JP2009098217A - Speech recognition device, navigation device with speech recognition device, speech recognition method, speech recognition program and recording medium - Google Patents
Speech recognition device, navigation device with speech recognition device, speech recognition method, speech recognition program and recording medium Download PDFInfo
- Publication number
- JP2009098217A JP2009098217A JP2007267128A JP2007267128A JP2009098217A JP 2009098217 A JP2009098217 A JP 2009098217A JP 2007267128 A JP2007267128 A JP 2007267128A JP 2007267128 A JP2007267128 A JP 2007267128A JP 2009098217 A JP2009098217 A JP 2009098217A
- Authority
- JP
- Japan
- Prior art keywords
- input
- voice
- recognition
- user
- voice recognition
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images



Abstract
Description
この発明は、音声認識装置、音声認識装置を備えたナビゲーション装置、音声認識方法、音声認識プログラム、および記録媒体に関する。 The present invention relates to a speech recognition device, a navigation device including the speech recognition device, a speech recognition method, a speech recognition program, and a recording medium.
近年、自動車などの車両には、目的地までの経路を探索して、当該目的地まで誘導するナビゲーション装置が搭載されている。このようなナビゲーション装置において、目的地の設定など各種設定や入力は、タッチパネルなどの操作入力によっておこなわれるものが知られている。また、このほかにも、音声認識機能を具備したものであれば、利用者からの発話により各種設定や入力がおこなわれるものが知られている。 In recent years, vehicles such as automobiles are equipped with navigation devices that search for a route to a destination and guide the vehicle to the destination. In such a navigation apparatus, various settings and inputs such as a destination setting are known to be performed by an operation input such as a touch panel. In addition, as long as it has a voice recognition function, it is known that various settings and inputs can be performed by speech from the user.
音声認識機能を具備した技術としては、たとえば、音声の誤認識の低減を図るために、利用者からの語彙のジャンルの発話に基づき、語彙のジャンルを指定し、指定されたジャンルの中から音声認識をおこなうようにした技術が提案されている(たとえば、特許文献1参照。)。 As a technology having a speech recognition function, for example, in order to reduce misrecognition of speech, a vocabulary genre is designated based on the utterance of the vocabulary genre from a user, and speech is designated from the designated genre. A technique for performing recognition has been proposed (see, for example, Patent Document 1).
しかしながら、上述した特許文献1の技術は、音声認識を開始させるためには、利用者がトークスイッチをオンにする必要があり、利用者にとって手間がかかるといった問題が一例として挙げられる。 However, the technique disclosed in Patent Document 1 described above includes, for example, a problem that the user needs to turn on the talk switch in order to start speech recognition, which is troublesome for the user.
上述した課題を解決し、目的を達成するため、請求項1の発明にかかる音声認識装置は、利用者からの音声が入力される入力手段と、利用者の身体のうち発話時に動作する部位を検知する検知手段と、前記検知手段による検知結果に基づいて、利用者の発話に関する行動状態を画像認識する画像認識手段と、前記画像認識手段によって利用者の発話に関する行動状態が画像認識された後に、前記入力手段に入力される音声に対する音声認識を開始する音声認識手段と、を備えることを特徴とする。 In order to solve the above-described problems and achieve the object, a speech recognition apparatus according to the invention of claim 1 includes an input means for inputting a voice from a user, and a part that operates during utterance in the user's body. Based on the detection means for detecting, the image recognition means for recognizing the action state related to the user's utterance based on the detection result by the detection means, and after the action state related to the user's utterance is image-recognized by the image recognition means And voice recognition means for starting voice recognition with respect to the voice inputted to the input means.
また、請求項8に記載のナビゲーション装置は、上記音声認識装置を備えることを特徴とする。 A navigation device according to an eighth aspect includes the voice recognition device.
また、請求項10の発明にかかる音声認識方法は、利用者からの音声が入力される入力工程と、利用者の発話に関する行動状態を検知する検知工程と、前記検知工程による検知結果に基づいて、利用者の発話に関する行動状態を画像認識する画像認識工程と、前記画像認識工程によって利用者の発話に関する行動状態が画像認識された後に、前記入力工程にて入力される音声に対する音声認識を開始する音声認識工程と、を含むことを特徴とする。 According to a tenth aspect of the present invention, there is provided a voice recognition method based on an input step in which voice from a user is input, a detection step of detecting an action state related to a user's utterance, and a detection result of the detection step. An image recognition process for recognizing an action state related to a user's utterance, and voice recognition for a voice input in the input process is started after the action state related to the user's utterance is recognized by the image recognition process. And a voice recognition step.
また、請求項11の発明にかかる音声認識プログラムは、請求項10に記載の音声認識方法をコンピュータに実行させることを特徴とする。 A speech recognition program according to the invention of claim 11 causes a computer to execute the speech recognition method according to claim 10.
また、請求項12の発明にかかる記録媒体は、請求項11に記載の音声認識プログラムをコンピュータに読み取り可能に記録したことを特徴とする。 According to a twelfth aspect of the present invention, there is provided a recording medium in which the voice recognition program according to the eleventh aspect is recorded in a computer-readable manner.
以下に添付図面を参照して、この発明にかかる音声認識装置、音声認識装置を備えたナビゲーション装置、音声認識方法、音声認識プログラム、および記録媒体の好適な実施の形態を詳細に説明する。 Exemplary embodiments of a speech recognition device, a navigation device including the speech recognition device, a speech recognition method, a speech recognition program, and a recording medium according to the present invention will be explained below in detail with reference to the accompanying drawings.
(実施の形態)
(音声認識装置の機能的構成)
この発明の実施の形態にかかる音声認識装置100の機能的構成について説明する。図1は、本実施の形態にかかる音声認識装置100の機能的構成の一例を示すブロック図である。図1において、音声認識装置100は、入力部101と、検知部102と、画像認識部103と、音声認識部104と、出力部105と、電源制御部106と、記録部107とを備えている。
(Embodiment)
(Functional configuration of voice recognition device)
A functional configuration of the
入力部101には、利用者からの音声が入力される。入力部101は、具体的には、マイクロフォンである。マイクロフォンには、たとえば、ハンズフリー・マイクロフォンが用いられ、ヘッドセットなどに小型のマイクを装着させたものや、車両などの移動体内に配置されるものなどが挙げられる。
Voice from the user is input to the
検知部102は、利用者の身体のうち発話時に動作する部位を検知する。検知部102には、たとえば、画像を撮影するカメラからの撮像信号を検知する。発話時に変化する部位は、たとえば、目、眉、鼻、頬のほか、人によっては手なども挙げられるが、代表的には、口元が挙げられる。
The
画像認識部103は、検知部102による検知結果に基づいて、利用者の発話に関する行動状態を画像認識する。発話に関する行動状態は、具体的には、利用者が発話する状態であり、目、眉、鼻、頬の動いた状態であってもよいが、代表的には、口元の動いた状態が挙げられる。
The
音声認識部104は、画像認識部103によって利用者の発話に関する行動状態が画像認識された後に、入力部101に入力される音声に対する音声認識を開始する。音声認識部104は、代表的には、画像認識部103によって利用者の口元に動きがあると画像認識された後に、入力部101に入力される音声に対する音声認識を開始する。この音声認識部104は、入力部101に入力された音声を音声解析し、解析した音声データを出力部105に出力する。音声認識部104による音声解析は、具体的には、記録部107に、予め記録される言語データと、入力された音声の特徴とを照らし合わせ、尤もらしい言語を推定することによりおこなわれる。
The
出力部105は、音声認識部104によって音声解析された音声データを出力する。出力部105から出力された音声データにより、たとえば、ナビゲーション装置において各種プログラムが実行され、各種設定や処理がおこなわれる。
The
また、本実施の形態において、電源制御部106を備えてもよい。電源制御部106は、画像認識部103によって利用者の発話に関する行動状態が画像認識された場合に、入力部101の電源をオンにする。この場合、音声認識部104は、入力部101の電源がオンになってから、入力部101に入力される音声に対する音声認識処理を開始すればよい。本構成は、音声認識をおこなう必要があるときに、入力部101の電源をオンにすることにより、消費電力の低減を図ったものである。
In the present embodiment, a
また、本実施の形態において、画像認識部103は、検知部102による検知結果に基づいて、利用者の口元の動きが所定時間ないことを画像認識してもよい。この場合、音声認識部104は、画像認識部103によって利用者の口元の動きが所定時間ないと画像認識された場合に、入力部101に入力される音声に対する音声認識を停止する。本構成は、利用者の口元の動きが所定時間ない場合に、利用者に発話する様子がないものと想定できることに基づき、音声認識を停止させることにより、誤認識や、これに伴う誤作動を防止するようにしたものである。
In the present embodiment, the
また、このような、音声認識部104が入力部101に入力される音声に対する音声認識を停止する条件下で、電源制御部106により、入力部101の電源をオフにさせてもよい。本構成は、音声認識をおこなう必要のないときに、入力部101の電源をオフにさせることにより、消費電力の低減を図ったものである。
In addition, the power
また、本実施の形態において、音声認識部104は、入力部101に所定時間以上音声が入力されていないと判断した場合に、入力部101に入力される音声に対する音声認識を停止してもよい。本構成は、所定時間以上音声が入力されない場合に、利用者に発話する様子がないものと想定できることに基づき、音声認識を停止させるようにしたものである。また、このような、音声認識部104が入力部101に入力される音声に対する音声認識を停止する条件下で、電源制御部106により入力部101の電源をオフにさせてもよい。
Further, in the present embodiment, the
また、本実施の形態において、音声認識部104は、入力部101に非言語音が入力された場合に、入力部101に入力される音声に対する音声認識を停止してもよい。非言語音は、具体的には、咳払い、あくび、くしゃみなどの音声である。本構成は、入力部101に非言語音が入力された場合に、利用者からの発話ではないものと認識できることにより、音声認識を停止させるようにしたものである。また、このような、音声認識部104が入力部101に入力される音声に対する音声認識を停止する条件下で、電源制御部106により入力部101の電源をオフにさせてもよい。
In the present embodiment, the
また、本実施の形態において、音声認識部104は、入力部101に一定の周波数の音声が所定時間以上入力された場合に、入力部101に入力される音声に対する音声認識を停止してもよい。一定の周波数の音声は、具体的には、ガムを噛んでいる場合などの音声である。本構成は、入力部101に一定の周波数の音声が所定時間以上入力された場合に、利用者からの発話ではないものと認識できることにより、音声認識を停止させるようにしたものである。また、このような、音声認識部104が入力部101に入力される音声に対する音声認識を停止する条件下で、電源制御部106により入力部101の電源をオフにさせてもよい。
Further, in the present embodiment, the
また、本実施の形態において、音声認識装置100を、移動体に搭載されるナビゲーション装置に用いてもよい。この場合、検知部102は、移動体に搭乗する複数の利用者のうち、少なくとも一人の身体のうち発話時に動作する部位を検知すればよい。移動体に搭乗する複数の利用者のうち、少なくとも一人とは、ナビゲーション装置に対して発話する利用者であり、たとえば、運転者や助手席の搭乗者が挙げられるが、後部座席の搭乗者であってもよい。
In the present embodiment, the
また、画像認識部103は、検知部102による検知結果に基づいて、少なくとも一人の発話に関する行動状態を画像認識する。音声認識部104は、画像認識部103によって少なくとも一人の発話に関する行動状態が画像認識された後に、入力部101に入力される音声に対する音声認識を開始する。本構成は、移動体に搭乗する利用者のうち、少なくとも一人の身体のうち発話時に動作する部位を検知するようにし、搭乗者からのナビゲーション装置に対する音声入力を可能にしたものである。
Further, the
(音声認識装置の音声認識処理手順)
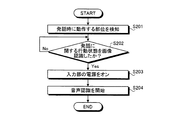
つぎに、図2を用いて、音声認識装置100の音声認識処理手順について説明する。図2は、本実施の形態にかかる音声認識装置100の音声認識処理手順の一例を示すフローチャートである。
(Voice recognition processing procedure of voice recognition device)
Next, the speech recognition processing procedure of the
図2のフローチャートにおいて、音声認識装置100は、検知部102により利用者の身体のうち発話時に動作する部位を検知する(ステップS201)。そして、検知部102による検知結果に基づいて、画像認識部103が利用者の発話に関する行動状態を画像認識するまで待機する(ステップS202:Noのループ)。
In the flowchart of FIG. 2, the
そして、利用者の発話に関する行動状態を画像認識すると(ステップS202:Yes)、電源制御部106が入力部101の電源をオンにする(ステップS203)。このあと、音声認識部104が入力部101に入力される音声に対する音声認識を開始し(ステップS204)、一連の処理を終了する。
When the action state related to the user's utterance is recognized as an image (step S202: Yes), the power
以上説明したように、本実施の形態にかかる音声認識装置100は、利用者の身体のうち発話時に動作する部位の検知結果に基づいて、利用者の発話に関する行動状態が画像認識された後に、入力される音声に対する音声認識を開始するようにした。これにより、利用者の操作によりトークスイッチをオンにすることなく、音声認識を開始させることができる。したがって、利用者の手間を軽減することが可能になる。
As described above, the
また、本実施の形態において、利用者の口元の検知結果に基づいて、利用者の口元の動きを画像認識するようにすれば、簡単に、利用者の発話に関する行動状態を画像認識することができる。 Further, in the present embodiment, if the movement of the user's mouth is image-recognized based on the detection result of the user's mouth, the action state relating to the user's utterance can be easily image-recognized. it can.
