JP2021197110A - Tactile sense metadata generation device, video tactile sense interlocking system, and program - Google Patents
Tactile sense metadata generation device, video tactile sense interlocking system, and program Download PDFInfo
- Publication number
- JP2021197110A JP2021197110A JP2020105700A JP2020105700A JP2021197110A JP 2021197110 A JP2021197110 A JP 2021197110A JP 2020105700 A JP2020105700 A JP 2020105700A JP 2020105700 A JP2020105700 A JP 2020105700A JP 2021197110 A JP2021197110 A JP 2021197110A
- Authority
- JP
- Japan
- Prior art keywords
- person
- tactile
- skeleton
- metadata
- locus
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images







Landscapes
- Image Analysis (AREA)
Abstract
Description
本発明は、映像から人物オブジェクトを抽出し、動的な人物オブジェクトに対応する触覚メタデータを生成する触覚メタデータ生成装置、生成した触覚メタデータを基に触覚提示デバイスを駆動制御する映像触覚連動システム、及びプログラムに関する。 The present invention is a tactile metadata generator that extracts a person object from an image and generates tactile metadata corresponding to a dynamic person object, and an image tactile interlocking that drives and controls a tactile presentation device based on the generated tactile metadata. Regarding systems and programs.
放送映像等の一般的なカメラ映像の映像コンテンツは、視覚と聴覚の2つの感覚に訴える情報を提供するメディアである。しかし、視覚障害者や聴覚障害者に対しては視聴覚情報だけでは不十分であり、番組コンテンツの状況を正確に伝えることができない。そのため、テレビを持っていない、若しくは持っていても視聴しない障害者も多い。そこで、映像コンテンツに対し、視覚・聴覚以外の“触覚”で感じられる情報を提示することで、視覚又は聴覚の障害者もテレビ放送を理解できるシステムの構築が望まれる。 The video content of a general camera image such as a broadcast image is a medium that provides information that appeals to the two senses of sight and hearing. However, audiovisual information alone is not sufficient for the visually impaired and the hearing impaired, and it is not possible to accurately convey the status of the program content. Therefore, many people with disabilities do not have a TV, or even if they do, they do not watch. Therefore, it is desired to construct a system that allows visually or hearing impaired people to understand television broadcasting by presenting information that can be felt by "tactile sense" other than visual and auditory senses to video contents.
また、視覚・聴覚の感覚を有する健常者にとっても、また、触覚刺激を提示することにより放送番組の視聴時の臨場感や没入感の向上が期待できる。特に、スポーツコンテンツにおける人物の動きは重要な情報であり、これを触覚刺激で提示することにより、コンテンツ視聴における臨場感が高まる。 Further, even for a healthy person having a sense of sight and hearing, by presenting a tactile stimulus, it can be expected to improve the sense of presence and immersiveness when watching a broadcast program. In particular, the movement of a person in sports content is important information, and by presenting this with a tactile stimulus, the sense of presence in viewing the content is enhanced.
例えば、野球映像を視聴する際、ボールがバットに当たるタイミングで触覚提示デバイスを介して視聴者に刺激を与えることで、バッターのヒッティングの感覚を疑似体験できる。また、視覚に障害のある方々に触覚刺激を提供することで、スポーツの試合状況を理解させることにも繋がると考えられる。このように、触覚は映像視聴における第3の感覚として期待されている。 For example, when watching a baseball video, the batter's hitting sensation can be simulated by stimulating the viewer via a tactile presentation device at the timing when the ball hits the bat. In addition, by providing tactile stimuli to visually impaired people, it is thought that it will lead to understanding the game situation of sports. Thus, tactile sensation is expected as a third sensation in video viewing.
特に、スポーツはリアルタイムでの映像視聴が重要視されるため、映像に対する触覚刺激の提示は、自動、且つリアルタイムで行われる必要がある。そこで、プレーの種類、タイミング、状況などに関する選手の動きに同期した触覚刺激の提示が、触覚を併用した映像コンテンツの映像視聴に効果的な場合が多い。そして、視覚又は聴覚に障害を持つ方々にもスポーツの状況を伝えることが可能となる。 In particular, since real-time video viewing is important in sports, the presentation of tactile stimuli for video needs to be performed automatically and in real time. Therefore, the presentation of tactile stimuli synchronized with the player's movements regarding the type, timing, situation, etc. of play is often effective for viewing video content that also uses tactile sensation. Then, it becomes possible to convey the situation of sports to people with visual or hearing disabilities.
このため、触覚を併用した映像コンテンツの映像視聴を実現するには、その映像コンテンツから人物オブジェクトの動きを抽出し、抽出した人物オブジェクトの動きに対応した触覚情報を触覚メタデータとして生成することが必要になる。 Therefore, in order to realize video viewing of video content that also uses tactile sensation, it is necessary to extract the movement of a person object from the video content and generate tactile information corresponding to the movement of the extracted person object as tactile metadata. You will need it.
しかし、従来の触覚メタデータの生成法では、触覚を併用した映像視聴を実現するとしても、触覚提示デバイスにより、どのようなタイミングで、またどのような刺激をユーザに提示するかを示す触覚メタデータを、映像と同期した態様で人手により編集する必要があった。 However, even if the conventional method of generating tactile metadata realizes video viewing using tactile sensation, tactile metadata indicating at what timing and what kind of stimulus is presented to the user by the tactile presentation device. It was necessary to manually edit the data in a manner synchronized with the video.
収録番組の場合、人手で時間をかけて触覚メタデータを編集することが可能である。しかし、生放送映像に対して触覚提示デバイスによる刺激提示を連動させるには、事前に触覚情報を編集することができないことから、リアルタイムで映像コンテンツの映像解析を行い、触覚メタデータを生成することが要求される。 In the case of recorded programs, it is possible to manually edit the tactile metadata over time. However, in order to link the stimulus presentation by the tactile presentation device to the live broadcast video, it is not possible to edit the tactile information in advance, so it is necessary to perform video analysis of the video content in real time and generate tactile metadata. Required.
近年、スポーツ映像解析技術は、目覚ましい成長を遂げている。ウィンブルドンでも使用されているテニスのホークアイシステムは、複数の固定カメラ映像をセンサとしてテニスボールを3次元的に追跡し、ジャッジに絡むIN/OUTの判定を行っている。また2014年のFIFAワールドカップでは、ゴールラインテクノロジーと称して、数台の固定カメラの映像を解析し、ゴールの判定を自動化している。更に、サッカースタジアムへ多数のステレオカメラを設定し、フィールド内の全選手をリアルタイムに追跡するTRACABシステム等、スポーツにおけるリアルタイム映像解析技術の高度化が進んでいる。 In recent years, sports video analysis technology has achieved remarkable growth. The tennis Hawkeye system, which is also used in Wimbledon, tracks a tennis ball three-dimensionally using a plurality of fixed camera images as sensors, and determines IN / OUT related to the judge. In addition, at the 2014 FIFA World Cup, called goal line technology, images from several fixed cameras are analyzed to automate goal determination. Furthermore, the sophistication of real-time video analysis technology in sports, such as the TRACAB system that sets a large number of stereo cameras in a soccer stadium and tracks all players in the field in real time, is advancing.
一方で、動的な人物オブジェクトとして選手の姿勢を計測するには、従来、マーカー式のモーションキャプチャー方式を用いた計測が一般的である。しかし、この方式は、選手の体に多数のマーカーを装着する必要があり、実試合には適用できない。そこで、近年では、選手の体に投光されている赤外線パターンを読み取り、その赤外線パターンの歪みから深度情報を得る深度センサを用いることで、マーカーレスでの人物姿勢計測が可能になっている。また、マーカー式ではなく、光学式のモーションキャプチャー方式を応用した種々の技術が開示されている(例えば、特許文献1,2参照)。 On the other hand, in order to measure the posture of a player as a dynamic person object, the measurement using a marker-type motion capture method is generally used. However, this method requires a large number of markers to be attached to the player's body and cannot be applied to actual games. Therefore, in recent years, it has become possible to measure a person's posture without a marker by using a depth sensor that reads an infrared pattern projected on a player's body and obtains depth information from the distortion of the infrared pattern. Further, various techniques applying an optical motion capture method instead of a marker type are disclosed (see, for example, Patent Documents 1 and 2).
例えば、特許文献1では、立体視を用いた仮想現実システムにおいて他者の模範動作映像を表示することにより使用者に対して動作を教示する際に、光学式のモーションキャプチャー方式により、計測対象者の骨格の3次元位置を計測する装置が開示されている。また、特許文献2には、光学式のモーションキャプチャー方式を利用してプレイヤーの動作を測定し、測定したデータとモデルのフォームに関するデータとに基づいて同プレイヤーのフォームを評価するトレーニング評価装置について開示されている。しかし、これらの技術は、モーションキャプチャー方式を利用するため、実際の試合に適用できず、汎用的なカメラ映像から人物のプレー動作を計測することは難しい。
For example, in Patent Document 1, when teaching an operation to a user by displaying a model operation image of another person in a virtual reality system using stereoscopic vision, a measurement target person uses an optical motion capture method. A device for measuring the three-dimensional position of the skeleton of the above is disclosed. Further,
また、モーションキャプチャー方式によらず、一人又は二人が一組となってバドミントンの試合やバドミントン練習を撮影したカメラ映像のみから、人物の動きをシミュレートする装置が開示されている(例えば、特許文献3参照)。特許文献3の技術では、撮影したカメラ映像から、ショットなどの動作を検出するものとなっているが、専用に設定したカメラによる撮影映像から処理することを前提としており、汎用的な放送カメラ映像から人物のプレー動作を計測することは難しい。 Further, regardless of the motion capture method, a device that simulates the movement of a person is disclosed only from a camera image of a badminton game or badminton practice taken by one or two people as a group (for example, a patent). See Document 3). In the technology of Patent Document 3, the motion such as a shot is detected from the captured camera image, but it is premised that the processing is performed from the captured image by the dedicated camera, and the general-purpose broadcast camera image is used. It is difficult to measure a person's playing behavior from.
ところで、近年の深層学習技術の発達により、深度センサを用いずに、従来では困難であった深度情報を含まない通常の静止画像から人物の骨格位置を推定することが可能になっている。この深層学習技術を用いることで、通常のカメラ映像から静止画像を抽出し、その静止画像に含まれる選手の姿勢を自動計測することが可能となっている。 By the way, with the development of deep learning technology in recent years, it has become possible to estimate the skeleton position of a person from a normal still image that does not include depth information, which was difficult in the past, without using a depth sensor. By using this deep learning technique, it is possible to extract a still image from a normal camera image and automatically measure the posture of the athlete included in the still image.
上述したように、触覚を併用した映像コンテンツの映像視聴を実現するには、その映像コンテンツから人物オブジェクトの動きを抽出し、抽出した人物オブジェクトの動きに対応した触覚情報を触覚メタデータとして生成することが必要になる。 As described above, in order to realize video viewing of video content using tactile sensation, the movement of a person object is extracted from the video content, and tactile information corresponding to the extracted movement of the person object is generated as tactile metadata. Is needed.
