JP2010010857A - 音声入力ロボット、遠隔会議支援システム、遠隔会議支援方法 - Google Patents
音声入力ロボット、遠隔会議支援システム、遠隔会議支援方法 Download PDFInfo
- Publication number
- JP2010010857A JP2010010857A JP2008165286A JP2008165286A JP2010010857A JP 2010010857 A JP2010010857 A JP 2010010857A JP 2008165286 A JP2008165286 A JP 2008165286A JP 2008165286 A JP2008165286 A JP 2008165286A JP 2010010857 A JP2010010857 A JP 2010010857A
- Authority
- JP
- Japan
- Prior art keywords
- voice input
- unit
- voice
- sound source
- sound
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
- 238000000034 method Methods 0.000 title claims description 31
- 238000012545 processing Methods 0.000 claims description 35
- 230000008569 process Effects 0.000 claims description 12
- 238000013507 mapping Methods 0.000 claims description 5
- 238000004891 communication Methods 0.000 abstract description 14
- 230000008859 change Effects 0.000 abstract description 10
- 230000010365 information processing Effects 0.000 description 15
- 238000010586 diagram Methods 0.000 description 14
- 238000001514 detection method Methods 0.000 description 8
- 230000009471 action Effects 0.000 description 6
- 230000002452 interceptive effect Effects 0.000 description 6
- 238000005070 sampling Methods 0.000 description 6
- 238000005516 engineering process Methods 0.000 description 5
- 230000000694 effects Effects 0.000 description 4
- 230000006870 function Effects 0.000 description 3
- NJPPVKZQTLUDBO-UHFFFAOYSA-N novaluron Chemical compound C1=C(Cl)C(OC(F)(F)C(OC(F)(F)F)F)=CC=C1NC(=O)NC(=O)C1=C(F)C=CC=C1F NJPPVKZQTLUDBO-UHFFFAOYSA-N 0.000 description 3
- 125000002066 L-histidyl group Chemical group [H]N1C([H])=NC(C([H])([H])[C@](C(=O)[*])([H])N([H])[H])=C1[H] 0.000 description 2
- 230000008901 benefit Effects 0.000 description 2
- 230000003111 delayed effect Effects 0.000 description 2
- 241000282412 Homo Species 0.000 description 1
- 230000003321 amplification Effects 0.000 description 1
- 238000013459 approach Methods 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- 230000001934 delay Effects 0.000 description 1
- 230000008451 emotion Effects 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 238000009434 installation Methods 0.000 description 1
- 230000003993 interaction Effects 0.000 description 1
