAACTAAAGTCAGCA AATACAGGAAACAATGAAAAGGATAATCAATGTATCAATTAAAAGCTGAAGAGGAAACCACCTTCCACAAATGCAGGGAGAAGACAGAAACACAGACTAACATGCCCTTCATGTGATTCTTATGAGAAAAAAAACCACCCAAAGAATTCCTAGAAAGATTCAAATCACTTCTCCAAAGATGATTCATCA at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトIL-21は、
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC(配列番号182)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multi-chain chimeric polypeptides, the soluble human IL-21 is
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCG CCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCCTCCACAAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCCTGCTGCAGAAGAT GATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC (SEQ ID NO: 182), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトIL-7配列は、
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEH(配列番号79)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multi-chain chimeric polypeptides, the soluble human IL-7 sequence is
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDHLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWN KILMGTKEH (SEQ ID NO: 79), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, sequences that are at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトIL-7は、
GATTGTGATATTGAAGGTAAAGATGGCAAACAATATGAGAGTGTTCTAATGGTCAGCATCGATCAATTATTGGACAGCATGAAAGAAATTGGTAGCAATTGCCTGAATAATGAATTTAACTTTTTTAAAAGACATATCTGTGATGCTAATAAGGAAGGTATGTTTTTATTCCGTGCTGCTCGCAAGTTGAGGCAATTTCTTAAAATGAATAGCACTGGTGATTTTGATCTCCACTTATTAAAAGTTTCAGAAGGCACAACAATACTGTTGAACTGCACTGGCCAGGTTAAAGGAAGAAAACCAGCTGCCCTGGGTGAAGCCCAACCAACAAAGAGTTTGGAAGAAAATAAATCTTTAAAGGAACAGAAAAAACTGAATGACTTGTGTTTCCTAAAGAGACTATTACAAGAGATAAAAACTTGTTGGAATAAAATTTTGATGGGCACTAAAGAACAC(配列番号198)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multi-chain chimeric polypeptides, the soluble human IL-7 is
GATTGTGATATTGAAGGTAAAGATGGCAAACAATATGAGAGTGTTCTAATGGTCAGCATCGATCAATTATTGGACAGCATGAAAAGAAATTGGTAGCAATTGCCTGAATAATGAATTTAACTTTTTTAAAAGACATATCTGTGATGCTAATAAGGAAGGTATGTTTTTAT TCCGTGCTGCTCGCAAGTTGAGGCAATTTCTTAAATGAATAGCACTGGTGATTTTGATCTCCACTTATTAAAGTTTCAGAAGGCCAACAATACTGTTGAACTGCACTGGCCAGGTTAAAAGGAAGAAAACCAGCTGCCCTGGGTGAAGCCCAACCAACAAAGAGTTTGGA AGAAAAAAATCTTAAAGGAACAGAAAAAAACTGAATGACTTGTGTTTCCTAAAGAGACTATTACAAGAGATAAAAACTTTGTTGGAATAAAATTTTGATGGGCACTAAAGAACAC (SEQ ID NO: 198), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDSSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(配列番号199)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the first chimeric polypeptide is
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDSSGTTNTVAAYNLTW KSTN FKTILEWEPKKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNNTFLSLRDVFGKDLIYTLY YWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVIDLKKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECE ELEEKNIKEFLQSFVHIVQMFINTS (SEQ ID NO: 199), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% sequences that are identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
CAAGGTCAAGATCGCCACATGATTAGAATGCGTCAACTTATAGATATTGTTGATCAGCTGAAAAATTATGTGAATGACTTGGTCCCTGAATTTCTGCCAGCTCCAGAAGATGTAGAGACAAACTGTGAGTGGTCAGCTTTTTCCTGTTTTCAGAAGGCCCAACTAAAGTCAGCAAATACAGGAAACAATGAAAGGATAATCAATGTATCAATTAAAAAGCTGAAGAGGAAACCACCTTCCACAAATGCAGGGAGAAGACAGAAACACAGACTAACATGCCCTTCATGTGATTCTTATGAGAAAAAACCACCCAAAGAATTCCTAGAAAGATTCAAATCACTTCTCCAAAAGATGATTCATCAGCATCTGTCCTCTAGAACACACGGAAGTGAAGATTCCTCAGGCACTACAAATACTGTGGCAGCATATAATTTAACTTGGAAATCAACTAATTTCAAGACAATTTTGGAGTGGGAACCCAAACCCGTCAATCAAGTCTACACTGTTCAAATAAGCACTAAGTCAGGAGATTGGAAAAGCAAATGCTTTTACACAACAGACACAGAGTGTGACCTCACCGACGAGATTGTGAAGGATGTGAAGCAGACGTACTTGGCACGGGTCTTCTCCTACCCGGCAGGGAATGTGGAGAGCACCGGTTCTGCTGGGGAGCCTCTGTATGAGAACTCCCCAGAGTTCACACCTTACCTGGAGACAAACCTCGGACAGCCAACAATTCAGAGTTTTGAACAGGTGGGAACAAAAGTGAATGTGACCGTAGAAGATGAACGGACTTTAGTCAGAAGGAACAACACTTTCCTAAGCCTCCGGGATGTTTTTGGCAAGGACTTAATTTATACACTTTATTATTGGAAATCTTCAAGTTCAGGAAAGAAAACAGCCAAAACAAACACTAATGAGTTTTTGATTGATGTGGATAAAGGAGAAAACTACTGTTTCAGTGTTCAAGCAGTGATTCCCTCCCGAACAGTTAACCGGAAGAGTACAGACAGCCCGGTAGAGTGTATGGGCCAGGAGAAAGGGGAATTCAGAGAAAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(配列番号200)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the first chimeric polypeptide is
CAAGGTCAAGATCGCCACATGATTAGAATGCGTCAACTTATAGATATTGTTGATCAGCTGAAAATTATGTGAATGACTTGGTCCCTGAATTTCTGCCAGCTCCAGAAGATGTAGAGACAAAACTGTGAGTGGTCAGCTTTTTCCTGTTTTCAGAAGGCCCAACTAAAGTCAGCA AATACAGGAAACAATGAAAAGGATAATCAATGTATCAATTAAAAGCTGAAGAGGAAACCACCTTCCACAAATGCAGGGAGAAGACAGAAACACAGACTAACATGCCCTTCATGTGATTCTTATGAGAAAAAAAACCACCCAAAGAATTCCTAGAAAGATTCAAATCACTTCTCCAAAGATGATTCATCA GCATCTGTCCCTCTAGAACACACGGAAGTGAAGATTCCTCAGGCACTACAAATACTGTGGCAGCATATAATTTAACTTGGAAATCAACTAATTTCAAGACAATTTTTGGAGTGGGAACCCAAAACCCGTCAATCAAGTCTACACTGTTCAAATAAGCACTAAGTCAGGAGATTGGAAAAGCA AATGCTTTTTACACAACAGACACAGGTGTGACCTCACCGACGAGATTGTGAAGGATGTGAAGCAGACGTACTTGGCACGGGTCTTCTCCTACGGGCAGGGGAATGTGGAGAGCACCGGTTCTGCTGGGGAGCCTCTGTATGAGAACTCCCCAGAGTTTCACACCTTACCTGGAGACAAACCTC GGACAGCCAACAATTCAGAGTTTTGAACAGGTGGGAACAAAGTGAATGTGACCGTAGAAGATGAACGGACTTTAGTCAGAAGGAACAACACTTTCCTAAGCCTCCGGGATGTTTTTGGCAAGGACTTAATTTATACACTTTATTATTGGAAATCTTCAAGTTTCAGGAAGAAAAAC AGCCAAAACAAAACACTAATGAGTTTTTGATTGATGTGGATAAAGGAGAAAAACTACTGTTTCAGTGTTCAAGCAGTGATTCCCTCCCGAACAGTTTAACCGGAAGAGTACAGACAGCCCGGTAGAGTGTATGGGCCAGGAGAAAAGGGAATTCAGAGAAAAACTGGGTGAACGT CATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTA ATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCCAAGGAGTGCGAAGAGGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC (SEQ ID NO: 200), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92 % identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
MGVKVLFALICIAVAEAQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDSSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(配列番号201)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the first chimeric polypeptide is
MGVKVLFALICIAVAEAQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSE DSSGTTNVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTF LSLRDVFGKDLIYTLYYWKSSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLII LANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS (SEQ ID NO: 201), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% sequences that are identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
ATGGGAGTGAAAGTTCTTTTTGCCCTTATTTGTATTGCTGTGGCCGAGGCCCAAGGTCAAGATCGCCACATGATTAGAATGCGTCAACTTATAGATATTGTTGATCAGCTGAAAAATTATGTGAATGACTTGGTCCCTGAATTTCTGCCAGCTCCAGAAGATGTAGAGACAAACTGTGAGTGGTCAGCTTTTTCCTGTTTTCAGAAGGCCCAACTAAAGTCAGCAAATACAGGAAACAATGAAAGGATAATCAATGTATCAATTAAAAAGCTGAAGAGGAAACCACCTTCCACAAATGCAGGGAGAAGACAGAAACACAGACTAACATGCCCTTCATGTGATTCTTATGAGAAAAAACCACCCAAAGAATTCCTAGAAAGATTCAAATCACTTCTCCAAAAGATGATTCATCAGCATCTGTCCTCTAGAACACACGGAAGTGAAGATTCCTCAGGCACTACAAATACTGTGGCAGCATATAATTTAACTTGGAAATCAACTAATTTCAAGACAATTTTGGAGTGGGAACCCAAACCCGTCAATCAAGTCTACACTGTTCAAATAAGCACTAAGTCAGGAGATTGGAAAAGCAAATGCTTTTACACAACAGACACAGAGTGTGACCTCACCGACGAGATTGTGAAGGATGTGAAGCAGACGTACTTGGCACGGGTCTTCTCCTACCCGGCAGGGAATGTGGAGAGCACCGGTTCTGCTGGGGAGCCTCTGTATGAGAACTCCCCAGAGTTCACACCTTACCTGGAGACAAACCTCGGACAGCCAACAATTCAGAGTTTTGAACAGGTGGGAACAAAAGTGAATGTGACCGTAGAAGATGAACGGACTTTAGTCAGAAGGAACAACACTTTCCTAAGCCTCCGGGATGTTTTTGGCAAGGACTTAATTTATACACTTTATTATTGGAAATCTTCAAGTTCAGGAAAGAAAACAGCCAAAACAAACACTAATGAGTTTTTGATTGATGTGGATAAAGGAGAAAACTACTGTTTCAGTGTTCAAGCAGTGATTCCCTCCCGAACAGTTAACCGGAAGAGTACAGACAGCCCGGTAGAGTGTATGGGCCAGGAGAAAGGGGAATTCAGAGAAAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(配列番号202)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the first chimeric polypeptide is
ATGGGAGTGAAAGTTCTTTTTTGCCCTTATTTGTATTGCTGTGGCCGAGGCCCAAGGTCAAGATCGCCACATGATTAGAATGCGTCAACTTATAGATATTGTTGATCAGCTGAAAATTATGTGAATGACTTGGTCCCTGAATTTCTGCCAGCTCCAGAAGATGTAGAGACAAA CTGTGAGTGGTCAGCTTTTTTCCTGTTTTCAGAGGCCCAACTAAAGTCAGCAAATACAGGAAACAATGAAAAGGATAATCAATGTATCAATTAAAAGCTGAAGAGGAAACCACCTTCCACAAATGCAGGGGAGAAGACAGAAAACACAGACTAACATGCCCTTCATGTGATTCTTATGAGAAAA AAACCACCCAAAGAATTCCTAGAAAGATTCAAATCACTTCTCCAAAGATGATTCATCAGCATCTGTCCTCTAGAACACACGGGAAGTGAAGTTCCTCAGGCACTACAAATACTGTGGCAGCATATAATTTAACTTGGAAATCAACTTAATTTCAAGACAATTTTTGGAGTGGGAACCCAAAACCCG TCAATCAAGTCTACACTGTTCAAATAAGCACTAAGTCAGGAGATTGGAAAAGCAAATGCTTTTACACACACGACACAGAGTGTGACCTCACCGACGAGATTGTGAAGGATGTGAAGCAGACGTACTTGGCACGGGTCTTCTCTCTACCCGGCAGGGAATGTGGGAGAGCACCGGTTCT GCTGGGGAGCCTCTGTATGAGAACTCCCCAGAGTTTCACACCTTACCTGGAGACAAAACCTCGGACAGCCAACAATTCAGAGTTTTGAACAGGTGGGAACAAAAGTGAATGTGACCGTAGAAGATGAACGGACTTTAGTCAGAAGGAACAACACTTTCCTAAGCCTCCGGGATGTTTTTG GCAAGGACTTAATTTATACACTTTATTATTGGAAATCTTCAAGTTCAGGAAAGAAAACAGCCAAAACAAAACACTAATGAGTTTTTGATTGATGTGGATAAAGGAGAAAAACTACTGTTTCAGTGTTCAAGCAGTGATTCCCTCCCGAACAGTTTAACCGGAAGAGTACAGACAGCCCG GTAGAGTGTATGGGCCAGGAGAAAAGGGGGAATTCAGAGAAAAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGAATTTAATTCAGTCCATGCATATCGACGCCACTTTATACAGAATCCGACGTGCACCCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTACTGGAG CTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGGAGAAGAACATCAAGGAGTTTCTGCCAATCCTTTGTGCACATTG TCCAGATGTTCATCAATACCTCC (SEQ ID NO: 202), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92 % identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEHITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR(配列番号203)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)の配列を含み得る。
In some embodiments, the second chimeric polypeptide is
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWN at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical , at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
GATTGTGATATTGAAGGTAAAGATGGCAAACAATATGAGAGTGTTCTAATGGTCAGCATCGATCAATTATTGGACAGCATGAAAGAAATTGGTAGCAATTGCCTGAATAATGAATTTAACTTTTTTAAAAGACATATCTGTGATGCTAATAAGGAAGGTATGTTTTTATTCCGTGCTGCTCGCAAGTTGAGGCAATTTCTTAAAATGAATAGCACTGGTGATTTTGATCTCCACTTATTAAAAGTTTCAGAAGGCACAACAATACTGTTGAACTGCACTGGCCAGGTTAAAGGAAGAAAACCAGCTGCCCTGGGTGAAGCCCAACCAACAAAGAGTTTGGAAGAAAATAAATCTTTAAAGGAACAGAAAAAACTGAATGACTTGTGTTTCCTAAAGAGACTATTACAAGAGATAAAAACTTGTTGGAATAAAATTTTGATGGGCACTAAAGAACACATCACGTGCCCTCCCCCCATGTCCGTGGAACACGCAGACATCTGGGTCAAGAGCTACAGCTTGTACTCCAGGGAGCGGTACATTTGTAACTCTGGTTTCAAGCGTAAAGCCGGCACGTCCAGCCTGACGGAGTGCGTGTTGAACAAGGCCACGAATGTCGCCCACTGGACAACCCCCAGTCTCAAATGCATTAGA(配列番号204)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the second chimeric polypeptide is
GATTGTGATATTGAAGGTAAAGATGGCAAACAATATGAGAGTGTTCTAATGGTCAGCATCGATCAATTATTGGACAGCATGAAAAGAAATTGGTAGCAATTGCCTGAATAATGAATTTAACTTTTTTAAAAGACATATCTGTGATGCTAATAAGGAAGGTATGTTTTTAT TCCGTGCTGCTCGCAAGTTGAGGCAATTTCTTAAATGAATAGCACTGGTGATTTTGATCTCCACTTATTAAAGTTTCAGAAGGCACAACAATACTGTTGAACTGCACTGGCCAGGTTAAAGGAAGAAAACCAGCTGCCCTGGGTGAAGCCCAACCAACAAAGAGTTTGGA AGAAAAAAATCTTAAAGGAACAGAAAAAAACTGAATGACTTGTGTTTCCTAAAGAGACTATTACAAGAGATAAAAACTTTGTTGGAATAAAATTTTGATGGGGCACTAAAGAACACATCACGTGCCCTCCCCCCATGTCCGTGGAACACGCAGACATCTGGGTCAAGAGCTACAGCTTG at least 80% identical (e.g., at least 82% identical, at least 84% identical , at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94 % identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
MGVKVLFALICIAVAEADCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEHITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR(配列番号205)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the second chimeric polypeptide is
MGVKVLFALICIAVAEADCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLND at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 9 2% identical, at least 94% identical , at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
ATGGGAGTGAAAGTTCTTTTTGCCCTTATTTGTATTGCTGTGGCCGAGGCCGATTGTGATATTGAAGGTAAAGATGGCAAACAATATGAGAGTGTTCTAATGGTCAGCATCGATCAATTATTGGACAGCATGAAAGAAATTGGTAGCAATTGCCTGAATAATGAATTTAACTTTTTTAAAAGACATATCTGTGATGCTAATAAGGAAGGTATGTTTTTATTCCGTGCTGCTCGCAAGTTGAGGCAATTTCTTAAAATGAATAGCACTGGTGATTTTGATCTCCACTTATTAAAAGTTTCAGAAGGCACAACAATACTGTTGAACTGCACTGGCCAGGTTAAAGGAAGAAAACCAGCTGCCCTGGGTGAAGCCCAACCAACAAAGAGTTTGGAAGAAAATAAATCTTTAAAGGAACAGAAAAAACTGAATGACTTGTGTTTCCTAAAGAGACTATTACAAGAGATAAAAACTTGTTGGAATAAAATTTTGATGGGCACTAAAGAACACATCACGTGCCCTCCCCCCATGTCCGTGGAACACGCAGACATCTGGGTCAAGAGCTACAGCTTGTACTCCAGGGAGCGGTACATTTGTAACTCTGGTTTCAAGCGTAAAGCCGGCACGTCCAGCCTGACGGAGTGCGTGTTGAACAAGGCCACGAATGTCGCCCACTGGACAACCCCCAGTCTCAAATGCATTAGA(配列番号206)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the second chimeric polypeptide is
ATGGGAGTGAAAGTTCTTTTTTGCCCTTATTTGTATTGCTGTGGGCCGAGGCCGATTGTGATATTGAAGGTAAAGATGGCAAACAATATGAGAGTGTTCTAATGGTCAGCATCGATCAATTATTGGACAGCATGAAGAAAATTGGTAGCAATTGCCTGAATAATGAATTTA ACTTTTTTAAAAGACATATCTGTGATGCTAATAAGGAAGGTATGTTTTTATTCCGTGCTGCTCGCAAGTTGAGGCAATTTCTTAAATGAATAGCACTGGTGATTTTGATCTCCACTTATTAAAAGTTTCAGAAGGCCACAACAATACTGTTGAACTGCACTGGCCAGG TTAAAGGAAGAAAAACCAGCTGCCCTGGGTGAAGCCCAACCAACAAAGAGTTTGGAAGAAAAAATCTTTTAAAGGAACAGAAAAAAACTGAATGACTTGTGTTTCCTAAAGAGACTATTACAAGAGATAAAAACTTGTTTGGAATAAAAATTTTGATGGGCACTAAAGAACACCATCAC GTGCCCTCCCCCCCCATGTCCGTGGAACACGCAGACATCTGGGTCAAGAGCTACAGCTTTGTACTCCAGGGGAGCGGTACATTTGTAACTCTGGTTTCAAGCGTAAAGCCGGCACGTCCAGCCTGACGGAGTGCGTGTTGAACAAGGCCACGAATGTCGCCCCACTGGACAACCCCCA GTCTCAAATGCATTAGA (SEQ ID NO: 206), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
例示的な多鎖キメラポリペプチド-タイプD
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは各々独立して、IL-7受容体又はIL-21受容体に特異的に結合する。これらの多鎖キメラポリペプチドのいくつかの例では、第1の標的結合ドメインと可溶性組織因子ドメインは、第1のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの例では、第1のキメラポリペプチドは、第1のキメラポリペプチド内の第1の標的結合ドメインと可溶性組織因子ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。
Exemplary Multichain Chimeric Polypeptides—Type D
In some embodiments of any of the multichain chimeric polypeptides described herein, the first target binding domain and the second target binding domain are each independently IL-7 receptor or IL It specifically binds to the -21 receptor. In some examples of these multichain chimeric polypeptides, the first target binding domain and the soluble tissue factor domain are directly adjacent to each other within the first chimeric polypeptide. In some examples of these multichain chimeric polypeptides, the first chimeric polypeptide has a linker sequence (e.g., any of the exemplary linkers described herein).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインは、第1のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1のキメラポリペプチドは、第1のキメラポリペプチド内の可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these multi-chain chimeric polypeptides, the soluble tissue factor domain and the first of the paired affinity domains are directly adjacent to each other within the first chimeric polypeptide. In some embodiments of these multi-chain chimeric polypeptides, the first chimeric polypeptide is between the soluble tissue factor domain and the first of the pair of affinity domains within the first chimeric polypeptide. Further includes a linker sequence (eg, any of the exemplary linkers described herein).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、一対の親和性ドメインの第2のドメインと第2の標的結合ドメインは、第2のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチド内の一対の親和性ドメインの第2のドメインと第2の標的結合ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these multi-chain chimeric polypeptides, the second domain and the second target binding domain of the pair of affinity domains are directly adjacent to each other within the second chimeric polypeptide. In some embodiments of these multichain chimeric polypeptides, the second chimeric polypeptide is a combination of the second of the pair of affinity domains within the second chimeric polypeptide and the second target binding domain. Further includes a linker sequence (eg, any of the exemplary linkers described herein) in between.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性組織因子ドメインは、本明細書に記載の例示的な可溶性組織因子ドメインのうちのいずれかであり得る。これらの多鎖キメラポリペプチドのいくつかの実施形態では、一対の親和性ドメインは、本明細書に記載の例示的な一対の親和性ドメインのうちのいずれかであり得る。 In some embodiments of these multichain chimeric polypeptides, the soluble tissue factor domain can be any of the exemplary soluble tissue factor domains described herein. In some embodiments of these multi-chain chimeric polypeptides, the pair of affinity domains can be any of the exemplary pair of affinity domains described herein.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方が、可溶性IL-21(例えば、可溶性ヒトIL-21ポリペプチド)又は可溶性IL-7(例えば、可溶性ヒトIL-7ポリペプチド)である。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは各々独立して、可溶性IL-21又は可溶性IL-7である。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインの両方が、IL-21受容体又はIL-7受容体に特異的に結合する。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは、同じエピトープに特異的に結合する。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは、同じアミノ酸配列を含む。 In some embodiments of these multichain chimeric polypeptides, one or both of the first and second target binding domains are soluble IL-21 (eg, soluble human IL-21 polypeptide) or Soluble IL-7 (eg, soluble human IL-7 polypeptide). In some embodiments of these multichain chimeric polypeptides, the first target binding domain and the second target binding domain are each independently soluble IL-21 or soluble IL-7. In some embodiments of these multichain chimeric polypeptides, both the first target binding domain and the second target binding domain specifically bind to IL-21 receptor or IL-7 receptor. In some embodiments of these multichain chimeric polypeptides, the first target binding domain and the second target binding domain specifically bind the same epitope. In some embodiments of these multichain chimeric polypeptides, the first target binding domain and the second target binding domain comprise the same amino acid sequence.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメインはIL-21受容体に特異的に結合し、第2の標的結合ドメインはIL-7受容体に特異的に結合する。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメインはIL-7受容体に特異的に結合し、第2の標的結合ドメインはIL-21受容体に特異的に結合する。 In some embodiments of these multichain chimeric polypeptides, the first target binding domain specifically binds the IL-21 receptor and the second target binding domain specifically binds the IL-7 receptor. Join. In some embodiments of these multichain chimeric polypeptides, the first target binding domain specifically binds the IL-7 receptor and the second target binding domain specifically binds the IL-21 receptor. Join.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトIL-21は、
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS(配列番号83)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multi-chain chimeric polypeptides, the soluble human IL-21 is
at least 80% identical to QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS (SEQ ID NO: 83), (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, sequences that are at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトIL-21は、
CAAGGTCAAGATCGCCACATGATTAGAATGCGTCAACTTATAGATATTGTTGATCAGCTGAAAAATTATGTGAATGACTTGGTCCCTGAATTTCTGCCAGCTCCAGAAGATGTAGAGACAAACTGTGAGTGGTCAGCTTTTTCCTGTTTTCAGAAGGCCCAACTAAAGTCAGCAAATACAGGAAACAATGAAAGGATAATCAATGTATCAATTAAAAAGCTGAAGAGGAAACCACCTTCCACAAATGCAGGGAGAAGACAGAAACACAGACTAACATGCCCTTCATGTGATTCTTATGAGAAAAAACCACCCAAAGAATTCCTAGAAAGATTCAAATCACTTCTCCAAAAGATGATTCATCAGCATCTGTCCTCTAGAACACACGGAAGTGAAGATTCC(配列番号197)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multi-chain chimeric polypeptides, the soluble human IL-21 is
CAAGGTCAAGATCGCCACATGATTAGAATGCGTCAACTTATAGATATTGTTGATCAGCTGAAAATTATGTGAATGACTTGGTCCCTGAATTTCTGCCAGCTCCAGAAGATGTAGAGACAAAACTGTGAGTGGTCAGCTTTTTCCTGTTTTCAGAAGGCCCAACTAAAGTCAGCA AATACAGGAAACAATGAAAAGGATAATCAATGTATCAATTAAAAGCTGAAGAGGAAACCACCTTCCACAAATGCAGGGAGAAGACAGAAACACAGACTAACATGCCCTTCATGTGATTCTTATGAGAAAAAAAACCACCCAAAGAATTCCTAGAAAGATTCAAATCACTTCTCCAAAGATGATTCATCA at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトIL-21は、
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC(配列番号182)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multi-chain chimeric polypeptides, the soluble human IL-21 is
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCG CCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCCTCCACAAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCCTGCTGCAGAAGAT GATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC (SEQ ID NO: 182), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトIL-7配列は、
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEH(配列番号79)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multi-chain chimeric polypeptides, the soluble human IL-7 sequence is
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWN KILMGTKEH (SEQ ID NO: 79), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, sequences that are at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトIL-7は、
GATTGTGATATTGAAGGTAAAGATGGCAAACAATATGAGAGTGTTCTAATGGTCAGCATCGATCAATTATTGGACAGCATGAAAGAAATTGGTAGCAATTGCCTGAATAATGAATTTAACTTTTTTAAAAGACATATCTGTGATGCTAATAAGGAAGGTATGTTTTTATTCCGTGCTGCTCGCAAGTTGAGGCAATTTCTTAAAATGAATAGCACTGGTGATTTTGATCTCCACTTATTAAAAGTTTCAGAAGGCACAACAATACTGTTGAACTGCACTGGCCAGGTTAAAGGAAGAAAACCAGCTGCCCTGGGTGAAGCCCAACCAACAAAGAGTTTGGAAGAAAATAAATCTTTAAAGGAACAGAAAAAACTGAATGACTTGTGTTTCCTAAAGAGACTATTACAAGAGATAAAAACTTGTTGGAATAAAATTTTGATGGGCACTAAAGAACAC(配列番号198)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multi-chain chimeric polypeptides, the soluble human IL-7 is
GATTGTGATATTGAAGGTAAAGATGGCAAACAATATGAGAGTGTTCTAATGGTCAGCATCGATCAATTATTGGACAGCATGAAAAGAAATTGGTAGCAATTGCCTGAATAATGAATTTAACTTTTTTAAAAGACATATCTGTGATGCTAATAAGGAAGGTATGTTTTTAT TCCGTGCTGCTCGCAAGTTGAGGCAATTTCTTAAATGAATAGCACTGGTGATTTTGATCTCCACTTATTAAAGTTTCAGAAGGCACAACAATACTGTTGAACTGCACTGGCCAGGTTAAAGGAAGAAAACCAGCTGCCCTGGGTGAAGCCCAACCAACAAAGAGTTTGGA AGAAAAAAATCTTAAAGGAACAGAAAAAAACTGAATGACTTGTGTTTCCTAAAGAGACTATTACAAGAGATAAAAACTTTGTTGGAATAAAATTTTGATGGGCACTAAAGAACAC (SEQ ID NO: 198), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEHSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(配列番号207)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the first chimeric polypeptide is
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWN KILMGTKEHSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTL VRRNNTFLSLRDVFGKDLIYTLYYWKSSSSSGKKTAKTNTNEFLIDVDKGENYCFSVVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHD at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% sequences that are identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCATAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(配列番号208)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the first chimeric polypeptide is
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCCACATCTGCGACGCCAACAAGGAGGGCATGTTCCT GTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGA ACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCATAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATG GGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAGATGTGAAAGATGTGAAAACAGACCTACCTCGCCCGGGTGTTTTAGCTACCCCGCCCGGCAATGTGGAGA GCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGGAACAACACCTTTCTCTCGCGG GATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAACCAACACAAACGAGTTTTAATCGACGTGGATAAAGGCGAAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAA GCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAGATTTAATTCAGTCCATGCATATCGACGCCACTTTTATACACAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAAT GTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCCAATC CTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC (SEQ ID NO: 208), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical to % identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
MKWVTFISLLFLFSSAYSDCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEHSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(配列番号209)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the first chimeric polypeptide is
MKWVTFISLLFFSSAYSDCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLN DLCFLKRLLQEIKTCWNKILMGTKEHSGTTNVAAYNLTWKSTNFKTILEWEPKKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSF EQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCCKVTAM at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% sequences that are identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCGATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCATAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(配列番号210)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the first chimeric polypeptide is
ATGAAGTGGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCCGATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGT TCAACTTCTTCAAGCGGCCACATCTGCGACGCCAACAAGGAGGGGCATGTTCCTGTTCAGGGCCGCCAGGAAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGG TGAAGGGCCGGAAACCTGCTGCTCTGGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCATAGCGGCCACAACCAAC ACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGAT GTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACA GTGGAGGACGAGCGGACTTTAGTGCGGCGGCGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAAACGAGTTTTTTAATCGACGTGGATAAAGGCGAAA ACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAGGGCGAGTTCCGGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATC GACGCCACTTTATACACAGAATCCGACGTGCACCCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCC GGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC (SEQ ID NO: 210), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% % identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDSITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR(配列番号211)と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the second chimeric polypeptide is
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDSITCPPPMSVEHADIWVKS at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, sequences that are at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCCATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG(配列番号212)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the second chimeric polypeptide is
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCG CCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCCTCCACAAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCCTGCTGCAGAAGAT GATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCCATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGCACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCTCTCACCGAGTGCG at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% % identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
MKWVTFISLLFLFSSAYSQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDSITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR(配列番号213)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the second chimeric polypeptide is
MKWVTFISLLFFSSAYSQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGS at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical to , at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCCAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCCATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG(配列番号214)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the second chimeric polypeptide is
ATGAAGTGGGGTGACCTTCATCAGCCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCCAGGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGA CCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTAC GAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCCATTACATGCCCCCCCTCCCATGAGCGTGGAGCACGCGACATCTGGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTAT ATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCCACCGAGTGCGTGCTGATAAGGCTACCAACGTGGCTCCACTGGACACACCCTTTTAAAAGTGCATCCGG (SEQ ID NO: 214), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% % identical, at least 92% identical, at least 94 % identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
例示的な多鎖キメラポリペプチド-タイプE
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは各々独立して、IL-18(例えば、可溶性ヒトIL-18)受容体、IL-12(例えば、可溶性ヒトIL-12)受容体、又はCD16(例えば、抗CD16scFv)に特異的に結合する。本明細書に記載のこれらの多鎖キメラポリペプチドのいくつかの実施形態では、第1のキメラポリペプチドは、追加の標的結合ドメインを更に含む。本明細書に記載のこれらの多鎖キメラポリペプチドのいくつかの実施形態では、第2のキメラポリペプチドは、追加の標的結合ドメインを更に含む。本明細書に記載のこれらの多鎖キメラポリペプチドのいくつかの実施形態では、追加の標的結合ドメインは、CD16又はIL-12受容体に特異的に結合する。
Exemplary Multichain Chimeric Polypeptides—Type E
In some embodiments of any of the multichain chimeric polypeptides described herein, the first target binding domain and the second target binding domain are each independently IL-18 (e.g., soluble specifically binds human IL-18) receptor, IL-12 (eg, soluble human IL-12) receptor, or CD16 (eg, anti-CD16 scFv). In some embodiments of these multi-chain chimeric polypeptides described herein, the first chimeric polypeptide further comprises an additional target binding domain. In some embodiments of these multi-chain chimeric polypeptides described herein, the second chimeric polypeptide further comprises an additional target binding domain. In some embodiments of these multichain chimeric polypeptides described herein, the additional target binding domain specifically binds to the CD16 or IL-12 receptor.
これらの多鎖キメラポリペプチドのいくつかの例では、第1の標的結合ドメインと可溶性組織因子ドメインは、第1のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの例では、第1のキメラポリペプチドは、第1のキメラポリペプチド内の第1の標的結合ドメインと可溶性組織因子ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some examples of these multichain chimeric polypeptides, the first target binding domain and the soluble tissue factor domain are directly adjacent to each other within the first chimeric polypeptide. In some examples of these multichain chimeric polypeptides, the first chimeric polypeptide has a linker sequence (e.g., any of the exemplary linkers described herein).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインは、第1のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1のキメラポリペプチドは、第1のキメラポリペプチド内の可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these multi-chain chimeric polypeptides, the soluble tissue factor domain and the first of the paired affinity domains are directly adjacent to each other within the first chimeric polypeptide. In some embodiments of these multi-chain chimeric polypeptides, the first chimeric polypeptide is between the soluble tissue factor domain and the first of the pair of affinity domains within the first chimeric polypeptide. Further includes a linker sequence (eg, any of the exemplary linkers described herein).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、一対の親和性ドメインの第2のドメインと第2の標的結合ドメインは、第2のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチド内の一対の親和性ドメインの第2のドメインと第2の標的結合ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these multi-chain chimeric polypeptides, the second domain and the second target binding domain of the pair of affinity domains are directly adjacent to each other within the second chimeric polypeptide. In some embodiments of these multichain chimeric polypeptides, the second chimeric polypeptide is a combination of the second of the pair of affinity domains within the second chimeric polypeptide and the second target binding domain. Further includes a linker sequence (eg, any of the exemplary linkers described herein) in between.
いくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチドのN末端又はC末端に1つ以上の追加の標的結合ドメインを更に含む。 In some embodiments, the second chimeric polypeptide further comprises one or more additional target binding domains at the N-terminus or C-terminus of the second chimeric polypeptide.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、追加の標的結合ドメイン及び一対の親和性ドメインの第2のドメインは、第2のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチド内の一対の親和性ドメインの第2のドメインと追加の標的結合ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these multi-chain chimeric polypeptides, the additional target binding domain and the second domain of the pair of affinity domains are directly adjacent to each other within the second chimeric polypeptide. In some embodiments of these multichain chimeric polypeptides, the second chimeric polypeptide is between the second of the pair of affinity domains and the additional target binding domain within the second chimeric polypeptide. further includes a linker sequence (eg, any of the exemplary linkers described herein).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、追加の標的結合ドメインと第2の標的結合ドメインは、第2のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチド内の第2の標的結合ドメインと追加の標的結合ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these multi-chain chimeric polypeptides, the additional target binding domain and the second target binding domain are directly adjacent to each other within the second chimeric polypeptide. In some embodiments of these multichain chimeric polypeptides, the second chimeric polypeptide has a linker sequence ( For example, any of the exemplary linkers described herein).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性組織因子ドメインは、本明細書に記載の例示的な可溶性組織因子ドメインのうちのいずれかであり得る。これらの多鎖キメラポリペプチドのいくつかの実施形態では、一対の親和性ドメインは、本明細書に記載の例示的な一対の親和性ドメインのうちのいずれかであり得る。 In some embodiments of these multichain chimeric polypeptides, the soluble tissue factor domain can be any of the exemplary soluble tissue factor domains described herein. In some embodiments of these multi-chain chimeric polypeptides, the pair of affinity domains can be any of the exemplary pair of affinity domains described herein.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び追加の抗原結合ドメインのうちの1つ以上は、アゴニスト抗原結合ドメインである。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び追加の抗原結合ドメインは各々、アゴニスト抗原結合ドメインである。これらの多鎖キメラポリペプチドのいくつかの実施形態では、抗原結合ドメインは、scFv又は単一ドメイン抗体を含む。 In some embodiments of these multichain chimeric polypeptides, one or more of the first target binding domain, the second target binding domain, and the additional antigen binding domain is an agonist antigen binding domain. In some embodiments of these multi-chain chimeric polypeptides, the first target binding domain, the second target binding domain, and the additional antigen binding domain are each agonist antigen binding domains. In some embodiments of these multi-chain chimeric polypeptides, the antigen binding domain comprises a scFv or single domain antibody.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方が、可溶性IL-15又は可溶性IL-18である。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは各々独立して、可溶性IL-15又は可溶性IL-18である。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインの両方が、IL-18受容体又はIL-12受容体に特異的に結合する。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは、同じエピトープに特異的に結合する。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは、同じアミノ酸配列を含む。 In some embodiments of these multichain chimeric polypeptides, one or both of the first target binding domain and the second target binding domain is soluble IL-15 or soluble IL-18. In some embodiments of these multichain chimeric polypeptides, the first target binding domain and the second target binding domain are each independently soluble IL-15 or soluble IL-18. In some embodiments of these multichain chimeric polypeptides, both the first target binding domain and the second target binding domain specifically bind to IL-18 receptor or IL-12 receptor. In some embodiments of these multichain chimeric polypeptides, the first target binding domain and the second target binding domain specifically bind the same epitope. In some embodiments of these multichain chimeric polypeptides, the first target binding domain and the second target binding domain comprise the same amino acid sequence.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメインはIL-12受容体に特異的に結合し、第2の標的結合ドメインはIL-18受容体に特異的に結合する。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメインはIL-18受容体に特異的に結合し、第2の標的結合ドメインはIL-12受容体に特異的に結合する。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメインはCD16に特異的に結合し、第2の標的結合ドメインはIL-18受容体に特異的に結合する。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメインはIL-18受容体に特異的に結合し、第2の標的結合ドメインはCD16に特異的に結合する。 In some embodiments of these multichain chimeric polypeptides, the first target binding domain specifically binds the IL-12 receptor and the second target binding domain specifically binds the IL-18 receptor. Join. In some embodiments of these multichain chimeric polypeptides, the first target binding domain specifically binds the IL-18 receptor and the second target binding domain specifically binds the IL-12 receptor. Join. In some embodiments of these multichain chimeric polypeptides, the first target binding domain specifically binds CD16 and the second target binding domain specifically binds the IL-18 receptor. In some embodiments of these multichain chimeric polypeptides, the first target binding domain specifically binds the IL-18 receptor and the second target binding domain specifically binds CD16.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの2つ以上が、同じ抗原に特異的に結合する。いくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの2つ以上が、同じエピトープに特異的に結合する。いくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの2つ以上が、同じアミノ酸配列を含む。 In some embodiments of these multichain chimeric polypeptides, two or more of the first target binding domain, the second target binding domain, and one or more additional target binding domains are directed to the same antigen. Binds specifically. In some embodiments, two or more of the first target binding domain, the second target binding domain, and the one or more additional target binding domains specifically bind the same epitope. In some embodiments, two or more of the first target binding domain, second target binding domain, and one or more additional target binding domains comprise the same amino acid sequence.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメインは、可溶性IL-18(例えば、可溶性ヒトIL-18)を含む。 In some embodiments of these multichain chimeric polypeptides, the first target binding domain comprises soluble IL-18 (eg, soluble human IL-18).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトIL-18は、
YFGKLESKLSVIRNLNDQVLFIDQGNRPLFEDMTDSDCRDNAPRTIFIISMYKDSQPRGMAVTISVKCEKISTLSCENKIISFKEMNPPDNIKDTKSDIIFFQRSVPGHDNKMQFESSSYEGYFLACEKERDLFKLILKKEDELGDRSIMFTVQNED(配列番号109)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multi-chain chimeric polypeptides, the soluble human IL-18 is
YFGKLESKLSVIRNLNDQVLFIDQGNRPLFEDMTDSDCRDNAPRTIFIISMYKDSQPRGMAVTISVKCEKISTLSCENKIISFKEMNPPDNIKDTKSDIIFFQRSVPGHDNKMQFESSSYEGYFLACEKERDLFKLILLKEDELGDRSIMFT VQNED (SEQ ID NO: 109), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, sequences that are at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトIL-18は、
TACTTCGGCAAACTGGAATCCAAGCTGAGCGTGATCCGGAATTTAAACGACCAAGTTCTGTTTATCGATCAAGGTAACCGGCCTCTGTTCGAGGACATGACCGACTCCGATTGCCGGGACAATGCCCCCCGGACCATCTTCATTATCTCCATGTACAAGGACAGCCAGCCCCGGGGCATGGCTGTGACAATTAGCGTGAAGTGTGAGAAAATCAGCACTTTATCTTGTGAGAACAAGATCATCTCCTTTAAGGAAATGAACCCCCCCGATAACATCAAGGACACCAAGTCCGATATCATCTTCTTCCAGCGGTCCGTGCCCGGTCACGATAACAAGATGCAGTTCGAATCCTCCTCCTACGAGGGCTACTTTTTAGCTTGTGAAAAGGAGAGGGATTTATTCAAGCTGATCCTCAAGAAGGAGGACGAGCTGGGCGATCGTTCCATCATGTTCACCGTCCAAAACGAGGAT(配列番号171)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multi-chain chimeric polypeptides, the soluble human IL-18 is
TACTTCGGCAAAACTGGAATCCAAGCTGAGCGTGATCCGGAATTTAAAACGACCAAGTTCTGTTTATCGATCAAGGTAACCGGCCTCTGTTCGAGGACATGACCGACTCCGATTGCCGGGACAATGCCCCCCGGACCATCTTCATTATCTCCATGTACAAGGACAGCCAGCCCCCGGGGCAT GGCTGTGACAATTAGCGTGAAGTGTGAGAAAATCAGCACTTTATCTTGTGAGAACAAGATCATCTCTTTAAGGAAATGAACCCCCCCCGATAACATCAAGGACACCAAGTCCGATATCATCTTCTTCCAGCGGTCCGTGCCCGGTCACGATAACAAGATGCAGTTCGAATCCTCCTCCTAC GAGGGCTACTTTTTAGCTTGTGAAAAGGAGAGGGATTTATTCAAGCTGATCCTCAAGAAGGAGGACGAGCTGGGCGGATCGTTCCATCATGTTCACCGTCCAAACGAGGAT (SEQ ID NO: 171), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2の標的結合ドメインは、可溶性IL-12(例えば、可溶性ヒトIL-12)を含む。これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトIL-15は、可溶性ヒトIL-12β(p40)配列及び可溶性ヒトIL-12α(p35)配列を含む。これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性IL-15(例えば、可溶性ヒトIL-15)は、可溶性IL-12β(p40)配列と可溶性ヒトIL-12α(p35)配列との間にリンカー配列(例えば、本明細書に記載の例示的なリンカー配列のうちのいずれか)を更に含む。これらの多鎖キメラポリペプチドのいくつかの例では、リンカー配列は、GGGGSGGGGSGGGGS(配列番号102)を含む。 In some embodiments of these multichain chimeric polypeptides, the second target binding domain comprises soluble IL-12 (eg, soluble human IL-12). In some embodiments of these multichain chimeric polypeptides, the soluble human IL-15 comprises a soluble human IL-12β (p40) sequence and a soluble human IL-12α (p35) sequence. In some embodiments of these multichain chimeric polypeptides, the soluble IL-15 (eg, soluble human IL-15) is a combination of a soluble IL-12β (p40) sequence and a soluble human IL-12α (p35) sequence. Further includes a linker sequence (eg, any of the exemplary linker sequences described herein) in between. In some examples of these multichain chimeric polypeptides, the linker sequence comprises GGGGSGGGGSGGGGS (SEQ ID NO: 102).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトIL-12β(p40)配列は、
IWELKKDVYVVELDWYPDAPGEMVVLTCDTPEEDGITWTLDQSSEVLGSGKTLTIQVKEFGDAGQYTCHKGGEVLSHSLLLLHKKEDGIWSTDILKDQKEPKNKTFLRCEAKNYSGRFTCWWLTTISTDLTFSVKSSRGSSDPQGVTCGAATLSAERVRGDNKEYEYSVECQEDSACPAAEESLPIEVMVDAVHKLKYENYTSSFFIRDIIKPDPPKNLQLKPLKNSRQVEVSWEYPDTWSTPHSYFSLTFCVQVQGKSKREKKDRVFTDKTSATVICRKNASISVRAQDRYYSSSWSEWASVPCS(配列番号81)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multi-chain chimeric polypeptides, the soluble human IL-12β (p40) sequence is
IWELKKDVYVVELDWYPDAPGEMVVLTCDTPEEDGITWTLDQSSEVLGSGKTLTIQVKEFGDAGQYTCHKGGEVLSHSLLLHKKEDGIWSTDILKDQKEPKNKTFLRCEAKNYSGRFTCWWLTTISTDLTFSVKSSR GSSDPQGVTCGAATLSAERVRGDNKEYEYSVECQEDSACPAAEESLPIEVMVDAVHKLKYENYTSSFFIRDIIKPDPPKNLQLKPLKNSRQVEVSWEYPDTWSTPHSYFSLTFCVQVQGKSKREKKDRVFTDKTSATVICRKNASISVRA QDRYYSSSWSEWASVPCS (SEQ ID NO: 81), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical , at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトIL-12β(p40)は、
ATTTGGGAACTGAAGAAGGACGTCTACGTGGTCGAACTGGACTGGTATCCCGATGCTCCCGGCGAAATGGTGGTGCTCACTTGTGACACCCCCGAAGAAGACGGCATCACTTGGACCCTCGATCAGAGCAGCGAGGTGCTGGGCTCCGGAAAGACCCTCACAATCCAAGTTAAGGAGTTCGGAGACGCTGGCCAATACACATGCCACAAGGGAGGCGAGGTGCTCAGCCATTCCTTATTATTATTACACAAGAAGGAAGACGGAATCTGGTCCACCGACATTTTAAAAGATCAGAAGGAGCCCAAGAATAAGACCTTTTTAAGGTGTGAGGCCAAAAACTACAGCGGTCGTTTCACTTGTTGGTGGCTGACCACCATTTCCACCGATTTAACCTTCTCCGTGAAAAGCAGCCGGGGAAGCTCCGACCCTCAAGGTGTGACATGTGGAGCCGCTACCCTCAGCGCTGAGAGGGTTCGTGGCGATAACAAGGAATACGAGTACAGCGTGGAGTGCCAAGAAGATAGCGCTTGTCCCGCTGCCGAAGAATCTTTACCCATTGAGGTGATGGTGGACGCCGTGCACAAACTCAAGTACGAGAACTACACCTCCTCCTTCTTTATCCGGGACATCATTAAGCCCGATCCTCCTAAGAATTTACAGCTGAAGCCTCTCAAAAATAGCCGGCAAGTTGAGGTCTCTTGGGAATATCCCGACACTTGGAGCACACCCCACAGCTACTTCTCTTTAACCTTTTGTGTGCAAGTTCAAGGTAAAAGCAAGCGGGAGAAGAAAGACCGGGTGTTTACCGACAAAACCAGCGCCACCGTCATCTGTCGGAAGAACGCCTCCATCAGCGTGAGGGCTCAAGATCGTTATTACTCCAGCAGCTGGTCCGAGTGGGCCAGCGTGCCTTGTTCC(配列番号172)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multichain chimeric polypeptides, the soluble human IL-12β (p40) is
ATTTGGGAACTGAAGAAGGACGTCTACGTGGTCGAACTGGACTGGTATCCCGATGCTCCCGGCGAAATGGTGGTGCTCACTTGTGACACCCCCGAAGAAGACGGCATCACTTGGACCCTCGATCAGAGCAGCGAGGTGCTGGGCTCCGGAAGAACCCTCACAATCCAAGTTAA GGAGTTCGGAGACGCTGGCCAATACACATGCCACAAGGGGAGGCGCGAGGTGCTCAGCCATTCCTTATTATTATTACACAAGAAGGAAGACGGAATCTGGTCCACCGACATTTTAAAGATCAGAAGGAGCCCAAGAATAAGACCTTTTTAAGGTGTGAGGCCAAAAAAACTACAGCGGG TCGTTTTCACTTGTTGGTGGCTGACCACCATTTCCACCGATTTAACCTTTCTCCGTGAAAGCAGCCGGGGGAAGCTCCGACCCTCAAGGTGTGACATGTGGAGCCGCTACCCTCAGCGCTGAGAGGGTTCGTGGCGCGATAACAAGGAATACGAGTACAGCGTGGAGTGCCAAGA AGATAGCGCTTGTCCCCGCTGCCGAAGAATCTTTACCCATTGAGGTGATGGTGGACGCCGTGCACAAAACTCAAGTACGAGAACTACACCCTCCTCCTTCTTATCCGGGACATCATTAAGCCCCGATCCTCCTAAGAATTTACAGCTGAAGCCTCTCAAAAAATAGCCGGCAAGTTGAGGTCT CTTGGGAATATCCCGACACTTGGAGCACACCCCACAGCTACTTCTCTTTAACCTTTTGTGTGCAAGTTCAAGGTAAAAGCAAGCGGGAGAAGAAAGACCGGGTGTTTACCGACAAAACCAGCGCCACCGTCATCTGTCGGAAGAACGCTCCATCAGCGTGAGGGCTCAAGATC GTTATTACTCCAGCAGCTGGTCCGAGTGGGCCAGCGTGCCTTGTTCC (SEQ ID NO: 172), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトIL-12α(p35)は、
RNLPVATPDPGMFPCLHHSQNLLRAVSNMLQKARQTLEFYPCTSEEIDHEDITKDKTSTVEACLPLELTKNESCLNSRETSFITNGSCLASRKTSFMMALCLSSIYEDLKMYQVEFKTMNAKLLMDPKRQIFLDQNMLAVIDELMQALNFNSETVPQKSSLEEPDFYKTKIKLCILLHAFRIRAVTIDRVMSYLNAS(配列番号80)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multi-chain chimeric polypeptides, the soluble human IL-12α (p35) is
RNLPVATPDPGMFPCLHHSQNLLRAVSNMLQKARQTLEFYPCTSEEIDHEDITKDKTSTVEACLPLELTKNESCLNSRETSFITNGSCLASRKTSFMMALCLSSSIYEDLKMYQVEFKTMNAKLMDPKRQIFLDQNMLAAVIDELMQALN FNSETVPQKSSLEEPDFYKTKIKLCILLHAFRIRAVTIDRVMSYLNAS (SEQ ID NO: 80), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical , at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトIL-12α(p35)は、
CGTAACCTCCCCGTGGCTACCCCCGATCCCGGAATGTTCCCTTGTTTACACCACAGCCAGAATTTACTGAGGGCCGTGAGCAACATGCTGCAGAAAGCTAGGCAGACTTTAGAATTTTACCCTTGCACCAGCGAGGAGATCGACCATGAAGATATCACCAAGGACAAGACATCCACCGTGGAGGCTTGTTTACCTCTGGAGCTGACAAAGAACGAGTCTTGTCTCAACTCTCGTGAAACCAGCTTCATCACAAATGGCTCTTGTTTAGCTTCCCGGAAGACCTCCTTTATGATGGCTTTATGCCTCAGCTCCATCTACGAGGATTTAAAGATGTACCAAGTGGAGTTCAAGACCATGAACGCCAAGCTGCTCATGGACCCTAAACGGCAGATCTTTTTAGACCAGAACATGCTGGCTGTGATTGATGAGCTGATGCAAGCTTTAAACTTCAACTCCGAGACCGTCCCTCAGAAGTCCTCCCTCGAGGAGCCCGATTTTTACAAGACAAAGATCAAACTGTGCATTTTACTCCACGCCTTTAGGATCCGGGCCGTGACCATTGACCGGGTCATGAGCTATTTAAACGCCAGC(配列番号173)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multi-chain chimeric polypeptides, the soluble human IL-12α (p35) is
CGTAACCTCCCCGTGGCTACCCCCGATCCCCGGAATGTTCCCTTGTTTACACCACAGCCAGAATTTACTGAGGGCCGTGAGCAACATGCTGCAGAAAGCTAGGCAGACTTTAGAATTTTACCCTTGCACCAGCGAGGAGATCGACCATGAAGATATCACCAAGGACAAGACATCCACCGTGGAGG CTTGTTTACCTCTGGAGCTGACAAAGAACGAGTCTTTGTCTCAACTCTCGTGAAACCAGCTTCATCACAAATGGCTCTTGTTTAGCTTCCCGGAAGACCTCCTTTATGATGGCTTTATGCCTCAGCTCCATCTACGAGGATTTAAAAGATGTACCAAGTGGAGTTCAAGACCCATGAACGCCAA GCTGCTCATGGACCCTAAACGGCAGATCTTTTTTAGACCAGAACATGCTGGCTGTGATTGATGAGCTGATGCAAGCTTTAAACTTCAACTCCGAGACCGTCCCTCAGAAGTCCTCCCTCGAGGAGCCCGATTTTTACAAGACAAAGATCAAACTGTGCATTTACTCCACGCCTTTAGGATCCG GGCCGTGACCATTGACCGGGTCATGAGCTATTAAACGCCAGC (SEQ ID NO: 173), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical % identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、追加の標的結合ドメインは、CD16に特異的に結合するscFv(例えば、抗CD16scFv)を含む。 In some embodiments of these multichain chimeric polypeptides, the additional target binding domain comprises an scFv that specifically binds CD16 (eg, anti-CD16 scFv).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、CD16に特異的に結合するscFvは、
SELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGH(配列番号215)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む軽鎖可変ドメインを含む。
In some embodiments of these multichain chimeric polypeptides, the scFv that specifically binds to CD16 is
at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、CD16に特異的に結合するscFvは、
TCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCAACCATGTGGTGTTCGGCGGCGGCACCAAGCTGACCGTGGGCCAT(配列番号216)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である軽鎖可変ドメイン配列によってコードされる。
In some embodiments of these multichain chimeric polypeptides, the scFv that specifically binds to CD16 is
TCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGGCTCCTGTGCTGGTGATCTACGGCAAGAACACAGGCCCTCCGGCATCCCTGACAGG at least 80% identical (e.g., at least 82% identical to , at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical , at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、CD16に特異的に結合するscFvは、
EVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSR(配列番号217)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む重鎖可変ドメインを含む。
In some embodiments of these multichain chimeric polypeptides, the scFv that specifically binds to CD16 is
EVQLVESGGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSR (SEQ ID NO: 217), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, heavy chain variable domains comprising sequences that are at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、CD16に特異的に結合するscFvは、
GAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGG(配列番号218)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である重鎖可変ドメイン配列によってコードされる。
In some embodiments of these multichain chimeric polypeptides, the scFv that specifically binds to CD16 is
GAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCCTCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGGAGGCAGGCTCCTGGAAAGGGCCTGGGAGTGGGTGTCCGGCATCAACTGGAACGG CGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCG TGTCCAGG (SEQ ID NO: 218), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
YFGKLESKLSVIRNLNDQVLFIDQGNRPLFEDMTDSDCRDNAPRTIFIISMYKDSQPRGMAVTISVKCEKISTLSCENKIISFKEMNPPDNIKDTKSDIIFFQRSVPGHDNKMQFESSSYEGYFLACEKERDLFKLILKKEDELGDRSIMFTVQNEDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(配列番号174)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the first chimeric polypeptide is
YFGKLESKLSVIRNLNDQVLFIDQGNRPLFEDMTDSDCRDNAPRTIFIISMYKDSQPRGMAVTISVKCEKISTLSCENKIISFKEMNPPDNIKDTKSDIIFFQRSVPGHDNKMQFESSSYEGYFLACEKERDLFKLILLKEDELGDRSIMFT VQNEDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRR NNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVIDLKKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVE at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% sequences that are identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
TACTTCGGCAAACTGGAATCCAAGCTGAGCGTGATCCGGAATTTAAACGACCAAGTTCTGTTTATCGATCAAGGTAACCGGCCTCTGTTCGAGGACATGACCGACTCCGATTGCCGGGACAATGCCCCCCGGACCATCTTCATTATCTCCATGTACAAGGACAGCCAGCCCCGGGGCATGGCTGTGACAATTAGCGTGAAGTGTGAGAAAATCAGCACTTTATCTTGTGAGAACAAGATCATCTCCTTTAAGGAAATGAACCCCCCCGATAACATCAAGGACACCAAGTCCGATATCATCTTCTTCCAGCGGTCCGTGCCCGGTCACGATAACAAGATGCAGTTCGAATCCTCCTCCTACGAGGGCTACTTTTTAGCTTGTGAAAAGGAGAGGGATTTATTCAAGCTGATCCTCAAGAAGGAGGACGAGCTGGGCGATCGTTCCATCATGTTCACCGTCCAAAACGAGGATAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(配列番号175)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the first chimeric polypeptide is
TACTTCGGCAAAACTGGAATCCAAGCTGAGCGTGATCCGGAATTTAAAACGACCAAGTTCTGTTTATCGATCAAGGTAACCGGCCTCTGTTCGAGGACATGACCGACTCCGATTGCCGGGACAATGCCCCCCGGACCATCTTCATTATCTCCATGTACAAGGACAGCCAGCCCCCGGGGCAT GGCTGTGACAATTAGCGTGAAGTGTGAGAAAATCAGCACTTTATCTTGTGAGAACAAGATCATCTCTTTAAGGAAATGAACCCCCCCGATAACATCAAGGACACCAAGTCCGATATCATCTTCTTCCAGCGGTCCGTGCCCGGTCACGATAACAAGATGCAGTTCGAATCCTCCTCCTAC GAGGGCTACTTTTTAGCTTGTGAAAAGGAGAGGGGATTATTCAAGCTGATCCTCAAGAAGGAGGACGAGCTGGGCGGATCGTTCCATCATGTTCACCGTCCAAACGAGGATAGCGGCCACAACCAACACAGTCGCGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCAT CCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAAACAGACCTACCTCGCCCGGGTGTTTTAGCTACCCCGCCGGCCA ATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGACAACACCTTTCTCA GCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAAT AGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCCACTTTATACAGAATCCGACGTGCACCCCCTCTTGTAAGGTGACC GCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCACGGCCAACGTGACAGAGTCCGGCTGCCAAGGAGTGCGAAGAGCTGGAGGGAGAAGAACATCAAGGAGTT TCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC (SEQ ID NO: 175), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical to % identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
MKWVTFISLLFLFSSAYSYFGKLESKLSVIRNLNDQVLFIDQGNRPLFEDMTDSDCRDNAPRTIFIISMYKDSQPRGMAVTISVKCEKISTLSCENKIISFKEMNPPDNIKDTKSDIIFFQRSVPGHDNKMQFESSSYEGYFLACEKERDLFKLILKKEDELGDRSIMFTVQNEDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(配列番号176)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the first chimeric polypeptide is
MKWVTFISLLFLFSSAYSYFGKLESKLSVIRNLNDQVLFIDQGNRPLFEDMTDSDCRDNAPRTIFIISMYKDSQPRGMAVTISVKCEKISTLSCENKIISFKEMNPPDNIKDTKSDIIFQRSVPGHDNKMQFESSSYEGYFLACEKERD LFKLILKKEDELGDRSIMFTVQNEDSGTTNTVAAYNLTWKSTNFKTILEWEPKKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQV GTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCF at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% sequences that are identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
ATGAAGTGGGTCACATTTATCTCTTTACTGTTCCTCTTCTCCAGCGCCTACAGCTACTTCGGCAAACTGGAATCCAAGCTGAGCGTGATCCGGAATTTAAACGACCAAGTTCTGTTTATCGATCAAGGTAACCGGCCTCTGTTCGAGGACATGACCGACTCCGATTGCCGGGACAATGCCCCCCGGACCATCTTCATTATCTCCATGTACAAGGACAGCCAGCCCCGGGGCATGGCTGTGACAATTAGCGTGAAGTGTGAGAAAATCAGCACTTTATCTTGTGAGAACAAGATCATCTCCTTTAAGGAAATGAACCCCCCCGATAACATCAAGGACACCAAGTCCGATATCATCTTCTTCCAGCGGTCCGTGCCCGGTCACGATAACAAGATGCAGTTCGAATCCTCCTCCTACGAGGGCTACTTTTTAGCTTGTGAAAAGGAGAGGGATTTATTCAAGCTGATCCTCAAGAAGGAGGACGAGCTGGGCGATCGTTCCATCATGTTCACCGTCCAAAACGAGGATAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(配列番号177)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the first chimeric polypeptide is
ATGAAGTGGGTCACATTTATCCTCTTTACTGTTCCTCTTCTCCAGCGCCTACAGCTACTTCGGCAAAACTGGAATCCAAGCTGAGCGTGATCCGGAATTTAAAACGACCAAGTTCTGTTTATCGATCAAGGTAACCGGCCTCTGTTCGAGGACATGACCGACTCCGATTGCCCGGGA CAATGCCCCCCGGACCATCTTCATTATCTCCATGTACAAGGACAGCCAGCCCCGGGGCATGGCTGTGACAATTAGCGTGAAGTGTGAGAAAATCAGCACTTTATCTTTGTGAGAACAAGATCATCTCCTTTAAGGAAATGAACCCCCCCGATAACATCAAGGACACCAAGTCCGATATCATCTTCTTCCA GCGGTCCGTGCCCGGGTCACGATAACAAGATGCAGTTCGAATCCTCCTCCTACGAGGGCTACTTTTTAGCTTGTGAAAAGGAGAGGGATTTATTCAAGCTGATCCTCAAGAAGGAGGACGAGCTGGGCGCGATCGTTTCCATCATGTTCACCGTCCAAAACGAGGATAGCGG CACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAACCATCCTCGAATGGGAACCCAAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCCGACACCGAGTGCGATCTCACCGATGAGATCGT GAAAGATGTGAAACAGACCTACCTCGCCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCCACCATCCAAAGCTTTTGAGCAAGTTTGGCACAAAGGTGA ATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAACCAACACAAACGAGTTTTAATCGACGTGGATAAAG GCGAAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGGCGAGTTCCGGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAAGAAGATCGAAGATTTAATTCAGTCCAT GCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGA CAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC (SEQ ID NO: 177), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, to % identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
IWELKKDVYVVELDWYPDAPGEMVVLTCDTPEEDGITWTLDQSSEVLGSGKTLTIQVKEFGDAGQYTCHKGGEVLSHSLLLLHKKEDGIWSTDILKDQKEPKNKTFLRCEAKNYSGRFTCWWLTTISTDLTFSVKSSRGSSDPQGVTCGAATLSAERVRGDNKEYEYSVECQEDSACPAAEESLPIEVMVDAVHKLKYENYTSSFFIRDIIKPDPPKNLQLKPLKNSRQVEVSWEYPDTWSTPHSYFSLTFCVQVQGKSKREKKDRVFTDKTSATVICRKNASISVRAQDRYYSSSWSEWASVPCSGGGGSGGGGSGGGGSRNLPVATPDPGMFPCLHHSQNLLRAVSNMLQKARQTLEFYPCTSEEIDHEDITKDKTSTVEACLPLELTKNESCLNSRETSFITNGSCLASRKTSFMMALCLSSIYEDLKMYQVEFKTMNAKLLMDPKRQIFLDQNMLAVIDELMQALNFNSETVPQKSSLEEPDFYKTKIKLCILLHAFRIRAVTIDRVMSYLNASITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRSELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGHGGGGSGGGGSGGGGSEVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSR(配列番号223)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the second chimeric polypeptide is
IWELKKDVYVVELDWYPDAPGEMVVLTCDTPEEDGITWTLDQSSEVLGSGKTLTIQVKEFGDAGQYTCHKGGEVLSHSLLLLLHKKEDGIWSTDILKDQKEPKNKTFLRCEAKNYSGRFTCWWLTTISTDLTFSVKSSR GSSDPQGVTCGAATLSAERVRGDNKEYEYSVECQEDSACPAAEESLPIEVMVDAVHKLKYENYTSSFFIRDIIKPDPPKNLQLKPLKNSRQVEVSWEYPDTWSTPHSYFSLTFCVQVQGKSKREKKDRVFTDKTSATVICRKNASISVRA QDRYYSSSWSEWASVPCSGGGGSGGGGGSGGGGSRNLPVATPDPGMFPCLHHSQNLLRAVSNMLQKARQTLEFYPCTSEEIDHEDITKDKTSTVEACLPLELTKNESCLNSRETSFITNGSCLASRKTSFMMALCLSSSIYEDLKMYQV EFKTMNAKLLMDPKRQIFLDQNMLAVIDELMQALNFNSETVPQKSSLEEPDFYKTKIKLCILLHAFRIRAVTIDRVMSYLNASITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRSELTQDPA VSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGGNHVVFGGGTKLTVGHGGGGGSGGGGGSGGGGSEVQLVESGGGVVRPGGSLRLSCAASG FTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSR (SEQ ID NO: 223), at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
ATTTGGGAACTGAAGAAGGACGTCTACGTGGTCGAACTGGACTGGTATCCCGATGCTCCCGGCGAAATGGTGGTGCTCACTTGTGACACCCCCGAAGAAGACGGCATCACTTGGACCCTCGATCAGAGCAGCGAGGTGCTGGGCTCCGGAAAGACCCTCACAATCCAAGTTAAGGAGTTCGGAGACGCTGGCCAATACACATGCCACAAGGGAGGCGAGGTGCTCAGCCATTCCTTATTATTATTACACAAGAAGGAAGACGGAATCTGGTCCACCGACATTTTAAAAGATCAGAAGGAGCCCAAGAATAAGACCTTTTTAAGGTGTGAGGCCAAAAACTACAGCGGTCGTTTCACTTGTTGGTGGCTGACCACCATTTCCACCGATTTAACCTTCTCCGTGAAAAGCAGCCGGGGAAGCTCCGACCCTCAAGGTGTGACATGTGGAGCCGCTACCCTCAGCGCTGAGAGGGTTCGTGGCGATAACAAGGAATACGAGTACAGCGTGGAGTGCCAAGAAGATAGCGCTTGTCCCGCTGCCGAAGAATCTTTACCCATTGAGGTGATGGTGGACGCCGTGCACAAACTCAAGTACGAGAACTACACCTCCTCCTTCTTTATCCGGGACATCATTAAGCCCGATCCTCCTAAGAATTTACAGCTGAAGCCTCTCAAAAATAGCCGGCAAGTTGAGGTCTCTTGGGAATATCCCGACACTTGGAGCACACCCCACAGCTACTTCTCTTTAACCTTTTGTGTGCAAGTTCAAGGTAAAAGCAAGCGGGAGAAGAAAGACCGGGTGTTTACCGACAAAACCAGCGCCACCGTCATCTGTCGGAAGAACGCCTCCATCAGCGTGAGGGCTCAAGATCGTTATTACTCCAGCAGCTGGTCCGAGTGGGCCAGCGTGCCTTGTTCCGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCTCGTAACCTCCCCGTGGCTACCCCCGATCCCGGAATGTTCCCTTGTTTACACCACAGCCAGAATTTACTGAGGGCCGTGAGCAACATGCTGCAGAAAGCTAGGCAGACTTTAGAATTTTACCCTTGCACCAGCGAGGAGATCGACCATGAAGATATCACCAAGGACAAGACATCCACCGTGGAGGCTTGTTTACCTCTGGAGCTGACAAAGAACGAGTCTTGTCTCAACTCTCGTGAAACCAGCTTCATCACAAATGGCTCTTGTTTAGCTTCCCGGAAGACCTCCTTTATGATGGCTTTATGCCTCAGCTCCATCTACGAGGATTTAAAGATGTACCAAGTGGAGTTCAAGACCATGAACGCCAAGCTGCTCATGGACCCTAAACGGCAGATCTTTTTAGACCAGAACATGCTGGCTGTGATTGATGAGCTGATGCAAGCTTTAAACTTCAACTCCGAGACCGTCCCTCAGAAGTCCTCCCTCGAGGAGCCCGATTTTTACAAGACAAAGATCAAACTGTGCATTTTACTCCACGCCTTTAGGATCCGGGCCGTGACCATTGACCGGGTCATGAGCTATTTAAACGCCAGCATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGTCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCAACCATGTGGTGTTCGGCGGCGGCACCAAGCTGACCGTGGGCCATGGCGGCGGCGGCTCCGGAGGCGGCGGCAGCGGCGGAGGAGGATCCGAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGG(配列番号224)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the second chimeric polypeptide is
ATTTGGGAACTGAAGAAGGACGTCTACGTGGTCGAACTGGACTGGTATCCCGATGCTCCCGGCGAAATGGTGGTGCTCACTTGTGACACCCCCGAAGAAGACGGCATCACTTGGACCCTCGATCAGAGCAGCGAGGTGCTGGGCTCCGGAAGAACCCTCACAATCCAAGTTAA GGAGTTCGGAGACGCTGGCCAATACACATGCCACAAGGGGAGGCGCGAGGTGCTCAGCCATTCCTTATTATTATTACACAAGAAGGAAGACGGAATCTGGTCCACCGACATTTTAAAGATCAGAAGGAGCCCAAGAATAAGACCTTTTTAAGGTGTGAGGCCAAAAAAACTACAGCGGG TCGTTTTCACTTGTTGGTGGCTGACCACCATTTCCACCGATTTAACCTTTCTCCGTGAAAGCAGCCGGGGGAAGCTCCGACCCTCAAGGTGTGACATGTGGAGCCGCTACCCTCAGCGCTGAGAGGGTTCGTGGCGCGATACAAGGAATACGAGTACAGCGTGGAGTGCCAAGA AGATAGCGCTTGTCCCCGCTGCCGAAGAATCTTTACCCATTGAGGTGATGGTGGACGCCGTGCACAAAACTCAAGTACGAGAACTACACCCTCCTCCTTCTTATCCGGGACATCATTAAGCCCCGATCCTCCTAAGAATTTACAGCTGAAGCCTCTCAAAAAATAGCCGGCAAGTTGAGGTCT CTTGGGAATATCCCGACACTTGGAGCACACCCCACAGCTACTTCTCTTTAACCTTTTGTGTGCAAGTTCAAGGTAAAAGCAAGCGGGAGAAGAAAGACCGGGTGTTTACCGACAAAAACCAGCGCCACCGTCATCTGTCGGAAGAACGCTCCATCAGCGTGAGGGCTCAAGATC GTTATTACTCCAGCAGCTGGTCCGAGTGGGCCAGCGTGCCTTGTTCCGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCTCGTAACCTCCCCGTGGCTACCCCCCGATCCCCGGAATGTTCCCTTGTTTACACCACAGCCAGAATTTACTGAGGGCCGTGGA GCAACATGCTGCAGAAAGCTAGGCAGACTTTAGAATTTTACCCTTGCACCAGCGAGGAGATCGACCATGAAGATATCACCAAGGACAAGACATCCACCGTGGAGGCTTGTTTACCTCTGGAGCTGACAAAGAACGAGTCTTGTCCTCAACTCTCGTGAAAACCAGCTTCATCACAAATGGCTCTTGT TTAGCTTCCCGGAAGACCTCCTTTATGATGGCTTTATGCCTCAGCTCCATCTACGAGGATTTAAAAGATGTACCAAGTGGAGTTCAAGACCATGAACGCCAAGCTGCTCATGGACCCTAAACGGCAGATCTTTTTAGACCAGAACATGCTGGCTGTGATTGATGAGCTGATGCAAGCTTTAA ACTTCAACTCCGAGACCGTCCCTCAGAAGTCCTCCCTCGAGGAGCCCGATTTTTACAAGACAAAGATCAAAACTGTGCATTTTTACTCACGCCTTTAGGATCCGGGCCGTGACCATTGACCGGGTCATGAGCTATTAAACGCCAGCATTACATGCCCCCTCCCCATGAGCGTGGAGCACGCC GACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACACACCCCTCTTAAAGTGCATCCGGTCCGAGCTGACCCAGGACCCTG CTGTGTCCGTGGCTCTGGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCCGGCA ACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCAACCATGTGGGTGTTCGGCGCGCGGCACCAAGCTGACCGTGGGCCATGGCGCGGCGGCGGCTCCGGAGGCGGCGGGCAGCGGCGGAGGAGGATCC GAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCCTCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGGCAGGCTCCTGGAAAGGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCG GATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTG TCCAGG (SEQ ID NO: 224), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
MKWVTFISLLFLFSSAYSIWELKKDVYVVELDWYPDAPGEMVVLTCDTPEEDGITWTLDQSSEVLGSGKTLTIQVKEFGDAGQYTCHKGGEVLSHSLLLLHKKEDGIWSTDILKDQKEPKNKTFLRCEAKNYSGRFTCWWLTTISTDLTFSVKSSRGSSDPQGVTCGAATLSAERVRGDNKEYEYSVECQEDSACPAAEESLPIEVMVDAVHKLKYENYTSSFFIRDIIKPDPPKNLQLKPLKNSRQVEVSWEYPDTWSTPHSYFSLTFCVQVQGKSKREKKDRVFTDKTSATVICRKNASISVRAQDRYYSSSWSEWASVPCSGGGGSGGGGSGGGGSRNLPVATPDPGMFPCLHHSQNLLRAVSNMLQKARQTLEFYPCTSEEIDHEDITKDKTSTVEACLPLELTKNESCLNSRETSFITNGSCLASRKTSFMMALCLSSIYEDLKMYQVEFKTMNAKLLMDPKRQIFLDQNMLAVIDELMQALNFNSETVPQKSSLEEPDFYKTKIKLCILLHAFRIRAVTIDRVMSYLNASITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRSELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGHGGGGSGGGGSGGGGSEVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSR(配列番号225)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the second chimeric polypeptide is
MKWVTFISLLFLFSSAYSIWELKKDVYVVELDWYPDAPGEMVVLTCDTPEEDGITWTLDQSSEVLGSGKTLTIQVKEFGDAGQYTCHKGGEVLSHSLLLLHKKEDGIWSTDILKDQKEPKNKTFLRCEAKNYSGRFTCWW LTTISTDLTFSVKSSRGSSDPQGVTCGAATTLSAERVRGDNKEYEYSVECQEDSACPAAEESLPIEVMVDAVHKLKYENYTSSFFIRDIIKPDPPKNLQLKPLKNSRQVEVSWEYPDTWSTPHSYFSLTFCVQVQGKSKREKKDRVF TDKTSATVICRKNASISVRAQDRYYSSSWSEWASVPCSGGGGGSGGGGSGGGGSRNLPPVATPDPGMFPCLHHSQNLLRAVSNMLQKARQTLEFYPCTSEEIDHEDITKDKTSTVEACLPLELTKNESCLNSRETSFITNGSCLASRKTSF MMALCLSSIYEDLKMYQVEFKTMNAKLLMDPKRQIFLDQNMLAVIDELMQALNFNSETVPQKSSLEEPDFYKTKIKLCILLHAFRIRAVTIDRVMSYLNASITCPPPMSVEHADIWVKSYSLYSRRYICNSGFKRKAGTSSLTECVLNKATNV AHWTTPSLKCIRSELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGHGGGGGSGGGGGSGGGGSEVQLVESG GGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSR (SEQ ID NO: 225), and at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86 % identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
ATGAAATGGGTGACCTTTATTTCTTTACTGTTCCTCTTTAGCAGCGCCTACTCCATTTGGGAACTGAAGAAGGACGTCTACGTGGTCGAACTGGACTGGTATCCCGATGCTCCCGGCGAAATGGTGGTGCTCACTTGTGACACCCCCGAAGAAGACGGCATCACTTGGACCCTCGATCAGAGCAGCGAGGTGCTGGGCTCCGGAAAGACCCTCACAATCCAAGTTAAGGAGTTCGGAGACGCTGGCCAATACACATGCCACAAGGGAGGCGAGGTGCTCAGCCATTCCTTATTATTATTACACAAGAAGGAAGACGGAATCTGGTCCACCGACATTTTAAAAGATCAGAAGGAGCCCAAGAATAAGACCTTTTTAAGGTGTGAGGCCAAAAACTACAGCGGTCGTTTCACTTGTTGGTGGCTGACCACCATTTCCACCGATTTAACCTTCTCCGTGAAAAGCAGCCGGGGAAGCTCCGACCCTCAAGGTGTGACATGTGGAGCCGCTACCCTCAGCGCTGAGAGGGTTCGTGGCGATAACAAGGAATACGAGTACAGCGTGGAGTGCCAAGAAGATAGCGCTTGTCCCGCTGCCGAAGAATCTTTACCCATTGAGGTGATGGTGGACGCCGTGCACAAACTCAAGTACGAGAACTACACCTCCTCCTTCTTTATCCGGGACATCATTAAGCCCGATCCTCCTAAGAATTTACAGCTGAAGCCTCTCAAAAATAGCCGGCAAGTTGAGGTCTCTTGGGAATATCCCGACACTTGGAGCACACCCCACAGCTACTTCTCTTTAACCTTTTGTGTGCAAGTTCAAGGTAAAAGCAAGCGGGAGAAGAAAGACCGGGTGTTTACCGACAAAACCAGCGCCACCGTCATCTGTCGGAAGAACGCCTCCATCAGCGTGAGGGCTCAAGATCGTTATTACTCCAGCAGCTGGTCCGAGTGGGCCAGCGTGCCTTGTTCCGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCTCGTAACCTCCCCGTGGCTACCCCCGATCCCGGAATGTTCCCTTGTTTACACCACAGCCAGAATTTACTGAGGGCCGTGAGCAACATGCTGCAGAAAGCTAGGCAGACTTTAGAATTTTACCCTTGCACCAGCGAGGAGATCGACCATGAAGATATCACCAAGGACAAGACATCCACCGTGGAGGCTTGTTTACCTCTGGAGCTGACAAAGAACGAGTCTTGTCTCAACTCTCGTGAAACCAGCTTCATCACAAATGGCTCTTGTTTAGCTTCCCGGAAGACCTCCTTTATGATGGCTTTATGCCTCAGCTCCATCTACGAGGATTTAAAGATGTACCAAGTGGAGTTCAAGACCATGAACGCCAAGCTGCTCATGGACCCTAAACGGCAGATCTTTTTAGACCAGAACATGCTGGCTGTGATTGATGAGCTGATGCAAGCTTTAAACTTCAACTCCGAGACCGTCCCTCAGAAGTCCTCCCTCGAGGAGCCCGATTTTTACAAGACAAAGATCAAACTGTGCATTTTACTCCACGCCTTTAGGATCCGGGCCGTGACCATTGACCGGGTCATGAGCTATTTAAACGCCAGCATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGTCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCAACCATGTGGTGTTCGGCGGCGGCACCAAGCTGACCGTGGGCCATGGCGGCGGCGGCTCCGGAGGCGGCGGCAGCGGCGGAGGAGGATCCGAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGG(配列番号226)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the second chimeric polypeptide is
ATGAAATGGGTGACCTTTATTTCTTTACTGTTCCTCTTTAGCAGCGCCTACTCCATTTGGGGAACTGAAGAAGGACGTCTACGTGGTCGAACTGGACTGGTATCCCGATGCTCCCGGCGAAAATGGTGGTGCTCACTTGTGACACCCCCCGAAGAAGACGGCATCACTTGGACCCT CGATCAGAGCAGCGAGGTGCTGGGCTCCGGAAAGACCCTCACAATCCAAGTTAAGGAGTTCGGAGACGCTGGCCAATACACATGCCACAAGGGAGGCGAGGTGCTCAGCCATTCCTTTATTATTATTACACAGAAGGAAGACGGGAATCTGGGTCCACCGACATTTTTAAAGATCAGAAG GAGCCCAAGAATAAGACCTTTTTTAAGGTGTGAGGCCAAAAACTACAGCGGGTCGTTTTCACTTGTTGGTGGCTGACCACCATTTCCACCGATTTAACCTTTCTCCGTGAAAAGCAGCCGGGGAAGCTCCGACCCTCAAGGTGTGACATGTGGAGCCGCTACCCCTCAGCGCTGAGA GGGTTCGTGGCGCGATAACAAGGAATACGAGTACAGCGTGGAGTGCCAAGAAGATAGCGCTTGTCCCGCTGCCGAAGAATCTTTACCCATTGAGGTGATGGTGGACGCCGTGCACAAACTCAAGTACGAGAACTACACCTCCTCCTTCTTTATCCGGGACATCATTAAGCCCCGATC CTCCTAAGAATTTACAGCTGAAGCCTCTCAAAATAGCCGGCAAGTTGAGGTCTCTTGGGGAATATCCCGACACTTGGAGCACACCCCCACAGCCTACTTCTCTTTAACCTTTTGTGTGCAAGTTCAAGGTAAAAGCAAGCGGGAGAAGAAAGACCGGGTGTTTACCGACAAAACCAGC GCCACCGTCATCTGTCGGAAGAACGCCTCCATCAGCGTGAGGGCTCAAGATCGTTATTACTCCAGCAGCTGGTCCGAGTGGGCCAGCGTGCCTTGTTCCGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGCGGCGGAGGATCTCGTAACCTCCCCGTGGCTACCCCCC GATCCCGGAATGTTCCCTTGTTTACACCACAGCCAGAATTTACTGAGGGCCGTGAGCAACATGCTGCAGAAAGCTAGGCAGACTTTAGAATTTTACCCTTGCACCAGCGAGGAGATCGACCATGAAGATATCACCAAGGACAAGACATCCACCGTGGAGGCTTGTTTACCTCTGGAGCTGACAAA GAACGAGTCTTGTCTCAACTCTCGTGAAAACCAGCTTCATCACAAATGGCTCTTGTTTAGCTTCCCGGAAGACCTCCTTTATGATGGCTTTATGCCTCAGCTCCATCTACGAGGATTTAAAGATGTACCAAGTGGAGTTCAAGACCATGAACGCCAAGCTGCTCATGGACCCTAAACGGCAG ATCTTTTAGACCAGAACATGCTGGCTGTGATTGATGAGCTGATGCAAGCTTTAAAACTTCAACTCCGAGACCGTCCCTCAGAAGTCCTCCCTCGAGGAGCCCCGATTTTTACAAGACAAAGATCAAACTGTGCATTTTACTCCACGCCTTTTAGGATCCGGGCCGTGACCATTGACCGGGTCAT GAGCTATTTAAAACGCCAGCATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCCTCACCGAGTGCGTGCTGATAAGGCTACCAACGTG GCTCACTGGACAACACCCTTTAAAGTGCATCCGGTCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCCAGGCTCCTGTGCTGGTGATCTACGG CAAGAACAACAGGCCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGGACGAGGCTGACTACTGCCAACTCCAGGGACTCCTCCGGCAACCATGTGGTGGTTCGGCGGCGGCGGCACCAAGCTGACCGTGGGCCAT GGCGGCGGCGGCTCCGGAGGCGCGCGGCAGCGGCGGAGGAGGATCCGAGGTGCAGCTGGTGGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCCTGGGTGAGGCAGG CTCCTGGAAAAGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGG GGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGG (SEQ ID NO: 226), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
例示的な多鎖キメラポリペプチド-タイプF
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは各々独立して、IL-7(例えば、可溶性ヒトIL-7)受容体、CD16(例えば、抗CD16scFv)、又はIL-21(例えば、可溶性ヒトIL-21)受容体に特異的に結合する。本明細書に記載のこれらの多鎖キメラポリペプチドのいくつかの実施形態では、第1のキメラポリペプチドは、追加の標的結合ドメインを更に含む。本明細書に記載のこれらの多鎖キメラポリペプチドのいくつかの実施形態では、第2のキメラポリペプチドは、追加の標的結合ドメインを更に含む。本明細書に記載のこれらの多鎖キメラポリペプチドのいくつかの実施形態では、追加の標的結合ドメインは、CD16又はIL-21受容体に特異的に結合する。
Exemplary Multichain Chimeric Polypeptides—Type F
In some embodiments of any of the multichain chimeric polypeptides described herein, the first target binding domain and the second target binding domain are each independently IL-7 (e.g., soluble human IL-7) receptor, CD16 (eg, anti-CD16 scFv), or IL-21 (eg, soluble human IL-21) receptor. In some embodiments of these multi-chain chimeric polypeptides described herein, the first chimeric polypeptide further comprises an additional target binding domain. In some embodiments of these multi-chain chimeric polypeptides described herein, the second chimeric polypeptide further comprises an additional target binding domain. In some embodiments of these multichain chimeric polypeptides described herein, the additional target binding domain specifically binds to the CD16 or IL-21 receptor.
これらの多鎖キメラポリペプチドのいくつかの例では、第1の標的結合ドメインと可溶性組織因子ドメインは、第1のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの例では、第1のキメラポリペプチドは、第1のキメラポリペプチド内の第1の標的結合ドメインと可溶性組織因子ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some examples of these multichain chimeric polypeptides, the first target binding domain and the soluble tissue factor domain are directly adjacent to each other within the first chimeric polypeptide. In some examples of these multichain chimeric polypeptides, the first chimeric polypeptide has a linker sequence (e.g., any of the exemplary linkers described herein).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインは、第1のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1のキメラポリペプチドは、第1のキメラポリペプチド内の可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these multi-chain chimeric polypeptides, the soluble tissue factor domain and the first of the paired affinity domains are directly adjacent to each other within the first chimeric polypeptide. In some embodiments of these multi-chain chimeric polypeptides, the first chimeric polypeptide is between the soluble tissue factor domain and the first of the pair of affinity domains within the first chimeric polypeptide. Further includes a linker sequence (eg, any of the exemplary linkers described herein).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、一対の親和性ドメインの第2のドメインと第2の標的結合ドメインは、第2のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチド内の一対の親和性ドメインの第2のドメインと第2の標的結合ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these multi-chain chimeric polypeptides, the second domain and the second target binding domain of the pair of affinity domains are directly adjacent to each other within the second chimeric polypeptide. In some embodiments of these multichain chimeric polypeptides, the second chimeric polypeptide is a combination of the second of the pair of affinity domains within the second chimeric polypeptide and the second target binding domain. Further includes a linker sequence (eg, any of the exemplary linkers described herein) in between.
いくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチドのN末端又はC末端に1つ以上の追加の標的結合ドメインを更に含む。 In some embodiments, the second chimeric polypeptide further comprises one or more additional target binding domains at the N-terminus or C-terminus of the second chimeric polypeptide.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、追加の標的結合ドメイン及び一対の親和性ドメインの第2のドメインは、第2のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチド内の一対の親和性ドメインの第2のドメインと追加の標的結合ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these multi-chain chimeric polypeptides, the additional target binding domain and the second domain of the pair of affinity domains are directly adjacent to each other within the second chimeric polypeptide. In some embodiments of these multichain chimeric polypeptides, the second chimeric polypeptide is between the second of the pair of affinity domains and the additional target binding domain within the second chimeric polypeptide. further includes a linker sequence (eg, any of the exemplary linkers described herein).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、追加の標的結合ドメインと第2の標的結合ドメインは、第2のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチド内の第2の標的結合ドメインと追加の標的結合ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these multi-chain chimeric polypeptides, the additional target binding domain and the second target binding domain are directly adjacent to each other within the second chimeric polypeptide. In some embodiments of these multichain chimeric polypeptides, the second chimeric polypeptide has a linker sequence ( For example, any of the exemplary linkers described herein).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性組織因子ドメインは、本明細書に記載の例示的な可溶性組織因子ドメインのうちのいずれかであり得る。これらの多鎖キメラポリペプチドのいくつかの実施形態では、一対の親和性ドメインは、本明細書に記載の例示的な一対の親和性ドメインのうちのいずれかであり得る。 In some embodiments of these multichain chimeric polypeptides, the soluble tissue factor domain can be any of the exemplary soluble tissue factor domains described herein. In some embodiments of these multi-chain chimeric polypeptides, the pair of affinity domains can be any of the exemplary pair of affinity domains described herein.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び追加の抗原結合ドメインのうちの1つ以上は、アゴニスト抗原結合ドメインである。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び追加の抗原結合ドメインは各々、アゴニスト抗原結合ドメインである。これらの多鎖キメラポリペプチドのいくつかの実施形態では、抗原結合ドメインは、scFv又は単一ドメイン抗体を含む。 In some embodiments of these multichain chimeric polypeptides, one or more of the first target binding domain, the second target binding domain, and the additional antigen binding domain is an agonist antigen binding domain. In some embodiments of these multi-chain chimeric polypeptides, the first target binding domain, the second target binding domain, and the additional antigen binding domain are each agonist antigen binding domains. In some embodiments of these multi-chain chimeric polypeptides, the antigen binding domain comprises a scFv or single domain antibody.
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメインは受容体IL-7に特異的に結合し、第2の標的結合ドメインはCD16又はIL-21受容体に特異的に結合する。本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメインは、可溶性IL-7タンパク質を含む。本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、可溶性IL-7タンパク質は、可溶性ヒトIL-7である。本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第2の抗原結合ドメインは、CD16に特異的に結合する標的結合ドメインを含む。本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第2の標的結合ドメインは、CD16に特異的に結合するscFvを含む。本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第2の標的結合ドメインは、IL-21受容体に特異的に結合する。本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第2の標的結合ドメインは、可溶性IL-21を含む。本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、可溶性IL-21は、可溶性ヒトIL-21である。本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第2のキメラポリペプチドは、IL-21受容体に特異的に結合する追加の標的結合ドメインを更に含む。本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、追加の標的結合ドメインは、可溶性IL-21を含む。本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、可溶性IL-21は、可溶性ヒトIL-21である。本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第2のキメラポリペプチドは、CD16に特異的に結合する追加の標的結合ドメインを更に含む。 In some embodiments of any of the multichain chimeric polypeptides described herein, the first target binding domain specifically binds the receptor IL-7 and the second target binding domain is Binds specifically to CD16 or IL-21 receptors. In some embodiments of any of the multichain chimeric polypeptides described herein, the first target binding domain comprises a soluble IL-7 protein. In some embodiments of any of the multichain chimeric polypeptides described herein, the soluble IL-7 protein is soluble human IL-7. In some embodiments of any of the multichain chimeric polypeptides described herein, the second antigen binding domain comprises a target binding domain that specifically binds CD16. In some embodiments of any of the multichain chimeric polypeptides described herein, the second target binding domain comprises an scFv that specifically binds CD16. In some embodiments of any of the multichain chimeric polypeptides described herein, the second target binding domain specifically binds the IL-21 receptor. In some embodiments of any of the multichain chimeric polypeptides described herein, the second target binding domain comprises soluble IL-21. In some embodiments of any of the multichain chimeric polypeptides described herein, the soluble IL-21 is soluble human IL-21. In some embodiments of any of the multichain chimeric polypeptides described herein, the second chimeric polypeptide further comprises an additional target binding domain that specifically binds to the IL-21 receptor. include. In some embodiments of any of the multichain chimeric polypeptides described herein, the additional target binding domain comprises soluble IL-21. In some embodiments of any of the multichain chimeric polypeptides described herein, the soluble IL-21 is soluble human IL-21. In some embodiments of any of the multichain chimeric polypeptides described herein, the second chimeric polypeptide further comprises an additional target binding domain that specifically binds CD16.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの2つ以上が、同じ抗原に特異的に結合する。いくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの2つ以上が、同じエピトープに特異的に結合する。いくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの2つ以上が、同じアミノ酸配列を含む。 In some embodiments of these multichain chimeric polypeptides, two or more of the first target binding domain, the second target binding domain, and one or more additional target binding domains are directed to the same antigen. Binds specifically. In some embodiments, two or more of the first target binding domain, the second target binding domain, and the one or more additional target binding domains specifically bind the same epitope. In some embodiments, two or more of the first target binding domain, second target binding domain, and one or more additional target binding domains comprise the same amino acid sequence.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメインは、可溶性IL-7(例えば、可溶性ヒトIL-7)を含む。 In some embodiments of these multichain chimeric polypeptides, the first target binding domain comprises soluble IL-7 (eg, soluble human IL-7).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトIL-7は、
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEH(配列番号79)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multi-chain chimeric polypeptides, the soluble human IL-7 is
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWN KILMGTKEH (SEQ ID NO: 79), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, sequences that are at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトIL-7は、
GATTGTGATATTGAAGGTAAAGATGGCAAACAATATGAGAGTGTTCTAATGGTCAGCATCGATCAATTATTGGACAGCATGAAAGAAATTGGTAGCAATTGCCTGAATAATGAATTTAACTTTTTTAAAAGACATATCTGTGATGCTAATAAGGAAGGTATGTTTTTATTCCGTGCTGCTCGCAAGTTGAGGCAATTTCTTAAAATGAATAGCACTGGTGATTTTGATCTCCACTTATTAAAAGTTTCAGAAGGCACAACAATACTGTTGAACTGCACTGGCCAGGTTAAAGGAAGAAAACCAGCTGCCCTGGGTGAAGCCCAACCAACAAAGAGTTTGGAAGAAAATAAATCTTTAAAGGAACAGAAAAAACTGAATGACTTGTGTTTCCTAAAGAGACTATTACAAGAGATAAAAACTTGTTGGAATAAAATTTTGATGGGCACTAAAGAACAC(配列番号198)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multi-chain chimeric polypeptides, the soluble human IL-7 is
GATTGTGATATTGAAGGTAAAGATGGCAAACAATATGAGAGTGTTCTAATGGTCAGCATCGATCAATTATTGGACAGCATGAAAAGAAATTGGTAGCAATTGCCTGAATAATGAATTTAACTTTTTTAAAAGACATATCTGTGATGCTAATAAGGAAGGTATGTTTTTAT TCCGTGCTGCTCGCAAGTTGAGGCAATTTCTTAAATGAATAGCACTGGTGATTTTGATCTCCACTTATTAAAGTTTCAGAAGGCACAACAATACTGTTGAACTGCACTGGCCAGGTTAAAGGAAGAAAACCAGCTGCCCTGGGTGAAGCCCAACCAACAAAGAGTTTGGA AGAAAAAAATCTTAAAGGAACAGAAAAAAACTGAATGACTTGTGTTTCCTAAAGAGACTATTACAAGAGATAAAAACTTTGTTGGAATAAAATTTTGATGGGCACTAAAGAACAC (SEQ ID NO: 198), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトIL-7は、
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCAT(配列番号227)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multi-chain chimeric polypeptides, the soluble human IL-7 is
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCCACATCTGCGACGCCAACAAGGAGGGCATGTTCCT GTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGA ACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCAT (SEQ ID NO: 227), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトIL-21配列は、
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS(配列番号83)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multi-chain chimeric polypeptides, the soluble human IL-21 sequence is
at least 80% identical to QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS (SEQ ID NO: 83), (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, sequences that are at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトIL-21は、
CAAGGTCAAGATCGCCACATGATTAGAATGCGTCAACTTATAGATATTGTTGATCAGCTGAAAAATTATGTGAATGACTTGGTCCCTGAATTTCTGCCAGCTCCAGAAGATGTAGAGACAAACTGTGAGTGGTCAGCTTTTTCCTGTTTTCAGAAGGCCCAACTAAAGTCAGCAAATACAGGAAACAATGAAAGGATAATCAATGTATCAATTAAAAAGCTGAAGAGGAAACCACCTTCCACAAATGCAGGGAGAAGACAGAAACACAGACTAACATGCCCTTCATGTGATTCTTATGAGAAAAAACCACCCAAAGAATTCCTAGAAAGATTCAAATCACTTCTCCAAAAGATGATTCATCAGCATCTGTCCTCTAGAACACACGGAAGTGAAGATTCC(配列番号197)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multi-chain chimeric polypeptides, the soluble human IL-21 is
CAAGGTCAAGATCGCCACATGATTAGAATGCGTCAACTTATAGATATTGTTGATCAGCTGAAAATTATGTGAATGACTTGGTCCCTGAATTTCTGCCAGCTCCAGAAGATGTAGAGACAAAACTGTGAGTGGTCAGCTTTTTCCTGTTTTCAGAAGGCCCAACTAAAGTCAGCA AATACAGGAAACAATGAAAAGGATAATCAATGTATCAATTAAAAGCTGAAGAGGAAACCACCTTCCACAAATGCAGGGAGAAGACAGAAACACAGACTAACATGCCCTTCATGTGATTCTTATGAGAAAAAAAACCACCCAAAGAATTCCTAGAAAGATTCAAATCACTTCTCCAAAGATGATTCATCA at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトIL-21は、
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC(配列番号182)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multi-chain chimeric polypeptides, the soluble human IL-21 is
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCG CCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCCTCCACAAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCCTGCTGCAGAAGAT GATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC (SEQ ID NO: 182), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、追加の標的結合ドメインは、CD16に特異的に結合するscFv(例えば、抗CD16scFv)を含む。 In some embodiments of these multichain chimeric polypeptides, the additional target binding domain comprises an scFv that specifically binds CD16 (eg, anti-CD16 scFv).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、CD16に特異的に結合するscFvは、
SELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGH(配列番号215)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む軽鎖可変ドメインを含む。
In some embodiments of these multichain chimeric polypeptides, the scFv that specifically binds to CD16 is
at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、CD16に特異的に結合するscFvは、
TCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCAACCATGTGGTGTTCGGCGGCGGCACCAAGCTGACCGTGGGCCAT(配列番号216)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である軽鎖可変ドメイン配列によってコードされる。
In some embodiments of these multichain chimeric polypeptides, the scFv that specifically binds to CD16 is
TCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACACAGGCCCTCCGGCATCCCTGACAGG at least 80% identical (e.g., at least 82% identical to , at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical , at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、CD16に特異的に結合するscFvは、
EVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSR(配列番号217)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む重鎖可変ドメインを含む。
In some embodiments of these multichain chimeric polypeptides, the scFv that specifically binds to CD16 is
EVQLVESGGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSR (SEQ ID NO: 217), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, heavy chain variable domains comprising sequences that are at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、CD16に特異的に結合するscFvは、
GAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGG(配列番号218)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である重鎖可変ドメイン配列によってコードされる。
In some embodiments of these multichain chimeric polypeptides, the scFv that specifically binds to CD16 is
GAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCCTCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGGTGAGGCAGGCTCCTGGAAAGGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGG CGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCG TGTCCAGG (SEQ ID NO: 218), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEHSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(配列番号207)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the first chimeric polypeptide is
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDHLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWN KILMGTKEHSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTL VRRNNTFLSLRDVFGKDLIYTLYYWKSSSSSGKKTAKTNTNEFLIDVDKGENYCFSVVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHD at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% sequences that are identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCATAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(配列番号208)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the first chimeric polypeptide is
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCCACATCTGCGACGCCAACAAGGAGGGCATGTTCCT GTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGA ACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCATAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATG GGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAGATGTGAAAGATGTGAAAACAGACCTACCTCGCCCGGGTGTTTTAGCTACCCCGCCCGGCAATGTGGAGA GCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGGAACAACACCTTTCTCTCGCGG GATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAACCAACACAAACGAGTTTTAATCGACGTGGATAAAGGCGAAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAA GCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAGATTTAATTCAGTCCATGCATATCGACGCCACTTTTATACACAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAAT GTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCCAATC CTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC (SEQ ID NO: 208), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical to % identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
MKWVTFISLLFLFSSAYSDCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEHSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(配列番号209)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the first chimeric polypeptide is
MKWVTFISLLFFSSAYSDCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLN DLCFLKRLLQEIKTCWNKILMGTKEHSGTTNVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSF EQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCCKVTAM at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% sequences that are identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCGATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCATAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(配列番号210)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the first chimeric polypeptide is
ATGAAGTGGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCCGATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGT TCAACTTCTTCAAGCGGCCACATCTGCGACGCCAACAAGGAGGGGCATGTTCCTGTTCAGGGCCGCCAGGAAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGG TGAAGGGCCGGAAACCTGCTGCTCTGGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCATAGCGGCCACAACCAAC ACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGAT GTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACA GTGGAGGACGAGCGGACTTTAGTGCGGCGGCGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAAACGAGTTTTTTAATCGACGTGGATAAAGGCGAAA ACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAGGGCGAGTTCCGGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATC GACGCCACTTTATACACAGAATCCGACGTGCACCCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCC GGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC (SEQ ID NO: 210), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical to % identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
SELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGHGGGGSGGGGSGGGGSEVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSRITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS(配列番号232)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the second chimeric polypeptide is
SELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGHGGGGGSGGGGSGGGGSEVQLVESGGGGVVRPGG SLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSRITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNK ATNVAHWTTPSLKCIRQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS (SEQ ID NO: 232), and at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% sequences that are identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
TCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCAACCATGTGGTGTTCGGCGGCGGCACCAAGCTGACCGTGGGCCATGGCGGCGGCGGCTCCGGAGGCGGCGGCAGCGGCGGAGGAGGATCCGAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGGATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGCAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC(配列番号233)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the second chimeric polypeptide is
TCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACACAGGCCCTCCGGCATCCCTGACAGG TTCTCCGGATCCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCGGCAACCATGTGGGTGTTCGGCGGCGGGCACCAAGCTGACCGTGGGCCATGGCGGCGGCGGCTGTCCGGAGGCGGCCG GCAGCGGCGGAGGAGGATCCGAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAGGGGCCTGGAGTGGGTGT CCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGA CAGGGCACCCTGGTGACCGTGTCCAGGATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCTCACCGAGTGCGTGCTGATAAGG CTACCAACGTGGCTCACTGGACAACACCCTCTTAAAGTGCATCCGGCAGGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTG GTCCGCCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCCACAACGCCGGCAGGAGGCAGAAGCACAGGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCA AGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCAGGCTCCGAGGACTCC (SEQ ID NO: 233), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
MKWVTFISLLFLFSSAYSSELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGHGGGGSGGGGSGGGGSEVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSRITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS(配列番号234)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the second chimeric polypeptide is
MKWVTFISLLFLFSSAYSSELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGHGGGGGSGGGGSGGG GSEVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSRITCPPPMSVEHADIWVKSYSLYSRERYICNS GFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMI HQHLSSRTHGSEDS (SEQ ID NO: 234), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% sequences that are identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCTCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCAACCATGTGGTGTTCGGCGGCGGCACCAAGCTGACCGTGGGCCATGGCGGCGGCGGCTCCGGAGGCGGCGGCAGCGGCGGAGGAGGATCCGAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGGATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGCAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC(配列番号235)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the second chimeric polypeptide is
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCTCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAG GCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGGTTCTCCGGATCCTCCTCCGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTGCAACTCCAGGGACTCCTCGGCAACCATGTGGGTGTTCGGCGGC GGCACCAAGCTGACCGTGGGCCATGGCGGCGGCGGCTCCCGGAGGCGGCGGCAGCGGGCGGAGGGAGGATCCGAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACG GCATGTCCTGGGTGAGGCAGGCTCCTGGAAAGGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACA CCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGGATTACATGCCCCCTCCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCG GCTTCAAGAGGAAGGCCGGCACCAGCAGCCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACACACCCTTTAAAGTGCATCCGGCAGGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGAC CTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCA GGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC (SEQ ID NO: 235), at least 80% identical (e.g., at least 82% identical, at least 84 % identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
例示的な多鎖キメラポリペプチド-タイプG
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは各々独立して、TGFβ(例えば、ヒトTGFβRII受容体)、CD16(例えば、抗CD16scFv)、又はIL-21(例えば、可溶性ヒトIL-21)受容体に特異的に結合する。本明細書に記載のこれらの多鎖キメラポリペプチドのいくつかの実施形態では、第1のキメラポリペプチドは、追加の標的結合ドメインを更に含む。本明細書に記載のこれらの多鎖キメラポリペプチドのいくつかの実施形態では、第2のキメラポリペプチドは、追加の標的結合ドメインを更に含む。本明細書に記載のこれらの多鎖キメラポリペプチドのいくつかの実施形態では、追加の標的結合ドメインは、CD16又はIL-21受容体に特異的に結合する。
Exemplary Multichain Chimeric Polypeptides—Type G
In some embodiments of any of the multichain chimeric polypeptides described herein, the first target binding domain and the second target binding domain are each independently TGFβ (e.g., human TGFβRII receptor CD16 (eg, anti-CD16 scFv), or IL-21 (eg, soluble human IL-21) receptors. In some embodiments of these multi-chain chimeric polypeptides described herein, the first chimeric polypeptide further comprises an additional target binding domain. In some embodiments of these multi-chain chimeric polypeptides described herein, the second chimeric polypeptide further comprises an additional target binding domain. In some embodiments of these multichain chimeric polypeptides described herein, the additional target binding domain specifically binds to the CD16 or IL-21 receptor.
これらの多鎖キメラポリペプチドのいくつかの例では、第1の標的結合ドメインと可溶性組織因子ドメインは、第1のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの例では、第1のキメラポリペプチドは、第1のキメラポリペプチド内の第1の標的結合ドメインと可溶性組織因子ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some examples of these multichain chimeric polypeptides, the first target binding domain and the soluble tissue factor domain are directly adjacent to each other within the first chimeric polypeptide. In some examples of these multichain chimeric polypeptides, the first chimeric polypeptide has a linker sequence (e.g., any of the exemplary linkers described herein).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインは、第1のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1のキメラポリペプチドは、第1のキメラポリペプチド内の可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these multi-chain chimeric polypeptides, the soluble tissue factor domain and the first of the paired affinity domains are directly adjacent to each other within the first chimeric polypeptide. In some embodiments of these multi-chain chimeric polypeptides, the first chimeric polypeptide is between the soluble tissue factor domain and the first of the pair of affinity domains within the first chimeric polypeptide. Further includes a linker sequence (eg, any of the exemplary linkers described herein).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、一対の親和性ドメインの第2のドメインと第2の標的結合ドメインは、第2のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチド内の一対の親和性ドメインの第2のドメインと第2の標的結合ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these multi-chain chimeric polypeptides, the second domain and the second target binding domain of the pair of affinity domains are directly adjacent to each other within the second chimeric polypeptide. In some embodiments of these multichain chimeric polypeptides, the second chimeric polypeptide is a combination of the second of the pair of affinity domains within the second chimeric polypeptide and the second target binding domain. Further includes a linker sequence (eg, any of the exemplary linkers described herein) in between.
いくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチドのN末端又はC末端に1つ以上の追加の標的結合ドメインを更に含む。 In some embodiments, the second chimeric polypeptide further comprises one or more additional target binding domains at the N-terminus or C-terminus of the second chimeric polypeptide.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、追加の標的結合ドメイン及び一対の親和性ドメインの第2のドメインは、第2のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチド内の一対の親和性ドメインの第2のドメインと追加の標的結合ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these multi-chain chimeric polypeptides, the additional target binding domain and the second domain of the pair of affinity domains are directly adjacent to each other within the second chimeric polypeptide. In some embodiments of these multichain chimeric polypeptides, the second chimeric polypeptide is between the second of the pair of affinity domains and the additional target binding domain within the second chimeric polypeptide. further includes a linker sequence (eg, any of the exemplary linkers described herein).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、追加の標的結合ドメインと第2の標的結合ドメインは、第2のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチド内の第2の標的結合ドメインと追加の標的結合ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these multi-chain chimeric polypeptides, the additional target binding domain and the second target binding domain are directly adjacent to each other within the second chimeric polypeptide. In some embodiments of these multichain chimeric polypeptides, the second chimeric polypeptide has a linker sequence ( For example, any of the exemplary linkers described herein).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性組織因子ドメインは、本明細書に記載の例示的な可溶性組織因子ドメインのうちのいずれかであり得る。これらの多鎖キメラポリペプチドのいくつかの実施形態では、一対の親和性ドメインは、本明細書に記載の例示的な一対の親和性ドメインのうちのいずれかであり得る。 In some embodiments of these multichain chimeric polypeptides, the soluble tissue factor domain can be any of the exemplary soluble tissue factor domains described herein. In some embodiments of these multi-chain chimeric polypeptides, the pair of affinity domains can be any of the exemplary pair of affinity domains described herein.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び追加の抗原結合ドメインのうちの1つ以上は、アゴニスト抗原結合ドメインである。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び追加の抗原結合ドメインは各々、アゴニスト抗原結合ドメインである。これらの多鎖キメラポリペプチドのいくつかの実施形態では、抗原結合ドメインは、scFv又は単一ドメイン抗体を含む。 In some embodiments of these multichain chimeric polypeptides, one or more of the first target binding domain, the second target binding domain, and the additional antigen binding domain is an agonist antigen binding domain. In some embodiments of these multi-chain chimeric polypeptides, the first target binding domain, the second target binding domain, and the additional antigen binding domain are each agonist antigen binding domains. In some embodiments of these multi-chain chimeric polypeptides, the antigen binding domain comprises a scFv or single domain antibody.
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは各々独立して、TGF-β、CD16、又はIL-21受容体に特異的に結合する。本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメインはTGF-βに特異的に結合し、第2の標的結合ドメインはCD16又はIL-21受容体に特異的に結合する。本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメインは、可溶性TGF-β受容体である。本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、可溶性TGF-β受容体は、可溶性TGFβRII受容体である。本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第2の標的結合ドメインは、CD16に特異的に結合する。本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第2の抗原結合ドメインは、CD16に特異的に結合する抗原結合ドメインを含む。本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第2の抗原結合ドメインは、CD16に特異的に結合するscFvを含む。本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第2の標的結合ドメインは、IL-21受容体に特異的に結合する。本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第2の標的結合ドメインは、可溶性IL-21を含む。本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第2の標的結合ドメインは、可溶性ヒトIL-21を含む。本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第2のキメラポリペプチドは、IL-21受容体に特異的に結合する追加の標的結合ドメインを更に含む。本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、追加の標的結合ドメインは、可溶性IL-21を含む。本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、可溶性IL-21は、可溶性ヒトIL-21である。本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第2のキメラポリペプチドは、CD16に特異的に結合する追加の標的結合ドメインを更に含む。 In some embodiments of any of the multichain chimeric polypeptides described herein, the first target binding domain and the second target binding domain are each independently TGF-β, CD16, or Binds specifically to the IL-21 receptor. In some embodiments of any of the multichain chimeric polypeptides described herein, the first target binding domain specifically binds TGF-β and the second target binding domain is CD16 or Binds specifically to the IL-21 receptor. In some embodiments of any of the multichain chimeric polypeptides described herein, the first target binding domain is a soluble TGF-beta receptor. In some embodiments of any of the multichain chimeric polypeptides described herein, the soluble TGF-β receptor is a soluble TGFβRII receptor. In some embodiments of any of the multichain chimeric polypeptides described herein, the second target binding domain specifically binds CD16. In some embodiments of any of the multichain chimeric polypeptides described herein, the second antigen binding domain comprises an antigen binding domain that specifically binds CD16. In some embodiments of any of the multichain chimeric polypeptides described herein, the second antigen binding domain comprises an scFv that specifically binds CD16. In some embodiments of any of the multichain chimeric polypeptides described herein, the second target binding domain specifically binds the IL-21 receptor. In some embodiments of any of the multichain chimeric polypeptides described herein, the second target binding domain comprises soluble IL-21. In some embodiments of any of the multichain chimeric polypeptides described herein, the second target binding domain comprises soluble human IL-21. In some embodiments of any of the multichain chimeric polypeptides described herein, the second chimeric polypeptide further comprises an additional target binding domain that specifically binds to the IL-21 receptor. include. In some embodiments of any of the multichain chimeric polypeptides described herein, the additional target binding domain comprises soluble IL-21. In some embodiments of any of the multichain chimeric polypeptides described herein, the soluble IL-21 is soluble human IL-21. In some embodiments of any of the multichain chimeric polypeptides described herein, the second chimeric polypeptide further comprises an additional target binding domain that specifically binds CD16.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの2つ以上が、同じ抗原に特異的に結合する。いくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの2つ以上が、同じエピトープに特異的に結合する。いくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの2つ以上が、同じアミノ酸配列を含む。 In some embodiments of these multichain chimeric polypeptides, two or more of the first target binding domain, the second target binding domain, and one or more additional target binding domains are directed to the same antigen. Binds specifically. In some embodiments, two or more of the first target binding domain, the second target binding domain, and the one or more additional target binding domains specifically bind the same epitope. In some embodiments, two or more of the first target binding domain, second target binding domain, and one or more additional target binding domains comprise the same amino acid sequence.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメインは、TGFβRII受容体(例えば、可溶性ヒトTGFβRII受容体)を含む。これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトTGFRβRIIは、第1の可溶性ヒトTGFRβRII配列及び第2の可溶性ヒトTGFRβRII配列を含む。これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトTGFRβRIIは、第1の可溶性ヒトTGFRβRII配列と第2の可溶性ヒトTGFRβRII配列との間に配置されたリンカーを含む。これらの多鎖キメラポリペプチドのいくつかの例では、リンカーは、配列GGGGSGGGGSGGGGS(配列番号102)を含む。 In some embodiments of these multichain chimeric polypeptides, the first target binding domain comprises a TGFβRII receptor (eg, a soluble human TGFβRII receptor). In some embodiments of these multichain chimeric polypeptides, the soluble human TGFRβRII comprises a first soluble human TGFRβRII sequence and a second soluble human TGFRβRII sequence. In some embodiments of these multichain chimeric polypeptides, the soluble human TGFRβRII comprises a linker positioned between the first soluble human TGFRβRII sequence and the second soluble human TGFRβRII sequence. In some examples of these multichain chimeric polypeptides, the linker comprises the sequence GGGGSGGGGSGGGGGS (SEQ ID NO: 102).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の可溶性ヒトTGFRβRII受容体配列は、
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD(配列番号183)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multichain chimeric polypeptides, the first soluble human TGFRβRII receptor sequence is
at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, sequences that are at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2の可溶性ヒトTGFRβRII受容体配列は、
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD(配列番号184)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multichain chimeric polypeptides, the second soluble human TGFRβRII receptor sequence is
at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, sequences that are at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の可溶性ヒトTGFRβRII受容体配列は、
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGAT(配列番号185)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multichain chimeric polypeptides, the first soluble human TGFRβRII receptor sequence is
ATCCCCCCCCCATGTGCAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAA GAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGAACCTTCTTTATGTGTTCCTGTAGCAG CGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGAT (SEQ ID NO: 185), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2の可溶性ヒトTGFRβRII受容体配列は、
ATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC(配列番号186)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multichain chimeric polypeptides, the second soluble human TGFRβRII receptor sequence is
ATTCCTCCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGG TGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAAACCGTCTGCCCACGATCCCCAAGCTGCCCTACCCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAAGAGAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGC at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性TGF-β受容体は、
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD(配列番号188)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multichain chimeric polypeptides, the soluble TGF-β receptor is
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNSITSITSICEKPQEVCVAVWRKNDINITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPDGGGGGSGGGGGSGGGGGSIPPHV at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical , at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトTGFβRII受容体は、
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC(配列番号187)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multichain chimeric polypeptides, the soluble human TGFβRII receptor is
ATCCCCCCCCCATGTGCAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAA GAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGAACCTTCTTTATGTGTTCCTGTAGCAG CGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCC CCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCCACGATCCCCAAGCTGCCCTAC CACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCCGAC (SEQ ID NO: 187), and at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトIL-21配列は、
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS(配列番号83)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multi-chain chimeric polypeptides, the soluble human IL-21 sequence is
at least 80% identical to QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS (SEQ ID NO: 83), (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, sequences that are at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトIL-21は、
CAAGGTCAAGATCGCCACATGATTAGAATGCGTCAACTTATAGATATTGTTGATCAGCTGAAAAATTATGTGAATGACTTGGTCCCTGAATTTCTGCCAGCTCCAGAAGATGTAGAGACAAACTGTGAGTGGTCAGCTTTTTCCTGTTTTCAGAAGGCCCAACTAAAGTCAGCAAATACAGGAAACAATGAAAGGATAATCAATGTATCAATTAAAAAGCTGAAGAGGAAACCACCTTCCACAAATGCAGGGAGAAGACAGAAACACAGACTAACATGCCCTTCATGTGATTCTTATGAGAAAAAACCACCCAAAGAATTCCTAGAAAGATTCAAATCACTTCTCCAAAAGATGATTCATCAGCATCTGTCCTCTAGAACACACGGAAGTGAAGATTCC(配列番号197)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multi-chain chimeric polypeptides, the soluble human IL-21 is
CAAGGTCAAGATCGCCACATGATTAGAATGCGTCAACTTATAGATATTGTTGATCAGCTGAAAATTATGTGAATGACTTGGTCCCTGAATTTCTGCCAGCTCCAGAAGATGTAGAGACAAAACTGTGAGTGGTCAGCTTTTTCCTGTTTTCAGAAGGCCCAACTAAAGTCAGCA AATACAGGAAACAATGAAAAGGATAATCAATGTATCAATTAAAAGCTGAAGAGGAAACCACCTTCCACAAATGCAGGGAGAAGACAGAAACACAGACTAACATGCCCTTCATGTGATTCTTATGAGAAAAAAAACCACCCAAAGAATTCCTAGAAAGATTCAAATCACTTCTCCAAAGATGATTCATCA at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトIL-21は、
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC(配列番号182)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multi-chain chimeric polypeptides, the soluble human IL-21 is
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCG CCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCCTCCACAAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCCTGCTGCAGAAGAT GATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC (SEQ ID NO: 182), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、CD16に特異的に結合するscFvは、
SELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGH(配列番号215)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む軽鎖可変ドメインを含む。
In some embodiments of these multichain chimeric polypeptides, the scFv that specifically binds to CD16 is
at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, light chain variable domains comprising sequences that are at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、CD16に特異的に結合するscFvは、
TCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCAACCATGTGGTGTTCGGCGGCGGCACCAAGCTGACCGTGGGCCAT(配列番号216)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である軽鎖可変ドメイン配列によってコードされる。
In some embodiments of these multichain chimeric polypeptides, the scFv that specifically binds to CD16 is
TCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGGCTCCTGTGCTGGTGATCTACGGCAAGAACACAGGCCCTCCGGCATCCCTGACAGG at least 80% identical (e.g., at least 82% identical to , at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical , at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、CD16に特異的に結合するscFvは、
EVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSR(配列番号217)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む重鎖可変ドメインを含む。
In some embodiments of these multichain chimeric polypeptides, the scFv that specifically binds to CD16 is
EVQLVESGGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSR (SEQ ID NO: 217), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, heavy chain variable domains comprising sequences that are at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、CD16に特異的に結合するscFvは、
GAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGG(配列番号218)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である重鎖可変ドメイン配列によってコードされる。
In some embodiments of these multichain chimeric polypeptides, the scFv that specifically binds to CD16 is
GAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCCTCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGGAGGCAGGCTCCTGGAAAGGGCCTGGGAGTGGGTGTCCGGCATCAACTGGAACGG CGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCG TGTCCAGG (SEQ ID NO: 218), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(配列番号236)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the first chimeric polypeptide is
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNSITSITSICEKPQEVCVAVWRKNDINITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPDGGGGGSGGGGGSGGGGGSIPPHV QKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDSGTTNTVAAYNLTWKSTNFKTILEWEPK PVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTA KTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVIDLKKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANSLSSNGNVTESGCKECEELEEKNIKEFLQ SFVHIVQMFINTS (SEQ ID NO: 236), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, % identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(配列番号237)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされ得る。
In some embodiments, the first chimeric polypeptide is
ATCCCCCCCCCATGTGCAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAA GAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGAACCTTCTTTATGTGTTCCTGTAGCAG CGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCC CCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCCACGATCCCCAAGCTGCCCTAC CACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACAGCGGCACAACCAACACAGTCGCTGCC TATAACCTCACTTGGAAGAGCACCAACTTCAAACCATCCTCGAATGGGAACCCAAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTAACCACCGACACCGAGTGCGATCTCACCGATGGAGATCGTGAAAAGATGTGAAAACAGACCT ACCTCGCCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAG CGGACTTTAGTGCGGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAG CGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGGAGTTCCGGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGAATTTAATTCAGTCCATGCATATCGACGCCACTTTATA CACAGAATCCGACGTGCACCCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAG at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(配列番号238)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the first chimeric polypeptide is
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGG GSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPDSGTTNTVAAY NLTWKSTNFKTILEWEPKKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNNTFLSLRDVFGKDLI YTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVIDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLILANNSLSSNGNVTESG CKECEELEEEKNIKEFLQSFVHIVQMFINTS (SEQ ID NO: 238), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical % identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(配列番号239)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the first chimeric polypeptide is
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCCATCCCCCCCCATGTGCAAAGAGCGTGAACAACGATATGATCGTGACCGACAACACGGCGCCGTGAAGTTTCCCCAGCTCTGCCAAGTTTCTGCGATGTCAGGGTTCAGCACCTGCGA TAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGC ATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCCACGTGCA GAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGGACAACCAGAAGTCCTGTATGAGCCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGGTGTGCGTGGCTGTCT GGCGGAAGAATGACGAGAATATCACCCTGGAAAACCGTCTGCCACGATCCCCAAGCTGCCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAAGAGAAAAGAAGCCTGGCGGAGACCTTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCAT CTTTAGCGAGGAATACAATACCAGCAACCCCGACAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAACCATCCTCGAATGGGAACCCAAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCT ATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCCTTACCTCGAGACCAATTTAGGACAGCCCACCAT CCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAAC CAACACAAACGAGTTTTTAATCGACGTGGATAAAGGGCGAAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAGGGCGAGTTCCGGGGAGAACTGGGTGAACGTCATCAG CGATTTAAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATT at least 80% identical (e.g., at least 82% identical, at least 84% identical , at least 86% identical, at least 88% identical, at least 90% identical , at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
SELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGHGGGGSGGGGSGGGGSEVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSRITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS(配列番号232)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the second chimeric polypeptide is
SELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGHGGGGGSGGGGSGGGGSEVQLVESGGGGVVRPGG SLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSRITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNK ATNVAHWTTPSLKCIRQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS (SEQ ID NO: 232), and at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% sequences that are identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
TCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCAACCATGTGGTGTTCGGCGGCGGCACCAAGCTGACCGTGGGCCATGGCGGCGGCGGCTCCGGAGGCGGCGGCAGCGGCGGAGGAGGATCCGAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGGATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGCAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC(配列番号233)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the second chimeric polypeptide is
TCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACACAGGCCCTCCGGCATCCCTGACAGG TTCTCCGGATCCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCGGCAACCATGTGGGTGTTCGGCGGCGGGCACCAAGCTGACCGTGGGCCATGGCGGCGGCGGCTGTCCGGAGGCGGCCG GCAGCGGCGGAGGAGGATCCGAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAGGGGCCTGGAGTGGGTGT CCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGA CAGGGCACCCTGGTGACCGTGTCCAGGATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCTCACCGAGTGCGTGCTGATAAGG CTACCAACGTGGCTCACTGGACAACACCCTCTTAAAGTGCATCCGGCAGGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTG GTCCGCCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCCACAACGCCGGCAGGAGGCAGAAGCACAGGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCA AGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCAGGCTCCGAGGACTCC (SEQ ID NO: 233), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
MKWVTFISLLFLFSSAYSSELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGHGGGGSGGGGSGGGGSEVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSRITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS(配列番号234)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the second chimeric polypeptide is
MKWVTFISLLFLFSSAYSSELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGHGGGGGSGGGGSGGG GSEVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSRITCPPPMSVEHADIWVKSYSLYSRERYICNS GFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMI HQHLSSRTHGSEDS (SEQ ID NO: 234), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% sequences that are identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCTCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCAACCATGTGGTGTTCGGCGGCGGCACCAAGCTGACCGTGGGCCATGGCGGCGGCGGCTCCGGAGGCGGCGGCAGCGGCGGAGGAGGATCCGAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGGATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGCAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC(配列番号235)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the second chimeric polypeptide is
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCTCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAG GCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGGTTCTCCGGATCCTCCTCCGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTGCAACTCCAGGGACTCCTCGGCAACCATGTGGGTGTTCGGCGGC GGCACCAAGCTGACCGTGGGCCATGGCGGCGGCGGCTCCCGGAGGCGGCGGCAGCGGGCGGAGGGAGGATCCGAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACG GCATGTCCTGGGTGAGGCAGGCTCCTGGAAAGGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACA CCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGGATTACATGCCCCCTCCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCG GCTTCAAGAGGAAGGCCGGCACCAGCAGCCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACACACCCTTTAAAGTGCATCCGGCAGGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGAC CTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCA GGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC (SEQ ID NO: 235), at least 80% identical (e.g., at least 82% identical, at least 84 % identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
例示的な多鎖キメラポリペプチド-タイプH
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは各々独立して、IL-7受容体に特異的に結合する。これらの多鎖キメラポリペプチドのいくつかの例では、第1の標的結合ドメイン及び可溶性組織因子ドメインは、第1のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの例では、第1のキメラポリペプチドは、第1のキメラポリペプチド内の第1の標的結合ドメインと可溶性組織因子ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。
Exemplary Multichain Chimeric Polypeptides—Type H
In some embodiments of any of the multi-chain chimeric polypeptides described herein, the first target binding domain and the second target binding domain are each independently specific for the IL-7 receptor. connect to each other. In some examples of these multichain chimeric polypeptides, the first target binding domain and the soluble tissue factor domain are directly adjacent to each other within the first chimeric polypeptide. In some examples of these multichain chimeric polypeptides, the first chimeric polypeptide has a linker sequence (e.g., any of the exemplary linkers described herein).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインは、第1のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1のキメラポリペプチドは、第1のキメラポリペプチド内の可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these multi-chain chimeric polypeptides, the soluble tissue factor domain and the first of the paired affinity domains are directly adjacent to each other within the first chimeric polypeptide. In some embodiments of these multi-chain chimeric polypeptides, the first chimeric polypeptide is between the soluble tissue factor domain and the first of the pair of affinity domains within the first chimeric polypeptide. Further includes a linker sequence (eg, any of the exemplary linkers described herein).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、一対の親和性ドメインの第2のドメインと第2の標的結合ドメインは、第2のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチド内の一対の親和性ドメインの第2のドメインと第2の標的結合ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these multi-chain chimeric polypeptides, the second domain and the second target binding domain of the pair of affinity domains are directly adjacent to each other within the second chimeric polypeptide. In some embodiments of these multichain chimeric polypeptides, the second chimeric polypeptide is a combination of the second of the pair of affinity domains within the second chimeric polypeptide and the second target binding domain. Further includes a linker sequence (eg, any of the exemplary linkers described herein) in between.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性組織因子ドメインは、本明細書に記載の例示的な可溶性組織因子ドメインのうちのいずれかであり得る。これらの多鎖キメラポリペプチドのいくつかの実施形態では、一対の親和性ドメインは、本明細書に記載の例示的な一対の親和性ドメインのうちのいずれかであり得る。 In some embodiments of these multichain chimeric polypeptides, the soluble tissue factor domain can be any of the exemplary soluble tissue factor domains described herein. In some embodiments of these multi-chain chimeric polypeptides, the pair of affinity domains can be any of the exemplary pair of affinity domains described herein.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは各々独立して、IL-7受容体に特異的に結合する。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは、同じエピトープに特異的に結合する。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは、同じアミノ酸配列を含む。 In some embodiments of these multichain chimeric polypeptides, the first target binding domain and the second target binding domain each independently specifically bind to the IL-7 receptor. In some embodiments of these multichain chimeric polypeptides, the first target binding domain and the second target binding domain specifically bind the same epitope. In some embodiments of these multichain chimeric polypeptides, the first target binding domain and the second target binding domain comprise the same amino acid sequence.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは、可溶性IL-7(例えば、可溶性ヒトIL-7)を含む。これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトIL-7は、
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEH(配列番号79)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multichain chimeric polypeptides, the first target binding domain and the second target binding domain comprise soluble IL-7 (eg, soluble human IL-7). In some embodiments of these multi-chain chimeric polypeptides, the soluble human IL-7 is
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDHLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWN KILMGTKEH (SEQ ID NO: 79), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, sequences that are at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトIL-7は、
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCAT(配列番号227)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multi-chain chimeric polypeptides, the soluble human IL-7 is
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCCACATCTGCGACGCCAACAAGGAGGGCATGTTCCT GTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGA ACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCAT (SEQ ID NO: 227), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEHSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(配列番号207)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the first chimeric polypeptide is
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDHLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWN KILMGTKEHSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTL VRRNNTFLSLRDVFGKDLIYTLYYWKSSSSSGKKTAKTNTNEFLIDVDKGENYCFSVVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHD at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% sequences that are identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCATAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(配列番号208)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the first chimeric polypeptide is
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCCACATCTGCGACGCCAACAAGGAGGGCATGTTCCT GTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGA ACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCATAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATG GGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAGATGTGAAAGATGTGAAAACAGACCTACCTCGCCCGGGTGTTTTAGCTACCCCGCCCGGCAATGTGGAGA GCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGGAACAACACCTTTCTCTCGCGG GATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAACCAACACAAACGAGTTTTAATCGACGTGGATAAAGGCGAAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAA GCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAGATTTAATTCAGTCCATGCATATCGACGCCACTTTTATACACAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAAT GTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCCAATC CTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC (SEQ ID NO: 208), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical to % identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
MKWVTFISLLFLFSSAYSDCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEHSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(配列番号209)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the first chimeric polypeptide is
MKWVTFISLLFFSSAYSDCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLN DLCFLKRLLQEIKTCWNKILMGTKEHSGTTNVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSF EQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCCKVTAM at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% sequences that are identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCGATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCATAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(配列番号210)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the first chimeric polypeptide is
ATGAAGTGGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCCGATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGT TCAACTTCTTCAAGCGGCCACATCTGCGACGCCAACAAGGAGGGGCATGTTCCTGTTCAGGGCCGCCAGGAAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGG TGAAGGGCCGGAAACCTGCTGCTCTGGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCATAGCGGCCACAACCAAC ACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGAT GTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACA GTGGAGGACGAGCGGACTTTAGTGCGGCGGCGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAAACGAGTTTTTTAATCGACGTGGATAAAGGCGAAA ACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAGGGCGAGTTCCGGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATC GACGCCACTTTATACACAGAATCCGACGTGCACCCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCC GGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC (SEQ ID NO: 210), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical to % identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEHITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR(配列番号203)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the second chimeric polypeptide is
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDHLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWN at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical , at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
GATTGTGATATTGAAGGTAAAGATGGCAAACAATATGAGAGTGTTCTAATGGTCAGCATCGATCAATTATTGGACAGCATGAAAGAAATTGGTAGCAATTGCCTGAATAATGAATTTAACTTTTTTAAAAGACATATCTGTGATGCTAATAAGGAAGGTATGTTTTTATTCCGTGCTGCTCGCAAGTTGAGGCAATTTCTTAAAATGAATAGCACTGGTGATTTTGATCTCCACTTATTAAAAGTTTCAGAAGGCACAACAATACTGTTGAACTGCACTGGCCAGGTTAAAGGAAGAAAACCAGCTGCCCTGGGTGAAGCCCAACCAACAAAGAGTTTGGAAGAAAATAAATCTTTAAAGGAACAGAAAAAACTGAATGACTTGTGTTTCCTAAAGAGACTATTACAAGAGATAAAAACTTGTTGGAATAAAATTTTGATGGGCACTAAAGAACACATCACGTGCCCTCCCCCCATGTCCGTGGAACACGCAGACATCTGGGTCAAGAGCTACAGCTTGTACTCCAGGGAGCGGTACATTTGTAACTCTGGTTTCAAGCGTAAAGCCGGCACGTCCAGCCTGACGGAGTGCGTGTTGAACAAGGCCACGAATGTCGCCCACTGGACAACCCCCAGTCTCAAATGCATTAGA(配列番号204)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the second chimeric polypeptide is
GATTGTGATATTGAAGGTAAAGATGGCAAACAATATGAGAGTGTTCTAATGGTCAGCATCGATCAATTATTGGACAGCATGAAAAGAAATTGGTAGCAATTGCCTGAATAATGAATTTAACTTTTTTAAAAGACATATCTGTGATGCTAATAAGGAAGGTATGTTTTTAT TCCGTGCTGCTCGCAAGTTGAGGCAATTTCTTAAATGAATAGCACTGGTGATTTTGATCTCCACTTATTAAAGTTTCAGAAGGCCAACAATACTGTTGAACTGCACTGGCCAGGTTAAAAGGAAGAAAACCAGCTGCCCTGGGTGAAGCCCAACCAACAAAGAGTTTGGA AGAAAAAAATCTTAAAGGAACAGAAAAAAACTGAATGACTTGTGTTTCCTAAAGAGACTATTACAAGAGATAAAAACTTTGTTGGAATAAAATTTTGATGGGGCACTAAAGAACACATCACGTGCCCTCCCCCCATGTCCGTGGAACACGCAGACATCTGGGTCAAGAGCTACAGCTTG at least 80% identical (e.g., at least 82% identical, at least 84% identical , at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94 % identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
MKWVTFISLLFLFSSAYSDCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEHITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR(配列番号250)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the second chimeric polypeptide is
MKWVTFISLLFFSSAYSDCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLN DLCFLKRLLQEIKTCWNKILMGTKEHITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSLTECVLNKATNVAHWTTPSLKCIR (SEQ ID NO: 250), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical , at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCGATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCATATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG(配列番号251)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the second chimeric polypeptide is
ATGAAGTGGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCCGATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGT TCAACTTCTTCAAGCGGCCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGG TGAAGGGCCGGAAACCTGCTGCTCTGGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCATATTACATGCCCCCCT CCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTCACCAACGTGGCTCACTGGACAACACCCTCTTAAAGTGCATCC GG (SEQ ID NO: 251), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
例示的な多鎖キメラポリペプチド-タイプI
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは各々独立して、TGF-βに特異的に結合する。これらの多鎖キメラポリペプチドのいくつかの例では、第1の標的結合ドメインと可溶性組織因子ドメインは、第1のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの例では、第1のキメラポリペプチドは、第1のキメラポリペプチド内の第1の標的結合ドメインと可溶性組織因子ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。
Exemplary Multichain Chimeric Polypeptides—Type I
In some embodiments of any of the multichain chimeric polypeptides described herein, the first target binding domain and the second target binding domain are each independently specific for TGF-β. Join. In some examples of these multichain chimeric polypeptides, the first target binding domain and the soluble tissue factor domain are directly adjacent to each other within the first chimeric polypeptide. In some examples of these multichain chimeric polypeptides, the first chimeric polypeptide has a linker sequence (e.g., any of the exemplary linkers described herein).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインは、第1のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1のキメラポリペプチドは、第1のキメラポリペプチド内の可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these multi-chain chimeric polypeptides, the soluble tissue factor domain and the first of the paired affinity domains are directly adjacent to each other within the first chimeric polypeptide. In some embodiments of these multi-chain chimeric polypeptides, the first chimeric polypeptide is between the soluble tissue factor domain and the first of the pair of affinity domains within the first chimeric polypeptide. Further includes a linker sequence (eg, any of the exemplary linkers described herein).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、一対の親和性ドメインの第2のドメインと第2の標的結合ドメインは、第2のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチド内の一対の親和性ドメインの第2のドメインと第2の標的結合ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these multi-chain chimeric polypeptides, the second domain and the second target binding domain of the pair of affinity domains are directly adjacent to each other within the second chimeric polypeptide. In some embodiments of these multichain chimeric polypeptides, the second chimeric polypeptide is a combination of the second of the pair of affinity domains within the second chimeric polypeptide and the second target binding domain. Further includes a linker sequence (eg, any of the exemplary linkers described herein) in between.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性組織因子ドメインは、本明細書に記載の例示的な可溶性組織因子ドメインのうちのいずれかであり得る。これらの多鎖キメラポリペプチドのいくつかの実施形態では、一対の親和性ドメインは、本明細書に記載の例示的な一対の親和性ドメインのうちのいずれかであり得る。 In some embodiments of these multichain chimeric polypeptides, the soluble tissue factor domain can be any of the exemplary soluble tissue factor domains described herein. In some embodiments of these multi-chain chimeric polypeptides, the pair of affinity domains can be any of the exemplary pair of affinity domains described herein.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは各々独立して、TGF-βに特異的に結合する。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは、同じエピトープに特異的に結合する。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは、同じアミノ酸配列を含む。 In some embodiments of these multichain chimeric polypeptides, the first target binding domain and the second target binding domain each independently specifically bind to TGF-β. In some embodiments of these multichain chimeric polypeptides, the first target binding domain and the second target binding domain specifically bind the same epitope. In some embodiments of these multichain chimeric polypeptides, the first target binding domain and the second target binding domain comprise the same amino acid sequence.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは、可溶性TGF-β受容体(例えば、可溶性TGFβRII受容体、例えば、可溶性ヒトTGFβRII)である。これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトTGFRβRIIは、第1の可溶性ヒトTGFRβRII配列及び第2の可溶性ヒトTGFRβRII配列を含む。これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトTGFRβRIIは、第1の可溶性ヒトTGFRβRII配列と第2の可溶性ヒトTGFRβRII配列との間に配置されたリンカーを含む。これらの多鎖キメラポリペプチドのいくつかの例では、リンカーは、配列GGGGSGGGGSGGGGS(配列番号102)を含む。 In some embodiments of these multichain chimeric polypeptides, the first target binding domain and the second target binding domain are a soluble TGF-β receptor (eg, a soluble TGFβRII receptor, such as soluble human TGFβRII) is. In some embodiments of these multichain chimeric polypeptides, the soluble human TGFRβRII comprises a first soluble human TGFRβRII sequence and a second soluble human TGFRβRII sequence. In some embodiments of these multichain chimeric polypeptides, the soluble human TGFRβRII comprises a linker positioned between the first soluble human TGFRβRII sequence and the second soluble human TGFRβRII sequence. In some examples of these multichain chimeric polypeptides, the linker comprises the sequence GGGGSGGGGSGGGGGS (SEQ ID NO: 102).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の可溶性ヒトTGFRβRII受容体配列は、
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD(配列番号183)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multichain chimeric polypeptides, the first soluble human TGFRβRII receptor sequence is
at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, sequences that are at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2の可溶性ヒトTGFRβRII受容体配列は、
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD(配列番号184)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multichain chimeric polypeptides, the second soluble human TGFRβRII receptor sequence is
at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, sequences that are at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の可溶性ヒトTGFRβRII受容体配列は、
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGAT(配列番号185)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multichain chimeric polypeptides, the first soluble human TGFRβRII receptor sequence is
ATCCCCCCCCCATGTGCCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTTCTGCGATGTCAGGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAA GAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGAACCTTCTTTATGTGTTCCTGTAGCAG CGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACCCAGCAACCCTGAT (SEQ ID NO: 185), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2の可溶性ヒトTGFRβRII受容体配列は、
ATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC(配列番号186)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multichain chimeric polypeptides, the second soluble human TGFRβRII receptor sequence is
ATTCCTCCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGG TGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAAACCGTCTGCCCACGATCCCCAAGCTGCCCTACCCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAAGAGAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGC at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性TGF-β受容体は、
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD(配列番号188)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multichain chimeric polypeptides, the soluble TGF-β receptor is
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNSITSITSICEKPQEVCVAVWRKNDINITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPDGGGGGSGGGGGSGGGGGSIPPHV at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical , at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性TGF-β受容体は、
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC(配列番号187)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multichain chimeric polypeptides, the soluble TGF-β receptor is
ATCCCCCCCCCATGTGCAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAA GAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGAACCTTCTTTATGTGTTCCTGTAGCAG CGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCC CCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCCACGATCCCCAAGCTGCCCTAC CACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCCGAC (SEQ ID NO: 187), and at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(配列番号236)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the first chimeric polypeptide is
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNSITSITSICEKPQEVCVAVWRKNDINITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPDGGGGGSGGGGGSGGGGGSIPPHV QKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDSGTTNTVAAYNLTWKSTNFKTILEWEPK PVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTA KTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVIDLKKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANSLSSNGNVTESGCKECEELEEKNIKEFLQ SFVHIVQMFINTS (SEQ ID NO: 236), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, % identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(配列番号237)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされ得る。
In some embodiments, the first chimeric polypeptide is
ATCCCCCCCCCATGTGCAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAA GAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGAACCTTCTTTATGTGTTCCTGTAGCAG CGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCC CCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCCACGATCCCCAAGCTGCCCTAC CACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACAGCGGCACAACCAACACAGTCGCTGCC TATAACCTCACTTGGAAGAGCACCAACTTCAAACCATCCTCGAATGGGAACCCAAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTAACCACCGACACCGAGTGCGATCTCACCGATGGAGATCGTGAAAAGATGTGAAAACAGACCT ACCTCGCCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAG CGGACTTTAGTGCGGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAG CGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGGAGTTCCGGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGAATTTAATTCAGTCCATGCATATCGACGCCACTTTATA CACAGAATCCGACGTGCACCCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAG at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(配列番号238)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the first chimeric polypeptide is
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGG GSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPDSGTTNTVAAY NLTWKSTNFKTILEWEPKKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNNTFLSLRDVFGKDLI YTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVIDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLILANNSLSSNGNVTESG CKECEELEEEKNIKEFLQSFVHIVQMFINTS (SEQ ID NO: 238), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical % identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(配列番号239)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the first chimeric polypeptide is
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCCATCCCCCCCCATGTGCAAAGAGCGTGAACAACGATATGATCGTGACCGACAACACGGCGCCGTGAAGTTTCCCCAGCTCTGCCAAGTTTCTGCGATGTCAGGGTTCAGCACCTGCGA TAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGC ATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCCACGTGCA GAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGGACAACCAGAAGTCCTGTATGAGCCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGGTGTGCGTGGCTGTCT GGCGGAAGAATGACGAGAATATCACCCTGGAAAACCGTCTGCCACGATCCCCAAGCTGCCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAAGAGAAAAGAAGCCTGGCGGAGACCTTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCAT CTTTAGCGAGGAATACAATACCAGCAACCCCGACAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAACCATCCTCGAATGGGAACCCAAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCT ATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCCTTACCTCGAGACCAATTTAGGACAGCCCACCAT CCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAAC CAACACAAACGAGTTTTTAATCGACGTGGATAAAGGGCGAAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAGGGCGAGTTCCGGGGAGAACTGGGTGAACGTCATCAG CGATTTAAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATT at least 80% identical (e.g., at least 82% identical, at least 84% identical , at least 86% identical, at least 88% identical, at least 90% identical , at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR(配列番号193)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the second chimeric polypeptide is
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNCSITSICEKPQEVCVAVWRKNDINITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPDGGGGGSGGGGGSGGGGSIPPHV QKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADIWVKSYSLYSRERYICNSG FKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR (SEQ ID NO: 193), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% sequences that are identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG(配列番号257)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the second chimeric polypeptide is
ATCCCCCCCCCATGTGCAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAA GAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGAACCTTCTTTATGTGTTCCTGTAGCAG CGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCC CCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCCACGATCCCCAAGCTGCCCTAC CACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAAGAGAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACATTACATGCCCCCCCTCCCATGAGCGTG GAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCTCACCGAGTGCGTGCTGAATAAGGCTCACCAACGTGGCTCACTGGACAACACCCTCTTAAAGTGCATCCGG (SEQ ID NO: 257) , at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical to , at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR(配列番号195)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the second chimeric polypeptide is
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGG GSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADI at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% sequences that are identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG(配列番号259)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the second chimeric polypeptide is
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCCATCCCCCCCCATGTGCAAAGAGCGTGAACAACGATATGATCGTGACCGACAACACGGCGCCGTGAAGTTTCCCCAGCTCTGCCAAGTTTCTGCGATGTCAGGGTTCAGCACCTGCGA TAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGC ATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCCACGTGCA GAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGGACAACCAGAAGTCCTGTATGAGCCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGGTGTGCGTGGCTGTCT GGCGGAAGAATGACGAGAATATCACCCTGGAAAACCGTCTGCCACGATCCCCAAGCTGCCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAAGAGAAAAGAAGCCTGGCGGAGACCTTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCAT CTTTAGCGAGGAATACAATACCAGCAACCCCCGACATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCTCACCGAGTGCGTGCTGAATAAG GCTACCAACGTGGCTCACTGGACACACCCTTTAAAGTGCATCCGG (SEQ ID NO: 259), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical , at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
例示的な多鎖キメラポリペプチド-タイプJ
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは各々独立して、IL-7受容体、IL-21受容体、又はCD137L受容体に特異的に結合する。本明細書に記載のこれらの多鎖キメラポリペプチドのいくつかの実施形態では、第2のキメラポリペプチドは、追加の標的結合ドメインを更に含む。本明細書に記載のこれらの多鎖キメラポリペプチドのいくつかの実施形態では、追加の標的結合ドメインは、IL-21(例えば、可溶性IL-21、例えば、可溶性ヒトIL-21)受容体又はCD137L(例えば、可溶性CD137L、例えば、可溶性ヒトCD137L)受容体に特異的に結合する。
Exemplary Multichain Chimeric Polypeptides—Type J
In some embodiments of any of the multichain chimeric polypeptides described herein, the first target binding domain and the second target binding domain are each independently IL-7 receptor, IL -21 receptor, or specifically binds to the CD137L receptor. In some embodiments of these multi-chain chimeric polypeptides described herein, the second chimeric polypeptide further comprises an additional target binding domain. In some embodiments of these multichain chimeric polypeptides described herein, the additional target binding domain is an IL-21 (eg, soluble IL-21, eg, soluble human IL-21) receptor or Binds specifically to the CD137L (eg, soluble CD137L, eg, soluble human CD137L) receptor.
これらの多鎖キメラポリペプチドのいくつかの例では、第1の標的結合ドメインと可溶性組織因子ドメインは、第1のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの例では、第1のキメラポリペプチドは、第1のキメラポリペプチド内の第1の標的結合ドメインと可溶性組織因子ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some examples of these multichain chimeric polypeptides, the first target binding domain and the soluble tissue factor domain are directly adjacent to each other within the first chimeric polypeptide. In some examples of these multichain chimeric polypeptides, the first chimeric polypeptide has a linker sequence (e.g., any of the exemplary linkers described herein).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインは、第1のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1のキメラポリペプチドは、第1のキメラポリペプチド内の可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these multi-chain chimeric polypeptides, the soluble tissue factor domain and the first of the paired affinity domains are directly adjacent to each other within the first chimeric polypeptide. In some embodiments of these multi-chain chimeric polypeptides, the first chimeric polypeptide is between the soluble tissue factor domain and the first of the pair of affinity domains within the first chimeric polypeptide. Further includes a linker sequence (eg, any of the exemplary linkers described herein).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、一対の親和性ドメインの第2のドメインと第2の標的結合ドメインは、第2のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチド内の一対の親和性ドメインの第2のドメインと第2の標的結合ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these multi-chain chimeric polypeptides, the second domain and the second target binding domain of the pair of affinity domains are directly adjacent to each other within the second chimeric polypeptide. In some embodiments of these multichain chimeric polypeptides, the second chimeric polypeptide is a combination of the second of the pair of affinity domains within the second chimeric polypeptide and the second target binding domain. Further includes a linker sequence (eg, any of the exemplary linkers described herein) in between.
いくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチドのN末端又はC末端に1つ以上の追加の標的結合ドメインを更に含む。 In some embodiments, the second chimeric polypeptide further comprises one or more additional target binding domains at the N-terminus or C-terminus of the second chimeric polypeptide.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、追加の標的結合ドメイン及び一対の親和性ドメインの第2のドメインは、第2のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチド内の一対の親和性ドメインの第2のドメインと追加の標的結合ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these multi-chain chimeric polypeptides, the additional target binding domain and the second domain of the pair of affinity domains are directly adjacent to each other within the second chimeric polypeptide. In some embodiments of these multichain chimeric polypeptides, the second chimeric polypeptide is between the second of the pair of affinity domains and the additional target binding domain within the second chimeric polypeptide. further includes a linker sequence (eg, any of the exemplary linkers described herein).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、追加の標的結合ドメインと第2の標的結合ドメインは、第2のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチド内の第2の標的結合ドメインと追加の標的結合ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these multi-chain chimeric polypeptides, the additional target binding domain and the second target binding domain are directly adjacent to each other within the second chimeric polypeptide. In some embodiments of these multichain chimeric polypeptides, the second chimeric polypeptide has a linker sequence ( For example, any of the exemplary linkers described herein).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性組織因子ドメインは、本明細書に記載の例示的な可溶性組織因子ドメインのうちのいずれかであり得る。これらの多鎖キメラポリペプチドのいくつかの実施形態では、一対の親和性ドメインは、本明細書に記載の例示的な一対の親和性ドメインのうちのいずれかであり得る。 In some embodiments of these multichain chimeric polypeptides, the soluble tissue factor domain can be any of the exemplary soluble tissue factor domains described herein. In some embodiments of these multi-chain chimeric polypeptides, the pair of affinity domains can be any of the exemplary pair of affinity domains described herein.
いくつかの実施形態では、第2のキメラポリペプチドは、追加の標的結合ドメインを含み得る。いくつかの実施形態では、追加の標的結合ドメイン及び。 In some embodiments, the second chimeric polypeptide may contain an additional target binding domain. In some embodiments, an additional target binding domain and.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び追加の標的結合ドメインのうちの1つ以上は、アゴニスト抗原結合ドメインである。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び追加の標的結合ドメインは各々、アゴニスト抗原結合ドメインである。これらの多鎖キメラポリペプチドのいくつかの実施形態では、抗原結合ドメインは、scFv又は単一ドメイン抗体を含む。 In some embodiments of these multichain chimeric polypeptides, one or more of the first target binding domain, the second target binding domain, and the additional target binding domain is an agonist antigen binding domain. In some embodiments of these multichain chimeric polypeptides, the first target binding domain, the second target binding domain, and the additional target binding domain are each agonist antigen binding domains. In some embodiments of these multi-chain chimeric polypeptides, the antigen binding domain comprises a scFv or single domain antibody.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメインはIL-7受容体に特異的に結合し、第2の標的結合ドメインはIL-21受容体又はCD137L受容体に特異的に結合する。いくつかの実施形態では、追加の標的結合ドメインは、IL-21受容体又はCD137L受容体に特異的に結合する。 In some embodiments of these multichain chimeric polypeptides, the first target binding domain specifically binds IL-7 receptor and the second target binding domain is IL-21 receptor or CD137L receptor. binds specifically to In some embodiments, the additional target binding domain specifically binds to IL-21 receptor or CD137L receptor.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメインは、可溶性IL-7(例えば、可溶性ヒトIL-7)である。これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトIL-7は、
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEH(配列番号79)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multichain chimeric polypeptides, the first target binding domain is soluble IL-7 (eg, soluble human IL-7). In some embodiments of these multi-chain chimeric polypeptides, the soluble human IL-7 is
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWN KILMGTKEH (SEQ ID NO: 79), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, sequences that are at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトIL-7は、
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCAT(配列番号227)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multi-chain chimeric polypeptides, the soluble human IL-7 is
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCCACATCTGCGACGCCAACAAGGAGGGCATGTTCCT GTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGA ACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCAT (SEQ ID NO: 227), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2の標的結合ドメイン又は追加の標的結合ドメインは、IL-21受容体に特異的に結合する。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2の標的結合ドメイン又は追加の標的結合ドメインは、可溶性IL-21(例えば、可溶性ヒトIL-21)である。 In some embodiments of these multichain chimeric polypeptides, the second target binding domain or additional target binding domain specifically binds to the IL-21 receptor. In some embodiments of these multichain chimeric polypeptides, the second or additional target binding domain is soluble IL-21 (eg, soluble human IL-21).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトIL-21は、
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS(配列番号83)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multi-chain chimeric polypeptides, the soluble human IL-21 is
at least 80% identical to QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS (SEQ ID NO: 83), (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, sequences that are at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトIL-21は、
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC(配列番号182)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multi-chain chimeric polypeptides, the soluble human IL-21 is
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCG CCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCCTCCACAAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCCTGCTGCAGAAGAT GATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC (SEQ ID NO: 182), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2の標的結合ドメインは、CD137L受容体に特異的に結合する。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2のキメラポリペプチドは、CD137L受容体に特異的に結合する追加の標的結合ドメインを更に含む。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2の標的結合ドメイン及び/又は追加の標的結合ドメインは、可溶性CD137L(例えば、可溶性ヒトCD137L)である。 In some embodiments of these multichain chimeric polypeptides, the second target binding domain specifically binds the CD137L receptor. In some embodiments of these multichain chimeric polypeptides, the second chimeric polypeptide further comprises an additional target binding domain that specifically binds to the CD137L receptor. In some embodiments of these multichain chimeric polypeptides, the second and/or additional target binding domains are soluble CD137L (eg, soluble human CD137L).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトCD137Lは、
REGPELSPDDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEIPAGLPSPRSE(配列番号260)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multi-chain chimeric polypeptides, the soluble human CD137L is
REGPELSPDDPAGLLDLLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSSVSLALHLQPLRSAAGAAALALTVDLLPPASSEARNSAFGFQGRLLHLSAGQRLGV HLHTEARARHAWQLTQGATVLGLFRVTPEIPAGLPSPRSSE (SEQ ID NO: 260), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical , at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトCD137Lは、
CGCGAGGGTCCCGAGCTTTCGCCCGACGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATCCCAGCCGGACTCCCTTCACCGAGGTCGGAA(配列番号261)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multi-chain chimeric polypeptides, the soluble human CD137L is
CGCGAGGGTCCCGAGCTTTCGCCCCGACGATCCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCGCAGCTGGTGGCCCAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCCAGGCCTGGCAGGGCGTGTCCCTGACGGGGGGC CTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTG GCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGG at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% % identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトCD137Lは、
DPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEI(配列番号262)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multi-chain chimeric polypeptides, the soluble human CD137L is
DPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARAR HAWQLTQGATVLGLFRVTPEI (SEQ ID NO: 262), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, sequences that are at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトCD137Lは、
GATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATC(配列番号263)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multichain chimeric polypeptides, the soluble human CD137L is
GATCCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGGCGTGTCCCTGACGGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGG TGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCT CCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGGCAGCTTACCCAGGGCGCCACAGTCTTTGGACTCTTCCGGGTGACCCCCGAAAATC (SEQ ID NO: 2) 63), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEHSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(配列番号207)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the first chimeric polypeptide is
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDHLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWN KILMGTKEHSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTL VRRNNTFLSLRDVFGKDLIYTLYYWKSSSSSGKKTAKTNTNEFLIDVDKGENYCFSVVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHD at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% sequences that are identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCATAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(配列番号208)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the first chimeric polypeptide is
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCCACATCTGCGACGCCAACAAGGAGGGCATGTTCCT GTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGA ACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCATAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATG GGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAGATGTGAAAGATGTGAAAACAGACCTACCTCGCCCGGGTGTTTTAGCTACCCCGCCCGGCAATGTGGAGA GCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGGAACAACACCTTTCTCTCGCGG GATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAACCAACACAAACGAGTTTTAATCGACGTGGATAAAGGCGAAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAA GCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAGATTTAATTCAGTCCATGCATATCGACGCCACTTTTATACACAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAAT GTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATC CTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC (SEQ ID NO: 208), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical to % identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
MKWVTFISLLFLFSSAYSDCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEHSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(配列番号209)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the first chimeric polypeptide is
MKWVTFISLLFFSSAYSDCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLN DLCFLKRLLQEIKTCWNKILMGTKEHSGTTNVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSF EQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCCKVTAM at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% sequences that are identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCGATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCATAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(配列番号210)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the first chimeric polypeptide is
ATGAAGTGGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCCGATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGT TCAACTTCTTCAAGCGGCCACATCTGCGACGCCAACAAGGAGGGGCATGTTCCTGTTCAGGGCCGCCAGGAAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGG TGAAGGGCCGGAAACCTGCTGCTCTGGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCATAGCGGCCACAACCAAC ACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGAT GTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACA GTGGAGGACGAGCGGACTTTAGTGCGGCGGCGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAAACGAGTTTTTTAATCGACGTGGATAAAGGCGAAA ACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAGGGCGAGTTCCGGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATC GACGCCACTTTATACACAGAATCCGACGTGCACCCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCC GGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC (SEQ ID NO: 210), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical to % identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDSITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRGGGGSGGGGSGGGGSREGPELSPDDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEIPAGLPSPRSE(配列番号268)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the second chimeric polypeptide is
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDSITCPPPMSVEHADIWVKS YSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRGGGGSGGGGSGGGGSREGPELSPDDPAGLLDLLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVV AGEGSGSVSLALHLQPLRSAAGAAAALALTTVDLPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEIPAGLPSPRSE (SEQ ID NO: 268), at least 90% identical, at least 92% identical, at least 94% sequences that are identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCCATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCTCGCGAGGGTCCCGAGCTTTCGCCCGACGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATCCCAGCCGGACTCCCTTCACCGAGGTCGGAA(配列番号269)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)の配列によってコードされる。
In some embodiments, the second chimeric polypeptide is
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCG CCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCCTCCACAAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCCTGCTGCAGAAGAT GATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCCATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCTCTCACCGAGTGCG TGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTTTAAAGTGCATCCGGGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGCGGCGGAGGATCTCGCGAGGGTCCCGAGCTTTCGCCCCGACGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATG TTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCCAGGCCTGGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCCAAGGCTGGAGTCTACTATGTCTTCTTTCAAC TAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCGCGCCTCCTCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCG at least 80% identical to CTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATCCCAGCCGGACTCCCTTCACCGAGGTCGGAA (SEQ ID NO: 269), (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical , at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
MKWVTFISLLFLFSSAYSQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDSITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRGGGGSGGGGSGGGGSREGPELSPDDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEIPAGLPSPRSE(配列番号270)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the second chimeric polypeptide is
MKWVTFISLLFFSSAYSQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGS EDSITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRGGGGSGGGGSGGGGSREGPELSPDDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVA at least 80% identical (e.g., at least 82% identical, at least 8 4% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% sequences that are identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCCAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCCATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCTCGCGAGGGTCCCGAGCTTTCGCCCGACGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATCCCAGCCGGACTCCCTTCACCGAGGTCGGAA(配列番号271)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the second chimeric polypeptide is
ATGAAGTGGGGTGACCTTCATCAGCCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCCAGGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGA CCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTAC GAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCCATTACATGCCCCCCCTCCCATGAGCGTGGAGCACGCGACATCTGGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTAT ATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACACACCCTCTTTAAAGTGCATCCGGGGCGGTGGAGGATCCGGAGGGAGGTGGCTCCGGCGGCGGAGGATCTCGCGAGGGTC CCGAGCTTTCGCCCCGACGATCCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGG ACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGGCTGCGGCGCGTGGGTGGCCGGCGCGGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGAC CTGCCACCCGCCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGAC at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDSITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRGGGGSGGGGSGGGGSDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEI(配列番号272)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the second chimeric polypeptide is
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDSITCPPPMSVEHADIWVKS YSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRGGGGSGGGGSGGGGSDPAGLLDLLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSV at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% sequences that are identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCCATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCTGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATC(配列番号273)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the second chimeric polypeptide is
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCG CCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCCTCCACAAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCCTGCTGCAGAAGAT GATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCCATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCTCTCACCGAGTGCG TGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGGCGGAGGATCTGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAAATGT TCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCCAGGCCTGGCAGGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTTAGAGCTGCGGCGCGTGGTGGCCGGG CGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGC at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical , at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
MKWVTFISLLFLFSSAYSQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDSITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRGGGGSGGGGSGGGGSDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEI(配列番号274)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the second chimeric polypeptide is
MKWVTFISLLFFSSAYSQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGS EDSITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRGGGSGGGGSGGGGSDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYV FFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTTVDLPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEI (SEQ ID NO: 274), and at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88 % identical, at least 90% identical, at least 92% identical, at least 94% sequences that are identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCCAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCCATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCTGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATC(配列番号275)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the second chimeric polypeptide is
ATGAAGTGGGGTGACCTTCATCAGCCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCCAGGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGA CCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTAC GAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCCATTACATGCCCCCCCTCCCATGAGCGTGGAGCACGCGACATCTGGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTAT ATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGATAAGGCCTACCAACGTGGCTCACTGGACACACCCTCTTTAAAGTGCATCCGGGGCGGTGGAGGATCCGGAGGGAGGTGGCTCCGGCGGCGGAGGATCTGATCCCGCCGGGC CTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGG CTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTC GGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATC (SEQ ID NO: 275), and at least 80% identical ( For example, at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical , at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
例示的な多鎖キメラポリペプチド-タイプK
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは各々独立して、IL-7受容体又はTGF-βに特異的に結合する。これらの多鎖キメラポリペプチドのいくつかの例では、第1の標的結合ドメイン及び可溶性組織因子ドメインは、第1のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの例では、第1のキメラポリペプチドは、第1のキメラポリペプチド内の第1の標的結合ドメインと可溶性組織因子ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。
Exemplary Multichain Chimeric Polypeptides—Type K
In some embodiments of any of the multi-chain chimeric polypeptides described herein, the first target binding domain and the second target binding domain are each independently IL-7 receptor or TGF. - binds specifically to β; In some examples of these multichain chimeric polypeptides, the first target binding domain and the soluble tissue factor domain are directly adjacent to each other within the first chimeric polypeptide. In some examples of these multichain chimeric polypeptides, the first chimeric polypeptide has a linker sequence (e.g., any of the exemplary linkers described herein).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインは、第1のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1のキメラポリペプチドは、第1のキメラポリペプチド内の可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these multi-chain chimeric polypeptides, the soluble tissue factor domain and the first of the paired affinity domains are directly adjacent to each other within the first chimeric polypeptide. In some embodiments of these multi-chain chimeric polypeptides, the first chimeric polypeptide is between the soluble tissue factor domain and the first of the pair of affinity domains within the first chimeric polypeptide. Further includes a linker sequence (eg, any of the exemplary linkers described herein).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、一対の親和性ドメインの第2のドメインと第2の標的結合ドメインは、第2のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチド内の一対の親和性ドメインの第2のドメインと第2の標的結合ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these multi-chain chimeric polypeptides, the second domain and the second target binding domain of the pair of affinity domains are directly adjacent to each other within the second chimeric polypeptide. In some embodiments of these multichain chimeric polypeptides, the second chimeric polypeptide is a combination of the second of the pair of affinity domains within the second chimeric polypeptide and the second target binding domain. Further includes a linker sequence (eg, any of the exemplary linkers described herein) in between.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性組織因子ドメインは、本明細書に記載の例示的な可溶性組織因子ドメインのうちのいずれかであり得る。これらの多鎖キメラポリペプチドのいくつかの実施形態では、一対の親和性ドメインは、本明細書に記載の例示的な一対の親和性ドメインのうちのいずれかであり得る。 In some embodiments of these multichain chimeric polypeptides, the soluble tissue factor domain can be any of the exemplary soluble tissue factor domains described herein. In some embodiments of these multi-chain chimeric polypeptides, the pair of affinity domains can be any of the exemplary pair of affinity domains described herein.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメインはIL-7受容体に特異的に結合し、第2の標的結合ドメインはTGF-βに特異的に結合する。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメインはTGF-βに特異的に結合し、第2の標的結合ドメインはIL-7受容体に特異的に結合する。 In some embodiments of these multichain chimeric polypeptides, the first target binding domain specifically binds IL-7 receptor and the second target binding domain specifically binds TGF-β. . In some embodiments of these multichain chimeric polypeptides, the first target binding domain specifically binds TGF-β and the second target binding domain specifically binds IL-7 receptor. .
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメインは、可溶性IL-7タンパク質(例えば、可溶性ヒトIL-7タンパク質)を含む。これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトIL-7タンパク質は、
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEH(配列番号79)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multichain chimeric polypeptides, the first target binding domain comprises a soluble IL-7 protein (eg, soluble human IL-7 protein). In some embodiments of these multi-chain chimeric polypeptides, the soluble human IL-7 protein is
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWN KILMGTKEH (SEQ ID NO: 79), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, sequences that are at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトIL-7は、
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCAT(配列番号227)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multi-chain chimeric polypeptides, the soluble human IL-7 is
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCCACATCTGCGACGCCAACAAGGAGGGCATGTTCCT GTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGA ACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCAT (SEQ ID NO: 227), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2の標的結合ドメインは、TGF-βに特異的に結合する標的結合ドメインを含む。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2の標的結合ドメインは、可溶性TGF-β受容体(例えば、可溶性TGFβRII受容体、例えば、可溶性ヒトTGFβRII受容体)である。これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトTGFRβRIIは、第1の可溶性ヒトTGFRβRII配列及び第2の可溶性ヒトTGFRβRII配列を含む。これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトTGFRβRIIは、第1の可溶性ヒトTGFRβRII配列と第2の可溶性ヒトTGFRβRII配列との間に配置されたリンカーを含む。これらの多鎖キメラポリペプチドのいくつかの例では、リンカーは、配列GGGGSGGGGSGGGGS(配列番号102)を含む。 In some embodiments of these multichain chimeric polypeptides, the second target binding domain comprises a target binding domain that specifically binds TGF-β. In some embodiments of these multichain chimeric polypeptides, the second target binding domain is a soluble TGF-β receptor (eg, soluble TGFβRII receptor, eg, soluble human TGFβRII receptor). In some embodiments of these multichain chimeric polypeptides, the soluble human TGFRβRII comprises a first soluble human TGFRβRII sequence and a second soluble human TGFRβRII sequence. In some embodiments of these multichain chimeric polypeptides, the soluble human TGFRβRII comprises a linker positioned between the first soluble human TGFRβRII sequence and the second soluble human TGFRβRII sequence. In some examples of these multichain chimeric polypeptides, the linker comprises the sequence GGGGSGGGGSGGGGGS (SEQ ID NO: 102).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の可溶性ヒトTGFRβRII受容体配列は、
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD(配列番号183)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multichain chimeric polypeptides, the first soluble human TGFRβRII receptor sequence is
at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, sequences that are at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2の可溶性ヒトTGFRβRII受容体配列は、
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD(配列番号184)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multichain chimeric polypeptides, the second soluble human TGFRβRII receptor sequence is
at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, sequences that are at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の可溶性ヒトTGFRβRII受容体配列は、
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGAT(配列番号185)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multichain chimeric polypeptides, the first soluble human TGFRβRII receptor sequence is
ATCCCCCCCCCATGTGCCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTTCTGCGATGTCAGGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAA GAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGAACCTTCTTTATGTGTTCCTGTAGCAG CGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACCCAGCAACCCTGAT (SEQ ID NO: 185), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2の可溶性ヒトTGFRβRII受容体配列は、
ATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC(配列番号186)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multichain chimeric polypeptides, the second soluble human TGFRβRII receptor sequence is
ATTCCTCCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGG TGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAAACCGTCTGCCCACGATCCCCAAGCTGCCCTACCCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAAGAGAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGC at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性TGF-β受容体は、
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD(配列番号188)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multichain chimeric polypeptides, the soluble TGF-β receptor is
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNSITSITSICEKPQEVCVAVWRKNDINITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPDGGGGGSGGGGGSGGGGGSIPPHV at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical , at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性TGF-β受容体は、
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC(配列番号187)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multichain chimeric polypeptides, the soluble TGF-β receptor is
ATCCCCCCCCCATGTGCAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAA GAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGAACCTTCTTTATGTGTTCCTGTAGCAG CGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCC CCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCCACGATCCCCAAGCTGCCCTAC CACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCCGAC (SEQ ID NO: 187), and at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEHSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(配列番号207)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the first chimeric polypeptide is
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWN KILMGTKEHSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTL VRRNNTFLSLRDVFGKDLIYTLYYWKSSSSSGKKTAKTNTNEFLIDVDKGENYCFSVVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHD at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% sequences that are identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCATAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(配列番号208)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the first chimeric polypeptide is
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCCACATCTGCGACGCCAACAAGGAGGGCATGTTCCT GTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGA ACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCATAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATG GGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAGATGTGAAAGATGTGAAAACAGACCTACCTCGCCCGGGTGTTTTAGCTACCCCGCCCGGCAATGTGGAGA GCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGGAACAACACCTTTCTCTCGCGG GATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAACCAACACAAACGAGTTTTAATCGACGTGGATAAAGGCGAAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAA GCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAGATTTAATTCAGTCCATGCATATCGACGCCACTTTTATACACAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAAT GTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCCAATC CTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC (SEQ ID NO: 208), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical to % identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
MKWVTFISLLFLFSSAYSDCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEHSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(配列番号209)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the first chimeric polypeptide is
MKWVTFISLLFFSSAYSDCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLN DLCFLKRLLQEIKTCWNKILMGTKEHSGTTNVAAYNLTWKSTNFKTILEWEPKKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSF EQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCCKVTAM at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% sequences that are identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCGATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCATAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(配列番号210)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the first chimeric polypeptide is
ATGAAGTGGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCCGATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGT TCAACTTCTTCAAGCGGCCACATCTGCGACGCCAACAAGGAGGGGCATGTTCCTGTTCAGGGCCGCCAGGAAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGG TGAAGGGCCGGAAACCTGCTGCTCTGGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCATAGCGGCCACAACCAAC ACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGAT GTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACA GTGGAGGACGAGCGGACTTTAGTGCGGCGGCGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAAACGAGTTTTTTAATCGACGTGGATAAAGGCGAAA ACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAGGGCGAGTTCCGGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATC GACGCCACTTTATACACAGAATCCGACGTGCACCCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCC GGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC (SEQ ID NO: 210), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% % identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR(配列番号193)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the second chimeric polypeptide is
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNCSITSICEKPQEVCVAVWRKNDINITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPDGGGGGSGGGGGSGGGGSIPPHV QKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADIWVKSYSLYSRERYICNSG FKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR (SEQ ID NO: 193), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% sequences that are identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG(配列番号257)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the second chimeric polypeptide is
ATCCCCCCCCCATGTGCAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAA GAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGAACCTTCTTTATGTGTTCCTGTAGCAG CGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCC CCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCCACGATCCCCAAGCTGCCCTAC CACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAAGAGAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACATTACATGCCCCCCCTCCCATGAGCGTG GAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCTCACCGAGTGCGTGCTGAATAAGGCTCACCAACGTGGCTCACTGGACAACACCCTCTTAAAGTGCATCCGG (SEQ ID NO: 257) , at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical to , at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR(配列番号195)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the second chimeric polypeptide is
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGG GSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADI at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% sequences that are identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG(配列番号259)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the second chimeric polypeptide is
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCCATCCCCCCCCATGTGCAAAGAGCGTGAACAACGATATGATCGTGACCGACAACACGGCGCCGTGAAGTTTCCCCAGCTCTGCCAAGTTTCTGCGATGTCAGGGTTCAGCACCTGCGA TAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGC ATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCCACGTGCA GAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGGACAACCAGAAGTCCTGTATGAGCCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGGTGTGCGTGGCTGTCT GGCGGAAGAATGACGAGAATATCACCCTGGAAAACCGTCTGCCACGATCCCCAAGCTGCCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAAGAGAAAAGAAGCCTGGCGGAGACCTTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCAT CTTTAGCGAGGAATACAATACCAGCAACCCCCGACATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCTCACCGAGTGCGTGCTGAATAAG GCTACCAACGTGGCTCACTGGACACACCCTTTAAAGTGCATCCGG (SEQ ID NO: 259), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical , at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
例示的な多鎖キメラポリペプチド-タイプL
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは各々独立して、TGF-β、IL-21受容体、又はCD137L受容体に特異的に結合する。本明細書に記載のこれらの多鎖キメラポリペプチドのいくつかの実施形態では、第2のキメラポリペプチドは、追加の標的結合ドメインを更に含む。本明細書に記載のこれらの多鎖キメラポリペプチドのいくつかの実施形態では、追加の標的結合ドメインは、IL-21(例えば、可溶性IL-21、例えば、可溶性ヒトIL-21)受容体又はCD137L(例えば、可溶性CD137L、例えば、可溶性ヒトCD137L)受容体に特異的に結合する。
Exemplary Multichain Chimeric Polypeptides—Type L
In some embodiments of any of the multichain chimeric polypeptides described herein, the first target binding domain and the second target binding domain are each independently TGF-β, IL-21 Binds specifically to the receptor, or CD137L receptor. In some embodiments of these multi-chain chimeric polypeptides described herein, the second chimeric polypeptide further comprises an additional target binding domain. In some embodiments of these multichain chimeric polypeptides described herein, the additional target binding domain is an IL-21 (eg, soluble IL-21, eg, soluble human IL-21) receptor or Binds specifically to the CD137L (eg, soluble CD137L, eg, soluble human CD137L) receptor.
これらの多鎖キメラポリペプチドのいくつかの例では、第1の標的結合ドメインと可溶性組織因子ドメインは、第1のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの例では、第1のキメラポリペプチドは、第1のキメラポリペプチド内の第1の標的結合ドメインと可溶性組織因子ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some examples of these multichain chimeric polypeptides, the first target binding domain and the soluble tissue factor domain are directly adjacent to each other within the first chimeric polypeptide. In some examples of these multichain chimeric polypeptides, the first chimeric polypeptide has a linker sequence (e.g., any of the exemplary linkers described herein).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインは、第1のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1のキメラポリペプチドは、第1のキメラポリペプチド内の可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these multi-chain chimeric polypeptides, the soluble tissue factor domain and the first of the paired affinity domains are directly adjacent to each other within the first chimeric polypeptide. In some embodiments of these multi-chain chimeric polypeptides, the first chimeric polypeptide is between the soluble tissue factor domain and the first of the pair of affinity domains within the first chimeric polypeptide. Further includes a linker sequence (eg, any of the exemplary linkers described herein).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、一対の親和性ドメインの第2のドメインと第2の標的結合ドメインは、第2のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチド内の一対の親和性ドメインの第2のドメインと第2の標的結合ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these multi-chain chimeric polypeptides, the second domain and the second target binding domain of the pair of affinity domains are directly adjacent to each other within the second chimeric polypeptide. In some embodiments of these multichain chimeric polypeptides, the second chimeric polypeptide is a combination of the second of the pair of affinity domains within the second chimeric polypeptide and the second target binding domain. Further includes a linker sequence (eg, any of the exemplary linkers described herein) in between.
いくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチドのN末端又はC末端に1つ以上の追加の標的結合ドメインを更に含む。 In some embodiments, the second chimeric polypeptide further comprises one or more additional target binding domains at the N-terminus or C-terminus of the second chimeric polypeptide.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、追加の標的結合ドメイン及び一対の親和性ドメインの第2のドメインは、第2のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチド内の一対の親和性ドメインの第2のドメインと追加の標的結合ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these multi-chain chimeric polypeptides, the additional target binding domain and the second domain of the pair of affinity domains are directly adjacent to each other within the second chimeric polypeptide. In some embodiments of these multichain chimeric polypeptides, the second chimeric polypeptide is between the second of the pair of affinity domains and the additional target binding domain within the second chimeric polypeptide. further includes a linker sequence (eg, any of the exemplary linkers described herein).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、追加の標的結合ドメインと第2の標的結合ドメインは、第2のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチド内の第2の標的結合ドメインと追加の標的結合ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these multi-chain chimeric polypeptides, the additional target binding domain and the second target binding domain are directly adjacent to each other within the second chimeric polypeptide. In some embodiments of these multichain chimeric polypeptides, the second chimeric polypeptide has a linker sequence ( For example, any of the exemplary linkers described herein).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性組織因子ドメインは、本明細書に記載の例示的な可溶性組織因子ドメインのうちのいずれかであり得る。これらの多鎖キメラポリペプチドのいくつかの実施形態では、一対の親和性ドメインは、本明細書に記載の例示的な一対の親和性ドメインのうちのいずれかであり得る。 In some embodiments of these multichain chimeric polypeptides, the soluble tissue factor domain can be any of the exemplary soluble tissue factor domains described herein. In some embodiments of these multi-chain chimeric polypeptides, the pair of affinity domains can be any of the exemplary pair of affinity domains described herein.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び追加の標的結合ドメインのうちの1つ以上は、アゴニスト抗原結合ドメインである。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン、第2の標的結合ドメイン、及び追加の標的結合ドメインは各々、アゴニスト抗原結合ドメインである。これらの多鎖キメラポリペプチドのいくつかの実施形態では、抗原結合ドメインは、scFv又は単一ドメイン抗体を含む。 In some embodiments of these multichain chimeric polypeptides, one or more of the first target binding domain, the second target binding domain, and the additional target binding domain is an agonist antigen binding domain. In some embodiments of these multichain chimeric polypeptides, the first target binding domain, the second target binding domain, and the additional target binding domain are each agonist antigen binding domains. In some embodiments of these multi-chain chimeric polypeptides, the antigen binding domain comprises a scFv or single domain antibody.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメインはTGF-βに特異的に結合し、第2の標的結合ドメインはIL-21受容体又はCD137L受容体に特異的に結合する。 In some embodiments of these multichain chimeric polypeptides, the first target binding domain specifically binds TGF-β and the second target binding domain is specific for IL-21 receptor or CD137L receptor. physically connect.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメインは、可溶性TGF-β受容体(例えば、可溶性TGFβRII受容体、例えば、可溶性ヒトTGFβRII受容体)である。これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトTGFRβRIIは、第1の可溶性ヒトTGFRβRII配列及び第2の可溶性ヒトTGFRβRII配列を含む。これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトTGFRβRIIは、第1の可溶性ヒトTGFRβRII配列と第2の可溶性ヒトTGFRβRII配列との間に配置されたリンカーを含む。これらの多鎖キメラポリペプチドのいくつかの例では、リンカーは、配列GGGGSGGGGSGGGGS(配列番号102)を含む。 In some embodiments of these multichain chimeric polypeptides, the first target binding domain is a soluble TGF-β receptor (eg, soluble TGFβRII receptor, eg, soluble human TGFβRII receptor). In some embodiments of these multichain chimeric polypeptides, the soluble human TGFRβRII comprises a first soluble human TGFRβRII sequence and a second soluble human TGFRβRII sequence. In some embodiments of these multichain chimeric polypeptides, the soluble human TGFRβRII comprises a linker positioned between the first soluble human TGFRβRII sequence and the second soluble human TGFRβRII sequence. In some examples of these multichain chimeric polypeptides, the linker comprises the sequence GGGGSGGGGSGGGGGS (SEQ ID NO: 102).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の可溶性ヒトTGFRβRII受容体配列は、
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD(配列番号183)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multichain chimeric polypeptides, the first soluble human TGFRβRII receptor sequence is
at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, sequences that are at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2の可溶性ヒトTGFRβRII受容体配列は、
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD(配列番号184)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multichain chimeric polypeptides, the second soluble human TGFRβRII receptor sequence is
at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, sequences that are at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の可溶性ヒトTGFRβRII受容体配列は、
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGAT(配列番号185)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multichain chimeric polypeptides, the first soluble human TGFRβRII receptor sequence is
ATCCCCCCCCCATGTGCAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAA GAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGAACCTTCTTTATGTGTTCCTGTAGCAG CGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGAT (SEQ ID NO: 185), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2の可溶性ヒトTGFRβRII受容体配列は、
ATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC(配列番号186)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multichain chimeric polypeptides, the second soluble human TGFRβRII receptor sequence is
ATTCCTCCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGG TGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAAACCGTCTGCCCACGATCCCCAAGCTGCCCTACCCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAAGAGAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGC at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性TGF-β受容体は、
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD(配列番号188)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multichain chimeric polypeptides, the soluble TGF-β receptor is
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNCSITSICEKPQEVCVAVWRKNDINITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPDGGGGGSGGGGGSGGGGSIPPHV at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical , at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性TGF-β受容体は、
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC(配列番号187)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multichain chimeric polypeptides, the soluble TGF-β receptor is
ATCCCCCCCCCATGTGCAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAA GAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGAACCTTCTTTATGTGTTCCTGTAGCAG CGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCC CCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCCACGATCCCCAAGCTGCCCTAC CACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCCGAC (SEQ ID NO: 187), and at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2の標的結合ドメイン又は追加の標的結合ドメインは、IL-21受容体に特異的に結合する。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2の標的結合ドメイン又は追加の標的結合ドメインは、可溶性IL-21(例えば、可溶性ヒトIL-21)を含む。 In some embodiments of these multichain chimeric polypeptides, the second target binding domain or additional target binding domain specifically binds to the IL-21 receptor. In some embodiments of these multichain chimeric polypeptides, the second or additional target binding domain comprises soluble IL-21 (eg, soluble human IL-21).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトIL-21は、
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS(配列番号83)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multi-chain chimeric polypeptides, the soluble human IL-21 is
at least 80% identical to QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS (SEQ ID NO: 83), (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, sequences that are at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトIL-21は、
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC(配列番号182)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multi-chain chimeric polypeptides, the soluble human IL-21 is
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCG CCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCCTCCACAAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCCTGCTGCAGAAGAT GATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC (SEQ ID NO: 182), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2の標的結合ドメイン又は追加の標的結合ドメインは、CD137L受容体に特異的に結合する。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2の標的結合ドメイン及び/又は追加の標的結合ドメインは、可溶性CD137L(例えば、可溶性ヒトCD137L)を含む。 In some embodiments of these multichain chimeric polypeptides, the second target binding domain or additional target binding domain specifically binds to the CD137L receptor. In some embodiments of these multichain chimeric polypeptides, the second and/or additional target binding domains comprise soluble CD137L (eg, soluble human CD137L).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性CD137Lは、
REGPELSPDDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEIPAGLPSPRSE(配列番号260)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multichain chimeric polypeptides, the soluble CD137L is
REGPELSPDDPAGLLDLLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSSVSLALHLQPLRSAAGAAALALTVDLLPPASSEARNSAFGFQGRLLHLSAGQRLGV HLHTEARARHAWQLTQGATVLGLFRVTPEIPAGLPSPRSSE (SEQ ID NO: 260), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical , at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性CD137Lは、
CGCGAGGGTCCCGAGCTTTCGCCCGACGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATCCCAGCCGGACTCCCTTCACCGAGGTCGGAA(配列番号261)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multichain chimeric polypeptides, the soluble CD137L is
CGCGAGGGTCCCGAGCTTTCGCCCCGACGATCCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCGCAGCTGGTGGCCCAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCCAGGCCTGGCAGGGCGTGTCCCTGACGGGGGGC CTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTG GCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGG at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% % identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトCD137Lは、
DPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEI(配列番号262)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multichain chimeric polypeptides, the soluble human CD137L is
DPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARAR HAWQLTQGATVLGLFRVTPEI (SEQ ID NO: 262), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, sequences that are at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトCD137Lは、
GATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATC(配列番号263)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multi-chain chimeric polypeptides, the soluble human CD137L is
GATCCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGGCGTGTCCCTGACGGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGG TGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCT CCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGGCGTCCATCTTCACACTGAGGCCAGGGCAGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTTGGACTCTTCCGGGTGACCCCCGAAAATC (SEQ ID NO: 2) 63), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(配列番号236)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the first chimeric polypeptide is
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNCSITSICEKPQEVCVAVWRKNDINITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPDGGGGGSGGGGGSGGGGSIPPHV QKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDSGTTNTVAAYNLTWKSTNFKTILEWEPK PVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTA KTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANSLSSNGNVTESGCKECEELEEKNIKEFLQ SFVHIVQMFINTS (SEQ ID NO: 236), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical % identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(配列番号237)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされ得る。
In some embodiments, the first chimeric polypeptide is
ATCCCCCCCCCATGTGCAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAA GAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGAACCTTCTTTATGTGTTCCTGTAGCAG CGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCC CCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCCACGATCCCCAAGCTGCCCTAC CACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACAGCGGCACAACCAACACAGTCGCTGCC TATAACCTCACTTGGAAGAGCACCAACTTCAAACCATCCTCGAATGGGAACCCAAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTAACCACCGACACCGAGTGCGATCTCACCGATGGAGATCGTGAAAAGATGTGAAAACAGACCT ACCTCGCCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAG CGGACTTTAGTGCGGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAG CGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGGAGTTCCGGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGAATTTAATTCAGTCCATGCATATCGACGCCACTTTATA CACAGAATCCGACGTGCACCCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAG at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(配列番号238)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the first chimeric polypeptide is
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGG GSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPDSGTTNTVAAY NLTWKSTNFKTILEWEPKKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNNTFLSLRDVFGKDLI YTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVIDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLILANNSLSSNGNVTESG CKECEELEEEKNIKEFLQSFVHIVQMFINTS (SEQ ID NO: 238), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical % identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(配列番号239)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the first chimeric polypeptide is
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCCATCCCCCCCCATGTGCAAAGAGCGTGAACAACGATATGATCGTGACCGACAACACGGCGCCGTGAAGTTTCCCCAGCTCTGCCAAGTTTCTGCGATGTCAGGGTTCAGCACCTGCGA TAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGC ATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCCACGTGCA GAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGGACAACCAGAAGTCCTGTATGAGCCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGGTGTGCGTGGCTGTCT GGCGGAAGAATGACGAGAATATCACCCTGGAAAACCGTCTGCCACGATCCCCAAGCTGCCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAAGAGAAAAGAAGCCTGGCGGAGACCTTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCAT CTTTAGCGAGGAATACAATACCAGCAACCCCGACAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAACCATCCTCGAATGGGAACCCAAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCT ATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCCTTACCTCGAGACCAATTTAGGACAGCCCACCAT CCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAAC CAACACAAACGAGTTTTTAATCGACGTGGATAAAGGGCGAAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAGGGCGAGTTCCGGGGAGAACTGGGTGAACGTCATCAG CGATTTAAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATT at least 80% identical (e.g., at least 82% identical, at least 84% identical , at least 86% identical, at least 88% identical, at least 90% identical , at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDSITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRGGGGSGGGGSGGGGSREGPELSPDDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEIPAGLPSPRSE(配列番号268)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the second chimeric polypeptide is
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDSITCPPPMSVEHADIWVKS YSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRGGGGSGGGGSGGGGSREGPELSPDDPAGLLDLLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVV at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% sequences that are identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCCATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCTCGCGAGGGTCCCGAGCTTTCGCCCGACGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATCCCAGCCGGACTCCCTTCACCGAGGTCGGAA(配列番号269)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the second chimeric polypeptide is
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCG CCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCCTCCACAAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCCTGCTGCAGAAGAT GATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCCATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCTCTCACCGAGTGCG TGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTTTAAAGTGCATCCGGGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGCGGCGGAGGATCTCGCGAGGGTCCCGAGCTTTCGCCCCGACGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATG TTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCCAGGCCTGGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCCAAGGCTGGAGTCTACTATGTCTTCTTTCAAC TAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCGCGCCTCCTCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCG at least 80% identical to CTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATCCCAGCCGGACTCCCTTCACCGAGGTCGGAA (SEQ ID NO: 269), (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical , at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
MKWVTFISLLFLFSSAYSQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDSITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRGGGGSGGGGSGGGGSREGPELSPDDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEIPAGLPSPRSE(配列番号270)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the second chimeric polypeptide is
MKWVTFISLLFFSSAYSQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGS EDSITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRGGGGSGGGGSGGGGSREGPELSPDDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVA at least 80% identical (e.g., at least 82% identical, at least 8 4% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% sequences that are identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCCAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCCATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCTCGCGAGGGTCCCGAGCTTTCGCCCGACGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATCCCAGCCGGACTCCCTTCACCGAGGTCGGAA(配列番号271)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the second chimeric polypeptide is
ATGAAGTGGGGTGACCTTCATCAGCCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCCAGGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGA CCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTAC GAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCCATTACATGCCCCCCCTCCCATGAGCGTGGAGCACGCGACATCTGGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTAT ATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACACACCCTCTTTAAAGTGCATCCGGGGCGGTGGAGGATCCGGAGGGAGGTGGCTCCGGCGGCGGAGGATCTCGCGAGGGTC CCGAGCTTTCGCCCCGACGATCCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGG ACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGGCTGCGGCGCGTGGGTGGCCGGCGCGGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGAC CTGCCACCCGCCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGAC at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDSITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRGGGGSGGGGSGGGGSDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEI(配列番号272)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the second chimeric polypeptide is
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDSITCPPPMSVEHADIWVKS YSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRGGGGSGGGGSGGGGSDPAGLLDLLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSV at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% sequences that are identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCCATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCTGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATC(配列番号273)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the second chimeric polypeptide is
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCG CCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCCTCCACAAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCCTGCTGCAGAAGAT GATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCCATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCTCTCACCGAGTGCG TGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGGCGGAGGATCTGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAAATGT TCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCCAGGCCTGGCAGGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTTAGAGCTGCGGCGCGTGGTGGCCGGG CGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGC at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical , at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
MKWVTFISLLFLFSSAYSQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDSITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRGGGGSGGGGSGGGGSDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEI(配列番号274)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the second chimeric polypeptide is
MKWVTFISLLFFSSAYSQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGS EDSITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRGGGSGGGGSGGGGSDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYV FFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTTVDLPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEI (SEQ ID NO: 274), and at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88 % identical, at least 90% identical, at least 92% identical, at least 94% sequences that are identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCCAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCCATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCTGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATC(配列番号275)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the second chimeric polypeptide is
ATGAAGTGGGGTGACCTTCATCAGCCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCCAGGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGA CCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTAC GAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCCATTACATGCCCCCCCTCCCATGAGCGTGGAGCACGCGACATCTGGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTAT ATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGATAAGGCCTACCAACGTGGCTCACTGGACACACCCTCTTTAAAGTGCATCCGGGGCGGTGGAGGATCCGGAGGGAGGTGGCTCCGGCGGCGGAGGATCTGATCCCGCCGGGC CTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGG CTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTC GGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATC (SEQ ID NO: 275), and at least 80% identical ( For example, at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical , at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
例示的な多鎖キメラポリペプチド-タイプM
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは各々独立して、TGF-β又はIL-21受容体に特異的に結合する。本明細書に記載のこれらの多鎖キメラポリペプチドのいくつかの実施形態では、第2のキメラポリペプチドは、追加の標的結合ドメインを更に含む。本明細書に記載のこれらの多鎖キメラポリペプチドのいくつかの実施形態では、追加の標的結合ドメインは、IL-21(例えば、可溶性IL-21、例えば、可溶性ヒトIL-21)受容体又はTGF-β受容体(例えば、可溶性TGF-β受容体、例えば、可溶性TGFβRII受容体)に特異的に結合する。
Exemplary Multichain Chimeric Polypeptides—Type M
In some embodiments of any of the multi-chain chimeric polypeptides described herein, the first target binding domain and the second target binding domain are each independently TGF-β or IL-21 Binds specifically to receptors. In some embodiments of these multi-chain chimeric polypeptides described herein, the second chimeric polypeptide further comprises an additional target binding domain. In some embodiments of these multichain chimeric polypeptides described herein, the additional target binding domain is an IL-21 (eg, soluble IL-21, eg, soluble human IL-21) receptor or Binds specifically to TGF-beta receptors (eg, soluble TGF-beta receptors, eg, soluble TGFβRII receptors).
これらの多鎖キメラポリペプチドのいくつかの例では、第1の標的結合ドメインと可溶性組織因子ドメインは、第1のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの例では、第1のキメラポリペプチドは、第1のキメラポリペプチド内の第1の標的結合ドメインと可溶性組織因子ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some examples of these multichain chimeric polypeptides, the first target binding domain and the soluble tissue factor domain are directly adjacent to each other within the first chimeric polypeptide. In some examples of these multichain chimeric polypeptides, the first chimeric polypeptide has a linker sequence (e.g., any of the exemplary linkers described herein).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインは、第1のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1のキメラポリペプチドは、第1のキメラポリペプチド内の可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these multi-chain chimeric polypeptides, the soluble tissue factor domain and the first of the paired affinity domains are directly adjacent to each other within the first chimeric polypeptide. In some embodiments of these multi-chain chimeric polypeptides, the first chimeric polypeptide is between the soluble tissue factor domain and the first of the pair of affinity domains within the first chimeric polypeptide. Further includes a linker sequence (eg, any of the exemplary linkers described herein).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、一対の親和性ドメインの第2のドメインと第2の標的結合ドメインは、第2のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチド内の一対の親和性ドメインの第2のドメインと第2の標的結合ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these multi-chain chimeric polypeptides, the second domain and the second target binding domain of the pair of affinity domains are directly adjacent to each other within the second chimeric polypeptide. In some embodiments of these multichain chimeric polypeptides, the second chimeric polypeptide is a combination of the second of the pair of affinity domains within the second chimeric polypeptide and the second target binding domain. Further includes a linker sequence (eg, any of the exemplary linkers described herein) in between.
いくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチドのN末端又はC末端に1つ以上の追加の標的結合ドメインを更に含む。 In some embodiments, the second chimeric polypeptide further comprises one or more additional target binding domains at the N-terminus or C-terminus of the second chimeric polypeptide.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、追加の標的結合ドメイン及び一対の親和性ドメインの第2のドメインは、第2のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチド内の一対の親和性ドメインの第2のドメインと追加の標的結合ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these multi-chain chimeric polypeptides, the additional target binding domain and the second domain of the pair of affinity domains are directly adjacent to each other within the second chimeric polypeptide. In some embodiments of these multichain chimeric polypeptides, the second chimeric polypeptide is between the second of the pair of affinity domains and the additional target binding domain within the second chimeric polypeptide. further includes a linker sequence (eg, any of the exemplary linkers described herein).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、追加の標的結合ドメインと第2の標的結合ドメインは、第2のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチド内の第2の標的結合ドメインと追加の標的結合ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these multi-chain chimeric polypeptides, the additional target binding domain and the second target binding domain are directly adjacent to each other within the second chimeric polypeptide. In some embodiments of these multichain chimeric polypeptides, the second chimeric polypeptide has a linker sequence ( For example, any of the exemplary linkers described herein).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性組織因子ドメインは、本明細書に記載の例示的な可溶性組織因子ドメインのうちのいずれかであり得る。これらの多鎖キメラポリペプチドのいくつかの実施形態では、一対の親和性ドメインは、本明細書に記載の例示的な一対の親和性ドメインのうちのいずれかであり得る。 In some embodiments of these multichain chimeric polypeptides, the soluble tissue factor domain can be any of the exemplary soluble tissue factor domains described herein. In some embodiments of these multi-chain chimeric polypeptides, the pair of affinity domains can be any of the exemplary pair of affinity domains described herein.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメインはTGF-βに特異的に結合し、第2の標的結合ドメインはTGF-β又はIL-21受容体に特異的に結合する。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメインは、可溶性TGF-β受容体(例えば、可溶性TGFβRII受容体、例えば、可溶性ヒトTGFβRII受容体)である。これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトTGFRβRIIは、第1の可溶性ヒトTGFRβRII配列及び第2の可溶性ヒトTGFRβRII配列を含む。これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトTGFRβRIIは、第1の可溶性ヒトTGFRβRII配列と第2の可溶性ヒトTGFRβRII配列との間に配置されたリンカーを含む。これらの多鎖キメラポリペプチドのいくつかの例では、リンカーは、配列GGGGSGGGGSGGGGS(配列番号102)を含む。 In some embodiments of these multichain chimeric polypeptides, the first target binding domain specifically binds TGF-β and the second target binding domain is specific for TGF-β or IL-21 receptor. physically connect. In some embodiments of these multichain chimeric polypeptides, the first target binding domain is a soluble TGF-β receptor (eg, soluble TGFβRII receptor, eg, soluble human TGFβRII receptor). In some embodiments of these multichain chimeric polypeptides, the soluble human TGFRβRII comprises a first soluble human TGFRβRII sequence and a second soluble human TGFRβRII sequence. In some embodiments of these multichain chimeric polypeptides, the soluble human TGFRβRII comprises a linker positioned between the first soluble human TGFRβRII sequence and the second soluble human TGFRβRII sequence. In some examples of these multichain chimeric polypeptides, the linker comprises the sequence GGGGSGGGGSGGGGGS (SEQ ID NO: 102).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の可溶性ヒトTGFRβRII受容体配列は、
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD(配列番号183)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multichain chimeric polypeptides, the first soluble human TGFRβRII receptor sequence is
at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, sequences that are at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2の可溶性ヒトTGFRβRII受容体配列は、
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD(配列番号184)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multichain chimeric polypeptides, the second soluble human TGFRβRII receptor sequence is
at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, sequences that are at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の可溶性ヒトTGFRβRII受容体配列は、
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGAT(配列番号185)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multichain chimeric polypeptides, the first soluble human TGFRβRII receptor sequence is
ATCCCCCCCCCATGTGCAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAA GAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGAACCTTCTTTATGTGTTCCTGTAGCAG CGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGAT (SEQ ID NO: 185), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2の可溶性ヒトTGFRβRII受容体配列は、
ATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC(配列番号186)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multichain chimeric polypeptides, the second soluble human TGFRβRII receptor sequence is
ATTCCTCCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGG TGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAAACCGTCTGCCCACGATCCCCAAGCTGCCCTACCCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAAGAGAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGC at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性TGF-β受容体は、
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD(配列番号188)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multichain chimeric polypeptides, the soluble TGF-β receptor is
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNCSITSICEKPQEVCVAVWRKNDINITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPDGGGGGSGGGGGSGGGGSIPPHV at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical , at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性TGF-β受容体は、
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC(配列番号187)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multichain chimeric polypeptides, the soluble TGF-β receptor is
ATCCCCCCCCCATGTGCAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAA GAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGAACCTTCTTTATGTGTTCCTGTAGCAG CGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCC CCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCCACGATCCCCAAGCTGCCCTAC CACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCCGAC (SEQ ID NO: 187), and at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2の標的結合ドメインは、IL-21受容体に特異的に結合する。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2の標的結合ドメインは、可溶性IL-21(例えば、ヒト可溶性IL-21)を含む。これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性IL-21は、
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS(配列番号83)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multichain chimeric polypeptides, the second target binding domain specifically binds the IL-21 receptor. In some embodiments of these multichain chimeric polypeptides, the second target binding domain comprises soluble IL-21 (eg, human soluble IL-21). In some embodiments of these multi-chain chimeric polypeptides, the soluble IL-21 is
at least 80% identical to QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS (SEQ ID NO: 83), (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, sequences that are at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性IL-21は、
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC(配列番号182)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multi-chain chimeric polypeptides, the soluble IL-21 is
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCG CCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCCTCCACAAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCCTGCTGCAGAAGAT GATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC (SEQ ID NO: 182), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(配列番号236)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the first chimeric polypeptide is
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNSITSITSICEKPQEVCVAVWRKNDINITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPDGGGGGSGGGGGSGGGGGSIPPHV QKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDSGTTNTVAAYNLTWKSTNFKTILEWEPK PVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTA KTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVIDLKKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANSLSSNGNVTESGCKECEELEEKNIKEFLQ SFVHIVQMFINTS (SEQ ID NO: 236), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, % identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(配列番号237)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされ得る。
In some embodiments, the first chimeric polypeptide is
ATCCCCCCCCCATGTGCAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAA GAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGAACCTTCTTTATGTGTTCCTGTAGCAG CGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCC CCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCCACGATCCCCAAGCTGCCCTAC CACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACAGCGGCACAACCAACACAGTCGCTGCC TATAACCTCACTTGGAAGAGCACCAACTTCAAACCATCCTCGAATGGGAACCCAAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTAACCACCGACACCGAGTGCGATCTCACCGATGGAGATCGTGAAAAGATGTGAAAACAGACCT ACCTCGCCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAG CGGACTTTAGTGCGGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAG CGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGGAGTTCCGGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGAATTTAATTCAGTCCATGCATATCGACGCCACTTTATA CACAGAATCCGACGTGCACCCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAG at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(配列番号238)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the first chimeric polypeptide is
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGG GSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPDSGTTNTVAAY NLTWKSTNFKTILEWEPKKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNNTFLSLRDVFGKDLI YTLYYWKSSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVIDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLILANNSLSSNGNVTESG CKECEELEEEKNIKEFLQSFVHIVQMFINTS (SEQ ID NO: 238), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical % identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(配列番号239)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the first chimeric polypeptide is
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCCATCCCCCCCCATGTGCAAAGAGCGTGAACAACGATATGATCGTGACCGACAACACGGCGCCGTGAAGTTTCCCCAGCTCTGCCAAGTTTCTGCGATGTCAGGGTTCAGCACCTGCGA TAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGC ATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCCACGTGCA GAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGGACAACCAGAAGTCCTGTATGAGCCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGGTGTGCGTGGCTGTCT GGCGGAAGAATGACGAGAATATCACCCTGGAAAACCGTCTGCCACGATCCCCAAGCTGCCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAAGAGAAAAGAAGCCTGGCGGAGACCTTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCAT CTTTAGCGAGGAATACAATACCAGCAACCCCGACAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAACCATCCTCGAATGGGAACCCAAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCT ATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCCTTACCTCGAGACCAATTTAGGACAGCCCACCAT CCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAAC CAACACAAACGAGTTTTTAATCGACGTGGATAAAGGGCGAAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAGGGCGAGTTCCGGGGAGAACTGGGTGAACGTCATCAG CGATTTAAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATT at least 80% identical (e.g., at least 82% identical, at least 84% identical , at least 86% identical, at least 88% identical, at least 90% identical , at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS(配列番号300)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the second chimeric polypeptide is
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNSITSITSICEKPQEVCVAVWRKNDINITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPDGGGGGSGGGGGSGGGGGSIPPHV QKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADIWVKSYSLYSRERYICNSG FKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIH QHLSSRTHGSEDS (SEQ ID NO: 300), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% sequences that are identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGCAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC(配列番号301)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the second chimeric polypeptide is
ATCCCCCCCCCATGTGCAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAA GAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGAACCTTCTTTATGTGTTCCTGTAGCAG CGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCC CCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCCACGATCCCCAAGCTGCCCTAC CACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAAGAGAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACATTACATGCCCCCCCTCCCATGAGCGTG GAGCACGCCGACATCTGGGTGAAGAGCTATAGCCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCTCACCGAGTGCGTGCTGTAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGCAGGGGCCAG GACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAAC AACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGCAGAAGATGATCCCATCAGCACCT GTCCTCCAGGACCCACGGCTCCGAGGACTCC (SEQ ID NO: 301), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical to % identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS(配列番号302)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the second chimeric polypeptide is
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGG GSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADI WVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEK at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% sequences that are identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGCAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC(配列番号303)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the second chimeric polypeptide is
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCCATCCCCCCCCATGTGCAAAGAGCGTGAACAACGATATGATCGTGACCGACAACACGGCGCCGTGAAGTTTCCCCAGCTCTGCCAAGTTTCTGCGATGTCAGGGTTCAGCACCTGCGA TAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGC ATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCCACGTGCA GAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGGACAACCAGAAGTCCTGTATGAGCCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGGTGTGCGTGGCTGTCT GGCGGAAGAATGACGAGAATATCACCCTGGAAAACCGTCTGCCACGATCCCCAAGCTGCCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAAGAGAAAAGAAGCCTGGCGGAGACCTTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCAT CTTTAGCGAGGAATACAATACCAGCAACCCCCGACATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCTCACCGAGTGCGTGCTGAATAAG GCTACCAACGTGGCTCACTGGACAACACCCTCTTAAAGTGCATCCGGCAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGT GGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCCACAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCC AAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC (SEQ ID NO: 303), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical to % identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
例示的な多鎖キメラポリペプチド-タイプN
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは各々独立して、TGF-β又はCD16に特異的に結合する。本明細書に記載のこれらの多鎖キメラポリペプチドのいくつかの実施形態では、第2のキメラポリペプチドは、追加の標的結合ドメインを更に含む。本明細書に記載のこれらの多鎖キメラポリペプチドのいくつかの実施形態では、追加の標的結合ドメインは、CD16(例えば、抗CD16scFv)又はTGF-β(例えば、可溶性TGF-β受容体、例えば、可溶性TGFβRII受容体)に特異的に結合する。
Exemplary Multichain Chimeric Polypeptides—Type N
In some embodiments of any of the multichain chimeric polypeptides described herein, the first target binding domain and the second target binding domain are each independently specific for TGF-β or CD16. connect to each other. In some embodiments of these multi-chain chimeric polypeptides described herein, the second chimeric polypeptide further comprises an additional target binding domain. In some embodiments of these multichain chimeric polypeptides described herein, the additional target binding domain is CD16 (eg, anti-CD16 scFv) or TGF-β (eg, a soluble TGF-β receptor, such as , the soluble TGFβRII receptor).
これらの多鎖キメラポリペプチドのいくつかの例では、第1の標的結合ドメインと可溶性組織因子ドメインは、第1のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの例では、第1のキメラポリペプチドは、第1のキメラポリペプチド内の第1の標的結合ドメインと可溶性組織因子ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some examples of these multichain chimeric polypeptides, the first target binding domain and the soluble tissue factor domain are directly adjacent to each other within the first chimeric polypeptide. In some examples of these multichain chimeric polypeptides, the first chimeric polypeptide has a linker sequence (e.g., any of the exemplary linkers described herein).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインは、第1のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1のキメラポリペプチドは、第1のキメラポリペプチド内の可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these multi-chain chimeric polypeptides, the soluble tissue factor domain and the first of the paired affinity domains are directly adjacent to each other within the first chimeric polypeptide. In some embodiments of these multi-chain chimeric polypeptides, the first chimeric polypeptide is between the soluble tissue factor domain and the first of the pair of affinity domains within the first chimeric polypeptide. Further includes a linker sequence (eg, any of the exemplary linkers described herein).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、一対の親和性ドメインの第2のドメインと第2の標的結合ドメインは、第2のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチド内の一対の親和性ドメインの第2のドメインと第2の標的結合ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these multi-chain chimeric polypeptides, the second domain and the second target binding domain of the pair of affinity domains are directly adjacent to each other within the second chimeric polypeptide. In some embodiments of these multichain chimeric polypeptides, the second chimeric polypeptide is a combination of the second of the pair of affinity domains within the second chimeric polypeptide and the second target binding domain. Further includes a linker sequence (eg, any of the exemplary linkers described herein) in between.
いくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチドのN末端又はC末端に1つ以上の追加の標的結合ドメインを更に含む。 In some embodiments, the second chimeric polypeptide further comprises one or more additional target binding domains at the N-terminus or C-terminus of the second chimeric polypeptide.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、追加の標的結合ドメイン及び一対の親和性ドメインの第2のドメインは、第2のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチド内の一対の親和性ドメインの第2のドメインと追加の標的結合ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these multi-chain chimeric polypeptides, the additional target binding domain and the second domain of the pair of affinity domains are directly adjacent to each other within the second chimeric polypeptide. In some embodiments of these multichain chimeric polypeptides, the second chimeric polypeptide is between the second of the pair of affinity domains and the additional target binding domain within the second chimeric polypeptide. further includes a linker sequence (eg, any of the exemplary linkers described herein).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、追加の標的結合ドメインと第2の標的結合ドメインは、第2のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチド内の第2の標的結合ドメインと追加の標的結合ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these multi-chain chimeric polypeptides, the additional target binding domain and the second target binding domain are directly adjacent to each other within the second chimeric polypeptide. In some embodiments of these multichain chimeric polypeptides, the second chimeric polypeptide has a linker sequence ( For example, any of the exemplary linkers described herein).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性組織因子ドメインは、本明細書に記載の例示的な可溶性組織因子ドメインのうちのいずれかであり得る。これらの多鎖キメラポリペプチドのいくつかの実施形態では、一対の親和性ドメインは、本明細書に記載の例示的な一対の親和性ドメインのうちのいずれかであり得る。 In some embodiments of these multichain chimeric polypeptides, the soluble tissue factor domain can be any of the exemplary soluble tissue factor domains described herein. In some embodiments of these multi-chain chimeric polypeptides, the pair of affinity domains can be any of the exemplary pair of affinity domains described herein.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメインはTGF-βに特異的に結合し、第2の標的結合ドメインはTGF-β又はCD16に特異的に結合する。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメインは、可溶性TGF-β受容体(例えば、可溶性TGFβRII受容体、例えば、可溶性ヒトTGFβRII受容体)である。これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトTGFRβRIIは、第1の可溶性ヒトTGFRβRII配列及び第2の可溶性ヒトTGFRβRII配列を含む。これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトTGFRβRIIは、第1の可溶性ヒトTGFRβRII配列と第2の可溶性ヒトTGFRβRII配列との間に配置されたリンカーを含む。これらの多鎖キメラポリペプチドのいくつかの例では、リンカーは、配列GGGGSGGGGSGGGGS(配列番号102)を含む。 In some embodiments of these multichain chimeric polypeptides, the first target binding domain specifically binds TGF-β and the second target binding domain specifically binds TGF-β or CD16. . In some embodiments of these multichain chimeric polypeptides, the first target binding domain is a soluble TGF-β receptor (eg, soluble TGFβRII receptor, eg, soluble human TGFβRII receptor). In some embodiments of these multichain chimeric polypeptides, the soluble human TGFRβRII comprises a first soluble human TGFRβRII sequence and a second soluble human TGFRβRII sequence. In some embodiments of these multichain chimeric polypeptides, the soluble human TGFRβRII comprises a linker positioned between the first soluble human TGFRβRII sequence and the second soluble human TGFRβRII sequence. In some examples of these multichain chimeric polypeptides, the linker comprises the sequence GGGGSGGGGSGGGGGS (SEQ ID NO: 102).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の可溶性ヒトTGFRβRII受容体配列は、
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD(配列番号183)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multichain chimeric polypeptides, the first soluble human TGFRβRII receptor sequence is
at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, sequences that are at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2の可溶性ヒトTGFRβRII受容体配列は、
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD(配列番号184)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multichain chimeric polypeptides, the second soluble human TGFRβRII receptor sequence is
at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, sequences that are at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の可溶性ヒトTGFRβRII受容体配列は、
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGAT(配列番号185)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multichain chimeric polypeptides, the first soluble human TGFRβRII receptor sequence is
ATCCCCCCCCCATGTGCCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTTCTGCGATGTCAGGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAA GAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGAACCTTCTTTATGTGTTCCTGTAGCAG CGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACCCAGCAACCCTGAT (SEQ ID NO: 185), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2の可溶性ヒトTGFRβRII受容体配列は、
ATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC(配列番号186)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multichain chimeric polypeptides, the second soluble human TGFRβRII receptor sequence is
ATTCCTCCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGG TGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAAACCGTCTGCCCACGATCCCCAAGCTGCCCTACCCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAAGAGAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGC at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性TGF-β受容体は、
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD(配列番号188)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multichain chimeric polypeptides, the soluble TGF-β receptor is
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNSITSITSICEKPQEVCVAVWRKNDINITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPDGGGGGSGGGGGSGGGGGSIPPHV at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical , at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性TGF-β受容体は、
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC(配列番号187)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multichain chimeric polypeptides, the soluble TGF-β receptor is
ATCCCCCCCCCATGTGCAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAA GAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGAACCTTCTTTATGTGTTCCTGTAGCAG CGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCC CCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCCACGATCCCCAAGCTGCCCTAC CACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCCGAC (SEQ ID NO: 187), and at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2の標的結合ドメインは、CD16に特異的に結合する。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2の標的結合ドメインは、抗CD16scFvを含む。これらの多鎖キメラポリペプチドのいくつかの実施形態では、CD16に特異的に結合するscFvは、
SELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGH(配列番号215)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む軽鎖可変ドメインを含む。
In some embodiments of these multichain chimeric polypeptides, the second target binding domain specifically binds CD16. In some embodiments of these multichain chimeric polypeptides, the second target binding domain comprises an anti-CD16 scFv. In some embodiments of these multichain chimeric polypeptides, the scFv that specifically binds to CD16 is
at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, light chain variable domains comprising sequences that are at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、CD16に特異的に結合するscFvは、
TCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCAACCATGTGGTGTTCGGCGGCGGCACCAAGCTGACCGTGGGCCAT(配列番号216)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である軽鎖可変ドメイン配列によってコードされる。
In some embodiments of these multichain chimeric polypeptides, the scFv that specifically binds to CD16 is
TCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACACAGGCCCTCCGGCATCCCTGACAGG at least 80% identical (e.g., at least 82% identical to , at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical , at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、CD16に特異的に結合するscFvは、
EVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSR(配列番号217)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む重鎖可変ドメインを含む。
In some embodiments of these multichain chimeric polypeptides, the scFv that specifically binds to CD16 is
EVQLVESGGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSR (SEQ ID NO: 217), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, heavy chain variable domains comprising sequences that are at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、CD16に特異的に結合するscFvは、
GAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGG(配列番号218)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である重鎖可変ドメイン配列によってコードされる。
In some embodiments of these multichain chimeric polypeptides, the scFv that specifically binds to CD16 is
GAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCCTCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGGAGGCAGGCTCCTGGAAAGGGCCTGGGAGTGGGTGTCCGGCATCAACTGGAACGG CGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCG TGTCCAGG (SEQ ID NO: 218), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(配列番号236)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the first chimeric polypeptide is
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNSITSITSICEKPQEVCVAVWRKNDINITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPDGGGGGSGGGGGSGGGGGSIPPHV QKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDSGTTNTVAAYNLTWKSTNFKTILEWEPK PVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTA KTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVIDLKKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANSLSSNGNVTESGCKECEELEEKNIKEFLQ SFVHIVQMFINTS (SEQ ID NO: 236), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, % identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(配列番号237)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the first chimeric polypeptide is
ATCCCCCCCCCATGTGCAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAA GAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGAACCTTCTTTATGTGTTCCTGTAGCAG CGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCC CCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCCACGATCCCCAAGCTGCCCTAC CACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACAGCGGCACAACCAACACAGTCGCTGCC TATAACCTCACTTGGAAGAGCACCAACTTCAAACCATCCTCGAATGGGAACCCAAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTAACCACCGACACCGAGTGCGATCTCACCGATGGAGATCGTGAAAAGATGTGAAAACAGACCT ACCTCGCCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAG CGGACTTTAGTGCGGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAG CGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGGAGTTCCGGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGAATTTAATTCAGTCCATGCATATCGACGCCACTTTATA CACAGAATCCGACGTGCACCCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAG at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(配列番号238)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the first chimeric polypeptide is
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGG GSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPDSGTTNTVAAY NLTWKSTNFKTILEWEPKKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNNTFLSLRDVFGKDLI YTLYYWKSSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVIDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLILANNSLSSNGNVTESG CKECEELEEEKNIKEFLQSFVHIVQMFINTS (SEQ ID NO: 238), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical % identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(配列番号239)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the first chimeric polypeptide is
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCCATCCCCCCCCATGTGCAAAGAGCGTGAACAACGATATGATCGTGACCGACAACACGGCGCCGTGAAGTTTCCCCAGCTCTGCCAAGTTTCTGCGATGTCAGGGTTCAGCACCTGCGA TAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGC ATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCCACGTGCA GAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGGACAACCAGAAGTCCTGTATGAGCCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGGTGTGCGTGGCTGTCT GGCGGAAGAATGACGAGAATATCACCCTGGAAAACCGTCTGCCACGATCCCCAAGCTGCCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAAGAGAAAAGAAGCCTGGCGGAGACCTTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCAT CTTTAGCGAGGAATACAATACCAGCAACCCCGACAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAACCATCCTCGAATGGGAACCCAAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCT ATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCCTTACCTCGAGACCAATTTAGGACAGCCCACCAT CCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAAC CAACACAAACGAGTTTTTAATCGACGTGGATAAAGGGCGAAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAGGGCGAGTTCCGGGGAGAACTGGGTGAACGTCATCAG CGATTTAAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATT at least 80% identical (e.g., at least 82% identical, at least 84% identical , at least 86% identical, at least 88% identical, at least 90% identical , at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRSELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGHGGGGSGGGGSGGGGSEVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSR(配列番号308)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)の配列を含み得る。
In some embodiments, the second chimeric polypeptide is
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNSITSITSICEKPQEVCVAVWRKNDINITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPDGGGGGSGGGGGSGGGGGSIPPHV QKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADIWVKSYSLYSRERYICNSG FKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRSELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGGTKLTVGHGGGGG at least 80% identical to (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, % identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGTCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCAACCATGTGGTGTTCGGCGGCGGCACCAAGCTGACCGTGGGCCATGGCGGCGGCGGCTCCGGAGGCGGCGGCAGCGGCGGAGGAGGATCCGAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGG(配列番号309)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the second chimeric polypeptide is
ATCCCCCCCCCATGTGCAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAA GAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGAACCTTCTTTATGTGTTCCTGTAGCAG CGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCC CCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCCACGATCCCCAAGCTGCCCTAC CACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAAGAGAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACATTACATGCCCCCCCTCCCATGAGCGTG GAGCACGCCGACGACATCTGGGTGAAGAGCTATAGCCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGTCCGAGCTGACC CAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGGTTCTCCGGATCCT CCTCCGGCCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCCAACCATGTGGTGTTCGGCGGCGGCACCAAGCTGACCGTGGGCCATGGCGGCGGCGCGGCTCCGGAGGCGGCGGCAGCGGCGGA GGAGGATCCGAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCTCTCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAGGGGCCTGGAGTGGGTGTCCGGCATCAACTG GAACGGCGGATCCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGG TGACCGTGTCCAGG (SEQ ID NO: 309), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRSELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGHGGGGSGGGGSGGGGSEVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSR(配列番号310)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the second chimeric polypeptide is
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGG GSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADI WVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRSELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVV FGGGTKLTVGHGGGGGSGGGGSGGGGSEVQLVESGGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVS R (SEQ ID NO: 310), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical % identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGTCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCAACCATGTGGTGTTCGGCGGCGGCACCAAGCTGACCGTGGGCCATGGCGGCGGCGGCTCCGGAGGCGGCGGCAGCGGCGGAGGAGGATCCGAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGG(配列番号311)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the second chimeric polypeptide is
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCCATCCCCCCCCATGTGCAAAGAGCGTGAACAACGATATGATCGTGACCGACAACACGGCGCCGTGAAGTTTCCCCAGCTCTGCCAAGTTTCTGCGATGTCAGGGTTCAGCACCTGCGA TAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGC ATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCCACGTGCA GAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGGACAACCAGAAGTCCTGTATGAGCCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGGTGTGCGTGGCTGTCT GGCGGAAGAATGACGAGAATATCACCCTGGAAAACCGTCTGCCACGATCCCCAAGCTGCCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAAGAGAAAAGAAGCCTGGCGGAGACCTTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCAT CTTTAGCGAGGAATACAATACCAGCAACCCCCGACATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCTCACCGAGTGCGTGCTGAATAAG GCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGTCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCCAGGCTCCTGTGCTG GTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCGGCAACACCGCCTCCCTGACCATCACAGGGCGCTCAGGCCGGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCAACCATGTGGTGTTCGGCGGCGGCACCAAGCTGA CCGTGGGCCATGGCGCGCGGCGGCTCCGGAGGCGGCGGCAGCGCGGCGGAGGAGGATCCGAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCCTCGGCTTCACCTTCGACGACTACGGCATGTCCTGG GTGAGGCAGGCTCCTGGAAAGGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTA at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
例示的な多鎖キメラポリペプチド-タイプO
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは各々独立して、TGF-β又はCD137L受容体に特異的に結合する。本明細書に記載のこれらの多鎖キメラポリペプチドのいくつかの実施形態では、第2のキメラポリペプチドは、追加の標的結合ドメインを更に含む。本明細書に記載のこれらの多鎖キメラポリペプチドのいくつかの実施形態では、追加の標的結合ドメインは、TGF-β受容体(例えば、可溶性TGF-β受容体、例えば、可溶性TGFβRII受容体)又はCD137L受容体に特異的に結合する。
Exemplary Multichain Chimeric Polypeptides—Type O
In some embodiments of any of the multichain chimeric polypeptides described herein, the first target binding domain and the second target binding domain are each independently TGF-beta or CD137L receptor binds specifically to In some embodiments of these multi-chain chimeric polypeptides described herein, the second chimeric polypeptide further comprises an additional target binding domain. In some embodiments of these multichain chimeric polypeptides described herein, the additional target binding domain is a TGF-β receptor (eg, a soluble TGF-β receptor, such as a soluble TGFβRII receptor) or specifically binds to the CD137L receptor.
これらの多鎖キメラポリペプチドのいくつかの例では、第1の標的結合ドメインと可溶性組織因子ドメインは、第1のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの例では、第1のキメラポリペプチドは、第1のキメラポリペプチド内の第1の標的結合ドメインと可溶性組織因子ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some examples of these multichain chimeric polypeptides, the first target binding domain and the soluble tissue factor domain are directly adjacent to each other within the first chimeric polypeptide. In some examples of these multichain chimeric polypeptides, the first chimeric polypeptide has a linker sequence (e.g., any of the exemplary linkers described herein).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインは、第1のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1のキメラポリペプチドは、第1のキメラポリペプチド内の可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these multi-chain chimeric polypeptides, the soluble tissue factor domain and the first of the paired affinity domains are directly adjacent to each other within the first chimeric polypeptide. In some embodiments of these multi-chain chimeric polypeptides, the first chimeric polypeptide is between the soluble tissue factor domain and the first of the pair of affinity domains within the first chimeric polypeptide. Further includes a linker sequence (eg, any of the exemplary linkers described herein).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、一対の親和性ドメインの第2のドメインと第2の標的結合ドメインは、第2のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチド内の一対の親和性ドメインの第2のドメインと第2の標的結合ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these multi-chain chimeric polypeptides, the second domain and the second target binding domain of the pair of affinity domains are directly adjacent to each other within the second chimeric polypeptide. In some embodiments of these multichain chimeric polypeptides, the second chimeric polypeptide is a combination of the second of the pair of affinity domains within the second chimeric polypeptide and the second target binding domain. Further includes a linker sequence (eg, any of the exemplary linkers described herein) in between.
いくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチドのN末端又はC末端に1つ以上の追加の標的結合ドメインを更に含む。 In some embodiments, the second chimeric polypeptide further comprises one or more additional target binding domains at the N-terminus or C-terminus of the second chimeric polypeptide.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、追加の標的結合ドメイン及び一対の親和性ドメインの第2のドメインは、第2のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチド内の一対の親和性ドメインの第2のドメインと追加の標的結合ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these multi-chain chimeric polypeptides, the additional target binding domain and the second domain of the pair of affinity domains are directly adjacent to each other within the second chimeric polypeptide. In some embodiments of these multichain chimeric polypeptides, the second chimeric polypeptide is between the second of the pair of affinity domains and the additional target binding domain within the second chimeric polypeptide. further includes a linker sequence (eg, any of the exemplary linkers described herein).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、追加の標的結合ドメインと第2の標的結合ドメインは、第2のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチド内の第2の標的結合ドメインと追加の標的結合ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these multi-chain chimeric polypeptides, the additional target binding domain and the second target binding domain are directly adjacent to each other within the second chimeric polypeptide. In some embodiments of these multichain chimeric polypeptides, the second chimeric polypeptide has a linker sequence ( For example, any of the exemplary linkers described herein).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性組織因子ドメインは、本明細書に記載の例示的な可溶性組織因子ドメインのうちのいずれかであり得る。これらの多鎖キメラポリペプチドのいくつかの実施形態では、一対の親和性ドメインは、本明細書に記載の例示的な一対の親和性ドメインのうちのいずれかであり得る。 In some embodiments of these multichain chimeric polypeptides, the soluble tissue factor domain can be any of the exemplary soluble tissue factor domains described herein. In some embodiments of these multi-chain chimeric polypeptides, the pair of affinity domains can be any of the exemplary pair of affinity domains described herein.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメインはTGF-βに特異的に結合し、第2の標的結合ドメインはCD137Lに特異的に結合する。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン又は追加の標的結合ドメインは、可溶性TGF-β受容体(例えば、可溶性TGFβRII受容体、例えば、可溶性ヒトTGFβRII受容体)である。 In some embodiments of these multichain chimeric polypeptides, the first target binding domain specifically binds TGF-β and the second target binding domain specifically binds CD137L. In some embodiments of these multichain chimeric polypeptides, the first target binding domain or additional target binding domain is a soluble TGF-β receptor (eg, a soluble TGFβRII receptor, such as a soluble human TGFβRII receptor). ).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトTGFRβRIIは、第1の可溶性ヒトTGFRβRII配列及び第2の可溶性ヒトTGFRβRII配列を含む。これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトTGFRβRIIは、第1の可溶性ヒトTGFRβRII配列と第2の可溶性ヒトTGFRβRII配列との間に配置されたリンカーを含む。これらの多鎖キメラポリペプチドのいくつかの例では、リンカーは、配列GGGGSGGGGSGGGGS(配列番号102)を含む。 In some embodiments of these multichain chimeric polypeptides, the soluble human TGFRβRII comprises a first soluble human TGFRβRII sequence and a second soluble human TGFRβRII sequence. In some embodiments of these multichain chimeric polypeptides, the soluble human TGFRβRII comprises a linker positioned between the first soluble human TGFRβRII sequence and the second soluble human TGFRβRII sequence. In some examples of these multichain chimeric polypeptides, the linker comprises the sequence GGGGSGGGGSGGGGGS (SEQ ID NO: 102).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の可溶性ヒトTGFRβRII受容体配列は、
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD(配列番号183)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multichain chimeric polypeptides, the first soluble human TGFRβRII receptor sequence is
at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, sequences that are at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2の可溶性ヒトTGFRβRII受容体配列は、
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD(配列番号184)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multichain chimeric polypeptides, the second soluble human TGFRβRII receptor sequence is
at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, sequences that are at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の可溶性ヒトTGFRβRII受容体配列は、
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGAT(配列番号185)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multichain chimeric polypeptides, the first soluble human TGFRβRII receptor sequence is
ATCCCCCCCCCATGTGCAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAA GAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGAACCTTCTTTATGTGTTCCTGTAGCAG CGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGAT (SEQ ID NO: 185), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2の可溶性ヒトTGFRβRII受容体配列は、
ATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC(配列番号186)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multichain chimeric polypeptides, the second soluble human TGFRβRII receptor sequence is
ATTCCTCCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGG TGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAAACCGTCTGCCCACGATCCCCAAGCTGCCCTACCCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAAGAGAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGC at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性TGF-β受容体は、
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD(配列番号188)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multichain chimeric polypeptides, the soluble TGF-β receptor is
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNSITSITSICEKPQEVCVAVWRKNDINITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPDGGGGGSGGGGGSGGGGGSIPPHV at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical , at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性TGF-β受容体は、
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC(配列番号187)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, in some embodiments of these multichain chimeric polypeptides, the soluble TGF-β receptor is
ATCCCCCCCCCATGTGCCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTTCTGCGATGTCAGGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAA GAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGAACCTTCTTTATGTGTTCCTGTAGCAG CGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCC CCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCCACGATCCCAAGCTGCCTAC CACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCCGAC (SEQ ID NO: 187), and at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2の標的結合ドメインは、可溶性CD137Lタンパク質(例えば、可溶性ヒトCD137Lタンパク質)を含む。これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトCD137Lは、
REGPELSPDDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEIPAGLPSPRSE(配列番号260)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multichain chimeric polypeptides, the second target binding domain comprises a soluble CD137L protein (eg, soluble human CD137L protein). In some embodiments of these multichain chimeric polypeptides, the soluble human CD137L is
REGPELSPDDPAGLLDLLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSSVSLALHLQPLRSAAGAAALALTVDLLPPASSEARNSAFGFQGRLLHLSAGQRLGV HLHTEARARHAWQLTQGATVLGLFRVTPEIPAGLPSPRSSE (SEQ ID NO: 260), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical , at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトCD137Lは、
CGCGAGGGTCCCGAGCTTTCGCCCGACGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATCCCAGCCGGACTCCCTTCACCGAGGTCGGAA(配列番号261)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multichain chimeric polypeptides, the soluble human CD137L is
CGCGAGGGTCCCGAGCTTTCGCCCCGACGATCCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCGCAGCTGGTGGCCCAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCCAGGCCTGGCAGGGCGTGTCCCTGACGGGGGGC CTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTG GCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGG at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% % identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトCD137Lは、
DPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEI(配列番号262)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multichain chimeric polypeptides, the soluble human CD137L is
DPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARAR HAWQLTQGATVLGLFRVTPEI (SEQ ID NO: 262), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, sequences that are at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトCD137Lは、
GATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATC(配列番号263)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multichain chimeric polypeptides, the soluble human CD137L is
GATCCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGGCGTGTCCCTGACGGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGG TGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCT CCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGGCAGCTTACCCAGGGCGCCACAGTCTTTGGACTCTTCCGGGTGACCCCCGAAAATC (SEQ ID NO: 2) 63), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(配列番号236)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the first chimeric polypeptide is
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNSITSITSICEKPQEVCVAVWRKNDINITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPDGGGGGSGGGGGSGGGGGSIPPHV QKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDSGTTNTVAAYNLTWKSTNFKTILEWEPK PVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTA KTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVIDLKKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANSLSSNGNVTESGCKECEELEEKNIKEFLQ SFVHIVQMFINTS (SEQ ID NO: 236), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, % identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(配列番号237)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされ得る。
In some embodiments, the first chimeric polypeptide is
ATCCCCCCCCCATGTGCAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAA GAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGAACCTTCTTTATGTGTTCCTGTAGCAG CGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCC CCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCCACGATCCCCAAGCTGCCCTAC CACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACAGCGGCACAACCAACACAGTCGCTGCC TATAACCTCACTTGGAAGAGCACCAACTTCAAACCATCCTCGAATGGGAACCCAAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTAACCACCGACACCGAGTGCGATCTCACCGATGGAGATCGTGAAAAGATGTGAAAACAGACCT ACCTCGCCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAG CGGACTTTAGTGCGGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAG CGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGGAGTTCCGGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGAATTTAATTCAGTCCATGCATATCGACGCCACTTTATA CACAGAATCCGACGTGCACCCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAG at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(配列番号238)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the first chimeric polypeptide is
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGG GSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPDSGTTNTVAAY NLTWKSTNFKTILEWEPKKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNNTFLSLRDVFGKDLI YTLYYWKSSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVIDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLILANNSLSSNGNVTESG CKECEELEEEKNIKEFLQSFVHIVQMFINTS (SEQ ID NO: 238), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical % identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(配列番号239)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the first chimeric polypeptide is
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCCATCCCCCCCCATGTGCAAAGAGCGTGAACAACGATATGATCGTGACCGACAACACGGCGCCGTGAAGTTTCCCCAGCTCTGCCAAGTTTCTGCGATGTCAGGGTTCAGCACCTGCGA TAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGC ATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCCACGTGCA GAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGGACAACCAGAAGTCCTGTATGAGCCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGGTGTGCGTGGCTGTCT GGCGGAAGAATGACGAGAATATCACCCTGGAAAACCGTCTGCCACGATCCCCAAGCTGCCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAAGAGAAAAGAAGCCTGGCGGAGACCTTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCAT CTTTAGCGAGGAATACAATACCAGCAACCCCGACAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAACCATCCTCGAATGGGAACCCAAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCT ATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCCTTACCTCGAGACCAATTTAGGACAGCCCACCAT CCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAAC CAACACAAACGAGTTTTTAATCGACGTGGATAAAGGGCGAAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAGGGCGAGTTCCGGGGAGAACTGGGTGAACGTCATCAG CGATTTAAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATT at least 80% identical (e.g., at least 82% identical, at least 84% identical , at least 86% identical, at least 88% identical, at least 90% identical , at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRGGGGSGGGGSGGGGSREGPELSPDDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEIPAGLPSPRSE(配列番号316)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the second chimeric polypeptide is
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNCSITSICEKPQEVCVAVWRKNDINITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPDGGGGGSGGGGGSGGGGSIPPHV QKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADIWVKSYSLYSRERYICNSG FKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRGGGGSGGGGSGGGGSREGPELSPDDPAGLLDLLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSSLALH at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical , at least 94 % identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCTCGCGAGGGTCCCGAGCTTTCGCCCGACGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATCCCAGCCGGACTCCCTTCACCGAGGTCGGAA(配列番号317)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the second chimeric polypeptide is
ATCCCCCCCCCATGTGCAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAA GAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGAACCTTCTTTATGTGTTCCTGTAGCAG CGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCC CCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCCACGATCCCCAAGCTGCCCTAC CACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAAGAGAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACATTACATGCCCCCCCTCCCATGAGCGTG GAGCACCGCCGACATCTGGGTGAAGAGCTATAGCCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCTCACCGAGTGCGTGCTGTAATAAGGCTACCAACGTGGCTCCACTGGACAACACCCTCTTTAAAGTGCATCCGGGCGGTG GAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCTCGCGAGGGTTCCCGAGCTTTCGCCCGACGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACC CAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGCGTGGTGGCCGGCGCGGGGCTCAGGCTCCGTTTTCACTTGCGCTGCACCT GCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCC ATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATCCCAGCCGGACTCCCTTCACCGAGGTCGGAA (SEQ ID NO: 317), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRGGGGSGGGGSGGGGSREGPELSPDDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEIPAGLPSPRSE(配列番号318)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the second chimeric polypeptide is
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGG GSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADI WVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRGGGGSGGGGSGGGGSREGPELSPDDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLEL at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 86% identical, at least 8 8% identical, at least 90% identical, at least 92% identical, at least 94 % identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCTCGCGAGGGTCCCGAGCTTTCGCCCGACGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATCCCAGCCGGACTCCCTTCACCGAGGTCGGAA(配列番号319)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the second chimeric polypeptide is
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCCATCCCCCCCCATGTGCAAAGAGCGTGAACAACGATATGATCGTGACCGACAACACGGCGCCGTGAAGTTTCCCCAGCTCTGCCAAGTTTCTGCGATGTCAGGGTTCAGCACCTGCGA TAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGC ATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCCACGTGCA GAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGGACAACCAGAAGTCCTGTATGAGCCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGGTGTGCGTGGCTGTCT GGCGGAAGAATGACGAGAATATCACCCTGGAAAACCGTCTGCCACGATCCCCAAGCTGCCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAAGAGAAAAGAAGCCTGGCGGAGACCTTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCAT CTTTAGCGAGGAATACAATACCAGCAACCCCCGACATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCTCACCGAGTGCGTGCTGAATAAG GCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGCGCGGAGGATCTCGCGAGGGTCCCGAGCTTTCGCCCCGACGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAG CTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCCAAGGCTGGAGTCTACTATGTCTTACTTTCAACTGAGCTGCGGG CGCGTGGTGGCCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCT at least 80% identical (e.g., at least 82% identical to , at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
例示的な多鎖キメラポリペプチド-タイプP
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは各々、TGF-βに特異的に結合する。本明細書に記載のこれらの多鎖キメラポリペプチドのいくつかの実施形態では、第1のキメラポリペプチドは、追加の標的結合ドメインを更に含む。このタイプの多鎖キメラポリペプチドの非限定的な例を、図209及び210に示す。
Exemplary Multichain Chimeric Polypeptides—Type P
In some embodiments of any of the multichain chimeric polypeptides described herein, the first target binding domain and the second target binding domain each specifically bind TGF-β. In some embodiments of these multi-chain chimeric polypeptides described herein, the first chimeric polypeptide further comprises an additional target binding domain. A non-limiting example of this type of multi-chain chimeric polypeptide is shown in FIGS.
これらの多鎖キメラポリペプチドのいくつかの例では、第1の標的結合ドメインと可溶性組織因子ドメインは、第1のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの例では、第1のキメラポリペプチドは、第1のキメラポリペプチド内の第1の標的結合ドメインと可溶性組織因子ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some examples of these multichain chimeric polypeptides, the first target binding domain and the soluble tissue factor domain are directly adjacent to each other within the first chimeric polypeptide. In some examples of these multichain chimeric polypeptides, the first chimeric polypeptide has a linker sequence (e.g., any of the exemplary linkers described herein).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインは、第1のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1のキメラポリペプチドは、第1のキメラポリペプチド内の可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these multi-chain chimeric polypeptides, the soluble tissue factor domain and the first of the paired affinity domains are directly adjacent to each other within the first chimeric polypeptide. In some embodiments of these multi-chain chimeric polypeptides, the first chimeric polypeptide is between the soluble tissue factor domain and the first of the pair of affinity domains within the first chimeric polypeptide. Further includes a linker sequence (eg, any of the exemplary linkers described herein).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、一対の親和性ドメインの第2のドメインと第2の標的結合ドメインは、第2のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチド内の一対の親和性ドメインの第2のドメインと第2の標的結合ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these multi-chain chimeric polypeptides, the second domain and the second target binding domain of the pair of affinity domains are directly adjacent to each other within the second chimeric polypeptide. In some embodiments of these multichain chimeric polypeptides, the second chimeric polypeptide is a combination of the second of the pair of affinity domains within the second chimeric polypeptide and the second target binding domain. Further includes a linker sequence (eg, any of the exemplary linkers described herein) in between.
いくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチドのN末端又はC末端に1つ以上の追加の標的結合ドメインを更に含む。 In some embodiments, the second chimeric polypeptide further comprises one or more additional target binding domains at the N-terminus or C-terminus of the second chimeric polypeptide.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、追加の標的結合ドメイン及び一対の親和性ドメインの第2のドメインは、第2のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチド内の一対の親和性ドメインの第2のドメインと追加の標的結合ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these multi-chain chimeric polypeptides, the additional target binding domain and the second domain of the pair of affinity domains are directly adjacent to each other within the second chimeric polypeptide. In some embodiments of these multichain chimeric polypeptides, the second chimeric polypeptide is between the second of the pair of affinity domains and the additional target binding domain within the second chimeric polypeptide. further includes a linker sequence (eg, any of the exemplary linkers described herein).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、追加の標的結合ドメインと第2の標的結合ドメインは、第2のキメラポリペプチド内で互いに直接隣接している。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2のキメラポリペプチドは、第2のキメラポリペプチド内の第2の標的結合ドメインと追加の標的結合ドメインとの間にリンカー配列(例えば、本明細書に記載の例示的なリンカーのうちのいずれか)を更に含む。 In some embodiments of these multi-chain chimeric polypeptides, the additional target binding domain and the second target binding domain are directly adjacent to each other within the second chimeric polypeptide. In some embodiments of these multichain chimeric polypeptides, the second chimeric polypeptide has a linker sequence ( For example, any of the exemplary linkers described herein).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性組織因子ドメインは、本明細書に記載の例示的な可溶性組織因子ドメインのうちのいずれかであり得る。これらの多鎖キメラポリペプチドのいくつかの実施形態では、一対の親和性ドメインは、本明細書に記載の例示的な一対の親和性ドメインのうちのいずれかであり得る。 In some embodiments of these multichain chimeric polypeptides, the soluble tissue factor domain can be any of the exemplary soluble tissue factor domains described herein. In some embodiments of these multi-chain chimeric polypeptides, the pair of affinity domains can be any of the exemplary pair of affinity domains described herein.
