JP2012155634A - Information processing program, information processing device and information processing method - Google Patents
Information processing program, information processing device and information processing method Download PDFInfo
- Publication number
- JP2012155634A JP2012155634A JP2011015894A JP2011015894A JP2012155634A JP 2012155634 A JP2012155634 A JP 2012155634A JP 2011015894 A JP2011015894 A JP 2011015894A JP 2011015894 A JP2011015894 A JP 2011015894A JP 2012155634 A JP2012155634 A JP 2012155634A
- Authority
- JP
- Japan
- Prior art keywords
- data
- update
- update data
- record
- latest
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images












Abstract
Description
本発明は更新ログを処理する情報処理プログラム、情報処理装置および情報処理方法に関する。 The present invention relates to an information processing program, an information processing apparatus, and an information processing method for processing an update log.
従来、システムとしての可用性や信頼性を向上するため、構成部品を冗長化して運用する情報処理システムが利用されている。その1つとして、例えば、データベースを冗長化するものがある。具体的には、一方のデータベースを運用系として業務処理に用い、他方のデータベースを待機系として用いる。当該情報処理システムは運用系での更新内容を待機系にも反映して、両方のデータベースを同期する。そして、運用系の障害時には、運用系での業務処理を待機系に引き継がせる。 Conventionally, in order to improve availability and reliability as a system, an information processing system that operates with redundant components has been used. One of them is to make a database redundant, for example. Specifically, one database is used as an operational system for business processing, and the other database is used as a standby system. The information processing system reflects the update contents in the active system in the standby system and synchronizes both databases. Then, in the event of a failure in the active system, business processing in the active system is handed over to the standby system.
ここで、データベースを冗長化する場合、両方のデータベースでデータの同期を高速に行えることが、信頼性の観点からは望ましい。そこで、一方のデータベースでの差分を記録した差分ログを取得し、当該差分ログを複数の並列処理対象に振り分けて、当該並列処理対象の差分ログを他方のデータベースに適用する処理を並列に行うことで、差分ログを高速に処理する方法が提案されている(例えば、特許文献1参照)。 Here, when making a database redundant, it is desirable from the viewpoint of reliability that data synchronization can be performed at high speed in both databases. Therefore, a difference log in which the difference in one database is recorded is acquired, the difference log is distributed to a plurality of parallel processing targets, and the process of applying the parallel processing target difference log to the other database is performed in parallel. Thus, a method of processing the differential log at high speed has been proposed (see, for example, Patent Document 1).
また、データベースの同じデータにアクセスする可能性のあるトランザクション同士を同じコネクションにまとめ、コネクションごとの複数のトランザクションを一まとめにしてコミットを実行することで、トランザクションの速度を高速化する方法も提案されている(例えば、特許文献2参照)。 In addition, a method has been proposed to increase the transaction speed by combining transactions that may access the same data in the database into the same connection, and committing multiple transactions for each connection together. (For example, refer to Patent Document 2).
ところで、障害の起きたデータベースが復旧した場合に、当該復旧したデータベースにそれまでの更新内容を反映することが考えられる。そのために、運用中のもう一方のデータベースで、更新内容を記録した更新ログを取得することがある。 By the way, when a database in which a failure has occurred is restored, it is conceivable to reflect the updated contents so far in the restored database. For this reason, an update log in which update contents are recorded may be acquired in the other database in operation.
その場合、片方のデータベースのみによる運用時間が長いほど、更新ログに蓄積されるデータ量は増加する。このため、一方が障害から復旧して、差分を同期しようとする場合に、更新ログのデータ量の分だけ処理時間が長くなるという問題がある。また、更新ログの最大データ量が所定量に制限されていることもあり、当該所定量を超えた更新ログの取得が困難になるという問題がある。 In this case, the longer the operation time using only one database, the greater the amount of data stored in the update log. For this reason, when one side recovers from a failure and tries to synchronize the difference, there is a problem that the processing time becomes longer by the amount of data in the update log. In addition, the maximum data amount of the update log may be limited to a predetermined amount, and there is a problem that it is difficult to acquire an update log exceeding the predetermined amount.
本発明はこのような点に鑑みてなされたものであり、更新ログのデータ量を効率的に低減できる情報処理プログラム、情報処理装置および情報処理方法を提供することを目的とする。 SUMMARY An advantage of some aspects of the invention is that it provides an information processing program, an information processing apparatus, and an information processing method capable of efficiently reducing the data amount of an update log.
コンピュータを記憶手段、特定手段および処理手段として機能させる情報処理プログラムが提供される。記憶手段は、複数のデータ項目を含むレコードの初期設定と、複数のデータ項目に対する初期設定からの更新内容を示す複数の第1の更新データとを記憶する。特定手段は、記憶手段を参照して、複数のデータ項目それぞれのうち、最新の更新データによる設定が初期設定と同一でないデータ項目につき最新の更新データを特定する。処理手段は、特定手段により特定された全てのデータ項目の最新の更新データを用いて、複数のデータ項目に対する1つの第2の更新データを生成して記憶手段に格納し、記憶手段から複数の第1の更新データを削除する。 An information processing program for causing a computer to function as a storage unit, a specifying unit, and a processing unit is provided. The storage means stores an initial setting of a record including a plurality of data items and a plurality of first update data indicating update contents from the initial setting for the plurality of data items. The specifying unit refers to the storage unit and specifies the latest update data for each of the plurality of data items for each data item whose setting by the latest update data is not the same as the initial setting. The processing means generates the second update data for a plurality of data items using the latest update data of all the data items specified by the specifying means, stores the second update data in the storage means, The first update data is deleted.
また、情報処理プログラムを実行するコンピュータと同様の機能を有する情報処理装置が提供される。
また、コンピュータの情報処理方法が提供される。この情報処理方法では、コンピュータが、複数のデータ項目を含むレコードの初期設定と、複数のデータ項目に対する初期設定からの更新内容を示す複数の第1の更新データとを記憶する記憶手段を参照して、複数のデータ項目それぞれのうち、最新の更新データによる設定が初期設定と同一でないデータ項目につき最新の更新データを特定する。そして、特定した全てのデータ項目の最新の更新データを用いて、複数のデータ項目に対する1つの第2の更新データを生成して記憶手段に格納し、記憶手段から複数の第1の更新データを削除する。
Further, an information processing apparatus having the same function as a computer that executes an information processing program is provided.
A computer information processing method is also provided. In this information processing method, the computer refers to storage means for storing an initial setting of a record including a plurality of data items and a plurality of first update data indicating update contents from the initial setting for the plurality of data items. Thus, among the plurality of data items, the latest update data is specified for a data item whose setting by the latest update data is not the same as the initial setting. Then, using the latest update data of all the specified data items, one second update data for the plurality of data items is generated and stored in the storage means, and the plurality of first update data is stored from the storage means. delete.
上記情報処理プログラム、情報処理装置および情報処理方法によれば、更新ログのデータ量を効率的に低減できる。 According to the information processing program, the information processing apparatus, and the information processing method, the data amount of the update log can be efficiently reduced.
以下、本実施の形態を図面を参照して説明する。
[第1の実施の形態]
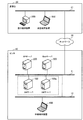
図1は、第1の実施の形態の情報処理装置を示す図である。情報処理装置1は、データベース上のテーブル“table−A”に関する更新ログを管理する。更新ログは、冗長化されたデータベースにつき両方の同期を行うためのものである。情報処理装置1は、記憶手段1a、特定手段1bおよび処理手段1cを有する。
Hereinafter, the present embodiment will be described with reference to the drawings.
