EP3962115B1 - Verfahren zur bewertung der sprachqualität eines sprachsignals mittels einer hörvorrichtung - Google Patents
Verfahren zur bewertung der sprachqualität eines sprachsignals mittels einer hörvorrichtung Download PDFInfo
- Publication number
- EP3962115B1 EP3962115B1 EP21190918.9A EP21190918A EP3962115B1 EP 3962115 B1 EP3962115 B1 EP 3962115B1 EP 21190918 A EP21190918 A EP 21190918A EP 3962115 B1 EP3962115 B1 EP 3962115B1
- Authority
- EP
- European Patent Office
- Prior art keywords
- signal
- speech
- speech signal
- ascertained
- input audio
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images

Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/0316—Speech enhancement, e.g. noise reduction or echo cancellation by changing the amplitude
- G10L21/0364—Speech enhancement, e.g. noise reduction or echo cancellation by changing the amplitude for improving intelligibility
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/03—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the type of extracted parameters
- G10L25/15—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the type of extracted parameters the extracted parameters being formant information
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/48—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 specially adapted for particular use
- G10L25/51—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 specially adapted for particular use for comparison or discrimination
- G10L25/60—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 specially adapted for particular use for comparison or discrimination for measuring the quality of voice signals
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/78—Detection of presence or absence of voice signals
- G10L25/84—Detection of presence or absence of voice signals for discriminating voice from noise
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R25/00—Deaf-aid sets, i.e. electro-acoustic or electro-mechanical hearing aids; Electric tinnitus maskers providing an auditory perception
- H04R25/30—Monitoring or testing of hearing aids, e.g. functioning, settings, battery power
- H04R25/305—Self-monitoring or self-testing
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R25/00—Deaf-aid sets, i.e. electro-acoustic or electro-mechanical hearing aids; Electric tinnitus maskers providing an auditory perception
- H04R25/40—Arrangements for obtaining a desired directivity characteristic
- H04R25/405—Arrangements for obtaining a desired directivity characteristic by combining a plurality of transducers
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R25/00—Deaf-aid sets, i.e. electro-acoustic or electro-mechanical hearing aids; Electric tinnitus maskers providing an auditory perception
- H04R25/40—Arrangements for obtaining a desired directivity characteristic
- H04R25/407—Circuits for combining signals of a plurality of transducers
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R25/00—Deaf-aid sets, i.e. electro-acoustic or electro-mechanical hearing aids; Electric tinnitus maskers providing an auditory perception
- H04R25/43—Electronic input selection or mixing based on input signal analysis, e.g. mixing or selection between microphone and telecoil or between microphones with different directivity characteristics
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R25/00—Deaf-aid sets, i.e. electro-acoustic or electro-mechanical hearing aids; Electric tinnitus maskers providing an auditory perception
- H04R25/50—Customised settings for obtaining desired overall acoustical characteristics
- H04R25/505—Customised settings for obtaining desired overall acoustical characteristics using digital signal processing
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R2225/00—Details of deaf aids covered by H04R25/00, not provided for in any of its subgroups
- H04R2225/43—Signal processing in hearing aids to enhance the speech intelligibility
Definitions
- the invention relates to a method for evaluating the speech quality of a speech signal by means of a hearing device, wherein a sound containing the speech signal is recorded from an environment of the hearing device by means of an acousto-electrical input transducer of the hearing device and converted into an input audio signal, wherein at least one property of the speech signal is quantitatively recorded by analyzing the input audio signal by means of signal processing.
- Noise suppression is usually carried out using parameters that primarily affect the noise or the overall signal, such as a signal-to-noise ratio (SNR), a background noise level (“noise foor”), or a level of the audio signal.
- SNR signal-to-noise ratio
- noise foor background noise level
- this approach to controlling noise reduction can ultimately lead to noise reduction being applied even when it is not actually necessary, despite noticeable background noise, because parts of the speech are still easily understandable despite the background noise.
- the risk of a deterioration in sound quality e.g. due to noise reduction artifacts, is taken without any real need.
- a speech signal that is only superimposed by a small amount of noise and has a good SNR can also have a poor speech quality if the speaker has poor articulation.
- the US 2004 / 0 167 774 A1 refers to a method for analyzing and evaluating voices.
- a test speech signal is processed using a hearing model, at least one feature of a speech quality is determined from the test speech signal, and the said feature of the speech quality is compared with a corresponding basic feature of the speech quality. Based on this, a measure of the speech quality of the test speech signal can be determined.
- the US 2018 / 0 255 406 A1 mentions a hearing aid comprising a number of microphones with a first microphone for generating a first microphone input signal and a processor for processing input signals into an electrical output signal.
- the hearing aid further comprises a receiver for converting the electrical output signal into an output sound signal and a control unit operatively connected to the number of microphones, wherein the control unit estimates an indicator of speech intelligibility based on one or more microphone input signals.
- the control unit is further configured to control the processor based on the indicator of speech intelligibility. For estimating said indicator, a pitch parameter of a first audio source is estimated.
- the indicator of speech intelligibility is based on the pitch parameter and a direction of the first audio source.
- the US 7,165,025 refers to an articulation analysis for use in speech quality assessment. Articulation analysis is based on a comparison between performances of articulatory and non-articulatory frequency ranges of a speech signal, with speech quality being assessed based on said comparison. Neither the source speech signal nor an estimate thereof is used in articulation analysis.
- the invention is therefore based on the object of specifying a method by means of which a speech component in an audio signal to be processed by a hearing device can be objectively assessed in terms of its quality.
- the invention is also based on the object of specifying a hearing device which is set up to objectively assess the quality of a speech component contained in an internal audio signal.
- the frequencies of certain vibrations are often given as integer multiples of a fundamental frequency, and are referred to as "harmonics" or overtones of this fundamental frequency.
- harmonics or overtones of this fundamental frequency.
- more complex spectral patterns can also develop, so that not all frequencies generated can be represented as harmonics of the same fundamental frequency.
- the resonance of the generated frequencies in the resonance chamber is also relevant for the sound image, since certain frequencies generated by the oscillator are often attenuated in the resonance chamber relative to the dominant frequencies of a sound.
- consonants can also be assigned to certain frequency bands in which the acoustic energy is concentrated. Due to the more percussive "noise-like" nature of consonants, these are generally above the formant ranges of vowels, namely primarily in the range of approx. 2 to 8 kHz, while the ranges of the most important formants F1 and F2 of vowels generally end at approx. 1.5 kHz (F1) and 4 kHz (F2).
- the precision of consonants is determined in particular by the degree to which the acoustic energy is concentrated in the corresponding frequency ranges and the resulting ability to identify the individual consonants.
- the lower The frequency range is selected such that it lies within the frequency interval [0 Hz, 2.5 kHz], particularly preferably within the frequency interval [0 Hz, 2 kHz].
- the higher frequency range is selected such that it lies within the frequency interval [3 kHz, 10 kHz], particularly preferably within the frequency interval [4 Hz, 8 kHz].
- voiced and unvoiced time sequences using a correlation measurement and/or a zero-crossing rate of the input audio signal or a signal derived from the input audio signal, wherein a transition from a voiced time sequence to an unvoiced time sequence or from an unvoiced time sequence to a voiced time sequence is determined, the energy contained in the voiced or unvoiced time sequence before the transition is determined for at least one frequency range, and the energy contained in the unvoiced or voiced time sequence after the transition is determined for the at least one frequency range, and the characteristic value is determined using the energy before the transition and the energy after the transition.
- the voiced and unvoiced time sequences of the speech signal in the input audio signal are determined, and from this a transition from voiced to unvoiced or from unvoiced to voiced is identified.
- the energy before the transition in the frequency range for the input audio signal or for a signal derived from it is then determined. This energy can be taken, for example, from the voiced or unvoiced time sequence immediately before the transition.
- the energy in the relevant frequency range after the transition is also determined, for example from the unvoiced or voiced time sequence following the transition.
- a characteristic value can now be determined which in particular enables a statement to be made about a change in the energy distribution at the transition.
- This characteristic value can, for example, be determined as a quotient or a relative deviation of the two energies before and after the transition.
- the characteristic value can also be formed as a comparison of the energy before and after the transition with the total (broadband) signal energy.
- the energies can also be determined for a further frequency range before and after the transition, so that the characteristic value can also be determined based on the energies before and after the transition in the further frequency band, e.g. as a rate of change of the energy distribution across the frequency ranges involved across the transition (i.e. a comparison of the distribution of energies in both frequency ranges before the transition with the distribution after the transition).
- the characteristic value can then be used to determine the characteristic value for the measure of speech quality that correlates with the precision of the transitions.
- the characteristic value can be used directly for this purpose, or the characteristic value can be compared with a reference value determined in advance for good articulation, in particular on the basis of corresponding empirical knowledge (e.g. as a quotient or relative deviation).
- the specific design, in particular with regard to the frequency ranges and limit or reference values to be used, can generally be carried out on the basis of empirical results on the corresponding significance of the respective frequency bands or groups of frequency bands.
- the frequency bands 13 to 24, preferably 16 to 23 of the Bark scale can be used as the at least one frequency range.
- a frequency range of lower frequencies can be used as a further frequency range.
- the acoustic energies of the speech signal concentrated in at least two different formant ranges are compared with one another in order to detect the characteristic value correlated with the precision of predetermined formants of vowels in the speech signal.
- a signal component of the Speech signal in at least one formant range in the frequency space is determined, a signal quantity correlated with the level is determined for the signal portion of the speech signal in at least one formant range, and the characteristic quantity is determined on the basis of a maximum value and/or on the basis of a time stability of the signal quantity correlated with the level.
- At least one prosodic property of the speech signal is quantitatively recorded, and the quantitative measure of the speech quality is additionally determined as a function of the at least one prosodic property of the speech signal (18).
- the fundamental frequency of the speech signal is recorded in a time-resolved manner, and a characteristic value characteristic of the time stability of the fundamental frequency is determined as a prosodic property of the speech signal.
- This characteristic value can be determined, for example, based on a relative Deviation of the fundamental frequency can be determined, or by recording a number of maxima and minima of the fundamental frequency over a given period of time.
- the temporal stability of the fundamental frequency is particularly important for the monotony of speech melody and accentuation, which is why quantitative recording also allows a statement to be made about the speech quality of the speech signal.
- a quantity correlated with the volume is recorded in a time-resolved manner for the speech signal, in particular by means of a corresponding analysis of the input audio signal or a signal derived therefrom, wherein a quotient of a maximum value of the quantity correlated with the volume to an average value of the said quantity determined over the predetermined period is formed over a predetermined period of time, and wherein a characteristic quantity is determined as a prosodic property of the speech signal as a function of the said quotient, which is formed from the maximum value and the average value of the quantity correlated with the volume over the predetermined period of time.
- At least two parameters that are each characteristic of articulatory and/or prosodic properties are determined based on the analysis of the input audio signal, wherein the quantitative measure of the speech quality is formed based on a product of these parameters and/or based on a weighted average and/or a maximum or minimum value of these parameters.
- a speech activity is detected and/or an SNR is determined in the input audio signal, wherein an analysis with regard to the at least one articulatory and/or prosodic property of the speech signal depending on the detected speech activity or the determined SNR.
- the hearing device is preferably designed as a hearing aid.
- the hearing aid can be a monaural device or a binaural device with two local devices, which the user of the hearing aid wears on his or her right or left ear.
- the hearing aid can also have at least one further acousto-electrical input transducer, which converts the sound of the environment into a corresponding further input audio signal, so that the quantitative detection of the at least one articulatory and/or prosodic property of a speech signal can be carried out by analyzing a plurality of input audio signals involved.
- two of the input audio signals used can each be generated in different local units of the hearing aid (i.e.
- the signal processing device can in particular comprise signal processors of both local units, wherein preferably locally generated measures of the speech quality are standardized in a suitable manner by averaging or a maximum or minimum value for both local units depending on the articulatory and/or prosodic property under consideration.
