JP2010003156A - 粒子挙動解析装置 - Google Patents
粒子挙動解析装置 Download PDFInfo
- Publication number
- JP2010003156A JP2010003156A JP2008162158A JP2008162158A JP2010003156A JP 2010003156 A JP2010003156 A JP 2010003156A JP 2008162158 A JP2008162158 A JP 2008162158A JP 2008162158 A JP2008162158 A JP 2008162158A JP 2010003156 A JP2010003156 A JP 2010003156A
- Authority
- JP
- Japan
- Prior art keywords
- calculation
- particle
- assigned
- particles
- interaction force
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
- 239000002245 particle Substances 0.000 title claims abstract description 218
- 238000004458 analytical method Methods 0.000 title claims abstract description 31
- 238000004364 calculation method Methods 0.000 claims abstract description 232
- 230000003993 interaction Effects 0.000 claims abstract description 116
- 239000011159 matrix material Substances 0.000 claims description 54
- 238000000034 method Methods 0.000 abstract description 18
- 230000006399 behavior Effects 0.000 description 36
- 238000004891 communication Methods 0.000 description 26
- 230000009977 dual effect Effects 0.000 description 17
- 238000010586 diagram Methods 0.000 description 7
- 230000007246 mechanism Effects 0.000 description 5
- 230000006870 function Effects 0.000 description 4
- 230000008569 process Effects 0.000 description 3
- 239000006185 dispersion Substances 0.000 description 1
- 230000009881 electrostatic interaction Effects 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 230000005415 magnetization Effects 0.000 description 1
- 239000000463 material Substances 0.000 description 1
- 239000000203 mixture Substances 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 230000002093 peripheral effect Effects 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
Images





Landscapes
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
Abstract
【解決手段】各々が複数のプロセッサコア(ノード)を持ち、並列分散処理アルゴリズムを用いてプロセッサコアごとに計算対象が割り当てられた複数の計算機を備える。この計算機は、プロセッサコアごとに、粒子間に働く相互作用力を計算する第1計算部と、計算された相互作用力に基づいて個々の粒子の挙動を計算する第2計算部とを備える。個々のプロセッサコアは、並列分散処理アルゴリズムにより、第2計算部の計算対象として、挙動を計算する対象である粒子が割り当てられる。また、第1計算部の計算対象として、相互作用力を計算する対象である粒子の組み合わせであって、同じ計算機上のプロセッサコアの第2計算部に割り当てられている粒子の組み合わせが割り当てられる。
【選択図】図6
Description