[First Embodiment]
FIG. 1 is a diagram illustrating the information processing apparatus according to the first embodiment. The
記憶手段1aは、レコード2の初期設定を記憶する。初期設定とは、更新ログの取得が開始された時点におけるレコード2の設定内容を示す。複数のレコードがある場合、初期設定はレコードごとに記憶される。当該レコードに複数のデータ項目があれば、初期設定は更にデータ項目ごとに記憶される。
The
レコード2は、複数のデータ項目を含む。例えば、データ項目2a,2b,2cを含むとする。ここで、データ項目2aは“data1”、データ項目2bは“data2”、データ項目2cは“data3”の項目名が付されている。初期設定は、データ項目2a,2b,2cの何れも“10”であるとする。
記憶手段1aは、データ項目2a,2b,2cに対する初期設定からの更新ログとして、第1の更新データ群3を記憶する。第1の更新データ群3は、例えば時系列の古い順に更新データ3a,3b,3c,3d,3e,3f,3gを有する。
The
特定手段1bは、記憶手段1aを参照して、データ項目2a,2b,2cそれぞれのうち、最新の更新データによる設定が初期設定と同一でないデータ項目につき最新の更新データを特定する。
The specifying
例えば、データ項目2aに関する最新の更新データ3eは“12”への更新を示す。よって、初期設定“10”と同一でないので、特定手段1bは当該最新の更新データ3eを特定する。また、データ項目2bに関する最新の更新データ3gは“10”への更新を示す。よって、初期設定“10”と同一であるので、特定の対象外となる。また、データ項目2cに関する最新の更新データ3dは“20”への更新を示す。よって、初期設定“10”と同一でないので、特定手段1bは当該最新の更新データ3dを特定する。
For example, the
処理手段1cは、特定手段1bにより特定された全てのデータ項目の最新の更新データを用いて、複数のデータ項目に対する1つの第2の更新データ4を生成して記憶手段1aに格納する。そして、処理手段1cは記憶手段1aから第1の更新データ群3を削除する。第2の更新データ4は、冗長化された両方のデータベースの同期を行うために、第1の更新データ群3に代えて用いることができる。
The
例えば、上述の例では特定手段1bは、データ項目2aに対して更新データ3eを、データ項目2cに対して更新データ3dを特定している。処理手段1cは、当該更新データ3d,3eを用いて、第2の更新データ4を生成する。第2の更新データ4は、データ項目2aを“12”に、データ項目2cを“20”に、それぞれ更新するためのデータである。そして、処理手段1cは記憶手段1aから第1の更新データ群3を削除する。
For example, in the example described above, the specifying
情報処理装置1によれば、特定手段1bにより、記憶手段1aが参照されて、データ項目2a,2b,2cそれぞれのうち、最新の更新データによる設定が初期設定と同一でないデータ項目2a,2cにつき最新の更新データ3d,3eが特定される。処理手段1cにより、特定手段1bが特定した更新データ3d,3eを用いて、データ項目2a,2b,2cに対する1つの第2の更新データ4が作成されて記憶手段1aに格納され、記憶手段1aから第1の更新データ群3が削除される。
According to the
これにより、更新ログのデータ量を効率的に低減できる。具体的には、データ項目2a,2b,2cそれぞれの最新の更新データを反映した第2の更新データ4を生成して、それ以外の更新データを削除するようにしたので、更新ログのデータ量を低減できる。ここで、データ項目2a,2b,2cそれぞれの最新の更新データのみから第2の更新データ4を生成できるのは、最新の更新データ以外の更新データが、最終的に新しい更新データによって別の設定に更新されるものだからである。このため、最新の更新データのみを参照することで、当該データ項目を同期させるために必要な情報を得ることができる。
Thereby, the data amount of an update log can be reduced efficiently. Specifically, since the
特に、レコード2に対して、1つの新たな更新データ(第2の更新データ4)を生成するので、レコード2に対して複数存在していた更新データのデータ量を効率的に低減できる。
In particular, since one new update data (second update data 4) is generated for the
更に、最新の更新データによる設定が初期設定と異なるデータ項目2a,2cについて第2の更新データ4を生成することで、第2の更新データ4の中に初期設定と同一設定のデータ項目2bにつき無駄な更新コマンドを含めずに済む。
Further, by generating the
このため、第2の更新データ4を用いて冗長化したデータベースの同期を行えば、同期処理に掛かる時間を短縮できる。また、更新ログの最大データ量が所定量に制限されていても、第2の更新データ4の生成および第1の更新データ群3の削除を定期的に行うことで、更新ログの増加量を緩和できる。
For this reason, if synchronization of the redundant database is performed using the
以下に説明する第2の実施の形態では、情報処理装置1を金融窓口システムに適用する場合を例示して説明する。
[第2の実施の形態]
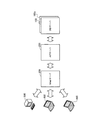
図2は、第2の実施の形態の金融窓口システムを示す図である。この金融窓口システムは、金融機関のセンタ10および営業店20における為替業務を支援する。ここで、以下では振込業務を例示して説明する。ただし、他の業務に関しても同様である。センタ10および営業店20には、金融窓口システムを構成するサーバ装置(以下、単にサーバということもある)や端末装置などの情報処理装置が設置されている。
In the second embodiment described below, a case where the
[Second Embodiment]
FIG. 2 is a diagram illustrating a financial window system according to the second embodiment. This financial window system supports the exchange business in the
この金融窓口システムは、DB(DataBase)サーバ100,100a、AP(Application)サーバ200、Webサーバ300、手続端末装置400、窓口端末装置500および承認端末装置600を含む。
This financial window system includes DB (DataBase)
DBサーバ100,100a、APサーバ200およびWebサーバ300はセンタ10内のネットワーク11に接続されている。手続端末装置400はセンタ10内のネットワーク12に接続されている。また、ネットワーク12はネットワーク11に接続されている。更に、窓口端末装置500および承認端末装置600は営業店20内のネットワーク21に接続されている。そして、ネットワーク11,21は、ネットワーク30を介して接続されている。ネットワーク30は、インターネット、イントラネットまたは当該金融窓口システムのための専用の通信網である。
The
DBサーバ100,100aは、金融窓口システムの処理に利用するデータを格納するためのサーバ装置である。DBサーバ100,100aは、冗長化(ミラーリング)されている。すなわち、DBサーバ100,100aは、一方(運用系)の更新内容を他方(待機系)へ同期する機能を有する。特に、DBサーバ100,100aは運用系が障害により運用継続できなくなると、待機系へ業務処理を引き継ぐ。例えば、DBサーバ100aが運用系であった場合に、DBサーバ100aで障害が発生し、運用継続できなくなると、待機系であるDBサーバ100に業務処理を引き継ぐ。その際、DBサーバ100は、DBサーバ100での更新内容を記録した更新ログを生成する。更新ログは、DBサーバ100aが復旧したときに、DBサーバ100での更新内容をDBサーバ100aに同期させるために用いる。
The
APサーバ200は、金融窓口システムの業務処理を実現するためのアプリケーションを実行するサーバ装置である。APサーバ200は、Webサーバ300から受け付けた要求に応じてDBサーバ100,100aを参照し、業務処理を実行する。
The
Webサーバ300は、手続端末装置400、窓口端末装置500および承認端末装置600から業務処理要求を受け付けるためのGUI(Graphical User Interface)を提供するサーバ装置である。手続端末装置400、窓口端末装置500および承認端末装置600の各オペレータは、各装置に設けられたブラウザによって当該GUIを利用できる。
The
手続端末装置400は、振込手続を行うための情報処理装置である。手続端末装置400は、センタ10に駐在する手続オペレータが操作する。
窓口端末装置500は、顧客が記入した振込伝票を受け付ける情報処理装置である。窓口端末装置500は、営業店20に駐在する窓口オペレータが操作する。
The
The
承認端末装置600は、振込手続の継続を承認するための情報処理装置である。承認端末装置600は、営業店20に駐在する承認者が操作する。
図3は、各装置の関係を示す図である。窓口端末装置500、承認端末装置600および手続端末装置400の各オペレータは、Webサーバ300にアクセスして業務処理要求を入力できる。窓口端末装置500、承認端末装置600および手続端末装置400はWebサーバ300のGUIをブラウザにより取得して表示する。
The
FIG. 3 is a diagram illustrating the relationship between the devices. Each operator of the
窓口端末装置500が表示するGUIは、振込伝票の受付完了の入力を受け付けるためのものである。
承認端末装置600が表示するGUIは、入力された振込伝票の情報に基づいて、振込手続を行ってもよい旨の承認を行うためのGUIである。
The GUI displayed on the
The GUI displayed by the
手続端末装置400が表示するGUIは、振込手続の確定の入力を行うためのGUIである。
Webサーバ300は、窓口端末装置500、承認端末装置600および手続端末装置400から取得した各業務処理要求に応じてAPサーバ200に対するリクエスト(APリクエストと称する)を生成し、APサーバ200に送信する。Webサーバ300は、APリクエストに応じた処理応答(APレスポンスと称する)をAPサーバ200から受信すると、当該APレスポンスに基づき業務処理応答を生成し、窓口端末装置500、承認端末装置600および手続端末装置400に送信する。
The GUI displayed by the
The
APサーバ200は、Webサーバ300から受信したAPリクエストに応じてDBサーバ100,100aに対するリクエスト(DBリクエストと称する)を生成し、DBサーバ100,100aに送信する。ここで、APサーバ200は、現在運用系のDBサーバに対してDBリクエストを送信する。例えば、DBサーバ100aが運用系であれば、DBサーバ100aにDBリクエストを送信する。すると、APサーバ200は、DBリクエストに応じた処理応答(DBレスポンスと称する)をDBサーバ100aから受信し、当該DBレスポンスに基づきAPレスポンスを生成してWebサーバ300に送信する。DBリクエストにはSQL文に対応する情報が含まれる。
The
DBサーバ100,100aは、APサーバ200から受信したDBリクエストに応じてデータ処理を行う。DBサーバ100,100aは、当該データ処理の結果に基づきAPサーバ200に対する応答を生成し、APサーバ200に送信する。ここで、DBサーバ100,100aのうち、運用系の一方が当該処理を行う。待機系の他方には、運用系で実行したデータ処理の結果が同期される。
The
以下の説明では、DBサーバ100aは障害により停止している場合を想定する。すなわち、金融窓口システムがDBサーバ100のみで縮退運用されている場合を想定する。ただし、DBサーバ100が障害で停止し、DBサーバ100aのみで縮退運用されている場合も以下の説明と同様である。
In the following description, it is assumed that the
図4は、振込ワークフローを例示する図である。振込ワークフロー50は、金融窓口システムの振込処理の順序を示す。振込ワークフロー50には、各拠点(営業店20およびセンタ10)における、業務処理要求の発生元(要求元)の装置、当該要求に伴う処理および当該処理後の伝票状態が示されている。ここで、伝票状態は、DBサーバ100,100aで管理される振込伝票の状態を示す。振込ワークフロー50による処理順序は、次の通りである。
FIG. 4 is a diagram illustrating a transfer workflow. The
まず、顧客が金融機関に対して振込依頼を行うための振込伝票を作成する。振込ワークフロー50では、要求元が“(顧客)”、処理が“(振込依頼)”、伝票状態が“(作成)”と括弧で括られている。これは、当該手順が顧客によって行われるものであり、金融窓口システムが行う手順ではないためである。ただし、金融窓口システムによる処理の起点となる入力データは当該伝票に基づいて生成されるため、それが分かり易いように図示している。以下、それ以降の手順を説明する。なお、DBサーバ100の処理は、上述したようにWebサーバ300およびAPサーバ200を介したDBリクエストに基づき実行される。
First, a transfer slip for a customer to make a transfer request to a financial institution is created. In the
(1)窓口端末装置500は、振込伝票の情報の登録要求をWebサーバ300に送信する。すると、DBサーバ100は当該伝票の情報を登録する。DBサーバ100は、伝票状態を“受付”に設定する。
(1) The
(2)窓口端末装置500は、振込伝票による振込の承認依頼要求をWebサーバ300に送信する。すると、DBサーバ100は、伝票状態を“承認待ち”に設定する。これによって、承認端末装置600による承認が可能となる。
(2) The
(3)承認端末装置600は、振込伝票の承認の設定要求をWebサーバ300に送信する。すると、DBサーバ100は伝票状態を“承認”に設定する。
(4)承認端末装置600は、振込伝票につき振込手続の委譲要求をWebサーバ300に送信する。すると、DBサーバ100は、伝票状態を“委譲”に設定する。
(3) The
(4) The
(5)手続端末装置400は、振込伝票による振込手続の実行要求をWebサーバ300に送信する。すると、DBサーバ100は、伝票状態を“手続中”に設定する。そして、APサーバ200により、他の支店や他の金融機関等との間で振込処理が実行される。
(5) The
(6)APサーバ200は、振込処理が完了すると、その旨をDBサーバ100に通知する。すると、DBサーバ100は、伝票状態を“完了”に設定する。
以上の順序で振込処理が行われ、DBサーバ100上の電子伝票の状態が更新される。DBサーバ100は、このように順次変更される電子伝票の更新の履歴を更新ログとして記録する。DBサーバ100aが復旧した際に、当該更新ログを用いてデータの同期を図るためである。その際、DBサーバ100は、当該更新ログのデータ量を効率的に低減する。以下では、そのようなDBサーバ100の構成を詳細に説明する。まず、DBサーバ100が備えるデバイス(ハードウェア)の構成を説明する。
(6) When the transfer process is completed, the
The transfer process is performed in the above order, and the state of the electronic slip on the
図5は、DBサーバのハードウェア構成を示す図である。DBサーバ100は、CPU(Central Processing Unit)101、ROM(Read Only Memory)102、RAM(Random Access Memory)103、HDD(Hard Disk Drive)104、グラフィック処理装置105、入力インタフェース106、記録媒体読取装置107および通信インタフェース108を有する。
FIG. 5 is a diagram illustrating a hardware configuration of the DB server. The
CPU101は、OS(Operating System)プログラムやアプリケーションプログラムを実行して、DBサーバ100全体を制御する。
ROM102は、DBサーバ100の起動時に実行されるBIOS(Basic Input / Output System)プログラムなどの所定のプログラムを記憶する。ROM102は、書き換え可能な不揮発性メモリであってもよい。
The
The
RAM103は、CPU101が実行するOSプログラムやアプリケーションプログラムの少なくとも一部を一時的に記憶する。また、RAM103は、CPU101の処理に用いられるデータの少なくとも一部を一時的に記憶する。
The
HDD104は、OSプログラムやアプリケーションプログラムを記憶する。また、HDD104は、CPU101の処理に用いられるデータを記憶する。なお、HDD104に代えて(または、HDD104と併せて)、SSD(Solid State Drive)など他の種類の不揮発性の記憶装置を用いてもよい。
The
グラフィック処理装置105は、モニタ13に接続される。グラフィック処理装置105は、CPU101からの命令に従って、画像をモニタ13に表示させる。
入力インタフェース106は、キーボード14やマウス15などの入力デバイスに接続される。入力インタフェース106は、入力デバイスから送られる入力信号をCPU101に出力する。
The
The
記録媒体読取装置107は、記録媒体16に格納されたデータを読み取る読取装置である。記録媒体16には、例えば、DBサーバ100に実行させるプログラムが記録されている。DBサーバ100は、例えば、記録媒体16に記録された情報処理プログラムを実行することで、後述するような更新ログの圧縮機能を実現することができる。すなわち、情報処理プログラムはコンピュータ読み取り可能な記録媒体16に記録して配布することが可能である。
The recording
記録媒体16としては、例えば、磁気記録装置、光ディスク、光磁気記録媒体、半導体メモリを使用できる。磁気記録装置には、HDD、フレキシブルディスク(FD)、磁気テープなどがある。光ディスクには、CD(Compact Disc)、CD−R(Recordable)/RW(ReWritable)、DVD(Digital Versatile Disc)、DVD−R/RW/RAMなどがある。光磁気記録媒体には、MO(Magneto-Optical disk)などがある。半導体メモリには、USB(Universal Serial Bus)メモリなどのフラッシュメモリがある。 As the recording medium 16, for example, a magnetic recording device, an optical disk, a magneto-optical recording medium, or a semiconductor memory can be used. Examples of the magnetic recording device include an HDD, a flexible disk (FD), and a magnetic tape. Optical disks include CD (Compact Disc), CD-R (Recordable) / RW (ReWritable), DVD (Digital Versatile Disc), DVD-R / RW / RAM, and the like. Magneto-optical recording media include MO (Magneto-Optical disk). Semiconductor memory includes flash memory such as USB (Universal Serial Bus) memory.
通信インタフェース108は、ネットワーク11に接続される。通信インタフェース108は、ネットワーク11を介してDBサーバ100a、APサーバ200、Webサーバ300、手続端末装置400、窓口端末装置500および承認端末装置600とデータ通信を行える。
The
なお、ネットワーク11やネットワーク30等に接続された他のサーバ装置(図示せず)に情報処理プログラムを格納しておいてもよい。その場合、DBサーバ100は、当該サーバ装置から情報処理プログラムをダウンロードして実行することもできる。
Note that the information processing program may be stored in another server device (not shown) connected to the
また、DBサーバ100a、APサーバ200、Webサーバ300、手続端末装置400、窓口端末装置500および承認端末装置600もDBサーバ100と同様のハードウェア構成により実現できる。
Further, the
図6は、DBサーバの機能構成を示す図である。DBサーバ100は、伝票データベース110、トランザクションログ記憶部120、更新ログ記憶部130、最新レコード記憶部140、通信部150、データベース管理部160、解析処理部170、圧縮処理部180および同期処理部190を有する。これらのユニットの機能は、CPU101が情報処理プログラムを実行することによりDBサーバ100上に実現される。ただし、これらのユニットの機能の全部または一部を専用のハードウェアで実現してもよい。
FIG. 6 is a diagram illustrating a functional configuration of the DB server. The
伝票データベース110は、電子伝票を保存し、管理するための記憶領域である。伝票データベース110は、1つの電子伝票を、複数の設定項目を含む1つのレコードとして管理する。
The
トランザクションログ記憶部120は、トランザクションログを記憶する。トランザクションログは、伝票データベース110に対する全てのトランザクションを記録したものである。トランザクションログは、伝票データベース110に対する個別のトランザクションのロールバックやロールフォワードを行うために用いられる。
The transaction
更新ログ記憶部130は、更新ログを記憶する。更新ログは、DBサーバ100aが障害により停止状態にあるときにデータベース管理部160により取得される。更新ログは、DBサーバ100aが障害から復旧した際に、DBサーバ100,100aで同期をとるために用いられる。
The update
最新レコード記憶部140は、最新レコード管理データを記憶する。最新レコード管理データは、伝票データベース110に記録されたレコードに含まれる各設定項目につき、最新の状態を特定するために用いる情報である。
The latest
通信部150は、APサーバ200と通信する。通信部150は、APサーバ200から受信したDBリクエストをデータベース管理部160に出力する。通信部150は、データベース管理部160から取得したDBレスポンスをAPサーバ200に送信する。
The
データベース管理部160は、通信部150から取得したDBリクエストを解析してSQL文を取得(あるいは生成)する。データベース管理部160は、当該SQL文を実行して伝票データベース110を操作する。操作内容は、例えば、更新(UPDATE)、削除(DELETE)および挿入(INSERT)である。
The
解析処理部170は、更新ログ記憶部130に記憶された更新ログを参照して、最新レコード管理データを生成し、最新レコード記憶部140に格納する。
圧縮処理部180は、最新レコード記憶部140に記憶された最新レコード管理データを参照して更新ログの圧縮処理を行う。
The
The
同期処理部190は、DBサーバ100aが障害から復旧した際に、更新ログ記憶部130に記憶された更新ログを参照して、DBサーバ100aが備える伝票データベースを伝票データベース110に同期させる。
When the
なお、DBサーバ100aもDBサーバ100と同様の機能構成である。
図7は、伝票管理テーブルのデータ構造例を示す図である。伝票管理テーブル111は、伝票データベース110に格納され、データベース管理部160によって更新される。伝票管理テーブル111は電子伝票を管理するためのデータである。伝票管理テーブル111には、レコード番号、エントリ店舗番号、伝票通番、伝票状態、取出中フラグおよびメディアファイルを示す項目が設けられている。各項目の横方向に並べられた情報同士が互いに関連付けられて、1つの電子伝票の情報を示す。
The
FIG. 7 is a diagram showing an example of the data structure of the slip management table. The slip management table 111 is stored in the
レコード番号の項目には、レコードを識別するための番号が設定される。エントリ店舗番号の項目には、営業店20を識別するための識別情報が設定される。伝票通番の項目には、電子伝票に付された通し番号が設定される。伝票状態の項目には、振込ワークフロー50上の伝票状態が設定される。取出中フラグの項目には、当該フラグがONまたはOFFの何れであるかを示す情報が設定される。ここで、取出中フラグとは、振込ワークフロー50における何れかの処理により利用を行っているため、他の処理によって更新できない状態(排他状態)であることを示すフラグである。このようなフラグは、排他フラグと呼ばれることもある。メディアファイルの項目には、振込伝票の記入内容を画像化したファイルが設定される(伝票管理テーブル111ではファイル名で示している)。
In the record number field, a number for identifying the record is set. Identification information for identifying the
例えば、伝票管理テーブル111には、レコード番号が“1”、エントリ店舗番号が“E001”、伝票通番が“D0001”、伝票状態が“受付”、取出中フラグが“OFF”、メディアファイルが“D0001.dat”という情報が設定されている。 For example, in the slip management table 111, the record number is “1”, the entry store number is “E001”, the slip serial number is “D0001”, the slip state is “accepted”, the fetching flag is “OFF”, and the media file is “ Information “D0001.dat” is set.
これは、当該電子伝票を示すレコード番号が“1”であること、営業店20で登録された伝票であること、伝票通番が“D0001”であること、伝票状態が振込ワークフロー50における“受付”の状態であることを示す。また、取出中フラグが“OFF”であるので、何れの処理にも用いられていないことを示す。更に、当該電子伝票に対応するメディアファイルが“D0001.dat”として、伝票管理テーブル111に格納されていることを示す。
This is because the record number indicating the electronic voucher is “1”, the voucher registered at the
また、例えば、伝票管理テーブル111には、レコード番号が“2”、エントリ店舗番号が“E001”、伝票通番が“D0002”、伝票状態が“承認待ち”、取出中フラグが“ON”、メディアファイルが“D0002.dat”という情報が設定される。 Further, for example, in the slip management table 111, the record number is “2”, the entry store number is “E001”, the slip serial number is “D0002”, the slip state is “waiting for approval”, the fetching flag is “ON”, the media Information that the file is “D0002.dat” is set.
これは、当該電子伝票を示すレコード番号が“2”であること、営業店20で登録された伝票であること、伝票通番が“D0002”であること、伝票状態が振込ワークフロー50における“承認待ち”の状態であることを示す。また、取出中フラグが“ON”であるので、何れかの処理(ここでは、振込ワークフロー50における(2)または(3)の何れか)に利用されており、当該処理以外の処理には、更新が禁止された状態であることを示す。更に、当該電子伝票に対応するメディアファイルが“D0002.dat”として、伝票管理テーブル111に格納されていることを示す。
This is because the record number indicating the electronic voucher is “2”, the voucher registered at the
ここで、以下の説明では電子伝票を示すそれぞれのレコードを伝票管理レコードと称することとする。
図8は、更新ログファイルのデータ構造例を示す図である。更新ログファイル131は、データベース管理部160により生成され、更新ログ記憶部130に格納される。更新ログファイル131には、複数の更新データが記述される。更新ログファイル131では、更新データに対応付けて、当該更新データを識別するための項番を便宜的に表記している。項番は、時系列に昇順に付されており、番号が小さい程古く、番号が大きいほど新しい。なお、各更新データにつき、テーブル名は“伝票管理”の表記によって伝票管理テーブル111を指定しているとする。
Here, in the following description, each record indicating an electronic slip is referred to as a slip management record.
FIG. 8 is a diagram illustrating an example of the data structure of the update log file. The
更新データには、データベース管理部160による伝票データベース110の更新内容が記述される。更新ログファイル131では、1つの電子伝票に関する新たなレコードの挿入(INSERT)から始まって、振込ワークフロー50の(1)〜(6)(以下、単に“(1)の処理”等と表記する)に示した一連の処理に対応する更新データを例示している。
In the update data, update contents of the
具体的には、新たな伝票の登録(レコードの挿入)は項番1の更新データに対応する。(1)の処理は項番2〜4の更新データに対応する。(2)の処理は項番5〜7の更新データに対応する。(3)の処理は項番8〜10の更新データに対応する。(4)の処理は項番11〜13の更新データに対応する。(5)の処理は項番14〜16の更新データに対応する。(6)の処理は項番17〜19の更新データに対応する。
Specifically, registration of a new slip (insertion of a record) corresponds to the update data of
ここで、(1)の処理に対応する項番2〜4の更新データが示す内容について説明する。更新対象のレコードのレコード番号は“1”とする。(1)の処理では、まず、項番2の更新データによって、取出中フラグが“ON”に設定される。これによって、当該レコードが排他状態となる。次に、項番3の更新データによって、伝票状態が“受付”に設定される。更に、項番4の更新データによって、取出中フラグが“OFF”に設定される。これによって、当該レコードの排他状態が解除される。
Here, the contents indicated by the update data of
(2)〜(6)の処理に関しても(1)の処理と同様にして、伝票状態が更新される。すなわち、まず、当該レコードを排他状態にし、伝票状態を更新して、排他状態を解除する。 Regarding the processes (2) to (6), the slip state is updated in the same manner as the process (1). That is, first, the record is put into an exclusive state, the slip state is updated, and the exclusive state is released.
また、更新ログファイル131において、項番1の更新データは更新種別が“INSERT”(新規追加)であるから更新ログファイル131の取得を開始した時点におけるレコード番号“1”の伝票管理レコードの状態を示している。すなわち、当該項番1の更新データは当該レコードに含まれる各データ項目の初期設定である。
Further, in the
一方、項番1の更新データの更新種別が“UPDATE”である場合もある。その場合、項番1の更新データは“UPDATE”対象のデータ項目の初期設定を示すことになる。そして、他のデータ項目の初期設定は、当該他のデータ項目が最初に更新対象となったときに取得され記憶される。よって、この場合、初期設定を示す更新データは複数存在することになる。
On the other hand, the update type of the update data of
図9は、最新レコードテーブルのデータ構造例を示す第1の図である。最新レコードテーブル141は、解析処理部170によって生成され、最新レコード記憶部140に格納される。最新レコードテーブル141a,141bは、解析処理部170による最新レコードテーブル141の更新の変遷を示すものである。最新レコードテーブルには、テーブル名、レコード番号、削除フラグおよび更新内容の項目が設けられている。各項目の横方向に並べられた情報同士が互いに関連付けられて、1つのレコードの最新の状態を示す。
FIG. 9 is a first diagram illustrating a data structure example of the latest record table. The latest record table 141 is generated by the
テーブル名の項目には、テーブルの名称が設定される。レコード番号の項目には、テーブル内のレコードを識別するための番号が設定される。削除フラグの項目には、当該レコードが削除(DELETE)されたものか否かを示す削除フラグが設定される。削除フラグは、当該レコードが削除されたものであれば“ON”、それ以外では“OFF”が設定される。更新内容の項目には、データの項目名と当該データ項目の更新値が設定される。更新内容の項目は、データ項目名ごとに設けられる。このため、複数のデータ項目の更新値を管理する場合には、更新内容の項目も複数設けられる。最新レコードテーブル141a,141bでは、更新内容(A),(B)の項目を設けて、複数の更新内容を区別する。 In the table name item, the name of the table is set. In the record number field, a number for identifying a record in the table is set. In the item of the deletion flag, a deletion flag indicating whether or not the record has been deleted (DELETE) is set. The deletion flag is set to “ON” if the record has been deleted, and “OFF” otherwise. In the item of update contents, the data item name and the update value of the data item are set. An update content item is provided for each data item name. For this reason, when managing update values of a plurality of data items, a plurality of items of update contents are also provided. In the latest record tables 141a and 141b, items of update contents (A) and (B) are provided to distinguish a plurality of update contents.
以下、最新レコードテーブル141の更新の変遷について具体的に説明する。
最新レコードテーブル141は、更新ログファイル131の項番2の更新データに対応する。すなわち、最新レコードテーブル141は、伝票管理テーブル111のレコード番号“1”のレコードにつき、項目名“取出中フラグ”を更新値“ON”に設定した旨を記録したものである。
Hereinafter, the transition of the update of the latest record table 141 will be specifically described.
The latest record table 141 corresponds to the update data of
最新レコードテーブル141aは、更新ログファイル131の項番3の更新データに対応する。すなわち、最新レコードテーブル141aは、伝票管理テーブル111のレコード番号“1”のレコードにつき、項目名“伝票状態”を更新値“受付”に設定した旨を記録したものである。
The latest record table 141 a corresponds to the update data of
最新レコードテーブル141bは、更新ログファイル131の項番4の更新データに対応する。すなわち、最新レコードテーブル141bは、伝票管理テーブル111のレコード番号“1”のレコードにつき、項目名“取出中フラグ”を更新値“OFF”に設定した旨を記録したものである。
The latest record table 141 b corresponds to the update data of
以下、更新ログファイル131の項番5〜19についても、同様にして最新レコードテーブル141bを更新していく。
図10は、最新レコードテーブルのデータ構造例を示す第2の図である。最新レコードテーブル141nは、更新ログファイル131の項番19の更新データに対応する。すなわち、最新レコードテーブル141nは、伝票管理テーブル111のレコード番号“1”のレコードの最新の状態を特定したものである。
Thereafter, the latest record table 141b is updated in the same manner for the
FIG. 10 is a second diagram illustrating a data structure example of the latest record table. The latest record table 141 n corresponds to the update data of item number 19 in the
次に、以上の構成のDBサーバ100の処理手順を説明する。以下に示す処理は、例えば縮退運用時に定期的に実行される。
図11は、更新ログ圧縮処理を示すフローチャートである。以下、図11に示す処理をステップ番号に沿って説明する。
Next, a processing procedure of the
FIG. 11 is a flowchart showing the update log compression processing. In the following, the process illustrated in FIG. 11 will be described in order of step number.
[ステップS1]解析処理部170は、更新ログ記憶部130に更新ログファイル131が有るか否かを判定する。更新ログファイル131が有る場合、処理をステップS2に進める。更新ログファイル131が無い場合、処理を終了する。
[Step S <b> 1] The
[ステップS2]解析処理部170は、更新ログファイル131から未処理の更新データのうち最も古い更新データを1つ取得する。
[ステップS3]解析処理部170は、更新データに記述された更新種別を判定する。“UPDATE”の場合、処理をステップS4に進める。“DELETE”の場合、処理をステップS5に進める。“INSERT”の場合、処理をステップS6に進める。
[Step S2] The
[Step S3] The
[ステップS4]解析処理部170は、最新レコード記憶部140に記憶された最新レコードテーブル141に更新内容を上書き記録する。
[ステップS5]解析処理部170は、最新レコード記憶部140に記憶された最新レコードテーブル141の削除フラグの項目を“ON”に設定する。
[Step S4] The
[Step S5] The
[ステップS6]解析処理部170は、更新ログファイル131に含まれる全ての更新データを処理済みであるか否かを判定する。全ての更新データを処理済みである場合、処理をステップS7に進める。なお、処理をステップS7に進める時点で最新レコード記憶部140には最新レコードテーブル141nが格納されているとする。未処理の更新データが有る場合、処理をステップS2に進める。
[Step S6] The
[ステップS7]圧縮処理部180は、最新レコードテーブル141nを参照して、レコードごとに単一の更新データを生成する。単一の更新データとは、当該レコードに対して1つの処理コマンド(“UPDATE”や“DELETE”)で、各データ項目の更新を行う更新データである。このとき、圧縮処理部180は最新レコードテーブル141nの更新値が初期設定と異なるデータ項目のみを、更新データに含める。レコードの更新を行う場合(削除フラグが“OFF”の場合)、更新種別“UPDATE”の更新データを生成する。レコードの削除を行う場合(削除フラグが“ON”の場合)、更新種別“DELETE”の更新データを生成する。圧縮処理部180は、生成した更新データを更新ログファイル131に記述する。
[Step S7] The
[ステップS8]圧縮処理部180は、更新ログ記憶部130に記憶されたステップS7で生成した更新データ以外の更新データ(初期設定の更新データを除く)を削除する。
このようにして、解析処理部170および圧縮処理部180は更新ログファイル131のデータ量を低減する。
[Step S8] The
In this way, the
図12は、圧縮処理後の更新ログファイルを例示する第1の図である。更新ログファイル131aは、更新ログファイル131および最新レコードテーブル141nに基づいて、圧縮処理部180により生成されたものであり、図11のステップS8の圧縮処理部180による処理後の更新ログである。更新ログファイル131と比較すると、項番20の更新データが追加されて、項番2〜19のデータが削除されていることが分かる。
FIG. 12 is a first diagram illustrating an update log file after compression processing. The
特に、項番20の更新データでは、対象の伝票管理レコードにつき伝票状態を“完了”に更新する処理が記述されている。これは、最新レコードテーブル141nの更新内容(B)に対応する。一方、項番20の更新データでは、最新レコードテーブル141nの更新内容(A)に対応する処理は記述されていない。これは、項番1の更新データに示される取出中フラグ“OFF”と、最新レコードテーブル141nの更新内容(A)で特定された取出中フラグの最新の設定“OFF”と、が同一だからである。すなわち、更新の必要がないため、当該データ項目に関する処理の記述を省ける。
In particular, the update data of
次に、最新レコードテーブル141nの他の例と、それに応じて圧縮処理部180により生成される更新ログファイル131aの他の例とを具体的に説明する。
図13は、圧縮処理後の更新ログファイルを例示する第2の図である。まず、最新レコードテーブル141xは、最新レコードテーブル141nの他の例を示す。具体的には、更新内容(C)の項目が追加されている。当該更新内容(C)の項目には、項目名“伝票通番”および更新値“D1001”が設定されている。これは、レコード番号“1”に対して、伝票通番が“D1001”に変更されていることを示す。更新内容(C)は、圧縮前の更新ログファイルから、更新内容(B)とは別個の更新データにより特定されたものである。
Next, another example of the latest record table 141n and another example of the
FIG. 13 is a second diagram illustrating an update log file after compression processing. First, the latest record table 141x shows another example of the latest record table 141n. Specifically, an item of update content (C) is added. In the item of the update content (C), the item name “slip serial number” and the update value “D1001” are set. This indicates that the slip serial number is changed to “D1001” for the record number “1”. The update content (C) is specified by update data separate from the update content (B) from the update log file before compression.
圧縮処理部180は、圧縮処理前の更新ログファイルと最新レコードテーブル141xとに基づいて更新ログファイル131bを生成する。ここで、圧縮処理前の更新ログファイルでは、初期設定(項番1)の更新データの更新種別が“INSERT”、取出中フラグが“OFF”、伝票状態が“完了”以外、伝票通番が“D1001”以外であったとする。この場合、更新種別が“UPDATE”なので、上述したように項番1の更新データも削除できる。
The
更新ログファイル131bには、項番1の更新データに加えて、項番31の更新データが記述されている。当該項番31の更新データでは、対象の伝票管理レコードにつき伝票状態を“完了”に、伝票通番を“D1001”に更新する処理が記述されている。これは、最新レコードテーブル141xの更新内容(B)、(C)に対応する。また、項番31の更新データでは最新レコードテーブル141xの更新内容(A)に対応する処理は記述されていない。これは、初期設定の取出中フラグ“OFF”と、最新レコードテーブル141xの更新内容(A)で特定された取出中フラグの最新の設定“OFF”と、が同一だからである。
In the
このように、圧縮処理部180は圧縮処理前には複数の更新データで記述されていた複数の更新内容を単一の更新データにまとめて、更新ログファイルに記述する。そして、当該伝票管理レコードの更新内容を記述していた複数の更新データを圧縮前の更新ログファイルから削除する。その結果、更新ログファイル131bが生成される。
As described above, the
これにより、更新ログファイルのデータ量を効率的に低減できる。特に、複数の更新内容を単一の更新データにまとめる。このため、当該更新ログファイル131bを用いて同期処理を行えば、圧縮前の更新ログファイルを用いて同期を行う場合に比べて、更新処理の回数を低減できる。よって、同期処理を高速に行える。
Thereby, the data amount of an update log file can be reduced efficiently. In particular, a plurality of update contents are combined into a single update data. Therefore, if the synchronization process is performed using the
このとき、初期設定と最新の設定とで相違がないデータ項目に関しては、更新データに更新処理を記述しない。よって、更新ログファイルのデータ量を一層低減できる。また、同期処理において当該データ項目に対する更新処理を行わずに済む。よって、同期処理を一層高速に行える。 At this time, the update process is not described in the update data for data items that are not different between the initial setting and the latest setting. Therefore, the data amount of the update log file can be further reduced. Further, it is not necessary to perform update processing for the data item in the synchronization processing. Therefore, the synchronization process can be performed at a higher speed.
このような制御は、更新ログファイル中に、取出中フラグなどの排他フラグのように、データ処理に用いる時だけ更新し、データ処理が完了すると元の設定に戻すようなデータ項目が含まれる場合に特に有効である。なぜなら、このような排他フラグは、一連のデータ処理において頻繁に更新されるにも関わらず、最終的には当初の設定値に戻される。したがって、これら全ての更新処理を同期処理の際に再現すると、処理に無駄が生じ易いためである。 Such control includes a data item in the update log file that is updated only when used for data processing, such as an exclusion flag such as a fetching flag, and returns to the original setting when the data processing is completed. Is particularly effective. This is because such an exclusive flag is finally returned to the original set value, although it is frequently updated in a series of data processing. Therefore, if all these update processes are reproduced during the synchronization process, the process is likely to be wasted.
図14は、圧縮処理後の更新ログファイルを例示する第3の図である。まず、最新レコードテーブル141yは、最新レコードテーブル141nの他の例を示す。具体的には、レコード番号“2”の伝票管理レコードに対して削除フラグが“ON”に設定されている。これは、レコード番号“2”に対して、“DELETE”の処理が行われたことを示す。なお、圧縮処理前の更新ログファイルには、レコード番号“2”の伝票管理レコードにつき、“UPDATE”の処理が複数記述されていたものとする。初期設定も“UPDATE”の更新種別を含む複数の更新データにより取得されていたものとする。 FIG. 14 is a third diagram illustrating the update log file after the compression processing. First, the latest record table 141y shows another example of the latest record table 141n. Specifically, the deletion flag is set to “ON” for the slip management record with the record number “2”. This indicates that “DELETE” processing has been performed on the record number “2”. It is assumed that a plurality of “UPDATE” processes are described for the slip management record with the record number “2” in the update log file before the compression process. It is assumed that the initial setting is also acquired by a plurality of update data including the update type “UPDATE”.
圧縮処理部180は、圧縮処理前の更新ログファイルと最新レコードテーブル141yとに基づいて、更新ログファイル131cを生成する。更新ログファイル131cには、項番41の更新データが記述されている。当該項番41の更新データでは、対象の伝票管理レコードを削除する処理が記述されている。
The
このように、圧縮処理部180は圧縮処理前には複数の更新データで複数の更新内容が記述されていたとしても、削除処理が行われた場合には当該削除処理を記述した更新データのみを生成し、他の更新データを削除する。削除処理を記述した更新データ以外の他の更新データを削除できるのは、削除された伝票管理レコードに対しては、その後新たな処理に用いられることは無いと考えられるからである。
In this way, even if a plurality of update contents are described with a plurality of update data before the compression processing, the
これにより、更新ログファイルのデータ量を一層効率的に低減できる。具体的には、削除処理以外の処理を示す更新データを削除するので、当該削除した更新データ分のデータ量を低減できる。また、更新ログファイル131cを用いれば、同期処理において、当該伝票管理レコードに対する削除処理以外の処理を行わずに済む。よって、同期処理を一層高速に行える。
Thereby, the data amount of an update log file can be reduced more efficiently. Specifically, since update data indicating processing other than the deletion processing is deleted, the amount of data corresponding to the deleted update data can be reduced. Further, if the
特に、レコードの削除処理用の更新データを生成する際には、更新ログファイル131cに示したように、更新種別“UPDATE”で記述された更新データを初期設定も含めて削除してもよい(更新種別“DELETE”で記述された更新データが残る)。削除されるレコードにつき同期時に更新処理を再現するのは無駄だからである。
In particular, when generating update data for record deletion processing, as shown in the
また、以上に示した圧縮処理を定期的に行えば、更新ログファイルの増加量を緩和できる。よって、更新ログファイルの最大データ量が所定量に制限されていたとしても、当該ファイルのデータ量が所定量に達するまでに時間的な余裕が得られる。その結果、縮退運転の稼働時間や保守用の時間等を確保し易くなる。 Further, if the above-described compression processing is periodically performed, the increase amount of the update log file can be reduced. Therefore, even if the maximum data amount of the update log file is limited to a predetermined amount, a time margin is obtained until the data amount of the file reaches the predetermined amount. As a result, it becomes easy to secure the operating time of the degenerate operation, the maintenance time, and the like.
以上、本発明の情報処理プログラム、情報処理装置および情報処理方法を図示の実施の形態に基づいて説明したが、これらに限定されるものではなく、各部の構成は同様の機能を有する任意の構成のものに置換することができる。また、他の任意の構成物や工程が付加されてもよい。更に、前述した実施の形態のうちの任意の2以上の構成(特徴)を組み合わせたものであってもよい。 The information processing program, information processing apparatus, and information processing method of the present invention have been described based on the illustrated embodiments. However, the present invention is not limited to these, and the configuration of each unit is an arbitrary configuration having the same function. Can be substituted. Moreover, other arbitrary structures and processes may be added. Further, any two or more configurations (features) of the above-described embodiments may be combined.
1 情報処理装置
1a 記憶手段
1b 特定手段
1c 処理手段
2 レコード
2a,2b,2c データ項目
3 第1の更新データ群
3a,3b,3c,3d,3e,3f,3g 第1の更新データ
4 第2の更新データ
DESCRIPTION OF
Claims (5)
複数のデータ項目を含むレコードの初期設定と、前記複数のデータ項目に対する前記初期設定からの更新内容を示す複数の第1の更新データとを記憶する記憶手段、
前記記憶手段を参照して、前記複数のデータ項目それぞれのうち、最新の更新データによる設定が前記初期設定と同一でないデータ項目につき前記最新の更新データを特定する特定手段、
前記特定手段により特定された全てのデータ項目の前記最新の更新データを用いて、前記複数のデータ項目に対する1つの第2の更新データを生成して前記記憶手段に格納し、前記記憶手段から前記複数の第1の更新データを削除する処理手段、
として機能させることを特徴とする情報処理プログラム。 Computer
Storage means for storing an initial setting of a record including a plurality of data items, and a plurality of first update data indicating update contents from the initial setting for the plurality of data items;
Referring to the storage means, a specifying means for specifying the latest update data for each of the plurality of data items for a data item whose setting by the latest update data is not the same as the initial setting;
Using the latest update data of all the data items specified by the specifying means, one second update data for the plurality of data items is generated and stored in the storage means, and the storage means Processing means for deleting a plurality of first update data;
An information processing program that functions as a computer program.
ことを特徴とする請求項1記載の情報処理プログラム。 The processing means includes a description of a process for deleting the record when deletion of the record is specified as the latest update data for any of the plurality of data items by the specifying means. Generate update data,
The information processing program according to claim 1.
前記記憶手段に記憶された前記第2の更新データを用いて前記レコードの設定と他のコンピュータが記憶するレコードの設定とを同期させる同期処理手段、
として機能させることを特徴とする請求項1または2の何れか一項に記載の情報処理プログラム。 The computer,
Synchronization processing means for synchronizing the setting of the record with the setting of the record stored in another computer using the second update data stored in the storage means;
The information processing program according to claim 1, wherein the information processing program is made to function as:
前記記憶手段を参照して、前記複数のデータ項目それぞれのうち、最新の更新データによる設定が前記初期設定と同一でないデータ項目につき前記最新の更新データを特定する特定手段と、
前記特定手段により特定された全てのデータ項目の前記最新の更新データを用いて、前記複数のデータ項目に対する1つの第2の更新データを生成して前記記憶手段に格納し、前記記憶手段から前記複数の第1の更新データを削除する処理手段と、
を有することを特徴とする情報処理装置。 Storage means for storing an initial setting of a record including a plurality of data items, and a plurality of first update data indicating update contents from the initial setting for the plurality of data items;
With reference to the storage means, among each of the plurality of data items, a specifying means for specifying the latest update data for a data item whose setting by the latest update data is not the same as the initial setting;
Using the latest update data of all the data items specified by the specifying means, one second update data for the plurality of data items is generated and stored in the storage means, and the storage means Processing means for deleting a plurality of first update data;
An information processing apparatus comprising:
複数のデータ項目を含むレコードの初期設定と、前記複数のデータ項目に対する前記初期設定からの更新内容を示す複数の第1の更新データとを記憶する記憶手段を参照して、前記複数のデータ項目それぞれのうち、最新の更新データによる設定が前記初期設定と同一でないデータ項目につき前記最新の更新データを特定し、
特定した全てのデータ項目の前記最新の更新データを用いて、前記複数のデータ項目に対する1つの第2の更新データを生成して前記記憶手段に格納し、前記記憶手段から前記複数の第1の更新データを削除する、
ことを特徴とする情報処理方法。 A computer information processing method,
With reference to storage means for storing an initial setting of a record including a plurality of data items and a plurality of first update data indicating update contents from the initial setting for the plurality of data items, the plurality of data items Of each, the latest update data is specified for the data item whose setting by the latest update data is not the same as the initial setting,
Using the latest update data of all the specified data items, one second update data for the plurality of data items is generated and stored in the storage unit, and the plurality of first items are stored in the storage unit. Delete update data,
An information processing method characterized by the above.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2011015894A JP2012155634A (en) | 2011-01-28 | 2011-01-28 | Information processing program, information processing device and information processing method |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2011015894A JP2012155634A (en) | 2011-01-28 | 2011-01-28 | Information processing program, information processing device and information processing method |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2012155634A true JP2012155634A (en) | 2012-08-16 |
Family
ID=46837274
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2011015894A Pending JP2012155634A (en) | 2011-01-28 | 2011-01-28 | Information processing program, information processing device and information processing method |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP2012155634A (en) |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2015064850A (en) * | 2013-09-26 | 2015-04-09 | 日本電気株式会社 | Database monitoring device, database monitoring method, and computer program |
| JP2017156950A (en) * | 2016-03-01 | 2017-09-07 | 日本電気株式会社 | Information processing device, information processing method and information processing program |
| JP2018128881A (en) * | 2017-02-09 | 2018-08-16 | 富士通株式会社 | Difference log application program, difference log application device, and difference log application method |
| JP2018181042A (en) * | 2017-04-17 | 2018-11-15 | 富士通株式会社 | Record reflecting program, record reflecting device and record reflecting method |
| JP7428894B2 (en) | 2020-04-20 | 2024-02-07 | 富士通株式会社 | Information processing device, information processing system, and information processing program |
-
2011
- 2011-01-28 JP JP2011015894A patent/JP2012155634A/en active Pending
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2015064850A (en) * | 2013-09-26 | 2015-04-09 | 日本電気株式会社 | Database monitoring device, database monitoring method, and computer program |
| JP2017156950A (en) * | 2016-03-01 | 2017-09-07 | 日本電気株式会社 | Information processing device, information processing method and information processing program |
| JP2018128881A (en) * | 2017-02-09 | 2018-08-16 | 富士通株式会社 | Difference log application program, difference log application device, and difference log application method |
| JP2018181042A (en) * | 2017-04-17 | 2018-11-15 | 富士通株式会社 | Record reflecting program, record reflecting device and record reflecting method |
| JP7428894B2 (en) | 2020-04-20 | 2024-02-07 | 富士通株式会社 | Information processing device, information processing system, and information processing program |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CA3121919C (en) | System and method for augmenting database applications with blockchain technology | |
| JP5124989B2 (en) | Storage system and data protection method and program | |
| US7103619B1 (en) | System and method for automatic audit data archiving within a remote database backup system | |
| US8799232B2 (en) | Method for generating copy of database | |
| CN102272751B (en) | Data integrity in a database environment through background synchronization | |
| JP4166056B2 (en) | Database operation history management device, database operation history management method, and database operation history management program | |
| US20150263909A1 (en) | System and method for monitoring a large number of information processing devices in a communication network | |
| JP2005301497A (en) | Storage management system, restoration method and its program | |
| KR20120140652A (en) | Buffer disk in flashcopy cascade | |
| KR101693683B1 (en) | Virtual database rewind | |
| JP2010527087A (en) | Data replication method and system in database management system (DBMS) | |
| US8762347B1 (en) | Method and apparatus for processing transactional file system operations to enable point in time consistent file data recreation | |
| US20120278429A1 (en) | Cluster system, synchronization controlling method, server, and synchronization controlling program | |
| JP6133396B2 (en) | Computer system, server, and data management method | |
| JP2012155634A (en) | Information processing program, information processing device and information processing method | |
| US20130138612A1 (en) | Provisioning and/or synchronizing using common metadata | |
| US9461884B2 (en) | Information management device and computer-readable medium recorded therein information management program | |
| US11893041B2 (en) | Data synchronization between a source database system and target database system | |
| US11144574B2 (en) | System and method for managing database | |
| CN102597995A (en) | Synchronizing database and non-database resources | |
| JP5577471B2 (en) | Server computer, server computer system, and server computer control method | |
| JP2005316624A (en) | Database reorganization program, database reorganization method, and database reorganization device | |
| US8074100B2 (en) | Method and apparatus for restore management | |
| US20230195582A1 (en) | Rolling back a database transaction | |
| US11188522B2 (en) | Streamlined database commit for synchronized nodes |