JP2020201337A - 音声処理装置及び音声処理方法 - Google Patents
音声処理装置及び音声処理方法 Download PDFInfo
- Publication number
- JP2020201337A JP2020201337A JP2019106859A JP2019106859A JP2020201337A JP 2020201337 A JP2020201337 A JP 2020201337A JP 2019106859 A JP2019106859 A JP 2019106859A JP 2019106859 A JP2019106859 A JP 2019106859A JP 2020201337 A JP2020201337 A JP 2020201337A
- Authority
- JP
- Japan
- Prior art keywords
- gain
- voice
- sound signal
- voice processing
- microphone
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
- 238000012545 processing Methods 0.000 title claims abstract description 112
- 238000003672 processing method Methods 0.000 title claims abstract 12
- 230000005236 sound signal Effects 0.000 claims abstract description 92
- 238000000605 extraction Methods 0.000 claims description 59
- 238000004364 calculation method Methods 0.000 claims description 31
- 239000000284 extract Substances 0.000 claims description 9
- 230000005540 biological transmission Effects 0.000 claims description 5
- 238000010801 machine learning Methods 0.000 claims description 4
- 238000010586 diagram Methods 0.000 description 16
- 230000004048 modification Effects 0.000 description 14
- 238000012986 modification Methods 0.000 description 14
- 238000004891 communication Methods 0.000 description 13
- 238000001228 spectrum Methods 0.000 description 11
- 230000006870 function Effects 0.000 description 8
- 230000014509 gene expression Effects 0.000 description 5
- 230000002087 whitening effect Effects 0.000 description 5
- 230000004907 flux Effects 0.000 description 3
- 238000000034 method Methods 0.000 description 3
- 230000003595 spectral effect Effects 0.000 description 3
- 238000013528 artificial neural network Methods 0.000 description 2
- 238000005314 correlation function Methods 0.000 description 2
- 230000000737 periodic effect Effects 0.000 description 2
- 238000004378 air conditioning Methods 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 238000006243 chemical reaction Methods 0.000 description 1
- 238000007716 flux method Methods 0.000 description 1
- 239000000203 mixture Substances 0.000 description 1
- 230000008569 process Effects 0.000 description 1
- 230000035945 sensitivity Effects 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
Images








Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/20—Speech recognition techniques specially adapted for robustness in adverse environments, e.g. in noise, of stress induced speech
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/0316—Speech enhancement, e.g. noise reduction or echo cancellation by changing the amplitude
- G10L21/0324—Details of processing therefor
- G10L21/034—Automatic adjustment
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F17/00—Digital computing or data processing equipment or methods, specially adapted for specific functions
- G06F17/10—Complex mathematical operations
- G06F17/18—Complex mathematical operations for evaluating statistical data, e.g. average values, frequency distributions, probability functions, regression analysis
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/16—Sound input; Sound output
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
- G10L15/16—Speech classification or search using artificial neural networks
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/0316—Speech enhancement, e.g. noise reduction or echo cancellation by changing the amplitude