しかし、従来技術では、リアルタイムで映像コンテンツの映像解析のみから、触覚メタデータを生成することが困難である。即ち、映像のみから触覚メタデータを生成する場合には、カメラ映像からリアルタイムで人物オブジェクトの動きを解析する必要がある。リアルタイムのスポーツ競技では、その競技に影響を与えることは好ましくないため、マーカー装着によるモーションキャプチャー方式や、撮影距離に制限のある深度センサなどを用いずに、撮影条件に制限の無い汎用的な放送カメラ映像のみから触覚メタデータを生成することが望ましい。 However, with the prior art, it is difficult to generate tactile metadata only from video analysis of video content in real time. That is, when generating tactile metadata only from a video, it is necessary to analyze the movement of a person object in real time from the camera video. In real-time sports competitions, it is not desirable to affect the competition, so general-purpose broadcasting with unlimited shooting conditions without using a motion capture method with markers or a depth sensor with a limited shooting distance. It is desirable to generate tactile metadata only from camera images.
つまり、スポーツを撮影する通常のカメラ映像のみから、自動、且つリアルタイムで人物オブジェクト(選手等)の動きに関する触覚メタデータを生成する技法が望まれる。 That is, a technique for automatically and in real time generating tactile metadata regarding the movement of a person object (player, etc.) is desired from only a normal camera image for shooting sports.
また、人物オブジェクトの動きを高精度に検出するために、人物以外の動オブジェクト(例えば、バドミントン競技であればシャトル、ラケット)を参考する技法も考えられるが、参考とする人物以外の動オブジェクトが存在しない競技(例えば、柔道やレスリング等)においても、人物オブジェクトの動きを高精度に検出する技法が望まれる。 Also, in order to detect the movement of a person object with high accuracy, a technique of referring to a motion object other than the person (for example, shuttle, racket in the case of badminton competition) can be considered, but the motion object other than the reference person is Even in non-existent competitions (for example, judo and wrestling), a technique for detecting the movement of a person object with high accuracy is desired.
尚、近年の深層学習技術の発達により、深度センサを用いずに、従来では困難であった深度情報を含まない通常の静止画像から人物の骨格位置を推定することが可能になっているが、これに代表される骨格検出アルゴリズムは基本的に静止画単位で骨格位置を検出するものである。このため、スポーツを撮影する通常のカメラ映像のみから、自動、且つリアルタイムで人物オブジェクト(選手等)の動きに関する触覚メタデータを生成するには、更なる工夫が必要になる。 With the recent development of deep learning technology, it has become possible to estimate the skeleton position of a person from a normal still image that does not include depth information, which was difficult in the past, without using a depth sensor. The skeleton detection algorithm represented by this basically detects the skeleton position in units of still images. For this reason, further ingenuity is required to automatically and in real time generate tactile metadata related to the movement of a person object (player, etc.) from only a normal camera image for shooting sports.
本発明の目的は、上述の問題に鑑みて、映像から人物オブジェクトを自動抽出し、動的な人物オブジェクトに対応する触覚メタデータを同期して自動生成する触覚メタデータ生成装置、生成した触覚メタデータを基に触覚提示デバイスを駆動制御する映像触覚連動システム、及びプログラムを提供することにある。 In view of the above problems, an object of the present invention is a tactile metadata generator that automatically extracts a person object from a video and synchronizes and automatically generates tactile metadata corresponding to a dynamic person object, and a generated tactile meta. It is an object of the present invention to provide a video-tactile interlocking system and a program for driving and controlling a tactile presentation device based on data.
本発明の触覚メタデータ生成装置は、映像から人物オブジェクトを抽出し、動的な人物オブジェクトに対応する触覚メタデータを生成する触覚メタデータ生成装置であって、入力された映像について、現フレーム画像を含む複数フレーム分の過去のフレーム画像を抽出する複数フレーム抽出手段と、前記現フレーム画像を含む複数フレーム分のフレーム画像の各々について、骨格検出アルゴリズムに基づき、各人物オブジェクトの第1の骨格座標集合を生成する人物骨格抽出手段と、前記現フレーム画像を含む複数フレーム分のフレーム画像の各々について、前記第1の骨格座標集合を基に探索範囲を可変設定し、各人物オブジェクトの骨格の位置及びサイズと、その周辺画像情報を抽出することにより人物オブジェクトを識別し、人物IDを付与した第2の骨格座標集合を生成する人物識別手段と、前記現フレーム画像を基準に、前記複数フレーム分のフレーム画像における前記第2の骨格座標集合を時系列に連結し、人物オブジェクト毎の骨格の軌跡を示す軌跡特徴量の集合として骨格軌跡集合を生成する軌跡特徴量生成手段と、前記現フレーム画像を基準に、当該複数フレーム分のフレーム画像における骨格軌跡集合を基準とした各人物オブジェクト間の距離、及び人物オブジェクト毎の各関節のオプティカルフロー量から各人物オブジェクトの人物動きの状況変化量を算出するとともに、骨格検出の成否、人物骨格の重心の移動量、及び前記探索範囲を表す骨格外接矩形のアスペクト比の変化量を算出し、これらを要素とする特徴ベクトルを、動作状況を表す動作状況特徴量として生成する動作状況計測手段と、前記骨格軌跡集合の軌跡特徴量と、当該骨格軌跡集合の軌跡特徴量に対応する動作状況特徴量とを基に、機械学習により、触覚提示デバイスを作動させる衝撃提示用の情報を検出する人物動作認識手段と、前記現フレーム画像に対応して、前記人物動作認識手段から得られる当該触覚提示デバイスを作動させる衝撃提示用の情報を含む第1の触覚メタデータを生成し、フレーム単位で外部出力する第1のメタデータ生成手段と、前記現フレーム画像に対応して、前記動作状況計測手段から得られる各人物オブジェクトの人物動きの状況変化量を示す動作状況提示用の情報を含む第2の触覚メタデータを生成し、フレーム単位で外部出力する第2のメタデータ生成手段と、を備えることを特徴とする。 The tactile metadata generation device of the present invention is a tactile metadata generation device that extracts a person object from an image and generates tactile metadata corresponding to a dynamic person object, and is a current frame image of the input image. The first skeletal coordinates of each person object based on the skeletal detection algorithm for each of the multi-frame extraction means for extracting the past frame images for a plurality of frames including the current frame image and the frame images for the plurality of frames including the current frame image. The search range is variably set based on the first skeleton coordinate set for each of the person skeleton extraction means for generating a set and the frame images for a plurality of frames including the current frame image, and the position of the skeleton of each person object is set. A person identification means that identifies a person object by extracting the size and its surrounding image information and generates a second skeleton coordinate set to which a person ID is given, and the plurality of frames based on the current frame image. A locus feature amount generating means that connects the second skeleton coordinate set in the frame image of the above in time series and generates a skeleton locus set as a set of locus features showing the locus of the skeleton for each person object, and the current frame image. The amount of change in the person movement of each person object is calculated from the distance between each person object based on the skeletal trajectory set in the frame image for the multiple frames and the optical flow amount of each joint for each person object. At the same time, the success or failure of skeletal detection, the amount of movement of the center of gravity of the human skeleton, and the amount of change in the aspect ratio of the skeletal circumscribing rectangle representing the search range are calculated, and the feature vector using these as elements is used as the operating status to represent the operating status. The tactile presentation device is operated by machine learning based on the motion status measuring means generated as the feature quantity, the trajectory feature quantity of the skeletal trajectory set, and the motion status feature quantity corresponding to the trajectory feature quantity of the skeletal trajectory set. A first tactile sensation including a person motion recognizing means for detecting information for impact presentation and information for impact presentation for activating the tactile sensation presenting device obtained from the person motion recognizing means corresponding to the current frame image. The amount of change in the person movement of each person object obtained from the operation state measurement means corresponding to the first metadata generation means that generates metadata and externally outputs it in frame units and the current frame image is shown. It is characterized by comprising a second metadata generation means for generating a second tactile data including information for presenting an operation status and externally outputting it in frame units.
また、本発明の触覚メタデータ生成装置において、前記人物識別手段は、前記探索範囲として、最大で人物骨格の全体を囲む人物探索範囲に限定し、最小で人物骨格のうち所定領域を注目探索範囲として定めた絞り込みによる可変設定を行い、状態推定アルゴリズムで得られる人物の骨格の状態遷移推定値に基づいて、少なくとも前記注目探索範囲を含むように前記探索範囲を決定して、当該人物オブジェクトを識別する処理を行う手段を有することを特徴とする。 Further, in the tactile metadata generation device of the present invention, the person identification means is limited to a person search range that surrounds the entire human skeleton at the maximum as the search range, and a predetermined area of the human skeleton is the attention search range at the minimum. The search range is determined so as to include at least the attention search range based on the state transition estimated value of the skeleton of the person obtained by the state estimation algorithm, and the person object is identified. It is characterized by having a means for performing the processing.
また、本発明の触覚メタデータ生成装置において、前記現フレーム画像を含む複数フレーム分のフレーム画像の各々を用いて隣接フレーム間の差分画像を基に動オブジェクトを検出し、各差分画像から検出した動オブジェクトのうち全ての人物オブジェクトの前記骨格軌跡集合を用いて特定の動オブジェクトを選定し、各差分画像から得られる特定の動オブジェクトの座標位置、大きさ、移動方向を要素とし連結した動オブジェクト情報を生成する動オブジェクト検出手段を更に備え、前記人物動作認識手段は、前記動オブジェクト情報を基に、全ての人物オブジェクトの前記骨格軌跡集合のうち前記触覚提示デバイスを作動させるための骨格軌跡集合を選定し、選定した骨格軌跡集合の軌跡特徴量と、その選定した骨格軌跡集合に対応する動作状況特徴量とを基に、機械学習により、人物オブジェクト毎の衝撃提示用のタイミング及び速さを示す情報を検出することを特徴とする。 Further, in the tactile metadata generation device of the present invention, a moving object is detected based on the difference image between adjacent frames using each of the frame images for a plurality of frames including the current frame image, and the moving object is detected from each difference image. A specific moving object is selected using the skeleton locus set of all the moving objects among the moving objects, and the moving object is connected with the coordinate position, size, and moving direction of the specific moving object obtained from each difference image as elements. The moving object detecting means for generating information is further provided, and the person motion recognition means is a skeleton locus set for operating the tactile presentation device among the skeleton locus sets of all the person objects based on the moving object information. Based on the locus feature amount of the selected skeletal locus set and the operation status feature amount corresponding to the selected skeletal locus set, the timing and speed for impact presentation for each person object can be determined by machine learning. It is characterized by detecting the indicated information.
また、本発明の映像触覚連動システムは、本発明の触覚メタデータ生成装置と、触覚刺激を提示する触覚提示デバイスと、前記触覚メタデータ生成装置から得られる第1及び第2の触覚メタデータを基に、予め定めた駆動基準データを参照し、前記触覚提示デバイスを駆動するよう制御する制御ユニットと、を備えることを特徴とする。 Further, the video-tactile interlocking system of the present invention uses the tactile metadata generation device of the present invention, the tactile presentation device for presenting the tactile stimulus, and the first and second tactile metadata obtained from the tactile metadata generation device. Based on this, it is characterized by including a control unit that controls to drive the tactile presentation device by referring to predetermined drive reference data.
更に、本発明のプログラムは、コンピュータを、本発明の触覚メタデータ生成装置として機能させるためのプログラムとして構成する。 Further, the program of the present invention is configured as a program for making the computer function as the tactile metadata generator of the present invention.