- a hearing device 1 is shown schematically in a circuit diagram, which is designed as a hearing aid 2 in the present case.
- the hearing aid 2 has an acousto-electrical input transducer 4, which is set up to convert a sound 6 from the environment of the hearing aid 2 into an input audio signal 8.
- a design of the hearing aid 2 with a further input transducer (not shown), which generates a corresponding further input audio signal from the sound 6 from the environment, is also conceivable here.
- the hearing aid 2 is designed as a stand-alone, monaural device in the present case.
- a design of the hearing aid 2 as a binaural hearing aid with two local devices (not shown), which are to be worn by the user of the hearing aid 2 on his or her right or left ear, is also conceivable.
- the sound 6 of the environment of the hearing aid 2, which is detected by the input transducer 4, includes, among other things, a speech signal 18 of a speaker (not shown in detail), as well as further sound components 20, which can in particular include directed and/or diffuse noise (noise or background noise), but can also include noises which, depending on the situation, could be regarded as a useful signal, for example music or acoustic warning or information signals relating to the environment.
- a speech signal 18 of a speaker not shown in detail
- further sound components 20 can in particular include directed and/or diffuse noise (noise or background noise), but can also include noises which, depending on the situation, could be regarded as a useful signal, for example music or acoustic warning or information signals relating to the environment.
- the signal processing of the input audio signal 8 carried out in the signal processing device 10 for generating the output audio signal 12 can in particular comprise a suppression of the signal components which suppress the noise contained in the sound 6, or a relative increase in the signal components representing the speech signal 18 compared to the signal components representing the other sound components 20.
- a frequency-dependent or broadband dynamic compression and/or amplification as well as algorithms for noise suppression can also be used here.
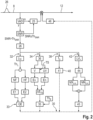
- Figure 2 shows in a block diagram a processing of the input audio signal 8 of the hearing aid 2 according to Figure 2 .
- a detection of speech activity VAD is carried out for the input audio signal 8. If there is no significant speech activity (path "n"), the signal processing of the input audio signal 8 to generate the output audio signal 12 takes place using a first algorithm 25.
- the first algorithm 25 evaluates signal parameters of the input audio signal 8 in a predetermined manner, such as level, background noise, transients or similar, broadband and/or in particular frequency band-wise, and determines individual parameters from this, e.g. frequency band-wise amplification factors and/or compression characteristics (i.e. knee point, ratio, attack, release), which are to be applied to the input audio signal 8.
- a center wavelength ⁇ c is first determined and compared with a predetermined limit value for the center wavelength Th ⁇ . If it is determined on the basis of the said limit value for the center wavelength Th ⁇ that the signal components in the input audio signal 8 are sufficiently high-frequency, the signal components are selected in the first signal path 32, if necessary after a suitably selected temporal smoothing (not shown), for a low frequency range NF and a higher frequency range HF lying above the low frequency range NF.
- a possible division can, for example, be such that the low frequency range NF includes all frequencies f N ⁇ 2500 Hz, in particular f N ⁇ 2000 Hz, and the higher frequency range HF includes frequencies f H with 2500 Hz ⁇ f H ⁇ 10000 Hz, in particular 4000 Hz ⁇ f H ⁇ 8000 Hz or 2500 Hz ⁇ f H ⁇ 5000 Hz.
- the selection can be carried out directly in the input audio signal 8, or it can also be carried out in such a way that the input audio signal 8 is divided into individual frequency bands by means of a filter bank (not shown), whereby individual frequency bands are assigned to the low or higher frequency range NF or HF depending on the respective band limits.
- a first energy E1 is then determined for the signal contained in the low frequency range NF and a second energy E2 is determined for the signal contained in the higher frequency range HF.
- a quotient QE is now formed from the second energy as the numerator and the first energy E1 as the denominator.
- the quotient QE can now be used as a parameter 33 which is correlated with the dominance of consonants in the speech signal 18.
- the parameter 33 thus enables a statement to be made about an articulatory property of the speech signal components 26 in the input audio signal 8. For example, for a value of the quotient QE >> 1 (i.e. QE > Th QE with a predetermined, not shown limit value Th QE >> 1) a high dominance for consonants can be concluded, while for a value QE ⁇ 1 a low dominance can be concluded.
- An energy Ev is now determined for the voiced time sequence V before the transition TS and an energy En for the unvoiced time sequence UV after the transition TS for at least one frequency range (e.g. a selection of particularly meaningful frequency bands determined to be suitable, e.g. frequency bands 16 to 23 of the Bark scale, or frequency bands 1 to 15 of the Bark scale).
- corresponding energies before and after the transition TS can also be determined separately for more than one frequency range. It is now determined how the energy changes at the transition TS, e.g. through a relative change ⁇ E TS or through a quotient (not shown) of the energies Ev, En before and after the transition TS.
- the measure of the change in energy i.e. in this case the relative change
- a limit value Th E for energy distribution at transitions determined in advance for good articulation.
- a parameter 35 can be formed based on a ratio of the relative change ⁇ E TS and the said limit value Th E or based on a relative deviation of the relative change ⁇ E TS from this limit value Th E.
- the said parameter 35 is correlated with the articulation of the transitions between voiced and unvoiced sounds in the speech signal 18 and thus enables information to be obtained about a further articulatory property of the speech signal components 26 in the input audio signal 8.
- an energy distribution in two frequency ranges (e.g. the above-mentioned frequency ranges according to the Bark scale, or also in the lower and higher frequency ranges LF, HF) can also be considered, e.g. via a quotient of the respective energies or a comparable parameter, and a change in the quotient or parameter across the transition can be used for the parameter.
- a rate of change of the quotient or parameter can be determined and compared with a reference value for the rate of change that has been previously determined to be suitable.
- transitions of unvoiced time sequences can also be considered in an analogous manner.
- the concrete design in particular with regard to the frequency ranges and limit or reference values to be used, can generally be carried out on the basis of empirical results on the corresponding significance of the respective frequency bands or groups of frequency bands.
- a fundamental frequency f G of the speech signal component 26 is detected in the input audio signal 8 in a time-resolved manner, and a time stability 40 is determined for said fundamental frequency f G on the basis of a variance of the fundamental frequency f G.
- the time stability 40 can be used as a parameter 41, which allows a statement to be made about a prosodic property of the speech signal components 26 in the input audio signal 8.
- a greater variance in the fundamental frequency f G can be used as an indicator for better speech intelligibility, while a monotonous fundamental frequency f G has a lower speech intelligibility.
- a level LVL is recorded in a time-resolved manner for the input audio signal 8 and/or for the speech signal component 26 contained therein, and a temporal average MN LVL is formed over a period 44 specified in particular on the basis of corresponding empirical findings. Furthermore, the maximum MX LVL of the level LVL is determined over the period 44. The maximum MX LVL of the level LVL is then divided by the temporal average MN LVL of the level LVL, and in this way a characteristic value 45 correlated with a volume of the speech signal 18 is determined, which enables further information to be provided about a prosodic property of the speech signal components 26 in the input audio signal 8. Instead of the level LVL, another value correlated with the volume and/or the energy content of the speech signal component 26 can also be used.
Landscapes
- Engineering & Computer Science (AREA)
- Health & Medical Sciences (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Signal Processing (AREA)
- General Health & Medical Sciences (AREA)
- Otolaryngology (AREA)
- Neurosurgery (AREA)
- Computational Linguistics (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Multimedia (AREA)
- Quality & Reliability (AREA)
- Measurement Of Mechanical Vibrations Or Ultrasonic Waves (AREA)
- Measurement Of The Respiration, Hearing Ability, Form, And Blood Characteristics Of Living Organisms (AREA)
- Circuit For Audible Band Transducer (AREA)
Description
- Die Erfindung betrifft ein Verfahren zur Bewertung der Sprachqualität eines Sprachsignals mittels einer Hörvorrichtung, wobei mittels eines akusto-elektrischen Eingangswandlers der Hörvorrichtung ein das Sprachsignal enthaltender Schall aus einer Umgebung der Hörvorrichtung aufgenommen und in ein Eingangs-Audiosignal umgewandelt wird, wobei durch Analyse des Eingangs-Audiosignals mittels einer Signalverarbeitung mindestens Eigenschaft des Sprachsignals quantitativ erfasst wird.
- Eine wichtige Aufgabe in der Anwendung von Hörvorrichtungen, wie z.B. von Hörgeräten, aber auch von Headsets oder Kommunikationsgeräten, besteht oftmals darin, ein Sprachsignal möglichst präzise, also insbesondere akustisch möglichst verständlich an einen Benutzer der Hörvorrichtung auszugeben. Oftmals werden hierzu in einem Audiosignal, welches anhand eines Schalls mit einem Sprachsignal erzeugt wird, Störgeräusche aus dem Schall unterdrückt, um die Signalanteile, welche das Sprachsignal repräsentieren, hervorzuheben und somit dessen Verständlichkeit zu verbessern. Oftmals kann jedoch durch Algorithmen zur Rauschunterdrückung die Klangqualität eines resultierenden Ausgangssignals verringert werden, wobei durch eine Signalverarbeitung des Audiosignals insbesondere Artefakte entstehen können, und/oder ein Höreindruck generell als weniger natürlich empfunden wird.
- Meist wird eine Rauschunterdrückung hierbei anhand von Kenngrößen durchgeführt, welche vorrangig das Rauschen oder das Gesamtsignal betreffen, also z.B. ein Signal-zu-Rausch-Verhältnis ("signal-to-noise-ratio", SNR), ein Grundrauschpegel ("noise foor"), oder auch einen Pegel des Audiosignals. Dieser Ansatz für eine Steuerung der Rauschunterdrückung kann jedoch letztlich dazu führen, dass die Rauschunterdrückung auch dann angewandt wird, wenn dies, obwohl merkliche Störgeräusche vorliegen, infolge von trotz der Störgeräusche weiter gut verständlichen Sprachanteilen gar nicht erforderlich wäre. In diesem Fall wird das Risiko einer nachlassenden Klangqualität, z.B. durch Artefakte der Rauschunterdrückung, ohne echte Notwendigkeit eingegangen. Umgekehrt kann ein Sprachsignal, welches nur von geringem Rauschen überlagert ist, und insofern das zugehörige Audiosignal ein gutes SNR aufweist, bei einer schwachen Artikulation des Sprechers auch eine geringe Sprachqualität aufweisen.
- Dies könnte vermieden werden, wenn in einer Hörvorrichtung Algorithmen zur Rauschunterdrückung im Besonderen, aber auch die Signalverarbeitung im Allgemeinen, in Abhängigkeit einer Qualität eines Sprachsignalanteils im zu verarbeitenden Audiosignal gesteuert würden. Hierfür ist jedoch erforderlich, eine solche Qualität überhaupt mess- und erfassbar bar zu machen.
- Die
US 2004 / 0 167 774 A1 nennt ein Verfahren zum Analysieren und Bewerten von Stimmen. Hierbei wird ein Testsprachsignal unter Verwendung eines Hörmodells verarbeitet, wenigstens ein Merkmal einer Sprachqualität aus dem Testsprachsignal ermittelt, und das besagte Merkmal der Sprachqualität mit einem entsprechenden Basis-Merkmal der Sprachqualität. Darauf basierend kann ein Maß für eine Sprachqualität des Testsprachsignals ermittelt werden. - In A. H. Andersen et al., "Nonintrusive Speech Intelligibility Prediction Using Convolutional Neural Networks", IEEE/ACM Transactions on Audio, Speech and Language Processing, IEEE, USA, Bd. 26, Nr. 10, 01.10.2018, Seiten 1925-1939, wird ein sog. Convolutional Neural Network (CNN) für eine nicht-intrusive Vorhersage der Sprachverständlichkeit ("Speech Intelligibility Prediction", SIP), welche kein sauberes (also rauschfreies) Sprachsignal für Vorhersagen benötigt. Die verwendete CNN-Architektur weist dabei Ähnlichkeit zu bestehenden SIP-Algorithmen auf, wodurch die trainierten Gewichte des CNN einfach und aussagekräftig zu interpretieren sind. Die vorgeschlagene Methode zeigt eine hohe Vorhersageleistung im Vergleich zu bestehenden intrusiven und nicht-intrusiven SIP-Algorithmen. Dies demonstriert das Potenzial von Deep Learning für die Vorhersage der Sprachverständlichkeit Vorhersage.
