JP2019028650A - Image identification device, learning device, image identification method, learning method and program - Google Patents
Image identification device, learning device, image identification method, learning method and program Download PDFInfo
- Publication number
- JP2019028650A JP2019028650A JP2017146337A JP2017146337A JP2019028650A JP 2019028650 A JP2019028650 A JP 2019028650A JP 2017146337 A JP2017146337 A JP 2017146337A JP 2017146337 A JP2017146337 A JP 2017146337A JP 2019028650 A JP2019028650 A JP 2019028650A
- Authority
- JP
- Japan
- Prior art keywords
- learning
- image
- identification
- unit
- discriminator
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Withdrawn
Links
- 238000000034 method Methods 0.000 title claims abstract description 44
- 238000006243 chemical reaction Methods 0.000 claims abstract description 79
- 238000003384 imaging method Methods 0.000 claims abstract description 23
- 230000006870 function Effects 0.000 claims description 30
- 238000000605 extraction Methods 0.000 claims description 24
- 238000013528 artificial neural network Methods 0.000 claims description 8
- 238000012886 linear function Methods 0.000 claims description 3
- 239000000284 extract Substances 0.000 claims 1
- 238000012545 processing Methods 0.000 abstract description 39
- 238000013527 convolutional neural network Methods 0.000 description 41
- 238000003860 storage Methods 0.000 description 27
- 238000011161 development Methods 0.000 description 22
- 230000018109 developmental process Effects 0.000 description 21
- 230000008569 process Effects 0.000 description 17
- 238000012937 correction Methods 0.000 description 16
- 230000005540 biological transmission Effects 0.000 description 15
- 230000008878 coupling Effects 0.000 description 13
- 238000010168 coupling process Methods 0.000 description 13
- 238000005859 coupling reaction Methods 0.000 description 13
- 238000013500 data storage Methods 0.000 description 12
- 239000013598 vector Substances 0.000 description 11
- 238000010586 diagram Methods 0.000 description 9
- 230000011218 segmentation Effects 0.000 description 5
- 238000004364 calculation method Methods 0.000 description 3
- 238000011176 pooling Methods 0.000 description 3
- 238000011160 research Methods 0.000 description 3
- 238000013135 deep learning Methods 0.000 description 2
- 238000003702 image correction Methods 0.000 description 2
- 230000006872 improvement Effects 0.000 description 2
- 238000005259 measurement Methods 0.000 description 2
- 230000003796 beauty Effects 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 125000004122 cyclic group Chemical group 0.000 description 1
- 238000001514 detection method Methods 0.000 description 1
- 238000006073 displacement reaction Methods 0.000 description 1
- 238000011478 gradient descent method Methods 0.000 description 1
- 238000003709 image segmentation Methods 0.000 description 1
- 230000010365 information processing Effects 0.000 description 1
- 230000004807 localization Effects 0.000 description 1
- 230000014759 maintenance of location Effects 0.000 description 1
- 239000004570 mortar (masonry) Substances 0.000 description 1
- 230000001537 neural effect Effects 0.000 description 1
- 238000010422 painting Methods 0.000 description 1
- 230000000644 propagated effect Effects 0.000 description 1
- 230000009467 reduction Effects 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
- 230000001502 supplementing effect Effects 0.000 description 1
- 230000000007 visual effect Effects 0.000 description 1
Images







Landscapes
- Image Analysis (AREA)
Abstract
Description
本発明は、画像を所定のクラスに分類する、画像を複数のクラスの領域に分割するなどの画像識別技術に関する。 The present invention relates to an image identification technique such as classifying an image into a predetermined class or dividing an image into regions of a plurality of classes.
画像を所定のクラスに分類する研究は、これまで広く行われてきており、近年では画像を非常に多くのクラスに分類するタスクも研究されてきている。非特許文献1には、深層学習による画像分類の技術が開示されている。
Research for classifying images into predetermined classes has been widely performed, and in recent years, tasks for classifying images into very many classes have been studied. Non-Patent
また、画像を複数の領域に分割する領域分割の研究も多く行われており、画像から人物の領域、自動車の領域、道路の領域、建物の領域、空の領域などの、意味的な領域を切り出す課題が盛んに研究されている。このような課題は、意味的領域分割(Semantic Segmentation)と呼ばれ、被写体の種類に対応した画像補正や、シーン解釈などに応用できると考えられている。 In addition, many researches on area division that divides an image into multiple areas have been conducted, and semantic areas such as human areas, automobile areas, road areas, building areas, and empty areas are also extracted from images. The problem of cutting out has been actively researched. Such a problem is called semantic segmentation and is considered to be applicable to image correction corresponding to the type of subject, scene interpretation, and the like.
意味的領域分割を行うにあたり、画像の各位置に関するクラスラベルの識別を小領域(superpixel)単位で行う手法が多く提案されている。小領域は主に類似した特徴を持つ小さな領域として画像から切り出されるもので、非特許文献2をはじめとして、さまざまな手法が提案されている。このようにして得られたそれぞれの小領域は、その内部の特徴量、あるいはその周辺のコンテクスト特徴量も一緒に用いてクラスラベルを識別することが行われる。通常はさまざまな学習画像を用いてこのような局所ベースの領域識別器を学習させることで領域識別を行う。 In performing semantic region division, many methods have been proposed in which class labels for each position of an image are identified in units of small regions (superpixels). The small area is mainly cut out from the image as a small area having similar characteristics, and various methods such as Non-Patent Document 2 have been proposed. Each small region obtained in this way is used to identify a class label using the internal feature amount or the surrounding context feature amount together. Usually, region identification is performed by learning such a local-based region classifier using various learning images.
近年では、深層学習を利用した領域分割の研究も行われてきている。非特許文献3では、CNN(Convolutional Neural Network)の中間層出力を特徴量として利用し、複数の中間層特徴による画素ごとのクラス判定結果を統合する。非特許文献3では、このようにして、画像の意味的領域分割を行っている。非特許文献3の手法では、前述のような小領域分割結果を利用することなく、画素ごとに直接クラス判定を行っている。 In recent years, research on region segmentation using deep learning has also been conducted. In Non-Patent Document 3, an intermediate layer output of CNN (Convolutional Neural Network) is used as a feature amount, and class determination results for each pixel based on a plurality of intermediate layer features are integrated. In Non-Patent Document 3, semantic region division of an image is performed in this way. In the method of Non-Patent Document 3, class determination is directly performed for each pixel without using the small region division result as described above.
このような画像分類や意味的領域分割などの画像識別を行うにあたり、識別器の入力データとして与えられるものは通常、カメラ内部処理もしくは撮影後にユーザの手により現像された画像である。本来、現像画像はユーザが目で見て楽しむものであるため、画像の現像方法は見た目の美しさを基準にして決定される。しかしながら、このような通常の現像方法が画像識別のタスクにおいて適しているとは限らない。例えば、白い壁を美しく見せるために露出をややオーバー気味に飛ばした画像では、曇天のテクスチャレスな空と壁を区別することは困難になる。これに対して、暗めに撮影して壁のテクスチャが見えるような画像であるほうが、壁と空を分類するのに適していると考えられる。 In performing such image classification such as image classification and semantic region division, what is given as input data of the discriminator is usually an image developed by the user's hand after camera internal processing or photographing. Originally, the developed image is something that the user can see and enjoy, so the image development method is determined based on the beauty of appearance. However, such a normal development method is not always suitable for an image identification task. For example, in an image that is slightly overexposed to make a white wall look beautiful, it is difficult to distinguish the cloudless sky and the wall. On the other hand, it is considered that an image in which the wall texture can be seen by photographing darkly is suitable for classifying the wall and the sky.
特許文献1では、撮像装置から得られたRAW画像の平均輝度値によって複数のガンマ補正関数の中から補正関数を選択することで、露出のアンダー/オーバーを抑えた画像を、表示用画像とは別に生成し、物体検出処理に利用することを提案している。
In
しかしながら、特許文献1で、用意される補正関数は人が直観的にパラメータを設定したものであって、補正値の良し悪しはその直観に頼るものであり、高精度な画像識別を行えない場合があった。そこで、本発明は、高精度な画像識別を行えるようにすることを目的とする。
However, in
本発明は、撮像装置のセンサ値による入力画像を取得する取得手段と、変換部を有する識別器を用いて、前記取得されたセンサ値による入力画像を識別する識別手段と、を有し、前記識別器のうち少なくとも前記変換部は、撮像装置のセンサ値による学習画像と当該学習画像に付与された正解データとに基づいて学習されていることを特徴とする。 The present invention includes an acquisition unit that acquires an input image based on a sensor value of an imaging device, and an identification unit that identifies the input image based on the acquired sensor value using a discriminator having a conversion unit, At least the conversion unit of the discriminator is learned based on a learning image based on sensor values of the imaging device and correct data provided to the learning image.
本発明によれば、高精度な画像識別を行うことができるようになる。 According to the present invention, highly accurate image identification can be performed.
