EP3863306A1 - Hearing system with at least one hearing instrument worn in or on the ear of the user and method for operating such a hearing system - Google Patents
Hearing system with at least one hearing instrument worn in or on the ear of the user and method for operating such a hearing system Download PDFInfo
- Publication number
- EP3863306A1 EP3863306A1 EP21151124.1A EP21151124A EP3863306A1 EP 3863306 A1 EP3863306 A1 EP 3863306A1 EP 21151124 A EP21151124 A EP 21151124A EP 3863306 A1 EP3863306 A1 EP 3863306A1
- Authority
- EP
- European Patent Office
- Prior art keywords
- signal
- user
- hearing
- component
- voice
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images

Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R25/00—Deaf-aid sets, i.e. electro-acoustic or electro-mechanical hearing aids; Electric tinnitus maskers providing an auditory perception
- H04R25/40—Arrangements for obtaining a desired directivity characteristic
- H04R25/407—Circuits for combining signals of a plurality of transducers
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R25/00—Deaf-aid sets, i.e. electro-acoustic or electro-mechanical hearing aids; Electric tinnitus maskers providing an auditory perception
- H04R25/35—Deaf-aid sets, i.e. electro-acoustic or electro-mechanical hearing aids; Electric tinnitus maskers providing an auditory perception using translation techniques
- H04R25/356—Amplitude, e.g. amplitude shift or compression
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R25/00—Deaf-aid sets, i.e. electro-acoustic or electro-mechanical hearing aids; Electric tinnitus maskers providing an auditory perception
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R25/00—Deaf-aid sets, i.e. electro-acoustic or electro-mechanical hearing aids; Electric tinnitus maskers providing an auditory perception
- H04R25/30—Monitoring or testing of hearing aids, e.g. functioning, settings, battery power
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R25/00—Deaf-aid sets, i.e. electro-acoustic or electro-mechanical hearing aids; Electric tinnitus maskers providing an auditory perception
- H04R25/43—Electronic input selection or mixing based on input signal analysis, e.g. mixing or selection between microphone and telecoil or between microphones with different directivity characteristics
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R25/00—Deaf-aid sets, i.e. electro-acoustic or electro-mechanical hearing aids; Electric tinnitus maskers providing an auditory perception
- H04R25/50—Customised settings for obtaining desired overall acoustical characteristics
- H04R25/505—Customised settings for obtaining desired overall acoustical characteristics using digital signal processing
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R25/00—Deaf-aid sets, i.e. electro-acoustic or electro-mechanical hearing aids; Electric tinnitus maskers providing an auditory perception
- H04R25/60—Mounting or interconnection of hearing aid parts, e.g. inside tips, housings or to ossicles
- H04R25/604—Mounting or interconnection of hearing aid parts, e.g. inside tips, housings or to ossicles of acoustic or vibrational transducers
- H04R25/606—Mounting or interconnection of hearing aid parts, e.g. inside tips, housings or to ossicles of acoustic or vibrational transducers acting directly on the eardrum, the ossicles or the skull, e.g. mastoid, tooth, maxillary or mandibular bone, or mechanically stimulating the cochlea, e.g. at the oval window
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R2225/00—Details of deaf aids covered by H04R25/00, not provided for in any of its subgroups
- H04R2225/41—Detection or adaptation of hearing aid parameters or programs to listening situation, e.g. pub, forest
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R2225/00—Details of deaf aids covered by H04R25/00, not provided for in any of its subgroups
- H04R2225/43—Signal processing in hearing aids to enhance the speech intelligibility
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R2430/00—Signal processing covered by H04R, not provided for in its groups
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R2430/00—Signal processing covered by H04R, not provided for in its groups
- H04R2430/03—Synergistic effects of band splitting and sub-band processing
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R25/00—Deaf-aid sets, i.e. electro-acoustic or electro-mechanical hearing aids; Electric tinnitus maskers providing an auditory perception
- H04R25/70—Adaptation of deaf aid to hearing loss, e.g. initial electronic fitting
Definitions
- the invention relates to a method for operating a hearing system to support the hearing ability of a user, with at least one hearing instrument worn in or on the user's ear.
- the invention also relates to such a hearing system.
- a hearing instrument is generally an electronic device that supports the hearing ability of a person wearing the hearing instrument (hereinafter referred to as “wearer” or “user”).
- the invention relates to hearing instruments which are set up to compensate for a hearing loss of a hearing-impaired user in whole or in part.
- a hearing instrument is also referred to as a “hearing aid”.
- hearing instruments that protect or improve the hearing ability of normal hearing users, for example to enable improved speech understanding in complex listening situations.
- Hearing instruments in general, and hearing aids in particular, are usually designed to be worn on him or on the user's ear, in particular as behind-the-ear devices (also referred to as BTE devices after the English term “behind the ear”) or in-the-ear devices (also referred to as ITE devices after the term “in the ear”).
- hearing instruments usually have at least one (acousto-electrical) input transducer, a signal processing unit (signal processor) and an output transducer.
- the input transducer picks up airborne sound from the surroundings of the hearing instrument and converts it Airborne sound is converted into an input audio signal (ie an electrical signal that carries information about the ambient sound).
- This input audio signal is also referred to below as the “recorded sound signal”.
- the input audio signal is processed (ie modified with regard to its sound information) in order to support the hearing ability of the user, in particular to compensate for a hearing loss of the user.
- the signal processing unit outputs a correspondingly processed audio signal (also referred to as “output audio signal” or “modified sound signal”) to the output transducer.
- the output transducer is designed as an electro-acoustic transducer, which converts the (electrical) output audio signal back into airborne sound, this airborne sound - modified compared to the ambient sound - being emitted into the user's ear canal.
- the output transducer In the case of a hearing instrument worn behind the ear, the output transducer, also referred to as a “receiver”, is usually integrated outside the ear in a housing of the hearing instrument. In this case, the sound emitted by the output transducer is conducted into the ear canal of the user by means of a sound tube. As an alternative to this, the output transducer can also be arranged in the auditory canal and thus outside the housing worn behind the ear. Such hearing instruments are also referred to as RIC devices (after the English term “receiver in canal”). Hearing instruments worn in the ear that are so small that they do not protrude beyond the auditory canal are also referred to as CIC devices (after the English term "completely in canal”).
- the output transducer can also be designed as an electro-mechanical transducer which converts the output audio signal into structure-borne sound (vibrations), this structure-borne sound being emitted, for example, into the skull bone of the user.
- structure-borne sound vibrations
- hearing system denotes a single device or a group of devices and possibly non-physical functional units that together are used in operation provide the necessary functions of a hearing instrument.
- the hearing system can consist of a single hearing instrument.
- the hearing system can comprise two interacting hearing instruments for supplying the two ears of the user. In this case we speak of a "binaural hearing system”.
- the hearing system can comprise at least one further electronic device, for example a remote control, a charger or a programming device for the or each hearing device.
- a control program in particular in the form of a so-called app, is often provided, this control program being designed to be implemented on an external computer, in particular a smartphone or tablet.
- the external computer itself is usually not part of the hearing system and, in particular, is usually not provided by the manufacturer of the hearing system.
- a frequent problem in the operation of a hearing system is that the hearing instrument or the hearing instruments of the hearing system alienate the user's own voice, in particular reproducing it too loudly and with a sound that is perceived as unnatural.
- This problem is at least partially solved in modern hearing systems by recognizing time segments (self-voicing intervals) of the recorded sound signal in which this sound signal contains the user's own voice. These self-voice intervals are processed differently in the hearing instrument, in particular less amplified, than other intervals of the recorded sound signal that do not contain the voice of the user.
- the invention is based on the object of enabling signal processing in a hearing system which is improved under this aspect.
- this object is achieved according to the invention by the features of claim 1.
- the object is achieved according to the invention by the features of claim 10.
- the invention is generally based on a hearing system for supporting the hearing ability of a user, the hearing system having at least one hearing instrument worn in or on an ear of the user.
- the hearing system in simple embodiments of the invention can consist exclusively of a single hearing instrument.
- the hearing system preferably comprises at least one further component, e.g. a further (in particular similar) hearing instrument for supplying the other ear of the user, a control program (in particular in the form of an app) for execution on an external computer (in particular a smartphone) the user and / or at least one other electronic device, e.g. B. a remote control or a charger.
- the hearing instrument and the at least one further component are in data exchange with one another, the functions of data storage and / or data processing of the hearing system being divided between the hearing instrument and the at least one further component.
- the hearing instrument has at least one input transducer for receiving a sound signal (in particular in the form of airborne sound) from the surroundings of the hearing instrument, a signal processing unit for processing (modifying) the recorded sound signal in order to support the hearing of the user, and an output transducer for outputting the modified sound signal on. If the hearing system is another hearing instrument to supply the other Has the ear of the user, this further hearing instrument also preferably has at least one input transducer, a signal processing unit and an output transducer.
- each hearing instrument of the hearing system is in particular in one of the designs described above (BTE device with internal or external output transducer, ITE device, e.g. CIC device, hearing implant, in particular cochlear implant, etc.).
- BTE device with internal or external output transducer ITE device, e.g. CIC device, hearing implant, in particular cochlear implant, etc.
- both hearing instruments are preferably designed in the same way.
- the or each input transducer is in particular an acousto-electrical transducer which converts airborne sound from the environment into an electrical input audio signal.
- the hearing system preferably comprises at least two input transducers, which can be arranged in the same hearing instrument or - if available - divided between the two hearing instruments of the hearing system.
- the output transducer is preferably designed as an electro-acoustic transducer (earpiece), which in turn converts the audio signal modified by the signal processing unit into airborne sound.
- the output transducer is designed to emit structure-borne sound or to directly stimulate the user's auditory nerve.
- the signal processing unit preferably comprises a plurality of signal processing functions, e.g. any selection from the functions of frequency-selective amplification, dynamic compression, spectral compression, direction-dependent damping (beamforming), noise suppression, in particular active noise cancellation (ANC for short), active feedback cancellation (active feedback cancellation) , AFC for short), wind noise suppression, which are applied to the recorded sound signal, ie the input audio signal, in order to process it to support the user's hearing.
- Each of these functions or at least a large part of these functions can be parameterized by one or more signal processing parameters.
- a variable is used as the signal processing parameter which can be assigned different values in order to influence the operation of the associated signal processing function.
- a signal processing parameter can be a binary variable with which the respective function is switched on and off.
- hearing aid parameters are formed by scalar floating point numbers, binary or continuously variable vectors or multidimensional arrays, etc.
- An example of such signal processing parameters is a set of gain factors for a number of frequency bands of the signal processing unit, which define the frequency-dependent gain of the hearing instrument.
- the at least one input transducer of the hearing instrument records a sound signal from the surroundings of the hearing instrument, this sound signal at least temporarily containing the user's own voice and an ambient noise.
- Ambient noise is used here and in the following to refer to the portion of the recorded sound signal that originates from the environment (and is therefore different from the user's own voice).
- the recorded sound signal (input audio signal) is modified in a signal processing step to support the hearing ability of a user.
- the modified sound signal is output by means of the output transducer of the hearing instrument.
- a first signal component and a second signal component are derived from the recorded sound signal (immediately or after preprocessing).
- the first signal component (also referred to below as “voice component”) is derived in such a way that the user's own voice is emphasized here in relation to the ambient noise;
- the user's own voice is either selectively amplified (that is, amplified to a greater extent than the ambient noise) or the ambient noise is selectively attenuated (that is, attenuated to a greater extent than the user's own voice).
- the second signal component (hereinafter also referred to as “ambient noise component”), on the other hand, is derived in such a way that the ambient noise is emphasized here compared to the user's own voice; here either the ambient noise is selectively amplified (i.e. amplified to a greater extent than one's own voice) or one's own voice is selectively attenuated (i.e. attenuated to a greater extent than the ambient noise).
- the user's own voice is preferably completely or at least removed from the second signal component as far as this is possible in terms of signal processing technology.
- the first signal component (self-voiced component) and the second signal component (ambient noise component) are processed in different ways in the signal processing step.
- the first signal component is amplified to a lesser extent than the second signal component and / or processed with modified dynamic compression (in particular with reduced dynamic compression, that is to say with a more linear gain characteristic).
- the first signal component is preferably processed in a way that is optimized for processing the user's own voice (in particular individually, i.e. user-specific).
- the second signal component is preferably processed in a way that is optimized for processing the ambient noise. This processing of the second signal component is optionally in turn varied depending on the type of ambient noise (voice noise, music, driving noise, construction noise, etc.) determined, e.g. as part of a classification of the hearing situation.
