JP2008542904A - ネットワークとメモリとを結合するメモリコントローラ及び方法 - Google Patents
ネットワークとメモリとを結合するメモリコントローラ及び方法 Download PDFInfo
- Publication number
- JP2008542904A JP2008542904A JP2008514294A JP2008514294A JP2008542904A JP 2008542904 A JP2008542904 A JP 2008542904A JP 2008514294 A JP2008514294 A JP 2008514294A JP 2008514294 A JP2008514294 A JP 2008514294A JP 2008542904 A JP2008542904 A JP 2008542904A
- Authority
- JP
- Japan
- Prior art keywords
- buffer
- memory
- data
- network interface
- network
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Withdrawn
Links
Images




Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F13/00—Interconnection of, or transfer of information or other signals between, memories, input/output devices or central processing units
- G06F13/14—Handling requests for interconnection or transfer
- G06F13/16—Handling requests for interconnection or transfer for access to memory bus
- G06F13/1668—Details of memory controller
- G06F13/1673—Details of memory controller using buffers
Abstract
メモリ(MEM)をネットワーク(N)に結合するためのメモリコントローラ(SMC)が提供される。ネットワーク(N)は、ネットワーク(N)上のフロー制御を実現するためにネットワークインターフェースバッファ(TPB、FCB)を有する少なくとも1つのネットワークインターフェース(PCIEI)を具える。メモリコントローラ(BMU)は、ネットワーク(N)からのデータのバッファリングをメモリ(MEM)とバースト単位でデータ交換するように管理するバッファマネジメントユニット(BMU)を具える。バッファマネジメントユニット(BMU)は、更に、データバーストをメモリ(MEM)に書き込むことができるような十分なデータがネットワークインターフェースバッファ(FCB)に存在するか、及び、メモリ(MEM)からのデータバーストをネットワークインターフェースバッファ(TPB)にバッファすることができるような十分なスペースがネットワークインターフェースバッファ(TPB)に使用可能であるかを決定するために、ネットワークインターフェースバッファ(TPB,FCB)をモニタする。バッファマネジメントユニット(BMU)はネットワークインターフェースバッファ(FCB,TPB)内のデータ量及び/又は使用可能スペースに従ってメモリ(MEM)へのアクセスを制御する。
Description
本発明は、メモリコントローラ及びネットワークとメモリとを結合する方法に関する。
高度モバイル携帯機器の複雑度が増している。益々厳しくなるこのような機器のアプリケーション、複雑度、フレキシビリティ及びプログラマビリティ要件はデコーダ内部のデータ交換を増大している。このようなアプリケーションを実施するデバイスは多くの場合いくつかの機能ブロック又は処理ブロック(ここではサブシステムという)からなる。これらのサブシステムは代表的には個別のICとして実現され、各ICはローカルプロセッサ、バス及びメモリなどからなる異なる内部アーキテクチャを有する。また、種々のサブシステムは一つのICに集積することもできる。システムレベルでは、これらのサブシステムはトップレベルのインターコネクトを介して互いに通信し、所定のサービスを多くの場合リアルタイムサポートで提供する。携帯電話アーキテクチャ内のサブシステムの例としては、特にベースバンドプロセッサ、ディスプレイ、メディアプロセッサ又は記憶素子がある。マルチメディアアプリケーションをサポートするために、これらのサブシステムはデータの大部分をストリーム形式で交換する。データストリーミングの一例として、メディアプロセッサによるMP3符号化オーディオファイルの読出し及び復号ストリームのスピーカへの送出がある。このような通信は、しばしばKahnプロセスネットワークと呼ばれている、FIFOバッファを経て接続されるプロセスのグラフとして記述できる。Kahnプロセスネットワークは、E.A. de Kochet al. ”YAPI: Application modeling for signal processing systems”,In Proc. Of the 37th Design Automation Conference, Los Angels, CA, June 2000, pp.402-405,IEEE 2000、に記載されているように、システムアーキテクチャにマップすることができる。このようなアーキテクチャでは、プロセスがサブシステムに、FIFOがメモリにマップされ、通信がシステムレベルインターコネクトにマップされる。
バッファリングは関連するプロセス間のデータストリーミングの適切なサポートに不可欠である。ストリーミングにFIFOバッファを使用することは極めて当然のことであり、これはストリーミングアプリケーションの(有界)Kahnプロセスネットワークモデルに従う。同時に実行し得るマルチメディアアプリケーションの数が増加すると、プロセスの数、リアルタイムストリームの数並びに関連するFIFOの数が相当増加ずる。
