JP2010521728A - データ圧縮のための回路及びこれを用いるプロセッサ - Google Patents
データ圧縮のための回路及びこれを用いるプロセッサ Download PDFInfo
- Publication number
- JP2010521728A JP2010521728A JP2009553163A JP2009553163A JP2010521728A JP 2010521728 A JP2010521728 A JP 2010521728A JP 2009553163 A JP2009553163 A JP 2009553163A JP 2009553163 A JP2009553163 A JP 2009553163A JP 2010521728 A JP2010521728 A JP 2010521728A
- Authority
- JP
- Japan
- Prior art keywords
- circuit
- data
- map
- value
- zero
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
- 238000013144 data compression Methods 0.000 title description 2
- 241001442055 Vipera berus Species 0.000 claims description 69
- 238000000034 method Methods 0.000 claims description 67
- 238000007906 compression Methods 0.000 claims description 65
- 230000006835 compression Effects 0.000 claims description 62
- 239000011159 matrix material Substances 0.000 claims description 59
- 230000006837 decompression Effects 0.000 claims description 28
- 238000005516 engineering process Methods 0.000 abstract description 2
- 238000010586 diagram Methods 0.000 description 6
- 238000004458 analytical method Methods 0.000 description 3
- 230000000694 effects Effects 0.000 description 3
- 102100033458 26S proteasome non-ATPase regulatory subunit 4 Human genes 0.000 description 2
- 102100031655 Cytochrome b5 Human genes 0.000 description 2
- 101000922386 Homo sapiens Cytochrome b5 Proteins 0.000 description 2
- -1 MCB3 Proteins 0.000 description 2
- 101150001079 PSMD4 gene Proteins 0.000 description 2
- 101150006293 Rpn10 gene Proteins 0.000 description 2
- 230000006399 behavior Effects 0.000 description 2
- 230000000295 complement effect Effects 0.000 description 2
- 230000000153 supplemental effect Effects 0.000 description 2
- 101150106653 Ren1 gene Proteins 0.000 description 1
- 101100116846 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) DID4 gene Proteins 0.000 description 1
- 238000004364 calculation method Methods 0.000 description 1
- 238000006243 chemical reaction Methods 0.000 description 1
- 238000000547 structure data Methods 0.000 description 1
Images







Classifications
-
- H—ELECTRICITY
- H03—ELECTRONIC CIRCUITRY
- H03M—CODING; DECODING; CODE CONVERSION IN GENERAL
- H03M7/00—Conversion of a code where information is represented by a given sequence or number of digits to a code where the same, similar or subset of information is represented by a different sequence or number of digits
- H03M7/30—Compression; Expansion; Suppression of unnecessary data, e.g. redundancy reduction
-
- H—ELECTRICITY
- H03—ELECTRONIC CIRCUITRY
- H03M—CODING; DECODING; CODE CONVERSION IN GENERAL
- H03M7/00—Conversion of a code where information is represented by a given sequence or number of digits to a code where the same, similar or subset of information is represented by a different sequence or number of digits
- H03M7/30—Compression; Expansion; Suppression of unnecessary data, e.g. redundancy reduction
- H03M7/3066—Compression; Expansion; Suppression of unnecessary data, e.g. redundancy reduction by means of a mask or a bit-map
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/3004—Arrangements for executing specific machine instructions to perform operations on memory
- G06F9/30043—LOAD or STORE instructions; Clear instruction
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/38—Concurrent instruction execution, e.g. pipeline or look ahead
- G06F9/3824—Operand accessing
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Software Systems (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Compression, Expansion, Code Conversion, And Decoders (AREA)
Abstract
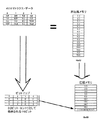
【解決手段】これは、メモリ技術又はプロセッサへの接続様式に関わらず、コンピュータ・システムの設計における基本的制約であり、所与の時間に転送可能なプロセッサとメモリとの間データについては、大きな制約、すなわち利用可能なメモリ帯域があり、利用可能なメモリ帯域によるコンピュータ計算力の制限は、しばしばメモリの壁と呼ばれている。本提供の解決においては、圧縮されるデータ構造体マップを生成し、該マップは該構造体における些少ではないデータ値の位置を表し(例えば、ゼロでない値)、圧縮構造体を提供するために該構造体から些少なデータ値を削除する。
【選択図】図1
Description

Claims (88)
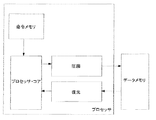
- 圧縮回路であって、
a)個々のデータ値の構造体を格納するためのデータメモリと、
b)マップを格納するためのマップ・メモリであって、前記マップは前記構造体内においてゼロでない値の位置を表すマップ・メモリと、
c)データ出力であって、前記回路は、前記データメモリからゼロでないデータを取り出し、前記取り出されたデータを前記データ出力において前記マップを表すデータを組み合わせた圧縮構造体として提供するよう構成されるデータ出力と、を含む圧縮回路。 - 前記データメモリは複数のレジスタを含む、請求項1に記載の回路。
- 前記データメモリはレジスタ・ファイルを含む、請求項1に記載の回路。
- 前記マップ・メモリはレジスタを含む、請求項1に記載の回路。
- 前記位置はビットマップとして格納される、請求項4に記載の回路。
- 前記ビットマップにおける各ビットは、前記格納された構造体における個々のデータの値に対応する、請求項5に記載の回路。
- 複数のコンパレータを更に含み、各コンパレータはデータ値がゼロでないかどうかを識別し、各コンパレータの出力は前記マップ・メモリへの入力として提供される、請求項1に記載の回路。
- 前記コンパレータ入力は、前記データメモリの読み込みポートによって設けられる、請求項7に記載の回路。
- 前記コンパレータは、前記データメモリの書き込みポートによって設けられる、請求項7に記載の回路。
- 前記コンパレータ入力は、プロセッサのロード/ストアポートによって設けられる、請求項7に記載の回路。
- 前記データ出力はデータバスを含み、前記回路は、前記メモリから前記データバスに前記圧縮した構造体を連続して出力するよう構成される、請求項2に記載の回路。
- 前記マップからゼロでない値の前記数を計算するために、少なくとも一つの加算器を更に含む、請求項2に記載の回路。
- 前記メモリから前記データ出力にゼロでない出力の前記書き込みを連続して可能にするためのロジックを更に含む、請求項2に記載の回路。
- 前記ロジックは加算器の構成を含む、請求項13に記載の回路。
- 前記構成におけるそれぞれの後続の加算器は、前記構成において先行する加算器の前記出力を、入力として有する、請求項14に記載の回路。
- 各加算器は前記構造体において付随するデータ値に対応し、各加算器は前記付随するデータ値に対応する前記マップから入力を受け付ける、請求項2に記載の回路。
- 更に整数コンパレータのツリーを含み、各整数コンパレータは二つの整数入力を比較するためのものであり、各コンパレータの第1の入力は前記加算器ツリーにおいて対応する加算器からの出力である、請求項14に記載の回路。
- 各コンパレータへの第2の入力は、配列信号である、請求項17に記載の回路。
- 前記データ出力に些少ではないデータを書き込む前記正しいシーケンスを確認するために、前記マップからの前記値を個々のコンパレータ出力と結合するためのコンバイナを更に含む、請求項17に記載の回路。
- 前記回路の前記動作を制御するためのコントローラを更に含む、請求項1に記載の回路。
- 前記データ値は、単精度浮動小数点数である、請求項1に記載の回路。
- 前記データ値は、倍精度浮動小数点数である、請求項1に記載の回路。
- 前記データ値は、拡張精度浮動小数点数である、請求項1に記載の回路。
- 前記データ値は、128ビット精度浮動小数点数である、請求項1に記載の回路。
- 前記データ値は、整数である、請求項1に記載の回路。
- 前記回路は、出力として前記マップの内容も提供するよう適合される、請求項1に記載の回路。
- 前記回路は、集積回路に設けられる、請求項1に記載の回路。
- 請求項1から請求項27のいずれか一つに記載の少なくとも一つの回路を含むプロセッサ。
- 前記回路の複数の実例が存在する、請求項28に記載のプロセッサ。
- 圧縮構造体から復元される構造体を提供するための復元回路であって、
a)個々の些少ではないデータ値の圧縮構造体を受け付けるための入力と、
b)復元構造体内において些少ではないデータ値の位置を識別するマップを受信するためのマップ・レジスタと、
c)復元構造体を格納するためのメモリであって、前記回路は前記マップ・レジスタの内容にしたがって個々の入力された些少ではないデータ値を前記メモリに投入するメモリと、を含む回路。 - 前記メモリは、複数のレジスタを含む、請求項30に記載の回路。
- 前記メモリは、レジスタ・ファイルを含む、請求項30に記載の回路。
- 前記位置は、ビットマップとして格納される、請求項30に記載の回路。
- 前記ビットマップにおける各ビットは、復元構造体の個々のデータ値に対応する、請求項33に記載の回路。
- 前記データ入力はデータバスを含み、前記回路は前記データバスから前記メモリに連続して前記圧縮構造体を入力するよう構成される、請求項30に記載の回路。
- 前記マップから些少ではない値の数を計算するための少なくとも一つの加算器を更に含む、請求項30に記載の回路。
- 前記データ入力からメモリに些少ではないデータの前記書き込みを可能にするためのロジックを更に含む、請求項30に記載の回路。
- 前記ロジックは、加算器の構成を含む、請求項37に記載の回路。
- 前記構成のそれぞれの後続する加算器は、前記構成の前記先行する加算器の前記出力を入力として有する、請求項38に記載の回路。
- 各加算器は、非圧縮の前記構造体における関連データ値に対応し、各加算器は前記関連データ値に対応する前記マップからの入力を受け付ける、請求項39に記載の回路。
- 整数コンパレータの構成を更に含み、各整数コンパレータは二つの整数を比較するためのものであり、各コンパレータの第1の入力は前記加算器構成において対応する加算器からの出力である、請求項40に記載の回路。
- 各コンパレータへの第2の入力は、配列信号である、請求項41に記載の回路。
- 前記データ出力へのゼロでないデータの書き込みの前記正しいシーケンスを確認するために、前記マップからの前記値を個々のコンパレータ出力と結合するためのコンバイナを更に含む、請求項41に記載の回路。
- 前記回路の動作を制御するためのコントローラを更に含む、請求項41に記載の回路。
- 前記データ値は、単精度浮動小数点数である、請求項30に記載の回路。
- 前記データ値は、倍精度浮動小数点数である、請求項30に記載の回路。
- 前記データ値は、整数である、請求項30に記載の回路。
- 更にマップ入力を含み、前記回路は、前記マップ入力から前記マップ・レジスタへマップをロードする用適合される、請求項30に記載の回路。
- 前記回路は、集積回路に設けられる、請求項30に記載の回路。
- 些少なデータ値はゼロのデータ値であり、些少ではないデータ値はゼロでないデータ値である、請求項30から請求項49のいずれかに記載の回路。
- 請求項30から請求項50のいずれかに記載の少なくとも一つの回路を含むプロセッサ。
- 前記回路の複数の実例が存在する、請求項51に記載のプロセッサ。
- データ構造体を格納する命令に応答する圧縮回路を含むプロセッサ・チップであって、前記圧縮回路は、格納に対して圧縮フォーマットを提供するために前記構造体から些少な値を除去するよう適合される、プロセッサ・チップ。
- 前記圧縮回路は、前記構造体において些少な値の位置を識別するマップを提供するよう適合される、請求項53に記載のプロセッサ・チップ。
- 前記圧縮フォーマット・データをロードする命令に応答する復元回路を更に含み、前記復元回路は、前記圧縮データにロード時に些少な値を再投入するよう適合される、請求項53に記載のプロセッサ。
- 前記復元回路は、些少な値を再投入するためにマップを使用する、請求項55に記載のプロセッサ。
- 些少なデータ値はゼロのデータ値であり、些少ではないデータ値はゼロでないデータ値である、請求項53から請求項56のいずれかに記載のプロセッサ。
- 前記回路は、前記データ出力に並行して、前記取り出された個々のデータを多重に提供するよう構成される、請求項1に記載の回路。
- 前記個々のデータ値はxビット長であり、前記データ出力はnxビットのデータバスを含み、nは1よりも大きな整数であり、nデータ値はある時刻に前記データバス上に配置される、請求項58に記載の回路。
- 前記回路は、個々の些少ではないデータ値の圧縮構造体を多重に受信するよう構成される、請求項30に記載の回路。
- 前記個々のデータ値はxビット長であり、前記データ入力はnxビットのデータバスを含み、nは1よりも大きな整数であり、nデータ値はある時刻に前記データバスから取り出される、請求項60に記載の回路。
- データ値の構造体を圧縮する方法であって、前記構造体内においてゼロの値の位置を識別するマップを生成するステップと、前記ゼロでない値及び前記マップのみからなる圧縮構造体を提供するために、前記構造体から前記識別された些少なエントリ値を除去するステップと、を含む方法。
- 前記データ値は、浮動小数点数である、請求項62に記載の方法。
- 前記データ値は、単精度又は倍精度浮動小数点数である、請求項62に記載の方法。
- 前記データ値は、拡張精度浮動小数点数又は128ビット精度浮動小数点数である、請求項62に記載の方法。
- 前記データ値は、整数である、請求項62に記載の方法。
- 前記マップは、個々のデータ値を表すビットマップの各ビットを有するビットマップを含む、請求項62〜66のいずれかに記載の方法。
- 前記位置を識別する前記ステップは、ゼロでない値であるかどうか決定するために、各データ値を比較することを含む、請求項62〜67のいずれかに記載の方法。
- 各比較の出力は、ゼロでない値の前記数に対して提供されるカウントに対して合計される、請求項68に記載の方法。
- 前記カウントは、前記圧縮構造体のサイズを決定するために用いられ、請求項68に記載の方法。
- 前記カウントは、前記圧縮構造体に設けられるエントリの前記数を決定するために用いる、請求項68に記載の方法。
- 各比較の前記出力は、前記圧縮構造体にデータ値の書込を有効化するために用いられる、請求項68に記載の方法。
- 前記構造体はマトリクスであり、前記マップは行及び列の前記数を識別する、請求項62から72のいずれかに記載の方法。
- 前記構造体は、行−列の構成に配列されるマトリクスを含む、請求項62に記載の方法。
- 圧縮データ構造体であって、複数のゼロでないデータ値と、前記構造体の非圧縮形態における複数の些少ではない値に対するゼロ・データ値の位置を表すマップとを含む、圧縮データ構造体。
- 前記マップはビットマップを含み、それぞれの独立したデータ値は独立したビットによって表される、請求項75に記載の圧縮データ構造体。
- 圧縮データ構造体を復元する方法であって、前記圧縮構造体は、複数のゼロでない値と、非圧縮構造体における前記ゼロでない値の位置を表すマップとを含み、前記方法は、
未占有の非圧縮構造体を提供することと、
前記ゼロでない値を取り出すことと、
占有された復元データ構造体を提供するために、前記マップに表される位置にしたがって、前記未占有の構造体内の前記ゼロでない値を占有することと、
のステップを含む方法。 - 前記未占有のマトリクスの前記値は、前記ゼロでない値によって占有の前にゼロまで初期化される)請求項77に記載の方法。
- 前記マップのゼロ値として識別される占有構造体における位置は、ゼロにセットされる、請求項77に記載の方法。
- 前記データ値は、浮動小数点数である、請求項77に記載の方法。
- 前記データ値は、単精度浮動小数点数である、請求項77に記載の方法。
- 前記データ値は、倍精度浮動小数点数である、請求項77に記載の方法。
- 前記データ値は、整数である、請求項77に記載の方法。
- 前記マップは、個々のデータ値を表す前記ビットマップの各ビットを有するビットマップからなる、請求項77から83のいずれかに記載の方法。
- 前記ビットマップの前記個々のビットは、前記圧縮構造体におけるゼロでない値の前記数のカウントを提供するために合計される、請求項84に記載の方法。
- 前記カウントは、前記未占有の構造体に読み込まれるデータ値の量を決定するために用いられる、請求項85に記載の方法。
- 前記マップは、前記非圧縮構造体へのデータ値の書き込みを有効化するために用いられる、請求項77から86のいずれかに記載の方法。
- 前記構造体は、行−列構成を有するマトリクスを含む、請求項77から87のいずれかに記載の方法。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| GB0704976A GB2447494A (en) | 2007-03-15 | 2007-03-15 | A method and circuit for compressing data using a bitmap to identify the location of data values |
| US91127307P | 2007-04-11 | 2007-04-11 | |
| PCT/EP2008/053133 WO2008110633A1 (en) | 2007-03-15 | 2008-03-14 | A circuit for compressing data and a processor employing same |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2010521728A true JP2010521728A (ja) | 2010-06-24 |
| JP2010521728A5 JP2010521728A5 (ja) | 2011-05-06 |
Family
ID=38008470
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2009553163A Ceased JP2010521728A (ja) | 2007-03-15 | 2008-03-14 | データ圧縮のための回路及びこれを用いるプロセッサ |
Country Status (8)
| Country | Link |
|---|---|
| US (1) | US8713080B2 (ja) |
| EP (1) | EP2137821A1 (ja) |
| JP (1) | JP2010521728A (ja) |
| KR (1) | KR20100029179A (ja) |
| CN (1) | CN101689863A (ja) |
| GB (1) | GB2447494A (ja) |
| IE (1) | IES20080201A2 (ja) |
| WO (1) | WO2008110633A1 (ja) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2011511986A (ja) * | 2008-02-11 | 2011-04-14 | リニア アルジェブラ テクノロジーズ リミテッド | プロセッサ |
| JP2016095600A (ja) * | 2014-11-13 | 2016-05-26 | カシオ計算機株式会社 | 電子機器およびプログラム |
| JP2022504995A (ja) * | 2019-10-12 | 2022-01-14 | バイドゥドットコム タイムズ テクノロジー (ベイジン) カンパニー リミテッド | アドバンストインタコネクト技術を利用してaiトレーニングを加速するための方法及びシステム |
Families Citing this family (32)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8751687B2 (en) * | 2010-04-30 | 2014-06-10 | Microsoft Corporation | Efficient encoding of structured data |
| CN102739444A (zh) * | 2012-06-12 | 2012-10-17 | 中兴通讯股份有限公司 | 一种性能数据传输方法、系统和网管 |
| US9256502B2 (en) * | 2012-06-19 | 2016-02-09 | Oracle International Corporation | Method and system for inter-processor communication |
| GB2551291B (en) | 2013-05-23 | 2018-02-14 | Linear Algebra Tech Limited | Corner detection |
| US9910675B2 (en) | 2013-08-08 | 2018-03-06 | Linear Algebra Technologies Limited | Apparatus, systems, and methods for low power computational imaging |
| US9727113B2 (en) | 2013-08-08 | 2017-08-08 | Linear Algebra Technologies Limited | Low power computational imaging |
| US11768689B2 (en) | 2013-08-08 | 2023-09-26 | Movidius Limited | Apparatus, systems, and methods for low power computational imaging |
| US10001993B2 (en) | 2013-08-08 | 2018-06-19 | Linear Algebra Technologies Limited | Variable-length instruction buffer management |
| US9934043B2 (en) | 2013-08-08 | 2018-04-03 | Linear Algebra Technologies Limited | Apparatus, systems, and methods for providing computational imaging pipeline |
| US9196017B2 (en) | 2013-11-15 | 2015-11-24 | Linear Algebra Technologies Limited | Apparatus, systems, and methods for removing noise from an image |
| US9270872B2 (en) | 2013-11-26 | 2016-02-23 | Linear Algebra Technologies Limited | Apparatus, systems, and methods for removing shading effect from image |
| US20170068458A1 (en) * | 2015-09-03 | 2017-03-09 | Qualcomm Incorporated | Hardware-accelerated storage compression |
| US10613756B2 (en) * | 2015-09-03 | 2020-04-07 | Qualcomm Incorporated | Hardware-accelerated storage compression |
| US10460704B2 (en) | 2016-04-01 | 2019-10-29 | Movidius Limited | Systems and methods for head-mounted display adapted to human visual mechanism |
| US10565207B2 (en) * | 2016-04-12 | 2020-02-18 | Hsilin Huang | Method, system and program product for mask-based compression of a sparse matrix |
| US11469772B2 (en) * | 2017-04-11 | 2022-10-11 | Joshua Huang | Method, system and program product for mask-based compression of a sparse matrix |
| EP3501010B1 (en) | 2016-08-19 | 2023-11-01 | Movidius Ltd. | Rendering operations using sparse volumetric data |
| WO2018174931A1 (en) | 2017-03-20 | 2018-09-27 | Intel Corporation | Systems, methods, and appartus for tile configuration |
| WO2019009870A1 (en) | 2017-07-01 | 2019-01-10 | Intel Corporation | SAVE BACKGROUND TO VARIABLE BACKUP STATUS SIZE |
| JP6986678B2 (ja) * | 2017-07-10 | 2021-12-22 | パナソニックIpマネジメント株式会社 | 映像信号処理装置及び映像信号伝送システム |
| WO2019079358A1 (en) | 2017-10-16 | 2019-04-25 | KOMENDA, J. Kyle | HASHING DENSITY COORDINATES FOR VOLUMETRIC DATA |
| US10949947B2 (en) | 2017-12-29 | 2021-03-16 | Intel Corporation | Foveated image rendering for head-mounted display devices |
| US20190362235A1 (en) | 2018-05-23 | 2019-11-28 | Xiaofan Xu | Hybrid neural network pruning |
| JP7074989B2 (ja) * | 2018-08-31 | 2022-05-25 | 国立大学法人 筑波大学 | データ圧縮器、データ圧縮方法、データ圧縮プログラム、データ解凍器、データ解凍方法、データ解凍プログラムおよびデータ圧縮解凍システム |
| WO2020125973A1 (en) * | 2018-12-19 | 2020-06-25 | Telefonaktiebolaget Lm Ericsson (Publ) | Compressing and decompressing information about data objects hosted at a device |
| US11379420B2 (en) | 2019-03-08 | 2022-07-05 | Nvidia Corporation | Decompression techniques for processing compressed data suitable for artificial neural networks |
| WO2020211000A1 (zh) * | 2019-04-17 | 2020-10-22 | 深圳市大疆创新科技有限公司 | 数据解压缩的装置与方法 |
| US11941633B2 (en) | 2019-09-06 | 2024-03-26 | U.S. Bancorp, National Association | System for identifying points of compromise |
| US11468447B2 (en) * | 2019-09-06 | 2022-10-11 | U.S. Bancorp, National Association | System for identifying points of compromise |
| US11586601B2 (en) * | 2020-02-05 | 2023-02-21 | Alibaba Group Holding Limited | Apparatus and method for representation of a sparse matrix in a neural network |
| US10911267B1 (en) | 2020-04-10 | 2021-02-02 | Apple Inc. | Data-enable mask compression on a communication bus |
| US11362672B2 (en) | 2020-05-08 | 2022-06-14 | Qualcomm Incorporated | Inline decompression |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2003516702A (ja) * | 1999-12-07 | 2003-05-13 | 任天堂株式会社 | 3d変換マトリックス圧縮および復元 |
Family Cites Families (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US3553651A (en) * | 1967-12-06 | 1971-01-05 | Singer General Precision | Memory storage system |
| DE2615790A1 (de) * | 1976-04-10 | 1977-10-20 | Bbc Brown Boveri & Cie | Verfahren zur datenreduktion auf bit-seriellen uebertragungswegen |
| US5057837A (en) * | 1987-04-20 | 1991-10-15 | Digital Equipment Corporation | Instruction storage method with a compressed format using a mask word |
| US5586300A (en) * | 1994-07-20 | 1996-12-17 | Emc Corporation | Flexible addressing memory controller wherein multiple memory modules may be accessed according to comparison of configuration addresses |
| US5963642A (en) * | 1996-12-30 | 1999-10-05 | Goldstein; Benjamin D. | Method and apparatus for secure storage of data |
-
2007
- 2007-03-15 GB GB0704976A patent/GB2447494A/en not_active Withdrawn
-
2008
- 2008-03-14 US US12/531,427 patent/US8713080B2/en active Active
- 2008-03-14 WO PCT/EP2008/053133 patent/WO2008110633A1/en active Application Filing
- 2008-03-14 CN CN200880016010A patent/CN101689863A/zh active Pending
- 2008-03-14 EP EP08717870A patent/EP2137821A1/en not_active Withdrawn
- 2008-03-14 JP JP2009553163A patent/JP2010521728A/ja not_active Ceased
- 2008-03-14 KR KR1020097021425A patent/KR20100029179A/ko not_active Application Discontinuation
- 2008-03-18 IE IE20080201A patent/IES20080201A2/en not_active IP Right Cessation
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2003516702A (ja) * | 1999-12-07 | 2003-05-13 | 任天堂株式会社 | 3d変換マトリックス圧縮および復元 |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2011511986A (ja) * | 2008-02-11 | 2011-04-14 | リニア アルジェブラ テクノロジーズ リミテッド | プロセッサ |
| JP2016095600A (ja) * | 2014-11-13 | 2016-05-26 | カシオ計算機株式会社 | 電子機器およびプログラム |
| JP2022504995A (ja) * | 2019-10-12 | 2022-01-14 | バイドゥドットコム タイムズ テクノロジー (ベイジン) カンパニー リミテッド | アドバンストインタコネクト技術を利用してaiトレーニングを加速するための方法及びシステム |
| JP7256811B2 (ja) | 2019-10-12 | 2023-04-12 | バイドゥドットコム タイムズ テクノロジー (ベイジン) カンパニー リミテッド | アドバンストインタコネクト技術を利用してaiトレーニングを加速するための方法及びシステム |
Also Published As
| Publication number | Publication date |
|---|---|
| KR20100029179A (ko) | 2010-03-16 |
| US8713080B2 (en) | 2014-04-29 |
| US20100106692A1 (en) | 2010-04-29 |
| CN101689863A (zh) | 2010-03-31 |
| EP2137821A1 (en) | 2009-12-30 |
| IES20080201A2 (en) | 2008-09-17 |
| WO2008110633A1 (en) | 2008-09-18 |
| GB2447494A (en) | 2008-09-17 |
| GB0704976D0 (en) | 2007-04-25 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP2010521728A (ja) | データ圧縮のための回路及びこれを用いるプロセッサ | |
| US10719318B2 (en) | Processor | |
| US8984043B2 (en) | Multiplying and adding matrices | |
| CN108388537B (zh) | 一种卷积神经网络加速装置和方法 | |
| US7836116B1 (en) | Fast fourier transforms and related transforms using cooperative thread arrays | |
| US7640284B1 (en) | Bit reversal methods for a parallel processor | |
| US8094157B1 (en) | Performing an occurence count of radices | |
| JP2744526B2 (ja) | 準16基数プロセッサおよび方法 | |
| EP2017743A2 (en) | High speed and efficient matrix multiplication hardware module | |
| US7689541B1 (en) | Reordering data using a series of offsets | |
| JP2010521728A5 (ja) | ||
| US10884736B1 (en) | Method and apparatus for a low energy programmable vector processing unit for neural networks backend processing | |
| KR20190028426A (ko) | Simd 아키텍처에서 레인 셔플을 위한 셔플러 회로 | |
| US7624107B1 (en) | Radix sort algorithm for graphics processing units | |
| US11550586B2 (en) | Method and tensor traversal engine for strided memory access during execution of neural networks | |
| CN117539546A (zh) | 基于非空列存储的稀疏矩阵向量乘加速方法及装置 | |
| US11586922B2 (en) | Tensor dropout in a neural network | |
| JP2009295159A (ja) | メモリのアクセス方法 | |
| Shahbahrami et al. | FPGA implementation of parallel histogram computation | |
| CN111158757B (zh) | 并行存取装置和方法以及芯片 | |
| CN112149049A (zh) | 用于变换矩阵的装置和方法、数据处理系统 | |
| KR101715456B1 (ko) | 스레드 오프셋 카운터 | |
| EP0655694B1 (en) | Discrete cosine transform processor | |
| CN111831207B (zh) | 一种数据处理方法、装置及其设备 | |
| IES85108Y1 (en) | A circuit for compressing data and a processor employing same |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20110309 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20110317 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20121218 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20130318 |
|
| A602 | Written permission of extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A602 Effective date: 20130326 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20130418 |
|
| A602 | Written permission of extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A602 Effective date: 20130425 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20130515 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20130611 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20130814 |
|
| A911 | Transfer to examiner for re-examination before appeal (zenchi) |
Free format text: JAPANESE INTERMEDIATE CODE: A911 Effective date: 20130911 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20131008 |
|
| A045 | Written measure of dismissal of application [lapsed due to lack of payment] |
Free format text: JAPANESE INTERMEDIATE CODE: A045 Effective date: 20140225 |