- Die
US 2018 / 0 255 406 A1 nennt ein Hörgerät, das eine Anzahl an Mikrofonen mit einem ersten Mikrofon zum Erzeugen eines ersten Mikrofoneingangssignals sowie und einen Prozessor zum Verarbeiten von Eingangssignalen zu einem elektrischen Ausgangssignal umfasst. Das Hörgerät umfasst weiter einen Receiver zum Umwandeln des elektrischen Ausgangssignals in ein Ausgangsschallsignal und eine Steuereinheit, die operativ mit der Anzahl an Mikrofonen verbunden ist, wobei die Steuereinheit basierend auf einem oder mehreren Mikrofoneingangssignale einen Indikator einer Sprachverständlichkeit schätzt. Die Steuereinheit ist weiter dazu eingerichtet, den Prozessor basierend auf dem Indikator der Sprachverständlichkeit zu steuern. Für das Schätzen des besagten Indikators wird ein Tonhöhenparameter einer ersten Audioquelle geschätzt. Der Indikator der Sprachverständlichkeit basiert auf dem Tonhöhenparameter und einer Richtung der ersten Audioquelle. - Die
US 7,165,025 nennt eine Artikulationsanalyse zur Verwendung bei der Sprachqualitätsbewertung. Die Artikulationsanalyse basiert auf einem Vergleich zwischen Leistungen von Artikulations- und Nicht-Artikulations-Frequenzbereichen eines Sprachsignals, wobei die Sprachqualität basierend auf dem besagten Vergleich bewertet wird. Weder das Ausgangssprachsignal noch eine Schätzung desselben wird in der Artikulationsanalyse verwendet. - Der Erfindung liegt daher die Aufgabe zugrunde, ein Verfahren anzugeben, mittels dessen ein Sprachanteil in einem von einer Hörvorrichtung zu verarbeitenden Audiosignal objektiv in seiner Qualität bewertet werden kann. Der Erfindung liegt weiter die Aufgabe zugrunde, eine Hörvorrichtung anzugeben, welche dazu eingerichtet ist, für ein internes Audiosignal eine Qualität eines darin enthaltenen Sprachanteils objektiv zu bewerten.
- Die erstgenannte Aufgabe wird erfindungsgemäß gelöst durch ein Verfahren zur Bewertung der Sprachqualität eines Sprachsignals mittels einer Hörvorrichtung, wobei mittels eines akusto-elektrischen Eingangswandlers der Hörvorrichtung ein das Sprachsignal enthaltender Schall aus einer Umgebung der Hörvorrichtung aufgenommen und in ein Eingangs-Audiosignal umgewandelt wird, wobei durch Analyse des Eingangs-Audiosignals mittels einer Signalverarbeitung, insbesondere einer Signalverarbeitung der Hörvorrichtung und/oder einer mit der Hörvorrichtung verbindbaren Hilfsvorrichtung, mindestens eine artikulatorische Eigenschaft des Sprachsignals quantitativ erfasst wird, und wobei in Abhängigkeit von der mindestens einen artikulatorischen Eigenschaft ein quantitatives Maß für die Sprachqualität abgeleitet wird. Vorteilhafte und teils für sich gesehen erfinderische Ausgestaltungen sind Gegenstand der Unteransprüche und der nachfolgenden Beschreibung.
- Die zweitgenannte Aufgabe wird erfindungsgemäß gelöst durch eine Hörvorrichtung, welche einen akusto-elektrischen Eingangswandler und eine insbesondere einen Signalprozessor aufweisende Signalverarbeitungseinrichtung umfasst, wobei der akusto-elektrischen Eingangswandler dazu eingerichtet ist, einen Schall aus einer Umgebung der Hörvorrichtung aufzunehmen und in ein Eingangs-Audiosignal umzuwandeln, und wobei die Signalverarbeitungseinrichtung dazu eingerichtet ist, durch eine Analyse des Eingangs-Audiosignals mindestens eine artikulatorische Eigenschaft eines im Eingangs-Audiosignal enthaltenen Anteils eines Sprachsignals quantitativ zu erfassen und in Abhängigkeit von der mindestens einen artikulatorischen Eigenschaft gemäß dem vorbeschriebenen Verfahren ein quantitatives Maß für die Sprachqualität abzuleiten.
- Die erfindungsgemäße Hörvorrichtung teilt die Vorzüge des erfindungsgemäßen Verfahrens, welches insbesondere mittels der erfindungsgemäßen Hörvorrichtung durchführbar ist. Die für das Verfahren und für seine Weiterbildungen nachfolgend genannten Vorteile können hierbei sinngemäß auf die Hörvorrichtung übertragen werden.
- Unter einem akusto-elektrischen Eingangswandler ist hierbei insbesondere jedweder Wandler umfasst, welcher dazu eingerichtet ist, aus einem Schall der Umgebung ein elektrisches Audiosignal zu erzeugen, sodass durch den Schall hervorgerufene Luftbewegungen und Luftdruckschwankungen am Ort des Wandlers durch entsprechende Oszillationen einer elektrischen Größe, insbesondere einer Spannung im erzeugten Audiosignal wiedergegeben werden. Insbesondere kann der akusto-elektrische Eingangswandler durch ein Mikrofon gegeben sein.
- Die Signalverarbeitung erfolgt insbesondere mittels einer entsprechenden Signalverarbeitungseinrichtung, welche mittels wenigstens eines Signalprozessors zur Durchführung der für die Signalverarbeitung vorgesehenen Berechnungen und/oder Algorithmen eingerichtet ist. Die Signalverarbeitungseinrichtung ist dabei insbesondere auf der Hörvorrichtung angeordnet. Die Signalverarbeitungseinrichtung kann jedoch auch auf einer Hilfsvorrichtung angeordnet sein, welche für eine Verbindung mit der Hörvorrichtung zum Datenaustausch eingerichtet ist, also z.B. ein Smartphone, eine Smartwatch o.ä. Die Hörvorrichtung kann dann z.B. das Eingangs-Audiosignal an die Hilfsvorrichtung übertragen, und die Analyse wird mittels der durch die Hilfsvorrichtung bereitgestellten Rechenressourcen durchgeführt. Abschließend kann als Ergebnis der Analyse das quantitative Maß an die Hörvorrichtung zurück übertragen werden.
- Die Analyse kann dabei direkt am Eingangs-Audiosignal durchgeführt werden, oder anhand eines vom Eingangs-Audiosignal abgeleiteten Signals. Ein solches kann hierbei insbesondere durch den isolierten Sprachsignalanteil gegeben sein, aber auch durch ein Audiosignal, wie es z.B. in einer Hörvorrichtung durch eine Rückkopplungsschleife mittels eines Kompensationssignals zur Kompensation einer akustischen Rückkopplung erzeugt werden kann o.ä., oder durch ein Richtsignal, welches anhand eines weiteren Eingangs-Audiosignals eines weiteren Eingangswandlers erzeugt wird.
- Unter einer artikulatorischen Eigenschaft des Sprachsignals sind hierbei eine Präzision von Formanten, besonders von Vokalen, sowie eine Dominanz von Konsonanten, besonders von Frikativen und/oder Plosiven, umfasst. Hierbei lässt sich die Aussage treffen, dass eine Sprachqualität als umso höher anzusetzen ist, je höher die Präzision der Formanten ist bzw. je höher die Dominanz und/oder Präzision von Konsonanten ist. Unter einer prosodischen Eigenschaft des Sprachsignals sind insbesondere eine Zeitstabilität einer Grundfrequenz des Sprachsignals und eine relative Schallintensität von Akzenten umfasst.
- Klangerzeugung umfasst üblicherweise drei physikalische Bestandteile einer Schallquelle: Einen mechanischen Oszillator wie z.B. eine Saite oder Membran, welcher eine den Oszillator umgebende Luft in Schwingungen versetzt, eine Anregung des Oszillators (z.B. durch ein Zupfen oder Streichen), und einen Resonanzkörper. Der Oszillator wird durch die Anregung in Oszillationen versetzt, sodass die den Oszillator umgebende Luft durch die Schwingungen des Oszillators in Druckschwingungen versetzt wird, welche sich als Schallwellen ausbreiten. Hierbei werden im mechanischen Oszillator meist nicht nur Schwingungen einer einzigen Frequenz angeregt, sondern Schwingungen verschiedener Frequenzen, wobei die spektrale Zusammensetzung der propagierenden Schwingungen das Klangbild bestimmt. Die Frequenzen von bestimmten Schwingungen sind dabei oft als ganzzahlige Vielfache einer Grundfrequenz gegeben, und werden als "Harmonische" oder als Obertöne dieser Grundfrequenz bezeichnet. Es können sich jedoch auch komplexere spektrale Muster herausbilden, sodass nicht alle erzeugten Frequenzen als Harmonische derselben Grundfrequenz darstellbar sind. Für das Klangbild ist hierbei auch die Resonanz der erzeugten Frequenzen im Resonanzraum relevant, da oftmals bestimmte, vom Oszillator erzeugte Frequenzen im Resonanzraum relativ zu den dominanten Frequenzen eines Klangs abgeschwächt werden.
- Auf die menschliche Stimme angewandt bedeutet dies, dass der mechanische Oszillator gegeben ist durch die Stimmbänder, und deren Anregung in der aus den Lungen an den Stimmbändern vorbeiströmenden Luft, wobei der Resonanzraum v.a. durch den Rachen- und Mundraum gebildet wird. Die Grundfrequenz einer männlichen Stimme liegt dabei meist im Bereich von 60 Hz bis 150 Hz, für Frauen meist im Bereich von 150 Hz bis 300 Hz. Infolge der anatomischen Unterschiede zwischen einzelnen Menschen sowohl hinsichtlich ihrer Stimmbänder, als auch insbesondere hinsichtlich des Rachen- und Mundraums bilden sich zunächst unterschiedliche klingende Stimmen aus. Durch eine Veränderung des Volumens und der Geometrie des Mundraums durch entsprechende Kiefer- und Lippenbewegungen kann dabei der Resonanzraum derart verändert werden, dass sich für die Erzeugung von Vokalen charakteristische Frequenzen ausbilden, sog. Formanten. Diese liegen jeweils für einzelne Vokale in unveränderlichen Frequenzbereichen (den sog. "Formantenbereichen"), wobei ein Vokal meist durch die ersten zwei Formanten F1 und F2 einer Reihe von oftmals vier Formanten bereits klar hörbar gegen andere Laute abgegrenzt ist (vgl. "Vokaldreieck" und "Vokaltrapez"). Die Formanten bilden sich hierbei unabhängig von der Grundfrequenz, also der Frequenz der Grundschwingung aus.
- Unter einer Präzision von Formanten ist in diesem Sinn insbesondere ein Grad einer Konzentration der akustischen Energie auf voneinander abgrenzbare Formantenbereiche, insbesondere jeweils auf einzelne Frequenzen in den Formantenbereichen, und eine hieraus resultierende Bestimmbarkeit der einzelnen Vokale anhand der Formanten zu verstehen.