多くのシステムオンチップ(SoC)及びマイクロプロセッサシステムでは、データのバッファリングにバックグラウンドメモリ(DRAM)が使用される。データをストリーミング方式で通信し、メモリにストリームとしてバッファするとき、プリフェッチバッファリングを使用できる。これは、SDRAMからのデータを前もって読み出し、特別の(プリフェッチ)バッファに保持することを意味する。リード要求が到来すると、この要求は、さもなければバックグラウンドメモリ(DRAM)により導入されるレイテンシなしで、(通常オンチップSRAMに実装される)ローカルプリフェッチバッファからサービスされる。これはプロセッサに対するランダムデータのキャッシュ技術に類似する。ストリーミングの場合には、キャッシュに使用されるランダムアドレスではなくデータの連続(又は予測可能)アドレス指定がプリフェッチバッファに使用される。
他方、DRAM技術のために、DRAMへのアクセス(リード又はライト)はバースト単位に行う方がよい。単一ワードがDRAMメモリからアクセスされるとき、ACTIVEコマンドの発行後にDRAMのデータアレイからセンス増幅器へのメモリページのプリフェッチを実行するためにオーバヘッドが必要とされる。データがセンス増幅器へ転送されたとき、READコマンド後にセンス増幅器から活性化されたデータを読み出すために、データアドレスをデコーディングしデータを出力バッファへ転送するための初期時間が必要とされる。このようなオーバヘッドはDRAMメモリからその仕様に基づいて容易に計算できる。代表的には、このようなオーバヘッドは、数クロックサイクル(Tactive_to_read + Tread_to_data = TRCD +TCAS =2+3 = 5クロックサイクル)程度である。
DRAMメモリへのバーストアクセスを可能にするために、多数の単一データアクセスを所定のバーストサイズのバーストに集めるライトバックバッファが実現されている。初期プロセシングが最初のDRAMアクセスに対して実行されると、メモリの次のサイクル毎にアクセスされる次のデータワードが、(例えばバーストポリシーに基づいて)その前のデータワードに関連するアドレスで、即ち1つのストリーミングプロセスで、格納又は取り出され、所定数のアクセス(例えば2/4/8フルページ)に対して何の追加の遅延も生じない(1サイクル以内)。従って、アドレスがアクセス毎に単調に増加又は減少する(例えば連続アドレス)際のメモリへのストリーミングアクセスに対して、バーストアクセスは単位アクセスデータあたり最低の電力消費で最大のスループットという最良のパフォーマンスをもたらす。DRAMメモリの原理に関するもっと詳しい情報については、例えばマイクロンの128ビットDDRAMの使用を参照されたい。例えば、
(http://download.micron.com/pdf/datasheets/dam/ddr/128MbDDRx4x8x16.pdf)を参照されたい。
(http://download.micron.com/pdf/datasheets/dam/ddr/128MbDDRx4x8x16.pdf)を参照されたい。
このような機能をDRAMメモリ用のメモリコントローラに実施する場合、内部バッファが存在しなければならない。メモリコントローラの内部バッファはデータキャッシュ、プリフェッチ及びライトバックバッファ、ストリーミング及びアービトレーションのためにも使用される。
DRAMメモリは頻繁にネットワーク又はバスを介してアクセスされるため、DRAMメモリのメモリコントローラをオンチップ/オフチップネットワークに結合でき、これはある種のフロー制御を実施できる。フロー制御は、一般にネットワーク内の各ネットワークノードでデータをバッファリングすることにより実施され、このバッファリングは、次のノードからアクノレッジが受信され、ネットワークハイアラーキネットワーク内の受信ノードのバッファが受信ノードへ転送されるデータパッケージを格納するのに使用できる十分なスペースを有することが確認されるまで行われる。このようなフロー制御メカニズムの利点は、バッファアンダーフロー/オーバフローが防止されるので、信頼できる転送が得られる点にある。
図4は、送信ノード(ソースデバイスSD)及び受信ノード(宛先デバイスDD)のブロック図の一例を示す。ソースデバイスSDは、トランザクションペンディングバッファTPBと、送信ユニットTUと、受信ユニットRUと、受信フロー制御パケットユニットRFCPと、リミットクレジットレジスタCLRと、消費クレジットレジスタCCRと、フロー制御ユニットCUとを具える。トランザクションペンディングバッファTPBは任意のペンディングトランザクションをバッファするために使用される。送信ユニットTUはデータパケットを宛先デバイスDDに送信するために使用される。受信ユニットRUは宛先デバイスDDからのデータを受信するために使用される。受信フロー制御パケットユニットRFCPは宛先デバイスDDからの任意のフロー制御パケットを取り出すために使用される。宛先デバイスDDからのフロー制御パケットの取り出しに応じて、リミットクレジットCLがリミットクレジットレジスタCLRに格納される。消費クレジットレジスタCCRは消費されたクレジットCCを格納するために使用される。制御ユニットCUはリミットクレジットCLと消費クレジットとを比較するために使用される。リミットクレジットCLと消費クレジットとの差がトランザクションペンディングバッファにペンディング中のトランザクションのデータサイズより大きい場合、トランザクションを送ることができ、そうでなければ宛先デバイスDDから更なるクレジットを待つ。
宛先デバイスDDは、受信ユニットRUと、送信ユニットTUと、送信フロー制御パケットユニットTFCPと、使用可能クレジットレジスタCARと、フロー制御バッファFCBとを具える。ソースデバイスSDからのトランザクションが受信ユニットRUにより受信される場合、このようなトランザクションはフロー制御バッファFCBに格納される。このトランザクションがフロー制御バッファFCBを出ると同時に、使用可能クレジットレジスタCARが増加される。使用可能クレジットレジスタCAR内の使用可能クレジットCAに従って、フロー制御パケットが送信フローパケットユニットTFCP内で用意され、送信ユニットTUに転送され、送信ユニットTUがフロー制御パケットをソースデバイスSDに送信する。
フロー制御を実施するこのようなネットワークに関するもっと詳しい情報については、”PCI Express Base Specification, Revision 1.0”、 PCI-SIG(2002年7月)、Jasmin Aianovic and Hong Jiang著, “Multimedia and Quality of Service Support in PCI Express Architecture”、ホワイトペイパー、インテルコーポレーション(2002年9月12日)、Edward Solari and Brad Congdon著、“The Computer PCI Express Reference”、インテルプレス(2003年)を参照されたい。これらの3つの文献は参考のために援用されている。
図5は、フロー制御をメモリ制御で実施するネットワークとSDRANメモリとの組合せを具えるアーキテクチャのブロック図を示す。ネットワークNはいくつかのフロー制御バッファFCB並びにいくつかのトランザクションペンディングバッファTPBを具えることができる。ネットワークNはフロー制御ロジックのような他の素子(図5の明瞭化のために省略されている)も具えることができる。メモリコントローラMCは書込みバッファWBと読出しバッファRBを具えることができる。書込みバッファWB及び読出しバッファRBは、SDRAMメモリへのアクセスはバーストに基づいて行うのが好ましいために、必要とされる。データがネットワークNから発生すると、このデータは書込みバッファWBへ転送される。ネットワークフロー制御を満足するためにネットワーク内のフロー制御バッファにおいてバッファリングが実行される。書込みバッファWBにおいて、データは規定のデータバーストが得られるまで集められ、次いで単一のバースト内でメモリに書き込まれる。最初の数個の読出しトランザクション要求は書込みバッファWBにおいてメモリから転送されるべきデータのために集められ、次いでデータが単一バーストにてメモリから読出しバッファRBへ転送される。
本発明の目的は、ネットワークとメモリとの間のフロー制御が改善された、ネットワークとメモリとを結合するメモリコントローラ並びにネットワークとメモリを結合する方法を提供することにある。
本発明の目的は、請求項1に係るメモリコントローラ及び請求項6に係るネットワークとメモリとの結合方法によって解決される。
従って、本発明によればメモリをネットワークに結合するためのメモリコントローラが提供される。ネットワークは、ネットワークのフロー制御を実現するためにネットワークインターフェースバッファを有する少なくとも1つのネットワークインターフェースを具える。メモリコントローラは、ネットワークからのデータのバッファリングをメモリとバースト単位にデータ交換するように管理するバッファマネジメントユニットを具える。バッファマネジメントユニットは、更に、ネットワークインターフェースバッファをモニタして、データバーストをメモリに書き込むことができるような十分なデータがネットワークインターフェースバッファに存在するか、及び、メモリからのデータバーストをネットワークインターフェースバッファにバッファすることができるような十分なスペースがネットワークインターフェースバッファに使用可能であるかを決定する。バッファマネジメントユニットはメモリへのアクセスをネットワークイメージバッファ内のデータ及び/又は使用可能スペースの量に従って制御する。
ネットワークインターフェースバッファ(フロー制御バッファ及びトランザクションペンディングバッファ)を用いて実施される上述の如きメモリコントローラのバッファリングは、シリコン利用効率が向上するので有利である。PCI Expressインターフェースのフロー制御バッファとメモリコントローラ内のバーストバッファを別個に実現する場合には、大きなシリコン領域が必要とされ、これが避けられる。更に、不必要なデータコピーも避けられるため、必要とされるアクティビティ、従ってパワーが低くなる。単一バッファ(リード用の単一バッファ及びライト用の単一バッファ)は、それぞれに2つのバッファを使用する場合より遅延及びレイテンシが小さくなり有利である。ネットワークインターフェースにおけるフロー制御バッファは構造的に変更する必要はない。
本発明の一つの態様では、ネットワークインターフェースは、PCI Expressネットワークの特性及びネットワークサービスをメモリコントローラで実現できるように、PCI Expressインターフェースとして実現される。
本発明の一つの態様では、バッファマネジメントユニットは、ネットワークインターフェースバッファ内のスペースの量を格納する第1のレジスタと、ネットワークインターフェースバッファ内のデータの量を格納する第2のレジスタと、メモリへの及びからのアクセスを、前記スペースの量と前記データの量とバーストサイズとに基づいて制御する制御手段とを具える。
本発明の一つの態様では、バーストマネジメントユニットは、前記第1及び第2のレジスタを更新するために、データがネットワークインターフェースからネットワークへ転送されるとき、第1の情報を、データがネットワークインターフェースからメモリへ転送されるとき、第2の情報を受信する。
本発明の一つの態様では、ネットワークインターフェースバッファは各フロー制御仮想チャネル毎に設ける。フロー制御バッファは各仮想チャネル毎に個別に実現されるので、種々のストリームの弁別をコントローラで実施する必要はない。
本発明は、メモリをネットワークに結合する方法にも関するものであり、前記ネットワークはネットワークのフロー制御を実施するためにバッファを有する少なくとも一つのネットワークインターフェースを具える。バッファマネジメントユニットによって、ネットワークからのデータを前記メモリとバースト単位にデータ交換するように管理する。更に、前記ネットワークインターフェース内のバッファをモニタして、データバーストをメモリに書き込むことができるような十分なデータがネットワークインターフェースバッファに存在するか、及び、メモリからのデータバーストをネットワークインターフェースバッファにバッファすることができるような十分なスペースがネットワークインターフェースバッファに使用可能であるかを決定する。前記ネットワークインターフェースバッファ内の前記データの量及び/又は前記使用可能なスペースの量に従ってメモリへのアクセスを制御する。
本発明は、フロー制御を実施するために使用されるネットワークインターフェースバッファを、メモリコントローラのバーストバッファとして利用するという着想に基づく。このようなフロー制御バッファ及びトランザクションペンディングバッファの実現は従来の別個のバッファより大きいが、フロー制御バッファ及びトランザクションペンディングバッファはフロー制御バッファと(SDRAM)メモリ用のメモリコントローラ内の従来のバーストバッファとの和より小さい。
他の特徴は従属請求項に特定されている。
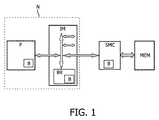
図1は、本発明に係るシステムオンチップの基本アーキテクチャのブロック図を示す。このシステムオンチップは、少なくとも1つの処理ユニットP(図1には1つの処理ユニットしか示されていない点に注意されたい)又はサブシステムと、処理ユニットPと任意の外部デバイスとを結合するインターコネクト手段IMを具える。処理ユニットP及びインターコネクト手段IMはネットワークNとみなすことができる。或は又、インターコネクト手段IMをネットワークNとみなすことができる。インターコネクト手段IMを介する処理ユニットP間の通信はストリーミング式に行われる。(外部)メモリMEMはメモリコントローラSMCを介してインターコネクト手段IM又はネットワークNに結合される。(外部)メモリはDRAMメモリ(例えば、SDRAM又はDDR−SDRAMメモリ)として実現できる。メモリコントローラSMCはインターコネクト手段IMのデータフォーマット及びアドレスフォーマットをメモリMEMのデータフォーマット及びアドレスフォーマットに変換するように作用する。
ストリームベース通信を実現するために、バッファが設けられる。バッファはメモリMEMに近接するメモリコントローラSMC内に置くことができる。しかし、バッファは、インターコネクトインフラストラクチャ内(例えばアービタ又はブリッジ内)に置くこともでき、またサブシステムPに近接して置くことさえでき、これはメモリMEMにアクセスする専用のASIC又はマイクロプロセッサとして実現することができる。バッファBはSRAMとして実現するのが好ましい。好ましくは、FIFO原理がバッファによるデータストリームのデータフローを編成するために使用される。加えて、システム内に実装される単一バッファをもっと多くすることができる。その一つの理由は多くのストリームを区別するためであり、一つのストリームにつき一つのバッファを実装するのが好ましい。
ネットワークはPCI−Expressネットワークを構成するのが好ましい。PCI−Expressネットワークの基本概念は、“PCI-Express Base Specification, Revision 1.0”,PCI-SIG, July 2000, www.pcisig.org.に記載されている。
サービスの品質、即ち予測可能なレイテンシ及び帯域幅を提供するネットワークの能力を保証するPCI−Expressの一つの特徴は、仮想チャネルVCの付与にある。仮想チャネルメカニズムは異なる優先順位を有する異なるクラスのトラフィックのデータ送信をサポートする。仮想チャネルVCは、一般に、キュー、バッファ及び関連するロジックのような独立構成のリソースを具える。仮想チャネルVCのトラフィックフローは、送信側で共通物理リンクリソースに多重され、受信側で個別の仮想チャネルVCに多重分離される。
PCI−Expressリンクの各終端のポートはフロー制御を実行するために使用できる。トランザクションパケットをリンクを介して受信ポート又は受信側へ送る前に、送信ポートは、受信ポートが送信されるトランザクションを受信するのに十分なバッファスペースを有することを確認しなければならない。このため、フロー制御バッファが異なる仮想チャネル毎に設けられる。フロー制御は所定のリンクに対する各仮想チャネル毎に別々に管理される。
図2は、本発明の第1の実施例に係る、メモリコントローラSMC、ネットワークN及びメモリMEMのブロック図を示す。メモリコントローラSMCは、PCI−Expressインターフェース、バッファマネジメントユニットBMU及び外部SDRAMメモリMEMに対するインターフェースとして作用するインターフェースIOUを具える。PCI−ExpressインターフェースPI、バッファマネジメントユニットBMU及びインターフェースIOUは、ネットワークNからSDRAMメモリへのアクセス並びにSDRAMメモリからネットワークNへのアクセスをバッファするとともにフロー制御を実行するために使用される。バッファマネジメントユニットBMUは、PCI−ExpressからSDRAMへのリード又はライトアクセスに応答して、バッファを管理するとともに、バッファ(SRAM)からSDRAMへ/SDRAMからバッファ(SRAM)へデータを中継するように働く。上述した全ての要素はストリーミングベース通信ができるように設計されている。
PCI−ExpressネットワークNは、特にネットワークNのフロー制御メカニズムを実行するPCI−ExpressネットワークインターフェースPCIEIを具える。ネットワークインターフェースPCIEIはいくつかのネットワークインターフェースバッファ、即ちフロー制御バッファFCBと、いくつかのトランザクションペンディングバッファTPB(例えば各仮想チャネルVCのためのバッファ)と、データ受信用のフロー制御ロジックFCLR及びデータ送信用のフロー制御ロジックFCLTとを具える。
第1の実施例では、ネットワークインターフェースPCIEI内のフロー制御バッファFCB及びトランザクションペンディングバッファTPBはバーストバッファとして使用され、メモリコントローラSMCでバースト単位にDRAMにアクセスするのに十分なデータが存在するまでデータをバッファする。これは特に有利である。その理由は、DRAMメモリコントローラのバーストバッファを除去することができるとともに、フロー制御バッファ及びトランザクションペンディングバッファから(S)DRAMメモリへの及びからのデータ移動を制御するために簡単な追加のロジックをメモリコントローラに追加する必要があるだけであるためである。更に、ネットワークインターフェースPCIEIの構成、特にフロー制御バッファFCB及びトランザクションペンディングバッファTPBの構成は基本的に変更されない。ネットワークN及びネットワークインターフェースPCIEIはPCI−Expressに基づくものとするのが好ましい。フロー制御バッファFCBはネットワークインターフェースPCIEIの受信側に仮想チャネル毎に実装される。トランザクションペンディングバッファTPBはネットワークインターフェースの送信側に実装される。
フロー制御バッファFCB及びトランザクションペンディングバッファTPBを用いてネットワークインターフェースを介してメモリへの及びからのデータ(又はデータバースト)をバッファすることにより、バッファマネジメントユニットBMUは、SDRAMへのアクセスをフロー制御バッファFCB及びトランザクションペンディングバッファTPB内のデータの量又はスペースの量に基づいて制御する簡単なロジックユニットで実現できる。
データは、ネットワークNから到来するライト要求毎にフロー制御バッファFCBに集められ、これはデータバーストとしてSDRAMメモリMEMへ送るのに十分なデータがフロー制御バッファFCB内にバッファされるまで行われる。換言すれば、ライト要求によるデータは、バーストサイズ(例えばメモリページ)になるまでフロー制御バッファFCBにバッファされ、ライトバーストが単一バースト内に発行される。リードトランザクションはトランザクションペンディングバッファTPBに、十分なデータがリードバースト用に集められるまでバッファされる。
このようなフロー制御バッファ及びトランザクションペンディングバッファの実施は従来技術によるそれぞれのバッファより大きくなるが、このようなフロー制御バッファ及びトランザクションペンディングバッファはフロー制御バッファとSDRAMメモリ用のメモリコントローラ内の従来のバーストバッファとの和より小さくなる。
図3は第1の実施例に係るネットワークインターフェース及びメモリコントローラのブロック図を示す。図3には、ネットワークインターフェースPCIEI及びメモリコントローラSMCが詳細に示されている。ネットワークインターフェースPCIEIの実施は図4に示すソースデバイスSD及び宛先デバイスDDの実施にほぼ一致する。このため、3つのレジスタ又はカウンタ、即ち消費クレジットCCを格納するクレジット消費レジスタ(全てのトランザクションの追跡のため)、リミットクレジットCLを格納するリミットクレジットレジスタCLR及び使用可能なクレジットCAを格納する使用可能クレジットレジスタCARが設けられる。更に、受信フロー制御パケットユニットRFCP及び送信フロー制御パケットユニットTFCPが設けられる。送信ユニットTUはデータをネットワークへ送信し、受信ユニットRUはネットワークからデータを受信する。制御ユニットCUは、リミットクレジットCLと消費クレジットCCとを差がデータサイズより大きいかどうかを決定するよう作用する。そうであれば、では送信ユニットTUからネットワークへ送出される。しかし、そうでなければ、後続のクレジットを待つ。
メモリコントローラSMCは、入力レジスタIR、出力レジスタOR及びバッファマネジメントユニットBMUを具える。バッファマネジメントユニットBMUは、使用可能スペースSAを格納する使用可能スペースレジスタ又はカウンタSAR、使用可能データDAを格納する使用可能データレジスタDAR、バーストサイズBSを格納するバーストサイズレジスタBSR、第1制御ユニットCU1及び第2制御ユニットCU2を具える。
ネットワークインターフェースPCIEI内の制御ユニットCUの出力は使用可能スペースカウンタSARに結合され、使用可能スペースSAのカウントを増加する。入力レジスタIRはトランザクションペンディングバッファTPBの入力に結合され、データdtをこのバッファに直接転送する。フロー制御バッファFCBの出力は出力レジスタORに結合され、データdtを出力レジスタORに直接転送する。受信ユニットRUの出力は、使用可能データカウンタDARに結合され、使用可能データDAを増加するとともに、第2制御ユニットCU2に結合され、新しいデータの到来を通知する。トランザクションペンディングバッファTPBの出力は第1制御ユニットCU1に結合され、データがネットワークNに送信されることを制御ユニットCU1に通知する。トランザクションペンディングバッファTPBの出力はクレジット消費レジスタCCRにも結合される。
ネットワークインターフェースPCIEIの受信側では、データdtがネットワークNから受信ユニットRUを経て到来し、フロー制御バッファFCB内にバッファされる。バッファマネジメントユニットBMU内の第2制御ユニットCU2がフロー制御バッファFCB内の実際のデータをモニタしてFCB内のデータが所要のバーストサイズを超えるかどうかを決定する。
フロー制御バッファFCB内のデータがバーストサイズBSを超える場合には、フロー制御バッファFCB内のデータがフロー制御バッファから読み出され、出力レジスタOR、即ち出力バッファを経由してメモリMEMに転送される。しかし、完全なバーストを形成するに十分なデータがフロー制御バッファFCB内に存在しない場合には、ネットワークNから更なるデータを待つ。フロー制御バッファFCB内のデータを追跡するために、使用可能データカウンタDARが使用される。このカウンタは処理の開始時に零にリセットされる。ネットワークからデータが到来する度にカウンタはカウントアップし、バーストライト毎にカウンタのカウントはバーストサイズだけ減少する。
