JP2010044485A - 文字認識装置、文字認識プログラム、および文字認識方法 - Google Patents
文字認識装置、文字認識プログラム、および文字認識方法 Download PDFInfo
- Publication number
- JP2010044485A JP2010044485A JP2008206722A JP2008206722A JP2010044485A JP 2010044485 A JP2010044485 A JP 2010044485A JP 2008206722 A JP2008206722 A JP 2008206722A JP 2008206722 A JP2008206722 A JP 2008206722A JP 2010044485 A JP2010044485 A JP 2010044485A
- Authority
- JP
- Japan
- Prior art keywords
- character
- length
- characters
- standard
- character string
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images








Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/10—Character recognition
- G06V30/14—Image acquisition
- G06V30/148—Segmentation of character regions
- G06V30/158—Segmentation of character regions using character size, text spacings or pitch estimation
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/10—Character recognition
Landscapes
- Engineering & Computer Science (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Multimedia (AREA)
- Theoretical Computer Science (AREA)
- Character Discrimination (AREA)
- Character Input (AREA)
Abstract
【解決手段】文字認識装置に、文字列画像を取得する文字列画像取得手段と、文字列方向の文字長を測定した測定文字長を前記文字列画像取得手段で取得した文字列画像から複数の文字について取得する測定文字長取得手段と、取得した測定文字長内の文字を仮マッチング処理により仮認識する文字仮認識手段と、仮認識できた文字の前記測定文字長に基づいて標準文字長を決定する標準文字長決定手段と、決定した標準文字長に基づいて前記文字列画像から認識対象の全ての文字を切り出す文字切出手段と、切り出した文字を本マッチング処理により本認識する文字認識手段とを備えた。
【選択図】図6
Description
詳述すると、特許文献1記載の文字認識装置は、文字幅が固定という前提で文字切り出しを行うものである。このため、この文字認識装置は、全角文字と半角文字が混合している文字列にうまく対応できないものである。
前記文字長は、文字列方向の1文字の長さを指し、例えば1文字における文字列方向の画素数とすることができる。
この発明により、接触文字、および縦横比変形文字による文字列であっても、正しく文字認識することが可能になる。
これにより、全角文字と半角文字を正しく認識することができる。
これにより、全角文字同士の文字幅のばらつきに適切に対応できる。すなわち、例えば文字「と」と文字「ど」では、濁点の分だけ文字幅が少し異なるが、このような文字幅のばらつきに適切に対応することができる。
これにより、「I」や「l」などの文字幅の小さい文字に対しても適切に対応できる。
この発明により、接触文字、および縦横比変形文字による文字列であっても、正しく文字認識することが適宜のハードウェアにて実行可能になる。
図1は、携帯端末1の斜視図を示し、図2は、携帯端末1の構成のブロック図を示す。
文字切出処理部34は、前記標準文字長で文字列を切り出して1文字単位に分離する。
辞書データ25は、文字コード、マッチング情報、全角/半角区別、結合文字区別、および左部品文字区別などの各項目によって構成されている。
マッチング情報は、各文字について特徴量データを記憶している。
結合文字区別は、結合文字か否かの区別を“1”/“0”で記憶している。
左部品文字区別は、左側の部品文字であるか否かの区別を“1”/“0”で記憶している。
認識画面40は、画像入力部3で取得した画像を画面中に大きく表示し、その中で認識したい文字列画像Pを認識対象特定枠41で囲んで表示している。なお、図示する例では、文字が横並びであるため、文字長は一般に言う文字幅となる。
戻るボタン42は、押下されると前の画面に戻るボタンである。
認識ボタン43は、押下されると文字認識を開始するボタンである。
図5(A)に示す文字列画像51を、文字部分が黒になるように2値化し、文字列方向に垂直な方向(図示の例では上下方向)の黒画素の数を、文字列方向にビット単位で並べると、図5(B)に示すように黒画素を投影させた射影データ52が得られる。
この射影データ52は、縦軸を黒画素数、横軸を文字列方向の位置とするヒストグラムである。
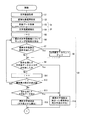
CPU11は、画像入力部3から文字画像を取得する(ステップS1)。この文字画像の取得は、操作部5から利用者の撮像操作を受け付け、この撮像操作に基づいて画像入力部3による撮像を実行し、画像入力部3が取得した撮像画像を文字画像としてデータ受信することで取得する。
CPU11は、文字長候補抽出処理部32としての機能を発揮し、射影データ52から測定文字長を抽出する(ステップS4)。このとき、図8(B)に示すように、「六」「月」「白」「勺」「宴」「会」「米」「斗」「理」…、の文字候補単位に区分して測定文字長を抽出したものとする。なお、区分した文字候補および測定文字長は、文字列が横並びであれば左から順番に番号を付し、文字列が縦並びであれば上から順番に番号を付すと良い。
条件1:マッチング信頼度が所定の基準値以上であること
条件2:マッチングにより認識した文字が、部品文字に該当しないこと
条件3:マッチングにより認識した文字が、結合文字に該当しないこと
標準文字長算出条件を満たさない場合(ステップS7:No)、CPU11は、そのまま処理をステップS9へ進める。
ここまでのステップS6からS14を実行するCPU11は、標準文字長算出部33として機能する。
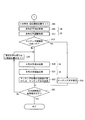
CPU11は、文字列画像の最後尾の文字か否か判定し(ステップS23)、最後尾の文字でなければ(ステップS23:No)、次の文字の切出開始位置をセットし(ステップS24)、ステップS20に処理を戻して繰り返す。次の文字の切出開始位置は、例えばステップS16の全角文字切出処理またはステップS20の半角文字切出処理で決定した文字終端側のカット位置とすればよい。
標準文字長Laを定める際に、マッチング信頼度がある閾値より良いという条件を課したため、正しく文字認識できてない文字、すなわち接触文字であったり文字が途中で切れていたり文字以外のノイズが写っていたりする画像を標準文字長Laの算出から排除することができる。
また、射影データ52からの文字切出処理において、射影データ52の切れ目あるいは谷となるところを文字切り出し座標の候補としたことで、文字の接触が頻発している文字列であっても、正しく1文字を切出して精度よく文字認識することができる。
この発明の文字認識装置は、実施形態の携帯端末1またはチップ15に対応し、
以下同様に、
文字列画像取得手段は、ステップS1を実行するCPU11に対応し、
測定文字長取得手段は、文字長候補抽出処理部32に対応し、
文字仮認識手段は、ステップS6を実行する標準文字長算出部33に対応し、
標準文字長決定手段は、標準文字長算出部33に対応し、
文字切出手段は、文字切出処理部34に対応し、
文字認識手段は、文字認識処理部35に対応し、
仮文字長は、切出範囲E1に対応し、
縮小文字長は、切出範囲E2に対応し、
所定誤差は、文字終端許容誤差αに対応し、
所定の範囲は、文字開始端カット範囲βに対応し、
所定の閾値は、基準値に対応し、
文字列取得ステップは、ステップS1に対応し、
測定文字長取得ステップは、ステップS4に対応し、
仮マッチング処理、仮認識、および文字仮認識ステップは、ステップS6に対応し、
標準文字長決定ステップは、ステップS6〜S14に対応し、
第1切出処理は、ステップS16に対応し、
全角文字本マッチング処理は、ステップS17に対応し、
文字切出ステップは、ステップS16,S20に対応し、
文字認識ステップおよび本マッチング処理は、ステップS17,S21に対応し、
第2切出処理は、ステップS20に対応し、
半角文字本マッチグ処理は、ステップS21に対応するが、
この発明は、上述の実施形態の構成のみに限定されるものではなく、多くの実施の形態を得ることができる。
Claims (8)
- 文字列画像を取得する文字列画像取得手段と、
文字列方向の文字長を測定した測定文字長を前記文字列画像取得手段で取得した文字列画像から複数の文字について取得する測定文字長取得手段と、
取得した測定文字長内の文字を仮マッチング処理により仮認識する文字仮認識手段と、
仮認識できた文字の前記測定文字長に基づいて標準文字長を決定する標準文字長決定手段と、
決定した標準文字長に基づいて前記文字列画像から認識対象の全ての文字を切り出す文字切出手段と、
切り出した文字を本マッチング処理により本認識する文字認識手段とを備えた
文字認識装置。 - 前記仮マッチング処理により仮認識した文字が、前記文字列画像の文字列方向に配置された2つの部品文字を結合してできる1つの結合文字である場合、前記標準文字長決定手段は、前記標準文字長の決定に利用する測定文字長から該結合文字の測定文字長を除外する構成とした
請求項1記載の文字認識装置。 - 前記仮マッチング処理により仮認識した文字が、当該文字に対して文字列方向の前後いずれかの文字を結合すると1つの結合文字を形成できる部品文字である場合、前記標準文字長決定手段は、前記標準文字長の決定に利用する測定文字長から該部品文字の測定文字長を除外する構成とした
請求項1または2記載の文字認識装置。 - 前記文字切出手段は、
前記文字列画像を文字列方向と垂直な方向に投射した射影データを作成し、該射影データの切れ目あるいは谷から次の切れ目あるいは谷までの仮文字長が前記標準文字長に対して所定誤差内にある文字を切り出す第1切出処理を実行する構成とし、
前記文字認識手段は、前記本マッチング処理として、切り出した文字について全角文字とマッチングする全角文字本マッチング処理を行う構成とし、
該全角文字本マッチング処理でのマッチング信頼度が所定の閾値よりも低い場合、
前記文字切出手段は、前記標準文字長のうち文字列前方から所定の範囲と文字列後方から前記所定誤差を切り落とした縮小文字長内にある文字を切り出す第2切出処理を実行する構成とし、
前記文字認識手段は、前記本マッチング処理として、切り出した文字について半角文字とマッチングする半角文字本マッチグ処理を行う構成とした
請求項1、2、または3記載の文字認識装置。 - 前記所定誤差を前記標準文字長の4分の1とした
請求項4記載の文字認識装置。 - 前記所定の範囲を前記標準文字長の16分の1とした
請求項4または5記載の文字認識装置。 - 文字列画像を文字列画像取得手段により取得する文字列取得ステップと、
文字列方向の文字長を測定した測定文字長を前記文字列画像から複数の文字について取得する測定文字長取得ステップと、
取得した測定文字長内の文字を仮マッチング処理により仮認識する文字仮認識ステップと、
仮認識できた文字の前記測定文字長に基づいて標準文字長を決定する標準文字長決定ステップと、
決定した標準文字長に基づいて前記文字列画像から認識対象の全ての文字を切り出す文字切出ステップと、
切り出した文字を本マッチング処理により本認識する文字認識ステップとをコンピュータに実行させる
文字認識プログラム。 - 文字列画像を文字列画像取得手段により取得する文字列取得ステップと、
文字列方向の文字長を測定した測定文字長を前記文字列画像から複数の文字について取得する測定文字長取得ステップと、
取得した測定文字長内の文字を仮マッチング処理により仮認識する文字仮認識ステップと、
仮認識できた文字の前記測定文字長に基づいて標準文字長を決定する標準文字長決定ステップと、
決定した標準文字長に基づいて前記文字列画像から認識対象の全ての文字を切り出す文字切出ステップと、
切り出した文字を本マッチング処理により本認識する文字認識ステップとを実行する
文字認識方法。
Priority Applications (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2008206722A JP5146190B2 (ja) | 2008-08-11 | 2008-08-11 | 文字認識装置、文字認識プログラム、および文字認識方法 |
| KR1020090070357A KR101050866B1 (ko) | 2008-08-11 | 2009-07-31 | 문자 인식 장치, 문자 인식 프로그램, 및 문자 인식 방법 |
| CN2009101590895A CN101650779B (zh) | 2008-08-11 | 2009-08-06 | 字符识别装置以及字符识别方法 |
| EP09167660.1A EP2154632B1 (en) | 2008-08-11 | 2009-08-11 | Character recognition device, program and method |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2008206722A JP5146190B2 (ja) | 2008-08-11 | 2008-08-11 | 文字認識装置、文字認識プログラム、および文字認識方法 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2010044485A true JP2010044485A (ja) | 2010-02-25 |
| JP5146190B2 JP5146190B2 (ja) | 2013-02-20 |
Family
ID=41347204
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2008206722A Expired - Fee Related JP5146190B2 (ja) | 2008-08-11 | 2008-08-11 | 文字認識装置、文字認識プログラム、および文字認識方法 |
Country Status (4)
| Country | Link |
|---|---|
| EP (1) | EP2154632B1 (ja) |
| JP (1) | JP5146190B2 (ja) |
| KR (1) | KR101050866B1 (ja) |
| CN (1) | CN101650779B (ja) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2013121648A1 (ja) | 2012-02-17 | 2013-08-22 | オムロン株式会社 | 文字認識方法、およびこの方法を用いた文字認識装置およびプログラム |
| WO2013121647A1 (ja) | 2012-02-17 | 2013-08-22 | オムロン株式会社 | 文字切り出し方法、およびこの方法を用いた文字認識装置およびプログラム |
| CN111626038A (zh) * | 2019-01-10 | 2020-09-04 | 北京字节跳动网络技术有限公司 | 背诵文本的提示方法、装置、设备及存储介质 |
Families Citing this family (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8494284B2 (en) * | 2011-11-21 | 2013-07-23 | Nokia Corporation | Methods and apparatuses for facilitating detection of text within an image |
| JP6055297B2 (ja) * | 2012-12-07 | 2016-12-27 | 株式会社日立情報通信エンジニアリング | 文字認識装置及び方法、文字認識プログラム |
| CN103020621B (zh) * | 2012-12-25 | 2016-02-24 | 深圳深讯和科技有限公司 | 中英文混排文字图像的切割方法及装置 |
| CN104134064B (zh) * | 2013-05-02 | 2018-05-04 | 百度国际科技(深圳)有限公司 | 文字识别方法和装置 |
| CN104143093B (zh) * | 2013-05-10 | 2018-01-09 | 百度在线网络技术(北京)有限公司 | 文字识别方法和装置 |
| CN105631450A (zh) * | 2015-12-28 | 2016-06-01 | 小米科技有限责任公司 | 字符识别方法及装置 |
| JP6804292B2 (ja) * | 2016-12-28 | 2020-12-23 | オムロンヘルスケア株式会社 | 端末装置 |
| JP2019159633A (ja) * | 2018-03-12 | 2019-09-19 | セイコーエプソン株式会社 | 画像処理装置、画像処理方法および画像処理プログラム |
| CN112215216B (zh) * | 2020-09-10 | 2024-08-13 | 中国东方电气集团有限公司 | 一种图像识别结果的字符串模糊匹配系统及方法 |
| CN115171137B (zh) * | 2022-07-28 | 2025-11-28 | 新恒汇电子股份有限公司 | 芯片ocr自动视觉识别训练方法及装置 |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH0415776A (ja) * | 1990-05-01 | 1992-01-21 | Fuji Facom Corp | 文字のサイズ情報抽出方法 |
| JPH05166009A (ja) * | 1991-12-13 | 1993-07-02 | Sumitomo Electric Ind Ltd | 文字切出し・認識方法及び装置 |
| JPH05290211A (ja) * | 1992-04-09 | 1993-11-05 | Matsushita Electric Ind Co Ltd | 文字種等の判別方法 |
| JPH09106437A (ja) * | 1995-10-11 | 1997-04-22 | Ricoh Co Ltd | 文字切出し装置および文字切出し方法 |
| JP2008084105A (ja) * | 2006-09-28 | 2008-04-10 | Oki Electric Ind Co Ltd | 文字切出方法及び文字認識装置 |
Family Cites Families (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2548579B2 (ja) | 1987-09-19 | 1996-10-30 | 富士通株式会社 | 文字認識装置 |
| JP2976445B2 (ja) | 1989-07-21 | 1999-11-10 | セイコーエプソン株式会社 | 文字認識装置 |
| EP0539158A2 (en) * | 1991-10-21 | 1993-04-28 | Canon Kabushiki Kaisha | Method and apparatus for character recognition |
| JPH05128307A (ja) | 1991-10-31 | 1993-05-25 | Toshiba Corp | 文字認識装置 |
| JPH05128308A (ja) | 1991-11-08 | 1993-05-25 | Sumitomo Electric Ind Ltd | 文字認識装置 |
| US5680479A (en) * | 1992-04-24 | 1997-10-21 | Canon Kabushiki Kaisha | Method and apparatus for character recognition |
| JP3236732B2 (ja) | 1994-03-28 | 2001-12-10 | 松下電器産業株式会社 | 文字認識装置 |
| JP3639126B2 (ja) * | 1998-01-22 | 2005-04-20 | 富士通株式会社 | 住所認識装置及び住所認識方法 |
| KR100593986B1 (ko) * | 2002-09-11 | 2006-07-03 | 삼성전자주식회사 | 영상화면 내의 글자 이미지를 인식하는 장치 및 방법 |
| JP4346942B2 (ja) * | 2003-04-14 | 2009-10-21 | キヤノン株式会社 | 文字認識方法 |
| KR20060050729A (ko) * | 2004-08-31 | 2006-05-19 | 엘지전자 주식회사 | 카메라로 촬영된 문서 영상 처리 방법과 장치 |
| KR101128185B1 (ko) * | 2005-04-01 | 2012-03-23 | 엘지전자 주식회사 | 카메라 폰에서의 문자 인식 장치 및 방법 |
| CN100347723C (zh) * | 2005-07-15 | 2007-11-07 | 清华大学 | 基于几何代价与语义-识别代价结合的脱机手写汉字字符的切分方法 |
| JP5361574B2 (ja) * | 2009-07-01 | 2013-12-04 | キヤノン株式会社 | 画像処理装置、画像処理方法、及びプログラム |
-
2008
- 2008-08-11 JP JP2008206722A patent/JP5146190B2/ja not_active Expired - Fee Related
-
2009
- 2009-07-31 KR KR1020090070357A patent/KR101050866B1/ko active Active
- 2009-08-06 CN CN2009101590895A patent/CN101650779B/zh not_active Expired - Fee Related
- 2009-08-11 EP EP09167660.1A patent/EP2154632B1/en active Active
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH0415776A (ja) * | 1990-05-01 | 1992-01-21 | Fuji Facom Corp | 文字のサイズ情報抽出方法 |
| JPH05166009A (ja) * | 1991-12-13 | 1993-07-02 | Sumitomo Electric Ind Ltd | 文字切出し・認識方法及び装置 |
| JPH05290211A (ja) * | 1992-04-09 | 1993-11-05 | Matsushita Electric Ind Co Ltd | 文字種等の判別方法 |
| JPH09106437A (ja) * | 1995-10-11 | 1997-04-22 | Ricoh Co Ltd | 文字切出し装置および文字切出し方法 |
| JP2008084105A (ja) * | 2006-09-28 | 2008-04-10 | Oki Electric Ind Co Ltd | 文字切出方法及び文字認識装置 |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2013121648A1 (ja) | 2012-02-17 | 2013-08-22 | オムロン株式会社 | 文字認識方法、およびこの方法を用いた文字認識装置およびプログラム |
| WO2013121647A1 (ja) | 2012-02-17 | 2013-08-22 | オムロン株式会社 | 文字切り出し方法、およびこの方法を用いた文字認識装置およびプログラム |
| US9224065B2 (en) | 2012-02-17 | 2015-12-29 | Omron Corporation | Character-recognition method and character-recognition device and program using said method |
| US9710945B2 (en) | 2012-02-17 | 2017-07-18 | Omron Corporation | Method for cutting out character, character recognition apparatus using this method, and program |
| CN111626038A (zh) * | 2019-01-10 | 2020-09-04 | 北京字节跳动网络技术有限公司 | 背诵文本的提示方法、装置、设备及存储介质 |
Also Published As
| Publication number | Publication date |
|---|---|
| EP2154632A3 (en) | 2012-03-21 |
| EP2154632B1 (en) | 2018-05-23 |
| CN101650779A (zh) | 2010-02-17 |
| EP2154632A2 (en) | 2010-02-17 |
| KR101050866B1 (ko) | 2011-07-20 |
| KR20100019961A (ko) | 2010-02-19 |
| CN101650779B (zh) | 2013-01-23 |
| JP5146190B2 (ja) | 2013-02-20 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5146190B2 (ja) | 文字認識装置、文字認識プログラム、および文字認識方法 | |