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/78—Detection of presence or absence of voice signals
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/0208—Noise filtering
- G10L21/0264—Noise filtering characterised by the type of parameter measurement, e.g. correlation techniques, zero crossing techniques or predictive techniques
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/03—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the type of extracted parameters
- G10L25/24—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the type of extracted parameters the extracted parameters being the cepstrum
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/78—Detection of presence or absence of voice signals
- G10L25/84—Detection of presence or absence of voice signals for discriminating voice from noise
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Health & Medical Sciences (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Computational Linguistics (AREA)
- Signal Processing (AREA)
- General Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Quality & Reliability (AREA)
- Mathematical Physics (AREA)
- Computational Mathematics (AREA)
- Pure & Applied Mathematics (AREA)
- Mathematical Optimization (AREA)
- Mathematical Analysis (AREA)
- General Engineering & Computer Science (AREA)
- Life Sciences & Earth Sciences (AREA)
- Artificial Intelligence (AREA)
- Evolutionary Biology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Evolutionary Computation (AREA)
- Operations Research (AREA)
- Probability & Statistics with Applications (AREA)
- Bioinformatics & Computational Biology (AREA)
- Algebra (AREA)
- Software Systems (AREA)
- Databases & Information Systems (AREA)
- General Health & Medical Sciences (AREA)
- Circuit For Audible Band Transducer (AREA)
- Telephonic Communication Services (AREA)
Abstract
Description
図1は、実施形態1に係る音声処理システム100の構成を示す図である。音声処理システム100は、ネットワーク2を介して互いに接続される複数の(図1では2つの)音声処理装置1及び音声処理装置3を備えている。
実施形態2の音声処理装置1及び音声処理装置3のCPU12Aについて、図8を参照して説明する。図8は、実施形態2のCPU12Aの機能的構成を示すブロック図である。なお、上述の実施形態1のCPU12と同じ構成には、同じ符号を付し、説明を省略する。また、実施形態2の音声処理装置1及び3は同じ構成及び同じ機能を有するものとし、以下の説明では、音声処理装置1のCPU12Aを代表して説明する。

実施形態3の音声処理装置1Aについて図9を参照して説明する。図9は、実施形態3の音声処理装置1Aの主要な構成を示すブロック図である。図10は、実施形態3の音声処理装置1AのCPU12Bの機能的構成を示すブロック図である。なお、音声処理装置3は、音声処理装置1Aと同じ構成及び機能を有しているので、以下の説明では、音声処理装置1Aを代表して説明する。また、音声処理装置1と同じ構成には、同じ符号を付し、説明を省略する。
変形例1の音声処理装置1の特徴量抽出部121について、説明する。音声処理装置1は、機械学習によって、音信号が近端側の話者の音声であるかどうか判定する。
変形例2の音声処理装置1の特徴量抽出部121について、説明する。変形例2の音声処理装置1の特徴量抽出部121は、音信号の基音と倍音の周波数分布によって、音声の特徴量を抽出する。
別の変形例について、以下に列挙する。
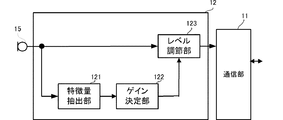
11…通信部(送信部)
15…マイク
121…特徴量抽出部(音声推定部)
122…ゲイン決定部
124…SN比算出部
125…相関算出部
Claims (18)
- マイクと、
前記マイクで収音された音信号から近端側の話者の音声である確率を求める音声推定部と、
前記音声推定部で推定された前記確率に基づいて、前記マイクで収音された前記音信号のゲインを決定するゲイン決定部と、
前記ゲイン決定部で決定された前記ゲインによって処理された信号を遠端側に送信する送信部と、を備えた、音声処理装置。 - 前記マイクで収音された前記音信号における音信号対雑音の比率を推定するSN比算出部をさらに備え、
前記ゲイン決定部は、前記確率と前記SN比算出部によって推定された前記比率とに基づいて前記マイクで収音された前記音信号の前記ゲインを決定する、請求項1に記載の音声処理装置。 - 前記マイクを複数備え、
前記複数のマイクで収音された前記音声の相関を推定する相関算出部をさらに備え、
前記ゲイン決定部は、前記確率及び前記相関を用いて前記複数のマイクで収音された前記音信号の前記ゲインを決定する、請求項1又は2に記載の音声処理装置。 - 前記ゲイン決定部は、前記ゲインを段階的に下げ、又は前記ゲインを瞬時に上げる、請求項1乃至3のいずれかに記載の音声処理装置。
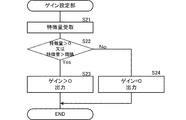
- 前記ゲイン決定部は、前記確率が所定の条件を満たさなかった場合、前記ゲインを最小に決定し、前記確率が前記所定の条件を満たした場合、前記ゲインを最小よりも大きい値に決定する、請求項1乃至4のいずれかに記載の音声処理装置。