データをネットワークNに送信する場合、トランザクションペンディングバッファTPBは、そのバッファ内に残存するスペースが単一バーストサイズBSより小さくなるまで満たされる。トランザクションペンディングバッファ内の実際のスペースが使用可能スペースカウンタSARによりモニタされる。特に、トランザクションペンディングバッファTPB内の使用可能スペースがバーストサイズBSを超えるかどうかがモニタされる。そうであれば、データバーストがメモリMEMから入力レジスタIRを経てワード単位で読み出され、トランザクションペンディングバッファTPBに転送される。十分な使用可能スペースがない場合には、新しいデータのトランザクションを待つ。トランザクションペンディングバッファTPB内の使用可能スペースの量を追跡するために、使用可能スペースカウンタSARが使用される。この使用可能スペースカウンタは処理の開始時にトランザクションペンディングバッファのサイズにリセットされる。トランザクションペンディングバッファからネットワークNへ送信されるデータ毎にこのカウンタはカウントアップし、メモリMEMからのバーストリード毎にこのカウンタのカウントはバーストサイズだけ減少する。
ネットワークインターフェースPCIEIのフロー制御バッファ及びトランザクションペンディングバッファを用いることでメモリコントローラのバッファを上記の如く実現することは、シリコン利用効率が向上するので有利である。PCI Expressインターフェースのフロー制御バッファとメモリコントローラ内のバーストバッファを別個に実現する場合には、大きなシリコン領域が必要とされる。更に、不必要なデータコピーも避けられるため、必要とされるアクティビティ、従ってパワーが低くなる。単一バッファ(リード用の単一バッファ及びライト用の単一バッファ)は、それぞれに2つのバッファを使用する場合より遅延及びレイテンシが小さくなり有利である。フロー制御バッファは各仮想チャネル毎に個別に実現されるので、異なるストリームの区別をコントローラで行う必要はない。ネットワークインターフェースにおけるフロー制御バッファは構造的に変更する必要はない。
上述の方式はフロー制御を実施するネットワークを経てDRAMメモリにアクセスする全てのシステムに実施することができる点に注意されたい。
最後に、上述の実施例は例示であり、本発明を限定するものではなく、当業者は添付の特許請求の範囲で特定される発明の範囲を逸脱することなく多くの代替実施例を設計可能であるということに留意する必要がある。特許請求の範囲において、括弧内の符号は請求項の記載を限定するものと解釈されるべきではない。「具えている」および「具える」などの単語は、請求項あるいは本明細書に列記されていない要素またはステップの存在を除外するものではない。単数形で述べる要素は複数の要素を除外するものではないし、その逆も成り立つ。いくつかの手段を列挙している装置請求項において、これらの手段のいくつかは、ハードウェアあるいはソフトウェアの同一の要素によって具現化できる。特定の手段が相互に異なる従属請求項に引用されているが、このことは、これらの手段の組合せが有利に使用できないことを示すものではない。
Claims (8)
- メモリをネットワークに結合するためのメモリコントローラであって、
前記ネットワークは前記ネットワークのフロー制御を実施するためにネットワークインターフェースバッファを有する少なくとも1つのネットワークインターフェースを具えており、
前記メモリコントローラは、前記ネットワークと前記メモリとの間でバースト単位にデータ交換すべくデータのバッファリングを管理するバッファマネジメントユニットを具え、該バッファマネジメントユニットは、前記ネットワークインターフェースバッファをモニタして、データバーストを前記メモリに書き込むことができるような十分なデータが前記ネットワークインターフェースバッファに存在するか、及び、前記メモリからのデータバーストを前記ネットワークインターフェースバッファにバッファすることができるような十分なスペースが前記ネットワークインターフェースバッファに使用可能であるかを決定し、前記メモリへの及びからのアクセスを、前記ネットワークインターフェースバッファ内の前記データ及び/又は前記使用可能スペースに従って制御するように構成されていることを特徴とするメモリコントローラ。 - 前記ネットワークインターフェースはPCI Expressインターフェースであることを特徴とする請求項1記載のメモリコントローラ。
- 前記バッファマネジメントユニットは、前記ネットワークインターフェースバッファ内の前記スペースの量を格納する第1のレジスタと、前記ネットワークインターフェースバッファ内の前記データの量を格納する第2のレジスタと、前記メモリへの及びからのアクセスを、前記スペースの量と前記データの量とバーストサイズとに基づいて制御する制御手段とを具えることを特徴とする請求項1記載のメモリコントローラ。
- 前記バーストマネジメントユニットは、前記第1及び第2のレジスタを更新するために、データが前記ネットワークインターフェースから前記ネットワークへ転送されるとき、第1の情報を、データが前記ネットワークインターフェースから前記メモリへ転送されるとき、第2の情報を受信することを特徴とする請求項3記載のメモリコントローラ。
- 前記ネットワークインターフェースバッファが各フロー制御仮想チャネル毎に設けられていることを特徴とする請求項2記載のメモリコントローラ。
- メモリをネットワークに結合する方法であって、
前記ネットワークのフロー制御がネットワークインターフェース内のネットワークインターフェースバッファにより実施され、
前記方法は、前記ネットワークと前記メモリとの間でバースト単位にデータ交換すべくデータのバッファリングを管理し、
前記ネットワークインターフェースバッファをモニタして、データバーストをメモリに書き込むことができるような十分なデータが前記ネットワークインターフェースバッファに存在するか、及び、前記メモリからのデータバーストを前記ネットワークインターフェースバッファにバッファすることができるような十分なスペースが前記ネットワークインターフェースバッファに使用可能であるかを決定し、
前記メモリへの及びからのアクセスを、前記ネットワークイメージバッファ内の前記データ及び/又は前記使用可能スペースに従って制御することを特徴とするメモリ結合方法。 - 複数の処理装置を結合するための少なくとも1つのネットワークインターフェースと、
前記複数の処理装置のデータを格納するメモリと、
請求項1−5のいずれかに記載のメモリコントローラと、
を具えるデータ処理システム。 - ネットワークのネットワークインターフェース内のフロー制御を実施するバッファを該ネットワークインターフェースに結合されるメモリコントローラ用のバーストバッファとして使用する使用方法。
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP05105094 | 2005-06-09 | ||
| PCT/IB2006/051842 WO2006131900A2 (en) | 2005-06-09 | 2006-06-09 | Memory controller and method for coupling a network and a memory |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2008542904A true JP2008542904A (ja) | 2008-11-27 |
Family
ID=37075836
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2008514294A Withdrawn JP2008542904A (ja) | 2005-06-09 | 2006-06-09 | ネットワークとメモリとを結合するメモリコントローラ及び方法 |
Country Status (6)
| Country | Link |
|---|---|
| US (1) | US8065493B2 (ja) |
| EP (1) | EP1894107B1 (ja) |
| JP (1) | JP2008542904A (ja) |
| CN (1) | CN101194242A (ja) |
| AT (1) | ATE538435T1 (ja) |
| WO (1) | WO2006131900A2 (ja) |
Families Citing this family (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7987469B2 (en) | 2006-12-14 | 2011-07-26 | Intel Corporation | RDMA (remote direct memory access) data transfer in a virtual environment |
| US7836198B2 (en) * | 2008-03-20 | 2010-11-16 | International Business Machines Corporation | Ethernet virtualization using hardware control flow override |
| US9489326B1 (en) * | 2009-03-09 | 2016-11-08 | Cypress Semiconductor Corporation | Multi-port integrated circuit devices and methods |
| US20100228926A1 (en) * | 2009-03-09 | 2010-09-09 | Cypress Semiconductor Corporation | Multi-port memory devices and methods |
| US8838901B2 (en) * | 2010-05-07 | 2014-09-16 | International Business Machines Corporation | Coordinated writeback of dirty cachelines |
| US8683128B2 (en) | 2010-05-07 | 2014-03-25 | International Business Machines Corporation | Memory bus write prioritization |
| US20120066444A1 (en) * | 2010-09-14 | 2012-03-15 | Advanced Micro Devices, Inc. | Resolution Enhancement of Video Stream Based on Spatial and Temporal Correlation |
| FR2982049B1 (fr) * | 2011-10-28 | 2014-02-28 | Kalray | Gestion de flux dans un reseau sur puce |
| US9542345B2 (en) * | 2012-09-28 | 2017-01-10 | Apple Inc. | Interrupt suppression strategy |
Family Cites Families (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| FR2797969A1 (fr) * | 1999-08-31 | 2001-03-02 | Koninkl Philips Electronics Nv | Dispositif a plusieurs processeurs partageant une memoire collective |
| US6557053B1 (en) * | 2000-01-04 | 2003-04-29 | International Business Machines Corporation | Queue manager for a buffer |
| US20020046251A1 (en) * | 2001-03-09 | 2002-04-18 | Datacube, Inc. | Streaming memory controller |
| DE60237433D1 (de) * | 2001-02-24 | 2010-10-07 | Ibm | Neuartiger massivparalleler supercomputer |
| JP2007503042A (ja) * | 2003-08-20 | 2007-02-15 | コーニンクレッカ フィリップス エレクトロニクス エヌ ヴィ | 動的メモリバッファ |
| JP2008522305A (ja) * | 2004-12-03 | 2008-06-26 | コーニンクレッカ フィリップス エレクトロニクス エヌ ヴィ | ストリーミングメモリコントローラ |
| EP1894108A2 (en) * | 2005-06-13 | 2008-03-05 | Nxp B.V. | Memory controller |
-
2006
- 2006-06-09 CN CNA2006800203705A patent/CN101194242A/zh active Pending
- 2006-06-09 JP JP2008514294A patent/JP2008542904A/ja not_active Withdrawn
- 2006-06-09 WO PCT/IB2006/051842 patent/WO2006131900A2/en active Application Filing
- 2006-06-09 US US11/917,020 patent/US8065493B2/en not_active Expired - Fee Related
- 2006-06-09 EP EP06756100A patent/EP1894107B1/en not_active Not-in-force
- 2006-06-09 AT AT06756100T patent/ATE538435T1/de active
Also Published As
| Publication number | Publication date |
|---|---|
| EP1894107B1 (en) | 2011-12-21 |
| US8065493B2 (en) | 2011-11-22 |
| US20090083500A1 (en) | 2009-03-26 |
| CN101194242A (zh) | 2008-06-04 |
| EP1894107A2 (en) | 2008-03-05 |
| ATE538435T1 (de) | 2012-01-15 |
| WO2006131900A2 (en) | 2006-12-14 |
| WO2006131900A3 (en) | 2007-04-26 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| EP1820309B1 (en) | Streaming memory controller | |
| JP2008542904A (ja) | ネットワークとメモリとを結合するメモリコントローラ及び方法 | |
| US9141568B2 (en) | Proportional memory operation throttling | |
| US7269709B2 (en) | Memory controller configurable to allow bandwidth/latency tradeoff | |
| TW201120644A (en) | Memory hub architecture having programmable lane widths | |
| US8359420B2 (en) | External memory based FIFO apparatus | |
| US8913616B2 (en) | System-on-chip-based network protocol in consideration of network efficiency | |
| KR101270848B1 (ko) | 트래픽 클래스들과 관련된 포트들을 갖는 다중 포트 메모리 제어기 | |
| US7240141B2 (en) | Programmable inter-virtual channel and intra-virtual channel instructions issuing rules for an I/O bus of a system-on-a-chip processor | |
| US20120137090A1 (en) | Programmable Interleave Select in Memory Controller | |
| US8612713B2 (en) | Memory switching control apparatus using open serial interface, operating method thereof, and data storage device therefor | |
| CN111656322A (zh) | 针对联动存储器设备调度存储器请求 | |
| Jang et al. | Application-aware NoC design for efficient SDRAM access | |
| EP1894108A2 (en) | Memory controller | |
| US8037254B2 (en) | Memory controller and method for coupling a network and a memory | |
| US8706925B2 (en) | Accelerating memory operations blocked by ordering requirements and data not yet received | |
| US8856459B1 (en) | Matrix for numerical comparison | |
| EP1704487B1 (en) | Dmac issue mechanism via streaming id method |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A761 | Written withdrawal of application |
Free format text: JAPANESE INTERMEDIATE CODE: A761 Effective date: 20090831 |