請求項2に記載の発明は、前記並列分散処理アルゴリズムは、行および列の一方に相互作用力を受ける粒子を割り当て、他方に当該相互作用力を作用させる粒子を割り当て、各粒子の行と列の交点を含む領域に当該相互作用力を計算する前記プロセッサコアを割り当てた力マトリクスに基づくことを特徴とする請求項1に記載の粒子挙動解析装置である。
請求項3に記載の発明は、前記計算機は、自身の個々の前記プロセッサコアにおける前記第1計算部による相互作用力の計算結果を、前記第2計算部に対する割り当てにしたがって、各粒子が割り当てられたプロセッサコアに収集し、各当該プロセッサコアにおいて、収集した計算結果の総和値を用いて運動方程式を解き、粒子の挙動を計算することを特徴とする請求項1に記載の粒子挙動解析装置である。
請求項4に記載の発明は、粒子間に働く相互作用力および個々の粒子の挙動を、並列分散処理アルゴリズムによる割り当てにしたがって、並列分散処理により計算する複数の計算ノードを備え、前記計算ノードは、複数のプロセッサコアを持つ計算機における個々の当該プロセッサコアであり、粒子間に働く相互作用力を計算する第1計算部と、前記第1計算部により計算された前記相互作用力に基づいて個々の粒子の挙動を計算する第2計算部とを備え、個々の前記計算ノードは、前記並列分散処理アルゴリズムにより、前記第2計算部の計算対象として、挙動を計算する対象である粒子が割り当てられ、前記並列分散処理アルゴリズムにより、前記第1計算部の計算対象として、相互作用力を計算する対象である粒子の組み合わせであって、同じ前記計算機上の前記プロセッサコアである前記計算ノードの前記第2計算部に割り当てられている粒子の組み合わせが割り当てられることを特徴とする粒子挙動解析装置である。
請求項5に記載の発明は、前記並列分散処理アルゴリズムは、行および列の一方に前記相互作用力を受ける粒子を割り当て、他方に当該相互作用力を作用させる粒子を割り当て、各粒子の行と列の交点を含む領域に当該相互作用力を計算する前記プロセッサコアを割り当てた力マトリクスに基づくことを特徴とする請求項4に記載の粒子挙動解析装置である。
請求項6に記載の発明は、前記計算ノードである前記プロセッサコアが設けられる前記計算機は、自身のプロセッサコアである個々の当該計算ノードにおける前記第1計算部による相互作用力の計算結果を、前記第2計算部に対する割り当てにしたがって、各粒子が割り当てられた当該計算ノードに収集し、各当該計算ノードにおいて、収集した計算結果の総和値を用いて運動方程式を解き、粒子の挙動を計算することを特徴とする請求項4に記載の粒子挙動解析装置である。
請求項7に記載の発明は、各々が複数のプロセッサコアを持ち、相互に接続され、並列分散処理アルゴリズムを用いて当該プロセッサコアごとに計算対象が割り当てられた複数の計算機を備え、前記計算機は、前記プロセッサコアごとに、粒子間に働く相互作用力を計算する第1計算部と、前記第1計算部により計算された前記相互作用力に基づいて個々の粒子の挙動を計算する第2計算部とを備え、個々の前記プロセッサコアは、前記並列分散処理アルゴリズムにより、前記第2計算部の計算対象として、挙動を計算する対象である粒子が割り当てられ、前記並列分散処理アルゴリズムにより、前記第1計算部の計算対象として、行および列の一方に前記相互作用力を受ける粒子を割り当て、他方に当該相互作用力を作用させる粒子を割り当て、各粒子の行と列の交点を含む領域に当該相互作用力を計算する前記プロセッサコアを割り当てた力マトリクスに基づいて、当該力マトリクスにおける当該相互作用力を受ける粒子を登録した行または列に沿って、同じ前記計算機上の前記プロセッサコアが並ぶように、当該相互作用力を計算する対象である粒子の組み合わせが割り当てられることを特徴とする粒子挙動解析装置である。
請求項8に記載の発明は、各前記プロセッサコアは、相互作用力の計算結果を、前記力マトリクスにおける相互作用力を受ける粒子を割り当てた行または列に沿って収集し、各当該プロセッサコアにおいて、収集した計算結果の総和値を用いて運動方程式を解き、粒子の挙動を計算することを特徴とする請求項7に記載の粒子挙動解析装置である。
請求項2の発明によれば、力マトリクスを用いることにより、同じ計算機上のプロセッサコア間で相互作用力の計算結果がやり取りされるように、計算機への割り当てを行うことができる。
請求項3の発明によれば、各計算機が自身のプロセッサコア間で相互作用力の計算結果をやり取りすることにより、プロセッサ間通信を削減することができる。
請求項4の発明によれば、同じ計算機上のプロセッサコアである計算ノード間で相互作用力の計算結果をやり取りすることにより、プロセッサ間通信を削減することができる。
請求項5の発明によれば、力マトリクスを用いることにより、同じ計算機上の計算ノード間で相互作用力の計算結果がやり取りされるように、計算機への割り当てを行うことができる。
請求項6の発明によれば、各計算機が自身に搭載された計算ノード間で相互作用力の計算結果をやり取りすることにより、プロセッサ間通信を削減することができる。