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメインは、TGF-βに特異的に結合し、第2の標的結合ドメインは、TGF-βに特異的に結合する。これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の標的結合ドメイン及び/又は第2の標的結合ドメインは、可溶性TGF-β受容体(例えば、可溶性TGFβRII受容体、例えば、可溶性ヒトTGFβRII受容体)である。 In some embodiments of these multichain chimeric polypeptides, the first target binding domain specifically binds TGF-beta and the second target binding domain specifically binds TGF-beta. . In some embodiments of these multichain chimeric polypeptides, the first target binding domain and/or the second target binding domain is a soluble TGF-β receptor (e.g., a soluble TGFβRII receptor, e.g., a soluble human TGFβRII receptor).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトTGFRβRIIは、第1の可溶性ヒトTGFRβRII配列及び第2の可溶性ヒトTGFRβRII配列を含む。これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性ヒトTGFRβRIIは、第1の可溶性ヒトTGFRβRII配列と第2の可溶性ヒトTGFRβRII配列との間に配置されたリンカーを含む。これらの多鎖キメラポリペプチドのいくつかの例では、リンカーは、配列GGGGSGGGGSGGGGS(配列番号102)を含む。 In some embodiments of these multichain chimeric polypeptides, the soluble human TGFRβRII comprises a first soluble human TGFRβRII sequence and a second soluble human TGFRβRII sequence. In some embodiments of these multichain chimeric polypeptides, the soluble human TGFRβRII comprises a linker positioned between the first soluble human TGFRβRII sequence and the second soluble human TGFRβRII sequence. In some examples of these multichain chimeric polypeptides, the linker comprises the sequence GGGGSGGGGSGGGGGS (SEQ ID NO: 102).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の可溶性ヒトTGFRβRII受容体配列は、
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD(配列番号183)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multichain chimeric polypeptides, the first soluble human TGFRβRII receptor sequence is
at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, sequences that are at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2の可溶性ヒトTGFRβRII受容体配列は、
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD(配列番号184)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multichain chimeric polypeptides, the second soluble human TGFRβRII receptor sequence is
at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, sequences that are at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第1の可溶性ヒトTGFRβRII受容体配列は、
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGAT(配列番号185)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multichain chimeric polypeptides, the first soluble human TGFRβRII receptor sequence is
ATCCCCCCCCCATGTGCAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAA GAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGAACCTTCTTTATGTGTTCCTGTAGCAG CGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGAT (SEQ ID NO: 185), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、第2の可溶性ヒトTGFRβRII受容体配列は、
ATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC(配列番号186)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments of these multichain chimeric polypeptides, the second soluble human TGFRβRII receptor sequence is
ATTCCTCCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGG TGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAAACCGTCTGCCCACGATCCCCAAGCTGCCCTACCCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAAGAGAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGC at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性TGF-β受容体は、
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD(配列番号188)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含む。
In some embodiments of these multichain chimeric polypeptides, the soluble TGF-β receptor is
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNSITSITSICEKPQEVCVAVWRKNDINITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPDGGGGGSGGGGGSGGGGGSIPPHV at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical , at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、これらの多鎖キメラポリペプチドのいくつかの実施形態では、可溶性TGF-β受容体は、
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC(配列番号187)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, in some embodiments of these multichain chimeric polypeptides, the soluble TGF-β receptor is
ATCCCCCCCCCATGTGCAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAA GAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGAACCTTCTTTATGTGTTCCTGTAGCAG CGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCC CCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCCACGATCCCCAAGCTGCCCTAC CACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCCGAC (SEQ ID NO: 187), and at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISNLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(配列番号238)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the first chimeric polypeptide is
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNCSITSICEKPQEVCVAVWRKNDINITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPDGGGGGSGGGGGSGGGGSIPPHV QKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDSGTTNTVAAYNLTWKSTNFKTILEWEPK PVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTA KTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISNLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANSLSSNGNVTESGCKECEELEEKNIKEFLQ SFVHIVQMFINTS (SEQ ID NO: 238), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, % identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
ATCCCACCGCACGTTCAGAAGTCGGTGAATAACGACATGATAGTCACTGACAACAACGGTGCAGTCAAGTTTCCACAACTGTGTAAATTTTGTGATGTGAGATTTTCCACCTGTGACAACCAGAAATCCTGCATGAGCAACTGCAGCATCACCTCCATCTGTGAGAAGCCACAGGAAGTCTGTGTGGCTGTATGGAGAAAGAATGACGAGAACATAACACTAGAGACAGTTTGCCATGACCCCAAGCTCCCCTACCATGACTTTATTCTGGAAGATGCTGCTTCTCCAAAGTGCATTATGAAGGAAAAAAAAAAGCCTGGTGAGACTTTCTTCATGTGTTCCTGTAGCTCTGATGAGTGCAATGACAACATCATCTTCTCAGAAGAATATAACACCAGCAATCCTGACGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACTCAGGCACTACAAATACTGTGGCAGCATATAATTTAACTTGGAAATCAACTAATTTCAAGACAATTTTGGAGTGGGAACCCAAACCCGTCAATCAAGTCTACACTGTTCAAATAAGCACTAAGTCAGGAGATTGGAAAAGCAAATGCTTTTACACAACAGACACAGAGTGTGACCTCACCGACGAGATTGTGAAGGATGTGAAGCAGACGTACTTGGCACGGGTCTTCTCCTACCCGGCAGGGAATGTGGAGAGCACCGGTTCTGCTGGGGAGCCTCTGTATGAGAACTCCCCAGAGTTCACACCTTACCTGGAGACAAACCTCGGACAGCCAACAATTCAGAGTTTTGAACAGGTGGGAACAAAAGTGAATGTGACCGTAGAAGATGAACGGACTTTAGTCAGAAGGAACAACACTTTCCTAAGCCTCCGGGATGTTTTTGGCAAGGACTTAATTTATACACTTTATTATTGGAAATCTTCAAGTTCAGGAAAGAAAACAGCCAAAACAAACACTAATGAGTTTTTGATTGATGTGGATAAAGGAGAAAACTACTGTTTCAGTGTTCAAGCAGTGATTCCCTCCCGAACAGTTAACCGGAAGAGTACAGACAGCCCGGTAGAGTGTATGGGCCAGGAGAAAGGGGAATTCAGAGAAAACTGGGTGAATGTAATAAGTAATTTGAAAAAAATTGAAGATCTTATTCAATCTATGCATATTGATGCTACTTTATATACGGAAAGTGATGTTCACCCCAGTTGCAAAGTAACAGCAATGAAGTGCTTTCTCTTGGAGTTACAAGTTATTTCACTTGAGTCCGGAGATGCAAGTATTCATGATACAGTAGAAAATCTGATCATCCTAGCAAACAACAGTTTGTCTTCTAATGGGAATGTAACAGAATCTGGATGCAAAGAATGTGAGGAACTGGAGGAAAAAAATATTAAAGAATTTTTGCAGAGTTTTGTACATATTGTCCAAATGTTCATCAACACTTCT(配列番号239)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the first chimeric polypeptide is
ATCCCCACCGCACGTTCAGAAGTCGGTGAATAACGACATGATAGTCACTGACAACAACGGTGCAGTCAAGTTTCCACAACTGTGTAAATTTTGTGATGTGAGATTTTCCACCTGTGACAACCAGAAATCCTGCATGAGCAACTGCAGCATCACCTCCATCTGTGAGAAGCCACAGGAA GTCTGTGTGGCTGTATGGAGAAAGAATGACGAGAACATAACACTAGAGACAGTTTGCCATGACCCCAAGCTCCCCTACCATGACTTTATTCTGGAAGATGCTGCTTCTCAAAGTGCATTATGAAGGAAAAAAAAAAGCCTGGTGAGACTTTCTTCATGTGTTCCTGTAGCTCTGAT GAGTGCAATGACAACATCATCTTCTCAGAAGAATATAACACCAGCAATCCTGACGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCCAGCT GTGCAAATTCTGCGATGTGGAGGTTTTCCACCTGCGCACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAAACCGTCTGCCACGATCCCCAAGCTGCCCTACCACGAT TTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAGAAGCCTGGCGAGACCTTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCCGACTCAGGCACTACAAATACTGTGGCAGCATATATAATT TAACTTGGAAATCAACTAATTTCAAGACAATTTTGGAGTGGGAACCCAAACCCGTCAATCAAGTCTACACTGTTCAAATAAGCACTAAGTCAGGAGATTGGAAAAGCAAATGCTTTTACACAACAGACACAGTGTGTGACCTCACCGACGAGATTGTGAAGGATGTGGAAGCAGACGTACT TGGCACGGGTCTTCTCCTACCCCGGCAGGGAATGTGGAGAGCACCGGTTCTGCTGGGGAGCCTCTGTATGAGAACTCCCCAGAGTTTCACACCTTACCTGGAGACAAACCTCGGACAGCCAACAATTCAGAGTTTTGAACAGGTGGGAACAAAGTGAATGTGACCGTAGAAGATGAACG GACTTTAGTCAGAAGGAACAACACTTTCCTAAGCCTCCGGGATGTTTTTGGCAAGGACTTAATTTATACACTTTATTATTGGAAATCTTCAAGTTTCAGGAAAGAAACAGCCAAAACAAAACACTAATGAGTTTTTGATTGATGTGGATAAAGGAGAAAAACTACTGTTTCAGTG TTCAAGCAGTGATTCCCTCCCGAACAGTTAACCGGAAGAGTACAGACAGCCCGGTAGAGGTGTATGGGCCAGGAGAAAAGGGGGAATTCAGAGAAAAACTGGGTGAATGTAATAAGTAATTTGAAAAAAAATTGAAGATCTTATTCAATCTATGCATATTGATGCTACTTTATATACGGAAA GTGATGTTCACCCCAGTTGCAAAGTAACAGCAATGAAGTGCTTTTCTCTTGGAGTTACAAGTTATTTCACTTGAGTCCGGAGATGCAAGTATTCATGATACAGTAGAAATCTGATCATCCTAGCAAACAACAGTTTTGTCTTCTAATGGGAATGTAACAGAAATCTGGATGCAAAGAAT at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、D8Nアミノ酸置換を含む可溶性IL-15を含み得、
(シグナルペプチド)
MGVKVLFALICIAVAEA
(一本鎖ヒトTGF-β受容体IIホモ二量体)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(組織因子)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(IL-15D8N)
NWVNVISNLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
(配列番号238)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を有し得る。
In some embodiments, the first chimeric polypeptide can comprise soluble IL-15 comprising a D8N amino acid substitution,
(signal peptide)
MGVKVLFALICIAVAEA
(single-chain human TGF-β receptor II homodimer)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNSITSITSICEKPQEVCVAVWRKNDINITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPDGGGGGSGGGGGSGGGGGSIPPHV QKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNSITSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(tissue factor)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTF LSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(IL-15D8N)
NWVNVISNLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
(SEQ ID NO: 238), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第1のキメラポリペプチドは、
(シグナルペプチド)
ATGGGAGTGAAAGTTCTTTTTGCCCTTATTTGTATTGCTGTGGCCGAGGCC
(一本鎖ヒトTGF-β受容体IIホモ二量体)
ATCCCACCGCACGTTCAGAAGTCGGTGAATAACGACATGATAGTCACTGACAACAACGGTGCAGTCAAGTTTCCACAACTGTGTAAATTTTGTGATGTGAGATTTTCCACCTGTGACAACCAGAAATCCTGCATGAGCAACTGCAGCATCACCTCCATCTGTGAGAAGCCACAGGAAGTCTGTGTGGCTGTATGGAGAAAGAATGACGAGAACATAACACTAGAGACAGTTTGCCATGACCCCAAGCTCCCCTACCATGACTTTATTCTGGAAGATGCTGCTTCTCCAAAGTGCATTATGAAGGAAAAAAAAAAGCCTGGTGAGACTTTCTTCATGTGTTCCTGTAGCTCTGATGAGTGCAATGACAACATCATCTTCTCAGAAGAATATAACACCAGCAATCCTGACGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC
(ヒト組織因子219)
TCAGGCACTACAAATACTGTGGCAGCATATAATTTAACTTGGAAATCAACTAATTTCAAGACAATTTTGGAGTGGGAACCCAAACCCGTCAATCAAGTCTACACTGTTCAAATAAGCACTAAGTCAGGAGATTGGAAAAGCAAATGCTTTTACACAACAGACACAGAGTGTGACCTCACCGACGAGATTGTGAAGGATGTGAAGCAGACGTACTTGGCACGGGTCTTCTCCTACCCGGCAGGGAATGTGGAGAGCACCGGTTCTGCTGGGGAGCCTCTGTATGAGAACTCCCCAGAGTTCACACCTTACCTGGAGACAAACCTCGGACAGCCAACAATTCAGAGTTTTGAACAGGTGGGAACAAAAGTGAATGTGACCGTAGAAGATGAACGGACTTTAGTCAGAAGGAACAACACTTTCCTAAGCCTCCGGGATGTTTTTGGCAAGGACTTAATTTATACACTTTATTATTGGAAATCTTCAAGTTCAGGAAAGAAAACAGCCAAAACAAACACTAATGAGTTTTTGATTGATGTGGATAAAGGAGAAAACTACTGTTTCAGTGTTCAAGCAGTGATTCCCTCCCGAACAGTTAACCGGAAGAGTACAGACAGCCCGGTAGAGTGTATGGGCCAGGAGAAAGGGGAATTCAGAGAA
(ヒトIL-15D8N)
AACTGGGTGAATGTAATAAGTAATTTGAAAAAAATTGAAGATCTTATTCAATCTATGCATATTGATGCTACTTTATATACGGAAAGTGATGTTCACCCCAGTTGCAAAGTAACAGCAATGAAGTGCTTTCTCTTGGAGTTACAAGTTATTTCACTTGAGTCCGGAGATGCAAGTATTCATGATACAGTAGAAAATCTGATCATCCTAGCAAACAACAGTTTGTCTTCTAATGGGAATGTAACAGAATCTGGATGCAAAGAATGTGAGGAACTGGAGGAAAAAAATATTAAAGAATTTTTGCAGAGTTTTGTACATATTGTCCAAATGTTCATCAACACTTCT(配列番号244)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the first chimeric polypeptide is
(signal peptide)
ATGGGAGTGAAAGTTCTTTTTGCCCTTTATTGTATTGCTGTGGCCCGAGGCC
(single-chain human TGF-β receptor II homodimer)
ATCCCCACCGCACGTTCAGAAGTCGGTGAATAACGACATGATAGTCACTGACAACAACGGTGCAGTCAAGTTTCCACAACTGTGTAAATTTTGTGATGTGAGATTTTCCACCTGTGACAACCAGAAATCCTGCATGAGCAACTGCAGCATCACCTCCATCTGTGAGAAGCCACAGGAA GTCTGTGTGGCTGTATGGAGAAAGAATGACGAGAACATAACACTAGAGACAGTTTGCCATGACCCCAAGCTCCCCTACCATGACTTTATTCTGGAAGATGCTGCTTCTCAAAGTGCATTATGAAGGAAAAAAAAAAGCCTGGTGAGACTTTCTTCATGTGTTCCTGTAGCTCTGAT GAGTGCAATGACAACATCATCTTCTCAGAAGAATATAACACCAGCAATCCTGACGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCCAGCT GTGCAAATTCTGCGATGTGGAGGTTTTCCACCTGCGCACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAAACCGTCTGCCACGATCCCCAAGCTGCCCTACCACGAT TTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAGAAGCCTGGCGAGACCTTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCCGAC
(human tissue factor 219)
TCAGGCACTACAAAATACTGTGGCAGCATATAATTTAACTTGGAAATCAACTAATTTCAAGACAATTTTGGAGTGGGAACCCAAAACCCGTCAATCAAGTCTACACTGTTCAAATAAGCACTAAGTCAGGAGATTGGAAAAGCAAATGCTTTTACACAACAGACACAGAGTGTGACCTCA CCGACGAGATTGTGAAGGATGTGAAGCAGACGTACTTGGCACGGGTCTTCTCCTACCCCGGCAGGGAATGTGGAGAGCACCGGTTCTGCTGGGGAGCTCTCGTATGAGAACTCCCCAGAGTTCACACCTTACCTGGAGACAAACCTCGGACAGCCAACAATTCAGAGTTTTGAACAGGT GGGAACAAAGTGAATGTGACCGTAGAAGATGAACGGACTTTAGTCAGAAGGAACAACACTTTCCTAAGCCTCCGGGATGTTTTTTGGCAAGGACTTAATTTATACACTTTATTATTGGAAATCTTCAAGTTCAGGAAAGAAACAGCCAAAACAAAACACTAATGAGTTTTTGATT GATGTGGATAAAGGAGAAAAACTACTGTTTCAGTGTTCAAGCAGTGATTCCCTCCCGAACAGTTAACCGGAAGAGTACAGACAGCCCCGGTAGAGTGTATGGGCCAGGAGAAAAGGGGGAATTCAGAGAA
(human IL-15D8N)
AACTGGGTGAATGTAATAAGTAATTTGAAAAAAAATTGAAGATCTTATTCAATCTATGCATATTGATGCTACTTTATATACGGAAAGTGATGTTCACCCCAGTTGCAAAGTAACAGCAATGAAGTGCTTTCTCTTGGAGTTACAAGTTATTTCACTTGAGTCCGGAGATGCA AGTATTCATGATACAGTAGAAATCTGATCATCCTAGCAAACAACAGTTTTGTCTTCTAATGGGAATGTAACAGAATCTGGATGCAAAGAATGTGAGGAACTGGAGGAAAAAAATATTAAAGAATTTTTGCAGAGTTTTGTACATATTGTCCAAATGTTCATCAACACTTCT (SEQ ID NO: 2 44), at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical to , at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR(配列番号240)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the second chimeric polypeptide is
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNSITSITSICEKPQEVCVAVWRKNDINITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPDGGGGGSGGGGGSGGGGGSIPPHV QKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADIWVKSYSLYSRERYICNSG at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% sequences that are identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG(配列番号241)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。
In some embodiments, the second chimeric polypeptide is
ATCCCCCCCCCATGTGCAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAA GAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGAACCTTCTTTATGTGTTCCTGTAGCAG CGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCC CCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCCACGATCCCCAAGCTGCCCTAC CACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAAGAGAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACATTACATGCCCCCCCTCCCATGAGCGTG GAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG (SEQ ID NO: 241) , at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical to , at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR(配列番号242)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列を含み得る。
In some embodiments, the second chimeric polypeptide is
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGG GSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADI at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical, at least 88% identical, at least 90% identical, at least 92% identical, at least 94% sequences that are identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
いくつかの実施形態では、第2のキメラポリペプチドは、ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG(配列番号243)、と少なくとも80%同一(例えば、少なくとも82%同一、少なくとも84%同一、少なくとも86%同一、少なくとも88%同一、少なくとも90%同一、少なくとも92%同一、少なくとも94%同一、少なくとも96%同一、少なくとも98%同一、少なくとも99%同一、又は100%同一)である配列によってコードされる。 In some embodiments, the second chimeric polypeptide is ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCCATCCCCCCCATGTGCAAAGAGCGTGAACAACGATATGATCGTGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGAT GTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGA GGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTG GGAGTATTCCTCCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGGACAACCAGAAGTCCTGTATGAGCCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGA GGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAAACCGTCTGCCACGATCCCCAAGCTGCCCTCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAAGAGAAAAGAAGCCTGGCGAGACCTTTTCATGTGCTCCTGCAGCA GCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCA at least 80% identical (e.g., at least 82% identical, at least 84% identical, at least 86% identical , at least 88% identical, at least 90% identical, at least 92% identical, at least 94% identical, at least 96% identical, at least 98% identical, at least 99% identical, or 100% identical).
加齢関連疾患又は状態を治療する方法
加齢関連疾患又は状態(例えば、本明細書に記載の又は当該技術分野で既知の例示的なタイプの加齢関連疾患又は状態のうちのいずれか)の治療を必要とする対象において加齢関連疾患又は状態を治療する方法であって、加齢関連疾患又は状態(例えば、本明細書に記載の又は当該技術分野で既知の例示的なタイプの加齢関連疾患又は状態のうちのいずれか)を有すると同定される対象に、治療有効量の1つ以上のナチュラルキラー(NK)細胞活性化物質(例えば、本明細書に記載の又は当該技術分野で既知のナチュラルキラー(NK)細胞活性化物質のうちのいずれか)を投与することを含む、方法が、本明細書に提供される。
Methods of Treating Age-Related Diseases or Conditions Age-related diseases or conditions (e.g., any of the exemplary types of age-related diseases or conditions described herein or known in the art) A method of treating an age-related disease or condition in a subject in need thereof, comprising: A therapeutically effective amount of one or more natural killer (NK) cell activators (e.g., as described herein or in the art) to a subject identified as having a relevant disease or condition Methods are provided herein comprising administering any of the known natural killer (NK) cell activators.
加齢関連疾患又は状態(例えば、本明細書に記載の又は当該技術分野で既知の例示的なタイプの加齢関連疾患又は状態のうちのいずれか)の治療を必要とする対象において加齢関連疾患又は状態を治療する方法であって、加齢関連疾患又は状態(例えば、本明細書に記載の又は当該技術分野で既知の例示的なタイプの加齢関連疾患又は状態のうちのいずれか)を有すると同定される対象に、治療有効量の活性化されたNK細胞(例えば、本明細書に記載の又は当該技術分野で既知の活性化されたNK細胞のうちのいずれか)を投与することを含む、方法が、本明細書に提供される。 Age-related diseases or conditions in a subject in need of treatment (e.g., any of the exemplary types of age-related diseases or conditions described herein or known in the art) A method of treating a disease or condition, which age-related disease or condition (e.g., any of the exemplary types of age-related diseases or conditions described herein or known in the art) administering a therapeutically effective amount of activated NK cells (e.g., any of the activated NK cells described herein or known in the art) to a subject identified as having A method is provided herein comprising:
これらの方法のいくつかの実施形態は、休止NK細胞を得ることと、1つ以上の休止NK細胞活性化物質を含む液体培養培地中でインビトロで休止NK細胞を接触させることであって、この接触が、その後、対象に投与される活性化されたNK細胞の発生をもたらす、接触させることと、を更に含む。これらの方法のいくつかの例では、休止NK細胞は、対象から得られた自己NK細胞である。これらの方法のいくつかの例では、休止NK細胞は、対象から得られたハプロタイプ一致のNK細胞である。これらの方法のいくつかの例では、休止NK細胞は、同種異系の休止NK細胞である。これらの方法のいくつかの例では、休止NK細胞は、人工NK細胞である。これらの方法のいずれかのいくつかの例では、休止NK細胞は、キメラ抗原受容体又は組換えT細胞受容体を有する遺伝子操作されたNK細胞である。 Some embodiments of these methods include obtaining resting NK cells and contacting the resting NK cells in vitro in a liquid culture medium comprising one or more resting NK cell activators, wherein Contacting results in the generation of activated NK cells that are then administered to the subject. In some examples of these methods, the resting NK cells are autologous NK cells obtained from the subject. In some examples of these methods, the resting NK cells are haploidentical NK cells obtained from the subject. In some examples of these methods, the resting NK cells are allogeneic resting NK cells. In some examples of these methods, the resting NK cells are induced NK cells. In some examples of any of these methods, the resting NK cells are genetically engineered NK cells with chimeric antigen receptors or recombinant T cell receptors.
これらの方法のいくつかの例では、液体培養培地は、無血清液体培養培地である。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、液体培養培地は、化学的に定義された液体培養培地である。これらの方法のいくつかの例は、活性化されたNK細胞を単離すること(及び任意選択で、活性化されたNK細胞の治療有効量を、対象、例えば、本明細書に記載の対象のうちのいずれかに更に投与すること)を更に含む。これらの方法のいくつかの実施形態では、接触ステップは、約2時間~約20日(又は本明細書に記載のこの範囲の部分範囲のうちのいずれか)の期間にわたって実施される。 In some examples of these methods, the liquid culture medium is a serum-free liquid culture medium. In some embodiments of any of the methods described herein, the liquid culture medium is a chemically defined liquid culture medium. Some examples of these methods include isolating activated NK cells (and optionally administering a therapeutically effective amount of the activated NK cells to a subject, e.g., a subject described herein). further administering to any of In some embodiments of these methods, the contacting step is carried out for a period of time from about 2 hours to about 20 days (or any subrange of this range described herein).
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、加齢関連疾患又は状態は、がん、自己免疫疾患、代謝性疾患、神経変性疾患、心臓血管疾患、皮膚疾患、早老症、及び脆弱性疾患の群から選択される。 In some embodiments of any of the methods described herein, the age-related disease or condition is cancer, autoimmune disease, metabolic disease, neurodegenerative disease, cardiovascular disease, skin disease, It is selected from the group of progeria and frailty diseases.
がんの非限定的な例には、固形腫瘍、血液腫瘍、肉腫、骨肉腫、膠芽細胞腫、神経芽細胞腫、黒色腫、横紋筋肉腫、ユーイング肉腫、骨肉腫、B細胞新生物、多発性骨髄腫、B細胞リンパ腫、B細胞非ホジキンリンパ腫、ホジキンリンパ腫、慢性リンパ球性白血病(CLL)、急性骨髄性白血病(AML)、慢性骨髄性白血病(CML)、急性リンパ性白血病(ALL)、骨髄異形成症候群(MDS)、皮膚T細胞リンパ腫、網膜芽細胞腫、胃がん、尿路上皮がん、肺がん、腎細胞がん、胃食道がん、膵臓がん、前立腺がん、乳がん、結腸直腸がん、卵巣がん、非小細胞肺がん、扁平上皮細胞頭頸部がん、子宮内膜がん、子宮頸がん、肝臓がん、及び肝細胞がんが挙げられる。 Non-limiting examples of cancer include solid tumors, hematologic tumors, sarcoma, osteosarcoma, glioblastoma, neuroblastoma, melanoma, rhabdomyosarcoma, Ewing's sarcoma, osteosarcoma, B-cell neoplasms. , multiple myeloma, B-cell lymphoma, B-cell non-Hodgkin's lymphoma, Hodgkin's lymphoma, chronic lymphocytic leukemia (CLL), acute myelogenous leukemia (AML), chronic myelogenous leukemia (CML), acute lymphocytic leukemia (ALL) ), myelodysplastic syndrome (MDS), cutaneous T-cell lymphoma, retinoblastoma, gastric cancer, urothelial cancer, lung cancer, renal cell cancer, gastroesophageal cancer, pancreatic cancer, prostate cancer, breast cancer, Colorectal cancer, ovarian cancer, non-small cell lung cancer, squamous cell head and neck cancer, endometrial cancer, cervical cancer, liver cancer, and hepatocellular carcinoma.
自己免疫疾患の非限定的な例は、1型糖尿病である。
A non-limiting example of an autoimmune disease is
代謝性疾患の非限定的な例には、肥満、脂肪異栄養症、及び2型糖尿病が含まれる。
Non-limiting examples of metabolic diseases include obesity, lipodystrophy, and
神経変性疾患の非限定的な例には、アルツハイマー病、パーキンソン病、及び認知症が含まれる。 Non-limiting examples of neurodegenerative diseases include Alzheimer's disease, Parkinson's disease, and dementia.
心臓血管疾患の非限定的な例には、冠状動脈疾患、アテローム性動脈硬化症、及び肺動脈性肺高血圧症が含まれる。 Non-limiting examples of cardiovascular disease include coronary artery disease, atherosclerosis, and pulmonary arterial hypertension.
皮膚疾患の非限定的な例には、創傷治癒、脱毛症、しわ、老人性黒子、皮膚の菲薄化、色素性乾皮症、及び先天性角化異常症が含まれる。 Non-limiting examples of skin disorders include wound healing, alopecia, wrinkles, senile lentigines, skin thinning, xeroderma pigmentosum, and dyskeratosis congenita.
早老症の非限定的な例には、早老症及びハッチンソン・ギルフォード早老症症候群が含まれる。 Non-limiting examples of progeria include progeria and Hutchinson-Guilford progeria syndrome.
脆弱性疾患の非限定的な例には、脆弱、ワクチン接種に対する応答、骨粗しょう症、及びサルコペニアが含まれる。 Non-limiting examples of frailty diseases include frailty, response to vaccination, osteoporosis, and sarcopenia.
本明細書に記載の加齢関連疾患又は状態のうちのいずれかのいくつかの実施形態では、加齢関連疾患又は状態は、加齢関連黄斑変性、骨関節炎、脂肪萎縮、慢性閉塞性肺疾患、特発性肺線維症、腎移植不全、肝線維症、骨量喪失、サルコペニア、加齢関連肺組織弾性喪失、骨粗しょう症、加齢関連腎機能障害、及び化学的に誘導された腎機能障害の群から選択される。 In some embodiments of any of the age-related diseases or conditions described herein, the age-related disease or condition is age-related macular degeneration, osteoarthritis, fat wasting, chronic obstructive pulmonary disease , idiopathic pulmonary fibrosis, renal graft failure, liver fibrosis, bone loss, sarcopenia, age-related pulmonary tissue elastic loss, osteoporosis, age-related renal dysfunction, and chemically-induced renal dysfunction selected from the group of
本明細書に記載の加齢関連疾患又は状態のうちのいずれかのいくつかの実施形態では、加齢関連疾患又は状態は、2型糖尿病又はアテローム性動脈硬化症である。
In some embodiments of any of the age-related diseases or conditions described herein, the age-related disease or condition is
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、対象は、加齢関連疾患又は状態(例えば、本明細書に記載の例示的な加齢関連疾患又は状態のうちのいずれか)を有すると同定又は診断されている。本明細書に記載の方法のうちのいずれかのいくつかの実施形態は、加齢関連疾患又は状態(例えば、本明細書に記載の例示的な加齢関連疾患又は状態のうちのいずれか)を有すると同定又は診断されている対象を選択するステップを含み得る。 In some embodiments of any of the methods described herein, the subject has an age-related disease or condition (e.g., one of the exemplary age-related diseases or conditions described herein) have been identified or diagnosed as having Some embodiments of any of the methods described herein use age-related diseases or conditions (e.g., any of the exemplary age-related diseases or conditions described herein). selecting subjects who have been identified or diagnosed as having
これらの方法のいくつかの実施形態では、投与は、例えば、対象における標的組織中の老化細胞の数における減少(例えば、少なくとも5%減少、少なくとも10%減少、少なくとも15%減少、少なくとも20%減少、少なくとも25%減少、少なくとも30%減少、少なくとも35%減少、少なくとも40%減少、少なくとも45%減少、少なくとも50%減少、少なくとも55%減少、少なくとも60%減少、少なくとも65%減少、少なくとも70%減少、少なくとも75%減少、少なくとも80%減少、少なくとも85%減少、少なくとも90%減少、又は少なくとも95%減少、又は約10%減少~約99%減少、約10%減少~約95%減少、約10%減少~約90%減少、約10%減少~約85%減少、約10%減少~約80%減少、約10%減少~約75%減少、約10%減少~約70%減少、約10%減少~約65%減少、約10%減少~約60%減少、約10%減少~約55%減少、約10%減少~約50%減少、約10%減少~約45%減少、約10%減少~約40%減少、約10%減少~約35%減少、約10%減少~約30%減少、約10%減少~約25%減少、約10%減少~約20%減少、約10%減少~約15%減少、約15%減少~約99%減少、約15%減少~約95%減少、約15%減少~約90%減少、約15%減少~約85%減少、約15%減少~約80%減少、約15%減少~約75%減少、約15%減少~約70%減少、約15%減少~約65%減少、約15%減少~約60%減少、約15%減少~約55%減少、約15%減少~約50%減少、約15%減少~約45%減少、約15%減少~約40%減少、約15%減少~約35%減少、約15%減少~約30%減少、約15%減少~約25%減少、約15%減少~約20%減少、約20%減少~約99%減少、約20%減少~約95%減少、約20%減少~約90%減少、約20%減少~約85%減少、約20%減少~約80%減少、約20%減少~約75%減少、約20%減少~約70%減少、約20%減少~約65%減少、約20%減少~約60%減少、約20%減少~約55%減少、約20%減少~約50%減少、約20%減少~約45%減少、約20%減少~約40%減少、約20%減少~約35%減少、約20%減少~約30%減少、約20%減少~約25%減少、約25%減少~約99%減少、約25%減少~約95%減少、約25%減少~約90%減少、約25%減少~約85%減少、約25%減少~約80%減少、約25%減少~約75%減少、約25%減少~約70%減少、約25%減少~約65%減少、約25%減少~約60%減少、約25%減少~約55%減少、約25%減少~約50%減少、約25%減少~約45%減少、約25%減少~約40%減少、約25%減少~約35%減少、約25%減少~約30%減少、約30%減少~約99%減少、約30%減少~約95%減少、約30%減少~約90%減少、約30%減少~約85%減少、約30%減少~約80%減少、約30%減少~約75%減少、約30%減少~約70%減少、約30%減少~約65%減少、約30%減少~約60%減少、約30%減少~約55%減少、約30%減少~約50%減少、約30%減少~約45%減少、約30%減少~約40%減少、約30%減少~約35%減少、約35%減少~約99%減少、約35%減少~約95%減少、約35%減少~約90%減少、約35%減少~約85%減少、約35%減少~約80%減少、約35%減少~約75%減少、約35%減少~約70%減少、約35%減少~約65%減少、約35%減少~約60%減少、約35%減少~約55%減少、約35%減少~約50%減少、約35%減少~約45%減少、約35%減少~約40%減少、約40%減少~約99%減少、約40%減少~約95%減少、約40%減少~約90%減少、約40%減少~約85%減少、約40%減少~約80%減少、約40%減少~約75%減少、約40%減少~約70%減少、約40%減少~約65%減少、約40%減少~約60%減少、約40%減少~約55%減少、約40%減少~約50%減少、約40%減少~約45%減少、約45%減少~約99%減少、約45%減少~約95%減少、約45%減少~約90%減少、約45%減少~約85%減少、約45%減少~約80%減少、約45%減少~約75%減少、約45%減少~約70%減少、約45%減少~約65%減少、約45%減少~約60%減少、約45%減少~約55%減少、約45%減少~約50%減少、約50%減少~約99%減少、約50%減少~約95%減少、約50%減少~約90%減少、約50%減少~約85%減少、約50%減少~約80%減少、約50%減少~約75%減少、約50%減少~約70%減少、約50%減少~約65%減少、約50%減少~約60%減少、約50%減少~約55%減少、約55%減少~約99%減少、約55%減少~約95%減少、約55%減少~約90%減少、約55%減少~約85%減少、約55%減少~約80%減少、約55%減少~約75%減少、約55%減少~約70%減少、約55%減少~約65%減少、約55%減少~約60%減少、約60%減少~約99%減少、約60%減少~約95%減少、約60%減少~約90%減少、約60%減少~約85%減少、約60%減少~約80%減少、約60%減少~約75%減少、約60%減少~約70%減少、約60%減少~約65%減少、約65%減少~約99%減少、約65%減少~約95%減少、約65%減少~約90%減少、約65%減少~約85%減少、約65%減少~約80%減少、約65%減少~約75%減少、約65%減少~約70%減少、約70%減少~約99%減少、約70%減少~約95%減少、約70%減少~約90%減少、約70%減少~約85%減少、約70%減少~約80%減少、約70%減少~約75%減少、約75%減少~約99%減少、約75%減少~約95%減少、約75%減少~約90%減少、約75%減少~約85%減少、約75%減少~約80%減少、約80%減少~約99%減少、約80%減少~約95%減少、約80%減少~約90%減少、約80%減少~約85%減少、約85%減少~約99%減少、約85%減少~約95%減少、約85%減少~約90%減少、約90%減少~約99%減少、約90%減少~約95%減少、又は約95%減少~約99%減少)をもたらす(治療前の対象における標的組織中の老化細胞の数と比較して)。 In some embodiments of these methods, administering, for example, results in a reduction (e.g., at least a 5% reduction, at least a 10% reduction, at least a 15% reduction, at least a 20% reduction in the number of senescent cells in a target tissue in a subject). , at least 25% reduced, at least 30% reduced, at least 35% reduced, at least 40% reduced, at least 45% reduced, at least 50% reduced, at least 55% reduced, at least 60% reduced, at least 65% reduced, at least 70% reduced , at least 75% reduced, at least 80% reduced, at least 85% reduced, at least 90% reduced, or at least 95% reduced, or about 10% reduced to about 99% reduced, about 10% reduced to about 95% reduced, about 10 % reduction to about 90% reduction, about 10% reduction to about 85% reduction, about 10% reduction to about 80% reduction, about 10% reduction to about 75% reduction, about 10% reduction to about 70% reduction, about 10 % reduction to about 65% reduction, about 10% reduction to about 60% reduction, about 10% reduction to about 55% reduction, about 10% reduction to about 50% reduction, about 10% reduction to about 45% reduction, about 10 % reduction to about 40% reduction, about 10% reduction to about 35% reduction, about 10% reduction to about 30% reduction, about 10% reduction to about 25% reduction, about 10% reduction to about 20% reduction, about 10 % reduction to about 15% reduction, about 15% reduction to about 99% reduction, about 15% reduction to about 95% reduction, about 15% reduction to about 90% reduction, about 15% reduction to about 85% reduction, about 15 % reduction to about 80% reduction, about 15% reduction to about 75% reduction, about 15% reduction to about 70% reduction, about 15% reduction to about 65% reduction, about 15% reduction to about 60% reduction, about 15 % reduction to about 55% reduction, about 15% reduction to about 50% reduction, about 15% reduction to about 45% reduction, about 15% reduction to about 40% reduction, about 15% reduction to about 35% reduction, about 15 % reduction to about 30% reduction, about 15% reduction to about 25% reduction, about 15% reduction to about 20% reduction, about 20% reduction to about 99% reduction, about 20% reduction to about 95% reduction, about 20 % reduction to about 90% reduction, about 20% reduction to about 85% reduction, about 20% reduction to about 80% reduction, about 20% reduction to about 75% reduction, about 20% reduction to about 70% reduction, about 20 % reduction to about 65% reduction, about 20% reduction to about 60% reduction, about 20% reduction to about 55% reduction, about 20% reduction to about 50% reduction, about 20% reduction to about 45% reduction, about 20 % reduction to about 40% reduction, about 20% reduction to about 35% reduction, about 20% reduction to about 30% reduction, about 20% reduction to about 25% reduction, about 25% reduction to about 99% reduction, about 25 % reduction to about 95% reduction, about 25% reduction to about 90% reduction, about 25% reduction to about 85% reduction, about 25% reduction to about 80% reduction, about 25% reduction to about 75% reduction, about 25 % reduction to about 70% reduction, about 25% reduction to about 65% reduction, about 25% reduction to about 60% reduction, about 25% reduction to about 55% reduction, about 25% reduction to about 50% reduction, about 25 % reduction to about 45% reduction, about 25% reduction to about 40% reduction, about 25% reduction to about 35% reduction, about 25% reduction to about 30% reduction, about 30% reduction to about 99% reduction, about 30 % reduction to about 95% reduction, about 30% reduction to about 90% reduction, about 30% reduction to about 85% reduction, about 30% reduction to about 80% reduction, about 30% reduction to about 75% reduction, about 30 % reduction to about 70% reduction, about 30% reduction to about 65% reduction, about 30% reduction to about 60% reduction, about 30% reduction to about 55% reduction, about 30% reduction to about 50% reduction, about 30 % reduction to about 45% reduction, about 30% reduction to about 40% reduction, about 30% reduction to about 35% reduction, about 35% reduction to about 99% reduction, about 35% reduction to about 95% reduction, about 35 % reduction to about 90% reduction, about 35% reduction to about 85% reduction, about 35% reduction to about 80% reduction, about 35% reduction to about 75% reduction, about 35% reduction to about 70% reduction, about 35 % reduction to about 65% reduction, about 35% reduction to about 60% reduction, about 35% reduction to about 55% reduction, about 35% reduction to about 50% reduction, about 35% reduction to about 45% reduction, about 35 % reduction to about 40% reduction, about 40% reduction to about 99% reduction, about 40% reduction to about 95% reduction, about 40% reduction to about 90% reduction, about 40% reduction to about 85% reduction, about 40 % reduction to about 80% reduction, about 40% reduction to about 75% reduction, about 40% reduction to about 70% reduction, about 40% reduction to about 65% reduction, about 40% reduction to about 60% reduction, about 40 % reduction to about 55% reduction, about 40% reduction to about 50% reduction, about 40% reduction to about 45% reduction, about 45% reduction to about 99% reduction, about 45% reduction to about 95% reduction, about 45 % reduction to about 90% reduction, about 45% reduction to about 85% reduction, about 45% reduction to about 80% reduction, about 45% reduction to about 75% reduction, about 45% reduction to about 70% reduction, about 45 % reduction to about 65% reduction, about 45% reduction to about 60% reduction, about 45% reduction to about 55% reduction, about 45% reduction to about 50% reduction, about 50% reduction to about 99% reduction, about 50 % reduction to about 95% reduction, about 50% reduction to about 90% reduction, about 50% reduction to about 85% reduction, about 50% reduction to about 80% reduction, about 50% reduction to about 75% reduction, about 50 % reduction to about 70% reduction, about 50% reduction to about 65% reduction, about 50% reduction to about 60% reduction, about 50% reduction to about 55% reduction, about 55% reduction to about 99% reduction, about 55 % reduction to about 95% reduction, about 55% reduction to about 90% reduction, about 55% reduction to about 85% reduction, about 55% reduction to about 80% reduction, about 55% reduction to about 75% reduction, about 55 % reduction to about 70% reduction, about 55% reduction to about 65% reduction, about 55% reduction to about 60% reduction, about 60% reduction to about 99% reduction, about 60% reduction to about 95% reduction, about 60 % reduction to about 90% reduction, about 60% reduction to about 85% reduction, about 60% reduction to about 80% reduction, about 60% reduction to about 75% reduction, about 60% reduction to about 70% reduction, about 60 % reduction to about 65% reduction, about 65% reduction to about 99% reduction, about 65% reduction to about 95% reduction, about 65% reduction to about 90% reduction, about 65% reduction to about 85% reduction, about 65 % reduction to about 80% reduction, about 65% reduction to about 75% reduction, about 65% reduction to about 70% reduction, about 70% reduction to about 99% reduction, about 70% reduction to about 95% reduction, about 70 % reduction to about 90% reduction, about 70% reduction to about 85% reduction, about 70% reduction to about 80% reduction, about 70% reduction to about 75% reduction, about 75% reduction to about 99% reduction, about 75 % reduction to about 95% reduction, about 75% reduction to about 90% reduction, about 75% reduction to about 85% reduction, about 75% reduction to about 80% reduction, about 80% reduction to about 99% reduction, about 80 % reduction to about 95% reduction, about 80% reduction to about 90% reduction, about 80% reduction to about 85% reduction, about 85% reduction to about 99% reduction, about 85% reduction to about 95% reduction, about 85 % reduction to about 90% reduction, about 90% reduction to about 99% reduction, about 90% reduction to about 95% reduction, or about 95% reduction to about 99% reduction in target tissue in a subject prior to treatment. (compared to the number of senescent cells in ).
これらの方法のいくつかの実施形態では、投与は、対象におけるIFN-γ、細胞傷害性顆粒グランザイム、及び/又はパーフォリンのレベルにおける増加(例えば、少なくとも5%増加、少なくとも10%増加、少なくとも15%増加、少なくとも20%増加、少なくとも25%増加、少なくとも30%増加、少なくとも35%増加、少なくとも40%増加、少なくとも45%増加、少なくとも50%増加、少なくとも55%増加、少なくとも60%増加、少なくとも65%増加、少なくとも70%増加、少なくとも75%増加、少なくとも80%増加、少なくとも85%増加、少なくとも90%増加、少なくとも95%増加、又は少なくとも99%増加、又は約10%増加~約500%増加(又は本明細書に記載のこの範囲の部分範囲のうちのいずれか)をもたらす(治療前の対象又は治療を受けていない同様の対照対象のレベルと比較して)。 In some embodiments of these methods, administering results in an increase in levels of IFN-γ, cytotoxic granule granzymes, and/or perforin in the subject (e.g., at least a 5% increase, at least a 10% increase, at least a 15% increase, at least 20% increase, at least 25% increase, at least 30% increase, at least 35% increase, at least 40% increase, at least 45% increase, at least 50% increase, at least 55% increase, at least 60% increase, at least 65% increase, at least 70% increase, at least 75% increase, at least 80% increase, at least 85% increase, at least 90% increase, at least 95% increase, or at least 99% increase, or about 10% increase to about 500% increase (or (any of the subranges of this range described herein) (compared to levels in pretreatment subjects or similar control subjects not receiving treatment).
いくつかの実施形態では、これらの方法は、対象におけるがんの1つ以上の症状の数、重症度、又は頻度の減少をもたらし得る(例えば、治療前の対象におけるがんの1つ以上の症状の数、重症度、又は頻度と比較して)。いくつかの実施形態では、これらの方法は、対象における1つ以上の固形腫瘍の体積の減少(例えば、約1%減少~約99%減少、約1%減少~約95%減少、約1%減少~約90%減少、約1%減少~約85%減少、約1%減少~約80%減少、約1%減少~約75%減少、約1%減少~約70%減少、約1%減少~約65%減少、約1%減少~約60%減少、約1%減少~約55%減少、約1%減少~約50%減少、約1%減少~約45%減少、約1%減少~約40%減少、約1%減少~約35%減少、約1%減少~約30%減少、約1%減少~約25%減少、約1%減少~約20%減少、約1%減少~約15%減少、約1%減少~約10%減少、約1%減少~約5%減少、約5%減少~約99%減少、約5%減少~約95%減少、約5%減少~約90%減少、約5%減少~約85%減少、約5%減少~約80%減少、約5%減少~約75%減少、約5%減少~約70%減少、約5%減少~約65%減少、約5%減少~約60%減少、約5%減少~約55%減少、約5%減少~約50%減少、約5%減少~約45%減少、約5%減少~約40%減少、約5%減少~約35%減少、約5%減少~約30%減少、約5%減少~約25%減少、約5%減少~約20%減少、約5%減少~約15%減少、約5%減少~約10%減少、約10%減少~約99%減少、約10%減少~約95%減少、約10%減少~約90%減少、約10%減少~約85%減少、約10%減少~約80%減少、約10%減少~約75%減少、約10%減少~約70%減少、約10%減少~約65%減少、約10%減少~約60%減少、約10%減少~約55%減少、約10%減少~約50%減少、約10%減少~約45%減少、約10%減少~約40%減少、約10%減少~約35%減少、約10%減少~約30%減少、約10%減少~約25%減少、約10%減少~約20%減少、約10%減少~約15%減少、約15%減少~約99%減少、約15%減少~約95%減少、約15%減少~約90%減少、約15%減少~約85%減少、約15%減少~約80%減少、約15%減少~約75%減少、約15%減少~約70%減少、約15%減少~約65%減少、約15%減少~約60%減少、約15%減少~約55%減少、約15%減少~約50%減少、約15%減少~約45%減少、約15%減少~約40%減少、約15%減少~約35%減少、約15%減少~約30%減少、約15%減少~約25%減少、約15%減少~約20%減少、約20%減少~約99%減少、約20%減少~約95%減少、約20%減少~約90%減少、約20%減少~約85%減少、約20%減少~約80%減少、約20%減少~約75%減少、約20%減少~約70%減少、約20%減少~約65%減少、約20%減少~約60%減少、約20%減少~約55%減少、約20%減少~約50%減少、約20%減少~約45%減少、約20%減少~約40%減少、約20%減少~約35%減少、約20%減少~約30%減少、約20%減少~約25%減少、約25%減少~約99%減少、約25%減少~約95%減少、約25%減少~約90%減少、約25%減少~約85%減少、約25%減少~約80%減少、約25%減少~約75%減少、約25%減少~約70%減少、約25%減少~約65%減少、約25%減少~約60%減少、約25%減少~約55%減少、約25%減少~約50%減少、約25%減少~約45%減少、約25%減少~約40%減少、約25%減少~約35%減少、約25%減少~約30%減少、約30%減少~約99%減少、約30%減少~約95%減少、約30%減少~約90%減少、約30%減少~約85%減少、約30%減少~約80%減少、約30%減少~約75%減少、約30%減少~約70%減少、約30%減少~約65%減少、約30%減少~約60%減少、約30%減少~約55%減少、約30%減少~約50%減少、約30%減少~約45%減少、約30%減少~約40%減少、約30%減少~約35%減少、約35%減少~約99%減少、約35%減少~約95%減少、約35%減少~約90%減少、約35%減少~約85%減少、約35%減少~約80%減少、約35%減少~約75%減少、約35%減少~約70%減少、約35%減少~約65%減少、約35%減少~約60%減少、約35%減少~約55%減少、約35%減少~約50%減少、約35%減少~約45%減少、約35%減少~約40%減少、約40%減少~約99%減少、約40%減少~約95%減少、約40%減少~約90%減少、約40%減少~約85%減少、約40%減少~約80%減少、約40%減少~約75%減少、約40%減少~約70%減少、約40%減少~約65%減少、約40%減少~約60%減少、約40%減少~約55%減少、約40%減少~約50%減少、約40%減少~約45%減少、約45%減少~約99%減少、約45%減少~約95%減少、約45%減少~約90%減少、約45%減少~約85%減少、約45%減少~約80%減少、約45%減少~約75%減少、約45%減少~約70%減少、約45%減少~約65%減少、約45%減少~約60%減少、約45%減少~約55%減少、約45%減少~約50%減少、約50%減少~約99%減少、約50%減少~約95%減少、約50%減少~約90%減少、約50%減少~約85%減少、約50%減少~約80%減少、約50%減少~約75%減少、約50%減少~約70%減少、約50%減少~約65%減少、約50%減少~約60%減少、約50%減少~約55%減少、約55%減少~約99%減少、約55%減少~約95%減少、約55%減少~約90%減少、約55%減少~約85%減少、約55%減少~約80%減少、約55%減少~約75%減少、約55%減少~約70%減少、約55%減少~約65%減少、約55%減少~約60%減少、約60%減少~約99%減少、約60%減少~約95%減少、約60%減少~約90%減少、約60%減少~約85%減少、約60%減少~約80%減少、約60%減少~約75%減少、約60%減少~約70%減少、約60%減少~約65%減少、約65%減少~約99%減少、約65%減少~約95%減少、約65%減少~約90%減少、約65%減少~約85%減少、約65%減少~約80%減少、約65%減少~約75%減少、約65%減少~約70%減少、約70%減少~約99%減少、約70%減少~約95%減少、約70%減少~約90%減少、約70%減少~約85%減少、約70%減少~約80%減少、約70%減少~約75%減少、約75%減少~約99%減少、約75%減少~約95%減少、約75%減少~約90%減少、約75%減少~約85%減少、約75%減少~約80%減少、約80%減少~約99%減少、約80%減少~約95%減少、約80%減少~約90%減少、約80%減少~約85%減少、約85%減少~約99%減少、約85%減少~約95%減少、約85%減少~約90%減少、約90%減少~約99%減少、約90%減少~約95%減少、又は約95%減少~約99%減少)(例えば、治療前又は治療開始時の1つ以上の固形腫瘍の体積と比較して)をもたらし得る。いくつかの実施形態では、これらの方法は、(例えば、治療前の対象又は異なる治療が施された同様の対象若しくは対象集団における転移を発症するリスク又は1つ以上の追加の転移を発症するリスクと比較して)対象における転移を発症するリスク又は1つ以上の追加の転移を発症するリスクを減少(例えば、約1%減少~約99%減少、又は本明細書に記載のこの範囲の部分範囲のうちのいずれか)させ得る。 In some embodiments, these methods can result in a reduction in the number, severity, or frequency of one or more symptoms of cancer in a subject (e.g., one or more symptoms of cancer in a subject prior to treatment). compared to the number, severity, or frequency of symptoms). In some embodiments, these methods reduce the volume of one or more solid tumors in a subject (e.g., about 1% to about 99% reduction, about 1% to about 95% reduction, about 1% Reduced to about 90%, Reduced about 1% to about 85%, Reduced about 1% to about 80%, Reduced about 1% to about 75%, Reduced about 1% to about 70%, Reduced about 1% Reduced to about 65% reduced, about 1% reduced to about 60% reduced, about 1% reduced to about 55% reduced, about 1% reduced to about 50% reduced, about 1% reduced to about 45% reduced, about 1% Decrease to about 40% decrease, about 1% decrease to about 35% decrease, about 1% decrease to about 30% decrease, about 1% decrease to about 25% decrease, about 1% decrease to about 20% decrease, about 1% Reduced to about 15% reduced, about 1% reduced to about 10% reduced, about 1% reduced to about 5% reduced, about 5% reduced to about 99% reduced, about 5% reduced to about 95% reduced, about 5% Reduced to about 90% reduced, about 5% reduced to about 85% reduced, about 5% reduced to about 80% reduced, about 5% reduced to about 75% reduced, about 5% reduced to about 70% reduced, about 5% Reduced to about 65% reduced, about 5% reduced to about 60% reduced, about 5% reduced to about 55% reduced, about 5% reduced to about 50% reduced, about 5% reduced to about 45% reduced, about 5% Decrease to about 40% decrease, about 5% decrease to about 35% decrease, about 5% decrease to about 30% decrease, about 5% decrease to about 25% decrease, about 5% decrease to about 20% decrease, about 5% about 15% reduction, about 5% reduction to about 10% reduction, about 10% reduction to about 99% reduction, about 10% reduction to about 95% reduction, about 10% reduction to about 90% reduction, about 10% about 85% reduction, about 10% reduction to about 80% reduction, about 10% reduction to about 75% reduction, about 10% reduction to about 70% reduction, about 10% reduction to about 65% reduction, about 10% About 10% to about 55% reduction, about 10% to about 50% reduction, about 10% to about 45% reduction, about 10% to about 40% reduction, about 10% about 10% to about 30% reduction, about 10% to about 25% reduction, about 10% to about 20% reduction, about 10% to about 15% reduction, about 15% about 99% reduction, about 15% reduction to about 95% reduction, about 15% reduction to about 90% reduction, about 15% reduction to about 85% reduction, about 15% reduction to about 80% reduction, about 15% Reduced to about 75% reduced, about 15% reduced to about 70% reduced, about 15% reduced to about 65% reduced, about 15% reduced to about 60% reduced, about 15% reduced to about 55% reduced, about 15% about 50% reduction, about 15% reduction to about 45% reduction, about 15% reduction to about 40% reduction, about 15% reduction to about 35% reduction, about 15% reduction to about 30% reduction, about 15% about 25% reduction, about 15% reduction to about 20% reduction, about 20% reduction to about 99% reduction, about 20% reduction to about 95% reduction, about 20% reduction to about 90% reduction, about 20% about 85% reduction, about 20% reduction to about 80% reduction, about 20% reduction to about 75% reduction, about 20% reduction to about 70% reduction, about 20% reduction to about 65% reduction, about 20% Reduced to about 60% reduced, about 20% reduced to about 55% reduced, about 20% reduced to about 50% reduced, about 20% reduced to about 45% reduced, about 20% reduced to about 40% reduced, about 20% Reduced to about 35% reduced, about 20% reduced to about 30% reduced, about 20% reduced to about 25% reduced, about 25% reduced to about 99% reduced, about 25% reduced to about 95% reduced, about 25% about 90% reduction, about 25% reduction to about 85% reduction, about 25% reduction to about 80% reduction, about 25% reduction to about 75% reduction, about 25% reduction to about 70% reduction, about 25% Reduced to about 65% reduced, about 25% reduced to about 60% reduced, about 25% reduced to about 55% reduced, about 25% reduced to about 50% reduced, about 25% reduced to about 45% reduced, about 25% about 40% reduction, about 25% reduction to about 35% reduction, about 25% reduction to about 30% reduction, about 30% reduction to about 99% reduction, about 30% reduction to about 95% reduction, about 30% about 90% reduction, about 30% reduction to about 85% reduction, about 30% reduction to about 80% reduction, about 30% reduction to about 75% reduction, about 30% reduction to about 70% reduction, about 30% Reduced to about 65% reduced, about 30% reduced to about 60% reduced, about 30% reduced to about 55% reduced, about 30% reduced to about 50% reduced, about 30% reduced to about 45% reduced, about 30% Reduced to about 40% reduced, about 30% reduced to about 35% reduced, about 35% reduced to about 99% reduced, about 35% reduced to about 95% reduced, about 35% reduced to about 90% reduced, about 35% Reduced to about 85% reduced, about 35% reduced to about 80% reduced, about 35% reduced to about 75% reduced, about 35% reduced to about 70% reduced, about 35% reduced to about 65% reduced, about 35% Reduced to about 60% reduced, about 35% reduced to about 55% reduced, about 35% reduced to about 50% reduced, about 35% reduced to about 45% reduced, about 35% reduced to about 40% reduced, about 40% about 99% reduction, about 40% reduction to about 95% reduction, about 40% reduction to about 90% reduction, about 40% reduction to about 85% reduction, about 40% reduction to about 80% reduction, about 40% Reduced to about 75% reduced, about 40% reduced to about 70% reduced, about 40% reduced to about 65% reduced, about 40% reduced to about 60% reduced, about 40% reduced to about 55% reduced, about 40% Reduced to about 50% reduced, about 40% reduced to about 45% reduced, about 45% reduced to about 99% reduced, about 45% reduced to about 95% reduced, about 45% reduced to about 90% reduced, about 45% Reduced to about 85% reduced, about 45% reduced to about 80% reduced, about 45% reduced to about 75% reduced, about 45% reduced to about 70% reduced, about 45% reduced to about 65% reduced, about 45% about 60% reduction, about 45% reduction to about 55% reduction, about 45% reduction to about 50% reduction, about 50% reduction to about 99% reduction, about 50% reduction to about 95% reduction, about 50% about 90% reduction, about 50% reduction to about 85% reduction, about 50% reduction to about 80% reduction, about 50% reduction to about 75% reduction, about 50% reduction to about 70% reduction, about 50% about 50% to about 60% reduction about 50% to about 55% reduction about 55% to about 99% reduction about 55% to about 95% reduction about 55% about 55% to about 85% reduction, about 55% to about 80% reduction, about 55% to about 75% reduction, about 55% to about 70% reduction, about 55% Reduced to about 65% reduced, about 55% reduced to about 60% reduced, about 60% reduced to about 99% reduced, about 60% reduced to about 95% reduced, about 60% reduced to about 90% reduced, about 60% about 60% to about 80% reduction, about 60% to about 75% reduction, about 60% to about 70% reduction, about 60% to about 65% reduction, about 65% about 99% reduction, about 65% reduction to about 95% reduction, about 65% reduction to about 90% reduction, about 65% reduction to about 85% reduction, about 65% reduction to about 80% reduction, about 65% Reduced to about 75% reduced, about 65% reduced to about 70% reduced, about 70% reduced to about 99% reduced, about 70% reduced to about 95% reduced, about 70% reduced to about 90% reduced, about 70% reduced to about 85% reduced, reduced about 70% reduced to about 80% reduced, reduced about 70% reduced to about 75% reduced, reduced about 75% reduced to about 99% reduced, reduced about 75% reduced to about 95% reduced, about 75% Reduced to about 90% reduced, about 75% reduced to about 85% reduced, about 75% reduced to about 80% reduced, about 80% reduced to about 99% reduced, about 80% reduced to about 95% reduced, about 80% Reduced to about 90% reduced, about 80% reduced to about 85% reduced, about 85% reduced to about 99% reduced, about 85% reduced to about 95% reduced, about 85% reduced to about 90% reduced, about 90% reduction to about 99% reduction, about 90% reduction to about 95% reduction, or about 95% reduction to about 99% reduction) (e.g., compared to the volume of one or more solid tumors prior to treatment or at initiation of treatment) ). In some embodiments, these methods determine the risk of developing metastasis (e.g., in a subject prior to treatment or in a similar subject or subject population receiving a different treatment, or the risk of developing one or more additional metastases reducing the risk of developing metastasis or developing one or more additional metastases in a subject (e.g., from about a 1% reduction to about a 99% reduction, or any portion of this range as described herein) any of the ranges).
いくつかの実施形態では、これらの方法は、対象における代謝性疾患の治療をもたらし得る。いくつかの実施形態では、代謝性疾患の治療は、例えば、1つ以上(例えば、2、3、4、5、又は6つ)の改善されたグルコース耐性、改善されたグルコース利用、糖尿病性骨関節症の重症度又は進行の低下、皮膚病変の重症度又は進行の低下、ケトーシスの重症度又は進行の減少、膵島細胞に対する自己抗体の生成の減少、インスリン感受性の増加、質量の減少、及び肥満度指数の減少をもたらし得る。対象の治療に対する反応は、標準的な技術に従って空腹時グルコース又はグルコース耐性を決定することによって監視することができる。典型的には、この方法によれば、血糖値は、100mg/dL未満の空腹時血糖値又は140mg/dL未満の2時間の75gの経口グルコース耐性試験値によって特徴付けられる血糖値を達成するように低下される。いくつかの実施形態では、治療に対する応答は、血圧、肥満度指数、PPAR-γ機能、脂質代謝、糖化ヘモグロビン(H1c)、及び腎機能を含む、前糖尿病、新たに発症する糖尿病、又は活動性糖尿病に関連する他の因子を決定することを含み得る。 In some embodiments, these methods can result in treatment of metabolic disease in a subject. In some embodiments, the treatment of metabolic disease is, for example, one or more (eg, 2, 3, 4, 5, or 6) improved glucose tolerance, improved glucose utilization, diabetic bone Reduced severity or progression of arthritis, reduced severity or progression of skin lesions, reduced severity or progression of ketosis, reduced production of autoantibodies against pancreatic islet cells, increased insulin sensitivity, decreased mass, and obesity. can result in a decrease in the degree index. A subject's response to treatment can be monitored by determining fasting glucose or glucose tolerance according to standard techniques. Typically, according to this method, the blood glucose level is adjusted to achieve a blood glucose level characterized by a fasting blood glucose level of less than 100 mg/dL or a 2-hour oral glucose tolerance test value of 75 g of less than 140 mg/dL. is reduced to In some embodiments, the response to treatment includes blood pressure, body mass index, PPAR-γ function, lipid metabolism, glycated hemoglobin (H1c), and renal function, prediabetes, new-onset diabetes, or active Determining other factors associated with diabetes may be included.
いくつかの実施形態では、これらの方法は、疾患の生化学的、組織学的、及び/又は行動上の症状、その合併症、及び疾患の発症中に現れる中間の病理学的表現型を含む、神経変性疾患の発症のリスクを排除又は減少し、重症度を軽減し、又は遅らせることができる。 In some embodiments, these methods include biochemical, histological, and/or behavioral symptoms of the disease, its complications, and intermediate pathological phenotypes that manifest during the development of the disease. , can eliminate or reduce the risk of, reduce the severity of, or delay the development of neurodegenerative diseases.
いくつかの実施形態では、皮膚疾患の効果的な治療は、治療前の皮膚の状態と比較して、皮膚の色、水分、温度、質感、可動性及び弾力、並びに皮膚病変を含む皮膚状態を検査することを含む、本明細書に記載の又は当該技術分野で既知の任意の方法によって評価することができる。 In some embodiments, effective treatment of skin disorders improves skin condition, including skin color, moisture, temperature, texture, mobility and elasticity, and skin lesions, compared to skin condition prior to treatment. It can be assessed by any method described herein or known in the art, including examining.
いくつかの実施形態では、自己免疫疾患の効果的な治療は、新たに単離されたPBMCの全血球数分析、総Igレベル、及び血清自己抗体力価の分析を含む、本明細書に記載の又は当該技術分野で既知の任意の方法によって評価することができる。 In some embodiments, effective treatment of autoimmune diseases is described herein, comprising analysis of freshly isolated PBMCs for complete blood counts, total Ig levels, and serum autoantibody titers. or by any method known in the art.
いくつかの実施形態では、脆弱性疾患の効果的な治療は、骨ミネラル密度、骨構築及び形状、骨代謝回転の生物医学的マーカー、ビタミンD測定、カルノフスキー・パフォーマンス・ステータス、及びECOGスコア、及びワクチン接種への反応性を監視することを含む、本明細書に記載の又は当該技術分野で既知の任意の方法によって評価することができる。 In some embodiments, effective treatment of frailty disease includes bone mineral density, bone architecture and shape, biomedical markers of bone turnover, vitamin D measurements, Karnofsky performance status, and ECOG score; and by any method described herein or known in the art, including monitoring responsiveness to vaccination.
対象における老化細胞を死滅させる又は老化細胞の数を減少させる方法
老化細胞(例えば、本明細書に記載の又は当該技術分野で既知の例示的なタイプの老化細胞のうちのいずれか)の死滅又は老化細胞の数の減少を必要とする対象において老化細胞を死滅させる又は老化細胞の数を減少させる方法であって、当該対象に、治療有効量の1つ以上のNK細胞活性化物質(例えば、本明細書に記載の又は当該技術分野で既知のNK細胞活性化物質のうちのいずれか)を投与することを含む、方法も本明細書に提供される。
A method of killing senescent cells or reducing the number of senescent cells in a subject Killing senescent cells (e.g., any of the exemplary types of senescent cells described herein or known in the art) or A method of killing senescent cells or reducing the number of senescent cells in a subject in need thereof, comprising administering to the subject a therapeutically effective amount of one or more NK cell activators (e.g., Also provided herein are methods comprising administering an NK cell activator (any of the NK cell activators described herein or known in the art).
老化細胞(例えば、本明細書に記載の又は当該技術分野で既知の例示的なタイプの老化細胞のうちのいずれか)の死滅又は老化細胞の数の減少を必要とする対象において老化細胞を死滅させる又は老化細胞の数を減少させる方法であって、当該対象に、治療有効量の1つ以上のNK細胞(例えば、本明細書に記載の又は当該技術分野で既知のNK細胞のうちのいずれか)を投与することを含む、方法も本明細書に提供される。 Killing senescent cells (e.g., any of the exemplary types of senescent cells described herein or known in the art) or killing senescent cells in a subject in need of reducing the number of senescent cells or reducing the number of senescent cells, wherein the subject is administered a therapeutically effective amount of one or more NK cells (e.g., any of the NK cells described herein or known in the art) Also provided herein is a method comprising administering ).
これらの方法のいくつかの実施形態は、休止NK細胞を得ることと、1つ以上の休止NK細胞活性化物質を含む液体培養培地中でインビトロで休止NK細胞を接触させることであって、この接触が、その後、対象に投与される活性化されたNK細胞の発生をもたらす、接触させることと、を更に含む。これらの方法のいくつかの例では、休止NK細胞は、対象から得られた自己NK細胞である。これらの方法のいくつかの例では、休止NK細胞は、対象から得られたハプロタイプ一致のNK細胞である。これらの方法のいくつかの例では、休止NK細胞は、同種異系の休止NK細胞である。これらの方法のいくつかの例では、休止NK細胞は、人工NK細胞である。これらの方法のいずれかのいくつかの例では、休止NK細胞は、キメラ抗原受容体又は組換えT細胞受容体を有する遺伝子操作されたNK細胞である。 Some embodiments of these methods include obtaining resting NK cells and contacting the resting NK cells in vitro in a liquid culture medium comprising one or more resting NK cell activators, wherein Contacting results in the generation of activated NK cells that are then administered to the subject. In some examples of these methods, the resting NK cells are autologous NK cells obtained from the subject. In some examples of these methods, the resting NK cells are haploidentical NK cells obtained from the subject. In some examples of these methods, the resting NK cells are allogeneic resting NK cells. In some examples of these methods, the resting NK cells are induced NK cells. In some examples of any of these methods, the resting NK cells are genetically engineered NK cells with chimeric antigen receptors or recombinant T cell receptors.
これらの方法のいくつかの例では、液体培養培地は、無血清液体培養培地である。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、液体培養培地は、化学的に定義された液体培養培地である。これらの方法のいくつかの例は、活性化されたNK細胞を単離すること(及び、活性化されたNK細胞の治療有効量を、対象、例えば、本明細書に記載の対象のうちのいずれかに更に投与すること)を更に含む。これらの方法のいくつかの実施形態では、接触ステップは、約2時間~約20日(又は本明細書に記載のこの範囲の部分範囲のうちのいずれか)の期間にわたって実施される。 In some examples of these methods, the liquid culture medium is a serum-free liquid culture medium. In some embodiments of any of the methods described herein, the liquid culture medium is a chemically defined liquid culture medium. Some examples of these methods include isolating activated NK cells (and administering a therapeutically effective amount of the activated NK cells to a subject, e.g., one of the subjects described herein). further administering to either). In some embodiments of these methods, the contacting step is carried out for a period of time from about 2 hours to about 20 days (or any subrange of this range described herein).
これらの方法のいくつかの実施形態では、老化細胞は、老化がん細胞、老化単球、老化リンパ球、老化星状細胞、老化ミクログリア、老化ニューロン、老化組織線維芽細胞、老化皮膚線維芽細胞、老化ケラチノサイト、又は他の分化組織特異的な分裂機能細胞である。これらの方法のいくつかの実施形態では、老化がん細胞は、化学療法誘導性老化細胞又は放射線によって誘導された老化細胞である。 In some embodiments of these methods, the senescent cells are senescent cancer cells, senescent monocytes, senescent lymphocytes, senescent astrocytes, senescent microglia, senescent neurons, senescent tissue fibroblasts, senescent skin fibroblasts , senescent keratinocytes, or other differentiated tissue-specific dividing functional cells. In some embodiments of these methods, the senescent cancer cells are chemotherapy-induced senescent cells or radiation-induced senescent cells.
これらの方法のいくつかの実施形態では、対象は、加齢関連疾患又は状態(例えば、本明細書に記載の又は当該技術分野で既知の加齢関連の疾患又は状態のうちのいずれか)を有すると同定又は診断されている。本明細書に記載の加齢関連疾患又は状態のうちのいずれかのいくつかの実施形態では、加齢関連疾患又は状態は、がん、自己免疫疾患、代謝性疾患、神経変性疾患、心臓血管疾患、皮膚疾患、早老症、及び脆弱性疾患の群から選択される。 In some embodiments of these methods, the subject has an age-related disease or condition (e.g., any of the age-related diseases or conditions described herein or known in the art). have been identified or diagnosed as having In some embodiments of any of the age-related diseases or conditions described herein, the age-related disease or condition is cancer, autoimmune disease, metabolic disease, neurodegenerative disease, cardiovascular selected from the group of diseases, skin diseases, progeria and frailty diseases.
がんの非限定的な例には、固形腫瘍、血液腫瘍、肉腫、骨肉腫、膠芽細胞腫、神経芽細胞腫、黒色腫、横紋筋肉腫、ユーイング肉腫、骨肉腫、B細胞新生物、多発性骨髄腫、B細胞リンパ腫、B細胞非ホジキンリンパ腫、ホジキンリンパ腫、慢性リンパ球性白血病(CLL)、急性骨髄性白血病(AML)、慢性骨髄性白血病(CML)、急性リンパ性白血病(ALL)、骨髄異形成症候群(MDS)、皮膚T細胞リンパ腫、網膜芽細胞腫、胃がん、尿路上皮がん、肺がん、腎細胞がん、胃食道がん、膵臓がん、前立腺がん、乳がん、結腸直腸がん、卵巣がん、非小細胞肺がん、扁平上皮細胞頭頸部がん、子宮内膜がん、子宮頸がん、肝臓がん、及び肝細胞がんが挙げられる。 Non-limiting examples of cancer include solid tumors, hematologic tumors, sarcoma, osteosarcoma, glioblastoma, neuroblastoma, melanoma, rhabdomyosarcoma, Ewing's sarcoma, osteosarcoma, B-cell neoplasms. , multiple myeloma, B-cell lymphoma, B-cell non-Hodgkin's lymphoma, Hodgkin's lymphoma, chronic lymphocytic leukemia (CLL), acute myelogenous leukemia (AML), chronic myelogenous leukemia (CML), acute lymphocytic leukemia (ALL) ), myelodysplastic syndrome (MDS), cutaneous T-cell lymphoma, retinoblastoma, gastric cancer, urothelial cancer, lung cancer, renal cell cancer, gastroesophageal cancer, pancreatic cancer, prostate cancer, breast cancer, Colorectal cancer, ovarian cancer, non-small cell lung cancer, squamous cell head and neck cancer, endometrial cancer, cervical cancer, liver cancer, and hepatocellular carcinoma.
自己免疫疾患の非限定的な例は、1型糖尿病である。
A non-limiting example of an autoimmune disease is
代謝性疾患の非限定的な例には、肥満、脂肪異栄養症、及び2型糖尿病が含まれる。
Non-limiting examples of metabolic diseases include obesity, lipodystrophy, and
神経変性疾患の非限定的な例には、アルツハイマー病、パーキンソン病、及び認知症が含まれる。 Non-limiting examples of neurodegenerative diseases include Alzheimer's disease, Parkinson's disease, and dementia.
心臓血管疾患の非限定的な例には、冠状動脈疾患、アテローム性動脈硬化症、及び肺動脈性肺高血圧症が含まれる。 Non-limiting examples of cardiovascular disease include coronary artery disease, atherosclerosis, and pulmonary arterial hypertension.
皮膚疾患の非限定的な例には、創傷治癒、脱毛症、しわ、老人性黒子、皮膚の菲薄化、色素性乾皮症、及び先天性角化異常症が含まれる。 Non-limiting examples of skin disorders include wound healing, alopecia, wrinkles, senile lentigines, skin thinning, xeroderma pigmentosum, and dyskeratosis congenita.
早老症の非限定的な例には、早老症及びハッチンソン・ギルフォード早老症症候群が含まれる。 Non-limiting examples of progeria include progeria and Hutchinson-Guilford progeria syndrome.
脆弱性疾患の非限定的な例には、脆弱、ワクチン接種に対する応答、骨粗しょう症、及びサルコペニアが含まれる。 Non-limiting examples of frailty diseases include frailty, response to vaccination, osteoporosis, and sarcopenia.
本明細書に記載の加齢関連疾患又は状態のうちのいずれかのいくつかの実施形態では、加齢関連疾患又は状態は、加齢関連黄斑変性、骨関節炎、脂肪萎縮、慢性閉塞性肺疾患、特発性肺線維症、腎移植不全、肝線維症、骨量喪失、サルコペニア、加齢関連肺組織弾性喪失、骨粗しょう症、加齢関連腎機能障害、及び化学的に誘導された腎機能障害の群から選択される。 In some embodiments of any of the age-related diseases or conditions described herein, the age-related disease or condition is age-related macular degeneration, osteoarthritis, fat wasting, chronic obstructive pulmonary disease , idiopathic pulmonary fibrosis, renal graft failure, liver fibrosis, bone loss, sarcopenia, age-related pulmonary tissue elastic loss, osteoporosis, age-related renal dysfunction, and chemically-induced renal dysfunction selected from the group of
本明細書に記載の加齢関連疾患又は状態のうちのいずれかのいくつかの実施形態では、加齢関連疾患又は状態は、2型糖尿病又はアテローム性動脈硬化症である。
In some embodiments of any of the age-related diseases or conditions described herein, the age-related disease or condition is
これらの方法のいくつかの実施形態では、投与は、対象における標的組織の老化細胞の数における減少(例えば、少なくとも5%減少、少なくとも10%減少、少なくとも15%減少、少なくとも20%減少、少なくとも25%減少、少なくとも30%減少、少なくとも35%減少、少なくとも40%減少、少なくとも45%減少、少なくとも50%減少、少なくとも55%減少、少なくとも60%減少、少なくとも65%減少、少なくとも70%減少、少なくとも75%減少、少なくとも80%減少、少なくとも85%減少、少なくとも90%減少、又は少なくとも95%減少、又は約10%減少~約99%減少(又は本明細書に記載のこの範囲の部分範囲のうちのいずれか))をもたらす(例えば、治療前の対象における標的組織の老化細胞の数と比較して)。これらの方法のいくつかの実施形態では、対象における標的組織は、脂肪組織、膵臓組織、肝臓組織、肺組織、血管系、骨組織、中枢神経系(CNS)組織、眼組織、皮膚組織、筋肉組織、及び二次リンパ器官組織のうちの1つ以上であり得る。 In some embodiments of these methods, administering results in a reduction (e.g., at least a 5% reduction, at least a 10% reduction, at least a 15% reduction, at least a 20% reduction, at least a 25% reduction, at least a 25% reduction in the number of senescent cells in the target tissue in the subject). % reduction, at least 30% reduction, at least 35% reduction, at least 40% reduction, at least 45% reduction, at least 50% reduction, at least 55% reduction, at least 60% reduction, at least 65% reduction, at least 70% reduction, at least 75 % reduction, at least 80% reduction, at least 85% reduction, at least 90% reduction, or at least 95% reduction, or about 10% reduction to about 99% reduction (or any subrange of this range described herein) either)) (eg, compared to the number of senescent cells in the target tissue in the subject prior to treatment). In some embodiments of these methods, the target tissue in the subject is adipose tissue, pancreatic tissue, liver tissue, lung tissue, vasculature, bone tissue, central nervous system (CNS) tissue, eye tissue, skin tissue, muscle. tissue, and one or more of secondary lymphoid organ tissue.
これらの方法のいくつかの実施形態では、投与は、対象におけるIFN-γ、細胞傷害性顆粒グランザイム、及び/又はパーフォリンのレベルにおける増加(例えば、少なくとも5%増加、少なくとも10%増加、少なくとも15%増加、少なくとも20%増加、少なくとも25%増加、少なくとも30%増加、少なくとも35%増加、少なくとも40%増加、少なくとも45%増加、少なくとも50%増加、少なくとも55%増加、少なくとも60%増加、少なくとも65%増加、少なくとも70%増加、少なくとも75%増加、少なくとも80%増加、少なくとも85%増加、少なくとも90%増加、少なくとも95%増加、又は少なくとも99%増加、又は約10%増加~約500%増加(又は本明細書に記載のこの範囲の部分範囲のうちのいずれか))をもたらす(治療前の対象又は治療を受けていない同様の対照対象のレベルと比較して)。 In some embodiments of these methods, administering results in an increase in levels of IFN-γ, cytotoxic granule granzymes, and/or perforin in the subject (e.g., at least a 5% increase, at least a 10% increase, at least a 15% increase, at least 20% increase, at least 25% increase, at least 30% increase, at least 35% increase, at least 40% increase, at least 45% increase, at least 50% increase, at least 55% increase, at least 60% increase, at least 65% increase, at least 70% increase, at least 75% increase, at least 80% increase, at least 85% increase, at least 90% increase, at least 95% increase, or at least 99% increase, or about 10% increase to about 500% increase (or any of the subranges of this range described herein)) (compared to levels in pre-treatment subjects or similar control subjects not receiving treatment).
これらの方法のいくつかの実施形態では、標的組織(例えば、本明細書に記載の標的組織のうちのいずれか)における老化細胞の数は、生検試料に対して免疫染色を行うことによって決定することができる。これらの方法のいくつかの実施形態では、標的組織(例えば、本明細書に記載の標的組織のうちのいずれか)における老化細胞の数は、対象における加齢関連疾患又は状態(例えば、本明細書に記載の加齢関連疾患又は状態の症状のうちのいずれか)の1つ以上の症状の改善を通じて間接的に観察することができる。 In some embodiments of these methods, the number of senescent cells in a target tissue (e.g., any of the target tissues described herein) is determined by immunostaining a biopsy sample. can do. In some embodiments of these methods, the number of senescent cells in a target tissue (e.g., any of the target tissues described herein) is determined by an age-related disease or condition in a subject (e.g., can be indirectly observed through improvement in one or more symptoms of age-related diseases or conditions described in the literature).
老化細胞
老化細胞は、形態、クロマチン構成、遺伝子発現、及び代謝の変化を含む重要な特有の特性を示す。細胞老化に関連するいくつかの生化学的及び機能的特性、例えば、(i)サイクリン依存性キナーゼの阻害物質であるp16INK4a及びp21CIP1の発現の増加、(ii)リソソーム活性のマーカーである老化関連β-ガラクトシダーゼの存在、(iii)老化関連ヘテロクロマチン病巣の出現及びラミンB1レベルのダウンレギュレーション、(iv)抗アポトーシスBCLファミリータンパク質の発現の増加によって引き起こされるアポトーシスに対する耐性、及び(v)CD26(DPP4)、CD36(スカベンジャー受容体)、フォークヘッドボックス4(FOXO4)、及び分泌キャリア膜タンパク質4(SCAMP4)のアップレギュレーションが存在する。老化細胞は、炎症特性、いわゆる老化関連分泌表現型(SASP)も発現する。SASPを介して、老化細胞は、細胞自律的様式で作動して老化を強化し(オートクリン効果)、微小環境と通信して修飾する(パラクリン効果)、広範囲の炎症性サイトカイン(IL-6、IL-8)、成長因子(TGF-β)、ケモカイン(CCL-2)、及びマトリックスメタロプロテイナーゼ(MMP-3、MMP-9)を産生する。SASP因子は、老化細胞の免疫介在性クリアランスである老化監視をトリガすることによって腫瘍抑制に寄与することができる。しかしながら、慢性炎症も腫瘍形成の既知の要因であり、累積証拠は、慢性SASPががん転移及び加齢関連疾患を後押しする可能性もあることを示す。
Senescent Cells Senescent cells exhibit important unique characteristics including changes in morphology, chromatin organization, gene expression, and metabolism. Several biochemical and functional properties associated with cellular senescence, such as (i) increased expression of p16 INK4a and p21 CIP1 , inhibitors of cyclin-dependent kinases, (ii) senescence, a marker of lysosomal activity (iii) appearance of senescence-associated heterochromatin foci and downregulation of Lamin B1 levels, (iv) resistance to apoptosis caused by increased expression of anti-apoptotic BCL family proteins, and (v) CD26 ( DPP4), CD36 (scavenger receptor), forkhead box 4 (FOXO4), and secretory carrier membrane protein 4 (SCAMP4) are upregulated. Senescent cells also express inflammatory properties, the so-called senescence-associated secretory phenotype (SASP). Through SASP, senescent cells operate in a cell-autonomous manner to enhance senescence (autocrine effect) and communicate with and modify the microenvironment (paracrine effect), a wide range of inflammatory cytokines (IL-6, IL-8), growth factors (TGF-β), chemokines (CCL-2), and matrix metalloproteinases (MMP-3, MMP-9). SASP factors can contribute to tumor suppression by triggering senescence surveillance, the immune-mediated clearance of senescent cells. However, chronic inflammation is also a known factor in tumorigenesis, and cumulative evidence indicates that chronic SASPs may also drive cancer metastasis and age-related diseases.
老化細胞の分泌プロファイルは、状況依存的である。例えば、ヒト線維芽細胞における様々なミトコンドリア機能障害によって誘導されるミトコンドリア機能障害関連老化(MiDAS)は、IL-1依存性炎症性因子が不足したSASPの出現をもたらした。NAD+/NADH比の減少は、p53の活性化によりMiDASを誘導したAMPKシグナル伝達を活性化した。結果として、p53は炎症促進性SASPの重要な誘導因子であるNF-κBシグナル伝達を阻害した。対照的に、ヒト細胞における持続的なDNA損傷によって引き起こされた細胞老化は、炎症性SASPを誘導し、これは、運動失調-毛細血管拡張症変異(ATM)キナーゼの活性化に依存したが、p53の活性化には依存しなかった。具体的には、IL-6及びIL-8の発現レベル及び分泌レベルが増加した。異所性発現p16INK4a及びp21CIP1によって引き起こされる細胞老化が、炎症性SASPなしでヒト線維芽細胞における老化表現型を誘導することも実証されており、成長停止自体はSASPを刺激しなかったことを示している。 The secretory profile of senescent cells is context dependent. For example, mitochondrial dysfunction-associated senescence (MiDAS) induced by various mitochondrial dysfunctions in human fibroblasts led to the emergence of SASPs deficient in IL-1-dependent inflammatory factors. A decrease in the NAD+/NADH ratio activated AMPK signaling that induced MiDAS through activation of p53. As a result, p53 inhibited NF-κB signaling, a key inducer of pro-inflammatory SASPs. In contrast, cellular senescence caused by persistent DNA damage in human cells induced inflammatory SASP, which depended on activation of the ataxia-telangiectasia mutated (ATM) kinase, It was independent of p53 activation. Specifically, IL-6 and IL-8 expression and secretion levels were increased. It has also been demonstrated that cellular senescence caused by ectopically expressed p16 INK4a and p21 CIP1 induces a senescent phenotype in human fibroblasts without inflammatory SASP, and that growth arrest itself did not stimulate SASP. is shown.
老化の最も明確な特徴の1つは、安定した成長停止である。これは、2つの重要な経路であるp16INK4a/Rb及びp53/p21CIP1によって達成され、これらはいずれも腫瘍抑制の中心である。DNA損傷は、(1)クロマチンにおけるγH2Ax(ヒストンコーディング遺伝子)及び53BP1(DNA損傷応答に関与)の高沈着(これは最終的にp53活性化をもたらすキナーゼカスケードの活性化につながる)、及び(2)p16INK4a及びARF(いずれもCDKN2Aによってコードされる)並びにP15INK4b(CDKN2Bによってコードされる)の活性化(p53はサイクリン依存性キナーゼ阻害物質(p21CIP1)の転写を誘導し、p16INK4a及びp15INK4bの両方とともに、細胞周期進行のために遺伝子を遮断する(CDK4及びCDK6))をもたらす。これは、最終的に網膜芽細胞腫タンパク質(Rb)の低リン酸化及びG1期での細胞周期停止につながる。 One of the most defining features of aging is steady growth arrest. This is accomplished by two key pathways, p16 INK4 a/Rb and p53/p21 CIP1 , both of which are central to tumor suppression. DNA damage is associated with (1) increased deposition of γH2Ax (a histone coding gene) and 53BP1 (involved in the DNA damage response) in chromatin, which leads to activation of kinase cascades that ultimately lead to p53 activation, and (2) ) activation of p16INK4a and ARF (both encoded by CDKN2A) and P15INK4b (encoded by CDKN2B) (p53 induces transcription of cyclin-dependent kinase inhibitor (p21 CIP1 ), both p16INK4a and p15INK4b , which shuts off genes for cell cycle progression (CDK4 and CDK6). This ultimately leads to hypophosphorylation of the retinoblastoma protein (Rb) and cell cycle arrest in the G1 phase.
老化細胞を選択的に死滅させることにより、正常な加齢との関連でマウスの健康スパンが大幅に改善され、加齢関連疾患又はがん療法の結果が改善されることが示されている(Ovadya,J Clin Invest.128(4):1247-1254,2018)。自然界では、老化細胞は、通常、自然免疫細胞によって除去される。老化の誘導は、損傷/変化した細胞の潜在的な増殖及び形質転換を阻止するのみならず、主にナチュラルキラー(NK)細胞(IL-15及びCCL2等)及びマクロファージ(CFS-1及びCCL2等)の化学誘引物質として機能するSASP因子の産生により組織修復も支持する。これらの自然免疫細胞は、ストレスを受けた細胞を排除するための免疫監視メカニズムを媒介する。老化細胞は、通常、ストレス誘導性リガンドのファミリーに属するNK細胞活性化受容体NKG2D及びDNAM1リガンドを上方調節し、これは、感染性疾患及び悪性腫瘍に対する最前線の免疫防御の重要な要素である。受容体が活性化されると、NK細胞は、それらの細胞溶解機構を介して老化細胞の死を特異的に誘導することができる。老化細胞の免疫監視におけるNK細胞の役割は、肝線維症(Sagiv,Oncogene 32(15):1971-1977,2013)、肝細胞がん(Iannello,J Exp Med 210(10):2057-2069,2013)、多発性骨髄腫(Soriani,Blood 113(15):3503-3511,2009)、及びメバロン酸経路の機能傷害によってストレスを受けた神経膠腫細胞(Ciaglia,Int J Cancer 142(1):176-190,2018)において指摘されている。子宮内膜細胞は、急性細胞老化を受け、脱落膜細胞に分化しない。分化した脱落膜細胞は、IL-15を分泌し、それにより、子宮NK細胞を動員して、未分化老化細胞を標的として排除し、子宮内膜の再構築及び若返りを助ける(Brighton,Elife 6:e31274,2017)。同様のメカニズムを用いて、肝線維症の間に、p53を発現する老化肝衛星細胞は、老化細胞除去活性を呈する常在性Kupferマクロファージ及び新たに浸潤したマクロファージの極性を炎症促進性M1表現型に向かって歪めた。F4/80+マクロファージが、分娩後の子宮機能を維持するためにマウス子宮老化細胞のクリアランスに重要な役割を果たすことが示されている。 Selectively killing senescent cells has been shown to significantly improve the health span of mice in the context of normal aging and improve outcome of age-related disease or cancer therapy ( Ovadya, J Clin Invest. 128(4):1247-1254, 2018). In nature, senescent cells are normally eliminated by innate immune cells. Induction of senescence not only blocks potential proliferation and transformation of damaged/altered cells, but also mainly natural killer (NK) cells (such as IL-15 and CCL2) and macrophages (such as CFS-1 and CCL2). It also supports tissue repair through the production of SASP factors that function as chemoattractants for ). These innate immune cells mediate immune surveillance mechanisms to eliminate stressed cells. Senescent cells normally upregulate the NK cell-activating receptors NKG2D and DNAM1 ligands, which belong to a family of stress-inducible ligands, which are key components of the first-line immune defense against infectious diseases and malignancies. . Upon receptor activation, NK cells can specifically induce senescent cell death through their cytolytic mechanism. The role of NK cells in immunosurveillance of senescent cells has been reported in liver fibrosis (Sagiv, Oncogene 32(15):1971-1977, 2013), hepatocellular carcinoma (Iannello, J Exp Med 210(10):2057-2069, 2013), multiple myeloma (Soriani, Blood 113(15):3503-3511, 2009), and glioma cells stressed by dysfunction of the mevalonate pathway (Ciaglia, Int J Cancer 142(1): 176-190, 2018). Endometrial cells undergo acute cellular senescence and do not differentiate into decidual cells. Differentiated decidual cells secrete IL-15, which recruits uterine NK cells to target and eliminate undifferentiated senescent cells, helping to remodel and rejuvenate the endometrium (Brighton, Elife 6). : e31274, 2017). Using a similar mechanism, during liver fibrosis, p53-expressing senescent hepatic satellite cells polarize resident Kupfer macrophages and newly infiltrating macrophages exhibiting senolytic activity to the proinflammatory M1 phenotype. distorted towards F4/80+ macrophages have been shown to play an important role in the clearance of mouse uterine senescent cells to maintain postpartum uterine function.
老化細胞は、主に、NKG2D(NK細胞で発現)、ケモカイン、及び他のSASP因子に対するリガンドをアップレギュレートすることによってNK細胞を動員する。肝線維症のインビボモデルは、活性化されたNK細胞による老化細胞の効果的なクリアランスを示している(Krizhanovsky,Cell 134(4):657-667,2008)。研究では、肝線維症(Krizhanovsky,Cell 134(4):657-667,2008)、変形性関節症(Xu,J Gerontol A Biol Sci Med Sci 72(6):780-785,2017)、及びパーキンソン病(Chinta,Cell Rep 22(4):930-940,2018)を含む老化を研究するための様々なモデルが説明されている。老化細胞を研究するための動物モデルは、Krizhanovsky,Cell 134(4):657-667,2008、Baker,Nature 479(7372):232-236,2011、Farr,Nat Med 23(9):1072-1079,2017、Bourgeois,FEBS Lett 592(12):2083-2097,2018、Xu,Nat Med 24(8):1246-1256,2018)で説明されている。 Senescent cells primarily recruit NK cells by upregulating ligands for NKG2D (expressed on NK cells), chemokines, and other SASP factors. An in vivo model of liver fibrosis shows effective clearance of senescent cells by activated NK cells (Krizhanovsky, Cell 134(4):657-667, 2008). Studies have investigated liver fibrosis (Krizhanovsky, Cell 134(4):657-667, 2008), osteoarthritis (Xu, J Gerontol A Biol Sci Med Sci 72(6):780-785, 2017), and Parkinson's disease. Various models have been described for studying aging, including disease (Chinta, Cell Rep 22(4):930-940, 2018). Animal models for studying senescent cells are described in Krizhanovsky, Cell 134(4):657-667, 2008, Baker, Nature 479(7372):232-236, 2011, Farr, Nat Med 23(9):1072- 1079, 2017, Bourgeois, FEBS Lett 592(12):2083-2097, 2018; Xu, Nat Med 24(8):1246-1256, 2018).
老化は、表現型の変化、アポトーシスへの耐性、及び損傷を感知するシグナル伝達経路の活性化を伴う不可逆的な成長停止の一形態である。細胞老化は、増殖する能力を失った培養ヒト線維芽細胞で最初に説明され、約50回の集団倍加(ヘイフリック限界と称される)後に永久停止に達した(Hayflick et al.,Exp.Cell Res.25:585-621,1961)。不死化されていないヒト線維芽細胞の培養における「複製老化」の現象が観察された。これは、細胞分裂ごとに進行するテロメアの短縮によって引き起こされ、ゲノムの不安定性及びそれによるDNA損傷の蓄積を防ぐ生理学的応答を表している(He et al.,Cell 169(6):1000-1011,2017)。 Senescence is a form of irreversible growth arrest that involves phenotypic changes, resistance to apoptosis, and activation of injury-sensing signaling pathways. Cellular senescence was first described in cultured human fibroblasts that lost the ability to proliferate, reaching permanent arrest after approximately 50 population doublings (termed the Hayflick limit) (Hayflick et al., Exp. Cell Res. 25:585-621, 1961). A phenomenon of “replicative senescence” was observed in cultures of non-immortalized human fibroblasts. This is caused by progressive shortening of telomeres with each cell division and represents a physiological response that prevents genomic instability and the consequent accumulation of DNA damage (He et al., Cell 169(6):1000- 1011, 2017).
老化は、酸化的ストレス及び遺伝毒性ストレス、DNA損傷、テロメア摩滅、又は発がん性活性化、ミトコンドリア機能障害、又は化学療法剤を含む、広範囲の内因性及び外因性傷害によって誘導され得るストレス応答とみなされる(McHugh et al.,J.Cell Biol.217(1):65-77,2018)。この加速された老化反応は、テロメアの短縮とは関係なく、早期老化として知られている。老化は、糖尿病、骨粗しょう症、心臓血管疾患、認知症、神経変性疾患、腎不全、サルコペニアなど、様々な加齢関連合併症に関連している。また、加齢ががんの最大の危険因子であることも興味深い点である(McHugh et al.,J.Cell Biol.217(1):65-77,2018;Childs et al.,Nat.Rev.Drug Discov.16(10):718-735,2017)。 Aging is viewed as a stress response that can be induced by a wide range of endogenous and exogenous insults, including oxidative and genotoxic stress, DNA damage, telomere attrition, or oncogenic activation, mitochondrial dysfunction, or chemotherapeutic agents. (McHugh et al., J. Cell Biol. 217(1):65-77, 2018). This accelerated aging response, independent of telomere shortening, is known as premature aging. Aging is associated with various age-related complications, such as diabetes, osteoporosis, cardiovascular disease, dementia, neurodegenerative disease, renal failure, and sarcopenia. It is also interesting that aging is the greatest risk factor for cancer (McHugh et al., J. Cell Biol. 217(1):65-77, 2018; Childs et al., Nat. Rev. .Drug Discov.16(10):718-735, 2017).
老化細胞は、代謝的に活性を維持し、それらの分泌表現型を介して組織の止血、疾患、加齢に影響を及ぼし得る(He et al.,Cell 169(6):1000-1011,2017)。老化は、生理学的プロセスとみなされており、創傷治癒、組織の恒常性(Brighton et al.,Elife 6,2017)、再生、胚形成、線維症の調節などを促進する上で重要である(von Kobbe,Cell Mol.Life Sci.2018)。例えば、老化細胞の一過性の誘導は、治癒中に観察され、創傷の消散に寄与する。おそらく、老化の最も重要な役割のうちの1つは、腫瘍形成抑制におけるその役割である(von Kobbe,Cell Mol.Life Sci.2018)。しかしながら、老化細胞の蓄積は、加齢及び加齢関連疾患も促進する。老化の表現型は、慢性炎症応答も引き起こし、その結果、慢性炎症状態を増強して、腫瘍の成長を促進する可能性がある。老化と加齢との間の関連性は、当初、老化細胞が加齢組織に蓄積するという観察に基づいていた。過去10年間で、加齢及び加齢関連病状における老化の有害な結果についての理解が大幅に拡大した。トランスジェニックモデルの使用により、多くの加齢関連病状において老化細胞を体系的に検出することが可能になった。老化細胞を選択的に排除するための遺伝学的戦略及び老化細胞除去薬戦略の開発は、老化細胞が実際に加齢及び関連病状において因果的役割を果たすことができることを実証している。
Senescent cells remain metabolically active and can influence tissue hemostasis, disease and aging through their secretory phenotype (He et al., Cell 169(6):1000-1011, 2017). ). Aging is considered a physiological process and is important in promoting wound healing, tissue homeostasis (Brighton et al.,
老化細胞は、形態、クロマチン構成、遺伝子発現、及び代謝の変化を含む重要な特有の特性を示す。細胞老化に関連するいくつかの生化学的及び機能的特性、例えば、(i)サイクリン依存性キナーゼの阻害物質であるp16INK4a及びp21CIP1の発現の増加、(ii)リソソーム活性のマーカーである老化関連β-ガラクトシダーゼの存在、(iii)老化関連ヘテロクロマチン病巣の出現及びラミンB1レベルのダウンレギュレーション、(iv)抗アポトーシスBCLファミリータンパク質の発現の増加によって引き起こされるアポトーシスに対する耐性、及び(v)CD26(DPP4)(Kim et al.,Genes Dev.31(15):1529-1534,2017)、CD36(スカベンジャー受容体)(Chong et al.,EMBO Rep.19(6),2018)、フォークヘッドボックス4(FOXO4)(Bourgeois et al.,FEBS Lett.592(12):2083-2097,2018)、及び分泌キャリア膜タンパク質4(SCAMP4)(Kim et al.,Genes Dev.32(13-14):909-914,2018)のアップレギュレーション、(vi)リポフスチンの蓄積、並びに(vii)胚性軟骨細胞1及びデコイ死受容体2の発現が存在する。老化細胞は、炎症特性、いわゆるSASPも発現する。SASPを介して、老化細胞は、細胞自律的様式で作動して老化を強化し(オートクリン効果)、微小環境と通信して修飾する(パラクリン効果)、広範囲の炎症性サイトカイン(IL-1α、IL-1β、IL-6、IL-8、TNF-α)、成長因子(TGF-β、PDGF-AA、インスリン様成長因子-結合タンパク質(IGFBPs))、ケモカイン(CCL-2、CCL-20、CCL-7、CXCL-4、CXCL1、及びCXCL-12)、及びマトリックスメタロプロテイナーゼ(MMP-3、MMP-9)を産生する(Milanovic et al.,Nature 553(7686):96-100,2018)。IL-1αは、SASPの主要制御因子の1つとみなされる。老化細胞によるIL-1αの放出は、老化を正常細胞に伝達する。IFNは、標的細胞のDNA損傷を誘発することによって老化を誘発することもできる。IGFBはインスリン様成長因子(IGF)経路を調節することができ、IGFは老化の強力な誘導因子として機能することができる。SASP因子の1つとして分泌されるTGF-βは、オートクリン/パラクリン様式で老化表現型及び加齢関連病的状態を誘発及び維持することができる。ポリコムタンパク質CBX7によって調節されるインテグリンβ3は、老化中にアップレギュレートされ、オートクリン/パラクリン様式でTGF-βシグナル伝達を活性化することによって老化を促進し、ヒト線維芽細胞のSASPを強化した。更に、特発性肺線維症では、TGF-βを介した老化細胞の蓄積が示唆されている。最近の報告では、TGF-βシグナル伝達がH4K20me3存在量の低減を誘発し、これによりDNA損傷修復が損なわれ、線維芽細胞のmiR-29a/cがアップレギュレートされ、Suv4-20hの標的がダウンレギュレートされることにより、老化が回復及び促進されることが示された。この経路はインビボで心臓の老化に寄与し、TGF-βシグナル伝達の阻害はH4K20me3を回復させ、高齢のマウスの心機能を改善した。
Senescent cells exhibit important unique characteristics including changes in morphology, chromatin organization, gene expression, and metabolism. Several biochemical and functional properties associated with cellular senescence, such as (i) increased expression of p16 INK4a and p21 CIP1 , inhibitors of cyclin-dependent kinases, (ii) senescence, a marker of lysosomal activity (iii) appearance of senescence-associated heterochromatin foci and downregulation of Lamin B1 levels, (iv) resistance to apoptosis caused by increased expression of anti-apoptotic BCL family proteins, and (v) CD26 ( DPP4) (Kim et al., Genes Dev. 31(15):1529-1534, 2017), CD36 (scavenger receptor) (Chong et al., EMBO Rep. 19(6), 2018), forkhead box 4 (FOXO4) (Bourgeois et al., FEBS Lett. 592(12):2083-2097, 2018) and secretory carrier membrane protein 4 (SCAMP4) (Kim et al., Genes Dev. 32(13-14):909 -914, 2018), (vi) accumulation of lipofuscin, and (vii) expression of
マトリックスメタロプロテイナーゼ(MMP)は、老化の調節要素として機能し得るMMP-1及びMMP-3を含む、SASPの重要な要素である。これらは、IL-8、IL-1、VEGF、及びその他のCXCL/CCLファミリーのケモカインを切断できる。更に、老化細胞は、ウロキナーゼ又は組織型プラスミノーゲン活性化因子のようなセリンプロテアーゼを分泌する。 Matrix metalloproteinases (MMPs) are key components of SASPs, including MMP-1 and MMP-3, which can function as regulatory elements of aging. They can cleave IL-8, IL-1, VEGF, and other chemokines of the CXCL/CCL family. In addition, senescent cells secrete serine proteases such as urokinase or tissue-type plasminogen activator.
SASPはまた、隣接細胞の表現型に影響を与え得る一酸化窒素及び活性酸素種などの非高分子要素で構成されている。 SASPs are also composed of non-polymeric elements such as nitric oxide and reactive oxygen species that can affect the phenotype of neighboring cells.
老化細胞の分泌プロファイルは、状況依存的である。例えば、ヒト線維芽細胞における様々なミトコンドリア機能障害によって誘導されるミトコンドリア機能障害関連老化(MiDAS)は、IL-1依存性炎症性因子が不足したSASPの出現をもたらした(Wiley et al.,Cell Metab.23(2):303-314,2016)。NAD+/NADH比の減少は、p53の活性化によりMiDASを誘導したAMPKシグナル伝達を活性化した。結果として、p53は炎症促進性SASPの重要な誘導因子であるNF-κBシグナル伝達を阻害した(Salminen et al.,Cell Signal.24(4):835-845,2012)。対照的に、ヒト細胞における持続的なDNA損傷によって引き起こされた細胞老化は、炎症性SASPを誘導し、これは、運動失調-毛細血管拡張症変異(ATM)キナーゼの活性化に依存したが、p53の活性化には依存しなかった(Rodier et al.,Nat.Cell Biol.11(8):973-979,2009)。具体的には、IL-6及びIL-8の発現レベル及び分泌レベルが増加した。異所性発現p16INK4a及びp21CIP1によって引き起こされる細胞老化が、炎症性SASPなしでヒト線維芽細胞における老化表現型を誘導することも実証されており、成長停止自体はSASPを刺激しなかったことを示している(Coppe et al.,J.Biol.Chem.286(42):36396-36403,2011)。これらは、老化表現型が、SASPの性質並びにその生理学的及び病理学的結果の制御において重要な役割を果たしていることを示す。 The secretory profile of senescent cells is context dependent. For example, mitochondrial dysfunction-associated senescence (MiDAS) induced by various mitochondrial dysfunctions in human fibroblasts led to the emergence of SASPs deficient in IL-1-dependent inflammatory factors (Wiley et al., Cell Metab.23(2):303-314, 2016). A decrease in the NAD+/NADH ratio activated AMPK signaling that induced MiDAS through activation of p53. As a result, p53 inhibited NF-κB signaling, a key inducer of pro-inflammatory SASPs (Salminen et al., Cell Signal. 24(4):835-845, 2012). In contrast, cellular senescence caused by persistent DNA damage in human cells induced inflammatory SASP, which depended on activation of the ataxia-telangiectasia mutated (ATM) kinase, It was independent of p53 activation (Rodier et al., Nat. Cell Biol. 11(8):973-979, 2009). Specifically, IL-6 and IL-8 expression and secretion levels were increased. It has also been demonstrated that cellular senescence caused by ectopically expressed p16 INK4a and p21 CIP1 induces a senescent phenotype in human fibroblasts without inflammatory SASP, and that growth arrest itself did not stimulate SASP. (Coppe et al., J. Biol. Chem. 286(42):36396-36403, 2011). These indicate that the aging phenotype plays an important role in regulating the properties of SASPs and their physiological and pathological consequences.
したがって、SASPの複数の成分は、老化細胞の総数を増やすために、近くの非老化細胞でパラクリン様式で老化を促進する能力を有する。SASPにより、老化細胞はパラクリンメカニズムを介して組織の微小環境にも影響を与え、隣接する増殖細胞に影響を与え、老化組織及び腫瘍における免疫細胞の動員及び活性化に影響を与えることができる。 Thus, multiple components of SASP have the ability to promote senescence in nearby non-senescent cells in a paracrine manner in order to increase the total number of senescent cells. Through SASPs, senescent cells can also influence the tissue microenvironment through paracrine mechanisms, influence neighboring proliferating cells, and influence the recruitment and activation of immune cells in senescent tissues and tumors.
SASP因子は、老化細胞の免疫介在性クリアランスである老化監視をトリガすることによって腫瘍抑制に寄与することができる。しかしながら、慢性炎症も腫瘍形成の既知の要因であり、累積証拠は、慢性SASPががん及び加齢関連疾患を後押しする可能性もあることを示す。最近では、老化細胞が細胞間タンパク質の直接伝達によって隣接細胞に影響を与えることも示されている(Biran et al.,Genes Dev.29(8):791-802,2015)。老化細胞からレシピエントの隣接細胞に移入されたタンパク質は、これらの細胞のシグナル伝達経路の活性化を引き起こし、細胞の挙動に変化をもたらした。最近の研究では、化学療法によって誘導された老化がん細胞が、隣接する老化又は非老化がん細胞を貪食したことが示された。貪食は、細胞死阻害物質p53の存在下でも発生した。摂取された細胞はリソソームで分解される。隣の細胞を食べた老化細胞は、食べなかった細胞よりも長く生き残った。これは、隣接細胞のリソソーム消化から得られた代謝構成要素が、老化細胞の生存を促進するために使用されていることを示唆している。貪食は、主に、エントシスの作用メカニズムではなく食作用によるものであった。細胞の共食いは、SASP応答をサポートすることにより、がんの進行に影響を与える可能性があることが提案された。しかしながら、化学療法によって誘導された老化がん細胞のこの新たに獲得された能力は、腫瘍微小環境から特定の細胞を除去することによって、がん細胞の転移を直接促進又は促進する(facilitate)可能性がある。正常な細胞も老化した組織の老化細胞によって除去されることが判明した場合、これは組織の劣化を直接引き起こす可能性がある。 SASP factors can contribute to tumor suppression by triggering senescence surveillance, the immune-mediated clearance of senescent cells. However, chronic inflammation is also a known factor in tumorigenesis, and cumulative evidence indicates that chronic SASPs may also drive cancer and age-related diseases. Recently, it has also been shown that senescent cells influence neighboring cells by direct transfer of intercellular proteins (Biran et al., Genes Dev. 29(8):791-802, 2015). Proteins transferred from senescent cells to recipient neighboring cells caused the activation of signaling pathways in these cells, resulting in changes in cell behavior. Recent studies have shown that chemotherapy-induced senescent cancer cells phagocytosed neighboring senescent or non-senescent cancer cells. Phagocytosis also occurred in the presence of the cell death inhibitor p53. Ingested cells are degraded by lysosomes. Senescent cells that ate neighboring cells survived longer than those that did not. This suggests that metabolic components obtained from lysosomal digestion of neighboring cells are used to promote survival of senescent cells. Phagocytosis was primarily due to phagocytosis rather than the mechanism of action of entosis. It was proposed that cell cannibalism may affect cancer progression by supporting the SASP response. However, this newly acquired ability of chemotherapy-induced senescent cancer cells can directly promote or facilitate cancer cell metastasis by removing specific cells from the tumor microenvironment. have a nature. If normal cells were also found to be removed by senescent cells in aged tissue, this could directly cause tissue deterioration.
要約すると、SASPの全ての成分は、局所的な炎症環境に寄与し、炎症現象に寄与する可能性がある。 In summary, all components of SASP contribute to the local inflammatory environment and may contribute to inflammatory phenomena.
SASP成分のほとんどは、活性化B細胞の核因子カッパ軽鎖エンハンサー(NF-κB)、CCAAT/エンハンサー結合タンパク質ベータ(CEBP/β)、及びmTORによって制御される。NF-κBの上流で作用する転写因子GATA4も、老化の確立及びSASPの誘導に必要である。SASPの別の調節因子は、ブロモドメイン及びエクストラターミナルドメイン(BET)ファミリーメンバーのブロモドメイン含有タンパク質4(BRD4)であり、老化セクレトームを積極的に調節し、老化免疫クリアランスを促進する。SASPは、特定の組織のシグナルトランスデューサー及び転写活性化因子3(STAT3)によっても調節されている。更に、混合系統白血病1(MLL1)も、主にDNA複製及びDDR活性化に必要な遺伝子を誘導することにより、SASPを可能にすることが報告されている。他のSASP調節因子としては、NOTCH1及び高移動度群Bタンパク質(HMGB1及びHMGB2)が挙げられる。最近のデータは、SASPがcGAS/STING経路によって制御できることも実証されている。cGASはDNAセンサーであり、アダプタータンパク質STINGを介して、細胞の老化及びSASPを制御する遺伝子の転写を引き起こす。 Most of the SASP components are regulated by activated B-cell nuclear factor kappa light chain enhancer (NF-κB), CCAAT/enhancer binding protein beta (CEBP/β), and mTOR. The transcription factor GATA4, which acts upstream of NF-κB, is also required for establishment of senescence and induction of SASP. Another regulator of SASPs is the bromodomain and extraterminal domain (BET) family member bromodomain-containing protein 4 (BRD4), which positively regulates the aging secretome and promotes aging immune clearance. SASP is also regulated by the tissue-specific signal transducer and activator of transcription 3 (STAT3). In addition, mixed lineage leukemia 1 (MLL1) has also been reported to enable SASP, primarily by inducing genes required for DNA replication and DDR activation. Other SASP regulators include NOTCH1 and high mobility group B proteins (HMGB1 and HMGB2). Recent data also demonstrate that SASP can be regulated by the cGAS/STING pathway. cGAS is a DNA sensor that, via the adapter protein STING, triggers the transcription of genes that regulate cellular senescence and SASP.
老化の最も明確な特徴の1つは、安定した成長停止である。これは、p53/p21CIP1p21cip1及びp16INK4a/Rb経路によって達成される(McHugh et al.,J.Cell Biol.217(1):65-77,2018)。DNA損傷及び/又はDNA損傷応答(DDR)は、これら2つの経路を決定的に制御する。 One of the most defining features of aging is steady growth arrest. This is accomplished by the p53/p21 CIP1 p21 cip1 and p16 INK4a /Rb pathways (McHugh et al., J. Cell Biol. 217(1):65-77, 2018). DNA damage and/or DNA damage response (DDR) critically regulate these two pathways.
(1)p53/p21CIP1p21cip1:p53は、細胞老化において極めて重要な役割を果たし、その活性化は、DDR依存性又はDDR非依存性であり得る。テロメアDDR依存の場合、テロメア摩滅、DNA損傷、並びに複製ストレスに起因するがん遺伝子の過剰活性化及びがん抑制因子の不活性化(がん遺伝子誘導老化、OIS)により、DNA損傷修復カスケードが活性化される。DDRは、ストレスセンサーの毛細血管拡張性運動失調症変異キナーゼ(ATM)又は毛細血管拡張性運動失調症及びRad3関連(ATR)キナーゼを活性化する。次に、ATM/ATRは、p53及びそのユビキチンリガーゼMdm2の両方をリン酸化することにより、p53/p21CIP1p21cip1軸を活性化し、p53レベルの安定化をもたらす。P53は、Ser-15で直接リン酸化され、Chk1/2を介してSer-20で間接的にリン酸化される。最近の多くの研究では、いくつかのOIS経路が実際にDDRをバイパスしてp53p35を活性化できることも実証されている。これらは、最初の変異の開始後の腫瘍形成の抑制に対するp53及びp53トリガ老化の重要な役割をもう一度実証した。 (1) p53/p21 CIP1 p21 cip1 : p53 plays a pivotal role in cellular senescence and its activation can be DDR dependent or DDR independent. In the case of telomere DDR dependence, overactivation of oncogenes and inactivation of tumor suppressors (oncogene-induced senescence, OIS) due to telomere attrition, DNA damage, and replication stress triggers DNA damage repair cascades. activated. DDR activates the stress sensors ataxia telangiectasia mutated kinase (ATM) or ataxia telangiectasia and Rad3-related (ATR) kinase. ATM/ATR then activates the p53/p21 CIP1 p21cip1 axis by phosphorylating both p53 and its ubiquitin ligase Mdm2, leading to stabilization of p53 levels. P53 is directly phosphorylated on Ser-15 and indirectly on Ser-20 via Chk1/2. A number of recent studies have also demonstrated that some OIS pathways can indeed bypass DDR and activate p53p35. These once again demonstrated an important role of p53 and p53-triggered senescence in suppressing tumorigenesis after initial mutational initiation.
p53タンパク質の安定化により、p21CIP1がアップレギュレートされる。p21CIP1p21cip1、哺乳動物のサイクリン依存性キナーゼ(CDK)阻害物質ファミリーのメンバーであるp21cip1は、G1/S又はG2/Mチェックポイントでのp53による細胞周期停止に必要である。ヒトの第6染色体に位置するCDKN1A遺伝子によってコードされるp21CIP1p21cip1は、強力なサイクリン依存性キナーゼ阻害物質(CKI)である。サイクリン-CDK2、-CDK1、及び-CDK4/6複合体に結合してその活性を阻害し、G1期及びS期における細胞周期進行の調節因子として機能する。p21CIP1p21cip1はまた、主にE4F4複合体動員を通じて、CDC25C、CDC25B、生存等の多くのp53標的の遺伝子発現調節を仲介する。p21CIP1p21cip1は、アポトーシスの阻害を通じて老化も促進する。これは、多くのカスパーゼを含む多くのアポトーシス薬に結合する。老化細胞におけるP21CIP1P21cip1ノックアウトは、カスパーゼ活性化カスケードを介してプログラム細胞死を引き起こす。p21CIP1p21cip1は、p53活性とは独立して老化を誘導することもできる。Chk2は、p53欠損細胞株でp21cip1発現を誘導し、Chk2媒介性老化に寄与することが示された。
Stabilization of the p53 protein upregulates p21 CIP1 . p21 CIP1 p21 cip1 , a member of the mammalian cyclin-dependent kinase (CDK) inhibitor family, p21 cip1 is required for cell cycle arrest by p53 at the G1/S or G2/M checkpoints. p21 CIP1 p21cip1, encoded by the CDKN1A gene located on
(2)p16INK4a/Rb:3つの腫瘍抑制因子がINK4/ARF遺伝子座に存在する:p16INK4a及びARFは両方ともCNDN2A遺伝子によってコードされ、p15INK4bはCDKN2B遺伝子によってコードされる。p15INK4b及びp16INK4aは、p21CIP1と同様に、CDK4及びCDK6に結合して阻害することにより細胞周期に影響を与えるCDKIである。対照的に、ARFはMDM2を阻害し、それによってp53/p21CIP1経路とのクロストークが可能になる。INK4/ARF遺伝子座は老化センサーとして動作する。若い正常な細胞では、抑制的なH3K27me3マークの沈着により、INK4/ARF遺伝子座がエピジェネティックにサイレンシングされる。H3K27のメチル化は、ポリコム抑制複合体、PRC2及びPRC3によって制御される。一部の成分の発現を枯渇させることによってPRC1又はPRC2の活性を破壊すると、p16INK4aが抑制され、老化が誘導される。老化の間、H3K27ヒストン脱メチル化酵素JMJD3は、INK4/ARF遺伝子座周辺の抑制マークを除去する役割を果たし、その誘導を促進する。INK4/ARFの誘導は、自然老化の間、組織で観察できる。特に、p16INK4aは老化のバイオマーカーとみなされる。 (2) p16 INK4a /Rb: Three tumor suppressors are present at the INK4/ARF locus: p16 INK4a and ARF are both encoded by the CNDN2A gene and p15 INK4b by the CDKN2B gene. p15 INK4b and p16 INK4a , like p21 CIP1 , are CDKIs that affect the cell cycle by binding to and inhibiting CDK4 and CDK6. In contrast, ARF inhibits MDM2, thereby allowing crosstalk with the p53/p21 CIP1 pathway. The INK4/ARF locus acts as an aging sensor. In young normal cells, deposition of repressive H3K27me3 marks epigenetically silences the INK4/ARF locus. Methylation of H3K27 is regulated by the Polycom repressive complexes, PRC2 and PRC3. Disruption of PRC1 or PRC2 activity by depleting the expression of some components represses p16 INK4a and induces senescence. During senescence, the H3K27 histone demethylase JMJD3 plays a role in removing repression marks around the INK4/ARF locus, facilitating its induction. Induction of INK4/ARF can be observed in tissues during natural aging. In particular, p16 INK4a is considered a biomarker of aging.
要約すると、p53はサイクリン依存性キナーゼ阻害物質p21CIP1の転写を誘導し、p16INK4a及びp15INK4bの両方とともに、細胞周期進行のために遺伝子を遮断する(CDK4及びCDK6)。これは、最終的に網膜芽細胞腫タンパク質(Rb)の低リン酸化及びG1期での細胞周期停止につながる(McHugh et al.,J.Cell Biol.217(1):65-77,2018)。 In summary, p53 induces transcription of the cyclin-dependent kinase inhibitor p21 CIP1 and together with both p16INK4a and p15INK4b shuts off genes for cell cycle progression (CDK4 and CDK6). This ultimately leads to hypophosphorylation of the retinoblastoma protein (Rb) and cell cycle arrest in the G1 phase (McHugh et al., J. Cell Biol. 217(1):65-77, 2018). .
p53/p21CIP1経路は老化の開始において重要な役割を果たしているようであるが、p16INK4a及びRBファミリーが関与する経路は、老化の維持において中心的な役割を果たしているようである。これは、老化の誘導後のp53レベルの減少の観察によって示唆されたが、p16INK4aレベルは着実に高く維持されている。老化細胞におけるp53のダウンレギュレーションは、p16の活性に応じて異なる影響を与えることも示されている。p53は、p16INK4aのレベルが低い細胞では複製及び細胞増殖の誘導に成功するが、p16INK4a活性が高い細胞では成功しない。これらの発見は、p16INK4a/Rb経路の活性化が、老化の2つの異なる段階の間に線を引くことに関与していることを示唆している。初期の可逆的段階はp53活性によって支配され、不可逆的段階はp16INK4a/Rb経路によって誘導される。 The p53/p21 CIP1 pathway appears to play a key role in initiating senescence, whereas pathways involving the p16 INK4a and RB family appear to play a central role in maintaining senescence. This was suggested by the observation of decreased p53 levels after induction of senescence, whereas p16 INK4a levels remain steadily elevated. Downregulation of p53 in senescent cells has also been shown to have differential effects depending on p16 activity. p53 is successful in inducing replication and cell proliferation in cells with low levels of p16INK4a, but not in cells with high p16INK4a activity. These findings suggest that activation of the p16 INK4a /Rb pathway is involved in drawing the line between two distinct stages of aging. The early reversible step is governed by p53 activity and the irreversible step is induced by the p16 INK4a /Rb pathway.
最近、cGAS-cGAMP-STING経路が、DNA損傷から炎症、細胞老化、及びがんへの重要なつながりとして明らかになる(Tuo et al.,J.Exp.Med.215(5):1287-1299,2018)。この経路は、DNA損傷後の細胞質DNAを検出し、I型IFN及びその他のサイトカインを活性化する。DNase2及びTREX1の両方が、老化前細胞の核から発する細胞質DNA断片を迅速に除去するが、これらのDNaseの発現は老化細胞ではダウンレギュレートされ、核DNAの細胞質蓄積をもたらす。これにより、cGAS-STING細胞質DNAセンサーの異常な活性化が引き起こされ、IFN-βの誘導を介してSASPが誘発される(Takahashi et al.,Nature Comm.9:1249,2018)。 Recently, the cGAS-cGAMP-STING pathway has emerged as an important link from DNA damage to inflammation, cellular senescence, and cancer (Tuo et al., J. Exp. Med. 215(5):1287-1299 , 2018). This pathway detects cytoplasmic DNA after DNA damage and activates type I IFNs and other cytokines. Both DNase2 and TREX1 rapidly remove cytoplasmic DNA fragments emanating from the nucleus of presenescent cells, but expression of these DNases is downregulated in senescent cells, resulting in cytoplasmic accumulation of nuclear DNA. This causes aberrant activation of the cGAS-STING cytoplasmic DNA sensor and triggers SASP through induction of IFN-β (Takahashi et al., Nature Comm. 9:1249, 2018).
トランスフォーミング増殖因子-β(TGF-β)は、進化的に保存されたサイトカインのスーパーファミリーであり、多様な範囲のシグナル伝達機能を媒介して、細胞の分化及び増殖の組織特異的な制御を提供する。また、細胞死を促進又は保護し、細胞外マトリックスタンパク質の発現、細胞の運動性及び浸潤を促進し、細胞の代謝を制御する。 Transforming growth factor-β (TGF-β) is an evolutionarily conserved superfamily of cytokines that mediate a diverse range of signaling functions to effect tissue-specific control of cell differentiation and proliferation. offer. It also promotes or protects cell death, promotes extracellular matrix protein expression, cell motility and invasion, and regulates cell metabolism.
ヒトTGF-βファミリーには、ホモ二量体又はヘテロ二量体の分泌サイトカインをコードする33の遺伝子が含まれる。ファミリーメンバーには、アクチビン、骨形成タンパク質、成長分化因子、ミュラー管阻害物質、結節及びTGF-βが含まれる。TGF-βファミリータンパク質は、シグナルペプチド、プロドメイン(TGF-βについて潜在関連ペプチド(LAP)と呼ばれる)、及び成熟ポリペプチドからなる前駆体分子として合成される。短いN末端シグナルペプチドの除去により、小胞体からゴルジ装置への輸送中の後続の生合成ステップでのタンパク質のフォールディング、グリコシル化、及びプロセシングが可能になる。ジスルフィド結合による二量体化に続いて、フューリンファミリープロテアーゼによるポリペプチドのタンパク質分解切断が行われ、N末端の長い二量体及びジスルフィド結合されたLAP、及びC末端の短い二量体のジスルフィド結合された成熟TGF-βが形成される。LAP及び成熟したTGF-βは互いに結合したままであり、小さな潜伏複合体(SLC)と呼ばれるリガンドの潜在的な形態を形成し、この潜在的TGF-βの形態の構造分析は、LAPが、後にシグナル伝達受容体との相互作用に使用され、成熟したTGF-β二量体の不活性化をもたらすC末端二量体の重要なアミノ酸を直接カバーすることを示す。TGF-βポリペプチドのプロセシングに付随して、他の分泌タンパク質である潜在的TGF-β結合タンパク質(LTBP)へのジスルフィド結合を介したN末端LAPの架橋が起こり、大きな潜在的複合体(LLC)を形成する。LTBPは細胞外タンパク質であり、分泌されると、フィブロネクチン及びフィブリリンなどのECMの他のタンパク質と架橋する能力を介して、細胞外マトリックス(EMC)へのLLCの沈着を媒介する。したがって、LTBPは、潜在的TGF-βをECMにつなぐ足場ユニットを提供する。3つのTGF-βの潜在的複合体は、成熟したリガンドを放出するために活性化メカニズムを必要とする。しかしながら、TGF-β1複合体の活性化のみが十分に特徴付けられている。タンパク質分解、低pH、活性酸素種、他のタンパク質への結合、及びせん断又はインテグリン媒介細胞引っ張りによる機械的変形を含む、生理学的に関連する設定における潜在的な細胞外潜在的TGF-β活性化の多様なモードは、シグナル伝達状況に依存する可能性のある組織選択的メカニズムを示唆する。様々な状況で、SLCのLAPの一方の側は、Cys33残基を介してLTBPの8-Cysドメインに共有結合で架橋結合され、これが次にECMに連結される。この抵抗により、インテグリン、特にαvβ1、αvβ6、及びαvβ8を介してLAPのもう一方の端を引っ張ると、潜在的TGF-β複合体の立体配座の変化が可能になり、LLCからの活性TGF-β1の放出がもたらされる。様々なプロテアーゼも、潜在的TGF-βの活性化をもたらす。多くの研究は、潜在的TGF-β1の生理学的活性化には、インテグリン及びプロテアーゼの複合活性が必要であることを強く示唆している。潜在的TGF-β複合体は、LTBPとの会合の代わりに、LRRC32としても知られるGARPという名前の膜結合タンパク質、又は密接に関連するLRRC33にジスルフィド結合していることも見出されている。GARPは、主に制御性T細胞(Treg)などの免疫細胞で発現する。GARPの機能はTregで広く研究されており、αvβ8インテグリンと複合体を形成して細胞の表面から活性TGF-βを放出する。GARPは、Treg媒介性末梢耐性の強化に関与していることが示された。血小板では、トロンビンがGARPを切断し、GARP-LAP-TGF-β1複合体から活性TGF-β1が遊離することも示されている。 The human TGF-β family includes 33 genes encoding homodimeric or heterodimeric secreted cytokines. Family members include activins, bone morphogenetic proteins, growth differentiation factors, Müllerian inhibitors, nodules and TGF-β. TGF-β family proteins are synthesized as precursor molecules consisting of a signal peptide, a prodomain (called latent associated peptide (LAP) for TGF-β), and a mature polypeptide. Removal of the short N-terminal signal peptide allows protein folding, glycosylation, and processing at subsequent biosynthetic steps during transport from the endoplasmic reticulum to the Golgi apparatus. Dimerization by disulfide bonds is followed by proteolytic cleavage of the polypeptide by a furin family protease, resulting in a long N-terminal dimer and disulfide-linked LAP and a short C-terminal dimer disulfide. Bound mature TGF-β is formed. LAP and mature TGF-β remain bound to each other and form a cryptic form of the ligand called the small latent complex (SLC), and structural analysis of this cryptic TGF-β form suggests that LAP It is shown to directly cover key amino acids of the C-terminal dimer that are later used to interact with signaling receptors and lead to inactivation of the mature TGF-β dimer. Concomitant with processing of the TGF-β polypeptide is cross-linking of the N-terminal LAP via disulfide bonds to another secreted protein, the latent TGF-β binding protein (LTBP), forming a large latent complex (LLC). ). LTBP is an extracellular protein that, when secreted, mediates LLC deposition into the extracellular matrix (EMC) through its ability to crosslink other proteins of the ECM such as fibronectin and fibrillin. LTBP thus provides a scaffolding unit that tethers potential TGF-β to the ECM. Three potential complexes of TGF-β require an activation mechanism to release the mature ligand. However, only activation of the TGF-β1 complex has been well characterized. Potential extracellular potential TGF-β activation in physiologically relevant settings, including proteolysis, low pH, reactive oxygen species, binding to other proteins, and mechanical deformation by shear or integrin-mediated cell pulling. The diverse modes of simplify tissue-selective mechanisms that may depend on signaling context. In various circumstances, one side of the LAP of SLC is covalently cross-linked via the Cys33 residue to the 8-Cys domain of LTBP, which is then linked to the ECM. This resistance allows for the conformational change of the latent TGF-β complex to pull the other end of LAP through the integrins, particularly αvβ1, αvβ6, and αvβ8, thus releasing active TGF-β from LLC. β1 release results. Various proteases also provide potential TGF-β activation. A number of studies strongly suggest that potential TGF-β1 physiological activation requires the combined activity of integrins and proteases. Latent TGF-β complexes have also been found to be disulfide-linked to a membrane-bound protein named GARP, also known as LRRC32, or the closely related LRRC33, instead of being associated with LTBP. GARP is expressed primarily on immune cells such as regulatory T cells (Treg). GARP's function has been extensively studied in Tregs, where it forms a complex with the αvβ8 integrin to release active TGF-β from the surface of the cell. GARP has been shown to be involved in enhancing Treg-mediated peripheral resistance. It has also been shown in platelets that thrombin cleaves GARP, releasing active TGF-β1 from the GARP-LAP-TGF-β1 complex.
LAPから活性化されると、3つのTGF-βアイソフォームは全て、二量体TGF-βI型受容体(RI)alk5(別名TβR1)及び二量体TGF-βII型受容体(RII)TGFβRIIによって形成される、同じヘテロマー膜貫通型TGF-β受容体複合体を介して作用する。TGF-βは最初にホモ二量体TGFβRIIと結合する。この相互作用は、リガンド及びTGFβRIIの界面でTGFβRIに対する新しい高親和性結合部位が形成されるように、リガンド及びTGFβRIIの間の立体構造の適応を引き起こす。TGFβRIの2つのユニットが動員されると、II型受容体キナーゼは、短いグリシン及びセリンに富むモチーフ(GS)を特徴とするTGFβRIの膜近傍サブドメイン内のセリン及びスレオニン残基をリン酸化し、それがGSドメインからイムノフィリンFKBP12を放出する立体構造の変化を誘発する。この解離により、キナーゼドメインとGSドメインの阻害性相互作用が緩和され、I型受容体のキナーゼが活性化される。リガンド誘導性の受容体活性化により、TGFβRIは2つのC末端セリン残基のリン酸化を介してエフェクターSMADを活性化する。具体的には、I型受容体は、TGF-β(及びアクチビン及びノーダルなどの他のファミリーメンバー)の場合は2つの異なるSMADタンパク質、SMAD2及びSMAD3、又はBMP(一部のGDF及び他のリガンドメンバー)の場合は3つの異なるSMADタンパク質、SMAD1、SMAD5、及びSMAD8をリン酸化する。次いで、これらの「受容体活性化SMAD」(R-SMAD)は受容体から解離し、SMAD4と結合して核内に移行する複合体を形成し、高親和性DNA結合転写因子及び補制御因子と協力して、標的遺伝子を活性化又は抑制する。SMAD複合体は、二次的な遺伝子発現の変化につながる遺伝子転写を指示するだけでなく、mRNAスプライシング、miRNAの発現及びプロセシング、及びエピジェネティックな変化も制御する。SMAD複合体形成の更なる多様性により、SMADシグナル伝達経路は、遺伝子発現を制御する非常に用途が広く、文脈依存的で微妙な経路である。 Upon activation from LAP, all three TGF-β isoforms are mediated by the dimeric TGF-β type I receptor (RI) alk5 (also known as TβR1) and the dimeric TGF-β type II receptor (RII) TGFβRII. It acts through the same heteromeric transmembrane TGF-β receptor complex that is formed. TGF-β first binds to the homodimeric TGFβRII. This interaction causes a conformational adaptation between the ligand and TGFβRII such that a new high-affinity binding site for TGFβRI is formed at the ligand-TGFβRII interface. Upon recruitment of the two units of TGFβRI, the type II receptor kinase phosphorylates serine and threonine residues within the juxtamembrane subdomain of TGFβRI, which is characterized by a short glycine- and serine-rich motif (GS), It induces a conformational change that releases the immunophilin FKBP12 from the GS domain. This dissociation relieves the inhibitory interaction of the kinase and GS domains and activates the type I receptor kinase. Upon ligand-induced receptor activation, TGFβRI activates the effector SMAD through phosphorylation of two C-terminal serine residues. Specifically, type I receptors are two different SMAD proteins, SMAD2 and SMAD3, in the case of TGF-β (and other family members such as activin and nodal), or BMPs (some GDFs and other ligands). members) phosphorylates three different SMAD proteins, SMAD1, SMAD5, and SMAD8. These "receptor-activated SMADs" (R-SMADs) then dissociate from their receptors and bind SMAD4 to form complexes that translocate into the nucleus, producing high-affinity DNA-binding transcription factors and co-regulators. to activate or repress target genes. The SMAD complex not only directs gene transcription leading to secondary gene expression changes, but also controls mRNA splicing, miRNA expression and processing, and epigenetic changes. Due to the additional diversity of SMAD complex formation, the SMAD signaling pathway is a highly versatile, context-dependent and subtle pathway that regulates gene expression.
標準的なSMADシグナル伝達に加えて、TGF-βは下流の細胞応答を他のシグナルトランスデューサーを介して文脈依存的に調節することもできる。これらには、ERK MAPキナーゼ経路、JNK及びp38MAPキナーゼ経路(TAK1経由)、PI3-AKT経路、JAK-STAT経路、Rho-(like)GTPase経路、TGF-βI型受容体ドメインシグナル伝達経路が含まれる。現在では、SMADSの広範な機能的多様性及び依存性がこれらの非標準的な経路にあることがよく知られている。 In addition to canonical SMAD signaling, TGF-β can also modulate downstream cellular responses through other signal transducers in a context-dependent manner. These include the ERK MAP kinase pathway, JNK and p38 MAP kinase pathway (via TAK1), PI3-AKT pathway, JAK-STAT pathway, Rho-(like) GTPase pathway, TGF-β type I receptor domain signaling pathway . It is now well known that the wide functional diversity and dependence of SMADS lies on these non-canonical pathways.
TGF-βは、全てではないにしてもほとんどの細胞系譜の分化を制御し、細胞及び組織の恒常性の多くの側面を調節するため、TGF-βシグナル伝達の調節解除は、発生異常及び疾患につながる。蓄積された証拠は、特定の細胞型におけるTGF-βシグナル伝達の障害及びTGF-βリガンドの調節が、細胞老化、細胞変性、組織線維症、炎症、再生能力の低下、及び代謝機能不全に寄与することを示す。 Because TGF-β controls the differentiation of most, if not all, cell lineages and regulates many aspects of cell and tissue homeostasis, deregulation of TGF-β signaling is associated with developmental abnormalities and diseases. leads to Accumulating evidence suggests that impaired TGF-β signaling and regulation of TGF-β ligands in specific cell types contributes to cellular senescence, cell degeneration, tissue fibrosis, inflammation, decreased regenerative capacity, and metabolic dysfunction. indicate that
SASP因子の1つとして分泌されるTGF-β1は、オートクリン/パラクリン様式で、線維芽細胞、気管支上皮細胞、及びがんを含む様々な細胞型で老化表現型を誘導又は加速し、維持することができる。ポリコムタンパク質CBX7によって調節されるインテグリンβ3は、老化中にアップレギュレートされ、オートクリン/パラクリン様式でTGF-βシグナル伝達を活性化することによって老化を促進し、ヒト線維芽細胞のSASPを強化した。更に、特発性肺線維症では、TGF-β1を介した老化細胞の蓄積が示唆されている。最近の報告では、TGF-β1シグナル伝達がH4K20me3存在量の低減を誘発し、これによりDNA損傷修復が損なわれ、線維芽細胞のmiR-29a/cがアップレギュレートされ、Suv4-20hの標的がダウンレギュレートされることにより、老化が回復及び促進されることが示された。この経路はインビボで心臓の老化に寄与し、TGF-βシグナル伝達の阻害はH4K20me3を回復させ、高齢のマウスの心機能を改善した。 Secreted as one of the SASP factors, TGF-β1 induces or accelerates and maintains the senescent phenotype in various cell types, including fibroblasts, bronchial epithelial cells, and cancer in an autocrine/paracrine manner. be able to. Integrin β3, which is regulated by the Polycom protein CBX7, was upregulated during senescence and promoted senescence by activating TGF-β signaling in an autocrine/paracrine manner, enhancing SASP in human fibroblasts. . Furthermore, TGF-β1-mediated accumulation of senescent cells has been suggested in idiopathic pulmonary fibrosis. A recent report showed that TGF-β1 signaling induced a reduction in H4K20me3 abundance, which impairs DNA damage repair, upregulates miR-29a/c in fibroblasts, and targets Suv4-20h. Down-regulation has been shown to restore and accelerate aging. This pathway contributes to cardiac aging in vivo, and inhibition of TGF-β signaling restored H4K20me3 and improved cardiac function in aged mice.
TGF-β1は老化ドライバーとして機能し、活性酸素種(ROS)刺激によるNF-κBシグナル伝達経路の活性化、及びプラスミノーゲンアクチベーター阻害物質1型(PAI-1、セルピン1)を含むSASP因子の発現を介して血管平滑筋細胞(VSMC)の老化を誘導する。PAI-1は細胞老化のバイオマーカーであるだけでなく、p53の下流の複製老化に必要かつ十分であり、老化プログラムの重要な誘導因子である。PAI-1/TGF-β1正のフィードフォワードメカニズムの存在を示唆する証拠が存在し、老化表現型の出現中のTGF-β1の上昇した組織レベルがPAI-1の発現を刺激するモデルを提供する。次に、老化したVSMC集団の維持、及びおそらく拡大を促進する継続的なTGF-β1合成を強化する(Seo et al.,Am.J.Nephrol.30:481-490,2009)。 TGF-β1 functions as a driver of senescence, activation of the NF-κB signaling pathway by reactive oxygen species (ROS) stimulation, and SASP factors including plasminogen activator inhibitor type 1 (PAI-1, serpin 1). induces senescence of vascular smooth muscle cells (VSMCs) through the expression of PAI-1 is not only a biomarker of cellular senescence, but it is necessary and sufficient for replicative senescence downstream of p53 and is a key inducer of the senescence program. Evidence exists to suggest the existence of a PAI-1/TGF-β1 positive feed-forward mechanism, providing a model in which elevated tissue levels of TGF-β1 during the emergence of the senescent phenotype stimulate PAI-1 expression. . Second, it enhances continued TGF-β1 synthesis, which promotes maintenance and possibly expansion of aged VSMC populations (Seo et al., Am. J. Nephrol. 30:481-490, 2009).
老化には、化学療法後の臨床的進行を遅らせる腫瘍抑制効果があることがよく知られている。過去10年間で、老化の生物学の理解が大きく前進し、特に、腫瘍抑制特性を持つものから、隣接するがん細胞、腫瘍微小環境における間質及び脈管構造への発がん促進効果につながる可能性のある複雑で動的かつ相互作用的なものへと変化した(Hoare et al.,Ann.Rev.Cancer Biol.2:175-194,2018)。Milanovicによる非常に洗練された研究では、原発性B細胞性慢性白血病患者の試料で、老化細胞が重要な幹細胞関連転写産物もアップレギュレートすることが示された(Milanovic et al.,Nature 553(7686):96-100,2018)。急性骨髄性白血病(AML)患者では、老化細胞が示されており、AML芽球が間質細胞に老化表現型を誘導し、これらの間質細胞がフィードバックされて、SASPを介してAML芽球の生存及び増殖を促進する(Abdul-Aziz et al.,Blood 133(5):446-456,2019)。腫瘍は、器官の発達又は組織の修復に関与することを目的とした成長調節の病態生理学的プログラムをつかみ、腫瘍の進行のための新しいメカニズムを作成する代わりに、発がん性パフォーマンスのためにこのプロセスを「ハイジャック」すると考えられている(Milanovic et al.,Trends Cell Biol.28(12):1049-1061,2018)。エピジェネティックなメカニズムは、老化の誘導(H3K9デメチラーゼ)とその後の幹細胞性の獲得(H3K9デメチラーゼ阻害)の原因であると説明されている(Yu et al.,Cancer Cell 33(2):322-336,2018)。 Aging is well known to have tumor suppressive effects that slow clinical progression after chemotherapy. Over the past decade, great advances have been made in understanding the biology of aging, particularly those with tumor suppressor properties that may lead to pro-oncogenic effects on adjacent cancer cells, stroma and vasculature in the tumor microenvironment. transformed into a highly complex, dynamic and interactive one (Hoare et al., Ann. Rev. Cancer Biol. 2:175-194, 2018). A highly sophisticated study by Milanovic showed that senescent cells also upregulated key stem cell-associated transcripts in primary B-cell chronic leukemia patient samples (Milanovic et al., Nature 553 ( 7686):96-100, 2018). In patients with acute myeloid leukemia (AML), senescent cells have been shown to induce senescent phenotypes in stromal cells, and these stromal cells feed back to AML blasts via SASP. (Abdul-Aziz et al., Blood 133(5):446-456, 2019). Tumors seize a pathophysiologic program of growth regulation aimed at engaging in organ development or tissue repair, and instead of creating new mechanisms for tumor progression, they subvert this process for oncogenic performance. (Milanovic et al., Trends Cell Biol. 28(12):1049-1061, 2018). Epigenetic mechanisms have been described as responsible for the induction of senescence (H3K9 demethylase) and subsequent acquisition of stemness (H3K9 demethylase inhibition) (Yu et al., Cancer Cell 33(2):322-336). , 2018).
TGF-β1は、特定の転写因子であるSnail及びZeb1/2の発現を誘導することにより、上皮間葉転換(EMT)を引き起こす。EMTは、細胞接着の変更による細胞への移動性及び侵襲性の動作を提供する。このプロセスには、運動性及び侵襲性につながる上皮機能と取得機能の損失が含まれる。EMTは、がん細胞の進行及び転移につながる重要なプロセスである。 TGF-β1 induces epithelial-mesenchymal transition (EMT) by inducing the expression of specific transcription factors Snail and Zeb1/2. EMT provides migratory and invasive behavior to cells by altering cell adhesion. This process involves loss of epithelial and acquired function leading to motility and invasiveness. EMT is an important process leading to cancer cell progression and metastasis.
免疫抑制性サイトカインとして、TGF-β1は、マクロファージ、ナチュラルキラー細胞、樹状細胞、T細胞などの自然免疫及び適応免疫系の機能及び発達を阻害する。最近のインビボ研究では、組織又は腫瘍由来のTGF-β1への曝露が、循環NK細胞の自然リンパ球I(ILC-I)様表現型への変換を促進することが実証されており、細胞障害能の低減、及びいくつかのILC1関連表面マーカーの獲得によって特徴付けられる。興味深いことに、TGF-β1はまた、MAPK経路を介してIL-15と相乗効果を発揮し、ヒトNK細胞のILC-1様表現型への変換を促進する。TGF-βはまた、標準的なシグナル伝達経路を介してヒトNK細胞の代謝を抑制し、NK細胞の細胞毒性を抑制する。TGF-β1は、他のリンパ球の機能を抑制する制御性T細胞も刺激する。これらの抑制機能は、TGF-β1に免疫破壊を回避する多くのがんの特徴の1つを与える。 As an immunosuppressive cytokine, TGF-β1 inhibits the function and development of innate and adaptive immune systems such as macrophages, natural killer cells, dendritic cells and T cells. Recent in vivo studies have demonstrated that exposure to tissue- or tumor-derived TGF-β1 promotes the conversion of circulating NK cells to an innate lymphocyte-I (ILC-I)-like phenotype, leading to cytotoxicity It is characterized by reduced potency and the acquisition of several ILC1-associated surface markers. Interestingly, TGF-β1 also synergizes with IL-15 through the MAPK pathway to promote conversion of human NK cells to an ILC-1-like phenotype. TGF-β also suppresses human NK cell metabolism and suppresses NK cell cytotoxicity through canonical signaling pathways. TGF-β1 also stimulates regulatory T cells that suppress the function of other lymphocytes. These suppressive functions give TGF-β1 one of the many hallmarks of cancer that evades immune destruction.
膵管腺がん(PDAC)は、膵臓の最も一般的な悪性腫瘍であり、5年生存率は7%で、生存期間の中央値は11ヶ月未満であり、予後は極めて不良である。PDACは、利用可能な全ての抗腫瘍薬理学的オプションに対して非常に難治性である。これは、PDACの進行に関連する強力な線維形成反応の結果であり、膵星細胞の強力な活性化と高密度の細胞外マトリックスの形成を示し、その結果、腫瘍の灌流が不十分になり、静脈内注入された抗がん剤又は化学療法剤に対する侵入できないバリアが形成される。TGF-β1は、線維芽細胞又は内皮細胞からがん関連線維芽細胞(CAF)としても知られる筋線維芽細胞への変換を促進することにより、PDAC線維形成に寄与する。攻撃性は、高レベルのTGF-βを産生する腫瘍微小環境に浸潤した免疫細胞及び線維芽細胞によって更に増幅される。TGF-βは、血管内皮増殖因子などの血管新生促進因子を誘導し、PDACの進行、浸潤、及び転移を可能にする。アシルCoA合成酵素長鎖3(ACSL3)は、PDACでアップレギュレートされていることがわかり、線維症の増加と相関している。Acsl3ノックアウトによる腫瘍細胞からのPAI-1分泌の減少は、腫瘍線維症及び腫瘍浸潤性免疫抑制細胞を著しく低減させ、マウスの細胞傷害性T細胞浸潤を増加させる。この研究では、PDACにおけるPAI-1の発現が、線維症及び免疫抑制のマーカーと正の相関があり、患者の生存率が低いことを予測することも見出されたPAI-1はSASPの重要な構成要素であり、細胞老化のメディエーターであり、TGF-β1によって調節されているため、TGF-β1が、膵臓がんの進行を促進する腫瘍間質クロストークを媒介するこのACSL3-PAI-1シグナル伝達軸で役割を果たすと考えられる。 Pancreatic ductal adenocarcinoma (PDAC) is the most common malignancy of the pancreas, with a 5-year survival rate of 7% and a median survival time of less than 11 months, with an extremely poor prognosis. PDAC is highly refractory to all available anti-tumor pharmacological options. This is the result of a strong fibrogenic response associated with PDAC progression, indicating strong activation of pancreatic stellate cells and the formation of a dense extracellular matrix, resulting in poor tumor perfusion. , an impenetrable barrier to intravenously infused anticancer or chemotherapeutic agents is formed. TGF-β1 contributes to PDAC fibrogenesis by promoting the conversion of fibroblasts or endothelial cells to myofibroblasts, also known as cancer-associated fibroblasts (CAFs). Aggression is further amplified by immune cells and fibroblasts infiltrating the tumor microenvironment that produce high levels of TGF-β. TGF-β induces pro-angiogenic factors such as vascular endothelial growth factor, allowing PDAC progression, invasion and metastasis. Acyl-CoA synthase long chain 3 (ACSL3) was found to be upregulated in PDAC and correlates with increased fibrosis. Reduction of PAI-1 secretion from tumor cells by Acsl3 knockout significantly reduces tumor fibrosis and tumor-infiltrating immunosuppressive cells and increases cytotoxic T-cell infiltration in mice. This study also found that PAI-1 expression in PDAC was positively correlated with markers of fibrosis and immunosuppression and predicted poor patient survival. This ACSL3-PAI-1 is an important component, a mediator of cellular senescence, and is regulated by TGF-β1, which mediates the tumor-stromal crosstalk that promotes pancreatic cancer progression. It is thought to play a role in the signaling axis.
線維性疾患では、細胞外マトリックス(EMC)タンパク質が過剰に沈着すると、組織の完全性が損なわれ、正常な臓器機能が妨げられる。線維症は、慢性的な傷害を受けた組織で発生する可能性があるが、腎臓、肝臓、肺、及び心臓で最も頻繁に観察される。線維症は、主にインターロイキン及びTGF-βスーパーファミリーのメンバーを含む炎症性サイトカインによって引き起こされる。これらのリガンドの多くは、損傷した組織に引き付けられる炎症細胞に浸潤することによって発現される。TGF-β1の過剰発現は、標準(SMADベース)及び非標準(非SMADベース)シグナル伝達経路の両方の活性化を介して線維症を誘発し、その結果、筋線維芽細胞の活性化、ECMの過剰な産生、及びECM分解の阻害が起こる。SMAD2/3の活性化は、コラーゲン(COL1A1、COL3A1、COL5A2、COL6A1、COL6A3、及びCOL7A1)、PAI-1、様々なプロテオグリカン、インテグリン、結合組織成長因子、及びマトリックスメタロプロテアーゼを含むいくつかの線維化促進遺伝子の発現を調節する。これにより、ECMが過剰に堆積し、局所組織構造が損なわれる。 In fibrotic diseases, excessive deposition of extracellular matrix (EMC) proteins compromises tissue integrity and interferes with normal organ function. Fibrosis can occur in chronically injured tissues, but is most frequently observed in the kidney, liver, lung, and heart. Fibrosis is primarily caused by inflammatory cytokines, including interleukins and members of the TGF-β superfamily. Many of these ligands are expressed by infiltrating inflammatory cells that are attracted to damaged tissue. Overexpression of TGF-β1 induces fibrosis through activation of both canonical (SMAD-based) and non-canonical (non-SMAD-based) signaling pathways, resulting in activation of myofibroblasts, ECM overproduction of and inhibition of ECM degradation occurs. Activation of SMAD2/3 is associated with several fibrotic pathways, including collagen (COL1A1, COL3A1, COL5A2, COL6A1, COL6A3, and COL7A1), PAI-1, various proteoglycans, integrins, connective tissue growth factors, and matrix metalloproteases. Regulates the expression of promoting genes. This results in excessive deposition of ECM and compromises local tissue architecture.
SMAD経路を介したシグナル伝達はTGF-βの線維形成において中心的な役割を果たしていると考えられているが、活性酸素種(ROS)もSMAD経路を含む様々な経路を介したTGF-βのシグナル伝達の調節に関与していることを示す新たな証拠がある。TGF-β1は、TGF-β誘導細胞アポトーシス、老化、EMT、線維性遺伝子発現、及び筋線維芽細胞分化を媒介する様々なタイプの細胞におけるミトコンドリアROS産生を増加させる。TGF-βは、貪食細胞及び非貪食細胞の両方のROS産生に重要なヘム含有膜貫通タンパク質のグループである、いくつかのNADPHオキシダーゼ(Nox)酵素(異なる種類の細胞のNox1、Nox2、及びNox4を含む)の発現を誘導することが示されている。Nox4由来のROSは、線維芽細胞の活性化/筋線維芽細胞の分化、上皮及び内皮細胞のアポトーシス、EMT、線維芽細胞/線維芽細胞促進遺伝子の発現など、TGF-βの線維形成効果を媒介する。IPFを含む線維性疾患でもNox4発現の増加が検出されており、これは筋線維芽細胞マーカーα-SMAの発現増加と相関しており、線維性疾患におけるNox4の役割を更に支持している。TGF-βによるNox4の誘導には、いくつかの経路が関与していることが示されている。これらには、SMAD経路、PI3K経路、MAPK経路、及びRHOA/ROCK経路が含まれる。 Signaling through the SMAD pathway is thought to play a central role in TGF-β fibrogenesis, but reactive oxygen species (ROS) also regulate TGF-β through various pathways, including the SMAD pathway. There is emerging evidence implicating it in regulating signal transduction. TGF-β1 increases mitochondrial ROS production in various cell types that mediate TGF-β-induced cell apoptosis, senescence, EMT, fibrotic gene expression, and myofibroblast differentiation. TGF-β is a group of heme-containing transmembrane proteins important for ROS production in both phagocytic and non-phagocytic cells, several NADPH oxidase (Nox) enzymes (Nox1, Nox2, and Nox4 in different types of cells). including ). Nox4-derived ROS mediate the fibrogenic effects of TGF-β, including fibroblast activation/myofibroblast differentiation, epithelial and endothelial cell apoptosis, EMT, and fibroblast/fibroblast-promoting gene expression. Mediate. Increased Nox4 expression has also been detected in fibrotic diseases, including IPF, which correlates with increased expression of the myofibroblast marker α-SMA, further supporting a role for Nox4 in fibrotic diseases. Several pathways have been shown to be involved in the induction of Nox4 by TGF-β. These include the SMAD, PI3K, MAPK, and RHOA/ROCK pathways.
新たな証拠は、ミトコンドリア及びNADPHオキシダーゼの間にクロストークがあることを示唆している。ミトコンドリア由来のROSは、TGF-βに応答してNOX発現の増加に寄与するが、NOXによって生成されたROSは、ミトコンドリアの機能不全を引き起こし、ミトコンドリアのROS産生を増加させる。ミトコンドリア及びNox酵素の間のクロストークも、TGF-βの線維形成促進効果を媒介することが示されている。TGF-β誘導ROS産生におけるミトコンドリア及びNox4間のフィードフォワード相互作用が関係している(Jain et al.,Journal of Biological Chemistry.288:770-777,2013)。 Emerging evidence suggests that there is crosstalk between mitochondria and NADPH oxidase. Mitochondrially-derived ROS contribute to increased NOX expression in response to TGF-β, whereas NOX-generated ROS cause mitochondrial dysfunction and increase mitochondrial ROS production. Cross-talk between mitochondria and Nox enzymes has also been shown to mediate the pro-fibrogenic effects of TGF-β. A feed-forward interaction between mitochondria and Nox4 in TGF-β-induced ROS production has been implicated (Jain et al., Journal of Biological Chemistry. 288:770-777, 2013).
2030年までに、人口の20%以上が65歳以上になり(census.gov/content/dam/Census/library/publications/2014/demo/p23-212.pdfを参照)、約40%が肥満になる(Finkelstein et al.,Am.J.Prev.Med.42(6):563-570,2012)。代謝疾患は、タンパク質、炭水化物、脂質の輸送又は処理を含む重要なプロセスを行う細胞の能力に影響を与える。加齢と肥満は、糖尿病、心臓血管疾患、脂肪肝などの疾患の素因となる慢性疾患の主要な危険因子であり、これらは全て主要な死因であり、したがって重大な公衆衛生上の懸念を引き起こす(Must et al.,“The Disease Burden Associated with Overweight and Obesity,”In:Feingold KR,Anawalt B.,Boyce A.,et al.,eds.,Endotext,South Dartmouth(MA),2000;Martin et al.,Nat.Rev.Cardiol.14(3):132,2017)。 By 2030, more than 20% of the population will be over 65 (see census.gov/content/dam/Census/library/publications/2014/demo/p23-212.pdf) and about 40% will be obese (Finkelstein et al., Am. J. Prev. Med. 42(6):563-570, 2012). Metabolic disorders affect the ability of cells to carry out important processes including the transport or processing of proteins, carbohydrates and lipids. Aging and obesity are major risk factors for chronic diseases that predispose to diseases such as diabetes, cardiovascular disease, and fatty liver, all of which are leading causes of death and thus raise significant public health concerns. (Must et al., "The Disease Burden Associated with Overweight and Obesity," In: Feingold KR, Anawalt B., Boyce A., et al., eds., Endotext, South Dartmouth (MA), 2000; Martin et al. ., Nat. Rev. Cardiol. 14(3):132, 2017).
過剰なカロリー摂取は、マウスの脂肪組織の酸化ストレスを促進し、マウスのp53、ベータガラクトシダーゼなどの老化マーカーの発現に付随して2型糖尿病の特徴をもたらした(Minamino et al.,Nat.Med.15(9):1082-1087,2009)。老化はまた、脂肪生成分化を妨げることによって脂肪組織の生物学的減少を促進した(Mitterberger et al.,Gerontol.A Biol.Sci.69(1):13-24,2014)。別の最近の研究では、肥満によって誘発される老化が、脳内の脂肪沈着を増加させることによって不安及び神経新生の障害を引き起こす可能性があり、これらの老化細胞のクリアランスが、マウスの肥満によって誘発される不安様行動の改善につながることが示されている(Ogrodnik et al.,Cell Metab.29(5):1061-1077,2019)。他の研究では、肥満も免疫細胞の機能を損なうことが示されている。NK細胞のエフェクター機能は、これらの細胞での脂質の蓄積により損なわれることが示され、このプロセスの逆転により機能が回復した(Michelet et al.,Nat.Immunol.19(12):1330-1340,2018)。追加の研究では、肥満におけるNK細胞の障害は年齢とは無関係であることが示されており、同様の欠陥が若年及び高齢の肥満者で観察された(Tobin et al.,JCI Insight2(24):e94939,2017;Michelet et al.,Nat.Immunol.19(12):1330-1340,2018)。
Excessive caloric intake promoted oxidative stress in adipose tissue in mice, resulting in hallmarks of
マウスでは、カロリー摂取量が増えると血管に脂肪が沈着し、単球が動員されてこれらの脂質を貪食し、最終的に内皮下腔に蓄積してアテローム硬化性プラークを引き起こす泡状のマクロファージになる(Bennett et al.,Nat.Rev.Cardiol.14(3):132,2017;Katsuumi et al.,Front.Cardiovasc.Med.5:18,2018)。欧米の高脂肪食(42%が脂肪由来のカロリーからなる食事)を与えられたマウスは、老化細胞の負荷がプラーク(脂質を含んだマクロファージ)の形成に正比例することも示した。トランスジェニックマウスでこれらの老化細胞をうまく排除すると、プラーク形成が大幅に低減した(Childs et al.,Science 354(6311):472-477,2016)。 In mice, increased caloric intake leads to lipid deposition in blood vessels, and monocytes are recruited to phagocytose these lipids, ultimately into frothy macrophages that accumulate in the subendothelial space and cause atherosclerotic plaques. (Bennett et al., Nat. Rev. Cardiol. 14(3):132, 2017; Katsuumi et al., Front. Cardiovasc. Med. 5:18, 2018). Mice fed a Western high-fat diet (42% fat-derived calories) also showed that senescent cell burden was directly proportional to plaque (lipid-laden macrophage) formation. Successful elimination of these senescent cells in transgenic mice greatly reduced plaque formation (Childs et al., Science 354(6311):472-477, 2016).
年齢、肥満、及びグルコースレベルの変化に関連するその他の要因、成長ホルモン(IGF)は糖尿病を引き起こす可能性がある(Palmer et al.,Diabetes 64(7):2289-2298,2015)。高脂肪食を与えられたマウスにおけるp53のような老化マーカーのアップレギュレーションはインスリン抵抗性と相関していたが、脂肪組織におけるp53活性の阻害は老化マーカーの減少につながり、マウスモデルにおけるインスリン抵抗性の改善と相関していた(Minamino et al.,Nat.Med.15(9):1082-1087,2009)。同時に、膵臓β細胞の老化は、肥満マウスの2型糖尿病の一因であることが示されている(Sone et al.,Diabetologia 48(1):58-67,2005)。
Other factors associated with age, obesity, and changes in glucose levels, growth hormone (IGF), can lead to diabetes (Palmer et al., Diabetes 64(7):2289-2298, 2015). Upregulation of senescence markers such as p53 in mice fed a high-fat diet correlated with insulin resistance, whereas inhibition of p53 activity in adipose tissue led to decreased senescence markers and insulin resistance in a mouse model. (Minamino et al., Nat. Med. 15(9):1082-1087, 2009). Concurrently, senescence of pancreatic β-cells has been shown to contribute to
TGF-βの視床下部産生は、高脂肪食条件下で過剰になる。これにより、視床下部の炎症、高血糖、耐糖能異常が引き起こされる。このデータは、過剰な量のTGF-βが視床下部のRNAストレス応答を誘発し、IκBαのmRNA崩壊を促進することを示唆している。IκBαはNF-κBの阻害物質である(Yan et al.,Nature Medicine 20:1001-1008,2014)。したがって、TGF-βシグナル伝達は、末梢神経系及び中枢神経系への作用を通じて肥満及び糖尿病を悪化させる。 Hypothalamic production of TGF-β is excessive under high-fat diet conditions. This causes hypothalamic inflammation, hyperglycemia, and glucose intolerance. This data suggests that excessive amounts of TGF-β induce a hypothalamic RNA stress response and promote IκBα mRNA decay. IκBα is an inhibitor of NF-κB (Yan et al., Nature Medicine 20:1001-1008, 2014). Thus, TGF-β signaling exacerbates obesity and diabetes through effects on the peripheral and central nervous system.
老化は、多くの神経変性疾患を発症する主要な危険因子である。神経系における老化細胞の蓄積は、老化及び神経変性疾患で示され、神経変性状態の出現の素因となるか、又はその経過を悪化させる可能性がある(Kritsilis et al.,Int.J.Mol.Sci.19(10:2937,2018)。細胞老化は、以下によって細胞機能を妨げる可能性がある:1.慢性炎症の促進(Huell et al.,Acta Neuropathol.89(6):544-551,1995;Nelson et al.,Aging Cell 11(2):345-349,2012)、2.ニューロン再生の消耗(Cipriani et al.,Cereb.Cortex 28(7):2458-2478,2018)、3.機能の喪失(De Stefano et al.,J.Neurol.Neurosurg.Psychiatry 87(1):93-99,2016)及び4.血液脳関門の機能不全(Yamazaki et al.,Stroke 47(4):1068-1077,2016)。研究では、ヒトで最も一般的な神経変性疾患であるアルツハイマー病(AD)において、アミロイド斑と誤って折り畳まれたタウタンパク質を含むAβペプチドの蓄積が示されている(Musi et al.,Aging Cell 17(6):e12840,2018)。これらの変化は最終的にニューロンに影響を与え、認知障害及び神経変性を引き起こす。AD患者から培養した星状細胞は、よく知られている老化マーカーであるCDKi p16INK4AとMMP-1及びIL-6の高発現を示した(Bhat et al.,PLoS One7(9):e45069,2012;Myung et al.,Age 30(4):209-215,2008)。アミロイドタンパク質を対象とした臨床試験は期待外れであった(Mehta et al.,Expert Opin.Invest.Drugs 26(6):735-739,2017)。最近の研究では、老化細胞の存在が動物モデルの神経障害の原因であることが示されている(Crews et al.,Hum.Mol.Genet.19(R1):R12-R20,2010;Chinta et al.,Cell Rep.22(4):930-940,2018)。ヒトADを反映した動物モデルでの研究は、有望な結果を示す。トランスジェニックマウスにおける老化細胞のクリアランスは、ニューロン内の神経原線維変化及びタウタンパク質の異常な蓄積を防止し、認知機能を維持した(Bussian et al.,Nature 562(7728):578-582,2018)。2番目に多い神経変性疾患であるパーキンソン病(PD)の患者は、黒質のドーパミン産生ニューロンの喪失による運動制御の喪失を示す。星状細胞は、CNS内で最も豊富な細胞タイプであり、ニューロンに構造的な代謝サポートを提供するために重要であり、血液脳関門と血流の制御にも役割を果たす。最近の画期的な研究では、PD患者の死後脳試料のアストロサイトに老化表現型が示された(Chinta et al.,Cell Rep.22(4):930-940,2018)。この研究では、環境神経毒(酸化ストレスを介して老化を誘発するパルコート)によって誘発されるPDの動物モデルも開発され、PDに関連する神経病理が示された。著者らは、トランスジェニックマウスで老化細胞を除去すると、パラコートが誘発する神経病理がなくなることを示した。 Aging is a major risk factor for developing many neurodegenerative diseases. Accumulation of senescent cells in the nervous system is shown in aging and neurodegenerative diseases and may predispose to the development of or exacerbate the course of neurodegenerative conditions (Kritsilis et al., Int. J. Mol. Sci 19 (10:2937, 2018) Cellular senescence can interfere with cellular function by: 1. Promoting chronic inflammation (Huell et al., Acta Neuropathol. 89(6):544-551). Nelson et al., Aging Cell 11(2):345-349, 2012), 2. Exhaustion of neuronal regeneration (Cipriani et al., Cereb. Cortex 28(7):2458-2478, 2018), 3 4. Blood-brain barrier dysfunction (Yamazaki et al., Stroke 47(4): 1068-1077, 2016) Studies have shown the accumulation of Aβ peptides, including amyloid plaques and misfolded tau proteins, in Alzheimer's disease (AD), the most common neurodegenerative disease in humans ( Musi et al., Aging Cell 17(6): e12840, 2018).These changes ultimately affect neurons, causing cognitive impairment and neurodegeneration.Astrocytes cultured from AD patients are well known. showed high expression of CDKi p16INK4A, MMP-1 and IL-6, which are known senescence markers (Bhat et al., PLoS One7(9): e45069, 2012; Myung et al., Age 30(4): 209-215, 2008).A clinical trial targeting amyloid protein was disappointing (Mehta et al., Expert Opin. Invest. Drugs 26(6):735-739, 2017). The presence of senescent cells has been shown to be responsible for neuropathy in animal models (Crews et al., Hum. Mol. Genet. 19(R1):R12-R20, 2010; Chinta et al., Cell Rep. .22(4):930-940, 2018). Studies in animal models reflective of human AD show encouraging results. Clearance of senescent cells in transgenic mice prevented abnormal accumulation of neurofibrillary tangles and tau protein in neurons and preserved cognitive function (Bussian et al., Nature 562(7728):578-582, 2018). ). Patients with Parkinson's disease (PD), the second most common neurodegenerative disease, exhibit loss of motor control due to loss of dopaminergic neurons in the substantia nigra. Astrocytes are the most abundant cell type within the CNS and are important for providing structural and metabolic support to neurons and also play a role in regulating the blood-brain barrier and blood flow. A recent landmark study demonstrated a senescent phenotype in astrocytes from postmortem brain samples from PD patients (Chinta et al., Cell Rep. 22(4):930-940, 2018). In this study, an animal model of PD induced by an environmental neurotoxin (palquat, which induces senescence via oxidative stress) was also developed, demonstrating neuropathology associated with PD. The authors showed that depleting senescent cells in transgenic mice abolished paraquat-induced neuropathology.
ヒトの皮膚の老化は、1.時間の経過に伴う生理学的及び遺伝的変化の結果である内因性(経時的)又は2.紫外線(UV)放射、環境毒素、及びDNA損傷を誘発する可能性のある他の作用物質などの外的要因への曝露によって引き起こされる外因性のいずれかである(Cavinato et al.,Exp.Gerontol.94:78-82,2017)。年齢とともに皮膚組織に影響を与える変化の中で、エラスチン産生の変化、分解及び/又は処理の増加によって引き起こされる弾性特性の喪失は、組織の美学及び健康に大きな影響を与える(Wang et al.,Front.Genet.9:247,2018)。急性の紫外線曝露は、日焼け、異常な皮膚の色素沈着、皮膚の下の血管の目に見える外観(毛細血管拡張症)及び免疫抑制につながるが、長期曝露は、早期の皮膚老化及び悪性腫瘍の発症リスクにさえつながる可能性がある(Rittie et al.,Cold Spring Harb.Perspective 5(1):a015370,2015)。医学の進化及び人口増加の間には直接的な相関関係があり、それは中年及び高齢者の数の増加を特徴とし、したがってアンチエイジング治療に対する大きな需要を特徴としている(Weihermann et al.,Int.J.Cosmet.Sci.39(3):241-247,2017)。日光からのUVBは変異原性があり、DNA複製中にDNA損傷を直接誘発する。光損傷を受けた皮膚の特徴は、組織化されていない真皮コラーゲンに加えて非晶質の弾性線維が蓄積していることである。研究によると、これは、弾性及びフィブリリン産生の障害、又はDNA損傷を受けた老化細胞によって分泌されるマトリックスメタロプロテイナーゼ(MMP)の分解の上昇のいずれかが原因である可能性があることが示されている(Pittayapruek et al.,Int.J.Mol.Sci.17(6):868,2016)。UVB照射後の活性酸素種(ROS)の産生は、核因子カッパ(NF-κB)及びマイトジェン活性化プロテインキナーゼ(MAPK)などの老化の中心となる因子の活性化につながる(Pittayapruek et al.,Int.J.Mol.Sci.17(6):868,2016)。UVB照射は、主にトランスフォーミング増殖因子β受容体II(TβRII)の合成を減少させることによって、ヒト皮膚線維芽細胞のTGF-βシグナル伝達経路を変化させることができる(Purohit et al.,J.Dermatol.83(1):80-83,2016)。いくつかの研究では、インビトロ及びインビボの両方で、老化した皮膚及び紫外線にさらされた皮膚に老化細胞が存在することが示されている。ケラチノサイト及び皮膚線維芽細胞は、p16INK4asd、βガラクトシダーゼ、ラミンB1及び老化関連分泌表現型(SASP)因子などの老化のマーカーを発現する光老化のモデルとして広く研究されてきた(Waaijer et al.,Aging 10(2):278-289,2018;Dimri et al.,Proc.Natl.Acad.Sci.U.S.A.92(20):9363-9367,1995;Wang et al.,Sci.Rep.7(1):15678,2017;Ghosh et al.,J.Invest.Dermatol.136(11):2133-2139,2016)。老化細胞はNKリガンドを発現することが知られているため、他の免疫細胞(制御性T細胞)の活性化とともにNK細胞を誘導することは、老化細胞を除去し、健康な皮膚を維持するための魅力的な戦略となる(Carr et al.,Clin.Immunol.105(2):126-140,2002;Ali et al.,Immunology 152(3):372-381,2017)。 Aging of human skin consists of:1. endogenous (chronological), which is the result of physiological and genetic changes over time;2. Either exogenous, caused by exposure to external factors such as ultraviolet (UV) radiation, environmental toxins, and other agents that can induce DNA damage (Cavinato et al., Exp. Gerontol. .94:78-82, 2017). Among the changes that affect skin tissue with age, the loss of elastic properties caused by changes in elastin production, degradation and/or increased processing has a significant impact on tissue aesthetics and health (Wang et al., Front. Genet. 9:247, 2018). Acute UV exposure leads to sunburn, abnormal skin pigmentation, visible appearance of blood vessels under the skin (telangiectasia) and immunosuppression, whereas long-term exposure is associated with premature skin aging and malignant tumors. It may even lead to an onset risk (Rittie et al., Cold Spring Harb. Perspective 5(1):a015370, 2015). There is a direct correlation between the evolution of medicine and population growth, which is characterized by an increasing number of middle-aged and elderly people, and thus a great demand for anti-aging treatments (Weihermann et al., Int. J. Cosmet.Sci.39(3):241-247, 2017). UVB from sunlight is mutagenic and directly induces DNA damage during DNA replication. Photodamaged skin is characterized by the accumulation of amorphous elastic fibers in addition to disorganized dermal collagen. Studies have shown that this may be due to either impaired elasticity and fibrillin production or increased degradation of matrix metalloproteinases (MMPs) secreted by DNA-damaged senescent cells. (Pittayapruek et al., Int. J. Mol. Sci. 17(6):868, 2016). Production of reactive oxygen species (ROS) after UVB irradiation leads to activation of factors central to aging such as nuclear factor kappa (NF-κB) and mitogen-activated protein kinase (MAPK) (Pittayapruek et al., Int. J. Mol. Sci. 17(6):868, 2016). UVB irradiation can alter the TGF-β signaling pathway in human skin fibroblasts, mainly by decreasing the synthesis of transforming growth factor-β receptor II (TβRII) (Purohit et al., J. .Dermatol.83(1):80-83, 2016). Several studies have shown the presence of senescent cells in aged and UV-exposed skin both in vitro and in vivo. Keratinocytes and dermal fibroblasts have been extensively studied as models of photoaging expressing markers of aging such as p16 INK4asd , β-galactosidase, lamin B1 and senescence-associated secretory phenotype (SASP) factors (Waaijer et al., Aging 10(2):278-289, 2018; Dimri et al., Proc.Natl.Acad.Sci USA 92(20):9363-9367,1995; Ghosh et al., J. Invest.Dermatol.136(11):2133-2139, 2016). Since senescent cells are known to express NK ligands, inducing NK cells along with activation of other immune cells (regulatory T cells) eliminates senescent cells and maintains healthy skin. (Carr et al., Clin. Immunol. 105(2):126-140, 2002; Ali et al., Immunology 152(3):372-381, 2017).
老化細胞を選択的に殺すと、正常な老化との関係においてはマウスの健康寿命が大幅に改善され、加齢関連疾患又はがん療法の結果が改善されることが確認されたことで、老化細胞を除去できる化合物の同定への関心が高まっている。自然界では、老化細胞は、通常、自然免疫細胞によって除去される。老化の誘導は、損傷/変化した細胞の潜在的な増殖及び形質転換を阻止するのみならず、主にナチュラルキラー(NK)細胞(IL-15及びCCL2など)及びマクロファージ(CFS-1及びCCL2など)の化学誘引物質として機能するSASP因子(Munoz-Espin et al.,Nat.Rev.Mol.Cell Biol.15(7):482-496,2014)の産生により組織修復も支持する。これらの自然免疫細胞は、ストレスを受けた細胞を排除するための免疫監視メカニズムを媒介する。老化細胞は、通常、ストレス誘導性リガンドのファミリーに属するNK細胞活性化受容体NKG2D及びDNAM1リガンドをアップレギュレートし、これは、感染性疾患及び悪性腫瘍に対する最前線の免疫防御の重要な要素である。受容体が活性化されると、NK細胞は、それらの細胞溶解機構を介して老化細胞の死を特異的に誘導することができる。老化細胞の免疫監視におけるNK細胞の役割は、肝線維症(Sagiv et al.,Oncogene 32(15):1971-1977,2013)、肝細胞がん(Iannello et al.,J.Exp.Med.210(10):2057-2069,2013)、多発性骨髄腫(Soriani et al.,Blood 113(15):3503-3511,2009)、及びメバロン酸経路の機能傷害によってストレスを受けた神経膠腫細胞(Ciaglia et al.,Int.J.Cancer 142(1):176-190,2018)において指摘されている。がんでは、併用化学療法がKRAS-変異肺腫瘍の老化マーカー及びNKリガンドをアップレギュレートすることが示されており、これらの細胞を標的とするためにNK細胞が必要であることを示唆している(Ruscetti et al.,Science 362(6421):1416-1422,2018)。子宮内膜細胞は、急性細胞老化を受け、脱落膜細胞に分化しない。分化した脱落膜細胞は、IL-15を分泌し、それにより、子宮NK細胞を動員して、未分化老化細胞を標的として排除し、子宮内膜の再構築及び若返りを助ける(Brighton et al.,Elife 6,2017)。同様のメカニズムを用いて、肝線維症の間に、p53を発現する老化肝衛星細胞は、老化細胞除去活性を呈する常在性Kupferマクロファージ及び新たに浸潤したマクロファージの極性を炎症促進性M1表現型に向かって歪めた。F4/80+マクロファージが、分娩後の子宮機能を維持するためにマウス子宮老化細胞のクリアランスに重要な役割を果たすことが示されている(Lujambio et al.,Cell 153(2):449-460,2013)。
Selective killing of senescent cells has been shown to significantly improve the healthy lifespan of mice in the context of normal aging, thus improving the outcome of age-related diseases or cancer therapy. There is growing interest in identifying compounds that can remove cells. In nature, senescent cells are normally eliminated by innate immune cells. Induction of senescence not only blocks potential proliferation and transformation of damaged/altered cells, but also mainly natural killer (NK) cells (such as IL-15 and CCL2) and macrophages (such as CFS-1 and CCL2). Tissue repair is also supported by the production of SASP factors (Munoz-Espin et al., Nat. Rev. Mol. Cell Biol. 15(7):482-496, 2014) that function as chemoattractants for . These innate immune cells mediate immune surveillance mechanisms to eliminate stressed cells. Senescent cells normally upregulate the NK cell-activating receptor NKG2D and DNAM1 ligand, which belong to the family of stress-inducible ligands, which are key components of the first line of immune defense against infectious diseases and malignancies. be. Upon receptor activation, NK cells can specifically induce senescent cell death through their cytolytic mechanism. The role of NK cells in immunosurveillance of senescent cells has been reported in liver fibrosis (Sagiv et al., Oncogene 32(15):1971-1977, 2013), hepatocellular carcinoma (Iannello et al., J. Exp. Med. 210(10):2057-2069, 2013), multiple myeloma (Soriani et al., Blood 113(15):3503-3511, 2009), and gliomas stressed by dysfunction of the mevalonate pathway. cells (Ciaglia et al., Int. J. Cancer 142(1):176-190, 2018). In cancer, combination chemotherapy has been shown to upregulate senescence markers and NK ligands in KRAS-mutant lung tumors, suggesting that NK cells are required to target these cells. (Ruscetti et al., Science 362(6421):1416-1422, 2018). Endometrial cells undergo acute cellular senescence and do not differentiate into decidual cells. Differentiated decidual cells secrete IL-15, which recruits uterine NK cells to target and eliminate undifferentiated senescent cells, helping to remodel and rejuvenate the endometrium (Brighton et al. ,
老化細胞クリアランスの戦略は、主に3つのカテゴリー:老化細胞除去剤、免疫療法、及びSASP阻害に分類される(He et al.,Cell 169(6):1000-1011,2017)。老化細胞を一掃するための老化細胞除去剤の有効性を示唆する体の証拠が増えている。老化細胞除去剤は一般に、BCL-2タンパク質ファミリー、p53/p21CIP1p21軸、PI3K/AKT、受容体チロシンキナーゼ、及びHSP90タンパク質などの老化細胞の抗アポトーシス経路(SCAP)を標的とすることによって作用する。マウスでは、老化細胞除去剤は、老化細胞の影響に関連する様々な状態を緩和する。これまでのところ、これらには心臓、血管、代謝、神経、放射線誘発、化学療法誘発、腎臓、及び肺機能への影響、並びにいくつかの動物モデルにおける運動性及び脆弱性が含まれる(Kirkland et al.,EBioMedicine 21:21-28,2017)。現在、更に多くの老化細胞除去薬が開発されている。最近、PI3K/AKT/p53/p21経路を阻害するFOXO4関連ペプチドが報告され、インビトロヒト線維芽細胞モデル及びマウスモデルの両方で有望な結果が示された。他の老化細胞除去剤には、BCL-2タンパク質に作用するABT-737及びABT-263(Tse et al.,Cancer Res.68(9):3421-3428,2008)、及びBCL-XL経路を標的とするA1331852及びA1155463(Zhu et al.,Aging(Albany NY)9(3):955-963,2017)が含まれ、チロシンキナーゼを標的とするダサチニブ及びケルシチンは、老化細胞のクリアランスを示す(Farr et al.,Nat.Med.23(9):1072-1079,2017)。BCL-2ファミリー阻害物質は、好中球減少症及び血小板減少症などの副作用を引き起こす可能性がある。老化細胞除去剤の多くは前臨床段階にあるだけであるため、臨床段階の試験に移行する前に、副作用の可能性について研究する必要がある。 Strategies for senescent cell clearance fall into three main categories: senolytic agents, immunotherapy, and SASP inhibition (He et al., Cell 169(6):1000-1011, 2017). There is increasing body evidence suggesting the efficacy of senolytic agents to clear out senescent cells. Senolytic agents generally act by targeting the senescent cell anti-apoptotic pathway (SCAP), such as the BCL-2 protein family, the p53/p21 CIP1 p21 axis, PI3K/AKT, receptor tyrosine kinases, and HSP90 proteins. do. In mice, senolytic agents alleviate various conditions associated with the effects of senescent cells. So far, these have included effects on cardiac, vascular, metabolic, neurological, radiation-induced, chemotherapy-induced, renal, and pulmonary function, as well as motility and frailty in several animal models (Kirkland et al. al., EBioMedicine 21:21-28, 2017). Currently, more senolytic drugs are being developed. Recently, FOXO4-related peptides that inhibit the PI3K/AKT/p53/p21 pathway were reported and showed promising results in both in vitro human fibroblast and mouse models. Other senolytic agents include ABT-737 and ABT-263 (Tse et al., Cancer Res. 68(9):3421-3428, 2008), which act on the BCL-2 protein, and the BCL-XL pathway. Dasatinib and quercitin, which target tyrosine kinases, including targets A1331852 and A1155463 (Zhu et al., Aging (Albany NY) 9(3):955-963, 2017), show clearance of senescent cells ( Farr et al., Nat. Med. 23(9):1072-1079, 2017). BCL-2 family inhibitors can cause side effects such as neutropenia and thrombocytopenia. Since many senolytics are only in preclinical stages, potential side effects need to be studied before moving to clinical trials.
SASP因子を遮断することは、老化細胞の有害な役割を防ぐための代替戦略である。これらの因子には、炎症性ケモカイン及びサイトカイン、成長因子、並びにマトリックス再構築プロテアーゼが含まれる。これらの効果に関与する中心的な経路は、NF-κB及びC/EBPβ経路である。ラパマイシン及びその類似体などのmTOR阻害物質は、膜結合型IL-1αの発現を低減させることによって、SASPを無効にすることができる。NF-κB及びC/EBPβ経路をインビボマウスモデルで阻害するために使用される他の2つの注目すべき薬物は、それぞれ、メトホルミン及びルキソリチニブである(Moiseeva et al.,Aging Cell 12(3):489-498,2013;Xu et al.,Proc.Natl.Acad.Sci.U.S.A.112(46):E6301-6310,2015)。シルツキシマブ又はトシリズマブなどの他の薬物は、別のSASP因子であるIL-6などのサイトカインを遮断する。繰り返すが、一部の老化細胞除去剤の使用と同様に、抗炎症薬での処理は潜在的な副作用を引き起こす可能性がある(Karkera et al.,Prostate 71(13):1455-1465,2011)。肺線維症の患者を対象に老化細胞除去剤(ダサチニブとケルセチン)を使用した最近の第I相臨床試験では、決定的な結果は得られなかった(Justice et al.,EBioMedicine 40:554-563,2019)。 Blocking SASP factors is an alternative strategy to prevent the detrimental role of senescent cells. These factors include inflammatory chemokines and cytokines, growth factors, and matrix remodeling proteases. The central pathways involved in these effects are the NF-κB and C/EBPβ pathways. mTOR inhibitors such as rapamycin and its analogues can abrogate SASP by reducing the expression of membrane-bound IL-1α. Two other notable drugs used to inhibit the NF-κB and C/EBPβ pathways in vivo mouse models are metformin and ruxolitinib, respectively (Moiseeva et al., Aging Cell 12(3): 489-498, 2013; Xu et al., Proc. Natl. Acad. Sci. USA 112(46):E6301-6310, 2015). Other drugs such as siltuximab or tocilizumab block cytokines such as IL-6, another SASP factor. Again, as with the use of some senolytic agents, treatment with anti-inflammatory drugs can cause potential side effects (Karkera et al., Prostate 71(13):1455-1465, 2011). ). A recent phase I clinical trial using senolytic agents (dasatinib and quercetin) in patients with pulmonary fibrosis yielded inconclusive results (Justice et al., EBioMedicine 40:554-563). , 2019).
上記の戦略よりも優れている可能性がある3つ目の戦略は、免疫媒介性介入である。上記のように、老化細胞を一掃するために動員される細胞には、NK細胞、マクロファージ、及び好中球が含まれる。老化細胞は、主に、NKG2D(NK細胞で発現)、ケモカイン、及び他のSASP因子に対するリガンドをアップレギュレートすることによってNK細胞を動員する。肝線維症のインビボモデルは、活性化されたNK細胞による老化細胞の効果的なクリアランスを示している(Krizhanovsky et al.,Cell 134(4):657-667,2008)。老化細胞は、アポトーシスを阻害するデコイ受容体DCR2をアップレギュレートし、主にグランザイム及びパーフォリン媒介経路によってそれらのクリアランスを制限することによって、NK細胞媒介クリアランスに抵抗する(Sagiv et al.,Oncogene 32(15):1971-1977,2013)。最近のデータは、肥満者に見られるNK細胞の脂質蓄積が、その頻度及びエフェクター細胞毒性機能の両方の低減につながり、これは年齢とは無関係であることを示す(Michelet et al.,Nat.Immunol.19(12):1330-1340,2018;Tobin et al.,JCI Insight 2(24):e94939,2017)。NK細胞媒介性抗体依存性細胞傷害(ADCC)が、最近報告された老化マーカーであるジペプチジルペプチダーゼ4(DPP4/CD26)に対するインビトロヒト老化細胞で実証されている(Kim et al.,Genes Dev.31(15):1529-1534,2017)。他の戦略には、CAR-T細胞を使用して老化細胞に対する免疫応答をリダイレクトすることが含まれる(Grupp et al.,N.Engl.J.Med.368(16):1509-1518,2013;Yousefzadeh et al.,Nature,published online on May 12,2021)。 A third strategy that may be superior to the above strategies is immune-mediated intervention. As noted above, cells recruited to clear out senescent cells include NK cells, macrophages, and neutrophils. Senescent cells primarily recruit NK cells by upregulating ligands for NKG2D (expressed on NK cells), chemokines, and other SASP factors. An in vivo model of liver fibrosis shows effective clearance of senescent cells by activated NK cells (Krizhanovsky et al., Cell 134(4):657-667, 2008). Senescent cells resist NK cell-mediated clearance by upregulating the apoptosis-inhibiting decoy receptor DCR2 and limiting their clearance primarily by granzyme- and perforin-mediated pathways (Sagiv et al., Oncogene 32 (15): 1971-1977, 2013). Recent data indicate that NK cell lipid accumulation in obese individuals leads to a reduction in both their frequency and effector cytotoxic function, which is independent of age (Michelet et al., Nat. Immunol.19(12):1330-1340, 2018; Tobin et al., JCI Insight 2(24):e94939, 2017). NK cell-mediated antibody-dependent cellular cytotoxicity (ADCC) has been demonstrated in in vitro human senescent cells against dipeptidyl peptidase 4 (DPP4/CD26), a recently reported marker of senescence (Kim et al., Genes Dev. 31(15):1529-1534, 2017). Other strategies include using CAR-T cells to redirect the immune response against senescent cells (Grupp et al., N. Engl. J. Med. 368(16):1509-1518, 2013 Yousefzadeh et al., Nature, published online on May 12, 2021).
研究では、肝線維症(Krizhanovsky et al.,Cell 134(4):657-667,2008)、変形性関節症(Xu et al.,J.Gerontol.A Biol.Sci.Med.Sci.72(6):780-785,2017)、パーキンソン病(Chinta et al.,Cell Rep.22(4):930-940,2018)、肥満による不安症(Ogrodnik et al.,Cell Metab.29(5):1061-1077,2019)、アテローム性動脈硬化症(Childs et al.,Science 354(6311):472-477,2016)、及び糖尿病(Sone et al.,Diabetologia 48(1):58-67,2005)を含む老化を研究するための様々なモデルが記載されている。最近の1つの研究では、インビトロ老化誘導細胞を若齢マウスに移植すると、身体機能障害が生じることが示された(Xu et al.,Nat.Med.24(8):1246-1256,2018)。残っている問題は、様々な組織の老化細胞を除去するのにどのタイプの療法が効果的かということである。利用可能なデータの大部分は、インビトロ実験及び少数のマウス研究に基づいている(Krizhanovsky et al.,Cell 134(4):657-667,2008;Xu et al.,Nat.Med.24(8):1246-1256,2018;Baker et al.,Nature 479(7372):232-236,2011;Farr et al.,Nat.Med.23(9):1072-1079,2017;Xu et al.,J.Gerontol.A Biol.Sci.Med.Sci.72(6):780-785,2017;Bourgeois et al.,FEBS Lett.592(12):2083-2097,2018)。NK細胞は、老化細胞の蓄積に対抗するための魅力的な戦略を提供する。しかしながら、老化モデルにおけるこの戦略を調査した研究はほとんどなかった(Krizhanovsky et al.,Cell 134(4):657-667,2008)。様々な臨床試験で、NK細胞の養子移入を利用して様々な形態のがんを治療することに成功したことが示されている(Sakamoto et al.,J.Transl.Med.13:277,2015;Miller et al.,Blood 105(8):3051-3057,2005;Cifaldi et al.,Trends Mol.Med.23(12):1156-1175,2017;Li et al.,Cytotherapy 20(1):134-148,2018)。重要なのは、結腸がん患者における自己由来のエクスビボ拡張NK細胞を利用する最近の臨床試験である(Li et al.,Cytotherapy 20(1):134-148,2018)。著者らは、化学療法と組み合わせたNK細胞療法が再発を防止し、許容できる副作用で生存期間を延長することを示した(Li et al.,Cytotherapy 20(1):134-148,2018)。IL-15、IL-12、IL-18、IL-21などのサイトカインによるサイトカイン活性化NK細胞の移入は、最小限の副作用で老化細胞を除去する潜在的な免疫療法戦略として使用できる(Romee et al.,Blood 120(24):4751-4760,2012;Song et al.,Eur.J.Immunol.48(4):670-682,2018)。更に、急性骨髄性白血病におけるNK細胞の使用の安全性が示されている(Romee et al.,Blood 120(24):4751-4760,2012;Fehniger et al.,Biol.Blood Marrow Transplant.2018)。他のアプローチは、TGF-β、IL-8、IL-6などの循環SASP因子を遮断することである(Ganesh et al.,Immunity 48(4):626-628,2018;Georgilis et al.,Cancer Cell 34(1):85-102,2018)。上記の老化のモデルは、これらのアプローチをテストするのに理想的である。したがって、加齢関連病状の解決策として外来化合物及び薬物を使用することによる望ましくない副作用を回避するような戦略について、より多くの考慮を払う必要がある。 Studies have shown liver fibrosis (Krizhanovsky et al., Cell 134(4):657-667, 2008), osteoarthritis (Xu et al., J. Gerontol. A Biol. Sci. Med. Sci. 72 ( 6): 780-785, 2017), Parkinson's disease (Chinta et al., Cell Rep. 22(4): 930-940, 2018), obesity-induced anxiety (Ogrodnik et al., Cell Metab. 29(5) : 1061-1077, 2019), atherosclerosis (Childs et al., Science 354(6311): 472-477, 2016), and diabetes (Sone et al., Diabetologia 48(1): 58-67, 2005) have been described to study aging. One recent study showed that transplantation of in vitro senescence-induced cells into young mice resulted in physical dysfunction (Xu et al., Nat. Med. 24(8):1246-1256, 2018). . A remaining question is what types of therapies are effective in eliminating senescent cells in various tissues. Most of the available data are based on in vitro experiments and a few mouse studies (Krizhanovsky et al., Cell 134(4):657-667, 2008; Xu et al., Nat. Med. 24(8). Baker et al., Nature 479(7372):232-236, 2011; Farr et al., Nat. Med.23(9):1072-1079, 2017; J. Gerontol.A Biol.Sci.Med.Sci.72(6):780-785, 2017;Bourgeois et al., FEBS Lett.592(12):2083-2097,2018). NK cells offer an attractive strategy to combat the accumulation of senescent cells. However, few studies have investigated this strategy in aging models (Krizhanovsky et al., Cell 134(4):657-667, 2008). Various clinical trials have shown that adoptive transfer of NK cells has been used successfully to treat various forms of cancer (Sakamoto et al., J. Transl. Med. 13:277, 2015; Miller et al., Blood 105(8):3051-3057, 2005; Cifaldi et al., Trends Mol.Med.23(12):1156-1175, 2017; : 134-148, 2018). Importantly, a recent clinical trial utilizing autologous ex vivo expanded NK cells in colon cancer patients (Li et al., Cytotherapy 20(1):134-148, 2018). The authors have shown that NK cell therapy combined with chemotherapy prevents relapse and prolongs survival with tolerable side effects (Li et al., Cytotherapy 20(1):134-148, 2018). Transfer of cytokine-activated NK cells with cytokines such as IL-15, IL-12, IL-18, IL-21 can be used as a potential immunotherapeutic strategy to eliminate senescent cells with minimal side effects (Romee et al. al., Blood 120(24):4751-4760, 2012; Song et al., Eur. J. Immunol.48(4):670-682, 2018). Furthermore, the safety of the use of NK cells in acute myeloid leukemia has been shown (Romee et al., Blood 120(24):4751-4760, 2012; Fehniger et al., Biol. Blood Marrow Transplant. 2018). . Another approach is to block circulating SASP factors such as TGF-β, IL-8, IL-6 (Ganesh et al., Immunity 48(4):626-628, 2018; Georgilis et al., Cancer Cell 34(1):85-102, 2018). The model of aging described above is ideal for testing these approaches. Therefore, more consideration needs to be given to strategies that avoid the unwanted side effects of using foreign compounds and drugs as a remedy for age-related medical conditions.
細胞老化は、最初の成長停止後に獲得される一連の進行性で表現型が多様な細胞状態である(Van Deursen,Nature 509(7501):439-446,2014)。したがって、老化細胞は、コア特性をほとんど共有しない不均一な細胞集団である(Dou et al.,Nature 550(7676):402-406,2017)。したがって、一般的な老化細胞除去薬の標的を同定することは困難である。これは更に、全身投与により老化細胞を選択的、安全、かつ効果的に除去する老化細胞除去剤を開発するという目標の達成を妨げる。上述のように、免疫細胞は、老化細胞が生理的役割を果たした後、老化細胞を自然に除去するためのエフェクター細胞である(Brighton et al.,Elife 6,2017)。老化プロセス中の免疫系の弱体化により、老化細胞が蓄積することを可能にする(Karin et al.,Nat Commun10(1):5495,2019)(Chambers et al.,Allergy Clin Immunol 145(5):1323-1331,2020)。更に、老化細胞のSASPの構成要素であるTGF-βは、組織内で過剰に産生されると、細胞の老化及び老化に関連する病態において苛酷な役割を果たす(Tominaga et al.,Int.J.Mol.Sci.20(20),2019)。共通ガンマ鎖サイトカイン及びそれらの同族受容体の複合体を使用して免疫細胞を促進及び活性化する方法、並びにTGF-βRIIを使用して老化組織及び腫瘍微小環境におけるTGF-βの活性型の量を皮下を通じて低減させて、老化細胞を低減させる能力を回復し、インビボで効果的、選択的、安全に慢性炎症を低減させる方法が本明細書に提供される。
Cellular senescence is a series of progressive and phenotypically diverse cellular states acquired after initial growth arrest (Van Deursen, Nature 509(7501):439-446, 2014). Senescent cells are therefore a heterogeneous population of cells that share few core properties (Dou et al., Nature 550(7676):402-406, 2017). Therefore, it is difficult to identify targets for common senolytic drugs. This further hinders the goal of developing senolytic agents that selectively, safely and effectively eliminate senescent cells by systemic administration. As mentioned above, immune cells are effector cells for the natural elimination of senescent cells after they have fulfilled their physiological role (Brighton et al.,
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、方法は、対象における老化した免疫細胞の若返り(例えば、代謝活性の増加(例えば、酸化的リン酸化の増加、解糖の増加、及び酸素消費の増加)のうちの1つ以上)、対象における老化した免疫細胞におけるp16、p21、及びSASP因子のうちの1つ以上のレベルの減少、並びに対象における老化した免疫細胞の細胞溶解活性の増加、例えば、処理前の対象のレベルと比較して)をもたらす。本明細書で使用する用語「老化した免疫細胞」は、例えば、年齢が対象集団の平均寿命の半分未満である健康な対象(免疫不全でない対象)から得られた対照免疫細胞と比較して、代謝活性の低下(例えば、酸化的リン酸化の低下、解糖の低下及び酸素消費の低下)、p16、p21、及びSASP因子のうちの1つ以上のレベルの増加、並びに細胞溶解活性の低下のうちの1つ以上を有する免疫細胞を意味する。老化した免疫細胞の非限定的な例としては、老化したNK細胞、老化したNKT細胞、老化したT細胞、老化したB細胞、老化した単球、老化したマクロファージ、老化した好中球、老化した好塩基球、老化した好酸球、クッパー細胞、及び老化したミクロギア細胞が挙げられる。 In some embodiments of any of the methods described herein, the method rejuvenates aged immune cells in the subject (e.g., increases metabolic activity (e.g., increases oxidative phosphorylation, glycolysis, and increased oxygen consumption)), decreased levels of one or more of p16, p21, and SASP factors in aged immune cells in the subject, and decreased levels of aged immune cells in the subject. resulting in an increase in cytolytic activity, eg, compared to the subject's level prior to treatment. As used herein, the term "senescent immune cells", e.g., compared to control immune cells obtained from healthy subjects (non-immunocompromised subjects) who are less than half the age of the subject population's life expectancy, decreased metabolic activity (e.g. decreased oxidative phosphorylation, decreased glycolysis and decreased oxygen consumption), increased levels of one or more of the p16, p21 and SASP factors, and decreased cytolytic activity means an immune cell that has one or more of: Non-limiting examples of senescent immune cells include senescent NK cells, senescent NKT cells, senescent T cells, senescent B cells, senescent monocytes, senescent macrophages, senescent neutrophils, senescent Basophils, senescent eosinophils, Kupffer cells, and senescent microgial cells.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、この方法は、対象におけるナイーブT細胞対メモリーT細胞比の増加をもたらす。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、この方法は、対象におけるCD4+T細胞対CD8+T細胞の比の減少をもたらす。 In some embodiments of any of the methods described herein, the method results in an increase in the naive to memory T cell ratio in the subject. In some embodiments of any of the methods described herein, the method results in a decrease in the ratio of CD4 + T cells to CD8 + T cells in the subject.
いくつかの実施形態では、老化した免疫細胞の若返りは、対象における罹患細胞又は感染病原体の数の低減をもたらす。いくつかの実施形態では、老化した免疫細胞には、老化したNK細胞、老化したNKT細胞、老化したT細胞、老化したB細胞、老化した単球、老化したマクロファージ、老化した好中球、老化した好塩基球、老化した好酸球、老化したクッパー細胞、及び老化したミクロギア細胞のうちの1つ以上が含まれる。いくつかの実施形態では、罹患細胞には、がん細胞、ウイルス感染細胞、及び細胞内細菌感染細胞が含まれる。いくつかの実施形態では、感染病原体には、ウイルス、細菌、真菌、及び寄生虫が含まれる。 In some embodiments, rejuvenation of aged immune cells results in a reduction in the number of diseased cells or infectious agents in the subject. In some embodiments, senescent immune cells include senescent NK cells, senescent NKT cells, senescent T cells, senescent B cells, senescent monocytes, senescent macrophages, senescent neutrophils, senescent senescent basophils, senescent eosinophils, senescent Kupffer cells, and senescent microgial cells. In some embodiments, diseased cells include cancer cells, virus-infected cells, and intracellular bacteria-infected cells. In some embodiments, infectious agents include viruses, bacteria, fungi, and parasites.
免疫系を若返らせるために、TGF-β受容体の活性化の減少をもたらす、共通のガンマ鎖サイトカイン及びそれらの同族受容体及び/又は作用物質の複合体を使用する方法も本明細書に提供される。 Also provided herein are methods of using conjugates of common gamma chain cytokines and their cognate receptors and/or agonists that result in decreased activation of TGF-β receptors to rejuvenate the immune system. be done.
皮膚及び/又は毛髪の質感及び/又は外観を改善する方法
ある期間(例えば、本明細書に記載の期間のうちのいずれか)にわたる皮膚及び/又は毛髪の質感及び/又は外観の改善を必要とする対象において皮膚及び/又は毛髪の質感及び/又は外観を改善する方法であって、当該対象に、治療有効量の1つ以上のナチュラルキラー(NK)細胞活性化物質(例えば、本明細書に記載の又は当該技術分野で既知のNK細胞活性化物質のうちのいずれか)を投与することを含む、方法も本明細書に提供される。
Methods of Improving Skin and/or Hair Texture and/or Appearance A method for improving skin and/or hair texture and/or appearance over a period of time (e.g., any of the periods described herein) is in need of improvement in skin and/or hair texture and/or appearance. A method of improving the texture and/or appearance of skin and/or hair in a subject suffering from cancer, comprising administering to the subject a therapeutically effective amount of one or more natural killer (NK) cell activators (e.g., Also provided herein are methods comprising administering an NK cell activator (any of the NK cell activators described or known in the art).
ある期間(例えば、本明細書に記載の期間のうちのいずれか)にわたる皮膚及び/又は毛髪の質感及び/又は外観の改善を必要とする対象において皮膚及び/又は毛髪の質感及び/又は外観を改善する方法であって、当該対象に、治療有効量の活性化されたNK細胞(例えば、本明細書に記載の又は当該技術分野で既知の活性化されたNK細胞のうちのいずれか)を投与することを含む、方法も本明細書に提供される。 Improving skin and/or hair texture and/or appearance in a subject in need of improved skin and/or hair texture and/or appearance over a period of time (e.g., any of the periods described herein) A method of amelioration, wherein the subject is provided with a therapeutically effective amount of activated NK cells (e.g., any of the activated NK cells described herein or known in the art). Methods are also provided herein that include administering.
これらの方法のいくつかの実施形態は、休止NK細胞を得ることと、1つ以上の休止NK細胞活性化物質を含む液体培養培地中でインビトロで休止NK細胞を接触させることであって、この接触が、その後、対象に投与される活性化されたNK細胞の発生をもたらす、接触させることと、を更に含む。これらの方法のいくつかの例では、休止NK細胞は、対象から得られた自己NK細胞である。これらの方法のいくつかの例では、休止NK細胞は、対象から得られたハプロタイプ一致のNK細胞である。これらの方法のいくつかの例では、休止NK細胞は、同種異系の休止NK細胞である。これらの方法のいくつかの例では、休止NK細胞は、人工NK細胞である。これらの方法のいずれかのいくつかの例では、休止NK細胞は、キメラ抗原受容体又は組換えT細胞受容体を有する遺伝子操作されたNK細胞である。 Some embodiments of these methods include obtaining resting NK cells and contacting the resting NK cells in vitro in a liquid culture medium comprising one or more resting NK cell activators, wherein Contacting results in the generation of activated NK cells that are then administered to the subject. In some examples of these methods, the resting NK cells are autologous NK cells obtained from the subject. In some examples of these methods, the resting NK cells are haploidentical NK cells obtained from the subject. In some examples of these methods, the resting NK cells are allogeneic resting NK cells. In some examples of these methods, the resting NK cells are induced NK cells. In some examples of any of these methods, the resting NK cells are genetically engineered NK cells with chimeric antigen receptors or recombinant T cell receptors.
これらの方法のいくつかの例では、液体培養培地は、無血清液体培養培地である。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、液体培養培地は、化学的に定義された液体培養培地である。これらの方法のいくつかの例は、活性化されたNK細胞を単離すること(及び、活性化されたNK細胞の治療有効量を、対象、例えば、本明細書に記載の対象のうちのいずれかに更に投与すること)を更に含む。これらの方法のいくつかの実施形態では、接触ステップは、約2時間~約20日(又は本明細書に記載のこの範囲の部分範囲のうちのいずれか)の期間にわたって実施される。 In some examples of these methods, the liquid culture medium is a serum-free liquid culture medium. In some embodiments of any of the methods described herein, the liquid culture medium is a chemically defined liquid culture medium. Some examples of these methods include isolating activated NK cells (and administering a therapeutically effective amount of the activated NK cells to a subject, e.g., one of the subjects described herein). further administering to either). In some embodiments of these methods, the contacting step is carried out for a period of time from about 2 hours to about 20 days (or any subrange of this range described herein).
これらの方法のいくつかの実施形態では、この方法は、ある期間(例えば、本明細書に記載の期間のうちのいずれか)にわたる対象の皮膚の質感及び/又は外観の改善を提供する。 In some embodiments of these methods, the methods provide an improvement in the subject's skin texture and/or appearance over a period of time (eg, any of the periods described herein).
これらの方法のいくつかの実施形態では、方法は、ある期間にわたる(例えば、本明細書に記載の期間のうちのいずれか)対象の皮膚におけるしわの形成速度の減少(例えば、少なくとも5%減少、少なくとも10%減少、少なくとも15%減少、少なくとも20%減少、少なくとも25%減少、少なくとも30%減少、少なくとも35%減少、少なくとも40%減少、少なくとも45%減少、少なくとも50%減少、少なくとも55%減少、少なくとも60%減少、少なくとも65%減少、少なくとも70%減少、少なくとも75%減少、少なくとも80%減少、少なくとも85%減少、少なくとも90%減少、又は少なくとも95%減少、又は約5%減少~約99%減少(又は本明細書に記載のこの範囲の部分範囲のうちのいずれか))をもたらす(例えば、治療前の対象におけるしわの形成速度又は治療を受けていない同様の対象におけるしわの形成速度と比較して)。 In some embodiments of these methods, the method reduces the rate of wrinkle formation in the subject's skin over a period of time (e.g., any of the time periods described herein) (e.g., a reduction of at least 5%) , at least 10% reduced, at least 15% reduced, at least 20% reduced, at least 25% reduced, at least 30% reduced, at least 35% reduced, at least 40% reduced, at least 45% reduced, at least 50% reduced, at least 55% reduced , at least 60% decreased, at least 65% decreased, at least 70% decreased, at least 75% decreased, at least 80% decreased, at least 85% decreased, at least 90% decreased, or at least 95% decreased, or about 5% decreased to about 99% % reduction (or any of the subranges of this range described herein) resulting in (e.g., the rate of wrinkle formation in a subject prior to treatment or the rate of wrinkle formation in a similar untreated subject compared to ).
これらの方法のいくつかの実施形態では、この方法は、ある期間(例えば、本明細書に記載の期間のうちのいずれか)にわたる対象の皮膚の着色の改善をもたらす。 In some embodiments of these methods, the methods result in an improvement in the subject's skin pigmentation over a period of time (eg, any of the periods of time described herein).
これらの方法のいくつかの実施形態では、この方法は、ある期間(例えば、本明細書に記載の期間のうちのいずれか)にわたる対象の皮膚の質感の改善をもたらす。 In some embodiments of these methods, the methods result in an improvement in the subject's skin texture over a period of time (eg, any of the periods of time described herein).
これらの方法のいくつかの実施形態では、この方法は、ある期間(例えば、本明細書に記載の期間のうちのいずれか)にわたる対象の毛髪の質感及び/又は外観の改善を提供する。 In some embodiments of these methods, the methods provide an improvement in the texture and/or appearance of the subject's hair over a period of time (eg, any of the periods described herein).
これらの方法のいくつかの実施形態では、方法は、ある期間にわたる(例えば、本明細書に記載の期間のうちのいずれか)対象の白髪の形成速度の減少(例えば、少なくとも5%減少、少なくとも10%減少、少なくとも15%減少、少なくとも20%減少、少なくとも25%減少、少なくとも30%減少、少なくとも35%減少、少なくとも40%減少、少なくとも45%減少、少なくとも50%減少、少なくとも55%減少、少なくとも60%減少、少なくとも65%減少、少なくとも70%減少、少なくとも75%減少、少なくとも80%減少、少なくとも85%減少、少なくとも90%減少、又は少なくとも95%減少、又は約5%減少~約99%減少(又は本明細書に記載のこの範囲の部分範囲のうちのいずれか))をもたらす(例えば、治療前の対象における白髪の形成速度又は治療を受けていない同様の対象における白髪の形成速度と比較して)。 In some embodiments of these methods, the method reduces the rate of gray hair formation in a subject over a period of time (e.g., any of the time periods described herein) (e.g., at least a 5% reduction, at least 10% reduced, at least 15% reduced, at least 20% reduced, at least 25% reduced, at least 30% reduced, at least 35% reduced, at least 40% reduced, at least 45% reduced, at least 50% reduced, at least 55% reduced, at least 60% reduced, at least 65% reduced, at least 70% reduced, at least 75% reduced, at least 80% reduced, at least 85% reduced, at least 90% reduced, or at least 95% reduced, or about 5% to about 99% reduced (or any of the subranges of this range described herein) (e.g., compared to the rate of gray hair formation in a subject prior to treatment or the rate of gray hair formation in a similar untreated subject) do).
これらの方法のいくつかの実施形態では、方法は、ある期間にわたる(例えば、本明細書に記載の期間のうちのいずれか)対象の白髪の数の減少(例えば、少なくとも5%減少、少なくとも10%減少、少なくとも15%減少、少なくとも20%減少、少なくとも25%減少、少なくとも30%減少、少なくとも35%減少、少なくとも40%減少、少なくとも45%減少、少なくとも50%減少、少なくとも55%減少、少なくとも60%減少、少なくとも65%減少、少なくとも70%減少、少なくとも75%減少、少なくとも80%減少、少なくとも85%減少、少なくとも90%減少、又は少なくとも95%減少、又は約5%減少~約99%減少(又は本明細書に記載のこの範囲の部分範囲のうちのいずれか))をもたらす(例えば、治療前の対象における白髪の数又は治療を受けていない同様の対象における白髪の形成速度と比較して)。 In some embodiments of these methods, the method reduces the number of gray hairs in the subject over a period of time (e.g., any of the time periods described herein) (e.g., at least a 5% reduction, at least 10 % reduction, at least 15% reduction, at least 20% reduction, at least 25% reduction, at least 30% reduction, at least 35% reduction, at least 40% reduction, at least 45% reduction, at least 50% reduction, at least 55% reduction, at least 60 % reduction, at least 65% reduction, at least 70% reduction, at least 75% reduction, at least 80% reduction, at least 85% reduction, at least 90% reduction, or at least 95% reduction, or about 5% reduction to about 99% reduction ( or any of the subranges of this range described herein) (e.g., compared to the number of gray hairs in a subject before treatment or the rate of gray hair formation in a similar untreated subject) ).
これらの方法のいくつかの実施形態では、方法は、ある期間にわたる(例えば、本明細書に記載の期間のうちのいずれか)対象の脱毛速度の減少(例えば、少なくとも5%減少、少なくとも10%減少、少なくとも15%減少、少なくとも20%減少、少なくとも25%減少、少なくとも30%減少、少なくとも35%減少、少なくとも40%減少、少なくとも45%減少、少なくとも50%減少、少なくとも55%減少、少なくとも60%減少、少なくとも65%減少、少なくとも70%減少、少なくとも75%減少、少なくとも80%減少、少なくとも85%減少、少なくとも90%減少、又は少なくとも95%減少、又は約5%減少~約99%減少(又は本明細書に記載のこの範囲の部分範囲のうちのいずれか))をもたらす(例えば、治療前の対象における脱毛速度又は治療を受けていない同様の対象における脱毛速度と比較して)。 In some embodiments of these methods, the methods reduce the hair loss rate (e.g., at least 5% reduction, at least 10% reduced, at least 15% reduced, at least 20% reduced, at least 25% reduced, at least 30% reduced, at least 35% reduced, at least 40% reduced, at least 45% reduced, at least 50% reduced, at least 55% reduced, at least 60% reduced, at least 65% reduced, at least 70% reduced, at least 75% reduced, at least 80% reduced, at least 85% reduced, at least 90% reduced, or at least 95% reduced, or about 5% reduced to about 99% reduced (or any of the subranges of this range described herein)) (eg, compared to the rate of hair loss in a subject prior to treatment or the rate of hair loss in a similar untreated subject).
これらの方法のいくつかの実施形態では、この方法は、ある期間(例えば、本明細書に記載の期間のいずれか)にわたる対象の毛髪の質感の改善をもたらす。 In some embodiments of these methods, the methods result in an improvement in the texture of the subject's hair over a period of time (eg, any of the periods of time described herein).
これらの方法のいくつかの実施形態では、方法は、ある期間にわたる(例えば、本明細書に記載の期間のうちのいずれか)対象の皮膚における老化皮膚細胞の数の減少(例えば、少なくとも5%減少、少なくとも10%減少、少なくとも15%減少、少なくとも20%減少、少なくとも25%減少、少なくとも30%減少、少なくとも35%減少、少なくとも40%減少、少なくとも45%減少、少なくとも50%減少、少なくとも55%減少、少なくとも60%減少、少なくとも65%減少、少なくとも70%減少、少なくとも75%減少、少なくとも80%減少、少なくとも85%減少、少なくとも90%減少、又は少なくとも95%減少、又は約5%減少~約99%減少(又は本明細書に記載のこの範囲の部分範囲のうちのいずれか))をもたらす(例えば、治療前の対象における老化皮膚細胞の数又は治療を受けていない同様の対象における老化皮膚細胞の数と比較して)。 In some embodiments of these methods, the methods reduce the number of senescent skin cells (e.g., by at least 5%) in the subject's skin over a period of time (e.g., any of the time periods described herein). reduced, at least 10% reduced, at least 15% reduced, at least 20% reduced, at least 25% reduced, at least 30% reduced, at least 35% reduced, at least 40% reduced, at least 45% reduced, at least 50% reduced, at least 55% reduced, at least 60% reduced, at least 65% reduced, at least 70% reduced, at least 75% reduced, at least 80% reduced, at least 85% reduced, at least 90% reduced, or at least 95% reduced, or about 5% to about 99% reduction (or any of the subranges of this range described herein) (e.g., the number of aging skin cells in a subject prior to treatment or aging skin in a similar subject not receiving treatment). compared to the number of cells).
これらの方法のいくつかの実施形態では、ある期間(例えば、本明細書に記載の期間のうちのいずれか)にわたる対象の皮膚の質感及び/又は外観の改善は、皮膚病変の存在、サイズ、及び形状、皮膚色及び皮膚色素沈着、皮膚の水分、温度、弾力、及び血管分布を検査することを含む、本明細書に記載の又は当該技術分野で既知の任意の方法によって評価することができる。 In some embodiments of these methods, an improvement in the subject's skin texture and/or appearance over a period of time (e.g., any of the periods described herein) is determined by the presence, size, and shape, skin color and pigmentation, skin moisture, temperature, elasticity, and vascularity. .
これらの方法のいくつかの実施形態では、ある期間(例えば、本明細書に記載の期間のうちのいずれか)にわたる対象の毛髪の質感及び/又は外観の改善は、本明細書に記載の又は当該技術分野で既知の任意の方法によって評価することができる。 In some embodiments of these methods, the improvement in the texture and/or appearance of the subject's hair over a period of time (e.g., any of the time periods described herein) is as described herein or It can be evaluated by any method known in the art.
これらの方法のいくつかの実施形態では、期間は、例えば、1ヶ月~10年、1ヶ月~9年、1ヶ月~8年、1ヶ月~7年、1ヶ月~6年、1ヶ月~5年、1ヶ月~4年、1ヶ月~3年、1ヶ月~2年、1ヶ月~18ヶ月、1ヶ月~12ヶ月、1ヶ月~10ヶ月、1ヶ月~8ヶ月、1ヶ月~6ヶ月、1ヶ月~4ヶ月、1ヶ月~2ヶ月、1ヶ月~6週間、6週間~10年、6週間~9年、6週間~8年、6週間~7年、6週間~6年、6週間~5年、6週間~4年、6週間~3年、6週間~2年、6週間~18ヶ月、6週間~12ヶ月、6週間~10ヶ月、6週間~8ヶ月、6週間~6ヶ月、6週間~4ヶ月、6週間~2ヶ月、2ヶ月~10年、2ヶ月~9年、2ヶ月~8年、2ヶ月~7年、2ヶ月~6年、2ヶ月~5年、2ヶ月~4年、2ヶ月~3年、2ヶ月~2年、2ヶ月~18ヶ月、2ヶ月~12ヶ月、2ヶ月~10ヶ月、2ヶ月~8ヶ月,]2ヶ月~6ヶ月、2ヶ月~4ヶ月、4ヶ月~10年、4ヶ月~9年、4ヶ月~8年、4ヶ月~7年、4ヶ月~6年、4ヶ月~5年、4ヶ月~4年、4ヶ月~3年、4ヶ月~2年、4ヶ月~18ヶ月、4ヶ月~12ヶ月、4ヶ月~10ヶ月、4ヶ月~8ヶ月、4ヶ月~6ヶ月、6ヶ月~10年、6ヶ月~9年、6ヶ月~8年、6ヶ月~7年、6ヶ月~6年、6ヶ月~5年、6ヶ月~4年、6ヶ月~3年、6ヶ月~2年、6ヶ月~18ヶ月、6ヶ月~12ヶ月、6ヶ月~10ヶ月、6ヶ月~8ヶ月、8ヶ月~10年、8ヶ月~9年、8ヶ月~8年、8ヶ月~7年、8ヶ月~6年、8ヶ月~5年、8ヶ月~4年、8ヶ月~3年、8ヶ月~2年、複数ヶ月~18ヶ月、8ヶ月~12ヶ月、8ヶ月~10ヶ月、10ヶ月~10年、10ヶ月~9年、10ヶ月~8年、10ヶ月~7年、10ヶ月~6年、10ヶ月~5年、10ヶ月~4年、10ヶ月~3年、10ヶ月~2年、10ヶ月~18ヶ月、10ヶ月~12ヶ月、12ヶ月~10年、12ヶ月~9年、12ヶ月~8年、12ヶ月~7年、12ヶ月~6年、12ヶ月~5年、12ヶ月~4年、12ヶ月~3年、12ヶ月~2年、12ヶ月~18ヶ月、18ヶ月~10年、18ヶ月~9年、18ヶ月~8年、18ヶ月~7年、18ヶ月~6年、18ヶ月~5年、18ヶ月~4年、18ヶ月~3年、18ヶ月~2年、2年~10年、2年~9年、2年~8年、2年~7年、2年~6年、2年~5年、2年~4年、2年~3年、3年~10年、3年~9年、3年~8年、3年~7年、3年~6年、3年~5年、3年~4年、4年~10年、4年~9年、4年~8年、4年~7年、4年~6年、4年~5年、5年~10年、5年~9年、5年~8年、5年~7年、5年~6年、6年~10年、6年~9年、6年~8年、6年~7年、7年~10年、7年~9年、7年~8年、8年~10年、8年~9年、又は9年~10年である。 In some embodiments of these methods, the time period is, for example, 1 month to 10 years, 1 month to 9 years, 1 month to 8 years, 1 month to 7 years, 1 month to 6 years, 1 month to 5 years. years, 1 month to 4 years, 1 month to 3 years, 1 month to 2 years, 1 month to 18 months, 1 month to 12 months, 1 month to 10 months, 1 month to 8 months, 1 month to 6 months, 1 month to 4 months, 1 month to 2 months, 1 month to 6 weeks, 6 weeks to 10 years, 6 weeks to 9 years, 6 weeks to 8 years, 6 weeks to 7 years, 6 weeks to 6 years, 6 weeks ~5 years, 6 weeks~4 years, 6 weeks~3 years, 6 weeks~2 years, 6 weeks~18 months, 6 weeks~12 months, 6 weeks~10 months, 6 weeks~8 months, 6 weeks~6 months, 6 weeks to 4 months, 6 weeks to 2 months, 2 months to 10 years, 2 months to 9 years, 2 months to 8 years, 2 months to 7 years, 2 months to 6 years, 2 months to 5 years, 2 months to 4 years, 2 months to 3 years, 2 months to 2 years, 2 months to 18 months, 2 months to 12 months, 2 months to 10 months, 2 months to 8 months,] 2 months to 6 months, 2 Months - 4 months, 4 months - 10 years, 4 months - 9 years, 4 months - 8 years, 4 months - 7 years, 4 months - 6 years, 4 months - 5 years, 4 months - 4 years, 4 months - 3 years, 4 months to 2 years, 4 months to 18 months, 4 months to 12 months, 4 months to 10 months, 4 months to 8 months, 4 months to 6 months, 6 months to 10 years, 6 months to 9 years , 6 months to 8 years, 6 months to 7 years, 6 months to 6 years, 6 months to 5 years, 6 months to 4 years, 6 months to 3 years, 6 months to 2 years, 6 months to 18 months, 6 Months - 12 months, 6 months - 10 months, 6 months - 8 months, 8 months - 10 years, 8 months - 9 years, 8 months - 8 years, 8 months - 7 years, 8 months - 6 years, 8 months - 5 years, 8 months to 4 years, 8 months to 3 years, 8 months to 2 years, multiple months to 18 months, 8 months to 12 months, 8 months to 10 months, 10 months to 10 years, 10 months to 9 years , 10 months to 8 years, 10 months to 7 years, 10 months to 6 years, 10 months to 5 years, 10 months to 4 years, 10 months to 3 years, 10 months to 2 years, 10 months to 18 months, 10 Months - 12 months, 12 months - 10 years, 12 months - 9 years, 12 months - 8 years, 12 months - 7 years, 12 months - 6 years, 12 months - 5 years, 12 months - 4 years, 12 months - 3 years, 12 months to 2 years, 12 months to 18 months, 18 months to 10 years, 18 months to 9 years, 18 months to 8 years, 18 months to 7 years, 18 months to 6 years, 18 months to 5 years , 18 months to 4 years, 18 months to 3 years, 18 months to 2 years, 2 years to 10 years, 2 years to 9 years, 2 years to 8 years, 2 years to 7 years, 2 years to 6 years, 2 Years to 5 years, 2 years to 4 years, 2 years to 3 years, 3 years to 10 years, 3 years to 9 years, 3 years to 8 years, 3 years to 7 years, 3 years to 6 years, 3 years and up 5 years, 3 years to 4 years, 4 years to 10 years, 4 years to 9 years, 4 years to 8 years, 4 years to 7 years, 4 years to 6 years, 4 years to 5 years, 5 years to 10 years , 5-9 years, 5-8 years, 5-7 years, 5-6 years, 6-10 years, 6-9 years, 6-8 years, 6-7 years, 7 years to 10 years, 7 years to 9 years, 7 years to 8 years, 8 years to 10 years, 8 years to 9 years, or 9 years to 10 years.
これらの方法のいくつかの実施形態では、対象の年齢は、約30~約35、約35~約40、約40~約45、約45~約50、約50~約55、約55~約60、約60~約65、約65~約70、約70~約75、約75~約80、約80~約85、約85~約90、約90~約95、約95~約100、約100~約105、約105~約110、約110~約115、又は約115~約120である。 In some embodiments of these methods, the age of the subject is from about 30 to about 35, from about 35 to about 40, from about 40 to about 45, from about 45 to about 50, from about 50 to about 55, from about 55 to about 60, about 60 to about 65, about 65 to about 70, about 70 to about 75, about 75 to about 80, about 80 to about 85, about 85 to about 90, about 90 to about 95, about 95 to about 100, about 100 to about 105, about 105 to about 110, about 110 to about 115, or about 115 to about 120.
対象において肥満の治療を支援する方法
ある期間(例えば、本明細書に記載の期間のうちのいずれか)にわたる肥満の治療の支援を必要とする対象において肥満の治療を支援する方法であって、当該対象に、治療有効量の1つ以上のナチュラルキラー(NK)細胞活性化物質(例えば、本明細書に記載の又は当該技術分野で既知のNK細胞活性化物質のうちのいずれか)を投与することを含む、方法が、本明細書に提供される。
Method of Helping Treat Obesity in a Subject A method of helping treat obesity in a subject in need of help treating obesity for a period of time (e.g., any of the time periods described herein) comprising: administering to the subject a therapeutically effective amount of one or more natural killer (NK) cell activators (e.g., any of the NK cell activators described herein or known in the art) A method is provided herein comprising:
ある期間(例えば、本明細書に記載の期間のうちのいずれか)にわたる肥満の治療の支援を必要とする対象において肥満の治療を支援する方法であって、当該対象に、治療有効量の活性化されたNK細胞(例えば、本明細書に記載の又は当該技術分野で既知の活性化されたNK細胞のうちのいずれか)を投与することを含む、方法も本明細書に提供される。 A method of helping treat obesity in a subject in need of help treating obesity for a period of time (e.g., any of the periods described herein) comprising administering to the subject a therapeutically effective amount of an active Also provided herein are methods comprising administering activated NK cells (e.g., any of the activated NK cells described herein or known in the art).
これらの方法のいくつかの実施形態は、休止NK細胞を得ることと、1つ以上の休止NK細胞活性化物質を含む液体培養培地中でインビトロで休止NK細胞を接触させることであって、この接触が、その後、対象に投与される活性化されたNK細胞の発生をもたらす、接触させることと、を更に含む。これらの方法のいくつかの例では、休止NK細胞は、対象から得られた自己NK細胞である。これらの方法のいくつかの例では、休止NK細胞は、対象から得られたハプロタイプ一致のNK細胞である。これらの方法のいくつかの例では、休止NK細胞は、同種異系の休止NK細胞である。これらの方法のいくつかの例では、休止NK細胞は、人工NK細胞である。これらの方法のいずれかのいくつかの例では、休止NK細胞は、キメラ抗原受容体又は組換えT細胞受容体を有する遺伝子操作されたNK細胞である。 Some embodiments of these methods are obtaining resting NK cells and contacting the resting NK cells in vitro in a liquid culture medium comprising one or more resting NK cell activators, wherein Contacting results in the generation of activated NK cells that are then administered to the subject. In some examples of these methods, the resting NK cells are autologous NK cells obtained from the subject. In some examples of these methods, the resting NK cells are haploidentical NK cells obtained from the subject. In some examples of these methods, the resting NK cells are allogeneic resting NK cells. In some examples of these methods, the resting NK cells are induced NK cells. In some examples of any of these methods, the resting NK cells are genetically engineered NK cells with chimeric antigen receptors or recombinant T cell receptors.
これらの方法のいくつかの例では、液体培養培地は、無血清液体培養培地である。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、液体培養培地は、化学的に定義された液体培養培地である。これらの方法のいくつかの例は、活性化されたNK細胞を単離すること(及び、活性化されたNK細胞の治療有効量を、対象、例えば、本明細書に記載の対象のうちのいずれかに更に投与すること)を更に含む。これらの方法のいくつかの実施形態では、接触ステップは、約2時間~約20日(又は本明細書に記載のこの範囲の部分範囲のうちのいずれか)の期間にわたって実施される。 In some examples of these methods, the liquid culture medium is a serum-free liquid culture medium. In some embodiments of any of the methods described herein, the liquid culture medium is a chemically defined liquid culture medium. Some examples of these methods include isolating activated NK cells (and administering a therapeutically effective amount of the activated NK cells to a subject, e.g., one of the subjects described herein). further administering to either). In some embodiments of these methods, the contacting step is carried out for a period of time from about 2 hours to about 20 days (or any subrange of this range described herein).
これらの方法のいくつかの実施形態では、方法は、ある期間にわたる(例えば、本明細書に記載の期間のうちのいずれか)対象の体重の減少(例えば、少なくとも5%減少、少なくとも10%減少、少なくとも15%減少、少なくとも20%減少、少なくとも25%減少、少なくとも30%減少、少なくとも35%減少、少なくとも40%減少、少なくとも45%減少、少なくとも50%減少、少なくとも55%減少、少なくとも60%減少、少なくとも65%減少、少なくとも70%減少、少なくとも75%減少、少なくとも80%減少、少なくとも85%減少、少なくとも90%減少、又は少なくとも95%減少、又は約5%減少~約99%減少(又は本明細書に記載のこの範囲の部分範囲のうちのいずれか))をもたらす(例えば、治療前の対象の体重と比較して)。 In some embodiments of these methods, the method reduces body weight (e.g., at least 5% loss, at least 10% loss) over a period of time (e.g., any of the time periods described herein) , at least 15% reduced, at least 20% reduced, at least 25% reduced, at least 30% reduced, at least 35% reduced, at least 40% reduced, at least 45% reduced, at least 50% reduced, at least 55% reduced, at least 60% reduced , at least 65% reduced, at least 70% reduced, at least 75% reduced, at least 80% reduced, at least 85% reduced, at least 90% reduced, or at least 95% reduced, or about 5% reduced to about 99% reduced (or this any of the subranges of this range described herein)) (eg, relative to the subject's weight prior to treatment).
これらの方法のいくつかの実施形態では、方法は、ある期間にわたる(例えば、本明細書に記載の期間のうちのいずれか)対象の肥満度指数(BMI)の減少(例えば、少なくとも5%減少、少なくとも10%減少、少なくとも15%減少、少なくとも20%減少、少なくとも25%減少、少なくとも30%減少、少なくとも35%減少、少なくとも40%減少、少なくとも45%減少、少なくとも50%減少、少なくとも55%減少、少なくとも60%減少、少なくとも65%減少、少なくとも70%減少、少なくとも75%減少、少なくとも80%減少、少なくとも85%減少、少なくとも90%減少、又は少なくとも95%減少、又は約5%減少~約99%減少(又は本明細書に記載のこの範囲の部分範囲のうちのいずれか))をもたらす(例えば、治療前の対象のBMIと比較して)。 In some embodiments of these methods, the method reduces a subject's body mass index (BMI) over a period of time (e.g., any of the time periods described herein) (e.g., a reduction of at least 5%) , at least 10% reduced, at least 15% reduced, at least 20% reduced, at least 25% reduced, at least 30% reduced, at least 35% reduced, at least 40% reduced, at least 45% reduced, at least 50% reduced, at least 55% reduced , at least 60% decreased, at least 65% decreased, at least 70% decreased, at least 75% decreased, at least 80% decreased, at least 85% decreased, at least 90% decreased, or at least 95% decreased, or about 5% decreased to about 99% % reduction (or any of the subranges of this range described herein)) (eg, as compared to the subject's BMI prior to treatment).
これらの方法のいくつかの実施形態では、方法は、対象の前糖尿病から2型糖尿病への進行速度の減少(例えば、少なくとも5%減少、少なくとも10%減少、少なくとも15%減少、少なくとも20%減少、少なくとも25%減少、少なくとも30%減少、少なくとも35%減少、少なくとも40%減少、少なくとも45%減少、少なくとも50%減少、少なくとも55%減少、少なくとも60%減少、少なくとも65%減少、少なくとも70%減少、少なくとも75%減少、少なくとも80%減少、少なくとも85%減少、少なくとも90%減少、又は少なくとも95%減少、又は約5%減少~約99%減少(又は本明細書に記載のこの範囲の部分範囲のうちのいずれか))をもたらす(例えば、治療前の対象における前糖尿病から2型糖尿病への進行速度又は治療を受けていない同様の対象における前糖尿病から2型糖尿病への進行速度と比較して)。
In some embodiments of these methods, the method reduces the rate of progression from prediabetes to
これらの方法のいくつかの実施形態では、方法は、対象における空腹時血清グルコース値の減少(例えば、少なくとも5%減少、少なくとも10%減少、少なくとも15%減少、少なくとも20%減少、少なくとも25%減少、少なくとも30%減少、少なくとも35%減少、少なくとも40%減少、少なくとも45%減少、少なくとも50%減少、少なくとも55%減少、少なくとも60%減少、少なくとも65%減少、少なくとも70%減少、少なくとも75%減少、少なくとも80%減少、少なくとも85%減少、少なくとも90%減少、又は少なくとも95%減少、又は約5%減少~約99%減少(又は本明細書に記載のこの範囲の部分範囲のうちのいずれか))をもたらす(例えば、治療前の対象における空腹時血清グルコース値と比較して)。 In some embodiments of these methods, the method reduces fasting serum glucose levels in the subject (e.g., at least 5% reduction, at least 10% reduction, at least 15% reduction, at least 20% reduction, at least 25% reduction) , at least 30% reduced, at least 35% reduced, at least 40% reduced, at least 45% reduced, at least 50% reduced, at least 55% reduced, at least 60% reduced, at least 65% reduced, at least 70% reduced, at least 75% reduced , at least 80% reduced, at least 85% reduced, at least 90% reduced, or at least 95% reduced, or from about 5% reduced to about 99% reduced (or any subrange of this range described herein) )) (eg, compared to fasting serum glucose levels in the subject prior to treatment).
これらの方法のいくつかの実施形態では、方法は、対象におけるインスリン感受性の増加(例えば、少なくとも5%増加、少なくとも10%増加、少なくとも15%増加、少なくとも20%増加、少なくとも25%増加、少なくとも30%増加、少なくとも35%増加、少なくとも40%増加、少なくとも45%増加、少なくとも50%増加、少なくとも55%増加、少なくとも60%増加、少なくとも65%増加、少なくとも70%増加、少なくとも75%増加、少なくとも80%増加、少なくとも85%増加、少なくとも90%増加、少なくとも95%増加、又は少なくとも99%増加、又は約10%増加~約500%増加(又は本明細書に記載のこの範囲の部分範囲のうちのいずれか))をもたらす(治療前の対象におけるインスリン感受性と比較して)。 In some embodiments of these methods, the methods increase insulin sensitivity in the subject (e.g., at least 5% increase, at least 10% increase, at least 15% increase, at least 20% increase, at least 25% increase, at least 30% increase, % increase, at least 35% increase, at least 40% increase, at least 45% increase, at least 50% increase, at least 55% increase, at least 60% increase, at least 65% increase, at least 70% increase, at least 75% increase, at least 80 % increase, at least 85% increase, at least 90% increase, at least 95% increase, or at least 99% increase, or from about 10% increase to about 500% increase (or any subrange of this range described herein) either)) (compared to insulin sensitivity in the subject prior to treatment).
これらの方法のいくつかの実施形態では、方法は、対象におけるアテローム性動脈硬化症の重症度の減少(例えば、少なくとも5%減少、少なくとも10%減少、少なくとも15%減少、少なくとも20%減少、少なくとも25%減少、少なくとも30%減少、少なくとも35%減少、少なくとも40%減少、少なくとも45%減少、少なくとも50%減少、少なくとも55%減少、少なくとも60%減少、少なくとも65%減少、少なくとも70%減少、少なくとも75%減少、少なくとも80%減少、少なくとも85%減少、少なくとも90%減少、又は少なくとも95%減少、又は約5%減少~約99%減少(又は本明細書に記載のこの範囲の部分範囲のうちのいずれか))をもたらす(例えば、治療前の対象におけるアテローム性動脈硬化症の重症度と比較して)。 In some embodiments of these methods, the method reduces the severity of atherosclerosis in the subject (e.g., at least 5% reduction, at least 10% reduction, at least 15% reduction, at least 20% reduction, at least 25% reduced, at least 30% reduced, at least 35% reduced, at least 40% reduced, at least 45% reduced, at least 50% reduced, at least 55% reduced, at least 60% reduced, at least 65% reduced, at least 70% reduced, at least 75% reduction, at least 80% reduction, at least 85% reduction, at least 90% reduction, or at least 95% reduction, or about 5% reduction to about 99% reduction (or any subrange of this range described herein) (e.g., compared to the severity of atherosclerosis in the subject prior to treatment).
これらの方法のいくつかの実施形態では、ある期間(例えば、本明細書に記載の期間のうちのいずれか)にわたる対象の肥満の治療は、例えば、体重及び/又は体の寸法、総体脂肪、全身性又は局所肥満症、及び肥満度指数(BMI)の測定を含む、本明細書に記載の又は当該技術分野で既知の任意の方法によって評価することができる。 In some embodiments of these methods, treating obesity in a subject over a period of time (e.g., any of the periods described herein) is, for example, body weight and/or body dimensions, total body fat, It can be assessed by any method described herein or known in the art, including systemic or regional obesity, and measuring body mass index (BMI).
これらの方法のいくつかの実施形態では、対象の治療に対する反応は、標準的な技術に従って空腹時血糖値又はグルコース耐性を決定することによって監視することができる。これらの方法のいくつかの実施形態では、インスリン感受性は、高インスリン正常血糖クランプ及び静脈グルコース耐性試験、ホメオスタシスモデル評価(HOMA)、及び定量的インスリン感受性チェックインデックス(QUICKI)を含む、本明細書に記載の又は当該技術分野で既知の任意の方法を使用して測定することができる。 In some embodiments of these methods, a subject's response to treatment can be monitored by determining fasting blood glucose levels or glucose tolerance according to standard techniques. In some embodiments of these methods, insulin sensitivity is measured as described herein, including Hyperinsulin Euglycemic Clamp and Intravenous Glucose Tolerance Test, Homeostasis Model Assessment (HOMA), and Quantitative Insulin Sensitivity Check Index (QUICKI). It can be measured using any method described or known in the art.
これらの方法のいくつかの実施形態では、対象におけるアテローム性動脈硬化症の重症度は、心臓カテーテル検査、ドップラー超音波検査、血圧比較、MUGA/放射性核種血管造影、タリウム/心筋灌流スキャン、及びコンピュータ断層撮影を含む、本明細書に記載の又は当該技術分野で既知の任意の方法を使用して測定することができる。 In some embodiments of these methods, the severity of atherosclerosis in a subject is determined by cardiac catheterization, Doppler ultrasonography, blood pressure comparison, MUGA/radionuclide angiography, thallium/myocardial perfusion scan, and computer It can be measured using any method described herein or known in the art, including tomography.
これらの方法のいくつかの実施形態では、期間は、1ヶ月~10年(又は本明細書に記載のこの範囲の部分範囲のうちのいずれか)である。 In some embodiments of these methods, the time period is from 1 month to 10 years (or any of the subranges of this range described herein).
これらの方法のいくつかの実施形態では、対象の年齢範囲は、約1~約5、約5~約10、約10~約15、約15~約20、約20~約25、約25~約30、約30~約35、約35~約40、約40~約45、約45~約50、約50~約55、約55~約60、約60~約65、約65~約70、約70~約75、約75~約80、約80~約85、約85~約90、約90~約95、約95~約100、約100~約105、約105~約110、約110~約115、又は約115~約120である。 In some embodiments of these methods, the subject's age range is from about 1 to about 5, from about 5 to about 10, from about 10 to about 15, from about 15 to about 20, from about 20 to about 25, from about 25 to about about 30, about 30 to about 35, about 35 to about 40, about 40 to about 45, about 45 to about 50, about 50 to about 55, about 55 to about 60, about 60 to about 65, about 65 to about 70 , about 70 to about 75, about 75 to about 80, about 80 to about 85, about 85 to about 90, about 90 to about 95, about 95 to about 100, about 100 to about 105, about 105 to about 110, about 110 to about 115, or about 115 to about 120.
追加の治療剤
本明細書に記載の方法のうちのいずれかのいくつかの実施形態は、1つ以上の追加の治療剤の治療有効量を対象(例えば、本明細書に記載の対象のうちのいずれか)に投与することを更に含み得る。1つ以上の追加の治療剤は、NK細胞活性化物質又は活性化されたNK細胞と実質的に同時に対象に投与され得る(例えば、単一製剤として又は2つ以上の製剤として対象に投与され得る)。いくつかの実施形態では、1つ以上の追加の治療剤は、NK細胞活性化物質又は活性化されたNK細胞を投与する前に、対象に投与され得る。いくつかの実施形態では、1つ以上の追加の治療剤は、NK細胞活性化物質又は活性化されたNK細胞を対象に投与した後に、対象に投与され得る。
Additional Therapeutic Agents Some embodiments of any of the methods described herein include administering a therapeutically effective amount of one or more additional therapeutic agents to a subject (e.g., among the subjects described herein). any of the above). The one or more additional therapeutic agents can be administered to the subject at substantially the same time as the NK cell activator or activated NK cells (e.g., administered to the subject as a single formulation or as two or more formulations). obtain). In some embodiments, one or more additional therapeutic agents may be administered to the subject prior to administering the NK cell activator or activated NK cells. In some embodiments, one or more additional therapeutic agents may be administered to the subject after administering the NK cell activator or activated NK cells to the subject.
追加の治療剤の非限定的な例には、抗がん剤、活性化受容体アゴニスト、免疫チェックポイント阻害物質、HLA特異的阻害受容体を遮断するための作用物質、グリコーゲンシンターゼキナーゼ(GSK)3阻害物質、及び抗体が挙げられる。 Non-limiting examples of additional therapeutic agents include anticancer agents, activating receptor agonists, immune checkpoint inhibitors, agents for blocking HLA-specific inhibitory receptors, glycogen synthase kinase (GSK) 3 inhibitors, and antibodies.
抗がん剤の非限定的な例には、代謝拮抗薬(例えば、5-フルオロウラシル(5-FU)、6-メルカプトプリン(6-MP)、カペシタビン、シタラビン、フロクスウリジン、フルダラビン、ゲムシタビン、ヒドロキシカルバミド、メトトレキサート、6-チオグアニン、クラドリビン、ネララビン、ペントスタチン、又はペメトレキセド)、植物アルカロイド(例えば、ビンブラスチン、ビンクリスチン、ビンデシン、カンプトセシン、9-メトキシカンプトセシン、コロナリジン、タキソール、ナウクレアオラル(naucleaoral)、ジプレニル化インドールアルカロイド、モンタミン、シシュキニイン、プロトベルベリン、ベルベリン、サンギナリン、ケレリトリン、ケリドニン、リリオデニン、クリボリン、β-カルボリン、アントフィン、チロホリン、クリプトレピン、ネオクリプトレピン、コリノリン、サンパンギン、カルバゾール、クリナミン、モンタニン、エリプチシン、パクリタキセル、ドセタキセル、エトポシド、テニポシド、イリノテカン、トポテカン、又はアクリドンアルカロイド)、プロテアソーム阻害物質(例えば、ラクタシスチン、ジスルフィラム、エピガロカテキン-3-ガレート、マリゾミブ(サリノスポラミドA)、オプロゾミブ(ONX-0912)、デランゾミブ(CEP-18770)、エポキソミシン、MG132、ベータ-ヒドロキシベータ-メチルブチラート、ボルテゾミブ、カルフィルゾミブ、又はイキサゾミブ)、抗腫瘍抗生物質(例えば、ドキソルビシン、ダウノルビシン、エピルビシン、ミトキサントロン、イダルビシン、アクチノマイシン、プリカマイシン、マイトマイシン、又はブレオマイシン)、ヒストンデアセチラーゼ阻害物質(例えば、ボリノスタット、パノビノスタット、ギビノスタット、アベキシノスタット、デプシペプチド、エンチノスタット、フェニルブチラート、バルプロ酸、トリコスタチンA、ダシノスタット、モセチノスタット、プラシノスタット、ニコチンアミド、カンビノール、テノビン1、テノビン6、シルチノール、リコリノスタット、テフィノスタット、ケベトリン、キシノスタット、レスミノスタット、タセジナリン、チダミド、又はセリシスタット)、チロシンキナーゼ阻害物質(例えば、アキシチニブ、ダサチニブ、エンコラフィニブ、エルロチニブ、イマチニブ、ニロチニブ、パゾパニブ、及びスニチニブ)、及び化学療法剤(例えば、オールトランスレチノイン酸、アザシチジン、アザチオプリン、ドキシフルリジン、エポチロン、ヒドロキシウレア、イマチニブ、テニポシド、チオグアニン、バルルビシン、ベムラフェニブ、及びレナリドミド)が挙げられる。化学療法剤の追加の例には、アルキル化剤、例えば、メクロレタミン、シクロホスファミド、クロラムブシル、メルファラン、イホスファミド、チオテパ、ヘキサメチルメラミン、ブスルファン、アルトレタミン、プロカルバジン、ダカルバジン、テモゾロミド、カルムスチン、ルムスチン、ストレプトゾシン、カルボプラチン、シスプラチン、及びオキサリプラチンが挙げられる。 Non-limiting examples of anticancer agents include antimetabolites such as 5-fluorouracil (5-FU), 6-mercaptopurine (6-MP), capecitabine, cytarabine, floxuridine, fludarabine, gemcitabine, hydroxycarbamide, methotrexate, 6-thioguanine, cladribine, nerarabine, pentostatin, or pemetrexed), plant alkaloids (e.g. vinblastine, vincristine, vindesine, camptothecin, 9-methoxycamptothecin, coronarysine, taxol, naucleaoral) , diprenylated indole alkaloids, montamine, shishkiniin, protoberberine, berberine, sanguinaline, chelerythrine, chelidonin, liriodenine, crivorine, β-carboline, antophine, tyrophorine, cryptotrepin, neocryptrepin, corinoline, sampangin, carbazole, clinamin, montanine , ellipticine, paclitaxel, docetaxel, etoposide, teniposide, irinotecan, topotecan, or acridone alkaloids), proteasome inhibitors (e.g., lactacystin, disulfiram, epigallocatechin-3-gallate, marizomib (salinosporamide A), oprozomib (ONX- 0912), delanzomib (CEP-18770), epoxomicin, MG132, beta-hydroxy beta-methylbutyrate, bortezomib, carfilzomib, or ixazomib), antitumor antibiotics (e.g., doxorubicin, daunorubicin, epirubicin, mitoxantrone, idarubicin, actinomycin, plicamycin, mitomycin, or bleomycin), histone deacetylase inhibitors (e.g., vorinostat, panobinostat, gibinostat, abexinostat, depsipeptide, entinostat, phenylbutyrate, valproic acid, trichostatin A, dacinostat, mosetinostat, prasinostat, nicotinamide, cambinol, tenovin 1, tenovin 6, sirtinol, licorinostat, tefinostat, cevetrin, xinostat, resminostat, tacedinaline, thidamide, or sericistat), tyrosine kinase inhibitors (e.g. , axitinib, dasatinib, encorafinib, erlotinib, imatinib, nilotinib, pazopanib, and sunitinib), and chemotherapeutic agents (e.g., all-trans retinoic acid, azacitidine, azathioprine, doxifluridine, epothilone, hydroxyurea, imatinib, teniposide, thioguanine, valrubicin, vemurafenib, and lenalidomide). Additional examples of chemotherapeutic agents include alkylating agents such as mechlorethamine, cyclophosphamide, chlorambucil, melphalan, ifosfamide, thiotepa, hexamethylmelamine, busulfan, altretamine, procarbazine, dacarbazine, temozolomide, carmustine, lumustine, Streptozocin, carboplatin, cisplatin, and oxaliplatin.