[第1の実施形態]
以下、本発明の第1の実施形態の詳細について図面を参照しつつ説明する。図1は、各実施形態に係る画像処理装置の機能構成を示す概略ブロック図であり、図1(a)が本実施形態に係る概略ブロック図である。画像処理装置は、学習時における学習装置、および識別時における画像識別装置として機能するものである。
[First Embodiment]
The details of the first embodiment of the present invention will be described below with reference to the drawings. FIG. 1 is a schematic block diagram illustrating a functional configuration of an image processing apparatus according to each embodiment, and FIG. 1A is a schematic block diagram according to the present embodiment. The image processing device functions as a learning device at the time of learning and an image identification device at the time of identification.
このような画像処理装置は、CPU、ROM、RAM、HDD等のハードウェア構成を備え、CPUがROMやHD等に格納されたプログラムを実行することにより、例えば、後述する各機能構成やフローチャートの処理が実現される。RAMは、CPUがプログラムを展開して実行するワークエリアとして機能する記憶領域を有する。ROMは、CPUが実行するプログラム等を格納する記憶領域を有する。HDDは、CPUが処理を実行する際に要する各種のプログラム、閾値に関するデータ等を含む各種のデータを格納する記憶領域を有する。 Such an image processing apparatus has a hardware configuration such as a CPU, a ROM, a RAM, and an HDD. When the CPU executes a program stored in a ROM, an HD, or the like, for example, each of the functional configurations and flowcharts described below are performed. Processing is realized. The RAM has a storage area that functions as a work area where the CPU develops and executes the program. The ROM has a storage area for storing programs executed by the CPU. The HDD has a storage area for storing various types of data including various programs necessary for the CPU to execute processing, data on threshold values, and the like.
まず、本実施形態における学習時の装置構成の概要について説明する。ここで学習とは、後述する識別時の処理を行うために利用される識別器を、事前に用意された学習画像から生成することである。処理内容の詳細については後述する。 First, an outline of a device configuration during learning in the present embodiment will be described. Here, learning is to generate a discriminator used for performing processing at the time of discrimination described later from a learning image prepared in advance. Details of the processing contents will be described later.
第1の学習データ記憶部5100には、あらかじめ第1の学習データが用意されている。第1の学習データは、複数の現像後の学習画像と、各学習画像に対して付与されたクラスラベルから構成される。第1の学習データ取得部2100では、第1の学習データ記憶部5100から、学習画像、クラスラベルを読み込む。第1の学習部2200では、学習画像を識別器に入力することによって得られる識別結果とクラスラベルとの誤差から、第1の識別器を学習する。学習して得られた第1の識別器は、第1の識別器記憶部5200に記憶される。
In the first learning
第2の学習データ記憶部5300には、あらかじめ第2の学習データが用意されている。第2の学習データは、デジタルカメラ等の撮像装置で得られた、現像される前のセンサ値による学習画像と、各学習画像に対して付与されたクラスラベルで構成される。第2の学習データ取得部2300では、第2の学習データ記憶部5300から、学習画像、クラスラベルを読み込む。変換部追加部2400では、第1の識別器記憶部5200から、第1の識別器を読み込み、その入力側に変換部を追加することで、第2の識別器を生成する。第2の学習部2500では、第2の学習データにおける学習データを、第2の識別器に入力して得られた識別結果とクラスラベルとの誤差から、第2の識別器を学習する。学習して得られた第2の識別器は、第2の識別器記憶部5400に記憶される。
Second learning data is prepared in advance in the second learning
次に、識別時の装置構成の概要に関して説明する。ここで識別とは、未知の入力画像に対して画像識別を行うことである。処理内容の詳細は後述する。 Next, an outline of the device configuration at the time of identification will be described. Here, the term “identification” refers to image identification for an unknown input image. Details of the processing contents will be described later.
入力データ取得部1100では、撮像装置で得られた、現像される前のセンサ値による入力画像と、その入力画像に対応する撮影情報が読み込まれる。識別器設定部1200では、あらかじめ学習によって得られている第2の識別器を、第2の識別器記憶部5400から読み込んで設定する。識別部1300では、設定された第2の識別器の変換部に取得された入力画像を入力し、識別結果を得る。得られた識別結果は識別結果出力部1400に送られ、ユーザもしくは別機器に結果が提示される。
In the input
本実施形態では、学習時の機能構成も、識別時の機能構成も同じ装置(画像処理装置)で実現されるものとして説明したが、それぞれ別の装置によって実現するようにしてもよい。また、第1の学習データ取得部2100、第1の学習部2200、第2の学習データ取得部2300、変換部追加部2400、および第2の学習部2500は、すべて同じ装置上で実現されるものとして説明したが、それぞれ独立したモジュールとしてもよい。また、装置上で実装されるプログラムとして実現してもよい。第1の学習データ記憶部5100、第1の識別器記憶部5200、第2の学習データ記憶部5300、および第2の識別器記憶部5400は、装置の内部もしくは外部のストレージとして実現される。
In the present embodiment, the functional configuration at the time of learning and the functional configuration at the time of identification are described as being realized by the same device (image processing device), but may be realized by different devices. The first learning
入力データ取得部1100、識別器設定部1200、識別部1300、および識別結果出力部1400は、すべて同じ装置上で実現されるものでもよいし、それぞれ独立したモジュールとしてもよい。また、装置上で実装されるプログラムとして実現してもよいし、カメラ等の撮影装置内部において回路もしくはプログラムとして実装してもよい。第2の識別器記憶部5400は、学習時と識別時で別々の装置で実現される場合には、それぞれで異なるストレージであってもよい。その場合には、学習時に得られた識別器を、識別用の装置におけるストレージにコピーもしくは移動して用いればよい。
The input
次に、本実施形態に係る処理の詳細について説明する。ここでは、画像識別として、画像の意味的な領域分割を例にして説明を進める。まず、本実施形態の学習時の処理について説明する。図2(a)は、本実施形態における学習時の処理を示すフローチャートである。 Next, details of processing according to the present embodiment will be described. Here, as image identification, explanation will be given by taking an example of semantic area division of an image. First, the processing at the time of learning of this embodiment will be described. FIG. 2A is a flowchart showing processing at the time of learning in the present embodiment.
第1の学習データ取得ステップS2100では、第1の学習データ取得部2100が、第1の学習データ記憶部5100から、学習画像とクラスラベルを、学習データとして読み込む。第1の学習データ記憶部5100には、あらかじめ複数の現像済み学習画像とクラスラベルが用意されている。学習画像は、具体的にはデジタルカメラ等で撮影され、カメラ内部もしくはカメラ外部の現像プログラムによって現像された画像データである。通常はJPEGやPNG、BMPなどの形式で与えられるが、本実施形態は学習画像のフォーマットに限定されるものではない。用意されている第1の学習画像の枚数をN1枚とし、n番目の第1の学習画像をIn(n=1,…,N1)と書くこととする。意味的領域分割におけるクラスラベルとは、学習画像の各領域に対して識別クラスがラベルとして割り振られているものである。
In the first learning data acquisition step S2100, the first learning
図3に意味的領域分割におけるクラスラベルの例を示す。図3(a)の500は学習画像の例で、図3(b)の540は学習画像500に対応するクラスラベルの例である。このように、画像に対応する正解クラスラベルが与えられた正解データを、画像識別では一般的にGT(Ground Truth)と呼ぶ。各領域に対して、空541、頭髪542、顔543、服544、花545、葉茎546といったクラスラベルが与えられている。ここでは意味的なクラスラベルを例に上げたが、光沢面やマット面、高周波領域といった領域の属性によるクラスラベルが与えられていてもよい。また、空と木の枝のような、複数種類の物体が混在して写っているクラスを定義してもよい。領域クラスは全部でM種類あるとする。学習画像Inの全画素に対応するクラスラベル集合をGTnとする。
FIG. 3 shows an example of class labels in semantic area division. 3A is an example of a learning image, and 540 in FIG. 3B is an example of a class label corresponding to the
第1の学習ステップS2200では、第1の学習部2200が、第1の学習データによって、第1の識別器を学習する。ここでは、第1の識別器としてCNN(Convolutional Neural Network)を利用することとして説明する。CNNは、畳み込み層とプーリング層が何層も繰り返されることによって入力信号の局所的な特徴が次第にまとめられ、変形や位置ずれに対してロバストな特徴に変換されることで、識別タスクを行うニューラルネットワークである。
In the first learning step S2200, the
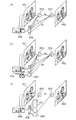
図4は、本実施形態で用いられるCNNの構造を説明する図である。CNNは、図4(a)の610と620によって構成されており、それぞれ畳み込み層、完全結合層と呼ばれている。これらは、それぞれの役割として特徴抽出とパターン分類を行っている部分であり、以降では一般性を失わないように、それぞれ特徴抽出部610、分類部620と記述することとする。611は入力層であり、入力画像630の各位置における畳み込み演算結果を信号として受け取る。612、613は中間層であり、複数の中間層を介して最終層615へと信号が送られる。各層では畳み込み層とプーリング層が逐次配置され、畳み込み演算と、プーリングによる信号の選択が繰り返される。特徴抽出部610の最終層615における出力信号は、分類部620へと送られる。分類部620では、各層の素子が前後の層と全結合しており、重み係数による積和演算によって信号が出力層640へと送られる。出力層640ではクラス数Mと同数の出力素子があり、それぞれの素子の信号強度を比較して、最も大きな信号を出力する素子に対応するクラスが、その画素の出力クラスラベルとなる。
FIG. 4 is a diagram for explaining the structure of the CNN used in this embodiment. The CNN is composed of 610 and 620 in FIG. 4A, and is called a convolution layer and a complete coupling layer, respectively. These are portions that perform feature extraction and pattern classification as their respective roles, and are hereinafter referred to as a
学習画像InをCNNに入力した際に出力層で得られる出力信号の値を教師信号と比較することで、学習が行われる。ここで、学習画像Inの画素(i,j)における、クラスmに対応する出力素子の教師信号t(n,i,j,m)は、GTnの画素(i,j)のクラスラベルがC(C=1,…,M)である場合に、下記の数式1のように定義される。
The value of the output signal obtained at the output layer when entering the learning image I n the CNN is compared with the teacher signal, the learning is performed. Here, the pixels of the learning image I n (i, j) in the teacher signal t output element corresponding to the class m (n, i, j, m) is the class label of the pixel of GT n (i, j) Is C (C = 1,..., M), the following

入力画像Inを識別器に入力した結果得られた出力層における位置(i,j)のクラスmに対応する出力素子(i,j,m)の出力信号をy(n,i,j,m)とすると、出力素子(i,j,m)における誤差は下記の数式2のように計算される。 Position in the input image I n obtained as a result of the input to the discriminator output layer (i, j) output element corresponding to the class m the (i, j, m) the output signal of y (n, i, j, m), the error in the output element (i, j, m) is calculated as shown in Equation 2 below.
E(n,i,j,m)=(y(n,i,j,m)−t(n,i,j,m))2 (数式2)
誤差逆伝搬法によって出力層から入力層へと誤差が順次逆伝搬されることで、確率的勾配降下法などによってCNNにおける各層の重み係数が更新される。
E (n, i, j, m) = (y (n, i, j, m) −t (n, i, j, m)) 2 (Formula 2)
By sequentially backpropagating the error from the output layer to the input layer by the error backpropagation method, the weight coefficient of each layer in the CNN is updated by the stochastic gradient descent method or the like.
学習におけるCNNの重み係数は、ランダムな初期値からスタートさせてもよいが、何かしらのタスクに対して学習済みの重み係数を初期値として与えてもよい。例えば、領域分割タスクのクラスラベルは画素ごとに与える必要があるが、画像分類タスクのクラスラベルは画像1枚に対して1つのラベルを付与すればよい。そのため、事前に人がGTとしてクラスラベルを入力する手間は数十倍から数百倍の差がある。そのため、大量の画像分類タスクの学習画像が一般に公開されており、簡単に入手することができる。例えば、ILSVRC(ImageNet Large−scale Visual Recognition Challenge)では120万枚の画像分類用学習用画像が公開されている。よって、CNNの重み係数の初期値を、このような画像分類タスクで一度初期学習しておき、その学習結果による重み係数を初期値として、領域分割タスクの学習を始めてもよい。このようにして、第1の学習ステップにて学習されたCNNの重み係数を、識別器のパラメータとして第1の識別器記憶部に記憶する。 The weight coefficient of CNN in learning may be started from a random initial value, but a learned weight coefficient may be given as an initial value for some task. For example, the class label of the area division task needs to be given for each pixel, but the class label of the image classification task may be given one label for one image. Therefore, there is a difference of several tens to several hundreds of times that a person inputs a class label as a GT in advance. For this reason, a large number of learning images for image classification tasks are publicly available and can be easily obtained. For example, in ILSVRC (ImageNet Large-scale Visual Recognition Challenge), 1.2 million learning images for image classification are disclosed. Therefore, the initial value of the weighting coefficient of CNN may be initially learned once by such an image classification task, and the learning of the area division task may be started using the weighting coefficient based on the learning result as the initial value. In this way, the weight coefficient of CNN learned in the first learning step is stored in the first discriminator storage unit as a discriminator parameter.
次に、第2の学習データ取得ステップS2300では、第2の学習データ取得部2300が、第2の学習データ記憶部5200から、現像されていない学習画像、撮影情報、およびクラスラベルを、学習データとして読み込む。
Next, in the second learning data acquisition step S2300, the second learning
第2の学習データ記憶部5200には、あらかじめ複数の現像されていない学習画像とクラスラベルが用意されている。また、学習画像に関する撮影情報も得られている。学習画像は、具体的にはデジタルカメラ等で撮影され、現像処理を行う前の状態における、CCDやCMOSのような画像素子におけるセンサ値の羅列であり、一般的にRAW画像と呼ばれる。RAW画像における輝度値は、撮影情報を使って以下のように各画素における各色チャンネルの輝度の絶対量を求めることができる。
In the second learning
撮影情報として、この画像全体における輝度Bv値、センサの適正レベル値optが得られているとする。ある画像における画素位置(i,j)に対応するRAW画像上のベイヤ配列におけるRチャネルのセンサ測定値がRRAWであったとき、画素(i,j)のRチャネルにおける輝度の絶対量であるRBvの値は、下記の数式3で求めることができる。 It is assumed that the brightness Bv value and the appropriate level value opt of the sensor are obtained as shooting information. When the sensor measurement value of the R channel in the Bayer array on the RAW image corresponding to the pixel position (i, j) in a certain image is R RAW , the absolute amount of luminance in the R channel of the pixel (i, j) The value of R Bv can be obtained by the following Equation 3.
GチャネルとBチャネルとの輝度絶対量であるGBvとBBvも、同様にして数式4、数式5より求められる。 Similarly, G Bv and B Bv which are absolute luminance amounts of the G channel and the B channel are also obtained from Equations 4 and 5.
このような変換式を用いることで、RAW画像による第2の学習画像に関する輝度絶対量のマップを得ることができる。 By using such a conversion formula, it is possible to obtain a map of absolute luminance amounts related to the second learning image by the RAW image.
用意されている第2の学習画像の枚数をN2枚とし、n番目の第2の学習画像から変換して得られた輝度絶対量のマップによる学習画像をJn(n=1,…,N2)と書くこととする。クラスラベルは、第1の学習画像におけるクラスラベルと同じ定義のものとする。学習画像Jnの全画素に対応するクラスラベル集合をGTnとする。RAW画像を伴った画像は、それを伴わない画像の収集に比べて困難であるため、第2の学習画像の数N2は、一般的にはN1より少ないことが多い。実際、多くのアマチュア写真家はRAW画像を公開しないため、ウェブなどで収集できる画像のほとんどはRAW画像を伴わないものである。また、第2の学習データで用いた学習画像は、現像することによって第1の学習データに利用することも可能である。 The number of prepared second learning images is N 2, and learning images based on the absolute luminance map obtained by conversion from the n-th second learning image are J n (n = 1,..., N 2 ). The class label has the same definition as the class label in the first learning image. The class label set corresponding to all pixels of the learning image J n and GT n. Since an image with a RAW image is more difficult than collecting images without it, the number N 2 of second learning images is generally less than N 1 in many cases. In fact, many amateur photographers do not publish RAW images, so most of the images that can be collected on the web or the like do not involve RAW images. Further, the learning image used in the second learning data can be used for the first learning data by developing.
変換部追加ステップS2400では、変換部追加部2400が、第1の識別器記憶部5200から第1の識別器を読み込み、読み込まれた第1の識別器の入力層側に、変換部を追加する。
In conversion unit addition step S2400, conversion
まず、第1の識別器記憶部5200から、第1の学習ステップS2200にて学習されたCNNの重み係数を読み込む。読み込まれた重み係数をCNNに設定する。設定されたCNNに対して、図4(b)のようにして変換部651を追加する。変換部651の入力側には、第2の学習データ取得ステップS2300で用意した、輝度絶対量による学習画像651が入力される。変換部650を通過して変換された画像652は、現像後の画像と同様にしてCNNの入力層611に入力される。
First, the CNN weighting factor learned in the first learning step S2200 is read from the first
変換部は、CNNの新しい層として追加される。通常、RAW画像から現像画像への変換は、ガンマ補正とホワイトバランスによる修正が行われる。ガンマ補正関数は下記の数式6のように定義される。 The converter is added as a new layer of CNN. Normally, conversion from a RAW image to a developed image is performed by gamma correction and correction by white balance. The gamma correction function is defined as Equation 6 below.
y=xγ (数式6)
ここで、xは任意の画素におけるRAW画像の値、すなわち撮像装置におけるセンサ値であり、yはその画素の現像後の輝度値である。制御パラメータγの値は、カメラやメーカ、撮影モードなどによって異なる。図5は、本実施形態におけるガンマ補正関数とその近似関数を説明する図であり、図5(a)にガンマ関数の例を示している。図5(a)の701はγ=1、702はγ=0.5、703はγ=2のときのガンマ補正関数のカーブである。ホワイトバランスは、これら補正された輝度値のチャネルごとの重み付けにあたる。ここで、入力信号に対するガンマ補正関数を下記の数式7のように近似することを考える。
y = x γ (Formula 6)
Here, x is a value of a RAW image at an arbitrary pixel, that is, a sensor value in the imaging device, and y is a luminance value after development of the pixel. The value of the control parameter γ varies depending on the camera, manufacturer, shooting mode, and the like. FIG. 5 is a diagram for explaining a gamma correction function and its approximate function in this embodiment, and FIG. 5A shows an example of the gamma function. In FIG. 5A, 701 is a curve of a gamma correction function when γ = 1, 702 is γ = 0.5, and 703 is γ = 2. The white balance is a weight for each channel of the corrected luminance values. Here, it is considered that the gamma correction function for the input signal is approximated as shown in Equation 7 below.
