KR20160145634A - 사용자 정의된 키워드를 검출하기 위한 키워드 모델 생성 - Google Patents
사용자 정의된 키워드를 검출하기 위한 키워드 모델 생성 Download PDFInfo
- Publication number
- KR20160145634A KR20160145634A KR1020167030186A KR20167030186A KR20160145634A KR 20160145634 A KR20160145634 A KR 20160145634A KR 1020167030186 A KR1020167030186 A KR 1020167030186A KR 20167030186 A KR20167030186 A KR 20167030186A KR 20160145634 A KR20160145634 A KR 20160145634A
- Authority
- KR
- South Korea
- Prior art keywords
- keyword
- user
- model
- sub
- sequence
- Prior art date
Links
Images




Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/02—Feature extraction for speech recognition; Selection of recognition unit
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/06—Creation of reference templates; Training of speech recognition systems, e.g. adaptation to the characteristics of the speaker's voice
- G10L15/065—Adaptation
- G10L15/07—Adaptation to the speaker
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/02—Feature extraction for speech recognition; Selection of recognition unit
- G10L2015/027—Syllables being the recognition units
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
- G10L2015/088—Word spotting
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/22—Procedures used during a speech recognition process, e.g. man-machine dialogue
- G10L2015/226—Procedures used during a speech recognition process, e.g. man-machine dialogue using non-speech characteristics
Abstract
본 개시물의 일 양태에 따르면, 전자 디바이스에서 사용자 정의된 키워드의 키워드 모델을 생성하는 방법이 개시된다. 본 방법은 사용자 정의된 키워드를 나타내는 적어도 하나의 입력을 수신하는 단계, 적어도 하나의 입력으로부터 서브워드들의 시퀀스를 결정하는 단계, 서브워드들의 시퀀스 및 서브워드들의 서브워드 모델에 기초하여 사용자 정의된 키워드와 연관된 키워드 모델을 생성하는 단계로서, 서브워드 모델은 스피치 데이터베이스에 기초하여 서브워드들의 복수의 음향 피처들을 모델링하도록 구성되는, 키워드 모델을 생성하는 단계; 및 사용자 정의된 키워드와 연관된 키워드 모델을, 미리 정해진 키워드와 연관된 키워드 모델로 구성되는 음성 활성화 유닛에 제공하는 단계를 포함한다.
Description
관련 출원(들)의 상호 참조
본 출원은 2014 년 8 월 22 일 출원되고 발명의 명칭이 "KEYWORD MODEL GENERATION FOR DETECTING USER-DEFINED KEYWORD" 인 미국 특허 출원 제 14/466,644 호 및 2014 년 4 월 17 일 출원되고 발명의 명칭이 "METHOD AND APPARATUS FOR GENERATING KEYWORD MODEL FOR USE IN DETECTING USER-DEFINED KEYWORD" 인 미국 특허 가출원 번호 제 61/980,911 호를 우선권으로 주장하며, 이들 전체 내용을 여기서는 참조로서 포함한다.
기술 분야
본 개시물은 일반적으로, 전자 디바이스에서 스피치 인식에 관련하며, 보다 구체적으로, 사용자 정의된 키워드를 검출하는 키워드 모델을 생성하는 것에 관련된다.
최근에, 전자 디바이스들, 이를 테면, 스마트폰들, 태블릿 컴퓨터들, 웨어러블 전자 디바이스들, 스마트 TV들 등이 점점더 소비자들 사이에 대중화되고 있다. 이들 디바이스들은 통상적으로, 유선 또는 무선 네트워크들을 통하여 음성 및/또는 데이터 통신 기능들을 제공한다. 또한, 이러한 전자 디바이스들은 일반적으로 사용자 편의를 증가시키도록 설계된 여러 기능들을 제공하는 다른 피처들을 포함한다.
통상의 전자 디바이스들은 종종 사용자로부터 음성 커맨드들을 수신하기 위한 스피치 인식 기능을 포함한다. 이러한 기능은 사용자로부터 음성 커맨드가 수신되어 인식될 때 전자 디바이스들이 음성 커맨드 (예를 들어, 키워드) 와 연관된 기능을 수행할 수 있게 허용한다. 예를 들어, 전자 디바이스는 사용자로부터의 음성 커맨드에 응답하여 음성 지원 애플리케이션을 활성화하거나, 오디오 파일을 플레이하거나, 또는 사진을 찍도록 할 수도 있다.
음성 인식 피처를 갖는 전자 디바이스들에서, 제조자들 또는 캐리어들은 종종 입력 사운드에서의 키워드들을 검출함에 있어서 이용될 수도 있는 미리 정해진 키워드들 및 연관된 사운드 모델들을 디바이스들에 탑재한다. 일부 전자 디바이스들은 또한 사용자가 음성 커맨드로서 키워드를 지정할 수 있게 허용할 수도 있다. 예를 들어, 전자 디바이스들은 사용자로부터 키워드의 수개의 발음들을 수신하고, 그 발음들로부터 지정된 키워드에 대한 키워드 모델을 생성할 수도 있다.
일반적으로, 키워드 모델의 검출 수행은 키워드 모델이 생성되는 발음들의 수에 관련된다. 즉, 키워드 모델의 검출 성능은 발음들의 수가 증가할 수록 개선할 수도 있다. 예를 들어, 제조자는 수천개 이상의 발음들로부터 생성되었던 키워드 모델을 전자 디바이스에 제공할 수도 있다.
그러나, 통상의 전자 디바이스들에서, 사용자로부터 수신된 키워드의 발음들의 수는 극히 작다 (예를 들어, 5 개). 따라서, 이러한 제한된 수의 발음들로부터 생성된 키워드 모델은 적절한 검출 성능을 생성하지 못할 수도 있다. 한편, 충분한 검출 성능을 제공할 수 있는 키워드 모델을 생성하기 위해 사용자로부터 상당한 개수의 발음들을 수신하는 것은 사용자에게 번거롭고 불편할 수도 있다.
본 개시물은 사용자 정의된 키워드를 검출하는데 사용하기 위한 키워드 모델을 생성하는 것에 관한 것이다.
본 개시물의 일 양태에 따르면, 전자 디바이스에서 사용자 정의된 키워드의 키워드 모델을 생성하는 방법이 개시된다. 이 방법에서, 사용자 정의된 키워드를 나타내는 적어도 하나의 입력이 수신된다. 적어도 하나의 입력으로부터 서브워드들의 시퀀스가 결정된다. 서브워드들의 시퀀스 및 서브워드들의 서브워드 모델에 기초하여, 사용자 정의된 키워드와 연관된 키워드 모델이 생성된다. 서브워드 모델은 스피치 데이터베이스에 기초하여 서브워드들의 복수의 음향 피처들을 모델링하거나 또는 표현하도록 구성된다. 사용자 정의된 키워드와 연관된 키워드 모델은 미리 정해진 키워드와 연관된 키워드 모델로 구성되는 음성 활성화 유닛에 제공된다. 본 개시물은 또한 이 방법에 관한 장치, 디바이스, 시스템, 수단들의 조합, 및 컴퓨터 판독가능 매체를 기술한다.
본 개시물의 다른 양태에 따르면, 사용자 정의된 키워드의 키워드 모델을 생성하기 위한 전자 디바이스가 개시된다. 전자 디바이스는 입력 유닛, 음성 활성화 유닛 및 사용자 정의된 키워드 모델 생성 유닛을 포함한다. 입력 유닛은 사용자 정의된 키워드를 나타내는 적어도 하나의 입력을 수신하도록 구성된다. 음성 활성화 유닛은 미리 정해진 키워드와 연관된 키워드 모델로 구성된다. 사용자 정의된 키워드 모델 생성 유닛은 적어도 하나의 입력으로부터 서브워드들의 시퀀스를 결정하고, 서브워드들의 시퀀스 및 서브워드들의 서브워드 모델에 기초하여 사용자 정의된 키워드와 연관된 키워드 모델을 생성하고, 사용자 정의된 키워드와 연관된 키워드 모델을 음성 활성화 유닛에 제공하도록 구성된다. 서브워드 모델은 스피치 데이터베이스에 기초하여 서브워드들의 복수의 음향 피처들을 모델링하거나 또는 표현하도록 구성된다.
도면의 간단한 설명
본 개시물의 진보적 양태들의 실시형태들은 첨부한 도면들과 연계하여 읽혀질 때 다음의 상세한 설명을 참조로 이해될 것이다.
도 1 은 본 개시물의 일 실시형태에 따라, 사용자 정의된 키워드를 나타내는 적어도 하나의 샘플 사운드로부터 사용자 정의된 키워드를 검출하는데 있어 이용하기 위한 키워드 모델을 생성하도록 구성되는 전자 디바이스를 예시한다.
도 2 는 본 개시물의 일 실시형태에 따라, 사용자 정의된 키워드를 나타내는 하나 이상의 샘플 사운드들 및 하나 이상의 잡음 유형들에 기초하여 하나 이상의 믹싱된 샘플 사운드들을 생성하기 위한 방법의 다이어그램을 예시한다.
도 3 은 본 개시물의 일 실시형태에 따라, 사용자 정의된 키워드에 대한 텍스트로부터 사용자 정의된 키워드를 검출하는데 있어 이용하기 위한 키워드 모델을 생성하도록 구성되는 전자 디바이스를 예시한다.
도 4 는 본 개시물의 일 실시형태에 따라, 사용자 정의된 키워드를 검출하기 위하여 키워드 모델을 생성하는데 사용될 수도 있는 서브워드 모델을 조정하도록 구성되는 전자 디바이스를 예시한다.
도 5 는 본 개시물의 일 실시형태에 따라, 입력 사운드에 기초하여 사용자 정의된 키워드를 검출하기 위하여 임계 스코어를 조정하도록 구성되는 전자 디바이스를 예시한다.
도 6 은 본 개시물의 일 실시형태에 따라, 입력 사운드로부터 키워드를 검출하는 것에 응답하여 전자 디바이스에서의 음성 지원 애플리케이션을 활성화하는 것을 예시한다.
도 7 은 본 개시물의 일 실시형태에 따라, 사용자 정의된 키워드를 포함하는 입력 사운드에 기초하여 사용자를 인식하도록 구성되는 전자 디바이스를 예시한다.
도 8 은 본 개시물의 일 실시형태에 따라, 사용자 정의된 키워드에 대한 키워드 모델을 생성하고, 키워드 모델에 기초하여 입력 사운드 스트림에서 사용자 정의된 키워드를 검출하도록 구성되는 전자 디바이스의 블록도를 예시한다.
도 9 는 본 개시물의 일 실시형태에 따라 사용자 정의된 키워드를 나타내는 적어도 하나의 입력으로부터 사용자 정의된 키워드의 키워드 모델을 생성하기 위하여, 전자 디바이스에서 수행되는 예시적인 방법의 흐름도이다.
도 10 은 본 개시물의 일 실시형태에 따라 사용자 정의된 키워드를 나타내는 적어도 하나의 샘플 사운드로부터 사용자 정의된 키워드의 키워드 모델을 생성하기 위하여, 전자 디바이스에서 수행되는 예시적인 방법의 흐름도이다.
도 11 은 본 개시물의 일 실시형태에 따라 사용자 정의된 키워드를 검출하기 위한 키워드 모델을 생성하는데 있어 사용되는 서브워드 모델을 조정하기 위하여 전자 디바이스에서 수행되는 예시적인 방법의 흐름도이다.
도 12 는 본 개시물의 일 실시형태에 따라 입력 사운드에 기초하여 사용자 정의된 키워드를 검출하기 위한 임계 스코어를 조정하기 위하여 전자 디바이스에서 수행되는 예시적인 방법의 흐름도이다.
도 13 은 본 개시물의 일부 실시형태들에 따라, 사용자 정의된 키워드에서 사용하기 위한 키워드 모델을 생성하기 위한 방법들 및 장치들이 구현될 수도 있는 예시적인 전자 디바이스의 블록도이다.
본 개시물의 진보적 양태들의 실시형태들은 첨부한 도면들과 연계하여 읽혀질 때 다음의 상세한 설명을 참조로 이해될 것이다.
도 1 은 본 개시물의 일 실시형태에 따라, 사용자 정의된 키워드를 나타내는 적어도 하나의 샘플 사운드로부터 사용자 정의된 키워드를 검출하는데 있어 이용하기 위한 키워드 모델을 생성하도록 구성되는 전자 디바이스를 예시한다.
도 2 는 본 개시물의 일 실시형태에 따라, 사용자 정의된 키워드를 나타내는 하나 이상의 샘플 사운드들 및 하나 이상의 잡음 유형들에 기초하여 하나 이상의 믹싱된 샘플 사운드들을 생성하기 위한 방법의 다이어그램을 예시한다.
도 3 은 본 개시물의 일 실시형태에 따라, 사용자 정의된 키워드에 대한 텍스트로부터 사용자 정의된 키워드를 검출하는데 있어 이용하기 위한 키워드 모델을 생성하도록 구성되는 전자 디바이스를 예시한다.
도 4 는 본 개시물의 일 실시형태에 따라, 사용자 정의된 키워드를 검출하기 위하여 키워드 모델을 생성하는데 사용될 수도 있는 서브워드 모델을 조정하도록 구성되는 전자 디바이스를 예시한다.
도 5 는 본 개시물의 일 실시형태에 따라, 입력 사운드에 기초하여 사용자 정의된 키워드를 검출하기 위하여 임계 스코어를 조정하도록 구성되는 전자 디바이스를 예시한다.
도 6 은 본 개시물의 일 실시형태에 따라, 입력 사운드로부터 키워드를 검출하는 것에 응답하여 전자 디바이스에서의 음성 지원 애플리케이션을 활성화하는 것을 예시한다.
도 7 은 본 개시물의 일 실시형태에 따라, 사용자 정의된 키워드를 포함하는 입력 사운드에 기초하여 사용자를 인식하도록 구성되는 전자 디바이스를 예시한다.
도 8 은 본 개시물의 일 실시형태에 따라, 사용자 정의된 키워드에 대한 키워드 모델을 생성하고, 키워드 모델에 기초하여 입력 사운드 스트림에서 사용자 정의된 키워드를 검출하도록 구성되는 전자 디바이스의 블록도를 예시한다.
도 9 는 본 개시물의 일 실시형태에 따라 사용자 정의된 키워드를 나타내는 적어도 하나의 입력으로부터 사용자 정의된 키워드의 키워드 모델을 생성하기 위하여, 전자 디바이스에서 수행되는 예시적인 방법의 흐름도이다.
도 10 은 본 개시물의 일 실시형태에 따라 사용자 정의된 키워드를 나타내는 적어도 하나의 샘플 사운드로부터 사용자 정의된 키워드의 키워드 모델을 생성하기 위하여, 전자 디바이스에서 수행되는 예시적인 방법의 흐름도이다.
도 11 은 본 개시물의 일 실시형태에 따라 사용자 정의된 키워드를 검출하기 위한 키워드 모델을 생성하는데 있어 사용되는 서브워드 모델을 조정하기 위하여 전자 디바이스에서 수행되는 예시적인 방법의 흐름도이다.
도 12 는 본 개시물의 일 실시형태에 따라 입력 사운드에 기초하여 사용자 정의된 키워드를 검출하기 위한 임계 스코어를 조정하기 위하여 전자 디바이스에서 수행되는 예시적인 방법의 흐름도이다.
도 13 은 본 개시물의 일부 실시형태들에 따라, 사용자 정의된 키워드에서 사용하기 위한 키워드 모델을 생성하기 위한 방법들 및 장치들이 구현될 수도 있는 예시적인 전자 디바이스의 블록도이다.
여러 가지 실시형태들에 대한 상세한 참조가 이루어질 것인데, 그 예들은 첨부된 도면들에서 예시된다. 다음의 상세한 설명에서, 본 청구물들의 완전한 이해를 제공하기 위해 다양한 구체적인 세부사항들이 제시된다. 그러나, 당해 기술 분야의 당업자는 이들 구체적인 세부사항들없이도 본 청구물들이 실시될 수 있음을 알고 있을 것이다. 다른 예들에서, 잘 알려진 방법들, 절차들, 시스템들, 및 컴포넌트들은 여러 실시형태들의 양태들을 불필요하게 모호하게 하지 않도록 하기 위해 자세하게 설명하지 않는다.
