JP2017515147A - ユーザ定義のキーワードを検出するためのキーワードモデル生成 - Google Patents
ユーザ定義のキーワードを検出するためのキーワードモデル生成 Download PDFInfo
- Publication number
- JP2017515147A JP2017515147A JP2016562023A JP2016562023A JP2017515147A JP 2017515147 A JP2017515147 A JP 2017515147A JP 2016562023 A JP2016562023 A JP 2016562023A JP 2016562023 A JP2016562023 A JP 2016562023A JP 2017515147 A JP2017515147 A JP 2017515147A
- Authority
- JP
- Japan
- Prior art keywords
- keyword
- user
- model
- subword
- sound
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images









Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/02—Feature extraction for speech recognition; Selection of recognition unit
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/06—Creation of reference templates; Training of speech recognition systems, e.g. adaptation to the characteristics of the speaker's voice
- G10L15/065—Adaptation
- G10L15/07—Adaptation to the speaker
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/02—Feature extraction for speech recognition; Selection of recognition unit
- G10L2015/027—Syllables being the recognition units
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
- G10L2015/088—Word spotting
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/22—Procedures used during a speech recognition process, e.g. man-machine dialogue
- G10L2015/226—Procedures used during a speech recognition process, e.g. man-machine dialogue using non-speech characteristics
Abstract
Description
本出願は、参照によりその全内容が本明細書に組み込まれている、2014年8月22日に出願した米国特許出願第14/466,644号、表題「KEYWORD MODEL GENERATION FOR DETECTING USER-DEFINED KEYWORD」、および、2014年4月17日に出願した米国仮特許出願第61/980,911号、表題「METHOD AND APPARATUS FOR GENERATING KEYWORD MODEL FOR USE IN DETECTING USER-DEFINED KEYWORD」に基づき、その優先権の利益を主張するものである。

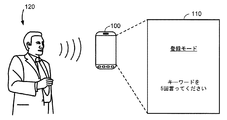
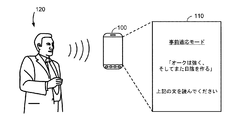
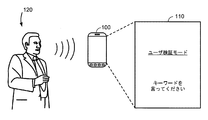
110 ディスプレイ画面
120 ユーザ
210 サンプルサウンド
220 混合サンプルサウンド
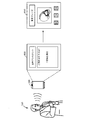
600 音声アシスタントアプリケーション
800 サウンドセンサ
810 プロセッサ
812 サブワード認識ユニット
814 事前適応ユニット
816 キーワードモデル生成ユニット
828 混合サウンド生成ユニット
830 I/Oユニット
840 記憶ユニット
Claims (30)
- ユーザ定義のキーワードのキーワードモデルを生成するための、電子デバイスにおいて実行される、方法であって、
前記ユーザ定義のキーワードを示す少なくとも1つの入力を受信するステップと、
前記少なくとも1つの入力からサブワードのシーケンスを判定するステップと、
前記サブワードのシーケンスおよび前記サブワードのサブワードモデルに基づいて前記ユーザ定義のキーワードに関連する前記キーワードモデルを生成するステップであり、前記サブワードモデルが、音声データベースに基づく前記サブワードの複数の音響特性をモデル化するように構成される、ステップと、
前記ユーザ定義のキーワードに関連する前記キーワードモデルを所定のキーワードに関連するキーワードモデルで構成された音声起動ユニットに提供するステップと
を含む、方法。 - 前記ユーザ定義のキーワードに関連する前記キーワードモデルおよび前記所定のキーワードに関連する前記キーワードモデルに基づいて、前記音声起動ユニットによって、入力サウンドにおいて前記ユーザ定義のキーワードまたは前記所定のキーワードを検出するステップ
をさらに含む、請求項1に記載の方法。 - 前記ユーザ定義のキーワードまたは前記所定のキーワードに関連する機能を実行するステップ
をさらに含む、請求項2に記載の方法。 - 前記サブワードモデルが、少なくとも1つの文の入力サウンドに基づいて適合される、請求項1に記載の方法。
- 前記ユーザ定義のキーワードに関連する前記キーワードモデルを生成するステップが、前記ユーザ定義のキーワードに関連する前記キーワードモデルの閾値スコアを判定するステップを含む、請求項1に記載の方法。
- 前記ユーザ定義のキーワードに関連する前記キーワードモデルが、
前記ユーザ定義のキーワードを示すテスト入力サウンドを受信するステップと、
前記ユーザ定義のキーワードに関連する前記キーワードモデルに基づいて前記テスト入力サウンドのマッチングスコアを判定するステップと、
前記マッチングスコアに基づいて前記ユーザ定義のキーワードに関連する前記キーワードモデルの前記閾値スコアを適合させるステップと
によって、適合される、請求項5に記載の方法。 - 前記少なくとも1つの入力が、前記ユーザ定義のキーワードのテキストを含む、請求項1に記載の方法。
- 前記少なくとも1つの入力が、前記ユーザ定義のキーワードを示す少なくとも1つのサンプルサウンドを含む、請求項1に記載の方法。
- 前記サブワードのシーケンスを判定するステップが、
前記サブワードモデルに基づいて前記少なくとも1つのサンプルサウンドからサブワードの少なくとも1つのシーケンスを生成するステップと、
前記サブワードの少なくとも1つのシーケンスに基づいて前記サブワードのシーケンスを判定するステップと
を含む、請求項8に記載の方法。 - 前記サブワードの少なくとも1つのシーケンスのうちの前記サブワードが、音、音素、トライフォン、および音節のうちの少なくとも1つを含む、請求項9に記載の方法。
- 前記少なくとも1つのサンプルサウンドを少なくとも1つのタイプのノイズと混ぜることによって少なくとも1つの混合サンプルサウンドを生成するステップ
をさらに含む、請求項8に記載の方法。 - 前記サブワードのシーケンスを判定するステップが、
前記サブワードモデルに基づいて前記少なくとも1つのサンプルサウンドおよび前記少なくとも1つの混合サンプルサウンドからサブワードの少なくとも2つのシーケンスを生成するステップと、
前記サブワードの少なくとも2つのシーケンスに基づいて前記サブワードのシーケンスを判定するステップと
を含む、請求項11に記載の方法。 - 前記サブワードの少なくとも1つのシーケンスに基づいて前記サブワードのシーケンスを判定するステップが、最も長い前記サブワードの少なくとも1つのシーケンスのうちの1つを前記サブワードのシーケンスとして選択するステップを含む、請求項9に記載の方法。
- 前記ユーザ定義のキーワードに関連する前記キーワードモデルを生成するステップが、
前記サブワードのシーケンス、前記サブワードモデル、前記少なくとも1つのサンプルサウンド、および前記少なくとも1つの混合サンプルサウンドに基づいて前記ユーザ定義のキーワードに関連する前記キーワードモデルを生成するステップ
を含む、請求項11に記載の方法。 - 前記サブワードのシーケンスの最初または最後にサブワード単位として沈黙部分を追加して前記サブワードのシーケンスを生成するステップ
をさらに含む、請求項1に記載の方法。 - 前記少なくとも1つの入力が、前記ユーザ定義のキーワードのテキストおよび前記ユーザ定義のキーワードを示す少なくとも1つのサンプルサウンドを含む、請求項1に記載の方法。
- ユーザ定義のキーワードのキーワードモデルを生成するための電子デバイスであって、
前記ユーザ定義のキーワードを示す少なくとも1つの入力を受信するように構成された入力ユニットと、
所定のキーワードに関連するキーワードモデルで構成された音声起動ユニットと、
前記少なくとも1つの入力からサブワードのシーケンスを判定し、前記サブワードのシーケンスおよび前記サブワードのサブワードモデルに基づいて前記ユーザ定義のキーワードに関連する前記キーワードモデルを生成し、前記ユーザ定義のキーワードに関連する前記キーワードモデルを前記音声起動ユニットに提供するように構成された、ユーザ定義のキーワードモデル生成ユニットと
を備え、
前記サブワードモデルが、音声データベースに基づいて前記サブワードの複数の音響特性をモデル化するように構成された、電子デバイス。 - 前記少なくとも1つの入力が、前記ユーザ定義のキーワードのテキストを含む、請求項17に記載の電子デバイス。
- 前記入力ユニットが、前記少なくとも1つの入力として前記ユーザ定義のキーワードを示す少なくとも1つのサンプルサウンドを受信するように構成されたサウンドセンサを含む、請求項17に記載の電子デバイス。
- 前記サブワードモデルに基づいて前記少なくとも1つのサンプルサウンドからサブワードの少なくとも1つのシーケンスを生成するように構成されたサブワード認識ユニットをさらに備える、請求項19に記載の電子デバイス。
- 前記少なくとも1つのサンプルサウンドを少なくとも1つのタイプのノイズと混ぜることによって少なくとも1つの混合サンプルサウンドを生成するように構成された混合サウンド生成ユニットをさらに備える、請求項19に記載の電子デバイス。
- 前記音声起動ユニットが、前記ユーザ定義のキーワードに関連する前記キーワードモデルおよび前記所定のキーワードに関連する前記キーワードモデルに基づいて入力サウンドにおいて前記ユーザ定義のキーワードまたは前記所定のキーワードを検出するように構成された、請求項17に記載の電子デバイス。
- 前記音声起動ユニットが、前記ユーザ定義のキーワードまたは前記所定のキーワードに関連する機能を実行するように構成された、請求項17に記載の電子デバイス。
- 前記サウンドセンサによって受信された少なくとも1つの文の入力サウンドに基づいて前記サブワードモデルを適合させるように構成された事前適応ユニットをさらに備える、請求項19に記載の電子デバイス。
- 前記ユーザ定義のキーワードモデル生成ユニットが、前記ユーザ定義のキーワードに関連する前記キーワードモデルの閾値スコアを判定するように構成された、請求項17に記載の電子デバイス。
- 前記ユーザ定義のキーワードモデル生成ユニットが、
前記ユーザ定義のキーワードに関連する前記キーワードモデルに基づいて前記サウンドセンサによって受信された前記ユーザ定義のキーワードを示すテスト入力サウンドのマッチングスコアを判定し、
前記マッチングスコアに基づいて前記ユーザ定義のキーワードに関連する前記キーワードモデルの前記閾値スコアを適合させる
ように構成された、請求項25に記載の電子デバイス。 - 電子デバイスにおいてユーザ定義のキーワードのキーワードモデルを生成するための命令を記憶する非一時的コンピュータ可読記憶媒体であって、前記命令が、
前記ユーザ定義のキーワードを示す少なくとも1つの入力を受信する動作と、
前記少なくとも1つの入力からサブワードのシーケンスを判定する動作と、
前記サブワードのシーケンスおよび前記サブワードのサブワードモデルに基づいて前記ユーザ定義のキーワードに関連する前記キーワードモデルを生成する動作であり、前記サブワードモデルが、音声データベースに基づいて前記サブワードの複数の音響特性をモデル化するように構成された、動作と、
前記ユーザ定義のキーワードに関連する前記キーワードモデルを所定のキーワードに関連するキーワードモデルで構成された音声起動ユニットに提供する動作と
をプロセッサに実行させる、非一時的コンピュータ可読記憶媒体。 - ユーザ定義のキーワードのキーワードモデルを生成するための電子デバイスであって、
前記ユーザ定義のキーワードを示す少なくとも1つの入力を受信するための手段と、
前記少なくとも1つの入力からサブワードのシーケンスを判定するための手段と、
前記サブワードのシーケンスおよび前記サブワードのサブワードモデルに基づいて前記ユーザ定義のキーワードに関連する前記キーワードモデルを生成するための手段であり、前記サブワードモデルが、音声データベースに基づいて前記サブワードの複数の音響特性をモデル化するように構成された、手段と、
前記ユーザ定義のキーワードに関連する前記キーワードモデルを所定のキーワードに関連するキーワードモデルで構成された音声起動ユニットに提供するための手段と
を備える、電子デバイス。 - 前記少なくとも1つの入力が、前記ユーザ定義のキーワードを示す少なくとも1つのサンプルサウンドを含む、請求項28に記載の電子デバイス。
- 前記少なくとも1つのサンプルサウンドを少なくとも1つのタイプのノイズと混ぜることによって少なくとも1つの混合サンプルサウンドを生成するための手段
をさらに備える、請求項29に記載の電子デバイス。
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201461980911P | 2014-04-17 | 2014-04-17 | |
| US61/980,911 | 2014-04-17 | ||
| US14/466,644 US9953632B2 (en) | 2014-04-17 | 2014-08-22 | Keyword model generation for detecting user-defined keyword |
| US14/466,644 | 2014-08-22 | ||
| PCT/US2015/024873 WO2015160586A1 (en) | 2014-04-17 | 2015-04-08 | Keyword model generation for detecting user-defined keyword |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2017515147A true JP2017515147A (ja) | 2017-06-08 |
| JP2017515147A5 JP2017515147A5 (ja) | 2018-05-10 |
Family
ID=54322537
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2016562023A Ceased JP2017515147A (ja) | 2014-04-17 | 2015-04-08 | ユーザ定義のキーワードを検出するためのキーワードモデル生成 |
Country Status (7)
| Country | Link |
|---|---|
| US (1) | US9953632B2 (ja) |
| EP (1) | EP3132442B1 (ja) |
| JP (1) | JP2017515147A (ja) |
| KR (1) | KR20160145634A (ja) |
| CN (1) | CN106233374B (ja) |
| BR (1) | BR112016024086A2 (ja) |
| WO (1) | WO2015160586A1 (ja) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2019191490A (ja) * | 2018-04-27 | 2019-10-31 | 東芝映像ソリューション株式会社 | 音声対話端末、および音声対話端末制御方法 |
| JP2021508848A (ja) * | 2017-12-31 | 2021-03-11 | 美的集団股▲フン▼有限公司Midea Group Co., Ltd. | ホームアシスタント装置を制御するための方法及びシステム |
Families Citing this family (36)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10019983B2 (en) * | 2012-08-30 | 2018-07-10 | Aravind Ganapathiraju | Method and system for predicting speech recognition performance using accuracy scores |
| US9866741B2 (en) * | 2015-04-20 | 2018-01-09 | Jesse L. Wobrock | Speaker-dependent voice-activated camera system |
| US10304440B1 (en) * | 2015-07-10 | 2019-05-28 | Amazon Technologies, Inc. | Keyword spotting using multi-task configuration |
| US9792907B2 (en) | 2015-11-24 | 2017-10-17 | Intel IP Corporation | Low resource key phrase detection for wake on voice |
| US9972313B2 (en) * | 2016-03-01 | 2018-05-15 | Intel Corporation | Intermediate scoring and rejection loopback for improved key phrase detection |
| CN105868182B (zh) * | 2016-04-21 | 2019-08-30 | 深圳市中兴移动软件有限公司 | 一种文本信息处理方法及装置 |
| US10043521B2 (en) | 2016-07-01 | 2018-08-07 | Intel IP Corporation | User defined key phrase detection by user dependent sequence modeling |
| US10083689B2 (en) * | 2016-12-23 | 2018-09-25 | Intel Corporation | Linear scoring for low power wake on voice |
| US10276161B2 (en) * | 2016-12-27 | 2019-04-30 | Google Llc | Contextual hotwords |
| JP6599914B2 (ja) * | 2017-03-09 | 2019-10-30 | 株式会社東芝 | 音声認識装置、音声認識方法およびプログラム |
| CN107146611B (zh) * | 2017-04-10 | 2020-04-17 | 北京猎户星空科技有限公司 | 一种语音响应方法、装置及智能设备 |
| US10313845B2 (en) * | 2017-06-06 | 2019-06-04 | Microsoft Technology Licensing, Llc | Proactive speech detection and alerting |
| TW201921336A (zh) * | 2017-06-15 | 2019-06-01 | 大陸商北京嘀嘀無限科技發展有限公司 | 用於語音辨識的系統和方法 |
| CN107564517A (zh) * | 2017-07-05 | 2018-01-09 | 百度在线网络技术(北京)有限公司 | 语音唤醒方法、设备及系统、云端服务器与可读介质 |
| CN109903751B (zh) * | 2017-12-08 | 2023-07-07 | 阿里巴巴集团控股有限公司 | 关键词确认方法和装置 |
| CN108665900B (zh) | 2018-04-23 | 2020-03-03 | 百度在线网络技术(北京)有限公司 | 云端唤醒方法及系统、终端以及计算机可读存储介质 |
| CN111445905B (zh) * | 2018-05-24 | 2023-08-08 | 腾讯科技(深圳)有限公司 | 混合语音识别网络训练方法、混合语音识别方法、装置及存储介质 |
| US10714122B2 (en) | 2018-06-06 | 2020-07-14 | Intel Corporation | Speech classification of audio for wake on voice |
| US10269376B1 (en) * | 2018-06-28 | 2019-04-23 | Invoca, Inc. | Desired signal spotting in noisy, flawed environments |
| US10650807B2 (en) | 2018-09-18 | 2020-05-12 | Intel Corporation | Method and system of neural network keyphrase detection |
| US11100923B2 (en) * | 2018-09-28 | 2021-08-24 | Sonos, Inc. | Systems and methods for selective wake word detection using neural network models |
| CN109635273B (zh) * | 2018-10-25 | 2023-04-25 | 平安科技(深圳)有限公司 | 文本关键词提取方法、装置、设备及存储介质 |
| CN109473123B (zh) * | 2018-12-05 | 2022-05-31 | 百度在线网络技术(北京)有限公司 | 语音活动检测方法及装置 |
| CN109767763B (zh) * | 2018-12-25 | 2021-01-26 | 苏州思必驰信息科技有限公司 | 自定义唤醒词的确定方法和用于确定自定义唤醒词的装置 |
| TW202029181A (zh) * | 2019-01-28 | 2020-08-01 | 正崴精密工業股份有限公司 | 語音識別用於特定目標喚醒的方法及裝置 |
| CN109979440B (zh) * | 2019-03-13 | 2021-05-11 | 广州市网星信息技术有限公司 | 关键词样本确定方法、语音识别方法、装置、设备和介质 |
| US11127394B2 (en) | 2019-03-29 | 2021-09-21 | Intel Corporation | Method and system of high accuracy keyphrase detection for low resource devices |
| CN110349566B (zh) * | 2019-07-11 | 2020-11-24 | 龙马智芯(珠海横琴)科技有限公司 | 语音唤醒方法、电子设备及存储介质 |
| WO2021030918A1 (en) * | 2019-08-22 | 2021-02-25 | Fluent.Ai Inc. | User-defined keyword spotting |
| CN110634468B (zh) * | 2019-09-11 | 2022-04-15 | 中国联合网络通信集团有限公司 | 语音唤醒方法、装置、设备及计算机可读存储介质 |
| US11295741B2 (en) | 2019-12-05 | 2022-04-05 | Soundhound, Inc. | Dynamic wakewords for speech-enabled devices |
| CN111128138A (zh) * | 2020-03-30 | 2020-05-08 | 深圳市友杰智新科技有限公司 | 语音唤醒方法、装置、计算机设备和存储介质 |
| CN111540363B (zh) * | 2020-04-20 | 2023-10-24 | 合肥讯飞数码科技有限公司 | 关键词模型及解码网络构建方法、检测方法及相关设备 |
| CN111798840B (zh) * | 2020-07-16 | 2023-08-08 | 中移在线服务有限公司 | 语音关键词识别方法和装置 |
| KR20220111574A (ko) | 2021-02-02 | 2022-08-09 | 삼성전자주식회사 | 전자 장치 및 그 제어 방법 |
| WO2023150132A1 (en) * | 2022-02-01 | 2023-08-10 | Apple Inc. | Keyword detection using motion sensing |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH11282486A (ja) * | 1998-03-31 | 1999-10-15 | Toshiba Corp | サブワード型不特定話者音声認識装置及び方法 |
| JP2001042891A (ja) * | 1999-07-27 | 2001-02-16 | Suzuki Motor Corp | 音声認識装置、音声認識搭載装置、音声認識搭載システム、音声認識方法、及び記憶媒体 |
| JP2002207496A (ja) * | 2000-11-20 | 2002-07-26 | Canon Inc | 音声処理システム |
| JP2003044079A (ja) * | 2001-08-01 | 2003-02-14 | Sony Corp | 音声認識装置および方法、記録媒体、並びにプログラム |
| WO2009147927A1 (ja) * | 2008-06-06 | 2009-12-10 | 株式会社レイトロン | 音声認識装置、音声認識方法および電子機器 |
| JP2011039222A (ja) * | 2009-08-10 | 2011-02-24 | Nec Corp | 音声認識システム、音声認識方法および音声認識プログラム |
Family Cites Families (18)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5199077A (en) * | 1991-09-19 | 1993-03-30 | Xerox Corporation | Wordspotting for voice editing and indexing |
| CA2088080C (en) * | 1992-04-02 | 1997-10-07 | Enrico Luigi Bocchieri | Automatic speech recognizer |
| US5623578A (en) * | 1993-10-28 | 1997-04-22 | Lucent Technologies Inc. | Speech recognition system allows new vocabulary words to be added without requiring spoken samples of the words |
| US5768474A (en) * | 1995-12-29 | 1998-06-16 | International Business Machines Corporation | Method and system for noise-robust speech processing with cochlea filters in an auditory model |
| US5960395A (en) | 1996-02-09 | 1999-09-28 | Canon Kabushiki Kaisha | Pattern matching method, apparatus and computer readable memory medium for speech recognition using dynamic programming |
| CN100397384C (zh) | 1997-02-07 | 2008-06-25 | 卡西欧计算机株式会社 | 车载终端装置 |
| US6292778B1 (en) * | 1998-10-30 | 2001-09-18 | Lucent Technologies Inc. | Task-independent utterance verification with subword-based minimum verification error training |
| US20060074664A1 (en) | 2000-01-10 | 2006-04-06 | Lam Kwok L | System and method for utterance verification of chinese long and short keywords |
| EP1215661A1 (en) * | 2000-12-14 | 2002-06-19 | TELEFONAKTIEBOLAGET L M ERICSSON (publ) | Mobile terminal controllable by spoken utterances |
| US7027987B1 (en) * | 2001-02-07 | 2006-04-11 | Google Inc. | Voice interface for a search engine |
| CN100349206C (zh) * | 2005-09-12 | 2007-11-14 | 周运南 | 文字语音互转装置 |
| KR100679051B1 (ko) | 2005-12-14 | 2007-02-05 | 삼성전자주식회사 | 복수의 신뢰도 측정 알고리즘을 이용한 음성 인식 장치 및방법 |
| CN101320561A (zh) * | 2007-06-05 | 2008-12-10 | 赛微科技股份有限公司 | 提升个人语音识别率的方法及模块 |
| US8438028B2 (en) * | 2010-05-18 | 2013-05-07 | General Motors Llc | Nametag confusability determination |
| US9117449B2 (en) | 2012-04-26 | 2015-08-25 | Nuance Communications, Inc. | Embedded system for construction of small footprint speech recognition with user-definable constraints |
| US9672815B2 (en) | 2012-07-20 | 2017-06-06 | Interactive Intelligence Group, Inc. | Method and system for real-time keyword spotting for speech analytics |
| US10019983B2 (en) | 2012-08-30 | 2018-07-10 | Aravind Ganapathiraju | Method and system for predicting speech recognition performance using accuracy scores |
| CN104700832B (zh) * | 2013-12-09 | 2018-05-25 | 联发科技股份有限公司 | 语音关键字检测系统及方法 |
-
2014
- 2014-08-22 US US14/466,644 patent/US9953632B2/en active Active
-
2015
- 2015-04-08 JP JP2016562023A patent/JP2017515147A/ja not_active Ceased
- 2015-04-08 KR KR1020167030186A patent/KR20160145634A/ko unknown
- 2015-04-08 WO PCT/US2015/024873 patent/WO2015160586A1/en active Application Filing
- 2015-04-08 CN CN201580020007.2A patent/CN106233374B/zh active Active
- 2015-04-08 EP EP15717387.3A patent/EP3132442B1/en active Active
- 2015-04-08 BR BR112016024086A patent/BR112016024086A2/pt not_active IP Right Cessation
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH11282486A (ja) * | 1998-03-31 | 1999-10-15 | Toshiba Corp | サブワード型不特定話者音声認識装置及び方法 |
| JP2001042891A (ja) * | 1999-07-27 | 2001-02-16 | Suzuki Motor Corp | 音声認識装置、音声認識搭載装置、音声認識搭載システム、音声認識方法、及び記憶媒体 |
| JP2002207496A (ja) * | 2000-11-20 | 2002-07-26 | Canon Inc | 音声処理システム |
| JP2003044079A (ja) * | 2001-08-01 | 2003-02-14 | Sony Corp | 音声認識装置および方法、記録媒体、並びにプログラム |
| WO2009147927A1 (ja) * | 2008-06-06 | 2009-12-10 | 株式会社レイトロン | 音声認識装置、音声認識方法および電子機器 |
| JP2011039222A (ja) * | 2009-08-10 | 2011-02-24 | Nec Corp | 音声認識システム、音声認識方法および音声認識プログラム |
Non-Patent Citations (1)
| Title |
|---|
| 中川聖一他: "任意語彙の追加登録可能な単語音声認識システム", 電気学会論文誌, vol. 118, no. 6, JPN6019005549, June 1998 (1998-06-01), pages 865 - 872, ISSN: 0003980360 * |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2021508848A (ja) * | 2017-12-31 | 2021-03-11 | 美的集団股▲フン▼有限公司Midea Group Co., Ltd. | ホームアシスタント装置を制御するための方法及びシステム |
| JP7044415B2 (ja) | 2017-12-31 | 2022-03-30 | 美的集団股▲フン▼有限公司 | ホームアシスタント装置を制御するための方法及びシステム |
| JP2019191490A (ja) * | 2018-04-27 | 2019-10-31 | 東芝映像ソリューション株式会社 | 音声対話端末、および音声対話端末制御方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| BR112016024086A2 (pt) | 2017-08-15 |
| US9953632B2 (en) | 2018-04-24 |
| EP3132442B1 (en) | 2018-07-04 |
| KR20160145634A (ko) | 2016-12-20 |
| CN106233374B (zh) | 2020-01-10 |
| US20150302847A1 (en) | 2015-10-22 |
| WO2015160586A1 (en) | 2015-10-22 |
| CN106233374A (zh) | 2016-12-14 |
| EP3132442A1 (en) | 2017-02-22 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US9953632B2 (en) | Keyword model generation for detecting user-defined keyword | |
| JP6740504B1 (ja) | 発話分類器 | |
| US9837068B2 (en) | Sound sample verification for generating sound detection model | |
| US11817094B2 (en) | Automatic speech recognition with filler model processing | |
| US9373321B2 (en) | Generation of wake-up words | |
| US9805715B2 (en) | Method and system for recognizing speech commands using background and foreground acoustic models | |
| US20150302856A1 (en) | Method and apparatus for performing function by speech input | |
| US11676585B1 (en) | Hybrid decoding using hardware and software for automatic speech recognition systems | |
| US8019604B2 (en) | Method and apparatus for uniterm discovery and voice-to-voice search on mobile device | |
| US9589564B2 (en) | Multiple speech locale-specific hotword classifiers for selection of a speech locale | |
| CN105632499B (zh) | 用于优化语音识别结果的方法和装置 | |
| WO2017071182A1 (zh) | 一种语音唤醒方法、装置及系统 | |
| JP2018120212A (ja) | 音声認識方法及び装置 | |
| WO2018192186A1 (zh) | 语音识别方法及装置 | |
| US11074909B2 (en) | Device for recognizing speech input from user and operating method thereof | |
| US20230368796A1 (en) | Speech processing | |
| KR102394912B1 (ko) | 음성 인식을 이용한 주소록 관리 장치, 차량, 주소록 관리 시스템 및 음성 인식을 이용한 주소록 관리 방법 | |
| US20150262575A1 (en) | Meta-data inputs to front end processing for automatic speech recognition | |
| US11564194B1 (en) | Device communication | |
| US11328713B1 (en) | On-device contextual understanding | |
| KR20210098250A (ko) | 전자 장치 및 이의 제어 방법 | |
| KR20180051301A (ko) | 자연어 대화체 음성을 인식하는 장치 및 방법 | |
| Guijarrubia et al. | Comparative Study of Several Phonotactic-Based Approaches to Spanish-Basque Language Identification |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20180319 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20180319 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20190131 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20190225 |
|
| A045 | Written measure of dismissal of application [lapsed due to lack of payment] |
Free format text: JAPANESE INTERMEDIATE CODE: A045 Effective date: 20190701 |