本発明によれば、映像から人物オブジェクトを自動抽出し、動的な人物オブジェクトに対応する触覚メタデータを同期して自動生成することができる。そして、人物オブジェクトに生じる「衝撃の種類とタイミング」を表す第1の触覚メタデータだけでなく、人物オブジェクトに係る連続的な「動作状況」を表す第2の触覚メタデータをも自動生成できるようになる。これにより、スポーツ映像のリアルタイム視聴時での触覚刺激の提示が可能となり、更には、人物オブジェクトの重なりやオクルージョンが生じやすい柔道等の試合映像での詳細な触覚提示も可能となる。つまり、視覚・聴覚への情報提供のみならず、触覚にも訴えることで、視覚や聴覚に障害を持つ方々へもスポーツの状況を分かりやすく伝えることが可能となる。さらに、視覚・聴覚の感覚を有する健常者の方々にとっても、従来の映像視聴では伝えきれない臨場感や没入感を提供することができる。 According to the present invention, a person object can be automatically extracted from a video, and tactile metadata corresponding to the dynamic person object can be automatically generated in synchronization. Then, not only the first tactile metadata representing the "type and timing of impact" generated in the person object but also the second tactile metadata representing the continuous "operation status" related to the person object can be automatically generated. become. As a result, it is possible to present tactile stimuli during real-time viewing of sports images, and it is also possible to present detailed tactile sensations in match images such as judo where overlapping of human objects and occlusion are likely to occur. In other words, by appealing not only to the sense of sight and hearing but also to the sense of touch, it is possible to convey the situation of sports to people with visual and hearing disabilities in an easy-to-understand manner. Furthermore, even for healthy people who have a sense of sight and hearing, it is possible to provide a sense of presence and immersiveness that cannot be conveyed by conventional video viewing.
特に、スポーツ映像視聴に際し、各選手の識別、位置座標、及びチーム競技であればその分類、並びに、触覚提示デバイスを作動させる種類(衝撃強度の種類)とタイミング(速さを含む)、並びに動作状況を示す情報を含む触覚メタデータを生成することで、触覚提示デバイスにより、動作の状況変化とともに、プレーの種類、タイミング、強度などに関する触覚刺激をユーザに提示できるようになる。これにより、触覚情報を用いたパブリックビューイング、エンターテインメント、将来の触覚放送などのサービス性の向上に繋がる。また、スポーツ以外でも、工場での触覚アラームへの応用や、監視カメラ映像解析に基づいたセキュリティシステムなど、様々な用途に応用することも可能になる。 In particular, when watching sports videos, the identification of each player, the position coordinates, and the classification if it is a team competition, the type (type of impact strength) and timing (including speed) of operating the tactile presentation device, and the operation. By generating tactile metadata that includes information indicating the situation, the tactile presentation device can present the user with tactile stimuli regarding the type, timing, intensity, etc. of play as well as changes in the situation of movement. This will lead to improvements in services such as public viewing using tactile information, entertainment, and future tactile broadcasting. In addition to sports, it can also be applied to various applications such as tactile alarms in factories and security systems based on surveillance camera image analysis.
(システム構成)
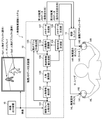
以下、図面を参照して、本発明による一実施形態の触覚メタデータ生成装置12を備える映像触覚連動システム1について詳細に説明する。図1は、本発明による一実施形態の触覚メタデータ生成装置12を備える映像触覚連動システム1の概略構成を示すブロック図である。
(System configuration)
Hereinafter, the image tactile interlocking system 1 provided with the tactile
図1に示す映像触覚連動システム1は、カメラや記録装置等の映像出力装置10から映像を入力し、入力された映像から人物オブジェクトを自動抽出し、動的な人物オブジェクトに対応する触覚メタデータ(第1の触覚メタデータと第2の触覚メタデータの2種類)を同期して自動生成する触覚メタデータ生成装置12と、生成した触覚メタデータを基に、本例では2台の触覚提示デバイス14L,14Rと、各触覚提示デバイス14L,14Rを個別に駆動制御する制御ユニット13と、を備える。
The video tactile interlocking system 1 shown in FIG. 1 inputs video from a
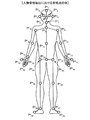
まず、映像出力装置10が出力する映像は、一例として柔道競技をリアルタイムで撮影されたものとしてディスプレイ11に表示され、ユーザUによって視覚されるものとする。
First, it is assumed that the video output by the
柔道競技は、二人の選手が組み合って、「抑え込み」や「投げ」などの技を競うスポーツであり、各人物に衝撃が生じた瞬間や各人物の動きの状況変化を触覚提示デバイス14L,14Rにより触覚刺激としてユーザUに提示することで、より臨場感を高め、また視聴覚障害者にも試合状況を伝えることが可能である。 Judo competition is a sport in which two athletes combine to compete for techniques such as "holding down" and "throwing". By presenting it to the user U as a tactile stimulus by 14R, it is possible to further enhance the sense of presence and to inform the audiovisually impaired person of the game situation.
特に、柔道競技では、映像上で選手同士の重なりやオクルージョンが多数生じるため、各選手に生じる衝撃の種類に応じたタイミングと速さ以外にも、各選手の押し引きなどの組み合い、投げ等に係る動作状況を連続的に触覚提示できるようにすることで、視覚や聴覚の障害者にも試合の緊迫感を伝えることができ、また臨場感を高めることができる。 In particular, in judo competitions, there are many overlaps and occlusions between players on the video, so in addition to the timing and speed according to the type of impact that occurs on each player, it is also possible to combine and throw each player's push and pull. By making it possible to continuously present the tactile sensation, it is possible to convey the sense of urgency of the game to the visually and hearing impaired, and to enhance the sense of presence.
そこで、ユーザUは、左手HLで触覚提示デバイス14Lを把持し、右手HRで触覚提示デバイス14Rを把持して、本例では映像解析に同期した振動刺激が提示されるものとする。制御ユニット13は、触覚メタデータ生成装置12から得られる各人物オブジェクトOp1,Op2に生じる衝撃の種類に応じたタイミングと速さを示す衝撃提示用の情報を含む第1の触覚メタデータと、各人物オブジェクトOp1,Op2に係る連続的な「動作状況」を表す動作状況提示用の情報を含む第2の触覚メタデータを基に、各人物オブジェクトOp1,Op2に対応付けられた2台の触覚提示デバイス14L,14Rの触覚提示を個別に制御する。ただし、制御ユニット13は、1台の触覚提示デバイスに対してのみ駆動制御する形態でもよいし、3台以上の触覚提示デバイスに対して個別に駆動制御する形態でもよい。また、限定するものではないが、本例の制御ユニット13は、映像内の人物オブジェクトOp1(選手)の動きに対応した振動刺激は触覚提示デバイス14Lで、人物オブジェクトOp2(選手)の動きに対応した振動刺激は触覚提示デバイス14Rで提示するように分類して制御するものとする。
Therefore, it is assumed that the user U grips the tactile presentation device 14L with the left hand HL and the tactile presentation device 14R with the right hand HR, and in this example, the vibration stimulus synchronized with the image analysis is presented. The
触覚提示デバイス14L,14Rは、球状のケース141内に、制御ユニット13の制御によって振動刺激を提示可能な振動アクチュエーター142が収容されている。尚、触覚提示デバイス14L,14Rは、振動刺激の他、電磁気パルス刺激を提示するものでもよい。本例では、制御ユニット13と各触覚提示デバイス14L,14Rとの間は有線接続され、触覚メタデータ生成装置12と制御ユニット13との間も有線接続されている形態を例に説明するが、それぞれ近距離無線通信で無線接続されている形態としてもよい。
In the tactile presentation devices 14L and 14R, a
触覚メタデータ生成装置12は、複数フレーム抽出部121、人物骨格抽出部122、人物識別部123、軌跡特徴量生成部124、動オブジェクト検出部125、人物動作認識部126、第1のメタデータ生成部127、動作状況計測部128、及び第2のメタデータ生成部129を備える。
The tactile
複数フレーム抽出部121は、入力された映像について、現フレーム画像を含むT(Tは2以上の整数)フレーム分の過去のフレーム画像を抽出し、人物骨格抽出部122及び動オブジェクト検出部125に出力する。
The
人物骨格抽出部122は、現フレーム画像を含むTフレーム分のフレーム画像の各々について、骨格検出アルゴリズムに基づき、各人物オブジェクト(以下、単に「人物」とも称する。)Op1,Op2の骨格座標集合Pn b(n:検出人数、b:骨格ID)を生成し、現フレーム画像を含むTフレーム分のフレーム画像とともに、人物識別部123に出力する。
The human
人物識別部123は、現フレーム画像を含むTフレーム分のフレーム画像の各々について、骨格座標集合Pn bを基に探索範囲(詳細は後述する。)を可変設定し、各人物の骨格の位置及びサイズと、その周辺画像情報を抽出することにより人物を識別し、人物IDを付与した骨格座標集合Pi b(i:人物ID、b:骨格ID)を生成し、軌跡特徴量生成部124に出力する。
The
軌跡特徴量生成部124は、現フレーム画像を基準に、Tフレーム分のフレーム画像における骨格座標集合Pi bを時系列に連結し、人物毎の骨格の軌跡を示す軌跡特徴量の集合として骨格軌跡集合Ti b(i:人物ID、b:骨格ID)を生成し、動オブジェクト検出部125、人物動作認識部126、及び動作状況計測部128に出力する。
Locus feature
動オブジェクト検出部125は、現フレーム画像を含むTフレーム分のフレーム画像の各々を用いて隣接フレーム間の差分画像を基に動オブジェクトを検出し、各差分画像から検出した動オブジェクトのうち軌跡特徴量生成部124から得られる全ての人物の骨格軌跡集合Ti bを用いて特定の動オブジェクトを選定し、各差分画像から得られる特定の動オブジェクトの座標位置、大きさ、移動方向を要素とし連結した動オブジェクト情報を生成し、人物動作認識部126に出力する。
The moving
動作状況計測部128は、現フレーム画像を基準に、Tフレーム分のフレーム画像における骨格軌跡集合Ti bを基準とした各人物オブジェクト間の距離、及び人物オブジェクト毎の各関節のオプティカルフロー量から各人物オブジェクトの人物動きの状況変化量K(t)を算出して第2のメタデータ生成部129に出力するとともに、骨格検出の成否D(t)、人物骨格の重心の移動量(縦Gv(t)、横Gh(t))、及び当該探索範囲を表す骨格外接矩形のアスペクト比の変化量S(t)を算出し、これらのK(t),D(t),Gv(t),Gh(t),S(t)を要素とする特徴ベクトルを、動作状況を表す動作状況特徴量Mi b(i:人物ID、b:骨格ID)として生成し、人物動作認識部126に出力する。
人物動作認識部126は、動オブジェクト情報を基に、全ての人物の骨格軌跡集合Ti bのうち、触覚提示デバイスを作動させるための骨格軌跡集合Ti bを選定し、選定した骨格軌跡集合Ti bの軌跡特徴量と、その選定した骨格軌跡集合Ti bの軌跡特徴量に対応する動作状況特徴量Mi bとを基に、機械学習(サポートベクターマシン、又はニューラルネットワーク等)により、現フレーム画像内の各人物の識別、位置座標(及び、本例では柔道競技としているため対象外となるが、チーム競技であればそのチーム分類)、並びに、触覚提示デバイスを作動させるタイミング及び速さを示す衝撃提示用の情報を検出し、第1のメタデータ生成部127に出力する。
The human
第1のメタデータ生成部127は、現フレーム画像に対応して、人物動作認識部126から得られる、現フレーム画像内の各人物の識別、位置座標(及び、本例では柔道競技としているため対象外となるが、チーム競技であればそのチーム分類)、並びに、触覚提示デバイスを作動させるタイミング及び速さを示す衝撃提示用の情報を含む第1の触覚メタデータ(衝撃提示用)を生成し、フレーム単位で制御ユニット13に出力する。
Since the first
第2のメタデータ生成部129は、現フレーム画像に対応して、動作状況計測部128から得られる各人物オブジェクトの人物動きの状況変化量K(t)を示す動作状況提示用の情報を含む第2の触覚メタデータ(動作状況提示用)を生成し、フレーム単位で制御ユニット13に出力する。