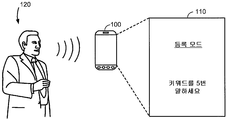
도 1 은 본 개시물의 일 실시형태에 따라, 사용자 정의된 키워드를 나타내는 적어도 하나의 샘플 사운드로부터 사용자 정의된 키워드를 검출하는데 있어 이용하기 위한 키워드 모델을 생성하도록 구성되는 전자 디바이스 (100) 를 예시한다. 전자 디바이스 (100) 는 사운드 캡처링 및 프로세싱 능력들을 갖춘 임의의 적절한 디바이스들, 이를 테면, 셀룰라 폰, 스마트폰, 퍼스널 컴퓨터, 랩톱 컴퓨터, 테블릿 퍼스널 컴퓨터, 스마트 텔레비전, 게임 디바이스, 멀티미디어 플레이어 등일 수도 있다. 본원에 이용된 용어, "키워드" 는 전자 디바이스 (100) 에서 기능 또는 애플리케이션을 활성화하는데 이용될 수 있는 하나 이상의 워드들 또는 사운드의 임의의 디지털 또는 아날로그 표현을 지칭할 수도 있다.
전자 디바이스 (100) 는 미리 정해진 키워드들의 세트 및/또는 사용자 정의된 키워드들의 다른 세트를 저장할 수도 있다. 본원에 이용된 용어 "미리 정해진 키워드" 는 전자 디바이스 (100) 에서 기능 또는 애플리케이션을 활성화하는데 미리 정해졌던 키워드를 지칭할 수도 있다. 미리 정해진 키워드에 대한 키워드 모델 또는 트레이닝된 키워드 모델은 전자 디바이스 (100) 로의 입력 사운드로부터의 미리 정해진 키워드를 검출하는데 있어 이용하기 위한 키워드 검출 모델을 지칭할 수도 있다. 일부 실시형태들에서, 복수의 미리 정해진 키워드들에 대한 복수의 키워드 모델들은 전자 디바이스 (100) 의 제조자 또는 제 3 제공자에 의해 생성되고, 전자 디바이스 (100) 에 미리 저장되고/되거나 외부 서버 또는 디바이스 (도시 생략) 로부터 다운로딩될 수도 있다. 또한, 용어 "사용자 정의된 키워드" 는 전자 디바이스 (100) 의 사용자에 의해 기능 또는 애플리케이션들을 활성화하기 위하여 정의 또는 지정될 수도 있는 키워드를 지칭할 수도 있다. 사용자 정의된 키워드에 대한 키워드 모델은 전자 디바이스 (100) 로의 입력 사운드로부터의 사용자 정의된 키워드를 검출하는데 있어 사용하기 위한 키워드 검출 모델을 지칭할 수도 있다. 일부 실시형태들에서, 사용자 정의된 키워드들에 대한 키워드 모델들은 도 4 를 참조하여 아래 설명될, 서브워드 모델들의 미리 정해진 세트에 기초하여 사용자에 의해 생성 또는 업데이트될 수도 있다.
일 실시형태에서, 전자 디바이스 (100) 는 전자 디바이스 (100) 에 저장된 복수의 미리 정해진 키워드들에 더하여, 사용자 (120) 에 의해 입력된 하나 이상의 샘플 사운드들에 응답하여 사용자 정의된 키워드를 지정하기 위한 기능 또는 애플리케이션으로 구성될 수도 있다. 사용자 정의된 키워드를 지정하기 위하여, 전자 디바이스 (100) 는 사용자 (120) 로부터의 사용자 정의된 키워드를 나타내는 하나 이상의 샘플 사운드들을 수신하도록 사용자 인터페이스를 제공할 수도 있다. 예를 들어, 메시지 "등록 모드 ... 키워드를 5번 말하세요 (REGISTERING MODE … SPEAK KEYWORD 5 TIMES)" 는 사용자 (120) 로부터의 사용자 정의된 키워드를 나타내는 샘플 사운드들을 수신하도록 전자 디바이스 (100) 의 디스플레이 스크린 (110) 상에 디스플레이될 수도 있다. 사용자 정의된 키워드에 대한 5 개의 발언들이 예시된 실시형태들에서 요청되고 있지만, 사용자 정의된 키워드에 대한 발언들의 수는 복수의 팩터들, 이를 테면, 사용자의 편의성, 성능 요건 등에 의존하여 변할 수도 있다. 예를 들어, 사용자 정의된 키워드에 대한 발언들의 수는 3 번 내지 5 번으로서 결정될 수도 있다.
사용자 정의된 키워드를 나타내는 수신된 샘플 사운드들에 기초하여, 전자 디바이스 (100) 는 도 8 을 참조하여 아래 자세하게 설명될 바와 같이, 사용자 정의된 키워드를 검출하기 위한 키워드 모델을 생성할 수도 있다. 생성된 키워드 모델은 전자 디바이스 (100) 에 저장되어, 전자 디바이스 (100) 에서 음성 활성화 유닛 (도시 생략) 에 제공될 수도 있다. 음성 활성화 유닛은 전자 디바이스 (100) 로의 입력 사운드에 있어서 특정 사용자의 음성 또는 특정 키워드들 (예를 들어, 사용자 정의된 키워드 또는 미리 정해진 키워드) 를 검출하도록 구성되는 전자 디바이스 (100) 에서의 임의의 적절한 프로세싱 유닛일 수도 있다. 일 실시형태에서, 음성 활성화 유닛은 키워드 인식을 위하여 생성된 키워드 모델에 액세스할 수도 있다. 사용자에 의해 발음된 키워드를 인식하는데 있어서, 음성 활성화 유닛은 미리 정해진 키워드들 뿐만 아니라 사용자 정의된 키워드들에 대한 키워드 모델들 중에서 최상의 매치를 탐색할 수도 있다.
일 실시형태에 따르면, 전자 디바이스 (100) 는 사용자 정의된 키워드가 연관되어지는 기능 또는 애플리케이션에 관련하여, 사용자 (120) 로부터의 입력을 수신하기 위해 사용자 인터페이스를 제공할 수도 있다. 예를 들어, 사용자 정의된 키워드를 나타내는 샘플 사운드가 사용자 (120) 로부터 수신된 후에, 전자 디바이스 (100) 는 사용자 (120) 로부터 기능 또는 애플리케이션을 선택하기 위한 입력을 수신할 수도 있고, 선택된 기능 또는 애플리케이션에 사용자 정의된 키워드를 할당할 수도 있다.
도 2 는 본 개시물의 일 실시형태에 따라, 사용자 정의된 키워드를 나타내는 하나 이상의 샘플 사운드들 (210) 및 하나 이상의 잡음 유형들에 기초하여 하나 이상의 믹싱된 샘플 사운드들 (220) 을 생성하기 위한 방법의 다이어그램 (200) 을 예시한다. 도 1 을 참조하여 위에 설명된 바와 같이, 사용자 정의된 키워드를 지정하기 위하여, 전자 디바이스 (100) 는 사용자 (120) 로부터 사용자 정의된 키워드를 나타내는 샘플 사운드들 (210) 을 수신할 수도 있다. 샘플 사운드들 (210) 을 수신시, 전자 디바이스 (100) 는 샘플 사운드들 (210) 과 연관된 사용자 정의된 키워드에 대한 키워드 모델을 생성하기 위하여 이용될 수도 있는 샘플 사운드들의 수를 증가시키기 위해 샘플 사운드들 (210) 에 적어도 하나의 잡음 유형을 추가하는 것에 의해 믹싱된 샘플 사운드들 (220) 을 생성할 수도 있다. 예를 들어, 차량 잡음 (230) 이 샘플 사운드들 (210) 각각에 추가되어, 하나 이상의 차량 잡음 내장된 샘플 사운드들 (250) 이 생성될 수도 있다. 이와 유사하게, 웅성거리는 (babble) 잡음 (240) 이 샘플 사운드들 (210) 각각에 추가되어, 하나 이상의 웅성거리는 잡음이 내장된 샘플 사운드들 (260) 이 생성될 수도 있다. 일 실시형태에서, 임의의 적절한 잡음 유형, 이를 테면, 차량 잡음, 웅성거리는 잡음, 거리 잡음, 바람 잡음 등 또는 이들의 조합이 샘플 사운드들 (210) 에 추가되어, 임의의 적절한 수의 잡음 내장된 샘플 사운드들이 생성될 수도 있다. 아래의 도 8 을 참조하여 설명될 바와 같이, 샘플 사운드들 (210) 및 잡음 내장된 샘플 사운드들 (250 및 260) 을 포함하는 실질적으로 잡음이 없는 환경과 잡음이 있는 환경을 포함하는 여러 사운드 환경들에서, 믹싱된 샘플 사운드들 (220) 은 샘플 사운드들 (210) 과 연관된 사용자 정의된 키워드를 검출하는데 사용될 수도 있다.
일부 실시형태들에서, 믹싱된 샘플 사운드들 (220) 은 샘플 사운드들 (210) 의 하나 이상의 중복하는 샘플 사운드들 (270) 을 포함할 수도 있다. 중복하는 샘플 사운드들 (270) 을 믹싱된 샘플 사운드들 (220) 에 추가하는 것은 샘플 사운드들 (210) 의 수를 증가시켜, 보다 큰 수의 샘플 사운드들 (210) 을 제공할 수도 있다. 믹싱된 샘플 사운드들 (220) 에서의 보다 큰 수의 샘플 사운드들 (210) 은 샘플 사운드들 (210) 의 수와, 잡음 내장된 샘플 사운드들 (250 및 260) 의 수의 비율을 밸런싱하여 밸런싱된 검출 성능을 제공할 수도 있다. 예를 들어, 잡음 내장된 샘플 사운들의 수가 샘플 사운드들 (210) 의 수보다 더 크다면, 샘플 사운드들 (210) 과 연관된 사용자 정의된 키워드가 잡음이 없거나 또는 실질적으로 잡음이 없는 환경에서 정확하게 검출되지 못할 수도 있다. 일 실시형태에서, 믹싱된 샘플 사운드들 (220) 은 임의의 적절한 수의 중복하는 샘플 사운드들 (270) 을 포함할 수도 있다.
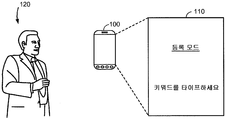
도 3 은 본 개시물의 일 실시형태에 따라, 사용자 정의된 키워드에 대한 텍스트로부터 사용자 정의된 키워드를 검출하는데 있어 이용하기 위한 키워드 모델을 생성하도록 구성되는 전자 디바이스 (100) 를 예시한다. 사용자 정의된 키워드를 지정하기 위하여, 전자 디바이스 (100) 는 사용자 (120) 로부터 사용자 정의된 키워드에 대한 텍스트를 수신하기 위해 사용자 인터페이스를 제공할 수도 있다. 예를 들어, 메시지 "등록 모드 ... 키워드를 타이프하세요 (REGISTERING MODE … TYPE KEYWORD)" 는 사용자 (120) 로부터의 사용자 정의된 키워드에 대한 텍스트 (예를 들어, 하나 이상의 워드들) 를 수신하기 위해 전자 디바이스 (100) 의 디스플레이 스크린 (110) 상에 디스플레이될 수도 있다.
사용자 정의된 키워드에 대한 수신된 텍스트에 기초하여, 전자 디바이스 (100) 는 사용자 정의된 키워드에 대한 텍스트를 사용자 정의된 키워드를 나타내는 서브워드들의 시퀀스로 변환할 수도 있다. 본원에 사용된 용어 "서브워드" 또는 "서브워드 유닛" 은 기본 사운드 유닛, 이를 테면, 단음, 음소, 3중 음소 (triphone), 음절 등을 지칭할 수도 있다. 키워드, 이를 테면, 사용자 정의된 키워드 또는 미리 정해진 키워드는 하나 이상의 서브워드들 또는 서브워드 유닛들의 조합으로서 표현될 수도 있다. 전자 디바이스 (100) 는 그 후, 도 8 을 참조하여 보다 자세하게 설명될 바와 같이, 사용자 정의된 키워드를 검출하는데 이용하기 위하여 사용자 정의된 키워드를 나타내는 사운드 데이터로부터 키워드 모델을 생성할 수도 있다. 일 실시형태에서, 전자 디바이스 (100) 는 또한 도 1 을 참조하여 위에 설명된 바와 같이 사용자 (120) 로부터 사용자 정의된 키워드를 나타내는 하나 이상의 샘플 사운드들을 수신하도록 사용자 인터페이스를 제공할 수도 있다. 이 경우, 전자 디바이스 (100) 는 사용자 정의된 키워드를 나타내는 사운드 데이터, 및 사용자 정의된 키워드를 나타내는 수신된 샘플 사운드들에 기초하여 사용자 정의된 키워드를 검출하기 위한 키워드 모델을 생성할 수도 있다.
도 4 는 본 개시물의 일 실시형태에 따라, 사용자 정의된 키워드를 검출하기 위하여 키워드 모델을 생성하는데 사용될 수도 있는 서브워드 모델을 조정하도록 구성되는 전자 디바이스 (100) 를 예시한다. 전자 디바이스 (100) 는 초기에, 적어도 하나의 서브워드 모델을 저장할 수도 있다. 용어, "서브워드 모델" 은 그래픽 모델, 이를 테면, HMM (hidden Markov model), SMM (semi-Markov model), 또는 이들의 조합 하에서 생성되고 업데이트될 수 있는 복수의 서브워드들 또는 서브워드 유닛들의 음향 피처를 표현하거나 나타내는 음향 모델을 지칭할 수도 있다.
전자 디바이스 (100) 는 전자 디바이스 (100) 에 미리 저장되고/되거나 외부 서버 또는 디바이스 (도시 생략) 로부터 다운로딩되는 하나 이상의 서브워드 모델들을 초기에 포함할 수도 있다. 서브워드 모델들은 스피치 코퍼스로 또한 지칭될 수도 있는 스피치 데이터베이스에 기초하여 생성될 수도 있다. 스피치 데이터베이스는 많은 수의 샘플 사운드 데이터 (예를 들어, 수천개 이상의 스피치 샘플들) 및/또는 텍스트를 포함할 수도 있다. 서브워드 모델들은 샘플 사운드 데이터로부터 복수의 음향 피처들을 추출하는 것에 의해 많은 수의 샘플 사운드 데이터로부터 생성될 수도 있고, 사용자 정의된 키워드에 대한 키워드 모델은 사용자로부터의 사용자 정의된 키워드를 나타내는 하나 이상의 서브워드 모델들 및 샘플 사운드들에 기초하여 생성될 수도 있다. 따라서 생성된 키워드 모델은 사용자로부터의 사용자 정의된 키워드를 나타내는 복수의 입력 샘플 사운드들이 비교적 작을 수도 있더라도 (예를 들어, 5 개), 높은 정도의 정확도로 사용자 정의된 키워드의 검출을 허용할 수도 있다.
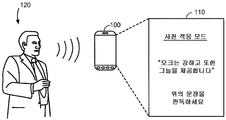
일 실시형태에서, 전자 디바이스 (100) 에 초기에 저장된 서브워드 모델들은 사용자 독립적일 수도 있고, 사용자의 특정 음성 피처들을 반영하지 못할 수도 있다. 이 경우에, 전자 디바이스 (100) 는 사용자의 입력 사운드에 기초하여 서브워드 모델들을 조정하도록 사전 적응을 위한 기능 또는 애플리케이션으로 구성될 수도 있다. 서브워드 모델들의 사전 적응을 위한 기능은 사용자 정의된 키워드를 검출하기 위하여 키워드 모델을 생성하기 이전에 수행될 수도 있다. 추가적으로 또는 대안으로서, 사전 적응을 위한 기능은 사용자 정의된 키워드를 검출하기 위한 키워드 모델이 생성된 후에 수행될 수도 있다.
사전 적응을 위하여, 전자 디바이스 (100) 는 사용자 (120) 로부터 미리 정해진 문장 (예를 들어, 구절) 을 나타내는 입력 사운드를 수신하도록 사용자 인터페이스를 제공할 수도 있다. 미리 정해진 문장은 음소가 언어에 나타날 수도 있을 때와 동일한 또는 유사한 빈도에서 특정 음소를 이용할 수도 있는 표음적으로 밸런싱되는 문장들 (예를 들어, Harvard 문장들) 중 적어도 하나일 수도 있다. 예를 들어, 표음적으로 밸런싱되는 문장들은 문장들, 이를 테면, "오크는 강하고 또한 그늘을 제공한다", "개와 고양이는 서로 싫어한다", "파이프는 견고하면서 새로워졌다", "상자를 열고 유리는 깨지 마세요" 등을 포함할 수도 있다. 전자 디바이스 (100) 는 미리 정해진 문장들 및 이들의 서브워드들의 시퀀스들 또는 네트워크들을 저장할 수도 있다.
예시된 실시형태에서, 메시지 "사전 적응 모드 ... 오크는 강하고 또한 그늘을 제공한다 ... 위의 문장을 판독하세요 (PRE-ADAPTATION MODE … OAK IS STRONG AND ALSO GIVES SHADE … READ THE ABOVE SENSTENCE)" 는 사용자 (120) 로부터 미리 정해진 문장 "오크는 강하고 또한 그늘을 제공한다"를 나타내는 입력 사운드를 수신하도록 전자 디바이스 (100) 의 디스플레이 스크린 (110) 상에 디스플레이될 수도 있다. 수신된 입력 사운드에 기초하여, 전자 디바이스 (100) 는 도 8 을 참조로 아래 설명될 바와 같은 방식으로 서브워드 모델들을 조정할 수도 있다. 예를 들어, 전자 디바이스 (100) 는 수신된 입력 사운드로부터 음향 피처들을 추출할 수도 있고, 추출된 음향 피처들 및 미리 정해진 문장에 대한 서브워드들의 저장된 시퀀스 또는 네트워크에 기초하여 서브워드 모델에서 음향 파라미터들을 조정할 수도 있다. 일 실시형태에서, 전자 디바이스 (100) 는 수신된 입력 사운드로부터 서브워드 유닛들의 시퀀스를 인식하고, 서브워드들의 인식된 시퀀스를 이용하여 미리 정해진 문장에 대한 서브워드들의 저장된 시퀀스 또는 네트워크를 업데이트할 수도 있다.
도 5 는 본 개시물의 일 실시형태에 따라, 입력 사운드에 기초하여 사용자 정의된 키워드를 검출하기 위하여 임계 스코어를 조정하도록 구성되는 전자 디바이스 (100) 를 예시한다. 본원에 이용된 용어 "매칭 스코어"는 입력 사운드와 임의의 키워드들 (예를 들어, 사용자 정의된 키워드 또는 미리 정해진 키워드) 사이의 유사성의 정도를 나타내는 값을 지칭할 수도 있다. 또한, 용어 "임계 스코어" 는 입력 사운드에서 키워드를 검출함에 있어서 원하는 정확도를 보장하도록 매칭 스코어에 대한 임계값을 지칭할 수도 있다. 예를 들어, 임계 스코어가 너무 높으면, 전자 디바이스 (100) 는 키워드를 포함하는 입력 사운드로부터 키워드를 검출하지 못할 수도 있다. 반면, 임계 스코어가 너무 낮으면, 전자 디바이스 (100) 는 키워드를 포함하지 않은 입력 사운드에서 키워드를 부정확하게 검출할 수도 있다. 이와 같이, 사용자 정의된 키워드에 대한 임계 스코어는 사용자 정의된 키워드에 대한 키워드 모델이 생성된 후에 원하는 검출 정확도를 보장하도록 업데이트될 수도 있다.
일 실시형태에서, 전자 디바이스 (100) 는 입력 사운드에서의 사용자 정의된 키워드를 검출함에 있어서 정확도를 추가로 개선하기 위해 임계 스코어를 조정하기 위한 기능 또는 애플리케이션으로 구성될 수도 있다. 임계 스코어를 조정하기 위한 기능은 사용자 정의된 키워드에 대한 키워드 모델이 생성되고 키워드 모델에 대한 임계 스코어가 결정된 후에 활성화될 수도 있다. 임계 스코어를 조정하기 위하여, 전자 디바이스 (100) 는 사용자 (120)로부터의 사용자 정의된 키워드를 나타내는 테스트 입력 사운드를 수신하도록 사용자 인터페이스를 제공할 수도 있다. 예를 들어, 메시지 "테스트 모드 ... 키워드를 말하세요 (TEST MODE … SPEAK KEYWORD)" 는 사용자 (120) 로부터의 사용자 정의된 키워드를 나타내는 테스트 입력 사운드를 수신하도록 전자 디바이스 (100) 의 디스플레이 스크린 (110) 상에 디스플레이될 수도 있다.
사용자 정의된 키워드를 나타내는 수신된 테스트 입력 사운드로부터, 전자 디바이스 (100) 는 사용자 정의된 키워드에 대한 키워드 모델에 기초하여 테스트 입력 사운드의 매칭 스코어를 계산할 수도 있다. 테스트 입력 사운드의 계산된 매칭 스코어에 기초하여, 전자 디바이스 (100) 는 사용자 정의된 키워드에 대한 임계 스코어를 조정할 수도 있다. 예를 들어, 계산된 매칭 스코어가 임계 스코어보다 더 낮을 때, 전자 디바이스 (100) 는 임계 스코어를 감소시킬 수도 있다.
도 6 은 본 개시물의 일 실시형태에 따라, 입력 사운드로부터 키워드를 검출하는 것에 응답하여 전자 디바이스 (100) 에서의 음성 지원 애플리케이션 (600) 을 활성화하는 것을 예시한다. 초기에, 전자 디바이스 (100) 는 미리 정해진 키워드들 및/또는 사용자 정의된 키워드들에 대한 키워드 모델들을 저장할 수도 있다. 음성 지원 애플리케이션 (600) 을 활성화하기 위해, 사용자 (120) 는 전자 디바이스 (100) 에 의해 수신되는 키워드 (예를 들어, 사용자 정의된 키워드 또는 미리 정해진 키워드) 를 말할 수도 있다. 전자 디바이스 (100) 가 키워드를 검출할 때, 음성 지원 애플리케이션 (600) 은 활성화될 수 있고 메시지, 이를 테면, "무엇을 도와 드릴까요? (MAY I HELP YOU?)" 를 디스플레이 스크린 상에 또는 전자 디바이스 (100) 의 스피커 유닛을 통하여 출력할 수도 있다.
이에 응답하여, 사용자 (120) 는 다른 음성 커맨드들을 말하는 것에 의해 음성 지원 애플리케이션 (600) 을 통하여 전자 디바이스 (100) 의 여러 기능들을 활성화할 수도 있다. 예를 들어, 사용자 (120) 는 음성 커맨드 "플레이 뮤직" 을 말하는 것에 의해 뮤직 플레이어 (610) 를 활성화할 수도 있다. 예시된 실시형태들이 키워드를 검출하는 것에 응답하여 음성 지원 애플리케이션 (600) 을 활성화하는 것을 예시하고 있지만, 다른 애플리케이션 또는 기능이 연관된 키워드를 검출하는 것에 응답하여 활성화될 수도 있다.
도 7 은 본 개시물의 일 실시형태에 따라, 사용자 정의된 키워드를 포함하는 입력 사운드에 기초하여 사용자를 인식하도록 구성되는 전자 디바이스 (100) 를 예시한다. 사용자 정의된 키워드에 대한 키워드 모델은 사용자를 인식하는데 이용될 수도 있는 사용자 특정 음향 피처들을 통합할 수도 있다. 일 실시형태에서, 전자 디바이스 (100) 는 사용자 정의된 키워드에 대한 키워드 모델에 포함된 이러한 사용자 정의된 음향 피처들을 이용하여 사용자 검증을 위한 기능 또는 애플리케이션으로 구성될 수도 있다. 추가적으로, 전자 디바이스 (100) 는 사용자 정의된 키워드에 대한 키워드 모델에 더하여, 사용자의 스피치를 검증하는데 이용되는 사용자 검증 모델을 포함할 수도 있다.
사용자 검증을 위하여, 전자 디바이스 (100) 는 사용자 (120) 로부터 사용자 정의된 키워드를 나타내는 입력 사운드를 수신하기 위한 사용자 인터페이스를 제공할 수도 있다. 예를 들어, 메시지 "사용자 검증 ... 키워드를 말하세요 (USER VERIFICATION … SPEAK KEYWORD)" 는 사용자 (120) 로부터의 사용자 정의된 키워드를 나타내는 테스트 입력 사운드를 수신하도록 전자 디바이스 (100) 의 디스플레이 스크린 (110) 상에 디스플레이될 수도 있다. 입력 사운드로부터, 전자 디바이스 (100) 는 사용자 정의된 키워드에 대한 키워드 모델에 기초하여 사용자 정의된 키워드를 검출하고 입력 사운드의 매칭 스코어를 계산할 수도 있다. 매칭 스코어가 키워드 검출 임계값보다 더 높으면, 전자 디바이스 (100) 는 사용자 정의된 키워드를 포함하는 것으로서 입력 사운드를 결정할 수도 있다. 전자 디바이스 (100) 는 그 후, 사용자 검증 모델에 기초하여 입력 사운드에 대한 사용자 검증 프로세스를 수행할 수도 있고 입력 사운드의 사용자 검증 스코어를 계산할 수도 있다. 사용자 검증 스코어가 사용자 검증 임계값보다 더 높으면, 전자 디바이스 (100) 는 등록된 사용자의 스피치를 포함하는 것으로서 입력 사운드를 결정할 수도 있다. 대안으로서, 전자 디바이스 (100) 는 키워드 검출 프로세스를 결정하기 전에 사용자 검증 프로세스를 수행할 수도 있다. 일부 실시형태들에서, 전자 디바이스 (100) 는 사용자 정의된 키워드를 검출하고 등록된 사용자의 스피치를 검증하기 위한 하나의 모델에 기초하여 키워드 검출 프로세스 및 사용자 검증 프로세스를 수행할 수도 있다.
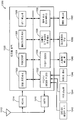
도 8 은 본 개시물의 일 실시형태에 따라, 사용자 정의된 키워드에 대한 키워드 모델을 생성하고, 키워드 모델에 기초하여 입력 사운드 스트림에서 사용자 정의된 키워드를 검출하도록 구성되는 전자 디바이스 (100) 의 블록도를 예시한다. 전자 디바이스 (100) 는 사운드 센서 (800), 프로세서 (810), I/O (input/output) 유닛 (830), 통신 유닛 (832) 및 저장 유닛 (840) 을 포함할 수도 있다. 프로세서 (810) 는 믹싱된 사운드 생성 유닛 (828), 서브워드 인식 유닛 (812), 사전 적응 유닛 (814), 사용자 정의된 키워드 모델 생성 유닛 (816), 스피치 검출기 (822), 음성 활성화 유닛 (824) 및 음성 지원 유닛 (826) 을 포함할 수도 있다. I/O 유닛 (830) 은 디스플레이 스크린 (110) 을 포함할 수도 있다. 디스플레이 스크린 (110) 은 사용자로부터의 터치 입력을 수신하도록 구성되는 터치 디스플레이 스크린일 수도 있다.
사운드 센서 (800) 는 사용자로부터의 입력 사운드 스트림을 수신하도록 구성될 수도 있다. 본원에 이용된 용어 "사운드 스트림" 은 하나 이상의 사운드 신호들 또는 사운드 데이터의 시퀀스를 지칭할 수도 있다. 사운드 센서 (800) 는 전자 디바이스 (100) 에 대한 사운드 입력을 수신, 캡처, 감지, 및/또는 검출하는데 이용될 수 있는 하나 이상의 마이크로폰들 또는 임의의 다른 유형들의 사운드 센서들을 포함할 수도 있다. 추가로, 사운드 센서 (800) 는 이러한 기능들을 수행하기 위한 임의의 적절한 소프트웨어 및/또는 하드웨어를 채용할 수도 있다. 사용자의 수신된 입력 사운드 스트림은 저장 유닛 (840) 에 저장될 수도 있다. 사운드 센서 (800) 는 사용자의 그 수신된 입력 사운드 스트림을 프로세싱을 위하여 프로세서 (810) 에 제공할 수도 있다.
일 실시형태에서, 사운드 센서 (800) 는 사용자로부터 사용자 정의된 키워드를 나타내는 하나 이상의 샘플 사운드들을 포함하는 입력 사운드 스트림을 수신할 수도 있다. 입력 사운드 스트림을 수신시, 사운드 센서 (800) 는 임의의 적절한 엔드포인트 검출 알고리즘들을 이용하여, 각각의 샘플 사운드들의 시작점 및 종점 또는 입력 사운드 스트림에서의 분리된 발음들을 검출하는 것에 의해 입력 사운드 스트림으로부터 샘플 사운드들의 각각을 검출할 수도 있다. 검출된 샘플 사운드들은 추출되어, 저장 유닛 (840) 에 저장될 수도 있다. 추출된 샘플 사운드들은 믹싱된 사운드 생성 유닛 (828) 및/또는 서브워드 인식 유닛 (812) 에 제공될 수도 있다. 대안으로서, 사운드 센서 (800) 는 믹싱된 사운드 생성 유닛 (828) 에 입력 사운드 스트림을 제공할 수도 있고, 믹싱된 사운드 생성 유닛 (828) 은 입력 사운드 스트림에 대한 적어도 하나의 유형의 잡음을 추가하는 것에 의해 적어도 하나의 믹싱된 사운드 스트림을 생성할 수도 있다. 서브워드 인식 유닛 (812) 은 믹싱된 사운드 생성 유닛 (828) 으로부터 믹싱된 사운드 스트림을 수신할 수도 있고, 믹싱된 사운드 스트림의 하나 이상의 유형들의 잡음과 함께 매립된 샘플 사운드들의 각각을 검출하고 추출할 수도 있다.
프로세서 (810) 에서의 믹싱된 사운드 생성 유닛 (828) 은 사운드 센서 (800) 로부터의 추출된 샘플 사운드들에 기초하여, 하나 이상의 믹싱된 샘플 사운드들을 생성하도록 구성될 수도 있다. 예를 들어, 믹싱된 샘플 사운드들은 추출된 샘플 사운드들에 적어도 하나의 유형의 잡음을 추가하는 것에 의해 생성될 수도 있다. 생성된 믹싱된 샘플 사운드들은 저장 유닛 (840) 에 저장될 수도 있다. 사운드 센서 (800) 로부터의 생성된 믹싱된 샘플 사운드들 및/또는 추출된 샘플 사운드들은 서브워드 인식 유닛 (812) 에 제공될 수도 있다. 일부 실시형태들에서, 믹싱된 샘플 사운드들은 또한, 추출된 샘플 사운드들의 하나 이상의 중복하는 사운드들을 포함할 수도 있다.
저장 유닛 (840) 은 사운드 센서 (800), 프로세서 (810), I/O 유닛 (830), 및 통신 유닛 (832) 을 동작시키기 위한 데이터 및 명령들, 그리고 사운드 센서 (800) 에 의해 수신된 입력 사운드 스트림을 저장하도록 구성될 수도 있다. 저장 유닛 (840) 은 또한, 딕셔너리 워드들의 발음 데이터를 포함하는 발음 딕셔너리 데이터베이스를 저장할 수도 있다. 발음 딕셔너리 데이터베이스는 저장 유닛 (840) 에 미리 저장될 수도 있고/있거나 통신 유닛 (832) 을 통하여 외부 서버 또는 디바이스 (도시 생략) 로부터 다운로딩될 수도 있다. 저장 유닛 (840) 은 임의의 적절한 저장부 또는 메모리 디바이스들, 이를 테면, RAM (Random Access Memory), ROM (Read-Only Memory), EEPROM (Electrically Erasable Programmable Read-Only Memory), 플래시 메모리 또는 SSD (solid state drive) 를 이용하여 구현될 수도 있다.
저장 유닛 (840) 은 또한, 적어도 하나의 서브워드 모델을 저장할 수도 있다. 서브워드 모델은 발음 딕셔너리 데이터베이스는 저장 유닛 (840) 에 미리 저장되고/되거나 통신 유닛 (832) 을 통하여 외부 서버 또는 디바이스 (도시 생략) 로부터 다운로딩되는 적어도 하나의 서브워드 모델을 포함할 수도 있다. 추가적으로, 서브워드 모델은 사전 적응 유닛 (814) 에 의해 초기에 저장된 서브워드 모델로부터 조정되었던 적어도 하나의 적응된 서브워드 모델을 포함할 수도 있다.
일부 실시형태들에서, 서브워드 모델은 서브워드 모델에 의해 표현되는 서브워드들의 유형에 따라 단음계 모델, 음소계 모델, 3중 음소계 모델, 음절계 모델 등일 수도 있고, 각각의 서브워드 유닛에 대한 모델 파라미터들, 및 서브워드 유닛들의 리스트를 포함할 수도 있다. 모델 파라미터들은 서브워드들의 스피치 데이터로부터 추출되는 피처 벡터들에 기초하여 획득 또는 추정될 수도 있다. 피처 벡터들은 MFCC (mel frequency cepstral coefficients), 델타 MFCC (cepstrum difference coefficients), LPC (linear predictive coding) 계수들, LSP (line spectral pair) 계수들 등 중 적어도 하나를 포함할 수도 있다. 서브워드 모델은 또한 단일 서브워드 유닛으로 병합될 수 있는 둘 이상의 서브워드 유닛들 (예를 들어, 서브워드들이 유사한 것으로 식별되면 병합된 서브워드 유닛들 중 하나) 을 나타내는 서브워드 타잉 (tying) 정보를 포함할 수도 있다. 서브워드 모델이 사전 적응 유닛 (814) 에 의해 조정될 때, 저장 유닛 (840) 은 서브워드 모델에 더하여 조정된 서브워드 모델을 저장할 수도 있다.
저장 유닛 (840) 은 또한 사용자 정의된 키워드들을 검출하기 위하여 미리 정해진 키워드들 및 하나 이상의 키워드 모델들을 검출하기 위한 하나 이상의 키워드 모델들을 저장할 수도 있다. 미리 정해진 키워드들을 검출하기 위한 키워드 모델들은 저장 유닛 (840) 에 미리 저장되거나 통신 유닛 (832) 을 통하여 외부 서버 또는 디바이스 (도시 생략) 로부터 다운로딩될 수도 있다. 일 실시형태에서, 키워드 모델은 사용자 정의된 키워드 모델 생성 유닛 (816) 에 의해 사용자 정의된 키워드를 나타내는 하나 이상의 샘플 사운드들로부터 결정될 수 있는 복수의 부분들 (즉, 복수의 서브워드들 또는 서브워드 유닛들) 을 포함하는 서브워드들의 시퀀스를 포함할 수도 있다. 키워드는 또한, 서브워드들의 시퀀스에서 복수의 서브워드들의 각각과 연관된 모델 파라미터들, 및 키워드를 검출하기 위하여 임계 스코어를 포함할 수도 있다.
다른 실시형태에서, 키워드 모델은 서브워드 네트워크를 포함할 수도 있다. 서브워드 네트워크는 복수의 노드들, 및 복수의 노드들 중 적어도 두개의 노드들을 접속할 수 있는 복수의 라인들을 포함할 수도 있다. 키워드 모델은 또한, 서브워드 네트워크의 노드에 대응하는, 적어도 하나의 그래픽 모델, 이를 테면, GMM (Gaussian mixture model), HMM (hidden Markov model), SMM (semi-Markov model) 등을 포함할 수도 있다. 그래픽 모델은 상태들의 수, 및 파라미터들, 이를 테면, 트랜지션 확률, 상태 출력 확률 등을 포함할 수도 있다.
저장 유닛 (840) 은 또한, 샘플 사운드들, 및 샘플 사운드들에 대한 검출 라벨들을 포함하는 검출 이력 데이터베이스를 저장할 수도 있다. 예를 들어, 샘플 사운드에 대한 검출 라벨은 샘플 사운드가 키워드 스피치 또는 비키워드 스피치로서 정확하게 검출되었는지의 여부를 나타낼 수도 있다. 이와 유사한 방식으로, 샘플 사운드에 대한 검출 라벨은 샘플 사운드가 키워드 스피치 또는 비키워드 스피치로서 부정확하게 검출되었는지의 여부를 나타낼 수도 있다. 검출 라벨들은 키워드 검출 프로세스 동안에 결정되거나 또는 I/O 유닛 (830) 을 통하여 사용자에 의해 제공될 수도 있다. 검출 이력 데이터베이스는 사용자 정의된 키워드에 대한 키워드 모델에 대한 결정론적인 트레이닝에 이용될 수도 있다. 저장 유닛 (840) 은 하나 이상의 표음적으로 밸런싱되는 문장들 (예를 들어, 하바드 문장들), 및 이들의 대응하는 서브워드들의 시퀀스들 또는 네트워크들을 저장할 수도 있다.
프로세서 (810) 에서의 서브워드 인식 유닛 (812) 은 저장 유닛 (840) 에 저장된 적어도 하나의 서브워드 모델을 이용하여 하나 이상의 샘플 사운드들의 서브워드 인식을 수행하도록 구성될 수도 있다. 일 실시형태에서, 서브워드 인식 유닛 (812) 은 사운드 센서 (800) 로부터의 하나 이상의 샘플 사운드들을 포함하는 입력 사운드 스트림을 수신할 수도 있고, 임의의 적절한 엔드포인트 검출 알고리즘들을 이용하여 입력 사운드 스트림으로부터 샘플 사운드들 각각을 추출할 수도 있다. 대안으로서, 적어도 하나의 믹싱된 사운드 스트림은 임의의 적절한 엔드포인트 검출 알고리즘들을 이용하여 적어도 하나의 믹싱된 사운드 스트림으로부터, 하나 이상의 잡음 유형들을 포함할 수도 있는 샘플 사운드들 각각을 추출하도록 믹싱된 사운드 생성 유닛 (828) 으로부터 수신될 수도 있다. 다른 실시형태에서, 서브워드 인식 유닛 (812) 은 입력 사운드 스트림으로부터 샘플 사운드들을 추출할 수도 있는 사운드 센서 (800) 로부터 하나 이상의 샘플 사운드들을 수신할 수도 있다. 대안으로서, 하나 이상의 믹싱된 샘플 사운드들은 믹싱된 사운드 생성 유닛 (828) 으로부터 수신될 수도 있다.
수신되거나 또는 추출되어진 샘플 사운드들 또는 믹싱된 샘플 사운드들에 대하여, 서브워드 인식 유닛 (812) 은 샘플 사운드들 또는 믹싱된 샘플 사운드들의 각각에 대하여 서브워드 인식을 수행할 수도 있다. 일 실시형태에서, 서브워드 인식 유닛 (812) 은 샘플 사운드들, 또는 믹싱된 샘플 사운드들의 각각에 대한 서브워드들의 시퀀스를 생성하기 위해 샘플 사운드들 또는 믹싱된 샘플 사운드들의 각각에 대하여 마이크로폰 인식을 수행할 수도 있다. 예를 들어, 서브워드 인식 유닛 (812) 은 표 1 에 나타낸 바와 같이, 5 개의 샘플 사운들로부터 서브워드들의 5 개의 시퀀스들을 각각 생성할 수도 있다.
[표 1]

표 1 에서, 각각의 시퀀스에서의 2 개의 서브워드들 사이의 공간은 2 개의 서브워드들을 구별할 수도 있다. 서브워드들의 예시된 시퀀스들에서, 서브워드 유닛 "sil"은 무음 (silence), 무음 사운드 (silent sound) 또는 사운드의 부재를 나타낼 수도 있다. 생성된 시퀀스들은 사전 적응 유닛 (814) 및 사용자 정의된 키워드 모델 생성 유닛 (816) 중 적어도 하나에 제공될 수도 있다.
일부 실시형태들에서, 서브워드 인식 유닛 (812) 은 서브워드 인식을 수행하는데 있어서 사용자 정의된 키워드에 대한 텍스트와 연관된 발음 정보를 이용할 수도 있다. 예를 들어, 사용자 정의된 키워드에 대한 텍스트가 I/O 유닛 (830) 으로부터 수신될 때, 서브워드 인식 유닛 (812) 은 저장 유닛 (840) 에 저장된 발음 딕셔너리 데이터베이스로부터 사용자 정의된 키워드와 연관된 발음 정보를 취출할 수도 있다. 대안으로서, 서브워드 인식 유닛 (812) 은 사용자 정의된 키워드와 연관된 발음 정보를 취출하기 위해 딕셔너리 워드들의 정보 또는 발음 데이터를 저장하는 외부 서버 또는 디바이스 (도시 생략) 와 통신할 수도 있다. 그 후, 사용자 정의된 키워드에 대한 서브워드들의 각각의 시퀀스는 사용자 정의된 키워드에 대한 텍스트와 연관된 발음 정보를 이용하여 샘플 사운드들 또는 믹싱된 샘플 사운드들 각각에 대하여 결정될 수도 있다.
사전 적응 유닛 (814) 은 미리 정해진 문장을 나타내는 적어도 하나의 샘플 사운드에 기초하여 저장 유닛 (840) 에 저장된 적어도 하나의 서브워드 모델을 조정하도록 구성될 수도 있다. 미리 정해진 문장은 음소가 언어에 나타날 수도 있을 때와 동일한 또는 유사한 빈도에서 특정 음소를 이용할 수도 있는 표음적으로 밸런싱되는 문장들 (예를 들어, Harvard 문장들) 중 적어도 하나일 수도 있다. 서브워드 모델의 사전 적응을 위하여 사운드 센서 (800) 는 미리 정해진 문장을 나타내는 적어도 하나의 샘플 사운드를 포함하는 입력 사운드 스트림을 수신할 수도 있다. 예를 들어, 사용자는 디스플레이 스크린 (110) 상에 디스플레이될 수도 있는 미리 정해진 문장을 판독하도록 프롬프트될 수도 있다. 사용자가 미리 정해진 문장을 판독할 때, 사전 적응 유닛 (814) 은 사용자에 의해 판독된 미리 정해진 문장을 포함하는 입력 사운드 스트림을 수신할 수도 있고 입력 사운드 스트림으로부터 음향 피처들을 추출할 수도 있다. 추출된 음향 피처들로부터, 사전 적응 유닛 (814) 은 저장 유닛 (840) 으로부터 서브워드 모델을 조정할 수도 있고, 저장 유닛 (840) 에 조정된 서브워드 모델을 저장할 수도 있다. 일 실시형태에서, 사전 적응 유닛 (814) 은 저장 유닛 (840) 에 저장된 미리 정해진 문장에 대한 추출된 음향 피처들 및 서브워드들의 시퀀스에 기초하여 서브워드 모델의 모델 파라미터들을 조정할 수도 있다.
일부 실시형태들에서, 사용자 정의된 키워드에 대한 키워드 모델이 사용자 정의된 키워드를 생성하는데 있어 이용된 서브워드 모델의 사전 적응 없이 생성되었을 때, 사전 적응 유닛 (814) 은 조정된 서브워드 모델에 기초하여 사용자 정의된 키워드에 대한 새로운 키워드 모델을 생성할 수도 있다. 예를 들어, 사전 적응 유닛 (814) 은 저장 유닛 (840) 으로부터 사용자 정의된 키워드를 나타내는 하나 이상의 샘플 사운드들을 취출하고 조정된 서브워드 모델을 이용하여 샘플 사운드들에 대한 서브워드 인식을 수행하기 위하여 서브워드 인식 유닛 (812) 에 신호를 송신할 수도 있다. 서브워드 인식 유닛 (812) 이 샘플 사운드들에 대한 서브워드들의 시퀀스를 생성하면, 사전 적응 유닛 (814) 은 사용자 정의된 키워드 모델 동작 유닛 (816) 에게, 서브워드 인식 유닛 (812) 으로부터의 서브워드들의 생성된 시퀀스들을 수신하고 조정된 서브워드 모델을 이용하여 사용자 정의된 키워드에 대한 새로운 키워드 모델을 생성하라고 명령하는 신호를 송신할 수도 있다.
사용자 정의된 키워드 모델 생성 유닛 (816) 은 서브워드 인식 유닛 (812) 으로부터 서브워드들의 생성된 시퀀스들에 기초하여 사용자 정의된 키워드에 대한 키워드 모델을 생성하도록 구성될 수도 있다. 사용자 정의된 키워드 모델 생성 유닛 (816) 은 서브워드 인식 유닛 (812) 으로부터 서브워드들의 시퀀스들을 수신하고, 그 수신된 시퀀스들로부터 서브워드들의 시퀀스를 결정할 수도 있다. 일 실시형태에서, 시퀀스들 각각에 대한 길이는 결정될 수도 있고 가장 긴 길이를 갖는 시퀀스들 중 하나가 서브워드들의 시퀀스로서 선택될 수도 있다. 서브워드들의 각각의 시퀀스의 길이는 각각의 시퀀스에서의 서브워드들의 수일 수도 있다. 예를 들어, 5 개의 시퀀스들 중에서 가장 긴 길이를 갖는 표 1 에서의 문장 1 은 서브워드들의 시퀀스로서 선택될 수도 있다.
추가적으로 또는 대안으로서, 사용자 정의된 키워드 모델 생성 유닛 (816) 은 서브워드들의 시퀀스를 생성하도록 서브워드들의 시퀀스들 중 적어도 2 개로부터 복수의 부분들 (예를 들어, 복수의 서브워드들) 을 결합할 수도 있다. 예를 들어, 서브워드들의 2 개의 시퀀스들이 주어지면, 시퀀스들에서의 하나 이상의 동일한 서브워드들 및 연관된 부분들이 식별될 수도 있다. 추가적으로, 시퀀스들에서 이러한 서브워드들의 부분들 뿐만 아니라 다른 시퀀스에 있지 않은 한 시퀀스에서의 하나 이상의 서브워드들이 식별될 수도 있다. 이 경우에, 동일한 서브워드들은 연관된 부분들에 따라 시퀀싱될 수도 있고, 한 시퀀스에는 있지만 다른 시퀀스에는 없는 하나 이상의 서브워드들은 연관된 부분들에 기초하여 시퀀스 내에 삽입될 수도 있다. 이러한 방식으로, 사용자 정의된 키워드 모델 생성 유닛 (816) 은 시퀀스들에서의 연관된 부분들에 따라 2 개의 시퀀스들로부터 식별된 서브워드들을 결합하는 것에 의해 서브워드들의 시퀀스를 결정할 수도 있다. 또한, 사용자 정의된 키워드 모델 생성 유닛 (816) 이 또한 서브워드들의 임의의 적절한 수의 시퀀스들로부터 서브워드들의 시퀀스를 생성할 수도 있음을 알아야 한다.
일부 실시형태들에서, 서브워드들의 시퀀스가 결정되었다면, 사용자 정의된 키워드 모델 생성 유닛 (816) 은 서브워드들의 시퀀스의 시작 또는 종료에 무음에 대한 서브워드들을 추가하는 것에 의해 서브워드들의 시퀀스를 수정할 수도 있다. 예를 들어, 무음에 대한 서브워드는 서브워드들의 시퀀스의 시작에 존재하지 않을 수도 있고 무음의 서브워드가 서브워드들의 시퀀스의 시작에 추가될 수도 있다. 이와 유사하게, 무음에 대한 서브워드는 서브워드들의 시퀀스의 끝에 존재하지 않을 수도 있고 무음의 서브워드가 서브워드들의 시퀀스의 끝에 추가될 수도 있다.