| KR101459766B1 (ko) | 휴대 단말에서 자동반주 악보를 인식하는 방법 | |
| TWI321294B (en) | Method and device for determining at least one recognition candidate for a handwritten pattern | |
| US8750616B2 (en) | Character image extracting apparatus and character image extracting method | |
| US7970213B1 (en) | Method and system for improving the recognition of text in an image | |
| US8300942B2 (en) | Area extraction program, character recognition program, and character recognition device | |
| KR101468231B1 (ko) | 라벨 검색 방법 및 장치 | |
| CN109791559B (zh) | 促进图像作为搜索查询的使用 | |
| JP6900164B2 (ja) | 情報処理装置、情報処理方法及びプログラム | |
| WO2019184464A1 (zh) | 检测近似重复图像 | |
| KR101078086B1 (ko) | 문자 인식 장치, 문자 인식 프로그램, 및 문자 인식 방법 | |
| US20150213333A1 (en) | Method and device for realizing chinese character input based on uncertainty information | |
| US9064191B2 (en) | Lower modifier detection and extraction from devanagari text images to improve OCR performance | |
| US10706581B2 (en) | Image processing apparatus for clipping and sorting images from read image according to cards and control method therefor | |
| CN102194101B (zh) | 字符串检测装置和方法、字符评价装置和方法 | |
| US11747914B2 (en) | System and method for providing electric book based on reading type | |
| KR101412953B1 (ko) | 악보 영상의 오선제거 방법 | |
| US20150169973A1 (en) | Incomplete patterns | |
| JP4570995B2 (ja) | マッチング方法およびマッチング装置ならびにプログラム | |
| JP5223739B2 (ja) | 携帯式文字認識装置、文字認識プログラム及び文字認識方法 | |
| JP3897999B2 (ja) | 手書き文字認識方法 | |
| JP2001236467A (ja) | パターン認識方法、装置、およびパターン認識プログラムを記録した記録媒体 | |
| JP2010218043A (ja) | 文字情報取得装置、文字情報取得プログラム、および文字情報取得方法 | |
| JP5841418B2 (ja) | 情報処理装置、情報処理方法、及びプログラム | |
| JP2002342711A (ja) | 画像認識装置、画像認識方法、及び画像認識方法を実現するプログラムとこのプログラムの記録媒体 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20110603 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20120426 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20120515 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20120711 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20121030 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20121112 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 5146190 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20151207 Year of fee payment: 3 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| LAPS | Cancellation because of no payment of annual fees |