The second
以下、より具体的に、図2を基に、図3乃至図8を参照しながら、触覚メタデータ生成装置12における触覚メタデータ生成処理について説明する。
Hereinafter, the tactile metadata generation process in the tactile
(触覚メタデータ生成処理)
図2は、本発明による一実施形態の触覚メタデータ生成装置12の処理例を示すフローチャートである。そして、図3は、触覚メタデータ生成装置12における人物骨格抽出処理に関する説明図である。また、図4(a)は1フレーム画像を例示する図であり、図4(b)は触覚メタデータ生成装置12における1フレーム画像における人物骨格抽出例を示す図である。図5(a),(b)は、それぞれ本発明による一実施形態の触覚メタデータ生成装置12における人物骨格抽出処理に関する人物オブジェクトの探索範囲の処理例を示す図である。図6は、触覚メタデータ生成装置12における軌跡特徴量の説明図である。図7は、本発明による一実施形態の触覚メタデータ生成装置12における動オブジェクト検出のために生成する差分画像例を示す図である。そして、図8(a)乃至(c)は、それぞれ本発明による一実施形態の触覚メタデータ生成装置12における動作状況検出処理に関する人物動きの状況変化量の説明図である。
(Tactile metadata generation process)
FIG. 2 is a flowchart showing a processing example of the tactile
図2に示すように、触覚メタデータ生成装置12は、まず、複数フレーム抽出部121により、入力された映像について、現フレーム画像を含むT(Tは2以上の整数)フレーム分の過去のフレーム画像を抽出する(ステップS1)。
As shown in FIG. 2, first, the tactile
続いて、触覚メタデータ生成装置12は、人物骨格抽出部122により、現フレーム画像を含むTフレーム分のフレーム画像の各々について、骨格検出アルゴリズムに基づき、各人物オブジェクトOp1,Op2の骨格座標集合Pn b(n:検出人数、b:骨格ID)を生成する(ステップS2)。
Subsequently, the tactile
近年の深層学習技術の発展により、通常の画像から人物の骨格位置を推定することが可能となった。OpenPoseやVisionPose(NextSystem社)に代表されるように、骨格検出アルゴリズムをオープンソースで公開しているものも存在する。そこで、本例の人物骨格抽出部122は、VisionPoseを用いて、図3に示すように、フレーム画像毎に人物の骨格30点を検出し、その位置座標を示す骨格座標集合Pn bを生成する。
Recent developments in deep learning technology have made it possible to estimate the skeleton position of a person from ordinary images. As represented by OpenPose and VisionPose (NextSystem), there are some open source skeleton detection algorithms. Therefore, the human
VisionPoseでは、図3において、Pn 1:“頭”、Pn 2:“鼻”、Pn 3:“左目”、Pn 4:“右目”、Pn 5:“左耳”、Pn 6:“右耳”、Pn 7:“首”、Pn 8:“背骨(肩)”、Pn 9:“左肩”、Pn 10:“右肩”、Pn 11:“左肘”、Pn 12:“右肘”、Pn 13:“左手首”、Pn 14:“右手首”、Pn 15:“左手”、Pn 16:“右手”、Pn 17:“左親指”、Pn 18:“右親指”、Pn 19:“左指先”、Pn 20:“右指先”、Pn 21:“背骨(中央)”、Pn 22:“背骨(基端部)”、Pn 23:“左尻部”、Pn 24:“右尻部”、Pn 25:“左膝”、Pn 26:“右膝”、Pn 27:“左足首”、Pn 28:“右足首”、Pn 29:“左足”、及び、Pn 30:“右足”、についての座標位置と、各座標位置を図示するような線で連結した描画が可能である。 In VisionPose, in FIG. 3, P n 1 : "head", P n 2 : "nose", P n 3 : "left eye", P n 4 : "right eye", P n 5 : "left ear", P n. 6 : "Right ear", P n 7 : "Neck", P n 8 : "Spine (shoulder)", P n 9 : "Left shoulder", P n 10 : "Right shoulder", P n 11 : "Left elbow" , P n 12 : "Right elbow", P n 13 : "Left wrist", P n 14 : "Right wrist", P n 15 : "Left hand", P n 16 : "Right hand", P n 17 : " Left thumb ”, P n 18 :“ Right thumb ”, P n 19 :“ Left fingertip ”, P n 20 :“ Right fingertip ”, P n 21 :“ Spine (center) ”, P n 22 :“ Spine (base) End) ”, P n 23 :“ Left butt ”, P n 24 :“ Right butt ”, P n 25 :“ Left knee ”, P n 26 :“ Right knee ”, P n 27 :“ Left ankle , P n 28 : "Right ankle", P n 29 : "Left foot", and P n 30 : "Right foot", and each coordinate position can be drawn by connecting them with a line as shown in the figure. Is.
このVisionPoseの骨格検出アルゴリズムに基づき、図4(a)に示す柔道競技の1フレーム画像Fに対して、人物の骨格抽出を行ったフレーム画像Faを図4(b)に示している。図4(a)に示すフレーム画像Fには、各人物オブジェクトOp1,Op2(選手)のみが映り込んでいる様子を示しているが、その他の人物オブジェクトである審判の動オブジェクトが映り込むことや、別のスポーツ競技であれば人物以外の動オブジェクト(バドミントン競技であればラケットやシャトル等)、或いは観客等のオブジェクト(実質的には、静オブジェクト)が写り込むことがある。しかし、VisionPoseの骨格検出アルゴリズムを適用すると、選手及び審判の人物オブジェクトの人物についてのみ人物の骨格抽出を抽出することができる。本例では、図4(b)に示すように、人物オブジェクトOp1,Op2にそれぞれ対応する骨格座標集合P1 b,P2 bを推定して生成することができる。図4(b)からも理解されるように、柔道競技においても、比較的精度よく各人物の骨格を推定できる。尚、骨格検出アルゴリズムは、静止画単位での推定に留まるので、触覚メタデータ生成装置12は、後続する処理として、人物の識別を行い、各人物の骨格位置の推移を軌跡特徴量として定量化し、時間軸を考慮した高精度な動作認識を行う。
Based on this Vision Pose skeleton detection algorithm, the frame image Fa obtained by extracting the skeleton of a person from the one-frame image F of the judo competition shown in FIG. 4 (a) is shown in FIG. 4 (b). The frame image F shown in FIG. 4A shows that only each person object Op1 and Op2 (players) are reflected, but other person objects such as the referee's moving object are reflected. In another sports competition, a moving object other than a person (such as a racket or shuttle in a badminton competition) or an object such as a spectator (substantially a static object) may be reflected. However, by applying VisionPose's skeleton detection algorithm, it is possible to extract the skeleton extraction of a person only for the person of the player and the referee's person object. In this example, as shown in FIG. 4 (b), the skeleton coordinate sets P 1 b and P 2 b corresponding to the person objects Op 1 and
続いて、触覚メタデータ生成装置12は、人物識別部123により、現フレーム画像を含むTフレーム分のフレーム画像の各々について、骨格座標集合Pn bを基に探索範囲を可変設定し、各人物の骨格の位置及びサイズと、その周辺画像情報を抽出することにより人物を識別し、人物IDを付与した骨格座標集合Pi b(i:人物ID、b:骨格ID)を生成する(ステップS3)。
Subsequently, the tactile
前述した人物骨格抽出部122により、現フレーム画像を含むTフレーム分のフレーム画像の各々について、骨格座標集合Pn bとして、1以上の人物の骨格の検出が可能となる。しかし、各フレーム画像の骨格座標集合Pn bでは、「誰」の情報は存在しないため、各人物の骨格を識別する必要がある。この識別には、各フレーム画像における各骨格座標集合Pn bの座標付近の画像情報を利用する。即ち、人物識別部123は、骨格座標集合Pn bを基に、各人物の骨格の位置及びサイズと、その周辺画像情報(色情報、及び顔又は背付近のテクスチャ情報)を抽出することにより、人物を識別し、人物IDを付与した骨格座標集合Pi b(i:人物ID、b:骨格ID)を生成する。
The human
例えば、柔道では白と青の道着で試合が行われるが、各骨格座標集合Pn bの骨格の位置付近の画像情報として、フレーム画像Fにおける色情報を参照することで、選手の識別が可能になる。また、バドミントン競技では、コートを縦に構えた画角で撮影される場合に、各骨格座標集合Pn bの骨格の位置がフレーム画像Fにおける画面上側であれば奥の選手、画面下側であれば手前の選手、として識別することができる。 For example, in judo, a match is played in white and blue dogi, but by referring to the color information in the frame image F as the image information near the position of the skeleton of each skeleton coordinate set P n b, the player can be identified. It will be possible. In the badminton competition, when the court is held vertically at an angle of view, if the position of the skeleton of each skeleton coordinate set P n b is on the upper side of the screen in the frame image F, the player in the back and the lower side of the screen. If there is, it can be identified as the player in the foreground.
従って、人物骨格抽出部122における骨格検出アルゴリズムは静止画単位での推定に留まるが、骨格座標集合Pn bを基に動オブジェクトとしての人物を認識することができ、各骨格位置の推移を軌跡特徴として扱うことで、時間軸を考慮した高精度な動作認識を可能となる。
Therefore, the skeleton detection algorithm in the human
尚、前述した人物骨格抽出部122では、選手以外にも審判や観客など、触覚刺激の提示対象としない他の人物の骨格を検出してしまうことも多い。審判は選手と別の衣服を着用することが多いため、色情報で識別できる。また、観客は選手に比べて遠くにいることが多いため、骨格のサイズで識別が可能である。このように、各競技のルールや撮影状況を考慮し、人物識別に適切な周辺画像情報(色情報、及び顔又は背付近のテクスチャ情報)を設定することにより、触覚刺激の提示対象とする選手の識別が可能となる。
In addition to the athletes, the above-mentioned human
ところで、本実施形態の人物識別部123は、各人物の重なりやオクルージョンにも対応するため、フレーム画像単位で探索範囲(人物探索範囲Ri及び注目探索範囲Rbi)を可変設定する。例えば、図5(a)に示す人物オブジェクトOp1,Op2(選手)と、人物オブジェクトOp3(審判)について、人物骨格抽出部122により各骨格座標集合Pn b(図示略)の抽出が行われると、人物識別部123は、フレーム画像単位で人物探索範囲Ri及び注目探索範囲Rbiを可変設定することができる。この探索範囲Riは、図5(a)において、人物ID(i)ごとに設定し、フレーム画像の画像座標上での人物の位置座標、及び人物の大きさ(幅及び高さ)を有するものとして外接矩形で表している。また、各人物の腰領域(Pn 22,Pn 23,Pn 24)を囲む領域を注目探索範囲Rbiとして表している。
By the way, the
より具体的には、本実施形態の人物識別部123は、各フレーム画像で人物の探索範囲を、最大で人物骨格の全体を囲む人物探索範囲Riに限定し、最小で人物骨格のうち所定領域(本例では腰領域(Pn 22,Pn 23,Pn 24)を囲む領域)を注目探索範囲Rbiとして定めた絞り込みによる可変設定を行い、状態推定アルゴリズムで得られる人物の骨格の状態遷移推定値に基づいて、少なくとも注目探索範囲Rbiを含むように探索範囲を決定して、当該人物オブジェクトを識別する処理を行う。これにより、例えば図5(b)に示すように各人物の動作が変化した場合やフレーム画像に対する相対的な人物の大きさが変化した場合でも、他の人物の誤認識を防ぎ、また処理速度も向上できる。特に、柔道のように識別対象の人物の重なりが激しく、背景も複雑な映像から精度よく選手を識別するには探索範囲の利用が有効である。
More specifically, the
つまり、本実施形態の人物識別部123は、各選手及び審判の人物オブジェクトのOp1,Op2,Op3における各骨格座標集合Pn bのうち、色識別を可能とする所定範囲(本例では腰領域(Pn 22,Pn 23,Pn 24)の色(青、白、茶色))を注目探索範囲Rbiとして予め定めているので、検出した複数の人物の骨格座標集合Pn bが重なる場合には注目探索範囲Rbiに絞って探索することで、各フレーム画像で精度よく人物を抽出・追跡できる。尚、背景に解析対象以外の骨格を検出する場合もあるため、解析対象の人物の骨格には、人物ID(i)を付与して判別することで、追跡対象の人物の骨格座標Pi bを識別できる。
That is, the
そして、探索範囲(人物探索範囲Ri及び注目探索範囲Rbi)の広さや形の決定は、カルマンフィルタやパーティクルフィルタなどの状態推定アルゴリズムで得られる人物の骨格の状態遷移推定値に基づいて、少なくとも注目探索範囲Rbi(本例では、各人物の腰領域)を含むように決定する。 The width and shape of the search range (person search range R i and attention search range R bi ) are determined at least based on the state transition estimates of the human skeleton obtained by a state estimation algorithm such as a Kalman filter or a particle filter. (in this example, the waist region of each person) interest search range Rb i is determined to contain.