y=w2tanh(w1x+b1・z1)+b2・z2 (数式7)
ここで、z1およびz2は撮影環境によって変動する変数で、w1、w2、b1およびb2は重み係数である。図5(b)に示すように、この関数はγ補正関数の近似とすることができる。図5(b)の711,712、713は、それぞれ下記の数式8、数式9、数式10のような関数である。
y = w 2 tanh (w 1 x + b 1 · z 1 ) + b 2 · z 2 (Formula 7)
Here, z 1 and z 2 are variables that vary depending on the shooting environment, and w 1 , w 2 , b 1, and b 2 are weighting factors. As shown in FIG. 5B, this function can be an approximation of the γ correction function.
y=1.1tanh(x−0.5)+0.5 (数式8)
y=5tanh(x+1)−3.8 (数式9)
y=5tanh(x−2)+4.8 (数式10)
図6は本実施形態における変換部の構成を示す図であり、数式7における形式は、図6(a)のような素子の組み合わせで表現することができる。輝度絶対量による学習画像651の任意の画素と、変換後の画像652における対応画素は、素子653および素子654によって結合される。学習画像651における輝度絶対値は、数式7ではxに相当し、重みw1で重みづけされて、入出力関数として非線形関数のtanhを持つ素子653に入力される。素子653の出力信号は重みw2で重みづけされ、単調増加の線形関数を入出力関数として持つ素子654に入力される。
y = 1.1 tanh (x−0.5) +0.5 (Formula 8)
y = 5 tanh (x + 1) -3.8 (Formula 9)
y = 5 tanh (x-2) +4.8 (Formula 10)
FIG. 6 is a diagram showing the configuration of the conversion unit in the present embodiment, and the format in Expression 7 can be expressed by a combination of elements as shown in FIG. An arbitrary pixel of the
学習画像651からは、シーン特徴抽出器655を通して、画像のシーンを記述する特徴量656が抽出される。シーン記述特徴量656は、HOGやFisherVector、色ヒストグラムなどを想定することができるが、本実施形態はその特徴量の種類によって限定されるものではない。また、シーン記述特徴は上記のように画像特徴だけに限らない。例えば、撮像画像における付帯情報として、地軸に対する撮像装置の向き情報としてのジャイロセンサ値や、時計による時刻情報から特徴量を抽出してもよい。その例を図6(b)に示す。例えば、ジャイロセンサの値から地面方向を3軸の値で得ることができるため、これは正規化などすれば3次元のシーン記述特徴ベクトルとして利用することができる。また、時計による時刻情報は、1時間を15degとして対応付けてsin、cosによる循環関数にすれば、1日を1周期とした特徴量として利用できる。カレンダーに関しても同様に1ヵ月を15degとして1年を1周期とした特徴量として利用することができる。シーン記述特徴量656は、数式7ではz1およびz2に相当する。そして、重みベクトルb1による積和演算により重みづけされて素子653へと入力され、重みベクトルb2による積和演算により重みづけされて、素子654へと入力される。
From the
ここでは、z1=z2として説明したが、シーン記述特徴は、例えばz1をHOG、z2をFisherVectorといったように、別々のものとして分けてもよい。シーン記述特徴は、tahhカーブのバイアスを調整するための特徴であって、重み係数ベクトルb1およびb2で重み付けすることは、一種のシーン識別を行うことに相当する。例えば、晴れた日の屋外のシーンと、白い壁に囲まれた屋内のシーンでは、画像中に写っている物体の相違と、輝度絶対量の違いにより、異なるシーン記述特徴が得られるため、画像変換のバイアスとして異なる補正量をかけることになる。また、シーン記述特徴656を素子653および654に送る際に、重み係数b1およびb2による線形和ではなく、多層構造のニューラルネットワークを加えてもよい。図6(c)はその例を示しており、657および658はそれぞれ、入力層にシーン記述特徴656を入力し、1つの出力信号f(z)およびg(z)を出力する多層ニューラルネットワークである。この場合、数式7は以下の数式11のようになる。また、以降の説明では、各ニューラルネットワークfおよびgの結合係数をb1およびb2と置き換えて読めばよい。
Here, z 1 = z 2 has been described, but the scene description feature may be divided as a separate item, for example, z 1 is HOG and z 2 is FisherVector. The scene description feature is a feature for adjusting the bias of the tahh curve, and weighting with the weight coefficient vectors b 1 and b 2 corresponds to performing a kind of scene identification. For example, in an outdoor scene on a sunny day and an indoor scene surrounded by a white wall, different scene description characteristics are obtained due to the difference in the objects reflected in the image and the difference in absolute luminance. Different correction amounts are applied as conversion biases. Further, when sending the
y=w2tanh(w1x+f(z1))+b2・g(z2) (数式11)
素子654の出力信号は、そのままCNNの入力層へ渡す画像652の対応画素の値として扱われる。このような結合をRBv、GBv、BBvの各チャネルに対して持たせたとき、w2およびb2の値は各チャネルのバランスを表現しており、これはホワイトバランスの値を近似するものである。このようにして、現像前の学習画像651は、輝度絶対量から現像処理と近似された変換により、画像変換されることになる。
y = w 2 tanh (w 1 x + f (z 1 )) + b 2 · g (z 2 ) (Formula 11)
The output signal of the
第2の学習ステップS2500では、第2の学習部2500が、変換部追加ステップS2400で追加された変換部とともに、識別器を学習する。変換部追加ステップS2400で設定された画像変換を定義する重み係数w1、w2、b1、b2は、第2の学習データ取得部によって取得された学習画像とクラスラベルによって学習される。学習画像Jnが図4(b)の変換部650に入力され、特徴抽出610と分類部620を介して出力信号が得られたら、その値をクラスラベルと比較することにより、CNN全体と変換部の重み係数を学習する。
In the second learning step S2500, the
特徴抽出部610と分類部620の結合係数は、第1の学習ステップS2200で得られた値を初期値とする。変換部650における重み係数は、ランダムな初期値から学習させてもよい。あるいは、変換部650だけCNNとは独立に学習させ、その状態を初期値としてCNNと一緒に学習させてもよい。変換部650だけを初期学習させるためには、変換部650を3層ニューラルネットワークとみなして、現像前の輝度絶対量マップによる学習画像651を入力とし、素子653の出力信号をネットワークの出力信号とみなす。教師信号として、適正露出による現像後画像の輝度値を与えることにより、誤差逆伝搬により回帰学習を行えばよい。変換部650、特徴抽出部610、分類部620の重み係数の初期値が決定されたら、全てを通して学習を行う。このようにして、変換部650と特徴抽出部610、分類部620をすべて通して学習画像で学習させることにより、変換部650のパラメータも、学習画像に対して識別誤差を軽減させる方向に修正することができる。これは、画像の現像方法を、見た目の良さではなく、識別し易いように修正していることに相当する。変換部650と畳み込み層610、完全結合層620が学習されたら、得られた重み係数を第2の識別器記憶部5400に記憶させる。
The coupling coefficient between the
このようにして学習された識別器を用いて実際の入力画像を識別する工程を、以下に詳細説明する。図2(b)は、本実施形態に係る識別時の処理を示すフローチャートである。 The step of identifying an actual input image using the classifier learned in this way will be described in detail below. FIG. 2B is a flowchart showing processing at the time of identification according to the present embodiment.
まず、入力データ取得ステップS1100では、入力データ取得部1100が、撮像装置から得られた現像前の画像データが取得される。入力データの方式は、第2の学習データ取得ステップS2300における現像前画像と同様であるとする。すなわち、撮像装置で得られたセンサ値によるRAW画像から、撮像情報を利用して、数式3、数式4、数式5を使って輝度絶対量のマップに変換したものである。
First, in input data acquisition step S1100, the input
識別器設定ステップS1200では、識別器設定部1200が、第2の識別器記憶部5400から学習済みの識別器を読み込む。なお、ここでは入力データ取得ステップS1100の後に識別器設定ステップS1200を行うようにしているが、この2つのステップの手順は逆でもよい。識別器を常にメモリに確保して入力画像を次々に処理する場合には、識別器設定ステップS1200の後で入力データ取得ステップS1100以降の処理を繰り返し行うとしてもよい。識別器設定ステップS1200で設定される識別器は、図4(b)で表わされる変換部とCNNで構成される識別器である。
In the classifier setting step S1200, the
識別ステップS1300では、識別部1300が、識別器設定ステップS1200で設定された識別器を用いて、入力データ取得ステップS1100で取得された入力画像の識別処理を行う。輝度絶対量のマップとして取得された入力画像は、図4(b)における識別器の変換部650に入力され、変換された画像はCNNの特徴抽出部610における入力層611へと入力される。畳み込み層610では入力画像の信号が各層に順伝搬され、変換された信号は全結合層620を介して、各識別クラスに割り当てられた出力素子621の出力信号になる。信号が最も大きい出力素子に対応するクラスラベルが、その画素のクラス識別結果となる。
In the identification step S1300, the
識別結果出力ステップS1400では、識別結果出力部1400が、識別ステップS1300で得られた識別結果を出力する。識別結果出力ステップS1400で行われる処理は、識別結果を利用するアプリケーションに依存するものであって、本実施形態を限定するものではない。例えば、領域ごとに与える画像処理を、領域クラスによって変更するような画像補正アプリケーションであれば、各画素のクラスラベルを画像補正プログラムに出力すればよい。その際、各クラスの曖昧さによって処理の重み付けなどが必要であるなら、各クラスラベルに対応する出力素子621の出力信号値をクラス尤度としてそのまま出力してもよい。特定のクラスに関する識別結果だけが必要であるなら、他のクラスに関する結果を捨てて、必要なクラスの識別結果だけを出力すればよい。
In the identification result output step S1400, the identification
以上の説明では、画像識別処理として、画像の領域分割を例に説明したが、画像分類タスクに対しても、本実施形態は適用可能である。図9は各実施形態における識別器の構造を説明する図であり、画像分類タスクの場合は、図9(a)のようにCNNの特徴抽出部610の最終層615の全画素における出力信号を、分類部620に入力すればよい。
In the above description, image segmentation has been described as an example of image identification processing, but the present embodiment can also be applied to an image classification task. FIG. 9 is a diagram for explaining the structure of the discriminator in each embodiment. In the case of an image classification task, as shown in FIG. 9A, output signals in all pixels of the
以上のように、本実施形態によれば、識別器への入力画像を変換する変換部を学習することにより、識別に適した画像が得られ、高精度な画像識別を実現することが可能になる。また、識別器の画像入力側に変換部を加えて現像前の学習画像を用いて追加学習することにより、現像処理も含めた識別器の学習を行うことができる。これにより、見た目重視の現像処理を介した画像で無理に識別処理を行うことなく、より高精度な識別が行えることが期待できる。また、変換部以外の部分を大量の現像後画像で事前学習し、それを初期値に変換部を含めた識別器の学習を行うプロセスにより、比較的少ない現像前画像による学習画像で、画像変換を含めた識別器を学習することができる。これは、現像後画像に比べて現像前画像による大量の学習画像を揃えることが困難な場合に有効である。 As described above, according to the present embodiment, by learning the conversion unit that converts the input image to the classifier, an image suitable for identification can be obtained, and highly accurate image identification can be realized. Become. Further, by adding a conversion unit to the image input side of the classifier and performing additional learning using a learning image before development, it is possible to learn the classifier including development processing. As a result, it can be expected that more accurate identification can be performed without forcibly performing identification processing on an image that has undergone appearance-oriented development processing. In addition, a part of the image other than the conversion unit is pre-learned with a large amount of the developed image, and the image is converted with a learning image with relatively few pre-development images by a process of learning the discriminator including the conversion unit as an initial value. Can be learned. This is effective when it is difficult to align a large number of learning images based on the pre-development image compared to the post-development image.
[第2の実施形態]
次に、本発明の第2の実施形態について説明する。第1の実施形態では、識別器にCNNを用いた場合の例を示したが、識別器にCNNを用いた場合、畳み込み処理の繰り返しによって、順伝搬信号からはエッジ情報などが強く残ることになり、輝度値などの絶対値情報は徐々に情報が薄れていく傾向がある。色や明るさが有効な特徴であるような場合、そのような情報が失われることは識別精度低下の原因になる。例えば、パステルカラーの無地な家の壁や、太陽のランプのように光る物体などは、各色チャネルの輝度があればより識別精度の向上が期待できる。
[Second Embodiment]
Next, a second embodiment of the present invention will be described. In the first embodiment, an example in which CNN is used as a discriminator is shown. However, when CNN is used as a discriminator, edge information and the like remain strongly from a forward propagation signal due to repetition of convolution processing. Thus, the absolute value information such as the luminance value tends to fade gradually. When color and brightness are effective features, the loss of such information causes a reduction in identification accuracy. For example, a solid wall of a pastel color or a shining object such as a sun lamp can be expected to improve the identification accuracy if the luminance of each color channel is sufficient.
また、撮像装置によっては、像面位相差AFなどによって距離情報が得られている場合もあり、距離情報との併用によって、被写体との距離によって発生するスケーリングに対するロバスト性が向上することも期待できる。本実施形態では、入力画像の各画素に対して与えられる絶対値情報を識別器に取り込む形態について説明する。 Further, depending on the imaging device, distance information may be obtained by image plane phase difference AF or the like, and combined use with distance information can be expected to improve robustness against scaling caused by the distance to the subject. . In the present embodiment, a mode will be described in which absolute value information given to each pixel of an input image is taken into a discriminator.
なお、第1の実施形態で既に説明をした構成については同一の符号を付し、その説明を省略する。本実施形態における装置構成は、第1の実施形態と同じく図1(a)で表わされるため、詳細な説明は省略する。 In addition, the same code | symbol is attached | subjected about the structure already demonstrated by 1st Embodiment, and the description is abbreviate | omitted. Since the apparatus configuration in this embodiment is represented in FIG. 1A as in the first embodiment, detailed description thereof is omitted.
まず、本実施形態の学習処理について説明する。そのフローチャートは、図2(a)で示される第1の実施形態の学習処理のフローチャートと同じであるが、一部のステップにおける処理の内容が第1の実施形態とは異なる。 First, the learning process of this embodiment will be described. The flowchart is the same as the flowchart of the learning process of the first embodiment shown in FIG. 2A, but the contents of the process in some steps are different from those of the first embodiment.
第1の学習データ取得ステップS2100,第1の学習ステップS2200、および第2の学習データ取得ステップS2300に関しては、第1の実施形態と同様であるため、説明は省略する。 Since the first learning data acquisition step S2100, the first learning step S2200, and the second learning data acquisition step S2300 are the same as those in the first embodiment, description thereof is omitted.
変換部追加ステップS2400では、まず、変換部追加部2400が、第1の識別器記憶部5200から、第1の学習ステップS2200にて学習されたCNNを読み込む。そして、変換部追加部2400は、このCNNに対して、図4(c)のように変換部650と、伝達部660を追加する。変換部650に関しては第1の実施形態と同様であるため、説明は省略する。伝達部660は、現像前の画像が持つ、各画素における絶対値情報を伝達するための多層ネットワークである。各層661、662、663、…、665は、CNNの各畳み込み層611、612,613、…、615に対応する層である。各層のチャネル数は、画像の各画素における情報の数に相当する。例えば、絶対値情報として第1の実施形態で示した輝度絶対量(RBv、GBv、BBv)を用いる場合には、各層はRBv、GBv、BBvに対応する3つのチャネルを持つことになる。層の各チャネルにおける特徴面のサイズは、CNNの対応層の特徴面のサイズと等しいものとする。伝達部660の各層は単純にスケーリングの関係にあり、線形補間やバイキュービック補間、最近傍法などによる手法でリサイズされる。演算時間を重視するのであれば、間引きによるテーブル参照でリサイズを行ってもよい。これら伝達部における層間の結合部分には学習によって修正される結合係数は割り振られない。また、CNNの入力層611に対応する伝達部660の層661のサイズは入力画像サイズそのものであるため、入力画像の画素情報がそのまま直接設定されることになる。伝達部660の最も入力側の層611における、出力部の画素位置に対応する位置669の値は、分類部620の入力層にそのまま入力される。
In the conversion unit addition step S2400, first, the conversion
伝達部660の各層における値は、対応するCNNの畳み込み層に対して、バイアス係数とともにバイアス値として入力される。第l番目の畳み込み層におけるチャネルmの位置(i,j)の素子に対する入力信号ulm(i,j)は、以下の数式12のように表わされる。
The value in each layer of the
ここで右辺第1項はCNNにおける結合を表わしており、KはCNNの第l−1層におけるチャネル数、Hは第l−1層と第l層の間における畳み込みフィルタの幅である。hlpqkmは、第l層の第mチャネルと第l−1層の第kチャネルを結合する畳み込みフィルタの、フィルタ中心座標における位置(p,q)の値である。また、zl−1(i,j,k)は、第l−1層における位置(i,j)の出力信号、blmは、第l層の第mチャネルにおけるバイアス係数である。右辺第2項は伝達部660からの結合を表わしており、Rは画素情報のチャネル数、Jl(i,j,r)は画素情報伝達部の第l層の第rチャネルにおける値、blrは同バイアス係数である。これらの中で、学習によって修正されるパラメータは、hlpqkm、blm、blrである。
Here, the first term on the right side represents coupling in the CNN, K is the number of channels in the 1-1 layer of the CNN, and H is the width of the convolution filter between the 1-1 layer and the 1st layer. h lpqkm is the value of the position (p, q) in the filter center coordinates of the convolution filter that combines the m-th channel of the l-th layer and the k-th channel of the ( 1-1) th layer. Further, z l−1 (i, j, k) is an output signal at the position (i, j) in the l− 1th layer, and b lm is a bias coefficient in the mth channel of the lth layer. The second term on the right side represents the coupling from the
第2の学習ステップS2500では、第2の学習部2500が、第2の学習データ取得ステップS2300で取得した学習画像を用いて、CNNの内部結合係数を学習する。また、第2の学習部2500は、CNNの内部結合係数とともに、学習画像を用いて、変換部追加ステップS2400で追加された変換部650および伝達部660とCNNを結合する係数を学習する。上述した結合係数が学習されるパラメータとして追加されたことを除けば、学習に関する基本的なアルゴリズムは第1の実施形態と同様であるため、その説明は省く。学習によって修正されたパラメータは、第2の識別器記憶部5400に記憶される。
In the second learning step S2500, the
次に、本実施形態の識別処理について説明する。そのフローチャートは、図2(b)で示される第1の実施形態の識別処理のフローチャートと同じであるが、一部のステップにおける処理の内容が第1の実施形態とは異なる。 Next, the identification process of this embodiment will be described. The flowchart is the same as the flowchart of the identification process of the first embodiment shown in FIG. 2B, but the contents of the process in some steps are different from those of the first embodiment.
