JP2017111760A - Emotion estimation device creation method, emotion estimation device creation device, emotion estimation method, emotion estimation device and program - Google Patents
Emotion estimation device creation method, emotion estimation device creation device, emotion estimation method, emotion estimation device and program Download PDFInfo
- Publication number
- JP2017111760A JP2017111760A JP2015247885A JP2015247885A JP2017111760A JP 2017111760 A JP2017111760 A JP 2017111760A JP 2015247885 A JP2015247885 A JP 2015247885A JP 2015247885 A JP2015247885 A JP 2015247885A JP 2017111760 A JP2017111760 A JP 2017111760A
- Authority
- JP
- Japan
- Prior art keywords
- emotion
- feature amount
- section
- mora
- speech
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images














Abstract
Description
本発明は、感情推定器生成方法、感情推定器生成装置、感情推定方法、感情推定装置及びプログラムに関する。 The present invention relates to an emotion estimator generation method, an emotion estimator generation device, an emotion estimation method, an emotion estimation device, and a program.
感情をラベリングした音声データ群を教師データとして機械学習により生成された感情推定装置を用いて、発話者の感情を推定する技術の開発が進められている。例えば、特許文献1は、音声の強度、音声のテンポ、音声の抑揚のそれぞれの変化量を求め、求めた変化量に基づいて発話者の感情を推定する技術を開示している。
Development of a technique for estimating a speaker's emotion using an emotion estimation device generated by machine learning using a voice data group in which emotions are labeled as teacher data is underway. For example,
一般に、興奮した状態で発話すると、通常の発話時よりも話し方が早くなり、声が高くなる傾向がある。また、落胆した状態で発話すると、通常の発話時よりも話し方が遅くなり、声が低くなる傾向がある。このように、発話時の発話者の感情と音声の特徴量とは相関性がある。特許文献1は、このような音声データの特徴量の変化を解析することにより、発話者の感情を推定する技術を開示している。
In general, speaking in an excited state tends to be faster and louder than normal speech. In addition, when speaking in a discouraged state, speaking tends to be slower than normal speech, and the voice tends to be low. Thus, there is a correlation between the emotion of the speaker at the time of speaking and the feature amount of the voice.
ところで、通常の感情状態で発話された音声の特徴量と怒った感情状態で発話された音声の特徴量とを比較した場合、短い言葉と長い言葉とでは特徴量の変化の傾向が異なる場合がある。例えば、発話しやすい短い言葉は、発話時の感情状態によって音声の特徴量の変化が大きい場合が多い。これに対して、早口言葉のように発話しにくい長い言葉は、発話時の感情状態によって音声の特徴量の変化が小さい場合がある。特許文献1が開示する技術は、このように発話時の感情状態によって音声の特徴量に変化が少ない言葉と変化が大きい言葉とを一律にして発話者の感情推定を行うので、推定精度が上がりにくいという問題があった。
By the way, when comparing the feature quantity of speech uttered in a normal emotional state with the feature quantity of speech uttered in an angry emotional state, the tendency of changes in feature quantities may differ between short words and long words. is there. For example, a short word that is easy to utter often has a large change in voice feature value depending on the emotional state at the time of utterance. On the other hand, a long word that is difficult to utter, such as a quick-speaking word, may have a small change in voice feature value depending on the emotional state at the time of utterance. Since the technique disclosed in
本発明は、このような状況を鑑みてなされたものであり、音声データから発話者の感情を推定する推定精度を向上することができる感情推定器生成方法、感情推定器生成装置、感情推定方法、感情推定装置及びプログラムを提供することを目的とする。 The present invention has been made in view of such circumstances, and an emotion estimator generation method, an emotion estimator generation device, and an emotion estimation method capable of improving the estimation accuracy for estimating the emotion of a speaker from speech data An object is to provide an emotion estimation apparatus and program.
上記目的を達成するため、本発明の第1の観点に係る感情推定器生成方法は、
教師データの元となる音声データの特徴量を解析する解析区間を設定する解析区間設定ステップと、
前記解析区間に含まれる音声データの特徴量の変化するパターンを、複数のクラスに分類された変化パターンに基づいて、前記解析区間に含まれる音声データの特徴量の変化パターンとして決定する変化パターン決定ステップと、
前記特徴量の変化パターンごとに分類された音声データを教師データとして、前記特徴量の変化パターンごとに、音声を発話したときの発話者の感情を推定する感情推定器を生成する感情推定器生成ステップと、
を含むことを特徴とする。
In order to achieve the above object, an emotion estimator generation method according to the first aspect of the present invention includes:
An analysis interval setting step for setting an analysis interval for analyzing the feature amount of the voice data that is the source of the teacher data;
Change pattern determination for determining a pattern in which the feature amount of the voice data included in the analysis section changes as a pattern of change in the feature amount of the voice data included in the analysis section, based on the change patterns classified into a plurality of classes. Steps,
Generation of an emotion estimator for generating an emotion estimator for estimating an emotion of a speaker when speech is uttered for each feature value change pattern, using the voice data classified for each feature value change pattern as teacher data Steps,
It is characterized by including.
また、本発明の第2の観点に係る感情推定器生成装置は、
教師データの元となる音声データの特徴量を解析する解析区間を設定する解析区間設定手段と、
前記解析区間に含まれる音声データの特徴量の変化するパターンを、複数のクラスに分類された変化パターンに基づいて、前記解析区間に含まれる音声データの特徴量の変化パターンとして決定する変化パターン決定手段と、
前記特徴量の変化パターンごとに分類された音声データを教師データとして、前記特徴量の変化パターンごとに、音声を発話したときの発話者の感情を推定する感情推定器を生成する感情推定器生成手段と、
を含むことを特徴とする。
Moreover, the emotion estimator generation device according to the second aspect of the present invention provides:
An analysis interval setting means for setting an analysis interval for analyzing a feature amount of voice data that is a source of teacher data;
Change pattern determination for determining a pattern in which the feature amount of the voice data included in the analysis section changes as a pattern of change in the feature amount of the voice data included in the analysis section, based on the change patterns classified into a plurality of classes. Means,
Generation of an emotion estimator for generating an emotion estimator for estimating an emotion of a speaker when speech is uttered for each feature value change pattern, using the voice data classified for each feature value change pattern as teacher data Means,
It is characterized by including.
また、本発明の第3の観点に係るプログラムは、
コンピュータを
教師データの元となる音声データの特徴量を解析する解析区間を設定する解析区間設定手段、
前記解析区間に含まれる音声データの特徴量の変化するパターンを、複数のクラスに分類された変化パターンに基づいて、前記解析区間に含まれる音声データの特徴量の変化パターンとして決定する変化パターン決定手段、
前記特徴量の変化パターンごとに分類された音声データを教師データとして、前記特徴量の変化パターンごとに、音声を発話したときの発話者の感情を推定する感情推定器を生成する感情推定器生成手段、
として機能させることを特徴とする。
A program according to the third aspect of the present invention is:
Analysis interval setting means for setting an analysis interval for analyzing features of speech data that is a source of teacher data on a computer;
Change pattern determination for determining a pattern in which the feature amount of the voice data included in the analysis section changes as a pattern of change in the feature amount of the voice data included in the analysis section, based on the change patterns classified into a plurality of classes. means,
Generation of an emotion estimator for generating an emotion estimator for estimating an emotion of a speaker when speech is uttered for each feature value change pattern, using the voice data classified for each feature value change pattern as teacher data means,
It is made to function as.
また、本発明の第4の観点に係る感情推定方法は、
解析対象とする音声データの特徴量を解析する解析区間を設定する解析区間設定ステップと、
前記解析区間に含まれる音声データの特徴量の変化するパターンを、複数のクラスに分類された変化パターンに基づいて、前記解析区間に含まれる音声データの特徴量の変化パターンとして決定する変化パターン決定ステップと、
前記特徴量の変化パターンごとに、同じ特徴量の変化パターンを有する教師データに基づいて生成された感情推定器を用いて、前記解析区間の音声を発話した時の発話者の感情を推定する感情推定ステップと、
を含むことを特徴とする。
Moreover, the emotion estimation method according to the fourth aspect of the present invention includes:
An analysis interval setting step for setting an analysis interval for analyzing the feature amount of the audio data to be analyzed;
Change pattern determination for determining a pattern in which the feature amount of the voice data included in the analysis section changes as a pattern of change in the feature amount of the voice data included in the analysis section, based on the change patterns classified into a plurality of classes. Steps,
Emotion that estimates the emotion of the speaker when the speech of the analysis section is uttered using an emotion estimator generated based on teacher data having the same feature amount change pattern for each feature amount change pattern An estimation step;
It is characterized by including.
また、本発明の第5の観点に係る感情推定装置は、
解析対象とする音声データの特徴量を解析する解析区間を設定する解析区間設定手段と、
前記解析区間に含まれる音声データの特徴量の変化するパターンを、複数のクラスに分類された変化パターンに基づいて、前記解析区間に含まれる音声データの特徴量の変化パターンとして決定する変化パターン決定手段と、
前記特徴量の変化パターンごとに、同じ特徴量の変化パターンを有する教師データに基づいて生成された感情推定器を用いて、前記解析区間の音声を発話した時の発話者の感情を推定する感情推定手段と、
を備えることを特徴とする。
An emotion estimation apparatus according to the fifth aspect of the present invention is:
Analysis interval setting means for setting an analysis interval for analyzing the feature amount of the audio data to be analyzed;
Change pattern determination for determining a pattern in which the feature amount of the voice data included in the analysis section changes as a pattern of change in the feature amount of the voice data included in the analysis section, based on the change patterns classified into a plurality of classes. Means,
Emotion that estimates the emotion of the speaker when the speech of the analysis section is uttered using an emotion estimator generated based on teacher data having the same feature amount change pattern for each feature amount change pattern An estimation means;
It is characterized by providing.
本発明によれば、音声データから発話者の感情を推定する推定精度を向上することができる。 ADVANTAGE OF THE INVENTION According to this invention, the estimation precision which estimates a speaker's emotion from audio | voice data can be improved.
以下、本発明の実施形態に係る感情推定器生成方法、感情推定器生成装置、感情推定方法、感情推定装置及びプログラムについて、図面を参照しながら説明する。なお、図中同一又は相当する部分には同一符号を付す。 Hereinafter, an emotion estimator generation method, an emotion estimator generation device, an emotion estimation method, an emotion estimation device, and a program according to an embodiment of the present invention will be described with reference to the drawings. In the drawings, the same or corresponding parts are denoted by the same reference numerals.
