JP2009199246A - ノード稼働監視システムおよびノード稼働監視方法 - Google Patents
ノード稼働監視システムおよびノード稼働監視方法 Download PDFInfo
- Publication number
- JP2009199246A JP2009199246A JP2008039006A JP2008039006A JP2009199246A JP 2009199246 A JP2009199246 A JP 2009199246A JP 2008039006 A JP2008039006 A JP 2008039006A JP 2008039006 A JP2008039006 A JP 2008039006A JP 2009199246 A JP2009199246 A JP 2009199246A
- Authority
- JP
- Japan
- Prior art keywords
- node
- information
- operation monitoring
- unit
- determined
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images



















Abstract
【課題】ネットワーク上のノード間で稼働監視情報を共有する。
【解決手段】ネットワーク2に接続された複数のノード1の各々が、タスク情報、リソース情報、およびハードウェア情報を含む自ノード情報を収集する自ノード情報収集部12と、収集された自ノード情報を解析してノード1の稼働状態を判定し、この判定結果と自ノード情報を含む稼働監視情報を出力する自ノード情報判定部13と、稼働状態が異常と判定された場合に、出力された稼働監視情報をネットワーク上の他のノードへ送信する送信部15と、他のノード1から送信された他の稼働監視情報を受信する受信部16と、受信された他の稼働監視情報に基づいて他のノードの稼働状態を判定する他ノード情報判定部17と、を有することで稼働監視情報をネットワーク2上のノード間で共有する。
【選択図】図1
【解決手段】ネットワーク2に接続された複数のノード1の各々が、タスク情報、リソース情報、およびハードウェア情報を含む自ノード情報を収集する自ノード情報収集部12と、収集された自ノード情報を解析してノード1の稼働状態を判定し、この判定結果と自ノード情報を含む稼働監視情報を出力する自ノード情報判定部13と、稼働状態が異常と判定された場合に、出力された稼働監視情報をネットワーク上の他のノードへ送信する送信部15と、他のノード1から送信された他の稼働監視情報を受信する受信部16と、受信された他の稼働監視情報に基づいて他のノードの稼働状態を判定する他ノード情報判定部17と、を有することで稼働監視情報をネットワーク2上のノード間で共有する。
【選択図】図1
Description
本発明は、ノード稼働監視システムおよびノード稼働監視方法に関する。
この種の技術としては、サーバー(監視ノード)がクライアント端末(被監視ノード)において所定の時間間隔で収集された稼働情報をネットワークを介して取得し、この稼働情報をサーバー側で解析することによって各クライアント端末の稼働状態を把握する稼働監視システムが知られている(例えば、特許文献1参照)。
特開2006−178851号公報
しかしながら、上記の技術においては、各クライアント端末はサーバーを介さなければ他のクライアント端末の稼動監視情報を知ることが出来ない。また、監視を行うサーバー自体が異常になった場合には、クライアント端末の監視が出来ないという問題があった。
そこで、本発明は、従来技術の問題に鑑み、ネットワーク上のノード間で稼働監視情報を共有できるノード稼働監視システムおよびノード稼働監視方法を提供することを目的とする。
本発明に係るノード稼働監視システムは、ネットワークに接続された複数のノードの各々が、タスク情報、リソース情報、およびハードウェア情報を含む自ノード情報を収集する自ノード情報収集部と、この自ノード情報収集部において収集された前記自ノード情報を解析して前記ノードの稼働状態を判定し、この判定結果を含む稼働監視情報を出力する自ノード情報判定部と、この自ノード情報判定部において前記稼働状態が異常と判定された場合に、前記出力された稼働監視情報を前記ネットワーク上の他のノードへ送信する送信部と、前記他のノードに係る前記送信部から送信された他の稼働監視情報を受信する受信部と、この受信部において受信された前記他の稼働監視情報に基づいて前記他のノードの稼働状態を判定する他ノード情報判定部と、を有することを特徴とする。
本発明に係るノード稼働監視方法は、ネットワークに接続された複数のノードの各々が、全ノードの稼働監視情報を共有するノード稼働監視方法であって、前記ノードが、タスク情報、リソース情報、およびハードウェア情報を含む自ノード情報を収集する自ノード情報収集ステップと、前記ノードが、前記自ノード情報収集ステップにおいて収集された前記自ノード情報を解析して前記ノードの稼働状態を判定し、この判定結果を含む稼働監視情報を出力する自ノード情報判定ステップと、この自ノード情報判定ステップにおいて前記稼働状態が異常と判定された場合に、前記ノードが、前記出力された稼働監視情報を前記ネットワーク上の他のノードへ送信する送信ステップと、前記ノードが、前記他のノードから送信された他の稼働監視情報を受信する受信ステップと、前記ノードが、前記受信ステップにおいて受信された前記他の稼働監視情報に基づいて前記他のノードの稼働状態を判定する他ノード情報判定ステップと、を有することを特徴とする。
本発明によれば、ネットワーク上のノード間で稼働監視情報を共有できるノード稼働監視システムおよびノード稼働監視方法が提供される。