入力データ取得ステップS1100、識別器設定ステップS1200の処理は、第1の実施形態と同様であるため、説明は省略する。 Since the processing of the input data acquisition step S1100 and the discriminator setting step S1200 is the same as that of the first embodiment, description thereof is omitted.
識別ステップS1300では、識別部1300が、現像前の輝度絶対値による入力画像を図4(c)に示すネットワークに入力することにより、識別結果を得る。識別時における順伝搬方向の信号の伝達に関しては、学習時と同じであるため、詳細な説明は省略する。
In the identification step S1300, the
識別結果出力ステップS1400における処理は、第1の実施形態と同様であるため、説明は省略する。 Since the processing in the identification result output step S1400 is the same as that in the first embodiment, description thereof is omitted.
絶対値情報としては、上記輝度絶対量以外にも、撮像系の像面位相差AFなどによって得られる距離情報を与えてもよい。距離情報は、対象物体の絶対的なサイズや立体形状に関する情報を与えるため、スケーリングによる類似物や、実物と写真や絵画などとの区別がつきやすくなる。例えば、看板に描かれた人物や巨大人物像と、実物の人間を区別する場合などで有効である。 As absolute value information, distance information obtained by image plane phase difference AF or the like of the imaging system may be given in addition to the absolute luminance value. Since the distance information gives information on the absolute size and three-dimensional shape of the target object, it is easy to distinguish between similar objects by scaling, real objects, and photographs and paintings. For example, this is effective in distinguishing between a person or a giant figure drawn on a signboard and a real person.
距離情報用の伝達部670を追加した場合の構成を図4(d)に示す。653は、各画素の距離情報を持つ距離マップである。画像の画素密度に対して測距点が疎である場合には、線形補間やバイキュービック補間、あるは最近傍法などによって、各画素の距離を補うことで、各画素に対する距離マップを算出すればよい。この場合、チャネル数は、RBv、GBv、BBv、距離情報の4チャネルになる。図4(d)の構成による学習処理や識別時の処理は、図4(c)の輝度絶対量による例と同様であるため、説明は省略する。さらに、輝度情報と距離情報を併用する場合には、図7(b)のように伝達部を2つ並列に用意すればよい。
FIG. 4D shows a configuration when a distance
なお、距離情報を利用する場合には、画像情報とは異なる勾配特徴を追加することも可能である。距離の勾配を特徴に組み込むことにより、写真と立体物の区別が容易にできるようになる。その場合は、図9(b)のように、特徴抽出部をもう1つ並列に並べる構成となる。この場合、学習時の変換部追加ステップS2400では、変換部650と伝達部660だけでなく、距離情報用の特徴抽出部710を追加することになる。距離情報用特徴抽出部710では、距離マップが入力層711に入力され、最終層715における出力信号は、分類部620への入力信号として与えられる。第2の学習ステップS2500では、学習画像に対する誤差信号が逆伝搬され、分類部620、画像用および距離情報用の特徴抽出部610と710、変換部650、画像用および距離情報用の伝達部660と670の重み係数が、学習によって更新される。
In addition, when using distance information, it is also possible to add a gradient feature different from image information. Incorporating a gradient of distance into the feature makes it easy to distinguish a photograph from a three-dimensional object. In this case, as shown in FIG. 9B, another feature extraction unit is arranged in parallel. In this case, not only the
以上のように、本実施形態では、輝度値情報または距離情報の少なくとも一方をニューラルネットワークの中間層に入力して識別精度の向上を図ることができる。特に、CNNの出力層に向けて薄れがちな絶対値による情報が、特徴抽出の中間層に入れ込まれることによって、色や明るさが重要な情報である対象物体の識別に対して識別精度の向上が期待できる。また、像面位相差などによって得ることのできる距離情報も、同様な方法にて識別器に利用することができ、さらに識別精度の向上が期待できる。 As described above, in this embodiment, it is possible to improve the identification accuracy by inputting at least one of the luminance value information and the distance information to the intermediate layer of the neural network. In particular, information with absolute values that tend to fade toward the output layer of the CNN is inserted into the intermediate layer of feature extraction, so that the accuracy of identification can be improved for the identification of target objects whose color and brightness are important information. Improvement can be expected. Further, the distance information that can be obtained by the image plane phase difference or the like can also be used for the discriminator by a similar method, and further improvement in discrimination accuracy can be expected.
[第3の実施形態]
次に、本発明の第3の実施形態について説明する。第1の実施形態では、入力画像のシーン特徴によって、入力画像全体に対して同じ画像変換を行う方法について説明をした。これは通常の現像方法を変換部で近似しつつ識別精度を向上させるための現像方法を学習によって得ることを意味する。ここで、さらに識別精度を向上させるために、領域によって異なる現像を行ってもよい。本実施形態では、領域ごとに変換部の変換パラメータを修正する形態について説明する。なお、第1、第2の実施形態で既に説明をした構成については同一の符号を付し、その説明は省略する。
[Third Embodiment]
Next, a third embodiment of the present invention will be described. In the first embodiment, the method of performing the same image conversion on the entire input image according to the scene characteristics of the input image has been described. This means that a developing method for improving identification accuracy while approximating a normal developing method at the conversion unit is obtained by learning. Here, in order to further improve the identification accuracy, different development may be performed depending on the region. This embodiment demonstrates the form which corrects the conversion parameter of a conversion part for every area | region. In addition, the same code | symbol is attached | subjected about the structure already demonstrated in 1st, 2nd embodiment, and the description is abbreviate | omitted.
図1(b)は、本実施形態に係る画像処理装置の機能構成を示す概略ブロック図である。まず、学習時の学習装置として機能する際の装置構成について説明する。第1の学習データ取得部2100、第1の学習部2200、第2の学習データ取得部2300、変換部追加部2400、および第2の学習部2500は、第1の実施と同様であるため、説明を省略する。また、第1の学習データ記憶部5100、第1の識別器記憶部5200、第2の学習データ記憶部5300、および第2の識別器記憶部5400についても、第1の実施形態と同様であるため、説明は省略する。
FIG. 1B is a schematic block diagram illustrating a functional configuration of the image processing apparatus according to the present embodiment. First, a device configuration when functioning as a learning device during learning will be described. Since the first learning
調整部追加部2600は、一次識別結果により変換部を調整する調整部を、識別器に追加する。第3の学習部2700は、第2の学習部2500によって学習された変換部と識別器を使って第2の学習データに対して識別処理を行い、そこで発生する誤差をもとに、調整部を学習する。学習された調整部のパラメータは、調整部記憶部5500に記憶される。
The adjustment
続いて、識別時の画像識別装置として機能する際の装置構成について説明する。入力データ取得部1100、識別器設定部1200、および識別部1300は、第1の実施形態と同様であるため、説明を省略する。調整部設定部1500は、調整部記憶部5500から調整部のパラメータを読み込み、変換部を調整する調整部を設定する。再識別部1600は、識別部1300における識別結果と調整部を使って、識別器による識別処理を再度行う。得られた再識別結果は識別結果出力部1400に送られ、ユーザもしくは別機器に結果が提示される。
Next, a device configuration when functioning as an image identification device at the time of identification will be described. The input
次に、図2(c)を用いて、本実施形態に係る学習処理について説明する。なお、第1の学習データ取得ステップS2100から第2の学習ステップS2500までは、第1の実施形態と同様の処理のため、説明を省略する。 Next, the learning process according to the present embodiment will be described with reference to FIG. Since the first learning data acquisition step S2100 to the second learning step S2500 are the same as those in the first embodiment, description thereof is omitted.