活性化受容体アゴニストの非限定的な例には、抗CD16抗体(例えば、抗CD16/CD30二重特異性モノクローナル抗体(BiMAb))及びFcベースの融合タンパク質を含む、NK細胞の細胞傷害性を活性化及び増強する活性化受容体のための任意のアゴニストが挙げられる。チェックポイント阻害物質の非限定的な例には、抗PD-1抗体(例えば、MEDI0680)、抗PD-L1抗体(例えば、BCD-135、BGB-A333、CBT-502、CK-301、CS1001、FAZ053、KN035、MDX-1105、MSB2311、SHR-1316、抗PD-L1/CTLA-4二重特異性抗体KN046、抗PD-L1/TGFβRII融合タンパク質M7824、抗PD-L1/TIM-3二重特異性抗体LY3415244、アテゾリズマブ、又はアベルマブ)、抗TIM3抗体(例えば、TSR-022、Sym023、又はMBG453)、及び抗CTLA-4抗体(例えば、AGEN1884、MK-1308、又は抗CTLA-4/OX40二重特異性抗体ATOR-1015)が挙げられる。HLA特異的阻害受容体を遮断するための作用物質の非限定的な例には、モナリズマブ(例えば、抗HLA-E NKG2A阻害受容体モノクローナル抗体)が挙げられる。GSK3阻害物質の非限定的な例には、チデグルシブ又はCHIR99021が挙げられる。追加の治療剤として使用され得る抗体の非限定的な例には、抗CD26抗体(例えば、YS110)、抗CD36抗体、及びNK細胞上のFc受容体(例えば、CD16)に結合して活性化することができる任意の他の抗体又は抗体構築物が挙げられる。いくつかの実施形態では、追加の治療剤は、インスリン又はメトホルミンであり得る。 Non-limiting examples of activating receptor agonists include anti-CD16 antibodies (e.g., anti-CD16/CD30 bispecific monoclonal antibodies (BiMAbs)) and Fc-based fusion proteins that induce NK cell cytotoxicity. Any agonist for an activated receptor that activates and potentiates is included. Non-limiting examples of checkpoint inhibitors include anti-PD-1 antibodies (eg, MEDI0680), anti-PD-L1 antibodies (eg, BCD-135, BGB-A333, CBT-502, CK-301, CS1001, FAZ053, KN035, MDX-1105, MSB2311, SHR-1316, anti-PD-L1/CTLA-4 bispecific antibody KN046, anti-PD-L1/TGFβRII fusion protein M7824, anti-PD-L1/TIM-3 bispecific anti-TIM3 antibody (e.g., TSR-022, Sym023, or MBG453), and anti-CTLA-4 antibody (e.g., AGEN1884, MK-1308, or anti-CTLA-4/OX40 dual specific antibody ATOR-1015). Non-limiting examples of agents for blocking HLA-specific inhibitory receptors include monalizumab (eg, anti-HLA-ENKG2A inhibitory receptor monoclonal antibody). Non-limiting examples of GSK3 inhibitors include Tideglusib or CHIR99021. Non-limiting examples of antibodies that can be used as additional therapeutic agents include anti-CD26 antibodies (e.g., YS110), anti-CD36 antibodies, and anti-CD36 antibodies that bind and activate Fc receptors (e.g., CD16) on NK cells. Any other antibody or antibody construct capable of In some embodiments, the additional therapeutic agent can be insulin or metformin.
1つ以上の共通ガンマ鎖ファミリーサイトカイン受容体活性化物質の投与を含む例示的な方法
治療有効量の1つ以上の共通ガンマ鎖ファミリーサイトカイン受容体活性化物質を対象に投与することを含む、対象における自然発生及び/若しくは治療誘導性老化細胞を死滅させるか又は老化細胞の数を低減させる方法が本明細書に提供される。
Exemplary Methods Comprising Administration of One or More Common Gamma Chain Family Cytokine Receptor Activators A subject comprising administering a therapeutically effective amount of one or more common gamma chain family cytokine receptor activators to the subject Provided herein are methods of killing naturally occurring and/or treatment-induced senescent cells in or reducing the number of senescent cells.
治療有効量の1つ以上の共通ガンマ鎖ファミリーサイトカイン受容体活性化物質を対象に投与することを含む、対象における自然発生及び/又は治療誘導性老化細胞の蓄積を減少させる方法も本明細書に提供される。 Also herein are methods of reducing spontaneous and/or treatment-induced accumulation of senescent cells in a subject comprising administering to the subject a therapeutically effective amount of one or more common gamma chain family cytokine receptor activators. provided.
治療有効量の1つ以上の共通ガンマ鎖ファミリーサイトカイン受容体活性化物質を対象に投与することを含む、対象における自然発生及び/又は治療誘導性老化細胞のマーカーのレベルを減少させる方法も本明細書に提供される。いくつかの実施形態では、自然発生及び/又は治療誘導性老化細胞のマーカーは、p21CIP1p21及びCD26である。自然発生及び/又は治療誘導性老化細胞の追加のマーカーが本明細書に記載されている。自然発生及び/又は治療誘導性老化細胞の更なるマーカーは、当該技術分野で既知である。 Also herein are methods of reducing the levels of markers of spontaneous and/or treatment-induced senescent cells in a subject comprising administering to the subject a therapeutically effective amount of one or more common gamma chain family cytokine receptor activators. provided in the book. In some embodiments, the markers of spontaneous and/or treatment-induced senescent cells are p21 CIP1 p21 and CD26. Additional markers of spontaneous and/or treatment-induced senescent cells are described herein. Additional markers of spontaneous and/or therapy-induced senescent cells are known in the art.
治療有効量の1つ以上の共通ガンマ鎖ファミリーサイトカイン受容体活性化物質を対象に投与することを含む、対象における自然発生及び/又は治療誘導性老化細胞の活性を低減させる方法も本明細書に提供される。 Also herein are methods of reducing spontaneous and/or treatment-induced senescent cell activity in a subject comprising administering to the subject a therapeutically effective amount of one or more common gamma chain family cytokine receptor activators. provided.
治療有効量の1つ以上の共通ガンマ鎖ファミリーサイトカイン受容体活性化物質を対象に投与することを含む、対象における自然発生及び/又は治療誘導性老化細胞に由来する1つ以上の老化関連分泌表現型(SASP)因子のレベル及び/又は活性を減少させる方法も本明細書に提供される。いくつかの実施形態では、老化細胞は、炎症特性を発現し、炎症特性はSASP因子である。いくつかの実施形態では、老化関連分泌表現型(SASP)因子としては、炎症性サイトカイン(例えば、IL-1α、IL-1β、IL-6、IL-8、TNF-α)、成長因子(例えば、TGF-β、PDGF-AA、及びインスリン様成長因子-結合タンパク質(IGFBPs))、ケモカイン(例えば、CCL-2、CCL-20、CCL-7、CXCL-4、CXCL1、及びCXCL-12)、及びマトリックスメタロプロテイナーゼ(例えば、MMP-3、MMP-9)が挙げられるが、これらに限定されない。いくつかの実施形態では、方法は、老化関連分泌表現型(SASP)因子のうちの1つ以上(例えば、2つ、3つ、4つ、又は5つ)の発現レベル及び/又は活性を減少させる。いくつかの実施形態では、SASP因子の発現レベル又は活性は、酵素結合免疫吸着アッセイ(ELISA)を使用して決定される。いくつかの実施形態では、SASP因子の発現レベル又は活性は、免疫ブロット法を使用して決定される。 One or more senescence-associated secretory expressions derived from naturally occurring and/or treatment-induced senescent cells in a subject, comprising administering to the subject a therapeutically effective amount of one or more common gamma chain family cytokine receptor activators. Also provided herein are methods of reducing the level and/or activity of a type (SASP) factor. In some embodiments, the senescent cells express inflammatory properties and the inflammatory properties are SASP factors. In some embodiments, senescence-associated secretory phenotype (SASP) factors include inflammatory cytokines (eg, IL-1α, IL-1β, IL-6, IL-8, TNF-α), growth factors (eg, , TGF-β, PDGF-AA, and insulin-like growth factor-binding proteins (IGFBPs)), chemokines (e.g., CCL-2, CCL-20, CCL-7, CXCL-4, CXCL1, and CXCL-12), and matrix metalloproteinases (eg, MMP-3, MMP-9). In some embodiments, the method reduces the expression level and/or activity of one or more (e.g., 2, 3, 4, or 5) of senescence-associated secretory phenotype (SASP) factors Let In some embodiments, the SASP factor expression level or activity is determined using an enzyme-linked immunosorbent assay (ELISA). In some embodiments, the SASP factor expression level or activity is determined using immunoblotting.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、対象は、加齢関連疾患(例えば、本明細書に記載の又は当該技術分野で既知の例示的なタイプの加齢関連疾患又は状態のうちのいずれか)又は炎症性疾患(例えば、本明細書に記載の又は当該技術分野で既知の例示的なタイプの加齢関連疾患又は状態)を有すると以前に診断又は同定されている。 In some embodiments of any of the methods described herein, the subject has an age-related disease (e.g., an exemplary type of aging described herein or known in the art). previously diagnosed or identified as having an age-related disease or condition) or an inflammatory disease (e.g., exemplary types of age-related diseases or conditions described herein or known in the art) It is
いくつかの実施形態では、加齢関連疾患は、炎症老化関連である。 In some embodiments, the age-related disease is inflammatory senescence-related.
いくつかの実施形態では、加齢関連疾患は、がんである(例えば、本明細書に記載の又は当該技術分野で既知のがんの例示的なタイプのうちのいずれか)。 In some embodiments, the age-related disease is cancer (eg, any of the exemplary types of cancer described herein or known in the art).
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、炎症性疾患は、リウマチ性関節炎、炎症性腸疾患、エリテマトーデス、ループス腎炎、糖尿病性腎症、CNS損傷、アルツハイマー病、パーキンソン病、筋萎縮性側索硬化症、クローン病、多発性硬化症、ギラン・バレー症候群、乾癬、グレーブス病、潰瘍性大腸炎、非アルコール性脂肪性肝炎、気分障害、及びがん治療関連認知障害からなる群から選択される。 In some embodiments of any of the methods described herein, the inflammatory disease is rheumatoid arthritis, inflammatory bowel disease, lupus erythematosus, lupus nephritis, diabetic nephropathy, CNS injury, Alzheimer's disease, Parkinson's disease, amyotrophic lateral sclerosis, Crohn's disease, multiple sclerosis, Guillain-Barré syndrome, psoriasis, Graves' disease, ulcerative colitis, nonalcoholic steatohepatitis, mood disorders, and cancer treatment-related cognition selected from the group consisting of disorders;
これらの方法のいくつかの例では、治療誘導老化細胞は、化学療法誘導性老化細胞である。 In some examples of these methods, the treatment-induced senescent cells are chemotherapy-induced senescent cells.
これらの方法のいくつかの実施形態では、投与は、対象の標的組織(例えば、本明細書に記載の又は当該技術分野で既知の標的組織の例示的なタイプのうちのいずれか)の自然発生及び/又は治療誘導性老化細胞の数の減少(例えば、少なくとも5%減少、少なくとも10%減少、少なくとも15%減少、少なくとも20%減少、少なくとも25%減少、少なくとも30%減少、少なくとも35%減少、少なくとも40%減少、少なくとも45%減少、少なくとも50%減少、少なくとも55%減少、少なくとも60%減少、少なくとも65%減少、少なくとも70%減少、少なくとも75%減少、少なくとも80%減少、少なくとも85%減少、少なくとも90%減少、又は少なくとも95%減少、又は約5%減少~約99%減少(又は本明細書に記載のこの範囲の部分範囲のうちのいずれか))をもたらす(例えば、治療前の対象における標的組織の自然発生及び/又は治療誘導性老化細胞の数と比較して)。 In some embodiments of these methods, administering is a naturally occurring target tissue of the subject (e.g., any of the exemplary types of target tissue described herein or known in the art). and/or a reduction in the number of treatment-induced senescent cells (e.g., at least 5% reduction, at least 10% reduction, at least 15% reduction, at least 20% reduction, at least 25% reduction, at least 30% reduction, at least 35% reduction, at least 40% reduced, at least 45% reduced, at least 50% reduced, at least 55% reduced, at least 60% reduced, at least 65% reduced, at least 70% reduced, at least 75% reduced, at least 80% reduced, at least 85% reduced, at least a 90% reduction, or at least a 95% reduction, or from about a 5% reduction to about a 99% reduction (or any of the subranges of this range described herein) (e.g., pre-treatment subjects) (compared to the number of spontaneous and/or treatment-induced senescent cells in the target tissue in the 2000s).
これらの方法のいくつかの実施形態では、投与は、(例えば、本明細書に記載の期間のうちのいずれか)対象における自然発生及び/又は治療誘導性老化細胞の蓄積の減少(例えば、少なくとも5%減少、少なくとも10%減少、少なくとも15%減少、少なくとも20%減少、少なくとも25%減少、少なくとも30%減少、少なくとも35%減少、少なくとも40%減少、少なくとも45%減少、少なくとも50%減少、少なくとも55%減少、少なくとも60%減少、少なくとも65%減少、少なくとも70%減少、少なくとも75%減少、少なくとも80%減少、少なくとも85%減少、少なくとも90%減少、又は少なくとも95%減少、又は約5%減少~約99%減少(又は本明細書に記載のこの範囲の部分範囲のうちのいずれか))をもたらす(例えば、治療前の対象における自然発生及び/若しくは治療誘導性老化細胞の蓄積、又は治療を受けていない同様の対象における自然発生及び/若しくは治療誘導性老化細胞の蓄積と比較して)。 In some embodiments of these methods, administering (e.g., for any of the time periods described herein) reduces the accumulation of spontaneous and/or treatment-induced senescent cells in the subject (e.g., at least 5% reduced, at least 10% reduced, at least 15% reduced, at least 20% reduced, at least 25% reduced, at least 30% reduced, at least 35% reduced, at least 40% reduced, at least 45% reduced, at least 50% reduced, at least 55% reduced, at least 60% reduced, at least 65% reduced, at least 70% reduced, at least 75% reduced, at least 80% reduced, at least 85% reduced, at least 90% reduced, or at least 95% reduced, or about 5% reduced to about a 99% reduction (or any of the subranges of this range described herein) (e.g., spontaneous and/or treatment-induced accumulation of senescent cells in the subject prior to treatment, or treatment (compared to spontaneous and/or treatment-induced accumulation of senescent cells in similar subjects not receiving treatment).
これらの方法のいくつかの実施形態では、投与は、対象における自然発生及び/又は治療誘導性老化細胞の1つ以上(例えば、2つ、3つ、又は4つ)のマーカーのレベルの減少(例えば、少なくとも5%減少、少なくとも10%減少、少なくとも15%減少、少なくとも20%減少、少なくとも25%減少、少なくとも30%減少、少なくとも35%減少、少なくとも40%減少、少なくとも45%減少、少なくとも50%減少、少なくとも55%減少、少なくとも60%減少、少なくとも65%減少、少なくとも70%減少、少なくとも75%減少、少なくとも80%減少、少なくとも85%減少、少なくとも90%減少、又は少なくとも95%減少、又は約5%減少~約99%減少(又は本明細書に記載のこの範囲の部分範囲のうちのいずれか))をもたらす(例えば、治療前の対象における自然発生及び/又は治療誘導性老化細胞の1つ以上のマーカーのレベルと比較して)。 In some embodiments of these methods, administration reduces the level of one or more (e.g., two, three, or four) markers of spontaneous and/or treatment-induced senescent cells in the subject ( For example, at least 5% decreased, at least 10% decreased, at least 15% decreased, at least 20% decreased, at least 25% decreased, at least 30% decreased, at least 35% decreased, at least 40% decreased, at least 45% decreased, at least 50% reduced, at least 55% reduced, at least 60% reduced, at least 65% reduced, at least 70% reduced, at least 75% reduced, at least 80% reduced, at least 85% reduced, at least 90% reduced, or at least 95% reduced, or about 5% to about 99% reduction (or any of the subranges of this range described herein) (e.g., one of the naturally occurring and/or treatment-induced senescent cells in the subject prior to treatment). compared to the levels of one or more markers).
本明細書に記載の「自然発生老化細胞」は、正常な老化又は炎症プロセスの結果として生成される老化細胞である。自然発生老化細胞は、個人の様々な組織及び臓器に時間の経過とともに蓄積する可能性がある。自然発生老化細胞は、治療的処理(例えば、化学療法又は放射線)によって誘導されない、本明細書に記載の老化細胞の例示的なタイプのうちのいずれかであり得る。 As used herein, "spontaneous senescent cells" are senescent cells that are produced as a result of normal aging or inflammatory processes. Spontaneously occurring senescent cells can accumulate over time in various tissues and organs of an individual. Spontaneous senescent cells can be any of the exemplary types of senescent cells described herein that are not induced by therapeutic treatment (eg, chemotherapy or radiation).
本明細書に記載の「治療誘導性老化細胞」は、治療的処理(例えば、化学療法又は放射線)の結果として生成される老化細胞である。 As used herein, "treatment-induced senescent cells" are senescent cells produced as a result of therapeutic treatment (eg, chemotherapy or radiation).
共通ガンマ鎖ファミリーサイトカイン受容体活性化物質
1つ以上の共通ガンマ鎖ファミリーサイトカイン受容体活性化物質の使用又は投与を含む方法が、本明細書に提供される。いくつかの実施形態では、共通ガンマ鎖ファミリーサイトカイン受容体活性化物質は、一本鎖キメラポリペプチド(例えば、本明細書に記載の例示的な一本鎖キメラポリペプチドのいずれか)、多鎖キメラポリペプチド(例えば、本明細書に記載の例示的な多鎖キメラポリペプチドのいずれか)、可溶性IL-15又はIL-15アゴニスト(例えば、本明細書に記載の可溶性IL-15又はIL-15アゴニストのいずれか)、可溶性IL-2又はIL-2アゴニスト(例えば、本明細書に記載の可溶性IL-2又はIL-2アゴニストのいずれか)、共通ガンマ鎖ファミリーサイトカイン(又はその機能的断片)の複合体、並びに共通ガンマ鎖ファミリーサイトカインに特異的に結合する抗体(又は抗体断片)又はその機能的断片、共通ガンマ鎖ファミリーのサイトカインに特異的に結合する抗体又は抗原結合抗体断片である。
Common Gamma Chain Family Cytokine Receptor Activators Methods are provided herein that involve the use or administration of one or more common gamma chain family cytokine receptor activators. In some embodiments, the common gamma chain family cytokine receptor activator is a single-chain chimeric polypeptide (eg, any of the exemplary single-chain chimeric polypeptides described herein), a multi-chain Chimeric polypeptides (eg, any of the exemplary multi-chain chimeric polypeptides described herein), soluble IL-15 or IL-15 agonists (eg, soluble IL-15 or IL-15 described herein) 15 agonists), soluble IL-2 or IL-2 agonists (eg, any of the soluble IL-2 or IL-2 agonists described herein), common gamma chain family cytokines (or functional fragments thereof) ), as well as antibodies (or antibody fragments) or functional fragments thereof that specifically bind to common gamma chain family cytokines, antibodies or antigen-binding antibody fragments that specifically bind to cytokines of the common gamma chain family.
例示的な一本鎖キメラポリペプチド
共通ガンマ鎖ファミリーサイトカイン受容体活性化物質の非限定的な例は、(i)第1の標的結合ドメイン、(ii)可溶性組織因子ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、及び(iii)第2の標的結合ドメインを含む一本鎖キメラポリペプチドであり、第1の標的結合ドメイン及び第2の標的結合ドメインのうちの一方又は両方は、可溶性共通ガンマ鎖ファミリーサイトカイン、共通ガンマ鎖ファミリーサイトカイン受容体に特異的に結合するアゴニスト抗原結合ドメイン、可溶性共通ガンマ鎖ファミリーサイトカイン受容体、又は共通ガンマ鎖ファミリーサイトカインに特異的に結合する抗原結合ドメインである。
Exemplary Single Chain Chimeric Polypeptides Non-limiting examples of common gamma chain family cytokine receptor activators include (i) a first target binding domain, (ii) a soluble tissue factor domain (e.g., or any of the exemplary target binding domains known in the art), and (iii) a second target binding domain, the first target binding domain and the second target binding domain is a soluble common gamma chain family cytokine, an agonist antigen binding domain that specifically binds to a common gamma chain family cytokine receptor, a soluble common gamma chain family cytokine receptor, or An antigen binding domain that specifically binds to common gamma chain family cytokines.
本明細書に記載の一本鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態は、そのN末端及び/又はC末端に1つ以上(例えば、2、3、4、5、6、7、8、9、又は10)の追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)を更に含み得る。 Some embodiments of any of the single-chain chimeric polypeptides described herein have one or more (e.g., 2, 3, 4, 5, 6, 7, 8, 9, or 10) additional target binding domains (eg, any of the exemplary target binding domains described herein or known in the art).
本明細書に記載の一本鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、第2の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、及び1つ以上の追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)のうちの1つ以上が、可溶性共通ガンマ鎖ファミリーサイトカインである。可溶性共通ガンマ鎖ファミリーサイトカインの非限定的な例としては、可溶性IL-2、可溶性IL-4、可溶性IL-7、可溶性IL-9、可溶性IL-15、及び可溶性IL-21が挙げられる。 In some embodiments of any of the single chain chimeric polypeptides described herein, the first target binding domain (e.g., an exemplary any of the target binding domains), a second target binding domain (e.g., any of the exemplary target binding domains described herein or known in the art), and one or more One or more of the additional target binding domains (eg, any of the exemplary target binding domains described herein or known in the art) are soluble common gamma chain family cytokines. Non-limiting examples of soluble common gamma chain family cytokines include soluble IL-2, soluble IL-4, soluble IL-7, soluble IL-9, soluble IL-15, and soluble IL-21.
いくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインのうちの一方又は両方は、可溶性共通ガンマ鎖ファミリーサイトカイン受容体(例えば、IL-2、IL-4、IL-7、IL-9、IL-15、及びIL-21に対する可溶性受容体)を含む。 In some embodiments, one or both of the first target binding domain and the second target binding domain are soluble common gamma chain family cytokine receptors (e.g., IL-2, IL-4, IL-7 , IL-9, IL-15, and IL-21).
本明細書に記載の一本鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、第2の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、及び1つ以上の追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)のうちの1つ以上が、共通ガンマ鎖ファミリーサイトカイン受容体に特異的に結合するアゴニスト抗原結合ドメインである。共通ガンマ鎖ファミリーサイトカイン受容体の非限定的な例としては、IL-2、IL-4、IL-7、IL-9、IL-15、及びIL-21のうちの1つ以上に対する受容体が挙げられる。 In some embodiments of any of the single chain chimeric polypeptides described herein, the first target binding domain (e.g., an exemplary any of the target binding domains), a second target binding domain (e.g., any of the exemplary target binding domains described herein or known in the art), and one or more one or more of the additional target binding domains (e.g., any of the exemplary target binding domains described herein or known in the art) are specific for a common gamma chain family cytokine receptor It is an agonist antigen-binding domain that specifically binds. Non-limiting examples of common gamma chain family cytokine receptors include receptors for one or more of IL-2, IL-4, IL-7, IL-9, IL-15, and IL-21. mentioned.
多鎖キメラポリペプチド
共通ガンマ鎖ファミリーサイトカイン受容体活性化物質の非限定的な例は、(a)(i)第1の標的結合ドメイン、(ii)可溶性組織因子ドメイン、及び(iii)一対の親和性ドメインの第1のドメインを含む第1のキメラポリペプチドと、(b)(i)一対の親和性ドメインの第2のドメイン、及び(ii)第2の標的結合ドメインを含む第2のキメラポリペプチドと、を含む多鎖キメラポリペプチドであり、第1の標的結合ドメイン及び第2の標的結合ドメインのうちの一方又は両方は、可溶性共通ガンマ鎖ファミリーサイトカイン、共通ガンマ鎖ファミリーサイトカイン受容体に特異的に結合するアゴニスト抗原結合ドメイン、可溶性共通ガンマ鎖ファミリーサイトカイン受容体、又は共通ガンマ鎖ファミリーサイトカインに特異的に結合する抗原結合ドメインである。
Multichain Chimeric Polypeptides Non-limiting examples of common gamma chain family cytokine receptor activators include (a) (i) a first target binding domain, (ii) a soluble tissue factor domain, and (iii) a pair of a first chimeric polypeptide comprising a first of the affinity domains; and (b) a second chimeric polypeptide comprising (i) a second of the pair of affinity domains and (ii) a second target binding domain. and wherein one or both of the first target binding domain and the second target binding domain are a soluble common gamma chain family cytokine, a common gamma chain family cytokine receptor , a soluble common gamma chain family cytokine receptor, or an antigen binding domain that specifically binds to a common gamma chain family cytokine.
多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1のキメラポリペプチドは、1つ以上(例えば、2つ、3つ、4つ、5つ、6つ、7つ、8つ、9つ、又は10)の追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)を更に含む。 In some embodiments of any of the multi-chain chimeric polypeptides, the first chimeric polypeptide has one or more (e.g., two, three, four, five, six, seven, 8, 9, or 10) additional target binding domains (eg, any of the exemplary target binding domains described herein or known in the art).
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、第2の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、及び1つ以上の追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)のうちの1つ以上(例えば、2つ、3つ、4つ、5つ、6つ、7つ、8つ、9つ、又は10)が、可溶性共通ガンマ鎖ファミリーサイトカインである。可溶性共通ガンマ鎖ファミリーサイトカインの非限定的な例としては、可溶性IL-2、可溶性IL-4、可溶性IL-7、可溶性IL-9、可溶性IL-15、及び可溶性IL-21が挙げられる。 In some embodiments of any of the multi-chain chimeric polypeptides described herein, the first target binding domain (e.g., exemplary targets described herein or known in the art) binding domain), a second target binding domain (e.g., any of the exemplary target binding domains described herein or known in the art), and one or more additional (e.g., any of the exemplary target binding domains described herein or known in the art) of (e.g., two, three, four, 5, 6, 7, 8, 9, or 10) are soluble common gamma chain family cytokines. Non-limiting examples of soluble common gamma chain family cytokines include soluble IL-2, soluble IL-4, soluble IL-7, soluble IL-9, soluble IL-15, and soluble IL-21.
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、第2の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、及び1つ以上の追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)のうちの1つ以上が、共通ガンマ鎖ファミリーサイトカイン受容体に特異的に結合するアゴニスト抗原結合ドメインである。共通ガンマ鎖ファミリーサイトカイン受容体の非限定的な例としては、IL-2、IL-4、IL-7、IL-9、IL-15、及びIL-21のうちの1つ以上に対する受容体が挙げられる。 In some embodiments of any of the multi-chain chimeric polypeptides described herein, the first target binding domain (e.g., exemplary targets described herein or known in the art) binding domain), a second target binding domain (e.g., any of the exemplary target binding domains described herein or known in the art), and one or more additional (e.g., any of the exemplary target binding domains described herein or known in the art) of are specific for a common gamma chain family cytokine receptor is an agonist antigen-binding domain that binds to Non-limiting examples of common gamma chain family cytokine receptors include receptors for one or more of IL-2, IL-4, IL-7, IL-9, IL-15, and IL-21. mentioned.
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、第2の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)、及び1つ以上の追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)のうちの1つ以上(例えば、2つ、3つ、4つ、5つ、6つ、7つ、8つ、9つ、又は10)が、可溶性共通ガンマ鎖ファミリーサイトカイン受容体である。 In some embodiments of any of the multi-chain chimeric polypeptides described herein, the first target binding domain (e.g., exemplary targets described herein or known in the art) binding domain), a second target binding domain (e.g., any of the exemplary target binding domains described herein or known in the art), and one or more additional (e.g., any of the exemplary target binding domains described herein or known in the art) of (e.g., two, three, four, 5, 6, 7, 8, 9, or 10) are soluble common gamma chain family cytokine receptors.
本明細書に記載の多鎖キメラポリペプチドのいくつかの実施形態では、一対の親和性ドメインの第1のドメイン又は第2のドメインは、可溶性共通ガンマ鎖ファミリーサイトカイン、又は共通ガンマ鎖ファミリーサイトカイン受容体に特異的に結合する抗原結合ドメインである。 In some embodiments of the multi-chain chimeric polypeptides described herein, the first domain or the second domain of the pair of affinity domains is a soluble common gamma chain family cytokine or a common gamma chain family cytokine receptor. It is an antigen-binding domain that specifically binds to the body.
可溶性共通ガンマ鎖ファミリーサイトカイン
本明細書に記載の一本鎖又は多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインのうちの一方又は両方は、可溶性共通ガンマ鎖ファミリーサイトカインであり得る。いくつかの実施形態では、共通ガンマ鎖ファミリーサイトカイン受容体活性化物質は、可溶性共通ガンマ鎖ファミリーサイトカインであり得る。可溶性共通ガンマ鎖ファミリーサイトカインの非限定的な例としては、可溶性IL-2、可溶性IL-4、可溶性IL-7、可溶性IL-9、可溶性IL-15、及び可溶性IL-21が挙げられる。可溶性IL-2、可溶性IL-7、可溶性IL-15、及び可溶性IL-21の配列の非限定的な例が本明細書に記載されている。可溶性IL-4及びIL-9配列の非限定的な例を以下に示す。
ヒト可溶性IL-4(配列番号335)


Human soluble IL-4 (SEQ ID NO:335)
抗原結合ドメイン
本明細書に記載の一本鎖又は多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインのうちの一方又は両方が、抗原結合ドメインである。本明細書に記載の一本鎖又は多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは各々、抗原結合ドメインである。本明細書に記載の一本鎖又は多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、抗原結合ドメインは、scFv又は単一ドメイン抗体(例えば、VaHH又はVNARドメイン)を含むか、又はそれである。
Antigen Binding Domains In some embodiments of any of the single-chain or multi-chain chimeric polypeptides described herein, one or both of the first target binding domain and the second target binding domain is the antigen-binding domain. In some embodiments of any of the single- or multi-chain chimeric polypeptides described herein, the first target binding domain and the second target binding domain are each antigen binding domains. In some embodiments of any of the single- or multi-chain chimeric polypeptides described herein, the antigen binding domain is a scFv or single domain antibody (eg, Va H H or V NAR domains) contains or is
本明細書に記載の一本鎖又は多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインのうちの一方又は両方は、共通ガンマ鎖ファミリーサイトカイン受容体に特異的に結合するアゴニスト抗原結合ドメインである。いくつかの例では、アゴニスト抗原結合ドメイン(例えば、本明細書に記載の抗原結合ドメインのうちのいずれか)は、IL-2、IL-4、IL-7、IL-9、IL-15又はIL-21に対する受容体に特異的に結合することができる。 In some embodiments of any of the single-chain or multi-chain chimeric polypeptides described herein, one or both of the first target binding domain and the second target binding domain share An agonist antigen-binding domain that specifically binds to gamma chain family cytokine receptors. In some examples, the agonist antigen binding domain (eg, any of the antigen binding domains described herein) is IL-2, IL-4, IL-7, IL-9, IL-15 or It can specifically bind to the receptor for IL-21.
本明細書に記載の一本鎖又は多鎖キメラポリペプチドのうちのいずれかに存在する抗原結合ドメインは各々独立して、VHHドメイン、VNARドメイン、及びscFvからなる群から選択される。いくつかの実施形態では、本明細書に記載の抗原結合ドメインのうちのいずれかは、BiTe、(scFv)2、ナノボディ、ナノボディ-HSA、DART、TandAb、scDiabody、scDiabody-CH3、scFv-CH-CL-scFv、HSAbody、scDiabody-HAS、又はタンデム-scFvである。一本鎖キメラポリペプチド又は多鎖キメラポリペプチドのうちのいずれかで使用することができる抗原結合ドメインの追加の例は、当該技術分野で既知である。 Each antigen-binding domain present in any of the single- or multi-chain chimeric polypeptides described herein is independently selected from the group consisting of VHH domains, VNAR domains, and scFv. In some embodiments, any of the antigen binding domains described herein are BiTe, (scFv) 2 , Nanobody, Nanobody-HSA, DART, TandAb, scDiabody, scDiabody-CH3, scFv-CH- CL-scFv, HSAbody, scDiabody-HAS, or tandem-scFv. Additional examples of antigen binding domains that can be used in either single-chain chimeric polypeptides or multi-chain chimeric polypeptides are known in the art.
いくつかの実施形態では、本明細書に記載の一本鎖又は多鎖キメラポリペプチド内の抗原結合ドメインは各々、いずれもVHHドメインであるか、又は少なくとも1つの抗原結合ドメインがVHHドメインである。いくつかの実施形態では、本明細書に記載の一本鎖又は多鎖キメラポリペプチド内の抗原結合ドメインは各々、いずれもVNARドメインであるか、又は少なくとも1つの抗原結合ドメインがVNARドメインである。いくつかの実施形態では、本明細書に記載の一本鎖又は多鎖キメラポリペプチドの抗原結合ドメインは各々、いずれもscFvドメインであるか、又は少なくとも1つの抗原結合ドメインがscFvドメインである。 In some embodiments, each of the antigen binding domains within the single-chain or multi-chain chimeric polypeptides described herein are both VHH domains, or at least one antigen binding domain is a VHH domain . In some embodiments, each of the antigen binding domains within the single or multi-chain chimeric polypeptides described herein are both VNAR domains, or at least one antigen binding domain is a VNAR domain. . In some embodiments, each of the antigen binding domains of the single or multi-chain chimeric polypeptides described herein are both scFv domains, or at least one antigen binding domain is an scFv domain.
いくつかの実施形態では、一本鎖又は多鎖キメラポリペプチドに存在する2つ以上のポリペプチドは、集合して(例えば、非共有結合的に集合して)、本明細書に記載の抗原結合ドメインのうちのいずれか、例えば、抗体の抗原結合断片(例えば、本明細書に記載の抗体の抗原結合断片のうちのいずれか)、VHH-scAb、VHH-Fab、二重scFab、F(ab’)2、ダイアボディ、crossMab、DAF(ツーインワン)、DAF(フォーインワン)、DutaMab、DT-IgG、ノブ・イン・ホール共通軽鎖、ノブ・イン・ホール集合体、電荷対、Fabアーム交換、SEEDbody、LUZ-Y、Fcab、κλ-ボディ、直交Fab、DVD-IgG、IgG(H)-scFv、scFv-(H)IgG、IgG(L)-scFv、scFv-(L)IgG、IgG(L,H)-Fv、IgG(H)-V、V(H)-IgG、IgG(L)-V、V(L)-IgG、KIH IgG-scFab、2scFv-IgG、IgG-2scFv、scFv4-Ig、Zybody、DVI-IgG、ダイアボディ-CH3、トリプルボディ、ミノ抗体、ミニボディ、TriBiミニボディ、scFv-CH3KIH、Fab-scFv、F(ab’)2-scFv2、scFv-KIH、Fab-scFv-Fc、四価HCAb、scダイアボディ-Fc、ダイアボディ-Fc、タンデムscFv-Fc、イントラボディ、ドック・アンド・ロック、lmmTAC、IgG-IgGコンジュゲート、Cov-X-Body、及びscFv1-PEG-scFv2を形成することができる。これらの要素の説明については、例えば、全体が本明細書に組み込まれるSpiess et al.,Mol.Immunol.67:95-106,2015を参照されたい。抗体の抗原結合断片の非限定的な例には、Fv断片、Fab断片、F(ab’)2断片、及びFab’断片が挙げられる。抗体の抗原結合断片の追加の例は、IgGの抗原結合断片(例えば、IgG1、IgG2、IgG3、又はIgG4の抗原結合断片)(例えば、ヒト又はヒト化IgG、例えば、ヒト又はヒト化IgG1、IgG2、IgG3、又はIgG4の抗原結合断片)、IgAの抗原結合断片(例えば、IgA1又はIgA2の抗原結合断片)(例えば、ヒト又はヒト化IgA、例えば、ヒト又はヒト化IgA1又はIgA2の抗原結合断片)、IgDの抗原結合断片(例えば、ヒト又はヒト化IgDの抗原結合断片)、IgEの抗原結合断片(例えば、ヒト又はヒト化IgEの抗原結合断片)、又はIgMの抗原結合断片(例えば、ヒト又はヒト化IgMの抗原結合断片)である。 In some embodiments, two or more polypeptides present in a single-chain or multi-chain chimeric polypeptide are assembled (e.g., non-covalently assembled) to form an antigen described herein. Any of the binding domains, e.g., an antigen-binding fragment of an antibody (e.g., any of the antigen-binding fragments of an antibody described herein), VHH-scAb, VHH-Fab, double scFab, F ( ab′) 2 , diabody, crossMab, DAF (two-in-one), DAF (four-in-one), DutaMab, DT-IgG, knob-in-hole common light chain, knob-in-hole assembly, charge pair, Fab arm exchange , SEEDbody, LUZ-Y, Fcab, κλ-body, Orthogonal Fab, DVD-IgG, IgG(H)-scFv, scFv-(H)IgG, IgG(L)-scFv, scFv-(L)IgG, IgG ( L,H)-Fv, IgG(H)-V, V(H)-IgG, IgG(L)-V, V(L)-IgG, KIH IgG-scFab, 2scFv-IgG, IgG-2scFv, scFv4- Ig, Zybody, DVI-IgG, Diabody-CH3, Triple body, Mino antibody, Minibody, TriBi minibody, scFv-CH3KIH, Fab-scFv, F(ab') 2 -scFv 2 , scFv-KIH, Fab- scFv-Fc, tetravalent HCAb, sc diabody-Fc, diabody-Fc, tandem scFv-Fc, intrabody, dock and lock, lmmTAC, IgG-IgG conjugate, Cov-X-Body, and scFv1- PEG-scFv 2 can be formed. For a description of these elements, see, for example, Spiess et al. , Mol. Immunol. 67:95-106, 2015. Non-limiting examples of antigen-binding fragments of antibodies include Fv, Fab, F(ab') 2 , and Fab' fragments. Additional examples of antigen-binding fragments of antibodies include antigen-binding fragments of IgG (e.g., antigen-binding fragments of IgG1, IgG2, IgG3, or IgG4) (e.g., human or humanized IgG, e.g., human or humanized IgG1, IgG2 , IgG3, or IgG4), antigen-binding fragments of IgA (e.g., antigen-binding fragments of IgA1 or IgA2) (e.g., human or humanized IgA, e.g., antigen-binding fragments of human or humanized IgA1 or IgA2) , an antigen-binding fragment of IgD (e.g., an antigen-binding fragment of human or humanized IgD), an antigen-binding fragment of IgE (e.g., an antigen-binding fragment of human or humanized IgE), or an antigen-binding fragment of IgM (e.g., human or antigen-binding fragment of humanized IgM).
可溶性IL-15及びIL-15アゴニスト
共通ガンマ鎖ファミリーサイトカイン受容体活性化物質の非限定的な例は、可溶性IL-15又はIL-15アゴニストである。IL-15は、IL-15に対する受容体特異性を付与する高親和性のユニークな結合IL-15Rα鎖と、IL-2と共有の共通IL-15Rβ及びγ鎖(IL-2Rβ/γとしても知られる)からなる三量体IL-15受容体複合体を介して機能する。
Soluble IL-15 and IL-15 Agonists Non-limiting examples of common gamma chain family cytokine receptor activators are soluble IL-15 or IL-15 agonists. IL-15 has a unique high-affinity binding IL-15Rα chain that confers receptor specificity for IL-15, and a common IL-15Rβ and γ chain shared with IL-2 (also known as IL-2Rβ/γ). It functions through a trimeric IL-15 receptor complex consisting of
いくつかの実施形態では、可溶性IL-15は、配列番号82と少なくとも90%(例えば、少なくとも91%、92%、93%、94%、95%、96%、97%、98%、又は99%)同一である。いくつかの実施形態では、可溶性IL-15は、組換え可溶性ヒトIL-15である。いくつかの実施形態では、可溶性IL-15は、野生型IL-15(例えば、配列番号82)と比較して1つ以上のアミノ酸置換を有する変異IL-15である。変異IL-15は、例えば、野生型IL-15と比較して、D8N又はD8Aアミノ酸置換を含み得る。いくつかの実施形態では、可溶性IL-15をポリマーにコンジュゲートすることができる(例えば、Miyazaki et al.,Proceed.Annual Meeting AACR,2019,Abstract3265)。 In some embodiments, the soluble IL-15 is SEQ ID NO: 82 and at least 90% (eg, at least 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, or 99% %) are identical. In some embodiments, the soluble IL-15 is recombinant soluble human IL-15. In some embodiments, the soluble IL-15 is mutant IL-15 having one or more amino acid substitutions compared to wild-type IL-15 (eg, SEQ ID NO:82). Mutant IL-15 can include, for example, a D8N or D8A amino acid substitution compared to wild-type IL-15. In some embodiments, soluble IL-15 can be conjugated to polymers (eg, Miyazaki et al., Proceed. Annual Meeting AACR, 2019, Abstract 3265).
本明細書に記載のIL-15アゴニストのいくつかの例には、IL-15と可溶性IL-15受容体(IL-15R)の全部又は一部との複合体が含まれ得る。IL-15と可溶性IL-15Rの全部又は一部との複合体は、遊離IL-15と比較して半減期が延長され、かつ/又は効力が高い可能性がある。いくつかの実施形態では、本明細書に記載のIL-15アゴニストは、Fcドメイン(例えば、本明細書に記載の例示的なFcドメインのうちのいずれか)を更に含む。 Some examples of IL-15 agonists described herein may include complexes of IL-15 with all or part of the soluble IL-15 receptor (IL-15R). Complexes of IL-15 with all or part of soluble IL-15R may have increased half-life and/or increased potency compared to free IL-15. In some embodiments, an IL-15 agonist described herein further comprises an Fc domain (eg, any of the exemplary Fc domains described herein).
いくつかの実施形態では、可溶性IL-15Rの一部は、IL-15Rαである。例えば、IL-15は、IL-15Rα-Fc融合物と結合して、IL-15:IL-15Rα-Fc複合体を形成することができる(例えば、Stoklasek et al.,J.Immunology 177:6072-80,2006、Dubios et al.,J.Immunol.180:2099-106,2008、Epardaud et al.,Cancer Res.68:2972-83,2008、Rubinstein et al.,Proc.Natl.Acad.Sci.U.S.A.103:9166-71,2006に記載のものを参照)。いくつかの実施形態では、可溶性IL-15及びIL-15Rαは、ヘテロ二量体を形成する(例えば、Colon et al.,Cancer Res.79(13Supplement):CT082,July 1,2019を参照)。 In some embodiments, the portion of soluble IL-15R is IL-15Rα. For example, IL-15 can bind to an IL-15Rα-Fc fusion to form an IL-15:IL-15Rα-Fc complex (see, eg, Stoklasek et al., J. Immunology 177:6072 -80, 2006, Dubios et al., J. Immunol.180:2099-106, 2008, Epardaud et al., Cancer Res.68:2972-83, 2008, Rubinstein et al., Proc.Natl.Acad.Sci. U.S.A. 103:9166-71, 2006). In some embodiments, soluble IL-15 and IL-15Rα form a heterodimer (see, eg, Colon et al., Cancer Res. 79 (13 Supplement): CT082, July 1, 2019).
いくつかの実施形態では、可溶性IL-15Rの一部は、IL-15Rαの一部(例えば、IL-15Rαのスシドメイン)である。 In some embodiments, the portion of soluble IL-15R is a portion of IL-15Rα (eg, the sushi domain of IL-15Rα).
複合体中のIL-15は、野生型IL-15又は変異IL-15であり得る。例えば、N72D変異を含む変異IL-15を使用して、可溶性IL-15R(例えば、IL-15Rαのスシドメイン)の全部又は一部と複合体を形成することができる。いくつかの実施形態では、複合体は、ALT-803であり、IL-15Rαスシ-Fc融合物と複合体を形成したヒトIL-15変異体IL-15N72Dを含む(例えば、Zhu et al.,J.Immunol.183(6):3598-607,2009を参照)。 IL-15 in the complex can be wild-type IL-15 or mutated IL-15. For example, a mutated IL-15 containing the N72D mutation can be used to form a complex with all or part of a soluble IL-15R (eg, the sushi domain of IL-15Rα). In some embodiments, the complex is ALT-803 and comprises the human IL-15 variant IL-15N72D complexed with an IL-15Rα sushi-Fc fusion (see, eg, Zhu et al., J. Immunol.183(6):3598-607, 2009).
IL-15アゴニストの非限定的な例としては、ALT-803/N-803(Altor Bioscience/ImmunityBio)、BNZ-1(Bioniz Therapeutics)、NIZ985(Novartis)、RTX-212(Rubius Therapeutics)、AM0015(rhIL-15)(Lilly)、IGM-7354(IGM)、XmAb24306(Roche/Xencor)、KD033(srKD033)(Kadmon)、OXS-C3550(GT Biopharma)、及びNKTR-255(Nektar Therapeutics)が挙げられる。 Non-limiting examples of IL-15 agonists include ALT-803/N-803 (Altor Bioscience/ImmunityBio), BNZ-1 (Bioniz Therapeutics), NIZ985 (Novartis), RTX-212 (Rubis Therapeutics), AM0 015 ( rhIL-15) (Lilly), IGM-7354 (IGM), XmAb24306 (Roche/Xencor), KD033 (srKD033) (Kadmon), OXS-C3550 (GT Biopharma), and NKTR-255 (Nektar Therapeutics) .
可溶性IL-2及びIL-2アゴニスト
共通ガンマ鎖ファミリーサイトカイン受容体活性化物質の非限定的な例は、可溶性IL-2又はIL-2アゴニストである。IL-2は、CD4+T制御細胞及びCD8+T細胞及びNK細胞などの細胞傷害性エフェクターリンパ球への影響により、免疫寛容及び免疫活性化に中心的に関与するサイトカインである。IL-2は、IL-2Rβ及びγ鎖からなる二量体IL-2受容体(IL-2R)、又は三量体αβγ受容体(IL-2Rαβγ)のいずれかを発現する細胞に作用し、三量体受容体は、二量体IL-2Rと比較してIL-2に対して10~100倍高い親和性を示す。CD4+制御性T細胞は、IL-2Rαの強力な構成的発現によって特徴付けられる。これにより、細胞はIL-2Rαβγを発現し、それによって低レベルのIL-2を使用できる。二量体IL-2Rは、抗原を経験した(メモリー)CD8+T細胞及びNK細胞で最も顕著である。したがって、高レベルのIL-2は、Treg細胞の活性化に加えて、CD8+T細胞及びNK細胞を強力に刺激する。
Soluble IL-2 and IL-2 Agonists Non-limiting examples of common gamma chain family cytokine receptor activators are soluble IL-2 or IL-2 agonists. IL-2 is a cytokine centrally involved in immune tolerance and immune activation through its effects on CD4 + T regulatory cells and cytotoxic effector lymphocytes such as CD8 + T cells and NK cells. IL-2 acts on cells expressing either the dimeric IL-2 receptor (IL-2R), which consists of the IL-2Rβ and γ chains, or the trimeric αβγ receptor (IL-2Rαβγ), The trimeric receptor exhibits a 10-100 fold higher affinity for IL-2 compared to the dimeric IL-2R. CD4 + regulatory T cells are characterized by strong constitutive expression of IL-2Rα. This allows the cells to express IL-2Rαβγ and thereby use lower levels of IL-2. Dimeric IL-2R is most prominent on antigen-experienced (memory) CD8 + T cells and NK cells. Thus, high levels of IL-2, in addition to activating Treg cells, potently stimulate CD8 + T cells and NK cells.
いくつかの実施形態では、可溶性IL-2は、配列番号78と少なくとも90%(例えば、少なくとも95%同一、少なくとも96%、少なくとも97%、少なくとも98%、少なくとも99%、又は100%)同一である。いくつかの実施形態では、可溶性IL-2は、組換えヒトIL-2である。可溶性IL-2は、IL-2バリアントであり得る。例えば、IL-2バリアントは、IL-2RαよりもIL-2Rβにより効果的に(例えば、少なくとも50、100、150又は200倍効果的に)結合することができる。例示的なIL-2バリアントは、MDNA109である(例えば、Rafei et al.,J.Clin.Oncol.37(15Suppl.),2019を参照)いくつかの実施形態では、IL-2バリアントは、CD25結合を無効にしている。例えば、CD25結合に関与する残基F42、Y45、及びL72を変異させることができる(例えば、Klein et al.,Oncoimmunology 6(3):e1277306,2017を参照)。 In some embodiments, the soluble IL-2 is at least 90% (eg, at least 95% identical, at least 96%, at least 97%, at least 98%, at least 99%, or 100%) identical to SEQ ID NO:78. be. In some embodiments, soluble IL-2 is recombinant human IL-2. Soluble IL-2 can be an IL-2 variant. For example, an IL-2 variant may bind IL-2Rβ more effectively (eg, at least 50, 100, 150 or 200 times more effectively) than IL-2Rα. An exemplary IL-2 variant is MDNA109 (see, eg, Rafei et al., J. Clin. Oncol. 37 (15Suppl.), 2019). Disabling bindings. For example, residues F42, Y45, and L72 involved in CD25 binding can be mutated (see, eg, Klein et al., Oncoimmunology 6(3): e1277306, 2017).
いくつかの実施形態では、IL-2アゴニストは、IL2Rαサブユニットへの結合が制限され、二量体IL2Rβγに優先的に結合するPEG化IL-2である(例えば、Bentebibel et al.,Cancer Discov.9(6):711-721,2019を参照)。 In some embodiments, the IL-2 agonist is pegylated IL-2, which has limited binding to the IL2Rα subunit and preferentially binds dimeric IL2Rβγ (eg, Bentebibel et al., Cancer Discov .9(6):711-721, 2019).
本明細書に記載のIL-2アゴニストのいくつかの例は、IL-2を含む融合タンパク質である。いくつかの実施形態では、融合タンパク質は、可溶性IL-2Rの全部又は一部に連結されたIL-2又はそのバリアントを含む。いくつかの実施形態では、可溶性IL-2Rの一部は、IL-2Rαである(例えば、Vaishampayan et al.,J.Clin.Oncol.35(15Suppl.),2017を参照)。融合タンパク質は、例えば、二量体IL-2Rβγを選択的に活性化することができる。IL-2融合タンパク質の更なる例には、毒素(例えば、ジフテリア毒素)に融合されたものが含まれる。 Some examples of IL-2 agonists described herein are fusion proteins that include IL-2. In some embodiments, the fusion protein comprises IL-2 or a variant thereof linked to all or part of a soluble IL-2R. In some embodiments, a portion of the soluble IL-2R is IL-2Rα (see, eg, Vaishampayan et al., J. Clin. Oncol. 35(15Suppl.), 2017). A fusion protein can, for example, selectively activate dimeric IL-2Rβγ. Further examples of IL-2 fusion proteins include those fused to toxins (eg, diphtheria toxin).
いくつかの実施形態では、融合タンパク質は、抗体(例えば、モノクローナル抗体又はscFv)に連結されたIL-2又はそのバリアント(例えば、本明細書に記載のIL-2バリアントのうちのいずれか)を含む。IL-2又はそのバリアントに連結され得る抗体の非限定的な例としては、線維芽細胞活性化タンパク質-アルファ(FAP)に対するヒトモノクローナル抗体(例えば、Soerensen et al.,J.Clin.Oncol.36,No.15Suppl.を参照)、抗CD20モノクローナル抗体(例えば、Lansigan et al.,Blood128(22):620,2016を参照)、テネイシン-CのA1ドメインに対するscFv(例えば、Catania et al.,Cell Adh.Migr.9(1-2):14-21,2015を参照)、及び抗CEA抗体(例えば、Klein et al.,Oncoimmunol.6(3):e1277306,2017を参照)が挙げられる。 In some embodiments, the fusion protein comprises IL-2 or a variant thereof (eg, any of the IL-2 variants described herein) linked to an antibody (eg, monoclonal antibody or scFv). include. Non-limiting examples of antibodies that can be linked to IL-2 or variants thereof include human monoclonal antibodies against fibroblast activation protein-alpha (FAP) (eg, Soerensen et al., J. Clin. Oncol. 36). , No. 15 Suppl.), anti-CD20 monoclonal antibodies (see, e.g., Lansigan et al., Blood 128(22):620, 2016), scFv against the A1 domain of tenascin-C (e.g., Catania et al., Cell Adh. Migr. 9(1-2):14-21, 2015), and anti-CEA antibodies (see, eg, Klein et al., Oncoimmunol. 6(3): e1277306, 2017).
IL-2アゴニストの追加の例としては、プロロイキン(Clinigen)、プルモロイキン(Immunservice)、NKTR-214(Nektar Therapeutics)、DI-Leu16-IL2(Alopexx/Provenance Biopharmaceuticals)、RG7461(Roche)、Teleukin(Philogen)、ALT-801803(Altor Bioscience)、ALT-801(Altor Bioscience)、ALKS4230(Alkermes)、セルグツズマブアムナロイキン(RG7813)(Roche)、カミダンルーマブテシリン(ADC Therapeutics/Genbmab)、NHS-IL2-LT/EMD521873(Merck KGaA)、NIZ985(Novartis)、MDNA109(Medicenna Therapeutics)、アンゲロキシン(Angelica Therapeutics)、PB101(Pivotal Biosciences)、抗IL-2プログラム(Xoma)、NKTR-255(Nektar Therapeutics)、NKTR-358/LY3471851(Nektar Therapeutics)/Lilly)、CYP0150(Cytunepharma)、NL-201(Neoleukin)、THOR-809(Sanofi/Synthorx)、BNT151/153(BioNTech)、トランスコンIL-2β/γ(Ascendis Pharma)、ILT-101(Servier)/ILT-101)及びAM0015(Lilly)が挙げられる。IL-2アゴニストの追加の例は、当該技術分野で既知である。 Additional examples of IL-2 agonists include proleukin (Clinigen), plumoleukin (Immunservice), NKTR-214 (Nektar Therapeutics), DI-Leu16-IL2 (Alopexx/Provenance Biopharmaceuticals), RG7461 (Roche ), Teleukin (Philogen ), ALT-801803 (Altor Bioscience), ALT-801 (Altor Bioscience), ALKS4230 (Alkermes), Sergutuzumab amnaleukin (RG7813) (Roche), Camidan lumabutecillin (ADC Therapeutics/Genbma b), NHS - IL2-LT/EMD521873 (Merck KGaA), NIZ985 (Novartis), MDNA109 (Medicenna Therapeutics), Angeloxin (Angelica Therapeutics), PB101 (Pivotal Biosciences), anti-IL-2 program (Xo ma), NKTR-255 (Nektar Therapeutics ), NKTR-358/LY3471851 (Nektar Therapeutics)/Lilly), CYP0150 (Cytunepharma), NL-201 (Neoleukin), THOR-809 (Sanofi/Synthorx), BNT151/153 (BioNTech) , transcon IL-2β/γ (Ascendis Pharma), ILT-101 (Servier)/ILT-101) and AM0015 (Lilly). Additional examples of IL-2 agonists are known in the art.
共通ガンマ鎖ファミリーサイトカインと抗体又は抗体断片との複合体
共通ガンマ鎖ファミリーサイトカイン受容体活性化物質の非限定的な例は、共通ガンマ鎖ファミリーサイトカイン(例えば、本明細書に記載の共通ガンマ鎖ファミリーサイトカインのうちのいずれか)及び共通ガンマ鎖ファミリーサイトカインに特異的に結合する抗体又は抗原結合抗体断片を含む複合体である。
Conjugates of Common Gamma Chain Family Cytokines with Antibodies or Antibody Fragments Non-limiting examples of common gamma chain family cytokine receptor activators include common gamma chain family cytokines (e.g., common gamma chain family cytokine) and an antibody or antigen-binding antibody fragment that specifically binds to a common gamma chain family cytokine.
いくつかの実施形態では、共通ガンマ鎖ファミリーサイトカインと、共通ガンマ鎖ファミリーサイトカインに特異的に結合する抗体又は抗原結合抗体断片との複合体は、共通ガンマ鎖ファミリーサイトカインの活性を増強し、CD8+T細胞及び/又はNK細胞の増殖をもたらす。いくつかの実施形態では、複合体は、遊離共通ガンマ鎖ファミリーサイトカインより循環中の半減期が長い。 In some embodiments, a complex of a common gamma chain family cytokine and an antibody or antigen-binding antibody fragment that specifically binds the common gamma chain family cytokine enhances the activity of the common gamma chain family cytokine and CD8 + Resulting in proliferation of T cells and/or NK cells. In some embodiments, the conjugate has a longer half-life in circulation than the free common gamma chain family cytokine.
いくつかの実施形態では、複合体は、可溶性IL-2(例えば、組換え可溶性ヒトIL-2)又はその機能的断片、及び抗IL-2抗体又はその抗原結合抗体断片を含み得る。可溶性IL-2及び抗IL-2抗体の複合体の非限定的な例としては、それぞれ抗IL-2抗体S4B6、JES6-5、又はMAB602と複合体を形成した可溶性IL-2が挙げられる(例えば、Tomala et al.,J.Immunol.183:4904-4912,2009、及びBoyman et al.,Science 311,2006を参考)。 In some embodiments, a conjugate may comprise soluble IL-2 (eg, recombinant soluble human IL-2) or functional fragment thereof and an anti-IL-2 antibody or antigen-binding antibody fragment thereof. Non-limiting examples of complexes of soluble IL-2 and anti-IL-2 antibodies include soluble IL-2 complexed with anti-IL-2 antibodies S4B6, JES6-5, or MAB602, respectively ( See, eg, Tomala et al., J. Immunol.183:4904-4912, 2009 and Boyman et al., Science 311, 2006).
いくつかの実施形態では、複合体は、可溶性IL-4(例えば、組換え可溶性ヒトIL-4)及び抗IL-4抗体又はその抗原結合抗体断片を含み得る。抗IL-4抗体の非限定的な例としては、例えば、Sato et al.,J.Immunol.150:2717-2723,1993、及びFinkelman et al.,J.Immunol.151:1235-1244,1993に記載されるものが挙げられる。 In some embodiments, a conjugate may comprise soluble IL-4 (eg, recombinant soluble human IL-4) and an anti-IL-4 antibody or antigen-binding antibody fragment thereof. Non-limiting examples of anti-IL-4 antibodies include, for example, Sato et al. , J. Immunol. 150:2717-2723, 1993, and Finkelman et al. , J. Immunol. 151:1235-1244, 1993.
いくつかの実施形態では、複合体は、可溶性IL-7(例えば、組換え可溶性ヒトIL-7)及び抗IL-7抗体又はその抗原結合抗体断片を含み得る。抗IL-7抗体の非限定的な例としては、例えば、Finkelman et al.,J.Immunol.151:1235-1244,1993、及びBoyman et al.,J.Immunol.180:7265-75,2008に記載されるものが挙げられる。 In some embodiments, a conjugate may comprise soluble IL-7 (eg, recombinant soluble human IL-7) and an anti-IL-7 antibody or antigen-binding antibody fragment thereof. Non-limiting examples of anti-IL-7 antibodies include, for example, Finkelman et al. , J. Immunol. 151:1235-1244, 1993, and Boyman et al. , J. Immunol. 180:7265-75, 2008.
複合体のいくつかの例では、共通ガンマ鎖ファミリーサイトカイン(又はその機能的断片)及び抗体(又はその抗原結合抗体断片)を別々に投与することができ、共通ガンマ鎖ファミリーサイトカインと、抗体又は抗原結合抗体断片との複合体は、インビボで形成することができる。 In some examples of conjugates, the common gamma chain family cytokine (or functional fragment thereof) and the antibody (or antigen-binding antibody fragment thereof) can be administered separately, wherein the common gamma chain family cytokine and the antibody or antigen Complexes with bound antibody fragments can be formed in vivo.
共通ガンマ鎖ファミリーサイトカイン及び対応する抗体又はそれに結合する抗原結合抗体断片の追加の例は、当該技術分野で既知である。 Additional examples of common gamma chain family cytokines and corresponding antibodies or antigen-binding antibody fragments that bind thereto are known in the art.
TGF-β受容体の活性化の減少をもたらす1つ以上の作用物質の投与を含む例示的な方法
TGF-β受容体の活性化の減少をもたらす1つ以上の作用物質の治療有効量を対象に投与することを含む、対象における自然発生及び/若しくは治療誘導性老化細胞を死滅させるか又は老化細胞の数を低減させる方法が本明細書に提供される。
Exemplary Methods Comprising Administration of One or More Agents That Result in Decreased Activation of TGF-β Receptors Subject to a therapeutically effective amount of one or more agents that result in decreased activation of TGF-β receptors Provided herein are methods of killing naturally occurring and/or treatment-induced senescent cells or reducing the number of senescent cells in a subject comprising administering to.
TGF-β受容体の活性化の減少をもたらす1つ以上の作用物質の治療有効量を対象に投与することを含む、対象における自然発生及び/又は治療誘導性老化細胞の蓄積を減少させる方法も本明細書に提供される。 Also a method of reducing spontaneous and/or treatment-induced accumulation of senescent cells in a subject comprising administering to the subject a therapeutically effective amount of one or more agents that result in reduced activation of TGF-β receptors. provided herein.
TGF-β受容体の活性化の減少をもたらす1つ以上の作用物質の治療有効量を対象に投与することを含む、対象における自然発生及び/又は治療誘導性老化細胞のマーカーのレベルを減少させる方法も本明細書に提供される。いくつかの実施形態では、自然発生及び/又は治療誘導性老化細胞のマーカーは、p21CIP1p21及びCD26である。自然発生及び/又は治療誘導性老化細胞の追加のマーカーが本明細書に記載されている。自然発生及び/又は治療誘導性老化細胞の更なるマーカーは、当該技術分野で既知である。 Reducing levels of spontaneous and/or treatment-induced markers of senescent cells in a subject comprising administering to the subject a therapeutically effective amount of one or more agents that result in reduced activation of TGF-beta receptors Methods are also provided herein. In some embodiments, the markers of spontaneous and/or treatment-induced senescent cells are p21 CIP1 p21 and CD26. Additional markers of spontaneous and/or treatment-induced senescent cells are described herein. Additional markers of spontaneous and/or therapy-induced senescent cells are known in the art.
TGF-β受容体の活性化の減少をもたらす1つ以上の作用物質の治療有効量を対象に投与することを含む、対象における自然発生及び/又は治療誘導性老化細胞の活性を低減させる方法も本明細書に提供される。 Also a method of reducing spontaneous and/or treatment-induced senescent cell activity in a subject comprising administering to the subject a therapeutically effective amount of one or more agents that result in reduced activation of TGF-beta receptors. provided herein.
TGF-β受容体の活性化の減少をもたらす1つ以上の作用物質の治療有効量を対象に投与することを含む、対象における自然発生及び/又は治療誘導性老化細胞に由来する1つ以上のSASP因子のレベル及び/又は活性を減少させる方法も本明細書に提供される。いくつかの実施形態では、老化細胞は、炎症特性を発現し、炎症特性はSASP因子である。いくつかの実施形態では、SASP因子としては、炎症性サイトカイン(例えば、IL-1α、IL-1β、IL-6、IL-8、TNF-α)、成長因子(例えば、TGF-β、PDGF-AA、及びインスリン様成長因子-結合タンパク質(IGFBPs))、ケモカイン(例えば、CCL-2、CCL-20、CCL-7、CXCL-4、CXCL1、及びCXCL-12)、及びマトリックスメタロプロテイナーゼ(例えば、MMP-3及びMMP-9)が挙げられるが、これらに限定されない。いくつかの実施形態では、方法は、SASP因子のうちの1つ以上の発現レベル又は活性を減少させる。いくつかの実施形態では、SASP因子の発現レベル又は活性は、酵素結合免疫吸着アッセイ(ELISA)を使用して決定される。いくつかの実施形態では、SASP因子の発現レベル又は活性は、免疫ブロット法を使用して決定される。 one or more treatments derived from naturally occurring and/or treatment-induced senescent cells in a subject, comprising administering to the subject a therapeutically effective amount of one or more agents that result in decreased activation of TGF-β receptors. Also provided herein are methods of reducing the level and/or activity of SASP factors. In some embodiments, the senescent cells express inflammatory properties and the inflammatory properties are SASP factors. In some embodiments, SASP factors include inflammatory cytokines (eg, IL-1α, IL-1β, IL-6, IL-8, TNF-α), growth factors (eg, TGF-β, PDGF- AA, and insulin-like growth factor-binding proteins (IGFBPs)), chemokines (e.g., CCL-2, CCL-20, CCL-7, CXCL-4, CXCL1, and CXCL-12), and matrix metalloproteinases (e.g., MMP-3 and MMP-9), but not limited to. In some embodiments, the method reduces the expression level or activity of one or more of the SASP factors. In some embodiments, the SASP factor expression level or activity is determined using an enzyme-linked immunosorbent assay (ELISA). In some embodiments, the SASP factor expression level or activity is determined using immunoblotting.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、対象は、加齢関連疾患(例えば、本明細書に記載の又は当該技術分野で既知の例示的なタイプの加齢関連疾患又は状態のうちのいずれか)又は炎症性疾患(例えば、本明細書に記載の又は当該技術分野で既知の例示的なタイプの加齢関連疾患又は状態)を有すると以前に診断又は同定されている。 In some embodiments of any of the methods described herein, the subject has an age-related disease (e.g., an exemplary type of aging described herein or known in the art). previously diagnosed or identified as having an age-related disease or condition) or an inflammatory disease (e.g., exemplary types of age-related diseases or conditions described herein or known in the art) It is
いくつかの実施形態では、加齢関連疾患は、炎症老化関連である。 In some embodiments, the age-related disease is inflammatory senescence-related.
いくつかの実施形態では、加齢関連疾患は、がんである(例えば、本明細書に記載の又は当該技術分野で既知のがんの例示的なタイプのうちのいずれか)。 In some embodiments, the age-related disease is cancer (eg, any of the exemplary types of cancer described herein or known in the art).
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、炎症性疾患は、リウマチ性関節炎、炎症性腸疾患、エリテマトーデス、ループス腎炎、糖尿病性腎症、CNS損傷、アルツハイマー病、パーキンソン病、筋萎縮性側索硬化症、クローン病、多発性硬化症、ギラン・バレー症候群、乾癬、グレーブス病、潰瘍性大腸炎、非アルコール性脂肪性肝炎、気分障害、及びがん治療関連認知障害からなる群から選択される。 In some embodiments of any of the methods described herein, the inflammatory disease is rheumatoid arthritis, inflammatory bowel disease, lupus erythematosus, lupus nephritis, diabetic nephropathy, CNS injury, Alzheimer's disease, Parkinson's disease, amyotrophic lateral sclerosis, Crohn's disease, multiple sclerosis, Guillain-Barré syndrome, psoriasis, Graves' disease, ulcerative colitis, nonalcoholic steatohepatitis, mood disorders, and cancer treatment-related cognition selected from the group consisting of disorders;
これらの方法のいくつかの例では、治療誘導老化細胞は、化学療法誘導性老化細胞である。 In some examples of these methods, the treatment-induced senescent cells are chemotherapy-induced senescent cells.
これらの方法のいくつかの実施形態では、投与は、対象の標的組織(例えば、本明細書に記載の又は当該技術分野で既知の標的組織の例示的なタイプのうちのいずれか)の自然発生及び/又は治療誘導性老化細胞の数の減少(例えば、少なくとも5%減少、少なくとも10%減少、少なくとも15%減少、少なくとも20%減少、少なくとも25%減少、少なくとも30%減少、少なくとも35%減少、少なくとも40%減少、少なくとも45%減少、少なくとも50%減少、少なくとも55%減少、少なくとも60%減少、少なくとも65%減少、少なくとも70%減少、少なくとも75%減少、少なくとも80%減少、少なくとも85%減少、少なくとも90%減少、又は少なくとも95%減少、又は約5%減少~約99%減少(又は本明細書に記載のこの範囲の部分範囲のうちのいずれか))をもたらす(例えば、治療前の対象における標的組織の自然発生及び/又は治療誘導性老化細胞の数と比較して)。 In some embodiments of these methods, administering is a naturally occurring target tissue of the subject (e.g., any of the exemplary types of target tissue described herein or known in the art). and/or a reduction in the number of treatment-induced senescent cells (e.g., at least 5% reduction, at least 10% reduction, at least 15% reduction, at least 20% reduction, at least 25% reduction, at least 30% reduction, at least 35% reduction, at least 40% reduced, at least 45% reduced, at least 50% reduced, at least 55% reduced, at least 60% reduced, at least 65% reduced, at least 70% reduced, at least 75% reduced, at least 80% reduced, at least 85% reduced, at least a 90% reduction, or at least a 95% reduction, or from about a 5% reduction to about a 99% reduction (or any of the subranges of this range described herein) (e.g., pre-treatment subjects) (compared to the number of spontaneous and/or treatment-induced senescent cells in the target tissue in 20 days).
これらの方法のいくつかの実施形態では、投与は、(例えば、本明細書に記載の期間のうちのいずれか)対象における自然発生及び/又は治療誘導性老化細胞の蓄積の減少(例えば、少なくとも5%減少、少なくとも10%減少、少なくとも15%減少、少なくとも20%減少、少なくとも25%減少、少なくとも30%減少、少なくとも35%減少、少なくとも40%減少、少なくとも45%減少、少なくとも50%減少、少なくとも55%減少、少なくとも60%減少、少なくとも65%減少、少なくとも70%減少、少なくとも75%減少、少なくとも80%減少、少なくとも85%減少、少なくとも90%減少、又は少なくとも95%減少、又は約5%減少~約99%減少(又は本明細書に記載のこの範囲の部分範囲のうちのいずれか))をもたらす(例えば、治療前の対象における自然発生及び/若しくは治療誘導性老化細胞の蓄積、又は治療を受けていない同様の対象における自然発生及び/若しくは治療誘導性老化細胞の蓄積と比較して)。 In some embodiments of these methods, administering (e.g., for any of the time periods described herein) reduces the accumulation of spontaneous and/or treatment-induced senescent cells in the subject (e.g., at least 5% reduced, at least 10% reduced, at least 15% reduced, at least 20% reduced, at least 25% reduced, at least 30% reduced, at least 35% reduced, at least 40% reduced, at least 45% reduced, at least 50% reduced, at least 55% reduced, at least 60% reduced, at least 65% reduced, at least 70% reduced, at least 75% reduced, at least 80% reduced, at least 85% reduced, at least 90% reduced, or at least 95% reduced, or about 5% reduced to about a 99% reduction (or any of the subranges of this range described herein) (e.g., spontaneous and/or treatment-induced accumulation of senescent cells in the subject prior to treatment, or treatment (compared to spontaneous and/or treatment-induced accumulation of senescent cells in similar subjects not receiving treatment).
これらの方法のいくつかの実施形態では、投与は、対象における自然発生及び/又は治療誘導性老化細胞の1つ以上(例えば、2つ、3つ、又は4つ)のマーカーのレベルの減少(例えば、少なくとも5%減少、少なくとも10%減少、少なくとも15%減少、少なくとも20%減少、少なくとも25%減少、少なくとも30%減少、少なくとも35%減少、少なくとも40%減少、少なくとも45%減少、少なくとも50%減少、少なくとも55%減少、少なくとも60%減少、少なくとも65%減少、少なくとも70%減少、少なくとも75%減少、少なくとも80%減少、少なくとも85%減少、少なくとも90%減少、又は少なくとも95%減少、又は約5%減少~約99%減少(又は本明細書に記載のこの範囲の部分範囲のうちのいずれか))をもたらす(例えば、治療前の対象における自然発生及び/又は治療誘導性老化細胞の1つ以上のマーカーのレベルと比較して)。 In some embodiments of these methods, administering reduces the levels of one or more (e.g., 2, 3, or 4) markers of spontaneous and/or treatment-induced senescent cells in the subject ( For example, at least 5% decreased, at least 10% decreased, at least 15% decreased, at least 20% decreased, at least 25% decreased, at least 30% decreased, at least 35% decreased, at least 40% decreased, at least 45% decreased, at least 50% reduced, at least 55% reduced, at least 60% reduced, at least 65% reduced, at least 70% reduced, at least 75% reduced, at least 80% reduced, at least 85% reduced, at least 90% reduced, or at least 95% reduced, or about 5% to about 99% reduction (or any of the subranges of this range described herein) (e.g., one of the naturally occurring and/or treatment-induced senescent cells in the subject prior to treatment). compared to the levels of one or more markers).
いくつかの実施形態では、TGF-β受容体は、TGF-β受容体II(TGF-βRII)である。 In some embodiments, the TGF-beta receptor is TGF-beta receptor II (TGF-betaRII).
いくつかの実施形態では、TGF-β受容体は、TGF-βRIIIである。 In some embodiments, the TGF-β receptor is TGF-βRIII.
いくつかの実施形態では、TGF-β受容体の活性化の減少をもたらす1つ以上の作用物質のうちの少なくとも1つは、可溶性TGF-β受容体、TGF-β受容体の細胞外ドメイン、TGF-βに特異的に結合する抗体、TGF-β受容体に結合するアンタゴニスト抗体、LAPに結合する作用物質、又はTGF-β/LAP複合体に結合する作用物質である。いくつかの実施形態では、TGF-β受容体の活性化の減少をもたらす1つ以上の作用物質は、LAPへの又はTGF-β/LAP複合体への結合を介してTGF-β受容体の活性化を減少させる。TGF-β受容体の活性化の減少をもたらす作用物質の非限定的な例を以下に記載する。 In some embodiments, at least one of the one or more agents that result in decreased TGF-beta receptor activation is a soluble TGF-beta receptor, an extracellular domain of a TGF-beta receptor, An antibody that specifically binds to TGF-beta, an antagonistic antibody that binds to a TGF-beta receptor, an agent that binds to LAP, or an agent that binds to the TGF-beta/LAP complex. In some embodiments, the one or more agents that result in decreased activation of the TGF-beta receptor are those of the TGF-beta receptor through binding to LAP or to the TGF-beta/LAP complex. Decrease activation. Non-limiting examples of agents that result in decreased activation of TGF-β receptors are described below.
TGF-β受容体の活性化の減少をもたらす作用物質
TGF-β受容体の活性化の減少をもたらす1つ以上の作用物質の使用又は投与を含む方法が、本明細書に提供される。いくつかの実施形態では、TGF-β受容体の活性化の減少をもたらす作用物質は、一本鎖キメラポリペプチド(例えば、本明細書に記載の例示的な一本鎖キメラポリペプチドのうちのいずれか)、多鎖キメラポリペプチド(例えば、本明細書に記載の例示的な多鎖キメラポリペプチドのうちのいずれか)、可溶性TGF-β受容体、TGF-β受容体の細胞外ドメイン、TGF-βに特異的に結合する抗体(又は抗体断片)、TGF-β受容体に結合するアンタゴニスト抗体、LAPに結合する作用物質、又はTGF-β/LAP複合体に結合する作用物質である。
Agents That Result in Decreased Activation of TGF-β Receptors Methods are provided herein that involve the use or administration of one or more agents that result in decreased activation of TGF-β receptors. In some embodiments, the agent that results in decreased TGF-β receptor activation is a single-chain chimeric polypeptide (eg, one of the exemplary single-chain chimeric polypeptides described herein). any), a multi-chain chimeric polypeptide (eg, any of the exemplary multi-chain chimeric polypeptides described herein), a soluble TGF-β receptor, the extracellular domain of a TGF-β receptor, An antibody (or antibody fragment) that specifically binds to TGF-beta, an antagonistic antibody that binds to a TGF-beta receptor, an agent that binds LAP, or an agent that binds to the TGF-beta/LAP complex.
例示的な一本鎖キメラポリペプチド
TGF-β受容体の活性化の減少をもたらす作用物質の非限定的な例は、(i)第1の標的結合ドメイン、(ii)可溶性組織因子ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な可溶性組織因子ドメインのうちのいずれか)、及び(iii)第2の標的結合ドメインを含む一本鎖キメラポリペプチドであり、第1の標的結合ドメイン及び第2の標的結合ドメインのうちの一方若しくは両方は、TGF-β受容体のリガンドに特異的に結合するか、又は第1の標的結合ドメイン及び第2の標的結合ドメインのうちの一方若しくは両方は、TGF-β受容体に特異的に結合するアンタゴニスト抗原結合ドメインである。いくつかの実施形態では、TGF-β受容体は、TGF-βRIIである。いくつかの実施形態では、TGF-β受容体は、TGF-βRIIIである。
Exemplary Single Chain Chimeric Polypeptides Non-limiting examples of agents that result in decreased activation of the TGF-β receptor include (i) a first target binding domain, (ii) a soluble tissue factor domain (e.g. any of the exemplary soluble tissue factor domains described herein or known in the art), and (iii) a second target binding domain; One or both of the one target-binding domain and the second target-binding domain specifically bind to a ligand of the TGF-β receptor, or the first target-binding domain and the second target-binding domain One or both of them are antagonist antigen binding domains that specifically bind to the TGF-β receptor. In some embodiments, the TGF-β receptor is TGF-βRII. In some embodiments, the TGF-β receptor is TGF-βRIII.
本明細書に記載の一本鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態は、そのN末端及び/又はC末端に1つ以上(例えば、2、3、4、5、6、7、8、9、又は10)の追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)を更に含み得る。 Some embodiments of any of the single-chain chimeric polypeptides described herein have one or more (e.g., 2, 3, 4, 5, 6, 7, 8, 9, or 10) additional target binding domains (eg, any of the exemplary target binding domains described herein or known in the art).
本明細書に記載の一本鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)及び/又は第2の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)は、可溶性TGF-β受容体である。可溶性TGF-β受容体の非限定的な例としては、可溶性TGFβRI、可溶性TGFβRII、可溶性TGFβRIII、及び可溶性エンドグリンが挙げられる。例示的な可溶性TGFβRIIの非限定的な配列は、本明細書に記載されている。 In some embodiments of any of the single chain chimeric polypeptides described herein, the first target binding domain (e.g., an exemplary any of the target binding domains) and/or the second target binding domain (e.g., any of the exemplary target binding domains described herein or known in the art) is a soluble TGF - Beta receptors. Non-limiting examples of soluble TGF-β receptors include soluble TGFβRI, soluble TGFβRII, soluble TGFβRIII, and soluble endoglin. Non-limiting sequences of exemplary soluble TGFβRII are described herein.
例示的な多鎖キメラポリペプチド
TGF-β受容体の活性化の減少をもたらす作用物質の非限定的な例は、(a)(i)第1の標的結合ドメイン、(ii)可溶性組織因子ドメイン、及び(iii)一対の親和性ドメインの第1のドメインを含む第1のキメラポリペプチドと、(b)(i)一対の親和性ドメインの第2のドメイン、及び(ii)第2の標的結合ドメインを含む第2のキメラポリペプチドと、を含む多鎖キメラポリペプチドであり、第1の標的結合ドメイン及び第2の標的結合ドメインのうちの一方若しくは両方は、TGF-β受容体のリガンドに特異的に結合するか、又は第1の標的結合ドメイン及び第2の標的結合ドメインのうちの一方若しくは両方は、TGF-β受容体に特異的に結合するアンタゴニスト抗原結合ドメインである。
Exemplary Multichain Chimeric Polypeptides Non-limiting examples of agents that result in decreased TGF-β receptor activation include (a) (i) a first target binding domain, (ii) a soluble tissue factor domain and (iii) a first chimeric polypeptide comprising a first of the pair of affinity domains, and (b) (i) a second of the pair of affinity domains, and (ii) a second target a second chimeric polypeptide comprising a binding domain, wherein one or both of the first target-binding domain and the second target-binding domain are a ligand of a TGF-β receptor or one or both of the first and second target binding domains is an antagonist antigen binding domain that specifically binds to the TGF-β receptor.
多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1のキメラポリペプチドは、1つ以上(例えば、2つ、3つ、4つ、5つ、6つ、7つ、8つ、9つ、又は10)の追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)を更に含む。 In some embodiments of any of the multi-chain chimeric polypeptides, the first chimeric polypeptide has one or more (e.g., two, three, four, five, six, seven, 8, 9, or 10) additional target binding domains (eg, any of the exemplary target binding domains described herein or known in the art).
多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第2のキメラポリペプチドは、1つ以上(例えば、2つ、3つ、4つ、5つ、6つ、7つ、8つ、9つ、又は10)の追加の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)を更に含む。 In some embodiments of any of the multi-chain chimeric polypeptides, the second chimeric polypeptide comprises one or more (e.g., two, three, four, five, six, seven, 8, 9, or 10) additional target binding domains (eg, any of the exemplary target binding domains described herein or known in the art).
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)及び/又は第2の標的結合ドメイン(例えば、本明細書に記載の又は当該技術分野で既知の例示的な標的結合ドメインのうちのいずれか)は、可溶性TGF-β受容体である。可溶性TGF-β受容体の非限定的な例としては、可溶性TGFβRI、可溶性TGFβRII、可溶性TGFβRIII、及び可溶性エンドグリンが挙げられる。 In some embodiments of any of the multi-chain chimeric polypeptides described herein, the first target binding domain (e.g., exemplary targets described herein or known in the art) binding domain) and/or the second target binding domain (eg, any of the exemplary target binding domains described herein or known in the art) is a soluble TGF- β-receptor. Non-limiting examples of soluble TGF-β receptors include soluble TGFβRI, soluble TGFβRII, soluble TGFβRIII, and soluble endoglin.
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、一対の親和性ドメインは、ヒトIL-15受容体のアルファ鎖(IL15Rα)由来のスシドメイン、及び可溶性IL-15である。本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、可溶性IL-15は、D8N又はD8Aアミノ酸置換を有する。いくつかの実施形態では、可溶性IL-15は、IL-15活性を低減又は排除するための変異を含む。 In some embodiments of any of the multi-chain chimeric polypeptides described herein, the pair of affinity domains are a sushi domain derived from the alpha chain of the human IL-15 receptor (IL15Rα) and a soluble IL-15. In some embodiments of any of the multi-chain chimeric polypeptides described herein, the soluble IL-15 has a D8N or D8A amino acid substitution. In some embodiments, soluble IL-15 comprises mutations to reduce or eliminate IL-15 activity.
本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、一対の親和性ドメインは、バルナーゼ及びバルンスター、PKA及びAKAP、変異RNaseI断片に基づくアダプター/ドッキングタグモジュール、並びに、タンパク質シンタキシン、シナプトタグミン、シナプトブレビン、及びSNAP25の相互作用に基づくSNAREモジュールからなる群から選択される。本明細書に記載の多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、一対の親和性ドメインの第1のドメイン又は第2のドメインは、可溶性共通ガンマ鎖ファミリーサイトカイン、又は共通ガンマ鎖ファミリーサイトカイン受容体に特異的に結合する抗原結合ドメインである。 In some embodiments of any of the multi-chain chimeric polypeptides described herein, the pair of affinity domains are barnase and barnstar, PKA and AKAP, adapter/docking tag modules based on mutated RNase I fragments. , and a SNARE module based on the interaction of proteins syntaxin, synaptotagmin, synaptobrevin, and SNAP25. In some embodiments of any of the multichain chimeric polypeptides described herein, the first domain or the second domain of the pair of affinity domains is a soluble common gamma chain family cytokine, or a common An antigen binding domain that specifically binds to gamma chain family cytokine receptors.
TGF-β受容体の活性化の減少をもたらす作用物質である多鎖キメラポリペプチドの非限定的な例は、「例示的な多鎖キメラポリペプチド-タイプB、G、I、K、L、M、N、O、及びP」と題された本明細書のサブセクションに記載されるものである。 Non-limiting examples of multi-chain chimeric polypeptides that are agents that result in decreased activation of TGF-β receptors are described in "Exemplary Multi-Chain Chimeric Polypeptides—Types B, G, I, K, L, M, N, O, and P” in the subsections herein.
可溶性TGF-β受容体
いくつかの実施形態では、TGF-β受容体の活性化の減少をもたらす1つ以上の作用物質は、可溶性TGF-β受容体である。いくつかの実施形態では、TGF-β受容体の活性化の減少をもたらす1つ以上の作用物質は、可溶性TGF-β受容体である。可溶性TGF-β受容体の非限定的な例としては、可溶性TGFβRI、可溶性TGFβRII、可溶性TGFβRIII、及び可溶性エンドグリンが挙げられる。
Soluble TGF-beta Receptor In some embodiments, the one or more agents that result in decreased activation of the TGF-beta receptor is a soluble TGF-beta receptor. In some embodiments, the one or more agents that result in decreased TGF-beta receptor activation are soluble TGF-beta receptors. Non-limiting examples of soluble TGF-β receptors include soluble TGFβRI, soluble TGFβRII, soluble TGFβRIII, and soluble endoglin.
いくつかの実施形態では、TGF-β受容体は、TGF-β受容体II(TGFβRII)である。いくつかの実施形態では、TGFβ受容体は、TGFβRIIIである。 In some embodiments, the TGF-beta receptor is TGF-beta receptor II (TGFβRII). In some embodiments, the TGFβ receptor is TGFβRIII.
I型受容体であるTGFβRIは、TGF-βに結合するためにTGFβRIIの存在を必要とする膜結合セリン/スレオニンキナーゼである。II型受容体であるTGFβRIIは、TGF-β1及びTGF-β3と高い親和性で結合し、TGF-β2とはるかに低い親和性で結合する膜結合セリン/スレオニンキナーゼである。いくつかの実施形態では、シグナル伝達は、TGFβRI及びTGFβRIIの両方の細胞質ドメインを必要とする。III型受容体であるTGF-βRIIIは、膜結合型及び可溶型で存在し、TGF-β1、TGF-β2、及びTGF-β3に結合するが、シグナル伝達には関与していないプロテオグリカンである。可溶性TGFβRIIの配列の非限定的な例は、本明細書に記載されている。 The type I receptor, TGFβRI, is a membrane bound serine/threonine kinase that requires the presence of TGFβRII to bind TGF-β. The type II receptor, TGFβRII, is a membrane-associated serine/threonine kinase that binds TGF-β1 and TGF-β3 with high affinity and TGF-β2 with much lower affinity. In some embodiments, signaling requires the cytoplasmic domains of both TGFβRI and TGFβRII. The type III receptor, TGF-βRIII, is a proteoglycan that exists in membrane-bound and soluble forms and binds TGF-β1, TGF-β2, and TGF-β3, but is not involved in signal transduction. . Non-limiting examples of sequences for soluble TGFβRII are described herein.
抗原結合ドメイン
本明細書に記載の一本鎖又は多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方が、抗原結合ドメインである。本明細書に記載の一本鎖又は多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインは各々、抗原結合ドメインである。本明細書に記載の一本鎖又は多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、抗原結合ドメインは、scFv又は単一ドメイン抗体(例えば、VHH又はVNARドメイン)を含むか、又はそれである。
Antigen Binding Domains In some embodiments of any of the single-chain or multi-chain chimeric polypeptides described herein, one or both of the first and second target binding domains It is an antigen-binding domain. In some embodiments of any of the single- or multi-chain chimeric polypeptides described herein, the first target binding domain and the second target binding domain are each antigen binding domains. In some embodiments of any of the single-chain or multi-chain chimeric polypeptides described herein, the antigen-binding domain comprises a scFv or single domain antibody (e.g., VHH or VNAR domains) , or it is.
本明細書に記載の一本鎖又は多鎖キメラポリペプチドのうちのいずれかのいくつかの実施形態では、第1の標的結合ドメイン及び第2の標的結合ドメインのうちの一方又は両方は、TGF-βに特異的に結合するアンタゴニスト抗原結合ドメインである。いくつかの例では、アンタゴニスト抗原結合ドメイン(例えば、本明細書に記載の抗原結合ドメインのうちのいずれか)は、可溶性TGFβRI、可溶性TGFβRII、可溶性TGFβRIII、又は可溶性エンドグリンに特異的に結合することができる。 In some embodiments of any of the single- or multi-chain chimeric polypeptides described herein, one or both of the first and second target binding domains are TGF - An antagonist antigen binding domain that specifically binds to β. In some examples, the antagonist antigen binding domain (e.g., any of the antigen binding domains described herein) specifically binds soluble TGFβRI, soluble TGFβRII, soluble TGFβRIII, or soluble endoglin. can be done.
いくつかの実施形態では、本明細書に記載の抗原結合ドメインのうちのいずれかは、BiTe、(scFv)2、ナノボディ、ナノボディ-HSA、DART、TandAb、scDiabody、scDiabody-CH3、scFv-CH-CL-scFv、HSAbody、scDiabody-HSA、又はタンデム-scFvである。一本鎖キメラポリペプチド又は多鎖キメラポリペプチドのうちのいずれかで使用することができる抗原結合ドメインの追加の例は、当該技術分野で既知である。 In some embodiments, any of the antigen binding domains described herein are BiTe, (scFv) 2 , Nanobody, Nanobody-HSA, DART, TandAb, scDiabody, scDiabody-CH3, scFv-CH- CL-scFv, HSAbody, scDiabody-HSA, or tandem-scFv. Additional examples of antigen binding domains that can be used in either single-chain chimeric polypeptides or multi-chain chimeric polypeptides are known in the art.
いくつかの実施形態では、一本鎖又は多鎖キメラポリペプチドに存在する2つ以上のポリペプチドは、集合して(例えば、非共有結合的に集合して)、本明細書に記載の抗原結合ドメインのうちのいずれか、例えば、抗体の抗原結合断片(例えば、本明細書に記載の抗体の抗原結合断片のうちのいずれか)、VHH-scAb、VHH-Fab、二重scFab、F(ab’)2、ダイアボディ、crossMab、DAF(ツーインワン)、DAF(フォーインワン)、DutaMab、DT-IgG、ノブ・イン・ホール共通軽鎖、ノブ・イン・ホール集合体、電荷対、Fabアーム交換、SEEDbody、LUZ-Y、Fcab、κλ-ボディ、直交Fab、DVD-IgG、IgG(H)-scFv、scFv-(H)IgG、IgG(L)-scFv、scFv-(L)IgG、IgG(L,H)-Fv、IgG(H)-V、V(H)-IgG、IgG(L)-V、V(L)-IgG、KIH IgG-scFab、2scFv-IgG、IgG-2scFv、scFv4-Ig、Zybody、DVI-IgG、ダイアボディ-CH3、トリプルボディ、ミノ抗体、ミニボディ、TriBiミニボディ、scFv-CH3KIH、Fab-scFv、F(ab’)2-scFv2、scFv-KIH、Fab-scFv-Fc、四価HCAb、scダイアボディ-Fc、ダイアボディ-Fc、タンデムscFv-Fc、イントラボディ、ドック・アンド・ロック、lmmTAC、IgG-IgGコンジュゲート、Cov-X-Body、及びscFv1-PEG-scFv2を形成することができる。これらの要素の説明については、例えば、全体が本明細書に組み込まれるSpiess et al.,Mol.Immunol.67:95-106,2015を参照されたい。 In some embodiments, two or more polypeptides present in a single-chain or multi-chain chimeric polypeptide are assembled (e.g., non-covalently assembled) to form an antigen described herein. Any of the binding domains, e.g., an antigen-binding fragment of an antibody (e.g., any of the antigen-binding fragments of an antibody described herein), VHH-scAb, VHH-Fab, double scFab, F ( ab′) 2 , diabody, crossMab, DAF (two-in-one), DAF (four-in-one), DutaMab, DT-IgG, knob-in-hole common light chain, knob-in-hole assembly, charge pair, Fab arm exchange , SEEDbody, LUZ-Y, Fcab, κλ-body, Orthogonal Fab, DVD-IgG, IgG(H)-scFv, scFv-(H)IgG, IgG(L)-scFv, scFv-(L)IgG, IgG ( L,H)-Fv, IgG(H)-V, V(H)-IgG, IgG(L)-V, V(L)-IgG, KIH IgG-scFab, 2scFv-IgG, IgG-2scFv, scFv4- Ig, Zybody, DVI-IgG, Diabody-CH3, Triple body, Mino antibody, Minibody, TriBi minibody, scFv-CH3KIH, Fab-scFv, F(ab') 2 -scFv 2 , scFv-KIH, Fab- scFv-Fc, tetravalent HCAb, sc diabody-Fc, diabody-Fc, tandem scFv-Fc, intrabody, dock and lock, lmmTAC, IgG-IgG conjugate, Cov-X-Body, and scFv1- PEG-scFv 2 can be formed. For a description of these elements, see, for example, Spiess et al. , Mol. Immunol. 67:95-106, 2015.
抗体の抗原結合断片の非限定的な例には、Fv断片、Fab断片、F(ab’)2断片、及びFab’断片が挙げられる。抗体の抗原結合断片の追加の例は、IgGの抗原結合断片(例えば、IgG1、IgG2、IgG3、又はIgG4の抗原結合断片)(例えば、ヒト又はヒト化IgG、例えば、ヒト又はヒト化IgG1、IgG2、IgG3、又はIgG4の抗原結合断片)、IgAの抗原結合断片(例えば、IgA1又はIgA2の抗原結合断片)(例えば、ヒト又はヒト化IgA、例えば、ヒト又はヒト化IgA1又はIgA2の抗原結合断片)、IgDの抗原結合断片(例えば、ヒト又はヒト化IgDの抗原結合断片)、IgEの抗原結合断片(例えば、ヒト又はヒト化IgEの抗原結合断片)、又はIgMの抗原結合断片(例えば、ヒト又はヒト化IgMの抗原結合断片)である。 Non-limiting examples of antigen-binding fragments of antibodies include Fv, Fab, F(ab') 2 , and Fab' fragments. Additional examples of antigen-binding fragments of antibodies include antigen-binding fragments of IgG (e.g., antigen-binding fragments of IgG1, IgG2, IgG3, or IgG4) (e.g., human or humanized IgG, e.g., human or humanized IgG1, IgG2 , IgG3, or IgG4), antigen-binding fragments of IgA (e.g., antigen-binding fragments of IgA1 or IgA2) (e.g., human or humanized IgA, e.g., antigen-binding fragments of human or humanized IgA1 or IgA2) , an antigen-binding fragment of IgD (e.g., an antigen-binding fragment of human or humanized IgD), an antigen-binding fragment of IgE (e.g., an antigen-binding fragment of human or humanized IgE), or an antigen-binding fragment of IgM (e.g., human or antigen-binding fragment of humanized IgM).
潜在関連ペプチド(LAP)に結合する作用物質
潜在関連ペプチド(LAP)に結合する作用物質の非限定的な例は、TGF-β1、トロンボスポンジン-1(TSP-1)、インテグリンαvβ6、又はKRFKペプチドである。いくつかの実施形態では、LAPは、TGF-β1に結合して潜在的複合体を形成し、LAPは、活性TGF-β1の封鎖剤として機能すると推定される。いくつかの実施形態では、潜在的TGF-β複合体のLAPはまた、生物学的に活性な複合体の一部としてトロンボスポンジン-1(TSP-1)と相互作用する。TSP-1/LAP複合体の形成には、TPS-1の活性化配列(KRFK)、及びTGF-β1-5に保存されているLAPのアミノ末端付近の配列(LSKL)が関与する。LSKLペプチドはTSP-1又はKRFK含有ペプチドによる潜在的TGF-β活性化を競合的に阻害できるため、LSKL及びKRFK配列を介したLAPとTSP-1との相互作用は、トロンボスポンジンを介した潜在的TGF-βの活性化にとって重要である。いくつかの実施形態では、インテグリンαvβ6は、TGF-β1 LAPに対して高い親和性を有し、TGF-β1潜在的複合体の活性化に関与することが示されている。
Agents that Bind Latent Associated Peptides (LAPs) Non-limiting examples of agents that bind latent associated peptides (LAPs) are TGF-β1, thrombospondin-1 (TSP-1), integrin αvβ6, or KRFK is a peptide. In some embodiments, LAP binds TGF-β1 to form a latent complex, and LAP is presumed to function as a sequestering agent of active TGF-β1. In some embodiments, LAP of a potential TGF-β complex also interacts with thrombospondin-1 (TSP-1) as part of a biologically active complex. Formation of the TSP-1/LAP complex involves the activation sequence of TPS-1 (KRFK) and a sequence near the amino terminus of LAP conserved in TGF-β1-5 (LSKL). The interaction of LAP with TSP-1 via the LSKL and KRFK sequences was thrombospondin-mediated, as LSKL peptides can competitively inhibit potential TGF-β activation by TSP-1 or KRFK-containing peptides. Important for potential TGF-β activation. In some embodiments, integrin αvβ6 has a high affinity for TGF-β1 LAP and has been shown to be involved in activation of the TGF-β1 latent complex.
TGF-β/LAP複合体に結合する作用物質
TFG-β/LAP複合体に結合する作用物質の非限定的な例は、潜在的TGF-β結合タンパク質(LTBP)である。いくつかの実施形態では、潜在的TGF-β結合タンパク質(LTBP)は、TFG-β/LAP複合体に結合し、大きな潜在的複合体(LLC)と呼ばれるより大きな複合体を形成する。いくつかの実施形態では、LTBPには、LTBP-1、LTBP-2、LTBP-3及びLTBP-4が含まれる。いくつかの実施形態では、LTBP-1は、小胞体内でTGFβプロペプチド(例えば、LAP)とジスルフィド結合複合体を形成する。いくつかの実施形態では、LTBP-4は、TGF-β1のみに結合し、したがって、LTBP-4の変異は、主にTGF-β1が関与する組織に特異的なTGF-β関連合併症を引き起こす可能性がある。
Agents that bind to the TGF-β/LAP complex A non-limiting example of an agent that binds to the TGF-β/LAP complex is the latent TGF-β binding protein (LTBP). In some embodiments, a latent TGF-beta binding protein (LTBP) binds to the TFG-beta/LAP complex to form a larger complex called the large latent complex (LLC). In some embodiments, LTBPs include LTBP-1, LTBP-2, LTBP-3 and LTBP-4. In some embodiments, LTBP-1 forms a disulfide-bonded complex with a TGFβ propeptide (eg, LAP) within the endoplasmic reticulum. In some embodiments, LTBP-4 binds only to TGF-β1, thus mutations in LTBP-4 lead to TGF-β-related complications that are primarily tissue-specific in which TGF-β1 is involved. there is a possibility.
投与方法
本明細書に記載の方法のいくつかの実施形態は、TGF-β受容体の活性化の減少をもたらす1つ以上の作用物質の1回又は2回以上(例えば、3回以上、4回以上、5回以上、6回以上、7回以上、8回以上、9回以上、10回以上)の用量を対象に投与することを含む。これらの方法のいくつかの実施形態では、2回以上の用量のうちの任意の2回の連続用量は、約1週間~約1年間隔(例えば、約1週間~約11ヶ月、約1週間~約10ヶ月、約1週間~約9ヶ月、約1週間~約8ヶ月、約1週間~約7ヶ月、約1週間~約6ヶ月、約1週間~約5ヶ月、約1週間~約4ヶ月、約1週間~約3ヶ月、約1週間~約2ヶ月、約1週間~約1ヶ月、約1週間~約3週間、約1週間~約2週間、約2週間~約12ヶ月、約2週間~約11ヶ月、約2週間~約10ヶ月、約2週間~約9ヶ月、約2週間~約8ヶ月、約2週間~約7ヶ月、約2週間~約6ヶ月、約2週間~約5ヶ月、約2週間~約4ヶ月、約2週間~約3ヶ月、約2週間~約2ヶ月、約2週間~約1ヶ月、約2週間~約3週間、約3週間~約12ヶ月、約3週間~約11ヶ月、約3週間~約10ヶ月、約3週間~約9ヶ月、約3週間~約8ヶ月、約3週間~約7ヶ月、約3週間~約6ヶ月、約3週間~約5ヶ月、約3週間~約4ヶ月、約3週間~約3ヶ月、約3週間~約2ヶ月、約3週間~約1ヶ月、約1ヶ月~約12ヶ月、約1ヶ月~約11ヶ月、約1ヶ月~約10ヶ月、約1ヶ月~約9ヶ月、約1ヶ月~約8ヶ月、約1ヶ月~約7ヶ月、約1ヶ月~約6ヶ月、約1ヶ月~約5ヶ月、約1ヶ月~約4ヶ月、約1ヶ月~約3ヶ月、約1ヶ月~約2ヶ月、約2ヶ月~約12ヶ月、約2ヶ月~約11ヶ月、約2ヶ月~約10ヶ月、約2ヶ月~約9ヶ月、約2ヶ月~約8ヶ月、約2ヶ月~約7ヶ月、約2ヶ月~約6ヶ月、約2ヶ月~約5ヶ月、約2ヶ月~約4ヶ月、約2ヶ月~約3ヶ月、約3ヶ月~約12ヶ月、約3ヶ月~約11ヶ月、約3ヶ月~約10ヶ月、約3ヶ月~約9ヶ月、約3ヶ月~約8ヶ月、約3ヶ月~約7ヶ月、約3ヶ月~約6ヶ月、約3ヶ月~約5ヶ月、約3ヶ月~約4ヶ月、約4ヶ月~約12ヶ月、約4ヶ月~約11ヶ月、約4ヶ月~約10ヶ月、約4ヶ月~約9ヶ月、約4ヶ月~約8ヶ月、約4ヶ月~約7ヶ月、約4ヶ月~約6ヶ月、約4ヶ月~約5ヶ月、約4ヶ月~約4ヶ月、約5ヶ月~約12ヶ月、約5ヶ月~約11ヶ月、約5ヶ月~約10ヶ月、約5ヶ月~約9ヶ月、約5ヶ月~約8ヶ月、約5ヶ月~約7ヶ月、約5ヶ月~約6ヶ月、約6ヶ月~約12ヶ月、約6ヶ月~約11ヶ月、約6ヶ月~約10ヶ月、約6ヶ月~約9ヶ月、約6ヶ月~約8ヶ月、約6ヶ月~約7ヶ月、約7ヶ月~約12ヶ月、約7ヶ月~約11ヶ月、約7ヶ月~約10ヶ月、約7ヶ月~約9ヶ月、約7ヶ月~約8ヶ月、約8ヶ月~約12ヶ月、約8ヶ月~約11ヶ月、約8ヶ月~約10ヶ月、約8ヶ月~約9ヶ月、約9ヶ月~約12ヶ月、約9ヶ月~約11ヶ月、約9ヶ月~約10ヶ月、約10ヶ月~約12ヶ月、約10ヶ月~約11ヶ月、又は約11ヶ月~約12ヶ月間隔)で投与される。
Methods of Administration Some embodiments of the methods described herein include administering one or more agents one or more times (e.g., three or more times, four 1 or more, 5 or more, 6 or more, 7 or more, 8 or more, 9 or more, 10 or more) doses to the subject. In some embodiments of these methods, any two sequential doses of the two or more doses are spaced about one week to about one year apart (eg, about one week to about 11 months, about one week ~ about 10 months, about 1 week to about 9 months, about 1 week to about 8 months, about 1 week to about 7 months, about 1 week to about 6 months, about 1 week to about 5 months, about 1 week to about 4 months, about 1 week to about 3 months, about 1 week to about 2 months, about 1 week to about 1 month, about 1 week to about 3 weeks, about 1 week to about 2 weeks, about 2 weeks to about 12 months , about 2 weeks to about 11 months, about 2 weeks to about 10 months, about 2 weeks to about 9 months, about 2 weeks to about 8 months, about 2 weeks to about 7 months, about 2 weeks to about 6 months, about 2 weeks to about 5 months, about 2 weeks to about 4 months, about 2 weeks to about 3 months, about 2 weeks to about 2 months, about 2 weeks to about 1 month, about 2 weeks to about 3 weeks, about 3 weeks ~ about 12 months, about 3 weeks to about 11 months, about 3 weeks to about 10 months, about 3 weeks to about 9 months, about 3 weeks to about 8 months, about 3 weeks to about 7 months, about 3 weeks to about 6 months, about 3 weeks to about 5 months, about 3 weeks to about 4 months, about 3 weeks to about 3 months, about 3 weeks to about 2 months, about 3 weeks to about 1 month, about 1 month to about 12 months , about 1 month to about 11 months, about 1 month to about 10 months, about 1 month to about 9 months, about 1 month to about 8 months, about 1 month to about 7 months, about 1 month to about 6 months, about 1 month to about 5 months, about 1 month to about 4 months, about 1 month to about 3 months, about 1 month to about 2 months, about 2 months to about 12 months, about 2 months to about 11 months, about 2 months ~ about 10 months, about 2 months to about 9 months, about 2 months to about 8 months, about 2 months to about 7 months, about 2 months to about 6 months, about 2 months to about 5 months, about 2 months to about 4 months, about 2 months to about 3 months, about 3 months to about 12 months, about 3 months to about 11 months, about 3 months to about 10 months, about 3 months to about 9 months, about 3 months to about 8 months , about 3 months to about 7 months, about 3 months to about 6 months, about 3 months to about 5 months, about 3 months to about 4 months, about 4 months to about 12 months, about 4 months to about 11 months, about 4 months to about 10 months, about 4 months to about 9 months, about 4 months to about 8 months, about 4 months to about 7 months, about 4 months to about 6 months, about 4 months to about 5 months, about 4 months ~ about 4 months, about 5 months to about 12 months, about 5 months to about 11 months, about 5 months to about 10 months, about 5 months to about 9 months, about 5 months to about 8 months, about 5 months to about 7 months, about 5 months to about 6 months, about 6 months to about 12 months, about 6 months to about 11 months, about 6 months to about 10 months, about 6 months to about 9 months, about 6 months to about 8 months , about 6 months to about 7 months, about 7 months to about 12 months, about 7 months to about 11 months, about 7 months to about 10 months, about 7 months to about 9 months, about 7 months to about 8 months, about 8 months to about 12 months, about 8 months to about 11 months, about 8 months to about 10 months, about 8 months to about 9 months, about 9 months to about 12 months, about 9 months to about 11 months, about 9 months about 10 months, about 10 months to about 12 months, about 10 months to about 11 months, or about 11 months to about 12 months).
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、1回又は2回以上の用量が皮下投与によって投与される。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、1回又は2回以上の用量が筋肉内投与によって投与される。 In some embodiments of any of the methods described herein, one or more doses are administered by subcutaneous administration. In some embodiments of any of the methods described herein, one or more doses are administered by intramuscular administration.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、2回以上の用量は、約1年~約60年(例えば、約1年~約55年、約1年~約50年、約1年~約45年、約1年~約40年、約1年~約35年、約1年~約30年、約1年~約25年、約1年~約20年、約1年~約15年、約1年~約10年、約1年~約5年、約5年~約60年、約5年~約55年、約5年~約50年、約5年~約45年、約5年~約40年、約5年~約35年、約5年~約30年、約5年~約25年、約5年~約20年、約5年~約15年、約5年~約10年、約10年~約60年、約10年~約55年、約10年~約50年、約10年~約45年、約10年~約40年、約10年~約35年、約10年~約30年、約10年~約25年、約10年~約20年、約10年~約15年、約15年~約60年、約15年~約55年、約15年~約50年、約15年~約45年、約15年~約40年、約15年~約35年、約15年~約30年、約15年~約25年、約15年~約20年、約20年~約60年、約20年~約55年、約20年~約50年、約20年~約45年、約20年~約40年、約20年~約35年、約20年~約30年、約20年~約25年、約25年~約60年、約25年~約55年、約25年~約50年、約25年~約45年、約25年~約40年、約25年~約35年、約25年~約30年、約30年~約60年、約30年~約55年、約30年~約50年、約30年~約45年、約30年~約40年、約30年~約35年、約35年~約60年、約35年~約55年、約35年~約50年、約35年~約45年、約35年~約40年、約40年~約60年、約40年~約55年、約40年~約50年、約40年~約45年、約45年~約60年、約45年~約55年、約45年~約50年、約50年~約60年、約50年~約55年、又は約55年~約60年)の期間にわたって投与される。 In some embodiments of any of the methods described herein, the two or more doses are administered from about 1 year to about 60 years (eg, from about 1 year to about 55 years, from about 1 year to about 50 years, about 1 year to about 45 years, about 1 year to about 40 years, about 1 year to about 35 years, about 1 year to about 30 years, about 1 year to about 25 years, about 1 year to about 20 years , about 1 year to about 15 years, about 1 year to about 10 years, about 1 year to about 5 years, about 5 years to about 60 years, about 5 years to about 55 years, about 5 years to about 50 years, about 5 years to about 45 years, about 5 years to about 40 years, about 5 years to about 35 years, about 5 years to about 30 years, about 5 years to about 25 years, about 5 years to about 20 years, about 5 years ~ about 15 years, about 5 years to about 10 years, about 10 years to about 60 years, about 10 years to about 55 years, about 10 years to about 50 years, about 10 years to about 45 years, about 10 years to about 40 years, about 10 years to about 35 years, about 10 years to about 30 years, about 10 years to about 25 years, about 10 years to about 20 years, about 10 years to about 15 years, about 15 years to about 60 years , about 15 to about 55 years, about 15 to about 50 years, about 15 to about 45 years, about 15 to about 40 years, about 15 to about 35 years, about 15 to about 30 years, about 15 years to about 25 years, about 15 years to about 20 years, about 20 years to about 60 years, about 20 years to about 55 years, about 20 years to about 50 years, about 20 years to about 45 years, about 20 years ~ about 40 years, about 20 years to about 35 years, about 20 years to about 30 years, about 20 years to about 25 years, about 25 years to about 60 years, about 25 years to about 55 years, about 25 years to about 50 years, about 25 years to about 45 years, about 25 years to about 40 years, about 25 years to about 35 years, about 25 years to about 30 years, about 30 years to about 60 years, about 30 years to about 55 years , about 30 to about 50 years, about 30 to about 45 years, about 30 to about 40 years, about 30 to about 35 years, about 35 to about 60 years, about 35 to about 55 years, about 35 years to about 50 years, about 35 years to about 45 years, about 35 years to about 40 years, about 40 years to about 60 years, about 40 years to about 55 years, about 40 years to about 50 years, about 40 years ~ about 45 years, about 45 years to about 60 years, about 45 years to about 55 years, about 45 years to about 50 years, about 50 years to about 60 years, about 50 years to about 55 years, or about 55 years ~ 60 years).
これらの方法のいくつかの実施形態では、1回又は2回以上の用量の各々は、TGF-β受容体の活性化の減少をもたらす各作用物質約0.01mg/kg~TGF-β受容体の活性化の減少をもたらす各作用物質約10mg/kg(例えば、TGF-β受容体の活性化の減少をもたらす各作用物質約0.01mg/kg~約9mg/kg、約0.01mg/kg~約8mg/kg、約0.01mg/kg~約7mg/kg、約0.01mg/kg~約6mg/kg、約0.01mg/kg~約5mg/kg、約0.01mg/kg~約4mg/kg、約0.01mg/kg~約3mg/kg、約0.01mg/kg~約2mg/kg、約0.01mg/kg~約1mg/kg、約0.01mg/kg~約0.5mg/kg、約0.01mg/kg~約0.1mg/kg、約0.01mg/kg~約0.05mg/kg、約0.05mg/kg~約10mg/kg、約0.05mg/kg~約9mg/kg、約0.05mg/kg~約8mg/kg、約0.05mg/kg~約7mg/kg、約0.05mg/kg~約6mg/kg、約0.05mg/kg~約5mg/kg、約0.05mg/kg~約4mg/kg、約0.05mg/kg~約3mg/kg、約0.05mg/kg~約2mg/kg、約0.05mg/kg~約1mg/kg、約0.05mg/kg~約0.5mg/kg、約0.05mg/kg~約0.1mg/kg、約0.1mg/kg~約10mg/kg、約0.1mg/kg~約9mg/kg、約0.1mg/kg~約8mg/kg、約0.1mg/kg~約7mg/kg、約0.1mg/kg~約6mg/kg、約0.1mg/kg~約5mg/kg、約0.1mg/kg~約4mg/kg、約0.1mg/kg~約3mg/kg、約0.1mg/kg~約2mg/kg、約0.1mg/kg~約1mg/kg、約0.1mg/kg~約0.5mg/kg、約0.5mg/kg~約10mg/kg、約0.5mg/kg~約9mg/kg、約0.5mg/kg~約8mg/kg、約0.5mg/kg~約7mg/kg、約0.5mg/kg~約6mg/kg、約0.5mg/kg~約5mg/kg、約0.5mg/kg~約4mg/kg、約0.5mg/kg~約3mg/kg、約0.5mg/kg~約2mg/kg、約0.5mg/kg~約1mg/kg、約1mg/kg~約10mg/kg、約1mg/kg~約9mg/kg、約1mg/kg~約8mg/kg、約1mg/kg~約7mg/kg、約1mg/kg~約6mg/kg、約1mg/kg~約5mg/kg、約1mg/kg~約4mg/kg、約1mg/kg~約3mg/kg、約1mg/kg~約2mg/kg、約2mg/kg~約10mg/kg、約2mg/kg~約9mg/kg、約2mg/kg~約8mg/kg、約2mg/kg~約7mg/kg、約2mg/kg~約6mg/kg、約2mg/kg~約5mg/kg、約2mg/kg~約4mg/kg、約2mg/kg~約3mg/kg、約3mg/kg~約10mg/kg、約3mg/kg~約9mg/kg、約3mg/kg~約8mg/kg、約3mg/kg~約7mg/kg、約3mg/kg~約6mg/kg、約3mg/kg~約5mg/kg、約3mg/kg~約4mg/kg、約4mg/kg~約10mg/kg、約4mg/kg~約9mg/kg、約4mg/kg~約8mg/kg、約4mg/kg~約7mg/kg、約4mg/kg~約6mg/kg、約4mg/kg~約5mg/kg、約5mg/kg~約10mg/kg、約5mg/kg~約9mg/kg、約5mg/kg~約8mg/kg、約5mg/kg~約7mg/kg、約5mg/kg~約6mg/kg、約6mg/kg~約10mg/kg、約6mg/kg~約9mg/kg、約6mg/kg~約8mg/kg、約6mg/kg~約7mg/kg、約7mg/kg~約10mg/kg、約7mg/kg~約9mg/kg、約7mg/kg~約8mg/kg、約8mg/kg~約10mg/kg、約8mg/kg~約9mg/kg、又は約8mg/kg~約10mg/kg)の投薬量で投与される。 In some embodiments of these methods, each of the one or more doses is about 0.01 mg/kg to about 0.01 mg/kg of each agent that results in decreased activation of the TGF-beta receptor. about 10 mg/kg of each agent that results in a decrease in activation of the TGF-β receptor (e.g., about 0.01 mg/kg to about 9 mg/kg, about 0.01 mg/kg of each agent that results in a decrease in TGF-β receptor activation). to about 8 mg/kg, about 0.01 mg/kg to about 7 mg/kg, about 0.01 mg/kg to about 6 mg/kg, about 0.01 mg/kg to about 5 mg/kg, about 0.01 mg/kg to about 4 mg/kg, about 0.01 mg/kg to about 3 mg/kg, about 0.01 mg/kg to about 2 mg/kg, about 0.01 mg/kg to about 1 mg/kg, about 0.01 mg/kg to about 0.4 mg/kg. 5 mg/kg, about 0.01 mg/kg to about 0.1 mg/kg, about 0.01 mg/kg to about 0.05 mg/kg, about 0.05 mg/kg to about 10 mg/kg, about 0.05 mg/kg to about 9 mg/kg, from about 0.05 mg/kg to about 8 mg/kg, from about 0.05 mg/kg to about 7 mg/kg, from about 0.05 mg/kg to about 6 mg/kg, from about 0.05 mg/kg to about 5 mg/kg, about 0.05 mg/kg to about 4 mg/kg, about 0.05 mg/kg to about 3 mg/kg, about 0.05 mg/kg to about 2 mg/kg, about 0.05 mg/kg to about 1 mg/kg kg, about 0.05 mg/kg to about 0.5 mg/kg, about 0.05 mg/kg to about 0.1 mg/kg, about 0.1 mg/kg to about 10 mg/kg, about 0.1 mg/kg to about 9 mg/kg, about 0.1 mg/kg to about 8 mg/kg, about 0.1 mg/kg to about 7 mg/kg, about 0.1 mg/kg to about 6 mg/kg, about 0.1 mg/kg to about 5 mg/kg kg, from about 0.1 mg/kg to about 4 mg/kg, from about 0.1 mg/kg to about 3 mg/kg, from about 0.1 mg/kg to about 2 mg/kg, from about 0.1 mg/kg to about 1 mg/kg, about 0.1 mg/kg to about 0.5 mg/kg, about 0.5 mg/kg to about 10 mg/kg, about 0.5 mg/kg to about 9 mg/kg, about 0.5 mg/kg to about 8 mg/kg, about 0.5 mg/kg to about 7 mg/kg, about 0.5 mg/kg to about 6 mg/kg, about 0.5 mg/kg to about 5 mg/kg, about 0.5 mg/kg to about 4 mg/kg, about 0 .5 mg/kg to about 3 mg/kg, about 0.5 mg/kg to about 2 mg/kg, about 0.5 mg/kg to about 1 mg/kg, about 1 mg/kg to about 10 mg/kg, about 1 mg/kg to about 9 mg/kg, about 1 mg/kg to about 8 mg/kg, about 1 mg/kg to about 7 mg/kg, about 1 mg/kg to about 6 mg/kg, about 1 mg/kg to about 5 mg/kg, about 1 mg/kg to about 4 mg/kg, about 1 mg/kg to about 3 mg/kg, about 1 mg/kg to about 2 mg/kg, about 2 mg/kg to about 10 mg/kg, about 2 mg/kg to about 9 mg/kg, about 2 mg/kg to about 8 mg/kg, about 2 mg/kg to about 7 mg/kg, about 2 mg/kg to about 6 mg/kg, about 2 mg/kg to about 5 mg/kg, about 2 mg/kg to about 4 mg/kg, about 2 mg/kg to about 3 mg/kg, about 3 mg/kg to about 10 mg/kg, about 3 mg/kg to about 9 mg/kg, about 3 mg/kg to about 8 mg/kg, about 3 mg/kg to about 7 mg/kg, about 3 mg/kg to about 6 mg/kg, about 3 mg/kg to about 5 mg/kg, about 3 mg/kg to about 4 mg/kg, about 4 mg/kg to about 10 mg/kg, about 4 mg/kg to about 9 mg/kg, about 4 mg/kg to about 8 mg/kg, about 4 mg/kg to about 7 mg/kg, about 4 mg/kg to about 6 mg/kg, about 4 mg/kg to about 5 mg/kg, about 5 mg/kg to about 10 mg/kg, about 5 mg/kg to about 9 mg/kg, about 5 mg/kg to about 8 mg/kg, about 5 mg/kg to about 7 mg/kg, about 5 mg/kg to about 6 mg/kg, about 6 mg/kg to about 10 mg/kg, about 6 mg/kg to about 9 mg/kg, about 6 mg/kg to about 8 mg/kg, about 6 mg/kg to about 7 mg/kg, about 7 mg/kg to about 10 mg/kg, about 7 mg/kg to about 9 mg/kg, about 7 mg/kg to about 8 mg/kg, about 8 mg/kg to about 10 mg/kg, about 8 mg/kg to about 9 mg/kg, or about 8 mg/kg to about 10 mg/kg).
これらの方法のいくつかの実施形態では、TGF-β受容体の活性化の減少をもたらす1つ以上の作用物質の単回又は初回投与は、対象が少なくとも30歳(例えば、少なくとも32、34、36、38、40、42、44、46、48、50、52、54、56、58、60、62、65、70、75、又は80歳)に達したときに始まる。 In some embodiments of these methods, the single or initial administration of one or more agents that result in decreased TGF-β receptor activation is administered to a subject at least 30 years of age (e.g., at least 32, 34, 36, 38, 40, 42, 44, 46, 48, 50, 52, 54, 56, 58, 60, 62, 65, 70, 75, or 80 years old).
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、対象は、加齢関連疾患(例えば、本明細書に記載の又は当該技術分野で既知の加齢関連疾患又は状態のうちのいずれか)又は炎症性疾患(例えば、本明細書に記載の又は当該技術分野で既知の加齢関連疾患又は状態のうちのいずれか)を有すると以前に診断も同定もされていない。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、対象は、化学療法剤(例えば、本明細書に記載の又は当該技術分野で既知の化学療法剤のうちのいずれか)で以前に治療されたことがない。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、対象は、細胞老化を誘導する治療剤(例えば、本明細書に記載の細胞老化を誘導する追加の治療剤のうちのいずれか)で以前に治療されたことがない。 In some embodiments of any of the methods described herein, the subject has an age-related disease (e.g., an age-related disease or condition described herein or known in the art). any of the above) or an inflammatory disease (eg, any of the age-related diseases or conditions described herein or known in the art). In some embodiments of any of the methods described herein, the subject is administered a chemotherapeutic agent (e.g., any of the chemotherapeutic agents described herein or known in the art) ) has never been treated before. In some embodiments of any of the methods described herein, the subject is a therapeutic agent that induces cellular senescence (e.g., among the additional therapeutic agents that induce cellular senescence described herein) have not been previously treated for
本明細書に記載の方法のいくつかの実施形態は、1つ以上の共通ガンマ鎖ファミリーサイトカイン受容体活性化物質の1回又は2回以上(例えば、3回以上、4回以上、5回以上、6回以上、7回以上、8回以上、9回以上、10回以上)の用量を対象に投与することを含む。これらの方法のいくつかの実施形態では、2回以上の用量のうちの任意の2回の連続用量は、約1週間~約1年間隔(例えば、約1週間~約11ヶ月、約1週間~約10ヶ月、約1週間~約9ヶ月、約1週間~約8ヶ月、約1週間~約7ヶ月、約1週間~約6ヶ月、約1週間~約5ヶ月、約1週間~約4ヶ月、約1週間~約3ヶ月、約1週間~約2ヶ月、約1週間~約1ヶ月、約1週間~約3週間、約1週間~約2週間、約2週間~約12ヶ月、約2週間~約11ヶ月、約2週間~約10ヶ月、約2週間~約9ヶ月、約2週間~約8ヶ月、約2週間~約7ヶ月、約2週間~約6ヶ月、約2週間~約5ヶ月、約2週間~約4ヶ月、約2週間~約3ヶ月、約2週間~約2ヶ月、約2週間~約1ヶ月、約2週間~約3週間、約3週間~約12ヶ月、約3週間~約11ヶ月、約3週間~約10ヶ月、約3週間~約9ヶ月、約3週間~約8ヶ月、約3週間~約7ヶ月、約3週間~約6ヶ月、約3週間~約5ヶ月、約3週間~約4ヶ月、約3週間~約3ヶ月、約3週間~約2ヶ月、約3週間~約1ヶ月、約1ヶ月~約12ヶ月、約1ヶ月~約11ヶ月、約1ヶ月~約10ヶ月、約1ヶ月~約9ヶ月、約1ヶ月~約8ヶ月、約1ヶ月~約7ヶ月、約1ヶ月~約6ヶ月、約1ヶ月~約5ヶ月、約1ヶ月~約4ヶ月、約1ヶ月~約3ヶ月、約1ヶ月~約2ヶ月、約2ヶ月~約12ヶ月、約2ヶ月~約11ヶ月、約2ヶ月~約10ヶ月、約2ヶ月~約9ヶ月、約2ヶ月~約8ヶ月、約2ヶ月~約7ヶ月、約2ヶ月~約6ヶ月、約2ヶ月~約5ヶ月、約2ヶ月~約4ヶ月、約2ヶ月~約3ヶ月、約3ヶ月~約12ヶ月、約3ヶ月~約11ヶ月、約3ヶ月~約10ヶ月、約3ヶ月~約9ヶ月、約3ヶ月~約8ヶ月、約3ヶ月~約7ヶ月、約3ヶ月~約6ヶ月、約3ヶ月~約5ヶ月、約3ヶ月~約4ヶ月、約4ヶ月~約12ヶ月、約4ヶ月~約11ヶ月、約4ヶ月~約10ヶ月、約4ヶ月~約9ヶ月、約4ヶ月~約8ヶ月、約4ヶ月~約7ヶ月、約4ヶ月~約6ヶ月、約4ヶ月~約5ヶ月、約4ヶ月~約4ヶ月、約5ヶ月~約12ヶ月、約5ヶ月~約11ヶ月、約5ヶ月~約10ヶ月、約5ヶ月~約9ヶ月、約5ヶ月~約8ヶ月、約5ヶ月~約7ヶ月、約5ヶ月~約6ヶ月、約6ヶ月~約12ヶ月、約6ヶ月~約11ヶ月、約6ヶ月~約10ヶ月、約6ヶ月~約9ヶ月、約6ヶ月~約8ヶ月、約6ヶ月~約7ヶ月、約7ヶ月~約12ヶ月、約7ヶ月~約11ヶ月、約7ヶ月~約10ヶ月、約7ヶ月~約9ヶ月、約7ヶ月~約8ヶ月、約8ヶ月~約12ヶ月、約8ヶ月~約11ヶ月、約8ヶ月~約10ヶ月、約8ヶ月~約9ヶ月、約9ヶ月~約12ヶ月、約9ヶ月~約11ヶ月、約9ヶ月~約10ヶ月、約10ヶ月~約12ヶ月、約10ヶ月~約11ヶ月、又は約11ヶ月~約12ヶ月間隔)で投与される。 Some embodiments of the methods described herein use one or more common gamma chain family cytokine receptor activators one or more times (e.g., three or more, four or more, five or more) , 6 or more, 7 or more, 8 or more, 9 or more, 10 or more) doses to the subject. In some embodiments of these methods, any two sequential doses of the two or more doses are spaced about one week to about one year apart (eg, about one week to about 11 months, about one week ~ about 10 months, about 1 week to about 9 months, about 1 week to about 8 months, about 1 week to about 7 months, about 1 week to about 6 months, about 1 week to about 5 months, about 1 week to about 4 months, about 1 week to about 3 months, about 1 week to about 2 months, about 1 week to about 1 month, about 1 week to about 3 weeks, about 1 week to about 2 weeks, about 2 weeks to about 12 months , about 2 weeks to about 11 months, about 2 weeks to about 10 months, about 2 weeks to about 9 months, about 2 weeks to about 8 months, about 2 weeks to about 7 months, about 2 weeks to about 6 months, about 2 weeks to about 5 months, about 2 weeks to about 4 months, about 2 weeks to about 3 months, about 2 weeks to about 2 months, about 2 weeks to about 1 month, about 2 weeks to about 3 weeks, about 3 weeks ~ about 12 months, about 3 weeks to about 11 months, about 3 weeks to about 10 months, about 3 weeks to about 9 months, about 3 weeks to about 8 months, about 3 weeks to about 7 months, about 3 weeks to about 6 months, about 3 weeks to about 5 months, about 3 weeks to about 4 months, about 3 weeks to about 3 months, about 3 weeks to about 2 months, about 3 weeks to about 1 month, about 1 month to about 12 months , about 1 month to about 11 months, about 1 month to about 10 months, about 1 month to about 9 months, about 1 month to about 8 months, about 1 month to about 7 months, about 1 month to about 6 months, about 1 month to about 5 months, about 1 month to about 4 months, about 1 month to about 3 months, about 1 month to about 2 months, about 2 months to about 12 months, about 2 months to about 11 months, about 2 months ~ about 10 months, about 2 months to about 9 months, about 2 months to about 8 months, about 2 months to about 7 months, about 2 months to about 6 months, about 2 months to about 5 months, about 2 months to about 4 months, about 2 months to about 3 months, about 3 months to about 12 months, about 3 months to about 11 months, about 3 months to about 10 months, about 3 months to about 9 months, about 3 months to about 8 months , about 3 months to about 7 months, about 3 months to about 6 months, about 3 months to about 5 months, about 3 months to about 4 months, about 4 months to about 12 months, about 4 months to about 11 months, about 4 months to about 10 months, about 4 months to about 9 months, about 4 months to about 8 months, about 4 months to about 7 months, about 4 months to about 6 months, about 4 months to about 5 months, about 4 months ~ about 4 months, about 5 months to about 12 months, about 5 months to about 11 months, about 5 months to about 10 months, about 5 months to about 9 months, about 5 months to about 8 months, about 5 months to about 7 months, about 5 months to about 6 months, about 6 months to about 12 months, about 6 months to about 11 months, about 6 months to about 10 months, about 6 months to about 9 months, about 6 months to about 8 months , about 6 months to about 7 months, about 7 months to about 12 months, about 7 months to about 11 months, about 7 months to about 10 months, about 7 months to about 9 months, about 7 months to about 8 months, about 8 months to about 12 months, about 8 months to about 11 months, about 8 months to about 10 months, about 8 months to about 9 months, about 9 months to about 12 months, about 9 months to about 11 months, about 9 months about 10 months, about 10 months to about 12 months, about 10 months to about 11 months, or about 11 months to about 12 months).
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、1回又は2回以上の用量が皮下投与によって投与される。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、1回又は2回以上の用量が筋肉内投与によって投与される。 In some embodiments of any of the methods described herein, one or more doses are administered by subcutaneous administration. In some embodiments of any of the methods described herein, one or more doses are administered by intramuscular administration.
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、2回以上の用量は、約1年~約60年(例えば、約1年~約55年、約1年~約50年、約1年~約45年、約1年~約40年、約1年~約35年、約1年~約30年、約1年~約25年、約1年~約20年、約1年~約15年、約1年~約10年、約1年~約5年、約5年~約60年、約5年~約55年、約5年~約50年、約5年~約45年、約5年~約40年、約5年~約35年、約5年~約30年、約5年~約25年、約5年~約20年、約5年~約15年、約5年~約10年、約10年~約60年、約10年~約55年、約10年~約50年、約10年~約45年、約10年~約40年、約10年~約35年、約10年~約30年、約10年~約25年、約10年~約20年、約10年~約15年、約15年~約60年、約15年~約55年、約15年~約50年、約15年~約45年、約15年~約40年、約15年~約35年、約15年~約30年、約15年~約25年、約15年~約20年、約20年~約60年、約20年~約55年、約20年~約50年、約20年~約45年、約20年~約40年、約20年~約35年、約20年~約30年、約20年~約25年、約25年~約60年、約25年~約55年、約25年~約50年、約25年~約45年、約25年~約40年、約25年~約35年、約25年~約30年、約30年~約60年、約30年~約55年、約30年~約50年、約30年~約45年、約30年~約40年、約30年~約35年、約35年~約60年、約35年~約55年、約35年~約50年、約35年~約45年、約35年~約40年、約40年~約60年、約40年~約55年、約40年~約50年、約40年~約45年、約45年~約60年、約45年~約55年、約45年~約50年、約50年~約60年、約50年~約55年、又は約55年~約60年)の期間にわたって投与される。 In some embodiments of any of the methods described herein, the two or more doses are administered from about 1 year to about 60 years (eg, from about 1 year to about 55 years, from about 1 year to about 50 years, about 1 year to about 45 years, about 1 year to about 40 years, about 1 year to about 35 years, about 1 year to about 30 years, about 1 year to about 25 years, about 1 year to about 20 years , about 1 year to about 15 years, about 1 year to about 10 years, about 1 year to about 5 years, about 5 years to about 60 years, about 5 years to about 55 years, about 5 years to about 50 years, about 5 years to about 45 years, about 5 years to about 40 years, about 5 years to about 35 years, about 5 years to about 30 years, about 5 years to about 25 years, about 5 years to about 20 years, about 5 years ~ about 15 years, about 5 years to about 10 years, about 10 years to about 60 years, about 10 years to about 55 years, about 10 years to about 50 years, about 10 years to about 45 years, about 10 years to about 40 years, about 10 years to about 35 years, about 10 years to about 30 years, about 10 years to about 25 years, about 10 years to about 20 years, about 10 years to about 15 years, about 15 years to about 60 years , about 15 to about 55 years, about 15 to about 50 years, about 15 to about 45 years, about 15 to about 40 years, about 15 to about 35 years, about 15 to about 30 years, about 15 years to about 25 years, about 15 years to about 20 years, about 20 years to about 60 years, about 20 years to about 55 years, about 20 years to about 50 years, about 20 years to about 45 years, about 20 years ~ about 40 years, about 20 years to about 35 years, about 20 years to about 30 years, about 20 years to about 25 years, about 25 years to about 60 years, about 25 years to about 55 years, about 25 years to about 50 years, about 25 years to about 45 years, about 25 years to about 40 years, about 25 years to about 35 years, about 25 years to about 30 years, about 30 years to about 60 years, about 30 years to about 55 years , about 30 to about 50 years, about 30 to about 45 years, about 30 to about 40 years, about 30 to about 35 years, about 35 to about 60 years, about 35 to about 55 years, about 35 years to about 50 years, about 35 years to about 45 years, about 35 years to about 40 years, about 40 years to about 60 years, about 40 years to about 55 years, about 40 years to about 50 years, about 40 years ~ about 45 years, about 45 years to about 60 years, about 45 years to about 55 years, about 45 years to about 50 years, about 50 years to about 60 years, about 50 years to about 55 years, or about 55 years ~ 60 years).
これらの方法のいくつかの実施形態では、1回又は2回以上の用量の各々は、各共通ガンマ鎖ファミリーサイトカイン受容体活性化物質約0.01mg/kg~各共通ガンマ鎖ファミリーサイトカイン受容体活性化物質約10mg/kg(例えば、各共通ガンマ鎖ファミリーサイトカイン受容体活性化物質約0.01mg/kg~約9mg/kg、約0.01mg/kg~約8mg/kg、約0.01mg/kg~約7mg/kg、約0.01mg/kg~約6mg/kg、約0.01mg/kg~約5mg/kg、約0.01mg/kg~約4mg/kg、約0.01mg/kg~約3mg/kg、約0.01mg/kg~約2mg/kg、約0.01mg/kg~約1mg/kg、約0.01mg/kg~約0.5mg/kg、約0.01mg/kg~約0.1mg/kg、約0.01mg/kg~約0.05mg/kg、約0.05mg/kg~約10mg/kg、約0.05mg/kg~約9mg/kg、約0.05mg/kg~約8mg/kg、約0.05mg/kg~約7mg/kg、約0.05mg/kg~約6mg/kg、約0.05mg/kg~約5mg/kg、約0.05mg/kg~約4mg/kg、約0.05mg/kg~約3mg/kg、約0.05mg/kg~約2mg/kg、約0.05mg/kg~約1mg/kg、約0.05mg/kg~約0.5mg/kg、約0.05mg/kg~約0.1mg/kg、約0.1mg/kg~約10mg/kg、約0.1mg/kg~約9mg/kg、約0.1mg/kg~約8mg/kg、約0.1mg/kg~約7mg/kg、約0.1mg/kg~約6mg/kg、約0.1mg/kg~約5mg/kg、約0.1mg/kg~約4mg/kg、約0.1mg/kg~約3mg/kg、約0.1mg/kg~約2mg/kg、約0.1mg/kg~約1mg/kg、約0.1mg/kg~約0.5mg/kg、約0.5mg/kg~約10mg/kg、約0.5mg/kg~約9mg/kg、約0.5mg/kg~約8mg/kg、約0.5mg/kg~約7mg/kg、約0.5mg/kg~約6mg/kg、約0.5mg/kg~約5mg/kg、約0.5mg/kg~約4mg/kg、約0.5mg/kg~約3mg/kg、約0.5mg/kg~約2mg/kg、約0.5mg/kg~約1mg/kg、約1mg/kg~約10mg/kg、約1mg/kg~約9mg/kg、約1mg/kg~約8mg/kg、約1mg/kg~約7mg/kg、約1mg/kg~約6mg/kg、約1mg/kg~約5mg/kg、約1mg/kg~約4mg/kg、約1mg/kg~約3mg/kg、約1mg/kg~約2mg/kg、約2mg/kg~約10mg/kg、約2mg/kg~約9mg/kg、約2mg/kg~約8mg/kg、約2mg/kg~約7mg/kg、約2mg/kg~約6mg/kg、約2mg/kg~約5mg/kg、約2mg/kg~約4mg/kg、約2mg/kg~約3mg/kg、約3mg/kg~約10mg/kg、約3mg/kg~約9mg/kg、約3mg/kg~約8mg/kg、約3mg/kg~約7mg/kg、約3mg/kg~約6mg/kg、約3mg/kg~約5mg/kg、約3mg/kg~約4mg/kg、約4mg/kg~約10mg/kg、約4mg/kg~約9mg/kg、約4mg/kg~約8mg/kg、約4mg/kg~約7mg/kg、約4mg/kg~約6mg/kg、約4mg/kg~約5mg/kg、約5mg/kg~約10mg/kg、約5mg/kg~約9mg/kg、約5mg/kg~約8mg/kg、約5mg/kg~約7mg/kg、約5mg/kg~約6mg/kg、約6mg/kg~約10mg/kg、約6mg/kg~約9mg/kg、約6mg/kg~約8mg/kg、約6mg/kg~約7mg/kg、約7mg/kg~約10mg/kg、約7mg/kg~約9mg/kg、約7mg/kg~約8mg/kg、約8mg/kg~約10mg/kg、約8mg/kg~約9mg/kg、又は約8mg/kg~約10mg/kg)の投薬量で投与される。 In some embodiments of these methods, each of the one or more doses is from about 0.01 mg/kg of each common gamma chain family cytokine receptor activator to each common gamma chain family cytokine receptor activity about 10 mg/kg of each common gamma chain family cytokine receptor activator, for example about 0.01 mg/kg to about 9 mg/kg, about 0.01 mg/kg to about 8 mg/kg, about 0.01 mg/kg to about 7 mg/kg, about 0.01 mg/kg to about 6 mg/kg, about 0.01 mg/kg to about 5 mg/kg, about 0.01 mg/kg to about 4 mg/kg, about 0.01 mg/kg to about 3 mg/kg, about 0.01 mg/kg to about 2 mg/kg, about 0.01 mg/kg to about 1 mg/kg, about 0.01 mg/kg to about 0.5 mg/kg, about 0.01 mg/kg to about 0.1 mg/kg, about 0.01 mg/kg to about 0.05 mg/kg, about 0.05 mg/kg to about 10 mg/kg, about 0.05 mg/kg to about 9 mg/kg, about 0.05 mg/kg to about 8 mg/kg, about 0.05 mg/kg to about 7 mg/kg, about 0.05 mg/kg to about 6 mg/kg, about 0.05 mg/kg to about 5 mg/kg, about 0.05 mg/kg to about 4 mg/kg, about 0.05 mg/kg to about 3 mg/kg, about 0.05 mg/kg to about 2 mg/kg, about 0.05 mg/kg to about 1 mg/kg, about 0.05 mg/kg to about 0.4 mg/kg. 5 mg/kg, about 0.05 mg/kg to about 0.1 mg/kg, about 0.1 mg/kg to about 10 mg/kg, about 0.1 mg/kg to about 9 mg/kg, about 0.1 mg/kg to about 8 mg/kg, about 0.1 mg/kg to about 7 mg/kg, about 0.1 mg/kg to about 6 mg/kg, about 0.1 mg/kg to about 5 mg/kg, about 0.1 mg/kg to about 4 mg/kg kg, about 0.1 mg/kg to about 3 mg/kg, about 0.1 mg/kg to about 2 mg/kg, about 0.1 mg/kg to about 1 mg/kg, about 0.1 mg/kg to about 0.5 mg/kg. kg, from about 0.5 mg/kg to about 10 mg/kg, from about 0.5 mg/kg to about 9 mg/kg, from about 0.5 mg/kg to about 8 mg/kg, from about 0.5 mg/kg to about 7 mg/kg, about 0.5 mg/kg to about 6 mg/kg, about 0.5 mg/kg to about 5 mg/kg, about 0.5 mg/kg to about 4 mg/kg, about 0.5 mg/kg to about 3 mg/kg, about 0 .5 mg/kg to about 2 mg/kg, about 0.5 mg/kg to about 1 mg/kg, about 1 mg/kg to about 10 mg/kg, about 1 mg/kg to about 9 mg/kg, about 1 mg/kg to about 8 mg/kg. kg, about 1 mg/kg to about 7 mg/kg, about 1 mg/kg to about 6 mg/kg, about 1 mg/kg to about 5 mg/kg, about 1 mg/kg to about 4 mg/kg, about 1 mg/kg to about 3 mg/kg. kg, about 1 mg/kg to about 2 mg/kg, about 2 mg/kg to about 10 mg/kg, about 2 mg/kg to about 9 mg/kg, about 2 mg/kg to about 8 mg/kg, about 2 mg/kg to about 7 mg/kg. kg, about 2 mg/kg to about 6 mg/kg, about 2 mg/kg to about 5 mg/kg, about 2 mg/kg to about 4 mg/kg, about 2 mg/kg to about 3 mg/kg, about 3 mg/kg to about 10 mg/kg. kg, about 3 mg/kg to about 9 mg/kg, about 3 mg/kg to about 8 mg/kg, about 3 mg/kg to about 7 mg/kg, about 3 mg/kg to about 6 mg/kg, about 3 mg/kg to about 5 mg/kg. kg, about 3 mg/kg to about 4 mg/kg, about 4 mg/kg to about 10 mg/kg, about 4 mg/kg to about 9 mg/kg, about 4 mg/kg to about 8 mg/kg, about 4 mg/kg to about 7 mg/kg. kg, about 4 mg/kg to about 6 mg/kg, about 4 mg/kg to about 5 mg/kg, about 5 mg/kg to about 10 mg/kg, about 5 mg/kg to about 9 mg/kg, about 5 mg/kg to about 8 mg/kg. kg, about 5 mg/kg to about 7 mg/kg, about 5 mg/kg to about 6 mg/kg, about 6 mg/kg to about 10 mg/kg, about 6 mg/kg to about 9 mg/kg, about 6 mg/kg to about 8 mg/kg. kg, about 6 mg/kg to about 7 mg/kg, about 7 mg/kg to about 10 mg/kg, about 7 mg/kg to about 9 mg/kg, about 7 mg/kg to about 8 mg/kg, about 8 mg/kg to about 10 mg/kg. kg, about 8 mg/kg to about 9 mg/kg, or about 8 mg/kg to about 10 mg/kg).
これらの方法のいくつかの実施形態では、1つ以上の共通ガンマ鎖ファミリーサイトカイン受容体活性化物質の単回又は初回投与は、対象が少なくとも30歳(例えば、少なくとも32、34、36、38、40、42、44、46、48、50、52、54、56、58、60、62、65、70、75、又は80歳)に達したときに始まる。 In some embodiments of these methods, a single or first dose of one or more common gamma chain family cytokine receptor activators is administered to a subject at least 30 years of age (e.g., at least 32, 34, 36, 38, 40, 42, 44, 46, 48, 50, 52, 54, 56, 58, 60, 62, 65, 70, 75, or 80 years old).
本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、対象は、加齢関連疾患(例えば、本明細書に記載の又は当該技術分野で既知の加齢関連疾患又は状態のうちのいずれか)又は炎症性疾患(例えば、本明細書に記載の又は当該技術分野で既知の加齢関連疾患又は状態のうちのいずれか)を有すると以前に診断も同定もされていない。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、対象は、化学療法剤(例えば、本明細書に記載の又は当該技術分野で既知の化学療法剤のうちのいずれか)で以前に治療されたことがない。本明細書に記載の方法のうちのいずれかのいくつかの実施形態では、対象は、細胞老化を誘導する治療剤(例えば、本明細書に記載の細胞老化を誘導する追加の治療剤のうちのいずれか)で以前に治療されたことがない。 In some embodiments of any of the methods described herein, the subject has an age-related disease (e.g., an age-related disease or condition described herein or known in the art). any of the above) or an inflammatory disease (eg, any of the age-related diseases or conditions described herein or known in the art). In some embodiments of any of the methods described herein, the subject is administered a chemotherapeutic agent (e.g., any of the chemotherapeutic agents described herein or known in the art) ) has never been treated before. In some embodiments of any of the methods described herein, the subject is a therapeutic agent that induces cellular senescence (e.g., among the additional therapeutic agents that induce cellular senescence described herein) have not been previously treated for
本発明は、以下の実施例に更に記載されており、これらの実施例は、特許請求の範囲に記載の本発明の範囲を限定しない。 The invention is further described in the following examples, which do not limit the scope of the invention described in the claims.
実施例1:多鎖ポリペプチドを使用したC57BL/6マウスにおける免疫刺激
材料及び方法
第1のポリペプチドが、2つのTGFβRIIドメイン、ヒト組織因子219断片、及びヒトIL-15の可溶性融合物であり、第2のポリペプチドが、2つのTGFβRIIドメイン及びヒトIL-15Rα鎖のスシドメインの可溶性融合物である、第1のポリペプチド及び第2のポリペプチドを含む例示的な多鎖ポリペプチド(本明細書に記載のタイプA多鎖ポリペプチド)が、生成された。
Example 1: Immune Stimulation in C57BL/6 Mice Using Multichain Polypeptides Materials and Methods The first polypeptide comprises two TGFβRII domains, a
結果
C57BL/6マウスにおける免疫刺激
野生型C57BL/6マウスを、それぞれ、対照PBS溶液又は0.3mg/kg、1mg/kg、3mg/kg、若しくは10mg/kgの投薬量の多鎖ポリペプチドのいずれかで皮下処理した。処理の4日後、脾臓の重量及び脾臓に存在する様々な免疫細胞型のパーセンテージを評価した。具体的には、単一の脾細胞懸濁液を生成し、抗CD4、抗CD8、抗NK1.1、及び抗CD19を含む蛍光色素結合抗体で染色した。対照処理マウス及び多鎖ポリペプチドのいずれかで処理されたマウスの脾臓に存在するCD4+T細胞、CD8+T細胞、ナチュラルキラー(NK)細胞、及びCD19+B細胞のパーセンテージを、フローサイトメトリーを使用して評価した。図1Aに示されるように、多鎖ポリペプチドで処理されたマウスにおける脾臓の重量は、多鎖ポリペプチドの投薬量の増加とともに増加した。更に、1mg/kg、3mg/kg、及び10mg/kgの多鎖ポリペプチドで処理したマウスにおける脾臓の重量は、それぞれ、対照溶液で処理したマウスと比較して著しく高かった。図1Bに示されるように、多鎖ポリペプチドで処理したマウスの脾臓では、CD8+T細胞及びNK細胞の両方のパーセンテージが、多鎖ポリペプチドの投薬量の増加とともに増加した。具体的には、CD8+T細胞のパーセンテージは、対照処理マウスと比較して、0.3mg/kg、3mg/kg、及び10mg/kgの多鎖ポリペプチドで処理したマウスで高く、NK細胞のパーセンテージは、対照処理マウスと比較して、0.3mg/kg、1mg/kg、3mg/kg、及び10mg/kgの多鎖ポリペプチドで処理したマウスで高かった。これらの結果は、例示的な多鎖ポリペプチドが、脾臓中の免疫細胞、特にCD8+T細胞及びNK細胞を刺激することができることを実証している。
Results Immune Stimulation in C57BL/6 Mice Wild-type C57BL/6 mice were treated with either control PBS solution or dosages of 0.3 mg/kg, 1 mg/kg, 3 mg/kg, or 10 mg/kg of the multichain polypeptide, respectively. It was treated subcutaneously with After 4 days of treatment, spleen weight and percentage of various immune cell types present in the spleen were assessed. Specifically, single splenocyte suspensions were generated and stained with fluorochrome-conjugated antibodies including anti-CD4, anti-CD8, anti-NK1.1, and anti-CD19. The percentage of CD4 + T cells, CD8 + T cells, natural killer (NK) cells, and CD19 + B cells present in the spleens of control-treated mice and mice treated with either multichain polypeptide was analyzed by flow cytometry. was evaluated using As shown in FIG. 1A, spleen weight in mice treated with multichain polypeptide increased with increasing dosage of multichain polypeptide. Furthermore, spleen weights in mice treated with 1 mg/kg, 3 mg/kg, and 10 mg/kg of multichain polypeptide, respectively, were significantly higher compared to mice treated with control solution. As shown in FIG. 1B, in the spleens of mice treated with multichain polypeptides, the percentage of both CD8 + T cells and NK cells increased with increasing dosage of multichain polypeptides. Specifically, the percentage of CD8 + T cells was higher in mice treated with 0.3 mg/kg, 3 mg/kg, and 10 mg/kg of the multichain polypeptide compared to control-treated mice, and NK cells increased. Percentages were higher in mice treated with 0.3 mg/kg, 1 mg/kg, 3 mg/kg, and 10 mg/kg of multichain polypeptide compared to control treated mice. These results demonstrate that exemplary multichain polypeptides can stimulate immune cells in the spleen, particularly CD8 + T cells and NK cells.
薬物動態
例示的な多鎖ポリペプチドの薬物動態を、野生型C57BL/6マウスで評価した。マウスを、3mg/kgの投薬量の多鎖ポリペプチドで皮下処理した。血液を様々な時点で尾静脈から採血し、血清を調製した。血清中の多鎖ポリペプチドの濃度は、ELISAで決定した。簡潔には、多鎖ポリペプチドを、抗ヒト組織因子抗体を使用して捕捉し、ビオチン化抗ヒトTGFβ受容体、ペルオキシダーゼ結合ストレプトアビジン、及びABTS基質を使用して検出した。結果は、例示的な多鎖ポリペプチドの半減期が12.66時間であることを示した。
Pharmacokinetics Pharmacokinetics of exemplary multichain polypeptides were evaluated in wild-type C57BL/6 mice. Mice were treated subcutaneously with a dosage of 3 mg/kg multichain polypeptide. Blood was drawn from the tail vein at various time points and serum was prepared. Concentrations of multichain polypeptides in serum were determined by ELISA. Briefly, multichain polypeptides were captured using anti-human tissue factor antibody and detected using biotinylated anti-human TGFβ receptor, peroxidase-conjugated streptavidin, and ABTS substrate. Results indicated that the half-life of the exemplary multi-chain polypeptide was 12.66 hours.
C57BL/6マウスにおける経時的な免疫刺激
多鎖ポリペプチドによる免疫刺激の効果を経時的に評価するために、マウスを、3mg/kgの多鎖ポリペプチドの単回投与で処理し、脾臓の重量及び脾臓に存在する免疫細胞型のパーセンテージを、上記の技術を使用して、処理直後に、及び処理後16、24、48、72、及び92時間時点で評価した。図2Aに示されるように、多鎖ポリペプチドで処理したマウスの脾臓重量は、処理後48時間時点で増加し、44時間にわたって増加し続けた。更に、図2Bに示されるように、多鎖ポリペプチドで処理したマウスの脾臓重量では、CD8+T細胞とNK細胞のパーセンテージは両方とも、処理後48時間時点で増加し、更に44時間にわたって増加し続けた。これらの結果は、例示的な多鎖ポリペプチドが、脾臓の免疫細胞、特にCD8+T細胞及びNK細胞を経時的に刺激することができることを更に実証している。
Immune Stimulation in C57BL/6 Mice Over Time To assess the effects of immune stimulation with multichain polypeptides over time, mice were treated with a single dose of 3 mg/kg multichain polypeptide and spleen weights were measured. and the percentage of immune cell types present in the spleen were assessed immediately after treatment and at 16, 24, 48, 72, and 92 hours after treatment using the techniques described above. As shown in Figure 2A, spleen weights of mice treated with multichain polypeptides increased at 48 hours after treatment and continued to increase over 44 hours. Furthermore, as shown in FIG. 2B, in the spleen weights of mice treated with multichain polypeptides, the percentages of both CD8 + T cells and NK cells increased at 48 hours after treatment and increased over a further 44 hours. kept doing. These results further demonstrate that exemplary multichain polypeptides can stimulate splenic immune cells, particularly CD8 + T cells and NK cells over time.
CD8+T細胞及びNK細胞による増殖及びグランザイムB発現の増加
多鎖ポリペプチドによって誘導される免疫細胞の増殖及び細胞傷害性の可能性を評価するために、マウスを、3mg/kgの多鎖ポリペプチドの単回投与で処理し、これらのマウスの脾臓を、処理直後に、及び処理後16、24、48、72、及び92時間時点で評価した。簡潔には、単一の脾細胞懸濁液を生成し、抗CD4、抗CD8、抗NK1.1、及び抗CD19を含む様々な細胞型の蛍光色素標識抗体、並びに抗Ki67抗体(すなわち、細胞増殖マーカー)及び抗グランザイムB抗体(すなわち、細胞傷害性マーカー)で染色した。各免疫細胞型のKi67及びグランザイムBの平均蛍光強度(MFI)を、フローサイトメトリーによって分析した。図3A及び3Bに示されるように、NK細胞によるKi67及びグランザイムBの発現は、処理直後(0時間)と比較して、24時間及びその後に評価された各時点で増加を示した。更に、CD8+T細胞によるKi67及びグランザイムBの発現は、処理直後(0時間)と比較して、48時間及びその後に評価された各時点で増加を示した。このように、多鎖ポリペプチドの単回投与は、処理後少なくとも4日間、CD8+T細胞及びNK細胞の増殖をもたらした。
Increased Proliferation and Granzyme B Expression by CD8 + T Cells and NK Cells To assess potential immune cell proliferation and cytotoxicity induced by multichain polypeptides, mice were treated with 3 mg/kg of multichain polypeptides. Treated with a single dose of peptide, the spleens of these mice were assessed immediately after treatment and at 16, 24, 48, 72, and 92 hours after treatment. Briefly, single splenocyte suspensions were generated and fluorochrome-labeled antibodies to various cell types, including anti-CD4, anti-CD8, anti-NK1.1, and anti-CD19, as well as anti-Ki67 antibodies (i.e., cell proliferation marker) and anti-granzyme B antibody (ie, cytotoxicity marker). Mean fluorescence intensity (MFI) of Ki67 and granzyme B of each immune cell type was analyzed by flow cytometry. As shown in Figures 3A and 3B, Ki67 and granzyme B expression by NK cells showed an increase at each time point assessed at 24 hours and thereafter compared to immediately after treatment (0 hours). In addition, Ki67 and Granzyme B expression by CD8 + T cells showed an increase at each time point assessed at 48 hours and thereafter compared to immediately after treatment (0 hours). Thus, a single dose of multichain polypeptide resulted in proliferation of CD8 + T cells and NK cells for at least 4 days after treatment.
これらの結果は、多鎖ポリペプチドがCD8+T細胞及びNK細胞の数を増加させるのみならず、これらの細胞の細胞傷害性も増強することを示す。 These results indicate that multichain polypeptides not only increase the number of CD8 + T cells and NK cells, but also enhance the cytotoxicity of these cells.
腫瘍細胞に対する細胞傷害性
次に、腫瘍細胞に対する多鎖ポリペプチドによって活性化された脾細胞の細胞傷害性を、C57BL/6マウスにおいて評価した。マウスモロニー白血病細胞(Yac-1)を、CellTrace Violetで標識し、腫瘍標的細胞として使用した。C57BL/6マウスを、3mg/kgの多鎖ポリペプチドの単回投与で処理し、脾細胞をその後様々な時点で調製し、エフェクター細胞として使用した。標的腫瘍細胞をエフェクター細胞とエフェクター:標的(E:T)比10:1で混合し、37℃で20時間インキュベートした。フローサイトメトリーを使用したヨウ化プロピジウム(PI)陽性のバイオレット標識Yac-1細胞の分析により、標的細胞の生存率を評価した。Yac-1腫瘍阻害のパーセンテージを、次の式を使用して計算した。
Yac-1腫瘍阻害のパーセンテージ=(1-実験試料中の生存Yac-1細胞数/脾細胞を含まない試料中の生存Yac-1細胞数)×100
Cytotoxicity to Tumor Cells Cytotoxicity of splenocytes activated by multichain polypeptides to tumor cells was next evaluated in C57BL/6 mice. Mouse Moloney leukemia cells (Yac-1) were labeled with CellTrace Violet and used as tumor target cells. C57BL/6 mice were treated with a single dose of 3 mg/kg multichain polypeptide and splenocytes were subsequently prepared at various time points and used as effector cells. Targeted tumor cells were mixed with effector cells at an effector:target (E:T) ratio of 10:1 and incubated at 37°C for 20 hours. Target cell viability was assessed by analysis of propidium iodide (PI)-positive, violet-labeled Yac-1 cells using flow cytometry. The percentage of Yac-1 tumor inhibition was calculated using the following formula.
Percentage of Yac-1 tumor inhibition=(1−number of viable Yac-1 cells in experimental sample/number of viable Yac-1 cells in sample without splenocytes)×100
図4に示されるように、多鎖ポリペプチドで24時間以上処理した後のマウスの脾細胞は、未処理のマウスの脾細胞と比較して、Yac-1細胞に対する細胞傷害性の増加を示した。 As shown in FIG. 4, splenocytes from mice after treatment with multichain polypeptides for more than 24 hours showed increased cytotoxicity to Yac-1 cells compared to splenocytes from untreated mice. rice field.
実施例2:高脂肪食ベースの2型糖尿病マウスモデルを使用したC57BL/6マウスにおける免疫刺激
材料及び方法
TGFRt15-TGFRsは、可溶性ヒトTGFβRII二量体(aa24-159)である2つのTGFβ結合ドメインを含む多鎖キメラポリペプチド(本明細書に記載のタイプA多鎖キメラポリペプチド)である。21t15-TGFRは、IL-21及びTGFβ結合ドメインを含む多鎖キメラポリペプチド(本明細書に記載のタイプA多鎖キメラポリペプチド)である。2t2は、2つのIL-2ポリペプチドを含むキメラポリペプチド(本明細書に記載のタイプBキメラポリペプチド)である。
Example 2: Immune Stimulation in C57BL/6 Mice Using a High Fat Diet-Based
結果
2型糖尿病の処置におけるTGFRt15-TGFRs、2t2、及び21t15-TGFRsの効果を評価するために、高脂肪食ベースの2型糖尿病マウスモデル(The Jackson LaboratoryからのB6.129P2-ApoEtm1Unc/J)を使用した。マウスに、対照食又は高脂肪食のいずれかを11週間与えた。高脂肪食を与えたマウスのサブセットも、TGFRt15-TGFRs、2t2、又は21t15-TGFRsで処理した。対照食、高脂肪食を与えたマウス、及び高脂肪食を与え、かつTGFRt15-TGFRs、2t2、又は21t15-TGFRsで処理したマウスを、処理の4日後に評価した。簡潔には、単一の脾細胞懸濁液を生成し、抗CD4、抗CD8、抗NK1.1、及び抗CD19を含む蛍光色素結合抗体で染色した。各群におけるマウスの脾臓に存在するCD4+T細胞、CD8+T細胞、ナチュラルキラー(NK)細胞、及びCD19+B細胞のパーセンテージを、フローサイトメトリーを使用して評価した。
Results To evaluate the effects of TGFRt15-TGFRs, 2t2, and 21t15-TGFRs in treating
図5Aに示されるように、高脂肪食を与えたマウスでは、未処理マウスと比較して、TGFRt15-TGFRs又は2t2で処理した後、PBMCのNK細胞のパーセンテージが著しく増加したが、21t15-TGFRsで処理した後には増加しなかった。更に、PBMCのCD8+T細胞のパーセンテージは、未処理マウスと比較して、TGFRt15-TGFRs、2t2、又は21t15-TGFRsで処理した後に著しく増加した。更に、PBMCのCD4+T細胞、CD8+T細胞、ナチュラルキラー(NK)細胞、及びCD19+B細胞の増殖も抗Ki67抗体を使用して評価した。図5Bに示されるように、増殖性NK細胞、CD4+T細胞、及びCD8+T細胞の数は、TGFRt15-TGFRsでの処理後に著しく増加したが、2t2又は21t15-TGFRsでの処理した後には増加しなかった。 As shown in FIG. 5A, the percentage of NK cells in PBMCs was significantly increased after treatment with TGFRt15-TGFRs or 2t2 in mice fed a high-fat diet compared to untreated mice, whereas 21t15-TGFRs did not increase after treatment with Furthermore, the percentage of CD8 + T cells in PBMCs was significantly increased after treatment with TGFRt15-TGFRs, 2t2, or 21t15-TGFRs compared to untreated mice. In addition, proliferation of PBMC CD4 + T cells, CD8 + T cells, natural killer (NK) cells, and CD19 + B cells was also assessed using anti-Ki67 antibody. As shown in FIG. 5B, the numbers of proliferating NK cells, CD4 + T cells, and CD8 + T cells were significantly increased after treatment with TGFRt15-TGFRs, but not after treatment with 2t2 or 21t15-TGFRs. did not increase.
動物の皮膚及び毛髪の外観及び質感に対するTGFRt15-TGFRs、2t2、及び21t15-TGFRsの効果を調べるために、マウスに、対照又は高脂肪食を7週間与え、高脂肪食を与えたマウスのサブセットにもTGFRt15-TGFRs、2t2、又は21t15-TGFRsで処理した。処理の1週間後、マウスの外観を評価した。高脂肪食を与え、未処理のマウス、又は高脂肪食を与え、21t15-TGFRsで処理したマウスは、毛繕いがなされず、毛が乱れているように見え、対照食を与えたマウスと比較して、白髪/脱毛が増加した(図6A、6B、及び6E)。驚いたことに、TGFRt15-TGFRs又は2t2の処理を受けた高脂肪食を与えたマウスは、TGFRt15-TGFRs又は2t2の処理を受けなかった高脂肪食を与えたマウス(図6B)と比較して、毛繕いが行われて健康的(白髪/脱毛が少ない)に見えた(図6C及び6D)。具体的には、TGFRt15-TGFRs又は2t2処理マウスは、対照マウスと比較して、優れた皮膚及び毛髪の外観及び質感を示した。これらの結果は、TGFRt15-TGFRs又は2t2での処理が哺乳動物の皮膚及び髪の外観及び質感を改善することを示す。 To examine the effects of TGFRt15-TGFRs, 2t2, and 21t15-TGFRs on the appearance and texture of animal skin and hair, mice were fed a control or high-fat diet for 7 weeks, and a subset of the high-fat-fed mice was were also treated with TGFRt15-TGFRs, 2t2, or 21t15-TGFRs. After one week of treatment, mice were evaluated for their appearance. High-fat diet-fed untreated mice, or high-fat diet-fed mice treated with 21t15-TGFRs, appeared ungroomed and disheveled, compared to control-fed mice. As a result, gray hair/hair loss increased (FIGS. 6A, 6B, and 6E). Surprisingly, high-fat diet-fed mice that received TGFRt15-TGFRs or 2t2 treatment compared with high-fat diet-fed mice that did not receive TGFRt15-TGFRs or 2t2 treatment (Fig. 6B). , groomed and looked healthy (less gray/hair loss) (FIGS. 6C and 6D). Specifically, TGFRt15-TGFRs or 2t2 treated mice exhibited superior skin and hair appearance and texture compared to control mice. These results indicate that treatment with TGFRt15-TGFRs or 2t2 improves the appearance and texture of mammalian skin and hair.
次に、マウスに、対照又は高脂肪食を9週間与え、高脂肪食を与えたマウスのサブセットを、TGFRt15-TGFRs、2t2、又は21t15-TGFRsで処理した。処理の4日後、各群のマウスの空腹時体重を測定した。高脂肪食を与え、未処理のマウス、並びに高脂肪食を与え、かつ21t15-TGFRsで処理したマウスの空腹時体重は、対照食を与えたマウスと比較して、著しく増加した。しかしながら、高脂肪食を与え、かつTGFRt15-TGFRs又は2t2で処理したマウスの空腹時体重は、上記の他の2つの高脂肪食群と比較して減少した。研究終了(9週間)時のマウスの空腹時体重を、図7に示す。 Mice were then fed a control or high-fat diet for 9 weeks, and a subset of the high-fat diet-fed mice were treated with TGFRt15-TGFRs, 2t2, or 21t15-TGFRs. Four days after treatment, fasting body weights of mice in each group were measured. Fasting body weights of high-fat-fed, untreated mice, as well as high-fat-fed, 21t15-TGFRs-treated mice were significantly increased compared to control-fed mice. However, the fasting body weight of mice fed a high-fat diet and treated with TGFRt15-TGFRs or 2t2 was decreased compared to the other two high-fat diet groups. Fasting body weights of mice at the end of the study (9 weeks) are shown in FIG.
各群のマウスの空腹時グルコース値を評価するために、マウスに、対照食又は高脂肪食のいずれかを与え、未処理又は44、59、及び73日目にTGFRt15-TGFRs、2t2、若しくは21t15-TGFRsで処理した。各群のマウスの空腹時血糖値を、処理の4日後に測定した。図8に示されるように、2回目及び3回目の投与後(それぞれ、59日目及び73日目)の空腹時血糖値は、高脂肪食を与えたが、未処理のマウス(黄色の線)と比較して、高脂肪食を与え、かつ2t2で処理したマウス(赤色の線)では、著しく低下した。空腹時血糖値は、高脂肪食を与え、かつTGFRt15-TGFRsで処理したマウス(緑色の線)では一定のままであったが、空腹時血糖値は、高脂肪食を与え、かつ21t15-TGFRsで処理したマウス(青色の線)では、上昇した。
To assess fasting glucose levels in each group of mice, mice were fed either a control diet or a high-fat diet and were untreated or TGFRt15-TGFRs, 2t2, or 21t15 on
実施例3:化学療法によって誘導された老化B16F10黒色腫細胞はNKリガンドを発現する
材料及び方法
B16F10黒色腫細胞の細胞老化を、細胞をドセタキセル(7.5μM、Sigma)で3日間処理した後、完全培地で4日間回復することによって誘導した。細胞老化は、細胞を老化関連β-ガラクトシダーゼ(SA β-gal)で染色することによってアクセスされた。簡潔には、B16F10対照及び老化細胞(B16F10-SNC)を、PBSで1回洗浄し、0.5%グルタルアルデヒド(PBS(pH7.2))で30分間固定した。細胞を、X-gal溶液(PBS中1mg/mLのX-gal、0.12mMのK3Fe[CN]6、0.12mMのK4Fe[CN]6、及び1mMのMgCl2(pH6.0))中で、37℃で一晩染色し、Nikon光学光学顕微鏡を使用して画像化した。
Example 3 Chemotherapy-Induced Senescent B16F10 Melanoma Cells Express NK Ligands Materials and Methods Cellular senescence of B16F10 melanoma cells was investigated by treating cells with docetaxel (7.5 μM, Sigma) for 3 days. After treatment, they were induced by recovery in complete medium for 4 days. Cellular senescence was accessed by staining cells with senescence-associated β-galactosidase (SA β-gal). Briefly, B16F10 control and senescent cells (B16F10-SNC) were washed once with PBS and fixed with 0.5% glutaraldehyde (PBS (pH 7.2)) for 30 minutes. Cells were washed with X-gal solution (1 mg/mL X-gal, 0.12 mM K 3 Fe[CN] 6 , 0.12 mM K 4 Fe[CN] 6 and 1 mM MgCl 2 (pH 6.0) in PBS. 0)) at 37° C. overnight and imaged using a Nikon light microscope.
結果
B16F10黒色腫細胞の細胞老化は、上記のように化学療法を使用して誘導した。図9Aに示されるように、化学療法によって誘導された老化B16F10細胞(B16F10-SNC)はSA β-gal染色に陽性であったが、対照B16F10細胞は、染色されなかった。次に、老化遺伝子の発現を、0日目、又はそれぞれ、4、8、12、16日目の老化誘導後に単離されたRNAを用いたRT-qPCRを使用して分析した。発現レベルは、対照B16F10細胞に対して正規化された。図9B~9Dに示されるように、p21、IL6、及びDPP4の発現は、実験期間中に老化細胞から単離されたRNAでアップレギュレートされた。更に、図9E及び9Fに示されるように、RATE1E及びULBP1(NK活性化受容体NKG2Dリガンド)の発現も老化細胞で誘導され、最高の発現レベルは16日目であった。これらの結果は、化学療法によって誘導された老化B16F10細胞が、対照B16F10細胞よりも活性化されたNK細胞のより強い細胞傷害性にさらされていることを示す。
Results Cellular senescence of B16F10 melanoma cells was induced using chemotherapy as described above. As shown in FIG. 9A, chemotherapy-induced senescent B16F10 cells (B16F10-SNC) were positive for SA β-gal staining, whereas control B16F10 cells did not stain. Expression of senescent genes was then analyzed using RT-qPCR using RNA isolated after induction of senescence on
化学療法によって誘導された老化B16F10黒色腫細胞における幹細胞特性の獲得
化学療法によって誘導された老化B16F10黒色腫細胞が幹細胞の特性を獲得したかどうかを調べるために、コロニー形成アッセイを行った。簡潔には、1000細胞/ウェルを6つのウェルプレートに播種し、培地を3日ごとに交換した。図10A(倍率100倍で撮影した画像)に示されるように、培養5週間後、老化細胞は、コロニーを形成することができた。コロニーによる幹細胞マーカーの発現を評価するために、RNAをコロニーから単離し、Oct4及びNotch4 mRNAの発現をRT-qPCRによって決定した。対照B16F10細胞と比較して、化学療法によって誘導された老化B16F10黒色腫細胞は、がん幹細胞マーカーであるOct4及びNotch4のアップレギュレーションを示した(図10B及び10C)。更に、幹細胞マーカーCD44、CD24、及びCD133の細胞表面発現は、CD44、CD24、及びCD133に対する抗体で染色した後、フローサイトメトリーで評価した。図10D~10Fに示されるように、化学療法によって誘導された老化幹細胞(B16F10-SNC-CSC)では、対照B16F10と比較して、二重陽性集団(CD44+CD24+、CD44+CD133+、及びCD24+CD133+)を増加した。
Acquisition of Stem Cell Properties in Chemotherapy-Induced Senescent B16F10 Melanoma Cells To investigate whether chemotherapy-induced senescent B16F10 melanoma cells acquired stem cell properties, a colony formation assay was performed. Briefly, 1000 cells/well were seeded in 6 well plates and medium was changed every 3 days. After 5 weeks in culture, senescent cells were able to form colonies, as shown in FIG. 10A (image taken at 100× magnification). To assess stem cell marker expression by colonies, RNA was isolated from colonies and Oct4 and Notch4 mRNA expression was determined by RT-qPCR. Compared to control B16F10 cells, chemotherapy-induced senescent B16F10 melanoma cells showed upregulation of cancer stem cell markers Oct4 and Notch4 (FIGS. 10B and 10C). In addition, cell surface expression of stem cell markers CD44, CD24 and CD133 was assessed by flow cytometry after staining with antibodies against CD44, CD24 and CD133. As shown in FIGS. 10D-10F, chemotherapy-induced senescent stem cells (B16F10-SNC-CSCs) had double-positive populations (CD44 + CD24 + , CD44 + CD133 + , and CD24 + CD133 + ).
幹細胞特性を有する化学療法によって誘導された老化(CIS)黒色腫細胞は、対照B16F10細胞よりも更に「移動性」及び「浸潤性」である
幹細胞特性を有する化学療法によって誘導された老化(CIS)黒色腫細胞(B16F10-SNC-CSC)の移動性は、移動アッセイを使用して分析された。簡潔には、対照B16F10細胞及びB16F10-SNC-CSC細胞を、6つのウェルプレートに播種し、p20ピペットチップで傷つけた。細胞の動きを、0、12、及び24時間後に画像化した。図11Aに示されるように、幹細胞特性を有する化学療法によって誘導された老化(CIS)黒色腫細胞(B16F10-SNC-CSC)は、対照B16F10細胞と比較して、インビトロ移動アッセイにおいてより移動した。
Chemotherapy-induced senescence with stem cell properties (CIS) melanoma cells are more 'migratory' and 'invasive' than control B16F10 cells Chemotherapy-induced senescence with stem cell properties (CIS) The migration of melanoma cells (B16F10-SNC-CSC) was analyzed using a migration assay. Briefly, control B16F10 cells and B16F10-SNC-CSC cells were seeded in 6-well plates and wounded with a p20 pipette tip. Cell movement was imaged after 0, 12, and 24 hours. As shown in FIG. 11A, chemotherapy-induced senescence (CIS) melanoma cells with stem cell properties (B16F10-SNC-CSC) migrated more in an in vitro migration assay compared to control B16F10 cells.
次に、幹細胞特性を有する化学療法誘導性老化細胞(B16F10-SNC-CSC)の浸潤特性を、浸潤アッセイを使用して分析した。浸潤アッセイは、マトリゲルでコーティングされた24ウェルトランスウェル挿入物で実施した。簡潔には、0.5×106の対照B16F10細胞及びB16F10-SNC-CSC細胞を無血清培地で上部チャンバーに播種し、下部チャンバーに10%FBSを添加した培地を充填した。16時間のインキュベーション後、フィルターの上面の細胞を取り除き、フィルターの下の細胞を固定し、0.02%クリスタルバイオレット溶液で染色した。細胞数を100倍の倍率で3つのフィールドでカウントした。図11B及び11Cに示されるように、幹細胞特性を有する化学療法誘導性老化細胞は、対照B16F10細胞と比較して、マトリゲルコーティングした膜への侵入においてより積極的であった。これらの結果は、化学療法によって誘導された老化B16F10腫瘍細胞がそれらの増殖能力を取り戻し、幹細胞の特性を得て、転移に対する移動能力及び侵襲性を高めたことを示す。 Next, the invasion properties of chemotherapy-induced senescent cells with stem cell properties (B16F10-SNC-CSCs) were analyzed using an invasion assay. Invasion assays were performed in 24-well transwell inserts coated with Matrigel. Briefly, 0.5×10 6 control B16F10 cells and B16F10-SNC-CSC cells were seeded in serum-free medium in the upper chamber and the lower chamber was filled with medium supplemented with 10% FBS. After 16 hours of incubation, the cells on the top surface of the filters were removed and the cells below the filters were fixed and stained with 0.02% crystal violet solution. Cell numbers were counted in three fields at 100x magnification. As shown in FIGS. 11B and 11C, chemotherapy-induced senescent cells with stem cell properties were more aggressive in invading Matrigel-coated membranes compared to control B16F10 cells. These results indicate that chemotherapy-induced senescent B16F10 tumor cells regained their proliferative capacity and acquired stem cell properties, increasing their migratory capacity and invasiveness to metastasis.
幹細胞特性を有する化学療法誘導性老化細胞に対するマウスNK細胞の細胞傷害性活性
インビボでNK細胞を増殖させるために、C57BL/6マウスに、TGFRt15-TGFRs(10mg/kg)を4日間皮下注射した。これらのマウスから脾臓を採取し、MACS Miltenyiカラムを使用してNK細胞を精製した。次に、精製したNK細胞を2t2でインビトロで増殖させた(図12A)。
Cytotoxic activity of mouse NK cells against chemotherapy-induced senescent cells with stem cell properties To expand NK cells in vivo, C57BL/6 mice were injected subcutaneously with TGFRt15-TGFRs (10 mg/kg) for 4 days. Spleens were harvested from these mice and NK cells were purified using MACS Miltenyi columns. Purified NK cells were then expanded in vitro with 2t2 (Fig. 12A).
増殖したNK細胞の細胞傷害性を評価するために、化学療法によって誘導された老化幹細胞(B16F10-SNC-CSC)又は対照B16F10細胞を、CellTrace violetで標識し、インビトロで活性化した2t2マウスNK細胞(10mg/kgのTGFRt15-TGFRsを4日間注射したC57BL/6の脾臓から分離)と様々なE:T比で16時間インキュベートした。B16F10-SNC-CSC及び対照B16F10細胞をトリプシン処理し、洗浄し、ヨウ化プロピジウム(PI)溶液を含む完全培地に再懸濁し、フローサイトメトリーで細胞傷害性によってアクセスした。図12Bに示されるように、NK細胞は、対照B16F10細胞と比較して、幹細胞特性を有する化学療法誘導性老化細胞(B16F10-SNC-CSC)を死滅させるのにより効果的であった。 To assess the cytotoxicity of expanded NK cells, chemotherapy-induced senescent stem cells (B16F10-SNC-CSC) or control B16F10 cells were labeled with CellTrace violet and activated 2t2 mouse NK cells in vitro. (isolated from spleens of C57BL/6 injected with 10 mg/kg TGFRt15-TGFRs for 4 days) and incubated at various E:T ratios for 16 hours. B16F10-SNC-CSC and control B16F10 cells were trypsinized, washed, resuspended in complete medium containing propidium iodide (PI) solution and accessed by cytotoxicity by flow cytometry. As shown in FIG. 12B, NK cells were more effective in killing chemotherapy-induced senescent cells with stem cell properties (B16F10-SNC-CSC) compared to control B16F10 cells.
黒色腫マウスモデルにおける併用療法
黒色腫の処理におけるTGFRt15-TGFRsの効果を、マウス黒色腫モデルで評価した。簡潔には、5×105 B16F10細胞を、C57BL/6マウスに皮下注射した。腫瘍体積が約100mm3に達したとき、マウスをドセタキセル(化学療法)(5mg/kg)又はTA99(200μg)の単剤又は3日ごとの組み合わせ、及びTGFRt15-TGFRs(3mg/kg)は週に1回施した(図13A)。生理食塩水、ドセタキセル(化学療法)/TA99のみ、又はTGFRt15-TGFRsのみを施したマウスを対照として使用した。各実験群及び対照群で5匹のマウスを試験した。腫瘍体積は、3日ごとに測定した。図13B及び13Cに示されるように、TGFRt15-TGFRsと化学療法又はTA99の組み合わせは、同系黒色腫マウスモデルにおいて、生理食塩水で処理したマウス又は化学療法又はTA99のみで処理したマウスと比較して腫瘍の進行を遅らせた。
Combination Therapy in a Mouse Model of Melanoma The effect of TGFRt15-TGFRs in treating melanoma was evaluated in a mouse model of melanoma. Briefly, 5×10 5 B16F10 cells were injected subcutaneously into C57BL/6 mice. When tumor volumes reached approximately 100 mm 3 , mice were treated with docetaxel (chemotherapy) (5 mg/kg) or TA99 (200 μg) alone or in combination every 3 days, and TGFRt15-TGFRs (3 mg/kg) weekly. One application was applied (Fig. 13A). Mice receiving saline, docetaxel (chemotherapy)/TA99 alone, or TGFRt15-TGFRs alone were used as controls. Five mice were tested in each experimental and control group. Tumor volumes were measured every 3 days. As shown in FIGS. 13B and 13C, the combination of TGFRt15-TGFRs and chemotherapy or TA99 was significantly more effective in a syngeneic melanoma mouse model compared to mice treated with saline or chemotherapy or TA99 alone. slowed tumor progression.
実施例4:ヒト膵臓細胞株SW1990における老化の化学療法的誘導
材料及び方法
β-ガラクトシダーゼ染色:化学療法によって誘導された老化の確認は、市販のキット(Cell Signaling Technology)を製造業者の指示に従って使用し、pH6.0で標準的なβ-ガラクトシダーゼ染色を行った。翌日、染色液を除去し、細胞をリン酸緩衝生理食塩水で洗浄し、70%グリセロールをウェルに添加した。β-ガラクトシダーゼ陽性細胞は、青色に染色されるが、対照未処理細胞は染色されない。
Example 4: Chemotherapeutic induction of senescence in the human pancreatic cell line SW1990 Materials and methods β-galactosidase staining: Confirmation of chemotherapy-induced senescence was obtained using a commercially available kit (Cell Signaling Technology) from the manufacturer. and standard β-galactosidase staining was performed at pH 6.0. The next day, staining solution was removed, cells were washed with phosphate buffered saline, and 70% glycerol was added to the wells. β-galactosidase positive cells stain blue, while control untreated cells do not.
フローサイトメトリー:100万個の対照細胞及び老化細胞を得て、製造業者の指示に従って、抗CD44抗体及び抗CD24抗体(Biolegend)などの幹細胞の表面マーカーに対する市販の抗体を使用して染色した。その後、細胞を洗浄し、BD Celestaフローサイトメーターを使用して分析した。幹細胞様特性を示す細胞は、CD44とCD24の両方に対して二重に陽性になる。 Flow cytometry: One million control and senescent cells were obtained and stained using commercially available antibodies against stem cell surface markers such as anti-CD44 and anti-CD24 antibodies (Biolegend) according to the manufacturer's instructions. Cells were then washed and analyzed using a BD Celesta flow cytometer. Cells exhibiting stem cell-like properties become doubly positive for both CD44 and CD24.
遺伝子発現アッセイ:100万個の対照細胞及び老化細胞を得て、Trizol(Thermofisher)を使用して溶解した後、RNA分離キット(Qiagen)を使用してRNAを精製した。Qiagen cDNA Quantitectキットを使用してRNAを定量し、cDNAに変換した。その後、cDNAを標準的なTaqman遺伝子発現アッセイ(Thermofisher)のテンプレートとして使用して、老化した幹細胞マーカー及びNKリガンドの相対的な存在量を定量化した。 Gene Expression Assays: One million control and senescent cells were obtained and lysed using Trizol (Thermofisher) followed by RNA purification using an RNA isolation kit (Qiagen). RNA was quantified and converted to cDNA using the Qiagen cDNA Quantitect kit. The cDNA was then used as a template for standard Taqman gene expression assays (Thermofisher) to quantify the relative abundance of senescent stem cell markers and NK ligands.
NK細胞細胞傷害性アッセイ:NK細胞は、市販のNK分離キット(幹細胞)を使用して健康なヒトドナー(n=2)から単離し、サイトカイン融合分子18t15-12s(100nM)を使用して一晩活性化させた。翌日、NK細胞を洗浄してサイトカイン分子を除去し、CellTrace Violet標識対照未処理腫瘍細胞又は化学療法によって誘導された老化腫瘍細胞のいずれかとE:T比4:1で20時間混合した。翌日、細胞をトリプシン処理し、フローサイトメトリーを使用して各ウェルの完全な内容物を分析し、細胞の阻害率を分析した。 NK cell cytotoxicity assay: NK cells were isolated from healthy human donors (n=2) using a commercial NK isolation kit (stem cells) and treated overnight with cytokine fusion molecule 18t15-12s (100 nM). activated. The following day, NK cells were washed to remove cytokine molecules and mixed with either CellTrace Violet-labeled control untreated tumor cells or chemotherapy-induced senescent tumor cells at an E:T ratio of 4:1 for 20 hours. The next day, cells were trypsinized and the complete contents of each well were analyzed using flow cytometry to analyze percent inhibition of cells.
結果
化学療法薬アブラキサン(Celgene)及びゲムシタビン(Sigma Aldrich)で2.5μM及び6.25μMで3日間処理することにより、それぞれ、ヒト膵臓腫瘍細胞株SW1990の老化を誘導した。未処理のSW1990細胞を、対照として使用した。3日後に培地を交換し、細胞を培養培地に4日間静置した。図14に示されるように、化学療法薬で処理された老化細胞は、β-ガラクトシダーゼ染色(青色)に陽性であったが、対照細胞は染色されなかった。老化細胞及び対照細胞は、治療後4日、11日、及び22日で老化及び幹細胞マーカーの発現について評価された。図14に示されるように、老化細胞は、対照細胞と比較して、CD44及びCD24の二重陽性染色の増加を経時的に示した。更に、化学療法によって誘導された老化SW1990細胞は、DPP4、IL6、及びp21を含む老化マーカー、Oct 3/4、CD24、及びCD44を含む幹細胞マーカー、並びに上記の遺伝子発現アッセイを使用した処理後0日目、並びに2、4、及び24日目にネクチン及びMICAを含むNKリガンドの発現についても分析された。図15に示されるように、言及された全てのマーカーの発現は、増加を経時的に示した。
Results Senescence was induced in the human pancreatic tumor cell line SW1990 by treatment with the chemotherapeutic drugs Abraxane (Celgene) and gemcitabine (Sigma Aldrich) for 3 days at 2.5 μM and 6.25 μM, respectively. Untreated SW1990 cells were used as a control. The medium was changed after 3 days and the cells were left in culture medium for 4 days. As shown in Figure 14, senescent cells treated with chemotherapy drugs were positive for β-galactosidase staining (blue), whereas control cells did not stain. Senescent and control cells were evaluated for expression of senescence and stem cell markers at 4, 11, and 22 days after treatment. As shown in Figure 14, senescent cells showed an increase in double-positive CD44 and CD24 staining over time compared to control cells. In addition, chemotherapy-induced senescent SW1990 cells were 0 after treatment using senescence markers including DPP4, IL6, and p21, stem cell
インビトロで活性化されたヒトNK細胞の細胞傷害性
インビトロで活性化されたヒトNK細胞(18t15-12sで処理)の細胞傷害性を評価するために、化学療法薬アブラキサン(Celgene)及びゲムシタビン(Sigma Aldrich)で2.5μM及び6.25μMで3日間処理することにより、それぞれ、ヒト膵臓腫瘍細胞株SW1990の老化を誘導した。未処理のSW1990細胞を、対照として使用した。3日後に培地を交換し、細胞を培養培地に30日間静置した。培養培地は、4日ごとに交換した。活性化されたNK細胞が得られ、化学療法によって誘導された老化腫瘍細胞及び未処理の対照腫瘍細胞に対するそれらの細胞傷害性が、上記のNK細胞細胞傷害性アッセイを使用して評価された。図16に示されるように、活性化されたNK細胞は、対照SW1990細胞(SW1990)及び老化SW1990細胞(SW1990s)の両方に対して細胞傷害性の増加を示した。
Cytotoxicity of In Vitro Activated Human NK Cells To assess the cytotoxicity of in vitro activated human NK cells (treated with 18t15-12s), the chemotherapeutic drugs Abraxane (Celgene) and gemcitabine (Sigma) Aldrich) induced senescence in the human pancreatic tumor cell line SW1990 by treatment with 2.5 μM and 6.25 μM for 3 days, respectively. Untreated SW1990 cells were used as a control. The medium was changed after 3 days and the cells were left in culture medium for 30 days. Culture medium was changed every 4 days. Activated NK cells were obtained and their cytotoxicity against chemotherapy-induced senescent tumor cells and untreated control tumor cells was assessed using the NK cell cytotoxicity assay described above. As shown in Figure 16, activated NK cells showed increased cytotoxicity against both control SW1990 cells (SW1990) and senescent SW1990 cells (SW1990s).
実施例5:IL-12/IL-15RαSu DNA構築物の作製
非限定的な例では、IL-12/IL-15RαSu DNA構築物を作製した(図17)。ヒトIL-12サブユニット配列、ヒトIL-15RαSu配列、ヒトIL-15配列、ヒト組織因子219配列、及びヒトIL-18配列をUniProtウェブサイトから入手し、これらの配列のDNAをGenewizによって合成した。GS(3)リンカーを用いてIL-12サブユニットベータ(p40)をIL-12サブユニットアルファ(p35)に結合してIL-12の一本鎖バージョンを生成し、その後、IL-12配列をIL-15RαSu配列に直接結合することによってDNA構築物を作製した。最終IL-12/IL-15RαSu DNA構築物配列をGenewizによって合成した。
Example 5 Generation of IL-12/IL-15RαSu DNA Construct In a non-limiting example, an IL-12/IL-15RαSu DNA construct was generated (FIG. 17). Human IL-12 subunit sequence, human IL-15RαSu sequence, human IL-15 sequence,
IL12/IL-15RαSu構築物の核酸配列(シグナルペプチド配列を含む)は、以下の通りである(配列番号181)。
(シグナルペプチド)
ATGAAATGGGTGACCTTTATTTCTTTACTGTTCCTCTTTAGCAGCGCCTACTCC
(ヒトIL-12サブユニットベータ(p40))
ATTTGGGAACTGAAGAAGGACGTCTACGTGGTCGAACTGGACTGGTATCCCGATGCTCCCGGCGAAATGGTGGTGCTCACTTGTGACACCCCCGAAGAAGACGGCATCACTTGGACCCTCGATCAGAGCAGCGAGGTGCTGGGCTCCGGAAAGACCCTCACAATCCAAGTTAAGGAGTTCGGAGACGCTGGCCAATACACATGCCACAAGGGAGGCGAGGTGCTCAGCCATTCCTTATTATTATTACACAAGAAGGAAGACGGAATCTGGTCCACCGACATTTTAAAAGATCAGAAGGAGCCCAAGAATAAGACCTTTTTAAGGTGTGAGGCCAAAAACTACAGCGGTCGTTTCACTTGTTGGTGGCTGACCACCATTTCCACCGATTTAACCTTCTCCGTGAAAAGCAGCCGGGGAAGCTCCGACCCTCAAGGTGTGACATGTGGAGCCGCTACCCTCAGCGCTGAGAGGGTTCGTGGCGATAACAAGGAATACGAGTACAGCGTGGAGTGCCAAGAAGATAGCGCTTGTCCCGCTGCCGAAGAATCTTTACCCATTGAGGTGATGGTGGACGCCGTGCACAAACTCAAGTACGAGAACTACACCTCCTCCTTCTTTATCCGGGACATCATTAAGCCCGATCCTCCTAAGAATTTACAGCTGAAGCCTCTCAAAAATAGCCGGCAAGTTGAGGTCTCTTGGGAATATCCCGACACTTGGAGCACACCCCACAGCTACTTCTCTTTAACCTTTTGTGTGCAAGTTCAAGGTAAAAGCAAGCGGGAGAAGAAAGACCGGGTGTTTACCGACAAAACCAGCGCCACCGTCATCTGTCGGAAGAACGCCTCCATCAGCGTGAGGGCTCAAGATCGTTATTACTCCAGCAGCTGGTCCGAGTGGGCCAGCGTGCCTTGTTCC
(リンカー)
GGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCT
(ヒトIL-12サブユニットアルファ(p35))
CGTAACCTCCCCGTGGCTACCCCCGATCCCGGAATGTTCCCTTGTTTACACCACAGCCAGAATTTACTGAGGGCCGTGAGCAACATGCTGCAGAAAGCTAGGCAGACTTTAGAATTTTACCCTTGCACCAGCGAGGAGATCGACCATGAAGATATCACCAAGGACAAGACATCCACCGTGGAGGCTTGTTTACCTCTGGAGCTGACAAAGAACGAGTCTTGTCTCAACTCTCGTGAAACCAGCTTCATCACAAATGGCTCTTGTTTAGCTTCCCGGAAGACCTCCTTTATGATGGCTTTATGCCTCAGCTCCATCTACGAGGATTTAAAGATGTACCAAGTGGAGTTCAAGACCATGAACGCCAAGCTGCTCATGGACCCTAAACGGCAGATCTTTTTAGACCAGAACATGCTGGCTGTGATTGATGAGCTGATGCAAGCTTTAAACTTCAACTCCGAGACCGTCCCTCAGAAGTCCTCCCTCGAGGAGCCCGATTTTTACAAGACAAAGATCAAACTGTGCATTTTACTCCACGCCTTTAGGATCCGGGCCGTGACCATTGACCGGGTCATGAGCTATTTAAACGCCAGC
(ヒトIL-15Rαスシドメイン)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
The nucleic acid sequence (including signal peptide sequence) of the IL12/IL-15RαSu construct is as follows (SEQ ID NO: 181).
(signal peptide)
ATGAAATGGGTGACCTTTATTTCTTTACTGTTCCTCTTTAGCAGCGCCTACTCC
(Human IL-12 subunit beta (p40))
ATTTGGGAACTGAAGAAGGACGTCTACGTGGTCGAACTGGACTGGTATCCCGATGCTCCCGGCGAAATGGTGGTGCTCACTTGTGACACCCCCGAAGAAGACGGCATCACTTGGACCCTCGATCAGAGCAGCGAGGTGCTGGGCTCCGGAAGAACCCTCACAATCCAAGTTAA GGAGTTCGGAGACGCTGGCCAATACACATGCCACAAGGGGAGGCGCGAGGTGCTCAGCCATTCCTTATTATTATTACACAAGAAGGAAGACGGAATCTGGTCCACCGACATTTTAAAGATCAGAAGGAGCCCAAGAATAAGACCTTTTTAAGGTGTGAGGCCAAAAAAACTACAGCGGG TCGTTTTCACTTGTTGGTGGCTGACCACCATTTCCACCGATTTAACCTTTCTCCGTGAAAGCAGCCGGGGGAAGCTCCGACCCTCAAGGTGTGACATGTGGAGCCGCTACCCTCAGCGCTGAGAGGGTTCGTGGCGCGATACAAGGAATACGAGTACAGCGTGGAGTGCCAAGA AGATAGCGCTTGTCCCCGCTGCCGAAGAATCTTTACCCATTGAGGTGATGGTGGACGCCGTGCACAAAACTCAAGTACGAGAACTACACCCTCCTCCTTCTTATCCGGGACATCATTAAGCCCCGATCCTCCTAAGAATTTACAGCTGAAGCCTCTCAAAAAATAGCCGGCAAGTTGAGGTCT CTTGGGAATATCCCGACACTTGGAGCACACCCCACAGCTACTTCTCTTTAACCTTTTGTGTGCAAGTTCAAGGTAAAAGCAAGCGGGAGAAGAAAGACCGGGTGTTTACCGACAAAAACCAGCGCCACCGTCATCTGTCGGAAGAACGCTCCATCAGCGTGAGGGCTCAAGATC GTTATTACTCCAGCAGCTGGTCCGAGTGGGCCAGCGTGCCTTGTTCC
(linker)
GGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGGCGGAGGATCT
(Human IL-12 subunit alpha (p35))
CGTAACCTCCCCGTGGCTACCCCCGATCCCCGGAATGTTCCCTTGTTTACACCACAGCCAGAATTTACTGAGGGCCGTGAGCAACATGCTGCAGAAAGCTAGGCAGACTTTAGAATTTTACCCTTGCACCAGCGAGGAGATCGACCATGAAGATATCACCAAGGACAAGACATCCACCGTGGAGG CTTGTTTACCTCTGGAGCTGACAAAGAACGAGTCTTTGTCTCAACTCTCGTGAAACCAGCTTCATCACAAATGGCTCTTGTTTAGCTTCCCGGAAGACCTCCTTTATGATGGCTTTATGCCTCAGCTCCATCTACGAGGATTTAAAAGATGTACCAAGTGGAGTTCAAGACCCATGAACGCCAA GCTGCTCATGGACCCTAAACGGCAGATCTTTTTTAGACCAGAACATGCTGGCTGTGATTGATGAGCTGATGCAAGCTTTAAACTTCAACTCCGAGACCGTCCCTCAGAAGTCCTCCCTCGAGGAGCCCGATTTTTACAAGACAAAGATCAAACTGTGCATTTACTCCACGCCTTTAGGATCCG GGCCGTGACCATTGACCGGGTCATGAGCCTATTTAAAACGCCAGC
(Human IL-15Rα sushi domain)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCT CTTTAAAGTGCATCCGG
実施例6:IL-18/TF/IL-15 DNA構築物の作製
非限定的な例では、IL-18配列を組織因子219のN末端コーディング領域に結合し、IL-18/TF構築物をIL-15のN末端コーディング領域に結合することによってIL-18/TF/IL-15構築物を作製した(図18)。Genewizによって合成したIL-18/TF/IL-15構築物の核酸配列(リーダー配列を含む)は、以下の通りである(配列番号177)。
(シグナルペプチド)
ATGAAGTGGGTCACATTTATCTCTTTACTGTTCCTCTTCTCCAGCGCCTACAGC
(ヒトIL-18)
TACTTCGGCAAACTGGAATCCAAGCTGAGCGTGATCCGGAATTTAAACGACCAAGTTCTGTTTATCGATCAAGGTAACCGGCCTCTGTTCGAGGACATGACCGACTCCGATTGCCGGGACAATGCCCCCCGGACCATCTTCATTATCTCCATGTACAAGGACAGCCAGCCCCGGGGCATGGCTGTGACAATTAGCGTGAAGTGTGAGAAAATCAGCACTTTATCTTGTGAGAACAAGATCATCTCCTTTAAGGAAATGAACCCCCCCGATAACATCAAGGACACCAAGTCCGATATCATCTTCTTCCAGCGGTCCGTGCCCGGTCACGATAACAAGATGCAGTTCGAATCCTCCTCCTACGAGGGCTACTTTTTAGCTTGTGAAAAGGAGAGGGATTTATTCAAGCTGATCCTCAAGAAGGAGGACGAGCTGGGCGATCGTTCCATCATGTTCACCGTCCAAAACGAGGAT
(ヒト組織因子219)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(ヒトIL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
Example 6: Generation of an IL-18/TF/IL-15 DNA Construct In a non-limiting example, an IL-18 sequence was ligated to the N-terminal coding region of
(signal peptide)
ATGAAGTGGGTCACATTTTATCTCTTTACTGTTCCTCTTCTCCAGCGCCTACAGC
(human IL-18)
TACTTCGGCAAAACTGGAATCCAAGCTGAGCGTGATCCGGAATTTAAAACGACCAAGTTCTGTTTATCGATCAAGGTAACCGGCCTCTGTTCGAGGACATGACCGACTCCGATTGCCGGGACAATGCCCCCCGGACCATCTTCATTATCTCCATGTACAAGGACAGCCAGCCCCCGGGGCAT GGCTGTGACAATTAGCGTGAAGTGTGAGAAAATCAGCACTTTATCTTGTGAGAACAAGATCATCTCTTTAAGGAAATGAACCCCCCCGATAACATCAAGGACACCAAGTCCGATATCATCTTCTTCCAGCGGTCCGTGCCCGGTCACGATAACAAGATGCAGTTCGAATCCTCCTCCTAC GAGGGCTACTTTTTAGCTTGTGAAAAGGAGAGGGATTTATTCAAGCTGATCCTCAAGAAGGAGGACGAGCTGGGCGATCGTTTCCATCATGTTCACCGTCCAAAACGAGGAT
(human tissue factor 219)
AGCGGCCAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAACCATCCTCGAATGGGAACCCAAACCCGTTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCG ATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCTTTATACGAGAACAGCCCCGAATTTACCCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCA CAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTAATCGACG TGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAGGGCGAGTTCCGGGAG
(human IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTACTGGAGCTGCCAAGTTATCTCTTTAGAGAGCGGGAGACGCTAGCAT CCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCCAAGGAGTGCGAAGAGCTGGAGGGAGAAGAACATCAAGGAGTTCTGCAATCCTTTGTGCCACATTGTCCAGATGTTCATCAATACCTCC
実施例7:IL-12/IL-15RαSu融合タンパク質及びIL-18/TF/IL-15融合タンパク質の分泌
IL-12/IL-15RαSu DNA構築物及びIL-18/TF/IL-15 DNA構築物をpMSGV-1修飾レトロウイルス発現ベクターにクローニングし(参照により本明細書に組み込まれる、Hughes,Hum Gene Ther 16:457-72,2005に記載のもの)、発現ベクターをCHO-K1細胞にトランスフェクトした。CHO-K1細胞でのこれらの2つの構築物の共発現により、可溶性IL-18/TF/IL-15:IL-12/IL-15RαSuタンパク質複合体(18t15-12sと称する、図19及び図20)の形成及び分泌が可能になった。18t15-12sタンパク質を、抗TF抗体アフィニティークロマトグラフィー及びサイズ排除クロマトグラフィーを使用してCHO-K1細胞培養上清から精製し、IL-12/IL-15RαSu融合タンパク質及びIL-18/TF/IL-15融合タンパク質からなる可溶性(非凝集)タンパク質複合体を得た。
Example 7: Secretion of IL-12/IL-15RαSu and IL-18/TF/IL-15 fusion proteins. -1 modified retroviral expression vector (as described in Hughes, Hum Gene Ther 16:457-72, 2005, incorporated herein by reference) and the expression vector was transfected into CHO-K1 cells. Co-expression of these two constructs in CHO-K1 cells resulted in the formation of a soluble IL-18/TF/IL-15:IL-12/IL-15RαSu protein complex (designated 18t15-12s, FIGS. 19 and 20). formation and secretion of The 18t15-12s protein was purified from CHO-K1 cell culture supernatants using anti-TF antibody affinity chromatography and size exclusion chromatography to isolate IL-12/IL-15RαSu fusion protein and IL-18/TF/IL-18t15-12s protein. A soluble (non-aggregated) protein complex consisting of 15 fusion proteins was obtained.
IL12/IL-15RαSu融合タンパク質のアミノ酸配列(シグナルペプチド配列を含む)は、以下の通りである(配列番号180)。
(シグナルペプチド)
MKWVTFISLLFLFSSAYS
(ヒトIL-12サブユニットベータ(p40))
IWELKKDVYVVELDWYPDAPGEMVVLTCDTPEEDGITWTLDQSSEVLGSGKTLTIQVKEFGDAGQYTCHKGGEVLSHSLLLLHKKEDGIWSTDILKDQKEPKNKTFLRCEAKNYSGRFTCWWLTTISTDLTFSVKSSRGSSDPQGVTCGAATLSAERVRGDNKEYEYSVECQEDSACPAAEESLPIEVMVDAVHKLKYENYTSSFFIRDIIKPDPPKNLQLKPLKNSRQVEVSWEYPDTWSTPHSYFSLTFCVQVQGKSKREKKDRVFTDKTSATVICRKNASISVRAQDRYYSSSWSEWASVPCS
(リンカー)
GGGGSGGGGSGGGGS
(ヒトIL-12サブユニットアルファ(p35))
RNLPVATPDPGMFPCLHHSQNLLRAVSNMLQKARQTLEFYPCTSEEIDHEDITKDKTSTVEACLPLELTKNESCLNSRETSFITNGSCLASRKTSFMMALCLSSIYEDLKMYQVEFKTMNAKLLMDPKRQIFLDQNMLAVIDELMQALNFNSETVPQKSSLEEPDFYKTKIKLCILLHAFRIRAVTIDRVMSYLNAS
(ヒトIL-15Rαスシドメイン)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
The amino acid sequence (including signal peptide sequence) of the IL12/IL-15RαSu fusion protein is as follows (SEQ ID NO: 180).
(signal peptide)
MKWVT FISLLFLFS SAYS
(Human IL-12 subunit beta (p40))
IWELKKDVYVVELDWYPDAPGEMVVLTCDTPEEDGITWTLDQSSEVLGSGKTLTIQVKEFGDAGQYTCHKGGEVLSHSLLLHKKEDGIWSTDILKDQKEPKNKTFLRCEAKNYSGRFTCWWLTTISTDLTFSVKSSR GSSDPQGVTCGAATLSAERVRGDNKEYEYSVECQEDSACPAAEESLPIEVMVDAVHKLKYENYTSSFFIRDIIKPDPPKNLQLKPLKNSRQVEVSWEYPDTWSTPHSYFSLTFCVQVQGKSKREKKDRVFTDKTSATVICRKNASISVRA QDRYYSSSWSEWASVPCS
(linker)
GGGGSGGGGSGGGGGS
(Human IL-12 subunit alpha (p35))
RNLPVATPDPGMFPCLHHSQNLLRAVSNMLQKARQTLEFYPCTSEEIDHEDITKDKTSTVEACLPLELTKNESCLNSRETSFITNGSCLASRKTSFMMALCLSSSIYEDLKMYQVEFKTMNAKLMDPKRQIFLDQNMLAAVIDELMQALN FNSETVPQKSSLEEPDFYKTKIKLCILLHAFRIRAVTIDRVMSYLNAS
(Human IL-15Rα sushi domain)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
IL-18/TF/IL-15融合タンパク質のアミノ酸配列(シグナルペプチド配列を含む)は、以下の通りである(配列番号176)。
(シグナルペプチド)
MKWVTFISLLFLFSSAYS
(ヒトIL-18)
YFGKLESKLSVIRNLNDQVLFIDQGNRPLFEDMTDSDCRDNAPRTIFIISMYKDSQPRGMAVTISVKCEKISTLSCENKIISFKEMNPPDNIKDTKSDIIFFQRSVPGHDNKMQFESSSYEGYFLACEKERDLFKLILKKEDELGDRSIMFTVQNED
(ヒト組織因子219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(ヒトIL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
The amino acid sequence (including signal peptide sequence) of the IL-18/TF/IL-15 fusion protein is as follows (SEQ ID NO: 176).
(signal peptide)
MKWVT FISLLFLFS SAYS
(human IL-18)
YFGKLESKLSVIRNLNDQVLFIDQGNRPLFEDMTDSDCRDNAPRTIFIISMYKDSQPRGMAVTISVKCEKISTLSCENKIISFKEMNPPDNIKDTKSDIIFFQRSVPGHDNKMQFESSSYEGYFLACEKERDLFKLILLKEDELGDRSIMFT VQNED
(human tissue factor 219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTF LSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(human IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
ある場合には、リーダー(シグナル配列)ペプチドをインタクトなポリペプチドから切断して、可溶性であり得るか、又は分泌され得る成熟形態を生成する。 In some cases, the leader (signal sequence) peptide is cleaved from the intact polypeptide to generate the mature form, which can be soluble or secreted.
実施例8:免疫親和性クロマトグラフィーによる18t15-12sの精製
抗TF抗体親和性カラムをGE Healthcare(商標)AKTA Avantタンパク質精製システムに接続した。流速は、2mL/分の溶出ステップを除く全てのステップで4mL/分であった。
Example 8: Purification of 18t15-12s by immunoaffinity chromatography An anti-TF antibody affinity column was connected to a GE Healthcare™ AKTA Avant protein purification system. The flow rate was 4 mL/min for all steps except the 2 mL/min elution step.
18t15-12sの細胞培養収集物を1Mトリス塩基でpH7.4に調整し、5カラム体積のPBSで平衡化した抗TF抗体アフィニティーカラムにロードした。試料をロードした後、カラムを5カラム体積のPBSで洗浄し、その後、6カラム体積の0.1M酢酸(pH2.9)で溶出した。280nmでの吸光度を収集し、その後、1Mトリス塩基の添加により、試料をpH7.5~8.0に中和した。その後、中和した試料を、分子量カットオフ30KDaでAmicon(登録商標)遠心フィルターを使用してPBSに緩衝液交換した。図21は、18t15-12s複合体が抗TF抗体親和性カラムに結合することを示しており、ここで、TFは、18t15-12s結合パートナーである。緩衝液交換したタンパク質試料を、更なる生化学的分析及び生物学的活性試験のために2~8℃で保管する。 The 18t15-12s cell culture harvest was adjusted to pH 7.4 with 1 M Tris base and loaded onto an anti-TF antibody affinity column equilibrated with 5 column volumes of PBS. After sample loading, the column was washed with 5 column volumes of PBS and then eluted with 6 column volumes of 0.1 M acetic acid (pH 2.9). Absorbance at 280 nm was collected, after which samples were neutralized to pH 7.5-8.0 by addition of 1 M Tris base. Neutralized samples were then buffer exchanged into PBS using Amicon® centrifugal filters with a molecular weight cutoff of 30 KDa. Figure 21 shows that the 18t15-12s conjugate binds to an anti-TF antibody affinity column, where TF is the 18t15-12s binding partner. Buffer-exchanged protein samples are stored at 2-8° C. for further biochemical analysis and biological activity testing.
各溶出後、抗TF抗体アフィニティーカラムを6カラム体積の0.1Mグリシン(pH2.5)を使用してストリッピングした。その後、カラムを、10カラム体積のPBS、0.05%アジ化ナトリウムを使用して中和し、2~8℃で保管した。 After each elution, the anti-TF antibody affinity column was stripped using 6 column volumes of 0.1 M glycine (pH 2.5). The column was then neutralized using 10 column volumes of PBS, 0.05% sodium azide and stored at 2-8°C.
実施例9:18t15-12sのサイズ排除クロマトグラフィー
GE Healthcare Superdex(登録商標)200 Increase 10/300 GLゲル濾過カラムを、GE Healthcare AKTA(商標)Avantタンパク質精製システムに接続した。カラムを2カラム体積のPBSで平衡化した。流速は0.8mL/分であった。キャピラリーループを使用して、1mg/mLの18t15-12s複合体200μLをカラムに注入した。注入を1.25カラム体積のPBSで追跡した。SECクロマトグラフを図22に示す。おそらく18t15-12s二量体又は凝集体のグリコシル化程度が異なるため、マイナーな高分子量ピークとともに主要な18t15-12sタンパク質ピークが存在する。
Example 9: Size Exclusion Chromatography of 18t15-12s A GE
実施例10:18t15-12sのSDS-PAGE
純度及びタンパク質分子量を決定するために、精製した18t15-12sタンパク質試料を、4~12%NuPageビス-トリスタンパク質ゲルSDS-PAGEを使用して分析した。ゲルをInstantBlue(商標)で約30分間染色し、その後、精製水中で一晩脱色した。図23は、抗TF抗体親和性精製18t15-12sのSDSゲルの例を示しており、予想された分子量(66kDa及び56kDa)にバンドがある。
Example 10: SDS-PAGE of 18t15-12s
Purified 18t15-12s protein samples were analyzed using 4-12% NuPage Bis-Tris protein gel SDS-PAGE to determine purity and protein molecular weight. Gels were stained with InstantBlue™ for approximately 30 minutes and then destained overnight in purified water. FIG. 23 shows an example of an SDS gel of anti-TF antibody affinity purified 18t15-12s with bands at the expected molecular weights (66 kDa and 56 kDa).
実施例11:CHO-K1細胞における18t15-12sのグリコシル化
CHO-K1細胞における18t15-12sのグリコシル化を、Protein Deglycosylation Mix IIキット(New England Biolabs)を製造業者の指示に従って使用して確認した。図24は、脱グリコシル化及び非脱グリコシル化18t15-12sのSDS PAGEの例を示す。図24のレーン4に見られるように、脱グリコシル化により18t15-12sの分子量が減少する。
Example 11: Glycosylation of 18t15-12s in CHO-K1 Cells Glycosylation of 18t15-12s in CHO-K1 cells was confirmed using the Protein Deglycosylation Mix II kit (New England Biolabs) according to the manufacturer's instructions. FIG. 24 shows examples of SDS PAGE of deglycosylated and non-deglycosylated 18t15-12s. As seen in
実施例12:18t15-12s複合体の組換えタンパク質定量
18t15-12s複合体を、標準のサンドイッチELISA法を使用して検出及び定量化した(図25~28)。抗ヒト組織因子抗体が捕捉抗体として機能し、ビオチン化抗ヒトIL-12、IL-15、又はIL-18抗体(BAF219、BAM247、D045-6、全てR&D Systems)が検出抗体として機能した。精製した18t15-12sタンパク質複合体の組織因子も、抗ヒト組織因子捕捉抗体(I43)及び抗ヒト組織因子抗体検出を使用して検出した。I43/抗TF抗体ELISAを、同様の濃度の精製組織因子と比較した。
Example 12: Recombinant Protein Quantification of 18t15-12s Complexes 18t15-12s complexes were detected and quantified using standard sandwich ELISA methods (Figures 25-28). An anti-human tissue factor antibody served as the capture antibody and a biotinylated anti-human IL-12, IL-15, or IL-18 antibody (BAF219, BAM247, D045-6, all R&D Systems) served as the detection antibody. Tissue factor in the purified 18t15-12s protein complex was also detected using anti-human tissue factor capture antibody (I43) and anti-human tissue factor antibody detection. The I43/anti-TF antibody ELISA was compared to similar concentrations of purified tissue factor.
実施例13:18t15-12s複合体の免疫刺激能力
18t15-12s複合体のIL-15免疫刺激活性を評価するために、増加濃度の18t15-12sを200μLのIMDM:10%FBS培地中の32Dβ細胞(104細胞/ウェル)に添加した。32Dβ細胞を37℃で3日間インキュベートした。4日目に、WST-1増殖試薬(10μL/ウェル)を添加し、4時間後、吸光度を450nmで測定して、WST-1の可溶性ホルマザン色素への切断に基づいて細胞増殖を測定した。ヒト組換えIL-15の生物活性を陽性対照として評価した。図29に示されるように、18t15-12sは、32Dβ細胞のIL-15依存性細胞増殖を示した。18t15-12s複合体は、おそらくIL-18及び組織因子のIL-15ドメインへの結合のため、ヒト組換えIL-15と比較して低下した活性を示した。
Example 13: Immunostimulatory Potential of 18t15-12s Complexes To assess the IL-15 immunostimulatory activity of 18t15-12s complexes, increasing concentrations of 18t15-12s were added to 200 μL of IMDM:32Dβ cells in 10% FBS medium. (104 cells/well). 32Dβ cells were incubated at 37° C. for 3 days. On
18t15-12s複合体におけるIL-12及びIL-18の個々の活性を評価するために、18t15-12sを、200μLのIMDM:10%熱不活性化FBS培地中のHEK-Blue IL-12及びHEK-Blue IL-18レポーター細胞に添加した(5×104細胞/ウェル、hkb-il12及びhkb-hmil18、InvivoGen)。細胞を37℃で一晩インキュベートした。20μlの誘導されたHEK-Blue IL-12及びHEK-Blue IL-18レポーター細胞上清を180μlのQUANTI-Blue(InvivoGen)に添加し、37℃で1~3時間インキュベートした。IL-12又はIL-18活性を、吸光度を620nmで測定することによって評価した。ヒト組換えIL-12又はIL-18を陽性又は陰性対照として評価した。図30及び図31に示されるように、18t15-12s複合体のサイトカインドメインは各々、特定の生物学的活性を保持する。18t15-12sの活性は、おそらくIL-15及び組織因子のIL-18ドメインへの結合、及びIL-12のIL-15Rαスシドメインへの結合のため、ヒト組換えIL-18又はIL-12の活性と比較して低下した。 To assess the individual activities of IL-12 and IL-18 in the 18t15-12s complex, 18t15-12s was mixed with HEK-Blue IL-12 and HEK in 200 μL of IMDM:10% heat-inactivated FBS medium. - added to Blue IL-18 reporter cells (5 x 104 cells/well, hkb-il12 and hkb-hmil18, InvivoGen). Cells were incubated overnight at 37°C. 20 μl of induced HEK-Blue IL-12 and HEK-Blue IL-18 reporter cell supernatant was added to 180 μl of QUANTI-Blue (InvivoGen) and incubated at 37° C. for 1-3 hours. IL-12 or IL-18 activity was assessed by measuring absorbance at 620 nm. Human recombinant IL-12 or IL-18 were evaluated as positive or negative controls. As shown in Figures 30 and 31, the cytokine domains of the 18t15-12s complex each retain specific biological activities. The activity of 18t15-12s is likely due to binding of IL-15 and tissue factor to the IL-18 domain, and binding of IL-12 to the IL-15Rα sushi domain, resulting in increased binding of human recombinant IL-18 or IL-12. decreased compared to activity.
実施例14:18t15-12s複合体によるサイトカイン誘導性メモリー様NK細胞の誘導
サイトカイン誘導性メモリー様NK細胞を、精製NK細胞を飽和量のIL-12(10ng/mL)、IL-15(50ng/mL)、及びIL-18(50ng/mL)で一晩刺激した後にエクスビボで誘導することができる。これらのメモリー様特性は、IL-2受容体α(IL-2Rα、CD25)、CD69(及び他の活性化マーカー)の発現、及びIFN-γ産生の増加により測定されている。サイトカイン誘導性メモリー様NK細胞の生成を促進する18t15-12s複合体の能力を評価するために、精製ヒトNK細胞(95%超のCD56+)を、0.01nM~10000nMの18t15-12s複合体又は個々のサイトカインの組み合わせ(組換えIL-12(10ng/ml)、IL-18(50ng/ml)、及びIL-15(50ng/ml))で14~18時間刺激した。細胞表面CD25及びCD69発現及び細胞内IFN-γレベルを、抗体染色及びフローサイトメトリーによって評価した。
Example 14: Induction of Cytokine-Inducible Memory-Like NK Cells by 18t15-12s Complex mL), and can be induced ex vivo after overnight stimulation with IL-18 (50 ng/mL). These memory-like properties have been measured by increased expression of IL-2 receptor alpha (IL-2Rα, CD25), CD69 (and other activation markers), and IFN-γ production. To assess the ability of the 18t15-12s complex to promote the generation of cytokine-induced memory-like NK cells, purified human NK cells (>95% CD56+) were treated with 0.01 nM to 10000 nM of the 18t15-12s complex or Individual cytokine combinations (recombinant IL-12 (10 ng/ml), IL-18 (50 ng/ml), and IL-15 (50 ng/ml)) were stimulated for 14-18 hours. Cell surface CD25 and CD69 expression and intracellular IFN-γ levels were assessed by antibody staining and flow cytometry.
新鮮なヒト白血球を血液バンクから入手し、CD56+NK細胞を、RosetteSep/ヒトNK細胞試薬(StemCell Technologies)を使用して単離した。NK細胞の純度は70%超であり、CD56-BV421、CD16-BV510、CD25-PE、CD69-APCFire750特異的抗体(BioLegend)で染色することにより確認した。細胞をカウントし、0.2mLの完全培地(RPMI1640(Gibco)、2mMのL-グルタミン(Thermo Life Technologies)、ペニシリン(Thermo Life Technologies)、ストレプトマイシン(Thermo Life Technologies)、及び10%FBS(Hyclone)を補充)中の96ウェル平底プレートに0.2×106/mLで再懸濁した。細胞を、サイトカインhIL-12(10ng/mL)(Biolegend)、hIL-18(50ng/mL)(R&D Systems)、及びhIL-15(50ng/mL)(NCI)の混合物、又は0.01nM~10000nMの18t15-12sのいずれかで、37℃、5%CO2で14~18時間刺激した。その後、細胞を収集し、CD56-BV421、CD16-BV510、CD25-PE、CD69-APCFire750特異的抗体(BioLegend)で30分間表面染色した。染色後、細胞を、FACS緩衝液(1×PBS(Hyclone)、0.5%BSA(EMD Millipore)及び0.001%アジ化ナトリウム(Sigma)を含む)中で洗浄した(1500RPM、室温で5分間)。2回洗浄した後、細胞を、BD FACSCelesta(商標)フローサイトメーターを使用して分析した(プロットされたデータ-平均蛍光強度、図32A及び図32B)。 Fresh human leukocytes were obtained from a blood bank and CD56+ NK cells were isolated using RosetteSep/human NK cell reagent (StemCell Technologies). The purity of NK cells was >70% and confirmed by staining with CD56-BV421, CD16-BV510, CD25-PE, CD69-APCFire750 specific antibodies (BioLegend). Cells were counted and added to 0.2 mL complete medium (RPMI 1640 (Gibco), 2 mM L-glutamine (Thermo Life Technologies), penicillin (Thermo Life Technologies), streptomycin (Thermo Life Technologies), and 10% FBS (Hyclone ) resuspended at 0.2×10 6 /mL in 96-well flat-bottom plates in medium (supplemented). Cells were treated with a mixture of cytokines hIL-12 (10 ng/mL) (Biolegend), hIL-18 (50 ng/mL) (R&D Systems), and hIL-15 (50 ng/mL) (NCI), or 0.01 nM-10000 nM. 18t15-12s at 37° C., 5% CO 2 for 14-18 hours. Cells were then harvested and surface stained with CD56-BV421, CD16-BV510, CD25-PE, CD69-APCFire750 specific antibodies (BioLegend) for 30 minutes. After staining, cells were washed in FACS buffer (containing 1×PBS (Hyclone), 0.5% BSA (EMD Millipore) and 0.001% sodium azide (Sigma)) (1500 RPM, 5 minutes at room temperature). minutes). After two washes, cells were analyzed using a BD FACSCelesta™ flow cytometer (plotted data-mean fluorescence intensity, Figures 32A and 32B).
新鮮なヒト白血球を血液バンクから入手し、CD56+NK細胞を、RosetteSep/ヒトNK細胞試薬(StemCell Technologies)を使用して単離した。NK細胞の純度は70%超であり、CD56-BV421、CD16-BV510、CD25-PE、CD69-APCFire750特異的抗体(BioLegend)で染色することにより確認した。細胞をカウントし、0.2mLの完全培地(RPMI1640(Gibco)、2mMのL-グルタミン(Thermo Life Technologies)、ペニシリン(Thermo Life Technologies)、ストレプトマイシン(Thermo Life Technologies)、及び10%FBS(Hyclone)を補充)中の96ウェル平底プレートに0.2×106/mLで再懸濁した。細胞を、hIL-12(10ng/mL)(Biolegend)、hIL-18(50ng/mL)(R&D)、及びhIL-15(50ng/mL)(NCI)のサイトカイン混合物、又は0.01nM~10000nMの18t15-12s複合体のいずれかで、37℃、5%CO2で14~18時間刺激した。その後、細胞を、10μg/mLのブレフェルジンA(Sigma)及び1Xモネンシン(eBioscience)で4時間処理し、収集した後、CD56-BV421、CD16-BV510、CD25-PE、CD69-APCFire750特異的抗体で30分間染色した。染色後、細胞を、FACS緩衝液(1×PBS(Hyclone)、0.5%BSA(EMD Millipore)及び0.001%アジ化ナトリウム(Sigma)を含む)中で洗浄し(1500RPM、室温で5分間)、室温で10分間固定した。固定後、細胞を1x透過処理緩衝液(eBioscience)中で洗浄し(1500RPM、室温で5分間)、IFN-γ-PE(Biolegend)で、室温で30分間染色した。細胞を1x透過処理緩衝液で再度洗浄し、その後、FACS緩衝液で洗浄した。細胞ペレットを300μlのFACS緩衝液中に再懸濁し、BD FACSCelesta(商標)フローサイトメーターを使用して分析した(IFN-γ陽性細胞のプロット%、図33)。 Fresh human leukocytes were obtained from a blood bank and CD56+ NK cells were isolated using RosetteSep/human NK cell reagent (StemCell Technologies). The purity of NK cells was >70% and confirmed by staining with CD56-BV421, CD16-BV510, CD25-PE, CD69-APCFire750 specific antibodies (BioLegend). Cells were counted and added to 0.2 mL complete medium (RPMI 1640 (Gibco), 2 mM L-glutamine (Thermo Life Technologies), penicillin (Thermo Life Technologies), streptomycin (Thermo Life Technologies), and 10% FBS (Hyclone ) resuspended at 0.2×10 6 /mL in 96-well flat-bottom plates in medium (supplemented). Cells were treated with a cytokine mixture of hIL-12 (10 ng/mL) (Biolegend), hIL-18 (50 ng/mL) (R&D), and hIL-15 (50 ng/mL) (NCI), or 0.01 nM-10000 nM Either 18t15-12s complex was stimulated at 37° C., 5% CO 2 for 14-18 hours. Cells were then treated with 10 μg/mL Brefeldin A (Sigma) and 1X monensin (eBioscience) for 4 hours, harvested and then 30-fold treated with CD56-BV421, CD16-BV510, CD25-PE, CD69-APCFire750 specific antibodies. Stained for minutes. After staining, cells were washed in FACS buffer (containing 1×PBS (Hyclone), 0.5% BSA (EMD Millipore) and 0.001% sodium azide (Sigma)) (1500 RPM, 5 minutes at room temperature). minutes) and fixed at room temperature for 10 minutes. After fixation, cells were washed in 1× permeabilization buffer (eBioscience) (1500 RPM, 5 minutes at room temperature) and stained with IFN-γ-PE (Biolegend) for 30 minutes at room temperature. Cells were washed again with 1x permeabilization buffer and then with FACS buffer. Cell pellets were resuspended in 300 μl of FACS buffer and analyzed using a BD FACSCelesta™ flow cytometer (plot % IFN-γ positive cells, FIG. 33).
実施例15:ヒト腫瘍細胞に対するNK細胞のインビトロ細胞傷害性
ヒト骨髄性白血病細胞K562(CellTrace violetで標識)を、増加濃度の18t15-12s複合体又は対照としてのサイトカイン混合物の存在下で、精製ヒトNK細胞とインキュベートした。20時間後、培養物を収集し、ヨウ化プロピジウム(PI)で染色し、フローサイトメトリーで評価した。図34に示されるように、18t15-12s複合体は、サイトカイン混合物と同様の又はそれよりも高いレベルで、K562に対するヒトNK細胞傷害性を誘導し、18t15-12s複合体及びサイトカイン混合物の両方が培地対照よりも高い細胞傷害性を誘導した。
Example 15: In vitro cytotoxicity of NK cells against human tumor cells Human myeloid leukemia cells K562 (labeled with CellTrace violet) were treated with purified human Incubated with NK cells. After 20 hours, cultures were harvested, stained with propidium iodide (PI) and evaluated by flow cytometry. As shown in Figure 34, the 18t15-12s complex induced human NK cytotoxicity against K562 at similar or higher levels than the cytokine mixture, and both the 18t15-12s complex and the cytokine mixture It induced higher cytotoxicity than the medium control.
実施例16:IL-12/IL-15RαSu/αCD16scFv DNA構築物及びIL-18/TF/IL-15 DNA構築物の作製
非限定的な例では、IL-12/IL-15RαSu/αCD16scFv DNA構築物及びIL-18/TF/IL-15 DNA構築物を作製した(図35及び図36)。ヒトIL-12サブユニット配列、ヒトIL-15RαSu配列、ヒトIL-15配列、ヒト組織因子219配列、及びヒトIL-18配列をGenewizによって合成した。GS(3)リンカーを用いてIL-12サブユニットベータ(p40)をIL-12サブユニットアルファ(p35)に結合してIL-12の一本鎖バージョンを生成し、IL-12配列をIL-15RαSu配列に、かつIL-12/IL-15RαSu構築物をαCD16scFvのN末端コーディング領域に直接結合することによってDNA構築物を作製した。
Example 16: Generation of IL-12/IL-15RαSu/αCD16scFv DNA Constructs and IL-18/TF/IL-15 DNA Constructs In a non-limiting example, IL-12/IL-15RαSu/αCD16scFv DNA constructs and IL-15RαSu/αCD16scFv DNA constructs A 18/TF/IL-15 DNA construct was generated (Figures 35 and 36). Human IL-12 subunit sequences, human IL-15RαSu sequences, human IL-15 sequences,
IL-12/IL-15RαSu/αCD16scFv構築物の核酸配列は、以下の通りである(配列番号226)。
(シグナルペプチド)
ATGAAATGGGTGACCTTTATTTCTTTACTGTTCCTCTTTAGCAGCGCCTACTCC
(ヒトIL-12サブユニットベータ(p40))
ATTTGGGAACTGAAGAAGGACGTCTACGTGGTCGAACTGGACTGGTATCCCGATGCTCCCGGCGAAATGGTGGTGCTCACTTGTGACACCCCCGAAGAAGACGGCATCACTTGGACCCTCGATCAGAGCAGCGAGGTGCTGGGCTCCGGAAAGACCCTCACAATCCAAGTTAAGGAGTTCGGAGACGCTGGCCAATACACATGCCACAAGGGAGGCGAGGTGCTCAGCCATTCCTTATTATTATTACACAAGAAGGAAGACGGAATCTGGTCCACCGACATTTTAAAAGATCAGAAGGAGCCCAAGAATAAGACCTTTTTAAGGTGTGAGGCCAAAAACTACAGCGGTCGTTTCACTTGTTGGTGGCTGACCACCATTTCCACCGATTTAACCTTCTCCGTGAAAAGCAGCCGGGGAAGCTCCGACCCTCAAGGTGTGACATGTGGAGCCGCTACCCTCAGCGCTGAGAGGGTTCGTGGCGATAACAAGGAATACGAGTACAGCGTGGAGTGCCAAGAAGATAGCGCTTGTCCCGCTGCCGAAGAATCTTTACCCATTGAGGTGATGGTGGACGCCGTGCACAAACTCAAGTACGAGAACTACACCTCCTCCTTCTTTATCCGGGACATCATTAAGCCCGATCCTCCTAAGAATTTACAGCTGAAGCCTCTCAAAAATAGCCGGCAAGTTGAGGTCTCTTGGGAATATCCCGACACTTGGAGCACACCCCACAGCTACTTCTCTTTAACCTTTTGTGTGCAAGTTCAAGGTAAAAGCAAGCGGGAGAAGAAAGACCGGGTGTTTACCGACAAAACCAGCGCCACCGTCATCTGTCGGAAGAACGCCTCCATCAGCGTGAGGGCTCAAGATCGTTATTACTCCAGCAGCTGGTCCGAGTGGGCCAGCGTGCCTTGTTCC
(リンカー)
GGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCT
(ヒトIL-12サブユニットアルファ(p35))
CGTAACCTCCCCGTGGCTACCCCCGATCCCGGAATGTTCCCTTGTTTACACCACAGCCAGAATTTACTGAGGGCCGTGAGCAACATGCTGCAGAAAGCTAGGCAGACTTTAGAATTTTACCCTTGCACCAGCGAGGAGATCGACCATGAAGATATCACCAAGGACAAGACATCCACCGTGGAGGCTTGTTTACCTCTGGAGCTGACAAAGAACGAGTCTTGTCTCAACTCTCGTGAAACCAGCTTCATCACAAATGGCTCTTGTTTAGCTTCCCGGAAGACCTCCTTTATGATGGCTTTATGCCTCAGCTCCATCTACGAGGATTTAAAGATGTACCAAGTGGAGTTCAAGACCATGAACGCCAAGCTGCTCATGGACCCTAAACGGCAGATCTTTTTAGACCAGAACATGCTGGCTGTGATTGATGAGCTGATGCAAGCTTTAAACTTCAACTCCGAGACCGTCCCTCAGAAGTCCTCCCTCGAGGAGCCCGATTTTTACAAGACAAAGATCAAACTGTGCATTTTACTCCACGCCTTTAGGATCCGGGCCGTGACCATTGACCGGGTCATGAGCTATTTAAACGCCAGC
(ヒトIL-15Rαスシドメイン)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
(抗ヒトCD16軽鎖可変ドメイン)
TCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCAACCATGTGGTGTTCGGCGGCGGCACCAAGCTGACCGTGGGCCAT
(リンカー)
GGCGGCGGCGGCTCCGGAGGCGGCGGCAGCGGCGGAGGAGGATCC
(抗ヒトCD16重鎖可変ドメイン)
GAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGG
The nucleic acid sequence of the IL-12/IL-15RαSu/αCD16scFv construct is as follows (SEQ ID NO:226).
(signal peptide)
ATGAAATGGGTGACCTTTATTTCTTTACTGTTCCTCTTTAGCAGCGCCTACTCC
(Human IL-12 subunit beta (p40))
ATTTGGGAACTGAAGAAGGACGTCTACGTGGTCGAACTGGACTGGTATCCCGATGCTCCCGGCGAAATGGTGGTGCTCACTTGTGACACCCCCGAAGAAGACGGCATCACTTGGACCCTCGATCAGAGCAGCGAGGTGCTGGGCTCCGGAAGAACCCTCACAATCCAAGTTAA GGAGTTCGGAGACGCTGGCCAATACACATGCCACAAGGGGAGGCGCGAGGTGCTCAGCCATTCCTTATTATTATTACACAAGAAGGAAGACGGAATCTGGTCCACCGACATTTTAAAGATCAGAAGGAGCCCAAGAATAAGACCTTTTTAAGGTGTGAGGCCAAAAAAACTACAGCGGG TCGTTTTCACTTGTTGGTGGCTGACCACCATTTCCACCGATTTAACCTTTCTCCGTGAAAGCAGCCGGGGGAAGCTCCGACCCTCAAGGTGTGACATGTGGAGCCGCTACCCTCAGCGCTGAGAGGGTTCGTGGCGCGATACAAGGAATACGAGTACAGCGTGGAGTGCCAAGA AGATAGCGCTTGTCCCCGCTGCCGAAGAATCTTTACCCATTGAGGTGATGGTGGACGCCGTGCACAAAACTCAAGTACGAGAACTACACCCTCCTCCTTCTTATCCGGGACATCATTAAGCCCCGATCCTCCTAAGAATTTACAGCTGAAGCCTCTCAAAAAATAGCCGGCAAGTTGAGGTCT CTTGGGAATATCCCGACACTTGGAGCACACCCCACAGCTACTTCTCTTTAACCTTTTGTGTGCAAGTTCAAGGTAAAAGCAAGCGGGAGAAGAAAGACCGGGTGTTTACCGACAAAAACCAGCGCCACCGTCATCTGTCGGAAGAACGCTCCATCAGCGTGAGGGCTCAAGATC GTTATTACTCCAGCAGCTGGTCCGAGTGGGCCAGCGTGCCTTGTTCC
(linker)
GGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGGCGGAGGATCT
(Human IL-12 subunit alpha (p35))
CGTAACCTCCCCGTGGCTACCCCCGATCCCCGGAATGTTCCCTTGTTTACACCACAGCCAGAATTTACTGAGGGCCGTGAGCAACATGCTGCAGAAAGCTAGGCAGACTTTAGAATTTTACCCTTGCACCAGCGAGGAGATCGACCATGAAGATATCACCAAGGACAAGACATCCACCGTGGAGG CTTGTTTACCTCTGGAGCTGACAAAGAACGAGTCTTTGTCTCAACTCTCGTGAAACCAGCTTCATCACAAATGGCTCTTGTTTAGCTTCCCGGAAGACCTCCTTTATGATGGCTTTATGCCTCAGCTCCATCTACGAGGATTTAAAAGATGTACCAAGTGGAGTTCAAGACCCATGAACGCCAA GCTGCTCATGGACCCTAAACGGCAGATCTTTTTTAGACCAGAACATGCTGGCTGTGATTGATGAGCTGATGCAAGCTTTAAACTTCAACTCCGAGACCGTCCCTCAGAAGTCCTCCCTCGAGGAGCCCGATTTTTACAAGACAAAGATCAAACTGTGCATTTACTCCACGCCTTTAGGATCCG GGCCGTGACCATTGACCGGGTCATGAGCCTATTTAAAACGCCAGC
(Human IL-15Rα sushi domain)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCT CTTTAAAGTGCATCCGG
(anti-human CD16 light chain variable domain)
TCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACACAGGCCCTCCGGCATCCCTGACAGG TTCTCCGGATCCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCGGCAACCATGTGGGTGTTCGGCGCGCGGCACCAAGCTGACCGTGGGCCAT
(linker)
GGCGGCGGCGGCTCCGGAGGCGCGCGGCAGCGGCGGAGGAGGATCC
(anti-human CD16 heavy chain variable domain)
GAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCCTCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGGTGAGGCAGGCTCCTGGAAAGGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGG CGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCG TGTCCAGG
IL-18配列を組織因子219のN末端コーディング領域に結合し、IL-18/TF構築物をIL-15のN末端コーディング領域に結合することによっても構築物を作製した(図36)。IL-18/TF/IL-15構築物の核酸配列(リーダー配列を含む)は、以下の通りである(配列番号177)。
(シグナルペプチド)
ATGAAGTGGGTCACATTTATCTCTTTACTGTTCCTCTTCTCCAGCGCCTACAGC
(ヒトIL-18)
TACTTCGGCAAACTGGAATCCAAGCTGAGCGTGATCCGGAATTTAAACGACCAAGTTCTGTTTATCGATCAAGGTAACCGGCCTCTGTTCGAGGACATGACCGACTCCGATTGCCGGGACAATGCCCCCCGGACCATCTTCATTATCTCCATGTACAAGGACAGCCAGCCCCGGGGCATGGCTGTGACAATTAGCGTGAAGTGTGAGAAAATCAGCACTTTATCTTGTGAGAACAAGATCATCTCCTTTAAGGAAATGAACCCCCCCGATAACATCAAGGACACCAAGTCCGATATCATCTTCTTCCAGCGGTCCGTGCCCGGTCACGATAACAAGATGCAGTTCGAATCCTCCTCCTACGAGGGCTACTTTTTAGCTTGTGAAAAGGAGAGGGATTTATTCAAGCTGATCCTCAAGAAGGAGGACGAGCTGGGCGATCGTTCCATCATGTTCACCGTCCAAAACGAGGAT
(ヒト組織因子219)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(ヒトIL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
Constructs were also made by joining the IL-18 sequence to the N-terminal coding region of
(signal peptide)
ATGAAGTGGGTCACATTTTATCTCTTTACTGTTCCTCTTCTCCAGCGCCTACAGC
(human IL-18)
TACTTCGGCAAAACTGGAATCCAAGCTGAGCGTGATCCGGAATTTAAAACGACCAAGTTCTGTTTATCGATCAAGGTAACCGGCCTCTGTTCGAGGACATGACCGACTCCGATTGCCGGGACAATGCCCCCCGGACCATCTTCATTATCTCCATGTACAAGGACAGCCAGCCCCCGGGGCAT GGCTGTGACAATTAGCGTGAAGTGTGAGAAAATCAGCACTTTATCTTGTGAGAACAAGATCATCTCTTTAAGGAAATGAACCCCCCCGATAACATCAAGGACACCAAGTCCGATATCATCTTCTTCCAGCGGTCCGTGCCCGGTCACGATAACAAGATGCAGTTCGAATCCTCCTCCTAC GAGGGCTACTTTTTAGCTTGTGAAAAGGAGAGGGATTTATTCAAGCTGATCCTCAAGAAGGAGGACGAGCTGGGCGATCGTTTCCATCATGTTCACCGTCCAAAACGAGGAT
(human tissue factor 219)
AGCGGCCAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAACCATCCTCGAATGGGAACCCAAACCCGTTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCG ATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCTTTATACGAGAACAGCCCCGAATTTACCCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCA CAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTAATCGACG TGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAGGGCGAGTTCCGGGAG
(human IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTACTGGAGCTGCCAAGTTATCTCTTTAGAGAGCGGGAGACGCTAGCAT CCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCCAAGGAGTGCGAAGAGCTGGAGGGAGAAGAACATCAAGGAGTTCTGCAATCCTTTGTGCCACATTGTCCAGATGTTCATCAATACCTCC
実施例17:IL-12/IL-15RαSu/αCD16scFv融合タンパク質及びIL-18/TF/IL-15融合タンパク質の分泌
IL-12/IL-15RαSu/αCD16scFv構築物及びIL-18/TF/IL-15構築物をpMSGV-1修飾レトロウイルス発現ベクター(参照により本明細書に組み込まれる、Hughes,Hum Gene Ther16:457-72,2005)にクローニングし、発現ベクターをCHO-K1細胞にトランスフェクトした。CHO-K1細胞でのこれらの2つの構築物の共発現により、可溶性IL-18/TF/IL-15:IL-12/IL-15RαSu/αCD16scFvタンパク質複合体(18t15-12s/αCD16と称する、図37及び図38)の分泌がもたらされた。CHO-K1細胞でのこれらの2つの構築物の共発現により、可溶性IL-18/TF/IL-15:IL-12/IL-15RαSu/αCD16scFvタンパク質複合体(18t15-12s/αCD16と称する、図37及び図38)の分泌がもたらされ、これを抗TF抗体親和性及び他のクロマトグラフィー法により精製することができる。ある場合には、シグナルペプチドをインタクトなポリペプチドから切断して、成熟形態を生成する。
Example 17: Secretion of IL-12/IL-15RαSu/αCD16scFv and IL-18/TF/IL-15 Fusion Proteins IL-12/IL-15RαSu/αCD16scFv and IL-18/TF/IL-15 Constructs was cloned into a pMSGV-1 modified retroviral expression vector (Hughes, Hum Gene Ther 16:457-72, 2005, incorporated herein by reference) and the expression vector was transfected into CHO-K1 cells. Co-expression of these two constructs in CHO-K1 cells yielded a soluble IL-18/TF/IL-15:IL-12/IL-15RαSu/αCD16scFv protein complex (designated 18t15-12s/αCD16, FIG. 37 and Figure 38) resulted in secretion. Co-expression of these two constructs in CHO-K1 cells yielded a soluble IL-18/TF/IL-15:IL-12/IL-15RαSu/αCD16scFv protein complex (designated 18t15-12s/αCD16, FIG. 37 and Figure 38), which can be purified by anti-TF antibody affinity and other chromatographic methods. In some cases, the signal peptide is cleaved from the intact polypeptide to produce the mature form.
IL-12/IL-15RαSu/αCD16scFv融合タンパク質のアミノ酸配列(シグナルペプチド配列を含む)は、以下の通りである(配列番号225)。
(シグナルペプチド)
MKWVTFISLLFLFSSAYS
(ヒトIL-12サブユニットベータ(p40))
IWELKKDVYVVELDWYPDAPGEMVVLTCDTPEEDGITWTLDQSSEVLGSGKTLTIQVKEFGDAGQYTCHKGGEVLSHSLLLLHKKEDGIWSTDILKDQKEPKNKTFLRCEAKNYSGRFTCWWLTTISTDLTFSVKSSRGSSDPQGVTCGAATLSAERVRGDNKEYEYSVECQEDSACPAAEESLPIEVMVDAVHKLKYENYTSSFFIRDIIKPDPPKNLQLKPLKNSRQVEVSWEYPDTWSTPHSYFSLTFCVQVQGKSKREKKDRVFTDKTSATVICRKNASISVRAQDRYYSSSWSEWASVPCS
(リンカー)
GGGGSGGGGSGGGGS
(ヒトIL-12サブユニットアルファ(p35))
RNLPVATPDPGMFPCLHHSQNLLRAVSNMLQKARQTLEFYPCTSEEIDHEDITKDKTSTVEACLPLELTKNESCLNSRETSFITNGSCLASRKTSFMMALCLSSIYEDLKMYQVEFKTMNAKLLMDPKRQIFLDQNMLAVIDELMQALNFNSETVPQKSSLEEPDFYKTKIKLCILLHAFRIRAVTIDRVMSYLNAS
(ヒトIL-15Rαスシドメイン)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
(抗ヒトCD16軽鎖可変ドメイン)
SELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGH
(リンカー)
GGGGSGGGGSGGGGS
(抗ヒトCD16重鎖可変ドメイン)
EVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSR
The amino acid sequence (including signal peptide sequence) of the IL-12/IL-15RαSu/αCD16scFv fusion protein is as follows (SEQ ID NO:225).
(signal peptide)
MKWVT FISLLFLFS SAYS
(Human IL-12 subunit beta (p40))
IWELKKDVYVVELDWYPDAPGEMVVLTCDTPEEDGITWTLDQSSEVLGSGKTLTIQVKEFGDAGQYTCHKGGEVLSHSLLLLLHKKEDGIWSTDILKDQKEPKNKTFLRCEAKNYSGRFTCWWLTTISTDLTFSVKSSR GSSDPQGVTCGAATLSAERVRGDNKEYEYSVECQEDSACPAAEESLPIEVMVDAVHKLKYENYTSSFFIRDIIKPDPPKNLQLKPLKNSRQVEVSWEYPDTWSTPHSYFSLTFCVQVQGKSKREKKDRVFTDKTSATVICRKNASISVRA QDRYYSSSWSEWASVPCS
(linker)
GGGGSGGGGSGGGGGS
(Human IL-12 subunit alpha (p35))
RNLPVATPDPGMFPCLHHSQNLLRAVSNMLQKARQTLEFYPCTSEEIDHEDITKDKTSTVEACLPLELTKNESCLNSRETSFITNGSCLASRKTSFMMALCLSSSIYEDLKMYQVEFKTMNAKLMDPKRQIFLDQNMLAAVIDELMQALN FNSETVPQKSSLEEPDFYKTKIKLCILLHAFRIRAVTIDRVMSYLNAS
(Human IL-15Rα sushi domain)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
(anti-human CD16 light chain variable domain)
SELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGH
(linker)
GGGGSGGGGSGGGGGS
(anti-human CD16 heavy chain variable domain)
EVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSR
IL-18/TF/IL-15融合タンパク質のアミノ酸配列(リーダー配列を含む)は、以下の通りである(配列番号221)。
(シグナルペプチド)
MKWVTFISLLFLFSSAYS
(ヒトIL-18)
YFGKLESKLSVIRNLNDQVLFIDQGNRPLFEDMTDSDCRDNAPRTIFIISMYKDSQPRGMAVTISVKCEKISTLSCENKIISFKEMNPPDNIKDTKSDIIFFQRSVPGHDNKMQFESSSYEGYFLACEKERDLFKLILKKEDELGDRSIMFTVQNED
(ヒト組織因子219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(ヒトIL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
The amino acid sequence (including leader sequence) of the IL-18/TF/IL-15 fusion protein is as follows (SEQ ID NO:221).