(実施形態1)
本実施形態では、音声データから発話者の感情を推定する感情推定器を生成する感情推定器生成装置について説明した後、音声を発話した時の発話者の感情を推定する感情推定装置について説明する。本実施形態では、感情推定装置が、発話者の感情を悲しんでいる状態(悲しみ)、退屈している状態(退屈)、怒っている状態(怒り)、驚いている状態(驚き)、落胆している状態(落胆)、嫌悪感を抱いている状態(嫌悪)、喜んでいる状態(喜び)、の基本的な7種類の感情状態のいずれかであると推定する場合について説明する。
なお、以下の実施形態では、音声データの特徴量の変化パターンをアクセント型と称する。
(Embodiment 1)
In the present embodiment, after describing an emotion estimator generating device that generates an emotion estimator that estimates an emotion of a speaker from speech data, an emotion estimating device that estimates the emotion of the speaker when speaking the speech will be described. . In this embodiment, the emotion estimation device is in a state of sadness (sadness), bored state (boring), angry state (anger), surprised state (surprise), and discouraged. A case where it is estimated that the state is one of the seven basic emotional states, that is, a state of being disappointed (disappointed), a state of being disgusted (disgust), and a state of being happy (joy).
In the following embodiment, the change pattern of the feature amount of the audio data is referred to as an accent type.
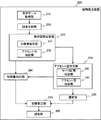
実施形態1に係る感情推定器生成装置100は、物理的には、図1に示すように、制御部1と、記憶部2と、入出力部3と、バス4と、を備える。
The emotion
制御部1は、ROM(Read Only Memory)と、RAM(Random Access Memory)と、CPU(Central Processing Unit)と、を備える。ROMは、本実施形態に係る感情推定器生成プログラム、及び、各種初期設定、ハードウェアの検査、プログラムのロード等を行うための初期プログラム等を記憶する。RAMは、CPUが実行する各種ソフトウェアプログラム、これらのソフトウェアプログラムの実行に必要なデータ等を一時的に記憶するワークエリアとして機能する。CPUは、各種ソフトウェアプログラムを実行することにより、様々な処理及び演算を実行する中央演算処理部である。
The
記憶部2は、ハードディスクドライブ、フラッシュメモリ等の不揮発性メモリを備える。記憶部2は、教師データとする音声データ等を記憶する。
The
入出力部3は、教師データとする音声データを取得するための音声入力装置、CD(Compact Disc)ドライブ、USB(Universal Serial Bus)インタフェースを備える。入出力部3は、教師データとする音声データを取得する。また、入出力部3は、生成した感情推定器をプログラムもしくは感情推定器の特性を決めるパラメータを外部装置に出力する。
The input /
バス4は、制御部1と、記憶部2と、入出力部3と、を接続する。
The
感情推定器生成装置100は、機能的には、図2に示すように、音声データ取得部110と、解析区間設定部120と、アクセント型決定部130と、特徴量抽出部140と、感情推定器生成部150と、を含む。また、解析区間設定部120は、形態素解析部121とアクセント句抽出部122と、を含む。また、アクセント型決定部130は、モーラ区間抽出部131と、アクセント型抽出部132と、を含む。
As shown in FIG. 2, the emotion
音声データ取得部110は、入出力部3を介して感情推定器を生成するために教師データとして使用する音声データを取得する。教師データは、例えば、悲しみ、退屈、怒り、驚き、落胆、嫌悪、喜び、の7種類の感情状態で発話された音声から構成される。また、教師データは、十分に多くの種類の語句を含む音声データで構成される。教師データを発話する人数及び教師データに含まれるアクセント句の種類は多い方が好ましい。アクセント句とは、名詞と助詞、もしくは動詞と助動詞を結合した音声データを区分する単位である。例えば、教師データとして、500人程度の多人数が7種類の感情状態で発話した、1000種類以上のアクセント句を含む音声データを準備する。
The voice
解析区間設定部120は、教師データとする音声データの特徴を解析する単位である解析区間を設定する。そのために、解析区間設定部120は、形態素解析部121とアクセント句抽出部122とを備える。
The analysis
形態素解析部121は、取得した音声データを形態素に分割する。形態素とは、言語としての意味を有する最小単位である。例えば、「坊主が屏風に上手に坊主の絵を描いた」という音声は、図3に示すように、「坊主」、「が」、「屏風」、「に」、「上手」、「に」、「坊主」、「の」、「絵」、「を」、「描い」、「た」の12個の形態素に分割される。
The
アクセント句抽出部122は、取得した音声データからアクセント句を抽出する。アクセント句とは、形態素に分割した名詞又は動詞に、それに続く助詞又は助動詞を結合した区間である。上述の例では、アクセント句は、「坊主が」、「屏風に」、「上手に」、「坊主の」、「絵を」、「描いた」となる。本実施形態では、このアクセント句の単位で音声データの特徴を解析する場合について説明する。アクセント句の単位で音声データを解析する理由は、アクセント句の単位で発話者の感情状態が変化する場合が多いからである。
The accent
アクセント型決定部130は、アクセント句のアクセント型を決定する。アクセント型とは、アクセント句を構成する音節が発話されている区間であるモーラ区間ごとに、音声の特徴量が平均特徴量に対して大きい場合には「H」、小さい場合には「L」を付与して得られる「H」と「L」の組み合わせのパターンである。アクセント型を決定するために、アクセント型決定部130は、モーラ区間抽出部131とアクセント型抽出部132とを備える。
The accent
モーラ区間抽出部131は、図4に示すように、解析対象のアクセント句区間の音声データから、モーラ区間を抽出する。モーラ区間は1つの音節が発話されている区間である。アクセント句「坊主が」の場合で説明すると、「ボ」、「ウ」、「ズ」、「ガ」のそれぞれの音節がモーラ区間である。
As illustrated in FIG. 4, the mora
アクセント型抽出部132は、モーラ区間のそれぞれが「H」もしくは「L」のいずれに該当するかを判別し、アクセント句のアクセント型を抽出する。アクセント型の抽出方法には、音声の強度、音声のピッチ、音素の発話時間長等の特徴量を使用する方法がある。ここでは、音声のピッチに着目した抽出方法について、図5と図6を参照しながら説明する。
The accent
アクセント型抽出部132は、図5に示すように、モーラ区間をさらに細分する所定時間の時間窓を設定する。1つのモーラ区間に対して、窓1を設定し、その窓内の音声データをFFT(Fast Fourier Transform)変換する。次に、窓1を所定時間dtずらした窓2内の音声データをFFT変換する。以下、同様に窓n内の音声データをFFT変換する。時間窓の設定方法は、例えば、モーラ区間内に10以上の時間窓を構成するように時間窓とずらす時間幅dtを設定する。時間窓の数が少なすぎると、計算精度が低下するからである。
As shown in FIG. 5, the accent
図6は、上記のFFT変換により得られた各窓内の音声データのスペクトル分布を示した例である。横軸は周波数であり、縦軸はスペクトルの強度である。このスペクトルの中で最も低い周波数領域に存在するピーク周波数をf0とする。このf0は、その窓区間の音声データから得られた発話者固有の基本周波数を示す。窓1から得られたf0をf0_1、窓2から得られたf0をf0_2、とする。同様にして、窓nから得られたf0をf0_nとする。そして、アクセント型抽出部132は、f0_1からf0_nまでの平均値を計算し、第1モーラ区間の平均基本周波数1_f0とする。
FIG. 6 is an example showing the spectral distribution of the audio data in each window obtained by the above-described FFT conversion. The horizontal axis is frequency, and the vertical axis is spectrum intensity. The peak frequency existing in the lowest frequency region in this spectrum is defined as f0. This f0 indicates the fundamental frequency unique to the speaker obtained from the audio data of the window section. Let f0 obtained from
アクセント型抽出部132は、アクセント句に含まれる全てのモーラ区間について同様の計算をする。第mモーラ区間の平均基本周波数m_f0は、式1を用いて算出することができる。
The accent
m_f0=1/n・Σf0_n (式1) m_f0 = 1 / n ・ Σf0_n (Formula 1)
次に、アクセント型抽出部132は、アクセント句区間における平均基本周波数m_thを式2を用いて求める。
Next, the accent
m_th={max(1_f0,・・・,n_f0)−min(1_f0,・・・,n_f0)}/2 (式2) m_th = {max (1_f0, ..., n_f0) -min (1_f0, ..., n_f0)} / 2 (Formula 2)
次に、アクセント型抽出部132は、モーラ区間の平均基本周波数m_f0とアクセント句区間の平均基本周波数m_thとを比較し、m_f0≧m_thであれば「H」、m_f0<m_thであれば「L」をそれぞれのモーラ区間に付与する。アクセント型抽出部132は、このようにアクセント句を構成するモーラ区間ごとに「H」と「L」を付与することにより、HとLの組み合わせで構成されるアクセント型を抽出する。
Next, the accent
アクセント型決定部130は、教師データから生成されたアクセント句の全てについて、この処理を行う。図7に示すアクセント型の例は、大量の教師データから得られたアクセント型の中で発生頻度が高い順に20種類のアクセント型を選択した、モーラ区間数が6以下の例である。解析対象のアクセント句に含まれるモーラ区間の数が6以下である場合、この20種類のアクセント型に対して順にクラス1からクラス20までのクラス名を付与する。アクセント型とクラスとは1対1に対応している。アクセント型決定部130は、教師データとするアクセント句単位の音声データとアクセント型(クラス)とを対応付けて記憶部2に記憶する。なお、この20種類のアクセント型に該当しなかったアクセント句は、教師データから除外する。以後、本実施形態では、解析対象とするアクセント句に含まれるモーラ区間数が6以下である場合について説明する。
The accent
ここで、アクセント句に含まれるモーラ区間数が6以下の場合における20種類のアクセント型の選択方法は、7種類の感情で発話された大量の日本語を統計処理した実験結果に基づいて、発生頻度が高い順に20種類のアクセント型を選択する。アクセント型のクラス数を減らすと、アクセント型に該当しない教師データの頻度が高くなり、生成された感情推定器を内蔵した感情推定装置の推定精度が低下することになる。一方、アクセント型のクラス数を増やすと、生成する感情推定器の種類が増えるので感情推定装置の製造コストが高くなることになる。したがって、この2つの兼ね合いでアクセント型のクラス数を決定する。なお、アクセント型を20種類としたのはアクセント句に含まれるモーラ区間数が6以下の場合である日本語の場合の例である。アクセント句に含まれるモーラ区間数が7以上である場合、もしくは他の言語の場合は、アクセント型の発生頻度についてさらに統計処理して決める必要がある。 Here, when the number of mora sections included in an accent phrase is 6 or less, 20 types of accent types are selected based on the result of statistical processing of a large amount of Japanese spoken with 7 types of emotions. Twenty accent types are selected in descending order of frequency. If the number of classes of the accent type is reduced, the frequency of teacher data that does not correspond to the accent type increases, and the estimation accuracy of the emotion estimation device incorporating the generated emotion estimator decreases. On the other hand, when the number of accent-type classes is increased, the number of types of emotion estimators to be generated increases, and the manufacturing cost of the emotion estimation device increases. Therefore, the number of accent-type classes is determined based on the balance between the two. Note that the 20 accent types are examples in the case of Japanese, where the number of mora sections included in the accent phrase is 6 or less. When the number of mora sections included in the accent phrase is 7 or more, or in other languages, the frequency of occurrence of the accent type needs to be further statistically determined.
図2に戻って、特徴量抽出部140は、アクセント句ごとの音声の特徴量を抽出する。音声の特徴量とは、音声の大きさ、音声のピッチ、音素の発話時間長等である。そして、抽出した特徴量にアクセント型決定部130で決定したクラス1からクラス20のクラス名を付与し、教師データとして記憶部2に記憶する。
Returning to FIG. 2, the feature
感情推定器生成部150は、教師データをクラスごとに記憶部2から取得し、それぞれのクラスに適応した感情推定器を生成する。具体的には、感情推定器生成部150は、クラス1に分類された教師データを取得し、その教師データの発話時の感情状態を、7種類の感情状態である悲しんでいる状態(悲しみ)、退屈している状態(退屈)、怒っている状態(怒り)、驚いている状態(驚き)、落胆している状態(落胆)、嫌悪感を抱いている状態(嫌悪)、喜んでいる状態(喜び)、に分類するクラス1用の感情推定器を生成する。図8は、7種類の感情に識別する識別閾値を2次元で表現したイメージ図である。教師データに基づいて感情推定器を生成する方法には公知の技術を用いることができる。次に、感情推定器生成部150は、クラス2に分類された教師データを取得し、その教師データの発話時の感情状態を、7種類の感情状態である悲しみ、退屈、怒り、驚き、落胆、嫌悪、喜び、に分類するクラス2用の感情推定器を生成する。同様にして、感情推定器生成部150は、クラス20までの感情推定器を生成する。
The emotion
次に、上記の説明により生成した20種類の感情推定器を内蔵する感情推定装置200の構成について、図9を参照しながら説明する。感情推定装置200は、物理的には、図1に示す構成と同じである。
Next, the configuration of the
制御部1が備えるROMは、本実施形態に係る感情推定器生成装置100で生成された感情推定プログラムを記憶する。記憶部2は、解析対象とする音声データ等を記憶する。入出力部3は、解析対象とする音声データを取得するための音声入力装置、CDドライブ、USBインタフェースを備える。また、入出力部3は、感情推定器生成装置100で生成された感情推定器の特性を決定するパラメータを取得するようにしてもよい。また、入出力部3は、感情を推定した結果を出力するための表示装置もしくは音声出力装置を備える。
The ROM included in the
感情推定装置200は、図9に示すように、音声データ取得部210と、話者分割部220と、解析区間設定部230と、アクセント型決定部240と、選択部250と、特徴量抽出部260と、感情推定部270と、統合部280と、の機能を含む。また、解析区間設定部230は、形態素解析部231とアクセント句抽出部232との機能を含む。また、アクセント型決定部240は、モーラ区間抽出部241とアクセント型抽出部242との機能を含む。
As shown in FIG. 9, the
音声データ取得部210は、ユーザが発話した解析対象とする音声を取得する。音声データ取得部210は、マイク等の音声取得装置から構成される。また、音声データ取得部210は、CDドライブ、USBインタフェースを備え、音声データとしてユーザの音声を取得することもできる。 The voice data acquisition unit 210 acquires voice to be analyzed which is spoken by the user. The audio data acquisition unit 210 includes an audio acquisition device such as a microphone. The audio data acquisition unit 210 includes a CD drive and a USB interface, and can acquire the user's audio as audio data.
話者分割部220は、取得した解析対象の音声データを話者ごとに分割する。音声データの中に複数人の音声データが存在する場合、1人の話者が発話した文ごとに発話者の感情を推定するためである。音声データを話者ごとに分割する方法は、公知の技術を用いて行う。例えば、音声の強度、音声のピッチ、音素の発話時間長等の相関性に基づいて分割することができる。
The
解析区間設定部230、アクセント型決定部240は、感情推定器の生成時と同じ条件下で解析対象の音声データを解析するために、感情推定器生成装置100と同じ構成を有している。つまり、解析区間設定部230は、音声データからアクセント句を抽出し、アクセント型決定部240は、アクセント句ごとにアクセント型(クラス)を決定する。
The analysis
選択部250は、クラス分けされたアクセント句ごとに、該当するクラスに対応する感情推定器を選択する。具体的には、感情推定装置200に内蔵している20種類の感情推定器の中から、解析対象のアクセント句のクラスに対応する感情推定器を選択する。
The
特徴量抽出部260は、感情推定器生成装置100と同じ構成を有しており、同じ条件下で音声データから特徴量を抽出する。そして、特徴量抽出部260は、抽出した特徴量とアクセント型を示すクラス名とを対応付けて記憶部2に記憶する。
The feature
感情推定部270は、選択部250が選択した感情推定器を用いて、アクセント句ごとに発話者の感情を推定する。具体的には、感情推定部270は、クラス1に分類されたアクセント句の感情を推定する場合には、クラス1用の感情推定器を選択して発話者の感情を推定する。感情推定部270は、クラスnに分類されたアクセント句の感情を推定する場合には、クラスn用の感情推定器を選択して発話者の感情を推定する。そして、感情推定部270は、解析対象のアクセント句を発話したときの発話者の感情状態が、悲しみ、退屈、怒り、驚き、落胆、嫌悪、喜び、のいずれの感情状態に該当するかを推定する。
The
統合部280は、発話者の感情を音声データの文単位で推定する。具体的には、統合部280は、1文の中で最も多かった感情をその文を発話した発話者の感情として推定する。例えば、「坊主が」、「屏風に」、「上手に」、「坊主の」、「絵を」、「描い」、「た」の7つのアクセント句から構成される「坊主が屏風に上手に坊主の絵を描いた」という文において、「喜び」と判別されたアクセント句の数が4であり、「怒り」と判別されたアクセント句の数が2であり、「驚き」と判別されたアクセント句の数が1であった場合、一番多い「喜び」をこの「坊主が屏風に上手に坊主の絵を描いた」を発話したときの発話者の感情として推定する。
The
次に、以上の構成を有する感情推定器生成装置100が感情推定器を生成する処理について、図10を参照しながら説明する。教師データとして使用する悲しみ、退屈、怒り、驚き、落胆、嫌悪、喜び、の7種類の感情状態で発話された音声データは、予め記憶部2に記憶されているものとする。解析対象の音声データに含まれるアクセント句のモーラ区間数は6以下であると仮定する。感情推定器を生成する担当者が、感情推定器生成装置100に予めインストールされている感情推定器生成プログラムを起動することにより、図10に示すフローチャートは開始される。
Next, a process in which the emotion
制御部1は、感情推定器生成プログラムが起動されると、記憶部2に記憶されている教師データを音声データ取得部110に取得する(ステップS11)。そして、形態素解析部121は、取得した音声データを形態素の単位で分割する(ステップS12)。次に、アクセント句抽出部122は、音声データの特徴を解析する単位であるアクセント句を抽出し、音声データをアクセント句に分割する(ステップS13)。
When the emotion estimator generation program is activated, the
次に、モーラ区間抽出部131は、アクセント句に含まれるモーラ区間を抽出する(ステップS14)。そして、アクセント型抽出部132は、アクセント句のアクセント型を抽出する(ステップS15)。具体的には、アクセント型抽出部132は、図7を用いて説明したように、教師データとして使用するアクセント句を20のクラスに分類する(ステップS16)。アクセント型抽出部132は、その分類をするために、図5と図6を用いて説明したように、モーラ区間ごとの平均基本周波数m_f0とアクセント句区間の平均基本周波数m_thとを比較し、m_f0≧m_thであれば「H」、m_f0<m_thであれば「L」をそれぞれのモーラ区間に付与する。アクセント型抽出部132は、このようにして教師データとして使用するアクセント句に対して、アクセント句を構成するモーラ区間ごとにHとLを付与し、HとLのパターンによりアクセント型を抽出する。そして、アクセント型決定部130は、教師データのアクセント型を図7に示す20のアクセント型(クラス)の何れかに決定する。
Next, the mora
次に、特徴量抽出部140は、教師データとする音声データの特徴量をアクセント句ごとに抽出し、抽出した特徴量のデータと分類されたクラスとを対応付けて教師データとして記憶部2に記憶する(ステップS17)。
Next, the feature
感情推定器生成部150は、アクセント型(クラス)ごとに分類された教師データに基づいて、それぞれのクラスごとに感情推定器を生成する(ステップS18)。具体的には、感情推定器生成部150は、クラス1に分類された教師データ(アクセント句)を取得して、その教師データの発話時の感情状態を、7種類の感情状態である悲しみ、退屈、怒り、驚き、落胆、嫌悪、喜び、に分類することが可能な感情推定器を生成する。より具体的には、図8に示すよな7種類の感情に分類するための識別閾値(分類器を構成する数式のパラメータ)を生成する。次に、感情推定器生成部150は、クラス2に分類された教師データ(アクセント句)を取得して、その教師データの発話時の感情状態を、7種類の感情状態である悲しみ、退屈、怒り、驚き、落胆、嫌悪、喜び、に分類することが可能な2つめの感情推定器を生成する。感情推定器生成部150は、このように20種類の感情推定器を生成する。以上で、感情推定器生成装置100の感情推定器生成処理の説明を終了する。
The emotion
次に、感情推定器生成装置100が生成した20種類の感情推定器を内蔵する感情推定装置200が発話者の感情を推定する感情推定処理について、図11を参照しながら説明する。ユーザが、感情推定装置200に予めインストールされている感情推定プログラムを起動し、解析対象とする音声データを感情推定装置200に入力することにより、図11に示すフローチャートは開始される。
Next, an emotion estimation process in which the
制御部1は、感情推定プログラムが起動され、ユーザが解析対象の音声データを感情推定装置200に入力すると、話者分割部220は、取得した音声データを話者ごとに分割して記憶部2に記憶する。次に、解析区間設定部230は、話者ごとに音声データを記憶部2から取得する(ステップS31)。次に、形態素解析部231は、任意の話者の音声データを形態素に分解し(ステップS32)、アクセント句抽出部232は、解析単位であるアクセント句を決定する(ステップS33)。
When the emotion estimation program is activated and the user inputs voice data to be analyzed to the
次に、アクセント型決定部240は、感情推定器生成装置100の動作説明と同様に、アクセント句ごとにアクセント型(クラス)を決定する。具体的には、モーラ区間抽出部241が、該当するアクセント句に含まれるモーラ区間を抽出し(ステップS34)、アクセント型抽出部242が、そのアクセント句のアクセント型を抽出する(ステップS35)。そして、アクセント型決定部240は、抽出したアクセント型からそのアクセント句が属するクラスを決定する。そして、選択部250は、該当するアクセント句を発話したときの発話者の感情を推定するために使用する感情推定器として、同じアクセント型(クラス)の教師データに基づいて感情推定器生成装置100が生成した感情推定器を選択する(ステップS36)。
Next, the accent
一方、特徴量抽出部260は、解析対象のアクセント句の音声の強度、音声のピッチ、音素の継続時間長といった音声の特徴量を抽出し、抽出した特徴量と判別したクラスとを対応付けて記憶部2に記憶する(ステップS37)。
On the other hand, the feature
次に、感情推定部270は、選択部250が選択した感情推定器を用いて、該当するアクセント句を発話したときの発話者の感情を推定する(ステップS38)。
Next, the
アクセント句の1つについて感情推定が完了すると、感情推定装置200は、まだ解析が完了していないアクセント句が存在するか否かを判別する(ステップS39)。解析が完了していないアクセント句が存在する場合(ステップS39:No)、解析が完了していない他のアクセント句を抽出し(ステップS40)、そのアクセント句に該当する感情を推定する。
When emotion estimation is completed for one of the accent phrases,
すべてのアクセント句の解析が完了している場合(ステップS39:Yes)、感情推定装置200は、解析した文単位で統合処理を行う(ステップS41)。具体的には、統合部280は、解析対象の文に含まれるアクセント句ごとの感情推定結果に基づいて、最も多かった感情をその文を発話したときの発話者の感情として推定する。
If the analysis of all accent phrases has been completed (step S39: Yes), the
次に、感情推定装置200は、最初に取得した任意の人が発話したすべての文について解析が完了したか否かを判別する(ステップS42)。すべての文について解析が完了していない場合は(ステップS42:No)、他の文を抽出し(ステップS43)、他の文について感情推定処理を継続する。
Next, the
一方、感情推定装置200は、すべての文について解析が完了している場合は(ステップS42:Yes)、音声データに含まれているすべての人について感情推定が完了しているか否かを判別する(ステップS44)。すべての人について解析が完了していない場合は(ステップS44:No)、他の人の音声データを抽出して感情推定処理を継続する(ステップS45)。すべての人について解析処理が完了している場合は(ステップS44:Yes)、感情推定処理を終了する。
On the other hand, if the analysis has been completed for all sentences (step S42: Yes),
以上に説明したように感情推定器生成装置100は、アクセント型ごとに分類した教師データに基づいて、アクセント型ごとに感情推定器を生成する。そして、感情推定装置200は、アクセント型ごとに生成された感情推定器を使用して、発話者の感情を推定する。具体的には、感情推定装置200は、解析対象の音声データをアクセント型ごとに分類し、同じアクセント型を有する教師データに基づいて生成された感情推定器を用いて発話者の感情を推定する。これにより、音声データから発話者の感情を推定する推定精度を向上することができる。
As described above, the emotion
また、アクセント型抽出部132は、モーラ区間の単位で音声の特徴量の変化を抽出するので、感情推定器生成装置100は、発話者の感情をより細かく解析することが可能な感情推定器を生成することができる。
In addition, since the accent
また、アクセント型抽出部132は、音声の基本周波数の変化に基づいてアクセント型を抽出する。発話時の感情状態により音声の基本周波数は変化する傾向がある。したがって、感情推定器生成装置100は、発話者の感情をより正確に推定することが可能な感情推定器を生成することができる。また、同じ理由により、感情推定装置200は、発話者の感情をより正確に推定することができる。
The accent
解析区間設定手段120は、形態素の単位で音声を解析するので、感情推定器生成装置100は、発話者の感情をより正確に解析することが可能な感情推定器を生成することができる。
Since the analysis
感情推定器生成装置100は、発話者の発話時の感情を、悲しみ、退屈、怒り、驚き、落胆、嫌悪、喜び、に分類する感情推定器を生成する。この推定器を内蔵する感情推定装置200は、発話者の発話時の感情状態を、悲しみ、退屈、怒り、驚き、落胆、嫌悪、喜び、に分類することができる。
The emotion
(変形例1)
実施形態1では、アクセント型を判別するために特徴量をモーラ区間の単位で解析する説明をした。変形例1では、モーラ区間の中の母音区間に限定して特徴量を解析する説明を行う。具体的には、図12に示すように、母音区間のみの音声データを取り出して、図13に示すように特徴量の解析を行う。基本周波数の解析方法は実施形態1の説明と同じである。
(Modification 1)
In the first embodiment, the feature amount is analyzed in units of mora sections in order to determine the accent type. In the first modification, a description will be given of analyzing the feature quantity limited to the vowel section in the mora section. Specifically, as shown in FIG. 12, the voice data of only the vowel section is taken out and the feature amount is analyzed as shown in FIG. The fundamental frequency analysis method is the same as that described in the first embodiment.
母音区間にのみ着目する理由は、子音区間よりも母音区間の方が音素の継続時間長が長く、含まれる音声のエネルギーも大きいので、感情の変化による特徴量の変化は、子音区間よりも母音区間の方に顕著に現れるからである。 The reason for focusing only on the vowel interval is that the vowel duration is longer than the consonant interval, and the energy of the included speech is larger than the consonant interval. This is because it appears prominently in the section.
このように、変形例1に係る感情推定装置200は、母音区間に限定して特徴量の解析を行うことにより、感情推定の推定精度を向上することができる。
As described above, the
(変形例2)
実施形態1の説明では、アクセント型抽出部132が、音声の特徴量として音声のピッチ情報(音声の基本周波数)を利用する場合について説明した。変形例2では、音声の特徴量として音声の強度情報を利用する場合について説明する。ここでは、発話時の感情状態によって母音の発話区間における音声のエネルギー分布が変化することに着目した技術について説明する。
(Modification 2)
In the description of the first embodiment, the case where the accent
具体的には、アクセント型抽出部132は、図14に点線の丸印で示した音声のエネルギーのピークが、母音区間の前半に存在するか後半に存在するかを判別する。例えば、前半にピークが存在した場合には「H」を付与し、後半にピークが存在した場合には「L」を付与する。これにより、アクセント型決定部130は、アクセント型を決定する。音声の強度によりアクセント型を分類する場合は、実験データに基づいてクラス分けの仕方を検討する必要がある。その他の説明は実施形態1の説明と同じである。
Specifically, the accent
なお、変形例2の説明では、音声エネルギーのピーク点の時間位置の変化に着目する解析方法を説明したが、音声の強度の変化を用いてアクセント型を抽出することもできる。怒った状態で発話すると音声の強度は高くなる傾向があり、悲しい状態で発話すると音声の強度は低くなる傾向があるので、この傾向を利用するものである。この場合、例えば、アクセント句区間に含まれるモーラ区間ごとの音声のピーク強度を計測して、アクセント句区間の平均ピーク強度を求める。そして、モーラ区間の音声のピーク強度と平均ピーク強度とを比較して、モーラ区間ごとに「H」又は「L」を付与することにより、アクセント型を抽出することもできる。 In the description of the second modification, the analysis method focusing on the change in the time position of the peak point of the voice energy has been described, but the accent type can be extracted using the change in the intensity of the voice. When speaking in an angry state, the strength of the voice tends to increase, and when speaking in a sad state, the strength of the voice tends to decrease, so this tendency is used. In this case, for example, the peak intensity of the voice for each mora section included in the accent phrase section is measured to obtain the average peak intensity of the accent phrase section. Then, the accent type can be extracted by comparing the peak intensity and the average peak intensity of the sound in the mora section and assigning “H” or “L” to each mora section.
このように、変形例2に係る感情推定装置200は、音声の発話時の感情状態を音声の強度の変化情報を利用して解析するので、感情推定の推定精度を向上することができる。
As described above, the
(変形例3)
変形例3では、音声の特徴量として音素の継続時間長を利用する場合について説明する。怒ったり喜んだりした状態で発話すると音素の継続時間長は短くなる傾向があり、退屈な状態や悲しい状態で発話すると音素の継続時間長が長くなる傾向があるので、この傾向を利用するものである。
(Modification 3)
In the third modification, a case will be described in which the phoneme duration is used as a voice feature. When speaking in an angry or happy state, the phoneme duration tends to be short, and when speaking in a boring or sad state, the phoneme duration tends to be long. is there.
具体的には、アクセント型抽出部132は、モーラ区間に含まれる母音の継続時間長と、教師データに含まれる同じ母音の平均継続時間長とを比較し、モーラ区間に含まれる母音の継続時間長が平均継続時間長よりも長い場合は「H」を、短い場合は「L]を付与する。これにより、アクセント型決定部130は、アクセント型を決定する。
Specifically, the accent
実施形態1、変形例1、変形例2の説明では、解析区間であるアクセント句の区間における音声の特徴量の平均値とモーラ区間の平均値とを比較した。しかし、音素の継続時間長で比較する場合、感情推定器生成装置100のアクセント型抽出部132は、平均継続時間長を解析区間内の音声データの平均ではなく、教師データ全体の平均継続時間長と比較する。母音によって継続時間長は異なるので、異なる母音の継続時間長と比較することはできない。アクセント句に含まれる同じ母音の数が少ないため、平均継続時間長のバラツキが大きくなり、誤判定の要因となるので、教師データ全体の平均をとることが好ましい。
In the description of the first embodiment, the first modified example, and the second modified example, the average value of the voice feature amount in the accent phrase section, which is the analysis section, is compared with the average value in the mora section. However, when comparing with the phoneme duration length, the accent
一方、感情推定装置200のアクセント型抽出部242は、話者分類部220が分類した話者ごとの音声データについて、母音ごとに平均継続時間長を計算することが好ましい。
On the other hand, it is preferable that the accent
音素の継続時間長によりアクセント型を分類する場合は、実験データに基づいてクラス分けの仕方を検討する必要がある。その他の説明は実施形態1の説明と同じである。 When classifying accent types according to phoneme durations, it is necessary to consider how to classify them based on experimental data. Other explanations are the same as those of the first embodiment.
このように、変形例3に係る感情推定装置200は、音声の発話時の感情状態を音素の発話時間長の変化情報を利用して解析するので、感情推定の推定精度を向上することができる。
As described above, the
(変形例4)
実施形態1と変形例1では、音声の特徴量として音声のピッチ情報を利用してアクセント型を抽出する技術の説明をした。また、変形例2では、音声の強度情報を利用してアクセント型を抽出する技術を紹介し、変形例3では、音素の継続時間長を利用してアクセント型を抽出する技術を紹介した。アクセント型を抽出する場合、これらの技術を単独で使用することもできるが、音声のピッチ情報と音声の強度情報のように2つ以上の技術を組み合わせてアクセント型を抽出することもできる。2つ以上の情報を組み合わせるとアクセント型の種類が増えることになるが、感情推定の精度を向上させることができる。
(Modification 4)
In the first embodiment and the first modification, the technique for extracting the accent type using the pitch information of the voice as the voice feature amount has been described. In the second modification, a technique for extracting an accent type using the intensity information of speech was introduced. In the third modification, a technique for extracting an accent type using the duration of phonemes was introduced. When extracting an accent type, these techniques can be used alone, but an accent type can also be extracted by combining two or more techniques such as voice pitch information and voice intensity information. Combining two or more pieces of information increases the number of accent types, but can improve the accuracy of emotion estimation.
なお、上記の説明では、音声の特徴量として、音声の強度、音声のピッチ、音素の継続時間長を例にして説明したが、これに限定する必要はない。例えば、音声の強度の変化量、音声のピッチの変化量、音素の継続時間長の変化量等を抽出してアクセント型を決定することもできる。 In the above description, the sound intensity, the pitch of the sound, and the duration of the phoneme have been described as examples of the feature amount of the sound. However, the present invention is not limited to this. For example, the accent type can be determined by extracting the change amount of the sound intensity, the change amount of the sound pitch, the change amount of the phoneme duration, and the like.
(変形例5)
実施形態1の説明では、解析対象の文に含まれるアクセント句ごとの感情推定結果に基づいて、最も多かった感情をその文を発話したときの発話者の感情として推定する技術について説明を行った。しかし、統合処理の仕方はこれに限定する必要は無い。例えば、「少し驚きを伴った喜び」のように、複数の感情を含む推定を行うこともできる。感情推定器を構成する分類器では、特徴量をベクトルとして取得し、そのベクトルと識別閾値との距離に基づいて、いずれの感情に分類するかを決める場合が多い。例えば、「坊主が」、「屏風に」、「上手に」、「坊主の」、「絵を」、「描いた」の7つのアクセント句に対応する特徴量を、図15に示す1から7に示す位置ベクトルで表し、7つの位置ベクトルを合成した平均ベクトルが、図15に「平均」で示した位置ベクトルであったとする。この場合、位置ベクトル「平均」は、喜びの領域に属しているが、喜びと驚きの境界に近い位置に存在する。このような場合には、「少し驚きの感情が混在している可能性がある」というニュアンスを含めた感情推定結果を出力するようにしてもよい。
(Modification 5)
In the description of the first embodiment, a technique has been described in which, based on the emotion estimation result for each accent phrase included in the sentence to be analyzed, the most common emotion is estimated as the speaker's emotion when the sentence is spoken. . However, the method of integration processing need not be limited to this. For example, estimation including a plurality of emotions such as “joy with a little surprise” can be performed. In a classifier that constitutes an emotion estimator, it is often the case that a feature quantity is acquired as a vector and the emotion to be classified is determined based on the distance between the vector and an identification threshold. For example, the feature amounts corresponding to seven accent phrases of “shaved is”, “bold in the screen”, “skilled”, “shaved”, “draw”, and “drawn” are represented by 1 to 7 shown in FIG. It is assumed that the average vector obtained by combining the seven position vectors is the position vector indicated by “average” in FIG. In this case, the position vector “average” belongs to the joy region, but exists near the boundary between joy and surprise. In such a case, an emotion estimation result including a nuance that “a little surprising emotion may be mixed” may be output.
図8と図15とは、7次元の識別空間を2次元でイメージ表現した図であるので、複雑な例を表現することは困難である。しかし、感情推定器を構成する分類器の中では、それぞれの識別境界との距離を数値で計算することが可能である。したがって、「怒りと悲しみ」、「怒りと落胆」のように、複数の感情の組み合わせと、その感情の度合い(識別境界との距離)を数値計算することが可能である。さらに、複数の閾値を設定することにより、「怒り、悲しみ、落胆」のように2つ以上の感情を含めた感情推定も可能である。また、複数の感情の複合度合いも推定することができる。 Since FIGS. 8 and 15 are two-dimensional image representations of a 7-dimensional identification space, it is difficult to represent a complex example. However, in the classifier constituting the emotion estimator, it is possible to calculate the distance from each identification boundary numerically. Accordingly, it is possible to numerically calculate a combination of a plurality of emotions and a degree of the emotion (distance from the identification boundary) such as “anger and sadness” and “anger and discouragement”. Furthermore, by setting a plurality of thresholds, emotion estimation including two or more emotions such as “anger, sadness, and discouragement” is possible. Moreover, the composite degree of several emotions can also be estimated.
変形例5で説明した構成および処理を設けることにより、感情推定器生成装置100は、複数の感情の度合いを推定可能な感情推定器を生成することが可能となる。また、複数の感情の度合いを推定可能な感情推定器を内蔵する感情推定装置200は、発話者の複数の感情度合いを推定することができる。
By providing the configuration and processing described in the modification example 5, the emotion
なお、実施形態1の説明では、発話者の感情状態を悲しみ、退屈、怒り、驚き、落胆、嫌悪、喜び、の7種類に分類する説明をしたが、感情の分類方法はこれに限定する必要はない。例えば、喜、怒、哀、楽の4種類に分類してもよい。 In the description of the first embodiment, the emotional state of the speaker is classified into seven types of sadness, boredom, anger, surprise, discouragement, disgust, and joy. However, the emotion classification method needs to be limited to this. There is no. For example, it may be classified into four types of joy, anger, sorrow, and comfort.
また、実施形態1の説明では、発話者の発話時の感情状態を、悲しみ、退屈、怒り、驚き、落胆、嫌悪、喜び、の7つの感情状態の何れかに分類する場合について説明し、いずれにも該当しない教師データは除外する説明をした。しかし、発話者の感情として、「普通」という感情状態を設け、7つの感情に分類できなかった教師データを感情「普通」に分類するようにしてもよい。これにより、感情推定器生成装置100は、発話者の感情を7つの感情に「普通」を加えた8つの感情に推定可能な感情推定器を生成することができる。また、感情推定装置200は、発話者の感情を7つの感情に「普通」を加えた8つの感情に推定することができる。
In the description of the first embodiment, the emotional state at the time of speaking of the speaker is described as being classified into any of the seven emotional states of sadness, boredom, anger, surprise, discouragement, disgust, and joy. Explained that teacher data that does not fall under is excluded. However, the emotional state of “normal” may be provided as the emotion of the speaker, and the teacher data that could not be classified into the seven emotions may be classified as the emotion “normal”. As a result, the emotion
また、実施形態1の説明では、解析区間をアクセント句の区間単位とする説明をしたが、解析区間はこれに限定する必要はない。例えば、解析区間を単語の発話区間としてもよいし、息継ぎ区間である呼気段落区間としてもよいし、文の発話区間としてもよい。解析区間を文の発話区間とした場合には、統合部280は、文単位で発話者の感情を推定してもよいし、さらに複数の文をまとめた単位で発話者の感情を推定するようにしてもよい。
In the description of the first embodiment, the analysis interval is described as the unit of the accent phrase. However, the analysis interval is not necessarily limited to this. For example, the analysis interval may be a word utterance interval, a breathing interval interval that is a breathing interval, or a sentence utterance interval. When the analysis section is a sentence utterance section, the
また、式1の説明では、平均値を用いてその区間の特徴量を代表する処理について説明したが、平均値の代わりに中央値を用いて処理を行ってもよい。また、最も低い周波数を代表値として処理を行うようにしてもよい。
In the description of
また、式2の説明では、中央値を用いてその区間の特徴量を代表する処理について説明したが、中央値の代わりに平均値を用いて処理を行ってもよい。
In the description of
また、本発明に係る機能を実現するための構成を予め備えた感情推定器生成装置100、感情推定装置200として提供できることはもとより、プログラムの適用により、既存のパーソナルコンピュータや情報端末機器等を、本発明に係る感情推定器生成装置100、感情推定装置200として機能させることもできる。すなわち、上記実施形態で例示した感情推定器生成装置100、感情推定装置200による各機能構成を実現させるためのプログラムを、既存のパーソナルコンピュータや情報端末機器等を制御するCPU等が実行できるように適用することで、本発明に係る感情推定器生成装置100、感情推定装置200として機能させることができる。また、本発明に係る感情推定器生成方法及び感情推定方法は、感情推定器生成装置100、感情推定装置200を用いて実施できる。
In addition to being able to provide the emotion
また、このようなプログラムの適用方法は任意である。プログラムを、例えば、コンピュータが読取可能な記録媒体(CD−ROM(Compact Disc Read-Only Memory)、DVD(Digital Versatile Disc)、MO(Magneto Optical disc)等)に格納して適用できる他、インターネット等のネットワーク上のストレージにプログラムを格納しておき、これをダウンロードさせることにより適用することもできる。 Moreover, the application method of such a program is arbitrary. For example, the program can be stored and applied to a computer-readable recording medium (CD-ROM (Compact Disc Read-Only Memory), DVD (Digital Versatile Disc), MO (Magneto Optical disc), etc.), the Internet, etc. It is also possible to apply the program by storing it in a storage on the network and downloading it.
以上、本発明の好ましい実施形態について説明したが、本発明は係る特定の実施形態に限定されるものではなく、本発明には、特許請求の範囲に記載された発明とその均等の範囲が含まれる。以下に、本願出願の当初の特許請求の範囲に記載された発明を付記する。 As mentioned above, although preferable embodiment of this invention was described, this invention is not limited to the specific embodiment which concerns, This invention includes the invention described in the claim, and its equivalent range It is. Hereinafter, the invention described in the scope of claims of the present application will be appended.
(付記1)
教師データの元となる音声データの特徴量を解析する解析区間を設定する解析区間設定ステップと、
前記解析区間に含まれる音声データの特徴量の変化するパターンを、複数のクラスに分類された変化パターンに基づいて、前記解析区間に含まれる音声データの特徴量の変化パターンとして決定する変化パターン決定ステップと、
前記特徴量の変化パターンごとに分類された音声データを教師データとして、前記特徴量の変化パターンごとに、音声を発話したときの発話者の感情を推定する感情推定器を生成する感情推定器生成ステップと、
を含む感情推定器生成方法。
(Appendix 1)
An analysis interval setting step for setting an analysis interval for analyzing the feature amount of the voice data that is the source of the teacher data;
Change pattern determination for determining a pattern in which the feature amount of the voice data included in the analysis section changes as a pattern of change in the feature amount of the voice data included in the analysis section, based on the change patterns classified into a plurality of classes. Steps,
Generation of an emotion estimator for generating an emotion estimator for estimating an emotion of a speaker when speech is uttered for each feature value change pattern, using the voice data classified for each feature value change pattern as teacher data Steps,
An emotion estimator generation method including:
(付記2)
前記変化パターン決定ステップは、
前記解析区間に含まれる音声データを、音節の単位であるモーラ区間に分割するモーラ区間抽出ステップと、
前記解析区間における音声データの特徴量の平均値と、前記モーラ区間における音声データの特徴量の平均値と、をモーラ区間ごとに比較した比較結果に基づいて、前記解析区間の音声データを発話したときのモーラ区間ごとに変化する音声の特徴量の変化パターンを抽出する変化パターン抽出ステップと、
を含むことを特徴とする付記1に記載の感情推定器生成方法。
(Appendix 2)
The change pattern determining step includes:
A mora section extraction step for dividing the speech data included in the analysis section into mora sections that are syllable units;
The speech data of the analysis section is uttered based on the comparison result of comparing the average value of the feature amount of the speech data in the analysis section and the average value of the feature amount of the speech data in the mora section for each mora section. A change pattern extraction step for extracting a change pattern of the feature amount of the sound that changes for each mora section;
The emotion estimator generation method according to
(付記3)
前記変化パターン抽出ステップでは、音声の特徴量として音声データから抽出した音声の基本周波数を用い、前記解析区間における音声の平均基本周波数と、前記モーラ区間における音声の平均基本周波数と、をモーラ区間ごとに比較し、モーラ区間の音声の平均基本周波数が解析区間の音声の平均基本周波数よりも高い場合にはHighを、低い場合にはLowを付与し、モーラ区間ごとにHighとLowに変化する音声の特徴量の変化パターンを抽出する、
ことを特徴とする付記2に記載の感情推定器生成方法。
(Appendix 3)
In the change pattern extraction step, the fundamental frequency of speech extracted from speech data is used as the feature amount of speech, and the average fundamental frequency of speech in the analysis interval and the average fundamental frequency of speech in the mora interval are determined for each mora interval. Compared to the above, when the average fundamental frequency of the voice in the mora section is higher than the average fundamental frequency of the voice in the analysis section, High is given, and when it is low, Low is given, and the voice changes to High and Low for each mora section. Extract the change pattern of the feature amount of
The method for generating an emotion estimator according to
(付記4)
前記変化パターン抽出ステップでは、音声の特徴量として音声データから抽出した音声の強度を用い、前記解析区間における音声の平均強度と、前記モーラ区間における音声の平均強度と、をモーラ区間ごとに比較し、モーラ区間の音声の平均強度が解析区間の音声の平均強度よりも高い場合にはHighを、低い場合にはLowを付与し、モーラ区間ごとにHighとLowに変化する音声の特徴量の変化パターンを抽出する、
ことを特徴とする付記2に記載の感情推定器生成方法。
(Appendix 4)
In the change pattern extraction step, the voice intensity extracted from the voice data is used as the voice feature value, and the average voice intensity in the analysis section and the average voice intensity in the mora section are compared for each mora section. When the average intensity of the voice in the mora section is higher than the average intensity of the voice in the analysis section, High is given, and when the average intensity is low, Low is given, and the change in the feature amount of the voice that changes between High and Low for each mora section Extract patterns,
The method for generating an emotion estimator according to
(付記5)
前記変化パターン抽出ステップでは、音声の特徴量として音声データから抽出した音素の継続時間長を用い、前記解析区間における音素の平均継続時間長と、前記モーラ区間における音素の平均継続時間長と、をモーラ区間ごとに比較し、モーラ区間の音素の平均継続時間長が解析区間の音素の平均継続時間長よりも長い場合にはHighを、短い場合にはLowを付与し、モーラ区間ごとにHighとLowに変化する音声の特徴量の変化パターンを抽出する、
ことを特徴とする付記2に記載の感情推定器生成方法。
(Appendix 5)
In the change pattern extraction step, the phoneme duration extracted from the speech data is used as the feature amount of speech, the average duration of phonemes in the analysis interval, and the average duration of phonemes in the mora interval, Compared for each mora section, High is given when the average duration of phonemes in the mora section is longer than the average duration of phonemes in the analysis section, Low is given when the phoneme is short, and High for each mora section. Extracting the change pattern of the feature amount of the voice that changes to Low,
The method for generating an emotion estimator according to
(付記6)
前記変化パターン抽出ステップでは、音声の特徴量として、音声の基本周波数、音声の強度、音素の継続時間長の少なくとも何れか1つを使用して音声の特徴量の変化パターンを抽出する、
ことを特徴とする付記2から5の何れか一つに記載の感情推定器生成方法。
(Appendix 6)
In the change pattern extraction step, a change pattern of the speech feature value is extracted using at least one of the fundamental frequency of the speech, the strength of the speech, and the duration of the phoneme as the feature amount of the speech.
The emotion estimator generation method according to any one of
(付記7)
前記解析区間設定ステップでは、音声データを、言語の意味を持つ最小の単位である形態素に分割し、当該形態素の後で発話された助詞又は助動詞と結合したアクセント句の区間を前記解析区間として設定する、
ことを特徴とする付記1から6の何れか一つに記載の感情推定器生成方法。
(Appendix 7)
In the analysis interval setting step, the speech data is divided into morphemes which are the smallest units having language meaning, and an accent phrase interval combined with a particle or an auxiliary verb spoken after the morpheme is set as the analysis interval. To
The emotion estimator generation method according to any one of
(付記8)
前記モーラ区間抽出ステップでは、音声データをテキスト表示した場合に、仮名文字1文字を1モーラ区間とし、小書きの仮名文字はその前の仮名文字と一緒にして1モーラ区間とし、長音は独立して1モーラ区間とする、
ことを特徴とする付記2に記載の感情推定器生成方法。
(Appendix 8)
In the mora section extraction step, when the voice data is displayed as text, one kana character is set as one mora section, the small kana character is combined with the preceding kana character as one mora section, and the long sound is independent. 1 mora section,
The method for generating an emotion estimator according to
(付記9)
前記感情推定器は、発話者の発話時の感情を、悲しみ、退屈、怒り、驚き、落胆、嫌悪、喜び、の何れかの感情であると推定する、
ことを特徴とする付記1から8の何れか一つに記載の感情推定器生成方法。
(Appendix 9)
The emotion estimator estimates the emotion at the time of speaking of the speaker as one of sadness, boredom, anger, surprise, discouragement, disgust, joy,
The emotion estimator generation method according to any one of
(付記10)
前記複数のクラスに分類された変化パターンを設定する変化パターン設定ステップを含む、
ことを特徴とする付記1から9の何れか一つに記載の感情推定器生成方法。
(Appendix 10)
Including a change pattern setting step for setting change patterns classified into the plurality of classes.
The emotion estimator generation method according to any one of
(付記11)
教師データの元となる音声データの特徴量を解析する解析区間を設定する解析区間設定手段と、
前記解析区間に含まれる音声データの特徴量の変化するパターンを、複数のクラスに分類された変化パターンに基づいて、前記解析区間に含まれる音声データの特徴量の変化パターンとして決定する変化パターン決定手段と、
前記特徴量の変化パターンごとに分類された音声データを教師データとして、前記特徴量の変化パターンごとに、音声を発話したときの発話者の感情を推定する感情推定器を生成する感情推定器生成手段と、
を含む感情推定器生成装置。
(Appendix 11)
An analysis interval setting means for setting an analysis interval for analyzing a feature amount of voice data that is a source of teacher data;
Change pattern determination for determining a pattern in which the feature amount of the voice data included in the analysis section changes as a pattern of change in the feature amount of the voice data included in the analysis section, based on the change patterns classified into a plurality of classes. Means,
Generation of an emotion estimator for generating an emotion estimator for estimating an emotion of a speaker when speech is uttered for each feature value change pattern, using the voice data classified for each feature value change pattern as teacher data Means,
An emotion estimator generator including:
(付記12)
コンピュータを
教師データの元となる音声データの特徴量を解析する解析区間を設定する解析区間設定手段、
前記解析区間に含まれる音声データの特徴量の変化するパターンを、複数のクラスに分類された変化パターンに基づいて、前記解析区間に含まれる音声データの特徴量の変化パターンとして決定する変化パターン決定手段、
前記特徴量の変化パターンごとに分類された音声データを教師データとして、前記特徴量の変化パターンごとに、音声を発話したときの発話者の感情を推定する感情推定器を生成する感情推定器生成手段、
として機能させるためのプログラム。
(Appendix 12)
Analysis interval setting means for setting an analysis interval for analyzing features of speech data that is a source of teacher data on a computer;
Change pattern determination for determining a pattern in which the feature amount of the voice data included in the analysis section changes as a pattern of change in the feature amount of the voice data included in the analysis section, based on the change patterns classified into a plurality of classes. means,
Generation of an emotion estimator for generating an emotion estimator for estimating an emotion of a speaker when speech is uttered for each feature value change pattern, using the voice data classified for each feature value change pattern as teacher data means,
Program to function as.
(付記13)
解析対象とする音声データの特徴量を解析する解析区間を設定する解析区間設定ステップと、
前記解析区間に含まれる音声データの特徴量の変化するパターンを、複数のクラスに分類された変化パターンに基づいて、前記解析区間に含まれる音声データの特徴量の変化パターンとして決定する変化パターン決定ステップと、
前記特徴量の変化パターンごとに、同じ特徴量の変化パターンを有する教師データに基づいて生成された感情推定器を用いて、前記解析区間の音声を発話した時の発話者の感情を推定する感情推定ステップと、
を含む感情推定方法。
(Appendix 13)
An analysis interval setting step for setting an analysis interval for analyzing the feature amount of the audio data to be analyzed;
Change pattern determination for determining a pattern in which the feature amount of the voice data included in the analysis section changes as a pattern of change in the feature amount of the voice data included in the analysis section, based on the change patterns classified into a plurality of classes. Steps,
Emotion that estimates the emotion of the speaker when the speech of the analysis section is uttered using an emotion estimator generated based on teacher data having the same feature amount change pattern for each feature amount change pattern An estimation step;
Emotion estimation method including
(付記14)
解析対象とする音声データの特徴量を解析する解析区間を設定する解析区間設定手段と、
前記解析区間に含まれる音声データの特徴量の変化するパターンを、複数のクラスに分類された変化パターンに基づいて、前記解析区間に含まれる音声データの特徴量の変化パターンとして決定する変化パターン決定手段と、
前記特徴量の変化パターンごとに、同じ特徴量の変化パターンを有する教師データに基づいて生成された感情推定器を用いて、前記解析区間の音声を発話した時の発話者の感情を推定する感情推定手段と、
を備えた感情推定装置。
(Appendix 14)
Analysis interval setting means for setting an analysis interval for analyzing the feature amount of the audio data to be analyzed;
Change pattern determination for determining a pattern in which the feature amount of the voice data included in the analysis section changes as a pattern of change in the feature amount of the voice data included in the analysis section, based on the change patterns classified into a plurality of classes. Means,
Emotion that estimates the emotion of the speaker when the speech of the analysis section is uttered using an emotion estimator generated based on teacher data having the same feature amount change pattern for each feature amount change pattern An estimation means;
Emotion estimation device with
1…制御部、2…記憶部、3…入出力部、4…バス、100…感情推定器生成装置、110、210…音声データ取得部、120、230…解析区間設定部、121、231…形態素解析部、122、232…アクセント句抽出部、130、240…アクセント型決定部、131、241…モーラ区間抽出部、132、242…アクセント型抽出部、140、260…特徴量抽出部、150…感情推定器生成部、200…感情推定装置、220…話者分割部、250…選択部、270…感情推定部、280…統合部
DESCRIPTION OF
Claims (14)
前記解析区間に含まれる音声データの特徴量の変化するパターンを、複数のクラスに分類された変化パターンに基づいて、前記解析区間に含まれる音声データの特徴量の変化パターンとして決定する変化パターン決定ステップと、
前記特徴量の変化パターンごとに分類された音声データを教師データとして、前記特徴量の変化パターンごとに、音声を発話したときの発話者の感情を推定する感情推定器を生成する感情推定器生成ステップと、
を含む感情推定器生成方法。 An analysis interval setting step for setting an analysis interval for analyzing the feature amount of the voice data that is the source of the teacher data;
Change pattern determination for determining a pattern in which the feature amount of the voice data included in the analysis section changes as a pattern of change in the feature amount of the voice data included in the analysis section, based on the change patterns classified into a plurality of classes. Steps,
Generation of an emotion estimator for generating an emotion estimator for estimating an emotion of a speaker when speech is uttered for each feature value change pattern, using the voice data classified for each feature value change pattern as teacher data Steps,
An emotion estimator generation method including:
前記解析区間に含まれる音声データを、音節の単位であるモーラ区間に分割するモーラ区間抽出ステップと、
前記解析区間における音声データの特徴量の平均値と、前記モーラ区間における音声データの特徴量の平均値と、をモーラ区間ごとに比較した比較結果に基づいて、前記解析区間の音声データを発話したときのモーラ区間ごとに変化する音声の特徴量の変化パターンを抽出する変化パターン抽出ステップと、
を含むことを特徴とする請求項1に記載の感情推定器生成方法。 The change pattern determining step includes:
A mora section extraction step for dividing the speech data included in the analysis section into mora sections that are syllable units;
The speech data of the analysis section is uttered based on the comparison result of comparing the average value of the feature amount of the speech data in the analysis section and the average value of the feature amount of the speech data in the mora section for each mora section. A change pattern extraction step for extracting a change pattern of the feature amount of the sound that changes for each mora section;
The emotion estimator generation method according to claim 1, wherein:
ことを特徴とする請求項2に記載の感情推定器生成方法。 In the change pattern extraction step, the fundamental frequency of speech extracted from speech data is used as the feature amount of speech, and the average fundamental frequency of speech in the analysis interval and the average fundamental frequency of speech in the mora interval are determined for each mora interval. Compared to the above, when the average fundamental frequency of the voice in the mora section is higher than the average fundamental frequency of the voice in the analysis section, High is given, and when it is low, Low is given, and the voice changes to High and Low for each mora section. Extract the change pattern of the feature amount of
The emotion estimator generation method according to claim 2.
ことを特徴とする請求項2に記載の感情推定器生成方法。 In the change pattern extraction step, the voice intensity extracted from the voice data is used as the voice feature value, and the average voice intensity in the analysis section and the average voice intensity in the mora section are compared for each mora section. When the average intensity of the voice in the mora section is higher than the average intensity of the voice in the analysis section, High is given, and when the average intensity is low, Low is given, and the change in the feature amount of the voice that changes between High and Low for each mora section Extract patterns,
The emotion estimator generation method according to claim 2.
ことを特徴とする請求項2に記載の感情推定器生成方法。 In the change pattern extraction step, the phoneme duration extracted from the speech data is used as the feature amount of speech, the average duration of phonemes in the analysis interval, and the average duration of phonemes in the mora interval, Compared for each mora section, High is given when the average duration of phonemes in the mora section is longer than the average duration of phonemes in the analysis section, Low is given when the phoneme is short, and High for each mora section. Extracting the change pattern of the feature amount of the voice that changes to Low,
The emotion estimator generation method according to claim 2.
ことを特徴とする請求項2から5の何れか一項に記載の感情推定器生成方法。 In the change pattern extraction step, a change pattern of the speech feature value is extracted using at least one of the fundamental frequency of the speech, the strength of the speech, and the duration of the phoneme as the feature amount of the speech.
The emotion estimator generation method according to any one of claims 2 to 5, wherein:
ことを特徴とする請求項1から6の何れか一項に記載の感情推定器生成方法。 In the analysis interval setting step, the speech data is divided into morphemes which are the smallest units having language meaning, and an accent phrase interval combined with a particle or an auxiliary verb spoken after the morpheme is set as the analysis interval. To
The emotion estimator generation method according to any one of claims 1 to 6.
ことを特徴とする請求項2に記載の感情推定器生成方法。 In the mora section extraction step, when the voice data is displayed as text, one kana character is set as one mora section, the small kana character is combined with the preceding kana character as one mora section, and the long sound is independent. 1 mora section,
The emotion estimator generation method according to claim 2.
ことを特徴とする請求項1から8の何れか一項に記載の感情推定器生成方法。 The emotion estimator estimates the emotion at the time of speaking of the speaker as one of sadness, boredom, anger, surprise, discouragement, disgust, joy,
The emotion estimator generation method according to any one of claims 1 to 8, wherein:
ことを特徴とする請求項1から9の何れか一項に記載の感情推定器生成方法。 Including a change pattern setting step for setting change patterns classified into the plurality of classes.
The emotion estimator generation method according to any one of claims 1 to 9, wherein:
前記解析区間に含まれる音声データの特徴量の変化するパターンを、複数のクラスに分類された変化パターンに基づいて、前記解析区間に含まれる音声データの特徴量の変化パターンとして決定する変化パターン決定手段と、
前記特徴量の変化パターンごとに分類された音声データを教師データとして、前記特徴量の変化パターンごとに、音声を発話したときの発話者の感情を推定する感情推定器を生成する感情推定器生成手段と、
を含む感情推定器生成装置。 An analysis interval setting means for setting an analysis interval for analyzing a feature amount of voice data that is a source of teacher data;
Change pattern determination for determining a pattern in which the feature amount of the voice data included in the analysis section changes as a pattern of change in the feature amount of the voice data included in the analysis section, based on the change patterns classified into a plurality of classes. Means,
Generation of an emotion estimator for generating an emotion estimator for estimating an emotion of a speaker when speech is uttered for each feature value change pattern, using the voice data classified for each feature value change pattern as teacher data Means,
An emotion estimator generator including:
教師データの元となる音声データの特徴量を解析する解析区間を設定する解析区間設定手段、
前記解析区間に含まれる音声データの特徴量の変化するパターンを、複数のクラスに分類された変化パターンに基づいて、前記解析区間に含まれる音声データの特徴量の変化パターンとして決定する変化パターン決定手段、
前記特徴量の変化パターンごとに分類された音声データを教師データとして、前記特徴量の変化パターンごとに、音声を発話したときの発話者の感情を推定する感情推定器を生成する感情推定器生成手段、
として機能させるためのプログラム。 Analysis interval setting means for setting an analysis interval for analyzing features of speech data that is a source of teacher data on a computer;
Change pattern determination for determining a pattern in which the feature amount of the voice data included in the analysis section changes as a pattern of change in the feature amount of the voice data included in the analysis section, based on the change patterns classified into a plurality of classes. means,
Generation of an emotion estimator for generating an emotion estimator for estimating an emotion of a speaker when speech is uttered for each feature value change pattern, using the voice data classified for each feature value change pattern as teacher data means,
Program to function as.
前記解析区間に含まれる音声データの特徴量の変化するパターンを、複数のクラスに分類された変化パターンに基づいて、前記解析区間に含まれる音声データの特徴量の変化パターンとして決定する変化パターン決定ステップと、
前記特徴量の変化パターンごとに、同じ特徴量の変化パターンを有する教師データに基づいて生成された感情推定器を用いて、前記解析区間の音声を発話した時の発話者の感情を推定する感情推定ステップと、
を含む感情推定方法。 An analysis interval setting step for setting an analysis interval for analyzing the feature amount of the audio data to be analyzed;
Change pattern determination for determining a pattern in which the feature amount of the voice data included in the analysis section changes as a pattern of change in the feature amount of the voice data included in the analysis section, based on the change patterns classified into a plurality of classes. Steps,
Emotion that estimates the emotion of the speaker when the speech of the analysis section is uttered using an emotion estimator generated based on teacher data having the same feature amount change pattern for each feature amount change pattern An estimation step;
Emotion estimation method including
前記解析区間に含まれる音声データの特徴量の変化するパターンを、複数のクラスに分類された変化パターンに基づいて、前記解析区間に含まれる音声データの特徴量の変化パターンとして決定する変化パターン決定手段と、
前記特徴量の変化パターンごとに、同じ特徴量の変化パターンを有する教師データに基づいて生成された感情推定器を用いて、前記解析区間の音声を発話した時の発話者の感情を推定する感情推定手段と、
を備えた感情推定装置。 Analysis interval setting means for setting an analysis interval for analyzing the feature amount of the audio data to be analyzed;
Change pattern determination for determining a pattern in which the feature amount of the voice data included in the analysis section changes as a pattern of change in the feature amount of the voice data included in the analysis section, based on the change patterns classified into a plurality of classes. Means,
Emotion that estimates the emotion of the speaker when the speech of the analysis section is uttered using an emotion estimator generated based on teacher data having the same feature amount change pattern for each feature amount change pattern An estimation means;
Emotion estimation device with
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2015247885A JP6720520B2 (en) | 2015-12-18 | 2015-12-18 | Emotion estimator generation method, emotion estimator generation device, emotion estimation method, emotion estimation device, and program |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2015247885A JP6720520B2 (en) | 2015-12-18 | 2015-12-18 | Emotion estimator generation method, emotion estimator generation device, emotion estimation method, emotion estimation device, and program |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2020104161A Division JP7001126B2 (en) | 2020-06-17 | 2020-06-17 | Emotion estimation device, emotion estimation method and program |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2017111760A true JP2017111760A (en) | 2017-06-22 |
| JP6720520B2 JP6720520B2 (en) | 2020-07-08 |
Family
ID=59080241
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2015247885A Active JP6720520B2 (en) | 2015-12-18 | 2015-12-18 | Emotion estimator generation method, emotion estimator generation device, emotion estimation method, emotion estimation device, and program |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP6720520B2 (en) |
Cited By (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| DE102018128195A1 (en) | 2017-11-28 | 2019-05-29 | Subaru Corporation | Driving recommendation device and driving recommendation method |
| JP2019128531A (en) * | 2018-01-26 | 2019-08-01 | 株式会社日立製作所 | Voice analysis apparatus and voice analysis method |
| JP2019129413A (en) * | 2018-01-24 | 2019-08-01 | 株式会社見果てぬ夢 | Broadcast wave receiving device, broadcast reception method, and broadcast reception program |
| CN110706689A (en) * | 2018-07-09 | 2020-01-17 | 富士施乐株式会社 | Emotion estimation system and computer-readable medium |
| KR20200109958A (en) * | 2019-03-15 | 2020-09-23 | 숭실대학교산학협력단 | Method of emotion recognition using audio signal, computer readable medium and apparatus for performing the method |
| WO2020196978A1 (en) * | 2019-03-25 | 2020-10-01 | 한국과학기술원 | Electronic device for multi-scale voice emotion recognition and operation method of same |
| CN112489682A (en) * | 2020-11-25 | 2021-03-12 | 平安科技(深圳)有限公司 | Audio processing method and device, electronic equipment and storage medium |
| KR20210144625A (en) * | 2018-10-29 | 2021-11-30 | 바이두 온라인 네트웍 테크놀러지 (베이징) 캄파니 리미티드 | Video data processing method, device and readable storage medium |
| US11721357B2 (en) | 2019-02-04 | 2023-08-08 | Fujitsu Limited | Voice processing method and voice processing apparatus |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2006113546A (en) * | 2004-09-14 | 2006-04-27 | Honda Motor Co Ltd | Information transmission device |
| WO2007148493A1 (en) * | 2006-06-23 | 2007-12-27 | Panasonic Corporation | Emotion recognizer |
| JP2009182433A (en) * | 2008-01-29 | 2009-08-13 | Seiko Epson Corp | Information provision system, information providing device, information providing method, and information provision program of call center |
-
2015
- 2015-12-18 JP JP2015247885A patent/JP6720520B2/en active Active
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2006113546A (en) * | 2004-09-14 | 2006-04-27 | Honda Motor Co Ltd | Information transmission device |
| WO2007148493A1 (en) * | 2006-06-23 | 2007-12-27 | Panasonic Corporation | Emotion recognizer |
| JP2009182433A (en) * | 2008-01-29 | 2009-08-13 | Seiko Epson Corp | Information provision system, information providing device, information providing method, and information provision program of call center |
Cited By (17)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10647326B2 (en) | 2017-11-28 | 2020-05-12 | Subaru Corporation | Driving advice apparatus and driving advice method |
| DE102018128195A1 (en) | 2017-11-28 | 2019-05-29 | Subaru Corporation | Driving recommendation device and driving recommendation method |
| JP7017755B2 (en) | 2018-01-24 | 2022-02-09 | 株式会社見果てぬ夢 | Broadcast wave receiver, broadcast reception method, and broadcast reception program |
| JP2019129413A (en) * | 2018-01-24 | 2019-08-01 | 株式会社見果てぬ夢 | Broadcast wave receiving device, broadcast reception method, and broadcast reception program |
| JP2019128531A (en) * | 2018-01-26 | 2019-08-01 | 株式会社日立製作所 | Voice analysis apparatus and voice analysis method |
| CN110706689A (en) * | 2018-07-09 | 2020-01-17 | 富士施乐株式会社 | Emotion estimation system and computer-readable medium |
| JP7159655B2 (en) | 2018-07-09 | 2022-10-25 | 富士フイルムビジネスイノベーション株式会社 | Emotion estimation system and program |
| US11355140B2 (en) | 2018-07-09 | 2022-06-07 | Fujifilm Business Innovation Corp. | Emotion estimation system and non-transitory computer readable medium |
| KR102416558B1 (en) * | 2018-10-29 | 2022-07-05 | 바이두 온라인 네트웍 테크놀러지 (베이징) 캄파니 리미티드 | Video data processing method, device and readable storage medium |
| KR20210144625A (en) * | 2018-10-29 | 2021-11-30 | 바이두 온라인 네트웍 테크놀러지 (베이징) 캄파니 리미티드 | Video data processing method, device and readable storage medium |
| US11605226B2 (en) | 2018-10-29 | 2023-03-14 | Baidu Online Network Technology (Beijing) Co., Ltd. | Video data processing method and apparatus, and readable storage medium |
| US11721357B2 (en) | 2019-02-04 | 2023-08-08 | Fujitsu Limited | Voice processing method and voice processing apparatus |
| KR102195246B1 (en) * | 2019-03-15 | 2020-12-24 | 숭실대학교산학협력단 | Method of emotion recognition using audio signal, computer readable medium and apparatus for performing the method |
| KR20200109958A (en) * | 2019-03-15 | 2020-09-23 | 숭실대학교산학협력단 | Method of emotion recognition using audio signal, computer readable medium and apparatus for performing the method |
| WO2020196978A1 (en) * | 2019-03-25 | 2020-10-01 | 한국과학기술원 | Electronic device for multi-scale voice emotion recognition and operation method of same |
| CN112489682A (en) * | 2020-11-25 | 2021-03-12 | 平安科技(深圳)有限公司 | Audio processing method and device, electronic equipment and storage medium |
| CN112489682B (en) * | 2020-11-25 | 2023-05-23 | 平安科技(深圳)有限公司 | Audio processing method, device, electronic equipment and storage medium |
Also Published As
| Publication number | Publication date |
|---|---|
| JP6720520B2 (en) | 2020-07-08 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6720520B2 (en) | Emotion estimator generation method, emotion estimator generation device, emotion estimation method, emotion estimation device, and program | |
| US7809572B2 (en) | Voice quality change portion locating apparatus | |
| Arias et al. | Shape-based modeling of the fundamental frequency contour for emotion detection in speech | |
| Mariooryad et al. | Compensating for speaker or lexical variabilities in speech for emotion recognition | |
| US8595004B2 (en) | Pronunciation variation rule extraction apparatus, pronunciation variation rule extraction method, and pronunciation variation rule extraction program | |
| JP2815579B2 (en) | Word candidate reduction device in speech recognition | |
| JP6370749B2 (en) | Utterance intention model learning device, utterance intention extraction device, utterance intention model learning method, utterance intention extraction method, program | |
| JP2007219286A (en) | Style detecting device for speech, its method and its program | |
| Vydana et al. | Vowel-based non-uniform prosody modification for emotion conversion | |
| JP2016151736A (en) | Speech processing device and program | |
| JP6013104B2 (en) | Speech synthesis method, apparatus, and program | |
| JPWO2016103652A1 (en) | Audio processing apparatus, audio processing method, and program | |
| JP7001126B2 (en) | Emotion estimation device, emotion estimation method and program | |
| Přibil et al. | GMM-based evaluation of emotional style transformation in czech and slovak | |
| JP7159655B2 (en) | Emotion estimation system and program | |
| JP6436806B2 (en) | Speech synthesis data creation method and speech synthesis data creation device | |
| JP5722295B2 (en) | Acoustic model generation method, speech synthesis method, apparatus and program thereof | |
| JP3378547B2 (en) | Voice recognition method and apparatus | |
| JP2011180308A (en) | Voice recognition device and recording medium | |
| JP6748607B2 (en) | Speech synthesis learning apparatus, speech synthesis apparatus, method and program thereof | |
| JP6370732B2 (en) | Utterance intention model learning device, utterance intention extraction device, utterance intention model learning method, utterance intention extraction method, program | |
| JP2020106643A (en) | Language processing unit, language processing program and language processing method | |
| Jauk et al. | Prosodic and spectral ivectors for expressive speech synthesis | |
| Cernak et al. | Emotional aspects of intrinsic speech variabilities in automatic speech recognition | |
| Khan et al. | detection of questions in Arabic audio monologues using prosodic features |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20181018 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20191210 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20200115 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20200519 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20200601 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6720520 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |