JP2009017331A - Voice processor, voice processing method, voice processing program, and its recording medium - Google Patents
Voice processor, voice processing method, voice processing program, and its recording medium Download PDFInfo
- Publication number
- JP2009017331A JP2009017331A JP2007178036A JP2007178036A JP2009017331A JP 2009017331 A JP2009017331 A JP 2009017331A JP 2007178036 A JP2007178036 A JP 2007178036A JP 2007178036 A JP2007178036 A JP 2007178036A JP 2009017331 A JP2009017331 A JP 2009017331A
- Authority
- JP
- Japan
- Prior art keywords
- sound
- unit
- echo
- voice
- output
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
- 238000003672 processing method Methods 0.000 title claims description 8
- 238000012360 testing method Methods 0.000 claims abstract description 60
- 238000004891 communication Methods 0.000 claims abstract description 31
- 238000001514 detection method Methods 0.000 claims abstract description 29
- 238000012545 processing Methods 0.000 claims description 97
- 230000005540 biological transmission Effects 0.000 claims description 32
- 230000005236 sound signal Effects 0.000 claims description 31
- 230000007274 generation of a signal involved in cell-cell signaling Effects 0.000 abstract description 16
- 238000000034 method Methods 0.000 description 22
- 210000004899 c-terminal region Anatomy 0.000 description 16
- 238000006243 chemical reaction Methods 0.000 description 14
- 230000003044 adaptive effect Effects 0.000 description 10
- 238000010586 diagram Methods 0.000 description 8
- 238000010295 mobile communication Methods 0.000 description 7
- VVNRQZDDMYBBJY-UHFFFAOYSA-M sodium 1-[(1-sulfonaphthalen-2-yl)diazenyl]naphthalen-2-olate Chemical compound [Na+].C1=CC=CC2=C(S([O-])(=O)=O)C(N=NC3=C4C=CC=CC4=CC=C3O)=CC=C21 VVNRQZDDMYBBJY-UHFFFAOYSA-M 0.000 description 4
- 230000006870 function Effects 0.000 description 3
- 238000005259 measurement Methods 0.000 description 3
- 238000005401 electroluminescence Methods 0.000 description 2
- 238000012986 modification Methods 0.000 description 2
- 230000004048 modification Effects 0.000 description 2
- 238000004364 calculation method Methods 0.000 description 1
- 230000008030 elimination Effects 0.000 description 1
- 238000003379 elimination reaction Methods 0.000 description 1
- 238000000605 extraction Methods 0.000 description 1
- 239000004973 liquid crystal related substance Substances 0.000 description 1
- 230000008929 regeneration Effects 0.000 description 1
- 238000011069 regeneration method Methods 0.000 description 1
- 230000004044 response Effects 0.000 description 1
- 230000008054 signal transmission Effects 0.000 description 1
Images








Landscapes
- Telephone Function (AREA)
- Circuit For Audible Band Transducer (AREA)
Abstract
Description
本発明は、音声処理装置、音声処理方法、音声処理プログラム、及び、当該音声処理プログラムが記録された記録媒体に関する。 The present invention relates to a voice processing device, a voice processing method, a voice processing program, and a recording medium on which the voice processing program is recorded.
近年、携帯電話等の移動通信端末装置による通信通話は、日常生活を行う上で、欠かせないものとなってきている。このため、移動通信端末装置による通信通話を、車両の運転中にも、運転操作に支障をきたさずに行うことが可能な、いわゆるハンズフリー通話が注目されている。 In recent years, communication calls using mobile communication terminals such as mobile phones have become indispensable for daily life. For this reason, attention is being paid to so-called hands-free calling, which allows a communication call by a mobile communication terminal device to be performed without hindering driving operation even during driving of a vehicle.
こうしたハンズフリー通話を行うことのできる車載用の装置については、ハンズフリー通話とハンドセット通話とを切り換えることができるもの(特許文献1参照:以下、「従来例1」という)等、様々な技術が提案されている。かかるハンズフリー通話が可能な装置では、送信音声を集音するマイクロフォンと、受信音声を出力するスピーカとを備えているが、通常の電話装置と比べて、スピーカから出力された音声が、マイクロフォンで集音されてしまうエコー現象が発生し易い。 Various in-vehicle devices that can perform such a hands-free call include those that can switch between a hands-free call and a handset call (see Patent Document 1: hereinafter referred to as “Conventional Example 1”). Proposed. A device capable of hands-free calling includes a microphone that collects transmission sound and a speaker that outputs reception sound. Compared to a normal telephone device, the sound output from the speaker is a microphone. Echo phenomenon that is collected easily occurs.
このため、車載用のハンズフリー通話通信装置の多くにおいては、エコーキャンセラが装備されている。かかるエコーキャンセラとしては、例えば、送信音声信号から伝送音声帯域以外の雑音をバンドエリミネーションフィルタで抽出し、その抽出結果を受信音声信号に加算した信号に基づいてエコーを推定する技術が提案されている(特許文献2参照;「従来例2」という)。
For this reason, many of the in-vehicle hands-free communication devices are equipped with an echo canceller. As such an echo canceller, for example, a technique has been proposed in which noise other than a transmission voice band is extracted from a transmission voice signal by a band elimination filter and an echo is estimated based on a signal obtained by adding the extraction result to a reception voice signal. (Refer to
ところで、近年において、多くの車両には音声のステレオ出力やマルチチャンネル出力のために、複数のスピーカを備える音響装置が搭載されている。こうした車両においてハンズフリー通話通信を実現する場合に、当該音響装置の複数のスピーカを利用することが考えられる。 By the way, in recent years, many vehicles are equipped with an audio device including a plurality of speakers for audio stereo output and multi-channel output. When hands-free call communication is realized in such a vehicle, it is conceivable to use a plurality of speakers of the acoustic device.
かかる場合において、通信通話時には、当該複数のスピーカの全てから同一の音量で受信音声を出力させることが最も簡易な方法である。しかしながら、この方法では、利用者にとっての聴取性を確保しつつ、当該複数のスピーカからマイクロフォンへの回り込みエコーを、従来例2のようなエコーキャンセラのみにより十分に除去することは困難であった。 In such a case, at the time of a communication call, it is the simplest method to output the received sound at the same volume from all of the plurality of speakers. However, with this method, it has been difficult to sufficiently remove the wraparound echo from the plurality of speakers to the microphone by using only the echo canceller as in the conventional example 2 while ensuring the audibility for the user.
このため、複数のスピーカを備える場合において、受話音声のスピーカからマイクロフォンへの回り込みエコーを低減することができる技術が切望されていた。かかる要請に応えることが、本発明が解決すべき課題の一つとして挙げられる。 For this reason, in the case where a plurality of speakers are provided, there has been a strong demand for a technique that can reduce the wraparound echo from the speaker of the received voice to the microphone. Meeting this requirement is one of the problems to be solved by the present invention.
本発明は、上記の事情を鑑みてなされたものであり、通話者間で快適な通信通話を行うことのできる新たな音声処理装置及び音声処理方法を提供することを目的とする。 The present invention has been made in view of the above circumstances, and an object of the present invention is to provide a new voice processing apparatus and voice processing method capable of performing a comfortable communication call between callers.
請求項1に記載の発明は、通話通信機能を有する音声処理装置であって、外部との通話のために発せられた音声を集音し、送信音声信号に変換する集音手段と;外部からの受信音声信号に基づいて受信音声を再生出力する複数のスピーカと;前記受信音声の再生に際して、前記複数のスピーカの中から再生出力用に選択される少なくとも1つの選択スピーカと、前記選択スピーカから出力される音声の音量との組み合わせから成る複数の受信音声再生条件候補が記憶された記憶手段と;前記複数の受信音声再生条件候補のそれぞれに従って、内部的に発生したテスト音声を、順次、前記選択スピーカから再生出力させるテスト音声出力制御手段と;前記テスト音声の再生出力に起因して前記集音手段により集音された音のエコー量を検出するエコー検出手段と;前記複数の受信音声再生条件候補のそれぞれに対応する前記エコー検出手段による検出結果に基づいて、前記複数の受信音声再生条件候補の中から最適条件を決定する最適条件決定手段と;通話通信中において、前記最適条件を受信音声再生条件として設定する条件設定手段と;を備えることを特徴とする音声処理装置である。
The invention according to
請求項6に記載の発明は、外部との通話のために発せられた音声を集音し、送信音声信号に変換する集音手段と;外部からの受信音声信号に基づいて受信音声を再生出力する複数のスピーカと;前記受信音声の再生に際して、前記複数のスピーカの中から再生出力用に選択される少なくとも1つの選択スピーカと、前記選択スピーカから出力される音声の音量との組み合わせから成る複数の受信音声再生条件候補が記憶された記憶手段とを備える音声処理装置において使用される音声処理方法であって、前記複数の受信音声再生条件候補のそれぞれに従って、内部的に発生したテスト音声を、順次、前記選択スピーカから再生出力するテスト音声出力工程と;前記テスト音声の再生出力に起因して前記集音手段により集音された音のエコー量を検出するエコー検出工程と;前記複数の受信音声再生条件候補のそれぞれに対応する前記エコー検出工程における検出結果に基づいて、前記複数の受信音声再生条件候補の中から最適条件を決定する最適条件決定工程と;通話通信中において、前記最適条件を受信音声再生条件として設定する条件設定工程と;を備えることを特徴とする音声処理方法である。 According to a sixth aspect of the present invention, there is provided sound collecting means for collecting a voice emitted for a call with the outside and converting it into a transmission voice signal; and reproducing and outputting the received voice based on the received voice signal from the outside. A plurality of speakers, each of which is a combination of at least one selected speaker selected for reproduction output from among the plurality of speakers and the volume of the sound output from the selected speaker. Is a voice processing method used in a voice processing device comprising a storage means storing received voice playback condition candidates, and internally generated test voices according to each of the plurality of received voice playback condition candidates, A test sound output step of sequentially reproducing and outputting from the selected speaker; and an echo amount of the sound collected by the sound collecting means due to the reproduction output of the test sound An echo detection step to detect; and an optimum condition determination for determining an optimum condition from among the plurality of received voice reproduction condition candidates based on a detection result in the echo detection step corresponding to each of the plurality of received voice reproduction condition candidates And a condition setting step of setting the optimum condition as a reception voice reproduction condition during a call communication.
請求項7に記載の発明は、請求項6に記載の音声処理方法を演算手段に実行させる、ことを特徴とする音声処理プログラムである。 A seventh aspect of the present invention is a voice processing program characterized by causing a calculation means to execute the voice processing method according to the sixth aspect.
請求項8に記載の発明は、請求項7に記載の音声処理プログラムが、演算手段により読み取り可能に記録された記録媒体である。 The invention according to claim 8 is a recording medium on which the sound processing program according to claim 7 is recorded so as to be readable by the arithmetic means.
以下、本発明の一実施形態を、図1〜図10を参照して説明する。なお、以下の説明及び図面においては、同一又は同等の要素には同一の符号を付し、重複する説明は省略する。 Hereinafter, an embodiment of the present invention will be described with reference to FIGS. In the following description and drawings, the same or equivalent elements will be denoted by the same reference numerals, and redundant description will be omitted.
[構成]
図1には、一実施形態に係る音声処理装置100の概略的な構成がブロック図にて示されている。なお、以下の説明においては、音声処理装置100は、車両CR(図2参照)に搭載される装置であるものとする。また、この音声処理装置100は、携帯電話装置900との間で無線通信を行うものである。音声処理装置100は、携帯電話装置900及び移動通信網を介して、通話相手とハンズフリーで通話通信を行うことができるものであるとする。
[Constitution]
FIG. 1 is a block diagram illustrating a schematic configuration of a
この図1に示されるように、音声処理装置100は、制御ユニット110と、ドライブユニット120とを備えている。
As shown in FIG. 1, the
また、音声処理装置100は、音出力ユニット130Lと、音出力ユニット130Rと、音出力ユニット130SLと、音出力ユニット130SRとを備えている。
In addition, the