저장 유닛 (840) 으로부터의 적어도 하나의 서브워드 모델 및 서브워드들의 시퀀스에 기초하여, 사용자 정의된 키워드 모델 생성 유닛 (816) 은 하나 이상의 샘플 사운드들과 연관된 사용자 정의된 키워드에 대한 키워드 모델을 생성할 수도 있다. 이 프로세스에서, 사용자 정의된 키워드 모델 생성 유닛 (816) 은 서브워드 모델로부터 서브워드들의 시퀀스에서 서브워드들 각각과 연관된 모델 파라미터들을 취출할 수도 있다. 그 후, 서브워드들의 시퀀스 및 서브워드들의 결정된 시퀀스에서 서브워드들 각각과 연관된 취출된 모델 파라미터들은 사용자 정의된 키워드에 대한 키워드 모델로서 지정되어 출력될 수도 있다. 일 실시형태에서, 사용자 정의된 키워드 모델 생성 유닛 (816) 은 서브워드들의 시퀀스 및/또는 사용자 정의된 키워드를 나타내는 하나 이상의 샘플 사운드들에 기초하여 저장 유닛 (840) 으로부터 적어도 하나의 서브워드 모델을 조정할 수도 있고 그 조정된 서브워드 모델을 저장 유닛 (840) 에 저장할 수도 있다.
사용자 정의된 키워드 모델 생성 유닛 (816) 은 서브워드 인식 유닛 (812) 으로부터 수신된 서브워드들의 복수의 시퀀스들에 기초하여 서브워드 네트워크를 생성하는 것에 의해 사용자 정의된 키워드에 대한 키워드 모델을 생성할 수도 있다. 일 실시형태에서, 사용자 정의된 키워드 모델 생성 유닛 (816) 은 그래픽 모델, 이를 테면, HMM (hidden Markov model), SMM (semi-Markov model), 또는 이들의 조합 하에서 복수의 노드들, 및 복수의 노드들 중 적어도 두개의 노드들을 연결할 수도 있는 복수의 라인들을 포함하는 단일의 네트워크로 서브워드들의 시퀀스들을 결합하는 것에 의해 서브워드 네트워크를 생성할 수도 있다. 사용자 정의된 키워드 모델 생성 유닛 (816) 은 또한 임의의 적절한 그래프 병합 알고리즘들에 기초하여 단일의 노드 (예를 들어, 유사한 노드들 중 하나) 로 둘 이상의 유사한 노드들을 병합하는 것에 의해 서브워드 네트워크를 프루닝 (예를 들어, 감소) 시킬 수도 있다. 그 후, 서브워드 네트워크에서의 복수의 노드들 및 서브워드 네트워크에서의 노드에 대응하는 적어도 하나의 그래픽 모델, 이를 테면, GMM (Gaussian mixture model), HMM (hidden Markov model) 등은 그 후, 사용자 정의된 키워드에 대한 키워드 모델로서 지정 및 출력될 수도 있다.
일부 실시형태들에서, I/O 유닛 (830) 은 사용자로부터 키워드 모델을 생성하는데 있어 이용하기 위한 사용자 정의된 키워드를 지정하는 텍스트를 수신할 수도 있다. 그 후, 사용자 정의된 키워드에 대한 텍스트는 사용자 정의된 키워드 모델 생성 유닛 (816) 에 제공될 수도 있다. 사용자 정의된 키워드를 지정하는 텍스트를 수신시, 사용자 정의된 키워드 모델 생성 유닛 (816) 은 사용자 정의된 키워드에 대한 텍스트를 사용자 정의된 키워드를 나타내는 서브워드들의 시퀀스로 변환할 수도 있다. 일 실시형태에서, 사용자 정의된 키워드에 대한 서브워드들의 시퀀스는 저장 유닛 (840) 에 저장된 발음 딕셔너리 데이터베이스에 액세스하는 것에 의해 사용자 정의된 키워드에 대한 텍스트와 연관된 발음 정보에 기초하여 결정될 수도 있다. 대안으로서, 사용자 정의된 키워드 모델 생성 유닛 (816) 은 사용자 정의된 키워드에 대한 텍스트와 연관된 발음 정보를 수신하기 위해 디셔너리 워드들의 정보 또는 발음 데이터를 저장하는 외부 서버 또는 디바이스 (도시 생략) 와 통신할 수도 있다. 사용자 정의된 키워드에 대한 텍스트가 발음 딕셔너리 데이터베이스에서의 임의의 딕셔너리 워드들에 매칭하지 않을 때, 사용자 정의된 키워드 모델 생성 유닛 (816) 은 임의의 적절한 언어적 및/또는 발음 규칙에 기초하여 텍스트에 대한 발음들을 결정하는 것에 의해 그리고 발음들에 기초하여 서브워드들의 시퀀스를 결정하는 것에 의해 서브워드들의 시퀀스를 생성할 수도 있다.
사용자 정의된 키워드를 검출하는 정확도를 강화하기 위해, 사용자 정의된 키워드 모델 생성 유닛 (816) 은 사용자 정의된 키워드를 검출하는데 있어 신뢰성 레벨을 나타내는 임계 스코어를 결정할 수도 있다. 초기에, 사용자 정의된 키워드 모델 생성 유닛 (816) 은 사용자 정의된 키워드와 연관된 키워드 모델에 기초하여 사용자로부터 수신된 사용자 정의된 키워드를 나타내는 하나 이상의 샘플 사운드들 각각에 대한 매칭 스코어를 계산할 수도 있다. 각각의 샘플 사운드에 대한 계산된 매칭 스코어에 기초하여, 사용자 정의된 키워드를 검출하기 위한 임계 스코어가 결정될 수도 있다. 예를 들어, 표 1 에서의 5 개의 시퀀스들에 대한 매칭 스코어는 9.5, 9.0, 8.3, 6.5, 및 6 로서 각각 결정될 수도 있다. 이 경우에, 임계 스코어는 5 개의 매칭 스코어보다 낮은 스코어 (예를 들어, 5.0) 인 것으로 결정될 수도 있고 입력 사운드 스트림에서 사용자 정의된 키워드를 검출하는데 있어 이용된다.
추가적인 실시형태에서, 믹싱된 사운드 생성 유닛 (828) 은 사용자로부터 수신되고 사용자 정의된 키워드를 나타내는 샘플 사운드들에 적어도 하나의 잡음 유형을 추가하는 것에 의해 하나 이상의 믹싱된 샘플 사운드들을 생성할 수도 있다. 사용자 정의된 키워드 모델 생성 유닛 (816) 은 믹싱된 샘플 사운드들을 수신하고 믹싱된 샘플 사운드들의 각각에 대한 매칭 사운드를 계산할 수도 있다. 그 후, 사용자 정의된 키워드를 검출하기 위한 임계 스코어는 샘플 사운드들 및 믹싱된 샘플 사운드들 각각에 대하여 계산된 매칭 스코어에 기초하여 결정될 수도 있다. 이 경우에, 임계 스코어는 샘플 사운드들 및 믹싱된 샘플 사운드들에 대한 모든 매칭 스코어들 보다 낮은 스코어인 것으로 결정될 수도 있다.
사용자 정의된 키워드 모델 생성 유닛 (816) 은 사용자 정의된 키워드에 대한 임계 스코어를 조정할 수도 있다. 임계 스코어를 조정하기 위하여, 사운드 센서 (800) 는 테스트 입력 사운드로서 사용자 정의된 키워드를 나타내는 입력 사운드 스트림을 수신할 수도 있다. 테스트 입력 사운드를 수신시, 사용자 정의된 키워드 모델 생성 유닛 (816) 은 테스트 입력 사운드로부터 복수의 사운드 피처들을 순차적으로 추출할 수도 있고, 사용자 정의된 키워드에 대한 키워드 모델에서 서브워드들의 시퀀스 또는 네트워크와 추출된 사운드 피처들 사이의 매칭 스코어를 계산할 수도 있다. 계산된 매칭 스코어에 기초하여, 사용자 정의된 키워드를 검출하기 위한 임계 스코어가 조정될 수도 있다. 예를 들어, 계산된 매칭 스코어가 4.5 일 때, 사용자 정의된 키워드 모델 생성 유닛 (816) 은 임계 스코어를 5.0 으로부터 4.5 미만 (예를 들어, 4) 인 스코어로 조정할 수도 있다.
일 실시형태에서, 사용자 정의된 키워드 모델 생성 유닛 (816) 은 서브워드 인식 유닛 (812) 에게 사용자 정의된 키워드를 나타내는 입력 스코어에 대하여 서브워드 인식을 수행하라고 명령하는 신호를 송신할 수도 있다. 이에 응답하여, 서브워드 인식 유닛 (812) 은 테스트 입력 사운드에 기초하여 서브워드들의 시퀀스를 생성할 수도 있다. 그 후, 사용자 정의된 키워드 모델 생성 유닛 (816) 은 서브워드 인식 유닛 (812) 으로부터 서브워드들의 생성된 시퀀스를 수신할 수도 있고, 서브워드들의 생성된 시퀀스에 기초하여 사용자 정의된 키워드에 대한 키워드 모델을 업데이트할 수도 있다.
사용자 정의된 키워드를 검출하기 위한 키워드 모델이 생성되었다면, 사용자 정의된 키워드 모델 생성 유닛 (816) 은 사용자 정의된 키워드를 검출하는데 있어 정확도를 강화하기 위해 키워드 모델에 대한 결정론적 트레이닝을 수행할 수도 있다. 이 프로세스에서, 사용자 정의된 키워드 모델 생성 유닛 (816) 은 저장 유닛 (840) 으로부터 검출 이력 데이터베이스에 액세스하고 그리고 미리 정해진 키워드와 연관되고 샘플 사운드들의 검출 라벨들에 기초하여 사용자 정의된 키워드를 포함하는 것으로서 부정확하게 검출되는 하나 이상의 샘플 사운드들을 식별할 수도 있다. 추가적으로, 사용자 정의된 키워드를 포함하는 것으로 정확하게 검출되지 않은 사용자 정의된 키워드와 연관된 하나 이상의 샘플 사운드들은 샘플 사운드들의 검출 라벨들에 기초하여 식별될 수도 있다. 그 후, 사용자 정의된 키워드 모델 생성 유닛 (816) 은, 부정확하게 검출되었던 미리 정해진 키워드와 연관된 샘플 사운드들이, 사용자 정의된 키워드를 포함하는 것으로서 검출되지 않고, 정확하게 검출되지 않았던 사용자 정의된 키워드와 연관된 샘플 사운드들이, 사용자 정의된 키워드를 포함하는 것으로서 검출되도록, 키워드 모델을 구성할 수도 있다.
스피치 검출기 (822) 는 사운드 센서 (800) 에 의해 수신되는 입력 사운드 스트림이 대상이 되는 사운드 (예를 들어, 스피치) 를 포함하는지의 여부를 결정하도록 구성될 수도 있다. 일 실시형태에서, 사운드 센서 (800) 는 듀티 사이클에 따라 주기적으로 미리 정해진 키워드 또는 사용자 정의된 키워드를 나타내는 입력 사운드 스트림을 수신할 수도 있다. 예를 들어, 사운드 센서 (800) 는 사운드 센서 (800) 가 10% 의 시간의 입력 사운드 스트림을 수신하도록 (예를 들어, 200 ms 주기에서 20 ms), 10 % 듀티 사이클 상에서 동작할 수도 있다. 이 경우에, 사운드 센서 (800) 는 입력 사운드 스트림의 수신된 부분의 신호 특징들을 분석할 수도 있고, 입력 사운드 스트림의 수신된 부분이 임계 사운드 강도를 초과하는지의 여부를 나타내는지의 여부를 결정할 수도 있다. 입력 사운드 스트림의 수신된 부분이 임계 사운드 강도를 초과하는 사운드라고 결정할 때, 사운드 센서 (800) 는 스피치 검출기 (822) 를 활성화할 수도 있고 스피치 검출기 (822) 에 수신된 부분을 제공할 수도 있다. 대안으로서, 수신된 부분이 임계 사운드 강도를 초과하는지 여부를 결정하지 않고, 사운드 센서 (800) 는 입력 사운드 스트림의 일부분을 주기적으로 수신할 수도 있고, 스피치 검출기 (822) 에 수신된 부분을 제공하기 위해 스피치 검출기 (822) 를 활성화할 수도 있다.
활성화될 때, 스피치 검출기 (822) 는 사운드 센서 (800) 로부터 입력 사운드 스트림의 일부분을 수신할 수도 있다. 일 실시형태에서, 스피치 검출기 (822) 는 임의의 적절한 사운드 분류 방법, 이를 테면, GMM (Gaussian mixture model) 기반 분류자, 신경망, HMM, 그래픽 모델 및 SVM (Support Vector Machine) 기술을 이용하는 것에 의해 수신된 부분으로부터 하나 이상의 사운드 피처들을 추출할 수도 있고, 추출된 사운드 피처들이 대상이 되는 사운드, 이를 테면, 스피치를 나타내는지의 여부를 결정할 수도 있다. 수신된 부분이 대상이 되는 사운드인 것으로 결정되면, 스피치 검출기 (822) 는 음성 활성화 유닛 (824) 을 활성화할 수도 있고, 입력 사운드 스트림의 수신된 부분 및 나머지 부분은 음성 활성화 유닛 (824) 에 제공될 수도 있다. 일부 다른 실시형태들에서, 스피치 검출기 (822) 는 프로세서에서 생략될 수도 있다. 이 경우에, 수신된 부분이 임계 사운드 강도를 초과하면, 사운드 센서 (800) 는 음성 활성화 유닛 (824) 을 활성화할 수도 있고, 입력 사운드 스트림의 수신된 부분 및 나머지 부분을 음성 활성화 유닛 (824) 에 직접 제공할 수도 있다.
음성 활성화 유닛 (824) 은 활성화될 때, 입력 사운드 스트림을 수신하고 적어도 하나의 사용자 정의된 키워드 및 적어도 하나의 미리 정해진 키워드에 대한 키워드 모델들에 기초하여, 적어도 하나의 사용자 정의된 키워드 또는 적어도 하나의 미리정해진 키워드를 검출하도록 구성될 수도 있다. 예를 들어, 음성 활성화 유닛 (824) 은 입력 사운드 스트림으로부터 복수의 사운드 피처들을 순차적으로 추출할 수도 있고, 키워드 모델들에 기초하여 적어도 하나의 키워드 (적어도 하나의 사용자 정의된 키워드 및 적어도 하나의 미리 정해진 키워드) 에 대한 매칭 스코어를 결정할 수도 있다. 적어도 하나의 키워드에 대한 매칭 스코어가 적어도 하나의 키워드와 연관된 임계 스코어를 초과하면, 음성 활성화 유닛 (824) 은 적어도 하나의 키워드를 포함하는 것으로서 입력 사운드 스트림을 검출할 수도 있다. 일 실시형태에 따르면, 음성 활성화 유닛 (824) 은 저장 유닛 (840) 의 검출 이력 데이터베이스에, 입력 사운드 스트림, 및 입력 사운드 스트림에 대한 검출 라벨을 저장할 수도 있다. 예를 들어, 매칭 스코어가 임계 스코어보다 더 높은 값으로 설정될 수도 있는 고신뢰성 임계값을 초과할 때, 샘플 사운드가 키워드 스피치로서 정확하게 검출되었음을 나타내는 검출 라벨이 생성될 수도 있고 입력 사운드 스트림과 함께 저장 유닛 (840) 에 저장될 수도 있다. 이와 유사한 방식으로, 매칭 스코어가 임계 스코어가 더 낮은 값으로 설정될 수도 있는 저신뢰성 임계값 미만일 때, 샘플 사운드가 비-키워드 스피치로서 정확하게 검출되었음을 나타내는 검출 라벨이 생성될 수도 있고 입력 사운드 스트림과 함께 저장 유닛 (840) 에 저장될 수도 있다. 추가적으로, 입력 사운드 스트림에 대한 검출 라벨은 I/O 유닛 (830) 을 통하여 사용자에 의해 제공될 수도 있다.
키워드를 검출시, 음성 활성화 유닛 (824) 은 키워드와 연관된 애플리케이션을 활성화하거나 또는 키워드와 연관된 기능을 수행할 수도 있다. 추가적으로, 또는 대안으로서, 음성 활성화 유닛 (824) 은 검출된 키워드와 연관될 수도 있는 음성 지원 유닛 (826) 을 턴온하도록 활성화 신호를 생성 및 송신할 수도 있다. 음성 지원 유닛 (826) 은 음성 활성화 유닛 (824) 으로부터 활성화 신호에 응답하여 활성화될 수도 있다. 활성화되면, 음성 지원 유닛 (826) 은 디스플레이 스크린 (110) 상에 및/또는 I/O 유닛 (830) 의 스피커를 통하여 메시지, 이를 테면, "무엇을 도와 드릴까요? (MAY I HELP YOU?)" 를 출력하는 것에 의해 음성 지원 기능을 수행할 수도 있다. 이에 응답하여, 사용자는 전자 디바이스 (100) 의 여러 연관된 기능들을 활성화하도록 음성 커맨드들을 말할 수도 있다. 예를 들어, 인터넷 검색에 대한 음성 커맨드가 수신될 때, 음성 지원 유닛 (826) 은 검색 커맨드로서 음성 커맨드를 인식할 수도 있고 통신 유닛 (832) 을 통하여 웹 검색을 수행할 수도 있다.
도 9 는 본 개시물의 일 실시형태에 따라 사용자 정의된 키워드를 나타내는 적어도 하나의 입력으로부터 사용자 정의된 키워드의 키워드 모델을 생성하기 위하여, 전자 디바이스 (100) 에서 수행되는 예시적인 방법 (900) 의 흐름도이다. 초기에, 910 에서, 전자 디바이스 (100) 는 사용자 정의된 키워드를 나타내는 적어도 하나의 입력을 수신할 수도 있다. 적어도 하나의 입력은 사용자 정의된 키워드에 대한 텍스트 및 사용자 정의된 키워드를 나타내는 적어도 하나의 샘플 사운드 중 적어도 하나를 포함할 수도 있다. 적어도 하나의 입력으로부터, 920 에서, 전자 디바이스 (100) 는 서브워드들의 시퀀스를 결정할 수도 있다. 서브워드들의 시퀀스 및 서브워드들의 서브워드 모델에 기초하여, 930 에서, 전자 디바이스 (100) 는 사용자 정의된 키워드와 연관된 키워드 모델을 생성할 수도 있다. 940 에서, 전자 디바이스 (100) 는 사용자 정의된 키워드와 연관된 키워드 모델을, 미리 정해진 키워드와 연관된 키워드 모델로 구성되는 음성 활성화 유닛에 제공할 수도 있다.
도 10 은 본 개시물의 일 실시형태에 따라 사용자 정의된 키워드를 나타내는 적어도 하나의 샘플 사운드로부터 사용자 정의된 키워드의 키워드 모델을 생성하기 위하여, 전자 디바이스 (100) 에서 수행되는 예시적인 방법 (1000) 의 흐름도이다. 초기에, 1010 에서, 전자 디바이스 (100) 는 사용자 정의된 키워드를 나타내는 적어도 하나의 샘플 사운드를 수신할 수도 있다. 1020 에서, 적어도 하나의 샘플 사운드로부터, 전자 디바이스 (100) 는 서브워드 모델에 기초하여 서브워드들의 적어도 하나의 시퀀스를 생성할 수도 있다. 1030 에서, 서브워드들의 적어도 하나의 시퀀스에 기초하여, 전자 디바이스 (100) 는 서브워드들의 시퀀스를 결정할 수도 있다. 1040 에서, 서브워드들의 시퀀스 및 서브워드 모델에 기초하여, 전자 디바이스 (100) 는 사용자 정의된 키워드와 연관된 키워드 모델을 생성할 수도 있다. 1050 에서, 전자 디바이스 (100) 는 사용자 정의된 키워드와 연관된 키워드 모델을, 미리 정해진 키워드에 대한 트레이닝된 키워드 모델로 구성되는 음성 활성화 유닛에 제공할 수도 있다.
도 11 은 본 개시물의 일 실시형태에 따라 사용자 정의된 키워드를 검출하기 위한 키워드 모델을 생성하는데 있어 사용되는 서브워드 모델을 조정하기 위하여 전자 디바이스 (100) 에서 수행되는 예시적인 방법 (1100) 의 흐름도이다. 1110 에서, 전자 디바이스 (100) 는 전자 디바이스 (100) 의 디스플레이 스크린 (110) 상에 적어도 하나의 문장을 출력할 수도 있다. 적어도 하나의 문장은 음소가 언어에 나타날 수도 있을 때와 동일한 또는 유사한 빈도에서 특정 음소를 이용할 수도 있는 표음적으로 밸런싱되는 문장들 (예를 들어, Harvard 문장들) 중 적어도 하나일 수도 있다. 1120 에서, 전자 디바이스 (100) 는 적어도 하나의 문장에 대한 입력 사운드를 수신할 수도 있다. 1130 에서, 전자 디바이스 (100) 는 서브워드 모델을 조정할 수도 있다.
도 12 는 본 개시물의 일 실시형태에 따라 입력 사운드에 기초하여 사용자 정의된 키워드를 검출하기 위한 임계 스코어를 조정하기 위하여 전자 디바이스 (100) 에서 수행되는 예시적인 방법 (1200) 의 흐름도이다. 1210 에서, 전자 디바이스 (100) 는 사용자 정의된 키워드와 연관된 키워드 모델의 임계 스코어를 결정할 수도 있다. 1220 에서, 전자 디바이스 (100) 는 사용자 정의된 키워드를 나타내는 테스트 입력 사운드를 수신할 수도 있다. 1230 에서, 전자 디바이스 (100) 는 사용자 정의된 키워드와 연관된 키워드 모델에 기초하여 테스트 입력 사운드의 매칭 스코어를 결정할 수도 있다. 1240 에서, 매칭 스코어에 기초하여, 전자 디바이스 (100) 는 사용자 정의된 키워드와 연관된 키워드 모델의 임계 스코어를 조정할 수도 있다.
도 13 은 본 개시물의 일부 실시형태들에 따라, 사용자 정의된 키워드에서 사용하기 위한 키워드 모델을 생성하기 위한 방법들 및 장치들이 구현될 수도 있는 예시적인 전자 디바이스 (1300) 의 블록도이다. 전자 디바이스 (1300) 의 구성은 도 1 내지 도 12 를 참조하여 설명된 위의 실시형태들에 따라 전자 디바이스들에서 구현될 수도 있다. 전자 디바이스 (1300) 는 셀룰라 폰, 스마트폰, 테블릿 컴퓨터, 랩톱 컴퓨터, 단말기, 핸드셋, 개인 휴대 정보 단말기 (PDA), 무선 모뎀, 무선 전화기 등일 수도 있다. 무선 통신 시스템은 CDMA (Code Division Multiple Access) 시스템, GSM (Global System for Mobile Communications) 시스템을 위한 브로드캐스트 시스템, W-CDMA (Wideband CDMA) 시스템, LTE (Long Term Evolution) 시스템, LTE 어드밴스드 시스템 등일 수도 있다. 또한, 전자 디바이스 (1300) 는 예를 들어, Wi-Fi 다이렉트 또는 블루투스를 이용하여, 다른 모바일 디바이스와 직접 통신할 수도 있다.
전자 디바이스 (1300) 는 수신 경로 및 송신 경로를 통해 양방향 통신을 제공가능하다. 수신 경로에서, 기지국들에 의해 송신된 신호들이 안테나 (1312) 에 의해 수신되어, 수신기 (RCVR) (1314) 로 제공된다. 수신기 (1314) 는 수신된 신호를 컨디셔닝하고 디지털화하여, 추가적인 프로세싱을 위해 디지털 섹션에 샘플들, 이를 테면, 컨디셔닝되고 디지털화된 신호를 제공한다. 송신 경로에서, 송신기 (TMTR) (1316) 가 디지털 섹션 (1320) 으로부터 송신될 데이터를 수신하여, 그 데이터를 프로세싱하고 컨디셔닝해서, 변조된 신호를 생성하며, 변조된 신호는 안테나 (1312) 를 통해 기지국들로 송신된다. 수신기 (1314) 및 송신기 (1316) 는 CDMA, GSM, LTE, LTE 어드밴스드 등을 지원할 수도 있는 트랜시버의 일부분일 수도 있다.
디지털 섹션 (1320) 은, 예를 들어, 모뎀 프로세서 (1322), RISC/DSP (reduced instruction set computer/digital signal processor) (1324), 제어기/프로세서 (1326), 내부 메모리 (1328), 일반화된 오디오/비디오 인코더 (1332), 일반화된 오디오 디코더 (1334), 그래픽/디스플레이 프로세서 (1336), 및 외부 버스 인터페이스 (external bus interface; EBI) (1338) 와 같은 다양한 프로세싱, 인터페이스, 및 메모리 유닛들을 포함한다. 모뎀 프로세서 (1322) 는 데이터 송신 및 수신을 위한 프로세싱, 예를 들어, 인코딩, 변조, 복조, 및 디코딩을 수행할 수도 있다. RISC/DSP (1324) 는 전자 디바이스 (1300) 에 대해 범용 프로세싱 및 특수 프로세싱을 수행할 수도 있다. 제어기/프로세서 (1326) 는 디지털 섹션 (1320) 내의 다양한 프로세싱 유닛 및 인터페이스 유닛의 동작을 제어할 수도 있다. 내부 메모리 (1328) 는 디지털 섹션 (1320) 내의 다양한 유닛들에 대한 데이터 및/또는 명령들을 저장할 수도 있다.
일반화된 오디오/비디오 인코더 (1332) 는 오디오/비디오 소스 (1342), 마이크로폰 (1344), 이미지 센서 (1346) 등으로부터의 입력 신호들에 대한 인코딩을 수행할 수도 있다. 일반화된 오디오 디코더 (1334) 는 코딩된 오디오 데이터에 대한 디코딩을 수행할 수도 있고, 출력된 신호들을 스피커/헤드셋 (1348) 으로 제공할 수도 있다. 그래픽/디스플레이 프로세서 (1036) 는 디스플레이 유닛 (1350) 에 제시될 수도 있는 그래픽들, 비디오들, 이미지들, 및 텍스트들에 대한 프로세싱을 수행할 수도 있다. EBI (1338) 는 디지털 섹션 (1320) 과 메인 메모리 (1352) 간의 데이터의 전송을 가능하게 할 수도 있다.
디지털 섹션 (1320) 은 하나 이상의 프로세서들, DSP들, 마이크로프로세서들, RISC들 등으로 구현될 수도 있다. 디지털 섹션 (1320) 은 또한 하나 이상의 ASIC (application specific integrated circuit) 들 및/또는 일부 다른 유형의 집적 회로 (IC) 들 상에 제작될 수도 있다.
일반적으로, 본원에 설명된 임의의 디바이스는, 무선 전화기, 셀룰러 전화기, 랩탑 컴퓨터, 무선 멀티미디어 디바이스, 무선 통신 PC (personal computer) 카드, PDA, 외부 모뎀이나 내부 모뎀, 무선 채널을 통해 통신하는 디바이스 등과 같은 다양한 유형의 디바이스들을 대표할 수도 있다. 디바이스는, 액세스 단말기 (access terminal; AT), 액세스 유닛, 가입자 유닛, 이동국, 모바일 디바이스, 모바일 유닛, 모바일 전화기, 모바일, 원격국, 원격 단말기, 원격 유닛, 사용자 디바이스, 사용자 장비, 핸드헬드 디바이스 등과 같은 다양한 이름들을 가질 수도 있다. 본원에 설명된 임의의 디바이스는 명령들 및 데이터를 저장하기 위한 메모리, 뿐만 아니라 하드웨어, 소프트웨어, 펌웨어, 또는 그 조합들을 가질 수도 있다.
본원에 기술된 기법들은 다양한 수단으로 구현될 수도 있다. 예를 들어, 이러한 기법들은 하드웨어, 펌웨어, 소프트웨어, 또는 그 조합으로 구현될 수도 있다. 본원의 개시물과 관련하여 설명된 다양한 예시적인 논리적 블록들, 모듈들, 회로들, 및 알고리즘 단계들은 전자 하드웨어, 컴퓨터 소프트웨어, 또는 양자의 조합들로 구현될 수도 있음을 당업자들은 더 이해할 것이다. 하드웨어 및 소프트웨어의 이러한 상호교환성을 명확하게 설명하기 위해, 다양한 예시적인 컴포넌트들, 블록들, 모듈들, 회로들, 및 단계들은 그들의 기능성의 관점에서 일반적으로 위에서 설명되었다. 그러한 기능이 하드웨어 또는 소프트웨어로 구현되는지 여부는 특정 애플리케이션 및 전체 시스템에 부과되는 설계 제약들에 따라 달라진다. 당업자들은 각각의 특정 애플리케이션을 위해 다양한 방식들로 설명된 기능을 구현할 수도 있으나, 그러한 구현 결정들이 본 개시물의 범위로부터 벗어나게 하는 것으로 해석되어서는 안된다.
하드웨어 구현에서, 기법들을 수행하는데 이용되는 프로세싱 유닛들은, 하나 이상의 ASIC 들, DSP 들, 디지털 신호 프로세싱 디바이스들 (digital signal processing device; DSPD) 들, 프로그램가능 논리 디바이스 (rogrammable logic device; PLD) 들, 필드 프로그램가능 게이트 어레이 (field programmable gate array; FPGA), 프로세서들, 제어기들, 마이크로 제어기들, 마이크로프로세서들, 전자 디바이스들, 본원에 설명된 기능들을 수행하도록 설계된 다른 전자 유닛들, 컴퓨터, 또는 그들의 조합 내에서 구현될 수도 있다.
따라서, 본원의 개시물과 관련하여 설명된 다양한 예시적인 논리 블록들, 모듈들, 및 회로들은 범용 프로세서, DSP, ASIC, FPGA 나 다른 프로그램 가능 논리 디바이스, 이산 게이트나 트랜지스터 로직, 이산 하드웨어 컴포넌트들, 또는 본원에 설명된 기능들을 수행하도록 설계된 것들의 임의의 조합으로 구현되거나 수행될 수도 있다. 범용 프로세서는 마이크로프로세서일 수도 있지만, 대안에서, 프로세서는 임의의 종래의 프로세서, 제어기, 마이크로제어기, 또는 상태 머신일 수도 있다. 프로세서는 또한 컴퓨팅 디바이스들의 조합, 예를 들면, DSP와 마이크로프로세서의 조합, 복수의 마이크로프로세서들, DSP 코어와 연계한 하나 이상의 마이크로프로세서들, 또는 임의의 다른 그러한 구성으로 구현될 수도 있다.
소프트웨어로 구현되면, 상기 기능들은 하나 이상의 명령들 또는 코드로서 컴퓨터 판독 가능한 매체 상에 저장되거나 또는 전송될 수도 있다. 컴퓨터 판독가능 매체들은 한 장소에서 다른 장소로 컴퓨터 프로그램의 전송을 가능하게 하는 임의의 매체를 포함하여 컴퓨터 저장 매체들 및 통신 매체들 양자를 포함한다. 저장 매체는 컴퓨터에 의해 액세스될 수 있는 임의의 이용 가능한 매체일 수도 있다. 비제한적인 예로서, 이러한 컴퓨터 판독 가능한 매체는 RAM, ROM, EEPROM, CD-ROM 또는 다른 광학 디스크 스토리지, 자기 디스크 스토리지 또는 다른 자기 스토리지 디바이스들, 또는 요구되는 프로그램 코드를 명령들 또는 데이터 구조들의 형태로 이송 또는 저장하기 위해 사용될 수 있으며 컴퓨터에 의해 액세스될 수 있는 임의의 다른 매체를 포함할 수 있다. 또한, 임의의 접속은 컴퓨터 판독 가능한 매체라고 적절히 지칭된다. 예를 들면, 소프트웨어가 동축 케이블, 광섬유 케이블, 연선, 디지털 가입자 회선, 또는 적외선, 무선, 및 마이크로파와 같은 무선 기술들을 사용하여 웹사이트, 서버, 또는 다른 원격 소스로부터 전송되면, 동축 케이블, 광섬유 케이블, 연선, 디지털 가입자 회선, 또는 적외선, 무선, 및 마이크로파와 같은 무선 기술들은 매체의 정의 내에 포함된다. 본원에서 이용된 디스크 (disk) 와 디스크 (disc) 는, 컴팩트 디스크(CD), 레이저 디스크, 광학 디스크, 디지털 다기능 디스크 (DVD), 플로피 디스크, 및 블루레이 디스크를 포함하며, 여기서 디스크 (disk) 들은 통상 자기적으로 데이터를 재생하는 반면, 디스크(disc) 들은 레이저들을 이용하여 광학적으로 데이터를 재생한다. 위의 조합들도 컴퓨터 판독가능 매체들의 범위 내에 포함되어야 한다.
앞서의 본 개시물의 설명은 당업자들이 개시물을 제조하거나 이용하는 것을 가능하게 하기 위해 제공된다. 본 개시물의 다양한 수정들이 당업자들에게 쉽게 자명할 것이고, 본원에 정의된 일반적인 원리들은 본 개시물의 사상 또는 범위를 벗어나지 않으면서 다양한 변형들에 적용될 수도 있다. 따라서, 본 개시물은 본원에 설명된 예시들에 제한되고자 하는 것이 아니라, 본원에 개시된 원리들 및 신규한 특징들과 일관되는 가장 넓은 범위에 일치되고자 한다.
비록 예시적인 실시형태들이 하나 이상의 독립형 컴퓨터 시스템의 맥락에서 현재 개시된 주재의 양상들을 이용하는 것을 언급할 수도 있으나, 본 주재는 그렇게 제한되지 않고, 오히려 네트워크나 분산된 컴퓨팅 환경과 같은 임의의 컴퓨팅 환경과 연결하여 구현될 수도 있다. 더 나아가, 현재 개시된 주재의 양태들은 복수의 프로세싱 칩들이나 디바이스들에서 또는 그에 걸쳐 구현될 수도 있고, 저장소는 복수의 디바이스들에 걸쳐 유사하게 영향을 받게 될 수도 있다. 이러한 디바이스들은 PC들, 네트워크 서버들, 및 핸드헬드 디바이스들을 포함할 수도 있다.
비록 본 청구물이 구조적 특징들 및/또는 방법론적 작용들에 대한 언어 특정적으로 설명되었으나, 첨부된 청구항들에서 정의된 청구물은 위에서 설명된 특정 특징들 또는 작용들로 반드시 제한되는 것은 아님이 이해될 것이다. 오히려, 위에서 설명된 특정 특징들 및 작용들은 청구항들을 구현하는 예시적인 형태로서 설명된다.
Claims (30)
- 사용자 정의된 키워드의 키워드 모델을 생성하기 위하여 전자 디바이스에서 수행되는 방법으로서,
상기 사용자 정의된 키워드를 나타내는 적어도 하나의 입력을 수신하는 단계;
상기 적어도 하나의 입력으로부터 서브워드들의 시퀀스를 결정하는 단계;
상기 서브워드들의 시퀀스 및 상기 서브워드들의 서브워드 모델에 기초하여 상기 사용자 정의된 키워드와 연관된 키워드 모델을 생성하는 단계로서, 상기 서브워드 모델은 스피치 데이터베이스에 기초하여 상기 서브워드들의 복수의 음향 피처들을 모델링하도록 구성되는, 상기 키워드 모델을 생성하는 단계; 및
상기 사용자 정의된 키워드와 연관된 상기 키워드 모델을, 미리 정해진 키워드와 연관된 키워드 모델로 구성되는 음성 활성화 유닛에 제공하는 단계를 포함하는, 사용자 정의된 키워드의 키워드 모델을 생성하기 위하여 전자 디바이스에서 수행되는 방법. - 제 1 항에 있어서,
상기 음성 활성화 유닛에 의해, 상기 사용자 정의된 키워드와 연관된 키워드 모델 및 상기 미리 정해진 키워드와 연관된 키워드 모델에 기초하여 입력 사운드에서 상기 사용자 정의된 키워드 또는 상기 미리 정해진 키워드를 검출하는 단계를 더 포함하는, 사용자 정의된 키워드의 키워드 모델을 생성하기 위하여 전자 디바이스에서 수행되는 방법. - 제 2 항에 있어서,
상기 사용자 정의된 키워드 또는 상기 미리 정해진 키워드와 연관된 기능을 수행하는 단계를 더 포함하는, 사용자 정의된 키워드의 키워드 모델을 생성하기 위하여 전자 디바이스에서 수행되는 방법. - 제 1 항에 있어서,
상기 서브워드 모델은 적어도 하나의 문장에 대한 입력 사운드에 기초하여 조정되는, 사용자 정의된 키워드의 키워드 모델을 생성하기 위하여 전자 디바이스에서 수행되는 방법. - 제 1 항에 있어서,
상기 사용자 정의된 키워드와 연관된 상기 키워드 모델을 생성하는 단계는, 상기 사용자 정의된 키워드와 연관된 상기 키워드 모델의 임계 스코어를 결정하는 단계를 포함하는, 사용자 정의된 키워드의 키워드 모델을 생성하기 위하여 전자 디바이스에서 수행되는 방법. - 제 5 항에 있어서,
상기 사용자 정의된 키워드와 연관된 상기 키워드 모델은:
상기 사용자 정의된 키워드를 나타내는 테스트 입력 사운드를 수신하는 것;
상기 사용자 정의된 키워드와 연관된 상기 키워드 모델에 기초하여 상기 테스트 입력 사운드의 매칭 스코어를 결정하는 것; 및
상기 매칭 스코어에 기초하여 상기 사용자 정의된 키워드와 연관된 상기 키워드 모델의 상기 임계 스코어를 조정하는 것에 의해 조정되는, 사용자 정의된 키워드의 키워드 모델을 생성하기 위하여 전자 디바이스에서 수행되는 방법. - 제 1 항에 있어서,
상기 적어도 하나의 입력은 상기 사용자 정의된 키워드에 대한 텍스트를 포함하는, 사용자 정의된 키워드의 키워드 모델을 생성하기 위하여 전자 디바이스에서 수행되는 방법. - 제 1 항에 있어서,
상기 적어도 하나의 입력은 상기 사용자 정의된 키워드를 나타내는 적어도 하나의 샘플 사운드를 포함하는, 사용자 정의된 키워드의 키워드 모델을 생성하기 위하여 전자 디바이스에서 수행되는 방법. - 제 8 항에 있어서,
상기 서브워드들의 시퀀스를 결정하는 단계는:
상기 서브워드 모델에 기초하여 상기 적어도 하나의 샘플 사운드로부터 서브워드들의 적어도 하나의 시퀀스를 생성하는 단계; 및
상기 서브워드들의 적어도 하나의 시퀀스에 기초하여 상기 서브워드들의 시퀀스를 결정하는 단계를 포함하는, 사용자 정의된 키워드의 키워드 모델을 생성하기 위하여 전자 디바이스에서 수행되는 방법. - 제 9 항에 있어서,
상기 서브워드들의 적어도 하나의 시퀀스에서의 서브워드들은 단음들 (phones), 3중 음소들 (phonemes), 및 음절들 (syllables) 중 적어도 하나를 포함하는, 사용자 정의된 키워드의 키워드 모델을 생성하기 위하여 전자 디바이스에서 수행되는 방법. - 제 8 항에 있어서,
적어도 하나의 잡음 유형과 상기 적어도 하나의 샘플 사운드를 믹싱하는 것에 의해 적어도 하나의 믹싱된 샘플 사운드를 생성하는 단계를 더 포함하는, 사용자 정의된 키워드의 키워드 모델을 생성하기 위하여 전자 디바이스에서 수행되는 방법. - 제 11 항에 있어서,
상기 서브워드들의 적어도 하나의 시퀀스를 결정하는 단계는:
상기 서브워드 모델에 기초하여, 상기 적어도 하나의 믹싱된 샘플 사운드 및 상기 적어도 하나의 샘플 사운드로부터 서브워드들의 적어도 2 개의 시퀀스들을 생성하는 단계; 및
상기 서브워드들의 적어도 2 개의 시퀀스들에 기초하여 상기 서브워드들의 시퀀스를 결정하는 단계를 포함하는, 사용자 정의된 키워드의 키워드 모델을 생성하기 위하여 전자 디바이스에서 수행되는 방법. - 제 9 항에 있어서,
상기 서브워드들의 적어도 하나의 시퀀스에 기초하여 상기 서브워드들의 시퀀스를 결정하는 단계는, 상기 서브워드들의 시퀀스로서, 상기 서브워드들의 적어도 하나의 시퀀스 중 가장 긴 길이를 갖는 서브워드를 선택하는 단계를 포함하는, 사용자 정의된 키워드의 키워드 모델을 생성하기 위하여 전자 디바이스에서 수행되는 방법. - 제 11 항에 있어서,
상기 사용자 정의된 키워드와 연관된 상기 키워드 모델을 생성하는 단계는:
상기 서브워드들의 시퀀스, 상기 서브워드 모델, 상기 적어도 하나의 샘플 사운드, 및 상기 적어도 하나의 믹싱된 샘플 사운드에 기초하여 상기 사용자 정의된 키워드와 연관된 상기 키워드 모델을 생성하는 단계를 포함하는, 사용자 정의된 키워드의 키워드 모델을 생성하기 위하여 전자 디바이스에서 수행되는 방법. - 제 1 항에 있어서,
상기 서브워드들의 시퀀스를 생성하기 위해 상기 서브워드들의 시퀀스의 시작 또는 끝에 서브워드 유닛으로서 무음 부분 (silence portion) 을 추가하는 단계를 더 포함하는, 사용자 정의된 키워드의 키워드 모델을 생성하기 위하여 전자 디바이스에서 수행되는 방법. - 제 1 항에 있어서,
상기 적어도 하나의 입력은 상기 사용자 정의된 키워드에 대한 텍스트 및 상기 사용자 정의된 키워드를 나타내는 적어도 하나의 샘플 사운드를 포함하는, 사용자 정의된 키워드의 키워드 모델을 생성하기 위하여 전자 디바이스에서 수행되는 방법. - 사용자 정의된 키워드의 키워드 모델을 생성하는 전자 디바이스로서,
상기 사용자 정의된 키워드를 나타내는 적어도 하나의 입력을 수신하도록 구성되는 입력 유닛;
미리 정해진 키워드와 연관된 키워드 모델로 구성되는 음성 활성화 유닛; 및
상기 적어도 하나의 입력으로부터 서브워드들의 시퀀스를 결정하고, 상기 서브워드들의 시퀀스 및 상기 서브워드들의 서브워드 모델에 기초하여 상기 사용자 정의된 키워드와 연관된 상기 키워드 모델을 생성하고, 상기 사용자 정의된 키워드와 연관된 키워드 모델을 상기 음성 활성화 유닛에 제공하도록 구성되는 사용자 정의된 키워드 모델 생성 유닛을 포함하고,
상기 서브워드 모델은 스피치 데이터베이스에 기초하여 상기 서브워드들의 복수의 음향 피처들을 모델링하도록 구성되는, 사용자 정의된 키워드의 키워드 모델을 생성하는 전자 디바이스. - 제 17 항에 있어서,
상기 적어도 하나의 입력은 상기 사용자 정의된 키워드에 대한 텍스트를 포함하는, 사용자 정의된 키워드의 키워드 모델을 생성하는 전자 디바이스. - 제 17 항에 있어서,
상기 입력 유닛은 상기 사용자 정의된 키워드를 나타내는 적어도 하나의 샘플 사운드를 상기 적어도 하나의 입력으로서 수신하도록 구성되는 사운드 센서를 포함하는, 사용자 정의된 키워드의 키워드 모델을 생성하는 전자 디바이스. - 제 19 항에 있어서,
상기 서브워드 모델에 기초하여 상기 적어도 하나의 샘플 사운드로부터 서브워드들의 적어도 하나의 시퀀스를 생성하도록 구성되는 서브워드 인식 유닛을 더 포함하는, 사용자 정의된 키워드의 키워드 모델을 생성하는 전자 디바이스. - 제 19 항에 있어서,
적어도 하나의 잡음 유형과 상기 적어도 하나의 샘플 사운드를 믹싱하는 것에 의해 적어도 하나의 믹싱된 샘플 사운드를 생성하도록 구성되는 믹싱된 사운드 생성 유닛을 더 포함하는, 사용자 정의된 키워드의 키워드 모델을 생성하는 전자 디바이스. - 제 17 항에 있어서,
상기 음성 활성화 유닛은 상기 사용자 정의된 키워드와 연관된 상기 키워드 모델 및 상기 미리 정해진 키워드와 연관된 상기 키워드 모델에 기초하여 입력 사운드에서 상기 사용자 정의된 키워드 또는 상기 미리 정해진 키워드를 검출하도록 구성되는, 사용자 정의된 키워드의 키워드 모델을 생성하는 전자 디바이스. - 제 17 항에 있어서,
상기 음성 활성화 유닛은 상기 사용자 정의된 키워드 또는 상기 미리 정해진 키워드와 연관된 기능을 수행하도록 구성되는, 사용자 정의된 키워드의 키워드 모델을 생성하는 전자 디바이스. - 제 19 항에 있어서,
상기 사운드 센서에 의해 수신된 적어도 하나의 문장에 대한 입력 사운드에 기초하여 상기 서브워드 모델을 조정하도록 구성되는 사전 적응 유닛을 더 포함하는, 사용자 정의된 키워드의 키워드 모델을 생성하는 전자 디바이스. - 제 17 항에 있어서,
상기 사용자 정의된 키워드 모델 생성 유닛은 상기 사용자 정의된 키워드와 연관된 상기 키워드 모델의 임계 스코어를 결정하도록 구성되는, 사용자 정의된 키워드의 키워드 모델을 생성하는 전자 디바이스. - 제 25 항에 있어서,
상기 사용자 정의된 키워드 모델 생성 유닛은:
상기 사용자 정의된 키워드와 연관된 상기 키워드 모델에 기초하여 상기 사운드 센서에 의해 수신된 상기 사용자 정의된 키워드를 나타내는 테스트 입력 사운드의 매칭 스코어를 결정하고; 그리고
상기 매칭 스코어에 기초하여 상기 사용자 정의된 키워드와 연관된 상기 키워드 모델의 상기 임계 스코어를 조정하도록 구성되는, 사용자 정의된 키워드의 키워드 모델을 생성하는 전자 디바이스. - 전자 디바이스에서 사용자 정의된 키워드의 키워드 모델을 생성하기 위한 명령들을 저장하는 비일시적 컴퓨터 판독가능 저장 매체로서,
상기 명령들은 프로세서로 하여금:
상기 사용자 정의된 키워드를 나타내는 적어도 하나의 입력을 수신하고;
상기 적어도 하나의 입력으로부터 서브워드들의 시퀀스를 결정하고;
상기 서브워드들의 시퀀스 및 상기 서브워드들의 서브워드 모델에 기초하여 상기 사용자 정의된 키워드와 연관된 키워드 모델을 생성하는 것으로서, 상기 서브워드 모델은 스피치 데이터베이스에 기초하여 상기 서브워드들의 복수의 음향 피처들을 모델링하도록 구성되는, 상기 키워드 모델을 생성하고; 그리고
상기 사용자 정의된 키워드와 연관된 상기 키워드 모델을, 미리 정해진 키워드와 연관된 키워드 모델로 구성되는 음성 활성화 유닛에 제공하는 동작들을 수행하게 하는, 사용자 정의된 키워드의 키워드 모델을 생성하기 위한 명령들을 저장하는 비일시적 컴퓨터 판독가능 저장 매체. - 사용자 정의된 키워드의 키워드 모델을 생성하는 전자 디바이스로서,
상기 사용자 정의된 키워드를 나타내는 적어도 하나의 입력을 수신하는 수단;
상기 적어도 하나의 입력으로부터 서브워드들의 시퀀스를 결정하는 수단;
상기 서브워드들의 시퀀스 및 상기 서브워드들의 서브워드 모델에 기초하여 상기 사용자 정의된 키워드와 연관된 키워드 모델을 생성하는 수단으로서, 상기 서브워드 모델은 스피치 데이터베이스에 기초하여 상기 서브워드들의 복수의 음향 피처들을 모델링하도록 구성되는, 상기 키워드 모델을 생성하는 수단; 및
상기 사용자 정의된 키워드와 연관된 상기 키워드 모델을, 미리 정해진 키워드와 연관된 키워드 모델로 구성되는 음성 활성화 유닛에 제공하는 수단을 포함하는, 사용자 정의된 키워드의 키워드 모델을 생성하는 전자 디바이스. - 제 28 항에 있어서,
상기 적어도 하나의 입력은 상기 사용자 정의된 키워드를 나타내는 적어도 하나의 샘플 사운드를 포함하는, 사용자 정의된 키워드의 키워드 모델을 생성하는 전자 디바이스. - 제 29 항에 있어서,
적어도 하나의 잡음 유형과 상기 적어도 하나의 샘플 사운드를 믹싱하는 것에 의해 적어도 하나의 믹싱된 샘플 사운드를 생성하는 수단을 더 포함하는, 사용자 정의된 키워드의 키워드 모델을 생성하는 전자 디바이스.
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201461980911P | 2014-04-17 | 2014-04-17 | |
| US61/980,911 | 2014-04-17 | ||
| US14/466,644 | 2014-08-22 | ||
| US14/466,644 US9953632B2 (en) | 2014-04-17 | 2014-08-22 | Keyword model generation for detecting user-defined keyword |
| PCT/US2015/024873 WO2015160586A1 (en) | 2014-04-17 | 2015-04-08 | Keyword model generation for detecting user-defined keyword |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20160145634A true KR20160145634A (ko) | 2016-12-20 |
Family
ID=54322537
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020167030186A KR20160145634A (ko) | 2014-04-17 | 2015-04-08 | 사용자 정의된 키워드를 검출하기 위한 키워드 모델 생성 |
Country Status (7)
| Country | Link |
|---|---|
| US (1) | US9953632B2 (ko) |
| EP (1) | EP3132442B1 (ko) |
| JP (1) | JP2017515147A (ko) |
| KR (1) | KR20160145634A (ko) |
| CN (1) | CN106233374B (ko) |
| BR (1) | BR112016024086A2 (ko) |
| WO (1) | WO2015160586A1 (ko) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20190100334A (ko) * | 2016-12-27 | 2019-08-28 | 구글 엘엘씨 | 문맥상의 핫워드들 |
| KR20200037245A (ko) * | 2018-09-28 | 2020-04-08 | 소노스 인코포레이티드 | 뉴럴 네트워크 모델을 사용하여 선택적 활성 단어 검출을 위한 시스템 및 방법 |
Families Citing this family (37)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10019983B2 (en) * | 2012-08-30 | 2018-07-10 | Aravind Ganapathiraju | Method and system for predicting speech recognition performance using accuracy scores |
| US9866741B2 (en) * | 2015-04-20 | 2018-01-09 | Jesse L. Wobrock | Speaker-dependent voice-activated camera system |
| US10304440B1 (en) * | 2015-07-10 | 2019-05-28 | Amazon Technologies, Inc. | Keyword spotting using multi-task configuration |
| US9792907B2 (en) | 2015-11-24 | 2017-10-17 | Intel IP Corporation | Low resource key phrase detection for wake on voice |
| US9972313B2 (en) * | 2016-03-01 | 2018-05-15 | Intel Corporation | Intermediate scoring and rejection loopback for improved key phrase detection |
| CN105868182B (zh) * | 2016-04-21 | 2019-08-30 | 深圳市中兴移动软件有限公司 | 一种文本信息处理方法及装置 |
| US10043521B2 (en) | 2016-07-01 | 2018-08-07 | Intel IP Corporation | User defined key phrase detection by user dependent sequence modeling |
| US10083689B2 (en) * | 2016-12-23 | 2018-09-25 | Intel Corporation | Linear scoring for low power wake on voice |
| JP6599914B2 (ja) * | 2017-03-09 | 2019-10-30 | 株式会社東芝 | 音声認識装置、音声認識方法およびプログラム |
| CN107146611B (zh) * | 2017-04-10 | 2020-04-17 | 北京猎户星空科技有限公司 | 一种语音响应方法、装置及智能设备 |
| US10313845B2 (en) * | 2017-06-06 | 2019-06-04 | Microsoft Technology Licensing, Llc | Proactive speech detection and alerting |
| CN110770819B (zh) * | 2017-06-15 | 2023-05-12 | 北京嘀嘀无限科技发展有限公司 | 语音识别系统和方法 |
| CN107564517A (zh) * | 2017-07-05 | 2018-01-09 | 百度在线网络技术(北京)有限公司 | 语音唤醒方法、设备及系统、云端服务器与可读介质 |
| CN109903751B (zh) * | 2017-12-08 | 2023-07-07 | 阿里巴巴集团控股有限公司 | 关键词确认方法和装置 |
| CN111357048A (zh) * | 2017-12-31 | 2020-06-30 | 美的集团股份有限公司 | 用于控制家庭助手装置的方法和系统 |
| CN108665900B (zh) | 2018-04-23 | 2020-03-03 | 百度在线网络技术(北京)有限公司 | 云端唤醒方法及系统、终端以及计算机可读存储介质 |
| JP2019191490A (ja) * | 2018-04-27 | 2019-10-31 | 東芝映像ソリューション株式会社 | 音声対話端末、および音声対話端末制御方法 |
| CN111445905B (zh) * | 2018-05-24 | 2023-08-08 | 腾讯科技(深圳)有限公司 | 混合语音识别网络训练方法、混合语音识别方法、装置及存储介质 |
| US10714122B2 (en) | 2018-06-06 | 2020-07-14 | Intel Corporation | Speech classification of audio for wake on voice |
| US10269376B1 (en) * | 2018-06-28 | 2019-04-23 | Invoca, Inc. | Desired signal spotting in noisy, flawed environments |
| US10650807B2 (en) | 2018-09-18 | 2020-05-12 | Intel Corporation | Method and system of neural network keyphrase detection |
| CN109635273B (zh) * | 2018-10-25 | 2023-04-25 | 平安科技(深圳)有限公司 | 文本关键词提取方法、装置、设备及存储介质 |
| CN109473123B (zh) * | 2018-12-05 | 2022-05-31 | 百度在线网络技术(北京)有限公司 | 语音活动检测方法及装置 |
| CN109767763B (zh) * | 2018-12-25 | 2021-01-26 | 苏州思必驰信息科技有限公司 | 自定义唤醒词的确定方法和用于确定自定义唤醒词的装置 |
| TW202029181A (zh) * | 2019-01-28 | 2020-08-01 | 正崴精密工業股份有限公司 | 語音識別用於特定目標喚醒的方法及裝置 |
| CN109979440B (zh) * | 2019-03-13 | 2021-05-11 | 广州市网星信息技术有限公司 | 关键词样本确定方法、语音识别方法、装置、设备和介质 |
| US11127394B2 (en) | 2019-03-29 | 2021-09-21 | Intel Corporation | Method and system of high accuracy keyphrase detection for low resource devices |
| CN110349566B (zh) * | 2019-07-11 | 2020-11-24 | 龙马智芯(珠海横琴)科技有限公司 | 语音唤醒方法、电子设备及存储介质 |
| US20220343895A1 (en) * | 2019-08-22 | 2022-10-27 | Fluent.Ai Inc. | User-defined keyword spotting |
| JP7098587B2 (ja) * | 2019-08-29 | 2022-07-11 | 株式会社東芝 | 情報処理装置、キーワード検出装置、情報処理方法およびプログラム |
| CN110634468B (zh) * | 2019-09-11 | 2022-04-15 | 中国联合网络通信集团有限公司 | 语音唤醒方法、装置、设备及计算机可读存储介质 |
| US11295741B2 (en) | 2019-12-05 | 2022-04-05 | Soundhound, Inc. | Dynamic wakewords for speech-enabled devices |
| CN111128138A (zh) * | 2020-03-30 | 2020-05-08 | 深圳市友杰智新科技有限公司 | 语音唤醒方法、装置、计算机设备和存储介质 |
| CN111540363B (zh) * | 2020-04-20 | 2023-10-24 | 合肥讯飞数码科技有限公司 | 关键词模型及解码网络构建方法、检测方法及相关设备 |
| CN111798840B (zh) * | 2020-07-16 | 2023-08-08 | 中移在线服务有限公司 | 语音关键词识别方法和装置 |
| KR20220111574A (ko) | 2021-02-02 | 2022-08-09 | 삼성전자주식회사 | 전자 장치 및 그 제어 방법 |
| WO2023150132A1 (en) * | 2022-02-01 | 2023-08-10 | Apple Inc. | Keyword detection using motion sensing |
Family Cites Families (24)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5199077A (en) * | 1991-09-19 | 1993-03-30 | Xerox Corporation | Wordspotting for voice editing and indexing |
| CA2088080C (en) * | 1992-04-02 | 1997-10-07 | Enrico Luigi Bocchieri | Automatic speech recognizer |
| US5623578A (en) * | 1993-10-28 | 1997-04-22 | Lucent Technologies Inc. | Speech recognition system allows new vocabulary words to be added without requiring spoken samples of the words |
| US5768474A (en) * | 1995-12-29 | 1998-06-16 | International Business Machines Corporation | Method and system for noise-robust speech processing with cochlea filters in an auditory model |
| US5960395A (en) | 1996-02-09 | 1999-09-28 | Canon Kabushiki Kaisha | Pattern matching method, apparatus and computer readable memory medium for speech recognition using dynamic programming |
| DE69838967T2 (de) | 1997-02-07 | 2008-05-08 | Casio Computer Co., Ltd. | Netzwerksystem zur informationsversorgung an mobilen terminal |
| JP3790038B2 (ja) * | 1998-03-31 | 2006-06-28 | 株式会社東芝 | サブワード型不特定話者音声認識装置 |
| US6292778B1 (en) * | 1998-10-30 | 2001-09-18 | Lucent Technologies Inc. | Task-independent utterance verification with subword-based minimum verification error training |
| JP2001042891A (ja) * | 1999-07-27 | 2001-02-16 | Suzuki Motor Corp | 音声認識装置、音声認識搭載装置、音声認識搭載システム、音声認識方法、及び記憶媒体 |
| US20060074664A1 (en) | 2000-01-10 | 2006-04-06 | Lam Kwok L | System and method for utterance verification of chinese long and short keywords |
| GB0028277D0 (en) * | 2000-11-20 | 2001-01-03 | Canon Kk | Speech processing system |
| EP1215661A1 (en) * | 2000-12-14 | 2002-06-19 | TELEFONAKTIEBOLAGET L M ERICSSON (publ) | Mobile terminal controllable by spoken utterances |
| US7027987B1 (en) * | 2001-02-07 | 2006-04-11 | Google Inc. | Voice interface for a search engine |
| JP4655184B2 (ja) * | 2001-08-01 | 2011-03-23 | ソニー株式会社 | 音声認識装置および方法、記録媒体、並びにプログラム |
| CN100349206C (zh) * | 2005-09-12 | 2007-11-14 | 周运南 | 文字语音互转装置 |
| KR100679051B1 (ko) | 2005-12-14 | 2007-02-05 | 삼성전자주식회사 | 복수의 신뢰도 측정 알고리즘을 이용한 음성 인식 장치 및방법 |
| CN101320561A (zh) * | 2007-06-05 | 2008-12-10 | 赛微科技股份有限公司 | 提升个人语音识别率的方法及模块 |
| DK2293289T3 (da) * | 2008-06-06 | 2012-06-25 | Raytron Inc | Talegenkendelsessystem og fremgangsmåde |
| JP5375423B2 (ja) * | 2009-08-10 | 2013-12-25 | 日本電気株式会社 | 音声認識システム、音声認識方法および音声認識プログラム |
| US8438028B2 (en) * | 2010-05-18 | 2013-05-07 | General Motors Llc | Nametag confusability determination |
| US9117449B2 (en) | 2012-04-26 | 2015-08-25 | Nuance Communications, Inc. | Embedded system for construction of small footprint speech recognition with user-definable constraints |
| US9672815B2 (en) | 2012-07-20 | 2017-06-06 | Interactive Intelligence Group, Inc. | Method and system for real-time keyword spotting for speech analytics |
| US10019983B2 (en) | 2012-08-30 | 2018-07-10 | Aravind Ganapathiraju | Method and system for predicting speech recognition performance using accuracy scores |
| CN104700832B (zh) * | 2013-12-09 | 2018-05-25 | 联发科技股份有限公司 | 语音关键字检测系统及方法 |
-
2014
- 2014-08-22 US US14/466,644 patent/US9953632B2/en active Active
-
2015
- 2015-04-08 WO PCT/US2015/024873 patent/WO2015160586A1/en active Application Filing
- 2015-04-08 JP JP2016562023A patent/JP2017515147A/ja not_active Ceased
- 2015-04-08 KR KR1020167030186A patent/KR20160145634A/ko unknown
- 2015-04-08 BR BR112016024086A patent/BR112016024086A2/pt not_active IP Right Cessation
- 2015-04-08 EP EP15717387.3A patent/EP3132442B1/en active Active
- 2015-04-08 CN CN201580020007.2A patent/CN106233374B/zh active Active
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20190100334A (ko) * | 2016-12-27 | 2019-08-28 | 구글 엘엘씨 | 문맥상의 핫워드들 |
| US11430442B2 (en) | 2016-12-27 | 2022-08-30 | Google Llc | Contextual hotwords |
| KR20200037245A (ko) * | 2018-09-28 | 2020-04-08 | 소노스 인코포레이티드 | 뉴럴 네트워크 모델을 사용하여 선택적 활성 단어 검출을 위한 시스템 및 방법 |
| KR20210120138A (ko) * | 2018-09-28 | 2021-10-06 | 소노스 인코포레이티드 | 뉴럴 네트워크 모델을 사용하여 선택적 활성 단어 검출을 위한 시스템 및 방법 |
| KR20230085214A (ko) * | 2018-09-28 | 2023-06-13 | 소노스 인코포레이티드 | 뉴럴 네트워크 모델을 사용하여 선택적 활성 단어 검출을 위한 시스템 및 방법 |
Also Published As
| Publication number | Publication date |
|---|---|
| BR112016024086A2 (pt) | 2017-08-15 |
| CN106233374B (zh) | 2020-01-10 |
| CN106233374A (zh) | 2016-12-14 |
| WO2015160586A1 (en) | 2015-10-22 |
| US9953632B2 (en) | 2018-04-24 |
| EP3132442A1 (en) | 2017-02-22 |
| US20150302847A1 (en) | 2015-10-22 |
| EP3132442B1 (en) | 2018-07-04 |
| JP2017515147A (ja) | 2017-06-08 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US9953632B2 (en) | Keyword model generation for detecting user-defined keyword | |
| JP6945695B2 (ja) | 発話分類器 | |
| US9837068B2 (en) | Sound sample verification for generating sound detection model | |
| US9443527B1 (en) | Speech recognition capability generation and control | |
| JP6550068B2 (ja) | 音声認識における発音予測 | |
| US8019604B2 (en) | Method and apparatus for uniterm discovery and voice-to-voice search on mobile device | |
| JP6507316B2 (ja) | 外部データソースを用いた音声の再認識 | |
| US11862174B2 (en) | Voice command processing for locked devices | |
| US20150302856A1 (en) | Method and apparatus for performing function by speech input | |
| CN111312231B (zh) | 音频检测方法、装置、电子设备及可读存储介质 | |
| US11495235B2 (en) | System for creating speaker model based on vocal sounds for a speaker recognition system, computer program product, and controller, using two neural networks | |
| US11074909B2 (en) | Device for recognizing speech input from user and operating method thereof | |
| KR102394912B1 (ko) | 음성 인식을 이용한 주소록 관리 장치, 차량, 주소록 관리 시스템 및 음성 인식을 이용한 주소록 관리 방법 | |
| US20240087562A1 (en) | Interactive content output | |
| US20230360633A1 (en) | Speech processing techniques | |
| US11564194B1 (en) | Device communication | |
| US11328713B1 (en) | On-device contextual understanding | |
| KR20210098250A (ko) | 전자 장치 및 이의 제어 방법 | |
| JP6811865B2 (ja) | 音声認識装置および音声認識方法 |