JP2015146145A - Customer analyzing program, customer analyzing method and customer analyzer - Google Patents
Customer analyzing program, customer analyzing method and customer analyzer Download PDFInfo
- Publication number
- JP2015146145A JP2015146145A JP2014019087A JP2014019087A JP2015146145A JP 2015146145 A JP2015146145 A JP 2015146145A JP 2014019087 A JP2014019087 A JP 2014019087A JP 2014019087 A JP2014019087 A JP 2014019087A JP 2015146145 A JP2015146145 A JP 2015146145A
- Authority
- JP
- Japan
- Prior art keywords
- cluster
- customer
- analysis
- period
- history data
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images

























Abstract
Description
本件は、顧客分析プログラム、顧客分析方法、及び顧客分析装置に関する。 This case relates to a customer analysis program, a customer analysis method, and a customer analysis apparatus.
例えば百貨店や量販店(以下、「販売店」と表記)は、来店した顧客を分析し、分析結果を、商品施策や売り場施策などの経営戦略に活用する。顧客分析は、例えば、顧客を年齢、性別、及び住所などに基づいて複数のグループに分類したり、顧客の購買情報(商品のブランド、金額、頻度など)などに基づいて複数のグループに分類することにより行われる。 For example, department stores and mass retailers (hereinafter referred to as “sales stores”) analyze customers who visit the stores, and use the analysis results in management strategies such as product measures and sales floor measures. Customer analysis, for example, categorizes customers into multiple groups based on age, gender, address, etc., or categorizes them into multiple groups based on customer purchase information (product brand, price, frequency, etc.) Is done.
分析手段に関し、例えば特許文献1には、人物の行動パタンを分析する点が記載されている。また、特許文献2には、選択可能な項目をグループ分けする点が記載されている。
Regarding the analysis means, for example,
しかし、顧客分析により得られた顧客グループの情報は、例えば、当該販売店が存在する地域の人口統計や商業関連の統計などの一般的な公開情報との比較分析に用いられることはあっても、複数の他の販売店に関する分析結果との比較分析に用いられることはない。したがって、他の販売店の顧客分析結果を用いた、詳細な顧客グループの比較分析が望まれている。 However, customer group information obtained by customer analysis may be used for comparative analysis with general public information such as demographic and commercial statistics of the region where the store is located. , It is not used for comparative analysis with the analysis results of a plurality of other dealers. Therefore, detailed comparison analysis of customer groups using customer analysis results of other dealers is desired.
さらに、比較分析は、顧客の購買内容に関し、時期のトレンドを考慮して行われることが望ましい。なお、この問題は、商品を販売する販売店に限られず、例えば飲食店のように特定のサービスを提供する店についても、同様に存在する。 Further, it is desirable that the comparative analysis is performed in consideration of the trend of the time with respect to the purchase contents of the customer. Note that this problem is not limited to a store that sells merchandise, and similarly exists for a store that provides a specific service, such as a restaurant.
一つの側面では、本発明は、時期のトレンドを考慮した顧客分析が可能な顧客分析プログラム、顧客分析方法、及び顧客分析装置を提供することを目的とする。 In one aspect, an object of the present invention is to provide a customer analysis program, a customer analysis method, and a customer analysis apparatus that can perform customer analysis in consideration of a trend of time.
一つの態様では、顧客分析プログラムは、期間の指定を分析対象期間とする指示、または、現在もしくは過去の時点からの所定期間を分析対象期間とする指示と、分析対象の店の購買履歴データとを受け付け、指示された前記分析対象期間における複数の店の購買履歴データに基づいて生成された顧客グループのうち、所定の類似関係を有する全ての顧客グループを含む統合顧客グループと、前記分析対象の店の購買履歴データに基づいて生成された顧客グループとの比較結果を出力する、処理をコンピュータに実行させる。 In one aspect, the customer analysis program includes an instruction to designate a period as an analysis target period, or an instruction to set a predetermined period from a current or past time point as an analysis target period, and purchase history data of a store to be analyzed. An integrated customer group including all customer groups having a predetermined similarity among customer groups generated based on purchase history data of a plurality of stores in the instructed analysis target period, and the analysis target A computer executes a process of outputting a comparison result with a customer group generated based on store purchase history data.
他の態様では、顧客分析プログラムは、期間の指定を分析対象期間とする指示、または、現在もしくは過去の時点からの所定期間を分析対象期間とする指示と、分析対象の店の購買履歴データとを受け付け、指示された前記分析対象期間における複数の店の購買履歴データに基づいて生成された顧客グループのうち、所定の類似関係を有する全ての顧客グループを含む統合顧客グループに含まれる各顧客グループを、各顧客グループの基礎とされた前記購買履歴データが示す時期と対応付けて記憶した記憶部を参照して、前記統合顧客グループのうち、指定された前記分析対象期間に含まれる時期の前記購買履歴データを基礎とする統合顧客グループを抽出し、抽出した前記統合顧客グループと、前記分析対象の店の購買履歴データに基づいて生成された顧客グループとの比較結果を出力する、処理を、コンピュータに実行させる。 In another aspect, the customer analysis program includes an instruction to designate a period as an analysis target period, or an instruction to set a predetermined period from a current or past time point as an analysis target period, purchase history data of an analysis target store, Each customer group included in an integrated customer group including all customer groups having a predetermined similar relationship among customer groups generated based on purchase history data of a plurality of stores in the analysis target period , Referring to the storage unit stored in association with the time indicated by the purchase history data based on each customer group, among the integrated customer group of the time included in the specified analysis target period Extracting an integrated customer group based on purchase history data, and based on the extracted integrated customer group and purchase history data of the analysis target store And outputs the result of comparison between the generated customer group, the process to be executed by a computer.
一つの態様では、顧客分析方法は、期間の指定を分析対象期間とする指示、または、現在もしくは過去の時点からの所定期間を分析対象期間とする指示と、分析対象の店の購買履歴データとを受け付ける工程と、
指示された前記分析対象期間における複数の店の購買履歴データに基づいて生成された顧客グループのうち、所定の類似関係を有する全ての顧客グループを含む統合顧客グループと、前記分析対象の店の購買履歴データに基づいて生成された顧客グループとの比較結果を出力する工程とを、コンピュータが実行する。
In one aspect, the customer analysis method includes an instruction to designate a period as an analysis target period, or an instruction to set a predetermined period from a current or past time point as an analysis target period, and purchase history data of a store to be analyzed. A process of accepting,
An integrated customer group including all customer groups having a predetermined similar relationship among customer groups generated based on purchase history data of a plurality of stores in the specified analysis target period, and purchase of the analysis target store The computer executes a process of outputting a comparison result with the customer group generated based on the history data.
他の態様では、顧客分析方法は、期間の指定を分析対象期間とする指示、または、現在もしくは過去の時点からの所定期間を分析対象期間とする指示と、分析対象の店の購買履歴データとを受け付ける工程と、指示された前記分析対象期間における複数の店の購買履歴データに基づいて生成された顧客グループのうち、所定の類似関係を有する全ての顧客グループを含む統合顧客グループに含まれる各顧客グループを、各顧客グループの基礎とされた前記購買履歴データが示す時期と対応付けて記憶した記憶部を参照して、前記統合顧客グループのうち、指定された前記分析対象期間に含まれる時期の前記購買履歴データを基礎とする統合顧客グループを抽出する工程と抽出した前記統合顧客グループと、前記分析対象の店の購買履歴データに基づいて生成された顧客グループとの比較結果を出力する工程とを、コンピュータが実行する。 In another aspect, the customer analysis method includes an instruction to designate a period as an analysis target period, or an instruction to set a predetermined period from a current or past time point as an analysis target period, and purchase history data of a store to be analyzed. And a customer group generated based on purchase history data of a plurality of stores in the instructed analysis target period, and included in an integrated customer group including all customer groups having a predetermined similarity relationship Referring to the storage unit that stores the customer group in association with the time indicated by the purchase history data based on each customer group, the time included in the specified analysis target period of the integrated customer group A process of extracting an integrated customer group based on the purchase history data, the extracted integrated customer group, and purchase history data of the analysis target store And a step of outputting the result of comparison between the generated customer groups based, computer executes.
一つの態様では、顧客分析装置は、期間の指定を分析対象期間とする指示、または、現在もしくは過去の時点からの所定期間を分析対象期間とする指示と、分析対象の店の購買履歴データとを受け付ける受付処理部と、指示された前記分析対象期間における複数の店の購買履歴データに基づいて生成された顧客グループのうち、所定の類似関係を有する全ての顧客グループを含む統合顧客グループと、前記分析対象の店の購買履歴データに基づいて生成された顧客グループとの比較結果を出力する出力処理部とを有する。 In one aspect, the customer analysis device includes an instruction to designate a period as an analysis target period, or an instruction to set a predetermined period from a current or past time point as an analysis target period, and purchase history data of a store to be analyzed. An integrated customer group including all customer groups having a predetermined similarity among customer groups generated based on purchase history data of a plurality of stores in the instructed analysis target period, An output processing unit that outputs a comparison result with the customer group generated based on the purchase history data of the analysis target store.
他の態様では、顧客分析装置は、期間の指定を分析対象期間とする指示、または、現在もしくは過去の時点からの所定期間を分析対象期間とする指示と、分析対象の店の購買履歴データとを受け付ける受付処理部と、指示された前記分析対象期間における複数の店の購買履歴データに基づいて生成された顧客グループのうち、所定の類似関係を有する全ての顧客グループを含む統合顧客グループに含まれる各顧客グループを、各顧客グループの基礎とされた前記購買履歴データが示す時期と対応付けて記憶した記憶部と、前記記憶部を参照して、前記統合顧客グループのうち、指定された前記分析対象期間に含まれる時期の前記購買履歴データを基礎とする統合顧客グループを抽出、抽出した前記統合顧客グループと、前記分析対象の店の購買履歴データに基づいて生成された顧客グループとの比較結果を出力する出力処理部とを有する。 In another aspect, the customer analysis device includes an instruction to designate a period as an analysis target period, or an instruction to set a predetermined period from a current or past time point as an analysis target period, and purchase history data of a store to be analyzed. Included in an integrated customer group that includes a reception processing unit that accepts and all customer groups having a predetermined similar relationship among customer groups generated based on purchase history data of a plurality of stores in the instructed analysis target period Each of the customer groups to be stored in association with the time indicated by the purchase history data based on each customer group, and the storage unit, with reference to the storage unit, the specified customer of the integrated customer group The integrated customer group based on the purchase history data in the period included in the analysis target period is extracted, the extracted integrated customer group, and the purchase of the analysis target store. And an output processing unit that outputs a result of comparison between customer groups that are generated based on historical data.
時期のトレンドを考慮した顧客分析ができる。 Customers can be analyzed in consideration of seasonal trends.
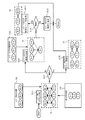
図1は、顧客分析システムの一例を示す構成図である。顧客分析システムは、顧客分析装置1と、百貨店A〜Xにそれぞれ設置された端末装置2とを有する。端末装置2は、例えばパーソナルコンピュータなどのコンピュータ装置であり、インターネットなどのネットワークNWを介して、顧客分析装置1に接続されている。なお、顧客分析装置1は、ネットワークNWに接続されていない状態(オフライン状態)でも、格納済みのデータを用いて顧客分析処理を実行することは可能である。
FIG. 1 is a configuration diagram illustrating an example of a customer analysis system. The customer analysis system includes a
顧客分析装置1は、例えば、サーバ装置などのコンピュータ装置であり、顧客分析サービスを提供する。顧客分析装置1は、端末装置2から各種のデータを取集することにより、各百貨店A〜Xの顧客を分析し、各百貨店A〜Xの顧客の分析結果を当該端末装置2に送信する。
The
より具体的には、顧客分析装置1は、複数の百貨店の購買履歴データに基づく顧客グループのうち、指定期間に応じた類似の顧客グループが属する統合顧客グループと、分析対象の百貨店Xの顧客グループとを比較して、比較結果を百貨店Xの端末装置2に送信する。これにより、顧客分析装置1は、時期のトレンドを考慮した顧客分析を行う。
More specifically, the
本実施例において、顧客分析装置1は、百貨店Xを分析対象とし、百貨店Xの顧客を、他の百貨店A,B,C,・・・の分析結果に基づいて構築されたデータベースを用いて分析する。なお、顧客分析装置1の分析対象は、百貨店Xに限定されず、量販店、コンビニエンスストア、及び自動車のディーラーなどの他種の販売店や、例えば飲食店のように、顧客に特定のサービスを提供する店であってもよい。
In the present embodiment, the
図2は、端末装置2の一例を示す構成図である。端末装置2は、CPU(Central Processing Unit)20、ROM(Read Only Memory)21、RAM(Random Access Memory)22、HDD(Hard Disk Drive)23、及び通信処理部24を備える。端末装置2は、さらに、可搬型記憶媒体用ドライブ25、入力処理部26、及び画像処理部27などを備えている。
FIG. 2 is a configuration diagram illustrating an example of the
CPU20は、演算処理手段であり、顧客分析装置1とデータを送受信するための通信処理プログラム(ソフトウェア)に従って動作する。CPU20は、各部21〜27とバス28を介して接続されている。なお、端末装置2は、ソフトウェアにより動作するものに限定されず、CPU20に代えて、特定用途向け集積回路などのハードウェアが用いられてもよい。
The
RAM22は、CPU20のワーキングメモリとして用いられる。また、ROM21及びHDD23は、プログラムなどを記憶する記憶手段として用いられる。HDD23は、さらに、百貨店A〜Xにおける顧客(当該百貨店に会員登録された客)の購買履歴を示す購買履歴データ230と、百貨店A〜Xの顧客の属性を示す顧客データ231とを格納する。
The
図3には、購買履歴データ230(図3(a)参照)及び顧客データ231(図3(b)参照)の一例が示されている。購買履歴データ230は、「店名」情報と、「部門」情報と、「ブランド名」情報と、「買上日」情報と、「買上時間」情報と、「顧客ID」とを含む。
FIG. 3 shows an example of purchase history data 230 (see FIG. 3A) and customer data 231 (see FIG. 3B). The
「店名」情報は、百貨店A〜Xの識別情報である。なお、「店名」情報は、百貨店A〜Xごとに、各欄で共通であり、顧客分析装置1が百貨店A〜Xを区別するために用いる。
“Store name” information is identification information of department stores A to X. The “store name” information is common to each column for each of the department stores A to X, and is used by the
「部門」情報は、購買が行われた商品の部門を示す。「ブランド名」情報は、購買された商品のブランド名(ブランドA,Bなど)を示す。「買上日」情報及び「買上時間」情報は、購買が行われた日付及び時刻をそれぞれ示す。「顧客ID」は、顧客の識別番号であり、例えば顧客の会員番号である。なお、「ブランド名」情報は、一例であり、これに代えて、購買された商品名を示す「商品名」情報、商品が購買されたフロア名を示す「フロア名」情報、または、商品以外のサービス名を示す「サービス名」情報などが用いられてもよい。 The “department” information indicates the department of the product for which purchase has been performed. The “brand name” information indicates the brand name (brand A, B, etc.) of the purchased product. The “purchase date” information and the “purchase time” information respectively indicate the date and time when the purchase was performed. “Customer ID” is a customer identification number, for example, a customer membership number. “Brand name” information is only an example. Instead, “product name” information indicating the name of the purchased product, “floor name” information indicating the name of the floor where the product was purchased, or other than the product. “Service name” information indicating the service name may be used.
顧客データ231は、「顧客ID」、「年齢」情報、「性別」情報、及び「郵便番号」を含む。「顧客ID」は、上述した顧客IDに対応する。「年齢」情報は、当該顧客の年齢を示す。なお、「年齢」情報は、図3(b)に示されるような具体的な年齢ではなく、一定幅の年齢層(例えば、10代、20代、・・・など)として示されてもよい。
The
「性別」情報は、当該顧客の性別を示す。「郵便番号」は、当該顧客の居住地区の郵便番号を示す。なお、「郵便番号」に代えて、当該顧客の住所、または住所の一部が用いられてもよい。 “Gender” information indicates the gender of the customer. “Postal code” indicates the postal code of the customer's residence area. Instead of “zip code”, the address of the customer or a part of the address may be used.
CPU20は、購買履歴データ230及び顧客データ231をHDD23から読み出して、通信処理部24に出力する。通信処理部24は、例えばネットワークカードであり、ネットワークNWを介して、顧客分析装置1などと通信する通信手段である。
The
可搬型記憶媒体用ドライブ25は、可搬型記憶媒体250に対して、情報の書き込みや情報の読み出しを行う装置である。可搬型記憶媒体250の例としては、USBメモリ(USB: Universal Serial Bus)、CD−R(Compact Disc Recordable)、及びメモリカードなどが挙げられる。なお、通信処理プログラムは、可搬型記憶媒体250に格納されてもよい。
The portable
端末装置2は、情報の入力操作を行うための入力デバイス260、及び、画像を表示するためのディスプレイ270を、さらに備える。入力デバイス260は、キーボード及びマウスなどの入力手段であり、入力された情報は、入力処理部26を介してCPU20に出力される。例えば、CPU20は、ユーザが入力デバイス260により入力操作した分析対象期間の指定情報が入力される。
The
分析対象期間は、顧客分析装置1において、購買履歴データ230に基づいて生成された顧客グループ情報(後述する個社クラスタ)の比較対象として使用される顧客グループ情報(後述する比較対象クラスタ及びユニバーサルクラスタ)の期間である。分析対象期間は、特定の期間(2010年など)、または、現在もしくは過去の時点からの所定期間(2011年以降や2009年以前など)として指定(指示)される。このように、端末装置2から、分析対象期間の指定が行われるので、顧客分析装置1は、時期のトレンドを考慮した顧客分析を行うことができる。なお、分析対象期間の指定は、顧客分析装置1において行われてもよい。
The analysis target period is customer group information (comparison target cluster and universal cluster described later) used as a comparison target of customer group information (individual company cluster described later) generated based on the
ディスプレイ270は、液晶ディスプレイなどの画像表示手段であり、表示される画像データは、CPU20から画像処理部27を介してディスプレイに出力される。なお、入力デバイス260及びディスプレイ270に代えて、これらの機能を備えるタッチパネルなどのデバイスを用いることもできる。
The
CPU20は、ROM21、またはHDD23などに格納されているプログラム、または可搬型記憶媒体用ドライブ25が可搬型記憶媒体250から読み取ったプログラムを実行する。このプログラムには、OS(Operating System)だけでなく、上記の通信処理プログラムも含まれる。なお、通信処理プログラムは、通信処理部24を介してダウンロードされたものであってもよい。
The
CPU20は、通信処理プログラムが実行されると、例えば入力処理部26を介して入力された購買履歴データ230及び顧客データ231をHDD23に書き込む。なお、購買履歴データ230及び顧客データ231の入力手段は、入力処理部26に限定されない。購買履歴データ230及び顧客データ231は、同一の百貨店A〜X内の他のコンピュータ装置から通信処理部24を介して入力されてもよいし、可搬型記憶媒体250から可搬型記憶媒体用ドライブ25を介して入力されてもよい。
When the communication processing program is executed, the
また、CPU20は、例えば、顧客分析装置1からの要求を受けたとき、または入力デバイス260で所定の入力操作が行われたとき、購買履歴データ230及び顧客データ231をHDD23から読み出して、顧客分析装置1に送信する。また、CPU20は、入力デバイス260で分析対象期間の入力操作が行われたとき、分析対象期間の指定情報を顧客分析装置1に送信する。さらに、CPU20は、顧客分析装置1から、顧客分析結果を示すデータを受信したとき、HDD23などの記憶手段に書き込み、ディスプレイ270に表示する。なお、分析対象期間の指定は、入力デバイス260に限定されず、通信処理部24により、ネットワークを介して行われてもよい。
Further, for example, when receiving a request from the
図4は、顧客分析装置1を示す構成図である。顧客分析装置1は、CPU10、ROM11、RAM12、HDD13、通信処理部14、可搬型記憶媒体用ドライブ15、入力処理部16、及び画像処理部17などを備えている。
FIG. 4 is a configuration diagram showing the
CPU10は、演算処理手段であり、顧客分析プログラム(ソフトウェア)に従って、後述する顧客分析方法を実行する。CPU10は、各部11〜17とバス18を介して接続されている。なお、顧客分析装置1は、ソフトウェアにより動作するものに限定されず、CPU10に代えて、特定用途向け集積回路などのハードウェアが用いられてもよい。
The
RAM12は、CPU10のワーキングメモリとして用いられる。また、ROM11及びHDD13は、CPU10を動作させる顧客分析プログラムなどを記憶する記憶手段として用いられる。通信処理部14は、例えばネットワークカードであり、ネットワークNWを介して、複数の端末装置2などと通信する通信手段である。
The
可搬型記憶媒体用ドライブ15は、可搬型記憶媒体150に対して、情報の書き込みや情報の読み出しを行う装置である。可搬型記憶媒体150の例としては、USBメモリ、CD−R、及びメモリカードなどが挙げられる。なお、顧客分析プログラムは、可搬型記憶媒体150に格納されてもよい。
The portable
顧客分析装置1は、情報の入力操作を行うための入力デバイス160、及び、画像を表示するためのディスプレイ170を、さらに備える。入力デバイス160は、キーボード及びマウスなどの入力手段であり、入力された情報は、入力処理部16を介してCPU10に出力される。上記の分析対象期間の指定情報は、入力デバイス160を介して入力されてもよい。
The
ディスプレイ170は、液晶ディスプレイなどの画像表示手段であり、表示される画像データは、CPU10から画像処理部17を介してディスプレイに出力される。なお、入力デバイス160及びディスプレイ170に代えて、これらの機能を備えるタッチパネルなどのデバイスを用いることもできる。
The
CPU10は、ROM11、またはHDD13などに格納されているプログラム、または可搬型記憶媒体用ドライブ15が可搬型記憶媒体150から読み取ったプログラムを実行する。このプログラムには、OS(Operating System)だけでなく、上記の顧客分析プログラムも含まれる。なお、顧客分析プログラムは、通信処理部14を介してダウンロードされたものであってもよい。
The
CPU10は、顧客分析プログラムを実行すると、複数の機能が形成される。第1実施例において、CPU10は、分析対象期間に応じた類似の顧客グループを含む統合顧客グループを生成し、生成した統合顧客グループと、分析対象の百貨店Xの顧客グループとを比較し、比較結果を出力する機能を有する。また、第2実施例において、CPU10は、類似の顧客グループを含む既存の統合顧客グループから、分析対象期間に応じた統合顧客グループを抽出し、抽出した統合顧客グループと、分析対象の百貨店Xの顧客グループとを比較し、比較結果を出力する機能を有する。
When the
(第1実施例)
まず、第1実施例について説明する。図5は、第1実施例に係る顧客分析装置1の機能構成例を示す構成図である。図5には、CPU10に形成される機能及びHDD13の格納情報の一例が示されている。
(First embodiment)
First, the first embodiment will be described. FIG. 5 is a configuration diagram illustrating a functional configuration example of the
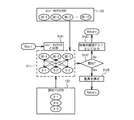
CPU10は、データクラスタリングにより顧客分析を行う。CPU10は、データ入力処理部(受付処理部)101と、クラスタ生成部102と、クラスタ処理部(出力処理部)103とを含む。クラスタ処理部103は、類似判定処理部103a及び比較対象クラスタ生成部103bを有する。
The
HDD13は、クラスタ生成用データ131と、個社クラスタデータベース(DB:Data Base)132と、ユニバーサルクラスタデータベース(DB)133とを記憶する。また、HDD13は、ユニバーサルクラスタ候補データベース(DB)134と、分析結果データベース(DB)135とを記憶する。
The
データ入力処理部101は、端末装置2から通信処理部14を介して、分析対象期間の指定情報、購買履歴データ230、及び顧客データ231が入力される。つまり、データ入力処理部101は、端末装置2から、分析対象期間の指定(指示)と、分析対象の百貨店Xの購買履歴データ230及び顧客データ231を受け付ける。データ入力処理部101は、分析対象期間の指定情報を比較対象クラスタ生成部103bに出力する。
The data
データ入力処理部101は、購買履歴データ230及び顧客データ231に基づいて、クラスタ生成用データ131を生成する。ここで、「クラスタ」とは、顧客を、各種の条件に従って、グループごとに分類することにより得られるデータの束、つまり、顧客のグループ情報を指す。
The data
クラスタ生成部102は、クラスタ生成用データ131に基づいて、百貨店A〜Xに関する個社クラスタを生成し、個社クラスタDB132に格納する。個社クラスタは、百貨店A〜Xごとに生成されたクラスタ、つまり、百貨店A〜Xの個別のクラスタである。つまり、クラスタ生成部102は、百貨店A〜Xごとの購買履歴データ230に基づいて、複数の顧客グループを生成する。
The
クラスタ処理部103は、分析対象の百貨店Xの個社クラスタの比較分析処理、及びユニバーサルクラスタの構築処理を行う。比較対象クラスタ生成部103bは、個社クラスタDB132から、指定(指示)された分析対象期間における百貨店A,B,・・・の購買履歴データ230に基づいて生成された個社クラスタ(顧客グループ)を抽出する。比較対象クラスタ生成部103bは、抽出した個社クラスタのうち、所定の類似関係を有する全ての個社クラスタを含む比較対象クラスタ(統合顧客グループ)を生成する。クラスタ処理部103は、分析対象の百貨店Xの個社クラスタと、比較対象クラスタとの類似性の有無を判定することにより、比較分析処理を実行する。このとき、類似関係(類似性)の判定処理は、類似判定処理部103aにより行われる。
The
また、クラスタ処理部103は、ユニバーサルクラスタの構築処理を行うことにより、ユニバーサルクラスタDB133及びユニバーサルクラスタ候補DB134を更新する。クラスタ処理部103は、個社クラスタDB132内の個社クラスタを、ユニバーサルクラスタDB133内のユニバーサルクラスタと比較し、比較結果に応じて、ユニバーサルクラスタDB133を更新する。ユニバーサルクラスタは、所定の条件に従って、類似性を有する複数の個社クラスタを束ねて得られる統合型クラスタである。
In addition, the
より具体的には、クラスタ処理部103は、ユニバーサルクラスタと類似性を有する個社クラスタを、当該ユニバーサルクラスタに含めることにより、当該ユニバーサルクラスタを更新する。つまり、クラスタ処理部103は、分析対象の百貨店Xの購買履歴データ230に基づいて生成され、統合顧客グループ(ユニバーサルクラスタ)と所定の類似関係を有する顧客グループ(個社クラスタ)を検出し、統合顧客グループに含めることにより、統合顧客グループを更新する。このとき、類似関係(類似性)の判定処理は、類似判定処理部103aにより行われる。
More specifically, the
また、クラスタ処理部103は、個社クラスタDB132内の個社クラスタを、ユニバーサルクラスタ候補DB134内のユニバーサルクラスタ候補と比較し、比較結果に応じて、ユニバーサルクラスタ候補DB134またはユニバーサルクラスタDB133を更新する。ユニバーサルクラスタ候補は、既存のユニバーサルクラスタの何れとも類似性を有していない個社クラスタであって、新たなユニバーサルクラスタとなり得るユニバーサルクラスタの候補である。
Further, the
より具体的には、クラスタ処理部103は、ユニバーサルクラスタ候補と類似性を有する個社クラスタを、当該ユニバーサルクラスタ候補に統合することにより、新たなユニバーサルクラスタを生成する。つまり、クラスタ処理部103は、クラスタ生成部102により生成された複数の顧客グループ(個社クラスタ)のうち、所定の類似関係を有する顧客グループが属する統合顧客グループ(ユニバーサルクラスタ)を生成する。
More specifically, the
また、クラスタ処理部103は、ユニバーサルクラスタ候補の何れとも類似性を有していない個社クラスタを、新たなユニバーサルクラスタ候補として、ユニバーサルクラスタ候補DB134に追加する。なお、類似関係(類似性)の判定処理は、類似判定処理部103aにより行われる。
In addition, the
図6は、ユニバーサルクラスタDB133(図6(a))及び個社クラスタDB132(図6(b))の例を示す。なお、ユニバーサルクラスタ候補DB134の内容は、個社クラスタDB132と同様である。
FIG. 6 shows an example of the universal cluster DB 133 (FIG. 6A) and the individual company cluster DB 132 (FIG. 6B). The contents of the universal
ユニバーサルクラスタ「UC−1」及び「UC−2」は、「人数」情報と、「年間購買金額」情報と、「年齢」情報と、「元クラスタ」情報とを含む。「人数」情報は、当該ユニバーサルクラスタに属する顧客の人数を示す。例えば、「UC−1」及び「UC−2」には、100000人の顧客が属する。 The universal clusters “UC-1” and “UC-2” include “number of people” information, “annual purchase amount” information, “age” information, and “original cluster” information. The “number of people” information indicates the number of customers belonging to the universal cluster. For example, “UC-1” and “UC-2” have 100,000 customers.
「年間購買金額」情報は、金額の程度(「Low」(少)、「Middle」(中)、「High」(多))ごとに顧客を分類したときの顧客の人数の比率を示す。「年齢」情報は、性別(「男性」及び「女性」)ごとに、年齢層(「20代」〜「80代」)ごとの顧客の人数の比率を示す。 The “annual purchase amount” information indicates the ratio of the number of customers when the customers are classified according to the amount of money (“Low” (small), “Middle” (medium), “High” (many)). The “age” information indicates the ratio of the number of customers for each age group (“20s” to “80s”) for each gender (“male” and “female”).
「元クラスタ」情報は、当該ユニバーサルクラスタの生成元となった個社クラスタを示す。例えば、ユニバーサルクラスタ「UC−1」は、個社クラスタ「A−1(2008)」及び「B−2(2010)」を統合することで生成され、ユニバーサルクラスタ「UC−2」は、個社クラスタ「C−3(2010)」及び「D−4(2009)」を統合することで生成される。ここで、個社クラスタのカッコ内の数字は、当該個社クラスタが、クラスタ生成部102により生成されたときに基礎とされた購買履歴データ230の年度(後述する「生成年度」情報)を示す。つまり、「A−1(2008)」及び「B−2(2010)」は、2008年度及び2010年度の購買履歴データ230に基づいてそれぞれ生成された個社クラスタである。
The “original cluster” information indicates the individual company cluster that is the generation source of the universal cluster. For example, the universal cluster “UC-1” is generated by integrating the individual company clusters “A-1 (2008)” and “B-2 (2010)”, and the universal cluster “UC-2” It is generated by integrating the clusters “C-3 (2010)” and “D-4 (2009)”. Here, the number in parentheses of the individual company cluster indicates the year (“generation year” information described later) of the
個社クラスタは、「生成年度」情報と、「人数」情報と、「年間購買金額」情報と、「年齢」情報と、「元クラスタ」情報とを含む。「人数」情報、「年間購買金額」情報、及び「年齢」情報は、上述した通りである。 The individual company cluster includes “generation year” information, “number of people” information, “annual purchase amount” information, “age” information, and “original cluster” information. The “number of people” information, the “annual purchase amount” information, and the “age” information are as described above.
「生成年度」情報は、当該個社クラスタが、クラスタ生成部102により生成されたときに基礎とされた購買履歴データ230の年度を示す。例えば、個社クラスタ「A−1」及び「B−2」の生成元の購買履歴データ230の年度は、それぞれ、2008年度及び2010年度である。
The “generation year” information indicates the year of the
「生成年度」情報は、個社クラスタの基礎(つまり生成元)とされた購買履歴データ230の「買上日」情報が示す時期に対応する。すなわち、クラスタ生成部102は、個社クラスタを生成するとき、「買上日」情報の年(「2011」など)に基づいて「生成年度」情報を生成する。後述するように、比較対象クラスタ生成部103bは、比較対象クラスタを生成するとき、「生成年度」情報が示す期間が、分析対象期間に含まれる個社クラスタを抽出する。なお、「生成年度」情報に代えて、当該個社クラスタが生成された月や季節などの情報が使用されてもよい。
The “generation year” information corresponds to the time indicated by the “purchase date” information in the
このように、HDD13(個社クラスタDB132)は、各顧客グループ(個社クラスタ)を、各顧客グループの基礎とされた購買履歴データ230が示す時期(「買上日」情報が示す年度)と対応付けて記憶する。このため、比較対象クラスタ生成部103bは、指定された分析対象期間に応じた個社クラスタを容易に抽出できる。
Thus, the HDD 13 (individual company cluster DB 132) corresponds each customer group (individual company cluster) with the time indicated by the
クラスタ処理部103は、生成された比較対象クラスタと、分析対象の百貨店Xの個社クラスタとを比較し、比較結果を分析結果DB135に格納する。なお、比較対象クラスタは、比較分析処理が終了すると、HDD13などに保存されることなく削除される。
The
クラスタ処理部103は、比較結果を示す情報を、所定のタイミングで分析結果DB135から読み出して、端末装置2に送信する。比較結果を示す情報としては、比較対象クラスタと非類似の個社クラスタ、及び、個社クラスタに類似する比較対象クラスタと当該個社クラスタの差異が挙げられる。比較対象クラスタと非類似の個社クラスタは、分析対象の百貨店Xの特徴的な顧客グループとして処理される。
The
つまり、クラスタ処理部103は、統合顧客グループ(比較対象クラスタ)と所定の類似関係を有していない顧客グループ(個社クラスタ)を検出し、分析対象の百貨店Xの特徴的な顧客グループとして出力する。さらに、クラスタ処理部103は、統合顧客グループと所定の類似関係を有する顧客グループと、統合顧客グループとの差異を検出して出力する。出力された比較結果の情報は、分析対象の百貨店Xにおいて、経営戦略の立案などに用いられる。以下に、上述した構成に基づく、顧客分析プログラムの詳細を述べる。
That is, the
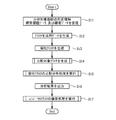
図7は、第1実施例に係る顧客分析プログラムのフローチャートである。図7は、1回の分析処理の流れを示す。なお、本例では、クラスタの比較分析処理に関連する処理(ステップSt4〜St6)及びユニバーサルクラスタの構築処理(ステップSt7)の両方が実行される場合を挙げるが、これに限定されず、何れか一方のみが実行されてもよい。 FIG. 7 is a flowchart of the customer analysis program according to the first embodiment. FIG. 7 shows the flow of one analysis process. In this example, a case where both the process related to the cluster comparative analysis process (steps St4 to St6) and the universal cluster construction process (step St7) are executed is described, but the present invention is not limited to this. Only one may be executed.
まず、データ入力処理部101は、端末装置2から分析対象期間の指定情報(指示情報)、購買履歴データ230、及び顧客データ231を受信する(ステップSt1)。すなわち、データ入力処理部101は、分析対象期間の指定(指示)と、分析対象の店の購買履歴データとを受け付ける。
First, the data
次に、データ入力処理部101は、購買履歴データ230及び顧客データ231に基づいて、クラスタ生成用データ131を生成する(ステップSt2)。
Next, the data
図8(a)は、クラスタ生成用データ131の一例を示す。クラスタ生成用データ131は、「顧客ID」及び「ブランド」情報を含む。「顧客ID」は、購買履歴データ230の顧客IDに対応する。「ブランド」情報は、購買履歴データ230の「ブランド名」に対応し、一定期間内(例えば特定の年度内、特定の季節内など)におけるブランド種別(「A」〜「C」)ごとの当該顧客の購買回数を示す。
FIG. 8A shows an example of the
例えば、顧客ID「0001」について、ブランドA〜Cの各購買回数は、それぞれ、3回,2回,0回であり、顧客ID「0002」について、ブランドA〜Cの各購買回数は、それぞれ、0回,1回,2回である。 For example, for customer ID “0001”, the number of purchases of brands A to C is 3, 2, and 0, respectively, and for customer ID “0002”, the number of purchases of brands A to C is 0 times, 1 time and 2 times.
次に、クラスタ生成部102は、クラスタ生成用データ131を読み出し、クラスタ生成用データ131に基づいて個社クラスタを生成する(ステップSt3)。つまり、クラスタ生成部102は、購買履歴データ230及び顧客データ231に基づいて、データクラスタリングを行うことで、個社クラスタを生成する。このとき、クラスタ生成部102は、購買履歴データ230に基づいて、上記の「生成年度」情報を生成する。生成された個社クラスタは、個社クラスタDB132に格納される。
Next, the
データクラスタリングの手法に限定はないが、一例として、図8(a)に示されたクラスタ生成用データ131に基づいて、顧客(顧客ID)を、3次元座標にマッピングする手法が挙げられる。
Although there is no limitation on the data clustering method, an example is a method of mapping customers (customer IDs) to three-dimensional coordinates based on the
図8(b)は、クラスタ生成用3次元座標の一例を示す。本例において、顧客(顧客ID)ごとの座標は、ブランドA〜Cの購入回数にそれぞれ対応する3つの座標軸A〜Cにより規定される。 FIG. 8B shows an example of the three-dimensional coordinates for cluster generation. In this example, the coordinates for each customer (customer ID) are defined by three coordinate axes A to C corresponding to the number of purchases of brands A to C, respectively.
例えば、顧客ID「0001」は、ブランドA〜Cの各購買回数が、それぞれ、3回,2回,0回であるため、当該座標は、(3,2,0)となる。また、顧客ID「0002」は、ブランドA〜Cの各購買回数が、それぞれ、0回,1回,2回であるため、当該座標は、(0,1,2)となる。同様に、顧客ID「0003」及び「0004」の座標は、それぞれ、(2,2,1)及び(0,2,3)となる。 For example, for customer ID “0001”, the number of purchases of brands A to C is 3, 2, and 0, respectively, and the coordinates are (3, 2, 0). In addition, since the customer ID “0002” has the number of purchases of the brands A to C being 0 times, 1 time, and 2 times, the coordinates are (0, 1, 2). Similarly, the coordinates of the customer IDs “0003” and “0004” are (2, 2, 1) and (0, 2, 3), respectively.
クラスタ生成部102は、マッピングされた座標が近い顧客ID同士を束ねることにより、顧客を複数のグループに分類することで、個社クラスタを生成する。例えば、顧客ID「0001」及び「0003」は、グループG1に分類され、顧客ID「0002」及び「0004」は、グループG2に分類される。グループG1に対応する個社クラスタDB132は、ブランドA,Bの購買傾向が強い顧客グループを示し、グループG2に対応する個社クラスタDB132は、ブランドB,Cの購買傾向が強い顧客グループを示す。
The
このように、クラスタ生成部102は、一例として、顧客ごとのブランドA〜Cの購買傾向に従って、個社クラスタを生成するため、購買傾向に従った顧客分析を可能とする。もっとも、個社クラスタを生成する基準は、ブランドA〜Cの購買傾向に限定されず、年齢層、居住地区、性別、及び購買の日付などの各種の情報(図3参照)であってもよい。
As described above, as an example, the
次に、比較対象クラスタ生成部103bは、分析対象の百貨店Xの個社クラスタの比較対象のクラスタ、つまり比較対象クラスタを生成する(ステップSt4)。比較対象クラスタは、個社クラスタDB132に格納済みの他の百貨店A,B,・・・の個社クラスタのうち、類似性を有する全ての個社クラスタ同士を統合することにより生成される。
Next, the comparison target cluster generation unit 103b generates a comparison target cluster of the individual company cluster of the analysis target department store X, that is, a comparison target cluster (step St4). The comparison target cluster is generated by integrating all the individual company clusters having similarities among the individual company clusters of other department stores A, B,... Stored in the individual
図9は、比較対象クラスタの生成処理を示すフローチャートである。まず、比較対象クラスタ生成部103bは、個社クラスタDB132から、分析対象期間に応じた個社クラスタを抽出する(ステップSt21)。 FIG. 9 is a flowchart showing the comparison target cluster generation processing. First, the comparison target cluster generation unit 103b extracts an individual company cluster corresponding to the analysis target period from the individual company cluster DB 132 (step St21).
分析対象期間の指定情報は、上述したように、特定の期間、または、現在もしくは過去の時点からの所定期間を示す。例えば、分析対象の百貨店Xの顧客グループの情報(個社クラスタ)を長期的なトレンドと比較する場合、分析対象期間として、過去の特定時期(例えば2011年度)より前の時期が指定される。この場合、比較対象クラスタ生成部103bは、比較対象クラスタの基礎(生成元のクラスタ)として、生成年度(「生成年度」情報)が、当該特定時期より前の時期(例えば、2009年度、2010年度、2011年度)の個社クラスタを抽出する。 As described above, the analysis target period designation information indicates a specific period or a predetermined period from the current or past time point. For example, when comparing the information of the customer group of the department store X to be analyzed (individual company cluster) with a long-term trend, a period prior to the past specific period (for example, 2011) is specified as the period to be analyzed. In this case, the comparison target cluster generation unit 103b uses the generation year (“generation year” information) as the basis of the comparison target cluster (the generation source cluster) before the specific time (for example, FY2009, FY2010). , 2011) is extracted.
また、分析対象の百貨店Xの顧客グループの情報を短期的なトレンドと比較する場合、分析対象期間として、過去の特定時期(例えば2012年度)より後の時期が指定される。この場合、比較対象クラスタ生成部103bは、比較対象クラスタの基礎として、生成年度が、当該特定時期より前の時期(例えば、2012年度、2013年度)の個社クラスタを抽出する。なお、分析対象期間の指定は、過去の時点を基準としたものに限定されず、現在を基準としたもの(例えば、「過去2年間分」など)であってもよい。 Moreover, when comparing the information of the customer group of the department store X to be analyzed with a short-term trend, a period after the past specific period (for example, 2012) is designated as the period to be analyzed. In this case, the comparison target cluster generation unit 103b extracts individual company clusters whose generation year is earlier than the specific time (for example, 2012, 2013) as the basis of the comparison target cluster. The designation of the analysis target period is not limited to the one based on the past time point, and may be one based on the present (for example, “for the past two years”).
さらに、分析対象の百貨店Xの顧客グループの情報を特定時期のトレンドと比較する場合、分析対象期間として、特定の期間(例えば2013年度)が指定される。この場合、比較対象クラスタ生成部103bは、比較対象クラスタの基礎として、生成年度が、当該特定時期(例えば、2013年度)の個社クラスタを抽出する。 Furthermore, when the information of the customer group of the department store X to be analyzed is compared with a trend at a specific time, a specific period (for example, 2013) is designated as the analysis target period. In this case, the comparison target cluster generation unit 103b extracts an individual company cluster whose generation year is the specific period (for example, 2013) as the basis of the comparison target cluster.
次に、比較対象クラスタ生成部103bは、抽出された個社クラスタが複数であるか否かを判定する(ステップSt22)。抽出された個社クラスタが1以下である場合(ステップSt22のNo)、比較対象クラスタ生成部103bは、処理を終了する。この場合、比較対象クラスタが生成されないため、図7のステップSt5及びSt6の処理は行われない。 Next, the comparison target cluster generation unit 103b determines whether there are a plurality of extracted individual company clusters (step St22). When the extracted individual company cluster is 1 or less (No in step St22), the comparison target cluster generation unit 103b ends the process. In this case, since the comparison target cluster is not generated, the processes of steps St5 and St6 in FIG. 7 are not performed.
また、抽出された個社クラスタが複数である場合(ステップSt22のYes)、比較対象クラスタ生成部103bは、抽出された個社クラスタ間の類似性の有無を判定する(ステップSt23)。個社クラスタの何れの組み合わせについても類似性が無い場合(ステップSt23のNo)、比較対象クラスタ生成部103bは、処理を終了する。この場合、比較対象クラスタが生成されないため、図7のステップSt5及びSt6の処理は行われない。 When there are a plurality of extracted individual company clusters (Yes in step St22), the comparison target cluster generation unit 103b determines whether there is similarity between the extracted individual company clusters (step St23). If there is no similarity for any combination of individual company clusters (No in step St23), the comparison target cluster generation unit 103b ends the process. In this case, since the comparison target cluster is not generated, the processes of steps St5 and St6 in FIG. 7 are not performed.
個社クラスタの何れかの組み合わせについて類似性が有る場合(ステップSt23のYes)、比較対象クラスタ生成部103bは、互いに類似する全ての個社クラスタ同士をマージする(ステップSt24)。これにより、互いに類似する複数の個社クラスタ(顧客グループ)を含む比較対象クラスタ(統合顧客グループ)が生成される。このようにして、比較対象クラスタの生成処理は行われる。なお、比較対象クラスタは、比較分析処理のために一時的に生成されるクラスタであり、HDD13などに格納されず、例えば、比較分析処理の終了後にクラスタ処理部103から削除される。
When there is similarity for any combination of individual company clusters (Yes in step St23), the comparison target cluster generation unit 103b merges all individual company clusters that are similar to each other (step St24). Thereby, a comparison target cluster (integrated customer group) including a plurality of individual company clusters (customer groups) similar to each other is generated. In this way, the comparison target cluster generation process is performed. The comparison target cluster is a cluster that is temporarily generated for the comparison analysis process, and is not stored in the
このように、本実施例では、個社クラスタDB132から抽出した個社クラスタから比較対象クラスタを生成するので、後述する第2実施例とは異なり、ユニバーサルクラスタDB133内に、分析対象期間に応じたユニバーサルクラスタがなくても、顧客分析が可能である。このため、顧客分析装置1は、例えば、ユニバーサルクラスタDB133の内容に応じて、本実施例に係る顧客分析方法と第2実施例に係る顧客分析方法の何れかを選択して用いてもよい。以下に、分析対象期間として、「2010年度」が指定された場合を例に挙げて、比較対象クラスタの生成例を説明する。
In this way, in this embodiment, since the comparison target cluster is generated from the individual company cluster extracted from the individual
図10は、比較対象クラスタの生成例を示す。図10(a)は、個社クラスタの抽出の様子を示し、図10(b)は、比較対象クラスタの生成の様子を示す。 FIG. 10 shows a generation example of the comparison target cluster. FIG. 10A shows a state of extraction of individual company clusters, and FIG. 10B shows a state of generation of comparison target clusters.
図10(a)に示されるように、比較対象クラスタ生成部103bは、個社クラスタDB132内の個社クラスタを、「生成年度」情報に基づいて、2010年度の個社クラスタと、2010年度以外の個社クラスタとに分類する。本例では、2010年度の個社クラスタとして、百貨店Bの「B−2(2010)」、百貨店Cの「C−3(2010)」、及び百貨店Dの「D−4(2010)」が示されている。
As shown in FIG. 10A, the comparison target cluster generation unit 103b determines that the individual company cluster in the individual
また、2010年度以外の個社クラスタとして、百貨店Aの「A−1(2008)」、及び百貨店Eの「E−5(2009)」が示されている。比較対象クラスタ生成部103bは、分析対象期間に応じた個社クラスタとして、「B−2(2010)」、「C−3(2010)」、及び「D−4(2010)」を抽出する。なお、以降の説明において、クラスタ番号(A−1やE−5など)に付与されたカッコ内の数字は、「生成年度」情報を示す。 In addition, “A-1 (2008)” of department store A and “E-5 (2009)” of department store E are shown as individual company clusters other than 2010. The comparison target cluster generation unit 103b extracts “B-2 (2010)”, “C-3 (2010)”, and “D-4 (2010)” as individual company clusters corresponding to the analysis target period. In the following description, the numbers in parentheses assigned to the cluster numbers (A-1, E-5, etc.) indicate “generation year” information.
次に、図10(b)に示されるように、比較対象クラスタ生成部103bは、抽出した個社クラスタの全組み合わせについて、類似性の有無を判定し、互いに類似する「B−2(2010)」及び「C−3(2010)」をマージ(統合)する。これにより、比較対象クラスタ「CC−1」が生成される。なお、「D−4(2010)」は、「B−2(2010)」及び「C−3(2010)」の何れにも類似しないため、比較対象クラスタの生成に用いられない。また、クラスタ間の類似性の有無の判定手法は、限定されないが、例えば、以下に述べるように、各クラスタの1以上の指標を比較することで類似性を判定してもよい。 Next, as illustrated in FIG. 10B, the comparison target cluster generation unit 103 b determines the presence or absence of similarity for all combinations of the extracted individual company clusters, and “B-2 (2010)” that are similar to each other. ”And“ C-3 (2010) ”are merged (integrated). Thereby, the comparison target cluster “CC-1” is generated. Since “D-4 (2010)” is not similar to either “B-2 (2010)” or “C-3 (2010)”, it is not used to generate the comparison target cluster. Moreover, although the determination method of the presence or absence of the similarity between clusters is not limited, For example, as described below, similarity may be determined by comparing one or more indices of each cluster.
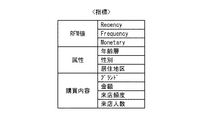
図11は、類似判定処理に用いられる指標の例を示す。指標としては、例えば、RFM値と顧客の属性及び購買内容が挙げられる。 FIG. 11 shows an example of an index used for the similarity determination process. Examples of the index include an RFM value, customer attributes, and purchase details.
RFM値は、「Recency」、「Frequency」、及び「Monetary」を含む。「Recency」は、顧客が最後に購買した日付からの経過日数を示す。「Frequency」は、顧客の購買の頻度を示す。「Monetary」は、顧客の購買の金額を示す。 The RFM value includes “Recency”, “Frequency”, and “Monetary”. “Recency” indicates the number of days that have elapsed since the last purchase by the customer. “Frequency” indicates the purchase frequency of the customer. “Monetary” indicates the purchase amount of the customer.
「Recency」、「Frequency」、及び「Monetary」の3つの指標の値(以下、「指標値」と表記)ごとの顧客数の分布の中央値または平均値を、3次元座標を用いて比較することで、クラスタの類似性を判定することができる。 The median or average value of the distribution of the number of customers for each of the three index values of “Recency”, “Frequency”, and “Monetary” (hereinafter referred to as “index value”) is compared using three-dimensional coordinates. Thus, the similarity of clusters can be determined.
顧客の属性は、「年齢層」、「男女比」、及び「居住地区分布」を含む。「年齢層」、「性別」、及び「居住地区」は、顧客データ231の「年齢」情報、「性別」情報、及び「郵便番号」からそれぞれ取得される。
The customer attributes include “age group”, “gender ratio”, and “residential area distribution”. The “age group”, “sex”, and “resident area” are acquired from the “age” information, the “sex” information, and the “zip code” in the
「年齢層」の指標値としては、例えば、顧客の年齢分布、中央値、及び平均値が用いられる。「性別」の指標値としては、例えば、男女比及び人数が挙げられる。「居住地区」の指標値としては、例えば、地区ごとの人数及び分布が挙げられる。 As the index value of “age group”, for example, customer age distribution, median value, and average value are used. Examples of the “sex” index value include a male-female ratio and the number of people. Examples of the index value of “resident area” include the number of people and the distribution for each area.
顧客の購買内容は、「ブランド」、「金額」、「来店頻度」、及び「来店人数」を含む。「ブランド」、「金額」、「来店頻度」、及び「来店人数」は、購買履歴データ230から取得される。
The purchase contents of the customer include “brand”, “amount”, “visit frequency”, and “number of customers”. “Brand”, “Price”, “Visit frequency”, and “Number of customers” are acquired from the
「ブランド」の指標値としては、例えば、顧客が購買した特徴的なブランド及びブランドのランキングが挙げられる。「金額」の指標値としては、例えば、顧客の年間の買上額、1回の来店ごとの買上額、及び曜日ごとの買上額が挙げられる。「来店頻度」の指標値としては、例えば、顧客の1週間内の来店日数及び1か月内の来店日数が挙げられる。「来店人数」の指標値としては、例えば、顧客の曜日ごとの来店人数が挙げられる。 Examples of the “brand” index value include a characteristic brand purchased by a customer and a ranking of the brand. Examples of the “money amount” index value include the annual purchase amount of the customer, the purchase amount for each visit to the store, and the purchase amount for each day of the week. Examples of the index value of “visit frequency” include the number of visits by customers in one week and the number of visits in one month. As an index value of “number of customers”, for example, the number of customers who visit each customer day of the week can be cited.
このように、クラスタ間の類似性の判定には、各種の指標値を用いることができる。以下の例では、2つの指標値の変化特性を判定に用いる場合を例に挙げて説明する。 Thus, various index values can be used to determine the similarity between clusters. In the following example, the case where the change characteristics of two index values are used for determination will be described as an example.
図12は、指標の変化特性を示すグラフである。図12は、期間がt1からt2に移行した場合における、クラスタ「A−1」、「B−1」、「C−1」の指標値x、yの変化特性を示す。なお、期間t1、t2は、特定の月(例えば、1月、6月など)であってもよいし、百貨店A〜Xの同一のイベント(販促、売場施策の実施など)を挟んだ前後の期間であってもよい。 FIG. 12 is a graph showing a change characteristic of the index. FIG. 12 shows the change characteristics of the index values x and y of the clusters “A-1”, “B-1”, and “C-1” when the period shifts from t1 to t2. The periods t1 and t2 may be a specific month (for example, January, June, etc.), or before and after the same event (promotion of sales, implementation of sales floor measures, etc.) of department stores A to X. It may be a period.
「A(t1)−1」、「B(t1)−1」、「C(t1)−1」は、期間t1における「A−1」、「B−1」、「C−1」の指標値の座標(x、y)を示す。また、「A(t2)−1」、「B(t2)−1」、「C(t2)−1」は、期間t2における「A−1」、「B−1」、「C−1」の指標値の座標(x、y)を示す。例えば、「A−1」の指標値(x、y)は、(xa1、ya1)から(xa2、ya2)に変化し、「B−1」の指標値(x、y)は、(xb1、yb1)から(xb2、yb2)に変化する。 “A (t1) -1”, “B (t1) -1”, and “C (t1) -1” are indices of “A-1”, “B-1”, and “C-1” in the period t1. Indicates the coordinates (x, y) of the value. “A (t2) -1”, “B (t2) -1”, and “C (t2) -1” are “A-1”, “B-1”, and “C-1” in the period t2. Indicates the coordinates (x, y) of the index value. For example, the index value (x, y) of “A-1” changes from (xa1, ya1) to (xa2, ya2), and the index value (x, y) of “B-1” is (xb1, It changes from yb1) to (xb2, yb2).
比較対象クラスタ生成部103bは、各クラスタの指標値x、yの変化特性を比較し、比較結果、同一の変化傾向を示すクラスタ同士を類似性有りと判定する。本例では、「A−1」及び「B−1」の指標値x、yが同一の変化傾向を示すため、「A−1」及び「B−1」は類似性を有するクラスタであると判定される。以下に、類似性の判定手段(1)〜(3)について例を挙げて説明する。 The comparison target cluster generation unit 103b compares the change characteristics of the index values x and y of each cluster, and determines that the clusters showing the same change tendency as the comparison result have similarity. In this example, since the index values x and y of “A-1” and “B-1” show the same change tendency, “A-1” and “B-1” are similar clusters. Determined. Hereinafter, the similarity determination means (1) to (3) will be described with examples.
(判定手段(1))
図13(a)は、判定手段(1)によるクラスタの類似性の判定例を示す。判定手段(1)では、期間がt1からt2になったとき、各指標値x、yの変化方向が、「増加」、「減少」、及び「変化なし」の何れであるかを検出し、両方の指標値x、yの変化方向が一致した場合、当該クラスタ同士は類似性を有すると判定する。なお、図13(a)〜図13(c)において、「No.」は判定例を区別するための番号を示す。
(Determination means (1))
FIG. 13A shows an example of determination of cluster similarity by the determination unit (1). The determination means (1) detects whether the change direction of each index value x, y is “increase”, “decrease”, or “no change” when the period changes from t1 to t2. When the change directions of both index values x and y coincide, it is determined that the clusters have similarity. In FIGS. 13A to 13C, “No.” indicates a number for distinguishing determination examples.
図12の例の場合、「A(t2)−1」の指標値xa2は、「A(t1)−1」の指標値xa1より大きいため、「A−1」の指標値xは「増加」を示す。また、「A(t2)−1」の指標値ya2は、「A(t1)−1」の指標値ya1より大きいため、「A−1」の指標値yは「増加」を示す。一方、「C−1」の指標値x、yは、ともに「減少」を示す。なお、指標値x、yの変化率が、例えば5(%)未満である場合、指標値x、yは、「変化なし」と判断される。 In the case of the example in FIG. 12, the index value xa2 of “A (t2) −1” is larger than the index value xa1 of “A (t1) −1”, and therefore the index value x of “A-1” is “increased”. Indicates. Further, since the index value ya2 of “A (t2) −1” is larger than the index value ya1 of “A (t1) −1”, the index value y of “A-1” indicates “increase”. On the other hand, the index values x and y of “C-1” both indicate “decrease”. When the rate of change of the index values x and y is less than 5 (%), for example, the index values x and y are determined as “no change”.
「No.1」は、クラスタ「A−1」及び「B−1」の判定例を示す。「A−1」の各指標値x、yは、「増加」を示し、「B−1」の各指標値x、yも、「増加」を示す。つまり、「A−1」及び「B−1」の変化方向は一致する。このため、「A−1」及び「B−1」の類似性は、「有」と判定される。 “No. 1” indicates a determination example of the clusters “A-1” and “B-1”. Each index value x, y of “A-1” indicates “increase”, and each index value x, y of “B-1” also indicates “increase”. That is, the change directions of “A-1” and “B-1” are the same. Therefore, the similarity between “A-1” and “B-1” is determined as “present”.
「No.2」は、クラスタ「A−1」及び「C−1」の判定例を示す。「A−1」の各指標値x、yは、「増加」を示し、「C−1」の各指標値x、yは、「減少」を示す。つまり、「A−1」及び「C−1」の変化方向は一致しない。このため、「A−1」及び「C−1」の類似性は、「無」と判定される。 “No. 2” indicates a determination example of the clusters “A-1” and “C-1”. Each index value x, y of “A-1” indicates “increase”, and each index value x, y of “C-1” indicates “decrease”. That is, the change directions of “A-1” and “C-1” do not match. Therefore, the similarity between “A-1” and “C-1” is determined as “none”.
「No.3」は、クラスタ「D−1」及び「E−1」の判定例を示す。「D−1」の各指標値x、yは、「増加」及び「減少」をそれぞれ示し、「E−1」の各指標値x、yは、「減少」及び「増加」をそれぞれ示す。つまり、「D−1」及び「E−1」の変化方向は一致しない。このため、「D−1」及び「E−1」の類似性は、「無」と判定される。 “No. 3” indicates a determination example of the clusters “D-1” and “E-1”. Each index value x, y of “D-1” indicates “increase” and “decrease”, respectively, and each index value x, y of “E-1” indicates “decrease” and “increase”, respectively. That is, the change directions of “D-1” and “E-1” do not match. Therefore, the similarity between “D-1” and “E-1” is determined as “none”.
「No.4」は、クラスタ「UC−2」及び「X−1」の判定例を示す。「UC−2」の各指標値x、yは、「増加」及び「変化なし」をそれぞれ示し、「X−1」の各指標値x、yは、「増加」及び「変化なし」をそれぞれ示す。つまり、「UC−2」及び「X−1」の変化方向は一致する。このため、「UC−2」及び「X−1」の類似性は、「有」と判定される。 “No. 4” indicates a determination example of the clusters “UC-2” and “X-1”. Each index value x, y of “UC-2” indicates “increase” and “no change”, and each index value x, y of “X-1” indicates “increase” and “no change”, respectively. Show. That is, “UC-2” and “X-1” change in the same direction. Therefore, the similarity between “UC-2” and “X-1” is determined as “present”.
このように、判定手段(1)では、指標値x、yの変化方向が、「増加」、「減少」、及び「変化なし」の何れかであるかを検出するだけで、類似性を容易に判定できる。 In this way, the determination means (1) facilitates similarity only by detecting whether the change direction of the index values x and y is “increase”, “decrease”, or “no change”. Can be determined.
(判定手段(2))
図13(b)は、判定手段(2)によるクラスタの類似性の判定例を示す。判定手段(2)では、指標値x、yの変化方向(増加または減少)が一致し、各期間t1、t2におけるクラスタ間の指標値x、yの差分の比率Δx、Δyが、それぞれ、所定の閾値THx、THy未満である場合、当該クラスタ同士は類似性を有すると判定する。ここで、比率Δx、Δyは、比較されるクラスタの一方を基準として算出される。
(Determination means (2))
FIG. 13B shows a determination example of cluster similarity by the determination unit (2). In the determination means (2), the change directions (increase or decrease) of the index values x and y coincide, and the ratios Δx and Δy of the difference between the index values x and y between the clusters in the periods t1 and t2 are respectively predetermined. If the threshold value THx is less than THy, it is determined that the clusters have similarity. Here, the ratios Δx and Δy are calculated based on one of the clusters to be compared.
図12の例において、「A−1」及び「B−1」を比較する場合、指標値xの期間t1の差分の比率Δx(t1)は、|xb1−xa1|×100/xa1×100であり、指標値xの期間t2の差分の比率Δx(t2)は、|xb2−xa2|/xa2×100である。また、指標値yの期間t1の差分の比率Δy(t1)は、|yb1−ya1|/ya1×100であり、指標値yの期間t2の差分の比率Δy(t2)は、|yb2−ya2|/ya2×100である。なお、指標値x、yの変化特性(増加)は一致する。なお、比率Δx(t1)、Δx(t2)、Δy(t1)、Δy(t2)は、クラスタ「A−1」を基準として算出されている。 In the example of FIG. 12, when “A-1” and “B-1” are compared, the ratio Δx (t1) of the difference between the index values x in the period t1 is | xb1-xa1 | × 100 / xa1 × 100. Yes, the difference ratio Δx (t2) of the index value x in the period t2 is | xb2-xa2 | / xa2 × 100. Further, the difference ratio Δy (t1) of the index value y in the period t1 is | yb1-ya1 | / ya1 × 100, and the difference ratio Δy (t2) of the index value y in the period t2 is | yb2-ya2. | / Ya2 × 100. Note that the change characteristics (increase) of the index values x and y coincide. Note that the ratios Δx (t1), Δx (t2), Δy (t1), and Δy (t2) are calculated based on the cluster “A-1”.
Δx(t1)<THx ・・・式(1)
Δx(t2)<THx ・・・式(2)
Δy(t1)<THy ・・・式(3)
Δy(t2)<THy ・・・式(4)
Δx (t1) <THx (1)
Δx (t2) <THx (2)
Δy (t1) <THy (3)
Δy (t2) <THy (4)
したがって、上記の式(1)〜(4)の全てが成立すれば、「A−1」及び「B−1」は、類似性を有すると判定される。なお、以下の判定例では、THx=20(%)及びTHy=5(%)とする。 Therefore, if all of the above formulas (1) to (4) hold, it is determined that “A-1” and “B-1” have similarity. In the following determination example, THx = 20 (%) and THy = 5 (%).
「No.5」は、クラスタ「A−1」及び「B−1」の判定例を示す。「A−1」の各指標値x、yは、「増加」を示し、「B−1」の各指標値x、yも、「増加」を示す。つまり、「A−1」及び「B−1」の変化方向は一致する。 “No. 5” indicates a determination example of the clusters “A-1” and “B-1”. Each index value x, y of “A-1” indicates “increase”, and each index value x, y of “B-1” also indicates “increase”. That is, the change directions of “A-1” and “B-1” are the same.
また、「A−1」及び「B−1」の指標値x、yの差分の比率Δx(t1)、Δx(t2)、Δy(t1)、Δy(t2)は、上記の式(1)〜(4)をそれぞれ満たす。このため、「A−1」及び「B−1」の類似性は、「有」と判定される。 The ratios Δx (t1), Δx (t2), Δy (t1), and Δy (t2) of the difference between the index values x and y of “A-1” and “B-1” are expressed by the above equation (1). Each of (4) is satisfied. Therefore, the similarity between “A-1” and “B-1” is determined as “present”.
「No.6」は、クラスタ「C−1」及び「D−1」の判定例を示す。「C−1」の各指標値x、yは、「増加」及び「減少」をそれぞれ示し、「D−1」の各指標値x、yも、「増加」及び「減少」をそれぞれ示す。つまり、「C−1」及び「D−1」の変化方向は一致する。 “No. 6” indicates a determination example of the clusters “C-1” and “D-1”. Each index value x, y of “C-1” indicates “increase” and “decrease”, respectively, and each index value x, y of “D-1” also indicates “increase” and “decrease”, respectively. That is, the change directions of “C-1” and “D-1” are the same.
また、「C−1」及び「D−1」の指標値x、yの差分の比率Δx(t1)、Δy(t1)は、上記の式(1)、(3)をそれぞれ満たすが、差分の比率Δx(t2)、Δy(t2)は、上記の式(2)、(4)をそれぞれ満たさない。このため、「C−1」及び「D−1」の類似性は、「無」と判定される。 Further, the difference ratios Δx (t1) and Δy (t1) between the index values x and y of “C-1” and “D-1” satisfy the above formulas (1) and (3), respectively. Ratios Δx (t2) and Δy (t2) do not satisfy the expressions (2) and (4), respectively. Therefore, the similarity between “C-1” and “D-1” is determined as “none”.
このように、判定手段(2)では、指標値x、yの変化方向だけでなく、クラスタ間の指標値x、yの差分の比率Δx、Δyに基づいて、判定手段(1)より高精度に類似性を判定できる。 Thus, the determination means (2) is more accurate than the determination means (1) based not only on the direction of change of the index values x and y but also on the ratios Δx and Δy of the index values x and y between the clusters. Similarity can be determined.
(判定手段(3))
図13(c)は、判定手段(3)によるクラスタの類似性の判定例を示す。判定手段(3)では、期間がt1からt2になったときの指標値x、yの変化率Rx、Ryのクラスタ間の差分ΔRx、ΔRyが、それぞれ、所定の閾値THrx、THry未満である場合、当該クラスタ同士は類似性を有すると判定する。なお、判定手段(3)においても、指標値x、yの変化方向の一致は、類似性の条件とされる。
(Determination means (3))
FIG. 13C shows an example of determination of cluster similarity by the determination unit (3). In the determination means (3), when the time periods change from t1 to t2, the change rates Rx and Ry of the index values x and y between the clusters ΔRx and ΔRy are less than the predetermined thresholds THrx and THry, respectively. The clusters are determined to have similarity. In the determination means (3), the coincidence of the change directions of the index values x and y is a similarity condition.
図12の例において、「A−1」及び「B−1」を比較する場合、「A−1」の指標値xの変化率Rx(A)は、(xa2−xa1)×100/xa1であり、「B−1」の指標値xの変化率Rx(B)は、(xb2−xb1)×100/xb1である。また、「A−1」の指標値yの変化率Ry(A)は、(ya2−ya1)×100/ya1であり、「B−1」の指標値yの変化率Ry(B)は、(yb2−yb1)×100/yb1である。 In the example of FIG. 12, when “A-1” and “B-1” are compared, the rate of change Rx (A) of the index value x of “A-1” is (xa2−xa1) × 100 / xa1. Yes, the rate of change Rx (B) of the index value x of “B-1” is (xb2−xb1) × 100 / xb1. Further, the rate of change Ry (A) of the index value y of “A-1” is (ya2−ya1) × 100 / ya1, and the rate of change Ry (B) of the index value y of “B-1” is (Yb2-yb1) × 100 / yb1.
ΔRx=Rx(A)−Rx(B)<THrx ・・・式(5)
ΔRy=Ry(A)−Ry(B)<THry ・・・式(6)
ΔRx = Rx (A) −Rx (B) <THrx (5)
ΔRy = Ry (A) −Ry (B) <THry (6)
したがって、上記の式(5)、(6)の全てが成立すれば、「A−1」及び「B−1」は、類似性を有すると判定される。なお、以下の判定例では、THrx=20(%)及びTHry=5(%)とする。 Therefore, if all of the above formulas (5) and (6) hold, “A-1” and “B-1” are determined to have similarity. In the following determination example, THrx = 20 (%) and THry = 5 (%).
「No.7」は、クラスタ「A−1」及び「B−1」の判定例を示す。「A−1」の各指標値x、yは、「増加」を示し、「B−1」の各指標値x、yも、「増加」を示す。つまり、「A−1」及び「B−1」の変化方向は一致する。 “No. 7” indicates a determination example of the clusters “A-1” and “B-1”. Each index value x, y of “A-1” indicates “increase”, and each index value x, y of “B-1” also indicates “increase”. That is, the change directions of “A-1” and “B-1” are the same.
また、「A−1」及び「B−1」の指標値xの変化率Rxは、それぞれ、10(%)及び20(%)であるので、その差分ΔRxは、10(%)である。一方、「A−1」及び「B−1」の指標値yの変化率Ryは、それぞれ、10(%)及び13(%)であるので、その差分ΔRyは、3(%)である。したがって、差分ΔRx、ΔRyは、上記の式(5)、(6)をそれぞれ満たす。このため、「A−1」及び「B−1」の類似性は、「有」と判定される。 Further, since the change rates Rx of the index values x of “A-1” and “B-1” are 10 (%) and 20 (%), respectively, the difference ΔRx is 10 (%). On the other hand, since the change rates Ry of the index values y of “A-1” and “B-1” are 10 (%) and 13 (%), respectively, the difference ΔRy is 3 (%). Therefore, the differences ΔRx and ΔRy satisfy the above equations (5) and (6), respectively. Therefore, the similarity between “A-1” and “B-1” is determined as “present”.
「No.8」は、クラスタ「C−1」及び「D−1」の判定例を示す。「C−1」の各指標値x、yは、「増加」を示し、「D−1」の各指標値x、yも、「増加」を示す。つまり、「C−1」及び「D−1」の変化方向は一致する。 “No. 8” indicates a determination example of the clusters “C-1” and “D-1”. Each index value x, y of “C-1” indicates “increase”, and each index value x, y of “D-1” also indicates “increase”. That is, the change directions of “C-1” and “D-1” are the same.
また、「C−1」及び「D−1」の指標値xの変化率Rxは、ともに10(%)であるので、その差分ΔRxは、0(%)である。一方、「C−1」及び「D−1」の指標値yの変化率Ryは、それぞれ、35(%)及び20(%)であるので、その差分ΔRyは、15(%)である。したがって、差分ΔRxは、上記の式(5)を満たすが、差分ΔRyは、上記の式(6)を満たさない。このため、「C−1」及び「D−1」の類似性は、「無」と判定される。 Further, since the change rates Rx of the index values x of “C-1” and “D-1” are both 10 (%), the difference ΔRx is 0 (%). On the other hand, since the change rates Ry of the index values y of “C-1” and “D-1” are 35 (%) and 20 (%), respectively, the difference ΔRy is 15 (%). Therefore, the difference ΔRx satisfies the above equation (5), but the difference ΔRy does not satisfy the above equation (6). Therefore, the similarity between “C-1” and “D-1” is determined as “none”.
このように、判定手段(3)では、指標値x、yの変化方向だけでなく、クラスタ間の指標値x、yの変化率Rx,Ryの差分ΔRx、ΔRyに基づいて、判定手段(1)より高精度に類似性を判定できる。 As described above, the determination unit (3) determines not only the change direction of the index values x and y but also the determination unit (1) based on the differences ΔRx and ΔRy between the change rates Rx and Ry of the index values x and y between clusters. ) Similarity can be determined with higher accuracy.
また、比較対象クラスタ生成部103bは、互いに類似する個社クラスタをマージして、比較対象クラスタ「CC−1」を生成する場合、当該個社クラスタに含まれる情報の数値を再計算により更新する。以下に、図6(b)に示された個社クラスタ「B−2(2010)」及び「C−3(2010)」をマージする場合を例に挙げて、計算例を述べる。 In addition, when the comparison target cluster generation unit 103 b merges similar individual company clusters to generate the comparison target cluster “CC-1”, the comparison target cluster generation unit 103 b updates the numerical values of the information included in the individual company cluster by recalculation. . Hereinafter, a calculation example will be described by taking as an example the case of merging the individual company clusters “B-2 (2010)” and “C-3 (2010)” shown in FIG.
図14は、比較対象クラスタの一例を示す。比較対象クラスタ「CC−1」は、個社クラスタ「B−2(2010)」及び「C−3(2010)」をマージすることにより生成される。以下に、「人数」情報及び「年間購買金額」情報の計算例について説明する。 FIG. 14 shows an example of the comparison target cluster. The comparison target cluster “CC-1” is generated by merging the individual company clusters “B-2 (2010)” and “C-3 (2010)”. Hereinafter, calculation examples of the “number of people” information and the “annual purchase amount” information will be described.
「B−3(2010)」の「人数」は5000人であり、「C−3(2010)」の「人数」は10000人である。したがって、「CC−1」の「人数」は、5000人と10000人の合計から、15000人と算出される。 The “number of people” of “B-3 (2010)” is 5000 people, and the “number of people” of “C-3 (2010)” is 10,000 people. Therefore, the “number of people” of “CC-1” is calculated as 15000 people from the sum of 5000 people and 10,000 people.
また、「B−3(2010)」の「年間購買金額」情報の「Low」は、5(%)であるので、当該顧客の人数は、250人(=5000人(「人数」参照)×5(%))である。「C−3(2010)」の「年間購買金額」情報の「Low」は、5(%)であるので、当該顧客の人数は、500人(=10000人(「人数」参照)×5(%))である。 In addition, since “Low” in the “annual purchase amount” information of “B-3 (2010)” is 5 (%), the number of customers is 250 (= 5000 (refer to “number”) × 5 (%)). Since “Low” in the “annual purchase amount” information of “C-3 (2010)” is 5 (%), the number of customers is 500 (= 10000 (refer to “number”) × 5 ( %)).
したがって、「CC−1」の「年間購買金額」情報の「Low」は、「B−3(2010)」の該当人数(250人)及び「C−3(2010)」の該当人数(500人)の合計を、「CC−1」の「人数」(15000人)で除算することにより、5(%)と算出される。このように、比較対象クラスタの各情報は、互いに類似する複数の個社クラスタの情報の数値の再計算により更新されるため、当該個社クラスタの数が多いほど、情報の精度が向上する。 Therefore, “Low” of the “annual purchase amount” information of “CC-1” is the number of people (250 people) of “B-3 (2010)” and the number of people (500 people of “C-3 (2010)”). ) Is divided by the “number of people” (15000 people) of “CC-1” to be calculated as 5 (%). As described above, each piece of information of the comparison target cluster is updated by recalculating the numerical values of the information of a plurality of individual company clusters that are similar to each other.
再び図7を参照すると、クラスタ処理部103は、比較対象クラスタ生成部103bにより生成した比較対象クラスタと分析対象の百貨店Xの個社クラスタとの比較分析処理を行う(ステップSt5)。これにより、分析結果(比較結果)が分析結果DB135に格納される。
Referring to FIG. 7 again, the
図15Aは、第1実施例におけるクラスタの比較分析処理のフローチャートである。図15Aでは、ステップSt51の処理の例が符号C51で示されている。 FIG. 15A is a flowchart of cluster comparison analysis processing in the first embodiment. In FIG. 15A, an example of the process of step St51 is indicated by reference numeral C51.
本例において、個社クラスタDB132には、既存の個社クラスタ「A−1(2008)」、「B−2(2010)」、及び「C−3(2010)」等と、分析対象の百貨店Xの個社クラスタ「X−1」〜「X−3」とが格納されている。ここで、比較対象クラスタ生成部103bは、既存の個社クラスタ「A−1(2008)」、「B−2(2010)」、及び「C−3(2010)」などから、比較対象クラスタ「CC−1」〜「CC−3」を生成すると仮定する。
In this example, the individual
まず、類似判定処理部103aは、個社クラスタ「X−1」〜「X−3」と比較対象クラスタ「CC−1」〜「CC−3」を比較する(ステップSt51)。このとき、類似判定処理部103aは、符号C51で示されるように、個社クラスタ「X−1」〜「X−3」と比較対象クラスタ「CC−1」〜「CC−3」の全ての組み合わせについて、類似性の有無を判定する。
First, the similarity
次に、クラスタ処理部103は、比較の結果、個社クラスタが比較対象クラスタの何れにも類似しない場合(ステップSt52のNo)、当該個社クラスタを特徴的顧客グループとして、分析結果DB135に格納する(ステップSt53)。すなわち、クラスタ処理部103は、分析対象の百貨店Xの購買履歴データ230に基づいて生成され、統合顧客グループ(比較対象クラスタ)と所定の類似関係を有していない顧客グループ(個社クラスタ)を検出し、分析対象の百貨店Xの特徴的顧客グループとして出力する。
Next, as a result of the comparison, if the individual company cluster is not similar to any of the comparison target clusters (No in step St52), the
また、個社クラスタが、比較対象クラスタの何れかと類似する場合(ステップSt52のYes)、クラスタ処理部103は、当該個社クラスタと当該比較対象クラスタの差異を検出する(ステップSt58)。個社クラスタと比較対象クラスタの差異を示す情報は、分析結果DB135に格納される。このようにして、クラスタの比較分析処理は行われる。
If the individual company cluster is similar to any of the comparison target clusters (Yes in step St52), the
このように、クラスタ処理部103は、所定の類似関係を有する全ての顧客グループを含む統合顧客グループ(比較対象クラスタ)と、分析対象の百貨店Xの購買履歴データ230に基づいて生成された顧客グループ(個社クラスタ)との比較結果を出力する。なお、上述したように、比較結果(顧客分析結果)は、分析結果DB135に一時的に格納される。
As described above, the
再び図7を参照すると、クラスタ処理部103は、上記のステップSt53,St58で得た分析結果(比較結果)を、分析結果DB135から読み出して、通信処理部14を介して端末装置2に出力(送信)する(ステップSt6)。百貨店A〜Xでは、端末装置2から分析結果が取り出され、経営戦略の立案などに活用される。次に、クラスタ処理部103は、ユニバーサルクラスタの構築処理を実行する(ステップSt7)。
Referring to FIG. 7 again, the
図15Bは、ユニバーサルクラスタの構築処理のフローチャートである。本処理では、ユニバーサルクラスタDB133及びユニバーサルクラスタ候補DB134の少なくとも一方が更新される。
FIG. 15B is a flowchart of a universal cluster construction process. In this process, at least one of the
また、図15Bは、ステップSt11,St14、St17,St19の処理の例を符号C1〜C4で示す。本例において、ユニバーサルクラスタDB133には、ユニバーサルクラスタ「UC−1」〜「UC−3」が格納され、ユニバーサルクラスタ候補DB134には、ユニバーサルクラスタ候補「A−2」、「B−3」、及び「D−4」が格納されている。また、個社クラスタDB132には、分析対象の百貨店Xの個社クラスタ「X−1」〜「X−3」が格納されている。
Moreover, FIG. 15B shows the example of a process of step St11, St14, St17, St19 by code | symbol C1-C4. In this example, universal clusters “UC-1” to “UC-3” are stored in the
まず、類似判定処理部103aは、個社クラスタ「X−1」〜「X−3」とユニバーサルクラスタ「UC−1」〜「UC−3」を比較することで類似判定を行う(ステップSt11)。このとき、類似判定処理部103aは、符号C1で示されるように、個社クラスタ「X−1」〜「X−3」とユニバーサルクラスタ「UC−1」〜「UC−3」の全ての組み合わせについて類似性の有無を判定する。なお、類似性の判定手段については、図13を参照して述べた通りである。
First, the similarity
クラスタ処理部103は、類似判定の結果、個社クラスタがユニバーサルクラスタの何れにも類似しない場合(ステップSt12のNo)、類似判定処理部103aにより、当該個社クラスタとユニバーサルクラスタ候補と比較する(ステップSt14)。ここで、個社クラスタ「X−3」が「UC−1」〜「UC−3」と類似性がない場合、符号C2で示されるように、「X−3」は、ユニバーサルクラスタ候補DB134内の全てのユニバーサルクラスタ候補「A−2」、「B−3」、及び「D−4」との間で類似性が判定される。なお、類似性の判定手段については、図13を参照して述べた通りである。
As a result of the similarity determination, when the individual company cluster is not similar to any of the universal clusters (No in step St12), the
クラスタ処理部103は、比較の結果、個社クラスタがユニバーサルクラスタ候補の何れにも類似しない場合(ステップSt15のNo)、当該個社クラスタを、ユニバーサルクラスタ候補としてユニバーサルクラスタ候補DB134に追加し(ステップSt16)、処理を終了する。つまり、クラスタ処理部103は、ユニバーサルクラスタ候補の何れにも類似関係を有していない顧客グループを検出し、ユニバーサルクラスタ候補に含めることにより、ユニバーサルクラスタ候補DB134を更新する。これにより、新たな統合顧客グループ(ユニバーサルクラスタ)になり得る顧客グループのクラスタが、新たなユニバーサルクラスタ候補としてユニバーサルクラスタ候補DB134に追加される。
As a result of the comparison, if the individual company cluster is not similar to any of the universal cluster candidates (No in step St15), the
また、クラスタ処理部103は、比較の結果、個社クラスタがユニバーサルクラスタ候補の何れかに類似する場合(ステップSt15のYes)、当該個社クラスタを、当該ユニバーサルクラスタ候補とマージすることで、新たなユニバーサルクラスタを生成する(ステップSt17)。例えば、個社クラスタ「X−3」とユニバーサルクラスタ候補「B−3」が類似する場合、符号C4で示されるように、「X−3」及び「B−3」は統合され、新たなユニバーサルクラスタ「UC−4」が生成される。クラスタ処理部103は、生成したユニバーサルクラスタをユニバーサルクラスタDB133に追加して、処理を終了する。
In addition, if the comparison result shows that the individual company cluster is similar to any of the universal cluster candidates (Yes in step St15), the
このように、クラスタ処理部103は、統合顧客グループ(ユニバーサルクラスタ)の候補と所定の類似関係を有している顧客グループ(個社クラスタ)を検出する。クラスタ処理部103は、検出した顧客グループを、統合顧客グループの候補(ユニバーサルクラスタ候補)に含めることにより、新たな統合顧客グループを生成する。したがって、顧客分析が繰り返されるほど、ユニバーサルクラスタDB133の内容が充実し、高精度な顧客分析が可能となる。
As described above, the
なお、ユニバーサルクラスタDB133に格納済みの「UC−1」〜「UC−3」も、ステップSt17の処理を経て生成されたものである。つまり、ステップSt11において分析対象の百貨店Xの個社クラスタ「X−1」〜「X−3」と比較される「UC−1」〜「UC−3」は、過去の顧客分析において実行されたステップSt17の処理により生成されたものである。
Note that “UC-1” to “UC-3” already stored in the
また、個社クラスタが、ユニバーサルクラスタの何れかと類似する場合(ステップSt12のYes)、クラスタ処理部103は、当該個社クラスタと当該ユニバーサルクラスタをマージすることにより、ユニバーサルクラスタDB133を更新し(ステップSt19)、処理を終了する。例えば、個社クラスタ「X−1」とユニバーサルクラスタ「UC−1」が類似する場合、符号C3で示されるように、「X−1」及び「UC−1」は統合され、「UC−1’」が生成される。また、個社クラスタ「X−2」とユニバーサルクラスタ「UC−2」が類似する場合、「X−2」及び「UC−2」は統合され、「UC−2’」が生成される。なお、生成された「UC−1’」及び「UC−2’」は、ユニバーサルクラスタDB133に格納される。
If the individual company cluster is similar to any of the universal clusters (Yes in step St12), the
このように、クラスタ処理部103は、分析対象の百貨店Xの購買履歴データ230に基づいて生成された該分析対象の百貨店Xの顧客グループ(個社クラスタ)が、統合顧客グループ(ユニバーサルクラスタ)と所定の類似関係を有することを検出する。クラスタ処理部103は、該顧客グループを統合顧客グループに含めることにより、統合顧客グループを更新する。クラスタ処理部103は、更新された統合顧客グループを、さらなる百貨店の顧客分析に用いる。したがって、顧客分析が行われるほど、ユニバーサルクラスタDB133の内容が充実し、高精度な顧客分析が可能となる。
As described above, the
このようにして、ユニバーサルクラスタの構築処理は行われる。ユニバーサルクラスタの構築処理の後、顧客分析処理は終了する。 In this way, the universal cluster construction process is performed. After the universal cluster construction process, the customer analysis process ends.
図16は、比較分析処理により得られる分析結果の出力例を示す。本例において、個社クラスタDB132には、分析対象の百貨店Xの個社クラスタ「X−1」〜「X−3」が格納されている。「X−1」及び「X−2」は、比較対象クラスタ「CC−1」及び「CC−2」と類似性をそれぞれ有し、「X−3」は、「CC−1」及び「CC−2」の何れとも類似性を有していない。
FIG. 16 shows an output example of the analysis result obtained by the comparative analysis process. In this example, the individual
このため、「X−3」は、分析対象の百貨店Xの特徴的顧客グループとして、分析結果DB135に格納される。また、「X−1」及び「CC−1」の差異を示す情報と、「X−2」及び「CC−2」の差異を示す情報も、分析結果DB135に格納される。
Therefore, “X-3” is stored in the
図17は、個社クラスタと比較対象クラスタの差異の出力例を示す。本例は、ユニバーサルクラスタ「CC−1」と個社クラスタ「X−1」の差異の情報を「項目」ごとに示す。 FIG. 17 shows an output example of the difference between the individual company cluster and the comparison target cluster. In this example, information on the difference between the universal cluster “CC-1” and the individual company cluster “X-1” is shown for each “item”.
差異の「項目」としては、例えば、顧客の「購買内容」(商品のカテゴリなど)、「金額/来店頻度」(年度ごと、月ごと、曜日ごとの数値など)、「年齢層」(年齢分布など)、「性別」(男女比など)、及び「居住地区」(居住地区分布など)が挙げられる。このように、個社クラスタと、当該個社クラスタと類似するユニバーサルクラスタとの差異を、分析結果として出力することにより、分析対象の百貨店Xの顧客グループに関し、類似する他の顧客グループと比較した詳細な情報が得られる。以下に、分析結果の活用に関して、顧客分析例1を挙げて説明する。 Examples of the “item” of the difference include, for example, “purchase details” of the customer (product category, etc.), “amount / frequency of visit” (number of each year, month, day of the week, etc.), “age group” (age distribution) Etc.), “gender” (gender ratio, etc.), and “residential area” (residential area distribution, etc.). In this way, the difference between the individual company cluster and the universal cluster similar to the individual company cluster is output as an analysis result, and the customer group of the department store X to be analyzed is compared with other similar customer groups. Detailed information can be obtained. Below, the customer analysis example 1 is given and demonstrated about utilization of an analysis result.
(顧客分析例1)
図18は、顧客分析例1における顧客分析処理前のクラスタを示す。
(Customer analysis example 1)
FIG. 18 shows a cluster before the customer analysis processing in the customer analysis example 1.
ユニバーサルクラスタDB133には、ユニバーサルクラスタ「UC−1」〜「UC−10」が格納され、ユニバーサルクラスタ候補DB134には、ユニバーサルクラスタ候補「A−4」(百貨店Aの個社クラスタから生成)及び「C−5」(百貨店Cの個社クラスタから生成)が格納されている。「UC−1」〜「UC−10」には、当該ユニバーサルクラスタに含まれる個社クラスタ(図6(a)の「元クラスタ」情報参照)及び該個社クラスタの「生成年度」情報(カッコ内の数字を参照)がそれぞれ付記されている。例えば、「UC−1」は、個社クラスタ「A−1(2010)」及び「B−1(2011)」を含み、「UC−2」は、個社クラスタ「B−2(2011)」及び「C−6(2012)」を含む。
The
また、個社クラスタDB132には、百貨店Aの個社クラスタ「A−1」〜「A−7」、百貨店Bの個社クラスタ「B−1」〜「B−5」、及び百貨店Cの個社クラスタ「C−1」〜「C−10」が格納されている。なお、各個社クラスタの「生成年度」情報は、カッコ内に記されている。
The individual
また、分析対象の百貨店Xの端末装置2からは、購買履歴データ230及び顧客データ231が取得される。購買履歴データ230及び顧客データ231のデータ量は、一例として、2012年度における1年分とする。
Further, purchase
図19(a)は、分析対象の百貨店Xの個社クラスタ「X−1(2012)」〜「X−5(2012)」を示す。「X−1(2012)」〜「X−5(2012)」は、購買履歴データ230及び顧客データ231から生成され、個社クラスタDB132に格納される。なお、「X−1(2012)」〜「X−5(2012)」の「生成年度」情報は、「2012」を示す。
FIG. 19A shows individual company clusters “X-1 (2012)” to “X-5 (2012)” of the department store X to be analyzed. “X-1 (2012)” to “X-5 (2012)” are generated from the
「X−1(2012)」〜「X−5(2012)」は、それぞれ、例えば1万人の顧客の購買内容に基づいて生成される。このため、分析対象の顧客数は、全体で5万人となる。 “X-1 (2012)” to “X-5 (2012)” are generated based on, for example, purchase contents of 10,000 customers. For this reason, the total number of customers to be analyzed is 50,000.
図19(b)は、クラスタの比較分析処理を行うときに、百貨店A〜Cの個社クラスタから生成された比較対象クラスタ「CC−1」〜「CC−6」を示す。本例では、分析対象期間として、2010年度及び2012年度の2年間が指定されたと仮定する。このため、「CC−1」〜「CC−6」の生成元の百貨店A〜Cの個社クラスタの「生成年度」情報は、「2010」及び「2012」の少なくとも一方を示す(点線の枠内参照)。 FIG. 19B shows the comparison target clusters “CC-1” to “CC-6” generated from the individual company clusters of the department stores A to C when the cluster comparative analysis processing is performed. In this example, it is assumed that two years of 2010 and 2012 are designated as the analysis target period. Therefore, the “generation year” information of the individual company clusters of the department stores A to C that are the generation sources of “CC-1” to “CC-6” indicates at least one of “2010” and “2012” (dotted line frame See inside).
「CC−1」〜「CC−6」には、当該比較対象クラスタに含まれる個社クラスタ及び該個社クラスタの「生成年度」情報(カッコ内の数字を参照)がそれぞれ付記されている。例えば、「CC−1」は、個社クラスタ「A−2(2010)」及び「C−8(2012)」を含み、「CC−2」は、個社クラスタ「A−3(2010)」及び「C−7(2012)」を含む。 In “CC-1” to “CC-6”, the individual company cluster included in the comparison target cluster and the “generation year” information (see numbers in parentheses) of the individual company cluster are appended respectively. For example, “CC-1” includes private company clusters “A-2 (2010)” and “C-8 (2012)”, and “CC-2” is private company cluster “A-3 (2010)”. And “C-7 (2012)”.
また、比較対象クラスタのうち、「CC−1」〜「CC−5」は、生成元の個社クラスタが、既存のユニバーサルクラスタと共通する(「既存クラスタ」参照)。ここで、当該既存のユニバーサルクラスタは、記号「=」の下部に示されている。例えば、「CC−1」及び「CC−2」は、生成元の個社クラスタが、「UC−9」及び「UC−7」とそれぞれ共通する。 Among the comparison target clusters, “CC-1” to “CC-5” have the same individual cluster as the generation source cluster (see “existing cluster”). Here, the existing universal cluster is shown below the symbol “=”. For example, “CC-1” and “CC-2” have the same individual cluster of the generation source as “UC-9” and “UC-7”, respectively.
また、「CC−6」は、生成元の個社クラスタが、既存のユニバーサルクラスタと共通しない新規のクラスタ(「新クラスタ」参照)である。「CC−6」は、個社クラスタ「A−1(2010)」及び「C−5(2012)」を含む。 “CC-6” is a new cluster (see “new cluster”) in which the individual company cluster of the generation source is not in common with the existing universal cluster. “CC-6” includes individual company clusters “A-1 (2010)” and “C-5 (2012)”.
「C−5(2012)」は、「A−1(2010)」との間で類似性が有ると判定されるが、一方で、「A−1(2010)」を含む「UC−1」との間には、類似性がないと判定される。これは、「UC−1」が、「A−1(2010)」だけでなく、「B−1(2011)」も含むため、「A−1(2010)」と同一の特徴を有するわけではないからである。 “C-5 (2012)” is determined to be similar to “A-1 (2010)”, while “UC-1” including “A-1 (2010)”. It is determined that there is no similarity between. This is because “UC-1” includes not only “A-1 (2010)” but also “B-1 (2011)”, so it does not have the same characteristics as “A-1 (2010)”. Because there is no.
このように、本実施例では、分析対象の百貨店Xの個社クラスタの比較対象として、分析対象期間に応じた個社クラスタから生成された比較対象クラスタを用いるので、既存のユニバーサルクラスタとは異なる新たなクラスタによる比較分析が可能である。 As described above, in this embodiment, the comparison target cluster generated from the individual company cluster corresponding to the analysis target period is used as the comparison target of the individual company cluster of the department store X to be analyzed, which is different from the existing universal cluster. Comparison analysis with new clusters is possible.
図20は、類似性を有する個社クラスタ及び比較対象クラスタを示す。図20において、互いに類似する個社クラスタ及び比較対象クラスタは、矢印により対応付けて示されている。例えば、「X−1(2012)」及び「X−2(2012)」は、「CC−1」及び「CC−6」にそれぞれ類似する。 FIG. 20 shows individual company clusters and comparison target clusters having similarities. In FIG. 20, individual company clusters and comparison target clusters that are similar to each other are shown in association with each other by arrows. For example, “X-1 (2012)” and “X-2 (2012)” are similar to “CC-1” and “CC-6”, respectively.
類似性を有する個社クラスタ及び比較対象クラスタは、図15AのステップSt58を参照して述べたように、互いに比較され、比較結果(分析結果)として、その差異が出力される。ここで、差異を示す情報については、図17を参照して述べたとおりである。 The individual company clusters and the comparison target clusters having similarities are compared with each other as described with reference to step St58 of FIG. 15A, and the difference is output as a comparison result (analysis result). Here, the information indicating the difference is as described with reference to FIG.
百貨店Xにおいて、「X−1(2012)」〜「X−5(2012)」に関する差異を示す情報は、例えば、百貨店Xの顧客基盤の強弱の評価(いわゆるベンチマーク評価)に活用される。さらに、百貨店Xでは、当該評価の結果を分析し、「X−1(2012)」〜「X−5(2012)」の顧客グループを独占的に確保することによる売上向上のための施策が検討される。このような施策としては、例えば、当該顧客グループが、他の百貨店A、B,C,・・・で購入し、百貨店Xでは購入していないブランドの商品を見つけて、商品や売場の見直しを行うこと(商品施策/売場施策)が挙げられる。 In the department store X, information indicating the difference regarding “X-1 (2012)” to “X-5 (2012)” is used for, for example, evaluation of the strength of the customer base of the department store X (so-called benchmark evaluation). Furthermore, department store X analyzes the results of the evaluation and considers measures to increase sales by securing exclusive customer groups from “X-1 (2012)” to “X-5 (2012)”. Is done. As such measures, for example, the customer group finds a product of a brand purchased at another department store A, B, C,..., But not purchased at department store X, and reviews the product or sales floor. Things to do (product measures / sales space measures).
なお、ユニバーサルクラスタの構築処理において、「UC−1」〜「UC−10」は、図15BのステップSt19を参照して述べたように、個社クラスタ「X−1(2012)」〜「X−5(2012)」との間で類似性の判定が行われ、類似性を有する個社クラスタとマージされることにより更新される。 In the universal cluster construction process, “UC-1” to “UC-10” are the individual company clusters “X-1 (2012)” to “X” as described with reference to step St19 in FIG. 15B. −5 (2012) ”, the similarity is determined, and is updated by being merged with the individual company cluster having the similarity.
これまで述べたように、第1実施例に係る顧客分析プログラムは、以下の処理をコンピュータ(CPU)10に実行させるものである。
処理(1):期間の指定を分析対象期間とする指示、または、現在もしくは過去の時点からの所定期間を分析対象期間とする指示と、分析対象の百貨店(店)Xの購買履歴データ230とを受け付ける。
処理(2):指示された分析対象期間における複数の百貨店(店)A,B,・・・の購買履歴データ230に基づいて生成された顧客グループ(個社クラスタ)のうち、所定の類似関係を有する全ての顧客グループを含む統合顧客グループ(比較対象クラスタ)と、分析対象の百貨店(店)Xの購買履歴データ230に基づいて生成された顧客グループ(個社クラスタ)との比較結果を出力する。
As described above, the customer analysis program according to the first embodiment causes the computer (CPU) 10 to execute the following processing.
Process (1): An instruction to designate the period as an analysis target period, or an instruction to set a predetermined period from the current or past time point as an analysis target period, and purchase
Process (2): A predetermined similarity relationship among customer groups (individual company clusters) generated based on
実施例に係る顧客分析プログラムによると、分析対象の店Xの顧客グループを、指定された分析対象期間の類似の顧客グループが属する統合顧客グループと比較して得られた比較結果が出力されるので、時期のトレンドを考慮した顧客分析が可能である。 According to the customer analysis program according to the embodiment, the comparison result obtained by comparing the customer group of the analysis target store X with the integrated customer group to which a similar customer group in the specified analysis target period belongs is output. It is possible to analyze customers taking into account the trend of the season.
また、第1実施例に係る顧客分析方法は、以下の工程をコンピュータ(CPU)10が実行するものである。
工程(1):期間の指定を分析対象期間とする指示、または、現在もしくは過去の時点からの所定期間を分析対象期間とする指示と、分析対象の百貨店(店)Xの購買履歴データ230とを受け付ける。
工程(2):指示された分析対象期間における複数の百貨店(店)A,B,・・・の購買履歴データ230に基づいて生成された顧客グループ(個社クラスタ)のうち、所定の類似関係を有する全ての顧客グループを含む統合顧客グループ(比較対象クラスタ)と、分析対象の百貨店(店)Xの購買履歴データ230に基づいて生成された顧客グループ(個社クラスタ)との比較結果を出力する。
In the customer analysis method according to the first embodiment, the computer (CPU) 10 executes the following steps.
Step (1): An instruction to designate a period as an analysis target period, or an instruction to set a predetermined period from the current or past time point as an analysis target period, and purchase
Step (2): a predetermined similarity relationship among customer groups (individual company clusters) generated based on
第1実施例に係る顧客分析方法は、第1実施例に係る顧客分析プログラムと同様の構成を含むので、上述した内容と同様の作用効果を奏する。 Since the customer analysis method according to the first embodiment includes the same configuration as that of the customer analysis program according to the first embodiment, the same effects as those described above can be obtained.
また、第1実施例に係る顧客分析装置1は、受付処理部(データ入力処理部)101及び出力処理部(クラスタ処理部)103を有する。受付処理部101は、期間の指定を分析対象期間とする指示、または、現在もしくは過去の時点からの所定期間を分析対象期間とする指示と、分析対象の店(百貨店)Xの購買履歴データとを受け付ける。
Further, the
出力処理部103は、指示された分析対象期間における複数の店(百貨店)A,B,・・・の購買履歴データ230に基づいて生成された顧客グループ(個社クラスタ)のうち、所定の類似関係を有する全ての顧客グループを含む統合顧客グループ(ユニバーサルクラスタ)と、分析対象の店Xの購買履歴データに基づいて生成された顧客グループ(個社クラスタ)との比較結果を出力する。
The
第1実施例に係る顧客分析装置1は、第1実施例に係る顧客分析プログラムと同様の構成を含むので、上述した内容と同様の作用効果を奏する。
Since the
(第2実施例)
次に、第2実施例について説明する。第2実施例において、分析対象の百貨店Xの個社クラスタは、分析対象期間に応じてユニバーサルクラスタDB133から抽出されたユニバーサルクラスタと比較され、比較結果が出力される。
(Second embodiment)
Next, a second embodiment will be described. In the second embodiment, the individual company cluster of the department store X to be analyzed is compared with the universal cluster extracted from the
図21は、第2実施例に係る顧客分析装置1の機能構成例を示す構成図である。図21には、CPU10に形成される機能及びHDD13の格納情報の一例が示されている。なお、図21において、図5と共通する構成については、同一の符号を付して、その説明を省略する。
FIG. 21 is a configuration diagram illustrating a functional configuration example of the
CPU10は、データ入力処理部(受付処理部)101と、クラスタ生成部102と、クラスタ処理部(出力処理部)103とを含む。クラスタ処理部103は、類似判定処理部103a及びユニバーサルクラスタ抽出部103cを有し、クラスタの比較分析処理及びユニバーサルクラスタの構築処理を行う。HDD(記憶部)13は、クラスタ生成用データ131と、個社クラスタDB132と、ユニバーサルクラスタDB133と、ユニバーサルクラスタ候補DB134と、分析結果DB135とを記憶する。
The
データ入力処理部101は、端末装置2から通信処理部14を介して、分析対象期間の指定情報、購買履歴データ230、及び顧客データ231が入力される。つまり、データ入力処理部101は、端末装置2から、分析対象期間の指定(指示)と、分析対象の百貨店Xの購買履歴データ230及び顧客データ231を受け付ける。データ入力処理部101は、分析対象期間の指定情報をユニバーサルクラスタ抽出部103cに出力する。
The data
ユニバーサルクラスタ抽出部103cは、指定(指示)された分析対象期間に基づいて、ユニバーサルクラスタDB133から、分析対象の百貨店Xの個社クラスタの比較対象のユニバーサルクラスタを抽出する。このとき、ユニバーサルクラスタ抽出部103cは、ユニバーサルクラスタに含まれる個社クラスタを示す「元クラスタ」情報及び「生成年度」情報(図6参照)を参照することにより、分析対象期間に応じた個社クラスタのみを含むユニバーサルクラスタを抽出する。
The universal
上述したように、HDD13は、統合顧客グループ(ユニバーサルクラスタ)に含まれる各顧客グループ(個社クラスタ)を、各顧客グループの基礎とされた購買履歴データ230が示す時期(「買上日」情報)と対応付けて記憶する。このため、ユニバーサルクラスタ抽出部103cは、「元クラスタ」情報及び「生成年度」情報を参照することで、ユニバーサルクラスタDB133からユニバーサルクラスタを容易に抽出できる。すなわち、ユニバーサルクラスタ抽出部103cは、HDD13を参照し、統合顧客グループ(ユニバーサルクラスタ)のうち、指定された分析対象期間に含まれる時期の購買履歴データ230だけを基礎とする統合顧客グループを抽出する。
As described above, the
本実施例において、クラスタ処理部103は、抽出したユニバーサルクラスタと、分析対象の百貨店Xの個社クラスタとを比較することにより、クラスタの比較分析処理を行う。クラスタ処理部103は、比較結果を分析結果DB135に格納する。クラスタ処理部103は、比較結果を示す情報を、分析結果DB135に格納し、所定のタイミングで分析結果DB135から読み出して、端末装置2に送信する。
In the present embodiment, the
比較結果を示す情報としては、抽出された全てのユニバーサルクラスタと非類似の個社クラスタ、及び、個社クラスタに類似するユニバーサルクラスタと当該個社クラスタの差異が挙げられる。抽出された全てのユニバーサルクラスタと非類似の個社クラスタは、分析対象の百貨店Xの特徴的な顧客グループとして処理される。比較結果の情報は、分析対象の百貨店Xにおいて、経営戦略の立案などに用いられる。 Information indicating the comparison result includes all extracted universal clusters that are dissimilar to the individual company cluster, and the difference between the universal cluster similar to the individual company cluster and the individual company cluster. Individual company clusters that are dissimilar to all the extracted universal clusters are processed as a characteristic customer group of the department store X to be analyzed. The information of the comparison result is used for planning a business strategy at the department store X to be analyzed.
後述するように、クラスタ処理部103は、顧客分析を行うごとに、上述したユニバーサルクラスタの構築処理を行うことで、ユニバーサルクラスタDB133を更新する。このため、顧客分析装置1は、顧客分析が繰り返されるほど、高精度な顧客分析が可能となる。以下に、上記の構成に基づく、顧客分析プログラムの詳細を述べる。
As will be described later, each time the customer analysis is performed, the
図22は、第2実施例に係る顧客分析プログラムのフローチャートである。図22は、1回の分析処理の流れを示す。なお、本例では、クラスタの比較分析処理に関連する処理(ステップSt34〜St36)及びユニバーサルクラスタの構築処理(ステップSt37)の両方が実行される場合を挙げるが、これに限定されず、何れか一方のみが実行されてもよい。 FIG. 22 is a flowchart of the customer analysis program according to the second embodiment. FIG. 22 shows the flow of one analysis process. In this example, a case where both the process related to the cluster comparative analysis process (steps St34 to St36) and the universal cluster construction process (step St37) are executed is not limited to this. Only one may be executed.
まず、データ入力処理部101は、端末装置2から分析対象期間の指定情報、購買履歴データ230、及び顧客データ231を受信する(ステップSt31)。すなわち、データ入力処理部101は、分析対象期間の指定(指示)と、分析対象の百貨店Xの購買履歴データ230とを受け付ける。
First, the data
次に、データ入力処理部101は、購買履歴データ230及び顧客データ231に基づいて、クラスタ生成用データ131を生成する(ステップSt32)。次に、クラスタ生成部102は、クラスタ生成用データ131を読み出し、クラスタ生成用データ131に基づいて個社クラスタを生成する(ステップSt33)。なお、クラスタ生成用データ131の生成処理及び個社クラスタの生成処理については、図8を参照して述べた通りである。
Next, the data
次に、ユニバーサルクラスタ抽出部103cは、データ入力処理部101から入力された分析対象期間の指定情報に基づいて、ユニバーサルクラスタDB133からユニバーサルクラスタを抽出する(ステップSt34)。以下に、抽出例を挙げて、ユニバーサルクラスタの抽出処理を説明する。
Next, the universal
図23は、ユニバーサルクラスタの抽出例を示す。本例において、ユニバーサルクラスタDB133には、ユニバーサルクラスタ「UC−1」〜「U−4」が格納されていると仮定する。
FIG. 23 shows an example of universal cluster extraction. In this example, it is assumed that universal clusters “UC-1” to “U-4” are stored in the
「UC−1」は、個社クラスタ「A−1(2008)」及び「B−2(2010)」を含み、「UC−2」は、個社クラスタ「C−3(2011)」及び「D−4(2009)」を含む。「UC−3」は、個社クラスタ「B−3(2010)」及び「E−2(2013)」を含み、「UC−4」は、個社クラスタ「E−3(2013)」及び「F−1(2013)」を含む。 “UC-1” includes individual company clusters “A-1 (2008)” and “B-2 (2010)”, and “UC-2” includes individual company clusters “C-3 (2011)” and “ D-4 (2009) ". “UC-3” includes individual company clusters “B-3 (2010)” and “E-2 (2013)”, and “UC-4” includes individual company clusters “E-3 (2013)” and “ F-1 (2013) ".
「抽出例(1)」は、分析対象期間として、「2010年度以前」の期間が指定された場合を示す。この場合、ユニバーサルクラスタ抽出部103cは、「生成年度」情報が「2010年度以前」の年度(2010年度、2009年度、2008年度、・・・)を示すユニバーサルクラスタを抽出する。したがって、抽出例(1)では、2008年度及び2010年度の個社クラスタを基礎とする「UC−1」が抽出される。
“Extraction example (1)” indicates a case where a period “before 2010” is designated as the analysis target period. In this case, the universal
「抽出例(2)」は、分析対象期間として、「2010年度以降」の期間が指定された場合を示す。この場合、ユニバーサルクラスタ抽出部103cは、「生成年度」情報が「2010年度以降」の年度(2010年度、2011年度、2012年度、・・・)を示すユニバーサルクラスタを抽出する。したがって、抽出例(2)では、2010年度及び2013年度の個社クラスタを基礎とする「UC−3」と、2013年度の個社クラスタを基礎とする「UC−4」が抽出される。
“Extraction example (2)” indicates a case where a period “2010 and after” is designated as the analysis target period. In this case, the universal
抽出例(3)では、分析対象期間として、「2009〜2011年度」の期間が指定されたとする。この場合、ユニバーサルクラスタ抽出部103cは、「生成年度」情報が「2009」〜「2011」年度を示すユニバーサルクラスタを抽出する。したがって、抽出例(3)では、2011年度及び2009年度の個社クラスタを基礎とする「UC−2」が抽出される。
In the extraction example (3), it is assumed that the period “2009-2011” is designated as the analysis target period. In this case, the universal
このように、ユニバーサルクラスタ抽出部103cは、「生成年度」情報が示す期間が、指定された分析対象期間に含まれる個社クラスタだけを含むユニバーサルクラスタを、ユニバーサルクラスタDB133から抽出する。したがって、顧客分析装置1は、時期のトレンドを考慮した顧客分析が可能である。
As described above, the universal
次に、クラスタ処理部103は、ユニバーサルクラスタ抽出部103cにより抽出したユニバーサルクラスタと分析対象の百貨店Xの個社クラスタとの比較分析処理を行う(ステップSt35)。これにより、分析結果(比較結果)が分析結果DB135に格納される。
Next, the
図24は、第2実施例におけるクラスタの比較分析処理のフローチャートである。図24では、ステップSt41の処理の例が、符号C11で示されている。 FIG. 24 is a flowchart of the cluster comparison analysis process in the second embodiment. In FIG. 24, an example of the process in step St41 is indicated by reference numeral C11.
本例において、個社クラスタDB132には、分析対象の百貨店Xの個社クラスタ「X−1」〜「X−3」が格納されている。また、ユニバーサルクラスタDB133には、ユニバーサルクラスタ「UC−1」〜「UC−10」が格納されており、ユニバーサルクラスタ抽出部103cは、指定された分析対象期間に応じて、ユニバーサルクラスタDB133から例えば「UC−1」〜「UC−3」を抽出する。
In this example, the individual
まず、類似判定処理部103aは、個社クラスタ「X−1」〜「X−3」と、ユニバーサルクラスタ抽出部103cにより抽出されたユニバーサルクラスタ「UC−1」〜「UC−3」を比較する(ステップSt41)。このとき、類似判定処理部103aは、符号C11で示されるように、個社クラスタ「X−1」〜「X−3」とユニバーサルクラスタ「UC−1」〜「UC−3」の全ての組み合わせについて類似性の有無を判定する。なお、類似性の判定手段については、図13を参照して述べた通りである。
First, the similarity
次に、クラスタ処理部103は、比較の結果、個社クラスタが、抽出されたユニバーサルクラスタの何れにも類似しない場合(ステップSt42のNo)、当該個社クラスタを特徴的顧客グループとして、分析結果DB135に格納し(ステップSt43)、処理を終了する。すなわち、クラスタ処理部103は、分析対象の百貨店Xの購買履歴データ230に基づいて生成され、指定された分析対象期間に含まれる時期の購買履歴データ230を基礎とする統合顧客グループ(ユニバーサルクラスタ)と所定の類似関係を有していない顧客グループ(個社クラスタ)を検出する。
Next, as a result of the comparison, if the individual company cluster is not similar to any of the extracted universal clusters (No in step St42), the
また、個社クラスタが、抽出されたユニバーサルクラスタの何れかと類似する場合(ステップSt42のYes)、クラスタ処理部103は、当該個社クラスタと当該ユニバーサルクラスタの差異を検出し(ステップSt48)、処理を終了する。個社クラスタとユニバーサルクラスタの差異を示す情報は、分析結果DB135に格納される。ここで、差異を示す情報については、図17を参照して述べた通りである。このようにして、クラスタの比較分析処理は行われる。
If the individual company cluster is similar to any of the extracted universal clusters (Yes in step St42), the
このように、クラスタ処理部103は、所定の類似関係を有する全ての顧客グループを含む統合顧客グループ(ユニバーサルクラスタ)と、分析対象の百貨店Xの購買履歴データ230に基づいて生成された顧客グループ(個社クラスタ)との比較結果を出力する。なお、上述したように、比較結果(顧客分析結果)は、分析結果DB135に一時的に格納される。
As described above, the
再び図22を参照すると、クラスタ処理部103は、上記のステップSt43,St48で得た分析結果(比較結果)を、分析結果DB135から読み出して、通信処理部14を介して端末装置2に出力(送信)する(ステップSt36)。百貨店A〜Xでは、端末装置2から分析結果が取り出され、経営戦略の立案などに活用される。
Referring to FIG. 22 again, the
次に、クラスタ処理部103は、ユニバーサルクラスタの構築処理を実行する(ステップSt37)。ユニバーサルクラスタの構築処理については、図15Bを参照して述べた通りであり、本処理により、ユニバーサルクラスタDB133及びユニバーサルクラスタ候補DB134の少なくとも一方が更新される。ユニバーサルクラスタの構築処理の後、顧客分析処理は終了する。
Next, the
上述したように、分析結果は、分析対象の百貨店Xにおいて、経営戦略の立案などに活用される。以下に、分析結果の活用に関して、顧客分析例2を挙げて説明する。 As described above, the analysis result is used for planning a business strategy in the department store X to be analyzed. Below, the customer analysis example 2 is given and demonstrated about utilization of an analysis result.
(顧客分析例2)
本例において、顧客分析処理前のクラスタは、図18に示された顧客分析例1のクラスタと同一とし、分析対象の百貨店Xの個社クラスタは、図19(a)に示されるように、「X−1(2012)」〜「X−5(2012)」とする。また、分析対象の購買履歴データ230は、2012年度の一年分とし、短期的なトレンドの比較分析のため、分析対象期間として、2011年度以降の期間が指定されたと仮定する。
(Customer analysis example 2)
In this example, the cluster before the customer analysis processing is the same as the cluster of the customer analysis example 1 shown in FIG. 18, and the individual company cluster of the department store X to be analyzed is as shown in FIG. “X-1 (2012)” to “X-5 (2012)”. Further, it is assumed that the
したがって、ユニバーサルクラスタ抽出部103cは、ユニバーサルクラスタDB133から、「生成年度」情報が「2011年度」以降を示す個社クラスタだけを含む「UC−2」、「UC−3」、「UC−8」、及び「UC−10」を抽出する(図22のステップSt34の処理)。また、類似判定処理部103aは、分析対象の百貨店Xの個社クラスタ「X−1(2012)」〜「X−5(2012)」と、抽出された「UC−2」、「UC−3」、「UC−8」、及び「UC−10」との類似性の有無を判定する(図24のステップSt41の処理)。
Therefore, the universal
図25は、顧客分析例2におけるクラスタの比較分析処理の結果を示す。比較分析処理にいて、「X−1(2012)」〜「X−5(2012)」を「UC−2」、「UC−3」、「UC−8」、及び「UC−10」と比較した結果、「X−1(2012)」は、何れのユニバーサルクラスタとも類似性を有していないと判定されたため、特徴的顧客グループとして出力される。 FIG. 25 shows the result of the cluster comparison analysis process in the customer analysis example 2. In the comparative analysis process, “X-1 (2012)” to “X-5 (2012)” are compared with “UC-2”, “UC-3”, “UC-8”, and “UC-10”. As a result, it is determined that “X-1 (2012)” has no similarity to any universal cluster, and thus is output as a characteristic customer group.
特徴的顧客グループである「X−1(2012)」は、百貨店Xにおいて、他の百貨店A、B,C,・・・には存在しない独自の顧客グループとして分析され、例えば、当該顧客グループを維持しつつ、売上を向上させるための施策の検討に活用される。このような施策としては、例えば、当該顧客グループが頻繁に購入するブランド品を充実させること(商品施策)が挙げられる。 The characteristic customer group “X-1 (2012)” is analyzed as a unique customer group that does not exist in the other department stores A, B, C,... It will be used to examine measures to increase sales while maintaining sales. Such measures include, for example, enriching branded products that the customer group frequently purchases (product measures).
一方、「X−2(2012)」〜「X−5(2012)」は、ユニバーサルクラスタの何れかと類似性を有していると判定されたため、相互の差異が出力される。 On the other hand, since it is determined that “X-2 (2012)” to “X-5 (2012)” have similarity to any of the universal clusters, the mutual difference is output.
図26は、顧客分析例2における類似性を有する個社クラスタ及びユニバーサルクラスタを示す。図26において、互いに類似する個社クラスタ及びユニバーサルクラスタは、矢印により対応付けて示されている。例えば、「X−3(2012)」及び「X−5(2012)」は、「UC−2」及び「UC−3」にそれぞれ類似する。 FIG. 26 shows individual company clusters and universal clusters having similarities in the customer analysis example 2. In FIG. 26, individual company clusters and universal clusters similar to each other are shown in correspondence with each other by arrows. For example, “X-3 (2012)” and “X-5 (2012)” are similar to “UC-2” and “UC-3”, respectively.
比較分析処理において、類似性を有する個社クラスタ及びユニバーサルクラスタは、図24のステップSt48を参照して述べたように、互いに比較され、比較結果(分析結果)として、その差異が出力される。ここで、差異を示す情報については、図17を参照して述べたとおりである。上述したように、百貨店Xにおいて、「X−2(2012)」〜「X−5(2012)」に関する差異を示す情報は、例えば、百貨店Xの顧客基盤の強弱の評価(いわゆるベンチマーク評価)に活用される。その後、ユニバーサルクラスタの構築処理(ステップSt37の処理)が実行されることにより、ユニバーサルクラスタ及びユニバーサルクラスタ候補が変更される。 In the comparative analysis process, the individual company clusters and the universal clusters having similarities are compared with each other as described with reference to step St48 in FIG. 24, and the difference is output as a comparison result (analysis result). Here, the information indicating the difference is as described with reference to FIG. As described above, in the department store X, the information indicating the difference regarding “X-2 (2012)” to “X-5 (2012)” is, for example, an evaluation of the strength of the customer base of the department store X (so-called benchmark evaluation). Be utilized. Thereafter, the universal cluster construction process (the process of step St37) is executed, whereby the universal cluster and the universal cluster candidate are changed.
図27は、顧客分析例2におけるユニバーサルクラスタ及びユニバーサルクラスタ候補の変更処理を示す。より具体的には、図27(a)は、ユニバーサルクラスタの更新処理(図15BのステップSt19参照)を示す。点線枠で囲まれたユニバーサルクラスタと個社クラスタは、互いに類似するため、統合されることにより、矢印で示されたユニバーサルクラスタに更新される。本例は、ユニバーサルクラスタの構築処理において、図26に示された類似関係が検出されたことを前提とする。 FIG. 27 shows the universal cluster and universal cluster candidate change processing in the customer analysis example 2. More specifically, FIG. 27A shows a universal cluster update process (see step St19 in FIG. 15B). Since the universal cluster and the individual company cluster surrounded by the dotted line frame are similar to each other, they are updated to the universal cluster indicated by the arrow by being integrated. This example is based on the assumption that the similarity relationship shown in FIG. 26 is detected in the universal cluster construction process.
ユニバーサルクラスタの構築処理において、例えば、「UC−2」及び「X−3(2012)」は、「UC−2’」に統合され、「UC−3」及び「X−5(2012)」は、「UC−3’」に統合(マージ)される。このとき、更新後の「UC−2’」の「元クラスタ」情報には、「X−3(2012)」が追加され、更新後の「UC−3’」の「元クラスタ」情報には、「X−5(2012)」が追加される。 In the universal cluster construction process, for example, “UC-2” and “X-3 (2012)” are integrated into “UC-2 ′”, and “UC-3” and “X-5 (2012)” are , “UC-3 ′”. At this time, “X-3 (2012)” is added to the “original cluster” information of “UC-2 ′” after the update, and the “original cluster” information of “UC-3 ′” after the update is added to , “X-5 (2012)” is added.
また、図27(b)は、ユニバーサルクラスタの追加処理及びユニバーサルクラスタ候補の更新処理(図15BのステップSt17及びSt16参照)を示す。何れのユニバーサルクラスタにも類似しない「X−1(2012)」は、図15BのステップSt14を参照して述べたように、ユニバーサルクラスタ候補「A−4(2010)」、「C−5(2012)」との類似性の有無が判定される。 FIG. 27B shows universal cluster addition processing and universal cluster candidate update processing (see steps St17 and St16 in FIG. 15B). As described with reference to step St14 in FIG. 15B, “X-1 (2012)” that is not similar to any universal cluster is a universal cluster candidate “A-4 (2010)”, “C-5 (2012)”. ) ”Is determined.
「A−4(2010)」及び「X−1(2012)」は、互いに類似するため、統合されて、新たなユニバーサルクラスタ「UC−11」が生成される。このとき、「UC−11」の「元クラスタ」情報は、「A−4(2010)」及び「X−1(2012)」を示す。なお、ユニバーサルクラスタ候補DB134には、「C−5(2012)」だけが格納されている。
Since “A-4 (2010)” and “X-1 (2012)” are similar to each other, they are integrated to generate a new universal cluster “UC-11”. At this time, the “original cluster” information of “UC-11” indicates “A-4 (2010)” and “X-1 (2012)”. The universal
図28は、顧客分析例2における顧客分析処理後のクラスタを示す。ユニバーサルクラスタの構築処理により、ユニバーサルクラスタDB133には、更新されたユニバーサルクラスタ「UC−2’」、「UC−3’」、「UC−8’」、「UC−10’」、及び、追加されたユニバーサルクラスタ「UC−11」が格納されている。ユニバーサルクラスタ候補DB134には、分析処理後も残留するユニバーサルクラスタ候補「C−5」が格納されている。なお、ユニバーサルクラスタ候補「A−4」は、個社クラスタ「X−1」と統合され、ユニバーサルクラスタ「UC−11」に変更されたため、ユニバーサルクラスタ候補DB134から削除される。
FIG. 28 shows a cluster after the customer analysis processing in the customer analysis example 2. By the universal cluster construction processing, the updated universal clusters “UC-2 ′”, “UC-3 ′”, “UC-8 ′”, “UC-10 ′”, and the like are added to the
個社クラスタDB132には、百貨店Aの個社クラスタ「A−1」〜「A−7」、百貨店Bの個社クラスタ「B−1」〜「B−5」、及び百貨店Cの個社クラスタ「C−1」〜「C−10」が格納されている。さらに、個社クラスタDB132には、分析対象の百貨店Xの個社クラスタ「X−1」〜「X−12」が追加され、格納されている。
The individual
このように、ユニバーサルクラスタDB133は、顧客分析が行われるたびに更新され、さらなる顧客分析に使用される。したがって、顧客分析が行われるほど、ユニバーサルクラスタDB133の内容が充実し、高精度な顧客分析が可能となる。
In this way, the
これまで述べたように、第2実施例に係る顧客分析プログラムは、以下の処理をコンピュータ(CPU)10に実行させるものである。
処理(1):期間の指定を分析対象期間とする指示、または、現在もしくは過去の時点からの所定期間を分析対象期間とする指示と、分析対象の店の購買履歴データ230とを受け付ける。
処理(2):指示された分析対象期間における複数の店(百貨店)A,B,・・・の購買履歴データ230に基づいて生成された顧客グループ(個社クラスタ)のうち、所定の類似関係を有する全ての顧客グループを含む統合顧客グループ(ユニバーサルクラスタ)に含まれる各顧客グループを、各顧客グループの基礎とされた購買履歴データ230が示す時期(「生成年度」情報)と対応付けて記憶した記憶部(HDD)13を参照して、統合顧客グループのうち、指定された分析対象期間に含まれる時期の購買履歴データを基礎とする統合顧客グループ(ユニバーサルクラスタ)を抽出する。
処理(3):抽出した統合顧客グループと、分析対象の店(百貨店)Xの購買履歴データ230に基づいて生成された顧客グループ(個社クラスタ)との比較結果を出力する。
As described above, the customer analysis program according to the second embodiment causes the computer (CPU) 10 to execute the following processing.
Process (1): An instruction to designate the period as an analysis target period, an instruction to set a predetermined period from the current or past time point as an analysis target period, and purchase
Process (2): A predetermined similarity relationship among customer groups (individual company clusters) generated based on
Process (3): A comparison result between the extracted integrated customer group and the customer group (individual company cluster) generated based on the
実施例に係る顧客分析プログラムによると、分析対象の店Xの顧客グループを、指定された分析対象期間の類似の顧客グループが属する統合顧客グループと比較して得られた比較結果が出力されるので、時期のトレンドを考慮した顧客分析が可能である。 According to the customer analysis program according to the embodiment, the comparison result obtained by comparing the customer group of the analysis target store X with the integrated customer group to which a similar customer group in the specified analysis target period belongs is output. It is possible to analyze customers taking into account the trend of the season.
また、第2実施例に係る顧客分析方法は、以下の工程をコンピュータ(CPU)10が実行するものである。
工程(1):期間の指定を分析対象期間とする指示、または、現在もしくは過去の時点からの所定期間を分析対象期間とする指示と、分析対象の店の購買履歴データ230とを受け付ける。
工程(2):指示された分析対象期間における複数の店(百貨店)A,B,・・・の購買履歴データ230に基づいて生成された顧客グループ(個社クラスタ)のうち、所定の類似関係を有する全ての顧客グループを含む統合顧客グループ(ユニバーサルクラスタ)に含まれる各顧客グループを、各顧客グループの基礎とされた購買履歴データ230が示す時期(「生成年度」情報)と対応付けて記憶した記憶部(HDD)13を参照して、統合顧客グループのうち、指定された分析対象期間に含まれる時期の購買履歴データを基礎とする統合顧客グループ(ユニバーサルクラスタ)を抽出する。
工程(3):抽出した統合顧客グループと、分析対象の店(百貨店)Xの購買履歴データ230に基づいて生成された顧客グループ(個社クラスタ)との比較結果を出力する。
In the customer analysis method according to the second embodiment, the computer (CPU) 10 executes the following steps.
Step (1): An instruction to specify the period as an analysis target period, or an instruction to set a predetermined period from the current or past time point as an analysis target period, and purchase
Step (2): a predetermined similarity relationship among customer groups (individual company clusters) generated based on
Step (3): A comparison result between the extracted integrated customer group and the customer group (individual company cluster) generated based on the
第2実施例に係る顧客分析方法は、第2実施例に係る顧客分析プログラムと同様の構成を含むので、上述した内容と同様の作用効果を奏する。 Since the customer analysis method according to the second embodiment includes the same configuration as that of the customer analysis program according to the second embodiment, the same effects as those described above can be obtained.
また、第2実施例に係る顧客分析装置1は、受付処理部(データ入力処理部)101と、記憶部(HDD)13と、出力処理部(クラスタ処理部)103とを有する。受付処理部101は、期間の指定を分析対象期間とする指示、または、現在もしくは過去の時点からの所定期間を分析対象期間とする指示と、分析対象の店の購買履歴データ230とを受け付ける。
The
記憶部13は、指示された分析対象期間における複数の店(百貨店)A,B,・・・の購買履歴データ230に基づいて生成された顧客グループ(個社クラスタ)のうち、所定の類似関係を有する全ての顧客グループを含む統合顧客グループ(ユニバーサルクラスタ)に含まれる各顧客グループを、各顧客グループの基礎とされた購買履歴データ230が示す時期(「生成年度」情報)と対応付けて記憶する。
The
出力処理部103は、記憶部13を参照して、統合顧客グループのうち、指示された分析対象期間に含まれる時期の購買履歴データ230を基礎とする統合顧客グループ(ユニバーサルクラスタ)を抽出する。出力処理部103は、抽出した統合顧客グループと、分析対象の店(百貨店)Xの購買履歴データ230に基づいて生成された顧客グループ(個社クラスタ)との比較結果を出力する。
The
第2実施例に係る顧客分析装置1は、第2実施例に係る顧客分析プログラムと同様の構成を含むので、上述した内容と同様の作用効果を奏する。
Since the
なお、上記の処理機能は、コンピュータによって実現することができる。その場合、処理装置が有すべき機能の処理内容を記述したプログラムが提供される。そのプログラムをコンピュータで実行することにより、上記処理機能がコンピュータ上で実現される。処理内容を記述したプログラムは、コンピュータで読み取り可能な記録媒体(ただし、搬送波は除く)に記録しておくことができる。 The above processing functions can be realized by a computer. In that case, a program describing the processing contents of the functions that the processing apparatus should have is provided. By executing the program on a computer, the above processing functions are realized on the computer. The program describing the processing contents can be recorded on a computer-readable recording medium (except for a carrier wave).
プログラムを実行するコンピュータは、例えば、可搬型記録媒体に記録されたプログラムもしくはサーバコンピュータから転送されたプログラムを、自己の記憶装置に格納する。そして、コンピュータは、自己の記憶装置からプログラムを読み取り、プログラムに従った処理を実行する。なお、コンピュータは、可搬型記録媒体から直接プログラムを読み取り、そのプログラムに従った処理を実行することもできる。また、コンピュータは、サーバコンピュータからプログラムが転送されるごとに、逐次、受け取ったプログラムに従った処理を実行することもできる。 The computer that executes the program stores, for example, the program recorded on the portable recording medium or the program transferred from the server computer in its own storage device. Then, the computer reads the program from its own storage device and executes processing according to the program. The computer can also read the program directly from the portable recording medium and execute processing according to the program. Further, each time the program is transferred from the server computer, the computer can sequentially execute processing according to the received program.
上述した実施形態は本発明の好適な実施の例である。但し、これに限定されるものではなく、本発明の要旨を逸脱しない範囲内において種々変形実施可能である。 The above-described embodiment is an example of a preferred embodiment of the present invention. However, the present invention is not limited to this, and various modifications can be made without departing from the scope of the present invention.
1 顧客分析装置
2 端末装置
10 CPU
13 HDD(記憶部)
101 データ入力処理部(受付処理部)
102 クラスタ生成部
103 クラスタ処理部(出力処理部)
132 個社クラスタデータベース
133 ユニバーサルクラスタデータベース
1
13 HDD (storage unit)
101 Data input processing unit (acceptance processing unit)
102
132
Claims (6)
指示された前記分析対象期間における複数の店の購買履歴データに基づいて生成された顧客グループのうち、所定の類似関係を有する全ての顧客グループを含む統合顧客グループと、前記分析対象の店の購買履歴データに基づいて生成された顧客グループとの比較結果を出力する、処理をコンピュータに実行させることを特徴とする顧客分析プログラム。 Accepts an instruction to specify the period as an analysis period, or an instruction to set a predetermined period from the current or past time point as an analysis period, and purchase history data of the store to be analyzed,
An integrated customer group including all customer groups having a predetermined similar relationship among customer groups generated based on purchase history data of a plurality of stores in the specified analysis target period, and purchase of the analysis target store A customer analysis program characterized by causing a computer to execute a process for outputting a comparison result with a customer group generated based on historical data.
指示された前記分析対象期間における複数の店の購買履歴データに基づいて生成された顧客グループのうち、所定の類似関係を有する全ての顧客グループを含む統合顧客グループに含まれる各顧客グループを、各顧客グループの基礎とされた前記購買履歴データが示す時期と対応付けて記憶した記憶部を参照して、前記統合顧客グループのうち、指示された前記分析対象期間に含まれる時期の前記購買履歴データを基礎とする統合顧客グループを抽出し、
抽出した前記統合顧客グループと、前記分析対象の店の購買履歴データに基づいて生成された顧客グループとの比較結果を出力する、処理を、コンピュータに実行させることを特徴とする顧客分析プログラム。 Accepts an instruction to specify the period as an analysis period, or an instruction to set a predetermined period from the current or past time point as an analysis period, and purchase history data of the store to be analyzed,
Each customer group included in an integrated customer group including all customer groups having a predetermined similar relationship among customer groups generated based on purchase history data of a plurality of stores in the specified analysis target period, With reference to the storage unit stored in association with the time indicated by the purchase history data based on the customer group, the purchase history data at the time included in the instructed analysis target period in the integrated customer group The integrated customer group based on
A customer analysis program that causes a computer to execute a process of outputting a comparison result between the extracted integrated customer group and a customer group generated based on purchase history data of the analysis target store.
指示された前記分析対象期間における複数の店の購買履歴データに基づいて生成された顧客グループのうち、所定の類似関係を有する全ての顧客グループを含む統合顧客グループと、前記分析対象の店の購買履歴データに基づいて生成された顧客グループとの比較結果を出力する工程とを、コンピュータが実行することを特徴とする顧客分析方法。 An instruction to designate the period as an analysis target period, or an instruction to set a predetermined period from the current or past time point as an analysis target period, and purchase history data of the analysis target store;
An integrated customer group including all customer groups having a predetermined similar relationship among customer groups generated based on purchase history data of a plurality of stores in the specified analysis target period, and purchase of the analysis target store A customer analysis method characterized in that a computer executes a step of outputting a comparison result with a customer group generated based on historical data.
指示された前記分析対象期間における複数の店の購買履歴データに基づいて生成された顧客グループのうち、所定の類似関係を有する全ての顧客グループを含む統合顧客グループに含まれる各顧客グループを、各顧客グループの基礎とされた前記購買履歴データが示す時期と対応付けて記憶した記憶部を参照して、前記統合顧客グループのうち、指示された前記分析対象期間に含まれる時期の前記購買履歴データを基礎とする統合顧客グループを抽出する工程と
抽出した前記統合顧客グループと、前記分析対象の店の購買履歴データに基づいて生成された顧客グループとの比較結果を出力する工程とを、コンピュータが実行することを特徴とする顧客分析方法。 An instruction to designate the period as an analysis target period, or an instruction to set a predetermined period from the current or past time point as an analysis target period, and purchase history data of the analysis target store;
Each customer group included in an integrated customer group including all customer groups having a predetermined similar relationship among customer groups generated based on purchase history data of a plurality of stores in the specified analysis target period, With reference to the storage unit stored in association with the time indicated by the purchase history data based on the customer group, the purchase history data at the time included in the instructed analysis target period in the integrated customer group A computer that extracts the integrated customer group based on the database, and outputs the comparison result between the extracted integrated customer group and the customer group generated based on the purchase history data of the analysis target store. A customer analysis method characterized by performing.
指示された前記分析対象期間における複数の店の購買履歴データに基づいて生成された顧客グループのうち、所定の類似関係を有する全ての顧客グループを含む統合顧客グループと、前記分析対象の店の購買履歴データに基づいて生成された顧客グループとの比較結果を出力する出力処理部とを有することを特徴とする顧客分析装置。 An acceptance processing unit that receives an instruction to designate a period as an analysis target period, or an instruction to set a predetermined period from the current or past time point as an analysis target period, and purchase history data of a store to be analyzed;
An integrated customer group including all customer groups having a predetermined similar relationship among customer groups generated based on purchase history data of a plurality of stores in the specified analysis target period, and purchase of the analysis target store An output processing unit that outputs a comparison result with a customer group generated based on history data.
指示された前記分析対象期間における複数の店の購買履歴データに基づいて生成された顧客グループのうち、所定の類似関係を有する全ての顧客グループを含む統合顧客グループに含まれる各顧客グループを、各顧客グループの基礎とされた前記購買履歴データが示す時期と対応付けて記憶した記憶部と、
前記記憶部を参照して、前記統合顧客グループのうち、指示された前記分析対象期間に含まれる時期の前記購買履歴データを基礎とする統合顧客グループを抽出し、抽出した前記統合顧客グループと、前記分析対象の店の購買履歴データに基づいて生成された顧客グループとの比較結果を出力する出力処理部とを有することを特徴とする顧客分析装置。 An acceptance processing unit that receives an instruction to designate a period as an analysis target period, or an instruction to set a predetermined period from the current or past time point as an analysis target period, and purchase history data of a store to be analyzed;
Each customer group included in an integrated customer group including all customer groups having a predetermined similar relationship among customer groups generated based on purchase history data of a plurality of stores in the specified analysis target period, A storage unit stored in association with the time indicated by the purchase history data based on the customer group;
Referring to the storage unit, extract the integrated customer group based on the purchase history data at the time included in the instructed analysis target period from the integrated customer group, and extract the integrated customer group, An output processing unit for outputting a comparison result with a customer group generated based on purchase history data of the analysis target store.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2014019087A JP2015146145A (en) | 2014-02-04 | 2014-02-04 | Customer analyzing program, customer analyzing method and customer analyzer |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2014019087A JP2015146145A (en) | 2014-02-04 | 2014-02-04 | Customer analyzing program, customer analyzing method and customer analyzer |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2015146145A true JP2015146145A (en) | 2015-08-13 |
Family
ID=53890340
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2014019087A Pending JP2015146145A (en) | 2014-02-04 | 2014-02-04 | Customer analyzing program, customer analyzing method and customer analyzer |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP2015146145A (en) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP7032594B1 (en) * | 2021-05-20 | 2022-03-08 | ヤフー株式会社 | Information providers, information processing methods, and programs |
| JP7101849B1 (en) | 2021-05-20 | 2022-07-15 | ヤフー株式会社 | Providing equipment, providing method, and providing program |
| JP7104214B1 (en) | 2021-05-20 | 2022-07-20 | ヤフー株式会社 | Providing equipment, providing method, and providing program |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2001023047A (en) * | 1999-07-12 | 2001-01-26 | Daikoku:Kk | Integrated customer management system |
| US20050177449A1 (en) * | 2003-09-22 | 2005-08-11 | Temares Mark E. | Method and system for purchase-based segmentation |
| JP2008293310A (en) * | 2007-05-25 | 2008-12-04 | Toyota Motor Corp | Method, system, and program for analyzing tendency of consumers' taste |
| JP2011203934A (en) * | 2010-03-25 | 2011-10-13 | Nomura Research Institute Ltd | Marketing system and method |
| JP2012150786A (en) * | 2010-12-28 | 2012-08-09 | Giken Shoji International Co Ltd | Profiling system using regional characteristic |
-
2014
- 2014-02-04 JP JP2014019087A patent/JP2015146145A/en active Pending
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2001023047A (en) * | 1999-07-12 | 2001-01-26 | Daikoku:Kk | Integrated customer management system |
| US20050177449A1 (en) * | 2003-09-22 | 2005-08-11 | Temares Mark E. | Method and system for purchase-based segmentation |
| JP2008293310A (en) * | 2007-05-25 | 2008-12-04 | Toyota Motor Corp | Method, system, and program for analyzing tendency of consumers' taste |
| JP2011203934A (en) * | 2010-03-25 | 2011-10-13 | Nomura Research Institute Ltd | Marketing system and method |
| JP2012150786A (en) * | 2010-12-28 | 2012-08-09 | Giken Shoji International Co Ltd | Profiling system using regional characteristic |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP7032594B1 (en) * | 2021-05-20 | 2022-03-08 | ヤフー株式会社 | Information providers, information processing methods, and programs |
| JP7101849B1 (en) | 2021-05-20 | 2022-07-15 | ヤフー株式会社 | Providing equipment, providing method, and providing program |
| JP7104214B1 (en) | 2021-05-20 | 2022-07-20 | ヤフー株式会社 | Providing equipment, providing method, and providing program |
| JP2022178712A (en) * | 2021-05-20 | 2022-12-02 | ヤフー株式会社 | Providing device, providing method and providing program |
| JP2022178713A (en) * | 2021-05-20 | 2022-12-02 | ヤフー株式会社 | Provision device, provision method, and provision program |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US9916594B2 (en) | Multidimensional personal behavioral tomography | |
| JP6014515B2 (en) | RECOMMENDATION INFORMATION PROVIDING SYSTEM, RECOMMENDATION INFORMATION GENERATION DEVICE, RECOMMENDATION INFORMATION PROVIDING METHOD, AND PROGRAM | |
| JP5785869B2 (en) | Behavior attribute analysis program and apparatus | |
| JP6352798B2 (en) | Marketing measure optimization apparatus, method, and program | |
| US20190121867A1 (en) | System for calculating competitive interrelationships in item-pairs | |
| US11727420B2 (en) | Time series clustering analysis for forecasting demand | |
| JP6916367B1 (en) | Estimating system and estimation method | |
| JP6810745B2 (en) | Systems and methods for segmenting customers with mixed attribute types using target clustering techniques | |
| JP2021056643A (en) | Information processor, information processing method and information processing system | |
| JP2015146126A (en) | Customer analyzing program, customer analyzing method and customer analyzer | |
| JP2015146145A (en) | Customer analyzing program, customer analyzing method and customer analyzer | |
| JP2021099718A (en) | Information processing device and program | |
| CN111127074A (en) | Data recommendation method | |
| JP5879004B1 (en) | Sales promotion support device and sales promotion support method | |
| KR20100123347A (en) | System and method for providing mobile shopping mall service | |
| JP6143930B1 (en) | Marketing support method, program, computer storage medium, and marketing support system | |
| JP2019168879A (en) | Apparatus, method, and program | |
| US20180211297A1 (en) | Automatic Update Of A Shadow Catalog Database Based On Transactions Made Using A Catalog Database | |
| WO2021065289A1 (en) | Store assistance system, store assistance method, and program | |
| WO2021065290A1 (en) | Store supporting system, learning device, store supporting method, generation method of learned model, and program | |
| US20170178167A1 (en) | Method for predicting a demand for a business | |
| JP6287280B2 (en) | Information processing method, program, and information processing apparatus | |
| JP3966378B2 (en) | Computer system for point management and customer management, point management and customer management method, program for point management and customer management method, and storage medium storing program for point management and customer management method | |
| JP2017059202A (en) | Sales promotion support device and sales promotion support method | |
| JP7000691B2 (en) | Programs, information processing equipment and information processing methods |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20161004 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20170929 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20171010 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20180403 |