ここで、音出力ユニット130Lはレフトスピーカ131L(以下、「Lスピーカ」とも記す)を有し、音出力ユニット130Rはライトスピーカ131R(以下、「Rスピーカ」とも記す)を有している。また、音出力ユニット130SLはサラウンドレフトスピーカ131SL(以下、「SLスピーカ」とも記す)を有し、音出力ユニット130SRはサラウンドライトスピーカ131SR(以下、「SRスピーカ」とも記す)を有している。
Here, the
さらに、音声処理装置100は、集音手段としての集音ユニット140と、表示ユニット150と、操作入力ユニット160と、記憶手段としてのハードディスク装置等の記憶装置170と、アンテナ180とを備えている。
Furthermore, the
なお、制御ユニット110以外の要素120〜180は、制御ユニット110に接続されている。
制御ユニット110は、音声処理装置100の全体を統括制御する。この制御ユニット110の詳細については、後述する。
The
ドライブユニット120は、音声コンテンツが記録されたコンパクトディスクCDが挿入されると、その旨を制御ユニット110に報告する。そして、ドライブユニット120は、コンパクトディスクCDが挿入された状態で、制御ユニット110から音声コンテンツの再生指令DVCを受けると、再生指定がなされた音声をコンパクトディスクCDから読み出す。かかる音声コンテンツの読み出し結果は、オーディオ信号であるコンテンツデータCTDとして、制御ユニット110へ向けて送られる。
When the compact disc CD on which the audio content is recorded is inserted, the
音出力ユニット130L〜130SRのそれぞれは、上述したスピーカ131L〜131SRの他に、制御ユニット110から受信した音声出力信号AOSL〜AOSSRを増幅する増幅器とを備えている。これらの音出力ユニット130L〜130SRは、制御ユニット110による制御のもとで、移動通信網及び携帯電話装置900を順次介した通話相手からの受信音声信号に対応する音声、制御ユニット110において生成されたテスト音声信号に対応する音声、楽曲等を再生して出力する。
Each of the
本実施形態では、図2に示されるように、音出力ユニット130Lのレフトスピーカ131Lは、助手席側の前方ドア筐体内に配置される。このレフトスピーカ131Lは、助手席側を向くように配設されている。
In the present embodiment, as shown in FIG. 2, the
音出力ユニット130Rのライトスピーカ131Rは、運転席側の前方ドア筐体内に配置される。このライトスピーカ131Rは、運転席側を向くように配設されている。
The
音出力ユニット130SLのサラウンドレフトスピーカ131SLは、助手席側後部の筐体内に配置される。このサラウンドレフトスピーカ131SLは、助手席側の後部座席を向くように配設されている。
Surround
音出力ユニット130SRのサラウンドライトスピーカ131SRは、運転席側後部の筐体内に配置される。このサラウンドライトスピーカ131SRは、運転席側の後部座席を向くように配設されている。
Surround
図1に戻り、集音ユニット140は、(i)周囲の音を収集して電気的なアナログ音声信号とするマイクロフォン141、(ii)マイクロフォンから出力されたアナログ音声信号を増幅する増幅器、(iii)増幅されたアナログ音声信号をデジタル音声信号に変換するAD変換器(Analog to Digital Converter)とを備えて構成されている。ここで、マイクロフォン141は、図2に示されるように、運転席の前方に配置され、その指向性は後部座席に向かって放射状になっている。集音ユニット150による集音結果は、集音結果データAADとして、制御ユニット110に報告される。
Returning to FIG. 1, the
図1に戻り、表示ユニット150は、(i)液晶パネル、有機EL(Electro Luminescence)パネル、PDP(Plasma Display Panel)等の表示デバイス151と、(ii)制御ユニット110から送出された表示制御データに基づいて、表示ユニット150全体の制御を行うグラフィックレンダラ等の表示コントローラと、(iii)表示画像データを記憶する表示画像メモリ等を備えて構成されている。この表示ユニット150は、制御ユニット110による制御のもとで、ドライブユニット120を利用した音声再生用の操作ガイダンスや、通信通話における通話相手の電話番号、電話番号に対応する氏名が登録されている場合には通話相手の氏名、通話時間等を表示する。
Returning to FIG. 1, the
操作入力ユニット160は、音声処理装置100の本体部に設けられたキー部、あるいはキー部を備えるリモート入力装置等により構成される。ここで、本体部に設けられたキー部としては、表示ユニット150の表示デバイス151に設けられたタッチパネルを用いることができる。なお、キー部を有する構成に代えて、音声入力する構成を採用することもできる。
The
この操作入力ユニット160を利用者が操作することにより、音声処理装置100の動作内容の設定が行われる。例えば、後述する受信音声再生条件情報171の設定、音声コンテンツの再生指令等を、利用者が操作入力ユニット160を利用して行う。こうした入力内容は、操作入力データIPDとして、操作入力ユニット160から制御ユニット110へ向けて送られる。
When the user operates the
記憶装置170は、不揮発性の記憶装置であるハードディスク装置等から構成される。記憶装置170内には、受信音声再生条件情報171などの様々な情報が記憶されている。
The
受信音声再生条件情報171とは、受信音声の再生に際して、スピーカ131L〜131SRの中から再生出力用に選択される選択スピーカと、選択スピーカから出力される音声の音量との組み合わせからなる複数の受信音声再生条件の候補(以下、「プリセット」ともいう)である。かかる受信音声再生条件情報171の例が、図3に示されている。この図3では、例えば、プリセット(P=1)が、選択スピーカを車両CRの前方に配置されるLスピーカとRスピーカとし、そのスピーカから出力される音声の音量レベルを6とするプリセットであり、プリセット(P=2)が、選択スピーカを車両CRの後方に配置されるSLスピーカとSRスピーカとし、そのスピーカから出力される音声の音量レベルを6とするプリセットとなっている。なお、本実施形態では、音声の音量レベルは0〜10までとする。
The received audio
図1に戻り、アンテナ180は、携帯電話装置900からの無線信号を受信するとともに、携帯電話装置900へ向けて無線信号を送信する。アンテナ180による受信結果は、受信音声信号RESとして、制御ユニット110へ向けて出力される。また、アンテナ180は、制御ユニット110からの送信音声信号TRSを受け、当該送信音声信号TRSに対応する無線信号を携帯電話装置900へ向けて送信する。
Returning to FIG. 1, the
制御ユニット110は、上述したように、音声処理装置100の全体を統括制御する。この制御ユニット110は、図4に示されるように、制御処理部111と、オーディオ処理部112と、通話音声処理部113とを備えている。また、制御ユニット110は、アナログ変換部114と、出力信号選択部115と、音量調整部116とを備えている。
As described above, the
制御処理部111は、操作入力ユニット160に入力された指令入力等に基づいて、オーディオ処理部112、通話音声処理部113、出力信号選択部115及び音量調整部116を制御する。また、制御処理部111は、ドライブユニット120及び表示ユニット150を制御する。この制御処理部111については、後述する。
The
オーディオ処理部112は、音声コンテンツを含む再生すべきコンテンツの指定入力がなされたことが操作入力ユニット160から報告された場合、及び、ドライブユニット120にコンパクトディスクCDが挿入されたときにコンテンツを自動再生すべき旨の設定がなされている場合に、制御処理部111からの音声コンテンツ処理制御指令APCに従って、当該再生すべきコンテンツに対応するコンテンツデータCTDをドライブユニット120から読み出して展開し、デジタル音データ信号を生成する。引き続き、オーディオ処理部112は、生成されたデジタル音データ信号を解析し、デジタル音データ信号に含まれるチャンネル指定情報に従って、デジタル音データ信号を、上述したスピーカ131L,131R,131SL,131SRのそれぞれに供給されるように分離する。このようにして分離された信号は、チャンネル処理信号PCDL,PCDR,PCDSL,PCDSRとして、アナログ変換部114へ向けて出力される。
The