請求項7の発明によれば、力マトリクスを用いて同じ計算機上のプロセッサコアである計算ノード間で相互作用力の計算結果をやり取りするように各計算ノードへの割り当てを行うことにより、プロセッサ間通信を削減することができる。
請求項8の発明によれば、各計算機が自身に搭載された計算ノード間で相互作用力の計算結果をやり取りすることにより、プロセッサ間通信を削減することができる。
<システム構成>
図1は、本実施形態が適用される並列計算システムの全体構成を示す図である。
図1に示す本実施形態のシステムは、複数台の計算ノード110を備えて構成される。各計算ノード110は、ネットワーク接続されており、いわゆるクラスタコンピューティングを実現する。また各ノードは、パーソナルコンピュータ等のコンピュータ(計算機)で実現される。また、特に図示しないが、複数の計算ノード110を統括的に制御し、解析を開始させたり、最終的な解析結果を取得して保存し、または出力したりする制御装置が、必要に応じて設けられる。
図2に示すコンピュータ10は、演算手段であるCPU(Central Processing Unit)10aと、記憶手段である主記憶装置(メインメモリ)10bおよび外部記憶装置10cを備える。CPU10aとしては、クアッド・コア(quad-core)やデュアル・コア(dual core)等のように複数のプロセッサコアを集積したマルチコア・プロセッサ(multi-core processor)が用いられる。外部記憶装置10cとしては、一般に磁気ディスク装置(HDD:Hard Disk Drive)が用いられるが、より高速にデータの読み書きを行うことができるSSD(Solid State Drive)を用いても良い。また、図2のコンピュータ10は、ネットワークを介して外部装置に接続するためのネットワークI/F(インターフェイス)10dと、ディスプレイ装置へ表示出力を行うための表示機構10eと、音声出力を行うための音声機構10fとを備える。さらに、キーボードやマウス等の入力デバイス10gを備える。CPU10aと他の構成要素との間には、図示しないチップセットやブリッジ回路が介在している。
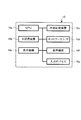
図3は、計算ノード110の機能構成を示す図である。
計算ノード110は、自ノードに割り当てられた解析対象に対する個々の処理を実行する装置である。図3に示すように、各計算ノード110は、それぞれ、並列分散処理アルゴリズムによる制御を行うための並列分散処理制御部120と、解析対象のデータや解析結果を保持する保持部121と、解析処理のための計算を行う第1計算部122および第2計算部123と、他の計算ノード110との間でデータの送受信を行うための通信部124とを備える。並列分散処理制御部120、第1計算部122および第2計算部123は、主記憶装置10bに読み込まれたプログラムをCPU10aが実行することで実現される機能である。保持部121は、例えば図2に示したコンピュータ10において、主記憶装置10bや外部記憶装置10cにより実現される。通信部124は、主記憶装置10bに読み込まれたプログラムをCPU10aが実行しネットワークI/F10dを制御することで実現される。このように、図3に示す計算ノード110の各機能ブロックは、ソフトウェアとハードウェア資源とが協働して実現される手段である。
力分割法では、粒子間に働く相互作用力の計算が分散処理により実行される。本実施形態では、この粒子間に働く相互作用力の計算とは別に、各粒子の挙動の計算についても分散処理により実行される。すなわち、本実施形態では、粒子間に働く相互作用力の計算と各粒子の挙動の計算とが個別のアルゴリズムにより分散処理される。したがって、力分割法による並列分散処理では、各計算ノード110に対し、挙動計算の対象である粒子が割り当てられ、かつ相互作用力の計算の対象である粒子の組み合わせが割り当てられる。
図4に示す力マトリクスは、32個の粒子(粒子番号0〜31)を16の計算ノード110(ノード番号0〜15)に割り当てた例を示している。例えば、ノード番号0の計算ノード110には粒子番号0、1の2つの粒子が割り当てられている。力マトリクスでは、行および列の一方に相互作用力を受ける粒子が登録され、他方に当該相互作用力を作用させる粒子が登録され、各粒子の行と列の交点を含む領域に当該相互作用力を計算する計算ノードが登録される。
・ノード番号4に割り当てられた2個の粒子とノード番号2、6、10、14に割り当てられた8個の粒子の相互作用力、
・ノード番号5に割り当てられた2個の粒子とノード番号2、6、10、14に割り当てられた8個の粒子の相互作用力、
・ノード番号6に割り当てられた2個の粒子とノード番号2、6、10、14に割り当てられた8個の粒子の相互作用力、
・ノード番号7に割り当てられた2個の粒子とノード番号2、6、10、14に割り当てられた8個の粒子の相互作用力、
をそれぞれ計算する。このノード#6において、ノード番号4に割り当てられた粒子番号8、9の粒子とノード番号2に割り当てられた粒子番号4、5の粒子の組み合わせでは、・粒子番号8の粒子に対して働く、粒子番号4の粒子による相互作用力、