- the first signal component and the second signal component are combined (superimposed) to generate the modified sound signal.
- the overall signal resulting from the combination of the two signals can, however, optionally, within the scope of the invention, go through further processing steps before being output by the output transducer, in particular be amplified again.
- the two signal components that is to say the natural voice component and the ambient noise component, are derived from the first and second sound signals in such a way that they (completely or at least partially) overlap in time.
- the two signal components therefore coexist in time and are processed in parallel to one another (i.e. on parallel signal processing paths). These signal components are therefore not consecutive intervals of the recorded sound signal.
- the derivation of the first signal component is preferably carried out using direction-dependent damping (beamforming), so that a spatial signal component corresponding to the ambient noise is selectively attenuated (i.e. more attenuated than another spatial signal component in which the ambient noise is not present or is only weakly pronounced).
- a static (time-immutable) damping algorithm also known as a beamforming algorithm or beamformer for short
- an adaptive, direction-dependent beamformer is used, the damping characteristic of which has at least one local or global damping maximum, that is to say at least one direction of maximum damping (notch).
- This notch (or, if applicable, one of several notches) is preferably aligned with a dominant noise source in a volume of space that is rearward with respect to the head of the user.
- the derivation of the second signal component is preferably also carried out by means of direction-dependent damping, with a static or adaptive beamformer also being optionally used.
- the direction-dependent attenuation is used here in such a way that a spatial signal component corresponding to the natural voice component is selectively attenuated (i.e. more attenuated than a spatial signal component in which the user's own voice is not present or is only weakly pronounced).
- a notch of the corresponding beamformer is expediently aligned exactly or approximately at the front with respect to the head of the user.
- a beamformer with a damping characteristic corresponding to an anti-cardioid is used.
- At least the beamformer used to derive the second signal component preferably has a frequency-dependent varying attenuation characteristic.
- This dependency of the damping characteristic is expressed in particular in a notch width, notch depth that varies with the frequency and / or in a notch direction that varies slightly with the frequency.
- the dependence of the attenuation characteristic on the frequency is set (e.g. empirically or using a numerical optimization method) in such a way that the attenuation of one's own voice in the second signal component is optimized (i.e. a local or global maximum is reached) and thus the own voice is eliminated as best as possible from the second signal component.
- This optimization is carried out, for example, when a static beamformer is used to derive the second signal component, when the hearing system is individually adapted to the user (fitting).
- an adaptive beamformer is used to derive the second signal component, which continuously optimizes the damping characteristics during operation of the hearing system with a view to the best possible damping of the user's own voice.
- This measure is based on the knowledge that the user's own voice is attenuated differently by a beamformer than the sound from a sound source arranged at a distance from the front of the user. In particular, the user's own voice is not always perceived as coming exactly from the front.
- the attenuation characteristic of the beamformer used to derive the first signal component also has a dependency on the frequency, this dependency being determined in such a way that the attenuation of the ambient signal is optimized in the first signal component (i.e. a local or global maximum is reached) and thus the ambient signal is eliminated as best as possible from the first signal component.
- spectral filtering of the recorded sound signal is preferably used in order to derive the first signal component (natural voice component) and the second signal component (ambient noise component).
- first signal component at least one frequency component of the recorded sound signal in which components of the user's own voice are not present or only weakly pronounced is selectively attenuated (i.e. more attenuated than frequency components of the recorded sound signal in which the user's own voice has dominant shares).
- second signal component at least one frequency component of the recorded sound signal, in which components of the ambient noise are not present or only weakly pronounced, is selectively attenuated (i.e. more attenuated than frequency components of the recorded sound signal in which the ambient noise has dominant components).
- the method described above namely the separation of the recorded sound signal into the natural voice component and the ambient noise component and the parallel, different processing of both signal components, can be carried out continuously (and according to the same unchanged method) within the scope of the invention while the hearing system is in operation, regardless of when and how often the recorded sound signal contains the user's own voice.
- the signal processing path containing the voice component runs virtually empty in this case and processes a signal that does not contain the user's own voice.
- the separation of the recorded sound signal into the natural voice component and the ambient noise component and the parallel, different processing of the two signal components are only carried out in natural voice intervals if the recorded sound signal also contains the user's own voice.
- own voice intervals of the recorded sound signal are recognized in a signal analysis step, e.g. B. using methods as they are in themselves US 2013/0148829 A1 or off WHERE 2016/078786 A1 are known.
- the recorded sound signal is separated into the first signal component and the second signal component only in recognized self-voicing intervals (not in intervals that do not contain the user's own voice).
- the separation of the recorded sound signal into the natural voice component and the ambient noise component and the parallel, different processing of the two signal components is basically carried out both in recognized natural voice intervals and in the absence of the user's own voice, but in this case the derivation of the second signal component (i.e. the ambient noise component), depending on the presence or absence of the user's own voice, takes place differently:
- an algorithm optimized for the attenuation of the user's own voice is preferably used in self-voice intervals to derive the ambient noise component, in particular - as described above - a static beamformer with an optimized frequency dependency of the damping characteristics or a self-optimizing dynamic beamformer.
- an algorithm different therefrom is preferably used to derive the ambient noise component, which is based on the attenuation of a noise source arranged on the front of the user but remote from the user (e.g. a speaker to whom the user turns) is aligned.
- This different algorithm is designed, for example, as a static beamformer with a direction-dependent damping characteristic corresponding to an anti-cardioid, this beamformer differing in terms of the shape and / or frequency dependence of the anti-cardioid from the beamformer used on self-tuning intervals to derive the ambient noise component.
- an anti-cardioid without frequency dependency ie an anti-cardioid constant over the frequency
- the processing of the first signal component is preferably also carried out here, depending on the presence or Absence of the user's own voice, in different ways:
- the first signal component is preferably - as described above - processed in a way that is optimized for processing the user's own voice, but in the absence of his own voice in a different way.
- the hearing system according to the invention is generally set up for the automatic implementation of the method according to the invention described above.
- the hearing system is thus set up to record a sound signal from the surroundings of the hearing instrument by means of the at least one input transducer of the at least one hearing instrument, the sound signal at least temporarily having the user's own voice and ambient noise, the recorded sound signal in the signal processing step to support hearing of a user and to output the modified sound signal by means of the output transducer of the hearing instrument.
- the hearing system is also set up to derive the first signal component (self-voiced component) and the second signal component (ambient noise component), which overlaps in time, from the recorded sound signal in the manner described above, to process these two signal components in different ways in the signal processing step and according to this Merge processing to generate the modified sound signal.
- the set-up of the hearing system for the automatic implementation of the method according to the invention is of a programming and / or circuitry nature.
- the hearing system according to the invention thus comprises program-technical means (software) and / or circuit-technical means (hardware, for example in the form of an ASIC) which automatically carry out the method according to the invention when the hearing system is in operation.
- the program-technical or circuit-technical means for carrying out the method can in this case be arranged exclusively in the hearing instrument (or the hearing instruments) of the hearing system.
- programming means for performing the method are distributed to the at least one hearing instrument of the hearing system and to a control program installed on an external electronic device (in particular a smartphone).
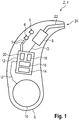
- Fig. 1 shows a hearing system 2 with a single hearing aid 4, ie a hearing instrument set up to support the hearing ability of a hearing-impaired user.
- the hearing aid 4 is a BTE hearing aid that can be worn behind an ear of a user.
- the hearing system 2 comprises a second hearing aid, not expressly shown, for supplying the second ear of the user, and / or a control app that can be installed on a smartphone of the user.
- the functional components of the hearing system 2 described below are preferably distributed between the two hearing aids or the at least one hearing aid and the control app.
- the hearing aid 4 includes within a housing 5 at least one microphone 6 (in the example shown, two microphones 6) as an input transducer and an earpiece 8 (receiver) as an output transducer. In the state worn behind the user's ear, the two microphones 6 are aligned such that one of the microphones 6 points forward (i.e. in the direction of view of the user), while the other microphone 6 is oriented towards the rear (opposite to the direction of view of the user).
- the hearing aid 4 further comprises a battery 10 and a signal processing unit in the form of a digital signal processor 12.
- the signal processor 12 preferably comprises both a programmable subunit (for example a microprocessor) and a non-programmable subunit (for example an ASIC).
- the signal processor 12 comprises a (self-voice recognition) unit 14 and a (signal separation) unit 16. In addition, the signal processor 12 has two parallel signal processing paths 18 and 20.
- the units 14 and 16 are preferably designed as software components that are implemented in the signal processor 12 so that they can run.
- the signal processing paths 18 and 20 are preferably formed by electronic hardware circuits (e.g. on the mentioned ASIC).
- the signal processor 12 is supplied with an electrical supply voltage U from the battery 10.
- the microphones 6 record airborne sound from the surroundings of the hearing aid 4.
- the microphones 6 convert the sound into an (input) audio signal I which contains information about the recorded sound.
- the input audio signal I is fed to the signal processor 12 within the hearing aid 4.
- the earpiece 8 converts the output sound signal O into a modified airborne sound.
- This modified airborne sound is transmitted via a sound channel 22, which connects the receiver 8 to a tip 24 of the housing 5, and via a (not explicitly shown) flexible sound tube, which connects the tip 24 with an earpiece inserted into the ear canal of the user, transferred into the ear canal of the user.
- FIG Fig. 2 The functional interconnection of the components of the signal processor 12 described above is shown in FIG Fig. 2 illustrated.
- the input audio signal I (and thus the recorded sound signal) is fed to the voice recognition unit 14 and the signal separation unit 16.
- the self-voice recognition unit 14 recognizes, for example using one or more of the in US 2013/0148829 A1 or WO 2016/078786 A1 methods described whether the input audio signal I contains the user's own voice.
- a status signal V dependent on the result of this test (which thus indicates whether or not the input audio signal I contains the user's own voice) feeds the self-voice recognition unit 14 to the signal separation unit 16.
- the signal separation unit 16 treats the input audio signal I supplied in different ways. In self-voicing intervals, i.e. time segments in which the self-voice recognition unit 14 has recognized the user's own voice in the input audio signal I, the signal separation unit 16 derives a first signal component (or self-voice component) S1 and a second signal component (or a second signal component) from the input audio signal I Ambient noise component) S2, and feeds these temporally overlapping signal components S1 and S2 to the parallel signal processing paths 18 and 20, respectively. On the other hand, at intervals in which the input audio signal I does not contain the user's own voice, the signal separation unit 16 feeds the entire input audio signal I to the signal path 20.
- self-voicing intervals i.e. time segments in which the self-voice recognition unit 14 has recognized the user's own voice in the input audio signal I
- the signal separation unit 16 derives a first signal component (or self-voice component) S1 and a second signal component (or a second signal component) from the input audio signal I Ambi
- the signal separation unit 16 routes the first signal component S1 and the second signal component S2 by application different beamformer 26 or 28 (that is, different algorithms for directional attenuation) from the input audio signal I from.
- an attenuation characteristic G1 of the beamformer 26 used to derive the first signal component (self-voiced component) S1 is shown by way of example.
- the beamformer 26 is an adaptive algorithm (that is, when the hearing system 2 is in operation, can be changed at any time) with two symmetrically mutually variable notches 30 (that is, directions of maximum attenuation).
- the damping characteristic G1 is set in such a way that one of the notches 30 is aligned with a dominant noise source 32 in a volume of space — rearward with respect to the head 34 of the user.
- the dominant noise source 32 is, for example, a speaker standing behind the user. Due to the in Fig.
- an attenuation characteristic G2 of the beamformer 28 used to derive the second signal component (ambient noise component) S2 is shown by way of example.
- This damping characteristic G2 is in particular static (that is to say unchanged over time after the hearing aid 4 has been individually adapted to the user) and corresponds, for example, to an anti-cardioid.
- a notch 36 of the damping characteristic G2 is aligned at the front with respect to the head 34 of the user, so that the user's own voice is at least largely masked out of the second signal component S2.
- the attenuation characteristic G2 of the beamformer 28 varies as a function of the frequency, so that the user's own voice is optimally attenuated.
- the attenuation characteristic G2 corresponding to an anti-cardioid arises from the fact that the signal from the microphone 6 pointing forward and the signal from the microphone pointing backwards, delayed by a time offset 6 are superimposed on each other (ie weighted or unweighted totaled).
- the time offset is specified as a frequency-dependent function so that the attenuation of one's own voice in the second signal component is optimized.
- An optimized frequency dependency of the time offset is determined by an audiologist during a training session in the course of hearing aid adjustment (fitting).
- the beamformer 28 is adaptive, with the attenuation characteristic G2 being adapted during ongoing operation of the hearing system 2 by the signal processor 12 (e.g. by minimizing the output energy of the beamformer 28 in self-tuning intervals).
- the first signal component S1 and the second signal component S2 are processed differently.
- the same signal processing algorithms are preferably used with different parameterization on the first signal component S1 and the second signal component S2.
- a parameter set of the signal processing parameters is used that is optimized for processing the user's own voice (in particular, individually tailored to the specific user).
- the first signal component S1 containing the user's own voice is amplified to a lesser extent than the second signal component S2 (or even not amplified at all).
- a lower dynamic compression that is to say a more linear gain characteristic
- the signal processing paths 18 and 20 emit processed and thus modified signal components S1 'and S2' to a recombination unit 38, which combines the modified signal components S1 'and S2' (in particular, weighted or unweighted totalized).
- the output audio signal O resulting therefrom is output to the listener 8 by the recombination unit 38 (directly or indirectly via further processing steps).
Abstract
Es werden ein Hörsystem (2) zur Unterstützung des Hörvermögens eines Nutzers, mit mindestens einem im oder am Ohr des Nutzers getragenen Hörinstrument (4), sowie ein Verfahren zum Betrieb dieses Hörsystems (2) angegeben. Im Betrieb des Hörsystems (2) wird mittels eines Eingangswandlers des Hörinstruments (4) ein Schallsignal aus einer Umgebung des Hörinstruments (4) aufgenommen und in einem Signalverarbeitungsschritt modifiziert. Das modifizierte Schallsignal wird mittels eines Ausgangswandlers (8) des Hörinstruments (4) ausgegeben. Aus dem aufgenommenen Schallsignal werden ein erster Signalanteil (S1) und ein zweiter Signalanteil (S2) abgeleitet, wobei diese Signalanteile (S1,S2) zeitlich überlappen. In dem ersten Signalanteil (S1) ist dabei die eigene Stimme des Nutzers gegenüber dem Umgebungsgeräusch hervorgehoben, während in dem zweiten Signalanteil (S2) das Umgebungsgeräusch gegenüber der eigenen Stimme des Nutzers hervorgehoben ist. Der erste Signalteil (S1) und der zweite Signalanteil (S2) werden in dem Signalverarbeitungsschritt in verschiedener Weise verarbeitet und nach dieser Verarbeitung zur Erzeugung des modifizierten Schallsignals zusammengeführt.A hearing system (2) to support the hearing ability of a user, with at least one hearing instrument (4) worn in or on the user's ear, and a method for operating this hearing system (2) are specified. When the hearing system (2) is in operation, an input transducer of the hearing instrument (4) records a sound signal from the surroundings of the hearing instrument (4) and modifies it in a signal processing step. The modified sound signal is output by means of an output transducer (8) of the hearing instrument (4). A first signal component (S1) and a second signal component (S2) are derived from the recorded sound signal, these signal components (S1, S2) overlapping in time. In the first signal component (S1), the user's own voice is emphasized in relation to the ambient noise, while in the second signal component (S2) the ambient noise is emphasized in relation to the user's own voice. The first signal part (S1) and the second signal part (S2) are processed in different ways in the signal processing step and, after this processing, are combined to generate the modified sound signal.
Description
Die Erfindung bezieht sich auf ein Verfahren zum Betrieb eines Hörsystems zur Unterstützung des Hörvermögens eines Nutzers, mit mindestens einem im oder am Ohr des Nutzers getragenen Hörinstrument. Die Erfindung bezieht sich weiterhin auf ein solches Hörsystem.The invention relates to a method for operating a hearing system to support the hearing ability of a user, with at least one hearing instrument worn in or on the user's ear. The invention also relates to such a hearing system.
Als Hörinstrument wird allgemein ein elektronisches Gerät bezeichnet, dass das Hörvermögen einer das Hörinstrument tragenden Person (die nachfolgend als "Träger" oder "Nutzer" bezeichnet ist) unterstützt. Insbesondere bezieht sich die Erfindung auf Hörinstrumente, die dazu eingerichtet sind, einen Hörverlust eines hörgeschädigten Nutzers ganz oder teilweise zu kompensieren. Ein solches Hörinstrument wird auch als "Hörgerät" bezeichnet. Daneben gibt es Hörinstrumente, die das Hörvermögen von normalhörenden Nutzern schützen oder verbessern, zum Beispiel in komplexen Hörsituationen ein verbessertes Sprachverständnis ermöglichen sollen.A hearing instrument is generally an electronic device that supports the hearing ability of a person wearing the hearing instrument (hereinafter referred to as “wearer” or “user”). In particular, the invention relates to hearing instruments which are set up to compensate for a hearing loss of a hearing-impaired user in whole or in part. Such a hearing instrument is also referred to as a “hearing aid”. There are also hearing instruments that protect or improve the hearing ability of normal hearing users, for example to enable improved speech understanding in complex listening situations.
Hörinstrumente im Allgemeinen, und Hörgeräte im Speziellen, sind meist dazu ausgebildet, ihm oder am Ohr des Nutzers getragen zu werden, insbesondere als Hinter-dem-Ohr-Geräte (nach dem englischen Begriff "behind the ear" auch als BTE-Geräte bezeichnet) oder In-dem-Ohr-Geräte (nach dem englischen Begriff "in the ear" auch als ITE-Geräte bezeichnet). Im Hinblick auf ihre interne Struktur weisen Hörinstrumente regelmäßig mindestens einen (akusto-elektrischen) Eingangswandler, eine Signalverarbeitungseinheit (Signalprozessor) und einen Ausgangswandler auf. Im Betrieb des Hörinstruments nimmt der Eingangswandler einen Luftschall aus der Umgebung des Hörinstruments auf und wandelt diesen Luftschall in ein Eingangs-Audiosignal (d. h. ein elektrisches Signal, dass eine Information über den Umgebungsschall transportiert) um. Dieses Eingangs-Audiosignal ist nachfolgend auch als "aufgenommenes Schallsignal" bezeichnet. In der Signalverarbeitungseinheit wird das Eingangs-Audiosignal verarbeitet (d. h. hinsichtlich seiner Schallinformation modifiziert), um das Hörvermögen des Nutzers zu unterstützen, insbesondere um einen Hörverlust des Nutzers auszugleichen. Die Signalverarbeitungseinheit gibt ein entsprechend verarbeitetes Audio-signal (auch als "Ausgangs-Audiosignal" oder "modifiziertes Schallsignal" bezeichnet) an den Ausgangswandler aus. In den meisten Fällen ist der Ausgangswandler als elektro-akustischer Wandler ausgebildet, der das (elektrische) Ausgangs-Audiosignal wieder in einen Luftschall umwandelt, wobei dieser - gegenüber dem Umgebungsschall modifizierte - Luftschall in den Gehörgang des Nutzers abgegeben wird. Bei einem hinter dem Ohr getragenen Hörinstrument ist der auch als "Hörer" ("Receiver") bezeichnete Ausgangswandler meist außerhalb des Ohrs in einem Gehäuse des Hörinstruments integriert. Der von dem Ausgangswandler ausgegebene Schall wird in diesem Fall mittels eines Schallschlauchs in den Gehörgang des Nutzers geleitet. Alternativ hierzu kann der Ausgangswandler auch in dem Gehörgang, und somit außerhalb des hinter dem Ohr getragenen Gehäuses, angeordnet sein. Solche Hörinstrumente werden (nach dem englischen Begriff "receiver in canal") auch als RIC-Geräte bezeichnet. Im Ohr getragene Hörinstrumente, die so klein dimensioniert sind, dass sie nach außen über den Gehörgang nicht hinausstehen, werden (nach dem englischen Begriff "completely in canal") auch als CIC-Geräte bezeichnet.Hearing instruments in general, and hearing aids in particular, are usually designed to be worn on him or on the user's ear, in particular as behind-the-ear devices (also referred to as BTE devices after the English term "behind the ear") or in-the-ear devices (also referred to as ITE devices after the term "in the ear"). With regard to their internal structure, hearing instruments usually have at least one (acousto-electrical) input transducer, a signal processing unit (signal processor) and an output transducer. When the hearing instrument is in operation, the input transducer picks up airborne sound from the surroundings of the hearing instrument and converts it Airborne sound is converted into an input audio signal (ie an electrical signal that carries information about the ambient sound). This input audio signal is also referred to below as the “recorded sound signal”. In the signal processing unit, the input audio signal is processed (ie modified with regard to its sound information) in order to support the hearing ability of the user, in particular to compensate for a hearing loss of the user. The signal processing unit outputs a correspondingly processed audio signal (also referred to as “output audio signal” or “modified sound signal”) to the output transducer. In most cases, the output transducer is designed as an electro-acoustic transducer, which converts the (electrical) output audio signal back into airborne sound, this airborne sound - modified compared to the ambient sound - being emitted into the user's ear canal. In the case of a hearing instrument worn behind the ear, the output transducer, also referred to as a “receiver”, is usually integrated outside the ear in a housing of the hearing instrument. In this case, the sound emitted by the output transducer is conducted into the ear canal of the user by means of a sound tube. As an alternative to this, the output transducer can also be arranged in the auditory canal and thus outside the housing worn behind the ear. Such hearing instruments are also referred to as RIC devices (after the English term "receiver in canal"). Hearing instruments worn in the ear that are so small that they do not protrude beyond the auditory canal are also referred to as CIC devices (after the English term "completely in canal").
In weiteren Bauformen kann der Ausgangswandler auch als elektro-mechanischer Wandler ausgebildet sein, der das Ausgangs-Audiosignal in Körperschall (Vibrationen) umwandelt, wobei dieser Körperschall zum Beispiel in den Schädelknochen des Nutzers abgegeben wird. Ferner gibt es implantierbare Hörinstrumente, insbesondere Cochlear-Implantate, und Hörinstrumente, deren Ausgangswandler den Hörnerv des Nutzers direkt stimulieren.In further designs, the output transducer can also be designed as an electro-mechanical transducer which converts the output audio signal into structure-borne sound (vibrations), this structure-borne sound being emitted, for example, into the skull bone of the user. There are also implantable hearing instruments, in particular cochlear implants, and hearing instruments whose output transducers directly stimulate the user's auditory nerve.
Der Begriff "Hörsystem" bezeichnet ein einzelnes Gerät oder eine Gruppe von Geräten und ggf. nicht-körperlichen Funktionseinheiten, die zusammen die im Betrieb eines Hörinstruments erforderlichen Funktionen bereitstellen. Das Hörsystem kann im einfachsten Fall aus einem einzelnen Hörinstrument bestehen. Alternativ hierzu kann das Hörsystem zwei zusammenwirkende Hörinstrumente zur Versorgung der beiden Ohren des Nutzers umfassen. In diesem Fall wird von einem "binauralen Hörsystem" gesprochen. Zusätzlich oder alternativ kann das Hörsystem mindestens ein weiteres elektronisches Gerät, zum Beispiel eine Fernbedienung, ein Ladegerät oder ein Programmiergerät für das oder jedes Hörgerät umfassen. Bei modernen Hörsystemen ist oft anstelle einer Fernbedienung oder eines dedizierten Programmiergerätes ein Steuerprogramm, insbesondere in Form einer sogenannten App, vorgesehen, wobei dieses Steuerprogramm zur Implementierung auf einem externen Computer, insbesondere einem Smartphone oder Tablet, ausgebildet ist. Der externe Computer ist dabei regelmäßig selbst kein Teil des Hörsystems und wird insbesondere in der Regel auch nicht von dem Hersteller des Hörsystems bereitgestellt.The term "hearing system" denotes a single device or a group of devices and possibly non-physical functional units that together are used in operation provide the necessary functions of a hearing instrument. In the simplest case, the hearing system can consist of a single hearing instrument. As an alternative to this, the hearing system can comprise two interacting hearing instruments for supplying the two ears of the user. In this case we speak of a "binaural hearing system". Additionally or alternatively, the hearing system can comprise at least one further electronic device, for example a remote control, a charger or a programming device for the or each hearing device. In modern hearing systems, instead of a remote control or a dedicated programming device, a control program, in particular in the form of a so-called app, is often provided, this control program being designed to be implemented on an external computer, in particular a smartphone or tablet. The external computer itself is usually not part of the hearing system and, in particular, is usually not provided by the manufacturer of the hearing system.
