JP2017126185A - 符号化プログラム、符号化方法、符号化装置、復号化プログラム、復号化方法および復号化装置 - Google Patents
符号化プログラム、符号化方法、符号化装置、復号化プログラム、復号化方法および復号化装置 Download PDFInfo
- Publication number
- JP2017126185A JP2017126185A JP2016004797A JP2016004797A JP2017126185A JP 2017126185 A JP2017126185 A JP 2017126185A JP 2016004797 A JP2016004797 A JP 2016004797A JP 2016004797 A JP2016004797 A JP 2016004797A JP 2017126185 A JP2017126185 A JP 2017126185A
- Authority
- JP
- Japan
- Prior art keywords
- encoding
- document
- character string
- unit
- code
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
- 238000000034 method Methods 0.000 title claims abstract description 112
- 238000010586 diagram Methods 0.000 description 36
- 230000003068 static effect Effects 0.000 description 28
- 230000036760 body temperature Effects 0.000 description 10
- 230000006870 function Effects 0.000 description 6
- 230000006835 compression Effects 0.000 description 5
- 238000007906 compression Methods 0.000 description 5
- 230000000694 effects Effects 0.000 description 5
- 238000004458 analytical method Methods 0.000 description 3
- 201000010099 disease Diseases 0.000 description 3
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 3
- 239000003814 drug Substances 0.000 description 2
- 229940079593 drug Drugs 0.000 description 2
- 230000010365 information processing Effects 0.000 description 2
- 238000004220 aggregation Methods 0.000 description 1
- 230000002776 aggregation Effects 0.000 description 1
- 238000004891 communication Methods 0.000 description 1
- 239000000470 constituent Substances 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 230000010354 integration Effects 0.000 description 1
- 238000005065 mining Methods 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 230000001105 regulatory effect Effects 0.000 description 1
- 239000004065 semiconductor Substances 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
- 238000012916 structural analysis Methods 0.000 description 1
Images


















Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/80—Information retrieval; Database structures therefor; File system structures therefor of semi-structured data, e.g. markup language structured data such as SGML, XML or HTML
- G06F16/81—Indexing, e.g. XML tags; Data structures therefor; Storage structures
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/10—Text processing
- G06F40/12—Use of codes for handling textual entities
- G06F40/14—Tree-structured documents
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/10—Text processing
- G06F40/12—Use of codes for handling textual entities
- G06F40/126—Character encoding
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/10—Text processing
- G06F40/12—Use of codes for handling textual entities
- G06F40/137—Hierarchical processing, e.g. outlines
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/10—Text processing
- G06F40/12—Use of codes for handling textual entities
- G06F40/14—Tree-structured documents
- G06F40/143—Markup, e.g. Standard Generalized Markup Language [SGML] or Document Type Definition [DTD]
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/10—Text processing
- G06F40/12—Use of codes for handling textual entities
- G06F40/14—Tree-structured documents
- G06F40/146—Coding or compression of tree-structured data
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/10—Text processing
- G06F40/12—Use of codes for handling textual entities
- G06F40/151—Transformation
- G06F40/157—Transformation using dictionaries or tables
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Computational Linguistics (AREA)
- General Health & Medical Sciences (AREA)
- Health & Medical Sciences (AREA)
- Artificial Intelligence (AREA)
- Software Systems (AREA)
- Data Mining & Analysis (AREA)
- Databases & Information Systems (AREA)
- Document Processing Apparatus (AREA)
- Compression, Expansion, Code Conversion, And Decoders (AREA)
Abstract
Description
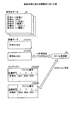
最初に、図1を用いて符号化処理の概要について説明する。図1は、符号化処理の流れを概略的に示した図である。以下では、構造化された文書が記憶された符号化対象ファイル30を符号化する場合を例に説明する。
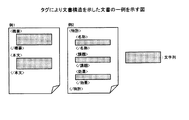
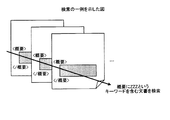
次に、図2Aを用いて、実施例1にかかる符号化装置10が実施する検索処理の概要について説明する。図2Aは、検索処理の流れを概略的に示した図である。図2Aの例では、図1により符号化された符号化データ32と、辞書データ31A、31Bと、インデックス33A、33Bが示されている。なお、図2Aの例では、圧縮データ32に符号化された文字列を識別しやすくするため、符号の後に括弧記号「()」で囲んで符号化された文字列を記載している。
次に、符号化装置10の構成について説明する。図3は、符号化装置の構成の一例を示す図である。符号化装置10は、構造化された文書の圧縮などの符号化を行う装置である。符号化装置10は、例えば、パーソナルコンピュータ、サーバコンピュータなどのコンピュータや、タブレット端末、スマートフォンなどの情報処理装置である。符号化装置10は、1台のコンピュータとして実装してもよく、また、複数台のコンピュータによるクラウドとして実装することもできる。なお、本実施例では、符号化装置10を1台のコンピュータとした場合を例として説明する。図3に示すように、符号化装置10は、記憶部20と、制御部21とを有する。なお、符号化装置10は、コンピュータや情報処理装置が有する上記の機器以外の他の機器を有してもよい。また、本実施例では、符号化装置10により符号化およびファイル検索を行う場合を例として説明するが、符号化とファイル検索は別な装置で行ってもよい。
本実施例に係る符号化装置10が符号化対象ファイル30を符号化する符号化処理の流れについて説明する。図11は、符号化処理の手順の一例を示すフローチャートである。この符号化処理は、所定のタイミング、例えば、符号化対象ファイル30を指定して符号化開始を指示する所定操作が行われたタイミングで実行される。
上述してきたように、本実施例に係る符号化装置10は、構造化された文書の文書構造を特定する。符号化装置10は、文書構造を特定した文書中の特定階層の文字列を、当該文書構造に対応した階層構造に応じた符号化方式により符号化する。これにより、符号化装置10は、特定階層の部分の符号のみを復号化できるため、活用する際の処理量を減らすことができる。
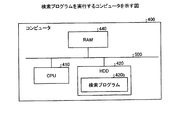
また、上記の実施例で説明した各種の処理は、あらかじめ用意されたプログラムをパーソナルコンピュータやワークステーションなどのコンピュータシステムで実行することによって実現することもできる。そこで、以下では、上記の実施例と同様の機能を有するプログラムを実行するコンピュータシステムの一例を説明する。最初に、符号化処理を行う符号化プログラムについて説明する。図16は、符号化プログラムを実行するコンピュータの一例を示す図である。
次に、符号化データ32を検索する検索プログラムについて説明する。図17は、復号化プログラムを実行するコンピュータの一例を示す図である。なお、図16と同一の部分については同一の符号を付して、説明を省略する。
次に、検索条件を満たすファイルを復号化する復号化プログラムについて説明する。図18は、復号化プログラムを実行するコンピュータの一例を示す図である。なお、図16および図17と同一の部分については同一の符号を付して、説明を省略する。
20 記憶部
21 制御部
30 符号化対象ファイル
31 辞書データ
32 符号化データ
33 インデックス
34 静的辞書
35 動的辞書
40 符号化処理部
41 特定部
42 符号化部
43 生成部
50 ファイル検索部
51 受付部
52 検索部
53 出力部
60 復号化処理部
61 受付部
62 復号化部
70 XMLスキーマ
Claims (11)
- コンピュータに、
構造化された第1の文書の文書構造を特定し、
文書構造を特定した前記第1の文書中の特定階層の文字列を、当該文書構造に対応した階層構造に応じた符号化方式により符号化する
処理を実行させることを特徴とする符号化プログラム。 - 前記符号化する処理は、前記第1の文書中の文書構造を規定する文字列を、共通の符号化方式により符号化する
ことを特徴とする請求項1に記載の符号化プログラム。 - 前記符号化する処理は、データ属性が類似する階層の文字列を同じ符号化方式により符号化する
ことを特徴とする請求項1または2に記載の符号化プログラム。 - 前記符号化する処理は、前記特定階層の文字列を、当該特定階層に出現する文字列の特性に対応した符号化方式により符号化する
ことを特徴とする請求項1〜3の何れか1つに記載の符号化プログラム。 - 前記符号化する処理は、1またはデータ属性が類似する複数の階層ごとに、出現頻度の高いパターンを短い符号に変換する符号化方式により符号化する
ことを特徴とする請求項1〜4の何れか1つに記載の符号化プログラム。 - コンピュータに、
符号化方式ごとに、符号化した文字列に出現したパターンを示したインデックスを生成する
処理をさらに実行させることを特徴とする請求項1〜5の何れか1つに記載の符号化プログラム。 - コンピュータが、
構造化された第1の文書の文書構造を特定し、
文書構造を特定した前記第1の文書中の特定階層の文字列を、当該文書構造に対応した階層構造に応じた符号化方式により符号化する
処理を実行することを特徴とする符号化方法。 - 構造化された第1の文書の文書構造を特定する特定部と、
前記特定部により文書構造が特定された前記第1の文書中の特定階層の文字列を、当該文書構造に対応した階層構造に応じた符号化方式により符号化する符号化部と、
を有することを特徴とする符号化装置。 - コンピュータに、
構造化された第1の文書が、当該第1の文書の文書構造に対応した階層構造に応じた符号化方式により符号化された符号化データの特定階層の文字列を、当該特定階層の符号化方式により復号化する
処理を実行させることを特徴とする復号化プログラム。 - コンピュータが、
構造化された第1の文書が、当該第1の文書の文書構造に対応した階層構造に応じた符号化方式により符号化された符号化データの特定階層の文字列を、当該特定階層の符号化方式により復号化する
処理を実行することを特徴とする復号化方法。 - 構造化された第1の文書が、当該第1の文書の文書構造に対応した階層構造に応じた符号化方式により符号化された符号化データの特定階層の文字列を、当該特定階層の符号化方式により復号化する復号化部
を有することを特徴とする復号化装置。
Priority Applications (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2016004797A JP2017126185A (ja) | 2016-01-13 | 2016-01-13 | 符号化プログラム、符号化方法、符号化装置、復号化プログラム、復号化方法および復号化装置 |
| US15/370,558 US20170199849A1 (en) | 2016-01-13 | 2016-12-06 | Encoding method, encoding device, decoding method, decoding device, and computer-readable recording medium |
| EP16203709.7A EP3193260A3 (en) | 2016-01-13 | 2016-12-13 | Encoding program, encoding method, encoding device, decoding program, decoding method, and decoding device |
| CN201611198404.1A CN107025212A (zh) | 2016-01-13 | 2016-12-22 | 编码方法、编码装置、解码方法和解码装置 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2016004797A JP2017126185A (ja) | 2016-01-13 | 2016-01-13 | 符号化プログラム、符号化方法、符号化装置、復号化プログラム、復号化方法および復号化装置 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2017126185A true JP2017126185A (ja) | 2017-07-20 |
Family
ID=57681263
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2016004797A Pending JP2017126185A (ja) | 2016-01-13 | 2016-01-13 | 符号化プログラム、符号化方法、符号化装置、復号化プログラム、復号化方法および復号化装置 |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US20170199849A1 (ja) |
| EP (1) | EP3193260A3 (ja) |
| JP (1) | JP2017126185A (ja) |
| CN (1) | CN107025212A (ja) |
Families Citing this family (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6737117B2 (ja) * | 2016-10-07 | 2020-08-05 | 富士通株式会社 | 符号化データ検索プログラム、符号化データ検索方法および符号化データ検索装置 |
| CN107608966A (zh) * | 2017-09-14 | 2018-01-19 | 武汉光谷信息技术股份有限公司 | 一种中文分词方法及系统 |
| JP7159557B2 (ja) * | 2017-12-28 | 2022-10-25 | 富士通株式会社 | 動的辞書の生成プログラム、動的辞書の生成方法および復号化装置 |
| CN110309376A (zh) * | 2019-07-10 | 2019-10-08 | 深圳市友华软件科技有限公司 | 嵌入式平台的配置条目管理方法 |
Family Cites Families (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP3277792B2 (ja) * | 1996-01-31 | 2002-04-22 | 株式会社日立製作所 | データ圧縮方法および装置 |
| US5991713A (en) * | 1997-11-26 | 1999-11-23 | International Business Machines Corp. | Efficient method for compressing, storing, searching and transmitting natural language text |
| JP2002297568A (ja) | 2001-03-29 | 2002-10-11 | Fujitsu Ltd | 構造化文書符号化装置及び記録媒体 |
| JP3832807B2 (ja) * | 2001-06-28 | 2006-10-11 | インターナショナル・ビジネス・マシーンズ・コーポレーション | データ処理方法及びその手法を用いたエンコーダ、デコーダ並びにxmlパーサ |
| JP2005018672A (ja) | 2003-06-30 | 2005-01-20 | Hitachi Ltd | 構造化文書の圧縮方法 |
| AU2003245222A1 (en) * | 2003-07-08 | 2005-01-21 | Telefonaktiebolaget Lm Ericsson (Publ) | Method for compressing markup languages files, by replacing a long word with a shorter word |
| JP4168946B2 (ja) | 2004-01-29 | 2008-10-22 | Kddi株式会社 | 文書データの符号化又は復号化方法及びそのプログラム |
| US20060085737A1 (en) * | 2004-10-18 | 2006-04-20 | Nokia Corporation | Adaptive compression scheme |
| US7441185B2 (en) * | 2005-01-25 | 2008-10-21 | Microsoft Corporation | Method and system for binary serialization of documents |
| US7739586B2 (en) * | 2005-08-19 | 2010-06-15 | Microsoft Corporation | Encoding of markup language data |
| US8850309B2 (en) * | 2008-03-27 | 2014-09-30 | Canon Kabushiki Kaisha | Optimized methods and devices for the analysis, processing and evaluation of expressions of the XPath type on data of the binary XML type |
| FR2943441A1 (fr) * | 2009-03-18 | 2010-09-24 | Canon Kk | Procede de codage ou decodage d'un document structure a l'aide d'un schema xml, dispositif et structure de donnees associes |
-
2016
- 2016-01-13 JP JP2016004797A patent/JP2017126185A/ja active Pending
- 2016-12-06 US US15/370,558 patent/US20170199849A1/en not_active Abandoned
- 2016-12-13 EP EP16203709.7A patent/EP3193260A3/en not_active Ceased
- 2016-12-22 CN CN201611198404.1A patent/CN107025212A/zh active Pending
Also Published As
| Publication number | Publication date |
|---|---|
| US20170199849A1 (en) | 2017-07-13 |
| CN107025212A (zh) | 2017-08-08 |
| EP3193260A3 (en) | 2017-08-09 |
| EP3193260A2 (en) | 2017-07-19 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP4755427B2 (ja) | データベース・アクセス・システム、データベース・アクセス方法 | |
| US7730099B2 (en) | Storage and retrieval of richly typed hierarchical network models | |
| WO2017059798A1 (zh) | 序列化与反序列化的方法、装置、系统以及电子设备 | |
| JP2017126185A (ja) | 符号化プログラム、符号化方法、符号化装置、復号化プログラム、復号化方法および復号化装置 | |
| CN105975495A (zh) | 大数据的存储、搜索方法及装置 | |
| US20170302292A1 (en) | Computer-readable recording medium, encoding device, and encoding method | |
| CN112912870A (zh) | 租户标识符的转换 | |
| US10303672B2 (en) | System and method for search indexing | |
| CN106570153A (zh) | 一种海量url的数据提取方法及系统 | |
| JP6613669B2 (ja) | 圧縮プログラム、圧縮方法、情報処理装置、置換プログラムおよび置換方法 | |
| EP4046052A1 (en) | Customizable delimited text compression framework | |
| CN111201532B (zh) | k-匿名化装置、方法以及记录介质 | |
| JP6977565B2 (ja) | 検索結果出力プログラム、検索結果出力装置および検索結果出力方法 | |
| JP7390356B2 (ja) | クローニング後のテナント識別子変換のためのレコードの識別 | |
| JP6931442B2 (ja) | 符号化プログラム、インデックス生成プログラム、検索プログラム、符号化装置、インデックス生成装置、検索装置、符号化方法、インデックス生成方法および検索方法 | |
| JP6299307B2 (ja) | ストレージシステム、ストレージ方法、及び、プログラム | |
| JP2016170750A (ja) | データ管理プログラム、情報処理装置およびデータ管理方法 | |
| JP5867208B2 (ja) | データモデル変換プログラム、データモデル変換方法およびデータモデル変換装置 | |
| US10803243B2 (en) | Method, device, and medium for restoring text using index which associates coded text and positions thereof in text data | |
| JP6123344B2 (ja) | 画面プログラム生成装置及びその画面プログラム生成方法、情報処理装置、並びにコンピュータ・プログラム | |
| CN114331745A (zh) | 数据处理方法、系统、程序产品、介质和电子设备 | |
| KR102738408B1 (ko) | 사물데이터 관리장치 및 그 동작 방법 | |
| KR102500278B1 (ko) | 대량의 lod 저장을 위한 맵리듀스 기반 데이터 변환 시스템 및 방법 | |
| US20160210304A1 (en) | Computer-readable recording medium, information processing apparatus, and conversion process method | |
| JP6658908B2 (ja) | 出力プログラム、出力方法および出力システム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20180912 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20190417 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20190604 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20190730 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20191224 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20200324 |
|
| C60 | Trial request (containing other claim documents, opposition documents) |
Free format text: JAPANESE INTERMEDIATE CODE: C60 Effective date: 20200324 |
|
| A911 | Transfer to examiner for re-examination before appeal (zenchi) |
Free format text: JAPANESE INTERMEDIATE CODE: A911 Effective date: 20200406 |
|
| C21 | Notice of transfer of a case for reconsideration by examiners before appeal proceedings |
Free format text: JAPANESE INTERMEDIATE CODE: C21 Effective date: 20200407 |
|
| A912 | Re-examination (zenchi) completed and case transferred to appeal board |
Free format text: JAPANESE INTERMEDIATE CODE: A912 Effective date: 20200515 |
|
| C211 | Notice of termination of reconsideration by examiners before appeal proceedings |
Free format text: JAPANESE INTERMEDIATE CODE: C211 Effective date: 20200519 |
|
| C22 | Notice of designation (change) of administrative judge |
Free format text: JAPANESE INTERMEDIATE CODE: C22 Effective date: 20201208 |
|
| C13 | Notice of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: C13 Effective date: 20210316 |
|
| C23 | Notice of termination of proceedings |
Free format text: JAPANESE INTERMEDIATE CODE: C23 Effective date: 20210615 |
|
| C609 | Written withdrawal of request for trial/appeal |
Free format text: JAPANESE INTERMEDIATE CODE: C609 Effective date: 20210617 |