JP2005158010A - Apparatus, method and program for classification evaluation - Google Patents
Apparatus, method and program for classification evaluation Download PDFInfo
- Publication number
- JP2005158010A JP2005158010A JP2004034729A JP2004034729A JP2005158010A JP 2005158010 A JP2005158010 A JP 2005158010A JP 2004034729 A JP2004034729 A JP 2004034729A JP 2004034729 A JP2004034729 A JP 2004034729A JP 2005158010 A JP2005158010 A JP 2005158010A
- Authority
- JP
- Japan
- Prior art keywords
- document
- class
- training
- similarity
- pattern
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
- 238000000034 method Methods 0.000 title claims description 42
- 238000011156 evaluation Methods 0.000 title claims 9
- 238000012549 training Methods 0.000 claims abstract description 129
- 239000013598 vector Substances 0.000 claims description 54
- 238000001514 detection method Methods 0.000 claims description 8
- 239000011159 matrix material Substances 0.000 claims description 8
- 238000012545 processing Methods 0.000 description 15
- 238000012360 testing method Methods 0.000 description 12
- 238000013459 approach Methods 0.000 description 9
- 238000007781 pre-processing Methods 0.000 description 9
- 230000010365 information processing Effects 0.000 description 6
- 238000004458 analytical method Methods 0.000 description 4
- 238000010586 diagram Methods 0.000 description 4
- 230000000877 morphologic effect Effects 0.000 description 4
- 238000004364 calculation method Methods 0.000 description 3
- 238000010276 construction Methods 0.000 description 3
- 238000002372 labelling Methods 0.000 description 3
- 238000003066 decision tree Methods 0.000 description 2
- 238000012552 review Methods 0.000 description 2
- 238000012706 support-vector machine Methods 0.000 description 2
- 230000007423 decrease Effects 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 230000000694 effects Effects 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 239000004615 ingredient Substances 0.000 description 1
- 238000002360 preparation method Methods 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 230000011218 segmentation Effects 0.000 description 1
- 230000017105 transposition Effects 0.000 description 1
Images





Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F17/00—Digital computing or data processing equipment or methods, specially adapted for specific functions
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/35—Clustering; Classification
- G06F16/353—Clustering; Classification into predefined classes
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/10—Pre-processing; Data cleansing
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/217—Validation; Performance evaluation; Active pattern learning techniques
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/22—Matching criteria, e.g. proximity measures
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Evolutionary Biology (AREA)
- Evolutionary Computation (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Bioinformatics & Computational Biology (AREA)
- Artificial Intelligence (AREA)
- Life Sciences & Earth Sciences (AREA)
- Databases & Information Systems (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Description
本発明は文書をはじめとするパターンの分類技術に関するものであり、特にその時々のクラスモデルの妥当性を適確に評価できるようにすることによってその運用の効率性を高めることを目的とする。 The present invention relates to a technique for classifying documents and other patterns, and in particular, an object of the present invention is to improve the efficiency of operation by making it possible to accurately evaluate the validity of the class model at that time.
文書分類は文書を予め決められたグループに振り分ける技術であり、情報の流通が増すにつれ、重要性が高まってきている。文書分類としてはこれまでに、ベクトル空間法、k-最近隣法(kNN法)、ナイーブベイズ法、決定木法、サポートベクターマシン法、ブースティング法など実に様々な方法が研究開発されてきた。文書の文書分類処理に関する最近の動向については、情報処理学会誌第42巻第1号(2001年1月)に掲載されている「テキスト分類‐学習理論の見本市‐」(著者:永田昌明、平博順)に詳しい。どのような分類法も、文書クラスに関する情報を何らかの形で記述し、入力文書と照合している。以下これをクラスモデルと呼ぶ。 Document classification is a technique for assigning documents to predetermined groups, and the importance of the information is increasing as the distribution of information increases. To date, various methods such as vector space method, k-nearest neighbor method (kNN method), naive Bayes method, decision tree method, support vector machine method, and boosting method have been researched and developed. For the recent trend of document classification processing of documents, "Text Classification-Trade Fair for Learning Theory" published in Journal of Information Processing Society of Japan, Vol. 42 No. 1 (January 2001) (Author: Masaaki Nagata, Heihei Detailed on Hiroshun). Any taxonomy describes some form of information about the document class and matches it against the input document. Hereinafter, this is called a class model.
このクラスモデルは、例えば、ベクトル空間法では各クラスに属する文書の平均ベクトルにより表現され、k-最近隣法では各クラスに属する文書のベクトルの集合により表現され、ブースティング法では単純な仮説の集合により表現されている。正確な分類を図るにはクラスモデルは各クラスを正確に記述したものでなければならない。クラスモデルは通常各クラスに訓練データとして用意された大量の文書を用いて作成される。
文書の分類は文字や音声と同じように認識技術をベースとするものであるが、文字認識や音声認識と比べた場合、次のような特質がある。
(1)文字認識や音声認識の場合、同じクラスに属するパターンが時々刻々変化することは考えられない。クラス“2”に属する文字パターンは現在も1年前も同じ筈である。ところが、文書の場合には同じクラスであっても文書の内容が刻々変化する場合がよくある。例えば、“国際政治”というクラスを想定したとき、このクラスに属する文書の話題は、“イラク戦争”の前後でかなり異なっているものと考えられる。従って、“国際政治”のクラスモデルは、時間の経過と共に更新される必要がある。
Document classification is based on recognition technology in the same way as characters and speech, but has the following characteristics when compared with character recognition and speech recognition.
(1) In the case of character recognition and speech recognition, it is not considered that patterns belonging to the same class change from moment to moment. Character patterns belonging to class “2” are the same now and a year ago. However, in the case of a document, the content of the document often changes every moment even if it is the same class. For example, assuming a class of “international politics”, the topics of documents belonging to this class are considered to be quite different before and after the “Iraq War”. Therefore, the class model of “international politics” needs to be updated over time.
(2)文字や音声の場合には、入力された文字や音声がどのクラスに属するかは人間は直ちに判断できるので、クラスモデルを構築するための訓練データを収集することは難しい問題ではない。しかし、文書の場合には、入力された文書を読まなければその文書の属するクラスを判断することができない。たとえ飛ばし読みにしても文書を人間が読む限り少なからぬ時間を必要とする。従って、文書の場合には大量の信頼の置ける訓練データを収集することの負担は極めて大きい。 (2) In the case of letters and voices, humans can immediately determine which class the inputted letters and voices belong to, so it is not a difficult problem to collect training data for constructing a class model. However, in the case of a document, the class to which the document belongs cannot be determined unless the input document is read. Even if skipping is read, it takes a considerable amount of time as long as a human reads the document. Therefore, in the case of documents, the burden of collecting a large amount of reliable training data is very large.
(3)(2)と同じ理由で、文書分類の場合、大量の未知文書に対してどの程度の正確さで分類が行われているか性能を把握することは容易ではない。
(4)文字や音声の場合には、入力される文字や音声にどのようなクラスが存在するかはほぼ自明である。例えば文字認識で数字を認識する場合クラス数は10である。しかし、文書分類ではクラスの設定には任意性があり、どのようなクラスを用意するかは利用者の要望やシステム設計者の意図などによって決まる。
(3) For the same reason as in (2), in the case of document classification, it is not easy to grasp the performance of how accurately a large number of unknown documents are classified.
(4) In the case of characters and voices, it is almost obvious what class exists in the input characters and voices. For example, when a number is recognized by character recognition, the number of classes is 10. However, in the document classification, there is an arbitrary setting of the class, and what kind of class is prepared depends on the user's request and the intention of the system designer.
従って、文書分類では、(1)の特質の故に、実際の運用においてその時々の文書を正しく分類するにはクラスモデルの頻繁な更新が必須である。しかしながら、クラスモデルの更新は(2)に述べた理由で決して容易なものではない。クラスモデルの更新の負担の軽減を図るには、全クラスを更新するのではなく、クラスモデルの陳腐化したクラスのみ更新するようにすればよいが、(3)に述べた理由で陳腐化したクラスを検出することも容易でない。このように文書分類を実際に運用するためのコストは決して安価なものではない。 Therefore, in document classification, due to the nature of (1), frequent updating of the class model is essential in order to correctly classify documents from time to time in actual operation. However, updating the class model is not easy for the reason described in (2). In order to reduce the burden of updating the class model, instead of updating all classes, it is only necessary to update the class model that has become obsolete, but it has become obsolete for the reason described in (3). It is not easy to detect classes. Thus, the cost for actually operating the document classification is not cheap.
さらに、文書分類の場合、人為的に設定された各クラスの話題が互いに離れていれば問題はないが、話題が接近するクラス対が存在してしまう場合がある。このようなクラス対は互いの間で誤分類を招き、システムの性能を劣化させる。従って文書分類システムの設計においては話題が接近するクラス対をいち早く検出し、クラスを再設定する必要がある。このとき文書分類システムを再設計した後、テストデータで評価して問題クラス対を検出するようにしてもよいが、これには労力と時間を必要とする。このような話題の接近が問題となるクラス対は、訓練データの準備が終了した時点、即ち訓練データの収集及び各文書に対するラベル付けが終わった段階で直ちに検出できるのが望ましい。 Further, in the case of document classification, there is no problem if the artificially set topics of each class are separated from each other, but there may be a class pair in which the topics are close to each other. Such class pairs cause misclassification between each other and degrade system performance. Therefore, in designing a document classification system, it is necessary to quickly detect a class pair with which a topic approaches, and reset the class. At this time, after redesigning the document classification system, the problem class pairs may be detected by evaluating with test data, but this requires labor and time. It is desirable that the class pair in which the approach of the topic is a problem can be detected immediately when the preparation of the training data is completed, that is, at the stage where the collection of the training data and the labeling of each document are finished.
本発明の目的は、話題が接近するクラス対やクラスモデルの陳腐化したクラスを容易に検出出来るようにすることにより、文書分類システム設計の負担やクラスモデルの更新の負担を軽減することにある。 An object of the present invention is to reduce the burden of designing a document classification system and updating a class model by making it possible to easily detect stale classes of class pairs and class models that are close in topic. .
先ずクラスモデルの陳腐化について考える。クラスAのクラスモデルが陳腐化した場合の影響としては次の2通りが考えられる。即ち、入力文書がクラスAに属していてもクラスAに属すると判定できなくなる場合と、クラスAとは別のクラスBに誤分類される場合とである。従って、クラスAの場合、「再現率」をクラスAに属する文書数に対するクラスAに属すると判定された文書数の割合と定義し、「精度」をクラスAに属すると判定された文書の中で実際にクラスAに属している文書数の割合と定義すると、クラスモデルの陳腐化の影響は、再現率や精度の低下となって現れる。従って、問題は再現率や精度の低下したクラスを如何にして検出するかである。本願発明では以下のようなアプローチを採用する。ここでは、再現率や精度の低下したクラスであっても正しくそのクラスに分類される文書は少なからず存在することを前提とする。 First, consider the obsolescence of the class model. There are two possible effects when the class model of class A becomes obsolete. That is, even when the input document belongs to class A, it cannot be determined that the input document belongs to class A, and the input document is misclassified to class B different from class A. Therefore, in the case of class A, “recall rate” is defined as the ratio of the number of documents determined to belong to class A to the number of documents belonging to class A, and “accuracy” is determined among the documents determined to belong to class A. If the definition is the ratio of the number of documents actually belonging to class A, the obsolescence of the class model appears as a reduction in recall and accuracy. Therefore, the problem is how to detect classes with reduced recall and accuracy. In the present invention, the following approach is adopted. Here, it is assumed that there are not a few documents that are correctly classified into the class even if the recall rate and accuracy are lowered.
クラスAの再現率が低下した場合、クラスAに属する入力文書の話題とクラスモデルが想定するクラスAの話題との間にミスマッチが生じていると考えられる。クラスモデルが想定するクラスAの話題はそのクラスモデルを構築したときのクラスAの訓練データによって決まる。文書分類システムの実際の運用時において、クラスAに分類された文書集合を「クラスAの実文書集合」と呼ぶこととする。上記ミスマッチを起こしているかどうかは、クラスAの実文書集合とクラスAのクラスモデル構築に用いた訓練文書集合との近さ、即ち「類似度」によって判定できる。この類似度が大きければ、クラスAの実文書集合はクラスモデル構築時の訓練文書集合と内容が近く、陳腐化は起こしていないと判断できる。反対に類似度が小さければ、クラスAに属する入力文書の話題はシフトし、クラスモデルは陳腐化を起こしていると判断できる。陳腐化していると判断されたクラスはクラスモデルの再構築が必要である。 When the recall rate of class A decreases, it is considered that a mismatch has occurred between the topic of the input document belonging to class A and the topic of class A assumed by the class model. The topic of class A assumed by the class model is determined by the training data of class A when the class model is constructed. In actual operation of the document classification system, a document set classified into class A is referred to as “class A actual document set”. Whether or not the above-mentioned mismatch has occurred can be determined by the closeness between the class A actual document set and the training document set used in class A class model construction, that is, “similarity”. If the degree of similarity is large, it can be determined that the class A actual document set is close in content to the training document set at the time of class model construction, and no obsolescence has occurred. On the other hand, if the degree of similarity is small, it can be determined that the topic of the input document belonging to class A has shifted and the class model has become obsolete. Classes that are determined to be obsolete need to be rebuilt.
また、クラスAに属する入力文書がクラスBに誤分類されるケースが多い場合には、クラスAに属する文書の話題がシフトし、クラスBのクラスモデルと非常に近くなっていると考えられる。従って、クラスAの実文書集合とクラスBのクラスモデル構築に用いた訓練文書集合との近さ、即ち類似度は大きくなっていると考えられる。従って、この類似度が大きいようであれば、これはクラスAに属する文書の話題がクラスBに接近していることの証拠となる。このときクラスA、Bの両方のクラスモデルが陳腐化を起こしていると判断できるので、クラスA、Bの両方のクラスモデルの再構築が必要となる。 Further, when there are many cases where an input document belonging to class A is misclassified to class B, the topic of the document belonging to class A is shifted and considered to be very close to the class model of class B. Therefore, it is considered that the closeness, that is, the similarity between the class A actual document set and the class B training model set used for the class model construction is increased. Therefore, if the similarity is high, this is evidence that the topic of a document belonging to class A is close to class B. At this time, since it can be determined that both the class models of classes A and B are obsolete, it is necessary to reconstruct both class models of classes A and B.
次に、話題が接近するクラス対について述べる。話題が接近するクラス対ではそれぞれの文書集合間の類似性も高くなっていると考えられる。従って、全てのクラス対間の類似度、即ち、各クラスの訓練文書集合間の類似度を求め、類似度が一定値より高いクラス対を選択するとこれらのクラス対は話題が接近するクラス対とみなすことができる。このようなクラス対はクラスを設定することの是非やクラスの定義を含めて再検討する必要がある。 Next, class pairs that are close to each other are discussed. It is thought that the similarity between each document set is high in the class pair in which the topics are close. Accordingly, the similarity between all the class pairs, that is, the similarity between the training document sets of each class is obtained, and when a class pair with a similarity higher than a certain value is selected, these class pairs are classified as class pairs with which the topic approaches. Can be considered. Such class pairs need to be reconsidered, including the pros and cons of setting the class and the definition of the class.
以上述べたように、本発明においては各クラスの訓練文書集合以外に、各クラスの実文書集合を求めておき、全てのクラス対の訓練文書集合間の類似度、各クラスの訓練文書集合と実文書集合の間の類似度、全てのクラス対の訓練文書集合と実文書集合間の類似度を求めることにより、更新あるいは見直しの必要のあるクラスを検出できるので、極めて容易に文書分類システム設計の変更やクラスモデルの更新を行うことができる。 As described above, in the present invention, in addition to the training document set of each class, the actual document set of each class is obtained, the similarity between the training document sets of all class pairs, the training document set of each class, It is very easy to design a document classification system because it can detect the class that needs to be updated or reviewed by finding the similarity between the actual document sets and the similarity between the training document set of all class pairs and the actual document set. Changes and class models can be updated.
図1は、本願発明を実施する装置を示している。筐体100の中には、記憶装置110、メインメモリ120、出力装置130、処理装置(CPU)140、操作部150、入力装置160が含まれている。処理装置(CPU)140は、メインメモリ120から制御するプログラムを読み込み、操作部150から入力された命令に従い、入力装置160から入力される文書データ、及び、記憶装置110に格納されている訓練文書や実文書の情報を使用して情報処理を行い、話題接近クラス対、及び、陳腐化した文書クラスなどを検出し出力装置130に出力する。
FIG. 1 shows an apparatus for carrying out the present invention. The
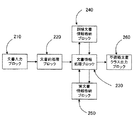
図2は、本発明の概要を示すブロック図である。210は文書入力ブロック、220は文書前処理ブロック、230は文書情報処理ブロック、240は訓練文書情報格納ブロック、250は実文書情報格納ブロック、260は不適格文書クラス出力ブロックを示す。文書入力ブロック210には、処理したい文書集合が入力される。文書前処理ブロック220では、入力された文書の用語検出、形態素解析、文書ベクトル作成等が行われる。文書ベクトルの各成分の値は対応する単語の文書内の頻度などをもとに求められる。訓練文書情報格納ブロック240には、作成されたクラス別訓練文書情報が格納される。実文書情報格納ブロック250には、分類結果に基づくクラス別実文書情報が格納される。文書情報処理ブロック230は、訓練文書集合の全クラス対の類似度算出、各クラスの訓練文書集合と同一クラスの実文書集合の間の類似度算出、各クラスの訓練文書集合と他の全てのクラスの実文書集合の間の類似度算出などを行って、話題接近クラス対、及び、陳腐化クラスを求める。不適格文書クラス出力ブロック260は文書情報処理ブロック230で得られた結果を、ディスプレー等の出力装置に出力する。
FIG. 2 is a block diagram showing an outline of the present invention. 210 denotes a document input block, 220 denotes a document preprocessing block, 230 denotes a document information processing block, 240 denotes a training document information storage block, 250 denotes an actual document information storage block, and 260 denotes an ineligible document class output block. A document set to be processed is input to the
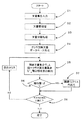
図3は与えられた訓練文書集合に対して、話題接近クラス対を検出する本発明の第1の実施例のフローチャートを示す。この発明の方法は、汎用コンピュータ上でこの発明を組み込んだプログラムを走らせることによって実施することができる。図3は、そのようなプログラムを走らせている状態でのコンピュータのフローチャートである。
ブロック21は訓練文書集合入力、ブロック22はクラスラベル付与、ブロック23は文書前処理、ブロック24はクラス別訓練文書データベース作成、ブロック25は訓練文書集合のクラス対の類似度算出、ブロック26は類似度と閾値との比較、ブロック27は、閾値を超える類似度を有するクラス対の出力を行う。ブロック28は終了チェック処理である。以下、英文文書を例にとって実施例1について説明する。
FIG. 3 shows a flowchart of the first embodiment of the present invention for detecting a topic approach class pair for a given training document set. The method of the present invention can be implemented by running a program incorporating the present invention on a general-purpose computer. FIG. 3 is a flowchart of the computer in a state where such a program is running.
先ず、訓練文書集合入力21において文書分類システム構築に用いる文書集合が入力される。クラスラベル付与22では、予め各クラスに対してなされていた定義に従って帰属するクラス名を各文書に付与する。ひとつの文書に対して2つ以上のクラス名が付与されることもありうる。文書前処理23においては各入力文書に対して、用語検出、形態素解析、文書ベクトル作成などの前処理が行われる。場合によっては、文書セグメント区分け、文書セグメントベクトル作成を行い、文書セグメントベクトルの集合として文書を表すこともある。用語検出としては、各入力文書から単語、数式、記号系列などを検出する。ここでは、単語や記号系列などを総称して「用語」と呼ぶ。英文の場合、用語同士を分けて書く正書法が確立しているので用語の検出は容易である。
First, a training document set
次に、形態素解析では、各入力文書に対して用語の品詞付けなどの形態素解析を行う。文書ベクトル作成では、先ず文書全体に出現する用語から作成すべきベクトルの次元数および各次元と各用語との対応を決定する。この際に出現する全ての用語の種類にベクトルの成分を対応させなければならないということはなく、品詞付け処理の結果を用い、例えば名詞と動詞と判定された用語のみを用いてベクトルを作成するようにしてもよい。次いで各文書に出現する単語の頻度値、もしくは頻度値を加工して得られる値を対応する文書ベクトルの成分に与える。文書セグメント区分けが行われる場合は各入力文書は文書セグメントに分解される。文書セグメントは文書を構成する要素であり、その最も基本的な単位は文である。英文の場合、文はピリオドで終わり、その後ろにスペースが続くので文の切出しは容易に行うことができる。その他の文書セグメントへの分解法としては、ひとつの文が複文からなる場合主節と従属節に分けておく方法、用語の数がほぼ同じになるように複数の文をまとめて文書セグメントとする方法、文書の先頭から含まれる用語の数が同じになるように文とは関係なく区分けする方法などがある。 Next, in morphological analysis, morphological analysis such as part-of-speech addition of terms is performed on each input document. In creating a document vector, first, the number of dimensions of a vector to be created and the correspondence between each dimension and each term are determined from terms appearing in the entire document. There is no need to associate vector components with all types of terms that appear at this time, and using the result of part-of-speech processing, for example, create a vector using only terms determined as nouns and verbs. You may do it. Next, a frequency value of a word appearing in each document, or a value obtained by processing the frequency value is given to a corresponding document vector component. When document segmentation is performed, each input document is broken down into document segments. A document segment is an element constituting a document, and its most basic unit is a sentence. In English, the sentence ends with a period and is followed by a space, so it is easy to cut out sentences. As a method of disassembling into other document segments, when a sentence consists of multiple sentences, it is divided into a main section and subordinate sections, and multiple sentences are grouped into a document segment so that the number of terms is almost the same. And a method of dividing the document so that the number of terms included from the beginning of the document is the same regardless of the sentence.
文書セグメントベクトル作成では、文書ベクトル作成と同じように、各文書セグメントに出現する単語の頻度値、もしくは頻度値を加工して得られる値を対応する文書セグメントベクトルの成分に与える。一例として、分類に用いられる用語の種類数をMとし、M次元のベクトルで文書ベクトルが表される場合を考える。当該文書ベクトルをdr とすると、用語が用いられている場合を「0」と、用いられていない場合を「1」としてその成分を与えると、dr = (1,0,0,..,1)Tのように、あるいは用語の出現頻度をその成分値として与えると、dr = (2,0,1,..,4)Tのように表すことが出来る。ここでTはベクトルの転置を表す。クラス別訓練文書データベース作成24では、ブロック22の結果に基づき、各文書の前処理結果をクラス別にソートし、データベースに格納する。訓練文書集合のクラス対の類似度算出25では、訓練文書集合を用いて指定されたクラス対に対して類似度を算出する。クラス対の指定は、最初の繰り返しでは予め決められたクラス対に基づいて、2回目以降の繰り返しではブロック28からの指令により行う。
In document segment vector creation, the frequency value of a word appearing in each document segment or a value obtained by processing the frequency value is given to the corresponding document segment vector component, as in document vector creation. As an example, let us consider a case where the number of types of terms used for classification is M and a document vector is represented by an M-dimensional vector. When the document vector and d r, a "0" when the term is used, the case where not used Given the ingredients as "1", d r = (1,0,0, .. , 1) as T, then or given a term frequency as the component value, d r = (2,0,1, .. , 4) represents that can as T. Here, T represents transposition of the vector. In the class-by-class training
文書集合間の類似度を求める方法としては種々の方法が知られている。例えば、クラスA、Bの文書集合をΩA、ΩBとする。また、文書rの文書ベクトルをdrとして、次式によりクラスA、Bの平均文書ベクトルdA、dBを定義する。 Various methods are known for obtaining the similarity between document sets. For example, a set of documents of classes A and B is assumed to be Ω A and Ω B. Further, with the document vector of the document r as dr, average document vectors d A and d B of classes A and B are defined by the following formula.

ここで、|ΩA|、|ΩB|は文書集合ΩA、ΩBの文書数を表す。クラスA、Bの訓練文書集合間の類似度をsim(ΩA,ΩB)とすると、これは余弦類似度により次のように求めることができる。 Here, | Ω A | and | Ω B | represent the number of documents in the document sets Ω A and Ω B. Assuming that the similarity between the training document sets of classes A and B is sim (Ω A , Ω B ), this can be obtained from the cosine similarity as follows.
ここで、||dA ||はベクトルdAのノルムを表す。式(1)で定義される類似度の例では、単語間の共起の情報は反映されない。そこで、以下の計算方法を用いると文書セグメントにおける単語共起の情報を反映した類似度を求めることが出来る。クラスAには複数の文書が含まれておりその集合をΩAと表す。集合をΩAのr番目の文書rはY個の文書セグメントから成るとし、y番目の文書セグメントベクトルをdryにより表す。図4(a)では、文書集合ΩAが文書1から文書Rまでの文書群で構成されていることを示している。図4(b)は文書集合ΩAのr番目の文書rがさらにY個の文書セグメントから構成されており、その中のy番目の文書セグメントから、文書セグメントベクトルdryを生成することをイメージ的に示している。ここで、文書rに対し次式で定義される行列を共起行列と呼ぶこととする。
Here, || d A || represents the norm of vector d A. In the example of similarity defined by Equation (1), information on co-occurrence between words is not reflected. Therefore, by using the following calculation method, it is possible to obtain the similarity reflecting the word co-occurrence information in the document segment. Class A includes a plurality of documents, and the set is represented as Ω A. Assume that the r-th document r in Ω A consists of Y document segments, and the y-th document segment vector is represented by d ry . FIG. 4A shows that the document set Ω A is composed of document groups from
さらに、クラスBの集合をΩBとし、クラスA、Bの各文書の共起行列の総和をSA、SBとすると、これらは以下により求められる。 Further, if the set of class B is Ω B and the sum of co-occurrence matrices of the documents of class A and B is S A and S B , these are obtained as follows.
この場合、クラスA、Bの訓練文書集合間の類似度sim(ΩA,ΩB)は行列SA、SBの各成分を用いて以下のように定義することができる。 In this case, the similarity sim (Ω A , Ω B ) between the training document sets of classes A and B can be defined as follows using the components of the matrices S A and S B.
ここで、SA mn はSAのm行n列の成分値であり、Mは文書セグメントベクトルの次元、即ち出現単語の種類数である。もし、文書セグメントベクトルの各成分をバイナリーで、即ちm番目の単語が出現すれば1、現れなければ0として表現した場合、SA mn、SB mnは式(2)(3)から明らかなようにクラスA、Bの訓練文書集合において単語mとnとが共起する文書セグメントの数となるので、式(4)には単語共起の情報が与えられていることが分かる。単語共起の情報を与えることでより的確な類似度を求めることができる。なお、式(4)において行列SA、SBの非対角成分を用いないようにすると式(1)で定義される類似度とほぼ等価になる。 Here, S A mn is the component value of m rows and n columns of S A , and M is the dimension of the document segment vector, that is, the number of types of appearance words. If each component of the document segment vector is expressed in binary, that is, 1 if the m-th word appears and 0 if it does not appear, S A mn and S B mn are clear from the equations (2) and (3). Thus, since the number of document segments in which the words m and n co-occur in the class A and B training document sets is obtained, it can be seen that the word co-occurrence information is given in the equation (4). By giving word co-occurrence information, a more accurate similarity can be obtained. If the non-diagonal components of the matrices S A and S B are not used in the equation (4), the degree of similarity defined by the equation (1) is almost equivalent.
ブロック26で、類似度(第1の類似度)が所定の閾値(第1の閾値)を超えるか否かを判断している。ブロック27では、指定されたクラス間の訓練文書集合の類似度が予め指定された閾値を超えている場合には、話題が接近しているクラス対として検出する。具体的には、αを閾値としたとき、
In
を満たす場合にクラスA、Bは話題が接近しているとみなす。αは話題内容のよく分かっている訓練文書集合を用いれば実験的に決めることは容易である。検出された話題接近クラス対に対しては、クラスの定義の見直しやそれらのクラスを設定すること自体の再検討、訓練文書のラベル付けの妥当性の確認を行うことになる。ブロック28では、ブロック25、26、27の処置を全てのクラス対に対して行ったかどうかのチェックを行い、未処理のクラスがなければ終了し、あれば次のクラス対を指定して次の処理をブロック25に戻す。
Class A and B are considered to be close to each other when the conditions are satisfied. α can be easily determined experimentally by using a set of training documents whose topics are well known. For the detected topic approach class pair, the class definition is reviewed, the setting of the class itself is reviewed, and the validity of the labeling of the training document is confirmed. In
図5(a)及び図5(b)は実際の文書分類システム上において、陳腐化クラスを検出する本発明の第2及び第3の実施例を示す。この発明の方法は、汎用コンピュータ上でこの発明を組み込んだプログラムを走らせることによって実施することができる。図5(a)及び図5(b)は、そのようなプログラムを走らせている状態でのコンピュータのフローチャートである。先ず、図5(a)で示される第2の実施例について説明する。ブロック31は文書入力、ブロック32は文書前処理、ブロック33は文書分類処理、ブロック34はクラス別実文書データベース作成、ブロック35は各クラスの訓練文書集合と同一クラスの実文書集合の間の類似度算出、ブロック36は類似度と閾値との比較、ブロック37は各クラスの訓練文書集合と同一クラスの実文書集合の間の類似度が閾値より大きい場合の処置、ブロック38は終了チェック処理である。
FIGS. 5 (a) and 5 (b) show second and third embodiments of the present invention for detecting an obsolete class on an actual document classification system. The method of the present invention can be implemented by running a program incorporating the present invention on a general-purpose computer. FIG. 5A and FIG. 5B are flowcharts of the computer in a state where such a program is running. First, the second embodiment shown in FIG. 5A will be described.
以下、図5(a)のフローチャートについて詳細に説明する。 先ず、ブロック31において運用状態の文書分類システムに実際に分類すべき文書が入力される。ブロック32では図2のブロック23と同様な文書前処理が行われ、ブロック33では入力文書に対して文書分類処理が行われる。文書分類の方法としては、これまでに、ベクトル空間法、k-最近隣法(kNN)、ナイーブベイズ法、決定木法、サポートベクターマシン法、ブースティング法など実に様々な方法が開発されてきており、本発明ではどの方法も用いることができる。ブロック34では、ブロック33の文書分類処理の結果を用いて、クラス毎に実文書データベース作成を作成する。ここではクラスA、Bに分類された実文書集合をΩ'A、Ω'Bにより表す。
Hereinafter, the flowchart of FIG. 5A will be described in detail. First, in
ブロック35では指定されたクラスの訓練文書集合と同一クラスの実文書集合の間の類似度の算出を行う。クラスの指定は最初の繰り返しでは予め指定されたクラスに基づいて、2回目以降はブロック38からの指令により行う。クラスAの訓練文書集合ΩAと同一クラスの実文書集合Ω'Aの間の類似度sim(ΩA,Ω'A) (第2の類似度)、は式(1)及び(4)と同様に求めることができる。
次いでブロック36では類似度と閾値との比較を行い、ブロック37において陳腐化を起こしたクラスモデルの検出を行う。その時の閾値をβとしたとき、
In
Next, in
を満たす場合にクラスAに属すべき実文書の話題はシフトしており、クラスAのクラスモデルは陳腐化していると判断される。ブロック38は、ブロック35、36、37の処理を、全てのクラスに対して行ったかどうかのチェックをおこない、未処理のクラスが無ければ終了し、あれば次のクラスを指定してブロック35に処理を戻す。
次に、図5(b)を用いて、第3の実施例について説明する。ブロック31からブロック34までは、図5(a)と同様であるので説明は割愛する。ブロック39は各クラスの訓練文書集合と他の全てのクラスの実文書集合の間の類似度を算出する。ブロック40及びブロック41は、各クラスの訓練文書集合と他のクラスの実文書集合の間の類似度が閾値を超えている場合の処置を示している。ブロック42は終了チェック処理である。
When the condition is satisfied, the topic of the actual document that should belong to class A is shifted, and it is determined that the class model of class A is obsolete. The
Next, a third embodiment will be described with reference to FIG.
以下、図5(b)のフローチャートについて詳細に説明する。 図5(a)と同様であるブロック31からブロック34に関する説明は割愛する。ブロック39では各クラスの訓練文書集合と他の全てのクラスの実文書集合の間の類似度の算出を行う。ブロック40及びブロック41は、指定されたクラスの訓練文書集合と指定された他のクラスの実文書集合の間の類似度が閾値を超えている場合の処置を示している。クラスAの訓練文書集合をΩAとクラスBの実文書集合Ω'Bと間の類似度sim(ΩA,Ω'B) (第3の類似度)は式(1)及び(4)と同様に求めることができる。クラス対の指定は、最初の繰り返しでは予め指定されたクラスに基づいて、2回目以降はブロック42からの指令により行う。ブロック40及びブロック41において、γを閾値としたとき、
Hereinafter, the flowchart of FIG. 5B will be described in detail. The description regarding the
を満たす場合にはクラスBに属する文書の話題がクラスAに接近し、クラスA、B共クラスモデルは陳腐化していると判断される。ブロック42は終了処理であり、ブロック39、40、41の処置を全てのクラス対に対して行ったかどうかのチェックを行い、未処理のクラス対がなければ終了し、あれば次のクラス対を指定して次の処理をブロック39に戻す。
なお、実施例2及び実施例3で用いたβ、γは話題内容のよく分かっている訓練文書集合を用いて予め実験的に決めておく必要がある。
When the condition is satisfied, it is determined that the topic of the document belonging to the class B approaches the class A, and the class A and B co-class models are obsolete.
Note that β and γ used in the second and third embodiments need to be experimentally determined in advance using a training document set whose topic content is well known.