そして、探索範囲(人物探索範囲Ri及び注目探索範囲Rbi)の安定検出時には範囲を狭め、検出が不安定な際には範囲を広げることができ、例えば、人物ID(i)ごとに人物の骨格の状態遷移推定値に基づいて定めた探索範囲を設定し、その状態遷移推定値が直前フレームから所定値以内であれば安定とし、そうでなければ不安定とすることや、状態推定アルゴリズムで得られる人物の骨格の状態遷移推定値に基づいて、Tフレーム分の時間窓間に、検出に成功した割合を計算し、その割合が所定値以上であれば安定とし、当該所定値を下回った場合に不安定とすることで、探索範囲を可変設定することができる。 Then, the range can be narrowed when the search range (person search range R i and attention search range R bi ) is stably detected, and the range can be expanded when the detection is unstable. For example, each person ID (i) can be expanded. A search range determined based on the state transition estimated value of the skeleton of is set, and if the state transition estimated value is within a predetermined value from the immediately preceding frame, it is made stable, otherwise it is made unstable, or a state estimation algorithm. Based on the state transition estimation value of the skeleton of the person obtained in, the ratio of successful detection is calculated during the time window for T frames, and if the ratio is equal to or more than the predetermined value, it is stabilized and falls below the predetermined value. In this case, the search range can be variably set by making it unstable.
続いて、触覚メタデータ生成装置12は、軌跡特徴量生成部124により、現フレーム画像を基準に、Tフレーム分のフレーム画像における骨格座標集合Pi bを時系列に連結し、人物毎の骨格の軌跡を示す軌跡特徴量の集合として骨格軌跡集合Ti b(i:人物ID、b:骨格ID)を生成する(ステップS4)。
Subsequently, the tactile metadata generation device 12 connects the skeleton coordinate set Pi b in the frame image for T frames in time series with the current frame image as a reference by the locus feature
ここで、骨格軌跡集合Ti bの生成にあたって、まず、任意のフレーム画像における骨格座標集合Pi bをPi b(t)とし、現フレーム画像をt=0として現フレーム画像における骨格座標集合Pi bをPi b(0)で表し、過去Tフレームのフレーム画像における骨格座標集合Pi bをPi b(T)で表す。つまり、軌跡特徴量生成部124は、現フレーム画像のフレーム番号をt=0として、過去Tフレームまでのフレーム番号をt=Tで表すと、現フレーム画像を基準に、t=0,1,…,Tの各フレーム画像Fを用いて、人物毎の骨格の軌跡を示す軌跡特徴量の集合として骨格軌跡集合Ti bを生成することができる。尚、骨格軌跡集合Ti bは、人物探索範囲Ri及び注目探索範囲Rbiのそれぞれについて分けて軌跡を算出できる。
Here, in generating the skeleton locus set Ti b , first, the skeleton coordinate set Pi b in an arbitrary frame image is set to Pi b (t), the current frame image is set to t = 0, and the skeleton coordinate set in the current frame image is set. P i b is represented by P i b (0), and the skeleton coordinate set P i b in the frame image of the past T frame is represented by P i b (T). That is, when the locus feature
尚、骨格軌跡集合Ti bの生成に用いる骨格座標は、必ずしも図3に示す30点全てを用いる必要はなく、予め定めた特定の骨格軌跡のみを使用して、処理速度を向上させる構成とすることもできる。また、骨格軌跡集合Ti bとしては、骨格座標集合Pi bの座標表現そのものを連結したものとしてもよいが、人物毎の骨格の軌跡を示すものであればよいことから、各競技のルールや撮影状況を考慮し、軌跡特徴を表わすのに適切な情報(動き量や移動加速度等)に変換したものとしてもよい。 It should be noted that the skeleton coordinates used to generate the skeleton locus set Ti b do not necessarily have to use all 30 points shown in FIG. 3, and only a predetermined specific skeleton locus is used to improve the processing speed. You can also do it. Further, the skeleton locus set Ti b may be a concatenation of the coordinate representations of the skeleton coordinate set Pi b , but it may be a rule of each competition as long as it shows the locus of the skeleton for each person. It may be converted into information (movement amount, movement acceleration, etc.) appropriate for expressing the locus characteristics in consideration of the shooting conditions and the shooting conditions.
例えば、骨格軌跡集合Ti bは、各骨格の移動量の二階微分を作成し、加速度に相当する値に変換するのが好適である。そこで、骨格座標集合Pi bの軌跡として、加速度に相当する骨格軌跡集合Ti bで表すことで、後段の人物動作認識部126における動作認識の精度を向上させることができる。
For example, it is preferable that the skeleton locus set Ti b creates a second derivative of the movement amount of each skeleton and converts it into a value corresponding to acceleration. Therefore, by expressing the locus of the skeleton coordinate set Pi b by the skeleton locus set Ti b corresponding to the acceleration, the accuracy of motion recognition in the person
まず、式(1)に示すように、隣接する画像フレーム間で、対応する骨格座標集合Pi b(t),Pi b(t+1)の位置座標の差(ユークリッド距離)を取り、その移動量Di b(t)を求める。 First, as shown in equation (1), between adjacent image frames, taking the difference between the position coordinates of the corresponding backbone coordinate set P i b (t), P i b (t + 1) ( Euclidean distance), the movement Find the quantity D i b (t).
![]()
![]()
ここで、Pi b(t),xはPi b(t)におけるx座標、Pi b(t),yはPi b(t)におけるy座標を表す。 Here, P i b (t), x is the x coordinate of P i b (t), P i b (t), y represents the y coordinate of P i b (t).
Di b(t)は、各座標点の速度に相当する特徴量となるが、式(2)に示すように、更にその差の絶対値をとることで、加速度に相当する特徴量Ai b(t)が得られる。ここで、abs()は、絶対値を返す関数である。 D i b (t) is a feature amount corresponding to the velocity of each coordinate point, but as shown in the equation (2), by taking the absolute value of the difference, the feature amount A i corresponding to the acceleration. b (t) is obtained. Here, abs () is a function that returns an absolute value.
![]()
![]()
この加速度に相当する特徴量Ai b(t)を用いて各人物の動作を追跡した軌跡を示す骨格軌跡集合Ti bを生成することができ、図6には、或るフレーム画像における人物オブジェクトOp1,Op2にそれぞれ対応する骨格座標集合の軌跡特徴量T1 b,T2 bを分かり易く描画したフレーム画像Fbを示している。 Using the feature amount A i b (t) corresponding to this acceleration, it is possible to generate a skeletal locus set Ti b showing a locus that traces the movement of each person, and FIG. 6 shows a person in a certain frame image. The frame image Fb in which the locus feature quantities T 1 b and T 2 b of the skeleton coordinate set corresponding to the objects Op1 and Op2 are drawn in an easy-to-understand manner is shown.
続いて、触覚メタデータ生成装置12は、動作状況計測部128により、現フレーム画像を基準に、Tフレーム分のフレーム画像における骨格軌跡集合Ti bを基準とした各人物オブジェクト間の距離、及び人物オブジェクト毎の各関節のオプティカルフロー量から各人物オブジェクトの人物動きの状況変化量K(t)を算出して第2のメタデータ生成部129に出力するとともに、骨格検出の成否D(t)、人物骨格の重心の移動量(縦Gv(t)、横Gh(t))、及び当該探索範囲を表す骨格外接矩形のアスペクト比の変化量S(t)を算出し、これらのK(t),D(t),Gv(t),Gh(t),S(t)を要素とする特徴ベクトルを、動作状況を表す動作状況特徴量Mi b(i:人物ID、b:骨格ID)として生成し、人物動作認識部126に出力する(ステップS5)。
Subsequently, the tactile
例えば柔道では、組手の状態から相手の隙を伺い、急激に投げの動作に入ることが多い。この閑から急に至る状況を触覚刺激として提示することで、映像コンテンツ視聴における臨場感を高めることができる。Tフレーム分のフレーム画像における骨格軌跡集合Ti bを基準とした各人物オブジェクト(選手)間の距離、及び人物オブジェクト(選手)毎の各関節のオプティカルフロー量から各各人物オブジェクト(選手)の人物動きの状況変化量K(t)を算出できる。 For example, in judo, it is often the case that the opponent's gap is heard from the state of the kumite and the action of throwing is suddenly started. By presenting the situation from this quiet to sudden as a tactile stimulus, it is possible to enhance the sense of presence in viewing video content. T frame distance between each person object (player) relative to the skeleton trajectory set T i b in the frame image, and each each person object from the optical flow of each joint of a person per object (player) of the (player) The amount of change in the situation of the person's movement K (t) can be calculated.
より具体的には、人物動きの状況変化量K(t)を以下に示す式(3)のように定義する。この人物動きの状況変化量K(t)は、第2のメタデータ生成部129により、第2の第2の触覚メタデータ(動作状況提示用)として外部出力される。
More specifically, the amount of change in the situation of the person's movement K (t) is defined by the following equation (3). The situation change amount K (t) of the movement of the person is externally output as the second second tactile metadata (for presenting the operation status) by the second
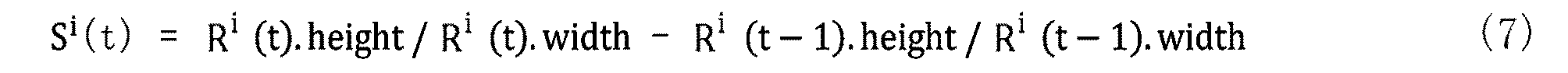
ここで、d(t)は各人物オブジェクト(選手)間の距離を表し、F(t)は、現フレーム画像の時刻tと直前フレームの時刻t−1における人物オブジェクトごとの骨格30点のオプティカルフローの平均値を表す。d(t)を算出する際のgは、重心(本例では、腰の位置であるPn 22,Pn 23,Pn 24の中央値座標)を表している。従って、P1 g(t)は、現フレーム画像の時刻tにおけるi=1の人物IDの人物オブジェクトOp1の重心位置を表し、P2 g(t)は、そのフレーム画像の時刻tにおけるi=2の人物IDの人物オブジェクトOp2の重心位置を表す。また、Lは双方の人物オブジェクトOp1,Op2の骨格30点のうち両選手の首から腰までの距離の平均値であり、Lで正規化することにより各選手の撮影サイズによる影響を排除できる。 Here, d (t) represents the distance between each person object (player), and F (t) is an optical of 30 points of the skeleton for each person object at the time t of the current frame image and the time t-1 of the immediately preceding frame. Represents the average value of the flow. g in calculating d (t) represents the center of gravity (in this example, the median coordinates of P n 22 , P n 23 , and P n 24, which are the positions of the waist). Therefore, P 1 g (t) represents the position of the center of gravity of the person object Op1 of the person ID of i = 1 at the time t of the current frame image, and P 2 g (t) represents i = at the time t of the frame image. Represents the position of the center of gravity of the person object Op2 having the person ID of 2. Further, L is the average value of the distances from the necks to the waists of both players out of the 30 skeletons of both person objects Op1 and Op2, and by normalizing with L, the influence of the shooting size of each player can be eliminated.
一方、動作状況を表す動作状況特徴量Mi b(i:人物ID、b:骨格ID)は、それぞれ式(4)、式(5)、式(6)、式(7)に示すように、骨格検出の成否D(t)、人物骨格の重心の移動量(縦Gv(t)、横Gh(t))、及び骨格外接矩形(人物探索範囲)のアスペクト比の変化量S(t)を算出し、人物動きの状況変化量K(t)に加えて、D(t),Gv(t),Gh(t),S(t)を要素として生成する。 On the other hand, operation conditions characteristic quantity M i b representing the operation status (i: People ID, b: skeletal ID), respectively formula (4), Equation (5), equation (6), as shown in Equation (7) , Success / failure of skeleton detection D (t), amount of movement of the center of gravity of the human skeleton (vertical Gv (t), horizontal Gh (t)), and amount of change in aspect ratio of the skeleton extrinsic rectangle (person search range) S (t) Is calculated, and in addition to the amount of change in the situation of the person's movement K (t), D (t), Gv (t), Gh (t), and S (t) are generated as elements.
![]()
![]()
![]()
![]()
![]()
![]()
ここで、Ri(t)は、時刻tのフレーム画像F(t)における人物オブジェクトOp1の当該探索範囲を表す骨格外接矩形を表し、その左上座標(x,y)と、幅(width)及び高さ(height)の情報を有し、“aaa.bbb”は、aaaのbbb成分を表す。 Here, R i (t) represents a skeleton enclosing rectangle representing the search range of a person object Op1 in the frame image F at time t (t), and its upper left coordinates (x, y), width (width) and It has height information, and "aaa.bbb" represents the bbb component of aaa.
柔道の「投げ」動作時は、急に重心が下がり、画像上で横長のアスペクト比になることが多い。また不自然な体勢になることも多く、しばしば骨格検出に失敗する。さらに、関節の移動量が全体的に増加する。そこで、人物動きの状況変化量K(t)に加えて、D(t),Gv(t),Gh(t),S(t)の要素からなる動作状況を表す動作状況特徴量Mi bを、後段の人物動作認識部126における機械学習の識別器に用いることで、例えば「投げ」動作を精度よく検出できる。
During the "throwing" motion of judo, the center of gravity suddenly drops, often resulting in a horizontally long aspect ratio on the image. In addition, they often have an unnatural posture and often fail to detect the skeleton. In addition, the amount of joint movement increases overall. Therefore, in addition to the status change amount K (t) of the person moves, D (t), Gv ( t), Gh (t), the operation conditions characteristic quantity representing the operating status of elements of S (t) M i b Is used as a machine learning classifier in the person
続いて、触覚メタデータ生成装置12は、動オブジェクト検出部125により、現フレーム画像を含むTフレーム分のフレーム画像の各々を用いて隣接フレーム間の差分画像を基に動オブジェクトを検出し、各差分画像から検出した動オブジェクトのうち軌跡特徴量生成部124から得られる全ての人物の骨格軌跡集合Ti bを用いて特定の動オブジェクトを選定し、各差分画像から得られる特定の動オブジェクトの座標位置、大きさ、移動方向を要素とし連結した動オブジェクト情報を生成する(ステップS6)。図7に示す差分画像Fcに示されているように、人物オブジェクトOp1’,Op2’が検出できていることが分かる。
Subsequently, the tactile
後段の人物動作認識部126では、骨格軌跡集合Ti bを用いて人物の動作認識を行うことが可能であるが、人物(選手)の動作は多種多様であり、誤検出や検出漏れが発生するケースも少なくない。そこで、動オブジェクト検出部125は、現フレーム画像を含むTフレーム分のフレーム画像の各々を用いて、解析対象とする人物の動オブジェクトの位置や動きに関する情報を抽出する(尚、バドミントン競技などの人物以外のラケットやシャトル等の動オブジェクトも参考とすることができるときは、その動オブジェクトも利用できる。)。この情報を利用することで、後段の人物動作認識部126は、動作認識の精度をより向上させることができる。
The person
続いて、触覚メタデータ生成装置12は、人物動作認識部126により、動オブジェクト情報を基に、全ての人物の骨格軌跡集合Ti bのうち、触覚提示デバイスを作動させるための骨格軌跡集合Ti bを選定し、選定した骨格軌跡集合Ti bの軌跡特徴量と、その選定した骨格軌跡集合Ti bの軌跡特徴量に対応する動作状況特徴量Mi bとを基に、機械学習(サポートベクターマシン、又はニューラルネットワーク等)により触覚提示デバイス14R,14Lを作動させる衝撃提示用の情報を検出する(ステップS7)。衝撃提示用の情報には、現フレーム画像内の各人物の識別、位置座標(及び、本例では柔道競技としているため対象外となるが、チーム競技であればそのチーム分類)、並びに、触覚提示デバイスを作動させるタイミング及び速さを示す情報が含まれる。
Subsequently, in the tactile
機械学習(サポートベクターマシン、又はニューラルネットワーク等)時には、事前に学習用の軌跡特徴量を作成して学習させておく。例えば、サポートベクターマシンを利用するときは、衝撃を表す瞬間の軌跡特徴量を正例、それ以外の軌跡特徴量を負例として学習することで、人物動作認識部126は、触覚提示デバイス14R,14Lを作動させるタイミング及び速さを示す情報を動作認識として検出することが可能となる。更に、人物動作認識部126は、選定した骨格軌跡集合Ti bの軌跡特徴量から、動作認識の精度を高めるとともに、どの選手がどのような衝撃を受けているか等、現フレーム画像内の各人物の識別、位置座標、(及びチーム分類)の情報も検出することも可能である。
At the time of machine learning (support vector machine, neural network, etc.), a locus feature for learning is created and trained in advance. For example, when using a support vector machine, the human
更に、動作状況特徴量Mi bを機械学習の識別器に加えることで、柔道などでの投げ動作などの動きに応じて生じる衝撃を認識することが可能となる。従って、人物動作認識部126は、その動作認識において、人物以外の動オブジェクトの情報を参照する技法もあるが、本例では人物以外の動オブジェクトを参照できない場合でも、高精度に柔道競技等の人物を認識するため、動作状況特徴量Mi bを用いるようにしている。この動作状況特徴量Mi bを加味することで、人物の動きの検出精度や動きの種類の判別を向上させている。
Furthermore, the addition of operation conditions characteristic quantity M i b to the machine learning classifier, it is possible to recognize the impact that occurs in response to movement, such as the throwing operation in judo. Therefore, the person
ただし、これらの選定した骨格軌跡集合Ti bの軌跡特徴量及び動作状況特徴量Mi bの各特徴量の変化は、その全特徴量が同時刻に変化するように発生するとは限らない。そこで、T=15フレームなど一定時間の時間窓を設けた特徴量とする。一定時間内の各特徴量を用いてSVMなどで機械学習を行うことで、各特徴量の変化に時間的なズレが生じても頑健な識別器を構成することができる。 However, the change of the characteristic of the trajectory characteristic amount and operating conditions characteristic quantity M i b of these selected skeletal trajectory set T i b are not necessarily the total feature value is generated so as to change at the same time. Therefore, a feature amount provided with a time window for a certain period of time such as T = 15 frames is used. By performing machine learning with SVM or the like using each feature amount within a certain period of time, it is possible to construct a robust classifier even if there is a time lag in the change of each feature amount.
最終的に、触覚メタデータ生成装置12は、第1のメタデータ生成部127により、現フレーム画像に対応して、各人物の識別、位置座標、(及びチーム分類)、並びに、触覚提示デバイスを作動させるタイミング及び速さを示す衝撃提示用の情報を含む第1の触覚メタデータ(衝撃提示用)を生成し、フレーム単位で制御ユニット13に出力する(ステップS8)。
Finally, the tactile
また、触覚メタデータ生成装置12は、第2のメタデータ生成部129により、現フレーム画像に対応して、各人物オブジェクトの人物動きの状況変化量を示す動作状況提示用の情報を含む第2の触覚メタデータ(動作状況提示用)を生成し、フレーム単位で制御ユニット13に出力する(ステップS9)。
Further, in the tactile
そして、触覚メタデータ生成装置12は、映像出力装置10から映像のフレーム画像が入力される度に、ステップS1乃至S9の処理を繰り返す。
Then, the tactile
人物動きの状況変化量K(t)による第2の触覚メタデータに応じて制御ユニット13が触覚提示デバイス14L,14Rを制御することで、各選手が組み合った際の近接時、且つ投げようと体が大きく動いた際に対応する触覚提示デバイスを大きく振動させることができる。制御ユニット13は、第1の触覚メタデータについては衝撃を表す単発的な刺激を与えるに留まるが、動作状況を示す第2の触覚メタデータを併せて取得し、対応する触覚提示デバイスを制御することで、映像コンテンツの状況を連続値で恒常的に提示することができ、ユーザUは、常に各人物オブジェクトOp1,Op2の動作状況を把握することができるようになる。
By controlling the tactile presentation devices 14L and 14R in response to the second tactile metadata based on the amount of change in the situation of the person's movement K (t), the
人物動きの状況変化量K(t)を可視化した例を図8に示している。図8(a)の左図は、人物オブジェクトOp1,Op2(選手)と人物オブジェクトOp3(審判)の動作状況“組み合い”の様子が見て取れる現フレームのフレーム画像Fであり、図8(a)の右図は、過去のフレーム画像の時刻tpから現フレーム画像の時刻tcまで(15フレームの経過期間)の最大値100で正規化した人物動きの状況変化量K(t)の大きさを表している。図8(a)の右図から理解されるように、“組み合い”の動作状況時(投げの動作状況時も同様)には人物動きの状況変化量K(t)が時間経過とともに大きくなり、各人物の動作量が増えていることが判別できる。 FIG. 8 shows an example of visualizing the amount of change in the situation of the person's movement K (t). The left figure of FIG. 8A is a frame image F of the current frame in which the state of the operation state “combination” of the person objects Op1 and Op2 (players) and the person object Op3 (referee) can be seen, and is the frame image F of FIG. 8 (a). The figure on the right shows the magnitude of the amount of change in the situation of the person movement K (t) normalized by the maximum value of 100 from the time tp of the past frame image to the time ct of the current frame image (elapsed period of 15 frames). There is. As can be understood from the right figure of FIG. 8 (a), the amount of change in the person movement K (t) increases with the passage of time during the “combination” operation status (the same applies to the throwing operation status). It can be determined that the amount of movement of each person is increasing.
また、図8(b)の左図は、人物オブジェクトOp1,Op2(選手)と人物オブジェクトOp3(審判)の動作状況“抑え込み”の様子が見て取れる現フレームのフレーム画像Fであり、図8(b)の右図は、過去のフレーム画像の時刻tpから現フレーム画像の時刻tcまで(15フレームの経過期間)の最大値100で正規化した人物動きの状況変化量K(t)の大きさを表している。図8(b)の右図から理解されるように、“抑え込み”の動作状況時には人物動きの状況変化量K(t)が時間経過とともに小さくなり、各人物の動作量が減少していることが判別できる。 Further, the left figure of FIG. 8B is a frame image F of the current frame in which the operation state “suppression” of the person objects Op1 and Op2 (players) and the person object Op3 (referee) can be seen, and is a frame image F of FIG. 8 (b). The figure on the right of) shows the magnitude of the change in the amount of human movement K (t) normalized by the maximum value of 100 from the time tp of the past frame image to the time ct of the current frame image (elapsed period of 15 frames). Represents. As can be understood from the right figure of FIG. 8 (b), the amount of change in the situation of the person's movement K (t) becomes smaller with the passage of time during the "suppressed" operation state, and the amount of movement of each person decreases. Can be determined.
また、図8(c)の左図は、人物オブジェクトOp1,Op2(選手)と人物オブジェクトOp3(審判)の動作状況“待て”の様子が見て取れる現フレームのフレーム画像Fであり、図8(c)の右図は、過去のフレーム画像の時刻tpから現フレーム画像の時刻tcまで(15フレームの経過期間)の最大値100で正規化した人物動きの状況変化量K(t)の大きさを表している。図8(c)の右図から理解されるように、“待て”の動作状況時(試合開始前、両選手の距離が離れている際も同様)には人物動きの状況変化量K(t)が時間経過を経ても小さく、各人物の動作量がほとんどないことが判別できる。 Further, the left figure of FIG. 8C is a frame image F of the current frame in which the operation status “waiting” of the person objects Op1 and Op2 (players) and the person object Op3 (referee) can be seen, and is a frame image F of FIG. 8 (c). The figure on the right of) shows the magnitude of the change in the amount of human movement K (t) normalized by the maximum value of 100 from the time tp of the past frame image to the time ct of the current frame image (elapsed period of 15 frames). Represents. As can be understood from the right figure of FIG. 8 (c), the amount of change in the movement of the person K (t) during the “wait” operation status (the same applies before the start of the game and when the two players are far apart). ) Is small even after the passage of time, and it can be determined that there is almost no movement amount of each person.
また、人物動きの状況変化量K(t)は動作状況特徴量Mi bに含まれる要素であり、この動作状況特徴量Mi bを用いることで、式(4)に示すようなif-thenルールを用いても各人物の動作認識を高精度に行うことができるようになる。即ち、図8(c)に示すように、選手2人と審判を独立に認識し、各人の関節の推移を軌跡特徴量から判別することで、審判が手を挙げて「待て」の動作を自動認識することが可能となる。触覚メタデータ生成装置12が、「待て」の動作に応じた第1及び第2の触覚メタデータを触覚提示デバイス14L,14Rに出力することで、触覚提示デバイス14L,14Rを利用するユーザUは、連続した一定量の刺激提示からほぼゼロの刺激提示に強制的に示すことが可能となり、「待て」の前後の動作で、試合開始前であるかのような試合状況を誤解させるおそれも少なくなる。従って、本実施形態の触覚メタデータ生成装置12は、スポーツ映像のリアルタイム視聴時でも触覚刺激を人物の動きに応じて提示することが可能となる。
Also, status change amount K of the person moves (t) is an element contained in the operating condition characteristic quantity M i b, by using the operating condition characteristic quantity M i b, as shown in Equation (4) if- Even if the then rule is used, the movement recognition of each person can be performed with high accuracy. That is, as shown in FIG. 8C, the referee raises his hand and "waits" by independently recognizing the two athletes and the referee and discriminating the transition of each person's joint from the locus feature amount. Can be automatically recognized. The tactile
(制御ユニット)
図9は、本発明による一実施形態の映像触覚連動システム1における制御ユニット13の概略構成を示すブロック図である。制御ユニット13は、メタデータ受信部131、解析部132、記憶部133、及び駆動部134‐1,134‐2を備える。
(Controller unit)
FIG. 9 is a block diagram showing a schematic configuration of a
メタデータ受信部131は、触覚メタデータ生成装置12から第1の触覚メタデータ(衝撃提示用)及び第2の触覚メタデータ(動作状況提示用)を入力し、解析部132に出力する機能部である。第1の触覚メタデータは、現フレーム画像内の各人物の識別、位置座標、(及びチーム競技であればそのチーム分類)、並びに、触覚提示デバイスを作動させるタイミング及び速さを示す情報を含む。第2の触覚メタデータは、図8に例示した動作状況の情報を含む。
The
解析部132は、触覚メタデータ生成装置12から得られる第1及び第2の触覚メタデータを基に、予め定めた駆動基準データを参照し、駆動部134‐1,134‐2を介して、対応する各触覚提示デバイス14L,14Rの振動アクチュエーター142を駆動するよう制御する機能部である。例えば、解析部132は、一方の選手が組合から投げ動作に移行するときは、第2の触覚メタデータにおける動作状況に応じた振動提示に加えて、第1の触覚メタデータにおける人物の識別、位置座標、(及びチーム分類)、並びに、触覚提示デバイスを作動させるタイミング及び速さから、予め定めた駆動基準データを参照して、触覚提示デバイス14Lの振動アクチュエーター142の作動タイミング、強さ、及び動作時間を決定して駆動制御する。
The
記憶部133は、第1及び第2の触覚メタデータに基づいた駆動部134‐1,134‐2の駆動を制御するための予め定めた駆動基準データを記憶している。駆動基準データは、第1及び第2の触覚メタデータに対応付けられた触覚刺激としての振動アクチュエーター142の作動タイミング、強さ、及び動作時間について、予め定めたテーブル又は関数で表されている。また、記憶部133は、制御ユニット13の機能を実現するためのプログラムを記憶している。即ち、制御ユニット13を構成するコンピュータにより当該プログラムを読み出して実行することで、制御ユニット13の機能を実現する。
The
駆動部134‐1,134‐2は、各触覚提示デバイス14L,14Rの振動アクチュエーター142を駆動するドライバである。
The drive units 134-1 and 134-2 are drivers that drive the
このように、本実施形態の触覚メタデータ生成装置12を備える映像触覚連動システム1によれば、映像から人物オブジェクトを自動抽出し、動的な人物オブジェクトに対応する触覚メタデータを同期して自動生成することができるので、触覚提示デバイスと映像を連動させることができるようになる。そして、人物オブジェクトに生じる「衝撃の種類とタイミング」を表す第1の触覚メタデータだけでなく、人物オブジェクトに係る連続的な「動作状況」を表す第2の触覚メタデータをも自動生成できるようになる。これにより、スポーツ映像のリアルタイム視聴時での触覚刺激の提示が可能となり、更には、人物オブジェクトの重なりやオクルージョンが生じやすい柔道等の試合映像での詳細な触覚提示も可能となる。つまり、視覚・聴覚への情報提供のみならず、触覚にも訴えることで、より詳細に、視覚や聴覚に障害を持つ方々へもスポーツの状況を分かりやすく伝えることが可能となる。さらに、視覚・聴覚の感覚を有する健常者の方々にとっても、従来の映像視聴では伝えきれない臨場感や没入感を提供することができる。特に、スポーツ映像視聴に際し、各選手の識別、位置座標、(及びチーム分類)、並びに、触覚提示デバイスを作動させるタイミング及び速さを示す情報を含む触覚メタデータを生成することで、より精度よく、より詳細に、1台以上の触覚提示デバイスにより、プレーの種類、タイミング、強度などに関する触覚刺激をユーザUに提示できるようになる。
As described above, according to the video tactile interlocking system 1 provided with the tactile
尚、上述した一実施形態の触覚メタデータ生成装置12をコンピュータとして機能させることができ、当該コンピュータに、本発明に係る各構成要素を実現させるためのプログラムは、当該コンピュータの内部又は外部に備えられるメモリに記憶される。コンピュータに備えられる中央演算処理装置(CPU)などの制御で、各構成要素の機能を実現するための処理内容が記述されたプログラムを、適宜、メモリから読み込んで、本実施形態の触覚メタデータ生成装置12の各構成要素の機能をコンピュータに実現させることができる。ここで、各構成要素の機能をハードウェアの一部で実現してもよい。
The tactile
以上、特定の実施形態の例を挙げて本発明を説明したが、本発明は前述の実施形態の例に限定されるものではなく、その技術思想を逸脱しない範囲で種々変形可能である。例えば、上述した実施形態の例では、主としてバドミントン競技の映像解析を例に説明したが、柔道や卓球、その他の様々なスポーツ種目、及びスポーツ以外の映像にも広く応用可能である。例えば、触覚情報を用いたパブリックビューイング、エンターテインメント、将来の触覚放送などのサービス性の向上に繋がる。また、スポーツ以外の例として、工場での触覚アラームへの応用や、監視カメラ映像解析に基づいたセキュリティシステムなど、様々な用途に応用することも可能である。従って、本発明は、前述の実施形態の例に限定されるものではなく、特許請求の範囲の記載によってのみ制限される。 Although the present invention has been described above with reference to examples of specific embodiments, the present invention is not limited to the examples of the above-described embodiments, and can be variously modified without departing from the technical idea. For example, in the example of the above-described embodiment, the video analysis of the badminton competition has been mainly described as an example, but it can be widely applied to judo, table tennis, various other sports events, and non-sports video. For example, it will lead to improvement of services such as public viewing using tactile information, entertainment, and future tactile broadcasting. In addition, as an example other than sports, it can be applied to various applications such as a tactile alarm in a factory and a security system based on surveillance camera image analysis. Therefore, the present invention is not limited to the example of the above-described embodiment, but is limited only by the description of the scope of claims.
本発明によれば、映像から人物オブジェクトを自動抽出し、動的な人物オブジェクトに対応する触覚メタデータを同期して自動生成することができるので、触覚提示デバイスと映像を連動させる用途に有用である。 According to the present invention, a person object can be automatically extracted from a video, and tactile metadata corresponding to a dynamic person object can be automatically generated in synchronization, which is useful for linking a tactile presentation device and a video. be.