調整部追加ステップS2600では、調整部追加部2600が、変換部による現像処理を、一次識別結果をもとに調整する調整部を追加する。図7は、各実施形態に係る識別器の構成を説明する図であり、本実施形態に係る構成例を図7(a)に示す。
In the adjustment unit addition step S2600, the adjustment
まず、本ステップでは、第2の学習ステップS2500までに学習された識別器に対して、学習画像を入力することで、クラス識別結果が素子621にて得られる。得られた識別結果から、第2の学習画像の中で、GTにおけるクラスラベルとの誤差が小さいもの、例えば誤差0.2以下の領域を学習データから除外する。残った学習データに関して、特徴抽出部610の最終層615における全チャネルに関する出力信号ベクトル691を抽出する。なお、ここではベクトル691を最終層615における出力信号と説明したが、他の層の値を用いてもよい。例えば、入力層611の値を使ってもいいし、すべての層611から615の値を連結して用いてもよい。これらの値は調整部690に入力され、そこから出力される信号は変換部650へと与えられ、画像変換処理が調整される。
First, in this step, a class identification result is obtained by the
ここで、図8を用いて、本実施形態に係る調整部690の構成を説明する。特徴抽出部610における最終層615の出力信号と、出力層640における各クラスの出力信号は、連結されて特徴量696とされる。特徴量696は、重みベクトルb3による重みづけがなされた上で、素子693に入力される。特徴量696は、また、重みベクトルb4による重みづけがなされ、素子654に入力される。このような構造によって得られた調整値は、第1の実施形態と同様にしてガンマ補正関数の近似である。素子654への入力信号は、変換部による変換関数と調整部による変換関数の和となっていることから、2つのガンマ補正関数の組み合わせによる現像処理を近似していることになる。変換部と調整部の双方によって補正された素子654の出力信号yは、下記の数式13のように記述される。
Here, the configuration of the
y=w2tanh(w1x+f(z1))+b2・g(z2)+w3tanh(b3・z3)+b4・z3 (数式13)
ここで、z3は、696で示される畳み込み層における最終層の出力信号と、出力層における各クラスの出力信号を結合した特徴ベクトルであり、w3、b3、およびb4は重み係数である。右辺第2項は、調整部からの入力であり、ここでは調整項と呼ぶことにする。
y = w 2 tanh (w 1 x + f (z 1 )) + b 2 · g (z 2 ) + w 3 tanh (b 3 · z 3 ) + b 4 · z 3 (Formula 13)
Here, z 3 is a feature vector obtained by combining the output signal of the final layer in the convolution layer indicated by 696 and the output signal of each class in the output layer, and w 3 , b 3 , and b 4 are weight coefficients. is there. The second term on the right side is an input from the adjustment unit, and is referred to as an adjustment term here.
次に、第3の学習ステップS2700では、第3の学習部2700が、これら調整部690の重み係数を学習する。第3の学習部2700は、調整部690に関する重み係数w3、b3、b4以外のすべての重み係数の学習係数を0にして固定し、w3、b3、b4についてのみ誤差逆伝搬して修正する。学習して得られた上記パラメータは、調整部記憶部5500に記憶される。
Next, in the third learning step S <b> 2700, the
ここで行われる学習は、特徴抽出部610における出力信号と、分類部におけるクラス識別信号を、入力特徴量として学習しているため、間違いパターンを学習していると解釈することができる。つまり、クラス識別結果とCNNの内部状態がどのようなときに間違いが発生し、そのときにどのような画像変換を行えば誤差が減少するかが学習されている。例えば、一次識別の時点で白い領域が飛び過ぎてしまい、識別結果が正しくなかった場合、本実施形態では、類似した間違いパターンのときに、その誤差を減らすために、輝度の明るい部分ではコントラストが強くなるように調整部の変換が修正される。
Since the learning performed here learns the output signal from the
次に、図2(d)を用いて、本実施形態に係る識別処理について説明する。まず、第1の実施形態と同様の処理にて入力データ取得ステップS1100から識別ステップS1300を行い、一次識別結果を得る。 Next, identification processing according to the present embodiment will be described with reference to FIG. First, the input data acquisition step S1100 to the identification step S1300 are performed by the same processing as in the first embodiment, and the primary identification result is obtained.
次に、調整部設定ステップS1500では、調整部設定部1500が、調整部記憶部5500から調整部の重み係数を読み込み、調整部690が設定される。
Next, in the adjustment unit setting step S1500, the adjustment
再識別ステップS1600では、再識別部1600が、一次識別結果のクラス識別信号と、特徴抽出部610における出力信号を連結した特徴ベクトル696を調整部690に入力することで、調整項の追加された画像変換関数が領域ごとに得られる。入力画像は、調整項による修正を加えた画像変換を介して、領域ごとに調整された画像変換が行われ、その変換結果が特徴抽出610に入力される。これにより、分類部620を介して、出力層640にて再識別結果が得られる。なお、ここでは図示しないが、再識別ステップS1600の結果をさらに用いて、調整項を使って繰り返し再識別を行ってもよい。その場合、適当な繰り返し数で打ち切るか、もしくは調整項の信号の変化が小さくなった時点で計算を打ち切るなどすればよい。
In the re-identification step S1600, the
識別結果出力ステップS1400は、第1の実施形態と同様の処理であるため、説明は省略する。 The identification result output step S1400 is the same process as that of the first embodiment, and thus the description thereof is omitted.
本実施形態では、このようにして、まず得られた一次識別結果をもとに、畳み込み層における出力信号とクラス識別信号を組み合わせた識別結果を反映した特徴量を用いて画像変換処理を調整させる。その調整の方法は、学習データによって誤差を縮小する方向に学習されているため、一次識別結果よりも精度よく識別されることが期待できる。 In the present embodiment, first, based on the primary identification result obtained in this way, the image conversion process is adjusted using the feature value reflecting the identification result obtained by combining the output signal and the class identification signal in the convolution layer. . Since the adjustment method is learned in a direction to reduce the error based on the learning data, it can be expected that the adjustment is performed with higher accuracy than the primary identification result.
[その他の実施形態]
上記の各実施形態では、CNNによる識別は、特徴抽出部610の最終層615と、分類部620接続した形式で説明を行った。しかし、被写体の細かいテクスチャが有効な特徴量である場合、最終層からの信号だけでは識別に不十分な場合もある。例えば、モルタルによる白壁と、曇天によるテクスチャのない空などを区別する場合などは、細かいテクスチャは重要な情報である。そのような場合には、特徴抽出部610のすべての層から信号を取り出すことで、それを分類部620に渡す方法もある。これはハイパーカラム構造と呼ばれ、非特許文献4などにも挙げられている公知の手法である。
[Other Embodiments]
In each of the above embodiments, the identification by the CNN has been described in the form of connecting the
ハイパーカラム構造を、これまで説明した構成に対して同様に採用しても、上記各実施形態と同様な処理を行うことができる。図7(c)に、ハイパーカラム構造のCNNを示す。681、682、683、…、685は、出力層640の画素621の位置における、特徴抽出部610における各層611、612、613、…、615における出力信号である。これらの信号値は特徴ベクトルとして扱われ、分類部620へと入力される。
Even if the hyper column structure is similarly adopted for the configuration described so far, the same processing as in each of the above embodiments can be performed. FIG. 7C shows a CNN having a hyper column structure. , 685 are output signals in the
図4(b)(c)および図5(d)(b)に関しても、同様な構造を入れ込むことができる。構造が上記のようなハイパーカラム構造になっても、学習処理や識別処理に関しては同様のアルゴリズムで可能であるため、詳細な説明は省略する。 A similar structure can be inserted in FIGS. 4B and 4C and FIGS. 5D and 5B. Even if the structure is a hyper column structure as described above, the learning process and the identification process can be performed with the same algorithm, and thus detailed description thereof is omitted.
本発明は、上述の実施形態の1以上の機能を実現するプログラムを、ネットワーク又は記憶媒体を介してシステム又は装置に供給し、そのシステム又は装置のコンピュータにおける1以上のプロセッサがプログラムを読出し実行する処理でも実現可能である。また、1以上の機能を実現する回路(例えば、ASIC)によっても実現可能である。 The present invention supplies a program that realizes one or more functions of the above-described embodiments to a system or apparatus via a network or a storage medium, and one or more processors in a computer of the system or apparatus read and execute the program. It can also be realized by processing. It can also be realized by a circuit (for example, ASIC) that realizes one or more functions.
1100 入力データ取得部
1200 識別器設定部
1300 識別部
1400 識別結果出力部
DESCRIPTION OF
Claims (16)
変換部を有する識別器を用いて、前記取得されたセンサ値による入力画像を識別する識別手段と、を有し、
前記識別器のうち少なくとも前記変換部は、撮像装置のセンサ値による学習画像と当該学習画像に付与された正解データとに基づいて学習されていることを特徴とする画像識別装置。 Acquisition means for acquiring an input image based on sensor values of the imaging device;
Using a discriminator having a conversion unit, and discriminating means for discriminating an input image based on the acquired sensor value,
At least the conversion unit of the classifier is learned based on a learning image based on a sensor value of the imaging device and correct data given to the learning image.
前記入力画像の各画素における輝度絶対量と、前記入力画像の全体から抽出したシーン特徴との、重み係数による重み付き線形和からなる入力信号を、非線形関数によって変換した出力信号を出力する第1層と、
前記シーン特徴と、前記第1層の出力信号との、重み係数による重み付き線形和からなる入力信号を、線形関数で変換した出力信号を出力する第2層と、
からなることを特徴とする請求項3から5のいずれか1項に記載の画像識別装置。 The converter is
A first output of an output signal obtained by converting an input signal composed of a weighted linear sum of weighting factors of an absolute luminance amount in each pixel of the input image and a scene feature extracted from the entire input image by a non-linear function. Layers,
A second layer that outputs an output signal obtained by converting an input signal composed of a weighted linear sum of the scene feature and the output signal of the first layer by a weighting function with a linear function;
The image identification device according to claim 3, comprising:
前記識別手段は、前記調整された変換部を有する識別器を用いて、前記入力画像を再識別することを特徴とする請求項1から8のいずれか1項に記載の画像識別装置。 Based on the identification result by the identification means, further comprising an adjustment means for adjusting the conversion unit,
The image identification apparatus according to claim 1, wherein the identification unit re-identifies the input image using a classifier having the adjusted conversion unit.
センサ値による画像が現像された学習画像と当該学習画像に対して付与された正解データとを含む第1の学習データに基づいて第1の識別器を学習する第1の学習手段と、
前記学習された第1の識別器に前記変換部を追加して第2の識別器を生成する追加手段と、
センサ値による学習画像と当該学習画像に付与された正解データとを含む第2の学習データに基づいて前記第2の識別器を学習することにより、前記識別手段で用いられる識別器を生成する第2の学習手段と、
を有することを特徴とする学習装置。 A learning device for learning a discriminator used for identifying an input image based on a sensor value of an imaging device,
First learning means for learning the first classifier based on first learning data including a learning image in which an image based on a sensor value is developed and correct data assigned to the learning image;
Adding means for adding the conversion unit to the learned first classifier to generate a second classifier;
A second discriminator used in the discriminating unit is generated by learning the second discriminator based on second learning data including a learning image based on a sensor value and correct data assigned to the learning image. 2 learning means,
A learning apparatus comprising:
変換部を有する識別器を用いて、前記取得されたセンサ値による入力画像を識別するステップと、を有し、
前記識別器のうち少なくとも前記変換部は、撮像装置のセンサ値による学習画像と当該学習画像に付与された正解データとに基づいて学習されていることを特徴とする画像識別方法。 Acquiring an input image based on sensor values of the imaging device;
Using a discriminator having a conversion unit to identify an input image based on the acquired sensor value, and
At least the conversion unit of the classifier is learned based on a learning image based on a sensor value of the imaging device and correct data given to the learning image.
センサ値による画像が現像された学習画像と当該学習画像に対して付与された正解データとを含む第1の学習データに基づいて第1の識別器を学習するステップと、
前記学習された第1の識別器に前記変換部を追加して第2の識別器を生成するステップと、
センサ値による学習画像と当該学習画像に付与された正解データとを含む第2の学習データに基づいて前記第2の識別器を学習することにより、前記識別手段で用いられる識別器を生成するステップと、
を有することを特徴とする学習方法。 A learning method for learning a discriminator used for identifying an input image based on sensor values of an imaging device,
Learning a first classifier based on first learning data including a learning image in which an image based on sensor values is developed and correct data assigned to the learning image;
Adding the converter to the learned first classifier to generate a second classifier;
A step of generating a discriminator used by the discriminating means by learning the second discriminator based on second learning data including a learning image based on sensor values and correct data assigned to the learning image. When,
A learning method characterized by comprising:
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2017146337A JP2019028650A (en) | 2017-07-28 | 2017-07-28 | Image identification device, learning device, image identification method, learning method and program |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2017146337A JP2019028650A (en) | 2017-07-28 | 2017-07-28 | Image identification device, learning device, image identification method, learning method and program |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2019028650A true JP2019028650A (en) | 2019-02-21 |
| JP2019028650A5 JP2019028650A5 (en) | 2020-08-20 |
Family
ID=65478449
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2017146337A Withdrawn JP2019028650A (en) | 2017-07-28 | 2017-07-28 | Image identification device, learning device, image identification method, learning method and program |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP2019028650A (en) |
Cited By (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2021043722A (en) * | 2019-09-11 | 2021-03-18 | 株式会社 日立産業制御ソリューションズ | Video processing equipment and video processing method |
| KR20210083726A (en) * | 2019-12-27 | 2021-07-07 | 재단법인대구경북과학기술원 | Method and apparatus for determining training data for updating algorithm |
| WO2021193103A1 (en) * | 2020-03-26 | 2021-09-30 | ソニーセミコンダクタソリューションズ株式会社 | Information processing device, information processing method, and program |
| CN115238884A (en) * | 2021-04-23 | 2022-10-25 | Oppo广东移动通信有限公司 | Image processing method, device, storage medium, device, and model training method |
| JP2023546722A (en) * | 2020-11-10 | 2023-11-07 | エヌイーシー ラボラトリーズ アメリカ インク | Divide and conquer for lane-aware diverse trajectory prediction |
| CN119027750A (en) * | 2024-10-29 | 2024-11-26 | 合肥综合性国家科学中心人工智能研究院(安徽省人工智能实验室) | A medical image classification method, device and medium based on prompt reverse learning |
| US12159448B2 (en) | 2019-07-26 | 2024-12-03 | Fujifilm Corporation | Learning image generation device, learning image generation method, learning image generation program, learning method, learning device, and learning program |
| CN119229262A (en) * | 2024-11-29 | 2024-12-31 | 中南大学 | A cultural and museum image processing method and system based on image recognition technology |
-
2017
- 2017-07-28 JP JP2017146337A patent/JP2019028650A/en not_active Withdrawn
Cited By (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US12159448B2 (en) | 2019-07-26 | 2024-12-03 | Fujifilm Corporation | Learning image generation device, learning image generation method, learning image generation program, learning method, learning device, and learning program |
| JP2021043722A (en) * | 2019-09-11 | 2021-03-18 | 株式会社 日立産業制御ソリューションズ | Video processing equipment and video processing method |
| KR20210083726A (en) * | 2019-12-27 | 2021-07-07 | 재단법인대구경북과학기술원 | Method and apparatus for determining training data for updating algorithm |
| KR102315622B1 (en) | 2019-12-27 | 2021-10-21 | 재단법인대구경북과학기술원 | Method and apparatus for determining training data for updating algorithm |
| WO2021193103A1 (en) * | 2020-03-26 | 2021-09-30 | ソニーセミコンダクタソリューションズ株式会社 | Information processing device, information processing method, and program |
| JP2023546722A (en) * | 2020-11-10 | 2023-11-07 | エヌイーシー ラボラトリーズ アメリカ インク | Divide and conquer for lane-aware diverse trajectory prediction |
| JP7539575B2 (en) | 2020-11-10 | 2024-08-23 | エヌイーシー ラボラトリーズ アメリカ インク | Divide and conquer for lane-aware diverse trajectory prediction |
| CN115238884A (en) * | 2021-04-23 | 2022-10-25 | Oppo广东移动通信有限公司 | Image processing method, device, storage medium, device, and model training method |
| CN119027750A (en) * | 2024-10-29 | 2024-11-26 | 合肥综合性国家科学中心人工智能研究院(安徽省人工智能实验室) | A medical image classification method, device and medium based on prompt reverse learning |
| CN119229262A (en) * | 2024-11-29 | 2024-12-31 | 中南大学 | A cultural and museum image processing method and system based on image recognition technology |
| CN119229262B (en) * | 2024-11-29 | 2025-02-28 | 中南大学 | Text blog image processing method and system based on image recognition technology |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP2019028650A (en) | Image identification device, learning device, image identification method, learning method and program | |
| CN115442515B (en) | Image processing methods and equipment | |
| US11244432B2 (en) | Image filtering based on image gradients | |
| Onzon et al. | Neural auto-exposure for high-dynamic range object detection | |
| US11810256B2 (en) | Image modification techniques | |
| CN110717851A (en) | Image processing method and device, neural network training method and storage medium | |
| CN111915526A (en) | Photographing method based on brightness attention mechanism low-illumination image enhancement algorithm | |
| JP7026456B2 (en) | Image processing device, learning device, focus control device, exposure control device, image processing method, learning method, and program | |
| JP2019032821A (en) | Data augmentation techniques using style transformation with neural network | |
| Krig | Computer Vision Metrics: Textbook Edition | |
| JP2014511608A (en) | Determination of model parameters based on model transformation of objects | |
| US20220335571A1 (en) | Methods and systems for super resolution for infra-red imagery | |
| CN113592726A (en) | High dynamic range imaging method, device, electronic equipment and storage medium | |
| JP7300027B2 (en) | Image processing device, image processing method, learning device, learning method, and program | |
| JP2019220174A (en) | Image processing using artificial neural network | |
| CN111080543A (en) | Image processing method and device, electronic equipment and computer readable storage medium | |
| JP2021089493A (en) | Information processing apparatus and learning method thereof | |
| CN115834996B (en) | Method and apparatus for image processing | |
| CN120047450B (en) | Remote sensing image change detection method based on double-current time-phase characteristic adapter | |
| CN109961083A (en) | For convolutional neural networks to be applied to the method and image procossing entity of image | |
| US20250200723A1 (en) | Image relighting with diffusion models | |
| Eisenmann | Setting the stage for 3D compositing with machine learning | |
| Liu et al. | Improved multi-feature fusion approach based on end-to-end convolutional neural network for dehazing | |
| Mishra et al. | AI in Computer Vision with Emerging Techniques and Their Scope | |
| CN115834996A (en) | Method and apparatus for image processing |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20200710 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20200710 |
|
| A761 | Written withdrawal of application |
Free format text: JAPANESE INTERMEDIATE CODE: A761 Effective date: 20200714 |