通話音声処理部113は、携帯電話装置900及び移動通信網を介した外部との通話音声の処理を行う。この通話音声処理部113は、図5に示されるにように、通信インターフェイス部210と、テスト信号発生部220と、信号切替部230とを備えている。また、通話音声処理部113は、エコーキャンセル手段としてのエコーキャンセル部240と、エコー検出手段としてのエコー検出部250とを備えている。
The call
通信インターフェイス部210は、携帯電話装置900との間における信号授受に関して利用される。この通信インターフェイス部210は、受信部211と、送信部212とを備えて構成されている。
The
受信部211は、携帯電話装置900からの受信音声信号RESを受ける。そして、受信部211は、受信音声信号RESを内部処理用の受信信号REDに変換して、信号切替部230へ向けて出力する。また、受信部211は、受信音声信号RESに基づいて通話通信の着信及び切断を検出し、検出結果を、着信指示REIとして、制御処理部111へ向けて出力する。
The receiving
送信部212は、エコーキャンセル部240からの送信信号TRDを受ける。そして、送信部212は、送信信号TRDを携帯電話装置900への送信用の送信音声信号TRSに変換して、携帯電話装置900へ向けて出力する。
The
テスト信号発生部220は、制御処理部111からテスト音声信号を発生すべき旨のテスト信号発生指令SGCを受けると、テスト音声信号SGDを発生させる。こうして発生させたテスト音声信号SGDは、信号切替部230へ向けて送られる。
When the test
信号切替部230は、スイッチ素子を備えている。このスイッチ素子は、入力端子としてA端子及びB端子を有するとともに、出力端子としてC端子を有している。端子Aは受信部211に接続された端子であり、B端子はテスト信号発生部220に接続された端子である。端子Aでは受信信号REDを受け、端子Bではテスト音声信号SGDを受ける。そして、制御処理部111からの指令RSCに従って、A端子とC端子とを導通したり、B端子とC端子とを導通したり、更には、A端子及びB端子のいずれともC端子を導通しなかったりする。C端子からは、選択された信号が、信号RSDとしてアナログ変換部114へ向けて送られるとともに、エコーキャンセル部240へ向けて送られる。
The
エコーキャンセル部240は、通信通話中の集音結果データAADに含まれるエコー音成分を除去するためのものである。このエコーキャンセル部240は、図6に示されるように、スイッチ241と、フィルタ手段としての適応フィルタ242と、減算手段としての減算器243とを備えている。
The
スイッチ素子241は、入力端子Aと出力端子Bとを有している。このスイッチ素子241は、減算器243の出力する送信信号TRDが、適応フィルタ242のフィルタ係数を算出するために適応フィルタ242へ送られる信号伝送路上に設けられている。スイッチ素子241のオン・オフの動作は、制御処理部111からの指令ECCに従って行われる。
The
適応フィルタ242は、不図示の係数更新部とフィルタ部とから構成されている。係数更新部は、LMS(Least Mean Square)アルゴリズムなどの学習同定法により、減算器243の出力する送信信号TRDのパワーが最小となるように、適応フィルタ242のフィルタ係数を算出し、このフィルタ係数をフィルタ部に設定する処理を繰り返す。フィルタ部は、係数更新部により設定された係数により定まるインパルス応答を有するFIRフィルタなどである。このフィルタ部は、信号RSDから擬似エコー信号ECDを生成する。こうして生成した擬似エコー信号ECDは、減算器243へ向けて送られる。
The
減算器243は、集音ユニット140からの集音結果データAADから、擬似エコー信号ECDを減算する。減算結果は、送信信号TRDとして、送信部212へ向けて送られるとともに、エコー検出部250へ向けて送られる。
The
図5に戻り、エコー検出部250は、エコーキャンセル部240から送られてくる送信信号TRDのエコー量を検出する。検出結果は、エコー量値EVDとして、エコー検出部250から制御処理部111へ向けて送られる。
Returning to FIG. 5, the
図4に戻り、アナログ変換部114は、オーディオ処理部112からのデジタル信号であるチャンネル処理信号PCDL〜PCDSRと、通話音声処理部113からのデジタル信号である信号RSDとを受ける。そして、アナログ変換部114は、オーディオ処理部112から受けたチャンネル処理信号PCDL〜PCDSRをアナログ信号PCSL〜PCSSRに変換し、通話音声処理部113から受けた信号RSDをアナログ信号RSSに変換する。このアナログ変換部114は、当該5種のデジタル信号に対応して、互いに同様に構成された5個のDA(Digital to Analogue)変換器を備えている。このアナログ変換部114による変換結果であるアナログ信号PCSL〜PCSSR,RSSは、出力信号選択部115へ向けて送られる。
Returning to FIG. 4, the
出力信号選択部115は、アナログ変換部114からのアナログ信号PCSL〜PCSSR,RSSを受ける。そして、出力信号選択部115は、制御処理部111からの出力信号選択指令ODSに従って、音量調整部116へ向けての、アナログ信号PCSL〜PCSSRの供給、アナログ信号RSSの供給、及び、いずれの信号も供給しないかを選択する。かかる機能を有する出力信号選択部115は、図7に示されるように、4個のスイッチ素子115L〜115SRを備えている。
The output
各スイッチ素子115L〜115SRは、入力端子としてA端子及びB端子を有するとともに、出力端子としてC端子を有している。端子A及び端子Bはアナログ変換部114に接続された端子である。また、端子Cは音量調整部116に接続された端子である。各スイッチ素子115L〜115SRでは、A端子でアナログ信号PCSL〜PCSSRを受けるとともに、B端子でアナログ信号RSSを受ける。そして、制御処理部111からの出力信号選択指令ODSにおける個別出力選択指令ODSL〜ODSSRに従って、A端子とC端子とを導通したり、B端子とC端子とを導通したり、更には、A端子及びB端子のいずれともC端子を導通しなかったりする。スイッチ素子115L〜115SRのC端子からは、選択された信号(無信号を含む)が、音出力選択信号PBSL〜PBSSRとして音量調整部116へ向けて送られる。
Each of the
図4に戻り、音量調整部116は、出力信号選択部115からの音出力選択信号PBSL〜PBSSRを受ける。この音量調整部116は、音出力選択信号PBSL〜PBSSRのそれぞれごとに、いわゆる電子ボリューム等により、互いに独立な音量調整が可能となっている。
Returning to FIG. 4, the
音量調整部116は、音出力選択信号PBSL〜PBSSRのそれぞれに対して、制御処理部111からの音量調整指令VLCL〜VLCSRに従った音量調整を行う。かかる調整結果は、音声出力信号AOSL〜AOSSRとして、音出力ユニット130L〜130SRへ向けて出力される。
The
制御処理部111は、上述した他の構成要素を制御しつつ、音声処理装置100の機能を発揮させる。この制御処理部は、図8に示されるように、最適条件決定手段としての最適条件決定部261と、テスト音声出力制御手段、条件設定手段及びエコーキャンセル制御手段としての制御部262とを備えている。
The
最適条件決定部261は、受信音声の出力に際して、受信音声再生条件情報171に設定された受信音声再生条件の候補の中から、最適条件を決定する。この最適条件決定部261は、後述する「最適条件決定モード」時のときのみ処理を行う。
The optimum
最適条件決定部261は、制御部262からの処理指令DMCを受けると、エコー検出部250から送られてくるエコー量値EVDを取得するとともに、当該エコー量値EVDを不図示のメモリに記憶する。このエコー量値EVDは、受信音声再生条件の候補の数(プリセットPの数)だけ、順次、エコー検出部250から送られてくる。そして、最適条件決定部261は、順次、送られてくるエコー量値EVDの中から、エコー量値EVDが最小となるときのプリセットPの値を決定する。このようにして決定したプリセットPの値は、値PBDとして、制御部262へ向けて送られる。
When receiving the processing command DMC from the
制御部262は、音声処理装置100における「コンテンツ再生モード」と「通話モード」の2つのモードの動作を制御する。ここで、「コンテンツ再生モード」とはコンパクトディスクCDから音声コンテンツを読み出してオーディオ信号を再生するモードである。また、「通話モード」とは、携帯電話装置900及び移動通信網を介して外部と通信通話を行うモードである。なお、「通話モード」には、通常通話を行う「通常通話モード」と、受信音声再生条件の候補の中から最適条件を決定する「最適条件決定モード」の2種類がある。
The
制御部262は、通常は、「コンテンツ再生モード」の動作の制御を行う。そして、制御部262は、操作入力ユニット160からの通話発信指令を受けた場合、及び、受信部211からの着信指示REIを受けた場合に、「通常通話モード」の動作制御を開始する。一方、制御部262は、「通常通話モード」にある状態において、操作入力ユニット160からの通話切断指令を受けた場合、及び、受信部211からの着信指示REIが途絶えた場合に、「コンテンツ再生モード」の動作制御に復帰する。なお、制御部262による「最適条件決定モード」の動作制御は、操作入力ユニット160からの最適条件決定指令を受けた場合にのみ行われる。
The
ここで、「コンテンツ再生モード」と「通話モード」との切替えは、出力信号選択部115におけるスイッチ操作で行われる。また、「通常通話モード」と「最適条件決定モード」との切替えは、信号切替部230におけるスイッチ操作で行われる。
Here, switching between the “content reproduction mode” and the “call mode” is performed by a switch operation in the output
「最適条件決定モード」の動作制御に際し、制御部262は、まず、受信音声再生条件情報171から、受信音声再生条件を取得する。この受信音声再生条件には複数の候補があり(図3参照)、制御部262は、1番目(プリセット(P=1))の候補に対応した音声処理装置100の設定を行う。
In the operation control of the “optimum condition determination mode”, the
この設定に際し、制御部262は、出力信号選択部115へ向けて、信号RSSを選択すべき旨の指令を送る。より具体的には、出力信号選択部115における最初の測定対象となるスピーカに対応するスイッチ素子のB端子とC端子とを導通させるとともに、他のスイッチ素子におけるC端子がA端子及びB端子のいずれとも導通しないことを指定する出力信号選択指令ODSを出力信号選択部115へ向けて送る。図3を例にとって説明すると、制御部262は、Lスピーカ、Rスピーカに対応するスイッチ素子115L,115RのB端子とC端子を導通させるとともに、SLスピーカ、SRスピーカに対応するスイッチ素子115SL,115SRにおけるC端子がA端子及びB端子のいずれとも導通しないことを指定する出力信号選択指令ODSを出力信号選択部115へ向けて送る。
In this setting, the
また、この設定に際し、制御部262は、信号切替部230へ向けて、テスト信号発生部220からのテスト音声信号SGDを選択すべき旨の指令、すなわち、スイッチ素子の端子Bと端子Cを導通させることを指定する指令RSCを送る(図5参照)。
In this setting, the
さらに、この設定に際し、制御部262は、スイッチ241へ向けて、減算器243からの送信信号TRDを適応フィルタ242へ送らない旨の指令、すなわち、スイッチ241をオフにすべき旨の指令ECCを送る(図6参照)。
Further, at the time of this setting, the
さらに、この設定に際し、制御部262は、音量調整部116へ向けて、LスピーカとRスピーカから出力すべき音量を、レベル6に調整すべき旨の音量調整指令VLCL,VLCRを送る。
Further, in this setting, the
このようにして、プリセット(P=1)の候補に対応した音声処理装置100の設定が、終了すると、制御部262は、次いで、テスト音声信号SGDを発生すべき旨のテスト信号発生指令SGCを、テスト信号発生部220へ向けて送る。また、制御部262は、テスト信号発生指令SGCと同時に、処理指令DMCを、最適条件決定部261へ向けて送る(図8参照)。
In this way, when the setting of the
制御部262は、エコー検出部250からエコー量値EVDを受けると、プリセット(P=1)の候補における処理が終了した判断し、次のプリセット(P=2)の候補に対応した音声処理装置100の設定を行う。
When the
すべての受信音声再生条件の候補についてのエコー量値EVDの検出が終了した後、制御部262は、最適条件決定部261から、最適条件のプリセットである値PBDを受ける。この値PBDは、制御部262内の不図示の記憶部に記憶される。
After the detection of the echo amount value EVD for all the received audio reproduction condition candidates is completed, the
こうして、受信音声再生条件の候補の中から最適条件が決定されると、制御部262は、「最適条件決定モード」の動作制御を終了する。
Thus, when the optimum condition is determined from the received audio reproduction condition candidates, the
前述したように、音声処理装置100は、通常は、「コンテンツ再生モード」の動作の制御を行うが、操作入力ユニット160からの通話発信指令を受けた場合、及び、受信部211からの着信指示REIを受けた場合に、「通常通話モード」の動作制御を開始する。
As described above, the
この「通常通話モード」の動作制御に際し、制御部262は、まず、最適条件決定部261から受けた最適条件のプリセットである値PBDを参照し、受信音声再生条件情報171から、最適条件となる受信音声再生条件(以下、単に「最適条件」という)を取得する。そして、この最適条件に対応した音声処理装置100の設定を行う。
In the operation control of the “normal call mode”, the
この設定に際し、制御部262は、出力信号選択部115へ向けて、信号RSSを最適条件の選択スピーカから出力することが可能なスイッチ操作をすべき旨の出力信号選択指令ODSを送る。
In this setting, the
また、この設定に際し、制御部262は、信号切替部230へ向けて、受信部211からの受信信号REDを選択すべき旨の指令、すなわち、スイッチ素子の端子Aと端子Cを導通させることを指定する指令RSCを送る(図5参照)。
In this setting, the
さらに、この設定に際し、制御部262は、スイッチ241へ向けて、減算器243からの送信信号TRDを適応フィルタ242へ送る旨の指令、すなわち、スイッチ241をオンにすべき旨の指令ECCを送る(図6参照)。
Further, at the time of this setting, the
さらに、この設定に際し、制御部262は、音量調整部116へ向けて、選択スピーカから出力すべき音量を、最適条件のレベルに調整すべき旨の音量調整指令VLCL〜VLCRを送る。
Furthermore, in this setting, the
「コンテンツ再生モード」の動作制御に際し、制御部262は、出力信号選択部115へ向けて、スイッチ素子115L〜115SRの全てについて、A端子とC端子とを導通させるべきことを指定する出力信号選択指令ODSを送る。この結果、アナログ変換部114からのアナログ信号PCSL〜PCSSRが、出力信号選択部115を介して、音出力選択信号PBSL〜PBSSRとして、音量調整部116へ向けて供給されるようになる。
In the operation control of the “content reproduction mode”, the
また、制御部262は、「コンテンツ再生モード」の動作制御に際し、利用者が再生すべき音声コンテンツの指定を支援するための案内画面を表示ユニット150に表示させる。そして、操作入力ユニット160から音声コンテンツを指定した再生指令が入力されると、制御部262は、ドライブユニット120を制御して、再生コンテンツのデータ読み出しを制御する。
In addition, the
また、制御部262は、「コンテンツ再生モード」の動作制御に際し、音量調整部116を制御して、音出力ユニット130L〜130SRのスピーカ131L〜131SRへの出力音量を調整する。この出力音量の制御に際して、制御部262は、操作入力ユニット160に入力された音量指定に基づいて音量調整指令VLCL〜VLCSRを生成し、音量調整部116へ向けて送る。
The
[動作]
次に、上記のように構成された音声処理装置100の動作について、「最適条件決定モード」のときの動作に主に着目して説明する。
