JP2005516296A - バイオテクノロジー産物を手配するコンピュータの操作方法、および/またはコンピュータネットワーク - Google Patents
バイオテクノロジー産物を手配するコンピュータの操作方法、および/またはコンピュータネットワーク Download PDFInfo
- Publication number
- JP2005516296A JP2005516296A JP2003564284A JP2003564284A JP2005516296A JP 2005516296 A JP2005516296 A JP 2005516296A JP 2003564284 A JP2003564284 A JP 2003564284A JP 2003564284 A JP2003564284 A JP 2003564284A JP 2005516296 A JP2005516296 A JP 2005516296A
- Authority
- JP
- Japan
- Prior art keywords
- sequence
- probe
- assay
- design
- user
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
- 238000011017 operating method Methods 0.000 title 1
- 239000000523 sample Substances 0.000 claims abstract description 135
- 238000000034 method Methods 0.000 claims abstract description 99
- 238000003556 assay Methods 0.000 claims abstract description 92
- 108091093088 Amplicon Proteins 0.000 claims abstract description 43
- 108091028043 Nucleic acid sequence Proteins 0.000 claims abstract description 43
- 150000007523 nucleic acids Chemical group 0.000 claims abstract description 39
- 230000000295 complement effect Effects 0.000 claims abstract description 13
- 238000013461 design Methods 0.000 claims description 96
- 108700028369 Alleles Proteins 0.000 claims description 11
- 238000012360 testing method Methods 0.000 claims description 11
- 238000001514 detection method Methods 0.000 claims description 8
- 238000011990 functional testing Methods 0.000 claims description 8
- 239000002773 nucleotide Substances 0.000 claims description 8
- 125000003729 nucleotide group Chemical group 0.000 claims description 8
- 238000004891 communication Methods 0.000 claims description 6
- 108091034117 Oligonucleotide Proteins 0.000 claims description 5
- 239000007850 fluorescent dye Substances 0.000 claims description 5
- 238000004458 analytical method Methods 0.000 claims description 4
- 238000004949 mass spectrometry Methods 0.000 claims description 4
- 238000012938 design process Methods 0.000 description 7
- 238000011144 upstream manufacturing Methods 0.000 description 7
- 239000003153 chemical reaction reagent Substances 0.000 description 6
- 238000003205 genotyping method Methods 0.000 description 6
- 108020004414 DNA Proteins 0.000 description 5
- 238000010586 diagram Methods 0.000 description 5
- 238000012790 confirmation Methods 0.000 description 4
- 230000014509 gene expression Effects 0.000 description 4
- 238000012797 qualification Methods 0.000 description 3
- 238000010791 quenching Methods 0.000 description 3
- 230000000171 quenching effect Effects 0.000 description 3
- 238000013515 script Methods 0.000 description 3
- 238000004422 calculation algorithm Methods 0.000 description 2
- 239000003814 drug Substances 0.000 description 2
- 238000011156 evaluation Methods 0.000 description 2
- 238000004519 manufacturing process Methods 0.000 description 2
- 238000002844 melting Methods 0.000 description 2
- 230000008018 melting Effects 0.000 description 2
- 102000054765 polymorphisms of proteins Human genes 0.000 description 2
- 108091033319 polynucleotide Proteins 0.000 description 2
- 102000040430 polynucleotide Human genes 0.000 description 2
- 239000002157 polynucleotide Substances 0.000 description 2
- 238000007781 pre-processing Methods 0.000 description 2
- 238000012795 verification Methods 0.000 description 2
- 108700024394 Exon Proteins 0.000 description 1
- 241000282412 Homo Species 0.000 description 1
- 238000012773 Laboratory assay Methods 0.000 description 1
- 238000002869 basic local alignment search tool Methods 0.000 description 1
- 238000005422 blasting Methods 0.000 description 1
- 238000003066 decision tree Methods 0.000 description 1
- 201000010099 disease Diseases 0.000 description 1
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 1
- 239000000284 extract Substances 0.000 description 1
- 238000000605 extraction Methods 0.000 description 1
- 230000006870 function Effects 0.000 description 1
- 238000003633 gene expression assay Methods 0.000 description 1
- 230000002452 interceptive effect Effects 0.000 description 1
- 238000012805 post-processing Methods 0.000 description 1
- 230000037452 priming Effects 0.000 description 1
- 238000012545 processing Methods 0.000 description 1
- 108090000623 proteins and genes Proteins 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 230000004044 response Effects 0.000 description 1
- 238000005070 sampling Methods 0.000 description 1
- 238000013077 scoring method Methods 0.000 description 1
- 238000012216 screening Methods 0.000 description 1
- 238000010845 search algorithm Methods 0.000 description 1
Images





Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6844—Nucleic acid amplification reactions
- C12Q1/686—Polymerase chain reaction [PCR]
Landscapes
- Chemical & Material Sciences (AREA)
- Organic Chemistry (AREA)
- Life Sciences & Earth Sciences (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Health & Medical Sciences (AREA)
- Engineering & Computer Science (AREA)
- Biophysics (AREA)
- Immunology (AREA)
- Microbiology (AREA)
- Molecular Biology (AREA)
- Biotechnology (AREA)
- Analytical Chemistry (AREA)
- Physics & Mathematics (AREA)
- Biochemistry (AREA)
- Bioinformatics & Cheminformatics (AREA)
- General Engineering & Computer Science (AREA)
- General Health & Medical Sciences (AREA)
- Genetics & Genomics (AREA)
- Measuring Or Testing Involving Enzymes Or Micro-Organisms (AREA)
Abstract
使用者に産物を手配する方法は、コンピュータネットワークを用いて使用者と交信し少なくとも一つの標的核酸シーケンスに関連する情報を得る工程と、指定の特性を有するフォワードプライマシーケンス、リバースプライマシーケンスおよびプローブシーケンスを提供する工程であって、フォワードプライマシーケンスおよびリバースプライマシーケンスは共同してアンプリコンシーケンスを定義し、アンプリコンは標的核酸シーケンス内に位置し、プローブシーケンスはアンプリコンシーケンスの一部に相補的である工程と、フォワードプライマシーケンスに従うフォワードプライマ、リバースプライマシーケンスに従うリバースプライマおよびプローブシーケンスに従うプローブを含む少なくとも一つのアッセイを製造する工程と、フォワードプライマ、リバースプライマおよびプローブの一つ以上を確認する工程と、製造されたアッセイを使用者に送る工程とを含む。
Description
(関連出願の相互参照)
本出願は、2002年1月25日出願の米国仮出願第60/352,039号、発明の名称「リクエスタに応じてカスタム・ポリヌクレオチドシーケンスを設計し製造する方法」、および2002年1月28日出願の米国仮出願第60/352,356号、発明の名称「リクエスタに応じてカスタム・ポリヌクレオチドシーケンスを設計し製造する方法」の利益を主張する。上記出願の開示は、その内容全体を本明細書中で参照として援用する。
(技術分野)
本発明はコンピュータシステムおよびネットワークに関し、より具体的には、たとえばバイオテクノロジー実験アッセイおよびサービスなど、産物およびサービスの注文を受理し応対するようなコンピュータシステムおよびネットワークを利用する方法に関する。
本出願は、2002年1月25日出願の米国仮出願第60/352,039号、発明の名称「リクエスタに応じてカスタム・ポリヌクレオチドシーケンスを設計し製造する方法」、および2002年1月28日出願の米国仮出願第60/352,356号、発明の名称「リクエスタに応じてカスタム・ポリヌクレオチドシーケンスを設計し製造する方法」の利益を主張する。上記出願の開示は、その内容全体を本明細書中で参照として援用する。
(技術分野)
本発明はコンピュータシステムおよびネットワークに関し、より具体的には、たとえばバイオテクノロジー実験アッセイおよびサービスなど、産物およびサービスの注文を受理し応対するようなコンピュータシステムおよびネットワークを利用する方法に関する。
(背景)
テーラーメード医療の一つの目的は、疾病の危険性および治療に対する反応を予測することによって医療を改善することである。現在利用可能なゲノムデータおよびそれに伴う一塩基変異多型(SNP)を用い、大規模研究を実施すれば、この目的を達成することができる。しかしながら、SNP遺伝子タイピングおよび遺伝子発現の研究の実施を試みる実験室では、現在、カスタムアッセイの設計に膨大な時間、費用、および手間を費やしている。
テーラーメード医療の一つの目的は、疾病の危険性および治療に対する反応を予測することによって医療を改善することである。現在利用可能なゲノムデータおよびそれに伴う一塩基変異多型(SNP)を用い、大規模研究を実施すれば、この目的を達成することができる。しかしながら、SNP遺伝子タイピングおよび遺伝子発現の研究の実施を試みる実験室では、現在、カスタムアッセイの設計に膨大な時間、費用、および手間を費やしている。
(要約)
上記に鑑み、本発明のいくつかの構成は、使用者に産物を供給する方法を提供する。この方法は、コンピュータネットワークを利用して使用者と交信し、少なくとも一つの標的核酸シーケンスに関連する情報を得るステップと;フォワードプライマーシーケンス、リバースプライマーシーケンス、およびプローブシーケンスを提供するステップであって、フォワードプライマーシーケンスおよびリバースプライマーシーケンスは共同してアンプリコンシーケンスを定義し、アンプリコンは標的核酸シーケンス内に位置し、プローブシーケンスはアンプリコンシーケンスの一部に相補的であるものとするステップと;フォワードプライマーシーケンスに従うフォワードプライマー、リバースプライマーシーケンスに従うリバースプライマー、およびプローブシーケンスに従うプローブを含む少なくとも一つのアッセイを製造するステップと;フォワードプライマー、リバースプライマー、およびプローブの一つ以上を確認するステップと;製造された少なくとも一つのアッセイを使用者に送付するステップとを含む。
上記に鑑み、本発明のいくつかの構成は、使用者に産物を供給する方法を提供する。この方法は、コンピュータネットワークを利用して使用者と交信し、少なくとも一つの標的核酸シーケンスに関連する情報を得るステップと;フォワードプライマーシーケンス、リバースプライマーシーケンス、およびプローブシーケンスを提供するステップであって、フォワードプライマーシーケンスおよびリバースプライマーシーケンスは共同してアンプリコンシーケンスを定義し、アンプリコンは標的核酸シーケンス内に位置し、プローブシーケンスはアンプリコンシーケンスの一部に相補的であるものとするステップと;フォワードプライマーシーケンスに従うフォワードプライマー、リバースプライマーシーケンスに従うリバースプライマー、およびプローブシーケンスに従うプローブを含む少なくとも一つのアッセイを製造するステップと;フォワードプライマー、リバースプライマー、およびプローブの一つ以上を確認するステップと;製造された少なくとも一つのアッセイを使用者に送付するステップとを含む。
本発明のいくつかの構成は、使用者に産物を供給する方法を提供する。この方法は、コンピュータネットワークを利用して使用者と交信し、少なくとも一つの標的核酸シーケンスに関連する情報を得るステップと;指定の特性を有するフォワードプライマーシーケンス、リバースプライマーシーケンス、およびプローブシーケンスを提供するステップであって、フォワードプライマーシーケンスおよびリバースプライマーシーケンスは共同してアンプリコンシーケンスを定義し、アンプリコンは標的核酸シーケンス内に位置し、プローブシーケンスはアンプリコンシーケンスの一部に相補的であるものとするステップと;フォワードプライマーシーケンスに従うフォワードプライマー、リバースプライマーシーケンスに従うリバースプライマー、およびプローブシーケンスに従うプローブを含む少なくとも一つのアッセイを製造するステップと;フォワードプライマー、リバースプライマー、およびプローブの一つ以上を確認するステップと;製造された少なくとも一つのアッセイを使用者に送付するステップとを含む。
本発明の種々の構成は、コンピュータシステムを操作する方法を提供する。この方法は、コンピュータ通信ネットワークによって少なくとも一つの標的核酸シーケンスを含む情報を受信するステップと;フォワードプライマーシーケンス、リバースプライマーシーケンス、およびプローブシーケンスを含むアッセイの設計を試行するステップであって、フォワードプライマーシーケンスおよびリバースプライマーシーケンスは共同してアンプリコンシーケンスを定義し、アンプリコンシーケンスは標的核酸シーケンス内に位置し、プローブシーケンスはアンプリコンシーケンスの一部に相補的であるものとするステップと;フォワードプライマーシーケンス、リバースプライマーシーケンス、およびプローブシーケンスの少なくとも一つをゲノムデータベースで確認するステップと;設計メトリクスおよびスコアリングメトリクスによって設定される制約との合致に成功したか、失敗したかを含め各設計試行をログファイルに記録するステップと;ログファイルを利用し、フォワードプライマーシーケンス、リバースプライマーシーケンス、およびプローブシーケンスの少なくとも一つに対し出力シーケンスデータを生成するステップとを含む。
本発明のいくつかの構成は、コンピュータシステムを操作する方法を提供する。この方法は、コンピュータ通信ネットワークによって少なくとも一つの標的核酸シーケンスを含む情報を受信するステップと;アッセイ設計メトリクスおよびスコアリングメトリクスを提供するステップと;フォワードプライマーシーケンス、リバースプライマーシーケンス、およびプローブシーケンスを含むアッセイの設計を試行するステップであって、フォワードプライマーシーケンスおよびリバースプライマーシーケンスは共同してアンプリコンシーケンスを定義し、アンプリコンシーケンスは標的核酸シーケンス内に位置し、プローブシーケンスはアンプリコンシーケンスの一部に相補的であるものとするステップと;フォワードプライマーシーケンス、リバースプライマーシーケンス、およびプローブシーケンスの少なくとも一つをゲノムデータベースで確認するステップと;各設計試行が設計メトリクスおよびスコアリングメトリクスによって設定される制約との合致に成功したのか、失敗したのかを含め各設計試行をログファイルに記録するステップと;ログファイルを利用し、フォワードプライマーシーケンス、リバースプライマーシーケンス、およびプローブシーケンスの少なくとも一つに対し出力シーケンスデータのバッチを生成するステップとを含む。
本発明の種々の構成によって、使用者はカスタムアッセイ設計にかかる膨大な時間、費用および手間を節約することができる。これによって、これまでにない高処理能力および低価格のSNP遺伝子タイピングまたは遺伝子発現検査の研究が可能になることは明らかである。さらに、種々の構成は、性能を確認するための即座に使用することができる機能性テストアッセイを提供する。
本発明のさらなる用途の範囲は以下に示す詳細な記載から明らかになる。当然のことながら、詳細な記載および特定の実施例は、本発明の好ましい実施の形態を示すが、単なる実例を示そうとするものであり、本発明の範囲を限定するものではない。
本発明は、詳細な記載および添付の図面をみればさらにはっきりとする。
(好ましい実施の形態の詳細な説明)
好ましい実施の形態についての以下の記載は、事実上、単なる例示にすぎず、本発明、その用途、またはその使用を何ら限定するものではない。
好ましい実施の形態についての以下の記載は、事実上、単なる例示にすぎず、本発明、その用途、またはその使用を何ら限定するものではない。
本明細書に使用される用語「手配する」および「提供する」は同義的に使用することがあり、販売または市場取引のほか、産物またはサービスを提供することを包含するものとする。これにならい、用語「手配者」および「供給者」は、売り手、販売業者のほか、該当する産物およびサービスの供給者を包含する。また、用語「使用者」は、顧客のほか、産物およびサービスのユーザを包含する。但し書きがない限り、本発明の構成は、手配した産物またはサービスに対し支払いまたは契約を受取次第、手配の前提条件を調整することができるが、これは必須ではない。
さらに、本明細書の英語の原文中に使用されている用語「a」、「an」、「the」、「said」および「at least one」、すなわち、本明細書に使用されている名詞、ならびに名詞を修飾する用語「前記」および「少なくとも一つ」は、但し書きがない限り、数を「1」に限定するものではなく、むしろ、「1を上回る数」(つまり複数)も同じく包含していると解釈するものとする。さらに、「プローブ」は、SNPアッセイの場合2対立遺伝子プローブを含むものとする。
本明細書に実施例を挙げているが、その実施例に限定されるものではない。
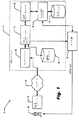
図1を参照する。本発明の種々の構成では、複数のコンピュータ12,16を備えるコンピュータシステム10を利用し使用者18に産物を手配する。コンピュータネットワーク14(たとえばインターネットのような公衆網)上の第1のコンピュータ12(つまり手配者コンピュータ)は、第2のコンピュータ16(つまり使用者コンピュータ)を利用して使用者18と交信し、ヒトまたはヒト以外の標的DNA(またはRNA)シーケンスに関係する情報、たとえば、SNPおよび/またはエキソンの位置、つまりシーケンスそのもの、SNPおよび/またはエキソン位置そのもの、またはたとえば遺伝子名、アクセッション番号などのようなアイテムがわかる他の情報を得る。いくつかの構成では、使用者18が使用者コンピュータ16上で動作しているウェブブラウザにユニフォーム・リソース・ロケータ(URL)をタイプ入力し、手配者コンピュータ12上で動作しているサーバ20からハイパーテキスト・マークアップ言語(HTML)または他のタイプのウェブページをダウンロードすることによって、上記の相互交信が開始する。使用者コンピュータ16に表示されているウェブページは、種々のタイプの紹介情報および販売情報を含んでいてもよく、承認ユーザ/購入者にログインを提供し、必要または所望に応じて、DNA(またはRNA)シーケンスおよび他の情報を求める。いくつかの構成では、情報を得るために使用者18と交信するサーバ34によって提供されるいくつかのウェブページの一つに初期ウェブページがある。たとえば、いくつかの構成によれば、使用者18がアクセスする初期ウェブページは、使用者18に情報を提供するほか、使用者18が使用者コンピュータ16を使用して識別情報をタイプするフォームを提供する企業ウェブサイトである。使用者18によって入力されたのち、コンピュータネットワーク14を介して使用者コンピュータ16によって送られる情報を手配者コンピュータ12が受け取る。いくつかの構成では、販売ページへのアクセス、および手配者からのアッセイ購入を許可するために、手配者コンピュータ12が使用者18の本人証明および使用者の資格を確認する。たとえば、この確認は、資格のある使用者および使用者本人確認物が示されている使用者データベース24を参照しつつ、手配者コンピュータ12上で動作するウェブ・アプリケーション・サーバ22(たとえばニューヨーク州アーモンク市のインターナショナル・ビジネス・マシーンズ・コーポレイション(International Business Machines Corporation)から市販されているIBM(登録商標) WEBSPHERER(登録商標) アプリケーション・サーバ)によって実行することができる。使用者18を確認することができない場合、または購入する資格がない場合、この情報をウェブ・アプリケーション・サーバ22およびウェブページ・サーバ20によってコンピュータネットワーク14を介し使用者18に戻してもよい。このとき、使用者18は、注文を完了させることができなくなるか、および/またはさらなる情報へアクセスすることができなくなる。
使用者18の本人確認をし、資格承認すると(または確認および/または資格承認を求めない構成の場合)、使用者18は少なくとも一つの標的核酸シーケンスを含む情報を指定する。いくつかの構成では、標的核酸シーケンスが標的DNAシーケンスである。使用者18が提供し、手配者コンピュータ12が得る情報は、さらにエキソンまたはその一部、および/または一塩基変異多型(SNP)を含んでいてもよい。使用者18が提供し、手配者コンピュータ12が得ることのできる他の情報として、SNP位置および/またはエキソン位置が含まれてもよい。たとえば、使用者18が使用者コンピュータ16を使用しコンピュータネットワーク14を介して手配コンピュータ12に送り、手配コンピュータが受け取る使用者18からの情報をウェブページフォーム上に提供してもよい。使用者18から情報を受け取る際、本発明のいくつかの構成は、使用者によって提供される標的核酸シーケンスのフォーマットエラーについて解析する。下記に示すように、特定の特性のリストを作るために、改良型コンフィギュレータ26(カリフォルニア州サンホゼのセレクティカ(Selectica)社から市販されているSELECTICA(登録商標) Configurator(商標)など)がネットワーク14を介して使用者18と交信する。コンフィギュレータ26は、アッセイ設計プログラム28用の入力を生成し、かつパラメータのアッセイ設計プログラム28への入力がプログラム28によって操作することのできる範囲内に確実にあるようにする実質的な自動決定木である。エラーがなければ、次にアッセイ設計プログラム28はルックアッププロセス、設計プロセス、または別の適切な方法を使用し、特定の特性を有するフォワードプライマーシーケンス、リバースプライマーシーケンス、およびプローブシーケンスを提供する。フォワードプライマーシーケンスおよびリバースプライマーシーケンスはアンプリコンシーケンスを定義し、アンプリコンシーケンスそれ自体は標的核酸シーケンス内に位置し、プローブシーケンスはアンプリコンシーケンスの部分に相補的である。本発明のいくつかの構成は、手配者コンピュータ12を利用し、ゲノムデータベース30、アッセイ設計プログラム28からの結果をたとえばヒトゲノムデータベースで確認するかまたは「BLAST」する。本明細書で使用する用語「BLAST」は、アルチュール(Altschul)らによって開発されたベーシック・ローカル・アラインメント・サーチ・ツール(Basic Local Alignment Search Tool)を参照するものとする(ジャーナル・オブ・モレキュラー・バイオロジー(J. Mol. Biol.)215:403−10,1990年)。このツールは、シーケンスの類似性に基づいてDNAデータベースを検索する迅速な検索アルゴリズムを備える。このようなBLAST検索ツールは、プローブおよびプライマーのシーケンスに対して使用することのできる種々の確認方法に対し有用なツールである。確認プロセスは、プローブおよびプライマーのシーケンスが標的領域に対して選択することのできるものなのか、つまりゲノムの他の領域ではなく標的領域へハイブリダイズするのかを確認するためのプロセスである。
確認が完了すると、オリゴ工場32は使用者18からの注文を受理し、フォワードプライマー、リバースプライマー、およびプローブを含む成分を有する少なくとも一つのアッセイを製造し、使用者へ製造したアッセイを送る。製造するフォワードプライマー、リバースプライマー、およびプローブは、確認されたシーケンスに従って製造される。いくつかの構成では、アッセイは、二次元バーコードを備える単一チューブ式のホモジニアスアッセイとして送られる。
種々の構成では、製造したアッセイを使用者に送付する前に、アッセイが指定の特性に合致していることを確認するためのテストをする。このテストに、たとえば、オリゴヌクレオチドシーケンスが正しいか判断するためにアッセイに実施する質量分析を含めてもよく、および/または、増幅され少なくとも一つの対立遺伝子の存在が確認されるのか判断するために実施する機能性テストをこのテストに含めてもよい。
いくつかの構成では、使用者に発送されたアッセイのプローブが、バックグラウンド蛍光を低減し消光効率を増加するように形成されている非蛍光色素を含む。このため、アプライド・バイオシステムズ(Applied Biosystems)PRISM(登録商標)7900HTシーケンス・ディテクション・システム(Sequence Detection System)など、高処理能力でSNP遺伝子タイピングを実施することができ、1日当たり約250,000の遺伝子型を解析し、各解析に必要な試料DNAはごくわずかであるPCRシーケンス検出システムを使用すれば、上記のアッセイは特に適切となり、使用者にとって大きな利益となる。
図1および2を参照する。本発明の種々の構成によって、使用者にバイオテクノロジー産物を手配する方法34を実施する。より具体的には、この方法は、36でコンピュータネットワーク14を利用して使用者18と交信し、少なくとも一つの核酸シーケンスに関連する(つまりシーケンスを表す)情報を得ることを含む。使用者から得た標的核酸シーケンスは、たとえば標的RNAまたはDNAシーケンスであり、それ自体は、エキソンまたはその一部、および/または一塩基変異多型(SNP)含んでいてもよい。情報は、SNP位置および/またはエキソン位置に関連する情報をさらに含んでいてもよい。38では、提供された核酸シーケンスのフォーマットエラーについて解析する。エラーが検知される場合、36でさらに交信を実施し、フォーマットエラーを修正してもよい。(いくつかの構成では、核酸シーケンスを含む情報を得るために36で使用者18と交信する前に、コンピュータネットワーク14によって使用者の本人確認、および/または注文するための使用者資格の確認を使用者18に要求する。)
使用者18から情報を得ると、本発明の種々の方法は、40で、指定の特性を有するフォワードプライマーシーケンス、リバースプライマーシーケンス、およびプローブシーケンスを提供する。指定の特性としては、たとえば、大きさの上限、標的Tm(融解温度)、最低Tm、ヘアピンステム中で対を成す塩基の合計、ヘアピンステム中で隣接して対を成すグループ、GC結合の含量、連続するG塩基群、連続する非G塩基群、および/またはC含量以下(G≦C)であるG含量が挙げられる。
使用者18から情報を得ると、本発明の種々の方法は、40で、指定の特性を有するフォワードプライマーシーケンス、リバースプライマーシーケンス、およびプローブシーケンスを提供する。指定の特性としては、たとえば、大きさの上限、標的Tm(融解温度)、最低Tm、ヘアピンステム中で対を成す塩基の合計、ヘアピンステム中で隣接して対を成すグループ、GC結合の含量、連続するG塩基群、連続する非G塩基群、および/またはC含量以下(G≦C)であるG含量が挙げられる。
フォワードプライマーシーケンスおよびリバースプライマーシーケンスは共同してアンプリコンシーケンスを定義する。アンプリコンは標的核酸シーケンス内に位置する。プローブシーケンスはアンプリコンシーケンスの一部に相補的である。次に種々の構成では、42で、フォワードプライマーシーケンス、リバースプライマーシーケンスおよびプローブシーケンスの一つ以上を、たとえばデータベース30のようなゲノムデータベースを使用し、有効性を確認する。確認には、シーケンスの一つ以上を上記のようにBLASTすることが挙げられる。少なくとも一つのアッセイを44で製造する。製造されたアッセイは、フォワードプライマーシーケンスに従うフォワードプライマー、リバースプライマーシーケンスに従うリバースプライマー、およびプローブシーケンスに従うプローブを含む。いくつかの構成では、フォワードプライマーシーケンス、リバースプライマーシーケンスおよび/またはプローブシーケンスは、42で有効であると確認されたシーケンスである。48でアッセイを使用者18に発送する。本発明のいくつかの構成は、二次元バーコードを備える単一チューブ式アッセイを発送する。いくつかの構成では、製造されたアッセイのプローブに、バックグラウンド蛍光を低減し消光効率を増加するように形成されている非蛍光色素が含まれている。アッセイ自体は、シーケンス検出システムでの使用に適切なものである。
いくつかの構成は、46で、アッセイが指定の特性に合致するか確認するために、製造されたフォワードプライマー、製造されたリバースプライマー、および/または製造されたプローブを送付前にテストする。46のテストとして、たとえば、オリゴヌクレオチドシーケンスが正しいか判断するためにアッセイに質量分析を実施したり、および/または増幅され少なくとも一つの対立遺伝子の存在が確認されるのか判断するために機能性テストを実施したりすることが挙げられる。
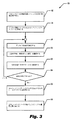
図3を参照すると、本発明の種々の構成によって、コンピュータシステムを操作する方法50が提供されている。この方法は、52で、図1のネットワーク14のようなコンピュータ通信ネットワークによって少なくとも一つの標的核酸シーケンスを含む情報を受け取ることを含む。54では、アッセイ設計メトリクス、つまりプローブおよびプライマーの指定の特性、ならびに指定の特性に対するスコアリング値が、たとえば局所記憶装置から提供される。スコアリングの方法には、指定の特性のそれぞれにプローブおよびプライマーがどの程度一致しているのか判断し、プローブおよびプライマーが受け入れ可能であるかどうかの判断に使用することのできる全体的な適性値の獲得に至ることが含まれている。
58では、52で受け取った情報を使用し、コンピュータシステムを用いて、フォワードプライマーシーケンス、リバースプライマーシーケンス、およびプローブシーケンスを含むアッセイの設計を試行する。フォワードプライマーシーケンスおよびリバースプライマーシーケンスは共同してアンプリコンシーケンスを定義する。アンプリコンシーケンスは標的核酸シーケンス内に位置し、プローブシーケンスはアンプリコンシーケンスの一部に相補的である。60では、得られるアッセイ設計、またはその部分に対し、設計メトリクスまたは制約の適用をいくつかの構成によって試行する。たとえば、制約は、大きさの上限、標的Tm(融解温度)、最低Tm、ヘアピンステム中で対を成す塩基の合計、ヘアピンステム中で隣接して対を成すグループ、GC結合の含量、連続するG塩基群、および連続する非G塩基群が挙げられる。これらの制約は、フォワードプライマーシーケンス、リバースプライマーシーケンス、またはプローブシーケンスのいずれか、またはその組み合わせに適用してもよい。いくつかの構成では、プライマーシーケンスの3’末端(5塩基)のG+Cに対する制限を含む少なくとも一つの制約に従いプライマーシーケンスを少なくとも一つ設計する試行を、58のアッセイ設計の試行にさらに含ませてもよい。
62では、各設計の試行が、設計メトリクスおよびスコアリングメトリクスによって設定される制約との合致に成功したか失敗したのかを含め、各設計の試行をログファイルに記録する。64で設計がこれらの制約に合っていなければ、58でアッセイ設計の別の試行をすることができる。これとは反対に、設計が適切であれば66に進み、ログファイルを使用し、プライマーシーケンス、リバースプライマーシーケンス、およびプローブシーケンスの少なくとも一つに対する出力シーケンスデータを生成する。さらに68では、いくつかの構成が、出力シーケンスデータの各バッチへシリアル番号を割り当てる。
図4を参照すると、いくつかの構成によって、アッセイ設計システム70が、バッチフォーマットによる対立遺伝子の識別および遺伝子発現のアッセイ用TAQMAN(登録商標)プライマーおよびプローブを高処理能力で自動設計することのできるコンピュータソフトウェアとして提供されている。このコンピュータソフトウェアは、何百または何千のアッセイを設計する場合に特に有用である。アッセイ設計プログラム28はTAQMAN(商標)プローブおよびプライマー試薬の設計用アルゴリズムの非インタラクティブルートである。いくつかの構成では、ヒューリスティック法をアッセイ設計プログラム28中で利用する。前処理および後処理のユーティリティプログラムおよびラッパースクリプトが、完全なアッセイ設計システム70のコンポーネントとして利用される。
アッセイ設計システム70のコンポーネントおよびデータフローは二つのデータファイル72および73を含む。シーケンス入力ファイル72はフォーマットされているアノテーション付きシーケンスデータを含む。パラメータファイル73は、設計中に適用されるルールおよびスコアリングを管理するキーワード関連の設定を含む。各設計を試行する前に、提供されるシーケンスデータのフォーマットのエラーについて74でチェックする。76で入力ファイル72からのシーケンスデータにエラーが発見されると、エラーログ88にエラーが報告され、プロセスは終了する。
ルールおよびスコアリングスキームをセットアップするためにパラメータファイル73を解析することによって、設計プログラム28が開始する。この初期設定段階でエラーがあると、エラーはログファイル88に報告され、アッセイ設計28プログラムが停止する。初期設定のエラーは、矛盾するオプション、あるいは正しくないファイル名またはフォーマットによって生じると考えられる。初期設定に成功すると、アッセイ設計プログラム28は、パラメータファイル73からの入力シーケンスデータに挙げられている各シーケンスの各標的部位に対するアッセイセットの設計を連続的に試行する。設計処理を実施すると、その設計を設計ログファイル80に記録する。失敗した設計試行もログファイル80に記録される。シーケンス標的に対し、ルールおよびスコアをすべて満たし仕様に合う一連の試薬が見つからない場合、設計失敗となる。
82で設計ログファイル80の中に有効な設計がないことがわかると、この事実をエラー報告88に報告する。有効な設計があれば、中核となる設計プロセスに続いて、設計ログファイル80を使用し、多くの異なるフォーマットで出力シーケンスデータを生成するようにしてもよい。設計ログ80データのこの前処理をログピックプログラム84が実施し、フォーマットされた出力86を生成する。UNIX(登録商標)オペレーティングシステムによってスクリプトを実施し、図4に示すプロセスをすべてまとめて結合することによってシステム全体を統合することができる。また、スクリプトはプロセス70の各実行について記録し、各出力バッチに追跡用のシリアル番号を割り当てる。
アッセイ設計プログラム28への入力は、設計ルールおよび一つ以上のシーケンスデータファイル72を指定するパラメータファイル73を含む。出力は、成功した各試薬設計(プローブ、プライマー、およびアンプリコンシーケンスを含む)を記載しているシステム設定および属性を報告するログファイル80を含む。いくつかの構成では、プログラムの動作中に、システムステータスを示す追加の出力を表示画面に報告する。
個別の設計ルールおよび制約は、見込みのあるプローブ、プライマー、および「アンプリコン」、つまり標的部位近傍にあるフォワードおよびリバースプライマーの組み合わせによって定義される領域に適用される。所定の実行から得られる設計はすべて、共通する一連のルールを共有する。プローブの制約としては、大きさ(つまりプローブ長さ)の上限、Tm(標的、最低、および最高温度)、内部ループ(ヘアピンステム中で対を成す塩基の合計および隣接して対を成す塩基)、G+Cの含量((つまりGC結合のパーセンテージ)、連続するGなどの所定塩基群が挙げられる。さらにプライマーの3’末端(5塩基)のG+Cの制限を含む類似の制約も、プライマーへ個々に適用する。アンプリコンに適用される制約として、長さ(プライマーを含む)、G+C含量、および不明の塩基数を含む(なお不明の塩基はプローブまたはプライマー内にあってはならない)。さらに、アプリコンを定義するプライマーは、内部プライミング部位(つまり、一つのプライマーの3’末端から始まり、もう一つのプライマーの任意の部分と相補的に対をなす連続する塩基数)の最大サイズを制限するように制約を受ける。
システム70は、既に挙げた多数の制約に対しフィルタまたはスコアのいずれかを適用することができる。フィルタとして適用する場合、制約は、仕様に合った設計を満たす制約か、または拒絶される設計を満たさない制約となる。スコアとして適用する場合、所定の設計がどの程度「最適」であるのかを反映させた格付け値を属性に付与してもよい。たとえば、制約されている属性のすべてがほぼ最適値をとる設計は、最適値から外れる属性を有するものよりも優先されることになる。スコアリングは、設計を評価し選択するためにシステム70が使用する制約を、良好に調節することができる。
本発明の種々の構成中のアッセイ設計プログラム28の論理を図5でさらに詳細に示す。プログラム28は92から開始する。初期設定段階98が、パラメータファイル73からパラメータデータを読み出し、シーケンスデータファイル72からシーケンスデータを読み出す。(図4に示すように、シーケンスデータ72はアッセイ設計プログラム28によって読み出される前に74および76でエラーの有無をチェックしてもよい。)初期設定98はパラメータファイル73の解析およびそれに続くプローブ設計のセットアップを含む。初期設定98の結果、100で何らかの問題が発生していれば、アッセイ設計プログラム28は104で判断メッセージを報告し停止する。発生していなければ、処理は継続する。本発明のいくつかの構成では、ほとんどのパラメータファイル73のオプションがデフォルト値を有し、コマンドラインオプションを優先してもよい。設計中に実際に使用されるオプションは、図4の設計ログ80の一部であるか、または設計ログの一部になるログファイルヘッダ102に報告される。
110ではアッセイ設計プログラム28が、仕様に合った各標的部位のアッセイセットの設計を試行する。これらの設計を112で記録する。114では、シーケンスデータファイル72からの各入力シーケンスレコードに対し仕様に合う設計を特定する試行がなされる。106でレコードがなくなれば、アッセイ設計プログラム28は104に進み終了する。レコードがあれば110に進み、各レコードの各標的を列挙順に試行する。標的情報が提供されていない場合、シーケンスの中間点(シーケンスがSNPアノテーションを含まない場合)または第1のSNP(アノテーションがある場合)を標的として使用する。108で所定のレコードに対する標的が残っていなければ、アッセイ設計プログラム28は106へ戻り次のレコードへ進む。
114では、標的部位について、アッセイ設計プログラム28が、設計メトリクスおよびスコアリングメトリクスに従い、設計の成功および失敗を判断する。標的に対する設計が失敗すると、この事実を、失敗した当該設計とともにログファイル80へ報告し、プログラムは108へ戻り、そのレコードに対する次の標的へ進む。標的に対する設計が成功すれば、選択しているレコードの詳細をログファイル80に報告する。通常は、設計が一つ成功すると、アッセイ設計プログラム28は106に戻り、次のレコードに移る。一方、いくつかの構成では、各レコードに対して挙げられている標的をすべて評価するオプションを116で実施することができるようにしており、この場合、設計が成功した後、アッセイ設計プログラム28は106に戻って次のレコードに進むのではなく、108に戻って次の標的に進む。
本発明の種々の構成による単一標的用試薬の設計手順110の論理を図6にさらに詳細に示す。122から開始する。レコード/標的用設計プログラム110が124で設計「ウィンドウ」、たとえば標的付近の一つまたは二つのサブシーケンスを抽出する。SNP標的の場合、124で、各対立遺伝子につき一つずつ、SNP標的部位付近で二つの別個のウィンドウを抽出する。さらに、ウィンドウのシーケンス内にあることがわかっている他のSNPは、それを任意のヌクレオチドNに変換することによってマスキングする。非SNP標的については、単一のサブシーケンスウィンドウを124で抽出する。ウィンドウは、提供されている入力シーケンスの長さによって、または受け入れ可能な最大アンプリコンサイズによってサイズが制限される。126で、ウィンドウ抽出の間に問題(たとえば不正確にフォーマットされているSNPアノテーション)が発生していれば、146に進み失敗となる。(通常、この手順、および他の手順または機能の失敗は、使用者に報告してもよく、結果的に発送する製品がないことになるかもしれない。種々の構成では、ソフトウェアが、オーダーの後またはオーダーによって生じる失敗の後に、それ自体をリセットし、次のオーダーに備えるように形成されているので、不適切なデータ、矛盾するデータ、規定外のデータなどに起因する失敗は致命的でない。)
問題が生じていなければ、128へすすみ、プライマーのみを設計するオプションを実施できるようになっていなければ、通常130にすすみ、プローブの配列を試行する。なお、オプションが実施できるのであれば、実行は134へ進む。(プライマーのみのオプションは、たとえば”−op”のようなコマンドラインオプションによって実施するようにしてもよい。)130でプローブを配列することによって、仕様に合うプローブを(非SNPおよびSNPに対しそれぞれ)一つまたは二つ獲得するが、プローブを獲得できないこともある。仕様に合うプローブが132で特定されない場合、146へ進み標的設計プロセス110は失敗する。特定されれば、134へ進み、プライマーに対する境界を設定する。
問題が生じていなければ、128へすすみ、プライマーのみを設計するオプションを実施できるようになっていなければ、通常130にすすみ、プローブの配列を試行する。なお、オプションが実施できるのであれば、実行は134へ進む。(プライマーのみのオプションは、たとえば”−op”のようなコマンドラインオプションによって実施するようにしてもよい。)130でプローブを配列することによって、仕様に合うプローブを(非SNPおよびSNPに対しそれぞれ)一つまたは二つ獲得するが、プローブを獲得できないこともある。仕様に合うプローブが132で特定されない場合、146へ進み標的設計プロセス110は失敗する。特定されれば、134へ進み、プライマーに対する境界を設定する。
134では、プライマーの境界を設定するために、設計ウィンドウ内にサブ領域を三つ定義する。プローブが設計されている場合(たとえば、プライマーだけでなくほかにも設計されている場合)、プローブの座標に対応する中央マスク領域を定義する。マスク領域の境界は、標的部位座標に対して明確に設計してもよい。たとえば、いくつかの構成では、コマンドラインオプション(”−pm”のような)を使用して、標的部位座標に対してマスク領域を明確に決め設計するように指定する。この場合、実際のマスク領域は、指定の境界またはプローブによって形成されるマスクよりも大きくなる。中央マスク領域を固定することによって、プライマーを設計することのできる二つのサブ領域を決定する。「上流ストランド」サブ領域はウィンドウの開始点から始まり、マスク領域の開始点まで延在する。「下流ストランド」サブ領域はマスクの後に続き、ウィンドウの端まで延在する。ウィンドウ(つまり上流ストランド、マスク、および下流ストランド)の三つのサブ領域は重複しない。
上流ストランドおよび下流ストランドのサブ領域を決定すると、設計手順110は、136で各サブ領域のプライマーを複数集めることを試行する。フォワードプライマーは上流ストランド領域から取得し、リバースプライマーは下流ストランド領域から取得する。見込みのあるプライマーの評価は、マスクに最も近い座標の各ヌクレオチド位置(つまり上流ストランド領域の終了座標および下流ストランド領域の開始座標)から始め、各位置で評価する。このような評価は、たとえば、先行技術の公知の認められている基準に従い、見込みのあるプライマーが仕様に合うものであるかを判断してもよい。いくつかの構成では、設計手順110が最大で10個のフォワードプライマーおよび10個のリバースプライマーを集めるが、コマンドラインオプション(”−np”のような)を設定することによって、上限10を別の数に変更することもできる。
138で、見込みのあるフォワードプライマー一つ、および見込みのあるリバースプライマー一つが最低でも見つからなければ、146に進み設計プロセス110は失敗する。プライマーのリストが二つ挙がると、設計プロセス110は140に進み、仕様に合うフォワード/リバースの対の特定を試行する。仕様に合うプライマー対が142で特定されなければ、設計プロセス110は146に進み失敗する。特定されれば、144へ進み完全な設計を見つけたことになる。
本発明の種々の構成によってプローブを配列する手順130の論理を図7にさらに詳細に示す。設計試行は150から開始し、プローブ配列の試行を実施する。152では、標的がSNP部位であるか非SNP部位であるかの判断に基づいて以降の論理が分かれるが、どちらの論理もわずかな違いはあるもののほぼ同じパスである。SNP部位の場合、156で、両方のストランドの両方の対立遺伝子上の試料シーケンスを検討する。非SNP部位の場合、156,158,または160で両ストランドを使用するのか、または一つのストランドのみを使用するのかについて154で判断する。次に、162または166で明確にストランドを決定し、非標的ストランドプローブを164または168で除去し、170または172で最良のプローブを取得する。最良のプローブを取得するために使用される特徴は、Tm値およびフィルタまたはスコアリング値に基づいて決定される。標的重複の最小値は入力パラメータである。非SNP標的の場合、大きいシーケンス領域をサンプリングできるようにするために、この値をネガティブにしてもよい。SNP標的の場合、標的重複の最小値を2塩基とするが、重複値を上げてもよい。フォワードおよびリバースストランドを標的にするプローブを両方とも評価する。プローブはGで開始しないようにしてもよく、通常はG含量がC含量を超えないようにしなければならないが、G≦Cルールを排除するオプションを設けておく。いくつかの構成中によれば、フォワードおよびリバースストランドどちらもTm設定に合うように正確に検討することもある。プローブスコアリングを適用する場合、最良のスコアリングプローブを選択する。それがなければ、標的部位と最も重複し制約を満たしているプローブを選択する。174または176でプローブが受け入れ可能であるかを判断し、プローブが合格すると178へ進み、プローブが選択される。また、判定基準を満たさないと、180へ進み選択のし直しとなる。
SNP標的部位については、両対立遺伝子に対応する(いくつかの構成では2対立遺伝子のSNP部位のみに対応する)シーケンスを明確に構築し、両対立遺伝子シーケンスの両ストランドに対する最良のプローブを上記のように特定する。仕様に合うSNPプローブ対は同じシーケンスストランドを標的にしなければならない。両ストランドに対し、仕様に合うプローブ対が複数見つかると、スコアの合計値が最大である対を産出するストランドを選択する。入力シーケンスが複数のSNP部位を示している場合、明確な標的対立遺伝子のそれぞれに対してシーケンスを構築するとき、非標的SNP部位をマスキングする(つまり、塩基Nに設定する)。
仕様に合うプローブ(またはSNPに対するプローブ対)が所定の標的に対して見つからない場合、システムはこの事実を報告し、提供されているシーケンス標的の数およびフォーマットに応じて試行を継続する。単一のシーケンスが入力として提供されている場合、プローブ(または対)の選択に失敗するとプログラムは終了する。複数の標的(またはSNP)座標が、所定のシーケンスに対して挙げられている場合、一つの標的座標でのプローブの配列に失敗すると、プローブ配列プロセス130は、挙げられている標的がすべてなくなるまで、次に挙げられている座標について検討する。複数シーケンス入力の場合、何らかの標的座標でプローブ配列に失敗すると、プログラムは、入力シーケンスがすべてなくなるまで、次に挙げられているシーケンスの処理をする。所定のシーケンスに対して多数の標的がある場合、個々の標的いずれか一つにプローブを配列することができてもできなくても、標的はすべてテストし、最良の設計を選択する。
一旦プローブ(またはプローブ対)シーケンスを選択すると、上流(フォワード)および下流(リバース)プライマーのリストの判別を、プローブ位置の直前および直後から開始する。これらは、Tm(いくつかの構成では、プローブ設計のために使用されるものとは異なるアルゴリズムを使用する)によって判別され、フィルタまたはスコアリングされる。SNPプローブ対を設計する場合、プライマーの判別を、両方のSNP標的プローブ位置に対応するフットプリントの直前および直後から開始する。少なくともフォワードプライマーを一つおよびリバースプライマーを一つ同定する必要がある。デフォルトによって、フォワードプライマーを10個、リバースプライマーを10個集めるが、上流および下流のプライマーの数はコマンドラインスイッチの使用などによって変更してもよい。いずれかのフォワードプライマーまたはいずれかのリバースプライマーの特定に失敗すると、プローブ配列プロセス130はその問題を報告し、上記のように次の標的座標または次のシーケンスについてプロセスを継続する。
フォワードおよびリバースプライマーを対の適合性についてチェックし、対応するアンプリコンをフィルタまたはスコアリングする。適合性チェックには、所定のプライマー対に関連するアンプリコンによるプライマー3’末端のスクリーニングが含まれる。同定された3’の合致が大きすぎる場合、プライマーは対にならない。デフォルトによって、最良のスコアのプライマー対、最短のアンプリコンを選択する。仕様に合うプライマー対の選択に失敗すると、プローブ配列プロセス130はこの問題を報告し、上記のようにプロセスを継続する。
一つまたは二つのプローブシーケンス(たとえばTAQMAN(登録商標)プローブを作るために使用することのできるプローブシーケンスなど)を、対応するフォワードおよびリバースプライマーシーケンスとともに含み仕様に合う設計をログファイルに記録する。シーケンスとともに、各プローブおよびプライマーについての座標、Tm値、およびスコアを報告する。設計に成功すれば、シーケンスおよび標的を入力している間にロードした関連する補助データ(例えば追跡情報)もすべて、ログファイルに報告する。仕様に合う設計が標的配列に対して見つからない場合、標的名だけをログファイルに記録する。
以上、本発明の種々の方法の構成がコンピュータシステムを操作する方法、および使用者に産物を手配するためにコンピュータシステムを使用する方法を提供することは明らかである。上記産物としては、カスタマイズされ、品質保証されている一塩基変異多型(SNP)遺伝子タイピングおよび遺伝子発現研究用アッセイが挙げられる。このサービスによって、使用者は自分用アッセイ設計に必要な莫大な時間、費用、および手間を節約することができるので、これまでにない高処理能力および低価格のSNP遺伝子タイピングまたは遺伝子発現調査の研究が可能になる。いくつかの構成では、使用者が出す情報に基づいてヒトまたはヒト以外の標的DNAシーケンスを提供することができる。種々の構成は、即座に使用することのできる性能確認用機能性テストアッセイを提供する。また、いくつかの構成は試料の追跡を容易にするための二次元バーコードを備える単一チューブ式プローブを提供する。いくつかの構成では非蛍光色素を使用することによって、バックグラウンド蛍光を低減し、消光効率を増やし、信号対雑音比を増やす。このため、アプライド・バイオシステムズ・インク(Applied Biosystems, Inc)PRISM(登録商標)7900HTシーケンスディテクションシステム(Sequence Detection System)などのように、高処理能力でSNP遺伝子タイピングを実施することができ、1日当たり約250,000の遺伝子型を解析し、各解析に必要な試料DNAはごくわずかであるシーケンス検出システムを使用すると、使用者にとって大きな利益となる。
本発明の明細書は、実質的な例示にすぎず、したがって、本発明の本質から外れていない変形は、本発明の範囲内にあるものとする。このような変形は本発明の精神および範囲から逸脱するものではない。
Claims (44)
- 使用者に産物を提供する方法であって、該方法は、
コンピュータネットワークを利用して前記使用者と交信し、少なくとも一つの標的核酸シーケンスに関連する情報を得るステップと、
フォワードプライマーシーケンス、リバースプライマーシーケンス、およびプローブシーケンスを提供するステップであって、該フォワードプライマーシーケンスおよび該リバースプライマーシーケンスは共同してアンプリコンシーケンスを定義し、該アンプリコンは前記標的核酸シーケンス内に位置し、該プローブシーケンスは該アンプリコンシーケンスの一部に相補的であるものとする該ステップと、
前記フォワードプライマーシーケンスに従うフォワードプライマー、前記リバースプライマーシーケンスに従うリバースプライマー、および前記プローブシーケンスに従うプローブを含む少なくとも一つのアッセイを製造するステップと、
前記フォワードプライマー、前記リバースプライマー、および前記プローブの一つ以上を確認するステップと、
前記製造された少なくとも一つのアッセイを前記使用者に送付するステップと
を含む方法。 - 前記フォワードプライマー、前記リバースプライマー、および前記プローブの一つ以上を確認する前記ステップは、該フォワードプライマーシーケンス、該リバースプライマーシーケンス、および該プローブシーケンスの一つ以上をゲノムデータベースで確認することを含む請求項1に記載の方法。
- 前記確認ステップは、前記製造された少なくとも一つのアッセイに質量分析を実施し、オリゴヌクレオチドシーケンスが正しいか判断することを含む請求項1に記載の方法。
- 前記確認ステップは、増幅されているか判断する機能テストを実施するステップを含む請求項1に記載の方法。
- 機能テストを実施する前記ステップは、少なくとも一つの対立遺伝子の存在を確認することをさらに含む請求項4に記載の方法。
- 前記使用者から得た前記標的核酸シーケンスに関連する前記情報は、標的DNAシーケンスに関連する情報である請求項1に記載の方法。
- 前記使用者から得た前記標的核酸シーケンスに関連する前記情報は、エキソンまたはその一部、および一塩基変異多型(SNP)からなる群の少なくとも1種に関連する情報を含む請求項1に記載の方法。
- 前記標的核酸シーケンスはSNPを含み、二つの2対立遺伝子プローブが提供される請求項7に記載の方法。
- 前記使用者から得た前記情報は、SNP位置およびエキソン位置からなる群の少なくとも1種に関連する情報をさらに含む請求項1に記載の方法。
- 前記製造された少なくとも一つのアッセイを前記使用者に送付する前記ステップは、該製造された少なくとも一つのアッセイを単一チューブ式にして送付することを含む請求項1に記載の方法。
- 前記製造された少なくとも一つのアッセイを前記使用者に送付する前記ステップは、該製造された少なくとも一つのアッセイに2次元バーコード表示を付けて送付することを含む請求項1に記載の方法。
- 前記プローブは非蛍光色素をさらに含む請求項1に記載の方法。
- 前記製造された少なくとも一つのアッセイはシーケンス検出システムでの使用に適している請求項1に記載の方法。
- 前記使用者と交信する前記ステップは、該使用者によって提供される標的核酸シーケンスのフォーマットエラーについて解析することをさらに含む請求項1に記載の方法。
- 前記標的核酸シーケンスはヒトのシーケンスである請求項1に記載の方法。
- コンピュータシステムを操作する方法であって、該方法は、
コンピュータ通信ネットワークによって少なくとも一つの標的核酸シーケンスを含む情報を受信するステップと、
フォワードプライマーシーケンス、リバースプライマーシーケンス、およびプローブシーケンスを含むアッセイの設計を試行するステップであって、該フォワードプライマーシーケンスおよび該リバースプライマーシーケンスは共同してアンプリコンシーケンスを定義し、該アンプリコンシーケンスは前記標的核酸シーケンス内に位置し、該プローブシーケンスは該アンプリコンシーケンスの一部に相補的であるものとする該ステップと、
前記フォワードプライマーシーケンス、前記リバースプライマーシーケンス、および前記プローブシーケンスの少なくとも一つをゲノムデータベースで確認するステップと、
各設計試行が前記確認に成功したか失敗したかを含め該各設計試行をログファイルに記録するステップと、
前記ログファイルを利用し、フォワードプライマーシーケンス、リバースプライマーシーケンス、およびプローブシーケンスの少なくとも一つに対し出力シーケンスデータを生成するステップと
を含む方法。 - 出力シーケンスデータの各バッチにシリアル番号を割り当てることをさらに含む請求項16に記載の方法。
- 使用者に産物を提供する方法であって、該方法は、
コンピュータネットワークを利用して前記使用者と交信し、少なくとも一つの標的核酸シーケンスに関連する情報を得るステップと、
指定の特性を有するフォワードプライマーシーケンス、リバースプライマーシーケンス、およびプローブシーケンスを提供するステップであって、該フォワードプライマーシーケンスおよび該リバースプライマーシーケンスは共同してアンプリコンシーケンスを定義し、該アンプリコンは前記標的核酸シーケンス内に位置し、該プローブシーケンスは該アンプリコンシーケンスの一部に相補的であるものとする該ステップと、
前記フォワードプライマーシーケンスに従うフォワードプライマー、前記リバースプライマーシーケンスに従うリバースプライマー、および前記プローブシーケンスに従うプローブを含む少なくとも一つのアッセイを製造するステップと、
前記フォワードプライマー、前記リバースプライマー、および前記プローブの一つ以上を確認するステップと、
前記製造された少なくとも一つのアッセイを前記使用者に送付するステップと
を含む方法。 - 前記フォワードプライマー、前記リバースプライマー、および前記プローブの一つ以上を確認する前記ステップは、該フォワードプライマーシーケンス、該リバースプライマーシーケンス、および該プローブシーケンスの一つ以上をゲノムデータベースで確認することを含む請求項18に記載の方法。
- 前記確認ステップは、前記製造された少なくとも一つのアッセイに質量分析を実施し、オリゴヌクレオチドシーケンスが正しいか判断することを含む請求項18に記載の方法。
- 前記確認ステップは、増幅されているか判断する機能テストを実施するステップを含む請求項18に記載の方法。
- 機能テストを実施する前記ステップは、少なくとも一つの対立遺伝子の存在を確認することをさらに含む請求項21に記載の方法。
- 前記使用者から得た前記標的核酸シーケンスは、標的DNAシーケンスである請求項18に記載の方法。
- 前記使用者から得た前記標的核酸シーケンスは、エキソンまたはその一部、および一塩基変異多型(SNP)からなる群の少なくとも1種を含む請求項18に記載の方法。
- 前記標的核酸シーケンスはSNPを含み、二つの2対立遺伝子プローブが提供される請求項24に記載の方法。
- 前記使用者から得た前記情報は、SNP位置およびエキソン位置からなる群の少なくとも1種をさらに含む請求項18に記載の方法。
- 前記製造された少なくとも一つのアッセイが前記指定の特性に合致するか確認するために、該製造された少なくとも一つのアッセイをテストするステップをさらに含む請求項18に記載の方法。
- 前記製造された少なくとも一つのアッセイをテストする前記ステップは、オリゴヌクレオチドシーケンスが正しいか判断するために、該製造された少なくとも一つのアッセイに質量分析を実施するテスト、および増幅され少なくとも一つの対立遺伝子の存在が確認されるか判断するために、機能性テストを実施するテストからなる群から選択される少なくとも一つのテストを含む前記請求項27に記載の方法。
- 前記製造された少なくとも一つのアッセイを前記使用者に送付する前記ステップは、該製造された少なくとも一つのアッセイを単一チューブ式にして送付することを含む請求項18に記載の方法。
- 前記製造された少なくとも一つのアッセイを前記使用者に送付する前記ステップは、該製造された少なくとも一つのアッセイに2次元バーコードを付けて送付することを含む請求項18に記載の方法。
- 前記プローブは非蛍光色素をさらに含む請求項18に記載の方法。
- 前記製造された少なくとも一つのアッセイはシーケンス検出システムでの使用に適している請求項18に記載の方法。
- 前記使用者と交信する前記ステップは、該使用者によって提供される前記標的核酸シーケンスのフォーマットエラーについて解析することをさらに含む請求項18に記載の方法。
- 大きさの上限、標的Tm、最低Tm、ヘアピンステム中で対を成す塩基の合計、ヘアピンステム中で隣接して対を成すグループ、GC結合の含量、連続するG塩基群、連続する非G塩基群、およびC含量以下のG含量からなる群から、前記指定の設計制約が選択される請求項18に記載の方法。
- 前記標的核酸シーケンスはヒトのシーケンスである請求項18に記載の方法。
- コンピュータシステムを操作する方法であって、該方法は、
コンピュータ通信ネットワークによって少なくとも一つの標的核酸シーケンスを含む情報を受信するステップと、
アッセイ設計メトリクスおよびスコアリングメトリクスを提供するステップと、
フォワードプライマーシーケンス、リバースプライマーシーケンス、およびプローブシーケンスを含むアッセイの設計を試行するステップであって、該フォワードプライマーシーケンスおよび該リバースプライマーシーケンスは共同してアンプリコンシーケンスを定義し、該アンプリコンシーケンスは前記標的核酸シーケンス内に位置し、該プローブシーケンスは該アンプリコンシーケンスの一部に相補的であるものとする該ステップと、
前記フォワードプライマーシーケンス、前記リバースプライマーシーケンス、および前記プローブシーケンスの少なくとも一つをゲノムデータベースで確認するステップと、
各設計試行が前記設計メトリクスおよびスコアリングメトリクスによって設定される制約との合致に成功したか、失敗したのかを含め該各設計試行をログファイルに記録するステップと、
前記ログファイルを利用し、フォワードプライマーシーケンス、リバースプライマーシーケンス、およびプローブシーケンスの少なくとも一つに対し出力シーケンスデータのバッチを生成するステップと
を含む方法。 - 出力シーケンスデータの各バッチにシリアル番号を割り当てることをさらに含む請求項36に記載の方法。
- アッセイを設計するステップは、大きさの上限、標的Tm、最低Tm、ヘアピンステム中で対を成す塩基の合計、ヘアピンステム中で隣接して対を成すグループ、GC結合の含量、連続するG塩基群、連続する非G塩基群、およびC含量以下のG含量からなる制約群から選択される少なくとも一つの制約に従うプローブシーケンスの設計を試行するステップを含む請求項36に記載の方法。
- 少なくとも一つの制約に従う前記プローブシーケンスの設計を試行するステップは、フィルタとして少なくとも一つの制約を適用することをさらに含み、これによって、前記制約を満たすのかに従い前記フォワードプライマーシーケンスを受け入れるか拒否する請求項38に記載の方法。
- 一つの制約に従う前記プローブシーケンスの設計を試行するステップは、少なくとも一つの制約をスコアとして適用することをさらに含み、前記フォワードプローブシーケンスは、異なるプローブシーケンスのスコアと比較することによって良し悪しが決まる請求項38に記載の方法。
- アッセイの設計を試行するステップは、前記プライマーシーケンスの3’末端(5塩基)でG+Cに対する制限を含む少なくとも一つの制約に従い該プライマーシーケンスを少なくとも一つ設計することを試行するステップを含む請求項36に記載の方法。
- アッセイの設計を試行するステップは、大きさの上限、標的Tm、最低Tm、ヘアピンステム中で対を成す塩基の合計、ヘアピンステム中で隣接して対を成すグループ、GC結合の含量、連続するG塩基群、連続する非G塩基群、およびC含量以下のG含量からなる群から選択される少なくとも一つの制約に従い、前記プライマーシーケンスを少なくとも一つ設計することを試行するステップを含む請求項36に記載の方法。
- 少なくとも一つの制約に従い前記プライマーシーケンスを少なくとも一つ設計することを試行するステップは、フィルタとして少なくとも一つの制約を適用することをさらに含み、これによって、前記制約を満たすのかに従い該プライマーシーケンスを受け入れるか拒否する請求項42に記載の方法。
- 少なくとも一つの制約に従う前記プライマーシーケンスを少なくとも一つ設計することを試行するステップは、少なくとも一つの制約をスコアとして適用することをさらに含み、前記プライマーシーケンスは、異なるプライマーシーケンスのスコアと比較することによって良し悪しが決まる請求項42に記載の方法。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US35203902P | 2002-01-25 | 2002-01-25 | |
| US35235602P | 2002-01-28 | 2002-01-28 | |
| PCT/US2002/034599 WO2003064694A1 (en) | 2002-01-25 | 2002-10-30 | Method for operating a computer and/or computer network to distribute biotechnology products |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2005516296A true JP2005516296A (ja) | 2005-06-02 |
| JP2005516296A5 JP2005516296A5 (ja) | 2005-12-22 |
Family
ID=27669050
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2003564284A Pending JP2005516296A (ja) | 2002-01-25 | 2002-10-30 | バイオテクノロジー産物を手配するコンピュータの操作方法、および/またはコンピュータネットワーク |
Country Status (4)
| Country | Link |
|---|---|
| EP (1) | EP1468111A4 (ja) |
| JP (1) | JP2005516296A (ja) |
| CA (1) | CA2474481A1 (ja) |
| WO (1) | WO2003064694A1 (ja) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2012014988A1 (ja) * | 2010-07-29 | 2012-02-02 | タカラバイオ株式会社 | 標的塩基検出用rna含有プローブの製造方法 |
| JP2015531121A (ja) * | 2012-08-03 | 2015-10-29 | ラベル インデペンデント,インク. | アッセイを設計し、開発し、共有するためのシステムおよび方法 |
| US9464320B2 (en) | 2002-01-25 | 2016-10-11 | Applied Biosystems, Llc | Methods for placing, accepting, and filling orders for products and services |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2006134188A (ja) * | 2004-11-08 | 2006-05-25 | Japan Science & Technology Agency | オリゴヌクレオチドデータ管理装置、オリゴヌクレオチドデータ管理システム、オリゴヌクレオチドデータ管理プログラムおよび記録媒体 |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6300058B1 (en) * | 1992-01-29 | 2001-10-09 | Hitachi Chemical Research Center, Inc. | Method for measuring messenger RNA |
| WO2001069415A2 (en) * | 2000-03-15 | 2001-09-20 | Genset | Methods, software, and apparati for designing, ordering, pricing, tracking and directing production of custom biologicals |
-
2002
- 2002-10-30 EP EP02784321A patent/EP1468111A4/en not_active Withdrawn
- 2002-10-30 WO PCT/US2002/034599 patent/WO2003064694A1/en active Application Filing
- 2002-10-30 JP JP2003564284A patent/JP2005516296A/ja active Pending
- 2002-10-30 CA CA002474481A patent/CA2474481A1/en not_active Abandoned
Cited By (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9464320B2 (en) | 2002-01-25 | 2016-10-11 | Applied Biosystems, Llc | Methods for placing, accepting, and filling orders for products and services |
| US10689692B2 (en) | 2002-01-25 | 2020-06-23 | Applied Biosystems, Llc | Methods for placing, accepting, and filling orders for products and services |
| WO2012014988A1 (ja) * | 2010-07-29 | 2012-02-02 | タカラバイオ株式会社 | 標的塩基検出用rna含有プローブの製造方法 |
| JP5711234B2 (ja) * | 2010-07-29 | 2015-04-30 | タカラバイオ株式会社 | 標的塩基検出用rna含有プローブの製造方法 |
| KR101613612B1 (ko) | 2010-07-29 | 2016-04-20 | 다카라 바이오 가부시키가이샤 | 표적 염기를 검출하기 위한 rna를 함유한 프로브를 제조하기 위한 방법 |
| US9336349B2 (en) | 2010-07-29 | 2016-05-10 | Takara Bio Inc. | Method for producing RNA-containing probe for detecting a target nucleotide |
| JP2015531121A (ja) * | 2012-08-03 | 2015-10-29 | ラベル インデペンデント,インク. | アッセイを設計し、開発し、共有するためのシステムおよび方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| EP1468111A4 (en) | 2005-05-25 |
| CA2474481A1 (en) | 2003-08-07 |
| WO2003064694A1 (en) | 2003-08-07 |
| EP1468111A1 (en) | 2004-10-20 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Ginalski et al. | ORFeus: detection of distant homology using sequence profiles and predicted secondary structure | |
| US10789147B1 (en) | System and method for building a script that retrieves information from a website | |
| De La Bastide et al. | Assembling genomic DNA sequences with PHRAP | |
| Matthijs et al. | Guidelines for diagnostic next-generation sequencing | |
| Fischer et al. | CAFASP2: the second critical assessment of fully automated structure prediction methods | |
| Cone et al. | Genetic, physical, and informatics resources for maize. On the road to an integrated map | |
| Ejigu et al. | Evaluation of normalization methods to pave the way towards large-scale LC-MS-based metabolomics profiling experiments | |
| JP2009522663A (ja) | ユーザーに提供されたケモゲノミックデータのリモートコンピューターに基づく解析のためのシステム及び方法 | |
| US20040002818A1 (en) | Method, system and computer software for providing microarray probe data | |
| US20060020398A1 (en) | Integration of gene expression data and non-gene data | |
| EP3916731A1 (en) | Methods and systems for interpretation and reporting of sequence-based genetic tests | |
| Morini et al. | Application of Next Generation Sequencing for personalized medicine for sudden cardiac death | |
| WO2001069430A1 (en) | Database system and method | |
| CA2474482A1 (en) | Methods for placing, accepting, and filling orders for products and services | |
| US20070106938A1 (en) | Technology platform for electronic commerce and a method thereof | |
| Werner | Computer-assisted analysis of transcription control regions: Matinspector and other programs | |
| O’Daniel et al. | Whole-genome and whole-exome sequencing in hereditary cancer: impact on genetic testing and counseling | |
| Tammi et al. | Correcting errors in shotgun sequences | |
| KR102587515B1 (ko) | 타겟 핵산 분자에 대한 타겟 핵산서열 데이터 세트의 제공 방법 | |
| JP2002149605A (ja) | 認証代行装置、認証代行方法及び記録媒体 | |
| JP2005516296A (ja) | バイオテクノロジー産物を手配するコンピュータの操作方法、および/またはコンピュータネットワーク | |
| Hu et al. | Using TWINSCAN to predict gene structures in genomic DNA sequences | |
| Sun et al. | Imputing missing genotypic data of single-nucleotide polymorphisms using neural networks | |
| Glick et al. | Panoramic: a package for constructing eukaryotic pan‐genomes | |
| US20030211501A1 (en) | Method and system for determining haplotypes from a collection of polymorphisms |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20051221 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20060518 |