- Für ein Erzeugung von Konsonanten wird der an den Stimmbändern vorbeiströmende Luftstrom an wenigstens einer Stelle teilweise oder ganz blockiert, wodurch u.a. auch Turbulenzen des Luftstroms gebildet werden, weswegen nur manchen Konsonanten eine ähnlich klare Formantenstruktur zugeordnet werden kann wie Vokalen, und andere Konsonanten eine eher breitbandige Frequenzstruktur aufweisen. Jedoch lassen sich auch Konsonanten bestimmte Frequenzbänder zuordnen, in welchen die akustische Energie konzentriert ist. Diese liegen infolge der eher perkussiven "Geräuschartigkeit" von Konsonanten allgemein oberhalb der Formantenbereiche von Vokalen, nämlich vorrangig im Bereich von ca. 2 bis 8 kHz, während die Bereiche der wichtigsten Formanten F1 und F2 von Vokalen allgemein bei ca. 1,5 kHz (F1) bzw. 4 kHz (F2) enden. Die Präzision von Konsonanten bestimmt sich dabei insbesondere aus einem Grad der Konzentration der akustischen Energie auf die entsprechenden Frequenzbereiche und eine hieraus resultierende Bestimmbarkeit der einzelnen Konsonanten.
- Die Unterscheidbarkeit der einzelnen Bestandteile eines Sprachsignals, und damit die Möglichkeit, diese Bestandteile auflösen zu können, hängt jedoch nicht nur ab von artikulatorischen Aspekten. Während diese vorrangig die akustische Präzision der kleinsten isolierten Klangereignisse von Sprache, der sog. Phoneme, betreffen, bestimmten auch prosodische Aspekte die Sprachqualität, da hier durch Intonation und Akzentsetzung insbesondere über mehrere Segmente, also mehrere Phoneme oder Phonemgruppen hinweg, einer Aussage ein besonderer Sinn aufgeprägt werden kann, wie z.B. durch das Anheben der Tonhöhe am Satzende zum Verdeutlichen einer Frage, oder durch das Betonen einer konkreten Silbe in einem Wort zur Unterscheidung verschiedener Bedeutungen (vgl. "umfahren" vs. "umfahren") oder das Betonen eines Wortes zu seiner Hervorhebung. Insofern lässt sich eine Sprachqualität für ein Sprachsignal auch anhand prosodischer Eigenschaften, insbesondere wie den eben genannten, quantitativ erfassen, indem z.B. Maße für eine zeitliche Variation der Tonhöhe der Stimme, also ihrer Grundfrequenz, und für die Deutlichkeit einer Abhebung der Amplituden- und/oder Pegelmaxima bestimmt werden.
- Anhand einer oder mehrerer der genannten und/oder weiterer, quantitativ erfassten artikulatorischen und/oder prosodischen Eigenschaften des Sprachsignals lässt sich somit das quantitative Maß für die Sprachqualität ableiten.
- Erfindungsgemäß wird dabei als artikulatorische Eigenschaft des Sprachsignals eine mit der Präzision von vorgegebenen Formanten von Vokalen in dem Sprachsignal korrelierte Kenngröße, eine mit der Dominanz von Konsonanten, insbesondere Frikativen, in dem Sprachsignal korrelierte Kenngröße und/oder eine mit der Präzision der Übergänge von stimmhaften und stimmlosen Lauten korrelierte Kenngröße erfasst. Das quantitative Maß für die Sprachqualität kann dann jeweils unmittelbar durch die besagte erfasste Kenngröße gegeben sein, oder anhand dieser gebildet werden, z.B. durch Gewichtung zweier Kenngrößen für unterschiedliche Formanten o.ä., oder auch durch die Gewichtung, also durch eine gewichtete Mittelwertbildung, von wenigstens zwei verschiedenen der genannten Kenngrößen zueinander. Das quantitative Maß für die Sprachqualität bezieht sich dabei also auf die Sprachproduktion eines Sprechers, welcher von einer als "sauber" empfundenen Aussprache Defizite (wie z.B. Lispeln oder Nuscheln) bis hin zu Sprachfehlern aufweisen kann, welche die Sprachqualität entsprechend reduzieren.
- Im Unterschied zu Größen, welche auf eine Propagation der Sprache in einer Umgebung bezogen sind, wie z.B. der Sprachverständlichkeitsindex ("Speech Intellegibility Index", SII), welcher bandweise die einzelnen Sprach- und Rauschanteile gewichtet, oder der Sprachübertragungsindex ("Speech Transmission Index", STI), welcher mittels eines die Modulationen de menschlichen Sprache nachbildenden Testsignals die Auswirkung eines Übertragungskanals auf die Modulationstiefe erfasst, ist hier das vorliegende Maß für die dabei insbesondere unabhängig von den externen Eigenschaften eines Übertragungskanals wie z.B. einer Propagation in einem möglicherweise nachhallenden Raum oder einer lauten Umgebung, sondern bevorzugt nur abhängig von den intrinsischen Eigenschaften der Spracherzeugung durch den Sprecher.
- Dies bedeutet insbesondere, dass in leisen Umgebungen und/oder Umgebungen mit nur geringem Rauschhintergrund eine reduzierte Sprachqualität (bezogen auf einen Referenzwert, welcher bevorzugt für als "sehr gut" empfundenen Sprachqualität festgelegt wird) erkannt wird.
- Im Rahmen der Erfindung wird dabei für eine Erfassung der mit der Dominanz von Konsonanten in dem Sprachsignal korrelierte Kenngröße eine in einem niedrigen Frequenzbereich beinhaltete erste Energie berechnet, eine in einem über dem niedrigen Frequenzbereich liegenden höheren Frequenzbereich beinhaltete zweite Energie berechnet, und die korrelierte Kenngröße anhand eines Verhältnisses und/oder eines über die jeweiligen Bandbreiten der genannten Frequenzbereiche gewichteten Verhältnisses der ersten Energie und der zweiten Energie gebildet. Insbesondere kann hierbei vorab eine zeitliche Glättung des Sprachsignals erfolgen. Für die Berechnung der ersten und der zweiten Energie kann insbesondere das Eingangs-Audiosignal in den niedrigen und den höheren Frequenzbereich aufgeteilt werden, z.B. mittels einer Filterbank und ggf. mittels einer entsprechenden Auswahl einzelner resultierender Frequenzbänder. Hierbei wird der niedere Frequenzbereich derart gewählt, dass er innerhalb des Frequenzintervalls [0 Hz, 2,5 kHz], besonders bevorzugt innerhalb des Frequenzintervalls [0 Hz, 2 kHz] liegt. Zudem wird der höhere Frequenzbereich derart gewählt, dass er innerhalb des Frequenzintervalls [3 kHz, 10 kHz], besonders bevorzugt innerhalb des Frequenzintervalls [4 Hz, 8 kHz] liegt.
- Im Rahmen der Erfindung wird für eine Erfassung der mit der Präzision der Übergänge von stimmhaften und stimmlosen Lauten korrelierten Kenngröße anhand eine Korrelationsmessung und/oder anhand einer Nulldurchgangsrate des Eingangs-Audiosignals oder eines vom Eingangs-Audiosignal abgeleiteten Signals eine Unterscheidung von stimmhaften und stimmlosen Zeitsequenzen durchgeführt wird, wobei ein Übergang von einer stimmhaften Zeitsequenz zu einer stimmlosen Zeitsequenz oder von einer stimmlosen Zeitsequenz zu einer stimmhaften Zeitsequenz ermittelt wird, für wenigstens einen Frequenzbereich die vor dem Übergang in der stimmhaften bzw. stimmlosen Zeitsequenz enthaltene Energie ermittelt wird, und für den wenigstens einen Frequenzbereich die nach dem Übergang in der stimmlosen bzw. stimmhaften Zeitsequenz enthaltene Energie ermittelt wird, und die Kenngröße anhand der Energie vor dem Übergang und anhand der Energie nach dem Übergang ermittelt wird.
- Dies bedeutet insbesondere: Es werden zunächst die stimmhaften und stimmlosen Zeitsequenzen des Sprachsignals im Eingangs-Audiosignal ermittelt, und hieraus ein Übergang von stimmhaft nach stimmlos oder von stimmlos nach stimmhaft identifiziert. Für wenigstens einen, insbesondere anhand empirischer Erkenntnisse für die Präzision der Übergänge vorgegebenen Frequenzbereich wird nun die Energie vor dem Übergang im Frequenzbereich für das Eingangs-Audiosignal oder für ein hieraus abgeleitetes Signal ermittelt. Diese Energie kann z.B. genommen werden über die stimmhafte bzw. stimmlose Zeitsequenz unmittelbar vor dem Übergang. Ebenso wird die Energie im betreffenden Frequenzbereich nach dem Übergang ermittelt, also z.B. über die dem Übergang nachfolgende stimmlose bzw. stimmhafte Zeitsequenz.
- Anhand dieser beiden Energien kann nun ein Kennwert ermittelt werden, welcher insbesondere eine Aussage über eine Änderung der Energieverteilung am Übergang ermöglicht. Dieser Kennwert kann beispielsweise bestimmt werden als ein Quotient oder eine relative Abweichung der beiden Energien vor und nach dem Übergang. Der Kennwert kann aber auch gebildet werden als ein Vergleich der Energie vor bzw. nach dem Übergang mit der gesamten (breitbandigen) Signalenergie. Insbesondere können jedoch auch für einen weiteren Frequenzbereich jeweils vor und nach dem Übergang die Energien ermittelt werden, sodass der Kennwert zusätzlich anhand der Energien vor und nach dem Übergang im weiteren Frequenzband ermittelt werden kann, z.B. als eine Änderungsrate der Energieverteilung auf die beteiligten Frequenzbereiche über den Übergang hinweg (also einen Vergleich der Verteilung der Energien in beiden Frequenzbereichen vor dem Übergang mit der Verteilung nach dem Übergang).
- Anhand des besagten Kennwertes kann dann die mit der Präzision der Übergänge korrelierte Kenngröße für das Maß der Sprachqualität ermittelt werden. Hierzu kann der Kennwert direkt verwendet werden, oder der Kennwert kann mit einem vorab für ein gute Artikulation insbesondere anhand entsprechender empirischer Kenntnisse ermittelten Referenzwert verglichen werden (z.B. als Quotient oder relative Abweichung). Die konkrete Ausgestaltung, insbesondere hinsichtlich der zu verwendenden Frequenzbereiche und Grenz- bzw. Referenzwertekann generell anhand empirischer Ergebnisse über eine entsprechende Aussagekraft der jeweiligen Frequenzbänder bzw. der Gruppen von Frequenzbändern erfolgen. Als der wenigstens eine Frequenzbereich können hierbei insbesondere die Frequenzbänder 13 bis 24, bevorzugt 16 bis 23 der Bark-Skala verwendet werden. Als ein weiterer Frequenzbereich kann insbesondere ein Frequenzbereich von niedrigeren Frequenzen verwendet werden.
- Im Rahmen der Erfindung werden für eine Erfassung der mit der Präzision von vorgegebenen Formanten von Vokalen in dem Sprachsignal korrelierten Kenngrö-ße die in wenigsten zwei verschiedenen Formantenbereichen konzentrierten akustischen Energien des Sprachsignals (oder mit besagten Energien korrelierte Grö-ßen) miteinander verglichen. Besonders bevorzugt wird ein Signalanteil des Sprachsignals in wenigstens einem Formantenbereich im Frequenzraum ermittelt, für den Signalanteil des Sprachsignals im wenigstens einen Formantenbereich eine mit dem Pegel korrelierte Signalgröße ermittelt wird, und die Kenngröße anhand eines Maximalwertes und/oder anhand einer Zeitstabilität der mit dem Pegel korrelierten Signalgröße ermittelt. Insbesondere kann hierbei als der wenigstens Formantenbereich der Frequenzbereich der ersten Formanten F1 (bevorzugt 250 Hz bis 1 kHz, besonders bevorzugt 300 Hz bis 750 Hz) oder der zweiten Formanten F2 (bevorzugt 500 Hz bis 3,5 kHz, besonders bevorzugt 600 Hz bis 2,5 kHz) gewählt werden, oder es werden zwei Formantenbereiche der ersten und zweiten Formanten gewählt. Insbesondere können auch mehrere, unterschiedliche Vokalen zugeordnete erste und/oder zweite Formantenbereiche (also die Frequenzbereiche, welche dem ersten bzw. zweiten Formanten des jeweiligen Vokals zugeordnet sind) gewählt werden. Für den oder die gewählten Formantenbereiche wird nun der Signalanteil ermittelt, und eine mit dem Pegel korrelierte Signalgröße des jeweiligen Signalanteils bestimmt. Die Signalgröße kann dabei durch den Pegel selbst, oder auch durch die ggf. geeignet geglättete maximale Signalamplitude gegeben sein. Anhand einer Zeitstabilität der Signalgröße, welche sich wiederum durch eine Varianz der Signalgröße über ein geeignetes Zeitfenster ermitteln lässt, und/oder anhand einer Abweichung der Signalgröße von ihrem Maximalwert über ein geeignetes Zeitfenster lässt sich nun eine Aussage über die Präzision von Formanten dahingehend treffen, dass eine geringe Varianz und geringe Abweichung vom Maximalpegel für einen artikulierten Laut (die Länge des Zeitfensters kann insbesondere abhängig von der Länge eines artikulierten Lautes gewählt werden) für eine hohe Präzision sprechen.
- Vorteilhafterweise wird durch Analyse des Eingangs-Audiosignals mittels der Signalverarbeitung weiter mindestens eine prosodische Eigenschaft des Sprachsignals quantitativ erfasst wird, und das quantitative Maß für die Sprachqualität zusätzlich in Abhängigkeit von der mindestens einen prosodischen Eigenschaft des Sprachsignals (18) ermittelt. Bevorzugt wird dabei die Grundfrequenz des Sprachsignals zeitaufgelöst erfasst, und als prosodische Eigenschaft des Sprachsignals eine für die Zeitstabilität der Grundfrequenz charakteristische Kenngröße ermittelt. Diese Kenngröße kann z.B. anhand vor einer über die Zeit kumulierten relative Abweichung der Grundfrequenz ermittelt werden, oder über das Erfassen einer Anzahl an Maxima und Minima der Grundfrequenz über einen vorgegebenen Zeitraum. Die Zeitstabilität der Grundfrequenz ist v.a. für eine Monotonie der Sprachmelodie und -akzentuierung von Bedeutung, weswegen eine quantitative Erfassung auch eine Aussage über die Sprachqualität des Sprachsignals erlaubt.
- Bevorzugt wird für das Sprachsignal, insbesondere durch eine entsprechende Analyse des Eingangs-Audiosignals oder eines hiervon abgeleiteten Signals, eine mit der Lautstärke korrelierte Größe, insbesondere eine Amplitude und/oder ein Pegel, zeitaufgelöst erfasst, wobei über einen vorgegebenen Zeitraum ein Quotient eines Maximalwertes der mit der Lautstärke korrelierten Größe zu einem über den vorgegebenen Zeitraum ermittelten Mittelwert der besagten Größe gebildet wird, und wobei als prosodische Eigenschaft des Sprachsignals eine Kenngröße in Abhängigkeit von besagtem Quotienten ermittelt wird, welcher aus dem Maximalwert und dem Mittelwert der mit der Lautstärke korrelierten Größe über den vorgegebenen Zeitraum gebildet wird. Auf diese Weise lässt sich anhand der mittelbar erfassten Lautstärkendynamik des Sprachsignals eine Aussage über eine Definition der Akzentuierung treffen.
- In einer vorteilhaften Ausgestaltung werden anhand der Analyse des Eingangs-Audiosignals wenigstens zwei jeweils für artikulatorische und/oder prosodische Eigenschaften charakteristische Kenngrößen ermittelt, wobei das quantitative Maß für die Sprachqualität anhand von einem Produkt dieser Kenngrößen und/oder anhand von einem gewichteten Mittelwert und/oder eines Maximal- oder Minimalwertes dieser Kenngrößen gebildet wird. Dies ist insbesondere dann vorteilhaft, wenn ein einziges Maß für die Sprachqualität erfordert oder gewünscht ist, oder wenn ein einziges Maß, welches alle artikulatorischen oder alle prosodischen Eigenschaften erfassen soll, gewünscht ist.
- Bevorzugt wird vor einem Erfassen der mindestens einen artikulatorische und/oder prosodischen Eigenschaft des Sprachsignals eine Sprachaktivität detektiert und/oder ein SNR im Eingangs-Audiosignal ermittelt, wobei eine Analyse hinsichtlich der mindestens einen artikulatorischen und/oder prosodischen Eigenschaft des Sprachsignals in Abhängigkeit der detektierten Sprachaktivität bzw. des ermittelten SNR durchgeführt wird. Hierdurch kann die Analyse der Sprachqualität des Sprachsignals auf diejenigen Fälle beschränkt werden, in welchen tatsächlich ein Sprachsignal vorliegt bzw. in welchen das SNR insbesondere oberhalb eines vorgegebenen Grenzwertes liegt, sodass davonausgegangen werden darf, dass eine hinreichend gute Erkennung der Signalanteile des Sprachsignals im Eingangs-Audiosignal überhaupt erst möglich ist, um eine entsprechende Bewertung vorzunehmen. Umgekehrt wird bei einer herkömmlichen Signalverarbeitung für ein hinreichend hohes SNR meist keine Maßnahme zur Hervorhebung o.ä. eines Sprachsignals getroffen, obwohl eine mangelhafte Sprachqualität, also bei schwacher Artikulation und/oder geringer Ausprägung prosodischer Merkmale wie Betonungen, von einer Verbesserung mittels der Signalverarbeitung profitieren würde.
- Bevorzugt ist die Hörvorrichtung als ein Hörgerät ausgestaltet. Das Hörgerät kann dabei durch ein monaurales Gerät, oder durch ein binaurales Gerät mit zwei lokalen Geräten gegeben sein, welche vom Benutzer des Hörgerätes jeweils an seinem rechten bzw. linken Ohr zu tragen sind. Insbesondere kann das Hörgerät zusätzlich zum genannten Eingangswandler auch noch mindestens einen weiteren akusto-elektrischen Eingangswandler aufweisen, welcher den Schall der Umgebung in ein entsprechendes weiteres Eingangs-Audiosignal umwandelt, sodass die quantitative Erfassung der mindestens einen artikulatorischen und/oder prosodischen Eigenschaft eines Sprachsignals durch eine Analyse einer Mehrzahl von beteiligten Eingangs-Audiosignalen erfolgen kann. Im Fall eines binauralen Gerätes können zwei der verwendeten Eingangs-Audiosignale jeweils in unterschiedlichen lokalen Einheiten des Hörgeräts (also jeweils am linken bzw. am rechten Ohr) erzeugt werden. Die Signalverarbeitungseinrichtung kann hierbei insbesondere Signalprozessoren beider lokaler Einheiten umfassen, wobei bevorzugt jeweils lokal erzeugte Maße für die Sprachqualität je nach betrachteter artikulatorischer und/oder prosodischer Eigenschaft in geeigneter Weise durch Mittelwertbildung oder einen Maximal- oder Minimalwert für beide lokalen Einheiten vereinheitlicht werden.
- Nachfolgend wird ein Ausführungsbeispiel der Erfindung anhand einer Zeichnung näher erläutert. Hierbei zeigen jeweils schematisch:
- Fig. 1
- in einem Schaltbild ein Hörgerät, welches einen Schall mit einem Sprachsignal erfasst, und
- Fig. 2
- in einem Blockdiagramm ein Verfahren zum Ermitteln eines quantitativen Maßes für die Sprachqualität des Sprachsignals nach
Fig. 1 . - Einander entsprechende Teile und Größen sind in allen Figuren jeweils mit denselben Bezugszeichen versehen.
- In
Figur 1 ist schematisch in einem Schaltbild eine Hörvorrichtung 1 dargestellt, welche vorliegend als ein Hörgerät 2 ausgestaltet ist. Das Hörgerät 2 weist einen akusto-elektrischen Eingangswandler 4 auf, welcher dazu eingerichtet ist, einen Schall 6 der Umgebung des Hörgerätes 2 in ein Eingangs-Audiosignal 8 umzuwandeln. Eine Ausgestaltung des Hörgerätes 2 mit einem weiteren Eingangswandler (nicht dargestellt), welcher ein entsprechendes weiteres Eingangs-Audiosignal aus dem Schall 6 der Umgebung erzeugt, ist hierbei ebenso denkbar. Das Hörgerät 2 ist vorliegend als ein alleinstehendes, monaurales Gerät ausgebildet. Ebenso denkbar ist eine Ausgestaltung des Hörgerätes 2 als ein binaurales Hörgerät mit zwei lokalen Geräten (nicht dargestellt), welche vom Benutzer des Hörgerätes 2 jeweils an seinem rechten bzw. linken Ohr zu tragen sind. - Das Eingangs-Audiosignal 8 wird einer Signalverarbeitungseinrichtung 10 des Hörgerätes 2 zugeführt, in welcher das Eingangs-Audiosignal 8 insbesondere gemäß den audiologischen Anforderungen des Benutzers des Hörgerätes 2 entsprechend verarbeitet und dabei zum Beispiel frequenzbandweise verstärkt und/oder komprimiert wird. Die Signalverarbeitungseinrichtung 10 ist hierfür insbesondere mittels eines entsprechenden Signalprozessors (in
Figur 1 nicht näher dargestellt) und eines über den Signalprozessor adressierbaren Arbeitsspeichers eingerichtet. Eine etwaige Vorverarbeitung des Eingangs-Audiosignals 8, wie z.B. eine A/D-Wandlung und/oder Vorverstärkung des erzeugten Eingangs-Audiosignals 8, soll hierbei als Teil des Eingangswandlers 4 betrachtet werden. - Die Signalverarbeitungseinrichtung 10 erzeugt hierbei durch die Verarbeitung des Eingangs-Audiosignals 8 ein Ausgangs-Audiosignal 12, welches mittels eines Elektro-akustischen Ausgangswandlers 14 in eine Ausgangsschallsignal 16 des Hörgerätes 2 umgewandelt wird. Der Eingangswandler 4 ist hierbei vorzugsweise gegeben durch ein Mikrofon, der Ausgangswandler 14 beispielsweise durch einen Lautsprecher (wie etwa einen Balanced Metal Case Receiver), kann aber auch durch einen Knochenleithörer o.ä. gegeben sein.
- Der Schall 6 der Umgebung des Hörgerätes 2, welcher vom Eingangswandler 4 erfasst wird, beinhaltet unter anderem ein Sprachsignal 18 eines nicht näher dargestellten Sprechers, sowie weitere Schallanteile 20, welche insbesondere durch gerichtete und/oder diffuse Störgeräusche (Störschall bzw. Hintergrundrauschen) umfassen können, aber auch solche Geräusche beinhalten können, welche je nach Situation als ein Nutzsignal angesehen werden könnten, also beispielsweise Musik oder die Umgebung betreffende, akustische Warn- oder Hinweis-Signale.
- Die in der Signalverarbeitungseinrichtung 10 zur Erzeugung des Ausgangs-Audiosignals 12 erfolgende Signalverarbeitung des Eingangs-Audiosignals 8 kann insbesondere eine Unterdrückung der Signalanteile umfassen, welche die im Schall 6 enthaltenen Störgeräusche unterdrücken, bzw. eine relative Anhebung der das Sprachsignal 18 repräsentierenden Signalanteile gegenüber den die weiteren Schallanteile 20 repräsentierenden Signalanteil. Insbesondere können hierbei auch eine frequenzabhängige oder breitbandige Dynamik-Kompression und/oder Verstärkung sowie Algorithmen zur Rauschunterdrückung angewandt werden.
- Um die Signalanteile im Eingangs-Audiosignal 8, welche das Sprachsignal 18 repräsentieren, im Ausgangs-Audiosignal 12 möglichst gut hörbar zu machen, und dem Benutzer des Hörgerätes 2 im Ausgangsschall 16 dennoch einen möglichst natürlichen Höreindruck vermitteln zu können, soll in der Signalverarbeitungseinrichtung 10 zur Steuerung der auf das Eingangs-Audiosignal 8 anzuwendenden Algorithmen ein quantitatives Maß für die Sprachqualität des Sprachsignals 18 ermittelt werden. Dies ist anhand von
Figur 2 beschrieben. -
Figur 2 zeigt in einem Blockdiagramm eine Verarbeitung des Eingangs-Audiosignals 8 des Hörgerätes 2 nachFigur 2 . Zunächst wird für das Eingangs-Audiosignal 8 eine Erkennung einer Sprachaktivität VAD durchgeführt. Liegt keine nennenswerte Sprachaktivität vor (Pfad "n"), so erfolgt die Signalverarbeitung des Eingangs-Audiosignals 8 zur Erzeugung des Ausgangs-Audiosignals 12 anhand eines ersten Algorithmus 25. Der erste Algorithmus 25 bewertet dabei in einer vorab vorgegebenen Weise Signalparameter des Eingangs-Audiosignals 8 wie z.B. Pegel, Rauschhintergrund, Transienten o.ä., breitbandig und/oder insbesondere frequenzbandweise, und ermittelt hieraus einzelne Parameter, z.B. frequenzbandweise Verstärkungsfaktoren und/oder Kompressions-Kenndaten (also v.a. Kniepunkt, Verhältnis, Attack, Release), welche auf das Eingangs-Audiosignal 8 anzuwenden sind. - Insbesondere kann der erste Algorithmus 25 auch eine Klassifizierung einer Hörsituation vorsehen, welche im Schall 6 realisiert ist, und in Abhängigkeit der Klassifizierung einzelne Parameter einstellen, ggf. als entsprechend für eine konkrete Hörsituation vorgesehenes Hörprogramm. Überdies können für den ersten Algorithmus 25 auch die individuellen audiologischen Anforderungen des Benutzers des Hörgerätes 2 berücksichtigt werden, um durch die Anwendung des ersten Algorithmus 25 auf das Eingangs-Audiosignal 8 eine Hörschwäche des Benutzers möglichst gut kompensieren zu können.
- Wird jedoch bei der Erkennung einer Sprachaktivität VAD eine nennenswerte Sprachaktivität festgestellt (Pfad "y" der), so wird als nächstes ein SNR ermittelt, und mit einem vorgegebenen Grenzwert THSNR verglichen. Liegt das SNR nicht oberhalb des Grenzwertes, also SNR ≤ THSNR, so wird auf das Eingangs-Audiosignal 8 zur Erzeugung des Ausgangs-Audiosignals 12 erneut der erste Algorithmus 25 angewandt. Liegt jedoch das SNR oberhalb des vorgegebenen Grenzwertes THSNR, also SNR > THSNR, so wird für die weitere Verarbeitung des Eingangs-Audiosignals 8 in nachfolgend beschriebener Weise ein quantitatives Maß 30 für die Sprachqualität des im Eingangs-Audiosignal 8 enthaltenen Sprachanteils 18 ermittelt. Hierfür werden artikulatorische und/oder prosodische Eigenschaften des Sprachsignals 18 quantitativ erfasst. Unter dem Begriff des im Eingangs-Audiosignal 8 enthaltenen Sprachsignalanteils 26 sind hierbei diejenigen Signalanteile des Eingangs-Audiosignals 8 zu verstehen, welche den Sprachanteil 18 des Schalls 6 repräsentieren, aus dem das Eingangs-Audiosignal 8 mittels des Eingangswandlers 4 erzeugt wird.
- Zum Ermitteln des besagten quantitativen Maßes 30 wird das Eingangs-Audiosignal 8 in einzelne Signalpfade aufgeteilt.
- Für einen ersten Signalpfad 32 des Eingangs-Audiosignals 8 wird zunächst eine Schwerpunktwellenlänge λc ermittelt, und mit einem vorgegebenen Grenzwert für die Schwerpunktwellenlänge Thλ verglichen. Wird anhand des besagten Grenzwertes für die Schwerpunktwellenlänge Thλ festgestellt, dass die Signalanteile im Eingangs-Audiosignal 8 hinreichend hochfrequent sind, so werden im ersten Signalpfad 32, ggf. nach einer geeignet zu wählenden zeitlichen Glättung (nicht dargestellt), für einen niedrigen Frequenzbereich NF und einen über dem niedrigen Frequenzbereich NF liegenden, höheren Frequenzbereich HF die Signalanteile ausgewählt. Eine mögliche Aufteilung kann beispielsweise derart sein, dass der niedrige Frequenzbereich NF alle Frequenzen fN ≤ 2500Hz, insbesondere fN ≤ 2000 Hz umfasst, und der höhere Frequenzbereich HF Frequenzen fH mit 2500 Hz < fH ≤ 10000 Hz, insbesondere 4000 Hz ≤ fH ≤ 8000 Hz oder 2500 Hz < fH ≤ 5000 Hz umfasst.
- Die Auswahl kann unmittelbar im Eingangs-Audiosignal 8 durchgeführt werden, oder auch derart erfolgen, dass das Eingangs-Audiosignal 8 mittels einer Filterbank (nicht dargestellt) in einzelne Frequenzbänder aufgeteilt wird, wobei einzelne Frequenzbänder in Abhängigkeit der jeweiligen Bandgrenzen dem niedrigen oder höheren Frequenzbereich NF bzw. HF zugeordnet werden.
- Anschließend werden für das im niedrigen Frequenzbereich NF enthaltene Signal eine erste Energie E1 und für das im höheren Frequenzbereich HF enthaltene Signal eine zweite Energie E2 ermittelt. Es wird nun ein Quotient QE aus der zweiten Energie als Zähler und der ersten Energie E1 als Nenner gebildet. Der Quotient QE kann nun bei geeignet gewähltem niederen und höheren Frequenzbereich NF, HF als eine Kenngröße 33 herangezogen werden, welche mit Dominanz von Konsonanten im Sprachsignal 18 korreliert ist. Die Kenngröße 33 ermöglicht somit eine Aussage über eine artikulatorische Eigenschaft der Sprachsignalanteile 26 im Eingangs-Audiosignal 8. So kann z.B. für einen Wert des Quotienten QE >> 1 (also QE > ThQE mit einem vorgegebenen, nicht näherdargestellten Grenzwert ThQE >> 1) eine hohe Dominanz für Konsonanten gefolgert werden, während für einen Wert QE < 1 eine geringe Dominanz gefolgert werden kann.
- In einem zweiten Signalpfad 34 wird im Eingangs-Audiosignal 8 anhand von Korrelationsmessungen und/oder anhand einer Nulldurchgangsrate des Eingangs-Audiosignals 8 eine Unterscheidung 36 in stimmhafte Zeitsequenzen V und stimmlose Zeitsequenzen UV durchgeführt. Anhand der stimmhaften und stimmlosen Zeitsequenzen V bzw. UV wird ein Übergang TS von einer stimmhaften Zeitsequenz V zu einer stimmlosen Zeitsequenz UV ermittelt. Die Länge einer stimmhaften oder stimmlosen Zeitsequenz kann z.B. zwischen 10 und 80 ms, insbesondere zwischen 20 und 50 ms betragen.
- Es wird nun für wenigstens einen Frequenzbereich (z.B. eine als geeignet ermittelte Auswahl an besonders aussagekräftigen Frequenzbändern, z.B. die Frequenzbänder 16 bis 23 der Bark-Skala, oder die Frequenzbänder 1 bis 15 der Bark-Skala) jeweils ein Energie Ev für die stimmhafte Zeitsequenz V vor dem Übergang TS und eine Energie En für die stimmlose Zeitsequenz UV nach dem Übergang TS ermittelt. Insbesondere können hierbei auch für mehr als einen Frequenzbereich jeweils getrennt entsprechende Energien vor und nach dem Übergang TS ermittelt werden. Es wird nun bestimmt, wie sich die Energie am Übergang TS verändert, z.B. durch eine relative Änderung ΔETS oder durch einen Quotienten (nicht dargestellt) der Energien Ev, En vor und nach dem Übergang TS.
- Das Maß für die Änderung der Energie, also vorliegend die relative Änderung wird nun mit einem vorab für eine gute Artikulation ermittelten Grenzwert ThE für Energieverteilung an Übergängen verglichen. Insbesondere kann eine Kenngröße 35 anhand eines Verhältnisses aus der relative Änderung ΔETS und dem besagten Grenzwert ThE oder anhand einer relativen Abweichung der relative Änderung ΔETS vom diesem Grenzwert ThE gebildet werden. Besagte Kenngröße 35 ist mit der Artikulation der Übergänge von stimmhaften und stimmlosen Lauten im Sprachsignal 18 korreliert ist, und ermöglicht somit einen Aufschluss über eine weitere artikulatorische Eigenschaft der Sprachsignalanteile 26 im Eingangs-Audiosignal 8. Generell gilt hierbei die Aussage, dass eine Übergang zwischen stimmhaften und stimmlosen Zeitsequenzen umso präziser artikuliert ist, je schneller, also zeitlich abgrenzbarer ein Wechsel der Energieverteilung über die für stimmhafte und stimmlose Laute relevanten Frequenzbereiche erfolgt.
- Für die Kenngröße 35 kann jedoch auch eine Energieverteilung in zwei Frequenzbereichen (z.B. die oben genannten Frequenzbereichen gemäß der Bark-Skala, oder auch im niederen und höheren Frequenzbereich NF, HF) betrachtet werden, z.B. über einen Quotienten der jeweiligen Energien oder einen vergleichbaren Kennwert, und eine Veränderung des Quotienten bzw. des Kennwertes über den Übergang hinweg für die Kenngröße herangezogen werden. So kann z.B. eine Änderungsrate des Quotienten bzw. der Kenngröße bestimmt und mit einem vorab als geeignet ermittelten Referenzwert für die Änderungsrate verglichen werden.
- Zur Bildung der Kenngröße 35 können auch Übergänge von stimmlosen Zeitsequenzen in analoger Weise betrachtet werden. Die konkrete Ausgestaltung, insbesondere hinsichtlich der zu verwendenden Frequenzbereiche und Grenz- bzw. Referenzwertekann generell anhand empirischer Ergebnisse über eine entsprechende Aussagekraft der jeweiligen Frequenzbänder bzw. der Gruppen von Frequenzbändern erfolgen.
- In einem dritten Signalpfad 38 wird im Eingangs-Audiosignal 8 zeitauflöst eine Grundfrequenz fG des Sprachsignalanteils 26 erfasst, und für besagte Grundfrequenz fG eine Zeitstabilität 40 anhand einer Varianz der Grundfrequenz fG ermittelt. Die Zeitstabilität 40 kann als eine Kenngröße 41 verwendet werden, welche eine Aussage über eine prosodische Eigenschaft der Sprachsignalanteile 26 im Eingangs-Audiosignal 8 ermöglicht. Eine stärkere Varianz in der Grundfrequenz fG kann dabei als ein Indikator für eine bessere Sprachverständlichkeit herangezogen werden, während eine monotone Grundfrequenz fG eine geringere Sprachverständlichkeit aufweist.
- In einem vierten Signalpfad 42 wird für das Eingangs-Audiosignal 8 und/oder für den darin enthaltenen Sprachsignalanteil 26 zeitaufgelöst ein Pegel LVL erfasst, und über einen insbesondere anhand entsprechender empirischer Erkenntnisse vorgegebenen Zeitraum 44 ein zeitlicher Mittelwert MNLVL gebildet. Des Weiteren wird über den Zeitraum 44 das Maximum MXLVL des Pegels LVL ermittelt. Das Maximum MXLVL des Pegels LVL wird nun durch den zeitlichen Mittelwert MNLVL des Pegels LVL dividiert, und so eine mit einer Lautstärke des Sprachsignals18 korrelierte Kenngröße 45 ermittelt, welche eine weitere Aussage über eine prosodische Eigenschaft der Sprachsignalanteile 26 im Eingangs-Audiosignal 8 ermöglicht. Anstatt des Pegels LVL kann hierbei auch eine andere mit der Lautstärke und/oder dem Energieinhalt des Sprachsignalanteils 26 korrelierte Größe verwendet werden.
- Die jeweils im ersten bis vierten Signalpfad 32, 34, 38, 42 wie beschrieben ermittelten Kenngrößen 33, 35, 41 bzw. 45 können nun jeweils einzeln als das quantitative Maß 30 für die Qualität des im Eingangs-Audiosignal 8 enthaltenen Sprachanteils 18 herangezogen werden, in dessen Abhängigkeit das Eingangs-Audiosignal nun ein zweiter Algorithmus 46 auf das Eingangs-Audiosignal 8 zur Signalverarbeitung angewandt wird. Der zweite Algorithmus 46 kann hierbei aus dem ersten Algorithmus 25 durch eine in Abhängigkeit des betreffenden quantitativen Maßes 30 erfolgende, entsprechende Veränderung eines oder mehrerer Parameter der Signalverarbeitung hervorgehen, oder ein gänzlich eigenständiges Hörprogramm vorsehen.
- Insbesondere kann als quantitatives Maß 30 für die Sprachqualität auch ein einzelner Wert anhand der wie beschrieben ermittelten Kenngrößen 33, 35, 41 bzw. 45 bestimmt werden, z.B. durch einen gewichteten Mittelwert oder ein Produkt der Kenngrößen 33, 35, 41, 45 (in
Fig. 2 schematisch durch das Zusammenführen der Kenngrößen 33, 35, 41, 45 dargestellt). Die Gewichtung der einzelnen Kenngrö-ßen kann hierbei insbesondere anhand von vorab empirisch ermittelten Gewichtungsfaktoren erfolgen, welche anhand einer Aussagekraft der durch die jeweilige Kenngröße erfasste artikulatorische bzw. prosodische Eigenschaft für die Sprachqualität bestimmt werden können. - Obwohl die Erfindung im Detail durch das bevorzugte Ausführungsbeispiel näher illustriert und beschrieben wurde, so ist die Erfindung nicht durch die offenbarten Beispiele eingeschränkt und andere Variationen können vom Fachmann hieraus abgeleitet werden, ohne den Schutzumfang der Erfindung zu verlassen.
-
- 1
- Hörvorrichtung
- 2
- Hörgerät
- 4
- Eingangswandler
- 6
- Schall der Umgebung
- 8
- Eingangs-Audiosignal
- 10
- Signalverarbeitungseinrichtung
- 12
- Ausgangs-Audiosignal
- 14
- Ausgangswandler
- 16
- Ausgangsschall
- 18
- Sprachsignal
- 20
- Schallanteile
- 25
- erster Algorithmus
- 26
- Sprachsignalanteil
- 30
- quantitatives Maß für Sprachqualität
- 32
- erster Signalpfad
- 33
- Kenngröße
- 34
- zweiter Signalpfad
- 35
- Kenngröße
- 36
- Unterscheidung
- 38
- dritter Signalpfad
- 40
- Zeitstabilität
- 41
- Kenngröße
- 42
- vierter Signalpfad
- 44
- Zeitraum
- 45
- Kenngröße
- 46
- zweiter Algorithmus
- ΔETS
- relative Änderung (der Energie am Übergang)
- λC
- Schwerpunktwellenlänge
- E1
- erste Energie
- E2
- zweite Energie
- Ev
- Energie (vor dem Übergang)
- En
- Energie (nach dem Übergang)
- fG
- Grundfrequenz
- LVL
- Pegel
- HF
- höherer Frequenzbereich
- MNLVL
- zeitlicher Mittelwert (des Pegels)
- MXLVL
- Maximum des Pegels
- NF
- niedriger Frequenzbereich
- QE
- Quotient
- SNR
- Signal-zu-Rausch-Verhältnis (SNR)
- Thλ
- Grenzwert (für die Schwerpunktwellenlänge)
- ThE
- Grenzwert (für relative Änderung der Energie)
- THSNR
- Grenzwert (für das SNR)
- TS
- Übergang
- V
- stimmhafte Zeitsequenz
- VAD
- Erkennung einer Sprachaktivität
- UV
- stimmlose Zeitsequenz
Claims (8)
- Verfahren zur Bewertung der Sprachqualität eines Sprachsignals (18) mittels einer Hörvorrichtung (1),- wobei mittels eines akusto-elektrischen Eingangswandlers (4) der Hörvorrichtung (1) ein das Sprachsignal (18) enthaltender Schall (6) aus einer Umgebung der Hörvorrichtung (1) aufgenommen und in ein Eingangs-Audiosignal (8) umgewandelt wird,- wobei durch Analyse des Eingangs-Audiosignals (8) mittels einer Signalverarbeitung mindestens eine artikulatorische Eigenschaft des Sprachsignals (18) quantitativ erfasst wird, und- wobei in Abhängigkeit von der mindestens einen artikulatorischen Eigenschaft ein quantitatives Maß (30) für die Sprachqualität abgeleitet wirdwobei als artikulatorische Eigenschaft des Sprachsignals (18)- eine mit der Präzision von vorgegebenen Formanten von Vokalen in dem Sprachsignal (18) korrelierte Kenngröße, und/oder- eine mit der Dominanz von Konsonanten, insbesondere Frikativen, in dem Sprachsignal (18) korrelierte Kenngröße (31) und/oder- eine mit der Präzision von Übergängen von stimmhaften und stimmlosen Lauten korrelierte Kenngröße (35)erfasst wird,dadurch gekennzeichnet,dass für eine Erfassung der mit der Dominanz von Konsonanten in dem Sprachsignal (18) korrelierte Kenngröße (33)- eine in einem niedrigen Frequenzbereich (NF) beinhaltete erste Energie (E1) berechnet wird, wobei der niedrige Frequenzbereich (NF) innerhalb des Frequenzintervalls [0 Hz, 2,5 kHz] gewählt wird,- eine in einem über dem niedrigen Frequenzbereich (E2) liegenden höheren Frequenzbereich (HF) beinhaltete zweite Energie (E2) berechnet wird, wobei der höheren Frequenzbereich (HF) innerhalb des Frequenzintervalls [3 kHz, 10 kHz] gewählt wird,- und die Kenngröße anhand eines Verhältnisses (QE) und/oder eines über die jeweiligen Bandbreiten der genannten Frequenzbereiche (NF, HF) gewichteten Verhältnisses der ersten Energie (E1) und der zweiten Energie (E2) gebildet wird, bzw.dass für eine Erfassung der mit Präzision der Übergänge von stimmhaften und stimmlosen Lauten korrelierten Kenngröße (35)- anhand eine Korrelationsmessung und/oder anhand einer Nulldurchgangsrate eine Unterscheidung (36) von stimmhaften Zeitsequenzen (V) und stimmlosen Zeitsequenzen (UV) durchgeführt wird,- ein Übergang (TS) von einer stimmhaften Zeitsequenz (V) zu einer stimmlosen Zeitsequenz (UV) oder von einer stimmlosen Zeitsequenz (UV) zu einer stimmhaften Zeitsequenz (V) ermittelt wird,- für wenigstens einen Frequenzbereich die vor dem Übergang (TS) in der stimmhaften bzw. stimmlosen Zeitsequenz (V, UV) enthaltene Energie (Ev) ermittelt wird, und für den wenigstens einen Frequenzbereich die nach dem Übergang (TS) in der stimmlosen bzw. stimmhaften Zeitsequenz (UV, V) enthaltene Energie (En) ermittelt wird, und- die Kenngröße (35) anhand der Energie (Ev) vor dem Übergang (TS) und anhand der Energie (En) nach dem Übergang (TS) ermittelt wird, bzw.dass für eine Erfassung der mit der Präzision von vorgegebenen Formanten von Vokalen in dem Sprachsignal (18) korrelierten Kenngröße- ein Signalanteil des Sprachsignals (18) in wenigstens einem Formantenbereich im Frequenzraum ermittelt wird,- für den Signalanteil des Sprachsignals (18) im wenigstens einen Formantenbereich eine mit dem Pegel korrelierte Signalgröße ermittelt wird, und- die Kenngröße anhand eines Maximalwertes und/oder anhand einer Zeitstabilität der mit dem Pegel korrelierten Signalgröße ermittelt wird.
- Verfahren nach Anspruch 1,- wobei durch Analyse des Eingangs-Audiosignals (8) mittels der Signalverarbeitung weiter mindestens eine prosodische Eigenschaft des Sprachsignals (18) quantitativ erfasst wird, und- wobei das quantitative Maß (30) für die Sprachqualität zusätzlich in Abhängigkeit von der mindestens einen prosodischen Eigenschaft des Sprachsignals (18) ermittelt wird.
- Verfahren nach Anspruch 2,wobei die Grundfrequenz (fG) des Sprachsignals (18) zeitaufgelöst erfasst wird, undwobei als prosodische Eigenschaft des Sprachsignals (18) eine für die Zeitstabilität (40) der Grundfrequenz (fG) charakteristische Kenngröße (41) ermittelt wird.
- Verfahren nach Anspruch 2 oder Anspruch 3,wobei für das Sprachsignal (18) eine mit der Lautstärke korrelierte Größe (LVL) zeitaufgelöst erfasst wird,wobei über einen vorgegebenen Zeitraum (44) ein Quotient eines Maximalwertes (MXLVL) der mit der Lautstärke korrelierten Größe (LVL) zu einem über den vorgegebenen Zeitraum (44) ermittelten Mittelwert (MNLVL) der besagten Größe (LVL) gebildet wird, undwobei als prosodische Eigenschaft des Sprachsignals (18) eine Kenngröße (45) in Abhängigkeit von besagtem Quotienten ermittelt wird, welcher aus dem Maximalwert (MXLVL) und dem Mittelwert (MNLVL) der mit der Lautstärke korrelierten Größe (VL) über den vorgegebenen Zeitraum (44) gebildet wird.
- Verfahren nach einem der vorhergehenden Ansprüche,wobei anhand der Analyse des Eingangs-Audiosignals (18) wenigstens zwei jeweils für artikulatorische und/oder prosodische Eigenschaften charakteristische Kenngrößen (33, 35, 41, 45) ermittelt werden, undwobei das quantitative Maß (30) für die Sprachqualität anhand von einem Produkt dieser Kenngrößen (33, 35, 41, 45) und/oder anhand von einem gewichteten Mittelwert dieser Kenngrößen (33, 35, 41, 45) gebildet wird.
- Verfahren nach einem der vorhergehenden Ansprüche,wobei vor einem Erfassen der mindestens einen artikulatorischen und/oder prosodischen Eigenschaft des Sprachsignals eine Sprachaktivität (VAD) detektiert und/oder ein Signal-zu-Rausch-Verhältnis (SNR) im Eingangs-Audiosignal (18) ermittelt wird, undwobei eine Analyse hinsichtlich der mindestens einen artikulatorischen und/oder prosodischen Eigenschaft des Sprachsignals (18) in Abhängigkeit der detektierten Sprachaktivität (VAD) bzw. des ermittelten Signal-zu-Rausch-Verhältnisses (SNR) durchgeführt wird.
- Hörvorrichtung (1), umfassend:- einen akusto-elektrischen Eingangswandler (4), welcher dazu eingerichtet ist, einen Schall (6) aus einer Umgebung der Hörvorrichtung (1) aufzunehmen und in ein Eingangs-Audiosignal (8) umzuwandeln, und- eine Signalverarbeitungseinrichtung (10), welche dazu eingerichtet ist, anhand einer Analyse des Eingangs-Audiosignals (8) mindestens eine artikulatorische Eigenschaft eines im Eingangs-Audiosignal (8) enthaltenen Anteils eines Sprachsignals (18) quantitativ zu erfassen und in Abhängigkeit von der mindestens einen artikulatorischen Eigenschaft ein quantitatives Maß (30) für die Sprachqualität gemäß dem Verfahren nach einem der vorhergehenden Ansprüche abzuleiten.
- Hörvorrichtung (1) nach Anspruch 7, ausgestaltet als ein Hörgerät (2).
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| DE102020210919.2A DE102020210919A1 (de) | 2020-08-28 | 2020-08-28 | Verfahren zur Bewertung der Sprachqualität eines Sprachsignals mittels einer Hörvorrichtung |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| EP3962115A1 EP3962115A1 (de) | 2022-03-02 |
| EP3962115C0 EP3962115C0 (de) | 2024-12-18 |
| EP3962115B1 true EP3962115B1 (de) | 2024-12-18 |
Family
ID=77316824
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| EP21190918.9A Active EP3962115B1 (de) | 2020-08-28 | 2021-08-12 | Verfahren zur bewertung der sprachqualität eines sprachsignals mittels einer hörvorrichtung |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US12009005B2 (de) |
| EP (1) | EP3962115B1 (de) |
| CN (1) | CN114121040B (de) |
| DE (1) | DE102020210919A1 (de) |
Family Cites Families (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP3731179B2 (ja) * | 1999-11-26 | 2006-01-05 | 昭栄株式会社 | 補聴器 |
| KR100312334B1 (ko) * | 1999-12-31 | 2001-11-03 | 대표이사 서승모 | 에너지와 lsp 파라메타를 이용한 음성신호처리부호화기에서의 음성 활동 검출 방법 |
| JP2001265379A (ja) * | 2000-03-21 | 2001-09-28 | Miyazaki Prefecture | 音声認識方法 |
| US7165025B2 (en) * | 2002-07-01 | 2007-01-16 | Lucent Technologies Inc. | Auditory-articulatory analysis for speech quality assessment |
| US20040167774A1 (en) * | 2002-11-27 | 2004-08-26 | University Of Florida | Audio-based method, system, and apparatus for measurement of voice quality |
| US9511225B2 (en) * | 2013-01-24 | 2016-12-06 | Advanced Bionics Ag | Hearing system comprising an auditory prosthesis device and a hearing aid |
| US9814879B2 (en) * | 2013-05-13 | 2017-11-14 | Cochlear Limited | Method and system for use of hearing prosthesis for linguistic evaluation |
| DE102013224417B3 (de) * | 2013-11-28 | 2015-05-07 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Hörhilfevorrichtung mit Grundfrequenzmodifizierung, Verfahren zur Verarbeitung eines Sprachsignals und Computerprogramm mit einem Programmcode zur Durchführung des Verfahrens |
| US11253193B2 (en) * | 2016-11-08 | 2022-02-22 | Cochlear Limited | Utilization of vocal acoustic biomarkers for assistive listening device utilization |
| DK3370440T3 (da) | 2017-03-02 | 2020-03-02 | Gn Hearing As | Høreapparat, fremgangsmåde og høresystem. |
-
2020
- 2020-08-28 DE DE102020210919.2A patent/DE102020210919A1/de active Pending
-
2021
- 2021-08-12 EP EP21190918.9A patent/EP3962115B1/de active Active
- 2021-08-27 CN CN202110993782.3A patent/CN114121040B/zh active Active
- 2021-08-30 US US17/460,555 patent/US12009005B2/en active Active
Also Published As
| Publication number | Publication date |
|---|---|
| EP3962115C0 (de) | 2024-12-18 |
| EP3962115A1 (de) | 2022-03-02 |
| US12009005B2 (en) | 2024-06-11 |
| CN114121040B (zh) | 2025-05-20 |
| US20220068294A1 (en) | 2022-03-03 |
| CN114121040A (zh) | 2022-03-01 |
| DE102020210919A1 (de) | 2022-03-03 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| DE602004004242T2 (de) | System und Verfahren zur Verbesserung eines Audiosignals | |
| Kozou et al. | The effect of different noise types on the speech and non-speech elicited mismatch negativity | |
| Alku et al. | Measuring the effect of fundamental frequency raising as a strategy for increasing vocal intensity in soft, normal and loud phonation | |
| US20040167774A1 (en) | Audio-based method, system, and apparatus for measurement of voice quality | |
| EP2364646A1 (de) | Hörtestverfahren | |
| EP1244094A1 (de) | Verfahren und Vorrichtung zur Bestimmung eines Qualitätsmasses eines Audiosignals | |
| DE10254612A1 (de) | Verfahren zur Ermittlung spezifisch relevanter akustischer Merkmale von Schallsignalen für die Analyse unbekannter Schallsignale einer Schallerzeugung | |
| DE60308336T2 (de) | Verfahren und system zur messung der übertragungsqualität eines systems | |
| DE102008031150B3 (de) | Verfahren zur Störgeräuschunterdrückung und zugehöriges Hörgerät | |
| EP3693960B1 (de) | Verfahren für eine individualisierte signalverarbeitung eines audiosignals eines hörgeräts | |
| Hansen et al. | A speech perturbation strategy based on “Lombard effect” for enhanced intelligibility for cochlear implant listeners | |
| Messing et al. | A non-linear efferent-inspired model of the auditory system; matching human confusions in stationary noise | |
| Henrich et al. | Just noticeable differences of open quotient and asymmetry coefficient in singing voice | |
| Parida et al. | Underlying neural mechanisms of degraded speech intelligibility following noise-induced hearing loss: The importance of distorted tonotopy | |
| EP2380171A2 (de) | Verfahren und vorrichtung zum verarbeiten von akustischen sprachsignalen | |
| DE102014207437A1 (de) | Spracherkennung mit einer Mehrzahl an Mikrofonen | |
| WO2001047335A2 (de) | Verfahren zur elimination von störsignalanteilen in einem eingangssignal eines auditorischen systems, anwendung des verfahrens und ein hörgerät | |
| EP2548382B1 (de) | Verfahren zum test des sprachverstehens einer mit einem hörhilfegerät versorgten person | |
| EP3962115B1 (de) | Verfahren zur bewertung der sprachqualität eines sprachsignals mittels einer hörvorrichtung | |
| DE60110541T2 (de) | Verfahren zur Spracherkennung mit geräuschabhängiger Normalisierung der Varianz | |
| Rao et al. | Speech enhancement for listeners with hearing loss based on a model for vowel coding in the auditory midbrain | |
| EP3961624B1 (de) | Verfahren zum betrieb einer hörvorrichtung in abhängigkeit eines sprachsignals | |
| Vainio et al. | Effect of noise type and level on focus related fundamental frequency changes | |
| Bapineedu et al. | Analysis of Lombard speech using excitation source information. | |
| EP2394271B1 (de) | Methode zur trennung von signalpfaden und anwendung auf die verbesserung von sprache mit elektro-larynx |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PUAI | Public reference made under article 153(3) epc to a published international application that has entered the european phase |
Free format text: ORIGINAL CODE: 0009012 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: THE APPLICATION HAS BEEN PUBLISHED |
|
| AK | Designated contracting states |
Kind code of ref document: A1 Designated state(s): AL AT BE BG CH CY CZ DE DK EE ES FI FR GB GR HR HU IE IS IT LI LT LU LV MC MK MT NL NO PL PT RO RS SE SI SK SM TR |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: REQUEST FOR EXAMINATION WAS MADE |
|
| 17P | Request for examination filed |
Effective date: 20220901 |
|
| RBV | Designated contracting states (corrected) |
Designated state(s): AL AT BE BG CH CY CZ DE DK EE ES FI FR GB GR HR HU IE IS IT LI LT LU LV MC MK MT NL NO PL PT RO RS SE SI SK SM TR |
|
| GRAP | Despatch of communication of intention to grant a patent |
Free format text: ORIGINAL CODE: EPIDOSNIGR1 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: GRANT OF PATENT IS INTENDED |
|
| RIC1 | Information provided on ipc code assigned before grant |
Ipc: G10L 25/15 20130101ALI20240322BHEP Ipc: G10L 25/60 20130101ALI20240322BHEP Ipc: H04R 25/00 20060101AFI20240322BHEP |
|
| INTG | Intention to grant announced |
Effective date: 20240419 |
|
| GRAJ | Information related to disapproval of communication of intention to grant by the applicant or resumption of examination proceedings by the epo deleted |
Free format text: ORIGINAL CODE: EPIDOSDIGR1 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: REQUEST FOR EXAMINATION WAS MADE |
|
| INTC | Intention to grant announced (deleted) | ||
| GRAS | Grant fee paid |
Free format text: ORIGINAL CODE: EPIDOSNIGR3 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: GRANT OF PATENT IS INTENDED |
|
| GRAP | Despatch of communication of intention to grant a patent |
Free format text: ORIGINAL CODE: EPIDOSNIGR1 |
|
| GRAJ | Information related to disapproval of communication of intention to grant by the applicant or resumption of examination proceedings by the epo deleted |
Free format text: ORIGINAL CODE: EPIDOSDIGR1 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: REQUEST FOR EXAMINATION WAS MADE |
|
| GRAS | Grant fee paid |
Free format text: ORIGINAL CODE: EPIDOSNIGR3 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: GRANT OF PATENT IS INTENDED |
|
| GRAP | Despatch of communication of intention to grant a patent |
Free format text: ORIGINAL CODE: EPIDOSNIGR1 |
|
| INTG | Intention to grant announced |
Effective date: 20240913 |
|
| GRAA | (expected) grant |
Free format text: ORIGINAL CODE: 0009210 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: THE PATENT HAS BEEN GRANTED |
|
| AK | Designated contracting states |
Kind code of ref document: B1 Designated state(s): AL AT BE BG CH CY CZ DE DK EE ES FI FR GB GR HR HU IE IS IT LI LT LU LV MC MK MT NL NO PL PT RO RS SE SI SK SM TR |
|
| REG | Reference to a national code |
Ref country code: CH Ref legal event code: EP |
|
| REG | Reference to a national code |
Ref country code: DE Ref legal event code: R096 Ref document number: 502021006138 Country of ref document: DE |
|
| REG | Reference to a national code |
Ref country code: IE Ref legal event code: FG4D Free format text: LANGUAGE OF EP DOCUMENT: GERMAN |
|
| U01 | Request for unitary effect filed |
Effective date: 20241218 |
|
| U07 | Unitary effect registered |
Designated state(s): AT BE BG DE DK EE FI FR IT LT LU LV MT NL PT RO SE SI Effective date: 20250103 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: HR Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20241218 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: NO Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20250318 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: GR Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20250319 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: RS Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20250318 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: SM Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20241218 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: PL Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20241218 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: ES Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20241218 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: IS Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20250418 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: SK Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20241218 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: CZ Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20241218 |
|
| U20 | Renewal fee for the european patent with unitary effect paid |
Year of fee payment: 5 Effective date: 20250723 |
|
| PGFP | Annual fee paid to national office [announced via postgrant information from national office to epo] |
Ref country code: GB Payment date: 20250724 Year of fee payment: 5 |
|
| PGFP | Annual fee paid to national office [announced via postgrant information from national office to epo] |
Ref country code: CH Payment date: 20250901 Year of fee payment: 5 |
|
| PLBE | No opposition filed within time limit |
Free format text: ORIGINAL CODE: 0009261 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: NO OPPOSITION FILED WITHIN TIME LIMIT |
|
| 26N | No opposition filed |
Effective date: 20250919 |