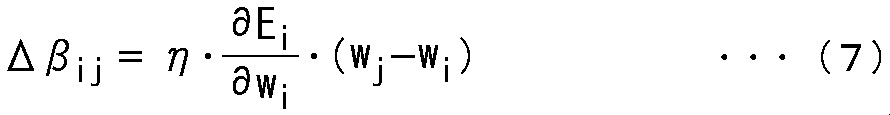図1は、本発明を適用する学習装置の基本となる学習装置の一実施の形態の構成例を示している。
図1において、学習装置は、複数であるN個の学習モジュール101ないし10Nと、モデルパラメータ共有部20とから構成される。
学習モジュール10i(i=1,2,・・・,N)は、パターン入力部11i、モデル学習部12i、及びモデル記憶部13iから構成され、入力データを用いて、パターン学習モデルの複数のモデルパラメータ(学習リソース)を更新する更新学習を行う。
すなわち、パターン入力部11iには、モデル記憶部13iに記憶されたパターン学習モデルに獲得(学習)させるパターン(カテゴリ)の入力データが、パターン学習モデルの学習に用いる学習データとして供給される。
パターン入力部11iは、そこに供給される学習データを、パターン学習モデルの学習に適切な形のデータにする処理をして、モデル学習部12iに供給する。すなわち、例えば、学習データが時系列のデータである場合には、パターン入力部11iは、例えば、その時系列のデータを、固定の長さに区切って、モデル学習部12iに供給する。
モデル学習部12iは、パターン入力部11iからの学習データを用いて、モデル記憶部13iに記憶されたパターン学習モデルの複数のモデルパラメータを更新する更新学習を行う。
モデル記憶部13iは、複数のモデルパラメータを有し、パターンを学習するパターン学習モデルを記憶する。すなわち、モデル記憶部13iは、パターン学習モデルの複数のモデルパラメータを記憶する。
ここで、パターン学習モデルとしては、例えば、時系列のパターンである時系列パターンや、時間変化する力学系を表すダイナミクスを学習(獲得)(記憶)するモデル等を採用することができる。
時系列パターンを学習するモデルとしては、例えば、HMM(Hidden Markov Model)等があり、ダイナミクスを学習するモデルとしては、例えば、RNN,FNN(Feed Forward Neural Network),RNNPB等のニューラルネットワークや、SVR(Support Vector Regression)等がある。
例えば、HMMについては、HMMにおいて状態が遷移する確率を表す状態遷移確率や、状態が遷移するときに、HMMからある観測値が出力される確率を表す出力確率、又は確率密度を表す出力確率密度関数が、HMMのモデルパラメータである。
また、例えば、ニューラルネットワークについては、ニューロンに相当するユニット(ノード)において、他のユニットからの入力に付されるウエイト(重み)が、ニューラルネットワークのモデルパラメータである。
なお、HMMの状態遷移確率や、出力確率、又は出力確率密度関数、ニューラルネットワークのウエイトは、いずれも複数存在する。
モデルパラメータ共有部20は、N個の学習モジュール101ないし10Nのうちの、2以上の学習モジュールに、モデルパラメータを共有させる共有処理を行う。モデルパラメータ共有部20が共有処理を行うことにより、N個の学習モジュール101ないし10Nのうちの、2以上の学習モジュールは、モデルパラメータを共有する。
なお、以下では、説明を簡単にするため、モデルパラメータ共有部20は、N個の学習モジュール101ないし10Nのすべてに、モデルパラメータを共有させる共有処理を行うこととする。
次に、図2のフローチャートを参照して、図1の学習装置が行う、パターン学習モデルを学習する学習処理について説明する。
ステップS11において、学習モジュール10iのモデル学習部12iは、モデル記憶部13iに記憶されたモデルパラメータを、例えば、乱数等によって初期化して、処理は、ステップS12に進む。
ステップS12では、学習モジュール10iが、その学習モジュール10iで学習すべき学習データが供給(入力)されるのを待って、その学習データを用いて、モデルパラメータを更新する更新学習を行う。
すなわち、ステップS12では、学習モジュール10iにおいて、パターン入力部11iが、学習モジュール10iに供給された学習データを、必要に応じて処理し、モデル学習部12iに供給する。
さらに、ステップS12では、モデル学習部12iが、パターン入力部11iからの学習データを用いて、モデル記憶部13iに記憶されたパターン学習モデルの複数のモデルパラメータを更新する更新学習を行い、その更新学習によって得られた新たな複数のモデルパラメータによって、モデル記憶部13iの記憶内容を更新する(上書きする)。
ここで、ステップS11及びS12の処理は、N個の学習モジュール101ないし10Nのすべてで行われる。
ステップS12の後、処理は、ステップS13に進み、モデルパラメータ共有部20は、N個の学習モジュール101ないし10Nのすべてに、モデルパラメータを共有させる共有処理を行う。
すなわち、学習モジュール10iが有する複数のモデルパラメータのうちの、例えば、m番目のモデルパラメータに注目すると、モデルパラメータ共有部20は、N個の学習モジュール101ないし10Nそれぞれのm番目のモデルパラメータに基づいて、学習モジュール101のm番目のモデルパラメータを補正する。
さらに、モデルパラメータ共有部20は、N個の学習モジュール101ないし10Nそれぞれのm番目のモデルパラメータに基づいて、学習モジュール102のm番目のモデルパラメータを補正し、以下、同様にして、学習モジュール103ないし10Nそれぞれのm番目のモデルパラメータを補正する。
以上のように、モデルパラメータ共有部20が、学習モジュール10iのm番目のモデルパラメータを、N個の学習モジュール101ないし10Nそれぞれのm番目のモデルパラメータに基づいて補正することで、N個の学習モジュール101ないし10Nのm番目のモデルパラメータのそれぞれは、N個の学習モジュール101ないし10Nのm番目のモデルパラメータのすべての影響を受ける(N個の学習モジュール101ないし10Nのm番目のモデルパラメータのそれぞれに、N個の学習モジュール101ないし10Nのm番目のモデルパラメータのすべてを影響させる)。
このように、複数の学習モジュールのモデルパラメータすべてを、その複数の学習モジュールのモデルパラメータのそれぞれに影響させること(複数の学習モジュールのモデルパラメータのそれぞれが、その複数の学習モジュールのモデルパラメータすべての影響を受けること)が、複数の学習モジュールによるモデルパラメータの共有である。
モデルパラメータ共有部20は、ステップS13において、学習モジュール10iのモデル記憶部13iに記憶された複数のモデルパラメータのすべてを対象に、共有処理を行い、その共有処理によって得られたモデルパラメータによって、モデル記憶部131ないし13Nの記憶内容を更新する。
ステップS13の後、処理は、ステップS14に進み、図1の学習装置は、学習の終了条件が満たされているかどうかを判定する。
ここで、ステップS14での学習の終了条件としては、例えば、学習の回数、つまり、ステップS12及びS13が繰り返された回数が、あらかじめ定められた所定の回数となったことや、あらかじめ用意された学習データのすべてを用いて、ステップS12の更新学習が行われたこと、あるいは、ある入力データに対して出力されるべき出力データの真値が分かっている場合に、その入力データに対してパターン学習モデルから出力される出力データの、真値に対する誤差が所定値以下であること、等を採用することができる。
ステップS14において、学習の終了条件が満たされていないと判定された場合、処理は、ステップS12に戻り、以下、同様の処理が繰り返される。
また、ステップS14において、学習の終了条件が満たされていると判定された場合、処理は終了する。