・粒子番号8の粒子に対して働く、粒子番号5の粒子による相互作用力、
・粒子番号9の粒子に対して働く、粒子番号4の粒子による相互作用力、
・粒子番号9の粒子に対して働く、粒子番号5の粒子による相互作用力、
の4種類の相互作用力が計算される。したがって、ノード番号の組み合わせごとに4種類ずつの相互作用力が計算される。ただし、ノード番号6とノード番号6の組み合わせは2個の粒子が同一なので、粒子番号12の粒子に対して働く粒子番号13の粒子による相互作用力と、粒子番号13の粒子に対して働く粒子番号12の粒子による相互作用力の2つの相互作用力のみが求められる。すなわち、個々の計算ノード110は、62(=8×8−2)組の粒子の組み合わせについて相互作用力の計算を行うこととなる。
なお、ノード番号6とノード番号6の組み合わせにおける2つの粒子間に働く相互作用力の大きさは同じ(反対方向)であるから、力の大きさの計算は1回だけ行うようにしても良い。
今日、1つのCPUパッケージ内に複数のプロセッサコアを備えたマルチコア・プロセッサが存在する。マルチコア・プロセッサの各プロセッサコアは独立して動作するため、各々のプロセッサコアを、別個の計算ノード110として用いて良い。このマルチコア・プロセッサでは、多くの場合、複数のプロセッサコアが2次キャッシュ等のキャッシュメモリやメインメモリを共有する構成が採られる。この場合、1つのマルチコア・プロセッサ上のプロセッサコア間でデータ交換する場合、共有するメモリへの読み書きを介してデータの受け渡しが行われ、プロセッサ間通信を行う必要がない。この特徴を利用して、マルチコア・プロセッサにおけるプロセッサコアを力マトリクスのマス目に適切に配置すれば、分散処理における通信コストがさらに低減する。
図6に示す例では、力マトリクスの行方向に並ぶ4つの計算ノード110に、1つのクアッド・コアCPU上のプロセッサコアが割り当てられている。具体的には、クアッド・コアCPU#0のプロセッサコアがノード#0〜#3に割り当てられ、クアッド・コアCPU#1のプロセッサコアがノード#4〜#7に割り当てられ、クアッド・コアCPU#2のプロセッサコアがノード#8〜#11に割り当てられ、クアッド・コアCPU#3のプロセッサコアがノード#12〜#15に割り当てられている。
デュアル・コアは、1つのマルチコア・プロセッサ(以下、デュアル・コアCPU)上に2個のプロセッサコアを備える。そこで、この2個のプロセッサコアを、それぞれ1つの計算ノード110に割り当てる。これにより、1つのクアッド・コアCPUを持つコンピュータ(例えば図2のコンピュータ10)が2つの計算ノード110に対応する。図4に示した力マトリクスでは、16個の計算ノード110が用いられているので、8つのクアッド・コアCPUで16個の計算ノード110全てに対応する。
図7に示す例では、力マトリクスの行方向に並ぶ2つの計算ノード110に、1つのデュアル・コアCPU上のプロセッサコアが割り当てられている。具体的には、デュアル・コアCPU#0のプロセッサコアがノード#0、#1に割り当てられ、デュアル・コアCPU#1のプロセッサコアがノード#2、#3に割り当てられ、デュアル・コアCPU#2のプロセッサコアがノード#4、#5に割り当てられ、デュアル・コアCPU#3のプロセッサコアがノード#6、#7に割り当てられ、デュアル・コアCPU#4のプロセッサコアがノード#8、#9に割り当てられ、デュアル・コアCPU#5のプロセッサコアがノード#10、#11に割り当てられ、デュアル・コアCPU#6のプロセッサコアがノード#12、#13に割り当てられ、デュアル・コアCPU#7のプロセッサコアがノード#14、#15に割り当てられている。
Claims (8)
- 各々が複数のプロセッサコアを持ち、相互に接続され、並列分散処理アルゴリズムを用いて当該プロセッサコアごとに計算対象が割り当てられた複数の計算機を備え、
前記計算機は、前記プロセッサコアごとに、
粒子間に働く相互作用力を計算する第1計算部と、
前記第1計算部により計算された前記相互作用力に基づいて個々の粒子の挙動を計算する第2計算部とを備え、
個々の前記プロセッサコアは、
前記並列分散処理アルゴリズムにより、前記第2計算部の計算対象として、挙動を計算する対象である粒子が割り当てられ、
前記並列分散処理アルゴリズムにより、前記第1計算部の計算対象として、相互作用力を計算する対象である粒子の組み合わせであって、同じ前記計算機上の前記プロセッサコアの前記第2計算部に割り当てられている粒子の組み合わせが割り当てられる
ことを特徴とする粒子挙動解析装置。 - 前記並列分散処理アルゴリズムは、行および列の一方に相互作用力を受ける粒子を割り当て、他方に当該相互作用力を作用させる粒子を割り当て、各粒子の行と列の交点を含む領域に当該相互作用力を計算する前記プロセッサコアを割り当てた力マトリクスに基づくことを特徴とする請求項1に記載の粒子挙動解析装置。
- 前記計算機は、自身の個々の前記プロセッサコアにおける前記第1計算部による相互作用力の計算結果を、前記第2計算部に対する割り当てにしたがって、各粒子が割り当てられたプロセッサコアに収集し、各当該プロセッサコアにおいて、収集した計算結果の総和値を用いて運動方程式を解き、粒子の挙動を計算することを特徴とする請求項1に記載の粒子挙動解析装置。
- 粒子間に働く相互作用力および個々の粒子の挙動を、並列分散処理アルゴリズムによる割り当てにしたがって、並列分散処理により計算する複数の計算ノードを備え、
前記計算ノードは、
複数のプロセッサコアを持つ計算機における個々の当該プロセッサコアであり、
粒子間に働く相互作用力を計算する第1計算部と、
前記第1計算部により計算された前記相互作用力に基づいて個々の粒子の挙動を計算する第2計算部とを備え、
個々の前記計算ノードは、
前記並列分散処理アルゴリズムにより、前記第2計算部の計算対象として、挙動を計算する対象である粒子が割り当てられ、
前記並列分散処理アルゴリズムにより、前記第1計算部の計算対象として、相互作用力を計算する対象である粒子の組み合わせであって、同じ前記計算機上の前記プロセッサコアである前記計算ノードの前記第2計算部に割り当てられている粒子の組み合わせが割り当てられる
ことを特徴とする粒子挙動解析装置。 - 前記並列分散処理アルゴリズムは、行および列の一方に前記相互作用力を受ける粒子を割り当て、他方に当該相互作用力を作用させる粒子を割り当て、各粒子の行と列の交点を含む領域に当該相互作用力を計算する前記プロセッサコアを割り当てた力マトリクスに基づくことを特徴とする請求項4に記載の粒子挙動解析装置。
- 前記計算ノードである前記プロセッサコアが設けられる前記計算機は、自身のプロセッサコアである個々の当該計算ノードにおける前記第1計算部による前記相互作用力の計算結果を、前記第2計算部に対する割り当てにしたがって、各粒子が割り当てられた計算ノードに収集し、各当該計算ノードにおいて、収集した計算結果の総和値を用いて運動方程式を解き、粒子の挙動を計算することを特徴とする請求項4に記載の粒子挙動解析装置。
- 各々が複数のプロセッサコアを持ち、相互に接続され、並列分散処理アルゴリズムを用いて当該プロセッサコアごとに計算対象が割り当てられた複数の計算機を備え、
前記計算機は、前記プロセッサコアごとに、
粒子間に働く相互作用力を計算する第1計算部と、
前記第1計算部により計算された前記相互作用力に基づいて個々の粒子の挙動を計算する第2計算部とを備え、
個々の前記プロセッサコアは、
前記並列分散処理アルゴリズムにより、前記第2計算部の計算対象として、挙動を計算する対象である粒子が割り当てられ、
前記並列分散処理アルゴリズムにより、前記第1計算部の計算対象として、行および列の一方に前記相互作用力を受ける粒子を割り当て、他方に当該相互作用力を作用させる粒子を割り当て、各粒子の行と列の交点を含む領域に当該相互作用力を計算する前記プロセッサコアを割り当てた力マトリクスに基づいて、当該力マトリクスにおける当該相互作用力を受ける粒子を登録した行または列に沿って、同じ前記計算機上の前記プロセッサコアが並ぶように、当該相互作用力を計算する対象である粒子の組み合わせが割り当てられる
ことを特徴とする粒子挙動解析装置。 - 各前記プロセッサコアは、前記相互作用力の計算結果を、前記力マトリクスにおける当該相互作用力を受ける粒子を割り当てた行または列に沿って収集し、各当該プロセッサコアにおいて、収集した計算結果の総和値を用いて運動方程式を解き、粒子の挙動を計算することを特徴とする請求項7に記載の粒子挙動解析装置。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2008162158A JP5439753B2 (ja) | 2008-06-20 | 2008-06-20 | 粒子挙動解析装置 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2008162158A JP5439753B2 (ja) | 2008-06-20 | 2008-06-20 | 粒子挙動解析装置 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2010003156A true JP2010003156A (ja) | 2010-01-07 |
| JP5439753B2 JP5439753B2 (ja) | 2014-03-12 |
Family
ID=41584812
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2008162158A Expired - Fee Related JP5439753B2 (ja) | 2008-06-20 | 2008-06-20 | 粒子挙動解析装置 |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP5439753B2 (ja) |
Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2000285081A (ja) * | 1999-03-31 | 2000-10-13 | Fuji Xerox Co Ltd | ノード間データ通信方法 |
| JP2007193152A (ja) * | 2006-01-20 | 2007-08-02 | Fuji Xerox Co Ltd | 粒子挙動解析方法および粒子挙動解析装置並びにプログラム |
| JP2007265143A (ja) * | 2006-03-29 | 2007-10-11 | Sony Computer Entertainment Inc | 情報処理方法、情報処理システム、情報処理装置、マルチプロセッサ、情報処理プログラム及び情報処理プログラムを記憶したコンピュータ読み取り可能な記憶媒体 |
| JP2007265097A (ja) * | 2006-03-29 | 2007-10-11 | Fuji Xerox Co Ltd | 粒子挙動解析方法および粒子挙動解析装置並びにプログラム |
| JP2007280242A (ja) * | 2006-04-11 | 2007-10-25 | Fuji Xerox Co Ltd | 粒子挙動解析方法および粒子挙動解析装置並びにプログラム |
| JP2007304904A (ja) * | 2006-05-12 | 2007-11-22 | Fuji Xerox Co Ltd | 粒子挙動解析方法および粒子挙動解析装置並びにプログラム |
| JP2008084009A (ja) * | 2006-09-27 | 2008-04-10 | Toshiba Corp | マルチプロセッサシステム |
-
2008
- 2008-06-20 JP JP2008162158A patent/JP5439753B2/ja not_active Expired - Fee Related
Patent Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2000285081A (ja) * | 1999-03-31 | 2000-10-13 | Fuji Xerox Co Ltd | ノード間データ通信方法 |
| JP2007193152A (ja) * | 2006-01-20 | 2007-08-02 | Fuji Xerox Co Ltd | 粒子挙動解析方法および粒子挙動解析装置並びにプログラム |
| JP2007265143A (ja) * | 2006-03-29 | 2007-10-11 | Sony Computer Entertainment Inc | 情報処理方法、情報処理システム、情報処理装置、マルチプロセッサ、情報処理プログラム及び情報処理プログラムを記憶したコンピュータ読み取り可能な記憶媒体 |
| JP2007265097A (ja) * | 2006-03-29 | 2007-10-11 | Fuji Xerox Co Ltd | 粒子挙動解析方法および粒子挙動解析装置並びにプログラム |
| JP2007280242A (ja) * | 2006-04-11 | 2007-10-25 | Fuji Xerox Co Ltd | 粒子挙動解析方法および粒子挙動解析装置並びにプログラム |
| JP2007304904A (ja) * | 2006-05-12 | 2007-11-22 | Fuji Xerox Co Ltd | 粒子挙動解析方法および粒子挙動解析装置並びにプログラム |
| JP2008084009A (ja) * | 2006-09-27 | 2008-04-10 | Toshiba Corp | マルチプロセッサシステム |
Non-Patent Citations (2)
| Title |
|---|
| CSNJ200810065010; 新井 佑介 外4名: 'Cell B.E.クラスタを用いた格子ガスオートマトンの実装' 第70回(平成20年)全国大会講演論文集(1) アーキテクチャ ソフトウェア科学・工学 データベース , 20080313, pp.1-19〜1-20 * |
| JPN6013017606; 新井 佑介 外4名: 'Cell B.E.クラスタを用いた格子ガスオートマトンの実装' 第70回(平成20年)全国大会講演論文集(1) アーキテクチャ ソフトウェア科学・工学 データベース , 20080313, pp.1-19〜1-20 * |
Also Published As
| Publication number | Publication date |
|---|---|
| JP5439753B2 (ja) | 2014-03-12 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| EP3698294B1 (en) | Machine learning runtime library for neural network acceleration | |
| CN102402462B (zh) | 用于对启用gpu的虚拟机进行负载平衡的技术 | |
| US20200372337A1 (en) | Parallelization strategies for training a neural network | |
| US9606808B2 (en) | Method and system for resolving thread divergences | |
| EP2657842B1 (en) | Workload optimization in a multi-processor system executing sparse-matrix vector multiplication | |
| CN116774968A (zh) | 具有一组线程束的高效矩阵乘法和加法 | |
| US9626216B2 (en) | Graphics processing unit sharing between many applications | |
| US20140331014A1 (en) | Scalable Matrix Multiplication in a Shared Memory System | |
| Torabzadehkashi et al. | Accelerating HPC applications using computational storage devices | |
| US9710381B2 (en) | Method and apparatus for cache memory data processing | |
| US9678792B2 (en) | Shared resources in a docked mobile environment | |
| CN103218259A (zh) | 计算任务的调度和执行 | |
| CN105957131A (zh) | 图形处理系统及其方法 | |
| JP2009087282A (ja) | 並列計算システムおよび並列計算方法 | |
| US20250348970A1 (en) | Dynamic dispatch for workgroup distribution | |
| US11119787B1 (en) | Non-intrusive hardware profiling | |
| Gschwind et al. | Optimizing the efficiency of deep learning through accelerator virtualization | |
| Kim et al. | Empowering storage systems research with nvmevirt: A comprehensive nvme device emulator | |
| JP5439753B2 (ja) | 粒子挙動解析装置 | |
| CN115362476A (zh) | 多租户图形处理单元中的完全利用硬件 | |
| Si et al. | Design of direct communication facility for many-core based accelerators | |
| Khetawat et al. | Predicting GPUDirect benefits for hpc workloads | |
| CN111274161A (zh) | 用于加速串行化算法的具有可变等待时间的位置感知型存储器 | |
| JP2009294762A (ja) | 解析システム | |
| JP2010003169A (ja) | 解析システムおよびプログラム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20110520 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20130416 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20130617 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20131119 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20131202 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 5439753 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| S533 | Written request for registration of change of name |
Free format text: JAPANESE INTERMEDIATE CODE: R313533 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |
|
| LAPS | Cancellation because of no payment of annual fees |