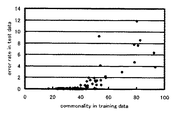
以上述べたように本発明によれば、話題の接近するクラス対、及び、陳腐化を起こしたクラス対を不適格クラスとして容易に検出することができる。文書分類の研究用に多く用いられている文書コーパスReuters-21578に対する実験結果を示す。文書分類法としてはkNN法を採用している。図4は各クラス対の話題の接近の程度とエラー率の関係を示す図であり、各点が特定のクラス対に対応している。 As described above, according to the present invention, it is possible to easily detect class pairs that are close to each other and class pairs that have become obsolete as ineligible classes. Experimental results for the document corpus Reuters-21578, which is widely used for document classification research, are shown. The kNN method is adopted as the document classification method. FIG. 4 is a diagram showing the relationship between the degree of topic approach of each class pair and the error rate, and each point corresponds to a specific class pair.
また、横軸は訓練文書集合のクラス間類似度(similarity)を百分率で示し、縦軸はテスト文書集合に対するクラス間エラー率(error rate)を百分率で示している。訓練文書集合とテスト文書集合はReuters-21578において指定されているもので、テスト文書集合は実文書集合に対応するものと見なされる。クラスA、Bのクラス間エラー率はクラスAでありながらクラスBに誤った文書数とクラスBでありながらクラスAに誤った文書数との和をクラスA、Bの文書数の和で除した値で与えられる。図4は訓練文書に対してクラス間類似度の高いクラス対、即ち、話題の接近するクラス対はテスト文書集合に対してエラー率が高いことを示している。従って、クラス間類似度が閾値より高いクラス対を検出して、クラスの定義の見直しやそれらのクラスを設定すること自体の再検討、訓練文書のラベル付けの妥当性の確認を行い、話題の接近するクラス対をなくすようにすれば文書分類システムの性能を向上させることができる。 The horizontal axis represents the similarity between classes of the training document set as a percentage, and the vertical axis represents the error rate between classes for the test document set as a percentage. The training document set and the test document set are specified in Reuters-21578, and the test document set is regarded as corresponding to the actual document set. The class-to-class error rate for class A and B is class A, but the sum of the number of documents mistaken for class B and the number of documents wrong for class A but class A is divided by the sum of the number of documents for class A and B. Is given as a value. FIG. 4 shows that a class pair having a high degree of similarity between classes with respect to the training document, that is, a class pair with a close topic has a high error rate with respect to the test document set. Therefore, detect class pairs whose similarity between classes is higher than the threshold, review the definition of the class, review those settings themselves, and confirm the validity of labeling the training document. Eliminating close class pairs can improve the performance of the document classification system.
図5は陳腐化したクラスを検出する例として、横軸は同じクラスの訓練文書集合とテスト文書集合の類似度(similarity)を百分率で示し、縦軸はテスト文書集合に対する再現率(recall)を百分率で示し、それらの関係を示すものであり、各点がひとつのクラスに対応している。図5から分かるように再現率が低いクラスでは訓練文書集合とテスト文書集合の類似度が小さい。従って、訓練文書集合とテスト文書集合の類似度が小さいクラスを選択することにより陳腐化を起こしたクラスを効率的に見出すことができる。クラスモデルの更新は上記類似度の小さいクラスのみ行えばよいことになるので、全てのクラスのクラスモデルの更新を行う場合に比べて著しいコストの低減が期待できる。 As an example of detecting an obsolete class, Fig. 5 shows the similarity between the training document set and test document set of the same class as a percentage, and the vertical axis shows the recall for the test document set. It is expressed as a percentage and shows their relationship, with each point corresponding to a class. As can be seen from FIG. 5, the similarity between the training document set and the test document set is small in the class with a low recall rate. Therefore, by selecting a class having a small similarity between the training document set and the test document set, it is possible to efficiently find a class that has become obsolete. Since the class model needs to be updated only for the class having a low similarity, a significant cost reduction can be expected as compared with the case where the class models of all classes are updated.
なお、上記実施例は文書を例にとって説明したが、実施例で示した文書と同じ様に表現でき、かつ、同様の性質を有するパターンについても適用できる。すなわち、実施例で示した、文書をパターン、用語を構成要素、訓練文書を訓練パターン、文書セグメントをパターンセグメント、文書セグメントベクトルをパターンセグメントベクトル等のように置き換えれば、本願発明が同様に適用できる。 Although the above embodiment has been described by taking a document as an example, it can also be applied to patterns that can be expressed in the same manner as the document shown in the embodiment and have similar properties. That is, the present invention can be similarly applied if the document is replaced with a pattern, a term as a component, a training document as a training pattern, a document segment as a pattern segment, a document segment vector as a pattern segment vector, etc. .
100:筐体
110:記憶装置
120:メインメモリー
130:出力装置
140:処理装置(CPU)
150:操作部
160:入力
210:文書入力ブロック
220:文書前処理ブロック
230:文書情報処理ブロック
240:訓練文書情報格納ブロック
250:実文書情報格納ブロック
260:不適格文書クラス出力ブロック
100: Housing 110: Storage device 120: Main memory 130: Output device 140: Processing device (CPU)
150: operation unit 160: input 210: document input block 220: document preprocessing block 230: document information processing block 240: training document information storage block 250: actual document information storage block 260: non-qualified document class output block
Claims (23)
(a)クラス毎の訓練文書集合を用いて全てのクラス対に対して第1の類似度を求める手段、及び
(b)前記第1の類似度が第1の閾値より大きいクラス対を検出する手段。 Means for classifying the input document by collating the input document with a class model for each class created based on the training document information for each class, and the following means (a) and (b) Document classification evaluation device including
(A) means for obtaining a first similarity for all class pairs using a training document set for each class; and (b) detecting a class pair for which the first similarity is greater than a first threshold. means.
(a)前記クラス対の検出に用いる用語を各訓練文書から検出して選択する手段と、
(b)前記各訓練文書を文書セグメントに分解する手段と、
(c)前記各訓練文書に対して前記文書セグメントに出現する用語の出現頻度に関連した値を対応する成分の値とする文書セグメントベクトルを生成する手段と、
(d)前記各訓練文書の前記文書セグメントベクトルを基に、全てのクラス対に対して訓練文書集合間の類似度を求める手段。 The document classification evaluation apparatus according to claim 1, wherein the means for obtaining the similarity includes the following means (a) to (d):
(A) means for detecting and selecting a term used for detecting the class pair from each training document;
(B) means for decomposing each training document into document segments;
(C) means for generating a document segment vector having a value related to an occurrence frequency of a term appearing in the document segment for each training document as a value of a corresponding component;
(D) Means for obtaining similarity between training document sets for all class pairs based on the document segment vector of each training document.
(a)訓練文書集合をもとに各文書クラスのクラスモデルを作成する手段と、
(b)前記入力文書を前記クラスモデルとを照合して分類を行ない、前記入力文書を帰属する文書クラスに振り分けて実文書集合を作成する手段と、
(c)全文書クラスに対して、前記訓練文書集合と同じクラスの前記実文書集合の間の第2の類似度を求める手段と、
(d)前記第2の類似度が第2の閾値より小さいクラスを検出する手段。 Means for collating the input document with a class model for each class created on the basis of the training document information for each class, and classifying the input document; and the following means (a) to (d) Document classification evaluation device including
(A) means for creating a class model for each document class based on the training document set;
(B) means for collating the input document with the class model, classifying the input document to a document class to which the input document belongs, and creating a real document set;
(C) means for obtaining a second similarity between the actual document sets of the same class as the training document set for all document classes;
(D) Means for detecting a class having the second similarity smaller than a second threshold.
(a)訓練文書集合をもとに各文書クラスのクラスモデルを作成する手段と、
(b)前記入力文書を前記クラスモデルとを照合して分類を行ない、前記入力文書を帰属する文書クラスに振り分けて実文書集合を作成する手段と、
(c)各文書クラスの前記訓練文書集合と他の全ての文書クラスの前記実文書集合との間の第3の類似度を求める手段と、
(d)前記第3の類似度が第3の閾値より大きいクラス対を検出する手段。 Means for collating the input document with a class model for each class created on the basis of the training document information for each class, and classifying the input document; and the following means (a) to (d) Document classification evaluation device including
(A) means for creating a class model for each document class based on the training document set;
(B) means for collating the input document with the class model, classifying the input document to a document class to which the input document belongs, and creating a real document set;
(C) means for determining a third similarity between the training document set of each document class and the actual document set of all other document classes;
(D) Means for detecting a class pair whose third similarity is greater than a third threshold.
(a)前記クラスまたはクラス対の検出に用いる用語を前記各訓練文書と前記各実文書からから検出して選択する手段と、
(b)前記各訓練文書と前記各実文書を文書セグメントに分解する手段と、
(c)前記各訓練文書と前記各実文書に対して前記文書セグメントに出現する用語の出現頻度に関連した値を対応する成分の値とする文書セグメントベクトルを生成する手段と、
(d)前記各訓練文書と前記実文書の前記文書セグメントベクトルを基に、前記第2の類似度、若しくは前記第3の類似度を求める手段。 The apparatus according to claim 3 and 4, wherein the means for obtaining the similarity includes the following means (a) to (d):
(A) means for detecting and selecting a term used for detection of the class or class pair from each training document and each actual document;
(B) means for decomposing each training document and each actual document into document segments;
(C) means for generating a document segment vector having a value related to an appearance frequency of a term appearing in the document segment for each training document and each actual document as a value of a corresponding component;
(D) Means for obtaining the second similarity or the third similarity based on each training document and the document segment vector of the actual document.
(a)前記クラス毎の訓練文書集合を用いて全てのクラス対に対して第1の類似度を求める手段、及び
(b)前記第1の類似度が第1の閾値より大きいクラス対を検出する手段。 The computer operates the means for classifying the input document by comparing the input document with the class model for each class created based on the training document information for each class, and further, the following (a) and (b) Document classification evaluation program that operates the means of
(A) means for obtaining a first similarity for all class pairs using the training document set for each class; and (b) detecting a class pair for which the first similarity is greater than a first threshold. Means to do.
(a)前記クラス対の検出に用いる用語を各訓練文書から検出して選択する手段と、
(b)前記各訓練文書を文書セグメントに分解する手段と、
(c)前記各訓練文書に対して前記文書セグメントに出現する用語の出現頻度に関連した値を対応する成分の値とする文書セグメントベクトルを生成する手段と、
(d)前記各訓練文書の前記文書セグメントベクトルを基に、全てのクラス対に対して訓練文書集合間の類似度を求める手段。 The document classification evaluation program according to claim 7, wherein the means for obtaining the similarity includes the following means (a) to (d):
(A) means for detecting and selecting a term used for detecting the class pair from each training document;
(B) means for decomposing each training document into document segments;
(C) means for generating a document segment vector having a value related to an occurrence frequency of a term appearing in the document segment for each training document as a value of a corresponding component;
(D) Means for obtaining similarity between training document sets for all class pairs based on the document segment vector of each training document.
(a)訓練文書集合をもとに各文書クラスのクラスモデルを作成する手段と、
(b)前記入力文書を前記クラスモデルとを照合して分類を行ない、前記入力文書を帰属する文書クラスに振り分けて実文書集合を作成する手段と、
(c)全文書クラスに対して、前記訓練文書集合と同じクラスの前記実文書集合の間の第2の類似度を求める手段と、
(d)前記第2の類似度が第2の閾値より小さいクラスを検出する手段。 By means of a computer, a means for collating the input document with a class model for each class created based on the training document information for each class and operating the input document is operated, and the following (a) to (d) Document classification evaluation program that operates the means of
(A) means for creating a class model for each document class based on the training document set;
(B) means for collating the input document with the class model, classifying the input document to a document class to which the input document belongs, and creating a real document set;
(C) means for obtaining a second similarity between the actual document sets of the same class as the training document set for all document classes;
(D) Means for detecting a class having the second similarity smaller than a second threshold.
(a)訓練文書集合をもとに各文書クラスのクラスモデルを作成する手段と、
(b)前記入力文書を前記クラスモデルとを照合して分類を行ない、前記入力文書を帰属する文書クラスに振り分けて実文書集合を作成する手段と、
(c)各文書クラスの前記訓練文書集合と他の全ての文書クラスの前記実文書集合との間の第3の類似度を求める手段と、
(d)前記第3の類似度が第3の閾値より大きいクラス対を検出する手段。 The computer operates the means for classifying the input document by collating the input document with the class model for each class created based on the training document information for each class, and further, the following (a) to (d) Document classification evaluation program for operating the means,
(A) means for creating a class model for each document class based on the training document set;
(B) means for collating the input document with the class model, classifying the input document to a document class to which the input document belongs, and creating a real document set;
(C) means for determining a third similarity between the training document set of each document class and the actual document set of all other document classes;
(D) Means for detecting a class pair whose third similarity is greater than a third threshold.
(a)前記クラスまたはクラス対の検出に用いる用語を前記各訓練文書と前記各実文書からから検出して選択する手段と、
(b)前記各訓練文書と前記各実文書を文書セグメントに分解する手段と、
(c)前記各訓練文書と前記各実文書に対して前記文書セグメントに出現する用語の出現頻度に関連した値を対応する成分の値とする文書セグメントベクトルを生成する手段と、
(d)前記各訓練文書と前記実文書の前記文書セグメントベクトルを基に、前記第2の類似度、若しくは前記第3の類似度を求める手段。 The means according to claim 9 and claim 10, wherein the means for obtaining the similarity includes the following means (a) to (d):
(A) means for detecting and selecting a term used for detection of the class or class pair from each training document and each actual document;
(B) means for decomposing each training document and each actual document into document segments;
(C) means for generating a document segment vector having a value related to an appearance frequency of a term appearing in the document segment for each training document and each actual document as a value of a corresponding component;
(D) Means for obtaining the second similarity or the third similarity based on each training document and the document segment vector of the actual document.
(a)クラス毎の訓練文書集合を用いて全てのクラス対に対して第1の類似度を求めるステップ、及び
(b)前記第1の類似度が第1の閾値より大きいクラス対を検出するステップ。 Collating the input document with a class model for each class created on the basis of the training document information for each class, and classifying the input document, and the following steps (a) and (b) Document classification evaluation method having
(A) obtaining a first similarity for all class pairs using a set of training documents for each class; and (b) detecting a class pair for which the first similarity is greater than a first threshold. Step.
(a)前記クラス対の検出に用いる用語を各訓練文書から検出して選択するステップと、
(b)前記各訓練文書を文書セグメントに分解するステップと、
(c)前記各訓練文書に対して前記文書セグメントに出現する用語の出現頻度に関連した値を対応する成分の値とする文書セグメントベクトルを生成するステップと、
(d)前記各訓練文書の前記文書セグメントベクトルを基に、全てのクラス対に対して訓練文書集合間の類似度を求めるステップ。 The document classification evaluation method according to claim 13, wherein the step of obtaining the similarity includes the following means (a) to (d):
(A) detecting and selecting a term used for detecting the class pair from each training document;
(B) decomposing each training document into document segments;
(C) generating a document segment vector having a value related to a value related to an appearance frequency of a term appearing in the document segment for each training document;
(D) obtaining similarities between training document sets for all class pairs based on the document segment vectors of the respective training documents.
(a)訓練文書集合をもとに各文書クラスのクラスモデルを作成するステップと、
(b)前記入力文書を前記クラスモデルとを照合して分類を行ない、前記入力文書を帰属する文書クラスに振り分けて実文書集合を作成するステップと、
(c)全文書クラスに対して、前記訓練文書集合と同じクラスの前記実文書集合の間の第2の類似度を求めるステップと、
(d)前記第2の類似度が第2の閾値より小さいクラスを検出するステップ。 Collating the input document with a class model for each class created based on the training document information for each class, and classifying the input document, and further comprising the following steps (a) to (d) Document classification evaluation method including
(A) creating a class model for each document class based on the training document set;
(B) collating the input document with the class model, classifying the input document into a document class to which the input document belongs, and creating a real document set;
(C) determining a second similarity between the actual document sets of the same class as the training document set for all document classes;
(D) detecting a class having the second similarity smaller than a second threshold.
(a)訓練文書集合をもとに各文書クラスのクラスモデルを作成するステップと、
(b)前記入力文書を前記クラスモデルとを照合して分類を行ない、前記入力文書を帰属する文書クラスに振り分けて実文書集合を作成するステップと、
(c)各文書クラスの前記訓練文書集合と他の全ての文書クラスの前記実文書集合との間の第3の類似度を求めるステップと、
(d)前記第3の類似度が第3の閾値より大きいクラス対を検出するステップ。 A step of collating the input document with a class model for each class created based on the training document information for each class, and classifying the input document; and the following means (a) to (d) Document classification evaluation method including
(A) creating a class model for each document class based on the training document set;
(B) collating the input document with the class model, classifying the input document into a document class to which the input document belongs, and creating a real document set;
(C) determining a third similarity between the training document set of each document class and the actual document set of all other document classes;
(D) detecting a class pair in which the third similarity is larger than a third threshold.
(a)前記クラスまたはクラス対の検出に用いる用語を前記各訓練文書と前記各実文書からから検出して選択するステップと、
(b)前記各訓練文書と前記各実文書を文書セグメントに分解するステップと、
(c)前記各訓練文書と前記各実文書に対して前記文書セグメントに出現する用語の出現頻度に関連した値を対応する成分の値とする文書セグメントベクトルを生成するステップと、
(d)前記各訓練文書と前記実文書の前記文書セグメントベクトルを基に、前記第2の類似度、若しくは前記第3の類似度を求めるステップ。 The method according to claim 15 and 16, wherein the step of determining the similarity includes the following steps (a) to (d):
(A) detecting and selecting a term used for detection of the class or class pair from each training document and each actual document;
(B) decomposing each training document and each actual document into document segments;
(C) generating a document segment vector having a value related to an occurrence frequency of a term appearing in the document segment for each training document and each actual document as a value of a corresponding component;
(D) A step of obtaining the second similarity or the third similarity based on each training document and the document segment vector of the actual document.
The number of types of terms that appear is given by M, it has Y document segments, and the y-th document segment vector is d y = (d y1, .., d yM ) T , where T is a vector The co-occurrence matrix S of the document,
(a)前記クラス毎の訓練パターン集合を用いて全てのクラス対に対して第1の類似度を求める手段、及び
(b)前記第1の類似度が第1の閾値より大きいクラス対を検出する手段。 The computer operates the means for classifying the input pattern by comparing the input pattern with the class model for each class created based on the training pattern information for each class, and further, the following (a) and (b) Pattern classification evaluation program that operates the means of
(A) means for obtaining a first similarity for all class pairs using the training pattern set for each class; and (b) detecting a class pair for which the first similarity is greater than a first threshold. Means to do.
(a)前記クラス対の検出に用いる構成要素を各訓練パターンから検出して選択する手段と、
(b)前記各訓練パターンをパターンセグメントに分解する手段と、
(c)前記各訓練パターンに対して前記パターンセグメントに出現する構成要素の出現頻度に関連した値を対応する成分の値とするパターンセグメントベクトルを生成する手段と、
(d)前記各訓練パターンの前記パターンセグメントベクトルを基に、全てのクラス対に対して訓練パターン集合間の類似度を求める手段。 The pattern classification evaluation program according to claim 19, wherein the means for obtaining the similarity includes the following means (a) to (d):
(A) means for detecting and selecting a component used for detection of the class pair from each training pattern;
(B) means for decomposing each training pattern into pattern segments;
(C) means for generating a pattern segment vector having a value related to an appearance frequency of a component appearing in the pattern segment for each training pattern as a value of a corresponding component;
(D) Means for obtaining similarity between training pattern sets for all class pairs based on the pattern segment vector of each training pattern.
(a)訓練パターン集合をもとに各パターンクラスのクラスモデルを作成する手段と、
(b)前記入力パターンを前記クラスモデルとを照合して分類を行ない、前記入力パターンを帰属するパターンクラスに振り分けて実パターン集合を作成する手段と、
(c)全パターンクラスに対して、前記訓練パターン集合と同じクラスの前記実パターン集合の間の第2の類似度を求める手段と、
(d)前記第2の類似度が第2の閾値より小さいクラスを検出する手段。 By means of a computer, the means for collating the input pattern with the class model for each class created on the basis of the training pattern information for each class and operating the input pattern is operated, and the following (a) to (d) Pattern classification evaluation program that operates the means of
(A) means for creating a class model of each pattern class based on the training pattern set;
(B) means for collating the input pattern with the class model, classifying the input pattern into a pattern class to which the input pattern belongs, and creating a real pattern set;
(C) For all pattern classes, means for obtaining a second similarity between the actual pattern sets of the same class as the training pattern set;
(D) Means for detecting a class having the second similarity smaller than a second threshold.
(a)訓練パターン集合をもとに各パターンクラスのクラスモデルを作成する手段と、
(b)前記入力パターンを前記クラスモデルとを照合して分類を行ない、前記入力パターンを帰属するパターンクラスに振り分けて実パターン集合を作成する手段と、
(c)各パターンクラスの前記訓練パターン集合と他の全てのパターンクラスの前記実パターン集合との間の第3の類似度を求める手段と、
(d)前記第3の類似度が第3の閾値より大きいクラス対を検出する手段。 The computer operates a means for classifying the input pattern by comparing the input pattern with the class model for each class created based on the training pattern information for each class, and further, the following (a) to (d) Pattern classification evaluation program for operating the means,
(A) means for creating a class model of each pattern class based on the training pattern set;
(B) means for collating the input pattern with the class model, classifying the input pattern into a pattern class to which the input pattern belongs, and creating a real pattern set;
(C) means for obtaining a third similarity between the training pattern set of each pattern class and the actual pattern sets of all other pattern classes;
(D) Means for detecting a class pair whose third similarity is greater than a third threshold.
(a)前記クラスまたはクラス対の検出に用いる構成要素を前記各訓練パターンと前記各実パターンからから検出して選択する手段と、
(b)前記各訓練パターンと前記各実パターンをパターンセグメントに分解する手段と、
(c)前記各訓練パターンと前記各実パターンに対して前記パターンセグメントに出現する構成要素の出現頻度に関連した値を対応する成分の値とするパターンセグメントベクトルを生成する手段と、
(d)前記各訓練パターンと前記実パターンの前記パターンセグメントベクトルを基に、前記第2の類似度、若しくは前記第3の類似度を求める手段。
The program according to claim 21 and claim 22, wherein the means for obtaining the similarity includes the following means (a) to (d):
(A) means for detecting and selecting a component used for detection of the class or class pair from each training pattern and each actual pattern;
(B) means for decomposing each training pattern and each actual pattern into pattern segments;
(C) means for generating a pattern segment vector having a value related to an appearance frequency of a component appearing in the pattern segment for each training pattern and each actual pattern as a value of a corresponding component;
(D) Means for obtaining the second similarity or the third similarity based on each training pattern and the pattern segment vector of the actual pattern.
Priority Applications (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2004034729A JP2005158010A (en) | 2003-10-31 | 2004-02-12 | Apparatus, method and program for classification evaluation |
| EP04256655A EP1528486A3 (en) | 2003-10-31 | 2004-10-28 | Classification evaluation system, method, and program |
| CNA2004100981935A CN1612134A (en) | 2003-10-31 | 2004-10-29 | Classification evaluation system, method, and program |
| US10/975,535 US20050097436A1 (en) | 2003-10-31 | 2004-10-29 | Classification evaluation system, method, and program |
| KR1020040087035A KR20050041944A (en) | 2003-10-31 | 2004-10-29 | Classification evaluation system, method, and program |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2003371881 | 2003-10-31 | ||
| JP2004034729A JP2005158010A (en) | 2003-10-31 | 2004-02-12 | Apparatus, method and program for classification evaluation |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2005158010A true JP2005158010A (en) | 2005-06-16 |
| JP2005158010A5 JP2005158010A5 (en) | 2007-11-29 |
Family
ID=34425419
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2004034729A Pending JP2005158010A (en) | 2003-10-31 | 2004-02-12 | Apparatus, method and program for classification evaluation |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US20050097436A1 (en) |
| EP (1) | EP1528486A3 (en) |
| JP (1) | JP2005158010A (en) |
| KR (1) | KR20050041944A (en) |
| CN (1) | CN1612134A (en) |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2008203933A (en) * | 2007-02-16 | 2008-09-04 | Dainippon Printing Co Ltd | Category creation method and apparatus and document classification method and apparatus |
| JP2009098810A (en) * | 2007-10-15 | 2009-05-07 | Toshiba Corp | Document classification device and program |
| WO2017138549A1 (en) * | 2016-02-12 | 2017-08-17 | 日本電気株式会社 | Information processing device, information processing method, and recording medium |
| CN112579729A (en) * | 2020-12-25 | 2021-03-30 | 百度(中国)有限公司 | Training method and device for document quality evaluation model, electronic equipment and medium |
Families Citing this family (31)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7475335B2 (en) * | 2004-11-03 | 2009-01-06 | International Business Machines Corporation | Method for automatically and dynamically composing document management applications |
| EP1796009A3 (en) * | 2005-12-08 | 2007-08-22 | Electronics and Telecommunications Research Institute | System for and method of extracting and clustering information |
| KR100822376B1 (en) | 2006-02-23 | 2008-04-17 | 삼성전자주식회사 | Method and system for classfying music theme using title of music |
| US9015569B2 (en) * | 2006-08-31 | 2015-04-21 | International Business Machines Corporation | System and method for resource-adaptive, real-time new event detection |
| JP5011947B2 (en) * | 2006-10-19 | 2012-08-29 | オムロン株式会社 | FMEA sheet creation method and FMEA sheet automatic creation apparatus |
| US8073682B2 (en) * | 2007-10-12 | 2011-12-06 | Palo Alto Research Center Incorporated | System and method for prospecting digital information |
| US8671104B2 (en) * | 2007-10-12 | 2014-03-11 | Palo Alto Research Center Incorporated | System and method for providing orientation into digital information |
| US8165985B2 (en) | 2007-10-12 | 2012-04-24 | Palo Alto Research Center Incorporated | System and method for performing discovery of digital information in a subject area |
| US8965865B2 (en) * | 2008-02-15 | 2015-02-24 | The University Of Utah Research Foundation | Method and system for adaptive discovery of content on a network |
| US7996390B2 (en) * | 2008-02-15 | 2011-08-09 | The University Of Utah Research Foundation | Method and system for clustering identified forms |
| US20100057577A1 (en) * | 2008-08-28 | 2010-03-04 | Palo Alto Research Center Incorporated | System And Method For Providing Topic-Guided Broadening Of Advertising Targets In Social Indexing |
| US8209616B2 (en) * | 2008-08-28 | 2012-06-26 | Palo Alto Research Center Incorporated | System and method for interfacing a web browser widget with social indexing |
| US20100057536A1 (en) * | 2008-08-28 | 2010-03-04 | Palo Alto Research Center Incorporated | System And Method For Providing Community-Based Advertising Term Disambiguation |
| US8010545B2 (en) * | 2008-08-28 | 2011-08-30 | Palo Alto Research Center Incorporated | System and method for providing a topic-directed search |
| US8549016B2 (en) * | 2008-11-14 | 2013-10-01 | Palo Alto Research Center Incorporated | System and method for providing robust topic identification in social indexes |
| US8239397B2 (en) * | 2009-01-27 | 2012-08-07 | Palo Alto Research Center Incorporated | System and method for managing user attention by detecting hot and cold topics in social indexes |
| US8356044B2 (en) * | 2009-01-27 | 2013-01-15 | Palo Alto Research Center Incorporated | System and method for providing default hierarchical training for social indexing |
| US8452781B2 (en) * | 2009-01-27 | 2013-05-28 | Palo Alto Research Center Incorporated | System and method for using banded topic relevance and time for article prioritization |
| US8868402B2 (en) * | 2009-12-30 | 2014-10-21 | Google Inc. | Construction of text classifiers |
| US9031944B2 (en) | 2010-04-30 | 2015-05-12 | Palo Alto Research Center Incorporated | System and method for providing multi-core and multi-level topical organization in social indexes |
| CN102214246B (en) * | 2011-07-18 | 2013-01-23 | 南京大学 | Method for grading Chinese electronic document reading on the Internet |
| CN103577462B (en) * | 2012-08-02 | 2018-10-16 | 北京百度网讯科技有限公司 | A kind of Document Classification Method and device |
| CN110147443B (en) * | 2017-08-03 | 2021-04-27 | 北京国双科技有限公司 | Topic classification judging method and device |
| CN108573031A (en) * | 2018-03-26 | 2018-09-25 | 上海万行信息科技有限公司 | A kind of complaint sorting technique and system based on content |
| KR102408628B1 (en) * | 2019-02-12 | 2022-06-15 | 주식회사 자이냅스 | A method for learning documents using a variable classifier with artificial intelligence technology |
| KR102410237B1 (en) * | 2019-02-12 | 2022-06-20 | 주식회사 자이냅스 | A method for providing an efficient learning process using a variable classifier |
| KR102375877B1 (en) * | 2019-02-12 | 2022-03-18 | 주식회사 자이냅스 | A device for efficiently learning documents based on big data and deep learning technology |
| KR102410239B1 (en) * | 2019-02-12 | 2022-06-20 | 주식회사 자이냅스 | A recording medium recording a document learning program using a variable classifier |
| KR102410238B1 (en) * | 2019-02-12 | 2022-06-20 | 주식회사 자이냅스 | A document learning program using variable classifier |
| KR102408637B1 (en) * | 2019-02-12 | 2022-06-15 | 주식회사 자이냅스 | A recording medium on which a program for providing an artificial intelligence conversation service is recorded |
| KR102408636B1 (en) * | 2019-02-12 | 2022-06-15 | 주식회사 자이냅스 | A program for learning documents using a variable classifier with artificial intelligence technology |
Family Cites Families (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6734880B2 (en) * | 1999-11-24 | 2004-05-11 | Stentor, Inc. | User interface for a medical informatics systems |
| JP2002169834A (en) * | 2000-11-20 | 2002-06-14 | Hewlett Packard Co <Hp> | Computer and method for making vector analysis of document |
| US6708205B2 (en) * | 2001-02-15 | 2004-03-16 | Suffix Mail, Inc. | E-mail messaging system |
| US7359936B2 (en) * | 2001-11-27 | 2008-04-15 | International Business Machines Corporation | Method and apparatus for electronic mail interaction with grouped message types |
| JP3726263B2 (en) * | 2002-03-01 | 2005-12-14 | ヒューレット・パッカード・カンパニー | Document classification method and apparatus |
-
2004
- 2004-02-12 JP JP2004034729A patent/JP2005158010A/en active Pending
- 2004-10-28 EP EP04256655A patent/EP1528486A3/en not_active Withdrawn
- 2004-10-29 US US10/975,535 patent/US20050097436A1/en not_active Abandoned
- 2004-10-29 CN CNA2004100981935A patent/CN1612134A/en active Pending
- 2004-10-29 KR KR1020040087035A patent/KR20050041944A/en not_active Application Discontinuation
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2008203933A (en) * | 2007-02-16 | 2008-09-04 | Dainippon Printing Co Ltd | Category creation method and apparatus and document classification method and apparatus |
| JP2009098810A (en) * | 2007-10-15 | 2009-05-07 | Toshiba Corp | Document classification device and program |
| WO2017138549A1 (en) * | 2016-02-12 | 2017-08-17 | 日本電気株式会社 | Information processing device, information processing method, and recording medium |
| US10803358B2 (en) | 2016-02-12 | 2020-10-13 | Nec Corporation | Information processing device, information processing method, and recording medium |
| CN112579729A (en) * | 2020-12-25 | 2021-03-30 | 百度(中国)有限公司 | Training method and device for document quality evaluation model, electronic equipment and medium |
Also Published As
| Publication number | Publication date |
|---|---|
| EP1528486A3 (en) | 2006-12-20 |
| CN1612134A (en) | 2005-05-04 |
| US20050097436A1 (en) | 2005-05-05 |
| KR20050041944A (en) | 2005-05-04 |
| EP1528486A2 (en) | 2005-05-04 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP2005158010A (en) | Apparatus, method and program for classification evaluation | |
| CN110765265B (en) | Information classification extraction method and device, computer equipment and storage medium | |
| Yasen et al. | Movies reviews sentiment analysis and classification | |
| CN107085581B (en) | Short text classification method and device | |
| CN109960724B (en) | Text summarization method based on TF-IDF | |
| CN109933780B (en) | Determining contextual reading order in a document using deep learning techniques | |
| CN110532353B (en) | Text entity matching method, system and device based on deep learning | |
| CN111897970A (en) | Text comparison method, device and equipment based on knowledge graph and storage medium | |
| CN109933656B (en) | Public opinion polarity prediction method, public opinion polarity prediction device, computer equipment and storage medium | |
| CN112395385B (en) | Text generation method and device based on artificial intelligence, computer equipment and medium | |
| WO2020198855A1 (en) | Method and system for mapping text phrases to a taxonomy | |
| EP1687738A2 (en) | Clustering of text for structuring of text documents and training of language models | |
| CN111368130A (en) | Quality inspection method, device and equipment for customer service recording and storage medium | |
| CN113806493A (en) | Entity relationship joint extraction method and device for Internet text data | |
| CN114995903A (en) | Class label identification method and device based on pre-training language model | |
| Khan et al. | A clustering framework for lexical normalization of Roman Urdu | |
| CN113935314A (en) | Abstract extraction method, device, terminal equipment and medium based on heteromorphic graph network | |
| Selamat | Improved N-grams approach for web page language identification | |
| CN110263345A (en) | Keyword extracting method, device and storage medium | |
| KR102517983B1 (en) | System and Method for correcting Context sensitive spelling error using Generative Adversarial Network | |
| US11580499B2 (en) | Method, system and computer-readable medium for information retrieval | |
| Khomytska et al. | Automated Identification of Authorial Styles. | |
| JP2005115628A (en) | Document classification apparatus using stereotyped expression, method, program | |
| CN111368068A (en) | Short text topic modeling method based on part-of-speech feature and semantic enhancement | |
| CN112949287B (en) | Hot word mining method, system, computer equipment and storage medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20061006 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20071016 |
|
| RD02 | Notification of acceptance of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7422 Effective date: 20071102 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20071113 |
|
| RD04 | Notification of resignation of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7424 Effective date: 20071220 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20090623 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20090924 |
|
| RD02 | Notification of acceptance of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7422 Effective date: 20091127 |
|
| RD04 | Notification of resignation of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7424 Effective date: 20091130 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20100308 |