(実施形態1)
以下、本発明の実施形態について図面を用いて説明する。図1は、本発明の一実施形態に係るノード稼働監視システムの全体構成例を示す図である。同図に示されるように、ノード稼働監視システムは、複数のノード1がネットワーク2を介して接続され、データの送受信が可能に構成されている。
以下、本発明の実施形態について図面を用いて説明する。図1は、本発明の一実施形態に係るノード稼働監視システムの全体構成例を示す図である。同図に示されるように、ノード稼働監視システムは、複数のノード1がネットワーク2を介して接続され、データの送受信が可能に構成されている。
ノード1は、記憶部11、自ノード情報収集部12、自ノード情報判定部13、表示部14、送信部15、受信部16、および他ノード情報判定部17から構成されるコンピュータである。ノード1の具体例としては、パーソナルコンピュータなど各種のコンピュータが挙げられる。
記憶部11は、タスク登録情報、リソース登録情報、ハードウェア登録情報、過去の稼働監視履歴情報等の各種の情報を記憶する記憶装置である。登録情報は設定ファイルとして記録されており、後述する自ノード情報収集部12からの要求に基づいてメモリ(図示省略する)に展開される。
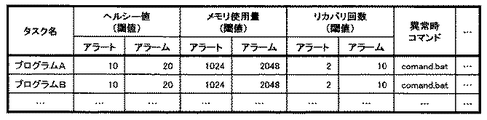
図2は、タスク登録情報の具体例を示す図である。ここでは、データ項目としてタスク名、ヘルシー値(閾値)、メモリ使用量(閾値)、リカバリ回数(閾値)、各項目の異常時コマンドが含まれている。また、閾値はアラート(警告)、アラーム(警報)の2つの異常レベルに応じて定義されている。
図3は、リソース登録情報の具体例を示す図である。ここでは、リソース登録情報が複数のプログラム同士でリソース(ファイルやメモリなど)を共有する際に排他や同期のための制御を行うセマフォとプロセス間で交わされるメッセージに大別されている。図3(a)は、セマフォに関する情報であり、データ項目にセマフォ登録キー名、セマフォ操作時間(閾値)、異常時コマンドが含まれている。図3(b)は、メッセージに関する情報であり、データ項目にメッセージ登録キー名、メッセージ数(閾値)、異常時コマンドが含まれている。また、タスク登録情報と同様に、閾値はアラート(警告)、アラーム(警報)の2つの異常レベルに応じて定義されている。
図4は、ハードウェア登録情報の具体例を示す図である。ここでは、データ項目として監視周期に加えて、温度、周辺温度、DI信号状態、本体内部温度状態、LAN状態、ファン状態、ハードディスク状態、およびバッテリー状態の異常時コマンドが含まれている。また、タスク登録情報などと同様に、閾値はアラート(警告)、アラーム(警報)の2つの異常レベルに応じて定義されている。
自ノード情報収集部12は、タスク登録情報、リソース登録情報、ハードウェア登録情報に基づいてノード1内のタスク情報、リソース情報、ハードウェア情報からなる自ノードの情報(以下、「自ノード情報」という。)を収集するプログラムである。
図5は、自ノード情報収集部12における情報収集処理を説明する図である。同図に示されるように、自ノード情報収集部12は、タスク情報収集プログラム121、リソース情報収集プログラム122、ハードウェア情報収集プログラム123を含んでいる。
タスク情報収集プログラム121は、上述したタスク登録情報に基づいて起動されたタスクの状態をタスク情報として定周期で収集するプログラムである。図6は、自ノード情報収集部12で収集されたタスク情報の具体例を示す図である。ここでは、各タスクの実行状態(実行中、停止中、実行待ちなど)を示すステータス、プロセスID(PID)、ヘルシー値、メモリ使用量、リカバリ(再起動)回数などをタスク情報として収集している。
リソース情報収集プログラム122は、リソース登録情報に基づいてシステム上のプログラムが使用するシステム上のリソースの状態をリソース情報として定周期に収集するプログラムである。図7は、自ノード情報収集部12で収集されたリソース情報の具体例を示す図である。ここでは、セマフォ(排他ロックキー)とメッセージに関する情報が収集されている。図7(a)は、セマフォに関する収集情報であり、データ項目にセマフォ登録キー名、OSキー名、操作時間(排他時間)、セマフォ操作時間(閾値)、最終使用プロセスID、異常時の最終使用プロセスIDなどが含まれている。図7(b)は、メッセージに関する収集情報であり、データ項目にメッセージ登録キー名、OSキー名、メッセージ数、メッセージ数(閾値)、最終使用プロセスID、異常時の最終使用プロセスIDなどが含まれている。
ハードウェア情報収集プログラム123は、ハードウェア登録情報に基づいてシステム上のハードウェアの状態を定周期で収集するプログラムである。図8は、自ノード情報収集部12で収集されたハードウェア情報の具体例を示す図である。ここでは、CPU使用率、メモリ使用量、監視周期、ハードウェアの温度、ハードディスク状態、ファン状態、電源状態、およびLAN状態に加えて、各項目の最終異常発生時刻などが収集されている。
自ノード情報判定部13は、自ノード情報収集部12で収集された自ノード情報から自ノードの稼働状態の正常/異常を判定し、稼働監視情報を生成するプログラムである。自ノード情報判定部13においては、タスク情報、リソース情報、およびハードウェア情報の各々について異常値の有無の判定が行われ、タスク監視情報、リソース監視情報、およびハードウェア監視情報からなる稼働監視情報を作成する。この稼働監視情報は記憶部11に格納され、定周期で更新が行われる。
図9は、稼働監視情報に含まれるタスク監視情報の具体例を示す図である。ここでは、上述したタスク情報に含まれる項目に対しての判定結果(異常フラグ)が付加されたタスク監視情報が示されている。
図10は、稼働監視情報に含まれるリソース監視情報の具体例を示す図である。図10(a)では、上述したリソース情報(セマフォ)内の項目に対する判定結果が付加されたリソース監視情報が示されている。同様に、図10(b)では上述したリソース情報(メッセージ)内の項目に対しての判定結果が付加されたリソース監視情報が示されている。
図11は、稼働監視情報に含まれるハードウェア監視情報の具体例を示す図である。ここでは、上述したハードウェア情報に含まれる項目に対しての判定結果が付加されたハードウェア監視情報が示されている。
表示部14は、自ノード情報判定部13や他ノード情報判定部17から出力される判定結果を表示する表示装置である。
送信部15は、自ノード情報収集部12で作成された稼動監視情報を他のノード1に対して送信する送信装置である。稼動監視情報の送信処理においては、自ノードにおける異常の有無やタイマーに基づいて送信すべきか否かの判定が行われる。また、タスクやリソースの情報はノード1の各々で異なる場合があるため、送信部15ではタスク名などの固定的な情報(以下、「固定情報」という。)と、タスクのメモリ使用量などの可変する情報(以下、「可変情報」という。)に分類して送信処理を行う。分類のルールは任意に変更可能である。各送信データは、予め定められた送信データのフォーマットの相違によって識別される。
更に、各ノード1における処理の負荷を軽減するために、伝送するデータをある特定のデータブロックサイズに分割して送受信を行い、各データブロックの処理が完了したら逐次CPUを開放すると好適である。
受信部16は、他のノード1から送信される稼動監視情報を受信する受信装置である。
他ノード情報判定部17は、受信部16で受信された他のノード1の稼動監視情報から他のノード1の稼動状態を判定するプログラムである。他のノード1において異常が検出されている場合には、自ノードを制御する制御部(図示省略する)へ通知する。尚、通知後の動作は、異常の検出内容などに応じて実装することができる。
以下、ノード稼働監視システムを構成する各ノード1内の動作を図面を用いて説明する。
図12は、自ノード情報収集部12における収集処理の具体例を示すフローチャートである。
S1201においては、記憶部11からタスク登録情報を取得し、このタスク登録情報に基づいてタスク情報を収集する。
S1202においては、記憶部11からリソース登録情報を取得し、リソース登録情報に基づいてセマフォおよびメッセージに関するリソース情報を収集する。
S1203においては、記憶部11からハードウェア登録情報を取得し、ハードウェア登録情報に基づいてハードウェア情報を収集する。
S1204においては、タスク情報、リソース情報、およびハードウェア情報からなる自ノード情報を自ノード情報判定部13へ出力し、処理を終了する。
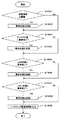
図13は、自ノード情報判定部13における判定処理の具体例を示すフローチャートである。
S1301においては、自ノード情報収集部12から出力されたタスク情報の解析によってタスクに関する異常項目の有無を判定し、この判定結果を含むタスク監視情報を作成する(タスク情報判定処理)。
S1302においては、自ノード情報収集部12から出力されたリソース情報の解析によってリソースに関する異常項目の有無を判定し、この判定結果を含むリソース監視情報を作成する(リソース情報判定処理)。
S1303においては、自ノード情報収集部12から出力されたハードウェア情報の解析によってハードウェアに関する異常項目の有無を判定し、この判定結果を含むハードウェア監視情報を作成する(ハードウェア情報判定処理)。
S1304においては、タスク監視情報、リソース監視情報、およびハードウェア監視情報からなる稼働監視情報を作成する。
S1305においては、稼働監視情報内に異常項目の情報が含まれているか否かを判定する。ここで、異常有りと判定された場合には、S1306へ進む。これに対し、異常無しと判定された場合には、処理を終了する。
S1306においては、制御部(図示省略する)に異常を出力し、処理を終了する。
図14は、図13のタスク情報判定処理の具体例を示すフローチャートである。
S1401においては、タスク判定数(変数)を初期化する。
S1402においては、タスク判定数がタスク登録数以下であるか判定を行う。ここで、タスク判定数がタスク情報に含まれるタスク登録数以下と判定された場合には、S1403へ進む。これに対し、タスク判定数がタスク登録数を超えると判定された場合には、全ての登録タスクに対する処理が終了しているのでS1411へ進む。
S1403においては、タスク情報から判定対象となるタスクの情報を取得する。
S1404においては、タスクのメモリ使用量が閾値(アラート・アラーム)以上か否かを判定する。ここで、タスクのメモリ使用量が閾値以上と判定された場合には、S1405に進む。これに対し、タスクのメモリ使用量が閾値未満と判定された場合には、S1406へ進む。
S1405においては、タスク監視情報にメモリ使用状態の異常を記録すると共に異常コマンドを発行する。
S1406においては、タスクのヘルシーカウンタが閾値(アラート・アラーム)以上か否かを判定する。本実施形態では、ヘルシーカウンタは、ヘルシー(ハートビート)値を一定間隔で記録した際に前回値より増加していないことを条件に加算される。したがって、ヘルシーカウンタが閾値以上となることは、プログラムが異常によって停止したことを示す。ここで、タスクのヘルシーカウンタが閾値以上と判定された場合には、S1407に進む。これに対し、タスクのヘルシーカウンタが閾値未満と判定された場合には、S1408へ進む。
S1407においては、タスク監視情報にヘルシー値の状態の異常を記録すると共に異常コマンドを発行する。
S1408においては、タスクの再起動回数が閾値(アラート・アラーム)以上か否かを判定する。本実施形態では、タスクに異常が生じた場合には全処理を終了するのではなく、タスクの再起動(リカバリ)が所定の回数行われる。すなわち、閾値は再起動の最大試行回数を示す。ここで、タスクの再起動回数が閾値以上と判定された場合には、S1409に進む。これに対し、タスクの再起動回数が閾値未満と判定された場合には、S14010へ進む。
S1409においては、タスク監視情報にタスクの再起動状態の異常を記録すると共に異常コマンドを発行する。
S1410においては、タスク判定数を加算し、S1402へ戻る。S1402〜S1410の処理は登録された全てのタスクの判定処理が終了されるまで繰り返される。
S1411においては、タスク監視情報を出力し、処理を終了する。
図15は、図13のリソース情報判定処理の具体例の具体例を示すフローチャートである。
S1501においては、セマフォ判定数(変数)を初期化する。
S1502においては、セマフォ判定数がリソース情報(セマフォ)に含まれるセマフォの登録数(以下、「セマフォ登録数」という。)以下であるか判定を行う。ここで、セマフォ判定数がセマフォ登録数以下と判定された場合には、S1503へ進む。これに対し、セマフォ判定数がセマフォ登録数を超えると判定された場合には、全ての登録セマフォに対する処理が終了しているのでS1507へ進む。
S1503においては、リソース情報から判定対象となるセマフォの情報を取得する。
S1504においては、セマフォ操作時間が閾値(アラート・アラーム)以上か否かを判定する。セマフォ操作時間は、タスクがリソースの排他制御を行っている時間であり、この時間が閾値以上となることは、リソースが解放されていないことを示す。ここで、セマフォ操作時間が閾値以上と判定された場合には、S1505に進む。これに対し、セマフォ操作時間が閾値未満と判定された場合には、S1506へ進む。
S1505においては、リソース監視情報にセマフォ操作時間の異常を記録すると共に異常コマンドを発行する。
S1506においては、セマフォ判定数を加算し、S1502へ戻る。S1502〜S1506の処理は登録された全てのセマフォの判定処理が終了されるまで繰り返される。
S1507においては、メッセージ判定数(変数)を初期化する。
S1508においては、メッセージ判定数がリソース情報(メッセージ)に含まれるメッセージの登録数(以下、「メッセージ登録数」という。)以下であるか判定を行う。ここで、メッセージ判定数がメッセージ登録数以下と判定された場合には、S1509へ進む。これに対し、メッセージ判定数がメッセージ登録数を超えると判定された場合には、全ての登録メッセージに対する処理が終了しているのでS1513へ進む。
S1509においては、リソース情報から判定対象となるメッセージの情報を取得する。
S1510においては、メッセージ数が閾値(アラート・アラーム)以上か否かを判定する。メッセージ数は、プロセス間で扱うメッセージ(データ)の数を示す。ここで、メッセージ数が閾値以上と判定された場合には、S1511に進む。これに対し、メッセージ数が閾値未満と判定された場合には、S1512へ進む。
S1511においては、リソース監視情報にメッセージ数の異常を記録すると共に異常コマンドを発行する。
S1512においては、メッセージ判定数を加算し、S1508へ戻る。S1508〜S1512の処理は登録された全てのメッセージの判定処理が終了されるまで繰り返される。
S1513においては、リソース監視情報を出力し、処理を終了する。
図16は、図13のハードウェア情報判定処理の具体例を示すフローチャートである。
S1601においては、装置の温度が閾値以上か否か判定される。ここで、装置温度が閾値以上と判定された場合には、S1602へ進む。これに対し、装置温度が閾値未満と判定された場合には、S1603へ進む。
S1602においては、ハードウェア監視情報に装置温度の異常を記録すると共に異常コマンドを発行する。
S1603においては、ハードディスク状態が異常か否か判定される。ここで、ハードディスク状態が異常と判定された場合には、S1604へ進む。これに対し、ハードディスク状態が正常と判定された場合には、S1605へ進む。
S1604においては、ハードウェア監視情報にハードディスク状態の異常を記録すると共に異常コマンドを発行する。
S1605においては、LAN状態が異常か否か判定される。ここで、LAN状態が異常と判定された場合には、S1606へ進む。これに対し、LAN状態が正常と判定された場合には、S1607へ進む。
S1606においては、ハードウェア監視情報にLAN状態の異常を記録すると共に異常コマンドを発行する。
S1607においては、ファン状態が異常か否か判定される。ここで、ファン状態が異常と判定された場合には、S1608へ進む。これに対し、ファン状態が正常と判定された場合には、S1609へ進む。
S1608においては、ハードウェア監視情報にファン状態の異常を記録すると共に異常コマンドを発行する。
S1609においては、ハードウェア監視情報を出力し、処理を終了する。
図17は、送信部15における処理の具体例を示すフローチャートである。
S1701においては、自ノード情報判定部13から出力された稼働監視情報の有無を判定する。ここで、稼働監視情報有りと判定された場合には、S1702へ進む。これに対し、稼働監視情報無しと判定された場合には、処理を終了する。
S1702においては、初回起動時か否かの判定を行う。ここで、初回起動時と判定された場合には、S1708へ進む。
S1703においては、記憶部11内の登録情報の更新の有無を判定する。ここで、登録情報の更新有りと判定された場合には、S1708へ進む。これに対し、登録情報の更新無しと判定された場合には、S1704へ進む。
S1704においては、記憶部11内の稼働監視情報の更新の有無を判定する。ここで、稼働監視情報の更新有りと判定された場合には、S1707へ進む。これに対し、稼働監視情報の更新無しと判定された場合には、S1705へ進む。
S1705においては、稼働監視情報の中に異常判定がなされた項目が含まれるか否かを判定する。ここで、異常項目有りと判定された場合には、S1707へ進む。これに対し、異常項目無しと判定された場合には、S1706へ進む。
S1706においては、現時刻が定周期の送信タイミングか否かを判定する。ここで、定周期の送信タイミングであると判定された場合には、S1707へ進む。これに対し、定周期の送信タイミングではないと判定された場合には、処理を終了する。
S1707においては、タスクのメモリ使用量や異常発生情報などの可変情報のみを他のノード1へ送信し、処理を終了する。
S1708においては、タスク名などの固定情報および可変情報を他のノード1へ送信し、処理を終了する。
図18は、受信部16における処理の具体例を示すフローチャートである。
S1801においては、他のノード1からの受信情報の有無を判定する。ここで、受信情報有りと判定された場合には、S1802へ進む。これに対し、受信情報無しと判定された場合には、処理を終了する。
S1802においては、受信情報が稼働監視情報か否かを判定する。ここで、受信情報が稼働監視情報であると判定された場合には、S1803へ進む。これに対し、受信情報が稼働監視情報でないと判定された場合には、処理を終了する。
S1803においては、受信された稼働監視情報を他ノード情報判定部17へ出力し処理を終了する。
図19は、他ノード情報判定部17における処理の具体例を示すフローチャートである。
S1901においては、受信部16から出力された稼働監視情報の有無を判定する。ここで、稼働監視情報有りと判定された場合には、S1902へ進む。これに対し、稼働監視情報無しと判定された場合には、処理を終了する。
S1902においては、他のノード1における稼働監視情報を解析し、異常が検出されているか否かを判定する。ここで、他のノード1において異常が検出されていると判定された場合には、S1903へ進む。これに対し、異常無しと判定された場合には、処理を終了する。
S1903においては、制御部(図示省略する)に対して他のノード1における異常を出力し、処理を終了する。尚、制御部では異常通知を受けて表示部14への表示指令等が行われる。
このように構成することにより、ネットワーク2上の全てのノード1において他のノード1の稼働状態が取得され、共有可能となる。
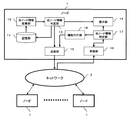
また、様々なシステムに適用可能な利点がある。図20は、本実施形態に係るノード稼働監視システムの適用例を示すブロック図である。ここでは、ノードAとノードBがサーバーであり、ノードAをマスタ、ノードBをスレーブとしてホットスタンバイの状態にある。また、ノードC、D、E、FはノードAのクライアント端末である。ここで、ノードBで異常が発生した場合には、その稼働監視情報が他のノード(A、C、D、E、F)に通知される。これにより、ノードBがノードAの代わりを出来ない状態にあることをノードAが正常に稼働している間に他のノード1において知ることが出来るので、システム全体が異常となる前段階で対応することができ、システム全体の信頼性が向上する。
更に、データを固定情報と可変情報に分類し、異なるタイミングで送信する仕組みを有するため、データ送信を効率的に行える。
(実施形態2)
図21は、本発明の実施形態2に係るノード稼働監視システムの全体構成例を示すブロック図である。本実施形態に係るノード稼働監視システムは、実施形態1に機能代行部18を加えた構成を有する。尚、図1と共通する符号は同一物を示すので説明を省略し、相違点についてのみ説明する。
図21は、本発明の実施形態2に係るノード稼働監視システムの全体構成例を示すブロック図である。本実施形態に係るノード稼働監視システムは、実施形態1に機能代行部18を加えた構成を有する。尚、図1と共通する符号は同一物を示すので説明を省略し、相違点についてのみ説明する。
機能代行部18は、他ノード情報判定部17の判定結果に基づいて他のノード1が実行していた機能の代行処理を行うプログラムである。
図22は、機能代行部18における機能代行処理の具体例を示すフローチャートである。
S2201においては、他のノード1からの稼働監視情報の有無を判定する。ここで、稼働監視情報有りと判定された場合には、S2202へ進む。これに対し、稼働監視情報無しと判定された場合には、処理を終了する。
S2202においては、他ノード情報判定部17から該当する稼働監視情報を読込む。
S2203においては、稼働監視情報が他のノード1の異常発生情報を含むか否かを判定する。ここで、異常発生情報を含むと判定された場合には、S2204へ進む。これに対し、異常発生情報を含まないと判定された場合には、処理を終了する。
S2204においては、異常発生情報に係るノードの機能代行処理が未実施か否かを判定する。ここで、機能代行処理が未実施であると判定された場合には、S2205へ進む。これに対し、機能代行処理が実施中であると判定された場合には、処理を終了する。
S2205においては、自ノードにおいて異常情報に係るノード1の機能代行が必要か否かを判定する。ここで、機能代行が必要と判定された場合には、S2206へ進む。これに対し、機能代行の必要が無いと判定された場合には、処理を終了する。
S2206においては、機能代行プログラムを実行する。
S2207においては、他のノード1に対する機能代行プログラムの実行情報の送信要求を送信部15へ出力し、処理を終了する。
尚、本発明は上記実施形態そのままに限定されるものではなく、実施段階ではその要旨を逸脱しない範囲で構成要素を変形して具体化できる。また、上記実施形態に開示されている複数の構成要素の適宜な組み合わせにより、種々の発明を形成できる。また、実施形態に示される全構成要素から幾つかの構成要素を削除してもよい。更に、異なる実施形態にわたる構成要素を適宜組み合わせてもよい。
例えば、組込み型のボード型装置(コンピュータ上のボードや、各種遠隔保守を必要とする監視対象に接続するための遠隔監視用のボード型装置など)をノード1として実装しても良い。この場合、N台で構成されるネットワーク上のボード型装置自体が他のボード型装置の状態を相互に監視することが可能になる。また、センターにあるサーバとのデータ伝送が出来なくても、ボード型装置が他のボード型装置の稼動監視状態に応じて自立的な処理を実現することが可能になる。N台の稼動監視状態を取得する場合には、ボード型装置上でアプリケーションを起動させるだけでN台全ての稼動監視ができる。これにより、容易にN台全ての遠隔監視を実現することが可能になる。
また、ノード1は計測センサー(例えば、流量計、濃度計、水位計等)でも良い。複数台の計測センサーをIPv6ネットワーク接続して実装することにより、計測センサーが他の計測センサーの状態を相互に監視することが可能になる。すなわち、ある計測センサーが故障しても、他の計測センサーが必要に応じて自立的にバックアップすることが可能になる。N台の計測センサーの稼動監視状態を取得する場合には、各ノード1においてアプリケーションを起動させるだけでN台全ての稼動監視ができる。
更に、複数個の装置から構成され、原則的に停止することが許されない制御装置(例えば、酸素製造装置、生命維持装置等)にも適用可能である。例えば、複数の酸素製造装置を無線LANやIPv6ネットワークで接続して構成される総合酸素製造装置において個々の装置が故障した場合には、故障した装置が行っていた仕事量(酸素の製造量)を故障していない他の装置が分担して製造することで、予め設定された酸素製造量の総量を自動的に維持することが可能になる。尚、稼動状態が正常な各装置が負担する仕事量は、装置の処理能力や台数などに応じた演算式などによって任意に定めることができる。
1…ノード、
2…ネットワーク、
11…記憶部、
12…自ノード情報収集部、
13…自ノード情報判定部、
14…表示部、
15…送信部、
16…受信部、
17…他ノード情報判定部、
18…機能代行部、
121…タスク情報収集プログラム、
122…リソース情報収集プログラム、
123…ハードウェア情報収集プログラム。
2…ネットワーク、
11…記憶部、
12…自ノード情報収集部、
13…自ノード情報判定部、
14…表示部、
15…送信部、
16…受信部、
17…他ノード情報判定部、
18…機能代行部、
121…タスク情報収集プログラム、
122…リソース情報収集プログラム、
123…ハードウェア情報収集プログラム。
Claims (5)
- ネットワークに接続された複数のノードの各々が、
タスク情報、リソース情報、およびハードウェア情報を含む自ノード情報を収集する自ノード情報収集部と、
この自ノード情報収集部において収集された前記自ノード情報を解析して前記ノードの稼働状態を判定し、この判定結果を含む稼働監視情報を出力する自ノード情報判定部と、
この自ノード情報判定部において前記稼働状態が異常と判定された場合に、前記出力された稼働監視情報を前記ネットワーク上の他のノードへ送信する送信部と、
前記他のノードに係る前記送信部から送信された他の稼働監視情報を受信する受信部と、
この受信部において受信された前記他の稼働監視情報に基づいて前記他のノードの稼働状態を判定する他ノード情報判定部と、
を有することを特徴とするノード稼働監視システム。 - 前記ノードが、前記他ノード情報判定部において前記他のノードの稼働状態が異常と判定された場合に、前記他の稼働監視情報に基づいて前記他のノードが担当していた機能を代行する機能代行部を更に有することを特徴とする請求項1記載のノード稼働監視システム。
- 前記機能代行部は、前記稼働状態が異常のノードが担当していた機能を前記稼働状態が正常な他のノードの数および処理能力に応じて算出される負担分について代行することを特徴とする請求項1および請求項2記載のノード稼働監視システム。
- ネットワークに接続された複数のノードの各々が、全ノードの稼働監視情報を共有するノード稼働監視方法であって、
前記ノードが、タスク情報、リソース情報、およびハードウェア情報を含む自ノード情報を収集する自ノード情報収集ステップと、
前記ノードが、前記自ノード情報収集ステップにおいて収集された前記自ノード情報を解析して前記ノードの稼働状態を判定し、この判定結果を含む稼働監視情報を出力する自ノード情報判定ステップと、
この自ノード情報判定ステップにおいて前記稼働状態が異常と判定された場合に、前記ノードが、前記出力された稼働監視情報を前記ネットワーク上の他のノードへ送信する送信ステップと、
前記ノードが、前記他のノードから送信された他の稼働監視情報を受信する受信ステップと、
前記ノードが、前記受信ステップにおいて受信された前記他の稼働監視情報に基づいて前記他のノードの稼働状態を判定する他ノード情報判定ステップと、
を有することを特徴とするノード稼働監視方法。 - 前記他ノード情報判定ステップにおいて前記他のノードの稼働状態が異常と判定された場合に、前記ノードが、前記他の稼働監視情報に基づいて前記他のノードが担当していた機能を代行する機能代行ステップを更に有することを特徴とする請求項4記載のノード稼働監視方法。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2008039006A JP2009199246A (ja) | 2008-02-20 | 2008-02-20 | ノード稼働監視システムおよびノード稼働監視方法 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2008039006A JP2009199246A (ja) | 2008-02-20 | 2008-02-20 | ノード稼働監視システムおよびノード稼働監視方法 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2009199246A true JP2009199246A (ja) | 2009-09-03 |
Family
ID=41142690
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2008039006A Pending JP2009199246A (ja) | 2008-02-20 | 2008-02-20 | ノード稼働監視システムおよびノード稼働監視方法 |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP2009199246A (ja) |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2011170445A (ja) * | 2010-02-16 | 2011-09-01 | Nec Corp | サーバシステムの障害監視装置、サーバシステム、及びサーバシステムの障害監視方法 |
| WO2012157471A1 (ja) * | 2011-05-13 | 2012-11-22 | インターナショナル・ビジネス・マシーンズ・コーポレーション | 複数の制御システムの異常を検知する異常検知システム |
| JP2014149753A (ja) * | 2013-02-04 | 2014-08-21 | Mitsubishi Electric Corp | 情報処理装置 |
| JPWO2013103001A1 (ja) * | 2012-01-04 | 2015-05-11 | 富士通株式会社 | 検出装置、検出方法、および検出プログラム |
| JP2016177358A (ja) * | 2015-03-18 | 2016-10-06 | キヤノン株式会社 | 情報処理装置およびその制御方法 |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH02110601A (ja) * | 1988-10-19 | 1990-04-23 | Mitsubishi Electric Corp | 協調分散制御方法 |
| JPH1023480A (ja) * | 1996-06-28 | 1998-01-23 | Fujitsu Ltd | 情報処理装置及び分散処理制御方法 |
| JPH10161907A (ja) * | 1996-12-02 | 1998-06-19 | Meidensha Corp | コンピュータシステムの状態監視方法 |
-
2008
- 2008-02-20 JP JP2008039006A patent/JP2009199246A/ja active Pending
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH02110601A (ja) * | 1988-10-19 | 1990-04-23 | Mitsubishi Electric Corp | 協調分散制御方法 |
| JPH1023480A (ja) * | 1996-06-28 | 1998-01-23 | Fujitsu Ltd | 情報処理装置及び分散処理制御方法 |
| JPH10161907A (ja) * | 1996-12-02 | 1998-06-19 | Meidensha Corp | コンピュータシステムの状態監視方法 |
Cited By (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2011170445A (ja) * | 2010-02-16 | 2011-09-01 | Nec Corp | サーバシステムの障害監視装置、サーバシステム、及びサーバシステムの障害監視方法 |
| WO2012157471A1 (ja) * | 2011-05-13 | 2012-11-22 | インターナショナル・ビジネス・マシーンズ・コーポレーション | 複数の制御システムの異常を検知する異常検知システム |
| GB2505367A (en) * | 2011-05-13 | 2014-02-26 | Ibm | Fault sensing system for sensing fault in plurality of control systems |
| JP5571847B2 (ja) * | 2011-05-13 | 2014-08-13 | インターナショナル・ビジネス・マシーンズ・コーポレーション | 複数の制御システムの異常を検知する異常検知システム |
| GB2505367B (en) * | 2011-05-13 | 2014-09-17 | Ibm | Anomaly Detection System for Detecting Anomaly In Multiple Control Systems |
| US9360855B2 (en) | 2011-05-13 | 2016-06-07 | International Business Machines Corporation | Anomaly detection system for detecting anomaly in multiple control systems |
| JPWO2013103001A1 (ja) * | 2012-01-04 | 2015-05-11 | 富士通株式会社 | 検出装置、検出方法、および検出プログラム |
| JP2014149753A (ja) * | 2013-02-04 | 2014-08-21 | Mitsubishi Electric Corp | 情報処理装置 |
| JP2016177358A (ja) * | 2015-03-18 | 2016-10-06 | キヤノン株式会社 | 情報処理装置およびその制御方法 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US10419540B2 (en) | Architecture for internet of things | |
| Hu et al. | An autonomic context management system for pervasive computing | |
| US8533731B2 (en) | Apparatus and method for distrubuting complex events based on correlations therebetween | |
| JP2009199246A (ja) | ノード稼働監視システムおよびノード稼働監視方法 | |
| JP5478722B2 (ja) | データ処理装置及びデータ処理方法及びプログラム | |
| JP2014134987A (ja) | 情報処理システム監視装置、監視方法、及び監視プログラム | |
| CN102859510A (zh) | 复杂分布式应用程序中的自动化恢复和升级 | |
| US20150205658A1 (en) | Network device and method of specifying data | |
| US10338994B1 (en) | Predicting and adjusting computer functionality to avoid failures | |
| CN112994935B (zh) | prometheus管控方法、装置、设备及存储介质 | |
| CN107682169B (zh) | 一种利用Kafka集群发送消息的方法和装置 | |
| Choi et al. | DART: fast and efficient distributed stream processing framework for internet of things | |
| WO2023221781A1 (zh) | 业务管理方法、系统、配置服务器及边缘计算设备 | |
| US20200159195A1 (en) | Selective data feedback for industrial edge system | |
| JP2007334716A (ja) | 運用管理システム、監視装置、被監視装置、運用管理方法及びプログラム | |
| JP2008033725A (ja) | 運用管理システム、監視装置、監視設定情報生成方法及びプログラム | |
| US11086919B2 (en) | Service regression detection using real-time anomaly detection of log data | |
| US20180091331A1 (en) | Distributed platform for robust execution of smart home applications | |
| Simić et al. | Towards edge computing as a service: Dynamic formation of the micro data-centers | |
| CN117130730A (zh) | 面向联邦Kubernetes集群的元数据管理方法 | |
| JP5779548B2 (ja) | 情報処理システム運用管理装置、運用管理方法及び運用管理プログラム | |
| AU2014305966A1 (en) | Managing data feeds | |
| US20140129863A1 (en) | Server, power management system, power management method, and program | |
| CN106407069B (zh) | 用于管理能量管理系统中的数据库的设备和方法 | |
| Baumgärtner et al. | Smart street lights and mobile citizen apps for resilient communication in a digital city |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20100401 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20110111 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20110705 |