なお、ステップS12とステップS13は、その処理の順番を逆にすることも可能である。即ち、N個の学習モジュール101ないし10Nのすべてに、モデルパラメータを共有させる共有処理を行った後、モデルパラメータを更新する更新学習を行うようにすることもできる。
次に、図3は、パターン学習モデルとして、RNNPBを採用した場合の、図1の学習装置の構成例を示している。
なお、図3においては、学習モジュール10iのパターン入力部11i及びモデル学習部12iの図示を省略してある。
モデル記憶部13iには、RNNPB(を定義するモデルパラメータ)が記憶されている。ここで、モデル記憶部13iに記憶されたRNNPBを、以下、適宜、RNNPB#iとも記載する。
RNNPBは、入力層、隠れ層(中間層)、及び出力層により構成されている。入力層、隠れ層、及び出力層は、それぞれ任意の数の、ニューロンに相当するユニットにより構成されている。
RNNPBでは、入力層の一部のユニットである入力ユニットに、時系列データ等の入力データxtが入力(供給)される。ここで、入力データxtとしては、例えば、画像や音声の特徴量や、ロボットの手や足に相当する部分の動きの軌道等を採用することができる。
また、入力層の、入力データxtが入力される入力ユニット以外のユニットの一部であるPBユニットには、PB(Parametric Bias)が入力される。PBによれば、同一の状態のRNNPBに対して、同一の入力データxtが入力されても、PBを変更することにより、異なる出力データx* t+1を得ることができる。
入力層の、入力データxtが入力される入力ユニット以外のユニットの残りであるコンテキストユニットには、出力層の一部のユニットより出力される出力データが、内部状態を表すコンテキストとしてフィードバックされる。
ここで、時刻tの入力データxtが入力層の入力ユニットに入力されるときに入力層のPBユニットとコンテキストユニットに入力される時刻tのPBとコンテキストを、それぞれ、PBtとctと記載する。
隠れ層のユニットは、入力層に入力される入力データxt,PBt,コンテキストctを対象として、所定のウエイト(重み)を用いた重み付け加算を行い、その重み付け加算の結果を引数とする非線形関数の演算を行って、その演算結果を、出力層のユニットに出力する。
出力層の一部のユニットからは、上述したように、次の時刻t+1のコンテキストct+1となる出力データが出力され、入力層にフィードバックされる。また、出力層の残りのユニットからは、例えば、入力データxtに対応する出力データとして、その入力データxtの次の時刻t+1の入力データxt+1の予測値x* t+1が出力される。
ここで、RNNPBでは、ユニットへの入力が重み付け加算されるが、この重み付け加算に用いられるウエイト(重み)が、RNNPBのモデルパラメータである。RNNPBのモデルパラメータとしてのウエイトには、入力ユニットから隠れ層のユニットへのウエイト、PBユニットから隠れ層のユニットへのウエイト、コンテキストユニットから隠れ層のユニットへウエイト、隠れ層のユニットから出力層のユニットへのウエイト、及び、隠れ層のユニットからコンテキストユニットへのウエイトの5種類がある。
パターン学習モデルとして、以上のようなRNNPBを採用した場合、モデルパラメータ共有部20には、RNNPBのモデルパラメータとしてのウエイトを、学習モジュール101ないし10Nに共有させるウエイトマトリクス共有部21が設けられる。
ここで、RNNPBのモデルパラメータとしてのウエイトは、複数あるが、その複数のウエイトをコンポーネントとするマトリクスを、ウエイトマトリクスという。
ウエイトマトリクス共有部21は、モデル記憶部131ないし13Nに記憶されたRNNPB#1ないしRNNPB#Nの複数のモデルパラメータとしてのウエイトマトリクスすべてを、学習モジュール101ないし10Nのそれぞれに共有させる。
すなわち、RNNPB#iのウエイトマトリクスをwiと表すこととすると、ウエイトマトリクス共有部21は、ウエイトマトリクスwiを、N個の学習モジュール101ないし10Nそれぞれのウエイトマトリクスw1ないしwNのすべてに基づいて補正することで、ウエイトマトリクスwiに、ウエイトマトリクスw1ないしwNのすべてを影響させる共有処理を行う。
具体的には、ウエイトマトリクス共有部21は、例えば、次式(1)に従い、RNNPB#iのウエイトマトリクスwiを補正する。
ここで、式(1)において、△wiは、ウエイトマトリクスwiを補正する補正成分であり、例えば、式(2)に従って求められる。
式(2)において、βijは、RNNPB#iのウエイトマトリクスwiに、RNNPB#j(j=1,2,・・・,N)のウエイトマトリクスwjを影響させる度合いを表す係数(固定値)である。
したがって、式(2)の右辺のサメーションΣβij(wj-wi)は、係数βijを重みとした、RNNPB#iのウエイトマトリクスwjに対するRNNPB#1ないしRNNPB#Nのウエイトマトリクスw1ないしwNそれぞれの偏差(差分)の重み付け平均値を表し、αiは、その重み付け平均値Σβij(wj-wi)を、ウエイトマトリクスwiに影響させる度合いを表す係数である。
係数αi及びβijとしては、例えば、0.0より大で1.0より小の値を採用することができる。
式(2)によれば、係数αiが小であるほど、いわば共有が弱くなり(ウエイトマトリクスwiが受ける重み付け平均値Σβij(wj-wi)の影響が小さくなり)、係数αiが大であるほど、いわば共有が強まる。
なお、ウエイトマトリクスwiの補正の方法は、式(1)に限定されるものではなく、例えば、式(3)に従って行うことが可能である。
ここで、式(3)において、βij 'は、RNNPB#iのウエイトマトリクスwiに、RNNPB#j(j=1,2,・・・,N)のウエイトマトリクスwjを影響させる度合いを表す係数である。
したがって、式(3)の右辺の第2項におけるサメーションΣβij 'wjは、係数βij 'を重みとした、RNNPB#1ないしRNNPB#Nのウエイトマトリクスw1ないしwNの重み付け平均値を表し、αi 'は、その重み付け平均値Σβij 'wjを、ウエイトマトリクスwiに影響させる度合いを表す係数である。
係数αi '及びβij 'としては、例えば、0.0より大で1.0より小の値を採用することができる。
式(3)によれば、係数αi 'が大であるほど、共有が弱くなり(ウエイトマトリクスwiが受ける重み付け平均値Σβij 'wjの影響が小さくなり)、係数αi 'が小であるほど、共有が強まる。
次に、図4のフローチャートを参照して、パターン学習モデルとして、RNNPBを採用した場合の、図1の学習装置の学習処理について説明する。
ステップS21において、学習モジュール10iのモデル学習部12iは、モデル記憶部13iに記憶されたRNNPB#iのモデルパラメータであるウエイトマトリクスwiを、例えば、乱数等によって初期化して、処理は、ステップS22に進む。
ステップS22では、学習モジュール10iが、その学習モジュール10iで学習すべき学習データxtが入力されるのを待って、その学習データxtを用いて、モデルパラメータを更新する更新学習を行う。
すなわち、ステップS22では、学習モジュール10iにおいて、パターン入力部11iが、学習モジュール10iに供給された学習データxtを、必要に応じて処理し、モデル学習部12iに供給する。
さらに、ステップS22では、モデル学習部12iが、パターン入力部11iからの学習データxtを用いて、モデル記憶部13iに記憶されたRNNPB#iのウエイトマトリクスwiを更新する更新学習を、例えば、BPTT(Back-Propagation Through Time)法により行い、その更新学習によって得られた新たなモデルパラメータとしてのウエイトマトリクスwiによって、モデル記憶部13iの記憶内容を更新する。
ここで、ステップS21及びS22の処理は、N個の学習モジュール101ないし10Nのすべてで行われる。
また、BPTT法については、例えば、特開2002-236904号公報等に記載されている。
ステップS22の後、処理は、ステップS23に進み、モデルパラメータ共有部20のウエイトマトリクス共有部21は、N個の学習モジュール101ないし10Nのすべてに、ウエイトマトリクスw1ないしwNのすべてを共有させる共有処理を行う。
すなわち、ステップS23において、ウエイトマトリクス共有部21は、例えば、式(2)に従い、モデル記憶部131ないし13Nに記憶されたウエイトマトリクスw1ないしwNを用いて補正成分△w1ないし△wNをそれぞれ求め、その補正成分△w1ないし△wNにより、モデル記憶部131ないし13Nに記憶されたウエイトマトリクスw1ないしwNを、式(1)に従ってそれぞれ補正する。
ステップS23の後、処理は、ステップS24に進み、図1の学習装置は、学習の終了条件が満たされているかどうかを判定する。
ここで、ステップS24での学習の終了条件としては、例えば、学習の回数、つまり、ステップS22及びS23が繰り返された回数が、あらかじめ定められた所定の回数となったことや、ある入力データxtに対してRNNPB#iが出力する出力データx* t+1、すなわち、入力データxt+1の予測値x* t+1の、入力データxt+1に対する誤差が所定値以下であること、等を採用することができる。
ステップS24において、学習の終了条件が満たされていないと判定された場合、処理は、ステップS22に戻り、以下、同様の処理、すなわち、ウエイトマトリクスwiの更新学習と、共有処理とが交互に繰り返される。
また、ステップS24において、学習の終了条件が満たされていると判定された場合、処理は終了する。
なお、図4においても、ステップS22とステップS23は、その処理の順番を逆にすることが可能である。
以上のように、規模拡張性に優れた複数の学習モジュール101ないし10Nそれぞれにおいて、モデルパラメータを共有しながら、その複数の学習モジュール101ないし10Nそれぞれのモデルパラメータを更新する更新学習を行うことにより、1つの学習モジュールだけで行われる学習で得られる汎化特性が、複数の学習モジュール101ないし10Nの全体で得ることができ、その結果、規模拡張性があり、同時に、汎化特性を有するパターン学習モデルを得ることができる。
すなわち、多くのパターンを獲得(記憶)することができ、かつ、複数のパターンの共通性を獲得することができる。さらに、複数のパターンの共通性を獲得することで、その共通性に基づいて、未学習のパターンの認識や生成を行うことが可能となる。
具体的には、学習データとして、例えば、N種類の音韻の音声データを、N個の学習モジュール101ないし10Nにそれぞれ与えて、パターン学習モデルの学習を行った場合に、そのパターン学習モデルによれば、学習に用いられていない時系列パターンの音声データの認識や生成を行うことができる。さらに、例えば、学習データとして、例えば、ロボットのアームを駆動するための、N種類の駆動データを、N個の学習モジュール101ないし10Nにそれぞれ与えて、パターン学習モデルの学習を行った場合に、そのパターン学習モデルによれば、学習に用いられていない時系列パターンの駆動データの生成を行うことができ、その結果、ロボットは、教えられていないアームの動きをすることが可能となる。
また、学習後のパターン学習モデルによれば、パターン学習モデル間のモデルパラメータ(リソース)どうしの距離に基づいて、パターン学習モデルどうしの類似性を評価し、類似性が高いパターン学習モデルどうしをクラスタとして、パターンのクラスタリングを行うことができる。
次に、図5ないし図9を参照して、本件発明者が行った、図1の学習装置による学習処理(以下、適宜、共有学習処理という)のシミュレーションの結果について説明する。
図5は、共有学習処理で学習を行ったパターン学習モデルについての各データを示している。
なお、シミュレーションでは、パターン学習モデルとして、2つのPBが入力層に入力され、3つのコンテキストが入力層にフィードバックされる9個のRNNPB#1ないしRNNPB#9を採用し、学習データとして、3つのパターンP#1,P#2,P#3の時系列データのそれぞれに、異なる3つのノイズN#1,N#2,N#3のそれぞれを重畳して得られる9個の時系列データを用いた。
また、RNNPB#1には、パターンP#1の時系列データにノイズN#1を重畳して得られる時系列データを、RNNPB#2には、パターンP#1の時系列データにノイズN#2を重畳して得られる時系列データを、RNNPB#2には、パターンP#1の時系列データにノイズN#3を重畳して得られる時系列データを、それぞれ、学習データとして与えた。
同様に、RNNPB#4には、パターンP#2の時系列データにノイズN#1を重畳して得られる時系列データを、RNNPB#5には、パターンP#2の時系列データにノイズN#2を重畳して得られる時系列データを、RNNPB#6には、パターンP#2の時系列データにノイズN#3を重畳して得られる時系列データを、それぞれ、学習データとして与え、RNNPB#7には、パターンP#3の時系列データにノイズN#1を重畳して得られる時系列データを、RNNPB#8には、パターンP#3の時系列データにノイズN#2を重畳して得られる時系列データを、RNNPB#9には、パターンP#3の時系列データにノイズN#3を重畳して得られる時系列データを、それぞれ、学習データとして与えた。
なお、更新学習は、入力データxtに対してRNNPBが出力する出力データとしての、入力データxt+1の予測値x* t+1の、入力データxt+1に対する誤差(予測誤差)を小さくするように行った。
図5上から1番目は、学習後のRNNPB#1ないしRNNPB#9に、学習時に与えられた学習データを入力データとして与えたときに、RNNPB#1ないしRNNPB#9それぞれが出力する出力データ(output)と、その出力データの予測誤差(error)とを示している。
図5上から1番目において、予測誤差は、ほぼ0になっており、したがって、RNNPB#1ないしRNNPB#9は、入力データ、つまり、学習時に与えられた学習データとほぼ一致する出力データを出力する。
図5上から2番目は、学習後のRNNPB#1ないしRNNPB#9が、図5上から1番目に示した出力データを出力するときの、3つのコンテキストの時間変化を示している。
また、図5上から3番目は、学習後のRNNPB#1ないしRNNPB#9が、図5上から1番目に示した出力データを出力するときの、2つのPB(以下、適宜、2つのPBそれぞれを、PB#1,PB#2と記載する)の時間変化を示している。
図6は、学習後のRNNPB#1ないしRNNPB#9のうちの、例えば、5番目のRNNPB#5が、各値のPB#1,PB#2に対して出力する出力データを示している。
なお、図6では、横軸がPB#1を表し、縦軸がPB#2を表している。
図6によれば、RNNPB#5は、PB#1が0.6程度のときに、学習時に与えられた学習データとほぼ一致する出力データを出力しており、これにより、RNNPB#5は、学習時に与えられた学習データのパターンP#2を獲得していることが分かる。
また、RNNPB#5は、PB#1が0.6より小さいときに、RNNPB#1ないしRNNPB#3に学習させたパターンP#1や、RNNPB#7ないしRNNPB#9に学習させたパターンP#3に類似する時系列データを出力しており、これにより、RNNPB#5が、RNNPB#1ないしRNNPB#3が獲得したパターンP#1や、RNNPB#7ないしRNNPB#9が獲得したパターンP#3の影響を受け、いわば、RNNPB#5に対して学習時に与えられた学習データのパターンP#2が、RNNPB#1ないしRNNPB#3が獲得したパターンP#1や、RNNPB#7ないしRNNPB#9が獲得したパターンP#3の方向に変形していくときに現れる中間のパターンをも獲得していることが分かる。
さらに、RNNPB#5は、PB#1が0.6より大であるときに、9個のRNNPB#1ないしRNNPB#9のいずれにも学習させていないパターンの時系列データを出力しており、これにより、RNNPB#5が、RNNPB#1ないしRNNPB#3が獲得したパターンP#1や、RNNPB#7ないしRNNPB#9が獲得したパターンP#3の影響を受け、いわば、RNNPB#5に対して学習時に与えられた学習データのパターンP#2が、RNNPB#1ないしRNNPB#3が獲得したパターンP#1や、RNNPB#7ないしRNNPB#9が獲得したパターンP#3の方向とは逆方向に変形していくときに現れるパターンをも獲得していることが分かる。
次に、図7は、9個のRNNPB#1ないしRNNPB#9それぞれのウエイトマトリクスどうしの相関としての距離、すなわち、例えば、ウエイトマトリクスを構成する各ウエイトをコンポーネントとするベクトルの空間における、そのベクトルどうしの距離を表す長方形状のマップを示している。
なお、ウエイトマトリクスどうしの距離が小であるほど、その2つのウエイトマトリクスどうしの相関が高い。
図7のマップでは、横軸と縦軸のそれぞれに、9個のRNNPB#1ないしRNNPB#9それぞれのウエイトマトリクスをとって、その横軸のウエイトマトリクスと、縦軸のウエイトマトリクスとの距離が、濃淡で示されており、濃い(黒い)部分ほど、距離が小であることを表す(淡い(白い)部分ほど、距離が大であることを表す)。
図7において、横×縦が5×3個のマップのうちの、左上のマップは、学習の回数が0回目であるときのウエイトマトリクスどうしの距離、すなわち、初期化がされたウエイトマトリクスどうしの距離を示しており、マップにおいて、対角線上に並ぶ、同一のRNNPB#iのウエイトマトリクスどうしの距離だけが小になっている。
以下、図7では、右に行くほど、そして、下に行くほど、学習が進行したときのマップが示されており、右下のマップが、学習の回数が1400回目であるときのウエイトマトリクスどうしの距離を示している。
図7によれば、学習が進行するにつれ、同一のパターンP#1の時系列データを学習したRNNPB#1ないしRNNPB#3のウエイトマトリクスどうしの距離、同一のパターンP#2の時系列データを学習したRNNPB#4ないしRNNPB#6のウエイトマトリクスどうしの距離、及び、同一のパターンP#3の時系列データを学習したRNNPB#7ないしRNNPB#9のウエイトマトリクスどうしの距離が小さくなることが分かる。
図8は、図5ないし図7の場合とは別の時系列データを用いて学習を行ったRNNPBのウエイトマトリクスどうしの相関としての距離を表す、図7と同様のマップを示している。
なお、図8のマップを作成するシミュレーションでは、図9に示す5種類のパターンP#1,P#2,P#3,P#4,P#5の時系列データのそれぞれに、異なる4つのノイズN#1,N#2,N#3,N#4のそれぞれを重畳して得られる20個の時系列データを用意し、各時系列データを、1つのRNNPBに学習させた。したがって、図8のマップを作成するシミュレーションで用いたRNNPBは、20個のRNNPB#1ないしRNNPB#20である。
また、学習では、RNNPB#1ないしRNNPB#4には、パターンP#1の時系列データを、RNNPB#5ないしRNNPB#8には、パターンP#2の時系列データを、RNNPB#9ないしRNNPB#12には、パターンP#3の時系列データを、RNNPB#13ないしRNNPB#16には、パターンP#4の時系列データを、RNNPB#17ないしRNNPB#20には、パターンP#5の時系列データを、それぞれ与えた。
図8左の5×3個のマップは、共有が弱い場合、すなわち、20個のRNNPB#1ないしRNNPB#20のウエイトマトリクスw1ないしw20それぞれに、その20個のウエイトマトリクスw1ないしw20のすべてを影響させる度合いが小さい場合、具体的には、式(2)の係数αiが小である場合(αiがほぼ0である場合)のマップを示している。
また、図8右の5×3個のマップは、共有が強い場合、すなわち、20個のRNNPB#1ないしRNNPB#20のウエイトマトリクスw1ないしw20それぞれに、その20個のウエイトマトリクスw1ないしw20のすべてを影響させる度合いが大きい場合、具体的には、式(1)の係数αiが小でない場合のマップを示している。
共有が弱い場合も強い場合も、学習の回数が0回目であるときの左上のマップでは、対角線上に並ぶ、同一のRNNPB#iのウエイトマトリクスどうしの距離だけが小になっている。
そして、共有が弱い場合には、図8左に示すように、学習が進行しても、ウエイトマトリクスどうしの距離に、特に傾向は現れないが、共有が強い場合には、図8右に示すように、同一のパターンの時系列データを学習したRNNPBの間で、ウエイトマトリクスどうしの距離が小さくなることが分かる。
したがって、共有処理によって、複数の学習モジュールをまたいで分散表現が形成され、複数のRNNPBが汎化特性を有するようになっていることが分かる。
なお、モデル学習部12iによるモデルパラメータの更新学習の方法、及び、モデルパラメータ共有部20による共有処理の方法は、上述した方法に限定されるものではない。
また、本実施の形態では、モデルパラメータ共有部20による共有処理において、N個の学習モジュール101ないし10Nのすべてに、モデルパラメータとしてのウエイトマトリクスを共有させるようにしたが、その他、例えば、N個の学習モジュール101ないし10Nのうちの一部だけに、モデルパラメータとしてのウエイトマトリクスを共有させることが可能である。
さらに、本実施の形態では、モデルパラメータ共有部20による共有処理において、学習モジュール10iに、複数のモデルパラメータとしての、ウエイトマトリクスを構成する複数のウエイトすべてを共有させるようにしたが、共有処理では、ウエイトマトリクスを構成する複数のウエイトすべてではなく、そのうちの一部のウエイトだけを共有させるようにすることが可能である。
また、N個の学習モジュール101ないし10Nのうちの一部だけに、ウエイトマトリクスを構成する複数のウエイトのうちの一部のウエイトだけを共有させることも可能である。
なお、図1の学習装置は、モデルパラメータ共有部20が、複数の学習モジュール101ないし10Nに、モデルパラメータを共有させる、つまり、各学習モジュール10iにおけるパターン学習モデルとしてのRNNPB#iのモデルパラメータであるウエイトマトリクスwiに、学習モジュール101ないし10NそれぞれにおけるRNNPB#1ないしRNNPB#Nのウエイトマトリクスw1ないしwNを影響させる点で、RNNの学習時に、2つのRNNのコンテキストどうしの誤差に基づいて、その2つのRNNのコンテキストを変化させる、つまり、各RNNのコンテキストに、2つのRNNのコンテキストを影響させる特許文献1に記載の技術と共通する。
しかしながら、図1の学習装置では、影響を受けるのが、モデルパラメータであるウエイトマトリクスである点で、モデルパラメータではなく、内部状態であるコンテキストが影響を受ける特許文献1に記載の技術と相違する。