(signal peptide)
MKWVT FISLLFLFS SAYS
(human IL-18)
YFGKLESKLSVIRNLNDQVLFIDQGNRPLFEDMTDSDCRDNAPRTIFIISMYKDSQPRGMAVTISVKCEKISTLSCENKIISFKEMNPPDNIKDTKSDIIFFQRSVPGHDNKMQFESSSYEGYFLACEKERDLFKLILLKEDELGDRSIMFT VQNED
(human tissue factor 219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTF LSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(human IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
実施例18:IL-18/IL-15RαSu DNA構築物及びIL-12/TF/IL-15 DNA構築物の作製
非限定的な例では、IL-18/IL-15RαSu DNA構築物及びIL-12/TF/IL-15 DNA構築物を作製した。ヒトIL-18サブユニット配列、ヒトIL-15RαSu配列、ヒトIL-12配列、ヒト組織因子219配列、及びヒトIL-15配列をGenewizによって合成した。IL-18をIL-15RαSuに直接結合することによってDNA構築物を作製した。IL-12配列をヒト組織因子219形態のN末端コーディング領域に結合し、更にIL-12/TF構築物をIL-15のN末端コーディング領域に結合することによって追加の構築物も作製した。上述のように、IL-12の一本鎖バージョン(p40-リンカー-p35)を使用した。
Example 18: Generation of IL-18/IL-15RαSu DNA Constructs and IL-12/TF/IL-15 DNA Constructs In a non-limiting example, IL-18 /IL-15RαSu DNA constructs and IL-12/TF/ An IL-15 DNA construct was made. Human IL-18 subunit sequences, human IL-15RαSu sequences, human IL-12 sequences,
IL-18/IL-15RαSu構築物の核酸配列(シグナルペプチド配列を含む)は、以下の通りである(配列番号320)。
(シグナルペプチド)
ATGAAGTGGGTCACATTTATCTCTTTACTGTTCCTCTTCTCCAGCGCCTACAGC
(ヒトIL-18)
TACTTCGGCAAACTGGAATCCAAGCTGAGCGTGATCCGGAATTTAAACGACCAAGTTCTGTTTATCGATCAAGGTAACCGGCCTCTGTTCGAGGACATGACCGACTCCGATTGCCGGGACAATGCCCCCCGGACCATCTTCATTATCTCCATGTACAAGGACAGCCAGCCCCGGGGCATGGCTGTGACAATTAGCGTGAAGTGTGAGAAAATCAGCACTTTATCTTGTGAGAACAAGATCATCTCCTTTAAGGAAATGAACCCCCCCGATAACATCAAGGACACCAAGTCCGATATCATCTTCTTCCAGCGGTCCGTGCCCGGTCACGATAACAAGATGCAGTTCGAATCCTCCTCCTACGAGGGCTACTTTTTAGCTTGTGAAAAGGAGAGGGATTTATTCAAGCTGATCCTCAAGAAGGAGGACGAGCTGGGCGATCGTTCCATCATGTTCACCGTCCAAAACGAGGAT
(ヒトIL-15Rαスシドメイン)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
The nucleic acid sequence (including signal peptide sequence) of the IL-18/IL-15RαSu construct is as follows (SEQ ID NO:320).
(signal peptide)
ATGAAGTGGGTCACATTTTATCTCTTTACTGTTCCTCTTCTCCAGCGCCTACAGC
(human IL-18)
TACTTCGGCAAAACTGGAATCCAAGCTGAGCGTGATCCGGAATTTAAAACGACCAAGTTCTGTTTATCGATCAAGGTAACCGGCCTCTGTTCGAGGACATGACCGACTCCGATTGCCGGGACAATGCCCCCCGGACCATCTTCATTATCTCCATGTACAAGGACAGCCAGCCCCCGGGGCAT GGCTGTGACAATTAGCGTGAAGTGTGAGAAAATCAGCACTTTATCTTGTGAGAACAAGATCATCTCTTTAAGGAAATGAACCCCCCCCGATAACATCAAGGACACCAAGTCCGATATCATCTTCTTCCAGCGGTCCGTGCCCGGTCACGATAACAAGATGCAGTTCGAATCCTCCTCCTAC GAGGGCTACTTTTTAGCTTGTGAAAAGGAGAGGGATTTATTCAAGCTGATCCTCAAGAAGGAGGACGAGCTGGGCGATCGTTTCCATCATGTTCACCGTCCAAAACGAGGAT
(Human IL-15Rα sushi domain)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCT CTTTAAAGTGCATCCGG
IL-12/TF/IL-15構築物の核酸配列(リーダー配列を含む)は、以下の通りである(配列番号321)。
(シグナルペプチド)
ATGAAATGGGTGACCTTTATTTCTTTACTGTTCCTCTTTAGCAGCGCCTACTCC
(ヒトIL-12サブユニットベータ(p40))
ATTTGGGAACTGAAGAAGGACGTCTACGTGGTCGAACTGGACTGGTATCCCGATGCTCCCGGCGAAATGGTGGTGCTCACTTGTGACACCCCCGAAGAAGACGGCATCACTTGGACCCTCGATCAGAGCAGCGAGGTGCTGGGCTCCGGAAAGACCCTCACAATCCAAGTTAAGGAGTTCGGAGACGCTGGCCAATACACATGCCACAAGGGAGGCGAGGTGCTCAGCCATTCCTTATTATTATTACACAAGAAGGAAGACGGAATCTGGTCCACCGACATTTTAAAAGATCAGAAGGAGCCCAAGAATAAGACCTTTTTAAGGTGTGAGGCCAAAAACTACAGCGGTCGTTTCACTTGTTGGTGGCTGACCACCATTTCCACCGATTTAACCTTCTCCGTGAAAAGCAGCCGGGGAAGCTCCGACCCTCAAGGTGTGACATGTGGAGCCGCTACCCTCAGCGCTGAGAGGGTTCGTGGCGATAACAAGGAATACGAGTACAGCGTGGAGTGCCAAGAAGATAGCGCTTGTCCCGCTGCCGAAGAATCTTTACCCATTGAGGTGATGGTGGACGCCGTGCACAAACTCAAGTACGAGAACTACACCTCCTCCTTCTTTATCCGGGACATCATTAAGCCCGATCCTCCTAAGAATTTACAGCTGAAGCCTCTCAAAAATAGCCGGCAAGTTGAGGTCTCTTGGGAATATCCCGACACTTGGAGCACACCCCACAGCTACTTCTCTTTAACCTTTTGTGTGCAAGTTCAAGGTAAAAGCAAGCGGGAGAAGAAAGACCGGGTGTTTACCGACAAAACCAGCGCCACCGTCATCTGTCGGAAGAACGCCTCCATCAGCGTGAGGGCTCAAGATCGTTATTACTCCAGCAGCTGGTCCGAGTGGGCCAGCGTGCCTTGTTCC
(リンカー)
GGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCT
(ヒトIL-12サブユニットアルファ(p35))
CGTAACCTCCCCGTGGCTACCCCCGATCCCGGAATGTTCCCTTGTTTACACCACAGCCAGAATTTACTGAGGGCCGTGAGCAACATGCTGCAGAAAGCTAGGCAGACTTTAGAATTTTACCCTTGCACCAGCGAGGAGATCGACCATGAAGATATCACCAAGGACAAGACATCCACCGTGGAGGCTTGTTTACCTCTGGAGCTGACAAAGAACGAGTCTTGTCTCAACTCTCGTGAAACCAGCTTCATCACAAATGGCTCTTGTTTAGCTTCCCGGAAGACCTCCTTTATGATGGCTTTATGCCTCAGCTCCATCTACGAGGATTTAAAGATGTACCAAGTGGAGTTCAAGACCATGAACGCCAAGCTGCTCATGGACCCTAAACGGCAGATCTTTTTAGACCAGAACATGCTGGCTGTGATTGATGAGCTGATGCAAGCTTTAAACTTCAACTCCGAGACCGTCCCTCAGAAGTCCTCCCTCGAGGAGCCCGATTTTTACAAGACAAAGATCAAACTGTGCATTTTACTCCACGCCTTTAGGATCCGGGCCGTGACCATTGACCGGGTCATGAGCTATTTAAACGCCAGC
(ヒト組織因子219)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(ヒトIL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
The nucleic acid sequence (including leader sequence) of the IL-12/TF/IL-15 construct is as follows (SEQ ID NO:321).
(signal peptide)
ATGAAATGGGTGACCTTTATTTCTTTACTGTTCCTCTTTAGCAGCGCCTACTCC
(Human IL-12 subunit beta (p40))
ATTTGGGAACTGAAGAAGGACGTCTACGTGGTCGAACTGGACTGGTATCCCGATGCTCCCGGCGAAATGGTGGTGCTCACTTGTGACACCCCCGAAGAAGACGGCATCACTTGGACCCTCGATCAGAGCAGCGAGGTGCTGGGCTCCGGAAGAACCCTCACAATCCAAGTTAA GGAGTTCGGAGACGCTGGCCAATACACATGCCACAAGGGGAGGCGCGAGGTGCTCAGCCATTCCTTATTATTATTACACAAGAAGGAAGACGGAATCTGGTCCACCGACATTTTAAAGATCAGAAGGAGCCCAAGAATAAGACCTTTTTAAGGTGTGAGGCCAAAAAAACTACAGCGGG TCGTTTTCACTTGTTGGTGGCTGACCACCATTTCCACCGATTTAACCTTTCTCCGTGAAAGCAGCCGGGGGAAGCTCCGACCCTCAAGGTGTGACATGTGGAGCCGCTACCCTCAGCGCTGAGAGGGTTCGTGGCGCGATACAAGGAATACGAGTACAGCGTGGAGTGCCAAGA AGATAGCGCTTGTCCCCGCTGCCGAAGAATCTTTACCCATTGAGGTGATGGTGGACGCCGTGCACAAAACTCAAGTACGAGAACTACACCCTCCTCCTTCTTATCCGGGACATCATTAAGCCCCGATCCTCCTAAGAATTTACAGCTGAAGCCTCTCAAAAAATAGCCGGCAAGTTGAGGTCT CTTGGGAATATCCCGACACTTGGAGCACACCCCACAGCTACTTCTCTTTAACCTTTTGTGTGCAAGTTCAAGGTAAAAGCAAGCGGGAGAAGAAAGACCGGGTGTTTACCGACAAAAACCAGCGCCACCGTCATCTGTCGGAAGAACGCTCCATCAGCGTGAGGGCTCAAGATC GTTATTACTCCAGCAGCTGGTCCGAGTGGGCCAGCGTGCCTTGTTCC
(linker)
GGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGGCGGAGGATCT
(Human IL-12 subunit alpha (p35))
CGTAACCTCCCCGTGGCTACCCCCGATCCCCGGAATGTTCCCTTGTTTACACCACAGCCAGAATTTACTGAGGGCCGTGAGCAACATGCTGCAGAAAGCTAGGCAGACTTTAGAATTTTACCCTTGCACCAGCGAGGAGATCGACCATGAAGATATCACCAAGGACAAGACATCCACCGTGGAGG CTTGTTTACCTCTGGAGCTGACAAAGAACGAGTCTTTGTCTCAACTCTCGTGAAACCAGCTTCATCACAAATGGCTCTTGTTTAGCTTCCCGGAAGACCTCCTTTATGATGGCTTTATGCCTCAGCTCCATCTACGAGGATTTAAAAGATGTACCAAGTGGAGTTCAAGACCCATGAACGCCAA GCTGCTCATGGACCCTAAACGGCAGATCTTTTTTAGACCAGAACATGCTGGCTGTGATTGATGAGCTGATGCAAGCTTTAAACTTCAACTCCGAGACCGTCCCTCAGAAGTCCTCCCTCGAGGAGCCCGATTTTTACAAGACAAAGATCAAACTGTGCATTTACTCCACGCCTTTAGGATCCG GGCCGTGACCATTGACCGGGTCATGAGCCTATTTAAAACGCCAGC
(human tissue factor 219)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAACCATCCTCGAATGGGAACCCAAACCGTTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCG ATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCTTTATACGAGAACAGCCCCGAATTTACCCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTTGAGCAAGTTTGGCA CAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTAATCGACG TGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAGGGCGAGTTCCGGGAG
(human IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTACTGGAGCTGCCAAGTTATCTCTTTAGAGAGCGGGAGACGCTAGCAT CCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCCAAGGAGTGCGAAGAGCTGGAGGGAGAAGAACATCAAGGAGTTCTGCAATCCTTTGTGCCACATTGTCCAGATGTTCATCAATACCTCC
実施例19:IL-18/IL-15RαSu融合タンパク質及びIL-12/TF/IL-15融合タンパク質の分泌
IL-18/IL-15RαSu構築物及びIL-12/TF/IL-15構築物をpMSGV-1修飾レトロウイルス発現ベクター(参照により本明細書に組み込まれる、Hughes,Hum Gene Ther16:457-72,2005)にクローニングし、発現ベクターをCHO-K1細胞にトランスフェクトした。CHO-K1細胞でのこれらの2つの構築物の共発現により、可溶性IL-12/TF/IL-15:IL-18/IL-15RαSuタンパク質複合体(12t15/s18と称する)の分泌がもたらされ、これを抗TF抗体親和性及び他のクロマトグラフィー法により精製することができる。
Example 19: Secretion of IL-18/IL-15RαSu and IL-12/TF/IL-15 fusion proteins Cloned into a modified retroviral expression vector (Hughes, Hum Gene Ther 16:457-72, 2005, incorporated herein by reference), and the expression vector was transfected into CHO-K1 cells. Co-expression of these two constructs in CHO-K1 cells resulted in the secretion of a soluble IL-12/TF/IL-15:IL-18/IL-15RαSu protein complex (termed 12t15/s18). , which can be purified by anti-TF antibody affinity and other chromatographic methods.
IL-18/IL-15RαSu融合タンパク質のアミノ酸配列(シグナルペプチド配列を含む)は、以下の通りである(配列番号322)。
(シグナルペプチド)
MKWVTFISLLFLFSSAYS
(ヒトIL-18)
YFGKLESKLSVIRNLNDQVLFIDQGNRPLFEDMTDSDCRDNAPRTIFIISMYKDSQPRGMAVTISVKCEKISTLSCENKIISFKEMNPPDNIKDTKSDIIFFQRSVPGHDNKMQFESSSYEGYFLACEKERDLFKLILKKEDELGDRSIMFTVQNED
(ヒトIL-15Rαスシドメイン)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
The amino acid sequence (including signal peptide sequence) of the IL-18/IL-15RαSu fusion protein is as follows (SEQ ID NO:322).
(signal peptide)
MKWVT FISLLFLFS SAYS
(human IL-18)
YFGKLESKLSVIRNLNDQVLFIDQGNRPLFEDMTDSDCRDNAPRTIFIISMYKDSQPRGMAVTISVKCEKISTLSCENKIISFKEMNPPDNIKDTKSDIIFFQRSVPGHDNKMQFESSSYEGYFLACEKERDLFKLILLKEDELGDRSIMFT VQNED
(Human IL-15Rα sushi domain)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
IL-12/TF/IL-15融合タンパク質のアミノ酸配列(リーダー配列を含む)は、以下の通りである(配列番号323)。
(シグナルペプチド)
MKWVTFISLLFLFSSAYS
(ヒトIL-12サブユニットベータ(p40))
IWELKKDVYVVELDWYPDAPGEMVVLTCDTPEEDGITWTLDQSSEVLGSGKTLTIQVKEFGDAGQYTCHKGGEVLSHSLLLLHKKEDGIWSTDILKDQKEPKNKTFLRCEAKNYSGRFTCWWLTTISTDLTFSVKSSRGSSDPQGVTCGAATLSAERVRGDNKEYEYSVECQEDSACPAAEESLPIEVMVDAVHKLKYENYTSSFFIRDIIKPDPPKNLQLKPLKNSRQVEVSWEYPDTWSTPHSYFSLTFCVQVQGKSKREKKDRVFTDKTSATVICRKNASISVRAQDRYYSSSWSEWASVPCS
(リンカー)
GGGGSGGGGSGGGGS
(ヒトIL-12サブユニットアルファ(p35))
RNLPVATPDPGMFPCLHHSQNLLRAVSNMLQKARQTLEFYPCTSEEIDHEDITKDKTSTVEACLPLELTKNESCLNSRETSFITNGSCLASRKTSFMMALCLSSIYEDLKMYQVEFKTMNAKLLMDPKRQIFLDQNMLAVIDELMQALNFNSETVPQKSSLEEPDFYKTKIKLCILLHAFRIRAVTIDRVMSYLNAS
(ヒト組織因子219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(ヒトIL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
The amino acid sequence (including leader sequence) of the IL-12/TF/IL-15 fusion protein is as follows (SEQ ID NO:323).
(signal peptide)
MKWVT FISLLFLFS SAYS
(Human IL-12 subunit beta (p40))
IWELKKDVYVVELDWYPDAPGEMVVLTCDTPEEDGITWTLDQSSEVLGSGKTLTIQVKEFGDAGQYTCHKGGEVLSHSLLLLLHKKEDGIWSTDILKDQKEPKNKTFLRCEAKNYSGRFTCWWLTTISTDLTFSVKSSR GSSDPQGVTCGAATLSAERVRGDNKEYEYSVECQEDSACPAAEESLPIEVMVDAVHKLKYENYTSSFFIRDIIKPDPPKNLQLKPLKNSRQVEVSWEYPDTWSTPHSYFSLTFCVQVQGKSKREKKDRVFTDKTSATVICRKNASISVRA QDRYYSSSWSEWASVPCS
(linker)
GGGGSGGGGSGGGGGS
(Human IL-12 subunit alpha (p35))
RNLPVATPDPGMFPCLHHSQNLLRAVSNMLQKARQTLEFYPCTSEEIDHEDITKDKTSTVEACLPLELTKNESCLNSRETSFITNGSCLASRKTSFMMALCLSSSIYEDLKMYQVEFKTMNAKLMDPKRQIFLDQNMLAAVIDELMQALN FNSETVPQKSSLEEPDFYKTKIKLCILLHAFRIRAVTIDRVMSYLNAS
(human tissue factor 219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTF LSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(human IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
いくつかの事例では、リーダーペプチドをインタクトなポリペプチドから切断して、可溶性であり得るか、又は分泌され得る成熟形態を生成する。 In some cases, the leader peptide is cleaved from the intact polypeptide to generate the mature form, which can be soluble or secreted.
実施例20:18t15-12s16複合体の組換えタンパク質定量
18t15-12s16複合体(IL-12/IL-15RαSu/αCD16scFv;IL-18/TF/IL-15を含む)を、標準のサンドイッチELISA法を使用して検出及び定量化した(図39)。抗ヒト組織因子抗体/IL-2又は抗TF抗体/IL-18が捕捉抗体として機能し、ビオチン化抗ヒトIL-12又はIL-18抗体(BAF219、D045-6、いずれもR&D Systems)が検出抗体として機能した。組織因子を、抗ヒト組織因子抗体(I43)及び抗ヒト組織因子抗体検出を使用して検出した。
Example 20: Recombinant Protein Determination of 18t15-12s16 Complexes 18t15-12s16 complexes (including IL-12/IL-15RαSu/αCD16scFv; IL-18/TF/IL-15) were assayed using standard sandwich ELISA methods. was detected and quantified using a (Figure 39). Anti-human tissue factor antibody/IL-2 or anti-TF antibody/IL-18 acted as a capture antibody, and biotinylated anti-human IL-12 or IL-18 antibody (BAF219, D045-6, both from R&D Systems) was detected. functioned as an antibody. Tissue factor was detected using anti-human tissue factor antibody (I43) and anti-human tissue factor antibody detection.
実施例21:TGFβRII/IL-15RαSu DNA構築物及びIL-21/TF/IL-15 DNA構築物の作製
非限定的な例では、TGFβRII/IL-15RαSu DNA構築物を作製した(図40)。ヒトTGFβRII二量体配列及びヒトIL-21配列をUniProtウェブサイトから入手し、これらの配列のDNAをGenewizによって合成した。リンカーを用いてTGFβRIIを別のTGFβRIIに結合してTGFβRIIの一本鎖バージョンを生成し、その後、TGFβRII一本鎖二量体配列をIL-15RαSuのN末端コーディング領域に直接結合することによってDNA構築物を作製した。
Example 21 Generation of TGFβRII/IL-15RαSu DNA Constructs and IL-21/TF/IL-15 DNA Constructs In a non-limiting example, a TGFβRII/IL-15RαSu DNA construct was generated (FIG. 40). Human TGFβRII dimer sequences and human IL-21 sequences were obtained from the UniProt website and DNA for these sequences was synthesized by Genewiz. DNA constructs by joining TGFβRII to another TGFβRII using a linker to generate a single-chain version of TGFβRII and then directly joining the TGFβRII single-chain dimer sequence to the N-terminal coding region of IL-15RαSu. was made.
TGFβRII/IL-15RαSu構築物の核酸配列(シグナル配列を含む)は、以下の通りである(配列番号196)。
(シグナルペプチド)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
((ヒトTGFβRII-第1の断片)
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCACGATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGAT
(リンカー)
GGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGT
(ヒトTGFβRII-第2の断片)
ATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCACAATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC
(ヒトIL-15Rαスシドメイン)
ATCACGTGTCCTCCTCCTATGTCCGTGGAACACGCAGACATCTGGGTCAAGAGCTACAGCTTGTACTCCAGGGAGCGGTACATTTGTAACTCTGGTTTCAAGCGTAAAGCCGGCACGTCCAGCCTGACGGAGTGCGTGTTGAACAAGGCCACGAATGTCGCCCACTGGACAACCCCCAGTCTCAAATGTATTAGA
The nucleic acid sequence (including signal sequence) of the TGFβRII/IL-15RαSu construct is as follows (SEQ ID NO: 196).
(signal peptide)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCC
((human TGFβRII-first fragment)
ATCCCCCCCCCATGTGCCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCACGATCACCTCCATCTGCGAGAAGCCCCAA GAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGAACCTTCTTTATGTGTTCCTGTAGCAG CGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGAT
(linker)
GGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGT
(Human TGFβRII-Second Fragment)
ATTCCTCCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCACAATCACCTCCATCTGTGAGAAGCCTCAGGAGG TGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAAACCGTCTGCCCACGATCCCCAAGCTGCCCTACCCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAAGAGAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGC GACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC
(Human IL-15Rα sushi domain)
ATCACGTGTCCTCCTCCTATGTCCGTGGAACACGCAGACATCTGGGTCAAGAGCTACAGCTTTGTACTCCAGGGGAGCGGTACATTTGTAACTCTGGTTTCAAGCGTAAAAGCCGGCACGTCCAGCCCTGACGGAGTGCGTGTTTGAACAAGGCCACGAATGTCGCCCCACT GGACAACCCCCCAGTCTCAAATGTATTAGA
加えて、IL-21配列を組織因子219のN末端コーディング領域に結合し、更にIL-21/TF構築物をIL-15のN末端コーディング領域に結合することによってIL-21/TF/IL-15構築物を作製した(図41)。IL-21/TF/IL-15構築物の核酸配列(リーダー配列を含む)は、以下の通りである(配列番号192)。
(シグナルペプチド)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(ヒトIL-21)
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC
(ヒト組織因子219)
TCCGGCACCACCAATACCGTGGCCGCTTATAACCTCACATGGAAGAGCACCAACTTCAAGACAATTCTGGAATGGGAACCCAAGCCCGTCAATCAAGTTTACACCGTGCAGATCTCCACCAAATCCGGAGACTGGAAGAGCAAGTGCTTCTACACAACAGACACCGAGTGTGATTTAACCGACGAAATCGTCAAGGACGTCAAGCAAACCTATCTGGCTCGGGTCTTTTCCTACCCCGCTGGCAATGTCGAGTCCACCGGCTCCGCTGGCGAGCCTCTCTACGAGAATTCCCCCGAATTCACCCCTTATTTAGAGACCAATTTAGGCCAGCCTACCATCCAGAGCTTCGAGCAAGTTGGCACCAAGGTGAACGTCACCGTCGAGGATGAAAGGACTTTAGTGCGGCGGAATAACACATTTTTATCCCTCCGGGATGTGTTCGGCAAAGACCTCATCTACACACTGTACTATTGGAAGTCCAGCTCCTCCGGCAAAAAGACCGCTAAGACCAACACCAACGAGTTTTTAATTGACGTGGACAAAGGCGAGAACTACTGCTTCAGCGTGCAAGCCGTGATCCCTTCTCGTACCGTCAACCGGAAGAGCACAGATTCCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(ヒトIL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
In addition, IL-21/TF/IL-15 by linking the IL-21 sequence to the N-terminal coding region of
(signal peptide)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCC
(human IL-21)
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCG CCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCCTCCACAAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCCTGCTGCAGAAGAT GATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC
(human tissue factor 219)
TCCGGCACCACCAATACCGTGGCCGCTTATAACCTCACATGGAAGAGCACCAACTTCAAGACAATTCTGGAATGGGAACCCAAGCCCCGTCAATCAAGTTTACACCGTGCAGATCTCCACCAAATCCGGAGACTGGAAGAGCAAGTGCTTCTACACAACAGACACCGAGTGTGATTTAACCGACGAA ATCGTCAAGGACGTCAAGCAAACCTATCTGGCTCGGGTCTTTTCCTACCCCGCTGGCAATGTCGAGTCCACCGGCTCCGCTGGCGAGCCTTCTACGAGAATTCCCCCGAATTCACCCTTATTTAGAGACCAATTTAGGCCAGCCCTACCATCCAGAGCTTCGAGCCAAGTTGGCACCAAGG TGAACGTCACCGTCGAGGATGAAAAGGACTTTAGTGCGGCCGGAATAACACATTTTTTATCCCTCCGGGATGTGTTCGGCAAAGACCTCATCTACACACTGTACTATTGGAAGTCCAGCTCCTCCGGCAAAAGACCGCTAAGACCAACACCAACGAGTTTTTAATTGACGTGGACAA AGGCGAGAACTACTGCTTCAGCGTGCAAGCCGTGATCCCTTCTCGTACCGTCAACCGGAAGAGCACAGATTCCCCCGTTGAGTGCATGGGCCAAGAAAGGGCGAGTTCCGGGAG
(human IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTACTGGAGCTGCCAAGTTATCTCTTTAGAGAGCGGGAGACGCTAGCAT CCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCCAAGGAGTGCGAAGAGCTGGAGGGAGAAGAACATCAAGGAGTTCTGCAATCCTTTGTGCCACATTGTCCAGATGTTCATCAATACCTCC
実施例22:TGFβRII/IL-15RαSu融合タンパク質及びIL-21/TF/IL-15融合タンパク質の分泌
TGFβRII/IL-15RαSu DNA構築物及びIL-21/TF/IL-15 DNA構築物をpMSGV-1修飾レトロウイルス発現ベクター(参照により本明細書に組み込まれる、Hughes et al.,Hum Gene Ther 16:457-72,2005に記載のもの)にクローニングし、発現ベクターをCHO-K1細胞にトランスフェクトした。CHO-K1細胞でのこれらの2つの構築物の共発現により、可溶性IL-21/TF/IL-15:TGFβRII/IL-15RαSuタンパク質複合体(21t15-TGFRsと称する、図42及び図43)の分泌がもたらされた。21t15-TGFRs複合体を、抗TF抗体親和性クロマトグラフィー及び他のクロマトグラフィー法を使用して、CHO-K1細胞培養上清から精製した。
Example 22: Secretion of TGFβRII/IL-15RαSu and IL-21/TF/IL-15 fusion proteins Cloned into a viral expression vector (as described in Hughes et al., Hum Gene Ther 16:457-72, 2005, incorporated herein by reference), and the expression vector was transfected into CHO-K1 cells. Co-expression of these two constructs in CHO-K1 cells resulted in secretion of soluble IL-21/TF/IL-15:TGFβRII/IL-15RαSu protein complexes (termed 21t15-TGFRs, FIGS. 42 and 43). was brought. 21t15-TGFRs complexes were purified from CHO-K1 cell culture supernatants using anti-TF antibody affinity chromatography and other chromatographic methods.
TGFβRII/IL-15RαSu構築物のアミノ酸配列(シグナルペプチド配列を含む)は、以下の通りである(配列番号195)。
(シグナルペプチド)
MKWVTFISLLFLFSSAYS
(ヒトTGFβRII-第1の断片)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(リンカー)
GGGGSGGGGSGGGGS
(ヒトTGFβRII-第2の断片)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(ヒトIL-15Rαスシドメイン)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
The amino acid sequence (including signal peptide sequence) of the TGFβRII/IL-15RαSu construct is as follows (SEQ ID NO: 195).
(signal peptide)
MKWVT FISLLFLFS SAYS
(Human TGFβRII-first fragment)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNSITSITSICEKPQEVCVAVWRKNDINITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPD
(linker)
GGGGSGGGGSGGGGGS
(Human TGFβRII-Second Fragment)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNSITSITSICEKPQEVCVAVWRKNDINITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPD
(Human IL-15Rα sushi domain)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
成熟IL-21/TF/IL-15融合タンパク質のアミノ酸配列(シグナルペプチド配列を含む)は、以下の通りである(配列番号191)。
(シグナルペプチド)
MKWVTFISLLFLFSSAYS
(ヒトIL-21)
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS
(ヒト組織因子219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(ヒトIL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
The amino acid sequence (including signal peptide sequence) of the mature IL-21/TF/IL-15 fusion protein is as follows (SEQ ID NO: 191).
(signal peptide)
MKWVT FISLLFLFS SAYS
(human IL-21)
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS
(human tissue factor 219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTF LSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(human IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
ある場合には、リーダーペプチドをインタクトなポリペプチドから切断して、可溶性であり得るか、又は分泌され得る成熟形態を生成する。 In some cases, the leader peptide is cleaved from the intact polypeptide to generate the mature form, which can be soluble or secreted.
実施例23:免疫親和性クロマトグラフィーによる21t15-TGFRsの精製
抗TF抗体親和性カラムをGE Healthcare AKTA(商標)Avantタンパク質精製システムに接続した。流速は、2mL/分の溶出ステップを除く全てのステップで4mL/分であった。
Example 23: Purification of 21t15-TGFRs by immunoaffinity chromatography An anti-TF antibody affinity column was attached to a GE Healthcare AKTA™ Avant protein purification system. The flow rate was 4 mL/min for all steps except the 2 mL/min elution step.
21t15-TGFRsの細胞培養収集物を1Mトリス塩基でpH7.4に調整し、5カラム体積のPBSで平衡化した抗TF抗体親和性カラムにロードした。試料をロードした後、カラムを5カラム体積のPBSで洗浄し、その後、6カラム体積の0.1M酢酸(pH2.9)で溶出した。280nmでの吸光度を収集し、その後、1Mトリス塩基の添加により、試料をpH7.5~8.0に中和した。その後、中和した試料を、分子量カットオフ30KDaでAmicon(登録商標)遠心フィルターを使用してPBSに緩衝液交換した。図44は、21t15-TGFRs複合体が抗TF抗体親和性カラムに結合することを示しており、ここで、TFは、21t15-TGFRs結合パートナーである。緩衝液交換したタンパク質試料を、更なる生化学的分析及び生物学的活性試験のために2~8℃で保管する。 A cell culture harvest of 21t15-TGFRs was adjusted to pH 7.4 with 1 M Tris base and loaded onto an anti-TF antibody affinity column equilibrated with 5 column volumes of PBS. After sample loading, the column was washed with 5 column volumes of PBS and then eluted with 6 column volumes of 0.1 M acetic acid (pH 2.9). Absorbance at 280 nm was collected, after which samples were neutralized to pH 7.5-8.0 by addition of 1 M Tris base. Neutralized samples were then buffer exchanged into PBS using Amicon® centrifugal filters with a molecular weight cutoff of 30 KDa. Figure 44 shows that the 21t15-TGFRs conjugate binds to an anti-TF antibody affinity column, where TF is the 21t15-TGFRs binding partner. Buffer-exchanged protein samples are stored at 2-8° C. for further biochemical analysis and biological activity testing.
各溶出後、抗TF抗体アフィニティーカラムを6カラム体積の0.1Mグリシン(pH2.5)を使用してストリッピングした。その後、カラムを、10カラム体積のPBS、0.05%アジ化ナトリウムを使用して中和し、2~8℃で保管した。 After each elution, the anti-TF antibody affinity column was stripped using 6 column volumes of 0.1 M glycine (pH 2.5). The column was then neutralized using 10 column volumes of PBS, 0.05% sodium azide and stored at 2-8°C.
実施例24:21t15-TGFRsのサイズ排除クロマトグラフィー
GE Healthcare Superdex(登録商標)200 Increase 10/300 GLゲル濾過カラムを、GE Healthcare AKTA(商標)Avantタンパク質精製システムに接続した。カラムを2カラム体積のPBSで平衡化した。流速は0.8mL/分であった。キャピラリーループを使用して、1mg/mLの21t15-TGFRs複合体200μLをカラムに注入した。その後、注入を1.25カラム体積のPBSで追跡した。SECクロマトグラフを図45に示した。21t15-TGFRsの単量体形態と二量体形態を表す可能性が高い2つのタンパク質ピークが存在した。
Example 24: Size Exclusion Chromatography of 21t15-TGFRs A GE
実施例25:21t15-TGFRsのSDS-PAGE
純度及びタンパク質分子量を決定するために、精製した21t15-TGFRs複合タンパク質試料を、還元条件下で4~12%NuPageビス-トリスタンパク質ゲルSDS-PAGEを使用して分析した。ゲルをInstantBlue(商標)で約30分間染色し、その後、精製水中で一晩脱色した。図46は、抗TF抗体親和性精製21t15-TGFRsのSDSゲルの例を示しており、39.08kDa及び53kDaにバンドがある。
Example 25: SDS-PAGE of 21t15-TGFRs
To determine purity and protein molecular weight, purified 21t15-TGFRs complex protein samples were analyzed using 4-12% NuPage Bis-Tris protein gel SDS-PAGE under reducing conditions. Gels were stained with InstantBlue™ for approximately 30 minutes and then destained overnight in purified water. FIG. 46 shows an example of an SDS gel of anti-TF antibody affinity purified 21t15-TGFRs with bands at 39.08 kDa and 53 kDa.
CHO細胞における21t15-TGFRsのグリコシル化は、Protein Deglycosylation Mix IIキット(New England Biolabs)及び製造業者の指示を使用して確認した。図46のレーン4に見られるように、脱グリコシル化により21t15-TGFRsの分子量が減少する。
Glycosylation of 21t15-TGFRs in CHO cells was confirmed using the Protein Deglycosylation Mix II kit (New England Biolabs) and manufacturer's instructions. As seen in
実施例26:21t15-TGFRs複合体の組換えタンパク質定量
21t15-TGFRs複合体を、標準のサンドイッチELISA法を使用して検出及び定量化した(図47~50)。抗ヒト組織因子抗体が捕捉抗体として機能し、ビオチン化抗ヒトIL-21、IL-15、又はTGFβRIIが検出抗体として機能した。組織因子も、抗ヒト組織因子捕捉抗体(I43)及び抗ヒト組織因子抗体検出を使用して検出した。I43/抗TF抗体ELISAを、同様の濃度の精製組織因子と比較した。
Example 26: Recombinant Protein Quantification of 21t15-TGFRs Complexes 21t15-TGFRs complexes were detected and quantified using standard sandwich ELISA methods (Figures 47-50). Anti-human tissue factor antibody served as the capture antibody and biotinylated anti-human IL-21, IL-15, or TGFβRII served as the detection antibody. Tissue factor was also detected using anti-human tissue factor capture antibody (I43) and anti-human tissue factor antibody detection. The I43/anti-TF antibody ELISA was compared to similar concentrations of purified tissue factor.
実施例27:21t15-TGFRs複合体の免疫刺激能力
21t15-TGFRs複合体のIL-15免疫刺激活性を評価するために、増加濃度の21t15-TGFRsを200μLのIMDM:10%FBS培地中の32Dβ細胞(104細胞/ウェル)に添加し、細胞を37℃で3日間インキュベートした。4日目に、WST-1増殖試薬(10μL/ウェル)を添加し、4時間後、吸光度を450nmで測定して、WST-1の可溶性ホルマザン色素への切断に基づいて細胞増殖を測定した。ヒト組換えIL-15の生物活性を陽性対照として評価した。図51に示されるように、21t15-TGFRsは、IL-15依存性32Dβ細胞増殖を示した。21t15-TGFRs複合体は、おそらくIL-21及び組織因子のIL-15ドメインへの結合のため、ヒト組換えIL-15と比較して低下した。
Example 27: Immunostimulatory Potential of 21t15-TGFRs Conjugates To assess the IL-15 immunostimulatory activity of 21t15-TGFRs conjugates, increasing concentrations of 21t15-TGFRs were added to 200 μL of IMDM:32Dβ cells in 10% FBS medium. (10 4 cells/well) and cells were incubated at 37° C. for 3 days. On
加えて、HEK-Blue TGFβレポーター細胞(hkb-tgfb、InvivoGen)を使用して、TGFβ1活性を遮断する21t15-TGFRsの能力を測定した(図52)。増加濃度の21t15-TGFRsを0.1nMのTGFβ1と混合し、200μLのIMDM:10%熱不活性化FBS培地中のHEK-Blue TGFβレポーター細胞(2.5×104細胞/ウェル)に添加した。細胞を37℃で一晩インキュベートした。翌日、20μlの誘導されたHEK-Blue TGFβレポーター細胞上清を180μlのQUANTI-Blue(InvivoGen)に添加し、37℃で1~3時間インキュベートした。21t15-TGFRs活性を、吸光度を620nmで測定することによって評価した。ヒト組換えTGFβRII/Fc活性を陽性対照として評価した。 In addition, HEK-Blue TGFβ reporter cells (hkb-tgfb, InvivoGen) were used to measure the ability of 21t15-TGFRs to block TGFβ1 activity (FIG. 52). Increasing concentrations of 21t15-TGFRs were mixed with 0.1 nM TGFβ1 and added to HEK-Blue TGFβ reporter cells (2.5×10 4 cells/well) in 200 μL IMDM:10% heat-inactivated FBS medium. . Cells were incubated overnight at 37°C. The next day, 20 μl of induced HEK-Blue TGFβ reporter cell supernatant was added to 180 μl of QUANTI-Blue (InvivoGen) and incubated at 37° C. for 1-3 hours. 21t15-TGFRs activity was assessed by measuring absorbance at 620 nm. Human recombinant TGFβRII/Fc activity was evaluated as a positive control.
これらの結果は、21t15-TGFRs複合体のTGFβRIIドメインがTGFβ1を捕捉する能力を保持することを示す。TGFβ1活性を遮断する21t15-TGFRsの能力は、おそらくTGFβRIIのIL-15Rαスシドメインへの結合のため、ヒト組換えTGFβRII/Fcの能力と比較して低下した。 These results indicate that the TGFβRII domain of the 21t15-TGFRs complex retains the ability to capture TGFβ1. The ability of 21t15-TGFRs to block TGFβ1 activity was reduced compared to that of human recombinant TGFβRII/Fc, possibly due to binding to the IL-15Rα sushi domain of TGFβRII.
実施例28:21t15-TGFRs複合体によるサイトカイン誘導性メモリー様NK細胞の誘導
サイトカイン誘導性メモリー様NK細胞を、精製NK細胞を飽和量のサイトカインで一晩刺激した後にエクスビボで誘導することができる。これらのメモリー様特性を、IL-2受容体α(IL-2Rα、CD25)、CD69(及び他の活性化マーカー)の発現、及びIFN-γ産生の増加により測定することができる。サイトカイン誘導性メモリー様NK細胞の生成を促進する21t15-TGFRs複合体の能力を評価するために、精製ヒトNK細胞(95%超のCD56+)を1nM~100nMの21t15-TGFRs複合体で14~18時間刺激した。細胞表面CD25及びCD69発現及び細胞内IFN-γレベルを、抗体染色及びフローサイトメトリーによって評価した。
Example 28 Induction of Cytokine-Induced Memory-Like NK Cells by 21t15-TGFRs Complexes Cytokine- induced memory-like NK cells can be induced ex vivo after overnight stimulation of purified NK cells with saturating amounts of cytokines. These memory-like properties can be measured by increased IL-2 receptor alpha (IL-2Rα, CD25), CD69 (and other activation markers) expression, and IFN-γ production. To assess the ability of 21t15-TGFRs complexes to promote the generation of cytokine-induced memory-like NK cells, purified human NK cells (>95% CD56+) were treated with 1 nM-100 nM of 21t15-TGFRs complexes. time stimulated. Cell surface CD25 and CD69 expression and intracellular IFN-γ levels were assessed by antibody staining and flow cytometry.
新鮮なヒト白血球を血液バンクから入手し、CD56+NK細胞を、RosetteSep/ヒトNK細胞試薬(StemCell Technologies)を使用して単離した。NK細胞の純度は70%超であり、CD56-BV421、CD16-BV510、CD25-PE、CD69-APCFire750特異的抗体(BioLegend)で染色することにより確認した。細胞をカウントし、0.2mLの完全培地(RPMI1640(Gibco)、2mMのL-グルタミン(Thermo Life Technologies)、ペニシリン(Thermo Life Technologies)、ストレプトマイシン(Thermo Life Technologies)、及び10%FBS(Hyclone)を補充)中の96ウェル平底プレートに0.2×106/mLで再懸濁した。細胞を、hIL-21(50ng/ml)(Biolegend)及びhIL-15(50ng/ml)(NCI)の混合サイトカイン、又は1nM、10nM、若しくは100nMの21t15-TGFRs複合体のいずれかで、37℃で一晩、5%CO2で14~18時間刺激した。その後細胞を収集し、CD56-BV421、CD16-BV510、CD25-PE、CD69-APCFire750特異的抗体で30分間表面染色した。染色後、細胞を、FACS緩衝液(1×PBS(Hyclone)、0.5%BSA(EMD Millipore)及び0.001%アジ化ナトリウム(Sigma)を含む)中で洗浄した(1500RPM、室温で5分間)。2回洗浄した後、細胞を、BD FACSCelesta(商標)フローサイトメーターを使用して分析した。(プロットされたデータ-平均蛍光強度、図53及び図54)。 Fresh human leukocytes were obtained from a blood bank and CD56+ NK cells were isolated using RosetteSep/human NK cell reagent (StemCell Technologies). The purity of NK cells was >70% and confirmed by staining with CD56-BV421, CD16-BV510, CD25-PE, CD69-APCFire750 specific antibodies (BioLegend). Cells were counted and added to 0.2 mL complete medium (RPMI 1640 (Gibco), 2 mM L-glutamine (Thermo Life Technologies), penicillin (Thermo Life Technologies), streptomycin (Thermo Life Technologies), and 10% FBS (Hyclone ) resuspended at 0.2×10 6 /mL in 96-well flat-bottom plates in medium (supplemented). Cells were incubated at 37° C. with either mixed cytokines of hIL-21 (50 ng/ml) (Biolegend) and hIL-15 (50 ng/ml) (NCI), or 21t15-TGFRs complexes at 1 nM, 10 nM, or 100 nM. overnight and 5% CO 2 for 14-18 hours. Cells were then harvested and surface stained with CD56-BV421, CD16-BV510, CD25-PE, CD69-APCFire750 specific antibodies for 30 minutes. After staining, cells were washed in FACS buffer (containing 1×PBS (Hyclone), 0.5% BSA (EMD Millipore) and 0.001% sodium azide (Sigma)) (1500 RPM, 5 minutes at room temperature). minutes). After two washes, cells were analyzed using a BD FACSCelesta™ flow cytometer. (Plotted data-mean fluorescence intensity, Figures 53 and 54).
新鮮なヒト白血球を血液バンクから入手し、CD56+NK細胞を、RosetteSep/ヒトNK細胞試薬(StemCell Technologies)を使用して単離した。NK細胞の純度は70%超であり、CD56-BV421、CD16-BV510、CD25-PE、CD69-APCFire750特異的抗体(BioLegend)で染色することにより確認した。細胞をカウントし、0.2mLの完全培地(RPMI1640(Gibco)、2mMのL-グルタミン(Thermo Life Technologies)、ペニシリン(Thermo Life Technologies)、ストレプトマイシン(Thermo Life Technologies)、及び10%FBS(Hyclone)を補充)中の96ウェル平底プレートに0.2×106/mlで再懸濁した。細胞を、hIL-21(50ng/ml)(Biolegend)及びhIL-15(50ng/ml)(NCI)の混合サイトカイン、又は1nM、10nM、若しくは100nMの21t15-TGFRs複合体のいずれかで、37℃で一晩、5%CO2で14~18時間刺激した。その後、細胞を、10μg/mlのブレフェルジンA(Sigma)及び1Xモネンシン(eBioscience)で4時間処理した。細胞を収集し、CD56-BV421、CD16-BV510、CD25-PE、CD69-APCFire750特異的抗体で30分間表面染色した。染色後、細胞を、FACS緩衝液(1×PBS(Hyclone)、0.5%BSA(EMD Millipore)及び0.001%アジ化ナトリウム(Sigma)を含む)中で洗浄し(1500RPM、室温で5分間)、室温で10分間固定した。固定後、細胞を1x透過処理緩衝液(eBioscience)で洗浄し(1500RPM、室温で5分間)、細胞内IFN-γ-PE(Biolegend)で、室温で30分間染色した。細胞を1x透過処理緩衝液で再度洗浄し、その後、FACS緩衝液で洗浄した。細胞ペレットを300μlのFACS緩衝液中に再懸濁し、BD FACSCelesta(商標)フローサイトメーターを使用して分析した。(プロットされたIFN-γ陽性細胞%、図55)。 Fresh human leukocytes were obtained from a blood bank and CD56+ NK cells were isolated using RosetteSep/human NK cell reagent (StemCell Technologies). The purity of NK cells was >70% and confirmed by staining with CD56-BV421, CD16-BV510, CD25-PE, CD69-APCFire750 specific antibodies (BioLegend). Cells were counted and added to 0.2 mL complete medium (RPMI 1640 (Gibco), 2 mM L-glutamine (Thermo Life Technologies), penicillin (Thermo Life Technologies), streptomycin (Thermo Life Technologies), and 10% FBS (Hyclone ) resuspended at 0.2 x 106/ml in a 96-well flat-bottom plate in medium (supplemented). Cells were incubated at 37° C. with either mixed cytokines of hIL-21 (50 ng/ml) (Biolegend) and hIL-15 (50 ng/ml) (NCI), or 21t15-TGFRs complexes at 1 nM, 10 nM, or 100 nM. overnight and 5% CO 2 for 14-18 hours. Cells were then treated with 10 μg/ml Brefeldin A (Sigma) and 1X monensin (eBioscience) for 4 hours. Cells were harvested and surface stained with CD56-BV421, CD16-BV510, CD25-PE, CD69-APCFire750 specific antibodies for 30 minutes. After staining, cells were washed in FACS buffer (containing 1×PBS (Hyclone), 0.5% BSA (EMD Millipore) and 0.001% sodium azide (Sigma)) (1500 RPM, 5 minutes at room temperature). minutes) and fixed at room temperature for 10 minutes. After fixation, cells were washed with 1× permeabilization buffer (eBioscience) (1500 RPM, 5 minutes at room temperature) and stained with intracellular IFN-γ-PE (Biolegend) for 30 minutes at room temperature. Cells were washed again with 1x permeabilization buffer and then with FACS buffer. Cell pellets were resuspended in 300 μl of FACS buffer and analyzed using a BD FACSCelesta™ flow cytometer. (% IFN-γ positive cells plotted, Figure 55).
実施例29:ヒト腫瘍細胞に対するNK細胞のインビトロ細胞傷害性
ヒト骨髄性白血病細胞K562(CellTrace violetで標識)を、増加濃度の21t15-TGFRs複合体の存在下で、精製ヒトNK細胞(StemCellヒトNK細胞精製キット(E:T比;2:1)を使用)とインキュベートした。20時間後、培養物を収集し、ヨウ化プロピジウム(PI)で染色し、フローサイトメトリーで評価した。図56に示されるように、21t15-TGFRs複合体は、対照と比較して、K562に対するヒトNK細胞傷害性を誘導した。
Example 29: In vitro cytotoxicity of NK cells against human tumor cells Human myeloid leukemia cells K562 (labeled with CellTrace violet) were treated with purified human NK cells (StemCell human NK cells) in the presence of increasing concentrations of 21t15-TGFRs complexes. Cell purification kit (E:T ratio; 2:1) was used). After 20 hours, cultures were harvested, stained with propidium iodide (PI) and evaluated by flow cytometry. As shown in Figure 56, the 21t15-TGFRs complex induced human NK cytotoxicity against K562 compared to controls.
実施例30:IL-21/TF変異体/IL-15 DNA構築物の作製、及びTGFβRII/IL-15RαSuとの結果として生じた融合タンパク質複合体
非限定的な例では、IL-21を組織因子219変異体のN末端コーディング領域に直接結合し、更にIL-21/TF変異体をIL-15のN末端コーディング領域に結合することによってIL-21/TF変異体/IL-15 DNA構築物を作製した。
Example 30: Generation of an IL-21/TF Mutant/IL-15 DNA Construct and Resultant Fusion Protein Complex with TGFβRII/IL-15RαSu In a non-limiting example, IL-21 was transformed into
IL-21/TF変異体/IL-15構築物の核酸配列(シグナルペプチド配列を含む)は、以下の通りである(配列番号324、影付きのヌクレオチドが変異体であり、変異体コドンには下線が引かれている)。
(シグナル配列)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(ヒトIL-21)
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC
(ヒト組織因子219変異体)

AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
The nucleic acid sequence of the IL-21/TF variant/IL-15 construct (including the signal peptide sequence) is as follows (SEQ ID NO:324, shaded nucleotides are variants, variant codons are underlined). is subtracted).
(signal sequence)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCC
(human IL-21)
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCG CCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCCTCCACAAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCCTGCTGCAGAAGAT GATCCATCAGCACCTGTCCTCCAGGACCCAGGCTCCGAGGACTCC
(
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTACTGGAGCTGCCAAGTTATCTCTTTAGAGAGCGGGAGACGCTAGCAT CCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCCAAGGAGTGCGAAGAGCTGGAGGGAGAAGAACATCAAGGAGTTCTGCAATCCTTTGTGCCACATTGTCCAGATGTTCATCAATACCTCC
IL-21/TF変異体/IL-15構築物のアミノ酸配列(シグナルペプチド配列を含む)は、以下の通りである(配列番号325、置換残基には影付けされている)。
(シグナルペプチド)
MKWVTFISLLFLFSSAYS
(ヒトIL-21)
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS
(ヒト組織因子219)

NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
The amino acid sequence (including signal peptide sequence) of the IL-21/TF variant/IL-15 construct is as follows (SEQ ID NO:325, substituted residues are shaded).
(signal peptide)
MKWVT FISLLFLFS SAYS
(human IL-21)
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS
(human tissue factor 219)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
ある場合には、リーダーペプチドをインタクトなポリペプチドから切断して、可溶性であり得るか、又は分泌され得る成熟形態を生成する。 In some cases, the leader peptide is cleaved from the intact polypeptide to generate the mature form, which can be soluble or secreted.
いくつかの実施形態では、IL-21/TF変異体/IL-15 DNA構築物を、TGFβRII/IL-15RαSu DNA構築物と組み合わせて、上述のようにレトロウイルスベクターを使用して細胞にトランスフェクトし、IL-21/TF変異体/IL-15融合タンパク質及びTGFβRII/IL-15RαSu融合タンパク質として発現させることができる。TGFβRII/IL-15RαSu融合タンパク質のIL-15RαSuドメインがIL-21/TF変異体/IL-15融合タンパク質のIL-15ドメインに結合して、IL-21/TF変異体/IL-15:TGFβRII/IL-15RαSu複合体を作製する。 In some embodiments, the IL-21/TF variant/IL-15 DNA construct is combined with the TGFβRII/IL-15RαSu DNA construct and transfected into cells using a retroviral vector as described above, It can be expressed as an IL-21/TF variant/IL-15 fusion protein and a TGFβRII/IL-15RαSu fusion protein. The IL-15RαSu domain of the TGFβRII/IL-15RαSu fusion protein binds to the IL-15 domain of the IL-21/TF variant/IL-15 fusion protein to form IL-21/TF variant/IL-15:TGFβRII/ An IL-15RαSu complex is made.
実施例31:IL-21/IL-15RαSu DNA構築物及びTGFβRII/TF/IL-15 DNA構築物の作製、並びに結果として生じた融合タンパク質複合体
非限定的な例では、IL-21をIL-15RαSuサブユニット配列に直接結合することによってIL-21/IL-15RαSu DNA構築物を作製した。IL-21/IL-15RαSu構築物の核酸配列(シグナル配列を含む)は、以下の通りである(配列番号214)。
(シグナル配列)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(ヒトIL-21)
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC
(ヒトIL-15Rαスシドメイン)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
Example 31: Generation of IL-21/IL-15RαSu DNA Constructs and TGFβRII/TF/IL-15 DNA Constructs and Resulting Fusion Protein Complexes In a non-limiting example, IL-21 An IL-21/IL-15RαSu DNA construct was generated by directly linking the unit sequences. The nucleic acid sequence (including signal sequence) of the IL-21/IL-15RαSu construct is as follows (SEQ ID NO:214).
(signal sequence)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCC
(human IL-21)
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCG CCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCCTCCACAAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCCTGCTGCAGAAGAT GATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC
(Human IL-15Rα sushi domain)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCT CTTTAAAGTGCATCCGG
IL-21/IL-15RαSu構築物のアミノ酸配列(シグナルペプチド配列を含む)は、以下の通りである(配列番号213)。
(シグナルペプチド)
MKWVTFISLLFLFSSAYS
(ヒトIL-21)
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS
(ヒトIL-15Rαスシドメイン)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
The amino acid sequence (including signal peptide sequence) of the IL-21/IL-15RαSu construct is as follows (SEQ ID NO:213).
(signal peptide)
MKWVT FISLLFLFS SAYS
(human IL-21)
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS
(Human IL-15Rα sushi domain)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
ある場合には、リーダーペプチドをインタクトなポリペプチドから切断して、可溶性であり得るか、又は分泌され得る成熟形態を生成する。 In some cases, the leader peptide is cleaved from the intact polypeptide to generate the mature form, which can be soluble or secreted.
いくつかの実施形態では、IL-21/IL-15RαSu DNA構築物を、TGFβRII/TF/IL-15 DNA構築物と組み合わせて、上述のようにレトロウイルスベクターにトランスフェクトし、IL-21/IL-15RαSu融合タンパク質及びTGFβRII/TF/IL-15融合タンパク質として発現させることができる。IL-21/IL-15RαSu融合タンパク質のIL-15RαSuドメインがTGFβRII/TF/IL-15融合タンパク質のIL-15ドメインに結合して、TGFβRII/TF/IL-15:IL-21/IL-15RαSu複合体を作製する。 In some embodiments, the IL-21/IL-15RαSu DNA construct is combined with the TGFβRII/TF/IL-15 DNA construct and transfected into a retroviral vector as described above to produce IL-21/IL-15RαSu It can be expressed as a fusion protein and a TGFβRII/TF/IL-15 fusion protein. The IL-15RαSu domain of the IL-21/IL-15RαSu fusion protein binds to the IL-15 domain of the TGFβRII/TF/IL-15 fusion protein to form the TGFβRII/TF/IL-15:IL-21/IL-15RαSu complex. Create a body.
TGFβRII配列をヒト組織因子219形態のN末端コーディング領域に結合し、その後、TGFβRII/TF構築物をIL-15のN末端コーディング領域に結合することによってTGFβRII/TF/IL-15RαSu DNA構築物を作製した。上述のように、TGFβRIIの一本鎖バージョン(TGFβRII-リンカー-TGFβRII)を使用した。TGFβRII/TF/IL-15構築物の核酸配列(リーダー配列を含む)は、以下の通りである(配列番号239)。
(シグナルペプチド)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(ヒトTGFβRII-第1の断片)
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCACGATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGAT
(リンカー)
GGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGT
(ヒトTGFβRII-第2の断片)
ATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCACAATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC
(ヒト組織因子219)
TCCGGCACCACCAATACCGTGGCCGCTTATAACCTCACATGGAAGAGCACCAACTTCAAGACAATTCTGGAATGGGAACCCAAGCCCGTCAATCAAGTTTACACCGTGCAGATCTCCACCAAATCCGGAGACTGGAAGAGCAAGTGCTTCTACACAACAGACACCGAGTGTGATTTAACCGACGAAATCGTCAAGGACGTCAAGCAAACCTATCTGGCTCGGGTCTTTTCCTACCCCGCTGGCAATGTCGAGTCCACCGGCTCCGCTGGCGAGCCTCTCTACGAGAATTCCCCCGAATTCACCCCTTATTTAGAGACCAATTTAGGCCAGCCTACCATCCAGAGCTTCGAGCAAGTTGGCACCAAGGTGAACGTCACCGTCGAGGATGAAAGGACTTTAGTGCGGCGGAATAACACATTTTTATCCCTCCGGGATGTGTTCGGCAAAGACCTCATCTACACACTGTACTATTGGAAGTCCAGCTCCTCCGGCAAAAAGACCGCTAAGACCAACACCAACGAGTTTTTAATTGACGTGGACAAAGGCGAGAACTACTGCTTCAGCGTGCAAGCCGTGATCCCTTCTCGTACCGTCAACCGGAAGAGCACAGATTCCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(ヒトIL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
The TGFβRII/TF/IL-15RαSu DNA construct was generated by ligating the TGFβRII sequence to the N-terminal coding region of the
(signal peptide)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCC
(Human TGFβRII-first fragment)
ATCCCCCCCCCATGTGCCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCACGATCACCTCCATCTGCGAGAAGCCCCAA GAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGAACCTTCTTTATGTGTTCCTGTAGCAG CGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGAT
(linker)
GGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGT
(Human TGFβRII-Second Fragment)
ATTCCTCCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCACAATCACCTCCATCTGTGAGAAGCCTCAGGAGG TGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAAACCGTCTGCCCACGATCCCCAAGCTGCCCTACCCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAAGAGAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGC GACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC
(human tissue factor 219)
TCCGGCACCACCAATACCGTGGCCGCTTATAACCTCACATGGAAGAGCACCAACTTCAAGACAATTCTGGAATGGGAACCCAAGCCCCGTCAATCAAGTTTACACCGTGCAGATCTCCACCAAATCCGGAGACTGGAAGAGCAAGTGCTTCTACACACAGACACCGAGTGTGATTTAACCGACGAA ATCGTCAAGGACGTCAAGCAAACCTATCTGGCTCGGGTCTTTTCCTACCCCGCTGGCAATGTCGAGTCCACCGGCTCCGCTGGCGAGCCTTCTACGAGAATTCCCCCGAATTCACCCTTATTTAGAGACCAATTTAGGCCAGCCCTACCATCCAGAGCTTCGAGCCAAGTTGGCACCAAGG TGAACGTCACCGTCGAGGATGAAAGGACTTTAGTGCGGCCGGAATAACACATTTTTATCCCCTCCGGGATGTGTTCGGCAAAGACCTCATCTACACACTGTACTATTGGAAGTCCAGCTCCTCCGGCAAAAGACCGCTAAGACCAACACCAACGAGTTTTTAATTGACGTGGACAA AGGCGAGAACTACTGCTTCAGCGTGCAAGCCGTGATCCCTTCTCGTACCGTCAACCGGAAGAGCACAGATTCCCCCGTTGAGTGCATGGGCCAAGAAAGGGCGAGTTCCGGGAG
(human IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTACTGGAGCTGCCAAGTTATCTCTTTAGAGAGCGGGAGACGCTAGCAT CCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCCAAGGAGTGCGAAGAGCTGGAGGGAGAAGAACATCAAGGAGTTCTGCAATCCTTTGTGCCACATTGTCCAGATGTTCATCAATACCTCC
TGFβRII/TF/IL-15融合タンパク質のアミノ酸配列(シグナルペプチドを含む)は、以下の通りである(配列番号238)。
(シグナルペプチド)
MKWVTFISLLFLFSSAYS
(ヒトTGFβRII-第1の断片)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(リンカー)
GGGGSGGGGSGGGGS
(ヒトTGFβRII-第2の断片)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(ヒト組織因子219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(ヒトIL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
The amino acid sequence (including signal peptide) of the TGFβRII/TF/IL-15 fusion protein is as follows (SEQ ID NO:238).
(signal peptide)
MKWVT FISLLFLFS SAYS
(Human TGFβRII-first fragment)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNSITSITSICEKPQEVCVAVWRKNDINITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPD
(linker)
GGGGSGGGGSGGGGGS
(Human TGFβRII-Second Fragment)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNSITSITSICEKPQEVCVAVWRKNDINITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPD
(human tissue factor 219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTF LSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(human IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
実施例32.例示的な一本鎖キメラポリペプチドの産生
抗CD3scFvである第1の標的結合ドメイン、可溶性ヒト組織因子ドメイン、及び抗CD28scFvである第2の標的結合ドメインを含む、例示的な一本鎖キメラポリペプチド(αCD3scFv/TF/αCD28scFv)を生成した(図57)。この一本鎖キメラポリペプチドの核酸及びアミノ酸配列を以下に示す。
例示的な一本鎖キメラポリペプチド(αCD3scFv/TF/αCD28scFv)をコードする核酸(配列番号158)
(シグナルペプチド)
ATGAAGTGGGTGACCTTCATCAGCTTATTATTTTTATTCAGCTCCGCCTATTCC
(αCD3軽鎖可変領域)
CAGATCGTGCTGACCCAAAGCCCCGCCATCATGAGCGCTAGCCCCGGTGAGAAGGTGACCATGACATGCTCCGCTTCCAGCTCCGTGTCCTACATGAACTGGTATCAGCAGAAAAGCGGAACCAGCCCCAAAAGGTGGATCTACGACACCAGCAAGCTGGCCTCCGGAGTGCCCGCTCATTTCCGGGGCTCTGGATCCGGCACCAGCTACTCTTTAACCATTTCCGGCATGGAAGCTGAAGACGCTGCCACCTACTATTGCCAGCAATGGAGCAGCAACCCCTTCACATTCGGATCTGGCACCAAGCTCGAAATCAATCGT
(リンカー)
GGAGGAGGTGGCAGCGGCGGCGGTGGATCCGGCGGAGGAGGAAGC
(αCD3重鎖可変領域)
CAAGTTCAACTCCAGCAGAGCGGCGCTGAACTGGCCCGGCCCGGCGCCTCCGTCAAGATGAGCTGCAAGGCTTCCGGCTATACATTTACTCGTTACACAATGCATTGGGTCAAGCAGAGGCCCGGTCAAGGTTTAGAGTGGATCGGATATATCAACCCTTCCCGGGGCTACACCAACTATAACCAAAAGTTCAAGGATAAAGCCACTTTAACCACTGACAAGAGCTCCTCCACCGCCTACATGCAGCTGTCCTCTTTAACCAGCGAGGACTCCGCTGTTTACTACTGCGCTAGGTATTACGACGACCACTACTGTTTAGACTATTGGGGACAAGGTACCACTTTAACCGTCAGCAGC
(ヒト組織因子219形態)
TCCGGCACCACCAATACCGTGGCCGCTTATAACCTCACATGGAAGAGCACCAACTTCAAGACAATTCTGGAATGGGAACCCAAGCCCGTCAATCAAGTTTACACCGTGCAGATCTCCACCAAATCCGGAGACTGGAAGAGCAAGTGCTTCTACACAACAGACACCGAGTGTGATTTAACCGACGAAATCGTCAAGGACGTCAAGCAAACCTATCTGGCTCGGGTCTTTTCCTACCCCGCTGGCAATGTCGAGTCCACCGGCTCCGCTGGCGAGCCTCTCTACGAGAATTCCCCCGAATTCACCCCTTATTTAGAGACCAATTTAGGCCAGCCTACCATCCAGAGCTTCGAGCAAGTTGGCACCAAGGTGAACGTCACCGTCGAGGATGAAAGGACTTTAGTGCGGCGGAATAACACATTTTTATCCCTCCGGGATGTGTTCGGCAAAGACCTCATCTACACACTGTACTATTGGAAGTCCAGCTCCTCCGGCAAAAAGACCGCTAAGACCAACACCAACGAGTTTTTAATTGACGTGGACAAAGGCGAGAACTACTGCTTCAGCGTGCAAGCCGTGATCCCTTCTCGTACCGTCAACCGGAAGAGCACAGATTCCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(αCD28軽鎖可変領域)
GTCCAGCTGCAGCAGAGCGGACCCGAACTCGTGAAACCCGGTGCTTCCGTGAAAATGTCTTGTAAGGCCAGCGGATACACCTTCACCTCCTATGTGATCCAGTGGGTCAAACAGAAGCCCGGACAAGGTCTCGAGTGGATCGGCAGCATCAACCCTTACAACGACTATACCAAATACAACGAGAAGTTTAAGGGAAAGGCTACTTTAACCTCCGACAAAAGCTCCATCACAGCCTACATGGAGTTCAGCTCTTTAACATCCGAGGACAGCGCTCTGTACTATTGCGCCCGGTGGGGCGACGGCAATTACTGGGGACGGGGCACAACACTGACCGTGAGCAGC
(リンカー)
GGAGGCGGAGGCTCCGGCGGAGGCGGATCTGGCGGTGGCGGCTCC
(αCD28軽鎖可変領域)
GACATCGAGATGACCCAGTCCCCCGCTATCATGTCCGCCTCTTTAGGCGAGCGGGTCACAATGACTTGTACAGCCTCCTCCAGCGTCTCCTCCTCCTACTTCCATTGGTACCAACAGAAACCCGGAAGCTCCCCTAAACTGTGCATCTACAGCACCAGCAATCTCGCCAGCGGCGTGCCCCCTAGGTTTTCCGGAAGCGGAAGCACCAGCTACTCTTTAACCATCTCCTCCATGGAGGCTGAGGATGCCGCCACCTACTTTTGTCACCAGTACCACCGGTCCCCCACCTTCGGAGGCGGCACCAAACTGGAGACAAAGAGG
例示的な一本鎖キメラポリペプチド(αCD3scFv/TF/αCD28scFv)(配列番号157)
(シグナルペプチド)
MKWVTFISLLFLFSSAYS
(αCD3軽鎖可変領域)
QIVLTQSPAIMSASPGEKVTMTCSASSSVSYMNWYQQKSGTSPKRWIYDTSKLASGVPAHFRGSGSGTSYSLTISGMEAEDAATYYCQQWSSNPFTFGSGTKLEINR
(リンカー)
GGGGSGGGGSGGGGS
(αCD3重鎖可変領域)
QVQLQQSGAELARPGASVKMSCKASGYTFTRYTMHWVKQRPGQGLEWIGYINPSRGYTNYNQKFKDKATLTTDKSSSTAYMQLSSLTSEDSAVYYCARYYDDHYCLDYWGQGTTLTVSS
(ヒト組織因子219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(αCD28軽鎖可変領域)
VQLQQSGPELVKPGASVKMSCKASGYTFTSYVIQWVKQKPGQGLEWIGSINPYNDYTKYNEKFKGKATLTSDKSSITAYMEFSSLTSEDSALYYCARWGDGNYWGRGTTLTVSS
(リンカー)
GGGGSGGGGSGGGGS
(αCD28重鎖可変領域)
DIEMTQSPAIMSASLGERVTMTCTASSSVSSSYFHWYQQKPGSSPKLCIYSTSNLASGVPPRFSGSGSTSYSLTISSMEAEDAATYFCHQYHRSPTFGGGTKLETKR
Example 32. Production of an Exemplary Single-Chain Chimeric Polypeptide A peptide (αCD3scFv/TF/αCD28scFv) was generated (Figure 57). The nucleic acid and amino acid sequences of this single-chain chimeric polypeptide are shown below.
Nucleic Acid (SEQ ID NO: 158) Encoding an Exemplary Single Chain Chimeric Polypeptide (αCD3scFv/TF/αCD28scFv)
(signal peptide)
ATGAAGTGGGTGACCTTCATCAGCTTATTATTTTTTATTCAGCTCCCGCCTATTCC
(αCD3 light chain variable region)
CAGATCGTGCTGACCCAAAGCCCCCGCCATCATGAGCGCTAGCCCCGGTGAGAAGGTGACCATGACATGCTCCGCTTCCAGCTCCGTGTCCTACATGAACTGGTATCAGCAGAAAAGCGGAACCAGCCCCAAAGGTGGATCTACGACACCAGCAAGCTGGCCTCCGGAGTGCCCG CTCATTTCCGGGGCTCTGGATCCGGCACCAGCTACTCTTTAACCATTTCGGCATGGAAGCTGAAGACGCTGCCACCTACTATTGCCAGCAATGGAGCAGCAACCCCTTCACATTCGGATCTGGCACCAAGCTCGAAATCAATCGT
(linker)
GGAGGAGGTGGCAGCGGCGGCGGTGGATCCGGCGCGAGGAGGAAGC
(αCD3 heavy chain variable region)
CAAGTTCAACTCCAGCAGAGCGGCGCTGAACTGGCCCGGCCCGGCGCCTCCGTCAAGATGAGCTGCAAGGCTTCCGGCTATACATTTACTCGTCATACAATGCATTGGGTCAAGCAGAGGCCCGGTCAAGGTTTTAGAGTGGATCGGATATATCAACCCTTCCCGGGG CTACACCAACTATAACCAAAGTTCAAGGATAAAGCCACTTTAACCACTGACAAGAGCTCCTCCACCGCCTACATGCAGCTGTCCTCTTTAACCAGCGGAGGACTCCGCTGTTACTACTGCGCTAGGTATTACGACGACCACTACTGTTTAGACTATTGGGGACAAGGTACCACTTTAACCGTCAGCA GC
(
TCCGGCACCACCAATACCGTGGCCGCTTATAACCTCACATGGAAGAGCACCAACTTCAAGACAATTCTGGAATGGGAACCCAAGCCCCGTCAATCAAGTTTACACCGTGCAGATCTCCACCAAATCCGGAGACTGGAAGAGCAAGTGCTTCTACACAACAGACACCGAGTGTGATTTAACCGACGAA ATCGTCAAGGACGTCAAGCAAACCTATCTGGCTCGGGTCTTTTCCTACCCCGCTGGCAATGTCGAGTCCACCGGCTCCGCTGGCGAGCCTTCTACGAGAATTCCCCCGAATTCACCCTTATTTAGAGACCAATTTAGGCCAGCCCTACCATCCAGAGCTTCGAGCCAAGTTGGCACCAAGG TGAACGTCACCGTCGAGGATGAAAAGGACTTTAGTGCGGCCGGAATAACACATTTTTTATCCCTCCGGGATGTGTTCGGCAAAGACCTCATCTACACACTGTACTATTGGAAGTCCAGCTCCTCCGGCAAAAGACCGCTAAGACCAACACCAACGAGTTTTTAATTGACGTGGACAA AGGCGAGAACTACTGCTTCAGCGTGCAAGCCGTGATCCCTTCTCGTACCGTCAACCGGAAGAGCACAGATTCCCCCGTTGAGTGCATGGGCCAAGAAAGGGCGAGTTCCGGGAG
(αCD28 light chain variable region)
GTCCAGCTGCAGCAGAGCGGACCCGAACTCGTGAAACCCGGTGCTTCCGTGAAAATGTCTTGTAAGGCCAGCGGATACACCTTTCACCTCCTATGTGATCCAGTGGGTCAAAACAGAAGCCCGGACAAGGTCTCGAGTGGATCGGCAGCATCAACCCTTACAACGACTATACCA AATACAACGAGAAGTTTAAGGGAAAGGCTACTTTAACCTCCGACAAAAGCTCCATCACAGCCTACATGGAGTTCAGCTCTTTAACATCCGAGGACAGCGCTCTGTACTATTGCGCCCGGTGGGGGCGACGGCAATTACTGGGGACGGGGGCCAACACTGACCGTGAGCAGC
(linker)
GGAGGCGGAGGCTCCGGCGGAGGCGCGGATCTGGCGGTGGCGGCTCC
(αCD28 light chain variable region)
GACATCGAGATGACCCAGTCCCCCGCTATCATGTCCGCCCTTTAGGCGAGCGGGTCACAATGACTTGTACAGCCTCCTCCAGCGTCTCCTCCTCCTACTTCCATTGGTACCACAGAAACCCGGAAGCTCCCCTAAACTGTGCATCTACAGCACCAGCAATCTCGCCAGCGGCGTG CCCCCTAGGTTTTCCGGAAGCGGAAGCACCAGCTACTCTTTAACCATCTCCTCCATGGAGGCTGAGGATGCCGCCCACCTACTTTTGTCACCAGTACCACCGGTCCCCCACCTTCGGAGGCGGCACCAAAACTGGAGACAAAGAGG
Exemplary Single Chain Chimeric Polypeptide (αCD3scFv/TF/αCD28scFv) (SEQ ID NO: 157)
(signal peptide)
MKWVT FISLLFLFSSAYS
(αCD3 light chain variable region)
QIVLTQSPAIMSASPGEKVTMTCSASSSVSYMNWYQQKSGTSPKRWIYDTSKLASGVPAHFRGSGSGTSYSLTISGMEAEDAATYYCQQWSSNPFTFGSGTKLEINR
(linker)
GGGGSGGGGSGGGGGS
(αCD3 heavy chain variable region)
QVQLQQSGAELARPGASVKMSCKASGYTFTRYTMHWVKQRPGQGLEWIGYINPSRGYTNYNQKFKDKATLTTTDKSSSSTAYMQLSSLTSEDSAVYYCARYYDDHYCLDYWGQGTTLTVSS
(human tissue factor 219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTF LSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(αCD28 light chain variable region)
VQLQQSGPELVKPGASVKMSCKASGYTFTSYVIQWVKQKPGQGLEWIGSINPYNDYTKYNEKFKGKATLTSDKSSSITAYMEFSSLTSEDSALYYCARWGDGNYWGRGTTLTVSS
(linker)
GGGGSGGGGSGGGGGS
(αCD28 heavy chain variable region)
DIEMTQSPAIMSASLGERVTMTCTASSSVSSSYFHWYQQKPGSSPKLCIYSTSNLASGVPPRFSGSGSTSYSLTISSMEAEDAATYFCHQYHRSPTFGGGTKLETKR
抗CD28scFvである第1の標的結合ドメイン、可溶性ヒト組織因子ドメイン、及び抗CD3scFvである第2の標的結合ドメインを含む第2の例示的な一本鎖キメラポリペプチドが生成された(αCD28scFv/TF/αCD3scFv)(図57)。この一本鎖キメラポリペプチドの核酸及びアミノ酸配列を以下に示す。
例示的な一本鎖キメラポリペプチド(αCD28scFv/TF/αCD3scFv)をコードする核酸(配列番号326)
(シグナルペプチド)
ATGAAATGGGTCACCTTCATCTCTTTACTGTTTTTATTTAGCAGCGCCTACAGC
(αCD28軽鎖可変領域)
GTGCAGCTGCAGCAGTCCGGACCCGAACTGGTCAAGCCCGGTGCCTCCGTGAAAATGTCTTGTAAGGCTTCTGGCTACACCTTTACCTCCTACGTCATCCAATGGGTGAAGCAGAAGCCCGGTCAAGGTCTCGAGTGGATCGGCAGCATCAATCCCTACAACGATTACACCAAGTATAACGAAAAGTTTAAGGGCAAGGCCACTCTGACAAGCGACAAGAGCTCCATTACCGCCTACATGGAGTTTTCCTCTTTAACTTCTGAGGACTCCGCTTTATACTATTGCGCTCGTTGGGGCGATGGCAATTATTGGGGCCGGGGAACTACTTTAACAGTGAGCTCC
(リンカー)
GGCGGCGGCGGAAGCGGAGGTGGAGGATCTGGCGGTGGAGGCAGC
(αCD28重鎖可変領域)
GACATCGAGATGACACAGTCCCCCGCTATCATGAGCGCCTCTTTAGGAGAACGTGTGACCATGACTTGTACAGCTTCCTCCAGCGTGAGCAGCTCCTATTTCCACTGGTACCAGCAGAAACCCGGCTCCTCCCCTAAACTGTGTATCTACTCCACAAGCAATTTAGCTAGCGGCGTGCCTCCTCGTTTTAGCGGCTCCGGCAGCACCTCTTACTCTTTAACCATTAGCTCTATGGAGGCCGAAGATGCCGCCACATACTTTTGCCATCAGTACCACCGGTCCCCTACCTTTGGCGGAGGCACAAAGCTGGAGACCAAGCGG
(ヒト組織因子219形態)
AGCGGCACCACCAACACAGTGGCCGCCTACAATCTGACTTGGAAATCCACCAACTTCAAGACCATCCTCGAGTGGGAGCCCAAGCCCGTTAATCAAGTTTATACCGTGCAGATTTCCACCAAGAGCGGCGACTGGAAATCCAAGTGCTTCTATACCACAGACACCGAGTGCGATCTCACCGACGAGATCGTCAAAGACGTGAAGCAGACATATTTAGCTAGGGTGTTCTCCTACCCCGCTGGAAACGTGGAGAGCACCGGATCCGCTGGAGAGCCTTTATACGAGAACTCCCCCGAATTCACCCCCTATCTGGAAACCAATTTAGGCCAGCCCACCATCCAGAGCTTCGAACAAGTTGGCACAAAGGTGAACGTCACCGTCGAAGATGAGAGGACTTTAGTGCGGAGGAACAATACATTTTTATCCTTACGTGACGTCTTCGGCAAGGATTTAATCTACACACTGTATTACTGGAAGTCTAGCTCCTCCGGCAAGAAGACCGCCAAGACCAATACCAACGAATTTTTAATTGACGTGGACAAGGGCGAGAACTACTGCTTCTCCGTGCAAGCTGTGATCCCCTCCCGGACAGTGAACCGGAAGTCCACCGACTCCCCCGTGGAGTGCATGGGCCAAGAGAAGGGAGAGTTTCGTGAG
(αCD3軽鎖可変領域)
CAGATCGTGCTGACCCAGTCCCCCGCTATTATGAGCGCTAGCCCCGGTGAAAAGGTGACTATGACATGCAGCGCCAGCTCTTCCGTGAGCTACATGAACTGGTATCAGCAGAAGTCCGGCACCAGCCCTAAAAGGTGGATCTACGACACCAGCAAGCTGGCCAGCGGCGTCCCCGCTCACTTTCGGGGCTCCGGCTCCGGAACAAGCTACTCTCTGACCATCAGCGGCATGGAAGCCGAGGATGCCGCTACCTATTACTGTCAGCAGTGGAGCTCCAACCCCTTCACCTTTGGATCCGGCACCAAGCTCGAGATTAATCGT
(リンカー)
GGAGGCGGAGGTAGCGGAGGAGGCGGATCCGGCGGTGGAGGTAGC
(αCD3重鎖可変領域)
CAAGTTCAGCTCCAGCAAAGCGGCGCCGAACTCGCTCGGCCCGGCGCTTCCGTGAAGATGTCTTGTAAGGCCTCCGGCTATACCTTCACCCGGTACACAATGCACTGGGTCAAGCAACGGCCCGGTCAAGGTTTAGAGTGGATTGGCTATATCAACCCCTCCCGGGGCTATACCAACTACAACCAGAAGTTCAAGGACAAAGCCACCCTCACCACCGACAAGTCCAGCAGCACCGCTTACATGCAGCTGAGCTCTTTAACATCCGAGGATTCCGCCGTGTACTACTGCGCTCGGTACTACGACGATCATTACTGCCTCGATTACTGGGGCCAAGGTACCACCTTAACAGTCTCCTCC
例示的な一本鎖キメラポリペプチド(αCD28scFv/TF/αCD3scFv)(配列番号327)
(シグナルペプチド)
MKWVTFISLLFLFSSAYS
(αCD28軽鎖可変領域)
VQLQQSGPELVKPGASVKMSCKASGYTFTSYVIQWVKQKPGQGLEWIGSINPYNDYTKYNEKFKGKATLTSDKSSITAYMEFSSLTSEDSALYYCARWGDGNYWGRGTTLTVSS
(リンカー)
GGGGSGGGGSGGGGS
(αCD28重鎖可変領域)
DIEMTQSPAIMSASLGERVTMTCTASSSVSSSYFHWYQQKPGSSPKLCIYSTSNLASGVPPRFSGSGSTSYSLTISSMEAEDAATYFCHQYHRSPTFGGGTKLETKR
(ヒト組織因子219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(αCD3軽鎖可変領域)
QIVLTQSPAIMSASPGEKVTMTCSASSSVSYMNWYQQKSGTSPKRWIYDTSKLASGVPAHFRGSGSGTSYSLTISGMEAEDAATYYCQQWSSNPFTFGSGTKLEINR
(リンカー)
GGGGSGGGGSGGGGS
(αCD3重鎖可変領域)
QVQLQQSGAELARPGASVKMSCKASGYTFTRYTMHWVKQRPGQGLEWIGYINPSRGYTNYNQKFKDKATLTTDKSSSTAYMQLSSLTSEDSAVYYCARYYDDHYCLDYWGQGTTLTVSS
A second exemplary single-chain chimeric polypeptide was generated comprising a first target binding domain that was anti-CD28 scFv, a soluble human tissue factor domain, and a second target binding domain that was anti-CD3 scFv (αCD28scFv/TF /αCD3scFv) (Figure 57). The nucleic acid and amino acid sequences of this single-chain chimeric polypeptide are shown below.
Nucleic Acid (SEQ ID NO:326) Encoding an Exemplary Single Chain Chimeric Polypeptide (αCD28scFv/TF/αCD3scFv)
(signal peptide)
ATGAAATGGGTCACCTTCATCTCTTTACTGTTTTTATTTAGCAGCGCCTACAGC
(αCD28 light chain variable region)
GTGCAGCTGCAGCAGTCCGGACCCGAACTGGTCAAGCCCGGTGCCTCCGTGAAAATGTCTTGTAAGGCTTCTGGCTACACCTTTACCTCCTACGTCATCCAATGGGTGAAGCAGAAGCCCCGGTCAAGGTTCTCGAGTGGATCGGCAGCATCAATCCCTACAACGATTACAC CAAGTATAACGAAAAGTTTAAGGGCAAGGCCACTCTGACAAGCGCACAAGAGCTCCATTACCGCCTACATGGAGTTTTCCTCTTTAACTTCTGAGGACTCCGCTTATACTATTGCGCTCGTTGGGGCGATGGCCAATTATTGGGGCCGGGGGAACTACTTTTAACAGTGAGCTCC
(linker)
GGCGGCGGCGGAAGCGGAGGTGGAGGATCTGGCGGGTGGAGGCAGC
(αCD28 heavy chain variable region)
GACATCGAGATGACACAGTCCCCCGCTATCATGAGCGCCCTCTTTAGGAGAACGTGTGACCATGACTTGTACAGCTTCCTCCAGCGTGAGCAGCTCCTATTTTCCACTGGTACCAGCAGAAACCCGGCTCCTCCCCCTAAACTGTGTATCTACTCCACAAGCAATTTAGCTAGCGGCGTGC CTCCTCGTTTTAGCGGCTCCGGCAGCACCTCTTACTCTTTAACCATTAGCTCTATGGAGGCCCGAAGATGCCGCCACATACTTTTGCCATCAGTACCACCGGTCCCCCTACCTTTGGCGCGGAGGCACAAAGCTGGAGACCAAGCGGG
(
AGCGGCACCACCAACACAGTGGCCGCCTACAATCTGACTTGGAAATCCACCAACTTCAAGACCATCCTCGAGTGGGAGCCCAAGCCCGTTAATCAAGTTTATACCGTGCAGATTTCCACCAAGAGCGGCGACTGGAAATCCAAGTGCTTCTATACCAGACACCGAGTGCGATCTCACCGAC GAGATCGTCAAAGACGTGAAGCAGACATATTTAGCTAGGGTGTTCTCTCTACCCCCGCTGGAAAACGTGGAGAGCACCGGATCCGCTGGAGAGCCTTTATACGAGAACTCCCCCGAATTCACCCCCTATCTGGAAACCAATTTAGGCCAGCCCACCATCCAGAGCTTCGAACAAGTTGGCACAAAGG TGAACGTCACCGTCGAAGATGAGAGGACTTTAGTGCGGGAGGAACAATACATTTTTATCCTTACGTGACGTCTTCGGCAAGGATTTAATCTACACACTGTATTACTGGAAGTCTAGCTCCTCCGGCAAGAAGACCGCCAAGACCAATACCAACGAATTTTTAATTGACGTGGACAAGGGC GAGAACTACTGCTTCTCCGTGCAAGCTGTGATCCCCTCCCGGACAGTGGAACCGGAAGTCCACCGACTCCCCCGTGGAGTGCATGGGCCAAGAGAAGGGGAGAGTTTCGTGAG
(αCD3 light chain variable region)
CAGATCGTGCTGACCCCAGTCCCCCGCTATTATGAGCGCTAGCCCCGGTGAAAGGTGACTATGACATGCAGCGCCAGCTCTTCCGTGAGCTACATGAACTGGTATCAGCAGAAGTCCGGCACCAGCCCTAAAGGTGGATCTACGACACCAGCAAGCTGGCCAGCGGCGTCC CCGCTCACTTTCGGGGCTCCGGCTCCGGAACAAGCTACTCTCTGACCATCAGCGGCATGGAAGCCGAGGATGCCGCTACCTATTACTGTCAGCAGTGGAGCTCCAACCCCTTCACCTTTGGATCCGGCACCAAGCTCGAGATTAATCGT
(linker)
GGAGGCGGAGGTAGCGGAGGAGGCGGATCCGGCGGGTGGAGGTAGC
(αCD3 heavy chain variable region)
CAAGTTCAGCTCCAGCAAAGCGGCGCCGAACTCGCTCGGCCCGGCGCTTCCGTGAAGATGTCTTGTAAGGCCTCCGGCTATACCTTCACCCGGTACACAATGCACTGGGTCAAGCAACGGCCCGGTCAAGGTTTAGAGTGGATTGGCTATATCAACCCCTCCCGGGGCTATACCAACTACAACCAGAAGTTCAAGGACAAAGCCACCCTCACCACCGACAAGTCCAGCAGCACCGCTTACATGCAGCTGAGCTCTTTAACATCCGAGGATTCCGCCGTGTACTACTGCGCTCGGTACTACGACGATCATTACTGCCTCGATTACTGGGGCCAAGGTACCACCTTAACAGTCTCCTCC
Exemplary Single Chain Chimeric Polypeptide (αCD28scFv/TF/αCD3scFv) (SEQ ID NO:327)
(signal peptide)
MKWVT FISLLFLFS SAYS
(αCD28 light chain variable region)
VQLQQSGPELVKPGASVKMSCKASGYTFTSYVIQWVKQKPGQGLEWIGSINPYNDYTKYNEKFKGKATLTSDKSSSITAYMEFSSLTSEDSALYYCARWGDGNYWGRGTTLTVSS
(linker)
GGGGSGGGGSGGGGGS
(αCD28 heavy chain variable region)
DIEMTQSPAIMSASLGERVTMTCTASSSVSSSYFHWYQQKPGSSPKLCIYSTSNLASGVPPRFSGSGSTSYSLTISSMEAEDAATYFCHQYHRSPTFGGGTKLETKR
(human tissue factor 219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTF LSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(αCD3 light chain variable region)
QIVLTQSPAIMSASPGEKVTMTCSASSSVSYMNWYQQKSGTSPKRWIYDTSKLASGVPAHFRGSGSGTSYSLTISGMEAEDAATYYCQQWSSNPFTFGSGTKLEINR
(linker)
GGGGSGGGGSGGGGGS
(αCD3 heavy chain variable region)
QVQLQQSGAELARPGASVKMSCKASGYTFTRYTMHWVKQRPGQGLEWIGYINPSRGYTNYNQKFKDKATLTTTDKSSSSTAYMQLSSLTSEDSAVYYCARYYDDHYCLDYWGQGTTLTVSS
αCD3scFv/TF/αCD28scFvをコードする核酸を、以前に記載されたように(Hughes et al.,Hum Gene Ther 16:457-72,2005)改変レトロウイルス発現ベクターにクローニングした。αCD3scFv/TF/αCD28scFvをコードする発現ベクターを、CHO-K1細胞にトランスフェクトした。CHO-K1細胞での発現ベクターの発現により、可溶性αCD3scFv/TF/αCD28scFv一本鎖キメラポリペプチド(3t28と称する)の分泌が可能になり、これを抗TF抗体親和性及び他のクロマトグラフィー法によって精製することができる。 Nucleic acids encoding αCD3scFv/TF/αCD28scFv were cloned into modified retroviral expression vectors as previously described (Hughes et al., Hum Gene Ther 16:457-72, 2005). Expression vectors encoding αCD3scFv/TF/αCD28scFv were transfected into CHO-K1 cells. Expression of the expression vector in CHO-K1 cells allowed secretion of a soluble αCD3scFv/TF/αCD28scFv single-chain chimeric polypeptide (termed 3t28), which was assayed by anti-TF antibody affinity and other chromatographic methods. It can be refined.
抗組織因子親和性カラムを使用して、αCD3scFv/TF/αCD28scFv一本鎖キメラポリペプチドを精製した。抗組織因子親和性カラムを、GE Healthcare AKTA Avantシステムに接続した。2mL/分の溶出ステップを除く全てのステップで4mL/分の流速を使用した。 The αCD3scFv/TF/αCD28scFv single chain chimeric polypeptide was purified using an anti-tissue factor affinity column. The anti-tissue factor affinity column was connected to a GE Healthcare AKTA Avant system. A flow rate of 4 mL/min was used for all steps except the 2 mL/min elution step.
αCD3scFv/TF/αCD28scFv一本鎖キメラポリペプチドを含む細胞培養収集物を、1Mトリス塩基でpH7.4に調整し、5カラム体積のPBSで平衡化した抗TF抗体アフィニティーカラム(上述)にロードした。試料をロードした後、カラムを5カラム体積のPBSで洗浄し、その後、6カラム体積の0.1M酢酸(pH2.9)で溶出した。A280溶出ピークを収集し、次いで、1Mトリス塩基を添加することによってpH7.5~8.0に中和した。その後、中和した試料を、分子量カットオフ30kDaでAmicon遠心フィルターを使用してPBSに緩衝液交換した。図58のデータは、抗組織因子親和性カラムが、ヒト可溶性組織因子ドメインを含むαCD3scFv/TF/αCD28scFv一本鎖キメラポリペプチドに結合することができることを示す。緩衝液交換したタンパク質試料を、更なる生化学的分析及び生物学的活性試験のために2~8℃で保管した。 A cell culture harvest containing the αCD3scFv/TF/αCD28scFv single-chain chimeric polypeptide was adjusted to pH 7.4 with 1 M Tris base and loaded onto an anti-TF antibody affinity column (described above) equilibrated with 5 column volumes of PBS. . After sample loading, the column was washed with 5 column volumes of PBS and then eluted with 6 column volumes of 0.1 M acetic acid (pH 2.9). The A280 elution peak was collected and then neutralized to pH 7.5-8.0 by adding 1M Tris base. Neutralized samples were then buffer exchanged into PBS using Amicon centrifugal filters with a molecular weight cutoff of 30 kDa. The data in FIG. 58 demonstrate that the anti-tissue factor affinity column can bind to αCD3scFv/TF/αCD28scFv single chain chimeric polypeptides containing a human soluble tissue factor domain. Buffer-exchanged protein samples were stored at 2-8° C. for further biochemical analysis and biological activity testing.
各溶出後、抗組織因子親和性カラムを6カラム体積の0.1Mグリシン(pH2.5)を使用してストリッピングした。その後、カラムを、10カラム体積のPBS、0.05%NaN3を使用して中和し、2~8℃で保管した。 After each elution, the anti-tissue factor affinity column was stripped using 6 column volumes of 0.1 M glycine (pH 2.5). The column was then neutralized using 10 column volumes of PBS, 0.05% NaN3 and stored at 2-8°C.
AKTA Avantシステム(GE Healthcare製)に接続したSuperdex 200 Increase 10/300 GLゲル濾過カラム(GE Healthcare製)を使用して、分析サイズ排除クロマトグラフィー(SEC)をαCD3scFv/TF/αCD28scFv一本鎖キメラポリペプチドで行った。カラムを2カラム体積のPBSで平衡化した。0.8mL/分の流速を使用した。200μLのαCD3scFv/TF/αCD28scFv一本鎖キメラポリペプチド(1mg/mL)を、キャピラリーループを使用してカラムに注入した。一本鎖キメラポリペプチドの注入後、1.25カラム体積のPBSをカラムに流し込んだ。SECクロマトグラフを図59に示す。データは、αCD3scFv/TF/αCD28scFv一本鎖キメラポリペプチドの単量体形態及び二量体形態、又は他の異なる形態を表す可能性が高い3つのタンパク質ピークが存在することを示す。
Analytical size exclusion chromatography (SEC) was performed using a
αCD3scFv/TF/αCD28scFv一本鎖キメラポリペプチドの純度及びタンパク質分子量を決定するために、抗組織因子親和性カラムから精製したαCD3scFv/TF/αCD28scFvタンパク質試料を、還元条件下で標準ドデシル硫酸ナトリウムポリアクリルアミドゲル(4~12%NuPageビス-トリスゲル)電気泳動(SDS-PAGE)法によって分析した。ゲルをInstantBlueで約30分間染色し、精製水中で一晩脱色した。図60は、抗組織因子親和性カラムを使用して精製したαCD3scFv/TF/αCD28scFv一本鎖キメラポリペプチドのSDSゲルを示す。結果は、精製されたαCD3scFv/TF/αCD28scFv一本鎖キメラポリペプチドが、還元SDSゲル中で予想された分子量(72kDa)を有することを示す。 To determine the purity and protein molecular weight of the αCD3scFv/TF/αCD28scFv single-chain chimeric polypeptides, αCD3scFv/TF/αCD28scFv protein samples purified from anti-tissue factor affinity columns were treated with standard sodium dodecyl sulfate polyacrylamide under reducing conditions. Gels (4-12% NuPage Bis-Tris gels) were analyzed by electrophoresis (SDS-PAGE) method. Gels were stained with InstantBlue for approximately 30 minutes and destained overnight in purified water. Figure 60 shows an SDS gel of αCD3scFv/TF/αCD28scFv single chain chimeric polypeptide purified using an anti-tissue factor affinity column. The results show that the purified αCD3scFv/TF/αCD28scFv single-chain chimeric polypeptide has the expected molecular weight (72 kDa) in reducing SDS gels.
実施例33.αCD3scFv/TF/αCD28scFv一本鎖キメラポリペプチドの機能的特性付け
ELISAベースの方法により、αCD3scFv/TF/αCD28scFv一本鎖キメラポリペプチドの形成を確認した。αCD3scFv/TF/αCD28scFv一本鎖キメラポリペプチドは、抗TF抗体(I43)/抗TF抗体特異的ELISAと捕捉抗体、抗ヒト組織因子抗体(I43)、及び検出抗体、抗TF抗体を使用して検出した(図61)。同様の濃度の精製組織因子タンパク質を対照として使用した。
Example 33. Functional Characterization of αCD3scFv/TF/αCD28scFv Single Chain Chimeric Polypeptides Formation of αCD3scFv/TF/αCD28scFv single chain chimeric polypeptides was confirmed by an ELISA-based method. αCD3scFv/TF/αCD28scFv single-chain chimeric polypeptides were isolated using an anti-TF antibody (I43)/anti-TF antibody specific ELISA and a capture antibody, an anti-human tissue factor antibody (I43), and a detection antibody, an anti-TF antibody. detected (Fig. 61). A similar concentration of purified tissue factor protein was used as a control.
αCD3scFv/TF/αCD28scFv一本鎖キメラポリペプチドがヒト末梢血単核細胞(PBMC)を活性化することができるかどうかを決定するために、更なるインビトロ実験を行った。新鮮なヒト白血球を血液バンクから入手し、密度勾配Histopaque(Sigma)を使用して末梢血単核細胞(PBMC)を単離した。細胞をカウントし、0.2mLの完全培地(RPMI1640(Gibco)、2mMのL-グルタミン(Thermo Life Technologies)、ペニシリン(Thermo Life Technologies)、ストレプトマイシン(Thermo Life Technologies)、及び10%FBS(Hyclone)を補充)中の96ウェル平底プレートに0.2×106/mLで再懸濁した。細胞を、37℃、5%CO2で3日間、0.01nM~1000nMのαCD3scFv/TF/αCD28scFv一本鎖キメラポリペプチドで刺激した。72時間後、細胞を収集し、CD4-488、CD8-PerCP Cy5.5、CD25-BV421、CD69-APCFire750、CD62L-PE Cy7、及びCD44-PE特異的抗体(Biolegend)を30分間表面染色した。表面染色後、細胞を、FACS緩衝液(1×PBS(Hyclone)、0.5%BSA(EMD Millipore)及び0.001%アジ化ナトリウム(Sigma)を含む)中で洗浄した(1500RPM、室温で5分間)。2回洗浄した後、細胞を300μLのFACS緩衝液中に再懸濁し、フローサイトメトリー(Celesta-BD Bioscience)によって分析した。図62及び63のデータは、αCD3scFv/TF/αCD28scFv一本鎖キメラポリペプチドがCD8+T細胞及びCD4+T細胞の両方を刺激することができることを示す。更なる実験を行い、Histopaque(Sigma)を使用して血液から単離されたPBMCをカウントし、0.2mLの完全培地(RPMI1640(Gibco)、2mMのL-グルタミン(Thermo Life Technologies)、ペニシリン(Thermo Life Technologies)、ストレプトマイシン(Thermo Life Technologies)、及び10%FBS(Hyclone)を補充)中の96ウェル平底プレートに0.2×106/mLで再懸濁した。次いで、細胞を、37℃、5%CO2で3日間、0.01nM~1000nMのαCD3scFv/TF/αCD28scFv一本鎖キメラポリペプチドで刺激した。72時間後、細胞を収集し、CD4-488、CD8-PerCP Cy5.5、CD25-BV421、CD69-APCFire750、CD62L-PE Cy7、及びCD44-PE(Biolegend)について30分間表面染色した。表面染色後、細胞を、FACS緩衝液(1×PBS(Hyclone)、0.5%BSA(EMD Millipore)及び0.001%アジ化ナトリウム(Sigma)を含む)中で洗浄した(1500RPM、室温で5分間)。2回洗浄した後、細胞を300μLのFACS緩衝液中に再懸濁し、フローサイトメトリー(Celesta-BD Bioscience)によって分析した。データは、αCD3scFv/TF/αCD28scFv一本鎖キメラポリペプチドが、CD4+T細胞の活性化を刺激することができたことを再び示す(図64)。 Further in vitro experiments were performed to determine whether the αCD3scFv/TF/αCD28scFv single-chain chimeric polypeptides were able to activate human peripheral blood mononuclear cells (PBMCs). Fresh human leukocytes were obtained from a blood bank and peripheral blood mononuclear cells (PBMC) were isolated using a density gradient Histopaque (Sigma). Cells were counted and added to 0.2 mL complete medium (RPMI 1640 (Gibco), 2 mM L-glutamine (Thermo Life Technologies), penicillin (Thermo Life Technologies), streptomycin (Thermo Life Technologies), and 10% FBS (Hyclone ) resuspended at 0.2×10 6 /mL in 96-well flat-bottom plates in medium (supplemented). Cells were stimulated with 0.01 nM to 1000 nM of αCD3scFv/TF/αCD28scFv single-chain chimeric polypeptides for 3 days at 37° C., 5% CO 2 . After 72 hours, cells were harvested and surface stained with CD4-488, CD8-PerCP Cy5.5, CD25-BV421, CD69-APCFire750, CD62L-PE Cy7, and CD44-PE specific antibodies (Biolegend) for 30 minutes. After surface staining, cells were washed (1500 RPM at room temperature) in FACS buffer containing 1×PBS (Hyclone), 0.5% BSA (EMD Millipore) and 0.001% sodium azide (Sigma). 5 minutes). After two washes, cells were resuspended in 300 μL FACS buffer and analyzed by flow cytometry (Celesta-BD Bioscience). The data in Figures 62 and 63 demonstrate that the αCD3scFv/TF/αCD28scFv single chain chimeric polypeptide can stimulate both CD8 + and CD4 + T cells. Further experiments were performed to count PBMCs isolated from blood using Histopaque (Sigma) and add 0.2 mL complete medium (RPMI 1640 (Gibco), 2 mM L-glutamine (Thermo Life Technologies), penicillin ( (Thermo Life Technologies), streptomycin (Thermo Life Technologies), and supplemented with 10% FBS (Hyclone)) at 0.2×10 6 /mL in 96-well flat bottom plates. Cells were then stimulated with 0.01 nM-1000 nM αCD3scFv/TF/αCD28scFv single-chain chimeric polypeptides for 3 days at 37° C., 5% CO 2 . After 72 hours, cells were harvested and surface stained for CD4-488, CD8-PerCP Cy5.5, CD25-BV421, CD69-APCFire750, CD62L-PE Cy7, and CD44-PE (Biolegend) for 30 minutes. After surface staining, cells were washed (1500 RPM at room temperature) in FACS buffer containing 1×PBS (Hyclone), 0.5% BSA (EMD Millipore) and 0.001% sodium azide (Sigma). 5 minutes). After two washes, cells were resuspended in 300 μL FACS buffer and analyzed by flow cytometry (Celesta-BD Bioscience). The data again show that the αCD3scFv/TF/αCD28scFv single chain chimeric polypeptide was able to stimulate the activation of CD4 + T cells (Figure 64).
実施例34:IL-7/IL-15RαSu DNA構築物の作製
非限定的な例では、IL-7/IL-15RαSu DNA構築物を作製した(図65を参照のこと)。ヒトIL-7配列、ヒトIL-15RαSu配列、ヒトIL-15配列、及びヒト組織因子219配列をUniProtウェブサイトから入手し、これらの配列のDNAをGenewizによって合成した。IL-7配列をIL-15RαSu配列に結合することによってDNA構築物を作製した。最終IL-7/IL-15RαSu DNA構築物配列をGenewizによって合成した。
Example 34: Generation of IL-7/IL-15RαSu DNA Construct In a non-limiting example, an IL-7/IL-15RαSu DNA construct was generated (see Figure 65). Human IL-7, human IL-15RαSu, human IL-15, and
IL-7/IL-15RαSu構築物の第2のキメラポリペプチドをコードする核酸配列(シグナルペプチド配列を含む)は、以下の通りである(配列番号206)。
(シグナルペプチド)
ATGGGAGTGAAAGTTCTTTTTGCCCTTATTTGTATTGCTGTGGCCGAGGCC
(ヒトIL-7)
GATTGTGATATTGAAGGTAAAGATGGCAAACAATATGAGAGTGTTCTAATGGTCAGCATCGATCAATTATTGGACAGCATGAAAGAAATTGGTAGCAATTGCCTGAATAATGAATTTAACTTTTTTAAAAGACATATCTGTGATGCTAATAAGGAAGGTATGTTTTTATTCCGTGCTGCTCGCAAGTTGAGGCAATTTCTTAAAATGAATAGCACTGGTGATTTTGATCTCCACTTATTAAAAGTTTCAGAAGGCACAACAATACTGTTGAACTGCACTGGCCAGGTTAAAGGAAGAAAACCAGCTGCCCTGGGTGAAGCCCAACCAACAAAGAGTTTGGAAGAAAATAAATCTTTAAAGGAACAGAAAAAACTGAATGACTTGTGTTTCCTAAAGAGACTATTACAAGAGATAAAAACTTGTTGGAATAAAATTTTGATGGGCACTAAAGAACAC
(ヒトIL-15Rαスシドメイン)
ATCACGTGCCCTCCCCCCATGTCCGTGGAACACGCAGACATCTGGGTCAAGAGCTACAGCTTGTACTCCAGGGAGCGGTACATTTGTAACTCTGGTTTCAAGCGTAAAGCCGGCACGTCCAGCCTGACGGAGTGCGTGTTGAACAAGGCCACGAATGTCGCCCACTGGACAACCCCCAGTCTCAAATGCATTAGA
The nucleic acid sequence (including signal peptide sequence) encoding the second chimeric polypeptide of the IL-7/IL-15RαSu construct is as follows (SEQ ID NO:206).
(signal peptide)
ATGGGAGTGAAAGTTCTTTTTGCCCTTTATTGTATTGCTGTGGCCCGAGGCC
(human IL-7)
GATTGTGATATTGAAGGTAAAGATGGCAAACAATATGAGAGTGTTCTAATGGTCAGCATCGATCAATTATTGGACAGCATGAAAAGAAATTGGTAGCAATTGCCTGAATAATGAATTTAACTTTTTTAAAAGACATATCTGTGATGCTAATAAGGAAGGTATGTTTTTAT TCCGTGCTGCTCGCAAGTTGAGGCAATTTCTTAAATGAATAGCACTGGTGATTTTGATCTCCACTTATTAAAGTTTCAGAAGGCCAACAATACTGTTGAACTGCACTGGCCAGGTTAAAAGGAAGAAAACCAGCTGCCCTGGGTGAAGCCCAACCAACAAAGAGTTTGGA AGAAAAAAATCTTTAAAGGAACAGAAAAAAACTGAATGACTTGTGTTTCCTAAAGAGACTATTACAAGAGATAAAAACTTTGTTGGAATAAAATTTTGATGGGCACTAAAGAACAC
(Human IL-15Rα sushi domain)
ATCACGTGCCCTCCCCCCCATGTCCGTGGAACACGCAGACATCTGGGTCAAGAGCTACAGCTTGTACTCCAGGGAGCGGTACATTTGTAACTCTGGTTTCAAGCGTAAAAGCCGGCACGTCCAGCCTGACGGAGTGCGTGTTTGAACAAGGCCACGAATGTCGCCCACTGGA CAACCCCCAGTTCTCAAATGCATTAGA
IL-7/IL-15RαSu構築物の第2のキメラポリペプチド(シグナルペプチド配列を含む)は、以下の通りである(配列番号205)。
(シグナルペプチド)
MKWVTFISLLFLFSSAYS
(ヒトIL-7)
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEH
(ヒト組織因子219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(ヒトIL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
A second chimeric polypeptide (including a signal peptide sequence) of the IL-7/IL-15RαSu construct is as follows (SEQ ID NO:205).
(signal peptide)
MKWVT FISLLFLFS SAYS
(human IL-7)
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDHLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWN KILMG TKEH
(human tissue factor 219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTF LSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(human IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
実施例35:IL-21/TF/IL-15 DNA構築物の作製
非限定的な例では、IL-21配列を組織因子219のN末端コーディング領域に結合し、更にIL-21/TF構築物をIL-15のN末端コーディング領域に結合することによってIL-21/TF/IL-15構築物を作製した(図66)。
Example 35: Generation of an IL-21/TF/IL-15 DNA Construct In a non-limiting example, an IL-21 sequence is ligated to the N-terminal coding region of
Genewizによって合成したIL-21/TF/IL-15構築物の第1のキメラポリペプチドをコードする核酸配列(リーダー配列を含む)は、以下の通りである(配列番号202)。
(シグナルペプチド)
ATGGGAGTGAAAGTTCTTTTTGCCCTTATTTGTATTGCTGTGGCCGAGGCC
(ヒトIL-21断片)
CAAGGTCAAGATCGCCACATGATTAGAATGCGTCAACTTATAGATATTGTTGATCAGCTGAAAAATTATGTGAATGACTTGGTCCCTGAATTTCTGCCAGCTCCAGAAGATGTAGAGACAAACTGTGAGTGGTCAGCTTTTTCCTGTTTTCAGAAGGCCCAACTAAAGTCAGCAAATACAGGAAACAATGAAAGGATAATCAATGTATCAATTAAAAAGCTGAAGAGGAAACCACCTTCCACAAATGCAGGGAGAAGACAGAAACACAGACTAACATGCCCTTCATGTGATTCTTATGAGAAAAAACCACCCAAAGAATTCCTAGAAAGATTCAAATCACTTCTCCAAAAGATGATTCATCAGCATCTGTCCTCTAGAACACACGGAAGTGAAGATTCC
(ヒト組織因子219)
TCAGGCACTACAAATACTGTGGCAGCATATAATTTAACTTGGAAATCAACTAATTTCAAGACAATTTTGGAGTGGGAACCCAAACCCGTCAATCAAGTCTACACTGTTCAAATAAGCACTAAGTCAGGAGATTGGAAAAGCAAATGCTTTTACACAACAGACACAGAGTGTGACCTCACCGACGAGATTGTGAAGGATGTGAAGCAGACGTACTTGGCACGGGTCTTCTCCTACCCGGCAGGGAATGTGGAGAGCACCGGTTCTGCTGGGGAGCCTCTGTATGAGAACTCCCCAGAGTTCACACCTTACCTGGAGACAAACCTCGGACAGCCAACAATTCAGAGTTTTGAACAGGTGGGAACAAAAGTGAATGTGACCGTAGAAGATGAACGGACTTTAGTCAGAAGGAACAACACTTTCCTAAGCCTCCGGGATGTTTTTGGCAAGGACTTAATTTATACACTTTATTATTGGAAATCTTCAAGTTCAGGAAAGAAAACAGCCAAAACAAACACTAATGAGTTTTTGATTGATGTGGATAAAGGAGAAAACTACTGTTTCAGTGTTCAAGCAGTGATTCCCTCCCGAACAGTTAACCGGAAGAGTACAGACAGCCCGGTAGAGTGTATGGGCCAGGAGAAAGGGGAATTCAGAGAA
(ヒトIL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
The nucleic acid sequence (including leader sequence) encoding the first chimeric polypeptide of the IL-21/TF/IL-15 construct synthesized by Genewiz is as follows (SEQ ID NO:202).
(signal peptide)
ATGGGAGTGAAAGTTCTTTTTGCCCTTTATTGTATTGCTGTGGCCCGAGGCC
(Human IL-21 fragment)
CAAGGTCAAGATCGCCACATGATTAGAATGCGTCAACTTATAGATATTGTTGATCAGCTGAAAATTATGTGAATGACTTGGTCCCTGAATTTCTGCCAGCTCCAGAAGATGTAGAGACAAAACTGTGAGTGGTCAGCTTTTTCCTGTTTTCAGAAGGCCCAACTAAAGTCAGCA AATACAGGAAACAATGAAAAGGATAATCAATGTATCAATTAAAAGCTGAAGAGGAAACCACCTTCCACAAATGCAGGGAGAAGACAGAAACACAGACTAACATGCCCTTCATGTGATTCTTATGAGAAAAAAAACCACCCAAAGAATTCCTAGAAAGATTCAAATCACTTCTCCAAAGATGATTCATCA GCATCTGTCCCTCTAGAACACACGGAAGTGAAGATTCC
(human tissue factor 219)
TCAGGCACTACAAAATACTGTGGCAGCATATAATTTAACTTGGAAATCAACTAATTTCAAGACAATTTTGGAGTGGGAACCCAAAACCCGTCAATCAAGTCTACACTGTTCAAATAAGCACTAAGTCAGGAGATTGGAAAAGCAAATGCTTTTACACAACAGACACAGAGTGTGACCTCA CCGACGAGATTGTGAAGGATGTGAAGCAGACGTACTTGGCACGGGTCTTCTCCTACCCCGGCAGGGAATGTGGAGAGCACCGGTTCTGCTGGGGAGCTCTCGTATGAGAACTCCCCAGAGTTCACACCTTACCTGGAGACAAACCTCGGACAGCCAACAATTCAGAGTTTTGAACAGGT GGGAACAAAGTGAATGTGACCGTAGAAGATGAACGGACTTTAGTCAGAAGGAACAACACTTTCCTAAGCCTCCGGGATGTTTTTTGGCAAGGACTTAATTTATACACTTTATTATTGGAAATCTTCAAGTTCAGGAAAGAAACAGCCAAAACAAAACACTAATGAGTTTTTGATT GATGTGGATAAAGGAGAAAAACTACTGTTTCAGTGTTCAAGCAGTGATTCCCTCCCGAACAGTTAACCGGAAGAGTACAGACAGCCCCGGTAGAGTGTATGGGCCAGGAGAAAAGGGGGAATTCAGAGAA
(human IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTACTGGAGCTGCCAAGTTATCTCTTTAGAGAGCGGGAGACGCTAGCAT CCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCCAAGGAGTGCGAAGAGCTGGAGGGAGAAGAACATCAAGGAGTTCTGCAATCCTTTGTGCCACATTGTCCAGATGTTCATCAATACCTCC
リーダー配列を含むIL-21/TF/IL-15構築物の第1のキメラポリペプチドは、配列番号201である。
(シグナルペプチド)
MGVKVLFALICIAVAEA(配列番号328)
(ヒトIL-21)
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS
(ヒト組織因子219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(ヒトIL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
A first chimeric polypeptide of the IL-21/TF/IL-15 construct that includes a leader sequence is SEQ ID NO:201.
(signal peptide)
MGVKVLFALICIAVAEA (SEQ ID NO: 328)
(human IL-21)
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS
(human tissue factor 219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTF LSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(human IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
実施例36:IL-7/IL-15RαSu融合タンパク質及びIL-21/TF/IL-15融合タンパク質の分泌
IL-7/IL-15RαSu DNA構築物及びIL-21/TF/IL-15 DNA構築物をpMSGV-1修飾レトロウイルス発現ベクターにクローニングし(参照により本明細書に組み込まれる、Hughes,Hum Gene Ther 16:457-72,2005に記載のもの)、発現ベクターをCHO-K1細胞にトランスフェクトした。CHO-K1細胞でのこれらの2つの構築物の共発現により、可溶性IL-21/TF/IL-15:IL-7/IL-15RαSuタンパク質複合体(21t15-7sと称する、図67及び図68)の形成及び分泌が可能になった。21t15-7sタンパク質を、抗TF抗体アフィニティークロマトグラフィー及びサイズ排除クロマトグラフィーを使用してCHO-K1細胞培養上清から精製し、IL-7/IL-15RαSu融合タンパク質及びIL-21/TF/IL-15融合タンパク質からなる可溶性(非凝集)タンパク質複合体を得た。
Example 36: Secretion of IL-7/IL-15RαSu and IL-21/TF/IL-15 fusion proteins -1 modified retroviral expression vector (as described in Hughes, Hum Gene Ther 16:457-72, 2005, incorporated herein by reference) and the expression vector was transfected into CHO-K1 cells. Co-expression of these two constructs in CHO-K1 cells resulted in the formation of a soluble IL-21/TF/IL-15:IL-7/IL-15RαSu protein complex (designated 21t15-7s, FIGS. 67 and 68). formation and secretion of The 21t15-7s protein was purified from CHO-K1 cell culture supernatants using anti-TF antibody affinity chromatography and size exclusion chromatography to produce IL-7/IL-15RαSu fusion protein and IL-21/TF/IL- A soluble (non-aggregated) protein complex consisting of 15 fusion proteins was obtained.
ある場合には、リーダー(シグナル配列)ペプチドをインタクトなポリペプチドから切断して、可溶性であり得るか、又は分泌され得る成熟形態を生成する。 In some cases, the leader (signal sequence) peptide is cleaved from the intact polypeptide to generate the mature form, which can be soluble or secreted.
実施例37:免疫親和性クロマトグラフィーによる21t15-7sの精製
抗TF抗体親和性カラムをGE Healthcare(商標)AKTA Avantタンパク質精製システムに接続した。流速は、2mL/分の溶出ステップを除く全てのステップで4mL/分であった。
Example 37: Purification of 21t15-7s by immunoaffinity chromatography An anti-TF antibody affinity column was connected to a GE Healthcare™ AKTA Avant protein purification system. The flow rate was 4 mL/min for all steps except the 2 mL/min elution step.
21t15-7sの細胞培養収集物を1Mトリス塩基でpH7.4に調整し、5カラム体積のPBSで平衡化した抗TF抗体アフィニティーカラムにロードした。試料をロードした後、カラムを5カラム体積のPBSで洗浄し、その後、6カラム体積の0.1M酢酸(pH2.9)で溶出した。280nmでの吸光度を収集し、その後、1Mトリス塩基の添加により、試料をpH7.5~8.0に中和した。その後、中和した試料を、分子量カットオフ30KDaでAmicon(登録商標)遠心フィルターを使用してPBSに緩衝液交換した。緩衝液交換したタンパク質試料を、更なる生化学的分析及び生物学的活性試験のために2~8℃で保管した。 The 21t15-7s cell culture harvest was adjusted to pH 7.4 with 1 M Tris base and loaded onto an anti-TF antibody affinity column equilibrated with 5 column volumes of PBS. After sample loading, the column was washed with 5 column volumes of PBS and then eluted with 6 column volumes of 0.1 M acetic acid (pH 2.9). Absorbance at 280 nm was collected, after which samples were neutralized to pH 7.5-8.0 by the addition of 1 M Tris base. Neutralized samples were then buffer exchanged into PBS using Amicon® centrifugal filters with a molecular weight cutoff of 30 KDa. Buffer-exchanged protein samples were stored at 2-8° C. for further biochemical analysis and biological activity testing.
各溶出後、抗TF抗体アフィニティーカラムを6カラム体積の0.1Mグリシン(pH2.5)を使用してストリッピングした。その後、カラムを、10カラム体積のPBS、0.05%アジ化ナトリウムを使用して中和し、2~8℃で保管した。 After each elution, the anti-TF antibody affinity column was stripped using 6 column volumes of 0.1 M glycine (pH 2.5). The column was then neutralized using 10 column volumes of PBS, 0.05% sodium azide and stored at 2-8°C.
実施例38:サイズ排除クロマトグラフィー
GE Healthcare Superdex(登録商標)200 Increase 10/300 GLゲル濾過カラムを、GE Healthcare AKTA(商標)Avantタンパク質精製システムに接続した。カラムを2カラム体積のPBSで平衡化した。流速は0.7mL/分であった。キャピラリーループを使用して、1mg/mLの7t15-21s複合体200μLをカラムに注入した。注入を1.25カラム体積のPBSで追跡した。
Example 38: Size Exclusion Chromatography A GE
実施例39:21t15-7s及び21t15-TGFRsのSDS-PAGE
純度及びとタンパク質分子量を決定するために、精製した21t15-7sタンパク質又は21t15-TGFRsタンパク質試料を、4~12%NuPageビス-トリスタンパク質ゲルSDS-PAGEを使用して分析した。ゲルをInstantBlue(商標)で約30分間染色し、その後、精製水中で一晩脱色する。
Example 39: SDS-PAGE of 21t15-7s and 21t15-TGFRs
Purified 21t15-7s protein or 21t15-TGFRs protein samples were analyzed using 4-12% NuPage Bis-Tris protein gel SDS-PAGE to determine purity and protein molecular weight. Gels are stained with InstantBlue™ for approximately 30 minutes and then destained overnight in purified water.
実施例40:CHO-K1細胞における21t15-7s及び21t15-TGFRsのグリコシル化
CHO-K1細胞における21t15-7s又はCHO-K1細胞における21t15-TGFRsのグリコシル化を、Protein Deglycosylation Mix IIキット(New England Biolabs)を製造業者の指示に従って使用して確認した。
Example 40: Glycosylation of 21t15-7s and 21t15-TGFRs in CHO-K1 Cells Glycosylation of 21t15-7s in CHO-K1 cells or 21t15-TGFRs in CHO-K1 cells was performed using the Protein Deglycosylation Mix II kit (New England Biolabs ) was used according to the manufacturer's instructions.
実施例41:21t15-7s複合体及び21t15-TGFRs複合体の組換えタンパク質定量
21t15-7s複合体又は21t15-TGFRs複合体を、標準のサンドイッチELISA法を使用して検出及び定量化した。抗ヒト組織因子抗体(IgG1)は捕捉抗体として機能し、ビオチン化抗ヒトIL-21、IL-15、若しくはIL-7抗体(21t15-7s)、又はビオチン化抗ヒトIL-21、IL-15、若しくはTGF-βRII抗体(21t15-TGFRs)が検出抗体として機能した。精製した21t15-7sタンパク質複合体又は21t15-TGFRsタンパク質複合体の組織因子を、抗ヒト組織因子捕捉抗体及び抗ヒト組織因子抗体(IgG1)検出抗体を使用して検出した。抗TF抗体ELISAを、同様の濃度の精製組織因子と比較する。
Example 41: Recombinant protein quantification of 21t15-7s and 21t15-TGFRs complexes 21t15-7s complexes or 21t15-TGFRs complexes were detected and quantified using standard sandwich ELISA methods. Anti-human tissue factor antibody (IgG1) served as a capture antibody, biotinylated anti-human IL-21, IL-15, or IL-7 antibody (21t15-7s), or biotinylated anti-human IL-21, IL-15 , or TGF-βRII antibodies (21t15-TGFRs) functioned as detection antibodies. Tissue factor in the purified 21t15-7s protein complex or 21t15-TGFRs protein complex was detected using an anti-human tissue factor capture antibody and an anti-human tissue factor antibody (IgG1) detection antibody. The anti-TF antibody ELISA is compared to similar concentrations of purified tissue factor.
実施例42:IL-21/IL-15RαSu DNA構築物の作製
非限定的な例では、IL-21/IL-15RαSu DNA構築物を作製した。ヒトIL-21配列及びヒトIL-15RαSu配列をUniProtウェブサイトから入手し、これらの配列のDNAをGenewizによって合成した。IL-21配列をIL-15RαSu配列に結合することによってDNA構築物を作製した。最終IL-21/IL-15RαSu DNA構築物配列をGenewizによって合成した。図69を参照されたい。
Example 42: Generation of IL-21/IL-15RαSu DNA Constructs In a non-limiting example, IL-21/IL-15RαSu DNA constructs were generated. Human IL-21 and human IL-15RαSu sequences were obtained from the UniProt website and DNA for these sequences was synthesized by Genewiz. A DNA construct was made by joining the IL-21 sequence to the IL-15RαSu sequence. The final IL-21/IL-15RαSu DNA construct sequence was synthesized by Genewiz. See FIG.
実施例43:IL-7/TF/IL-15 DNA構築物の作製
非限定的な例では、IL-7配列を組織因子219のN末端コーディング領域に結合し、更にIL-7/TF構築物をIL-15のN末端コーディング領域に結合することによってIL-7/TF/IL-15構築物を作製した。図70を参照されたい。
Example 43: Generation of an IL-7/TF/IL-15 DNA Construct In a non-limiting example, an IL-7 sequence is ligated to the N-terminal coding region of
実施例44:IL-21/IL-15RαスシDNA構築物の作製
非限定的な例では、IL-21/IL-15RαSuの第2のキメラポリペプチドを生成した。ヒトIL-21配列及びヒトIL-15Rαスシ配列をUniProtウェブサイトから入手し、これらの配列のDNAをGenewizによって合成した。IL-21配列をIL-15Rαスシ配列に結合することによってDNA構築物を作製した。最終IL-21/IL-15RαSu DNA構築物配列をGenewizによって合成した。
Example 44: Generation of IL-21/IL-15Rα Sushi DNA Constructs In a non-limiting example, a second chimeric polypeptide of IL-21/IL-15RαSu was generated. Human IL-21 and human IL-15Rα sushi sequences were obtained from the UniProt website and DNA for these sequences was synthesized by Genewiz. A DNA construct was made by joining the IL-21 sequence to the IL-15Rα sushi sequence. The final IL-21/IL-15RαSu DNA construct sequence was synthesized by Genewiz.
Genewizによって合成したIL-21/IL-15RαSuドメインの第2のキメラポリペプチドをコードする核酸配列(リーダー配列を含む)は、以下の通りである(配列番号214)。
(シグナルペプチド)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(ヒトIL-21)
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC
(ヒトIL-15Rαスシドメイン)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
The nucleic acid sequence (including leader sequence) encoding the second chimeric polypeptide of the IL-21/IL-15RαSu domain synthesized by Genewiz is as follows (SEQ ID NO:214).
(signal peptide)
ATGAAGTGGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCC
(human IL-21)
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCG CCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCCTCCACAAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCCTGCTGCAGAAGAT GATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC
(Human IL-15Rα sushi domain)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCT CTTTAAAGTGCATCCGG
IL-21/IL-15Rαスシドメインの第2のキメラポリペプチド(リーダー配列を含む)は、以下の通りである(配列番号213)。
(シグナル配列)
MKWVTFISLLFLFSSAYS
(ヒトIL-21)
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS
(ヒトIL-15Rαスシドメイン)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
A second chimeric polypeptide (including a leader sequence) of the IL-21/IL-15Rα sushi domain is as follows (SEQ ID NO:213).
(signal sequence)
MKWVT FISLLFLFSSAYS
(human IL-21)
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS
(Human IL-15Rα sushi domain)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
実施例45:IL-7/TF/IL-15 DNA構築物の作製
非限定的な例では、IL-7配列を組織因子219のN末端コーディング領域に結合し、更にIL-7/TF構築物をIL-15のN末端コーディング領域に結合することによってIL-7/TF/IL-15の例示的な第1のキメラポリペプチドを作製した。Genewizによって合成したIL-7/TF/IL-15の第1のキメラポリペプチドをコードする核酸配列(リーダー配列を含む)は、以下の通りである(配列番号210)。
(シグナルペプチド)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(ヒトIL-7断片)
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCAT
(ヒト組織因子219)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(ヒトIL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
Example 45: Generation of an IL-7/TF/IL-15 DNA Construct In a non-limiting example, an IL-7 sequence is ligated to the N-terminal coding region of
(signal peptide)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCC
(Human IL-7 fragment)
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCCACATCTGCGACGCCAACAAGGAGGGCATGTTCCT GTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGA ACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCAT
(human tissue factor 219)
AGCGGCCAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAACCATCCTCGAATGGGAACCCAAACCCGTTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCG ATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCTTTATACGAGAACAGCCCCGAATTTACCCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCA CAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTAATCGACG TGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAGGGCGAGTTCCGGGAG
(human IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTACTGGAGCTGCCAAGTTATCTCTTTAGAGAGCGGGAGACGCTAGCAT CCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCCAAGGAGTGCGAAGAGCTGGAGGGAGAAGAACATCAAGGAGTTCTGCAATCCTTTGTGCCACATTGTCCAGATGTTCATCAATACCTCC
IL-7/TF/IL-15の第1のキメラポリペプチド(リーダー配列を含む)は、以下の通りである(配列番号209)。
(シグナルペプチド)
MKWVTFISLLFLFSSAYS
(ヒトIL-7)
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEH
(ヒト組織因子219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(ヒトIL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
A first chimeric polypeptide (including a leader sequence) of IL-7/TF/IL-15 is as follows (SEQ ID NO:209).
(signal peptide)
MKWVT FISLLFLFS SAYS
(human IL-7)
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDHLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWN KILMG TKEH
(human tissue factor 219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTF LSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(human IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
実施例46:IL-21/IL-15RαSu融合タンパク質及びIL-7/TF/IL-15融合タンパク質の分泌
IL-21/IL-15RαSu DNA構築物及びIL-7/TF/IL-15 DNA構築物をpMSGV-1修飾レトロウイルス発現ベクターにクローニングし(参照により本明細書に組み込まれる、Hughes,Hum Gene Ther16:457-72,2005に記載のもの)、発現ベクターをCHO-K1細胞にトランスフェクトした。CHO-K1細胞でのこれらの2つの構築物の共発現により、可溶性IL-7/TF/IL-15:IL-21/IL-15RαSuタンパク質複合体(7t15-21sと称する)の形成及び分泌が可能になった。7t15-21sタンパク質を、抗TF抗体(IgG1)親和性クロマトグラフィー及びサイズ排除クロマトグラフィーを使用してCHO-K1細胞培養上清から精製し、IL-21/IL-15RαSu融合タンパク質及びIL-7/TF/IL-15融合タンパク質からなる可溶性(非凝集)タンパク質複合体を得た。図71及び図72を参照されたい。
Example 46: Secretion of IL-21/IL-15RαSu and IL-7/TF/IL-15 fusion proteins -1 modified retroviral expression vector (as described in Hughes, Hum Gene Ther 16:457-72, 2005, incorporated herein by reference) and the expression vector was transfected into CHO-K1 cells. Co-expression of these two constructs in CHO-K1 cells allows formation and secretion of a soluble IL-7/TF/IL-15:IL-21/IL-15RαSu protein complex (termed 7t15-21s). Became. The 7t15-21s protein was purified from CHO-K1 cell culture supernatants using anti-TF antibody (IgG1) affinity chromatography and size exclusion chromatography, and the IL-21/IL-15RαSu fusion protein and IL-7/ A soluble (non-aggregated) protein complex consisting of the TF/IL-15 fusion protein was obtained. See Figures 71 and 72.
実施例47:7t15-21s複合体+抗TF IgG1抗体による初代ナチュラルキラー(NK)細胞の増殖能力
初代ナチュラルキラー(NK)細胞を増殖する7t15-21s複合体の能力を評価するために、7t15-21s複合体及び7t15-21s複合体+抗TF IgG1抗体を、新鮮なヒト白血球の試料から得たNK細胞に添加する。細胞を、25nMの抗TF IgG1抗体又は抗TF IgG4抗体を有する又は有しない50nMの7t15-21s複合体で、37℃及び5%CO2で刺激する。細胞を、48~72時間ごとにカウントすることにより0.5×106/mL~2.0×106/mL未満の濃度で維持し、培地に新鮮な刺激剤を補充する。7t15-21s複合体又は抗TF IgG1抗体若しくは抗TF IgG4抗体若しくは抗TF IgG4+7t15-21s複合体で刺激した細胞を5日目まで維持する。21t15-7s複合体+抗TF IgG1抗体とのインキュベーション時の初代NK細胞の増殖が観察される。
Example 47: Ability to Proliferate Primary Natural Killer (NK) Cells by 7t15-21s Complex + Anti-TF IgG1 Antibody The 21s conjugate and 7t15-21s conjugate plus anti-TF IgG1 antibody are added to NK cells obtained from fresh human leukocyte samples. Cells are stimulated with 50 nM 7t15-21s complex with or without 25 nM anti-TF IgG1 or anti-TF IgG4 antibodies at 37° C. and 5% CO 2 . Cells are maintained at a concentration of 0.5×10 6 /mL to less than 2.0× 10 6 /mL by counting every 48-72 hours and medium is supplemented with fresh stimulant. Cells stimulated with 7t15-21s conjugate or anti-TF IgG1 antibody or anti-TF IgG4 antibody or anti-TF IgG4 plus 7t15-21s conjugate are maintained for up to 5 days. Proliferation of primary NK cells upon incubation with 21t15-7s complex plus anti-TF IgG1 antibody is observed.
実施例48:7t15-21s複合体+抗TF IgG1抗体による増殖したNK細胞の活性化
初代NK細胞を、精製NK細胞を7t15-21s複合体+抗TF IgG1抗体で一晩刺激した後にエクスビボで誘導することができる。新鮮なヒト白血球を血液バンクから入手し、CD56+NK細胞を、RosetteSep/ヒトNK細胞試薬(StemCell Technologies)を使用して単離する。NK細胞の純度は80%超であり、CD56-BV421及びCD16-BV510特異的抗体(BioLegend)で染色することにより確認する。細胞をカウントし、1mLの完全培地(RPMI1640(Gibco)、4mMのL-グルタミン(Thermo Life Technologies)、ペニシリン(Thermo Life Technologies)、ストレプトマイシン(Thermo Life Technologies)、非必須アミノ酸(Thermo Life Technologies)、ピルビン酸ナトリウム(Thermo Life Technologies)、及び10%FBS(Hyclone)を補充)中の24ウェル平底プレートに1×106/mLで再懸濁する。細胞を、25nMの抗TF IgG1抗体を有する又は有しない50nMの7t15-21sで、37℃及び5%CO2で刺激する。細胞を48~72時間ごとにカウントし、14日目まで0.5×106/mL~2.0×106/mLの濃度で維持する。培地に新鮮な刺激剤を定期的に補充する。細胞を収集し、3日目に、CD56-BV421、CD16-BV510、CD25-PE、CD69-APCFire750特異的抗体(Biolegendで表面染色し、Flow Cytometry-Celeste-BD Bioscienceによって分析する。活性化マーカーCD25 MFIは、7t15-21s複合体+抗TF IgG1抗体刺激で増加するが、7t15-21s複合体刺激では増加しないことが観察される。活性化マーカーCD69MFIは、7t15-21s複合体+抗TF IgG1抗体及び7t15-21s複合体単独の両方で増加することが観察される。
Example 48: Activation of Expanded NK Cells by 7t15-21s Conjugate + Anti-TF IgG1 Antibody Primary NK cells are induced ex vivo after overnight stimulation of purified NK cells with 7t15-21s conjugate + anti-TF IgG1 antibody can do. Fresh human leukocytes are obtained from a blood bank and CD56+ NK cells are isolated using RosetteSep/human NK cell reagent (StemCell Technologies). NK cell purity is >80% and is confirmed by staining with CD56-BV421 and CD16-BV510 specific antibodies (BioLegend). Cells were counted and added to 1 mL complete medium (RPMI 1640 (Gibco), 4 mM L-glutamine (Thermo Life Technologies), penicillin (Thermo Life Technologies), streptomycin (Thermo Life Technologies), non-essential amino acids (Thermo Life T technologies), pyruvin Resuspend at 1×10 6 /mL in 24-well flat-bottom plates in sodium phosphate (Thermo Life Technologies), and supplemented with 10% FBS (Hyclone). Cells are stimulated with 50 nM 7t15-21s with or without 25 nM anti-TF IgG1 antibody at 37° C. and 5% CO 2 . Cells are counted every 48-72 hours and maintained at a concentration of 0.5×10 6 /mL to 2.0× 10 6 /mL until
実施例49:18t15-12sを使用したNK細胞のグルコース代謝の増加
一連の実験を行い、ヒト血液から精製したNK細胞の酸素消費速度及び細胞外酸性化速度(ECAR)に対する18t15-12s構築物の効果を決定した。
Example 49: Increased Glucose Metabolism of NK Cells Using 18t15-12s A series of experiments were performed demonstrating the effect of the 18t15-12s construct on the rate of oxygen consumption and extracellular acidification (ECAR) of NK cells purified from human blood. It was determined.
これらの実験では、2名の異なるヒトドナー由来の血液バンクから新鮮なヒト白血球を入手し、NK細胞を、RosetteSep/ヒトNK細胞試薬(StemCell Technologies)を使用した陰性選択により単離した。NK細胞の純度は80%超であり、CD56-BV421及びCD16-BV510特異的抗体(BioLegend)で染色することにより確認した。細胞をカウントし、1mLの完全培地(RPMI1640(Gibco)、4mMのL-グルタミン(Thermo Life Technologies)、ペニシリン(Thermo Life Technologies)、ストレプトマイシン(Thermo Life Technologies)、非必須アミノ酸(Thermo Life Technologies)、ピルビン酸ナトリウム(Thermo Life Technologies)、及び10%FBS(Hyclone)を補充)中の24ウェル平底プレートに2×106/mLで再懸濁した。細胞を、(1)培地のみ、(2)100nMの18t15-12s、又は(3)単一サイトカインである組換えヒトIL-12(0.25μg)、組換えヒトIL-15(1.25μg)、及び組換えヒトIL-18(1.25μg)の混合物のいずれかで、37℃、5%CO2で一晩刺激した。翌日、細胞を収集し、増殖したNK細胞の細胞外フラックスアッセイを、XFp分析器(Seahorse Bioscience)を使用して行った。収集した細胞を洗浄し、OCR(酸素消費速度)及びECAR(細胞外酸性化速度)の細胞外フラックス分析のために少なくとも二連で、2.0×105細胞/ウェルでプレーティングした。解糖ストレス試験を、2mMのグルタミンを含有するSeahorse培地中で行った。以下のものをアッセイ中に使用した:10mMのグルコース、100nMのオリゴマイシン、及び100mMの2-デオキシ-D-グリコーゼ(2DG)。 In these experiments, fresh human leukocytes were obtained from blood banks from two different human donors and NK cells were isolated by negative selection using RosetteSep/human NK cell reagent (StemCell Technologies). The purity of NK cells was >80% and confirmed by staining with CD56-BV421 and CD16-BV510 specific antibodies (BioLegend). Cells were counted and added to 1 mL complete medium (RPMI 1640 (Gibco), 4 mM L-glutamine (Thermo Life Technologies), penicillin (Thermo Life Technologies), streptomycin (Thermo Life Technologies), non-essential amino acids (Thermo Life T technologies), pyruvin resuspended at 2×10 6 /mL in 24-well flat-bottom plates in sodium phosphate (Thermo Life Technologies), and supplemented with 10% FBS (Hyclone). Cells were treated with (1) media alone, (2) 100 nM 18t15-12s, or (3) the single cytokines recombinant human IL-12 (0.25 μg), recombinant human IL-15 (1.25 μg). and recombinant human IL-18 (1.25 μg) overnight at 37° C., 5% CO 2 . The next day, cells were harvested and an extracellular flux assay of expanded NK cells was performed using an XFp analyzer (Seahorse Bioscience). Harvested cells were washed and plated at 2.0×10 5 cells/well at least in duplicate for extracellular flux analysis of OCR (oxygen consumption rate) and ECAR (extracellular acidification rate). Glycolytic stress tests were performed in Seahorse medium containing 2 mM glutamine. The following were used in the assay: 10 mM glucose, 100 nM oligomycin, and 100 mM 2-deoxy-D-glycose (2DG).
データは、18t15-12sが、組換えヒトIL-12、組換えヒトIL-15、及び組換えヒトIL-18の組み合わせで活性化された同じ細胞と比較して、酸素消費速度(図73)及び細胞外酸性化速度(ECAR)を著しく増加させることを示す(図74)。 The data show that 18t15-12s compared to the same cells activated with a combination of recombinant human IL-12, recombinant human IL-15, and recombinant human IL-18 increased the oxygen consumption rate (Figure 73). and markedly increased the extracellular acidification rate (ECAR) (Figure 74).
実施例50:7t15-16s21融合タンパク質の生成及び特徴付け
抗CD16scFv/IL-15RαSu/IL-21融合タンパク質及びIL-7/TF/IL-15融合タンパク質からなる融合タンパク質複合体を生成した。ヒトIL-7配列及びヒトIL-21配列をUniProtウェブサイトから入手し、これらの配列のDNAをGenewizによって合成した。具体的には、IL-7配列を組織因子219のN末端コーディング領域に、続いて、IL-15のN末端コーディング領域に結合することによって構築物を作製した。
Example 50 Generation and Characterization of 7t15-16s21 Fusion Protein A fusion protein complex consisting of an anti-CD16scFv/IL-15RαSu/IL-21 fusion protein and an IL-7/TF/IL-15 fusion protein was generated. Human IL-7 and human IL-21 sequences were obtained from the UniProt website and DNA for these sequences was synthesized by Genewiz. Specifically, a construct was made by joining the IL-7 sequence to the N-terminal coding region of
組織因子219のN末端に、続いて、IL-15のN末端に結合したIL-7を含む構築物の核酸配列及びタンパク質配列を以下に示す。
The nucleic acid and protein sequences of a construct containing IL-7 attached to the N-terminus of
IL-7/TF/IL-15構築物の核酸配列(シグナルペプチド配列を含む)は、以下の通りである。
(シグナルペプチド)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(ヒトIL-7)
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCAT
(ヒト組織因子219)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(ヒトIL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
The nucleic acid sequence (including signal peptide sequence) of the IL-7/TF/IL-15 construct is as follows.
(signal peptide)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCC
(human IL-7)
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCCACATCTGCGACGCCAACAAGGAGGGCATGTTCCT GTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGA ACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCAT
(human tissue factor 219)
AGCGGCCAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAACCATCCTCGAATGGGAACCCAAACCCGTTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCG ATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCTTTATACGAGAACAGCCCCGAATTTACCCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCA CAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTAATCGACG TGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAGGGCGAGTTCCGGGAG
(human IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTACTGGAGCTGCCAAGTTATCTCTTTAGAGAGCGGGAGACGCTAGCAT CCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCCAAGGAGTGCGAAGAGCTGGAGGGAGAAGAACATCAAGGAGTTCTGCAATCCTTTGTGCCACATTGTCCAGATGTTCATCAATACCTCC
IL-7/TF/IL-15融合タンパク質のアミノ酸配列(リーダー配列を含む)は、以下の通りである。
(シグナルペプチド)
MKWVTFISLLFLFSSAYS
(ヒトIL-7)
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEH
(ヒト組織因子219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(ヒトIL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
The amino acid sequence (including leader sequence) of the IL-7/TF/IL-15 fusion protein is as follows.
(signal peptide)
MKWVT FISLLFLFS SAYS
(human IL-7)
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDHLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWN KILMG TKEH
(human tissue factor 219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTF LSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(human IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
抗CD16scFv配列をGenewizによって合成したIL-15RαSu鎖のN末端コーディング領域に、続いて、IL-21のN末端コーディング領域に結合することによっても構築物を作製した。IL-15RαSu鎖のN末端に、続いて、IL-21のN末端コーディング領域に結合した抗CD16scFvを含む構築物の核酸配列及びタンパク質配列を以下に示す。 A construct was also made by joining the anti-CD16 scFv sequence to the N-terminal coding region of the IL-15RαSu chain synthesized by Genewiz, followed by the N-terminal coding region of IL-21. The nucleic acid and protein sequences of a construct containing anti-CD16 scFv attached to the N-terminus of IL-15RαSu chain followed by the N-terminal coding region of IL-21 are shown below.
抗CD16SscFv/IL-15RαSu/IL-21構築物の核酸配列(シグナルペプチド配列を含む)は、以下の通りである。
(シグナルペプチド)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
((抗ヒトCD16scFv)
TCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCAACCATGTGGTGTTCGGCGGCGGCACCAAGCTGACCGTGGGCCATGGCGGCGGCGGCTCCGGAGGCGGCGGCAGCGGCGGAGGAGGATCCGAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGG
(ヒトIL-15Rαスシドメイン)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
(ヒトIL-21)
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC
The nucleic acid sequence (including signal peptide sequence) of the anti-CD16SscFv/IL-15RαSu/IL-21 construct is as follows.
(signal peptide)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCC
((anti-human CD16scFv)
TCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACACAGGCCCTCCGGCATCCCTGACAGG TTCTCCGGATCCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCGGCAACCATGTGGGTGTTCGGCGGCGGGCACCAAGCTGACCGTGGGCCATGGCGGCGGCGGCTGTCCGGAGGCGGCCG GCAGCGGCGGAGGAGGATCCGAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAGGGGCCTGGAGTGGGTGT CCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGA CAGGGCACCCTGGTGACCGTGTCCCAGG
(Human IL-15Rα sushi domain)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCT CTTTAAAGTGCATCCGG
(human IL-21)
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCG CCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCCTCCACAAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCCTGCTGCAGAAGAT GATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC
抗CD16scFv/IL-15RαSu/IL-21構築物のアミノ酸配列(シグナルペプチド配列を含む)は、以下の通りである。
(シグナルペプチド)
MKWVTFISLLFLFSSAYS
(抗ヒトCD16scFv)
SELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGHGGGGSGGGGSGGGGSEVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSR
(ヒトIL-15Rαスシドメイン)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
(ヒトIL-21)
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS
The amino acid sequence (including signal peptide sequence) of the anti-CD16 scFv/IL-15RαSu/IL-21 construct is as follows.
(signal peptide)
MKWVT FISLLFLFS SAYS
(Anti-human CD16scFv)
SELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGHGGGGGSGGGGSGGGGSEVQLVESGGGGVVRPGG SLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSR
(Human IL-15Rα sushi domain)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
(human IL-21)
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS
いくつかの事例では、リーダーペプチドをインタクトなポリペプチドから切断して、可溶性であり得るか、又は分泌され得る成熟形態を生成する。 In some cases, the leader peptide is cleaved from the intact polypeptide to generate the mature form, which can be soluble or secreted.
抗CD16scFv/IL-15RαSu/IL-21構築物及びIL-7/TF/IL-15構築物を前述の修飾レトロウイルス発現ベクターにクローニングし(Hughes MS,Yu YY,Dudley ME,Zheng Z,Robbins PF,Li Y,et al.Transfer of a TCR gene derived from a patient with a marked antitumor response conveys highly active T-cell effector functions.Hum Gene Ther2005;16:457-72)、発現ベクターをCHO-K1細胞にトランスフェクトした。CHO-K1細胞での2つの構築物の共発現により、可溶性IL-7/TF/IL-15:抗CD16scFv/IL-15RαSu/IL-21タンパク質複合体(7t15-16s21と称する、図75及び図76)の形成及び分泌が可能になり、これを抗TF IgG1抗体ベースの親和性及び他のクロマトグラフィー法によって精製することができる。 The anti-CD16 scFv/IL-15RαSu/IL-21 and IL-7/TF/IL-15 constructs were cloned into modified retroviral expression vectors previously described (Hughes MS, Yu YY, Dudley ME, Zheng Z, Robbins PF, Li Y, et al.Transfer of a TCR gene derived from a patient with a marked antitumor response conveys highly active T-cell effector functions.Hum Gene Ther2005 16:457-72), and the expression vector was transfected into CHO-K1 cells. . Co-expression of the two constructs in CHO-K1 cells yielded a soluble IL-7/TF/IL-15:anti-CD16scFv/IL-15RαSu/IL-21 protein complex (designated 7t15-16s21, FIGS. 75 and 76). ), which can be purified by anti-TF IgG1 antibody-based affinity and other chromatographic methods.
ヒトCD16bを発現するCHO細胞への7t15-16s21の結合
CHO細胞をpMCプラスミド中のヒトCD16bでトランスフェクトし、10μg/mLのブラストサイジンで10日間選択した。CD16bを安定的に発現するCHO細胞を、1.2μg/mLの抗ヒトCD16scFvを含む7t15-16s21又は陰性対照として抗ヒトCD16scFvを含まない18t15-12sで染色し、その後、ビオチン化抗ヒト組織因子及びPE結合ストレプトアビジンで染色した。図77Aに示されるように、抗ヒトCD16scFvを含む7t15-16s21のみが細胞を染色した。図77Bに示されるように、18t15-12sは、ヒトCD16bを発現するCHO細胞を染色しなかった。
Binding of 7t15-16s21 to CHO Cells Expressing Human CD16b CHO cells were transfected with human CD16b in the pMC plasmid and selected with 10 μg/mL blasticidin for 10 days. CHO cells stably expressing CD16b were stained with 7t15-16s21 containing 1.2 μg/mL anti-human CD16 scFv or 18t15-12s without anti-human CD16 scFv as a negative control followed by biotinylated anti-human tissue factor. and stained with PE-conjugated streptavidin. As shown in Figure 77A, only 7t15-16s21 containing anti-human CD16 scFv stained cells. As shown in Figure 77B, 18t15-12s did not stain CHO cells expressing human CD16b.
ELISAを使用した7t15-16s21におけるIL-15、IL-21、及びIL-7の検出
96ウェルプレートをR5(コーティング緩衝液)中100μL(8μg/mL)の抗TF IgG1でコーティングし、室温(RT)で2時間インキュベートした。プレートを3回洗浄し、PBS中100μLの1%BSAでブロックした。連続希釈の7t15-16s21(1:3比)をウェルに添加し、室温で60分間インキュベートした。3回洗浄した後、50ng/mLのビオチン化抗IL15抗体(BAM247、R&D Systems)、500ng/mLのビオチン化抗IL-21抗体(13-7218-81、R&D Systems)、又は500ng/mLのビオチン化抗IL-7抗体(506602、R&D Systems)をウェルと室温で60分間インキュベートした。プレートを3回洗浄し、0.25μg/mLのHRP-SA(Jackson ImmunoResearch)と100μL/ウェルで、室温で30分間インキュベートし、その後、4回洗浄し、100μlのABTSと室温で2分間インキュベートした。吸光度を405nmで読み取った。図78A~78Cに示されるように、7t15-16s21中のIL-15ドメイン、IL-21ドメイン、及びIL-7ドメインを個々の抗体によって検出した。
Detection of IL-15, IL-21 and IL-7 in 7t15-16s21 using ELISA 96-well plates were coated with 100 μL (8 μg/mL) of anti-TF IgG1 in R5 (coating buffer) and treated at room temperature (RT ) for 2 hours. Plates were washed three times and blocked with 100 μL of 1% BSA in PBS. Serial dilutions of 7t15-16s21 (1:3 ratio) were added to the wells and incubated for 60 minutes at room temperature. After three washes, 50 ng/mL biotinylated anti-IL15 antibody (BAM247, R&D Systems), 500 ng/mL biotinylated anti-IL-21 antibody (13-7218-81, R&D Systems), or 500 ng/mL biotin. Anti-IL-7 antibody (506602, R&D Systems) was incubated with the wells for 60 minutes at room temperature. Plates were washed 3 times and incubated with 0.25 μg/mL HRP-SA (Jackson ImmunoResearch) at 100 μL/well for 30 minutes at room temperature, then washed 4 times and incubated with 100 μl ABTS for 2 minutes at room temperature. . Absorbance was read at 405 nm. As shown in Figures 78A-78C, the IL-15, IL-21, and IL-7 domains in 7t15-16s21 were detected by individual antibodies.
7t15-16s21におけるIL-15は、IL-2Rβ及び共通γ鎖含有32Dβ細胞の増殖を促進する
7t15-16s21におけるIL-15の活性を分析するために、7t15-16s21のIL-15活性を、IL2Rβ及び共通γ鎖を発現する32Dβ細胞を使用して組換えIL-15と比較し、細胞増殖の促進に対するそれらの効果を評価した。IL-15依存性32Dβ細胞をIMDM-10%FBSで5回洗浄し、2×104細胞/ウェルでウェル中に播種した。連続希釈した7t15-16s21又はIL-15を細胞に添加した(図79)。細胞をCO2インキュベーター内で、37℃で3日間インキュベートした。3日目に10μlのWST1を各ウェルに添加し、CO2インキュベーター内で、37℃で更に3時間インキュベートすることにより、細胞増殖を検出した。生成されたホルマザン色素の量を分析することにより、吸光度を450nmで測定した。図79に示されるように、7t15-16s21及びIL-15は32Dβ細胞増殖を促進し、7t15-16s21及びIL-15のEC50は、それぞれ、172.2pM及び16.63pMであった。
IL-15 at 7t15-16s21 Promotes Proliferation of IL-2Rβ and Common γ Chain Containing 32Dβ Cells To analyze IL-15 activity at 7t15-16s21, IL-15 activity at 7t15-16s21 and 32Dβ cells expressing the common γ chain were used to compare recombinant IL-15 and assess their effects on promoting cell proliferation. IL-15 dependent 32Dβ cells were washed 5 times with IMDM-10% FBS and seeded in wells at 2×10 4 cells/well. Serially diluted 7t15-16s21 or IL-15 were added to the cells (Figure 79). Cells were incubated for 3 days at 37°C in a CO2 incubator. Cell proliferation was detected by adding 10 μl of WST1 to each well on
抗TF抗体親和性カラムからの7t15-16s21の精製溶出クロマトグラフ
細胞培養物から収集した7t15-16s21を、5カラム体積のPBSで平衡化した抗TF抗体親和性カラムにロードした。次いで、カラムを5カラム体積のPBSで洗浄し、その後、6カラム体積の0.1M酢酸(pH2.9)で溶出した。A280溶出ピークを収集し、1Mトリス塩基でpH7.5~8.0に中和した。中和した試料を、分子量カットオフ30KDaでAmicon遠心フィルターを使用してPBSに緩衝液交換した。図80は、抗TF抗体樹脂への結合及びその上での溶出後の7t15-16s21タンパク質含有細胞培養上清のクロマトグラフィープロファイルを示す線グラフである。図80に示されるように、抗TF抗体親和性カラムは、TFを含む7t15-16s21に結合した。緩衝液交換したタンパク質試料を、更なる生化学的分析及び生物学的活性試験のために2~8℃で保管した。各溶出後、抗TF抗体アフィニティーカラムを6カラム体積の0.1Mグリシン(pH2.5)を使用してストリッピングした。その後、カラムを、保管のために5カラム体積のPBS及び7カラム体積の20%エタノールを使用して中和した。抗TF抗体アフィニティーカラムを、GE Healthcare AKTA Avantシステムに接続した。流速は、2mL/分の溶出ステップを除く全てのステップで4mL/分であった。
Purification Elution Chromatography of 7t15-16s21 from Anti-TF Antibody Affinity Column 7t15-16s21 harvested from cell culture was loaded onto an anti-TF antibody affinity column equilibrated with 5 column volumes of PBS. The column was then washed with 5 column volumes of PBS and then eluted with 6 column volumes of 0.1 M acetic acid (pH 2.9). The A280 elution peak was collected and neutralized to pH 7.5-8.0 with 1M Tris base. Neutralized samples were buffer exchanged into PBS using Amicon centrifugal filters with a molecular weight cutoff of 30 KDa. FIG. 80 is a line graph showing the chromatographic profile of 7t15-16s21 protein-containing cell culture supernatant after binding to and elution on anti-TF antibody resin. As shown in Figure 80, the anti-TF antibody affinity column bound 7t15-16s21 containing TF. Buffer-exchanged protein samples were stored at 2-8° C. for further biochemical analysis and biological activity testing. After each elution, the anti-TF antibody affinity column was stripped using 6 column volumes of 0.1 M glycine (pH 2.5). The column was then neutralized using 5 column volumes of PBS and 7 column volumes of 20% ethanol for storage. The anti-TF antibody affinity column was connected to a GE Healthcare AKTA Avant system. The flow rate was 4 mL/min for all steps except the 2 mL/min elution step.
7t15-16s21の分析的サイズ排除クロマトグラフィー(SEC)分析
7t15-16s21のサイズ排除クロマトグラフィー(SEC)分析を行うために、AKTA Avantシステム(GE Healthcare)に接続したSuperdex200 Increase10/300 GLゲル濾過カラム(GE Healthcare)を使用した。カラムを2カラム体積のPBSで平衡化した。流速は0.7mL/分であった。PBS中7t15-16s21を含む試料を、キャピラリーループを使用してSuperdex200カラムに注入し、SECによって分析した。図81に示されるように、SEC結果は、7t15-16s21の2つのタンパク質ピークを示した。
Analytical Size Exclusion Chromatography (SEC) Analysis of 7t15-16s21 To perform size exclusion chromatography (SEC) analysis of 7t15-16s21, a
実施例51:TGFRt15-16s21融合タンパク質の生成及び特徴付け
抗ヒトCD16scFv/IL-15RαSu/IL21とTGFβ受容体II/TF/IL-15融合タンパク質とを含む融合タンパク質複合体を生成した(図82及び図83)。ヒトTGFβ受容体II(Ile24-Asp159)、組織因子219、及びIL-15配列をUniProtウェブサイトから入手し、これらの配列のDNAをGenewizによって合成した。具体的には、G4S(3)リンカーを用いて2つのTGFβ受容体II配列を結合してTGFβ受容体IIの一本鎖バージョンを生成し、その後、組織因子219のN末端コーディング領域に、続いて、IL-15のN末端コーディング領域に直接結合することによって構築物を作製した。
Example 51: Generation and Characterization of TGFRt15-16s21 Fusion Protein A fusion protein complex comprising anti-human CD16scFv/IL-15RαSu/IL21 and a TGFβ receptor II/TF/IL-15 fusion protein was generated (FIGS. 82 and Figure 83). Human TGFβ receptor II (Ile24-Asp159),
組織因子219のN末端に、続いて、IL-15のN末端に結合した2つのTGFβ受容体IIを含む構築物の核酸配列及びタンパク質配列を以下に示す。
The nucleic acid and protein sequences of a construct containing two TGFβ receptor II bound to the N-terminus of
2つのTGFβ受容体II/TF/IL-15構築物の核酸配列(シグナルペプチド配列を含む)は、以下の通りである。
(シグナルペプチド)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(2つのヒトTGFβ受容体II断片)
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC
(ヒト組織因子219)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(ヒトIL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
The nucleic acid sequences (including signal peptide sequences) of the two TGFβ receptor II/TF/IL-15 constructs are as follows.
(signal peptide)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCC
(two human TGFβ receptor II fragments)
ATCCCCCCCCCATGTGCAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAA GAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGAACCTTCTTTATGTGTTCCTGTAGCAG CGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCC CCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCCACGATCCCCAAGCTGCCCTAC CACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCCGAC
(human tissue factor 219)
AGCGGCCAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAACCATCCTCGAATGGGAACCCAAACCCGTTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCG ATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCTTTATACGAGAACAGCCCCGAATTTACCCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCA CAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTAATCGACG TGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAGGGCGAGTTCCGGGAG
(human IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTACTGGAGCTGCCAAGTTATCTCTTTAGAGAGCGGGAGACGCTAGCAT CCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCCAAGGAGTGCGAAGAGCTGGAGGGAGAAGAACATCAAGGAGTTCTGCAATCCTTTGTGCCACATTGTCCAGATGTTCATCAATACCTCC
TGFβ受容体II/TF/IL-15融合タンパク質のアミノ酸配列(リーダー配列を含む)は、以下の通りである。
(シグナルペプチド)
MKWVTFISLLFLFSSAYS
(ヒトTGFβ受容体II)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(ヒト組織因子219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(ヒトIL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
The amino acid sequence (including leader sequence) of the TGFβ receptor II/TF/IL-15 fusion protein is as follows.
(signal peptide)
MKWVT FISLLFLFS SAYS
(human TGFβ receptor II)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNCSITSICEKPQEVCVAVWRKNDINITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPDGGGGGSGGGGGSGGGGSIPPHV QKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNSITSICEKPQEVCVAVWRKNDINITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(human tissue factor 219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTF LSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(human IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
抗ヒトCD16scFvをGenewizによって合成したIL-15RαSu鎖のN末端コーディング領域に、続いて、IL-21のN末端コーディング領域に直接結合することによっても構築物を作製した。IL-15RαSuのN末端に、続いて、IL-21のN末端コーディング領域に結合した抗ヒトCD16scFvを含む構築物の核酸配列及びタンパク質配列を以下に示す。 Constructs were also made by directly linking the anti-human CD16 scFv to the N-terminal coding region of the IL-15RαSu chain synthesized by Genewiz, followed by the N-terminal coding region of IL-21. The nucleic acid and protein sequences of a construct containing anti-human CD16 scFv attached to the N-terminus of IL-15RαSu followed by the N-terminal coding region of IL-21 are shown below.
抗CD16scFv/IL-15RαSu/IL-21構築物の核酸配列(シグナルペプチド配列を含む)は、以下の通りである。
(シグナルペプチド)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(抗ヒトCD16scFv)
TCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCAACCATGTGGTGTTCGGCGGCGGCACCAAGCTGACCGTGGGCCATGGCGGCGGCGGCTCCGGAGGCGGCGGCAGCGGCGGAGGAGGATCCGAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGG
(ヒトIL-15Rαスシドメイン)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
(ヒトIL-21)
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC
The nucleic acid sequence (including signal peptide sequence) of the anti-CD16 scFv/IL-15RαSu/IL-21 construct is as follows.
(signal peptide)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCC
(Anti-human CD16scFv)
TCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGGCTCCTGTGCTGGTGATCTACGGCAAGAACACAGGCCCTCCGGCATCCCTGACAGG TTCTCCGGATCCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCGGCAACCATGTGGGTGTTCGGCGGCGGGCACCAAGCTGACCGTGGGCCATGGCGGCGGCGGCTCCGGAGGCGGCCG GCAGCGGCGGAGGAGGATCCGAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGGCTCCTGGAAAGGGGCCTGGAGTGGGTGT CCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGA CAGGGCACCCTGGTGACCGTGTCCCAGG
(Human IL-15Rα sushi domain)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCT CTTTAAAGTGCATCCGG
(human IL-21)
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCG CCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCCTCCACAAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCCTGCTGCAGAAGAT GATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC
抗CD16scFv/IL-15RαSu/IL-21構築物のアミノ酸配列(シグナルペプチド配列を含む)は、以下の通りである。
(シグナルペプチド)
MKWVTFISLLFLFSSAYS
(抗ヒトCD16scFv)
SELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGHGGGGSGGGGSGGGGSEVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSR
(ヒトIL-15Rαスシドメイン)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
(ヒトIL-21)
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS
The amino acid sequence (including signal peptide sequence) of the anti-CD16 scFv/IL-15RαSu/IL-21 construct is as follows.
(signal peptide)
MKWVT FISLLFLFSSAYS
(anti-human CD16scFv)
SELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGHGGGGGSGGGGSGGGGSEVQLVESGGGGVVRPGG SLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSR
(Human IL-15Rα sushi domain)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
(human IL-21)
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS
いくつかの事例では、リーダーペプチドをインタクトなポリペプチドから切断して、可溶性であり得るか、又は分泌され得る成熟形態を生成する。 In some cases, the leader peptide is cleaved from the intact polypeptide to generate the mature form, which can be soluble or secreted.
抗CD16scFv/IL-15RαSu/IL-21構築物及びTGFR/TF/IL-15構築物を前述の修飾レトロウイルス発現ベクターにクローニングし(Hughes MS,Yu YY,Dudley ME,Zheng Z,Robbins PF,Li Y,et al.Transfer of a TCR gene derived from a patient with a marked antitumor response conveys highly active T-cell effector functions.Hum Gene Ther2005;16:457-72)、発現ベクターをCHO-K1細胞にトランスフェクトした。CHO-K1細胞でのこれらの2つの構築物の共発現により、可溶性TGFR/TF/IL-15:CD16scFv/IL-15RαSu/IL-21タンパク質複合体(TGFRt15-16s21と称する)の形成及び分泌が可能になり、これを抗TF IgG1ベースの親和性及び他のクロマトグラフィー法によって精製することができる。 The anti-CD16 scFv/IL-15RαSu/IL-21 and TGFR/TF/IL-15 constructs were cloned into modified retroviral expression vectors previously described (Hughes MS, Yu YY, Dudley ME, Zheng Z, Robbins PF, Li Y, et al.Transfer of a TCR gene derived from a patient with a marked antitumor response conveys highly active T-cell effector functions.Hum Gene Ther2005;1 6:457-72), the expression vector was transfected into CHO-K1 cells. Co-expression of these two constructs in CHO-K1 cells allows formation and secretion of a soluble TGFR/TF/IL-15:CD16scFv/IL-15RαSu/IL-21 protein complex (termed TGFRt15-16s21). , which can be purified by anti-TF IgG1-based affinity and other chromatographic methods.
TGFRt15-16s21とヒトCD16bを発現するCHO細胞との間の相互作用
CHO細胞をpMCプラスミド中のヒトCD16bでトランスフェクトし、10μg/mLのブラストサイジンで10日間選択した。CD16bを安定的に発現する細胞を、1.2μg/mLの抗ヒトCD16scFvを含むTGFRt15-16s21又は陰性対照として抗ヒトCD16scFvを含まない7t15-21sで染色し、ビオチン化抗ヒト組織因子抗体及びPE結合ストレプトアビジンで染色した。図84A及び84Bに示されるように、抗ヒトCD16scFvを含むTGFRt15-16s21が陽性結合を示した一方で、7t15-21sは結合を示さなかった。
Interaction between TGFRt15-16s21 and CHO cells expressing human CD16b CHO cells were transfected with human CD16b in the pMC plasmid and selected with 10 μg/mL blasticidin for 10 days. Cells stably expressing CD16b were stained with TGFRt15-16s21 containing 1.2 μg/mL anti-human CD16 scFv or 7t15-21s without anti-human CD16 scFv as a negative control, biotinylated anti-human tissue factor antibody and PE. Stained with conjugated streptavidin. As shown in Figures 84A and 84B, TGFRt15-16s21 containing anti-human CD16 scFv showed positive binding, while 7t15-21s showed no binding.
HEK-Blue TGFβ細胞におけるTGFβ1活性に対するTGFRt15-16s21の効果
TGFRt15-16s21中のTGFβRIIの活性を評価するために、HEK-Blue TGFβ細胞におけるTGFβ1活性に対するTGFRt15-16s21の効果を分析した。HEK-Blue TGFβ細胞(Invivogen)を予熱したPBSで2回洗浄し、試験培地(DMEM、10%熱不活性化FCS、1×グルタミン、1×抗-抗、及び2×グルタミン)中に5×105細胞/mLで再懸濁した。平底96ウェルプレート中、50μLの細胞を各ウェルに添加し(2.5×104細胞/ウェル)、その後、50μlの0.1nM TGFβ1(R&D systems)を添加した。その後、1:3連続希釈で調製したTGFRt15-16s21又はTGFR-Fc(R&D Systems)をプレートに添加して、総量を200μLにした。37℃で24時間インキュベートした後、40μLの誘導されたHEK-Blue TGFβ細胞上清を平底96ウェルプレート中の160μLの予熱したQUANTI-Blue(Invivogen)に添加し、37℃で1~3時間インキュベートした。その後、OD値を、プレートリーダー(Multiscan Sky)を使用して620~655nMで決定した。各タンパク質試料のIC50を、GraphPad Prism7.04を用いて計算した。TGFRt15-16s21及びTGFR-FcのIC50は、それぞれ、9127pM及び460.6pMであった。これらの結果は、TGFRt15-16s21中のTGFβRIIドメインがHEK-Blue TGFβ細胞におけるTGFβ-1活性を遮断することができたことを示した。
Effect of TGFRt15-16s21 on TGFβ1 Activity in HEK-Blue TGFβ Cells To assess the activity of TGFβRII in TGFRt15-16s21, the effect of TGFRt15-16s21 on TGFβ1 activity in HEK-Blue TGFβ cells was analyzed. HEK-Blue TGFβ cells (Invivogen) were washed twice with prewarmed PBS and plated 5× in test medium (DMEM, 10% heat-inactivated FCS, 1× glutamine, 1× anti-anti, and 2× glutamine). Resuspend at 10 5 cells/mL. In a flat bottom 96-well plate, 50 μL of cells were added to each well (2.5×10 4 cells/well) followed by 50 μl of 0.1 nM TGFβ1 (R&D systems). TGFRt15-16s21 or TGFR-Fc (R&D Systems) prepared in 1:3 serial dilutions were then added to the plate to a total volume of 200 μL. After 24 hours of incubation at 37°C, 40 μL of induced HEK-Blue TGFβ cell supernatant is added to 160 μL of prewarmed QUANTI-Blue (Invivogen) in a flat bottom 96-well plate and incubated for 1-3 hours at 37°C. bottom. OD values were then determined at 620-655 nM using a plate reader (Multiscan Sky). The IC50 for each protein sample was calculated using GraphPad Prism 7.04. The IC 50 for TGFRt15-16s21 and TGFR-Fc were 9127 pM and 460.6 pM, respectively. These results indicated that the TGFβRII domain in TGFRt15-16s21 was able to block TGFβ-1 activity in HEK-Blue TGFβ cells.
TGFRt15-16s21におけるIL-15は、IL-2Rβ及び共通γ鎖含有32Dβ細胞の増殖を促進する
TGFRt15-16s21におけるIL-15の活性を分析するために、TGFRt15-16s21のIL-15活性を、IL2Rβ及び共通γ鎖を発現する32Dβ細胞を使用して組換えIL-15と比較し、細胞増殖の促進に対するそれらの効果を評価した。IL-15依存性32Dβ細胞をIMDM-10%FBSで5回洗浄し、2×104細胞/ウェルでウェル中に播種した。連続希釈したTGFRt15-16s21又はIL-15を細胞に添加した(図86)。細胞をCO2インキュベーター内で、37℃で3日間インキュベートした。3日目に10μLのWST1を各ウェルに添加し、CO2インキュベーター内で、37℃で更に3時間インキュベートすることにより、細胞増殖を検出した。生成されたホルマザン色素の量を分析することにより、吸光度を450nmで測定した。データを図85に示す。図86に示されるように、TGFRt15-16s21及びIL-15は32Dβ細胞増殖を促進し、TGFRt15-16s21及びIL-15のEC50は、それぞれ、51298pM及び10.63pMであった。
IL-15 at TGFRt15-16s21 Promotes Proliferation of IL-2Rβ and Common γ Chain-Containing 32Dβ Cells To analyze the activity of IL-15 at TGFRt15-16s21, IL-15 activity of and 32Dβ cells expressing the common γ chain were used to compare recombinant IL-15 and assess their effects on promoting cell proliferation. IL-15 dependent 32Dβ cells were washed 5 times with IMDM-10% FBS and seeded in wells at 2×10 4 cells/well. Serial dilutions of TGFRt15-16s21 or IL-15 were added to the cells (Figure 86). Cells were incubated for 3 days at 37°C in a CO2 incubator. Cell proliferation was detected by adding 10 μL of WST1 to each well on
ELISAを使用したTGFRt15-16s21におけるIL-15、IL-21、及びTGFβRIIの検出
96ウェルプレートをR5(コーティング緩衝液)中100μL(8μg/mL)の抗TF IgG1でコーティングし、室温(RT)で2時間インキュベートした。プレートを3回洗浄し、PBS中100μLの1%BSAでブロックした。1:3比で連続希釈したTGFRt15-16s21を添加し、室温で60分間インキュベートした。3回洗浄した後、50ng/mLのビオチン化抗IL-15抗体(BAM247、R&D Systems)、500ng/mLのビオチン化抗IL-21抗体(13-7218-81、R&D Systems)、又は200ng/mLのビオチン化抗TGFβRII抗体(BAF241、R&D Systems)をウェルごとに適用し、室温で60分間インキュベートした。3回洗浄した後、0.25μg/mLのHRP-SA(Jackson ImmunoResearchと100μL/ウェルで、室温で30分間インキュベートし、その後、4回洗浄し、100μLのABTSと室温で2分間インキュベートした。吸光度を405nmで読み取った。図87A~87Cに示されるように、TGFRt15-16s21中のIL-15ドメイン、IL-21ドメイン、及びTGFβRIIドメインをそれぞれの抗体によって検出した。
Detection of IL-15, IL-21 and TGFβRII in TGFRt15-16s21 using ELISA 96-well plates were coated with 100 μL (8 μg/mL) of anti-TF IgG1 in R5 (coating buffer) and incubated at room temperature (RT). Incubated for 2 hours. Plates were washed three times and blocked with 100 μL of 1% BSA in PBS. TGFRt15-16s21 serially diluted in a 1:3 ratio was added and incubated for 60 minutes at room temperature. After three washes, 50 ng/mL biotinylated anti-IL-15 antibody (BAM247, R&D Systems), 500 ng/mL biotinylated anti-IL-21 antibody (13-7218-81, R&D Systems), or 200 ng/mL of biotinylated anti-TGFβRII antibody (BAF241, R&D Systems) was applied per well and incubated for 60 minutes at room temperature. After 3 washes, 0.25 μg/mL HRP-SA (Jackson ImmunoResearch) was incubated with 100 μL/well for 30 minutes at room temperature, followed by 4 washes and incubation with 100 μL ABTS for 2 minutes at room temperature. was read at 405 nm, IL-15, IL-21, and TGFβRII domains in TGFRt15-16s21 were detected by the respective antibodies, as shown in Figures 87A-87C.
抗TF抗体親和性カラムを使用したTGFRt15-16s21の精製溶出クロマトグラフ
細胞培養物から収集したTGFRt15-16s21を、5カラム体積のPBSで平衡化した抗TF抗体親和性カラムにロードした。試料をロードした後、カラムを5カラム体積のPBSで洗浄し、その後、6カラム体積の0.1M酢酸(pH2.9)で溶出した。A280溶出ピークを収集し、その後、1Mトリス塩基でpH7.5~8.0に中和した。その後、中和した試料を、分子量カットオフ30KDaでAmicon遠心フィルターを使用してPBSに緩衝液交換した。図88に示されるように、抗TF抗体親和性カラムは、融合パートナーとして組織因子を含むTGFRt15-16s21に結合した。緩衝液交換したタンパク質試料を、更なる生化学的分析及び生物学的活性試験のために2~8℃で保管した。各溶出後、抗TF抗体アフィニティーカラムを6カラム体積の0.1Mグリシン(pH2.5)を使用してストリッピングした。その後、カラムを、保管のために5カラム体積のPBS及び7カラム体積の20%エタノールを使用して中和した。抗TF抗体アフィニティーカラムを、GE Healthcare AKTA Avantシステムに接続した。流速は、2mL/分の溶出ステップを除く全てのステップで4mL/分であった。
Purification Elution Chromatography of TGFRt15-16s21 Using Anti-TF Antibody Affinity Column TGFRt15-16s21 collected from cell culture was loaded onto an anti-TF antibody affinity column equilibrated with 5 column volumes of PBS. After sample loading, the column was washed with 5 column volumes of PBS and then eluted with 6 column volumes of 0.1 M acetic acid (pH 2.9). The A280 elution peak was collected and then neutralized to pH 7.5-8.0 with 1M Tris base. Neutralized samples were then buffer exchanged into PBS using Amicon centrifugal filters with a molecular weight cutoff of 30 KDa. As shown in Figure 88, the anti-TF antibody affinity column bound TGFRt15-16s21 with tissue factor as a fusion partner. Buffer-exchanged protein samples were stored at 2-8° C. for further biochemical analysis and biological activity testing. After each elution, the anti-TF antibody affinity column was stripped using 6 column volumes of 0.1 M glycine (pH 2.5). The column was then neutralized using 5 column volumes of PBS and 7 column volumes of 20% ethanol for storage. The anti-TF antibody affinity column was connected to a GE Healthcare AKTA Avant system. The flow rate was 4 mL/min for all steps except the 2 mL/min elution step.
TGFRt15-16s21の還元SDS-PAGE
TGFRt15-16s21タンパク質の純度及び分子量を決定するために、抗TF抗体親和性カラムで精製したタンパク質試料を、還元条件下でドデシル硫酸ナトリウムポリアクリルアミドゲル(4~12%NuPageビス-トリスゲル)電気泳動(SDS-PAGE)によって分析した。電気泳動後、ゲルをInstantBlueで約30分間染色し、その後、精製水中で一晩脱色した。
Reducing SDS-PAGE of TGFRt15-16s21
To determine the purity and molecular weight of the TGFRt15-16s21 protein, anti-TF antibody affinity column purified protein samples were subjected to sodium dodecyl sulfate polyacrylamide gel (4-12% NuPage Bis-Tris gel) electrophoresis under reducing conditions ( analyzed by SDS-PAGE). After electrophoresis, gels were stained with InstantBlue for approximately 30 minutes and then destained overnight in purified water.
TGFRt15-16s21タンパク質がCHO細胞において翻訳後にグリコシル化を受けることを検証するために、脱グリコシル化実験を、New England Biolabs製のProtein Deglycosylation Mix IIキットを製造業者の指示に従って使用して実施した。図89は、非脱グリコシル化状態(赤色の縁内のレーン1)及び脱グリコシル化状態(黄色の縁内のレーン2)での試料の還元SDS-PAGE分析の結果を示す。結果は、TGFRt15-16s21タンパク質がCHO細胞で発現されるとグリコシル化されることを示した。脱グリコシル化後、精製した試料は、還元SDSゲル中で予想された分子量(69kDa及び48kDa)を示した。レーンMには、10μLのSeeBlue Plus2 Prestained Standardをロードした。
To verify that the TGFRt15-16s21 protein undergoes post-translational glycosylation in CHO cells, deglycosylation experiments were performed using the Protein Deglycosylation Mix II kit from New England Biolabs according to the manufacturer's instructions. FIG. 89 shows the results of reducing SDS-PAGE analysis of samples in the non-deglycosylated state (
実施例52:7t15-7s融合タンパク質の生成及び特徴付け
IL-7/TF/IL-15融合タンパク質及びIL-7/IL-15RαSu融合タンパク質を含む融合タンパク質複合体を生成した(図90及び図91)。ヒトIL-7、組織因子219、及びIL-15配列をUniProtウェブサイトから入手し、これらの配列のDNAをGenewizによって合成した。具体的には、IL-7配列を組織因子219のN末端コーディング領域に、続いて、IL-15のN末端コーディング領域に結合することによって構築物を作製した。
Example 52 Generation and Characterization of 7t15-7s Fusion Proteins Fusion protein complexes containing IL-7/TF/IL-15 fusion proteins and IL-7/IL-15RαSu fusion proteins were generated (FIGS. 90 and 91) ). Human IL-7,
組織因子219のN末端に、続いて、IL-15のN末端に結合したIL-7を含む構築物の核酸配列及びタンパク質配列を以下に示す。
The nucleic acid and protein sequences of a construct containing IL-7 attached to the N-terminus of
7t15構築物の核酸配列(シグナルペプチド配列を含む)は、以下の通りである。
(シグナルペプチド)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(ヒトIL7)
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCAT
(ヒト組織因子219)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(ヒトIL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
The nucleic acid sequence (including signal peptide sequence) of the 7t15 construct is as follows.
(signal peptide)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCC
(human IL7)
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCCACATCTGCGACGCCAACAAGGAGGGCATGTTCCT GTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGA ACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCAT
(human tissue factor 219)
AGCGGCCAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAACCATCCTCGAATGGGAACCCAAACCCGTTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCG ATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCTTTATACGAGAACAGCCCCGAATTTACCCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCA CAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTAATCGACG TGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAGGGCGAGTTCCGGGAG
(human IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTACTGGAGCTGCCAAGTTATCTCTTTAGAGAGCGGGAGACGCTAGCAT CCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCCAAGGAGTGCGAAGAGCTGGAGGGAGAAGAACATCAAGGAGTTCTGCAATCCTTTGTGCCACATTGTCCAGATGTTCATCAATACCTCC
7t15融合タンパク質のアミノ酸配列(リーダー配列を含む)は、以下の通りである。
(シグナルペプチド)
MKWVTFISLLFLFSSAYS
(ヒトIL7)
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEH
(ヒト組織因子219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(ヒトIL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
The amino acid sequence (including the leader sequence) of the 7t15 fusion protein is as follows.
(signal peptide)
MKWVT FISLLFLFS SAYS
(human IL7)
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWN KILMG TKEH
(human tissue factor 219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTF LSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(human IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
IL-7配列をGenewizによって合成したIL-15RαSu鎖のN末端コーディング領域に連結することによっても構築物を作製した。IL-15RαSu鎖のN末端に結合したIL-7を含む構築物の核酸配列及びタンパク質配列を以下に示す。 A construct was also made by joining the IL-7 sequence to the N-terminal coding region of the IL-15RαSu chain synthesized by Genewiz. The nucleic acid and protein sequences of constructs containing IL-7 attached to the N-terminus of IL-15RαSu chain are shown below.
7s構築物の核酸配列(シグナルペプチド配列を含む)は、以下の通りである。
(シグナルペプチド)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(ヒトIL7)
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCAT
(ヒトIL-15Rαスシドメイン)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
The nucleic acid sequence of the 7s construct (including signal peptide sequence) is as follows.
(signal peptide)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCC
(human IL7)
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCCACATCTGCGACGCCAACAAGGAGGGCATGTTCCT GTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGA ACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCAT
(Human IL-15Rα sushi domain)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCT CTTTAAAGTGCATCCGG
7s融合タンパク質のアミノ酸配列(リーダー配列を含む)は、以下の通りである。
(シグナルペプチド)
MKWVTFISLLFLFSSAYS
(ヒトIL7)
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEH
(ヒトIL-15Rαスシドメイン)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
The amino acid sequence (including leader sequence) of the 7s fusion protein is as follows.
(signal peptide)
MKWVT FISLLFLFS SAYS
(human IL7)
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDHLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWN KILMG TKEH
(Human IL-15Rα sushi domain)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
IL-7/TF/IL-15構築物及びIL-7/IL-15RαSu構築物を前述の修飾レトロウイルス発現ベクターにクローニングし(Hughes MS,Yu YY,Dudley ME,Zheng Z,Robbins PF,Li Y,et al.Transfer of a TCR gene derived from a patient with a marked antitumor response conveys highly active T-cell effector functions.Hum Gene Ther 2005;16:457-72)、発現ベクターをCHO-K1細胞にトランスフェクトした。CHO-K1細胞でのこれらの2つの構築物の共発現により、7t15-7sと称する可溶性IL-7/TF/IL-15:IL-7/IL-15RαSuタンパク質複合体の形成及び分泌が可能になり、これを抗TF抗体IgG1親和性及び他のクロマトグラフィー法によって精製することができる。
The IL-7/TF/IL-15 and IL-7/IL-15RαSu constructs were cloned into modified retroviral expression vectors previously described (Hughes MS, Yu YY, Dudley ME, Zheng Z, Robbins PF, Li Y, et al. al.Transfer of a TCR gene derived from a patient with a marked antitumor response conveys highly active T-cell effector functions.
抗TF抗体親和性カラムを使用した7t15-7sの精製溶出クロマトグラフ
細胞培養物から収集した7t15-7sを、5カラム体積のPBSで平衡化した抗TF抗体親和性カラムにロードした。試料をロードした後、カラムを5カラム体積のPBSで洗浄し、その後、6カラム体積の0.1M酢酸(pH2.9)で溶出した。A280溶出ピークを収集し、その後、1Mトリス塩基でpH7.5~8.0に中和した。その後、中和した試料を、分子量カットオフ30KDaでAmicon遠心フィルターを使用してPBSに緩衝液交換した。図92に示されるように、抗TF抗体親和性カラムは、融合パートナーとして組織因子(TF)を含む7t15-7sに結合した。緩衝液交換したタンパク質試料を、更なる生化学的分析及び生物学的活性試験のために2~8℃で保管した。各溶出後、抗TF抗体アフィニティーカラムを6カラム体積の0.1Mグリシン(pH2.5)を使用してストリッピングした。その後、カラムを、保管のために5カラム体積のPBS及び7カラム体積の20%エタノールを使用して中和した。抗TF抗体親和性カラムを、GE Healthcare AKTA Avantシステムに接続した。流速は、2mL/分の溶出ステップを除く全てのステップで4mL/分であった。
Purification Elution Chromatography of 7t15-7s Using Anti-TF Antibody Affinity Column 7t15-7s harvested from cell culture was loaded onto an anti-TF antibody affinity column equilibrated with 5 column volumes of PBS. After sample loading, the column was washed with 5 column volumes of PBS and then eluted with 6 column volumes of 0.1 M acetic acid (pH 2.9). The A280 elution peak was collected and then neutralized to pH 7.5-8.0 with 1M Tris base. Neutralized samples were then buffer exchanged into PBS using Amicon centrifugal filters with a molecular weight cutoff of 30 KDa. As shown in Figure 92, the anti-TF antibody affinity column bound 7t15-7s with tissue factor (TF) as a fusion partner. Buffer-exchanged protein samples were stored at 2-8° C. for further biochemical analysis and biological activity testing. After each elution, the anti-TF antibody affinity column was stripped using 6 column volumes of 0.1 M glycine (pH 2.5). The column was then neutralized using 5 column volumes of PBS and 7 column volumes of 20% ethanol for storage. The anti-TF antibody affinity column was connected to a GE Healthcare AKTA Avant system. The flow rate was 4 mL/min for all steps except the 2 mL/min elution step.
C57BL/6マウスにおける7t15-7sの免疫刺激
7t15-7sは、ヒトIL-7、ヒト組織因子219断片、及びヒトIL-15の可溶性融合物(7t15)である第1のポリペプチドと、ヒトIL-7及びヒトIL-15受容体アルファ鎖のスシドメインの可溶性融合物(7s)である第2のポリペプチドとを含む多鎖ポリペプチド(本明細書に記載のタイプA多鎖ポリペプチド)である。
Immunostimulation of 7t15-7s in C57BL/6 Mice -7 and a second polypeptide that is a soluble fusion (7s) of the sushi domain of the human IL-15 receptor alpha chain (a type A multichain polypeptide described herein) be.
CHO細胞を、IL7-TF-IL-15(7t15)及びIL7-IL-15Raスシドメイン(7s)ベクターで共トランスフェクトした。7t15-7s複合体を、トランスフェクトしたCHO細胞培養上清から精製した。図93に示されるように、複合体中のIL-7、IL-15、及び組織因子(TF)成分をELISAによって実証した。ヒト化抗TF抗体モノクローナル抗体(抗TF IgG1)を捕捉抗体として使用して、7t15-7s中のTFを決定し、ビオチン化抗ヒトIL-15抗体(R&D systems)及びビオチン化抗ヒトIL-7抗体(R&D Systems)を検出抗体として使用して、それぞれ、7t15-7s中のIL-15及びIL-7を検出し、その後、ペルオキシダーゼ結合ストレプトアビジン(Jackson ImmunoResearch Lab)及びABTS基質(Surmodics IVD,Inc.)を使用した。 CHO cells were co-transfected with IL7-TF-IL-15 (7t15) and IL7-IL-15Ra sushi domain (7s) vectors. The 7t15-7s complex was purified from transfected CHO cell culture supernatants. IL-7, IL-15, and tissue factor (TF) components in the complex were demonstrated by ELISA, as shown in FIG. Humanized anti-TF antibody monoclonal antibody (anti-TF IgG1) was used as capture antibody to determine TF in 7t15-7s, biotinylated anti-human IL-15 antibody (R&D systems) and biotinylated anti-human IL-7 Antibodies (R&D Systems) were used as detection antibodies to detect IL-15 and IL-7 in 7t15-7s, respectively, followed by peroxidase-conjugated streptavidin (Jackson ImmunoResearch Lab) and ABTS substrate (Surmodics IVD, Inc.). .)It was used.
7t15-7sをC57BL/6マウスに10mg/kgで皮下注射し、インビボでの7t15-7sの免疫刺激活性を決定した。PBSで皮下処理したC57BL/6マウスを対照として使用した。マウスの脾臓を収集し、処理後4日目に秤量した。単一脾細胞懸濁液を調製し、蛍光色素結合抗CD4、抗CD8、及び抗NK1.1抗体で、CD4+T細胞、CD8+T細胞、及びNK細胞のパーセンテージをフローサイトメトリーによって分析した。結果は、7t15-7sが脾臓重量に基づいて脾臓細胞を拡大するのに効果的であり(図94A)、具体的には、CD8+T細胞とNK細胞のパーセンテージが対照処理マウスと比較して高かったことを示した(図94B)。 7t15-7s was injected subcutaneously into C57BL/6 mice at 10 mg/kg to determine the immunostimulatory activity of 7t15-7s in vivo. C57BL/6 mice treated subcutaneously with PBS were used as controls. Mouse spleens were harvested and weighed 4 days after treatment. Single splenocyte suspensions were prepared and analyzed by flow cytometry for percentages of CD4 + T cells, CD8 + T cells, and NK cells with fluorochrome-conjugated anti-CD4, anti - CD8, and anti-NK1.1 antibodies. . The results showed that 7t15-7s was effective in expanding splenocytes based on spleen weight (FIG. 94A), specifically the percentage of CD8 + T cells and NK cells increased compared to control treated mice. was higher (Fig. 94B).
実施例53:TGFRt15-TGFRs融合タンパク質の生成及び特徴付け
TGFβ受容体II/IL-15RαSu融合タンパク質及びTGFβ受容体II/TF/IL-15融合タンパク質からなる融合タンパク質複合体を生成した(図95及び図96)。ヒトTGFβ受容体II(Ile24-Asp159)、組織因子219、及びIL-15配列をUniProtウェブサイトから入手し、これらの配列のDNAをGenewizによって合成した。具体的には、G4S(3)リンカーを用いて2つのTGFβ受容体II配列を結合してTGFβ受容体IIの一本鎖バージョンを生成し、その後、組織因子219のN末端コーディング領域に、続いて、IL-15のN末端コーディング領域に直接連結することによって構築物を作製した。
Example 53: Generation and Characterization of TGFRt15-TGFRs Fusion Proteins A fusion protein complex consisting of a TGFβ receptor II/IL-15RαSu fusion protein and a TGFβ receptor II/TF/IL-15 fusion protein was generated (FIGS. 95 and Figure 96). Human TGFβ receptor II (Ile24-Asp159),
組織因子219のN末端に、続いて、IL-15のN末端に結合した2つのTGFβ受容体IIを含む構築物の核酸配列及びタンパク質配列を以下に示す。
The nucleic acid and protein sequences of a construct containing two TGFβ receptor II bound to the N-terminus of
2つのTGFβ受容体II/TF/IL-15構築物の核酸配列(シグナルペプチド配列を含む)は、以下の通りである。
(シグナルペプチド)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(2つのヒトTGFβ受容体II断片)
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC
(ヒト組織因子219)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(ヒトIL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
The nucleic acid sequences (including signal peptide sequences) of the two TGFβ receptor II/TF/IL-15 constructs are as follows.
(signal peptide)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCC
(two human TGFβ receptor II fragments)
ATCCCCCCCCCATGTGCAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAA GAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGAACCTTCTTTATGTGTTCCTGTAGCAG CGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCC CCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCCACGATCCCCAAGCTGCCCTAC CACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCCGAC
(human tissue factor 219)
AGCGGCCAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAACCATCCTCGAATGGGAACCCAAACCCGTTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCG ATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCTTTATACGAGAACAGCCCCGAATTTACCCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCA CAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTAATCGACG TGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAGGGCGAGTTCCGGGAG
(human IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTACTGGAGCTGCCAAGTTATCTCTTTAGAGAGCGGGAGACGCTAGCAT CCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCCAAGGAGTGCGAAGAGCTGGAGGGAGAAGAACATCAAGGAGTTCTGCAATCCTTTGTGCCACATTGTCCAGATGTTCATCAATACCTCC
TGFβ受容体II/TF/IL-15融合タンパク質のアミノ酸配列(リーダー配列を含む)は、以下の通りである。
(シグナルペプチド)
MKWVTFISLLFLFSSAYS
(ヒトTGFβ受容体II)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(ヒト組織因子219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(ヒトIL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
The amino acid sequence (including leader sequence) of the TGFβ receptor II/TF/IL-15 fusion protein is as follows.
(signal peptide)
MKWVT FISLLFLFS SAYS
(human TGFβ receptor II)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNCSITSICEKPQEVCVAVWRKNDINITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPDGGGGGSGGGGGSGGGGSIPPHV QKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNSITSICEKPQEVCVAVWRKNDINITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(human tissue factor 219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTF LSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(human IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
2つのTGFβ受容体IIをGenewizによって合成したIL-15RαSu鎖に直接結合することによっても構築物を作製した。IL-15RαSuのN末端に結合したTGFβ受容体IIを含む構築物の核酸配列及びタンパク質配列を以下に示す。 Constructs were also made by directly coupling two TGFβ receptor II to IL-15RαSu chains synthesized by Genewiz. The nucleic acid and protein sequences of a construct containing TGFβ receptor II attached to the N-terminus of IL-15RαSu are shown below.
TGFβ受容体II/IL-15RαSu構築物の核酸配列(シグナルペプチド配列を含む)は、以下の通りである。
(シグナルペプチド)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(2つのヒトTGFβ受容体II断片)
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC
(ヒトIL-15Rαスシドメイン)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
The nucleic acid sequence (including signal peptide sequence) of the TGFβ receptor II/IL-15RαSu construct is as follows.
(signal peptide)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCC
(two human TGFβ receptor II fragments)
ATCCCCCCCCCATGTGCAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAA GAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGAACCTTCTTTATGTGTTCCTGTAGCAG CGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCC CCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCCACGATCCCCAAGCTGCCCTAC CACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCCGAC
(Human IL-15Rα sushi domain)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCT CTTTAAAGTGCATCCGG
2つのTGFβ受容体II/IL-15RαSu構築物のアミノ酸配列(シグナルペプチド配列を含む)は、以下の通りである。
(シグナルペプチド)
MKWVTFISLLFLFSSAYS
(2つのヒトTGFβ受容体II細胞外ドメイン)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(ヒトIL-15Rαスシドメイン)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
The amino acid sequences (including signal peptide sequences) of the two TGFβ receptor II/IL-15RαSu constructs are as follows.
(signal peptide)
MKWVT FISLLFLFS SAYS
(two human TGFβ receptor II extracellular domains)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNSITSITSICEKPQEVCVAVWRKNDINITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPDGGGGGSGGGGGSGGGGGSIPPHV QKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNSITSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(Human IL-15Rα sushi domain)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
いくつかの事例では、リーダーペプチドをインタクトなポリペプチドから切断して、可溶性であり得るか、又は分泌され得る成熟形態を生成する。 In some cases, the leader peptide is cleaved from the intact polypeptide to generate the mature form, which can be soluble or secreted.
TGFβR/IL-15RαSu構築物及びTGFβR/TF/IL-15構築物を前述の改変レトロウイルス発現ベクターにクローニングし(Hughes MS,Yu YY,Dudley ME,Zheng Z,Robbins PF,Li Y,et al.Transfer of a TCR gene derived from a patient with a marked antitumor response conveys highly active T-cell effector functions.Hum Gene Ther2005;16:457-72)、発現ベクターをCHO-K1細胞にトランスフェクトした。CHO-K1細胞でのこれらの2つの構築物の共発現により、可溶性TGFβR/TF/IL-15:TGFβR/IL-15RαSuタンパク質複合体(TGFRt15-TGFRsと称する)の形成及び分泌が可能になり、これを抗TF IgG1アフィニティークロマトグラフィー法及び他のクロマトグラフィー法によって精製することができる。
The TGFβR/IL-15RαSu and TGFβR/TF/IL-15 constructs were cloned into the modified retroviral expression vector described previously (Hughes MS, Yu YY, Dudley ME, Zheng Z, Robbins PF, Li Y, et al. Transfer of a TCR gene derived from a patient with a marked antitumor response conveys highly active T-cell effector functions.
HEK-Blue TGFβ細胞におけるTGFβ1活性に対するTGFRt15-TGFRsの効果
TGFRt15-16s21中のTGFβRIIの活性を評価するために、HEK-Blue TGFβ細胞におけるTGFβ1活性に対するTGFRt15-TGFRsの効果を分析した。HEK-Blue TGFβ細胞(Invivogen)を予熱したPBSで2回洗浄し、試験培地(DMEM、10%熱不活性化FCS、1×グルタミン、1×抗-抗、及び2×グルタミン)中に5×105細胞/mLで再懸濁した。平底96ウェルプレート中、50μLの細胞を各ウェルに添加し(2.5×104細胞/ウェル)、その後、50μLの0.1nM TGFβ1(R&D systems)を添加した。その後、1:3連続希釈で調製したTGFRt15-16s21又はTGFR-Fc(R&D Systems)をプレートに添加して、総量を200μLにした。37℃で24時間インキュベートした後、40μLの誘導されたHEK-Blue TGFβ細胞上清を平底96ウェルプレート中の160μLの予熱したQUANTI-Blue(Invivogen)に添加し、37℃で1~3時間インキュベートした。その後、OD値を、プレートリーダー(Multiscan Sky)を使用して620~655nMで決定した(図97)。各タンパク質試料のIC50を、GraphPad Prism7.04を用いて計算した。TGFRt15-TGFRs及びTGFR-FcのIC50は、それぞれ、216.9pM及び460.6pMであった。これらの結果は、TGFRt15-TGFRs中のTGFβRIIドメインがHEK-Blue TGFβ細胞におけるTGFβ1活性を遮断することができたことを示した。
Effect of TGFRt15-TGFRs on TGFβ1 Activity in HEK-Blue TGFβ Cells To assess the activity of TGFβRII in TGFRt15-16s21, the effect of TGFRt15-TGFRs on TGFβ1 activity in HEK-Blue TGFβ cells was analyzed. HEK-Blue TGFβ cells (Invivogen) were washed twice with prewarmed PBS and plated 5× in test medium (DMEM, 10% heat-inactivated FCS, 1× glutamine, 1× anti-anti, and 2× glutamine). Resuspend at 10 5 cells/mL. In a flat bottom 96-well plate, 50 μL of cells were added to each well (2.5×10 4 cells/well) followed by 50 μL of 0.1 nM TGFβ1 (R&D systems). TGFRt15-16s21 or TGFR-Fc (R&D Systems) prepared in 1:3 serial dilutions were then added to the plate to a total volume of 200 μL. After 24 hours of incubation at 37°C, 40 μL of induced HEK-Blue TGFβ cell supernatant is added to 160 μL of prewarmed QUANTI-Blue (Invivogen) in a flat bottom 96-well plate and incubated for 1-3 hours at 37°C. bottom. OD values were then determined at 620-655 nM using a plate reader (Multiscan Sky) (Figure 97). The IC50 for each protein sample was calculated using GraphPad Prism 7.04. The IC 50 for TGFRt15-TGFRs and TGFR-Fc were 216.9 pM and 460.6 pM, respectively. These results indicated that the TGFβRII domain in TGFRt15-TGFRs could block TGFβ1 activity in HEK-Blue TGFβ cells.
TGFRt15-TGFRs中のIL-15は、IL-2Rβ及び共通γ鎖含有32Dβ細胞の増殖を促進する
TGFRt15-TGFRs中のIL-15の活性を評価するために、TGFRt15-TGFRsのIL-15活性を、IL2Rβ及び共通γ鎖を発現する32Dβ細胞を使用して組換えIL-15と比較し、細胞増殖の促進に対するそれらの効果を評価した。IL-15依存性32Dβ細胞をIMDM-10%FBSで5回洗浄し、2×104細胞/ウェルでウェル中に播種した。連続希釈したTGFRt15-TGFRs又はIL-15を細胞に添加した(図98)。細胞をCO2インキュベーター内で、37℃で3日間インキュベートした。3日目に10μLのWST1を各ウェルに添加し、CO2インキュベーター内で、37℃で更に3時間インキュベートすることにより、細胞増殖を検出した。生成されたホルマザン色素の量を分析することにより、吸光度を450nmで測定した。図98に示されるように、TGFRt15-TGFRs及びIL-15は32Dβ細胞増殖を促進し、TGFRt15-16s21及びIL-15のEC50は、それぞれ、1901pM及び10.63pMであった。
IL-15 in TGFRt15-TGFRs Promotes Proliferation of IL-2Rβ and Common γ Chain Containing 32Dβ Cells , IL2Rβ and 32Dβ cells expressing the common γ chain were used to compare recombinant IL-15 and assess their effects on promoting cell proliferation. IL-15 dependent 32Dβ cells were washed 5 times with IMDM-10% FBS and seeded in wells at 2×10 4 cells/well. Serially diluted TGFRt15-TGFRs or IL-15 were added to the cells (Figure 98). Cells were incubated for 3 days at 37°C in a CO2 incubator. Cell proliferation was detected by adding 10 μL of WST1 to each well on
ELISAを使用した対応する抗体を用いたTGFRt15-TGFRs中のIL-15ドメイン及びTGFβRIIドメインの検出
96ウェルプレートをR5(コーティング緩衝液)中100μL(8μg/mL)の抗TF IgG1でコーティングし、室温(RT)で2時間インキュベートした。プレートを3回洗浄し、PBS中100μLの1%BSAでブロックした。TGFRt15-TGFRsを1:3連続希釈で添加し、室温で60分間インキュベートした。3回洗浄した後、50ng/mLのビオチン化抗IL-15抗体(BAM247、R&D Systems)又は200ng/mLのビオチン化抗TGFbRII抗体(BAF241、R&D Systems)をウェルに添加し、室温で60分間インキュベートした。次いで、プレートを3回洗浄し、0.25μg/mLのHRP-SA(Jackson ImmunoResearch)を100μL/ウェルで添加し、室温で30分間インキュベートし、その後、4回洗浄し、100μLのABTSと室温で2分間インキュベートした。吸光度を405nmで読み取った。図99A及び99Bに示されるように、TGFRt15-TGFRs中のIL-15ドメイン及びTGFβRIIドメインを個々の抗体によって検出した。
Detection of IL-15 and TGFβRII domains in TGFRt15-TGFRs using corresponding antibodies using ELISA A 96-well plate was coated with 100 μL (8 μg/mL) of anti-TF IgG1 in R5 (coating buffer) and incubated at room temperature. (RT) for 2 hours. Plates were washed three times and blocked with 100 μL of 1% BSA in PBS. TGFRt15-TGFRs were added at 1:3 serial dilutions and incubated for 60 minutes at room temperature. After three washes, 50 ng/mL biotinylated anti-IL-15 antibody (BAM247, R&D Systems) or 200 ng/mL biotinylated anti-TGFbRII antibody (BAF241, R&D Systems) is added to the wells and incubated for 60 minutes at room temperature. bottom. Plates were then washed 3 times and 0.25 μg/mL HRP-SA (Jackson ImmunoResearch) was added at 100 μL/well and incubated at room temperature for 30 minutes, followed by 4 washes and 100 μL ABTS at room temperature. Incubate for 2 minutes. Absorbance was read at 405 nm. As shown in Figures 99A and 99B, the IL-15 and TGFβRII domains in TGFRt15-TGFRs were detected by individual antibodies.
抗TF抗体アフィニティーカラムからのTGFRt15-TGFRsの精製溶出クロマトグラフ
細胞培養物から収集したTGFRt15-TGFRsを、5カラム体積のPBSで平衡化した抗TF抗体アフィニティーカラムにロードした。試料をロードした後、カラムを5カラム体積のPBSで洗浄し、その後、6カラム体積の0.1M酢酸(pH2.9)で溶出した。A280溶出ピークを収集し、その後、1Mトリス塩基でpH7.5~8.0に中和した。その後、中和した試料を、分子量カットオフ30KDaでAmicon遠心フィルターを使用してPBSに緩衝液交換した。図100に示されるように、抗TF抗体親和性カラムは、融合パートナーとしてTFを含むTGFRt15-TGFRsに結合した。緩衝液交換したタンパク質試料を、更なる生化学的分析及び生物学的活性試験のために2~8℃で保管した。各溶出後、抗TF抗体アフィニティーカラムを6カラム体積の0.1Mグリシン(pH2.5)を使用してストリッピングした。その後、カラムを、保管のために5カラム体積のPBS及び7カラム体積の20%エタノールを使用して中和した。抗TF抗体アフィニティーカラムを、GE Healthcare AKTA Avantシステムに接続した。流速は、2mL/分の溶出ステップを除く全てのステップで4mL/分であった。
Purification Elution Chromatography of TGFRt15-TGFRs from Anti-TF Antibody Affinity Column TGFRt15-TGFRs collected from cell culture were loaded onto an anti-TF antibody affinity column equilibrated with 5 column volumes of PBS. After sample loading, the column was washed with 5 column volumes of PBS and then eluted with 6 column volumes of 0.1 M acetic acid (pH 2.9). The A280 elution peak was collected and then neutralized to pH 7.5-8.0 with 1M Tris base. Neutralized samples were then buffer exchanged into PBS using Amicon centrifugal filters with a molecular weight cutoff of 30 KDa. As shown in Figure 100, the anti-TF antibody affinity column bound TGFRt15-TGFRs containing TF as a fusion partner. Buffer-exchanged protein samples were stored at 2-8° C. for further biochemical analysis and biological activity testing. After each elution, the anti-TF antibody affinity column was stripped using 6 column volumes of 0.1 M glycine (pH 2.5). The column was then neutralized using 5 column volumes of PBS and 7 column volumes of 20% ethanol for storage. The anti-TF antibody affinity column was connected to a GE Healthcare AKTA Avant system. The flow rate was 4 mL/min for all steps except the 2 mL/min elution step.
TGFRt15-TGFRsの分析的サイズ排除クロマトグラフィー(SEC)分析
Superdex200 Increase10/300 GLゲル濾過カラム(GE Healthcare製)をAKTA Avantシステム(GE Healthcare製)に接続した。カラムを2カラム体積のPBSで平衡化した。流速は0.7mL/分であった。PBS中TGFRt15-TGFRsを含む試料を、キャピラリーループを使用してSuperdex200カラムに注入し、SECによって分析した。試料のSECクロマトグラフを図101に示す。SECの結果は、TGFRt15-TGFRsの4つのタンパク質ピークを示した。
Analytical Size Exclusion Chromatography (SEC) Analysis of TGFRt15-TGFRs
TGFRt15-TGFRsの還元SDS-PAGE分析
TGFRt15-TGFRsタンパク質の純度及び分子量を決定するために、抗TF抗体アフィニティーカラムで精製したタンパク質試料を、還元条件下でドデシル硫酸ナトリウムポリアクリルアミドゲル(4~12%NuPageビス-トリスゲル)電気泳動(SDS-PAGE)法によって分析した。電気泳動後、ゲルをInstantBlueで約30分間染色し、その後、精製水中で一晩脱色した。
Reducing SDS-PAGE Analysis of TGFRt15-TGFRs To determine the purity and molecular weight of TGFRt15-TGFRs proteins, anti-TF antibody affinity column-purified protein samples were run on sodium dodecyl sulfate polyacrylamide gels (4-12%) under reducing conditions. were analyzed by NuPage Bis-Tris gel) electrophoresis (SDS-PAGE) method. After electrophoresis, gels were stained with InstantBlue for approximately 30 minutes and then destained overnight in purified water.
TGFRt15-TGFRsタンパク質がCHO細胞において翻訳後にグリコシル化を受けることを検証するために、脱グリコシル化実験を、New England Biolabs製のProtein Deglycosylation Mix IIキット及び製造業者の指示を使用して実施した。図102は、非脱グリコシル化状態(赤色の縁内のレーン1)及び脱グリコシル化状態(黄色の縁内のレーン2)での試料の還元SDS-PAGE分析を示す。結果は、TGFRt15-TGFRsタンパク質がCHO細胞で発現されるとグリコシル化されることを示した。脱グリコシル化後、精製した試料は、還元SDSゲル中で予想された分子量(69kDa及び39kDa)を示した。レーンMには、10ulのSeeBlue Plus 2 Prestained Standardをロードした。
To verify that the TGFRt15-TGFRs proteins undergo post-translational glycosylation in CHO cells, deglycosylation experiments were performed using the Protein Deglycosylation Mix II kit from New England Biolabs and the manufacturer's instructions. FIG. 102 shows reducing SDS-PAGE analysis of samples in the non-deglycosylated state (
C57BL/6マウスにおけるTGFRt15-TGFRsの免疫刺激活性
TGFRt15-TGFRsは、2つのTGFβRIIドメイン、ヒト組織因子219断片、及びヒトIL-15の可溶性融合物である第1のポリペプチドと、2つのTGFβRIIドメイン及びヒトIL-15受容体アルファ鎖のスシドメインの可溶性融合物である第2のポリペプチドとを含む多鎖ポリペプチド(本明細書に記載のタイプA多鎖ポリペプチド)である。
Immunostimulatory Activity of TGFRt15-TGFRs in C57BL/6 Mice and a second polypeptide that is a soluble fusion of the sushi domain of the human IL-15 receptor alpha chain (a type A multichain polypeptide described herein).
野生型C57BL/6マウスを、対照溶液、又は0.3mg/kg、1mg/kg、3mg/kg、若しくは10mg/kgの投薬量のTGFRt15-TGFRsのいずれかで皮下処理した。処理の4日後、脾臓の重量及び脾臓に存在する様々な免疫細胞型のパーセンテージを評価した。図103Aに示されるように、TGFRt15-TGFRsで処理したマウスにおける脾臓の重量は、TGFRt15-TGFRsの投薬量の増加とともに増加した。更に、1mg/kg、3mg/kg、及び10mg/kgのTGFRt15-TGFRsで処理したマウスにおける脾臓の重量は、それぞれ、対照溶液で処理したマウスと比較して高かった。加えて、対照処理マウス及びTGFRt15-TGFRs処理マウスの脾臓に存在するCD4+T細胞、CD8+T細胞、NK細胞、及びCD19+B細胞のパーセンテージを評価した。図103Bに示されるように、TGFRt15-TGFRsで処理したマウスの脾臓では、CD8+T細胞及びNK細胞の両方のパーセンテージが、TGFRt15-TGFRsの投薬量の増加とともに増加した。具体的には、CD8+T細胞のパーセンテージは、対照処理マウスと比較して、0.3mg/kg、3mg/kg、及び10mg/kgのTGFRt15-TGFRsで処理したマウスで高く、NK細胞のパーセンテージは、対照処理マウスと比較して、0.3mg/kg、1mg/kg、3mg/kg、及び10mg/kgのTGFRt15-TGFRsで処理したマウスで高かった。これらの結果は、TGFRt15-TGFRsが、脾臓中の免疫細胞、特にCD8+T細胞及びNK細胞を刺激することができることを示す。 Wild-type C57BL/6 mice were treated subcutaneously with either control solution or TGFRt15-TGFRs at dosages of 0.3 mg/kg, 1 mg/kg, 3 mg/kg, or 10 mg/kg. After 4 days of treatment, spleen weight and percentage of various immune cell types present in the spleen were assessed. As shown in FIG. 103A, spleen weight in mice treated with TGFRt15-TGFRs increased with increasing dosage of TGFRt15-TGFRs. In addition, spleen weights in mice treated with 1 mg/kg, 3 mg/kg, and 10 mg/kg of TGFRt15-TGFRs, respectively, were higher compared to mice treated with control solution. In addition, the percentage of CD4 + T cells, CD8 + T cells, NK cells, and CD19 + B cells present in the spleens of control-treated and TGFRt15-TGFRs-treated mice was assessed. As shown in FIG. 103B, in the spleen of mice treated with TGFRt15-TGFRs, the percentage of both CD8 + T cells and NK cells increased with increasing dosage of TGFRt15-TGFRs. Specifically, the percentage of CD8 + T cells was higher in mice treated with 0.3 mg/kg, 3 mg/kg, and 10 mg/kg of TGFRt15-TGFRs compared to control-treated mice, and the percentage of NK cells was higher. was higher in mice treated with 0.3 mg/kg, 1 mg/kg, 3 mg/kg, and 10 mg/kg of TGFRt15-TGFRs compared to control-treated mice. These results indicate that TGFRt15-TGFRs can stimulate immune cells in the spleen, especially CD8 + T cells and NK cells.
TGFRt15-TGFRs分子の薬物動態を、野生型C57BL/6マウスで評価した。マウスを、3mg/kgの投薬量のTGFRt15-TGFRsで皮下処理した。マウス血液を様々な時点で尾静脈から採取し、血清を調製した。マウス血清中のTGFRt15-TGFRs濃度を、ELISAを用いて測定した(捕捉:抗ヒト組織因子抗体、検出:ビオチン化抗ヒトTGFβ受容体抗体、その後、ペルオキシダーゼ結合ストレプトアビジン及びABTS基質)。結果は、C57BL/6マウスにおけるTGFRt15-TGFRsの半減期が12.66時間であることを示した。 The pharmacokinetics of TGFRt15-TGFRs molecules were evaluated in wild-type C57BL/6 mice. Mice were treated subcutaneously with TGFRt15-TGFRs at a dosage of 3 mg/kg. Mouse blood was collected from the tail vein at various time points and serum was prepared. TGFRt15-TGFRs concentrations in mouse sera were measured using ELISA (capture: anti-human tissue factor antibody, detection: biotinylated anti-human TGFβ receptor antibody followed by peroxidase-conjugated streptavidin and ABTS substrate). Results showed that the half-life of TGFRt15-TGFRs in C57BL/6 mice was 12.66 hours.
マウスにおけるTGFRt15-TGFRsの免疫刺激活性を経時的に評価するために、マウス脾細胞を調製した。図104Aに示されるように、TGFRt15-TGFRsで処理したマウスの脾臓重量は、処理後48時間時点で増加し、経時的に増加し続けた。加えて、対照処理マウス及びTGFRt15-TGFRs処理マウスの脾臓に存在するCD4+T細胞、CD8+T細胞、NK細胞、及びCD19+B細胞のパーセンテージを評価した。図104Bに示されるように、TGFRt15-TGFRsで処理したマウスの脾臓では、CD8+T細胞及びNK細胞の両方のパーセンテージが処理後48時間時点で増加し、単回投与処理後に経時的に高くなった。これらの結果は、TGFRt15-TGFRsが、脾臓中の免疫細胞、特にCD8+T細胞及びNK細胞を刺激することができることを更に示す。 Mouse splenocytes were prepared to evaluate the immunostimulatory activity of TGFRt15-TGFRs in mice over time. As shown in Figure 104A, spleen weights of mice treated with TGFRt15-TGFRs increased at 48 hours after treatment and continued to increase over time. In addition, the percentage of CD4 + T cells, CD8 + T cells, NK cells, and CD19 + B cells present in the spleens of control-treated and TGFRt15-TGFRs-treated mice was assessed. As shown in FIG. 104B, in the spleens of mice treated with TGFRt15-TGFRs, the percentages of both CD8 + T cells and NK cells increased at 48 hours after treatment and increased over time after single dose treatment. rice field. These results further demonstrate that TGFRt15-TGFRs can stimulate immune cells in the spleen, especially CD8 + T cells and NK cells.
更に、脾細胞のKi67発現に基づく免疫細胞の動的増殖及びグランザイムB発現に基づく細胞傷害性の潜在性を、TGFRt15-TGFRsの単回投与(3mg/kg)後にマウスから単離した脾細胞で評価した。図105A及び105Bに示されるように、TGFRt15-TGFRsで処理したマウスの脾臓では、NK細胞によるKi67及びグランザイムBの発現は処理後24時間時点で増加し、CD8+T細胞及びNK細胞の発現はいずれも単回投与処理後48時間及びその後の時点で増加した。これらの結果は、TGFRt15-TGFRsがCD8+T細胞及びNK細胞の数を増加させるのみならず、これらの細胞の細胞傷害性も増強することを示す。TGFRt15-TGFRsの単回投与処理により、CD8+T細胞及びNK細胞が少なくとも4日間増殖した。 Furthermore, dynamic proliferation of immune cells based on splenocyte Ki67 expression and cytotoxic potential based on granzyme B expression were examined in splenocytes isolated from mice after a single dose of TGFRt15-TGFRs (3 mg/kg). evaluated. As shown in Figures 105A and 105B, in the spleen of mice treated with TGFRt15-TGFRs, NK cell expression of Ki67 and granzyme B was increased at 24 hours post-treatment, and CD8 + T cell and NK cell expression was Both increased at 48 hours and later after single dose treatment. These results indicate that TGFRt15-TGFRs not only increase the number of CD8 + T cells and NK cells, but also enhance the cytotoxicity of these cells. A single dose treatment of TGFRt15-TGFRs proliferated CD8 + T cells and NK cells for at least 4 days.
腫瘍細胞に対するTGFRt15-TGFRs処理マウス由来の脾細胞の細胞傷害性も評価した。マウスモロニーMoloney白血病細胞(Yac-1)をCellTrace Violetで標識し、腫瘍標的細胞として使用した。脾細胞を、TGFRt15-TGFRs(3mg/kg)で処理したマウス脾臓から処理後の様々な時点で調製し、エフェクター細胞として使用した。標的細胞をエフェクター細胞とE:T比10:1で混合し、37℃で20時間インキュベートした。フローサイトメトリーを使用したヨウ化プロピジウム陽性のバイオレット標識Yac-1細胞の分析により、標的細胞の生存率を評価した。Yac-1腫瘍阻害のパーセンテージを、式(1-[実験試料中の生存Yac-1細胞数]/[脾細胞を含まない試料中の生存Yac-1細胞数])×100を使用して計算した。図106に示されるように、TGFRt15-TGFRsで処理したマウス由来の脾細胞は、対照マウス脾細胞よりもYac-1細胞に対してより強い細胞傷害性を有した。 Cytotoxicity of splenocytes from TGFRt15-TGFRs treated mice against tumor cells was also assessed. Mouse Moloney leukemia cells (Yac-1) were labeled with CellTrace Violet and used as tumor target cells. Splenocytes were prepared from mouse spleens treated with TGFRt15-TGFRs (3 mg/kg) at various time points after treatment and used as effector cells. Target cells were mixed with effector cells at an E:T ratio of 10:1 and incubated at 37° C. for 20 hours. Target cell viability was assessed by analysis of propidium iodide-positive violet-labeled Yac-1 cells using flow cytometry. Percentage of Yac-1 tumor inhibition was calculated using the formula (1−[number of viable Yac-1 cells in experimental sample]/[number of viable Yac-1 cells in sample without splenocytes])×100. bottom. As shown in Figure 106, splenocytes from mice treated with TGFRt15-TGFRs had greater cytotoxicity against Yac-1 cells than control mouse splenocytes.
化学療法及び/又はTGFRt15-TGFRsに応答した腫瘍サイズ分析
膵臓がん細胞(SW1990、ATCC(登録商標)CRL-2172)をC57BL/6 scidマウス(The Jackson Laboratory、001913、2x106細胞/マウス、100μLのHBSS中)に皮下(s.c.)注射して、膵臓がんマウスモデルを確立した。腫瘍細胞注射の2週間後、アブラキサン(Celgene、68817-134、5mg/kg、腹腔内)とゲムシタビン(Sigma Aldrich、G6423、40mg/kg、腹腔内)との組み合わせを用いた化学療法をこれらのマウスに腹腔内で開始し、続いて、2日後にTGFRt15-TGFRs(3mg/kg、皮下注射)を用いた免疫療法を行った。上記の手順を1つの処理サイクルとみなし、更に3サイクル(1サイクル/週)繰り返した。対照群を、PBS、化学療法(ゲムシタビン及びアブラキサン)、又はTGFRt15-TGFRsのみを受けたSW1990注射マウスとして設定した。処理サイクルに加えて、各動物の腫瘍サイズを、SW1990細胞を注射した2ヶ月後に実験を終了するまで1日おきに測定及び記録した。腫瘍体積の測定を群ごとに分析し、結果は、化学療法とTGFRt15-TGFRsとの組み合わせを受けた動物がPBS群と比較して有意に小さい腫瘍を有した一方で、化学療法もTGFRt15-TGFRs療法も単独では組み合わせほどには十分に機能しないことを示した(図107)。
Tumor Size Analysis in Response to Chemotherapy and/or TGFRt15-TGFRs Pancreatic cancer cells (SW1990, ATCC® CRL-2172) were transferred to C57BL/6 scid mice (The Jackson Laboratory, 001913, 2×10 6 cells/mouse, 100 μL). in HBSS) to establish a pancreatic cancer mouse model. Two weeks after tumor cell injection, these mice received chemotherapy with a combination of Abraxane (Celgene, 68817-134, 5 mg/kg, ip) and gemcitabine (Sigma Aldrich, G6423, 40 mg/kg, ip). Immunotherapy with TGFRt15-TGFRs (3 mg/kg, s.c.) was initiated ip at 2 days later. The above procedure was considered one treatment cycle and was repeated for 3 more cycles (1 cycle/week). Control groups were set up as SW1990-injected mice receiving PBS, chemotherapy (gemcitabine and Abraxane), or TGFRt15-TGFRs alone. In addition to treatment cycles, the tumor size of each animal was measured and recorded every other day until termination of the experiment two months after injection of SW1990 cells. Tumor volume measurements were analyzed by group and the results showed that animals receiving the combination of chemotherapy and TGFRt15-TGFRs had significantly smaller tumors compared to the PBS group, whereas chemotherapy was also associated with TGFRt15-TGFRs It was shown that therapy alone also did not work as well as the combination (Figure 107).
インビトロ老化B16F10黒色腫モデル
その後、活性化マウスNK細胞による老化B16F10黒色腫細胞のインビトロ死滅を評価した。B16F10老化細胞(B16F10-SNC)細胞をCellTrace violetで標識し、異なるE:T比のインビトロ2t2活性化マウスNK細胞(TGFRt15-TGFRsを10mg/kgで4日間注射したC57BL/6マウスの脾臓から単離したもの)と16時間インキュベートした。細胞をトリプシン処理し、洗浄し、ヨウ化プロピジウム(PI)溶液を含有する完全培地中に再懸濁した。細胞傷害性をフローサイトメトリーによって評価した(図108)。
In Vitro Senescent B16F10 Melanoma Model In vitro killing of senescent B16F10 melanoma cells by activated mouse NK cells was then assessed. B16F10 senescent (B16F10-SNC) cells were labeled with CellTrace violet and isolated from the spleens of C57BL/6 mice injected with different E:T ratios of in vitro 2t2-activated mouse NK cells (TGFRt15-TGFRs at 10 mg/kg for 4 days). separated) and incubated for 16 hours. Cells were trypsinized, washed and resuspended in complete medium containing propidium iodide (PI) solution. Cytotoxicity was assessed by flow cytometry (Figure 108).
実施例54:7t15-21s137L(ロングバージョン)融合タンパク質の作製及び特徴付け
IL-21/IL-15RαSu/CD137L融合タンパク質及びIL-7/TF/IL-15融合タンパク質からなる融合タンパク質複合体を生成した(図109及び図110)。具体的には、IL-7配列を組織因子219のN末端コーディング領域に、続いて、IL-15のN末端コーディング領域に結合することによって構築物を作製した。組織因子219のN末端に、続いて、IL-15のN末端に結合したIL-7を含む構築物の核酸配列及びタンパク質配列を以下に示す。
Example 54: Generation and Characterization of 7t15-21s137L (Long Version) Fusion Protein A fusion protein complex consisting of an IL-21/IL-15RαSu/CD137L fusion protein and an IL-7/TF/IL-15 fusion protein was generated (Figures 109 and 110). Specifically, a construct was made by joining the IL-7 sequence to the N-terminal coding region of
7t15構築物の核酸配列(シグナルペプチド配列を含む)は、以下の通りである。
(シグナルペプチド)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(ヒトIL7)
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCAT
(ヒト組織因子219)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(ヒトIL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
The nucleic acid sequence (including signal peptide sequence) of the 7t15 construct is as follows.
(signal peptide)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCC
(human IL7)
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCCACATCTGCGACGCCAACAAGGAGGGCATGTTCCT GTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGA ACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCAT
(human tissue factor 219)
AGCGGCCAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAACCATCCTCGAATGGGAACCCAAACCCGTTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCG ATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCTTTATACGAGAACAGCCCCGAATTTACCCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCA CAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTAATCGACG TGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAGGGCGAGTTCCGGGAG
(human IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTACTGGAGCTGCCAAGTTATCTCTTTAGAGAGCGGGAGACGCTAGCAT CCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCCAAGGAGTGCGAAGAGCTGGAGGGAGAAGAACATCAAGGAGTTCTGCAATCCTTTGTGCCACATTGTCCAGATGTTCATCAATACCTCC
7t15融合タンパク質のアミノ酸配列(リーダー配列を含む)は、以下の通りである。
(シグナルペプチド)
MKWVTFISLLFLFSSAYS
(ヒトIL7)
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEH
(ヒト組織因子219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(ヒトIL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
The amino acid sequence (including the leader sequence) of the 7t15 fusion protein is as follows.
(signal peptide)
MKWVT FISLLFLFS SAYS
(human IL7)
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDHLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWN KILMG TKEH
(human tissue factor 219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTF LSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(human IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
21s137Lの核酸配列及びタンパク質配列が以下に示される。21s137L構築物の核酸配列(シグナルペプチド配列を含む)は、以下の通りである。
(シグナルペプチド)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(ヒトIL-21)
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC
(ヒトIL-15Rαスシドメイン)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
((G4S)3リンカー)
GGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCT
(ヒトCD137L)
CGCGAGGGTCCCGAGCTTTCGCCCGACGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATCCCAGCCGGACTCCCTTCACCGAGGTCGGAA
The nucleic acid and protein sequences for 21s137L are shown below. The nucleic acid sequence (including signal peptide sequence) of the 21s137L construct is as follows.
(signal peptide)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCC
(human IL-21)
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCG CCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCCTCCACAAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCCTGCTGCAGAAGAT GATCCATCAGCACCTGTCCTCCAGGACCCAGGCTCCGAGGACTCC
(Human IL-15Rα sushi domain)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCT CTTTAAAGTGCATCCGG
((G4S)3 linker)
GGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGGCGGAGGATCT
(human CD137L)
CGCGAGGGTCCCGAGCTTTCGCCCCGACGATCCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCGCAGCTGGTGGCCCAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCCAGGCCTGGCAGGGCGTGTCCCTGACGGGGGGC CTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTG GCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGG GACTCTTCCGGGTGACCCCCGAAAATCCCAGCCGGACTCCCTTCACCGAGGTCGGAA
21s137L融合タンパク質のアミノ酸配列(リーダー配列を含む)は、以下の通りである。
(シグナルペプチド)
MKWVTFISLLFLFSSAYS
(ヒトIL-21)
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS
(ヒトIL-15Rαスシドメイン)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
((G4S)3リンカー)
GGGGSGGGGSGGGGS
(ヒトCD137L)
REGPELSPDDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEIPAGLPSPRSE
The amino acid sequence (including the leader sequence) of the 21s137L fusion protein is as follows.
(signal peptide)
MKWVT FISLLFLFS SAYS
(human IL-21)
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS
(Human IL-15Rα sushi domain)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
((G4S)3 linker)
GGGGSGGGGSGGGGGS
(human CD137L)
REGPELSPDDPAGLLDLLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSSVSLALHLQPLRSAAGAAALALTVDLLPPASSEARNSAFGFQGRLLHLSAGQRLGV HLHTEARARHAWQLTQGATVLGLFRVTPEIPAGLPSPRSSE
いくつかの事例では、リーダーペプチドをインタクトなポリペプチドから切断して、可溶性であり得るか、又は分泌され得る成熟形態を生成する。 In some cases, the leader peptide is cleaved from the intact polypeptide to generate the mature form, which can be soluble or secreted.
IL-21/IL-15RαSu/CD137L構築物及びIL-7/TF/IL-15構築物を前述の修飾レトロウイルス発現ベクターにクローニングし(Hughes MS,Yu YY,Dudley ME,Zheng Z,Robbins PF,Li Y,et al.Transfer of a TCR gene derived from a patient with a marked antitumor response conveys highly active T-cell effector functions.Hum Gene Ther 2005;16:457-72)、発現ベクターをCHO-K1細胞にトランスフェクトした。CHO-K1細胞でのこれらの2つの構築物の共発現により、可溶性IL-7/TF/IL-15:IL-21/IL-15RαSu/CD137Lタンパク質複合体(7t15-21s137Lと称する)の形成及び分泌が可能になり、これを抗TF抗体IgG1親和性及び他のクロマトグラフィー法によって精製することができる。
The IL-21/IL-15RαSu/CD137L and IL-7/TF/IL-15 constructs were cloned into modified retroviral expression vectors previously described (Hughes MS, Yu YY, Dudley ME, Zheng Z, Robbins PF, Li Y , et al.Transfer of a TCR gene derived from a patient with a marked antitumor response conveys highly active T-cell effector functions.
抗TF抗体親和性カラムを使用した7t15-21s137Lの精製溶出クロマトグラフ
細胞培養物から収集した7t15-21s137Lを、5カラム体積のPBSで平衡化した抗TF抗体親和性カラムにロードした。試料をロードした後、カラムを5カラム体積のPBSで洗浄し、その後、6カラム体積の0.1M酢酸(pH2.9)で溶出した。A280溶出ピークを収集し、その後、1Mトリス塩基でpH7.5~8.0に中和した。その後、中和した試料を、分子量カットオフ30KDaでAmicon遠心フィルターを使用してPBSに緩衝液交換した。図111に示されるように、抗TF抗体親和性カラムは、融合パートナーとしてTFを含む7t15-21s137Lに結合した。緩衝液交換したタンパク質試料を、更なる生化学的分析及び生物学的活性試験のために2~8℃で保管した。各溶出後、抗TF抗体アフィニティーカラムを6カラム体積の0.1Mグリシン(pH2.5)を使用してストリッピングした。その後、カラムを、保管のために5カラム体積のPBS及び7カラム体積の20%エタノールを使用して中和した。抗TF抗体親和性カラムを、GE Healthcare AKTA Avantシステムに接続した。流速は、2mL/分の溶出ステップを除く全てのステップで4mL/分であった。図112は、7t15-21s137Lの分析的SECプロファイルを示す。
Purification Elution Chromatography of 7t15-21s137L Using Anti-TF Antibody Affinity Column 7t15-21s137L harvested from cell culture was loaded onto an anti-TF antibody affinity column equilibrated with 5 column volumes of PBS. After sample loading, the column was washed with 5 column volumes of PBS and then eluted with 6 column volumes of 0.1 M acetic acid (pH 2.9). The A280 elution peak was collected and then neutralized to pH 7.5-8.0 with 1M Tris base. Neutralized samples were then buffer exchanged into PBS using Amicon centrifugal filters with a molecular weight cutoff of 30 KDa. As shown in Figure 111, the anti-TF antibody affinity column bound to 7t15-21s137L containing TF as a fusion partner. Buffer-exchanged protein samples were stored at 2-8° C. for further biochemical analysis and biological activity testing. After each elution, the anti-TF antibody affinity column was stripped using 6 column volumes of 0.1 M glycine (pH 2.5). The column was then neutralized using 5 column volumes of PBS and 7 column volumes of 20% ethanol for storage. The anti-TF antibody affinity column was connected to a GE Healthcare AKTA Avant system. The flow rate was 4 mL/min for all steps except the 2 mL/min elution step. Figure 112 shows the analytical SEC profile of 7t15-21s137L.
実施例55:7t15-21s137L(ショートバージョン)融合タンパク質の生成及び特徴付け
IL-21/IL-15RαSu/CD137L融合タンパク質及びIL-7/TF/IL-15融合タンパク質からなる融合タンパク質複合体を生成した。具体的には、IL-7配列を組織因子219のN末端コーディング領域に、続いて、IL-15のN末端コーディング領域に結合することによって構築物を作製した。組織因子219のN末端に、続いて、IL-15のN末端に結合したIL-7を含む構築物の核酸配列及びタンパク質配列を以下に示す。
Example 55: Generation and characterization of 7t15-21s137L (short version) fusion protein A fusion protein complex consisting of an IL-21/IL-15RαSu/CD137L fusion protein and an IL-7/TF/IL-15 fusion protein was generated . Specifically, a construct was made by joining the IL-7 sequence to the N-terminal coding region of
7t15構築物の核酸配列(シグナルペプチド配列を含む)は、以下の通りである。
(シグナルペプチド)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(ヒトIL7)
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCAT
(ヒト組織因子219)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(ヒトIL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
The nucleic acid sequence (including signal peptide sequence) of the 7t15 construct is as follows.
(signal peptide)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCC
(human IL7)
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCCACATCTGCGACGCCAACAAGGAGGGCATGTTCCT GTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGA ACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCAT
(human tissue factor 219)
AGCGGCCAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAACCATCCTCGAATGGGAACCCAAACCCGTTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCG ATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCTTTATACGAGAACAGCCCCGAATTTACCCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCA CAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTAATCGACG TGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAGGGCGAGTTCCGGGAG
(human IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTACTGGAGCTGCCAAGTTATCTCTTTAGAGAGCGGGAGACGCTAGCAT CCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCCAAGGAGTGCGAAGAGCTGGAGGGAGAAGAACATCAAGGAGTTCTGCAATCCTTTGTGCCACATTGTCCAGATGTTCATCAATACCTCC
7t15融合タンパク質のアミノ酸配列(リーダー配列を含む)は、以下の通りである。
(シグナルペプチド)
MKWVTFISLLFLFSSAYS
(ヒトIL7)
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEH
(ヒト組織因子219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(ヒトIL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
The amino acid sequence (including leader sequence) of the 7t15 fusion protein is as follows.
(signal peptide)
MKWVT FISLLFLFS SAYS
(human IL7)
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDHLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWN KILMG TKEH
(human tissue factor 219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTF LSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(human IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
21s137L(ショートバージョン)の核酸配列及びタンパク質配列が以下に示される。21s137L(ショートバージョン)構築物(シグナルペプチド配列を含む)の核酸配列は、以下の通りである。
(シグナルペプチド)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(ヒトIL-21)
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC
(ヒトIL-15Rαスシドメイン)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
((G4S)3リンカー)
GGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCT
(ヒトCD137リガンドショートバージョン)
GATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATC
The nucleic acid and protein sequences for 21s137L (short version) are shown below. The nucleic acid sequence of the 21s137L (short version) construct (including signal peptide sequence) is as follows.
(signal peptide)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCC
(human IL-21)
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCG CCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCCTCCACAAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCCTGCTGCAGAAGAT GATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC
(Human IL-15Rα sushi domain)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCT CTTTAAAGTGCATCCGG
((G4S)3 linker)
GGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGGCGGAGGATCT
(human CD137 ligand short version)
GATCCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGGCGTGTCCCTGACGGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGG TGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCT CCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGCGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCCGAAATC
21s137L(ショートバージョン)構築物のアミノ酸配列(シグナルペプチド配列を含む)は、以下の通りである。
(シグナルペプチド)
MKWVTFISLLFLFSSAYS
(ヒトIL-21)
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS
(ヒトIL-15Rαスシドメイン)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
((G4S)3リンカー)
GGGGSGGGGSGGGGS
(ヒトCD137リガンドショートバージョン)
DPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEI
The amino acid sequence (including signal peptide sequence) of the 21s137L (short version) construct is as follows.
(signal peptide)
MKWVT FISLLFLFS SAYS
(human IL-21)
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS
(Human IL-15Rα sushi domain)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
((G4S)3 linker)
GGGGSGGGGSGGGGGS
(human CD137 ligand short version)
DPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARAR HAWQLTQGATVLGLFRVTPEI
IL-21/IL-15RαSu/CD137L(ショートバージョン)構築物及びIL-7/TF/IL-15構築物を前述の修飾レトロウイルス発現ベクターにクローニングし(Hughes MS,Yu YY,Dudley ME,Zheng Z,Robbins PF,Li Y,et al.Transfer of a TCR gene derived from a patient with a marked antitumor response conveys highly active T-cell effector functions.Hum Gene Ther 2005;16:457-72)、発現ベクターをCHO-K1細胞にトランスフェクトした。CHO-K1細胞でのこれらの2つの構築物の共発現により、可溶性IL-7/TF/IL-15:IL-21/IL-15RαSu/CD137Lタンパク質複合体(7t15-21s137L(ショートバージョン)と称する)の形成及び分泌が可能になり、これを抗TF抗体IgG1親和性及び他のクロマトグラフィー法によって精製することができる。
The IL-21/IL-15RαSu/CD137L (short version) and IL-7/TF/IL-15 constructs were cloned into modified retroviral expression vectors previously described (Hughes MS, Yu YY, Dudley ME, Zheng Z, Robbins PF, Li Y, et al.Transfer of a TCR gene derived from a patient with a marked antitumor response conveyors highly active T-cell effector functions.Hum
7t15-21s137L(ショートバージョン)のCD137(4.1BB)への結合
1日目に、96ウェルプレートを、R5(コーティング緩衝液)中100μL(2.5μg/mL)のGAH IgG Fc(G-102-C、R&D Systems)又はR5のみでコーティングし、4℃で一晩インキュベートした。2日目に、プレートを3回洗浄し、PBS中の1%BSA300μLで37℃で2時間ブロックした。10ng/mLの4.1BB/Fc(838-4B、R&D Systems)を100μL/ウェルで添加し、室温で2時間インキュベートした。3回洗浄した後、7t15-21s137L又は7t15-21sを1/3比で連続希釈し(10nMから開始)、4℃で一晩インキュベートした。3日目に、3回洗浄した後、300ng/mLのビオチン化抗hTF抗体(BAF2339、R&D Systems)を100μL/ウェルで添加し、室温で2時間インキュベートした。次いで、プレートを3回洗浄し、0.25μg/mLのHRP-SA(Jackson ImmuneResearch)と100μL/ウェルで30分間インキュベートし、その後、3回洗浄し、100μLのABTSと室温で2分間インキュベートした。吸光度を405nmで読み取った。図113に示されるように、7t15-21s137L(ショートバージョン)は、7t15-21sと比較して4.1BB/Fc(青色の線)との有意な相互作用を示した。
Binding of 7t15-21s137L (short version) to CD137 (4.1BB) On
ELISAを用いた7t15-21s137L(ショートバージョン)中のIL-15、IL-21、及びIL-7の検出
96ウェルプレートをR5(コーティング緩衝液)中100μL(8μg/mL)の抗TF抗体IgG1でコーティングし、室温で2時間インキュベートした。プレートを3回洗浄し、PBS中100μLの1%BSAでブロックした。1:3比で連続希釈した7t15-21s137L(ショートバージョン)を添加し、室温で60分間インキュベートした。3回洗浄した後、50ng/mLのビオチン化抗IL-15抗体(BAM247、R&D Systems)、500ng/mLのビオチン化抗IL21抗体(13-7218-81、R&D Systems)、又は500ng/mLのビオチン化抗IL7抗体(506602、R&D Systems)をウェルに添加し、室温で60分間インキュベートした。3回洗浄し、0.25μg/mLのHRP-SA(Jackson ImmunoResearch)と100μL/ウェルで、室温で30分間インキュベートした後、4回洗浄し、100μLのABTSと室温で2分間インキュベートした。吸光度を405nmで読み取った。図114A-114Cに示されるように、7t15-21s137L(ショートバージョン)中のIL-15ドメイン、IL-21ドメイン、及びIL-7ドメインをそれぞれの抗体によって検出した。
Detection of IL-15, IL-21 and IL-7 in 7t15-21s137L (short version) using ELISA A 96-well plate was coated with 100 μL (8 μg/mL) anti-TF antibody IgG1 in R5 (coating buffer). Coated and incubated for 2 hours at room temperature. Plates were washed three times and blocked with 100 μL of 1% BSA in PBS. 7t15-21s137L (short version) serially diluted in a 1:3 ratio was added and incubated for 60 minutes at room temperature. After three washes, 50 ng/mL biotinylated anti-IL-15 antibody (BAM247, R&D Systems), 500 ng/mL biotinylated anti-IL21 antibody (13-7218-81, R&D Systems), or 500 ng/mL biotin. Anti-IL7 antibody (506602, R&D Systems) was added to the wells and incubated for 60 minutes at room temperature. Washed 3 times and incubated with 0.25 μg/mL HRP-SA (Jackson ImmunoResearch) at 100 μL/well for 30 minutes at room temperature, then washed 4 times and incubated with 100 μL ABTS for 2 minutes at room temperature. Absorbance was read at 405 nm. As shown in Figures 114A-114C, the IL-15, IL-21, and IL-7 domains in 7t15-21s137L (short version) were detected by the respective antibodies.
7t15-1s137L(ショートバージョン)におけるIL-15は、IL2Rαβγ含有CTLL2細胞の増殖を促進する
7t15-21s137L(ショートバージョン)のIL-15活性を評価するために、7t15-21s137L(ショートバージョン)を、IL2Rαβγを発現するCTLL2細胞の増殖の促進について組換えIL-15と比較した。IL-15依存性CTLL2細胞をIMDM-10%FBSで5回洗浄し、2×104細胞/ウェルでウェルに播種した。連続希釈した7t15-21s137L(ショートバージョン)又はIL-15を細胞に添加した(図115)。細胞をCO2インキュベーター内で、37℃で3日間インキュベートした。3日目に10μLのWST1を各ウェルに添加し、CO2インキュベーター内で、37℃で更に3時間インキュベートすることにより、細胞増殖を検出した。吸光度を450nmで測定することにより、生成されたホルマザン色素の量を分析した。図115に示されるように、7t15-21s137L(ショートバージョン)及びIL-15は、CTLL2細胞の増殖を促進した。7t15-21s137L(ショートバージョン)及びIL-15のEC50は、それぞれ、55.91pM及び6.22pMであった。
IL-15 in 7t15-1s137L (Short Version) Promotes Proliferation of IL2Rαβγ-Containing CTLL2 Cells was compared to recombinant IL-15 for promotion of proliferation of CTLL2 cells expressing IL-15 dependent CTLL2 cells were washed 5 times with IMDM-10% FBS and seeded in wells at 2×10 4 cells/well. Serially diluted 7t15-21s137L (short version) or IL-15 were added to the cells (Figure 115). Cells were incubated for 3 days at 37°C in a CO2 incubator. Cell proliferation was detected by adding 10 μL of WST1 to each well on
7t15-1s137L(ショートバージョン)におけるIL-21は、IL21R含有B9細胞の増殖を促進する
7t15-21s137L(ショートバージョン)のIL-21活性を評価するために、7t15-21s137L(ショートバージョン)を、IL-21Rを発現するB9細胞の増殖の促進について組換えIL-21と比較した。IL-21R含有B9細胞をRPMI-10%FBSで5回洗浄し、1×104細胞/ウェルでウェルに播種した。連続希釈した7t15-21s137L(ショートバージョン)又はIL-21を細胞に添加した(図116)。細胞をCO2インキュベーター内で、37℃で5日間インキュベートした。5日目に10μLのWST1を各ウェルに添加し、CO2インキュベーター内で、37℃で更に4時間インキュベートすることにより、細胞増殖を検出した。吸光度を450nmで測定することにより、生成されたホルマザン色素の量を分析した。図116に示されるように、7t15-21s137L(ショートバージョン)及びIL-21は、B9細胞の増殖を促進した。7t15-21s137L(ショートバージョン)及びIL-21のEC50は、それぞれ、104.1nM及び72.55nMであった。
IL-21 in 7t15-1s137L (Short Version) Promotes Proliferation of IL21R-Containing B9 Cells To assess the IL-21 activity of 7t15-21s137L (short version) Recombinant IL-21 was compared for promotion of proliferation of B9 cells expressing -21R. IL-21R-containing B9 cells were washed five times with RPMI-10% FBS and seeded in wells at 1×10 4 cells/well. Serially diluted 7t15-21s137L (short version) or IL-21 were added to the cells (Figure 116). Cells were incubated for 5 days at 37°C in a CO2 incubator. Cell proliferation was detected by adding 10 μL of WST1 to each well on
実施例56:7t15-TGFRs融合タンパク質の生成及び特徴付け
TGFβ受容体II/IL-15RαSu融合タンパク質及びIL-7/TF/IL-15融合タンパク質からなる融合タンパク質複合体を生成した(図117及び図118)。ヒトTGFβ受容体II(Ile24-Asp159)、組織因子219、IL-15、及びIL-7配列をUniProtウェブサイトから入手し、これらの配列のDNAをGenewizによって合成した。具体的には、IL-7配列を組織因子219のN末端コーディング領域に、続いて、IL-15のN末端コーディング領域に結合することによって構築物を作製した。組織因子219のN末端に、続いて、IL-15のN末端に結合したIL-7を含む構築物の核酸配列及びタンパク質配列を以下に示す。
Example 56 Generation and Characterization of 7t15-TGFRs Fusion Proteins A fusion protein complex consisting of a TGFβ receptor II/IL-15RαSu fusion protein and an IL-7/TF/IL-15 fusion protein was generated (FIG. 117 and FIG. 118). Human TGFβ receptor II (Ile24-Asp159),
7t15構築物の核酸配列(シグナルペプチド配列を含む)は、以下の通りである。
(シグナルペプチド)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(ヒトIL7)
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCAT
(ヒト組織因子219)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(ヒトIL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
The nucleic acid sequence (including signal peptide sequence) of the 7t15 construct is as follows.
(signal peptide)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCC
(human IL7)
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCCACATCTGCGACGCCAACAAGGAGGGCATGTTCCT GTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGA ACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCAT
(human tissue factor 219)
AGCGGCCAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAACCATCCTCGAATGGGAACCCAAACCCGTTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCG ATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCTTTATACGAGAACAGCCCCGAATTTACCCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCA CAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTAATCGACG TGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAGGGCGAGTTCCGGGAG
(human IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTACTGGAGCTGCCAAGTTATCTCTTTAGAGAGCGGGAGACGCTAGCAT CCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCCAAGGAGTGCGAAGAGCTGGAGGGAGAAGAACATCAAGGAGTTCTGCAATCCTTTGTGCCACATTGTCCAGATGTTCATCAATACCTCC
7t15融合タンパク質のアミノ酸配列(リーダー配列を含む)は、以下の通りである。
(シグナルペプチド)
MKWVTFISLLFLFSSAYS
(ヒトIL7)
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEH
(ヒト組織因子219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(ヒトIL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
The amino acid sequence (including leader sequence) of the 7t15 fusion protein is as follows.
(signal peptide)
MKWVT FISLLFLFSSAYS
(human IL7)
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWN KILMG TKEH
(human tissue factor 219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTF LSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(human IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
2つのTGFβ受容体IIをGenewizによって合成したIL-15RαSu鎖に直接結合することによっても構築物を作製した。IL-15RαSuのN末端に結合したTGFβ受容体IIを含む構築物の核酸配列及びタンパク質配列を以下に示す。 Constructs were also made by directly coupling two TGFβ receptor II to IL-15RαSu chains synthesized by Genewiz. The nucleic acid and protein sequences of a construct containing TGFβ receptor II attached to the N-terminus of IL-15RαSu are shown below.
TGFRs構築物の核酸配列(シグナルペプチド配列を含む)は、以下の通りである。
(シグナルペプチド)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(ヒトTGFβ受容体II断片)
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC
(ヒトIL-15Rαスシドメイン)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
The nucleic acid sequences of the TGFRs constructs (including signal peptide sequences) are as follows.
(signal peptide)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCC
(Human TGFβ receptor II fragment)
ATCCCCCCCCCATGTGCAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAA GAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGAACCTTCTTTATGTGTTCCTGTAGCAG CGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCC CCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCCACGATCCCCAAGCTGCCCTAC CACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCCGAC
(Human IL-15Rα sushi domain)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCT CTTTAAAGTGCATCCGG
TGFRs融合タンパク質のアミノ酸配列(リーダー配列を含む)は、以下の通りである。
(シグナルペプチド)
MKWVTFISLLFLFSSAYS
(ヒトTGFβ受容体II)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(ヒトIL-15Rαスシドメイン)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
The amino acid sequence (including leader sequence) of the TGFRs fusion protein is as follows.
(signal peptide)
MKWVT FISLLFLFSSAYS
(human TGFβ receptor II)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNCSITSICEKPQEVCVAVWRKNDINITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPDGGGGGSGGGGGSGGGGSIPPHV QKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNSITSICEKPQEVCVAVWRKNDINITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(Human IL-15Rα sushi domain)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
HEK-Blue TGFβ細胞におけるTGFβ1活性に対する7t15-TGFRsの効果
7t15-TGFRs中のTGFβRの活性を評価するために、HEK-Blue TGFβ細胞におけるTGFβ1活性に対する7t15-TGFRsの効果を分析した。HEK-Blue TGFβ細胞(Invivogen)を予熱したPBSで2回洗浄し、試験培地(DMEM、10%熱不活性化FCS、1×グルタミン、1×抗-抗、及び2×グルタミン)中に5×105細胞/mLで再懸濁した。平底96ウェルプレート中、50μLの細胞を各ウェルに添加し(2.5×104細胞/ウェル)、その後、50μLの0.1nM TGFβ1(R&D systems)を添加した。その後、1:3連続希釈で調製した7t15-TGFRs又はTGFR-Fc(R&D Systems)をプレートに添加して、総量を200μLにした。37℃で24時間インキュベートした後、40μLの誘導されたHEK-Blue TGFβ細胞上清を平底96ウェルプレート中の160μLの予熱したQUANTI-Blue(Invivogen)に添加し、37℃で1~3時間インキュベートした。その後、OD値を、プレートリーダー(Multiscan Sky)を使用して620~655nMで決定した。データを図119に示す。各タンパク質試料のIC50を、GraphPad Prism7.04を用いて計算した。7t15-TGFRs及びTGFR-FcのIC50は、それぞれ、1142pM及び558.6pMであった。これらの結果は、7t15-TGFRs中のTGFβRがHEK-Blue TGFβ細胞におけるTGFβ1活性を遮断することができたことを示した。
Effect of 7t15-TGFRs on TGFβ1 Activity in HEK-Blue TGFβ Cells To assess the activity of TGFβR in 7t15-TGFRs, the effect of 7t15-TGFRs on TGFβ1 activity in HEK-Blue TGFβ cells was analyzed. HEK-Blue TGFβ cells (Invivogen) were washed twice with prewarmed PBS and plated 5× in test medium (DMEM, 10% heat-inactivated FCS, 1× glutamine, 1× anti-anti, and 2× glutamine). Resuspend at 10 5 cells/mL. In a flat bottom 96-well plate, 50 μL of cells were added to each well (2.5×10 4 cells/well) followed by 50 μL of 0.1 nM TGFβ1 (R&D systems). 7t15-TGFRs or TGFR-Fc (R&D Systems) prepared in 1:3 serial dilutions were then added to the plate to a total volume of 200 μL. After 24 hours of incubation at 37°C, 40 μL of induced HEK-Blue TGFβ cell supernatant is added to 160 μL of prewarmed QUANTI-Blue (Invivogen) in a flat bottom 96-well plate and incubated for 1-3 hours at 37°C. bottom. OD values were then determined at 620-655 nM using a plate reader (Multiscan Sky). Data are shown in FIG. The IC50 for each protein sample was calculated using GraphPad Prism 7.04. The IC50s for 7t15-TGFRs and TGFR-Fc were 1142 pM and 558.6 pM, respectively. These results indicated that TGFβR in 7t15-TGFRs could block TGFβ1 activity in HEK-Blue TGFβ cells.
ELISAを用いた7t15-TGFRs中のIL-15、TGFβRII、及びIL-7の検出
96ウェルプレートをR5(コーティング緩衝液)中100μL(8μg/mL)の抗TF抗体IgG1でコーティングし、室温(RT)で2時間インキュベートした。プレートを3回洗浄し、PBS中100μLの1%BSAでブロックした。連続希釈の7t15-TGFRs(1:3比)を添加し、室温で60分間インキュベートした。3回洗浄した後、50ng/mLのビオチン化抗IL-15抗体(BAM247、R&D Systems)、200ng/mLのビオチン化抗TGFbRII抗体(BAF241、R&D Systems)、又は500ng/mLのビオチン化抗IL-7抗体(506602、R&D Systems)を添加し、室温で60分間インキュベートした。3回洗浄した後、0.25μg/mLのHRP-SA(Jackson ImmunoResearch)と100μL/ウェルで、室温で30分間インキュベートし、その後、4回洗浄し、100μLのABTSと室温で2分間インキュベートした。吸光度を405nmで読み取った。図120A~120Cに示されるように、7t15-TGFRs中のIL-15、TGFR、及びIL-7をそれぞれの抗体によって検出した。
Detection of IL-15, TGFβRII, and IL-7 in 7t15-TGFRs Using ELISA A 96-well plate was coated with 100 μL (8 μg/mL) of anti-TF antibody IgG1 in R5 (coating buffer) and incubated at room temperature (RT ) for 2 hours. Plates were washed three times and blocked with 100 μL of 1% BSA in PBS. Serial dilutions of 7t15-TGFRs (1:3 ratio) were added and incubated for 60 minutes at room temperature. After three washes, 50 ng/mL biotinylated anti-IL-15 antibody (BAM247, R&D Systems), 200 ng/mL biotinylated anti-TGFbRII antibody (BAF241, R&D Systems), or 500 ng/mL biotinylated anti-IL-15 antibody (BAF241, R&D Systems). 7 antibody (506602, R&D Systems) was added and incubated for 60 minutes at room temperature. After 3 washes, cells were incubated with 0.25 μg/mL HRP-SA (Jackson ImmunoResearch) at 100 μL/well for 30 minutes at room temperature, followed by 4 washes and incubation with 100 μL ABTS for 2 minutes at room temperature. Absorbance was read at 405 nm. As shown in Figures 120A-120C, IL-15, TGFR, and IL-7 in 7t15-TGFRs were detected by their respective antibodies.
7t15-TGFRs中のIL-15は、IL-2Rβ及び共通γ鎖含有32Dβ細胞の増殖を促進する
7t15-TGFRs中のIL-15の活性を評価するために、7t15-TGFRsを、IL2Rβ及び共通γ鎖を発現する32Dβ細胞を使用して組換えIL-15と比較し、細胞増殖の促進に対するそれらの効果を評価した。IL-15依存性32Dβ細胞をIMDM-10%FBSで5回洗浄し、2×104細胞/ウェルでウェル中に播種した。連続希釈した7t15-TGFRs又はIL-15を細胞に添加した(図121)。細胞をCO2インキュベーター内で、37℃で3日間インキュベートした。3日目に10μLのWST1を各ウェルに添加し、CO2インキュベーター内で、37℃で更に3時間インキュベートすることにより、細胞増殖を検出した。吸光度を450nmで測定することにより、生成されたホルマザン色素の量を分析した。図121に示されるように、7t15-TGFRs及びIL-15は32Dβ細胞増殖を促進し、7t15-TGFRs及びIL-15のEC50は、それぞれ、126nM及び16.63pMであった。
IL-15 in 7t15-TGFRs Promotes Proliferation of 32Dβ Cells Containing IL-2Rβ and Common γ Chain 32Dβ cells expressing the chains were used to compare with recombinant IL-15 to assess their effect on promoting cell proliferation. IL-15 dependent 32Dβ cells were washed 5 times with IMDM-10% FBS and seeded in wells at 2×10 4 cells/well. Serially diluted 7t15-TGFRs or IL-15 were added to the cells (Figure 121). Cells were incubated for 3 days at 37°C in a CO2 incubator. Cell proliferation was detected by adding 10 μL of WST1 to each well on
抗TF抗体親和性カラムを使用した7t15-TGFRsの精製溶出クロマトグラフ
細胞培養物から収集した7t15-TGFRsを、5カラム体積のPBSで平衡化した抗TF抗体親和性カラムにロードした。試料をロードした後、カラムを5カラム体積のPBSで洗浄し、その後、6カラム体積の0.1M酢酸(pH2.9)で溶出した。A280溶出ピークを収集し、その後、1Mトリス塩基でpH7.5~8.0に中和した。その後、中和した試料を、分子量カットオフ30KDaでAmicon遠心フィルターを使用してPBSに緩衝液交換した。図122に示されるように、抗TF抗体親和性カラムは、7t15-TGFRsの融合パートナーとしてTFを含む7t15-TGFRsに結合することができる。緩衝液交換したタンパク質試料を、更なる生化学的分析及び生物学的活性試験のために2~8℃で保管した。各溶出後、抗TF抗体アフィニティーカラムを6カラム体積の0.1Mグリシン(pH2.5)を使用してストリッピングした。その後、カラムを、保管のために5カラム体積のPBS及び7カラム体積の20%エタノールを使用して中和した。抗TF抗体アフィニティーカラムを、GE Healthcare AKTA Avantシステムに接続した。流速は、2mL/分の溶出ステップを除く全てのステップで4mL/分であった。
Purification Elution Chromatography of 7t15-TGFRs Using Anti-TF Antibody Affinity Column 7t15-TGFRs harvested from cell culture were loaded onto an anti-TF antibody affinity column equilibrated with 5 column volumes of PBS. After sample loading, the column was washed with 5 column volumes of PBS and then eluted with 6 column volumes of 0.1 M acetic acid (pH 2.9). The A280 elution peak was collected and then neutralized to pH 7.5-8.0 with 1M Tris base. Neutralized samples were then buffer exchanged into PBS using Amicon centrifugal filters with a molecular weight cutoff of 30 KDa. As shown in Figure 122, the anti-TF antibody affinity column can bind 7t15-TGFRs with TF as a fusion partner for 7t15-TGFRs. Buffer-exchanged protein samples were stored at 2-8° C. for further biochemical analysis and biological activity testing. After each elution, the anti-TF antibody affinity column was stripped using 6 column volumes of 0.1 M glycine (pH 2.5). The column was then neutralized using 5 column volumes of PBS and 7 column volumes of 20% ethanol for storage. The anti-TF antibody affinity column was connected to a GE Healthcare AKTA Avant system. The flow rate was 4 mL/min for all steps except the 2 mL/min elution step.
7t15-TGFRsの還元SDS-PAGE分析
タンパク質の純度及び分子量を決定するために、抗TF抗体親和性カラムで精製した7t15-TGFRsタンパク質試料を、還元条件下でドデシル硫酸ナトリウムポリアクリルアミドゲル(4~12%NuPageビス-トリスゲル)電気泳動(SDS-PAGE)法によって分析した。電気泳動後、ゲルをInstantBlueで約30分間染色し、その後、精製水中で一晩脱色した。
Reducing SDS-PAGE Analysis of 7t15-TGFRs To determine protein purity and molecular weight, 7t15-TGFRs protein samples purified with anti-TF antibody affinity columns were run on sodium dodecyl sulfate polyacrylamide gels (4-12%) under reducing conditions. % NuPage Bis-Tris gel) electrophoresis (SDS-PAGE) method. After electrophoresis, gels were stained with InstantBlue for approximately 30 minutes and then destained overnight in purified water.
7t15-TGFRsタンパク質がCHO細胞において翻訳後にグリコシル化を受けることを検証するために、脱グリコシル化実験を、New England Biolabs製のProtein Deglycosylation Mix IIキット及び製造業者の指示を使用して実施した。図123は、非脱グリコシル化状態(赤色の縁内のレーン1)及び脱グリコシル化状態(黄色の縁内のレーン2)での試料の還元SDS-PAGE分析を示す。これらの結果は、タンパク質がCHO細胞で発現されるとグリコシル化されることを示した。脱グリコシル化後、精製した試料は、還元SDSゲル中で予想された分子量(55kDa及び39kDa)を示した。レーンMには、10ulのSeeBlue Plus2 Prestained Standardをロードした。
To verify that the 7t15-TGFRs proteins undergo post-translational glycosylation in CHO cells, deglycosylation experiments were performed using the Protein Deglycosylation Mix II kit from New England Biolabs and the manufacturer's instructions. FIG. 123 shows reducing SDS-PAGE analysis of samples in the non-deglycosylated state (
7t15-TGFRsの特徴付け
7t15-TGFRsは、ヒトIL-7、ヒト組織因子219断片、及びヒトIL-15の可溶性融合物(7t15)である第1のポリペプチドと、一本鎖の2つのTGFβRIIドメイン及びヒトIL-15受容体アルファ鎖のスシドメインの可溶性融合物(TGFRs)である第2のポリペプチドとを含む多鎖ポリペプチド(本明細書に記載のタイプA多鎖ポリペプチド)である。
Characterization of 7t15-TGFRs 7t15-TGFRs consist of a first polypeptide that is a soluble fusion (7t15) of human IL-7, a
CHO細胞を、7t15及びTGFRsベクターで共トランスフェクトした。7t15-TGFRs複合体を、トランスフェクトしたCHO細胞培養上清から精製した。図124に示されるように、複合体中のIL-7、IL-15、TGFβ受容体、及び組織因子(TF)成分をELISAによって実証した。ヒト化抗抗体TFモノクローナル抗体(抗TF抗体IgG1)を捕捉抗体として使用して、7t15-TGFRs中のTFを決定し、ヒトIL-15(R&D systems)、ヒトIL-7(Biolegend)、抗TGFβ受容体(R&D Systems)に対するビオチン化抗体を検出抗体として使用して、それぞれ、7t15-TGFRs中のIL-7、IL-15、及びTGFβ受容体を決定した。その後、ペルオキシダーゼ結合ストレプトアビジン(Jackson ImmunoResearch Lab)及びABTS基質(Surmodics IVD,Inc.)を使用して、結合したビオチン化抗体を検出した。結果をELISAによって分析した(図124)。 CHO cells were co-transfected with 7t15 and TGFRs vectors. 7t15-TGFRs complexes were purified from transfected CHO cell culture supernatants. IL-7, IL-15, TGFβ receptor, and tissue factor (TF) components in the complex were demonstrated by ELISA, as shown in FIG. Humanized anti-TF monoclonal antibody (anti-TF antibody IgG1) was used as capture antibody to determine TF in 7t15-TGFRs, human IL-15 (R&D systems), human IL-7 (Biolegend), anti-TGFβ Biotinylated antibodies to the receptors (R&D Systems) were used as detection antibodies to determine IL-7, IL-15, and TGFβ receptors in the 7t15-TGFRs, respectively. Bound biotinylated antibody was then detected using peroxidase-conjugated streptavidin (Jackson ImmunoResearch Lab) and ABTS substrate (Surmodics IVD, Inc.). Results were analyzed by ELISA (Figure 124).
C57BL/6マウスにおける7t15-TGFRsのインビボ特徴付け
インビボでの7t15-TGFRsの免疫刺激活性を決定するために、C57BL/6マウスを、対照溶液(PBS)又は0.3、1、3、及び10mg/kgの7t15-TGFRsで皮下処理した。処理したマウスを安楽死させた。マウスの脾臓を収集し、処理後4日目に秤量した。単一脾細胞懸濁液を調製し、蛍光色素結合抗CD4、抗CD8、及び抗NK1.1抗体で染色し、CD4+T細胞、CD8+T細胞、及びNK細胞のパーセンテージをフローサイトメトリーによって分析した。結果は、脾臓重量に基づいて、7t15-TGFRsが特に1~10mg/kgで脾臓細胞を増殖させるのに効果的であることを示した(図125A)。CD8+T細胞及びNK細胞のパーセンテージは、試験した全ての用量で対照処理マウスと比較して高かった(図125B)。
In Vivo Characterization of 7t15-TGFRs in C57BL/6 Mice To determine the immunostimulatory activity of 7t15-TGFRs in vivo, C57BL/6 mice were treated with control solution (PBS) or 0.3, 1, 3, and 10 mg. /kg of 7t15-TGFRs subcutaneously. Treated mice were euthanized. Mouse spleens were harvested and weighed 4 days after treatment. Single splenocyte suspensions were prepared, stained with fluorochrome-conjugated anti-CD4, anti-CD8, and anti-NK1.1 antibodies, and the percentages of CD4 + T cells, CD8 + T cells, and NK cells were determined by flow cytometry. analyzed. Results showed that 7t15-TGFRs were effective in expanding splenocytes, especially at 1-10 mg/kg, based on spleen weight (FIG. 125A). The percentages of CD8 + T cells and NK cells were higher compared to control treated mice at all doses tested (Fig. 125B).
CD4+T細胞及びCD8+T細胞のCD44発現
IL-15がT細胞でのCD44発現及びメモリーT細胞の成長を誘導することが知られている。7t15-TGFRsで処理したマウスにおけるCD4+T細胞及びCD8+T細胞のCD44発現を評価した。C57BL/6マウスを7t15-TGFRsで皮下処理した。脾細胞を、免疫細胞サブセット用の蛍光色素結合抗CD4、抗CD8、及び抗CD44モノクローナル抗体で染色した。総CD4+T細胞のCD4+CD44高T細胞及び総CD8+T細胞のCD8+CD44高T細胞のパーセンテージをフローサイトメトリーによって分析した。図126A及び図126Bに示されるように、7t15-TGFRsは、CD4+T細胞及びCD8+T細胞を有意に活性化して、メモリーT細胞に分化した。
CD44 Expression on CD4+ and CD8+ T Cells IL-15 is known to induce CD44 expression on T cells and the growth of memory T cells. CD44 expression on CD4 + and CD8 + T cells in mice treated with 7t15-TGFRs was assessed. C57BL/6 mice were treated subcutaneously with 7t15-TGFRs. Splenocytes were stained with fluorochrome-conjugated anti-CD4, anti-CD8, and anti-CD44 monoclonal antibodies for immune cell subsets. The percentage of CD4 + CD44 high T cells of total CD4 + T cells and CD8 + CD44 high T cells of total CD8 + T cells was analyzed by flow cytometry. As shown in Figures 126A and 126B, 7t15-TGFRs significantly activated CD4 + and CD8 + T cells to differentiate into memory T cells.
更に、脾細胞のKi67発現に基づく免疫細胞の動的増殖及びマウスの単回投与処理後に7t15-TGFRsによって誘導された脾細胞のグランザイムB発現に基づく細胞傷害性の潜在性も評価した。C57BL/6マウスを3mg/kgの7t15-TGFRsで皮下処理した。処理したマウスを安楽死させ、脾細胞を調製した。調製した脾細胞を、免疫細胞サブセット用の蛍光色素結合抗CD4、抗CD8、及び抗NK1.1(NK)抗体で染色し、その後、細胞増殖用の抗Ki67抗体及び細胞傷害性マーカー用の抗グランザイムB抗体で細胞内染色した。対応する免疫細胞サブセットのKi67及びグランザイムBの平均蛍光強度(MFI)をフローサイトメトリーによって分析した。図127A及び図127Bに示されるように、7t15-TGFRsで処理したマウスの脾臓では、CD8+T細胞及びNK細胞によるKi67及びグランザイムBの発現がPBS対照処理と比較して増加した。これらの結果は、7t15-TGFRsがCD8+T細胞及びNK細胞の数を増加させるのみならず、これらの細胞の潜在的な細胞傷害性も増強することを示す。 In addition, dynamic proliferation of immune cells based on splenocyte Ki67 expression and cytotoxic potential based on splenocyte granzyme B expression induced by 7t15-TGFRs after single-dose treatment of mice were also evaluated. C57BL/6 mice were treated subcutaneously with 3 mg/kg 7t15-TGFRs. Treated mice were euthanized and splenocytes were prepared. Prepared splenocytes were stained with fluorochrome-conjugated anti-CD4, anti-CD8, and anti-NK1.1 (NK) antibodies for immune cell subsets, followed by anti-Ki67 antibody for cell proliferation and anti-Ki67 antibody for cytotoxicity markers. Intracellular staining was performed with a granzyme B antibody. Mean fluorescence intensity (MFI) of Ki67 and granzyme B of corresponding immune cell subsets was analyzed by flow cytometry. As shown in Figures 127A and 127B, the expression of Ki67 and granzyme B by CD8 + T cells and NK cells was increased in the spleens of mice treated with 7t15-TGFRs compared to PBS control treatment. These results indicate that 7t15-TGFRs not only increase the numbers of CD8 + T cells and NK cells, but also enhance the cytotoxic potential of these cells.
加えて、腫瘍細胞に対するマウス脾細胞の細胞傷害性も評価した。マウスYac-1細胞をCellTrace Violetで標識し、腫瘍標的細胞として使用した。脾細胞を7t15-TGFRsで処理したマウスから調製し、エフェクター細胞として使用した。標的細胞を、100nMの7t15-TGFRsを有する又は有しないRPMI-10培地中でエフェクター細胞とE:T比10:1で混合し、37℃で20時間インキュベートした。標的Yac-1細胞阻害を、フローサイトメトリーを使用した生存violet標識Yac-1細胞の分析によって評価した。Yac-1阻害のパーセンテージを、式(1-実験試料中の生存Yac-1細胞数/脾細胞を含まない試料中の生存Yac-1細胞数)×100を使用して計算した。図128に示されるように、7t15-TGFRsで処理したマウス脾細胞は、対照マウス脾細胞よりもYac-1細胞に対して強い細胞傷害性を示し、細胞傷害性アッセイ中に7t15-TGFRsを添加することにより、Yac-1標的細胞に対する脾細胞の細胞傷害性が更に増強された。 In addition, the cytotoxicity of mouse splenocytes against tumor cells was also evaluated. Mouse Yac-1 cells were labeled with CellTrace Violet and used as tumor target cells. Splenocytes were prepared from mice treated with 7t15-TGFRs and used as effector cells. Target cells were mixed with effector cells at an E:T ratio of 10:1 in RPMI-10 medium with or without 100 nM 7t15-TGFRs and incubated at 37° C. for 20 hours. Targeted Yac-1 cell inhibition was assessed by analysis of viable violet-labeled Yac-1 cells using flow cytometry. The percentage of Yac-1 inhibition was calculated using the formula (1−number of viable Yac-1 cells in experimental sample/number of viable Yac-1 cells in sample without splenocytes)×100. As shown in Figure 128, mouse splenocytes treated with 7t15-TGFRs exhibited stronger cytotoxicity against Yac-1 cells than control mouse splenocytes, indicating that 7t15-TGFRs were added during the cytotoxicity assay. This further enhanced splenocyte cytotoxicity against Yac-1 target cells.
実施例57:TGFRt15-21s137L融合タンパク質の生成及び特徴付け
IL-21/IL-15RαSu/CD137L融合タンパク質及びTGFβ受容体II/TF/IL-15融合タンパク質を含む融合タンパク質複合体を生成した(図129及び図130)。ヒトTGFβ受容体II(Ile24-Asp159)、組織因子219、及びIL-15配列をUniProtウェブサイトから入手し、これらの配列のDNAをGenewizによって合成した。具体的には、G4S(3)リンカーを用いて2つのTGFβ受容体II配列を結合してTGFβ受容体IIの一本鎖バージョンを生成し、その後、組織因子219のN末端コーディング領域に、続いて、IL-15のN末端コーディング領域に直接連結することによって構築物を作製した。
Example 57: Generation and Characterization of TGFRt15-21s137L Fusion Protein A fusion protein complex comprising an IL-21/IL-15RαSu/CD137L fusion protein and a TGFβ receptor II/TF/IL-15 fusion protein was generated (FIG. 129). and FIG. 130). Human TGFβ receptor II (Ile24-Asp159),
TGFRt15構築物の核酸配列(シグナルペプチド配列を含む)は、以下の通りである。
(シグナルペプチド)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(ヒトTGFβ受容体II断片)
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC
(ヒト組織因子219)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(ヒトIL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
The nucleic acid sequence (including signal peptide sequence) of the TGFRt15 construct is as follows.
(signal peptide)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCC
(Human TGFβ receptor II fragment)
ATCCCCCCCCCATGTGCAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAA GAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGAACCTTCTTTATGTGTTCCTGTAGCAG CGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCC CCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCCACGATCCCCAAGCTGCCCTAC CACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCCGAC
(human tissue factor 219)
AGCGGCCAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAACCATCCTCGAATGGGAACCCAAACCCGTTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCG ATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCTTTATACGAGAACAGCCCCGAATTTACCCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCA CAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTAATCGACG TGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAGGGCGAGTTCCGGGAG
(human IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTACTGGAGCTGCCAAGTTATCTCTTTAGAGAGCGGGAGACGCTAGCAT CCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCCAAGGAGTGCGAAGAGCTGGAGGGAGAAGAACATCAAGGAGTTCTGCAATCCTTTGTGCCACATTGTCCAGATGTTCATCAATACCTCC
TGFRt15融合タンパク質のアミノ酸配列(リーダー配列を含む)は、以下の通りである。
(シグナルペプチド)
MKWVTFISLLFLFSSAYS
(ヒトTGFβ受容体II)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(ヒト組織因子219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(ヒトIL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
The amino acid sequence (including leader sequence) of the TGFRt15 fusion protein is as follows.
(signal peptide)
MKWVT FISLLFLFS SAYS
(human TGFβ receptor II)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNSITSITSICEKPQEVCVAVWRKNDINITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPDGGGGGSGGGGGSGGGGGSIPPHV QKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNSITSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(human tissue factor 219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTF LSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(human IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
21s137Lの核酸配列及びタンパク質配列が以下に示される。21s137L構築物の核酸配列(シグナルペプチド配列を含む)は、以下の通りである。
(シグナルペプチド)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(ヒトIL-21)
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC
(ヒトIL-15Rαスシドメイン)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
((G4S)3リンカー)
GGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCT
(ヒトCD137L)
CGCGAGGGTCCCGAGCTTTCGCCCGACGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATCCCAGCCGGACTCCCTTCACCGAGGTCGGAA
The nucleic acid and protein sequences for 21s137L are shown below. The nucleic acid sequence (including signal peptide sequence) of the 21s137L construct is as follows.
(signal peptide)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCC
(human IL-21)
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCG CCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCCTCCACAAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCCTGCTGCAGAAGAT GATCCATCAGCACCTGTCCTCCAGGACCCAGGCTCCGAGGACTCC
(Human IL-15Rα sushi domain)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCT CTTTAAAGTGCATCCGG
((G4S)3 linker)
GGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGGCGGAGGATCT
(human CD137L)
CGCGAGGGTCCCGAGCTTTCGCCCCGACGATCCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCGCAGCTGGTGGCCCAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCCAGGCCTGGCAGGGCGTGTCCCTGACGGGGGGC CTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTG GCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGG GACTCTTCCGGGTGACCCCCGAAAATCCCAGCCGGACTCCCTTCACCGAGGTCGGAA
21s137L融合タンパク質のアミノ酸配列(リーダー配列を含む)は、以下の通りである。
(シグナルペプチド)
MKWVTFISLLFLFSSAYS
(ヒトIL-21)
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS
(ヒトIL-15Rαスシドメイン)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
((G4S)3リンカー)
GGGGSGGGGSGGGGS
(ヒトCD137L)
REGPELSPDDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEIPAGLPSPRSE
The amino acid sequence (including the leader sequence) of the 21s137L fusion protein is as follows.
(signal peptide)
MKWVT FISLLFLFS SAYS
(human IL-21)
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS
(Human IL-15Rα sushi domain)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
((G4S)3 linker)
GGGGSGGGGSGGGGGS
(human CD137L)
REGPELSPDDPAGLLDLLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSSVSLALHLQPLRSAAGAAALALTVDLLPPASSEARNSAFGFQGRLLHLSAGQRLGV HLHTEARARHAWQLTQGATVLGLFRVTPEIPAGLPSPRSSE
いくつかの事例では、リーダーペプチドをインタクトなポリペプチドから切断して、可溶性であり得るか、又は分泌され得る成熟形態を生成する。 In some cases, the leader peptide is cleaved from the intact polypeptide to generate the mature form, which can be soluble or secreted.
IL-21/IL-15RαSu/CD137L構築物及びTGFR/TF/IL-15構築物を前述の修飾レトロウイルス発現ベクターにクローニングし(Hughes MS,Yu YY,Dudley ME,Zheng Z,Robbins PF,Li Y,et al.Transfer of a TCR gene derived from a patient with a marked antitumor response conveys highly active T-cell effector functions.Hum Gene Ther2005;16:457-72)、発現ベクターをCHO-K1細胞にトランスフェクトした。CHO-K1細胞でのこれらの2つの構築物の共発現により、可溶性TGFR/TF/IL-15:IL-21/IL-15RαSu/CD137Lタンパク質複合体(TGFRt15-21s137Lと称する)の形成及び分泌が可能になり、これを抗TF抗体IgG1親和性及び他のクロマトグラフィー法によって精製することができる。
The IL-21/IL-15RαSu/CD137L and TGFR/TF/IL-15 constructs were cloned into modified retroviral expression vectors previously described (Hughes MS, Yu YY, Dudley ME, Zheng Z, Robbins PF, Li Y, et al. al.Transfer of a TCR gene derived from a patient with a marked antitumor response conveys highly active T-cell effector functions.
抗TF抗体親和性カラムを使用したTGFRt15-21s137Lの精製溶出クロマトグラフ
細胞培養物から収集したTGFRt15-21s137Lを、5カラム体積のPBSで平衡化した抗TF抗体親和性カラムにロードした。試料をロードした後、カラムを5カラム体積のPBSで洗浄し、その後、6カラム体積の0.1M酢酸(pH2.9)で溶出した。A280溶出ピークを収集し、その後、1Mトリス塩基でpH7.5~8.0に中和した。その後、中和した試料を、分子量カットオフ30KDaでAmicon遠心フィルターを使用してPBSに緩衝液交換した。図131に示されるように、抗TF抗体親和性カラムは、TGFRt15-21s137Lの融合パートナーとしてTFを含むTGFRt15-21s137Lに結合した。緩衝液交換したタンパク質試料を、更なる生化学的分析及び生物学的活性試験のために2~8℃で保管した。各溶出後、抗TF抗体アフィニティーカラムを6カラム体積の0.1Mグリシン(pH2.5)を使用してストリッピングした。その後、カラムを、保管のために5カラム体積のPBS及び7カラム体積の20%エタノールを使用して中和した。抗TF抗体アフィニティーカラムを、GE Healthcare AKTA Avantシステムに接続した。流速は、2mL/分の溶出ステップを除く全てのステップで4mL/分であった。
Purification Elution Chromatography of TGFRt15-21s137L Using Anti-TF Antibody Affinity Column TGFRt15-21s137L harvested from cell culture was loaded onto an anti-TF antibody affinity column equilibrated with 5 column volumes of PBS. After sample loading, the column was washed with 5 column volumes of PBS and then eluted with 6 column volumes of 0.1 M acetic acid (pH 2.9). The A280 elution peak was collected and then neutralized to pH 7.5-8.0 with 1M Tris base. Neutralized samples were then buffer exchanged into PBS using Amicon centrifugal filters with a molecular weight cutoff of 30 KDa. As shown in Figure 131, the anti-TF antibody affinity column bound to TGFRt15-21s137L containing TF as a fusion partner of TGFRt15-21s137L. Buffer-exchanged protein samples were stored at 2-8° C. for further biochemical analysis and biological activity testing. After each elution, the anti-TF antibody affinity column was stripped using 6 column volumes of 0.1 M glycine (pH 2.5). The column was then neutralized using 5 column volumes of PBS and 7 column volumes of 20% ethanol for storage. The anti-TF antibody affinity column was connected to a GE Healthcare AKTA Avant system. The flow rate was 4 mL/min for all steps except the 2 mL/min elution step.
実施例58:TGFRt15-TGFRs21融合タンパク質の生成及び特徴付け
TGFβ受容体II/IL-15RαSu/IL-21融合タンパク質及びTGFβ受容体II/TF/IL-15融合タンパク質からなる融合タンパク質複合体を生成した(図132及び図133)。ヒトTGFβ受容体II(Ile24-Asp159)、組織因子219、IL-21、及びIL-15配列をUniProtウェブサイトから入手し、これらの配列のDNAをGenewizによって合成した。具体的には、G4S(3)リンカーを用いて2つのTGFβ受容体II配列を結合してTGFβ受容体IIの一本鎖バージョンを生成し、その後、組織因子219のN末端コーディング領域に、続いて、IL-15のN末端コーディング領域に直接連結することによって構築物を作製した。
Example 58: Generation and Characterization of TGFRt15-TGFRs21 Fusion Proteins A fusion protein complex consisting of a TGFβ receptor II/IL-15RαSu/IL-21 fusion protein and a TGFβ receptor II/TF/IL-15 fusion protein was generated (Figures 132 and 133). Human TGFβ receptor II (Ile24-Asp159),
組織因子219のN末端に、続いて、IL-15のN末端に結合した2つのTGFβ受容体IIを含む構築物の核酸配列及びタンパク質配列を以下に示す。
The nucleic acid and protein sequences of a construct containing two TGFβ receptor II bound to the N-terminus of
TGFRt15構築物の核酸配列(シグナルペプチド配列を含む)は、以下の通りである。
(シグナルペプチド)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(ヒトTGFβ受容体II断片)
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC
(ヒト組織因子219)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(ヒトIL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
The nucleic acid sequence (including signal peptide sequence) of the TGFRt15 construct is as follows.
(signal peptide)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCC
(Human TGFβ receptor II fragment)
ATCCCCCCCCCATGTGCAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAA GAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGAACCTTCTTTATGTGTTCCTGTAGCAG CGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCC CCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCCACGATCCCCAAGCTGCCCTAC CACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCCGAC
(human tissue factor 219)
AGCGGCCAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAACCATCCTCGAATGGGAACCCAAACCCGTTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCG ATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCTTTATACGAGAACAGCCCCGAATTTACCCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCA CAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTAATCGACG TGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAGGGCGAGTTCCGGGAG
(human IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTACTGGAGCTGCCAAGTTATCTCTTTAGAGAGCGGGAGACGCTAGCAT CCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCCAAGGAGTGCGAAGAGCTGGAGGGAGAAGAACATCAAGGAGTTCTGCAATCCTTTGTGCCACATTGTCCAGATGTTCATCAATACCTCC
TGFRt15融合タンパク質のアミノ酸配列(リーダー配列を含む)は、以下の通りである。
(シグナルペプチド)
MKWVTFISLLFLFSSAYS
(ヒトTGFβ受容体II)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(ヒト組織因子219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(ヒトIL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
The amino acid sequence (including leader sequence) of the TGFRt15 fusion protein is as follows.
(signal peptide)
MKWVT FISLLFLFS SAYS
(human TGFβ receptor II)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNSITSITSICEKPQEVCVAVWRKNDINITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPDGGGGGSGGGGGSGGGGGSIPPHV QKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNSITSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(human tissue factor 219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTF LSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(human IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
2つのTGFβ受容体IIをGenewizによって合成したIL-15RαSu鎖に、続いて、IL-21のN末端コーディング領域に直接結合することによっても構築物を作製した。IL-15RαSuのN末端に、続いて、IL-21のN末端に結合したTGFβ受容体IIを含む構築物の核酸配列及びタンパク質配列を以下に示す。 Constructs were also made by linking two TGFβ receptor II directly to the IL-15RαSu chain synthesized by Genewiz, followed by the N-terminal coding region of IL-21. The nucleic acid and protein sequences of a construct containing TGFβ receptor II attached to the N-terminus of IL-15RαSu followed by the N-terminus of IL-21 are shown below.
TGFRs21構築物の核酸配列(シグナルペプチド配列を含む)は、以下の通りである。
(シグナルペプチド)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(ヒトTGFβ受容体II断片)
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC
(ヒトIL-15Rαスシドメイン)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
(ヒトIL-21)
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC
The nucleic acid sequence (including signal peptide sequence) of the TGFRs21 construct is as follows.
(signal peptide)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCC
(Human TGFβ receptor II fragment)
ATCCCCCCCCCATGTGCAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAA GAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGAACCTTCTTTATGTGTTCCTGTAGCAG CGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCC CCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCCACGATCCCCAAGCTGCCCTAC CACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCCGAC
(Human IL-15Rα sushi domain)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCT CTTTAAAGTGCATCCGG
(human IL-21)
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCG CCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCCTCCACAAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCCTGCTGCAGAAGAT GATCCATCAGCACCTGTCCTCCAGGACCCAGGCTCCGAGGACTCC
TGFRs21融合タンパク質のアミノ酸配列(リーダー配列を含む)は、以下の通りである。
(シグナルペプチド)
MKWVTFISLLFLFSSAYS
(ヒトTGFβ受容体II)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(ヒトIL-15Rαスシドメイン)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
(ヒトIL-21)
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS
The amino acid sequence (including leader sequence) of the TGFRs21 fusion protein is as follows.
(signal peptide)
MKWVT FISLLFLFS SAYS
(human TGFβ receptor II)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNCSITSICEKPQEVCVAVWRKNDINITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPDGGGGGSGGGGGSGGGGSIPPHV QKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNSITSICEKPQEVCVAVWRKNDINITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(Human IL-15Rα sushi domain)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
(human IL-21)
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS
いくつかの事例では、リーダーペプチドをインタクトなポリペプチドから切断して、可溶性であり得るか、又は分泌され得る成熟形態を生成する。 In some cases, the leader peptide is cleaved from the intact polypeptide to generate the mature form, which can be soluble or secreted.
TGFR/IL-15RαSu/IL-21構築物及びTGFR/TF/IL-15構築物を前述の修飾レトロウイルス発現ベクターにクローニングし(Hughes MS,Yu YY,Dudley ME,Zheng Z,Robbins PF,Li Y,et al.Transfer of a TCR gene derived from a patient with a marked antitumor response conveys highly active T-cell effector functions.Hum Gene Ther2005;16:457-72)、発現ベクターをCHO-K1細胞にトランスフェクトした。CHO-K1細胞でのこれらの2つの構築物の共発現により、可溶性TGFR/TF/IL-15:TGFR/IL-15RαSu/IL-21タンパク質複合体(TGFRt15-TGFRs21と称する)の形成及び分泌が可能になり、これを抗TF抗体IgG1親和性及び他のクロマトグラフィー法によって精製することができる。
The TGFR/IL-15RαSu/IL-21 and TGFR/TF/IL-15 constructs were cloned into modified retroviral expression vectors previously described (Hughes MS, Yu YY, Dudley ME, Zheng Z, Robbins PF, Li Y, et al. al.Transfer of a TCR gene derived from a patient with a marked antitumor response conveys highly active T-cell effector functions.
抗TF抗体親和性カラムを使用したTGFRt15-TGFRs21の精製溶出クロマトグラフ
細胞培養物から収集したTGFRt15-TGFRs21を、5カラム体積のPBSで平衡化した抗TF抗体親和性カラムにロードした。試料をロードした後、カラムを5カラム体積のPBSで洗浄し、その後、6カラム体積の0.1M酢酸(pH2.9)で溶出した。A280溶出ピークを収集し、その後、1Mトリス塩基でpH7.5~8.0に中和した。その後、中和した試料を、分子量カットオフ30KDaでAmicon遠心フィルターを使用してPBSに緩衝液交換した。図134に示されるように、抗TF抗体親和性カラムは、融合パートナーとしてTFを含むTGFRt15-TGFRs21に結合した。緩衝液交換したタンパク質試料を、更なる生化学的分析及び生物学的活性試験のために2~8℃で保管した。各溶出後、抗TF抗体アフィニティーカラムを6カラム体積の0.1Mグリシン(pH2.5)を使用してストリッピングした。その後、カラムを、保管のために5カラム体積のPBS及び7カラム体積の20%エタノールを使用して中和した。抗TF抗体アフィニティーカラムを、GE Healthcare AKTA Avantシステムに接続した。流速は、2mL/分の溶出ステップを除く全てのステップで4mL/分であった。
Purification Elution Chromatography of TGFRt15-TGFRs21 Using Anti-TF Antibody Affinity Column TGFRt15-TGFRs21 collected from cell culture was loaded onto an anti-TF antibody affinity column equilibrated with 5 column volumes of PBS. After sample loading, the column was washed with 5 column volumes of PBS and then eluted with 6 column volumes of 0.1 M acetic acid (pH 2.9). The A280 elution peak was collected and then neutralized to pH 7.5-8.0 with 1M Tris base. Neutralized samples were then buffer exchanged into PBS using Amicon centrifugal filters with a molecular weight cutoff of 30 KDa. As shown in Figure 134, the anti-TF antibody affinity column bound TGFRt15-TGFRs21 with TF as a fusion partner. Buffer-exchanged protein samples were stored at 2-8° C. for further biochemical analysis and biological activity testing. After each elution, the anti-TF antibody affinity column was stripped using 6 column volumes of 0.1 M glycine (pH 2.5). The column was then neutralized using 5 column volumes of PBS and 7 column volumes of 20% ethanol for storage. The anti-TF antibody affinity column was connected to a GE Healthcare AKTA Avant system. The flow rate was 4 mL/min for all steps except the 2 mL/min elution step.
TGFRt15-TGFRs21の還元SDS-PAGE分析
タンパク質の純度及び分子量を決定するために、抗TF抗体親和性カラムで精製したTGFRt15-TGFRs21タンパク質試料を、還元条件下でドデシル硫酸ナトリウムポリアクリルアミドゲル(4~12%NuPageビス-トリスゲル)電気泳動(SDS-PAGE)法によって分析した。電気泳動後、ゲルをInstantBlueで約30分間染色し、その後、精製水中で一晩脱色した。
Reducing SDS-PAGE Analysis of TGFRt15-TGFRs21 To determine protein purity and molecular weight, anti-TF antibody affinity column-purified TGFRt15-TGFRs21 protein samples were run on sodium dodecyl sulfate polyacrylamide gels (4-12%) under reducing conditions. % NuPage Bis-Tris gel) electrophoresis (SDS-PAGE) method. After electrophoresis, gels were stained with InstantBlue for approximately 30 minutes and then destained overnight in purified water.
TGFRt15-TGFRs21タンパク質がCHO細胞において翻訳後にグリコシル化を受けることを検証するために、脱グリコシル化実験を、New England Biolabs製のProtein Deglycosylation Mix IIキット及び製造業者の指示を使用して実施した。図135は、非脱グリコシル化状態(赤色の縁内のレーン1)及び脱グリコシル化状態(黄色の縁内のレーン2)での試料の還元SDS-PAGE分析を示す。タンパク質がCHO細胞で発現されるとグリコシル化されることは明らかである。脱グリコシル化後、精製した試料は、還元SDSゲル中で予想された分子量(69kDa及び55kDa)を示した。レーンMには、10ulのSeeBlue Plus2 Prestained Standardをロードした。
To verify that the TGFRt15-TGFRs21 proteins undergo post-translational glycosylation in CHO cells, deglycosylation experiments were performed using the Protein Deglycosylation Mix II kit from New England Biolabs and the manufacturer's instructions. FIG. 135 shows reducing SDS-PAGE analysis of samples in the non-deglycosylated state (
C57BL/6マウスにおけるTGFRt15-TGFRs21の免疫刺激
TGFRt15-TGFRs21は、一本鎖の2つのTGFβRIIドメイン、ヒト組織因子219断片、及びヒトIL-15の可溶性融合物(TGFRt15)である第1のポリペプチドと、一本鎖の2つのTGFβRIIドメイン、ヒトIL-15受容体アルファ鎖のスシドメイン、及びヒトIL-21の可溶性融合物(TGFRs21)である第2のポリペプチドとを含む多鎖ポリペプチド(本明細書に記載のタイプA多鎖ポリペプチド)である。
Immunostimulation of TGFRt15-TGFRs21 in C57BL/6 Mice TGFRt15-TGFRs21 is a first polypeptide that is a single-chain soluble fusion of two TGFβRII domains, a
CHO細胞を、TGFRt15及びTGFRs21ベクターで共トランスフェクトした。TGFRt15-TGFRs21複合体を、トランスフェクトしたCHO細胞培養上清から精製した。図136に示されるように、複合体中のTGFβ受容体、IL-15、IL-21、及び組織因子(TF)成分をELISAによって実証した。ヒト化抗TFモノクローナル抗体(抗TF IgG1)を捕捉抗体として使用して、TGFRt15-TGFRs21、ビオチン化抗ヒトIL-15抗体(R&D systems)、ビオチン化抗ヒトTGFβ受容体抗体(R&D systems)中のTFを決定し、ビオチン化抗ヒトIL-21抗体(R&D Systems)を検出抗体として使用して、それぞれ、TGFRt15-TGFRs21中のIL-15、TGFβ受容体、及びIL-21を決定した。検出のために、ペルオキシダーゼ結合ストレプトアビジン(Jackson ImmunoResearch Lab)及びABTSを使用した。 CHO cells were co-transfected with TGFRt15 and TGFRs21 vectors. TGFRt15-TGFRs21 complexes were purified from transfected CHO cell culture supernatants. As shown in Figure 136, TGFβ receptor, IL-15, IL-21, and tissue factor (TF) components in the complex were demonstrated by ELISA. Using humanized anti-TF monoclonal antibody (anti-TF IgG1) as capture antibody, TF was determined and biotinylated anti-human IL-21 antibody (R&D Systems) was used as detection antibody to determine IL-15, TGFβ receptor and IL-21 in TGFRt15-TGFRs21, respectively. For detection, peroxidase-conjugated streptavidin (Jackson ImmunoResearch Lab) and ABTS were used.
野生型C57BL/6マウスを、対照溶液(PBS)又は3mg/kgのTGFRt15-TGFRs21のいずれかで皮下処理した。処理の4日後、脾臓の重量及び脾臓に存在する様々な免疫細胞型のパーセンテージを評価した。図137Aに示されるように、対照処理マウス及びTGFRt15-TGFRs21処理マウスの脾臓に存在するCD4+T細胞、CD8+T細胞、及びNK細胞のパーセンテージを評価した。TGFRt15-TGFRs21処理後のKi67発現に基づく免疫細胞の動的増殖も評価した。脾細胞を蛍光色素結合抗CD4、抗CD8、及び抗NK1.1(NK)抗体で染色し、抗Ki67抗体で細胞内染色した。CD4+T細胞、CD8+T細胞、及びNK細胞のパーセンテージ、並びに対応する免疫細胞サブセットのKi67の平均蛍光強度(MFI)をフローサイトメトリーによって分析した(図137A及び図137B)。更に、マウスの単回投与処理後にTGFRt15-TGFRs21によって誘導された脾細胞のグランザイムB発現に基づく細胞傷害性の潜在性も評価した。図138に示されるように、TGFRt15-TGFRs21で処理したマウスの脾臓では、NK細胞によるグランザイムBの発現が処理後に増加した。TGFRt15-TGFRs21で処理したマウスの脾細胞を、蛍光色素結合抗CD4、抗CD8、及び抗NK1.1(NK)抗体で染色し、抗グランザイムB抗体で細胞内染色した。対応する免疫細胞サブセットのグランザイムBの平均蛍光強度(MFI)をフローサイトメトリーによって分析した(図138)。 Wild-type C57BL/6 mice were treated subcutaneously with either control solution (PBS) or 3 mg/kg TGFRt15-TGFRs21. After 4 days of treatment, spleen weight and percentage of various immune cell types present in the spleen were assessed. The percentages of CD4 + T cells, CD8 + T cells, and NK cells present in the spleens of control-treated and TGFRt15-TGFRs21-treated mice were assessed, as shown in FIG. 137A. Dynamic proliferation of immune cells based on Ki67 expression after TGFRt15-TGFRs21 treatment was also assessed. Splenocytes were stained with fluorochrome-conjugated anti-CD4, anti-CD8, and anti-NK1.1 (NK) antibodies and intracellularly with anti-Ki67 antibody. The percentages of CD4 + T cells, CD8 + T cells, and NK cells and the mean fluorescence intensity (MFI) of Ki67 of the corresponding immune cell subsets were analyzed by flow cytometry (FIGS. 137A and 137B). In addition, the cytotoxic potential based on splenocyte granzyme B expression induced by TGFRt15-TGFRs21 after single-dose treatment of mice was also assessed. As shown in Figure 138, in the spleen of mice treated with TGFRt15-TGFRs21, expression of granzyme B by NK cells increased after treatment. Splenocytes from TGFRt15-TGFRs21 treated mice were stained with fluorochrome-conjugated anti-CD4, anti-CD8, and anti-NK1.1 (NK) antibodies and intracellularly with anti-granzyme B antibody. Granzyme B mean fluorescence intensity (MFI) of the corresponding immune cell subsets was analyzed by flow cytometry (Figure 138).
図137Aに示されるように、TGFRt15-TGFRs21で処理したマウスの脾臓では、CD8+T細胞及びNK細胞の両方のパーセンテージが、単回TGFRt15-TGFRs21処理後4日目に増加した。これらの結果は、TGFRt15-TGFRs21が免疫細胞を誘導して、マウス脾臓、特にCD8+T細胞及びNK細胞を増殖させることができることを示す。 As shown in FIG. 137A, in the spleen of mice treated with TGFRt15-TGFRs21, the percentage of both CD8 + T cells and NK cells increased 4 days after single TGFRt15-TGFRs21 treatment. These results indicate that TGFRt15-TGFRs21 can induce immune cells to proliferate mouse spleens, especially CD8 + T cells and NK cells.
加えて、腫瘍細胞に対するマウス脾細胞の細胞傷害性も評価した。マウスYac-1細胞をCellTrace Violetで標識し、腫瘍標的細胞として使用した。脾細胞をTGFRt15-TGFRs21で処理したマウスから調製し、エフェクター細胞として使用した。標的細胞を、100nMのTGFRt15-TGFRs21を有する又は有しないRPMI-10培地中でエフェクター細胞とE:T比10:1で混合し、37℃で24時間インキュベートした。標的Yac-1細胞阻害を、フローサイトメトリーを使用した生存violet標識Yac-1細胞の分析によって評価した。Yac-1阻害のパーセンテージを、式(1-[実験試料中の生存Yac-1細胞数]/[脾細胞を含まない試料中の生存Yac-1細胞数])×100を使用して計算した。図139に示されるように、TGFRt15-TGFRs21で処理したマウス脾細胞は、細胞傷害性アッセイ中にTGFRt15-TGFRs21の存在下で対照マウス細胞よりもYac-1細胞に対して強い細胞傷害性を示した(図139)。 In addition, the cytotoxicity of mouse splenocytes against tumor cells was also evaluated. Mouse Yac-1 cells were labeled with CellTrace Violet and used as tumor target cells. Splenocytes were prepared from mice treated with TGFRt15-TGFRs21 and used as effector cells. Target cells were mixed with effector cells at an E:T ratio of 10:1 in RPMI-10 medium with or without 100 nM TGFRt15-TGFRs21 and incubated at 37° C. for 24 hours. Targeted Yac-1 cell inhibition was assessed by analysis of viable violet-labeled Yac-1 cells using flow cytometry. The percentage of Yac-1 inhibition was calculated using the formula (1−[number of viable Yac-1 cells in experimental sample]/[number of viable Yac-1 cells in sample without splenocytes])×100. . As shown in Figure 139, mouse splenocytes treated with TGFRt15-TGFRs21 exhibited stronger cytotoxicity against Yac-1 cells than control mouse cells in the presence of TGFRt15-TGFRs21 during the cytotoxicity assay. (Fig. 139).
実施例59:TGFRt15-TGFRs16融合タンパク質の生成
TGFβ受容体II/IL-15RαSu/抗CD16scFv融合タンパク質及びTGFβ受容体II/TF/IL-15融合タンパク質からなる融合タンパク質複合体を生成した(図140及び図141)。ヒトTGFβ受容体II(Ile24-Asp159)、組織因子219、及びIL-15配列をUniProtウェブサイトから入手し、これらの配列のDNAをGenewizによって合成した。具体的には、G4S(3)リンカーを用いて2つのTGFβ受容体II配列を結合してTGFβ受容体IIの一本鎖バージョンを生成し、その後、組織因子219のN末端コーディング領域に、続いて、IL-15のN末端コーディング領域に直接連結することによって構築物を作製した。
Example 59 Generation of TGFRt15-TGFRs16 Fusion Proteins A fusion protein complex consisting of a TGFβ receptor II/IL-15RαSu/anti-CD16 scFv fusion protein and a TGFβ receptor II/TF/IL-15 fusion protein was generated (FIGS. 140 and Figure 141). Human TGFβ receptor II (Ile24-Asp159),
組織因子219のN末端に、続いて、IL-15のN末端に結合した2つのTGFβ受容体IIを含む構築物の核酸配列及びタンパク質配列を以下に示す。
The nucleic acid and protein sequences of a construct containing two TGFβ receptor II bound to the N-terminus of
TGFRt15構築物の核酸配列(シグナルペプチド配列を含む)は、以下の通りである。
(シグナルペプチド)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(ヒトTGFβ受容体II断片)
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC
(ヒト組織因子219)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(ヒトIL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
The nucleic acid sequence (including signal peptide sequence) of the TGFRt15 construct is as follows.
(signal peptide)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCC
(Human TGFβ receptor II fragment)
ATCCCCCCCCCATGTGCAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAA GAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGAACCTTCTTTATGTGTTCCTGTAGCAG CGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCC CCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCCACGATCCCCAAGCTGCCCTAC CACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCCGAC
(human tissue factor 219)
AGCGGCCAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAACCATCCTCGAATGGGAACCCAAACCCGTTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCG ATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCTTTATACGAGAACAGCCCCGAATTTACCCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCA CAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTAATCGACG TGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAGGGCGAGTTCCGGGAG
(human IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTACTGGAGCTGCCAAGTTATCTCTTTAGAGAGCGGGAGACGCTAGCAT CCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCCAAGGAGTGCGAAGAGCTGGAGGGAGAAGAACATCAAGGAGTTCTGCAATCCTTTGTGCCACATTGTCCAGATGTTCATCAATACCTCC
TGFRt15融合タンパク質のアミノ酸配列(リーダー配列を含む)は、以下の通りである。
(シグナルペプチド)
MKWVTFISLLFLFSSAYS
(ヒトTGFβ受容体II)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(ヒト組織因子219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(ヒトIL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
The amino acid sequence (including leader sequence) of the TGFRt15 fusion protein is as follows.
(signal peptide)
MKWVT FISLLFLFS SAYS
(human TGFβ receptor II)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNSITSITSICEKPQEVCVAVWRKNDINITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPDGGGGGSGGGGGSGGGGGSIPPHV QKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNSITSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(human tissue factor 219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTF LSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(human IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
2つのTGFβ受容体IIをGenewizによって合成したIL-15RαSu鎖に、続いて、抗CD16scFv配列に直接結合することによっても構築物を作製した。IL-15RαSuのN末端に、続いて、抗CD16scFv配列に結合したTGFβ受容体IIを含む構築物の核酸配列及びタンパク質配列を以下に示す。 Constructs were also made by linking two TGFβ receptor II directly to IL-15RαSu chains synthesized by Genewiz followed by anti-CD16 scFv sequences. The nucleic acid and protein sequences of a construct containing TGFβ receptor II linked to the N-terminus of IL-15RαSu followed by an anti-CD16 scFv sequence are shown below.
TGFRs16構築物の核酸配列(シグナルペプチド配列を含む)は、以下の通りである。
(シグナルペプチド)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(ヒトTGFβ受容体II断片)
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC
(ヒトIL-15Rαスシドメイン)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
(抗ヒトCD16scFv)
TCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCAACCATGTGGTGTTCGGCGGCGGCACCAAGCTGACCGTGGGCCATGGCGGCGGCGGCTCCGGAGGCGGCGGCAGCGGCGGAGGAGGATCCGAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGG
The nucleic acid sequence (including signal peptide sequence) of the TGFRs16 construct is as follows.
(signal peptide)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCC
(Human TGFβ receptor II fragment)
ATCCCCCCCCCATGTGCAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAA GAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGAACCTTCTTTATGTGTTCCTGTAGCAG CGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCC CCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCCACGATCCCCAAGCTGCCCTAC CACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCCGAC
(Human IL-15Rα sushi domain)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCT CTTTAAAGTGCATCCGG
(anti-human CD16scFv)
TCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACACAGGCCCTCCGGCATCCCTGACAGG TTCTCCGGATCCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCGGCAACCATGTGGGTGTTCGGCGGCGGGCACCAAGCTGACCGTGGGCCATGGCGGCGGCGGCTGTCCGGAGGCGGCCG GCAGCGGCGGAGGAGGATCCGAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAGGGGCCTGGAGTGGGTGT CCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGA CAGGGCACCCTGGTGACCGTGTCCCAGG
TGFRs16融合タンパク質のアミノ酸配列(リーダー配列を含む)は、以下の通りである。
(シグナルペプチド)
MKWVTFISLLFLFSSAYS
(ヒトTGFβ受容体II)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(ヒトIL-15Rαスシドメイン)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
(抗ヒトCD16scFv)
SELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGHGGGGSGGGGSGGGGSEVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSR
The amino acid sequence (including leader sequence) of the TGFRs16 fusion protein is as follows.
(signal peptide)
MKWVT FISLLFLFS SAYS
(human TGFβ receptor II)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNSITSITSICEKPQEVCVAVWRKNDINITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPDGGGGGSGGGGGSGGGGGSIPPHV QKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNSITSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(Human IL-15Rα sushi domain)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
(anti-human CD16scFv)
SELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGHGGGGGSGGGGSGGGGSEVQLVESGGGGVVRPGG SLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSR
いくつかの事例では、リーダーペプチドをインタクトなポリペプチドから切断して、可溶性であり得るか、又は分泌され得る成熟形態を生成する。 In some cases, the leader peptide is cleaved from the intact polypeptide to generate the mature form, which can be soluble or secreted.
TGFR/IL-15RαSu/抗CD16scFv構築物及びTGFR/TF/IL-15構築物を前述の修飾レトロウイルス発現ベクターにクローニングし(Hughes MS,Yu YY,Dudley ME,Zheng Z,Robbins PF,Li Y,et al.Transfer of a TCR gene derived from a patient with a marked antitumor response conveys highly active T-cell effector functions.Hum Gene Ther2005;16:457-72)、発現ベクターをCHO-K1細胞にトランスフェクトした。CHO-K1細胞でのこれらの2つの構築物の共発現により、可溶性TGFR/TF/IL-15:TGFR/IL-15RαSu/anti-CD16scFvタンパク質複合体(TGFRt15-TGFRs16と称する)の形成及び分泌が可能になり、これを抗TF IgG1親和性及び他のクロマトグラフィー法によって精製することができる。
The TGFR/IL-15RαSu/anti-CD16 scFv and TGFR/TF/IL-15 constructs were cloned into modified retroviral expression vectors previously described (Hughes MS, Yu YY, Dudley ME, Zheng Z, Robbins PF, Li Y, et al. Transfer of a TCR gene derived from a patient with a marked antitumor response conveys highly active T-cell effector functions
実施例60:TGFRt15-TGFRs137L融合タンパク質の生成
TGFβ受容体II/IL-15RαSu/CD137L融合タンパク質及びTGFβ受容体II/TF/IL-15融合タンパク質からなる融合タンパク質複合体を生成した(図142及び図143)。ヒトTGFβ受容体II(Ile24-Asp159)、組織因子219、CD137L、及びIL-15配列をUniProtウェブサイトから入手し、これらの配列のDNAをGenewizによって合成した。具体的には、G4S(3)リンカーを用いて2つのTGFβ受容体II配列を結合してTGFβ受容体IIの一本鎖バージョンを生成し、その後、組織因子219のN末端コーディング領域に、続いて、IL-15のN末端コーディング領域に直接連結することによって構築物を作製した。
Example 60 Generation of TGFRt15-TGFRs137L Fusion Protein A fusion protein complex consisting of a TGFβ receptor II/IL-15RαSu/CD137L fusion protein and a TGFβ receptor II/TF/IL-15 fusion protein was generated (FIGS. 142 and 142). 143). Human TGFβ receptor II (Ile24-Asp159),
組織因子219のN末端に、続いて、IL-15のN末端に結合した2つのTGFβ受容体IIを含む構築物の核酸配列及びタンパク質配列を以下に示す。
The nucleic acid and protein sequences of a construct containing two TGFβ receptor II bound to the N-terminus of
TGFRt15構築物の核酸配列(シグナルペプチド配列を含む)は、以下の通りである。
(シグナルペプチド)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(ヒトTGFβ受容体II断片)
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC
(ヒト組織因子219)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(ヒトIL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
The nucleic acid sequence (including signal peptide sequence) of the TGFRt15 construct is as follows.
(signal peptide)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCC
(Human TGFβ receptor II fragment)
ATCCCCCCCCCATGTGCAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAA GAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGAACCTTCTTTATGTGTTCCTGTAGCAG CGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCC CCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCCACGATCCCCAAGCTGCCCTAC CACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCCGAC
(human tissue factor 219)
AGCGGCCAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAACCATCCTCGAATGGGAACCCAAACCCGTTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCG ATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCTTTATACGAGAACAGCCCCGAATTTACCCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCA CAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTAATCGACG TGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAGGGCGAGTTCCGGGAG
(human IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTACTGGAGCTGCCAAGTTATCTCTTTAGAGAGCGGGAGACGCTAGCAT CCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCCAAGGAGTGCGAAGAGCTGGAGGGAGAAGAACATCAAGGAGTTCTGCAATCCTTTGTGCCACATTGTCCAGATGTTCATCAATACCTCC
TGFRt15融合タンパク質のアミノ酸配列(リーダー配列を含む)は、以下の通りである。
(シグナルペプチド)
MKWVTFISLLFLFSSAYS
(ヒトTGFβ受容体II)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(ヒト組織因子219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(ヒトIL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
The amino acid sequence (including leader sequence) of the TGFRt15 fusion protein is as follows.
(signal peptide)
MKWVT FISLLFLFS SAYS
(human TGFβ receptor II)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNCSITSICEKPQEVCVAVWRKNDINITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPDGGGGGSGGGGGSGGGGSIPPHV QKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNSITSICEKPQEVCVAVWRKNDINITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(human tissue factor 219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTF LSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(human IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
2つのTGFβ受容体IIをGenewizによって合成したIL-15RαSu鎖に、続いて、(G4S)3リンカー及びCD137L配列に直接結合することによっても構築物を作製した。IL-15RαSuのN末端に、続いて、(G4S)3リンカー及びCD137L配列に結合したTGFβ受容体IIを含む構築物の核酸配列及びタンパク質配列を以下に示す。 Constructs were also made by linking two TGFβ receptor II directly to the IL-15RαSu chain synthesized by Genewiz, followed by the (G4S)3 linker and CD137L sequence. The nucleic acid and protein sequences of a construct containing TGFβ receptor II attached to the N-terminus of IL-15RαSu followed by a (G4S)3 linker and a CD137L sequence are shown below.
TGFRs137L構築物の核酸配列(シグナルペプチド配列を含む)は、以下の通りである。
(シグナルペプチド)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(ヒトTGFβ受容体II断片)
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC
(ヒトIL-15Rαスシドメイン)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
((G4S)3リンカー)
GGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCT
(ヒトCD137L)
CGCGAGGGTCCCGAGCTTTCGCCCGACGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATCCCAGCCGGACTCCCTTCACCGAGGTCGGAA
The nucleic acid sequence (including signal peptide sequence) of the TGFRs137L construct is as follows.
(signal peptide)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCC
(Human TGFβ receptor II fragment)
ATCCCCCCCCCATGTGCAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAA GAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGAACCTTCTTTATGTGTTCCTGTAGCAG CGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCC CCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCCACGATCCCCAAGCTGCCCTAC CACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCCGAC
(Human IL-15Rα sushi domain)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCT CTTTAAAGTGCATCCGG
((G4S)3 linker)
GGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGGCGGAGGATCT
(human CD137L)
CGCGAGGGTCCCGAGCTTTCGCCCCGACGATCCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCGCAGCTGGTGGCCCAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCCAGGCCTGGCAGGGCGTGTCCCTGACGGGGGGC CTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTG GCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGG GACTCTTCCGGGTGACCCCCGAAAATCCCAGCCGGACTCCCTTCACCGAGGTCGGAA
TGFRs137L融合タンパク質のアミノ酸配列(リーダー配列を含む)は、以下の通りである。
(シグナルペプチド)
MKWVTFISLLFLFSSAYS
(ヒトTGFβ受容体II)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(ヒトIL-15Rαスシドメイン)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
((G4S)3リンカー)
GGGGSGGGGSGGGGS
(ヒトCD137L)
REGPELSPDDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEIPAGLPSPRSE
The amino acid sequence (including the leader sequence) of the TGFRs137L fusion protein is as follows.
(signal peptide)
MKWVT FISLLFLFS SAYS
(human TGFβ receptor II)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNCSITSICEKPQEVCVAVWRKNDINITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPDGGGGGSGGGGGSGGGGSIPPHV QKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNSITSICEKPQEVCVAVWRKNDINITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(Human IL-15Rα sushi domain)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
((G4S)3 linker)
GGGGSGGGGSGGGGGS
(human CD137L)
REGPELSPDDPAGLLDLLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSSVSLALHLQPLRSAAGAAALALTVDLLPPASSEARNSAFGFQGRLLHLSAGQRLGV HLHTEARARHAWQLTQGATVLGLFRVTPEIPAGLPSPRSSE
いくつかの事例では、リーダーペプチドをインタクトなポリペプチドから切断して、可溶性であり得るか、又は分泌され得る成熟形態を生成する。 In some cases, the leader peptide is cleaved from the intact polypeptide to generate the mature form, which can be soluble or secreted.
TGFR/IL-15RαSu/CD137L構築物及びTGFR/TF/IL-15構築物を前述の修飾レトロウイルス発現ベクターにクローニングし(Hughes MS,Yu YY,Dudley ME,Zheng Z,Robbins PF,Li Y,et al.Transfer of a TCR gene derived from a patient with a marked antitumor response conveys highly active T-cell effector functions.Hum Gene Ther 2005;16:457-72)、発現ベクターをCHO-K1細胞にトランスフェクトした。CHO-K1細胞でのこれらの2つの構築物の共発現により、可溶性TGFR/TF/IL-15:TGFR/IL-15RαSu/CD137Lタンパク質複合体(TGFRt15-TGFRs137Lと称する)の形成及び分泌が可能になり、これを抗TF IgG1親和性及び他のクロマトグラフィー法によって精製することができる。
The TGFR/IL-15RαSu/CD137L and TGFR/TF/IL-15 constructs were cloned into modified retroviral expression vectors previously described (Hughes MS, Yu YY, Dudley ME, Zheng Z, Robbins PF, Li Y, et al. Transfer of a TCR gene derived from a patient with a marked antitumor response conveys highly active T-cell effector functions.
実施例61.例示的な一本鎖キメラポリペプチド2t2の産生及び特徴付け
IL-2受容体に結合する第1の標的結合ドメイン、可溶性ヒト組織因子ドメイン、及びIL-2受容体に結合する第2の標的結合ドメインを含む例示的な一本鎖キメラポリペプチドが生成された(IL-2/TF/IL-2、2t2と称される)(図144)。この一本鎖キメラポリペプチドの核酸及びアミノ酸配列を以下に示す。
例示的な一本鎖キメラポリペプチド(IL-2/TF/IL-2)をコードする核酸(配列番号164)
(シグナルペプチド)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(第1のIL-2断片)
GCCCCCACCTCCTCCTCCACCAAGAAGACCCAGCTGCAGCTGGAGCATTTACTGCTGGATTTACAGATGATTTTAAACGGCATCAACAACTACAAGAACCCCAAGCTGACTCGTATGCTGACCTTCAAGTTCTACATGCCCAAGAAGGCCACCGAGCTGAAGCATTTACAGTGTTTAGAGGAGGAGCTGAAGCCCCTCGAGGAGGTGCTGAATTTAGCCCAGTCCAAGAATTTCCATTTAAGGCCCCGGGATTTAATCAGCAACATCAACGTGATCGTTTTAGAGCTGAAGGGCTCCGAGACCACCTTCATGTGCGAGTACGCCGACGAGACCGCCACCATCGTGGAGTTTTTAAATCGTTGGATCACCTTCTGCCAGTCCATCATCTCCACTTTAACC
(ヒト組織因子219形態)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(第2のIL-2断片)
GCACCTACTTCAAGTTCTACAAAGAAAACACAGCTACAACTGGAGCATTTACTGCTGGATTTACAGATGATTTTGAATGGAATTAATAATTACAAGAATCCCAAACTCACCAGGATGCTCACATTTAAGTTTTACATGCCCAAGAAGGCCACAGAACTGAAACATCTTCAGTGTCTAGAAGAAGAACTCAAACCTCTGGAGGAAGTGCTAAATTTAGCTCAAAGCAAAAACTTTCACTTAAGACCCAGGGACTTAATCAGCAATATCAACGTAATAGTTCTGGAACTAAAGGGATCTGAAACAACATTCATGTGTGAATATGCTGATGAGACAGCAACCATTGTAGAATTTCTGAACAGATGGATTACCTTTTGTCAAAGCATCATCTCAACACTAACT
例示的な一本鎖キメラポリペプチド(IL-2/TF/IL-2)(配列番号163)
(シグナルペプチド)
MKWVTFISLLFLFSSAYS
(ヒトIL-2)
APTSSSTKKTQLQLEHLLLDLQMILNGINNYKNPKLTRMLTFKFYMPKKATELKHLQCLEEELKPLEEVLNLAQSKNFHLRPRDLISNINVIVLELKGSETTFMCEYADETATIVEFLNRWITFCQSIISTLT
(ヒト組織因子219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(ヒトIL-2)
APTSSSTKKTQLQLEHLLLDLQMILNGINNYKNPKLTRMLTFKFYMPKKATELKHLQCLEEELKPLEEVLNLAQSKNFHLRPRDLISNINVIVLELKGSETTFMCEYADETATIVEFLNRWITFCQSIISTLT
Example 61. Production and Characterization of an Exemplary Single Chain Chimeric Polypeptide 2t2 A First Target Binding Domain That Binds the IL-2 Receptor, a Soluble Human Tissue Factor Domain, and a Second Target Binding that Binds the IL-2 Receptor An exemplary single-chain chimeric polypeptide containing the domain was generated (IL-2/TF/IL-2, designated 2t2) (Figure 144). The nucleic acid and amino acid sequences of this single-chain chimeric polypeptide are shown below.
Nucleic Acid (SEQ ID NO: 164) Encoding an Exemplary Single Chain Chimeric Polypeptide (IL-2/TF/IL-2)
(signal peptide)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCC
(First IL-2 fragment)
GCCCCCACCTCCTCCTCCACCAAGAAGACCCAGCTGCAGCTGGAGCATTTACTGCTGGATTTACAGATGATTTTAAACGGCATCAACAACTACAAGAACCCCCAAGCTGACTCGTATGCTGACCTTCAAGTTTCTACATGCCCAAGAAGGCCACCGAGCTGAAGCATTTACAGTGTTTAGAGGAGGA GCTGAAGCCCCTCGAGGAGGTGCTGAATTTAGCCCAGTCCAAGAATTTCCATTTAAGGCCCCGGGATTTAATCAGCAACATCAACGTGATCGTTTTAGAGCTGAAGGGCTCCGAGACCACCTTCATGTGCGAGTACGCCGACGAGACCGCCACCATCGTGGAGTTTTTAAATCGTTGGG ATCACCTTCTGCCAGTTCCATCATCTCCACTTTAACC
(
AGCGGCCAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAACCATCCTCGAATGGGAACCCAAACCCGTTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCG ATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCTTTATACGAGAACAGCCCCGAATTTACCCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCA CAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTAATCGACG TGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAGGGCGAGTTCCGGGAG
(second IL-2 fragment)
GCACCTACTTCAAGTTTCTACAAAGAAAACACAGCTACAACTGGAGCATTTACTGCTGGATTTACAGATGATTTTGAATGGAATTAATAATTACAAGAATCCCAAACTCCACCAGGATGCTCACATTTTAAGTTTTTACATGCCCAGAAGGCCCACAGAACTGAACATCTTCAGTGTCTAGAAGA AGAACTCAAAACCTCTGGAGGAAGTGCTAAAATTTAGCTACAAAGCAAAACTTTCACTTAAGACCCAGGGACTTAATCAGCAATATCAACGTAATAGTTTCTGGAACTAAAGGGATCTGAAAACAATTCATGTGTGAATATGCTGATGAGACAGCAACCATTGTAGAATTTCTGAACAGATGGATTACCT TTTGTCAAAGCATCATCTCTCAACACTAACT
Exemplary Single Chain Chimeric Polypeptide (IL-2/TF/IL-2) (SEQ ID NO: 163)
(signal peptide)
MKWVT FISLLFLFS SAYS
(human IL-2)
APTSSSTKKTQLQLEHLLLDLQMILNGINNYKNPKLTRMLTFKFYMPKKATELKHLQCLEEELKPLEEVLNLAQSKNFHLRPRDLISNINVIVLKGSETTFMCEYADETATIVEFLNRWITFCQSIISTLT
(human tissue factor 219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTF LSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(human IL-2)
APTSSSTKKTQLQLEHLLLDLQMILNGINNYKNPKLTRMLTFKFYMPKKATELKHLQCLEEELKPLEEVLNLAQSKNFHLRPRDLISNINVIVLKGSETTFMCEYADETATIVEFLNRWITFCQSIISTLT
IL-2/TF/IL-2をコードする核酸を、以前に記載されたように(Hughes et al.,Hum Gene Ther16:457-72,2005)改変レトロウイルス発現ベクターにクローニングした。IL-2/TF/IL-2をコードする発現ベクターを、CHO-K1細胞にトランスフェクトした。CHO-K1細胞での発現ベクターの発現により、可溶性IL-2/TF/IL-2一本鎖キメラポリペプチド(2t2と称する)の分泌が可能になり、これを抗TF抗体アフィニティー及び他のクロマトグラフィー法によって精製することができる。 Nucleic acids encoding IL-2/TF/IL-2 were cloned into modified retroviral expression vectors as previously described (Hughes et al., Hum Gene Ther 16:457-72, 2005). An expression vector encoding IL-2/TF/IL-2 was transfected into CHO-K1 cells. Expression of the expression vector in CHO-K1 cells allowed secretion of a soluble IL-2/TF/IL-2 single-chain chimeric polypeptide (designated 2t2), which was analyzed for anti-TF antibody affinity and other chromatographic It can be purified by graphic methods.
IL-2及び2t2は、同様の様式でIL-2Rβ及び共通γ鎖含有32Dβ細胞増殖を促進した
2t2のIL-2活性を評価するために、IL-2Rβ及び共通γ鎖を発現する32Dβ細胞の増殖の促進について、2t2を組換えIL-2と比較した。IL-2依存性32Dβ細胞をIMDM-10%FBSで5回洗浄し、2×104細胞/ウェルでウェルに播種した。連続希釈した2t2又はIL-2を細胞に添加した(図145)。細胞をCO2インキュベーター内で、37℃で3日間インキュベートした。3日目に10μlのWST1を各ウェルに添加し、CO2インキュベーター内で、37℃で更に3時間インキュベートすることにより、細胞増殖を検出した。吸光度を450nmで測定することにより、生成されたホルマザン色素の量を分析した。図145に示されるように、2t2及びIL-2は、同様の様式において32Dβ細胞を活性化した。2t2及びIL-2のEC50は、それぞれ、158.1pM及び140pMであった。
IL-2 and 2t2 promoted IL-2Rβ and common γ chain-containing 32Dβ cell proliferation in a similar manner. 2t2 was compared to recombinant IL-2 for promotion of proliferation. IL-2-dependent 32Dβ cells were washed five times with IMDM-10% FBS and seeded in wells at 2×10 4 cells/well. Serial dilutions of 2t2 or IL-2 were added to the cells (Figure 145). Cells were incubated for 3 days at 37°C in a CO2 incubator. Cell proliferation was detected by adding 10 μl of WST1 to each well on
2t2は、IL-2と比較して、CTLL-2細胞増殖を含むIL-2Rαβγを促進する改善された能力を示した
2t2のIL-2活性を評価するために、IL-2Rα、IL-2Rβ、及び共通γ鎖を発現するCTLL-2細胞の増殖の促進について、2t2を組換えIL-2と比較した。IL-2依存性CTLL-2細胞をIMDM-10%FBSで5回洗浄し、2×104細胞/ウェルでウェルに播種した。連続希釈した2t2又はIL-2を細胞に添加した(図146)。細胞をCO2インキュベーター内で、37℃で3日間インキュベートした。3日目に10μlのWST1を各ウェルに添加し、CO2インキュベーター内で、37℃で更に3時間インキュベートすることにより、細胞増殖を検出した。吸光度を450nmで測定することにより、生成されたホルマザン色素の量を分析した。図146に示されるように、2t2は、IL-2よりも4~5倍強力にCTLL-2細胞の増殖を促進した。2t2のEC50は123.2pMであり、IL-2は548.2pMであった。
2t2 showed an improved ability to promote IL-2Rαβγ, including CTLL-2 cell proliferation compared to IL-2 To assess the IL-2 activity of 2t2, IL-2Rα, IL-2Rβ , and promotion of proliferation of CTLL-2 cells expressing the common γ chain, 2t2 was compared to recombinant IL-2. IL-2 dependent CTLL-2 cells were washed 5 times with IMDM-10% FBS and seeded in wells at 2×10 4 cells/well. Serial dilutions of 2t2 or IL-2 were added to the cells (Figure 146). Cells were incubated for 3 days at 37°C in a CO2 incubator. Cell proliferation was detected by adding 10 μl of WST1 to each well on
2t2は、ApoE-/-マウスにおける高脂肪誘発性高血糖の増加を抑制した
6週齢の雌ApoE-/-マウス(Jackson Lab)に、標準的な飼料食餌、又は21%脂肪、0.15%コレステロール、34.1%スクロース、19.5%カゼイン、及び15%デンプンを含む高脂肪食(TD88137、Harlan Laboratories)を与え、標準的な条件で維持した。7週目に、高脂肪食を与えたマウスは、対照群及び処理群にランダムに割り当てられた。次に、マウスは、3mg/kgの投薬量で皮下注射当たり2t2(処理群)又はPBS(飼料食餌群及び対照群)のいずれかを受けた。投与の3日後、マウスを一晩絶食させ、血液試料を後眼窩静脈叢穿刺によって収集した。一晩の空腹時グルコース値は、OneTouch血糖測定器を使用して測定した。図147に示されるように、結果は、2t2注射がApoE-/-マウスにおけるグルコース値の上昇を効果的に抑制することを示した。
2t2 suppressed hyperfat-induced increases in hyperglycemia in ApoE −/ − mice They were fed a high-fat diet (TD88137, Harlan Laboratories) containing % cholesterol, 34.1% sucrose, 19.5% casein, and 15% starch and maintained under standard conditions. At
2t2は、血液リンパ球においてCD4+CD25+FoxP3+T制御性(Treg)細胞の比率を大幅にアップレギュレートする
6週齢の雌ApoE-/-マウス(Jackson Lab)に、標準的な飼料食餌、又は21%脂肪、0.15%コレステロール、34.1%スクロース、19.5%カゼイン、及び15%デンプンを含む高脂肪食(TD88137、Harlan Laboratories)を与え、標準的な条件で維持した。7週目に、高脂肪食を与えたマウスを、対照群と処理群にランダムに割り当てた。次に、マウスは、3mg/kgの投薬量で皮下注射当たり2t2(処理群)又はPBS(飼料食餌群及び対照群)のいずれかを受けた。投与の3日後、一晩絶食後の血液試料を、後眼窩静脈叢穿刺によって採取し、ACK溶解緩衝液(Thermo Fisher Scientific)とともに37℃で5分間インキュベートした。その後、試料を、FACS緩衝液(0.5%BSA(EMD Millipore)及び0.001%アジ化ナトリウム(Sigma)を含む1X PBS(Hyclone))中に再懸濁し、FITC-抗CD4及びAPC-抗CD25抗体(BioLegend)で30分間表面染色した。表面染色した試料を更に固定し、Fix/Perm緩衝液(BioLegend)でプレメタライズし、PE-抗Foxp3抗体(BioLegend)で細胞内染色した。染色後、細胞をFACs緩衝液で2回洗浄した後、1500RPMで、室温で5分間遠心分離した。細胞をフローサイトメトリー(Celesta-BD Bioscience)によって分析した。図148に示されるように、2t2処理は、未処理群(固形食群では0.4%±0.16、高脂肪食群では0.46%±0.09)と比較して、血中リンパ球のTreg集団を著しく増加させた(3.5%±0.32)。
2t2 significantly upregulates the proportion of CD4 + CD25 + FoxP3 + T regulatory (Treg) cells in blood lymphocytes Six-week-old female ApoE −/− mice (Jackson Lab) were fed a standard chow diet. , or a high-fat diet containing 21% fat, 0.15% cholesterol, 34.1% sucrose, 19.5% casein, and 15% starch (TD88137, Harlan Laboratories) and maintained under standard conditions. At
抗TF抗体親和性カラムからの2t2の精製溶出クロマトグラフ
細胞培養物から収集した2t2を、5カラム体積のPBSで平衡化した抗TF抗体親和性カラムにロードした。試料をロードした後、カラムを5カラム体積のPBSで洗浄し、その後、6カラム体積の0.1M酢酸(pH2.9)で溶出した。A280溶出ピークを収集し、その後、1Mトリス塩基でpH7.5~8.0に中和した。その後、中和した試料を、分子量カットオフ30kDaでAmicon遠心フィルターを使用してPBSに緩衝液交換した。図149に示されるように、抗TF抗体親和性カラムは、融合ドメインとしてTFを含む2t2に結合した。緩衝液交換したタンパク質試料を、更なる生化学的分析及び生物学的活性試験のために2~8℃で保管した。各溶出後、抗TF抗体アフィニティーカラムを6カラム体積の0.1Mグリシン(pH2.5)を使用してストリッピングした。その後、カラムを、保管のために5カラム体積のPBS及び7カラム体積の20%エタノールを使用して中和した。抗TF抗体アフィニティーカラムを、GE Healthcare AKTA Avantシステムに接続した。流速は、2mL/分の溶出ステップを除く全てのステップで4mL/分であった。
Purification Elution Chromatography of 2t2 from Anti-TF Antibody Affinity Column 2t2 harvested from cell culture was loaded onto an anti-TF antibody affinity column equilibrated with 5 column volumes of PBS. After sample loading, the column was washed with 5 column volumes of PBS and then eluted with 6 column volumes of 0.1 M acetic acid (pH 2.9). The A280 elution peak was collected and then neutralized to pH 7.5-8.0 with 1M Tris base. Neutralized samples were then buffer exchanged into PBS using Amicon centrifugal filters with a molecular weight cutoff of 30 kDa. As shown in Figure 149, the anti-TF antibody affinity column bound 2t2 containing TF as the fusion domain. Buffer-exchanged protein samples were stored at 2-8° C. for further biochemical analysis and biological activity testing. After each elution, the anti-TF antibody affinity column was stripped using 6 column volumes of 0.1 M glycine (pH 2.5). The column was then neutralized using 5 column volumes of PBS and 7 column volumes of 20% ethanol for storage. The anti-TF antibody affinity column was connected to a GE Healthcare AKTA Avant system. The flow rate was 4 mL/min for all steps except the 2 mL/min elution step.
2t2の分析的サイズ排除クロマトグラフィー(SEC)分析
分析的サイズ排除クロマトグラフィー(SEC)を使用して2t2を分析するために、Superdex 200 Increase 10/300 GLゲル濾過カラム(GE Healthcare製)をAKTA Avantシステム(GE Healthcare製)に接続した。カラムを2カラム体積のPBSで平衡化した。流速は0.7mL/分であった。PBS中2t2を含む試料を、キャピラリーループを使用してSuperdex 200カラムに注入し、SECによって分析した。試料のSECクロマトグラフを図150に示す。SECの結果は、2t2の2つのタンパク質ピークを示した。
Analytical Size Exclusion Chromatography (SEC) Analysis of 2t2 To analyze 2t2 using analytical size exclusion chromatography (SEC), a
2t2の還元SDS-PAGE
タンパク質の純度及び分子量を決定するために、抗TF抗体親和性カラムで精製した2t2タンパク質試料を、還元条件下でドデシル硫酸ナトリウムポリアクリルアミドゲル(4~12%NuPageビス-トリスゲル)電気泳動(SDS-PAGE)法によって分析した。電気泳動後、ゲルをInstantBlueで約30分間染色し、その後、精製水中で一晩脱色した。
Reducing SDS-PAGE of 2t2
To determine protein purity and molecular weight, anti-TF antibody affinity column purified 2t2 protein samples were subjected to sodium dodecyl sulfate polyacrylamide gel (4-12% NuPage Bis-Tris gel) electrophoresis (SDS- PAGE) method. After electrophoresis, gels were stained with InstantBlue for approximately 30 minutes and then destained overnight in purified water.
2t2タンパク質がCHO細胞において翻訳後にグリコシル化を受けることを検証するために、脱グリコシル化実験を、New England Biolabs製のProtein Deglycosylation Mix IIキットを製造業者の指示に従って使用して実施した。図151A及び151Bは、非脱グリコシル化状態(赤色の縁内のレーン1)及び脱グリコシル化状態(黄色の縁内のレーン2)での試料の還元SDS-PAGE分析を示す。結果は、2t2タンパク質がCHO細胞で発現されるとグリコシル化されることを示した。脱グリコシル化後、精製した試料は、還元SDSゲル中で予想された分子量(56kDa)で処理された。レーンMには、10μLのSeeBlue Plus2 Prestained Standardをロードした。
To verify that the 2t2 protein undergoes post-translational glycosylation in CHO cells, deglycosylation experiments were performed using the Protein Deglycosylation Mix II kit from New England Biolabs according to the manufacturer's instructions. Figures 151A and 151B show reducing SDS-PAGE analysis of samples in the non-deglycosylated state (
2t2のインビボ特徴付け
2t2をC57BL/6マウスに様々な用量で皮下注射し、インビボでの2t2の免疫刺激活性を決定した。マウスを、対照溶液(PBS)又は0.1、0.4、2、及び10mg/kgの2t2で皮下処理した。処理したマウスを、処理後3日目に安楽死させた。マウスの脾臓を採取し、処理後3日目に秤量した。単一脾細胞懸濁液を調製し、調製した脾細胞をCD4+T細胞、CD8+T細胞、及びNK細胞(蛍光色素結合抗CD4、抗CD8、及び抗NK1.1抗体で)を染色し、フローサイトメトリーによって分析した。結果は、脾臓重量に基づいて、2t2が特に0.1~10mg/kgで脾臓細胞を増殖させるのに効果的であることを示した(図152A)。CD8+T細胞のパーセンテージは、2及び10mg/kgで対照処理マウスと比較して高かった(図152B)。NK細胞のパーセンテージは、試験した全ての用量で対照処理マウスと比較して高かった(図152B)。
In Vivo Characterization of 2t2 2t2 was injected subcutaneously into C57BL/6 mice at various doses to determine the immunostimulatory activity of 2t2 in vivo. Mice were treated subcutaneously with control solution (PBS) or 0.1, 0.4, 2, and 10 mg/kg of 2t2. Treated mice were euthanized 3 days after treatment. Spleens of mice were harvested and weighed 3 days after treatment. A single splenocyte suspension was prepared and the prepared splenocytes were stained for CD4 + T cells, CD8 + T cells, and NK cells (with fluorochrome-conjugated anti-CD4, anti-CD8, and anti-NK1.1 antibodies). , analyzed by flow cytometry. The results showed that 2t2 was effective in expanding splenocytes, especially at 0.1-10 mg/kg, based on spleen weight (Figure 152A). The percentage of CD8 + T cells was higher compared to control treated mice at 2 and 10 mg/kg (Fig. 152B). The percentage of NK cells was higher compared to control-treated mice at all doses tested (Fig. 152B).
IL-2が免疫細胞によるCD25発現をアップレギュレートすることが知られている。したがって、2t2処理マウスにおけるCD4+T細胞、CD8+T細胞、及びNK細胞のCD25発現にアクセスした。上記の段落で説明したように、C57BL/6マウスを2t2で皮下処理した。脾細胞を、蛍光色素結合抗CD4、抗CD8、CD25、及びNK1.1モノクローナル抗体で染色した。脾細胞サブセットのCD25発現(MFI)をフローサイトメトリーによって分析した。図153に示されるように、試験した用量及び時点で、2t2は、CD4+T細胞によるCD25発現を有意にアップレギュレートしたが、CD8+T細胞又はNK細胞ではアップレギュレートしなかった。 IL-2 is known to upregulate CD25 expression by immune cells. Therefore, CD25 expression on CD4 + T cells, CD8 + T cells, and NK cells in 2t2-treated mice was accessed. C57BL/6 mice were treated subcutaneously with 2t2 as described in the paragraph above. Splenocytes were stained with fluorochrome-conjugated anti-CD4, anti-CD8, CD25, and NK1.1 monoclonal antibodies. CD25 expression (MFI) of splenocyte subsets was analyzed by flow cytometry. As shown in Figure 153, at the doses and time points tested, 2t2 significantly upregulated CD25 expression by CD4 + T cells, but not CD8 + T cells or NK cells.
C57BL/6マウスにおける2t2の薬物動態も調査した。2t2を、C57BL/6マウスに1mg/kgで皮下注射した。マウスの血液を、図154に示されるように、様々な時点で尾静脈から排出し、血清を調製した。2t2濃度を、ELISAを用いて測定した(捕捉:抗組織因子抗体;検出:ビオチン化抗ヒトIL-2抗体、その後SA-HRP及びABTS基質)。2t2の半減期は、PK Solutions2.0(Summit Research Services)を用いて計算して1.83時間であった。 The pharmacokinetics of 2t2 in C57BL/6 mice was also investigated. 2t2 was injected subcutaneously into C57BL/6 mice at 1 mg/kg. Mice were bled from the tail vein at various time points and sera were prepared, as shown in FIG. 2t2 concentrations were measured using an ELISA (capture: anti-tissue factor antibody; detection: biotinylated anti-human IL-2 antibody followed by SA-HRP and ABTS substrate). The half-life of 2t2 was 1.83 hours calculated using PK Solutions 2.0 (Summit Research Services).
2t2は、ApoE-/-マウスにおける高脂肪誘発性アテローム性動脈硬化症プラークの形成を減弱した
6週齢の雌ApoE-/-マウス(Jackson Laboratory)に、標準的な飼料食餌、又は高脂肪食(21%脂肪、0.15%コレステロール、34.1%スクロース、19.5%カゼイン、及び15%デンプン)(TD88137、Harlan Laboratories)を与え、標準的な条件で維持した。7週目に、高脂肪食(HFD)を与えたマウスを、対照群と処理群にランダムに割り当てた。その後、マウスに、3mg/kgの投薬量で2t2(処理群)又はPBS(固形食群及び対照群)のいずれかを4週間毎週皮下投与した。12週目に、全てのマウスをイソフルランにより安楽死させた。大動脈を収集し、縦方向に開き、正面法を使用してスーダンIV溶液(0.5%)で染色した。その後、総大動脈面積に対するプラーク面積(図155Aに示されるように、赤色)のパーセンテージを、ImageJソフトウェアで定量化した。図155Aは、各群からのアテローム性動脈硬化症のプラークの代表的な図を示す。図155Bは、各群のアテローム性動脈硬化症のプラークの定量分析の結果を示す。対照群(HF食)のプラーク面積のパーセンテージは、処理群(HFD+2t2)よりもはるかに高く、10.28%対4.68%であった。
2t2 Attenuated High Fat-Induced Atherosclerotic Plaque Formation in ApoE −/ − Mice (21% fat, 0.15% cholesterol, 34.1% sucrose, 19.5% casein, and 15% starch) (TD88137, Harlan Laboratories) and maintained under standard conditions. At
2t2は2型糖尿病の進行を抑制する
雄BKS.Cg-Dock7m+/+Leprdb/J(db/db(Jackson Lab))マウスに、標準的な飼料食餌を与え、飲料水を自由に受けた。6週齢で、マウスは、対照群及び処理群にランダムに割り当てられた。処理群は、隔週で3mg/kgの皮下注射により2t2を投与されたが、一方で、対照群は、ビヒクル(PBS)のみを投与された。一晩の空腹時グルコース値は、OneTouch血糖測定器を使用して毎週測定した。結果は、2t2がBKS.Cg-Dock7m+/+Leprdb/Jマウスにおけるグルコース値の上昇を効果的に抑制したことを示した(図156)。
2t2 suppresses
2t2は、最初の注射後、血液リンパ球においてCD4+CD25+FoxP3+T制御性細胞の比率を大幅にアップレギュレートする
雄BKS.Cg-Dock7m+/+Leprdb/J(db/db)(Jackson Laboratory)マウスに、標準的な飼料食餌を与え、飲料水を自由に受けた。6週齢で、マウスは、対照群及び処理群にランダムに割り当てられた。処理群は、隔週で3mg/kgの皮下注射により2t2を投与されたが、一方で、対照群は、ビヒクル(PBS)のみを投与された。最初の薬物注射の4日後、一晩の空腹時血液試料を収集し、ACK溶解緩衝液(Thermo Fisher Scientific)と37℃で5分間インキュベートした。その後、試料を、FACS緩衝液(0.5%BSA(EMD Millipore)及び0.001%アジ化ナトリウム(Sigma)を含む1×PBS(Hyclone))中に再懸濁し、FITC-抗CD4及びAPC-抗CD25抗体(BioLegend)で30分間表面染色した。表面染色した試料を更に固定し、Fix/Perm緩衝液(BioLegend)でプレメタライズし、PE-抗Fox p3抗体(BioLegend)で細胞内染色した。染色後、細胞をFACs緩衝液で2回洗浄し、フローサイトメトリー(Celesta-BD Bioscience)によって分析した。血中リンパ球中のCD4+CD25+FoxP3+Tregsのパーセンテージを測定した。図157に示されるように、結果は、2t2が血中リンパ球のTregsの比率を有意にアップレギュレートすることを示した(*p<0.05)。
2t2 significantly upregulates the proportion of CD4 + CD25 + FoxP3 + T regulatory cells in blood lymphocytes after the first injection Male BKS. Cg-Dock7 m +/+Lepr db /J(db/db) (Jackson Laboratory) mice were fed a standard chow diet and had access to drinking water ad libitum. At 6 weeks of age, mice were randomly assigned to control and treatment groups. The treatment group received 2t2 by subcutaneous injection at 3 mg/kg every other week, while the control group received vehicle only (PBS). Four days after the first drug injection, overnight fasting blood samples were collected and incubated with ACK lysis buffer (Thermo Fisher Scientific) for 5 minutes at 37°C. Samples were then resuspended in FACS buffer (1×PBS (Hyclone) containing 0.5% BSA (EMD Millipore) and 0.001% sodium azide (Sigma)) and FITC-anti-CD4 and APC were - Surface staining with anti-CD25 antibody (BioLegend) for 30 minutes. Surface-stained samples were further fixed, premetallized with Fix/Perm buffer (BioLegend) and intracellularly stained with PE-anti-Fox p3 antibody (BioLegend). After staining, cells were washed twice with FACs buffer and analyzed by flow cytometry (Celesta-BD Bioscience). The percentage of CD4 + CD25 + FoxP3 + Tregs in blood lymphocytes was measured. As shown in Figure 157, the results showed that 2t2 significantly upregulated the proportion of Tregs in blood lymphocytes (*p<0.05).
実施例62.例示的な一本鎖キメラポリペプチド15t15の産生及び特徴付け
IL-15受容体に結合する第1の標的結合ドメイン、可溶性ヒト組織因子ドメイン、及びIL-15受容体に結合する第2の標的結合ドメインを含む第2の例示的な一本鎖キメラポリペプチドが生成された(IL-15/TF/IL-15、15t15と称される)(図158)。この一本鎖キメラポリペプチドの核酸及びアミノ酸配列を以下に示す。
例示的な一本鎖キメラポリペプチド(IL-15/TF/IL-15)をコードする核酸(配列番号170)
(シグナルペプチド)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(第1のIL-15断片)
AACTGGGTGAACGTGATCAGCGATTTAAAGAAGATCGAGGATTTAATCCAGAGCATGCACATCGACGCCACTCTGTACACTGAGAGCGACGTGCACCCTAGCTGCAAGGTGACTGCCATGAAGTGCTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGCGATGCCAGCATCCACGACACTGTGGAGAATTTAATCATTTTAGCCAACAACTCTTTAAGCAGCAACGGCAACGTGACAGAGAGCGGCTGCAAGGAGTGCGAGGAGCTGGAGGAGAAGAACATCAAGGAGTTTTTACAGAGCTTCGTGCACATCGTGCAGATGTTCATCAACACTAGC
(ヒト組織因子219形態)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(第2のIL-15断片)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
例示的な一本鎖キメラポリペプチド(IL-15/TF/IL-15)(配列番号169)
(シグナルペプチド)
MKWVTFISLLFLFSSAYS
(ヒトIL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
(ヒト組織因子219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(ヒトIL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
Example 62. Production and Characterization of an Exemplary Single Chain Chimeric Polypeptide 15t15 A First Target Binding Domain That Binds the IL-15 Receptor, a Soluble Human Tissue Factor Domain, and a Second Target Binding that Binds the IL-15 Receptor A second exemplary single-chain chimeric polypeptide containing the domain was generated (IL-15/TF/IL-15, designated 15t15) (Figure 158). The nucleic acid and amino acid sequences of this single-chain chimeric polypeptide are shown below.
Nucleic Acid (SEQ ID NO: 170) Encoding an Exemplary Single Chain Chimeric Polypeptide (IL-15/TF/IL-15)
(signal peptide)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCC
(First IL-15 fragment)
AACTGGGTGAACGTGATCAGCGATTTAAAGAAGATCGAGGATTTAATCCAGAGCATGCACATCGACGCCCACTCTGTACACTGAGAGCGACGTGCACCCTAGGCTGCAAGGTGACTGCCATGAAGTGCTTTTTACTGGAGCTGCCAAGTTATCTCTTTAGAGAGCGGCGATGCCAG CATCCACGACACTGTGGAGAATTTAATCATTTTAGCCAACAACTCTTTAAGCAGCAACGGCAACGTGACAGAGAGCGGCTGCAAGGAGTGCGAGGAGCTGGAGGGAGAAGAACATCAAGGAGTTTTTACAGAGCTTCGTGCACATCGTGCAGATGTTCATCAACACTTAGC
(
AGCGGCCAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAACCATCCTCGAATGGGAACCCAAACCCGTTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCG ATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCTTTATACGAGAACAGCCCCGAATTTACCCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCA CAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTAATCGACG TGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAGGGCGAGTTCCGGGAG
(second IL-15 fragment)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTACTGGAGCTGCCAAGTTATCTCTTTAGAGAGCGGGAGACGCTAGCAT CCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCCAAGGAGTGCGAAGAGCTGGAGGGAGAAGAACATCAAGGAGTTCTGCAATCCTTTGTGCCACATTGTCCAGATGTTCATCAATACCTCC
Exemplary Single Chain Chimeric Polypeptide (IL-15/TF/IL-15) (SEQ ID NO: 169)
(signal peptide)
MKWVT FISLLFLFS SAYS
(human IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
(human tissue factor 219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTF LSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(human IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
IL-15/TF/IL-15をコードする核酸を、以前に記載されるように(Hughes et al.,Hum Gene Ther 16:457-72,2005)修飾レトロウイルス発現ベクターにクローニングした。IL-15/TF/IL-15をコードする発現ベクターを、CHO-K1細胞にトランスフェクトした。CHO-K1細胞での発現ベクターの発現により、可溶性IL-15/TF/IL-15一本鎖キメラポリペプチド(15t15と称する)の分泌が可能になり、これを抗TF抗体親和性及び他のクロマトグラフィー法によって精製することができる。 Nucleic acids encoding IL-15/TF/IL-15 were cloned into modified retroviral expression vectors as previously described (Hughes et al., Hum Gene Ther 16:457-72, 2005). Expression vectors encoding IL-15/TF/IL-15 were transfected into CHO-K1 cells. Expression of the expression vector in CHO-K1 cells allowed secretion of a soluble IL-15/TF/IL-15 single-chain chimeric polypeptide (designated 15t15), which was tested for anti-TF antibody affinity and other It can be purified by chromatographic methods.
15t15は、IL-2Rβ及び共通γ鎖含有32Dβ細胞の増殖を促進する
15t15のIL-15活性を、IL2Rβ及び共通γ鎖発現32Dβ細胞において組換えIL-15と比較した。IL-15依存性32Dβ細胞をIMDM-10%FBSで5回洗浄し、ウェルに2×104細胞/ウェルで播種した。連続希釈した15t15又はIL-15を細胞に添加した(図159)。細胞をCO2インキュベーター内で、37℃で3日間インキュベートした。3日目に10μlのWST1を各ウェルに添加し、CO2インキュベーター内で、37℃で更に3時間インキュベートすることにより、細胞増殖を検出した。吸光度を450nmで測定することにより、生成されたホルマザン色素の量を分析した。図159に示されるように、15t15は、IL-15と比較して32Dβ細胞の増殖を効率的に促進しなかった。15t15及びIL-15のEC50は、それぞれ、161.4pM及び1.6pMであった。
15t15 Promotes Proliferation of IL-2Rβ and Common γ Chain Containing 32Dβ Cells The IL-15 activity of 15t15 was compared to recombinant IL-15 in IL2Rβ and common γ chain expressing 32Dβ cells. IL-15 dependent 32Dβ cells were washed 5 times with IMDM-10% FBS and seeded in wells at 2×10 4 cells/well. Serial dilutions of 15t15 or IL-15 were added to the cells (Figure 159). Cells were incubated for 3 days at 37°C in a CO2 incubator. Cell proliferation was detected by adding 10 μl of WST1 to each well on
抗TF抗体親和性カラムからの15t15の精製溶出クロマトグラフ
細胞培養物から収集した15t15を、5カラム体積のPBSで平衡化した抗TF抗体親和性カラムにロードした。試料をロードした後、カラムを5カラム体積のPBSで洗浄し、その後、6カラム体積の0.1M酢酸(pH2.9)で溶出した。A280溶出ピークを収集し、その後、1Mトリス塩基でpH7.5~8.0に中和した。その後、中和した試料を、分子量カットオフ30kDaでAmicon遠心フィルターを使用してPBSに緩衝液交換した。図160に示されるように、抗TF抗体アフィニティーカラムは、融合ドメインとしてTFを含む15t15に結合した。緩衝液交換したタンパク質試料を、更なる生化学的分析及び生物学的活性試験のために2~8℃で保管した。各溶出後、抗TF抗体アフィニティーカラムを6カラム体積の0.1Mグリシン(pH2.5)を使用してストリッピングした。その後、カラムを、保管のために5カラム体積のPBS及び7カラム体積の20%エタノールを使用して中和した。抗TF抗体アフィニティーカラムを、GE Healthcare AKTA Avantシステムに接続した。流速は、2mL/分の溶出ステップを除く全てのステップで4mL/分であった。
Purification Elution Chromatography of 15t15 from Anti-TF Antibody Affinity Column 15t15 harvested from cell culture was loaded onto an anti-TF antibody affinity column equilibrated with 5 column volumes of PBS. After sample loading, the column was washed with 5 column volumes of PBS and then eluted with 6 column volumes of 0.1 M acetic acid (pH 2.9). The A280 elution peak was collected and then neutralized to pH 7.5-8.0 with 1M Tris base. Neutralized samples were then buffer exchanged into PBS using Amicon centrifugal filters with a molecular weight cutoff of 30 kDa. As shown in Figure 160, the anti-TF antibody affinity column bound to 15t15 containing TF as the fusion domain. Buffer-exchanged protein samples were stored at 2-8° C. for further biochemical analysis and biological activity testing. After each elution, the anti-TF antibody affinity column was stripped using 6 column volumes of 0.1 M glycine (pH 2.5). The column was then neutralized using 5 column volumes of PBS and 7 column volumes of 20% ethanol for storage. The anti-TF antibody affinity column was connected to a GE Healthcare AKTA Avant system. The flow rate was 4 mL/min for all steps except the 2 mL/min elution step.
15t15の還元SDS-PAGE
タンパク質の純度及び分子量を決定するために、抗TF抗体親和性カラムで精製した15t15タンパク質試料を、還元条件下でドデシル硫酸ナトリウムポリアクリルアミドゲル(4~12%NuPageビス-トリスゲル)電気泳動(SDS-PAGE)法によって分析した。電気泳動後、ゲルをInstantBlueで約30分間染色し、その後、精製水中で一晩脱色した。
Reducing SDS-PAGE of 15t15
To determine protein purity and molecular weight, anti-TF antibody affinity column purified 15t15 protein samples were subjected to sodium dodecyl sulfate polyacrylamide gel (4-12% NuPage Bis-Tris gel) electrophoresis (SDS- PAGE) method. After electrophoresis, gels were stained with InstantBlue for approximately 30 minutes and then destained overnight in purified water.
15t15タンパク質がCHO細胞において翻訳後にグリコシル化を受けることを検証するために、脱グリコシル化実験を、New England Biolabs製のProtein Deglycosylation Mix IIキット及び製造業者の指示を使用して実施した。図161A及び161Bは、非脱グリコシル化状態(赤色の縁内のレーン1)及び脱グリコシル化状態(黄色の縁内のレーン2)での試料の還元SDS-PAGE分析を示す。結果は、15t15タンパク質がCHO細胞で発現されるとグリコシル化されることを示した。脱グリコシル化後、精製した試料は、還元SDSゲル中で予想された分子量(50kDa)で処理された。レーンMには、10μLのSeeBlue Plus2 Prestained Standardをロードした。
To verify that the 15t15 protein undergoes post-translational glycosylation in CHO cells, deglycosylation experiments were performed using the Protein Deglycosylation Mix II kit from New England Biolabs and the manufacturer's instructions. Figures 161A and 161B show reducing SDS-PAGE analysis of samples in the non-deglycosylated state (
実施例63:インビトロでのNK細胞の刺激
18t15-12s、18t15-12s16、及び7t15-21s+抗TF抗体で刺激した後のNK細胞の表面表現型の変化を評価するために一連の実験を行った。これらの実験では、新鮮なヒト白血球を血液バンクから入手し、CD56+NK細胞をRosetteSep/ヒトNK細胞試薬(StemCell Technologies)で単離した。NK細胞の純度は90%超であり、CD56-BV421、CD16-BV510、CD25-PE、及びCD69-APCFire750抗体(BioLegend)で染色することによって確認した。細胞をカウントし、0.2mLの完全培地(RPMI 1640(Gibco)、2mMのL-グルタミン(Thermo Life Technologies)、ペニシリン(Thermo Life Technologies)、ストレプトマイシン(Thermo Life Technologies)、及び10%FBS(Hyclone)を補充)中の96ウェル平底プレートに0.2×106/mLで再懸濁した。細胞を、18t15-12s(100nM)、18t15-12s16(100nM)、単一サイトカインrhIL-15(50ng/mL)(Miltenyi)とrhIL18(50ng/mL)(Invivogen)とrhIL-12(10ng/mL)(Peprotech)との混合物、7t15-21s+抗TF抗体(100nM~50nM)、7t15-21s(100nM)、又は抗TF抗体(50nM)で、37℃及び5%CO2で16時間刺激した。翌日、細胞を収集し、CD56、CD16、CD25、CD69、CD27、CD62L、NKp30、及びNKp44に特異的な抗体で30分間表面染色した。表面染色後、細胞を、FACS緩衝液(1×PBS(Hyclone)、0.5%BSA(EMD Millipore)及び0.001%アジ化ナトリウム(Sigma)を含む)中で洗浄した(1500RPM、室温で5分間)。2回洗浄した後、細胞をフローサイトメトリー(Celesta-BD Bioscience)によって分析した。図162A及び162Bは、精製NK細胞を18t15-12s、18t15-12s16、又は7t15-21s+抗TF抗体と一晩インキュベートすることにより、CD25、CD69、NKp44、及びNKp30活性化マーカーを発現する細胞のパーセンテージが増加し、CD62Lを発現する細胞のパーセンテージを減少したことを示す。全ての活性化マーカーデータは、CD56+ゲートリンパ球からのものである。
Example 63: In Vitro Stimulation of NK Cells A series of experiments were performed to assess changes in the surface phenotype of NK cells following stimulation with 18t15-12s, 18t15-12s16, and 7t15-21s plus anti-TF antibodies. . For these experiments, fresh human leukocytes were obtained from a blood bank and CD56 + NK cells were isolated with RosetteSep/human NK cell reagent (StemCell Technologies). NK cell purity was greater than 90% and confirmed by staining with CD56-BV421, CD16-BV510, CD25-PE, and CD69-APCFire750 antibodies (BioLegend). Cells were counted and added to 0.2 mL complete medium (RPMI 1640 (Gibco), 2 mM L-glutamine (Thermo Life Technologies), penicillin (Thermo Life Technologies), streptomycin (Thermo Life Technologies), and 10% FBS (Hyclon e) resuspended at 0.2×10 6 /mL in a 96-well flat-bottom plate in Cells were treated with 18t15-12s (100 nM), 18t15-12s16 (100 nM), the single cytokines rhIL-15 (50 ng/mL) (Miltenyi) and rhIL18 (50 ng/mL) (Invivogen) and rhIL-12 (10 ng/mL). (Peprotech), 7t15-21s plus anti-TF antibody (100 nM-50 nM), 7t15-21s (100 nM), or anti-TF antibody (50 nM) for 16 h at 37° C. and 5% CO 2 . The next day, cells were harvested and surface stained with antibodies specific for CD56, CD16, CD25, CD69, CD27, CD62L, NKp30, and NKp44 for 30 minutes. After surface staining, cells were washed (1500 RPM at room temperature) in FACS buffer containing 1×PBS (Hyclone), 0.5% BSA (EMD Millipore) and 0.001% sodium azide (Sigma). 5 minutes). After washing twice, cells were analyzed by flow cytometry (Celesta-BD Bioscience). Figures 162A and 162B show the percentage of cells expressing CD25, CD69, NKp44, and NKp30 activation markers by overnight incubation of purified NK cells with 18t15-12s, 18t15-12s16, or 7t15-21s plus anti-TF antibody. increased and decreased the percentage of cells expressing CD62L. All activation marker data are from CD56 + gated lymphocytes.
18t15-12s、18t15-12s16、及び7t15-21sで刺激した後のリンパ球集団の表面表現型の変化を評価するために一連の実験を行った。これらの実験では、新鮮なヒト白血球を血液バンクから入手した。末梢血リンパ球を、Ficoll-PAQUE Plus(GE Healthcare)密度勾配培地で単離した。細胞をカウントし、0.2mLの完全培地(RPMI 1640(Gibco)、2mMのL-グルタミン(Thermo Life Technologies)、ペニシリン(Thermo Life Technologies)、ストレプトマイシン(Thermo Life Technologies)、及び10%FBS(Hyclone)を補充)中の96ウェル平底プレートに0.2×106/mLで再懸濁した。細胞を、18t15-12s(100nM)、18t15-12s16(100nM)、単一サイトカインrhIL-15(50ng/mL)(Miltenyi)とrhIL18(50ng/mL)(Invivogen)とrhIL-12(10ng/mL)(Peprotech)との混合物、7t15-21s(100nM)+抗TF抗体(50nM)、7t15-21s(100nM)、又は抗TF抗体(50nM)で、37℃及び5%CO2で16時間刺激した。翌日、細胞を収集し、CD4又はCD8、CD62L、及びCD69に特異的な抗体で30分間表面染色した。表面染色後、細胞を、FACS緩衝液(1×PBS(Hyclone)、0.5%BSA(EMD Millipore)及び0.001%アジ化ナトリウム(Sigma)を含む)中で洗浄した(1500RPM、室温で5分間)。2回洗浄した後、細胞をフローサイトメトリー(Celesta-BD Bioscience)によって分析した。図163は、精製リンパ球集団(CD4及びCD8 T細胞)を18t15-12s、18t15-12s16、又は7t15-21s+抗TF抗体と一晩インキュベートすることにより、CD69を発現するCD8及びCD4 T細胞のパーセンテージが増加したことを示す。更に、7t15-21s+抗TF抗体とインキュベートすることにより、CD62Lを発現するCD8及びCD4 T細胞のパーセンテージが増加した(図163)。 A series of experiments were performed to assess changes in the surface phenotype of lymphocyte populations following stimulation with 18t15-12s, 18t15-12s16, and 7t15-21s. For these experiments, fresh human leukocytes were obtained from a blood bank. Peripheral blood lymphocytes were isolated on Ficoll-PAQUE Plus (GE Healthcare) density gradient medium. Cells were counted and added to 0.2 mL complete medium (RPMI 1640 (Gibco), 2 mM L-glutamine (Thermo Life Technologies), penicillin (Thermo Life Technologies), streptomycin (Thermo Life Technologies), and 10% FBS (Hyclon e) resuspended at 0.2×10 6 /mL in a 96-well flat-bottom plate in Cells were treated with 18t15-12s (100 nM), 18t15-12s16 (100 nM), the single cytokines rhIL-15 (50 ng/mL) (Miltenyi) and rhIL18 (50 ng/mL) (Invivogen) and rhIL-12 (10 ng/mL). (Peprotech), 7t15-21s (100 nM) plus anti-TF antibody (50 nM), 7t15-21s (100 nM), or anti-TF antibody (50 nM) for 16 h at 37° C. and 5% CO 2 . The next day, cells were harvested and surface stained with antibodies specific for CD4 or CD8, CD62L, and CD69 for 30 minutes. After surface staining, cells were washed (1500 RPM at room temperature) in FACS buffer containing 1×PBS (Hyclone), 0.5% BSA (EMD Millipore) and 0.001% sodium azide (Sigma). 5 minutes). After washing twice, cells were analyzed by flow cytometry (Celesta-BD Bioscience). Figure 163 shows the percentage of CD8 and CD4 T cells expressing CD69 by overnight incubation of purified lymphocyte populations (CD4 and CD8 T cells) with 18t15-12s, 18t15-12s16, or 7t15-21s plus anti-TF antibody. increased. Furthermore, incubation with 7t15-21s plus anti-TF antibody increased the percentage of CD8 and CD4 T cells expressing CD62L (FIG. 163).
一連の実験を行い、ヒト血液から精製したNK細胞の細胞外酸性化速度(ECAR)に対する18t15-12sの効果を決定した。ECARは、解糖を測定するために使用することができる。解糖は、1分子のグルコースが2分子のピルビン酸に細胞内で生化学的変換され、同時に2分子のATPが生成されることである。解糖の増加は、Seahorse XF96アナライザーによって測定されたECARの増加によって示された。これらの実験では、新鮮なヒト白血球を血液バンクから入手し、CD56+NK細胞をRosetteSep/ヒトNK細胞試薬(StemCell Technologies)で単離した。NK細胞の純度は70%超であり、CD56-BV421、CD16-BV510、CD25-PE、及びCD69-APCFire750抗体(BioLegend)で染色することによって確認した。細胞をカウントし、0.2mLの完全培地(RPMI1640(Gibco)、2mMのL-グルタミン(Thermo Life Technologies)、ペニシリン(Thermo Life Technologies)、ストレプトマイシン(Thermo Life Technologies)、及び10%FBS(Hyclone)を補充)中の96ウェル平底プレートに0.2×106/mLで再懸濁した。細胞を、hIL-12(10ng/mL)(Biolegend)、hIL-18(50ng/mL)(R&D)、及びhIL-15(50ng/mL)(NCI)の混合物、又は18t15-12s(100nM)のいずれかで、37℃及び5%CO2で14~18時間刺激した。翌日、細胞を収集し、Seahorse培地で2回洗浄した。細胞(2×105細胞/ウェル)を、10μLのポリ-L-リジン(Sigma)でコーティングされた96ウェルフラックスプレートに播種した。NK細胞は、アッセイ前に30分間プレートに接着した。グルコース、オリゴマイシン、及び2DG溶液を、緩衝化されたSeahorse培地で10倍の濃度で調製し、較正プレートのポートA、B、及びCに注入した。ECARの読み取り値は、6.5~7分ごとに取得され、ECARの結果は、80分以上の平均読み取り値又は各時点での平均読み取り値を表す。図164は、18t15-12sでNK細胞を一晩刺激すると、基礎ECARレベルが上昇したことを示す。グルコース及びオリゴマイシンの添加は、18t15-12sで一晩刺激されたNK細胞の解糖及び解糖能力の増強をそれぞれ示した(図164)。培地のみ、又はIL12、IL18、及びIL-15の混合物で一晩処理したNK細胞を、比較のために使用した(図164)。 A series of experiments was performed to determine the effect of 18t15-12s on the extracellular acidification rate (ECAR) of NK cells purified from human blood. ECAR can be used to measure glycolysis. Glycolysis is the intracellular biochemical conversion of one molecule of glucose into two molecules of pyruvate with the simultaneous production of two molecules of ATP. Increased glycolysis was indicated by an increase in ECAR measured by a Seahorse XF96 analyzer. For these experiments, fresh human leukocytes were obtained from a blood bank and CD56 + NK cells were isolated with RosetteSep/human NK cell reagent (StemCell Technologies). NK cell purity was greater than 70% and confirmed by staining with CD56-BV421, CD16-BV510, CD25-PE, and CD69-APCFire750 antibodies (BioLegend). Cells were counted and added to 0.2 mL complete medium (RPMI 1640 (Gibco), 2 mM L-glutamine (Thermo Life Technologies), penicillin (Thermo Life Technologies), streptomycin (Thermo Life Technologies), and 10% FBS (Hyclone ) resuspended at 0.2×10 6 /mL in 96-well flat-bottom plates in medium (supplemented). Cells were treated with a mixture of hIL-12 (10 ng/mL) (Biolegend), hIL-18 (50 ng/mL) (R&D), and hIL-15 (50 ng/mL) (NCI), or 18t15-12s (100 nM). Either was stimulated at 37° C. and 5% CO 2 for 14-18 hours. The next day, cells were harvested and washed twice with Seahorse medium. Cells (2×10 5 cells/well) were seeded in 96-well flux plates coated with 10 μL of poly-L-lysine (Sigma). NK cells were allowed to adhere to the plates for 30 minutes prior to assay. Glucose, oligomycin, and 2DG solutions were prepared in buffered Seahorse medium at 10x concentrations and injected into ports A, B, and C of the calibration plate. ECAR readings were taken every 6.5-7 minutes and ECAR results represent the average reading over 80 minutes or the average reading at each time point. FIG. 164 shows that overnight stimulation of NK cells with 18t15-12s increased basal ECAR levels. Addition of glucose and oligomycin showed enhanced glycolytic and glycolytic capacity of NK cells stimulated overnight with 18t15-12s, respectively (FIG. 164). NK cells treated overnight with medium alone or a mixture of IL12, IL18, and IL-15 were used for comparison (Figure 164).
18t15-12sで刺激した後のNK細胞におけるホスホ-STAT4及びホスホ-STAT5レベルの増加を決定するために一連の実験を行った。これらの実験では、新鮮なヒト白血球を血液バンクから入手し、CD56+NK細胞をRosetteSep/ヒトNK細胞試薬(StemCell Technologies)で単離した。NK細胞の純度は70%超であり、CD56-BV421、CD16-BV510、CD25-PE、及びCD69-APCFire750特異的抗体(BioLegend)で染色することによって確認した。細胞をカウントし、0.1mLの完全培地(RPMI1640(Gibco)、2mMのL-グルタミン(Thermo Life Technologies)、ペニシリン(Thermo Life Technologies)、ストレプトマイシン(Thermo Life Technologies)、及び10%FBS(Hyclone)を補充)中の96ウェル平底プレートに0.05×106/mLで再懸濁した。細胞を、hIL-12(10ng/mL)(Biolegend)若しくはhIL-15(50ng/mL)(NCI)(単一サイトカイン)、又は18t15-12s(100nM)で、37℃及び5%CO2で90分間刺激した。刺激していないNK細胞(US)を対照として使用した。細胞を収集し、パラホルムアルデヒド(Sigma)で固定して、最終濃度1.6%にした。プレートを暗所で、室温で10分間インキュベートした。FACS緩衝液(0.5%BSA(EMD Millipore)及び0.001%アジ化ナトリウム(Sigma)を含む1×PBS(Hyclone))(100μL)を添加し、細胞を96ウェル「V」ボトムプレートに移した。細胞を1500RPMで、室温で5分間洗浄した。細胞ペレットを100μLの冷却メタノールと上下に穏やかにピペッティングしながら混合し、細胞を4℃で30分間インキュベートした。細胞を100mLのFACS緩衝液と混合し、1500RPMで、室温で5分間洗浄した。細胞ペレットを、4mLのpSTAT4(BD Bioscience)及びpSTAT5抗体(BD Bioscience)を含む50mLのFACS緩衝液と混合し、その後、暗所で、室温で30分間インキュベートした。細胞を100mLのFACS緩衝液と混合し、1500RPMで、室温で5分間洗浄した。細胞ペレットを50mLのFACS緩衝液と混合し、細胞をフローサイトメトリー(Celesta-BD Bioscience)によって分析した。図165は、NK細胞を18t15-12sとインキュベートすることにより、pSTAT4及びpSTAT5の増加が誘導されたことを示す(プロットされたデータ、正規化された倍率変化)。 A series of experiments were performed to determine the increase in phospho-STAT4 and phospho-STAT5 levels in NK cells after stimulation with 18t15-12s. For these experiments, fresh human leukocytes were obtained from a blood bank and CD56 + NK cells were isolated with RosetteSep/human NK cell reagent (StemCell Technologies). The purity of NK cells was >70% and confirmed by staining with CD56-BV421, CD16-BV510, CD25-PE, and CD69-APCFire750 specific antibodies (BioLegend). Cells were counted and added to 0.1 mL complete medium (RPMI 1640 (Gibco), 2 mM L-glutamine (Thermo Life Technologies), penicillin (Thermo Life Technologies), streptomycin (Thermo Life Technologies), and 10% FBS (Hyclone ) resuspended at 0.05×10 6 /mL in 96-well flat-bottom plates in medium (supplemented). Cells were incubated with hIL-12 (10 ng/mL) (Biolegend) or hIL-15 (50 ng/mL) (NCI) (single cytokines) or 18t15-12s (100 nM) for 90 minutes at 37° C. and 5% CO 2 . Stimulated for minutes. Unstimulated NK cells (US) were used as controls. Cells were harvested and fixed with paraformaldehyde (Sigma) to a final concentration of 1.6%. Plates were incubated in the dark for 10 minutes at room temperature. FACS buffer (1×PBS (Hyclone) with 0.5% BSA (EMD Millipore) and 0.001% sodium azide (Sigma)) was added (100 μL) and the cells plated in 96-well “V” bottom plates. moved. Cells were washed at 1500 RPM for 5 minutes at room temperature. The cell pellet was mixed with 100 μL of chilled methanol by gently pipetting up and down and the cells were incubated at 4° C. for 30 minutes. Cells were mixed with 100 mL FACS buffer and washed at 1500 RPM for 5 minutes at room temperature. Cell pellets were mixed with 4 mL of pSTAT4 (BD Bioscience) and pSTAT5 antibodies (BD Bioscience) in 50 mL of FACS buffer, then incubated for 30 minutes at room temperature in the dark. Cells were mixed with 100 mL FACS buffer and washed at 1500 RPM for 5 minutes at room temperature. Cell pellets were mixed with 50 mL of FACS buffer and cells were analyzed by flow cytometry (Celesta-BD Bioscience). Figure 165 shows that incubation of NK cells with 18t15-12s induced an increase in pSTAT4 and pSTAT5 (plotted data, normalized fold change).
一連の実験を行い、ヒト血液から精製したNK細胞の酸素消費速度(OCR)及び細胞外酸性化速度(ECAR)に対する18t15-12s又はサイトカイン(例えば、IL12、IL18、及びIL-15)の混合物の効果を決定した。OCR及びECARを、Seahorse XF96アナライザーによって測定した。これらの実験では、新たにヒトNK細胞を、RosetteSep/ヒトNK細胞試薬(StemCell Technologies)を使用した陰性選択によりヒト白血病から単離した。新たに精製したNK細胞を、18t15-12s(100nM)又はrhIL12(10ng/mL)、rhIL18(50ng/mL)、及び対照としてrhIL-15(50ng/mL)サイトカインの混合物のいずれかで一晩(16時間)刺激した。翌日、細胞を洗浄してカウントし、同数の細胞を緩衝化したSeahorse培地に播種した。グルコース、オリゴマイシン、及び2DG溶液を、緩衝化されたSeahorse培地で10倍の濃度で調製し、較正プレートのポートA、B、及びCに注入した。図166は、2体の個別のドナーからのOCR(左)及びECAR(右)のデータを示す。18t15-12sでNK細胞を一晩刺激すると、基礎ECARレベル及びOCRレベルが上昇したことを示す。グルコース及びオリゴマイシンの添加は、18t15-12sで一晩刺激されたNK細胞の解糖及び解糖能力の増強をそれぞれ示した。培地のみ、又はIL12、IL18、及びIL-15の混合物で一晩処理したNK細胞を、比較のために使用した。 A series of experiments were performed to demonstrate the effects of 18t15-12s or a mixture of cytokines (eg, IL12, IL18, and IL-15) on the oxygen consumption rate (OCR) and extracellular acidification rate (ECAR) of NK cells purified from human blood. determined the effect. OCR and ECAR were measured by a Seahorse XF96 analyzer. In these experiments, human NK cells were freshly isolated from human leukemia by negative selection using RosetteSep/human NK cell reagent (StemCell Technologies). Freshly purified NK cells were treated overnight with either 18t15-12s (100 nM) or a mixture of rhIL12 (10 ng/mL), rhIL18 (50 ng/mL), and rhIL-15 (50 ng/mL) cytokines as a control ( 16 hours). The next day, cells were washed, counted, and equal numbers of cells were plated in buffered Seahorse medium. Glucose, oligomycin, and 2DG solutions were prepared in buffered Seahorse medium at 10x concentrations and injected into ports A, B, and C of the calibration plate. Figure 166 shows OCR (left) and ECAR (right) data from two independent donors. 18 shows that overnight stimulation of NK cells with 18t15-12s increased basal ECAR and OCR levels. Addition of glucose and oligomycin showed enhanced glycolytic and glycolytic capacity of NK cells stimulated overnight with 18t15-12s, respectively. NK cells treated overnight with medium alone or a mixture of IL12, IL18, and IL-15 were used for comparison.
実施例64:2t2及び/又はTGFRt15-TGFRsによるインビボでのNK細胞の刺激
C57BL/6マウスにおける免疫刺激に対する2t2構築物の効果を決定するために一連の実験を行った。これらの実験では、C57BL/6マウスを、対照溶液(PBS)、又は0.1、0.4、2、及び10mg/kgの2t2で皮下処理した。処理したマウスを処理の3日後に安楽死させた。脾臓重量を測定し、単一脾細胞懸濁液を調製した。脾細胞懸濁液を、結合抗CD4、抗CD8、及び抗NK1.1(NK)抗体で染色した。CD4+T細胞、CD8+T細胞、及びNK細胞のパーセンテージ、並びにリンパ球サブセットのCD25発現をフローサイトメトリーによって分析した。図167Aは、特に0.1~10mg/kgの用量レベルで、脾臓重量に基づいて2t2が脾細胞の増殖に効果的であることを示す。処理後、CD8+T細胞のパーセンテージは、2及び10mg/kgで対照処理マウスと比較して2t2処理マウスにおいて高かった(図167B)。NK細胞のパーセンテージはまた、試験した2t2の全ての用量で対照処理マウスと比較して2t2処理マウスにおいて高かった(図167B)。加えて、2t2は、CD4+T細胞によるCD25発現を有意にアップレギュレートしたが、0.4~10mg/kgで処理した後に、CD8+T細胞及びNK細胞ではCD25発現を有意にアップレギュレートしなかった(図167C)。
Example 64: Stimulation of NK cells in vivo by 2t2 and/or TGFRt15-TGFRs A series of experiments were performed to determine the effect of 2t2 constructs on immune stimulation in C57BL/6 mice. In these experiments, C57BL/6 mice were treated subcutaneously with control solution (PBS) or 0.1, 0.4, 2, and 10 mg/kg of 2t2. Treated mice were euthanized 3 days after treatment. Spleen weights were measured and single splenocyte suspensions were prepared. Splenocyte suspensions were stained with conjugated anti-CD4, anti-CD8, and anti-NK1.1 (NK) antibodies. The percentages of CD4 + T cells, CD8 + T cells, and NK cells, and CD25 expression of lymphocyte subsets were analyzed by flow cytometry. FIG. 167A shows that 2t2 is effective in splenocyte proliferation based on spleen weight, especially at dose levels of 0.1-10 mg/kg. After treatment, the percentage of CD8 + T cells was higher in 2t2-treated mice compared to control-treated mice at 2 and 10 mg/kg (Fig. 167B). The percentage of NK cells was also higher in 2t2-treated mice compared to control-treated mice at all doses of 2t2 tested (FIG. 167B). In addition, 2t2 significantly upregulated CD25 expression by CD4 + T cells, but significantly upregulated CD25 expression on CD8 + T cells and NK cells after treatment at 0.4-10 mg/kg. It did not (Figure 167C).
C57BL/6マウスにおける免疫刺激に対するTGFRt15-TGFRs構築物の効果を決定するために一連の実験を行った。これらの実験では、C57BL/6マウスを、対照溶液(PBS)、又は0.3、1、3、及び10mg/kgのTGFRt15-TGFRsで皮下処理した。処理したマウスを処理の4日後に安楽死させた。脾臓重量を測定し、単一脾細胞懸濁液を調製した。脾細胞懸濁液を、結合抗CD4、抗CD8、及び抗NK1.1(NK)抗体で染色した。CD4+T細胞、CD8+T細胞、及びNK細胞のパーセンテージをフローサイトメトリーによって分析した。図168Aは、TGFRt15-TGFRsで処理したマウスにおける脾臓の重量がTGFRt15-TGFRsの投薬量の増加とともに増加したことを示す。加えて、1mg/kg、3mg/kg、及び10mg/kgのTGFRt15-TGFRsで処理したマウスにおける脾臓重量は、対照溶液で処理したマウスと比較して高かった。図168Bは、CD8+T細胞及びNK細胞の両方のパーセンテージが、TGFRt15-TGFRsの投薬量の増加とともに増加したことを示す。具体的には、CD8+T細胞のパーセンテージは、対照処理マウスと比較して、0.3mg/kg、3mg/kg、及び10mg/kgのTGFRt15-TGFRsで処理したマウスで高く、NK細胞のパーセンテージは、対照処理マウスと比較して、0.3mg/kg、1mg/kg、3mg/kg、及び10mg/kgのTGFRt15-TGFRsで処理したマウスで高かった。 A series of experiments were performed to determine the effect of the TGFRt15-TGFRs construct on immune stimulation in C57BL/6 mice. In these experiments, C57BL/6 mice were treated subcutaneously with control solution (PBS) or 0.3, 1, 3, and 10 mg/kg of TGFRt15-TGFRs. Treated mice were euthanized 4 days after treatment. Spleen weights were measured and single splenocyte suspensions were prepared. Splenocyte suspensions were stained with conjugated anti-CD4, anti-CD8, and anti-NK1.1 (NK) antibodies. The percentages of CD4 + T cells, CD8 + T cells and NK cells were analyzed by flow cytometry. FIG. 168A shows that spleen weight in mice treated with TGFRt15-TGFRs increased with increasing dosage of TGFRt15-TGFRs. In addition, spleen weights in mice treated with 1 mg/kg, 3 mg/kg, and 10 mg/kg of TGFRt15-TGFRs were higher compared to mice treated with control solution. Figure 168B shows that the percentage of both CD8 + T cells and NK cells increased with increasing dosage of TGFRt15-TGFRs. Specifically, the percentage of CD8 + T cells was higher in mice treated with 0.3 mg/kg, 3 mg/kg, and 10 mg/kg of TGFRt15-TGFRs compared to control-treated mice, and the percentage of NK cells was higher. was higher in mice treated with 0.3 mg/kg, 1 mg/kg, 3 mg/kg, and 10 mg/kg of TGFRt15-TGFRs compared to control-treated mice.
西洋食を与えたApoE-/-マウスにおける免疫刺激に対するTGFRt15-TGFRs構築物又は2t2構築物の効果を決定するために一連の実験を行った。これらの実験では、6週齢の雌B6.129P2-ApoEtm1Unc/Jマウス(Jackson Laboratory)に、21%脂肪、0.15%コレステロール、34.1%スクロース、19.5%カゼイン、及び15%デンプンを含む西洋食(TD88137、Envigo Laboratories)を与えた。西洋食餌の8週間後、マウスにTGFRt15-TGFRs又は2t2を3mg/kgで皮下注射した。処理の3日後、マウスを16時間絶食させ、その後、血液試料を後眼窩静脈叢穿刺によって収集した。血液を10μLの0.5M EDTAと混合し、リンパ球サブセット分析のために血液を20μL採取した。赤血球を、ACK(0.15M NH4Cl、1.0mM KHCO3、0.1mM Na2EDTA、pH7.4)で溶解し、リンパ球を、FACS染色緩衝液(PBS中1%BSA)中、抗マウスCD8a及び抗マウスNK1.1抗体で、4℃で30分間染色した。細胞を1回洗浄し、BD FACS Celestaを用いて分析した。Treg染色の場合、ACKで処理した血液リンパ球を、FACS染色緩衝液中、抗マウスCD4及び抗マウスCD25抗体で、4℃で30分間染色した。細胞を1回洗浄し、固定/透過処理希釈標準溶液中に再懸濁し、室温で60分間インキュベートした。細胞を1回洗浄し、透過処理緩衝液中に再懸濁した。試料を300~400×gで、室温で5分間遠心分離し、上清を廃棄した。細胞ペレットを残留体積中に再懸濁し、体積を1×透過処理緩衝液で約100μLに調整した。抗Fox p3抗体を細胞に添加し、細胞を室温で30分間インキュベートした。透過処理緩衝液(200μL)を細胞に添加し、細胞を300~-400×gで、室温で5分間遠心分離した。細胞をフローサイトメトリー染色緩衝液中に再懸濁し、フローサイトメーター上で分析した。図169B~169Cは、TGFRt15-TGFRs及び2t2での処理により、西洋食を与えたApoE-/-マウスにおけるNK細胞及びCD8+T細胞のパーセンテージが増加したことを示す。図169Aは、2t2で処理するとTreg細胞のパーセンテージも増加したことを示す。 A series of experiments were performed to determine the effect of TGFRt15-TGFRs or 2t2 constructs on immune stimulation in Western-fed ApoE −/− mice. In these experiments, 6-week-old female B6.129P2-ApoE tm1Unc /J mice (Jackson Laboratory) were fed 21% fat, 0.15% cholesterol, 34.1% sucrose, 19.5% casein, and 15% They were fed a western diet containing starch (TD88137, Envigo Laboratories). After 8 weeks on the Western diet, mice were injected subcutaneously with TGFRt15-TGFRs or 2t2 at 3 mg/kg. After 3 days of treatment, mice were fasted for 16 hours, after which blood samples were collected by retro-orbital venous puncture. Blood was mixed with 10 μL of 0.5 M EDTA and 20 μL of blood was taken for lymphocyte subset analysis. Erythrocytes were lysed with ACK (0.15 M NH4Cl , 1.0 mM KHCO3 , 0.1 mM Na2EDTA , pH 7.4) and lymphocytes were lysed in FACS staining buffer (1% BSA in PBS). Anti-mouse CD8a and anti-mouse NK1.1 antibodies were stained for 30 minutes at 4°C. Cells were washed once and analyzed using a BD FACS Celesta. For Treg staining, ACK-treated blood lymphocytes were stained with anti-mouse CD4 and anti-mouse CD25 antibodies in FACS staining buffer for 30 minutes at 4°C. Cells were washed once, resuspended in fixation/permeabilization working solution and incubated for 60 minutes at room temperature. Cells were washed once and resuspended in permeabilization buffer. Samples were centrifuged at 300-400×g for 5 minutes at room temperature and the supernatant was discarded. The cell pellet was resuspended in the residual volume and the volume adjusted to approximately 100 μL with 1× permeabilization buffer. Anti-Fox p3 antibody was added to the cells and the cells were incubated for 30 minutes at room temperature. Permeabilization buffer (200 μL) was added to the cells and the cells were centrifuged at 300-400×g for 5 minutes at room temperature. Cells were resuspended in flow cytometry staining buffer and analyzed on a flow cytometer. Figures 169B-169C show that treatment with TGFRt15-TGFRs and 2t2 increased the percentage of NK cells and CD8 + T cells in ApoE −/− mice fed a Western diet. Figure 169A shows that treatment with 2t2 also increased the percentage of Treg cells.
実施例65:インビボでの免疫細胞の増殖の誘導
C57BL/6マウスにおける免疫細胞刺激に対する2t2構築物の効果を決定するために一連の実験を行った。これらの実験では、C57BL/6マウスを、対照溶液(PBS)、又は0.1、0.4、2、及び10mg/kgの2t2で皮下処理した。処理したマウスを処理の3日後に安楽死させた。脾臓重量を測定し、単一脾細胞懸濁液を調製した。脾細胞懸濁液を、結合抗CD4、抗CD8、及び抗NK1.1(NK)抗体で染色した。CD4+T細胞、CD8+T細胞、及びNK細胞のパーセンテージをフローサイトメトリーによって分析した。図170Aは、特に0.1~10mg/kgで、脾臓重量に基づいて2t2が脾細胞の増殖に効果的であることを示す。CD8+T細胞のパーセンテージは、2及び10mg/kgで対照処理マウスと比較して高かった(図170B)。加えて、NK細胞のパーセンテージは、試験した2t2の全ての用量で対照処理マウスと比較して高かった(図170B)。これらの結果は、2t2処理が、C57BL/6マウスにおけるCD8+T細胞及びNK細胞の増殖を誘導することができたことを実証する。
Example 65 Induction of Immune Cell Proliferation In Vivo A series of experiments were performed to determine the effect of the 2t2 construct on immune cell stimulation in C57BL/6 mice. In these experiments, C57BL/6 mice were treated subcutaneously with control solution (PBS) or 0.1, 0.4, 2, and 10 mg/kg of 2t2. Treated mice were euthanized 3 days after treatment. Spleen weights were measured and single splenocyte suspensions were prepared. Splenocyte suspensions were stained with conjugated anti-CD4, anti-CD8, and anti-NK1.1 (NK) antibodies. The percentages of CD4 + T cells, CD8 + T cells and NK cells were analyzed by flow cytometry. FIG. 170A shows that 2t2 is effective in splenocyte proliferation based on spleen weight, especially at 0.1-10 mg/kg. The percentage of CD8 + T cells was higher compared to control treated mice at 2 and 10 mg/kg (Fig. 170B). In addition, the percentage of NK cells was higher at all doses of 2t2 tested compared to control-treated mice (FIG. 170B). These results demonstrate that 2t2 treatment was able to induce proliferation of CD8 + T cells and NK cells in C57BL/6 mice.
C57BL/6マウスにおける免疫刺激に対するTGFRt15-TGFRs構築物の効果を決定するために一連の実験を行った。これらの実験では、C57BL/6マウスを、対照溶液(PBS)、又は0.1、0.3、1、3、及び10mg/kgのTGFRt15-TGFRsで皮下処理した。処理したマウスを処理の4日後に安楽死させた。脾臓重量を測定し、脾臓細胞懸濁液を調製した。脾細胞懸濁液を、結合抗CD4、抗CD8、及び抗NK1.1(NK)抗体で染色した。細胞を増殖マーカーKi67について更に染色した。図171Aは、TGFRt15-TGFRsで処理したマウスにおける脾臓重量がTGFRt15-TGFRsの投薬量の増加とともに増加したことを示す。加えて、1mg/kg、3mg/kg、及び10mg/kgのTGFRt15-TGFRsで処理したマウスにおける脾臓の重量は、対照溶液のみで処理したマウスと比較して高かった。CD8+T細胞及びNK細胞の両方のパーセンテージが、TGFRt15-TGFRsの投薬量の増加とともに増加した(図171B)。最後に、TGFRt15-TGFRsは、試験したTGFRt15-TGFRsの全ての用量で、CD8+T細胞及びNK細胞の両方での細胞増殖マーカーKi67の発現を有意にアップレギュレートした。これらの結果は、TGFRt15-TGFRsでの処理が、C57BL/6におけるCD8+T細胞及びNK細胞の両方の増殖を誘導したことを示す。 A series of experiments were performed to determine the effect of the TGFRt15-TGFRs construct on immune stimulation in C57BL/6 mice. In these experiments, C57BL/6 mice were treated subcutaneously with control solution (PBS) or 0.1, 0.3, 1, 3, and 10 mg/kg of TGFRt15-TGFRs. Treated mice were euthanized 4 days after treatment. Spleen weights were measured and splenocyte suspensions were prepared. Splenocyte suspensions were stained with conjugated anti-CD4, anti-CD8, and anti-NK1.1 (NK) antibodies. Cells were additionally stained for the proliferation marker Ki67. FIG. 171A shows that spleen weight in mice treated with TGFRt15-TGFRs increased with increasing dosage of TGFRt15-TGFRs. In addition, spleen weights in mice treated with 1 mg/kg, 3 mg/kg, and 10 mg/kg of TGFRt15-TGFRs were higher compared to mice treated with control solution alone. The percentages of both CD8 + T cells and NK cells increased with increasing dosage of TGFRt15-TGFRs (FIG. 171B). Finally, TGFRt15-TGFRs significantly upregulated the expression of the cell proliferation marker Ki67 on both CD8 + T cells and NK cells at all doses of TGFRt15-TGFRs tested. These results indicate that treatment with TGFRt15-TGFRs induced proliferation of both CD8 + T cells and NK cells in C57BL/6.
西洋食を与えたApoE-/-マウスにおける免疫刺激に対するTGFRt15-TGFRs構築物又は2t2構築物の効果を決定するために一連の実験を行った。これらの実験では、6週齢の雌B6.129P2-ApoEtm1Unc/Jマウス(Jackson Laboratory)に、21%脂肪、0.15%コレステロール、34.1%スクロース、19.5%カゼイン、及び15%デンプンを含む西洋食(TD88137、Envigo Laboratories)を与えた。西洋食餌の8週間後、マウスにTGFRt15-TGFRs又は2t2を3mg/kgで皮下注射した。処理の3日後、マウスを16時間絶食させ、その後、血液試料を後眼窩静脈叢穿刺によって収集した。血液を10μLの0.5M EDTAと混合し、20μLの血液をリンパ球サブセット分析のために採取した。赤血球を、ACK(0.15M NH4Cl、1.0mM KHCO3、0.1mM Na2EDTA、pH7.4)で溶解し、リンパ球を、FACS染色緩衝液(PBS中1%BSA)中、抗マウスCD8a及び抗マウスNK1.1抗体で、4℃で30分間染色した。細胞を1回洗浄し、Fixation Buffer(BioLegendカタログ番号420801)中に室温で20分間再懸濁した。細胞を350×gで5分間遠心分離し、固定した細胞をIntracellular Staining Permeabilization Wash Buffer(BioLegendカタログ番号421002)中に再懸濁し、その後、350×gで5分間遠心分離した。その後、細胞を抗Ki67抗体で、室温で20分間染色した。細胞をIntracellular Staining Permeabilization Wash Bufferで2回洗浄し、350×gで5分間遠心分離した。その後、細胞をFACS染色緩衝液中に再懸濁した。リンパ球サブセットを、BD FACS Celestaを用いて分析した。図172Aに記載されるように、ApoE-/-マウスをTGFRt15-TGFRsで処理することにより、NK細胞及びCD8+T細胞の増殖(Ki67陽性染色)が誘導された。加えて、図172Bは、ApoE-/-マウスを2t2で処理することにより、NK細胞及びCD8+T細胞の増殖(Ki67陽性染色)が誘導されたことを示す。 A series of experiments were performed to determine the effect of TGFRt15-TGFRs or 2t2 constructs on immune stimulation in Western-fed ApoE −/− mice. In these experiments, 6-week-old female B6.129P2-ApoE tm1Unc /J mice (Jackson Laboratory) were fed 21% fat, 0.15% cholesterol, 34.1% sucrose, 19.5% casein, and 15% They were fed a western diet containing starch (TD88137, Envigo Laboratories). After 8 weeks on the Western diet, mice were injected subcutaneously with TGFRt15-TGFRs or 2t2 at 3 mg/kg. After 3 days of treatment, mice were fasted for 16 hours, after which blood samples were collected by retro-orbital venous puncture. Blood was mixed with 10 μL of 0.5 M EDTA and 20 μL of blood was collected for lymphocyte subset analysis. Erythrocytes were lysed with ACK (0.15 M NH4Cl , 1.0 mM KHCO3 , 0.1 mM Na2EDTA , pH 7.4) and lymphocytes were lysed in FACS staining buffer (1% BSA in PBS). Anti-mouse CD8a and anti-mouse NK1.1 antibodies were stained for 30 minutes at 4°C. Cells were washed once and resuspended in Fixation Buffer (BioLegend Catalog #420801) for 20 minutes at room temperature. Cells were centrifuged at 350 xg for 5 minutes and fixed cells were resuspended in Intracellular Staining Permeabilization Wash Buffer (BioLegend Catalog No. 421002) followed by centrifugation at 350 xg for 5 minutes. Cells were then stained with anti-Ki67 antibody for 20 minutes at room temperature. Cells were washed twice with Intracellular Staining Permeabilization Wash Buffer and centrifuged at 350×g for 5 minutes. Cells were then resuspended in FACS staining buffer. Lymphocyte subsets were analyzed using a BD FACS Celesta. As described in FIG. 172A, treatment of ApoE −/− mice with TGFRt15-TGFRs induced proliferation of NK cells and CD8 + T cells (Ki67 positive staining). In addition, FIG. 172B shows that treatment of ApoE −/− mice with 2t2 induced proliferation of NK cells and CD8 + T cells (Ki67 positive staining).
7t15-21s、TGFRt15-TGFRs、及び2t2で処理した後にNSGマウスにおける7t15-21s+抗TF抗体増殖NK細胞の影響を決定するために、一連の実験を行った。これらの実験では、新鮮なヒト白血球を血液バンクから入手し、CD56+NK細胞をRosetteSep/ヒトNK細胞試薬(StemCell Technologies)で単離した。NK細胞の純度は90%超であり、CD56-BV421、CD16-BV510、CD25-PE、及びCD69-APCFire750抗体(BioLegend)で染色することによって確認した。細胞をカウントし、2mLの完全培地(RPMI1640(Gibco)、2mMのL-グルタミン(Thermo Life Technologies)、ペニシリン(Thermo Life Technologies)、ストレプトマイシン(Thermo Life Technologies)、及び10%FBS(Hyclone)を補充)中の24ウェル平底プレートに2×106/mLで再懸濁した。細胞を、7t15-21s(100nM)及び抗TF抗体(50nM)で15日間刺激した。2日ごとに、細胞を、100nMの7t15-21s及び50nMの抗TF抗体を含有する新鮮な培地で、2x106/mLで再懸濁した。培養物の体積が増加するにつれて、細胞をより大きな体積のフラスコに移した。増殖倍率にアクセスするためにトリパンブルーを使用して細胞をカウントした。7t15-21s+抗TF抗体増殖NK細胞を、温かいHBSS緩衝液(Hyclone)中で、1000RPMで10分間室温で3回洗浄した。7t15-21s+抗TF抗体で増殖させたNK細胞を、10×106/0.2mL HBSS緩衝液に再懸濁し、NSGマウス(NOD scid共通ガンママウス)(Jackson Laboratories)の尾静脈に静脈内注射した。移入されたNK細胞を、7t15-21s(10ng/用量、腹腔内)、TGFRt15-TGFRs(10ng/用量、腹腔内)、又は2t2(10ng/用量、腹腔内)のいずれかで最大21日間、48時間ごとに支持した。ヒト7t15-21s+抗TF抗体で増殖させたNK細胞の生着及び持続性を、フローサイトメトリー(Celesta-BD Bioscience)によるhCD45、mCD45、hCD56、hCD3、及びhCD16抗体の血液染色で毎週測定した(データは、1群当たり3匹のマウスを表す)。図173は、養子導入した7t15-21s+抗TF抗体で増殖させたNK細胞を有するマウスを、対照処理マウスと比較して養子導入したNK細胞の7t15-21s-、TGFRt15-TGFRs-、又は2t2によって誘導された増殖及び持続性で処理したことを示す。 A series of experiments were performed to determine the effects of 7t15-21s plus anti-TF antibody-proliferating NK cells in NSG mice after treatment with 7t15-21s, TGFRt15-TGFRs, and 2t2. For these experiments, fresh human leukocytes were obtained from a blood bank and CD56 + NK cells were isolated with RosetteSep/human NK cell reagent (StemCell Technologies). NK cell purity was greater than 90% and confirmed by staining with CD56-BV421, CD16-BV510, CD25-PE, and CD69-APCFire750 antibodies (BioLegend). Cells were counted and supplemented with 2 mL of complete medium (RPMI 1640 (Gibco), 2 mM L-glutamine (Thermo Life Technologies), penicillin (Thermo Life Technologies), streptomycin (Thermo Life Technologies), and 10% FBS (Hyclone)). replenishment) Resuspended at 2×10 6 /mL in medium 24-well flat bottom plates. Cells were stimulated with 7t15-21s (100 nM) and anti-TF antibody (50 nM) for 15 days. Every two days, cells were resuspended at 2×10 6 /mL in fresh medium containing 100 nM 7t15-21s and 50 nM anti-TF antibody. As the culture volume increased, the cells were transferred to larger volume flasks. Cells were counted using trypan blue to access fold growth. 7t15-21s+anti-TF antibody-expanded NK cells were washed three times in warm HBSS buffer (Hyclone) at 1000 RPM for 10 minutes at room temperature. 7t15-21s + anti-TF antibody-expanded NK cells were resuspended in 10×10 6 /0.2 mL HBSS buffer and injected intravenously into the tail vein of NSG mice (NOD scid common gamma mice) (Jackson Laboratories). bottom. Transfected NK cells were treated with either 7t15-21s (10 ng/dose, i.p.), TGFRt15-TGFRs (10 ng/dose, i.p.), or 2t2 (10 ng/dose, i.p.) for up to 21 days for 48 days. Upheld every hour. Engraftment and persistence of NK cells expanded with human 7t15-21s plus anti-TF antibody was measured weekly by blood staining for hCD45, mCD45, hCD56, hCD3, and hCD16 antibodies by flow cytometry (Celesta-BD Bioscience) ( Data represent 3 mice per group). FIG. 173 shows that mice with adoptively transferred 7t15-21s + anti-TF antibody expanded NK cells by adoptively transferred NK cells 7t15-21s−, TGFRt15−TGFRs−, or 2t2 compared to control treated mice. Shown are treated with induced proliferation and persistence.
実施例66:一本鎖構築物又は多鎖構築物での処理後のNK媒介性細胞傷害性
NK細胞をTGFRt15-TGFRsで処理することによりNK細胞の細胞傷害性が増強されるかを決定するために一連の実験を行った。これらの実験では、ヒトDaudi Bリンパ腫細胞をCellTrace Violet(CTV)で標識し、腫瘍標的細胞として使用した。マウスNKエフェクター細胞を、3mg/kgでのTGFRt15-TGFRs皮下処理の4日後のC57BL/6雌マウス脾臓の磁気細胞選別法(Miltenyi Biotec)を使用したNK1.1陽性選択で単離した。ヒトNKエフェクター細胞を、RosetteSep/ヒトNK細胞試薬(Stemcell Technologies)を用いて、ヒト血液バフィーコート由来の末梢血単核細胞から単離した。標的細胞(ヒトDaudi Bリンパ腫細胞)を、50nMのTGFRt15-TGFRsの存在下又はTGFRt15-TGFRsの不在下(対照)でエフェクター細胞(マウスNKエフェクター細胞又はヒトNKエフェクター細胞のいずれか)と混合し、マウスNK細胞の場合は44時間、ヒトNK細胞の場合は20時間、37℃でインキュベートした。フローサイトメトリーを使用したヨウ化プロピジウム陽性のCTV標識細胞の分析によって標的細胞(Daudi)の生存率を評価した。Daudi阻害のパーセンテージを、式(1-実験試料中の生存腫瘍細胞数/NK細胞を含まない試料中の生存腫瘍細胞数)×100を使用して計算した。図174は、マウス(図174A)及びヒト(図174B)NK細胞が、TGFRt15-TGFRs活性化の不在下よりも、TGFRt15-TGFRsによるNK細胞活性化後にDaudi B細胞に対する有意に強い細胞傷害性を有したことを示す。
Example 66: NK-mediated cytotoxicity after treatment with single- or multi-chain constructs To determine whether treatment of NK cells with TGFRt15-TGFRs enhances NK cell cytotoxicity A series of experiments were performed. In these experiments, human Daudi B lymphoma cells were labeled with CellTrace Violet (CTV) and used as tumor target cells. Mouse NK effector cells were isolated by NK1.1 positive selection using magnetic cell sorting (Miltenyi Biotec) of C57BL/6
TGFRt15-TGFRsで処理した後のマウス及びヒトNK細胞の抗体依存性細胞傷害性(ADCC)を決定するために一連の実験を行った。これらの実験では、ヒトDaudi Bリンパ腫細胞をCellTrace Violet(CTV)で標識し、腫瘍標的細胞として使用した。マウスNKエフェクター細胞を、3mg/kgでのTGFRt15-TGFRs皮下処理の4日後のC57BL/6雌マウス脾臓の磁気細胞選別法(Miltenyi Biotec)を使用したNK1.1陽性選択で単離した。ヒトNKエフェクター細胞を、RosetteSep/ヒトNK細胞試薬(Stemcell Technologies)を用いて、ヒト血液バフィーコート由来の末梢血単核細胞から単離した。標的細胞(Daudi B細胞)を、抗CD20抗体(10nMリツキシマブ、Genentech)の存在下及び50nMのTGFRt15-TGFRsの存在下、又はTGFRt15-TGFRsの不在下(対照)で、エフェクター細胞(マウスNKエフェクター細胞又はヒトNKエフェクター細胞のいずれか)と混合し、マウスNK細胞の場合は44時間、ヒトNK細胞の場合は20時間、37℃でインキュベートした。Daudi B細胞は、抗CD20抗体のCD20標的を発現する。フローサイトメトリーを使用したヨウ化プロピジウム陽性のCTV標識標的細胞の分析によってインキュベーション後の標的細胞の生存率を評価した。Daudi阻害のパーセンテージを、式(1-実験試料中の生存腫瘍細胞数/NK細胞を含まない試料中の生存腫瘍細胞数)×100を使用して計算した。図175は、マウスNK細胞(図175A)及びヒトNK細胞(図175B)が、TGFRt15-TGFRs活性化の不在下よりも、TGFRt15-TGFRsによるNK細胞の活性化後にDaudi B細胞に対する強いADCC活性を有したことを示す。
A series of experiments were performed to determine antibody-dependent cellular cytotoxicity (ADCC) of mouse and human NK cells after treatment with TGFRt15-TGFRs. In these experiments, human Daudi B lymphoma cells were labeled with CellTrace Violet (CTV) and used as tumor target cells. Mouse NK effector cells were isolated by NK1.1 positive selection using magnetic cell sorting (Miltenyi Biotec) of C57BL/6
老化B16F10黒色腫細胞に対するTGFRt15-TGFRsで活性化したマウスNK細胞の細胞傷害性を決定するために一連の実験を行った。これらの実験では、C57BL/6マウスに10mg/kgのTGFRt15-TGFRsを4日間注入した後、脾臓NK細胞を単離することにより、マウスNK細胞をインビボで活性化した。その後、NK細胞を、100nMの2t2の存在下で7日間、インビトロで増殖させた。B16F10老化標的細胞(B16F10-SNC)を、CellTrace Violet(CTV)で標識し、異なるエフェクター:標的(E:T)比で活性化マウスNKエフェクター細胞と16時間インキュベートした。細胞をトリプシン処理し、洗浄し、ヨウ化プロピジウム(PI)溶液を含む完全培地に再懸濁した。老化細胞標的に対するTGFRt15-TGFRs/2t2で活性化されたNK細胞の細胞傷害性は、CTV標識細胞のPI染色に基づくフローサイトメトリーによってアクセスされた。所見は、TGFRt15-TGFRsによるNK細胞のインビボでの活性化と、それに続く2t2によるインビボでの増殖及び活性化により、NK細胞による老化黒色腫腫瘍細胞の死滅が増加したことを示す(図176)。 A series of experiments were performed to determine the cytotoxicity of mouse NK cells activated with TGFRt15-TGFRs against senescent B16F10 melanoma cells. In these experiments, mouse NK cells were activated in vivo by injecting C57BL/6 mice with 10 mg/kg TGFRt15-TGFRs for 4 days followed by isolation of splenic NK cells. NK cells were then grown in vitro in the presence of 100 nM 2t2 for 7 days. B16F10 senescent target cells (B16F10-SNC) were labeled with CellTrace Violet (CTV) and incubated with activated mouse NK effector cells at different effector:target (E:T) ratios for 16 hours. Cells were trypsinized, washed and resuspended in complete medium containing propidium iodide (PI) solution. Cytotoxicity of TGFRt15-TGFRs/2t2-activated NK cells against senescent cell targets was accessed by flow cytometry based on PI staining of CTV-labeled cells. The findings indicate that in vivo activation of NK cells by TGFRt15-TGFRs, followed by in vivo proliferation and activation by 2t2, increased killing of senescent melanoma tumor cells by NK cells (FIG. 176). .
実施例67:がん、糖尿病、及びアテローム性動脈硬化症の治療
黒色腫マウスモデルにおける化学療法と組み合わせたTGFRt15-TGFRs+抗TRP1抗体(TA99)の抗腫瘍活性を評価するために一連の実験を行った。これらの実験では、C57BL/6マウスに0.5×106個のB16F10黒色腫細胞を皮下注射した。マウスを、1日目、4日目、及び7日目に化学療法ドセタキセル(10mg/kg)(DTX)の3回投与で処理、その後、9日目に組み合わせ免疫療法TGFRt15-TGFRs(3mg/kg)+抗TRP1抗体TA99(200μg)の単回投与で処理した。図177Aは、処理レジメンの概略図を示す。腫瘍成長をキャリパー測定によって監視し、腫瘍体積を式V=(L×W2)/2を使用して計算し、式中、Lは最大腫瘍直径であり、Wは垂直腫瘍直径である。図177Bは、DTX+TGFRt15-TGFRs+TA99での処理が、生理食塩水対照群及びDTX処理群と比較して腫瘍成長を有意に抑制したことを示す(N=10、****p<0.001、複数のt検定分析)。
Example 67: A series of experiments were conducted to evaluate the anti-tumor activity of TGFRt15-TGFRs plus anti-TRP1 antibody (TA99) in combination with chemotherapy in a therapeutic melanoma mouse model of cancer, diabetes and atherosclerosis. rice field. In these experiments, C57BL/6 mice were injected subcutaneously with 0.5×10 6 B16F10 melanoma cells. Mice were treated with three doses of chemotherapy docetaxel (10 mg/kg) (DTX) on
B16F10腫瘍モデルにおける免疫細胞サブセットを評価するために、末梢血分析を行った。これらの実験では、C57BL/6マウスにB16F10細胞を注射し、DTX、DTX+TGFRt15-TGFRs+TA99、又は生理食塩水で処理した。DTX+TGFRt15-TGFRs+TA99群の免疫療法後2、5、及び8日目、及びDTX群及び生理食塩水群の腫瘍注射後11日目に、B16F10担腫瘍マウスの顎下静脈から血液を採取した。RBCをACK溶解緩衝液中に溶解させ、リンパ球を洗浄し、抗NK1.1、抗CD8、及び抗CD4抗体で染色した。細胞をフローサイトメトリー(Celesta-BD Bioscience)によって分析した。図177C~177Eは、DTX+TGFRt15-TGFRs+TA99処理が、生理食塩水処理群及びDTX処理群と比較して、腫瘍内のNK細胞及びCD8+T細胞のパーセンテージの増加を誘導したことを示す。
Peripheral blood analysis was performed to assess immune cell subsets in the B16F10 tumor model. In these experiments, C57BL/6 mice were injected with B16F10 cells and treated with DTX, DTX+TGFRt15-TGFRs+TA99, or saline. Blood was collected from the submandibular vein of B16F10 tumor-bearing
17日目に、全RNAを、Trizolを使用して、生理食塩水、DTX、又はDTX+TGFRt15-TGFRs+TA99で処理したマウスの腫瘍から抽出した。全RNA(1μg)を、QuantiTect逆転写キット(Qiagen)を使用したcDNA合成に使用した。リアルタイムPCRを、老化細胞マーカー(F)p21(G)DPP4及び(H)IL6用のFAM標識事前設計プライマーを使用して、CFX96 Detection System(Bio-Rad)で実行した。ハウスキーピング遺伝子18SリボソームRNAを、発現レベルの変動を正規化するための内部対照として使用した。18S rRNAに対する各標的mRNAの発現を、Ctに基づいて2-Δ(ΔCt)として計算し、式中、ΔCt=Cttarget-Ct18Sである。データを、生理食塩水対照と比較した倍率変化として表す。図177F~177Hは、DTX処理が老化腫瘍細胞の増加を誘導し、その後、TGFRt15-TGFRs+TA99免疫療法での処理後に減少したことを示す。
On
2t2によるApoE-/-マウスの西洋食誘発性高血糖の改善を調査するために一連の実験を行った。これらの実験では、6週齢の雌B6.129P2-ApoEtm1Unc/Jマウス(Jackson Laboratory)に、21%脂肪、0.15%コレステロール、34.1%スクロース、19.5%カゼイン、及び15%デンプンを含む西洋食(TD88137、Envigo Laboratories)を与えた。西洋食餌の8週間後、マウスにTGFRt15-TGFRs又は2t2を3mg/kgで皮下注射した。処理の3日後、マウスを16時間絶食させ、その後、血液試料を後眼窩静脈叢穿刺によって収集した。血糖値を、一滴の新鮮な血液を使用して血糖値計(OneTouch UltraMini)及びGenUltimated試験条片で検出した。図178Aに示されるように、2t2処理は、西洋食によって誘発された高血糖を軽減した(p<0.04)。血漿インスリンレベル及びレジスチンレベルを、Eve Technologies製のMouse Rat Metabolic Arrayを用いて分析した。HOMA-IRを、以下の式:恒常性モデル評価-インスリン抵抗性=グルコース(mg/dL)×インスリン(mU/mL)/405を使用して計算した。図178Bに示されるように、2t2及びTGFRt15-TGFRs処理は、未処理群と比較してインスリン抵抗性を低下させた。2t2(p<0.02)及びTGFRt15-TGFRs(p<0.05)は両方とも、図178Cに示されるように、未処理群と比較してレジスチンレベルを有意に低下させ、これは、2t2及びTGFRt15-TGFRsによって誘導されたインスリン抵抗性の低下に関連している可能性がある(図F3B)。 A series of experiments were performed to investigate the amelioration of Western diet-induced hyperglycemia in ApoE −/− mice by 2t2. In these experiments, 6-week-old female B6.129P2-ApoE tm1Unc /J mice (Jackson Laboratory) were fed 21% fat, 0.15% cholesterol, 34.1% sucrose, 19.5% casein, and 15% They were fed a western diet containing starch (TD88137, Envigo Laboratories). After 8 weeks on the Western diet, mice were injected subcutaneously with TGFRt15-TGFRs or 2t2 at 3 mg/kg. After 3 days of treatment, mice were fasted for 16 hours, after which blood samples were collected by retro-orbital venous puncture. Blood glucose levels were detected with a blood glucose meter (OneTouch UltraMini) and GenUltimate test strips using a drop of fresh blood. As shown in Figure 178A, 2t2 treatment attenuated Western diet-induced hyperglycemia (p<0.04). Plasma insulin and resistin levels were analyzed using the Mouse Rat Metabolic Array from Eve Technologies. HOMA-IR was calculated using the following formula: Homeostasis model assessment-insulin resistance = glucose (mg/dL) x insulin (mU/mL)/405. As shown in Figure 178B, 2t2 and TGFRt15-TGFRs treatment reduced insulin resistance compared to the untreated group. Both 2t2 (p<0.02) and TGFRt15-TGFRs (p<0.05) significantly reduced resistin levels compared to the untreated group, as shown in FIG. 178C, indicating that 2t2 and TGFRt15-TGFRs-induced decrease in insulin resistance (Fig. F3B).
実施例68:NK細胞のサイトカイン誘導性メモリー様NK細胞への分化の誘導
18t15-12sで刺激した後のNK細胞のサイトカイン誘導性メモリー様NK細胞(CIMK-NK細胞)への分化を評価するために一連の実験を行った。これらの実験では、新鮮なヒト白血球を血液バンクから入手し、CD56+NK細胞をRosetteSep/ヒトNK細胞試薬(StemCell Technologies)で単離した。NK細胞の純度は90%超であり、CD56-BV421、CD16-BV510、CD25-PE、及びCD69-APCFire750抗体(BioLegend)で染色することによって確認した。細胞をカウントし、2mLの完全培地(RPMI1640(Gibco)、2mMのL-グルタミン(Thermo Life Technologies)、ペニシリン(Thermo Life Technologies)、ストレプトマイシン(Thermo Life Technologies)、及び10%FBS(Hyclone)を補充)中の24ウェル平底プレートに2×106/mLで再懸濁した。細胞を、刺激しない(「スパイクなし」)か、又は18t15-12s(100nM)、若しくはrhIL-15(50ng/mL)(Miltenyi)、rhIL18(50ng/mL)(Invivogen)、及びrhIL-12(10ng/mL)(Peprotech)を含む単一サイトカイン混合物(「単一サイトカイン」)で、37℃及び5%CO2で16時間刺激した。翌日、細胞を収集し、温かい完全培地で2回、1000RPMで、室温で10分間洗浄した。細胞を、rhIL-15(1ng/mL)を含む2mLの完全培地中の24ウェル平底プレートに2×106/mLで再懸濁した。2日ごとに、培地の半分を、rhIL-15を含む新鮮な完全培地と交換した。
Example 68: Induction of NK Cells to Cytokine-Induced Differentiation into Memory-Like NK Cells To assess the differentiation of NK cells into cytokine-induced memory-like NK cells (CIMK-NK cells) after stimulation with 18t15-12s conducted a series of experiments. For these experiments, fresh human leukocytes were obtained from a blood bank and CD56 + NK cells were isolated with RosetteSep/human NK cell reagent (StemCell Technologies). NK cell purity was greater than 90% and confirmed by staining with CD56-BV421, CD16-BV510, CD25-PE, and CD69-APCFire750 antibodies (BioLegend). Cells were counted and supplemented with 2 mL of complete medium (RPMI 1640 (Gibco), 2 mM L-glutamine (Thermo Life Technologies), penicillin (Thermo Life Technologies), streptomycin (Thermo Life Technologies), and 10% FBS (Hyclone)). replenishment) Resuspended at 2×10 6 /mL in medium 24-well flat bottom plates. Cells were either unstimulated (“unspiked”) or 18t15-12s (100 nM), or rhIL-15 (50 ng/mL) (Miltenyi), rhIL18 (50 ng/mL) (Invivogen), and rhIL-12 (10 ng). /mL) (Peprotech) for 16 h at 37° C. and 5% CO 2 with a single cytokine mixture (“single cytokine”). The next day, cells were harvested and washed twice with warm complete medium at 1000 RPM for 10 minutes at room temperature. Cells were resuspended at 2×10 6 /mL in 2 mL complete medium containing rhIL-15 (1 ng/mL) in 24-well flat bottom plates. Every 2 days, half of the medium was replaced with fresh complete medium containing rhIL-15.
7日目のNK細胞のメモリー表現型の変化を評価するために、細胞を、細胞表面CD56、CD16、CD27、CD62L、NKp30、及びNKp44(BioLegend)に対する抗体で染色した。表面染色後、細胞を、FACS緩衝液(1×PBS(Hyclone)、0.5%BSA(EMD Millipore)及び0.001%アジ化ナトリウム(Sigma)を含む)中で洗浄した(1500RPM、室温で5分間)。2回洗浄した後、細胞をフローサイトメトリー(Celesta-BD Bioscience)によって分析した。図179は、NK細胞を18t15-12sとインキュベートすることにより、CD27、CD62L、及びNKp44を発現するCD16+CD56+NK細胞のパーセンテージが増加し、CD16+CD56+NK細胞中のNKp30のレベル(MFI)が増加したことを示す。
To assess changes in the memory phenotype of NK cells on
実施例69.CD44メモリーT細胞のアップレギュレーション
C57BL/6マウスをTGFRt15-TGFRs又は2t2で皮下処理した。処理したマウスを安楽死させ、単一脾細胞懸濁液を処理の4日後(TGFRt15-TGFRs)又は3日後(2t2)に調製した。調製した脾細胞を、蛍光色素結合抗CD4、抗CD8、及び抗CD44抗体で染色し、CD4+T細胞又はCD8+T細胞中のCD44高T細胞のパーセンテージを、フローサイトメトリーによって分析した。結果は、TGFRt15-TGFRs及び2t2がCD4+及びCD8+T細胞でのメモリーマーカーCD44の発現をアップレギュレートしたことを示す(図180)。これらの所見は、TGFRt15-TGFRs及び2t2がマウスT細胞のメモリーT細胞への分化を誘導することができたことを示す。
Example 69. Upregulation of CD44 memory T cells C57BL/6 mice were treated subcutaneously with TGFRt15-TGFRs or 2t2. Treated mice were euthanized and single splenocyte suspensions were prepared 4 days (TGFRt15-TGFRs) or 3 days (2t2) after treatment. Prepared splenocytes were stained with fluorochrome-conjugated anti-CD4, anti-CD8, and anti-CD44 antibodies and the percentage of CD44- rich T cells among CD4 + T cells or CD8 + T cells was analyzed by flow cytometry. The results show that TGFRt15-TGFRs and 2t2 upregulated the expression of memory marker CD44 on CD4 + and CD8 + T cells (FIG. 180). These findings indicate that TGFRt15-TGFRs and 2t2 were able to induce differentiation of mouse T cells into memory T cells.
実施例70:質感及び/又は外観及び/又は毛髪の改善
毛髪の再成長に対する2t2の効果を調べるために、C57BL6/Jマウス(Jackson Laboratory)の背側の毛を最初にバリカンで短くし、続いて脱毛クリーム(Nair)を剃毛した領域に30秒間塗布してから、きれいに拭いた。4時間後、2t2(3mg/kg、単回投与)、低用量組換えIL-2(25000IU、連続5日、1用量/日)、又はPBSを皮下投与した。マウスを、毛髪の再成長に関連する皮膚の色素沈着について観察し、画像を撮影し、ImageJソフトウェアを使用して分析した。図181Aは、PBS、2t2、又はIL-2で処理したマウスの脱毛から10日後の皮膚の色素沈着を示す。図181Bは、Image Jソフトウェアを使用して分析した、処理の10日後のマウスの各群の色素沈着率を示す。結果は、2t2又はIL-2でマウスを処理すると、PBSで処理したマウスと比較して、脱毛後の毛髪の再成長が促進したことを示した。
Example 70: Improving Texture and/or Appearance and/or Hair To investigate the effect of 2t2 on hair regrowth, the hair on the dorsal side of C57BL6/J mice (Jackson Laboratory) was first clipped short, followed by hair clippers. A depilatory cream (Nair) was applied to the shaved area for 30 seconds and then wiped clean. Four hours later, 2t2 (3 mg/kg, single dose), low-dose recombinant IL-2 (25000 IU, 5 consecutive days, 1 dose/day), or PBS were administered subcutaneously. Mice were observed for skin pigmentation associated with hair regrowth, imaged and analyzed using ImageJ software. FIG. 181A shows
C57BL6/Jマウス(Jackson Laboratory)の背側の毛を最初にバリカンで短くした後に、脱毛クリーム(Nair)を剃毛した領域にちょうど30秒間塗布してから、きれいに拭いた。4時間後、2t2(3mg/kg、単回投与)、低用量組換えIL-2(25000IU、連続5日、1用量/日)、又はPBSを皮下投与した。マウスを、毛髪の再成長に関連する皮膚の色素沈着について観察し、画像を撮影し、ImageJソフトウェアを使用して分析した。図182は、PBS、2t2、又はIL-2で処理したマウスの脱毛から14日後の皮膚の色素沈着を示す。結果は、2t2又はIL-2でマウスを処理すると、PBSで処理したマウスと比較して、脱毛後の毛髪の再成長が促進したことを示した。
After the dorsal hair of C57BL6/J mice (Jackson Laboratory) was first clipped short, depilatory cream (Nair) was applied to the shaved area for exactly 30 seconds and then wiped clean. Four hours later, 2t2 (3 mg/kg, single dose), low-dose recombinant IL-2 (25000 IU, 5 consecutive days, 1 dose/day), or PBS were administered subcutaneously. Mice were observed for skin pigmentation associated with hair regrowth, imaged and analyzed using ImageJ software. Figure 182 shows
実施例71:一本鎖又は多鎖キメラポリペプチドでの処理後の組織因子凝固アッセイ
一本鎖又は多鎖キメラポリペプチドでの処理後の血液凝固を評価するために一連の実験を行った。血液凝固カスケード経路を開始するために、組織因子(TF)を第VIIa因子(FVIIa)に結合して、TF/FVIIa複合体を形成する。その後、TF/FVIIa複合体を第X因子(FX)に結合し、FXをFXaに変換する。
Example 71 Tissue Factor Coagulation Assay After Treatment with Single- or Multi-Chain Chimeric Polypeptides A series of experiments were performed to assess blood clotting after treatment with single- or multi-chain chimeric polypeptides. To initiate the blood clotting cascade pathway, tissue factor (TF) binds to factor VIIa (FVIIa) to form the TF/FVIIa complex. The TF/FVIIa complex then binds to Factor X (FX), converting FX to FXa.
第VIIa因子(FVIIa)活性アッセイ
血液凝固を測定するための1つのアッセイは、第VIIa因子(FVIIa)活性の測定を含む。このタイプのアッセイは、組織因子及びカルシウムの存在を必要とする。TF/FVIIa複合体活性を、小さい基質又は天然タンパク質基質、例えば、第X因子(FX)を用いて測定することができる。FXを基質として使用する場合、リン脂質もTF/FVIIa活性に必要とされる。このアッセイでは、FVIIa活性を、FVIIa特異的発色性基質S-2288(Diapharma,West Chester,OH)を用いて決定する。S-2288基質の色の変化を分光光度法で測定することができ、これは、FVIIa(TF/FVIIa複合体等)のタンパク質分解活性に比例する。
Factor VIIa (FVIIa) Activity Assay One assay for measuring blood clotting involves measuring Factor VIIa (FVIIa) activity. This type of assay requires the presence of tissue factor and calcium. TF/FVIIa complex activity can be measured using small substrates or natural protein substrates such as Factor X (FX). Phospholipids are also required for TF/FVIIa activity when FX is used as a substrate. In this assay, FVIIa activity is determined using the FVIIa-specific chromogenic substrate S-2288 (Diapharma, West Chester, Ohio). The color change of the S-2288 substrate can be measured spectrophotometrically and is proportional to the proteolytic activity of FVIIa (such as the TF/FVIIa complex).
これらの実験では、以下の群:組織因子ドメインの219アミノ酸細胞外ドメイン(TF219)、野生型組織因子ドメインを有する多鎖キメラポリペプチド、及び変異体組織因子ドメインを有する多鎖キメラポリペプチドのFVIIa活性を比較した。変異体組織因子分子を含むキメラポリペプチドを、アミノ酸部位:Lys20、Ile22、Asp58、Arg135、及びPhe140でのTFドメインへの変異により構築した。 In these experiments, the following groups were tested: the 219-amino acid extracellular domain of the tissue factor domain ( TF219 ), multi-chain chimeric polypeptides with wild-type tissue factor domains, and multi-chain chimeric polypeptides with mutant tissue factor domains. FVIIa activity was compared. A chimeric polypeptide containing a mutant tissue factor molecule was constructed by mutation to the TF domain at amino acid sites: Lys20, Ile22, Asp58, Arg135, and Phe140.
FVIIaの活性を評価するために、FVIIa、及びTF219又はTF219含有多鎖キメラポリペプチドを、96ウェルELISAプレートの全てのウェル中に全体積70μL中等モル濃度(10nM)で混合した。37℃で10分間インキュベートした後、10μLの8mM S-2288基質を添加して、反応を開始した。その後、37℃で20分間インキュベートし続けた。最後に、色の変化を、吸光度を405nmで読み取ることによって監視した。様々なTF/VIIa複合体のOD値を表1及び表2に示す。表1は、TF219、21t15-21s野生型(WT)、及び21t15-21s変異体(Mut)の比較を示す。表2は、TF219、21t15-TGFRs野生型(WT)、及び21t15-TGFRs変異体(Mut)の比較を示す。これらのデータは、発色性S-2288を基質として使用した場合、TF219含有多鎖キメラポリペプチド(例えば、21t15-21s-WT、21t15-21s-Mut、21t15-TGFRS-WT、及び21t15-TGFRS-Mut)がTF219よりも低いFVIIa活性を有することを示す。注目すべきことに、TF219変異を含む多鎖キメラポリペプチドは、野生型TF219を含む多鎖キメラポリペプチドと比較した場合、はるかに低いFVIIa活性を示した。 To assess the activity of FVIIa, FVIIa and TF 219 or TF 219- containing multichain chimeric polypeptides were mixed in a total volume of 70 μL in all wells of a 96-well ELISA plate at equimolar concentrations (10 nM). After a 10 minute incubation at 37° C., 10 μL of 8 mM S-2288 substrate was added to initiate the reaction. After that, incubation was continued for 20 minutes at 37°C. Finally, color change was monitored by reading the absorbance at 405 nm. OD values for various TF/VIIa complexes are shown in Tables 1 and 2. Table 1 shows a comparison of TF 219 , 21t15-21s wild type (WT), and 21t15-21s mutant (Mut). Table 2 shows a comparison of TF 219 , 21t15-TGFRs wild-type (WT), and 21t15-TGFRs mutant (Mut). These data demonstrate that TF 219- containing multichain chimeric polypeptides (eg, 21t15-21s-WT, 21t15-21s-Mut, 21t15-TGFRS-WT, and 21t15-TGFRS) when chromogenic S-2288 is used as a substrate. -Mut) has lower FVIIa activity than TF219 . Notably, multi-chain chimeric polypeptides containing the TF219 mutation exhibited much lower FVIIa activity when compared to multi-chain chimeric polypeptides containing wild-type TF219 .
(表1)FVIIa活性

(表2)FVIIa活性

第X因子(FX)活性化アッセイ
血液凝固を測定するための追加のアッセイは、第X因子(FX)の活性化の測定を含む。簡潔には、TF/VIIaは、カルシウム及びリン脂質の存在下で、血液凝固第X因子(FX)を第Xa因子(FXa)に活性化する。TFの膜貫通ドメインを含むTF243は、FXをFXaに活性化する際に膜貫通ドメインを含まないTF219よりもはるかに高い活性を有する。FXのTF/VIIa依存性活性化を、FXa特異的発色性基質S-2765(Diapharma,West Chester,OH)を使用してFXa活性を測定することによって決定する。S-2765の色の変化を分光光度法で監視することができ、これは、FXaのタンパク質分解活性に比例する。
Factor X (FX) Activation Assay An additional assay for measuring blood clotting involves measuring activation of Factor X (FX). Briefly, TF/VIIa activates blood coagulation factor X (FX) to factor Xa (FXa) in the presence of calcium and phospholipids. TF 243 , which contains the transmembrane domain of TF, has much higher activity than TF 219 , which does not contain the transmembrane domain, in activating FX to FXa. TF/VIIa-dependent activation of FX is determined by measuring FXa activity using the FXa-specific chromogenic substrate S-2765 (Diapharma, West Chester, Ohio). The color change of S-2765 can be monitored spectrophotometrically and is proportional to the proteolytic activity of FXa.
これらの実験では、多鎖キメラポリペプチド(18t15-12s、マウス(m)21t15、21t15-TGFRs、及び21t15-7s)によるFX活性化を、陽性対照(Innovin)又はTF219と比較した。TF219(又はTF219含有多鎖キメラポリペプチド)/FVIIa複合体を、96ウェルELISAプレートの丸底ウェル中に50μLの体積中等モル濃度(各0.1nM)で混合し、その後、10μLの180nM FXを添加した。37℃で15分間インキュベートしている間にFXをFXaに変換し、その後、8μLの0.5M EDTA(カルシウムをキレート化し、ひいてはTF/VIIaによるFX活性化を終了させる)を各ウェルに添加して、FX活性化を停止した。次に、10μLの3.2mM S-2765基質を反応混合物に添加した。直ちにプレート吸光度を405nmで測定し、0時点での吸光度として記録した。その後、プレートを37℃で10~20分間インキュベートした。色の変化を、インキュベートした後に吸光度を405nmで読み取ることによって監視した。発色性基質S-2765を使用してFXa活性によって測定されたFX活性化の結果を図183に示す。この実験では、脂質化組換えヒトTF243を含む市販のプロトロンビン試薬であるInnovinを、FX活性化の陽性対照として使用した。Innovinを精製水で再構成して、約10nMのTF243にした。次に、等体積の0.2nMのFVIIaを0.2nMのInnovinと混合することにより、0.1nMのTF/VIIa複合体を作製した。Innovinが非常に強力なFX活性化活性を示した一方で、TF219及びTF219含有多鎖キメラポリペプチドは非常に低いFX活性化活性を有し、TF219がインビボで天然基質FXを活性化するためにTF/FVIIa複合体では活性でないことを確認した。
In these experiments, FX activation by multichain chimeric polypeptides (18t15-12s, mouse (m) 21t15, 21t15-TGFRs, and 21t15-7s) was compared to a positive control (Innovin) or TF219 . TF 219 (or TF 219- containing multichain chimeric polypeptide)/FVIIa complexes were mixed in 50 μL volumes of equimolar concentrations (0.1 nM each) in round-bottom wells of 96-well ELISA plates, followed by 10 μL of 180 nM. FX was added. FX was converted to FXa during a 15 min incubation at 37° C., after which 8 μL of 0.5 M EDTA (which chelates calcium and thus terminates FX activation by TF/VIIa) was added to each well. to stop FX activation. 10 μL of 3.2 mM S-2765 substrate was then added to the reaction mixture. The plate absorbance was immediately measured at 405 nm and recorded as the absorbance at
プロトロンビン時間試験
血液凝固を測定するための第3のアッセイは、血液凝固活性を測定するプロトロンビン時間(PT)試験である。ここでは、PT試験を、市販の正常ヒト血漿(Ci-Trol Coagulation Control,Level I)を使用して行った。標準PT試験のために、凝固反応を、カルシウムの存在下で、脂質化組換えヒトTF243であるInnovinの添加によって開始した。凝固時間を、STart PTアナライザー(Diagnostica Stago,Parsippany,N.J.)によって監視及び報告した。PTアッセイを、PTアッセイ緩衝液(50mMトリス-HCl、pH7.5、14.6mM CaCl2、0.1%BSA)中に希釈した0.2mLの様々なInnovin希釈物を37℃で予熱した0.1mLの正常ヒト血漿を含むキュベットに注入することによって開始した。PTアッセイでは、PT時間(凝固時間)が短いほどTF依存性凝固活性が高いことを示し、PT(凝固時間)が長いほどTF依存性凝固活性が低いことを意味する。
Prothrombin Time Test A third assay for measuring blood clotting is the prothrombin time (PT) test, which measures blood clotting activity. Here, PT tests were performed using commercially available normal human plasma (Ci-Trol Coagulation Control, Level I). For the standard PT test, the clotting reaction was initiated by addition of Innovin, a lipidated recombinant human TF 243 , in the presence of calcium. Clotting times were monitored and reported by a START PT Analyzer (Diagnostica Stago, Parsippany, N.J.). The PT assay was performed by prewarming 0.2 mL of various Innovin dilutions in PT assay buffer (50 mM Tris-HCl, pH 7.5, 14.6 mM CaCl 2 , 0.1% BSA) at 37°C. .By injecting into a cuvette containing 1 mL of normal human plasma. In the PT assay, a shorter PT time (clotting time) indicates higher TF-dependent coagulation activity, and a longer PT (clotting time) means lower TF-dependent coagulation activity.
図184に見られるように、異なる量のInnovin(例えば、10nMの脂質化組換えヒトTF243と同等の精製水で再構成したInnovinを100%のInnovinとみなす)のPTアッセイへの添加は、用量反応関係を示し、TF243濃度が低いほどPT時間が長くなった(凝固活性が低くなった)。例えば、0.001%のInnovinのPT時間は110秒を超え、これは緩衝液のみの場合とほぼ同じであった。 As seen in Figure 184, the addition of different amounts of Innovin (e.g., Innovin reconstituted in purified water equivalent to 10 nM lipidated recombinant human TF 243 is considered 100% Innovin) to the PT assay. A dose-response relationship was demonstrated, with lower TF 243 concentrations leading to longer PT times (lower clotting activity). For example, 0.001% Innovin had a PT time of over 110 seconds, which was about the same as buffer alone.
別の実験では、PT試験を、TF219、並びに18t15-12s、7t15-21s、21t15-TGFRs-WT、及び21t15-TGFRs-Mutを含む多鎖キメラポリペプチドに対して行った。図185は、TF219及びTF219含有多鎖キメラポリペプチド(100nMの濃度)が長時間のPT時間を有し、非常に低い凝固活性又は凝固活性なしを示す。 In another experiment, PT studies were performed on multichain chimeric polypeptides containing TF 219 and 18t15-12s, 7t15-21s, 21t15-TGFRs-WT, and 21t15-TGFRs-Mut. Figure 185 shows that TF 219 and TF 219- containing multichain chimeric polypeptides (100 nM concentration) have long PT times and very low or no clotting activity.
多鎖キメラポリペプチドのサイトカイン成分に対する受容体を有する他の細胞(32Dβ又はヒトPBMC)の存在下で多鎖キメラポリペプチドをインキュベートすることがPTアッセイにおける凝固時間に影響を及ぼすかを評価するための研究も実施した。IL-15受容体を発現する細胞(32Dβ細胞)又はIL-15受容体及びIL-21受容体を発現する細胞(PBMC)が、IL-15含有多鎖キメラポリペプチドを細胞FVIIa受容体として模倣天然TFに結合するかを試験するために、TF219含有多鎖キメラポリペプチド(各分子100nMの濃度)をPTアッセイ緩衝液中に希釈し、32Dβ細胞(2×105細胞/mL)又はPBMC(1×105細胞/mL)と室温で20~30分間プレインキュベートした。その後、PTアッセイを上述のように実施した。図186及び図187は、100nMの最終濃度で32Dβ細胞(図186)又はPBMC(図187)と混合したTF219及びTF219含有多鎖キメラポリペプチドが、0.001~0.01%のInnovinと同様の長時間のPT時間を有したことを示す(0.1pM~1.0pMのTF243と同等)。相対的TF243活性のパーセンテージで表すと、TF219含有多鎖キメラポリペプチドは、Innovinと比較して100,000~1,000,000倍低いTF依存性凝固活性を有した。これは、分子が32Dβ又はPBMC等のインタクトな細胞膜表面に結合している間でさえも、TF219含有多鎖キメラポリペプチドが非常に低いTF依存性凝固活性を有した又はTF依存性凝固活性を有しなかったことを示した。 To assess whether incubating a multichain chimeric polypeptide in the presence of other cells (32Dβ or human PBMC) that have receptors for the cytokine components of the multichain chimeric polypeptide affects clotting time in the PT assay We also conducted a study on Cells expressing IL-15 receptor (32Dβ cells) or IL-15 and IL-21 receptors (PBMC) mimic IL-15-containing multichain chimeric polypeptides as cellular FVIIa receptors To test for binding to native TF, TF 219- containing multichain chimeric polypeptides (at a concentration of 100 nM each molecule) were diluted in PT assay buffer and plated with 32Dβ cells (2 x 10 5 cells/mL) or PBMCs. (1×10 5 cells/mL) for 20-30 minutes at room temperature. PT assays were then performed as described above. Figures 186 and 187 demonstrate that TF 219 and TF 219 -containing multi-chain chimeric polypeptides mixed with 32Dβ cells (Figure 186) or PBMCs (Figure 187) at a final concentration of 100 nM showed that 0.001-0.01% Innovin (equivalent to 0.1 pM to 1.0 pM TF 243 ). Expressed as a percentage of relative TF 243 activity, TF 219- containing multichain chimeric polypeptides had 100,000- to 1,000,000-fold lower TF-dependent coagulant activity compared to Innovin. This suggests that TF 219- containing multichain chimeric polypeptides had very low TF-dependent coagulant activity, even while the molecule was bound to intact cell membrane surfaces such as 32Dβ or PBMC. showed that it did not have
実施例72:7t15-21s137L(ロングバージョン)の特徴付け
7t15構築物の核酸配列(シグナルペプチド配列を含む)は、以下の通りである(配列番号210)。
(シグナルペプチド)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(ヒトIL7)
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCAT
(ヒト組織因子219)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(ヒトIL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
Example 72: Characterization of 7t15-21s137L (long version) The nucleic acid sequence (including signal peptide sequence) of the 7t15 construct is as follows (SEQ ID NO:210).
(signal peptide)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCC
(human IL7)
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCCACATCTGCGACGCCAACAAGGAGGGCATGTTCCT GTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGA ACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCAT
(human tissue factor 219)
AGCGGCCAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAACCATCCTCGAATGGGAACCCAAACCCGTTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCG ATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCTTTATACGAGAACAGCCCCGAATTTACCCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCA CAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTAATCGACG TGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAGGGCGAGTTCCGGGAG
(human IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTACTGGAGCTGCCAAGTTATCTCTTTAGAGAGCGGGAGACGCTAGCAT CCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCCAAGGAGTGCGAAGAGCTGGAGGGAGAAGAACATCAAGGAGTTCTGCAATCCTTTGTGCCACATTGTCCAGATGTTCATCAATACCTCC
7t15融合タンパク質のアミノ酸配列(リーダー配列を含む)は、以下の通りである(配列番号209)。
(シグナルペプチド)
MKWVTFISLLFLFSSAYS
(ヒトIL7)
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEH
(ヒト組織因子219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(ヒトIL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
The amino acid sequence (including leader sequence) of the 7t15 fusion protein is as follows (SEQ ID NO:209).
(signal peptide)
MKWVT FISLLFLFS SAYS
(human IL7)
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDHLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWN KILMG TKEH
(human tissue factor 219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTF LSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(human IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
21s137L構築物の核酸配列(シグナルペプチド配列を含む)は、以下の通りである(配列番号331)。
(シグナルペプチド)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(ヒトIL-21)
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC
(ヒトIL-15Rαスシドメイン)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
((G4S)3リンカー)
GGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCT
(ヒトCD137L)
CGCGAGGGTCCCGAGCTTTCGCCCGACGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATCCCAGCCGGACTCCCTTCACCGAGGTCGGAA
The nucleic acid sequence (including signal peptide sequence) of the 21s137L construct is as follows (SEQ ID NO:331).
(signal peptide)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCC
(human IL-21)
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCG CCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCCTCCACAAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCCTGCTGCAGAAGAT GATCCATCAGCACCTGTCCTCCAGGACCCAGGCTCCGAGGACTCC
(Human IL-15Rα sushi domain)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCT CTTTAAAGTGCATCCGG
((G4S)3 linker)
GGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGGCGGAGGATCT
(human CD137L)
CGCGAGGGTCCCGAGCTTTCGCCCCGACGATCCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCGCAGCTGGTGGCCCAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCCAGGCCTGGCAGGGCGTGTCCCTGACGGGGGGC CTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTG GCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGG GACTCTTCCGGGTGACCCCCGAAAATCCCAGCCGGACTCCCTTCACCGAGGTCGGAA
21s137L融合タンパク質のアミノ酸配列(リーダー配列を含む)は、以下の通りである(配列番号332)。
(シグナルペプチド)
MKWVTFISLLFLFSSAYS
(ヒトIL-21)
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS
(ヒトIL-15Rαスシドメイン)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
((G4S)3リンカー)
GGGGSGGGGSGGGGS
(ヒトCD137L)
REGPELSPDDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEIPAGLPSPRSE
The amino acid sequence (including leader sequence) of the 21s137L fusion protein is as follows (SEQ ID NO:332).
(signal peptide)
MKWVT FISLLFLFS SAYS
(human IL-21)
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS
(Human IL-15Rα sushi domain)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
((G4S)3 linker)
GGGGSGGGGSGGGGGS
(human CD137L)
REGPELSPDDPAGLLDLLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSSVSLALHLQPLRSAAGAAALALTVDLLPPASSEARNSAFGFQGRLLHLSAGQRLGV HLHTEARARHAWQLTQGATVLGLFRVTPEIPAGLPSPRSSE
7t15-21s137L中のCD137L部分がCD137(4.1BB)に結合するためにインタクトであるかを評価するために以下の実験を実施した。1日目に、96ウェルプレートをR5(コーティング緩衝液)中100μL(2.5μg/mL)のGAH IgG Fc(G-102-C、R&D Systems)で一晩コーティングした。2日目に、プレートを3回洗浄し、PBS中の1%BSA300μLで37℃で2時間ブロックした。10ng/mLの4.1BB/Fc(838-4B、R&D Systems)を100μl/ウェルで、室温で2時間添加した。3回洗浄した後、7t15-21s137L(ロングバージョン)若しくは7t15-21s137L(ショートバージョン)を10nMから、又は組換えヒト4.1BBLを180ng/mLから、1/3希釈で添加し、その後、4℃で一晩インキュベートした。3日目に、プレートを3回洗浄し、500ng/mLのビオチン化ヤギ抗ヒト4.1BBL(BAF2295、R&D Systems)を100μL/ウェルで適用し、その後、室温で2時間インキュベートした。プレートを3回洗浄し、0.25μg/mLのHRP-SA(Jackson ImmuneResearch)と100μL/ウェルで30分間インキュベートした。その後、プレートを3回洗浄し、100μLのABTSと室温で2分間インキュベートした。結果を405nmで読み取った。図188に示されるように、7t15-21s137L(ロングバージョン)及び7t15-21s137L(ショートバージョン)はいずれも、組換えヒト4.1BBリガンド(rhCD137L、薄灰色の星)と比較して、4.1BB/Fc(濃色のひし形及び灰色の四角)と相互作用することができた。7t15-21s137L(ロングバージョン)(濃色のひし形)は、7t15-21s137L(ショートバージョン)(灰色の四角)と比較して4.1BB/Fcとより良好に相互作用した。
The following experiments were performed to assess whether the CD137L portion in 7t15-21s137L is intact to bind CD137 (4.1BB). On
7t15-21s137L(ロングバージョン)中の成分IL7、IL21、IL15、及び4.1BBLがELISAを使用して個々の抗体によって検出されるためにインタクトであるかを評価するために以下の実験を実施した。96ウェルプレートをR5(コーティング緩衝液)中100μL(4μg/mL)の抗TF(ヒトIgG1)でコーティングし、室温で2時間インキュベートした。プレートを3回洗浄し、PBS中100μLの1%BSAでブロックした。精製した7t15-21s137L(ロングバージョン)を10nMから1/3希釈で添加し、その後、室温で60分間インキュベートした。プレートを3回洗浄し、500ng/mLのビオチン化抗IL7(506602、R&D Systems)、500ng/mLのビオチン化抗IL21(13-7218-81、R&D Systems)、50ng/mLのビオチン化抗IL15(BAM247、R&D Systems)、又は500ng/mLのビオチン化ヤギ抗ヒト4.1BBL(BAF2295、R&D Systems)を各ウェルに添加し、室温で60分間インキュベートした。プレートを3回洗浄し、0.25μg/mLのHRP-SA(Jackson ImmunoResearch)と100μL/ウェルで、室温で30分間インキュベートした。プレートを4回洗浄し、100μLのABTSと室温で2分間インキュベートした。吸光度結果を405nmで読み取った。図189A~189Dに示されるように、7t15-21s137L(ロングバージョン)中のIL7、IL21、IL15、4.1BBLを含む成分を個々の抗体によって検出した。 The following experiments were performed to assess whether the components IL7, IL21, IL15, and 4.1BBL in 7t15-21s137L (long version) are intact for detection by individual antibodies using ELISA. . A 96-well plate was coated with 100 μL (4 μg/mL) of anti-TF (human IgG1) in R5 (coating buffer) and incubated for 2 hours at room temperature. Plates were washed three times and blocked with 100 μL of 1% BSA in PBS. Purified 7t15-21s137L (long version) was added at a 1/3 dilution from 10 nM, followed by incubation for 60 minutes at room temperature. Plates were washed 3 times and added with 500 ng/mL biotinylated anti-IL7 (506602, R&D Systems), 500 ng/mL biotinylated anti-IL21 (13-7218-81, R&D Systems), 50 ng/mL biotinylated anti-IL15 (506602, R&D Systems). BAM247, R&D Systems) or 500 ng/mL biotinylated goat anti-human 4.1BBL (BAF2295, R&D Systems) was added to each well and incubated for 60 minutes at room temperature. Plates were washed three times and incubated with 0.25 μg/mL HRP-SA (Jackson ImmunoResearch) at 100 μL/well for 30 minutes at room temperature. Plates were washed 4 times and incubated with 100 μL ABTS for 2 minutes at room temperature. Absorbance results were read at 405 nm. As shown in Figures 189A-189D, components including IL7, IL21, IL15, 4.1BBL in 7t15-21s137L (long version) were detected by individual antibodies.
7t15-21s137L(ロングバージョン)及び7t15-21s137L(ショートバージョン)におけるIL15の活性を評価するために以下の実験を実施した。IL2Rαβγ発現CTLL2細胞の増殖を促進する7t15-21s137L(ロングバージョン)及び7t15-21s137L(ショートバージョン)の能力を、組換えIL15の能力と比較した。IL15依存性CTLL2細胞をIMDM-10%FBSで5回洗浄し、ウェルに2×104細胞/ウェルで播種した。連続希釈した7t15-21s137L(ロングバージョン)、7t15-21s137L(ショートバージョン)、又はIL15を細胞に添加した。細胞をCO2インキュベーター内で、37℃で3日間インキュベートした。3日目に20μLのPrestoBlue(A13261、ThermoFisher)を各ウェルに添加し、CO2インキュベーター内で、37℃で更に4時間インキュベートすることにより、細胞増殖を検出した。570~610nmでの生吸光度をマイクロタイタープレートリーダーで読み取った。図190に示されるように、7t15-21s137L(ロングバージョン)、7t15-21s137L(ショートバージョン)、及びIL15は全て、CTLL2細胞増殖を促進した。7t15-21s137L(ロングバージョン)、7t15-21s137L(ショートバージョン)、及びIL15のEC50は、それぞれ、51.19pM、55.75pM、及び4.947pMである。
The following experiments were performed to assess the activity of IL15 in 7t15-21s137L (long version) and 7t15-21s137L (short version). The ability of 7t15-21s137L (long version) and 7t15-21s137L (short version) to promote proliferation of IL2Rαβγ-expressing CTLL2 cells was compared to that of recombinant IL15. IL15-dependent CTLL2 cells were washed five times with IMDM-10% FBS and seeded in wells at 2×10 4 cells/well. Serially diluted 7t15-21s137L (long version), 7t15-21s137L (short version), or IL15 were added to the cells. Cells were incubated for 3 days at 37°C in a CO2 incubator. Cell proliferation was detected by adding 20 μL of PrestoBlue (A13261, ThermoFisher) to each well on
実施例73:2t2によるTreg細胞の誘導
健常なドナー(ドナー163)の末梢血単核細胞(PBMC)は、Ficoll Paque Plus(GE17144003)によって5mLの全血バフィーコートから単離された。その後、PBMCをACKで溶解して、赤血球を除去した。細胞をIMDM-10%FBSで洗浄し、カウントした。1.8×106細胞(100μL/チューブ)を、フローチューブに播種し、50μLの下行性2t2又はIL2(15000、1500、150、15、1.5、0.15、又は0pM)及び50μLの前染色抗体(抗CD8-BV605及び抗CD127-AF647)とインキュベートした。細胞を水浴中で、37℃で30分間インキュベートした。200μLの予熱したBD Phosflow Fix Buffer I(カタログ番号557870、Becton Dickinson Biosciences)を、水浴中に37℃で10分間かけて添加して、刺激を停止した。細胞(4.5×105細胞/100μL)を、V字型96ウェルプレートに移し、遠心沈殿させた後、100μLの-20℃に予冷したBD Phosflow Perm Buffer III(カタログ番号BD Biosciences)で、氷上で30分間透過処理した。その後、細胞を200μLのFACS緩衝液で2回徹底的に洗浄し、蛍光抗体のパネル(抗CD25-PE、CD4-PerCP-Cy5.5、CD56-BV421、CD45RA-PE-Cy7、及びpSTAT5a-AF488)で染色して、異なるリンパ球亜集団を区別し、pSTAT5aの状態を評価した。細胞を遠心沈殿させ、FACSCelesta分析のために200μLのFACS緩衝液中に再懸濁した。図191Aに示されるように、2t2の6pMはCD4+CD25高Treg細胞におけるStat5aのリン酸化を誘導するのに十分であったが、43.11pMのIL-2がリンパ球の同じ集団におけるStat5aのリン酸化を誘導するために必要であった。対照的に、CD4+CD25-Tcon及びCD8+Tcon細胞におけるStat5aのリン酸化を誘導する際に、IL2と比較して、2t2は活性が低かった(図191B)又は同等に活性であった(図191C)。これらの結果は、2t2が、ヒトPBMCにおけるTregの活性化において、IL2と比較して優れていることと、2t2が、ヒト血液リンパ球pStat5a応答において、IL-2と比較してTregの選択性を高めることを実証することとを示唆する。
Example 73: Induction of Treg cells by 2t2 Peripheral blood mononuclear cells (PBMC) of a healthy donor (donor 163) were isolated from 5 mL of whole blood buffy coat by Ficoll Paque Plus (GE17144003). PBMC were then lysed with ACK to remove red blood cells. Cells were washed with IMDM-10% FBS and counted. 1.8×10 6 cells (100 μL/tube) were seeded in flow tubes and 50 μL of descending 2t2 or IL2 (15000, 1500, 150, 15, 1.5, 0.15, or 0 pM) and 50 μL of Incubated with prestaining antibodies (anti-CD8-BV605 and anti-CD127-AF647). Cells were incubated in a water bath at 37°C for 30 minutes. Stimulation was stopped by adding 200 μL of pre-warmed BD Phosflow Fix Buffer I (Cat#557870, Becton Dickinson Biosciences) in a water bath at 37° C. for 10 minutes. Cells (4.5×10 5 cells/100 μL) were transferred to a V-shaped 96-well plate, spun down, and then spun down with 100 μL of BD Phosflow Perm Buffer III (catalog number BD Biosciences) precooled to −20° C. Permeabilize for 30 minutes on ice. Cells were then extensively washed twice with 200 μL of FACS buffer and tested with a panel of fluorescent antibodies (anti-CD25-PE, CD4-PerCP-Cy5.5, CD56-BV421, CD45RA-PE-Cy7, and pSTAT5a-AF488). ) to distinguish different lymphocyte subpopulations and assess pSTAT5a status. Cells were spun down and resuspended in 200 μL FACS buffer for FACSCelesta analysis. As shown in Figure 191A, 6 pM of 2t2 was sufficient to induce phosphorylation of Stat5a in CD4 + CD25 high T reg cells, whereas 43.11 pM IL-2 reduced Stat5a in the same population of lymphocytes. was required to induce the phosphorylation of In contrast, 2t2 was less active (FIG. 191B) or equally active in inducing Stat5a phosphorylation in CD4 + CD25 − T con and CD8 + T con cells when compared to IL2. (Fig. 191C). These results demonstrate that 2t2 is superior to IL2 in activating T regs in human PBMCs, and that 2t2 is superior to IL2 in activating T regs in human blood lymphocyte pStat5a responses. and to demonstrate that it enhances selectivity.
実施例74.一本鎖キメラポリペプチドを使用した毛髪の成長の改善
7週齢のC57BL6/Jマウスの背側の毛を剃り、市販の脱毛クリームを使用して脱毛した。マウスに、同じ日に2t2の単回投与又は低用量の市販の組換えIL-2を皮下注射し、その後、更に4日間毎日投与した。未処理マウスを対照として使用した。10日目に、マウスを殺処分し、剃毛した領域の皮膚切片を調製した。脱毛の10日後にC57BL6Jマウスの皮膚切片の代表的なH&E染色を、図192A~192Eに示す。図192Aは、毛を剃った後に脱毛を行った対照マウスのみを示し、図192Bは、脱毛の後に低用量のIL-2(1mg/kg)を投与したマウスを示し、図192C~192Eは、脱毛の後に0.3mg/kg(図192C)、1mg/kg(図192D)、及び3mg/kg(図192E)の2t2を投与したマウスを示す。黒い矢印は、後で真皮に伸び、発毛を促進する、成長期の毛包を示す。図194は、各処理群の10フィールド当たりにカウントされた成長期の毛包の総数を示す。要約すると、データは、2t2分子が脱毛のみと比較して、成長期の毛包の数の増加をもたらしたことを示す。この効果も用量依存的であった。
Example 74. Improving Hair Growth Using Single-Chain Chimeric Polypeptides Seven-week-old C57BL6/J mice were shaved dorsally and depilated using a commercial depilatory cream. Mice were injected subcutaneously with a single dose of 2t2 or a low dose of commercially available recombinant IL-2 on the same day, followed by daily dosing for an additional 4 days. Untreated mice were used as controls. On
実施例75:免疫細胞のメモリー様免疫細胞への分化
新鮮なヒト白血球を血液バンクから入手し、CD56+NK細胞をRosetteSep/ヒトNK細胞試薬(StemCell Technologies)で単離した。NK細胞の純度は70%超であり、CD56-BV421、CD16-BV510、CD25-PE、CD69-APCFire750(BioLegend)で染色することにより確認した。細胞をカウントし、2mMのL-グルタミン(Thermo Life Technologies)、抗生物質(ペニシリン、10,000ユニット/mL、10,000μg/mL;Thermo Life Technologies)、及び10%FBS(Hyclone)を補充したRPMI1640培地(Gibco)中の2×106細胞/mLの密度で再懸濁した。細胞(1mL)を24ウェル平底プレートに移し、処理なし、又は7t15-21s+抗組織因子(TF)抗体(IgG1)(50nM)で、培地で14日間増殖させた。細胞に、約1×106細胞/mLの細胞密度を保つために新鮮な7t15-21s+抗TF抗体(IgG1)(50nM)を補充した。
Example 75 Differentiation of Immune Cells into Memory-Like Immune Cells Fresh human leukocytes were obtained from a blood bank and CD56 + NK cells were isolated with RosetteSep/human NK cell reagent (StemCell Technologies). The purity of NK cells was >70% and confirmed by staining with CD56-BV421, CD16-BV510, CD25-PE, CD69-APCFire750 (BioLegend). Cells were counted in RPMI 1640 supplemented with 2 mM L-glutamine (Thermo Life Technologies), antibiotics (penicillin, 10,000 units/mL, 10,000 μg/mL; Thermo Life Technologies), and 10% FBS (Hyclone). Resuspended at a density of 2×10 6 cells/mL in medium (Gibco). Cells (1 mL) were transferred to 24-well flat bottom plates and grown in culture for 14 days with no treatment or 7t15-21s plus anti-tissue factor (TF) antibody (IgG1) (50 nM). Cells were supplemented with fresh 7t15-21s plus anti-TF antibody (IgG1) (50 nM) to maintain a cell density of approximately 1×10 6 cells/mL.
処理群に対する非増殖NK細胞を、完全なDNAメチル化レベルの陽性対照として使用した(データには示されていない)。NK細胞をペレット化し(1x106)、QIAamp UCP DNA Micro Kit(Qiagen)を使用してゲノムDNA(nDNA)を単離した。500ngの精製nDNAを、EZ DNA Methylation-Directキット(Zymo Research)を製造業者のプロトコルに従って使用して、亜硫酸水素ナトリウム処理にかけた。重亜硫酸塩処理により、DNAにメチル化依存性の変化が生じ、脱メチル化されたシトシンがウラシルに変換されるが、メチル化されたシトシンは変化しない。重亜硫酸塩で処理したnDNA(10~50ng)を、順方向プライマーIFNG127F(5’-ATGGTATAGGTGGGTATAATGG-3’)及びビオチン化リバースプライマーIFNG355R-ビオ(ビオチン-5’-CAATATACTACACCTCCTCTAACTAC-3’)(GENEWIZ)を用いてPyromark PCRキット(Qiagen)を使用してT細胞中のDNAメチル化によって高度に調整されることが知られている、2つのCpG部位(CpG-186及びCpG-54、転写開始部位TSSに対する位置)を含むIFNγプロモーターの228bp領域をテンプレートとしてPCR増幅した。PCR条件は、95℃で15分、95℃で30秒、56℃で30秒、72℃で60秒、続いて72℃で10分の48サイクルであった。PCR増幅産物の完全性及び品質は、1.2%TAEアガロースゲルで視覚化した。これら2つのCpG部位のDNAメチル化状態は、単一のCpG部位でのDNAメチル化を定量的に測定するための究極の判断基準技術であるピロシーケンスによって決定される。ピロシーケンス反応は、それぞれ、CpG部位186及び54に特異的なDNAシーケンシングプライマーC186-IFNG135F(5’-GGTGGGTATAATGGG-3’)(配列番号333)及びC54-IFNG261F(5’-ATTATTTTATTTTAAAAAATTTGTG-3’)(配列番号334)を使用して、Johns Hopkins Universityの遺伝資源コア施設で行われた。市販の非メチル化及びメチル化DNA(Zymo Research)を、DNAメチル化の対照として使用した。2つのCpG部位(-186及び-54)のメチル化パーセンテージは、各処理についてプールした。DNAメチル化の差異パーセントは、非曝露NK細胞で観察された2つのCpG部位でのDNAメチル化のレベルに対して計算した。
Non-proliferating NK cells for treatment groups were used as a positive control for complete DNA methylation levels (data not shown). NK cells were pelleted (1×10 6 ) and genomic DNA (nDNA) was isolated using the QIAamp UCP DNA Micro Kit (Qiagen). 500 ng of purified nDNA was subjected to sodium bisulfite treatment using the EZ DNA Methylation-Direct kit (Zymo Research) according to the manufacturer's protocol. Bisulfite treatment produces methylation-dependent changes in DNA, converting demethylated cytosines to uracil, but leaving methylated cytosines unchanged. Bisulfite-treated nDNA (10-50 ng) was treated with forward primer IFNG127F (5′-ATGGTATAGGTGGGTATAATGG-3′) and biotinylated reverse primer IFNG355R-bio (biotin-5′-CAATATATACACCTCTCCTCTAACTAC-3′) (GENEWIZ). Two CpG sites (CpG-186 and CpG-54, for the transcription start site TSS), known to be highly regulated by DNA methylation in T cells using the Pyrmark PCR kit (Qiagen) A 228 bp region of the IFNγ promoter containing the position ) was PCR amplified as a template. The PCR conditions were 95°C for 15 minutes, 95°C for 30 seconds, 56°C for 30 seconds, 72°C for 60 seconds, followed by 48 cycles of 72°C for 10 minutes. The integrity and quality of PCR amplification products were visualized on 1.2% TAE agarose gels. The DNA methylation status of these two CpG sites is determined by pyrosequencing, the gold standard technique for quantitatively measuring DNA methylation at single CpG sites. Pyrosequencing reactions were performed using DNA sequencing primers C186-IFNG135F (5′-GGTGGGTATAATGGG-3′) (SEQ ID NO: 333) and C54-IFNG261F (5′-ATTATTTTATTTTAAAAAATTTGTG-3′) specific for
これら2つのIFNγ CpG部位のDNAメチル化状態の分析により、非曝露NK細胞と比較して、7t15-21s+抗TF抗体によって支持されるNK細胞においてより高いレベルのDNA脱メチル化が明らかになった(図194)。これらの7t15-21s+抗TF抗体支持NK細胞は、非曝露NK細胞と比較して、DNAメチル化(すなわち、脱メチル化)において47.70%±11.76の差異を呈した。これら2つのIFNγ CpG部位のDNAメチル化レベルは、7t15-21s+抗TF抗体による処理後のIFNγの増加された発現と相関していた。これらのデータは、7t15-21s+抗TF抗体の組み合わせレジメンによるNK細胞の長期曝露(培養で14日間の増殖)が、2つの低メチル化IFNγ CpG部位(-186及び-54)のDNA脱メチル化を誘導することができること、及び7t15-21s+抗TF抗体(IgG1)が、CpG部位のDNA脱メチル化を介してIFNγの遺伝子発現を後生的に再プログラムし、NK細胞の自然免疫メモリーNK細胞への相互変換をもたらすことができることを示唆する。 Analysis of the DNA methylation status of these two IFNγ CpG sites revealed higher levels of DNA demethylation in NK cells supported by 7t15-21s + anti-TF antibody compared to unexposed NK cells. (Fig. 194). These 7t15-21s+ anti-TF antibody-bearing NK cells exhibited a 47.70%±11.76 difference in DNA methylation (ie, demethylation) compared to unexposed NK cells. DNA methylation levels at these two IFNγ CpG sites correlated with increased expression of IFNγ following treatment with 7t15-21s plus anti-TF antibody. These data demonstrate that long-term exposure of NK cells (expansion for 14 days in culture) with a combined regimen of 7t15-21s plus an anti-TF antibody results in DNA demethylation of two hypomethylated IFNγ CpG sites (−186 and −54). and that 7t15-21s plus anti-TF antibody (IgG1) epigenetically reprograms gene expression of IFNγ through DNA demethylation of CpG sites, transforming NK cells into innate immune memory NK cells. suggest that the interconversion of
実施例76:化学療法は、C57BL/6マウスにおいてp21CIP1p21老化関連遺伝子発現を誘導する
化学療法は、C57BL/6マウスにおいてp21CIP1p21老化関連遺伝子発現を誘導する。図203Aは、治療レジメンを示す模式図である。C57BL/6マウスは、1日目、4日目、7日目に3回の化学療法ドセタキセル(DTX)(10mg/kg)で処理された。9日目にマウスを屠殺し、老化マーカーを評価するために肺及び肝臓組織を収集した。図203B及び203Cは、それぞれ肺(B)及び肝臓(C)組織におけるp21CIP1p21の発現を示す。液体窒素中で乳鉢及び乳棒を使用して、肺及び肝臓の組織を均質化した。均質化した組織を、1mLのTrizol(Thermo Fischer)を含有する新しいエッペンドルフチューブに移した。全RNAを、RNeasyミニキット(Qiagen番号74106)を製造業者の指示に従って使用して抽出した。1μgの全RNAを、QuantiTect逆転写キット(Qiagen)を使用したcDNA合成に使用した。リアルタイムPCRを、Thermo Scientificから購入したFAM標識事前設計プライマーp21CIP1p21を使用したCFX96検出システム(Bio-Rad)で行った。反応を試験した全ての遺伝子に対して三連で行った。ハウスキーピング遺伝子18SリボソームRNAを、発現レベルの変動を正規化するための内部対照として使用した。18S rRNAに対する各標的mRNAの発現を、Ctに基づいて2-Δ(ΔCt)として計算し、式中、ΔCt=Cttarget-Ct18Sである。図203A~203Cに示されるように、老化マーカーp21CIP1p21は、ドセタキセルで処理したマウスの肺及び肝臓組織において誘導された。
Example 76: Chemotherapy induces p21 CIP1 p21 senescence-related gene expression in C57BL/6 mice Chemotherapy induces p21 CIP1 p21 senescence-related gene expression in C57BL/6 mice. FIG. 203A is a schematic diagram showing a treatment regimen. C57BL/6 mice were treated with chemotherapy docetaxel (DTX) (10 mg/kg) three times on
実施例77:IL-15ベースの作用物質での処理後の免疫表現型及び細胞増殖(治療後3日目)
TGFRt15-TGFRsで処理した後の免疫細胞の異なるサブセットを評価するために、マウス血液を調製した。6週齢のC57BL/6マウスをJackson Laboratoryから購入した。マウスは、温度及び光が制御された環境で飼育された。マウスを以下のように群に分けた:生理食塩水対照群(n=6)、ドセタキセル群(n=6)、TGFRt15-TGFRs群のドセタキセル(n=6)、IL-15SA群のドセタキセル(n=6)。IL-15スーパーアゴニスト(IL-15SA)を構築し、以前に記載されたように投与した(Zhu et al.,J.Immunol.183(6):3598-3607,2009)。1、4、及び7日目にドセタキセル(10mg/kg)を3回投与すると、マウスの老化が誘導された。8日目に、PBS又はTGFRt15-TGFRs(3mg/kg)又はIL-15SA(0.2mg/kg)のいずれかでマウスを皮下処理した。マウスの血液は、EDTA含有チューブで処理後3日目に顎下静脈から収集した。全血をマイクロ遠心機で3000RPMで10分間遠心分離して血漿を収集した。血漿は-80℃で保存し、全血をフローサイトメトリーによる免疫細胞表現型解析のために処理した。全血を室温で5分間ACK緩衝液に溶解した。細胞を、FACS緩衝液(1×PBS(Hyclone)、0.5%BSA(EMD Millipore)及び0.001%アジ化ナトリウム(Sigma)を含む)中で洗浄した。血液中の異なる種類の免疫細胞を評価するために、細胞表面のCD4、CD45、CD8、及びNK1.1(Biolegend)ついて室温で30分間染色した。表面染色後、細胞を、FACS緩衝液(0.5%BSA(EMD Millipore)及び0.001%アジ化ナトリウム(Sigma)を含む1×PBS(Hyclone))中で洗浄した(1500RPM、室温で5分間)。細胞を透過化緩衝液(Invitrogen)で4℃で20分間処理した後、Perm緩衝液(Invitrogen)で洗浄した。次いで、細胞を細胞内マーカー(Ki67)及びFoxP3について室温で30分間染色した。2回洗浄した後、細胞をフローサイトメトリー(Celesta-BD Bioscience)によって分析した。これらのデータは、IL-15ベースの作用物質TGFRt15-TGFRs及びIL-15SAが、ドセタキセル処理後にNK及びCD8+T細胞の拡大及び増殖を刺激及び促進できることを示している(図204)。
Example 77: Immunophenotype and Cell Proliferation After Treatment with IL-15-Based Agents (
Mouse blood was prepared to evaluate different subsets of immune cells after treatment with TGFRt15-TGFRs. Six-week-old C57BL/6 mice were purchased from Jackson Laboratory. Mice were housed in a temperature and light controlled environment. Mice were divided into groups as follows: saline control group (n=6), docetaxel group (n=6), docetaxel in TGFRt15-TGFRs group (n=6), docetaxel in IL-15SA group (n=6) = 6). An IL-15 superagonist (IL-15SA) was constructed and administered as previously described (Zhu et al., J. Immunol. 183(6):3598-3607, 2009). Three doses of docetaxel (10 mg/kg) on
実施例78:TGFRt15-TGFRs処理は、C57BL/6マウスにおける老化関連遺伝子発現を低減させる
化学療法誘発老化関連遺伝子発現は、C57BL/6マウスの肺及び肝臓においてTGFRt15-TGFRsで大幅に低減した。C57BL/6マウスは、1日目、4日目、7日目に3回の化学療法ドセタキセル(10mg/kg)で処理された。8日目に、ドセタキセルで処理したマウスを3つの群に分けた。最初の群は処理を受けず、2番目の群はTGFRt15-TGFRsを受け、3番目の群はIL-15SAを受けた。生理食塩水で処理したマウスを対照として使用した。TGFRt15-TGFRsは、3mg/kgの投薬量で投与され、IL-15SAは、0.2mg/kgで投与された。研究薬物処理後3日目に、マウスを屠殺し、肺及び肝臓を収集した。グラフ205A~205Cは、それぞれ肺(A及びB)組織におけるp21CIP1p21及びCD26の発現並びに肝臓(C)組織におけるp21CIP1p21の発現を示す。液体窒素中で乳鉢及び乳棒を使用して、肺及び肝臓の組織を均質化した。均質化した組織を、1mLのTrizol(Thermo Fischer)を含有する新しいエッペンドルフチューブに移した。全RNAを、RNeasyミニキット(Qiagen番号74106)を製造業者の指示に従って使用して抽出した。1μgの全RNAを、QuantiTect逆転写キット(Qiagen)を使用したcDNA合成に使用した。リアルタイムPCRを、Thermo Scientificから購入したFAM標識事前設計プライマーp21CIP1p21及びCD26を使用したCFX96検出システム(Bio-Rad)で行った。反応を試験した全ての遺伝子に対して三連で行った。ハウスキーピング遺伝子18SリボソームRNAを、発現レベルの変動を正規化するための内部対照として使用した。18S rRNAに対する各標的mRNAの発現を、Ctに基づいて2-Δ(ΔCt)として計算し、式中、ΔCt=Cttarget-Ct18Sである。
Example 78: TGFRt15-TGFRs treatment reduces senescence-related gene expression in C57BL/6 mice Chemotherapy-induced senescence- related gene expression was significantly reduced in lung and liver of C57BL/6 mice with TGFRt15-TGFRs. C57BL/6 mice were treated with chemotherapy docetaxel (10 mg/kg) three times on
図205A~205Cに示されるように、TGFRt15-TGFRsで処理したマウスの肺組織及び肝臓組織において、療法誘導性老化マーカーp21CIP1p21が大幅に低減した。TGFRt15-TGFRsで処理したマウスの肺組織において、療法誘導性老化マーカーCD26も大幅に低減した。 As shown in Figures 205A-205C, therapy-induced senescence markers p21 CIP1 p21 were significantly reduced in lung and liver tissues of mice treated with TGFRt15-TGFRs. The therapy-induced senescence marker CD26 was also significantly reduced in lung tissue from mice treated with TGFRt15-TGFRs.
実施例79:IL-15ベースの作用物質での処理後の免疫表現型
マウスの血液は、IL-15ベースの作用物質:TGFRt15-TGFRs、IL-15スーパーアゴニスト(IL-15SA)、及びIL-15活性をノックアウトしたD8N変異体のIL-15融合体(TGFRt15*-TGFRs)で処理した後の免疫細胞の様々なサブセットを評価するために調製された。6週齢のC57BL/6マウスをJackson Laboratoryから購入した。マウスは、温度及び光が制御された環境で飼育された。マウスを群に分け(n=6/群)、以下で処理した:1)PBS(生理食塩水)対照、2)ドセタキセル、3)TGFRt15-TGFRsを含むドセタキセル、4)IL-15SAを含むドセタキセル、5)IL-15変異体(TGFRt15*-TGFRs)を含むドセタキセル及び6)IL-15スーパーアゴニスト(IL-15SA)とTGFRt15*-TGFRsを含むドセタキセル。1、4、及び7日目にドセタキセル(10mg/kg)を3回投与すると、マウスの老化が誘導された。8日目に、PBS、TGFRt15-TGFRs、TGFRt15*-TGFRs、IL-15SA、又は上記の組み合わせでマウスを皮下処理した。TGFRt15-TGFRs及びTGFRt15*-TGFRsは、3mg/kgの投薬量で投与され、IL-15SAは、0.05mg/kgで投与された。研究薬物処理後3日目にマウス血液を顎下静脈からEDTAチューブに収集した。全血をマイクロ遠心機で3000RPMで10分間遠心分離して血漿を収集した。血漿は-80℃で保存し、全血をフローサイトメトリーによる免疫細胞表現型解析のために処理した。全血をACK緩衝液で37℃で5分間溶解した。細胞を、FACS緩衝液(1×PBS(Hyclone)、0.5%BSA(EMD Millipore)及び0.001%アジ化ナトリウム(Sigma)を含む)中で洗浄した。血液中の異なる種類の免疫細胞を評価するために、細胞表面のCD4、CD45、CD19CD8、及びNK1.1(Biolegend)ついて室温(RT)で30分間染色した。表面染色後、細胞を、FACS緩衝液(0.5%BSA(EMD Millipore)及び0.001%アジ化ナトリウム(Sigma)を含む1×PBS(Hyclone))中で洗浄した(1500RPM、室温で5分間)。細胞を透過化緩衝液(Invitrogen)で4℃で20分間処理した後、Perm緩衝液(Invitrogen)で洗浄した。次いで、細胞を細胞内マーカー(Ki67)について室温で30分間染色した。2回洗浄した後、細胞をフローサイトメトリー(Celesta-BD Bioscience)によって分析した(図206及び207)。
Example 79: Blood of immunophenotypic mice after treatment with IL-15-based agents showed IL-15-based agents: TGFRt15-TGFRs, IL-15 superagonist (IL-15SA), and IL-15- were prepared to evaluate various subsets of immune cells after treatment with IL-15 fusions of D8N mutants that knocked out the 15 activity (TGFRt15*-TGFRs). Six-week-old C57BL/6 mice were purchased from Jackson Laboratory. Mice were housed in a temperature and light controlled environment. Mice were divided into groups (n=6/group) and treated with: 1) PBS (saline) control, 2) docetaxel, 3) docetaxel with TGFRt15-TGFRs, 4) docetaxel with IL-15SA. 5) docetaxel with IL-15 variants (TGFRt15*-TGFRs) and 6) docetaxel with IL-15 superagonist (IL-15SA) and TGFRt15*-TGFRs. Three doses of docetaxel (10 mg/kg) on
これらのデータは、IL-15ベースの作用物質TGFRt15-TGFRs及びIL-15SAが、ドセタキセル処理後にNK及びCD8+T細胞の拡大及び増殖を刺激及び促進できることを示している。IL-15活性を欠く融合タンパク質(すなわち、TGFRt15*-TGFRs)では、NK及びCD8+T細胞の拡大及び増殖の増加は見られなかった。 These data demonstrate that the IL-15-based agents TGFRt15-TGFRs and IL-15SA can stimulate and promote NK and CD8 + T cell expansion and proliferation after docetaxel treatment. Fusion proteins lacking IL-15 activity (ie, TGFRt15*-TGFRs) did not result in increased expansion and proliferation of NK and CD8 + T cells.
実施例80:肺及び肝臓組織における老化マーカーp21CIP1p21及びCD26の評価
細胞老化のマーカーは、化学療法及び研究処理の投与後の正常なマウスの組織で評価された。6週齢のC57BL/6マウスをJackson Laboratoryから購入した。マウスは、温度及び光が制御された環境で飼育された。マウスを6つの群に分け、以下で処理した:1)PBS(生理食塩水)対照(n=5)、2)ドセタキセル(n=8)、3)TGFRt15-TGFRsを含むドセタキセル(n=8)、4)IL15SAを含むドセタキセル(n=8)、5)IL-15変異体(TGFRt15*-TGFRs)を含むドセタキセル(n=8)及び6)IL-15スーパーアゴニスト(IL-15SA)とTGFRt15*-TGFRsを含むドセタキセル(n=6)。1、4、及び7日目にドセタキセル(10mg/kg)を3回投与すると、マウスの老化が誘導された。8日目に、PBS、TGFRt15-TGFRs、TGFRt15*-TGFRs、IL-15SA、又は以下の組み合わせでマウスを皮下処理した。TGFRt15-TGFRs及びTGFRt15*-TGFRsは、3mg/kgの投薬量で投与され、IL-15SAは、0.05mg/kgで投与された。異なる老化マーカーを評価するために、マウス組織を調製した。研究薬物処理後7日目にマウスを安楽死させ、肝臓及び肺組織を収集し、1.7mLエッペンドルフチューブ内の液体窒素で保存した。液体窒素中で乳鉢及び乳棒を使用して、試料を均質化した。均質化した組織を、1mLのTrizol(Thermo Fischer)を含有する新しいエッペンドルフチューブに移した。RNeasyミニキット(Qiagen番号74106)を使用して製造元の指示に従って全RNAを抽出し、1μgの全RNAを、QuantiTect逆転写キット(Qiagen)を使用したcDNA合成に使用した。リアルタイムPCRを、Thermo Scientificから購入したFAM標識事前設計プライマーを使用したCFX96検出システム(Bio-Rad)で行った。反応を試験した全ての遺伝子に対して三連で行った。ハウスキーピング遺伝子18SリボソームRNAを、発現レベルの変動を正規化するための内部対照として使用した。18S rRNAに対する各標的mRNAの発現を、Ctに基づいて2-Δ(ΔCt)として計算し、式中、ΔCt=Cttarget-Ct18Sである。図208A~208Cに示されるように、ドセタキセルで処理したマウスの肺[それぞれ(A)及び(B)]組織において老化マーカーp21及びCD26が誘導され、肝臓(C)組織においてp21CIP1p21が誘導された。肺の老化マーカーp21CIP1p21及びCD26並びに肝臓の老化マーカーp21CIP1p21は、TGFRt15-TGFRs、IL-15SA、及びIL-15SAとTGFRt15*-TGFRs変異体との組み合わせで処理したマウスで低減した。しかしながら、TGFRt15*-TGFRs変異体で処理されたマウスの肺は、これらの組織の老化マーカーを除去できなかった。これらの結果は、IL-15活性がTIS老化細胞の除去に重要であることを示す。
Example 80 Evaluation of Senescence Markers p21CIP1p21 and CD26 in Lung and Liver Tissues Markers of cellular senescence were evaluated in tissues of normal mice after administration of chemotherapy and study treatments. Six-week-old C57BL/6 mice were purchased from Jackson Laboratory. Mice were housed in a temperature and light controlled environment. Mice were divided into 6 groups and treated with: 1) PBS (saline) control (n=5), 2) docetaxel (n=8), 3) docetaxel with TGFRt15-TGFRs (n=8). 4) docetaxel with IL15SA (n=8), 5) docetaxel with IL-15 variants (TGFRt15*-TGFRs) (n=8) and 6) IL-15 superagonist (IL-15SA) with TGFRt15*. - Docetaxel with TGFRs (n=6). Three doses of docetaxel (10 mg/kg) on
実施例81:TGFRt15-TGFRsでの処理後の免疫表現型
TGFRt15-TGFRsで処理した後の免疫細胞の異なるサブセットを評価するために、マウス血液を調製した。76週齢のC57BL/6老齢マウスをJackson Laboratoryから購入した。マウスは、温度及び光が制御された環境で飼育された。マウスを以下のように2つの群に分けた:PBS対照群(n=6)及びTGFRt15-TGFRs群(n=6)。0日目に、PBS又は3mg/kgの投薬量のTGFRt15-TGFRsでマウスを皮下処理した。研究処理の初回投与後4日目に、EDTA含有チューブの顎下静脈からマウス血液を収集した。全血をマイクロ遠心機で3000RPMで10分間遠心分離して血漿を収集した。血漿は-80℃で保存し、血液をフローサイトメトリーによる免疫細胞表現型解析のために処理した。全血をACK緩衝液で室温で5分間溶解した。細胞を、FACS緩衝液(1×PBS(Hyclone)、0.5%BSA(EMD Millipore)及び0.001%アジ化ナトリウム(Sigma)を含む)中で洗浄した。血液中の異なる種類の免疫細胞を評価するために、細胞表面のCD4、CD45、CD19CD8、及びNK1.1(Biolegend)ついて室温(RT)で30分間染色した。表面染色後、細胞を、FACS緩衝液(0.5%BSA(EMD Millipore)及び0.001%アジ化ナトリウム(Sigma)を含む1×PBS(Hyclone))中で洗浄した(1500RPM、室温で5分間)。細胞を透過化緩衝液(Invitrogen)で4℃で20分間処理した後、Perm緩衝液(Invitrogen)で洗浄した。次いで、細胞を細胞内マーカー(Ki67)について室温で30分間染色した。2回洗浄した後、細胞をフローサイトメトリー(Celesta-BD Bioscience)によって分析した。
Example 81: Immunophenotypes after treatment with TGFRt15-TGFRs To assess different subsets of immune cells after treatment with TGFRt15-TGFRs, mouse blood was prepared. 76-week-old C57BL/6 aged mice were purchased from Jackson Laboratory. Mice were housed in a temperature and light controlled environment. Mice were divided into two groups as follows: PBS control group (n=6) and TGFRt15-TGFRs group (n=6). On
図195に示されるように、Ki67によって測定されたCD8+T細胞のパーセンテージ及びCD8+T細胞の増殖は、TGFRt15-TGFRsの初回投与の4日後に有意に増加した。また、図196に示されるように、NK細胞の増加及びNK細胞の増殖も観察された。TGFRt15-TGFRsの初回投与後、CD19+細胞の有意な減少が観察された。これらの結果は、単回用量のTGFRt15-TGFRsを皮下投与すると、CD8+T細胞及びNK細胞などの免疫細胞を刺激して、老齢マウスの血液中で増殖させることができることを実証している。 As shown in Figure 195, the percentage of CD8 + T cells and proliferation of CD8 + T cells measured by Ki67 were significantly increased 4 days after the first dose of TGFRt15-TGFRs. In addition, as shown in Figure 196, an increase in NK cells and proliferation of NK cells were also observed. A significant decrease in CD19 + cells was observed after the first dose of TGFRt15-TGFRs. These results demonstrate that subcutaneous administration of a single dose of TGFRt15-TGFRs can stimulate immune cells such as CD8 + T cells and NK cells to proliferate in the blood of aged mice.
実施例82:TGFRt15-TGFRsは肝臓及び肺組織からの老化関連β-Galを低減させる
TGFRt15-TGFRsで処理した後の組織における老化関連β-galを評価するために、マウスの肝臓及び肺を調製した。76週齢のC57BL/6老齢マウスをJackson Laboratoryから購入した。マウスは、温度及び光が制御された環境で飼育された。マウスを以下のように2つの群に分けた:PBS対照群(n=6)及びTGFRt15-TGFRs群(n=6)。0日目及び10日目に、PBS又は3mg/kgの投薬量のTGFRt15-TGFRsでマウスを皮下処理した。研究処理の2回目の投与後7日目に、マウスを安楽死させ、肝臓及び肺を収集し、2%PBSを含有するPBSで均質化し、70ミクロンのフィルターでろ過して単一細胞懸濁液を得た。細胞をスピンダウンし、14mL丸底チューブに0.5mg/mLコラゲナーゼIV及び0.02mg/mL DNAseを含有する5mL RPMIに再懸濁した。次いで、細胞をオービタルシェーカーで37℃で1時間振とうした。細胞をRPMIで2回洗浄した。細胞を、2mLの完全培地(RPMI1640(Gibco)、2mMのL-グルタミン(Thermo Life Technologies)、ペニシリン(Thermo Life Technologies)、ストレプトマイシン(Thermo Life Technologies)、及び10%FBS(Hyclone)を補充)中の24ウェル平底プレートに2×106/mLで再懸濁し、37℃、5%CO2で48時間培養した。細胞を収集し、暖かい完全培地で1000rpmで10分間、室温で1回洗浄した。細胞ペレットを、チューブ当たり1.5μLのセネッセンス色素を含有する500μLの新鮮な培地に再懸濁した。次いで、細胞を更に37℃、5%CO2で1~2時間インキュベートし、500μLの洗浄緩衝液で2回洗浄した。細胞ペレットは、500μLの洗浄緩衝液に細胞を再懸濁し、直ちにフローサイトメトリー(Celesta-BD Bioscience)で分析した。
Example 82: TGFRt15-TGFRs Reduce Senescence-Associated β-Gal from Liver and Lung Tissue Liver and lungs of mice were prepared to assess senescence-associated β-gal in tissues after treatment with TGFRt15-TGFRs. bottom. 76-week-old C57BL/6 aged mice were purchased from Jackson Laboratory. Mice were housed in a temperature and light controlled environment. Mice were divided into two groups as follows: PBS control group (n=6) and TGFRt15-TGFRs group (n=6). On
図197に示すように、老化関連β-gal+細胞のパーセンテージは、TGFRt15-TGFRsの2回目の投与の7日後に減少した。これらの結果は、TGFRt15-TGFRsが老齢マウスの組織で老化関連β-galを低減させることができることを実証している。 As shown in Figure 197, the percentage of senescence-associated β-gal + cells decreased 7 days after the second dose of TGFRt15-TGFRs. These results demonstrate that TGFRt15-TGFRs can reduce senescence-associated β-gal in tissues of aged mice.
実施例83:腎臓、皮膚、肝臓及び肺組織における老化マーカーCD26、IL-1α、p16INK4及びp21CIP1
TGFRt15-TGFRs又はPBS対照群で処理した後の組織において、老化マーカーCD26、IL-1α、p16、及びp21を定量的PCRで評価するためにマウスの腎臓、皮膚、肝臓、肺を収集した。76週齢のC57BL/6老齢マウスをJackson Laboratoryから購入した。マウスは、任意の研究を実施する前に、温度及び光が制御された環境で1週間飼育された。マウスを以下のように2つの群に分けた:PBS対照群(n=6)及びTGFRt15-TGFRs群(n=6)。0日目及び10日目に、PBS又は3mg/kgの投薬量のTGFRt15-TGFRsのいずれかでマウスを皮下処理した。研究処理の2回目の投与後7日目に、マウスを安楽死させ、腎臓、皮膚、肝臓、及び肺を収集し、1.7mLエッペンドルフチューブ内の液体窒素で保存した。液体窒素中で乳鉢及び乳棒を使用して、試料を均質化した。均質化した組織を、1mLのTrizol(Thermo Fischer)を含有する新しいエッペンドルフチューブに移した。RNeasyミニキット(Qiagen番号74106)を使用して製造元の指示に従って全RNAを抽出し、1μgの全RNAを、QuantiTect逆転写キット(Qiagen)を使用したcDNA合成に使用した。リアルタイムPCRを、Thermo Scientificから購入したFAM標識事前設計プライマーを使用したCFX96検出システム(Bio-Rad)で行った。反応を試験した全ての遺伝子に対して三連で行った。ハウスキーピング遺伝子18SリボソームRNAを、発現レベルの変動を正規化するための内部対照として使用した。18S rRNAに対する各標的mRNAの発現を、Ctに基づいて2-Δ(ΔCt)として計算し、式中、ΔCt=Cttarget-Ct18Sである。
Example 83: Senescence Markers CD26, IL-1α, p16INK4 and p21CIP1 in Kidney, Skin, Liver and Lung Tissues
Kidney, skin, liver, and lungs of mice were collected for quantitative PCR evaluation of senescence markers CD26, IL-1α, p16, and p21 in tissues after treatment with TGFRt15-TGFRs or PBS control groups. 76 week old C57BL/6 aged mice were purchased from Jackson Laboratory. Mice were housed in a temperature and light controlled environment for one week prior to performing any studies. Mice were divided into two groups as follows: PBS control group (n=6) and TGFRt15-TGFRs group (n=6). Mice were treated subcutaneously on
図198~201に示されるように、老化マーカーCD26及びIL-1αに差はなかったが、p21CIP1は、TGFRt15-TGFRs処理マウスの肝臓(図198)、肺(図201)及び皮膚(図200)における発現の減少を示した。腎臓(図199)では、p21CIP1及びIL1αマーカーの両方が、TGFRt15-TGFRsの2回目の投与の7日後に老齢マウスで有意に減少した。
As shown in Figures 198-201, p21 CIP1 decreased in liver (Figure 198), lung (Figure 201) and skin (Figure 200) of TGFRt15-TGFRs treated mice, although there was no difference in the senescence markers CD26 and IL-1α. ) showed a decrease in expression. In the kidney (FIG. 199), both p21 CIP1 and IL1α markers were significantly decreased in
実施例84:組織学による腎臓組織のβ-Gal染色
TGFRt15-TGFRsで処理した後の腎臓組織における老化マーカーβ-galを評価するために、マウスの腎臓を調製した。76週齢のC57BL/6老齢マウスをJackson Laboratoryから購入した。マウスは、温度及び光が制御された環境で飼育された。マウスを以下のように2つの群に分けた:PBS対照群(n=6)及びTGFRt15-TGFRs群(n=6)。0日目及び10日目に、PBS又は3mg/kgの投薬量のTGFRt15-TGFRsでマウスを皮下処理した。研究処理の2回目の投与後7日目に、マウスを安楽死させ、腎臓を採取し、腎臓組織の半分をOCT化合物を含有するティシュー・テッククリオモルド(cyromold)に包埋した。組織を含有するティシュー・テッククリオモルド(cyromold)を、液体窒素の蒸気相で直ちに凍結した。試料を更に処理して、厚さ4~8umのクライオスタット切片(Lecia Cm1800 Cryostat)を切断し、スーパーフロストプラススライドに取り付けた。製造業者のプロトコルに従って、切片を含むスライドを老化β-ガラクトシダーゼ染色キット(Cell Signaling)用に処理した。組織切片を顕微鏡下で観察した。
Example 84: β-Gal Staining of Kidney Tissue by Histology Mouse kidneys were prepared to assess the senescence marker β-gal in kidney tissue after treatment with TGFRt15-TGFRs. 76-week-old C57BL/6 aged mice were purchased from Jackson Laboratory. Mice were housed in a temperature and light controlled environment. Mice were divided into two groups as follows: PBS control group (n=6) and TGFRt15-TGFRs group (n=6). On
図202に示されるように、対照マウス(n=3)と比較して、TGFRt15-TGFRs処理マウスにおいて老化関連β-gal+細胞数の減少が観察された。これらの結果は、TGFRt15-TGFRs処理が老齢マウスの組織で老化関連β-galを低減させることができることを実証している。 As shown in Figure 202, a decrease in senescence-associated β-gal + cell numbers was observed in TGFRt15-TGFRs treated mice compared to control mice (n=3). These results demonstrate that TGFRt15-TGFRs treatment can reduce senescence-associated β-gal in tissues of aged mice.
