JP2010066957A - 誤り表記検出装置、誤り表記生成装置、それらの方法、プログラムおよび記録媒体 - Google Patents
誤り表記検出装置、誤り表記生成装置、それらの方法、プログラムおよび記録媒体 Download PDFInfo
- Publication number
- JP2010066957A JP2010066957A JP2008231956A JP2008231956A JP2010066957A JP 2010066957 A JP2010066957 A JP 2010066957A JP 2008231956 A JP2008231956 A JP 2008231956A JP 2008231956 A JP2008231956 A JP 2008231956A JP 2010066957 A JP2010066957 A JP 2010066957A
- Authority
- JP
- Japan
- Prior art keywords
- notation
- correct
- word
- error
- pronunciation
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images





Landscapes
- Machine Translation (AREA)
- Document Processing Apparatus (AREA)
Abstract
【解決手段】誤り表記検出対象文書1を形態素解析部110にて各単語に分解し、第1表記判定部120にて各単語について正誤表記対照表3と照合し、当該単語が正誤表記対照表3の正解表記のみに存在するか又は正解表記と誤り表記のいずれにも存在しない場合には当該単語は正しい表記であると判定して結果を出力し、誤り表記のみに存在する場合には当該単語は誤った表記であると判定して結果を出力し、正解表記と誤り表記のいずれにも存在する場合には、更に言語スコア計算部130にて、統計的言語モデル4を用いて各表記の言語スコアを計算し、第2表記判定部140にて各言語スコアの比較により正しい表記であるか誤った表記であるかを判定して結果を出力する。
【選択図】図1
Description
(1)任意に定めた統一基準による正解表記と誤り表記との組情報を予め持ち、文書から誤り表記が検出された場合に、その組情報に基づき訂正候補を提示する手法。
(2)ルールを作成して外来語や送り仮名などのゆらぎを訂正する手法。例えば、「ター」を「タ」に(ex.「インターフェース」→「インタフェース」)、「込み」を「込」に(ex.「振込み」→「振込」)、訂正するというルールを作成する。
(1)表記のみで正解、誤りを判断しているため、同じ表記であるにもかかわらず、ある読み方としては誤りであり、ある読み方としては正解であるような場合に対応できない。例えば、「今日」という表記がある場合、「キョウ」と読みたい場合には「きょう」が正解表記(つまり「今日」は誤り表記)であり、「コンニチ」と読みたい場合には「今日」が正解表記であると統一基準として定めた時、文書に「今日」という表記が現われた時に「きょう」に訂正すべきか「今日」のままよいかの切り分けができない。
(2)外来語や送り仮名以外にも表記を統一する必要があり、また統一の規則は単語ごとに異なるため、例えば、必ずしも全ての「ター」を「タ」に訂正すべきであるとは限らず、ルールだけでは限界がある。
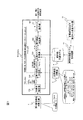
図1に本発明の誤り表記検出装置100の機能構成例を、図2にその処理フロー例を示す。誤り表記検出装置100は、形態素解析部110と第1表記判定部120と言語スコア計算部130と第2表記判定部140とから構成され、入力された誤り表記検出対象文書1の各単語それぞれについて正解表記であるか誤り表記であるかを判定し結果を出力する。
Pe(S)=P(w1,・・・,wk-2,wk-1,wk´,wk+1,wk+2,・・・,wn)
統計的言語モデルとは、与えられた文書に対して、その文書を構成する単語列の生成確率を求めるためのモデルである。統計的言語モデルには連続音声認識などで盛んに使用されているN−gramを始めとして、任意の統計的言語モデルを使用できるが、ここではTrigramを使用した場合を例にとって言語スコアの計算方法を説明する。
Trigramは、単語列中のある単語wtの出現確率を直前の2単語から予測するモデルでP(wt|wt-2,wt-1)として表現される。従って、文書全体の言語スコアは次式により求めることができる。

〔参考文献2〕鹿野清宏、外4名編著、情報処理学会編、「音声認識システム」、第1版、株式会社オーム社、2001年5月、p.53-68
統計的言語モデル4の生成に用いる正解表記のみで記された任意の文書11は、本発明での主な誤り表記検出対象文書である法律に係わる文書や議会の議事録が標準的な用字用語に則るものであることから、そのような既存の文書や議会の議事録を適宜選定してそれをそのまま利用することができる。また、参考文献3に記載された文部省用字用語例や参考文献4の用字用語辞典に記載された標準的な用字用語を正解表記として利用し、これに基づいて任意の文書11を容易に構成することもできる。特に、議会の議事録が対象である場合は、参考文献5、6を正解表記として利用し、これに基づいて任意の文書11を構成すればよい。
〔参考文献4〕NHK放送文化研究所編、「NHK 新用字用語辞典」、第3版、株式会社日本放送出版協会、2004年3月
〔参考文献5〕衆議院事務局記録部、参議院事務局記録部編、「国会会議録用字例」、衆議院事務局記録部、参議院事務局記録部、1975年
〔参考文献6〕日本速記協会編、「改訂 標準用字用例辞典」、社団法人日本速記協会、2007年
なお、正解表記のみで記された任意の文書11のデータ量は多ければ多いに越したことはないが、一例として、のべ約650時間、単語(形態素)にして約700万語規模を目安とすることが考えられる(参考文献7参照)。
第2表記判定部140は、単語wkと、当該単語wkについて求めた言語スコアPc(S)、Pe(S)が入力され、単語wkの表記が正しい表記であるか誤った表記であるかを判定して、判定結果を出力する(S4)。判定方法は、例えば単純に、Pe(S)>Pc(S)である場合に単語wkの表記は誤っていると判定してもよいし、正誤判定の性能を調整するために、Pe(S)>α・Pc(S)(αは正の定数)である場合に単語wkの表記は誤っていると判定してもよい。後者の場合、αが小さいほど単語を誤りとして検出しやすくなる。なお、単語wkが誤り表記として含まれる組が複数ある場合は、それぞれの組の比較表記wk´について言語スコアPe(S)を算出し、算出した全てのPe(S)のうち最もスコアが高いものを選択して上記のようにPc(S)との比較判定を行う。
以上のように誤り表記検出装置を構成することで、誤り検出を表記に加えて発音も用いて行うため、同じ表記であるにもかかわらず、ある読み方としては誤りであり、ある読み方としては正解であるような場合にも、高い精度で表記のゆらぎや誤りを自動検出することができる。
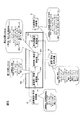
図3に本発明の誤り表記検出装置200の機能構成例を、図4にその処理フロー例を示す。誤り表記検出装置200は、第1表記判定部220と発音判定部260と言語スコア計算部230と第2表記判定部140とから構成され、入力された誤り表記検出対象文書2の各単語それぞれについて正解表記であるか誤り表記であるかを判定し結果を出力する。
以上のように誤り表記検出装置を構成することで、第1実施形態と同様、誤り検出を表記に加えて発音も用いて行うため、同じ表記であるにもかかわらず、ある読み方としては誤りであり、ある読み方としては正解であるような場合にも、高い精度で表記のゆらぎや誤りを自動検出することができる。
第3実施形態の誤り表記検出装置101及び201は、図1及び図3の点線で示すように、第1実施形態の誤り表記検出装置100及び第2実施形態の誤り表記検出装置200の判定結果出力端に、それぞれメッセージ表示部151を接続した構成である。メッセージ表示部151は、第1表記判定部120(220)、第2表記判定部140及び発音判定部260での判定結果が入力され、誤った表記であると判定された単語wkについて、誤っている旨のメッセージを表示するか、誤り表記検出対象文書全体を表示する中でその他の単語と別の色で表示するか、又は正しい表記への訂正を促すメッセージを表示する。
このようにメッセージを表示することで、表記の誤りを直接視認することができる。
上記各実施形態は誤り表記検出装置に係るものであったが、第4実施形態は上記各実施形態における誤り表記検出処理の中で用いる正誤表記対照表3を生成する誤り表記生成装置300に係るものである。図5に本発明の誤り表記生成装置300の機能構成例を、図6にその処理フロー例を示す。また、誤り表記検出装置100(200)と誤り表記生成装置300とを組み合わせた全体構成イメージを図7に示す。
Claims (10)
- 誤り表記検出対象文書が入力され、単語単位に分割して単語列を出力する形態素解析部と、
上記単語列が入力され、当該単語列を構成する各単語について、正解表記とその正しい発音と当該発音の正解表記以外の表記(以下、「誤り表記」という)との組がリスト化された正誤表記対照表を参照して、当該単語の表記が正解表記のみに存在するか又は正解表記と誤り表記のいずれにも存在しない場合には当該単語は正しい表記であるとの判定結果を出力し、誤り表記のみに存在する場合には当該単語は誤った表記であるとの判定結果を出力し、正解表記と誤り表記のいずれにも存在する場合には、当該単語の表記と、当該単語の表記が誤り表記として含まれる組の正解表記(以下、「比較表記」という)とを出力する第1表記判定部と、
上記第1表記判定部にて上記単語の表記が上記正誤表記対照表の正解表記と誤り表記のいずれにも存在すると確認された場合に、上記単語列と当該単語の表記と上記比較表記とが入力され、当該単語列において当該単語の表記を、そのままにした場合の言語スコアと、当該比較表記に置き換えた場合の言語スコアを、正解表記のみで記された任意の文書から作成した統計的言語モデルを用いて、それぞれ計算して当該単語とともに出力する言語スコア計算部と、
上記言語スコア計算部で求めたそれぞれの言語スコアが入力され、上記単語の表記が正しい表記であるか誤った表記であるかの判定結果を出力する第2表記判定部と、
を備える誤り表記検出装置。 - 単語ごとに発音が付された誤り表記検出対象文書が入力され、各単語について、正解表記とその正しい発音と当該発音の正解表記以外の表記(以下、「誤り表記」という)との組がリスト化された正誤表記対照表を参照して、当該単語が正解表記のみに存在するか又は正解表記と誤り表記のいずれにも存在しない場合には当該単語は正しい表記であるとの判定結果を出力し、誤り表記のみに存在する場合には誤った表記であるとの判定結果を出力し、正解表記と誤り表記のいずれにも存在する場合には、当該単語とその発音を出力する第1表記判定部と、
上記第1表記判定部にて上記単語が上記正誤表記対照表の正解表記と誤り表記のいずれにも存在すると確認された場合に、上記単語とその発音が入力され、当該単語の発音について上記正誤表記対照表を参照して、その発音において当該単語が正解表記のみに存在する場合には正しい表記であるとの判定結果を出力し、誤り表記のみに存在する場合には誤った表記であるとの判定結果を出力し、正解表記と誤り表記のいずれにも存在する場合には、当該単語と、当該単語が誤り表記として含まれる組の正解表記(以下、「比較表記」という)とを出力する発音判定部と、
上記発音判定部にて上記単語が上記正誤表記対照表の正解表記と誤り表記のいずれにも存在すると確認された場合に、上記誤り表記検出対象文書と当該単語と上記比較表記とが入力され、当該誤り表記検出対象文書において当該単語の表記を、そのままにした場合の言語スコアと、当該比較表記に置き換えた場合の言語スコアを、正解表記のみで記された任意の文書から作成した統計的言語モデルを用いて、それぞれ計算して当該単語とともに出力する言語スコア計算部と、
上記言語スコア計算部で求めたそれぞれの言語スコアが入力され、上記単語が正しい表記であるか誤った表記であるかの判定結果を出力する第2表記判定部と、
を備える誤り表記検出装置。 - 請求項1又は2のいずれかに記載の誤り表記検出装置において、
更に、上記判定結果が入力され、誤った表記であると判定された単語について、誤っている旨のメッセージを表示するか、誤り表記検出対象文書中にその他の単語と別の色で表示するか、又は正しい表記への訂正を促すメッセージを表示するメッセージ表示部を備えることを特徴とする誤り表記検出装置。 - それぞれの単語に対して任意に定めた正解表記とその正しい発音との組がリスト化された正解表記・発音対照表の各正解表記について、それぞれの単語の表記とその読み方として想定される1以上の発音との組がリスト化された表記・発音対照辞書の同じ表記の組に係る発音を検索し、当該正解表記の発音以外の発音を当該正解表記の発音に追記して生成した第1中間リストを出力する表記同一発音検索部と、
上記第1中間リストが入力され、当該第1中間リストに含まれる上記正解表記の各発音をキーに、上記表記・発音対照辞書を検索して、当該各発音に対応する当該正解表記以外の表記を抽出し、抽出した表記を誤り表記候補として上記第1中間リストの当該正解表記に関連付けて追加して生成した第2中間リストを出力する発音同一表記検索部と、
上記第2中間リストが入力され、当該第2中間リストの上記誤り表記候補から同音異義語を削除して、正解表記とその正しい発音と当該発音の正解表記以外の表記との組がリスト化された正誤表記対照表を生成して出力する同音異義語削除部と、
を備える誤り表記生成装置。 - 形態素解析部が、誤り表記検出対象文書を単語単位に分割して単語列を出力する形態素解析ステップと、
第1表記判定部が、上記単語列を構成する各単語について、正解表記とその正しい発音と当該発音の正解表記以外の表記(以下、「誤り表記」という)との組がリスト化された正誤表記対照表を参照して、当該単語の表記が正解表記のみに存在するか又は正解表記と誤り表記のいずれにも存在しない場合には当該単語は正しい表記であると判定して結果を出力し、誤り表記のみに存在する場合には当該単語は誤った表記であると判定して結果を出力し、正解表記と誤り表記のいずれにも存在する場合には、当該単語の表記と、当該単語の表記が誤り表記として含まれる組の正解表記(以下、「比較表記」という)とを出力する第1表記判定ステップと、
言語スコア計算部が、上記第1表記判定ステップにて上記単語の表記が上記正誤表記対照表の正解表記と誤り表記のいずれにも存在すると確認された場合に、上記単語列において当該単語の表記を、そのままにした場合の言語スコアと、上記比較表記に置き換えた場合の言語スコアを、正解表記のみで記された任意の文書から作成した統計的言語モデルを用いて、それぞれ計算して当該単語とともに出力する言語スコア計算ステップと、
第2表記判定部が、上記言語スコア計算ステップで求めたそれぞれの言語スコアから、上記単語の表記が正しい表記であるか誤った表記であるかを判定して結果を出力する第2表記判定ステップと、
を実行する誤り表記検出方法。 - 第1表記判定部が、単語ごとに発音が付された誤り表記検出対象文書の各単語について、正解表記とその正しい発音と当該発音の正解表記以外の表記(以下、「誤り表記」という)との組がリスト化された正誤表記対照表を参照して、当該単語が正解表記のみに存在するか又は正解表記と誤り表記のいずれにも存在しない場合には当該単語は正しい表記であると判定して結果を出力し、誤り表記のみに存在する場合には誤った表記であると判定して結果を出力し、正解表記と誤り表記のいずれにも存在する場合には、当該単語とその発音を出力する第1表記判定ステップと、
発音判定部が、上記第1表記判定ステップにて上記単語が上記正誤表記対照表の正解表記と誤り表記のいずれにも存在すると確認された場合に、上記単語の発音について上記正誤表記対照表を参照して、その発音において当該単語が正解表記のみに存在する場合には正しい表記であると判定して結果を出力し、誤り表記のみに存在する場合には誤った表記であると判定して結果を出力し、正解表記と誤り表記のいずれにも存在する場合には、当該単語と、当該単語が誤り表記として含まれる組の正解表記(以下、「比較表記」という)とを出力する発音判定ステップと、
言語スコア計算部が、上記発音判定ステップにて上記単語が上記正誤表記対照表の正解表記と誤り表記のいずれにも存在すると確認された場合に、上記誤り表記検出対象文書において当該単語の表記を、そのままにした場合の言語スコアと、上記比較表記に置き換えた場合の言語スコアを、正解表記のみで記された任意の文書から作成した統計的言語モデルを用いて、それぞれ計算して当該単語とともに出力する言語スコア計算ステップと、
第2表記判定部が、上記言語スコア計算ステップで求めたそれぞれの言語スコアから、上記単語の表記が正しい表記であるか誤った表記であるかを判定して結果を出力する第2表記判定ステップと、
を実行する誤り表記検出方法。 - 請求項5又は6のいずれかに記載の誤り表記検出方法において、
更に、メッセージ表示部が、上記判定の結果、誤った表記であると判定された単語について、誤っている旨のメッセージを表示するか、誤り表記検出対象文書中にその他の単語と別の色で表示するか、又は正しい表記への訂正を促すメッセージを表示するメッセージ表示ステップを実行することを特徴とする誤り表記検出方法。 - 表記同一発音検索部が、それぞれの単語に対して任意に定めた正解表記とその正しい発音との組がリスト化された正解表記・発音対照表の各正解表記について、それぞれの単語の表記とその読み方として想定される1以上の発音との組がリスト化された表記・発音対照辞書の同じ表記の組に係る発音を検索し、当該正解表記の正しい発音以外の発音を当該正解表記の発音として追記して生成した第1中間リストを出力する表記同一発音検索ステップと、
発音同一表記検索部が、上記第1中間リストに含まれる上記正解表記の各発音をキーに、上記表記・発音対照辞書を検索して、当該各発音に対応する当該正解表記以外の表記を抽出し、抽出した表記を誤り表記候補として上記第1中間リストの当該正解表記に関連付けて追加して生成した第2中間リストを出力する発音同一表記検索ステップと、
同音異義語削除部が、上記第2中間リストの上記誤り表記候補から同音異義語を削除して、正解表記とその正しい発音と当該発音の正解表記以外の表記との組がリスト化された正誤表記対照表を生成して出力する同音異義語削除ステップと、
を実行する誤り表記生成方法。 - 請求項1〜4のいずれかに記載した装置としてコンピュータを機能させるためのプログラム。
- 請求項9に記載したプログラムを記録したコンピュータが読み取り可能な記録媒体。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2008231956A JP5069194B2 (ja) | 2008-09-10 | 2008-09-10 | 誤り表記検出装置、誤り表記生成装置、それらの方法、プログラムおよび記録媒体 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2008231956A JP5069194B2 (ja) | 2008-09-10 | 2008-09-10 | 誤り表記検出装置、誤り表記生成装置、それらの方法、プログラムおよび記録媒体 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2010066957A true JP2010066957A (ja) | 2010-03-25 |
| JP5069194B2 JP5069194B2 (ja) | 2012-11-07 |
Family
ID=42192497
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2008231956A Expired - Fee Related JP5069194B2 (ja) | 2008-09-10 | 2008-09-10 | 誤り表記検出装置、誤り表記生成装置、それらの方法、プログラムおよび記録媒体 |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP5069194B2 (ja) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2020516994A (ja) * | 2017-03-29 | 2020-06-11 | 北京捜狗科技▲発▼展有限公司 | テキスト編集方法、装置及び電子機器 |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS62212871A (ja) * | 1986-03-14 | 1987-09-18 | Fujitsu Ltd | 文章読み上げ校正装置 |
| JP2003196636A (ja) * | 2001-12-26 | 2003-07-11 | Communication Research Laboratory | 教師あり機械学習法を用いた表記誤り検出処理方法、その処理装置、およびその処理プログラム |
-
2008
- 2008-09-10 JP JP2008231956A patent/JP5069194B2/ja not_active Expired - Fee Related
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS62212871A (ja) * | 1986-03-14 | 1987-09-18 | Fujitsu Ltd | 文章読み上げ校正装置 |
| JP2003196636A (ja) * | 2001-12-26 | 2003-07-11 | Communication Research Laboratory | 教師あり機械学習法を用いた表記誤り検出処理方法、その処理装置、およびその処理プログラム |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2020516994A (ja) * | 2017-03-29 | 2020-06-11 | 北京捜狗科技▲発▼展有限公司 | テキスト編集方法、装置及び電子機器 |
Also Published As
| Publication number | Publication date |
|---|---|
| JP5069194B2 (ja) | 2012-11-07 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN109783796B (zh) | 预测文本内容中的样式破坏 | |
| US9626152B2 (en) | Methods and systems for recommending responsive sticker | |
| JP5362095B2 (ja) | インプットメソッドエディタ | |
| US8447602B2 (en) | System for speech recognition and correction, correction device and method for creating a lexicon of alternatives | |
| KR102348845B1 (ko) | 실시간 오류 후보 생성을 이용한 문맥의존 철자오류 교정 장치 및 방법 | |
| JP4887264B2 (ja) | 音声データ検索システム | |
| US9881010B1 (en) | Suggestions based on document topics | |
| US10803241B2 (en) | System and method for text normalization in noisy channels | |
| US20160210279A1 (en) | Methods and systems for analyzing communication situation based on emotion information | |
| US20150370780A1 (en) | Predictive conversion of language input | |
| US20190361961A1 (en) | Fact validation in document editors | |
| CN109791761A (zh) | 使用校正的术语的声学模型训练 | |
| US9542383B2 (en) | Example-based error detection system for automatic evaluation of writing, method for same, and error detection apparatus for same | |
| US11568150B2 (en) | Methods and apparatus to improve disambiguation and interpretation in automated text analysis using transducers applied on a structured language space | |
| US20160210117A1 (en) | Methods and systems for recommending dialogue sticker based on similar situation detection | |
| CN106462564A (zh) | 在文档内提供实际建议 | |
| KR20120045906A (ko) | 코퍼스 오류 교정 장치 및 그 방법 | |
| JP5069194B2 (ja) | 誤り表記検出装置、誤り表記生成装置、それらの方法、プログラムおよび記録媒体 | |
| JP5623380B2 (ja) | 誤り文修正装置、誤り文修正方法およびプログラム | |
| US11288451B2 (en) | Machine based expansion of contractions in text in digital media | |
| JP4839291B2 (ja) | 音声認識装置およびコンピュータプログラム | |
| US12026148B2 (en) | Dynamic updating of digital data | |
| JP5583230B2 (ja) | 情報検索装置及び情報検索方法 | |
| JP2013109125A (ja) | 単語追加装置、単語追加方法、およびプログラム | |
| JP5169602B2 (ja) | 形態素解析装置、形態素解析方法及びコンピュータプログラム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20100726 |
|
| RD03 | Notification of appointment of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7423 Effective date: 20110810 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20120807 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20120816 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20150824 Year of fee payment: 3 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| S531 | Written request for registration of change of domicile |
Free format text: JAPANESE INTERMEDIATE CODE: R313531 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |
|
| LAPS | Cancellation because of no payment of annual fees |