すなわち、例えば、関数で表現されるパターン学習モデルを例にすれば、パターン学習モデルのモデルパラメータは、そのパターン学習モデルを表現する関数を定義する、学習によって求められる定数(例えば、入力がuと、出力がyと、内部状態がxと、それぞれ表されるシステムをモデル化する状態方程式y=Cx+Du、及びx'=Ax+Bu(x'はxの微分を表す)を例にすれば、A,B,C,Dにあたる)であり、そもそも定数ではない内部状態(状態方程式の例では、内部状態x)とは異なる。
同様に、図1の学習装置は、各学習モジュール10iにおけるパターン学習モデルとしてのRNNPB#iのモデルパラメータであるウエイトマトリクスwiに、学習モジュール101ないし10NそれぞれにおけるRNNPB#1ないしRNNPB#Nのウエイトマトリクスw1ないしwNを影響させる点で、RNNPBの学習時に、2つのRNNPBのPBどうしの差に基づいて、その2つのRNNPBのPBを変化させる、つまり、各RNNPBのPBに、2つのRNNPBのPBを影響させる非特許文献1に記載の技術と共通する。
しかしながら、図1の学習装置では、影響を受けるのが、モデルパラメータであるウエイトマトリクスである点で、モデルパラメータではなく、内部状態である(あるいは、内部状態に相当する)PBが影響を受ける非特許文献1に記載の技術と相違する。
すなわち、上述したように、パターン学習モデルのモデルパラメータとは、パターン学習モデルを表現する関数を定義する、学習によって求められる定数であり、定数ではない内部状態とは異なる。
そして、モデルパラメータは、パターン学習モデルを表現する関数を定義する、学習によって求められる定数であるがゆえに、学習時は、学習をしようとするパターンに対応する値になるように更新(変更)されるが、出力データを生成するとき(パターン学習モデルとしてのRNNPBの入力層に入力データを入力し、その入力データに対応する出力データを、RNNPBの出力層から出力するとき)には、変更されない。
一方、特許文献1に記載の技術が対象としているコンテキスト、及び、非特許文献1に記載の技術が対象としているPBは、モデルパラメータとは異なる内部状態であるがゆえに、学習時は勿論、出力データを生成するときも変更される。
以上のように、図1の学習装置は、特許文献1及び非特許文献1に記載の技術のいずれとも相違し、その結果、規模拡張性があり、同時に、汎化特性を有するパターン学習モデルを得ることができる。
すなわち、図1の学習装置では、例えば、図10に示すように、RNNPBなどのパターン学習モデルのモデルパラメータを共有させる。
その結果、図1の学習装置によれば、図11に示すように、規模拡張性に優れるが、汎化特性に欠ける「局所表現」スキームと、汎化特性があるが、規模拡張性に欠ける「分散表現」スキームとの2種類の学習の両方の長所を有する、いわば「中間表現」スキームの学習を行い、規模拡張性があり、同時に、汎化特性を有するパターン学習モデルを得ることができる。
ところで、上述した実施の形態においては、パターン学習モデルとしてRNNPBを採用した場合の係数βijに相当する、学習モジュール間のモデルパラメータの共有の強度(以下、共有強度とも称する)を、ユーザが決定し、設定する必要があるが、この共有強度を、最適に設定することが難しいという問題がある。
すなわち、設定した共有強度が強すぎると、学習モジュール間の共通化が促進され汎化性能は高くなるが、各学習モジュールの独立性は弱くなり学習が進まない(学習に時間がかかる)。反対に、設定された共有強度が弱すぎると、学習モジュールの共通化が進まず、図1の学習装置の特徴の1つである汎化特性が弱くなり、各学習モジュールが独立に学習することと、さほど差がなくなってしまうという問題がある。
パターンの学習では、理想的には、類似するパターンを学習する学習モジュールどうしについては共有強度を強く設定し、類似しないパターンを学習する学習モジュールとの共有強度は弱く設定したい。しかしながら、パターン間の類似性は、学習する前にはわからないので、そのように設定することが難しいという側面がある。
そこで、次に、そのような問題を解決する学習装置について説明する。すなわち、学習モジュール間の共有強度が、類似するパターンを学習する学習モジュールに対しては強く、類似しないパターンを学習する学習モジュールに対しては弱くなるように、学習の過程で動的に変化(制御)させることができるようにした学習装置の実施の形態について説明する。
なお、以下では、パターン学習モデルとして、RNNPBより一般的な、入力層にPBユニットを持たないRNNを採用し、RNNの上述した係数βijを共有強度として動的に制御する場合を例にした実施の形態について説明する。RNNは、PBユニットを有していない以外は、更新学習等、上述したRNNPBと同様に行うことができるので、上述したRNNPB#iをRNN#iに置きかえて説明する。
図12は、本発明を適用した学習装置であって、共有強度(係数βij)の動的制御を可能とする学習装置の一実施の形態の構成例を示している。
図12において、上述した図1の学習装置と対応する部分については同一の符号を付してあり、その説明は省略する。
即ち、図12の学習装置101は、図1の学習装置と同様の構成を有するパターン学習部111と、共有強度を制御する共有強度制御部112とにより構成されている。
パターン学習部111は、N個の学習モジュール101ないし10Nによって構成され、パターン学習モデルの複数のモデルパラメータ(学習リソース)、即ち、RNN#iのウエイトマトリクスwiを学習(更新)する更新学習を行う。
共有強度制御部112は、パラメータ更新ベクトル取得部121、パラメータ差分ベクトル生成部122、共有強度更新部123、および共有強度記憶部124を備え、N個の学習モジュール101ないし10Nそれぞれが学習したときの学習誤差が最小化されるように共有強度を制御(更新)する。
図13を参照して、共有強度制御部112による共有強度の更新について説明する。
パターン学習モデルとしてRNNを採用した場合の共有強度である係数βijは、方向性をもつ係数であって、図13に示されるように、学習モジュール10jから10iへの影響の強さを表す係数である。換言すれば、係数βijは、RNN#iのウエイトマトリクスwiに対する、RNN#jのウエイトマトリクスwjの影響の強さを表している。
共有強度制御部112は、学習により学習モジュール10iのモデルパラメータを更新したときの学習誤差Eiが最小化されるように係数βijを更新する。即ち、係数βijの更新量を△βijとすると、係数βijを更新する式は、次式(4)のように表すことができ、式(4)の更新量△βijは、式(5)のように表すことができる。
式(5)において、∂Ei/∂βijは、学習誤差Eiが最小化される方向(勾配)を表し、ηは、その最小化される方向に沿って1回あたりどれだけ進むかを表す係数(学習率)を表す。
ここで、式(5)は、さらに次式(6)のように展開することができる。
式(6)の∂wi/∂△wiは、式(1)を△wiで偏微分した結果であり、1に等しい。また、式(6)の∂△wi/∂βijは、式(2)をβijで偏微分した結果であり、実質的には(wj−wi)のみで表すことができる。したがって、式(5)は、実質的に、式(7)のように表すことができる。
式(7)の∂Ei/∂wiは、学習時のBPTTの過程で求まるウエイトマトリクスwiを更新するときの更新量(更新量ベクトル)を表す。一方、式(7)の(wj−wi)は、ウエイトマトリクスwjからウエイトマトリクスwiを引いた差分ベクトルである。従って、係数βijの更新量△βijは、学習によるウエイトマトリクスwiの更新量ベクトルと、ウエイトマトリクスwjからウエイトマトリクスwiを引いた差分ベクトルの相関(内積)で求められることになる。
換言すれば、共有強度の更新量は、学習モジュール10iの学習時のパラメータ更新ベクトル(学習モジュール10iのモデルパラメータ更新の際の更新量ベクトル)と、学習モジュール10jのモデルパラメータから学習モジュール10iのモデルパラメータを引き算することにより得られるモデルパラメータ差分ベクトルの相関(内積)となっている。
式(7)は、概念的には、学習モジュール10iに注目したとき、学習モジュール10jが、自分(学習モジュール10i)と同じ学習方向の成分をより多く有している場合には、学習モジュール10jとの共有度合いを強めて、βijを大きくし、学習モジュール10jが、自分(学習モジュール10i)と違う学習方向の成分をより多く有している場合には、学習モジュール10jとの共有度合いを弱めて、βijを小さくすることを表している。
したがって、共有強度制御部112は、学習によりモデルパラメータが更新されるごとに、各学習モジュールについて、モデルパラメータ更新による更新量ベクトルと、モデルパラメータ差分ベクトルの内積を計算し、その結果を用いて、式(4)により共有強度を更新する。
図12に戻り、パラメータ更新ベクトル取得部121、パラメータ差分ベクトル生成部122、共有強度更新部123、および共有強度記憶部124それぞれの処理を説明する。
パラメータ更新ベクトル取得部121は、学習モジュール10iの共有強度の更新量を計算するための、学習モジュール10iのモデルパラメータを学習により更新した際の更新量ベクトルを取得する。RNNを採用したパターン学習モデルでは、パラメータ更新ベクトル取得部121は、RNN#iのBPTTの過程で求まった式(7)の∂Ei/∂wiを取得する。
パラメータ差分ベクトル生成部122は、学習モジュール10iの共有強度の更新量を計算するための、学習モジュール10iのモデルパラメータと学習モジュール10jのモデルパラメータをパターン学習部111から取得する。そして、パラメータ差分ベクトル生成部122は、学習モジュール10jのモデルパラメータから学習モジュール10iのモデルパラメータを引き算することにより得られるモデルパラメータ差分ベクトルを生成する。RNNを採用したパターン学習モデルでは、パラメータ差分ベクトル生成部122は、ウエイトマトリクスwiとウエイトマトリクスwjを取得し、ウエイトマトリクスwjからウエイトマトリクスwiを引いた差分ベクトル(wj−wi)を生成する。
共有強度更新部123は、パラメータ更新ベクトル取得部121が取得したパラメータ更新ベクトルと、パラメータ差分ベクトル生成部122が生成したモデルパラメータ差分ベクトルを用いて共有強度を更新する。RNNを採用したパターン学習モデルでは、共有強度更新部123は、式(7)により更新量△βijを求め、さらに式(4)により更新後の係数βijを求める。
共有強度更新部123は、更新後の共有強度(係数βij)をパターン学習部111の各学習モジュール101ないし10Nに供給するとともに、共有強度記憶部124に記憶させる。共有強度記憶部124に記憶された共有強度は、次の更新時に共有強度更新部123により取得され、式(4)における、現在の共有強度(係数βij)として使用される。
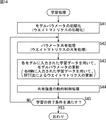
次に、図14のフローチャートを参照して、共有強度の動的制御も行う、学習装置101の学習処理について説明する。
ステップS41において、学習モジュール10iのモデル学習部12iは、モデル記憶部13iに記憶されたモデルパラメータを、例えば、乱数等によって初期化する。RNNを採用したパターン学習モデルでは、モデル記憶部13iに記憶されたRNN#iのモデルパラメータであるウエイトマトリクスwiが、例えば、乱数等によって初期化される。
なお、ステップS41と後述するステップS43の処理は、上述した図2および図4の学習処理と同様に、N個の学習モジュール101ないし10Nのすべてについて行われる。
ステップS42において、モデルパラメータ共有部20は、N個の学習モジュール101ないし10Nのすべてに、モデルパラメータを共有させる共有処理を行う。RNNを採用したパターン学習モデルでは、ウエイトマトリクス共有部21が、N個の学習モジュール101ないし10Nのすべてに、ウエイトマトリクスw1ないしwNのすべてを共有させる共有処理を行う。
ステップS43において、学習モジュール10iが、その学習モジュール10iで学習すべき学習データが供給(入力)されるのを待って、その学習データを用いて、モデルパラメータを更新する更新学習を行う。
RNNを採用したパターン学習モデルでは、ステップS43において、モデル学習部12iが、パターン入力部11iからの学習データxtを用いて、モデル記憶部13iに記憶されたRNN#iのウエイトマトリクスwiを更新する更新学習を、例えば、BPTT(Back-Propagation Through Time)法により行い、その更新学習によって得られた新たなモデルパラメータとしてのウエイトマトリクスwiによって、モデル記憶部13iの記憶内容を更新する。
ステップS44において、共有強度制御部112が、N個の学習モジュール101ないし10Nのすべてについて、学習後のパラメータ更新ベクトルとモデルパラメータ差分ベクトルを用いて、学習モジュール間の共有強度を更新する共有強度の動的制御処理を行う。ステップS44の処理の詳細は、図15を参照して後述する。
ステップS44の後、処理はステップS45に進み、学習装置101は、学習の終了条件が満たされているかどうかを判定する。
ステップS45において、学習の終了条件が満たされていないと判定された場合、処理は、ステップS42に戻り、以下、同様の処理が繰り返される。
また、ステップS45において、学習の終了条件が満たされていると判定された場合、処理は終了する。
図14の学習処理では、図2の学習処理と比較すると、モデルパラメータの更新とモデルパラメータの共有処理の順序が逆になっている。即ち、図2の学習処理では、ステップS12で、モデルパラメータの更新を行った後、ステップS13で、パラメータの共有処理を行っているが、図14の学習処理では、ステップS42で、モデルパラメータの共有処理を行った後、ステップS43で、モデルパラメータの更新を行っている。
図2の学習処理では、上述したように、ステップS12とステップS13の処理の順番は、どちらが先であってもよいが、共有強度の動的制御も行う学習処理では、図14に示したように、モデルパラメータの共有処理を行ってから、モデルパラメータの更新を行う方がよい。
なぜなら、共有強度の動的制御も行う学習処理では、上述したように、共有強度の更新量の計算に、モデルパラメータの更新直後の更新量ベクトルそのままの値を利用することができるからである。換言すれば、モデルパラメータの更新を行ってから、モデルパラメータの共有処理を行った場合には、共有強度の更新量の計算に、モデルパラメータの更新直後の更新量ベクトルそのままの値ではなく、モデルパラメータの共有処理後(共通化後)の更新量ベクトルを利用することになり、更新直後の更新量ベクトルそのままの値との誤差を、共有強度の更新量の計算に含むことになるからである。なお、その誤差が無視できる場合には、図2の学習処理と同様の順番で処理を行ってもよい。
図15は、図14のステップS44における共有強度の動的制御処理の詳細なフローチャートを示している。
初めに、ステップS61において、パラメータ更新ベクトル取得部121は、学習モジュール10iの学習時のパラメータ更新ベクトル(学習モジュール10iのモデルパラメータ更新の際の更新量ベクトル)を取得する。RNNを採用したパターン学習モデルでは、パラメータ更新ベクトル取得部121は、ステップS43のウエイトマトリクスwiを更新するBPTTの過程で求まった、式(7)の∂Ei/∂wiを取得する。
ステップS62において、パラメータ差分ベクトル生成部122は、学習モジュール10iのモデルパラメータと学習モジュール10jのモデルパラメータをパターン学習部111から取得し、学習モジュール10jのモデルパラメータから学習モジュール10iのモデルパラメータを引き算することにより得られるモデルパラメータ差分ベクトルを生成する。RNNを採用したパターン学習モデルでは、パラメータ差分ベクトル生成部122は、ウエイトマトリクスwiとウエイトマトリクスwjをパターン学習部111から取得し、ウエイトマトリクスwjからウエイトマトリクスwiを引いた差分ベクトル(wj−wi)を生成する。
ステップS63において、共有強度更新部123は、パラメータ更新ベクトル取得部121が取得したパラメータ更新ベクトルと、パラメータ差分ベクトル生成部122が生成したモデルパラメータ差分ベクトルを用いて共有強度を更新する。RNNを採用したパターン学習モデルでは、共有強度更新部123は、ウエイトマトリクスwiの更新量ベクトルと、ウエイトマトリクスwjからウエイトマトリクスwiを引いた差分ベクトル(wj−wi)の内積により更新量△βijを求め、さらに式(4)により更新後の係数βijを求める。
ステップS64において、共有強度更新部123は、更新後の共有強度を、次回の共有強度の更新のため、共有強度記憶部124に記憶させる。RNNを採用したパターン学習モデルでは、共有強度更新部123は、更新後の係数βijを、共有強度記憶部124に供給し、記憶させる。
以上の処理が、共有強度の動的制御処理として、図14のステップS44で行われる。
次に、図16ないし図21を参照して、図12の学習装置101による共有強度の動的制御処理を検証した実験結果について説明する。
図16は、実験を行った環境を示している。
本件発明者は、実験として、図12の学習装置101を備える移動ロボット141に2次元平面上の移動を行動パターンとして学習させることを行った。なお、パターン学習モデルには、3つのコンテキストが入力層にフィードバックされるRNNを採用した。
具体的には、本件発明者は、移動ロボット141を、図16に示される、4面の壁で囲まれた空間(部屋)161内に置き、その空間161内を移動する6つの行動パターンACT#1ないしACT#6を移動ロボット141の各RNNに学習させた。なお、空間161のなかには、障壁171ないし174とライト175が設けられている。また、移動ロボット141には、6つの行動パターンACT#1ないしACT#6のほかに、壁(障壁)を避ける、光に近づくなどの反射行動が予め入力(学習)されている。
移動ロボット141は、距離センサと光センサを内蔵している。より具体的には、図17に示されるように、移動ロボット141は、2次元平面(XY平面)と並行な所定の面上で、かつ、自分の周囲360度を等分割した8方向の検出方向(点線で示される方向)の距離または光を検出する距離センサおよび光センサを備える。距離センサの8方向の入力値はd1ないしd8であり、光センサの8方向の入力値はh1ないしh8である。
そして、移動ロボット141に行動パターンを学習させるとは、移動ロボット141に2次元平面上の軌道(位置の軌跡)を学習させるのではなく、移動ロボット141が各軌道を通過したときに、センサが取得したセンサ入力値と、移動ロボット141の駆動部の出力値の時系列データを学習させることを意味する。
従って、実験では、移動ロボット141の、距離センサの入力値d1ないしd8と光センサの入力値h1ないしh8、および、所定のモータ出力に対応する移動ベクトル(mx,my)からなる18次元(mx,my,d1,・・,d8,h1,・・,h8)のベクトルパターン(時系列データ)を学習させた。
なお、本件発明者は、6つの行動パターンACT#1ないしACT#6それぞれについて、互いに軌道を少し異なるものとした5つのバリエーションを学習させたので、学習させた行動パターンのサンプル数は、合計で30個(6つの行動パターン×5バリエーション)となる。
図18は、30個のRNN#1ないしRNN#30に学習させた行動パターンACT#1ないしACT#6を示している。
図18に示されるように、本件発明者は、行動パターンACT#1についての5つのバリエーションをRNN#1ないしRNN#5に学習させ、行動パターンACT#2についての5つのバリエーションをRNN#6ないしRNN#10に学習させ、行動パターンACT#3についての5つのバリエーションをRNN#11ないしRNN#15に学習させ、行動パターンACT#4についての5つのバリエーションをRNN#16ないしRNN#20に学習させ、行動パターンACT#5についての5つのバリエーションをRNN#21ないしRNN#25に学習させ、行動パターンACT#6についての5つのバリエーションをRNN#26ないしRNN#30に学習させた。
図19は、共有強度の動的制御処理を含む学習処理後の学習モジュール間(RNN間)の共有強度とウエイト距離を濃淡で示した図である。
図19Aは、学習処理後の学習モジュール間(RNN間)の共有強度を濃淡で示している。図19Aの横軸と縦軸は、それぞれ30個のRNN#1ないしRNN#30を表す。図19Aでは、横軸のRNN#iのウエイトマトリクスwiに対する、縦軸のRNN#jのウエイトマトリクスwjの共有強度である係数βijが濃淡で示されており、濃淡は、0.0より大で1.0より小の範囲で、淡い(白い)ほど共有強度が強く(係数βijが大きく)、濃い(黒い)ほど共有強度が弱い(係数βijが小さい)ことを表す。
図19Aにおいては、同一のウエイトマトリクスどうしの共有強度のラインである対角線を中心とする数個のRNNどうしの共有強度が強く、それ以外のRNNとの共有強度が弱くなっている。このことは、共有強度の動的制御処理により、同じ行動パターンを学習する学習モジュール(RNN)間で共有強度が強くなるように制御(更新)されたことを表している。即ち、図19Aは、動的制御により、適切に共有強度が設定されたことを表している。
一方、図19Bは、学習処理後の学習モジュール間(RNN間)のウエイト距離を濃淡で示している。
ウエイト距離とは、2つのRNNのウエイトマトリクス間のユークリッド距離であり、例えば、RNN#1のウエイトマトリクスw1の各ウエイトをw1,k,l(1≦k≦Q,1≦l≦R)、RNN#2のウエイトマトリクスw2の各ウエイトをw2,k,lとしたとき、RNN#1とRNN#2のウエイト距離Dweight(1,2)は、式(8)で表すことができる。
図19Bの横軸と縦軸は、それぞれ30個のRNN#1ないしRNN#30を表す。図19Bでは、横軸のRNN#iと、縦軸のRNN#jのウエイト距離Dweight(i,j)が濃淡で示されており、濃淡は、0.0より大で200.0より小の範囲で、濃い(黒い)ほどウエイト距離が小さく、淡い(白い)ほどウエイト距離が大きいことを表す。
図19Bにおいては、同一のウエイトマトリクスどうしのウエイト距離のラインである対角線を中心とする数個のRNNどうしのウエイト距離が小さく、それ以外のRNNとのウエイト距離が大きくなっている。このことは、共有強度の動的制御処理により、同じ行動パターンを学習する学習モジュール間でウエイト距離が小さくなるように制御(更新)されたことを表している。即ち、図19Bも、動的制御により、適切に共有強度が設定されたことを表している。
図20は、共有強度の動的制御処理を含む学習処理後の各RNN間のウエイト距離を、2次元空間に射影したサモンマップ(sammon map)を示している。
サモンマップは、n次元入力ベクトルを、入力ベクトル空間での関係を維持したまま2次元平面上へ写像することができる手法であり、その詳細は、JOHN W.SAMMON.JR.,A Nonlinear Mapping For Data Structure Analysis,IEEE TRANSACTIONS ON COMPUTERS,VOL.C-18,NO.5,MAY 1969に開示されている。
図20において、番号が付されたバツ印(×)は、その番号iに対応するRNN#iのサモンマップ上の位置を表す。そして、バツ印間の距離は、RNN間のウエイト距離を反映している。なお、バツ印を中心とする細線の円は、RNN間のウエイト距離の近さ(RNN間の重なり)をわかりやすくするため、ウエイト距離が10となる範囲を示したものである。
また、図20においては、同一の行動パターンACT#2ないしACT#6の学習データを学習した学習モジュール(RNN)群が、それぞれ、太い点線の円で示されている。これにより、行動パターンACT#1を除いて、類似した学習データ(学習サンプル)を学習した学習モジュール間では、ウエイト距離が小さくなっている(所定の範囲内に収まっている)ことが分かる。
従って、共有強度の動的制御処理によれば、類似した学習データ(学習サンプル)を学習した学習モジュール間では、ウエイト距離が小さい状態(共通化)を維持しつつも、類似していない学習サンプルを学習した学習モジュール間では、ウエイト距離が大きい状態を維持できている。即ち、共有強度の動的制御処理を行っても、規模拡張性と汎化特性の両立が可能となっていることが分かる。
比較のため、30個のRNN#1ないしRNN#30すべての係数βijを0.3,0.1,0.01の固定値(βij=0.3,βij=0.1,βij=0.01)で学習処理を行った場合のサモンマップを図21に示す。
図21Aは、係数βijが0.3の固定値(βij=0.3)の場合であり、図21Bは、係数βijが0.1の固定値(βij=0.1)の場合であり、図21Cは、係数βijが0.01の固定値(βij=0.01)の場合である。
なお、図20と図21Aないし図21Cは、互いに表示範囲が異なるので、縦軸と横軸のスケールが異なっている。ただし、ウエイト距離が10となる範囲を示した細線の円は、図20と図21Aないし図21Cにおいて共通である。
図21Aないし図21Cによれば、例えば、図21Cに示されるように、共有強度を小さく設定した場合には、各RNNが他のRNNのいずれとも独立する(ウエイト距離が大きい状態となる)ように位置し、反対に、図21Aに示されるように、共有強度を大きく設定した場合には、各RNNが他のRNNのいずれとも共通化する(ウエイト距離が小さい状態となる)ように位置している。図21Bは、図21Aと図21Cの中間的な分布となっている。
また、図21Bを参照すると、類似した学習データ(学習サンプル)を学習した学習モジュール間でウエイト距離が小さく、類似していない学習サンプルを学習した学習モジュール間でウエイト距離が大きいというような位置の傾向は小さい。
従って、図20と図21Aないし図21Cとを比較してみても、図12の学習装置101が、規模拡張性と汎化特性を両立させた状態で、類似するパターンを学習する学習モジュールどうしについては共有強度を強く設定し、類似しないパターンを学習する学習モジュールとの共有強度は弱く設定することができるということが言える。
以上のように、学習装置101によれば、学習モジュール間の共有強度を、ユーザが決定し、設定しなくても(自動的に)、最適に設定することができる。
上述した一連の処理は、ハードウェアにより行うこともできるし、ソフトウェアにより行うこともできる。一連の処理をソフトウェアによって行う場合には、そのソフトウェアを構成するプログラムが、汎用のコンピュータ等にインストールされる。
そこで、図22は、上述した一連の処理を実行するプログラムがインストールされるコンピュータの一実施の形態の構成例を示している。
プログラムは、コンピュータに内蔵されている記録媒体としてのハードディスク205やROM203に予め記録しておくことができる。
あるいはまた、プログラムは、フレキシブルディスク、CD-ROM(Compact Disc Read Only Memory),MO(Magneto Optical)ディスク,DVD(Digital Versatile Disc)、磁気ディスク、半導体メモリなどのリムーバブル記録媒体211に、一時的あるいは永続的に格納(記録)しておくことができる。このようなリムーバブル記録媒体211は、いわゆるパッケージソフトウエアとして提供することができる。
なお、プログラムは、上述したようなリムーバブル記録媒体211からコンピュータにインストールする他、ダウンロードサイトから、ディジタル衛星放送用の人工衛星を介して、コンピュータに無線で転送したり、LAN(Local Area Network)、インターネットといったネットワークを介して、コンピュータに有線で転送し、コンピュータでは、そのようにして転送されてくるプログラムを、通信部208で受信し、内蔵するハードディスク205にインストールすることができる。
コンピュータは、CPU(Central Processing Unit)202を内蔵している。CPU202には、バス201を介して、入出力インタフェース210が接続されており、CPU202は、入出力インタフェース210を介して、ユーザによって、キーボードや、マウス、マイク等で構成される入力部207が操作等されることにより指令が入力されると、それにしたがって、ROM(Read Only Memory)203に格納されているプログラムを実行する。あるいは、また、CPU202は、ハードディスク205に格納されているプログラム、衛星若しくはネットワークから転送され、通信部208で受信されてハードディスク205にインストールされたプログラム、またはドライブ209に装着されたリムーバブル記録媒体211から読み出されてハードディスク205にインストールされたプログラムを、RAM(Random Access Memory)204にロードして実行する。これにより、CPU202は、上述したフローチャートにしたがった処理、あるいは上述したブロック図の構成により行われる処理を行う。そして、CPU202は、その処理結果を、必要に応じて、例えば、入出力インタフェース210を介して、LCD(Liquid Crystal Display)やスピーカ等で構成される出力部206から出力、あるいは、通信部208から送信、さらには、ハードディスク205に記録等させる。
ここで、本明細書において、コンピュータに各種の処理を行わせるためのプログラムを記述する処理ステップは、必ずしもフローチャートとして記載された順序に沿って時系列に処理する必要はなく、並列的あるいは個別に実行される処理(例えば、並列処理あるいはオブジェクトによる処理)も含むものである。
また、プログラムは、1のコンピュータにより処理されるものであっても良いし、複数のコンピュータによって分散処理されるものであっても良い。さらに、プログラムは、遠方のコンピュータに転送されて実行されるものであっても良い。
なお、本発明の実施の形態は、上述した実施の形態に限定されるものではなく、本発明の要旨を逸脱しない範囲において種々の変更が可能である。
即ち、本発明は、ある特定の空間パターン、時系列シーケンス及びパターンに特化した方法ではない。したがって、コンピュータのユーザインタフェースにおけるユーザ入力のパターン、ロボットのセンサ入力及びモータ出力のパターン、音楽データに関するパターン、画像データに関するパターン、言語処理における音素、単語、センテンスなどのパターンの学習及び学習結果に基づくパターンの予測や分類に適用することができる。