実施例85:TGFRt15*-TGFRs融合タンパク質の生成
TGFR/IL15RαSu融合タンパク質及びTGFR/TF/IL-15D8N融合タンパク質からなる融合タンパク質複合体を生成した(図209及び210)。ヒトTGF-β受容体(TGFR)、IL-15アルファ受容体スシドメイン(IL15RaSu)、組織因子(TF)、及びD8N変異体(IL15D8N)配列を含むIL-15は、GenBankのウェブサイトから入手し、これらの配列のDNA断片をGenewizによって合成した。具体的には、TGFR配列を、IL15RaSuのN末端コーディング領域及び組織因子219のN末端、続いてIL-15D8NのN末端コーディング領域に結合することによって構築物を作製した。
Example 85 Generation of TGFRt15*-TGFRs Fusion Proteins A fusion protein complex consisting of a TGFR/IL15RαSu fusion protein and a TGFR/TF/IL-15D8N fusion protein was generated (FIGS. 209 and 210). Human TGF-β receptor (TGFR), IL-15 alpha receptor sushi domain (IL15RaSu), tissue factor (TF), and IL-15 containing D8N variant (IL15D8N) sequences were obtained from the GenBank website. , DNA fragments of these sequences were synthesized by Genewiz. Specifically, a construct was made by joining the TGFR sequence to the N-terminal coding region of IL15RaSu and the N-terminal coding region of
TGFR/IL15RaSu構築物の核酸配列(シグナルペプチド配列を含む)は、以下の通りである。
(シグナルペプチド)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(一本鎖ヒトTGF-β受容体IIホモ二量体)
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC
(IL15受容体α鎖のスシドメイン)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
The nucleic acid sequence (including signal peptide sequence) of the TGFR/IL15RaSu construct is as follows.
(signal peptide)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTTCTCCAGCGCCTACTCC
(single-chain human TGF-β receptor II homodimer)
ATCCCCCCCCCATGTGCAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAA GAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGAACCTTCTTTATGTGTTCCTGTAGCAG CGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCC CCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCCACGATCCCCAAGCTGCCCTAC CACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCCGAC
(Sushi domain of IL15 receptor α chain)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCT CTTTAAAGTGCATCCGG
TGFR/TF/IL15D8N構築物の核酸配列(シグナルペプチド配列を含む)は、以下の通りである。
(シグナルペプチド)
ATGGGAGTGAAAGTTCTTTTTGCCCTTATTTGTATTGCTGTGGCCGAGGCC
(一本鎖ヒトTGF-β受容体IIホモ二量体)
ATCCCACCGCACGTTCAGAAGTCGGTGAATAACGACATGATAGTCACTGACAACAACGGTGCAGTCAAGTTTCCACAACTGTGTAAATTTTGTGATGTGAGATTTTCCACCTGTGACAACCAGAAATCCTGCATGAGCAACTGCAGCATCACCTCCATCTGTGAGAAGCCACAGGAAGTCTGTGTGGCTGTATGGAGAAAGAATGACGAGAACATAACACTAGAGACAGTTTGCCATGACCCCAAGCTCCCCTACCATGACTTTATTCTGGAAGATGCTGCTTCTCCAAAGTGCATTATGAAGGAAAAAAAAAAGCCTGGTGAGACTTTCTTCATGTGTTCCTGTAGCTCTGATGAGTGCAATGACAACATCATCTTCTCAGAAGAATATAACACCAGCAATCCTGACGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC
(ヒト組織因子219)
TCAGGCACTACAAATACTGTGGCAGCATATAATTTAACTTGGAAATCAACTAATTTCAAGACAATTTTGGAGTGGGAACCCAAACCCGTCAATCAAGTCTACACTGTTCAAATAAGCACTAAGTCAGGAGATTGGAAAAGCAAATGCTTTTACACAACAGACACAGAGTGTGACCTCACCGACGAGATTGTGAAGGATGTGAAGCAGACGTACTTGGCACGGGTCTTCTCCTACCCGGCAGGGAATGTGGAGAGCACCGGTTCTGCTGGGGAGCCTCTGTATGAGAACTCCCCAGAGTTCACACCTTACCTGGAGACAAACCTCGGACAGCCAACAATTCAGAGTTTTGAACAGGTGGGAACAAAAGTGAATGTGACCGTAGAAGATGAACGGACTTTAGTCAGAAGGAACAACACTTTCCTAAGCCTCCGGGATGTTTTTGGCAAGGACTTAATTTATACACTTTATTATTGGAAATCTTCAAGTTCAGGAAAGAAAACAGCCAAAACAAACACTAATGAGTTTTTGATTGATGTGGATAAAGGAGAAAACTACTGTTTCAGTGTTCAAGCAGTGATTCCCTCCCGAACAGTTAACCGGAAGAGTACAGACAGCCCGGTAGAGTGTATGGGCCAGGAGAAAGGGGAATTCAGAGAA
(ヒトIL-15D8N)
AACTGGGTGAATGTAATAAGTAATTTGAAAAAAATTGAAGATCTTATTCAATCTATGCATATTGATGCTACTTTATATACGGAAAGTGATGTTCACCCCAGTTGCAAAGTAACAGCAATGAAGTGCTTTCTCTTGGAGTTACAAGTTATTTCACTTGAGTCCGGAGATGCAAGTATTCATGATACAGTAGAAAATCTGATCATCCTAGCAAACAACAGTTTGTCTTCTAATGGGAATGTAACAGAATCTGGATGCAAAGAATGTGAGGAACTGGAGGAAAAAAATATTAAAGAATTTTTGCAGAGTTTTGTACATATTGTCCAAATGTTCATCAACACTTCT
The nucleic acid sequence (including signal peptide sequence) of the TGFR/TF/IL15D8N construct is as follows.
(signal peptide)
ATGGGAGTGAAAGTTCTTTTTGCCCTTTATTGTATTGCTGTGGCCCGAGGCC
(single-chain human TGF-β receptor II homodimer)
ATCCCCACCGCACGTTCAGAAGTCGGTGAATAACGACATGATAGTCACTGACAACAACGGTGCAGTCAAGTTTCCACAACTGTGTAAATTTTGTGATGTGAGATTTTCCACCTGTGACAACCAGAAATCCTGCATGAGCAACTGCAGCATCACCTCCATCTGTGAGAAGCCACAGGAA GTCTGTGTGGCTGTATGGAGAAAGAATGACGAGAACATAACACTAGAGACAGTTTGCCATGACCCCAAGCTCCCCTACCATGACTTTATTCTGGAAGATGCTGCTTCTCAAAGTGCATTATGAAGGAAAAAAAAAAGCCTGGTGAGACTTTCTTCATGTGTTCCTGTAGCTCTGAT GAGTGCAATGACAACATCATCTTCTCAGAAGAATATAACACCAGCAATCCTGACGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCCAGCT GTGCAAATTCTGCGATGTGGAGGTTTTCCACCTGCGCACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAAACCGTCTGCCACGATCCCCAAGCTGCCCTACCACGAT TTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAGAAGCCTGGCGAGACCTTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCCGAC
(human tissue factor 219)
TCAGGCACTACAAAATACTGTGGCAGCATATAATTTAACTTGGAAATCAACTAATTTCAAGACAATTTTGGAGTGGGAACCCAAAACCCGTCAATCAAGTCTACACTGTTCAAATAAGCACTAAGTCAGGAGATTGGAAAAGCAAATGCTTTTACACAACAGACACAGAGTGTGACCTCA CCGACGAGATTGTGAAGGATGTGAAGCAGACGTACTTGGCACGGGTCTTCTCCTACCCCGGCAGGGAATGTGGAGAGCACCGGTTCTGCTGGGGAGCTCTCGTATGAGAACTCCCCAGAGTTCACACCTTACCTGGAGACAAACCTCGGACAGCCAACAATTCAGAGTTTTGAACAGGT GGGAACAAAGTGAATGTGACCGTAGAAGATGAACGGACTTTAGTCAGAAGGAACAACACTTTCCTAAGCCTCCGGGATGTTTTTTGGCAAGGACTTAATTTATACACTTTATTATTGGAAATCTTCAAGTTCAGGAAAGAAACAGCCAAAACAAAACACTAATGAGTTTTTGATT GATGTGGATAAAGGAGAAAAACTACTGTTTCAGTGTTCAAGCAGTGATTCCCTCCCGAACAGTTAACCGGAAGAGTACAGACAGCCCCGGTAGAGTGTATGGGCCAGGAGAAAAGGGGGAATTCAGAGAA
(human IL-15D8N)
AACTGGGTGAATGTAATAAGTAATTTGAAAAAAAATTGAAGATCTTATTCAATCTATGCATATTGATGCTACTTTATATACGGAAAGTGATGTTCACCCCAGTTGCAAAGTAACAGCAATGAAGTGCTTTCTCTTGGAGTTACAAGTTATTTCACTTGAGTCCGGAGATGCA AGTATTCATGATACAGTAGAAATCTGATCATCCTAGCAAACAACAGTTTTGTCTTCTAATGGGAATGTAACAGAATCTGGATGCAAAGAATGTGAGGAACTGGAGGAAAAAAATATTAAAGAATTTTTGCAGAGTTTTGTACATATTGTCCAAATGTTCATCAACACTTCT
TGFR/IL15RaSu融合タンパク質のアミノ酸配列(シグナルペプチド配列を含む)は、以下の通りである。
(シグナルペプチド)
MKWVTFISLLFLFSSAYS
(一本鎖ヒトTGF-β受容体IIホモ二量体)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(ヒトIL-15受容体α sushiドメイン)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
The amino acid sequence (including signal peptide sequence) of the TGFR/IL15RaSu fusion protein is as follows.
(signal peptide)
MKWVT FISLLFLFS SAYS
(single-chain human TGF-β receptor II homodimer)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNCSITSICEKPQEVCVAVWRKNDINITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPDGGGGGSGGGGGSGGGGSIPPHV QKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNSITSICEKPQEVCVAVWRKNDINITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(Human IL-15 receptor α sushi domain)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
TGFR/TF/IL15D8N融合タンパク質のアミノ酸配列(シグナルペプチド配列を含む)は、以下の通りである。
(シグナルペプチド)
MGVKVLFALICIAVAEA
(一本鎖ヒトTGF-β受容体IIホモ二量体)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(組織因子)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(IL-15D8N)
NWVNVISNLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
The amino acid sequence (including signal peptide sequence) of the TGFR/TF/IL15D8N fusion protein is as follows.
(signal peptide)
MGVKVLFALICIAVAEA
(single-chain human TGF-β receptor II homodimer)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNCSITSICEKPQEVCVAVWRKNDINITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSSSDECNDNIIFSEEYNTSNPDGGGGGSGGGGGSGGGGSIPPHV QKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMNSITSICEKPQEVCVAVWRKNDINITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(tissue factor)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTF LSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(IL-15D8N)
NWVNVISNLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEEELEEKNIKEFLQSFVHIVQMFINTS
TGFR/IL15RαSu及びTGFR/TF/IL-15D8N構築物を前述の修飾レトロウイルス発現ベクターにクローニングした(Hughes MS,Yu YY,Dudley ME,Zheng Z,Robbins PF,Li Y,et al)。発現ベクターをCHO-K1細胞にトランスフェクトした。CHO-K1細胞でのこれらの2つの構築物の共発現により、可溶性TGFR/IL15RαSu-TGFR/TF/IL-15D8Nタンパク質複合体(TGFRt15*-TGFRsと称する)の形成及び分泌が可能になり、これを抗TF抗体親和性によって精製することができる。 The TGFR/IL15RαSu and TGFR/TF/IL-15D8N constructs were cloned into the modified retroviral expression vectors previously described (Hughes MS, Yu YY, Dudley ME, Zheng Z, Robbins PF, Li Y, et al). The expression vector was transfected into CHO-K1 cells. Co-expression of these two constructs in CHO-K1 cells allowed the formation and secretion of soluble TGFR/IL15RαSu-TGFR/TF/IL-15D8N protein complexes (termed TGFRt15*-TGFRs), which It can be purified by anti-TF antibody affinity.
実施例86:TGFRt15-TGFRs及びTGFRt15*-TGFRsのTGF-β1及びLAPへの結合活性
TGFRt15-TGFRsのTGF-β1及びLAPへの結合活性は、ELISAによって決定された。TGFRt15-TGFRs(5mg/mL)を使用して、滴定されたTGF-β1(TGFβ1、BioLegendとして標識)及びTGF-β1の潜在的関連ペプチド(LAP、R&D Systems)を捕捉した。TGF-β1はビオチン化抗TGF-β1(0.2mg/mL、R&D Systems)によって検出され、LAPはビオチン化抗LAP(0.2mg/mL、R&D Systems)、続いてペルオキシダーゼ共役ストレプトアビジン(Jackson ImmunoResearch Lab)によって検出された。2,2’-アジノ-ビス(3-エチルベンゾチアゾリン-6-スルホン酸)(ABTS、Surmodics IVD)を基質として使用し、プレートリーダーで測定した。図211Aに示されるように、結果は、TGFRt15-TGFRsがTGF-β1及びLAPに同様に結合し、Fc融合よりも強く結合することを実証している。
Example 86: Binding Activity of TGFRt15-TGFRs and TGFRt15*-TGFRs to TGF-β1 and LAP The binding activity of TGFRt15-TGFRs to TGF-β1 and LAP was determined by ELISA. TGFRt15-TGFRs (5 mg/mL) were used to capture titrated TGF-β1 (TGFβ1, labeled as BioLegend) and potentially related peptides of TGF-β1 (LAP, R&D Systems). TGF-β1 was detected by biotinylated anti-TGF-β1 (0.2 mg/mL, R&D Systems) and LAP was detected by biotinylated anti-LAP (0.2 mg/mL, R&D Systems) followed by peroxidase-conjugated streptavidin (Jackson ImmunoResearch). Lab). 2,2′-azino-bis(3-ethylbenzothiazoline-6-sulfonic acid) (ABTS, Surmodics IVD) was used as substrate and measured with a plate reader. As shown in FIG. 211A, the results demonstrate that TGFRt15-TGFRs bind TGF-β1 and LAP similarly and more strongly than Fc fusions.
TGF-β1受容体/Fc融合体のTGF-β1及びLAPへの結合活性は、ELISAによって決定された。市販のTGF-β1受容体II-Fc融合(TGFRII/Fc)を使用して、TGFRt15-TGFRsのTGF-β1及びLAPへの結合活性を比較した。TGFRII/Fc(5mg/mL、R&D Systems)を使用して、滴定されたTGF-β1及びLAPを捕捉した。他の手順は上述と同じであった。図211Bに示されるように、結果は、TGFRII/FcがTGF-β1及びLAPに同様に結合し、その結合がTGFRt15-TGFRsに匹敵し、Fc融合よりも強いことを実証している。 The binding activity of TGF-β1 receptor/Fc fusions to TGF-β1 and LAP was determined by ELISA. A commercially available TGF-β1 receptor II-Fc fusion (TGFRII/Fc) was used to compare the binding activity of TGFRt15-TGFRs to TGF-β1 and LAP. TGFRII/Fc (5 mg/mL, R&D Systems) was used to capture titrated TGF-β1 and LAP. Other procedures were the same as described above. As shown in FIG. 211B, the results demonstrate that TGFRII/Fc binds to TGF-β1 and LAP similarly, with binding comparable to TGFRt15-TGFRs and stronger than Fc fusion.
TGFRt15-TGFRs及びTGFRt15*-TGFRsのTGF-β1及びLAPへの結合活性
TGFRt15-TGFRs及びTGFRt15*-TGFRs(10mg/mL)を使用して、滴定されたTGF-β1LAPを捕捉した。他の手順は上述と同じであった。図211C及びDに示されるように、結果は、TGFRt15*-TGFRsがTGF-β1及びLAPに同様に結合し、その結合がTGFRt15-TGFRsに匹敵し、Fc融合よりも強いことを実証している。
Binding Activity of TGFRt15-TGFRs and TGFRt15*-TGFRs to TGF-β1 and LAP TGFRt15-TGFRs and TGFRt15*-TGFRs (10 mg/mL) were used to capture titrated TGF-β1 LAP. Other procedures were the same as described above. As shown in Figures 211C and D, the results demonstrate that TGFRt15*-TGFRs bind to TGF-β1 and LAP similarly, with binding comparable to TGFRt15-TGFRs and stronger than Fc fusions. .
TGFRt15-TGFRs及びTGFRt15*-TGFRsのCTLL-2細胞への結合
IL-2依存性CTLL-2細胞を、TGFRt15-TGFRs(50nM)、TGFRt15*-TGFRs(50nM)、7t15-21s(50nM、IL-7-TF-IL15及びIL-21-IL-15RaSu)(対照融合分子として、TGF-β1受容体IIを含有しない)、及びPBS(陰性対照として)を60分間、ビオチン化二次染色抗体(抗TF:抗ヒト組織因子、HCW Biologics及び抗-TGFR:抗-TGF-β受容体II:R&D Systems)、次いでその後R-フィコエリトリン-ストレプトアビジン(Jackson ImmunoResearch Lab)で染色した。染色の平均蛍光強度(MFI)を、フローサイトメトリーによって測定した。図211Eに示されるように、結果は、TGFRt15-TGFRsが他の分子より有意に良好にCTLL-2細胞に結合し、TGFRt15*-TGFRsはIL-15変異体のためにTGFRt15-TGFRsより少ないことを示す。しかしながら、CTLL-2細胞への7t15-21sの結合は、抗TFでは検出できたが、抗TGFRでは検出できなかった。
Binding of TGFRt15-TGFRs and TGFRt15*-TGFRs to CTLL-2 Cells IL-2-dependent CTLL-2 cells were treated with TGFRt15-TGFRs (50 nM), 7-TF-IL15 and IL-21-IL-15RaSu) (as control fusion molecules without TGF-β1 receptor II), and PBS (as negative control) for 60 min, biotinylated secondary staining antibody (anti TF: anti-human tissue factor, HCW Biologics and anti-TGFR: anti-TGF-β receptor II: R&D Systems) followed by staining with R-phycoerythrin-streptavidin (Jackson ImmunoResearch Lab). Mean fluorescence intensity (MFI) of staining was measured by flow cytometry. As shown in FIG. 211E, the results show that TGFRt15-TGFRs bind CTLL-2 cells significantly better than other molecules, and TGFRt15*-TGFRs are less than TGFRt15-TGFRs due to IL-15 variants. indicates However, binding of 7t15-21s to CTLL-2 cells was detectable with anti-TF but not with anti-TGFR.
実施例87:細胞ベースのアッセイによるTGFRt15-TGFRs及びTGFRt15*-TGFRsの生物学的活性
TGFRt15-TGFRs及びTGFRt15*-TGFRsのTGF-β1遮断活性
HEK-Blue TGF-β細胞(InvivoGen)を、TGF-β1(0.1nM、BioLegend)の存在下で、滴定したTGFRt15-TGFRs、TGFRt15*-TGFRs、及び対照としてTGFRII/Fcを含むIMDM-10中でインキュベートした。TGFRII/Fcは、市販のTGF-β1受容体II-Fc融合(R&D Systems)である。24時間のインキュベーション後、培養上清をQUANTI-Blue(InvivoGen)と混合し、1~3時間インキュベートした。OD620値をプレートリーダーで測定した。図212Aに示されるように、TGFRt15-TGFRs及びTGFRt15*-TGFRsは、同じTGF-β1遮断活性を有していた。対照的に、TGFRII/Fc(IC50=470.2pM)は、TGFRt15-TGFRs(IC50=43.2pM)又はTGFRt15*-TGFRs(45.2pM)よりも約10倍低いTGF-β1遮断活性を有していた。遮断活性を、GraphPad Prism7.04で計算した。
Example 87: Biological activity of TGFRt15-TGFRs and TGFRt15*-TGFRs by cell-based assay TGF -β1 blocking activity of TGFRt15-TGFRs and TGFRt15*-TGFRs HEK-Blue TGF-β cells (InvivoGen) were Incubated in IMDM-10 with titrated TGFRt15-TGFRs, TGFRt15*-TGFRs, and TGFRII/Fc as a control in the presence of β1 (0.1 nM, BioLegend). TGFRII/Fc is a commercially available TGF-β1 receptor II-Fc fusion (R&D Systems). After 24 hours of incubation, culture supernatants were mixed with QUANTI-Blue (InvivoGen) and incubated for 1-3 hours. OD620 values were measured with a plate reader. As shown in Figure 212A, TGFRt15-TGFRs and TGFRt15*-TGFRs had the same TGF-β1 blocking activity. In contrast, TGFRII/Fc (IC50 = 470.2 pM) has approximately 10-fold lower TGF-β1 blocking activity than TGFRt15-TGFRs (IC50 = 43.2 pM) or TGFRt15*-TGFRs (45.2 pM). was Blocking activity was calculated with GraphPad Prism 7.04.
TGFRt15-TGFRs及びTGFRt15*-TGFRsのIL-15活性
IL-15依存性32Dβ細胞を、滴定されたTGFRt15-TGFRs、TGFRt15*-TGFRs、及び対照としてIL15を含むIMDM-10中で培養した。2日後にWST-1(Fisher Scientific)を添加し、OD450値をプレートリーダーで測定した。図212Bに示すように、TGFRt15-TGFRs(EC50=1641pM)は、IL-15自体(IC50=81.8pM)より約20倍低いIL-15生物活性を有していた。予想通り、TGFRt15*-TGFRsには検出可能なIL-15活性はなかった。IL-15活性を、GraphPad Prism7.04で計算した。
IL-15 Activity of TGFRt15-TGFRs and TGFRt15*-TGFRs IL-15 dependent 32Dβ cells were cultured in IMDM-10 with titrated TGFRt15-TGFRs, TGFRt15*-TGFRs and IL15 as a control. Two days later WST-1 (Fisher Scientific) was added and OD450 values were measured with a plate reader. As shown in Figure 212B, TGFRt15-TGFRs (EC50 = 1641 pM) had approximately 20-fold lower IL-15 bioactivity than IL-15 itself (IC50 = 81.8 pM). As expected, TGFRt15*-TGFRs had no detectable IL-15 activity. IL-15 activity was calculated with GraphPad Prism 7.04.
TGFRt15*-TGFRsによるCTLL-2のTGF-β増殖抑制の逆転
TGF-βは、類似の生物学的機能を有する、3つのアイソフォーム(TGF-β1、TGF-β2及びTGF-β3)を含む。この研究では、CTLL-2細胞を使用してTGFRt15*-TGFRsの生物学的遮断活性を比較した。TGFRt15*-TGFRsは、TGFRt15-TGFRsと構造的に非常に似ているが、TGFRt15-TGFRsのIL-15活性のために使用することはできない。CTLL-2細胞を、滴定されたマウスIL-4(Biolegend)、TGF-β(5ng/ml、TGF-β1(Biolegend)、TGF-β2、β3(R&D Systems))及びTGFRt15*TGFRs(21nM、TGFRt15*-TGFRs:TGF-βモル比=100:1)を含むRPMI-10で5日間培養した。細胞増殖(OD570-600値)を、培養最終日にPrestoBlue(Fisher Scientific)を添加した後、プレートリーダーで測定した。図212Cは、3つ全てのTGF-βが、TGFRt15*-TGFRsの非存在下でIL-4誘導CTLL-2増殖を同様に阻害したことを示している。図212Dは、TGFRt15*-TGFRs(21nM、TGF-β:TGFRt15*-TGFRsのモル比=1:100)が、IL-4誘導CTLL-2細胞増殖のTGF-β1及びTGF-β3の阻害を有意に逆転させたことを示し、対照的に、TGFRt15*-TGFRsは最小の逆転TGF-β2阻害活性を有していた。
Reversal of TGF-β Proliferation Suppression of CTLL-2 by TGFRt15*-TGFRs TGF-β comprises three isoforms (TGF-β1, TGF-β2 and TGF-β3) with similar biological functions. In this study, CTLL-2 cells were used to compare the biological blocking activity of TGFRt15*-TGFRs. TGFRt15*-TGFRs are structurally very similar to TGFRt15-TGFRs, but cannot be used for the IL-15 activity of TGFRt15-TGFRs. CTLL-2 cells were treated with titrated murine IL-4 (Biolegend), TGF-β (5 ng/ml, TGF-β1 (Biolegend), TGF-β2, β3 (R&D Systems)) and TGFRt15*TGFRs (21 nM, TGFRt15). *—The cells were cultured in RPMI-10 containing TGFRs:TGF-β (molar ratio=100:1) for 5 days. Cell proliferation (OD 570-600 values) was measured with a plate reader after addition of PrestoBlue (Fisher Scientific) on the last day of culture. Figure 212C shows that all three TGF-βs similarly inhibited IL-4-induced CTLL-2 proliferation in the absence of TGFRt15*-TGFRs. FIG. 212D shows that TGFRt15*-TGFRs (21 nM, molar ratio of TGF-β:TGFRt15*-TGFRs=1:100) significantly inhibited TGF-β1 and TGF-β3 of IL-4-induced CTLL-2 cell proliferation. In contrast, TGFRt15*-TGFRs had minimal reversal TGF-β2 inhibitory activity.
実施例88:TGFRt15-TGFRsの安定性
ELISAによるTGFRt15-TGFRsの安定性TGFRt15-TGFRsを50%ヒト血清を含むRPMI培地で4℃、室温(RT)又は37℃で10日間プレインキュベートした。TGFRt15-TGFRsのIL-15ドメイン及びTGFβRIIドメインをELISAで評価した。抗TF抗体(HCW Biologics)を使用してTGFRt15-TGFRs分子を捕捉し、ビオチン化抗IL-15(R&D Systems)を使用してIL-15ドメインを検出し、ビオチン化抗TGFβRII(R&D Systems)を使用してTGFβRIIドメインを検出した。ビオチン化された検出抗体を、ペルオキシダーゼ-ストレプトアビジン(Jackson ImmunoResearch Lab)によってプローブした。2,2’-アジノ-ビス(3-エチルベンゾチアゾリン-6-スルホン酸)(ABTS、Surmodics IVD)を基質として使用し、OD405値をプレートリーダーで測定した。図213A及びBに示されるように、結果は、4℃、RT、又は37℃で10日間のインキュベーション後にTGFRt15-TGFRsのドメインに有意な変化がなかったことを示す。これらの発見は、評価された条件下でヒト血清とインキュベートした場合、TGFRt15-TGFRsのIL-15ドメイン及びTGFβRIIドメインが無傷のままであることを実証している。
Example 88: Stability of TGFRt15-TGFRs Stability of TGFRt15-TGFRs by ELISA TGFRt15-TGFRs were preincubated in RPMI medium containing 50% human serum at 4°C, room temperature (RT) or 37°C for 10 days. The IL-15 and TGFβRII domains of TGFRt15-TGFRs were assessed by ELISA. Anti-TF antibody (HCW Biologics) was used to capture TGFRt15-TGFRs molecules, biotinylated anti-IL-15 (R&D Systems) was used to detect the IL-15 domain, and biotinylated anti-TGFβRII (R&D Systems) was detected. was used to detect the TGFβRII domain. A biotinylated detection antibody was probed with peroxidase-streptavidin (Jackson ImmunoResearch Lab). 2,2′-azino-bis(3-ethylbenzothiazoline-6-sulfonic acid) (ABTS, Surmodics IVD) was used as substrate and OD405 values were measured with a plate reader. As shown in Figures 213A and B, the results indicate that there were no significant changes in the domains of TGFRt15-TGFRs after 10 days of incubation at 4°C, RT, or 37°C. These findings demonstrate that the IL-15 and TGFβRII domains of TGFRt15-TGFRs remain intact when incubated with human serum under the conditions evaluated.
細胞ベースのアッセイによるTGFRt15-TGFRsの生物学的活性の安定性
TGFRt15-TGFRsを50%ヒト血清を含むRPMI-10で4℃、室温(RT)又は37℃で10日間プレインキュベートした。TGFRt15-TGFRsのTGF-β1中和活性は、HEK-Blue TGF-β細胞(TGF-β1活性報告細胞株、InvivoGen)を使用してアクセスされた。HEK-Blue TGF-β細胞を、TGF-β1(0.1nM)の存在下で、滴定したTGFRt15-TGFRsを含むIMDM-10中でインキュベートした。24時間のインキュベーション後、培養上清をQUANTI-Blue(InvivoGen)と混合し、1~3時間インキュベートした。OD620値をプレートリーダーで測定した。図213Cに示されるように、結果は、4℃、RT、又は37℃で10日間、ヒト血清中でのインキュベーション後にTGFRt15-TGFRsのTGF-β1中和活性に変化がなかったことを示す。TGFRt15-TGFRsのIL-15活性を、IL-15依存性32Dβ細胞で評価した。32Dβ細胞を、滴定されたTGFRt15-TGFRsを含むIMDM-10中で培養した。2日後にWST-1(InvitroGen)を添加し、OD450値をプレートリーダーで測定した。図213Dに示されるように、結果は、4℃、RT、又は37℃で10日間、ヒト血清中でのインキュベーション後にTGFRt15-TGFRsのIL-15活性に変化がなかったことを示す。
Stability of biological activity of TGFRt15-TGFRs by cell-based assay TGFRt15-TGFRs were pre-incubated with RPMI-10 containing 50% human serum at 4°C, room temperature (RT) or 37°C for 10 days. The TGF-β1 neutralizing activity of TGFRt15-TGFRs was accessed using HEK-Blue TGF-β cells (TGF-β1 activity reporting cell line, InvivoGen). HEK-Blue TGF-β cells were incubated in IMDM-10 containing titrated TGFRt15-TGFRs in the presence of TGF-β1 (0.1 nM). After 24 hours of incubation, culture supernatants were mixed with QUANTI-Blue (InvivoGen) and incubated for 1-3 hours. OD620 values were measured with a plate reader. As shown in Figure 213C, the results indicate that there was no change in the TGF-β1 neutralizing activity of TGFRt15-TGFRs after incubation in human serum for 10 days at 4°C, RT, or 37°C. IL-15 activity of TGFRt15-TGFRs was assessed in IL-15 dependent 32Dβ cells. 32Dβ cells were cultured in IMDM-10 with titrated TGFRt15-TGFRs. Two days later WST-1 (InvitroGen) was added and OD450 values were measured with a plate reader. As shown in Figure 213D, the results indicate that there was no change in IL-15 activity of TGFRt15-TGFRs after incubation in human serum for 10 days at 4°C, RT, or 37°C.
実施例89:TGFRt15-TGFRs及びTGFRt15*-TGFRsによるヒトNK細胞及びPBMCに対するTGF-β1免疫抑制の逆転
ヒトNK細胞を、StemCellの指示に従って、RosetteSep(商標)ヒトNK Cell Enrichment Cocktail(StemCell)により血液バフィーコート(ドナー4人、1つの血液)から精製し、PBMCを、Ficoll-Paque(Sigma-Aldrich)密度遠心分離により血液バフィーコート(ドナー6人)から単離した。NK細胞及びPBMCを、IL-15(10ng/mL、PeproTech)及び/又はTGF-β1(10ng/mL、Biolegend)、TGFRt15-TGFRs(42nM又は4.2nM)又はTGFRt15*-TGFRs(42nM又は4.2nM)を含むRPMI-10で3日間培養した。培養物を収集し、以下のアッセイに使用した:細胞媒介性細胞毒性アッセイ(図214A及びB)並びに細胞内グランザイムB(図214C及びD)及びインターフェロンガンマ(IFNγ、図214E及びF)のフローサイトメトリー分析。
Example 89: Reversal of TGF-β1 Immunosuppression on Human NK Cells and PBMC by TGFRt15-TGFRs and TGFRt15*-TGFRs Purified from buffy coats (4 donors, 1 blood), PBMCs were isolated from blood buffy coats (6 donors) by Ficoll-Paque (Sigma-Aldrich) density centrifugation. NK cells and PBMCs were treated with IL-15 (10 ng/mL, PeproTech) and/or TGF-β1 (10 ng/mL, Biolegend), TGFRt15-TGFRs (42 nM or 4.2 nM) or TGFRt15*-TGFRs (42 nM or 4.2 nM). 2 nM) in RPMI-10 for 3 days. Cultures were harvested and used in the following assays: cell-mediated cytotoxicity assays (Figures 214A and B) and intracellular granzyme B (Figures 214C and D) and interferon gamma (IFNγ, Figures 214E and F) flow cytometry. metric analysis.
培養NK細胞及びPBMCをエフェクター細胞として使用し、K562腫瘍細胞(ATCC)を細胞媒介性細胞毒性アッセイの標的細胞として使用した。エフェクター細胞とK562腫瘍細胞との混合物を、RPMI-10中で37℃、4時間、E:T比=NK細胞の場合は4:1(図214A)、PBMCの場合は20:1(図214B)でインキュベートした。死んだK562細胞のレベルを、フローサイトメトリーによって決定した。図214A及びBに示されるように、結果は、TGF-β1の存在下で死んだK562標的細胞が培地対照培養物で観察されたものより有意に少ないことを示し、TGF-β1が免疫細胞の細胞毒性を阻害することを示した。しかしながら、TGF-β1及びTGFRt15-TGFRs又はTGFRt15*-TGFRsの存在下では、TGF-β1のみの条件で培養した場合よりも有意に多くの死んだK562標的細胞が存在した。これらの知見は、TGFRt15-TGFRs及びTGFRt15*-TGFRsが、TGF-β1免疫抑制を有意に低減させ、K562標的細胞に対するヒトNK細胞及びPBMCの細胞毒性を濃度依存的に増強したことを実証している。更に、TGFRt15-TGFRsのIL-15活性は、TGFRt15*-TGFRsの活性と比較して、ヒトNK細胞及びPBMCの細胞毒性を更に増強する。 Cultured NK cells and PBMC were used as effector cells and K562 tumor cells (ATCC) were used as target cells for cell-mediated cytotoxicity assays. A mixture of effector cells and K562 tumor cells was incubated in RPMI-10 at 37° C. for 4 hours at an E:T ratio of 4:1 for NK cells (FIG. 214A) and 20:1 for PBMCs (FIG. 214B). ). The level of dead K562 cells was determined by flow cytometry. As shown in FIGS. 214A and B, the results show that significantly fewer K562 target cells died in the presence of TGF-β1 than observed in medium control cultures, suggesting that TGF-β1 kills immune cells. It has been shown to inhibit cytotoxicity. However, in the presence of TGF-β1 and TGFRt15-TGFRs or TGFRt15*-TGFRs, there were significantly more dead K562 target cells than when cultured in TGF-β1-only conditions. These findings demonstrate that TGFRt15-TGFRs and TGFRt15*-TGFRs significantly reduced TGF-β1 immunosuppression and enhanced human NK cell and PBMC cytotoxicity against K562 target cells in a concentration-dependent manner. there is Furthermore, the IL-15 activity of TGFRt15-TGFRs further enhances human NK cell and PBMC cytotoxicity compared to that of TGFRt15*-TGFRs.
培養NK細胞及びPBMCを、蛍光色素標識抗CD56及び抗CD16ヒトNK細胞表面マーカーで染色した後、蛍光色素標識グランザイムB及びIFNγ細胞内分子(BioLegend)で染色した。PBMC培養の精製NK細胞及びゲートNK細胞(CD56+及び/又はCD16+)におけるグランザイムB及びIFNγ発現(MFI:平均蛍光強度)を、フローサイトメトリーによって分析した。図214C及びDに示されるように、TGF-β1の存在下で培養されたNK細胞におけるグランザイムB(図214C及び214D)及びIFNγ(図214E及び214F)発現は、培地のみで培養された細胞で観察されたよりも有意に少なく、TGF-β1が免疫細胞の活性化を阻害することを示した。しかしながら、TGF-β1及びTGFRt15-TGFRs又はTGFRt15*-TGFRsの存在下では、TGF-β1単独で培養した細胞で観察されたよりも有意に高いグランザイムB及びIFNγ発現NK細胞培養が存在した。TGFRt15*-TGFRsは、4.2nM濃度でグランザイムB及びIFNγ発現に最小限の影響を及ぼした。これらの発見は、TGFRt15-TGFRs及びTGFRt15*-TGFRsが、IL-15及びTGFβRIIドメインの活性を介して濃度依存的にヒトNK細胞のグランザイムB及びIFNγ発現を有意に増強したことを実証している。 Cultured NK cells and PBMCs were stained with fluorochrome-labeled anti-CD56 and anti-CD16 human NK cell surface markers followed by fluorochrome-labeled granzyme B and IFNγ intracellular molecules (BioLegend). Granzyme B and IFNγ expression (MFI: mean fluorescence intensity) in purified NK cells and gated NK cells (CD56 + and/or CD16 + ) of PBMC cultures were analyzed by flow cytometry. As shown in Figures 214C and D, granzyme B (Figures 214C and 214D) and IFNγ (Figures 214E and 214F) expression in NK cells cultured in the presence of TGF-β1 was higher than that in cells cultured in medium alone. Significantly less than observed, indicating that TGF-β1 inhibits immune cell activation. However, in the presence of TGF-β1 and TGFRt15-TGFRs or TGFRt15*-TGFRs, there were significantly higher granzyme B and IFNγ expressing NK cell cultures than observed in cells cultured with TGF-β1 alone. TGFRt15*-TGFRs had minimal effects on granzyme B and IFNγ expression at 4.2 nM concentration. These findings demonstrate that TGFRt15-TGFRs and TGFRt15*-TGFRs significantly enhanced granzyme B and IFNγ expression in human NK cells in a concentration-dependent manner through activation of IL-15 and TGFβRII domains. .
実施例90:C57BL/6マウスにおけるTGFRt15-TGFRsの半減期
TGFRt15-TGFRsの薬物動態(半減期、t1/2)を雌C57BL/6マウスで評価した。マウスを、3mg/kgの投薬量のTGFRt15-TGFRsで皮下処理した。マウスの血液を様々な時点で尾静脈から収集し、血清を調製した。マウス血清中のTGFRt15-TGFRs濃度をELISAで決定した。抗TF抗体(HCW Biologicsで生成された抗ヒト組織因子抗体)を使用してTGFRt15-TGFRs分子を捕捉し、ビオチン化抗TGFβRII(R&D Systems)を使用してTGFβRIIドメインを検出した。ビオチン化された検出抗体を、ペルオキシダーゼ-ストレプトアビジン(Jackson ImmunoResearch Lab)によってプローブした。2,2’-アジノ-ビス(3-エチルベンゾチアゾリン-6-スルホン酸)(ABTS、Surmodics IVD)を基質として使用し、OD405値をプレートリーダーで測定した。図215に示されるように、GraphPad Prism7.04で計算したTGFRt15-TGFRの半減期は、C57BL/6マウスで18.22時間であった。
Example 90 Half-Life of TGFRt15-TGFRs in C57BL/6 Mice The pharmacokinetics (half-life, t1/2) of TGFRt15-TGFRs were evaluated in female C57BL/6 mice. Mice were treated subcutaneously with TGFRt15-TGFRs at a dosage of 3 mg/kg. Mouse blood was collected from the tail vein at various time points and serum was prepared. TGFRt15-TGFRs concentration in mouse serum was determined by ELISA. Anti-TF antibody (anti-human tissue factor antibody generated at HCW Biologics) was used to capture TGFRt15-TGFRs molecules and biotinylated anti-TGFβRII (R&D Systems) was used to detect TGFβRII domains. A biotinylated detection antibody was probed with peroxidase-streptavidin (Jackson ImmunoResearch Lab). 2,2′-azino-bis(3-ethylbenzothiazoline-6-sulfonic acid) (ABTS, Surmodics IVD) was used as substrate and OD405 values were measured with a plate reader. As shown in Figure 215, the half-life of TGFRt15-TGFR calculated with GraphPad Prism 7.04 was 18.22 hours in C57BL/6 mice.
実施例91:C57BL/6マウスにおけるTGFRt15-TGFRsの毒性
TGFRt15-TGFRs(50~400mg/kg)の単回用量を、C57BL/6雌マウス(7週齢、n=4)に皮下注射した。マウスの体重を図216に示されるように測定し、実験期間中に臨床徴候(死亡率、病的状態、フリルの毛、猫背の姿勢、無気力など)を評価した。200mg/kg又は400mg/kgのTGFRt15-TGFRsを投与されたマウスは、処理後6~8日で活動が低下し、他の有意な臨床徴候は見られなかった。200mg/kg又は400mg/kgのTGFRt15-TGFRsは、特に処理後7日目に、PBS群と比較してマウスの体重減少を引き起こした(p<0.05)。影響を受けたマウスは、10日後に死亡又は罹患することなく徐々に回復した。図216に示されるように、これらの所見は、C57BL/6マウスが最大100mg/kgでTGFRt15-TGFRsの単回投与に耐えることができることを示している。
Example 91 Toxicity of TGFRt15-TGFRs in C57BL/6 Mice A single dose of TGFRt15-TGFRs (50-400 mg/kg) was injected subcutaneously into C57BL/6 female mice (7 weeks old, n=4). Mice were weighed as shown in Figure 216 and clinical signs (mortality, morbidity, frilly hair, hunched posture, lethargy, etc.) were assessed during the experimental period. Mice administered 200 mg/kg or 400 mg/kg of TGFRt15-TGFRs exhibited decreased activity 6-8 days after treatment and no other significant clinical signs. TGFRt15-TGFRs at 200 mg/kg or 400 mg/kg caused weight loss in mice compared to the PBS group, especially on
実施例92:C57BL/6マウス黒色腫モデルにおけるTGFRt15-TGFRsの抗腫瘍活性
マウスB16F10黒色腫細胞をC57BL/6マウス(Jackson Laboratory)に皮下注射して、マウス黒色腫モデルを確立した。腫瘍細胞注射の4日後、マウスを異なる群に分けて、以下の免疫療法を受けた。群1:PBSビヒクル対照、群2:抗腫瘍抗体TA99(10mg/kg)のみの対照、群3:TA99とIL-15SA(0.05mg/kg)の併用、群4:TA99とTGFRt15-TGFRs(4.93mg/kg、0.05mg/kgのIL-15SAの同等のIL-15活性)の併用、群5:TA99とTGFRt15*-TGFRs(4.93mg/kg。IL-15活性を持たないIL-15D8N変異体)の併用。腫瘍体積を、長さ×幅×幅/2の式を使用して測定及び計算した。図217に示されるように、TGFRt15-TGFRs又はIL15SAと組み合わせた抗腫瘍抗体TA99を投与されたマウスは、PBS、TA99抗体単独、及びTGFRt15*-TGFRsと組み合わせたTA99と比較して、腫瘍接種後11日目に有意に小さい腫瘍を有することが結果から示された(p<0.05)。群1、2、及び5との間、及び群3と4との間で有意差はなかった。これらの知見は、TGFRt15-TGFRsのIL-15活性が、TGFRt15-TGFRsの抗腫瘍活性に重要であることを実証した。
Example 92: Antitumor Activity of TGFRt15-TGFRs in C57BL/6 Mouse Melanoma Model Mouse B16F10 melanoma cells were injected subcutaneously into C57BL/6 mice (Jackson Laboratory) to establish a mouse melanoma model. Four days after tumor cell injection, mice were divided into different groups and received the following immunotherapies. Group 1: PBS vehicle control, Group 2: anti-tumor antibody TA99 (10 mg/kg) only control, Group 3: TA99 in combination with IL-15SA (0.05 mg/kg), Group 4: TA99 with TGFRt15-TGFRs ( 4.93 mg/kg, equivalent IL-15 activity of IL-15SA at 0.05 mg/kg), Group 5: TA99 and TGFRt15*-TGFRs (4.93 mg/kg; IL-15 activity without IL-15 activity); -15D8N mutant). Tumor volume was measured and calculated using the formula length x width x width/2. As shown in FIG. 217, mice administered anti-tumor antibody TA99 in combination with TGFRt15-TGFRs or IL15SA were significantly more stable after tumor inoculation compared to PBS, TA99 antibody alone, and TA99 in combination with TGFRt15*-TGFRs. Results showed that they had significantly smaller tumors on day 11 (p<0.05). There were no significant differences between
実施例93:肺線維症のモデル-TGFRt15-TGFRsでの処理
炎症性及び線維性肺疾患(特発性肺線維症、慢性閉塞性肺疾患及び嚢胞性線維症を含む)は主要な死因であり、処理の選択肢は限られている。更に、様々な治療法は、肺線維症につながる肺損傷の副作用をもたらす。例えば、肺毒性は、ブレオマイシン化学療法を受けているがん患者の約10%で発生する。これらの効果は、げっ歯類におけるブレオマイシン処理の使用につながり、線維形成に関与するメカニズムの研究及び潜在的な治療法の評価のために肺線維症をモデル化した。このモデルにおけるTGFRt15-TGFRsの活性を評価するために、9週齢のC57Bl6/j雄マウスに50μLのブレオマイシン(2.5mg/kg、単回)を口腔咽頭経路で投与した。ブレオマイシン処理後17日目に、マウスにTGFRt15-TGFRsを皮下投与(3mg/kg)した。ブレオマイシン投与後28日目にマウスを屠殺した。肺を単離し、左肺を均質化し、市販のキットを製造者の説明書に従って使用して、コラーゲン沈着の尺度として、100μLのホモジネートをヒドロキシプロリン含有量についてアッセイした。データは、肺1グラム当たりのヒドロキシプロリン含有量のμgとして表された。図218に示されるように、結果は、TGFRt15-TGFRs療法が、ブレオマイシン処理マウスの肺におけるコラーゲン沈着(すなわち線維症)を有意に低減させたことを示している。
Example 93: Model of Pulmonary Fibrosis - Treatment with TGFRt15-TGFRs Inflammatory and fibrotic lung disease (including idiopathic pulmonary fibrosis, chronic obstructive pulmonary disease and cystic fibrosis) is a leading cause of death, Treatment options are limited. In addition, various treatments have the side effect of lung damage leading to pulmonary fibrosis. For example, pulmonary toxicity occurs in about 10% of cancer patients receiving bleomycin chemotherapy. These effects have led to the use of bleomycin treatment in rodents to model pulmonary fibrosis for the study of mechanisms involved in fibrogenesis and evaluation of potential therapeutics. To evaluate the activity of TGFRt15-TGFRs in this model, 9-week-old C57B16/j male mice were administered 50 μL of bleomycin (2.5 mg/kg, single dose) by oropharyngeal route. Seventeen days after bleomycin treatment, mice were subcutaneously administered TGFRt15-TGFRs (3 mg/kg). Mice were sacrificed 28 days after bleomycin administration. Lungs were isolated, left lungs were homogenized, and 100 μL of homogenate was assayed for hydroxyproline content as a measure of collagen deposition using a commercial kit according to the manufacturer's instructions. Data are expressed as μg of hydroxyproline content per gram of lung. As shown in Figure 218, the results indicate that TGFRt15-TGFRs therapy significantly reduced collagen deposition (ie, fibrosis) in the lungs of bleomycin-treated mice.
実施例94:TGFRt15-TGFRs及びTGFRt15*-TGFRsの活性のインビボ特徴付け
レプチン欠損ob/obマウスにおける肥満及び糖尿病からの保護は、TGF-β/Smad3シグナル伝達の遮断によって達成できることが示されている。TGFRt15-TGFRs又はTGFRt15*-TGFRsが、TGF-β/Smad3シグナル伝達の遮断によってマウスを肥満及び糖尿病から保護できるかどうかを評価するために、レプチン受容体欠損db/dbマウス系統(BKS.Cg Dock7m+/+Leprdb/J)を研究に使用した。6週齢のdb/dbマウスを3つの群に分けた(群当たりN=8)。マウスにTGFRt15-TGFRs、TGFRt15*-TGFRs、又はPBSを3mg/kgで皮下注射した。マウスを20時間絶食させた後、注射後4日目に顎下静脈から血液を収集した。空腹時血糖は、採血直後にOneTouch UltraMiniメーターで測定した。図219に示されるように、TGFRt15-TGFRs及びTGFRt15*-TGFRsの両方が、空腹時血漿グルコースレベルを有意に低減させることができる。
Example 94: In vivo characterization of the activity of TGFRt15-TGFRs and TGFRt15*-TGFRs It has been shown that protection from obesity and diabetes in leptin-deficient ob/ob mice can be achieved by blocking TGF-β/Smad3 signaling . To assess whether TGFRt15-TGFRs or TGFRt15*-TGFRs can protect mice from obesity and diabetes by blocking TGF-β/Smad3 signaling, a leptin receptor-deficient db/db mouse strain (BKS.Cg Dock7m +/+ Leprdb/J) were used in the study. Six-week-old db/db mice were divided into three groups (N=8 per group). Mice were injected subcutaneously with TGFRt15-TGFRs, TGFRt15*-TGFRs, or PBS at 3 mg/kg. After fasting the mice for 20 hours, blood was collected from the
血漿TGFβ1-3レベルを評価して、db/dbマウスにおける空腹時血漿グルコースの処理に関連した低減の原因を特定した。処理の4日後、血漿を単離し、30μLの血漿をEVE Technologies(Calgary,AB Canada)に送り、TGF-β3-Plex(TGFB1-3)アッセイによってTGFβ1~3レベルを評価した。図220A~Cに示されるように、TGFRt15-TGFRs及びTGFRt15*-TGFRsの両方が、血漿TGFβ1を完全に枯渇させ(図220A)、TGFβ2を部分的に低減させ(図220B)、TGFβ3に影響を与えなかった(図220C)。 Plasma TGFβ1-3 levels were assessed to identify the cause of the treatment-related reduction in fasting plasma glucose in db/db mice. After 4 days of treatment, plasma was isolated and 30 μL of plasma was sent to EVE Technologies (Calgary, AB Canada) to assess TGFβ1-3 levels by the TGF-β3-Plex (TGFB1-3) assay. As shown in FIGS. 220A-C, both TGFRt15-TGFRs and TGFRt15*-TGFRs completely depleted plasma TGFβ1 (FIG. 220A), partially reduced TGFβ2 (FIG. 220B), and had no effect on TGFβ3. No (Figure 220C).
リンパ球サブセットを評価して、db/dbマウスにおける空腹時血漿グルコースの処理に関連した低減の原因を特定した。処理の4日後、全血球(50μl)をACK(塩化アンモニウム-カリウム)溶解緩衝液で処理して、赤血球を溶解した。次いで、リンパ球をPE-Cy7-抗-CD3、BV605-抗-CD45、PerCP-Cy5.5-抗-CD8a、BV510-抗-CD4、及びAPC-抗-NKp46(全てBioLegendの抗体)で染色して、T細胞及びNK細胞の集団を評価した。細胞を更に透過処理し、eBioscience Foxp3/転写因子染色緩衝液セット(カタログ番号00-5523-00、ThermoFisher)で固定し、eBioscience透過処理緩衝液(カタログ番号00-8333-56、ThermoFisher)のAF700-抗-Ki67及びFITC-抗-グランザイムBで染色して、T細胞及びNK細胞の増殖及び活性化を評価した。リンパ球の別のセットを、最初にPE-Cy7-抗-CD3、BV605-抗-CD45、BV510-抗-CD4、及びapc-Cy7-抗-CD25で染色し、次いで透過処理し、eBioscience Foxp3/転写因子染色緩衝液セット(カタログ番号00-5523-00、ThermoFisher)で固定し、eBioscience透過処理緩衝液(カタログ番号00-8333-56、ThermoFisher)中のPE-抗-Foxp3で染色して、Treg細胞の集団を評価した。 Lymphocyte subsets were evaluated to identify the cause of the treatment-related reduction in fasting plasma glucose in db/db mice. Four days after treatment, whole blood cells (50 μl) were treated with ACK (ammonium chloride-potassium) lysis buffer to lyse red blood cells. Lymphocytes were then stained with PE-Cy7-anti-CD3, BV605-anti-CD45, PerCP-Cy5.5-anti-CD8a, BV510-anti-CD4, and APC-anti-NKp46 (all antibodies from BioLegend). to assess T cell and NK cell populations. Cells were further permeabilized, fixed with eBioscience Foxp3/Transcription Factor Staining Buffer Set (Cat #00-5523-00, ThermoFisher) and AF700- in eBioscience Permeabilization Buffer (Cat #00-8333-56, ThermoFisher). Staining with anti-Ki67 and FITC-anti-granzyme B was used to assess proliferation and activation of T cells and NK cells. Another set of lymphocytes was first stained with PE-Cy7-anti-CD3, BV605-anti-CD45, BV510-anti-CD4, and apc-Cy7-anti-CD25, then permeabilized and analyzed by eBioscience Foxp3/ Treg were stained with PE-anti-Foxp3 in eBioscience Permeabilization Buffer (Cat. #00-8333-56, ThermoFisher) and fixed with Transcription Factor Staining Buffer Set (Cat. #00-5523-00, ThermoFisher). Cell populations were evaluated.
TGFRt15-TGFRsは、NK細胞(図221A)及びCD8+T細胞(図221D)の集団を増加させ、NK細胞(図221B)及びCD8+T細胞(図221E)の増殖を刺激し、NK細胞(図221C)を活性化した。TGFRt15*-TGFRsは、いずれの細胞集団にも影響を与えなかった(図221A~E)。TGFRt15-TGFRs及びTGFRt15*-TGFRsの両方は、CD4+T細胞、CD19+B細胞、及びCD4+CD25+Foxp3+Treg細胞に影響を与えなかった。 TGFRt15-TGFRs increased populations of NK cells (Figure 221A) and CD8 + T cells (Figure 221D), stimulated proliferation of NK cells (Figure 221B) and CD8 + T cells (Figure 221E), Figure 221C) was activated. TGFRt15*-TGFRs had no effect on either cell population (FIGS. 221A-E). Both TGFRt15-TGFRs and TGFRt15*-TGFRs had no effect on CD4 + T cells, CD19 + B cells and CD4 + CD25 + Foxp3 + Treg cells.
結論として、db/dbマウスでは、TGFRt15-TGFRs及びTGFRt15*-TGFRsの両方が空腹時血漿グルコースレベルを低減させ、TGFRt15-TGFRs及びTGFRt15*-TGFRsの両方が血漿TGFβ1を完全に枯渇させた。しかしながら、TGFRt15-TGFRsのみがNK細胞を活性化し、CD8+T細胞及びNK細胞の増殖を増強した。これらの結果に基づいて、TGFβ1の枯渇は空腹時血漿グルコースの低減に関与している可能性が高く、TGF-β/Smad3シグナル伝達の遮断がob/obマウスの肥満及び糖尿病の予防に役割を果たすことを示す。 In conclusion, both TGFRt15-TGFRs and TGFRt15*-TGFRs reduced fasting plasma glucose levels and both TGFRt15-TGFRs and TGFRt15*-TGFRs completely depleted plasma TGFβ1 in db/db mice. However, only TGFRt15-TGFRs activated NK cells and enhanced proliferation of CD8 + T cells and NK cells. Based on these results, depletion of TGFβ1 is likely involved in reducing fasting plasma glucose, and blockade of TGF-β/Smad3 signaling has a role in preventing obesity and diabetes in ob/ob mice. Show fulfillment.
実施例95:TGFRt15-TGFRs及びTGFRt15*-TGFRsの活性のインビトロ特徴付け
TGFRIIはTGFβ1-3と相互作用することが実証された。TGFRIIと潜在的TGFβとの間の相互作用を示す文献の報告はない。TGFRt15-TGFRs、TGFRt15*-TGFRs、及びTGFRII-Fcが潜在的TGFβと相互作用するかどうかを評価するために、2.5nMのヒト潜在的TGFβ1-hisタグ(カタログ番号TG1-H524x、Acro Biosystems)又は対照タンパク質CD39-hisタグ(ロット番号58-49/51、HCW Biologics)を50mM炭酸緩衝液pH9.4(100μl/ウェル)に溶解し、ELISAプレート(カタログ番号80040LE0910、ThermoFisher)を4℃で一晩コーティングした。翌日、プレートをELISA洗浄緩衝液(0.05%Tween20を含むリン酸緩衝生理食塩水)で3回洗浄し、プレートをブロッキング緩衝液(1%BSA-PBS)で1時間遮断した後、200nM~0.09nMのブロッキング緩衝液中のTGFRt15-TGFRs、TGFRt15*-TGFRs、又はTGFRII-Fcの減少濃度をプレートに添加し、プレートを25℃で1時間インキュベートした。プレートをELISA洗浄緩衝液で3回洗浄した。0.1μg/mLの検出抗体であるビオチン化抗TGFRII抗体(カタログ番号BAF241、R&D Systems)をプレートに添加し、25℃で1時間インキュベートした。プレートを洗浄し、0.25μg/mLの西洋ワサビペルオキシダーゼ-ストレプトアビジン(コード番号016-030-084、Jackson ImmunoResearch)をプレートに添加し、25℃で30分間インキュベートした。プレートを洗浄し、HRPの基質であるABTS(カタログ番号ABTS-1000-01、Surmodics)をプレートに添加し、25℃で20分間インキュベートした。プレートを、マイクロプレートリーダー(Multiscan Sky、Thermo Scientific)を用いてOD405nmで読み取った。図222Aに示されるように、TGFRt15-TGFRs及びTGFRt15*-TGFRsの両方が潜在的TGFβ1と同様に相互作用した。しかしながら、TGFRII-Fcは、潜在的TGFβ1と、TGFRt15*-TGFRsで見られたよりも低い親和性で相互作用した(図222B)。結果は、TGFRt15-TGFRs、TGFRt15*-TGFRs、及びTGFRII-Fcが潜在的TGFβ1と相互作用し、TGFRt15-TGFRs、TGFRt15*-TGFRsが驚くべきことにTGFRII-Fcよりも高い親和性相互作用を示すことを実証した。
Example 95 In Vitro Characterization of Activity of TGFRt15-TGFRs and TGFRt15*-TGFRs TGFRII was demonstrated to interact with TGFβ1-3. There are no literature reports showing interactions between TGFRII and potential TGFβ. To assess whether TGFRt15-TGFRs, TGFRt15*-TGFRs, and TGFRII-Fc interact with cryptic TGFβ, a 2.5 nM human cryptic TGFβ1-his tag (catalog number TG1-H524x, Acro Biosystems) was used. Alternatively, the control protein CD39-his tag (Lot #58-49/51, HCW Biologics) was dissolved in 50 mM carbonate buffer pH 9.4 (100 μl/well) and plated on an ELISA plate (Cat #80040LE0910, ThermoFisher) at 4°C. Coated overnight. The next day, the plates were washed three times with ELISA wash buffer (phosphate buffered saline containing 0.05% Tween 20) and the plates were blocked with blocking buffer (1% BSA-PBS) for 1 hour before Decreasing concentrations of TGFRt15-TGFRs, TGFRt15*-TGFRs, or TGFRII-Fc in 0.09 nM blocking buffer were added to the plates and the plates were incubated at 25° C. for 1 hour. Plates were washed 3 times with ELISA wash buffer. A biotinylated anti-TGFRII antibody (catalog number BAF241, R&D Systems) at 0.1 μg/mL detection antibody was added to the plate and incubated at 25° C. for 1 hour. Plates were washed and 0.25 μg/mL horseradish peroxidase-streptavidin (Code No. 016-030-084, Jackson ImmunoResearch) was added to the plates and incubated at 25° C. for 30 minutes. Plates were washed and HRP substrate ABTS (catalog number ABTS-1000-01, Surmodics) was added to the plates and incubated at 25° C. for 20 minutes. Plates were read at OD405 nm using a microplate reader (Multiscan Sky, Thermo Scientific). As shown in FIG. 222A, both TGFRt15-TGFRs and TGFRt15*-TGFRs interacted similarly with potential TGFβ1. However, TGFRII-Fc interacted with cryptic TGFβ1 with lower affinity than that seen with TGFRt15*-TGFRs (FIG. 222B). The results show that TGFRt15-TGFRs, TGFRt15*-TGFRs, and TGFRII-Fc interact with potential TGFβ1, with TGFRt15-TGFRs, TGFRt15*-TGFRs surprisingly exhibiting higher affinity interactions than TGFRII-Fc. We proved that.
実施例96:プロトロンビン時間試験
プロトロンビン時間(PT)試験は、組織因子及び最適濃度のカルシウムと混合した後、血漿が凝固するのにかかる時間を測定するように設計されている。リン脂質との組織因子混合物(トロンビンプラスチンと呼ばれる)は、プロトロンビンをトロンビンに変換する酵素として作用し、フィブリノーゲンをフィブリンに変換することで血液凝固を引き起こす。Innovinは、脂質化された組換えヒトTF243であり、実験の標準として使用される。PTアッセイでは、PT時間(凝固時間)が短いほどTF依存性凝固活性が高いことを示し、PT(凝固時間)が長いほどTF依存性凝固活性が低いことを意味する。
Example 96: Prothrombin Time Test The Prothrombin Time (PT) test is designed to measure the time it takes plasma to clot after mixing with tissue factor and an optimal concentration of calcium. A mixture of tissue factor with phospholipids (called thrombinplastin) acts as an enzyme that converts prothrombin to thrombin and fibrinogen to fibrin, thereby causing blood clotting. Innovin is a lipidated recombinant human TF243 and is used as an experimental standard. In the PT assay, a shorter PT time (clotting time) indicates higher TF-dependent coagulation activity, and a longer PT (clotting time) means lower TF-dependent coagulation activity.
簡潔には、0.1mLの正常ヒト血漿(Ci-Trol Coagulation Control、レベルI)を37℃で3分間予熱した。0.2mLの様々な希釈のInnovin又はPTアッセイ緩衝液(50mM Tris-HCl、pH7.5、14.6mMのCaCl2、0.1%BSA)で希釈した試験試料(TGFRt15-TGFRs)を血漿に添加することにより、血漿凝固反応を開始した。凝固時間を、STart PTアナライザー(Diagnostica Stago,Parsippany,NJ.)によって監視及び報告した。 Briefly, 0.1 mL of normal human plasma (Ci-Trol Coagulation Control, Level I) was preheated to 37° C. for 3 minutes. Test samples (TGFRt15-TGFRs) diluted in 0.2 mL of various dilutions of Innovin or PT assay buffer (50 mM Tris-HCl, pH 7.5, 14.6 mM CaCl 2 , 0.1% BSA) were added to plasma. Plasma clotting reaction was initiated by addition. Clotting times were monitored and reported by a START PT Analyzer (Diagnostica Stago, Parsippany, NJ.).
図223に見られるように、PTアッセイに添加された異なる量のInnovin(10nMの脂質化組換えヒトTF243に相当する精製水で再構成されたInnovinは、100%Innovinであるとみなされる)は、実際に、PTアッセイ及びPT時間において添加されたTF243の量の間の逆相関を示した。例えば、1%のInnovinのPT時間は約25.0秒であったが、100%InnovinのPT時間は8.5秒であった。 As seen in Figure 223, different amounts of Innovin added to the PT assay (Innovin reconstituted in purified water equivalent to 10 nM lipidated recombinant human TF243 is considered to be 100% Innovin) , indeed showed an inverse correlation between the amount of TF243 added in the PT assay and PT time. For example, 1% Innovin had a PT time of approximately 25.0 seconds, while 100% Innovin had a PT time of 8.5 seconds.
図224は、TGFRt15-TGFRsのPT試験の結果を示す。Innovinとは対照的に、TGFRt15-TGFRsは緩衝液とほぼ同じ長時間のPT時間を示し、凝固活性が非常に低いか又はまったくないことを示す。 Figure 224 shows the results of the PT study of TGFRt15-TGFRs. In contrast to Innovin, TGFRt15-TGFRs exhibit prolonged PT times nearly identical to buffer, indicating very low or no clotting activity.
CTLL細胞の存在下でのTGFRt15-TGFRsの凝固効果も評価した。実施した結合実験により、TGFRt15-TGFRsがCTLL細胞に結合できることが確認された。CTLL細胞の存在下でのTGFRt15-TGFRs凝固試験は、インビボでの強力な凝固活性をより厳密に反映する。TGFRt15-TGFRsをCTLL細胞と37℃で20~30分間、PTアッセイ緩衝液中でプレインキュベートした。次いで、上述のようにPTアッセイを進めた。図224は、TGFRt15-TGFRsとCTLL細胞との混合物が、TGFRt15-TGFRs単独(167.6秒)又はCTLL細胞単独(161.9秒)よりも凝固時間(154.6秒)が少し短かったことを示す。しかしながら、154.6秒の凝固時間は、8.5秒のInnovin凝固時間よりも依然としてかなり長い。 The coagulant effect of TGFRt15-TGFRs in the presence of CTLL cells was also evaluated. Binding experiments performed confirmed that TGFRt15-TGFRs can bind to CTLL cells. The TGFRt15-TGFRs clotting assay in the presence of CTLL cells more closely reflects their potent clotting activity in vivo. TGFRt15-TGFRs were pre-incubated with CTLL cells at 37° C. for 20-30 minutes in PT assay buffer. The PT assay was then proceeded as described above. Figure 224 shows that the mixture of TGFRt15-TGFRs and CTLL cells had a slightly shorter clotting time (154.6 seconds) than TGFRt15-TGFRs alone (167.6 seconds) or CTLL cells alone (161.9 seconds). indicate. However, the clotting time of 154.6 seconds is still significantly longer than the Innovin clotting time of 8.5 seconds.
要約すると、TGFRt15-TGFRsは、TGFRt15-TGFRsに結合できる細胞が存在する場合でも、TF依存性凝固活性が非常に低いか、又はまったくない(すなわち、ヒト血漿中の凝固因子の生理学的範囲内)。 In summary, TGFRt15-TGFRs have very low or no TF-dependent clotting activity (i.e., within the physiological range of clotting factors in human plasma) even in the presence of cells capable of binding to TGFRt15-TGFRs. .
実施例97:TGFRt15-TGFRs又はPBSによる処理及び短期(10日)又は長期(60日)追跡調査後の若齢マウス及び老齢マウスの組織における老化マーカーの遺伝子発現
72週齢のC57BL/6マウスをJackson Laboratoryから購入した。マウスは、温度及び光が制御された環境で飼育された。マウスを2群に分け、PBS(PBS対照群)又は3mg/kgの投薬量のTGFRt15-TGFRs(TGFRt15-TGFRs群)のいずれかで皮下処理した。処理後10日目又は60日目のいずれかにマウスを安楽死させ、老化マーカーPAI1、IL-1α、IL6、及びTNFαの発現レベルを定量的PCRで評価するために腎臓を収集した。収集した腎臓を1.7mLのエッペンドルフチューブ内の液体窒素に保存した。試料を、1mLのTrizol(Thermo Fischer)でホモジナイザーを使用して均質化した。均質化した組織を新たなエッペンドルフチューブに移した。全RNAを、RNeasyミニキット(Qiagen番号74106)を製造業者の指示に従って使用して抽出した。1μgの全RNAを、QuantiTect逆転写(Qiagen)を使用したcDNA合成に使用した。リアルタイムPCRを、Thermo Scientificから購入したFAM標識事前設計プライマーを使用したCFX96検出システム(Bio-Rad)で行った。反応を試験した全ての遺伝子に対して三連で行った。ハウスキーピング遺伝子18SリボソームRNAを、発現レベルの変動を正規化するための内部対照として使用した。18S rRNAに対する各標的mRNAの発現を、Ctに基づいて2-Δ(ΔCt)として計算し、式中、ΔCt=Ct target-Ct18Sである。未処理の6週齢マウス(若齢)を対照として使用して、遺伝子発現レベルを老齢マウスと比較した。
Example 97: Gene Expression of Senescence Markers in Tissues of Young and Aged Mice After Treatment with TGFRt15-TGFRs or PBS and Short-Term (10 Days) or Long-Term (60 Days) Follow-up Purchased from Jackson Laboratory. Mice were housed in a temperature and light controlled environment. Mice were divided into two groups and treated subcutaneously with either PBS (PBS control group) or TGFRt15-TGFRs at a dosage of 3 mg/kg (TGFRt15-TGFRs group). Mice were euthanized either 10 or 60 days after treatment and kidneys were harvested for quantitative PCR assessment of expression levels of senescence markers PAI1, IL-1α, IL6, and TNFα. Harvested kidneys were stored in liquid nitrogen in 1.7 mL Eppendorf tubes. Samples were homogenized with 1 mL of Trizol (Thermo Fischer) using a homogenizer. The homogenized tissue was transferred to a new Eppendorf tube. Total RNA was extracted using the RNeasy mini kit (Qiagen #74106) according to the manufacturer's instructions. 1 μg of total RNA was used for cDNA synthesis using QuantiTect reverse transcription (Qiagen). Real-time PCR was performed on a CFX96 detection system (Bio-Rad) using FAM-labeled pre-designed primers purchased from Thermo Scientific. Reactions were performed in triplicate for all genes tested. Housekeeping gene 18S ribosomal RNA was used as an internal control to normalize variations in expression levels. The expression of each target mRNA relative to 18S rRNA was calculated as 2 − Δ(ΔCt) based on Ct, where ΔCt=Ct target−Ct18S. Untreated 6-week-old mice (young) were used as controls to compare gene expression levels with aged mice.
図225に示されるように、結果は、腎臓におけるPAI-1、IL-1α、IL6、及びIL-1βの遺伝子発現が、細胞老化の年齢依存的な増加で予想されるように、マウスの年齢とともに増加したことを示している。TGFRt15-TGFRsの単回投与での72ヶ月齢マウスの処理により、腎臓における老化マーカーの遺伝子発現の減少に有意かつ長期的な影響がもたらされ、老齢マウスの腎臓における自然発生の老化細胞の処理関連減少を示唆する。 As shown in FIG. 225, the results show that gene expression of PAI-1, IL-1α, IL6, and IL-1β in the kidney increased as mice age, as expected with an age-dependent increase in cellular senescence. It shows that it increased with Treatment of 72-month-old mice with a single dose of TGFRt15-TGFRs resulted in a significant and long-lasting effect on decreased gene expression of senescence markers in the kidneys and treatment of spontaneous senescent cells in the kidneys of aged mice. suggesting an associated decrease.
図226に示されるように、結果は、TGFRt15-TGFRsの単回投与での72ヶ月齢マウスの処理により、肝臓におけるIL-1α及びIL6遺伝子発現の低減に有意かつ長期的な影響が媒介されることが示され、老齢マウスの肝臓における自然発生の老化細胞の処理関連減少を示唆する。 As shown in Figure 226, the results show that treatment of 72-month-old mice with a single dose of TGFRt15-TGFRs mediated significant and long-term effects in reducing IL-1α and IL6 gene expression in the liver. , suggesting a treatment-related reduction of spontaneous senescent cells in the liver of aged mice.
72週齢のC57BL/6マウスをJackson Laboratoryから購入した。マウスは、温度及び光が制御された環境で飼育された。マウスを2群に分け、PBS(PBS対照群)又は3mg/kgの投薬量のTGFRt15-TGFRs(TGFRt15-TGFRs群)のいずれかで皮下処理した。処理後10日目又は60日目のいずれかにマウスを安楽死させ、老化マーカーPAI-1のタンパク質レベルを組織ELISAで評価するために腎臓を収集した。収集した腎臓を1.7mLのエッペンドルフチューブ内の液体窒素に保存した。試料を、0.3mLの抽出緩衝液(Abcam)でホモジナイザーを使用して均質化した。均質化した組織を新たなエッペンドルフチューブに移した。均質化された組織のタンパク質レベルを、BCA Proteinアッセイキット(Pierce)を使用して定量化した。マウスPAI-1 ELISA(R&D System)を、200mgの組織ホモジネートを使用して実施した。標準曲線に基づいて、組織1ミリグラム当たりのピコグラムとしてPAI-1の濃度を計算した。 72 week old C57BL/6 mice were purchased from Jackson Laboratory. Mice were housed in a temperature and light controlled environment. Mice were divided into two groups and treated subcutaneously with either PBS (PBS control group) or TGFRt15-TGFRs at a dosage of 3 mg/kg (TGFRt15-TGFRs group). Mice were euthanized either 10 or 60 days after treatment and kidneys were harvested for assessment of protein levels of the senescence marker PAI-1 by tissue ELISA. Harvested kidneys were stored in liquid nitrogen in 1.7 mL Eppendorf tubes. Samples were homogenized with 0.3 mL of extraction buffer (Abcam) using a homogenizer. The homogenized tissue was transferred to a new Eppendorf tube. Protein levels in homogenized tissues were quantified using the BCA Protein assay kit (Pierce). Mouse PAI-1 ELISA (R&D System) was performed using 200 mg of tissue homogenate. Concentrations of PAI-1 were calculated as picograms per milligram of tissue based on the standard curve.
図227に示されるように、老化マーカーPAI-1のタンパク質レベルは、TGFRt15-TGFRs処理老齢マウスの腎臓において、処理後60日でPBS群と比較して減少した。これらの結果は、老齢マウスの腎臓におけるPAI-1遺伝子発現に対するTGFRt15-TGFRs処理の効果と一致している。まとめると、これらの結果は、TGFRt15-TGFRsの1回の処理が、老齢マウスの組織における自然発生の老化細胞の低減に有意かつ長期的な効果をもたらしたことを示す(老化マーカーの遺伝子及びタンパク質発現の低減によって測定)。
As shown in FIG. 227, protein levels of the senescence marker PAI-1 were decreased in the kidneys of TGFRt15-TGFRs-treated aged mice compared to the
実施例98:老齢マウスの組織における老化マーカーの遺伝子発現の低減におけるTGFRt15-TGFRs及びTGFRt15*-TGFRs(IL-15変異体)処理の比較
72週齢のC57BL/6マウスをJackson Laboratoryから購入した。マウスは、温度及び光が制御された環境で飼育された。マウスは以下のように5つの群に分けた:生理食塩水対照群(n=8)、TGFRt15-TGFRs群(n=8)、IL15SA群(n=8)、TGFRt15*-TGFRs群(n=8)、及びIL15SA+TGFRt15*-TGFRs群(n=8)。マウスに、PBS、TGFRt15-TGFRs(3mg/kg)、TGFRt15*-TGFRs(3mg/kg)、IL15SA(0.5mg/kg)、又はTGFRt15*-TGFRs(3mg/kg)+IL15SA(0.5mg/kg)を皮下投与した。TGFRt15-TGFRs及び他の作用物質で処理した後の免疫細胞の異なるサブセットを評価するために、マウス血液を調製した。マウス血液を17日目に顎下静脈からEDTAを含有するチューブ内に収集した。全血をマイクロ遠心機で3000RPMで10分間遠心分離して血漿を収集した。血漿は-80℃で保存し、全血をフローサイトメトリーによる免疫細胞表現型解析のために処理した。全血RBCを室温で5分間ACK緩衝液に溶解した。残りの細胞を、FACS緩衝液(1×PBS(Hyclone)、0.5%BSA(EMD Millipore)及び0.001%アジ化ナトリウム(Sigma)を含む)中で洗浄した。液中の異なる種類の免疫細胞を評価するために、細胞表面のCD3、CD45、CD8、及びNK1.1(BioLegend)に特異的な抗体で細胞を室温(RT)で30分間染色した。表面染色後、細胞を、FACS緩衝液(0.5%BSA(EMD Millipore)及び0.001%アジ化ナトリウム(Sigma)を含む1×PBS(Hyclone))中で洗浄した(1500RPM、室温で5分間)。2回洗浄した後、細胞をフローサイトメトリー(Celesta-BD Bioscience)によって分析した。
Example 98: Comparison of TGFRt15-TGFRs and TGFRt15*-TGFRs (IL-15 Mutants) Treatment in Reducing Gene Expression of Senescence Markers in Aged Mice Tissues 72-week-old C57BL/6 mice were purchased from Jackson Laboratory. Mice were housed in a temperature and light controlled environment. Mice were divided into five groups as follows: saline control group (n = 8), TGFRt15-TGFRs group (n = 8), IL15SA group (n = 8), TGFRt15*-TGFRs group (n = 8), and the IL15SA+TGFRt15*-TGFRs group (n=8). Mice were given PBS, TGFRt15-TGFRs (3 mg/kg), TGFRt15*-TGFRs (3 mg/kg), IL15SA (0.5 mg/kg), or TGFRt15*-TGFRs (3 mg/kg) + IL15SA (0.5 mg/kg). ) was administered subcutaneously. Mouse blood was prepared to evaluate different subsets of immune cells after treatment with TGFRt15-TGFRs and other agents. Mouse blood was collected on
図228に示されるように、結果は老齢マウスをTGFRt15-TGFRsで処理したことを示している。IL15SA(陽性対照)又はTGFRt15*-TGFRs+IL15SAが、血液中のCD3+CD8+、CD3-NK1.1+、及びCD3+CD45+免疫細胞のパーセンテージの増加を媒介したが、TGFRt15*-TGFRでの処理は、これらの細胞集団のパーセンテージにほとんど又はまったく影響を与えなかった。これらの結果は、TGFRt15-TGFRsのIL-15活性が老齢マウスの血液中のCD8+T細胞及びNK細胞の増加に役割を果たすことを示唆している。 As shown in Figure 228, the results indicate that aged mice were treated with TGFRt15-TGFRs. IL15SA (positive control) or TGFRt15*-TGFRs+IL15SA mediated an increase in the percentage of CD3 + CD8 + , CD3 − NK1.1 + , and CD3 + CD45 + immune cells in the blood, whereas treatment with TGFRt15*-TGFR had little or no effect on the percentages of these cell populations. These results suggest that IL-15 activity of TGFRt15-TGFRs plays a role in increasing CD8 + T cells and NK cells in the blood of aged mice.
図229に示されるように、結果は老齢マウスをTGFRt15-TGFRsで処理したことを示している。IL15SA(陽性対照)又はTGFRt15*-TGFRs+IL15SAが、脾臓のCD3+CD8+、CD3-NK1.1+、及びCD3+CD45+免疫細胞のパーセンテージの増加を媒介したが、TGFRt15*-TGFRでの処理は、これらの細胞集団のパーセンテージにほとんど又はまったく影響を与えなかった。これらの結果は、TGFRt15-TGFRsのIL-15活性が老齢マウスの脾臓のCD8+T細胞及びNK細胞の増加に役割を果たすことを示唆している。 As shown in Figure 229, the results indicate that aged mice were treated with TGFRt15-TGFRs. IL15SA (positive control) or TGFRt15*-TGFRs+IL15SA mediated an increase in the percentage of splenic CD3 + CD8 + , CD3 − NK1.1 + , and CD3 + CD45 + immune cells, whereas treatment with TGFRt15*-TGFR , had little or no effect on the percentages of these cell populations. These results suggest that IL-15 activity of TGFRt15-TGFRs plays a role in increasing splenic CD8 + T cells and NK cells in aged mice.
72週齢のC57BL/6マウスをJackson Laboratoryから購入した。マウスは、温度及び光が制御された環境で飼育された。マウスは以下のように5つの群に分けた:生理食塩水対照群(n=8)、TGFRt15-TGFRs群(n=8)、IL15SA群(n=8)、TGFRt15*-TGFRs群(n=8)、及びTGFRt15*-TGFRs群(n=8)を含むIL15SA。マウスに、PBS、TGFRt15-TGFRs(3mg/kg)、TGFRt15*-TGFRs(3mg/kg)、IL15SA(0.5mg/kg)、又はTGFRt15*-TGFRs(3mg/kg)+IL15SA(0.5mg/kg)を皮下投与した。TGFRt15-TGFRs、TGFRt15*-TGFRs、又は対照群で処理した後の組織における定量的PCRによって、老化マーカーp21、PAI1、IL-1α、及びIL6の遺伝子発現を評価するために、マウスの腎臓、肝臓、及び肺を収集した。マウスを処理後17日目に安楽死させ、腎臓、肝臓、及び肺を収集し、1.7mLエッペンドルフチューブ内の液体窒素で保存した。試料を、1mLのTrizol(Thermo Fischer)でホモジナイザーを使用して均質化した。均質化した組織を新たなエッペンドルフチューブに移した。全RNAを、RNeasyミニキット(Qiagen番号74106)を製造業者の指示に従って使用して抽出した。1μgの全RNAを、QuantiTect逆転写(Qiagen)を使用したcDNA合成に使用した。リアルタイムPCRを、Thermo Scientificから購入したFAM標識事前設計プライマーを使用したCFX96検出システム(Bio-Rad)で行った。反応を試験した全ての遺伝子に対して三連で行った。ハウスキーピング遺伝子18SリボソームRNAを、発現レベルの変動を正規化するための内部対照として使用した。18S rRNAに対する各標的mRNAの発現を、Ctに基づいて2-Δ(ΔCt)として計算し、式中、ΔCt=Ct target-Ct18Sである。 72 week old C57BL/6 mice were purchased from Jackson Laboratory. Mice were housed in a temperature and light controlled environment. Mice were divided into five groups as follows: saline control group (n = 8), TGFRt15-TGFRs group (n = 8), IL15SA group (n = 8), TGFRt15*-TGFRs group (n = 8), and IL15SA, including the TGFRt15*-TGFRs group (n=8). Mice were given PBS, TGFRt15-TGFRs (3 mg/kg), TGFRt15*-TGFRs (3 mg/kg), IL15SA (0.5 mg/kg), or TGFRt15*-TGFRs (3 mg/kg) + IL15SA (0.5 mg/kg). ) was administered subcutaneously. Mouse kidney, liver to assess gene expression of senescence markers p21, PAI1, IL-1α, and IL6 by quantitative PCR in tissues after treatment with TGFRt15-TGFRs, TGFRt15*-TGFRs, or control groups. , and lungs were collected. Mice were euthanized 17 days after treatment and kidneys, livers and lungs were collected and stored in liquid nitrogen in 1.7 mL Eppendorf tubes. Samples were homogenized with 1 mL of Trizol (Thermo Fischer) using a homogenizer. The homogenized tissue was transferred to a new Eppendorf tube. Total RNA was extracted using the RNeasy mini kit (Qiagen #74106) according to the manufacturer's instructions. 1 μg of total RNA was used for cDNA synthesis using QuantiTect reverse transcription (Qiagen). Real-time PCR was performed on a CFX96 detection system (Bio-Rad) using FAM-labeled pre-designed primers purchased from Thermo Scientific. Reactions were performed in triplicate for all genes tested. Housekeeping gene 18S ribosomal RNA was used as an internal control to normalize variations in expression levels. The expression of each target mRNA relative to 18S rRNA was calculated as 2 − Δ(ΔCt) based on Ct, where ΔCt=Ct target−Ct18S.
図230A~Dに示されるように、TGFRt15-TGFRs又はTGFRt15*-TGFRsの単回投与による72ヶ月齢のマウスの処理は、腎臓及び肝臓におけるp21、PAI1、IL-1α、及びIL6遺伝子発現の有意な減少を媒介し、老齢マウスの腎臓及び肝臓における自然発生の老化細胞の減少に関連する処理を示唆している。この研究の結果は、TGFRt15-TGFRsのIL-15及びTGF-βトラップ活性の両方が、老齢マウスの組織で自然発生の老化細胞を低減させることができることを示唆している。 As shown in Figures 230A-D, treatment of 72-month-old mice with a single dose of TGFRt15-TGFRs or TGFRt15*-TGFRs significantly reduced p21, PAI1, IL-1α, and IL6 gene expression in kidney and liver. suggesting a process associated with the reduction of spontaneous senescent cells in the kidney and liver of aged mice. The results of this study suggest that both the IL-15 and TGF-β trap activities of TGFRt15-TGFRs can reduce spontaneous senescent cells in aged mouse tissues.
実施例99:IL-15ベースの作用物質での処理後の免疫表現型
マウスの血液は、IL-15ベースの作用物質:TGFRt15-TGFRs、IL-15スーパーアゴニスト(IL-15SA)、及びIL-15活性をノックアウトしたD8N変異体のIL-15融合体(TGFRt15*-TGFRs)で処理した後の免疫細胞の様々なサブセットの変化を評価するために調製された。6週齢のC57BL/6マウスをJackson Laboratoryから購入した。マウスは、温度及び光が制御された環境で飼育された。マウスを群に分け(n=6/群)、以下で処理した:1)PBS(生理食塩水)対照、2)ドセタキセル、3)TGFRt15-TGFRsを含むドセタキセル、4)IL15SAを含むドセタキセル、5)IL-15変異体(TGFRt15*-TGFRs)を含むドセタキセル及び6)IL-15スーパーアゴニスト(IL-15SA)とTGFRt15*-TGFRsを含むドセタキセル。1、4、及び7日目にドセタキセル(10mg/kg)を3回投与すると、マウスの老化が誘導された。8日目に、PBS、TGFRt15-TGFRs、TGFRt15*-TGFRs、IL-15SA、又は上記の組み合わせでマウスを皮下処理した。TGFRt15-TGFRs及びTGFRt15*-TGFRsは、3mg/kgの投薬量で投与され、IL-15SAは、0.05mg/kgで投与された。研究薬物処理後3日目にマウス血液を顎下静脈からEDTAチューブに収集した。全血をマイクロ遠心機で3000RPMで10分間遠心分離して血漿を収集した。血漿は-80℃で保存し、全血をフローサイトメトリーによる免疫細胞表現型解析のために処理した。RBCをACK緩衝液で37℃、5分間溶解した。残りの細胞を、FACS緩衝液(1×PBS(Hyclone)、0.5%BSA(EMD Millipore)及び0.001%アジ化ナトリウム(Sigma)を含む)中で洗浄した。血液中の異なる種類の免疫細胞を評価するために、細胞表面のCD4、CD45、CD19、CD8、及びNK1.1(BioLegend)に対する抗体で室温(RT)で30分間染色した。表面染色後、細胞を、FACS緩衝液(0.5%BSA(EMD Millipore)及び0.001%アジ化ナトリウム(Sigma)を含む1×PBS(Hyclone))中で洗浄した(1500RPM、室温で5分間)。細胞を透過化緩衝液(Invitrogen)で40℃で20分間処理した後、透過化緩衝液(Invitrogen)で洗浄した。次いで、細胞を増殖の細胞内マーカー(Ki67)について室温で30分間染色した。2回洗浄した後、細胞をフローサイトメトリー(Celesta-BD Bioscience)によって分析した。
Example 99: Blood of Immunophenotypic Mice After Treatment with IL-15 Based Agents : IL-15 Based Agents: TGFRt15-TGFRs, IL-15 Superagonist (IL-15SA), and IL- were prepared to assess changes in various subsets of immune cells after treatment with IL-15 fusions of D8N mutants that knocked out 15 activity (TGFRt15*-TGFRs). Six-week-old C57BL/6 mice were purchased from Jackson Laboratory. Mice were housed in a temperature and light controlled environment. Mice were divided into groups (n=6/group) and treated with: 1) PBS (saline) control, 2) docetaxel, 3) docetaxel with TGFRt15-TGFRs, 4) docetaxel with IL15SA, 5) Docetaxel with IL-15 variants (TGFRt15*-TGFRs) and 6) IL-15 superagonist (IL-15SA) and Docetaxel with TGFRt15*-TGFRs. Three doses of docetaxel (10 mg/kg) on
図231A及び231Bに示されるように、結果は、TGFRt15-TGFRs、IL15SA(陽性対照)、又はTGFRt15*-TGFRs+IL15SAによるマウスの処理が、血中のCD8+T細胞及びNK1.1+細胞のパーセンテージ及び増殖(Ki67によって測定)の増加を媒介したことを示すが、TGFRt15*-TGFRsによる処理は、これらの細胞集団のパーセンテージにほとんど又はまったく影響を与えなかった。これらの結果は、TGFRt15-TGFRsのIL-15活性が、化学療法後の老齢マウスの血液中のCD8+T細胞及びNK細胞の増加に役割を果たすことを示唆している。 As shown in FIGS. 231A and 231B, the results show that treatment of mice with TGFRt15-TGFRs, IL15SA (positive control), or TGFRt15*-TGFRs+IL15SA increased the percentage of CD8 + T cells and NK1.1 + cells in the blood and Treatment with TGFRt15*-TGFRs had little or no effect on the percentage of these cell populations, indicating that it mediated an increase in proliferation (measured by Ki67). These results suggest that the IL-15 activity of TGFRt15-TGFRs plays a role in the increase of CD8 + T cells and NK cells in the blood of aged mice after chemotherapy.
実施例100:化学療法及びIL-15系作用物質による処理後のマウスの肺及び肝臓組織における老化マーカーp21及びCD26の遺伝子発現の評価
細胞老化のマーカーの遺伝子発現は、化学療法及び研究処理の投与後の正常なマウスの組織で評価された。6週齢のC57BL/6マウスをJackson Laboratoryから購入した。マウスは、温度及び光が制御された環境で飼育された。マウスを6つの群に分け、以下で処理した:1)PBS(生理食塩水)対照(n=5)、2)ドセタキセル(n=8)、3)TGFRt15-TGFRsを含むドセタキセル(n=8)、4)IL15SAを含むドセタキセル(n=8)、5)IL-15変異体(TGFRt15*-TGFRs)を含むドセタキセル(n=8)及び6)IL-15スーパーアゴニスト(IL-15SA)とTGFRt15*-TGFRsを含むドセタキセル(n=6)。1、4、及び7日目にドセタキセル(10mg/kg)を3回投与すると、マウスの老化が誘導された。8日目に、PBS、TGFRt15-TGFRs、TGFRt15*-TGFRs、IL-15SA、又は以下の組み合わせでマウスを皮下処理した。TGFRt15-TGFRs及びTGFRt15*-TGFRsは、3mg/kgの投薬量で投与され、IL-15SAは、0.5mg/kgで投与された。老化マーカーの異なる遺伝子発現を評価するために、マウス組織を調製した。研究薬物処理後7日目にマウスを安楽死させ、肝臓及び肺組織を収集し、1.7mLエッペンドルフチューブ内の液体窒素で保存した。液体窒素中で乳鉢及び乳棒を使用して、試料を均質化した。均質化した組織を、1mLのTrizol(Thermo Fischer)を含有する新しいエッペンドルフチューブに移した。RNeasyミニキット(Qiagen番号74106)を使用して製造元の指示に従って全RNAを抽出し、1μgの全RNAを、QuantiTect逆転写キット(Qiagen)を使用したcDNA合成に使用した。リアルタイムPCRを、Thermo Scientificから購入したFAM標識事前設計プライマーを使用したCFX96検出システム(Bio-Rad)で行った。反応を試験した全ての遺伝子に対して三連で行った。ハウスキーピング遺伝子18SリボソームRNAを、発現レベルの変動を正規化するための内部対照として使用した。18S rRNAに対する各標的mRNAの発現を、Ctに基づいて2-Δ(ΔCt)として計算し、式中、ΔCt=Ct target-Ct18Sである。
Example 100 Evaluation of Gene Expression of Senescence Markers p21 and CD26 in Lung and Liver Tissues of Mice After Chemotherapy and Treatment with IL-15 Based Agents It was later evaluated on tissues from normal mice. Six-week-old C57BL/6 mice were purchased from Jackson Laboratory. Mice were housed in a temperature and light controlled environment. Mice were divided into 6 groups and treated with: 1) PBS (saline) control (n=5), 2) docetaxel (n=8), 3) docetaxel with TGFRt15-TGFRs (n=8). 4) docetaxel with IL15SA (n=8), 5) docetaxel with IL-15 variants (TGFRt15*-TGFRs) (n=8) and 6) IL-15 superagonist (IL-15SA) with TGFRt15*. - Docetaxel with TGFRs (n=6). Three doses of docetaxel (10 mg/kg) on
図232に示されるように、老化マーカーp21及びCD26の遺伝子発現は、生理食塩水で処理したマウスの組織における遺伝子発現と比較して、ドセタキセルで処理されたマウスの肺組織(図232A)及び(図232B)、並びに肝臓組織(図232C)においてp21が誘導された。肺における老化マーカーp21及びCD26並びに肝臓におけるp21の遺伝子発現は、化学療法を受けた対照と比較して、TGFRt15-TGFRs、IL-15SA、及びIL-15SAとTGFRt15*-TGFRs変異体との組み合わせによるその後の処理後に化学療法治療マウスで低減した。しかしながら、TGFRt15*-TGFRs変異体処理は、これらの組織での化学療法によって誘導された老化マーカー遺伝子発現に影響を与えることができなかった。これらの結果は、IL-15活性がマウスの正常組織におけるTIS老化細胞の除去に重要であることを示す。 As shown in Figure 232, gene expression of the senescence markers p21 and CD26 was significantly higher in lung tissues of docetaxel-treated mice (Figure 232A) and (Fig. 232A) compared to gene expression in tissues of saline-treated mice. p21 was induced in Figure 232B), as well as in liver tissue (Figure 232C). Senescence markers p21 and CD26 in the lung and p21 gene expression in the liver by TGFRt15-TGFRs, IL-15SA, and IL-15SA in combination with the TGFRt15*-TGFRs mutant compared to chemotherapy-treated controls decreased in chemotherapy-treated mice after subsequent treatments. However, TGFRt15*-TGFRs mutant treatment was unable to affect chemotherapy-induced senescence marker gene expression in these tissues. These results indicate that IL-15 activity is important for elimination of TIS senescent cells in normal tissues of mice.
実施例101:TGFRt15-TGFRs処理は、B16F10担腫瘍マウスの末梢血における免疫細胞の増殖、拡大、及び活性化を増強する
C57BL/6マウスに、0.5x106個のB16F10細胞を皮下注射した。腫瘍接種(0日目)後、マウスにドキセタキセル化学療法(10mg/kg)を1、4、7日目に3回投与し、腫瘍抗原抗TYRP-1抗体TA99(200μg)を標的とするモノクローナル抗体と組み合わせてTGFRt15-TGFRs(3mg/kg)を8日目に単回投与した。1、4、及び7日目に生理食塩水又はドキセタキセル化学療法(10mg/kg)で処理した腫瘍担持マウスを対照として使用した。免疫療法処理後(8日目)、3、5、及び10日目に顎下静脈から採血した。RBCをACK溶解緩衝液で溶解し、リンパ球を洗浄し、室温(RT)で30分間、NK、CD8、CD25、及びグランザイムB(GzB)(BioLegend)の細胞表面発現に特異的な抗体で染色した。表面染色後、細胞を、FACS緩衝液(0.5%BSA(EMD Millipore)及び0.001%アジ化ナトリウム(Sigma)を含む1×PBS(Hyclone))中で洗浄した(1500RPM、室温で5分間)。2回洗浄した後、細胞を固定緩衝液に再懸濁した。固定後、細胞を洗浄し、4℃で20分間透過処理緩衝液(Invitrogen)で処理した後、透過処理緩衝液(Invitrogen)で洗浄した。次いで、細胞を増殖の細胞内マーカー(Ki67)について室温で30分間染色した。2回洗浄した後、細胞をフローサイトメトリー(Celesta-BD Bioscience)によって分析した。
Example 101: TGFRt15-TGFRs Treatment Enhances Immune Cell Proliferation, Expansion, and Activation in the Peripheral Blood of B16F10 Tumor-Bearing Mice C57BL/6 mice were injected subcutaneously with 0.5×10 6 B16F10 cells . After tumor inoculation (day 0), mice were dosed with doxetaxel chemotherapy (10 mg/kg) three times on
図233A及びBに示されるように、生理食塩水又は化学療法処理群と比較した場合、末梢血分析は、TGFRt15-TGFRs+TA99療法後3日目に増殖性Ki67陽性NK及びCD8+細胞が主に存在することを示した。NK及びCD8+細胞の拡大は、免疫療法後3日目及び5日目に見られた。免疫療法後10日目には、NK細胞がまだ増殖したが、CD8+細胞は血液中で増殖しなかった。これらの細胞は、生理食塩水又は化学療法処理群の免疫細胞と比較した場合、TGFRt15-TGFRs+TA99療法後に活性化マーカーCD25及びグランザイムBも発現した。これらの効果は、TGFRt15-TGFRsの免疫刺激活性と一致している。
As shown in Figures 233A and B, peripheral blood analysis revealed predominantly proliferating Ki67-positive NK and CD8 + cells on
実施例102:TGFRt15-TGFRs処理は、B16F10腫瘍担持マウスの血漿中のTGFβレベルを減少させる
C57BL/6マウスに、0.5x106個のB16F10細胞を皮下注射した。腫瘍接種(0日目)後、マウスにドキセタキセル化学療法(10mg/kg)を1、4、7日目に3回投与し、腫瘍抗原抗TYRP-1抗体TA99(200μg)を標的とするモノクローナル抗体と組み合わせてTGFRt15-TGFRs(3mg/kg)を8日目に単回投与した。1、4、及び7日目に生理食塩水又はドキセタキセル化学療法(10mg/kg)で処理した腫瘍担持マウスを対照として使用した。血液を、EDTAを含有するチューブで免疫療法処理後1、3、5、及び10日目に顎下から収集し、直ちに氷上に置いた。血液を室温で3,000rpmで15分間遠心分離し、血漿を分離した。血漿試料を分注し、-80℃で保存した。血漿TGFβレベルを、Eve Technologies,Calgary,AL,Canadaからのサイトカインアレイ、TGFβ3プレックス(TGFβ1-3)を使用することによって分析した。
Example 102: TGFRt15-TGFRs Treatment Decreases TGFβ Levels in Plasma of B16F10 Tumor-Bearing Mice C57BL/6 mice were injected subcutaneously with 0.5×10 6 B16F10 cells. After tumor inoculation (day 0), mice were dosed with doxetaxel chemotherapy (10 mg/kg) three times on
図234に示されるように、結果は、TGFRt15-TGFRs+TA99の投与が、生理食塩水又は化学療法処理群と比較した場合、処理後3~5日間、腫瘍担持マウスにおけるTGF-β1、TGF-β2、及びTGF-β3の血漿レベルの低減をもたらしたことを示している。この効果は、TGFRt15-TGFRsのTGF-βアゴニスト活性と一致している。 As shown in Figure 234, the results showed that administration of TGFRt15-TGFRs + TA99 increased TGF-β1, TGF-β2, TGF-β1, TGF-β2, and reduced plasma levels of TGF-β3. This effect is consistent with the TGF-β agonistic activity of TGFRt15-TGFRs.
実施例103:TGFRt15-TGFRs処理は、B16F10腫瘍担持マウスの血漿中の炎症誘発性サイトカインのレベルを低減させる
C57BL/6マウスに、0.5x106個のB16F10細胞を皮下注射した。腫瘍接種(0日目)後、マウスにドキセタキセル化学療法(10mg/kg)を1、4、7日目に3回投与し、腫瘍抗原抗TYRP-1抗体TA99(200μg)を標的とするモノクローナル抗体と組み合わせてTGFRt15-TGFRs(3mg/kg)を8日目に単回投与した。1、4、及び7日目に生理食塩水又はドキセタキセル化学療法(10mg/kg)で処理した腫瘍担持マウスを対照として使用した。免疫療法処理後(8日目)1、3、5、及び10日目に、EDTAを含有するチューブに顎下静脈から採血し、直ちに氷上に置いた。血液を室温で3,000rpmで15分間遠心分離し、血漿を分離した。血漿試料を分注し、-80℃で保存した。アリコートをPBSで2倍に希釈し、マウスサイトカインアレイ炎症誘発性フォーカス10プレックス(MDF10)アッセイを使用して分析した。
Example 103: TGFRt15-TGFRs Treatment Reduces Levels of Proinflammatory Cytokines in Plasma of B16F10 Tumor-Bearing Mice C57BL/6 mice were injected subcutaneously with 0.5×10 6 B16F10 cells. After tumor inoculation (day 0), mice were dosed with doxetaxel chemotherapy (10 mg/kg) three times on
図235に示されるように、結果は、TGFRt15-TGFR+TA99の投与が、化学療法群と比較した場合、処理後10日目に腫瘍担持マウスにおけるIL2、IL-1β、IL6、MCP-1、及びGM-CSFの血漿レベルを低減させたことを示している。この効果は、TGFRt15-TGFRsの免疫刺激活性と一致している。
As shown in FIG. 235, the results showed that administration of TGFRt15-TGFR+TA99 increased IL2, IL-1β, IL6, MCP-1, and GM in tumor-bearing
実施例104:TGFRt15-TGFRs処理が、B16F10腫瘍担持マウスの脾臓におけるNK及びCD8+拡大を増強する
C57BL/6マウスに、0.5x106個のB16F10細胞を皮下注射した。腫瘍接種(0日目)後、マウスにドキセタキセル化学療法(10mg/kg)を1、4、7日目に3回投与し、腫瘍抗原抗TYRP-1抗体TA99(200μg)を標的とするモノクローナル抗体と組み合わせてTGFRt15-TGFRs(3mg/kg)を8日目に単回投与した。1、4、及び7日目に生理食塩水又はドキセタキセル化学療法(10mg/kg)で処理した腫瘍担持マウスを対照として使用した。免疫療法(8日目)後3、5、及び10日目にマウスを屠殺し、脾臓を収集した。脾細胞を解放するために、3ccシリンジの無菌ピストン/プランジャーの平らな後端で脾臓を破砕した。脾細胞を70μMセルストレーナーに通し、均質化して単一細胞懸濁液にした。RBCをACK溶解緩衝液で溶解し、脾細胞を洗浄し、NK及びCD8の細胞表面発現のための抗体(BioLegend)で室温で30分間染色した。2回洗浄した後、細胞をフローサイトメトリー(Celesta-BD Bioscience)によって分析した。
Example 104: TGFRt15-TGFRs Treatment Enhances NK and CD8+ Expansion in the Spleens of B16F10 Tumor-Bearing Mice C57BL/6 mice were injected subcutaneously with 0.5×10 6 B16F10 cells. After tumor inoculation (day 0), mice were dosed with doxetaxel chemotherapy (10 mg/kg) three times on
図236に示されるように、生理食塩水又は化学療法処理群と比較した場合、TGFRt15-TGFRs+TA99療法後3日目及び5日目にNK細胞及びCD8+細胞の拡大が脾臓で見られた。NK細胞(CD8+細胞ではない)のレベルは、化学療法群の脾臓のレベルと比較した場合、腫瘍担持マウスの脾臓で免疫療法後10日目にまだ上昇していることがわかった。これらの効果は、TGFRt15-TGFRsの免疫刺激活性と一致している。
As shown in Figure 236, an expansion of NK cells and CD8 + cells was seen in the spleen on
実施例105:TGFRt15-TGFRs処理が、B16F10腫瘍担持マウスにおける脾細胞の解糖活性を増強する
C57BL/6マウスに、0.5x106個のB16F10細胞を皮下注射した。腫瘍接種(0日目)後、マウスにドキセタキセル化学療法(10mg/kg)を1、4、7日目に3回投与し、腫瘍抗原抗TYRP-1抗体TA99(200μg)を標的とするモノクローナル抗体と組み合わせてTGFRt15-TGFRs(3mg/kg)を8日目に単回投与した。1、4、及び7日目に生理食塩水又はドキセタキセル化学療法(10mg/kg)で処理した腫瘍担持マウスを対照として使用した。免疫療法(8日目)後3、5、及び10日目にマウスを屠殺し、脾臓を収集した。脾細胞を解放するために、3ccシリンジの無菌ピストン/プランジャーの平らな後端で脾臓を破砕した。脾細胞を70μMセルストレーナーに通し、均質化して単一細胞懸濁液にした。RBCをACK溶解緩衝液で溶解し、脾細胞を洗浄してカウントした。脾細胞の解糖活性を測定するために、細胞を洗浄し、seahorse培地に再懸濁し、4x106細胞/mLに再懸濁した。細胞を、解糖ストレス試験のために2mM L-グルタミンを補充したpH7.4のSeahorse XF RPMI培地中のCell-TakコーティングSeahorse Bioanalyzer XFe96培養プレート中に50μL/ウェルで播種した。細胞を37℃で30分間かけてプレートに付着させた。更に、130μLのアッセイ培地をプレートの各ウェルに(バックグラウンドウェルにも)添加した。プレートを37℃、非CO2インキュベーターで1時間インキュベートした。解糖ストレス試験では、キャリブレーションプレートには、Seahorseアッセイ培地で調製されたグルコース/オリゴマイシン/2DGの10倍溶液が含まれており、20μLのグルコース/オリゴマイシン/2DGが、一晩キャリブレーションされた細胞外フラックスプレートの各ポートに添加された。解糖ストレス試験は、細胞外酸性化速度(ECAR)に基づいており、解糖、解糖能力、及び解糖予備力を含む解糖機能の3つの重要なパラメータを測定する。完全なECAR分析は、非解糖酸性化(薬物なし)、解糖(10mMグルコース)、最大解糖誘導/解糖能力(2μMオリゴマイシン)、及び解糖予備(100mM 2-DG)の4つの段階で構成される。実験の最後に、データをGraph Pad Prismファイルとしてエクスポートした。XF解糖ストレス試験レポートジェネレーターは、WaveデータからXF細胞解糖ストレス試験のパラメータを自動的に計算した。Waveソフトウェア(Agilent)を使用してデータを分析した。
Example 105: TGFRt15-TGFRs Treatment Enhances Glycolytic Activity of Splenocytes in B16F10 Tumor-Bearing Mice C57BL/6 mice were injected subcutaneously with 0.5×10 6 B16F10 cells. After tumor inoculation (day 0), mice were dosed with doxetaxel chemotherapy (10 mg/kg) three times on
図237A及びBに示されるように、TGFRt15-TGFRs+TA99療法後3日目及び5日目に腫瘍担持マウスから単離された脾細胞は、生理食塩水又は化学療法処理群の脾細胞と比較した場合、基礎解糖、能力及び予備率の増強を示した。しかしながら、免疫療法後10日目に脾細胞の解糖活性に有意差は観察されなかった。これらの効果は、TGFRt15-TGFRsの免疫刺激活性と一致している。
As shown in Figures 237A and B, splenocytes isolated from tumor-bearing mice on
実施例106:TGFRt15-TGFRs処理が、B16F10担腫瘍マウスにおける脾細胞のミトコンドリア呼吸を増強する
C57BL/6マウスに、0.5x106個のB16F10細胞を皮下注射した。腫瘍接種(0日目)後、マウスにドキセタキセル化学療法(10mg/kg)を1、4、7日目に3回投与し、腫瘍抗原抗TYRP-1抗体TA99(200μg)を標的とするモノクローナル抗体と組み合わせてTGFRt15-TGFRs(3mg/kg)を8日目に単回投与した。1、4、及び7日目に生理食塩水又はドキセタキセル化学療法(10mg/kg)で処理した腫瘍担持マウスを対照として使用した。免疫療法(8日目)後3、5、及び10日目にマウスを屠殺し、脾臓を収集した。脾細胞を解放するために、3ccシリンジの無菌ピストン/プランジャーの平らな後端で脾臓を破砕した。脾細胞を70μMセルストレーナーに通し、均質化して単一細胞懸濁液にした。RBCをACK溶解緩衝液で溶解し、脾細胞を洗浄してカウントした。脾細胞のミトコンドリア呼吸を測定するために、細胞を洗浄し、seahorse培地に再懸濁し、4x106細胞/mLに再懸濁した。細胞を、解糖ストレス試験のために2mM L-グルタミンを補充したpH7.4のSeahorse XF RPMI培地中のCell-TakコーティングSeahorse Bioanalyzer XFe96培養プレート中に50μL/ウェルで播種した。ミトコンドリアストレス試験では、細胞を、10mMグルコース及び2mM L-グルタミン補充したpH7.4のSeahorse XF RPMI培地に播種した。細胞を37℃で30分間かけてプレートに付着させた。更に、130μLのアッセイ培地をプレートの各ウェルに(バックグラウンドウェルにも)添加した。プレートを37℃、非CO2インキュベーターで1時間インキュベートした。ミトコンドリアストレス試験では、キャリブレーションプレートには、Seahorseアッセイ培地で調製された10倍のオリゴマイシン/FCCP/ロテノン溶液が含まれており、20μLのオリゴマイシン、FCCP、及びロテノンが、一晩キャリブレーションされた細胞外フラックスプレートの各ポートに添加された。酸素消費速度(OCR)を、XFe96 Extracellular Flux Analyzerを使用して測定した。完全なOCR分析は、基礎呼吸(薬物なし)、ATP関連呼吸/プロトン漏出(1.5μM mMオリゴマイシン)、最大呼吸(2μM FCCP)、及び予備呼吸(0.5μMロテノン)の4つの段階からなった。実験の最後に、データをGraph Pad Prismファイルとしてエクスポートした。XFミトコンドリアストレス試験レポートジェネレーターは、ExcelにエクスポートされたWaveデータからXFミトコンドリアストレス試験のパラメータを自動的に計算する。Waveソフトウェア(Agilent)を使用することによってデータを分析した。
Example 106: TGFRt15-TGFRs Treatment Enhances Splenocyte Mitochondrial Respiration in B16F10 Tumor-Bearing Mice C57BL/6 mice were injected subcutaneously with 0.5×10 6 B16F10 cells. After tumor inoculation (day 0), mice were dosed with doxetaxel chemotherapy (10 mg/kg) three times on
図238A及びBに示されるように、TGFRt15-TGFR+TA99療法後3日目及び5日目に腫瘍担持マウスから単離された脾細胞は、生理食塩水又は化学療法処理群の脾細胞と比較した場合、基礎呼吸、ミトコンドリア呼吸、能力及びATP産生の増強を示した。しかしながら、免疫療法後10日目に脾細胞のミトコンドリア呼吸に有意差は観察されなかった。これらの効果は、TGFRt15-TGFRsの免疫刺激活性と一致している。酸化的代謝及び解糖などの代謝経路は、免疫細胞の細胞運命の決定及びエフェクター機能を優先的に促進することが知られている。したがって、TGFRt15-TGFRsは解糖活性の増加を媒介し、ミトコンドリア呼吸は、マウスの血液、脾臓、及び腫瘍におけるNK及びCD8+免疫細胞の活性化と関連している可能性がある。
As shown in FIGS. 238A and B, splenocytes isolated from tumor-bearing mice on
実施例107:TGFRt15-TGFRs処理が、B16F10腫瘍担持マウスの腫瘍へのNK及びCD8免疫細胞浸潤(TIL)を増強する
C57BL/6マウスに、0.5x106個のB16F10細胞を皮下注射した。腫瘍接種(0日目)後、マウスにドキセタキセル化学療法(10mg/kg)を1、4、7日目に3回投与し、腫瘍抗原抗TYRP-1抗体TA99(200μg)を標的とするモノクローナル抗体と組み合わせてTGFRt15-TGFRs(3mg/kg)を8日目に単回投与した。1、4、及び7日目に生理食塩水又はドキセタキセル化学療法(10mg/kg)で処理した腫瘍担持マウスを対照として使用した。免疫療法後3、5、及び10日目にマウスを屠殺し、腫瘍を収集した。腫瘍浸潤免疫細胞を決定するために、コラゲナーゼ消化によって腫瘍組織を単一細胞懸濁液に解離した。単一細胞懸濁液をFicoll-Paque培地に重層し、続いて密度勾配遠心分離を行ってリンパ球及び腫瘍細胞を分離した。細胞をゆっくり加速し、ブレークをオフにして、20℃で1000g、20分間遠心分離した。遠心分離後、Ficoll-Paqueは2つの層を明確に分離する。TILは、培地及びFicoll-Paqueの間の界面に見られるが、ペレットは腫瘍細胞で構成されている。TILを界面から慎重に取り外し、完全なRPMI培地で洗浄した。洗浄後、RBCを室温で5分間ACK緩衝液に溶解した。細胞を、FACS緩衝液(1×PBS(Hyclone)、0.5%BSA(EMD Millipore)及び0.001%アジ化ナトリウム(Sigma)を含む)中で洗浄した。腫瘍内の異なる種類の免疫細胞を評価するために、細胞を細胞表面のCD8、NK1.1、CD25、及びGzB(BioLegend)に対する抗体で室温で30分間染色した。表面染色後、残りの細胞を、FACS緩衝液(1×PBS(Hyclone)、0.5%BSA(EMD Millipore)及び0.001%アジ化ナトリウム(Sigma)を含む)中で洗浄した(1500RPM、室温で5分間)。2回洗浄した後、細胞を固定緩衝液に再懸濁した。固定後、細胞を洗浄し、4℃で20分間透過処理緩衝液(Invitrogen)で処理した後、透過処理緩衝液(Invitrogen)で洗浄した。次いで、細胞を増殖の細胞内マーカー(Ki67)について室温で30分間染色した。2回洗浄した後、細胞をフローサイトメトリー(Celesta-BD Bioscience)によって分析した。図239A及びBに示されるように、腫瘍分析は、療法後3日目に高レベルのKi67陽性NK及びCD8細胞を示した。NK及びCD8+細胞の拡大(腫瘍中のリンパ球の%に基づく)は、化学療法処理群と比較した場合、TGFRt15-TGFRs+TA99療法後3日目及び5日目に見られた。腫瘍CD8+細胞は、免疫療法後10日目でさえ上昇していた。化学療法処理群の免疫細胞と比較した場合、NK及びCD8+の両方が、TGFRt15-TGFRs+TA99療法後3日目に活性化マーカーCD25及びグランザイムBの発現を示した。これらの効果は、TGFRt15-TGFRsの免疫刺激活性と一致しており、腫瘍担持マウスの血液及び脾細胞に見られる変化に匹敵する。
Example 107: TGFRt15-TGFRs Treatment Enhances NK and CD8 Immune Cell Infiltration (TIL) into Tumors in B16F10 Tumor-Bearing Mice C57BL/6 mice were injected subcutaneously with 0.5×10 6 B16F10 cells . After tumor inoculation (day 0), mice were dosed with doxetaxel chemotherapy (10 mg/kg) three times on
実施例108:TGFRt15-TGFRs処理後の腫瘍の組織病理学的分析
C57BL/6マウスに、0.5x106個のB16F10細胞を皮下注射した。腫瘍接種(0日目)後、マウスにドキセタキセル化学療法(10mg/kg)を1、4、7日目に3回投与し、腫瘍抗原抗TYRP-1抗体TA99(200μg)を標的とするモノクローナル抗体と組み合わせてTGFRt15-TGFRs(3mg/kg)を8日目に単回投与した。1、4、及び7日目に生理食塩水又はドキセタキセル化学療法(10mg/kg)で処理した腫瘍担持マウスを対照として使用した。免疫療法処理後(8日目)1、3、5、及び10日目に顎下静脈から採血した。免疫療法後10日目にマウスを屠殺し、腫瘍を単離した。組織学的分析のために、腫瘍試料を10%ホルマリン溶液で固定し、パラフィンに包埋して5μmに切断した。切片をH&Eで染色して、組織及び細胞の形態を評価した。切片は、腫瘍の有糸分裂及び壊死活性に基づいてスコア化された。腫瘍の壊死のパーセンテージは、+1(0~20%)、+2(20~40%)、及び+3(40~60%)としてスコア化された。腫瘍の有糸分裂指数は、+1=中等度(高倍率視野当たり1~5)及び+2=広範囲(高倍率視野当たり>5)としてスコア化された。
Example 108: Histopathological Analysis of Tumors After TGFRt15-TGFRs Treatment C57BL/6 mice were injected subcutaneously with 0.5×10 6 B16F10 cells. After tumor inoculation (day 0), mice were dosed with doxetaxel chemotherapy (10 mg/kg) three times on
図240に示されるように、TGFRt15-TGFRs+TA99処理後、腫瘍はより少ない有糸分裂及び壊死活性を示した。有糸分裂指数は分裂細胞と相関しており、壊死の存在はより攻撃的な特徴及び予後不良の尺度である。したがって、TGFRt15-TGFRsは、併用腫瘍免疫療法の試験のための前臨床マウスモデルにおける有望な療法である。 As shown in Figure 240, tumors exhibited less mitotic and necrotic activity after TGFRt15-TGFRs + TA99 treatment. The mitotic index correlates with dividing cells and the presence of necrosis is a more aggressive feature and a measure of poor prognosis. Therefore, TGFRt15-TGFRs are promising therapies in preclinical mouse models for testing combination tumor immunotherapies.
実施例109:B16F10黒色腫マウスモデルにおけるTGFRt15-TGFRs+TA99及び化学療法と組み合わせた抗PD-L1抗体
C57BL/6マウスに、0.5x106個のB16F10細胞を皮下注射した。腫瘍接種(0日目)後、マウスにドキセタキセル化学療法(10mg/kg)を1、4、7日目に3回投与した。1、4、及び7日目に生理食塩水又はドキセタキセル化学療法(10mg/kg)のみで処理した腫瘍担持マウスを対照として使用した。残りのマウスは無作為に2つの群に分けられ、一方の群は抗mPD-L1抗体(2x10mg/kg)で処理され、もう一方の群は、8日目にTA99(200μg)を含むTGFRt15-TGFRs(3mg/kg)で処理された。6日後、TA99を含むTGFRt15-TGFRsを投与されたマウスに、抗mPD-L1抗体(2x10mg/kg)を投与し、抗mPD-L1抗体を投与されたマウスを、TA99(200μg)を含むTGFRt15-TGFRs(3mg/kg)で処理した。抗mPD-L1抗体は、8日目及び10日目、又は14日目及び16日目の2回投与された。腫瘍成長をキャリパー測定によって監視し、腫瘍体積を式V=(L×W2)/2を使用して計算し、式中、Lは最大腫瘍直径であり、Wは垂直腫瘍直径である。N=6-8マウス/群。
Example 109: Anti-PD-L1 Antibody Combined with TGFRt15-TGFRs+TA99 and Chemotherapy in B16F10 Melanoma Mouse Model C57BL/6 mice were injected subcutaneously with 0.5×10 6 B16F10 cells. After tumor inoculation (day 0), mice received three doses of doxetaxel chemotherapy (10 mg/kg) on
図24Iに示されるように、TGFRt15-TGFR+TA99の投与に続く抗PD-L1抗体処理は、抗PD-L1抗体で処理した後にTGFRt15-TGFRs+TA99を処理した場合と比較して、B16F10腫瘍担持マウスにおいてより良好な抗腫瘍活性をもたらした。したがって、TGFRt15-TGFRsと抗PD-L1抗体の併用は、抗PD-L1抗体療法に耐性のある腫瘍の処理に有利である可能性がある。 As shown in FIG. 24I, administration of TGFRt15-TGFR+TA99 followed by anti-PD-L1 antibody treatment was associated with higher cytotoxicity in B16F10 tumor-bearing mice compared to treatment with anti-PD-L1 antibody followed by TGFRt15-TGFRs+TA99. Resulted in good anti-tumor activity. Therefore, the combination of TGFRt15-TGFRs and anti-PD-L1 antibodies may be advantageous in treating tumors resistant to anti-PD-L1 antibody therapy.
実施例110:B16F10黒色腫マウスモデルにおけるTGFRt15-TGFRsの抗腫瘍効果は、NK及びCD8+T細胞に依存する
C57BL/6マウスの群(N=6~8マウス/群)を、3日おきにNK1.1Ab(500μg)又はCD8+a(500μg)抗体の3投薬量で腹腔内投与して、NK及びCD8細胞を枯渇させた。B16F10腫瘍移植前に血液を採取し、NK及びCD8+リンパ球レベルについて分析した。未処理のマウスは、免疫適格性対照として機能した。C57BL/6マウスに、0.5x106個のB16F10細胞を皮下注射した。腫瘍接種(0日目)後、マウスにドセタキセル(10mg/kg)を1、4、及び7日目に3回投与した後、TGFRt15-TGFRs(3mg/kg)+TA99(200μg)を8日目に単回投与した。腫瘍成長をキャリパー測定によって監視し、腫瘍体積を式V=(L×W2)/2を使用して計算し、式中、Lは最大腫瘍直径であり、Wは垂直腫瘍直径である。
Example 110: The anti-tumor effect of TGFRt15-TGFRs in the B16F10 melanoma mouse model was demonstrated by treating groups of NK- and CD8+ T cell-dependent C57BL/6 mice (N=6-8 mice/group) with NK1. Three doses of 1Ab (500 μg) or CD8 + a (500 μg) antibodies were administered intraperitoneally to deplete NK and CD8 cells. Blood was collected prior to B16F10 tumor implantation and analyzed for NK and CD8 + lymphocyte levels. Untreated mice served as an immunocompetent control. C57BL/6 mice were injected subcutaneously with 0.5×10 6 B16F10 cells. After tumor inoculation (day 0), mice were dosed with docetaxel (10 mg/kg) three times on
図242に示されるように、TA99及び化学療法と組み合わせたTGFRt15-TGFRsで処理されたB16F10腫瘍担持マウスは、生理食塩水又は化学療法処理群の腫瘍と比較した場合、B16F10腫瘍体積の有意な低減を示した。しかしながら、マウスのNK及びCD8+細胞サブセットを枯渇させた場合、抗抗腫瘍活性に対する免疫療法の効果はなかった。この実験は、NK及びCD8+免疫細胞の両方が、TGFRt15-TGFRs媒介抗腫瘍活性において重要な役割を果たすことを示している。 As shown in Figure 242, B16F10 tumor-bearing mice treated with TGFRt15-TGFRs in combination with TA99 and chemotherapy showed a significant reduction in B16F10 tumor volume when compared to tumors in saline or chemotherapy treated groups. showed that. However, there was no effect of immunotherapy on anti-antitumor activity when NK and CD8 + cell subsets in mice were depleted. This experiment indicates that both NK and CD8 + immune cells play important roles in TGFRt15-TGFRs-mediated anti-tumor activity.
実施例111:化学療法後のB16F10腫瘍担持マウスの肝臓及び肺組織における老化マーカーの低減におけるTGFRt15-TGFRs及びTGFRt15*-TGFRs処理の比較
6~8週齢のC57BL/6マウスをJackson Laboratoryから購入した。マウスは、温度及び光が制御された環境で飼育された。マウスを以下のように5つの群に分けた:生理食塩水対照群(n=7)、ドセタキセル(DTX)群(n=7)、DTX+TGFRt15-TGFRs群(n=7)、DTX+TGFRt15*-TGFRs群(n=7)、及びDTX+IL15SA群(n=7)。B16F10腫瘍細胞(1×107細胞/マウス)を0日目にマウスに移植した。マウスを、1、4、及び7日目に10mg/kgドセタキセルで皮下処理した。8日目に、マウスに、PBS、TGFRt15-TGFRs(3mg/kg)、TGFRt15*-TGFRs(3mg/kg)、又はIL15SA(0.5mg/kg)を皮下投与した。処理後17日目にマウスを安楽死させ、TGFRt15-TGFRs、又はTGFRt15*-TGFRs、及び対照群で処理した後の組織における定量的PCRによって、肝臓については老化マーカーp21、IL-1α、及びIL6、肺についてはp21及びIL-1αの遺伝子発現を評価するために、肝臓及び肺を収集した。収集した腎臓を1.7mLのエッペンドルフチューブ内の液体窒素に保存した。試料を、1mLのTrizol(Thermo Fischer)でホモジナイザーを使用して均質化した。均質化した組織を新たなエッペンドルフチューブに移した。全RNAを、RNeasyミニキット(Qiagen番号74106)を製造業者の指示に従って使用して抽出した。1μgの全RNAを、QuantiTect逆転写(Qiagen)を使用したcDNA合成に使用した。リアルタイムPCRを、Thermo Scientificから購入したFAM標識事前設計プライマーを使用したCFX96検出システム(Bio-Rad)で行った。反応を試験した全ての遺伝子に対して三連で行った。ハウスキーピング遺伝子18SリボソームRNAを、発現レベルの変動を正規化するための内部対照として使用した。18S rRNAに対する各標的mRNAの発現を、Ctに基づいて2-Δ(ΔCt)として計算し、式中、ΔCt=Ct target-Ct18Sである。
Example 111: Comparison of TGFRt15-TGFRs and TGFRt15*-TGFRs Treatment in Reducing Senescence Markers in Liver and Lung Tissues of B16F10 Tumor-Bearing Mice After Chemotherapy 6-8 week old C57BL/6 mice were purchased from Jackson Laboratory . Mice were housed in a temperature and light controlled environment. Mice were divided into five groups as follows: saline control group (n=7), docetaxel (DTX) group (n=7), DTX+TGFRt15-TGFRs group (n=7), DTX+TGFRt15*-TGFRs group. (n=7), and the DTX+IL15SA group (n=7). Mice were implanted on
図243に示されるように、老化マーカーp21、IL-1α、及びIL6は、化学療法で処理されたマウスの組織における遺伝子発現と比較した場合、TGFRt15-TGFRs及びTGFRt15*-TGFRsで処理された腫瘍担持マウスの両方において、肝臓(A)及び肺(B)組織における遺伝子発現の減少を示した。 As shown in FIG. 243, senescence markers p21, IL-1α, and IL6 increased significantly in tumors treated with TGFRt15-TGFRs and TGFRt15*-TGFRs when compared to gene expression in tissues of chemotherapy-treated mice. Both bearing mice showed decreased gene expression in liver (A) and lung (B) tissues.
実施例112:インビボでの化学療法によって誘導された老化腫瘍細胞の低減におけるTGFRt15-TGFRs処理
B16F10黒色腫細胞にGFPレンチウイルスプラスミドを安定的に形質導入し、GFPを発現する腫瘍細胞(B16F10-GFP)をピューロマイシン含有培地での増殖によって選択した。FACSで分析すると、ほぼ95%のB16F10黒色腫細胞が、GFP陽性であった。老化を誘導するために、B16F10-GFP細胞を7.5μMドセタキセル(DTX)で3日間処理した後、通常の増殖培地で4日間回復させた。老化マーカー及びNK細胞リガンドの遺伝子発現を定量化するために、ドセタキセル処理B16F10GFP細胞(B16F10-GFP-SNC)を1mLのTrizol(Thermo Fischer)でホモジナイザーを使用することによって均質化した。均質化した細胞を新たなエッペンドルフチューブに移した。全RNAを、RNeasyミニキット(Qiagen番号74106)を製造業者の指示に従って使用して抽出した。1μgの全RNAを、QuantiTect逆転写(Qiagen)を使用したcDNA合成に使用した。リアルタイムPCRを、Thermo Scientificから購入したFAM標識事前設計プライマーを使用したCFX96検出システム(Bio-Rad)で行った。反応を試験した全ての遺伝子に対して三連で行った。ハウスキーピング遺伝子18SリボソームRNAを、発現レベルの変動を正規化するための内部対照として使用した。18S rRNAに対する各標的mRNAの発現を、Ctに基づいて2-Δ(ΔCt)として計算し、式中、ΔCt=Ct target-Ct18Sである。異なる遺伝子の発現は、未処理のB16F10-GFP細胞と比較したB16F10-GFP-SNC細胞の倍率変化としてプロットされている。
Example 112: TGFRt15-TGFRs-treated B16F10 melanoma cells in reduction of chemotherapy-induced senescent tumor cells in vivo were stably transduced with a GFP lentiviral plasmid and tumor cells expressing GFP (B16F10-GFP ) were selected by growth on puromycin-containing medium. Approximately 95% of B16F10 melanoma cells were GFP-positive when analyzed by FACS. To induce senescence, B16F10-GFP cells were treated with 7.5 μM docetaxel (DTX) for 3 days and then allowed to recover in normal growth medium for 4 days. To quantify gene expression of senescence markers and NK cell ligands, docetaxel-treated B16F10-GFP cells (B16F10-GFP-SNC) were homogenized with 1 mL of Trizol (Thermo Fischer) by using a homogenizer. Homogenized cells were transferred to a new Eppendorf tube. Total RNA was extracted using the RNeasy mini kit (Qiagen #74106) according to the manufacturer's instructions. 1 μg of total RNA was used for cDNA synthesis using QuantiTect reverse transcription (Qiagen). Real-time PCR was performed on a CFX96 detection system (Bio-Rad) using FAM-labeled pre-designed primers purchased from Thermo Scientific. Reactions were performed in triplicate for all genes tested. Housekeeping gene 18S ribosomal RNA was used as an internal control to normalize variations in expression levels. The expression of each target mRNA relative to 18S rRNA was calculated as 2 − Δ(ΔCt) based on Ct, where ΔCt=Ct target−Ct18S. Expression of different genes is plotted as fold change in B16F10-GFP-SNC cells compared to untreated B16F10-GFP cells.
図244に示されるように、リアルタイムPCR分析は、ドセタキセルでインビトロで処理されたB16F10-GFP細胞が、老化マーカー、p21、H2AX、及びIL6、並びにNK細胞リガンド、Rae-1e及びULBP-1の遺伝子発現を、未処理のB16F10-GFP細胞に比較した場合、アップレギュレートしたことを示した。 As shown in FIG. 244, real-time PCR analysis revealed that B16F10-GFP cells treated in vitro with docetaxel increased genes for senescence markers p21, H2AX, and IL6, and NK cell ligands Rae-1e and ULBP-1. Expression was shown to be upregulated when compared to untreated B16F10-GFP cells.
化学療法誘発性老化腫瘍細胞がインビボで免疫療法によって低減するかどうかを決定するために、B16F10親黒色腫細胞(0.75x106)を、B16F10-GFP-SNC細胞(0.75x106)と混合し、C57BL/6マウスにおいて細胞混合物を皮下注射した。マウスにも、対照としてB16F10及びB16F10-GFP細胞を注射した。B16F10親細胞は成長して腫瘍を形成し、B16F10-GFP-SNC細胞は腫瘍微小環境の一部になる。腫瘍が約350mm3に達したとき、混合腫瘍担持マウスを2群に分けた。1つの群は対照としてPBSを投与し、もう1つの群はTA99(200μg)を含むTGFRt15-TGFRs(3mg/kg)を皮下投与した。免疫療法処理後4日目にマウスを屠殺した。腫瘍浸潤免疫細胞を決定するために、コラゲナーゼ消化によって腫瘍組織を単一細胞懸濁液に解離した。単一細胞懸濁液をFicoll-Paque培地に重層し、続いて密度勾配遠心分離を行ってリンパ球及び腫瘍細胞を分離した。細胞をゆっくり加速し、ブレークをオフにして、20℃で1000g、20分間遠心分離した。遠心分離後、Ficoll-Paqueは2つの層を明確に分離する。TILは、培地及びFicoll-Paqueの間の界面に見られるが、ペレットは腫瘍細胞で構成されている。TILを界面から慎重に取り外し、完全なRPMI培地で洗浄した。洗浄後、RBCを室温で5分間ACK緩衝液に溶解した。残りの細胞を、FACS緩衝液(1×PBS(Hyclone)、0.5%BSA(EMD Millipore)及び0.001%アジ化ナトリウム(Sigma)を含む)中で洗浄した。腫瘍内の異なる種類の免疫細胞を評価するために、細胞表面のCD3、CD45、CD8、及びNK1.1(BioLegend)に特異的な抗体で細胞を室温で30分間染色した。表面染色後、細胞を、FACS緩衝液(0.5%BSA(EMD Millipore)及び0.001%アジ化ナトリウム(Sigma)を含む1×PBS(Hyclone))中で洗浄した(1500RPM、室温で5分間)。2回洗浄した後、細胞を固定緩衝液に再懸濁した。固定後、細胞を洗浄し、4℃で20分間透過処理緩衝液(Invitrogen)で処理した後、透過処理緩衝液(Invitrogen)で洗浄した。次いで、細胞を増殖のための細胞内マーカー(Ki67)について室温で30分間染色した。2回洗浄した後、細胞をフローサイトメトリー(Celesta-BD Bioscience)によって分析した。 To determine whether chemotherapy-induced senescent tumor cells are reduced by immunotherapy in vivo, B16F10 parental melanoma cells (0.75×10 6 ) were mixed with B16F10-GFP-SNC cells (0.75×10 6 ). and injected the cell mixture subcutaneously in C57BL/6 mice. Mice were also injected with B16F10 and B16F10-GFP cells as controls. B16F10 parental cells grow to form tumors and B16F10-GFP-SNC cells become part of the tumor microenvironment. When tumors reached approximately 350 mm 3 , mixed tumor-bearing mice were divided into two groups. One group received PBS as a control and the other group received subcutaneous TGFRt15-TGFRs (3 mg/kg) containing TA99 (200 μg). Mice were sacrificed 4 days after immunotherapy treatment. To determine tumor-infiltrating immune cells, tumor tissue was dissociated into single cell suspensions by collagenase digestion. Single cell suspensions were layered onto Ficoll-Paque medium followed by density gradient centrifugation to separate lymphocytes and tumor cells. Cells were centrifuged at 1000 g for 20 minutes at 20° C. with slow acceleration and break off. After centrifugation, Ficoll-Paque clearly separates the two layers. TILs are found at the interface between medium and Ficoll-Paque, while the pellet is composed of tumor cells. TILs were carefully removed from the interface and washed with complete RPMI medium. After washing, RBCs were lysed in ACK buffer for 5 minutes at room temperature. The remaining cells were washed in FACS buffer containing 1×PBS (Hyclone), 0.5% BSA (EMD Millipore) and 0.001% sodium azide (Sigma). To assess different types of immune cells within the tumor, cells were stained with antibodies specific for cell surface CD3, CD45, CD8, and NK1.1 (BioLegend) for 30 minutes at room temperature. After surface staining, cells were washed in FACS buffer (1×PBS (Hyclone) containing 0.5% BSA (EMD Millipore) and 0.001% sodium azide (Sigma)) (1500 RPM, 5 minutes at room temperature). minutes). After two washes, cells were resuspended in fixation buffer. After fixation, cells were washed and treated with permeabilization buffer (Invitrogen) for 20 min at 4° C. followed by washing with permeabilization buffer (Invitrogen). Cells were then stained for an intracellular marker for proliferation (Ki67) for 30 minutes at room temperature. After washing twice, cells were analyzed by flow cytometry (Celesta-BD Bioscience).
図245に示されるように、TGFRt15-TGFRs+TA99処理後の腫瘍において、CD8+T細胞及びナチュラルキラー(NK)細胞のパーセンテージは、対照と比較して、処理後4日後に増加した。これらの結果は、TGFRt15-TGFRsが、腫瘍中のCD8+T細胞及びNK細胞の浸潤を刺激することができることを実証している。Ki67マーカーで測定すると、CD8+T細胞及びNK免疫細胞の両方が腫瘍内で増殖することもできた。 As shown in FIG. 245, in tumors after TGFRt15-TGFRs+TA99 treatment, the percentage of CD8 + T cells and natural killer (NK) cells increased after 4 days of treatment compared to controls. These results demonstrate that TGFRt15-TGFRs can stimulate the infiltration of CD8 + T cells and NK cells in tumors. Both CD8 + T cells and NK immune cells were also able to proliferate within the tumor as measured by the Ki67 marker.
化学療法誘発性老化腫瘍細胞がインビボで免疫療法によって低減するかどうかを決定するために、B16F10親黒色腫細胞(0.75x106)を、B16F10-GFP-SNC細胞(0.75x106)と混合し、C57BL/6マウスにおいて細胞混合物を皮下注射した。マウスにも、対照としてB16F10及びB16F10-GFP細胞を注射した。B16F10親細胞は成長して腫瘍を形成し、B16F10-GFP-SNC細胞は腫瘍微小環境の一部になる。腫瘍が約350mm3に達したとき、混合腫瘍担持マウスを2群に分けた。1つの群は対照としてPBSを投与し、もう1つの群はTA99(200μg)を含むTGFRt15-TGFRs(3mg/kg)を皮下投与した。免疫療法後4日目及び10日目にマウスを屠殺した。腫瘍内の腫瘍浸潤免疫細胞及びGFP陽性細胞を決定するために、腫瘍組織は、コラゲナーゼ消化によって単一細胞懸濁液に解離した。腫瘍細胞のフローサイトメトリー分析(図246A)は、免疫療法処理を受けたマウスが、PBS対照群と比較して、処理後4日目及び10日目でより少ない数のGFP陽性細胞を示したことを示した。腫瘍細胞を24ウェルプレートに播種し、蛍光顕微鏡で評価した(図246B)。
To determine whether chemotherapy-induced senescent tumor cells are reduced by immunotherapy in vivo, B16F10 parental melanoma cells (0.75×10 6 ) were mixed with B16F10-GFP-SNC cells (0.75×10 6 ). and injected the cell mixture subcutaneously in C57BL/6 mice. Mice were also injected with B16F10 and B16F10-GFP cells as controls. B16F10 parental cells grow to form tumors and B16F10-GFP-SNC cells become part of the tumor microenvironment. When tumors reached approximately 350 mm 3 , mixed tumor-bearing mice were divided into two groups. One group received PBS as a control and the other group received subcutaneous TGFRt15-TGFRs (3 mg/kg) containing TA99 (200 μg). Mice were sacrificed on
顕微鏡画像はまた、対照PBS処理群と比較して、免疫療法処理マウスの腫瘍におけるGFP陽性細胞が少ないことを示した。腫瘍におけるGFP発現は、化学療法によって誘導されたB16F10-GFP老化細胞と関連しているため、免疫療法治療後のGFP発現の低減は、担腫瘍マウスにおける老化腫瘍細胞の除去に成功したことを示す。 Microscopic images also showed fewer GFP-positive cells in the tumors of immunotherapy-treated mice compared to the control PBS-treated group. Since GFP expression in tumors is associated with chemotherapy-induced B16F10-GFP senescent cells, reduction of GFP expression after immunotherapy treatment indicates successful elimination of senescent tumor cells in tumor-bearing mice. .
実施例113:組織ELISAによる、シスプラチン及びTGFRt15-TGFRsによる処理による腎損傷の誘発後の腎臓におけるTGFβレベル
マウスの腎臓は、シスプラチンによる腎障害の誘発及びTGFRt15-TGFRsによる処理後の老化マーカーTGFβのタンパク質レベルの変化を評価するために収集された。8週齢のC57BL/6マウスをJackson Laboratoryから購入した。マウスは、温度及び光が制御された環境で飼育された。マウスにシスプラチン(5mg/kg、腹腔内)を毎週3週間注射して、腎障害を誘導した。シスプラチンの1週間後、マウスに、PBS又はTGFRt15-TGFRs(3mg/kg)を処理した(n=8/群)。マウスを免疫療法処理の30日後に安楽死させ、腎臓を収集し、1.7mLエッペンドルフチューブ内の液体窒素で保存した。試料を、0.3mLの抽出緩衝液(Abcam)でホモジナイザーを使用して均質化した。均質化した組織を新たなエッペンドルフチューブに移した。均質化された組織のタンパク質レベルを、BCA Proteinアッセイキット(Pierce)を使用して定量化した。マウスTGFβ ELISA(R&D System)を、200μgの組織で実施した。TGFβの濃度を、組織1ミリグラム当たりで計算した。
Example 113: TGFβ Levels in Kidneys After Induction of Renal Injury by Treatment with Cisplatin and TGFRt15-TGFRs by Tissue ELISA. Collected to assess changes in levels. Eight-week-old C57BL/6 mice were purchased from Jackson Laboratory. Mice were housed in a temperature and light controlled environment. Mice were injected with cisplatin (5 mg/kg, ip) weekly for 3 weeks to induce renal injury. One week after cisplatin, mice were treated with PBS or TGFRt15-TGFRs (3 mg/kg) (n=8/group). Mice were euthanized 30 days after immunotherapy treatment and kidneys were collected and stored in liquid nitrogen in 1.7 mL Eppendorf tubes. Samples were homogenized with 0.3 mL of extraction buffer (Abcam) using a homogenizer. The homogenized tissue was transferred to a new Eppendorf tube. Protein levels in homogenized tissues were quantified using the BCA Protein assay kit (Pierce). A mouse TGFβ ELISA (R&D System) was performed on 200 μg of tissue. Concentrations of TGFβ were calculated per milligram of tissue.
図247に示されるように、TGFβレベルは、TGFRt15-TGFRsで処理されたマウスの腎臓において、PBS対照群と比較して減少した。これらの結果は、TGFRt15-TGFRs処理が、化学療法処理マウスの組織におけるTGFβレベルを低減させる上で長期持続する活性を提供できることを示している。 As shown in Figure 247, TGFβ levels were decreased in the kidneys of mice treated with TGFRt15-TGFRs compared to the PBS control group. These results indicate that TGFRt15-TGFRs treatment can provide long-lasting activity in reducing TGFβ levels in tissues of chemotherapy-treated mice.
実施例114:マウスにおけるTGFRt15-TGFRsの皮下投与の毒性
TGFRt15-TGFRsの用量依存的な毒物学的影響を更に評価するために、雌C57BL/6マウス(N=3/群)にPBS又はTGFRt15-TGFRsを3、10、50及び200mg/kgで1回又は2回(2週間ごとに)皮下投与した。動物は、試験薬物関連毒性の徴候、試験期間中の体重変化、及び投与後7日目の血液学及び血清化学パラメータについてモニターされた。200mg/kgのTGFRt15-TGFRsを投与されたマウスは、最初の注射の4日後(研究日(SD)0)に始まり、SD6~9の間で最下点に達した後、SD11までに投与前のレベルに戻る前に、有意な体重減少を示した(図248A)。SD9で200mg/kg群の1匹のマウスで死亡が観察された。体重又は他の臨床徴候に対する明らかな処理による影響は、他の投与群でも、200mg/kgでの2回目のTGFRt15-TGFRs投与後でも存在しなかった。TGFRt15-TGFRsの1回又は2回の投与後、脾臓重量は用量依存的に増加した(図248B)。PBS群と比較して、マウスはTGFRt15-TGFRsの単回200mg/kg投与の7日後にWBC数が25倍増加したことを示し、2回目の200mg/kg投与の7日後も5倍高いままであった(図248C、表3及び4)。WBCサブセット分析では、200mg/kg群のSD7で絶対リンパ球数が16倍増加し、好中球、単球、好酸球、及び好塩基球数が50倍以上増加したことが示された。これらの変化は、より低いTGFRt15-TGFRsの用量レベルでは観察されなかったが、IL-15/IL-15Rα複合体を皮下処理で処理したC57BL/6マウスで報告されたものと同様であった(Liu et al.,Cytokine 107:105-112,2018)。他の血液学及び血清化学パラメータは、TGFRt15-TGFRs及びPBS処理動物で類似しており、一般にC57BL/6マウスの予想範囲内であった(表3及び4)。TGFRt15-TGFRsを介した効果は、初回投与の7日後に最大となり、2回目の投与後に低減し、これは、IL-15/IL-15Rαの反復投与後のマウスにおける免疫応答の減少を示す以前の研究と一致している(Elpek et al.,PNAS107:21647-21652,2010;Frutoso et al.,J Immunol 201:493-506,2018)。全体として、TGFRt15-TGFRsは、50mg/kgまでの用量レベルでC57BL/6マウスに十分に許容された。
Example 114: Toxicity of Subcutaneous Administration of TGFRt15-TGFRs in Mice To further evaluate the dose-dependent toxicological effects of TGFRt15-TGFRs, female C57BL/6 mice (N=3/group) were injected with PBS or TGFRt15- TGFRs were administered subcutaneously once or twice (every two weeks) at 3, 10, 50 and 200 mg/kg. Animals were monitored for signs of study drug-related toxicity, body weight changes during the study, and hematology and serum chemistry parameters on
(表3)TGFRt15-TGFRsの単回投与後の試験7日目のC57BL/6マウスの血液学及び血清化学パラメータ


(表4)TGFRt15-TGFRsの2回投与後の試験21日目のC57BL/6マウスの血液学及び血清化学パラメータ


実施例115:マウスにおけるTGFRt15-TGFRs及びTGFRt15*-TGFRsによるTGF-βの隔離
雌C57BL/6マウスにPBS又は3mg/kgのTGFRt15-TGFRs又はTGFRt15*-TGFRsを皮下注射し、処理後の様々な時点で血漿を収集した。TGF-β1及びTGF-β2の血漿レベルを、TGFβ3-Plexアッセイ(Eve Technologies,Calgary,AL,Canada)を使用して決定した。TGFRt15-TGFRs及びTGFRt15*-TGFRsは、処理の2日後にC57BL/6マウスにおいて血漿TGF-β1及びTGF-β2レベルを有意に減少させることが見出され(図249)、これらの融合タンパク質のTGFβRIIドメインの活性と一致した。
Example 115: Sequestration of TGF-β by TGFRt15-TGFRs and TGFRt15*-TGFRs in Mice Female C57BL/6 mice were injected subcutaneously with PBS or 3 mg/kg of TGFRt15-TGFRs or TGFRt15*-TGFRs and treated with various doses. Plasma was collected at time points. Plasma levels of TGF-β1 and TGF-β2 were determined using the TGFβ3-Plex assay (Eve Technologies, Calgary, Ala., Canada). TGFRt15-TGFRs and TGFRt15*-TGFRs were found to significantly decrease plasma TGF-β1 and TGF-β2 levels in C57BL/6 mice after 2 days of treatment (FIG. 249), suggesting that TGFβRII of these fusion proteins consistent with domain activity.
実施例116:インビボ及びインビトロでの免疫細胞代謝に対するTGFRt15-TGFRs及びTGFRt15*-TGFRsの効果
免疫細胞代謝に対する処理媒介効果を評価するために、PBS、TGFRt15-TGFR、TGFRt15*-TGFR、又はIL-15/IL-15R(IL15SA)投与の4日後にマウスから単離された脾細胞で細胞外フラックスアッセイを実施した。マウス脾細胞の細胞外フラックスアッセイを、XFp分析器(Seahorse Bioscience)を使用し実施した。予想通り、TGFRt15-TGFRs及びIL-15は、単離された脾細胞の解糖能力(ECAR)(図250A)及びミトコンドリア呼吸能力(OCR)(図250B)の割合を用量レベル依存的に増加させた。インビボTGFRt15*-TGFRs処理は、脾細胞のECAR及びOCRも増加させた。この現象は、未処理のC57BL/6マウスの脾細胞をインビトロでTGFRt15*-TGFRsと4日間インキュベートした場合には観察されなかった。TGFRt15-TGFRsのみが(TGFRt15*-TGFRsではなく)、生理学的に適切な濃度でインビトロで脾細胞ECAR及びOCRを増加させることができた(図251A~251B)。これは、TGFRt15-TGFRsのIL-15ドメイン及びTGFβRIIドメインの両方が、インビボで免疫細胞の代謝を刺激する役割を果たしていることを示唆している。
Example 116 Effects of TGFRt15-TGFRs and TGFRt15*-TGFRs on Immune Cell Metabolism In Vivo and In Vitro Extracellular flux assays were performed on splenocytes isolated from
実施例117:C57BL/6マウスにおけるB16F10黒色腫に対するTGFRt15-TGFRs及びTGFRt15*-TGFRsの抗腫瘍効果
TGFRt15-TGFRs及びTGFRt15*-TGFRsの抗腫瘍効果を評価するために、マウスB16F10腫瘍モデルが選択された。これは、攻撃性が高く、免疫原性が低く、免疫浸潤がなく、その成長に役割を果たすTGF-βを発現し、サイトカイン及びチェックポイント遮断免疫療法に耐性があるためである。B16F10黒色腫細胞(5x105細胞)(CRL-6475、ATCC)をC57BL/6マウスに皮下注射し、続いてPBS、TGFRt15-TGFRs(3又は20mg/kg)又はTGFRt15*-TGFRs(3又は20mg/kg)腫瘍移植後1日目と4日目に皮下注射した。腫瘍体積を隔日で測定し、4000mm3以上の腫瘍を有するマウスをIACUC規則に従って屠殺した。研究期間中、マウスの生存率も評価された。SD15を通して比較すると(すなわち、動物死亡前)、20mg/kgのTGFRt15-TGFRs又はTGFRt15*-TGFRsによる処理は、PBS処理マウスで観察されたよりも有意に遅い腫瘍増殖をもたらした(図252A)。20mg/kgのTGFRt15-TGFRsで処理した腫瘍担持マウスもまた、3mg/kgのTGFRt15-TGFRs及びPBS処理群と比較した場合、延長された生存を示した(図252B)。これらの結果は、TGFRt15-TGFRs及びTGFRt15*-TGFRsが固形B16F10黒色腫腫瘍に対して抗腫瘍活性を有し、二機能性TGFRt15-TGFRs複合体がより大きな有効性を示すことを示す。したがって、TGFβRIIドメイン及びIL-15/IL-15RαSuドメインの両方が、B16F10腫瘍に対するTGFRt15-TGFRsを介した活性において役割を果たす。
Example 117: Antitumor Effects of TGFRt15-TGFRs and TGFRt15*-TGFRs Against B16F10 Melanoma in C57BL/6 Mice To evaluate the antitumor effects of TGFRt15-TGFRs and TGFRt15*-TGFRs , a mouse B16F10 tumor model was selected. rice field. It is highly aggressive, poorly immunogenic, lacks immune infiltration, expresses TGF-β that plays a role in its growth, and is resistant to cytokine and checkpoint blocking immunotherapy. B16F10 melanoma cells (5×10 5 cells) (CRL-6475, ATCC) were injected subcutaneously into C57BL/6 mice followed by PBS, TGFRt15-TGFRs (3 or 20 mg/kg) or TGFRt15*-TGFRs (3 or 20 mg/kg). kg) injected subcutaneously on
TGFRt15-TGFRs処理は、インビボでNK細胞及びT細胞の数を大幅に増加させることができる。これらの免疫細胞がTGFRt15-TGFRsを介した抗腫瘍効果に関与しているかどうかを決定するために、TGFRt15-TGFRs処理の前に、腫瘍担持マウスにおいてCD8+T細胞及びNK1.1+細胞のAb免疫除去を実施した。NK1.1+細胞の枯渇(単独で、又はCD8+T細胞の枯渇と組み合わせて)は、B16F10腫瘍担持マウスにおいて処理後の最初の2週間の間にTGFRt15-TGFRsの抗腫瘍効果を排除することが見出された(図252C)が、NK1.1+細胞枯渇又はCD8+T細胞枯渇のいずれかが、TGFRt15-TGFRsで見られる生存利益を低減させた(図252D)。これらの所見と一致して、TGFRt15-TGFRs処理は、B16F10腫瘍へのNK細胞及びCD8+T細胞浸潤の増加も促進した(図252E)。これらの結果は、CD8+T細胞とNK細胞の両方が、C57BL/6マウスの黒色腫腫瘍細胞に対するTGFRt15-TGFRsを介した活性において主要な役割を果たしているという結論を支持している。 TGFRt15-TGFRs treatment can significantly increase the number of NK and T cells in vivo. To determine whether these immune cells are involved in TGFRt15-TGFRs-mediated anti-tumor effects, we tested CD8 + T cells and NK1.1 + cells in tumor-bearing mice prior to TGFRt15-TGFRs treatment with Ab Immunodepletion was performed. Depletion of NK1.1 + cells (alone or in combination with depletion of CD8 + T cells) abrogates the anti-tumor effect of TGFRt15-TGFRs during the first two weeks after treatment in B16F10 tumor-bearing mice (FIG. 252C), but either NK1.1 + cell depletion or CD8 + T cell depletion reduced the survival benefit seen with TGFRt15-TGFRs (FIG. 252D). Consistent with these findings, TGFRt15-TGFRs treatment also promoted increased NK cell and CD8 + T cell infiltration into B16F10 tumors (FIG. 252E). These results support the conclusion that both CD8 + T cells and NK cells play a major role in TGFRt15-TGFRs-mediated activity against melanoma tumor cells in C57BL/6 mice.
実施例118:TGFRt15-TGFRsは、db/dbマウスにおいてグルコース制御を改善した
5週齢の雄のBKS.Cg-Dock7m+/+Leprdb/J(db/db)マウス(Jackson Lab)に標準的な固形飼料を与え、標準的な条件で維持した。マウス(n=5/群)は、試験開始から6週目及び12週目、PBS(対照群)又はTGFRt15-TGFRs(3mg/kg)(処理群)のいずれかの皮下注射を受けた。1回目投与から3週間後に空腹時血糖及びインスリンをチェックした。TGFRt15-TFGRs処理後、対照と比較して空腹時血糖は有意に低減したが(図253A)、血中インスリンレベルは変化しなかった(図253B)。
Example 118: TGFRt15-TGFRs improved glucose control in db/db mice, 5-week-old male BKS. Cg-Dock7m+/+Leprdb/J (db/db) mice (Jackson Lab) were fed standard chow and maintained under standard conditions. Mice (n=5/group) received subcutaneous injections of either PBS (control group) or TGFRt15-TGFRs (3 mg/kg) (treatment group) at 6 and 12 weeks from the start of the study. Fasting blood glucose and insulin were checked 3 weeks after the first administration. After TGFRt15-TFGRs treatment, fasting blood glucose was significantly reduced compared to controls (FIG. 253A), but blood insulin levels were unchanged (FIG. 253B).
実施例119:TGFRt15-TGFRsは大幅にダウンレギュレートされた老化指数及びSASP指数
5週齢の雄BKS.Cg-Dock7m+/+Leprdb/J(db/db)マウスに、標準的な飼料食餌を与え、飲料水を自由に受けた。6週齢で、マウスは無作為に対照群及び処理群に割り当てられた(n=5/群)。処理群は、研究開始から6週目及び12週目に3mg/kgで皮下注射によりTGFRt15-TGFRsを投与されたが、一方で、対照群はビヒクル(PBS)のみを投与された。試験終了時(2回目の投与から4週間後)、マウスを安楽死させ、膵臓を収集した。膵臓の半分をTRIzol試薬(Invitrogen)で均質化し、全組織RNAをRNeasyミニキット(Qiagen)で精製した。cDNAの合成を、QuantiTect逆転写キット(Qiagen)を使用して実施し、定量的PCRを、製造業者のプロトコルに従う比較閾値サイクル法に従って、SsoAdvanced(商標)Universal SYBR(登録商標)Green Supermix(BioRad)及びQuantiStudio 3リアルタイムPCRシステム(Applied Biosystems)を使用して実施した。増幅反応は2回実施し、蛍光曲線をQuantiStudio 3リアルタイムPCRシステムに付属のソフトウェアで分析した。ハウスキーピング遺伝子の18sリボソームRNAを内因性対照基準として使用した。18s rRNAに対する各標的mRNAの発現を、Ctに基づいて2-Δ(ΔCt)として計算し、式中、ΔCt=Cttarget-Ct18Sである。図254Aに示されるように、db/dbマウスのTGFRt15-TGFRs処理は、対照群と比較した場合、老化遺伝子指数のp16、p21、Igfr1、及びBamb1、並びにSASP遺伝子指数のIL-1α、IL-6、MCP-1、及びTNFαについての膵臓遺伝子発現の低減をもたらした。一般に、SASP指数及び老化指数の遺伝子の膵臓発現は、対照と比較してTGFRt15-TGFRs処理後に有意に低減したが、ベータ細胞指数の膵臓遺伝子発現は、TGFRt15-TGFRs及びPBS処理db/dbでは有意に変化しなかった(図254B、254C、254D)。データは、TGFRt15-TGFRsがdb/dbマウスの膵臓の老化細胞及びSASP因子を低減させる強力な老化細胞除去特性及び老化細胞阻害活性を有していることを示唆している。
Example 119: TGFRt15-TGFRs significantly downregulated senescence index and SASP index in 5-week-old male BKS. Cg-Dock7m+/+Leprdb/J (db/db) mice were fed a standard chow diet and had access to drinking water ad libitum. At 6 weeks of age, mice were randomly assigned to control and treatment groups (n=5/group). The treatment group received TGFRt15-TGFRs by subcutaneous injection at 3 mg/kg at
実施例120:TGFRt15-TGFRsは膵臓ベータ細胞の老化細胞を低減させた
5週齢の雄BKS.Cg-Dock7m+/+Leprdb/J(db/db)マウスに、標準的な飼料食餌(Irradiated 2018 Teklad global 18% protein rodent diet,Envigo)を与え、飲料水を自由に受けた。6週齢で、マウスは無作為に対照群及び処理群に割り当てられた(n=5/群)。処理群は、研究開始から6週目及び12週目に3mg/kgで皮下注射によりTGFRt15-TGFRsを投与されたが、一方で、対照群はビヒクル(PBS)のみを投与された。試験終了時(2回目の投与から4週間後)、マウスを安楽死させ、膵臓をまとめて取り出し、4%ホルムアルデヒド(0.1Mリン酸緩衝液中4%ホルムアルデヒド、PBSpH7.4)で浸漬固定し、更に処理するまで4℃で保存した。解剖した膵臓をパラフィン処理し、包埋し、切片にし、各ブロックから3つの10mm切片(150mm離れた)を切り取り、合計で各動物からの膵臓全体の系統的で均一な無作為試料を表す。
Example 120: TGFRt15-TGFRs reduced pancreatic beta-cell senescent cells in 5-week-old male BKS. Cg-Dock7m+/+Leprdb/J (db/db) mice were fed a standard chow diet (Irradiated 2018 Teklad global 18% protein rodent diet, Envigo) and received drinking water ad libitum. At 6 weeks of age, mice were randomly assigned to control and treatment groups (n=5/group). The treatment group received TGFRt15-TGFRs by subcutaneous injection at 3 mg/kg at
マルチスペクトル画像を、Akoya Vectra Polaris装置を使用して実施した。この計測器は、ホルマリン固定パラフィン包埋生検切片における組織浸潤の表現型分析、定量化、及び空間関係分析を可能にする。膵臓のインスリン+島領域におけるp21のレベルを定量化するために、ホルマリン固定パラフィン包埋組織切片を、Akoyaによって提供され、HIMSRによって日常的に実施される標準プロトコルに従って、特異的な一次抗体で連続的に染色した。簡潔には、切片を脱パラフィンし、抗原回復緩衝液で熱処理し、遮断し、インスリン(番号4590、Cell Signaling Technology)及びp21(EPR362、Abcam)に対するウサギ一次抗体、続いてホースラディッシュペルオキシダーゼ(HRP)結合二次抗体ポリマー(抗ウサギ)とともにインキュベートし、HRP反応性OPAL蛍光試薬(インスリンの場合はOPAL-520、p21の場合はOPAL-570、Akoya)は、TSA化学を使用して各HRP分子のすぐ周囲の組織に色素を沈着させる。その後の染色ステップで蛍光色素が更に沈着するのを防ぐために、各染色の間に切片を剥がし、抗原検索緩衝液(インスリンの場合はクエン酸緩衝液、p21の場合はEDTA緩衝液)で熱処理を行った。切片全体のスキャンは、Akoya Vectra Polaris装置で、解像度0.5ミクロンの20倍の対物レンズを使用して収集された。3つのカラー画像をinFormソフトウェア(Akoya)で分析して、隣接する蛍光色素を分離し、自己蛍光を差し引き、組織のインスリン+領域をセグメント化し、細胞の頻度及び位置を比較し、細胞の細胞質及び核領域をセグメント化し、細胞マーカー発現による浸潤細胞の表現型化を行った。 Multispectral imaging was performed using an Akoya Vectra Polaris instrument. This instrument allows phenotypic analysis, quantification, and spatial relationship analysis of tissue invasion in formalin-fixed, paraffin-embedded biopsy sections. To quantify levels of p21 in insulin+ islet regions of the pancreas, formalin-fixed, paraffin-embedded tissue sections were serially treated with specific primary antibodies according to standard protocols provided by Akoya and routinely performed by HIMSR. specifically dyed. Briefly, sections were deparaffinized, heat treated with antigen retrieval buffer, blocked, rabbit primary antibodies against insulin (#4590, Cell Signaling Technology) and p21 (EPR362, Abcam) followed by horseradish peroxidase (HRP). Incubated with a conjugated secondary antibody polymer (anti-rabbit), HRP-reactive OPAL fluorescent reagents (OPAL-520 for insulin, OPAL-570 for p21, Akoya) were labeled for each HRP molecule using TSA chemistry. It pigments the tissue in the immediate surroundings. Sections were stripped and heat treated with antigen retrieval buffer (citrate buffer for insulin, EDTA buffer for p21) between each staining to prevent further deposition of fluorescent dye in subsequent staining steps. gone. Whole-section scans were collected on an Akoya Vectra Polaris instrument using a 20× objective with a resolution of 0.5 microns. Three color images were analyzed with inForm software (Akoya) to separate adjacent fluorochromes, subtract autofluorescence, segment insulin + regions of tissue, compare cell frequency and location, and analyze cell cytoplasm and We segmented the nuclear region and phenotyped the infiltrating cells by cell marker expression.
図255A~255Dに示されるように、対照群の膵臓ではp21陽性の老化細胞(OPAL-570)は、インスリン陽性の膵島ベータ細胞(OPAL-520)においてより多く蓄積し(図255A)、TGFRt15-TGFRs処理群の膵臓でこれらの老化細胞は低減した(図255B)。インスリン陽性膵島細胞は、対照群と比較して、TGFRt15-TGFRs処理群で有意に増加した(p=0.0278、図255C)。p21陽性老化ベータ細胞(インスリン陽性)は、対照群と比較してTGFRt15-TGFRs処理群で低減したが、差は統計的に有意ではなかった(図255D)。全体として、データは、TGFR15-TGFRsが老化細胞を除去する老化細胞除去活性を有し、db/dbマウスの膵臓で正常な機能性膵島ベータ細胞の回復を促進することを示唆している。 As shown in Figures 255A-255D, p21-positive senescent cells (OPAL-570) accumulated more in insulin-positive islet beta cells (OPAL-520) in the control pancreas (Figure 255A), indicating that TGFRt15- These senescent cells were reduced in the pancreas of the TGFRs-treated group (Fig. 255B). Insulin-positive islet cells were significantly increased in the TGFRt15-TGFRs treated group compared to the control group (p=0.0278, FIG. 255C). p21-positive senescent beta cells (insulin positive) were reduced in the TGFRt15-TGFRs treated group compared to the control group, but the difference was not statistically significant (FIG. 255D). Overall, the data suggest that TGFR15-TGFRs have senolytic activity to eliminate senescent cells and promote restoration of normal functional islet beta cells in the pancreas of db/db mice.
実施例121:TGFRt15-TGFRsは、NK、NKT、及びCD8+T細胞を増加させることによって膵臓ベータ細胞の老化細胞を低減させた
5週齢の雄BKS.Cg-Dock7m+/+Leprdb/J(db/db)マウスに、標準的な飼料食餌(Irradiated 2018 Teklad global 18% protein rodent diet,Envigo)を与え、飲料水を自由に受けた。6週齢で、マウスは無作為に対照群及び処理群に割り当てられた(n=5/群)。処理群は、研究開始から6週目及び12週目に3mg/kgで皮下注射によりTGFRt15-TGFRsを投与されたが、一方で、対照群はビヒクル(PBS)のみを投与された。
Example 121: TGFRt15-TGFRs reduced pancreatic beta-cell senescent cells by increasing NK, NKT, and CD8+ T cells in 5-week-old male BKS. Cg-Dock7m+/+Leprdb/J (db/db) mice were fed a standard chow diet (Irradiated 2018 Teklad global 18% protein rodent diet, Envigo) and received drinking water ad libitum. At 6 weeks of age, mice were randomly assigned to control and treatment groups (n=5/group). The treatment group received TGFRt15-TGFRs by subcutaneous injection at 3 mg/kg at
1回目の投与処理の4日後、血液を収集し、全血球(50mL)をACK(アンモニウム-塩化物-カリウム)溶解緩衝液で処理して、赤血球を溶解した。次いで、リンパ球をPE-Cy7-抗-CD3、BV605-抗-CD45、PerCP-Cy5.5-抗-CD8a、BV510-抗-CD4、及びAPC-抗-NKp46抗体(全てBioLegendの抗体)で染色して、T細胞、NKT細胞、及びNK細胞の集団を評価した。図256A~256Cに示されるように、TGFRt15-TGFRsでの処理後、db/dbマウスの血液中のCD8+T細胞、CD3+NKP46+NKT細胞、及びCD3-NKP46+NK細胞のパーセンテージを、PBS処理マウスと比較して増加した。 Four days after the first dose treatment, blood was collected and whole blood cells (50 mL) were treated with ACK (ammonium-chloride-potassium) lysis buffer to lyse red blood cells. Lymphocytes were then stained with PE-Cy7-anti-CD3, BV605-anti-CD45, PerCP-Cy5.5-anti-CD8a, BV510-anti-CD4, and APC-anti-NKp46 antibodies (all from BioLegend). to assess T cell, NKT cell, and NK cell populations. As shown in Figures 256A-256C, after treatment with TGFRt15-TGFRs, the percentages of CD8+ T cells, CD3 + NKP46 + NKT cells, and CD3 - NKP46 + NK cells in the blood of db/db mice were compared with those of PBS-treated mice. increased compared to
実施例122:TGFRt15-TGFRsの投与後のカニクイザルの末梢血における免疫細胞サブセットの表現型解析
カニクイザル(1群当たり5M:5F)を、研究の1日目及び15日目に1、3、又は10mg/kgのPBS(ビヒクル)又はTGFRt15-TGFRsで皮下処理した。血液を、処理前日(1日目)及び処理後5、22、及び29日目に収集した。PBMCを調製し、蛍光標識抗体のパネルで染色して、フローサイトメトリーによってB細胞、NK細胞、NK-T細胞、Treg細胞、CD4+及びCD8+T細胞の表現型を評価した。図257は、TGFRt15-TGFRsの投与により、処理後5日目にKi67+NK細胞、NK-T細胞、Treg細胞及びCD4+及びCD8+T細胞のパーセンテージが有意に増加したことを示す。これらの発見は、TGFRt15-TGFRs処理が非ヒト霊長類でこれらのリンパ球サブセットの増殖を誘導したことを示す。B細胞におけるKi67発現に対する処理効果は観察されなかった。
Example 122 Phenotyping of Immune Cell Subsets in Peripheral Blood of Cynomolgus Monkeys Following Administration of TGFRt15-TGFRs /kg of PBS (vehicle) or TGFRt15-TGFRs subcutaneously. Blood was collected the day before treatment (Day 1) and 5, 22, and 29 days after treatment. PBMC were prepared and stained with a panel of fluorescently labeled antibodies to assess the phenotype of B cells, NK cells, NK-T cells, Treg cells, CD4 + and CD8 + T cells by flow cytometry. Figure 257 shows that administration of TGFRt15-TGFRs significantly increased the percentage of Ki67 + NK cells, NK-T cells, Treg cells and CD4 + and CD8 + T cells 5 days after treatment. These findings indicate that TGFRt15-TGFRs treatment induced proliferation of these lymphocyte subsets in non-human primates. No treatment effect on Ki67 expression in B cells was observed.
実施例123:TGFRt15-TGFRsのIL-15免疫賦活及びTGF-βアンタゴニスト活性
6週齢(若齢)及び72週齢(老齢)のC57BL/6マウスに、PBS、TGFRt15-TGFRs(3mg/kg)又はTGFRt15*-TGFRs(3mg/kg)を単回投与で皮下注射した。処理後4日目にマウスを屠殺し、脾臓を収集した。脾細胞を解放するために、3ccシリンジの無菌ピストン/プランジャーの平らな後端で脾臓を破砕した。脾細胞を70μMセルストレーナーに通し、均質化して単一細胞懸濁液にした。RBCをACK溶解緩衝液で溶解し、脾細胞を洗浄してカウントした。脾細胞の解糖活性を測定するために、細胞を洗浄し、Seahorse培地に再懸濁し、4x106細胞/mLに再懸濁した。細胞を、解糖ストレス試験のために2mM L-グルタミンを補充したpH7.4のSeahorse XF RPMI培地中のCell-TakコーティングSeahorse Bioanalyzer XFe96培養プレート中に50μL/ウェルで播種した。細胞を37℃で30分間かけてプレートに付着させた。更に、130μLのアッセイ培地をプレートの各ウェルに(バックグラウンドウェルにも)添加した。プレートを37℃、非CO2インキュベーターで1時間インキュベートした。解糖ストレス試験では、キャリブレーションプレートには、Seahorseアッセイ培地で調製されたグルコース/オリゴマイシン/2DGの10倍溶液が含まれており、20μLのグルコース/オリゴマイシン/2DGが、一晩キャリブレーションされた細胞外フラックスプレートの各ポートに添加された。解糖ストレス試験は、細胞外酸性化速度(ECAR)に基づいており、解糖、解糖能力、及び解糖予備力を含む解糖機能の3つの重要なパラメータを測定する。完全なECAR分析は、非解糖酸性化(薬物なし)、解糖(10mMグルコース)、最大解糖誘導/解糖能力(2μMオリゴマイシン)、及び解糖予備(100mM 2-DG)の4つの段階で構成される。実験の最後に、データをGraph Pad Prismファイルとしてエクスポートした。XF解糖ストレス試験レポートジェネレーターは、WaveデータからXF細胞解糖ストレス試験のパラメータを自動的に計算した。Waveソフトウェア(Agilent)を使用してデータを分析した。
Example 123: IL-15 Immunostimulatory and TGF-β Antagonist Activity of TGFRt15-TGFRs In 6-week-old (young) and 72-week-old (old) C57BL/6 mice, PBS, TGFRt15-TGFRs (3 mg/kg) or TGFRt15*-TGFRs (3 mg/kg) were injected subcutaneously as a single dose. Mice were sacrificed 4 days after treatment and spleens were collected. The spleen was crushed with the flat back end of a sterile piston/plunger of a 3cc syringe to release the splenocytes. Splenocytes were passed through a 70 μM cell strainer and homogenized into a single cell suspension. RBCs were lysed with ACK lysis buffer and splenocytes were washed and counted. To measure splenocyte glycolytic activity, cells were washed, resuspended in Seahorse medium, and resuspended at 4×10 6 cells/mL. Cells were seeded at 50 μL/well in Cell-Tak coated Seahorse Bioanalyzer XFe96 culture plates in Seahorse XF RPMI medium pH 7.4 supplemented with 2 mM L-glutamine for glycolytic stress studies. Cells were allowed to attach to the plates for 30 minutes at 37°C. Additionally, 130 μL of assay medium was added to each well of the plate (also background wells). Plates were incubated for 1 hour at 37°C, non- CO2 incubator. For the glycolytic stress test, the calibration plate contained a 10x solution of glucose/oligomycin/2DG prepared in Seahorse assay medium and 20 μL of glucose/oligomycin/2DG was calibrated overnight. was added to each port of the extracellular flux plate. The glycolytic stress test is based on extracellular acidification rate (ECAR) and measures three key parameters of glycolytic function including glycolysis, glycolytic capacity, and glycolytic reserve. A complete ECAR assay was performed in four phases: non-glycolytic acidification (no drug), glycolytic (10 mM glucose), maximal glycolytic induction/glycolytic capacity (2 μM oligomycin), and glycolytic reserve (100 mM 2-DG). consists of stages. At the end of the experiment, data were exported as Graph Pad Prism files. The XF Glycolytic Stress Test Report Generator automatically calculated the parameters of the XF Cellular Glycolytic Stress Test from the Wave data. Data were analyzed using Wave software (Agilent).
図258に示されるように、TGFRt15-TGFRs処理後4日目に老齢マウスから単離された脾細胞は、PBS又はTGFRt15*-TGFRs処理群の脾細胞と比較して、基礎解糖、解糖能力、及び解糖予備率の増強を示した。老齢対照マウスの脾細胞の解糖機能は、若齢対照マウスよりも低かった。TGFRt15*-TGFRsによる若齢及び老齢マウスの処理は、脾細胞の解糖機能を増加させることができた。しかしながら、老齢マウスのTGFRt15-TGFRs処理は、脾細胞の基礎解糖率、解糖能力、及び解糖予備能を、TGFRt15-TGFRs処理した若齢マウスの脾細胞で観察されたレベルと同等のレベルまで増加させることができた。これらの発見は、TGFRt15-TGFRsのIL-15免疫刺激及びTGF-βアンタゴニスト活性が、老齢マウスの免疫細胞の代謝活性の低下を効果的に刺激し、若返らせることを示唆している。
As shown in FIG. 258, splenocytes isolated from
6週齢(若齢)及び72週齢(老齢)のC57BL/6マウスに、PBS、TGFRt15-TGFRs(3mg/kg)又はTGFRt15*-TGFRs(3mg/kg)を単回投与で皮下注射した。処理後4日目にマウスを屠殺し、脾臓を収集した。脾細胞を解放するために、3ccシリンジの無菌ピストン/プランジャーの平らな後端で脾臓を破砕した。脾細胞を70μMセルストレーナーに通し、均質化して単一細胞懸濁液にした。RBCをACK溶解緩衝液で溶解し、脾細胞を洗浄してカウントした。脾細胞のミトコンドリア呼吸を測定するために、細胞を洗浄し、Seahorse培地に再懸濁し、4x106細胞/mLに再懸濁した。細胞を、解糖ストレス試験のために2mM L-グルタミンを補充したpH7.4のSeahorse XF RPMI培地中のCell-TakコーティングSeahorse Bioanalyzer XFe96培養プレート中に50μL/ウェルで播種した。ミトコンドリアストレス試験では、細胞を、10mMグルコース及び2mM L-グルタミン補充したpH7.4のSeahorse XF RPMI培地に播種した。細胞を37℃で30分間かけてプレートに付着させた。更に、130μLのアッセイ培地をプレートの各ウェルに(バックグラウンドウェルにも)添加した。プレートを37℃、非CO2インキュベーターで1時間インキュベートした。ミトコンドリアストレス試験では、キャリブレーションプレートには、Seahorseアッセイ培地で調製された10倍のオリゴマイシン/FCCP/ロテノン溶液が含まれており、20μLのオリゴマイシン、FCCP、及びロテノンが、一晩キャリブレーションされた細胞外フラックスプレートの各ポートに添加された。酸素消費速度(OCR)を、XFe96 Extracellular Flux Analyzerを使用して測定した。完全なOCR分析は、基礎呼吸(薬物なし)、ATP関連呼吸/プロトン漏出(1.5μMオリゴマイシン)、最大呼吸(2μM FCCP)、及び予備呼吸(0.5μMロテノン)の4つの段階からなった。実験の最後に、データをGraph Pad Prismファイルとしてエクスポートした。XFミトコンドリアストレス試験レポートジェネレーターは、ExcelにエクスポートされたWaveデータからXFミトコンドリアストレス試験のパラメータを自動的に計算する。Waveソフトウェア(Agilent)を使用することによってデータを分析した。 Six-week-old (young) and 72-week-old (old) C57BL/6 mice were injected subcutaneously with PBS, TGFRt15-TGFRs (3 mg/kg) or TGFRt15*-TGFRs (3 mg/kg) in a single dose. Mice were sacrificed 4 days after treatment and spleens were collected. The spleen was crushed with the flat back end of a sterile piston/plunger of a 3cc syringe to release the splenocytes. Splenocytes were passed through a 70 μM cell strainer and homogenized into a single cell suspension. RBCs were lysed with ACK lysis buffer and splenocytes were washed and counted. To measure splenocyte mitochondrial respiration, cells were washed, resuspended in Seahorse medium, and resuspended at 4×10 6 cells/mL. Cells were seeded at 50 μL/well in Cell-Tak coated Seahorse Bioanalyzer XFe96 culture plates in Seahorse XF RPMI medium pH 7.4 supplemented with 2 mM L-glutamine for glycolytic stress studies. For mitochondrial stress tests, cells were seeded in Seahorse XF RPMI medium, pH 7.4, supplemented with 10 mM glucose and 2 mM L-glutamine. Cells were allowed to attach to the plates for 30 minutes at 37°C. Additionally, 130 μL of assay medium was added to each well of the plate (also background wells). Plates were incubated for 1 hour at 37°C in a non-CO2 incubator. For the mitochondrial stress test, the calibration plate contained a 10x oligomycin/FCCP/rotenone solution prepared in Seahorse assay medium and 20 μL of oligomycin, FCCP, and rotenone were calibrated overnight. was added to each port of the extracellular flux plate. Oxygen consumption rate (OCR) was measured using an XFe96 Extracellular Flux Analyzer. A complete OCR analysis consisted of four stages: basal respiration (no drug), ATP-related respiration/proton leak (1.5 μM oligomycin), maximal respiration (2 μM FCCP), and pre-respiration (0.5 μM rotenone). . At the end of the experiment, data were exported as Graph Pad Prism files. The XF Mitochondrial Stress Test Report Generator automatically calculates the parameters of the XF Mitochondrial Stress Test from Wave data exported to Excel. Data were analyzed by using Wave software (Agilent).
図259に示されるように、TGFRt15-TGFRs療法後4日目に老齢マウスから分離された脾細胞は、PBS又はTGFRt15*-TGFRs処理群の脾細胞と比較した場合、基礎呼吸、ATP関連呼吸、最大呼吸、及び予備能の増強を示した。TGFRt15*-TGFRsによる若齢及び老齢マウスの処理は、脾細胞のミトコンドリア呼吸を増加させることができた。しかしながら、老齢マウスのTGFRt15-TGFRs処理は、基礎解糖率、ATP関連呼吸、最大呼吸及び予備能の速度を増加させ、TGFRt15-TGFRs処理した若齢マウスの脾細胞で観察されるレベルと同等以上のレベルまで増加させることができた。これらの発見は、TGFRt15-TGFRsのIL-15免疫刺激及びTGF-βアンタゴニスト活性が、老齢マウスの免疫細胞の代謝活性の低下を効果的に刺激し、若返らせることを示唆している。
As shown in FIG. 259, splenocytes isolated from aged mice on
実施例124:TGFRt15-TGFRsのIL-15活性は、CD8+T細胞及びNK細胞の増加に役割を果たす
6週齢(若齢)及び72週齢(老齢)のC57BL/6マウスをJackson Laboratoryから購入した。マウスは、温度及び光が制御された環境で飼育された。マウス(n=6/群)をPBS、TGFRt15-TGFRs(3mg/kg)及びTGFRt15*-TGFRs(3mg/kg)で皮下処理した。免疫細胞の異なるサブセットの変化を評価するために、EDTAを含有するチューブで処理後4日目にマウス血液を顎下静脈から収集した。全血RBCを室温で5分間ACK緩衝液に溶解した。残りの細胞を、FACS緩衝液(1×PBS(Hyclone)、0.5%BSA(EMD Millipore)及び0.001%アジ化ナトリウム(Sigma)を含む)中で洗浄した。液中の異なる種類の免疫細胞を評価するために、細胞表面のCD3、CD4、CD45、CD8、及びNK1.1(BioLegend)に特異的な抗体で細胞を室温(RT)で30分間染色した。表面染色後、細胞を、FACS緩衝液(0.5%BSA(EMD Millipore)及び0.001%アジ化ナトリウム(Sigma)を含む1×PBS(Hyclone))中で洗浄した(1500RPM、室温で5分間)。2回洗浄した後、細胞をフローサイトメトリー(Celesta-BD Bioscience)によって分析した。
Example 124: TGFRt15-IL-15 activity of TGFRs plays a role in the expansion of CD8+ T cells and NK cells 6-week-old (young) and 72-week-old (old) C57BL/6 mice were purchased from Jackson Laboratory . Mice were housed in a temperature and light controlled environment. Mice (n=6/group) were treated subcutaneously with PBS, TGFRt15-TGFRs (3 mg/kg) and TGFRt15*-TGFRs (3 mg/kg). To assess changes in different subsets of immune cells, mouse blood was collected from the
図260に示されるように、結果は、TGFRt15-TGFRsによる老齢マウスの処理が、血中のCD3+CD45+、CD3+CD8+、及びCD3-NK1.1+免疫細胞のパーセンテージの増加を誘導したことを示すが、TGFRt15*-TGFRsによる老齢マウスの処理は、これらの血液細胞集団のパーセンテージに影響を与えなかった。これらの結果は、TGFRt15-TGFRsのIL-15活性が老齢マウスの血液中のCD8+T細胞及びNK細胞の増加に役割を果たすことを示唆している。老齢の対照マウスの血中T細胞及びNK細胞のパーセンテージは、若齢対照マウスよりも低かった。しかしながら、TGFRt15-TGFRsによる老齢マウスの処理が、血中のCD3+CD45+、CD3+CD8+、及びCD3-NK1.1+免疫細胞のパーセンテージを、TGFRt15-TGFRsで処理した若齢マウスの血液で観察されるレベルと同様のレベルまで増加させた。 As shown in Figure 260, the results showed that treatment of aged mice with TGFRt15-TGFRs induced an increase in the percentage of CD3 + CD45 + , CD3 + CD8 + , and CD3 − NK1.1 + immune cells in the blood. However, treatment of aged mice with TGFRt15*-TGFRs did not affect the percentages of these blood cell populations. These results suggest that IL-15 activity of TGFRt15-TGFRs plays a role in increasing CD8 + T cells and NK cells in the blood of aged mice. The percentage of circulating T cells and NK cells in old control mice was lower than in young control mice. However, treatment of aged mice with TGFRt15-TGFRs decreased the percentage of CD3 + CD45 + , CD3 + CD8 + , and CD3 − NK1.1 + immune cells in the blood to that of young mice treated with TGFRt15-TGFRs. It was increased to levels similar to those observed.
6週齢(若齢)及び72週齢(老齢)のC57BL/6マウスをJackson Laboratoryから購入した。マウスは、温度及び光が制御された環境で飼育された。マウス(n=6/群)をPBS、TGFRt15-TGFRs(3mg/kg)及びTGFRt15*-TGFRs(3mg/kg)で皮下処理した。処理の4日後、マウスを安楽死させ、脾臓を収集し、単一細胞懸濁液に処理した。免疫細胞の異なるサブセットを評価するために、単一細胞懸濁液を調製した。RBCを室温で5分間ACK緩衝液中で溶解した。残りの細胞を、FACS緩衝液(1×PBS(Hyclone)、0.5%BSA(EMD Millipore)及び0.001%アジ化ナトリウム(Sigma)を含む)中で洗浄した。脾臓内の異なる種類の免疫細胞を評価するために、細胞表面のCD3、CD45、CD8、及びNK1.1(BioLegend)に特異的な抗体で細胞を室温で30分間染色した。表面染色後、細胞を、FACS緩衝液(0.5%BSA(EMD Millipore)及び0.001%アジ化ナトリウム(Sigma)を含む1×PBS(Hyclone))中で洗浄した(1500RPM、室温で5分間)。2回洗浄した後、細胞をフローサイトメトリー(Celesta-BD Bioscience)によって分析した。 6-week-old (young) and 72-week-old (old) C57BL/6 mice were purchased from Jackson Laboratory. Mice were housed in a temperature and light controlled environment. Mice (n=6/group) were treated subcutaneously with PBS, TGFRt15-TGFRs (3 mg/kg) and TGFRt15*-TGFRs (3 mg/kg). Four days after treatment, mice were euthanized and spleens were harvested and processed into single cell suspensions. Single cell suspensions were prepared to evaluate different subsets of immune cells. RBCs were lysed in ACK buffer for 5 minutes at room temperature. The remaining cells were washed in FACS buffer containing 1×PBS (Hyclone), 0.5% BSA (EMD Millipore) and 0.001% sodium azide (Sigma). To assess the different types of immune cells in the spleen, cells were stained with antibodies specific for cell surface CD3, CD45, CD8, and NK1.1 (BioLegend) for 30 minutes at room temperature. After surface staining, cells were washed in FACS buffer (1×PBS (Hyclone) containing 0.5% BSA (EMD Millipore) and 0.001% sodium azide (Sigma)) (1500 RPM, 5 minutes at room temperature). minutes). After washing twice, cells were analyzed by flow cytometry (Celesta-BD Bioscience).
図261に示されるように、結果は、TGFRt15-TGFRsによる老齢マウスの処理が、脾臓中のCD3+CD45+、CD3+CD8+、及びCD3-NK1.1+免疫細胞のパーセンテージの増加を誘導したことを示すが、TGFRt15*-TGFRsによる老齢マウスの処理は、これらの脾細胞集団のパーセンテージに影響を与えなかった。これらの結果は、TGFRt15-TGFRsのIL-15活性が老齢マウスの血液中のCD8+T細胞及びNK細胞の増加に役割を果たすことを示唆している。老齢の対照マウスの脾臓T細胞及びNK細胞のパーセンテージは、若齢対照マウスよりも低かった。しかしながら、TGFRt15-TGFRsによる老齢マウスの処理が、脾臓中のCD3+CD45+、CD3+CD8+、及びCD3-NK1.1+免疫細胞のパーセンテージを、TGFRt15-TGFRsで処理した若齢マウスの脾臓で観察されるレベルと同様のレベルまで増加させた。 As shown in Figure 261, the results showed that treatment of aged mice with TGFRt15-TGFRs induced an increase in the percentage of CD3 + CD45 + , CD3 + CD8 + , and CD3 − NK1.1 + immune cells in the spleen. However, treatment of aged mice with TGFRt15*-TGFRs did not affect the percentage of these splenocyte populations. These results suggest that IL-15 activity of TGFRt15-TGFRs plays a role in increasing CD8 + T cells and NK cells in the blood of aged mice. The percentage of splenic T cells and NK cells in old control mice was lower than in young control mice. However, treatment of old mice with TGFRt15-TGFRs decreased the percentage of CD3 + CD45 + , CD3 + CD8 + , and CD3 − NK1.1 + immune cells in the spleen to that of young mice treated with TGFRt15-TGFRs. It was increased to levels similar to those observed.
実施例125:肝臓における自然発生の老化細胞におけるTGFRt15-TGFRs関連の減少
72週齢(老齢)のC57BL/6マウスをJackson Laboratoryから購入した。マウスは、温度及び光が制御された環境で飼育された。マウス(n=8/群)を、PBS又はTGFRt15-TGFRs(3mg/kg)の1回投与若しくは2回投与(0日目と60日目)のいずれかで皮下処理した。処理後71日目に、マウスを安楽死させ、肝臓を収集し、1.7mLエッペンドルフチューブ内の液体窒素で保存した。組織試料を、1mLのTrizol(Thermo Fischer)でホモジナイザーを使用して均質化した。均質化した組織を新たなエッペンドルフチューブに移し、全RNAを、RNeasyミニキット(Qiagen番号74106)を製造業者の指示に従って使用して抽出した。1μgの全RNAを、QuantiTect逆転写(Qiagen)を使用したcDNA合成に使用した。リアルタイムPCRを、Thermo Scientificから購入したFAM標識事前設計プライマーを使用したCFX96検出システム(Bio-Rad)で行った。反応を試験した全ての遺伝子に対して三連で行った。ハウスキーピング遺伝子18SリボソームRNAを、遺伝子発現レベルの変動を正規化するための内部対照として使用した。18S rRNAに対する各標的mRNAの発現を、Ctに基づいて2-Δ(ΔCt)として計算し、式中、ΔCt=Cttarget-Ct18Sである。未処理の6週齢マウスを対照として使用して、遺伝子発現レベルを老齢マウスと比較した。結果は、肝臓におけるIL-1α、IL-1β、IL-6、p21、及びPAI-1の遺伝子発現が、細胞老化関連転写産物の年齢依存的な増加で予想されるように、マウスの年齢とともに増加することを示した。72週齢のマウスにTGFRt15-TGFRsを1回又は2回での処理は、PBS対照群と比較した場合、肝臓の老化マーカーIL-1α、IL-1β、IL-6、p21、及びPAI-1の遺伝子発現が大幅に低減した(図262)。これらの発見は、老齢マウスの肝臓における自然発生の老化細胞のTGFRt15-TGFRs関連の減少を示唆している。
Example 125: TGFRt15-TGFRs Associated Decrease in Spontaneous Senescent Cells in the Liver 72-week-old (aged) C57BL/6 mice were purchased from Jackson Laboratory. Mice were housed in a temperature and light controlled environment. Mice (n=8/group) were treated subcutaneously with either 1 dose or 2 doses (
実施例126:TGFRt15-TGFRs処理は肝組織の炎症を低減することができる
72週齢(老齢)のC57BL/6マウスをJackson Laboratoryから購入した。マウスは、温度及び光が制御された環境で飼育された。マウス(n=10/群)を、PBS又はTGFRt15-TGFRs(3mg/kg)の1回投与若しくは2回投与のいずれかで皮下処理した。処理後120日目に、マウスを安楽死させ、マウス肝臓を組織化学によって評価するために調製した。肝臓組織標本を10%ホルムアルデヒドで固定し、パラフィンブロッキング手順の後、断面をヘマトキシリン-エオジンで染色した。肝障害の程度は、盲検法で組織学的に評価された。肝臓全体の組織切片は、0~4のスケールを使用した炎症のスコアであった(0、存在せず正常に見える、1、軽い、2、中等度、3、強い、及び4、強い)。図263に示されるように、TGFRt15-TGFRsの2回投与は、TGFRt15-TGFRsの単回投与又はPBS対照群と比較して、老齢マウスの肝臓における肝臓炎症スコアを減少させる。これらの結果は、TGFRt15-TGFRs処理が老齢マウスの肝臓組織の炎症を低減できることを示唆している。
Example 126: TGFRt15-TGFRs Treatment Can Reduce Hepatic Tissue Inflammation 72-week-old (senile) C57BL/6 mice were purchased from Jackson Laboratory. Mice were housed in a temperature and light controlled environment. Mice (n=10/group) were treated subcutaneously with either one or two doses of PBS or TGFRt15-TGFRs (3 mg/kg). 120 days after treatment, mice were euthanized and mouse livers were prepared for evaluation by histochemistry. Liver tissue specimens were fixed with 10% formaldehyde and sections were stained with hematoxylin-eosin after a paraffin blocking procedure. The degree of liver injury was assessed histologically in a blinded fashion. Histological sections of whole liver were scored for inflammation using a scale of 0 to 4 (0, absent and normal-appearing, 1, mild, 2, moderate, 3, strong, and 4, strong). As shown in Figure 263, two doses of TGFRt15-TGFRs reduce liver inflammation scores in livers of aged mice compared to single doses of TGFRt15-TGFRs or PBS control group. These results suggest that TGFRt15-TGFRs treatment can reduce inflammation in liver tissue of aged mice.
実施例127:TGFRt15-TGFRs処理が、IL1-α、IL-6、IL-8、PAI-1及びフィブロネクチンタンパク質レベルを低減させることができる
72週齢(老齢)のC57BL/6マウスをJackson Laboratoryから購入した。マウスは、温度及び光が制御された環境で飼育された。マウス(n=10/群)を、PBS又はTGFRt15-TGFRs(3mg/kg)の1回投与若しくは2回投与(0日目及び60日目)のいずれかで処理した。処理後120日目に、マウスを安楽死させ、肝臓を収集し、1.7mLエッペンドルフチューブ内の液体窒素で保存した。組織試料を、0.3mLの抽出緩衝液(Abcam)でホモジナイザーを使用して均質化した。均質化した組織を新たなエッペンドルフチューブに移した。均質化された組織のタンパク質レベルを、BCA Proteinアッセイキット(Pierce)を使用して定量化した。IL-1α、IL-1β、IL-6、IL-8、TGF-β、PAI-1、コラーゲン及びフィブロネクチンを検出するためのELISA(R&D System)を、25μgの組織ホモジナイズを使用して実施した。図264に示されるように、IL-1α、IL-6、IL-8、PAI-1、及びフィブロネクチンのタンパク質レベルを、PBS対照又はTGFRt15-TGFRs処理群の1回投与と比較して、TGFRt15-TGFRsの2回投与で処理されたマウスの肝臓で低減した。これらの結果は、TGFRt15-TGFRs処理の2回の投与が、老齢マウスの肝臓のIL-1α、IL-6、IL-8、PAI-1、及びフィブロネクチンタンパク質レベルを低減させることができることを示す。IL-1β、TGF-β、及びコラーゲンのタンパク質レベルも、PBS対照と比較して、2用量のTGFRt15-TGFRsで処理したマウスの肝臓で低かった。しかしながら、これらの変更は統計的有意性に達しなかった。
Example 127: TGFRt15-TGFRs Treatment Can Reduce IL1-α, IL-6, IL-8, PAI-1 and Fibronectin Protein Levels 72-week-old (senile) C57BL/6 mice from Jackson Laboratory Purchased. Mice were housed in a temperature and light controlled environment. Mice (n=10/group) were treated with either one or two doses (
実施例128:TGFRt15-TGFRsは老化細胞を低減させる
Jackson Laboratoryから購入した72週齢(老齢)C57BL/6老齢マウスマウスは、温度及び光が制御された環境で飼育された。マウス(n=5/群)を、PBS又はTGFRt15-TGFRs(3mg/kg)のいずれかで皮下処理した。処理後4日目にマウスを安楽死させ、肝臓を収集し、2%PBSを含有するFBSで均質化し、70ミクロンのフィルターでろ過して単一細胞懸濁液を得た。細胞をスピンダウンし、14mL丸底チューブに0.5mg/mLコラゲナーゼIV及び0.02mg/mL DNAseを含有する5mL RPMIに再懸濁した。次いで、細胞をオービタルシェーカーで37℃で1時間振とうし、RPMIで2回洗浄した。細胞を、2mLの完全培地(RPMI1640(Gibco)、2mMのL-グルタミン(Thermo Life Technologies)、ペニシリン(Thermo Life Technologies)、ストレプトマイシン(Thermo Life Technologies)、及び10%FBS(Hyclone)を補充)中の24ウェル平底プレートに2×106/mLで再懸濁し、37℃、5%CO2で48時間培養した。細胞を収集し、暖かい完全培地で1000rpmで10分間、室温で1回洗浄した。細胞ペレットを、チューブ当たり1.5μLのセネッセンス色素(Abcam)を含有する500μLの新鮮な培地に再懸濁した。細胞を更に37℃、5%CO2で1~2時間インキュベートし、500μLの洗浄緩衝液で2回洗浄した。ペレットは、500μLの洗浄緩衝液に再懸濁し、直ちにフローサイトメトリー(Celesta-BD Bioscience)で分析した。図265に示されるように、老化マーカーβ-gal+細胞のパーセンテージは、TGFRt15-TGFRでのインビボ処理の4日後に減少した。これらの結果は、TGFRt15-TGFRsが老齢マウスの肝臓の老化細胞を(β-galマーカーに基づいて)低減させることができることを実証している。
Example 128: TGFRt15-TGFRs Reduce Senescent Cells 72-week-old (aged) C57BL/6 aged mice purchased from Jackson Laboratory were housed in a temperature and light controlled environment. Mice (n=5/group) were treated subcutaneously with either PBS or TGFRt15-TGFRs (3 mg/kg). Mice were euthanized 4 days after treatment and livers were collected, homogenized with FBS containing 2% PBS and filtered through a 70 micron filter to obtain a single cell suspension. Cells were spun down and resuspended in 5 mL RPMI containing 0.5 mg/mL collagenase IV and 0.02 mg/mL DNAse in a 14 mL round bottom tube. Cells were then shaken on an orbital shaker at 37° C. for 1 hour and washed twice with RPMI. Cells were cultured in 2 mL complete medium (supplemented with RPMI 1640 (Gibco), 2 mM L-glutamine (Thermo Life Technologies), penicillin (Thermo Life Technologies), streptomycin (Thermo Life Technologies), and 10% FBS (Hyclone)). inside Resuspended at 2×10 6 /mL in 24-well flat bottom plates and incubated at 37° C., 5% CO 2 for 48 hours. Cells were harvested and washed once with warm complete medium at 1000 rpm for 10 minutes at room temperature. Cell pellets were resuspended in 500 μL of fresh medium containing 1.5 μL of senescence dye (Abcam) per tube. Cells were further incubated at 37° C., 5% CO 2 for 1-2 hours and washed twice with 500 μL of wash buffer. Pellets were resuspended in 500 μL of wash buffer and immediately analyzed by flow cytometry (Celesta-BD Bioscience). As shown in Figure 265, the percentage of senescence marker β-gal + cells decreased after 4 days of in vivo treatment with TGFRt15-TGFR. These results demonstrate that TGFRt15-TGFRs can reduce hepatic senescent cells (based on the β-gal marker) in aged mice.
実施例129:老齢マウスの生存に対するTGFRt15-TGFRsの効果
72週齢のC57BL/6マウスをJackson Laboratoryから購入した。マウスは、温度及び光が制御された環境で飼育された。マウスを、PBS又はTGFRt15-TGFRs(3mg/kg)の1回投与のいずれかで皮下処理した(n=20/群)。マウスは、処理後120週間までの生存について毎日モニターされた。Mantel-Coxログランク検定に基づく処理群の生存確率を図266に示す。TGFRt15-TGFRsと比較して、対照マウスではより高い死亡率が見られ、これはマウスの生存率の低下によって表された。処理後120週までに、TGFRt15-TGFRsで処理したマウスの45%の死亡率と比較して、PBS対照マウスの死亡率は70%であった。
Example 129 Effect of TGFRt15-TGFRs on Survival of Aged Mice 72-week-old C57BL/6 mice were purchased from Jackson Laboratory. Mice were housed in a temperature and light controlled environment. Mice were treated subcutaneously with either PBS or a single dose of TGFRt15-TGFRs (3 mg/kg) (n=20/group). Mice were monitored daily for survival up to 120 weeks after treatment. The survival probabilities of treatment groups based on the Mantel-Cox log-rank test are shown in FIG. Higher mortality was seen in control mice compared to TGFRt15-TGFRs, which was represented by decreased mouse survival. By 120 weeks post-treatment, PBS control mice had a mortality rate of 70% compared to 45% mortality in mice treated with TGFRt15-TGFRs.
実施例130:化学療法後のB16F10腫瘍担持マウスの肝臓におけるSASP因子の低減におけるTGFRt15-TGFRsの効果
化学療法後のB16F10腫瘍担持マウスにおけるSASP因子のタンパク質レベルの低減におけるTGFRt15-TGFR処理の効果を更に評価した。B16F10腫瘍細胞(1×107細胞/マウス)を0日目にマウスに移植した。マウスを、1、4、及び7日目に10mg/kgドセタキセルで皮下処理した。8日目に、マウスに、PBS又はTGFRt15-TGFRs(3mg/kg)を皮下投与した。腫瘍接種後17日目にマウスを安楽死させ、肝臓を収集して均質化した。肝臓ホモジネート中のSASP因子のタンパク質レベルは、ELISAによって決定された。図267に示されるように、TGFRt15-TGFRsでのインビボ処理は、化学療法後のB16F10腫瘍担持マウスにおける肝臓IL-1α、IL-6、TNFα及びIL-8SASP因子のレベルの有意な低減をもたらした。
Example 130: Effect of TGFRt15-TGFRs in reducing SASP factors in the liver of B16F10 tumor-bearing mice after chemotherapy The effect of TGFRt15-TGFR treatment in reducing protein levels of SASP factors in B16F10 tumor-bearing mice after chemotherapy was further investigated. evaluated. Mice were implanted on
実施例131:B16F10黒色腫マウスモデルにおけるTGFRt15-TGFRs媒介性老化腫瘍細胞の排除における免疫細胞サブセットの役割
TGFRt15-TGFRs媒介性老化腫瘍細胞の排除における免疫細胞サブセットの役割を評価するために、インビトロドセタキセル誘導老化B16F10-GFP腫瘍細胞を親B16F10細胞と混合し、抗NK1.1又は抗CD8a抗体での処理後にマウスの皮下に移植した。腫瘍が約350mm3に達したとき、PBS又はTGFRt15-TGFRs(3mg/kg)+TA99(200μg)による皮下処理を受けるようにマウスを無作為化した。治療後4日目にマウスを屠殺し、腫瘍を収集して分析した。腫瘍中のGFP陽性B16F10-GFP TIS細胞及びNK及びCD8+T細胞のレベルをフローサイトメトリーによって評価した。図268Aに示されるように、TGFRt15-TGFRs処理混合腫瘍は、免疫枯渇のないか、又はCD8+T免疫細胞が枯渇しており、対照処理マウスよりも有意に少ないGFP発現老化腫瘍細胞を含んでいた。CD8+枯渇マウスの腫瘍にはNK細胞が有意に浸潤し、NK枯渇マウスの腫瘍にはCD8+T細胞が有意に浸潤したことも観察された(図268B)。これらの結果は、NK細胞及びCD8+T細胞の両方が腫瘍成長の制御に役割を果たしており、NK細胞が主にTGFRt15-TGFRsの活性を媒介してTIS腫瘍細胞を枯渇させることを示唆している。
Example 131: Role of Immune Cell Subsets in TGFRt15-TGFRs-Mediated Senescent Tumor Cell Clearance in B16F10 Melanoma Mouse Model Induced senescent B16F10-GFP tumor cells were mixed with parental B16F10 cells and implanted subcutaneously into mice after treatment with anti-NK1.1 or anti-CD8a antibodies. When tumors reached approximately 350 mm 3 , mice were randomized to receive subcutaneous treatment with PBS or TGFRt15-TGFRs (3 mg/kg) plus TA99 (200 μg). Mice were sacrificed 4 days after treatment and tumors were collected and analyzed. Levels of GFP-positive B16F10-GFP TIS cells and NK and CD8 + T cells in tumors were assessed by flow cytometry. As shown in FIG. 268A, TGFRt15-TGFRs-treated mixed tumors were either non-immunodepleted or depleted of CD8 + T immune cells and contained significantly fewer GFP-expressing senescent tumor cells than control-treated mice. board. It was also observed that the tumors of CD8 + depleted mice were significantly infiltrated by NK cells and the tumors of NK depleted mice were significantly infiltrated by CD8 + T cells (Fig. 268B). These results suggest that both NK cells and CD8 + T cells play a role in regulating tumor growth, with NK cells primarily mediating the activity of TGFRt15-TGFRs to deplete TIS tumor cells. there is
実施例132:B16F10黒色腫マウスモデルにおけるTGFRt15-TGFRs+TA99及び化学療法と組み合わせた抗PD-L1抗体
TGFRt15-TGFRs-免疫チェックポイント阻害物質による逐次治療法(実施例109に記載)を更に評価するために、B16F10腫瘍担持マウスを最初にドキセタキセル(DTX)で処理し、次いでTGFRt15-TGFRs+TA99のいずれかで処理し、続いて抗PD-L1抗体又は抗PD-L1抗体、続いてTGFRt15-TGFRs+TA99(図269A)で処理した。18日目の腫瘍成長曲線及びエンドポイント腫瘍体積は、両方の併用戦略(TGFRt15-TGFRs+TA99に続いて抗PD-L1及びその逆)が、個々の免疫療法(TGFRt15-TGFRs+TA99又は抗PD-L1単独のいずれか)又はDTX単独(図269B)と比較して、有意な腫瘍体積の低減を示したことを示した。興味深いことに、TGFRt15-TGFRs+TA99処理腫瘍は、抗PD-L1で処理した腫瘍と比較して、併用治療の開始前の13日目に有意に低い腫瘍体積を示し、腫瘍成長の初期制御におけるTGFRt15-TGFRs+TA99の効果を示した。エンドポイント分析はまた、TGFRt15-TGFRs+TA99及び抗PD-L1抗体の組み合わせで処理された腫瘍は、単一処理群と比較して、腫瘍浸潤CD8+T細胞及びNK細胞のレベルを有意に増加させることを示した。併用治療は、単一処理と比較してCD8+TIL上の共刺激受容体CD28の発現を増加させ、チェックポイント遮断が、腫瘍微小環境内のTGFRt15-TGFRsのIL-15活性によって更に活性化される機能不全のCD8+TILをレスキューできることを示唆している(図269C)。これは、PMA/イオノマイシンによる刺激後の併用処理群からの脾臓CD8+T細胞の活性化表現型(IFNγ分泌)の増強に付随していた(図269D)。併用処理はまた、個々の免疫療法処理と比較して、腫瘍中の全CD8+T細胞及びCD44高CD8+T細胞でのNKG2D発現の増加を示した(図269E)。これらのデータはまとめて、TGFRt15-TGFRs+TA99及び抗PD-L1抗体の併用療法が、効果的な腫瘍制御に寄与する可能性があるCD8+T細胞の活性化及び浸潤をもたらしたことを示す。
Example 132: To further evaluate sequential treatment with anti-PD-L1 antibody TGFRt15-TGFRs-immune checkpoint inhibitor in combination with TGFRt15-TGFRs + TA99 and chemotherapy in B16F10 melanoma mouse model (described in Example 109) , B16F10 tumor-bearing mice were first treated with doxetaxel (DTX) and then either TGFRt15-TGFRs+TA99 followed by anti-PD-L1 antibody or anti-PD-L1 antibody followed by TGFRt15-TGFRs+TA99 (FIG. 269A). processed with Tumor growth curves and endpoint tumor volumes at
実施例133:C57BL/6SCIDマウスにおけるSW1990ヒト膵臓腫瘍に対する化学療法と組み合わせたTGFRt15-TGFRsの抗腫瘍効果
化学療法と組み合わせたTGFRt15-TGFRsの抗腫瘍活性を更に評価するために、SW1990ヒト膵臓がん細胞(2x106細胞/マウス)をC57BL/6scidマウスに皮下(sc)注射した。腫瘍細胞移植の9日後、ゲムシタビン(40mg/kg、腹腔内)及びnab-パクリタキセル(アブラキサン)(5mg/kg、腹腔内)化学療法が開始され、2日後にTGFRt15-TGFRs(3mg/kg、腹腔内)が開始された。これを1つの処理サイクルとみなし、更に3サイクル(1サイクル/週)繰り返した(図270A)。担がん対照群は、PBS、化学療法、又はTGFRt15-TGFRs処理のみを受けた。試験処理中及び処理後に、腫瘍体積を測定し、腫瘍体積<4000mm3に基づく動物の生存を評価した。結果は、TGFRt15-TGFRs及び化学療法の組み合わせを受けた動物は、PBS群と比較してSW1990腫瘍成長が有意に遅かったことを示した(図270B~270C)。TGFRt15-TGFRs+化学療法もまた、SW1990腫瘍担持マウスの生存を延長した(図270D)。これらの結果は、TGFRt15-TGFRsが、マウス異種移植腫瘍モデルにおけるヒト膵臓腫瘍に対する標準治療化学療法の有効性を高めたことを裏付けている。
Example 133: Anti-tumor effect of TGFRt15-TGFRs in combination with chemotherapy against SW1990 human pancreatic tumors in C57BL/6SCID mice To further evaluate the anti-tumor activity of TGFRt15-TGFRs in combination with chemotherapy, SW1990 human pancreatic cancer Cells (2×10 6 cells/mouse) were injected subcutaneously (sc) into C57BL/6 scid mice. Nine days after tumor cell implantation, gemcitabine (40 mg/kg, ip) and nab-paclitaxel (Abraxane) (5 mg/kg, ip) chemotherapy was initiated, followed 2 days later by TGFRt15-TGFRs (3 mg/kg, ip). ) was started. This was considered one treatment cycle and was repeated for 3 more cycles (1 cycle/week) (Figure 270A). Tumor-bearing control groups received PBS, chemotherapy, or TGFRt15-TGFRs treatment alone. Tumor volumes were measured during and after study treatment and animal survival was assessed based on tumor volume <4000 mm 3 . Results showed that animals receiving the combination of TGFRt15-TGFRs and chemotherapy had significantly slower SW1990 tumor growth compared to the PBS group (FIGS. 270B-270C). TGFRt15-TGFRs+chemotherapy also prolonged survival of SW1990 tumor-bearing mice (FIG. 270D). These results confirm that TGFRt15-TGFRs enhanced the efficacy of standard-of-care chemotherapy against human pancreatic tumors in mouse xenograft tumor models.
他の実施形態
本発明が発明を実施するための形態と併せて記載されているが、前述の記載が例証することを意図しており、添付の特許請求の範囲によって定義される本発明の範囲を限定することを意図するものではないことを理解されたい。他の態様、利点、及び修正は、以下の特許請求の範囲内である。
OTHER EMBODIMENTS While the invention has been described in conjunction with the Detailed Description, the foregoing description is intended to be illustrative, the scope of the invention being defined by the appended claims. It should be understood that it is not intended to limit the Other aspects, advantages, and modifications are within the scope of the following claims.
例示的な実施形態
実施形態A1.一本鎖キメラポリペプチドであって、
(i)第1の標的結合ドメイン、
(ii)可溶性組織因子ドメイン、及び
(iii)第2の標的結合ドメイン
を含む、一本鎖キメラポリペプチド。
Exemplary Embodiments Embodiment A1. A single-chain chimeric polypeptide,
(i) a first target binding domain;
(ii) a soluble tissue factor domain; and (iii) a second target binding domain.
実施形態A2.第1の標的結合ドメインと可溶性組織因子ドメインが、互いに直接隣接している、実施形態A1に記載の一本鎖キメラポリペプチド。 Embodiment A2. The single-chain chimeric polypeptide of embodiment A1, wherein the first target binding domain and the soluble tissue factor domain are directly adjacent to each other.
実施形態A3.一本鎖キメラポリペプチドが、第1の標的結合ドメインと可溶性組織因子ドメインとの間にリンカー配列を更に含む、実施形態A1に記載の一本鎖キメラポリペプチド。 Embodiment A3. The single chain chimeric polypeptide of embodiment A1, wherein the single chain chimeric polypeptide further comprises a linker sequence between the first target binding domain and the soluble tissue factor domain.
実施形態A4.可溶性組織因子ドメイン及び第2の標的結合ドメインが、互いに直接隣接している、実施形態A1~A3のいずれか1つに記載の一本鎖キメラポリペプチド。 Embodiment A4. The single chain chimeric polypeptide of any one of embodiments A1-A3, wherein the soluble tissue factor domain and the second target binding domain are directly adjacent to each other.
実施形態A5.一本鎖キメラポリペプチドが、可溶性組織因子ドメインと第2の標的結合ドメインとの間にリンカー配列を更に含む、実施形態A1~A3のいずれか1つに記載の一本鎖キメラポリペプチド。 Embodiment A5. The single chain chimeric polypeptide of any one of embodiments A1-A3, wherein the single chain chimeric polypeptide further comprises a linker sequence between the soluble tissue factor domain and the second target binding domain.
実施形態A6.第1の標的結合ドメインと第2の標的結合ドメインが、互いに直接隣接している、実施形態A1に記載の一本鎖キメラポリペプチド。 Embodiment A6. The single-chain chimeric polypeptide of embodiment A1, wherein the first target binding domain and the second target binding domain are directly adjacent to each other.
実施形態A7.一本鎖キメラポリペプチドが、第1の標的結合ドメインと第2の標的結合ドメインとの間にリンカー配列を更に含む、実施形態A1に記載の一本鎖キメラポリペプチド。 Embodiment A7. The single-chain chimeric polypeptide of embodiment A1, wherein the single-chain chimeric polypeptide further comprises a linker sequence between the first target binding domain and the second target binding domain.
実施形態A8.第2の標的結合ドメインと可溶性組織因子ドメインが、互いに直接隣接している、実施形態A6又はA7に記載の一本鎖キメラポリペプチド。 Embodiment A8. The single-chain chimeric polypeptide of embodiment A6 or A7, wherein the second target binding domain and the soluble tissue factor domain are directly adjacent to each other.
実施形態A9.一本鎖キメラポリペプチドが、第2の標的結合ドメインと可溶性組織因子ドメインとの間にリンカー配列を更に含む、実施形態A6又はA7に記載の一本鎖キメラポリペプチド。 Embodiment A9. The single chain chimeric polypeptide of embodiment A6 or A7, wherein the single chain chimeric polypeptide further comprises a linker sequence between the second target binding domain and the soluble tissue factor domain.
実施形態A10.第1の標的結合ドメイン及び第2の標的結合ドメインが同じ抗原に特異的に結合する、実施形態A1~A9のいずれか1つに記載の一本鎖キメラポリペプチド。 Embodiment A10. The single-chain chimeric polypeptide of any one of embodiments A1-A9, wherein the first target binding domain and the second target binding domain specifically bind the same antigen.
実施形態A11.第1の標的結合ドメイン及び第2の標的結合ドメインが同じエピトープに特異的に結合する、実施形態A10に記載の一本鎖キメラポリペプチド。 Embodiment A11. The single-chain chimeric polypeptide of embodiment A10, wherein the first target binding domain and the second target binding domain specifically bind to the same epitope.
実施形態A12.第1の標的結合ドメイン及び第2の標的結合ドメインが同じアミノ酸配列を含む、実施形態A11に記載の一本鎖キメラポリペプチド。 Embodiment A12. The single-chain chimeric polypeptide of embodiment A11, wherein the first target binding domain and the second target binding domain comprise the same amino acid sequence.
実施形態A13.第1の標的結合ドメイン及び第2の標的結合ドメインが異なる抗原に特異的に結合する、実施形態A1~A9のいずれか1つに記載の一本鎖キメラポリペプチド。 Embodiment A13. The single-chain chimeric polypeptide of any one of embodiments A1-A9, wherein the first target binding domain and the second target binding domain specifically bind different antigens.
実施形態A14.第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方が、抗原結合ドメインである、実施形態A1~A13のいずれか1つに記載の一本鎖キメラポリペプチド。 Embodiment A14. The single-chain chimeric polypeptide of any one of embodiments A1-A13, wherein one or both of the first target binding domain and the second target binding domain are antigen binding domains.
実施形態A15.第1の標的結合ドメイン及び第2の標的結合ドメインが各々、抗原結合ドメインである、実施形態A14に記載の一本鎖キメラポリペプチド。 Embodiment A15. The single-chain chimeric polypeptide of embodiment A14, wherein the first target binding domain and the second target binding domain are each antigen binding domains.
実施形態A16.抗原結合ドメインが、scFv又は単一ドメイン抗体を含む、実施形態A13に記載の一本鎖キメラポリペプチド。 Embodiment A16. The single-chain chimeric polypeptide of embodiment A13, wherein the antigen binding domain comprises a scFv or single domain antibody.
実施形態A17.第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方が、CD16a、CD28、CD3、CD33、CD20、CD19、CD22、CD123、IL-1R、IL-1、VEGF、IL-6R、IL-4、IL-10、PDL-1、TIGIT、PD-1、TIM3、CTLA4、MICA、MICB、IL-6、IL-8、TNFα、CD26、CD36、ULBP2、CD30、CD200、IGF-1R、MUC4AC、MUC5AC、Trop-2、CMET、EGFR、HER1、HER2、HER3、PSMA、CEA、B7H3、EPCAM、BCMA、P-カドヘリン、CEACAM5、UL16結合タンパク質、HLA-DR、DLL4、TYRO3、AXL、MER、CD122、CD155、PDGF-DD、TGF-β受容体II(TGF-βRII)リガンド、TGF-βRIIIリガンド、DNAM1リガンド、NKp46リガンド、NKp44リガンド、NKG2Dリガンド、NKp30リガンド、scMHCIリガンド、scMHCIIリガンド、scTCRリガンド、IL-1受容体、IL-2受容体、IL-3受容体、IL-7受容体、IL-8受容体、IL-10受容体、IL-12受容体、IL-15受容体、IL-17受容体、IL-18受容体、IL-21受容体、PDGF-D受容体、幹細胞因子(SCF)受容体、幹細胞様チロシンキナーゼ3リガンド(FLT3L)受容体、MICA受容体、MICB受容体、ULP16結合タンパク質受容体、CD155受容体、CD122受容体、及びCD28受容体からなる群から選択される標的に結合する、実施形態A1~A16のいずれか1つに記載の一本鎖キメラポリペプチド。 Embodiment A17. one or both of the first target binding domain and the second target binding domain are CD16a, CD28, CD3, CD33, CD20, CD19, CD22, CD123, IL-1R, IL-1, VEGF, IL-6R, IL -4, IL-10, PDL-1, TIGIT, PD-1, TIM3, CTLA4, MICA, MICB, IL-6, IL-8, TNFα, CD26, CD36, ULBP2, CD30, CD200, IGF-1R, MUC4AC , MUC5AC, Trop-2, CMET, EGFR, HER1, HER2, HER3, PSMA, CEA, B7H3, EPCAM, BCMA, P-cadherin, CEACAM5, UL16 binding protein, HLA-DR, DLL4, TYRO3, AXL, MER, CD122 , CD155, PDGF-DD, TGF-β receptor II (TGF-βRII) ligand, TGF-βRIII ligand, DNAM1 ligand, NKp46 ligand, NKp44 ligand, NKG2D ligand, NKp30 ligand, scMHCI ligand, scMHCII ligand, scTCR ligand, IL -1 receptor, IL-2 receptor, IL-3 receptor, IL-7 receptor, IL-8 receptor, IL-10 receptor, IL-12 receptor, IL-15 receptor, IL-17 receptor, IL-18 receptor, IL-21 receptor, PDGF-D receptor, stem cell factor (SCF) receptor, stem cell-like tyrosine kinase 3 ligand (FLT3L) receptor, MICA receptor, MICB receptor, ULP16 The single-chain chimeric polypeptide of any one of embodiments A1-A16, which binds a target selected from the group consisting of binding protein receptor, CD155 receptor, CD122 receptor, and CD28 receptor.
実施形態A18.第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方が、可溶性インターロイキン又はサイトカインタンパク質である、実施形態A1~A16のいずれか1つに記載の一本鎖キメラポリペプチド。 Embodiment A18. The single-chain chimeric polypeptide of any one of embodiments A1-A16, wherein one or both of the first and second target binding domains is a soluble interleukin or cytokine protein.
実施形態A19.可溶性インターロイキン、サイトカイン、又はリガンドタンパク質が、IL-1、IL-2、IL-3、IL-7、IL-8、IL-10、IL-12、IL-15、IL-17、IL-18、IL-21、PDGF-D、及びSCF、FLT3L、MICA、MICB、及びULP16結合タンパク質からなる群から選択される、実施形態A18に記載の一本鎖キメラポリペプチド。 Embodiment A19. soluble interleukin, cytokine, or ligand protein is IL-1, IL-2, IL-3, IL-7, IL-8, IL-10, IL-12, IL-15, IL-17, IL-18 , IL-21, PDGF-D, and SCF, FLT3L, MICA, MICB, and ULP16 binding proteins.
実施形態A20.第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方が、可溶性インターロイキン又はサイトカイン受容体である、実施形態A1~A16のいずれか1つに記載の一本鎖キメラポリペプチド。 Embodiment A20. The single-chain chimeric polypeptide of any one of embodiments A1-A16, wherein one or both of the first and second target binding domains is a soluble interleukin or cytokine receptor.
実施形態A21.可溶性インターロイキン又はサイトカイン受容体が、可溶性TGF-β受容体II(TGF-βRII)、可溶性TGF-βRIII、可溶性NKG2D、可溶性NKp30、可溶性NKp44、可溶性NKp46、可溶性DNAM1、scMHCI、scMHCII、scTCR、可溶性CD155、又は可溶性CD28である、実施形態A20に記載の一本鎖キメラポリペプチド。 Embodiment A21. Soluble interleukin or cytokine receptor is soluble TGF-β receptor II (TGF-βRII), soluble TGF-βRIII, soluble NKG2D, soluble NKp30, soluble NKp44, soluble NKp46, soluble DNAM1, scMHCI, scMHCII, scTCR, soluble CD155 , or soluble CD28.
実施形態A22.可溶性組織因子ドメインが、可溶性ヒト組織因子ドメインである、実施形態A1~A21のいずれか1つに記載の一本鎖キメラポリペプチド。 Embodiment A22. The single-chain chimeric polypeptide of any one of embodiments A1-A21, wherein the soluble tissue factor domain is a soluble human tissue factor domain.
実施形態A23.可溶性ヒト組織因子ドメインが、配列番号93と少なくとも80%同一である配列を含む、実施形態A22に記載の一本鎖キメラポリペプチド。 Embodiment A23. The single-chain chimeric polypeptide of embodiment A22, wherein the soluble human tissue factor domain comprises a sequence that is at least 80% identical to SEQ ID NO:93.
実施形態A24.可溶性ヒト組織因子ドメインが、配列番号93と少なくとも90%同一である配列を含む、実施形態A23に記載の一本鎖キメラポリペプチド。 Embodiment A24. The single-chain chimeric polypeptide of embodiment A23, wherein the soluble human tissue factor domain comprises a sequence that is at least 90% identical to SEQ ID NO:93.
実施形態A25.可溶性ヒト組織因子ドメインが、配列番号93と少なくとも95%同一である配列を含む、実施形態A24に記載の一本鎖キメラポリペプチド。 Embodiment A25. The single-chain chimeric polypeptide of embodiment A24, wherein the soluble human tissue factor domain comprises a sequence that is at least 95% identical to SEQ ID NO:93.
実施形態A26.可溶性ヒト組織因子ドメインが、
成熟野生型ヒト組織因子タンパク質のアミノ酸20位に対応するアミノ酸の位置にリジン、
成熟野生型ヒト組織因子タンパク質のアミノ酸22位に対応するアミノ酸の位置にイソロイシン、
成熟野生型ヒト組織因子タンパク質のアミノ酸45位に対応するアミノ酸の位置にトリプトファン、
成熟野生型ヒト組織因子タンパク質のアミノ酸58位に対応するアミノ酸の位置にアスパラギン酸、
成熟野生型ヒト組織因子タンパク質のアミノ酸94位に対応するアミノ酸の位置にチロシン、
成熟野生型ヒト組織因子タンパク質のアミノ酸135位に対応するアミノ酸の位置にアルギニン、及び
成熟野生型ヒト組織因子タンパク質のアミノ酸140位に対応するアミノ酸の位置にフェニルアラニンのうちの1つ以上を含まない、実施形態A22~A25のいずれか一項に記載の方法。
Embodiment A26. A soluble human tissue factor domain is
a lysine at the amino acid position corresponding to
an isoleucine at the amino acid position corresponding to
tryptophan at the amino acid position corresponding to
an aspartic acid at the amino acid position corresponding to amino acid position 58 of the mature wild-type human tissue factor protein;
a tyrosine at the amino acid position corresponding to amino acid position 94 of the mature wild-type human tissue factor protein;
does not contain one or more of arginine at the amino acid position corresponding to amino acid position 135 of the mature wild-type human tissue factor protein and phenylalanine at the amino acid position corresponding to
実施形態A27.可溶性ヒト組織因子ドメインが、
成熟野生型ヒト組織因子タンパク質のアミノ酸20位に対応するアミノ酸の位置にリジン、
成熟野生型ヒト組織因子タンパク質のアミノ酸22位に対応するアミノ酸の位置にイソロイシン、
成熟野生型ヒト組織因子タンパク質のアミノ酸45位に対応するアミノ酸の位置にトリプトファン、
成熟野生型ヒト組織因子タンパク質のアミノ酸58位に対応するアミノ酸の位置にアスパラギン酸、
成熟野生型ヒト組織因子タンパク質のアミノ酸94位に対応するアミノ酸の位置にチロシン、
成熟野生型ヒト組織因子タンパク質のアミノ酸135位に対応するアミノ酸の位置にアルギニン、及び
成熟野生型ヒト組織因子タンパク質のアミノ酸140位に対応するアミノ酸の位置にフェニルアラニンのうちのいずれも含まない、実施形態A26に記載の方法。
Embodiment A27. A soluble human tissue factor domain is
a lysine at the amino acid position corresponding to
an isoleucine at the amino acid position corresponding to
tryptophan at the amino acid position corresponding to
an aspartic acid at the amino acid position corresponding to amino acid position 58 of the mature wild-type human tissue factor protein;
a tyrosine at the amino acid position corresponding to amino acid position 94 of the mature wild-type human tissue factor protein;
An embodiment that does not include either arginine at the amino acid position corresponding to amino acid position 135 of the mature wild-type human tissue factor protein and phenylalanine at the amino acid position corresponding to
実施形態A28.可溶性組織因子ドメインが、第VIIa因子に結合することができない、実施形態A1~A27のいずれか1つに記載の一本鎖キメラポリペプチド。 Embodiment A28. The single-chain chimeric polypeptide of any one of embodiments A1-A27, wherein the soluble tissue factor domain is incapable of binding Factor VIIa.
実施形態A29.可溶性組織因子ドメインが、不活性第X因子を第Xa因子に変換しない、実施形態A1~A28のいずれか1つに記載の一本鎖キメラポリペプチド。 Embodiment A29. The single-chain chimeric polypeptide of any one of embodiments A1-A28, wherein the soluble tissue factor domain does not convert inactive factor X to factor Xa.
実施形態A30.一本鎖キメラポリペプチドが、哺乳動物における血液凝固を刺激しない、実施形態A1~A29のいずれか1つに記載の一本鎖キメラポリペプチド。 Embodiment A30. The single chain chimeric polypeptide of any one of embodiments A1-A29, wherein the single chain chimeric polypeptide does not stimulate blood clotting in a mammal.
実施形態A31.一本鎖キメラポリペプチドが、そのN末端及び/又はC末端に1つ以上の追加の標的結合ドメインを更に含む、実施形態A1~A30のいずれか1つに記載の一本鎖キメラポリペプチド。 Embodiment A31. The single chain chimeric polypeptide according to any one of embodiments A1-A30, wherein the single chain chimeric polypeptide further comprises one or more additional target binding domains at its N-terminus and/or C-terminus.
実施形態A32.一本鎖キメラポリペプチドが、そのN末端に1つ以上の追加の標的結合ドメインを含む、実施形態A31に記載の一本鎖キメラポリペプチド。 Embodiment A32. The single chain chimeric polypeptide of embodiment A31, wherein the single chain chimeric polypeptide comprises one or more additional target binding domains at its N-terminus.
実施形態A33.1つ以上追加の標的結合ドメインが、第1の標的結合ドメイン、第2の標的結合ドメイン、又は可溶性組織因子ドメインに直接隣接している、実施形態A32に記載の一本鎖キメラポリペプチド。 Embodiment A33. The single chain chimera of embodiment A32, wherein one or more additional target binding domains are directly adjacent to the first target binding domain, second target binding domain, or soluble tissue factor domain Polypeptide.
実施形態A34.一本鎖キメラポリペプチドが、少なくとも1つの追加の標的結合ドメインのうちの1つと、第1の標的結合ドメイン、第2の標的結合ドメイン、又は可溶性組織因子ドメインとの間にリンカー配列を更に含む、実施形態A33に記載の一本鎖キメラポリペプチド。 Embodiment A34. The single-chain chimeric polypeptide further comprises a linker sequence between one of the at least one additional target binding domain and the first target binding domain, the second target binding domain, or the soluble tissue factor domain , a single-chain chimeric polypeptide according to embodiment A33.
実施形態A35.一本鎖キメラポリペプチドが、そのC末端に1つ以上の追加の標的結合ドメインを含む、実施形態A31に記載の一本鎖キメラポリペプチド。 Embodiment A35. The single chain chimeric polypeptide of embodiment A31, wherein the single chain chimeric polypeptide comprises one or more additional target binding domains at its C-terminus.
実施形態A36.1つ以上追加の標的結合ドメインのうちの1つが、第1の標的結合ドメイン、第2の標的結合ドメイン、又は可溶性組織因子ドメインに直接隣接している、実施形態A35に記載の一本鎖キメラポリペプチド。 Embodiment A36. According to embodiment A35, wherein one of the one or more additional target binding domains is directly adjacent to the first target binding domain, the second target binding domain, or the soluble tissue factor domain. Single chain chimeric polypeptide.
実施形態A37.一本鎖キメラポリペプチドが、少なくとも1つの追加の標的結合ドメインのうちの1つと、第1の標的結合ドメイン、第2の標的結合ドメイン、又は可溶性組織因子ドメインとの間にリンカー配列を更に含む、実施形態A35に記載の一本鎖キメラポリペプチド。 Embodiment A37. The single-chain chimeric polypeptide further comprises a linker sequence between one of the at least one additional target binding domain and the first target binding domain, the second target binding domain, or the soluble tissue factor domain , a single-chain chimeric polypeptide according to embodiment A35.
実施形態A38.一本鎖キメラポリペプチドが、そのN末端及びC末端に1つ以上の追加の標的結合ドメインを含む、実施形態A31に記載の一本鎖キメラポリペプチド。 Embodiment A38. The single chain chimeric polypeptide of embodiment A31, wherein the single chain chimeric polypeptide comprises one or more additional target binding domains at its N-terminus and C-terminus.
実施形態A39.N末端での1つ以上追加の抗原結合ドメインのうちの1つが、第1の標的結合ドメイン、第2の標的結合ドメイン、又は可溶性組織因子ドメインに直接隣接している、実施形態A38に記載の一本鎖キメラポリペプチド。 Embodiment A39. According to embodiment A38, wherein one of the one or more additional antigen binding domains at the N-terminus is directly adjacent to the first target binding domain, the second target binding domain, or the soluble tissue factor domain. Single chain chimeric polypeptide.
実施形態A40.一本鎖キメラポリペプチドが、N末端での1つ以上の追加の抗原結合ドメインのうちの1つと、第1の標的結合ドメイン、第2の標的結合ドメイン、又は可溶性組織因子ドメインとの間にリンカー配列を更に含む、実施形態A38に記載の一本鎖キメラポリペプチド。 Embodiment A40. a single-chain chimeric polypeptide between one of the one or more additional antigen binding domains at the N-terminus and the first target binding domain, the second target binding domain, or the soluble tissue factor domain; The single-chain chimeric polypeptide of embodiment A38, further comprising a linker sequence.
実施形態A41.C末端での1つ以上追加の抗原結合ドメインのうちの1つが、第1の標的結合ドメイン、第2の標的結合ドメイン、又は可溶性組織因子ドメインに直接隣接している、実施形態A38に記載の一本鎖キメラポリペプチド。 Embodiment A41. According to embodiment A38, wherein one of the one or more additional antigen binding domains at the C-terminus is directly adjacent to the first target binding domain, the second target binding domain, or the soluble tissue factor domain. Single chain chimeric polypeptide.
実施形態A42.一本鎖キメラポリペプチドが、C末端での1つ以上の追加の抗原結合ドメインのうちの1つと、第1の標的結合ドメイン、第2の標的結合ドメイン、又は可溶性組織因子ドメインとの間にリンカー配列を更に含む、実施形態A38に記載の一本鎖キメラポリペプチド。 Embodiment A42. a single chain chimeric polypeptide between one of the one or more additional antigen binding domains at the C-terminus and the first target binding domain, the second target binding domain, or the soluble tissue factor domain; The single-chain chimeric polypeptide of embodiment A38, further comprising a linker sequence.
実施形態A43.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの2つ以上が同じ抗原に特異的に結合する、実施形態A31~A42のいずれか1つに記載の一本鎖キメラポリペプチド。 Embodiment A43. Any one of embodiments A31-A42, wherein two or more of the first target binding domain, the second target binding domain, and the one or more additional target binding domains specifically bind to the same antigen A single-chain chimeric polypeptide according to .
実施形態A44.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの2つ以上が同じエピトープに特異的に結合する、実施形態A43に記載の一本鎖キメラポリペプチド。 Embodiment A44. The single chain chimera of embodiment A43, wherein two or more of the first target binding domain, the second target binding domain, and the one or more additional target binding domains specifically bind the same epitope. Polypeptide.
実施形態A45.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの2つ以上が同じアミノ酸配列を含む、実施形態A44に記載の一本鎖キメラポリペプチド。 Embodiment A45. The single-chain chimeric polypeptide of embodiment A44, wherein two or more of the first target binding domain, second target binding domain, and one or more additional target binding domains comprise the same amino acid sequence.
実施形態A46.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインが各々、同じ抗原に特異的に結合する、実施形態A43に記載の一本鎖キメラポリペプチド。 Embodiment A46. The single-chain chimeric polypeptide of embodiment A43, wherein the first target binding domain, the second target binding domain, and the one or more additional target binding domains each specifically bind the same antigen.
実施形態A47.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインが各々、同じエピトープに特異的に結合する、実施形態A46に記載の一本鎖キメラポリペプチド。 Embodiment A47. The single-chain chimeric polypeptide of embodiment A46, wherein the first target binding domain, the second target binding domain, and the one or more additional target binding domains each specifically bind the same epitope.
実施形態A48.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインが各々、同じアミノ酸配列を含む、実施形態A47に記載の一本鎖キメラポリペプチド。 Embodiment A48. The single-chain chimeric polypeptide of embodiment A47, wherein the first target binding domain, the second target binding domain, and the one or more additional target binding domains each comprise the same amino acid sequence.
実施形態A49.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインが異なる抗原に特異的に結合する、実施形態A31~A42のいずれか1つに記載の一本鎖キメラポリペプチド。 Embodiment A49. The single chain of any one of embodiments A31-A42, wherein the first target binding domain, the second target binding domain, and the one or more additional target binding domains specifically bind different antigens. chimeric polypeptide.
実施形態A50.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の標的結合ドメインのうちの1つ以上が、抗原結合ドメインである、実施形態A31~A49のいずれか1つに記載の一本鎖キメラポリペプチド。 Embodiment A50. One according to any one of embodiments A31-A49, wherein one or more of the first target binding domain, the second target binding domain, and the one or more target binding domains are antigen binding domains. Main chain chimeric polypeptides.
実施形態A51.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインが各々、抗原結合ドメインである、実施形態A50に記載の一本鎖キメラポリペプチド。 Embodiment A51. The single-chain chimeric polypeptide of embodiment A50, wherein the first target binding domain, the second target binding domain, and the one or more additional target binding domains are each antigen binding domains.
実施形態A52.抗原結合ドメインが、scFv又は単一ドメイン抗体を含む、実施形態A51に記載の一本鎖キメラポリペプチド。 Embodiment A52. The single-chain chimeric polypeptide of embodiment A51, wherein the antigen binding domain comprises a scFv or single domain antibody.
実施形態A53.第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方、並びに1つ以上の標的結合ドメインが、CD16a、CD28、CD3、CD33、CD20、CD19、CD22、CD123、IL-1R、IL-1、VEGF、IL-6R、IL-4、IL-10、PDL-1、TIGIT、PD-1、TIM3、CTLA4、MICA、MICB、IL-6、IL-8、TNFα、CD26、CD36、ULBP2、CD30、CD200、IGF-1R、MUC4AC、MUC5AC、Trop-2、CMET、EGFR、HER1、HER2、HER3、PSMA、CEA、B7H3、EPCAM、BCMA、P-カドヘリン、CEACAM5、UL16結合タンパク質、HLA-DR、DLL4、TYRO3、AXL、MER、CD122、CD155、PDGF-DD、TGF-β受容体II(TGF-βRII)リガンド、TGF-βRIIIリガンド、DNAM1リガンド、NKp46リガンド、NKp44リガンド、NKG2Dリガンド、NKp30リガンド、scMHCIリガンド、scMHCIIリガンド、scTCRリガンド、IL-1受容体、IL-2受容体、IL-3受容体、IL-7受容体、IL-8受容体、IL-10受容体、IL-12受容体、IL-15受容体、IL-17受容体、IL-18受容体、IL-21受容体、PDGF-D受容体、幹細胞因子(SCF)受容体、幹細胞様チロシンキナーゼ3リガンド(FLT3L)受容体、MICA受容体、MICB受容体、ULP16結合タンパク質受容体、CD155受容体、CD122受容体、及びCD28受容体からなる群から選択される標的に特異的に結合する、実施形態A31~A52のいずれか1つに記載の一本鎖キメラポリペプチド。 Embodiment A53. One or both of the first target binding domain and the second target binding domain, and one or more of the target binding domains are CD16a, CD28, CD3, CD33, CD20, CD19, CD22, CD123, IL-1R, IL- 1, VEGF, IL-6R, IL-4, IL-10, PDL-1, TIGIT, PD-1, TIM3, CTLA4, MICA, MICB, IL-6, IL-8, TNFα, CD26, CD36, ULBP2, CD30, CD200, IGF-1R, MUC4AC, MUC5AC, Trop-2, CMET, EGFR, HER1, HER2, HER3, PSMA, CEA, B7H3, EPCAM, BCMA, P-cadherin, CEACAM5, UL16 binding protein, HLA-DR, DLL4, TYRO3, AXL, MER, CD122, CD155, PDGF-DD, TGF-β receptor II (TGF-βRII) ligand, TGF-βRIII ligand, DNAM1 ligand, NKp46 ligand, NKp44 ligand, NKG2D ligand, NKp30 ligand, scMHCI ligand, scMHCII ligand, scTCR ligand, IL-1 receptor, IL-2 receptor, IL-3 receptor, IL-7 receptor, IL-8 receptor, IL-10 receptor, IL-12 receptor, IL-15 receptor, IL-17 receptor, IL-18 receptor, IL-21 receptor, PDGF-D receptor, stem cell factor (SCF) receptor, stem cell-like tyrosine kinase 3 ligand (FLT3L) receptor, Any one of embodiments A31-A52 that specifically binds to a target selected from the group consisting of MICA receptor, MICB receptor, ULP16 binding protein receptor, CD155 receptor, CD122 receptor, and CD28 receptor A single-chain chimeric polypeptide according to 1.
実施形態A54.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの1つ以上が、可溶性インターロイキン又はサイトカインタンパク質である、実施形態A31~A52のいずれか1つに記載の一本鎖キメラポリペプチド。 Embodiment A54. Any one of embodiments A31-A52, wherein one or more of the first target binding domain, the second target binding domain, and the one or more additional target binding domains is a soluble interleukin or cytokine protein A single-chain chimeric polypeptide according to 1.
実施形態A55.可溶性インターロイキン、サイトカイン、又はリガンドタンパク質が、IL-1、IL-2、IL-3、IL-7、IL-8、IL-10、IL-12、IL-15、IL-17、IL-18、IL-21、PDGF-D、及びSCF、FLT3L、MICA、MICB、及びULP16結合タンパク質からなる群から選択される、実施形態A54に記載の一本鎖キメラポリペプチド。 Embodiment A55. soluble interleukin, cytokine, or ligand protein is IL-1, IL-2, IL-3, IL-7, IL-8, IL-10, IL-12, IL-15, IL-17, IL-18 , IL-21, PDGF-D, and SCF, FLT3L, MICA, MICB, and ULP16 binding proteins.
実施形態A56.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの1つ以上が、可溶性インターロイキン又はサイトカイン受容体である、実施形態A31~A52のいずれか1つに記載の一本鎖キメラポリペプチド。
Embodiment A56. Any of embodiments A31-A52, wherein one or more of the first target binding domain, the second target binding domain, and the one or more additional target binding domains is a soluble interleukin or
実施形態A57.可溶性受容体が、可溶性TGF-β受容体II(TGF-βRII)、可溶性TGF-βRIII、可溶性NKG2D、可溶性NKp30、可溶性NKp44、可溶性NKp46、可溶性DNAM1、scMHCI、scMHCII、scTCR、可溶性CD155、可溶性CD122、可溶性CD3、又は可溶性CD28である、実施形態A56に記載の一本鎖キメラポリペプチド。 Embodiment A57. the soluble receptor is soluble TGF-β receptor II (TGF-βRII), soluble TGF-βRIII, soluble NKG2D, soluble NKp30, soluble NKp44, soluble NKp46, soluble DNAM1, scMHCI, scMHCII, scTCR, soluble CD155, soluble CD122, The single-chain chimeric polypeptide of embodiment A56, which is soluble CD3, or soluble CD28.
実施形態A58.一本鎖キメラポリペプチドが、そのN末端にシグナル配列を更に含む、実施形態A1~A57のいずれか1つに記載の一本鎖キメラポリペプチド。 Embodiment A58. The single chain chimeric polypeptide of any one of embodiments A1-A57, wherein the single chain chimeric polypeptide further comprises a signal sequence at its N-terminus.
実施形態A59.一本鎖キメラポリペプチドが、一本鎖キメラポリペプチドのN末端又はC末端に位置付けられたペプチドタグを更に含む、実施形態A1~A58のいずれか1つに記載の一本鎖キメラポリペプチド。 Embodiment A59. The single chain chimeric polypeptide of any one of embodiments A1-A58, wherein the single chain chimeric polypeptide further comprises a peptide tag positioned at the N-terminus or C-terminus of the single chain chimeric polypeptide.
実施形態A60.実施形態A1~A59に記載の一本鎖キメラポリペプチドのうちのいずれかを含む、組成物。 Embodiment A60. A composition comprising any of the single-chain chimeric polypeptides of embodiments A1-A59.
実施形態A61.組成物が、医薬組成物である、実施形態A60に記載の組成物。 Embodiment A61. The composition of embodiment A60, wherein the composition is a pharmaceutical composition.
実施形態A62.実施形態A60又はA61に記載の組成物の少なくとも1つの用量を含む、キット。 Embodiment A62. A kit comprising at least one dose of the composition of embodiment A60 or A61.
実施形態A63.実施形態A1~A59のいずれか1つに記載の一本鎖キメラポリペプチドのうちのいずれかをコードする、核酸。 Embodiment A63. A nucleic acid encoding any of the single-chain chimeric polypeptides of any one of embodiments A1-A59.
実施形態A64.実施形態A63に記載の核酸を含む、ベクター。 Embodiment A64. A vector comprising the nucleic acid of embodiment A63.
実施形態A65.ベクターが、発現ベクターである、実施形態A64に記載のベクター。 Embodiment A65. The vector of embodiment A64, wherein the vector is an expression vector.
実施形態A66.実施形態A63に記載の核酸又は実施形態A64若しくはA65に記載のベクターを含む、細胞。 Embodiment A66. A cell comprising the nucleic acid of embodiment A63 or the vector of embodiment A64 or A65.
実施形態A67.一本鎖キメラポリペプチドを産生する方法であって、
一本鎖キメラポリペプチドの産生をもたらすのに十分な条件下で、実施形態A66に記載の細胞を培養培地中で培養することと、
一本キメラポリペプチドを細胞及び/又は培養培地から回収することと
を含む、方法。
Embodiment A67. A method of producing a single-chain chimeric polypeptide, comprising:
culturing the cells of embodiment A66 in a culture medium under conditions sufficient to result in the production of the single-chain chimeric polypeptide;
recovering the single chimeric polypeptide from the cells and/or the culture medium.
実施形態A68.実施形態A67に記載の方法によって産生された一本鎖キメラポリペプチド。 Embodiment A68. A single-chain chimeric polypeptide produced by the method of embodiment A67.
実施形態A69.可溶性ヒト組織因子ドメインが、配列番号97と少なくとも80%同一である配列を含む、実施形態A26に記載の一本鎖キメラポリペプチド。 Embodiment A69. The single-chain chimeric polypeptide of embodiment A26, wherein the soluble human tissue factor domain comprises a sequence that is at least 80% identical to SEQ ID NO:97.
実施形態A70.可溶性ヒト組織因子ドメインが、配列番号97と少なくとも90%同一である配列を含む、実施形態A69に記載の一本鎖キメラポリペプチド。 Embodiment A70. The single-chain chimeric polypeptide of embodiment A69, wherein the soluble human tissue factor domain comprises a sequence that is at least 90% identical to SEQ ID NO:97.
実施形態A71.可溶性ヒト組織因子ドメインが、配列番号97と少なくとも95%同一である配列を含む、実施形態A70に記載の一本鎖キメラポリペプチド。 Embodiment A71. The single-chain chimeric polypeptide of embodiment A70, wherein the soluble human tissue factor domain comprises a sequence that is at least 95% identical to SEQ ID NO:97.
実施形態A72.可溶性ヒト組織因子ドメインが、配列番号97と100%同一である配列を含む、実施形態A71に記載の一本鎖キメラポリペプチド。 Embodiment A72. The single-chain chimeric polypeptide of embodiment A71, wherein the soluble human tissue factor domain comprises a sequence that is 100% identical to SEQ ID NO:97.
実施形態A73.可溶性ヒト組織因子ドメインが、配列番号98と少なくとも80%同一である配列を含む、実施形態A26に記載の一本鎖キメラポリペプチド。 Embodiment A73. The single-chain chimeric polypeptide of embodiment A26, wherein the soluble human tissue factor domain comprises a sequence that is at least 80% identical to SEQ ID NO:98.
実施形態A74.可溶性ヒト組織因子ドメインが、配列番号98と少なくとも90%同一である配列を含む、実施形態A73に記載の一本鎖キメラポリペプチド。 Embodiment A74. The single-chain chimeric polypeptide of embodiment A73, wherein the soluble human tissue factor domain comprises a sequence that is at least 90% identical to SEQ ID NO:98.
実施形態A75.可溶性ヒト組織因子ドメインが、配列番号98と少なくとも95%同一である配列を含む、実施形態A74に記載の一本鎖キメラポリペプチド。 Embodiment A75. The single-chain chimeric polypeptide of embodiment A74, wherein the soluble human tissue factor domain comprises a sequence that is at least 95% identical to SEQ ID NO:98.
実施形態A76.可溶性ヒト組織因子ドメインが、配列番号98と100%同一である配列を含む、実施形態A75に記載の一本鎖キメラポリペプチド。 Embodiment A76. The single-chain chimeric polypeptide of embodiment A75, wherein the soluble human tissue factor domain comprises a sequence that is 100% identical to SEQ ID NO:98.
実施形態B1.一本鎖キメラポリペプチドであって、
(i)第1の標的結合ドメイン、
(ii)可溶性組織因子ドメイン、及び
(iii)第2の標的結合ドメイン
を含み、
第1の標的結合ドメイン及び第2の標的結合ドメインが各々、IL-2受容体に特異的に結合するか、又は
第1の標的結合ドメイン及び第2の標的結合ドメインが各々、IL-15受容体に特異的に結合する、
一本鎖キメラポリペプチド。
Embodiment B1. A single-chain chimeric polypeptide,
(i) a first target binding domain;
(ii) a soluble tissue factor domain, and (iii) a second target binding domain,
The first target binding domain and the second target binding domain each specifically bind to an IL-2 receptor, or the first target binding domain and the second target binding domain each bind an IL-15 receptor binds specifically to the body,
Single chain chimeric polypeptide.
実施形態B2.第1の標的結合ドメインと可溶性組織因子ドメインが、互いに直接隣接している、実施形態B1に記載の一本鎖キメラポリペプチド。 Embodiment B2. The single-chain chimeric polypeptide of embodiment B1, wherein the first target binding domain and the soluble tissue factor domain are directly adjacent to each other.
実施形態B3.一本鎖キメラポリペプチドが、第1の標的結合ドメインと可溶性組織因子ドメインとの間にリンカー配列を更に含む、実施形態B1に記載の一本鎖キメラポリペプチド。 Embodiment B3. The single chain chimeric polypeptide of embodiment B1, wherein the single chain chimeric polypeptide further comprises a linker sequence between the first target binding domain and the soluble tissue factor domain.
実施形態B4.可溶性組織因子ドメイン及び第2の標的結合ドメインが、互いに直接隣接している、実施形態B1~B3のいずれか1つに記載の一本鎖キメラポリペプチド。 Embodiment B4. The single chain chimeric polypeptide of any one of embodiments B1-B3, wherein the soluble tissue factor domain and the second target binding domain are directly adjacent to each other.
実施形態B5.一本鎖キメラポリペプチドが、可溶性組織因子ドメインと第2の標的結合ドメインとの間にリンカー配列を更に含む、実施形態B1~B3のいずれか1つに記載の一本鎖キメラポリペプチド。 Embodiment B5. The single chain chimeric polypeptide of any one of embodiments B1-B3, wherein the single chain chimeric polypeptide further comprises a linker sequence between the soluble tissue factor domain and the second target binding domain.
実施形態B6.第1の標的結合ドメインと第2の標的結合ドメインが、互いに直接隣接している、実施形態B1に記載の一本鎖キメラポリペプチド。 Embodiment B6. The single-chain chimeric polypeptide of embodiment B1, wherein the first target binding domain and the second target binding domain are directly adjacent to each other.
実施形態B7.一本鎖キメラポリペプチドが、第1の標的結合ドメインと第2の標的結合ドメインとの間にリンカー配列を更に含む、実施形態B1に記載の一本鎖キメラポリペプチド。 Embodiment B7. The single-chain chimeric polypeptide of embodiment B1, wherein the single-chain chimeric polypeptide further comprises a linker sequence between the first target binding domain and the second target binding domain.
実施形態B8.第2の標的結合ドメインと可溶性組織因子ドメインが、互いに直接隣接している、実施形態B6又はB7に記載の一本鎖キメラポリペプチド。 Embodiment B8. The single-chain chimeric polypeptide of embodiment B6 or B7, wherein the second target binding domain and the soluble tissue factor domain are directly adjacent to each other.
実施形態B9.一本鎖キメラポリペプチドが、第2の標的結合ドメインと可溶性組織因子ドメインとの間にリンカー配列を更に含む、実施形態B6又はB7に記載の一本鎖キメラポリペプチド。 Embodiment B9. The single chain chimeric polypeptide of embodiment B6 or B7, wherein the single chain chimeric polypeptide further comprises a linker sequence between the second target binding domain and the soluble tissue factor domain.
実施形態B10.第1標的結合ドメイン及び第2の標的結合ドメインの両方が、可溶性インターロイキンタンパク質である、実施形態B1~B9のいずれか1つに記載の一本鎖キメラポリペプチド。 Embodiment B10. The single chain chimeric polypeptide of any one of embodiments B1-B9, wherein both the first target binding domain and the second target binding domain are soluble interleukin proteins.
実施形態B11.第1の標的結合ドメインと第2の標的結合ドメインが、可溶性IL-2タンパク質である、実施形態B10に記載の一本鎖キメラポリペプチド。 Embodiment B11. The single chain chimeric polypeptide of embodiment B10, wherein the first target binding domain and the second target binding domain are soluble IL-2 proteins.
実施形態B12.可溶性IL-2タンパク質が、可溶性ヒトIL-2タンパク質である、実施形態B11に記載の一本鎖キメラポリペプチド。 Embodiment B12. The single-chain chimeric polypeptide of embodiment B11, wherein the soluble IL-2 protein is soluble human IL-2 protein.
実施形態B13.可溶性IL-2タンパク質が、配列番号78を含む、実施形態B12に記載の一本鎖キメラポリペプチド。 Embodiment B13. The single-chain chimeric polypeptide of embodiment B12, wherein the soluble IL-2 protein comprises SEQ ID NO:78.
実施形態B14.第1の標的結合ドメインと第2の標的結合ドメインが、可溶性IL-15タンパク質である、実施形態B10に記載の一本鎖キメラポリペプチド。 Embodiment B14. The single-chain chimeric polypeptide of embodiment B10, wherein the first target binding domain and the second target binding domain are soluble IL-15 protein.
実施形態B15.可溶性IL-15タンパク質が、可溶性ヒトIL-15タンパク質である、実施形態B14に記載の一本鎖キメラポリペプチド。 Embodiment B15. The single-chain chimeric polypeptide of embodiment B14, wherein the soluble IL-15 protein is soluble human IL-15 protein.
実施形態B16.可溶性ヒトIL-15タンパク質が、配列番号82を含む、実施形態B15に記載の一本鎖キメラポリペプチド。 Embodiment B16. The single-chain chimeric polypeptide of embodiment B15, wherein the soluble human IL-15 protein comprises SEQ ID NO:82.
実施形態B17.可溶性組織因子ドメインが、可溶性ヒト組織因子ドメインである、実施形態B1~B16のいずれか1つに記載の一本鎖キメラポリペプチド。 Embodiment B17. The single-chain chimeric polypeptide of any one of embodiments B1-B16, wherein the soluble tissue factor domain is a soluble human tissue factor domain.
実施形態B18.可溶性ヒト組織因子ドメインが、配列番号93と少なくとも80%同一である配列を含む、実施形態B17に記載の一本鎖キメラポリペプチド。 Embodiment B18. The single-chain chimeric polypeptide of embodiment B17, wherein the soluble human tissue factor domain comprises a sequence that is at least 80% identical to SEQ ID NO:93.
実施形態B19.可溶性ヒト組織因子ドメインが、配列番号93と少なくとも90%同一である配列を含む、実施形態B18に記載の一本鎖キメラポリペプチド。 Embodiment B19. The single-chain chimeric polypeptide of embodiment B18, wherein the soluble human tissue factor domain comprises a sequence that is at least 90% identical to SEQ ID NO:93.
実施形態B20.可溶性ヒト組織因子ドメインが、配列番号93と少なくとも95%同一である配列を含む、実施形態B19に記載の一本鎖キメラポリペプチド。 Embodiment B20. The single-chain chimeric polypeptide of embodiment B19, wherein the soluble human tissue factor domain comprises a sequence that is at least 95% identical to SEQ ID NO:93.
実施形態B21.可溶性ヒト組織因子ドメインが、
成熟野生型ヒト組織因子タンパク質のアミノ酸20位に対応するアミノ酸の位置にリジン、
成熟野生型ヒト組織因子タンパク質のアミノ酸22位に対応するアミノ酸の位置にイソロイシン、
成熟野生型ヒト組織因子タンパク質のアミノ酸45位に対応するアミノ酸の位置にトリプトファン、
成熟野生型ヒト組織因子タンパク質のアミノ酸58位に対応するアミノ酸の位置にアスパラギン酸、
成熟野生型ヒト組織因子タンパク質のアミノ酸94位に対応するアミノ酸の位置にチロシン、
成熟野生型ヒト組織因子タンパク質のアミノ酸135位に対応するアミノ酸の位置にアルギニン、及び
成熟野生型ヒト組織因子タンパク質のアミノ酸140位に対応するアミノ酸の位置にフェニルアラニンのうちの1つ以上を含まない、実施形態B17~B20のいずれか一つに記載の方法。
Embodiment B21. A soluble human tissue factor domain is
a lysine at the amino acid position corresponding to
an isoleucine at the amino acid position corresponding to
tryptophan at the amino acid position corresponding to
an aspartic acid at the amino acid position corresponding to amino acid position 58 of the mature wild-type human tissue factor protein;
a tyrosine at the amino acid position corresponding to amino acid position 94 of the mature wild-type human tissue factor protein;
does not contain one or more of arginine at the amino acid position corresponding to amino acid position 135 of the mature wild-type human tissue factor protein and phenylalanine at the amino acid position corresponding to
実施形態B22.可溶性ヒト組織因子ドメインが、
成熟野生型ヒト組織因子タンパク質のアミノ酸20位に対応するアミノ酸の位置にリジン、
成熟野生型ヒト組織因子タンパク質のアミノ酸22位に対応するアミノ酸の位置にイソロイシン、
成熟野生型ヒト組織因子タンパク質のアミノ酸45位に対応するアミノ酸の位置にトリプトファン、
成熟野生型ヒト組織因子タンパク質のアミノ酸58位に対応するアミノ酸の位置にアスパラギン酸、
成熟野生型ヒト組織因子タンパク質のアミノ酸94位に対応するアミノ酸の位置にチロシン、
成熟野生型ヒト組織因子タンパク質のアミノ酸135位に対応するアミノ酸の位置にアルギニン、及び
成熟野生型ヒト組織因子タンパク質のアミノ酸140位に対応するアミノ酸の位置にフェニルアラニンのうちのいずれも含まない、実施形態B21に記載の方法。
Embodiment B22. A soluble human tissue factor domain is
a lysine at the amino acid position corresponding to
an isoleucine at the amino acid position corresponding to
tryptophan at the amino acid position corresponding to
an aspartic acid at the amino acid position corresponding to amino acid position 58 of the mature wild-type human tissue factor protein;
a tyrosine at the amino acid position corresponding to amino acid position 94 of the mature wild-type human tissue factor protein;
An embodiment that does not include either arginine at the amino acid position corresponding to amino acid position 135 of the mature wild-type human tissue factor protein and phenylalanine at the amino acid position corresponding to
実施形態B23.可溶性組織因子ドメインが、第VIIa因子に結合することができない、実施形態B1~B22のいずれか1つに記載の一本鎖キメラポリペプチド。 Embodiment B23. The single-chain chimeric polypeptide of any one of embodiments B1-B22, wherein the soluble tissue factor domain is incapable of binding Factor VIIa.
実施形態B24.可溶性組織因子ドメインが、不活性第X因子を第Xa因子に変換しない、実施形態B1~B23のいずれか1つに記載の一本鎖キメラポリペプチド。 Embodiment B24. The single-chain chimeric polypeptide of any one of embodiments B1-B23, wherein the soluble tissue factor domain does not convert inactive factor X to factor Xa.
実施形態B25.一本鎖キメラポリペプチドが、哺乳動物における血液凝固を刺激しない、実施形態B1~B24のいずれか1つに記載の一本鎖キメラポリペプチド。 Embodiment B25. The single chain chimeric polypeptide of any one of embodiments B1-B24, wherein the single chain chimeric polypeptide does not stimulate blood clotting in a mammal.
実施形態B26.一本鎖キメラポリペプチドが、そのN末端及び/又はC末端に1つ以上の追加の標的結合ドメインを更に含む、実施形態B1~B25のいずれか1つに記載の一本鎖キメラポリペプチド。 Embodiment B26. The single chain chimeric polypeptide according to any one of embodiments B1-B25, wherein the single chain chimeric polypeptide further comprises one or more additional target binding domains at its N-terminus and/or C-terminus.
実施形態B27.一本鎖キメラポリペプチドが、そのN末端に1つ以上の追加の標的結合ドメインを含む、実施形態B26に記載の一本鎖キメラポリペプチド。 Embodiment B27. The single chain chimeric polypeptide of embodiment B26, wherein the single chain chimeric polypeptide comprises one or more additional target binding domains at its N-terminus.
実施形態B28.1つ以上追加の標的結合ドメインが、第1の標的結合ドメイン、第2の標的結合ドメイン、又は可溶性組織因子ドメインに直接隣接している、実施形態B27に記載の一本鎖キメラポリペプチド。 Embodiment B28. The single chain chimera of embodiment B27, wherein one or more additional target binding domains are directly adjacent to the first target binding domain, the second target binding domain, or the soluble tissue factor domain. Polypeptide.
実施形態B29.一本鎖キメラポリペプチドが、少なくとも1つの追加の標的結合ドメインのうちの1つと、第1の標的結合ドメイン、第2の標的結合ドメイン、又は可溶性組織因子ドメインとの間にリンカー配列を更に含む、実施形態B28に記載の一本鎖キメラポリペプチド。 Embodiment B29. The single-chain chimeric polypeptide further comprises a linker sequence between one of the at least one additional target binding domain and the first target binding domain, the second target binding domain, or the soluble tissue factor domain , a single-chain chimeric polypeptide according to embodiment B28.
実施形態B30.一本鎖キメラポリペプチドが、そのC末端に1つ以上の追加の標的結合ドメインを含む、実施形態B26に記載の一本鎖キメラポリペプチド。 Embodiment B30. The single chain chimeric polypeptide of embodiment B26, wherein the single chain chimeric polypeptide comprises one or more additional target binding domains at its C-terminus.
実施形態B31.1つ以上追加の標的結合ドメインのうちの1つが、第1の標的結合ドメイン、第2の標的結合ドメイン、又は可溶性組織因子ドメインに直接隣接している、実施形態B30に記載の一本鎖キメラポリペプチド。 Embodiment B31. According to embodiment B30, wherein one of the one or more additional target binding domains is directly adjacent to the first target binding domain, the second target binding domain, or the soluble tissue factor domain. Single chain chimeric polypeptide.
実施形態B32.一本鎖キメラポリペプチドが、少なくとも1つの追加の標的結合ドメインのうちの1つと、第1の標的結合ドメイン、第2の標的結合ドメイン、又は可溶性組織因子ドメインとの間にリンカー配列を更に含む、実施形態B30に記載の一本鎖キメラポリペプチド。 Embodiment B32. The single-chain chimeric polypeptide further comprises a linker sequence between one of the at least one additional target binding domain and the first target binding domain, the second target binding domain, or the soluble tissue factor domain , a single-chain chimeric polypeptide according to embodiment B30.
実施形態B33.一本鎖キメラポリペプチドが、そのN末端及びC末端に1つ以上の追加の標的結合ドメインを含む、実施形態B26に記載の一本鎖キメラポリペプチド。 Embodiment B33. The single chain chimeric polypeptide of embodiment B26, wherein the single chain chimeric polypeptide comprises one or more additional target binding domains at its N-terminus and C-terminus.
実施形態B34.N末端での1つ以上追加の抗原結合ドメインのうちの1つが、第1の標的結合ドメイン、第2の標的結合ドメイン、又は可溶性組織因子ドメインに直接隣接している、実施形態B33に記載の一本鎖キメラポリペプチド。 Embodiment B34. According to embodiment B33, wherein one of the one or more additional antigen binding domains at the N-terminus is directly adjacent to the first target binding domain, the second target binding domain, or the soluble tissue factor domain. Single chain chimeric polypeptide.
実施形態B35.一本鎖キメラポリペプチドが、N末端での1つ以上の追加の抗原結合ドメインのうちの1つと、第1の標的結合ドメイン、第2の標的結合ドメイン、又は可溶性組織因子ドメインとの間にリンカー配列を更に含む、実施形態B33に記載の一本鎖キメラポリペプチド。 Embodiment B35. a single-chain chimeric polypeptide between one of the one or more additional antigen binding domains at the N-terminus and the first target binding domain, the second target binding domain, or the soluble tissue factor domain; The single-chain chimeric polypeptide of embodiment B33, further comprising a linker sequence.
実施形態B36.C末端での1つ以上追加の抗原結合ドメインのうちの1つが、第1の標的結合ドメイン、第2の標的結合ドメイン、又は可溶性組織因子ドメインに直接隣接している、実施形態B33に記載の一本鎖キメラポリペプチド。 Embodiment B36. According to embodiment B33, wherein one of the one or more additional antigen binding domains at the C-terminus is directly adjacent to the first target binding domain, the second target binding domain, or the soluble tissue factor domain. Single chain chimeric polypeptide.
実施形態B37.一本鎖キメラポリペプチドが、C末端での1つ以上の追加の抗原結合ドメインのうちの1つと、第1の標的結合ドメイン、第2の標的結合ドメイン、又は可溶性組織因子ドメインとの間にリンカー配列を更に含む、実施形態B33に記載の一本鎖キメラポリペプチド。 Embodiment B37. a single chain chimeric polypeptide between one of the one or more additional antigen binding domains at the C-terminus and the first target binding domain, the second target binding domain, or the soluble tissue factor domain; The single-chain chimeric polypeptide of embodiment B33, further comprising a linker sequence.
実施形態B38.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインの各々がIL-2受容体又はIL-15受容体に特異的に結合する、実施形態B26~B37のいずれか1つに記載の一本鎖キメラポリペプチド。 Embodiment B38. Embodiments B26-B37, wherein the first target binding domain, the second target binding domain, and the one or more additional target binding domains each specifically bind to the IL-2 receptor or IL-15 receptor A single-chain chimeric polypeptide according to any one of
実施形態B39.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインの各々が同じアミノ酸配列を含む、実施形態B38に記載の一本鎖キメラポリペプチド。 Embodiment B39. The single-chain chimeric polypeptide of embodiment B38, wherein the first target binding domain, the second target binding domain, and the one or more additional target binding domains each comprise the same amino acid sequence.
実施形態B40.1つ以上の追加の標的結合ドメインが、抗原結合ドメインである、実施形態B26~B37のいずれか1つに記載の一本鎖キメラポリペプチド。 Embodiment B40. The single-chain chimeric polypeptide of any one of embodiments B26-B37, wherein the one or more additional target binding domains are antigen binding domains.
実施形態B41.抗原結合ドメインが、scFv又は単一ドメイン抗体を含む、実施形態B40に記載の一本鎖キメラポリペプチド。 Embodiment B41. The single-chain chimeric polypeptide of embodiment B40, wherein the antigen binding domain comprises a scFv or single domain antibody.
実施形態B42.1つ以上の追加の標的結合ドメインが、CD16a、CD28、CD3、CD33、CD20、CD19、CD22、CD123、IL-1R、IL-1、VEGF、IL-6R、IL-4、IL-10、PDL-1、TIGIT、PD-1、TIM3、CTLA4、MICA、MICB、IL-6、IL-8、TNFα、CD26、CD36、ULBP2、CD30、CD200、IGF-1R、MUC4AC、MUC5AC、Trop-2、CMET、EGFR、HER1、HER2、HER3、PSMA、CEA、B7H3、EPCAM、BCMA、P-カドヘリン、CEACAM5、UL16結合タンパク質、HLA-DR、DLL4、TYRO3、AXL、MER、CD122、CD155、PDGF-DD、TGF-β受容体II(TGF-βRII)リガンド、TGF-βRIIIリガンド、DNAM1リガンド、NKp46リガンド、NKp44リガンド、NKG2Dリガンド、NKp30リガンド、scMHCIリガンド、scMHCIIリガンド、scTCRリガンド、IL-1受容体、IL-2受容体、IL-3受容体、IL-7受容体、IL-8受容体、IL-10受容体、IL-12受容体、IL-15受容体、IL-17受容体、IL-18受容体、IL-21受容体、PDGF-DD受容体、幹細胞因子(SCF)受容体、幹細胞様チロシンキナーゼ3リガンド(FLT3L)受容体、MICA受容体、MICB受容体、ULP16結合タンパク質受容体、CD155受容体、CD122受容体、及びCD28受容体からなる群から選択される標的に特異的に結合する、実施形態B26~B37、B40、及びB41のいずれか1つに記載の一本鎖キメラポリペプチド。 Embodiment B42. The one or more additional target binding domains are CD16a, CD28, CD3, CD33, CD20, CD19, CD22, CD123, IL-1R, IL-1, VEGF, IL-6R, IL-4, IL -10, PDL-1, TIGIT, PD-1, TIM3, CTLA4, MICA, MICB, IL-6, IL-8, TNFα, CD26, CD36, ULBP2, CD30, CD200, IGF-1R, MUC4AC, MUC5AC, Trop -2, CMET, EGFR, HER1, HER2, HER3, PSMA, CEA, B7H3, EPCAM, BCMA, P-cadherin, CEACAM5, UL16 binding protein, HLA-DR, DLL4, TYRO3, AXL, MER, CD122, CD155, PDGF -DD, TGF-β receptor II (TGF-βRII) ligand, TGF-βRIII ligand, DNAM1 ligand, NKp46 ligand, NKp44 ligand, NKG2D ligand, NKp30 ligand, scMHCI ligand, scMHCII ligand, scTCR ligand, IL-1 receptor , IL-2 receptor, IL-3 receptor, IL-7 receptor, IL-8 receptor, IL-10 receptor, IL-12 receptor, IL-15 receptor, IL-17 receptor, IL -18 receptor, IL-21 receptor, PDGF-DD receptor, stem cell factor (SCF) receptor, stem cell-like tyrosine kinase 3 ligand (FLT3L) receptor, MICA receptor, MICB receptor, ULP16 binding protein receptor , CD155 receptor, CD122 receptor, and CD28 receptor. Polypeptide.
実施形態B43.1つ以上の追加の標的結合ドメインが、可溶性インターロイキン又はサイトカインタンパク質である、実施形態B6~B37、B40、及びB41のいずれか1つに記載の一本鎖キメラポリペプチド。 Embodiment B43. The single-chain chimeric polypeptide of any one of embodiments B6-B37, B40, and B41, wherein the one or more additional target binding domains are soluble interleukin or cytokine proteins.
実施形態B44.可溶性インターロイキン又はサイトカインタンパクが、IL-1、IL-2、IL-3、IL-7、IL-8、IL-10、IL-12、IL-15、IL-17、IL-18、IL-21、PDGF-DD、及びSCFからなる群から選択される、実施形態B43に記載の一本鎖キメラポリペプチド。 Embodiment B44. Soluble interleukin or cytokine protein is IL-1, IL-2, IL-3, IL-7, IL-8, IL-10, IL-12, IL-15, IL-17, IL-18, IL- 21, PDGF-DD, and SCF. The single-chain chimeric polypeptide of embodiment B43.
実施形態B45.1つ以上の追加の標的結合ドメインが、可溶性インターロイキン又はサイトカイン受容体である、実施形態B6~B37、B40、及びB41のいずれか1つに記載の一本鎖キメラポリペプチド。 Embodiment B45. The single-chain chimeric polypeptide of any one of embodiments B6-B37, B40, and B41, wherein the one or more additional target binding domains is a soluble interleukin or cytokine receptor.
実施形態B46.可溶性受容体が、可溶性TGF-β受容体II(TGF-βRII)及び可溶性TGF-βRIIIである、実施形態B45に記載の一本鎖キメラポリペプチド。 Embodiment B46. The single-chain chimeric polypeptide of embodiment B45, wherein the soluble receptors are soluble TGF-beta receptor II (TGF-βRII) and soluble TGF-βRIII.
実施形態B47.一本鎖キメラポリペプチドが、そのN末端にシグナル配列を更に含む、実施形態B1~B46のいずれか1つに記載の一本鎖キメラポリペプチド。 Embodiment B47. The single chain chimeric polypeptide of any one of embodiments B1-B46, wherein the single chain chimeric polypeptide further comprises a signal sequence at its N-terminus.
実施形態B48.一本鎖キメラポリペプチドが、一本鎖キメラポリペプチドのN末端又はC末端に位置付けられたペプチドタグを更に含む、実施形態B1~B47のいずれか1つに記載の一本鎖キメラポリペプチド。 Embodiment B48. The single chain chimeric polypeptide according to any one of embodiments B1-B47, wherein the single chain chimeric polypeptide further comprises a peptide tag positioned at the N-terminus or C-terminus of the single chain chimeric polypeptide.
実施形態B49.実施形態B1~B48に記載の一本鎖キメラポリペプチドのうちのいずれかを含む、組成物。 Embodiment B49. A composition comprising any of the single chain chimeric polypeptides of embodiments B1-B48.
実施形態B50.組成物が、医薬組成物である、実施形態B49に記載の組成物。 Embodiment B50. The composition of embodiment B49, wherein the composition is a pharmaceutical composition.
実施形態B51.実施形態B49又はB50に記載の組成物の少なくとも1つの用量を含む、キット。 Embodiment B51. A kit comprising at least one dose of the composition of embodiment B49 or B50.
実施形態B52.実施形態B1~B48のいずれか1つに記載の一本鎖キメラポリペプチドのうちのいずれかをコードする、核酸。 Embodiment B52. A nucleic acid encoding any of the single-chain chimeric polypeptides of any one of embodiments B1-B48.
実施形態B53.実施形態B52に記載の核酸を含む、ベクター。 Embodiment B53. A vector comprising the nucleic acid of embodiment B52.
実施形態B54.ベクターが、発現ベクターである、実施形態B53に記載のベクター。 Embodiment B54. The vector of embodiment B53, wherein the vector is an expression vector.
実施形態B55.実施形態B52に記載の核酸又は実施形態B53若しくはB54に記載のベクターを含む、細胞。 Embodiment B55. A cell comprising the nucleic acid of embodiment B52 or the vector of embodiment B53 or B54.
実施形態B56.一本鎖キメラポリペプチドを産生する方法であって、
一本鎖キメラポリペプチドの産生をもたらすのに十分な条件下で、実施形態B55に記載の細胞を培養培地中で培養することと、
一本キメラポリペプチドを細胞及び/又は培養培地から回収することと
を含む、方法。
Embodiment B56. A method of producing a single-chain chimeric polypeptide, comprising:
culturing the cells of embodiment B55 in a culture medium under conditions sufficient to result in the production of the single-chain chimeric polypeptide;
recovering the single chimeric polypeptide from the cells and/or the culture medium.
実施形態B57.実施形態B56に記載の方法によって産生された一本鎖キメラポリペプチド。 Embodiment B57. A single-chain chimeric polypeptide produced by the method of embodiment B56.
実施形態B58.可溶性ヒト組織因子ドメインが、配列番号97と少なくとも80%同一である配列を含む、実施形態B21に記載の一本鎖キメラポリペプチド。 Embodiment B58. The single-chain chimeric polypeptide of embodiment B21, wherein the soluble human tissue factor domain comprises a sequence that is at least 80% identical to SEQ ID NO:97.
実施形態B59.可溶性ヒト組織因子ドメインが、配列番号97と少なくとも90%同一である配列を含む、実施形態B58に記載の一本鎖キメラポリペプチド。 Embodiment B59. The single-chain chimeric polypeptide of embodiment B58, wherein the soluble human tissue factor domain comprises a sequence that is at least 90% identical to SEQ ID NO:97.
実施形態B60.可溶性ヒト組織因子ドメインが、配列番号97と少なくとも95%同一である配列を含む、実施形態B59に記載の一本鎖キメラポリペプチド。 Embodiment B60. The single-chain chimeric polypeptide of embodiment B59, wherein the soluble human tissue factor domain comprises a sequence that is at least 95% identical to SEQ ID NO:97.
実施形態B61.可溶性ヒト組織因子ドメインが、配列番号97と100%同一である配列を含む、実施形態B60に記載の一本鎖キメラポリペプチド。 Embodiment B61. The single-chain chimeric polypeptide of embodiment B60, wherein the soluble human tissue factor domain comprises a sequence that is 100% identical to SEQ ID NO:97.
実施形態B62.可溶性ヒト組織因子ドメインが、配列番号98と少なくとも80%同一である配列を含む、実施形態B21に記載の一本鎖キメラポリペプチド。 Embodiment B62. The single-chain chimeric polypeptide of embodiment B21, wherein the soluble human tissue factor domain comprises a sequence that is at least 80% identical to SEQ ID NO:98.
実施形態B63.可溶性ヒト組織因子ドメインが、配列番号98と少なくとも90%同一である配列を含む、実施形態B62に記載の一本鎖キメラポリペプチド。 Embodiment B63. The single-chain chimeric polypeptide of embodiment B62, wherein the soluble human tissue factor domain comprises a sequence that is at least 90% identical to SEQ ID NO:98.
実施形態B64.可溶性ヒト組織因子ドメインが、配列番号98と少なくとも95%同一である配列を含む、実施形態B63に記載の一本鎖キメラポリペプチド。 Embodiment B64. The single-chain chimeric polypeptide of embodiment B63, wherein the soluble human tissue factor domain comprises a sequence that is at least 95% identical to SEQ ID NO:98.
実施形態B65.可溶性ヒト組織因子ドメインが、配列番号98と100%同一である配列を含む、実施形態B64に記載の一本鎖キメラポリペプチド。 Embodiment B65. The single-chain chimeric polypeptide of embodiment B64, wherein the soluble human tissue factor domain comprises a sequence that is 100% identical to SEQ ID NO:98.
実施形態C1.多鎖キメラポリペプチドであって、
(a)第1のキメラポリペプチドであって、
(i)第1の標的結合ドメイン、
(ii)可溶性組織因子ドメイン、及び
(iii)一対の親和性ドメインの第1のドメイン
を含む、第1のキメラポリペプチド、
(b)第2のキメラポリペプチドであって、
(i)一対の親和性ドメインの第2のドメイン、及び
(ii)第2の標的結合ドメイン
を含む、第2のキメラポリペプチド
を含み、
第1のキメラポリペプチドと第2のキメラポリペプチドが、一対の親和性ドメインの第1のドメインと第2のドメインとの結合を介して会合する、
多鎖キメラポリペプチド。
Embodiment C1. A multi-chain chimeric polypeptide,
(a) a first chimeric polypeptide,
(i) a first target binding domain;
(ii) a soluble tissue factor domain, and (iii) a first domain of a pair of affinity domains,
(b) a second chimeric polypeptide,
a second chimeric polypeptide comprising (i) a second of the pair of affinity domains, and (ii) a second target binding domain;
the first chimeric polypeptide and the second chimeric polypeptide associate via binding of the first and second domains of a pair of affinity domains;
Multi-chain chimeric polypeptides.
実施形態C2.第1の標的結合ドメインと可溶性組織因子ドメインが、第1のキメラポリペプチド内で互いに直接隣接している、実施形態C1に記載の多鎖キメラポリペプチド。 Embodiment C2. The multichain chimeric polypeptide of embodiment C1, wherein the first target binding domain and the soluble tissue factor domain are directly adjacent to each other within the first chimeric polypeptide.
実施形態C3.第1のキメラポリペプチドが、第1のキメラポリペプチド内の第1の標的結合ドメインと可溶性組織因子ドメインとの間にリンカー配列を更に含む、実施形態C1に記載の多鎖キメラポリペプチド。 Embodiment C3. The multichain chimeric polypeptide of embodiment C1, wherein the first chimeric polypeptide further comprises a linker sequence between the first target binding domain and the soluble tissue factor domain within the first chimeric polypeptide.
実施形態C4.可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインが、第1のキメラポリペプチド内で互いに直接隣接している、実施形態C1~C3のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment C4. The multichain chimeric polypeptide of any one of embodiments C1-C3, wherein the soluble tissue factor domain and the first of the paired affinity domains are directly adjacent to each other within the first chimeric polypeptide. .
実施形態C5.第1のキメラポリペプチドが、第1のキメラポリペプチド内の可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間にリンカー配列を更に含む、実施形態C1~C3のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment C5. Any one of embodiments C1-C3, wherein the first chimeric polypeptide further comprises a linker sequence between the soluble tissue factor domain and the first of the pair of affinity domains within the first chimeric polypeptide A multi-chain chimeric polypeptide according to 1.
実施形態C6.一対の親和性ドメインの第2のドメインと第2の標的結合ドメインが、第2のキメラポリペプチド内で互いに直接隣接している、実施形態C1~C5のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment C6. The multichain chimera of any one of embodiments C1-C5, wherein the second domain and the second target binding domain of the pair of affinity domains are directly adjacent to each other within the second chimeric polypeptide. Polypeptide.
実施形態C7.第2のキメラポリペプチドが、第2のキメラポリペプチド内の一対の親和性ドメインの第2のドメインと第2の標的結合ドメインとの間にリンカー配列を更に含む、実施形態C1~C5のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment C7. Any of embodiments C1-C5, wherein the second chimeric polypeptide further comprises a linker sequence between the second of the pair of affinity domains and the second target binding domain within the second chimeric polypeptide. or a multi-chain chimeric polypeptide according to any one of the above.
実施形態C8.第1の標的結合ドメイン及び第2の標的結合ドメインが同じ抗原に特異的に結合する、実施形態C1~C7のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment C8. The multichain chimeric polypeptide of any one of embodiments C1-C7, wherein the first target binding domain and the second target binding domain specifically bind the same antigen.
実施形態C9.第1の標的結合ドメイン及び第2の標的結合ドメインが同じエピトープに特異的に結合する、実施形態C8に記載の多鎖キメラポリペプチド。 Embodiment C9. The multichain chimeric polypeptide of embodiment C8, wherein the first target binding domain and the second target binding domain specifically bind to the same epitope.
実施形態C10.第1の標的結合ドメイン及び第2の標的結合ドメインが同じアミノ酸配列を含む、実施形態C9に記載の多鎖キメラポリペプチド。 Embodiment C10. The multichain chimeric polypeptide of embodiment C9, wherein the first target binding domain and the second target binding domain comprise the same amino acid sequence.
実施形態C11.第1の標的結合ドメイン及び第2の標的結合ドメインが異なる抗原に特異的に結合する、実施形態C1~C7のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment C11. The multichain chimeric polypeptide of any one of embodiments C1-C7, wherein the first target binding domain and the second target binding domain specifically bind different antigens.
実施形態C12.第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方が、抗原結合ドメインである、実施形態C1~C11のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment C12. The multi-chain chimeric polypeptide of any one of embodiments C1-C11, wherein one or both of the first target binding domain and the second target binding domain are antigen binding domains.
実施形態C13.第1の標的結合ドメイン及び第2の標的結合ドメインが各々、抗原結合ドメインである、実施形態C12に記載の多鎖キメラポリペプチド。 Embodiment C13. The multi-chain chimeric polypeptide of embodiment C12, wherein the first target binding domain and the second target binding domain are each antigen binding domains.
実施形態C14.抗原結合ドメインが、scFv又は単一ドメイン抗体を含む、実施形態C12又はC13に記載の多鎖キメラポリペプチド。 Embodiment C14. The multi-chain chimeric polypeptide of embodiment C12 or C13, wherein the antigen binding domain comprises a scFv or single domain antibody.
実施形態C15.第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方が、CD16a、CD28、CD3、CD33、CD20、CD19、CD22、CD123、IL-1R、IL-1、VEGF、IL-6R、IL-4、IL-10、PDL-1、TIGIT、PD-1、TIM3、CTLA4、MICA、MICB、IL-6、IL-8、TNFα、CD26、CD36、ULBP2、CD30、CD200、IGF-1R、MUC4AC、MUC5AC、Trop-2、CMET、EGFR、HER1、HER2、HER3、PSMA、CEA、B7H3、EPCAM、BCMA、P-カドヘリン、CEACAM5、UL16結合タンパク質、HLA-DR、DLL4、TYRO3、AXL、MER、CD122、CD155、PDGF-DD、TGF-β受容体II(TGF-βRII)リガンド、TGF-βRIIIリガンド、DNAM1リガンド、NKp46リガンド、NKp44リガンド、NKG2Dリガンド、NKp30リガンド、scMHCIリガンド、scMHCIIリガンド、scTCRリガンド、IL-1受容体、IL-2受容体、IL-3受容体、IL-7受容体、IL-8受容体、IL-10受容体、IL-12受容体、IL-15受容体、IL-17受容体、IL-18受容体、IL-21受容体、PDGF-DD受容体、幹細胞因子(SCF)受容体、幹細胞様チロシンキナーゼ3リガンド(FLT3L)受容体、MICA受容体、MICB受容体、ULP16結合タンパク質受容体、CD155受容体、CD122受容体、及びCD28受容体からなる群から選択される標的に特異的に結合する、実施形態C1~C14のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment C15. one or both of the first target binding domain and the second target binding domain are CD16a, CD28, CD3, CD33, CD20, CD19, CD22, CD123, IL-1R, IL-1, VEGF, IL-6R, IL -4, IL-10, PDL-1, TIGIT, PD-1, TIM3, CTLA4, MICA, MICB, IL-6, IL-8, TNFα, CD26, CD36, ULBP2, CD30, CD200, IGF-1R, MUC4AC , MUC5AC, Trop-2, CMET, EGFR, HER1, HER2, HER3, PSMA, CEA, B7H3, EPCAM, BCMA, P-cadherin, CEACAM5, UL16 binding protein, HLA-DR, DLL4, TYRO3, AXL, MER, CD122 , CD155, PDGF-DD, TGF-β receptor II (TGF-βRII) ligand, TGF-βRIII ligand, DNAM1 ligand, NKp46 ligand, NKp44 ligand, NKG2D ligand, NKp30 ligand, scMHCI ligand, scMHCII ligand, scTCR ligand, IL -1 receptor, IL-2 receptor, IL-3 receptor, IL-7 receptor, IL-8 receptor, IL-10 receptor, IL-12 receptor, IL-15 receptor, IL-17 receptor, IL-18 receptor, IL-21 receptor, PDGF-DD receptor, stem cell factor (SCF) receptor, stem cell-like tyrosine kinase 3 ligand (FLT3L) receptor, MICA receptor, MICB receptor, ULP16 The multichain chimeric polypeptide of any one of embodiments C1-C14, which specifically binds a target selected from the group consisting of binding protein receptor, CD155 receptor, CD122 receptor, and CD28 receptor. .
実施形態C16.第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方が、可溶性インターロイキン又はサイトカインタンパク質である、実施形態C1~C14のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment C16. The multichain chimeric polypeptide of any one of embodiments C1-C14, wherein one or both of the first and second target binding domains is a soluble interleukin or cytokine protein.
実施形態C17.可溶性インターロイキン又はサイトカインタンパク質が、IL-1、IL-2、IL-3、IL-7、IL-8、IL-10、IL-12、IL-15、IL-17、IL-18、IL-21、PDGF-D、SCF、FLT3L、MICA、MICB、及びULP16結合タンパク質からなる群から選択される、実施形態C16に記載の多鎖キメラポリペプチド。 Embodiment C17. Soluble interleukin or cytokine proteins are IL-1, IL-2, IL-3, IL-7, IL-8, IL-10, IL-12, IL-15, IL-17, IL-18, IL- 21, PDGF-D, SCF, FLT3L, MICA, MICB, and ULP16 binding protein.
実施形態C18.第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方が、可溶性インターロイキン又はサイトカイン受容体である、実施形態C1~C14のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment C18. The multichain chimeric polypeptide of any one of embodiments C1-C14, wherein one or both of the first target binding domain and the second target binding domain is a soluble interleukin or cytokine receptor.
実施形態C19.可溶性受容体が、可溶性TGF-β受容体II(TGF-βRII)、可溶性TGF-βRIII、可溶性NKG2D、可溶性NKp30、可溶性NKp44、可溶性NKp46、可溶性DNAM1、scMHCI、scMHCII、scTCR、可溶性CD155、又は可溶性CD28である、実施形態C18に記載の多鎖キメラポリペプチド。 Embodiment C19. the soluble receptor is soluble TGF-β receptor II (TGF-βRII), soluble TGF-βRIII, soluble NKG2D, soluble NKp30, soluble NKp44, soluble NKp46, soluble DNAM1, scMHCI, scMHCII, scTCR, soluble CD155, or soluble CD28 The multi-chain chimeric polypeptide of embodiment C18, which is
実施形態C20.第1のキメラポリペプチドが、1つ以上の追加の標的結合ドメインを更に含み、1つ以上の追加の抗原結合ドメインのうちの少なくとも1つが、可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間に位置付けられている、実施形態C1~C19のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment C20. The first chimeric polypeptide further comprises one or more additional target binding domains, wherein at least one of the one or more additional antigen binding domains comprises the soluble tissue factor domain and the first of the paired affinity domains. The multi-chain chimeric polypeptide of any one of embodiments C1-C19, which is positioned between a domain of
実施形態C21.第1のキメラポリペプチドが、可溶性組織因子ドメインと1つ以上の追加の抗原結合ドメインのうちの少なくとも1つとの間にリンカー配列、及び/又は1つ以上の追加の抗原結合ドメインのうちの少なくとも1つと一対の親和性ドメインの第1のドメインとの間にリンカー配列を更に含む、実施形態C20に記載の多鎖キメラポリペプチド。 Embodiment C21. The first chimeric polypeptide comprises a linker sequence between the soluble tissue factor domain and at least one of the one or more additional antigen binding domains, and/or at least one of the one or more additional antigen binding domains. The multichain chimeric polypeptide of embodiment C20, further comprising a linker sequence between one and the first of the pair of affinity domains.
実施形態C22.第1のキメラポリペプチドが、第1のキメラポリペプチドのN末端及び/又はC末端に1つ以上の追加の標的結合ドメインを更に含む、実施形態C1~C19のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment C22. The multiple according to any one of embodiments C1-C19, wherein the first chimeric polypeptide further comprises one or more additional target binding domains at the N-terminus and/or C-terminus of the first chimeric polypeptide. chain chimeric polypeptides.
実施形態C23.1つ以上の追加の標的結合ドメインのうちの少なくとも1つが、第1のキメラポリペプチド内の一対の親和性ドメインの第1のドメインに直接隣接している、実施形態C22に記載の多鎖キメラポリペプチド。 Embodiment C23. According to embodiment C22, wherein at least one of the one or more additional target binding domains is directly adjacent to the first of the pair of affinity domains within the first chimeric polypeptide multi-chain chimeric polypeptide of.
実施形態C24.第1のキメラポリペプチドが、1つ以上の追加の標的結合ドメインのうちの少なくとも1つと一対の親和性ドメインの第1のドメインとの間にリンカー配列を更に含む、実施形態C22に記載の多鎖キメラポリペプチド。 Embodiment C24. The multiple of embodiment C22, wherein the first chimeric polypeptide further comprises a linker sequence between at least one of the one or more additional target binding domains and the first of the pair of affinity domains. chain chimeric polypeptides.
実施形態C25.1つ以上の追加の標的結合ドメインのうちの少なくとも1つが、第1のキメラポリペプチド内の第1の標的結合ドメインに直接隣接している、実施形態C22に記載の多鎖キメラポリペプチド。 Embodiment C25. The multichain chimera of embodiment C22, wherein at least one of the one or more additional target binding domains is directly adjacent to the first target binding domain within the first chimeric polypeptide Polypeptide.
実施形態C26.第1のキメラポリペプチドが、1つ以上の追加の標的結合ドメインのうちの少なくとも1つと第1の標的結合ドメインとの間にリンカー配列を更に含む、実施形態C22に記載の多鎖キメラポリペプチド。 Embodiment C26. The multichain chimeric polypeptide of embodiment C22, wherein the first chimeric polypeptide further comprises a linker sequence between at least one of the one or more additional target binding domains and the first target binding domain. .
実施形態C27.1つ以上の追加の標的結合ドメインのうちの少なくとも1つが、第1のキメラポリペプチドのN末端及び/又はC末端に配置されており、1つ以上の追加の標的結合ドメインのうちの少なくとも1つが、第1のキメラポリペプチド内の可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間に位置付けられている、実施形態C22に記載の多鎖キメラポリペプチド。 Embodiment C27. At least one of the one or more additional target binding domains is located at the N-terminus and/or C-terminus of the first chimeric polypeptide, wherein the one or more additional target binding domains The multichain chimeric polypeptide of embodiment C22, wherein at least one of is positioned between the soluble tissue factor domain and the first of the pair of affinity domains within the first chimeric polypeptide.
実施形態C28.N末端に配置された1つ以上の追加の標的結合ドメインのうちの少なくとも1つの追加の標的結合ドメインが、第1のキメラポリペプチド内の第1の標的結合ドメイン又は一対の親和性ドメインの第1のドメインに直接隣接している、実施形態C27に記載の多鎖キメラポリペプチド。 Embodiment C28. At least one additional target binding domain of the one or more additional target binding domains located at the N-terminus is the first target binding domain in the first chimeric polypeptide or the first of the pair of affinity domains The multichain chimeric polypeptide of embodiment C27, which is directly contiguous to one domain.
実施形態C29.第1のキメラポリペプチドが、第1のキメラポリペプチド内の少なくとも1つの追加の標的結合ドメインと第1の標的結合ドメイン又は一対の親和性ドメインの第1のドメインとの間に配置されたリンカー配列を更に含む、実施形態C27に記載の多鎖キメラポリペプチド。 Embodiment C29. a linker wherein the first chimeric polypeptide is positioned between at least one additional target binding domain within the first chimeric polypeptide and the first target binding domain or the first domain of the pair of affinity domains The multichain chimeric polypeptide of embodiment C27, further comprising a sequence.
実施形態C30.C末端に配置された1つ以上の追加の標的結合ドメインのうちの少なくとも1つの追加の標的結合ドメインが、第1のキメラポリペプチド内の第1の標的結合ドメイン又は一対の親和性ドメインの第1のドメインに直接隣接している、実施形態C27に記載の多鎖キメラポリペプチド。 Embodiment C30. At least one additional target binding domain of the one or more additional target binding domains located at the C-terminus is the first target binding domain in the first chimeric polypeptide or the first of the pair of affinity domains The multichain chimeric polypeptide of embodiment C27, which is directly contiguous to one domain.
実施形態C31.第1のキメラポリペプチドが、第1のキメラポリペプチド内の少なくとも1つの追加の標的結合ドメインと第1の標的結合ドメイン又は一対の親和性ドメインの第1のドメインとの間に配置されたリンカー配列を更に含む、実施形態C27に記載の多鎖キメラポリペプチド。 Embodiment C31. a linker wherein the first chimeric polypeptide is positioned between at least one additional target binding domain within the first chimeric polypeptide and the first target binding domain or the first domain of the pair of affinity domains The multichain chimeric polypeptide of embodiment C27, further comprising a sequence.
実施形態C32.可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間に位置付けられた1つ以上の追加の標的結合ドメインのうちの少なくとも1つが、可溶性組織因子ドメイン、及び/又は一対の親和性ドメインの第1のドメインに直接隣接している、実施形態C27に記載の多鎖キメラポリペプチド。 Embodiment C32. at least one of the one or more additional target binding domains positioned between the soluble tissue factor domain and the first domain of the pair of affinity domains is the soluble tissue factor domain and/or the affinity pair The multi-chain chimeric polypeptide of embodiment C27, wherein the domains are directly adjacent to the first domain.
実施形態C33.第1のキメラポリペプチドが、(i)可溶性組織因子ドメインと、可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間に位置付けられた1つ以上の追加の標的結合ドメインのうちの少なくとも1つとの間、及び/又は(ii)一対の親和性ドメインの第1のドメインと、可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間に位置付けられた1つ以上の追加の標的結合ドメインのうちの少なくとも1つとの間に配置されたリンカー配列を更に含む、実施形態C27に記載の多鎖キメラポリペプチド。 Embodiment C33. the first chimeric polypeptide comprises: (i) the soluble tissue factor domain and one or more additional target binding domains positioned between the soluble tissue factor domain and the first of the pair of affinity domains; and/or (ii) between the first domain of the pair of affinity domains and the soluble tissue factor domain and the first domain of the pair of affinity domains The multichain chimeric polypeptide of embodiment C27, further comprising a linker sequence interposed with at least one of the additional target binding domains of embodiment C27.
実施形態C34.第2のキメラポリペプチドが、第2のキメラポリペプチドのN末端又はC末端に1つ以上の追加の標的結合ドメインを更に含む、実施形態C1~C33のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment C34. The multichain chimera of any one of embodiments C1-C33, wherein the second chimeric polypeptide further comprises one or more additional target binding domains at the N-terminus or C-terminus of the second chimeric polypeptide. Polypeptide.
実施形態C35.1つ以上の追加の標的結合ドメインのうちの少なくとも1つが、第2のキメラポリペプチド内の一対の親和性ドメインの第2のドメインに直接隣接している、実施形態C34に記載の多鎖キメラポリペプチド。 Embodiment C35. Described in embodiment C34, wherein at least one of the one or more additional target binding domains is directly adjacent to a second of the pair of affinity domains within the second chimeric polypeptide multi-chain chimeric polypeptide of.
実施形態C36.第2のキメラポリペプチドが、第2のキメラポリペプチド内の1つ以上の追加の標的結合ドメインのうちの少なくとも1つと一対の親和性ドメインの第2のドメインとの間にリンカー配列を更に含む、実施形態C34に記載の多鎖キメラポリペプチド。 Embodiment C36. The second chimeric polypeptide further comprises a linker sequence between at least one of the one or more additional target binding domains in the second chimeric polypeptide and the second of the pair of affinity domains , embodiment C34.
実施形態C37.1つ以上の追加の標的結合ドメインのうちの少なくとも1つが、第2のキメラポリペプチド内の第2の標的結合ドメインに直接隣接している、実施形態C34に記載の多鎖キメラポリペプチド。 Embodiment C37. The multichain chimera of embodiment C34, wherein at least one of the one or more additional target binding domains is directly adjacent to the second target binding domain within the second chimeric polypeptide Polypeptide.
実施形態C38.第2のキメラポリペプチドが、第2のキメラポリペプチド内の1つ以上の追加の標的結合ドメインのうちの少なくとも1つと第2の標的結合ドメインとの間にリンカー配列を更に含む、実施形態C34に記載の多鎖キメラポリペプチド。 Embodiment C38. Embodiment C34, wherein the second chimeric polypeptide further comprises a linker sequence between at least one of the one or more additional target binding domains within the second chimeric polypeptide and the second target binding domain. 3. A multi-chain chimeric polypeptide according to .
実施形態C39.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの2つ以上が同じ抗原に特異的に結合する、実施形態C20~C38のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment C39. Any one of embodiments C20-C38, wherein two or more of the first target binding domain, the second target binding domain, and the one or more additional target binding domains specifically bind to the same antigen. 3. A multi-chain chimeric polypeptide according to .
実施形態C40.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの2つ以上が同じエピトープに特異的に結合する、実施形態C39に記載の多鎖キメラポリペプチド。 Embodiment C40. The multichain chimeric poly of embodiment C39, wherein two or more of the first target binding domain, the second target binding domain, and the one or more additional target binding domains specifically bind the same epitope. peptide.
実施形態C41.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの2つ以上が同じアミノ酸配列を含む、実施形態C40に記載の多鎖キメラポリペプチド。 Embodiment C41. The multichain chimeric polypeptide of embodiment C40, wherein two or more of the first target binding domain, the second target binding domain, and the one or more additional target binding domains comprise the same amino acid sequence.
実施形態C42.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインが各々、同じ抗原に特異的に結合する、実施形態C39に記載の多鎖キメラポリペプチド。 Embodiment C42. The multichain chimeric polypeptide of embodiment C39, wherein the first target binding domain, the second target binding domain, and the one or more additional target binding domains each specifically bind the same antigen.
実施形態C43.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインが各々、同じエピトープに特異的に結合する、実施形態C42に記載の多鎖キメラポリペプチド。 Embodiment C43. The multichain chimeric polypeptide of embodiment C42, wherein the first target binding domain, the second target binding domain, and the one or more additional target binding domains each specifically bind the same epitope.
実施形態C44.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインが各々、同じアミノ酸配列を含む、実施形態C43に記載の多鎖キメラポリペプチド。 Embodiment C44. The multichain chimeric polypeptide of embodiment C43, wherein the first target binding domain, the second target binding domain, and the one or more additional target binding domains each comprise the same amino acid sequence.
実施形態C45.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインが異なる抗原に特異的に結合する、実施形態C20~C38のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment C45. The multichain chimera of any one of embodiments C20-C38, wherein the first target binding domain, the second target binding domain, and the one or more additional target binding domains specifically bind different antigens. Polypeptide.
実施形態C46.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の標的結合ドメインのうちの1つ以上が、抗原結合ドメインである、実施形態C20~C45のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment C46. The multiple of any one of embodiments C20-C45, wherein one or more of the first target binding domain, the second target binding domain, and the one or more target binding domains are antigen binding domains. chain chimeric polypeptides.
実施形態C47.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインが各々、抗原結合ドメインである、実施形態C46に記載の多鎖キメラポリペプチド。 Embodiment C47. The multi-chain chimeric polypeptide of embodiment C46, wherein each of the first target binding domain, the second target binding domain, and the one or more additional target binding domains is an antigen binding domain.
実施形態C48.抗原結合ドメインが、scFvを含む、実施形態C47に記載の多鎖キメラポリペプチド。 Embodiment C48. The multi-chain chimeric polypeptide of embodiment C47, wherein the antigen binding domain comprises a scFv.
実施形態C49.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の標的結合ドメインのうちの1つ以上が、CD16a、CD28、CD3、CD33、CD20、CD19、CD22、CD123、IL-1R、IL-1、VEGF、IL-6R、IL-4、IL-10、PDL-1、TIGIT、PD-1、TIM3、CTLA4、MICA、MICB、IL-6、IL-8、TNFα、CD26、CD36、ULBP2、CD30、CD200、IGF-1R、MUC4AC、MUC5AC、Trop-2、CMET、EGFR、HER1、HER2、HER3、PSMA、CEA、B7H3、EPCAM、BCMA、P-カドヘリン、CEACAM5、UL16結合タンパク質、HLA-DR、DLL4、TYRO3、AXL、MER、CD122、CD155、PDGF-DD、TGF-β受容体II(TGF-βRII)リガンド、TGF-βRIIIリガンド、DNAM1リガンド、NKp46リガンド、NKp44リガンド、NKG2Dリガンド、NKp30リガンド、scMHCIリガンド、scMHCIIリガンド、scTCRリガンド、IL-1受容体、IL-2受容体、IL-3受容体、IL-7受容体、IL-8受容体、IL-10受容体、IL-12受容体、IL-15受容体、IL-17受容体、IL-18受容体、IL-21受容体、PDGF-DD受容体、幹細胞因子(SCF)受容体、幹細胞様チロシンキナーゼ3リガンド(FLT3L)受容体、MICA受容体、MICB受容体、ULP16結合タンパク質受容体、CD155受容体、CD122受容体、及びCD3受容体、及びCD28受容体からなる群から選択される標的に特異的に結合する、実施形態C20~C48のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment C49. one or more of the first target binding domain, the second target binding domain, and the one or more target binding domains are CD16a, CD28, CD3, CD33, CD20, CD19, CD22, CD123, IL-1R, IL-1, VEGF, IL-6R, IL-4, IL-10, PDL-1, TIGIT, PD-1, TIM3, CTLA4, MICA, MICB, IL-6, IL-8, TNFα, CD26, CD36, ULBP2, CD30, CD200, IGF-1R, MUC4AC, MUC5AC, Trop-2, CMET, EGFR, HER1, HER2, HER3, PSMA, CEA, B7H3, EPCAM, BCMA, P-cadherin, CEACAM5, UL16 binding protein, HLA- DR, DLL4, TYRO3, AXL, MER, CD122, CD155, PDGF-DD, TGF-β receptor II (TGF-βRII) ligand, TGF-βRIII ligand, DNAM1 ligand, NKp46 ligand, NKp44 ligand, NKG2D ligand, NKp30 ligand , scMHC I ligand, scMHC II ligand, scTCR ligand, IL-1 receptor, IL-2 receptor, IL-3 receptor, IL-7 receptor, IL-8 receptor, IL-10 receptor, IL-12 receptor receptor, IL-15 receptor, IL-17 receptor, IL-18 receptor, IL-21 receptor, PDGF-DD receptor, stem cell factor (SCF) receptor, stem cell-like tyrosine kinase 3 ligand (FLT3L) receptor specifically binds to a target selected from the group consisting of receptors, MICA receptors, MICB receptors, ULP16 binding protein receptors, CD155 receptors, CD122 receptors, and CD3 receptors, and CD28 receptors. A multi-chain chimeric polypeptide according to any one of C20-C48.
実施形態C50.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの1つ以上が、可溶性インターロイキン又はサイトカインタンパク質である、実施形態C20~C48のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment C50. Any one of embodiments C20-C48, wherein one or more of the first target binding domain, the second target binding domain, and the one or more additional target binding domains is a soluble interleukin or cytokine protein A multi-chain chimeric polypeptide according to 1.
実施形態C51.可溶性インターロイキン、サイトカイン、又はリガンドタンパク質が、IL-1、IL-2、IL-3、IL-7、IL-8、IL-10、IL-12、IL-15、IL-17、IL-18、IL-21、PDGF-DD、及びSCF、FLT3L、MICA、MICB、及びULP16結合タンパク質からなる群から選択される、実施形態C50に記載の多鎖キメラポリペプチド。 Embodiment C51. soluble interleukin, cytokine, or ligand protein is IL-1, IL-2, IL-3, IL-7, IL-8, IL-10, IL-12, IL-15, IL-17, IL-18 , IL-21, PDGF-DD, and SCF, FLT3L, MICA, MICB, and ULP16 binding proteins.
実施形態C52.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの1つ以上が、可溶性インターロイキン又はサイトカイン受容体である、実施形態C20~C48のいずれか1つに記載の多鎖キメラポリペプチド。
Embodiment C52. Any of embodiments C20-C48, wherein one or more of the first target binding domain, the second target binding domain, and the one or more additional target binding domains is a soluble interleukin or
実施形態C53.可溶性受容体が、可溶性TGF-β受容体II(TGF-βRII)、可溶性TGF-βRIII、可溶性NKG2D、可溶性NKp30、可溶性NKp44、可溶性NKp46、可溶性DNAM1、scMHCI、scMHCII、scTCR、可溶性CD155、可溶性CD122、可溶性CD3、又は可溶性CD28である、実施形態C52に記載の多鎖キメラポリペプチド。 Embodiment C53. the soluble receptor is soluble TGF-β receptor II (TGF-βRII), soluble TGF-βRIII, soluble NKG2D, soluble NKp30, soluble NKp44, soluble NKp46, soluble DNAM1, scMHCI, scMHCII, scTCR, soluble CD155, soluble CD122, The multichain chimeric polypeptide of embodiment C52, which is soluble CD3, or soluble CD28.
実施形態C54.第1のキメラポリペプチドが、第1のキメラポリペプチドのN末端又はC末端にペプチドタグを更に含む、実施形態C1~C53のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment C54. The multi-chain chimeric polypeptide of any one of embodiments C1-C53, wherein the first chimeric polypeptide further comprises a peptide tag at the N-terminus or C-terminus of the first chimeric polypeptide.
実施形態C55.第2のキメラポリペプチドが、第2のキメラポリペプチドN末端又はC末端にペプチドタグを更に含む、実施形態C1~C53のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment C55. The multi-chain chimeric polypeptide of any one of embodiments C1-C53, wherein the second chimeric polypeptide further comprises a peptide tag at the N-terminus or C-terminus of the second chimeric polypeptide.
実施形態C56.可溶性組織因子ドメインが、可溶性ヒト組織因子ドメインである、実施形態C1~C55のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment C56. The multichain chimeric polypeptide of any one of embodiments C1-C55, wherein the soluble tissue factor domain is a soluble human tissue factor domain.
実施形態C57.可溶性ヒト組織因子ドメインが、配列番号93と少なくとも80%同一である配列を含む、実施形態C56に記載の多鎖キメラポリペプチド。 Embodiment C57. The multichain chimeric polypeptide of embodiment C56, wherein the soluble human tissue factor domain comprises a sequence that is at least 80% identical to SEQ ID NO:93.
実施形態C58.可溶性ヒト組織因子ドメインが、配列番号93と少なくとも90%同一である配列を含む、実施形態C57に記載の多鎖キメラポリペプチド。 Embodiment C58. The multichain chimeric polypeptide of embodiment C57, wherein the soluble human tissue factor domain comprises a sequence that is at least 90% identical to SEQ ID NO:93.
実施形態C59.可溶性ヒト組織因子ドメインが、配列番号93と少なくとも95%同一である配列を含む、実施形態C58に記載の多鎖キメラポリペプチド。 Embodiment C59. The multichain chimeric polypeptide of embodiment C58, wherein the soluble human tissue factor domain comprises a sequence that is at least 95% identical to SEQ ID NO:93.
実施形態C60.可溶性ヒト組織因子ドメインが、
成熟野生型ヒト組織因子タンパク質のアミノ酸20位に対応するアミノ酸の位置にリジン、
成熟野生型ヒト組織因子タンパク質のアミノ酸22位に対応するアミノ酸の位置にイソロイシン、
成熟野生型ヒト組織因子タンパク質のアミノ酸45位に対応するアミノ酸の位置にトリプトファン、
成熟野生型ヒト組織因子タンパク質のアミノ酸58位に対応するアミノ酸の位置にアスパラギン酸、
成熟野生型ヒト組織因子タンパク質のアミノ酸94位に対応するアミノ酸の位置にチロシン、
成熟野生型ヒト組織因子タンパク質のアミノ酸135位に対応するアミノ酸の位置にアルギニン、及び
成熟野生型ヒト組織因子タンパク質のアミノ酸140位に対応するアミノ酸の位置にフェニルアラニンのうちのいずれも含まない、実施形態C56~C59のいずれか一つに記載の方法。
Embodiment C60. A soluble human tissue factor domain is
a lysine at the amino acid position corresponding to
an isoleucine at the amino acid position corresponding to
tryptophan at the amino acid position corresponding to
an aspartic acid at the amino acid position corresponding to amino acid position 58 of the mature wild-type human tissue factor protein;
a tyrosine at the amino acid position corresponding to amino acid position 94 of the mature wild-type human tissue factor protein;
An embodiment that does not include either arginine at the amino acid position corresponding to amino acid position 135 of the mature wild-type human tissue factor protein and phenylalanine at the amino acid position corresponding to
実施形態C61.可溶性ヒト組織因子ドメインが、
成熟野生型ヒト組織因子タンパク質のアミノ酸20位に対応するアミノ酸の位置にリジン、
成熟野生型ヒト組織因子タンパク質のアミノ酸22位に対応するアミノ酸の位置にイソロイシン、
成熟野生型ヒト組織因子タンパク質のアミノ酸45位に対応するアミノ酸の位置にトリプトファン、
成熟野生型ヒト組織因子タンパク質のアミノ酸58位に対応するアミノ酸の位置にアスパラギン酸、
成熟野生型ヒト組織因子タンパク質のアミノ酸94位に対応するアミノ酸の位置にチロシン、
成熟野生型ヒト組織因子タンパク質のアミノ酸135位に対応するアミノ酸の位置にアルギニン、及び
成熟野生型ヒト組織因子タンパク質のアミノ酸140位に対応するアミノ酸の位置にフェニルアラニンのうちのいずれも含まない、実施形態C60に記載の方法。
Embodiment C61. A soluble human tissue factor domain is
a lysine at the amino acid position corresponding to
an isoleucine at the amino acid position corresponding to
tryptophan at the amino acid position corresponding to
an aspartic acid at the amino acid position corresponding to amino acid position 58 of the mature wild-type human tissue factor protein;
a tyrosine at the amino acid position corresponding to amino acid position 94 of the mature wild-type human tissue factor protein;
An embodiment that does not include either arginine at the amino acid position corresponding to amino acid position 135 of the mature wild-type human tissue factor protein and phenylalanine at the amino acid position corresponding to
実施形態C62.可溶性組織因子ドメインが、第VIIa因子に結合することができない、実施形態C1~C61のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment C62. The multichain chimeric polypeptide of any one of embodiments C1-C61, wherein the soluble tissue factor domain is incapable of binding Factor VIIa.
実施形態C63.可溶性組織因子ドメインが、不活性第X因子を第Xa因子に変換しない、実施形態C1~C62のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment C63. The multichain chimeric polypeptide of any one of embodiments C1-C62, wherein the soluble tissue factor domain does not convert inactive factor X to factor Xa.
実施形態C64.多鎖キメラポリペプチドが、哺乳動物における血液凝固を刺激しない、実施形態C1~C63のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment C64. The multi-chain chimeric polypeptide of any one of embodiments C1-C63, wherein the multi-chain chimeric polypeptide does not stimulate blood clotting in a mammal.
実施形態C65.一対の親和性ドメインが、ヒトIL-15受容体のアルファ鎖(IL15Rα)由来のスシドメイン、及び可溶性IL-15である、実施形態C1~C64のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment C65. The multichain chimeric polypeptide of any one of embodiments C1-C64, wherein the pair of affinity domains is a sushi domain derived from the alpha chain of the human IL-15 receptor (IL15Rα) and soluble IL-15. .
実施形態C66.可溶性IL-15が、D8N又はD8Aアミノ酸置換を有する、実施形態C65に記載の多鎖キメラポリペプチド。 Embodiment C66. The multi-chain chimeric polypeptide of embodiment C65, wherein the soluble IL-15 has a D8N or D8A amino acid substitution.
実施形態C67.ヒトIL-15Rαが、成熟全長IL-15Rαである、実施形態C65又はC66に記載の多鎖キメラポリペプチド。 Embodiment C67. The multi-chain chimeric polypeptide of embodiment C65 or C66, wherein the human IL-15Rα is mature full-length IL-15Rα.
実施形態C68.一対の親和性ドメインが、バルナーゼとバルンスター、PKAとAKAP、変異RNaseI断片に基づくアダプター/ドッキングタグモジュール、並びに、タンパク質シンタキシン、シナプトタグミン、シナプトブレビン、及びSNAP25の相互作用に基づくSNAREモジュールからなる群から選択される、実施形C1~C64のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment C68. The paired affinity domains are selected from the group consisting of barnase and barnstar, PKA and AKAP, adapter/docking tag modules based on mutated RNase I fragments, and SNARE modules based on interactions of proteins syntaxin, synaptotagmin, synaptobrevin, and SNAP25. A multi-chain chimeric polypeptide according to any one of embodiments C1-C64, wherein:
実施形態C69.第1のキメラポリペプチド及び/又は第2のキメラポリペプチドが、そのN末端にシグナル配列を更に含む、実施形態C1~C68のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment C69. The multichain chimeric polypeptide according to any one of embodiments C1-C68, wherein the first chimeric polypeptide and/or the second chimeric polypeptide further comprises a signal sequence at its N-terminus.
実施形態C70.実施形態C1~C69に記載の多鎖キメラポリペプチドのうちのいずれかを含む、組成物。 Embodiment C70. A composition comprising any of the multi-chain chimeric polypeptides of embodiments C1-C69.
実施形態C71.組成物が、医薬組成物である、実施形態C70に記載の組成物。 Embodiment C71. The composition of embodiment C70, wherein the composition is a pharmaceutical composition.
実施形態C72.実施形態C70又はC71に記載の組成物の少なくとも1つの用量を含む、キット。 Embodiment C72. A kit comprising at least one dose of the composition of embodiment C70 or C71.
実施形態C73.実施形態C1~C69のいずれか1つに記載の多鎖キメラポリペプチドのうちのいずれかをコードする、核酸。 Embodiment C73. A nucleic acid encoding any of the multi-chain chimeric polypeptides of any one of embodiments C1-C69.
実施形態C74.実施形態C73に記載の核酸を含む、ベクター。 Embodiment C74. A vector comprising the nucleic acid of embodiment C73.
実施形態C75.ベクターが、発現ベクターである、実施形態C74に記載のベクター。 Embodiment C75. The vector of embodiment C74, wherein the vector is an expression vector.
実施形態C76.実施形態C73に記載の核酸又は実施形態C74若しくはC75に記載のベクターを含む、細胞。 Embodiment C76. A cell comprising the nucleic acid of embodiment C73 or the vector of embodiment C74 or C75.
実施形態C77.多鎖キメラポリペプチドを産生する方法であって、
多鎖キメラポリペプチドの産生をもたらすのに十分な条件下で、実施形態C76に記載の細胞を培養培地中で培養することと、
多鎖キメラポリペプチドを細胞及び/又は培養培地から回収することと
を含む、方法。
Embodiment C77. A method of producing a multi-chain chimeric polypeptide comprising:
culturing the cells of embodiment C76 in a culture medium under conditions sufficient to result in the production of the multi-chain chimeric polypeptide;
recovering the multi-chain chimeric polypeptide from the cells and/or the culture medium.
実施形態C78.実施形態C77に記載の方法によって産生された多鎖キメラポリペプチド。 Embodiment C78. A multi-chain chimeric polypeptide produced by the method of embodiment C77.
実施形態C79.可溶性ヒト組織因子ドメインが、配列番号97と少なくとも80%同一である配列を含む、実施形態A56に記載の多鎖キメラポリペプチド。 Embodiment C79. The multichain chimeric polypeptide of embodiment A56, wherein the soluble human tissue factor domain comprises a sequence that is at least 80% identical to SEQ ID NO:97.
実施形態C80.可溶性ヒト組織因子ドメインが、配列番号97と少なくとも90%同一である配列を含む、実施形態C79に記載の多鎖キメラポリペプチド。 Embodiment C80. The multichain chimeric polypeptide of embodiment C79, wherein the soluble human tissue factor domain comprises a sequence that is at least 90% identical to SEQ ID NO:97.
実施形態C81.可溶性ヒト組織因子ドメインが、配列番号97と少なくとも95%同一である配列を含む、実施形態C80に記載の多鎖キメラポリペプチド。 Embodiment C81. The multichain chimeric polypeptide of embodiment C80, wherein the soluble human tissue factor domain comprises a sequence that is at least 95% identical to SEQ ID NO:97.
実施形態C82.可溶性ヒト組織因子ドメインが、配列番号97と100%同一である配列を含む、実施形態C81に記載の多鎖キメラポリペプチド。 Embodiment C82. The multichain chimeric polypeptide of embodiment C81, wherein the soluble human tissue factor domain comprises a sequence that is 100% identical to SEQ ID NO:97.
実施形態C83.可溶性ヒト組織因子ドメインが、配列番号98と少なくとも80%同一である配列を含む、実施形態C56に記載の多鎖キメラポリペプチド。 Embodiment C83. The multichain chimeric polypeptide of embodiment C56, wherein the soluble human tissue factor domain comprises a sequence that is at least 80% identical to SEQ ID NO:98.
実施形態C84.可溶性ヒト組織因子ドメインが、配列番号98と少なくとも90%同一である配列を含む、実施形態C83に記載の多鎖キメラポリペプチド。 Embodiment C84. The multichain chimeric polypeptide of embodiment C83, wherein the soluble human tissue factor domain comprises a sequence that is at least 90% identical to SEQ ID NO:98.
実施形態C85.可溶性ヒト組織因子ドメインが、配列番号98と少なくとも95%同一である配列を含む、実施形態C84に記載の多鎖キメラポリペプチド。 Embodiment C85. The multichain chimeric polypeptide of embodiment C84, wherein the soluble human tissue factor domain comprises a sequence that is at least 95% identical to SEQ ID NO:98.
実施形態C86.可溶性ヒト組織因子ドメインが、配列番号98と100%同一である配列を含む、実施形態C85に記載の多鎖キメラポリペプチド。 Embodiment C86. The multichain chimeric polypeptide of embodiment C85, wherein the soluble human tissue factor domain comprises a sequence that is 100% identical to SEQ ID NO:98.
実施形態D1.多鎖キメラポリペプチドであって、
(a)第1のキメラポリペプチドであって、
(i)第1の標的結合ドメイン、
(ii)可溶性組織因子ドメイン、及び
(iii)一対の親和性ドメインの第1のドメイン
を含む、第1のキメラポリペプチド、
(b)第2のキメラポリペプチドであって、
(i)一対の親和性ドメインの第2のドメイン、及び
(ii)第2の標的結合ドメインを含む、
第2のキメラポリペプチド
を含み、
第1のキメラポリペプチドと第2のキメラポリペプチドが、一対の親和性ドメインの第1のドメインと第2のドメインとの結合を介して会合し、
第1の標的結合ドメイン及び第2の標的結合ドメインが各々独立して、IL-18受容体又はIL-12受容体に特異的に結合する、
多鎖キメラポリペプチド。
Embodiment D1. A multi-chain chimeric polypeptide,
(a) a first chimeric polypeptide,
(i) a first target binding domain;
(ii) a soluble tissue factor domain, and (iii) a first domain of a pair of affinity domains,
(b) a second chimeric polypeptide,
(i) a second domain of the pair of affinity domains, and (ii) a second target binding domain,
comprising a second chimeric polypeptide;
the first chimeric polypeptide and the second chimeric polypeptide associate via binding of the first and second domains of a pair of affinity domains;
the first target binding domain and the second target binding domain each independently specifically bind to the IL-18 receptor or the IL-12 receptor;
Multi-chain chimeric polypeptides.
実施形態D2.第1の標的結合ドメインと可溶性組織因子ドメインが、第1のキメラポリペプチド内で互いに直接隣接している、実施形態D1に記載の多鎖キメラポリペプチド。 Embodiment D2. The multichain chimeric polypeptide of embodiment D1, wherein the first target binding domain and the soluble tissue factor domain are directly adjacent to each other within the first chimeric polypeptide.
実施形態D3.第1のキメラポリペプチドが、第1のキメラポリペプチド内の第1の標的結合ドメインと可溶性組織因子ドメインとの間にリンカー配列を更に含む、実施形態D1に記載の多鎖キメラポリペプチド。 Embodiment D3. The multichain chimeric polypeptide of embodiment D1, wherein the first chimeric polypeptide further comprises a linker sequence between the first target binding domain and the soluble tissue factor domain within the first chimeric polypeptide.
実施形態D4.可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインが、第1のキメラポリペプチド内で互いに直接隣接している、実施形態D1~D3のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment D4. The multichain chimeric polypeptide of any one of embodiments D1-D3, wherein the soluble tissue factor domain and the first of the paired affinity domains are directly adjacent to each other within the first chimeric polypeptide. .
実施形態D5.第1のキメラポリペプチドが、第1のキメラポリペプチド内の可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間にリンカー配列を更に含む、実施形態D1~D3のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment D5. Any one of embodiments D1-D3, wherein the first chimeric polypeptide further comprises a linker sequence between the soluble tissue factor domain within the first chimeric polypeptide and the first of the pair of affinity domains. A multi-chain chimeric polypeptide according to 1.
実施形態D6.一対の親和性ドメインの第2のドメインと第2の標的結合ドメインが、第2のキメラポリペプチド内で互いに直接隣接している、実施形態D1~D5のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment D6. The multichain chimera of any one of embodiments D1-D5, wherein the second domain and the second target binding domain of the pair of affinity domains are directly adjacent to each other within the second chimeric polypeptide. Polypeptide.
実施形態D7.第2のキメラポリペプチドが、第2のキメラポリペプチド内の一対の親和性ドメインの第2のドメインと第2の標的結合ドメインとの間にリンカー配列を更に含む、実施形態D1~D5のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment D7. Any of embodiments D1-D5, wherein the second chimeric polypeptide further comprises a linker sequence between the second of the pair of affinity domains and the second target binding domain within the second chimeric polypeptide. or a multi-chain chimeric polypeptide according to any one of the preceding claims.
実施形態D8.可溶性組織因子ドメインが、可溶性ヒト組織因子ドメインである、実施形態D1~D7のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment D8. The multichain chimeric polypeptide of any one of embodiments D1-D7, wherein the soluble tissue factor domain is a soluble human tissue factor domain.
実施形態D9.可溶性ヒト組織因子ドメインが、配列番号93と少なくとも80%同一である配列を含む、実施形態D8に記載の多鎖キメラポリペプチド。 Embodiment D9. The multichain chimeric polypeptide of embodiment D8, wherein the soluble human tissue factor domain comprises a sequence that is at least 80% identical to SEQ ID NO:93.
実施形態D10.可溶性ヒト組織因子ドメインが、配列番号93と少なくとも90%同一である配列を含む、実施形態D9に記載の多鎖キメラポリペプチド。 Embodiment D10. The multichain chimeric polypeptide of embodiment D9, wherein the soluble human tissue factor domain comprises a sequence that is at least 90% identical to SEQ ID NO:93.
実施形態D11.可溶性ヒト組織因子ドメインが、配列番号93と少なくとも95%同一である配列を含む、実施形態D10に記載の多鎖キメラポリペプチド。 Embodiment D11. The multichain chimeric polypeptide of embodiment D10, wherein the soluble human tissue factor domain comprises a sequence that is at least 95% identical to SEQ ID NO:93.
実施形態D12.可溶性ヒト組織因子ドメインが、
成熟野生型ヒト組織因子タンパク質のアミノ酸20位に対応するアミノ酸の位置にリジン、
成熟野生型ヒト組織因子タンパク質のアミノ酸22位に対応するアミノ酸の位置にイソロイシン、
成熟野生型ヒト組織因子タンパク質のアミノ酸45位に対応するアミノ酸の位置にトリプトファン、
成熟野生型ヒト組織因子タンパク質のアミノ酸58位に対応するアミノ酸の位置にアスパラギン酸、
成熟野生型ヒト組織因子タンパク質のアミノ酸94位に対応するアミノ酸の位置にチロシン、
成熟野生型ヒト組織因子タンパク質のアミノ酸135位に対応するアミノ酸の位置にアルギニン、及び
成熟野生型ヒト組織因子タンパク質のアミノ酸140位に対応するアミノ酸の位置にフェニルアラニンのうちのいずれも含まない、実施形態D8~D11のいずれか一つに記載の方法。
Embodiment D12. A soluble human tissue factor domain is
a lysine at the amino acid position corresponding to
an isoleucine at the amino acid position corresponding to
tryptophan at the amino acid position corresponding to
an aspartic acid at the amino acid position corresponding to amino acid position 58 of the mature wild-type human tissue factor protein;
a tyrosine at the amino acid position corresponding to amino acid position 94 of the mature wild-type human tissue factor protein;
An embodiment that does not include either arginine at the amino acid position corresponding to amino acid position 135 of the mature wild-type human tissue factor protein and phenylalanine at the amino acid position corresponding to
実施形態D13.可溶性ヒト組織因子ドメインが、
成熟野生型ヒト組織因子タンパク質のアミノ酸20位に対応するアミノ酸の位置にリジン、
成熟野生型ヒト組織因子タンパク質のアミノ酸22位に対応するアミノ酸の位置にイソロイシン、
成熟野生型ヒト組織因子タンパク質のアミノ酸45位に対応するアミノ酸の位置にトリプトファン、
成熟野生型ヒト組織因子タンパク質のアミノ酸58位に対応するアミノ酸の位置にアスパラギン酸、
成熟野生型ヒト組織因子タンパク質のアミノ酸94位に対応するアミノ酸の位置にチロシン、
成熟野生型ヒト組織因子タンパク質のアミノ酸135位に対応するアミノ酸の位置にアルギニン、及び
成熟野生型ヒト組織因子タンパク質のアミノ酸140位に対応するアミノ酸の位置にフェニルアラニンのうちのいずれも含まない、実施形態D12のいずれか一つに記載の方法。
Embodiment D13. A soluble human tissue factor domain is
a lysine at the amino acid position corresponding to
an isoleucine at the amino acid position corresponding to
tryptophan at the amino acid position corresponding to
an aspartic acid at the amino acid position corresponding to amino acid position 58 of the mature wild-type human tissue factor protein;
a tyrosine at the amino acid position corresponding to amino acid position 94 of the mature wild-type human tissue factor protein;
An embodiment that does not include either arginine at the amino acid position corresponding to amino acid position 135 of the mature wild-type human tissue factor protein and phenylalanine at the amino acid position corresponding to
実施形態D14.可溶性組織因子ドメインが、第VIIa因子に結合することができない、実施形態D1~D13のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment D14. The multichain chimeric polypeptide of any one of embodiments D1-D13, wherein the soluble tissue factor domain is incapable of binding Factor VIIa.
実施形態D15.可溶性組織因子ドメインが、不活性第X因子を第Xa因子に変換しない、実施形態D1~D14のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment D15. The multichain chimeric polypeptide of any one of embodiments D1-D14, wherein the soluble tissue factor domain does not convert inactive factor X to factor Xa.
実施形態D16.多鎖キメラポリペプチドが、哺乳動物における血液凝固を刺激しない、実施形態D1~D15のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment D16. The multi-chain chimeric polypeptide of any one of embodiments D1-D15, wherein the multi-chain chimeric polypeptide does not stimulate blood clotting in a mammal.
実施形態D17.第1のキメラポリペプチドが、第1のキメラポリペプチドのN末端又はC末端にペプチドタグを更に含む、実施形態D1~D16のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment D17. The multi-chain chimeric polypeptide of any one of embodiments D1-D16, wherein the first chimeric polypeptide further comprises a peptide tag at the N-terminus or C-terminus of the first chimeric polypeptide.
実施形態D18.第2のキメラポリペプチドが、第2のキメラポリペプチドN末端又はC末端にペプチドタグを更に含む、実施形態D1~D17のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment D18. The multi-chain chimeric polypeptide of any one of embodiments D1-D17, wherein the second chimeric polypeptide further comprises a peptide tag at the N-terminus or C-terminus of the second chimeric polypeptide.
実施形態D19.第1のキメラポリペプチド及び/又は第2のキメラポリペプチドが、そのN末端にシグナル配列を更に含む、実施形態D1~D18のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment D19. The multi-chain chimeric polypeptide according to any one of embodiments D1-D18, wherein the first chimeric polypeptide and/or the second chimeric polypeptide further comprises a signal sequence at its N-terminus.
実施形態D20.シグナル配列が、配列番号117を含む、実施形態D19に記載の多鎖キメラポリペプチド。 Embodiment D20. The multichain chimeric polypeptide of embodiment D19, wherein the signal sequence comprises SEQ ID NO:117.
実施形態D21.シグナル配列が、配列番号117である、実施形態D20に記載の多鎖キメラポリペプチド。 Embodiment D21. The multichain chimeric polypeptide of embodiment D20, wherein the signal sequence is SEQ ID NO:117.
実施形態D22.一対の親和性ドメインが、ヒトIL-15受容体のアルファ鎖(IL-15Rα)由来のスシドメイン、及び可溶性IL-15である、実施形態D1~D21のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment D22. The multichain chimera of any one of embodiments D1-D21, wherein the pair of affinity domains is a sushi domain derived from the alpha chain of the human IL-15 receptor (IL-15Rα) and soluble IL-15 Polypeptide.
実施形態D23.可溶性IL-15が、D8N又はD8Aアミノ酸置換を有する、実施形態D22に記載の多鎖キメラポリペプチド。 Embodiment D23. The multi-chain chimeric polypeptide of embodiment D22, wherein the soluble IL-15 has a D8N or D8A amino acid substitution.
実施形態D24.可溶性IL-15が、配列番号82と80%同一である配列を含む、実施形態D22に記載の多鎖キメラポリペプチド。 Embodiment D24. The multichain chimeric polypeptide of embodiment D22, wherein the soluble IL-15 comprises a sequence that is 80% identical to SEQ ID NO:82.
実施形態D25.可溶性IL-15が、配列番号82と90%同一である配列を含む、実施形態D24に記載の多鎖キメラポリペプチド。 Embodiment D25. The multichain chimeric polypeptide of embodiment D24, wherein the soluble IL-15 comprises a sequence that is 90% identical to SEQ ID NO:82.
実施形態D26.可溶性IL-15が、配列番号82と95%同一である配列を含む、実施形態D25に記載の多鎖キメラポリペプチド。 Embodiment D26. The multichain chimeric polypeptide of embodiment D25, wherein the soluble IL-15 comprises a sequence that is 95% identical to SEQ ID NO:82.
実施形態D27.可溶性IL-15が、配列番号82を含む、実施形態D26に記載の多鎖キメラポリペプチド。 Embodiment D27. The multichain chimeric polypeptide of embodiment D26, wherein the soluble IL-15 comprises SEQ ID NO:82.
実施形態D28.IL-15Rαのスシドメインが、ヒトIL-15Rα由来のスシドメインを含む、実施形態D22~D27のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment D28. The multi-chain chimeric polypeptide of any one of embodiments D22-D27, wherein the sushi domain of IL-15Rα comprises a sushi domain derived from human IL-15Rα.
実施形態D29.ヒトIL-15Rα由来のスシドメインが、配列番号113と80%同一である配列を含む、実施形態D28に記載の多鎖キメラポリペプチド。 Embodiment D29. The multi-chain chimeric polypeptide of embodiment D28, wherein the sushi domain from human IL-15Rα comprises a sequence that is 80% identical to SEQ ID NO:113.
実施形態D30.ヒトIL-15Rα由来のスシドメインが、配列番号113と90%同一である配列を含む、実施形態D29に記載の多鎖キメラポリペプチド。 Embodiment D30. The multi-chain chimeric polypeptide of embodiment D29, wherein the sushi domain from human IL-15Rα comprises a sequence that is 90% identical to SEQ ID NO:113.
実施形態D31.ヒトIL-15Rα由来のスシドメインが、配列番号113と95%同一である配列を含む、実施形態D30に記載の多鎖キメラポリペプチド。 Embodiment D31. The multi-chain chimeric polypeptide of embodiment D30, wherein the sushi domain from human IL-15Rα comprises a sequence that is 95% identical to SEQ ID NO:113.
実施形態D32.ヒトIL-15Rα由来のスシドメインが、配列番号113を含む、実施形態D31に記載の多鎖キメラポリペプチド。 Embodiment D32. The multi-chain chimeric polypeptide of embodiment D31, wherein the sushi domain from human IL-15Rα comprises SEQ ID NO:113.
実施形態D33.ヒトIL-15Rα由来のスシドメインが、成熟全長IL-15Rαである、実施形態D28に記載の多鎖キメラポリペプチド。 Embodiment D33. The multi-chain chimeric polypeptide of embodiment D28, wherein the sushi domain derived from human IL-15Rα is mature full-length IL-15Rα.
実施形態D34.一対の親和性ドメインが、バルナーゼとバルンスター、PKAとAKAP、変異RNaseI断片に基づくアダプター/ドッキングタグモジュール、並びに、タンパク質シンタキシン、シナプトタグミン、シナプトブレビン、及びSNAP25の相互作用に基づくSNAREモジュールからなる群から選択される、実施形D1~D21のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment D34. The paired affinity domains are selected from the group consisting of barnase and barnstar, PKA and AKAP, adapter/docking tag modules based on mutated RNase I fragments, and SNARE modules based on interactions of proteins syntaxin, synaptotagmin, synaptobrevin, and SNAP25. A multi-chain chimeric polypeptide according to any one of embodiments D1-D21, wherein:
実施形態D35.第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方が、アゴニスト抗原結合ドメインである、実施形態D1~D34のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment D35. The multichain chimeric polypeptide of any one of embodiments D1-D34, wherein one or both of the first target binding domain and the second target binding domain are agonist antigen binding domains.
実施形態D36.第1の標的結合ドメイン及び第2の標的結合ドメインが各々、アゴニスト抗原結合ドメインである、実施形態D35に記載の多鎖キメラポリペプチド。 Embodiment D36. The multichain chimeric polypeptide of embodiment D35, wherein the first target binding domain and the second target binding domain are each agonist antigen binding domains.
実施形態D37.抗原結合ドメインが、scFv又は単一ドメイン抗体を含む、実施形態D35又はD36に記載の多鎖キメラポリペプチド。 Embodiment D37. The multi-chain chimeric polypeptide of embodiment D35 or D36, wherein the antigen binding domain comprises a scFv or single domain antibody.
実施形態D38.第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方が、可溶性IL-15又は可溶性IL-18である、実施形態D1~D34のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment D38. The multichain chimeric polypeptide of any one of embodiments D1-D34, wherein one or both of the first and second target binding domains is soluble IL-15 or soluble IL-18.
実施形態D39.第1の標的結合ドメイン及び第2の標的結合ドメインが各々独立して、可溶性IL-15又は可溶性IL-18である、実施形態D38に記載の多鎖キメラポリペプチド。 Embodiment D39. The multichain chimeric polypeptide of embodiment D38, wherein the first target binding domain and the second target binding domain are each independently soluble IL-15 or soluble IL-18.
実施形態D40.第1の標的結合ドメイン及び第2の標的結合ドメインの両方が、IL-18受容体又はIL-12受容体に特異的に結合する、実施形態D1~D39のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment D40. The multichain of any one of embodiments D1-D39, wherein both the first target binding domain and the second target binding domain specifically bind to IL-18 receptor or IL-12 receptor. chimeric polypeptide.
実施形態D41.第1の標的結合ドメイン及び第2の標的結合ドメインが同じエピトープに特異的に結合する、実施形態B40に記載の多鎖キメラポリペプチド。 Embodiment D41. The multichain chimeric polypeptide of embodiment B40, wherein the first target binding domain and the second target binding domain specifically bind to the same epitope.
実施形態D42.第1の標的結合ドメイン及び第2の標的結合ドメインが同じアミノ酸配列を含む、実施形態D41に記載の多鎖キメラポリペプチド。 Embodiment D42. The multichain chimeric polypeptide of embodiment D41, wherein the first target binding domain and the second target binding domain comprise the same amino acid sequence.
実施形態D43.第1の標的結合ドメインがIL-12受容体に特異的に結合し、第2の標的結合ドメインがIL-18受容体に特異的に結合する、実施形態D1~D39のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment D43. Any one of embodiments D1-D39, wherein the first target binding domain specifically binds the IL-12 receptor and the second target binding domain specifically binds the IL-18 receptor multi-chain chimeric polypeptide of.
実施形態D44.第1の標的結合ドメインがIL-18受容体に特異的に結合し、第2の標的結合ドメインがIL-12受容体に特異的に結合する、実施形態D1~D39のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment D44. Any one of embodiments D1-D39, wherein the first target binding domain specifically binds the IL-18 receptor and the second target binding domain specifically binds the IL-12 receptor multi-chain chimeric polypeptide of.
実施形態D45.第1の標的結合ドメインが、可溶性IL-18を含む、実施形態D44に記載の多鎖キメラポリペプチド。 Embodiment D45. The multichain chimeric polypeptide of embodiment D44, wherein the first target binding domain comprises soluble IL-18.
実施形態D46.可溶性IL-18が、可溶性ヒトIL-18である、実施形態D45に記載の多鎖キメラポリペプチド。 Embodiment D46. The multichain chimeric polypeptide of embodiment D45, wherein the soluble IL-18 is soluble human IL-18.
実施形態D47.可溶性ヒトIL-18が、配列番号109と少なくとも80%同一の配列を含む、実施形態D46に記載の多鎖キメラポリペプチド。 Embodiment D47. The multichain chimeric polypeptide of embodiment D46, wherein the soluble human IL-18 comprises a sequence that is at least 80% identical to SEQ ID NO:109.
実施形態D48.可溶性ヒトIL-18が、配列番号109と少なくとも90%同一の配列を含む、実施形態D47に記載の多鎖キメラポリペプチド。 Embodiment D48. The multichain chimeric polypeptide of embodiment D47, wherein the soluble human IL-18 comprises a sequence that is at least 90% identical to SEQ ID NO:109.
実施形態D49.可溶性ヒトIL-18が、配列番号109と少なくとも95%同一の配列を含む、実施形態D48に記載の多鎖キメラポリペプチド。 Embodiment D49. The multichain chimeric polypeptide of embodiment D48, wherein the soluble human IL-18 comprises a sequence that is at least 95% identical to SEQ ID NO:109.
実施形態D50.可溶性ヒトIL-18が、配列番号109の配列を含む、実施形態D49に記載の多鎖キメラポリペプチド。 Embodiment D50. The multichain chimeric polypeptide of embodiment D49, wherein the soluble human IL-18 comprises the sequence of SEQ ID NO:109.
実施形態D51.第2の標的結合ドメインが、可溶性IL-12を含む、実施形態D44~D50のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment D51. The multichain chimeric polypeptide of any one of embodiments D44-D50, wherein the second target binding domain comprises soluble IL-12.
実施形態D52.可溶性IL-18が、可溶性ヒトIL-12である、実施形態D51に記載の多鎖キメラポリペプチド。 Embodiment D52. The multichain chimeric polypeptide of embodiment D51, wherein the soluble IL-18 is soluble human IL-12.
実施形態D53.可溶性ヒトIL-15が、可溶性ヒトIL-12β(p40)配列及び可溶性ヒトIL-12α(p35)配列を含む、実施形態D52に記載の多鎖キメラポリペプチド。 Embodiment D53. The multichain chimeric polypeptide of embodiment D52, wherein the soluble human IL-15 comprises a soluble human IL-12β (p40) sequence and a soluble human IL-12α (p35) sequence.
実施形態D54.可溶性ヒトIL-15が、可溶性IL-12β(p40)配列と可溶性ヒトIL-12α(p35)配列との間にリンカー配列を更に含む、実施形態D53に記載の多鎖キメラポリペプチド。 Embodiment D54. The multichain chimeric polypeptide of embodiment D53, wherein the soluble human IL-15 further comprises a linker sequence between the soluble human IL-12β (p40) and soluble human IL-12α (p35) sequences.
実施形態D55.リンカー配列が、配列番号102を含む、実施形態D54に記載の多鎖キメラポリペプチド。 Embodiment D55. The multichain chimeric polypeptide of embodiment D54, wherein the linker sequence comprises SEQ ID NO:102.
実施形態D56.可溶性ヒトIL-12β(p40)配列が、配列番号81と少なくとも80%同一である配列を含む、実施形態D53~D55のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment D56. The multichain chimeric polypeptide of any one of embodiments D53-D55, wherein the soluble human IL-12β (p40) sequence comprises a sequence that is at least 80% identical to SEQ ID NO:81.
実施形態D57.可溶性ヒトIL-12β(p40)配列が、配列番号81と少なくとも90%同一である配列を含む、実施形態D56に記載の多鎖キメラポリペプチド。 Embodiment D57. The multichain chimeric polypeptide of embodiment D56, wherein the soluble human IL-12β (p40) sequence comprises a sequence that is at least 90% identical to SEQ ID NO:81.
実施形態D58.可溶性ヒトIL-12β(p40)配列が、配列番号81と少なくとも95%同一である配列を含む、実施形態D57に記載の多鎖キメラポリペプチド。 Embodiment D58. The multichain chimeric polypeptide of embodiment D57, wherein the soluble human IL-12β (p40) sequence comprises a sequence that is at least 95% identical to SEQ ID NO:81.
実施形態D59.可溶性ヒトIL-12β(p40)配列が、配列番号81を含む、実施形態D58に記載の多鎖キメラポリペプチド。 Embodiment D59. The multichain chimeric polypeptide of embodiment D58, wherein the soluble human IL-12β (p40) sequence comprises SEQ ID NO:81.
実施形態D60.可溶性ヒトIL-12α(p35)配列が、配列番号80と少なくとも80%同一である配列を含む、実施形態D53~D59のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment D60. The multichain chimeric polypeptide of any one of embodiments D53-D59, wherein the soluble human IL-12α (p35) sequence comprises a sequence that is at least 80% identical to SEQ ID NO:80.
実施形態D61.可溶性ヒトIL-12α(p35)配列が、配列番号80と少なくとも90%同一である配列を含む、実施形態D60に記載の多鎖キメラポリペプチド。 Embodiment D61. The multichain chimeric polypeptide of embodiment D60, wherein the soluble human IL-12α (p35) sequence comprises a sequence that is at least 90% identical to SEQ ID NO:80.
実施形態D62.可溶性ヒトIL-12α(p35)配列が、配列番号80と少なくとも95%同一である配列を含む、実施形態D61に記載のミュール鎖キメラポリペプチド。 Embodiment D62. The mule chain chimeric polypeptide of embodiment D61, wherein the soluble human IL-12α (p35) sequence comprises a sequence that is at least 95% identical to SEQ ID NO:80.
実施形態D63.可溶性ヒトIL-12α(p35)配列が、配列番号80を含む、実施形態D62に記載の多鎖キメラポリペプチド。 Embodiment D63. The multichain chimeric polypeptide of embodiment D62, wherein the soluble human IL-12α (p35) sequence comprises SEQ ID NO:80.
実施形態D64.第1のキメラポリペプチドが、配列番号174と少なくとも80%同一である配列を含む、実施形態D1に記載の多鎖キメラポリペプチド。 Embodiment D64. The multi-chain chimeric polypeptide of embodiment D1, wherein the first chimeric polypeptide comprises a sequence that is at least 80% identical to SEQ ID NO:174.
実施形態D65.第1のキメラポリペプチドが、配列番号174と少なくとも90%同一である配列を含む、実施形態D64に記載の多鎖キメラポリペプチド。 Embodiment D65. The multi-chain chimeric polypeptide of embodiment D64, wherein the first chimeric polypeptide comprises a sequence that is at least 90% identical to SEQ ID NO:174.
実施形態D66.第1のキメラポリペプチドが、配列番号174と少なくとも95%同一である配列を含む、実施形態D65に記載の多鎖キメラポリペプチド。 Embodiment D66. The multi-chain chimeric polypeptide of embodiment D65, wherein the first chimeric polypeptide comprises a sequence that is at least 95% identical to SEQ ID NO:174.
実施形態D67.第1のキメラポリペプチドが、配列番号174を含む、実施形態D66に記載の多鎖キメラポリペプチド。 Embodiment D67. The multi-chain chimeric polypeptide of embodiment D66, wherein the first chimeric polypeptide comprises SEQ ID NO:174.
実施形態D68.第1のキメラポリペプチドが、配列番号176を含む、実施形態D67に記載の多鎖キメラポリペプチド。 Embodiment D68. The multi-chain chimeric polypeptide of embodiment D67, wherein the first chimeric polypeptide comprises SEQ ID NO:176.
実施形態D69.第2のキメラポリペプチドが、配列番号178と少なくとも80%同一である配列を含む、実施形態D1及びD64~D68のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment D69. The multi-chain chimeric polypeptide of any one of embodiments D1 and D64-D68, wherein the second chimeric polypeptide comprises a sequence that is at least 80% identical to SEQ ID NO:178.
実施形態D70.第2のキメラポリペプチドが、配列番号178と少なくとも90%同一である配列を含む、実施形態D69に記載の多鎖キメラポリペプチド。 Embodiment D70. The multi-chain chimeric polypeptide of embodiment D69, wherein the second chimeric polypeptide comprises a sequence that is at least 90% identical to SEQ ID NO:178.
実施形態D71.第2のキメラポリペプチドが、配列番号178と少なくとも95%同一である配列を含む、実施形態D70に記載の多鎖キメラポリペプチド。 Embodiment D71. The multi-chain chimeric polypeptide of embodiment D70, wherein the second chimeric polypeptide comprises a sequence that is at least 95% identical to SEQ ID NO:178.
実施形態D72.第2のキメラポリペプチドが、配列番号178を含む、実施形態D71に記載の多鎖キメラポリペプチド。 Embodiment D72. The multi-chain chimeric polypeptide of embodiment D71, wherein the second chimeric polypeptide comprises SEQ ID NO:178.
実施形態D73.第2のキメラポリペプチドが、配列番号180を含む、実施形態D72に記載の多鎖キメラポリペプチド。 Embodiment D73. The multi-chain chimeric polypeptide of embodiment D72, wherein the second chimeric polypeptide comprises SEQ ID NO:180.
実施形態D74.第1のキメラポリペプチドが、1つ以上の追加の標的結合ドメインを更に含み、1つ以上の追加の抗原結合ドメインのうちの少なくとも1つが、可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間に位置付けられている、実施形態D1~D63のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment D74. The first chimeric polypeptide further comprises one or more additional target binding domains, wherein at least one of the one or more additional antigen binding domains comprises the soluble tissue factor domain and the first of the paired affinity domains. A multi-chain chimeric polypeptide according to any one of embodiments D1-D63, which is positioned between a domain of
実施形態D75.第1のキメラポリペプチドが、可溶性組織因子ドメインと1つ以上の追加の抗原結合ドメインのうちの少なくとも1つとの間にリンカー配列、及び/又は1つ以上の追加の抗原結合ドメインのうちの少なくとも1つと一対の親和性ドメインの第1のドメインとの間にリンカー配列を更に含む、実施形態D74に記載の多鎖キメラポリペプチド。 Embodiment D75. The first chimeric polypeptide comprises a linker sequence between the soluble tissue factor domain and at least one of the one or more additional antigen binding domains, and/or at least one of the one or more additional antigen binding domains. The multichain chimeric polypeptide of embodiment D74, further comprising a linker sequence between one and the first of the pair of affinity domains.
実施形態D76.第1のキメラポリペプチドが、第1のキメラポリペプチドのN末端及び/又はC末端に1つ以上の追加の標的結合ドメインを更に含む、実施形態D1~D63のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment D76. The multi-domain of any one of embodiments D1-D63, wherein the first chimeric polypeptide further comprises one or more additional target binding domains at the N-terminus and/or C-terminus of the first chimeric polypeptide. chain chimeric polypeptides.
実施形態D77.1つ以上の追加の標的結合ドメインのうちの少なくとも1つが、第1のキメラポリペプチド内の一対の親和性ドメインの第1のドメインに直接隣接している、実施形態D76に記載の多鎖キメラポリペプチド。 Embodiment D77. Described in embodiment D76, wherein at least one of the one or more additional target binding domains is directly adjacent to the first of the pair of affinity domains within the first chimeric polypeptide multi-chain chimeric polypeptide of.
実施形態D78.第1のキメラポリペプチドが、1つ以上の追加の標的結合ドメインのうちの少なくとも1つと一対の親和性ドメインの第1のドメインとの間にリンカー配列を更に含む、実施形態D76に記載の多鎖キメラポリペプチド。 Embodiment D78. The multiple of embodiment D76, wherein the first chimeric polypeptide further comprises a linker sequence between at least one of the one or more additional target binding domains and the first of the pair of affinity domains. chain chimeric polypeptides.
実施形態D79.1つ以上の追加の標的結合ドメインのうちの少なくとも1つが、第1のキメラポリペプチド内の第1の標的結合ドメインに直接隣接している、実施形態D76に記載の多鎖キメラポリペプチド。 Embodiment D79. The multichain chimera of embodiment D76, wherein at least one of the one or more additional target binding domains is directly adjacent to the first target binding domain within the first chimeric polypeptide Polypeptide.
実施形態D80.第1のキメラポリペプチドが、1つ以上の追加の標的結合ドメインのうちの少なくとも1つと第1の標的結合ドメインとの間にリンカー配列を更に含む、実施形態D76に記載の多鎖キメラポリペプチド。 Embodiment D80. The multichain chimeric polypeptide of embodiment D76, wherein the first chimeric polypeptide further comprises a linker sequence between at least one of the one or more additional target binding domains and the first target binding domain. .
実施形態D81.1つ以上の追加の標的結合ドメインのうちの少なくとも1つが、第1のキメラポリペプチドのN末端及び/又はC末端に配置されており、1つ以上の追加の標的結合ドメインのうちの少なくとも1つが、第1のキメラポリペプチド内の可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間に位置付けられている、実施形態D76に記載の多鎖キメラポリペプチド。 Embodiment D81.At least one of the one or more additional target binding domains is located at the N-terminus and/or C-terminus of the first chimeric polypeptide, wherein the one or more additional target binding domains The multichain chimeric polypeptide of embodiment D76, at least one of which is positioned between the soluble tissue factor domain and the first of the pair of affinity domains within the first chimeric polypeptide.
実施形態D82.N末端に配置された1つ以上の追加の標的結合ドメインのうちの少なくとも1つの追加の標的結合ドメインが、第1のキメラポリペプチド内の第1の標的結合ドメイン又は一対の親和性ドメインの第1のドメインに直接隣接している、実施形態D81に記載の多鎖キメラポリペプチド。 Embodiment D82. At least one additional target binding domain of the one or more additional target binding domains located at the N-terminus is the first target binding domain in the first chimeric polypeptide or the first of the pair of affinity domains The multichain chimeric polypeptide of embodiment D81, which is directly contiguous to one domain.
実施形態D83.第1のキメラポリペプチドが、第1のキメラポリペプチド内の少なくとも1つの追加の標的結合ドメインと第1の標的結合ドメイン又は一対の親和性ドメインの第1のドメインとの間に配置されたリンカー配列を更に含む、実施形態D81に記載の多鎖キメラポリペプチド。 Embodiment D83. a linker wherein the first chimeric polypeptide is positioned between at least one additional target binding domain within the first chimeric polypeptide and the first target binding domain or the first domain of the pair of affinity domains The multichain chimeric polypeptide of embodiment D81, further comprising a sequence.
実施形態D84.C末端に配置された1つ以上の追加の標的結合ドメインのうちの少なくとも1つの追加の標的結合ドメインが、第1のキメラポリペプチド内の第1の標的結合ドメイン又は一対の親和性ドメインの第1のドメインに直接隣接している、実施形態D81に記載の多鎖キメラポリペプチド。 Embodiment D84. At least one additional target binding domain of the one or more additional target binding domains located at the C-terminus is the first target binding domain in the first chimeric polypeptide or the first of the pair of affinity domains The multichain chimeric polypeptide of embodiment D81, which is directly contiguous to one domain.
実施形態D85.第1のキメラポリペプチドが、第1のキメラポリペプチド内の少なくとも1つの追加の標的結合ドメインと第1の標的結合ドメイン又は一対の親和性ドメインの第1のドメインとの間に配置されたリンカー配列を更に含む、実施形態D81に記載の多鎖キメラポリペプチド。 Embodiment D85. a linker wherein the first chimeric polypeptide is positioned between at least one additional target binding domain within the first chimeric polypeptide and the first target binding domain or the first domain of the pair of affinity domains The multichain chimeric polypeptide of embodiment D81, further comprising a sequence.
実施形態D86.可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間に位置付けられた1つ以上の追加の標的結合ドメインのうちの少なくとも1つが、可溶性組織因子ドメイン、及び/又は一対の親和性ドメインの第1のドメインに直接隣接している、実施形態D81に記載の多鎖キメラポリペプチド。 Embodiment D86. at least one of the one or more additional target binding domains positioned between the soluble tissue factor domain and the first domain of the pair of affinity domains is the soluble tissue factor domain and/or the affinity pair The multi-chain chimeric polypeptide of embodiment D81, wherein the domains are directly adjacent to the first domain.
実施形態D87.第1のキメラポリペプチドが、(i)可溶性組織因子ドメインと、可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間に位置付けられた1つ以上の追加の標的結合ドメインのうちの少なくとも1つとの間、及び/又は(ii)一対の親和性ドメインの第1のドメインと、可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間に位置付けられた1つ以上の追加の標的結合ドメインのうちの少なくとも1つとの間に配置されたリンカー配列を更に含む、実施形態D81に記載の多鎖キメラポリペプチド。 Embodiment D87. the first chimeric polypeptide comprises: (i) the soluble tissue factor domain and one or more additional target binding domains positioned between the soluble tissue factor domain and the first of the pair of affinity domains; and/or (ii) between the first domain of the pair of affinity domains and the soluble tissue factor domain and the first domain of the pair of affinity domains The multichain chimeric polypeptide of embodiment D81, further comprising a linker sequence interposed between and at least one of the additional target binding domains of embodiment D81.
実施形態D88.第2のキメラポリペプチドが、第2のキメラポリペプチドのN末端又はC末端に1つ以上の追加の標的結合ドメインを更に含む、実施形態D1~D63及びD74~D87のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment D88. Any one of embodiments D1-D63 and D74-D87, wherein the second chimeric polypeptide further comprises one or more additional target binding domains at the N-terminus or C-terminus of the second chimeric polypeptide multi-chain chimeric polypeptide of.
実施形態D89.1つ以上の追加の標的結合ドメインのうちの少なくとも1つが、第2のキメラポリペプチド内の一対の親和性ドメインの第2のドメインに直接隣接している、実施形態D88に記載の多鎖キメラポリペプチド。 Embodiment D89. Described in embodiment D88, wherein at least one of the one or more additional target binding domains is directly adjacent to a second of the pair of affinity domains in the second chimeric polypeptide multi-chain chimeric polypeptide of.
実施形態D90.第2のキメラポリペプチドが、第2のキメラポリペプチド内の1つ以上の追加の標的結合ドメインのうちの少なくとも1つと一対の親和性ドメインの第2のドメインとの間にリンカー配列を更に含む、実施形態D88に記載の多鎖キメラポリペプチド。 Embodiment D90. The second chimeric polypeptide further comprises a linker sequence between at least one of the one or more additional target binding domains in the second chimeric polypeptide and the second of the pair of affinity domains , embodiment D88.
実施形態D91.1つ以上の追加の標的結合ドメインのうちの少なくとも1つが、第2のキメラポリペプチド内の第2の標的結合ドメインに直接隣接している、実施形態D88に記載の多鎖キメラポリペプチド。 Embodiment D91. The multichain chimera of embodiment D88, wherein at least one of the one or more additional target binding domains is directly adjacent to the second target binding domain within the second chimeric polypeptide Polypeptide.
実施形態D92.第2のキメラポリペプチドが、第2のキメラポリペプチド内の1つ以上の追加の標的結合ドメインのうちの少なくとも1つと第2の標的結合ドメインとの間にリンカー配列を更に含む、実施形態B88に記載の多鎖キメラポリペプチド。 Embodiment D92. Embodiment B88, wherein the second chimeric polypeptide further comprises a linker sequence between at least one of the one or more additional target binding domains within the second chimeric polypeptide and the second target binding domain. 3. A multi-chain chimeric polypeptide according to .
実施形態D93.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの2つ以上が同じ抗原に特異的に結合する、実施形態D74~D92のいずれか1つに記載の多鎖キメラポリペプチド。
Embodiment D93. Any one of embodiments D74-D92, wherein two or more of the first target binding domain, the second target binding domain, and the one or more additional target binding domains specifically bind to the
実施形態D94.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの2つ以上が同じエピトープに特異的に結合する、実施形態B93に記載の多鎖キメラポリペプチド。 Embodiment D94. The multichain chimeric poly of embodiment B93, wherein two or more of the first target binding domain, the second target binding domain, and the one or more additional target binding domains specifically bind the same epitope. peptide.
実施形態D95.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの2つ以上が同じアミノ酸配列を含む、実施形態B94に記載の多鎖キメラポリペプチド。 Embodiment D95. The multichain chimeric polypeptide of embodiment B94, wherein two or more of the first target binding domain, second target binding domain, and one or more additional target binding domains comprise the same amino acid sequence.
実施形態D96.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインが異なる抗原に特異的に結合する、実施形態D74~D92のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment D96. The multichain chimera of any one of embodiments D74-D92, wherein the first target binding domain, the second target binding domain, and the one or more additional target binding domains specifically bind different antigens. Polypeptide.
実施形態D97.1つ以上の追加の抗原結合ドメインが、CD16a、CD28、CD3、CD33、CD20、CD19、CD22、CD123、IL-1R、IL-1、VEGF、IL-6R、IL-4、IL-10、PDL-1、TIGIT、PD-1、TIM3、CTLA4、MICA、MICB、IL-6、IL-8、TNFα、CD26、CD36、ULBP2、CD30、CD200、IGF-1R、MUC4AC、MUC5AC、Trop-2、CMET、EGFR、HER1、HER2、HER3、PSMA、CEA、B7H3、EPCAM、BCMA、P-カドヘリン、CEACAM5、UL16結合タンパク質、HLA-DR、DLL4、TYRO3、AXL、MER、CD122、CD155、PDGF-DD、TGF-β受容体II(TGF-βRII)リガンド、TGF-βRIIIリガンド、DNAM1リガンド、NKp46リガンド、NKp44リガンド、NKG2Dリガンド、NKp30リガンド、scMHCIリガンド、scMHCIIリガンド、scTCRリガンド、IL-1受容体、IL-2受容体、IL-3受容体、IL-7受容体、IL-8受容体、IL-10受容体、IL-12受容体、IL-15受容体、IL-17受容体、IL-18受容体、IL-21受容体、PDGF-DD受容体、幹細胞因子(SCF)受容体、幹細胞様チロシンキナーゼ3リガンド(FLT3L)受容体、MICA受容体、MICB受容体、ULP16結合タンパク質受容体、CD155受容体、及びCD28受容体からなる群から選択される標的に特異的に結合する、実施形態D74~D96のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment D97.The one or more additional antigen binding domains comprises CD16a, CD28, CD3, CD33, CD20, CD19, CD22, CD123, IL-1R, IL-1, VEGF, IL-6R, IL-4, IL -10, PDL-1, TIGIT, PD-1, TIM3, CTLA4, MICA, MICB, IL-6, IL-8, TNFα, CD26, CD36, ULBP2, CD30, CD200, IGF-1R, MUC4AC, MUC5AC, Trop -2, CMET, EGFR, HER1, HER2, HER3, PSMA, CEA, B7H3, EPCAM, BCMA, P-cadherin, CEACAM5, UL16 binding protein, HLA-DR, DLL4, TYRO3, AXL, MER, CD122, CD155, PDGF -DD, TGF-β receptor II (TGF-βRII) ligand, TGF-βRIII ligand, DNAM1 ligand, NKp46 ligand, NKp44 ligand, NKG2D ligand, NKp30 ligand, scMHCI ligand, scMHCII ligand, scTCR ligand, IL-1 receptor , IL-2 receptor, IL-3 receptor, IL-7 receptor, IL-8 receptor, IL-10 receptor, IL-12 receptor, IL-15 receptor, IL-17 receptor, IL -18 receptor, IL-21 receptor, PDGF-DD receptor, stem cell factor (SCF) receptor, stem cell-like tyrosine kinase 3 ligand (FLT3L) receptor, MICA receptor, MICB receptor, ULP16 binding protein receptor , CD155 receptor, and CD28 receptor.
実施形態D98.1つ以上の追加の標的結合ドメインが、可溶性インターロイキン又はサイトカインタンパク質である、実施形態D74~D96のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment D98. The multichain chimeric polypeptide of any one of embodiments D74-D96, wherein the one or more additional target binding domains is a soluble interleukin or cytokine protein.
実施形態D99.可溶性インターロイキン、サイトカイン、又はリガンドタンパク質が、IL-1、IL-2、IL-3、IL-7、IL-8、IL-10、IL-12、IL-15、IL-17、IL-18、IL-21、PDGF-DD、SCF、FLT3L、MICA、MICB、及びULP16結合タンパク質からなる群から選択される、実施形態B98に記載の多鎖キメラポリペプチド。 Embodiment D99. soluble interleukin, cytokine, or ligand protein is IL-1, IL-2, IL-3, IL-7, IL-8, IL-10, IL-12, IL-15, IL-17, IL-18 , IL-21, PDGF-DD, SCF, FLT3L, MICA, MICB, and ULP16 binding protein.
実施形態D100.1つ以上の追加の標的結合ドメインが、可溶性インターロイキン又はサイトカイン受容体である、実施形態D74~D96のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment D100. The multichain chimeric polypeptide of any one of embodiments D74-D96, wherein the one or more additional target binding domains is a soluble interleukin or cytokine receptor.
実施形態D101.可溶性受容体が、可溶性TGF-β受容体II(TGF-βRII)、可溶性TGF-βRIII、可溶性NKG2D、可溶性NKp30、可溶性NKp44、可溶性NKp46、可溶性DNAM1、scMHCI、scMHCII、scTCR、可溶性CD155、可溶性CD122、又は可溶性CD28である、実施形態B100に記載の多鎖キメラポリペプチド。 Embodiment D101. the soluble receptor is soluble TGF-β receptor II (TGF-βRII), soluble TGF-βRIII, soluble NKG2D, soluble NKp30, soluble NKp44, soluble NKp46, soluble DNAM1, scMHCI, scMHCII, scTCR, soluble CD155, soluble CD122, or the multichain chimeric polypeptide of embodiment B100, which is soluble CD28.
実施形態D102.実施形態D1~D101に記載の多鎖キメラポリペプチドのうちのいずれかを含む、組成物。 Embodiment D102. A composition comprising any of the multi-chain chimeric polypeptides of embodiments D1-D101.
実施形態D103.組成物が、医薬組成物である、実施形態D102に記載の組成物。 Embodiment D103. The composition of embodiment D102, wherein the composition is a pharmaceutical composition.
実施形態D104.実施形態D102又はD103の組成物の少なくとも1つの用量を含むキット。 Embodiment D104. A kit comprising at least one dose of the composition of embodiment D102 or D103.
実施形態D105.実施形態D1~D101のいずれか1つに記載の多鎖キメラポリペプチドのうちのいずれかをコードする、核酸。 Embodiment D105. A nucleic acid encoding any of the multi-chain chimeric polypeptides of any one of embodiments D1-D101.
実施形態D106.実施形態D105に記載の核酸を含む、ベクター。 Embodiment D106. A vector comprising the nucleic acid of embodiment D105.
実施形態D107.ベクターが、発現ベクターである、実施形態D106に記載のベクター。 Embodiment D107. The vector of embodiment D106, wherein the vector is an expression vector.
実施形態D108.実施形態D105に記載の核酸又は実施形態D106若しくはD107に記載のベクターを含む、細胞。 Embodiment D108. A cell comprising the nucleic acid of embodiment D105 or the vector of embodiment D106 or D107.
実施形態D109.多鎖キメラポリペプチドを産生する方法であって、
多鎖キメラポリペプチドの産生をもたらすのに十分な条件下で、実施形態D108に記載の細胞を培養培地中で培養することと、
多鎖キメラポリペプチドを細胞及び/又は培養培地から回収することと
を含む、方法。
Embodiment D109. A method of producing a multi-chain chimeric polypeptide comprising:
culturing the cells of embodiment D108 in a culture medium under conditions sufficient to result in the production of the multi-chain chimeric polypeptide;
recovering the multi-chain chimeric polypeptide from the cells and/or the culture medium.
実施形態D110.実施形態D109に記載の方法によって産生された多鎖キメラポリペプチド。 Embodiment D110. A multi-chain chimeric polypeptide produced by the method of embodiment D109.
実施形態D111.可溶性ヒト組織因子ドメインが、配列番号97と少なくとも80%同一である配列を含む、実施形態D8に記載の多鎖キメラポリペプチド。 Embodiment D111. The multichain chimeric polypeptide of embodiment D8, wherein the soluble human tissue factor domain comprises a sequence that is at least 80% identical to SEQ ID NO:97.
実施形態D112.可溶性ヒト組織因子ドメインが、配列番号97と少なくとも90%同一である配列を含む、実施形態D111に記載の多鎖キメラポリペプチド。 Embodiment D112. The multichain chimeric polypeptide of embodiment D111, wherein the soluble human tissue factor domain comprises a sequence that is at least 90% identical to SEQ ID NO:97.
実施形態D113.可溶性ヒト組織因子ドメインが、配列番号97と少なくとも95%同一である配列を含む、実施形態D112に記載の多鎖キメラポリペプチド。 Embodiment D113. The multichain chimeric polypeptide of embodiment D112, wherein the soluble human tissue factor domain comprises a sequence that is at least 95% identical to SEQ ID NO:97.
実施形態D114.可溶性ヒト組織因子ドメインが、配列番号97と100%同一である配列を含む、実施形態D113に記載の多鎖キメラポリペプチド。 Embodiment D114. The multichain chimeric polypeptide of embodiment D113, wherein the soluble human tissue factor domain comprises a sequence that is 100% identical to SEQ ID NO:97.
実施形態D115.可溶性ヒト組織因子ドメインが、配列番号98と少なくとも80%同一である配列を含む、実施形態D8に記載の多鎖キメラポリペプチド。 Embodiment D115. The multichain chimeric polypeptide of embodiment D8, wherein the soluble human tissue factor domain comprises a sequence that is at least 80% identical to SEQ ID NO:98.
実施形態D116.可溶性ヒト組織因子ドメインが、配列番号98と少なくとも90%同一である配列を含む、実施形態D115に記載の多鎖キメラポリペプチド。 Embodiment D116. The multichain chimeric polypeptide of embodiment D115, wherein the soluble human tissue factor domain comprises a sequence that is at least 90% identical to SEQ ID NO:98.
実施形態D117.可溶性ヒト組織因子ドメインが、配列番号98と少なくとも95%同一である配列を含む、実施形態D116に記載の多鎖キメラポリペプチド。 Embodiment D117. The multichain chimeric polypeptide of embodiment D116, wherein the soluble human tissue factor domain comprises a sequence that is at least 95% identical to SEQ ID NO:98.
実施形態D118.可溶性ヒト組織因子ドメインが、配列番号98と100%同一である配列を含む、実施形態D117に記載の多鎖キメラポリペプチド。 Embodiment D118. The multichain chimeric polypeptide of embodiment D117, wherein the soluble human tissue factor domain comprises a sequence that is 100% identical to SEQ ID NO:98.
実施形態E1.多鎖キメラポリペプチドであって、
(a)第1のキメラポリペプチドであって、
(i)第1の標的結合ドメイン、
(ii)可溶性組織因子ドメイン、及び
(iii)一対の親和性ドメインの第1のドメイン
を含む、第1のキメラポリペプチド、
(b)第2のキメラポリペプチドであって、
(i)一対の親和性ドメインの第2のドメイン、及び
(ii)第2の標的結合ドメイン
を含む、第2のキメラポリペプチド
を含み、
第1のキメラポリペプチドと第2のキメラポリペプチドが、一対の親和性ドメインの第1のドメインと第2のドメインとの結合を介して会合し、
第1の標的結合ドメイン及び第2の標的結合ドメインが各々独立して、IL-21受容体又は腫瘍成長因子受容体βII(TGFβRII)リガンドに特異的に結合する、
多鎖キメラポリペプチド。
Embodiment E1. A multi-chain chimeric polypeptide,
(a) a first chimeric polypeptide,
(i) a first target binding domain;
(ii) a soluble tissue factor domain, and (iii) a first domain of a pair of affinity domains,
(b) a second chimeric polypeptide,
a second chimeric polypeptide comprising (i) a second of the pair of affinity domains, and (ii) a second target binding domain;
the first chimeric polypeptide and the second chimeric polypeptide associate via binding of the first and second domains of a pair of affinity domains;
the first target binding domain and the second target binding domain each independently specifically bind to an IL-21 receptor or tumor growth factor receptor βII (TGFβRII) ligand;
Multi-chain chimeric polypeptides.
実施形態E2.第1の標的結合ドメインと可溶性組織因子ドメインが、第1のキメラポリペプチド内で互いに直接隣接している、実施形態E1に記載の多鎖キメラポリペプチド。 Embodiment E2. The multichain chimeric polypeptide of embodiment E1, wherein the first target binding domain and the soluble tissue factor domain are directly adjacent to each other within the first chimeric polypeptide.
実施形態E3.第1のキメラポリペプチドが、第1のキメラポリペプチド内の第1の標的結合ドメインと可溶性組織因子ドメインとの間にリンカー配列を更に含む、実施形態E1に記載の多鎖キメラポリペプチド。 Embodiment E3. The multichain chimeric polypeptide of embodiment E1, wherein the first chimeric polypeptide further comprises a linker sequence between the first target binding domain and the soluble tissue factor domain within the first chimeric polypeptide.
実施形態E4.可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインが、第1のキメラポリペプチド内で互いに直接隣接している、実施形態E1~E3のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment E4. The multichain chimeric polypeptide of any one of embodiments E1-E3, wherein the soluble tissue factor domain and the first of the paired affinity domains are directly adjacent to each other within the first chimeric polypeptide. .
実施形態E5.第1のキメラポリペプチドが、第1のキメラポリペプチド内の可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間にリンカー配列を更に含む、実施形態E1~E3のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment E5. Any one of embodiments E1-E3, wherein the first chimeric polypeptide further comprises a linker sequence between the soluble tissue factor domain within the first chimeric polypeptide and the first of the pair of affinity domains. A multi-chain chimeric polypeptide according to 1.
実施形態E6.一対の親和性ドメインの第2のドメインと第2の標的結合ドメインが、第2のキメラポリペプチド内で互いに直接隣接している、実施形態E1~E5のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment E6. The multichain chimera of any one of embodiments E1-E5, wherein the second domain and the second target binding domain of the pair of affinity domains are directly adjacent to each other within the second chimeric polypeptide. Polypeptide.
実施形態E7.第2のキメラポリペプチドが、第2のキメラポリペプチド内の一対の親和性ドメインの第2のドメインと第2の標的結合ドメインとの間にリンカー配列を更に含む、実施形態E1~E5のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment E7. Any of embodiments E1-E5, wherein the second chimeric polypeptide further comprises a linker sequence between the second of the pair of affinity domains and the second target binding domain within the second chimeric polypeptide. or a multi-chain chimeric polypeptide according to any one of the above.
実施形態E8.可溶性組織因子ドメインが、可溶性ヒト組織因子ドメインである、実施形態E1~E7のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment E8. The multichain chimeric polypeptide of any one of embodiments E1-E7, wherein the soluble tissue factor domain is a soluble human tissue factor domain.
実施形態E9.可溶性ヒト組織因子ドメインが、配列番号93と少なくとも80%同一である配列を含む、実施形態E8に記載の多鎖キメラポリペプチド。 Embodiment E9. The multichain chimeric polypeptide of embodiment E8, wherein the soluble human tissue factor domain comprises a sequence that is at least 80% identical to SEQ ID NO:93.
実施形態E10.可溶性ヒト組織因子ドメインが、配列番号93と少なくとも90%同一である配列を含む、実施形態E9に記載の多鎖キメラポリペプチド。 Embodiment E10. The multichain chimeric polypeptide of embodiment E9, wherein the soluble human tissue factor domain comprises a sequence that is at least 90% identical to SEQ ID NO:93.
実施形態E11.可溶性ヒト組織因子ドメインが、配列番号93と少なくとも95%同一である配列を含む、実施形態E10に記載の多鎖キメラポリペプチド。 Embodiment E11. The multichain chimeric polypeptide of embodiment E10, wherein the soluble human tissue factor domain comprises a sequence that is at least 95% identical to SEQ ID NO:93.
実施形態E12.可溶性ヒト組織因子ドメインが、
成熟野生型ヒト組織因子タンパク質のアミノ酸20位に対応するアミノ酸の位置にリジン、
成熟野生型ヒト組織因子タンパク質のアミノ酸22位に対応するアミノ酸の位置にイソロイシン、
成熟野生型ヒト組織因子タンパク質のアミノ酸45位に対応するアミノ酸の位置にトリプトファン、
成熟野生型ヒト組織因子タンパク質のアミノ酸58位に対応するアミノ酸の位置にアスパラギン酸、
成熟野生型ヒト組織因子タンパク質のアミノ酸94位に対応するアミノ酸の位置にチロシン、
成熟野生型ヒト組織因子タンパク質のアミノ酸135位に対応するアミノ酸の位置にアルギニン、及び
成熟野生型ヒト組織因子タンパク質のアミノ酸140位に対応するアミノ酸の位置にフェニルアラニンのうちのいずれも含まない、実施形態E8~E11のいずれか一つに記載の方法。
Embodiment E12. A soluble human tissue factor domain is
a lysine at the amino acid position corresponding to
an isoleucine at the amino acid position corresponding to
tryptophan at the amino acid position corresponding to
an aspartic acid at the amino acid position corresponding to amino acid position 58 of the mature wild-type human tissue factor protein;
a tyrosine at the amino acid position corresponding to amino acid position 94 of the mature wild-type human tissue factor protein;
An embodiment that does not include either arginine at the amino acid position corresponding to amino acid position 135 of the mature wild-type human tissue factor protein and phenylalanine at the amino acid position corresponding to
実施形態E13.可溶性ヒト組織因子ドメインが、
成熟野生型ヒト組織因子タンパク質のアミノ酸20位に対応するアミノ酸の位置にリジン、
成熟野生型ヒト組織因子タンパク質のアミノ酸22位に対応するアミノ酸の位置にイソロイシン、
成熟野生型ヒト組織因子タンパク質のアミノ酸45位に対応するアミノ酸の位置にトリプトファン、
成熟野生型ヒト組織因子タンパク質のアミノ酸58位に対応するアミノ酸の位置にアスパラギン酸、
成熟野生型ヒト組織因子タンパク質のアミノ酸94位に対応するアミノ酸の位置にチロシン、
成熟野生型ヒト組織因子タンパク質のアミノ酸135位に対応するアミノ酸の位置にアルギニン、及び
成熟野生型ヒト組織因子タンパク質のアミノ酸140位に対応するアミノ酸の位置にフェニルアラニンのうちのいずれも含まない、実施形態E12に記載の方法。
Embodiment E13. A soluble human tissue factor domain is
a lysine at the amino acid position corresponding to
an isoleucine at the amino acid position corresponding to
tryptophan at the amino acid position corresponding to
an aspartic acid at the amino acid position corresponding to amino acid position 58 of the mature wild-type human tissue factor protein;
a tyrosine at the amino acid position corresponding to amino acid position 94 of the mature wild-type human tissue factor protein;
An embodiment that does not include either arginine at the amino acid position corresponding to amino acid position 135 of the mature wild-type human tissue factor protein and phenylalanine at the amino acid position corresponding to
実施形態E14.可溶性組織因子ドメインが、第VIIa因子に結合することができない、実施形態E1~E13のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment E14. The multichain chimeric polypeptide of any one of embodiments E1-E13, wherein the soluble tissue factor domain is incapable of binding Factor VIIa.
実施形態E15.可溶性組織因子ドメインが、不活性第X因子を第Xa因子に変換しない、実施形態E1~E14のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment E15. The multichain chimeric polypeptide of any one of embodiments E1-E14, wherein the soluble tissue factor domain does not convert inactive factor X to factor Xa.
実施形態E16.多鎖キメラポリペプチドが、哺乳動物における血液凝固を刺激しない、実施形態E1~E15のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment E16. The multi-chain chimeric polypeptide of any one of embodiments E1-E15, wherein the multi-chain chimeric polypeptide does not stimulate blood clotting in a mammal.
実施形態E17.第1のキメラポリペプチドが、第1のキメラポリペプチドのN末端又はC末端にペプチドタグを更に含む、実施形態E1~E16のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment E17. The multi-chain chimeric polypeptide of any one of embodiments E1-E16, wherein the first chimeric polypeptide further comprises a peptide tag at the N-terminus or C-terminus of the first chimeric polypeptide.
実施形態E18.第2のキメラポリペプチドが、第2のキメラポリペプチドN末端又はC末端にペプチドタグを更に含む、実施形態E1~E17のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment E18. The multi-chain chimeric polypeptide of any one of embodiments E1-E17, wherein the second chimeric polypeptide further comprises a peptide tag at the N-terminus or C-terminus of the second chimeric polypeptide.
実施形態E19.第1のキメラポリペプチド及び/又は第2のキメラポリペプチドが、そのN末端にシグナル配列を更に含む、実施形態E1~E18のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment E19. The multi-chain chimeric polypeptide according to any one of embodiments E1-E18, wherein the first chimeric polypeptide and/or the second chimeric polypeptide further comprises a signal sequence at its N-terminus.
実施形態E20.シグナル配列が、配列番号117を含む、実施形態E19に記載の多鎖キメラポリペプチド。 Embodiment E20. The multichain chimeric polypeptide of embodiment E19, wherein the signal sequence comprises SEQ ID NO:117.
実施形態E21.シグナル配列が、配列番号117である、実施形態E20に記載の多鎖キメラポリペプチド。 Embodiment E21. The multichain chimeric polypeptide of embodiment E20, wherein the signal sequence is SEQ ID NO:117.
実施形態E22.一対の親和性ドメインが、ヒトIL-15受容体のアルファ鎖(IL-15Rα由来のスシドメイン、及び可溶性IL-15である、実施形態E1~E21のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment E22. The multichain chimeric poly(polychain) of any one of embodiments E1-E21, wherein the pair of affinity domains is the alpha chain of the human IL-15 receptor (a sushi domain from IL-15Rα, and a soluble IL-15). peptide.
実施形態E23.可溶性IL-15が、D8N又はD8Aアミノ酸置換を有する、実施形態E22に記載の多鎖キメラポリペプチド。 Embodiment E23. The multi-chain chimeric polypeptide of embodiment E22, wherein the soluble IL-15 has a D8N or D8A amino acid substitution.
実施形態E24.可溶性IL-15が、配列番号82と80%同一である配列を含む、実施形態E22に記載の多鎖キメラポリペプチド。 Embodiment E24. The multichain chimeric polypeptide of embodiment E22, wherein the soluble IL-15 comprises a sequence that is 80% identical to SEQ ID NO:82.
実施形態E25.可溶性IL-15が、配列番号82と90%同一である配列を含む、実施形態E24に記載の多鎖キメラポリペプチド。 Embodiment E25. The multichain chimeric polypeptide of embodiment E24, wherein the soluble IL-15 comprises a sequence that is 90% identical to SEQ ID NO:82.
実施形態E26.可溶性IL-15が、配列番号82と95%同一である配列を含む、実施形態E25に記載の多鎖キメラポリペプチド。 Embodiment E26. The multichain chimeric polypeptide of embodiment E25, wherein the soluble IL-15 comprises a sequence that is 95% identical to SEQ ID NO:82.
実施形態E27.可溶性IL-15が、配列番号82を含む、実施形態E26に記載の多鎖キメラポリペプチド。 Embodiment E27. The multichain chimeric polypeptide of embodiment E26, wherein the soluble IL-15 comprises SEQ ID NO:82.
実施形態E28.IL-15Rαのスシドメインが、ヒトIL-15Rα由来のスシドメインを含む、実施形態E22~E27のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment E28. The multi-chain chimeric polypeptide of any one of embodiments E22-E27, wherein the sushi domain of IL-15Rα comprises a sushi domain derived from human IL-15Rα.
実施形態E29.ヒトIL-15Rα由来のスシドメインが、配列番号113と80%同一である配列を含む、実施形態E28に記載の多鎖キメラポリペプチド。 Embodiment E29. The multi-chain chimeric polypeptide of embodiment E28, wherein the sushi domain from human IL-15Rα comprises a sequence that is 80% identical to SEQ ID NO:113.
実施形態E30.ヒトIL-15Rα由来のスシドメインが、配列番号113と90%同一である配列を含む、実施形態E29に記載の多鎖キメラポリペプチド。 Embodiment E30. The multi-chain chimeric polypeptide of embodiment E29, wherein the sushi domain from human IL-15Rα comprises a sequence that is 90% identical to SEQ ID NO:113.
実施形態E31.ヒトIL-15Rα由来のスシドメインが、配列番号113と95%同一である配列を含む、実施形態E30に記載の多鎖キメラポリペプチド。 Embodiment E31. The multi-chain chimeric polypeptide of embodiment E30, wherein the sushi domain from human IL-15Rα comprises a sequence that is 95% identical to SEQ ID NO:113.
実施形態E32.ヒトIL-15Rα由来のスシドメインが、配列番号113を含む、実施形態E31に記載の多鎖キメラポリペプチド。 Embodiment E32. The multi-chain chimeric polypeptide of embodiment E31, wherein the sushi domain from human IL-15Rα comprises SEQ ID NO:113.
実施形態E33.ヒトIL-15Rα由来のスシドメインが、成熟全長IL-15Rαである、実施形態E28に記載の多鎖キメラポリペプチド。 Embodiment E33. The multi-chain chimeric polypeptide of embodiment E28, wherein the sushi domain derived from human IL-15Rα is mature full-length IL-15Rα.
実施形態E34.一対の親和性ドメインが、バルナーゼとバルンスター、PKAとAKAP、変異RNaseI断片に基づくアダプター/ドッキングタグモジュール、並びに、タンパク質シンタキシン、シナプトタグミン、シナプトブレビン、及びSNAP25の相互作用に基づくSNAREモジュールからなる群から選択される、実施形態E1~E21のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment E34. The paired affinity domains are selected from the group consisting of barnase and barnstar, PKA and AKAP, adapter/docking tag modules based on mutated RNase I fragments, and SNARE modules based on interactions of proteins syntaxin, synaptotagmin, synaptobrevin, and SNAP25. The multi-chain chimeric polypeptide of any one of embodiments E1-E21, wherein
実施形態E35.第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方が、抗原結合ドメインである、実施形態E1~E34のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment E35. The multichain chimeric polypeptide of any one of embodiments E1-E34, wherein one or both of the first target binding domain and the second target binding domain are antigen binding domains.
実施形態E36.第1の標的結合ドメイン及び第2の標的結合ドメインが、抗原結合ドメインである、実施形態E35に記載の多鎖キメラポリペプチド。 Embodiment E36. The multichain chimeric polypeptide of embodiment E35, wherein the first target binding domain and the second target binding domain are antigen binding domains.
実施形態E37.抗原結合ドメインが、scFv又は単一ドメイン抗体を含む、実施形態E35又はE36に記載の多鎖キメラポリペプチド。 Embodiment E37. The multi-chain chimeric polypeptide of embodiment E35 or E36, wherein the antigen binding domain comprises a scFv or single domain antibody.
実施形態E38.第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方が、可溶性IL-21又は可溶性TGFβRIIである、実施形態E1~E34のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment E38. The multichain chimeric polypeptide of any one of embodiments E1-E34, wherein one or both of the first and second target binding domains is soluble IL-21 or soluble TGFβRII.
実施形態E39.第1の標的結合ドメイン及び第2の標的結合ドメインの両方が、IL-21受容体又はTGFβRIIリガンドに特異的に結合する、実施形態E1~E38のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment E39. The multichain chimeric polypeptide of any one of embodiments E1-E38, wherein both the first target binding domain and the second target binding domain specifically bind to IL-21 receptor or TGFβRII ligand. .
実施形態E40.第1の標的結合ドメイン及び第2の標的結合ドメインが同じエピトープに特異的に結合する、実施形態E39に記載の多鎖キメラポリペプチド。 Embodiment E40. The multichain chimeric polypeptide of embodiment E39, wherein the first target binding domain and the second target binding domain specifically bind to the same epitope.
実施形態E41.第1の標的結合ドメイン及び第2の標的結合ドメインが同じアミノ酸配列を含む、実施形態E40に記載の多鎖キメラポリペプチド。 Embodiment E41. The multichain chimeric polypeptide of embodiment E40, wherein the first target binding domain and the second target binding domain comprise the same amino acid sequence.
実施形態E42.第1の標的結合ドメインがTGFβRIIリガンドに特異的に結合し、第2の標的結合ドメインがIL-21受容体に特異的に結合する、実施形態E1~E38のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment E42. The multichain of any one of embodiments E1-E38, wherein the first target binding domain specifically binds a TGFβRII ligand and the second target binding domain specifically binds an IL-21 receptor. chimeric polypeptide.
実施形態E43.第1の標的結合ドメインがIL-21受容体に特異的に結合し、第2の標的結合ドメインがTGFβRIIリガンドに特異的に結合する、実施形態E1~E38のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment E43. The multichain of any one of embodiments E1-E38, wherein the first target binding domain specifically binds the IL-21 receptor and the second target binding domain specifically binds the TGFβRII ligand. chimeric polypeptide.
実施形態E44.第1の標的結合ドメインが、可溶性IL-21を含む、実施形態E43に記載の多鎖キメラポリペプチド。 Embodiment E44. The multichain chimeric polypeptide of embodiment E43, wherein the first target binding domain comprises soluble IL-21.
実施形態E45.可溶性IL-21が、可溶性ヒトIL-21である、実施形態E44に記載の多鎖キメラポリペプチド。 Embodiment E45. The multichain chimeric polypeptide of embodiment E44, wherein the soluble IL-21 is soluble human IL-21.
実施形態E46.可溶性ヒトIL-21が、配列番号83と少なくとも80%同一の配列を含む、実施形態E45に記載の多鎖キメラポリペプチド。 Embodiment E46. The multichain chimeric polypeptide of embodiment E45, wherein the soluble human IL-21 comprises a sequence at least 80% identical to SEQ ID NO:83.
実施形態E47.可溶性ヒトIL-21が、配列番号83と少なくとも90%同一の配列を含む、実施形態E46に記載の多鎖キメラポリペプチド。 Embodiment E47. The multichain chimeric polypeptide of embodiment E46, wherein the soluble human IL-21 comprises a sequence that is at least 90% identical to SEQ ID NO:83.
実施形態E48.可溶性ヒトIL-21が、配列番号83と少なくとも95%同一の配列を含む、実施形態E47に記載の多鎖キメラポリペプチド。 Embodiment E48. The multichain chimeric polypeptide of embodiment E47, wherein the soluble human IL-21 comprises a sequence that is at least 95% identical to SEQ ID NO:83.
実施形態E49.可溶性ヒトIL-21が、配列番号83の配列を含む、実施形態E48に記載の多鎖キメラポリペプチド。 Embodiment E49. The multichain chimeric polypeptide of embodiment E48, wherein the soluble human IL-21 comprises the sequence of SEQ ID NO:83.
実施形態E50.第2の標的結合ドメインが、可溶性TGFβRIIを含む、実施形態E43~E49のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment E50. The multichain chimeric polypeptide of any one of embodiments E43-E49, wherein the second target binding domain comprises soluble TGFβRII.
実施形態E51.可溶性TGFβRIIが、可溶性ヒトTGFβRIIである、実施形態E50に記載の多鎖キメラポリペプチド。 Embodiment E51. The multichain chimeric polypeptide of embodiment E50, wherein the soluble TGFβRII is soluble human TGFβRII.
実施形態E52.可溶性ヒトTGFβRIIが、第1の可溶性ヒトTGFβRII配列及び第2の可溶性ヒトTGFβRII配列を含む、実施形態E51に記載の多鎖キメラポリペプチド。 Embodiment E52. The multichain chimeric polypeptide of embodiment E51, wherein the soluble human TGFβRII comprises a first soluble human TGFβRII sequence and a second soluble human TGFβRII sequence.
実施形態E53.可溶性ヒトTGFβRIIが、第1の可溶性ヒトTGFβRII配列と第2の可溶性ヒトTGFβRII配列との間にリンカー配列を更に含む、実施形態E52に記載の多鎖キメラポリペプチド。 Embodiment E53. The multichain chimeric polypeptide of embodiment E52, wherein the soluble human TGFβRII further comprises a linker sequence between the first soluble human TGFβRII sequence and the second soluble human TGFβRII sequence.
実施形態E54.リンカー配列が、配列番号102を含む、実施形態E53に記載の多鎖キメラポリペプチド。 Embodiment E54. The multichain chimeric polypeptide of embodiment E53, wherein the linker sequence comprises SEQ ID NO:102.
実施形態E55.第1の可溶性ヒトTGFβRII配列が、配列番号183と少なくとも80%同一である配列を含む、実施形態E52~E54のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment E55. The multichain chimeric polypeptide of any one of embodiments E52-E54, wherein the first soluble human TGFβRII sequence comprises a sequence that is at least 80% identical to SEQ ID NO:183.
実施形態E56.第1の可溶性ヒトTGFβRII配列が、配列番号183と少なくとも90%同一である配列を含む、実施形態E55に記載の多鎖キメラポリペプチド。 Embodiment E56. The multichain chimeric polypeptide of embodiment E55, wherein the first soluble human TGFβRII sequence comprises a sequence that is at least 90% identical to SEQ ID NO:183.
実施形態E57.第1の可溶性ヒトTGFβRII配列が、配列番号183と少なくとも95%同一である配列を含む、実施形態E56に記載の多鎖キメラポリペプチド。 Embodiment E57. The multichain chimeric polypeptide of embodiment E56, wherein the first soluble human TGFβRII sequence comprises a sequence that is at least 95% identical to SEQ ID NO:183.
実施形態E58.第1の可溶性ヒトTGFβRII配列が、配列番号183を含む、実施形態E57に記載の多鎖キメラポリペプチド。 Embodiment E58. The multichain chimeric polypeptide of embodiment E57, wherein the first soluble human TGFβRII sequence comprises SEQ ID NO:183.
実施形態E59.第2の可溶性ヒトTGFβRII配列が、配列番号184と少なくとも80%同一である配列を含む、実施形態E52~E58のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment E59. The multichain chimeric polypeptide of any one of embodiments E52-E58, wherein the second soluble human TGFβRII sequence comprises a sequence that is at least 80% identical to SEQ ID NO:184.
実施形態E60.第2の可溶性ヒトTGFβRII配列が、配列番号184と少なくとも90%同一である配列を含む、実施形態E59に記載の多鎖キメラポリペプチド。 Embodiment E60. The multichain chimeric polypeptide of embodiment E59, wherein the second soluble human TGFβRII sequence comprises a sequence that is at least 90% identical to SEQ ID NO:184.
実施形態E61.第2の可溶性ヒトTGFβRII配列が、配列番号184と少なくとも95%同一である配列を含む、実施形態E60に記載のミュール鎖キメラポリペプチド。 Embodiment E61. The mule chain chimeric polypeptide of embodiment E60, wherein the second soluble human TGFβRII sequence comprises a sequence that is at least 95% identical to SEQ ID NO:184.
実施形態E62.第2の可溶性ヒトTGFβRII配列が、配列番号184を含む、実施形態E61に記載の多鎖キメラポリペプチド。 Embodiment E62. The multichain chimeric polypeptide of embodiment E61, wherein the second soluble human TGFβRII sequence comprises SEQ ID NO:184.
実施形態E63.第1のキメラポリペプチドが、配列番号189と少なくとも80%同一である配列を含む、実施形態E1に記載の多鎖キメラポリペプチド。 Embodiment E63. The multi-chain chimeric polypeptide of embodiment E1, wherein the first chimeric polypeptide comprises a sequence that is at least 80% identical to SEQ ID NO:189.
実施形態E64.第1のキメラポリペプチドが、配列番号189と少なくとも90%同一である配列を含む、実施形態E63に記載の多鎖キメラポリペプチド。 Embodiment E64. The multichain chimeric polypeptide of embodiment E63, wherein the first chimeric polypeptide comprises a sequence that is at least 90% identical to SEQ ID NO:189.
実施形態E65.第1のキメラポリペプチドが、配列番号189と少なくとも95%同一である配列を含む、実施形態E64に記載の多鎖キメラポリペプチド。 Embodiment E65. The multichain chimeric polypeptide of embodiment E64, wherein the first chimeric polypeptide comprises a sequence that is at least 95% identical to SEQ ID NO:189.
実施形態E66.第1のキメラポリペプチドが、配列番号189を含む、実施形態E65に記載の多鎖キメラポリペプチド。 Embodiment E66. The multi-chain chimeric polypeptide of embodiment E65, wherein the first chimeric polypeptide comprises SEQ ID NO:189.
実施形態E67.第1のキメラポリペプチドが、配列番号191を含む、実施形態E66に記載の多鎖キメラポリペプチド。 Embodiment E67. The multi-chain chimeric polypeptide of embodiment E66, wherein the first chimeric polypeptide comprises SEQ ID NO:191.
実施形態E68.第2のキメラポリペプチドが、配列番号193と少なくとも80%同一である配列を含む、実施形態E1及びE63~E67のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment E68. The multi-chain chimeric polypeptide of any one of embodiments E1 and E63-E67, wherein the second chimeric polypeptide comprises a sequence that is at least 80% identical to SEQ ID NO:193.
実施形態E69.第2のキメラポリペプチドが、配列番号193と少なくとも90%同一である配列を含む、実施形態E68に記載の多鎖キメラポリペプチド。 Embodiment E69. The multichain chimeric polypeptide of embodiment E68, wherein the second chimeric polypeptide comprises a sequence that is at least 90% identical to SEQ ID NO:193.
実施形態E70.第2のキメラポリペプチドが、配列番号193と少なくとも95%同一である配列を含む、実施形態E69に記載の多鎖キメラポリペプチド。 Embodiment E70. The multi-chain chimeric polypeptide of embodiment E69, wherein the second chimeric polypeptide comprises a sequence that is at least 95% identical to SEQ ID NO:193.
実施形態E71.第2のキメラポリペプチドが、配列番号193を含む、実施形態E70に記載の多鎖キメラポリペプチド。 Embodiment E71. The multi-chain chimeric polypeptide of embodiment E70, wherein the second chimeric polypeptide comprises SEQ ID NO:193.
実施形態E72.第2のキメラポリペプチドが、配列番号195を含む、実施形態E71に記載の多鎖キメラポリペプチド。 Embodiment E72. The multi-chain chimeric polypeptide of embodiment E71, wherein the second chimeric polypeptide comprises SEQ ID NO:195.
実施形態E73.第1のキメラポリペプチドが、1つ以上の追加の標的結合ドメインを更に含み、1つ以上の追加の抗原結合ドメインのうちの少なくとも1つが、可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間に位置付けられている、実施形態E1~E62のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment E73. The first chimeric polypeptide further comprises one or more additional target binding domains, wherein at least one of the one or more additional antigen binding domains comprises the soluble tissue factor domain and the first of the paired affinity domains. A multi-chain chimeric polypeptide according to any one of embodiments E1-E62, which is positioned between a domain of
実施形態E74.第1のキメラポリペプチドが、可溶性組織因子ドメインと1つ以上の追加の抗原結合ドメインのうちの少なくとも1つとの間にリンカー配列、及び/又は1つ以上の追加の抗原結合ドメインのうちの少なくとも1つと一対の親和性ドメインの第1のドメインとの間にリンカー配列を更に含む、実施形態E73に記載の多鎖キメラポリペプチド。 Embodiment E74. The first chimeric polypeptide comprises a linker sequence between the soluble tissue factor domain and at least one of the one or more additional antigen binding domains, and/or at least one of the one or more additional antigen binding domains. The multichain chimeric polypeptide of embodiment E73, further comprising a linker sequence between one and the first of the pair of affinity domains.
実施形態E75.第1のキメラポリペプチドが、第1のキメラポリペプチドのN末端及び/又はC末端に1つ以上の追加の標的結合ドメインを更に含む、実施形態E1~E62のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment E75. The multiple according to any one of embodiments E1-E62, wherein the first chimeric polypeptide further comprises one or more additional target binding domains at the N-terminus and/or C-terminus of the first chimeric polypeptide. chain chimeric polypeptides.
実施形態E76.1つ以上の追加の標的結合ドメインのうちの少なくとも1つが、第1のキメラポリペプチド内の一対の親和性ドメインの第1のドメインに直接隣接している、実施形態E75に記載の多鎖キメラポリペプチド。 Embodiment E76. Described in embodiment E75, wherein at least one of the one or more additional target binding domains is directly adjacent to the first of the pair of affinity domains within the first chimeric polypeptide multi-chain chimeric polypeptide of.
実施形態E77.第1のキメラポリペプチドが、1つ以上の追加の標的結合ドメインのうちの少なくとも1つと一対の親和性ドメインの第1のドメインとの間にリンカー配列を更に含む、実施形態E75に記載の多鎖キメラポリペプチド。 Embodiment E77. The multiple of embodiment E75, wherein the first chimeric polypeptide further comprises a linker sequence between at least one of the one or more additional target binding domains and the first of the pair of affinity domains. chain chimeric polypeptides.
実施形態E78.1つ以上の追加の標的結合ドメインのうちの少なくとも1つが、第1のキメラポリペプチド内の第1の標的結合ドメインに直接隣接している、実施形態E75に記載の多鎖キメラポリペプチド。 Embodiment E78. The multichain chimera of embodiment E75, wherein at least one of the one or more additional target binding domains is directly adjacent to the first target binding domain within the first chimeric polypeptide Polypeptide.
実施形態E79.第1のキメラポリペプチドが、1つ以上の追加の標的結合ドメインのうちの少なくとも1つと第1の標的結合ドメインとの間にリンカー配列を更に含む、実施形態E75に記載の多鎖キメラポリペプチド。 Embodiment E79. The multichain chimeric polypeptide of embodiment E75, wherein the first chimeric polypeptide further comprises a linker sequence between at least one of the one or more additional target binding domains and the first target binding domain. .
実施形態E80.1つ以上の追加の標的結合ドメインのうちの少なくとも1つが、第1のキメラポリペプチドのN末端及び/又はC末端に配置されており、1つ以上の追加の標的結合ドメインのうちの少なくとも1つが、第1のキメラポリペプチド内の可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間に位置付けられている、実施形態E75に記載の多鎖キメラポリペプチド。 Embodiment E80. At least one of the one or more additional target binding domains is located at the N-terminus and/or C-terminus of the first chimeric polypeptide, wherein the one or more additional target binding domains are The multichain chimeric polypeptide of embodiment E75, wherein at least one of is positioned between the soluble tissue factor domain and the first of the pair of affinity domains within the first chimeric polypeptide.
実施形態E81.N末端に配置された1つ以上の追加の標的結合ドメインのうちの少なくとも1つの追加の標的結合ドメインが、第1のキメラポリペプチド内の第1の標的結合ドメイン又は一対の親和性ドメインの第1のドメインに直接隣接している、実施形態E80に記載の多鎖キメラポリペプチド。 Embodiment E81. At least one additional target binding domain of the one or more additional target binding domains located at the N-terminus is the first target binding domain in the first chimeric polypeptide or the first of the pair of affinity domains The multichain chimeric polypeptide of embodiment E80, which is directly contiguous to one domain.
実施形態E82.第1のキメラポリペプチドが、第1のキメラポリペプチド内の少なくとも1つの追加の標的結合ドメインと第1の標的結合ドメイン又は一対の親和性ドメインの第1のドメインとの間に配置されたリンカー配列を更に含む、実施形態E80に記載の多鎖キメラポリペプチド。 Embodiment E82. a linker wherein the first chimeric polypeptide is positioned between at least one additional target binding domain within the first chimeric polypeptide and the first target binding domain or the first domain of the pair of affinity domains The multichain chimeric polypeptide of embodiment E80, further comprising a sequence.
実施形態E83.C末端に配置された1つ以上の追加の標的結合ドメインのうちの少なくとも1つの追加の標的結合ドメインが、第1のキメラポリペプチド内の第1の標的結合ドメイン又は一対の親和性ドメインの第1のドメインに直接隣接している、実施形態E80に記載の多鎖キメラポリペプチド。 Embodiment E83. At least one additional target binding domain of the one or more additional target binding domains located at the C-terminus is the first target binding domain in the first chimeric polypeptide or the first of the pair of affinity domains The multichain chimeric polypeptide of embodiment E80, which is directly contiguous to one domain.
実施形態E84.第1のキメラポリペプチドが、第1のキメラポリペプチド内の少なくとも1つの追加の標的結合ドメインと第1の標的結合ドメイン又は一対の親和性ドメインの第1のドメインとの間に配置されたリンカー配列を更に含む、実施形態E80に記載の多鎖キメラポリペプチド。 Embodiment E84. a linker wherein the first chimeric polypeptide is positioned between at least one additional target binding domain within the first chimeric polypeptide and the first target binding domain or the first domain of the pair of affinity domains The multichain chimeric polypeptide of embodiment E80, further comprising a sequence.
実施形態E85.可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間に位置付けられた1つ以上の追加の標的結合ドメインのうちの少なくとも1つが、可溶性組織因子ドメイン、及び/又は一対の親和性ドメインの第1のドメインに直接隣接している、実施形態E80に記載の多鎖キメラポリペプチド。 Embodiment E85. at least one of the one or more additional target binding domains positioned between the soluble tissue factor domain and the first domain of the pair of affinity domains is the soluble tissue factor domain and/or the affinity pair The multi-chain chimeric polypeptide of embodiment E80, wherein the domains are directly adjacent to the first domain.
実施形態E86.第1のキメラポリペプチドが、(i)可溶性組織因子ドメインと、可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間に位置付けられた1つ以上の追加の標的結合ドメインのうちの少なくとも1つとの間、及び/又は(ii)一対の親和性ドメインの第1のドメインと、可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間に位置付けられた1つ以上の追加の標的結合ドメインのうちの少なくとも1つとの間に配置されたリンカー配列を更に含む、実施形態E80に記載の多鎖キメラポリペプチド。 Embodiment E86. the first chimeric polypeptide comprises: (i) the soluble tissue factor domain and one or more additional target binding domains positioned between the soluble tissue factor domain and the first of the pair of affinity domains; and/or (ii) between the first domain of the pair of affinity domains and the soluble tissue factor domain and the first domain of the pair of affinity domains The multichain chimeric polypeptide of embodiment E80, further comprising a linker sequence interposed with at least one of the additional target binding domains of embodiment E80.
実施形態E87.第2のキメラポリペプチドが、第2のキメラポリペプチドのN末端又はC末端に1つ以上の追加の標的結合ドメインを更に含む、実施形態E1~E62及びE73~E86のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment E87. Any one of embodiments E1-E62 and E73-E86, wherein the second chimeric polypeptide further comprises one or more additional target binding domains at the N-terminus or C-terminus of the second chimeric polypeptide multi-chain chimeric polypeptide of.
実施形態E88.1つ以上の追加の標的結合ドメインのうちの少なくとも1つが、第2のキメラポリペプチド内の一対の親和性ドメインの第2のドメインに直接隣接している、実施形態E87に記載の多鎖キメラポリペプチド。 Embodiment E88. Described in embodiment E87, wherein at least one of the one or more additional target binding domains is directly adjacent to a second of the pair of affinity domains within the second chimeric polypeptide multi-chain chimeric polypeptide of.
実施形態E89.第2のキメラポリペプチドが、第2のキメラポリペプチド内の1つ以上の追加の標的結合ドメインのうちの少なくとも1つと一対の親和性ドメインの第2のドメインとの間にリンカー配列を更に含む、実施形態E87に記載の多鎖キメラポリペプチド。 Embodiment E89. The second chimeric polypeptide further comprises a linker sequence between at least one of the one or more additional target binding domains in the second chimeric polypeptide and the second of the pair of affinity domains , embodiment E87.
実施形態E90.1つ以上の追加の標的結合ドメインのうちの少なくとも1つが、第2のキメラポリペプチド内の第2の標的結合ドメインに直接隣接している、実施形態E87に記載の多鎖キメラポリペプチド。 Embodiment E90. The multichain chimera of embodiment E87, wherein at least one of the one or more additional target binding domains is directly adjacent to the second target binding domain within the second chimeric polypeptide Polypeptide.
実施形態E91.第2のキメラポリペプチドが、第2のキメラポリペプチド内の1つ以上の追加の標的結合ドメインのうちの少なくとも1つと第2の標的結合ドメインとの間にリンカー配列を更に含む、実施形態E87に記載の多鎖キメラポリペプチド。 Embodiment E91. Embodiment E87, wherein the second chimeric polypeptide further comprises a linker sequence between at least one of the one or more additional target binding domains within the second chimeric polypeptide and the second target binding domain. 3. A multi-chain chimeric polypeptide according to .
実施形態E92.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの2つ以上が同じ抗原に特異的に結合する、実施形態E73~E91のいずれか1つに記載の多鎖キメラポリペプチド。
Embodiment E92. Any one of embodiments E73-E91, wherein two or more of the first target binding domain, the second target binding domain, and the one or more additional target binding domains specifically bind to the
実施形態E93.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの2つ以上が同じエピトープに特異的に結合する、実施形態E92に記載の多鎖キメラポリペプチド。 Embodiment E93. The multichain chimeric poly of embodiment E92, wherein two or more of the first target binding domain, the second target binding domain, and the one or more additional target binding domains specifically bind the same epitope. peptide.
実施形態E94.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの2つ以上が同じアミノ酸配列を含む、実施形態E93に記載の多鎖キメラポリペプチド。 Embodiment E94. The multichain chimeric polypeptide of embodiment E93, wherein two or more of the first target binding domain, second target binding domain, and one or more additional target binding domains comprise the same amino acid sequence.
実施形態E95.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインが異なる抗原に特異的に結合する、実施形態E73~E91のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment E95. The multichain chimera of any one of embodiments E73-E91, wherein the first target binding domain, the second target binding domain, and the one or more additional target binding domains specifically bind different antigens. Polypeptide.
実施形態E96.1つ以上の追加の抗原結合ドメインが、CD16a、CD28、CD3、CD33、CD20、CD19、CD22、CD123、IL-1R、IL-1、VEGF、IL-6R、IL-4、IL-10、PDL-1、TIGIT、PD-1、TIM3、CTLA4、MICA、MICB、IL-6、IL-8、TNFα、CD26、CD36、ULBP2、CD30、CD200、IGF-1R、MUC4AC、MUC5AC、Trop-2、CMET、EGFR、HER1、HER2、HER3、PSMA、CEA、B7H3、EPCAM、BCMA、P-カドヘリン、CEACAM5、UL16結合タンパク質、HLA-DR、DLL4、TYRO3、AXL、MER、CD122、CD155、PDGF-D、TGF-β受容体II(TGF-βRII)リガンド、TGF-βRIIIリガンド、DNAM1リガンド、NKp46リガンド、NKp44リガンド、NKG2Dリガンド、NKp30リガンド、scMHCIリガンド、scMHCIIリガンド、scTCRリガンド、IL-1受容体、IL-2受容体、IL-3受容体、IL-7受容体、IL-8受容体、IL-10受容体、IL-12受容体、IL-15受容体、IL-17受容体、IL-18受容体、IL-21受容体、PDGF-DD受容体、幹細胞因子(SCF)受容体、幹細胞様チロシンキナーゼ3リガンド(FLT3L)受容体、MICA受容体、MICB受容体、ULP16結合タンパク質受容体、CD155受容体、及びCD28受容体からなる群から選択される標的に特異的に結合する、実施形態E73~E95のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment E96.The one or more additional antigen binding domains comprises CD16a, CD28, CD3, CD33, CD20, CD19, CD22, CD123, IL-1R, IL-1, VEGF, IL-6R, IL-4, IL -10, PDL-1, TIGIT, PD-1, TIM3, CTLA4, MICA, MICB, IL-6, IL-8, TNFα, CD26, CD36, ULBP2, CD30, CD200, IGF-1R, MUC4AC, MUC5AC, Trop -2, CMET, EGFR, HER1, HER2, HER3, PSMA, CEA, B7H3, EPCAM, BCMA, P-cadherin, CEACAM5, UL16 binding protein, HLA-DR, DLL4, TYRO3, AXL, MER, CD122, CD155, PDGF -D, TGF-β receptor II (TGF-βRII) ligand, TGF-βRIII ligand, DNAM1 ligand, NKp46 ligand, NKp44 ligand, NKG2D ligand, NKp30 ligand, scMHCI ligand, scMHCII ligand, scTCR ligand, IL-1 receptor , IL-2 receptor, IL-3 receptor, IL-7 receptor, IL-8 receptor, IL-10 receptor, IL-12 receptor, IL-15 receptor, IL-17 receptor, IL -18 receptor, IL-21 receptor, PDGF-DD receptor, stem cell factor (SCF) receptor, stem cell-like tyrosine kinase 3 ligand (FLT3L) receptor, MICA receptor, MICB receptor, ULP16 binding protein receptor , CD155 receptor, and CD28 receptor.
実施形態E97.1つ以上の追加の標的結合ドメインが、可溶性インターロイキン又はサイトカインタンパク質である、実施形態E73~E95のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment E97. The multichain chimeric polypeptide of any one of embodiments E73-E95, wherein the one or more additional target binding domains is a soluble interleukin or cytokine protein.
実施形態E98.可溶性インターロイキン、サイトカイン、又はリガンドタンパク質が、IL-1、IL-2、IL-3、IL-7、IL-8、IL-10、IL-12、IL-15、IL-17、IL-18、IL-21、PDGF-DD、SCF、FLT3L、MICA、MICB、及びULP16結合タンパク質からなる群から選択される、実施形態E97に記載の多鎖キメラポリペプチド。 Embodiment E98. soluble interleukin, cytokine, or ligand protein is IL-1, IL-2, IL-3, IL-7, IL-8, IL-10, IL-12, IL-15, IL-17, IL-18 , IL-21, PDGF-DD, SCF, FLT3L, MICA, MICB, and ULP16 binding protein.
実施形態E99.1つ以上の追加の標的結合ドメインが、可溶性インターロイキン又はサイトカイン受容体である、実施形態E73~E95のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment E99. The multichain chimeric polypeptide of any one of embodiments E73-E95, wherein the one or more additional target binding domains is a soluble interleukin or cytokine receptor.
実施形態E100.可溶性受容体が、可溶性TGF-β受容体II(TGF-βRII)、可溶性TGF-βRIII、可溶性NKG2D、可溶性NKp30、可溶性NKp44、可溶性NKp46、可溶性DNAM1、scMHCI、scMHCII、scTCR、可溶性CD155、又は可溶性CD28である、実施形態E99に記載の多鎖キメラポリペプチド。 Embodiment E100. the soluble receptor is soluble TGF-β receptor II (TGF-βRII), soluble TGF-βRIII, soluble NKG2D, soluble NKp30, soluble NKp44, soluble NKp46, soluble DNAM1, scMHCI, scMHCII, scTCR, soluble CD155, or soluble CD28 The multi-chain chimeric polypeptide of embodiment E99, which is
実施形態E101.実施形態E1~E100に記載の多鎖キメラポリペプチドのうちのいずれかを含む、組成物。 Embodiment E101. A composition comprising any of the multi-chain chimeric polypeptides of embodiments E1-E100.
実施形態E102.組成物が、医薬組成物である、実施形態E101に記載の組成物。 Embodiment E102. The composition of embodiment E101, wherein the composition is a pharmaceutical composition.
実施形態E103.実施形態E101又はE102の組成物の少なくとも1つの用量を含むキット。 Embodiment E103. A kit comprising at least one dose of the composition of embodiment E101 or E102.
実施形態E104.実施形態E1~E100のいずれか1つに記載の多鎖キメラポリペプチドのうちのいずれかをコードする、核酸。 Embodiment E104. A nucleic acid encoding any of the multi-chain chimeric polypeptides of any one of embodiments E1-E100.
実施形態E105.実施形態E104に記載の核酸を含む、ベクター。 Embodiment E105. A vector comprising the nucleic acid of embodiment E104.
実施形態E106.ベクターが、発現ベクターである、実施形態E105に記載のベクター。 Embodiment E106. The vector of embodiment E105, wherein the vector is an expression vector.
実施形態E107.実施形態C104に記載の核酸又は実施形態E105又はE106に記載のベクターを含む、細胞。 Embodiment E107. A cell comprising the nucleic acid of embodiment C104 or the vector of embodiment E105 or E106.
実施形態E108.多鎖キメラポリペプチドを産生する方法であって、
多鎖キメラポリペプチドの産生をもたらすのに十分な条件下で、実施形態E107に記載の細胞を培養培地中で培養することと、
多鎖キメラポリペプチドを細胞及び/又は培養培地から回収することと
を含む、方法。
Embodiment E108. A method of producing a multi-chain chimeric polypeptide comprising:
culturing the cells of embodiment E107 in a culture medium under conditions sufficient to result in the production of the multi-chain chimeric polypeptide;
recovering the multi-chain chimeric polypeptide from the cells and/or the culture medium.
実施形態E109.実施形態E108に記載の方法によって産生された多鎖キメラポリペプチド。 Embodiment E109. A multi-chain chimeric polypeptide produced by the method of embodiment E108.
実施形態E110.可溶性ヒト組織因子ドメインが、配列番号97と少なくとも80%同一である配列を含む、実施形態E12に記載の多鎖キメラポリペプチド。 Embodiment E110. The multichain chimeric polypeptide of embodiment E12, wherein the soluble human tissue factor domain comprises a sequence that is at least 80% identical to SEQ ID NO:97.
実施形態E111.可溶性ヒト組織因子ドメインが、配列番号97と少なくとも90%同一である配列を含む、実施形態E110に記載の多鎖キメラポリペプチド。 Embodiment E111. The multichain chimeric polypeptide of embodiment E110, wherein the soluble human tissue factor domain comprises a sequence that is at least 90% identical to SEQ ID NO:97.
実施形態E112.可溶性ヒト組織因子ドメインが、配列番号97と少なくとも95%同一である配列を含む、実施形態E111に記載の多鎖キメラポリペプチド。 Embodiment E112. The multichain chimeric polypeptide of embodiment E111, wherein the soluble human tissue factor domain comprises a sequence that is at least 95% identical to SEQ ID NO:97.
実施形態E113.可溶性ヒト組織因子ドメインが、配列番号97と100%同一である配列を含む、実施形態E112に記載の多鎖キメラポリペプチド。 Embodiment E113. The multichain chimeric polypeptide of embodiment E112, wherein the soluble human tissue factor domain comprises a sequence that is 100% identical to SEQ ID NO:97.
実施形態E114.可溶性ヒト組織因子ドメインが、配列番号98と少なくとも80%同一である配列を含む、実施形態E12に記載の多鎖キメラポリペプチド。 Embodiment E114. The multichain chimeric polypeptide of embodiment E12, wherein the soluble human tissue factor domain comprises a sequence that is at least 80% identical to SEQ ID NO:98.
実施形態E115.可溶性ヒト組織因子ドメインが、配列番号98と少なくとも90%同一である配列を含む、実施形態E114に記載の多鎖キメラポリペプチド。 Embodiment E115. The multichain chimeric polypeptide of embodiment E114, wherein the soluble human tissue factor domain comprises a sequence that is at least 90% identical to SEQ ID NO:98.
実施形態E116.可溶性ヒト組織因子ドメインが、配列番号98と少なくとも95%同一である配列を含む、実施形態E115に記載の多鎖キメラポリペプチド。 Embodiment E116. The multichain chimeric polypeptide of embodiment E115, wherein the soluble human tissue factor domain comprises a sequence that is at least 95% identical to SEQ ID NO:98.
実施形態E117.可溶性ヒト組織因子ドメインが、配列番号98と100%同一である配列を含む、実施形態E116に記載の多鎖キメラポリペプチド。 Embodiment E117. The multichain chimeric polypeptide of embodiment E116, wherein the soluble human tissue factor domain comprises a sequence that is 100% identical to SEQ ID NO:98.
実施形態F1.多鎖キメラポリペプチドであって、
(c)第1のキメラポリペプチドであって、
(i)第1の標的結合ドメイン、
(ii)可溶性組織因子ドメイン、及び
(iii)一対の親和性ドメインの第1のドメイン
を含む、第1のキメラポリペプチド、
(d)第2のキメラポリペプチドであって、
(i)一対の親和性ドメインの第2のドメイン、及び
(ii)第2の標的結合ドメイン
を含む、第2のキメラポリペプチド
を含み、
第1のキメラポリペプチドと第2のキメラポリペプチドが、一対の親和性ドメインの第1のドメインと第2のドメインとの結合を介して会合し、
第1の標的結合ドメイン及び第2の標的結合ドメインが各々独立して、IL-21受容体又はIL-7受容体に特異的に結合する、
多鎖キメラポリペプチド。
Embodiment F1. A multi-chain chimeric polypeptide,
(c) a first chimeric polypeptide,
(i) a first target binding domain;
(ii) a soluble tissue factor domain, and (iii) a first domain of a pair of affinity domains,
(d) a second chimeric polypeptide,
a second chimeric polypeptide comprising (i) a second of the pair of affinity domains, and (ii) a second target binding domain;
the first chimeric polypeptide and the second chimeric polypeptide associate via binding of the first and second domains of a pair of affinity domains;
the first target binding domain and the second target binding domain each independently specifically bind to the IL-21 receptor or the IL-7 receptor;
Multi-chain chimeric polypeptides.
実施形態F2.第1の標的結合ドメインと可溶性組織因子ドメインが、第1のキメラポリペプチド内で互いに直接隣接している、実施形態F1に記載の多鎖キメラポリペプチド。 Embodiment F2. The multichain chimeric polypeptide of embodiment F1, wherein the first target binding domain and the soluble tissue factor domain are directly adjacent to each other within the first chimeric polypeptide.
実施形態F3.第1のキメラポリペプチドが、第1のキメラポリペプチド内の第1の標的結合ドメインと可溶性組織因子ドメインとの間にリンカー配列を更に含む、実施形態F1に記載の多鎖キメラポリペプチド。 Embodiment F3. The multichain chimeric polypeptide of embodiment F1, wherein the first chimeric polypeptide further comprises a linker sequence between the first target binding domain and the soluble tissue factor domain within the first chimeric polypeptide.
実施形態F4.可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインが、第1のキメラポリペプチド内で互いに直接隣接している、実施形態F1~F3のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment F4. The multichain chimeric polypeptide of any one of embodiments F1-F3, wherein the soluble tissue factor domain and the first of the paired affinity domains are directly adjacent to each other within the first chimeric polypeptide. .
実施形態F5.第1のキメラポリペプチドが、第1のキメラポリペプチド内の可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間にリンカー配列を更に含む、実施形態F1~F3のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment F5. Any one of embodiments F1-F3, wherein the first chimeric polypeptide further comprises a linker sequence between the soluble tissue factor domain and the first of the pair of affinity domains within the first chimeric polypeptide. A multi-chain chimeric polypeptide according to 1.
実施形態F6.一対の親和性ドメインの第2のドメインと第2の標的結合ドメインが、第2のキメラポリペプチド内で互いに直接隣接している、実施形態F1~F5のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment F6. The multichain chimera of any one of embodiments F1-F5, wherein the second domain and the second target binding domain of the pair of affinity domains are directly adjacent to each other within the second chimeric polypeptide. Polypeptide.
実施形態F7.第2のキメラポリペプチドが、第2のキメラポリペプチド内の一対の親和性ドメインの第2のドメインと第2の標的結合ドメインとの間にリンカー配列を更に含む、実施形態F1~F5のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment F7. Any of embodiments F1-F5, wherein the second chimeric polypeptide further comprises a linker sequence between the second of the pair of affinity domains and the second target binding domain within the second chimeric polypeptide. or a multi-chain chimeric polypeptide according to any one of the above.
実施形態F8.可溶性組織因子ドメインが、可溶性ヒト組織因子ドメインである、実施形態F1~F7のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment F8. The multichain chimeric polypeptide of any one of embodiments F1-F7, wherein the soluble tissue factor domain is a soluble human tissue factor domain.
実施形態F9.可溶性ヒト組織因子ドメインが、配列番号93と少なくとも80%同一である配列を含む、実施形態F8に記載の多鎖キメラポリペプチド。 Embodiment F9. The multichain chimeric polypeptide of embodiment F8, wherein the soluble human tissue factor domain comprises a sequence that is at least 80% identical to SEQ ID NO:93.
実施形態F10.可溶性ヒト組織因子ドメインが、配列番号93と少なくとも90%同一である配列を含む、実施形態F9に記載の多鎖キメラポリペプチド。 Embodiment F10. The multichain chimeric polypeptide of embodiment F9, wherein the soluble human tissue factor domain comprises a sequence that is at least 90% identical to SEQ ID NO:93.
実施形態F11.可溶性ヒト組織因子ドメインが、配列番号93と少なくとも95%同一である配列を含む、実施形態F10に記載の多鎖キメラポリペプチド。 Embodiment F11. The multichain chimeric polypeptide of embodiment F10, wherein the soluble human tissue factor domain comprises a sequence that is at least 95% identical to SEQ ID NO:93.
実施形態F12.可溶性ヒト組織因子ドメインが、配列番号93を含む、実施形態F11に記載の多鎖キメラポリペプチド。 Embodiment F12. The multichain chimeric polypeptide of embodiment F11, wherein the soluble human tissue factor domain comprises SEQ ID NO:93.
実施形態F13.可溶性ヒト組織因子ドメインが、配列番号97と少なくとも80%同一である配列を含む、実施形態F8に記載の多鎖キメラポリペプチド。 Embodiment F13. The multichain chimeric polypeptide of embodiment F8, wherein the soluble human tissue factor domain comprises a sequence that is at least 80% identical to SEQ ID NO:97.
実施形態F14.可溶性ヒト組織因子ドメインが、配列番号97と少なくとも90%同一である配列を含む、実施形態F13に記載の多鎖キメラポリペプチド。 Embodiment F14. The multichain chimeric polypeptide of embodiment F13, wherein the soluble human tissue factor domain comprises a sequence that is at least 90% identical to SEQ ID NO:97.
実施形態F15.可溶性ヒト組織因子ドメインが、配列番号97と少なくとも95%同一である配列を含む、実施形態F14に記載の多鎖キメラポリペプチド。 Embodiment F15. The multichain chimeric polypeptide of embodiment F14, wherein the soluble human tissue factor domain comprises a sequence that is at least 95% identical to SEQ ID NO:97.
実施形態F16.可溶性ヒト組織因子ドメインが、配列番号97を含む、実施形態F15に記載の多鎖キメラポリペプチド。 Embodiment F16. The multichain chimeric polypeptide of embodiment F15, wherein the soluble human tissue factor domain comprises SEQ ID NO:97.
実施形態F17.可溶性ヒト組織因子ドメインが、配列番号98と少なくとも80%同一である配列を含む、実施形態F8に記載の多鎖キメラポリペプチド。 Embodiment F17. The multichain chimeric polypeptide of embodiment F8, wherein the soluble human tissue factor domain comprises a sequence that is at least 80% identical to SEQ ID NO:98.
実施形態F18.可溶性ヒト組織因子ドメインが、配列番号98と少なくとも90%同一である配列を含む、実施形態F17に記載の多鎖キメラポリペプチド。 Embodiment F18. The multichain chimeric polypeptide of embodiment F17, wherein the soluble human tissue factor domain comprises a sequence that is at least 90% identical to SEQ ID NO:98.
実施形態F19.可溶性ヒト組織因子ドメインが、配列番号98と少なくとも95%同一である配列を含む、実施形態F18に記載の多鎖キメラポリペプチド。 Embodiment F19. The multichain chimeric polypeptide of embodiment F18, wherein the soluble human tissue factor domain comprises a sequence that is at least 95% identical to SEQ ID NO:98.
実施形態F20.可溶性ヒト組織因子ドメインが、配列番号98を含む、実施形態F19に記載の多鎖キメラポリペプチド。 Embodiment F20. The multichain chimeric polypeptide of embodiment F19, wherein the soluble human tissue factor domain comprises SEQ ID NO:98.
実施形態F21.可溶性ヒト組織因子ドメインが、
成熟野生型ヒト組織因子タンパク質のアミノ酸20位に対応するアミノ酸の位置にリジン、
成熟野生型ヒト組織因子タンパク質のアミノ酸22位に対応するアミノ酸の位置にイソロイシン、
成熟野生型ヒト組織因子タンパク質のアミノ酸45位に対応するアミノ酸の位置にトリプトファン、
成熟野生型ヒト組織因子タンパク質のアミノ酸58位に対応するアミノ酸の位置にアスパラギン酸、
成熟野生型ヒト組織因子タンパク質のアミノ酸94位に対応するアミノ酸の位置にチロシン、
成熟野生型ヒト組織因子タンパク質のアミノ酸135位に対応するアミノ酸の位置にアルギニン、及び
成熟野生型ヒト組織因子タンパク質のアミノ酸140位に対応するアミノ酸の位置にフェニルアラニンのうちのいずれも含まない、実施形態F8~F11、F13~F15、及びF17~F19のいずれか一つに記載の方法。
Embodiment F21. A soluble human tissue factor domain is
a lysine at the amino acid position corresponding to
an isoleucine at the amino acid position corresponding to
tryptophan at the amino acid position corresponding to
an aspartic acid at the amino acid position corresponding to amino acid position 58 of the mature wild-type human tissue factor protein;
a tyrosine at the amino acid position corresponding to amino acid position 94 of the mature wild-type human tissue factor protein;
An embodiment that does not include either arginine at the amino acid position corresponding to amino acid position 135 of the mature wild-type human tissue factor protein and phenylalanine at the amino acid position corresponding to
実施形態F22.可溶性ヒト組織因子ドメインが、
成熟野生型ヒト組織因子タンパク質のアミノ酸20位に対応するアミノ酸の位置にリジン、
成熟野生型ヒト組織因子タンパク質のアミノ酸22位に対応するアミノ酸の位置にイソロイシン、
成熟野生型ヒト組織因子タンパク質のアミノ酸45位に対応するアミノ酸の位置にトリプトファン、
成熟野生型ヒト組織因子タンパク質のアミノ酸58位に対応するアミノ酸の位置にアスパラギン酸、
成熟野生型ヒト組織因子タンパク質のアミノ酸94位に対応するアミノ酸の位置にチロシン、
成熟野生型ヒト組織因子タンパク質のアミノ酸135位に対応するアミノ酸の位置にアルギニン、及び
成熟野生型ヒト組織因子タンパク質のアミノ酸140位に対応するアミノ酸の位置にフェニルアラニンのうちのいずれも含まない、実施形態F21に記載の方法。
Embodiment F22. A soluble human tissue factor domain is
a lysine at the amino acid position corresponding to
an isoleucine at the amino acid position corresponding to
tryptophan at the amino acid position corresponding to
an aspartic acid at the amino acid position corresponding to amino acid position 58 of the mature wild-type human tissue factor protein;
a tyrosine at the amino acid position corresponding to amino acid position 94 of the mature wild-type human tissue factor protein;
An embodiment that does not include either arginine at the amino acid position corresponding to amino acid position 135 of the mature wild-type human tissue factor protein and phenylalanine at the amino acid position corresponding to
実施形態F23.可溶性組織因子ドメインが、第VIIa因子に結合することができない、実施形態F1~F22のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment F23. The multichain chimeric polypeptide of any one of embodiments F1-F22, wherein the soluble tissue factor domain is incapable of binding Factor VIIa.
実施形態F24.可溶性組織因子ドメインが、不活性第X因子を第Xa因子に変換しない、実施形態F1~F23のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment F24. The multichain chimeric polypeptide of any one of embodiments F1-F23, wherein the soluble tissue factor domain does not convert inactive Factor X to Factor Xa.
実施形態F25.多鎖キメラポリペプチドが、哺乳動物における血液凝固を刺激しない、実施形態F1~F24のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment F25. The multi-chain chimeric polypeptide of any one of embodiments F1-F24, wherein the multi-chain chimeric polypeptide does not stimulate blood clotting in a mammal.
実施形態F26.第1のキメラポリペプチドが、第1のキメラポリペプチドのN末端又はC末端にペプチドタグを更に含む、実施形態F1~F25のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment F26. The multi-chain chimeric polypeptide of any one of embodiments F1-F25, wherein the first chimeric polypeptide further comprises a peptide tag at the N-terminus or C-terminus of the first chimeric polypeptide.
実施形態F27.第2のキメラポリペプチドが、第2のキメラポリペプチドN末端又はC末端にペプチドタグを更に含む、実施形態F1~F26のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment F27. The multi-chain chimeric polypeptide of any one of embodiments F1-F26, wherein the second chimeric polypeptide further comprises a peptide tag at the N-terminus or C-terminus of the second chimeric polypeptide.
実施形態F28.第1のキメラポリペプチド及び/又は第2のキメラポリペプチドが、そのN末端にシグナル配列を更に含む、実施形態F1~F27のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment F28. The multi-chain chimeric polypeptide according to any one of embodiments F1-F27, wherein the first chimeric polypeptide and/or the second chimeric polypeptide further comprises a signal sequence at its N-terminus.
実施形態F29.シグナル配列が、配列番号117を含む、実施形態F28に記載の多鎖キメラポリペプチド。 Embodiment F29. The multichain chimeric polypeptide of embodiment F28, wherein the signal sequence comprises SEQ ID NO:117.
実施形態F30.シグナル配列が、配列番号328である、実施形態F28に記載の多鎖キメラポリペプチド。 Embodiment F30. The multichain chimeric polypeptide of embodiment F28, wherein the signal sequence is SEQ ID NO:328.
実施形態F31.一対の親和性ドメインが、ヒトIL-15受容体のアルファ鎖(IL-15Rα)由来のスシドメイン、及び可溶性IL-15である、実施形態F1~F30のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment F31. The multi-chain chimera of any one of embodiments F1-F30, wherein the pair of affinity domains is a sushi domain derived from the alpha chain of the human IL-15 receptor (IL-15Rα) and soluble IL-15. Polypeptide.
実施形態F32.可溶性IL-15が、D8N又はD8Aアミノ酸置換を有する、実施形態F31に記載の多鎖キメラポリペプチド。 Embodiment F32. The multi-chain chimeric polypeptide of embodiment F31, wherein the soluble IL-15 has a D8N or D8A amino acid substitution.
実施形態F33.可溶性IL-15が、配列番号82と少なくとも80%同一である配列を含む、実施形態F31に記載の多鎖キメラポリペプチド。 Embodiment F33. The multichain chimeric polypeptide of embodiment F31, wherein the soluble IL-15 comprises a sequence that is at least 80% identical to SEQ ID NO:82.
実施形態F34.可溶性IL-15が、配列番号82と少なくとも90%同一である配列を含む、実施形態F33に記載の多鎖キメラポリペプチド。 Embodiment F34. The multichain chimeric polypeptide of embodiment F33, wherein the soluble IL-15 comprises a sequence that is at least 90% identical to SEQ ID NO:82.
実施形態F35.可溶性IL-15が、配列番号82と少なくとも95%同一である配列を含む、実施形態F34に記載の多鎖キメラポリペプチド。 Embodiment F35. The multichain chimeric polypeptide of embodiment F34, wherein the soluble IL-15 comprises a sequence that is at least 95% identical to SEQ ID NO:82.
実施形態F36.可溶性IL-15が、配列番号82を含む、実施形態F35に記載の多鎖キメラポリペプチド。 Embodiment F36. The multichain chimeric polypeptide of embodiment F35, wherein the soluble IL-15 comprises SEQ ID NO:82.
実施形態F37.IL-15Rαのスシドメインが、ヒトIL-15Rα由来のスシドメインを含む、実施形態F31~F36のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment F37. The multi-chain chimeric polypeptide of any one of embodiments F31-F36, wherein the sushi domain of IL-15Rα comprises a sushi domain derived from human IL-15Rα.
実施形態F38.ヒトIL-15Rα由来のスシドメインが、配列番号113と80%同一である配列を含む、実施形態F37に記載の多鎖キメラポリペプチド。 Embodiment F38. The multi-chain chimeric polypeptide of embodiment F37, wherein the sushi domain from human IL-15Rα comprises a sequence that is 80% identical to SEQ ID NO:113.
実施形態F39.ヒトIL-15Rα由来のスシドメインが、配列番号113と90%同一である配列を含む、実施形態F38に記載の多鎖キメラポリペプチド。 Embodiment F39. The multi-chain chimeric polypeptide of embodiment F38, wherein the sushi domain from human IL-15Rα comprises a sequence that is 90% identical to SEQ ID NO:113.
実施形態F40.ヒトIL-15Rα由来のスシドメインが、配列番号113と95%同一である配列を含む、実施形態F39に記載の多鎖キメラポリペプチド。 Embodiment F40. The multi-chain chimeric polypeptide of embodiment F39, wherein the sushi domain from human IL-15Rα comprises a sequence that is 95% identical to SEQ ID NO:113.
実施形態F41.ヒトIL-15Rα由来のスシドメインが、配列番号113を含む、実施形態F40に記載の多鎖キメラポリペプチド。 Embodiment F41. The multi-chain chimeric polypeptide of embodiment F40, wherein the sushi domain from human IL-15Rα comprises SEQ ID NO:113.
実施形態F42.ヒトIL-15Rα由来のスシドメインが、成熟全長IL-15Rαである、実施形態F37に記載の多鎖キメラポリペプチド。 Embodiment F42. The multi-chain chimeric polypeptide of embodiment F37, wherein the sushi domain derived from human IL-15Rα is mature full-length IL-15Rα.
実施形態F43.一対の親和性ドメインが、バルナーゼとバルンスター、PKAとAKAP、変異RNaseI断片に基づくアダプター/ドッキングタグモジュール、並びに、タンパク質シンタキシン、シナプトタグミン、シナプトブレビン、及びSNAP25の相互作用に基づくSNAREモジュールからなる群から選択される、実施形F1~F30のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment F43. The paired affinity domains are selected from the group consisting of barnase and barnstar, PKA and AKAP, adapter/docking tag modules based on mutated RNase I fragments, and SNARE modules based on interactions of proteins syntaxin, synaptotagmin, synaptobrevin, and SNAP25. A multi-chain chimeric polypeptide according to any one of embodiments F1-F30, wherein:
実施形態F44.第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方が、アゴニスト抗原結合ドメインである、実施形態F1~F43のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment F44. The multichain chimeric polypeptide of any one of embodiments F1-F43, wherein one or both of the first target binding domain and the second target binding domain are agonist antigen binding domains.
実施形態F45.第1の標的結合ドメイン及び第2の標的結合ドメインが各々、アゴニスト抗原結合ドメインである、実施形態F44に記載の多鎖キメラポリペプチド。 Embodiment F45. The multi-chain chimeric polypeptide of embodiment F44, wherein the first target binding domain and the second target binding domain are each agonist antigen binding domains.
実施形態F46.抗原結合ドメインが、scFv又は単一ドメイン抗体を含む、実施形態F44又はF45に記載の多鎖キメラポリペプチド。 Embodiment F46. The multi-chain chimeric polypeptide of embodiment F44 or F45, wherein the antigen binding domain comprises a scFv or single domain antibody.
実施形態F47.第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方が、可溶性IL-21又は可溶性IL-7である、実施形態F1~F43のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment F47. The multichain chimeric polypeptide of any one of embodiments F1-F43, wherein one or both of the first and second target binding domains is soluble IL-21 or soluble IL-7.
実施形態F48.第1の標的結合ドメイン及び第2の標的結合ドメインが各々独立して、可溶性IL-21又は可溶性IL-7である、実施形態F47に記載の多鎖キメラポリペプチド。 Embodiment F48. The multichain chimeric polypeptide of embodiment F47, wherein the first target binding domain and the second target binding domain are each independently soluble IL-21 or soluble IL-7.
実施形態F49.第1の標的結合ドメイン及び第2の標的結合ドメインの両方が、IL-21受容体又はIL-7受容体に特異的に結合する、実施形態F1~F48のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment F49. The multichain of any one of embodiments F1-F48, wherein both the first target binding domain and the second target binding domain specifically bind to IL-21 receptor or IL-7 receptor. chimeric polypeptide.
実施形態F50.第1の標的結合ドメイン及び第2の標的結合ドメインが同じエピトープに特異的に結合する、実施形態F49に記載の多鎖キメラポリペプチド。 Embodiment F50. The multichain chimeric polypeptide of embodiment F49, wherein the first target binding domain and the second target binding domain specifically bind to the same epitope.
実施形態F51.第1の標的結合ドメイン及び第2の標的結合ドメインが同じアミノ酸配列を含む、実施形態F50に記載の多鎖キメラポリペプチド。 Embodiment F51. The multi-chain chimeric polypeptide of embodiment F50, wherein the first target binding domain and the second target binding domain comprise the same amino acid sequence.
実施形態F52.第1の標的結合ドメインがIL-21受容体に特異的に結合し、第2の標的結合ドメインがIL-7受容体に特異的に結合する、実施形態F1~F48のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment F52. Any one of embodiments F1-F48, wherein the first target binding domain specifically binds the IL-21 receptor and the second target binding domain specifically binds the IL-7 receptor. multi-chain chimeric polypeptide of.
実施形態F53.第1の標的結合ドメインがIL-7受容体に特異的に結合し、第2の標的結合ドメインがIL-21受容体に特異的に結合する、実施形態F1~F48のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment F53. Any one of embodiments F1-F48, wherein the first target binding domain specifically binds the IL-7 receptor and the second target binding domain specifically binds the IL-21 receptor. multi-chain chimeric polypeptide of.
実施形態F54.第1の標的結合ドメインが、可溶性IL-21を含む、実施形態F53に記載の多鎖キメラポリペプチド。 Embodiment F54. The multichain chimeric polypeptide of embodiment F53, wherein the first target binding domain comprises soluble IL-21.
実施形態F55.可溶性IL-21が、可溶性ヒトIL-21である、実施形態F54に記載の多鎖キメラポリペプチド。 Embodiment F55. The multichain chimeric polypeptide of embodiment F54, wherein the soluble IL-21 is soluble human IL-21.
実施形態F56.可溶性ヒトIL-21が、配列番号83と少なくとも80%同一の配列を含む、実施形態F55に記載の多鎖キメラポリペプチド。 Embodiment F56. The multichain chimeric polypeptide of embodiment F55, wherein the soluble human IL-21 comprises a sequence at least 80% identical to SEQ ID NO:83.
実施形態F57.可溶性ヒトIL-21が、配列番号83と少なくとも90%同一の配列を含む、実施形態F56に記載の多鎖キメラポリペプチド。 Embodiment F57. The multichain chimeric polypeptide of embodiment F56, wherein the soluble human IL-21 comprises a sequence at least 90% identical to SEQ ID NO:83.
実施形態F58.可溶性ヒトIL-21が、配列番号83と少なくとも95%同一の配列を含む、実施形態F57に記載の多鎖キメラポリペプチド。 Embodiment F58. The multichain chimeric polypeptide of embodiment F57, wherein the soluble human IL-21 comprises a sequence that is at least 95% identical to SEQ ID NO:83.
実施形態F59.可溶性ヒトIL-21が、配列番号83の配列を含む、実施形態F58に記載の多鎖キメラポリペプチド。 Embodiment F59. The multichain chimeric polypeptide of embodiment F58, wherein the soluble human IL-21 comprises the sequence of SEQ ID NO:83.
実施形態F60.第2の標的結合ドメインが、可溶性IL-7を含む、実施形態F53~F59のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment F60. The multichain chimeric polypeptide of any one of embodiments F53-F59, wherein the second target binding domain comprises soluble IL-7.
実施形態F61.可溶性IL-7が、可溶性ヒトIL-7である、実施形態D60に記載の多鎖キメラポリペプチド。 Embodiment F61. The multichain chimeric polypeptide of embodiment D60, wherein the soluble IL-7 is soluble human IL-7.
実施形態F62.可溶性ヒトIL-7が、配列番号79と少なくとも80%同一の配列を含む、実施形態F61に記載の多鎖キメラポリペプチド。 Embodiment F62. The multichain chimeric polypeptide of embodiment F61, wherein the soluble human IL-7 comprises a sequence that is at least 80% identical to SEQ ID NO:79.
実施形態F63.可溶性ヒトIL-7が、配列番号79と少なくとも90%同一の配列を含む、実施形態F62に記載の多鎖キメラポリペプチド。 Embodiment F63. The multichain chimeric polypeptide of embodiment F62, wherein the soluble human IL-7 comprises a sequence that is at least 90% identical to SEQ ID NO:79.
実施形態F64.可溶性ヒトIL-7が、配列番号79と少なくとも95%同一の配列を含む、実施形態F63に記載の多鎖キメラポリペプチド。 Embodiment F64. The multichain chimeric polypeptide of embodiment F63, wherein the soluble human IL-7 comprises a sequence that is at least 95% identical to SEQ ID NO:79.
実施形態F65.可溶性ヒトIL-7が、配列番号79の配列を含む、実施形態F64に記載の多鎖キメラポリペプチド。 Embodiment F65. The multichain chimeric polypeptide of embodiment F64, wherein the soluble human IL-7 comprises the sequence of SEQ ID NO:79.
実施形態F66.第1のキメラポリペプチドが、配列番号207と少なくとも80%同一である配列を含む、実施形態F1に記載の多鎖キメラポリペプチド。 Embodiment F66. The multi-chain chimeric polypeptide of embodiment F1, wherein the first chimeric polypeptide comprises a sequence that is at least 80% identical to SEQ ID NO:207.
実施形態F67.第1のキメラポリペプチドが、配列番号207と少なくとも90%同一である配列を含む、実施形態F66に記載の多鎖キメラポリペプチド。 Embodiment F67. The multi-chain chimeric polypeptide of embodiment F66, wherein the first chimeric polypeptide comprises a sequence that is at least 90% identical to SEQ ID NO:207.
実施形態F68.第1のキメラポリペプチドが、配列番号207と少なくとも95%同一である配列を含む、実施形態F67に記載の多鎖キメラポリペプチド。 Embodiment F68. The multi-chain chimeric polypeptide of embodiment F67, wherein the first chimeric polypeptide comprises a sequence that is at least 95% identical to SEQ ID NO:207.
実施形態F69.第1のキメラポリペプチドが、配列番号207を含む、実施形態F68に記載の多鎖キメラポリペプチド。 Embodiment F69. A multi-chain chimeric polypeptide according to embodiment F68, wherein the first chimeric polypeptide comprises SEQ ID NO:207.
実施形態F70.第1のキメラポリペプチドが、配列番号209を含む、実施形態F69に記載の多鎖キメラポリペプチド。 Embodiment F70. The multi-chain chimeric polypeptide of embodiment F69, wherein the first chimeric polypeptide comprises SEQ ID NO:209.
実施形態F71.第2のキメラポリペプチドが、配列番号211と少なくとも80%同一である配列を含む、実施形態F1及びF66~F70のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment F71. The multi-chain chimeric polypeptide of any one of embodiments F1 and F66-F70, wherein the second chimeric polypeptide comprises a sequence that is at least 80% identical to SEQ ID NO:211.
実施形態F72.第2のキメラポリペプチドが、配列番号211と少なくとも90%同一である配列を含む、実施形態F71に記載の多鎖キメラポリペプチド。 Embodiment F72. The multi-chain chimeric polypeptide of embodiment F71, wherein the second chimeric polypeptide comprises a sequence that is at least 90% identical to SEQ ID NO:211.
実施形態F73.第2のキメラポリペプチドが、配列番号211と少なくとも95%同一である配列を含む、実施形態F72に記載の多鎖キメラポリペプチド。 Embodiment F73. The multi-chain chimeric polypeptide of embodiment F72, wherein the second chimeric polypeptide comprises a sequence that is at least 95% identical to SEQ ID NO:211.
実施形態F74.第2のキメラポリペプチドが、配列番号211を含む、実施形態F73に記載の多鎖キメラポリペプチド。 Embodiment F74. The multi-chain chimeric polypeptide of embodiment F73, wherein the second chimeric polypeptide comprises SEQ ID NO:211.
実施形態F75.第2のキメラポリペプチドが、配列番号213を含む、実施形態F74に記載の多鎖キメラポリペプチド。 Embodiment F75. The multi-chain chimeric polypeptide of embodiment F74, wherein the second chimeric polypeptide comprises SEQ ID NO:213.
実施形態F76.第1のキメラポリペプチドが、配列番号199と少なくとも80%同一である配列を含む、実施形態F1に記載の多鎖キメラポリペプチド。 Embodiment F76. The multi-chain chimeric polypeptide of embodiment F1, wherein the first chimeric polypeptide comprises a sequence that is at least 80% identical to SEQ ID NO:199.
実施形態F77.第1のキメラポリペプチドが、配列番号199と少なくとも90%同一である配列を含む、実施形態F76に記載の多鎖キメラポリペプチド。 Embodiment F77. The multi-chain chimeric polypeptide of embodiment F76, wherein the first chimeric polypeptide comprises a sequence that is at least 90% identical to SEQ ID NO:199.
実施形態F78.第1のキメラポリペプチドが、配列番号199と少なくとも95%同一である配列を含む、実施形態F77に記載の多鎖キメラポリペプチド。 Embodiment F78. The multi-chain chimeric polypeptide of embodiment F77, wherein the first chimeric polypeptide comprises a sequence that is at least 95% identical to SEQ ID NO:199.
実施形態F79.第1のキメラポリペプチドが、配列番号199を含む、実施形態F68に記載の多鎖キメラポリペプチド。 Embodiment F79. The multi-chain chimeric polypeptide of embodiment F68, wherein the first chimeric polypeptide comprises SEQ ID NO:199.
実施形態F80.第1のキメラポリペプチドが、配列番号201を含む、実施形態F69に記載の多鎖キメラポリペプチド。 Embodiment F80. The multi-chain chimeric polypeptide of embodiment F69, wherein the first chimeric polypeptide comprises SEQ ID NO:201.
実施形態F81.第2のキメラポリペプチドが、配列番号203と少なくとも80%同一である配列を含む、実施形態F1及びF76~E80のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment F81. The multi-chain chimeric polypeptide of any one of embodiments F1 and F76-E80, wherein the second chimeric polypeptide comprises a sequence that is at least 80% identical to SEQ ID NO:203.
実施形態F82.第2のキメラポリペプチドが、配列番号203と少なくとも90%同一である配列を含む、実施形態F81に記載の多鎖キメラポリペプチド。 Embodiment F82. The multi-chain chimeric polypeptide of embodiment F81, wherein the second chimeric polypeptide comprises a sequence that is at least 90% identical to SEQ ID NO:203.
実施形態F83.第2のキメラポリペプチドが、配列番号203と少なくとも95%同一である配列を含む、実施形態F82に記載の多鎖キメラポリペプチド。 Embodiment F83. The multi-chain chimeric polypeptide of embodiment F82, wherein the second chimeric polypeptide comprises a sequence that is at least 95% identical to SEQ ID NO:203.
実施形態F84.第2のキメラポリペプチドが、配列番号203を含む、実施形態F83に記載の多鎖キメラポリペプチド。 Embodiment F84. The multi-chain chimeric polypeptide of embodiment F83, wherein the second chimeric polypeptide comprises SEQ ID NO:203.
実施形態F85.第2のキメラポリペプチドが、配列番号209を含む、実施形態F84に記載の多鎖キメラポリペプチド。 Embodiment F85. The multi-chain chimeric polypeptide of embodiment F84, wherein the second chimeric polypeptide comprises SEQ ID NO:209.
実施形態F86.第1のキメラポリペプチドが、1つ以上の追加の標的結合ドメインを更に含み、1つ以上の追加の抗原結合ドメインのうちの少なくとも1つが、可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間に位置付けられている、実施形態F1~F65のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment F86. The first chimeric polypeptide further comprises one or more additional target binding domains, wherein at least one of the one or more additional antigen binding domains comprises the soluble tissue factor domain and the first of the paired affinity domains. The multi-chain chimeric polypeptide of any one of embodiments F1-F65, wherein the multi-chain chimeric polypeptide of any one of embodiments F1-F65 is positioned between a domain of
実施形態F87.第1のキメラポリペプチドが、可溶性組織因子ドメインと1つ以上の追加の抗原結合ドメインのうちの少なくとも1つとの間にリンカー配列、及び/又は1つ以上の追加の抗原結合ドメインのうちの少なくとも1つと一対の親和性ドメインの第1のドメインとの間にリンカー配列を更に含む、実施形態F86に記載の多鎖キメラポリペプチド。 Embodiment F87. The first chimeric polypeptide comprises a linker sequence between the soluble tissue factor domain and at least one of the one or more additional antigen binding domains, and/or at least one of the one or more additional antigen binding domains. The multi-chain chimeric polypeptide of embodiment F86, further comprising a linker sequence between one and the first of the pair of affinity domains.
実施形態F88.第1のキメラポリペプチドが、第1のキメラポリペプチドのN末端及び/又はC末端に1つ以上の追加の標的結合ドメインを更に含む、実施形態F1~F65のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment F88. The multiple according to any one of embodiments F1-F65, wherein the first chimeric polypeptide further comprises one or more additional target binding domains at the N-terminus and/or C-terminus of the first chimeric polypeptide. chain chimeric polypeptides.
実施形態F89.1つ以上の追加の標的結合ドメインのうちの少なくとも1つが、第1のキメラポリペプチド内の一対の親和性ドメインの第1のドメインに直接隣接している、実施形態F88に記載の多鎖キメラポリペプチド。 Embodiment F89. According to embodiment F88, wherein at least one of the one or more additional target binding domains is directly adjacent to the first of the pair of affinity domains within the first chimeric polypeptide multi-chain chimeric polypeptide of.
実施形態F90.第1のキメラポリペプチドが、1つ以上の追加の標的結合ドメインのうちの少なくとも1つと一対の親和性ドメインの第1のドメインとの間にリンカー配列を更に含む、実施形態F88に記載の多鎖キメラポリペプチド。 Embodiment F90. The multiple of embodiment F88, wherein the first chimeric polypeptide further comprises a linker sequence between at least one of the one or more additional target binding domains and the first of the pair of affinity domains. chain chimeric polypeptides.
実施形態F91.1つ以上の追加の標的結合ドメインのうちの少なくとも1つが、第1のキメラポリペプチド内の第1の標的結合ドメインに直接隣接している、実施形態F88に記載の多鎖キメラポリペプチド。 Embodiment F91. The multichain chimera of embodiment F88, wherein at least one of the one or more additional target binding domains is directly adjacent to the first target binding domain within the first chimeric polypeptide Polypeptide.
実施形態F92.第1のキメラポリペプチドが、1つ以上の追加の標的結合ドメインのうちの少なくとも1つと第1の標的結合ドメインとの間にリンカー配列を更に含む、実施形態F88に記載の多鎖キメラポリペプチド。 Embodiment F92. The multichain chimeric polypeptide of embodiment F88, wherein the first chimeric polypeptide further comprises a linker sequence between at least one of the one or more additional target binding domains and the first target binding domain. .
実施形態F93.1つ以上の追加の標的結合ドメインのうちの少なくとも1つが、第1のキメラポリペプチドのN末端及び/又はC末端に配置されており、1つ以上の追加の標的結合ドメインのうちの少なくとも1つが、第1のキメラポリペプチド内の可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間に位置付けられている、実施形態F88に記載の多鎖キメラポリペプチド。 Embodiment F93. At least one of the one or more additional target binding domains is located at the N-terminus and/or C-terminus of the first chimeric polypeptide, wherein the one or more additional target binding domains The multichain chimeric polypeptide of embodiment F88, wherein at least one of is positioned between the soluble tissue factor domain and the first of the pair of affinity domains within the first chimeric polypeptide.
実施形態F94.N末端に配置された1つ以上の追加の標的結合ドメインのうちの少なくとも1つの追加の標的結合ドメインが、第1のキメラポリペプチド内の第1の標的結合ドメイン又は一対の親和性ドメインの第1のドメインに直接隣接している、実施形態F93に記載の多鎖キメラポリペプチド。 Embodiment F94. At least one additional target binding domain of the one or more additional target binding domains located at the N-terminus is the first target binding domain in the first chimeric polypeptide or the first of the pair of affinity domains A multi-chain chimeric polypeptide according to embodiment F93, which is directly contiguous to one domain.
実施形態F95.第1のキメラポリペプチドが、第1のキメラポリペプチド内の少なくとも1つの追加の標的結合ドメインと第1の標的結合ドメイン又は一対の親和性ドメインの第1のドメインとの間に配置されたリンカー配列を更に含む、実施形態F93に記載の多鎖キメラポリペプチド。 Embodiment F95. a linker wherein the first chimeric polypeptide is positioned between at least one additional target binding domain within the first chimeric polypeptide and the first target binding domain or the first domain of the pair of affinity domains The multichain chimeric polypeptide of embodiment F93, further comprising a sequence.
実施形態F96.C末端に配置された1つ以上の追加の標的結合ドメインのうちの少なくとも1つの追加の標的結合ドメインが、第1のキメラポリペプチド内の第1の標的結合ドメイン又は一対の親和性ドメインの第1のドメインに直接隣接している、実施形態F93に記載の多鎖キメラポリペプチド。 Embodiment F96. At least one additional target binding domain of the one or more additional target binding domains located at the C-terminus is the first target binding domain in the first chimeric polypeptide or the first of the pair of affinity domains A multi-chain chimeric polypeptide according to embodiment F93, which is directly contiguous to one domain.
実施形態F97.第1のキメラポリペプチドが、第1のキメラポリペプチド内の少なくとも1つの追加の標的結合ドメインと第1の標的結合ドメイン又は一対の親和性ドメインの第1のドメインとの間に配置されたリンカー配列を更に含む、実施形態F93に記載の多鎖キメラポリペプチド。 Embodiment F97. a linker wherein the first chimeric polypeptide is positioned between at least one additional target binding domain within the first chimeric polypeptide and the first target binding domain or the first domain of the pair of affinity domains The multichain chimeric polypeptide of embodiment F93, further comprising a sequence.
実施形態F98.可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間に位置付けられた1つ以上の追加の標的結合ドメインのうちの少なくとも1つが、可溶性組織因子ドメイン、及び/又は一対の親和性ドメインの第1のドメインに直接隣接している、実施形態F93に記載の多鎖キメラポリペプチド。 Embodiment F98. at least one of the one or more additional target binding domains positioned between the soluble tissue factor domain and the first domain of the pair of affinity domains is the soluble tissue factor domain and/or the affinity pair The multi-chain chimeric polypeptide of embodiment F93, wherein the domains are directly adjacent to the first domain.
実施形態F99.第1のキメラポリペプチドが、(i)可溶性組織因子ドメインと、可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間に位置付けられた1つ以上の追加の標的結合ドメインのうちの少なくとも1つとの間、及び/又は(ii)一対の親和性ドメインの第1のドメインと、可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間に位置付けられた1つ以上の追加の標的結合ドメインのうちの少なくとも1つとの間に配置されたリンカー配列を更に含む、実施形態F93に記載の多鎖キメラポリペプチド。 Embodiment F99. the first chimeric polypeptide comprises: (i) the soluble tissue factor domain and one or more additional target binding domains positioned between the soluble tissue factor domain and the first of the pair of affinity domains; and/or (ii) between the first domain of the pair of affinity domains and the soluble tissue factor domain and the first domain of the pair of affinity domains The multi-chain chimeric polypeptide of embodiment F93, further comprising a linker sequence interposed with at least one of the additional target binding domains of embodiment F93.
実施形態F100.第2のキメラポリペプチドが、第2のキメラポリペプチドのN末端又はC末端に1つ以上の追加の標的結合ドメインを更に含む、実施形態F1~F65及びF86~F99のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment F100. Any one of embodiments F1-F65 and F86-F99, wherein the second chimeric polypeptide further comprises one or more additional target binding domains at the N-terminus or C-terminus of the second chimeric polypeptide multi-chain chimeric polypeptide of.
実施形態F101.1つ以上の追加の標的結合ドメインのうちの少なくとも1つが、第2のキメラポリペプチド内の一対の親和性ドメインの第2のドメインに直接隣接している、実施形態F100に記載の多鎖キメラポリペプチド。 Embodiment F101. According to embodiment F100, wherein at least one of the one or more additional target binding domains is directly adjacent to a second domain of the pair of affinity domains within the second chimeric polypeptide multi-chain chimeric polypeptide of.
実施形態F102.第2のキメラポリペプチドが、第2のキメラポリペプチド内の1つ以上の追加の標的結合ドメインのうちの少なくとも1つと一対の親和性ドメインの第2のドメインとの間にリンカー配列を更に含む、実施形態F100に記載の多鎖キメラポリペプチド。 Embodiment F102. The second chimeric polypeptide further comprises a linker sequence between at least one of the one or more additional target binding domains in the second chimeric polypeptide and the second of the pair of affinity domains , embodiment F100.
実施形態F103.1つ以上の追加の標的結合ドメインのうちの少なくとも1つが、第2のキメラポリペプチド内の第2の標的結合ドメインに直接隣接している、実施形態F100に記載の多鎖キメラポリペプチド。 Embodiment F103. The multichain chimera of embodiment F100, wherein at least one of the one or more additional target binding domains is directly adjacent to the second target binding domain within the second chimeric polypeptide. Polypeptide.
実施形態F104.第2のキメラポリペプチドが、第2のキメラポリペプチド内の1つ以上の追加の標的結合ドメインのうちの少なくとも1つと第2の標的結合ドメインとの間にリンカー配列を更に含む、実施形態F100に記載の多鎖キメラポリペプチド。 Embodiment F104. Embodiment F100, wherein the second chimeric polypeptide further comprises a linker sequence between at least one of the one or more additional target binding domains within the second chimeric polypeptide and the second target binding domain. 3. A multi-chain chimeric polypeptide according to .
実施形態F105.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの2つ以上が同じ抗原に特異的に結合する、実施形態F86~F104のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment F105. Any one of embodiments F86-F104, wherein two or more of the first target binding domain, the second target binding domain, and the one or more additional target binding domains specifically bind to the same antigen. 3. A multi-chain chimeric polypeptide according to .
実施形態F106.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの2つ以上が同じエピトープに特異的に結合する、実施形態F105に記載の多鎖キメラポリペプチド。 Embodiment F106. The multichain chimeric poly of embodiment F105, wherein two or more of the first target binding domain, the second target binding domain, and the one or more additional target binding domains specifically bind the same epitope. peptide.
実施形態F107.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの2つ以上が同じアミノ酸配列を含む、実施形態F106に記載の多鎖キメラポリペプチド。 Embodiment F107. The multichain chimeric polypeptide of embodiment F106, wherein two or more of the first target binding domain, second target binding domain, and one or more additional target binding domains comprise the same amino acid sequence.
実施形態F108.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインが異なる抗原に特異的に結合する、実施形態F86~F104のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment F108. The multichain chimera of any one of embodiments F86-F104, wherein the first target binding domain, the second target binding domain, and the one or more additional target binding domains specifically bind different antigens. Polypeptide.
実施形態F109.1つ以上の追加の抗原結合ドメインが、CD16a、CD28、CD3、CD33、CD20、CD19、CD22、CD123、IL-1R、IL-1、VEGF、IL-6R、IL-4、IL-10、PDL-1、TIGIT、PD-1、TIM3、CTLA4、MICA、MICB、IL-6、IL-8、TNFα、CD26、CD36、ULBP2、CD30、CD200、IGF-1R、MUC4AC、MUC5AC、Trop-2、CMET、EGFR、HER1、HER2、HER3、PSMA、CEA、B7H3、EPCAM、BCMA、P-カドヘリン、CEACAM5、UL16結合タンパク質、HLA-DR、DLL4、TYRO3、AXL、MER、CD122、CD155、PDGF-DD、TGF-β受容体II(TGF-βRII)リガンド、TGF-βRIIIリガンド、DNAM1リガンド、NKp46リガンド、NKp44リガンド、NKG2Dリガンド、NKp30リガンド、scMHCIリガンド、scMHCIIリガンド、scTCRリガンド、IL-1受容体、IL-2受容体、IL-3受容体、IL-7受容体、IL-8受容体、IL-10受容体、IL-12受容体、IL-15受容体、IL-17受容体、IL-18受容体、IL-21受容体、PDGF-DD受容体、幹細胞因子(SCF)受容体、幹細胞様チロシンキナーゼ3リガンド(FLT3L)受容体、MICA受容体、MICB受容体、ULP16結合タンパク質受容体、CD155受容体、及びCD28受容体からなる群から選択される標的に特異的に結合する、実施形態F86~F108のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment F109. The one or more additional antigen binding domains comprises CD16a, CD28, CD3, CD33, CD20, CD19, CD22, CD123, IL-1R, IL-1, VEGF, IL-6R, IL-4, IL -10, PDL-1, TIGIT, PD-1, TIM3, CTLA4, MICA, MICB, IL-6, IL-8, TNFα, CD26, CD36, ULBP2, CD30, CD200, IGF-1R, MUC4AC, MUC5AC, Trop -2, CMET, EGFR, HER1, HER2, HER3, PSMA, CEA, B7H3, EPCAM, BCMA, P-cadherin, CEACAM5, UL16 binding protein, HLA-DR, DLL4, TYRO3, AXL, MER, CD122, CD155, PDGF -DD, TGF-β receptor II (TGF-βRII) ligand, TGF-βRIII ligand, DNAM1 ligand, NKp46 ligand, NKp44 ligand, NKG2D ligand, NKp30 ligand, scMHCI ligand, scMHCII ligand, scTCR ligand, IL-1 receptor , IL-2 receptor, IL-3 receptor, IL-7 receptor, IL-8 receptor, IL-10 receptor, IL-12 receptor, IL-15 receptor, IL-17 receptor, IL -18 receptor, IL-21 receptor, PDGF-DD receptor, stem cell factor (SCF) receptor, stem cell-like tyrosine kinase 3 ligand (FLT3L) receptor, MICA receptor, MICB receptor, ULP16 binding protein receptor , CD155 receptor, and CD28 receptor.
実施形態F110.1つ以上の追加の標的結合ドメインが、可溶性インターロイキン又はサイトカインタンパク質である、実施形態F86~F108のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment F110. The multichain chimeric polypeptide of any one of embodiments F86-F108, wherein the one or more additional target binding domains are soluble interleukin or cytokine proteins.
実施形態F111.可溶性インターロイキン、サイトカイン、又はリガンドタンパク質が、IL-1、IL-2、IL-3、IL-7、IL-8、IL-10、IL-12、IL-15、IL-17、IL-18、IL-21、PDGF-DD、SCF、FLT3L、MICA、MICB、及びULP16結合タンパク質からなる群から選択される、実施形態F110に記載の多鎖キメラポリペプチド。 Embodiment F111. soluble interleukin, cytokine, or ligand protein is IL-1, IL-2, IL-3, IL-7, IL-8, IL-10, IL-12, IL-15, IL-17, IL-18 , IL-21, PDGF-DD, SCF, FLT3L, MICA, MICB, and ULP16 binding protein.
実施形態F112.1つ以上の追加の標的結合ドメインが、可溶性インターロイキン又はサイトカイン受容体である、実施形態F86~F108のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment F112. The multichain chimeric polypeptide of any one of embodiments F86-F108, wherein the one or more additional target binding domains is a soluble interleukin or cytokine receptor.
実施形態F113.可溶性受容体が、可溶性TGF-β受容体II(TGF-βRII)、可溶性TGF-βRIII、可溶性NKG2D、可溶性NKp30、可溶性NKp44、可溶性NKp46、可溶性DNAM1、scMHCI、scMHCII、scTCR、可溶性CD155、可溶性CD122、又は可溶性CD28である、実施形態F112に記載の多鎖キメラポリペプチド。 Embodiment F113. the soluble receptor is soluble TGF-β receptor II (TGF-βRII), soluble TGF-βRIII, soluble NKG2D, soluble NKp30, soluble NKp44, soluble NKp46, soluble DNAM1, scMHCI, scMHCII, scTCR, soluble CD155, soluble CD122, or the multichain chimeric polypeptide of embodiment F112, which is soluble CD28.
実施形態F114.実施形態F1~F113に記載の多鎖キメラポリペプチドのうちのいずれかを含む、組成物。 Embodiment F114. A composition comprising any of the multi-chain chimeric polypeptides of embodiments F1-F113.
実施形態F115.組成物が、医薬組成物である、実施形態F114に記載の組成物。 Embodiment F115. The composition of embodiment F114, wherein the composition is a pharmaceutical composition.
実施形態F116.実施形態F114又はF115の組成物の少なくとも1つの用量を含むキット。 Embodiment F116. A kit comprising at least one dose of the composition of embodiment F114 or F115.
実施形態F117.実施形態F1~F113のいずれか1つに記載の多鎖キメラポリペプチドのうちのいずれかをコードする、核酸。 Embodiment F117. A nucleic acid encoding any of the multi-chain chimeric polypeptides of any one of embodiments F1-F113.
実施形態F118.実施形態F117に記載の核酸を含む、ベクター。 Embodiment F118. A vector comprising the nucleic acid of embodiment F117.
実施形態F119.ベクターが、発現ベクターである、実施形態F118に記載のベクター。 Embodiment F119. The vector of embodiment F118, wherein the vector is an expression vector.
実施形態F120.実施形態F117に記載の核酸又は実施形態F118若しくはF119に記載のベクターを含む、細胞。 Embodiment F120. A cell comprising the nucleic acid of embodiment F117 or the vector of embodiment F118 or F119.
実施形態F121.多鎖キメラポリペプチドを産生する方法であって、
多鎖キメラポリペプチドの産生をもたらすのに十分な条件下で、実施形態F120に記載の細胞を培養培地中で培養することと、
多鎖キメラポリペプチドを細胞及び/又は培養培地から回収することと
を含む、方法。
Embodiment F121. A method of producing a multi-chain chimeric polypeptide comprising:
culturing the cells of embodiment F120 in a culture medium under conditions sufficient to result in the production of the multi-chain chimeric polypeptide;
recovering the multi-chain chimeric polypeptide from the cells and/or the culture medium.
実施形態F122.実施形態F121に記載の方法によって産生された多鎖キメラポリペプチド。 Embodiment F122. A multi-chain chimeric polypeptide produced by the method of embodiment F121.
実施形態G1.多鎖キメラポリペプチドであって、
(e)第1のキメラポリペプチドであって、
(i)第1の標的結合ドメイン、
(ii)可溶性組織因子ドメイン、及び
(iii)一対の親和性ドメインの第1のドメイン
を含む、第1のキメラポリペプチド、
(f)第2のキメラポリペプチドであって、
(i)一対の親和性ドメインの第2のドメイン、及び
(ii)第2の標的結合ドメイン
を含む、第2のキメラポリペプチド
を含み、
第1のキメラポリペプチドと第2のキメラポリペプチドが、一対の親和性ドメインの第1のドメインと第2のドメインとの結合を介して会合し、
第1の標的結合ドメイン及び第2の標的結合ドメインが各々独立して、IL-7受容体、CD16、IL-21受容体、TGF-β、又はCD137L受容体に特異的に結合する、
多鎖キメラポリペプチド。
Embodiment G1. A multi-chain chimeric polypeptide,
(e) a first chimeric polypeptide,
(i) a first target binding domain;
(ii) a soluble tissue factor domain, and (iii) a first domain of a pair of affinity domains,
(f) a second chimeric polypeptide,
a second chimeric polypeptide comprising (i) a second of the pair of affinity domains, and (ii) a second target binding domain;
the first chimeric polypeptide and the second chimeric polypeptide associate via binding of the first and second domains of a pair of affinity domains;
the first target binding domain and the second target binding domain each independently specifically bind to IL-7 receptor, CD16, IL-21 receptor, TGF-β, or CD137L receptor;
Multi-chain chimeric polypeptides.
実施形態G2.第1の標的結合ドメインと可溶性組織因子ドメインが、第1のキメラポリペプチド内で互いに直接隣接している、実施形態G1に記載の多鎖キメラポリペプチド。 Embodiment G2. The multichain chimeric polypeptide of embodiment G1, wherein the first target binding domain and the soluble tissue factor domain are directly adjacent to each other within the first chimeric polypeptide.
実施形態G3.第1のキメラポリペプチドが、第1のキメラポリペプチド内の第1の標的結合ドメインと可溶性組織因子ドメインとの間にリンカー配列を更に含む、実施形態G1に記載の多鎖キメラポリペプチド。 Embodiment G3. The multichain chimeric polypeptide of embodiment G1, wherein the first chimeric polypeptide further comprises a linker sequence between the first target binding domain and the soluble tissue factor domain within the first chimeric polypeptide.
実施形態G4.可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインが、第1のキメラポリペプチド内で互いに直接隣接している、実施形態G1~G3のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment G4. The multichain chimeric polypeptide of any one of embodiments G1-G3, wherein the soluble tissue factor domain and the first of the paired affinity domains are directly adjacent to each other within the first chimeric polypeptide. .
実施形態G5.第1のキメラポリペプチドが、第1のキメラポリペプチド内の可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間にリンカー配列を更に含む、実施形態G1~G3のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment G5. Any one of embodiments G1-G3, wherein the first chimeric polypeptide further comprises a linker sequence between the soluble tissue factor domain within the first chimeric polypeptide and the first of the pair of affinity domains. A multi-chain chimeric polypeptide according to 1.
実施形態G6.一対の親和性ドメインの第2のドメインと第2の標的結合ドメインが、第2のキメラポリペプチド内で互いに直接隣接している、実施形態G1~G5のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment G6. The multichain chimera of any one of embodiments G1-G5, wherein the second domain and the second target binding domain of the pair of affinity domains are directly adjacent to each other within the second chimeric polypeptide. Polypeptide.
実施形態G7.第2のキメラポリペプチドが、第2のキメラポリペプチド内の一対の親和性ドメインの第2のドメインと第2の標的結合ドメインとの間にリンカー配列を更に含む、実施形態G1~G5のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment G7. Any of embodiments G1-G5, wherein the second chimeric polypeptide further comprises a linker sequence between the second of the pair of affinity domains and the second target binding domain within the second chimeric polypeptide. or a multi-chain chimeric polypeptide according to any one of the above.
実施形態G8.可溶性組織因子ドメインが、可溶性ヒト組織因子ドメインである、実施形態G1~G7のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment G8. The multichain chimeric polypeptide of any one of embodiments G1-G7, wherein the soluble tissue factor domain is a soluble human tissue factor domain.
実施形態G9.可溶性ヒト組織因子ドメインが、配列番号93と少なくとも80%同一である配列を含む、実施形態G8に記載の多鎖キメラポリペプチド。 Embodiment G9. The multichain chimeric polypeptide of embodiment G8, wherein the soluble human tissue factor domain comprises a sequence that is at least 80% identical to SEQ ID NO:93.
実施形態G10.可溶性ヒト組織因子ドメインが、配列番号93と少なくとも90%同一である配列を含む、実施形態G9に記載の多鎖キメラポリペプチド。 Embodiment G10. The multichain chimeric polypeptide of embodiment G9, wherein the soluble human tissue factor domain comprises a sequence that is at least 90% identical to SEQ ID NO:93.
実施形態G11.可溶性ヒト組織因子ドメインが、配列番号93と少なくとも95%同一である配列を含む、実施形態G10に記載の多鎖キメラポリペプチド。 Embodiment G11. The multichain chimeric polypeptide of embodiment G10, wherein the soluble human tissue factor domain comprises a sequence that is at least 95% identical to SEQ ID NO:93.
実施形態G12.可溶性ヒト組織因子ドメインが、
成熟野生型ヒト組織因子タンパク質のアミノ酸20位に対応するアミノ酸の位置にリジン、
成熟野生型ヒト組織因子タンパク質のアミノ酸22位に対応するアミノ酸の位置にイソロイシン、
成熟野生型ヒト組織因子タンパク質のアミノ酸45位に対応するアミノ酸の位置にトリプトファン、
成熟野生型ヒト組織因子タンパク質のアミノ酸58位に対応するアミノ酸の位置にアスパラギン酸、
成熟野生型ヒト組織因子タンパク質のアミノ酸94位に対応するアミノ酸の位置にチロシン、
成熟野生型ヒト組織因子タンパク質のアミノ酸135位に対応するアミノ酸の位置にアルギニン、及び
成熟野生型ヒト組織因子タンパク質のアミノ酸140位に対応するアミノ酸の位置にフェニルアラニンのうちのいずれも含まない、実施形態G8~G11のいずれか一つに記載の方法。
Embodiment G12. A soluble human tissue factor domain is
a lysine at the amino acid position corresponding to
an isoleucine at the amino acid position corresponding to
tryptophan at the amino acid position corresponding to
an aspartic acid at the amino acid position corresponding to amino acid position 58 of the mature wild-type human tissue factor protein;
a tyrosine at the amino acid position corresponding to amino acid position 94 of the mature wild-type human tissue factor protein;
An embodiment that does not include either arginine at the amino acid position corresponding to amino acid position 135 of the mature wild-type human tissue factor protein and phenylalanine at the amino acid position corresponding to
実施形態G13.可溶性ヒト組織因子ドメインが、
成熟野生型ヒト組織因子タンパク質のアミノ酸20位に対応するアミノ酸の位置にリジン、
成熟野生型ヒト組織因子タンパク質のアミノ酸22位に対応するアミノ酸の位置にイソロイシン、
成熟野生型ヒト組織因子タンパク質のアミノ酸45位に対応するアミノ酸の位置にトリプトファン、
成熟野生型ヒト組織因子タンパク質のアミノ酸58位に対応するアミノ酸の位置にアスパラギン酸、
成熟野生型ヒト組織因子タンパク質のアミノ酸94位に対応するアミノ酸の位置にチロシン、
成熟野生型ヒト組織因子タンパク質のアミノ酸135位に対応するアミノ酸の位置にアルギニン、及び
成熟野生型ヒト組織因子タンパク質のアミノ酸140位に対応するアミノ酸の位置にフェニルアラニンのうちのいずれも含まない、実施形態G12に記載の方法。
Embodiment G13. A soluble human tissue factor domain is
a lysine at the amino acid position corresponding to
an isoleucine at the amino acid position corresponding to
tryptophan at the amino acid position corresponding to
an aspartic acid at the amino acid position corresponding to amino acid position 58 of the mature wild-type human tissue factor protein;
a tyrosine at the amino acid position corresponding to amino acid position 94 of the mature wild-type human tissue factor protein;
An embodiment that does not include either arginine at the amino acid position corresponding to amino acid position 135 of the mature wild-type human tissue factor protein and phenylalanine at the amino acid position corresponding to
実施形態G14.可溶性組織因子ドメインが、第VIIa因子に結合することができない、実施形態G1~G13のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment G14. The multichain chimeric polypeptide of any one of embodiments G1-G13, wherein the soluble tissue factor domain is incapable of binding Factor VIIa.
実施形態G15.可溶性組織因子ドメインが、不活性第X因子を第Xa因子に変換しない、実施形態G1~G14のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment G15. The multichain chimeric polypeptide of any one of embodiments G1-G14, wherein the soluble tissue factor domain does not convert inactive factor X to factor Xa.
実施形態G16.多鎖キメラポリペプチドが、哺乳動物における血液凝固を刺激しない、実施形態G1~G15のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment G16. The multi-chain chimeric polypeptide of any one of embodiments G1-G15, wherein the multi-chain chimeric polypeptide does not stimulate blood clotting in a mammal.
実施形態G17.第1のキメラポリペプチドが、第1のキメラポリペプチドのN末端又はC末端にペプチドタグを更に含む、実施形態G1~G16のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment G17. The multi-chain chimeric polypeptide of any one of embodiments G1-G16, wherein the first chimeric polypeptide further comprises a peptide tag at the N-terminus or C-terminus of the first chimeric polypeptide.
実施形態G18.第2のキメラポリペプチドが、第2のキメラポリペプチドN末端又はC末端にペプチドタグを更に含む、実施形態G1~G17のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment G18. The multi-chain chimeric polypeptide of any one of embodiments G1-G17, wherein the second chimeric polypeptide further comprises a peptide tag at the N-terminus or C-terminus of the second chimeric polypeptide.
実施形態G19.第1のキメラポリペプチド及び/又は第2のキメラポリペプチドが、そのN末端にシグナル配列を更に含む、実施形態G1~G18のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment G19. The multi-chain chimeric polypeptide according to any one of embodiments G1-G18, wherein the first chimeric polypeptide and/or the second chimeric polypeptide further comprises a signal sequence at its N-terminus.
実施形態G20.シグナル配列が、配列番号117を含む、実施形態G19に記載の多鎖キメラポリペプチド。 Embodiment G20. The multichain chimeric polypeptide of embodiment G19, wherein the signal sequence comprises SEQ ID NO:117.
実施形態G21.シグナル配列が、配列番号117である、実施形態G20に記載の多鎖キメラポリペプチド。 Embodiment G21. The multichain chimeric polypeptide of embodiment G20, wherein the signal sequence is SEQ ID NO:117.
実施形態G22.一対の親和性ドメインが、ヒトIL-15受容体のアルファ鎖(IL-15Rα)由来のスシドメイン、及び可溶性IL-15である、実施形態G1~G21のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment G22. The multichain chimera of any one of embodiments G1-G21, wherein the paired affinity domains are a sushi domain derived from the alpha chain of the human IL-15 receptor (IL-15Rα) and soluble IL-15. Polypeptide.
実施形態G23.可溶性IL-15が、D8N又はD8Aアミノ酸置換を有する、実施形態G22に記載の多鎖キメラポリペプチド。 Embodiment G23. The multi-chain chimeric polypeptide of embodiment G22, wherein the soluble IL-15 has a D8N or D8A amino acid substitution.
実施形態G24.可溶性IL-15が、配列番号82と80%同一である配列を含む、実施形態G22に記載の多鎖キメラポリペプチド。 Embodiment G24. The multichain chimeric polypeptide of embodiment G22, wherein the soluble IL-15 comprises a sequence that is 80% identical to SEQ ID NO:82.
実施形態G25.可溶性IL-15が、配列番号82と90%同一である配列を含む、実施形態G24に記載の多鎖キメラポリペプチド。 Embodiment G25. The multichain chimeric polypeptide of embodiment G24, wherein the soluble IL-15 comprises a sequence that is 90% identical to SEQ ID NO:82.
実施形態G26.可溶性IL-15が、配列番号82と95%同一である配列を含む、実施形態G25に記載の多鎖キメラポリペプチド。 Embodiment G26. The multichain chimeric polypeptide of embodiment G25, wherein the soluble IL-15 comprises a sequence that is 95% identical to SEQ ID NO:82.
実施形態G27.可溶性IL-15が、配列番号82を含む、実施形態G26に記載の多鎖キメラポリペプチド。 Embodiment G27. The multichain chimeric polypeptide of embodiment G26, wherein the soluble IL-15 comprises SEQ ID NO:82.
実施形態G28.IL-15Rαのスシドメインが、ヒトIL-15Rα由来のスシドメインを含む、実施形態G22~G27のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment G28. The multi-chain chimeric polypeptide of any one of embodiments G22-G27, wherein the sushi domain of IL-15Rα comprises a sushi domain derived from human IL-15Rα.
実施形態G29.ヒトIL-15Rα由来のスシドメインが、配列番号113と80%同一である配列を含む、実施形態G28に記載の多鎖キメラポリペプチド。 Embodiment G29. The multi-chain chimeric polypeptide of embodiment G28, wherein the sushi domain from human IL-15Rα comprises a sequence that is 80% identical to SEQ ID NO:113.
実施形態G30.ヒトIL-15Rα由来のスシドメインが、配列番号113と90%同一である配列を含む、実施形態G29に記載の多鎖キメラポリペプチド。 Embodiment G30. The multi-chain chimeric polypeptide of embodiment G29, wherein the sushi domain from human IL-15Rα comprises a sequence that is 90% identical to SEQ ID NO:113.
実施形態G31.ヒトIL-15Rα由来のスシドメインが、配列番号113と95%同一である配列を含む、実施形態G30に記載の多鎖キメラポリペプチド。 Embodiment G31. The multi-chain chimeric polypeptide of embodiment G30, wherein the sushi domain from human IL-15Rα comprises a sequence that is 95% identical to SEQ ID NO:113.
実施形態G32.ヒトIL-15Rα由来のスシドメインが、配列番号113を含む、実施形態G31に記載の多鎖キメラポリペプチド。 Embodiment G32. The multi-chain chimeric polypeptide of embodiment G31, wherein the sushi domain from human IL-15Rα comprises SEQ ID NO:113.
実施形態G33.ヒトIL-15Rα由来のスシドメインが、成熟全長IL-15Rαである、実施形態G28に記載の多鎖キメラポリペプチド。 Embodiment G33. The multi-chain chimeric polypeptide of embodiment G28, wherein the sushi domain derived from human IL-15Rα is mature full-length IL-15Rα.
実施形態G34.一対の親和性ドメインが、バルナーゼとバルンスター、PKAとAKAP、変異RNaseI断片に基づくアダプター/ドッキングタグモジュール、並びに、タンパク質シンタキシン、シナプトタグミン、シナプトブレビン、及びSNAP25の相互作用に基づくSNAREモジュールからなる群から選択される、実施形態G1~G21のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment G34. The paired affinity domains are selected from the group consisting of barnase and barnstar, PKA and AKAP, adapter/docking tag modules based on mutated RNase I fragments, and SNARE modules based on interactions of proteins syntaxin, synaptotagmin, synaptobrevin, and SNAP25. The multi-chain chimeric polypeptide of any one of embodiments G1-G21, wherein:
実施形態G35.第1の標的結合ドメイン及び第2の標的結合ドメインが各々独立して、IL-7受容体、CD16、又はIL-21受容体に特異的に結合する、実施形態G1~G34のいずれか1つに記載の多鎖キメラポリペプチド。
Embodiment G35. Any one of embodiments G1-G34, wherein the first target binding domain and the second target binding domain each independently specifically bind to IL-7 receptor, CD16, or IL-21
実施形態G36.第1の標的結合ドメインがIL-7受容体に特異的に結合し、第2の標的結合ドメインが、CD16又はIL-21受容体に特異的に結合する、実施形態G35に記載の多鎖キメラポリペプチド。 Embodiment G36. The multichain chimera of embodiment G35, wherein the first target binding domain specifically binds the IL-7 receptor and the second target binding domain specifically binds the CD16 or IL-21 receptor. Polypeptide.
実施形態G37.第1の標的結合ドメインが、可溶性IL-7タンパク質を含む、実施形態G36に記載の多鎖キメラポリペプチド。 Embodiment G37. The multichain chimeric polypeptide of embodiment G36, wherein the first target binding domain comprises a soluble IL-7 protein.
実施形態G38.可溶性IL-7タンパク質が、可溶性ヒトIL-7である、実施形態G37に記載の多鎖キメラポリペプチド。 Embodiment G38. The multichain chimeric polypeptide of embodiment G37, wherein the soluble IL-7 protein is soluble human IL-7.
実施形態G39.第2の抗原結合ドメインが、CD16に特異的に結合する抗原結合ドメインを含む、実施形態G36~G38のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment G39. The multichain chimeric polypeptide of any one of embodiments G36-G38, wherein the second antigen binding domain comprises an antigen binding domain that specifically binds CD16.
実施形態G40.第2の抗原結合ドメインが、CD16に特異的に結合するscFvを含む、実施形態G39に記載の多鎖キメラポリペプチド。 Embodiment G40. The multichain chimeric polypeptide of embodiment G39, wherein the second antigen binding domain comprises an scFv that specifically binds CD16.
実施形態G41.第2の抗原結合ドメインが、IL-21受容体に特異的に結合する、実施形態G36~G38のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment G41. The multi-chain chimeric polypeptide of any one of embodiments G36-G38, wherein the second antigen binding domain specifically binds the IL-21 receptor.
実施形態G42.第2の抗原結合ドメインが、可溶性IL-21を含む、実施形態G41に記載の多鎖キメラポリペプチド。 Embodiment G42. The multichain chimeric polypeptide of embodiment G41, wherein the second antigen binding domain comprises soluble IL-21.
実施形態G43.可溶性IL-21が、可溶性ヒトIL-21である、実施形態G42に記載の多鎖キメラポリペプチド。 Embodiment G43. The multichain chimeric polypeptide of embodiment G42, wherein the soluble IL-21 is soluble human IL-21.
実施形態G44.第2のキメラポリペプチドが、IL-21受容体に特異的に結合する追加の標的結合ドメインを更に含む、実施形態G36~G40のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment G44. The multichain chimeric polypeptide of any one of embodiments G36-G40, wherein the second chimeric polypeptide further comprises an additional target binding domain that specifically binds the IL-21 receptor.
実施形態G45.追加の標的結合ドメインが、可溶性IL-21を含む、実施形態G44に記載の多鎖キメラポリペプチド。 Embodiment G45. The multichain chimeric polypeptide of embodiment G44, wherein the additional target binding domain comprises soluble IL-21.
実施形態G46.可溶性IL-21が、可溶性ヒトIL-12である、実施形態G45に記載の多鎖キメラポリペプチド。 Embodiment G46. The multichain chimeric polypeptide of embodiment G45, wherein the soluble IL-21 is soluble human IL-12.
実施形態G47.第1の標的結合ドメイン及び第2の標的結合ドメインが各々独立して、TGF-β、CD16、又はIL-21受容体に特異的に結合する、実施形態G1~G34のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment G47. Any one of embodiments G1-G34, wherein the first target binding domain and the second target binding domain each independently specifically bind to a TGF-beta, CD16, or IL-21 receptor. multi-chain chimeric polypeptide of.
実施形態G48.第1の標的結合ドメインがTGF-βに特異的に結合し、第2の標的結合ドメインが、CD16又はIL-21受容体に特異的に結合する、実施形態G47に記載の多鎖キメラポリペプチド。 Embodiment G48. The multichain chimeric polypeptide of embodiment G47, wherein the first target binding domain specifically binds TGF-beta and the second target binding domain specifically binds the CD16 or IL-21 receptor. .
実施形態G49.第1の標的結合ドメインが、可溶性TGF-β受容体である、実施形態G48に記載の多重特異性キメラポリペプチド。 Embodiment G49. The multispecific chimeric polypeptide of embodiment G48, wherein the first target binding domain is a soluble TGF-beta receptor.
実施形態G50.可溶性TGF-β受容体が、可溶性TGFβRII受容体である、実施形態G49に記載の多重特異性キメラポリペプチド。 Embodiment G50. The multispecific chimeric polypeptide of embodiment G49, wherein the soluble TGF-beta receptor is a soluble TGFbetaRII receptor.
実施形態G51.第2の標的結合ドメインが、CD16に特異的に結合する、実施形態G48~G50のいずれか1つに記載の多重特異性キメラポリペプチド。 Embodiment G51. The multispecific chimeric polypeptide of any one of embodiments G48-G50, wherein the second target binding domain specifically binds CD16.
実施形態G52.第2の抗原結合ドメインが、CD16に特異的に結合する抗原結合ドメインを含む、実施形態G51に記載の多重特異性キメラポリペプチド。 Embodiment G52. The multispecific chimeric polypeptide of embodiment G51, wherein the second antigen binding domain comprises an antigen binding domain that specifically binds CD16.
実施形態G53.第2の抗原結合ドメインが、CD16に特異的に結合するscFvを含む、実施形態G52に記載の多鎖キメラポリペプチド。 Embodiment G53. The multichain chimeric polypeptide of embodiment G52, wherein the second antigen binding domain comprises an scFv that specifically binds CD16.
実施形態G54.第2の標的結合ドメインが、IL-21受容体に特異的に結合する、実施形態G48~G50のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment G54. The multichain chimeric polypeptide of any one of embodiments G48-G50, wherein the second target binding domain specifically binds to the IL-21 receptor.
実施形態G55.第2の標的結合ドメインが、可溶性IL-21を含む、実施形態G54に記載の多鎖キメラポリペプチド。 Embodiment G55. The multichain chimeric polypeptide of embodiment G54, wherein the second target binding domain comprises soluble IL-21.
実施形態G56.第2の標的結合ドメインが、可溶性ヒトIL-21を含む、実施形態G55に記載の多鎖キメラポリペプチド。 Embodiment G56. The multichain chimeric polypeptide of embodiment G55, wherein the second target binding domain comprises soluble human IL-21.
実施形態G57.第2のキメラポリペプチドが、IL-21受容体に特異的に結合する追加の標的結合ドメインを更に含む、実施形態G48~G53のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment G57. The multichain chimeric polypeptide of any one of embodiments G48-G53, wherein the second chimeric polypeptide further comprises an additional target binding domain that specifically binds the IL-21 receptor.
実施形態G58.追加の標的結合ドメインが、可溶性IL-21を含む、実施形態G57に記載の多鎖キメラポリペプチド。 Embodiment G58. The multichain chimeric polypeptide of embodiment G57, wherein the additional target binding domain comprises soluble IL-21.
実施形態G59.可溶性IL-21が、可溶性ヒトIL-21である、実施形態G58に記載の多鎖キメラポリペプチド。 Embodiment G59. The multichain chimeric polypeptide of embodiment G58, wherein the soluble IL-21 is soluble human IL-21.
実施形態G60.第1の標的結合ドメイン及び第2の標的結合ドメインが各々独立して、IL-7受容体に特異的に結合する、実施形態G1~G34のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment G60. The multichain chimeric polypeptide of any one of embodiments G1-G34, wherein the first target binding domain and the second target binding domain each independently specifically bind to IL-7 receptor.
実施形態G61.第1の標的結合ドメイン及び第2の標的結合ドメインが、可溶性IL-7を含む、実施形態G60に記載の多鎖キメラポリペプチド。 Embodiment G61. The multichain chimeric polypeptide of embodiment G60, wherein the first target binding domain and the second target binding domain comprise soluble IL-7.
実施形態G62.可溶性IL-7が、可溶性ヒトIL-7である、実施形態G61に記載の多鎖キメラポリペプチド。 Embodiment G62. The multichain chimeric polypeptide of embodiment G61, wherein the soluble IL-7 is soluble human IL-7.
実施形態G63.第1の標的結合ドメイン及び第2の標的結合ドメインが各々独立して、TGF-βに特異的に結合する、実施形態G1~G34のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment G63. The multichain chimeric polypeptide of any one of embodiments G1-G34, wherein the first target binding domain and the second target binding domain each independently specifically bind to TGF-β.
実施形態G64.第1の標的結合ドメイン及び第2の標的結合ドメインが、可溶性TGF-β受容体である、実施形態G63に記載の多重特異性キメラポリペプチド。 Embodiment G64. The multispecific chimeric polypeptide of embodiment G63, wherein the first target binding domain and the second target binding domain are soluble TGF-beta receptors.
実施形態G65.可溶性TGF-β受容体が、可溶性TGFβRII受容体である、実施形態G64に記載の多重特異性キメラポリペプチド。 Embodiment G65. The multispecific chimeric polypeptide of embodiment G64, wherein the soluble TGF-beta receptor is a soluble TGFbetaRII receptor.
実施形態G66.第1の標的結合ドメイン及び第2の標的結合ドメインが各々独立して、IL-7受容体、IL-21受容体、又はCD137L受容体に特異的に結合する、実施形態G1~G34のいずれか1つに記載の多重特異性キメラポリペプチド。
Embodiment G66. Any of embodiments G1-G34, wherein the first target binding domain and the second target binding domain each independently specifically bind to IL-7 receptor, IL-21 receptor, or
実施形態G67.第1の標的結合ドメインがIL-7受容体に特異的に結合し、第2の標的結合ドメインがIL-21受容体又はCD137L受容体に特異的に結合する、実施形態G66に記載の多鎖キメラポリペプチド。 Embodiment G67. The multichain of embodiment G66, wherein the first target binding domain specifically binds IL-7 receptor and the second target binding domain specifically binds IL-21 receptor or CD137L receptor. chimeric polypeptide.
実施形態G68.第1の標的結合ドメインが、可溶性IL-7である、実施形態G67に記載の多重特異性キメラポリペプチド。 Embodiment G68. The multispecific chimeric polypeptide of embodiment G67, wherein the first target binding domain is soluble IL-7.
実施形態G69.可溶性IL-7が、可溶性ヒトIL-7である、実施形態G68に記載の多重特異性キメラポリペプチド。 Embodiment G69. The multispecific chimeric polypeptide of embodiment G68, wherein the soluble IL-7 is soluble human IL-7.
実施形態G70.第2の標的結合ドメインが、IL-21受容体に特異的に結合する、実施形態G67~G69のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment G70. The multichain chimeric polypeptide of any one of embodiments G67-G69, wherein the second target binding domain specifically binds the IL-21 receptor.
実施形態G71.第2の標的結合ドメインが、可溶性IL-21である、実施形態G70に記載の多鎖キメラポリペプチド。 Embodiment G71. The multichain chimeric polypeptide of embodiment G70, wherein the second target binding domain is soluble IL-21.
実施形態G72.可溶性IL-21が、可溶性ヒトIL-21である、実施形態G71に記載の多鎖キメラポリペプチド。 Embodiment G72. The multichain chimeric polypeptide of embodiment G71, wherein the soluble IL-21 is soluble human IL-21.
実施形態G73.第2の抗原結合ドメインが、CD137L受容体に特異的に結合する、実施形態G67~G69のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment G73. The multichain chimeric polypeptide of any one of embodiments G67-G69, wherein the second antigen binding domain specifically binds to the CD137L receptor.
実施形態G74.第2の抗原結合ドメインが、可溶性CD137Lである、実施形態G73に記載の多鎖キメラポリペプチド。 Embodiment G74. The multichain chimeric polypeptide of embodiment G73, wherein the second antigen binding domain is soluble CD137L.
実施形態G75.可溶性CD137Lが、可溶性ヒトCD137Lである、実施形態G74に記載の多鎖キメラポリペプチド。 Embodiment G75. The multichain chimeric polypeptide of embodiment G74, wherein the soluble CD137L is soluble human CD137L.
実施形態G76.第2のキメラポリペプチドが、CD137L受容体に特異的に結合する追加の標的結合ドメインを更に含む、実施形態G67~G72のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment G76. The multichain chimeric polypeptide of any one of embodiments G67-G72, wherein the second chimeric polypeptide further comprises an additional target binding domain that specifically binds to the CD137L receptor.
実施形態G77.追加の標的結合ドメインが、可溶性CD137Lを含む、実施形態G76に記載の多鎖キメラポリペプチド。 Embodiment G77. The multichain chimeric polypeptide of embodiment G76, wherein the additional target binding domain comprises soluble CD137L.
実施形態G78.可溶性CD137Lが、可溶性ヒトCD137Lである、実施形態G77に記載の多鎖キメラポリペプチド。 Embodiment G78. The multichain chimeric polypeptide of embodiment G77, wherein the soluble CD137L is soluble human CD137L.
実施形態G79.第1の標的結合ドメイン及び第2の標的結合ドメインが各々独立して、IL-7受容体又はTGF-βに特異的に結合する、実施形態G1~G34のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment G79. The multichain of any one of embodiments G1-G34, wherein the first target binding domain and the second target binding domain each independently specifically bind to IL-7 receptor or TGF-β. chimeric polypeptide.
実施形態G80.第1の標的結合ドメインがIL-7受容体に特異的に結合し、第2の標的結合ドメインがTGF-βに特異的に結合する、実施形態G79に記載の多鎖キメラポリペプチド。 Embodiment G80. The multichain chimeric polypeptide of embodiment G79, wherein the first target binding domain specifically binds IL-7 receptor and the second target binding domain specifically binds TGF-β.
実施形態G81.第1の標的結合ドメインが、可溶性IL-7タンパク質を含む、実施形態G80に記載の多鎖キメラポリペプチド。 Embodiment G81. The multichain chimeric polypeptide of embodiment G80, wherein the first target binding domain comprises a soluble IL-7 protein.
実施形態G82.可溶性IL-7タンパク質が、可溶性ヒトIL-7である、実施形態G81に記載の多鎖キメラポリペプチド。 Embodiment G82. The multichain chimeric polypeptide of embodiment G81, wherein the soluble IL-7 protein is soluble human IL-7.
実施形態G83.第2の抗原結合ドメインが、TGF-βに特異的に結合する抗原結合ドメインを含む、実施形態G80~G82のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment G83. The multichain chimeric polypeptide of any one of embodiments G80-G82, wherein the second antigen binding domain comprises an antigen binding domain that specifically binds TGF-β.
実施形態G84.第2の標的結合ドメインが、可溶性TGF-β受容体である、実施形態G83に記載の多重特異性キメラポリペプチド。 Embodiment G84. The multispecific chimeric polypeptide of embodiment G83, wherein the second target binding domain is a soluble TGF-beta receptor.
実施形態G85.可溶性TGF-β受容体が、可溶性TGFβRII受容体である、実施形態G84に記載の多重特異性キメラポリペプチド。 Embodiment G85. The multispecific chimeric polypeptide of embodiment G84, wherein the soluble TGF-beta receptor is a soluble TGFbetaRII receptor.
実施形態G86.第1の標的結合ドメイン及び第2の標的結合ドメインが各々独立して、TGF-β、IL-21受容体、又はCD137L受容体に特異的に結合する、実施形態G1~G34のいずれか1つに記載の多鎖キメラポリペプチド。
Embodiment G86. Any one of embodiments G1-G34, wherein the first target binding domain and the second target binding domain each independently specifically bind to TGF-β, IL-21 receptor, or
実施形態G87.第1の標的結合ドメインがTGF-βに特異的に結合し、第2の標的結合ドメインがIL-21受容体又はCD137L受容体に特異的に結合する、実施形態G86に記載の多鎖キメラポリペプチド。 Embodiment G87. The multichain chimeric poly of embodiment G86, wherein the first target binding domain specifically binds TGF-β and the second target binding domain specifically binds IL-21 receptor or CD137L receptor. peptide.
実施形態G88.第1の標的結合ドメインが、可溶性TGF-β受容体である、実施形態G87に記載の多重特異性キメラポリペプチド。 Embodiment G88. The multispecific chimeric polypeptide of embodiment G87, wherein the first target binding domain is a soluble TGF-beta receptor.
実施形態G89.可溶性TGF-β受容体が、可溶性TGFβRII受容体である、実施形態G88に記載の多重特異性キメラポリペプチド。 Embodiment G89. The multispecific chimeric polypeptide of embodiment G88, wherein the soluble TGF-beta receptor is a soluble TGFbetaRII receptor.
実施形態G90.第2の標的結合ドメインが、IL-21受容体に特異的に結合する、実施形態G87~G89のいずれか1つに記載の多重特異性キメラポリペプチド。 Embodiment G90. The multispecific chimeric polypeptide of any one of embodiments G87-G89, wherein the second target binding domain specifically binds the IL-21 receptor.
実施形態G91.第2の標的結合ドメインが、可溶性IL-21を含む、実施形態G90に記載の多鎖キメラポリペプチド。 Embodiment G91. The multichain chimeric polypeptide of embodiment G90, wherein the second target binding domain comprises soluble IL-21.
実施形態G92.第2の標的結合ドメインが、可溶性ヒトIL-21を含む、実施形態G91に記載の多鎖キメラポリペプチド。 Embodiment G92. The multichain chimeric polypeptide of embodiment G91, wherein the second target binding domain comprises soluble human IL-21.
実施形態G93.第2の標的結合ドメインが、CD137L受容体に特異的に結合する、実施形態G87~G89のいずれか1つに記載の多重特異性キメラポリペプチド。 Embodiment G93. The multispecific chimeric polypeptide of any one of embodiments G87-G89, wherein the second target binding domain specifically binds to the CD137L receptor.
実施形態G94.第2の標的結合ドメインが、可溶性CD137Lを含む、実施形態G93に記載の多鎖キメラポリペプチド。 Embodiment G94. The multichain chimeric polypeptide of embodiment G93, wherein the second target binding domain comprises soluble CD137L.
実施形態G95.第2の標的結合ドメインが、可溶性ヒトCD137Lを含む、実施形態G94に記載の多鎖キメラポリペプチド。 Embodiment G95. The multichain chimeric polypeptide of embodiment G94, wherein the second target binding domain comprises soluble human CD137L.
実施形態G96.第2のキメラポリペプチドが、CD137L受容体に特異的に結合する追加の標的結合ドメインを更に含む、実施形態G87~G92のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment G96. The multichain chimeric polypeptide of any one of embodiments G87-G92, wherein the second chimeric polypeptide further comprises an additional target binding domain that specifically binds to the CD137L receptor.
実施形態G97.追加の標的結合ドメインが、可溶性CD137Lを含む、実施形態G96に記載の多鎖キメラポリペプチド。 Embodiment G97. The multichain chimeric polypeptide of embodiment G96, wherein the additional target binding domain comprises soluble CD137L.
実施形態G98.可溶性CD137Lが、可溶性ヒトCD137Lである、実施形態G97に記載の多鎖キメラポリペプチド。 Embodiment G98. The multichain chimeric polypeptide of embodiment G97, wherein the soluble CD137L is soluble human CD137L.
実施形態G99.第1の標的結合ドメイン及び第2の標的結合ドメインが各々独立して、TGF-β又はIL-21受容体に特異的に結合する、実施形態G1~G34のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment G99. The multichain of any one of embodiments G1-G34, wherein the first target binding domain and the second target binding domain each independently specifically bind to TGF-β or IL-21 receptor. chimeric polypeptide.
実施形態G100.第1の標的結合ドメインがTGF-βに特異的に結合し、第2の標的結合ドメインがTGF-β又はIL-21受容体に特異的に結合する、実施形態G99に記載の多鎖キメラポリペプチド。 Embodiment G100. The multichain chimeric poly of embodiment G99, wherein the first target binding domain specifically binds TGF-beta and the second target binding domain specifically binds TGF-beta or IL-21 receptor. peptide.
実施形態G101.第1の標的結合ドメインが、可溶性TGF-β受容体である、実施形態G100に記載の多重特異性キメラポリペプチド。 Embodiment G101. The multispecific chimeric polypeptide of embodiment G100, wherein the first target binding domain is a soluble TGF-beta receptor.
実施形態G102.可溶性TGF-β受容体が、可溶性TGFβRII受容体である、実施形態G101に記載の多重特異性キメラポリペプチド。 Embodiment G102. The multispecific chimeric polypeptide of embodiment G101, wherein the soluble TGF-beta receptor is a soluble TGFbetaRII receptor.
実施形態G103.第2の標的結合ドメインが、IL-21受容体に特異的に結合する、実施形態G100~G102のいずれか1つに記載の多重特異性キメラポリペプチド。 Embodiment G103. The multispecific chimeric polypeptide of any one of embodiments G100-G102, wherein the second target binding domain specifically binds the IL-21 receptor.
実施形態G104.第2の標的結合ドメインが、可溶性IL-21を含む、実施形態G103に記載の多鎖キメラポリペプチド。 Embodiment G104. The multichain chimeric polypeptide of embodiment G103, wherein the second target binding domain comprises soluble IL-21.
実施形態G105.第2の標的結合ドメインが、可溶性ヒトIL-21を含む、実施形態G104に記載の多鎖キメラポリペプチド。 Embodiment G105. The multichain chimeric polypeptide of embodiment G104, wherein the second target binding domain comprises soluble human IL-21.
実施形態G106.第2の標的結合ドメインが、TGF-βに特異的に結合する、実施形態G100~G102のいずれか1つに記載の多重特異性キメラポリペプチド。 Embodiment G106. The multispecific chimeric polypeptide of any one of embodiments G100-G102, wherein the second target binding domain specifically binds TGF-β.
実施形態G107.第1の標的結合ドメインが、可溶性TGF-β受容体である、実施形態G106に記載の多重特異性キメラポリペプチド。 Embodiment G107. The multispecific chimeric polypeptide of embodiment G106, wherein the first target binding domain is a soluble TGF-beta receptor.
実施形態G108.可溶性TGF-β受容体が、可溶性TGFβRII受容体である、実施形態G107に記載の多重特異性キメラポリペプチド。 Embodiment G108. The multispecific chimeric polypeptide of embodiment G107, wherein the soluble TGF-beta receptor is a soluble TGFbetaRII receptor.
実施形態G109.第2のポリペプチドが、TGF-βに特異的に結合する追加の標的結合ドメインを更に含む、実施形態G100~G105のいずれか1つに記載の多重特異性キメラポリペプチド。 Embodiment G109. The multispecific chimeric polypeptide of any one of embodiments G100-G105, wherein the second polypeptide further comprises an additional target binding domain that specifically binds TGF-β.
実施形態G110.第1の標的結合ドメインが、可溶性TGF-β受容体である、実施形態G109に記載の多重特異性キメラポリペプチド。 Embodiment G110. The multispecific chimeric polypeptide of embodiment G109, wherein the first target binding domain is a soluble TGF-beta receptor.
実施形態G111.可溶性TGF-β受容体が、可溶性TGFβRII受容体である、実施形態G110に記載の多重特異性キメラポリペプチド。 Embodiment G111. The multispecific chimeric polypeptide of embodiment G110, wherein the soluble TGF-beta receptor is a soluble TGFbetaRII receptor.
実施形態G112.第1の標的結合ドメイン及び第2の標的結合ドメインが各々独立して、TGF-β又はIL-16に特異的に結合する、実施形態G1~G34のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment G112. The multichain chimeric poly of any one of embodiments G1-G34, wherein the first target binding domain and the second target binding domain each independently specifically bind to TGF-β or IL-16. peptide.
実施形態G113.第1の標的結合ドメインがTGF-βに特異的に結合し、第2の標的結合ドメインがTGF-β又はIL-16に特異的に結合する、実施形態G112に記載の多鎖キメラポリペプチド。 Embodiment G113. The multichain chimeric polypeptide of embodiment G112, wherein the first target binding domain specifically binds TGF-beta and the second target binding domain specifically binds TGF-beta or IL-16.
実施形態G114.第1の標的結合ドメインが、可溶性TGF-β受容体である、実施形態G113に記載の多重特異性キメラポリペプチド。 Embodiment G114. The multispecific chimeric polypeptide of embodiment G113, wherein the first target binding domain is a soluble TGF-beta receptor.
実施形態G115.可溶性TGF-β受容体が、可溶性TGFβRII受容体である、実施形態G114に記載の多重特異性キメラポリペプチド。 Embodiment G115. The multispecific chimeric polypeptide of embodiment G114, wherein the soluble TGF-beta receptor is a soluble TGFbetaRII receptor.
実施形態G116.第2の標的結合ドメインが、IL-16に特異的に結合する、実施形態G113~G115のいずれか1つに記載の多重特異性キメラポリペプチド。 Embodiment G116. The multispecific chimeric polypeptide of any one of embodiments G113-G115, wherein the second target binding domain specifically binds IL-16.
実施形態G117.第2の抗原結合ドメインが、CD16に特異的に結合する抗原結合ドメインを含む、実施形態G116に記載の多重特異性キメラポリペプチド。 Embodiment G117. The multispecific chimeric polypeptide of embodiment G116, wherein the second antigen binding domain comprises an antigen binding domain that specifically binds CD16.
実施形態G118.第2の抗原結合ドメインが、CD16に特異的に結合するscFvを含む、実施形態G117に記載の多鎖キメラポリペプチド。 Embodiment G118. The multichain chimeric polypeptide of embodiment G117, wherein the second antigen binding domain comprises an scFv that specifically binds CD16.
実施形態G119.第2の標的結合ドメインが、TGF-βに特異的に結合する、実施形態G113~G115のいずれか1つに記載の多重特異性キメラポリペプチド。 Embodiment G119. The multispecific chimeric polypeptide of any one of embodiments G113-G115, wherein the second target binding domain specifically binds TGF-β.
実施形態G120.第1の標的結合ドメインが、可溶性TGF-β受容体である、実施形態G119に記載の多重特異性キメラポリペプチド。 Embodiment G120. The multispecific chimeric polypeptide of embodiment G119, wherein the first target binding domain is a soluble TGF-beta receptor.
実施形態G121.可溶性TGF-β受容体が、可溶性TGFβRII受容体である、実施形態G120に記載の多重特異性キメラポリペプチド。 Embodiment G121. The multispecific chimeric polypeptide of embodiment G120, wherein the soluble TGF-beta receptor is a soluble TGFbetaRII receptor.
実施形態G122.第2のキメラポリペプチドが、TGF-βに特異的に結合する追加の標的結合ドメインを更に含む、実施形態G113~G118のいずれか1つに記載の多重特異性キメラポリペプチド。 Embodiment G122. The multispecific chimeric polypeptide of any one of embodiments G113-G118, wherein the second chimeric polypeptide further comprises an additional target binding domain that specifically binds TGF-β.
実施形態G123.第1の標的結合ドメインが、可溶性TGF-β受容体である、実施形態G122に記載の多重特異性キメラポリペプチド。 Embodiment G123. The multispecific chimeric polypeptide of embodiment G122, wherein the first target binding domain is a soluble TGF-beta receptor.
実施形態G124.可溶性TGF-β受容体が、可溶性TGFβRII受容体である、実施形態G123に記載の多重特異性キメラポリペプチド。 Embodiment G124. The multispecific chimeric polypeptide of embodiment G123, wherein the soluble TGF-beta receptor is a soluble TGFbetaRII receptor.
実施形態G125.第1の標的結合ドメイン及び第2の標的結合ドメインが各々独立して、TGF-β又はCD137L受容体に特異的に結合する、実施形態G1~G34のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment G125. The multichain chimeric poly of any one of embodiments G1-G34, wherein the first target binding domain and the second target binding domain each independently specifically bind to TGF-β or CD137L receptor. peptide.
実施形態G126.第1の標的結合ドメインがTGF-βに特異的に結合し、第2の標的結合ドメインがCD137L受容体に特異的に結合する、実施形態G125に記載の多鎖キメラポリペプチド。 Embodiment G126. The multichain chimeric polypeptide of embodiment G125, wherein the first target binding domain specifically binds TGF-β and the second target binding domain specifically binds the CD137L receptor.
実施形態G127.第1の標的結合ドメインが、可溶性TGF-β受容体である、実施形態G126に記載の多重特異性キメラポリペプチド。 Embodiment G127. The multispecific chimeric polypeptide of embodiment G126, wherein the first target binding domain is a soluble TGF-beta receptor.
実施形態G128.可溶性TGF-β受容体が、可溶性TGFβRII受容体である、実施形態G127に記載の多重特異性キメラポリペプチド。 Embodiment G128. The multispecific chimeric polypeptide of embodiment G127, wherein the soluble TGF-beta receptor is a soluble TGFbetaRII receptor.
実施形態G129.第2の標的結合ドメインが、可溶性CD137Lタンパク質を含む、実施形態G128に記載の多鎖キメラポリペプチド。 Embodiment G129. The multichain chimeric polypeptide of embodiment G128, wherein the second target binding domain comprises a soluble CD137L protein.
実施形態G130.可溶性CD137Lタンパク質が、可溶性ヒトCD137Lである、実施形態G129に記載の多鎖キメラポリペプチド。 Embodiment G130. The multichain chimeric polypeptide of embodiment G129, wherein the soluble CD137L protein is soluble human CD137L.
実施形態G131.第2のキメラポリペプチドが、TGF-βに特異的に結合する追加の標的結合ドメインを更に含む、実施形態G126~G130のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment G131. The multichain chimeric polypeptide of any one of embodiments G126-G130, wherein the second chimeric polypeptide further comprises an additional target binding domain that specifically binds TGF-β.
実施形態G132.追加の標的結合ドメインが、可溶性TGF-β受容体である、実施形態G131に記載の多重特異性キメラポリペプチド。 Embodiment G132. The multispecific chimeric polypeptide of embodiment G131, wherein the additional target binding domain is a soluble TGF-beta receptor.
実施形態G133.可溶性TGF-β受容体が、可溶性TGFβRII受容体である、実施形態G132に記載の多重特異性キメラポリペプチド。 Embodiment G133. The multispecific chimeric polypeptide of embodiment G132, wherein the soluble TGF-beta receptor is a soluble TGFbetaRII receptor.
実施形態G134.第1のキメラポリペプチドが、配列番号207と少なくとも80%同一である配列を含む、実施形態G1に記載の多鎖キメラポリペプチド。 Embodiment G134. The multi-chain chimeric polypeptide of embodiment G1, wherein the first chimeric polypeptide comprises a sequence that is at least 80% identical to SEQ ID NO:207.
実施形態G135.第1のキメラポリペプチドが、配列番号207と少なくとも90%同一である配列を含む、実施形態G134に記載の多鎖キメラポリペプチド。 Embodiment G135. The multi-chain chimeric polypeptide of embodiment G134, wherein the first chimeric polypeptide comprises a sequence that is at least 90% identical to SEQ ID NO:207.
実施形態G136.第1のキメラポリペプチドが、配列番号207と少なくとも95%同一である配列を含む、実施形態G135に記載の多鎖キメラポリペプチド。 Embodiment G136. The multi-chain chimeric polypeptide of embodiment G135, wherein the first chimeric polypeptide comprises a sequence that is at least 95% identical to SEQ ID NO:207.
実施形態G137.第1のキメラポリペプチドが、配列番号207を含む、実施形態G136に記載の多鎖キメラポリペプチド。 Embodiment G137. The multi-chain chimeric polypeptide of embodiment G136, wherein the first chimeric polypeptide comprises SEQ ID NO:207.
実施形態G138.第1のキメラポリペプチドが、配列番号209を含む、実施形態G137に記載の多鎖キメラポリペプチド。 Embodiment G138. The multi-chain chimeric polypeptide of embodiment G137, wherein the first chimeric polypeptide comprises SEQ ID NO:209.
実施形態G139.第2のキメラポリペプチドが、配列番号232と少なくとも80%同一である配列を含む、実施形態G1及びG134~G138のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment G139. The multichain chimeric polypeptide of any one of embodiments G1 and G134-G138, wherein the second chimeric polypeptide comprises a sequence that is at least 80% identical to SEQ ID NO:232.
実施形態G140.第2のキメラポリペプチドが、配列番号232と少なくとも90%同一である配列を含む、実施形態G139に記載の多鎖キメラポリペプチド。 Embodiment G140. The multi-chain chimeric polypeptide of embodiment G139, wherein the second chimeric polypeptide comprises a sequence that is at least 90% identical to SEQ ID NO:232.
実施形態G141.第2のキメラポリペプチドが、配列番号232と少なくとも95%同一である配列を含む、実施形態G140に記載の多鎖キメラポリペプチド。 Embodiment G141. The multi-chain chimeric polypeptide of embodiment G140, wherein the second chimeric polypeptide comprises a sequence that is at least 95% identical to SEQ ID NO:232.
実施形態G142.第2のキメラポリペプチドが、配列番号232を含む、実施形態G141に記載の多鎖キメラポリペプチド。 Embodiment G142. The multi-chain chimeric polypeptide of embodiment G141, wherein the second chimeric polypeptide comprises SEQ ID NO:232.
実施形態G143.第2のキメラポリペプチドが、配列番号234を含む、実施形態G142に記載の多鎖キメラポリペプチド。 Embodiment G143. The multi-chain chimeric polypeptide of embodiment G142, wherein the second chimeric polypeptide comprises SEQ ID NO:234.
実施形態G144.第1のキメラポリペプチドが、配列番号236と少なくとも80%同一である配列を含む、実施形態G1に記載の多鎖キメラポリペプチド。 Embodiment G144. The multi-chain chimeric polypeptide of embodiment G1, wherein the first chimeric polypeptide comprises a sequence that is at least 80% identical to SEQ ID NO:236.
実施形態G145.第1のキメラポリペプチドが、配列番号236と少なくとも90%同一である配列を含む、実施形態G144に記載の多鎖キメラポリペプチド。 Embodiment G145. The multi-chain chimeric polypeptide of embodiment G144, wherein the first chimeric polypeptide comprises a sequence that is at least 90% identical to SEQ ID NO:236.
実施形態G146.第1のキメラポリペプチドが、配列番号236と少なくとも95%同一である配列を含む、実施形態G145に記載の多鎖キメラポリペプチド。 Embodiment G146. The multi-chain chimeric polypeptide of embodiment G145, wherein the first chimeric polypeptide comprises a sequence that is at least 95% identical to SEQ ID NO:236.
実施形態G147.第1のキメラポリペプチドが、配列番号236を含む、実施形態G146に記載の多鎖キメラポリペプチド。 Embodiment G147. The multi-chain chimeric polypeptide of embodiment G146, wherein the first chimeric polypeptide comprises SEQ ID NO:236.
実施形態G148.第1のキメラポリペプチドが、配列番号238を含む、実施形態G147に記載の多鎖キメラポリペプチド。 Embodiment G148. The multi-chain chimeric polypeptide of embodiment G147, wherein the first chimeric polypeptide comprises SEQ ID NO:238.
実施形態G149.第2のキメラポリペプチドが、配列番号232と少なくとも80%同一である配列を含む、実施形態G1及びG144~G148のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment G149. The multichain chimeric polypeptide of any one of embodiments G1 and G144-G148, wherein the second chimeric polypeptide comprises a sequence that is at least 80% identical to SEQ ID NO:232.
実施形態G150.第2のキメラポリペプチドが、配列番号232と少なくとも90%同一である配列を含む、実施形態G149に記載の多鎖キメラポリペプチド。 Embodiment G150. The multichain chimeric polypeptide of embodiment G149, wherein the second chimeric polypeptide comprises a sequence that is at least 90% identical to SEQ ID NO:232.
実施形態G151.第2のキメラポリペプチドが、配列番号232と少なくとも95%同一である配列を含む、実施形態G150に記載の多鎖キメラポリペプチド。 Embodiment G151. The multi-chain chimeric polypeptide of embodiment G150, wherein the second chimeric polypeptide comprises a sequence that is at least 95% identical to SEQ ID NO:232.
実施形態G152.第2のキメラポリペプチドが、配列番号232を含む、実施形態G151に記載の多鎖キメラポリペプチド。 Embodiment G152. The multi-chain chimeric polypeptide of embodiment G151, wherein the second chimeric polypeptide comprises SEQ ID NO:232.
実施形態G153.第2のキメラポリペプチドが、配列番号234を含む、実施形態G152に記載の多鎖キメラポリペプチド。 Embodiment G153. The multi-chain chimeric polypeptide of embodiment G152, wherein the second chimeric polypeptide comprises SEQ ID NO:234.
実施形態G154.第1のキメラポリペプチドが、配列番号207と少なくとも80%同一である配列を含む、実施形態G1に記載の多鎖キメラポリペプチド。 Embodiment G154. The multi-chain chimeric polypeptide of embodiment G1, wherein the first chimeric polypeptide comprises a sequence that is at least 80% identical to SEQ ID NO:207.
実施形態G155.第1のキメラポリペプチドが、配列番号207と少なくとも90%同一である配列を含む、実施形態G154に記載の多鎖キメラポリペプチド。 Embodiment G155. The multi-chain chimeric polypeptide of embodiment G154, wherein the first chimeric polypeptide comprises a sequence that is at least 90% identical to SEQ ID NO:207.
実施形態G156.第1のキメラポリペプチドが、配列番号207と少なくとも95%同一である配列を含む、実施形態G155に記載の多鎖キメラポリペプチド。 Embodiment G156. The multi-chain chimeric polypeptide of embodiment G155, wherein the first chimeric polypeptide comprises a sequence that is at least 95% identical to SEQ ID NO:207.
実施形態G157.第1のキメラポリペプチドが、配列番号207を含む、実施形態G156に記載の多鎖キメラポリペプチド。 Embodiment G157. The multi-chain chimeric polypeptide of embodiment G156, wherein the first chimeric polypeptide comprises SEQ ID NO:207.
実施形態G158.第1のキメラポリペプチドが、配列番号209を含む、実施形態G157に記載の多鎖キメラポリペプチド。 Embodiment G158. The multi-chain chimeric polypeptide of embodiment G157, wherein the first chimeric polypeptide comprises SEQ ID NO:209.
実施形態G159.第2のキメラポリペプチドが、配列番号203と少なくとも80%同一である配列を含む、実施形態G1及びG154~G158のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment G159. The multichain chimeric polypeptide of any one of embodiments G1 and G154-G158, wherein the second chimeric polypeptide comprises a sequence that is at least 80% identical to SEQ ID NO:203.
実施形態G160.第2のキメラポリペプチドが、配列番号203と少なくとも90%同一である配列を含む、実施形態G159に記載の多鎖キメラポリペプチド。 Embodiment G160. The multichain chimeric polypeptide of embodiment G159, wherein the second chimeric polypeptide comprises a sequence that is at least 90% identical to SEQ ID NO:203.
実施形態G161.第2のキメラポリペプチドが、配列番号203と少なくとも95%同一である配列を含む、実施形態G160に記載の多鎖キメラポリペプチド。 Embodiment G161. The multi-chain chimeric polypeptide of embodiment G160, wherein the second chimeric polypeptide comprises a sequence that is at least 95% identical to SEQ ID NO:203.
実施形態G162.第2のキメラポリペプチドが、配列番号203を含む、実施形態G161に記載の多鎖キメラポリペプチド。 Embodiment G162. The multi-chain chimeric polypeptide of embodiment G161, wherein the second chimeric polypeptide comprises SEQ ID NO:203.
実施形態G163.第2のキメラポリペプチドが、配列番号250を含む、実施形態G162に記載の多鎖キメラポリペプチド。 Embodiment G163. The multi-chain chimeric polypeptide of embodiment G162, wherein the second chimeric polypeptide comprises SEQ ID NO:250.
実施形態G164.第1のキメラポリペプチドが、配列番号236と少なくとも80%同一である配列を含む、実施形態G1に記載の多鎖キメラポリペプチド。 Embodiment G164. The multi-chain chimeric polypeptide of embodiment G1, wherein the first chimeric polypeptide comprises a sequence that is at least 80% identical to SEQ ID NO:236.
実施形態G165.第1のキメラポリペプチドが、配列番号236と少なくとも90%同一である配列を含む、実施形態G164に記載の多鎖キメラポリペプチド。 Embodiment G165. The multi-chain chimeric polypeptide of embodiment G164, wherein the first chimeric polypeptide comprises a sequence that is at least 90% identical to SEQ ID NO:236.
実施形態G166.第1のキメラポリペプチドが、配列番号236と少なくとも95%同一である配列を含む、実施形態G165に記載の多鎖キメラポリペプチド。 Embodiment G166. The multi-chain chimeric polypeptide of embodiment G165, wherein the first chimeric polypeptide comprises a sequence that is at least 95% identical to SEQ ID NO:236.
実施形態G167.第1のキメラポリペプチドが、配列番号236を含む、実施形態G166に記載の多鎖キメラポリペプチド。 Embodiment G167. The multi-chain chimeric polypeptide of embodiment G166, wherein the first chimeric polypeptide comprises SEQ ID NO:236.
実施形態G168.第1のキメラポリペプチドが、配列番号238を含む、実施形態G167に記載の多鎖キメラポリペプチド。 Embodiment G168. The multi-chain chimeric polypeptide of embodiment G167, wherein the first chimeric polypeptide comprises SEQ ID NO:238.
実施形態G169.第2のキメラポリペプチドが、配列番号193と少なくとも80%同一である配列を含む、実施形態G1及びG164~G168のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment G169. The multichain chimeric polypeptide of any one of embodiments G1 and G164-G168, wherein the second chimeric polypeptide comprises a sequence that is at least 80% identical to SEQ ID NO:193.
実施形態G170.第2のキメラポリペプチドが、配列番号193と少なくとも90%同一である配列を含む、実施形態G169に記載の多鎖キメラポリペプチド。 Embodiment G170. The multichain chimeric polypeptide of embodiment G169, wherein the second chimeric polypeptide comprises a sequence that is at least 90% identical to SEQ ID NO:193.
実施形態G171.第2のキメラポリペプチドが、配列番号193と少なくとも95%同一である配列を含む、実施形態G170に記載の多鎖キメラポリペプチド。 Embodiment G171. The multi-chain chimeric polypeptide of embodiment G170, wherein the second chimeric polypeptide comprises a sequence that is at least 95% identical to SEQ ID NO:193.
実施形態G172.第2のキメラポリペプチドが、配列番号193を含む、実施形態G171に記載の多鎖キメラポリペプチド。 Embodiment G172. The multi-chain chimeric polypeptide of embodiment G171, wherein the second chimeric polypeptide comprises SEQ ID NO:193.
実施形態G173.第2のキメラポリペプチドが、配列番号195を含む、実施形態G172に記載の多鎖キメラポリペプチド。 Embodiment G173. The multi-chain chimeric polypeptide of embodiment G172, wherein the second chimeric polypeptide comprises SEQ ID NO:195.
実施形態G174.第1のキメラポリペプチドが、配列番号207と少なくとも80%同一である配列を含む、実施形態G1に記載の多鎖キメラポリペプチド。 Embodiment G174. The multi-chain chimeric polypeptide of embodiment G1, wherein the first chimeric polypeptide comprises a sequence that is at least 80% identical to SEQ ID NO:207.
実施形態G175.第1のキメラポリペプチドが、配列番号207と少なくとも90%同一である配列を含む、実施形態G174に記載の多鎖キメラポリペプチド。 Embodiment G175. The multi-chain chimeric polypeptide of embodiment G174, wherein the first chimeric polypeptide comprises a sequence that is at least 90% identical to SEQ ID NO:207.
実施形態G176.第1のキメラポリペプチドが、配列番号207と少なくとも95%同一である配列を含む、実施形態G175に記載の多鎖キメラポリペプチド。 Embodiment G176. The multi-chain chimeric polypeptide of embodiment G175, wherein the first chimeric polypeptide comprises a sequence that is at least 95% identical to SEQ ID NO:207.
実施形態G177.第1のキメラポリペプチドが、配列番号207を含む、実施形態G176に記載の多鎖キメラポリペプチド。 Embodiment G177. The multi-chain chimeric polypeptide of embodiment G176, wherein the first chimeric polypeptide comprises SEQ ID NO:207.
実施形態G178.第1のキメラポリペプチドが、配列番号209を含む、実施形態G177に記載の多鎖キメラポリペプチド。 Embodiment G178. The multi-chain chimeric polypeptide of embodiment G177, wherein the first chimeric polypeptide comprises SEQ ID NO:209.
実施形態G179.第2のキメラポリペプチドが、配列番号268と少なくとも80%同一である配列を含む、実施形態G1及びG174~G178のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment G179. The multichain chimeric polypeptide of any one of embodiments G1 and G174-G178, wherein the second chimeric polypeptide comprises a sequence that is at least 80% identical to SEQ ID NO:268.
実施形態G180.第2のキメラポリペプチドが、配列番号268と少なくとも90%同一である配列を含む、実施形態G179に記載の多鎖キメラポリペプチド。 Embodiment G180. The multi-chain chimeric polypeptide of embodiment G179, wherein the second chimeric polypeptide comprises a sequence that is at least 90% identical to SEQ ID NO:268.
実施形態G181.第2のキメラポリペプチドが、配列番号268と少なくとも95%同一である配列を含む、実施形態G180に記載の多鎖キメラポリペプチド。 Embodiment G181. The multi-chain chimeric polypeptide of embodiment G180, wherein the second chimeric polypeptide comprises a sequence that is at least 95% identical to SEQ ID NO:268.
実施形態G182.第2のキメラポリペプチドが、配列番号268を含む、実施形態G181に記載の多鎖キメラポリペプチド。 Embodiment G182. The multi-chain chimeric polypeptide of embodiment G181, wherein the second chimeric polypeptide comprises SEQ ID NO:268.
実施形態G183.第2のキメラポリペプチドが、配列番号270を含む、実施形態G182に記載の多鎖キメラポリペプチド。 Embodiment G183. The multi-chain chimeric polypeptide of embodiment G182, wherein the second chimeric polypeptide comprises SEQ ID NO:270.
実施形態G184.第1のキメラポリペプチドが、配列番号207と少なくとも80%同一である配列を含む、実施形態G1に記載の多鎖キメラポリペプチド。 Embodiment G184. The multi-chain chimeric polypeptide of embodiment G1, wherein the first chimeric polypeptide comprises a sequence that is at least 80% identical to SEQ ID NO:207.
実施形態G185.第1のキメラポリペプチドが、配列番号207と少なくとも90%同一である配列を含む、実施形態G184に記載の多鎖キメラポリペプチド。 Embodiment G185. The multi-chain chimeric polypeptide of embodiment G184, wherein the first chimeric polypeptide comprises a sequence that is at least 90% identical to SEQ ID NO:207.
実施形態G186.第1のキメラポリペプチドが、配列番号207と少なくとも95%同一である配列を含む、実施形態G185に記載の多鎖キメラポリペプチド。 Embodiment G186. The multi-chain chimeric polypeptide of embodiment G185, wherein the first chimeric polypeptide comprises a sequence that is at least 95% identical to SEQ ID NO:207.
実施形態G187.第1のキメラポリペプチドが、配列番号207を含む、実施形態G186に記載の多鎖キメラポリペプチド。 Embodiment G187. The multi-chain chimeric polypeptide of embodiment G186, wherein the first chimeric polypeptide comprises SEQ ID NO:207.
実施形態G188.第1のキメラポリペプチドが、配列番号209を含む、実施形態G187に記載の多鎖キメラポリペプチド。 Embodiment G188. The multi-chain chimeric polypeptide of embodiment G187, wherein the first chimeric polypeptide comprises SEQ ID NO:209.
実施形態G189.第2のキメラポリペプチドが、配列番号272と少なくとも80%同一である配列を含む、実施形態G1及びG184~G188のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment G189. The multichain chimeric polypeptide of any one of embodiments G1 and G184-G188, wherein the second chimeric polypeptide comprises a sequence that is at least 80% identical to SEQ ID NO:272.
実施形態G190.第2のキメラポリペプチドが、配列番号272と少なくとも90%同一である配列を含む、実施形態G189に記載の多鎖キメラポリペプチド。 Embodiment G190. The multi-chain chimeric polypeptide of embodiment G189, wherein the second chimeric polypeptide comprises a sequence that is at least 90% identical to SEQ ID NO:272.
実施形態G191.第2のキメラポリペプチドが、配列番号272と少なくとも95%同一である配列を含む、実施形態G190に記載の多鎖キメラポリペプチド。 Embodiment G191. The multichain chimeric polypeptide of embodiment G190, wherein the second chimeric polypeptide comprises a sequence that is at least 95% identical to SEQ ID NO:272.
実施形態G192.第2のキメラポリペプチドが、配列番号272を含む、実施形態G191に記載の多鎖キメラポリペプチド。 Embodiment G192. The multi-chain chimeric polypeptide of embodiment G191, wherein the second chimeric polypeptide comprises SEQ ID NO:272.
実施形態G193.第2のキメラポリペプチドが、配列番号272を含む、実施形態G192に記載の多鎖キメラポリペプチド。 Embodiment G193. The multi-chain chimeric polypeptide of embodiment G192, wherein the second chimeric polypeptide comprises SEQ ID NO:272.
実施形態G194.第1のキメラポリペプチドが、配列番号207と少なくとも80%同一である配列を含む、実施形態G1に記載の多鎖キメラポリペプチド。 Embodiment G194. The multi-chain chimeric polypeptide of embodiment G1, wherein the first chimeric polypeptide comprises a sequence that is at least 80% identical to SEQ ID NO:207.
実施形態G195.第1のキメラポリペプチドが、配列番号207と少なくとも90%同一である配列を含む、実施形態G194に記載の多鎖キメラポリペプチド。 Embodiment G195. The multi-chain chimeric polypeptide of embodiment G194, wherein the first chimeric polypeptide comprises a sequence that is at least 90% identical to SEQ ID NO:207.
実施形態G196.第1のキメラポリペプチドが、配列番号207と少なくとも95%同一である配列を含む、実施形態G195に記載の多鎖キメラポリペプチド。 Embodiment G196. The multi-chain chimeric polypeptide of embodiment G195, wherein the first chimeric polypeptide comprises a sequence that is at least 95% identical to SEQ ID NO:207.
実施形態G197.第1のキメラポリペプチドが、配列番号207を含む、実施形態G196に記載の多鎖キメラポリペプチド。 Embodiment G197. The multi-chain chimeric polypeptide of embodiment G196, wherein the first chimeric polypeptide comprises SEQ ID NO:207.
実施形態G198.第1のキメラポリペプチドが、配列番号209を含む、実施形態G197に記載の多鎖キメラポリペプチド。 Embodiment G198. The multi-chain chimeric polypeptide of embodiment G197, wherein the first chimeric polypeptide comprises SEQ ID NO:209.
実施形態G199.第2のキメラポリペプチドが、配列番号193と少なくとも80%同一である配列を含む、実施形態G1及びG194~G198のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment G199. The multichain chimeric polypeptide of any one of embodiments G1 and G194-G198, wherein the second chimeric polypeptide comprises a sequence that is at least 80% identical to SEQ ID NO:193.
実施形態G200.第2のキメラポリペプチドが、配列番号193と少なくとも90%同一である配列を含む、実施形態G199に記載の多鎖キメラポリペプチド。 Embodiment G200. The multichain chimeric polypeptide of embodiment G199, wherein the second chimeric polypeptide comprises a sequence that is at least 90% identical to SEQ ID NO:193.
実施形態G201.第2のキメラポリペプチドが、配列番号193と少なくとも95%同一である配列を含む、実施形態G200に記載の多鎖キメラポリペプチド。 Embodiment G201. The multichain chimeric polypeptide of embodiment G200, wherein the second chimeric polypeptide comprises a sequence that is at least 95% identical to SEQ ID NO:193.
実施形態G202.第2のキメラポリペプチドが、配列番号193を含む、実施形態G201に記載の多鎖キメラポリペプチド。 Embodiment G202. The multi-chain chimeric polypeptide of embodiment G201, wherein the second chimeric polypeptide comprises SEQ ID NO:193.
実施形態G203.第2のキメラポリペプチドが、配列番号195を含む、実施形態G202に記載の多鎖キメラポリペプチド。 Embodiment G203. The multi-chain chimeric polypeptide of embodiment G202, wherein the second chimeric polypeptide comprises SEQ ID NO:195.
実施形態G204.第1のキメラポリペプチドが、配列番号236と少なくとも80%同一である配列を含む、実施形態G1に記載の多鎖キメラポリペプチド。 Embodiment G204. The multi-chain chimeric polypeptide of embodiment G1, wherein the first chimeric polypeptide comprises a sequence that is at least 80% identical to SEQ ID NO:236.
実施形態G205.第1のキメラポリペプチドが、配列番号236と少なくとも90%同一である配列を含む、実施形態G204に記載の多鎖キメラポリペプチド。 Embodiment G205. The multi-chain chimeric polypeptide of embodiment G204, wherein the first chimeric polypeptide comprises a sequence that is at least 90% identical to SEQ ID NO:236.
実施形態G206.第1のキメラポリペプチドが、配列番号236と少なくとも95%同一である配列を含む、実施形態G205に記載の多鎖キメラポリペプチド。 Embodiment G206. The multi-chain chimeric polypeptide of embodiment G205, wherein the first chimeric polypeptide comprises a sequence that is at least 95% identical to SEQ ID NO:236.
実施形態G207.第1のキメラポリペプチドが、配列番号236を含む、実施形態G206に記載の多鎖キメラポリペプチド。 Embodiment G207. The multi-chain chimeric polypeptide of embodiment G206, wherein the first chimeric polypeptide comprises SEQ ID NO:236.
実施形態G208.第1のキメラポリペプチドが、配列番号238を含む、実施形態G207に記載の多鎖キメラポリペプチド。 Embodiment G208. The multi-chain chimeric polypeptide of embodiment G207, wherein the first chimeric polypeptide comprises SEQ ID NO:238.
実施形態G209.第2のキメラポリペプチドが、配列番号268と少なくとも80%同一である配列を含む、実施形態G1及びG204~G208のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment G209. The multichain chimeric polypeptide of any one of embodiments G1 and G204-G208, wherein the second chimeric polypeptide comprises a sequence that is at least 80% identical to SEQ ID NO:268.
実施形態G210.第2のキメラポリペプチドが、配列番号268と少なくとも90%同一である配列を含む、実施形態G209に記載の多鎖キメラポリペプチド。 Embodiment G210. The multi-chain chimeric polypeptide of embodiment G209, wherein the second chimeric polypeptide comprises a sequence that is at least 90% identical to SEQ ID NO:268.
実施形態G211.第2のキメラポリペプチドが、配列番号268と少なくとも95%同一である配列を含む、実施形態G210に記載の多鎖キメラポリペプチド。 Embodiment G211. The multi-chain chimeric polypeptide of embodiment G210, wherein the second chimeric polypeptide comprises a sequence that is at least 95% identical to SEQ ID NO:268.
実施形態G212.第2のキメラポリペプチドが、配列番号268を含む、実施形態G211に記載の多鎖キメラポリペプチド。 Embodiment G212. The multi-chain chimeric polypeptide of embodiment G211, wherein the second chimeric polypeptide comprises SEQ ID NO:268.
実施形態G213.第2のキメラポリペプチドが、配列番号270を含む、実施形態G212に記載の多鎖キメラポリペプチド。 Embodiment G213. The multi-chain chimeric polypeptide of embodiment G212, wherein the second chimeric polypeptide comprises SEQ ID NO:270.
実施形態G214.第1のキメラポリペプチドが、配列番号236と少なくとも80%同一である配列を含む、実施形態G1に記載の多鎖キメラポリペプチド。 Embodiment G214. The multi-chain chimeric polypeptide of embodiment G1, wherein the first chimeric polypeptide comprises a sequence that is at least 80% identical to SEQ ID NO:236.
実施形態G215.第1のキメラポリペプチドが、配列番号236と少なくとも90%同一である配列を含む、実施形態G214に記載の多鎖キメラポリペプチド。 Embodiment G215. The multi-chain chimeric polypeptide of embodiment G214, wherein the first chimeric polypeptide comprises a sequence that is at least 90% identical to SEQ ID NO:236.
実施形態G216.第1のキメラポリペプチドが、配列番号236と少なくとも95%同一である配列を含む、実施形態G215に記載の多鎖キメラポリペプチド。 Embodiment G216. The multi-chain chimeric polypeptide of embodiment G215, wherein the first chimeric polypeptide comprises a sequence that is at least 95% identical to SEQ ID NO:236.
実施形態G217.第1のキメラポリペプチドが、配列番号236を含む、実施形態G216に記載の多鎖キメラポリペプチド。 Embodiment G217. The multi-chain chimeric polypeptide of embodiment G216, wherein the first chimeric polypeptide comprises SEQ ID NO:236.
実施形態G218.第1のキメラポリペプチドが、配列番号238を含む、実施形態G217に記載の多鎖キメラポリペプチド。 Embodiment G218. The multi-chain chimeric polypeptide of embodiment G217, wherein the first chimeric polypeptide comprises SEQ ID NO:238.
実施形態G219.第2のキメラポリペプチドが、配列番号300と少なくとも80%同一である配列を含む、実施形態G1及びG214~G218のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment G219. The multichain chimeric polypeptide of any one of embodiments G1 and G214-G218, wherein the second chimeric polypeptide comprises a sequence that is at least 80% identical to SEQ ID NO:300.
実施形態G220.第2のキメラポリペプチドが、配列番号300と少なくとも90%同一である配列を含む、実施形態G219に記載の多鎖キメラポリペプチド。 Embodiment G220. The multi-chain chimeric polypeptide of embodiment G219, wherein the second chimeric polypeptide comprises a sequence that is at least 90% identical to SEQ ID NO:300.
実施形態G221.第2のキメラポリペプチドが、配列番号300と少なくとも95%同一である配列を含む、実施形態G220に記載の多鎖キメラポリペプチド。 Embodiment G221. The multi-chain chimeric polypeptide of embodiment G220, wherein the second chimeric polypeptide comprises a sequence that is at least 95% identical to SEQ ID NO:300.
実施形態G222.第2のキメラポリペプチドが、配列番号300を含む、実施形態G221に記載の多鎖キメラポリペプチド。 Embodiment G222. The multi-chain chimeric polypeptide of embodiment G221, wherein the second chimeric polypeptide comprises SEQ ID NO:300.
実施形態G223.第2のキメラポリペプチドが、配列番号302を含む、実施形態G222に記載の多鎖キメラポリペプチド。 Embodiment G223. The multi-chain chimeric polypeptide of embodiment G222, wherein the second chimeric polypeptide comprises SEQ ID NO:302.
実施形態G224.第1のキメラポリペプチドが、配列番号236と少なくとも80%同一である配列を含む、実施形態G1に記載の多鎖キメラポリペプチド。 Embodiment G224. The multi-chain chimeric polypeptide of embodiment G1, wherein the first chimeric polypeptide comprises a sequence that is at least 80% identical to SEQ ID NO:236.
実施形態G225.第1のキメラポリペプチドが、配列番号236と少なくとも90%同一である配列を含む、実施形態G224に記載の多鎖キメラポリペプチド。 Embodiment G225. The multi-chain chimeric polypeptide of embodiment G224, wherein the first chimeric polypeptide comprises a sequence that is at least 90% identical to SEQ ID NO:236.
実施形態G226.第1のキメラポリペプチドが、配列番号236と少なくとも95%同一である配列を含む、実施形態G225に記載の多鎖キメラポリペプチド。 Embodiment G226. The multi-chain chimeric polypeptide of embodiment G225, wherein the first chimeric polypeptide comprises a sequence that is at least 95% identical to SEQ ID NO:236.
実施形態G227.第1のキメラポリペプチドが、配列番号236を含む、実施形態G226に記載の多鎖キメラポリペプチド。 Embodiment G227. The multi-chain chimeric polypeptide of embodiment G226, wherein the first chimeric polypeptide comprises SEQ ID NO:236.
実施形態G228.第1のキメラポリペプチドが、配列番号238を含む、実施形態G227に記載の多鎖キメラポリペプチド。 Embodiment G228. The multi-chain chimeric polypeptide of embodiment G227, wherein the first chimeric polypeptide comprises SEQ ID NO:238.
実施形態G229.第2のキメラポリペプチドが、配列番号308と少なくとも80%同一である配列を含む、実施形態G1及びG224~G228のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment G229. The multichain chimeric polypeptide of any one of embodiments G1 and G224-G228, wherein the second chimeric polypeptide comprises a sequence that is at least 80% identical to SEQ ID NO:308.
実施形態G230.第2のキメラポリペプチドが、配列番号308と少なくとも90%同一である配列を含む、実施形態G229に記載の多鎖キメラポリペプチド。 Embodiment G230. The multi-chain chimeric polypeptide of embodiment G229, wherein the second chimeric polypeptide comprises a sequence that is at least 90% identical to SEQ ID NO:308.
実施形態G231.第2のキメラポリペプチドが、配列番号308と少なくとも95%同一である配列を含む、実施形態G230に記載の多鎖キメラポリペプチド。 Embodiment G231. The multichain chimeric polypeptide of embodiment G230, wherein the second chimeric polypeptide comprises a sequence that is at least 95% identical to SEQ ID NO:308.
実施形態G232.第2のキメラポリペプチドが、配列番号308を含む、実施形態G231に記載の多鎖キメラポリペプチド。 Embodiment G232. The multi-chain chimeric polypeptide of embodiment G231, wherein the second chimeric polypeptide comprises SEQ ID NO:308.
実施形態G233.第2のキメラポリペプチドが、配列番号310を含む、実施形態G232に記載の多鎖キメラポリペプチド。 Embodiment G233. The multi-chain chimeric polypeptide of embodiment G232, wherein the second chimeric polypeptide comprises SEQ ID NO:310.
実施形態G234.第1のキメラポリペプチドが、配列番号236と少なくとも80%同一である配列を含む、実施形態G1に記載の多鎖キメラポリペプチド。 Embodiment G234. The multi-chain chimeric polypeptide of embodiment G1, wherein the first chimeric polypeptide comprises a sequence that is at least 80% identical to SEQ ID NO:236.
実施形態G235.第1のキメラポリペプチドが、配列番号236と少なくとも90%同一である配列を含む、実施形態G234に記載の多鎖キメラポリペプチド。 Embodiment G235. The multi-chain chimeric polypeptide of embodiment G234, wherein the first chimeric polypeptide comprises a sequence that is at least 90% identical to SEQ ID NO:236.
実施形態G236.第1のキメラポリペプチドが、配列番号236と少なくとも95%同一である配列を含む、実施形態G235に記載の多鎖キメラポリペプチド。 Embodiment G236. The multi-chain chimeric polypeptide of embodiment G235, wherein the first chimeric polypeptide comprises a sequence that is at least 95% identical to SEQ ID NO:236.
実施形態G237.第1のキメラポリペプチドが、配列番号236を含む、実施形態G236に記載の多鎖キメラポリペプチド。 Embodiment G237. The multi-chain chimeric polypeptide of embodiment G236, wherein the first chimeric polypeptide comprises SEQ ID NO:236.
実施形態G238.第1のキメラポリペプチドが、配列番号238を含む、実施形態G237に記載の多鎖キメラポリペプチド。 Embodiment G238. The multi-chain chimeric polypeptide of embodiment G237, wherein the first chimeric polypeptide comprises SEQ ID NO:238.
実施形態G239.第2のキメラポリペプチドが、配列番号316と少なくとも80%同一である配列を含む、実施形態G1及びG234~G238のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment G239. The multichain chimeric polypeptide of any one of embodiments G1 and G234-G238, wherein the second chimeric polypeptide comprises a sequence that is at least 80% identical to SEQ ID NO:316.
実施形態G240.第2のキメラポリペプチドが、配列番号316と少なくとも90%同一である配列を含む、実施形態G239に記載の多鎖キメラポリペプチド。 Embodiment G240. The multi-chain chimeric polypeptide of embodiment G239, wherein the second chimeric polypeptide comprises a sequence that is at least 90% identical to SEQ ID NO:316.
実施形態G241.第2のキメラポリペプチドが、配列番号316と少なくとも95%同一である配列を含む、実施形態G240に記載の多鎖キメラポリペプチド。 Embodiment G241. The multi-chain chimeric polypeptide of embodiment G240, wherein the second chimeric polypeptide comprises a sequence that is at least 95% identical to SEQ ID NO:316.
実施形態G242.第2のキメラポリペプチドが、配列番号316を含む、実施形態G241に記載の多鎖キメラポリペプチド。 Embodiment G242. The multi-chain chimeric polypeptide of embodiment G241, wherein the second chimeric polypeptide comprises SEQ ID NO:316.
実施形態G243.第2のキメラポリペプチドが、配列番号318を含む、実施形態G242に記載の多鎖キメラポリペプチド。 Embodiment G243. The multi-chain chimeric polypeptide of embodiment G242, wherein the second chimeric polypeptide comprises SEQ ID NO:318.
実施形態G244.第1のキメラポリペプチドが、1つ以上の追加の標的結合ドメインを更に含み、1つ以上の追加の抗原結合ドメインのうちの少なくとも1つが、可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間に位置付けられている、実施形態G1~G133のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment G244. The first chimeric polypeptide further comprises one or more additional target binding domains, wherein at least one of the one or more additional antigen binding domains comprises the soluble tissue factor domain and the first of the paired affinity domains. A multi-chain chimeric polypeptide according to any one of embodiments G1-G133, which is positioned between a domain of
実施形態G245.第1のキメラポリペプチドが、可溶性組織因子ドメインと1つ以上の追加の抗原結合ドメインのうちの少なくとも1つとの間にリンカー配列、及び/又は1つ以上の追加の抗原結合ドメインのうちの少なくとも1つと一対の親和性ドメインの第1のドメインとの間にリンカー配列を更に含む、実施形態G244に記載の多鎖キメラポリペプチド。 Embodiment G245. The first chimeric polypeptide comprises a linker sequence between the soluble tissue factor domain and at least one of the one or more additional antigen binding domains, and/or at least one of the one or more additional antigen binding domains. The multichain chimeric polypeptide of embodiment G244, further comprising a linker sequence between one and the first of the pair of affinity domains.
実施形態G246.第1のキメラポリペプチドが、第1のキメラポリペプチドのN末端及び/又はC末端に1つ以上の追加の標的結合ドメインを更に含む、実施形態G1~G133のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment G246. The multiple according to any one of embodiments G1-G133, wherein the first chimeric polypeptide further comprises one or more additional target binding domains at the N-terminus and/or C-terminus of the first chimeric polypeptide. chain chimeric polypeptides.
実施形態G247.1つ以上の追加の標的結合ドメインのうちの少なくとも1つが、第1のキメラポリペプチド内の一対の親和性ドメインの第1のドメインに直接隣接している、実施形態G246に記載の多鎖キメラポリペプチド。 Embodiment G247. According to embodiment G246, wherein at least one of the one or more additional target binding domains is directly adjacent to the first of the pair of affinity domains within the first chimeric polypeptide multi-chain chimeric polypeptide of.
実施形態G248.第1のキメラポリペプチドが、1つ以上の追加の標的結合ドメインのうちの少なくとも1つと一対の親和性ドメインの第1のドメインとの間にリンカー配列を更に含む、実施形態G246に記載の多鎖キメラポリペプチド。 Embodiment G248. The multiple of embodiment G246, wherein the first chimeric polypeptide further comprises a linker sequence between at least one of the one or more additional target binding domains and the first of the pair of affinity domains. chain chimeric polypeptides.
実施形態G249.1つ以上の追加の標的結合ドメインのうちの少なくとも1つが、第1のキメラポリペプチド内の第1の標的結合ドメインに直接隣接している、実施形態G246に記載の多鎖キメラポリペプチド。 Embodiment G249. The multichain chimera of embodiment G246, wherein at least one of the one or more additional target binding domains is directly adjacent to the first target binding domain within the first chimeric polypeptide Polypeptide.
実施形態G250.第1のキメラポリペプチドが、1つ以上の追加の標的結合ドメインのうちの少なくとも1つと第1の標的結合ドメインとの間にリンカー配列を更に含む、実施形態G246に記載の多鎖キメラポリペプチド。 Embodiment G250. The multichain chimeric polypeptide of embodiment G246, wherein the first chimeric polypeptide further comprises a linker sequence between at least one of the one or more additional target binding domains and the first target binding domain. .
実施形態G251.1つ以上の追加の標的結合ドメインのうちの少なくとも1つが、第1のキメラポリペプチドのN末端及び/又はC末端に配置されており、1つ以上の追加の標的結合ドメインのうちの少なくとも1つが、第1のキメラポリペプチド内の可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間に位置付けられている、実施形態G246に記載の多鎖キメラポリペプチド。 Embodiment G251. At least one of the one or more additional target binding domains is located at the N-terminus and/or C-terminus of the first chimeric polypeptide, wherein the one or more additional target binding domains are The multichain chimeric polypeptide of embodiment G246, at least one of which is positioned between the soluble tissue factor domain and the first of the pair of affinity domains within the first chimeric polypeptide.
実施形態G252.N末端に配置された1つ以上の追加の標的結合ドメインのうちの少なくとも1つの追加の標的結合ドメインが、第1のキメラポリペプチド内の第1の標的結合ドメイン又は一対の親和性ドメインの第1のドメインに直接隣接している、実施形態G251に記載の多鎖キメラポリペプチド。 Embodiment G252. At least one additional target binding domain of the one or more additional target binding domains located at the N-terminus is the first target binding domain in the first chimeric polypeptide or the first of the pair of affinity domains The multichain chimeric polypeptide of embodiment G251, which is directly contiguous to one domain.
実施形態G253.第1のキメラポリペプチドが、第1のキメラポリペプチド内の少なくとも1つの追加の標的結合ドメインと第1の標的結合ドメイン又は一対の親和性ドメインの第1のドメインとの間に配置されたリンカー配列を更に含む、実施形態G251に記載の多鎖キメラポリペプチド。 Embodiment G253. a linker wherein the first chimeric polypeptide is positioned between at least one additional target binding domain within the first chimeric polypeptide and the first target binding domain or the first domain of the pair of affinity domains The multichain chimeric polypeptide of embodiment G251, further comprising a sequence.
実施形態G254.C末端に配置された1つ以上の追加の標的結合ドメインのうちの少なくとも1つの追加の標的結合ドメインが、第1のキメラポリペプチド内の第1の標的結合ドメイン又は一対の親和性ドメインの第1のドメインに直接隣接している、実施形態G251に記載の多鎖キメラポリペプチド。 Embodiment G254. At least one additional target binding domain of the one or more additional target binding domains located at the C-terminus is the first target binding domain in the first chimeric polypeptide or the first of the pair of affinity domains The multichain chimeric polypeptide of embodiment G251, which is directly contiguous to one domain.
実施形態G255.第1のキメラポリペプチドが、第1のキメラポリペプチド内の少なくとも1つの追加の標的結合ドメインと第1の標的結合ドメイン又は一対の親和性ドメインの第1のドメインとの間に配置されたリンカー配列を更に含む、実施形態G251に記載の多鎖キメラポリペプチド。 Embodiment G255. a linker wherein the first chimeric polypeptide is positioned between at least one additional target binding domain within the first chimeric polypeptide and the first target binding domain or the first domain of the pair of affinity domains The multichain chimeric polypeptide of embodiment G251, further comprising a sequence.
実施形態G256.可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間に位置付けられた1つ以上の追加の標的結合ドメインのうちの少なくとも1つが、可溶性組織因子ドメイン、及び/又は一対の親和性ドメインの第1のドメインに直接隣接している、実施形態G251に記載の多鎖キメラポリペプチド。 Embodiment G256. at least one of the one or more additional target binding domains positioned between the soluble tissue factor domain and the first domain of the pair of affinity domains is the soluble tissue factor domain and/or the affinity pair The multi-chain chimeric polypeptide of embodiment G251, wherein the domains are directly adjacent to the first domain.
実施形態G257.第1のキメラポリペプチドが、(i)可溶性組織因子ドメインと、可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間に位置付けられた1つ以上の追加の標的結合ドメインのうちの少なくとも1つとの間、及び/又は(ii)一対の親和性ドメインの第1のドメインと、可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間に位置付けられた1つ以上の追加の標的結合ドメインのうちの少なくとも1つとの間に配置されたリンカー配列を更に含む、実施形態G251に記載の多鎖キメラポリペプチド。 Embodiment G257. the first chimeric polypeptide comprises: (i) the soluble tissue factor domain and one or more additional target binding domains positioned between the soluble tissue factor domain and the first of the pair of affinity domains; and/or (ii) between the first domain of the pair of affinity domains and the soluble tissue factor domain and the first domain of the pair of affinity domains The multichain chimeric polypeptide of embodiment G251, further comprising a linker sequence interposed with at least one of the additional target binding domains of embodiment G251.
実施形態G258.第2のキメラポリペプチドが、第2のキメラポリペプチドのN末端又はC末端に追加の標的結合ドメインを更に含む、実施形態G44~G46、G57~G59、G76~G78、G96~G98、G109~G111、G122~G124、及びG131~G133のいずれか1つに記載の多鎖キメラポリペプチド。 Embodiment G258. Embodiments G44-G46, G57-G59, G76-G78, G96-G98, G109-, wherein the second chimeric polypeptide further comprises an additional target binding domain at the N-terminus or C-terminus of the second chimeric polypeptide The multichain chimeric polypeptide of any one of G111, G122-G124, and G131-G133.
実施形態G259.追加の標的結合ドメインが、第2のキメラポリペプチド内の一対の親和性ドメインの第2のドメインに直接隣接している、実施形態G258に記載の多鎖キメラポリペプチド。 Embodiment G259. The multichain chimeric polypeptide of embodiment G258, wherein the additional target binding domain is directly adjacent to a second of the pair of affinity domains within the second chimeric polypeptide.
実施形態G260.第2のキメラポリペプチドが、第2のキメラポリペプチド内の追加の標的結合ドメインと一対の親和性ドメインの第2のドメインとの間にリンカー配列を更に含む、実施形態G258に記載の多鎖キメラポリペプチド。 Embodiment G260. The multichain of embodiment G258, wherein the second chimeric polypeptide further comprises a linker sequence between an additional target binding domain in the second chimeric polypeptide and the second of the pair of affinity domains. chimeric polypeptide.
実施形態G261.追加の標的結合ドメインが、第2のキメラポリペプチド内の第2の標的結合ドメインに直接隣接している、実施形態G258に記載の多鎖キメラポリペプチド。 Embodiment G261. The multichain chimeric polypeptide of embodiment G258, wherein the additional target binding domain is directly adjacent to the second target binding domain within the second chimeric polypeptide.
実施形態G262.第2のキメラポリペプチドが、第2のキメラポリペプチド内の追加の標的結合ドメインと第2の標的結合ドメインとの間にリンカー配列を更に含む、実施形態G258に記載の多鎖キメラポリペプチド。 Embodiment G262. The multichain chimeric polypeptide of embodiment G258, wherein the second chimeric polypeptide further comprises a linker sequence between the additional target binding domain and the second target binding domain within the second chimeric polypeptide.
実施形態G263.実施形態G1~G262に記載の多鎖キメラポリペプチドのうちのいずれかを含む、組成物。 Embodiment G263. A composition comprising any of the multi-chain chimeric polypeptides of embodiments G1-G262.
実施形態G264.組成物が、医薬組成物である、実施形態G263に記載の組成物。 Embodiment G264. The composition of embodiment G263, wherein the composition is a pharmaceutical composition.
実施形態G265.実施形態G263又はG264の組成物の少なくとも1つの用量を含むキット。 Embodiment G265. A kit comprising at least one dose of the composition of embodiment G263 or G264.
実施形態G266.実施形態G1~G262のいずれか1つに記載の多鎖キメラポリペプチドのうちのいずれかをコードする、核酸。 Embodiment G266. A nucleic acid encoding any of the multi-chain chimeric polypeptides of any one of embodiments G1-G262.
実施形態G267.実施形態G266に記載の核酸を含む、ベクター。 Embodiment G267. A vector comprising the nucleic acid of embodiment G266.
実施形態G268.ベクターが、発現ベクターである、実施形態G267に記載のベクター。 Embodiment G268. The vector of embodiment G267, wherein the vector is an expression vector.
実施形態G269.実施形態G323に記載の核酸又は実施形態G267又はG268に記載のベクターを含む、細胞。 Embodiment G269. A cell comprising the nucleic acid of embodiment G323 or the vector of embodiment G267 or G268.
実施形態G270.多鎖キメラポリペプチドを産生する方法であって、
多鎖キメラポリペプチドの産生をもたらすのに十分な条件下で、実施形態G269に記載の細胞を培養培地中で培養することと、
多鎖キメラポリペプチドを細胞及び/又は培養培地から回収することと
を含む、方法。
Embodiment G270. A method of producing a multi-chain chimeric polypeptide comprising:
culturing the cells of embodiment G269 in a culture medium under conditions sufficient to result in the production of the multi-chain chimeric polypeptide;
recovering the multi-chain chimeric polypeptide from the cells and/or the culture medium.
実施形態G271.実施形態G270に記載の方法によって産生された多鎖キメラポリペプチド。 Embodiment G271. A multi-chain chimeric polypeptide produced by the method of embodiment G270.
実施形態G272.可溶性ヒト組織因子ドメインが、配列番号97と少なくとも80%同一である配列を含む、実施形態G8に記載の多鎖キメラポリペプチド。 Embodiment G272. The multichain chimeric polypeptide of embodiment G8, wherein the soluble human tissue factor domain comprises a sequence that is at least 80% identical to SEQ ID NO:97.
実施形態G273.可溶性ヒト組織因子ドメインが、配列番号97と少なくとも90%同一である配列を含む、実施形態G272に記載の多鎖キメラポリペプチド。 Embodiment G273. The multichain chimeric polypeptide of embodiment G272, wherein the soluble human tissue factor domain comprises a sequence that is at least 90% identical to SEQ ID NO:97.
実施形態G274.可溶性ヒト組織因子ドメインが、配列番号97と少なくとも95%同一である配列を含む、実施形態G273に記載の多鎖キメラポリペプチド。 Embodiment G274. The multichain chimeric polypeptide of embodiment G273, wherein the soluble human tissue factor domain comprises a sequence that is at least 95% identical to SEQ ID NO:97.
実施形態G275.可溶性ヒト組織因子ドメインが、配列番号97と100%同一である配列を含む、実施形態G274に記載の多鎖キメラポリペプチド。 Embodiment G275. The multichain chimeric polypeptide of embodiment G274, wherein the soluble human tissue factor domain comprises a sequence that is 100% identical to SEQ ID NO:97.
実施形態G276.可溶性ヒト組織因子ドメインが、配列番号98と少なくとも80%同一である配列を含む、実施形態G8に記載の多鎖キメラポリペプチド。 Embodiment G276. The multichain chimeric polypeptide of embodiment G8, wherein the soluble human tissue factor domain comprises a sequence that is at least 80% identical to SEQ ID NO:98.
実施形態G277.可溶性ヒト組織因子ドメインが、配列番号98と少なくとも90%同一である配列を含む、実施形態G276に記載の多鎖キメラポリペプチド。 Embodiment G277. The multichain chimeric polypeptide of embodiment G276, wherein the soluble human tissue factor domain comprises a sequence that is at least 90% identical to SEQ ID NO:98.
実施形態G278.可溶性ヒト組織因子ドメインが、配列番号98と少なくとも95%同一である配列を含む、実施形態G277に記載の多鎖キメラポリペプチド。 Embodiment G278. The multichain chimeric polypeptide of embodiment G277, wherein the soluble human tissue factor domain comprises a sequence that is at least 95% identical to SEQ ID NO:98.
実施形態G279.可溶性ヒト組織因子ドメインが、配列番号98と100%同一である配列を含む、実施形態G278に記載の多鎖キメラポリペプチド。 Embodiment G279. The multichain chimeric polypeptide of embodiment G278, wherein the soluble human tissue factor domain comprises a sequence that is 100% identical to SEQ ID NO:98.
実施形態H1.加齢関連疾患又は状態の治療を必要とする対象において加齢関連疾患又は状態を治療する方法であって、加齢関連疾患又は状態を有すると同定される対象に、治療有効量の1つ以上のナチュラルキラー(NK)細胞活性化物質を投与することを含む、方法。 Embodiment H1. A method of treating an age-related disease or condition in a subject in need thereof, comprising administering to a subject identified as having an age-related disease or condition a therapeutically effective amount of one or more administering a natural killer (NK) cell activator of
実施形態H2.老化細胞の死滅又は老化細胞の数の減少を必要とする対象において老化細胞を死滅させる又は老化細胞の数を減少させる方法であって、対象に、治療有効量の1つ以上のNK細胞活性化物質を投与することを含む、方法。 Embodiment H2. A method of killing senescent cells or reducing the number of senescent cells in a subject in need thereof, comprising administering to the subject a therapeutically effective amount of one or more NK cell activating A method comprising administering a substance.
実施形態H3.老化細胞が、老化がん細胞、老化単球、老化リンパ球、老化星状細胞、老化ミクログリア、老化ニューロン、老化組織線維芽細胞、老化皮膚線維芽細胞、老化ケラチノサイト、又は他の分化組織特異的な分裂機能細胞である、実施形態H2に記載の方法。 Embodiment H3. Senescent cells are senescent cancer cells, senescent monocytes, senescent lymphocytes, senescent astrocytes, senescent microglia, senescent neurons, senescent tissue fibroblasts, senescent skin fibroblasts, senescent keratinocytes, or other differentiated tissue-specific The method of embodiment H2, wherein the cell is a dividing functional cell.
実施形態H4.老化がん細胞が、化学療法誘導性老化細胞又は放射線によって誘導された老化細胞である、実施形態H3に記載の方法。 Embodiment H4. The method of embodiment H3, wherein the senescent cancer cells are chemotherapy-induced senescent cells or radiation-induced senescent cells.
実施形態H5.対象が、加齢関連疾患又は状態を有すると同定又は診断されている、実施形態H2に記載の方法。 Embodiment H5. The method of embodiment H2, wherein the subject has been identified or diagnosed as having an age-related disease or condition.
実施形態H6.加齢関連疾患又は状態が、がん、自己免疫疾患、代謝性疾患、神経変性疾患、心臓血管疾患、皮膚疾患、早老症、及び脆弱性疾患からなる群から選択される、実施形態H1又はH5に記載の方法。 Embodiment H6. Embodiments H1 or H5, wherein the age-related disease or condition is selected from the group consisting of cancer, autoimmune disease, metabolic disease, neurodegenerative disease, cardiovascular disease, skin disease, progeria, and frailty disease. The method described in .
実施形態H7.がんが、固形腫瘍、血液腫瘍、肉腫、骨肉腫、膠芽細胞腫、神経芽細胞腫、黒色腫、横紋筋肉腫、ユーイング肉腫、骨肉腫、B細胞新生物、多発性骨髄腫、B細胞リンパ腫、B細胞非ホジキンリンパ腫、ホジキンリンパ腫、慢性リンパ球性白血病(CLL)、急性骨髄性白血病(AML)、慢性骨髄性白血病(CML)、急性リンパ性白血病(ALL)、骨髄異形成症候群(MDS)、皮膚T細胞リンパ腫、網膜芽細胞腫、胃がん、尿路上皮がん、肺がん、腎細胞がん、胃食道がん、膵臓がん、前立腺がん、乳がん、結腸直腸がん、卵巣がん、非小細胞肺がん、扁平上皮細胞頭頸部がん、子宮内膜がん、子宮頸がん、肝臓がん、及び肝細胞がんからなる群から選択される、実施形態H6に記載の方法。 Embodiment H7. Cancer is solid tumor, hematologic tumor, sarcoma, osteosarcoma, glioblastoma, neuroblastoma, melanoma, rhabdomyosarcoma, Ewing sarcoma, osteosarcoma, B-cell neoplasm, multiple myeloma, B cell lymphoma, B-cell non-Hodgkin's lymphoma, Hodgkin's lymphoma, chronic lymphocytic leukemia (CLL), acute myelogenous leukemia (AML), chronic myelogenous leukemia (CML), acute lymphocytic leukemia (ALL), myelodysplastic syndrome ( MDS), cutaneous T-cell lymphoma, retinoblastoma, gastric cancer, urothelial cancer, lung cancer, renal cell cancer, gastroesophageal cancer, pancreatic cancer, prostate cancer, breast cancer, colorectal cancer, ovarian cancer cancer, non-small cell lung cancer, squamous cell head and neck cancer, endometrial cancer, cervical cancer, liver cancer, and hepatocellular carcinoma. .
実施形態H8.自己免疫疾患が、1型糖尿病である、実施形態H6に記載の方法。
Embodiment H8. The method of embodiment H6, wherein the autoimmune disease is
実施形態H9.代謝性疾患が、肥満、リポジストロフィー、及び2型真性糖尿病からなる群から選択される、実施形態H6に記載の方法。
Embodiment H9. The method of embodiment H6, wherein the metabolic disease is selected from the group consisting of obesity, lipodystrophy, and
実施形態H10.神経変性疾患が、アルツハイマー病、パーキンソン病、及び認知症からなる群から選択される、実施形態H6に記載の方法。 Embodiment H10. The method of embodiment H6, wherein the neurodegenerative disease is selected from the group consisting of Alzheimer's disease, Parkinson's disease, and dementia.
実施形態H11.心臓血管疾患が、冠動脈疾患、アテローム性動脈硬化症、及び肺動脈高血圧症からなる群から選択される、実施形態H6に記載の方法。 Embodiment H11. The method of embodiment H6, wherein the cardiovascular disease is selected from the group consisting of coronary artery disease, atherosclerosis, and pulmonary artery hypertension.
実施形態H12.皮膚疾患が、創傷治癒、脱毛症、しわ、老年性黒子、皮膚の菲薄化、色素性乾皮症、及び先天性角化異常症からなる群から選択される、実施形態H6に記載の方法。 Embodiment H12. The method of embodiment H6, wherein the skin disorder is selected from the group consisting of wound healing, alopecia, wrinkles, senile lentigines, skin thinning, xeroderma pigmentosum, and dyskeratosis congenita.
実施形態H13.早老症が、早老症及びハッチンソン・ギルフォード早老症症候群からなる群から選択される、実施形態H6に記載の方法。 Embodiment H13. The method of embodiment H6, wherein the progeria is selected from the group consisting of progeria and Hutchinson-Guilford progeria syndrome.
実施形態H14.脆弱性疾患が、脆弱、ワクチン接種に対する応答、骨粗しょう症、及びサルコペニアからなる群から選択される、実施形態H6に記載の方法。 Embodiment H14. The method of embodiment H6, wherein the fragility disease is selected from the group consisting of fragility, response to vaccination, osteoporosis, and sarcopenia.
実施形態H15.加齢関連疾患又は状態が、加齢関連黄斑変性、骨関節炎、脂肪萎縮、慢性閉塞性肺疾患、特発性肺線維症、腎移植不全、肝線維症、骨量喪失、サルコペニア、加齢関連肺組織弾性喪失、骨粗しょう症、加齢関連腎機能障害、及び化学的に誘導された腎機能障害の群から選択される、実施形態H1又はH5に記載の方法。 Embodiment H15. Age-related disease or condition is age-related macular degeneration, osteoarthritis, fat atrophy, chronic obstructive pulmonary disease, idiopathic pulmonary fibrosis, renal graft failure, liver fibrosis, bone loss, sarcopenia, age-related lung The method of embodiment H1 or H5, which is selected from the group of loss of tissue elasticity, osteoporosis, age-related renal dysfunction, and chemically induced renal dysfunction.
実施形態H16.加齢関連疾患又は状態が、2型真性糖尿病又はアテローム性動脈硬化症である、実施形態H1又はH5に記載の方法。
Embodiment H16. The method of embodiment H1 or H5, wherein the age-related disease or condition is
実施形態H17.投与が、対象における標的組織の老化細胞の数の減少をもたらす、実施形態H1~H16のいずれか1つに記載の方法。 Embodiment H17. The method of any one of embodiments H1-H16, wherein administering results in a decrease in the number of senescent cells in the target tissue in the subject.
実施形態H18.標的組織が、脂肪組織、膵臓組織、肝臓組織、肺組織、血管系、骨組織、中枢神経系(CNS)組織、眼組織、皮膚組織、筋肉組織、及び二次リンパ器官組織からなる群から選択される、実施形態H17に記載の方法。 Embodiment H18. The target tissue is selected from the group consisting of adipose tissue, pancreatic tissue, liver tissue, lung tissue, vascular system, bone tissue, central nervous system (CNS) tissue, eye tissue, skin tissue, muscle tissue, and secondary lymphoid organ tissue. The method of embodiment H17.
実施形態H19.投与が、活性化されたNK細胞におけるCD25、CD69、MTOR-C1、SREBP1、IFN-γ、及びグランザイムBの発現レベルの増加をもたらす、実施形態H1~H18のいずれか1つに記載の方法。 Embodiment H19. The method of any one of embodiments H1-H18, wherein administration results in increased expression levels of CD25, CD69, MTOR-C1, SREBP1, IFN-γ, and granzyme B on activated NK cells.
実施形態H20.加齢関連疾患又は状態の治療を必要とする対象において加齢関連疾患又は状態を治療する方法であって、加齢関連疾患又は状態を有すると同定される対象に、治療有効数の活性化されたNK細胞を投与することを含む、方法。 Embodiment H20. A method of treating an age-related disease or condition in a subject in need of treatment of an age-related disease or condition, comprising administering to a subject identified as having an age-related disease or condition a therapeutically effective number of activated administering NK cells.
実施形態H21.老化細胞の死滅又は老化細胞の数の減少を必要とする対象において老化細胞を死滅させる又は老化細胞の数を減少させる方法であって、対象に、治療有効数の活性化されたNK細胞を投与することを含む、方法。 Embodiment H21. A method of killing senescent cells or reducing the number of senescent cells in a subject in need of killing senescent cells or reducing the number of senescent cells, comprising administering to the subject a therapeutically effective number of activated NK cells A method comprising:
実施形態H22.老化細胞が、老化がん細胞、老化単球、老化リンパ球、老化星状細胞、老化ミクログリア、老化ニューロン、老化組織線維芽細胞、老化皮膚線維芽細胞、老化ケラチノサイト、又は他の分化組織特異的な分裂機能細胞である、実施形態H21に記載の方法。 Embodiment H22. Senescent cells are senescent cancer cells, senescent monocytes, senescent lymphocytes, senescent astrocytes, senescent microglia, senescent neurons, senescent tissue fibroblasts, senescent skin fibroblasts, senescent keratinocytes, or other differentiated tissue-specific The method of embodiment H21, wherein the cell is a dividing functional cell.
実施形態H23.老化がん細胞が、化学療法誘導性老化細胞又は放射線によって誘導された老化細胞である、実施形態H22に記載の方法。 Embodiment H23. The method of embodiment H22, wherein the senescent cancer cells are chemotherapy-induced senescent cells or radiation-induced senescent cells.
実施形態H24.対象が、加齢関連疾患又は状態を有すると同定又は診断されている、実施形態H21に記載の方法。 Embodiment H24. The method of embodiment H21, wherein the subject has been identified or diagnosed as having an age-related disease or condition.
実施形態H25.加齢関連疾患又は状態が、がん、自己免疫疾患、代謝性疾患、神経変性疾患、心臓血管疾患、皮膚疾患、早老症、及び脆弱性疾患からなる群から選択される、実施形態H20又はH24に記載の方法。 Embodiment H25. Embodiments H20 or H24, wherein the age-related disease or condition is selected from the group consisting of cancer, autoimmune disease, metabolic disease, neurodegenerative disease, cardiovascular disease, skin disease, progeria, and frailty disease. The method described in .
実施形態H26.がんが、固形腫瘍、血液腫瘍、肉腫、骨肉腫、膠芽細胞腫、神経芽細胞腫、黒色腫、横紋筋肉腫、ユーイング肉腫、骨肉腫、B細胞新生物、多発性骨髄腫、B細胞リンパ腫、B細胞非ホジキンリンパ腫、ホジキンリンパ腫、慢性リンパ球性白血病(CLL)、急性骨髄性白血病(AML)、慢性骨髄性白血病(CML)、急性リンパ性白血病(ALL)、骨髄異形成症候群(MDS)、皮膚T細胞リンパ腫、網膜芽細胞腫、胃がん、尿路上皮がん、肺がん、腎細胞がん、胃食道がん、膵臓がん、前立腺がん、乳がん、結腸直腸がん、卵巣がん、非小細胞肺がん、扁平上皮細胞頭頸部がん、子宮内膜がん、子宮頸がん、肝臓がん、及び肝細胞がんからなる群から選択される、実施形態H25に記載の方法。 Embodiment H26. Cancer is solid tumor, hematologic tumor, sarcoma, osteosarcoma, glioblastoma, neuroblastoma, melanoma, rhabdomyosarcoma, Ewing sarcoma, osteosarcoma, B-cell neoplasm, multiple myeloma, B cell lymphoma, B-cell non-Hodgkin's lymphoma, Hodgkin's lymphoma, chronic lymphocytic leukemia (CLL), acute myelogenous leukemia (AML), chronic myelogenous leukemia (CML), acute lymphocytic leukemia (ALL), myelodysplastic syndrome ( MDS), cutaneous T-cell lymphoma, retinoblastoma, gastric cancer, urothelial cancer, lung cancer, renal cell cancer, gastroesophageal cancer, pancreatic cancer, prostate cancer, breast cancer, colorectal cancer, ovarian cancer cancer, non-small cell lung cancer, squamous cell head and neck cancer, endometrial cancer, cervical cancer, liver cancer, and hepatocellular carcinoma. .
実施形態H27.自己免疫疾患が、1型糖尿病である、実施形態H25に記載の方法。
Embodiment H27. The method of embodiment H25, wherein the autoimmune disease is
実施形態H28.代謝性疾患が、肥満、リポジストロフィー、及び2型真性糖尿病からなる群から選択される、実施形態H25に記載の方法。
Embodiment H28. The method of embodiment H25, wherein the metabolic disease is selected from the group consisting of obesity, lipodystrophy, and
実施形態H29.神経変性疾患が、アルツハイマー病、パーキンソン病、及び認知症からなる群から選択される、実施形態H25に記載の方法。 Embodiment H29. The method of embodiment H25, wherein the neurodegenerative disease is selected from the group consisting of Alzheimer's disease, Parkinson's disease, and dementia.
実施形態H30.心臓血管疾患が、冠動脈疾患、アテローム性動脈硬化症、及び肺動脈高血圧症からなる群から選択される、実施形態H25に記載の方法。 Embodiment H30. The method of embodiment H25, wherein the cardiovascular disease is selected from the group consisting of coronary artery disease, atherosclerosis, and pulmonary artery hypertension.
実施形態H31.皮膚疾患が、創傷治癒、脱毛症、しわ、老年性黒子、皮膚の菲薄化、色素性乾皮症、及び先天性角化異常症からなる群から選択される、実施形態H25に記載の方法。 Embodiment H31. The method of embodiment H25, wherein the skin disorder is selected from the group consisting of wound healing, alopecia, wrinkles, senile lentigines, skin thinning, xeroderma pigmentosum, and dyskeratosis congenita.
実施形態H32.早老症が、早老症及びハッチンソン・ギルフォード早老症症候群からなる群から選択される、実施形態H25に記載の方法。 Embodiment H32. The method of embodiment H25, wherein the progeria is selected from the group consisting of progeria and Hutchinson-Guilford progeria syndrome.
実施形態H33.脆弱性疾患が、脆弱、ワクチン接種に対する応答、骨粗しょう症、及びサルコペニアからなる群から選択される、実施形態H25に記載の方法。 Embodiment H33. The method of embodiment H25, wherein the fragility disease is selected from the group consisting of fragility, response to vaccination, osteoporosis, and sarcopenia.
実施形態H34.加齢関連疾患又は状態が、加齢関連黄斑変性、骨関節炎、脂肪萎縮、慢性閉塞性肺疾患、特発性肺線維症、腎移植不全、肝線維症、骨量喪失、サルコペニア、加齢関連肺組織弾性喪失、骨粗しょう症、加齢関連腎機能障害、及び化学的に誘導された腎機能障害からなる群から選択される、実施形態H20又はH24に記載の方法。 Embodiment H34. Age-related disease or condition is age-related macular degeneration, osteoarthritis, fat atrophy, chronic obstructive pulmonary disease, idiopathic pulmonary fibrosis, renal graft failure, liver fibrosis, bone loss, sarcopenia, age-related lung The method of embodiment H20 or H24, which is selected from the group consisting of loss of tissue elasticity, osteoporosis, age-related renal dysfunction, and chemically-induced renal dysfunction.
実施形態H35.
休止NK細胞を得ることと、
1つ以上のNK細胞活性化物質を含む液体培養培地中でインビトロで休止NK細胞を接触させることであって、この接触が、その後、対象に投与される活性化されたNK細胞の発生をもたらす、接触させることと
を更に含む、実施形態H20~H34のいずれか1つに記載の方法。
Embodiment H35.
obtaining resting NK cells;
Contacting resting NK cells in vitro in a liquid culture medium containing one or more NK cell activators, which contact results in the generation of activated NK cells that are then administered to the subject. , contacting. The method of any one of embodiments H20-H34.
実施形態H36.休止NK細胞が、対象から得られた自己NK細胞である、実施形態H35に記載の方法。 Embodiment H36. The method of embodiment H35, wherein the resting NK cells are autologous NK cells obtained from the subject.
実施形態H37.休止NK細胞が、同種異系の休止NK細胞である、実施形態H35に記載の方法。 Embodiment H37. The method of embodiment H35, wherein the resting NK cells are allogeneic resting NK cells.
実施形態H38.休止NK細胞が、人工NK細胞である、実施形態H35に記載の方法。 Embodiment H38. The method of embodiment H35, wherein the resting NK cells are induced NK cells.
実施形態H39.休止NK細胞が、ハプロタイプ一致の休止NK細胞である、実施形態H35に記載の方法。 Embodiment H39. The method of embodiment H35, wherein the resting NK cells are haploidentical resting NK cells.
実施形態H40.休止NK細胞が、キメラ抗原受容体又は組換えT細胞受容体を有する遺伝子組み換えNK細胞である、実施形態H35~H39のいずれか1つに記載の方法。 Embodiment H40. The method of any one of embodiments H35-H39, wherein the resting NK cells are genetically engineered NK cells with chimeric antigen receptors or recombinant T cell receptors.
実施形態H41.活性化されたNK細胞が対象に投与される前に、活性化されたNK細胞を単離することを更に含む、実施形態H35~H40のいずれか1つに記載の方法。 Embodiment H41. The method of any one of embodiments H35-H40, further comprising isolating the activated NK cells before the activated NK cells are administered to the subject.
実施形態H42.ある期間にわたる皮膚及び/又は毛髪の質感及び/又は外観の改善を必要とする対象において皮膚及び/又は毛髪の質感及び/又は外観を改善する方法であって、対象に、治療有効量の1つ以上のナチュラルキラー(NK)細胞活性化物質を投与することを含む、方法。 Embodiment H42. 1. A method of improving skin and/or hair texture and/or appearance in a subject in need thereof over a period of time comprising administering to the subject a therapeutically effective amount of one A method comprising administering the above natural killer (NK) cell activator.
実施形態H43.ある期間にわたる皮膚及び/又は毛髪の質感及び/又は外観の改善を必要とする対象において皮膚及び/又は毛髪の質感及び/又は外観を改善する方法であって、対象に、治療有効数の活性化されたNK細胞を投与することを含む、方法。 Embodiment H43. 1. A method of improving skin and/or hair texture and/or appearance in a subject in need thereof over a period of time, comprising administering to the subject a therapeutically effective number of activated administering the NK cells.
実施形態H44.
休止NK細胞を得ることと、
1つ以上のNK細胞活性化物質を含む液体培養培地中でインビトロで休止NK細胞を接触させることであって、この接触が、その後、対象に投与される活性化されたNK細胞の発生をもたらす、接触させることと
を更に含む、実施形態H43に記載の方法。
Embodiment H44.
obtaining resting NK cells;
Contacting resting NK cells in vitro in a liquid culture medium containing one or more NK cell activators, which contact results in the generation of activated NK cells that are then administered to the subject. , contacting. The method of embodiment H43.
実施形態H45.休止NK細胞が、対象から得られた自己NK細胞である、実施形態H44に記載の方法。 Embodiment H45. The method of embodiment H44, wherein the resting NK cells are autologous NK cells obtained from the subject.
実施形態H46.休止NK細胞が、同種異系の休止NK細胞である、実施形態H44に記載の方法。 Embodiment H46. The method of embodiment H44, wherein the resting NK cells are allogeneic resting NK cells.
実施形態H47.休止NK細胞が、人工NK細胞である、実施形態H44に記載の方法。 Embodiment H47. The method of embodiment H44, wherein the resting NK cells are induced NK cells.
実施形態H48.休止NK細胞が、ハプロタイプ一致の休止NK細胞である、実施形態H44に記載の方法。 Embodiment H48. The method of embodiment H44, wherein the resting NK cells are haploidentical resting NK cells.
実施形態H49.休止NK細胞が、キメラ抗原受容体又は組換えT細胞受容体を有する遺伝子組み換えNK細胞である、実施形態H44~H48のいずれか1つに記載の方法。 Embodiment H49. The method of any one of embodiments H44-H48, wherein the resting NK cells are genetically engineered NK cells with chimeric antigen receptors or recombinant T cell receptors.
実施形態H50.活性化されたNK細胞が対象に投与される前に、活性化されたNK細胞を単離することを更に含む、実施形態H44~H49のいずれか1つに記載の方法。 Embodiment H50. The method of any one of embodiments H44-H49, further comprising isolating the activated NK cells before the activated NK cells are administered to the subject.
実施形態H51.前記期間にわたる対象の皮膚の質感及び/又は外観の改善を提供する、実施形態H42~H50のいずれか1つに記載の方法。 Embodiment H51. The method of any one of embodiments H42-H50, which provides an improvement in the subject's skin texture and/or appearance over said time period.
実施形態H52.前記期間にわたる対象の皮膚のしわの形成速度の減少をもたらす、実施形態H51に記載の方法。 Embodiment H52. The method of embodiment H51, which results in a decrease in the rate of wrinkling of the subject's skin over said time period.
実施形態H53.前記期間にわたる対象の皮膚の着色の改善をもたらす、実施形態H51又はH52に記載の方法。 Embodiment H53. The method of embodiment H51 or H52, which results in improvement of the subject's skin pigmentation over said time period.
実施形態H54.前記期間にわたる対象の皮膚の質感の改善をもたらす、実施形態H51~H53のいずれか1つに記載の方法。 Embodiment H54. The method of any one of embodiments H51-H53, which results in an improvement in the subject's skin texture over said time period.
実施形態H55.前記期間にわたる対象の毛髪の質感及び/又は外観の改善を提供する、実施形態H42~H50のいずれか1つに記載の方法。 Embodiment H55. The method of any one of embodiments H42-H50, which provides an improvement in the texture and/or appearance of the subject's hair over said period of time.
実施形態H56.前記期間にわたる対象の白髪の形成速度の減少をもたらす、実施形態H55に記載の方法。 Embodiment H56. The method of embodiment H55, which results in a decrease in the rate of gray hair formation in the subject over said time period.
実施形態H57.前記期間にわたる対象の白髪の数の減少をもたらす、実施形態H55又はH56に記載の方法。 Embodiment H57. The method of embodiment H55 or H56, which results in a decrease in the number of gray hairs in the subject over said time period.
実施形態H58.経時的に対象の脱毛速度の減少をもたらす、実施形態H55~H57のいずれか1つに記載の方法。 Embodiment H58. The method of any one of embodiments H55-H57, which results in a decrease in the subject's rate of hair loss over time.
実施形態H59.前記期間にわたる対象の毛髪の質感の改善をもたらす、実施形態H55~H58のいずれか1つに記載の方法。 Embodiment H59. The method of any one of embodiments H55-H58, which results in improved texture of the subject's hair over said time period.
実施形態H60.前記期間が、約1ヶ月間~約10年間である、実施形態H42~H59のいずれか1つに記載の方法。 Embodiment H60. The method of any one of embodiments H42-H59, wherein said period of time is from about 1 month to about 10 years.
実施形態H61.前記期間にわたる対象の皮膚の老化皮膚線維芽細胞の数の減少をもたらす、実施形態H42~H60のいずれか1つに記載の方法。 Embodiment H61. The method of any one of embodiments H42-H60, which results in a decrease in the number of senescent dermal fibroblasts in the subject's skin over said time period.
実施形態H62.ある期間にわたる肥満の治療の支援を必要とする対象において肥満の治療を支援する方法であって、対象に、治療有効量の1つ以上のナチュラルキラー(NK)細胞活性化物質を投与することを含む、方法。 Embodiment H62. A method of helping treat obesity in a subject in need of help treating obesity over a period of time comprising administering to the subject a therapeutically effective amount of one or more natural killer (NK) cell activators. including, method.
実施形態H63.ある期間にわたる肥満の治療の支援を必要とする対象において肥満の治療を支援する方法であって、対象に、治療有効数の活性化されたNK細胞を投与することを含む、方法。 Embodiment H63. A method of helping treat obesity in a subject in need of help treating obesity over a period of time, the method comprising administering to the subject a therapeutically effective number of activated NK cells.
実施形態H64.
休止NK細胞を得ることと、
1つ以上のNK細胞活性化物質を含む液体培養培地中でインビトロで休止NK細胞を接触させることであって、この接触が、その後、対象に投与される活性化されたNK細胞の発生をもたらす、接触させることと
を更に含む、実施形態H63に記載の方法。
Embodiment H64.
obtaining resting NK cells;
Contacting resting NK cells in vitro in a liquid culture medium containing one or more NK cell activators, which contact results in the generation of activated NK cells that are then administered to the subject. , contacting. The method of embodiment H63.
実施形態H65.休止NK細胞が、対象から得られた自己NK細胞である、実施形態H64に記載の方法。 Embodiment H65. The method of embodiment H64, wherein the resting NK cells are autologous NK cells obtained from the subject.
実施形態H66.休止NK細胞が、同種異系の休止NK細胞である、実施形態H64に記載の方法。 Embodiment H66. The method of embodiment H64, wherein the resting NK cells are allogeneic resting NK cells.
実施形態H67.休止NK細胞が、人工NK細胞である、実施形態H64に記載の方法。 Embodiment H67. The method of embodiment H64, wherein the resting NK cells are induced NK cells.
実施形態H68.休止NK細胞が、ハプロタイプ一致の休止NK細胞である、実施形態H64に記載の方法。 Embodiment H68. The method of embodiment H64, wherein the resting NK cells are haploidentical resting NK cells.
実施形態H69.休止NK細胞が、キメラ抗原受容体又は組換えT細胞受容体を有する遺伝子組み換えNK細胞である、実施形態H64~H68のいずれか1つに記載の方法。 Embodiment H69. The method of any one of embodiments H64-H68, wherein the resting NK cells are genetically engineered NK cells with chimeric antigen receptors or recombinant T cell receptors.
実施形態H70.活性化されたNK細胞が対象に投与される前に、活性化されたNK細胞を単離することを更に含む、実施形態H64~H69のいずれか1つに記載の方法。 Embodiment H70. The method of any one of embodiments H64-H69, further comprising isolating the activated NK cells before the activated NK cells are administered to the subject.
実施形態H71.前記期間にわたる対象の体重の減少をもたらす、実施形態H62~H70のいずれか1つに記載の方法。 Embodiment H71. The method of any one of embodiments H62-H70, which results in the subject losing weight over said time period.
実施形態H72.前記期間にわたる対象の肥満度指数(BMI)の減少をもたらす、実施形態H62~H71のいずれか1つに記載の方法。 Embodiment H72. The method of any one of embodiments H62-H71, which results in a reduction in the subject's body mass index (BMI) over said time period.
実施形態H73.対象における前糖尿病から2型糖尿病への進行速度の減少をもたらす、実施形態H62~H70のいずれか1つに記載の方法。
Embodiment H73. The method of any one of embodiments H62-H70, which results in a decrease in the rate of progression from prediabetes to
実施形態H74.対象における空腹時血糖値の減少をもたらす、実施形態H62~H70のいずれか1つに記載の方法。 Embodiment H74. The method of any one of embodiments H62-H70, which results in decreased fasting blood glucose levels in the subject.
実施形態H75.対象におけるインスリン感受性の増加をもたらす、実施形態H62~H70のいずれか1つに記載の方法。 Embodiment H75. The method of any one of embodiments H62-H70, which results in increased insulin sensitivity in the subject.
実施形態H76.対象におけるアテローム性動脈硬化症の重症度の減少をもたらす、実施形態H62~H70のいずれか1つに記載の方法。 Embodiment H76. The method of any one of embodiments H62-H70, which results in a reduction in the severity of atherosclerosis in the subject.
実施形態H77.前記期間が、約2週間~約10年間である、実施形態H62~H76のいずれか1つに記載の方法。 Embodiment H77. The method of any one of embodiments H62-H76, wherein said period of time is from about 2 weeks to about 10 years.
実施形態H78.1つ以上のNK細胞活性化物質(s)のうちの少なくとも1つが、IL-2受容体、IL-7受容体、IL-12受容体、IL-15受容体、IL-18受容体、IL-21受容体、IL-33受容体、CD16、CD69、CD25、CD36、CD59、CD352、NKp80、DNAM-1、2B4、NKp30、NKp44、NKp46、NKG2D、KIR2DS1、KIR2Ds2/3、KIR2DL4、KIR2DS4、KIR2DS5、及びKIR3DS1のうちの1つ以上の活性化をもたらす、実施形態H1~H19、H35~H42、H44~H62、及びH64~H77のいずれか1つに記載の方法。 Embodiment H78. At least one of the one or more NK cell activator(s) is IL-2 receptor, IL-7 receptor, IL-12 receptor, IL-15 receptor, IL-18 receptor, IL-21 receptor, IL-33 receptor, CD16, CD69, CD25, CD36, CD59, CD352, NKp80, DNAM-1, 2B4, NKp30, NKp44, NKp46, NKG2D, KIR2DS1, KIR2Ds2/3, KIR2DL4 , KIR2DS4, KIR2DS5, and KIR3DS1, the method of any one of embodiments H1-H19, H35-H42, H44-H62, and H64-H77.
実施形態H79.IL-2受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つが、可溶性IL-2又はIL-2受容体に特異的に結合するアゴニスト抗体である、実施形態H78に記載の方法。 Embodiment H79. Embodiment H78, wherein at least one of the one or more NK cell activators that result in IL-2 receptor activation is soluble IL-2 or an agonistic antibody that specifically binds IL-2 receptor. The method described in .
実施形態H80.IL-7受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つが、可溶性IL-7又はIL-7受容体に特異的に結合するアゴニスト抗体である、実施形態H78に記載の方法。 Embodiment H80. Embodiment H78, wherein at least one of the one or more NK cell activators that result in IL-7 receptor activation is soluble IL-7 or an agonistic antibody that specifically binds IL-7 receptor. The method described in .
実施形態H81.IL-12受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つが、可溶性IL-12又はIL-12受容体に特異的に結合するアゴニスト抗体である、実施形態H78に記載の方法。 Embodiment H81. Embodiment H78, wherein at least one of the one or more NK cell activators that result in IL-12 receptor activation is soluble IL-12 or an agonistic antibody that specifically binds IL-12 receptor. The method described in .
実施形態H82.IL-15受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つが、可溶性IL-15又はIL-15受容体に特異的に結合するアゴニスト抗体である、実施形態H78に記載の方法。 Embodiment H82. Embodiment H78, wherein at least one of the one or more NK cell activators that result in IL-15 receptor activation is soluble IL-15 or an agonist antibody that specifically binds IL-15 receptor. The method described in .
実施形態H83.IL-21受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つが、可溶性IL-21又はIL-21受容体に特異的に結合するアゴニスト抗体である、実施形態H78に記載の方法。 Embodiment H83. Embodiment H78, wherein at least one of the one or more NK cell activators that result in IL-21 receptor activation is soluble IL-21 or an agonist antibody that specifically binds IL-21 receptor. The method described in .
実施形態H84.IL-33受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つが、可溶性IL-33又はIL-33受容体に特異的に結合するアゴニスト抗体である、実施形態H78に記載の方法。 Embodiment H84. Embodiment H78, wherein at least one of the one or more NK cell activators that result in IL-33 receptor activation is soluble IL-33 or an agonistic antibody that specifically binds IL-33 receptor. The method described in .
実施形態H85.CD16受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つが、CD16に特異的に結合するアゴニスト抗体である、実施形態H78に記載の方法。 Embodiment H85. The method of embodiment H78, wherein at least one of the one or more NK cell activators that result in CD16 receptor activation is an agonistic antibody that specifically binds CD16.
実施形態H86.CD69受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つが、CD69に特異的に結合するアゴニスト抗体である、実施形態H78に記載の方法。 Embodiment H86. The method of embodiment H78, wherein at least one of the one or more NK cell activators that result in CD69 receptor activation is an agonistic antibody that specifically binds CD69.
実施形態H87.CD25、CD36、CD59受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つが、CD25、CD6、CD59に特異的に結合するアゴニスト抗体である、実施形態H78に記載の方法。 Embodiment H87. According to embodiment H78, wherein at least one of the one or more NK cell activators that result in CD25, CD36, CD59 receptor activation is an agonistic antibody that specifically binds CD25, CD6, CD59. Method.
実施形態H88.CD352受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つが、CD352に特異的に結合するアゴニスト抗体である、実施形態H78に記載の方法。 Embodiment H88. The method of embodiment H78, wherein at least one of the one or more NK cell activators that result in CD352 receptor activation is an agonistic antibody that specifically binds CD352.
実施形態H89.NKp80受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つが、NKp80に特異的に結合するアゴニスト抗体である、実施形態H78に記載の方法。 Embodiment H89. The method of embodiment H78, wherein at least one of the one or more NK cell activators that result in activation of the NKp80 receptor is an agonistic antibody that specifically binds NKp80.
実施形態H90.DNAM-1受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つが、DNAM-1に特異的に結合するアゴニスト抗体である、実施形態H78に記載の方法。 Embodiment H90. The method of embodiment H78, wherein at least one of the one or more NK cell activators that result in activation of the DNAM-1 receptor is an agonistic antibody that specifically binds DNAM-1.
実施形態H91.2B4受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つが、2B4に特異的に結合するアゴニスト抗体である、実施形態H78に記載の方法。 Embodiment H91. The method of embodiment H78, wherein at least one of the one or more NK cell activators that result in activation of the 2B4 receptor is an agonistic antibody that specifically binds 2B4.
実施形態H92.NKp30受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つが、NKp30に特異的に結合するアゴニスト抗体である、実施形態H78に記載の方法。 Embodiment H92. The method of embodiment H78, wherein at least one of the one or more NK cell activators that result in activation of the NKp30 receptor is an agonistic antibody that specifically binds NKp30.
実施形態H93.NKp44受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つが、NKp44に特異的に結合するアゴニスト抗体である、実施形態H78に記載の方法。 Embodiment H93. The method of embodiment H78, wherein at least one of the one or more NK cell activators that result in activation of the NKp44 receptor is an agonistic antibody that specifically binds NKp44.
実施形態H94.NKp46受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つが、NKp46に特異的に結合するアゴニスト抗体である、実施形態H78に記載の方法。 Embodiment H94. The method of embodiment H78, wherein at least one of the one or more NK cell activators that result in activation of the NKp46 receptor is an agonistic antibody that specifically binds NKp46.
実施形態H95.NKG2D受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つが、NKG2Dに特異的に結合するアゴニスト抗体である、実施形態H78に記載の方法。 Embodiment H95. The method of embodiment H78, wherein at least one of the one or more NK cell activators that result in NKG2D receptor activation is an agonistic antibody that specifically binds NKG2D.
実施形態H96.KIR2DS1受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つが、KIR2DS1に特異的に結合するアゴニスト抗体である、実施形態H78に記載の方法。 Embodiment H96. The method of embodiment H78, wherein at least one of the one or more NK cell activators that result in activation of the KIR2DS1 receptor is an agonistic antibody that specifically binds KIR2DS1.
実施形態H97.KIR2DS2/3受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つが、KIR2DS2/3に特異的に結合するアゴニスト抗体である、実施形態H78に記載の方法。 Embodiment H97. The method of embodiment H78, wherein at least one of the one or more NK cell activators that result in activation of the KIR2DS2/3 receptor is an agonistic antibody that specifically binds KIR2DS2/3.
実施形態H98.KIR2DL4受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つが、KIR2DL4に特異的に結合するアゴニスト抗体である、実施形態H78に記載の方法。 Embodiment H98. The method of embodiment H78, wherein at least one of the one or more NK cell activators that result in activation of the KIR2DL4 receptor is an agonistic antibody that specifically binds KIR2DL4.
実施形態H99.KIR2DS4受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つが、KIR2DS4に特異的に結合するアゴニスト抗体である、実施形態H78に記載の方法。 Embodiment H99. The method of embodiment H78, wherein at least one of the one or more NK cell activators that result in activation of the KIR2DS4 receptor is an agonistic antibody that specifically binds KIR2DS4.
実施形態H100.KIR2DS5受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つが、KIR2DS5に特異的に結合するアゴニスト抗体である、実施形態H78に記載の方法。 Embodiment H100. The method of embodiment H78, wherein at least one of the one or more NK cell activators that result in activation of the KIR2DS5 receptor is an agonistic antibody that specifically binds KIR2DS5.
実施形態H101.KIR3DS1受容体の活性化をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つが、KIR3DS1に特異的に結合するアゴニスト抗体である、実施形態H78に記載の方法。 Embodiment H101. The method of embodiment H78, wherein at least one of the one or more NK cell activators that result in activation of the KIR3DS1 receptor is an agonistic antibody that specifically binds KIR3DS1.
実施形態H102.1つ以上のNK細胞活性化物質のうちの少なくとも1つが、PD-1、TGF-β受容体、TIGIT、CD1、TIM-3、Siglec-7、IRP60、Tactile、IL1R8、NKG2A/KLRD1、KIR2DL1、KIR2DL2/3、KIR2DL5、KIR3DL1、KIR3DL2、ILT2/LIR-1、及びLAG-2のうちの1つ以上の活性化の減少をもたらす、実施形態H1~H19、H35~H42、H44~H62、及びH64~H101のいずれか1つに記載の方法。 Embodiment H102. At least one of the one or more NK cell activators is PD-1, TGF-beta receptor, TIGIT, CD1, TIM-3, Siglec-7, IRP60, Tactile, IL1R8, NKG2A/ Embodiments H1-H19, H35-H42, H44-, which result in decreased activation of one or more of KLRD1, KIR2DL1, KIR2DL2/3, KIR2DL5, KIR3DL1, KIR3DL2, ILT2/LIR-1, and LAG-2 H62, and the method of any one of H64-H101.
実施形態H103.PD-1の活性化の減少をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つが、PD-1に特異的に結合するアンタゴニスト抗体、可溶性PD-1、可溶性PD-L1、又はPD-L1に特異的に結合する抗体である、実施形態H102に記載の方法。 Embodiment H103. at least one of the one or more NK cell activators that results in decreased activation of PD-1, an antagonist antibody that specifically binds to PD-1, soluble PD-1, soluble PD-L1, or PD - The method of embodiment H102, which is an antibody that specifically binds to L1.
実施形態H104.TGF-β受容体の活性化の減少をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つが、可溶性TGF-β受容体、TGF-βに特異的に結合する抗体、又はTGF-β受容体に特異的に結合するアンタゴニスト抗体である、実施形態H102に記載の方法。 Embodiment H104. at least one of the one or more NK cell activators that results in decreased TGF-β receptor activation is a soluble TGF-β receptor, an antibody that specifically binds TGF-β, or TGF-β The method of embodiment H102, which is an antagonist antibody that specifically binds to the receptor.
実施形態H105.TIGITの活性化の減少をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つが、TIGITに特異的に結合するアンタゴニスト抗体、可溶性TIGIT、又はTIGITのリガンドに特異的に結合する抗体である、実施形態H102に記載の方法。 Embodiment H105. at least one of the one or more NK cell activators that result in decreased activation of TIGIT is an antagonist antibody that specifically binds TIGIT, a soluble TIGIT, or an antibody that specifically binds a ligand of TIGIT , embodiment H102.
実施形態H106.CD1の活性化の減少をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つが、CD1に特異的に結合するアンタゴニスト抗体、可溶性CD1、又はCD1のリガンドに特異的に結合する抗体である、実施形態H102に記載の方法。 Embodiment H106. at least one of the one or more NK cell activators that result in decreased activation of CD1 is an antagonist antibody that specifically binds CD1, soluble CD1, or an antibody that specifically binds a ligand of CD1 , embodiment H102.
実施形態H107.TIM-3の活性化の減少をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つが、TIM-3に特異的に結合するアンタゴニスト抗体、可溶性TIM-3、又はTIM-3のリガンドに特異的に結合する抗体である、実施形態H102に記載の方法。 Embodiment H107. at least one of the one or more NK cell activators that results in decreased activation of TIM-3 is an antagonist antibody that specifically binds TIM-3, soluble TIM-3, or a ligand of TIM-3; The method of embodiment H102, which is a specifically binding antibody.
実施形態H108.Siglec-7の活性化の減少をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つが、Siglec-7に特異的に結合するアンタゴニスト抗体又はSiglec-7のリガンドに特異的に結合する抗体である、実施形態H102に記載の方法。 Embodiment H108. At least one of the one or more NK cell activators that results in decreased activation of Siglec-7 is an antagonist antibody that specifically binds to Siglec-7 or an antibody that specifically binds to a ligand of Siglec-7 The method of embodiment H102, wherein
実施形態H109.IRP60の活性化の減少をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つが、IRP60に特異的に結合するアンタゴニスト抗体又はIRP60のリガンドに特異的に結合する抗体である、実施形態H102に記載の方法。 Embodiment H109. Embodiment H102, wherein at least one of the one or more NK cell activators that result in decreased activation of IRP60 is an antagonist antibody that specifically binds IRP60 or an antibody that specifically binds a ligand of IRP60. The method described in .
実施形態H110.Tactileの活性化の減少をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つが、Tactileに特異的に結合するアンタゴニスト抗体又はTactileのリガンドに特異的に結合する抗体である、実施形態H102に記載の方法。 Embodiment H110. Embodiment H102 wherein at least one of the one or more NK cell activators that result in decreased activation of Tactile is an antagonist antibody that specifically binds Tactile or an antibody that specifically binds a ligand of Tactile. The method described in .
実施形態H111.IL1R8の活性化の減少をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つが、IL1R8に特異的に結合するアンタゴニスト抗体又はIL1R8のリガンドに特異的に結合する抗体である、実施形態H102に記載の方法。 Embodiment H111. Embodiment H102, wherein at least one of the one or more NK cell activators that result in decreased activation of IL1R8 is an antagonist antibody that specifically binds to IL1R8 or an antibody that specifically binds to a ligand of IL1R8. The method described in .
実施形態H112.NKG2A/KLRD1の活性化の減少をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つが、NKG2A/KLRD1に特異的に結合するアンタゴニスト抗体又はNKG2A/KLRD1のリガンドに特異的に結合する抗体である、実施形態H102に記載の方法。 Embodiment H112. at least one of the one or more NK cell activators that results in decreased activation of NKG2A/KLRD1 is an antagonist antibody that specifically binds to NKG2A/KLRD1 or an antibody that specifically binds to a ligand of NKG2A/KLRD1 The method of embodiment H102, wherein
実施形態H113.KIR2DL1の活性化の減少をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つが、KIR2DL1に特異的に結合するアンタゴニスト抗体又はKIR2DL1のリガンドに特異的に結合する抗体である、実施形態H102に記載の方法。 Embodiment H113. Embodiment H102, wherein at least one of the one or more NK cell activators that result in decreased activation of KIR2DL1 is an antagonist antibody that specifically binds KIR2DL1 or an antibody that specifically binds a ligand of KIR2DL1. The method described in .
実施形態H114.KIR2DL2/3の活性化の減少をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つが、KIR2DL2/3に特異的に結合するアンタゴニスト抗体又はKIR2DL2/3のリガンドに特異的に結合する抗体である、実施形態H102に記載の方法。 Embodiment H114. at least one of the one or more NK cell activators that results in decreased activation of KIR2DL2/3 is an antagonist antibody that specifically binds to KIR2DL2/3 or an antibody that specifically binds to a ligand of KIR2DL2/3 The method of embodiment H102, wherein
実施形態H115.KIR2DL5の活性化の減少をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つが、KIR2DL5に特異的に結合するアンタゴニスト抗体又はKIR2DL5のリガンドに特異的に結合する抗体である、実施形態H102に記載の方法。 Embodiment H115. Embodiment H102, wherein at least one of the one or more NK cell activators that result in decreased activation of KIR2DL5 is an antagonist antibody that specifically binds KIR2DL5 or an antibody that specifically binds a ligand of KIR2DL5. The method described in .
実施形態H116.KIR3DL1の活性化の減少をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つが、KIR3DL1に特異的に結合するアンタゴニスト抗体又はKIR3DL1のリガンドに特異的に結合する抗体である、実施形態H102に記載の方法。 Embodiment H116. Embodiment H102, wherein at least one of the one or more NK cell activators that result in decreased activation of KIR3DL1 is an antagonist antibody that specifically binds KIR3DL1 or an antibody that specifically binds a ligand of KIR3DL1. The method described in .
実施形態H117.KIR3DL2の活性化の減少をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つが、KIR3DL2に特異的に結合するアンタゴニスト抗体又はKIR3DL2のリガンドに特異的に結合する抗体である、実施形態H102に記載の方法。 Embodiment H117. Embodiment H102, wherein at least one of the one or more NK cell activators that result in decreased activation of KIR3DL2 is an antagonist antibody that specifically binds KIR3DL2 or an antibody that specifically binds a ligand of KIR3DL2. The method described in .
実施形態H118.ILT2/LIR-1の活性化の減少をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つが、ILT2/LIR-1に特異的に結合するアンタゴニスト抗体又はILT2/LIR-1のリガンドに特異的に結合する抗体である、実施形態H102に記載の方法。 Embodiment H118. at least one of the one or more NK cell activators that results in decreased activation of ILT2/LIR-1 is an antagonist antibody that specifically binds to ILT2/LIR-1 or a ligand for ILT2/LIR-1; The method of embodiment H102, which is a specifically binding antibody.
実施形態H119.LAG-2の活性化の減少をもたらす1つ以上のNK細胞活性化物質のうちの少なくとも1つが、LAG-2に特異的に結合するアンタゴニスト抗体又はLAG-2のリガンドに特異的に結合する抗体である、実施形態H102に記載の方法。 Embodiment H119. At least one of the one or more NK cell activators that results in decreased activation of LAG-2 is an antagonist antibody that specifically binds LAG-2 or an antibody that specifically binds a ligand of LAG-2 The method of embodiment H102, wherein
実施形態H120.1つ以上のNK細胞活性化物質のうちの少なくとも1つが、
(i)第1の標的結合ドメイン、
(ii)可溶性組織因子ドメイン、及び
(iii)第2の標的結合ドメイン
を含む、実施形態H1~H19、H35~H42,H44~H62、及びH64~H77のいずれか1つに記載の方法。
Embodiment H120. At least one of the one or more NK cell activators is
(i) a first target binding domain;
(ii) a soluble tissue factor domain; and (iii) a second target binding domain.
実施形態H121.第1の標的結合ドメインと可溶性組織因子ドメインが、互いに直接隣接している、実施形態H120に記載の方法。 Embodiment H121. The method of embodiment H120, wherein the first target binding domain and the soluble tissue factor domain are directly adjacent to each other.
実施形態H122.一本鎖キメラポリペプチドが、第1の標的結合ドメインと可溶性組織因子ドメインとの間にリンカー配列を更に含む、実施形態H120に記載の方法。 Embodiment H122. The method of embodiment H120, wherein the single-chain chimeric polypeptide further comprises a linker sequence between the first target binding domain and the soluble tissue factor domain.
実施形態H123.可溶性組織因子ドメインと第2の標的結合ドメインが、互いに直接隣接している、実施形態H120~H122のいずれか1つに記載の方法。 Embodiment H123. The method of any one of embodiments H120-H122, wherein the soluble tissue factor domain and the second target binding domain are directly adjacent to each other.
実施形態H124.一本鎖キメラポリペプチドが、可溶性組織因子ドメインと第2の標的結合ドメインとの間にリンカー配列を更に含む、実施形態H120~H122のいずれか1つに記載の方法。 Embodiment H124. The method of any one of embodiments H120-H122, wherein the single-chain chimeric polypeptide further comprises a linker sequence between the soluble tissue factor domain and the second target binding domain.
実施形態H125.第1の標的結合ドメインと第2の標的結合ドメインが、互いに直接隣接している、実施形態H120に記載の方法。 Embodiment H125. The method of embodiment H120, wherein the first target binding domain and the second target binding domain are directly adjacent to each other.
実施形態H126.一本鎖キメラポリペプチドが、第1の標的結合ドメインと第2の標的結合ドメインとの間にリンカー配列を更に含む、実施形態H120に記載の方法。 Embodiment H126. The method of embodiment H120, wherein the single-chain chimeric polypeptide further comprises a linker sequence between the first target binding domain and the second target binding domain.
実施形態H127.第2の標的結合ドメインと可溶性組織因子ドメインが、互いに直接隣接している、実施形態H125又はH126に記載の方法。 Embodiment H127. The method of embodiment H125 or H126, wherein the second target binding domain and the soluble tissue factor domain are directly adjacent to each other.
実施形態H128.一本鎖キメラポリペプチドが、第2の標的結合ドメインと可溶性組織因子ドメインとの間にリンカー配列を更に含む、実施形態H125又はH126に記載の方法。 Embodiment H128. The method of embodiment H125 or H126, wherein the single-chain chimeric polypeptide further comprises a linker sequence between the second target binding domain and the soluble tissue factor domain.
実施形態H129.第1の標的結合ドメイン及び第2の標的結合ドメインが、同じ抗原に特異的に結合する、実施形態H120~H128のいずれか1つに記載の方法。 Embodiment H129. The method of any one of embodiments H120-H128, wherein the first target binding domain and the second target binding domain specifically bind the same antigen.
実施形態H130.第1の標的結合ドメイン及び第2の標的結合ドメインが、同じエピトープに特異的に結合する、実施形態H129に記載の方法。 Embodiment H130. The method of embodiment H129, wherein the first target binding domain and the second target binding domain specifically bind to the same epitope.
実施形態H131.第1の標的結合ドメイン及び第2の標的結合ドメインが、同じアミノ酸配列を含む、実施形態H130に記載の方法。 Embodiment H131. The method of embodiment H130, wherein the first target binding domain and the second target binding domain comprise the same amino acid sequence.
実施形態H132.第1の標的結合ドメイン及び第2の標的結合ドメインが、異なる抗原に特異的に結合する、実施形態H120~H128のいずれか1つに記載の方法。 Embodiment H132. The method of any one of embodiments H120-H128, wherein the first target binding domain and the second target binding domain specifically bind different antigens.
実施形態H133.第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方が、抗原結合ドメインである、実施形態H120~H132のいずれか1つに記載の方法。 Embodiment H133. The method of any one of embodiments H120-H132, wherein one or both of the first target binding domain and the second target binding domain are antigen binding domains.
実施形態H134.第1の標的結合ドメイン及び第2の標的結合ドメインが各々、抗原結合ドメインである、実施形態H133に記載の方法。 Embodiment H134. The method of embodiment H133, wherein the first target binding domain and the second target binding domain are each antigen binding domains.
実施形態H135.抗原結合ドメインが、scFv又は単一ドメイン抗体を含む、実施形態H134に記載の方法。 Embodiment H135. The method of embodiment H134, wherein the antigen binding domain comprises a scFv or single domain antibody.
実施形態H136.第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方が、CD16a、CD33、CD20、CD19、CD22、CD123、PDL-1、TIGIT、PD-1、TIM3、CTLA4、MICA、MICB、IL-6、IL-8、TNFα、CD26、CD36、ULBP2、CD30、CD200、IGF-1R、MUC4AC、MUC5AC、Trop-2、CMET、EGFR、HER1、HER2、HER3、PSMA、CEA、B7H3、EPCAM、BCMA、P-カドヘリン、CEACAM5、UL16結合タンパク質、HLA-DR、DLL4、TYRO3、AXL、MER、CD122、CD155、PDGF-DD、TGF-β受容体II(TGF-βRII)リガンド、TGF-βRIIIリガンド、DNAM1リガンド、NKp46リガンド、NKp44リガンド、NKG2Dリガンド、NKP30リガンド、scMHCIリガンド、scMHCIIリガンド、scTCRリガンド、PDGF-DD受容体、幹細胞因子(SCF)受容体、幹細胞様チロシンキナーゼ3リガンド(FLT3L)受容体、MICA受容体、MICB受容体、ULP16結合タンパク質受容体、CD155受容体、及びCD122受容体からなる群から選択される標的に結合する、実施形態H120~H135のいずれか1つに記載の方法。
Embodiment H136. one or both of the first target binding domain and the second target binding domain are CD16a, CD33, CD20, CD19, CD22, CD123, PDL-1, TIGIT, PD-1, TIM3, CTLA4, MICA, MICB, IL -6, IL-8, TNFα, CD26, CD36, ULBP2, CD30, CD200, IGF-1R, MUC4AC, MUC5AC, Trop-2, CMET, EGFR, HER1, HER2, HER3, PSMA, CEA, B7H3, EPCAM, BCMA , P-cadherin, CEACAM5, UL16 binding protein, HLA-DR, DLL4, TYRO3, AXL, MER, CD122, CD155, PDGF-DD, TGF-β receptor II (TGF-βRII) ligand, TGF-βRIII ligand, DNAM1 ligand, NKp46 ligand, NKp44 ligand, NKG2D ligand, NKP30 ligand, scMHCI ligand, scMHCII ligand, scTCR ligand, PDGF-DD receptor, stem cell factor (SCF) receptor, stem cell-
実施形態H137.第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方が、可溶性インターロイキン又はサイトカインタンパク質である、実施形態H120~H128のいずれか1つに記載の方法。 Embodiment H137. The method of any one of embodiments H120-H128, wherein one or both of the first target binding domain and the second target binding domain is a soluble interleukin or cytokine protein.
実施形態H138.可溶性インターロイキン又はサイトカインタンパク質が、IL-1、IL-2、IL-3、IL-7、IL-8、IL-10、IL-12、IL-15、IL-17、IL-18、IL-21、PDGF-DD、及びSCFからなる群から選択される、実施形態H137に記載の方法。 Embodiment H138. Soluble interleukin or cytokine proteins are IL-1, IL-2, IL-3, IL-7, IL-8, IL-10, IL-12, IL-15, IL-17, IL-18, IL- 21, PDGF-DD, and SCF.
実施形態H139.第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方が、可溶性インターロイキン又はサイトカイン受容体である、実施形態H120~H128のいずれか1つに記載の方法。 Embodiment H139. The method of any one of embodiments H120-H128, wherein one or both of the first target binding domain and the second target binding domain is a soluble interleukin or cytokine receptor.
実施形態H140.インターロイキン又はサイトカイン受容体が、可溶性TGF-β受容体II(TGF-βRII)、可溶性TGF-βRIII、可溶性TNFα受容体、可溶性IL-4受容体、又は可溶性IL-10受容体である、実施形態H139に記載の方法。 Embodiment H140. Embodiments wherein the interleukin or cytokine receptor is soluble TGF-beta receptor II (TGF-βRII), soluble TGF-βRIII, soluble TNFα receptor, soluble IL-4 receptor, or soluble IL-10 receptor The method described in H139.
実施形態H141.可溶性組織因子ドメインが、可溶性ヒト組織因子ドメインである、実施形態H120~H140のいずれか1つに記載の方法。 Embodiment H141. The method of any one of embodiments H120-H140, wherein the soluble tissue factor domain is a soluble human tissue factor domain.
実施形態H142.可溶性ヒト組織因子ドメインが、配列番号93と少なくとも80%同一である配列を含む、実施形態H141に記載の方法。 Embodiment H142. The method of embodiment H141, wherein the soluble human tissue factor domain comprises a sequence that is at least 80% identical to SEQ ID NO:93.
実施形態H143.可溶性ヒト組織因子ドメインが、配列番号93と少なくとも90%同一である配列を含む、実施形態H142に記載の方法。 Embodiment H143. The method of embodiment H142, wherein the soluble human tissue factor domain comprises a sequence that is at least 90% identical to SEQ ID NO:93.
実施形態H144.可溶性ヒト組織因子ドメインが、配列番号93と少なくとも95%同一である配列を含む、実施形態H143に記載の方法。 Embodiment H144. The method of embodiment H143, wherein the soluble human tissue factor domain comprises a sequence that is at least 95% identical to SEQ ID NO:93.
実施形態H145.可溶性ヒト組織因子ドメインが、
成熟野生型ヒト組織因子タンパク質のアミノ酸20位に対応するアミノ酸の位置にリジン、
成熟野生型ヒト組織因子タンパク質のアミノ酸22位に対応するアミノ酸の位置にイソロイシン、
成熟野生型ヒト組織因子タンパク質のアミノ酸45位に対応するアミノ酸の位置にトリプトファン、
成熟野生型ヒト組織因子タンパク質のアミノ酸58位に対応するアミノ酸の位置にアスパラギン酸、
成熟野生型ヒト組織因子タンパク質のアミノ酸94位に対応するアミノ酸の位置にチロシン、
成熟野生型ヒト組織因子タンパク質のアミノ酸135位に対応するアミノ酸の位置にアルギニン、及び
成熟野生型ヒト組織因子タンパク質のアミノ酸140位に対応するアミノ酸の位置にフェニルアラニンのうちのいずれも含まない、実施形態H141~H144のいずれか一つに記載の方法。
Embodiment H145. A soluble human tissue factor domain is
a lysine at the amino acid position corresponding to
an isoleucine at the amino acid position corresponding to
tryptophan at the amino acid position corresponding to
an aspartic acid at the amino acid position corresponding to amino acid position 58 of the mature wild-type human tissue factor protein;
a tyrosine at the amino acid position corresponding to amino acid position 94 of the mature wild-type human tissue factor protein;
An embodiment that does not include either arginine at the amino acid position corresponding to amino acid position 135 of the mature wild-type human tissue factor protein and phenylalanine at the amino acid position corresponding to
実施形態H146.可溶性ヒト組織因子ドメインが、
成熟野生型ヒト組織因子タンパク質のアミノ酸20位に対応するアミノ酸の位置にリジン、
成熟野生型ヒト組織因子タンパク質のアミノ酸22位に対応するアミノ酸の位置にイソロイシン、
成熟野生型ヒト組織因子タンパク質のアミノ酸45位に対応するアミノ酸の位置にトリプトファン、
成熟野生型ヒト組織因子タンパク質のアミノ酸58位に対応するアミノ酸の位置にアスパラギン酸、
成熟野生型ヒト組織因子タンパク質のアミノ酸94位に対応するアミノ酸の位置にチロシン、
成熟野生型ヒト組織因子タンパク質のアミノ酸135位に対応するアミノ酸の位置にアルギニン、及び
成熟野生型ヒト組織因子タンパク質のアミノ酸140位に対応するアミノ酸の位置にフェニルアラニンのうちのいずれも含まない、実施形態H145に記載の方法。
Embodiment H146. A soluble human tissue factor domain is
a lysine at the amino acid position corresponding to
an isoleucine at the amino acid position corresponding to
tryptophan at the amino acid position corresponding to
an aspartic acid at the amino acid position corresponding to amino acid position 58 of the mature wild-type human tissue factor protein;
a tyrosine at the amino acid position corresponding to amino acid position 94 of the mature wild-type human tissue factor protein;
An embodiment that does not include either arginine at the amino acid position corresponding to amino acid position 135 of the mature wild-type human tissue factor protein and phenylalanine at the amino acid position corresponding to
実施形態H147.可溶性組織因子ドメインが、第VIIa因子に結合することができない、実施形態H120~H146のいずれか1つに記載の方法。 Embodiment H147. The method of any one of embodiments H120-H146, wherein the soluble tissue factor domain is incapable of binding Factor VIIa.
実施形態H148.可溶性組織因子ドメインが、不活性第X因子を第Xa因子に変換しない、実施形態H120~H147のいずれか1つに記載の方法。 Embodiment H148. The method of any one of embodiments H120-H147, wherein the soluble tissue factor domain does not convert inactive factor X to factor Xa.
実施形態H149.一本鎖キメラポリペプチドが、哺乳動物における血液凝固を刺激しない、実施形態H120~H148のいずれか1つに記載の方法。 Embodiment H149. The method of any one of embodiments H120-H148, wherein the single-chain chimeric polypeptide does not stimulate blood clotting in a mammal.
実施形態H150.一本鎖キメラポリペプチドが、そのN末端及び/又はC末端に1つ以上の追加の標的結合ドメインを更に含む、実施形態H120~H149のいずれか1つに記載の方法。 Embodiment H150. The method of any one of embodiments H120-H149, wherein the single chain chimeric polypeptide further comprises one or more additional target binding domains at its N-terminus and/or C-terminus.
実施形態H151.一本鎖キメラポリペプチドが、そのN末端に1つ以上の追加の標的結合ドメインを含む、実施形態H150に記載の方法。 Embodiment H151. The method of embodiment H150, wherein the single-chain chimeric polypeptide comprises one or more additional target binding domains at its N-terminus.
実施形態H152.1つ以上の追加の標的結合ドメインが、第1の標的結合ドメイン、第2の標的結合ドメイン、又は可溶性組織因子ドメインに直接隣接している、実施形態H151に記載の方法。 Embodiment H152. The method of embodiment H151, wherein the one or more additional target binding domains are directly adjacent to the first target binding domain, the second target binding domain, or the soluble tissue factor domain.
実施形態H153.一本鎖キメラポリペプチドが、少なくとも1つの追加の標的結合ドメインのうちの1つと第1の標的結合ドメイン、第2の標的結合ドメイン、又は可溶性組織因子ドメインとの間にリンカー配列を更に含む、実施形態H152に記載の方法。 Embodiment H153. the single-chain chimeric polypeptide further comprises a linker sequence between one of the at least one additional target binding domain and the first target binding domain, the second target binding domain, or the soluble tissue factor domain; The method of embodiment H152.
実施形態H154.一本鎖キメラポリペプチドが、そのC末端に1つ以上の追加の標的結合ドメインを含む、実施形態H150に記載の方法。 Embodiment H154. The method of embodiment H150, wherein the single-chain chimeric polypeptide comprises one or more additional target binding domains at its C-terminus.
実施形態H155.1つ以上の追加の標的結合ドメインのうちの1つが、第1の標的結合ドメイン、第2の標的結合ドメイン、又は可溶性組織因子ドメインに直接隣接している、実施形態H154に記載の方法。 Embodiment H155. Described in Embodiment H154, wherein one of the one or more additional target binding domains is directly adjacent to the first target binding domain, the second target binding domain, or the soluble tissue factor domain. the method of.
実施形態H156.一本鎖キメラポリペプチドが、少なくとも1つの追加の標的結合ドメインのうちの1つと第1の標的結合ドメイン、第2の標的結合ドメイン、又は可溶性組織因子ドメインとの間にリンカー配列を更に含む、実施形態H154に記載の方法。 Embodiment H156. the single-chain chimeric polypeptide further comprises a linker sequence between one of the at least one additional target binding domain and the first target binding domain, the second target binding domain, or the soluble tissue factor domain; The method of embodiment H154.
実施形態H157.一本鎖キメラポリペプチドが、そのN末端及びC末端に1つ以上の追加の標的結合ドメインを含む、実施形態H150に記載の方法。 Embodiment H157. The method of embodiment H150, wherein the single-chain chimeric polypeptide comprises one or more additional target binding domains at its N-terminus and C-terminus.
実施形態H158.N末端における1つ以上の追加の抗原結合ドメインのうちの1つが、第1の標的結合ドメイン、第2の標的結合ドメイン、又は可溶性組織因子ドメインに直接隣接している、実施形態H157に記載の方法。 Embodiment H158. According to embodiment H157, wherein one of the one or more additional antigen binding domains at the N-terminus is directly adjacent to the first target binding domain, the second target binding domain, or the soluble tissue factor domain. Method.
実施形態H159.一本鎖キメラポリペプチドが、N末端における1つ以上の追加の抗原結合ドメインのうちの1つと第1の標的結合ドメイン、第2の標的結合ドメイン、又は可溶性組織因子ドメインとの間にリンカー配列を更に含む、実施形態H157に記載の方法。 Embodiment H159. the single-chain chimeric polypeptide has a linker sequence between one of the one or more additional antigen binding domains at the N-terminus and the first target binding domain, the second target binding domain, or the soluble tissue factor domain; The method of embodiment H157, further comprising
実施形態H160.C末端における1つ以上の追加の抗原結合ドメインのうちの1つが、第1の標的結合ドメイン、第2の標的結合ドメイン、又は可溶性組織因子ドメインに直接隣接している、実施形態H157に記載の方法。 Embodiment H160. According to embodiment H157, wherein one of the one or more additional antigen binding domains at the C-terminus is directly adjacent to the first target binding domain, the second target binding domain, or the soluble tissue factor domain. Method.
実施形態H161.一本鎖キメラポリペプチドが、C末端における1つ以上の追加の抗原結合ドメインのうちの1つと第1の標的結合ドメイン、第2の標的結合ドメイン、又は可溶性組織因子ドメインとの間にリンカー配列を更に含む、実施形態H157に記載の方法。 Embodiment H161. the single-chain chimeric polypeptide has a linker sequence between one of the one or more additional antigen binding domains at the C-terminus and the first target binding domain, the second target binding domain, or the soluble tissue factor domain; The method of embodiment H157, further comprising
実施形態H162.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの2つ以上が、同じ抗原に特異的に結合する、実施形態H150~H161のいずれか1つに記載の方法。
Embodiment H162. any one of embodiments H150-H161, wherein two or more of the first target binding domain, the second target binding domain, and the one or more additional target binding domains specifically bind to the same antigen the method described in
実施形態H163.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの2つ以上が、同じエピトープに特異的に結合する、実施形態H162に記載の方法。 Embodiment H163. The method of embodiment H162, wherein two or more of the first target binding domain, the second target binding domain, and the one or more additional target binding domains specifically bind to the same epitope.
実施形態H164.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの2つ以上が、同じアミノ酸配列を含む、実施形態H163に記載の方法。 Embodiment H164. The method of embodiment H163, wherein two or more of the first target binding domain, the second target binding domain, and the one or more additional target binding domains comprise the same amino acid sequence.
実施形態H165.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインが各々、同じ抗原に特異的に結合する、実施形態H162に記載の方法。 Embodiment H165. The method of embodiment H162, wherein the first target binding domain, the second target binding domain, and the one or more additional target binding domains each specifically bind the same antigen.
実施形態H166.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインが各々、同じエピトープに特異的に結合する、実施形態H165に記載の方法。 Embodiment H166. The method of embodiment H165, wherein the first target binding domain, the second target binding domain, and the one or more additional target binding domains each specifically bind the same epitope.
実施形態H167.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインが各々、同じアミノ酸配列を含む、実施形態H166に記載の方法。 Embodiment H167. The method of embodiment H166, wherein the first target binding domain, the second target binding domain, and the one or more additional target binding domains each comprise the same amino acid sequence.
実施形態H168.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインが、異なる抗原に特異的に結合する、実施形態H150~H161のいずれか1つに記載の方法。 Embodiment H168. The method of any one of embodiments H150-H161, wherein the first target binding domain, the second target binding domain, and the one or more additional target binding domains specifically bind different antigens.
実施形態H169.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の標的結合ドメインのうちの1つ以上が、抗原結合ドメインである、実施形態H150~H168のいずれか1つに記載の方法。 Embodiment H169. The method of any one of embodiments H150-H168, wherein one or more of the first target binding domain, the second target binding domain, and the one or more target binding domains are antigen binding domains. .
実施形態H170.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインが各々、抗原結合ドメインである、実施形態H169に記載の方法。 Embodiment H170. The method of embodiment H169, wherein the first target binding domain, the second target binding domain, and the one or more additional target binding domains are each antigen binding domains.
実施形態H171.抗原結合ドメインが、scFv又は単一ドメイン抗体を含む、実施形態H170に記載の方法。 Embodiment H171. The method of embodiment H170, wherein the antigen binding domain comprises a scFv or single domain antibody.
実施形態H172.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の標的結合ドメインのうちの1つ以上が、CD16a、CD33、CD20、CD19、CD22、CD123、PDL-1、TIGIT、PD-1、TIM3、CTLA4、MICA、MICB、IL-6、IL-8、TNFα、CD26、CD36、ULBP2、CD30、CD200、IGF-1R、MUC4AC、MUC5AC、Trop-2、CMET、EGFR、HER1、HER2、HER3、PSMA、CEA、B7H3、EPCAM、BCMA、P-カドヘリン、CEACAM5、UL16結合タンパク質、HLA-DR、DLL4、TYRO3、AXL、MER、CD122、CD155、PDGF-DD、TGF-β受容体II(TGF-βRII)リガンド、TGF-βRIIIリガンド、DNAM-1リガンド、NKp46リガンド、NKp44リガンド、NKG2Dリガンド、NKP30リガンド、scMHCIリガンド、scMHCIIリガンド、scTCRリガンド、PDGF-DD受容体、幹細胞因子(SCF)受容体、幹細胞様チロシンキナーゼ3リガンド(FLT3L)受容体、MICA受容体、MICB受容体、ULP16結合タンパク質受容体、CD155受容体、及びCD122受容体からなる群から選択される標的に特異的に結合する、実施形態H150~H171のいずれか1つに記載の方法。
Embodiment H172. one or more of the first target binding domain, the second target binding domain, and the one or more target binding domains are CD16a, CD33, CD20, CD19, CD22, CD123, PDL-1, TIGIT, PD- 1, TIM3, CTLA4, MICA, MICB, IL-6, IL-8, TNFα, CD26, CD36, ULBP2, CD30, CD200, IGF-1R, MUC4AC, MUC5AC, Trop-2, CMET, EGFR, HER1, HER2, HER3, PSMA, CEA, B7H3, EPCAM, BCMA, P-cadherin, CEACAM5, UL16 binding protein, HLA-DR, DLL4, TYRO3, AXL, MER, CD122, CD155, PDGF-DD, TGF-beta receptor II (TGF -βRII) ligand, TGF-βRIII ligand, DNAM-1 ligand, NKp46 ligand, NKp44 ligand, NKG2D ligand, NKP30 ligand, scMHCI ligand, scMHCII ligand, scTCR ligand, PDGF-DD receptor, stem cell factor (SCF) receptor, specifically binds to a target selected from the group consisting of stem cell-
実施形態H173.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの1つ以上が、可溶性インターロイキン又はサイトカインタンパク質である、実施形態H150~H161のいずれか1つに記載の方法。
Embodiment H173. any one of embodiments H150-H161, wherein one or more of the first target binding domain, the second target binding domain, and the one or more additional target binding domains is a soluble interleukin or cytokine protein the method described in
実施形態H174.可溶性インターロイキン又はサイトカインタンパク質が、IL-1、IL-2、IL-3、IL-7、IL-8、IL-10、IL-12、IL-15、IL-17、IL-18、IL-21、PDGF-DD、及びSCFからなる群から選択される、実施形態H173に記載の方法。 Embodiment H174. Soluble interleukin or cytokine proteins are IL-1, IL-2, IL-3, IL-7, IL-8, IL-10, IL-12, IL-15, IL-17, IL-18, IL- 21, PDGF-DD, and SCF.
実施形態H175.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの1つ以上が、可溶性インターロイキン又はサイトカイン受容体である、実施形態H150~H161のいずれか1つに記載の方法。 Embodiment H175. Any of embodiments H150-H161 wherein one or more of the first target binding domain, the second target binding domain, and the one or more additional target binding domains is a soluble interleukin or cytokine receptor The method described in 1.
実施形態H176.可溶性受容体が、可溶性TGF-β受容体II(TGF-βRII)、可溶性TGF-βRIII、可溶性TNFα受容体、可溶性IL-4受容体、又は可溶性IL-10受容体である、実施形態H175に記載の方法。 Embodiment H176. Described in embodiment H175, wherein the soluble receptor is soluble TGF-beta receptor II (TGF-βRII), soluble TGF-βRIII, soluble TNFα receptor, soluble IL-4 receptor, or soluble IL-10 receptor the method of.
実施形態H177.1つ以上のNK細胞活性化物質のうちの少なくとも1つが多鎖キメラポリペプチドを含み、多鎖キメラポリペプチドが、
(c)第1のキメラポリペプチドであって、
(i)第1の標的結合ドメイン、
(ii)可溶性組織因子ドメイン、及び
(iii)一対の親和性ドメインの第1のドメイン
を含む、第1のキメラポリペプチド、
(d)第2のキメラポリペプチドであって、
(i)一対の親和性ドメインの第2のドメイン、及び
(ii)第2の標的結合ドメイン
を含む、第2のキメラポリペプチド
を含み、
第1のキメラポリペプチドと第2のキメラポリペプチドが、一対の親和性ドメインの第1のドメインと第2のドメインとの結合を介して会合する、
実施形態H1~H19、H35~H42、H44-H62、及びH64-H77のいずれか1つに記載の方法。
Embodiment H177. At least one of the one or more NK cell activators comprises a multi-chain chimeric polypeptide, wherein the multi-chain chimeric polypeptide comprises
(c) a first chimeric polypeptide,
(i) a first target binding domain;
(ii) a soluble tissue factor domain, and (iii) a first domain of a pair of affinity domains,
(d) a second chimeric polypeptide,
a second chimeric polypeptide comprising (i) a second of the pair of affinity domains, and (ii) a second target binding domain;
the first chimeric polypeptide and the second chimeric polypeptide associate via binding of the first and second domains of a pair of affinity domains;
The method of any one of embodiments H1-H19, H35-H42, H44-H62, and H64-H77.
実施形態H178.第1の標的結合ドメインと可溶性組織因子ドメインが、第1のキメラポリペプチド内で互いに直接隣接している、実施形態H177に記載の方法。 Embodiment H178. The method of embodiment H177, wherein the first target binding domain and the soluble tissue factor domain are directly adjacent to each other within the first chimeric polypeptide.
実施形態H179.第1のキメラポリペプチドが、第1のキメラポリペプチド内の第1の標的結合ドメインと可溶性組織因子ドメインとの間にリンカー配列を更に含む、実施形態H177に記載の方法。 Embodiment H179. The method of embodiment H177, wherein the first chimeric polypeptide further comprises a linker sequence between the first target binding domain and the soluble tissue factor domain within the first chimeric polypeptide.
実施形態H180.可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインが、第1のキメラポリペプチド内で互いに直接隣接している、実施形態H177~H179のいずれか1つに記載の方法。 Embodiment H180. The method of any one of embodiments H177-H179, wherein the soluble tissue factor domain and the first of the paired affinity domains are directly adjacent to each other within the first chimeric polypeptide.
実施形態H181.第1のキメラポリペプチドが、第1のキメラポリペプチド内の可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間にリンカー配列を更に含む、実施形態H177~H179のいずれか1つに記載の方法。
Embodiment H181. Any one of embodiments H177-H179, wherein the first chimeric polypeptide further comprises a linker sequence between the soluble tissue factor domain and the first of the pair of affinity domains within the first chimeric polypeptide. the method described in
実施形態H182.一対の親和性ドメインの第2のドメインと第2の標的結合ドメインが、第2のキメラポリペプチド内で互いに直接隣接している、実施形態H177~H181のいずれか1つに記載の方法。 Embodiment H182. The method of any one of embodiments H177-H181, wherein the second domain and the second target binding domain of the pair of affinity domains are directly adjacent to each other within the second chimeric polypeptide.
実施形態H183.第2のキメラポリペプチドが、第2のキメラポリペプチド内の一対の親和性ドメインの第2のドメインと第2の標的結合ドメインとの間にリンカー配列を更に含む、実施形態H177~H181のいずれか1つに記載の方法。
Embodiment H183. Any of embodiments H177-H181, wherein the second chimeric polypeptide further comprises a linker sequence between the second of the pair of affinity domains and the second target binding domain within the second chimeric polypeptide or the method of
実施形態H184.第1の標的結合ドメイン及び第2の標的結合ドメインが、同じ抗原に特異的に結合する、実施形態H177~H183のいずれか1つに記載の方法。 Embodiment H184. The method of any one of embodiments H177-H183, wherein the first target binding domain and the second target binding domain specifically bind the same antigen.
実施形態H185.第1の標的結合ドメイン及び第2の標的結合ドメインが、同じエピトープに特異的に結合する、実施形態H184に記載の方法。 Embodiment H185. The method of embodiment H184, wherein the first target binding domain and the second target binding domain specifically bind to the same epitope.
実施形態H186.第1の標的結合ドメイン及び第2の標的結合ドメインが、同じアミノ酸配列を含む、実施形態H185に記載の方法。 Embodiment H186. The method of embodiment H185, wherein the first target binding domain and the second target binding domain comprise the same amino acid sequence.
実施形態H187.第1の標的結合ドメイン及び第2の標的結合ドメインが、異なる抗原に特異的に結合する、実施形態H177~H183のいずれか1つに記載の方法。 Embodiment H187. The method of any one of embodiments H177-H183, wherein the first target binding domain and the second target binding domain specifically bind different antigens.
実施形態H188.第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方が、抗原結合ドメインである、実施形態H177~H187のいずれか1つに記載の方法。 Embodiment H188. The method of any one of embodiments H177-H187, wherein one or both of the first target binding domain and the second target binding domain are antigen binding domains.
実施形態H189.第1の標的結合ドメイン及び第2の標的結合ドメインが各々、抗原結合ドメインである、実施形態H188に記載の方法。 Embodiment H189. The method of embodiment H188, wherein the first target binding domain and the second target binding domain are each antigen binding domains.
実施形態H190.抗原結合ドメインが、scFv又は単一ドメイン抗体を含む、実施形態H188又はH189に記載の方法。 Embodiment H190. The method of embodiment H188 or H189, wherein the antigen binding domain comprises a scFv or single domain antibody.
実施形態H191.第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方が、CD16a、CD33、CD20、CD19、CD22、CD123、PDL-1、TIGIT、PD-1、TIM3、CTLA4、MICA、MICB、IL-6、IL-8、TNFα、CD26、CD36、ULBP2、CD30、CD200、IGF-1R、MUC4AC、MUC5AC、Trop-2、CMET、EGFR、HER1、HER2、HER3、PSMA、CEA、B7H3、EPCAM、BCMA、P-カドヘリン、CEACAM5、UL16結合タンパク質、HLA-DR、DLL4、TYRO3、AXL、MER、CD122、CD155、PDGF-DD、TGF-β受容体II(TGF-βRII)リガンド、TGF-βRIIIリガンド、DNAM1リガンド、NKp46リガンド、NKp44リガンド、NKG2Dリガンド、NKP30リガンド、scMHCIリガンド、scMHCIIリガンド、scTCRリガンド、PDGF-DD受容体、幹細胞因子(SCF)受容体、幹細胞様チロシンキナーゼ3リガンド(FLT3L)受容体、MICA受容体、MICB受容体、ULP16結合タンパク質受容体、CD155受容体、及びCD122受容体からなる群から選択される標的に特異的に結合する、実施形態H177~H190のいずれか1つに記載の方法。
Embodiment H191. one or both of the first target binding domain and the second target binding domain are CD16a, CD33, CD20, CD19, CD22, CD123, PDL-1, TIGIT, PD-1, TIM3, CTLA4, MICA, MICB, IL -6, IL-8, TNFα, CD26, CD36, ULBP2, CD30, CD200, IGF-1R, MUC4AC, MUC5AC, Trop-2, CMET, EGFR, HER1, HER2, HER3, PSMA, CEA, B7H3, EPCAM, BCMA , P-cadherin, CEACAM5, UL16 binding protein, HLA-DR, DLL4, TYRO3, AXL, MER, CD122, CD155, PDGF-DD, TGF-β receptor II (TGF-βRII) ligand, TGF-βRIII ligand, DNAM1 ligand, NKp46 ligand, NKp44 ligand, NKG2D ligand, NKP30 ligand, scMHCI ligand, scMHCII ligand, scTCR ligand, PDGF-DD receptor, stem cell factor (SCF) receptor, stem cell-
実施形態H192.第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方が、可溶性インターロイキン又はサイトカインタンパク質である、実施形態H177~H183のいずれか1つに記載の方法。 Embodiment H192. The method of any one of embodiments H177-H183, wherein one or both of the first target binding domain and the second target binding domain is a soluble interleukin or cytokine protein.
実施形態H193.可溶性インターロイキン又はサイトカインタンパク質が、IL-1、IL-2、IL-3、IL-7、IL-8、IL-10、IL-12、IL-15、IL-17、IL-18、IL-21、PDGF-DD、及びSCFからなる群から選択される、実施形態H192に記載の方法。 Embodiment H193. Soluble interleukin or cytokine proteins are IL-1, IL-2, IL-3, IL-7, IL-8, IL-10, IL-12, IL-15, IL-17, IL-18, IL- 21, PDGF-DD, and SCF.
実施形態H194.第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方が、可溶性インターロイキン又はサイトカイン受容体である、実施形態H177~H183のいずれか1つに記載の方法。 Embodiment H194. The method of any one of embodiments H177-H183, wherein one or both of the first target binding domain and the second target binding domain is a soluble interleukin or cytokine receptor.
実施形態H195.可溶性受容体が、可溶性TGF-β受容体II(TGF-βRII)、可溶性TGF-βRIII、可溶性TNFα受容体、可溶性IL-4受容体、又は可溶性IL-10受容体である、実施形態H194に記載の方法。 Embodiment H195. Described in embodiment H194, wherein the soluble receptor is soluble TGF-beta receptor II (TGF-βRII), soluble TGF-βRIII, soluble TNFα receptor, soluble IL-4 receptor, or soluble IL-10 receptor the method of.
実施形態H196.第1のキメラポリペプチドが、1つ以上の追加の標的結合ドメインを更に含み、1つ以上の追加の抗原結合ドメインのうちの少なくとも1つが、可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間に位置付けられている、実施形態H177~H195のいずれか1つに記載の方法。 Embodiment H196. The first chimeric polypeptide further comprises one or more additional target binding domains, wherein at least one of the one or more additional antigen binding domains comprises the soluble tissue factor domain and the first of the paired affinity domains. The method of any one of embodiments H177-H195, wherein the method is positioned between a domain of
実施形態H197.第1のキメラポリペプチドが、可溶性組織因子ドメインと1つ以上の追加の抗原結合ドメインのうちの少なくとも1つとの間にリンカー配列、及び/又は1つ以上の追加の抗原結合ドメインのうちの少なくとも1つと一対の親和性ドメインの第1のドメインとの間にリンカー配列を更に含む、実施形態H196に記載の方法。 Embodiment H197. The first chimeric polypeptide comprises a linker sequence between the soluble tissue factor domain and at least one of the one or more additional antigen binding domains, and/or at least one of the one or more additional antigen binding domains. The method of embodiment H196, further comprising a linker sequence between one and the first of the pair of affinity domains.
実施形態H198.第1のキメラポリペプチドが、第1のキメラポリペプチドのN末端及び/又はC末端に1つ以上の追加の標的結合ドメインを更に含む、実施形態H177~H195のいずれか1つに記載の方法。 Embodiment H198. The method of any one of embodiments H177-H195, wherein the first chimeric polypeptide further comprises one or more additional target binding domains at the N-terminus and/or C-terminus of the first chimeric polypeptide .
実施形態H199.1つ以上の追加の標的結合ドメインのうちの少なくとも1つが、第1のキメラポリペプチド内の一対の親和性ドメインの第1のドメインに直接隣接している、実施形態H198に記載の方法。 Embodiment H199. According to embodiment H198, wherein at least one of the one or more additional target binding domains is directly adjacent to the first of the pair of affinity domains in the first chimeric polypeptide the method of.
実施形態H200.第1のキメラポリペプチドが、1つ以上の追加の標的結合ドメインのうちの少なくとも1つと一対の親和性ドメインの第1のドメインとの間にリンカー配列を更に含む、実施形態H198に記載の方法。 Embodiment H200. The method of embodiment H198, wherein the first chimeric polypeptide further comprises a linker sequence between at least one of the one or more additional target binding domains and the first of the pair of affinity domains. .
実施形態H201.1つ以上の追加の標的結合ドメインのうちの少なくとも1つが、第1のキメラポリペプチド内の第1の標的結合ドメインに直接隣接している、実施形態H198に記載の方法。 Embodiment H201. The method of embodiment H198, wherein at least one of the one or more additional target binding domains is directly adjacent to the first target binding domain within the first chimeric polypeptide.
実施形態H202.第1のキメラポリペプチドが、1つ以上の追加の標的結合ドメインのうちの少なくとも1つと第1の標的結合ドメインとの間にリンカー配列を更に含む、実施形態H198に記載の方法。 Embodiment H202. The method of embodiment H198, wherein the first chimeric polypeptide further comprises a linker sequence between at least one of the one or more additional target binding domains and the first target binding domain.
実施形態H203.1つ以上の追加の標的結合ドメインのうちの少なくとも1つが、第1のキメラポリペプチドのN末端及び/又はC末端に配置されており、1つ以上の追加の標的結合ドメインのうちの少なくとも1つが、第1のキメラポリペプチド内の可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間に位置付けられている、実施形態H198に記載の方法。 Embodiment H203. At least one of the one or more additional target binding domains is positioned at the N-terminus and/or C-terminus of the first chimeric polypeptide, wherein the one or more additional target binding domains are The method of embodiment H198, wherein at least one of is positioned between the soluble tissue factor domain and the first of the pair of affinity domains in the first chimeric polypeptide.
実施形態H204.N末端に配置された1つ以上の追加の標的結合ドメインのうちの少なくとも1つの追加の標的結合ドメインが、第1のキメラポリペプチド内の第1の標的結合ドメイン又は一対の親和性ドメインの第1のドメインに直接隣接している、実施形態H203に記載の方法。 Embodiment H204. At least one additional target binding domain of the one or more additional target binding domains located at the N-terminus is the first target binding domain in the first chimeric polypeptide or the first of the pair of affinity domains The method of embodiment H203, which is directly adjacent to one domain.
実施形態H205.第1のキメラポリペプチドが、第1のキメラポリペプチド内の少なくとも1つの追加の標的結合ドメインと第1の標的結合ドメイン又は一対の親和性ドメインの第1のドメインとの間に配置されたリンカー配列を更に含む、実施形態H203に記載の方法。 Embodiment H205. a linker wherein the first chimeric polypeptide is positioned between at least one additional target binding domain within the first chimeric polypeptide and the first target binding domain or the first domain of the pair of affinity domains The method of embodiment H203, further comprising a sequence.
実施形態H206.C末端に配置された1つ以上の追加の標的結合ドメインのうちの少なくとも1つの追加の標的結合ドメインが、第1のキメラポリペプチド内の第1の標的結合ドメイン又は一対の親和性ドメインの第1のドメインに直接隣接している、実施形態H203に記載の方法。 Embodiment H206. At least one additional target binding domain of the one or more additional target binding domains located at the C-terminus is the first target binding domain in the first chimeric polypeptide or the first of the pair of affinity domains The method of embodiment H203, which is directly adjacent to one domain.
実施形態H207.第1のキメラポリペプチドが、第1のキメラポリペプチド内の少なくとも1つの追加の標的結合ドメインと第1の標的結合ドメイン又は一対の親和性ドメインの第1のドメインとの間に配置されたリンカー配列を更に含む、実施形態H203に記載の方法。 Embodiment H207. a linker wherein the first chimeric polypeptide is positioned between at least one additional target binding domain within the first chimeric polypeptide and the first target binding domain or the first domain of the pair of affinity domains The method of embodiment H203, further comprising a sequence.
実施形態H208.可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間に位置付けられた1つ以上の追加の標的結合ドメインのうちの少なくとも1つが、可溶性組織因子ドメイン、及び/又は一対の親和性ドメインの第1のドメインに直接隣接している、実施形態H203に記載の方法。 Embodiment H208. at least one of the one or more additional target binding domains positioned between the soluble tissue factor domain and the first domain of the pair of affinity domains is the soluble tissue factor domain and/or the affinity pair The method of embodiment H203, wherein the domain is directly adjacent to the first domain.
実施形態H209.第1のキメラポリペプチドが、(i)可溶性組織因子ドメインと、可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間に位置付けられた1つ以上の追加の標的結合ドメインのうちの少なくとも1つとの間、及び/又は(ii)一対の親和性ドメインの第1のドメインと、可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間に位置付けられた1つ以上の追加の標的結合ドメインのうちの少なくとも1つとの間に配置されたリンカー配列を更に含む、実施形態H203に記載の方法。 Embodiment H209. the first chimeric polypeptide comprises: (i) the soluble tissue factor domain and one or more additional target binding domains positioned between the soluble tissue factor domain and the first of the pair of affinity domains; and/or (ii) between the first domain of the pair of affinity domains and the soluble tissue factor domain and the first domain of the pair of affinity domains The method of embodiment H203, further comprising a linker sequence interposed between and at least one of the additional target binding domains of.
実施形態H210.第2のキメラポリペプチドが、第2のキメラポリペプチドのN末端又はC末端に1つ以上の追加の標的結合ドメインを更に含む、実施形態H177~H209のいずれか1つに記載の方法。 Embodiment H210. The method of any one of embodiments H177-H209, wherein the second chimeric polypeptide further comprises one or more additional target binding domains at the N-terminus or C-terminus of the second chimeric polypeptide.
実施形態H211.1つ以上の追加の標的結合ドメインのうちの少なくとも1つが、第2のキメラポリペプチド内の一対の親和性ドメインの第2のドメインに直接隣接している、実施形態H210に記載の方法。 Embodiment H211. Described in embodiment H210, wherein at least one of the one or more additional target binding domains is directly adjacent to a second domain of the pair of affinity domains within the second chimeric polypeptide the method of.
実施形態H212.第2のキメラポリペプチドが、第2のキメラポリペプチド内の1つ以上の追加の標的結合ドメインのうちの少なくとも1つと一対の親和性ドメインの第2のドメインとの間にリンカー配列を更に含む、実施形態H210に記載の方法。 Embodiment H212. The second chimeric polypeptide further comprises a linker sequence between at least one of the one or more additional target binding domains in the second chimeric polypeptide and the second of the pair of affinity domains , embodiment H210.
実施形態H213.1つ以上の追加の標的結合ドメインのうちの少なくとも1つが、第2のキメラポリペプチド内の第2の標的結合ドメインに直接隣接している、実施形態H210に記載の方法。 Embodiment H213. The method of embodiment H210, wherein at least one of the one or more additional target binding domains is directly adjacent to the second target binding domain within the second chimeric polypeptide.
実施形態H214.第2のキメラポリペプチドが、第2のキメラポリペプチド内の1つ以上の追加の標的結合ドメインのうちの少なくとも1つと第2の標的結合ドメインとの間にリンカー配列を更に含む、実施形態H210に記載の方法。 Embodiment H214. Embodiment H210, wherein the second chimeric polypeptide further comprises a linker sequence between at least one of the one or more additional target binding domains within the second chimeric polypeptide and the second target binding domain. The method described in .
実施形態H215.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの2つ以上が、同じ抗原に特異的に結合する、実施形態H196~H214のいずれか1つに記載の方法。
Embodiment H215. any one of embodiments H196-H214, wherein two or more of the first target binding domain, the second target binding domain, and the one or more additional target binding domains specifically bind to the same antigen the method described in
実施形態H216.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの2つ以上が、同じエピトープに特異的に結合する、実施形態H215に記載の方法。 Embodiment H216. The method of embodiment H215, wherein two or more of the first target binding domain, the second target binding domain, and the one or more additional target binding domains specifically bind to the same epitope.
実施形態H217.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの2つ以上が、同じアミノ酸配列を含む、実施形態H216に記載の方法。 Embodiment H217. The method of embodiment H216, wherein two or more of the first target binding domain, the second target binding domain, and the one or more additional target binding domains comprise the same amino acid sequence.
実施形態H218.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインが各々、同じ抗原に特異的に結合する、実施形態H215に記載の方法。 Embodiment H218. The method of embodiment H215, wherein the first target binding domain, the second target binding domain, and the one or more additional target binding domains each specifically bind the same antigen.
実施形態H219.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインが各々、同じエピトープに特異的に結合する、実施形態H218に記載の方法。 Embodiment H219. The method of embodiment H218, wherein the first target binding domain, the second target binding domain, and the one or more additional target binding domains each specifically bind the same epitope.
実施形態H220.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインが各々、同じアミノ酸配列を含む、実施形態H219に記載の方法。 Embodiment H220. The method of embodiment H219, wherein the first target binding domain, the second target binding domain, and the one or more additional target binding domains each comprise the same amino acid sequence.
実施形態H221.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインが、異なる抗原に特異的に結合する、実施形態H196~H214のいずれか1つに記載の方法。 Embodiment H221. The method of any one of embodiments H196-H214, wherein the first target binding domain, the second target binding domain, and the one or more additional target binding domains specifically bind different antigens.
実施形態H222.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の標的結合ドメインのうちの1つ以上が、抗原結合ドメインである、実施形態H196~H221のいずれか1つに記載の方法。 Embodiment H222. The method of any one of embodiments H196-H221, wherein one or more of the first target binding domain, the second target binding domain, and the one or more target binding domains are antigen binding domains. .
実施形態H223.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインが各々、抗原結合ドメインである、実施形態H222に記載の方法。 Embodiment H223. The method of embodiment H222, wherein the first target binding domain, the second target binding domain, and the one or more additional target binding domains are each an antigen binding domain.
実施形態H224.抗原結合ドメインが、scFvを含む、実施形態H223に記載の方法。 Embodiment H224. The method of embodiment H223, wherein the antigen binding domain comprises an scFv.
実施形態H225.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の標的結合ドメインのうちの1つ以上が、CD16a、CD33、CD20、CD19、CD22、CD123、PDL-1、TIGIT、PD-1、TIM3、CTLA4、MICA、MICB、IL-6、IL-8、TNFα、CD26、CD36、ULBP2、CD30、CD200、IGF-1R、MUC4AC、MUC5AC、Trop-2、CMET、EGFR、HER1、HER2、HER3、PSMA、CEA、B7H3、EPCAM、BCMA、P-カドヘリン、CEACAM5、UL16結合タンパク質、HLA-DR、DLL4、TYRO3、AXL、MER、CD122、CD155、PDGF-DD、TGF-β受容体II(TGF-βRII)リガンド、TGF-βRIIIリガンド、DNAM1リガンド、NKp46リガンド、NKp44リガンド、NKG2Dリガンド、NKp30リガンド、scMHCIリガンド、scMHCIIリガンド、scTCRリガンド、PDGF-DD受容体、幹細胞因子(SCF)受容体、幹細胞様チロシンキナーゼ3リガンド(FLT3L)受容体、MICA受容体、MICB受容体、ULP16結合タンパク質受容体、CD155受容体、及びCD122受容体からなる群から選択される標的に特異的に結合する、実施形態H196~H224のいずれか1つに記載の方法。
Embodiment H225. one or more of the first target binding domain, the second target binding domain, and the one or more target binding domains are CD16a, CD33, CD20, CD19, CD22, CD123, PDL-1, TIGIT, PD- 1, TIM3, CTLA4, MICA, MICB, IL-6, IL-8, TNFα, CD26, CD36, ULBP2, CD30, CD200, IGF-1R, MUC4AC, MUC5AC, Trop-2, CMET, EGFR, HER1, HER2, HER3, PSMA, CEA, B7H3, EPCAM, BCMA, P-cadherin, CEACAM5, UL16 binding protein, HLA-DR, DLL4, TYRO3, AXL, MER, CD122, CD155, PDGF-DD, TGF-beta receptor II (TGF -βRII) ligand, TGF-βRIII ligand, DNAM1 ligand, NKp46 ligand, NKp44 ligand, NKG2D ligand, NKp30 ligand, scMHCI ligand, scMHCII ligand, scTCR ligand, PDGF-DD receptor, stem cell factor (SCF) receptor, stem cell-like Embodiment H196 specifically binds to a target selected from the group consisting of the
実施形態H226.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの1つ以上が、可溶性インターロイキン又はサイトカインタンパク質である、実施形態H196~H214のいずれか1つに記載の方法。
Embodiment H226. any one of embodiments H196-H214, wherein one or more of the first target binding domain, the second target binding domain, and the one or more additional target binding domains is a soluble interleukin or cytokine protein the method described in
実施形態H227.可溶性インターロイキン又はサイトカインタンパク質が、IL-1、IL-2、IL-3、IL-7、IL-8、IL-10、IL-12、IL-15、IL-17、IL-18、IL-21、PDGF-DD、及びSCFからなる群から選択される、実施形態H226に記載の方法。 Embodiment H227. Soluble interleukin or cytokine proteins are IL-1, IL-2, IL-3, IL-7, IL-8, IL-10, IL-12, IL-15, IL-17, IL-18, IL- 21, PDGF-DD, and SCF.
実施形態H228.第1の標的結合ドメイン、第2の標的結合ドメイン、及び1つ以上の追加の標的結合ドメインのうちの1つ以上が、可溶性インターロイキン又はサイトカイン受容体である、実施形態H196~H214のいずれか1つに記載の方法。 Embodiment H228. Any of embodiments H196-H214 wherein one or more of the first target binding domain, the second target binding domain, and the one or more additional target binding domains is a soluble interleukin or cytokine receptor The method described in 1.
実施形態H229.可溶性受容体が、可溶性TGF-β受容体II(TGF-βRII)、可溶性TGF-βRIII、可溶性TNFα受容体、可溶性IL-4受容体、又は可溶性IL-10受容体である、実施形態H228に記載の方法。 Embodiment H229. Described in embodiment H228, wherein the soluble receptor is soluble TGF-beta receptor II (TGF-βRII), soluble TGF-βRIII, soluble TNFα receptor, soluble IL-4 receptor, or soluble IL-10 receptor the method of.
実施形態H230.可溶性組織因子ドメインが、可溶性ヒト組織因子ドメインである、実施形態H196~H229のいずれか1つに記載の方法。 Embodiment H230. The method of any one of embodiments H196-H229, wherein the soluble tissue factor domain is a soluble human tissue factor domain.
実施形態H231.可溶性ヒト組織因子ドメインが、配列番号93と少なくとも80%同一である配列を含む、実施形態H230に記載の方法。 Embodiment H231. The method of embodiment H230, wherein the soluble human tissue factor domain comprises a sequence that is at least 80% identical to SEQ ID NO:93.
実施形態H232.可溶性ヒト組織因子ドメインが、配列番号93と少なくとも90%同一である配列を含む、実施形態H231に記載の方法。 Embodiment H232. The method of embodiment H231, wherein the soluble human tissue factor domain comprises a sequence that is at least 90% identical to SEQ ID NO:93.
実施形態H233.可溶性ヒト組織因子ドメインが、配列番号93と少なくとも95%同一である配列を含む、実施形態H232に記載の方法。 Embodiment H233. The method of embodiment H232, wherein the soluble human tissue factor domain comprises a sequence that is at least 95% identical to SEQ ID NO:93.
実施形態H234.可溶性ヒト組織因子ドメインが、
成熟野生型ヒト組織因子タンパク質のアミノ酸20位に対応するアミノ酸の位置にリジン、
成熟野生型ヒト組織因子タンパク質のアミノ酸22位に対応するアミノ酸の位置にイソロイシン、
成熟野生型ヒト組織因子タンパク質のアミノ酸45位に対応するアミノ酸の位置にトリプトファン、
成熟野生型ヒト組織因子タンパク質のアミノ酸58位に対応するアミノ酸の位置にアスパラギン酸、
成熟野生型ヒト組織因子タンパク質のアミノ酸94位に対応するアミノ酸の位置にチロシン、
成熟野生型ヒト組織因子タンパク質のアミノ酸135位に対応するアミノ酸の位置にアルギニン、及び
成熟野生型ヒト組織因子タンパク質のアミノ酸140位に対応するアミノ酸の位置にフェニルアラニンのうちのいずれも含まない、実施形態H230~H233のいずれか一つに記載の方法。
Embodiment H234. A soluble human tissue factor domain is
a lysine at the amino acid position corresponding to
an isoleucine at the amino acid position corresponding to
tryptophan at the amino acid position corresponding to
an aspartic acid at the amino acid position corresponding to amino acid position 58 of the mature wild-type human tissue factor protein;
a tyrosine at the amino acid position corresponding to amino acid position 94 of the mature wild-type human tissue factor protein;
An embodiment that does not include either arginine at the amino acid position corresponding to amino acid position 135 of the mature wild-type human tissue factor protein and phenylalanine at the amino acid position corresponding to
実施形態H235.可溶性ヒト組織因子ドメインが、
成熟野生型ヒト組織因子タンパク質のアミノ酸20位に対応するアミノ酸の位置にリジン、
成熟野生型ヒト組織因子タンパク質のアミノ酸22位に対応するアミノ酸の位置にイソロイシン、
成熟野生型ヒト組織因子タンパク質のアミノ酸45位に対応するアミノ酸の位置にトリプトファン、
成熟野生型ヒト組織因子タンパク質のアミノ酸58位に対応するアミノ酸の位置にアスパラギン酸、
成熟野生型ヒト組織因子タンパク質のアミノ酸94位に対応するアミノ酸の位置にチロシン、
成熟野生型ヒト組織因子タンパク質のアミノ酸135位に対応するアミノ酸の位置にアルギニン、及び
成熟野生型ヒト組織因子タンパク質のアミノ酸140位に対応するアミノ酸の位置にフェニルアラニンのうちのいずれも含まない、実施形態H234に記載の方法。
Embodiment H235. A soluble human tissue factor domain is
a lysine at the amino acid position corresponding to
an isoleucine at the amino acid position corresponding to
tryptophan at the amino acid position corresponding to
an aspartic acid at the amino acid position corresponding to amino acid position 58 of the mature wild-type human tissue factor protein;
a tyrosine at the amino acid position corresponding to amino acid position 94 of the mature wild-type human tissue factor protein;
An embodiment that does not include either arginine at the amino acid position corresponding to amino acid position 135 of the mature wild-type human tissue factor protein and phenylalanine at the amino acid position corresponding to
実施形態H236.可溶性組織因子ドメインが、第VIIa因子に結合することができない、実施形態H196~H235のいずれか1つに記載の方法。 Embodiment H236. The method of any one of embodiments H196-H235, wherein the soluble tissue factor domain is incapable of binding Factor VIIa.
実施形態H237.可溶性組織因子ドメインが、不活性第X因子を第Xa因子に変換しない、実施形態H196~H236のいずれか1つに記載の方法。 Embodiment H237. The method of any one of embodiments H196-H236, wherein the soluble tissue factor domain does not convert inactive factor X to factor Xa.
実施形態H238.多鎖キメラポリペプチドが、哺乳動物における血液凝固を刺激しない、実施形態H196~H237のいずれか1つに記載の方法。 Embodiment H238. The method of any one of embodiments H196-H237, wherein the multichain chimeric polypeptide does not stimulate blood clotting in the mammal.
実施形態H239.一対の親和性ドメインが、ヒトIL-15受容体のアルファ鎖(IL-15Rα)由来のスシドメイン、及び可溶性IL-15である、実施形態H196~H238のいずれか1つに記載の方法。 Embodiment H239. The method of any one of embodiments H196-H238, wherein the paired affinity domains are a sushi domain from the alpha chain of the human IL-15 receptor (IL-15Rα) and soluble IL-15.
実施形態H240.可溶性IL-15が、D8N又はD8Aアミノ酸置換を有する、実施形態H239に記載の方法。 Embodiment H240. The method of embodiment H239, wherein the soluble IL-15 has a D8N or D8A amino acid substitution.
実施形態H241.ヒトIL-15Rαが、成熟全長IL-15Rαである、実施形態H239又はH240に記載の方法。 Embodiment H241. The method of embodiment H239 or H240, wherein the human IL-15Rα is mature full-length IL-15Rα.
実施形態H242.一対の親和性ドメインが、バルナーゼとバルンスター、PKAとAKAP、変異RNaseI断片に基づくアダプター/ドッキングタグモジュール、並びに、タンパク質シンタキシン、シナプトタグミン、シナプトブレビン、及びSNAP25の相互作用に基づくSNAREモジュールからなる群から選択される、実施形態H196~H238のいずれか1つに記載の方法。 Embodiment H242. The paired affinity domains are selected from the group consisting of barnase and barnstar, PKA and AKAP, adapter/docking tag modules based on mutated RNase I fragments, and SNARE modules based on interactions of proteins syntaxin, synaptotagmin, synaptobrevin, and SNAP25. The method of any one of embodiments H196-H238, wherein the method is
実施形態H243.1つ以上のNK細胞活性化物質のうちの少なくとも1つが多鎖キメラポリペプチドを含み、多鎖キメラポリペプチドが、
(a)第1及び第2のキメラポリペプチドであって、各々が、
(i)第1の標的結合ドメイン、
(ii)Fcドメイン、及び
(iii)一対の親和性ドメインの第1のドメイン
を含む、第1及び第2のキメラポリペプチド、
(b)第3及び第4のキメラポリペプチドであって、各々が、
(i)一対の親和性ドメインの第2のドメイン、及び
(ii)第2の標的結合ドメイン
を含む、第3及び第4のキメラポリペプチド
を含み、
第1及び第2のキメラポリペプチドと第3及び第4のキメラポリペプチドが、一対の親和性ドメインの第1のドメインと第2のドメインとの結合を介して会合し、かつ第1及び第2のキメラポリペプチドが、それらのFcドメインを介して会合する、
実施形態H1~H19、H35~H42、H44~H62、及びH64~H77のいずれか1つに記載の方法。
Embodiment H243. At least one of the one or more NK cell activators comprises a multi-chain chimeric polypeptide, wherein the multi-chain chimeric polypeptide comprises
(a) first and second chimeric polypeptides, each comprising:
(i) a first target binding domain;
(ii) an Fc domain, and (iii) a first domain of a pair of affinity domains,
(b) third and fourth chimeric polypeptides, each comprising:
(i) a second of the pair of affinity domains, and (ii) a second target binding domain, comprising third and fourth chimeric polypeptides,
The first and second chimeric polypeptides and the third and fourth chimeric polypeptides associate via binding of the first and second domains of a pair of affinity domains, and two chimeric polypeptides associated through their Fc domains;
The method of any one of embodiments H1-H19, H35-H42, H44-H62, and H64-H77.
実施形態H244.第1の標的結合ドメインとFcドメインが、第1及び第2のキメラポリペプチド内で互いに直接隣接している、実施形態H243に記載の方法。 Embodiment H244. The method of embodiment H243, wherein the first target binding domain and the Fc domain are directly adjacent to each other within the first and second chimeric polypeptides.
実施形態H245.第1及び第2のキメラポリペプチドが、第1及び第2のキメラポリペプチド内の第1の標的結合ドメインとFcドメインとの間にリンカー配列を更に含む、実施形態H243に記載の方法。 Embodiment H245. The method of embodiment H243, wherein the first and second chimeric polypeptides further comprise a linker sequence between the first target binding domain and the Fc domain within the first and second chimeric polypeptides.
実施形態H246.Fcドメインと一対の親和性ドメインの第1のドメインが、第1及び第2のキメラポリペプチド内で互いに直接隣接している、実施形態H243~H245のいずれか1つに記載の方法。 Embodiment H246. The method of any one of embodiments H243-H245, wherein the Fc domain and the first of the paired affinity domains are directly adjacent to each other within the first and second chimeric polypeptides.
実施形態H247.第1のキメラポリペプチドが、第1及び第2のキメラポリペプチド内のFcドメインと一対の親和性ドメインの第1のドメインとの間にリンカー配列を更に含む、実施形態H243~H245のいずれか1つに記載の方法。 Embodiment H247. Any of embodiments H243-H245, wherein the first chimeric polypeptide further comprises a linker sequence between the Fc domain and the first of the pair of affinity domains in the first and second chimeric polypeptides The method described in 1.
実施形態H248.一対の親和性ドメインの第2のドメインと第2の標的結合ドメインが、第3及び第4のキメラポリペプチド内で互いに直接隣接している、実施形態H243~H247のいずれか1つに記載の方法。 Embodiment H248. Any one of embodiments H243-H247, wherein the second domain and the second target binding domain of the pair of affinity domains are directly adjacent to each other within the third and fourth chimeric polypeptides. Method.
実施形態H249.第3及び第4のキメラポリペプチドが、第3及び第4のキメラポリペプチド内の一対の親和性ドメインの第2のドメインと第2の標的結合ドメインとの間にリンカー配列を更に含む、実施形態H243~H247のいずれか1つに記載の方法。 Embodiment H249. wherein the third and fourth chimeric polypeptides further comprise a linker sequence between the second of the pair of affinity domains within the third and fourth chimeric polypeptides and the second target binding domain; The method of any one of forms H243-H247.
実施形態H250.第1の標的結合ドメイン及び第2の標的結合ドメインが、同じ抗原に特異的に結合する、実施形態H243~H249のいずれか1つに記載の方法。 Embodiment H250. The method of any one of embodiments H243-H249, wherein the first target binding domain and the second target binding domain specifically bind the same antigen.
実施形態H251.第1の標的結合ドメイン及び第2の標的結合ドメインが、同じエピトープに特異的に結合する、実施形態H250に記載の方法。 Embodiment H251. The method of embodiment H250, wherein the first target binding domain and the second target binding domain specifically bind to the same epitope.
実施形態H252.第1の標的結合ドメイン及び第2の標的結合ドメインが、同じアミノ酸配列を含む、実施形態H251に記載の方法。 Embodiment H252. The method of embodiment H251, wherein the first target binding domain and the second target binding domain comprise the same amino acid sequence.
実施形態H253.第1の標的結合ドメイン及び第2の標的結合ドメインが、異なる抗原に特異的に結合する、実施形態H243~H249のいずれか1つに記載の方法。 Embodiment H253. The method of any one of embodiments H243-H249, wherein the first target binding domain and the second target binding domain specifically bind to different antigens.
実施形態H254.第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方が、抗原結合ドメインである、実施形態H243~H253のいずれか1つに記載の方法。 Embodiment H254. The method of any one of embodiments H243-H253, wherein one or both of the first target binding domain and the second target binding domain are antigen binding domains.
実施形態H255.第1の標的結合ドメイン及び第2の標的結合ドメインが各々、抗原結合ドメインである、実施形態H254に記載の方法。 Embodiment H255. The method of embodiment H254, wherein the first target binding domain and the second target binding domain are each antigen binding domains.
実施形態H256.抗原結合ドメインが、scFv又は単一ドメイン抗体を含む、実施形態H254又はH255に記載の方法。 Embodiment H256. The method of embodiment H254 or H255, wherein the antigen binding domain comprises a scFv or single domain antibody.
実施形態H257.第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方が、CD16a、CD33、CD20、CD19、CD22、CD123、PDL-1、TIGIT、PD-1、TIM3、CTLA4、MICA、MICB、IL-6、IL-8、TNFα、CD26、CD36、ULBP2、CD30、CD200、IGF-1R、MUC4AC、MUC5AC、Trop-2、CMET、EGFR、HER1、HER2、HER3、PSMA、CEA、B7H3、EPCAM、BCMA、P-カドヘリン、CEACAM5、UL16結合タンパク質、HLA-DR、DLL4、TYRO3、AXL、MER、CD122、CD155、PDGF-DD、TGF-β受容体II(TGF-βRII)リガンド、TGF-βRIIIリガンド、DNAM1リガンド、NKp46リガンド、NKp44リガンド、NKG2Dリガンド、NKp30リガンド、scMHCIリガンド、scMHCIIリガンド、scTCRリガンド、PDGF-DD受容体、幹細胞因子(SCF)受容体、幹細胞様チロシンキナーゼ3リガンド(FLT3L)受容体、MICA受容体、MICB受容体、ULP16結合タンパク質受容体、CD155受容体、及びCD122受容体からなる群から選択される標的に特異的に結合する、実施形態H243~H256のいずれか1つに記載の方法。
Embodiment H257. one or both of the first target binding domain and the second target binding domain are CD16a, CD33, CD20, CD19, CD22, CD123, PDL-1, TIGIT, PD-1, TIM3, CTLA4, MICA, MICB, IL -6, IL-8, TNFα, CD26, CD36, ULBP2, CD30, CD200, IGF-1R, MUC4AC, MUC5AC, Trop-2, CMET, EGFR, HER1, HER2, HER3, PSMA, CEA, B7H3, EPCAM, BCMA , P-cadherin, CEACAM5, UL16 binding protein, HLA-DR, DLL4, TYRO3, AXL, MER, CD122, CD155, PDGF-DD, TGF-β receptor II (TGF-βRII) ligand, TGF-βRIII ligand, DNAM1 ligand, NKp46 ligand, NKp44 ligand, NKG2D ligand, NKp30 ligand, scMHCI ligand, scMHCII ligand, scTCR ligand, PDGF-DD receptor, stem cell factor (SCF) receptor, stem cell-
実施形態H258.第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方が、可溶性インターロイキン又はサイトカインタンパク質である、実施形態H243~H256のいずれか1つに記載の方法。 Embodiment H258. The method of any one of embodiments H243-H256, wherein one or both of the first target binding domain and the second target binding domain is a soluble interleukin or cytokine protein.
実施形態H259.可溶性インターロイキン又はサイトカインタンパク質が、IL-1、IL-2、IL-3、IL-7、IL-8、IL-10、IL-12、IL-15、IL-17、IL-18、IL-21、PDGF-DD、及びSCFからなる群から選択される、実施形態H258に記載の方法。 Embodiment H259. Soluble interleukin or cytokine proteins are IL-1, IL-2, IL-3, IL-7, IL-8, IL-10, IL-12, IL-15, IL-17, IL-18, IL- 21, PDGF-DD, and SCF.
実施形態H260.第1の標的結合ドメイン及び第2の標的結合ドメインの一方又は両方が、可溶性インターロイキン又はサイトカイン受容体である、実施形態H243~H256のいずれか1つに記載の方法。 Embodiment H260. The method of any one of embodiments H243-H256, wherein one or both of the first target binding domain and the second target binding domain is a soluble interleukin or cytokine receptor.
実施形態H261.可溶性受容体が、可溶性TGF-β受容体II(TGF-βRII)、可溶性TGF-βRIII、可溶性TNFα受容体、可溶性IL-4受容体、又は可溶性IL-10受容体である、実施形態H260に記載の方法。 Embodiment H261. Described in embodiment H260, wherein the soluble receptor is soluble TGF-beta receptor II (TGF-βRII), soluble TGF-βRIII, soluble TNFα receptor, soluble IL-4 receptor, or soluble IL-10 receptor the method of.
実施形態I1.加齢関連疾患又は状態の治療を必要とする対象において加齢関連疾患又は状態を治療する方法であって、加齢関連疾患又は状態を有すると同定される対象に、治療有効量の1つ以上のナチュラルキラー(NK)細胞活性化物質を投与することを含む、方法。 Embodiment I1. A method of treating an age-related disease or condition in a subject in need thereof, comprising administering to a subject identified as having an age-related disease or condition a therapeutically effective amount of one or more administering a natural killer (NK) cell activator of
実施形態I2.老化細胞の死滅又は老化細胞の数の減少を必要とする対象において老化細胞を死滅させる又は老化細胞の数を減少させる方法であって、対象に、治療有効量の1つ以上のNK細胞活性化物質を投与することを含む、方法。 Embodiment I2. A method of killing senescent cells or reducing the number of senescent cells in a subject in need thereof, comprising administering to the subject a therapeutically effective amount of one or more NK cell activating A method comprising administering a substance.
実施形態I3.投与が、対象における標的組織の老化細胞の数の減少をもたらす、実施形態I1又はI2に記載の方法。 Embodiment I3. The method of embodiment I1 or I2, wherein administering results in a decrease in the number of senescent cells in the target tissue in the subject.
実施形態I4.標的組織が、脂肪組織、膵臓組織、肝臓組織、肺組織、血管系、骨組織、中枢神経系(CNS)組織、眼組織、皮膚組織、筋肉組織、及び二次リンパ器官組織からなる群から選択される、実施形態I3に記載の方法。 Embodiment I4. The target tissue is selected from the group consisting of adipose tissue, pancreatic tissue, liver tissue, lung tissue, vascular system, bone tissue, central nervous system (CNS) tissue, eye tissue, skin tissue, muscle tissue, and secondary lymphoid organ tissue. The method of embodiment I3, wherein:
実施形態I5.加齢関連疾患又は状態の治療を必要とする対象において加齢関連疾患又は状態を治療する方法であって、加齢関連疾患又は状態を有すると同定される対象に、治療有効数の活性化されたNK細胞を投与することを含む、方法。 Embodiment I5. A method of treating an age-related disease or condition in a subject in need of treatment of an age-related disease or condition, comprising administering to a subject identified as having an age-related disease or condition a therapeutically effective number of activated administering NK cells.
実施形態I6.老化細胞の死滅又は老化細胞の数の減少を必要とする対象において老化細胞を死滅させる又は老化細胞の数を減少させる方法であって、対象に、治療有効数の活性化されたNK細胞を投与することを含む、方法。 Embodiment I6. A method of killing senescent cells or reducing the number of senescent cells in a subject in need of killing senescent cells or reducing the number of senescent cells, comprising administering to the subject a therapeutically effective number of activated NK cells A method comprising:
実施形態I7.対象が、加齢関連疾患又は状態を有すると同定又は診断されている、実施形態I1~I6のいずれか1つに記載の方法。 Embodiment I7. The method of any one of embodiments I1-I6, wherein the subject has been identified or diagnosed as having an age-related disease or condition.
実施形態I8.加齢関連疾患又は状態が、がん、自己免疫疾患、代謝性疾患、神経変性疾患、心臓血管疾患、皮膚疾患、早老症、及び脆弱性疾患からなる群から選択される、実施形態I7に記載の方法。 Embodiment I8. According to embodiment I7, wherein the age-related disease or condition is selected from the group consisting of cancer, autoimmune disease, metabolic disease, neurodegenerative disease, cardiovascular disease, skin disease, progeria, and frailty disease. the method of.
実施形態I9.がんが、固形腫瘍、血液腫瘍、肉腫、骨肉腫、膠芽細胞腫、神経芽細胞腫、黒色腫、横紋筋肉腫、ユーイング肉腫、骨肉腫、B細胞新生物、多発性骨髄腫、B細胞リンパ腫、B細胞非ホジキンリンパ腫、ホジキンリンパ腫、慢性リンパ球性白血病(CLL)、急性骨髄性白血病(AML)、慢性骨髄性白血病(CML)、急性リンパ性白血病(ALL)、骨髄異形成症候群(MDS)、皮膚T細胞リンパ腫、網膜芽細胞腫、胃がん、尿路上皮がん、肺がん、腎細胞がん、胃食道がん、膵臓がん、前立腺がん、乳がん、結腸直腸がん、卵巣がん、非小細胞肺がん、扁平上皮細胞頭頸部がん、子宮内膜がん、子宮頸がん、肝臓がん、及び肝細胞がんからなる群から選択される、実施形態I8に記載の方法。 Embodiment I9. Cancer is solid tumor, hematologic tumor, sarcoma, osteosarcoma, glioblastoma, neuroblastoma, melanoma, rhabdomyosarcoma, Ewing sarcoma, osteosarcoma, B-cell neoplasm, multiple myeloma, B cell lymphoma, B-cell non-Hodgkin's lymphoma, Hodgkin's lymphoma, chronic lymphocytic leukemia (CLL), acute myelogenous leukemia (AML), chronic myelogenous leukemia (CML), acute lymphocytic leukemia (ALL), myelodysplastic syndrome ( MDS), cutaneous T-cell lymphoma, retinoblastoma, gastric cancer, urothelial cancer, lung cancer, renal cell cancer, gastroesophageal cancer, pancreatic cancer, prostate cancer, breast cancer, colorectal cancer, ovarian cancer cancer, non-small cell lung cancer, squamous cell head and neck cancer, endometrial cancer, cervical cancer, liver cancer, and hepatocellular carcinoma. .
実施形態I10.自己免疫疾患が、1型糖尿病である、実施形態I8に記載の方法。
Embodiment I10. The method of embodiment I8, wherein the autoimmune disease is
実施形態I11.代謝性疾患が、肥満、リポジストロフィー、及び2型真性糖尿病からなる群から選択される、実施形態I8に記載の方法。
Embodiment I11. The method of embodiment I8, wherein the metabolic disease is selected from the group consisting of obesity, lipodystrophy, and
実施形態I12.神経変性疾患が、アルツハイマー病、パーキンソン病、筋萎縮性側索硬化症、及び認知症からなる群から選択される、実施形態I8に記載の方法。 Embodiment I12. The method of embodiment I8, wherein the neurodegenerative disease is selected from the group consisting of Alzheimer's disease, Parkinson's disease, amyotrophic lateral sclerosis, and dementia.
実施形態I13.心臓血管疾患が、冠動脈疾患、アテローム性動脈硬化症、及び肺動脈高血圧症からなる群から選択される、実施形態8に記載の方法。
Embodiment I13. 9. The method of
実施形態I14.皮膚疾患が、創傷治癒、脱毛症、しわ、老年性黒子、皮膚の菲薄化、色素性乾皮症、及び先天性角化異常症からなる群から選択される、実施形態I8に記載の方法。 Embodiment I14. The method of embodiment I8, wherein the skin disorder is selected from the group consisting of wound healing, alopecia, wrinkles, senile lentigines, skin thinning, xeroderma pigmentosum, and dyskeratosis congenita.
実施形態I15.早老症が、早老症及びハッチンソン・ギルフォード早老症症候群からなる群から選択される、実施形態I8に記載の方法。 Embodiment I15. The method of embodiment I8, wherein the progeria is selected from the group consisting of progeria and Hutchinson-Guilford progeria syndrome.
実施形態I16.脆弱性疾患が、脆弱、ワクチン接種に対する応答、骨粗しょう症、及びサルコペニアからなる群から選択される、実施形態I8に記載の方法。 Embodiment I16. The method of embodiment I8, wherein the fragility disease is selected from the group consisting of fragility, response to vaccination, osteoporosis, and sarcopenia.
実施形態I17.加齢関連疾患又は状態が、骨関節炎、脂肪萎縮、慢性閉塞性肺疾患、特発性肺線維症、腎移植不全、肝線維症、骨量喪失、サルコペニア、加齢関連肺組織弾性喪失、骨粗しょう症、加齢関連腎機能障害、及び化学的に誘導された腎機能障害からなる群から選択される、実施形態I1~I6のいずれか1つに記載の方法。 Embodiment I17. Age-related disease or condition is osteoarthritis, fat atrophy, chronic obstructive pulmonary disease, idiopathic pulmonary fibrosis, renal graft failure, liver fibrosis, bone loss, sarcopenia, age-related loss of lung tissue elasticity, osteoporosis The method of any one of embodiments I1-I6, wherein the method is selected from the group consisting of disease, age-related renal impairment, and chemically-induced renal impairment.
実施形態I18.加齢関連疾患又は状態が、2型真性糖尿病又はアテローム性動脈硬化症である、実施形態I1~I6のいずれか1つに記載の方法。
Embodiment I18. The method of any one of embodiments I1-I6, wherein the age-related disease or condition is
実施形態I19.ある期間にわたる皮膚及び/又は毛髪の質感及び/又は外観の改善を必要とする対象において皮膚及び/又は毛髪の質感及び/又は外観を改善する方法であって、対象に、治療有効量の1つ以上のナチュラルキラー(NK)細胞活性化物質を投与することを含む、方法。 Embodiment I19. 1. A method of improving skin and/or hair texture and/or appearance in a subject in need thereof over a period of time comprising administering to the subject a therapeutically effective amount of one A method comprising administering the above natural killer (NK) cell activator.
実施形態I20.ある期間にわたる皮膚及び/又は毛髪の質感及び/又は外観の改善を必要とする対象において皮膚及び/又は毛髪の質感及び/又は外観を改善する方法であって、対象に、治療有効数の活性化されたNK細胞を投与することを含む、方法。 Embodiment I20. 1. A method of improving skin and/or hair texture and/or appearance in a subject in need thereof over a period of time, comprising administering to the subject a therapeutically effective number of activated administering the NK cells.
実施形態I21.前記期間にわたる対象の皮膚の質感及び/又は外観の改善を提供する、実施形態I19又はI20に記載の方法。 Embodiment I21. The method of embodiment I19 or I20, which provides an improvement in the subject's skin texture and/or appearance over said period of time.
実施形態I22.前記期間にわたる対象の皮膚のしわの形成速度の減少をもたらす、実施形態I21に記載の方法。 Embodiment I22. The method of embodiment I21, which results in a decrease in the rate of wrinkling of the subject's skin over said period of time.
実施形態I23.前記期間にわたる対象の皮膚の着色の改善をもたらす、実施形態I21又はI22に記載の方法。 Embodiment I23. The method of embodiment I21 or I22, which results in an improvement in the subject's skin pigmentation over said period of time.
実施形態I24.前記期間にわたる対象の皮膚の質感の改善をもたらす、実施形態I21~I23のいずれか1つに記載の方法。 Embodiment I24. The method of any one of embodiments I21-I23, which results in an improvement in the subject's skin texture over said period of time.
実施形態I25.前記期間にわたる対象の毛髪の質感及び/又は外観の改善を提供する、実施形態I20~I24のいずれか1つに記載の方法。 Embodiment I25. The method of any one of embodiments I20-I24, which provides an improvement in the texture and/or appearance of the subject's hair over said period of time.
実施形態I26.前記期間にわたる対象の白髪の形成速度の減少をもたらす、実施形態I25に記載の方法。
Embodiment I26. The method of
実施形態I27.前記期間にわたる対象の白髪の数の減少をもたらす、実施形態I25又はI26に記載の方法。 Embodiment I27. The method of embodiment I25 or I26, which results in a decrease in the number of gray hairs in the subject over said time period.
実施形態I28.経時的に対象の脱毛速度の減少をもたらす、実施形態I25~I27のいずれか1つに記載の方法。 Embodiment I28. The method of any one of embodiments I25-I27, which results in a decrease in the subject's rate of hair loss over time.
実施形態I29.前記期間にわたる対象の毛髪の質感の改善をもたらす、実施形態I25~I28のいずれか1つに記載の方法。 Embodiment I29. The method of any one of embodiments I25-I28, which results in an improvement in the subject's hair texture over said period of time.
実施形態I30.前記期間にわたる対象の皮膚の老化皮膚線維芽細胞の数の減少をもたらす、実施形態I19~I29のいずれか1つに記載の方法。 Embodiment I30. The method of any one of embodiments I19-I29, which results in a decrease in the number of senescent dermal fibroblasts in the subject's skin over said period of time.
実施形態I31.ある期間にわたる肥満の治療の支援を必要とする対象において肥満の治療を支援する方法であって、対象に、治療有効量の1つ以上のナチュラルキラー(NK)細胞活性化物質を投与することを含む、方法。 Embodiment I31. A method of helping treat obesity in a subject in need of help treating obesity over a period of time comprising administering to the subject a therapeutically effective amount of one or more natural killer (NK) cell activators. including, method.
実施形態I32.ある期間にわたる肥満の治療の支援を必要とする対象において肥満の治療を支援する方法であって、対象に、治療有効数の活性化されたNK細胞を投与することを含む、方法。 Embodiment I32. A method of helping treat obesity in a subject in need of help treating obesity over a period of time, the method comprising administering to the subject a therapeutically effective number of activated NK cells.
実施形態I33.
休止NK細胞を得ることと、
1つ以上のNK細胞活性化物質を含む液体培養培地中でインビトロで休止NK細胞を接触させることであって、この接触が、その後、対象に投与される活性化されたNK細胞の発生をもたらす、接触させることと
を更に含む、実施形態I1~I32のいずれか1つに記載の方法。
Embodiment I33.
obtaining resting NK cells;
Contacting resting NK cells in vitro in a liquid culture medium containing one or more NK cell activators, which contact results in the generation of activated NK cells that are then administered to the subject. , contacting. The method of any one of embodiments I1-I32.
実施形態I34.休止NK細胞が、キメラ抗原受容体又は組換えT細胞受容体を有する遺伝子組み換えNK細胞である、実施形態I33に記載の方法。 Embodiment I34. The method of embodiment I33, wherein the resting NK cells are genetically engineered NK cells with chimeric antigen receptors or recombinant T cell receptors.
実施形態I35.対象への投与前に、キメラ抗原受容体又は組換えT細胞受容体をコードする核酸を、休止NK細胞又は活性化されたNK細胞に導入することを更に含む、実施形態I33に記載の方法。 Embodiment I35. The method of embodiment I33, further comprising introducing nucleic acid encoding the chimeric antigen receptor or recombinant T cell receptor into resting or activated NK cells prior to administration to the subject.
実施形態I36.前記期間にわたる対象の体重の減少をもたらす、実施形態I31~I35のいずれか1つに記載の方法。 Embodiment I36. The method of any one of embodiments I31-I35, which results in the subject losing weight over said time period.
実施形態I37.前記期間にわたる対象の肥満度指数(BMI)の減少をもたらす、実施形態I31~I36のいずれか1つに記載の方法。 Embodiment I37. The method of any one of embodiments I31-I36, which results in a decrease in the subject's body mass index (BMI) over said time period.
実施形態I38.対象における前糖尿病から2型糖尿病への進行速度の減少をもたらす、実施形態I31~I35のいずれか1つに記載の方法。
Embodiment I38. The method of any one of embodiments I31-I35, which results in a decrease in the rate of progression from prediabetes to
実施形態I39.対象における空腹時血糖値の減少をもたらす、実施形態I31~I35のいずれか1つに記載の方法。 Embodiment I39. The method of any one of embodiments I31-I35, which results in decreased fasting blood glucose levels in the subject.
実施形態I40.対象におけるインスリン感受性の増加をもたらす、実施形態I31~I35のいずれか1つに記載の方法。 Embodiment I40. The method of any one of embodiments I31-I35, which results in increased insulin sensitivity in the subject.
実施形態I41.対象におけるアテローム性動脈硬化症の重症度の減少をもたらす、実施形態I31~I35のいずれか1つに記載の方法。 Embodiment I41. The method of any one of embodiments I31-I35, which results in a reduction in the severity of atherosclerosis in the subject.
実施形態I42.1つ以上のNK細胞活性化物質が、IL-2受容体、IL-7受容体、IL-12受容体、IL-15受容体、IL-18受容体、IL-21受容体、IL-33受容体、CD16、CD69、CD25、CD36、CD59、CD352、NKp80、DNAM-1、2B4、NKp30、NKp44、NKp46、NKG2D、KIR2DS1、KIR2Ds2/3、KIR2DL4、KIR2DS4、KIR2DS5、及びKIR3DS1のうちの1つ以上の活性化をもたらす、実施形態I1~I41のいずれか1つに記載の方法。 Embodiment I42.The one or more NK cell activators is IL-2 receptor, IL-7 receptor, IL-12 receptor, IL-15 receptor, IL-18 receptor, IL-21 receptor , IL-33 receptor, CD16, CD69, CD25, CD36, CD59, CD352, NKp80, DNAM-1, 2B4, NKp30, NKp44, NKp46, NKG2D, KIR2DS1, KIR2Ds2/3, KIR2DL4, KIR2DS4, KIR2DS5, and KIR3DS1 The method of any one of embodiments I1-I41, which results in activation of one or more of:
実施形態I43.1つ以上のNK細胞活性化物質のうちの少なくとも1つが、PD-1、TGF-β受容体、TIGIT、CD1、TIM-3、Siglec-7、IRP60、Tactile、IL1R8、NKG2A/KLRD1、KIR2DL1、KIR2DL2/3、KIR2DL5、KIR3DL1、KIR3DL2、ILT2/LIR-1、及びLAG-2のうちの1つ以上の活性化の減少をもたらす、実施形態I1~I42のいずれか1つに記載の方法。 Embodiment I43. At least one of the one or more NK cell activators is PD-1, TGF-beta receptor, TIGIT, CD1, TIM-3, Siglec-7, IRP60, Tactile, IL1R8, NKG2A/ according to any one of embodiments I1-I42, which results in decreased activation of one or more of KLRD1, KIR2DL1, KIR2DL2/3, KIR2DL5, KIR3DL1, KIR3DL2, ILT2/LIR-1, and LAG-2 the method of.
実施形態I44.1つ以上のNK細胞活性化物質のうちの少なくとも1つが、
(i)第1の標的結合ドメイン、
(ii)可溶性組織因子ドメイン、及び
(iii)第2の標的結合ドメイン
を含む、実施形態I1~I41のいずれか1つに記載の方法。
Embodiment I44. At least one of the one or more NK cell activators is
(i) a first target binding domain;
(ii) a soluble tissue factor domain; and (iii) a second target binding domain.
実施形態I45.第1の標的結合ドメインと可溶性組織因子ドメインが、互いに直接隣接している、実施形態I44に記載の方法。 Embodiment I45. The method of embodiment I44, wherein the first target binding domain and the soluble tissue factor domain are directly adjacent to each other.
実施形態I46.一本鎖キメラポリペプチドが、第1の標的結合ドメインと可溶性組織因子ドメインとの間にリンカー配列を更に含む、実施形態I44に記載の方法。 Embodiment I46. The method of embodiment I44, wherein the single-chain chimeric polypeptide further comprises a linker sequence between the first target binding domain and the soluble tissue factor domain.
実施形態I47.可溶性組織因子ドメインと第2の標的結合ドメインが、互いに直接隣接している、実施形態I44~I46のいずれか1つに記載の方法。 Embodiment I47. The method of any one of embodiments I44-I46, wherein the soluble tissue factor domain and the second target binding domain are directly adjacent to each other.
実施形態I48.一本鎖キメラポリペプチドが、可溶性組織因子ドメインと第2の標的結合ドメインとの間にリンカー配列を更に含む、実施形態I44~I46のいずれか1つに記載の方法。 Embodiment I48. The method of any one of embodiments I44-I46, wherein the single-chain chimeric polypeptide further comprises a linker sequence between the soluble tissue factor domain and the second target binding domain.
実施形態I49.1つ以上のNK細胞活性化物質のうちの少なくとも1つが多鎖キメラポリペプチドを含み、多鎖キメラポリペプチドが、
(a)第1のキメラポリペプチドであって、
(i)第1の標的結合ドメイン、
(ii)可溶性組織因子ドメイン、及び
(iii)一対の親和性ドメインの第1のドメイン
を含む、第1のキメラポリペプチド、
(b)第2のキメラポリペプチドであって、
(i)一対の親和性ドメインの第2のドメイン、及び
(ii)第2の標的結合ドメイン
を含む、第2のキメラポリペプチド
を含み、
第1のキメラポリペプチドと第2のキメラポリペプチドが、一対の親和性ドメインの第1のドメインと第2のドメインとの結合を介して会合する、
I1~I41のいずれか1つに記載の方法。
Embodiment I49. At least one of the one or more NK cell activators comprises a multi-chain chimeric polypeptide, wherein the multi-chain chimeric polypeptide comprises
(a) a first chimeric polypeptide,
(i) a first target binding domain;
(ii) a soluble tissue factor domain, and (iii) a first domain of a pair of affinity domains,
(b) a second chimeric polypeptide,
a second chimeric polypeptide comprising (i) a second of the pair of affinity domains, and (ii) a second target binding domain;
the first chimeric polypeptide and the second chimeric polypeptide associate via binding of the first and second domains of a pair of affinity domains;
The method according to any one of I1-I41.
実施形態I50.第1の標的結合ドメインと可溶性組織因子ドメインが、第1のキメラポリペプチド内で互いに直接隣接している、実施形態I49に記載の方法。 Embodiment I50. The method of embodiment I49, wherein the first target binding domain and the soluble tissue factor domain are directly adjacent to each other within the first chimeric polypeptide.
実施形態I51.第1のキメラポリペプチドが、第1のキメラポリペプチド内の第1の標的結合ドメインと可溶性組織因子ドメインとの間にリンカー配列を更に含む、実施形態I49に記載の方法。 Embodiment I51. The method of embodiment I49, wherein the first chimeric polypeptide further comprises a linker sequence between the first target binding domain and the soluble tissue factor domain within the first chimeric polypeptide.
実施形態I52.可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインが、第1のキメラポリペプチド内で互いに直接隣接している、実施形態I49~I51のいずれか1つに記載の方法。 Embodiment I52. The method of any one of embodiments I49-I51, wherein the soluble tissue factor domain and the first of the paired affinity domains are directly adjacent to each other within the first chimeric polypeptide.
実施形態I53.第1のキメラポリペプチドが、第1のキメラポリペプチド内の可溶性組織因子ドメインと一対の親和性ドメインの第1のドメインとの間にリンカー配列を更に含む、実施形態I49~I51のいずれか1つに記載の方法。
Embodiment I53. Any one of embodiments I49-I51, wherein the first chimeric polypeptide further comprises a linker sequence between the soluble tissue factor domain and the first of the pair of affinity domains within the first chimeric polypeptide the method described in
実施形態I54.一対の親和性ドメインの第2のドメインと第2の標的結合ドメインが、第2のキメラポリペプチド内で互いに直接隣接している、実施形態I49~I53のいずれか1つに記載の方法。 Embodiment I54. The method of any one of embodiments I49-I53, wherein the second domain and the second target binding domain of the pair of affinity domains are directly adjacent to each other within the second chimeric polypeptide.
実施形態I55.第2のキメラポリペプチドが、第2のキメラポリペプチド内の一対の親和性ドメインの第2のドメインと第2の標的結合ドメインとの間にリンカー配列を更に含む、実施形態I49~I53のいずれか1つに記載の方法。
Embodiment I55. Any of embodiments I49-I53, wherein the second chimeric polypeptide further comprises a linker sequence between the second of the pair of affinity domains and the second target binding domain within the second chimeric polypeptide or the method of
実施形態I56.1つ以上のNK細胞活性化物質のうちの少なくとも1つが多鎖キメラポリペプチドを含み、多鎖キメラポリペプチドが、
(a)第1及び第2のキメラポリペプチドであって、各々が、
(i)第1の標的結合ドメイン、
(ii)Fcドメイン、及び
(iii)一対の親和性ドメインの第1のドメインを含む、第1及び第2のキメラポリペプチド、
(b)第3及び第4のキメラポリペプチドであって、各々が、
(i)一対の親和性ドメインの第2のドメイン、及び
(ii)第2の標的結合ドメイン
を含む、第3及び第4のキメラポリペプチド
を含み、
第1及び第2のキメラポリペプチドと第3及び第4のキメラポリペプチドが、一対の親和性ドメインの第1のドメインと第2のドメインとの結合を介して会合し、かつ第1及び第2のキメラポリペプチドが、それらのFcドメインを介して会合する、
実施形態I1~I41のいずれか1つに記載の方法。
Embodiment I56. At least one of the one or more NK cell activators comprises a multi-chain chimeric polypeptide, wherein the multi-chain chimeric polypeptide comprises
(a) first and second chimeric polypeptides, each comprising:
(i) a first target binding domain;
(ii) an Fc domain, and (iii) a first of a pair of affinity domains, first and second chimeric polypeptides,
(b) third and fourth chimeric polypeptides, each comprising:
(i) a second of the pair of affinity domains, and (ii) a second target binding domain, comprising third and fourth chimeric polypeptides,
The first and second chimeric polypeptides and the third and fourth chimeric polypeptides associate via binding of the first and second domains of a pair of affinity domains, and two chimeric polypeptides associated through their Fc domains;
The method of any one of embodiments I1-I41.
実施形態I57.第1の標的結合ドメイン及び第2の標的結合ドメインのうちの一方又は両方が、CD16a、CD33、CD20、CD19、CD22、CD123、PDL-1、TIGIT、PD-1、TIM3、CTLA4、MICA、MICB、IL-6、IL-8、TNFα、CD26、CD36、ULBP2、CD30、CD200、IGF-1R、MUC4AC、MUC5AC、Trop-2、CMET、EGFR、HER1、HER2、HER3、PSMA、CEA、B7H3、EPCAM、BCMA、P-カドヘリン、CEACAM5、UL16結合タンパク質、HLA-DR、DLL4、TYRO3、AXL、MER、CD122、CD155、PDGF-DD、TGF-β受容体II(TGF-βRII)リガンド、TGF-βRIIIリガンド、DNAM1リガンド、NKp46リガンド、NKp44リガンド、NKG2Dリガンド、NKp30リガンド、scMHCIリガンド、scMHCIIリガンド、scTCRリガンド、PDGF-DD受容体、幹細胞因子(SCF)受容体、幹細胞様チロシンキナーゼ3リガンド(FLT3L)受容体、MICA受容体、MICB受容体、ULP16結合タンパク質受容体、CD155受容体、及びCD122受容体からなる群から選択される標的に特異的に結合する、実施形態I44~I56のいずれか1つに記載の方法。
Embodiment I57. one or both of the first target binding domain and the second target binding domain are CD16a, CD33, CD20, CD19, CD22, CD123, PDL-1, TIGIT, PD-1, TIM3, CTLA4, MICA, MICB , IL-6, IL-8, TNFα, CD26, CD36, ULBP2, CD30, CD200, IGF-1R, MUC4AC, MUC5AC, Trop-2, CMET, EGFR, HER1, HER2, HER3, PSMA, CEA, B7H3, EPCAM , BCMA, P-cadherin, CEACAM5, UL16 binding protein, HLA-DR, DLL4, TYRO3, AXL, MER, CD122, CD155, PDGF-DD, TGF-β receptor II (TGF-βRII) ligand, TGF-βRIII ligand , DNAM1 ligand, NKp46 ligand, NKp44 ligand, NKG2D ligand, NKp30 ligand, scMHCI ligand, scMHCII ligand, scTCR ligand, PDGF-DD receptor, stem cell factor (SCF) receptor, stem cell-
実施形態I58.第1の標的結合ドメイン及び第2の標的結合ドメインのうちの一方又は両方が、可溶性インターロイキン又はサイトカインタンパク質である、実施形態I44~I56のいずれか1つに記載の方法。 Embodiment I58. The method of any one of embodiments I44-I56, wherein one or both of the first target binding domain and the second target binding domain is a soluble interleukin or cytokine protein.
実施形態I59.可溶性インターロイキン又はサイトカインタンパク質が、IL-1、IL-2、IL-3、IL-7、IL-8、IL-10、IL-12、IL-15、IL-17、IL-18、IL-21、PDGF-DD、及びSCFからなる群から選択される、実施形態I58に記載の方法。 Embodiment I59. Soluble interleukin or cytokine proteins are IL-1, IL-2, IL-3, IL-7, IL-8, IL-10, IL-12, IL-15, IL-17, IL-18, IL- 21, PDGF-DD, and SCF.
実施形態I60.第1の標的結合ドメイン及び第2の標的結合ドメインのうちの一方又は両方が、可溶性インターロイキン又はサイトカイン受容体である、実施形態I44~I56のいずれか1つに記載の方法。 Embodiment I60. The method of any one of embodiments I44-I56, wherein one or both of the first target binding domain and the second target binding domain is a soluble interleukin or cytokine receptor.
実施形態I61.可溶性受容体が、可溶性TGF-β受容体II(TGF-βRII)、可溶性TGF-βRIII、可溶性TNFα受容体、可溶性IL-4受容体、又は可溶性IL-10受容体である、実施形態I60に記載の方法。 Embodiment I61. Described in embodiment I60, wherein the soluble receptor is soluble TGF-beta receptor II (TGF-βRII), soluble TGF-βRIII, soluble TNFα receptor, soluble IL-4 receptor, or soluble IL-10 receptor the method of.
実施形態I62.可溶性組織因子ドメインが、血液凝固を刺激しない可溶性ヒト組織因子ドメインである、実施形態I44~I55のいずれか1つに記載の方法。 Embodiment I62. The method of any one of embodiments I44-I55, wherein the soluble tissue factor domain is a soluble human tissue factor domain that does not stimulate blood clotting.
実施形態I63.可溶性組織因子ドメインが、野生型可溶性ヒト組織因子由来の配列を含むか、又はそれからなる実施形態I43~I55のいずれか1つに記載の方法。 Embodiment I63. The method of any one of embodiments I43-I55, wherein the soluble tissue factor domain comprises or consists of a sequence derived from wild-type soluble human tissue factor.
Claims (194)
(e)第1のキメラポリペプチドであって、
(i)第1の標的結合ドメイン、
(ii)可溶性組織因子ドメイン、及び
(iii)一対の親和性ドメインの第1のドメイン
を含む、前記第1のキメラポリペプチド、
(f)第2のキメラポリペプチドであって、
(i)一対の親和性ドメインの第2のドメイン、及び
(ii)第2の標的結合ドメイン
を含む、前記第2のキメラポリペプチド
を含み、
前記第1の標的結合ドメイン及び前記第2の標的結合ドメインのうちの一方若しくは両方が、TGF-β受容体のリガンドに特異的に結合するか、又は
前記第1の標的結合ドメイン及び前記第2の標的結合ドメインのうちの一方若しくは両方が、TGF-β受容体に特異的に結合するアンタゴニスト抗原結合ドメインである、
請求項1~15のいずれか一項に記載の方法。 at least one of said one or more agents that result in decreased activation of a TGF-beta receptor is a multi-chain chimeric polypeptide, said multi-chain chimeric polypeptide comprising:
(e) a first chimeric polypeptide,
(i) a first target binding domain;
(ii) a soluble tissue factor domain, and (iii) a first of a pair of affinity domains,
(f) a second chimeric polypeptide,
(i) a second of a pair of affinity domains; and (ii) a second target binding domain;
one or both of said first target binding domain and said second target binding domain specifically bind to a ligand of a TGF-β receptor, or said first target binding domain and said second target binding domain one or both of the target binding domains of is an antagonist antigen binding domain that specifically binds to the TGF-β receptor;
A method according to any one of claims 1-15.
(i)第1の標的結合ドメイン、
(ii)可溶性組織因子ドメイン、及び
(iii)第2の標的結合ドメイン
を含む一本鎖キメラポリペプチドであり、
前記第1の標的結合ドメイン及び前記第2の標的結合ドメインのうちの一方若しくは両方が、TGF-β受容体のリガンドに特異的に結合するか、又は
前記第1の標的結合ドメイン及び前記第2の標的結合ドメインのうちの一方若しくは両方が、TGF-β受容体に特異的に結合するアンタゴニスト抗原結合ドメインである、
請求項1~15のいずれか一項に記載の方法。 at least one of the one or more agents that results in decreased activation of the TGF-β receptor;
(i) a first target binding domain;
(ii) a soluble tissue factor domain, and (iii) a second target binding domain, a single chain chimeric polypeptide,
one or both of said first target binding domain and said second target binding domain specifically bind to a ligand of a TGF-β receptor, or said first target binding domain and said second target binding domain one or both of the target binding domains of is an antagonist antigen binding domain that specifically binds to the TGF-β receptor;
A method according to any one of claims 1-15.
(i)第1の標的結合ドメイン、
(ii)可溶性組織因子ドメイン、及び
(iii)第2の標的結合ドメイン
を含む一本鎖キメラポリペプチドであり、
前記第1の標的結合ドメイン及び前記第2の標的結合ドメインのうちの一方又は両方が、可溶性共通ガンマ鎖ファミリーサイトカイン、共通ガンマ鎖ファミリーサイトカイン受容体に特異的に結合するアゴニスト抗原結合ドメイン、可溶性共通ガンマ鎖ファミリーサイトカイン受容体、又は共通ガンマ鎖ファミリーサイトカインに特異的に結合する抗原結合ドメインである、
請求項98~110のいずれか一項に記載の方法。 at least one of the one or more common gamma chain family cytokine receptor activators
(i) a first target binding domain;
(ii) a soluble tissue factor domain, and (iii) a second target binding domain, a single chain chimeric polypeptide,
one or both of said first target binding domain and said second target binding domain is a soluble common gamma chain family cytokine, an agonist antigen binding domain that specifically binds to a common gamma chain family cytokine receptor, a soluble common an antigen binding domain that specifically binds a gamma chain family cytokine receptor or a common gamma chain family cytokine;
The method of any one of claims 98-110.
(a)第1のキメラポリペプチドであって、
(i)第1の標的結合ドメイン、
(ii)可溶性組織因子ドメイン、及び
(iii)一対の親和性ドメインの第1のドメイン
を含む、前記第1のキメラポリペプチド、
(b)第2のキメラポリペプチドであって、
(i)一対の親和性ドメインの第2のドメイン、及び
(ii)第2の標的結合ドメイン
を含む、前記第2のキメラポリペプチド
を含み、
前記第1の標的結合ドメイン及び前記第2の標的結合ドメインのうちの一方又は両方が、可溶性共通ガンマ鎖ファミリーサイトカイン、共通ガンマ鎖ファミリーサイトカイン受容体に特異的に結合するアゴニスト抗原結合ドメイン、可溶性共通ガンマ鎖ファミリーサイトカイン受容体、又は共通ガンマ鎖ファミリーサイトカインに特異的に結合する抗原結合ドメインである、
請求項98~110のいずれか一項に記載の方法。 at least one of said one or more common gamma chain family cytokine receptor activators is a multi-chain chimeric polypeptide, said multi-chain chimeric polypeptide comprising:
(a) a first chimeric polypeptide,
(i) a first target binding domain;
(ii) a soluble tissue factor domain, and (iii) a first of a pair of affinity domains,
(b) a second chimeric polypeptide,
(i) a second of a pair of affinity domains; and (ii) a second target binding domain;
one or both of said first target binding domain and said second target binding domain is a soluble common gamma chain family cytokine, an agonist antigen binding domain that specifically binds to a common gamma chain family cytokine receptor, a soluble common an antigen binding domain that specifically binds a gamma chain family cytokine receptor or a common gamma chain family cytokine;
The method of any one of claims 98-110.
Applications Claiming Priority (7)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US202063032933P | 2020-06-01 | 2020-06-01 | |
| PCT/US2020/035598 WO2021247003A1 (en) | 2020-06-01 | 2020-06-01 | Methods of treating aging-related disorders |
| US63/032,933 | 2020-06-01 | ||
| USPCT/US2020/035598 | 2020-06-01 | ||
| US202063118536P | 2020-11-25 | 2020-11-25 | |
| US63/118,536 | 2020-11-25 | ||
| PCT/US2021/035285 WO2021247604A1 (en) | 2020-06-01 | 2021-06-01 | Methods of treating aging-related disorders |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2023527869A true JP2023527869A (en) | 2023-06-30 |
Family
ID=76523519
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2022573633A Pending JP2023527869A (en) | 2020-06-01 | 2021-06-01 | Treatments for age-related disorders |
Country Status (7)
| Country | Link |
|---|---|
| EP (1) | EP4157460A1 (en) |
| JP (1) | JP2023527869A (en) |
| KR (1) | KR20230031280A (en) |
| AU (1) | AU2021283199A1 (en) |
| CA (1) | CA3184756A1 (en) |
| IL (1) | IL298608A (en) |
| WO (1) | WO2021247604A1 (en) |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| IL310164A (en) * | 2021-08-11 | 2024-03-01 | Hcw Biologics Inc | Multi-chain chimeric polypeptides and use thereof in the treatment of liver diseases |
| WO2023168363A1 (en) * | 2022-03-02 | 2023-09-07 | HCW Biologics, Inc. | Method of treating pancreatic cancer |
Family Cites Families (65)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| GB9324807D0 (en) | 1993-12-03 | 1994-01-19 | Cancer Res Campaign Tech | Tumour antibody |
| US6117980A (en) | 1997-02-21 | 2000-09-12 | Genentech, Inc. | Humanized anti-IL-8 monoclonal antibodies |
| JP2001206899A (en) | 1999-11-18 | 2001-07-31 | Japan Tobacco Inc | HUMAN MONOCLONAL ANTIBODY AGAINST TGF-beta II TYPE RECEPTOR AND MEDICINAL USE THEREOF |
| WO2002051871A2 (en) | 2000-12-26 | 2002-07-04 | Institut National De La Sante Et De La Recherche Medicale (Inserm) | Anti-cd28 antibody |
| WO2003104425A2 (en) | 2002-06-07 | 2003-12-18 | The Government Of The United States Of America, As Represented By The Secretary Of The Department Of Health And Human Services | Novel stable anti-cd22 antibodies |
| CN1678744B (en) | 2002-08-30 | 2010-05-26 | 财团法人化学及血清疗法研究所 | Human antihuman interleukin-6 antibody and fragment of the antibody |
| EP1400534B1 (en) | 2002-09-10 | 2015-10-28 | Affimed GmbH | Human CD3-specific antibody with immunosuppressive properties |
| BR0316880A (en) | 2002-12-23 | 2005-10-25 | Wyeth Corp | Pd-1 Antibodies and Uses |
| KR20060015482A (en) | 2003-03-21 | 2006-02-17 | 와이어쓰 | Treating immunological disorder using agonists of interleukin-21/interleukin-21 receptor |
| US9005613B2 (en) | 2003-06-16 | 2015-04-14 | Immunomedics, Inc. | Anti-mucin antibodies for early detection and treatment of pancreatic cancer |
| NZ549040A (en) | 2004-02-17 | 2009-07-31 | Schering Corp | Use for interleukin-33 (IL33) and the IL-33 receptor complex |
| ATE531732T1 (en) | 2004-03-30 | 2011-11-15 | Yissum Res Dev Co | BI-SPECIFIC ANTIBODIES TARGETING CELLS INVOLVED IN ALLERGIC-TYPE REACTIONS, COMPOSITIONS AND USES THEREOF |
| CA2604357C (en) | 2005-04-26 | 2012-01-17 | Pfizer Inc. | P-cadherin antibodies |
| GB0510790D0 (en) | 2005-05-26 | 2005-06-29 | Syngenta Crop Protection Ag | Anti-CD16 binding molecules |
| US7612181B2 (en) | 2005-08-19 | 2009-11-03 | Abbott Laboratories | Dual variable domain immunoglobulin and uses thereof |
| US8092804B2 (en) | 2007-12-21 | 2012-01-10 | Medimmune Limited | Binding members for interleukin-4 receptor alpha (IL-4Rα)-173 |
| EP2604280A3 (en) | 2008-03-27 | 2013-10-16 | ZymoGenetics, Inc. | Compositions and methods for inhibiting PDGFRBETA and VEGF-A |
| RU2531523C3 (en) | 2008-06-25 | 2022-05-04 | Новартис Аг | STABLE AND SOLUBLE ANTIBODIES INHIBITING VEGF |
| JP5674654B2 (en) | 2008-07-08 | 2015-02-25 | アッヴィ・インコーポレイテッド | Prostaglandin E2 double variable domain immunoglobulin and use thereof |
| US9273136B2 (en) | 2008-08-04 | 2016-03-01 | The United States Of America, As Represented By The Secretary, Department Of Health And Human Services | Fully human anti-human NKG2D monoclonal antibodies |
| US8298533B2 (en) | 2008-11-07 | 2012-10-30 | Medimmune Limited | Antibodies to IL-1R1 |
| CN102245640B (en) | 2008-12-09 | 2014-12-31 | 霍夫曼-拉罗奇有限公司 | Anti-PD-L1 antibodies and their use to enhance T-cell function |
| TW201119673A (en) | 2009-09-01 | 2011-06-16 | Abbott Lab | Dual variable domain immunoglobulins and uses thereof |
| DE102009045006A1 (en) | 2009-09-25 | 2011-04-14 | Technische Universität Dresden | Anti-CD33 antibodies and their use for immuno-targeting in the treatment of CD33-associated diseases |
| TW201119676A (en) | 2009-10-15 | 2011-06-16 | Abbott Lab | Dual variable domain immunoglobulins and uses thereof |
| UY32979A (en) | 2009-10-28 | 2011-02-28 | Abbott Lab | IMMUNOGLOBULINS WITH DUAL VARIABLE DOMAIN AND USES OF THE SAME |
| SG182823A1 (en) | 2010-02-11 | 2012-09-27 | Alexion Pharma Inc | Therapeutic methods using an ti-cd200 antibodies |
| WO2011127324A2 (en) | 2010-04-08 | 2011-10-13 | JN Biosciences, LLC | Antibodies to cd122 |
| EP3363499A1 (en) | 2010-06-11 | 2018-08-22 | Kyowa Hakko Kirin Co., Ltd. | Anti-tim-3 antibody |
| CA2807014A1 (en) | 2010-08-03 | 2012-02-09 | Abbvie Inc. | Dual variable domain immunoglobulins and uses thereof |
| JP2012034668A (en) | 2010-08-12 | 2012-02-23 | Tohoku Univ | Fragment of humanized anti-egfr antibody substituted-lysine variable region, and use thereof |
| GB201103955D0 (en) | 2011-03-09 | 2011-04-20 | Antitope Ltd | Antibodies |
| MX336197B (en) | 2011-04-19 | 2016-01-11 | Merrimack Pharmaceuticals Inc | Monospecific and bispecific anti-igf-1r and anti-erbb3 antibodies. |
| LT2703486T (en) | 2011-04-25 | 2018-05-25 | Daiichi Sankyo Company, Limited | Anti-b7-h3 antibody |
| SG10201603962TA (en) | 2011-05-25 | 2016-07-28 | Innate Pharma Sa | Anti-kir antibodies for the treatment of inflammatory disorders |
| US8753640B2 (en) | 2011-05-31 | 2014-06-17 | University Of Washington Through Its Center For Commercialization | MIC-binding antibodies and methods of use thereof |
| US9403911B2 (en) | 2011-06-06 | 2016-08-02 | Board Of Regents Of The University Of Nebraska | Compositions and methods for detection and treatment of cancer |
| EP2723377B1 (en) | 2011-06-22 | 2018-06-13 | INSERM (Institut National de la Santé et de la Recherche Médicale) | Anti-axl antibodies and uses thereof |
| SG11201401699WA (en) | 2011-11-11 | 2014-09-26 | Rinat Neuroscience Corp | Antibodies specific for trop-2 and their uses |
| KR101535341B1 (en) | 2012-07-02 | 2015-07-13 | 한화케미칼 주식회사 | Novel monoclonal antibody that specifically binds to DLL4 and use thereof |
| CN104540848B (en) | 2012-08-08 | 2019-05-31 | 罗切格利卡特公司 | Interleukin-10 fusion protein and application thereof |
| US20150218280A1 (en) | 2012-08-10 | 2015-08-06 | University Of Southern California | CD20 scFv-ELPs METHODS AND THERAPEUTICS |
| WO2014033130A1 (en) | 2012-08-28 | 2014-03-06 | Institut Curie | Cluster of differentiation 36 (cd36) as a therapeutic target for hiv infection |
| LT2922875T (en) | 2012-11-20 | 2017-06-12 | Sanofi | Anti-ceacam5 antibodies and uses thereof |
| ES2895848T3 (en) | 2012-12-17 | 2022-02-22 | Cell Medica Inc | Antibodies against IL-1 beta |
| UY35340A (en) | 2013-02-20 | 2014-09-30 | Novartis Ag | EFFECTIVE MARKING OF HUMAN LEUKEMIA USING CELLS DESIGNED WITH AN ANTIGEN CHEMERIC RECEIVER ANTI-CD123 |
| US9790274B2 (en) | 2013-03-14 | 2017-10-17 | The Board Of Regents Of The University Of Texas System | Monoclonal antibodies targeting EpCAM for detection of prostate cancer lymph node metastases |
| US9701758B2 (en) | 2013-05-24 | 2017-07-11 | Board Of Regents, The University Of Texas System | Anti-CD19 scFv (FMC63) polypeptide |
| KR102127408B1 (en) | 2014-01-29 | 2020-06-29 | 삼성전자주식회사 | Anti-Her3 scFv fragment and Bispecific anti-c-Met/anti-Her3 antibodies comprising the same |
| JOP20200096A1 (en) | 2014-01-31 | 2017-06-16 | Children’S Medical Center Corp | Antibody molecules to tim-3 and uses thereof |
| FR3021970B1 (en) | 2014-06-06 | 2018-01-26 | Universite Sciences Technologies Lille | ANTIBODY AGAINST GALECTIN 9 AND INHIBITOR OF THE SUPPRESSIVE ACTIVITY OF T REGULATORY LYMPHOCYTES |
| TWI790593B (en) | 2014-08-19 | 2023-01-21 | 美商默沙東有限責任公司 | Anti-tigit antibodies |
| US10221248B2 (en) | 2014-12-22 | 2019-03-05 | The Rockefeller University | Anti-MERTK agonistic antibodies and uses thereof |
| US10744157B2 (en) | 2015-03-26 | 2020-08-18 | The Trustees Of Dartmouth College | Anti-MICA antigen binding fragments, fusion molecules, cells which express and methods of using |
| WO2016166348A1 (en) | 2015-04-17 | 2016-10-20 | Elsalys Biotech | Anti-tyro3 antibodies and uses thereof |
| PL3328894T3 (en) | 2015-08-06 | 2019-05-31 | Agency Science Tech & Res | Il2rbeta/common gamma chain antibodies |
| KR20200087283A (en) | 2015-09-25 | 2020-07-20 | 제넨테크, 인크. | Anti-tigit antibodies and methods of use |
| CN114853907A (en) | 2015-11-13 | 2022-08-05 | 达纳-法伯癌症研究所有限公司 | NKG2D-IG fusion protein for cancer immunotherapy |
| BR112018067522A2 (en) | 2016-03-01 | 2019-02-05 | Univ Of Rijeka Faculty Of Medicine | human poliovirus receptor (pvr) specific antibodies |
| WO2017189526A1 (en) | 2016-04-25 | 2017-11-02 | Musc Foundation For Research Development | Activated cd26-high immune cells and cd26-negative immune cells and uses thereof |
| EP3565846A4 (en) * | 2017-01-03 | 2020-01-22 | Bioatla, LLC | Protein therapeutics for treatment of senescent cells |
| US11161890B2 (en) * | 2017-08-28 | 2021-11-02 | Altor Bioscience LLC. | IL-15-based fusions to IL-7 and IL-21 |
| EP3843788A1 (en) * | 2018-08-30 | 2021-07-07 | HCW Biologics, Inc. | Single-chain chimeric polypeptides and uses thereof |
| US11518792B2 (en) * | 2018-08-30 | 2022-12-06 | HCW Biologics, Inc. | Multi-chain chimeric polypeptides and uses thereof |
| JP2021534835A (en) * | 2018-08-30 | 2021-12-16 | エイチシーダブリュー バイオロジックス インコーポレイテッド | Single-chain and multi-chain chimeric polypeptides and how to use them |
-
2021
- 2021-06-01 KR KR1020237000057A patent/KR20230031280A/en unknown
- 2021-06-01 EP EP21733685.8A patent/EP4157460A1/en active Pending
- 2021-06-01 JP JP2022573633A patent/JP2023527869A/en active Pending
- 2021-06-01 IL IL298608A patent/IL298608A/en unknown
- 2021-06-01 CA CA3184756A patent/CA3184756A1/en active Pending
- 2021-06-01 WO PCT/US2021/035285 patent/WO2021247604A1/en unknown
- 2021-06-01 AU AU2021283199A patent/AU2021283199A1/en active Pending
Also Published As
| Publication number | Publication date |
|---|---|
| WO2021247604A1 (en) | 2021-12-09 |
| EP4157460A1 (en) | 2023-04-05 |
| AU2021283199A1 (en) | 2023-01-05 |
| KR20230031280A (en) | 2023-03-07 |
| CA3184756A1 (en) | 2021-12-09 |
| IL298608A (en) | 2023-01-01 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7449292B2 (en) | Treatments for age-related disorders | |
| US20220073578A1 (en) | Methods of treating aging-related disorders | |
| KR102616429B1 (en) | Anti-cd123 chimeric antigen receptor (car) for use in cancer treatment | |
| RU2708032C2 (en) | CANCER TREATMENT USING CHIMERIC ANTIGEN-SPECIFIC RECEPTOR BASED ON HUMANISED ANTI-EGFRvIII ANTIBODY | |
| JP2019206538A (en) | Treatment of cancer using chimeric antigen receptor | |
| TW201841940A (en) | Anti-lag3 antibodies | |
| JP2019513347A (en) | Cells expressing multiple chimeric antigen receptor (CAR) molecules and uses thereof | |
| US11883398B2 (en) | Dipeptidylpeptidase 4 inhibition enhances lymphocyte trafficking, improving both naturally occurring tumor immunity and immunotherapy | |
| CA2939543C (en) | Il-21 antibodies | |
| JP2023527869A (en) | Treatments for age-related disorders | |
| JP2020503252A (en) | Method for promoting a T cell response | |
| TW202108629A (en) | Antibodies for t-cell activation | |
| US20230332104A1 (en) | Zbtb32 inhibitors and uses thereof | |
| EP3101035B1 (en) | Bifunctional fusion protein, preparation method therefor, and use thereof | |
| WO2021247003A1 (en) | Methods of treating aging-related disorders | |
| WO2023019215A1 (en) | Multi-chain chimeric polypeptides and use thereof in the treatment of liver diseases | |
| CN117120072A (en) | Methods of treating aging-related disorders | |
| TWI790193B (en) | Methods and antibodies for modulation of immunoresponse | |
| Mansurov | Exploiting Tumor-Intrinsic Cues to Engineer Interleukin-12 for Cancer Immunotherapy |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20221212 |
|
| RD04 | Notification of resignation of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7424 Effective date: 20230628 |