Ein häufiges Problem im Betrieb eines Hörsystems besteht darin, dass durch das Hörinstrument oder die Hörinstrumente des Hörsystems die eigene Stimme des Nutzers verfremdet, insbesondere zu laut und mit einem als unnatürlich empfundenen Klang, wiedergegeben wird. Dieses Problem wird bei modernen Hörsystemen zumindest teilweise gelöst, indem dort zeitliche Abschnitte (Eigenstimmintervalle) des aufgenommenen Schallsignals, in denen dieses Schallsignal die eigene Stimme des Nutzers enthält, erkannt werden. Diese Eigenstimmintervalle werden in dem Hörinstrument anders verarbeitet, insbesondere weniger verstärkt, als andere Intervalle des aufgenommenen Schallsignals, die die Stimme des Nutzers nicht enthalten.A frequent problem in the operation of a hearing system is that the hearing instrument or the hearing instruments of the hearing system alienate the user's own voice, in particular reproducing it too loudly and with a sound that is perceived as unnatural. This problem is at least partially solved in modern hearing systems by recognizing time segments (self-voicing intervals) of the recorded sound signal in which this sound signal contains the user's own voice. These self-voice intervals are processed differently in the hearing instrument, in particular less amplified, than other intervals of the recorded sound signal that do not contain the voice of the user.
Durch solche Signalverarbeitungsverfahren werden in Eigenstimmintervallen allerdings neben der eigenen Stimme des Nutzers auch andere Anteile (Umgebungsgeräusch) des aufgenommenen Schallsignals durch die veränderte Signalverarbeitung beeinflusst. Wenn der Nutzer im Betrieb des Hörsystems intermittierend (also in kurzen, durch Sprachpausen unterbrochenen Intervallen) spricht, führt dies regelmäßig zu einer Modulation des Umgebungsgeräuschs, die häufig als störend empfunden wird.By means of such signal processing methods, however, in addition to the user's own voice, other components (ambient noise) of the recorded sound signal are also influenced by the changed signal processing in natural voice intervals. If the user speaks intermittently (i.e. at short intervals interrupted by speech pauses) while the hearing system is in operation, this regularly leads to a modulation of the ambient noise, which is often perceived as annoying.
Der Erfindung liegt die Aufgabe zugrunde, eine unter diesem Aspekt verbesserte Signalverarbeitung in einem Hörsystem zu ermöglichen.The invention is based on the object of enabling signal processing in a hearing system which is improved under this aspect.
Bezüglich eines Verfahrens wird diese Aufgabe erfindungsgemäß gelöst durch die Merkmale des Anspruchs 1. Bezüglich eines Hörsystems wird die Aufgabe erfindungsgemäß gelöst durch die Merkmale des Anspruchs 10. Vorteilhafte und teils für sich gesehen erfinderische Ausgestaltungen oder Weiterentwicklungen der Erfindung sind in den Unteransprüchen und der nachfolgenden Beschreibung dargelegt.With regard to a method, this object is achieved according to the invention by the features of claim 1. With regard to a hearing system, the object is achieved according to the invention by the features of
Die Erfindung geht allgemein aus von einem Hörsystem zur Unterstützung des Hörvermögens eines Nutzers, wobei das Hörsystem mindestens ein im oder an einem Ohr des Nutzers getragenes Hörinstrument aufweist. Wie vorstehend beschrieben, kann das Hörsystem in einfachen Ausführungen der Erfindung ausschließlich aus einem einzigen Hörinstrument bestehen. Vorzugsweise umfasst das Hörsystem aber zusätzlich zu dem Hörinstrument mindestens eine weitere Komponente, z.B. ein weiteres (insbesondere gleichartiges) Hörinstrument zur Versorgung des anderen Ohrs des Nutzers, ein Steuerprogramm (insbesondere in Form einer App) zur Ausführung auf einem externen Computer (insbesondere einem Smartphone) des Nutzers und/oder mindestens ein weiteres elektronisches Gerät, z. B. eine Fernbedienung oder ein Ladegerät. Das Hörinstrument und die mindestens eine weitere Komponente stehen dabei miteinander in Datenaustausch, wobei Funktionen der Datenspeicherung und/oder Datenverarbeitung des Hörsystems unter dem Hörinstrument und der mindestens einen weiteren Komponente aufgeteilt sind.The invention is generally based on a hearing system for supporting the hearing ability of a user, the hearing system having at least one hearing instrument worn in or on an ear of the user. As described above, the hearing system in simple embodiments of the invention can consist exclusively of a single hearing instrument. In addition to the hearing instrument, the hearing system preferably comprises at least one further component, e.g. a further (in particular similar) hearing instrument for supplying the other ear of the user, a control program (in particular in the form of an app) for execution on an external computer (in particular a smartphone) the user and / or at least one other electronic device, e.g. B. a remote control or a charger. The hearing instrument and the at least one further component are in data exchange with one another, the functions of data storage and / or data processing of the hearing system being divided between the hearing instrument and the at least one further component.
Das Hörinstrument weist mindestens einen Eingangswandler zur Aufnahme eines Schallsignals (insbesondere in Form von Luftschall) aus einer Umgebung des Hörinstruments, eine Signalverarbeitungseinheit zur Verarbeitung (Modifizierung) des aufgenommenen Schallsignals, um das Hörvermögen des Nutzers zu unterstützen, und einen Ausgangswandler zur Ausgabe des modifizierten Schallsignals auf. Sofern das Hörsystem ein weiteres Hörinstrument zur Versorgung des anderen Ohrs des Nutzers aufweist, weist auch dieses weitere Hörinstrument vorzugsweise mindestens einen Eingangswandler, eine Signalverarbeitungseinheit und einen Ausgangswandler auf.The hearing instrument has at least one input transducer for receiving a sound signal (in particular in the form of airborne sound) from the surroundings of the hearing instrument, a signal processing unit for processing (modifying) the recorded sound signal in order to support the hearing of the user, and an output transducer for outputting the modified sound signal on. If the hearing system is another hearing instrument to supply the other Has the ear of the user, this further hearing instrument also preferably has at least one input transducer, a signal processing unit and an output transducer.
Das oder jedes Hörinstrument des Hörsystems liegt insbesondere in einer der eingangs beschriebenen Bauformen (BTE-Gerät mit internem oder externen Ausgangswandler, ITE-Gerät, z.B. CIC-Gerät, Hörimplantat, insbesondere Cochlear-Implantat, etc.) vor. Im Falle eines binauralen Hörsystems sind vorzugsweise beide Hörinstrumente gleichartig ausgebildet.The or each hearing instrument of the hearing system is in particular in one of the designs described above (BTE device with internal or external output transducer, ITE device, e.g. CIC device, hearing implant, in particular cochlear implant, etc.). In the case of a binaural hearing system, both hearing instruments are preferably designed in the same way.
Bei dem oder jedem Eingangswandler handelt es sich insbesondere um einen akusto-elektrischen Wandler, der einen Luftschall aus der Umgebung in ein elektrisches Eingangs-Audiosignal umwandelt. Um eine richtungsabhängige Analyse und Verarbeitung des aufgenommenen Schallsignals zu ermöglichen, umfasst das Hörsystem vorzugsweise mindestens zwei Eingangswandler, die in demselben Hörinstrument angeordnet oder - falls vorhanden - auf die zwei Hörinstrumente des Hörsystems aufgeteilt sein können. Der Ausgangswandler ist vorzugsweise als elektro-akustischer Wandler (Hörer) ausgebildet, der das von der Signalverarbeitungseinheit modifizierte Audiosignal wiederum in einen Luftschall umwandelt. Alternativ ist der Ausgangswandler zur Abgabe eines Körperschalls oder zur direkten Stimulierung des Hörnervs des Nutzers ausgebildet.The or each input transducer is in particular an acousto-electrical transducer which converts airborne sound from the environment into an electrical input audio signal. In order to enable a direction-dependent analysis and processing of the recorded sound signal, the hearing system preferably comprises at least two input transducers, which can be arranged in the same hearing instrument or - if available - divided between the two hearing instruments of the hearing system. The output transducer is preferably designed as an electro-acoustic transducer (earpiece), which in turn converts the audio signal modified by the signal processing unit into airborne sound. Alternatively, the output transducer is designed to emit structure-borne sound or to directly stimulate the user's auditory nerve.
Die Signalverarbeitungseinheit umfasst bevorzugt eine Mehrzahl von Signalverarbeitungsfunktionen, z.B. eine beliebige Auswahl aus den Funktionen frequenzselektive Verstärkung, dynamische Kompression, spektrale Kompression, richtungsabhängige Dämpfung (Beamforming), Störgeräuschunterdrückung, insbesondere aktive Störgeräuschunterdrückung (Active Noise Cancellation kurz ANC), aktive Rückkopplungsunterdrückung (Active Feedback Cancellation, kurz AFC), Windgeräuschunterdrückung, die auf das aufgenommene Schallsignal, d.h. das Eingangs-Audiosignal, angewendet werden, um dieses zur Unterstützung des Hörvermögens des Nutzers aufzubereiten. Jede dieser Funktionen oder zumindest ein Großteil dieser Funktionen ist dabei durch einen oder mehrere Signalverarbeitungsparameter parametrierbar. Als Signalverarbeitungsparameter wird eine Variable bezeichnet, die mit unterschiedlichen Werten belegt werden kann, um die Wirkungsweise der zugehörigen Signalverarbeitungsfunktion zu beeinflussen. Bei einem Signalverarbeitungsparameter kann es sich im einfachsten Fall um eine binäre Variable handeln, mit der die jeweilige Funktion an- und ausgeschaltet wird. In komplexeren Fällen sind Hörgeräteparameter durch skalare Fließkommazahlen, binäre oder kontinuierlich variable Vektoren oder mehrdimensionale Arrays, etc. gebildet. Ein Beispiel für solche Signalverarbeitungsparameter ist ein Set von Verstärkungsfaktoren für eine Anzahl von Frequenzbändern der Signalverarbeitungseinheit, die die frequenzabhängige Verstärkung des Hörinstruments definieren.The signal processing unit preferably comprises a plurality of signal processing functions, e.g. any selection from the functions of frequency-selective amplification, dynamic compression, spectral compression, direction-dependent damping (beamforming), noise suppression, in particular active noise cancellation (ANC for short), active feedback cancellation (active feedback cancellation) , AFC for short), wind noise suppression, which are applied to the recorded sound signal, ie the input audio signal, in order to process it to support the user's hearing. Each of these functions or at least a large part of these functions can be parameterized by one or more signal processing parameters. A variable is used as the signal processing parameter which can be assigned different values in order to influence the operation of the associated signal processing function. In the simplest case, a signal processing parameter can be a binary variable with which the respective function is switched on and off. In more complex cases, hearing aid parameters are formed by scalar floating point numbers, binary or continuously variable vectors or multidimensional arrays, etc. An example of such signal processing parameters is a set of gain factors for a number of frequency bands of the signal processing unit, which define the frequency-dependent gain of the hearing instrument.
Im Zuge des mittels des Hörsystems ausgeführten Verfahrens wird von dem mindestens einen Eingangswandler des Hörinstruments ein Schallsignal aus der Umgebung des Hörinstruments aufgenommen, wobei dieses Schallsignal zumindest zeitweise die eigene Stimme des Nutzers sowie ein Umgebungsgeräusch enthält. Als "Umgebungsgeräusch" wird hier und im Folgenden der aus der Umgebung stammende (und somit von der eigenen Stimme des Nutzers verschiedene) Anteil des aufgenommenen Schallsignals bezeichnet. Das aufgenommene Schallsignal (Eingangs-Audio-Signal) wird in einem Signalverarbeitungsschritt zur Unterstützung des Hörvermögens eines Nutzers modifiziert. Das modifizierte Schallsignal wird mittels des Ausgangswandlers des Hörinstruments ausgegeben.In the course of the method carried out by means of the hearing system, the at least one input transducer of the hearing instrument records a sound signal from the surroundings of the hearing instrument, this sound signal at least temporarily containing the user's own voice and an ambient noise. "Ambient noise" is used here and in the following to refer to the portion of the recorded sound signal that originates from the environment (and is therefore different from the user's own voice). The recorded sound signal (input audio signal) is modified in a signal processing step to support the hearing ability of a user. The modified sound signal is output by means of the output transducer of the hearing instrument.
Verfahrensgemäß werden aus dem aufgenommenen Schallsignal (unmittelbar oder nach einer Vorverarbeitung) ein erster Signalanteil und ein zweiter Signalanteil abgeleitet.According to the method, a first signal component and a second signal component are derived from the recorded sound signal (immediately or after preprocessing).
Der erste Signalanteil (nachfolgend auch "Eigenstimmanteil") wird derart abgeleitet, dass hierin die eigene Stimme des Nutzers gegenüber dem Umgebungsgeräusch hervorgehoben ist; hier wird die eigene Stimme des Nutzers entweder selektiv verstärkt (also in größerem Maße verstärkt als das Umgebungsgeräusch) oder es wird das Umgebungsgeräusch selektiv gedämpft (also in stärkerem Maße gedämpft als die eigene Stimme des Nutzers).The first signal component (also referred to below as “voice component”) is derived in such a way that the user's own voice is emphasized here in relation to the ambient noise; Here the user's own voice is either selectively amplified (that is, amplified to a greater extent than the ambient noise) or the ambient noise is selectively attenuated (that is, attenuated to a greater extent than the user's own voice).
Das zweite Signalanteil (nachfolgend auch als "Umgebungsgeräuschanteil" bezeichnet) wird dagegen wird derart abgeleitet, dass hierin das Umgebungsgeräusch gegenüber der eigenen Stimme des Nutzers hervorgehoben ist; hier wird also entweder das Umgebungsgeräusch selektiv verstärkt (also in größerem Maße verstärkt als die eigene Stimme) oder es wird die eigene Stimme selektiv gedämpft (also in stärkerem Maße gedämpft als das Umgebungsgeräusch). Vorzugsweise wird die eigene Stimme des Nutzers aus dem zweiten Signalanteil vollständig oder zumindest soweit wie dies signalverarbeitungstechnisch möglich ist entfernt.The second signal component (hereinafter also referred to as “ambient noise component”), on the other hand, is derived in such a way that the ambient noise is emphasized here compared to the user's own voice; here either the ambient noise is selectively amplified (i.e. amplified to a greater extent than one's own voice) or one's own voice is selectively attenuated (i.e. attenuated to a greater extent than the ambient noise). The user's own voice is preferably completely or at least removed from the second signal component as far as this is possible in terms of signal processing technology.
Verfahrensgemäß werden der erste Signalteil (Eigenstimmanteil) und der zweite Signalanteil (Umgebungsgeräuschanteil) in dem Signalverarbeitungsschritt in verschiedener Weise verarbeitet. Insbesondere wird der erste Signalanteil im Vergleich zu dem zweiten Signalanteil in geringerem Maße verstärkt und/oder mit veränderter dynamischer Kompression (insbesondere mit verringerter dynamischer Kompression, also mit linearerer Verstärkungskennlinie) verarbeitet. Der erste Signalanteil wird hierbei vorzugsweise auf eine für die Verarbeitung der eigenen Stimme des Nutzers (insbesondere individuell, d.h. nutzerspezifisch) optimierte Weise verarbeitet. Der zweite Signalanteil wird dagegen vorzugsweise auf eine für die Verarbeitung des Umgebungsgeräuschs optimierte Weise verarbeitet. Diese Verarbeitung des zweiten Signalanteils wird hierbei optional wiederum in Abhängigkeit der - z.B. im Rahmen einer Klassifizierung der Hörsituation ermittelten - Art des Umgebungsgeräuschs (Stimmgeräusch, Musik, Fahrgeräusch, Baulärm, etc.) variiert.According to the method, the first signal component (self-voiced component) and the second signal component (ambient noise component) are processed in different ways in the signal processing step. In particular, the first signal component is amplified to a lesser extent than the second signal component and / or processed with modified dynamic compression (in particular with reduced dynamic compression, that is to say with a more linear gain characteristic). The first signal component is preferably processed in a way that is optimized for processing the user's own voice (in particular individually, i.e. user-specific). The second signal component, on the other hand, is preferably processed in a way that is optimized for processing the ambient noise. This processing of the second signal component is optionally in turn varied depending on the type of ambient noise (voice noise, music, driving noise, construction noise, etc.) determined, e.g. as part of a classification of the hearing situation.
Nach dieser unterschiedlichen Verarbeitung werden der erste Signalanteil und der zweite Signalanteil zur Erzeugung des modifizieren Schallsignals zusammengeführt (überlagert). Das aus der Zusammenführung der beiden Signale resultierende Gesamtsignal kann aber optional im Rahmen der Erfindung vor der Ausgabe durch den Ausgangswandler noch weitere Verarbeitungsschritte durchlaufen, insbesondere noch einmal verstärkt werden.After this different processing, the first signal component and the second signal component are combined (superimposed) to generate the modified sound signal. The overall signal resulting from the combination of the two signals can, however, optionally, within the scope of the invention, go through further processing steps before being output by the output transducer, in particular be amplified again.
Die beiden Signalanteile, also der Eigenstimmanteil und der Umgebungsgeräuschanteil, werden dabei verfahrensgemäß derart aus dem ersten und zweiten Schallsignal abgeleitet, dass sie sich zeitlich (vollständig oder zumindest teilweise) überlappen. Die beiden Signalanteile existieren also zeitlich nebeneinander und werden parallel zueinander (d.h. auf parallelen Signalverarbeitungspfaden) verarbeitet. Bei diesen Signalanteilen handelt es sich mithin nicht um zeitlich aufeinanderfolgende Intervalle des aufgenommenen Schallsignals.According to the method, the two signal components, that is to say the natural voice component and the ambient noise component, are derived from the first and second sound signals in such a way that they (completely or at least partially) overlap in time. The two signal components therefore coexist in time and are processed in parallel to one another (i.e. on parallel signal processing paths). These signal components are therefore not consecutive intervals of the recorded sound signal.
Die Ableitung des ersten Signalanteils erfolgt vorzugsweise unter Nutzung richtungsabhängiger Dämpfung (Beamforming), so dass ein dem Umgebungsgeräusch entsprechender räumlicher Signalanteil selektiv gedämpft wird (also stärker gedämpft wird als ein anderer räumlicher Signalanteil, in dem das Umgebungsgeräusch nicht vorhanden oder nur schwach ausgeprägt ist). Hierzu kann im Rahmen der Erfindung ein statischer (zeitlich unveränderlicher) Dämpfungsalgorithmus (auch Beamforming-Algorithmus oder kurz Beamformer) eingesetzt werden. Vorzugsweise wird aber ein adaptiver richtungsabhängiger Beamformer eingesetzt, dessen Dämpfungscharakteristik mindestens ein lokales oder globales Dämpfungsmaximum, also mindestens eine Richtung maximaler Dämpfung (Notch) aufweist. Diese Notch (oder ggf. eine von mehreren Notches) wird dabei vorzugsweise auf eine dominante Geräuschquelle in einem bezüglich des Kopfes des Nutzers rückwärtigen Raumvolumen ausgerichtet.The derivation of the first signal component is preferably carried out using direction-dependent damping (beamforming), so that a spatial signal component corresponding to the ambient noise is selectively attenuated (i.e. more attenuated than another spatial signal component in which the ambient noise is not present or is only weakly pronounced). For this purpose, within the scope of the invention, a static (time-immutable) damping algorithm (also known as a beamforming algorithm or beamformer for short) can be used. Preferably, however, an adaptive, direction-dependent beamformer is used, the damping characteristic of which has at least one local or global damping maximum, that is to say at least one direction of maximum damping (notch). This notch (or, if applicable, one of several notches) is preferably aligned with a dominant noise source in a volume of space that is rearward with respect to the head of the user.
Die Ableitung des zweiten Signalanteils erfolgt vorzugsweise ebenfalls mittels richtungsabhängiger Dämpfung, wobei ebenfalls wahlweise ein statischer oder adaptiver Beamformer eingesetzt wird. Die richtungsabhängige Dämpfung wird hier derart eingesetzt, dass ein dem Eigenstimmanteil entsprechender räumlicher Signalanteil selektiv gedämpft wird (also stärker gedämpft wird als ein räumlicher Signalanteil, in dem die eigene Stimme des Nutzers nicht vorhanden oder nur schwach ausgeprägt ist). Eine Notch des entsprechenden Beamformers wird dabei zweckmäßigerweise bezüglich des Kopfes des Nutzers exakt oder näherungsweise frontseitig ausgerichtet. Insbesondere wird ein Beamformer mit einer einem Anti-Cardioid entsprechenden Dämpfungscharakteristik eingesetzt.The derivation of the second signal component is preferably also carried out by means of direction-dependent damping, with a static or adaptive beamformer also being optionally used. The direction-dependent attenuation is used here in such a way that a spatial signal component corresponding to the natural voice component is selectively attenuated (i.e. more attenuated than a spatial signal component in which the user's own voice is not present or is only weakly pronounced). A notch of the corresponding beamformer is expediently aligned exactly or approximately at the front with respect to the head of the user. In particular, a beamformer with a damping characteristic corresponding to an anti-cardioid is used.
Zumindest der zur Ableitung des zweiten Signalanteils eingesetzte Beamformer hat dabei vorzugsweise eine frequenzabhängig variierende Dämpfungscharakteristik. Diese Abhängigkeit der Dämpfungscharakteristik äußert sich insbesondere in einer mit der Frequenz variierenden Notch-Breite, Notch-Tiefe und/oder in einer geringfügig mit der Frequenz variierenden Notch-Richtung. Die Abhängigkeit der Dämpfungscharakteristik von der Frequenz wird hierbei (z. B. empirisch oder unter Nutzung eines numerischen Optimierungsverfahrens) derart eingestellt, dass die Dämpfung der eigenen Stimme in dem zweiten Signalanteil optimiert wird (also ein lokales oder globales Maximum erreicht) und dass somit die eigene Stimme bestmöglich aus dem zweiten Signalanteil eliminiert wird. Diese Optimierung wird bespielsweise - wenn zur Ableitung des zweiten Signalanteils ein statischer Beamformer eingesetzt wird - bei der individuellen Anpassung des Hörsystems an den Nutzer (Fitting) vorgenommen. Alternativ hierzu wird zur Ableitung des zweiten Signalanteils ein adaptiver Beamformer eingesetzt, der die Dämpfungscharakteristik im Betrieb des Hörsystems laufend in Hinblick auf eine bestmögliche Dämpfung der eigenen Stimme des Nutzers optimiert. Dieser Maßnahme liegt die Erkenntnis zugrunde, dass die eigene Stimme des Nutzers durch einen Beamformer anders gedämpft wird als der Schall einer mit Abstand zum Nutzer frontseitig angeordneten Schallquelle. Insbesondere wird die eigene Stimme von dem Nutzer nicht immer als exakt von vorne kommend wahrgenommen. Vielmehr ergibt sich für die eigene Stimme infolge von geringfügigen Unsymmetrien in der Anatomie des Kopfes, der individuellen Sprechgewohnheiten des Nutzers und/oder der Übertragung der eigenen Stimme durch Körperschall für die eigene Stimme bei vielen Nutzern eine Herkunftsrichtung (Schalleinfallrichtung), die von der Symmterieebene des Kopfes abweicht.At least the beamformer used to derive the second signal component preferably has a frequency-dependent varying attenuation characteristic. This dependency of the damping characteristic is expressed in particular in a notch width, notch depth that varies with the frequency and / or in a notch direction that varies slightly with the frequency. The dependence of the attenuation characteristic on the frequency is set (e.g. empirically or using a numerical optimization method) in such a way that the attenuation of one's own voice in the second signal component is optimized (i.e. a local or global maximum is reached) and thus the own voice is eliminated as best as possible from the second signal component. This optimization is carried out, for example, when a static beamformer is used to derive the second signal component, when the hearing system is individually adapted to the user (fitting). As an alternative to this, an adaptive beamformer is used to derive the second signal component, which continuously optimizes the damping characteristics during operation of the hearing system with a view to the best possible damping of the user's own voice. This measure is based on the knowledge that the user's own voice is attenuated differently by a beamformer than the sound from a sound source arranged at a distance from the front of the user. In particular, the user's own voice is not always perceived as coming exactly from the front. Rather, as a result of minor asymmetries in the anatomy of the head, the individual speaking habits of the user and / or the transmission of their own voice through structure-borne sound for their own voice, many users have a direction of origin (direction of sound incidence) that depends on the level of symmetry of the Head deviates.