また、本実施の形態において、利用者の発話に関する行動状態が画像認識された場合に、入力部101の電源をオンにし、音声に対する音声認識処理を開始するようにすれば、音声認識をおこなう必要があるときにのみ、電源をオンにすることができ、消費電力を低減させることができる。
Also, in this embodiment, when the behavior state related to the user's utterance is recognized as an image, it is necessary to perform speech recognition by turning on the
また、本実施の形態において、利用者の口元の動きが所定時間ない場合など、利用者に発話する様子がないものと想定できる場合や、非言語音など利用者からの発話ではないものと認識できる場合に、音声認識を停止させるようにすれば、不要な音声認識をおこなうことなく、音声認識における誤認識や、これに伴う誤作動を防止することができる。特に、このような、入力される音声に対する音声認識を停止する条件下で、入力部101の電源をオフにさせるようにすれば、消費電力を低減させることができる。
Also, in this embodiment, when it is assumed that there is no state of speaking to the user, such as when there is no movement of the user's mouth for a predetermined time, it is recognized that the speech is not from the user such as a non-language sound. If the voice recognition is stopped when possible, it is possible to prevent erroneous recognition in voice recognition and malfunctions associated therewith without performing unnecessary voice recognition. In particular, if the power of the
また、本実施の形態において、音声認識装置100を備えたナビゲーション装置によれば、利用者がトークスイッチを操作する手間を省くことができることにより、利用者は、運転動作に早く就くことができるとともに、運転に専念することができる。
Further, in the present embodiment, according to the navigation device provided with the
また、同乗者移動体に搭乗する複数の利用者のうち、少なくとも一人の身体のうち発話時に動作する部位を検知するようにすれば、たとえば、運転者以外の搭乗者からの発話を受け付けることも可能になる。 In addition, among the plurality of users who board the passenger moving body, for example, it is possible to accept utterances from passengers other than the driver by detecting a part that operates during utterance in at least one body. It becomes possible.
以下に、本発明の実施例について説明する。本実施例では、車両に搭載されるナビゲーション装置によって、本発明の音声認識装置100を実施した場合の一例について説明する。
Examples of the present invention will be described below. In the present embodiment, an example in which the
(ナビゲーション装置のハードウェア構成)
図3を用いて、本実施例にかかるナビゲーション装置300のハードウェア構成について説明する。図3は、本実施例にかかるナビゲーション装置300のハードウェア構成の一例を示すブロック図である。図3において、ナビゲーション装置300は、車両などの移動体に搭載されており、CPU301と、ROM302と、RAM303と、磁気ディスクドライブ304と、磁気ディスク305と、光ディスクドライブ306と、光ディスク307と、音声I/F(インターフェース)308と、マイク309と、スピーカ310と、入力デバイス311と、映像I/F312と、ディスプレイ313と、通信I/F314と、GPSユニット315と、各種センサ316と、カメラ317と、を備えている。また、各構成部301〜317はバス320によってそれぞれ接続されている。
(Hardware configuration of navigation device)
The hardware configuration of the
CPU301は、ナビゲーション装置300の全体の制御を司る。ROM302は、ブートプログラム、現在位置算出プログラム、経路探索プログラム、経路誘導プログラム、音声認識プログラムなどの各種プログラムを記録している。また、RAM303は、CPU301のワークエリアとして使用される。
The
現在位置算出プログラムは、たとえば、後述するGPSユニット315および各種センサ316の出力情報に基づいて、車両の現在位置(ナビゲーション装置300の現在位置)を算出させる。
The current position calculation program, for example, calculates the current position of the vehicle (current position of the navigation device 300) based on output information from a
経路探索プログラムは、後述する磁気ディスク305に記録されている地図データなどを利用して、出発地点から目的地点までの最適な経路を探索させる。ここで、最適な経路とは、目的地点までの最短(または最速)経路やユーザが指定した条件に最も合致する経路などである。また、目的地点のみならず、立ち寄り地点や休憩地点までの経路を探索してもよい。探索された誘導経路は、CPU301を介して音声I/F308や映像I/F312へ出力される。
The route search program searches for an optimal route from the departure point to the destination point using map data or the like recorded on a
経路誘導プログラムは、経路探索プログラムを実行することによって探索された誘導経路情報、現在位置算出プログラムを実行することによって算出された車両の現在位置情報、磁気ディスク305から読み出された地図データに基づいて、リアルタイムな経路誘導情報を生成させる。生成された経路誘導情報は、CPU301を介して音声I/F308や映像I/F312へ出力される。
The route guidance program is based on guidance route information searched by executing the route search program, vehicle current location information calculated by executing the current position calculation program, and map data read from the
音声認識プログラムは、カメラ317によって撮影された利用者の口元の撮像結果に基づいて、利用者の口元の動きが画像認識された後に、音声I/F308から入力される音声に対する音声認識を開始させる。
The voice recognition program starts voice recognition for the voice input from the voice I /
磁気ディスクドライブ304は、CPU301の制御にしたがって磁気ディスク305に対するデータの読み取り/書き込みを制御する。磁気ディスク305は、磁気ディスクドライブ304の制御で書き込まれたデータを記録する。磁気ディスク305としては、たとえば、HD(ハードディスク)やFD(フレキシブルディスク)を用いることができる。
The
光ディスクドライブ306は、CPU301の制御にしたがって光ディスク307に対するデータの読み取り/書き込みを制御する。光ディスク307は、光ディスクドライブ306の制御にしたがってデータの読み出される着脱自在な記録媒体である。光ディスク307は、書き込み可能な記録媒体を利用することもできる。また、この着脱可能な記録媒体として、光ディスク307のほか、MO、メモリカードなどであってもよい。
The
音声I/F308は、音声入力用のマイク309および音声出力用のスピーカ310に接続される。マイク309は、車室内の音を収集するハンズフリー・マイクロフォンによって構成される。マイク309は、たとえば、車両のサンバイザー付近に設置され、その数は単数でも複数でもよい。マイク309に受音された音声は、音声I/F308内でA/D変換される。スピーカ310からは、音声が出力される。
The audio I /
入力デバイス311は、文字、数値、各種指示などの入力のための複数のキーを備えたリモコン、キーボード、マウス、タッチパネルなどが挙げられる。
Examples of the
映像I/F312は、ディスプレイ313と接続される。映像I/F312は、具体的には、たとえば、ディスプレイ313全体の制御をおこなうグラフィックコントローラと、即時表示可能な画像情報を一時的に記録するVRAM(Video RAM)などのバッファメモリと、グラフィックコントローラから出力される画像データに基づいて、ディスプレイ313を表示制御する制御ICなどによって構成される。
The video I /
ディスプレイ313には、アイコン、カーソル、メニュー、ウインドウ、あるいは文字や画像などの各種データが表示される。このディスプレイ313は、たとえば、CRT、TFT液晶ディスプレイ、プラズマディスプレイなどを採用することができる。
The
通信I/F314は、無線を介してネットワークに接続され、ナビゲーション装置300とCPU301とのインターフェースとして機能する。通信I/F314は、さらに、無線を介してインターネットなどの通信網に接続され、この通信網とCPU301とのインターフェースとしても機能する。
The communication I /
通信網には、LAN、WAN、公衆回線網や携帯電話網などがある。具体的には、通信I/F314は、たとえば、FMチューナー、VICS(Vehicle Information and Communication System)/ビーコンレシーバ、無線ナビゲーション装置、およびそのほかのナビゲーション装置によって構成され、VICSセンターから配信される渋滞や交通規制などの道路交通情報を取得する。なお、VICSは登録商標である。
Communication networks include LANs, WANs, public line networks and mobile phone networks. Specifically, the communication I /
また、通信I/F314は、たとえば、DSRC(Dedicated Short Range Communication)を用いた場合は、路側に設置された無線装置と双方向の無線通信をおこなう車載無線装置によって構成され、交通情報や地図情報などの各種情報を取得する。なお、DSRCの具体例としては、ETC(ノンストップ自動料金支払いシステム)が挙げられる。
The communication I /
GPSユニット315は、GPS衛星からの電波を受信し、車両の現在位置を示す情報を出力する。GPSユニット315の出力情報は、後述する各種センサ316の出力値とともに、CPU301による車両の現在位置の算出に際して利用される。現在位置を示す情報は、たとえば緯度・経度、高度などの、地図情報上の1点を特定する情報である。
The
各種センサ316は、車速センサや加速度センサ、角速度センサなどを含み、車両の位置や挙動を判断することが可能な情報を出力する。各種センサ316の出力値は、CPU301による車両の現在位置の算出や、速度や方位の変化量の測定などに用いられる。
The
カメラ317は、たとえば、運転者の口元の映像を撮影する。なお、カメラ317は、助手席や後部座席の搭乗者の口元の映像を撮影してもよい。映像は、動画が用いられる。
For example, the
図1に示した音声認識装置100が備える入力部101と、検知部102と、画像認識部103と、音声認識部104と、出力部105と、電源制御部106とは、図3に示したナビゲーション装置300におけるROM302、RAM303、磁気ディスク305、光ディスク307などに記録されたプログラムやデータを用いて、CPU301が所定のプログラムを実行し、ナビゲーション装置300における各部を制御することによって、その機能を実現する。
The
すなわち、本実施例のナビゲーション装置300は、ナビゲーション装置300における記録媒体としてのROM302に記録されている音声認識プログラムを実行することにより、図1に示した音声認識装置100が備える機能を、図2に示した音声認識処理手順で実行することができる。
That is, the
(ナビゲーション装置の音声認識処理の一例)
つぎに、図4を用いて、本実施例にかかるナビゲーション装置300がおこなう音声認識処理の一例について説明する。図4は、本実施例にかかるナビゲーション装置300の音声認識処理の一例を示すフローチャートである。
(Example of voice recognition processing of navigation device)
Next, an example of speech recognition processing performed by the
図4のフローチャートにおいて、ナビゲーション装置300は、カメラ317により利用者の口元を撮像する(ステップS401)。そして、利用者の口元の動きを画像認識するまで(ステップS402:Noのループ)、ステップS401に移行し、利用者の口元の動きを画像認識すると(ステップS402:Yes)、マイク309の電源をオンにする(ステップS403)。
In the flowchart of FIG. 4, the
このあと、マイク309に入力される音声に対する音声認識を開始する(ステップS404)。そして、所定時間以上、口元の動きがないか否かを判断する(ステップS405)。ステップS405において、所定時間内に口元の動きがあると判断した場合(ステップS405:No)、所定時間以上、音声の入力がないか否かを判断する(ステップS406)。
Thereafter, voice recognition for the voice input to the
ステップS406において、所定時間内に音声の入力があると判断した場合(ステップS406:No)、入力された音声が非言語音か否かを判断する(ステップS407)。なお、非言語音は、咳払い、くしゃみ、あくびなどの音声である。ステップS407において、入力された音声が非言語音ではないと判断した場合(ステップS407:No)、一定の周波数の音声が所定時間以上入力されているか否かを判断する(ステップS408)。一定の周波数の音声が所定時間以上入力されている場合とは、たとえば、ガムを噛んでいる場合などである。 In step S406, when it is determined that there is a voice input within a predetermined time (step S406: No), it is determined whether or not the input voice is a non-verbal sound (step S407). The non-speech sounds are sounds such as coughing, sneezing, and yawning. If it is determined in step S407 that the input voice is not a non-verbal sound (step S407: No), it is determined whether or not a voice having a certain frequency has been input for a predetermined time or more (step S408). The case where sound of a certain frequency is input for a predetermined time or longer is, for example, a case where a gum is chewed.