1 映像触覚連動システム
10 映像出力装置
11 ディスプレイ
12 触覚メタデータ生成装置
13 制御ユニット
14L,14R 触覚提示デバイス
121 複数フレーム抽出部
122 人物骨格抽出部
123 人物識別部
124 軌跡特徴量生成部
125 動オブジェクト検出部
126 人物動作認識部
127 第1のメタデータ生成部
128 動作状況計測部
129 第2のメタデータ生成部
131 メタデータ受信部
132 解析部
133 記憶部
134‐1,134‐2 駆動部
141 ケース
142 振動アクチュエーター
1 Video
Claims (5)
入力された映像について、現フレーム画像を含む複数フレーム分の過去のフレーム画像を抽出する複数フレーム抽出手段と、
前記現フレーム画像を含む複数フレーム分のフレーム画像の各々について、骨格検出アルゴリズムに基づき、各人物オブジェクトの第1の骨格座標集合を生成する人物骨格抽出手段と、
前記現フレーム画像を含む複数フレーム分のフレーム画像の各々について、前記第1の骨格座標集合を基に探索範囲を可変設定し、各人物オブジェクトの骨格の位置及びサイズと、その周辺画像情報を抽出することにより人物オブジェクトを識別し、人物IDを付与した第2の骨格座標集合を生成する人物識別手段と、
前記現フレーム画像を基準に、前記複数フレーム分のフレーム画像における前記第2の骨格座標集合を時系列に連結し、人物オブジェクト毎の骨格の軌跡を示す軌跡特徴量の集合として骨格軌跡集合を生成する軌跡特徴量生成手段と、
前記現フレーム画像を基準に、当該複数フレーム分のフレーム画像における骨格軌跡集合を基準とした各人物オブジェクト間の距離、及び人物オブジェクト毎の各関節のオプティカルフロー量から各人物オブジェクトの人物動きの状況変化量を算出するとともに、骨格検出の成否、人物骨格の重心の移動量、及び前記探索範囲を表す骨格外接矩形のアスペクト比の変化量を算出し、これらを要素とする特徴ベクトルを、動作状況を表す動作状況特徴量として生成する動作状況計測手段と、
前記骨格軌跡集合の軌跡特徴量と、当該骨格軌跡集合の軌跡特徴量に対応する動作状況特徴量とを基に、機械学習により、触覚提示デバイスを作動させる衝撃提示用の情報を検出する人物動作認識手段と、
前記現フレーム画像に対応して、前記人物動作認識手段から得られる当該触覚提示デバイスを作動させる衝撃提示用の情報を含む第1の触覚メタデータを生成し、フレーム単位で外部出力する第1のメタデータ生成手段と、
前記現フレーム画像に対応して、前記動作状況計測手段から得られる各人物オブジェクトの人物動きの状況変化量を示す動作状況提示用の情報を含む第2の触覚メタデータを生成し、フレーム単位で外部出力する第2のメタデータ生成手段と、
を備えることを特徴とする触覚メタデータ生成装置。 A tactile metadata generator that extracts a person object from a video and generates tactile metadata corresponding to a dynamic person object.
A multi-frame extraction means for extracting past frame images for multiple frames including the current frame image for the input video, and
A person skeleton extraction means that generates a first skeleton coordinate set of each person object based on a skeleton detection algorithm for each of the frame images for a plurality of frames including the current frame image.
For each of the frame images for a plurality of frames including the current frame image, the search range is variably set based on the first skeleton coordinate set, and the position and size of the skeleton of each person object and its peripheral image information are extracted. A person identification means that identifies a person object and generates a second skeletal coordinate set to which a person ID is given.
Based on the current frame image, the second skeleton coordinate set in the frame images for the plurality of frames is connected in time series, and a skeleton locus set is generated as a set of locus features showing the locus of the skeleton for each person object. Trajectory feature amount generation means and
Based on the current frame image, the distance between each person object based on the skeletal trajectory set in the frame images for the plurality of frames, and the optical flow amount of each joint for each person object, the state of the person movement of each person object. In addition to calculating the amount of change, the success or failure of skeleton detection, the amount of movement of the center of gravity of the human skeleton, and the amount of change in the aspect ratio of the skeleton circumscribing rectangle representing the search range are calculated, and the feature vector using these as elements is used as the operating status. The operation status measuring means generated as the operation status feature quantity representing
Based on the locus feature amount of the skeletal locus set and the motion state feature amount corresponding to the locus feature amount of the skeletal locus set, the human motion that detects the information for impact presentation that operates the tactile presentation device by machine learning. Recognition means and
A first tactile metadata including information for impact presentation that operates the tactile presentation device obtained from the person motion recognition means corresponding to the current frame image is generated and externally output in frame units. Metadata generation means and
Corresponding to the current frame image, second tactile metadata including information for presenting the motion status indicating the amount of change in the status of the person movement of each person object obtained from the motion status measuring means is generated, and is generated in frame units. A second metadata generation means to output externally,
A tactile metadata generator characterized by comprising.
前記人物動作認識手段は、前記動オブジェクト情報を基に、全ての人物オブジェクトの前記骨格軌跡集合のうち前記触覚提示デバイスを作動させるための骨格軌跡集合を選定し、選定した骨格軌跡集合の軌跡特徴量と、その選定した骨格軌跡集合に対応する動作状況特徴量とを基に、機械学習により、人物オブジェクト毎の衝撃提示用のタイミング及び速さを示す情報を検出することを特徴とする、請求項1又は2に記載の触覚メタデータ生成装置。 A moving object is detected based on the difference image between adjacent frames using each of the frame images for a plurality of frames including the current frame image, and the skeleton locus of all the person objects among the moving objects detected from each difference image. It is further equipped with a moving object detection means that selects a specific moving object using a set and generates moving object information concatenated with the coordinate position, size, and moving direction of the specific moving object obtained from each difference image as elements.
The person motion recognition means selects a skeleton locus set for operating the tactile presentation device from the skeleton locus sets of all the person objects based on the motion object information, and the locus features of the selected skeleton locus set. A claim characterized by detecting information indicating the timing and speed for impact presentation for each person object by machine learning based on the amount and the operation state feature amount corresponding to the selected skeletal locus set. Item 2. The tactile metadata generator according to Item 1 or 2.
触覚刺激を提示する触覚提示デバイスと、
前記触覚メタデータ生成装置から得られる第1及び第2の触覚メタデータを基に、予め定めた駆動基準データを参照し、前記触覚提示デバイスを駆動するよう制御する制御ユニットと、
を備えることを特徴とする映像触覚連動システム。 The tactile metadata generator according to any one of claims 1 to 3.
A tactile presentation device that presents tactile stimuli,
A control unit that controls to drive the tactile presentation device by referring to predetermined drive reference data based on the first and second tactile metadata obtained from the tactile metadata generator.
A video-tactile interlocking system characterized by being equipped with.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2020105700A JP7488704B2 (en) | 2020-06-18 | 2020-06-18 | Haptic metadata generating device, video-haptic linking system, and program |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2020105700A JP7488704B2 (en) | 2020-06-18 | 2020-06-18 | Haptic metadata generating device, video-haptic linking system, and program |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2021197110A true JP2021197110A (en) | 2021-12-27 |
| JP7488704B2 JP7488704B2 (en) | 2024-05-22 |
Family
ID=79195767
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2020105700A Active JP7488704B2 (en) | 2020-06-18 | 2020-06-18 | Haptic metadata generating device, video-haptic linking system, and program |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP7488704B2 (en) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2023115775A (en) * | 2022-02-08 | 2023-08-21 | 日本放送協会 | Haptic sense presentation signal generation device, visual haptic interlocking system, and program |
| CN117079664A (en) * | 2023-08-16 | 2023-11-17 | 北京百度网讯科技有限公司 | Lip-sync driver and its model training methods, devices, equipment and media |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2013008869A1 (en) * | 2011-07-14 | 2013-01-17 | 株式会社ニコン | Electronic device and data generation method |
| JP2020031406A (en) * | 2018-08-24 | 2020-02-27 | 独立行政法人日本スポーツ振興センター | Judgment system and judgment method |
| JP2020042476A (en) * | 2018-09-10 | 2020-03-19 | 国立大学法人 東京大学 | Method and apparatus for acquiring joint position, and method and apparatus for acquiring motion |
-
2020
- 2020-06-18 JP JP2020105700A patent/JP7488704B2/en active Active
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2013008869A1 (en) * | 2011-07-14 | 2013-01-17 | 株式会社ニコン | Electronic device and data generation method |
| JP2020031406A (en) * | 2018-08-24 | 2020-02-27 | 独立行政法人日本スポーツ振興センター | Judgment system and judgment method |
| JP2020042476A (en) * | 2018-09-10 | 2020-03-19 | 国立大学法人 東京大学 | Method and apparatus for acquiring joint position, and method and apparatus for acquiring motion |
Non-Patent Citations (1)
| Title |
|---|
| 高橋 正樹、外4名: ""人物の姿勢解析に基づくスポーツ映像からの触覚提示情報抽出"", 映像情報メディア学会 2019年冬季大会講演予稿集, JPN6024011361, 28 November 2019 (2019-11-28), JP, pages 1 - 2, ISSN: 0005304390 * |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2023115775A (en) * | 2022-02-08 | 2023-08-21 | 日本放送協会 | Haptic sense presentation signal generation device, visual haptic interlocking system, and program |
| CN117079664A (en) * | 2023-08-16 | 2023-11-17 | 北京百度网讯科技有限公司 | Lip-sync driver and its model training methods, devices, equipment and media |
Also Published As
| Publication number | Publication date |
|---|---|
| JP7488704B2 (en) | 2024-05-22 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11941915B2 (en) | Golf game video analytic system | |
| US11132533B2 (en) | Systems and methods for creating target motion, capturing motion, analyzing motion, and improving motion | |
| US20210166574A1 (en) | Virtual team sport trainer | |
| CN100349188C (en) | Method and system for synchronously integrating video sequences in time and space | |
| EP2585896B1 (en) | User tracking feedback | |
| US9418470B2 (en) | Method and system for selecting the viewing configuration of a rendered figure | |
| KR101738420B1 (en) | System and method for automatically creating image information on golf | |
| US12179086B2 (en) | Mixed reality simulation and training system | |
| WO2019130527A1 (en) | Extraction program, extraction method, and information processing device | |
| US11458400B2 (en) | Information processing device, information processing method, and program for generating an added related to a predicted future behavior | |
| US20070021199A1 (en) | Interactive games with prediction method | |
| KR20180112656A (en) | Interactive trampoline play system and control method for the same | |
| JP5446572B2 (en) | Image generation system, control program, and recording medium | |
| JP2023115775A (en) | Haptic sense presentation signal generation device, visual haptic interlocking system, and program | |
| US20070021207A1 (en) | Interactive combat game between a real player and a projected image of a computer generated player or a real player with a predictive method | |
| CN106504283A (en) | Information broadcasting method, apparatus and system | |
| CN116328279A (en) | A real-time auxiliary training method and device based on visual human pose estimation | |
| JP7488704B2 (en) | Haptic metadata generating device, video-haptic linking system, and program | |
| CN110989839A (en) | Human-machine combat system and method | |
| KR101864039B1 (en) | System for providing solution of justice on martial arts sports and analyzing bigdata using augmented reality, and Drive Method of the Same | |
| CN111672089B (en) | An electronic scoring system and implementation method for multiplayer confrontation projects | |
| JP7054276B2 (en) | Physical activity support system, method, and program | |
| JP7502957B2 (en) | Haptic metadata generating device, video-haptic interlocking system, and program | |
| US11331551B2 (en) | Augmented extended realm system | |
| JP7344096B2 (en) | Haptic metadata generation device, video-tactile interlocking system, and program |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20230518 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20240319 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20240326 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20240329 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20240416 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20240510 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 7488704 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |