JP2010015202A - Information collection method, device and program - Google Patents
Information collection method, device and program Download PDFInfo
- Publication number
- JP2010015202A JP2010015202A JP2008171883A JP2008171883A JP2010015202A JP 2010015202 A JP2010015202 A JP 2010015202A JP 2008171883 A JP2008171883 A JP 2008171883A JP 2008171883 A JP2008171883 A JP 2008171883A JP 2010015202 A JP2010015202 A JP 2010015202A
- Authority
- JP
- Japan
- Prior art keywords
- information
- attribute
- tag
- item
- extracted
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
- 238000000034 method Methods 0.000 title claims description 25
- 238000004891 communication Methods 0.000 claims abstract description 11
- 238000000605 extraction Methods 0.000 claims description 24
- 239000000284 extract Substances 0.000 claims description 10
- 230000001419 dependent effect Effects 0.000 claims description 4
- 230000002596 correlated effect Effects 0.000 abstract 1
- 230000003287 optical effect Effects 0.000 description 7
- 238000010586 diagram Methods 0.000 description 4
- 230000006870 function Effects 0.000 description 4
- 230000000694 effects Effects 0.000 description 3
- 230000010365 information processing Effects 0.000 description 3
- 239000004065 semiconductor Substances 0.000 description 3
- 238000000926 separation method Methods 0.000 description 2
- 238000005516 engineering process Methods 0.000 description 1
- 230000004044 response Effects 0.000 description 1
Images



Landscapes
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Description
本発明は、Web文書に記載された情報を収集する情報収集方法、装置及びプログラムに関する。 The present invention relates to an information collection method, apparatus, and program for collecting information described in a Web document.
従来、ある特定の項目に関しWeb文書から情報を得たい場合、Web文書を一つ一つ閲覧し、情報を収集しなければならなかった。 Conventionally, when it is desired to obtain information from a Web document regarding a specific item, the Web document has to be browsed and collected.
そこで、パソコンに関する情報を調べたい場合には、非特許文献1に記載の技術によれば、一覧表等で表示する情報に基づいて、ユーザは、様々なメーカー、販売会社毎にパソコンに関するを情報を探索することができるようになっている。
しかしながら、非特許文献1に記載の技術によっても、パソコンに関する情報を人手により収集、蓄積して再編集しているために、その作業に要する時間と労力は膨大なものとなる。また、非特許文献1に記載の技術は、特定の商品について提供されるものであり、取り扱いのない商品や、商品以外のものについて調べようとすると、蓄積情報のカバレッジの面で限界がある。
However, even with the technique described in Non-Patent
そこで、本発明は、このような事情を考慮して提案されるものであり、Webページ上に分散して存在している共通の項目やその属性および属性値の関係にある情報を自動的に収集する情報収集方法、装置及びプログラムを提供することを目的とする。 Therefore, the present invention is proposed in consideration of such circumstances, and automatically displays information on a common item existing in a distributed manner on a Web page and information related to its attribute and attribute value. An object of the present invention is to provide an information collection method, apparatus, and program to be collected.
上記目的を達成するために、本発明者は、項目に関する情報を複数のWeb文書から自動的に収集する仕組みを見出し、本発明を想到するに至った。 In order to achieve the above object, the present inventor has found a mechanism for automatically collecting information on items from a plurality of Web documents, and has come up with the present invention.
本発明に係る情報収集方法は、Web文書に含まれるタグに基づいて、項目、属性及び属性値の関係を有する情報を抽出することにより、項目に関する情報をWeb文書から自動的に収集するものである。 The information collection method according to the present invention automatically collects information on items from a Web document by extracting information having a relationship between items, attributes, and attribute values based on tags included in the Web document. is there.
(1) 情報収集装置が、通信ネットワークを介してアクセス可能なWeb文書から、前記Web文書に含まれるタグに基づいて表形式あるいはデータベース形式の情報を抽出するステップと、
抽出した前記表形式あるいはデータベース形式の情報から、前記タグが示す各情報間の従属関係に基づいて、所定の項目に対して従属する関係にある属性及び前記属性の内容を示す属性値の関係を有する情報を抽出するステップと、
抽出した前記項目、属性及び属性値の関係を有する情報を関連付けて記憶手段に記憶するステップと、を少なくとも実行することを特徴とする情報収集方法。
(1) an information collecting apparatus extracting information in a table format or a database format from a Web document accessible via a communication network based on a tag included in the Web document;
From the extracted information in the table format or database format, based on the dependency relationship between the information indicated by the tag, the relationship between the attribute dependent on the predetermined item and the attribute value indicating the content of the attribute Extracting information having,
And a step of associating and storing in the storage means information having a relationship between the extracted item, attribute and attribute value.
(1)に記載の発明の構成によれば、Web文書に含まれるタグに基づいて表形式あるいはデータベース形式の情報を抽出し、抽出した表形式あるいはデータベース形式の情報から、タグが示す各情報間の従属関係に基づいて、所定の項目に対して従属する関係にある属性及び当該属性の内容を示す属性値の関係を有する情報を抽出する。 According to the configuration of the invention described in (1), information in a table format or a database format is extracted based on a tag included in a Web document, and each piece of information indicated by the tag is extracted from the extracted table format or database format information. Based on the subordinate relationship, information having a relationship between an attribute subordinate to a predetermined item and an attribute value indicating the content of the attribute is extracted.
このことにより、項目、属性及び属性値の関係を有する情報を複数のWeb文書から自動的に収集することが可能となる。 This makes it possible to automatically collect information having a relationship between items, attributes, and attribute values from a plurality of Web documents.
ここで、前記表形式の情報とは、カンマ区切り、スペース区切りなどにより表と同等の表現がされた平文により示された情報も含む。 Here, the information in the table format includes information indicated in plain text expressed in the same way as the table by comma separation, space separation, or the like.
また、所定の項目に対して、より多くのWeb文書において共通して従属する情報を、より大きなウェイトを掛けて属性及び属性値として抽出してもよい。また、所定の項目に対して、所定の閾値を超える数のWeb文書において共通して従属することがない情報は、当該属性及び属性値として抽出しないこととしてもよい。 In addition, information that is commonly subordinated in a larger number of Web documents with respect to a predetermined item may be extracted as an attribute and an attribute value with a greater weight. In addition, information that does not commonly depend on a predetermined item in a number of Web documents exceeding a predetermined threshold may not be extracted as the attribute and the attribute value.
ここで、抽出して記憶した属性及び属性値は、項目に関するWeb文書を検索する際の検索クエリーの示唆等に活用することができる。 Here, the attribute and the attribute value extracted and stored can be used for suggesting a search query when searching for a Web document related to an item.
(2) 前記抽出するステップは、前記表形式の情報の直上方、直下方あるいは直左方に位置する情報を前記項目として抽出する(1)に記載の方法。 (2) The method according to (1), wherein the extracting step extracts, as the item, information located immediately above, immediately below, or immediately to the left of the tabular information.
(2)に記載の発明の構成によれば、表形式の情報の直上方、直下方あるいは直左方に位置する情報を前記項目として抽出する。 According to the configuration of the invention described in (2), information located immediately above, directly below, or immediately to the left of the tabular information is extracted as the item.
このことにより、Web文書において表形式の情報のタイトルが表示されることが多い位置に位置する情報を当該表形式の情報に対する項目として抽出することができる。 This makes it possible to extract information located at a position where a title of tabular information is often displayed in a Web document as an item for the tabular information.
ここで、上述の様に、当該関係を有する頻度に応じて、ウェイトを掛けたり、当該頻度が所定の閾値に達するまで、当該抽出を行なわないこととして、精度を上げてもよい。 Here, as described above, the accuracy may be increased by multiplying the weight according to the frequency having the relationship or not performing the extraction until the frequency reaches a predetermined threshold.
(3) 前記抽出するステップは、前記表形式の情報において、上端行あるいは左端列に位置する情報を属性として、それぞれその下方あるいは右方に位置する情報を属性値として抽出する(1)または(2)に記載の方法。 (3) In the extracting step, the information located in the uppermost row or the leftmost column is extracted as the attribute in the tabular information, and the information located below or on the right is extracted as the attribute value (1) or ( The method according to 2).
(3)に記載の発明の構成によれば、前記表形式の情報において、上端行あるいは左端列に位置する情報を属性として、それぞれその下方あるいは右方に位置する情報を属性値として抽出する。 According to the configuration of the invention described in (3), in the tabular information, the information located in the upper row or the left column is extracted as the attribute, and the information located below or to the right is extracted as the attribute value.
このことにより、Web文書において表形式の情報の属性が表示されることが多い位置に位置する情報を属性として、その属性の内容が表示されることが多い位置に位置する情報を属性値として抽出することができる。 As a result, information located at positions where attributes of tabular information are often displayed in Web documents are extracted as attributes, and information located at positions where the contents of the attributes are often displayed are extracted as attribute values. can do.
ここで、上述の様に、当該関係を有する頻度に応じて、ウェイトを掛けたり、当該頻度が所定の閾値に達するまで、当該抽出を行なわないこととして、精度を上げてもよい。 Here, as described above, the accuracy may be increased by multiplying the weight according to the frequency having the relationship or not performing the extraction until the frequency reaches a predetermined threshold.
(4) 前記抽出するステップは、前記データベース形式の情報の直左方に位置する情報を属性として、前記データベース形式の情報をその属性値として抽出する(1)から(3)のいずれかに記載の方法。 (4) In the extracting step, information located immediately to the left of the database format information is used as an attribute, and the database format information is extracted as an attribute value thereof. the method of.
(4)に記載の発明の構成によれば、データベース形式の情報の直左方に位置する情報を属性として、前記データベース形式の情報をその属性値として抽出する。 According to the configuration of the invention described in (4), information located immediately to the left of the database format information is used as an attribute, and the database format information is extracted as its attribute value.
このことにより、Web文書においてデータベース形式の情報の属性が表示されることが多い位置に位置する情報を属性として、その属性の内容が表示されることが多いデータベース形式の情報を属性値として抽出することができる。 As a result, information located in a position where the attribute of the information in the database format is often displayed in the Web document is used as an attribute, and information in the database format in which the content of the attribute is often displayed is extracted as an attribute value. be able to.
ここで、上述の様に、当該関係を有する頻度に応じて、ウェイトを掛けたり、当該頻度が所定の閾値に達するまで、当該抽出を行なわないこととして、精度を上げてもよい。 Here, as described above, the accuracy may be increased by multiplying the weight according to the frequency having the relationship or not performing the extraction until the frequency reaches a predetermined threshold.
(5) 前記表形式あるいはデータベース形式の情報を抽出する際に基づく前記タグが、プルダウンリストを形成するHTML(HyperText Markup Language)タグ、XML(Extensible Markup Language)文書に含まれるタグ又はHTMLのテーブルタグである(1)から(4)のいずれかに記載の方法。 (5) The tag based on extracting the information in the table format or the database format is an HTML (HyperText Markup Language) tag that forms a pull-down list, a tag included in an XML (Extensible Markup Language) document, or an HTML table tag The method according to any one of (1) to (4).