[Operation]
Next, the operation of the
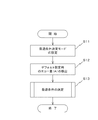
利用者が操作入力ユニット160を利用して、受信音声再生条件の候補の中から最適条件を決定すべき旨の指令を入力することにより、音声処理装置100の「最適条件決定モード」の動作が開始する。こうして、「最適条件決定モード」の動作が開始すると、図9のステップS11において、「最適条件決定モード」の設定が行われる。
When the user uses the
このステップS11では、制御部262は、通話音声処理部113内の信号切替部230へ向けて、テスト信号発生部220からのテスト音声信号SGDを選択すべき旨の指令RSCを送る。この指令RSCに従って、信号切替部230によりテスト音声信号SGDが選択され、信号RSDとしてアナログ変換部114へ送られることになる。
In step S <b> 11, the
また、制御部262は、通話音声処理部113におけるエコーキャンセル部240内のスイッチ241へ向けて、減算器243からの送信信号TRDを適応フィルタ242へ送らない旨の指令ECCを送る。この指令ECCにより、スイッチ241はオフとなる。この結果、エコーキャンセル部240におけるエコーキャンセルの処理は行われない。これらの設定が終了すると、処理はステップS12へ進む。
In addition, the
ステップS12では、デフォルト設定時におけるテスト音声のエコー量値EVDを検出する。ここで、デフォルト設定とは、本実施形態では、テスト音声を出力する選択スピーカをスピーカ131L〜131SRのすべてとし、その音量レベルを6とするものであるとする。
In step S12, the echo amount value EVD of the test voice at the time of default setting is detected. Here, in this embodiment, the default setting is that all the
このステップS12では、制御部262は、まず、上述したデフォルト設定を行う。このデフォルト設定に際し、制御部262は、出力信号選択部115へ向けて、全てのスイッチ素子115L〜115SRについて、B端子とC端子を導通させるべき旨の出力信号選択指令ODSを送る。次いで、制御部262は、音量調整部116へ向けて、スピーカ131L〜131SRから出力すべき音量を、レベル6に調整すべき旨の音量調整指令VLCL〜VLC SRを送る。この設定後、制御部262は、テスト信号発生部220へ向けて、テスト音声信号SGDを発生すべき旨のテスト信号発生指令SGCを送る。
In step S12, the
テスト信号発生指令SGCを受けたテスト信号発生部220は、テスト音声信号SGDを発生させる。こうして発生させたテスト音声信号SGDは、信号切替部230へ向けて送られる。この結果、信号切替部230、アナログ変換部114、出力信号選択部115音量調整部116を経由して、音出力ユニット130L〜130SRからテスト音声が出力される。
The
このテスト音声は、集音ユニット140で集音され、集音結果データAADとして、減算器243へ向けて送られる(図6参照)。なお、前述したように、「最適条件決定モード」ではスイッチ241がオフとなっているため、減算器243からエコー検出部250へ向けて送られる送信信号TRDは、エコーキャンセルの処理が施されていない。そして、エコー検出部250は、減算器243から送られてくる送信信号TRDを受けて、そのエコー量を検出する。検出結果は、エコー量値EVDとして、最適条件決定部261へ向けて送られる。そして、最適条件決定部261は、このエコー量値EVDをエコー量(A)として内部の記憶部に記憶する。
The test sound is collected by the
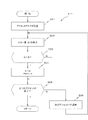
次いで、ステップS13において、受信音声を再生するための最適条件の決定処理が行われる。この処理では、図10に示されるように、まず、ステップS21において、制御部262は、受信音声再生条件情報171から受信音声再生条件を取得し、プリセット(P=1)の設定を行う。かかるプリセットに対応する選択スピーカの設定については、出力信号選択部115へ向けての出力信号選択指令ODSで行い、選択スピーカの音量の設定については、音量調整部116へ向けての音量調整指令VLCL〜VLCSRで行う。この設定が完了すると、処理はステップS22へ進む。
Next, in step S13, an optimum condition determination process for reproducing the received sound is performed. In this process, as shown in FIG. 10, first, in step S21, the
ステップS22では、当該プリセットにおけるテスト音声のエコー量値EVDを検出する。このステップでは、制御部262は、テスト音声信号SGDを発生すべき旨のテスト信号発生指令SGCを、テスト信号発生部220へ向けて送る。この結果、テスト信号発生部220からテスト音声信号SGDが発生し、このテスト音声信号SGDは、信号切替部230、アナログ変換部114、出力信号選択部115及び音量調整部116を経由して、音出力ユニット130L〜130SRからテスト音声として出力される。そして、その後はステップS12におけるのと同様に、テスト音声は、集音ユニット140で集音され、集音結果データAADとして、減算器243へ向けて送られる。そして、減算器243からは、エコーキャンセルの処理が施されていない送信信号TRDがエコー検出部250へ向けて送られる。エコー検出部250は、減算器243から送られてくる送信信号TRDを受けて、そのエコー量を検出する。検出結果は、エコー量値EVDとして、最適条件決定部261へ向けて送られる。そして、最適条件決定部261は、このエコー量値EVDをエコー量(B)として内部の記憶部に記憶する。この後、処理はステップS23へ進む。
In step S22, the echo amount value EVD of the test sound in the preset is detected. In this step, the
ステップS23では、最適条件決定部261が、数値化されたエコー量(A)とエコー量(B)の大きさを比較し、エコー量(A)がエコー量(B)より大きいか否かを判定する。この判定の結果が肯定的であった場合(ステップS23:Y)には、処理はステップS24へ進む。
In step S23, the optimum
ステップS24では、最適条件決定部261が、エコー量(B)をエコー量(A)に置き換えるとともに、このときのプリセットPの値を値PBDに設定する。これらの設定が完了すると、処理はステップS25へ進む。
In step S24, the optimum
一方、ステップS23における判定の結果が否定的であった場合(ステップS23:N)には、処理はステップS25へ進む。 On the other hand, when the result of the determination in step S23 is negative (step S23: N), the process proceeds to step S25.
ステップS25では、制御部262が、すべてのプリセットに関するテスト音声の音量検出が終了したか否かを判定する。この判定の結果が否定的であった場合(ステップS25:N)には、処理はステップS26へ進む。
In step S25, the
ステップS26では、次の測定対象となるプリセットに対する音声処理装置100の設定が行われる。この設定も、ステップS21におけるのと同様に、制御部262は、受信音声再生条件情報171から受信音声再生条件を基にして、測定対象となるプリセットに対する設定を行う。
In step S26, the
ステップS26の処理が終了すると、処理はステップS22へ戻る。以後、ステップS25における判定の結果が肯定的となるまで、ステップS22〜S26の処理が繰り返される。 When the process of step S26 ends, the process returns to step S22. Thereafter, the processes in steps S22 to S26 are repeated until the result of the determination in step S25 becomes affirmative.
全てのプリセットに対応する計測処理が終了し、ステップS25における判定の結果が肯定的になると(ステップS25:Y)、最適条件決定部261が、最適条件のプリセットである値PBDを制御部262へ報告する。そして、制御部262が、値PBDを記憶部に記憶すると、「最適条件決定モード」の動作が終了する。
When the measurement processing corresponding to all the presets is completed and the determination result in step S25 becomes affirmative (step S25: Y), the optimum
「最適条件決定モード」の動作が終了すると、音声処理装置100は「コンテンツ再生モード」になる。なお、前述したように、音声処理装置100は、通常時は「コンテンツ再生モード」の動作を行うが、制御部262が、操作入力ユニット160からの通話発信指令、または、受信部211から着信指示REIを受けた場合に、「通常通話モード」となる。
When the operation of the “optimum condition determination mode” ends, the
音声処理装置100が「通常通話モード」になると、制御部262は、まず、最適条件決定部261から受けた最適条件のプリセットである値PBDを参照し、受信音声再生条件情報171から、最適条件となる受信音声再生条件を取得する。次いで、出力信号選択部115へ向けて、信号RSSを最適条件の選択スピーカから出力することが可能なスイッチ操作をすべき旨の出力信号選択指令ODSを送る。
When the
さらに、制御部262は、信号切替部230へ向けて、受信部211からの受信信号REDを選択すべき旨の指令を送り、スイッチ241へ向けて、減算器243からの送信信号TRDを適応フィルタ242へ送る旨の指令を送る。このスイッチ241の設定により、エコーキャンセル部240において、エコーキャンセル処理が行われる。さらに、制御部262は、音量調整部116へ向けて、選択スピーカから出力すべき音量を、最適条件のレベルに調整すべき旨の音量調整指令VLCL〜VLCSRを送る。
Further, the
「通常通話モード」時において、操作入力ユニット160からの通話切断指令を受けた場合、及び、受信部211からの着信指示REIが途絶えた場合に、音声処理装置100は、「コンテンツ再生モード」の動作を再開する。
When receiving a call disconnect command from the
制御部262は、「コンテンツ再生モード」時には、利用者が再生すべき音声コンテンツの指定を支援するための案内画面を表示ユニット150に表示させる。そして、操作入力ユニット160に音声コンテンツを指定した再生指令が入力されると、制御部262は、ドライブユニット120を制御して、音声コンテンツのデータ読み出しを制御する。
The
また、制御部262は、「コンテンツ再生モード」時には、オーディオ処理部112を制御して、ドライブユニット120からのコンテンツデータCTDを4個のチャンネル処理信号PCDL〜PCDSRに分離させる。
In the “content reproduction mode”, the
また、制御部262は、「コンテンツ再生モード」時には、音量調整部116を制御して、音出力ユニット130L〜130SRのスピーカ131L〜131SRのからの出力音量を調整する。
The
以上説明したように、本実施形態では、車両内でハンズフリー通話を行う際に、受信音声を再生するために4個のスピーカ131L〜131SRを使用する。これらのスピーカの中から、受信音声の再生出力用に選択される選択スピーカと、その選択スピーカから出力される音量との組み合わせからなる複数の受信音声再生条件の候補を、利用者が設定する。そして、各受信音声再生条件のもとで、テスト音声を順次、発生させ、その条件下でのエコー音成分を計測する。そして、この計測結果を基にして、受話音声のスピーカから出力のマイクロフォンへの回り込みエコーが最小となる最適条件を自動的に決定する。これにより、複数のスピーカを備える場合において、受話音声のスピーカから出力のマイクロフォンへの回り込みエコーを低減することができる。
As described above, in the present embodiment, the four
したがって、本実施形態によれば、車両の運転中にハンズフリー通話を行う際に、通話者間で快適な通信通話を行うことができる。 Therefore, according to the present embodiment, when a hands-free call is made during driving of the vehicle, a comfortable communication call can be made between the callers.
[実施形態の変形]
本発明は、上記の実施形態に限定されるものではなく、様々な変形が可能である。
[Modification of Embodiment]
The present invention is not limited to the above-described embodiment, and various modifications are possible.
例えば、上記の実施形態では、音声処理装置100と携帯電話装置900との間の通信を無線通信で実現することとしたが、例えば、音声処理装置100と携帯電話装置900との間をケーブルを用いて接続し、音声処理装置100と携帯電話装置900との間の通信を有線通信とするものであってもよい。
For example, in the above embodiment, communication between the
また、上記の実施形態では、音声処理装置100は携帯電話装置900と無線通信を行うとしたが、携帯電話装置に限定せず、PHSやPDA、自動車電話等の移動通信端末装置と無線通信を行うものであってもよい。
In the above embodiment, the
また、上記の実施形態では、受信音声を再生するスピーカとして4個のスピーカを備えることとしたが、2個、3個、又は、5個以上のスピーカから受信音声を再生出力させるようにすることもできる。 In the above embodiment, the four speakers are provided as the speakers for reproducing the received sound. However, the received sound is reproduced and output from two, three, or five or more speakers. You can also.
また、上記の実施形態においては、車両に搭載される音声処理装置に本発明を適用したが、車両以外の他の移動体に搭載される音声処理装置にも本発明を適用することもできるし、また、例えば、家庭内等において使用される音声処理装置に本発明を適用することもできる。 In the above embodiment, the present invention is applied to a sound processing device mounted on a vehicle. However, the present invention can also be applied to a sound processing device mounted on a moving body other than the vehicle. Also, for example, the present invention can be applied to a sound processing device used in a home or the like.
なお、上記の実施形態における制御ユニット110の一部又は全部を中央処理装置(CPU:Central Processing Unit)、DSP(Digital Signal Processor)、読出専用メモリ(ROM:Read Only Memory)、ランダムアクセスメモリ(RAM:Random Access Memory)等を備えた演算手段としてのコンピュータとして構成し、予め用意されたプログラムを当該コンピュータで実行することにより、上記の実施形態における処理の一部又は全部を実行するようにしてもよい。このプログラムはハードディスク、CD−ROM、DVD等のコンピュータで読み取り可能な記録媒体に記録され、当該コンピュータによって記録媒体から読み出されて実行される。また、このプログラムは、CD−ROM、DVD等の可搬型記録媒体に記録された形態で取得されるようにしてもよいし、インターネットなどのネットワークを介した配送の形態で取得されるようにしてもよい。
In addition, a part or all of the
100 … 音声処理装置
130 … 記憶装置(記憶手段)
131L〜131SR … スピーカ
140 … 集音ユニット(集音手段)
240 … エコーキャンセル部(エコーキャンセル手段)
242 … 適応フィルタ(フィルタ手段)
243 … 減算器(減算手段)
250 … エコー検出部(エコー検出手段)
261 … 最適条件決定部(最適条件決定手段)
262 … 制御部(テスト音声出力制御手段、条件設定手段、エコーキャ
ンセル制御手段)
DESCRIPTION OF
131 L to 131 SR ...
240 ... Echo canceling part (echo canceling means)
242 ... Adaptive filter (filter means)
243 ... Subtractor (subtraction means)
250 ... Echo detection unit (echo detection means)
261 ... Optimal condition determination unit (optimum condition determination means)
262... Control unit (test sound output control means, condition setting means, echo
Canceling control means)
Claims (8)
外部との通話のために発せられた音声を集音し、送信音声信号に変換する集音手段と;
外部からの受信音声信号に基づいて受信音声を再生出力する複数のスピーカと;
前記受信音声の再生に際して、前記複数のスピーカの中から再生出力用に選択される少なくとも1つの選択スピーカと、前記選択スピーカから出力される音声の音量との組み合わせから成る複数の受信音声再生条件候補が記憶された記憶手段と;
前記複数の受信音声再生条件候補のそれぞれに従って、内部的に発生したテスト音声を、順次、前記選択スピーカから再生出力させるテスト音声出力制御手段と;
前記テスト音声の再生出力に起因して前記集音手段により集音された音のエコー量を検出するエコー検出手段と;
前記複数の受信音声再生条件候補のそれぞれに対応する前記エコー検出手段による検出結果に基づいて、前記複数の受信音声再生条件候補の中から最適条件を決定する最適条件決定手段と;
通話通信中において、前記最適条件を受信音声再生条件として設定する条件設定手段と;
を備えることを特徴とする音声処理装置。 A voice processing device having a call communication function,
A sound collecting means for collecting a voice emitted for a call with the outside and converting it into a transmission voice signal;
A plurality of speakers that reproduce and output received audio based on externally received audio signals;
A plurality of reception sound reproduction condition candidates comprising a combination of at least one selected speaker selected for reproduction output from the plurality of speakers and the volume of the sound output from the selected speaker when the reception sound is reproduced. Storage means in which is stored;
Test audio output control means for sequentially reproducing and outputting internally generated test audio from the selected speaker in accordance with each of the plurality of received audio playback condition candidates;
Echo detecting means for detecting an echo amount of the sound collected by the sound collecting means due to the reproduction output of the test sound;
An optimum condition determining means for determining an optimum condition from the plurality of received voice reproduction condition candidates based on a detection result by the echo detection means corresponding to each of the plurality of received voice reproduction condition candidates;
A condition setting means for setting the optimum condition as a reception voice reproduction condition during call communication;
An audio processing apparatus comprising:
前記受信音声信号に基づいて、前記エコー成分を擬似する擬似エコー信号を生成するフィルタ手段と;
前記集音手段における集音結果から前記擬似エコー信号を減算して前記送信音声信号を生成する減算手段と;
を備えることを特徴とする請求項2に記載の音声処理装置。 The echo canceling means is
Filter means for generating a pseudo echo signal that simulates the echo component based on the received audio signal;
Subtracting means for generating the transmission voice signal by subtracting the pseudo echo signal from the sound collection result in the sound collecting means;
The speech processing apparatus according to claim 2, further comprising:
前記複数の受信音声再生条件候補のそれぞれに従って、内部的に発生したテスト音声を、順次、前記選択スピーカから再生出力するテスト音声出力工程と;
前記テスト音声の再生出力に起因して前記集音手段により集音された音のエコー量を検出するエコー検出工程と;
前記複数の受信音声再生条件候補のそれぞれに対応する前記エコー検出工程における検出結果に基づいて、前記複数の受信音声再生条件候補の中から最適条件を決定する最適条件決定工程と;
通話通信中において、前記最適条件を受信音声再生条件として設定する条件設定工程と;
を備えることを特徴とする音声処理方法。 Sound collecting means for collecting sound that is emitted for a call with the outside and converting it into a transmission sound signal; a plurality of speakers that reproduce and output received sound based on a received sound signal from the outside; and the received sound Are stored, a plurality of reception sound reproduction condition candidates that are combinations of at least one selected speaker selected for reproduction output from the plurality of speakers and the volume of the sound output from the selected speaker are stored. A voice processing method used in a voice processing apparatus comprising a storage means,
A test sound output step of sequentially reproducing and outputting internally generated test sound from the selected speaker according to each of the plurality of received sound reproduction condition candidates;
An echo detection step of detecting an echo amount of the sound collected by the sound collecting means due to the reproduction output of the test sound;
An optimum condition determining step for determining an optimum condition from the plurality of received voice reproduction condition candidates based on the detection result in the echo detection step corresponding to each of the plurality of received voice reproduction condition candidates;
A condition setting step of setting the optimum condition as a reception voice reproduction condition during call communication;
An audio processing method comprising:
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2007178036A JP2009017331A (en) | 2007-07-06 | 2007-07-06 | Voice processor, voice processing method, voice processing program, and its recording medium |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2007178036A JP2009017331A (en) | 2007-07-06 | 2007-07-06 | Voice processor, voice processing method, voice processing program, and its recording medium |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2009017331A true JP2009017331A (en) | 2009-01-22 |
Family
ID=40357643
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2007178036A Pending JP2009017331A (en) | 2007-07-06 | 2007-07-06 | Voice processor, voice processing method, voice processing program, and its recording medium |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP2009017331A (en) |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2011135272A (en) * | 2009-12-24 | 2011-07-07 | Brother Industries Ltd | Terminal, processing method, and processing program |
| WO2012127791A1 (en) * | 2011-03-23 | 2012-09-27 | 株式会社デンソー | Device for vehicle, mobile telephone, and device cooperation system |
| WO2016024345A1 (en) * | 2014-08-13 | 2016-02-18 | 三菱電機株式会社 | Echo canceler device |
| WO2018179506A1 (en) * | 2017-03-28 | 2018-10-04 | 株式会社ディーアンドエムホールディングス | Audio device and computer readable program |
-
2007
- 2007-07-06 JP JP2007178036A patent/JP2009017331A/en active Pending
Cited By (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2011135272A (en) * | 2009-12-24 | 2011-07-07 | Brother Industries Ltd | Terminal, processing method, and processing program |
| WO2012127791A1 (en) * | 2011-03-23 | 2012-09-27 | 株式会社デンソー | Device for vehicle, mobile telephone, and device cooperation system |
| JP2012213141A (en) * | 2011-03-23 | 2012-11-01 | Denso Corp | Vehicular device, mobile phone and apparatus cooperation system |
| US9055158B2 (en) | 2011-03-23 | 2015-06-09 | Denso Corporation | Vehicular apparatus, mobile phone, and instrument coordination system |
| WO2016024345A1 (en) * | 2014-08-13 | 2016-02-18 | 三菱電機株式会社 | Echo canceler device |
| JPWO2016024345A1 (en) * | 2014-08-13 | 2017-04-27 | 三菱電機株式会社 | Echo canceller |
| US9818426B2 (en) | 2014-08-13 | 2017-11-14 | Mitsubishi Electric Corporation | Echo canceller |
| WO2018179506A1 (en) * | 2017-03-28 | 2018-10-04 | 株式会社ディーアンドエムホールディングス | Audio device and computer readable program |
| JP2018165787A (en) * | 2017-03-28 | 2018-10-25 | 株式会社ディーアンドエムホールディングス | Audio device and computer-readable program |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5192901B2 (en) | Noise canceling headphones | |
| US7986802B2 (en) | Portable electronic device and personal hands-free accessory with audio disable | |
| EP2966643B1 (en) | Adaptive noise canceling system with source audio leakage detection | |
| US9066167B2 (en) | Method and device for personalized voice operated control | |
| US20080165988A1 (en) | Audio blending | |
| JP2016519906A (en) | System and method for multimode adaptive noise cancellation for audio headsets | |
| JP2010045574A (en) | Hands-free communication device, audio player with hands-free communication function, hands-free communication method | |
| JP2007053748A (en) | Sound input / output expansion method and sound input / output expansion system | |
| JP2009017331A (en) | Voice processor, voice processing method, voice processing program, and its recording medium | |
| US8705758B2 (en) | Audio processing device and method for reducing echo from a second signal in a first signal | |
| JP5417821B2 (en) | Audio signal playback device, mobile phone terminal | |
| JP2004128751A (en) | Hands-free speech device and program for hands-free speech | |
| JP3994341B2 (en) | Hands-free call system and method for setting ringtone in hands-free call system | |
| JP2008219713A (en) | Noise canceling headphones | |
| JP2008252722A (en) | Handsfree device, control method therefor, and control program | |
| JP2021173881A (en) | Voice processing device and voice processing method | |
| WO2010109614A1 (en) | Audio signal processing device and audio signal processing method | |
| JP5022459B2 (en) | Sound collection device, sound collection method, and sound collection program | |
| US8280449B2 (en) | Audio usage detection | |
| JP2005341329A (en) | Portable telephone terminal and portable telephone system | |
| KR20030076041A (en) | Remote controller for portable audio device with a function of hands-free | |
| CN103096150B (en) | Audio block | |
| JP2009089139A (en) | Voice processing apparatus, voice processing method, voice processing program, and recording medium therefor | |
| JP2006304032A (en) | Sound reinforcement system | |
| JP2009049620A (en) | Cell phone unit |