Optional weist auch die Dämpfungscharakteristik des zur Ableitung des ersten Signalanteils eingesetzten Beamformers eine Abhängigkeit von der Frequenz auf, wobei diese Abhängigkeit derart bestimmt wird, dass die Dämpfung des Umgebungssignals in dem ersten Signalanteil optimiert wird (also ein lokales oder globales Maximum erreicht) und dass somit das Umgebungssignal bestmöglich aus dem ersten Signalanteil eliminiert wird.Optionally, the attenuation characteristic of the beamformer used to derive the first signal component also has a dependency on the frequency, this dependency being determined in such a way that the attenuation of the ambient signal is optimized in the first signal component (i.e. a local or global maximum is reached) and thus the ambient signal is eliminated as best as possible from the first signal component.
Weiterhin, insbesondere zusätzlich zu der vorstehend beschriebenen richtungsabhängigen Filterung, wird vorzugsweise eine spektrale Filterung des aufgenommenen Schallsignals eingesetzt, um den ersten Signalanteil (Eigenstimmanteil) und den zweiten Signalanteil (Umgebungsgeräuschanteil) abzuleiten. Zur Ableitung des ersten Signalanteils wird dabei vorzugsweise mindestens ein Frequenzanteil des aufgenommenen Schallsignals, in dem Anteile der eigenen Stimme des Nutzers nicht vorhanden oder nur schwach ausgeprägt sind, selektiv gedämpft (d.h. stärker gedämpft als Frequenzanteile des aufgenommenen Schallsignals, in denen die eigene Stimme des Nutzers dominante Anteile aufweist). Zur Ableitung des zweiten Signalanteils wird vorzugsweise mindestens ein Frequenzanteil des aufgenommenen Schallsignals, in dem Anteile des Umgebungsgeräuschs nicht vorhanden oder nur schwach ausgeprägt sind, selektiv gedämpft (d.h. stärker gedämpft als Frequenzanteile des aufgenommenen Schallsignals, in denen das Umgebungsgeräusch dominante Anteile aufweist).Furthermore, in particular in addition to the direction-dependent filtering described above, spectral filtering of the recorded sound signal is preferably used in order to derive the first signal component (natural voice component) and the second signal component (ambient noise component). To derive the first signal component, at least one frequency component of the recorded sound signal in which components of the user's own voice are not present or only weakly pronounced is selectively attenuated (i.e. more attenuated than frequency components of the recorded sound signal in which the user's own voice has dominant shares). To derive the second signal component, at least one frequency component of the recorded sound signal, in which components of the ambient noise are not present or only weakly pronounced, is selectively attenuated (i.e. more attenuated than frequency components of the recorded sound signal in which the ambient noise has dominant components).
Das vorstehend beschriebene Verfahren, nämlich die Trennung des aufgenommenen Schallsignals in den Eigenstimmanteil und den Umgebungsgeräuschanteil und die parallele, unterschiedliche Verarbeitung beider Signalanteile, kann im Rahmen der Erfindung im Betrieb des Hörsystems ununterbrochen (und nach demselben unveränderten Verfahren) durchgeführt werden, unabhängig davon, wann und wie häufig das aufgenommene Schallsignal die eigene Stimme des Nutzers enthält. In Intervallen des aufgenommenen Schallsignals, in denen die eigene Stimme des Nutzers nicht enthalten ist, läuft der den Eigenstimmanteil enthaltene Signalverarbeitungspfad in diesem Fall quasi leer und verarbeitet ein Signal, das nicht die eigene Stimme des Nutzers enthält.The method described above, namely the separation of the recorded sound signal into the natural voice component and the ambient noise component and the parallel, different processing of both signal components, can be carried out continuously (and according to the same unchanged method) within the scope of the invention while the hearing system is in operation, regardless of when and how often the recorded sound signal contains the user's own voice. In intervals of the recorded sound signal in which the user's own voice is not included, the signal processing path containing the voice component runs virtually empty in this case and processes a signal that does not contain the user's own voice.
Vorzugsweise werden die Trennung des aufgenommenen Schallsignals in den Eigenstimmanteil und den Umgebungsgeräuschanteil und die parallele, unterschiedliche Verarbeitung beider Signalanteile aber nur in Eigenstimmintervallen vorgenommen, wenn das aufgenommene Schallsignal auch die eigene Stimme des Nutzers enthält. Hierzu werden in einem Signalanalyseschritt EigenStimmintervalle des aufgenommenen Schallsignals erkannt, z. B. unter Anwendung von Methoden, wie sie an sich
Wiederum alternativ wird die Trennung des aufgenommenen Schallsignals in den Eigenstimmanteil und den Umgebungsgeräuschanteil und die parallele, unterschiedliche Verarbeitung der beiden Signalanteile zwar grundsätzlich sowohl in erkannten Eigenstimmintervallen als auch in Abwesenheit der eigenen Stimme des Nutzers durchgeführt, wobei in diesem Fall aber die Ableitung des zweiten Signalanteils (also des Umgebungsgeräuschanteils), abhängig von der Anwesenheit oder Abwesenheit der eigenen Stimme des Nutzers, unterschiedlich erfolgt: In Eigenstimmintervallen wird in dieser Ausführungsform zur Ableitung des Umgebungsgeräuschanteils vorzugsweise ein auf die Dämpfung der eigenen Stimme optimierter Algorithmus verwendet, insbesondere - wie vorstehend beschrieben - ein statischer Beamformer mit einer optimierten Frequenzabhängigkeit der Dämpfungscharakteristik oder ein sich selbst optimierender dynamischer Beamformer. Auf Intervalle des aufgenommenen Schallsignals, die die eigene Stimme des Nutzers nicht enthalten, wird dagegen zur Ableitung des Umgebungsgeräuschanteils vorzugsweise ein davon verschiedener (jedenfalls verschieden parametrierter) Algorithmus angewendet, der auf die Dämpfung einer frontseitig zu dem Nutzer angeordneten, aber von dem Nutzer entfernten Geräuschquelle (z.B. eines Sprechers, dem sich der Nutzer zuwendet) ausgerichtet ist. Dieser verschiedene Algorithmus ist beispielsweise als statischer Beamformer mit einer einem Anti-Cardioid entsprechenden richtungsabhängigen Dämpfungscharakteristik ausgebildet, wobei sich dieser Beamformer hinsichtlich der Form und/oder Frequenzabhängigkeit des Anti-Cardioids von dem auf Eigenstimmintervalle zur Ableitung des Umgebungsgeräuschanteils angewendeten Beamformer unterscheidet. Beispielsweise wird in Abwesenheit der eigenen Stimme des Nutzers zur Ableitung des Umgebungsgeräuschanteils ein Anti-Cardioid ohne Frequenzabhängigkeit (d.h. ein über die Frequenz konstantes Anti-Cardioid) herangezogen. Vorzugsweise erfolgt hierbei auch die Verarbeitung des ersten Signalanteils (der in Eigenstimmintervallen die eigene Stimme des Nutzers transportiert), abhängig von der Anwesenheit oder Abwesenheit der eigenen Stimme des Nutzers, in unterschiedlicher Weise: In Eigenstimmintervallen wird der erste Signalanteil vorzugsweise - wie vorstehend beschrieben - auf eine für die Verarbeitung der eigenen Stimme des Nutzers optimierte Weise verarbeitet, in Abwesenheit der eigenen Stimme dagegen auf eine hiervon verschiedene Weise.Again, as an alternative, the separation of the recorded sound signal into the natural voice component and the ambient noise component and the parallel, different processing of the two signal components is basically carried out both in recognized natural voice intervals and in the absence of the user's own voice, but in this case the derivation of the second signal component (i.e. the ambient noise component), depending on the presence or absence of the user's own voice, takes place differently: In this embodiment, an algorithm optimized for the attenuation of the user's own voice is preferably used in self-voice intervals to derive the ambient noise component, in particular - as described above - a static beamformer with an optimized frequency dependency of the damping characteristics or a self-optimizing dynamic beamformer. At intervals of the recorded sound signal that do not contain the user's own voice, on the other hand, an algorithm different therefrom (at least with different parameters) is preferably used to derive the ambient noise component, which is based on the attenuation of a noise source arranged on the front of the user but remote from the user (e.g. a speaker to whom the user turns) is aligned. This different algorithm is designed, for example, as a static beamformer with a direction-dependent damping characteristic corresponding to an anti-cardioid, this beamformer differing in terms of the shape and / or frequency dependence of the anti-cardioid from the beamformer used on self-tuning intervals to derive the ambient noise component. For example, in the absence of the user's own voice, an anti-cardioid without frequency dependency (ie an anti-cardioid constant over the frequency) is used to derive the ambient noise component. The processing of the first signal component (which transports the user's own voice in self-voicing intervals) is preferably also carried out here, depending on the presence or Absence of the user's own voice, in different ways: In self-voice intervals, the first signal component is preferably - as described above - processed in a way that is optimized for processing the user's own voice, but in the absence of his own voice in a different way.
Das erfindungsgemäße Hörsystem ist allgemein zur automatischen Durchführung des vorstehend beschriebenen erfindungsgemäßen Verfahrens eingerichtet. Das Hörsystem ist also dazu eingerichtet, mittels des mindestens einen Eingangswandlers des mindestens einen Hörinstruments ein Schallsignal aus einer Umgebung des Hörinstruments aufzunehmen, wobei das Schallsignal zumindest zeitweise die eigene Stimme des Nutzers sowie ein Umgebungsgeräusch aufweist, das aufgenommene Schallsignal in dem Signalverarbeitungsschritt zur Unterstützung des Hörvermögens eines Nutzers zu modifizieren und das modifizierte Schallsignal mittels des Ausgangswandlers des Hörinstruments auszugeben.The hearing system according to the invention is generally set up for the automatic implementation of the method according to the invention described above. The hearing system is thus set up to record a sound signal from the surroundings of the hearing instrument by means of the at least one input transducer of the at least one hearing instrument, the sound signal at least temporarily having the user's own voice and ambient noise, the recorded sound signal in the signal processing step to support hearing of a user and to output the modified sound signal by means of the output transducer of the hearing instrument.
Das Hörsystem ist weiterhin dazu eingerichtet, aus dem aufgenommenen Schallsignal in der vorstehend beschriebenen Weise den ersten Signalanteil (Eigenstimmanteil) und den - zeitlich damit überlappenden - zweiten Signalanteil (Umgebungsgeräuschanteil) abzuleiten, diese beiden Signalanteile in dem Signalverarbeitungsschritt in verschiedener Weise zu verarbeiten und nach dieser Verarbeitung zur Erzeugung der modifizierten Schallsignals zusammenzuführen.The hearing system is also set up to derive the first signal component (self-voiced component) and the second signal component (ambient noise component), which overlaps in time, from the recorded sound signal in the manner described above, to process these two signal components in different ways in the signal processing step and according to this Merge processing to generate the modified sound signal.
Die Einrichtung des Hörsystems zur automatischen Durchführung des erfindungsgemäßen Verfahrens ist programmtechnischer und/oder schaltungstechnischer Natur. Das erfindungsgemäße Hörsystem umfasst also programmtechnische Mittel (Software) und/oder schaltungstechnische Mittel (Hardware, z.B. in Form eines ASIC), die im Betrieb des Hörsystems das erfindungsgemäße Verfahren automatisch durchführen. Die programmtechnischen bzw. schaltungstechnischen Mittel zur Durchführung des Verfahrens können hierbei ausschließlich in dem Hörinstrument (oder dem Hörinstrumenten) des Hörsystems angeordnet sein. Alternativ sind die programmtechnischen bzw. schaltungstechnischen Mittel zur Durchführung des Verfahrens auf das Hörinstrument bzw. die Hörgeräte sowie mindestens auf ein weiteres Gerät oder eine Softwarekomponente des Hörsystems verteilt. Beispielsweise sind programmtechnische Mittel zur Durchführung des Verfahrens auf das mindestens eine Hörinstrument des Hörsystems sowie auf ein auf einem externen elektronischen Gerät (insbesondere einem Smartphone) installiertes Steuerprogramm verteilt.The set-up of the hearing system for the automatic implementation of the method according to the invention is of a programming and / or circuitry nature. The hearing system according to the invention thus comprises program-technical means (software) and / or circuit-technical means (hardware, for example in the form of an ASIC) which automatically carry out the method according to the invention when the hearing system is in operation. The program-technical or circuit-technical means for carrying out the method can in this case be arranged exclusively in the hearing instrument (or the hearing instruments) of the hearing system. Alternatively, the programming or circuitry means for performing the method on the hearing instrument or the hearing aids and at least distributed to another device or a software component of the hearing system. For example, programming means for performing the method are distributed to the at least one hearing instrument of the hearing system and to a control program installed on an external electronic device (in particular a smartphone).
Die vorstehend beschriebenen Ausführungsformen des erfindungsgemäßen Verfahrens korrespondieren mit entsprechenden Ausführungsformen des erfindungsgemäßen Hörsystems. Die vorstehenden Ausführungen zu dem erfindungsgemäßen Verfahren sind entsprechend auf das erfindungsgemäße Hörsystem übertragbar und umgekehrt.The embodiments of the method according to the invention described above correspond to corresponding embodiments of the hearing system according to the invention. The above statements on the method according to the invention can be transferred accordingly to the hearing system according to the invention and vice versa.
Nachfolgend werden Ausführungsbeispiele der Erfindung anhand einer Zeichnung näher erläutert. Darin zeigen:
- Fig. 1
- in einer schematischen Darstellung ein aus einem einzelnen Hörinstrument bestehendes Hörsystem in Form eines hinter einem Ohr eines Nutzers tragbaren Hörgeräts, in dem ein aus der Umgebung des Hörgeräts aufgenommenes Schallsignal in einen Eigenstimmanteil und einen damit zeitlich überlappenden Umgebungsgeräuschanteil getrennt wird, und in dem diese beiden Signalanteile unterschiedlich verarbeitet sowie anschließend wieder zusammengeführt werden,
- Fig. 2
- in einem schematischen Blockschaltbild eine Signalverarbeitung in dem Hörinstrument, sowie
- Fig. 3 und 4
- in zwei schematischen Diagrammen jeweils eine Dämpfungscharakteristik zweier richtungsabhängiger Dämpfungsalgorithmen (Beamformer), die bei dem Hörgerät aus
Fig. 1 zur Ableitung des Eigenstimmanteils bzw. des Umgebungsgeräuschanteils aus dem aufgenommenen Schallsignal eingesetzt werden.
- Fig. 1
- In a schematic representation, a hearing system consisting of a single hearing instrument in the form of a hearing aid that can be worn behind one ear of a user, in which a sound signal recorded from the surroundings of the hearing aid is separated into an inherent voice component and an ambient noise component that overlaps in time, and in which these two signal components processed differently and then brought together again,
- Fig. 2
- in a schematic block diagram a signal processing in the hearing instrument, as well as
- Figs. 3 and 4
- in two schematic diagrams, one attenuation characteristic of two direction-dependent attenuation algorithms (beamformer), which are used in the hearing aid
Fig. 1 can be used to derive the natural voice component or the ambient noise component from the recorded sound signal.
Gleiche Teile und Größen sind in allen Figuren stets mit gleichen Bezugszeichen versehen.The same parts and sizes are always provided with the same reference symbols in all figures.
Optional, in weiteren Ausführungsformen der Erfindung, umfasst das Hörsystem 2 ein nicht ausdrücklich dargestelltes zweites Hörgerät zur Versorgung des zweiten Ohrs des Nutzers, und/oder eine auf einem Smartphone des Nutzers installierbare Steuer-App. Die nachstehend beschriebenen funktionalen Komponenten des Hörsystems 2 sind bei diesen Ausführungsformen vorzugsweise auf die beiden Hörgeräte bzw. auf das mindestens eine Hörgerät und die Steuer-App verteilt.Optionally, in further embodiments of the invention, the
Das Hörgerät 4 umfasst innerhalb eines Gehäuses 5 mindestens ein Mikrofon 6 (im dargestellten Beispiel zwei Mikrofone 6) als Eingangswandler sowie einen Hörer 8 (Receiver) als Ausgangswandler. In dem hinter dem Ohr des Nutzers getragenen Zustand sind die beiden Mikrofone 6 derart ausgerichtet, dass eines der Mikrofone 6 nach vorne (d.h. in Blickrichtung des Nutzers) zeigt, während das andere Mikrofon 6 nach hinten (entgegen der Blickrichtung des Nutzers) ausgerichtet ist. Das Hörgerät 4 umfasst weiterhin eine Batterie 10 und eine Signalverarbeitungseinheit in Form eines digitalen Signalprozessors 12. Vorzugsweise umfasst der Signalprozessor 12 sowohl eine programmierbare Untereinheit (zum Beispiel einen Mikroprozessor) als auch eine nicht-programmierbare Untereinheit (zum Beispiel einen ASIC). Der Signalprozessor 12 umfasst eine (Eigenstimmerkennungs-) Einheit 14 und eine (Signaltrennungs-) Einheit 16. Zusätzlich weist der Signalprozessor 12 zwei parallele Signalverarbeitungspfade 18 und 20 auf.The hearing aid 4 includes within a
Vorzugsweise sind die Einheiten 14 und 16 als Softwarekomponenten ausgebildet, die in dem Signalprozessor 12 lauffähig implementiert sind. Die Signalverarbeitungspfade 18 und 20 sind vorzugsweise durch elektronische Hardware-Schaltkreise (z. B. auf dem erwähnten ASIC) gebildet.The
Der Signalprozessor 12 wird aus der Batterie 10 mit einer elektrischen Versorgungsspannung U versorgt.The
Im Normalbetrieb des Hörgeräts 4 nehmen die Mikrofone 6 einen Luftschall aus der Umgebung des Hörgeräts 4 auf. Die Mikrofone 6 wandeln den Schall in ein (Eingangs-)Audiosignal I um, das Information über den aufgenommenen Schall enthält. Das Eingangs-Audiosignal I wird innerhalb des Hörgeräts 4 dem Signalprozessor 12 zugeführt.During normal operation of the hearing aid 4, the
Der Signalprozessor 12 verarbeitet das Eingangs-Audiosignal I in den Signalverarbeitungspfaden 18 und 20 jeweils unter Anwendung einer Mehrzahl von Signalverarbeitungs-Algorithmen, beispielsweise
- Störgeräusch- und/oder Rückkopplung-Unterdrückung,
- dynamischer Kompression und
- frequenzabhängiger Verstärkung basierend auf Audiogramm-Daten,
- Noise and / or feedback suppression,
- dynamic compression and
- frequency-dependent amplification based on audiogram data,
Der Hörer 8 wandelt das Ausgangs-Schallsignal O in einen modifizierten Luftschall um. Dieser modifizierte Luftschall wird über einen Schallkanal 22, der den Hörer 8 mit einer Spitze 24 des Gehäuses 5 verbindet, sowie über einen (nicht explizit gezeigten) flexiblen Schallschlauch, der die Spitze 24 mit einem in den Gehörgang des Nutzers eingesetzten Ohrstück verbindet, in den Gehörgang des Nutzers übertragen.The
Die funktionale Verschaltung der vorstehend beschriebenen Komponenten des Signalprozessors 12 ist in
Das Eingangs-Audiosignal I (und somit das aufgenommene Schallsignal) wird der Eigenstimmerkennungseinheit 14 und der Signaltrennungseinheit 16 zugeführt.The input audio signal I (and thus the recorded sound signal) is fed to the
Die Eigenstimmerkennungseinheit 14 erkennt, beispielsweise unter Anwendung einer oder mehrerer der in
In Abhängigkeit von dem Wert des Statussignals V behandelt die Signaltrennungseinheit 16 das zugeführte Eingangs-Audiosignal I in unterschiedlicher Weise. In Eigenstimmintervallen, also zeitlichen Abschnitten, in denen die Eigenstimmerkennungseinheit 14 die eigene Stimme des Nutzers in dem Eingangs-Audiosignal I erkannt hat, leitet die Signaltrennungseinheit 16 aus dem Eingangs-Audiosignal I einen ersten Signalanteil (oder Eigenstimmanteil) S1 und einen zweiten Signalanteil (oder Umgebungsgeräuschanteil) S2 ab, und führt diese zeitlich überlappenden Signalanteile S1 und S2 den parallelen Signalverarbeitungspfaden 18 bzw. 20 zu. In Intervallen, in denen das Eingangs-Audiosignal I nicht die eigene Stimme des Nutzers enthält, leitet die Signaltrennungseinheit 16 dagegen das gesamte Eingangs-Audiosignal I dem Signalpfad 20 zu.Depending on the value of the status signal V, the
Wie in den
In
In
Zudem variiert die Dämpfungscharakteristik G2 des Beamformers 28 frequenzabhängig, so dass die eigene Stimme des Nutzers optimal gedämpft wird. In dem in
In einer alternativen Ausführungsform ist der Beamformer 28 adaptiv, wobei die Dämpfungscharakteristik G2 im laufenden Betrieb des Hörsystems 2 durch den Signalprozessor 12 (z.B. durch Minimierung der Ausgabeenergie des Beamformers 28 in Eigenstimmintervallen) angepasst wird.In an alternative embodiment, the
In den Signalverarbeitungspfaden 18 und 20 werden der erste Signalanteil S1 und der zweite Signalanteil S2 unterschiedlich verarbeitet. Dabei werden vorzugsweise die gleiche Signalverarbeitungsalgorithmen in unterschiedlicher Parametrierung auf den ersten Signalanteil S1 und den zweiten Signalanteil S2 angewendet. Zur Verarbeitung des ersten Signalanteils S1 wird ein Parametersatz der Signalverarbeitungsparameter herangezogen, der für die Verarbeitung der eigenen Stimme des Nutzers (insbesondere in individueller Abstimmung auf den spezifischen Nutzer) optimiert ist. Unter anderem wird der die eigene Stimme des Nutzers enthaltende erste Signalanteil S1 in geringerem Maß verstärkt als der zweite Signalanteil S2 (oder sogar gar nicht verstärkt). Zudem wird auf den Signalanteil S1 eine geringere dynamische Kompression (also eine linearere Verstärkungskennlinie) angewendet als auf den Signalanteil S2.In the
Die Signalverarbeitungspfade 18 und 20 geben verarbeitete und somit modifizierte Signalanteile S1' bzw. S2' an eine Rekombinationseinheit 38 ab, die die modifizierten Signalanteile S1' bzw. S2' zusammenführt (insbesondere gewichtet oder ungewichtet summiert). Das hieraus resultierende Ausgangs-Audiosignal O wird durch die Rekombinationseinheit 38 (unmittelbar oder mittelbar über weitere Verarbeitungsschritte) an den Hörer 8 ausgegeben.The
Die Erfindung wird an den vorstehend beschriebenen Ausführungsbeispielen besonders deutlich, ist gleichwohl auf diese Ausführungsbeispiele aber nicht beschränkt. Vielmehr können weitere Ausführungsformen der Erfindung von dem Fachmann aus den Ansprüchen und der vorstehenden Beschreibung abgeleitet werden.The invention is particularly clear from the exemplary embodiments described above, but is nevertheless not limited to these exemplary embodiments. Rather, further embodiments of the invention can be derived by a person skilled in the art from the claims and the above description.
- 22
- HörsystemHearing aid
- 44th
- HörgerätHearing aid
- 55
- Gehäusecasing
- 66th
- Mikrofonmicrophone
- 88th
- HörerListener
- 1010
- Batteriebattery
- 1212th
- SignalprozessorSignal processor
- 1414th
- (Eigenstimmerkennungs-)Einheit(Voice recognition) unit
- 1616
- (Signaltrennungs-)Einheit(Signal separation) unit
- 1818th
- SignalverarbeitungspfadSignal processing path
- 2020th
- SignalverarbeitungspfadSignal processing path
- 2222nd
- SchallkanalSound channel
- 2424
- Spitzetop
- 2626th
- BeamformerBeamformer
- 2828
- BeamformerBeamformer
- 3030th
- NotchNotch
- 3232
- GeräuschquelleSource of noise
- 3434
- Kopfhead
- 3636
- NotchNotch
- 3838
- RekombinationseinheitRecombination unit
- G1G1
- DämpfungscharakteristikDamping characteristics
- G2G2
- DämpfungscharakteristikDamping characteristics
- II.
- (Eingangs-)Audiosignal(Input) audio signal
- OO
- (Ausgangs-)Audiosignal(Output) audio signal
- S1, S1'S1, S1 '
- (erster) Signalanteil(first) signal component
- S2, S2'S2, S2 '
- (zweiter) Signalanteil(second) signal component
- UU
- VersorgungsspannungSupply voltage
- VV
- StatussignalStatus signal
Claims (11)
wobei zur Ableitung des ersten Signalanteils (S1) mittels richtungsabhängiger Dämpfung ein dem Umgebungsgeräusch entsprechender räumlicher Signalanteil selektiv gedämpft wird.Method according to claim 1,
wherein, in order to derive the first signal component (S1), a spatial signal component corresponding to the ambient noise is selectively attenuated by means of direction-dependent damping.
wobei zur Ableitung des ersten Signalanteils (S1) eine Richtung maximaler Dämpfung auf eine dominante Geräuschquelle (32) in einem bezüglich des Kopfes (34) des Nutzers rückwärtigen Raumvolumen ausgerichtet wird.Method according to claim 2,
wherein, in order to derive the first signal component (S1), a direction of maximum damping is directed towards a dominant noise source (32) in a space volume at the rear with respect to the head (34) of the user.
wobei zur Ableitung des zweiten Signalanteils (S2) mittels richtungsabhängiger Dämpfung ein dem Eigenstimmanteil entsprechender räumlicher Signalanteil selektiv gedämpft wird.Method according to one of Claims 1 to 3,
wherein, in order to derive the second signal component (S2), a spatial signal component corresponding to the natural voice component is selectively attenuated by means of direction-dependent attenuation.
wobei zur Ableitung des zweiten Signalanteils (S2) eine Richtung maximaler Dämpfung bezüglich des Kopfes (34) des Nutzers exakt oder näherungsweise frontseitig ausgerichtet wird.Method according to claim 4,
wherein, in order to derive the second signal component (S2), a direction of maximum attenuation with respect to the head (34) of the user is aligned exactly or approximately at the front.
wobei die zur Ableitung des zweiten Signalanteils (S2) herangezogene richtungsabhängige Dämpfung eine räumliche Dämpfungscharakteristik aufweist, die derart von der Frequenz des aufgenommenen Schallsignals abhängig ist, dass die Dämpfung der eigenen Stimme optimiert ist.Method according to claim 4 or 5,
wherein the direction-dependent attenuation used to derive the second signal component (S2) has a spatial attenuation characteristic which is dependent on the frequency of the recorded sound signal in such a way that the attenuation of one's own voice is optimized.
wobei zur Ableitung des ersten Signalanteils (S1) mindestens ein Frequenzanteil des aufgenommenen Schallsignals, in dem Anteile der eigenen Stimme des Nutzers nicht vorhanden oder nur schwach ausgeprägt sind, selektiv gedämpft wird.Method according to one of Claims 1 to 6,
wherein, in order to derive the first signal component (S1), at least one frequency component of the recorded sound signal in which components of the user's own voice are not present or are only weakly pronounced is selectively attenuated.
wobei zur Ableitung des zweiten Signalanteils (S2) mindestens ein Frequenzanteil des aufgenommenen Schallsignals, in dem Anteile des Umgebungsgeräuschs nicht vorhanden oder nur schwach ausgeprägt sind, selektiv gedämpft wird.Method according to one of Claims 1 to 7,
wherein, in order to derive the second signal component (S2), at least one frequency component of the recorded sound signal, in which components of the ambient noise are not present or are only weakly pronounced, is selectively attenuated.
wobei der erste Signalanteil (S1) in dem Signalverarbeitungsschritt in geringerem Maße verstärkt und/oder mit anderer dynamischer Kompression verarbeitet wird als der zweite Signalanteil (S2).Method according to one of Claims 1 to 8,
wherein the first signal component (S1) in the signal processing step is amplified to a lesser extent and / or processed with a different dynamic compression than the second signal component (S2).
wobei in einem Signalanalyseschritt Eigenstimmintervalle des aufgenommenen Schallsignals erkannt werden, in denen das aufgenommene Schallsignal die eigene Stimme des Nutzers enthält, und wobei die Trennung des aufgenommenen Schallsignals in den ersten Signalanteil (S1) und den zweiten Signalanteil (S2) nur in erkannten Eigen-stimmintervallen vorgenommen wird.Method according to one of Claims 1 to 9,
In a signal analysis step, self-voicing intervals of the recorded sound signal are recognized in which the recorded sound signal contains the user's own voice, and the separation of the recorded sound signal into the first signal component (S1) and the second signal component (S2) only in recognized self-voicing intervals is made.
wobei das Hörinstrument (4) umfasst:
wherein the hearing instrument (4) comprises:
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| DE102020201615.1A DE102020201615B3 (en) | 2020-02-10 | 2020-02-10 | Hearing system with at least one hearing instrument worn in or on the user's ear and a method for operating such a hearing system |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| EP3863306A1 true EP3863306A1 (en) | 2021-08-11 |
Family
ID=74175644
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| EP21151124.1A Pending EP3863306A1 (en) | 2020-02-10 | 2021-01-12 | Hearing system with at least one hearing instrument worn in or on the ear of the user and method for operating such a hearing system |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US11463818B2 (en) |
| EP (1) | EP3863306A1 (en) |
| CN (1) | CN113259822B (en) |
| DE (1) | DE102020201615B3 (en) |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6661901B1 (en) * | 2000-09-01 | 2003-12-09 | Nacre As | Ear terminal with microphone for natural voice rendition |
| EP2352312A1 (en) * | 2009-12-03 | 2011-08-03 | Oticon A/S | A method for dynamic suppression of surrounding acoustic noise when listening to electrical inputs |
| US20130148829A1 (en) | 2011-12-08 | 2013-06-13 | Siemens Medical Instruments Pte. Ltd. | Hearing apparatus with speaker activity detection and method for operating a hearing apparatus |
| WO2016078786A1 (en) | 2014-11-19 | 2016-05-26 | Sivantos Pte. Ltd. | Method and apparatus for fast recognition of a user's own voice |
| EP3101919A1 (en) * | 2015-06-02 | 2016-12-07 | Oticon A/s | A peer to peer hearing system |
| EP3188507A1 (en) * | 2015-12-30 | 2017-07-05 | GN Resound A/S | A head-wearable hearing device |
Family Cites Families (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6240192B1 (en) * | 1997-04-16 | 2001-05-29 | Dspfactory Ltd. | Apparatus for and method of filtering in an digital hearing aid, including an application specific integrated circuit and a programmable digital signal processor |
| US6738485B1 (en) * | 1999-05-10 | 2004-05-18 | Peter V. Boesen | Apparatus, method and system for ultra short range communication |
| US8249284B2 (en) * | 2006-05-16 | 2012-08-21 | Phonak Ag | Hearing system and method for deriving information on an acoustic scene |
| EP2071874B1 (en) * | 2007-12-14 | 2016-05-04 | Oticon A/S | Hearing device, hearing device system and method of controlling the hearing device system |
| DK2091266T3 (en) * | 2008-02-13 | 2012-09-24 | Oticon As | Hearing aid and use of a hearing aid device |
| EP2991379B1 (en) | 2014-08-28 | 2017-05-17 | Sivantos Pte. Ltd. | Method and device for improved perception of own voice |
| EP3057340B1 (en) * | 2015-02-13 | 2019-05-22 | Oticon A/s | A partner microphone unit and a hearing system comprising a partner microphone unit |
| DE102015204639B3 (en) | 2015-03-13 | 2016-07-07 | Sivantos Pte. Ltd. | Method for operating a hearing device and hearing aid |
| US9967682B2 (en) * | 2016-01-05 | 2018-05-08 | Bose Corporation | Binaural hearing assistance operation |
| EP3396978B1 (en) * | 2017-04-26 | 2020-03-11 | Sivantos Pte. Ltd. | Hearing aid and method for operating a hearing aid |
| EP3429230A1 (en) * | 2017-07-13 | 2019-01-16 | GN Hearing A/S | Hearing device and method with non-intrusive speech intelligibility prediction |
| DE102018216667B3 (en) | 2018-09-27 | 2020-01-16 | Sivantos Pte. Ltd. | Process for processing microphone signals in a hearing system and hearing system |
-
2020
- 2020-02-10 DE DE102020201615.1A patent/DE102020201615B3/en active Active
-
2021
- 2021-01-12 EP EP21151124.1A patent/EP3863306A1/en active Pending
- 2021-02-07 CN CN202110167932.5A patent/CN113259822B/en active Active
- 2021-02-10 US US17/172,289 patent/US11463818B2/en active Active
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6661901B1 (en) * | 2000-09-01 | 2003-12-09 | Nacre As | Ear terminal with microphone for natural voice rendition |
| EP2352312A1 (en) * | 2009-12-03 | 2011-08-03 | Oticon A/S | A method for dynamic suppression of surrounding acoustic noise when listening to electrical inputs |
| US20130148829A1 (en) | 2011-12-08 | 2013-06-13 | Siemens Medical Instruments Pte. Ltd. | Hearing apparatus with speaker activity detection and method for operating a hearing apparatus |
| WO2016078786A1 (en) | 2014-11-19 | 2016-05-26 | Sivantos Pte. Ltd. | Method and apparatus for fast recognition of a user's own voice |
| EP3101919A1 (en) * | 2015-06-02 | 2016-12-07 | Oticon A/s | A peer to peer hearing system |
| EP3188507A1 (en) * | 2015-12-30 | 2017-07-05 | GN Resound A/S | A head-wearable hearing device |
Also Published As
| Publication number | Publication date |
|---|---|
| DE102020201615B3 (en) | 2021-08-12 |
| US20210250705A1 (en) | 2021-08-12 |
| CN113259822B (en) | 2022-12-20 |
| US11463818B2 (en) | 2022-10-04 |
| CN113259822A (en) | 2021-08-13 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| EP3451705B1 (en) | Method and apparatus for the rapid detection of own voice | |
| EP1379102B1 (en) | Sound localization in binaural hearing aids | |
| DE102007017761B4 (en) | Method for adapting a binaural hearing aid system | |
| EP2164283B1 (en) | Hearing aid and operation of a hearing aid with frequency transposition | |
| DE102018216667B3 (en) | Process for processing microphone signals in a hearing system and hearing system | |
| EP2991379B1 (en) | Method and device for improved perception of own voice | |
| EP1931172A1 (en) | Hearing aid with noise cancellation and corresponding method | |
| EP2229010A2 (en) | Method for compensating for interference in a hearing aid, hearing aid and method for adjusting same | |
| DE102007035171A1 (en) | Method for adapting a hearing aid by means of a perceptive model | |
| DE102012203349B4 (en) | Method for adapting a hearing device based on the sensory memory and adaptation device | |
| EP2434781A1 (en) | Method for reconstructing a speech signal and hearing aid | |
| EP2023667A2 (en) | Method for adjusting a hearing aid with a perceptive model for binaural hearing and corresponding hearing system | |
| DE102020201615B3 (en) | Hearing system with at least one hearing instrument worn in or on the user's ear and a method for operating such a hearing system | |
| EP2262282A2 (en) | Method for determining a frequency response and corresponding hearing aid | |
| DE102007030067B4 (en) | Hearing aid with passive, input-level-dependent noise reduction and method | |
| WO2012019636A1 (en) | Method for operating a hearing aid and corresponding hearing aid | |
| EP2590437B1 (en) | Periodic adaptation of a feedback suppression device | |
| DE102020202725B4 (en) | Binaural hearing system with two hearing instruments worn in or on the user's ear and method for operating such a hearing system | |
| EP3926983A2 (en) | Hearing system with at least one hearing instrument worn in or on the ear of the user and method for operating such a hearing system | |
| DE102022202266A1 (en) | Method of operating a hearing aid | |
| EP3913618A1 (en) | Hearing aid and method for operating a hearing aid | |
| DE102021210098A1 (en) | Method of operating a hearing aid | |
| DE102021203584A1 (en) | Method of operating a hearing aid | |
| WO2014049455A1 (en) | Hearing system and transmission method | |
| DE102008064382A1 (en) | Hearing device i.e. behind-the-ear hearing device, has transposition device for transposing part of frequency range of output signal, and control device releasing transposing of transposition device in cent steps |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PUAI | Public reference made under article 153(3) epc to a published international application that has entered the european phase |
Free format text: ORIGINAL CODE: 0009012 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: THE APPLICATION HAS BEEN PUBLISHED |
|
| AK | Designated contracting states |
Kind code of ref document: A1 Designated state(s): AL AT BE BG CH CY CZ DE DK EE ES FI FR GB GR HR HU IE IS IT LI LT LU LV MC MK MT NL NO PL PT RO RS SE SI SK SM TR |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: REQUEST FOR EXAMINATION WAS MADE |
|
| 17P | Request for examination filed |
Effective date: 20220210 |
|
| RBV | Designated contracting states (corrected) |
Designated state(s): AL AT BE BG CH CY CZ DE DK EE ES FI FR GB GR HR HU IE IS IT LI LT LU LV MC MK MT NL NO PL PT RO RS SE SI SK SM TR |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: EXAMINATION IS IN PROGRESS |
|
| 17Q | First examination report despatched |
Effective date: 20230901 |