- 238000003199 nucleic acid amplification method Methods 0.000 description 1
- 230000005236 sound signal Effects 0.000 description 1
Images







Landscapes
- Details Of Audible-Bandwidth Transducers (AREA)
- Obtaining Desirable Characteristics In Audible-Bandwidth Transducers (AREA)
- Circuit For Audible Band Transducer (AREA)
- Telephone Function (AREA)
Abstract
【解決手段】音声の入力を受け付ける音声入力部111と、音声入力部111が受け付けた音声の音源位置を推定する音源位置推定部121と、音声入力部111の位置を可変する動作部112と、を備え、音源位置推定部121は、音声入力部111が受け付けた複数の音声の音源位置を推定し、動作部112は、音源位置推定部121の推定結果に基づき、音声入力部111と複数の音声の音源位置との間の位置関係を変更する。
【選択図】図1
Description
特に発話者が複数人存在するような状況では、発話者各人の発話音量の差、マイクとの距離・位置関係などにより、発話者毎に音声の聴き取りやすさが異なってしまう。
しかし、このようなやり取りは発話の中断を招き、コミュニケーションの円滑な進行を妨げ、参加者に余計なストレスを与えてしまう。
しかし、この動作は人間とロボットが対話するためのものであり、遠隔コミュニケーションを円滑に行うためのものではない。
しかし、遠隔会議のように複数の人間がコミュニケーションに参加する環境下では、ロボットとその対話相手との2者間関係のみを最適化したとしても、必ずしも会議全体の進行を最適化することにはならない。
即ち、会議に複数の人間が参加している環境、換言すると、複数の音源から生じる音声を全体的に収集することが求められる環境下では、上記特許文献1〜3に記載の技術は必ずしも適していない。
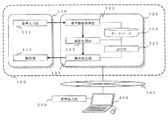
図1は、本発明の実施の形態1に係る遠隔会議支援システムの構成図である。
本実施の形態1に係る遠隔会議支援システムは、音声入力ロボット100、会議端末200を有する。音声入力ロボット100と会議端末200は、例えばLAN(Local Area Network)やインターネットのようなネットワーク300を介して遠隔接続されている。
ロボット本体部110は、音声入力ロボット100の本体筐体と、本体筐体に取り付けられた各構成部分とを備える。具体的な構成は後述する。
ロボット制御部120は、音声入力ロボット100の動作を制御する。具体的な構成は後述する。ロボット制御部120およびその各構成部は、その機能を実現する回路デバイスのようなハードウェアで構成することもできるし、マイコンやCPU(Central Processing Unit)のような演算装置とその動作を規定するソフトウェアで構成することもできる。また、必要な記憶装置やネットワークインターフェースを適宜備える。
音声入力ロボット100が姿勢を変えることなく全方位からの音声を収集できるようにするためには、マイクロフォンアレイで音声入力部111を構成するのが好適である。例えば、単一指向性マイクを円周上に複数配置し、指向方向を円の外側に向ける、といった手法が考えられる。
音声入力部111が収集した音声は、後述の音声情報処理部121に出力される。
また、音声情報処理部121は、ネットワーク300を介して、音声入力部111から受け取った音声を会議端末200に送信する。
統計処理部122が行う統計処理の対象となるのは、音声情報処理部121が処理した前述の各情報、即ち音源の推定位置、推定音源位置の音量、時間(サンプリングタイム)などである。
具体的には、例えばネットワークインターフェースや画面入力を介して、上述の設定情報の入力を受け付ける、といった構成が考えられる。
設定部125が受け取った設定情報と統計処理部122が作成した音声分布マップから、動作決定部123が出力する可変指令の内容が決定される。
この場合は、複数音源からの音声を同時に取得する。音量が発話者の発話音量に大きく影響を受けるため、声量による発話者の感情を読み取りやすい。
この場合も、複数音源からの音声を同時に取得する。発話・主張の強さに関して、音量差の影響を受けにくい。
これは、特定発話者の発言が多い状況、例えば、ある発話者が資料説明を行っているような状況に相当する。
この場合は、発話頻度の高い話者の位置に着目し、発話者の声が大きすぎるときは音量を小さくし、声が小さすぎるときは音量を大きくしたい、といった要望があるものと想定される。
この点は、上記特許文献1〜3に記載の対話型ロボットのように、プログラムされた規定の目的に従った動作しか行わない、人間とロボットの間のコミュニケーションを前提とした技術とは異なる。
また、「動作部」は、動作部112およびその動作内容を決定する動作決定部123が相当する。
会議端末200は、ネットワーク300を介して、ロボット制御部120が送信した音声を受信し、音声出力部210よりその音声を音声出力する。遠隔の会議参加者は、その音声を聴取することにより、音声入力ロボット100周辺の会議参加者の音声を聴くことができる。
次に、動作部112の具体的な構成例を説明する。
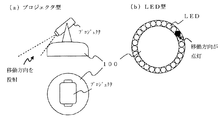
車両で構成された動作部112は、動作決定部123の指示に基づき車輪を駆動させ、指示された方向に音声入力ロボット100を移動させる。
可動スイングアームで構成された動作部112は、動作決定部123の指示に基づきアームの姿勢(ヨー・ピッチ角)や長さを可変することで、音声入力部111の空間位置を移動させる。
次に、統計処理部122が作成する音声分布マップの例について、先に述べた設定部125に入力される「音声の聴き手側が望む音声環境」との関連から説明する。
なお、ここでは上述の設定情報として、「(1)各発話者からほぼ等距離となるような位置関係で発話を聴きたい。」が設定部125に入力されたものとする。
図3(a)の状態では、音声入力ロボット100と会議参加者2の距離が最も近く、他の会議参加者と音声入力ロボット100の距離は遠い。
統計処理部122は、各会議参加者の音源位置の推定結果を用いて、図3(a)のような2次元平面座標上に各会議参加者の位置をマッピングした音声分布マップを作成する。
動作決定部123は、図3(a)に示す音声分布マップおよび設定部125が受け取った設定情報に基づき、音声入力ロボット100(または音声入力部111、以下同様)と各会議参加者の距離がそれぞれ等距離となるように、音声入力ロボット100の移動先を決定する。
なお、ここでは上述の設定情報として、「(2)発話者達の発話を同等の音量で聴きたい。」が設定部125に入力されたものとする。
図4(a)の状態では、音声入力ロボット100と会議参加者1の距離が最も近く、これに対応して会議参加者1から集音される音量が最も大きくなっている。
ここでいう発話音量とは、例えばサンプリングタイム内での最大/最小音量、あるいはサンプリングタイム内での音量の平均値、といった値のことである。
統計処理部122は、各会議参加者の音源位置の推定結果を用いて、図4(a)のような2次元平面座標上に各会議参加者の位置と発話音量をマッピングした音声分布マップを作成する。
動作決定部123は、図4(a)に示す音声分布マップおよび設定部125が受け取った設定情報に基づき、音声入力ロボット100が集音する各会議参加者の発話音量がそれぞれ同等になるように、音声入力ロボット100の移動先を決定する。
なお、ここでは上述の設定情報として、「(3)特定発話者の発話を聴きやすい状況で聴きたい。」が設定部125に入力されたものとする。
なお、聴き手側は、会議参加者3の発話を聴きやすい状況を希望しているものとする。
統計処理部122は、各会議参加者の音源位置の推定結果を用いて、図5(a)のような2次元平面座標上に各会議参加者の位置、発話音量、および発話回数をマッピングした音声分布マップを作成する。
動作決定部123は、図5(a)に示す音声分布マップおよび設定部125が受け取った設定情報に基づき、音声入力ロボット100が集音する会議参加者3の発話音量が最も大きくなるように、音声入力ロボット100の移動先を決定する。
音声入力ロボット100の空間位置が移動することにより、音声入力ロボット100が集音する会議参加者3の発話音量(円の大きさ)が最も大きくなり、他の会議参加者の発話音量は小さくなる。
なお、音声入力ロボット100が移動しても発話回数自体は変化しないため、各円の輪数は変化しない。
(条件2)各音源から発生する音量が一定レベル以下の状態になる。
具体的には、動作決定部123より統計処理部122にその旨を指示するとよい。
音声入力部111を通しての音声のやり取りが終了するまで、以下のステップが繰り返される。音声のやり取りが終了するとは、例えば遠隔会議が終了することを指す。
(S602)
音声入力部111は、音声入力ロボット100が存在する空間、ここでは発話側の会議室の音声を取得する。取得した音声は、ロボット制御部120へ送信される。
音声情報処理部121は、音声入力部111から受け取った音声に基づき、音源位置の推定、推定音源の音量、推定音源の音声出力回数、などの演算処理を実行する。また、音声入力部111から受け取った音声を会議端末200に送信する。
(S604)
音声情報処理部121は、ステップS603の結果をデータベース124に格納する。
(S605)
音声入力ロボット100が移動中である場合はステップS611へ進み、移動中でない場合はステップS606へ進む。
統計処理部122は、データベース124に格納されている各データ、および設定部125が受け取った設定情報(聴き手側が望む音声環境)に基づき、先に説明した統計処理を実行する。
(S607)
統計処理部122は、ステップS606の処理結果に基づき、図3〜図5で説明したような音声分布マップを作成する。作成した音声分布マップは、任意のデータ形式でデータベース124に格納する。
動作決定部123は、ステップS607で作成された音声分布マップ、および設定部125が受け取った設定情報に基づき、音声環境を聴き手側が望むように改善するために、音声入力ロボット100の位置を変更する必要があるか否かを判定する。
位置を変更する必要がある場合はステップS609へ進み、必要がない場合はステップS602に戻って繰り返し処理を継続する。
(S609)
動作決定部123は、ステップS607で作成された音声分布マップ、および設定部125が受け取った設定情報に基づき、音声入力ロボット100の移動先位置を決定する。
動作決定部123は、音声入力ロボット100の移動・動作を開始・実行してよいか否かを判断する。ここでの判断とは、上述の条件1〜2が満たされているか否かを判断することを指す。
音声入力ロボット100の移動・動作を許可する場合はステップS611へ進み、許可しない場合はステップS602に戻って繰り返し処理を継続する。
(S611)
動作決定部123は、動作部112に動作指令を出す。動作部112は、その動作指令に基づき音声入力ロボット100を駆動して音声入力部111の空間位置を可変する。
音声入力ロボット100を動作させることにより、音声入力部111の集音状態が聴き手側の望む状態に変化する。
例えば、聴き手側から「声がよく聴こえない」といった会話によるフィードバックを得る以外に、フィードバックを得る手段がない。したがって、聴き手側が会話によるフィードバックをしなければ、発話者側が得られるフィードバックはない。
また、聴き手側から会話によるフィードバックを都度行っているようでは、円滑なコミュニケーションの妨げになる。
発話者側は、例えば音声入力ロボット100が自分に近づいてくるといった動作を見ることで、自分の発話が聴き手側によく聴こえていないのではないか、といったことに気づくことができる。
これに対し、本実施の形態1では、音声入力ロボット100自体が移動するという動作により、集音状態の改善と、発話者へのフィードバックとを、同時に行うことができるのである。
実施の形態1では、音声入力ロボット100が移動する際に、音声入力ロボット100自身から発生する音の影響や、音声入力ロボット100が移動することによる集音状態の変化に鑑み、所定の条件を満たすまでは音声入力ロボット100の移動を許可しないこととした。
音声入力ロボット100の移動やフィードバックが遅れれば、その分だけ聴き手側の要望が反映されるのが遅れ、発話を聴き取りづらい状態が継続することを余儀なくされる。
本実施の形態2に係る遠隔会議支援システムは、実施の形態1の図1で説明した構成に加え、ロボット本体部110に表示部113を備える。その他の構成は図1と概ね同様であるため、以下では差異点を中心に説明する。
動作決定部123は、統計処理部122の統計処理に基づき音声入力ロボット100の移動先位置や方向を決定した後、動作部112にその旨の指示を出す前に、表示部113にその位置や方向を表示させる。
また、表示のみを行うので、音声入力ロボット100の移動による音声環境の変化を生じさせることもない。
即ち、音声入力ロボット100が移動を開始するために、発話者は発話を一時中断し、音声入力ロボット100の移動が完了するまで発話の間を空ける、といった行動をとることが可能になる。
具体的には、例えば矢印の向きで移動方向を表し、矢印の長さで移動距離を表す、といった手法が考えられる。これ以外の手法でもよいし、矢印や文字以外の表現方法を用いてもよい。
図6のステップS601〜S609と同様であるため、説明を省略する。
(S910)
動作決定部123は、表示部113に音声入力ロボット100の移動方向を表示するよう指示を出す。表示部113は、その指示に基づき音声入力ロボット100の移動方向を表示する。
動作決定部123は、音声入力ロボット100の移動・動作を開始・実行してよいか否か、即ち実施の形態1で説明した条件1〜2が満たされているか否かを判断する。
音声入力ロボット100の移動・動作を許可する場合はステップS912へ進み、許可しない場合はステップS901のループを継続する。
(S912)
図6のステップS611と同様であるため、説明を省略する。
例えば、発話を中断したくはないが、現在の発話内容に対して質問がある、といった聴き手側の意思を表示して発話者にその旨をフィードバックしてもよい。このような表示により、コミュニケーションの円滑を図ることができる。
フィードバックを得た発話者は、音声入力ロボット100が移動しようとしている方向から、自己の発話状態を変更する、音声入力ロボット100の移動開始条件を満たすように発話の間を取る、といった対応を取ることができる。
以上の実施の形態1〜2では、音声情報処理部121は音声入力部111から受け取った音声をそのまま会議端末200に送信することとした。
音声情報処理部121は、必要に応じて、音声入力部111から受け取った音声に対して、発話者側のノイズ除去、その他のノイズキャンセリング処理などを施した上で、会議端末200に送信するようにしてもよい。
なお、ノイズキャンセリング処理を施す際には、データベース124に蓄積された音声データを用いて必要な統計処理や学習処理を行うとよい。
特許文献1〜3に記載されているような従来の技術では、対話ロボットが以後の動作を実行する方向を絞り込むために音源位置を推定し、動作方向の候補から外れた音源に関しては、以後の処理対象から除外している。
一方、以上の実施の形態1〜3では、推定した音源位置や音量を除外するといった、音源の取捨選択は行わない。
これは、従来の技術のように対話ロボットと発話者が1対1で対話することを意識した技術と異なり、本発明では複数の発話者の音声を集音することを目的としたものであることによる。
即ち本発明では、音源位置を処理対象から除外する必要はないため、音源位置の取捨選択は行わないのである。
図3〜図5において、音声分布マップを2次元平面座標上で表した例を説明したが、3次元空間座標上に音声分布をマッピングしてもよい。例えば、音声の大きさや発話回数を高さで表現する、といった手法が考えられる。後者の場合は、円の輪数が等高線のように用いられて高さが表現されるイメージとなる。
例えば遠隔会議では、発話者がノートパソコンを自己の目の前に広げて会議を行うことがあり、ノートパソコンが壁になって音声収集に影響を与える。そこで、上記のように高さ方向にも音声入力部111の配置や音声入力ロボット100の移動範囲を拡張し、より柔軟な音声収集を行うことができるようにするとよい。
以上の実施の形態1〜5において、ロボット制御部120に、音声入力ロボット100の自己位置を推定する機能部を設けてもよい。
例えば、図2(a)で説明した自走式構成の場合は、車輪の回転方向、回転数、車輪直径などの値を用いて自己位置を推定する。
図2(b)で説明した固定可動式構成の場合は、アームの長さ、アームの姿勢(ヨー・ピッチ角)などの値を用いて自己位置を推定する。
自己位置推定を用いることにより、図3〜図5で説明した音声分布マップは、音声入力ロボット100の位置を中心とした相対座標系ではなく、絶対座標系のマップとなる。絶対座標軸上の音源における最大/最小音量、発話発生頻度などに基づき、絶対座標上における音声入力ロボット100の理想位置が求められる。
これにより、音声入力ロボット100の理想位置を素早く判断することができる。
以上の実施の形態1〜6では、説明の便宜上、発話者側に音声入力ロボット100を設置し、聴き手側に会議端末200を設置した例を説明した。
しかし、遠隔会議のような双方向のコミュニケーションでは、双方が発話を行うので、双方の拠点に音声入力ロボット100と会議端末200を設置して同等の環境となるように構成してもよい。
Claims (14)
- 音声の入力を受け付ける音声入力部と、
前記音声入力部が受け付けた音声の音源位置を推定する音源位置推定部と、
前記音声入力部の位置を可変する動作部と、
を備え、
前記音源位置推定部は、
前記音声入力部が受け付けた複数の音声の音源位置を推定し、
前記動作部は、
前記音源位置推定部の推定結果に基づき、
前記音声入力部と前記複数の音声の音源位置との間の位置関係を変更する
ことを特徴とする音声入力ロボット。 - 前記音源位置推定部の推定結果を時系列順に保持するデータベースを格納した記憶部を備えた
ことを特徴とする請求項1記載の音声入力ロボット。 - 前記データベースが保持する前記推定結果を統計処理する統計処理部を備えた
ことを特徴とする請求項2記載の音声入力ロボット。 - 前記統計処理部は、
前記統計処理の結果を当該音声入力ロボット周辺の2次元平面座標上または3次元空間座標上にマッピングし、そのマッピング結果を前記記憶部に格納する
ことを特徴とする請求項3記載の音声入力ロボット。 - 前記動作部は、
前記マッピング結果に基づき前記位置関係を変更する
ことを特徴とする請求項4記載の音声入力ロボット。 - 前記位置関係を指定する設定情報を受け付ける設定入力部を備え、
前記動作部は、
前記マッピング結果に基づき、
前記位置関係が前記設定情報で指定される位置関係となるように、
前記音声入力部の位置を可変する
ことを特徴とする請求項4記載の音声入力ロボット。 - 各前記音声に対する前記音声入力部の集音状態を通知する手段を備えた
ことを特徴とする請求項1ないし請求項6のいずれかに記載の音声入力ロボット。 - 各前記音声に対する前記音声入力部の集音状態を表示する表示部を備えた
ことを特徴とする請求項1ないし請求項6のいずれかに記載の音声入力ロボット。 - 前記動作部の可変方向を可変実行前に表示する表示部を備えた
ことを特徴とする請求項1ないし請求項6のいずれかに記載の音声入力ロボット。 - 前記動作部は、
前記音源位置推定部の推定結果に基づき、
各前記音源位置から前記音声入力部までの距離が等しくなるように、
前記音声入力部の位置を可変する
ことを特徴とする請求項1ないし請求項9のいずれかに記載の音声入力ロボット。 - 前記動作部は、
前記音源位置推定部の推定結果に基づき、
前記音声入力部が受け取る各前記音声の集音音量が等しくなるように、
前記音声入力部の位置を可変する
ことを特徴とする請求項1ないし請求項9のいずれかに記載の音声入力ロボット。 - 前記動作部は、
前記音源位置推定部の推定結果に基づき、
前記音源位置のうち特定のものから生じる音声の集音音量が所定条件を満たすように、
前記音声入力部の位置を可変する
ことを特徴とする請求項1ないし請求項9のいずれかに記載の音声入力ロボット。 - 請求項1ないし請求項12のいずれかに記載の音声入力ロボットと、
音声を出力する音声出力部を備えた端末と、
を有し、
前記音声入力ロボットと前記端末はネットワークを介して接続され、
前記音声入力ロボットは、
前記ネットワークを介して前記音声入力部が受け付けた音声を前記端末に送信し、
前記端末は、
その音声を受信して前記音声出力部よりその音声を音声出力する
ことを特徴とする遠隔会議支援システム。 - 遠隔会議を支援する方法であって、
音声の入力を受け付ける音声入力部と、
前記音声入力部が受け付けた音声の音源位置を推定する音源位置推定部と、
前記音声入力部の位置を可変する動作部と、
を備えた音声入力ロボットを会議空間に配置しておき、
前記音声入力部が受け付けた複数の音声の音源位置を推定するステップと、
前記音源位置推定部の推定結果に基づき、前記音声入力部と前記複数の音声の音源位置との間の位置関係を変更するステップと、
を有することを特徴とする遠隔会議支援方法。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2008165286A JP5206151B2 (ja) | 2008-06-25 | 2008-06-25 | 音声入力ロボット、遠隔会議支援システム、遠隔会議支援方法 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2008165286A JP5206151B2 (ja) | 2008-06-25 | 2008-06-25 | 音声入力ロボット、遠隔会議支援システム、遠隔会議支援方法 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2010010857A true JP2010010857A (ja) | 2010-01-14 |
| JP5206151B2 JP5206151B2 (ja) | 2013-06-12 |
Family
ID=41590863
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2008165286A Expired - Fee Related JP5206151B2 (ja) | 2008-06-25 | 2008-06-25 | 音声入力ロボット、遠隔会議支援システム、遠隔会議支援方法 |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP5206151B2 (ja) |
Cited By (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2015502716A (ja) * | 2011-12-02 | 2015-01-22 | フラウンホーファー−ゲゼルシャフト・ツール・フェルデルング・デル・アンゲヴァンテン・フォルシュング・アインゲトラーゲネル・フェライン | 空間パワー密度に基づくマイクロフォン位置決め装置および方法 |
| WO2015046034A1 (ja) * | 2013-09-30 | 2015-04-02 | 株式会社Jvcケンウッド | 声量報知装置、データ送信機、データ受信機及び声量報知システム |
| JP2015521450A (ja) * | 2012-05-31 | 2015-07-27 | ヒロシ・カンパニー・リミテッド | モバイル機器を用いた駆動システムおよびその制御方法 |
| JP2018511962A (ja) * | 2015-08-31 | 2018-04-26 | 深▲せん▼前海達闥科技有限公司Cloudminds (Shenzhen) Technologies Co., Ltd. | 声を受信する処理方法、装置、記憶媒体、携帯端末及びロボット |
| JP2018121322A (ja) * | 2017-01-20 | 2018-08-02 | パナソニックIpマネジメント株式会社 | 通信制御方法、通信制御装置、テレプレゼンスロボット、及び通信制御プログラム |
| JP2019095523A (ja) * | 2017-11-20 | 2019-06-20 | 富士ソフト株式会社 | ロボットおよびロボット制御方法 |
| WO2023017745A1 (ja) * | 2021-08-10 | 2023-02-16 | 本田技研工業株式会社 | コミュニケーションロボット、コミュニケーションロボット制御方法、およびプログラム |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH05153582A (ja) * | 1991-11-26 | 1993-06-18 | Fujitsu Ltd | Tv会議人物カメラ旋回システム |
| JPH06351015A (ja) * | 1993-06-10 | 1994-12-22 | Olympus Optical Co Ltd | テレビジョン会議システム用の撮像システム |
| JPH1141577A (ja) * | 1997-07-18 | 1999-02-12 | Fujitsu Ltd | 話者位置検出装置 |
| JP2000224685A (ja) * | 1999-02-03 | 2000-08-11 | Aiwa Co Ltd | マイクロホン装置 |
| JP2005529421A (ja) * | 2002-06-05 | 2005-09-29 | コーニンクレッカ フィリップス エレクトロニクス エヌ ヴィ | 可動ユニット及び可動ユニットを制御する方法 |
| JP2007329702A (ja) * | 2006-06-08 | 2007-12-20 | Toyota Motor Corp | 受音装置と音声認識装置とそれらを搭載している可動体 |
-
2008
- 2008-06-25 JP JP2008165286A patent/JP5206151B2/ja not_active Expired - Fee Related
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH05153582A (ja) * | 1991-11-26 | 1993-06-18 | Fujitsu Ltd | Tv会議人物カメラ旋回システム |
| JPH06351015A (ja) * | 1993-06-10 | 1994-12-22 | Olympus Optical Co Ltd | テレビジョン会議システム用の撮像システム |
| JPH1141577A (ja) * | 1997-07-18 | 1999-02-12 | Fujitsu Ltd | 話者位置検出装置 |
| JP2000224685A (ja) * | 1999-02-03 | 2000-08-11 | Aiwa Co Ltd | マイクロホン装置 |
| JP2005529421A (ja) * | 2002-06-05 | 2005-09-29 | コーニンクレッカ フィリップス エレクトロニクス エヌ ヴィ | 可動ユニット及び可動ユニットを制御する方法 |
| JP2007329702A (ja) * | 2006-06-08 | 2007-12-20 | Toyota Motor Corp | 受音装置と音声認識装置とそれらを搭載している可動体 |
Cited By (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2015502716A (ja) * | 2011-12-02 | 2015-01-22 | フラウンホーファー−ゲゼルシャフト・ツール・フェルデルング・デル・アンゲヴァンテン・フォルシュング・アインゲトラーゲネル・フェライン | 空間パワー密度に基づくマイクロフォン位置決め装置および方法 |
| US10284947B2 (en) | 2011-12-02 | 2019-05-07 | Fraunhofer-Gesellschaft Zur Foerderung Der Angewandten Forschung E.V. | Apparatus and method for microphone positioning based on a spatial power density |
| JP2015521450A (ja) * | 2012-05-31 | 2015-07-27 | ヒロシ・カンパニー・リミテッド | モバイル機器を用いた駆動システムおよびその制御方法 |
| WO2015046034A1 (ja) * | 2013-09-30 | 2015-04-02 | 株式会社Jvcケンウッド | 声量報知装置、データ送信機、データ受信機及び声量報知システム |
| JP2018511962A (ja) * | 2015-08-31 | 2018-04-26 | 深▲せん▼前海達闥科技有限公司Cloudminds (Shenzhen) Technologies Co., Ltd. | 声を受信する処理方法、装置、記憶媒体、携帯端末及びロボット |
| JP2018121322A (ja) * | 2017-01-20 | 2018-08-02 | パナソニックIpマネジメント株式会社 | 通信制御方法、通信制御装置、テレプレゼンスロボット、及び通信制御プログラム |
| JP2019095523A (ja) * | 2017-11-20 | 2019-06-20 | 富士ソフト株式会社 | ロボットおよびロボット制御方法 |
| WO2023017745A1 (ja) * | 2021-08-10 | 2023-02-16 | 本田技研工業株式会社 | コミュニケーションロボット、コミュニケーションロボット制御方法、およびプログラム |
| JP7657304B2 (ja) | 2021-08-10 | 2025-04-04 | 本田技研工業株式会社 | コミュニケーションロボット、コミュニケーションロボット制御方法、およびプログラム |
Also Published As
| Publication number | Publication date |
|---|---|
| JP5206151B2 (ja) | 2013-06-12 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US12278932B2 (en) | Methods and apparatus to assist listeners in distinguishing between electronically generated binaural sound and physical environment sound | |
| JP7275227B2 (ja) | 複合現実デバイスにおける仮想および実オブジェクトの記録 | |
| KR102115222B1 (ko) | 사운드를 제어하는 전자 장치 및 그 동작 방법 | |
| JP5206151B2 (ja) | 音声入力ロボット、遠隔会議支援システム、遠隔会議支援方法 | |
| JP6520878B2 (ja) | 音声取得システムおよび音声取得方法 | |
| US20150189457A1 (en) | Interactive positioning of perceived audio sources in a transformed reproduced sound field including modified reproductions of multiple sound fields | |
| JP2017509181A (ja) | ジェスチャ相互作用式の装着可能な空間オーディオシステム | |
| CN114208209A (zh) | 适应性空间音频回放 | |
| CN104800950A (zh) | 自闭症儿童辅助机器人及系统 | |
| CN109429132A (zh) | 耳机系统 | |
| TWI222622B (en) | Robotic vision-audition system | |
| CN204637246U (zh) | 自闭症儿童辅助机器人及系统 | |
| JP7400364B2 (ja) | 音声認識システム及び情報処理方法 | |
| CN115988381A (zh) | 定向发声方法及装置、设备 | |
| WO2016078415A1 (zh) | 一种终端拾音控制方法、终端及终端拾音控制系统 | |
| JP2018075657A (ja) | 生成プログラム、生成装置、制御プログラム、制御方法、ロボット装置及び通話システム | |
| Panek et al. | Challenges in adopting speech control for assistive robots | |
| US20240281203A1 (en) | Information processing device, information processing method, and storage medium | |
| AU2021100005A4 (en) | An automated microphone system | |
| KR102168812B1 (ko) | 사운드를 제어하는 전자 장치 및 그 동작 방법 | |
| EP3772735B1 (en) | Assistance system and method for providing information to a user using speech output | |
| Bellotto | A multimodal smartphone interface for active perception by visually impaired | |
| CN116057928A (zh) | 信息处理装置、信息处理终端、信息处理方法和程序 | |
| CN118339857A (zh) | 基于空间变换的音频滤波效果 | |
| JP2024056580A (ja) | 情報処理装置及びその制御方法及びプログラム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20110215 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20120515 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20120618 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20130122 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20130204 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20160301 Year of fee payment: 3 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 5206151 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| LAPS | Cancellation because of no payment of annual fees |