- 前記音声推定部は、ケプストラムを用いて、前記確率を求める、請求項1乃至5のいずれかに記載の音声処理装置。
- 前記音声推定部は、機械学習方法を用いて、前記確率を求める、請求項1乃至5のいずれかに記載の音声処理装置。
- 前記音声推定部は、前記マイクで収音された前記音信号の基音及び倍音の周波数分布を用いて、前記確率を求める、請求項1乃至5のいずれかに記載の音声処理装置。
- マイクと、
前記マイクで収音された音信号から近端側の話者の音声の特徴量を抽出する特徴量抽出部と、
前記特徴量抽出部が抽出した前記音声の特徴量に基づいて、前記マイクで収音された前記音信号のゲインを決定するゲイン決定部と、
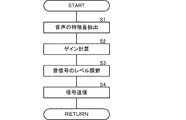
前記ゲイン決定部で決定された前記ゲインによって処理された信号を遠端側に送信する送信部と、を備えた、音声処理装置。 - マイクで収音された音信号から近端側の話者の音声である確率を求め、
求められた前記確率に基づいて、前記マイクで収音された前記音信号のゲインを決定し、
決定された前記ゲインによって処理された信号を遠端側に送信する、音声処理方法。 - 前記マイクで収音された前記音信号における音信号対雑音の比率を推定し、
前記確率と前記比率とに基づいて前記マイクで収音された前記音信号の前記ゲインを決定する、請求項10に記載の音声処理方法。 - 複数の前記マイクで収音された前記音声の相関を推定し、
前記確率及び前記相関を用いて前記マイクで収音された前記音信号の前記ゲインを決定する、請求項10又は11に記載の音声処理方法。 - 前記ゲインを段階的に下げ、又は前記ゲインを瞬時に上げる、請求項10乃至12のいずれかに記載の音声処理方法。
- 前記確率が所定の条件を満たさなかった場合、前記ゲインを最小に決定し、前記確率が前記所定の条件を満たした場合、前記ゲインを最小よりも大きい値に決定する、請求項10乃至13のいずれかに記載の音声処理方法。
- ケプストラムを用いて、前記確率を求める、請求項10乃至14のいずれかに記載の音声処理方法。
- 機械学習方法を用いて、前記確率を求める、請求項10乃至14のいずれかに記載の音声処理方法。
- 前記マイクで収音された前記音信号の基音及び倍音の周波数分布を用いて、前記確率を求める、請求項10乃至14のいずれかに記載の音声処理方法。
- マイクで収音された音信号から近端側の話者の音声の特徴量を抽出し、
抽出した前記音声の特徴量に基づいて、前記マイクで収音された前記音信号のゲインを決定し、
決定された前記ゲインによって処理された信号を遠端側に送信する、音声処理方法。
Priority Applications (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2019106859A JP7404664B2 (ja) | 2019-06-07 | 2019-06-07 | 音声処理装置及び音声処理方法 |
| US16/889,965 US11922933B2 (en) | 2019-06-07 | 2020-06-02 | Voice processing device and voice processing method |
| EP20177961.8A EP3748636A1 (en) | 2019-06-07 | 2020-06-03 | Voice processing device and voice processing method |
| CN202010493978.1A CN112133320B (zh) | 2019-06-07 | 2020-06-03 | 语音处理装置及语音处理方法 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2019106859A JP7404664B2 (ja) | 2019-06-07 | 2019-06-07 | 音声処理装置及び音声処理方法 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2020201337A true JP2020201337A (ja) | 2020-12-17 |
| JP7404664B2 JP7404664B2 (ja) | 2023-12-26 |
Family
ID=70977388
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2019106859A Active JP7404664B2 (ja) | 2019-06-07 | 2019-06-07 | 音声処理装置及び音声処理方法 |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US11922933B2 (ja) |
| EP (1) | EP3748636A1 (ja) |
| JP (1) | JP7404664B2 (ja) |
| CN (1) | CN112133320B (ja) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11425163B2 (en) * | 2020-02-05 | 2022-08-23 | King Fahd University Of Petroleum And Minerals | Control of cyber physical systems subject to cyber and physical attacks |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2006194959A (ja) * | 2005-01-11 | 2006-07-27 | Sony Corp | 音声検出装置、自動撮像装置、および音声検出方法 |
| JP2009175473A (ja) * | 2008-01-25 | 2009-08-06 | Yamaha Corp | 音処理装置およびプログラム |
| JP2009294537A (ja) * | 2008-06-06 | 2009-12-17 | Raytron:Kk | 音声区間検出装置および音声区間検出方法 |
| JP2010541010A (ja) * | 2007-09-28 | 2010-12-24 | クゥアルコム・インコーポレイテッド | 複数マイクロホン音声アクティビティ検出器 |
| JP2015215463A (ja) * | 2014-05-09 | 2015-12-03 | 富士通株式会社 | 音声強調装置、音声強調方法及び音声強調用コンピュータプログラム |
Family Cites Families (28)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP0763810B1 (en) * | 1990-05-28 | 2001-09-26 | Matsushita Electric Industrial Co., Ltd. | Speech signal processing apparatus for detecting a speech signal from a noisy speech signal |
| US6084967A (en) * | 1997-10-29 | 2000-07-04 | Motorola, Inc. | Radio telecommunication device and method of authenticating a user with a voice authentication token |
| JP4247037B2 (ja) * | 2003-01-29 | 2009-04-02 | 株式会社東芝 | 音声信号処理方法と装置及びプログラム |
| EP1569200A1 (en) * | 2004-02-26 | 2005-08-31 | Sony International (Europe) GmbH | Identification of the presence of speech in digital audio data |
| US7555432B1 (en) * | 2005-02-10 | 2009-06-30 | Purdue Research Foundation | Audio steganography method and apparatus using cepstrum modification |
| JP4667082B2 (ja) * | 2005-03-09 | 2011-04-06 | キヤノン株式会社 | 音声認識方法 |
| CN101192411B (zh) * | 2007-12-27 | 2010-06-02 | 北京中星微电子有限公司 | 大距离麦克风阵列噪声消除的方法和噪声消除系统 |
| EP2083417B1 (en) | 2008-01-25 | 2015-07-29 | Yamaha Corporation | Sound processing device and program |
| US8917885B2 (en) * | 2008-09-24 | 2014-12-23 | Yamaha Corporation | Loop gain estimating apparatus and howling preventing apparatus |
| JP5197458B2 (ja) * | 2009-03-25 | 2013-05-15 | 株式会社東芝 | 受音信号処理装置、方法およびプログラム |
| WO2010142320A1 (en) * | 2009-06-08 | 2010-12-16 | Nokia Corporation | Audio processing |
| WO2014043024A1 (en) * | 2012-09-17 | 2014-03-20 | Dolby Laboratories Licensing Corporation | Long term monitoring of transmission and voice activity patterns for regulating gain control |
| US9516442B1 (en) * | 2012-09-28 | 2016-12-06 | Apple Inc. | Detecting the positions of earbuds and use of these positions for selecting the optimum microphones in a headset |
| US20140358552A1 (en) * | 2013-05-31 | 2014-12-04 | Cirrus Logic, Inc. | Low-power voice gate for device wake-up |
| EP2876900A1 (en) * | 2013-11-25 | 2015-05-27 | Oticon A/S | Spatial filter bank for hearing system |
| JP5863928B1 (ja) | 2014-10-29 | 2016-02-17 | シャープ株式会社 | 音声調整装置 |
| US9706300B2 (en) * | 2015-09-18 | 2017-07-11 | Qualcomm Incorporated | Collaborative audio processing |
| JP6903884B2 (ja) * | 2016-09-15 | 2021-07-14 | 沖電気工業株式会社 | 信号処理装置、プログラム及び方法、並びに、通話装置 |
| EP3312838A1 (en) * | 2016-10-18 | 2018-04-25 | Fraunhofer Gesellschaft zur Förderung der Angewand | Apparatus and method for processing an audio signal |
| KR102535726B1 (ko) * | 2016-11-30 | 2023-05-24 | 삼성전자주식회사 | 이어폰 오장착 검출 방법, 이를 위한 전자 장치 및 저장 매체 |
| WO2018173267A1 (ja) * | 2017-03-24 | 2018-09-27 | ヤマハ株式会社 | 収音装置および収音方法 |
| WO2018186656A1 (ko) * | 2017-04-03 | 2018-10-11 | 가우디오디오랩 주식회사 | 오디오 신호 처리 방법 및 장치 |
| WO2018217059A1 (en) * | 2017-05-25 | 2018-11-29 | Samsung Electronics Co., Ltd. | Method and electronic device for managing loudness of audio signal |
| US11609737B2 (en) * | 2017-06-27 | 2023-03-21 | Dolby International Ab | Hybrid audio signal synchronization based on cross-correlation and attack analysis |
| WO2019142072A1 (en) * | 2018-01-16 | 2019-07-25 | Cochlear Limited | Individualized own voice detection in a hearing prosthesis |
| US10957338B2 (en) * | 2018-05-16 | 2021-03-23 | Synaptics Incorporated | 360-degree multi-source location detection, tracking and enhancement |
| EP4221257A1 (en) * | 2019-03-13 | 2023-08-02 | Oticon A/s | A hearing device configured to provide a user identification signal |
| US11164592B1 (en) * | 2019-05-09 | 2021-11-02 | Amazon Technologies, Inc. | Responsive automatic gain control |
-
2019
- 2019-06-07 JP JP2019106859A patent/JP7404664B2/ja active Active
-
2020
- 2020-06-02 US US16/889,965 patent/US11922933B2/en active Active
- 2020-06-03 CN CN202010493978.1A patent/CN112133320B/zh active Active
- 2020-06-03 EP EP20177961.8A patent/EP3748636A1/en not_active Withdrawn
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2006194959A (ja) * | 2005-01-11 | 2006-07-27 | Sony Corp | 音声検出装置、自動撮像装置、および音声検出方法 |
| JP2010541010A (ja) * | 2007-09-28 | 2010-12-24 | クゥアルコム・インコーポレイテッド | 複数マイクロホン音声アクティビティ検出器 |
| JP2009175473A (ja) * | 2008-01-25 | 2009-08-06 | Yamaha Corp | 音処理装置およびプログラム |
| JP2009294537A (ja) * | 2008-06-06 | 2009-12-17 | Raytron:Kk | 音声区間検出装置および音声区間検出方法 |
| JP2015215463A (ja) * | 2014-05-09 | 2015-12-03 | 富士通株式会社 | 音声強調装置、音声強調方法及び音声強調用コンピュータプログラム |
Non-Patent Citations (1)
| Title |
|---|
| 大淵 康成,外2名: "統計的雑音抑圧法の強調的適用による雑音環境下音声区間検出", 情報処理学会研究報告, vol. Vol.2012-SLP-94, No.18, JPN6023003554, December 2012 (2012-12-01), pages 1 - 6, ISSN: 0005103572 * |
Also Published As
| Publication number | Publication date |
|---|---|
| CN112133320B (zh) | 2024-02-20 |
| JP7404664B2 (ja) | 2023-12-26 |
| CN112133320A (zh) | 2020-12-25 |
| US11922933B2 (en) | 2024-03-05 |
| US20200388275A1 (en) | 2020-12-10 |
| EP3748636A1 (en) | 2020-12-09 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN111149370B (zh) | 会议系统中的啸叫检测 | |
| US9812147B2 (en) | System and method for generating an audio signal representing the speech of a user | |
| US9269367B2 (en) | Processing audio signals during a communication event | |
| JP4764995B2 (ja) | 雑音を含む音響信号の高品質化 | |
| CN108235181B (zh) | 在音频处理装置中降噪的方法 | |
| TW201030733A (en) | Systems, methods, apparatus, and computer program products for enhanced active noise cancellation | |
| JP2013168857A (ja) | ノイズ低減装置、音声入力装置、無線通信装置、およびノイズ低減方法 | |
| WO2011141772A1 (en) | Method and apparatus for processing an audio signal based on an estimated loudness | |
| CN103124165A (zh) | 自动增益控制 | |
| JP2014137405A (ja) | 音響処理装置及び音響処理方法 | |
| EP2700161B1 (en) | Processing audio signals | |
| US11380312B1 (en) | Residual echo suppression for keyword detection | |
| CN112565981B (zh) | 啸叫抑制方法、装置、助听器及存储介质 | |
| CN105491495B (zh) | 基于确定性序列的反馈估计 | |
| CN113593612B (zh) | 语音信号处理方法、设备、介质及计算机程序产品 | |
| US6999920B1 (en) | Exponential echo and noise reduction in silence intervals | |
| EP3025516A1 (en) | Automatic timbre, loudness and equalization control | |
| JP2010139571A (ja) | 音声加工装置及び音声加工方法 | |
| WO2022256577A1 (en) | A method of speech enhancement and a mobile computing device implementing the method | |
| CN112017639B (zh) | 语音信号的检测方法、终端设备及存储介质 | |
| CN117939360A (zh) | 一种用于蓝牙音箱的音频增益控制方法及系统 | |
| US11373669B2 (en) | Acoustic processing method and acoustic device | |
| EP2663979B1 (en) | Processing audio signals | |
| JP7404664B2 (ja) | 音声処理装置及び音声処理方法 | |
| CN113314121B (zh) | 无声语音识别方法、装置、介质、耳机及电子设备 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20220419 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20230127 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20230131 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20230403 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20230711 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20230830 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20231114 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20231127 |
|
| R151 | Written notification of patent or utility model registration |
Ref document number: 7404664 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R151 |
|
| S531 | Written request for registration of change of domicile |
Free format text: JAPANESE INTERMEDIATE CODE: R313532 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |