JP2010088444A - ユビキチン依存型タンパク質分解系を利用した生体内タンパク質分解システム,及びそのシステムを利用したタンパク質の機能解明方法 - Google Patents
ユビキチン依存型タンパク質分解系を利用した生体内タンパク質分解システム,及びそのシステムを利用したタンパク質の機能解明方法 Download PDFInfo
- Publication number
- JP2010088444A JP2010088444A JP2009278073A JP2009278073A JP2010088444A JP 2010088444 A JP2010088444 A JP 2010088444A JP 2009278073 A JP2009278073 A JP 2009278073A JP 2009278073 A JP2009278073 A JP 2009278073A JP 2010088444 A JP2010088444 A JP 2010088444A
- Authority
- JP
- Japan
- Prior art keywords
- protein
- amino acid
- seq
- acid sequence
- rfd
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
- 238000000034 method Methods 0.000 title claims abstract description 64
- 230000017854 proteolysis Effects 0.000 title description 6
- 230000014848 ubiquitin-dependent protein catabolic process Effects 0.000 title 1
- 108090000623 proteins and genes Proteins 0.000 claims abstract description 421
- 102000004169 proteins and genes Human genes 0.000 claims abstract description 366
- 125000003275 alpha amino acid group Chemical group 0.000 claims abstract description 197
- 101710173438 Late L2 mu core protein Proteins 0.000 claims abstract description 127
- 101710188315 Protein X Proteins 0.000 claims abstract description 127
- 102000044159 Ubiquitin Human genes 0.000 claims abstract description 91
- 108090000848 Ubiquitin Proteins 0.000 claims abstract description 91
- 125000000539 amino acid group Chemical group 0.000 claims abstract description 39
- 102000004190 Enzymes Human genes 0.000 claims abstract description 26
- 108090000790 Enzymes Proteins 0.000 claims abstract description 26
- 238000001727 in vivo Methods 0.000 claims abstract description 10
- 241001465754 Metazoa Species 0.000 claims description 23
- 238000004519 manufacturing process Methods 0.000 claims description 20
- 150000001413 amino acids Chemical class 0.000 claims description 15
- 101100165918 Caenorhabditis elegans cam-1 gene Proteins 0.000 claims description 14
- 101100396142 Arabidopsis thaliana IAA14 gene Proteins 0.000 claims description 12
- 101150110992 SLR1 gene Proteins 0.000 claims description 12
- 108060008747 Ubiquitin-Conjugating Enzyme Proteins 0.000 claims description 9
- 102000003431 Ubiquitin-Conjugating Enzyme Human genes 0.000 claims description 9
- 101100495990 Oryza sativa subsp. japonica CIGR2 gene Proteins 0.000 claims description 8
- 230000004853 protein function Effects 0.000 claims description 6
- 238000004458 analytical method Methods 0.000 claims description 5
- 230000000415 inactivating effect Effects 0.000 claims 1
- 238000010230 functional analysis Methods 0.000 abstract description 8
- 238000012217 deletion Methods 0.000 abstract 1
- 230000037430 deletion Effects 0.000 abstract 1
- 238000006467 substitution reaction Methods 0.000 abstract 1
- 235000018102 proteins Nutrition 0.000 description 279
- 108020001507 fusion proteins Proteins 0.000 description 33
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 32
- 102000037865 fusion proteins Human genes 0.000 description 32
- 241000196324 Embryophyta Species 0.000 description 27
- 238000010586 diagram Methods 0.000 description 27
- 229920001213 Polysorbate 20 Polymers 0.000 description 24
- 239000000256 polyoxyethylene sorbitan monolaurate Substances 0.000 description 24
- 210000004027 cell Anatomy 0.000 description 23
- 229940088598 enzyme Drugs 0.000 description 22
- 230000034512 ubiquitination Effects 0.000 description 20
- 238000010798 ubiquitination Methods 0.000 description 20
- 239000013612 plasmid Substances 0.000 description 19
- QKNYBSVHEMOAJP-UHFFFAOYSA-N 2-amino-2-(hydroxymethyl)propane-1,3-diol;hydron;chloride Chemical compound Cl.OCC(N)(CO)CO QKNYBSVHEMOAJP-UHFFFAOYSA-N 0.000 description 17
- 239000011780 sodium chloride Substances 0.000 description 16
- 241000209094 Oryza Species 0.000 description 15
- 235000007164 Oryza sativa Nutrition 0.000 description 15
- 235000009566 rice Nutrition 0.000 description 15
- 235000001014 amino acid Nutrition 0.000 description 14
- 239000002609 medium Substances 0.000 description 14
- NWONKYPBYAMBJT-UHFFFAOYSA-L zinc sulfate Chemical compound [Zn+2].[O-]S([O-])(=O)=O NWONKYPBYAMBJT-UHFFFAOYSA-L 0.000 description 13
- 229910000368 zinc sulfate Inorganic materials 0.000 description 13
- 239000011686 zinc sulphate Substances 0.000 description 13
- 235000009529 zinc sulphate Nutrition 0.000 description 13
- 230000004048 modification Effects 0.000 description 12
- 238000012986 modification Methods 0.000 description 12
- 238000005406 washing Methods 0.000 description 12
- 238000006243 chemical reaction Methods 0.000 description 10
- 239000012634 fragment Substances 0.000 description 10
- 230000002797 proteolythic effect Effects 0.000 description 10
- 235000004279 alanine Nutrition 0.000 description 9
- 125000003295 alanine group Chemical group N[C@@H](C)C(=O)* 0.000 description 9
- 230000001419 dependent effect Effects 0.000 description 9
- 230000014509 gene expression Effects 0.000 description 9
- 239000013598 vector Substances 0.000 description 9
- 102100031673 Corneodesmosin Human genes 0.000 description 8
- YQYJSBFKSSDGFO-UHFFFAOYSA-N Epihygromycin Natural products OC1C(O)C(C(=O)C)OC1OC(C(=C1)O)=CC=C1C=C(C)C(=O)NC1C(O)C(O)C2OCOC2C1O YQYJSBFKSSDGFO-UHFFFAOYSA-N 0.000 description 8
- TWRXJAOTZQYOKJ-UHFFFAOYSA-L Magnesium chloride Chemical compound [Mg+2].[Cl-].[Cl-] TWRXJAOTZQYOKJ-UHFFFAOYSA-L 0.000 description 8
- 108010068086 Polyubiquitin Proteins 0.000 description 8
- 102100037935 Polyubiquitin-C Human genes 0.000 description 8
- 230000015556 catabolic process Effects 0.000 description 8
- 239000002299 complementary DNA Substances 0.000 description 8
- 238000006731 degradation reaction Methods 0.000 description 8
- 230000004927 fusion Effects 0.000 description 8
- 239000000499 gel Substances 0.000 description 8
- 239000012528 membrane Substances 0.000 description 8
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 8
- 238000001962 electrophoresis Methods 0.000 description 7
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 description 6
- 241000589158 Agrobacterium Species 0.000 description 6
- 102000000584 Calmodulin Human genes 0.000 description 6
- 108010041952 Calmodulin Proteins 0.000 description 6
- 108091006027 G proteins Proteins 0.000 description 6
- 102000030782 GTP binding Human genes 0.000 description 6
- 108091000058 GTP-Binding Proteins 0.000 description 6
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 6
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 6
- 108090000708 Proteasome Endopeptidase Complex Proteins 0.000 description 6
- 102000004245 Proteasome Endopeptidase Complex Human genes 0.000 description 6
- 229940096437 Protein S Drugs 0.000 description 6
- 238000010367 cloning Methods 0.000 description 6
- 238000010828 elution Methods 0.000 description 6
- 230000003993 interaction Effects 0.000 description 6
- 125000003588 lysine group Chemical group [H]N([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])(N([H])[H])C(*)=O 0.000 description 6
- 239000006228 supernatant Substances 0.000 description 6
- OWEGMIWEEQEYGQ-UHFFFAOYSA-N 100676-05-9 Natural products OC1C(O)C(O)C(CO)OC1OCC1C(O)C(O)C(O)C(OC2C(OC(O)C(O)C2O)CO)O1 OWEGMIWEEQEYGQ-UHFFFAOYSA-N 0.000 description 5
- 101710139375 Corneodesmosin Proteins 0.000 description 5
- 241000588724 Escherichia coli Species 0.000 description 5
- GUBGYTABKSRVRQ-PICCSMPSSA-N Maltose Natural products O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CO)O[C@@H]1O[C@@H]1[C@@H](CO)OC(O)[C@H](O)[C@H]1O GUBGYTABKSRVRQ-PICCSMPSSA-N 0.000 description 5
- 239000011543 agarose gel Substances 0.000 description 5
- 238000001502 gel electrophoresis Methods 0.000 description 5
- 108020004707 nucleic acids Proteins 0.000 description 5
- 102000039446 nucleic acids Human genes 0.000 description 5
- 150000007523 nucleic acids Chemical class 0.000 description 5
- 239000000047 product Substances 0.000 description 5
- 241000894007 species Species 0.000 description 5
- 239000005631 2,4-Dichlorophenoxyacetic acid Substances 0.000 description 4
- 241000894006 Bacteria Species 0.000 description 4
- 101500025132 Bos taurus Ubiquitin Proteins 0.000 description 4
- 101500027500 Bos taurus Ubiquitin Proteins 0.000 description 4
- 101500027539 Bos taurus Ubiquitin Proteins 0.000 description 4
- 101500028979 Bos taurus Ubiquitin Proteins 0.000 description 4
- 206010020649 Hyperkeratosis Diseases 0.000 description 4
- 239000007836 KH2PO4 Substances 0.000 description 4
- 101000761238 Oryza sativa subsp. japonica Ubiquitin-conjugating enzyme E2 5B Proteins 0.000 description 4
- 239000002033 PVDF binder Substances 0.000 description 4
- 102000003992 Peroxidases Human genes 0.000 description 4
- 230000009471 action Effects 0.000 description 4
- 238000003776 cleavage reaction Methods 0.000 description 4
- 230000007423 decrease Effects 0.000 description 4
- 230000000593 degrading effect Effects 0.000 description 4
- BNIILDVGGAEEIG-UHFFFAOYSA-L disodium hydrogen phosphate Chemical compound [Na+].[Na+].OP([O-])([O-])=O BNIILDVGGAEEIG-UHFFFAOYSA-L 0.000 description 4
- 229910000397 disodium phosphate Inorganic materials 0.000 description 4
- 235000019800 disodium phosphate Nutrition 0.000 description 4
- 108010002685 hygromycin-B kinase Proteins 0.000 description 4
- 229910001629 magnesium chloride Inorganic materials 0.000 description 4
- 229910000402 monopotassium phosphate Inorganic materials 0.000 description 4
- 235000019796 monopotassium phosphate Nutrition 0.000 description 4
- 108040007629 peroxidase activity proteins Proteins 0.000 description 4
- 229920002401 polyacrylamide Polymers 0.000 description 4
- 235000010486 polyoxyethylene sorbitan monolaurate Nutrition 0.000 description 4
- 229920002981 polyvinylidene fluoride Polymers 0.000 description 4
- GNSKLFRGEWLPPA-UHFFFAOYSA-M potassium dihydrogen phosphate Chemical compound [K+].OP(O)([O-])=O GNSKLFRGEWLPPA-UHFFFAOYSA-M 0.000 description 4
- 238000011160 research Methods 0.000 description 4
- 239000012723 sample buffer Substances 0.000 description 4
- 230000007017 scission Effects 0.000 description 4
- 235000020183 skimmed milk Nutrition 0.000 description 4
- 230000001629 suppression Effects 0.000 description 4
- 238000012795 verification Methods 0.000 description 4
- 101100220717 Arabidopsis thaliana CIP8 gene Proteins 0.000 description 3
- 241001198387 Escherichia coli BL21(DE3) Species 0.000 description 3
- 101150022478 GID2 gene Proteins 0.000 description 3
- 108091030071 RNAI Proteins 0.000 description 3
- 102000007056 Recombinant Fusion Proteins Human genes 0.000 description 3
- 108010008281 Recombinant Fusion Proteins Proteins 0.000 description 3
- 229930006000 Sucrose Natural products 0.000 description 3
- CZMRCDWAGMRECN-UGDNZRGBSA-N Sucrose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 CZMRCDWAGMRECN-UGDNZRGBSA-N 0.000 description 3
- 108010031318 Vitronectin Proteins 0.000 description 3
- 239000002253 acid Substances 0.000 description 3
- 229960000723 ampicillin Drugs 0.000 description 3
- AVKUERGKIZMTKX-NJBDSQKTSA-N ampicillin Chemical compound C1([C@@H](N)C(=O)N[C@H]2[C@H]3SC([C@@H](N3C2=O)C(O)=O)(C)C)=CC=CC=C1 AVKUERGKIZMTKX-NJBDSQKTSA-N 0.000 description 3
- 230000000903 blocking effect Effects 0.000 description 3
- 210000004899 c-terminal region Anatomy 0.000 description 3
- 229960003669 carbenicillin Drugs 0.000 description 3
- FPPNZSSZRUTDAP-UWFZAAFLSA-N carbenicillin Chemical compound N([C@H]1[C@H]2SC([C@@H](N2C1=O)C(O)=O)(C)C)C(=O)C(C(O)=O)C1=CC=CC=C1 FPPNZSSZRUTDAP-UWFZAAFLSA-N 0.000 description 3
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 3
- 238000005119 centrifugation Methods 0.000 description 3
- 238000000354 decomposition reaction Methods 0.000 description 3
- 238000002474 experimental method Methods 0.000 description 3
- 230000009368 gene silencing by RNA Effects 0.000 description 3
- 125000003630 glycyl group Chemical group [H]N([H])C([H])([H])C(*)=O 0.000 description 3
- RAXXELZNTBOGNW-UHFFFAOYSA-N imidazole Natural products C1=CNC=N1 RAXXELZNTBOGNW-UHFFFAOYSA-N 0.000 description 3
- BPHPUYQFMNQIOC-NXRLNHOXSA-N isopropyl beta-D-thiogalactopyranoside Chemical compound CC(C)S[C@@H]1O[C@H](CO)[C@H](O)[C@H](O)[C@H]1O BPHPUYQFMNQIOC-NXRLNHOXSA-N 0.000 description 3
- 108020004999 messenger RNA Proteins 0.000 description 3
- 239000000203 mixture Substances 0.000 description 3
- 230000035772 mutation Effects 0.000 description 3
- 108010058731 nopaline synthase Proteins 0.000 description 3
- 108091008146 restriction endonucleases Proteins 0.000 description 3
- 238000003757 reverse transcription PCR Methods 0.000 description 3
- 101150055492 sel-11 gene Proteins 0.000 description 3
- 238000002741 site-directed mutagenesis Methods 0.000 description 3
- 238000000527 sonication Methods 0.000 description 3
- 239000005720 sucrose Substances 0.000 description 3
- 239000000725 suspension Substances 0.000 description 3
- 238000010257 thawing Methods 0.000 description 3
- 238000012546 transfer Methods 0.000 description 3
- 230000009466 transformation Effects 0.000 description 3
- PRPINYUDVPFIRX-UHFFFAOYSA-N 1-naphthaleneacetic acid Chemical compound C1=CC=C2C(CC(=O)O)=CC=CC2=C1 PRPINYUDVPFIRX-UHFFFAOYSA-N 0.000 description 2
- 108010022579 ATP dependent 26S protease Proteins 0.000 description 2
- 229920000856 Amylose Polymers 0.000 description 2
- 108020004705 Codon Proteins 0.000 description 2
- 229930191978 Gibberellin Natural products 0.000 description 2
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Natural products NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 2
- 239000004471 Glycine Substances 0.000 description 2
- 102000011931 Nucleoproteins Human genes 0.000 description 2
- 108010061100 Nucleoproteins Proteins 0.000 description 2
- 102000018478 Ubiquitin-Activating Enzymes Human genes 0.000 description 2
- 108010091546 Ubiquitin-Activating Enzymes Proteins 0.000 description 2
- 102000006275 Ubiquitin-Protein Ligases Human genes 0.000 description 2
- 108010083111 Ubiquitin-Protein Ligases Proteins 0.000 description 2
- OJOBTAOGJIWAGB-UHFFFAOYSA-N acetosyringone Chemical compound COC1=CC(C(C)=O)=CC(OC)=C1O OJOBTAOGJIWAGB-UHFFFAOYSA-N 0.000 description 2
- 238000001042 affinity chromatography Methods 0.000 description 2
- 210000004102 animal cell Anatomy 0.000 description 2
- 238000013459 approach Methods 0.000 description 2
- 238000003556 assay Methods 0.000 description 2
- 230000008901 benefit Effects 0.000 description 2
- 230000015572 biosynthetic process Effects 0.000 description 2
- 230000000694 effects Effects 0.000 description 2
- 238000004520 electroporation Methods 0.000 description 2
- 230000007613 environmental effect Effects 0.000 description 2
- 238000001641 gel filtration chromatography Methods 0.000 description 2
- IXORZMNAPKEEDV-UHFFFAOYSA-N gibberellic acid GA3 Natural products OC(=O)C1C2(C3)CC(=C)C3(O)CCC2C2(C=CC3O)C1C3(C)C(=O)O2 IXORZMNAPKEEDV-UHFFFAOYSA-N 0.000 description 2
- 239000003448 gibberellin Substances 0.000 description 2
- 230000002209 hydrophobic effect Effects 0.000 description 2
- 238000011534 incubation Methods 0.000 description 2
- 229960000318 kanamycin Drugs 0.000 description 2
- 229930027917 kanamycin Natural products 0.000 description 2
- SBUJHOSQTJFQJX-NOAMYHISSA-N kanamycin Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CN)O[C@@H]1O[C@H]1[C@H](O)[C@@H](O[C@@H]2[C@@H]([C@@H](N)[C@H](O)[C@@H](CO)O2)O)[C@H](N)C[C@@H]1N SBUJHOSQTJFQJX-NOAMYHISSA-N 0.000 description 2
- 229930182823 kanamycin A Natural products 0.000 description 2
- 239000003550 marker Substances 0.000 description 2
- 239000006870 ms-medium Substances 0.000 description 2
- 238000002703 mutagenesis Methods 0.000 description 2
- 231100000350 mutagenesis Toxicity 0.000 description 2
- 239000002773 nucleotide Substances 0.000 description 2
- 125000003729 nucleotide group Chemical group 0.000 description 2
- 238000002360 preparation method Methods 0.000 description 2
- 239000011347 resin Substances 0.000 description 2
- 229920005989 resin Polymers 0.000 description 2
- 230000014616 translation Effects 0.000 description 2
- 238000000539 two dimensional gel electrophoresis Methods 0.000 description 2
- HXKWSTRRCHTUEC-UHFFFAOYSA-N 2,4-Dichlorophenoxyaceticacid Chemical compound OC(=O)C(Cl)OC1=CC=C(Cl)C=C1 HXKWSTRRCHTUEC-UHFFFAOYSA-N 0.000 description 1
- 125000004042 4-aminobutyl group Chemical group [H]C([*])([H])C([H])([H])C([H])([H])C([H])([H])N([H])[H] 0.000 description 1
- 239000004475 Arginine Substances 0.000 description 1
- 241000193830 Bacillus <bacterium> Species 0.000 description 1
- 0 C*c1c(C=C2C(CC3)=C3C=C2)cccc1CCC1=CC=CC1 Chemical compound C*c1c(C=C2C(CC3)=C3C=C2)cccc1CCC1=CC=CC1 0.000 description 1
- BHPQYMZQTOCNFJ-UHFFFAOYSA-N Calcium cation Chemical compound [Ca+2] BHPQYMZQTOCNFJ-UHFFFAOYSA-N 0.000 description 1
- 102000005701 Calcium-Binding Proteins Human genes 0.000 description 1
- 108010045403 Calcium-Binding Proteins Proteins 0.000 description 1
- 201000009030 Carcinoma Diseases 0.000 description 1
- 229920002101 Chitin Polymers 0.000 description 1
- 241000270281 Coluber constrictor Species 0.000 description 1
- FBPFZTCFMRRESA-FSIIMWSLSA-N D-Glucitol Natural products OC[C@H](O)[C@H](O)[C@@H](O)[C@H](O)CO FBPFZTCFMRRESA-FSIIMWSLSA-N 0.000 description 1
- 230000033616 DNA repair Effects 0.000 description 1
- 208000035240 Disease Resistance Diseases 0.000 description 1
- 101710204837 Envelope small membrane protein Proteins 0.000 description 1
- 241000588722 Escherichia Species 0.000 description 1
- 241000701959 Escherichia virus Lambda Species 0.000 description 1
- 241000206602 Eukaryota Species 0.000 description 1
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 1
- 101100175482 Glycine max CG-3 gene Proteins 0.000 description 1
- 241000238631 Hexapoda Species 0.000 description 1
- 101001128156 Homo sapiens Nanos homolog 3 Proteins 0.000 description 1
- 101001124309 Homo sapiens Nitric oxide synthase, endothelial Proteins 0.000 description 1
- 101000772904 Homo sapiens Ubiquitin-conjugating enzyme E2 D1 Proteins 0.000 description 1
- 108010025815 Kanamycin Kinase Proteins 0.000 description 1
- FAIXYKHYOGVFKA-UHFFFAOYSA-N Kinetin Natural products N=1C=NC=2N=CNC=2C=1N(C)C1=CC=CO1 FAIXYKHYOGVFKA-UHFFFAOYSA-N 0.000 description 1
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 1
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical compound CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 description 1
- 239000004472 Lysine Substances 0.000 description 1
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 1
- 102000043136 MAP kinase family Human genes 0.000 description 1
- 108091054455 MAP kinase family Proteins 0.000 description 1
- 108700005084 Multigene Family Proteins 0.000 description 1
- 102100031893 Nanos homolog 3 Human genes 0.000 description 1
- 108091005804 Peptidases Proteins 0.000 description 1
- 102000035195 Peptidases Human genes 0.000 description 1
- 102000004160 Phosphoric Monoester Hydrolases Human genes 0.000 description 1
- 108090000608 Phosphoric Monoester Hydrolases Proteins 0.000 description 1
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 description 1
- 108010026552 Proteome Proteins 0.000 description 1
- 101100208548 Rattus norvegicus Ube2g1 gene Proteins 0.000 description 1
- 101710088839 Replication initiation protein Proteins 0.000 description 1
- 241000235070 Saccharomyces Species 0.000 description 1
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 1
- 241000235346 Schizosaccharomyces Species 0.000 description 1
- 239000005708 Sodium hypochlorite Substances 0.000 description 1
- 101000611441 Solanum lycopersicum Pathogenesis-related leaf protein 6 Proteins 0.000 description 1
- 108090000190 Thrombin Proteins 0.000 description 1
- 108700009124 Transcription Initiation Site Proteins 0.000 description 1
- 102100030433 Ubiquitin-conjugating enzyme E2 D1 Human genes 0.000 description 1
- 108010005705 Ubiquitinated Proteins Proteins 0.000 description 1
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Natural products CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 1
- 230000003321 amplification Effects 0.000 description 1
- 238000012197 amplification kit Methods 0.000 description 1
- 230000019552 anatomical structure morphogenesis Effects 0.000 description 1
- 239000003242 anti bacterial agent Substances 0.000 description 1
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 1
- 235000003704 aspartic acid Nutrition 0.000 description 1
- OQFSQFPPLPISGP-UHFFFAOYSA-N beta-carboxyaspartic acid Natural products OC(=O)C(N)C(C(O)=O)C(O)=O OQFSQFPPLPISGP-UHFFFAOYSA-N 0.000 description 1
- 230000003115 biocidal effect Effects 0.000 description 1
- 230000008512 biological response Effects 0.000 description 1
- 229910001424 calcium ion Inorganic materials 0.000 description 1
- 239000001506 calcium phosphate Substances 0.000 description 1
- 229910000389 calcium phosphate Inorganic materials 0.000 description 1
- 235000011010 calcium phosphates Nutrition 0.000 description 1
- 239000007795 chemical reaction product Substances 0.000 description 1
- 238000012411 cloning technique Methods 0.000 description 1
- 239000013599 cloning vector Substances 0.000 description 1
- 238000004440 column chromatography Methods 0.000 description 1
- 230000000295 complement effect Effects 0.000 description 1
- 239000002131 composite material Substances 0.000 description 1
- 238000006482 condensation reaction Methods 0.000 description 1
- 238000012258 culturing Methods 0.000 description 1
- 125000000151 cysteine group Chemical group N[C@@H](CS)C(=O)* 0.000 description 1
- 230000003247 decreasing effect Effects 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 230000009881 electrostatic interaction Effects 0.000 description 1
- 239000005712 elicitor Substances 0.000 description 1
- 239000003623 enhancer Substances 0.000 description 1
- 210000003527 eukaryotic cell Anatomy 0.000 description 1
- 238000011156 evaluation Methods 0.000 description 1
- 238000000605 extraction Methods 0.000 description 1
- OQZCSNDVOWYALR-UHFFFAOYSA-N flurochloridone Chemical compound FC(F)(F)C1=CC=CC(N2C(C(Cl)C(CCl)C2)=O)=C1 OQZCSNDVOWYALR-UHFFFAOYSA-N 0.000 description 1
- -1 for example Proteins 0.000 description 1
- 239000008103 glucose Substances 0.000 description 1
- 239000010903 husk Substances 0.000 description 1
- 229910052739 hydrogen Inorganic materials 0.000 description 1
- 239000001257 hydrogen Substances 0.000 description 1
- 230000036046 immunoreaction Effects 0.000 description 1
- 230000006698 induction Effects 0.000 description 1
- 230000031146 intracellular signal transduction Effects 0.000 description 1
- QANMHLXAZMSUEX-UHFFFAOYSA-N kinetin Chemical compound N=1C=NC=2N=CNC=2C=1NCC1=CC=CO1 QANMHLXAZMSUEX-UHFFFAOYSA-N 0.000 description 1
- 229960001669 kinetin Drugs 0.000 description 1
- 238000001638 lipofection Methods 0.000 description 1
- XIXADJRWDQXREU-UHFFFAOYSA-M lithium acetate Chemical compound [Li+].CC([O-])=O XIXADJRWDQXREU-UHFFFAOYSA-M 0.000 description 1
- 238000012423 maintenance Methods 0.000 description 1
- 238000004949 mass spectrometry Methods 0.000 description 1
- 238000006011 modification reaction Methods 0.000 description 1
- 238000010369 molecular cloning Methods 0.000 description 1
- 238000003199 nucleic acid amplification method Methods 0.000 description 1
- 229920001542 oligosaccharide Polymers 0.000 description 1
- 150000002482 oligosaccharides Chemical class 0.000 description 1
- 229920001184 polypeptide Polymers 0.000 description 1
- 230000004481 post-translational protein modification Effects 0.000 description 1
- 230000008569 process Effects 0.000 description 1
- 102000004196 processed proteins & peptides Human genes 0.000 description 1
- 108090000765 processed proteins & peptides Proteins 0.000 description 1
- 238000001814 protein method Methods 0.000 description 1
- 230000009145 protein modification Effects 0.000 description 1
- 238000003257 protein preparation method Methods 0.000 description 1
- 230000022983 regulation of cell cycle Effects 0.000 description 1
- 230000014493 regulation of gene expression Effects 0.000 description 1
- 230000001105 regulatory effect Effects 0.000 description 1
- 230000003938 response to stress Effects 0.000 description 1
- 239000012882 rooting medium Substances 0.000 description 1
- 238000012216 screening Methods 0.000 description 1
- 238000012163 sequencing technique Methods 0.000 description 1
- 230000019491 signal transduction Effects 0.000 description 1
- 150000003384 small molecules Chemical class 0.000 description 1
- SUKJFIGYRHOWBL-UHFFFAOYSA-N sodium hypochlorite Chemical compound [Na+].Cl[O-] SUKJFIGYRHOWBL-UHFFFAOYSA-N 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
- 239000000600 sorbitol Substances 0.000 description 1
- 239000000126 substance Substances 0.000 description 1
- 230000006918 subunit interaction Effects 0.000 description 1
- 238000003786 synthesis reaction Methods 0.000 description 1
- 229960004072 thrombin Drugs 0.000 description 1
- 238000006276 transfer reaction Methods 0.000 description 1
- 238000011426 transformation method Methods 0.000 description 1
- 238000013519 translation Methods 0.000 description 1
- QORWJWZARLRLPR-UHFFFAOYSA-H tricalcium bis(phosphate) Chemical compound [Ca+2].[Ca+2].[Ca+2].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O QORWJWZARLRLPR-UHFFFAOYSA-H 0.000 description 1
- 101150102218 ube2d2 gene Proteins 0.000 description 1
- 238000011144 upstream manufacturing Methods 0.000 description 1
- 239000004474 valine Substances 0.000 description 1
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 1
- 238000001262 western blot Methods 0.000 description 1
Images




Landscapes
- Measuring Or Testing Involving Enzymes Or Micro-Organisms (AREA)
- Peptides Or Proteins (AREA)
- Breeding Of Plants And Reproduction By Means Of Culturing (AREA)
Abstract
【課題】タンパク質の機能解析方法を提供する。
【解決手段】タンパク質A−RFDを生体内で発現させ,タンパク質Aとタンパク質Xとの複合体を形成させ,RFDと相互作用したユビキチン結合酵素に結合したユビキチンをタンパク質Xに転移させることにより,タンパク質Xを分解し,タンパク質X,又はタンパク質A−X複合体の機能を失活させ,RFDは,特定アミノ酸配列において134-181番のアミノ酸配列又は1〜4個のアミノ酸残基が置換,欠損,付加又は挿入したアミノ酸配列からなるタンパク質であり,タンパク質A−RFDは,タンパク質AとRFDとが別の特定配列に記載されるアミノ酸配列からなるリンカー,又は,該特定配列に記載されるアミノ酸配列から1〜4個のアミノ酸残基が置換,欠損,付加又は挿入したアミノ酸配列からなるリンカーにより結合される,タンパク質の機能解析方法。
【選択図】図1
【解決手段】タンパク質A−RFDを生体内で発現させ,タンパク質Aとタンパク質Xとの複合体を形成させ,RFDと相互作用したユビキチン結合酵素に結合したユビキチンをタンパク質Xに転移させることにより,タンパク質Xを分解し,タンパク質X,又はタンパク質A−X複合体の機能を失活させ,RFDは,特定アミノ酸配列において134-181番のアミノ酸配列又は1〜4個のアミノ酸残基が置換,欠損,付加又は挿入したアミノ酸配列からなるタンパク質であり,タンパク質A−RFDは,タンパク質AとRFDとが別の特定配列に記載されるアミノ酸配列からなるリンカー,又は,該特定配列に記載されるアミノ酸配列から1〜4個のアミノ酸残基が置換,欠損,付加又は挿入したアミノ酸配列からなるリンカーにより結合される,タンパク質の機能解析方法。
【選択図】図1
Description
本発明は,タンパク質の機能解析方法,及び機能抑制方法などに関する。より詳細には,本発明は,真核細胞に普遍的な機能であるユビキチン依存型タンパク質分解系を利用して,特定のタンパク質を選択的に分解することによりタンパク質の機能を解析・抑制する方法や,それを利用したノックアウト生物の作出方法などに関する。
タンパク質の多くは単体で機能するのではなく,複合体を形成してその機能を発揮する。そのため,興味の対象であるタンパク質が,生体内でどのようなタンパク質と相互作用し,どのような機能を持つのかということを調べることは,重要である。したがって,ある特定のタンパク質の結合相手を決定する手法,及び複合体の機能を解明する手法を確立することが期待される。
一方,高等動植物細胞ではユビキチン化を受けたタンパク質が選択的に分解され,これは生体の維持に重要な役割を果たすとされている。ユビキチン依存型タンパク質分解系は,生体内に普遍的に存在しており,様々な研究が行われている(文献名:Pickart, C.M. (2001) Annu. Rev. Biochem. 70, 503-533)。たとえば,イネのユビキチン依存型タンパク質分解系において標的タンパク質を選択的にユビキチン化する酵素(ユビキチンリガーゼ:E3)の一つであるEL5と呼ばれる酵素の部分構造及び活性相関が解明され,リングフィンガードメインがユビキチン結合酵素(E2)との相互作用に必須であることが知られている(下記非特許文献1(Katoh et al. (2003), J. Biol. Chem. 278(17), 15341-15348)参照。)。しかし,ユビキチン依存型タンパク質分解系を利用して,タンパク質の機能を解明又は抑制した報告はない。
Katoh et al. (2003), J. Biol. Chem. 278(17), 15341-15348.
本発明の目的は,ユビキチン依存型タンパク質分解系を利用してタンパク質を選択的に分解することにより,タンパク質の機能を解析する方法を提供することである。本発明の別の目的は,RNAiなどによって機能を解析できないタンパク質の機能を解明できる新たな機能解析方法を提供することである。
本発明の別の目的は,ユビキチン依存型タンパク質分解系を利用してタンパク質を分解することにより,タンパク質の機能を抑制した非ヒトノックアウト動物又はノックアウト植物の製造方法を提供することである。
本発明は,基本的には,ユビキチン修飾化により所定のタンパク質が分解されるという機能を応用したものである。すなわち,標的タンパク質(タンパク質A)と,ユビキチン結合酵素と相互作用できるタンパク質(RFD)とを融合したタンパク質(タンパク質A−RFD)複合体を発現する。そして,タンパク質Aと結合するタンパク質Xをユビキチン修飾化することにより分解する。これにより,タンパク質Xなどの機能を解明等するものである。
本発明の第1の側面は,
標的タンパク質(タンパク質A)と,ユビキチン結合酵素と相互作用できるタンパク質(RFD)とを融合したタンパク質(タンパク質A−RFD)を用い,
前記標的タンパク質と複合体を形成し,ユビキチン修飾化されることにより分解されるタンパク質(タンパク質X)の機能,又は前記タンパク質Aと前記タンパク質Xとの複合体タンパク質(タンパク質A−X複合体)の機能を解析する方法であって,
前記タンパク質A−RFDを生体内で発現させ,
前記タンパク質Aと前記タンパク質Xとの複合体を形成させ,
前記RFDと相互作用したユビキチン結合酵素に結合したユビキチンを前記タンパク質Xに転移させることにより,前記タンパク質Xを分解し,タンパク質X,又はタンパク質A−X複合体の機能を失活させ,
タンパク質X,又はタンパク質A−X複合体の機能を解析し,
ここで,前記“ユビキチン結合酵素と相互作用できるタンパク質(RFD)”が,
配列番号1に記載されるアミノ酸配列において134-181番のアミノ酸配列からなるタンパク質,
又は配列番号1に記載されるアミノ酸配列において134-181番のアミノ酸配列から1〜4個のアミノ酸残基が置換,欠損,付加又は挿入したアミノ酸配列からなるタンパク質である,
タンパク質の機能解析方法であって,
前記タンパク質A−RFDは,タンパク質AとRFDとがリンカーにより結合され,
前記リンカーは,配列番号13又は配列番号14に記載されるアミノ酸配列からなるリンカー,
又は,配列番号13又は配列番号14に記載されるアミノ酸配列から1〜4個のアミノ酸残基が置換,欠損,付加又は挿入したアミノ酸配列からなるリンカーである,
タンパク質の機能解析方法に関する。
標的タンパク質(タンパク質A)と,ユビキチン結合酵素と相互作用できるタンパク質(RFD)とを融合したタンパク質(タンパク質A−RFD)を用い,
前記標的タンパク質と複合体を形成し,ユビキチン修飾化されることにより分解されるタンパク質(タンパク質X)の機能,又は前記タンパク質Aと前記タンパク質Xとの複合体タンパク質(タンパク質A−X複合体)の機能を解析する方法であって,
前記タンパク質A−RFDを生体内で発現させ,
前記タンパク質Aと前記タンパク質Xとの複合体を形成させ,
前記RFDと相互作用したユビキチン結合酵素に結合したユビキチンを前記タンパク質Xに転移させることにより,前記タンパク質Xを分解し,タンパク質X,又はタンパク質A−X複合体の機能を失活させ,
タンパク質X,又はタンパク質A−X複合体の機能を解析し,
ここで,前記“ユビキチン結合酵素と相互作用できるタンパク質(RFD)”が,
配列番号1に記載されるアミノ酸配列において134-181番のアミノ酸配列からなるタンパク質,
又は配列番号1に記載されるアミノ酸配列において134-181番のアミノ酸配列から1〜4個のアミノ酸残基が置換,欠損,付加又は挿入したアミノ酸配列からなるタンパク質である,
タンパク質の機能解析方法であって,
前記タンパク質A−RFDは,タンパク質AとRFDとがリンカーにより結合され,
前記リンカーは,配列番号13又は配列番号14に記載されるアミノ酸配列からなるリンカー,
又は,配列番号13又は配列番号14に記載されるアミノ酸配列から1〜4個のアミノ酸残基が置換,欠損,付加又は挿入したアミノ酸配列からなるリンカーである,
タンパク質の機能解析方法に関する。
本発明の第2の側面は,標的タンパク質(タンパク質A)と,ユビキチン結合酵素と相互作用できるタンパク質(RFD)とを融合したタンパク質(タンパク質A−RFD)を用い,前記標的タンパク質と複合体を形成し,ユビキチン修飾化されることにより分解されるタンパク質(タンパク質X)の機能,又は前記タンパク質Aと前記タンパク質Xとの複合体タンパク質(タンパク質A−X)の機能を破壊したヒト以外のノックアウト動物又はノックアウト植物の製造方法であって,
前記タンパク質A−RFDを生体内で発現させ,
前記タンパク質Aと前記タンパク質Xとの複合体を形成させ,
前記RFDと相互作用したユビキチン結合酵素に結合したユビキチンを前記タンパク質Xに転移させることにより,前記タンパク質Xの機能又は前記タンパク質A−Xの機能を失活させ,
ヒト以外のノックアウト動物又はノックアウト植物を製造し,
ここで,前記“ユビキチン結合酵素と相互作用できるタンパク質(RFD)”が,
配列番号1に記載されるアミノ酸配列において134-181番のアミノ酸配列からなるタンパク質,
又は配列番号1に記載されるアミノ酸配列において134-181番のアミノ酸配列から1〜4個のアミノ酸残基が置換,欠損,付加又は挿入したアミノ酸配列からなるタンパク質である
非ヒトノックアウト動物又はノックアウト植物の製造方法に関する。
前記タンパク質A−RFDを生体内で発現させ,
前記タンパク質Aと前記タンパク質Xとの複合体を形成させ,
前記RFDと相互作用したユビキチン結合酵素に結合したユビキチンを前記タンパク質Xに転移させることにより,前記タンパク質Xの機能又は前記タンパク質A−Xの機能を失活させ,
ヒト以外のノックアウト動物又はノックアウト植物を製造し,
ここで,前記“ユビキチン結合酵素と相互作用できるタンパク質(RFD)”が,
配列番号1に記載されるアミノ酸配列において134-181番のアミノ酸配列からなるタンパク質,
又は配列番号1に記載されるアミノ酸配列において134-181番のアミノ酸配列から1〜4個のアミノ酸残基が置換,欠損,付加又は挿入したアミノ酸配列からなるタンパク質である
非ヒトノックアウト動物又はノックアウト植物の製造方法に関する。
本発明の第2の側面の好ましい態様は,前記タンパク質A−RFDは,タンパク質AとRFDとがリンカーにより結合され,
前記リンカーは,配列番号13又は配列番号14に記載されるアミノ酸配列からなるリンカー,
又は,配列番号13又は配列番号14に記載されるアミノ酸配列から1〜4個のアミノ酸残基が置換,欠損,付加又は挿入したアミノ酸配列からなるリンカーである,
上記に記載の非ヒトノックアウト動物又はノックアウト植物の製造方法に関する。
前記リンカーは,配列番号13又は配列番号14に記載されるアミノ酸配列からなるリンカー,
又は,配列番号13又は配列番号14に記載されるアミノ酸配列から1〜4個のアミノ酸残基が置換,欠損,付加又は挿入したアミノ酸配列からなるリンカーである,
上記に記載の非ヒトノックアウト動物又はノックアウト植物の製造方法に関する。
本発明の第2の側面の好ましい態様は,前記タンパク質Aが,
配列番号5に記載されるアミノ酸配列からなるタンパク質,
配列番号5に記載されるアミノ酸配列から1〜4個のアミノ酸残基が置換,欠損,付加又は挿入したアミノ酸配列からなるタンパク質,
配列番号5に記載されるアミノ酸配列の117-211番目のアミノ酸を有するドメインタンパク質,
又は配列番号5に記載されるアミノ酸配列の117-211番目のアミノ酸配列から1〜4個のアミノ酸残基が置換,欠損,付加又は挿入したアミノ酸配列からなるタンパク質であり,
前記タンパク質Xが,
配列番号6に記載されるタンパク質(SLR1),
又は配列番号6に記載されるアミノ酸配列から1〜4個のアミノ酸残基が置換,欠損,付加又は挿入したアミノ酸配列からなるタンパク質である
上記に記載の非ヒトノックアウト動物又はノックアウト植物の製造方法に関する。
配列番号5に記載されるアミノ酸配列からなるタンパク質,
配列番号5に記載されるアミノ酸配列から1〜4個のアミノ酸残基が置換,欠損,付加又は挿入したアミノ酸配列からなるタンパク質,
配列番号5に記載されるアミノ酸配列の117-211番目のアミノ酸を有するドメインタンパク質,
又は配列番号5に記載されるアミノ酸配列の117-211番目のアミノ酸配列から1〜4個のアミノ酸残基が置換,欠損,付加又は挿入したアミノ酸配列からなるタンパク質であり,
前記タンパク質Xが,
配列番号6に記載されるタンパク質(SLR1),
又は配列番号6に記載されるアミノ酸配列から1〜4個のアミノ酸残基が置換,欠損,付加又は挿入したアミノ酸配列からなるタンパク質である
上記に記載の非ヒトノックアウト動物又はノックアウト植物の製造方法に関する。
本発明の第2の側面の好ましい態様は,前記タンパク質Aが,
配列番号7に記載されるタンパク質(MAPKP),
配列番号7に記載されるアミノ酸配列の362-467番目のアミノ酸を有するドメインタンパク質,
配列番号7に記載されるアミノ酸配列から1〜4個のアミノ酸残基が置換,欠損,付加又は挿入したアミノ酸配列からなるタンパク質,
又は配列番号7に記載されるアミノ酸配列の362-467番目のアミノ酸配列から1〜4個のアミノ酸残基が置換,欠損,付加又は挿入したアミノ酸配列からなるタンパク質であり,
前記タンパク質Xが,
配列番号8に記載されるタンパク質(CaM1),
配列番号8に記載されるアミノ酸配列から1〜4個のアミノ酸残基が置換,欠損,付加又は挿入したアミノ酸配列からなるタンパク質,
配列番号9に記載されるタンパク質(CaM3),
及び配列番号9に記載されるアミノ酸配列から1〜4個のアミノ酸残基が置換,欠損,付加又は挿入したアミノ酸配列からなるタンパク質のうちいずれか又は二つ以上である
上記に記載の非ヒトノックアウト動物又はノックアウト植物の製造方法に関する。
配列番号7に記載されるタンパク質(MAPKP),
配列番号7に記載されるアミノ酸配列の362-467番目のアミノ酸を有するドメインタンパク質,
配列番号7に記載されるアミノ酸配列から1〜4個のアミノ酸残基が置換,欠損,付加又は挿入したアミノ酸配列からなるタンパク質,
又は配列番号7に記載されるアミノ酸配列の362-467番目のアミノ酸配列から1〜4個のアミノ酸残基が置換,欠損,付加又は挿入したアミノ酸配列からなるタンパク質であり,
前記タンパク質Xが,
配列番号8に記載されるタンパク質(CaM1),
配列番号8に記載されるアミノ酸配列から1〜4個のアミノ酸残基が置換,欠損,付加又は挿入したアミノ酸配列からなるタンパク質,
配列番号9に記載されるタンパク質(CaM3),
及び配列番号9に記載されるアミノ酸配列から1〜4個のアミノ酸残基が置換,欠損,付加又は挿入したアミノ酸配列からなるタンパク質のうちいずれか又は二つ以上である
上記に記載の非ヒトノックアウト動物又はノックアウト植物の製造方法に関する。
本発明の第2の側面の好ましい態様は,前記タンパク質Aが,
配列番号10に記載されるタンパク質(Gγ),
又は配列番号10に記載されるアミノ酸配列から1〜4個のアミノ酸残基が置換,欠損,付加又は挿入したアミノ酸配列からなるタンパク質であり,
前記タンパク質Xが,
配列番号11に記載されるタンパク質(Gβ),
又は配列番号11に記載されるアミノ酸配列から1〜4個のアミノ酸残基が置換,欠損,付加又は挿入したアミノ酸配列からなるタンパク質である
上記に記載の非ヒトノックアウト動物又はノックアウト植物の製造方法に関する。
配列番号10に記載されるタンパク質(Gγ),
又は配列番号10に記載されるアミノ酸配列から1〜4個のアミノ酸残基が置換,欠損,付加又は挿入したアミノ酸配列からなるタンパク質であり,
前記タンパク質Xが,
配列番号11に記載されるタンパク質(Gβ),
又は配列番号11に記載されるアミノ酸配列から1〜4個のアミノ酸残基が置換,欠損,付加又は挿入したアミノ酸配列からなるタンパク質である
上記に記載の非ヒトノックアウト動物又はノックアウト植物の製造方法に関する。
本発明の第2の側面の好ましい態様は,前記タンパク質Aが,
配列番号12に記載されるタンパク質(CIGR2),
又は配列番号12に記載されるアミノ酸配列から1〜4個のアミノ酸残基が置換,欠損,付加又は挿入したアミノ酸配列からなるタンパク質である
上記に記載の非ヒトノックアウト動物又はノックアウト植物の製造方法に関する。
配列番号12に記載されるタンパク質(CIGR2),
又は配列番号12に記載されるアミノ酸配列から1〜4個のアミノ酸残基が置換,欠損,付加又は挿入したアミノ酸配列からなるタンパク質である
上記に記載の非ヒトノックアウト動物又はノックアウト植物の製造方法に関する。
本発明によれば,ユビキチン依存型タンパク質分解系を利用してタンパク質を選択的に分解することにより,タンパク質の機能を解析する方法を提供することができる。
本発明によれば,ユビキチン依存型タンパク質分解系を利用してタンパク質を分解することにより,タンパク質の機能を抑制した非ヒトノックアウト動物又はノックアウト植物の製造方法を提供することができる。
(1.タンパク質の機能解析方法,又は非ヒトノックアウト動物又はノックアウト植物の製造方法の概要)
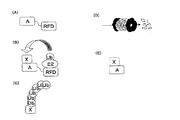
以下,図面に従って,本発明の“タンパク質の機能を解析・抑制する方法”(これらをまとめて“タンパク質の機能を解析する方法”ともいう)について説明する。図1は,本発明の方法に用いられるシステムを説明するための図である。図1(A)は,タンパク質AとRFD(後述)との融合体タンパク質の概念図である。図1(A)に示される例では,タンパク質AとRFDとがリンカーにより接続されている。図1(B)は,ユビキチンとタンパク質Xとが物理的に接近し,タンパク質Xがユビキチン修飾化される様子を示す概念図である。図1(C)は,タンパク質Xがポリユビキチン修飾化され続けポリユビキチンタグが形成される様子を示す概念図である。図1(D)は,ポリユビキチン化されたタンパク質Xが分解されることを示す概念図である。図1(E)は,タンパク質Xが分解され,タンパク質Aとタンパク質Xとの複合体の機能が消滅したことを示す概念図である。なお,図1(E)では,タンパク質Xが分解されたことを示すために,タンパク質Xが点線で表されている。
以下,図面に従って,本発明の“タンパク質の機能を解析・抑制する方法”(これらをまとめて“タンパク質の機能を解析する方法”ともいう)について説明する。図1は,本発明の方法に用いられるシステムを説明するための図である。図1(A)は,タンパク質AとRFD(後述)との融合体タンパク質の概念図である。図1(A)に示される例では,タンパク質AとRFDとがリンカーにより接続されている。図1(B)は,ユビキチンとタンパク質Xとが物理的に接近し,タンパク質Xがユビキチン修飾化される様子を示す概念図である。図1(C)は,タンパク質Xがポリユビキチン修飾化され続けポリユビキチンタグが形成される様子を示す概念図である。図1(D)は,ポリユビキチン化されたタンパク質Xが分解されることを示す概念図である。図1(E)は,タンパク質Xが分解され,タンパク質Aとタンパク質Xとの複合体の機能が消滅したことを示す概念図である。なお,図1(E)では,タンパク質Xが分解されたことを示すために,タンパク質Xが点線で表されている。
図1に示されるように,本発明の“タンパク質の機能を解析する方法”は,以下の通りである。標的タンパク質(タンパク質A)とユビキチン結合酵素と相互作用できるタンパク質(RFD)とを融合させた複合タンパク質(A−RFD)を形成する(図1(A))。そして,前記タンパク質A−RFDの標的タンパク質(タンパク質A)と,ユビキチン修飾化により分解するタンパク質Xとを相互作用させ,複合体(タンパク質A−X複合体)を形成する(図1(B))。するとRFDと相互作用したユビキチン結合酵素(E2)に連結されたユビキチン(図1(C))が,タンパク質Xに転移し,タンパク質Xがユビキチン修飾化されることにより分解される(図1(D))。このようにすれば,タンパク質X,又はタンパク質Xとタンパク質Aとの複合体タンパク質の機能を解析できる。また,それらの機能を破壊した生物を作出できる。以下では,本明細書において用いられる用語などについて説明する。なお,本明細書では,ポリペプチドも含めて“タンパク質”と表現する。
(1.1.
タンパク質X)
“ユビキチン修飾化されることにより分解されるタンパク質” (以下,「タンパク質X」ともいう)は,ユビキチン修飾化されることにより分解されるものである。またタンパク質Xは,後述のタンパク質Aと相互作用することにより複合体を形成し,その結果,タンパク質X,又はタンパク質Aとタンパク質Xとの複合体タンパク質が機能を発揮するものであれば,特に限定されない。そして,好ましくは,タンパク質Xは,本発明によってその機能が解明され,またその機能を抑制(破壊)される。
タンパク質X)
“ユビキチン修飾化されることにより分解されるタンパク質” (以下,「タンパク質X」ともいう)は,ユビキチン修飾化されることにより分解されるものである。またタンパク質Xは,後述のタンパク質Aと相互作用することにより複合体を形成し,その結果,タンパク質X,又はタンパク質Aとタンパク質Xとの複合体タンパク質が機能を発揮するものであれば,特に限定されない。そして,好ましくは,タンパク質Xは,本発明によってその機能が解明され,またその機能を抑制(破壊)される。
なお,タンパク質Xが“ユビキチン修飾化”されるとは,タンパク質Xのリシン残基のε(イプシロン)-アミノ基がユビキチンのC末端グリシンのカルボキシル基と縮合してイソペプチド結合を形成し,さらにユビキチン自身のリシン残基のε-アミノ基が他のユビキチンのC末端グリシンのカルボキシル基と縮合反応を繰り返し,ポリユビキチンタグ(又はユビキチンタグ)を形成することを意味する。その結果,本発明では,タンパク質Xが分解され,その機能が破壊される。そのようなポリユビキチンタグの形成(ユビキチン修飾化)は,ユビキチンがチオエステル化したユビキチン結合酵素と,タンパク質Xが物理的に接近することにより引き起こされる。一般的に,“ユビキチン修飾化”とは,ユビキチンによるタンパク質の翻訳後の修飾反応を意味し,ユビキチンのカルボキシル基とタンパク質のリシン残基のε-アミノ基が結合する反応である。タンパク質に結合した第一のユビキチンのアミノ酸残基のうち,リシンのε-アミノ基に第二のユビキチンが結合し,この反応が繰り返されてタンパク質の特定のリシン残基に多数のユビキチン分子が結合する(ポリユビキチン化)。そして,このポリユビキチン化されたタンパク質は26Sプロテアソーム等のタンパク質分解酵素により分解されることとなる。
タンパク質Xとして,具体的には,配列番号6に記載されるアミノ酸配列からなるタンパク質(SLR1),配列番号8に記載されるアミノ酸配列からなるタンパク質(CaM1),配列番号9に記載されるアミノ酸配列からなるタンパク質(CaM3),配列番号11に記載されるアミノ酸配列からなるタンパク質(Gβ),及びこれらのアミノ酸配列から1〜数個(2,3,4,5個)のアミノ酸が置換・欠損・付加又は挿入したタンパク質があげられる。
(1.2.
タンパク質A)
標的タンパク質(以下,「タンパク質A」ともいう)は,ユビキチン結合酵素と相互作用できるタンパク質(RFD)と,リンカーなどにより連結されうるタンパク質である。タンパク質Aは,RFDと融合タンパク質を形成した状態で,生体内においてタンパク質Xと複合体を形成する。タンパク質Aとタンパク質Xとは,複合体タンパク質(タンパク質A−X複合体)を形成することにより,その機能が発現するものであってもよい。
タンパク質A)
標的タンパク質(以下,「タンパク質A」ともいう)は,ユビキチン結合酵素と相互作用できるタンパク質(RFD)と,リンカーなどにより連結されうるタンパク質である。タンパク質Aは,RFDと融合タンパク質を形成した状態で,生体内においてタンパク質Xと複合体を形成する。タンパク質Aとタンパク質Xとは,複合体タンパク質(タンパク質A−X複合体)を形成することにより,その機能が発現するものであってもよい。
具体的なタンパク質Aとして配列番号5(NCBI accession (アクセッション) No.BAC81428)に記載されるアミノ酸配列からなるタンパク質(GID2),配列番号5に記載されるアミノ酸配列の117-211番目をドメインタンパク質,配列番号7(NCBI accession No.BAD00043)に記載されるアミノ酸を有するタンパク質(MAPKP),配列番号7に記載されるアミノ酸配列の362-467番目のアミノ酸を有するドメインタンパク質,配列番号10(NCBI accession No. BAA07405)に記載されるアミノ酸配列からなるタンパク質(Gγ),配列番号12(NCBI accession No. AAL62810)に記載されるアミノ酸配列からなるタンパク質(CIGR2),及びこれらから1個〜数個(2,3,4,5個)のアミノ酸が置換・欠失・付加又は挿入したタンパク質があげられる。
上記のタンパク質Aが,上記のタンパク質Xとの複合体を形成することについては,
“Gomi et al., (2004) Plant J. 37, 626-34.”; “Yamakawa et al., (2004) J Biol Chem. 279, 928-36.”;及び“kato et al., (2004) Plant J. 2004 Apr;38(2):320-31.”に記載されている。
“Gomi et al., (2004) Plant J. 37, 626-34.”; “Yamakawa et al., (2004) J Biol Chem. 279, 928-36.”;及び“kato et al., (2004) Plant J. 2004 Apr;38(2):320-31.”に記載されている。
(1.3.
RFD)
“ユビキチン結合酵素と相互作用できるタンパク質”(本明細書において,その代表例であるリングフィンガードメインにちなんで「RFD」ともいう)は,ユビキチン結合酵素と相互作用できるタンパク質であり,しかもタンパク質Aと融合タンパク質(タンパク質A−RFD)を形成しうるものであれば,特に限定されない。
RFD)
“ユビキチン結合酵素と相互作用できるタンパク質”(本明細書において,その代表例であるリングフィンガードメインにちなんで「RFD」ともいう)は,ユビキチン結合酵素と相互作用できるタンパク質であり,しかもタンパク質Aと融合タンパク質(タンパク質A−RFD)を形成しうるものであれば,特に限定されない。
具体的なRFDとして,配列番号1(NCBI accessionNo.BAD16550(EL5))に記載されるアミノ酸配列の134-181番目のアミノ酸配列からなるタンパク質(Takai et al.,
(2002) Plant J. 30(4), 447-55.),配列番号2(NCBI accession No. NP 201297(CIP8))の257-297番目のアミノ酸配列からなるタンパク質(Hardtke et al., (2002) Plant J. 30(4),385-94.),配列番号3(NCBI accession No. NP 974506(Rma1))の48-101番目のアミノ酸配列からなるタンパク質(Matsuda et al.,
(2001) J. Cell Sci. 114, 1949-1957.),配列番号4(NCBI accession No. NP AAL26903(Hrd1))の272-343番目のアミノ酸配列からなるタンパク質(Marjolein et al., (2004) J. Biol. Chem. 279 3525-3534.),及びこれらのアミノ酸配列から1個〜数個(2,3,4,又は5個)のアミノ酸が置換・欠失・付加又は挿入したタンパク質があげられる。
(2002) Plant J. 30(4), 447-55.),配列番号2(NCBI accession No. NP 201297(CIP8))の257-297番目のアミノ酸配列からなるタンパク質(Hardtke et al., (2002) Plant J. 30(4),385-94.),配列番号3(NCBI accession No. NP 974506(Rma1))の48-101番目のアミノ酸配列からなるタンパク質(Matsuda et al.,
(2001) J. Cell Sci. 114, 1949-1957.),配列番号4(NCBI accession No. NP AAL26903(Hrd1))の272-343番目のアミノ酸配列からなるタンパク質(Marjolein et al., (2004) J. Biol. Chem. 279 3525-3534.),及びこれらのアミノ酸配列から1個〜数個(2,3,4,又は5個)のアミノ酸が置換・欠失・付加又は挿入したタンパク質があげられる。
導入するタンパク質A-RFD融合タンパク質の遺伝子は、宿主に応じて選択することが望ましい。たとえば植物にはRFD領域が配列番号1(NCBI accession No.BAD16550(EL5))に記載されるアミノ酸配列の134-181番目のアミノ酸配列からなるタンパク質をコードする遺伝子,配列番号2(NCBI accession No. NP 201297(CIP8))の257-297番目のアミノ酸配列からなるタンパク質をコードする遺伝子,配列番号3(NCBI accession No. NP 974506(Rma1))の48-101番目のアミノ酸配列からなるタンパク質をコードする遺伝子が好ましい。一方、動物(ヒト又は非ヒト動物)には配列番号4(NCBI accession No. NP AAL26903(Hrd1))の272-343番目のアミノ酸配列からなるタンパク質をコードする遺伝子が好ましい。
(1.4.
E2)
ユビキチン結合酵素(以下,「E2」ともいう)は,ユビキチンを他のタンパク質に転移しうる酵素であれば,特に限定されない。しかし、導入するRFDに相互作用するE2には特異性がある。例えば、上記した配列番号1又は配列番号1に記載されるアミノ酸配列の134-181番目のアミノ酸配列からなるRFDに対応したE2として,OsUbc5b, Ubc4,及び UbcH5があげられる(Takai et al. (2002) Plant J.
30(4) 1-10.).上記した配列番号2又は配列番号2の257-297番目のアミノ酸配列からなるRFDに対応したE2として,UbcH5aがあげられる(Matsuda et al., (2001)J. Cell Sci. 114(10) 1949-1957.)。また,上記した配列番号3又は配列番号3の48-101番目のアミノ酸配列からなるRFDに対応したE2として,AtUBC7があげられる(Hardtke et al., (2002) Plant J.30 (4) 385-94.)。上記した配列番号4又は配列番号4の272-343番目のアミノ酸配列からなるRFDに対応したE2として,Ubc4p, UbcH5b 及びUbc7があげられる(Kikkert et al., (2004)
279 3525-3534.)。ただし、E2の選択性は種を超えて保存されている。
E2)
ユビキチン結合酵素(以下,「E2」ともいう)は,ユビキチンを他のタンパク質に転移しうる酵素であれば,特に限定されない。しかし、導入するRFDに相互作用するE2には特異性がある。例えば、上記した配列番号1又は配列番号1に記載されるアミノ酸配列の134-181番目のアミノ酸配列からなるRFDに対応したE2として,OsUbc5b, Ubc4,及び UbcH5があげられる(Takai et al. (2002) Plant J.
30(4) 1-10.).上記した配列番号2又は配列番号2の257-297番目のアミノ酸配列からなるRFDに対応したE2として,UbcH5aがあげられる(Matsuda et al., (2001)J. Cell Sci. 114(10) 1949-1957.)。また,上記した配列番号3又は配列番号3の48-101番目のアミノ酸配列からなるRFDに対応したE2として,AtUBC7があげられる(Hardtke et al., (2002) Plant J.30 (4) 385-94.)。上記した配列番号4又は配列番号4の272-343番目のアミノ酸配列からなるRFDに対応したE2として,Ubc4p, UbcH5b 及びUbc7があげられる(Kikkert et al., (2004)
279 3525-3534.)。ただし、E2の選択性は種を超えて保存されている。
なお,“ユビキチン結合酵素(「E2」)が,RFDと相互作用する”とは,主にこれらが結合することを意味するが,疎水的相互作用,電気的相互作用,又は水素結合などにより結合状態が形成されることを含むものとする。
(1.5.
Ub)
ユビキチン(以下,「Ub」ともいう)は,76個のアミノ酸からなるタンパク質である。ユビキチンは,真核生物に普遍的に存在する。ユビキチン(GenBank M26880)は,C末のグリシン残基により,E1(ユビキチン活性化酵素)のシステイン残基と結合した後,E1からE2(ユビキチン結合酵素)に転移される。そして,E3(ユビキチンリガーゼ)によって認識されるタンパク質のリジン側鎖のε(イプシロン)-アミノ基にイソペプチド結合する。タンパク質のリシン残基に結合したユビキチンの48番目のリシン残基にユビキチンのC末端がイソペプチド結合を繰り返す。これにより,ポリユビキチン鎖が形成される。ユビキチンシステムにより付加されたポリユビキチン鎖が26Sプロテアソームの調節サブユニットによる認識シグナルとして機能し,ユビキチン化されたタンパク質はプロテアソームにより分解される。ユビキチンは,タンパク質分解の目印として機能する他,遺伝子発現の調節,ストレス応答,リボソーム生合成,DNA修復,細胞周期制御など,種々の生体応答に関与することが知られている。
Ub)
ユビキチン(以下,「Ub」ともいう)は,76個のアミノ酸からなるタンパク質である。ユビキチンは,真核生物に普遍的に存在する。ユビキチン(GenBank M26880)は,C末のグリシン残基により,E1(ユビキチン活性化酵素)のシステイン残基と結合した後,E1からE2(ユビキチン結合酵素)に転移される。そして,E3(ユビキチンリガーゼ)によって認識されるタンパク質のリジン側鎖のε(イプシロン)-アミノ基にイソペプチド結合する。タンパク質のリシン残基に結合したユビキチンの48番目のリシン残基にユビキチンのC末端がイソペプチド結合を繰り返す。これにより,ポリユビキチン鎖が形成される。ユビキチンシステムにより付加されたポリユビキチン鎖が26Sプロテアソームの調節サブユニットによる認識シグナルとして機能し,ユビキチン化されたタンパク質はプロテアソームにより分解される。ユビキチンは,タンパク質分解の目印として機能する他,遺伝子発現の調節,ストレス応答,リボソーム生合成,DNA修復,細胞周期制御など,種々の生体応答に関与することが知られている。
(1.6.
タンパク質Aとタンパク質Xとの複合体)
“タンパク質Aとタンパク質Xとの複合体”は,タンパク質Xとタンパク質Aとを含む複合体タンパク質である。
タンパク質Aとタンパク質Xとの複合体)
“タンパク質Aとタンパク質Xとの複合体”は,タンパク質Xとタンパク質Aとを含む複合体タンパク質である。
(1.7.
融合タンパク質)
“融合タンパク質”は,タンパク質A及びRFDが連結したタンパク質である。融合タンパク質は,これらのタンパク質が,この順に連結されていてもよい。また,タンパク質A及びRFDの順は反転しても良い。また,それぞれの間にいくつかのアミノ酸残基(リンカー)が挿入されていてもよい。特に,タンパク質Aと,RFDとの間には,所定のアミノ酸残基からなるリンカー部が設けられていることが好ましい。このようなリンカー部を有するので,タンパク質Xと,ユビキチンとが生体内で相互作用しやすくなる。よって,このような観点からタンパク質Aと,RFDとの間のリンカー部のアミノ酸残基の数として,1〜100,5〜40,及び5〜20があげられ,好ましくは,30〜60であり,より好ましくは,40〜50である。例えば,タンパク質Aが,S−tagの系では,好ましくは,このリンカー部のアミノ酸残基の数を30〜40となるように設計する。リンカーに用いるアミノ酸シーケンスは、特定の二次構造を形成せず、ランダムコイルを形成するものが望ましい。このようなリンカーとして,配列番号13及び配列番号14に記載されるアミノ酸配列からなるリンカーや,これらの部分配列からなるリンカー,及び配列番号13及び配列番号14に記載されるアミノ酸配列から1〜4個のアミノ酸残基が置換,欠損,付加又は挿入したアミノ酸配列からなるリンカーなどがあげられる。
融合タンパク質)
“融合タンパク質”は,タンパク質A及びRFDが連結したタンパク質である。融合タンパク質は,これらのタンパク質が,この順に連結されていてもよい。また,タンパク質A及びRFDの順は反転しても良い。また,それぞれの間にいくつかのアミノ酸残基(リンカー)が挿入されていてもよい。特に,タンパク質Aと,RFDとの間には,所定のアミノ酸残基からなるリンカー部が設けられていることが好ましい。このようなリンカー部を有するので,タンパク質Xと,ユビキチンとが生体内で相互作用しやすくなる。よって,このような観点からタンパク質Aと,RFDとの間のリンカー部のアミノ酸残基の数として,1〜100,5〜40,及び5〜20があげられ,好ましくは,30〜60であり,より好ましくは,40〜50である。例えば,タンパク質Aが,S−tagの系では,好ましくは,このリンカー部のアミノ酸残基の数を30〜40となるように設計する。リンカーに用いるアミノ酸シーケンスは、特定の二次構造を形成せず、ランダムコイルを形成するものが望ましい。このようなリンカーとして,配列番号13及び配列番号14に記載されるアミノ酸配列からなるリンカーや,これらの部分配列からなるリンカー,及び配列番号13及び配列番号14に記載されるアミノ酸配列から1〜4個のアミノ酸残基が置換,欠損,付加又は挿入したアミノ酸配列からなるリンカーなどがあげられる。
(2.作用)
タンパク質Xは,RFDと結合したユビキチン化されたE2からユビキチンの転移反応によりユビキチン化され,プロテアソームにより分解される。タンパク質Xが分解されると,複合体タンパク質A−Xの機能又はタンパク質Xの機能が破壊される。この作用を利用すれば,目的とするタンパク質である複合タンパク質A−Xの機能又はタンパク質Xの機能を解析及び抑制できる。なお,タンパク質Xは,1種類であるとは限らず,複数種類(X1, X2,・・・)が存在する場合もある。また,タンパク質Xは複数のドメインを構成するものも含まれる。そこで,以下では,タンパク質Xを場合分けして,本発明のタンパク質の機能を解析する方法をより具体的に説明する。
タンパク質Xは,RFDと結合したユビキチン化されたE2からユビキチンの転移反応によりユビキチン化され,プロテアソームにより分解される。タンパク質Xが分解されると,複合体タンパク質A−Xの機能又はタンパク質Xの機能が破壊される。この作用を利用すれば,目的とするタンパク質である複合タンパク質A−Xの機能又はタンパク質Xの機能を解析及び抑制できる。なお,タンパク質Xは,1種類であるとは限らず,複数種類(X1, X2,・・・)が存在する場合もある。また,タンパク質Xは複数のドメインを構成するものも含まれる。そこで,以下では,タンパク質Xを場合分けして,本発明のタンパク質の機能を解析する方法をより具体的に説明する。
(2.1)
タンパク質Xが1種類の系
以下では,タンパク質Aと相互作用するタンパク質Xが1種類の系について説明する。この系では,まずRFDにタンパク質Aを連結し,RFDとタンパク質Aとの融合体タンパク質(タンパク質A−RFD)を作製する。その後,タンパク質Aとタンパク質Xとを相互作用させ,またE2を介して,タンパク質Xを,ユビキチン修飾化することにより,タンパク質Xを分解する。
タンパク質Xが1種類の系
以下では,タンパク質Aと相互作用するタンパク質Xが1種類の系について説明する。この系では,まずRFDにタンパク質Aを連結し,RFDとタンパク質Aとの融合体タンパク質(タンパク質A−RFD)を作製する。その後,タンパク質Aとタンパク質Xとを相互作用させ,またE2を介して,タンパク質Xを,ユビキチン修飾化することにより,タンパク質Xを分解する。
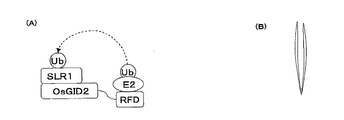
図2は,本発明の“タンパク質の機能を解析する方法”を用いて,イネのタンパク質が分解される例を示す概念図である。図2(A)は,タンパク質分解システムの概略を示す概念図である。図2(B)はイネが徒長する様子を示す図である。図2に示すように,イネにおけるジベレリンシグナルの負の調節因子である配列番号6に記載のアミノ酸配列からなるSLR1(タンパク質Xに相当)は,配列番号5に記載されるアミノ酸配列からなるGID2(タンパク質Aに相当)と相互作用する(文献Gomi
et al., (2004) Plant J. 37, 626-34.)。そこで,GID2(又は配列番号5に記載されるアミノ酸配列のうち117番目〜211番目のアミノ酸配列からなるドメインタンパク質)とRFDとの融合タンパク質を作製し,RFDに結合したE2の作用によりユビキチンをSLR1に転移する。SLR1は,このユビキチンタグによりプロテアソームに認識され,分解される。SLR1は,イネの草丈を抑制する機能を有するため,プロテアソームによりSLR1が分解された後のイネは,徒長する。
et al., (2004) Plant J. 37, 626-34.)。そこで,GID2(又は配列番号5に記載されるアミノ酸配列のうち117番目〜211番目のアミノ酸配列からなるドメインタンパク質)とRFDとの融合タンパク質を作製し,RFDに結合したE2の作用によりユビキチンをSLR1に転移する。SLR1は,このユビキチンタグによりプロテアソームに認識され,分解される。SLR1は,イネの草丈を抑制する機能を有するため,プロテアソームによりSLR1が分解された後のイネは,徒長する。
以下,タンパク質Xが1種類の別の系の例を説明する。シグナル伝達に関与する植物3量体型Gタンパク質は植物の形態形成に重要な役割を持つことが知られている。特にこの中でものサブユニットGβ(配列番号11)とGγの相互作用が強いことが知られている(文献 kato et al.,
(2004) Plant J. 2004 Apr;38(2):320-31.)。この機能に着目し,そのGタンパク質の機能を破壊したイネを作出する。すなわち,イネの3量体型Gタンパク質Gβサブユニットの分解を目的としてGγ−RFDを導入したイネを作出する。まず,配列番号10に記載のアミノ酸配列からなるGタンパク質GγとRFDとの融合タンパク質を公知の方法により作製する。すると,RFDに結合したE2の作用によりユビキチンをGタンパク質Gβに転移する。Gタンパク質Gβは,このユビキチンタグによりプロテアソームに認識され,分解される。Gβサブユニットが分解されることによってイネがわい化し,開茎型になる。このようにすれば,所定のタンパク質の機能をノックアウトした生物を作出できる。
(2004) Plant J. 2004 Apr;38(2):320-31.)。この機能に着目し,そのGタンパク質の機能を破壊したイネを作出する。すなわち,イネの3量体型Gタンパク質Gβサブユニットの分解を目的としてGγ−RFDを導入したイネを作出する。まず,配列番号10に記載のアミノ酸配列からなるGタンパク質GγとRFDとの融合タンパク質を公知の方法により作製する。すると,RFDに結合したE2の作用によりユビキチンをGタンパク質Gβに転移する。Gタンパク質Gβは,このユビキチンタグによりプロテアソームに認識され,分解される。Gβサブユニットが分解されることによってイネがわい化し,開茎型になる。このようにすれば,所定のタンパク質の機能をノックアウトした生物を作出できる。
(2.2)
タンパク質Xが複数種類の系
以下では,タンパク質Xが複数種類の系について説明する。タンパク質の中には,類似した機能を有し,ファミリーを形成するタンパク質が存在する。例えば,カルモジュリン(CaM)は,細胞内のシグナル伝達にかかわる極めて重要なカルシウム結合タンパク質である。動物細胞では,一種類の生物には一または二種類のCaMしか存在しないことが報告されているが,植物では,同じ植物から複数のCaM分子種が存在することが報告されている(文献名:Ishida et al., (2001) J. Biol. Chem. 129, 745-753.)。これらのCaM分子種は,植物間で良く保存されていることから,各分子種ごとに機能分担がされており,進化的に保存されていると考えられる。CaM分子種の中でもCaM1及びCaM3は,MAPキナーゼフォスファターゼ(MAPKP:配列番号7),又はMAPKPのドメインタンパク質(配列番号7に記載されるアミノ酸配列の362〜467番目のアミノ酸配列からなるドメインタンパク質)に結合し耐病性に関与するなど,タンパク質機能が類似していることが知られている。このような場合,RNAiなどの手法を用いてCaM1(配列番号8)又はCaM3(配列番号9)のいずれかをノックアウトしてもその機能は互いに補うことから,機能及び表現型を確認することは困難である。
タンパク質Xが複数種類の系
以下では,タンパク質Xが複数種類の系について説明する。タンパク質の中には,類似した機能を有し,ファミリーを形成するタンパク質が存在する。例えば,カルモジュリン(CaM)は,細胞内のシグナル伝達にかかわる極めて重要なカルシウム結合タンパク質である。動物細胞では,一種類の生物には一または二種類のCaMしか存在しないことが報告されているが,植物では,同じ植物から複数のCaM分子種が存在することが報告されている(文献名:Ishida et al., (2001) J. Biol. Chem. 129, 745-753.)。これらのCaM分子種は,植物間で良く保存されていることから,各分子種ごとに機能分担がされており,進化的に保存されていると考えられる。CaM分子種の中でもCaM1及びCaM3は,MAPキナーゼフォスファターゼ(MAPKP:配列番号7),又はMAPKPのドメインタンパク質(配列番号7に記載されるアミノ酸配列の362〜467番目のアミノ酸配列からなるドメインタンパク質)に結合し耐病性に関与するなど,タンパク質機能が類似していることが知られている。このような場合,RNAiなどの手法を用いてCaM1(配列番号8)又はCaM3(配列番号9)のいずれかをノックアウトしてもその機能は互いに補うことから,機能及び表現型を確認することは困難である。
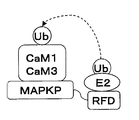
このような系であっても,本発明の“非ヒトノックアウト動物又はノックアウト植物の製造方法”を用いれば,CaM1及びCaM3を同時に分解できるので,CaM1及びCaM3の機能を完全に抑制できる。図3は,本発明の方法を用いたCaM1,CaM3の機能解明・抑制方法を説明する図である。すなわち,CaM1,及びCaM3に結合するMAPKPの一部領域(たとえば,配列番号7に記載されるアミノ酸配列の362〜467番目のアミノ酸配列からなるドメイン)とRFD融合タンパク質をデザインし,CaM1及びCaM3を同時にユビキチン修飾化して分解すればよい。すなわち,本発明は,タンパク質Xが複数種類の系について特に有効に用いることができる。
また,MAPKP(配列番号7)及びMAPKPのドメインタンパク質(配列番号7に記載されるアミノ酸配列の362-467番目のアミノ酸を有するドメインタンパク質)と,CaM1(配列番号8)及びCaM3(配列番号9)が相互作用することは,“Yamakawa et al., (2004) J Biol Chem. 279, 928-36.”に記載されている。
なお,特に詳細に記載しないが,タンパク質Xが複数種類の系においても,タンパク質Xが一種類の系と同様にして所定のタンパク質の機能をノックアウトした生物を作出できる。
(2.3)
タンパク質Xが未知の系
環境刺激によって発現が変化する遺伝子は多数知られている。しかし,それらの機能はほとんど解明されていない。また,他のタンパク質とどのように相互作用し,どのような機能を発現するのか不明なタンパク質も多い。本発明の方法を用いれば,あるタンパク質と相互作用することによって機能を発現するタンパク質を同定できる。すなわち,あるタンパク質と,ユビキチン結合酵素と相互作用することができるタンパク質との融合タンパク質をコードする遺伝子を構築する。この構築された遺伝子を植物体等の宿主に導入する。得られた宿主からタンパク質を抽出し,プロテオーム解析を行う。例えば,植物体から抽出したタンパク質を二次元電気泳動解析及び質量分析にかけ,ユビキチン分解により量が減少しているタンパク質の同定を行う。
タンパク質Xが未知の系
環境刺激によって発現が変化する遺伝子は多数知られている。しかし,それらの機能はほとんど解明されていない。また,他のタンパク質とどのように相互作用し,どのような機能を発現するのか不明なタンパク質も多い。本発明の方法を用いれば,あるタンパク質と相互作用することによって機能を発現するタンパク質を同定できる。すなわち,あるタンパク質と,ユビキチン結合酵素と相互作用することができるタンパク質との融合タンパク質をコードする遺伝子を構築する。この構築された遺伝子を植物体等の宿主に導入する。得られた宿主からタンパク質を抽出し,プロテオーム解析を行う。例えば,植物体から抽出したタンパク質を二次元電気泳動解析及び質量分析にかけ,ユビキチン分解により量が減少しているタンパク質の同定を行う。
本発明においては,キチンオリゴ糖エリシター及びジベレリンで早期に発現が誘導される核タンパク質を解析の対象とすることができる。核タンパク質として,例えば配列番号12に記載されるアミノ酸配列からなるCIGR2(NCBI accession No.
AAL62810)があげられる。CIGR2は,PRタンパク質遺伝子発現の誘導及びジベレリン抑制タンパク質発現の抑制に関与していると考えられ,また,CIGR2は直接DNAに結合するモチーフを持たないことから,他のタンパク質と相互作用することによって機能を発現すると考えられる。そこで,CIGR2と相互作用するタンパク質の同定を行うことができる。
AAL62810)があげられる。CIGR2は,PRタンパク質遺伝子発現の誘導及びジベレリン抑制タンパク質発現の抑制に関与していると考えられ,また,CIGR2は直接DNAに結合するモチーフを持たないことから,他のタンパク質と相互作用することによって機能を発現すると考えられる。そこで,CIGR2と相互作用するタンパク質の同定を行うことができる。
(2.4.タンパク質の組み合わせ例)
上記したタンパク質X,タンパク質A及びRFDの好ましい組合せとして,以下ものがあげられる。
(1)タンパク質X:配列番号6に記載されるアミノ酸配列からなるタンパク質(SLR1),
タンパク質A: 配列番号5に記載されるアミノ酸配列からなるタンパク質(GID2),及び/又は配列番号5に記載されるアミノ酸配列の117-211番目のアミノ酸配列からなるタンパク質,
RFD:配列番号1(EL5)に記載されるアミノ酸配列の134-181番目のアミノ酸配列からなるタンパク質(Gomi et al.,
(2004) Plant J. 37, 626-34.);
(2)タンパク質X:配列番号8に記載されるアミノ酸配列からなるタンパク質(CaM1)及び配列番号9に記載されるアミノ酸配列からなるタンパク質(CaM3),
タンパク質A:配列番号7に記載されるアミノ酸配列からなるタンパク質(MAPKP),及び/又は配列番号7に記載されるアミノ酸配列の362−467番目のアミノ酸を有するドメインタンパク質,
RFD:配列番号1(EL5)に記載されるアミノ酸配列の134-181番目のアミノ酸配列からなるタンパク質 (Yamakawa et al.,
(2004) J Biol Chem. 279, 928-36.) ;及び
(3)タンパク質X: 配列番号11に記載されるアミノ酸配列からなるタンパク質(Gβ),
タンパク質A: 配列番号10に記載されるアミノ酸配列からなるタンパク質(Gγ),
RFD:配列番号1(EL5)に記載されるアミノ酸配列の134-181番目のアミノ酸配列からなるタンパク質(kato et al.,
(2004) Plant J. 2004 Apr;38(2):320-31.)である。
上記したタンパク質X,タンパク質A及びRFDの好ましい組合せとして,以下ものがあげられる。
(1)タンパク質X:配列番号6に記載されるアミノ酸配列からなるタンパク質(SLR1),
タンパク質A: 配列番号5に記載されるアミノ酸配列からなるタンパク質(GID2),及び/又は配列番号5に記載されるアミノ酸配列の117-211番目のアミノ酸配列からなるタンパク質,
RFD:配列番号1(EL5)に記載されるアミノ酸配列の134-181番目のアミノ酸配列からなるタンパク質(Gomi et al.,
(2004) Plant J. 37, 626-34.);
(2)タンパク質X:配列番号8に記載されるアミノ酸配列からなるタンパク質(CaM1)及び配列番号9に記載されるアミノ酸配列からなるタンパク質(CaM3),
タンパク質A:配列番号7に記載されるアミノ酸配列からなるタンパク質(MAPKP),及び/又は配列番号7に記載されるアミノ酸配列の362−467番目のアミノ酸を有するドメインタンパク質,
RFD:配列番号1(EL5)に記載されるアミノ酸配列の134-181番目のアミノ酸配列からなるタンパク質 (Yamakawa et al.,
(2004) J Biol Chem. 279, 928-36.) ;及び
(3)タンパク質X: 配列番号11に記載されるアミノ酸配列からなるタンパク質(Gβ),
タンパク質A: 配列番号10に記載されるアミノ酸配列からなるタンパク質(Gγ),
RFD:配列番号1(EL5)に記載されるアミノ酸配列の134-181番目のアミノ酸配列からなるタンパク質(kato et al.,
(2004) Plant J. 2004 Apr;38(2):320-31.)である。
なお,特に詳細に記載しないが,タンパク質Xが未知の系においても,タンパク質Xが一種類の系と同様にして所定のタンパク質の機能をノックアウトした生物を作出できる。
(3.機能解析・抑制方法)
以下では,本発明に係る“タンパク質の機能を解析・抑制する方法”の例を説明する。本発明の方法は,基本的には特に説明するまでもなく,バイオテクノロジーの分野における公知の手法を用いることにより達成できる。
以下では,本発明に係る“タンパク質の機能を解析・抑制する方法”の例を説明する。本発明の方法は,基本的には特に説明するまでもなく,バイオテクノロジーの分野における公知の手法を用いることにより達成できる。
(3.1.
融合タンパク質生成工程)
融合タンパク質(タンパク質A−RFD)を生成するためには,バイオテクノロジーの分野で行われている常法に従って,タンパク質A及びRFDを含む融合タンパク質をコードする遺伝子(以下,これらを「融合遺伝子(A−RFD)」ともいう。)を設計し,タンパク質を生成すればよい。なお,遺伝子を設計する際に,好ましくは,先に説明したとおり,ユビキチンがタンパク質Xと相互作用しやすくなるようにリンカー部分となる遺伝子を設計する。
融合タンパク質生成工程)
融合タンパク質(タンパク質A−RFD)を生成するためには,バイオテクノロジーの分野で行われている常法に従って,タンパク質A及びRFDを含む融合タンパク質をコードする遺伝子(以下,これらを「融合遺伝子(A−RFD)」ともいう。)を設計し,タンパク質を生成すればよい。なお,遺伝子を設計する際に,好ましくは,先に説明したとおり,ユビキチンがタンパク質Xと相互作用しやすくなるようにリンカー部分となる遺伝子を設計する。
タンパク質A及びRFDを含む融合タンパク質をコードする遺伝子は,当業者が通常行うクローニング手法により得ることができる。具体的には,mRNAからcDNAライブラリーを作製し,スクリーニングする方法があげられる。mRNAの調製,RT-PCR法などは,市販のキットを用いることにより容易に実施することが可能である。例えば,mRNAの調製にはISOGEN(日本ジーン社製),Oligotexシリーズキット(タカラバイオ社)を使用することができ,RT-PCRには“SuperScriptTM One-StepTMRT-PCR System”などを使用することができる。また,各遺伝子の塩基配列は,市販のライブラリーから入手し,化学的に合成してもよい。
このようにして得られたDNAをプラスミド等の適当なクローニングベクターに組み込んで組換えベクターを作製する。また,プラスミド以外のクローニングベクター,例えばλファージ等を用いることもできる。
cDNAの塩基配列が部分的に判明しているときは,いわゆるRACE(Rapid Amplification cDNA ends)法を採用してもよい。RACE法も当分野において周知であり,市販のキット,例えばGENE
RACER(インビトロジェン社製),“SMART RACE cDNA Amplification kit” (クロンテック社製)などを使用して行うことができる。
RACER(インビトロジェン社製),“SMART RACE cDNA Amplification kit” (クロンテック社製)などを使用して行うことができる。
融合遺伝子(A−RFD)は,ベクター内の所定の制限酵素部位において,一方のDNAを適当な制限酵素で切断し,これに,同じ制限酵素で切断しておいた他方のDNAを,該DNAによりコードされるタンパク質のアミノ酸配列の読み枠がずれないように連結し増幅すればよい。この際,遺伝子の向きは任意であり,同じ方向であっても,互いに向き合う方向でもよい。
先に説明したとおり,本発明においては,遺伝子を融合するために用いる複数の遺伝子結合領域に,それぞれの遺伝子翻訳産物が適切に機能するコンフォメーションがとれるように人工的なヌクレオチド配列(リンカー)を挿入することもが好ましい。例えば図1において,タンパク質A遺伝子とRFD遺伝子との間にリンカーとなる配列を挿入する。リンカーの長さは,タンパク質Aの立体構造,実験結果等を考慮して適宜設定することができ,例えばリンカーが短い場合(0〜20塩基)はユビキチン化が阻害または低下する。好ましくは30〜50塩基である。リンカーは,通常の化学合成により得ることができる。
融合遺伝子が目的のものであるかを確認するため,得られたクローン又はDNA断片について塩基配列を決定してもよい。塩基配列は公知の方法により決定すればよく,例えば,自動塩基配列決定機を用いて塩基配列を決定してもよい。
タンパク質A及びRFDを含む融合タンパク質をコードする遺伝子は,機能解析の目的に応じて,当分野において周知の部位特異的突然変異誘発法によって,変異体を作製して用いることもできる。変異誘発法は,市販の部位特異的突然変異誘発用キットを用いて行うことができる(例えば“TaKaRa Site-Directed Mutagenesis System(Mutan-K,Mutan-Super Express Km”(タカラバイオ)等)。
上記融合遺伝子は,目的となる遺伝子が発現し得るように宿主中に導入することで,形質転換体を得ることができる。形質転換は,宿主などに応じて適宜選択することができ,例えばカルシウムイオンを用いる方法,エレクトロポレーション法,スフェロプラスト法,酢酸リチウム法等,リン酸カルシウム法,リポフェクション法,アグロバクテリウム法など公知の方法を採用でき,具体的には,“Sambrook J and Russel D. Molecular Cloning, A Laboratory Manual, 3rd
edition, CSHL Press, 2001”に記載の方法を採用すればよい。
edition, CSHL Press, 2001”に記載の方法を採用すればよい。
上記形質転換における宿主は,特に限定されない。宿主として,例えば,エッシェリヒア属,バチルス属等の細菌,サッカロミセス,シゾサッカロミセス等の酵母,植物体(カルス,植物培養細胞,植物生体を含む),動物細胞,昆虫細胞等があげられる。
(3.2.
タンパク質分解工程)
本発明では,タンパク質Xが,RFDと相互作用したユビキチン結合酵素からユビキチンの転移を受け,タンパク質Xがユビキチン修飾化されることによりユビキチン化され,その結果タンパク質Xが分解される。これにより,目的とするタンパク質の機能がどのように変化するのかを解析できる。また,同様にして,目的とするタンパク質の機能を抑制できる。目的とするタンパク質の機能を抑制した生物を作出することで,所定のタンパク質の機能をノックアウトした生物を作出できる。
タンパク質分解工程)
本発明では,タンパク質Xが,RFDと相互作用したユビキチン結合酵素からユビキチンの転移を受け,タンパク質Xがユビキチン修飾化されることによりユビキチン化され,その結果タンパク質Xが分解される。これにより,目的とするタンパク質の機能がどのように変化するのかを解析できる。また,同様にして,目的とするタンパク質の機能を抑制できる。目的とするタンパク質の機能を抑制した生物を作出することで,所定のタンパク質の機能をノックアウトした生物を作出できる。
(4.機能の確認)
タンパク質の機能は,公知の方法によって確認できる。以下では,機能が抑制されたことを確認する具体例と,その評価方法について説明する。
タンパク質の機能は,公知の方法によって確認できる。以下では,機能が抑制されたことを確認する具体例と,その評価方法について説明する。
機能を確認するアッセイとして,植物体などの生体内で前記融合遺伝子を発現させ,得られる反応産物を抽出して解析する方法があげられる。解析法は,二次元電気泳動,ウエスタン解析など公知の方法を採用できる。
ユビキチン化には,ユビキチンと上記融合遺伝子のほか,ユビキチン活性化酵素,ユビキチン結合酵素,ユビキチン化に必要な低分子の存在が考えられるため,補助的にこれらの物質の量を測定してもよい。
具体的には,ユビキチン化アッセイは基本的にマツダら(Matsuda te al., (2001) J. Cell.Sci., 114, 1949-1957.)の方法に従って行えばよい。以下では,その具体的な方法の例を説明する。全量75μlの反応液(40 mM
Tris-HCl, pH7.5, 5 mM MgCl2, 2 mM ATP, 2 mM DTT, 300 ng/μl ウシ由来ユビキチン(Sigma), 50 ng マウスE1, 100 ng OsUBC5b:E2)に, 300 ngのA-RFD融合タンパク質を加え,30℃2時間で反応させる。反応終了後,等量のSDS-PAGEサンプルバッファーを加え,100 ℃で5分間加熱し,7.5%ポリアクリルアミドゲルでSDS-PAGEを行う。泳動後,ゲルをPVDFメンブレン(Immobilon-P ;
Millipore)に転写し,5% (w/v)スキムミルクを含むPBS-Tween20 (8.1 mM Na2HPO4, 1.47 mM KH2PO4, 137 mM NaCl, 2.68 mM
KCl, 0.1% Tween20, pH7.4)中で室温30分間振盪することによりブロッキングする。このメンブレンを5000分の1容量の抗MBP抗体(New England Biolabs, Beverly, MA)を含むPBS-Tween20中で4℃一晩反応させる。PBS-Tween20で5分間×3回洗浄した後,4000分の1容量のペルオキシダーゼ標識抗ウサギIgG抗体(Jacskon Immuno
Research)を含むPBS-Tween20で室温1時間反応させる。PBS-Tween20で5分間×3回およびPBSで5分間洗浄後,DABを用いて発色する。
Tris-HCl, pH7.5, 5 mM MgCl2, 2 mM ATP, 2 mM DTT, 300 ng/μl ウシ由来ユビキチン(Sigma), 50 ng マウスE1, 100 ng OsUBC5b:E2)に, 300 ngのA-RFD融合タンパク質を加え,30℃2時間で反応させる。反応終了後,等量のSDS-PAGEサンプルバッファーを加え,100 ℃で5分間加熱し,7.5%ポリアクリルアミドゲルでSDS-PAGEを行う。泳動後,ゲルをPVDFメンブレン(Immobilon-P ;
Millipore)に転写し,5% (w/v)スキムミルクを含むPBS-Tween20 (8.1 mM Na2HPO4, 1.47 mM KH2PO4, 137 mM NaCl, 2.68 mM
KCl, 0.1% Tween20, pH7.4)中で室温30分間振盪することによりブロッキングする。このメンブレンを5000分の1容量の抗MBP抗体(New England Biolabs, Beverly, MA)を含むPBS-Tween20中で4℃一晩反応させる。PBS-Tween20で5分間×3回洗浄した後,4000分の1容量のペルオキシダーゼ標識抗ウサギIgG抗体(Jacskon Immuno
Research)を含むPBS-Tween20で室温1時間反応させる。PBS-Tween20で5分間×3回およびPBSで5分間洗浄後,DABを用いて発色する。
(5.タンパク質Xの同定)
上記の方法を用いれば,タンパク質Aと複合体を形成するタンパク質Xを同定することができる。
すなわち,タンパク質Xは,標的タンパク質(タンパク質A)とユビキチン結合酵素と相互作用できるタンパク質(RFD)とを連結したタンパク質(タンパク質A−RFD)を用い,前記標的タンパク質と複合体を形成しユビキチンと相互作用することにより分解されるタンパク質(タンパク質X)を同定する方法であって,先に説明した手法に従って,複合体タンパク質A−RFDを生体内で発現させ,前記タンパク質Aと前記タンパク質Xとの複合体を形成させ,前記RFDと相互作用したユビキチン結合酵素に結合したユビキチンを前記タンパク質Xに転移し,前記タンパク質Xを破壊し,前記タンパク質Xが破壊された生体からタンパク質を抽出し,減少しているタンパク質を解析することでタンパク質Xを同定することにより標的タンパク質と結合するタンパク質であるタンパク質Xを同定できる。
上記の方法を用いれば,タンパク質Aと複合体を形成するタンパク質Xを同定することができる。
すなわち,タンパク質Xは,標的タンパク質(タンパク質A)とユビキチン結合酵素と相互作用できるタンパク質(RFD)とを連結したタンパク質(タンパク質A−RFD)を用い,前記標的タンパク質と複合体を形成しユビキチンと相互作用することにより分解されるタンパク質(タンパク質X)を同定する方法であって,先に説明した手法に従って,複合体タンパク質A−RFDを生体内で発現させ,前記タンパク質Aと前記タンパク質Xとの複合体を形成させ,前記RFDと相互作用したユビキチン結合酵素に結合したユビキチンを前記タンパク質Xに転移し,前記タンパク質Xを破壊し,前記タンパク質Xが破壊された生体からタンパク質を抽出し,減少しているタンパク質を解析することでタンパク質Xを同定することにより標的タンパク質と結合するタンパク質であるタンパク質Xを同定できる。
(6.
タンパク質Xの分解速度の制御)
タンパク質Xの分解速度は,以下のようにして制御できる。ユビキチン化の効率はRFDと相互作用するユビキチン結合酵素との結合の強度に依存する。RFDとユビキチン結合酵素の相互作用は主に疎水的相互作用と一部静電的相互作用により制御されており、その相互作用に直接関与しているアミノ酸残基を置換することによりRFDとユビキチン結合酵素との結合の強度を制御できる。たとえば,配列番号1に記載されるアミノ酸配列のロイシン138をアラニンに置換したRFD変異体(又はそのような変異体の134〜181番目のアミノ酸配列からなるタンパク質)を用いると,ユビキチン化の効率が減少する。また,配列番号1に記載されるアミノ酸配列のロイシン174をアラニンに置換した変異体(又はそのような変異体の134〜181番目のアミノ酸配列からなるタンパク質)でもユビキチン化の効率が減少する。つまりこれらの変異体は,ユビキチン化の効率を制御できることを示しており、ユビキチン化の効率が減少すれば、プロテアソーム系に認識される効率も減少することとなり、分解が抑制される。すなわち,RFDのアミノ酸配列をわずかに変化させるとユビキチン化の効率が,変化するので,所望の分解速度に応じたRFDを設計することによりタンパク質Xの分解速度を制御できる。このような具体例は,上記に説明したとおり,RFDとして配列番号1に記載されるアミノ酸配列からなるタンパク質(又はそのような変異体の134〜181番目のアミノ酸配列からなるタンパク質)を用いるものと,配列番号1に記載されるアミノ酸配列のうち138番目をアラニンに置換したタンパク質(又はそのような変異体の134〜181番目のアミノ酸配列からなるタンパク質)を用いるものと,配列番号1に記載されるアミノ酸配列のうち174番目をアラニンに置換したタンパク質(又はそのような変異体の134〜181番目のアミノ酸配列からなるタンパク質)を用いるものとを使い分けることによりタンパク質Xの分解速度を制御するものである。
タンパク質Xの分解速度の制御)
タンパク質Xの分解速度は,以下のようにして制御できる。ユビキチン化の効率はRFDと相互作用するユビキチン結合酵素との結合の強度に依存する。RFDとユビキチン結合酵素の相互作用は主に疎水的相互作用と一部静電的相互作用により制御されており、その相互作用に直接関与しているアミノ酸残基を置換することによりRFDとユビキチン結合酵素との結合の強度を制御できる。たとえば,配列番号1に記載されるアミノ酸配列のロイシン138をアラニンに置換したRFD変異体(又はそのような変異体の134〜181番目のアミノ酸配列からなるタンパク質)を用いると,ユビキチン化の効率が減少する。また,配列番号1に記載されるアミノ酸配列のロイシン174をアラニンに置換した変異体(又はそのような変異体の134〜181番目のアミノ酸配列からなるタンパク質)でもユビキチン化の効率が減少する。つまりこれらの変異体は,ユビキチン化の効率を制御できることを示しており、ユビキチン化の効率が減少すれば、プロテアソーム系に認識される効率も減少することとなり、分解が抑制される。すなわち,RFDのアミノ酸配列をわずかに変化させるとユビキチン化の効率が,変化するので,所望の分解速度に応じたRFDを設計することによりタンパク質Xの分解速度を制御できる。このような具体例は,上記に説明したとおり,RFDとして配列番号1に記載されるアミノ酸配列からなるタンパク質(又はそのような変異体の134〜181番目のアミノ酸配列からなるタンパク質)を用いるものと,配列番号1に記載されるアミノ酸配列のうち138番目をアラニンに置換したタンパク質(又はそのような変異体の134〜181番目のアミノ酸配列からなるタンパク質)を用いるものと,配列番号1に記載されるアミノ酸配列のうち174番目をアラニンに置換したタンパク質(又はそのような変異体の134〜181番目のアミノ酸配列からなるタンパク質)を用いるものとを使い分けることによりタンパク質Xの分解速度を制御するものである。
(7.配列番号の説明)
以下では,本明細書に用いる配列番号で示されるタンパク質又は核酸について説明する。
〔1〕配列番号1は,NCBI accession No.BAD16550(EL5)のアミノ酸配列に関する。本明細書では,配列番号1に記載されるアミノ酸配列の134-181番目のアミノ酸配列からなるタンパク質をRFDとして用いた。
〔2〕配列番号2は,NCBI accession No. NP 201297(CIP8)のアミノ酸配列に関する。本明細書では,配列番号2に記載されるアミノ酸配列の257-297番目のアミノ酸配列からなるタンパク質をRFDとして用いた。
〔3〕配列番号3は,NCBI accession No. NP 974506(Rma1)のアミノ酸配列に関する。本明細書では,配列番号3に記載されるアミノ酸配列の48-101番目のアミノ酸配列からなるタンパク質をRFDとして用いた。
〔4〕配列番号4は,NCBI accession No. AAL26903(Hrd1)のアミノ酸配列に関する。本明細書では,配列番号4に記載されるアミノ酸配列の272-343番目のアミノ酸配列からなるタンパク質をRFDとして用いた。
〔5〕配列番号5は, NCBI accession No.BAC81428(GID2)に記載されるアミノ酸配列に関する。本明細書では,配列番号5に記載されるアミノ酸配列からなるタンパク質(GID2),及び配列番号5に記載されるアミノ酸配列の117-211番目のアミノ酸配列からなるドメインタンパク質をタンパク質Aとして用いた。
〔6〕配列番号6は,NCBI accession No.BAB97367(SLR1)のアミノ酸配列に関する。本明細書では,配列番号6に記載されるアミノ酸配列からなるタンパク質をタンパク質Xとして用いた。
〔7〕配列番号7は,NCBI accession No.BAD00043(MAPKP)のアミノ酸配列に関する。本明細書では,配列番号7に記載されるアミノ酸配列からなるタンパク質(MAPKP),及び配列番号7に記載されるアミノ酸配列の362-467番目のアミノ酸を有するドメインタンパク質をタンパク質Aとして用いた。
〔8〕配列番号8は,NCBI accession No.BAB61907(CaM1)のアミノ酸配列に関する。本明細書では,配列番号8に記載されるアミノ酸配列からなるタンパク質をタンパク質Xとして用いた。
〔9〕配列番号9は,NCBI accession No. BAB61908(CaM3)のアミノ酸配列に関する。本明細書では,配列番号9に記載されるアミノ酸配列からなるタンパク質をタンパク質Xとして用いた。
〔10〕配列番号10は,NCBI accession No. BAA07405(Gγ)のアミノ酸配列に関する。本明細書では,配列番号10に記載されるアミノ酸配列からなるタンパク質(Gγ)をタンパク質Aとして用いた。
〔11〕配列番号11は,NCBI accession No. BAD15277(Gβ)のアミノ酸配列に関する。本明細書では,配列番号11に記載されるアミノ酸配列からなるタンパク質(Gβ)をタンパク質Xとして用いた。
〔12〕配列番号12は,NCBI accession No. AAL62810(CIGR2)のアミノ酸配列に関する。本明細書では,配列番号12に記載されるアミノ酸配列からなるタンパク質をタンパク質Aとして用いた。
以下では,本明細書に用いる配列番号で示されるタンパク質又は核酸について説明する。
〔1〕配列番号1は,NCBI accession No.BAD16550(EL5)のアミノ酸配列に関する。本明細書では,配列番号1に記載されるアミノ酸配列の134-181番目のアミノ酸配列からなるタンパク質をRFDとして用いた。
〔2〕配列番号2は,NCBI accession No. NP 201297(CIP8)のアミノ酸配列に関する。本明細書では,配列番号2に記載されるアミノ酸配列の257-297番目のアミノ酸配列からなるタンパク質をRFDとして用いた。
〔3〕配列番号3は,NCBI accession No. NP 974506(Rma1)のアミノ酸配列に関する。本明細書では,配列番号3に記載されるアミノ酸配列の48-101番目のアミノ酸配列からなるタンパク質をRFDとして用いた。
〔4〕配列番号4は,NCBI accession No. AAL26903(Hrd1)のアミノ酸配列に関する。本明細書では,配列番号4に記載されるアミノ酸配列の272-343番目のアミノ酸配列からなるタンパク質をRFDとして用いた。
〔5〕配列番号5は, NCBI accession No.BAC81428(GID2)に記載されるアミノ酸配列に関する。本明細書では,配列番号5に記載されるアミノ酸配列からなるタンパク質(GID2),及び配列番号5に記載されるアミノ酸配列の117-211番目のアミノ酸配列からなるドメインタンパク質をタンパク質Aとして用いた。
〔6〕配列番号6は,NCBI accession No.BAB97367(SLR1)のアミノ酸配列に関する。本明細書では,配列番号6に記載されるアミノ酸配列からなるタンパク質をタンパク質Xとして用いた。
〔7〕配列番号7は,NCBI accession No.BAD00043(MAPKP)のアミノ酸配列に関する。本明細書では,配列番号7に記載されるアミノ酸配列からなるタンパク質(MAPKP),及び配列番号7に記載されるアミノ酸配列の362-467番目のアミノ酸を有するドメインタンパク質をタンパク質Aとして用いた。
〔8〕配列番号8は,NCBI accession No.BAB61907(CaM1)のアミノ酸配列に関する。本明細書では,配列番号8に記載されるアミノ酸配列からなるタンパク質をタンパク質Xとして用いた。
〔9〕配列番号9は,NCBI accession No. BAB61908(CaM3)のアミノ酸配列に関する。本明細書では,配列番号9に記載されるアミノ酸配列からなるタンパク質をタンパク質Xとして用いた。
〔10〕配列番号10は,NCBI accession No. BAA07405(Gγ)のアミノ酸配列に関する。本明細書では,配列番号10に記載されるアミノ酸配列からなるタンパク質(Gγ)をタンパク質Aとして用いた。
〔11〕配列番号11は,NCBI accession No. BAD15277(Gβ)のアミノ酸配列に関する。本明細書では,配列番号11に記載されるアミノ酸配列からなるタンパク質(Gβ)をタンパク質Xとして用いた。
〔12〕配列番号12は,NCBI accession No. AAL62810(CIGR2)のアミノ酸配列に関する。本明細書では,配列番号12に記載されるアミノ酸配列からなるタンパク質をタンパク質Aとして用いた。
〔13〕配列番号13は,リンカー(linker)1のアミノ酸配列に関する。
〔14〕配列番号14は,linker2のアミノ酸配列に関する。
〔15〕配列番号15は,S-tag-RFD融合タンパク質のアミノ酸配列に関する。
〔16〕配列番号16は,MBP-(13)-RFDのアミノ酸配列に関する。
〔17〕配列番号17は,MBP-(46)-RFDのアミノ酸配列に関する。
〔18〕配列番号18は,MBP-(82)-RFDのアミノ酸配列に関する。
〔19〕配列番号19は,MBP-RFD(L174A)のアミノ酸配列に関する。
〔20〕配列番号20は,MBP-RFD(L138A)のアミノ酸配列に関する。
〔21〕配列番号21は,RFD-GID2のアミノ酸配列に関する。
〔22〕配列番号22は,NCBI accession No.AB045120(EL5)の遺伝子配列に関する。
〔23〕配列番号23は,S-tag-RFDの遺伝子を増幅する際の5'末側のプライマー配列に関する。
〔24〕配列番号24は,S-tag-RFDの遺伝子を増幅する際の3'末側のプライマー配列に関する。
〔25〕配列番号25は,MBP-(13)-RFDを作成する際に、遺伝子を増幅する際の5'末側のプライマー配列に関する。
〔26〕配列番号26は,MBP-(13)-RFDを作成する際に用いる、遺伝子を増幅する際の3'末側のプライマー配列に関する。
〔27〕配列番号27は,MBP-(46)-RFDを作成する際に用いる、遺伝子を増幅する際の5'末側のプライマー配列に関する。
〔28〕配列番号28は,MBP-(46)-RFDを作成する際に用いる、遺伝子を増幅する際の3'末側のプライマー配列に関する。
〔29〕配列番号29は,MBP-(82)-RFDを作成する際に用いる、遺伝子を増幅する際の5'末側のプライマー配列に関する。
〔30〕配列番号30は,MBP-(82)-RFDを作成する際に用いる、遺伝子を増幅する際の3'末側のプライマー配列に関する。
〔14〕配列番号14は,linker2のアミノ酸配列に関する。
〔15〕配列番号15は,S-tag-RFD融合タンパク質のアミノ酸配列に関する。
〔16〕配列番号16は,MBP-(13)-RFDのアミノ酸配列に関する。
〔17〕配列番号17は,MBP-(46)-RFDのアミノ酸配列に関する。
〔18〕配列番号18は,MBP-(82)-RFDのアミノ酸配列に関する。
〔19〕配列番号19は,MBP-RFD(L174A)のアミノ酸配列に関する。
〔20〕配列番号20は,MBP-RFD(L138A)のアミノ酸配列に関する。
〔21〕配列番号21は,RFD-GID2のアミノ酸配列に関する。
〔22〕配列番号22は,NCBI accession No.AB045120(EL5)の遺伝子配列に関する。
〔23〕配列番号23は,S-tag-RFDの遺伝子を増幅する際の5'末側のプライマー配列に関する。
〔24〕配列番号24は,S-tag-RFDの遺伝子を増幅する際の3'末側のプライマー配列に関する。
〔25〕配列番号25は,MBP-(13)-RFDを作成する際に、遺伝子を増幅する際の5'末側のプライマー配列に関する。
〔26〕配列番号26は,MBP-(13)-RFDを作成する際に用いる、遺伝子を増幅する際の3'末側のプライマー配列に関する。
〔27〕配列番号27は,MBP-(46)-RFDを作成する際に用いる、遺伝子を増幅する際の5'末側のプライマー配列に関する。
〔28〕配列番号28は,MBP-(46)-RFDを作成する際に用いる、遺伝子を増幅する際の3'末側のプライマー配列に関する。
〔29〕配列番号29は,MBP-(82)-RFDを作成する際に用いる、遺伝子を増幅する際の5'末側のプライマー配列に関する。
〔30〕配列番号30は,MBP-(82)-RFDを作成する際に用いる、遺伝子を増幅する際の3'末側のプライマー配列に関する。
〔31〕配列番号31は,配列番号17の遺伝子配列に関する。
〔32〕配列番号32は,配列番号19のL138A変異体を作成する際に用いた5'末側のプライマー配列に関する。
〔33〕配列番号33は,配列番号19のL138A変異体を作成する際に用いた3'末側のプライマー配列に関する。
〔34〕配列番号34は,配列番号20のL174A変異体を作成する際に用いた5'末側のプライマー配列に関する。
〔35〕配列番号35は,配列番号20のL174A変異体を作成する際に用いた3'末側のプライマー配列に関する。
〔36〕配列番号36は,GID2-RFDを作成する際に用いるRFD遺伝子断片を作成する際に用いた5'末側のプライマー配列に関する。
〔37〕配列番号37は,GID2-RFDを作成する際に用いるRFD遺伝子断片を作成する際に用いた3'末側のプライマー配列に関する。
〔38〕配列番号38は,NCBI accession No.AB100246(GID2)に記載される遺伝子配列に関する。
〔39〕配列番号39は,GID2-RFDを作成する際に用いるGID2遺伝子断片を作成する際に用いた5'末側のプライマー配列に関する。
〔40〕配列番号40は,GID2-RFDを作成する際に用いるGID2遺伝子断片を作成する際に用いた3'末側のプライマー配列に関する。
〔41〕配列番号41は,GID2-RFD遺伝子配列のアミノ酸配列に関する。
〔32〕配列番号32は,配列番号19のL138A変異体を作成する際に用いた5'末側のプライマー配列に関する。
〔33〕配列番号33は,配列番号19のL138A変異体を作成する際に用いた3'末側のプライマー配列に関する。
〔34〕配列番号34は,配列番号20のL174A変異体を作成する際に用いた5'末側のプライマー配列に関する。
〔35〕配列番号35は,配列番号20のL174A変異体を作成する際に用いた3'末側のプライマー配列に関する。
〔36〕配列番号36は,GID2-RFDを作成する際に用いるRFD遺伝子断片を作成する際に用いた5'末側のプライマー配列に関する。
〔37〕配列番号37は,GID2-RFDを作成する際に用いるRFD遺伝子断片を作成する際に用いた3'末側のプライマー配列に関する。
〔38〕配列番号38は,NCBI accession No.AB100246(GID2)に記載される遺伝子配列に関する。
〔39〕配列番号39は,GID2-RFDを作成する際に用いるGID2遺伝子断片を作成する際に用いた5'末側のプライマー配列に関する。
〔40〕配列番号40は,GID2-RFDを作成する際に用いるGID2遺伝子断片を作成する際に用いた3'末側のプライマー配列に関する。
〔41〕配列番号41は,GID2-RFD遺伝子配列のアミノ酸配列に関する。
−Sタンパク質によるモデル実験−S-tag-RFD融合タンパク質(配列番号15)の作成方法
図4は,実施例1を説明するための概念図である。図4(A)は,実施例1における実験系の概念図である。図4(B)は,所定のタンパク質がユビキチン化されたことを示す図面に代わるゲル電気泳動図である。配列番号1に記載されるアミノ酸配列からなるタンパク質をコードする遺伝子(cDNA配列番号22)を鋳型とし,5末にNcoI サイトを付加したプライマー5'-CATGC CATG GGGGT CGACC
CGGAG GTG-3'(配列番号23)および3末にBamHI サイトを付加したプライマー5'-CGGGA TCCTT ACACG
ACGAC GGTGA GGC-3'(配列番号24)を用い,公知の手法に従ってPCRを行った。 すなわち,98℃で2分後,98℃で30秒,60℃で30秒,72℃で1分を1サイクルとし,このサイクルを25回繰り返すことにより核酸を増幅した。
図4は,実施例1を説明するための概念図である。図4(A)は,実施例1における実験系の概念図である。図4(B)は,所定のタンパク質がユビキチン化されたことを示す図面に代わるゲル電気泳動図である。配列番号1に記載されるアミノ酸配列からなるタンパク質をコードする遺伝子(cDNA配列番号22)を鋳型とし,5末にNcoI サイトを付加したプライマー5'-CATGC CATG GGGGT CGACC
CGGAG GTG-3'(配列番号23)および3末にBamHI サイトを付加したプライマー5'-CGGGA TCCTT ACACG
ACGAC GGTGA GGC-3'(配列番号24)を用い,公知の手法に従ってPCRを行った。 すなわち,98℃で2分後,98℃で30秒,60℃で30秒,72℃で1分を1サイクルとし,このサイクルを25回繰り返すことにより核酸を増幅した。
増幅したPCR産物は電気泳動を行いアガロースゲルより抽出した。挿入するpUC19 ベクター(TAKARA)についてはHincII処理を行い、Ligaton high(TOYOBO)を用いて目的断片をライゲーションした後、大腸菌へ形質転換し,クローンを作製した。
次にこのクローンを培養した後、大腸菌からプラスミド抽出を行った。得られたプラスミドはプライマーデザイン時に挿入した配列であるNcoIおよびBamHIにより酵素処理した後、電気泳動を行いアガロースゲルから目的断片を抽出した。さらにS-Tagを含むpET32 ベクター(NOVAGEN)
についても同様にNcoIおよびBamHIで酵素処理をしLigaton high(TOYOBO)を用いて目的断片をライゲーションした後、大腸菌へ形質転換し目的クローンを作製した。得られたプラスミドの塩基配列に関してはシーケンサーを用いてシーケンスを読み取ることにより目的の塩基配列が存在することを確認した。得られたプラスミドを用いて大腸菌BL21 (DE3)を形質転換した。このようにして、得られた形質転換体(菌体)を用いてタンパク質の大量発現を行った。アンピシリンを含む2×YT培地で37℃4時間前培養し、5分間10,000×gで遠心後、回収した菌体を再び培地に移し、さらに37℃で,3時間,培養を行った。その後、最終濃度1 mMのIPTGを加え,組換えタンパク質の発現を誘導し、さらに37℃で3時間培養した。
についても同様にNcoIおよびBamHIで酵素処理をしLigaton high(TOYOBO)を用いて目的断片をライゲーションした後、大腸菌へ形質転換し目的クローンを作製した。得られたプラスミドの塩基配列に関してはシーケンサーを用いてシーケンスを読み取ることにより目的の塩基配列が存在することを確認した。得られたプラスミドを用いて大腸菌BL21 (DE3)を形質転換した。このようにして、得られた形質転換体(菌体)を用いてタンパク質の大量発現を行った。アンピシリンを含む2×YT培地で37℃4時間前培養し、5分間10,000×gで遠心後、回収した菌体を再び培地に移し、さらに37℃で,3時間,培養を行った。その後、最終濃度1 mMのIPTGを加え,組換えタンパク質の発現を誘導し、さらに37℃で3時間培養した。
その後、菌体を15分間5,000×gで遠心し,回収し-80℃で保存した。凍結させた菌体を解凍後50 mM Tris-HCl, 500 mM
NaCl, 50 μM ZnSO4, 2.5 mMβ-ME,
pH 7.4で懸濁し、超音波処理により細胞を破砕した。懸濁液を4℃で30分間27,000×gで遠心し、上清を回収した。得られた上清をNi アフィニティークロマトグラフィーに供した。 50 mM Tris-HCl, 500
mM NaCl, 50 μM ZnSO4, 2.5 mM b-ME, pH 7.4から50 mM Tris-HCl,500 mM NaCl, 50 μM ZnSO4, 500
mM イミダゾール(imidazole), 2.5 mMβ-ME, pH 7.4への直線濃度勾配によって溶出した。溶出画分をGel濾過クロマトグラフィーに供した。溶出は50mM Tris-HCl, 100mM NaCl, 20 mM ZnSO4, 2.5 mMβ-ME, pH 7.4で行った。この溶出画分にトロンビン(Thrombin)を添加し25℃で3時間放置しQカラムクロマトグラフィーに供した。50 mM Tris-HCl, 20 μM ZnSO4, 2.5mMβ-ME, pH 7.4から50 mM Tris-HCl, 600 mM NaCl, 20
mM ZnSO4, 2.5 mM b-ME, pH 7.4への直線濃度勾配によって溶出した。得られた溶出画分をNi
アフィニティークロマトグラフィーに供した。素通り画分をGel濾過クロマトグラフィーに供した。溶出は50 mM Tris-HCl, 100 mM NaCl, 20 mM ZnSO4, 2.5 mMβ-ME, pH 7.4で行った。このようにして,S-tag-RFD融合タンパク質(配列番号15)を得た。
NaCl, 50 μM ZnSO4, 2.5 mMβ-ME,
pH 7.4で懸濁し、超音波処理により細胞を破砕した。懸濁液を4℃で30分間27,000×gで遠心し、上清を回収した。得られた上清をNi アフィニティークロマトグラフィーに供した。 50 mM Tris-HCl, 500
mM NaCl, 50 μM ZnSO4, 2.5 mM b-ME, pH 7.4から50 mM Tris-HCl,500 mM NaCl, 50 μM ZnSO4, 500
mM イミダゾール(imidazole), 2.5 mMβ-ME, pH 7.4への直線濃度勾配によって溶出した。溶出画分をGel濾過クロマトグラフィーに供した。溶出は50mM Tris-HCl, 100mM NaCl, 20 mM ZnSO4, 2.5 mMβ-ME, pH 7.4で行った。この溶出画分にトロンビン(Thrombin)を添加し25℃で3時間放置しQカラムクロマトグラフィーに供した。50 mM Tris-HCl, 20 μM ZnSO4, 2.5mMβ-ME, pH 7.4から50 mM Tris-HCl, 600 mM NaCl, 20
mM ZnSO4, 2.5 mM b-ME, pH 7.4への直線濃度勾配によって溶出した。得られた溶出画分をNi
アフィニティークロマトグラフィーに供した。素通り画分をGel濾過クロマトグラフィーに供した。溶出は50 mM Tris-HCl, 100 mM NaCl, 20 mM ZnSO4, 2.5 mMβ-ME, pH 7.4で行った。このようにして,S-tag-RFD融合タンパク質(配列番号15)を得た。
全量75 μlの反応液(40 mM
Tris-HCl, pH7.5, 5 mM MgCl2, 2 mM ATP, 2 mM DTT, 300 ng/μl ウシ由来ユビキチン(シグマ社製),
50 ng マウスE1, 100 ng OsUBC5b:E2,
500 ng S-タンパク質(シグマ社製))に, 500 ngのS-tag-RFD融合タンパク質(配列番号15)を加え,30℃で16時間反応させた。なお,この例において,S-tagがタンパク質Aに相当し,Sタンパク質がタンパク質Xに相当する。
Tris-HCl, pH7.5, 5 mM MgCl2, 2 mM ATP, 2 mM DTT, 300 ng/μl ウシ由来ユビキチン(シグマ社製),
50 ng マウスE1, 100 ng OsUBC5b:E2,
500 ng S-タンパク質(シグマ社製))に, 500 ngのS-tag-RFD融合タンパク質(配列番号15)を加え,30℃で16時間反応させた。なお,この例において,S-tagがタンパク質Aに相当し,Sタンパク質がタンパク質Xに相当する。
反応終了後,等量のSDS-PAGEサンプルバッファーを加え,100 ℃で5分間加熱し,7.5% SDSポリアクリルアミドゲルでSDS-PAGEを行った。泳動後,ゲルをPVDFメンブレン(Immobilon-P ; Millipore)に転写し,5 % (w/v)スキムミルクを含むPBS-Tween20 (8.1 mM Na2HPO4, 1.47 mM KH2PO4, 137 mM NaCl, 2.68 mM
KCl, 0.1% Tween20, pH7.4)中で室温30分間振盪することによりブロッキングした。このメンブレンを500分の1容量の抗S-タンパク質抗体を含むPBS-Tween20中で室温において1時間反応させた。PBS-Tween20で5分間×3回洗浄した後,4000分の1容量のペルオキシダーゼ標識抗ウサギIgG抗体(Jacskon Immuno Research)を含むPBS-Tween20で4℃一晩反応させた。PBS-Tween20で5分間×3回およびPBSで5分間洗浄後,DABを用いて発色した。
KCl, 0.1% Tween20, pH7.4)中で室温30分間振盪することによりブロッキングした。このメンブレンを500分の1容量の抗S-タンパク質抗体を含むPBS-Tween20中で室温において1時間反応させた。PBS-Tween20で5分間×3回洗浄した後,4000分の1容量のペルオキシダーゼ標識抗ウサギIgG抗体(Jacskon Immuno Research)を含むPBS-Tween20で4℃一晩反応させた。PBS-Tween20で5分間×3回およびPBSで5分間洗浄後,DABを用いて発色した。
その結果を,図4(B)に示す。図4(B)において,左からレーン番号が付されており,第1,第3及び第5レーンは0時間,第2,第4及び第6レーンは12時間後のものを示す。第1及び第2レーンは,S-tag-RFD融合タンパク質を用いたものを示す。第3及び第4レーンは,Sタンパク質を用いたものを示す。第5及び第6レーンは,S-tag-RFD融合タンパク質及びSタンパク質を用いたものを示す。図4(B)から,S-タンパク質のユビキチン化が確認できる。この結果は,RFDと融合して発現したタンパク質Aと相互作用するタンパク質Xのユビキチン化が促進されることを示しており,本発明の方法を用いることにより人工的にタンパク質分解を制御できることが示された。よって,本発明の方法によれば,タンパク質A(S-tag)とRFDを融合させたタンパク質A−RFDを生体内で発現させることで,タンパク質Aと複合体を形成するタンパク質X(Sタンパク質)を分解できることが実証された。これの方法を用いれば,Sタンパク質以外のタンパク質Xであっても,分解できることは明白である。したがって,本発明によれば,タンパク質X,又はタンパク質A−X複合体の機能を破壊できることが実証された。また,そのような機能を破壊したノックアウト生物を作出できることも実証された。さらには,破壊された機能を分析することで,タンパク質X又はタンパク質A−X複合体の機能をも解明できることも実証された。
−リンカーの長さによるユビキチン化効率の検証−
マルトース結合(MBP)-(リンカー)-RFD融合タンパク質の作成方法
以下では,タンパク質A−RFDにおけるリンカー部位が,タンパク質Xのユビキチン修飾化にもたらす影響について検討するための実験を行った。リンカーの長さとして13,46及び82のアミノ酸残基を含むものを用意した。MBP-(13)-RFD, MBP-(46)-RFD, MBP-(82)-RFD (括弧の中はリンカーの長さを示す)は、それぞれ5'-CCGA ATTCG GAGGA GGGGT CGACC
CGGAG-3': (配列番号25)と5'-CCGGA
TCCTT ACACG ACGAC GGTGA GGCG-3': (配列番号26), 5'-CCGAA TTCGG AGGAG GGGTC GACCC GGAG-3': (配列番号27)と5'-CCGGA TCCTT ACACG ACGAC GGTGA
GGCG-3': (配列番号28), 5'-CCGAA
TTCTG CTACT GCGAC GAGCG GCGC-3': (配列番号29)と5'-CCGGA TCCTC AATCC GGACA TGCGC -3': (配列番号30)の両プライマーを用いてEL5の全長鎖cDNA(配列番号22)を鋳型としてPCRを行った。すなわち,98℃で2分後,98℃で30秒,50℃で30秒,72℃で2分を1サイクルとし,このサイクルを25回繰り返すことにより核酸を増幅した。
マルトース結合(MBP)-(リンカー)-RFD融合タンパク質の作成方法
以下では,タンパク質A−RFDにおけるリンカー部位が,タンパク質Xのユビキチン修飾化にもたらす影響について検討するための実験を行った。リンカーの長さとして13,46及び82のアミノ酸残基を含むものを用意した。MBP-(13)-RFD, MBP-(46)-RFD, MBP-(82)-RFD (括弧の中はリンカーの長さを示す)は、それぞれ5'-CCGA ATTCG GAGGA GGGGT CGACC
CGGAG-3': (配列番号25)と5'-CCGGA
TCCTT ACACG ACGAC GGTGA GGCG-3': (配列番号26), 5'-CCGAA TTCGG AGGAG GGGTC GACCC GGAG-3': (配列番号27)と5'-CCGGA TCCTT ACACG ACGAC GGTGA
GGCG-3': (配列番号28), 5'-CCGAA
TTCTG CTACT GCGAC GAGCG GCGC-3': (配列番号29)と5'-CCGGA TCCTC AATCC GGACA TGCGC -3': (配列番号30)の両プライマーを用いてEL5の全長鎖cDNA(配列番号22)を鋳型としてPCRを行った。すなわち,98℃で2分後,98℃で30秒,50℃で30秒,72℃で2分を1サイクルとし,このサイクルを25回繰り返すことにより核酸を増幅した。
得られたPCR産物をEcoRIおよびBamHIで消化し、あらかじめEcoRIおよびBamHIで消化したpMAL-c2xにライゲーションした。得られたプラスミドの塩基配列を確認し、変異が導入されていないことを確認した。得られたプラスミドを用いて大腸菌BL21 (DE3)を形質転換した。得られた形質転換体(菌体)を用いてタンパク質の大量発現を行った。アンピシリンを含む2×YT培地で37℃4時間前培養し、5分間10,000×gで遠心後、回収した菌体を再び培地に移した。その後、さらに37 ℃で3時間培養を行った。その後、最終濃度1 mMのIPTGを加え組換えタンパク質の発現を誘導した。さらに37 ℃3時間培養した後、菌体を15分間5,000×gで遠心し,回収し-80℃で保存した。凍結させた菌体を解凍後50 mM Tris-HCl, 200 mM NaCl, 20 mM ZnSO4, 2.5 mM b-ME, pH 7.4で懸濁し、超音波処理により細胞を破砕した、懸濁液を4 ℃で30分間27,000×gで遠心し、上清を回収した。得られた上清をアミロースレジンに吸着させ、50 mM
Tris-HCl, 200 mM NaCl, 20 mM ZnSO4, 2.5 mM b-ME, pH 7.4で洗浄後、10 mM maltose, 50 mM Tris-HCl, 200 mM NaCl, 20 mM ZnSO4, 2.5 mM
b-ME, pH 7.4で溶出した。なお,MBPは,タンパク質Aではなく,ユビキチン修飾化されるタンパク質である。このようにして,マルトース結合(MBP)-(リンカー)-RFD融合タンパク質(配列番号16,17,18)を得た。
Tris-HCl, 200 mM NaCl, 20 mM ZnSO4, 2.5 mM b-ME, pH 7.4で洗浄後、10 mM maltose, 50 mM Tris-HCl, 200 mM NaCl, 20 mM ZnSO4, 2.5 mM
b-ME, pH 7.4で溶出した。なお,MBPは,タンパク質Aではなく,ユビキチン修飾化されるタンパク質である。このようにして,マルトース結合(MBP)-(リンカー)-RFD融合タンパク質(配列番号16,17,18)を得た。
全量75 μlの反応液(40 mM
Tris-HCl, pH7.5, 5 mM MgCl2, 2 mM ATP, 2 mM DTT, 300 ng/μl ウシ由来ユビキチン(シグマ社製),
50 ng マウスE1, 100 ng OsUBC5b:E2に,
500 ngのマルトース結合(MBP)-(リンカー)-RFD融合タンパク質(配列番号16,17,18)を加え,30 ℃で1時間反応させた。リンカーの長さはアミノ酸残基の数が13,46および82のものを検討した。
Tris-HCl, pH7.5, 5 mM MgCl2, 2 mM ATP, 2 mM DTT, 300 ng/μl ウシ由来ユビキチン(シグマ社製),
50 ng マウスE1, 100 ng OsUBC5b:E2に,
500 ngのマルトース結合(MBP)-(リンカー)-RFD融合タンパク質(配列番号16,17,18)を加え,30 ℃で1時間反応させた。リンカーの長さはアミノ酸残基の数が13,46および82のものを検討した。
反応終了後,等量のSDS-PAGEサンプルバッファーを加え,100 ℃で5分間加熱し,7.5 % SDSポリアクリルアミドゲルでSDS-PAGEを行った。泳動後,ゲルをPVDFメンブレン(Immobilon-P ; Millipore)に転写し,5% (w/v)スキムミルクを含むPBS-Tween20 (8.1 mM Na2HPO4, 1.47 mM KH2PO4, 137 mM NaCl, 2.68 mM
KCl, 0.1% Tween20, pH7.4)中で室温30分間振盪することによりブロッキングした。このメンブレンを500分の1容量の抗S-タンパク質抗体を含むPBS-Tween20中で室温において4℃で一晩反応させた。PBS-Tween20で5分間×3回洗浄した後,4000分の1容量のペルオキシダーゼ標識抗ウサギIgG抗体(Jacskon Immuno Research)を含むPBS-Tween20で室温1時間反応させた。PBS-Tween20で5分間×3回およびPBSで5分間洗浄後,DABを用いて発色した。
KCl, 0.1% Tween20, pH7.4)中で室温30分間振盪することによりブロッキングした。このメンブレンを500分の1容量の抗S-タンパク質抗体を含むPBS-Tween20中で室温において4℃で一晩反応させた。PBS-Tween20で5分間×3回洗浄した後,4000分の1容量のペルオキシダーゼ標識抗ウサギIgG抗体(Jacskon Immuno Research)を含むPBS-Tween20で室温1時間反応させた。PBS-Tween20で5分間×3回およびPBSで5分間洗浄後,DABを用いて発色した。
その結果を,図5に示す。図5は,実験結果を示す図面に代わるゲル電気泳動写真図である。左から第1番目及び第2番目のレーンはMBPのものを示す。左から第3番目及び第4番目のレーンはMBP-(13)-RFDを示し,左から第5番目〜第6番目のレーンは MBP-(46)-RFDを示し, 左から第7番目〜第8番目のレーンはMBP-(82)-RFDを示す。上記レーンのうち奇数番号のレーンは0時間後,偶数番号のレーンは1時間後のものを示す。図中kDaは,キロダルトンを示す。図5から,リンカーの長さを変えてもユビキチン修飾化は進行するものの,その進行速度をリンカーの長さにより制御できることが確認できた。このことは,RFDと,ユビキチンにより分解されるタンパク質との融合タンパク質を作出すれば,そのタンパク質を分解することができること,及びその分解速度を制御できることをも意味している。
−RFD変異体によるユビキチン化効率の制御の検証−
以下のようにして,配列番号1のロイシン138又はロイシン174をそれぞれアラニンに置換した変異体は、ユビキチン化効率が減少することを確認した。
以下のようにして,配列番号1のロイシン138又はロイシン174をそれぞれアラニンに置換した変異体は、ユビキチン化効率が減少することを確認した。
変異体の作成方法:
L138AおよびL174A変異体は,配列番号17のアミノ酸配列をコードするcDNA(配列番号31)を鋳型としQuickchange Site-Directed
Mutagenesis Kit (stratagene)を用いたPCRにより作成した。PCRには、L138A : 5'-GTGCG CGGTG TGCGC GGCGG
AGCTC G-3' (配列番号32 )および5'-CGAGC
TCCGC CGCGC ACACC GCGCA C-3' (配列番号33)、 L174A : 5'-CACTC CACCT GCCCG GCGTG CCGCC TCACC-3' (配列番号34)および5'-GGTGA GGGGC ACGCC GGGCA GGTGG
AGTG-3' (配列番号35)を用いた。PCRは,95℃で30秒後,95℃で30秒,55℃で1分を1サイクルとし,このサイクルを12回繰り返した。
L138AおよびL174A変異体は,配列番号17のアミノ酸配列をコードするcDNA(配列番号31)を鋳型としQuickchange Site-Directed
Mutagenesis Kit (stratagene)を用いたPCRにより作成した。PCRには、L138A : 5'-GTGCG CGGTG TGCGC GGCGG
AGCTC G-3' (配列番号32 )および5'-CGAGC
TCCGC CGCGC ACACC GCGCA C-3' (配列番号33)、 L174A : 5'-CACTC CACCT GCCCG GCGTG CCGCC TCACC-3' (配列番号34)および5'-GGTGA GGGGC ACGCC GGGCA GGTGG
AGTG-3' (配列番号35)を用いた。PCRは,95℃で30秒後,95℃で30秒,55℃で1分を1サイクルとし,このサイクルを12回繰り返した。
得られたプラスミドの塩基配列を確認し、目的の部位に変異が導入されていることを確認した。得られたプラスミドで大腸菌BL21 (DE3)を形質転換し、得られた形質転換体(菌体)を用いてタンパク質の大量発現を行った。アンピシリンを含む2×YT培地で37 ℃で4時間前培養し、5分間10,000×gで遠心後、回収した菌体を再び培地に移し、さらに37℃で3時間培養を行った。その後、最終濃度1 mMのIPTGを加え組換えタンパク質の発現を誘導し、さらに37 ℃3時間培養した後、菌体を15分間5,000×gで遠心し回収し-80 ℃で保存した。凍結させた菌体を解凍後50 mM Tris-HCl, 200 mM NaCl, 20 mM ZnSO4, 2.5 mM b-ME, pH 7.4で懸濁し、超音波処理により細胞を破砕し、懸濁液を4 ℃で30分間27,000×gで遠心し、上清を回収した。得られた上清をアミロースレジンに吸着させ、50 mM
Tris-HCl, 200 mM NaCl, 20 mM ZnSO4, 2.5 mM b-ME, pH 7.4で洗浄後、10 mM maltose, 50 mM Tris-HCl, 200 mM NaCl, 20 mM ZnSO4, 2.5 mM
b-ME, pH 7.4で溶出した。このようにして(MBP)-RFD変異体融合タンパク質(配列番号19,20)を得た。
Tris-HCl, 200 mM NaCl, 20 mM ZnSO4, 2.5 mM b-ME, pH 7.4で洗浄後、10 mM maltose, 50 mM Tris-HCl, 200 mM NaCl, 20 mM ZnSO4, 2.5 mM
b-ME, pH 7.4で溶出した。このようにして(MBP)-RFD変異体融合タンパク質(配列番号19,20)を得た。
全量75 μlの反応液(40 mM
Tris-HCl, pH7.5, 5 mM MgCl2, 2 mM ATP, 2 mM DTT, 300 ng/μl ウシ由来ユビキチン(シグマ社製),
50 ng マウスE1, 100 ng OsUBC5b:E2に,
500 ngの (MBP)-RFD変異体融合タンパク質(配列番号19,20)を加え,30℃で2時間反応させた。
Tris-HCl, pH7.5, 5 mM MgCl2, 2 mM ATP, 2 mM DTT, 300 ng/μl ウシ由来ユビキチン(シグマ社製),
50 ng マウスE1, 100 ng OsUBC5b:E2に,
500 ngの (MBP)-RFD変異体融合タンパク質(配列番号19,20)を加え,30℃で2時間反応させた。
反応終了後,等量のSDS-PAGEサンプルバッファーを加え,100 ℃で5分間加熱し,7.5% SDSポリアクリルアミドゲルでSDS-PAGEを行った。泳動後,ゲルをPVDFメンブレン(Immobilon-P ; Millipore)に転写し,5% (w/v)スキムミルクを含むPBS-Tween20 (8.1 mM Na2HPO4, 1.47 mM KH2PO4, 137 mM NaCl, 2.68 mM
KCl, 0.1% Tween20, pH7.4)中で室温30分間振盪することによりブロッキングした。このメンブレンを500分の1容量の抗S-タンパク質抗体を含むPBS-Tween20中で室温において1時間反応させた。PBS-Tween20で5分間×3回洗浄した後,4000分の1容量のペルオキシダーゼ標識抗ウサギIgG抗体(Jacskon Immuno Research)を含むPBS-Tween20で室温1時間反応させた。PBS-Tween20で5分間×3回およびPBSで5分間洗浄後,DABを用いて発色した。なお,配列番号1のアルギニン148をアラニンに置換した変異体R148A,配列番号1のバリン162をアラニンに置換した変異体V162A,配列番号1のアスパラギン酸163をアラニンに置換した変異体D163Aについても同様にして製造し,測定を行った。
KCl, 0.1% Tween20, pH7.4)中で室温30分間振盪することによりブロッキングした。このメンブレンを500分の1容量の抗S-タンパク質抗体を含むPBS-Tween20中で室温において1時間反応させた。PBS-Tween20で5分間×3回洗浄した後,4000分の1容量のペルオキシダーゼ標識抗ウサギIgG抗体(Jacskon Immuno Research)を含むPBS-Tween20で室温1時間反応させた。PBS-Tween20で5分間×3回およびPBSで5分間洗浄後,DABを用いて発色した。なお,配列番号1のアルギニン148をアラニンに置換した変異体R148A,配列番号1のバリン162をアラニンに置換した変異体V162A,配列番号1のアスパラギン酸163をアラニンに置換した変異体D163Aについても同様にして製造し,測定を行った。
その結果を,図6に示す。図6において,左から第1及び第2レーンはMBPを示し,第3及び第4レーンは無変異体を示し,第5及び第6レーンはL138A変異体を示し,第7及び第8レーンはR148A変異体を示し,第9及び第10レーンはV162A変異体を示し,第11及び第12レーンはD163A変異体を示し,第13及び第14レーンはL174A変異体を示す。無変異体の左から第4レーンでは,複数のポリユビキチン化したタンパク質に由来するバンドが見られた。一方,変異体のレーンでは第4レーンに比べてポリユビキチン化に由来するバンドが少なかった。このことから,変異体は変異がないものに比べ,それぞれタンパク質Xのユビキチン化効率が劣っていることがわかる。また,この結果から,ロイシン138又はロイシン174をそれぞれアラニンに置換した変異体などによりユビキチン修飾化を制御できることが確認できた。
−GID2-RFD融合タンパク質によるSLR1タンパク質分解の検証−
GID2-RFD融合タンパク質の作成方法
配列番号13をコードする遺伝子(配列番号22)を鋳型とし5末にCACC配列とクローニングサイト (Xba I, Spe I, BamH I)を付加したプライマー:5'-CACCT
CTAGA ACTAG TGGAT CCATG CCAGA TCTGG GTACC GACGA CG-3'(配列番号36)および3末に終止コドンとSma Iサイトを付加したプライマー5'- CCCGG GTCAC ACGAC GACGG TGAGG CGGCA-3'(配列番号37)を用いてPCRを行った。 すなわち,98℃で2分後,98℃で30秒,50℃で30秒,72℃で3分を1サイクルとし,このサイクルを25回繰り返すことにより核酸を増幅した。
GID2-RFD融合タンパク質の作成方法
配列番号13をコードする遺伝子(配列番号22)を鋳型とし5末にCACC配列とクローニングサイト (Xba I, Spe I, BamH I)を付加したプライマー:5'-CACCT
CTAGA ACTAG TGGAT CCATG CCAGA TCTGG GTACC GACGA CG-3'(配列番号36)および3末に終止コドンとSma Iサイトを付加したプライマー5'- CCCGG GTCAC ACGAC GACGG TGAGG CGGCA-3'(配列番号37)を用いてPCRを行った。 すなわち,98℃で2分後,98℃で30秒,50℃で30秒,72℃で3分を1サイクルとし,このサイクルを25回繰り返すことにより核酸を増幅した。
増幅したPCR産物は電気泳動を行いアガロースゲルより抽出し、TOPO cloning
kit(Invitrogen)を用いてクローニングを行い、RFDのエントリーベクターを作製した。挿入する配列番号5で表されるタンパク質の遺伝子についてはGID2のcDNA(配列番号38)を鋳型とし5末にCACC配列とXba Iサイトを付加したプライマー5'-CACCT CTAGA ATGAA GTTCC GCTCT GATTC-3'(配列番号39)および3末に終止コドンを削除しさらにBamH Iサイトを付加したプライマー5'- GGATC CCCCG CATTG
GCCCC CTCCA TTCTT ATC-3'(配列番号40)を用いてPCRを行った。すなわち,98℃で2分後,98℃で30秒,50℃で30秒,72℃で3分を1サイクルとし,このサイクルを25回繰り返すことにより核酸を増幅した。
増幅したPCR産物は電気泳動を行いアガロースゲルより抽出し、TOPO
cloning kit(Invitrogen)を用いてクローニングを行い、GID2エントリークローンを作製した。
kit(Invitrogen)を用いてクローニングを行い、RFDのエントリーベクターを作製した。挿入する配列番号5で表されるタンパク質の遺伝子についてはGID2のcDNA(配列番号38)を鋳型とし5末にCACC配列とXba Iサイトを付加したプライマー5'-CACCT CTAGA ATGAA GTTCC GCTCT GATTC-3'(配列番号39)および3末に終止コドンを削除しさらにBamH Iサイトを付加したプライマー5'- GGATC CCCCG CATTG
GCCCC CTCCA TTCTT ATC-3'(配列番号40)を用いてPCRを行った。すなわち,98℃で2分後,98℃で30秒,50℃で30秒,72℃で3分を1サイクルとし,このサイクルを25回繰り返すことにより核酸を増幅した。
増幅したPCR産物は電気泳動を行いアガロースゲルより抽出し、TOPO
cloning kit(Invitrogen)を用いてクローニングを行い、GID2エントリークローンを作製した。
次にGID2のエントリープラスミドをプライマーに挿入した配列であるXba IおよびBamH Iにより酵素処理し、電気泳動を行いアガロースゲルからGID2断片を抽出した。さらにRFDエントリーベクター についても同様にXba IおよびBamH Iで酵素処理をしLigaton high(TOYOBO)を用いてGID2断片をライゲーション後、大腸菌へ形質転換しGID2-RFDクローンを作製した。得られたプラスミドの塩基配列に関してはシーケンスにより目的の塩基配列が存在することを確認した。
遺伝子の導入方法
CaMV 35Sプロモーターのエンハンサー領域を4反復させたプロモーターとノパリンシンターゼ遺伝子由来ターミネーターの間に、GID2遺伝子(配列番号38)あるいはGID2-RING遺伝子(配列番号41)を連結し、バイナリーベクターpBI121(Clontech社)のT-DNA領域に35Sプロモーターとハイグロマイシンフォスフォフォトランスフェレース(HPT)遺伝子とノパリンシンターゼ遺伝子由来ターミネーターを有するプラスミドpBI-HPTに導入し、pBI-EN4-GID2およびpBI-EN4-GID2RINGを構築した。これらのプラスミドの構造を図7に示す。図7(A)は,プラスミド“pBI-EN4-GID2”の開裂地図である。図7(B)は,プラスミド“pBI-EN4-GID2RING”の開裂地図である。図中,35Sは,CaMV 35Sプロモーターを示し,HPTは,大腸菌ハイグロマイシンリン酸転移酵素遺伝子(ハイグロマイシン耐性遺伝子)を示し,CaMV3'は CaMVターミネーターを示し,EN4は35Sプロモーターの転写開始点の上流-290から-90の領域を4反復させた人工35Sプロモーターを示し,NOS3'はノパリン合成酵素遺伝子のターミネーターを示し,RBはT-DNA領域right
border配列を示し,LBは T-DNA領域left border配列を示し,NPTIIIは ネオマイシンリン酸転移酵素遺伝子(カナマイシン耐性遺伝子)を示す。
CaMV 35Sプロモーターのエンハンサー領域を4反復させたプロモーターとノパリンシンターゼ遺伝子由来ターミネーターの間に、GID2遺伝子(配列番号38)あるいはGID2-RING遺伝子(配列番号41)を連結し、バイナリーベクターpBI121(Clontech社)のT-DNA領域に35Sプロモーターとハイグロマイシンフォスフォフォトランスフェレース(HPT)遺伝子とノパリンシンターゼ遺伝子由来ターミネーターを有するプラスミドpBI-HPTに導入し、pBI-EN4-GID2およびpBI-EN4-GID2RINGを構築した。これらのプラスミドの構造を図7に示す。図7(A)は,プラスミド“pBI-EN4-GID2”の開裂地図である。図7(B)は,プラスミド“pBI-EN4-GID2RING”の開裂地図である。図中,35Sは,CaMV 35Sプロモーターを示し,HPTは,大腸菌ハイグロマイシンリン酸転移酵素遺伝子(ハイグロマイシン耐性遺伝子)を示し,CaMV3'は CaMVターミネーターを示し,EN4は35Sプロモーターの転写開始点の上流-290から-90の領域を4反復させた人工35Sプロモーターを示し,NOS3'はノパリン合成酵素遺伝子のターミネーターを示し,RBはT-DNA領域right
border配列を示し,LBは T-DNA領域left border配列を示し,NPTIIIは ネオマイシンリン酸転移酵素遺伝子(カナマイシン耐性遺伝子)を示す。
形質転換アグロバクテリウムは、Nagelらの方法(Nagel et al., (1990) Microbiol.
Lett., 67, 325.)に従ってバイナリーベクターpBI-EN4-GID2およびpBI-EN4-GID2RINGをエレクトロポーレーション法により癌腫菌(アグロバクテリウム ツメファシエンス:Agrobacterium tumefacience)に導入した後、50μg/mlのカナマイシンと50μg/mlのハイグロマイシンを含むLB培地上、28℃で2日間培養することによって得た。
Lett., 67, 325.)に従ってバイナリーベクターpBI-EN4-GID2およびpBI-EN4-GID2RINGをエレクトロポーレーション法により癌腫菌(アグロバクテリウム ツメファシエンス:Agrobacterium tumefacience)に導入した後、50μg/mlのカナマイシンと50μg/mlのハイグロマイシンを含むLB培地上、28℃で2日間培養することによって得た。
イネの形質転換は超迅速形質転換法(特許3141084号公報)に従って行った。すなわち、籾殻を取り除いたイネの完熟種子を無傷の状態で2.5%次亜塩素酸ナトリウム溶液中で殺菌し、滅菌水で十分に洗浄後2,4−ジクロロフェノキシ酢酸(2,4−D)を含むN6D培地(30g/Lスクロース、0.3g/Lカザミノ酸、2.8g/Lプロリン、2mg/L
2,4−D、4g/Lゲルライト、pH5.8)に播種し、5日間28℃に静置した。
2,4−D、4g/Lゲルライト、pH5.8)に播種し、5日間28℃に静置した。
形質転換されたアグロバクテリウムの懸濁液に前培養した上記の種子を浸漬した後、2N6・AS培地(30g/Lスクロース、10g/Lグルコース、0.3g/Lカザミノ酸、2mg/L
2,4−D、10mg/L アセトシリンゴン、4g/Lゲルライト、pH5.2)に移植し、28℃暗黒下で3日間共存培養した。
2,4−D、10mg/L アセトシリンゴン、4g/Lゲルライト、pH5.2)に移植し、28℃暗黒下で3日間共存培養した。
ゲルライトを除いたN6D培地にアグロバクテリウム用抗生物質であるカルベニシリンを500mg/Lを加えた洗浄液を用いて種子からアグロバクテリウムを十分洗浄した後、カルベニシリン500mg/Lと選抜マーカーとしてハイグロマイシンを50mg/L加えたN6D培地(選抜培地)に洗浄した種子を置床して28℃で2週間培養した。
ハイグロマイシン耐性カルスを約2週間ごとに新しい選抜培地に4回植え継ぎ、GID2遺伝子、あるいはGID2-RING遺伝子導入イネカルス系統とした。
ハイグロマイシン耐性カルスを再分化培地(500mg/Lカルベニシリン、30mg/Lハイグロマイシン、30g/Lスクロース、30g/Lソルビトール、2g/Lカザミノ酸、2mg/Lカイネチン、0.002mg/L
α−ナフチル酢酸(NAA)、4g/Lゲルライト、pH5.8となるよう添加したMS培地)に移植して、28℃で再分化するまで培養を続けた。
α−ナフチル酢酸(NAA)、4g/Lゲルライト、pH5.8となるよう添加したMS培地)に移植して、28℃で再分化するまで培養を続けた。
再分化固体を発根培地(ハイグロマイシン30mg/Lとなるように添加した、ホルモンフリーのMS培地)に置床し、ハイグロマイシン耐性を検定した。非形質転換体は新しい根が伸長せず1週間ほどで枯死するのに対し、遺伝子が導入されたと考えられる形質転換体は耐性を示し、野生株と同様の成育を示した。形質転換植物が大きくなったところで、馴化を経てポットに移植し温室内で生育させた。
本発明のタンパク質の機能を解析する方法は,タンパク質及びそのタンパク質をコードする遺伝子の機能を解析するために利用できる。
本発明のタンパク質の機能を解析する方法は,特に遺伝子破壊法やRNAiなどの手法とは別の方法によりタンパク質の機能を解析するので,これらの解析法では解析することが難しい多重遺伝子族の機能を解析することに特に有効に利用できる。
本発明のタンパク質の機能を抑制する方法は,タンパク質及びそのタンパク質をコードする遺伝子の機能を抑制するために利用できる。また,その機能をノックアウトしたノックアウト動物の作生に有効に利用できる。
また,本発明で用いるユビキチン依存型タンパク質分解系は動植物に普遍的であるため,本発明の方法は,その応用範囲が広いものである。
Claims (7)
- 標的タンパク質(タンパク質A)と,ユビキチン結合酵素と相互作用できるタンパク質(RFD)とを融合したタンパク質(タンパク質A−RFD)を用い,
前記標的タンパク質と複合体を形成し,ユビキチン修飾化されることにより分解されるタンパク質(タンパク質X)の機能,又は前記タンパク質Aと前記タンパク質Xとの複合体タンパク質(タンパク質A−X複合体)の機能を解析する方法であって,
前記タンパク質A−RFDを生体内で発現させ,
前記タンパク質Aと前記タンパク質Xとの複合体を形成させ,
前記RFDと相互作用したユビキチン結合酵素に結合したユビキチンを前記タンパク質Xに転移させることにより,前記タンパク質Xを分解し,タンパク質X,又はタンパク質A−X複合体の機能を失活させ,
タンパク質X,又はタンパク質A−X複合体の機能を解析し,
ここで,前記“ユビキチン結合酵素と相互作用できるタンパク質(RFD)”が,
配列番号1に記載されるアミノ酸配列において134-181番のアミノ酸配列からなるタンパク質,
又は配列番号1に記載されるアミノ酸配列において134-181番のアミノ酸配列から1〜4個のアミノ酸残基が置換,欠損,付加又は挿入したアミノ酸配列からなるタンパク質であり,
前記タンパク質A−RFDは,タンパク質AとRFDとがリンカーにより結合され,
前記リンカーは,配列番号13又は配列番号14に記載されるアミノ酸配列からなるリンカー,
又は,配列番号13又は配列番号14に記載されるアミノ酸配列から1〜4個のアミノ酸残基が置換,欠損,付加又は挿入したアミノ酸配列からなるリンカーである,
タンパク質の機能解析方法。 - 標的タンパク質(タンパク質A)と,ユビキチン結合酵素と相互作用できるタンパク質(RFD)とを融合したタンパク質(タンパク質A−RFD)を用い,前記標的タンパク質と複合体を形成し,ユビキチン修飾化されることにより分解されるタンパク質(タンパク質X)の機能,又は前記タンパク質Aと前記タンパク質Xとの複合体タンパク質(タンパク質A−X)の機能を破壊したヒト以外のノックアウト動物又はノックアウト植物の製造方法であって,
前記タンパク質A−RFDを生体内で発現させ,
前記タンパク質Aと前記タンパク質Xとの複合体を形成させ,
前記RFDと相互作用したユビキチン結合酵素に結合したユビキチンを前記タンパク質Xに転移させることにより,前記タンパク質Xの機能又は前記タンパク質A−Xの機能を失活させ,
ヒト以外のノックアウト動物又はノックアウト植物を製造し,
ここで,前記“ユビキチン結合酵素と相互作用できるタンパク質(RFD)”が,
配列番号1に記載されるアミノ酸配列において134-181番のアミノ酸配列からなるタンパク質,
又は配列番号1に記載されるアミノ酸配列において134-181番のアミノ酸配列から1〜4個のアミノ酸残基が置換,欠損,付加又は挿入したアミノ酸配列からなるタンパク質である,
非ヒトノックアウト動物又はノックアウト植物の製造方法。 - 前記タンパク質A−RFDは,タンパク質AとRFDとがリンカーにより結合され,
前記リンカーは,配列番号13又は配列番号14に記載されるアミノ酸配列からなるリンカー,
又は,配列番号13又は配列番号14に記載されるアミノ酸配列から1〜4個のアミノ酸残基が置換,欠損,付加又は挿入したアミノ酸配列からなるリンカーである,
請求項2に記載の非ヒトノックアウト動物又はノックアウト植物の製造方法。 - 前記タンパク質Aが,
配列番号5に記載されるアミノ酸配列からなるタンパク質,
配列番号5に記載されるアミノ酸配列から1〜4個のアミノ酸残基が置換,欠損,付加又は挿入したアミノ酸配列からなるタンパク質,
配列番号5に記載されるアミノ酸配列の117-211番目のアミノ酸を有するドメインタンパク質,
又は配列番号5に記載されるアミノ酸配列の117-211番目のアミノ酸配列から1〜4個のアミノ酸残基が置換,欠損,付加又は挿入したアミノ酸配列からなるタンパク質であり,
前記タンパク質Xが,
配列番号6に記載されるタンパク質(SLR1),
又は配列番号6に記載されるアミノ酸配列から1〜4個のアミノ酸残基が置換,欠損,付加又は挿入したアミノ酸配列からなるタンパク質である
請求項2又は3に記載の非ヒトノックアウト動物又はノックアウト植物の製造方法。 - 前記タンパク質Aが,
配列番号7に記載されるタンパク質(MAPKP),
配列番号7に記載されるアミノ酸配列の362-467番目のアミノ酸を有するドメインタンパク質,
配列番号7に記載されるアミノ酸配列から1〜4個のアミノ酸残基が置換,欠損,付加又は挿入したアミノ酸配列からなるタンパク質,
又は配列番号7に記載されるアミノ酸配列の362-467番目のアミノ酸配列から1〜4個のアミノ酸残基が置換,欠損,付加又は挿入したアミノ酸配列からなるタンパク質であり,
前記タンパク質Xが,
配列番号8に記載されるタンパク質(CaM1),
配列番号8に記載されるアミノ酸配列から1〜4個のアミノ酸残基が置換,欠損,付加又は挿入したアミノ酸配列からなるタンパク質,
配列番号9に記載されるタンパク質(CaM3),
及び配列番号9に記載されるアミノ酸配列から1〜4個のアミノ酸残基が置換,欠損,付加又は挿入したアミノ酸配列からなるタンパク質のうちいずれか又は二つ以上である
請求項2又は3に記載の非ヒトノックアウト動物又はノックアウト植物の製造方法。 - 前記タンパク質Aが,
配列番号10に記載されるタンパク質(Gγ),
又は配列番号10に記載されるアミノ酸配列から1〜4個のアミノ酸残基が置換,欠損,付加又は挿入したアミノ酸配列からなるタンパク質であり,
前記タンパク質Xが,
配列番号11に記載されるタンパク質(Gβ),
又は配列番号11に記載されるアミノ酸配列から1〜4個のアミノ酸残基が置換,欠損,付加又は挿入したアミノ酸配列からなるタンパク質である
請求項2又は3に記載の非ヒトノックアウト動物又はノックアウト植物の製造方法。 - 前記タンパク質Aが,
配列番号12に記載されるタンパク質(CIGR2),
又は配列番号12に記載されるアミノ酸配列から1〜4個のアミノ酸残基が置換,欠損,付加又は挿入したアミノ酸配列からなるタンパク質である
請求項2又は3に記載の非ヒトノックアウト動物又はノックアウト植物の製造方法。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2009278073A JP4879314B2 (ja) | 2009-12-07 | 2009-12-07 | ユビキチン依存型タンパク質分解系を利用した生体内タンパク質分解システム,及びそのシステムを利用したタンパク質の機能解明方法 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2009278073A JP4879314B2 (ja) | 2009-12-07 | 2009-12-07 | ユビキチン依存型タンパク質分解系を利用した生体内タンパク質分解システム,及びそのシステムを利用したタンパク質の機能解明方法 |
Related Parent Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2004247434A Division JP4465444B2 (ja) | 2004-08-26 | 2004-08-26 | ユビキチン依存型タンパク質分解系を利用した生体内タンパク質分解システム,及びそのシステムを利用したタンパク質の機能解明方法 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2010088444A true JP2010088444A (ja) | 2010-04-22 |
| JP4879314B2 JP4879314B2 (ja) | 2012-02-22 |
Family
ID=42251802
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2009278073A Expired - Fee Related JP4879314B2 (ja) | 2009-12-07 | 2009-12-07 | ユビキチン依存型タンパク質分解系を利用した生体内タンパク質分解システム,及びそのシステムを利用したタンパク質の機能解明方法 |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP4879314B2 (ja) |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH07147987A (ja) * | 1993-05-28 | 1995-06-13 | Wisconsin Alumni Res Found | ユビキチン接合性酵素(e2)融合タンパク質 |
| WO2000047220A1 (en) * | 1999-02-12 | 2000-08-17 | Proteinix, Inc. | Controlling protein levels in eucaryotic organisms |
| WO2000050631A2 (en) * | 1999-02-25 | 2000-08-31 | Cyclacel Limited | Compositions and methods for monitoring the modification of natural binding partners |
| WO2002070662A2 (en) * | 2001-03-02 | 2002-09-12 | Gpc Biotech Ag | Three hybrid assay system |
| JP2003169673A (ja) * | 2001-12-07 | 2003-06-17 | Japan Science & Technology Corp | タンパク質分解排除酵素とその用途 |
| JP2004516848A (ja) * | 2000-11-13 | 2004-06-10 | サントル ナシオナル ドゥ ラ ルシェルシュ サイアンティフィック | 細胞内化合物を標的とした修飾 |
-
2009
- 2009-12-07 JP JP2009278073A patent/JP4879314B2/ja not_active Expired - Fee Related
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH07147987A (ja) * | 1993-05-28 | 1995-06-13 | Wisconsin Alumni Res Found | ユビキチン接合性酵素(e2)融合タンパク質 |
| WO2000047220A1 (en) * | 1999-02-12 | 2000-08-17 | Proteinix, Inc. | Controlling protein levels in eucaryotic organisms |
| WO2000050631A2 (en) * | 1999-02-25 | 2000-08-31 | Cyclacel Limited | Compositions and methods for monitoring the modification of natural binding partners |
| JP2004516848A (ja) * | 2000-11-13 | 2004-06-10 | サントル ナシオナル ドゥ ラ ルシェルシュ サイアンティフィック | 細胞内化合物を標的とした修飾 |
| WO2002070662A2 (en) * | 2001-03-02 | 2002-09-12 | Gpc Biotech Ag | Three hybrid assay system |
| JP2003169673A (ja) * | 2001-12-07 | 2003-06-17 | Japan Science & Technology Corp | タンパク質分解排除酵素とその用途 |
Also Published As
| Publication number | Publication date |
|---|---|
| JP4879314B2 (ja) | 2012-02-22 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Helm et al. | Localization of small heat shock proteins to the higher plant endomembrane system | |
| Monks et al. | Hyperosmotic stress induces the rapid phosphorylation of a soybean phosphatidylinositol transfer protein homolog through activation of the protein kinases SPK1 and SPK2 | |
| Li et al. | Identification of the self-incompatibility locus F-box protein-containing complex in Petunia inflata | |
| Lu et al. | The myristoylated amino-terminus of an Arabidopsis calcium-dependent protein kinase mediates plasma membrane localization | |
| Chew et al. | Characterization of the targeting signal of dual-targeted pea glutathione reductase | |
| Knopf et al. | Rhomboid proteins in the chloroplast envelope affect the level of allene oxide synthase in Arabidopsis thaliana | |
| Ke et al. | Functional divergence of chloroplast Cpn60α subunits during Arabidopsis embryo development | |
| Yashiroda et al. | Hub1 is an essential ubiquitin‐like protein without functioning as a typical modifier in fission yeast | |
| Park et al. | Identification and molecular properties of SUMO-binding proteins in Arabidopsis | |
| Su et al. | Purification and biochemical characterization of Arabidopsis At-NEET, an ancient iron-sulfur protein, reveals a conserved cleavage motif for subcellular localization | |
| Chigri et al. | Arabidopsis OBG-like GTPase (AtOBGL) is localized in chloroplasts and has an essential function in embryo development | |
| JP4465444B2 (ja) | ユビキチン依存型タンパク質分解系を利用した生体内タンパク質分解システム,及びそのシステムを利用したタンパク質の機能解明方法 | |
| Zakharova et al. | Global proteomics of the extremophile black fungus Cryomyces antarcticus using 2D-electrophoresis | |
| JP4879314B2 (ja) | ユビキチン依存型タンパク質分解系を利用した生体内タンパク質分解システム,及びそのシステムを利用したタンパク質の機能解明方法 | |
| Avendaño-Borromeo et al. | Identification of the gene encoding the TATA box-binding protein-associated factor 1 (TAF1) and its putative role in the heat shock response in the protozoan parasite Entamoeba histolytica | |
| Kwon et al. | Recombinant adenylate kinase 3 from liver fluke Clonorchis sinensis for histochemical analysis and serodiagnosis of clonorchiasis | |
| CN103756982B (zh) | 郁金香黄酮醇合成酶TfFLS蛋白及其编码基因 | |
| CN101649308A (zh) | 显示作为除虫菊酯生物合成酶的活性的蛋白质、编码该蛋白质的基因和整合有该基因的载体 | |
| Garcia et al. | Expression of a maize δ‐type DNA polymerase during seed germination | |
| Siriwan et al. | Study of interaction between Papaya ringspot virus coat protein and infected Carica papaya proteins | |
| US20060234222A1 (en) | Soluble recombinant protein production | |
| Benelli et al. | In vitro studies of archaeal translational initiation | |
| JP4849670B2 (ja) | トバモウイルス抵抗性遺伝子Tm−1 | |
| JP4346449B2 (ja) | UGPPaseの製造 | |
| Bretz | A Molecular Toolset for the in Vivo Detection of a Sulfolobus Islandicus Leucyl tRNA Synthetase Paralog |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20111122 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20111129 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20141209 Year of fee payment: 3 |
|
| LAPS | Cancellation because of no payment of annual fees |