ステップS408において、一定の周波数の音声が所定時間以上入力されていないと判断した場合(ステップS408:No)、ステップS404に移行する。一方、ステップS408において、一定の周波数の音声が所定時間以上入力されていると判断した場合(ステップS408:Yes)、マイク309の電源をオフにし(ステップS409)、一連の処理を終了する。
In step S408, when it is determined that the voice of a certain frequency has not been input for a predetermined time or longer (step S408: No), the process proceeds to step S404. On the other hand, if it is determined in step S408 that sound of a certain frequency has been input for a predetermined time or longer (step S408: Yes), the
また、ステップS405において、所定時間以上、口元の動きがないと判断した場合(ステップS405:Yes)、ステップS409に移行する。また、ステップS406において、所定時間以上、音声の入力がないと判断した場合(ステップS406:Yes)、ステップS409に移行する。また、ステップS407において、入力された音声が非言語音であると判断した場合(ステップS407:Yes)、ステップS409に移行する。 If it is determined in step S405 that there is no movement of the mouth for a predetermined time or more (step S405: Yes), the process proceeds to step S409. If it is determined in step S406 that there is no voice input for a predetermined time or longer (step S406: Yes), the process proceeds to step S409. If it is determined in step S407 that the input voice is a non-verbal sound (step S407: Yes), the process proceeds to step S409.
以上説明したように、本実施例にかかるナビゲーション装置300は、利用者の口元の撮像結果に基づいて、利用者の口元の動きが画像認識された後に、マイクの電源をオンにし、入力される音声に対する音声認識を開始するようにした。これにより、利用者の操作によりトークスイッチをオンにすることなく、音声認識を開始させることができる。したがって、利用者の手間を軽減することが可能になる。
As described above, the
また、本実施例において、利用者の発話に関する行動状態が画像認識された場合に、マイクの電源をオンにし、音声に対する音声認識処理を開始するようにすれば、音声認識をおこなう必要があるときにのみ、電源をオンにすることができ、消費電力を低減させることができる。 Also, in this embodiment, when the action state related to the user's utterance is recognized as an image, if the microphone is turned on and the voice recognition process for the voice is started, it is necessary to perform voice recognition. Only the power can be turned on, and the power consumption can be reduced.
また、本実施例において、利用者の口元の動きが所定時間ない場合など、利用者に発話する様子がないものと想定できる場合や、非言語音など利用者からの発話ではないものと認識できる場合に、音声認識を停止させるようにしたので、不要な音声認識をおこなうことなく、音声認識における誤認識や、これに伴う誤作動を防止することができる。特に、このような、入力される音声に対する音声認識を停止する条件下で、マイクの電源をオフにしたので、消費電力を低減させることができる。 Also, in this embodiment, it can be recognized that there is no state of speaking to the user, such as when there is no movement of the user's mouth for a predetermined time, or that the speech is not from the user such as a non-language sound. In this case, since the voice recognition is stopped, it is possible to prevent erroneous recognition in voice recognition and a malfunction caused thereby without performing unnecessary voice recognition. In particular, since the power supply of the microphone is turned off under such a condition that the speech recognition for the input speech is stopped, the power consumption can be reduced.
また、本実施例にかかるナビゲーション装置300によれば、利用者がトークスイッチを操作する手間を省くことができることにより、利用者は、運転動作に早く就くことができるとともに、運転に専念することができる。また、同乗者移動体に搭乗する複数の利用者のうち、助手席や後部座席に搭乗する少なくとも一人の口元を検知するようにすれば、運転者以外の搭乗者からの発話を受け付けることも可能になる。
Further, according to the
以上説明したように、本発明の音声認識装置、音声認識装置を備えたナビゲーション装置、音声認識方法、音声認識プログラム、および記録媒体は、利用者の身体のうち発話時に動作する部位の検知結果に基づいて、利用者の発話に関する行動状態が画像認識された後に、入力される音声に対する音声認識を開始するようにした。これにより、利用者の操作によりトークスイッチをオンにすることなく、音声認識を開始させることができる。したがって、利用者の手間を軽減することが可能になる。 As described above, the voice recognition device, the navigation device including the voice recognition device, the voice recognition method, the voice recognition program, and the recording medium according to the present invention can be used to detect a part of a user's body that operates during speech. Based on this, after the action state related to the user's utterance is image-recognized, voice recognition for the input voice is started. Thereby, voice recognition can be started without turning on the talk switch by the user's operation. Therefore, it is possible to reduce the labor of the user.
なお、本実施例で説明した音声認識方法は、予め用意されたプログラムをパーソナル・コンピュータやワークステーションなどのコンピュータで実行することにより実現することができる。このプログラムは、ハードディスク、フレキシブルディスク、CD−ROM、MO、DVDなどのコンピュータで読み取り可能な記録媒体に記録され、コンピュータによって記録媒体から読み出されることによって実行される。またこのプログラムは、インターネットなどのネットワークを介して配布することが可能な伝送媒体であってもよい。 The voice recognition method described in the present embodiment can be realized by executing a program prepared in advance on a computer such as a personal computer or a workstation. This program is recorded on a computer-readable recording medium such as a hard disk, a flexible disk, a CD-ROM, an MO, and a DVD, and is executed by being read from the recording medium by the computer. The program may be a transmission medium that can be distributed via a network such as the Internet.
100 音声認識装置
101 入力部
102 検知部
103 画像認識部
104 音声認識部
105 出力部
106 電源制御部
300 ナビゲーション装置
DESCRIPTION OF
Claims (12)
利用者の身体のうち発話時に動作する部位を検知する検知手段と、
前記検知手段による検知結果に基づいて、利用者の発話に関する行動状態を画像認識する画像認識手段と、
前記画像認識手段によって利用者の発話に関する行動状態が画像認識された後に、前記入力手段に入力される音声に対する音声認識処理を開始する音声認識手段と、
を備えることを特徴とする音声認識装置。 An input means for inputting voice from the user;
A detecting means for detecting a part of the user's body that operates when speaking,
Image recognition means for recognizing an action state related to a user's utterance based on a detection result by the detection means;
Voice recognition means for starting voice recognition processing for voice input to the input means after the action state related to the user's utterance is recognized by the image recognition means;
A speech recognition apparatus comprising:
前記画像認識手段は、前記検知手段による検知結果に基づいて、利用者の口元に動きがあることを画像認識し、
前記音声認識手段は、前記画像認識手段によって利用者の口元に動きがあると画像認識された後に、前記入力手段に入力される音声に対する音声認識処理を開始することを特徴とする請求項1に記載の音声認識装置。 The detection means detects a user's mouth,
The image recognizing unit recognizes that there is movement in the user's mouth based on the detection result by the detecting unit,
The speech recognition means starts speech recognition processing for speech input to the input means after the image recognition means recognizes that there is a movement in the user's mouth and the speech input to the input means. The speech recognition apparatus described.
前記音声認識手段は、前記画像認識手段によって利用者の口元の動きが所定時間ないことを画像認識された場合に、前記入力手段に入力される音声に対する音声認識処理を停止することを特徴とする請求項1に記載の音声認識装置。 The image recognition means recognizes that there is no movement of the user's mouth for a predetermined time based on the detection result by the detection means,
The voice recognition means stops the voice recognition processing for the voice input to the input means when the image recognition means recognizes that there is no movement of the user's mouth for a predetermined time. The speech recognition apparatus according to claim 1.
前記音声認識手段は、前記入力手段の電源がオンになってから、前記入力手段に入力される音声に対する音声認識処理を開始することを特徴とする請求項1〜6のいずれか一つに記載の音声認識装置。 A power control unit that turns on the power of the input unit when the action state related to the user's utterance is recognized by the image recognition unit;
The voice recognition means starts voice recognition processing for voice inputted to the input means after the input means is turned on. Voice recognition device.
前記検知手段は、前記移動体に搭乗する複数の利用者のうち、少なくとも一人の身体のうち発話時に動作する部位を検知し、
前記画像認識手段は、前記検知手段による検知結果に基づいて、少なくとも一人の発話に関する行動状態を画像認識し、
前記音声認識手段は、前記画像認識手段によって少なくとも一人の発話に関する行動状態が画像認識された後に、前記入力手段に入力される音声に対する音声認識を開始することを特徴とするナビゲーション装置。 A navigation device comprising the voice recognition device according to any one of claims 1 to 8, and mounted on a mobile body,
The detecting means detects a part that operates at the time of speaking out of at least one body among a plurality of users boarding the moving body,
The image recognition means recognizes an action state related to at least one utterance based on a detection result by the detection means,
The navigation apparatus according to claim 1, wherein the voice recognition means starts voice recognition for the voice input to the input means after the image recognition means recognizes an action state related to at least one utterance.
利用者の発話に関する行動状態を検知する検知工程と、
前記検知工程による検知結果に基づいて、利用者の発話に関する行動状態を画像認識する画像認識工程と、
前記画像認識工程によって利用者の発話に関する行動状態が画像認識された後に、前記入力工程にて入力される音声に対する音声認識処理を開始する音声認識工程と、
を含むことを特徴とする音声認識方法。 An input process in which voice from the user is input;
A detection process for detecting an action state related to the user's utterance;
Based on the detection result of the detection step, an image recognition step for recognizing an action state related to the user's utterance,
A voice recognition step of starting a voice recognition process for the voice input in the input step after the behavioral state relating to the user's utterance is recognized by the image recognition step;
A speech recognition method comprising:
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2007267128A JP2009098217A (en) | 2007-10-12 | 2007-10-12 | Speech recognition device, navigation device with speech recognition device, speech recognition method, speech recognition program and recording medium |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2007267128A JP2009098217A (en) | 2007-10-12 | 2007-10-12 | Speech recognition device, navigation device with speech recognition device, speech recognition method, speech recognition program and recording medium |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2009098217A true JP2009098217A (en) | 2009-05-07 |
Family
ID=40701325
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2007267128A Pending JP2009098217A (en) | 2007-10-12 | 2007-10-12 | Speech recognition device, navigation device with speech recognition device, speech recognition method, speech recognition program and recording medium |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP2009098217A (en) |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2014110554A (en) * | 2012-12-03 | 2014-06-12 | Denso Corp | Hands-free speech apparatus |
| WO2014178491A1 (en) * | 2013-04-30 | 2014-11-06 | 포항공과대학교 산학협력단 | Speech recognition method and apparatus |
| JP2015535952A (en) * | 2012-09-29 | 2015-12-17 | シェンジェン ピーアールテック カンパニー リミテッド | Voice control system and method for multimedia device and computer storage medium |
| CN107004405A (en) * | 2014-12-18 | 2017-08-01 | 三菱电机株式会社 | Speech recognition equipment and audio recognition method |
-
2007
- 2007-10-12 JP JP2007267128A patent/JP2009098217A/en active Pending
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2015535952A (en) * | 2012-09-29 | 2015-12-17 | シェンジェン ピーアールテック カンパニー リミテッド | Voice control system and method for multimedia device and computer storage medium |
| JP2014110554A (en) * | 2012-12-03 | 2014-06-12 | Denso Corp | Hands-free speech apparatus |
| WO2014178491A1 (en) * | 2013-04-30 | 2014-11-06 | 포항공과대학교 산학협력단 | Speech recognition method and apparatus |
| CN107004405A (en) * | 2014-12-18 | 2017-08-01 | 三菱电机株式会社 | Speech recognition equipment and audio recognition method |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP4973722B2 (en) | Voice recognition apparatus, voice recognition method, and navigation apparatus | |
| JP4736982B2 (en) | Operation control device, program | |
| JP6604151B2 (en) | Speech recognition control system | |
| JP6612707B2 (en) | Information provision device | |
| US20110288871A1 (en) | Information presentation system | |
| JP2017090613A (en) | Voice recognition control system | |
| US11450316B2 (en) | Agent device, agent presenting method, and storage medium | |
| US20200319841A1 (en) | Agent apparatus, agent apparatus control method, and storage medium | |
| WO2007049596A1 (en) | Information recording apparatus, information recording method, information recording program and computer readable recording medium | |
| US9476728B2 (en) | Navigation apparatus, method and program | |
| JP2009098217A (en) | Speech recognition device, navigation device with speech recognition device, speech recognition method, speech recognition program and recording medium | |
| JP2009031943A (en) | Facility specification device, facility specification method, and computer program | |
| JP6619316B2 (en) | Parking position search method, parking position search device, parking position search program, and moving object | |
| JP4900197B2 (en) | Route deriving device, vehicle control device, and navigation device | |
| JP2020144264A (en) | Agent device, control method of agent device, and program | |
| JP2001202579A (en) | Emergency information transmitting system | |
| JP2019211599A (en) | Voice recognition device, voice recognition method, and program | |
| JP5160653B2 (en) | Information providing apparatus, communication terminal, information providing system, information providing method, information output method, information providing program, information output program, and recording medium | |
| JP2009223187A (en) | Display content controller, display content control method and display content control method program | |
| JP2009086132A (en) | Speech recognition device, navigation device provided with speech recognition device, electronic equipment provided with speech recognition device, speech recognition method, speech recognition program and recording medium | |
| JP2007057805A (en) | Information processing apparatus for vehicle | |
| JP4776627B2 (en) | Information disclosure device | |
| JP2007263651A (en) | On-vehicle navigation device and vehicle signal detection method | |
| JP2008157885A (en) | Information guide device, navigation device, information guide method, navigation method, information guide program, navigation program, and recording medium | |
| JP4575493B2 (en) | Navigation device, route guidance method and program |