(5)に記載の発明の構成によれば、プルダウンリストを形成するHTMLタグ、XML文書に含まれるタグ又はHTMLのテーブルタグに基づいて表形式あるいはデータベース形式の情報と判断するので、Web文書に含まれるタグの一致を判定することにより自動的に表形式あるいはデータベース形式の情報を抽出することができる。 According to the configuration of the invention described in (5), since it is determined as information in a table format or a database format based on an HTML tag forming a pull-down list, a tag included in an XML document, or an HTML table tag, By determining the matching of the included tags, information in a table format or a database format can be automatically extracted.
(6) (1)から(5)のいずれかに記載の方法をコンピュータに実行させることを特徴としたプログラム。 (6) A program that causes a computer to execute the method according to any one of (1) to (5).
(7) 通信ネットワークを介してアクセス可能なWeb文書から、前記Web文書に含まれるタグに基づいて表形式あるいはデータベース形式の情報を抽出する情報群抽出手段と、
抽出した前記表形式あるいはデータベース形式の情報から、前記タグが示す各情報間の従属関係に基づいて、所定の項目に対して従属する関係にある属性及び前記属性の内容を示す属性値の関係を有する情報を抽出し、抽出した前記項目、属性及び属性値の関係を有する情報を関連付けて記憶手段に記憶する属性関係抽出手段と、を備えたことを特徴とする情報収集装置。
(7) Information group extracting means for extracting information in a table format or a database format from a Web document accessible via a communication network based on a tag included in the Web document;
From the extracted information in the table format or database format, based on the dependency relationship between the information indicated by the tag, the relationship between the attribute dependent on the predetermined item and the attribute value indicating the content of the attribute An information collection apparatus comprising: an attribute relationship extraction unit that extracts information stored therein and associates information having a relationship between the extracted item, attribute, and attribute value and stores the information in a storage unit.
この発明によれば、Web文書に含まれるタグに基づいて、項目、属性及び属性値の関係を有する情報を抽出することにより、Webページ上に分散して存在している共通の項目やその属性および属性値の関係にある情報を自動的に収集することができる。 According to the present invention, by extracting information having a relationship between items, attributes, and attribute values based on tags included in the Web document, common items existing on the Web page and their attributes are distributed. And information related to attribute values can be automatically collected.
以下、本発明を実施するための最良の形態について図を参照しながら説明する。なお、これはあくまでも一例であって、本発明の技術的範囲はこれに限られるものではない。
[情報収集装置と関連要素の全体構成]
Hereinafter, the best mode for carrying out the present invention will be described with reference to the drawings. This is merely an example, and the technical scope of the present invention is not limited to this.
[Overall configuration of information collection device and related elements]
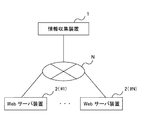
図1において、情報収集装置1は、通信ネットワークとしてのインターネットNを通じて複数のWebサーバ装置2に接続される。インターネットNとの接続は、有線であるか無線であるかを問わない。
In FIG. 1, an
情報収集装置1は、複数のWebサーバ装置2からWeb文書を取得する。各Webサーバ装置2は、情報収集装置1からのリクエストに応じて種々のWeb文書を提供する。
[情報収集装置の機能構成]
The
[Functional configuration of information collection device]
図2は、本実施形態に係る情報収集装置1の機能構成の概要を示す図である。情報収集装置1は、Web文書蓄積手段11、情報群抽出手段12及び属性関係抽出手段13を備えている。また、Web文書DB15、情報群記憶部16及び属性関係DB17を有する(DBはデータベースの略)。
FIG. 2 is a diagram illustrating an outline of a functional configuration of the
Web文書蓄積手段11は、Webサーバ装置2からWeb文書を取得しWeb文書DB15に格納する。情報群抽出手段12は、Web文書DB15に蓄積されたWeb文書を読み出し、読み出した当該Web文書に含まれるタグに基づき、表形式又はデータベース形式の情報を抽出し情報群記憶部16に格納する。属性関係抽出手段13は、情報群記憶部16に格納された表形式又はデータベース形式の情報を読み出し、読み出した当該情報に含まれるタグに基づき、当該情報に含まれる項目、属性及び属性値の関係を有する情報を抽出し、抽出した当該情報を属性関係DB17に登録する。Web文書蓄積手段11、情報群抽出手段12及び属性関係抽出手段13は、コンピュータがプログラムを実行することによって実現される。
The Web
また、Web文書DB15、情報群記憶部16及び属性関係DB17は、後述のハードウェアに含まれる記憶装置410の一領域に設けられている。
[各種データベースと関連要素の構成]
The
[Configuration of various databases and related elements]
図3は、Web文書DB15、情報群記憶部16及び属性関係DB17と関連要素の構成の概要を示す図である。
FIG. 3 is a diagram showing an outline of the configuration of the
図3(a)に示すように、Web文書DB15は、文書IDと、通信ネットワーク上で配信されているWeb文書のURL等のネットワーク上のアドレス及びこのWeb文書の記述であるソースコードと、をそれぞれ対応付けて記憶している。 As shown in FIG. 3A, the Web document DB 15 includes a document ID, a network address such as a URL of a Web document distributed on the communication network, and a source code that is a description of the Web document. They are stored in association with each other.
図3(b)及び(c)に示すように、情報群記憶部16には、Web文書のソースコードから抽出された表形式又はデータベース形式の情報が当該表形式又はデータベース形式を構成するタグと共に格納される。
As shown in FIGS. 3B and 3C, the information
図3(e)に示すように、属性関係DBには、表形式又はデータベース形式の情報から抽出された項目、属性及び属性値の関係を有する情報が格納される。 As shown in FIG. 3E, the attribute relationship DB stores information having a relationship between items, attributes, and attribute values extracted from information in a table format or a database format.
図3(d)に示すように、本実施形態では、表形式又はデータベース形式の情報から項目、属性及び属性値の関係を有する情報を抽出する際に利用する属性辞書14を備えている。
As shown in FIG. 3D, the present embodiment includes an
図3(b)及び(c)は、Web文書から抽出される表形式又はデータベース形式の情報の例である。例えば、PC販売会社AのWebページ(Web文書)が、図3(b)に示す表形式又はデータベース形式の情報を含んでおり、PC販売会社BのWebページ(Web文書)が、図3(c)に示す表形式又はデータベース形式の情報を含んでいるものとする。 FIGS. 3B and 3C are examples of information in a table format or database format extracted from a Web document. For example, the Web page (Web document) of the PC sales company A includes information in the table format or database format shown in FIG. 3B, and the Web page (Web document) of the PC sales company B is shown in FIG. It is assumed that the information in the table format or database format shown in c) is included.
当該情報は、プルダウンリストを形成する一群のHTMLとして記述されている場合、XML文書として記述されている場合、テーブルタグにより表を形成する一群のHTMLとして記述されている場合など、種々考えられる。 The information may be variously described as a group of HTML forming a pull-down list, described as an XML document, or described as a group of HTML forming a table with a table tag.
プルダウンリストを形成する一群のHTMLとして記載されている場合は、例えば<Select>タグの開始タグと終了タグを判定し、当該開始タグおよび終了タグとその間にある要素の内容とを抽出することが考えられる。 If it is described as a group of HTML forming a pull-down list, for example, the start tag and end tag of the <Select> tag can be determined, and the start tag and end tag and the contents of the elements in between can be extracted. Conceivable.
また、XML文書として記載されている場合は、XMLインスタンスが情報の階層構造を持つので、例えば、XMLインスタンスの最上位の開始タグと終了タグとの間にある要素の内容を抽出することが考えられる。 If the XML instance is described as an XML document, the XML instance has a hierarchical structure of information. For example, it is considered to extract the contents of an element between the top start tag and end tag of the XML instance. It is done.
また、テーブルタグにより表を形成する一群のHTMLとして記述されている場合は、例えば、<Table>タグの開始タグと終了タグを判定し、当該開始タグおよび終了タグとその間にある要素の内容とを抽出することが考えられる。 In addition, when the table tags are described as a group of HTML forming a table, for example, the start tag and end tag of the <Table> tag are determined, and the start tag and end tag and the contents of elements between them are determined. Can be considered.
本実施形態において、図3(b)の情報は、テーブルタグにより、1列目に項目「ノートPC」が記述され、1行目にノートPCの属性として「CPU」、「クロック」が記述され、「CPU xxx」、「CPU yyy」が属性「CPU」の属性値として記述され、「1.5GHz」、「2.0GHz」が属性「クロック」の属性値として記述されているものとする。 In the present embodiment, in the information of FIG. 3B, the table tag describes the item “note PC” in the first column, and “CPU” and “clock” as the attributes of the notebook PC in the first row. , “CPU xxx” and “CPU yyy” are described as attribute values of the attribute “CPU”, and “1.5 GHz” and “2.0 GHz” are described as attribute values of the attribute “clock”.
なお、項目、属性及び属性値の関係がこれらのWeb文書の基礎となるデータを格納しているデータベースサーバ等に蓄積され、CGI等のプログラムを用いて取得する構造となっている場合には、これらのCGI等のプログラムを実行することにより、これらの関係を有する情報を収集する。 When the relationship between items, attributes, and attribute values is accumulated in a database server or the like that stores the data that is the basis of these Web documents and is acquired using a program such as CGI, Information having these relationships is collected by executing a program such as CGI.
また、本実施形態において、図3(c)の情報は、テーブルタグにより形成されているものとし、<Table>タグの要素内容として記述された<Caption>タグの要素内容の一部に、項目「ノートパソコン」が記述され、その直後の表の1行目に、項目「ノートパソコン」の属性として「CPU」、「クロック」が記述され、以降、属性「CPU」の属性値として、「CPU zzz」、「CPU ppp」が記述され、属性「クロック」の属性値として、「800MHz」、「3.2GHz」が記述されているものとする。 In the present embodiment, the information in FIG. 3C is assumed to be formed by a table tag, and an item is included in a part of the <Caption> tag element content described as the <Table> tag element content. “Note PC” is described, and “CPU” and “Clock” are described as attributes of the item “Note PC” in the first row of the table immediately after that, and thereafter, “CPU” is set as an attribute value of the attribute “CPU”. “zzzz” and “CPU ppp” are described, and “800 MHz” and “3.2 GHz” are described as attribute values of the attribute “clock”.
図3(d)は、属性関係抽出手段が利用する属性辞書14の例である。属性辞書14は、後述のハードウェアに含まれる記憶装置410に格納されている。本実施形態において、属性辞書14は、項目と属性とを関連付けている。例えば、項目には「ノートパソコン」のほか、その類義語である「ノートPC」等が登録されている。一方、項目に関連する属性として「CPU」「HDD」「バッテリ」「価格」等が登録されている。更に、属性(属性1)に関する下位の属性(属性2)が登録されている。例えば、属性1「CPU」に関し、属性2「クロック」「キャッシュ」等が登録されている。
FIG. 3D is an example of the
図3(e)は、属性関係DBに格納される項目、属性及び属性値の関係を有する情報の例を示している。ユニークな番号である属性関係IDごとに、項目、属性及び属性値を関連付けて保存している。例えば、ある項目「ノートパソコン」は、属性1「CPU」の属性値が「CPU xxx」であり、かつ、属性2「クロック」の属性値が「1.5GHz」であるとして保存される。
[情報収集装置のハードウェア構成図]
FIG. 3E shows an example of information having a relationship between items, attributes, and attribute values stored in the attribute relationship DB. For each attribute relationship ID that is a unique number, an item, an attribute, and an attribute value are stored in association with each other. For example, an item “notebook personal computer” is stored assuming that the attribute value of
[Hardware configuration diagram of information collection device]
図4は、本実施形態に係る情報収集装置1のハードウェア構成を示す図である。
情報収集装置1は、制御部300を構成するCPU(Central Processing Unit)310(マルチプロセッサ構成ではCPU320等複数のCPUが追加されてもよい)、バスライン200、通信I/F(I/F:インタフェース)330、メインメモリ340、BIOS(Basic Input Output System)350、I/Oコントローラ360、ハードディスク370、光ディスクドライブ380、並びに半導体メモリ390を備える。尚、ハードディスク370、光ディスクドライブ380、並びに、半導体メモリ390はまとめて記憶装置410と呼ばれる。
FIG. 4 is a diagram illustrating a hardware configuration of the
The
制御部300は、情報収集装置1を統括的に制御する部分であり、ハードディスク370(後述)に記憶された各種プログラムを適宜読み出して実行することにより、上述したハードウェアと協働し、本発明に係る各種機能を実現している。
The
通信I/F330は、情報収集装置1が、インターネットN(図1)を介してWebサーバ装置2(#1)〜2(#N)等(図1)と情報を送受信する場合のネットワーク・アダプタである。通信I/F330は、モデム、ケーブル・モデム及びイーサネット(登録商標)・アダプタを含んでよい。
The communication I /
BIOS350は、情報収集装置1の起動時にCPU310が実行するブートプログラムや、情報収集装置1がハードウェアに依存するプログラム等を記録する。
The
I/Oコントローラ360には、ハードディスク370、光ディスクドライブ380、及び半導体メモリ390等の記憶装置410を接続することができる。
A
ハードディスク370は、本ハードウェアを情報収集装置1として機能させるための各種プログラム、本発明の機能を実行するプログラム及び前述の各DB15,17、情報群記憶部16及び属性辞書14を記憶する。なお、情報収集装置1は、外部に別途設けたハードディスク(図示せず)を外部記憶装置として利用することもできる。
The
光ディスクドライブ380としては、例えば、DVD−ROMドライブ、CD−ROMドライブ、DVD−RAMドライブ、CD−RAMドライブを使用することができる。この場合は各ドライブに対応した光ディスク400を使用する。光ディスク400から光ディスクドライブ380によりプログラムまたはデータを読み取り、I/Oコントローラ360を介してメインメモリ340またはハードディスク370に提供することもできる。
As the
なお、本発明でいうコンピュータとは、記憶装置、制御部等を備えた情報処理装置をいい、情報収集装置1は、記憶装置410、制御部300等を備えた情報処理装置により構成され、この情報処理装置は、本発明のコンピュータの概念に含まれる。
[Webサーバ装置のハードウェア構成]
The computer referred to in the present invention refers to an information processing device including a storage device, a control unit, and the like, and the
[Hardware configuration of Web server device]
Webサーバ装置2も、上述の情報収集装置1と同様なハードウェア構成を持つ。
[本発明の実施形態に係るフローチャート]
The
[Flowchart According to Embodiment of the Present Invention]
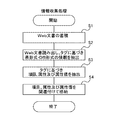
図5は、本発明の実施形態に係る情報収集処理のフローチャートを示している。 FIG. 5 shows a flowchart of information collection processing according to the embodiment of the present invention.
S1:Web文書蓄積手段11は、ネットワークN上に配信されているWeb文書を任意のWebサーバ装置2からダウンロードし、このWeb文書のURLをネットワーク上のアドレスとして、自動生成した文書IDとこの通信アドレスとを対応付けてWeb文書DB15に記憶する。また、Web文書蓄積手段11は、このWeb文書の文書IDと、このWeb文書の記述であるソースコードとを関連付けて記憶する。
S1: The Web
S2:情報群抽出手段12は、Web文書DB15に蓄積されたWeb文書のソースコードを解析し、当該ソースコードに含まれるタグの記述に基づいて表形式又はデータベース形式の情報の存在を判定し、表形式又はデータベース形式の情報を見つけた場合は当該情報を抽出して情報群記憶部16に格納する。
S2: The information
表形式又はデータベース形式の情報をタグに基づいて判定する方法としては、前述したように、プルダウンリストを構成するタグを見つける方法、XML宣言を判定する方法、テーブルタグを見つける方法等が考えられる。 As described above, as a method for determining information in a table format or a database format based on a tag, a method for finding a tag constituting a pull-down list, a method for judging an XML declaration, a method for finding a table tag, or the like can be considered.
本実施形態においては、例えば、図3(b)に示すPC販売会社AのWebページに掲載されていた情報と、図3(c)に示すPC販売会社BのWebページに掲載されていた情報とを抽出できたとする。図3(b)及び(c)の情報は、前述したようにテーブルタグによって構成されているものとする。 In the present embodiment, for example, information posted on the Web page of the PC sales company A shown in FIG. 3B and information posted on the Web page of the PC sales company B shown in FIG. And can be extracted. The information in FIGS. 3B and 3C is assumed to be constituted by table tags as described above.
S3:属性関係抽出手段13は、情報群記憶部16に格納された表形式又はデータベース形式の情報を解析し、当該情報に含まれる項目、属性及び属性値の関係にある情報を抽出する。
S3: The attribute
抽出にあたり、属性関係抽出手段13は、項目、属性及び属性値の関係にある情報の所在を推定する。推定の方法は幾つか考えられる。
(1)表形式又はデータベース形式の情報が、<Select>タグによりプルダウンリストを形成している場合、例えば<Select>タグのname属性の値を項目であると推定し、同<Select>タグの要素内容に列記された<Option>タグの要素内容を当該項目に関する属性及び属性値であると推定することが可能である。例えば、
<select name=”ノートPC”>
<option>CPU xxx 1.5GHz</option>
<option>CPU yyy 2.0GHz</option>
</select>
上記において、項目「ノートPC」、属性「CPU」の属性値「CPU xxx」と推定することができる。また、属性「CPU」に続く属性は「クロック」と推定し、属性「クロック」の属性値「1.5GHz」と推定することができる。同様に、項目「ノートパソコン」、属性「CPU」の属性値「CPU yyy」、属性「クロック」の属性値「2.0GHz」と推定することができる。
(2)表形式又はデータベース形式の情報が、XMLインスタンスの場合、階層構造を成している上位のタグ要素名を「項目」と推定し、その一つ下位のタグ要素名を「属性」と推定し、当該「属性」を示すタグ要素名の属性又は要素内容を「属性値」と推定することが可能である。例えば、
<ノートパソコン>
<CPU type=”CPU zzz”>
<クロック>1.1GHz</クロック>
</CPU>
<CPU type=”CPU ppp”>
<クロック>3.2GHz</クロック>
</CPU>
</ノートパソコン>
上記において、項目「ノートパソコン」、属性「CPU」の属性値「CPU zzz」、属性「クロック」の属性値「1.1GHz」を推定することができる。同様に、項目「ノートパソコン」、属性「CPU」の属性値「CPU ppp」、属性「クロック」の属性値「3.2GHz」を推定することができる。
(3)表形式又はデータベース形式の情報がテーブルタグによって構成されている場合、例えば、表のタイトルを「項目」と推定し、1行目にある要素の列を各「属性」と推定し、2行目以降にある要素を同列の属性に対応する「属性値」と推定することが考えられる。例えば、
<table>
<caption>ノートパソコン</caption>
<tr>
<td>CPU</td>
<td>クロック</td>
</tr>
<tr>
<td>CPU zzz</td>
<td>1.1GHz</td>
</tr>
<tr>
<td>CPU ppp</td>
<td>3.2GHz</td>
</tr>
</table>
上記において、項目「ノートパソコン」、属性「CPU」の属性値「CPU zzz」、属性「クロック」の属性値「1.1GHz」を推定することができる。同様に、項目「ノートパソコン」、属性「CPU」の属性値「CPU ppp」、属性「クロック」の属性値「3.2GHz」を推定することができる。
At the time of extraction, the attribute
(1) When the information in the table format or the database format forms a pull-down list by the <Select> tag, for example, the value of the name attribute of the <Select> tag is estimated as an item, and the <Select> tag It is possible to presume that the element contents of the <Option> tag listed in the element contents are attributes and attribute values related to the item. For example,
<Select name = "Note PC">
<Option> CPU xxx 1.5 GHz </ option>
<Option> CPU yyy 2.0GHz </ option>
</ Select>
In the above description, the attribute value “CPU xxx” of the item “notebook PC” and the attribute “CPU” can be estimated. The attribute following the attribute “CPU” can be estimated as “clock”, and the attribute value “1.5 GHz” of the attribute “clock” can be estimated. Similarly, the attribute value “CPU yy” of the item “notebook computer”, the attribute “CPU”, and the attribute value “2.0 GHz” of the attribute “clock” can be estimated.
(2) If the information in the table format or the database format is an XML instance, the upper tag element name forming the hierarchical structure is estimated as “item”, and the tag element name one lower level is set as “attribute” It is possible to estimate, and the attribute or element content of the tag element name indicating the “attribute” can be estimated as the “attribute value”. For example,
<Notebook PC>
<CPU type = “CPU zzz”>
<Clock> 1.1GHz </ Clock>
</ CPU>
<CPU type = “CPU ppp”>
<Clock> 3.2GHz </ Clock>
</ CPU>
</ Notebook PC>
In the above, the attribute value “CPU zzz” of the item “notebook computer”, the attribute “CPU”, and the attribute value “1.1 GHz” of the attribute “clock” can be estimated. Similarly, the attribute value “CPU pp” of the item “notebook computer”, the attribute “CPU”, and the attribute value “3.2 GHz” of the attribute “clock” can be estimated.
(3) When the information in the table format or the database format is configured by a table tag, for example, the table title is estimated as “item”, the element column in the first row is estimated as each “attribute”, It is conceivable that the elements in the second and subsequent rows are estimated as “attribute values” corresponding to the attributes in the same column. For example,
<Table>
<Caption> notebook computer </ caption>
<Tr>
<Td> CPU </ td>
<Td> clock </ td>
</ Tr>
<Tr>
<Td> CPU zzz </ td>
<Td> 1.1 GHz </ td>
</ Tr>
<Tr>
<Td> CPU ppp </ td>
<Td> 3.2 GHz </ td>
</ Tr>
</ Table>
In the above, the attribute value “CPU zzz” of the item “notebook computer”, the attribute “CPU”, and the attribute value “1.1 GHz” of the attribute “clock” can be estimated. Similarly, the attribute value “CPU pp” of the item “notebook computer”, the attribute “CPU”, and the attribute value “3.2 GHz” of the attribute “clock” can be estimated.
(4)属性辞書14を利用する方法も考えられる。属性関係抽出手段13は、属性辞書14に登録された項目を参照し、情報群記憶部16に格納された情報Aに同一の項目が含まれているか判定する。同一の項目が含まれていたら、属性辞書14においてその項目に関連付けられている属性を参照し、同一の属性が情報Aに含まれているか判定する。同一の属性が含まれていたら、情報Aにおいて当該属性の例えば直後にある要素内容を当該属性についての属性値であると推定する。属性辞書14を利用すると、項目や属性を表すテキストが不要な語句を一部に含んでいても、当該不要な語句を無視して項目名や属性名を取得することができる。
(4) A method using the
なお、属性関係抽出手段13は、表形式の情報の直上方、直下方あるいは直左方に位置する情報を前記項目として抽出してもよい。また、表形式の情報において、上端行あるいは左端列に位置する情報を属性として、それぞれその下方あるいは右方に位置する情報を属性値として抽出してもよい。さらに、前記データベース形式の情報の直左方に位置する情報を属性として、前記データベース形式の情報をその属性値として抽出してもよい。
Note that the attribute
S4:属性関係抽出手段13は、S3において抽出した項目、属性及び属性値の関係を有する情報を属性関係DB17に登録する。本実施形態において、属性関係抽出手段13は、この登録の際に属性辞書14を参照し、項目の類義語を1種類に統一する。例えば、図3(b)に示す情報から得た項目「ノートPC」は、図3(d)に示した属性辞書の項目を参照し「ノートパソコン」に統一して属性関係DB17に登録する。このようにすると、項目が統一されることによって、生成された属性関係DB17の情報を活用しやすくなる。もっとも、属性辞書14とは別に類義語辞書を備え、この類義語辞書を参照することにより、項目や属性の類義語を統一してもよい。図3に示した情報の例によると、図3(b)及び(c)に示した表形式又はデータベース形式の情報から、図3(e)に示した属性関係DBを生成することができる。
S4: The attribute
以上説明したように、情報群抽出手段12及び属性関係抽出手段13が、Web文書に含まれるタグに基づいて、項目、属性及び属性値の関係を有する情報を抽出するので、項目に関する情報をサイトの異なる複数のWeb文書から自動的に収集し、属性ごとに整理された情報として取得することができる。
As described above, the information
以上、本発明の実施形態について説明したが、本発明は上述した実施形態に限るものではない。例えば、「項目」は本実施形態の例示に限られず、「属性」及び「属性値」を伴うものはすべて「項目」になり得る。また、表形式データベース形式の情報を抽出する方法及び当該情報から項目、属性及び属性値の関係を有する情報を抽出する方法は、本実施形態の例示に限られるものではない。また、図6に示した各ステップは、1つのWeb文書を蓄積するごとに全てのステップを一通り実行する必要はない。各ステップが非同期でバッチ処理を行なってもよい。 As mentioned above, although embodiment of this invention was described, this invention is not restricted to embodiment mentioned above. For example, “item” is not limited to the example of the present embodiment, and anything with “attribute” and “attribute value” can be “item”. Further, a method for extracting information in a tabular database format and a method for extracting information having a relationship between items, attributes, and attribute values from the information are not limited to the examples in the present embodiment. In addition, each step shown in FIG. 6 does not need to be executed all at once every time one Web document is accumulated. Each step may perform batch processing asynchronously.
また、本発明の実施形態に記載された効果は、本発明から生じる最も好適な効果を列挙したに過ぎず、本発明による効果は、本発明の実施例に記載されたものに限定されるものではない。 The effects described in the embodiments of the present invention are only the most preferable effects resulting from the present invention, and the effects of the present invention are limited to those described in the embodiments of the present invention. is not.
1 情報収集装置
2 Webサーバ装置
11 Web文書蓄積手段
12 情報群抽出手段
13 属性関係抽出手段
14 属性辞書
15 Web文書DB
16 情報群記憶部
17 属性関係DB
DESCRIPTION OF
16 Information
Claims (7)
抽出した前記表形式あるいはデータベース形式の情報から、前記タグが示す各情報間の従属関係に基づいて、所定の項目に対して従属する関係にある属性及び前記属性の内容を示す属性値の関係を有する情報を抽出するステップと、
抽出した前記項目、属性及び属性値の関係を有する情報を関連付けて記憶手段に記憶するステップと、を少なくとも実行することを特徴とする情報収集方法。 A step of extracting information in a table format or a database format from a Web document accessible via a communication network, based on a tag included in the Web document;
From the extracted information in the table format or database format, based on the dependency relationship between the information indicated by the tag, the relationship between the attribute dependent on the predetermined item and the attribute value indicating the content of the attribute Extracting information having,
And a step of associating and storing in the storage means information having a relationship between the extracted item, attribute and attribute value.
抽出した前記表形式あるいはデータベース形式の情報から、前記タグが示す各情報間の従属関係に基づいて、所定の項目に対して従属する関係にある属性及び前記属性の内容を示す属性値の関係を有する情報を抽出し、抽出した前記項目、属性及び属性値の関係を有する情報を関連付けて記憶手段に記憶する属性関係抽出手段と、を備えたことを特徴とする情報収集装置。 Information group extraction means for extracting information in a table format or a database format from a Web document accessible via a communication network based on a tag included in the Web document;
From the extracted information in the table format or database format, based on the dependency relationship between the information indicated by the tag, the relationship between the attribute dependent on the predetermined item and the attribute value indicating the content of the attribute An information collection apparatus comprising: an attribute relationship extraction unit that extracts information stored therein and associates information having a relationship between the extracted item, attribute, and attribute value and stores the information in a storage unit.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2008171883A JP5108660B2 (en) | 2008-06-30 | 2008-06-30 | Information collection method, apparatus, and program |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2008171883A JP5108660B2 (en) | 2008-06-30 | 2008-06-30 | Information collection method, apparatus, and program |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2010015202A true JP2010015202A (en) | 2010-01-21 |
| JP5108660B2 JP5108660B2 (en) | 2012-12-26 |
Family
ID=41701290
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2008171883A Active JP5108660B2 (en) | 2008-06-30 | 2008-06-30 | Information collection method, apparatus, and program |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP5108660B2 (en) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2016081526A (en) * | 2014-10-10 | 2016-05-16 | 富士通株式会社 | Table reconstruction device and method |
| JP2018180874A (en) * | 2017-04-12 | 2018-11-15 | 富士通株式会社 | Date/time information extraction method, date/time information extraction device, and date/time information extraction program |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2001325284A (en) * | 2000-05-12 | 2001-11-22 | Nippon Telegr & Teleph Corp <Ntt> | Method and device for extracting information from table structure area and recording medium stored with information extracting program |
| JP2003281160A (en) * | 2002-03-25 | 2003-10-03 | Ntt Comware Corp | Meta-data creating system, meta-data creating method, meta-data creating program and record medium |
| JP2005141296A (en) * | 2003-11-04 | 2005-06-02 | Just Syst Corp | Device, method and program for retrieving document |
| JP2005326970A (en) * | 2004-05-12 | 2005-11-24 | Mitsubishi Electric Corp | Structured document ambiguity retrieving device and its program |
-
2008
- 2008-06-30 JP JP2008171883A patent/JP5108660B2/en active Active
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2001325284A (en) * | 2000-05-12 | 2001-11-22 | Nippon Telegr & Teleph Corp <Ntt> | Method and device for extracting information from table structure area and recording medium stored with information extracting program |
| JP2003281160A (en) * | 2002-03-25 | 2003-10-03 | Ntt Comware Corp | Meta-data creating system, meta-data creating method, meta-data creating program and record medium |
| JP2005141296A (en) * | 2003-11-04 | 2005-06-02 | Just Syst Corp | Device, method and program for retrieving document |
| JP2005326970A (en) * | 2004-05-12 | 2005-11-24 | Mitsubishi Electric Corp | Structured document ambiguity retrieving device and its program |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2016081526A (en) * | 2014-10-10 | 2016-05-16 | 富士通株式会社 | Table reconstruction device and method |
| JP2018180874A (en) * | 2017-04-12 | 2018-11-15 | 富士通株式会社 | Date/time information extraction method, date/time information extraction device, and date/time information extraction program |
Also Published As
| Publication number | Publication date |
|---|---|
| JP5108660B2 (en) | 2012-12-26 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP2013531289A (en) | Use of model information group in search | |
| JP6165955B1 (en) | Method and system for matching images and content using whitelist and blacklist in response to search query | |
| JP2007286701A (en) | Electronic shopping mall system and computer device for electronic shopping mall system | |
| JP2010097461A (en) | Document search apparatus, document search method, and document search program | |
| JP4542993B2 (en) | Structured document extraction apparatus, structured document extraction method, and structured document extraction program | |
| JP2012008610A (en) | Search apparatus, method, and program | |
| JP4750628B2 (en) | Information ranking method and apparatus, program, and computer-readable recording medium | |
| JP2007193697A (en) | Information collection apparatus, information collection method and program | |
| JP2006331292A (en) | Weblog community search support method, search support device, and recording medium recording program for search support method | |
| JP5108660B2 (en) | Information collection method, apparatus, and program | |
| JP4920642B2 (en) | Web search support method, apparatus and program | |
| JP2008102773A (en) | Method for converting data into common format | |
| JP5499546B2 (en) | Important word extraction method, apparatus, program, recording medium | |
| JP2009265770A (en) | Significant sentence presentation system | |
| CN102521288A (en) | Acquisition method of Web service information on Internet | |
| US20090216756A1 (en) | Recording medium carrying data search program, data search apparatus, and data search method | |
| JP5187187B2 (en) | Experience information search system | |
| JP2012027525A (en) | File storage auxiliary system, method and program | |
| JP2011076264A (en) | Retrieval control device, retrieval control method, and program | |
| JP4962973B2 (en) | Search server, method and program | |
| JP2011086156A (en) | System and program for tracking of leaked information | |
| JP5416023B2 (en) | Reading terminal and method | |
| JP2010003256A (en) | Method, apparatus and system for adjusting place name display mode | |
| JP2001155021A (en) | Information retrieval device and method, and record medium recorded with program | |
| JP5769648B2 (en) | Related word acquisition apparatus and related word acquisition method |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20120110 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20120309 |
|
| RD04 | Notification of resignation of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7424 Effective date: 20120312 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20120424 |
|
| RD02 | Notification of acceptance of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7422 Effective date: 20120501 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20120723 |
|
| A911 | Transfer to examiner for re-examination before appeal (zenchi) |
Free format text: JAPANESE INTERMEDIATE CODE: A911 Effective date: 20120730 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20120911 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20121005 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 Ref document number: 5108660 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20151012 Year of fee payment: 3 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| S531 | Written request for registration of change of domicile |
Free format text: JAPANESE INTERMEDIATE CODE: R313531 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| S533 | Written request for registration of change of name |
Free format text: JAPANESE INTERMEDIATE CODE: R313533 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |
|
| S111 | Request for change of ownership or part of ownership |
Free format text: JAPANESE INTERMEDIATE CODE: R313111 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| S111 | Request for change of ownership or part of ownership |
Free format text: JAPANESE INTERMEDIATE CODE: R313111 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |